 +
+ 🧬 DeepCode
-OPEN-SOURCE CODE AGENT
-⚡ DATA INTELLIGENCE LAB @ HKU • REVOLUTIONIZING RESEARCH REPRODUCIBILITY ⚡
-|
+ |
+
+ ██████╗ ███████╗███████╗██████╗ ██████╗ ██████╗ ██████╗ ███████╗ + ██╔══██╗██╔════╝██╔════╝██╔══██╗██╔════╝██╔═══██╗██╔══██╗██╔════╝ + ██║ ██║█████╗ █████╗ ██████╔╝██║ ██║ ██║██║ ██║█████╗ + ██║ ██║██╔══╝ ██╔══╝ ██╔═══╝ ██║ ██║ ██║██║ ██║██╔══╝ + ██████╔╝███████╗███████╗██║ ╚██████╗╚██████╔╝██████╔╝███████╗ + ╚═════╝ ╚══════╝╚══════╝╚═╝ ╚═════╝ ╚═════╝ ╚═════╝ ╚══════╝+ |
+
+ 
+
 +
+
+
+
+
|
+
+#### 🖥️ **命令行界面**
+**基于终端的开发环境**
+
+
+
+
+
+ +
+
+
+
+ 🚀 高级终端体验
+
+ *专业终端界面,适合高级用户和CI/CD集成*
++ ⚡ 快速命令行工作流 🔧 开发者友好界面 📊 实时进度跟踪 + |
+
+
+#### 🌐 **Web界面**
+**可视化交互体验**
+
+
+
+
+
+ +
+
+
+
+ 🎨 现代化Web仪表板
+
+ *美观的Web界面,为所有技能水平用户提供流畅的工作流程*
++ 🖱️ 直观的拖拽操作 📱 响应式设计 🎯 可视化进度跟踪 + |
+
|
+
+
+
+
+🚀 论文转代码+
+
+
+
+
+
+复杂算法的自动化实现 +
+
+
+
+
+轻松将研究论文中的复杂算法转换为高质量、生产就绪的代码,加速算法复现。 + |
+
+
+
+
+
+🎨 文本转Web+
+
+
+
+
+
+自动化前端Web开发 +
+
+
+
+
+将纯文本描述转换为功能完整、视觉美观的前端Web代码,快速创建界面。 + |
+
+
+
+
+
+⚙️ 文本转后端+
+
+
+
+
+
+自动化后端开发 +
+
+
+
+
+从简单的文本输入生成高效、可扩展和功能丰富的后端代码,简化服务器端开发。 + |
+
|
+💡 输入层 +📄 研究论文 • 💬 自然语言 • 🌐 URL • 📋 需求 + |
+||
|
+🎯 中央编排 +战略决策制定 • 工作流程协调 • 智能体管理 + |
+||
|
+📝 文本分析 +需求处理 + |
++ |
+📄 文档分析 +论文和规范处理 + |
+
|
+📋 复现规划 +深度论文分析 • 代码需求解析 • 复现策略开发 + |
+||
|
+🔍 参考分析 +存储库发现 + |
++ |
+📚 代码索引 +知识图谱构建 + |
+
|
+🧬 代码实现 +实现生成 • 测试 • 文档 + |
+||
|
+⚡ 输出交付 +📦 完整代码库 • 🧪 测试套件 • 📚 文档 • 🚀 部署就绪 + |
+||
|
+
+
+🎯 自适应流程+基于输入复杂性的动态智能体选择 + |
+
+
+
+🧠 智能协调+智能任务分配和并行处理 + |
+
+
+
+🔍 上下文感知+通过CodeRAG集成的深度理解 + |
+
+
+
+⚡ 质量保证+全程自动化测试和验证 + |
+
|
+
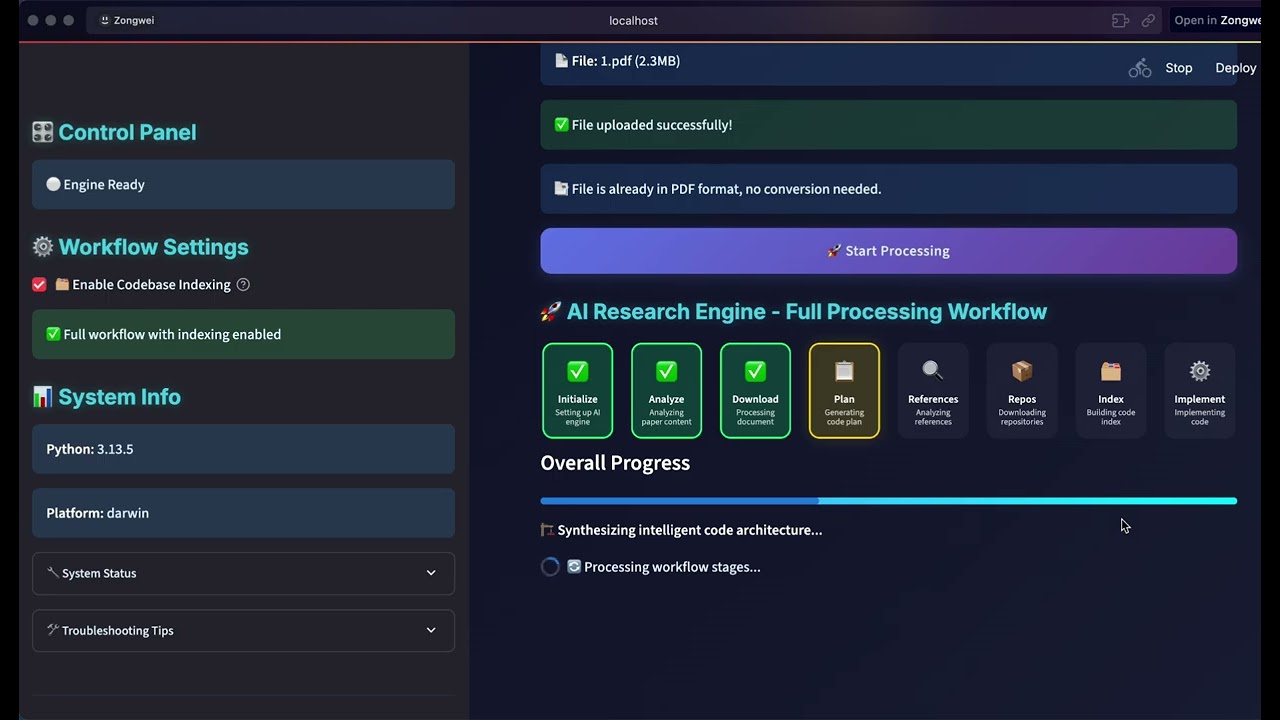
+#### 📄 **论文转代码演示**
+**研究到实现**
+
+
+
+
+
+ +
+
+ **[▶️ 观看演示](https://www.youtube.com/watch?v=MQZYpLkzsbw)**
+
+ *自动将学术论文转换为生产就绪代码*
+
+
+
+ **[▶️ 观看演示](https://www.youtube.com/watch?v=MQZYpLkzsbw)**
+
+ *自动将学术论文转换为生产就绪代码*
+ |
+
+
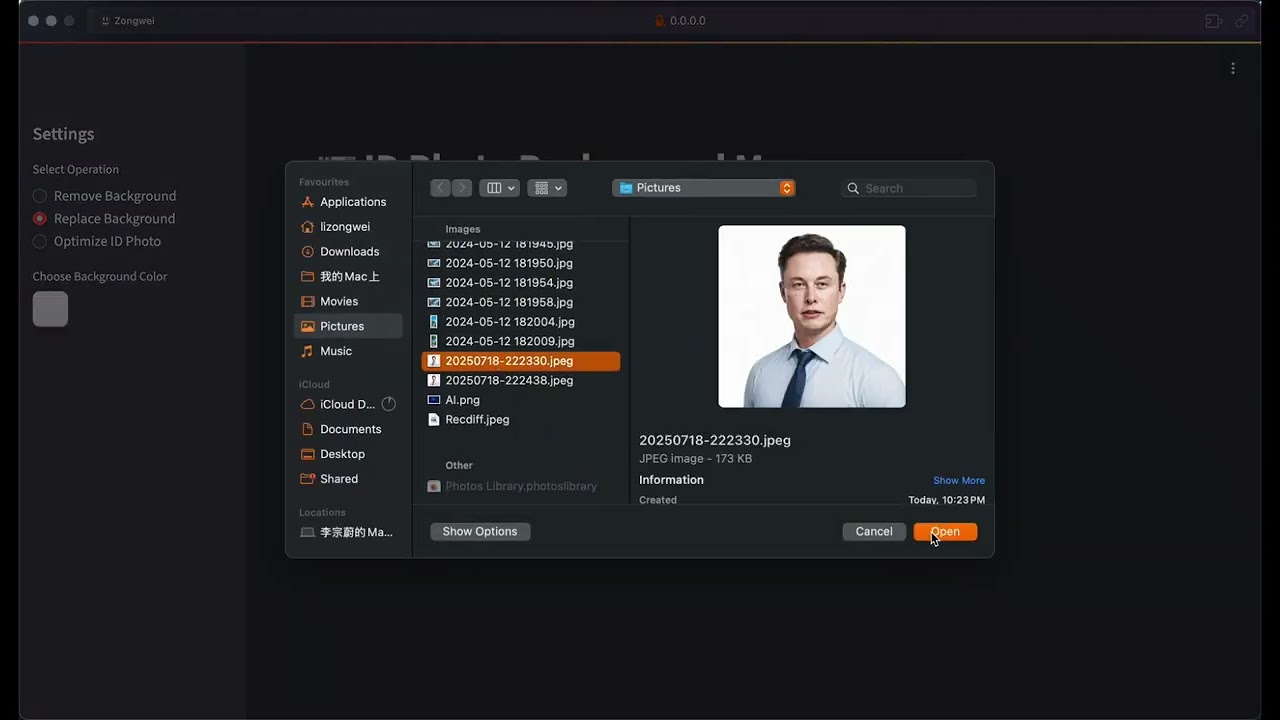
+#### 🖼️ **图像处理演示**
+**AI驱动的图像工具**
+
+
+
+
+
+ +
+
+ **[▶️ 观看演示](https://www.youtube.com/watch?v=nFt5mLaMEac)**
+
+ *智能图像处理,具有背景移除和增强功能*
+
+
+
+ **[▶️ 观看演示](https://www.youtube.com/watch?v=nFt5mLaMEac)**
+
+ *智能图像处理,具有背景移除和增强功能*
+ |
+
+
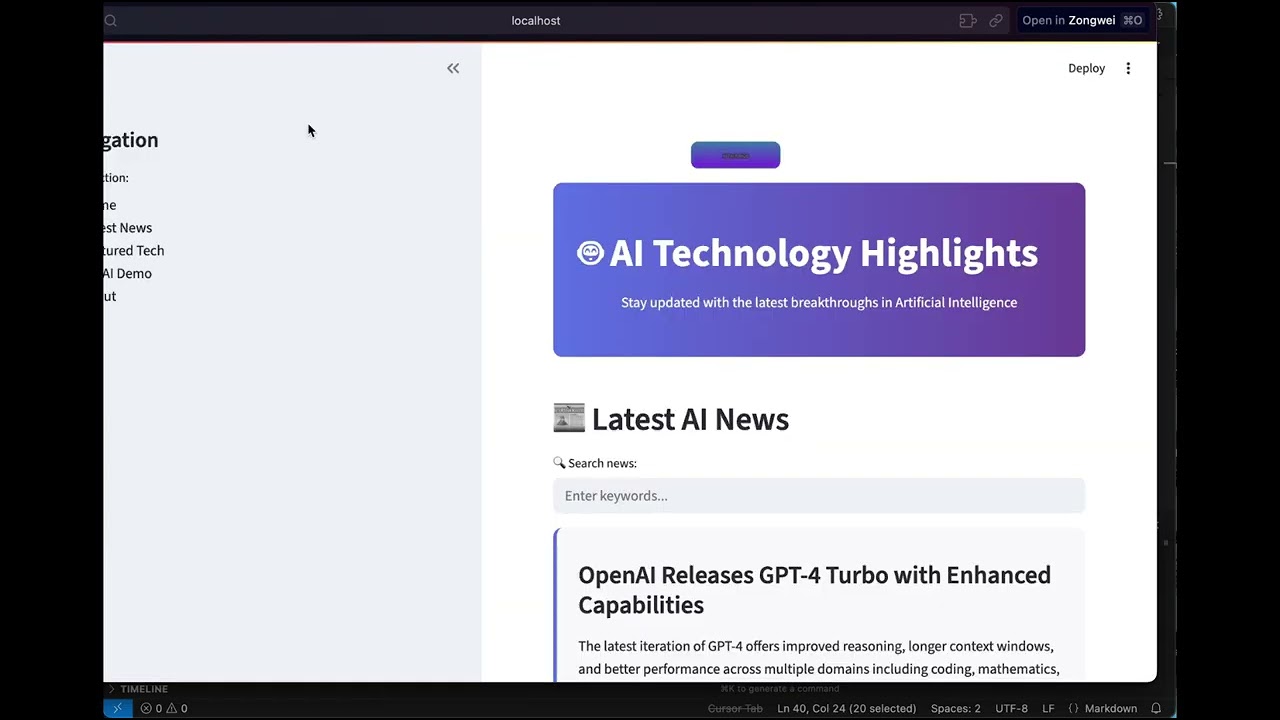
+#### 🌐 **前端实现**
+**完整Web应用程序**
+
+
+
+
+
+ +
+
+ **[▶️ 观看演示](https://www.youtube.com/watch?v=78wx3dkTaAU)**
+
+ *从概念到部署的全栈Web开发*
+
+
+
+ **[▶️ 观看演示](https://www.youtube.com/watch?v=78wx3dkTaAU)**
+
+ *从概念到部署的全栈Web开发*
+ |
+
+
+
+
+
⚡ DATA INTELLIGENCE LAB @ HKU • REVOLUTIONIZING RESEARCH REPRODUCIBILITY ⚡
-Advancing Code Generation with Multi-Agent Systems
-Automated Implementation of Complex Algorithms
-Multi-modal document analysis engine that extracts algorithmic logic and mathematical models from academic papers, generating optimized implementations with proper data structures while preserving computational complexity characteristics.
-Natural Language to Front-End Code Synthesis
-Neural document processing and algorithmic synthesis
Context-aware code generation using fine-tuned language models. Intelligent scaffolding system generating complete application structures including frontend components, maintaining architectural consistency across modules.
-Semantic analysis of requirements
-Component design & structure
-Functional interface creation
-Automated testing & validation
-Intelligent Server-Side Development
+Generates efficient, scalable backend systems with database schemas, API endpoints, and microservices architecture. Uses dependency analysis to ensure scalable architecture from initial generation with comprehensive testing.
-RESTful endpoints
-Schema & relationships
-Authentication & authorization
-CI/CD integration
-Advanced Multi-Agent Orchestration
+Advanced retrieval-augmented generation combining semantic vector embeddings with graph-based dependency analysis. Central orchestrating agent coordinates specialized agents with dynamic task planning and intelligent memory management.
-Central decision-making with dynamic planning algorithms
-Semantic analysis with dependency graph mapping
-Automated testing, validation, and documentation
-+ Select how you'd like to provide your requirements +
++ Please answer the following questions to help us generate better code. You can skip any question. +
++ Based on your input, here's the detailed requirements document we've generated. +
++ Review the current requirements and tell us how you'd like to modify them. +
+- Tell us what you want to build. Our AI will analyze your requirements and generate a comprehensive implementation plan. + Describe your coding requirements directly. Our AI will analyze and generate a comprehensive implementation plan.
+ Let our AI guide you through a series of questions to better understand your requirements. +
+