
Inside Convolutional Neural Networks
Human vision is fast and forgiving. We can recognise a scene in moments, even when it is dim, blurry, or partially blocked. Our brains use context to fill in missing detail, so identification still works when conditions are imperfect.
For a model, this ability has to be learned from data. Convolutional neural networks build understanding layer by layer, transforming raw pixels into edges, textures, shapes, and eventually object-level signals.
MapExtrackt opens that process up. Inspect feature maps, compare activations, and trace what the network focuses on as an image moves through the model.
First import / gather your model (this does not have to be a pretrained pytorch model).
import torchvision
model = torchvision.models.vgg19(pretrained=True)Import MapExtract's Feature Extractor and load in the model
from MapExtrackt import FeatureExtractor
fe = FeatureExtractor(model)Set image to be analysed - input can be PIL Image, Numpy array or filepath. We are using the path
fe.set_image("pug.jpg")View Layers
fe.display_from_map(layer_no=1)
View Single Cells At a Time
fe.display_from_map(layer_no=2, cell_no=4)
Slice the class to get a range of cells (Layer 2 Cells 0-9)
fe[2,0:10]
Or Export Layers To Video
fe.write_video(out_size=(1200,800), file_name="output.avi", time_for_layer=60, transition_perc_layer=0.2)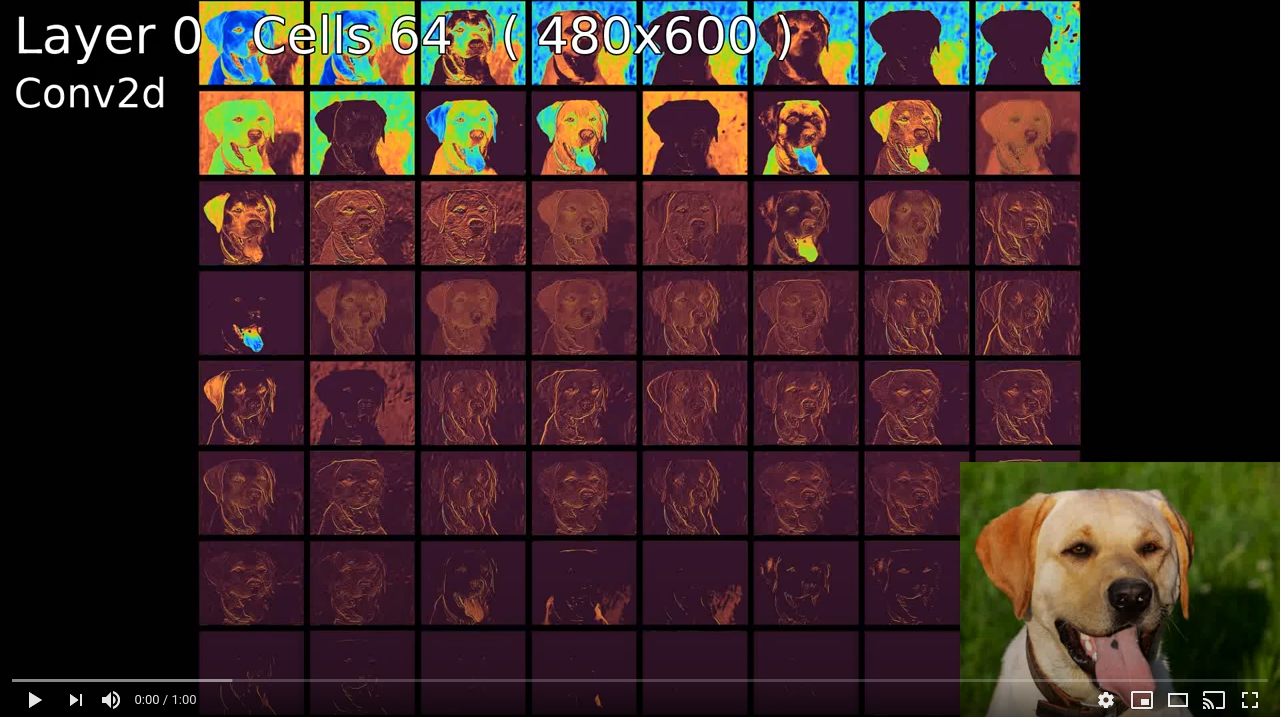
For LOTS more - view the jupyter notebook.
pip install mapextrackt
or build from source in terminal
git clone https://github.com/lewis-morris/mapextrackt &&\
cd mapextrackt &&\
pip install -e .
- Add the ability to slice the class i.e FeatureExtractor[1,3]
- Show parameters on the image
- Fix video generation
- Enable individual cells to be added to video
- Add video parameters such as duration in seconds.
- Clean up code
- Make speed improvements
Created by me, initially to view the outputs for my own pleasure.
If anyone has any suggestions or requests please send them over I'd be more than happy to consider.