 ](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)
-
](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)
-
 +
+这句话表面上看似有道理,但实际上却暴露了一个人的**无知和偏执**。
+
+**知识越贫乏的人,相信的东西就越绝对**,因为他们从未认真了解过与自己观点相对立的角度,也缺乏对技术发展的全局认识。
+
+举个例子,我刚开始学习 Java 后端开发的时候,完全没什么经验,就随便买了一本书开始看。当时看的是 **《Java Web 整合开发王者归来》** 这本书(梦开始的地方)。
+
+在我上大学那会儿,这本书的很多内容其实已经过时了,比如它花了大量篇幅介绍 JSP、Struts、Hibernate、EJB 和 SVN 等技术。不过,直到现在,我依然非常感谢这本书,带我走进了 Java 后端开发的大门。
+
+
+
+这本书一共 **1010** 页,我当时可以说是废寝忘食地学,花了很长时间才把整本书完全“啃”下来。
+
+回头来看,我如果能有意识地避免学习这些已经淘汰的技术,真的可以节省大量时间去学习更加主流和实用的内容。
+
+那么,这些被淘汰的技术有用吗?说句实话,**屁用没有,纯粹浪费时间**。
+
+**既然都要花时间学习,为什么不去学那些更主流、更有实际价值的技术呢?**
+
+现在本身就很卷,不管是 Java 方向还是其他技术方向,要学习的技术都很多。
+
+想要理解所谓的“底层思想”,与其浪费时间在 JSP 这种已经不具备实际应用价值的技术上,不如深入学习一下 Servlet,研究 Spring 的 AOP 和 IoC 原理,从源码角度理解 Spring MVC 的工作机制。
+
+这些内容,不仅能帮助你掌握核心的思想,还能在实际开发中真正派上用场,这难道不比花大量时间在 JSP 上更有意义吗?
+
+## 还有公司在用的技术就要学吗?
+
+我把这篇文章的相关言论发表在我的[公众号](https://mp.weixin.qq.com/s/lf2dXHcrUSU1pn28Ercj0w)之后,又收到另外一类在我看来非常傻叉的言论:
+
+- “虽然 JSP 很老了,但还是得学学,会用就行,因为我们很多老项目还在用。”
+- “很多央企和国企的老项目还在用,肯定得学学啊!”
+
+这种观点完全是钻牛角尖!如果按这种逻辑,那你还需要去学 Struts2、SVN、JavaFX 等过时技术,因为它们也还有公司在用。我有一位大学同学毕业后去了武汉的一家国企,写了一年 JavaFX 就受不了跑了。他在之前从来没有接触过 JavaFX,招聘时也没被问过相关问题。
+
+一定不要假设自己要面对的是过时技术栈的项目。你要找工作肯定要用主流技术栈去找,还要尽量找能让自己技术有成长,干着也舒服点。真要是找不到合适的工作,去维护老项目,那都是后话,现学现卖就行了。
+
+**对于初学者来说别人劝了还非要学习淘汰的技术,多少脑子有点不够用,基本可以告别这一行了!**
diff --git a/docs/about-the-author/readme.md b/docs/about-the-author/readme.md
deleted file mode 100644
index 12f6eab7f3f..00000000000
--- a/docs/about-the-author/readme.md
+++ /dev/null
@@ -1,70 +0,0 @@
----
-title: 个人介绍 Q&A
-category: 走近作者
----
-
-
-
-这篇文章我会通过 Q&A 的形式简单介绍一下我自己。
-
-## 我是什么时候毕业的?
-
-很多老读者应该比较清楚,我是 19 年本科毕业的,刚毕业就去了某家外企“养老”。
-
-我的学校背景是比较差的,高考失利,勉强过了一本线 20 来分,去了荆州的一所很普通的双非一本。不过,还好我没有因为学校而放弃自己,反倒是比身边的同学都要更努力,整个大学还算过的比较充实。
-
-下面这张是当时拍的毕业照(后排最中间的就是我):
-
-
-
-## 我坚持写了多久博客?
-
-时间真快啊!我自己是从大二开始写博客的。那时候就是随意地在博客平台上发发自己的学习笔记和自己写的程序。就比如 [谢希仁老师的《计算机网络》内容总结](../cs-basics/network/computer-network-xiexiren-summary.md) 这篇文章就是我在大二学习计算机网络这门课的时候对照着教材总结的。
-
-身边也有很多小伙伴经常问我:“我现在写博客还晚么?”
-
-我觉得哈!如果你想做什么事情,尽量少问迟不迟,多问自己值不值得,只要你觉得有意义,就尽快开始做吧!人生很奇妙,我们每一步的重大决定,都会对自己未来的人生轨迹产生影响。是好还是坏,也只有我们自己知道了!
-
-对我自己来说,坚持写博客这一项决定对我人生轨迹产生的影响是非常正面的!所以,我也推荐大家养成坚持写博客的习惯。
-
-## 我在大学期间赚了多少钱?
-
-在校期间,我还通过办培训班、接私活、技术培训、编程竞赛等方式变现 20w+,成功实现“经济独立”。我用自己赚的钱去了重庆、三亚、恩施、青岛等地旅游,还给家里补贴了很多,减轻了父母的负担。
-
-下面这张是我大一下学期办补习班的时候拍的(离开前的最后一顿饭):
-
-
-
-下面这张是我大三去三亚的时候拍的:
-
-
-
-其实,我在大学就这么努力地开始赚钱,也主要是因为家庭条件太一般,父母赚钱都太辛苦了!也正是因为我自己迫切地想要减轻父母的负担,所以才会去尝试这么多赚钱的方法。
-
-我发现做咱们程序员这行的,很多人的家庭条件都挺一般的,选择这个行业的很大原因不是因为自己喜欢,而是为了多赚点钱。
-
-如果你也想通过接私活变现的话,可以在我的公众号后台回复“**接私活**”来了解一些我的个人经验分享。
-
-::: center
-
-
-
-:::
-
-## 为什么自称 Guide?
-
-可能是因为我的项目名字叫做 JavaGuide , 所以导致有很多人称呼我为 **Guide 哥**。
-
-后面,为了读者更方便称呼,我就将自己的笔名改成了 **Guide**。
-
-我早期写文章用的笔名是 SnailClimb 。很多人不知道这个名字是啥意思,给大家拆解一下就清楚了。SnailClimb=Snail(蜗牛)+Climb(攀登)。我从小就非常喜欢听周杰伦的歌曲,特别是他的《蜗牛》🐌 这首歌曲,另外,当年我高考发挥的算是比较失常,上了大学之后还算是比较“奋青”,所以,我就给自己起的笔名叫做 SnailClimb ,寓意自己要不断向上攀登,嘿嘿 😁
-
-
-
-## 后记
-
-凡心所向,素履所往,生如逆旅,一苇以航。
-
-生活本就是有苦有甜。共勉!
-
-
diff --git a/docs/books/readme.md b/docs/books/README.md
similarity index 100%
rename from docs/books/readme.md
rename to docs/books/README.md
diff --git a/docs/cs-basics/algorithms/10-classical-sorting-algorithms.md b/docs/cs-basics/algorithms/10-classical-sorting-algorithms.md
index 355875f9658..d583b936a12 100644
--- a/docs/cs-basics/algorithms/10-classical-sorting-algorithms.md
+++ b/docs/cs-basics/algorithms/10-classical-sorting-algorithms.md
@@ -367,31 +367,60 @@ public static int[] merge(int[] arr_1, int[] arr_2) {
### 代码实现
-> 来源:[使用 Java 实现快速排序(详解)](https://segmentfault.com/a/1190000040022056)
-
```java
-public static int partition(int[] array, int low, int high) {
- int pivot = array[high];
- int pointer = low;
- for (int i = low; i < high; i++) {
- if (array[i] <= pivot) {
- int temp = array[i];
- array[i] = array[pointer];
- array[pointer] = temp;
- pointer++;
+import java.util.concurrent.ThreadLocalRandom;
+
+class Solution {
+ public int[] sortArray(int[] a) {
+ quick(a, 0, a.length - 1);
+ return a;
+ }
+
+ // 快速排序的核心递归函数
+ void quick(int[] a, int left, int right) {
+ if (left >= right) { // 递归终止条件:区间只有一个或没有元素
+ return;
}
- System.out.println(Arrays.toString(array));
+ int p = partition(a, left, right); // 分区操作,返回分区点索引
+ quick(a, left, p - 1); // 对左侧子数组递归排序
+ quick(a, p + 1, right); // 对右侧子数组递归排序
}
- int temp = array[pointer];
- array[pointer] = array[high];
- array[high] = temp;
- return pointer;
-}
-public static void quickSort(int[] array, int low, int high) {
- if (low < high) {
- int position = partition(array, low, high);
- quickSort(array, low, position - 1);
- quickSort(array, position + 1, high);
+
+ // 分区函数:将数组分为两部分,小于基准值的在左,大于基准值的在右
+ int partition(int[] a, int left, int right) {
+ // 随机选择一个基准点,避免最坏情况(如数组接近有序)
+ int idx = ThreadLocalRandom.current().nextInt(right - left + 1) + left;
+ swap(a, left, idx); // 将基准点放在数组的最左端
+ int pv = a[left]; // 基准值
+ int i = left + 1; // 左指针,指向当前需要检查的元素
+ int j = right; // 右指针,从右往左寻找比基准值小的元素
+
+ while (i <= j) {
+ // 左指针向右移动,直到找到一个大于等于基准值的元素
+ while (i <= j && a[i] < pv) {
+ i++;
+ }
+ // 右指针向左移动,直到找到一个小于等于基准值的元素
+ while (i <= j && a[j] > pv) {
+ j--;
+ }
+ // 如果左指针尚未越过右指针,交换两个不符合位置的元素
+ if (i <= j) {
+ swap(a, i, j);
+ i++;
+ j--;
+ }
+ }
+ // 将基准值放到分区点位置,使得基准值左侧小于它,右侧大于它
+ swap(a, j, left);
+ return j;
+ }
+
+ // 交换数组中两个元素的位置
+ void swap(int[] a, int i, int j) {
+ int t = a[i];
+ a[i] = a[j];
+ a[j] = t;
}
}
```
diff --git a/docs/cs-basics/data-structure/linear-data-structure.md b/docs/cs-basics/data-structure/linear-data-structure.md
index cc5cc6a5db2..e8ae63a19d5 100644
--- a/docs/cs-basics/data-structure/linear-data-structure.md
+++ b/docs/cs-basics/data-structure/linear-data-structure.md
@@ -326,9 +326,9 @@ myStack.pop();//报错:java.lang.IllegalArgumentException: Stack is empty.
当我们需要按照一定顺序来处理数据的时候可以考虑使用队列这个数据结构。
- **阻塞队列:** 阻塞队列可以看成在队列基础上加了阻塞操作的队列。当队列为空的时候,出队操作阻塞,当队列满的时候,入队操作阻塞。使用阻塞队列我们可以很容易实现“生产者 - 消费者“模型。
-- **线程池中的请求/任务队列:** 线程池中没有空闲线程时,新的任务请求线程资源时,线程池该如何处理呢?答案是将这些请求放在队列中,当有空闲线程的时候,会循环中反复从队列中获取任务来执行。队列分为无界队列(基于链表)和有界队列(基于数组)。无界队列的特点就是可以一直入列,除非系统资源耗尽,比如:`FixedThreadPool` 使用无界队列 `LinkedBlockingQueue`。但是有界队列就不一样了,当队列满的话后面再有任务/请求就会拒绝,在 Java 中的体现就是会抛出`java.util.concurrent.RejectedExecutionException` 异常。
-- 栈:双端队列天生便可以实现栈的全部功能(`push`、`pop` 和 `peek`),并且在 Deque 接口中已经实现了相关方法。Stack 类已经和 Vector 一样被遗弃,现在在 Java 中普遍使用双端队列(Deque)来实现栈。
-- 广度优先搜索(BFS),在图的广度优先搜索过程中,队列被用于存储待访问的节点,保证按照层次顺序遍历图的节点。
+- **线程池中的请求/任务队列:** 当线程池中没有空闲线程时,新的任务请求线程资源会被如何处理呢?答案是这些任务会被放入任务队列中,等待线程池中的线程空闲后再从队列中取出任务执行。任务队列分为无界队列(基于链表实现)和有界队列(基于数组实现)。无界队列的特点是队列容量理论上没有限制,任务可以持续入队,直到系统资源耗尽。例如:`FixedThreadPool` 使用的阻塞队列 `LinkedBlockingQueue`,其默认容量为 `Integer.MAX_VALUE`,因此可以被视为“无界队列”。而有界队列则不同,当队列已满时,如果再有新任务提交,由于队列无法继续容纳任务,线程池会拒绝这些任务,并抛出 `java.util.concurrent.RejectedExecutionException` 异常。
+- **栈**:双端队列天生便可以实现栈的全部功能(`push`、`pop` 和 `peek`),并且在 Deque 接口中已经实现了相关方法。Stack 类已经和 Vector 一样被遗弃,现在在 Java 中普遍使用双端队列(Deque)来实现栈。
+- **广度优先搜索(BFS)**:在图的广度优先搜索过程中,队列被用于存储待访问的节点,保证按照层次顺序遍历图的节点。
- Linux 内核进程队列(按优先级排队)
- 现实生活中的派对,播放器上的播放列表;
- 消息队列
diff --git a/docs/cs-basics/network/application-layer-protocol.md b/docs/cs-basics/network/application-layer-protocol.md
index 5764a72c020..cb809b9157d 100644
--- a/docs/cs-basics/network/application-layer-protocol.md
+++ b/docs/cs-basics/network/application-layer-protocol.md
@@ -15,7 +15,7 @@ HTTP 使用客户端-服务器模型,客户端向服务器发送 HTTP Request
HTTP 协议基于 TCP 协议,发送 HTTP 请求之前首先要建立 TCP 连接也就是要经历 3 次握手。目前使用的 HTTP 协议大部分都是 1.1。在 1.1 的协议里面,默认是开启了 Keep-Alive 的,这样的话建立的连接就可以在多次请求中被复用了。
-另外, HTTP 协议是”无状态”的协议,它无法记录客户端用户的状态,一般我们都是通过 Session 来记录客户端用户的状态。
+另外, HTTP 协议是“无状态”的协议,它无法记录客户端用户的状态,一般我们都是通过 Session 来记录客户端用户的状态。
## Websocket:全双工通信协议
diff --git a/docs/cs-basics/network/arp.md b/docs/cs-basics/network/arp.md
index c4ece76011c..d8b647b1762 100644
--- a/docs/cs-basics/network/arp.md
+++ b/docs/cs-basics/network/arp.md
@@ -21,7 +21,7 @@ tag:
MAC 地址的全称是 **媒体访问控制地址(Media Access Control Address)**。如果说,互联网中每一个资源都由 IP 地址唯一标识(IP 协议内容),那么一切网络设备都由 MAC 地址唯一标识。
-
+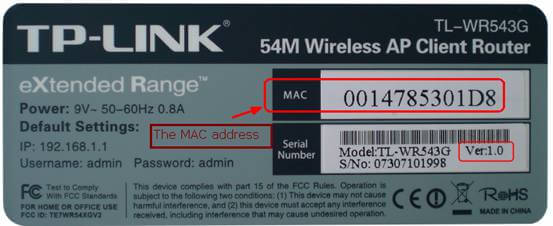
可以理解为,MAC 地址是一个网络设备真正的身份证号,IP 地址只是一种不重复的定位方式(比如说住在某省某市某街道的张三,这种逻辑定位是 IP 地址,他的身份证号才是他的 MAC 地址),也可以理解为 MAC 地址是身份证号,IP 地址是邮政地址。MAC 地址也有一些别称,如 LAN 地址、物理地址、以太网地址等。
diff --git a/docs/cs-basics/network/computer-network-xiexiren-summary.md b/docs/cs-basics/network/computer-network-xiexiren-summary.md
index fc9f60fd39a..85f7c3f54d2 100644
--- a/docs/cs-basics/network/computer-network-xiexiren-summary.md
+++ b/docs/cs-basics/network/computer-network-xiexiren-summary.md
@@ -191,7 +191,7 @@ tag:
5. **子网掩码(subnet mask )**:它是一种用来指明一个 IP 地址的哪些位标识的是主机所在的子网以及哪些位标识的是主机的位掩码。子网掩码不能单独存在,它必须结合 IP 地址一起使用。
6. **CIDR( Classless Inter-Domain Routing )**:无分类域间路由选择 (特点是消除了传统的 A 类、B 类和 C 类地址以及划分子网的概念,并使用各种长度的“网络前缀”(network-prefix)来代替分类地址中的网络号和子网号)。
7. **默认路由(default route)**:当在路由表中查不到能到达目的地址的路由时,路由器选择的路由。默认路由还可以减小路由表所占用的空间和搜索路由表所用的时间。
-8. **路由选择算法(Virtual Circuit)**:路由选择协议的核心部分。因特网采用自适应的,分层次的路由选择协议。
+8. **路由选择算法(Routing Algorithm)**:路由选择协议的核心部分。因特网采用自适应的,分层次的路由选择协议。
### 4.2. 重要知识点总结
diff --git a/docs/cs-basics/network/images/arp/2008410143049281.png b/docs/cs-basics/network/images/arp/2008410143049281.png
deleted file mode 100644
index 759fb441f6c..00000000000
Binary files a/docs/cs-basics/network/images/arp/2008410143049281.png and /dev/null differ
diff --git a/docs/cs-basics/network/nat.md b/docs/cs-basics/network/nat.md
index 5634ba07387..4567719b81e 100644
--- a/docs/cs-basics/network/nat.md
+++ b/docs/cs-basics/network/nat.md
@@ -45,7 +45,7 @@ SOHO 子网的“代理人”,也就是和外界的窗口,通常由路由器
针对以上过程,有以下几个重点需要强调:
1. 当请求报文到达路由器,并被指定了新端口号时,由于端口号有 16 位,因此,通常来说,一个路由器管理的 LAN 中的最大主机数 $≈65500$($2^{16}$ 的地址空间),但通常 SOHO 子网内不会有如此多的主机数量。
-2. 对于目的服务器来说,从来不知道“到底是哪个主机给我发送的请求”,它只知道是来自`138.76.29.7:5001`的路由器转发的请求。因此,可以说,**路由器在 WAN 和 LAN 之间起到了屏蔽作用,**所有内部主机发送到外部的报文,都具有同一个 IP 地址(不同的端口号),所有外部发送到内部的报文,也都只有一个目的地(不同端口号),是经过了 NAT 转换后,外部报文才得以正确地送达内部主机。
+2. 对于目的服务器来说,从来不知道“到底是哪个主机给我发送的请求”,它只知道是来自`138.76.29.7:5001`的路由器转发的请求。因此,可以说,**路由器在 WAN 和 LAN 之间起到了屏蔽作用**,所有内部主机发送到外部的报文,都具有同一个 IP 地址(不同的端口号),所有外部发送到内部的报文,也都只有一个目的地(不同端口号),是经过了 NAT 转换后,外部报文才得以正确地送达内部主机。
3. 在报文穿过路由器,发生 NAT 转换时,如果 LAN 主机 IP 已经在 NAT 转换表中注册过了,则不需要路由器新指派端口,而是直接按照转换记录穿过路由器。同理,外部报文发送至内部时也如此。
总结 NAT 协议的特点,有以下几点:
@@ -55,6 +55,6 @@ SOHO 子网的“代理人”,也就是和外界的窗口,通常由路由器
3. WAN 的 ISP 变更接口地址时,无需通告 LAN 内主机。
4. LAN 主机对 WAN 不可见,不可直接寻址,可以保证一定程度的安全性。
-然而,NAT 协议由于其独特性,存在着一些争议。比如,可能你已经注意到了,**NAT 协议在 LAN 以外,标识一个内部主机时,使用的是端口号,因为 IP 地址都是相同的。**这种将端口号作为主机寻址的行为,可能会引发一些误会。此外,路由器作为网络层的设备,修改了传输层的分组内容(修改了源 IP 地址和端口号),同样是不规范的行为。但是,尽管如此,NAT 协议作为 IPv4 时代的产物,极大地方便了一些本来棘手的问题,一直被沿用至今。
+然而,NAT 协议由于其独特性,存在着一些争议。比如,可能你已经注意到了,**NAT 协议在 LAN 以外,标识一个内部主机时,使用的是端口号,因为 IP 地址都是相同的**。这种将端口号作为主机寻址的行为,可能会引发一些误会。此外,路由器作为网络层的设备,修改了传输层的分组内容(修改了源 IP 地址和端口号),同样是不规范的行为。但是,尽管如此,NAT 协议作为 IPv4 时代的产物,极大地方便了一些本来棘手的问题,一直被沿用至今。
diff --git a/docs/cs-basics/network/network-attack-means.md b/docs/cs-basics/network/network-attack-means.md
index 86a1d7f6393..748999d6eba 100644
--- a/docs/cs-basics/network/network-attack-means.md
+++ b/docs/cs-basics/network/network-attack-means.md
@@ -363,11 +363,11 @@ MD5 可以用来生成一个 128 位的消息摘要,它是目前应用比较
**SHA**
-安全散列算法。**SHA** 分为 **SHA1** 和 **SH2** 两个版本。该算法的思想是接收一段明文,然后以一种不可逆的方式将它转换成一段(通常更小)密文,也可以简单的理解为取一串输入码(称为预映射或信息),并把它们转化为长度较短、位数固定的输出序列即散列值(也称为信息摘要或信息认证代码)的过程。
+安全散列算法。**SHA** 包括**SHA-1**、**SHA-2**和**SHA-3**三个版本。该算法的基本思想是:接收一段明文数据,通过不可逆的方式将其转换为固定长度的密文。简单来说,SHA 将输入数据(即预映射或消息)转化为固定长度、较短的输出值,称为散列值(或信息摘要、信息认证码)。SHA-1 已被证明不够安全,因此逐渐被 SHA-2 取代,而 SHA-3 则作为 SHA 系列的最新版本,采用不同的结构(Keccak 算法)提供更高的安全性和灵活性。
**SM3**
-国密算法**SM3**。加密强度和 SHA-256算法 相差不多。主要是受到了国家的支持。
+国密算法**SM3**。加密强度和 SHA-256 算法 相差不多。主要是受到了国家的支持。
**总结**:
diff --git a/docs/cs-basics/network/other-network-questions.md b/docs/cs-basics/network/other-network-questions.md
index 2f3617dbe5b..8a266d5496b 100644
--- a/docs/cs-basics/network/other-network-questions.md
+++ b/docs/cs-basics/network/other-network-questions.md
@@ -27,7 +27,7 @@ tag:
-#### TCP/IP 四层模型是什么?每一层的作用是什么?
+#### ⭐️TCP/IP 四层模型是什么?每一层的作用是什么?
**TCP/IP 四层模型** 是目前被广泛采用的一种模型,我们可以将 TCP / IP 模型看作是 OSI 七层模型的精简版本,由以下 4 层组成:
@@ -40,7 +40,7 @@ tag:

-关于每一层作用的详细介绍,请看 [OSI 和 TCP/IP 网络分层模型详解(基础)](./osi-and-tcp-ip-model.md) 这篇文章。
+关于每一层作用的详细介绍,请看 [OSI 和 TCP/IP 网络分层模型详解(基础)](https://javaguide.cn/cs-basics/network/osi-and-tcp-ip-model.html) 这篇文章。
#### 为什么网络要分层?
@@ -64,7 +64,7 @@ tag:
### 常见网络协议
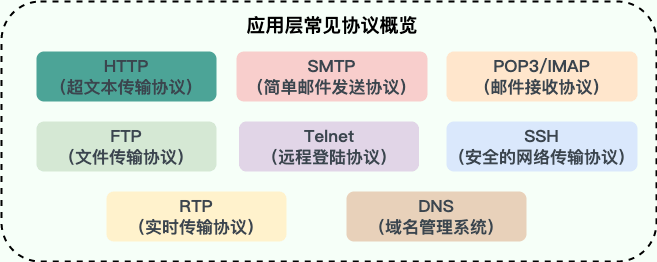
-#### 应用层有哪些常见的协议?
+#### ⭐️应用层有哪些常见的协议?
@@ -100,7 +100,7 @@ tag:
## HTTP
-### 从输入 URL 到页面展示到底发生了什么?(非常重要)
+### ⭐️从输入 URL 到页面展示到底发生了什么?(非常重要)
> 类似的问题:打开一个网页,整个过程会使用哪些协议?
@@ -120,15 +120,15 @@ tag:
6. 浏览器收到 HTTP 响应报文后,解析响应体中的 HTML 代码,渲染网页的结构和样式,同时根据 HTML 中的其他资源的 URL(如图片、CSS、JS 等),再次发起 HTTP 请求,获取这些资源的内容,直到网页完全加载显示。
7. 浏览器在不需要和服务器通信时,可以主动关闭 TCP 连接,或者等待服务器的关闭请求。
-详细介绍可以查看这篇文章:[访问网页的全过程(知识串联)](./the-whole-process-of-accessing-web-pages.md)(强烈推荐)。
+详细介绍可以查看这篇文章:[访问网页的全过程(知识串联)](https://javaguide.cn/cs-basics/network/the-whole-process-of-accessing-web-pages.html)(强烈推荐)。
-### HTTP 状态码有哪些?
+### ⭐️HTTP 状态码有哪些?
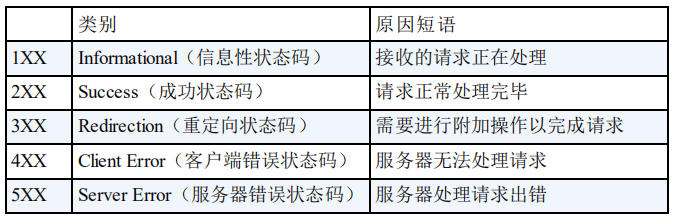
HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被成功处理。
-关于 HTTP 状态码更详细的总结,可以看我写的这篇文章:[HTTP 常见状态码总结(应用层)](./http-status-codes.md)。
+关于 HTTP 状态码更详细的总结,可以看我写的这篇文章:[HTTP 常见状态码总结(应用层)](https://javaguide.cn/cs-basics/network/http-status-codes.html)。
### HTTP Header 中常见的字段有哪些?
@@ -167,7 +167,7 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
| Via | 向服务器告知,这个请求是由哪些代理发出的。 | Via: 1.0 fred, 1.1 example.com (Apache/1.1) |
| Warning | 一个一般性的警告,告知,在实体内容体中可能存在错误。 | Warning: 199 Miscellaneous warning |
-### HTTP 和 HTTPS 有什么区别?(重要)
+### ⭐️HTTP 和 HTTPS 有什么区别?(重要)

@@ -176,7 +176,7 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
- **安全性和资源消耗**:HTTP 协议运行在 TCP 之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS 是运行在 SSL/TLS 之上的 HTTP 协议,SSL/TLS 运行在 TCP 之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。所以说,HTTP 安全性没有 HTTPS 高,但是 HTTPS 比 HTTP 耗费更多服务器资源。
- **SEO(搜索引擎优化)**:搜索引擎通常会更青睐使用 HTTPS 协议的网站,因为 HTTPS 能够提供更高的安全性和用户隐私保护。使用 HTTPS 协议的网站在搜索结果中可能会被优先显示,从而对 SEO 产生影响。
-关于 HTTP 和 HTTPS 更详细的对比总结,可以看我写的这篇文章:[HTTP vs HTTPS(应用层)](./http-vs-https.md) 。
+关于 HTTP 和 HTTPS 更详细的对比总结,可以看我写的这篇文章:[HTTP vs HTTPS(应用层)](https://javaguide.cn/cs-basics/network/http-vs-https.html) 。
### HTTP/1.0 和 HTTP/1.1 有什么区别?
@@ -188,14 +188,15 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
- **带宽**:HTTP/1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP/1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
- **Host 头(Host Header)处理** :HTTP/1.1 引入了 Host 头字段,允许在同一 IP 地址上托管多个域名,从而支持虚拟主机的功能。而 HTTP/1.0 没有 Host 头字段,无法实现虚拟主机。
-关于 HTTP/1.0 和 HTTP/1.1 更详细的对比总结,可以看我写的这篇文章:[HTTP/1.0 vs HTTP/1.1(应用层)](./http1.0-vs-http1.1.md) 。
+关于 HTTP/1.0 和 HTTP/1.1 更详细的对比总结,可以看我写的这篇文章:[HTTP/1.0 vs HTTP/1.1(应用层)](https://javaguide.cn/cs-basics/network/http1.0-vs-http1.1.html) 。
-### HTTP/1.1 和 HTTP/2.0 有什么区别?
+### ⭐️HTTP/1.1 和 HTTP/2.0 有什么区别?

-- **多路复用(Multiplexing)**:HTTP/2.0 在同一连接上可以同时传输多个请求和响应(可以看作是 HTTP/1.1 中长链接的升级版本),互不干扰。HTTP/1.1 则使用串行方式,每个请求和响应都需要独立的连接,而浏览器为了控制资源会有 6-8 个 TCP 连接的限制。。这使得 HTTP/2.0 在处理多个请求时更加高效,减少了网络延迟和提高了性能。
+- **多路复用(Multiplexing)**:HTTP/2.0 在同一连接上可以同时传输多个请求和响应(可以看作是 HTTP/1.1 中长链接的升级版本),互不干扰。HTTP/1.1 则使用串行方式,每个请求和响应都需要独立的连接,而浏览器为了控制资源会有 6-8 个 TCP 连接的限制。这使得 HTTP/2.0 在处理多个请求时更加高效,减少了网络延迟和提高了性能。
- **二进制帧(Binary Frames)**:HTTP/2.0 使用二进制帧进行数据传输,而 HTTP/1.1 则使用文本格式的报文。二进制帧更加紧凑和高效,减少了传输的数据量和带宽消耗。
+- **队头阻塞**:HTTP/2 引入了多路复用技术,允许多个请求和响应在单个 TCP 连接上并行交错传输,解决了 HTTP/1.1 应用层的队头阻塞问题,但 HTTP/2 依然受到 TCP 层队头阻塞 的影响。
- **头部压缩(Header Compression)**:HTTP/1.1 支持`Body`压缩,`Header`不支持压缩。HTTP/2.0 支持对`Header`压缩,使用了专门为`Header`压缩而设计的 HPACK 算法,减少了网络开销。
- **服务器推送(Server Push)**:HTTP/2.0 支持服务器推送,可以在客户端请求一个资源时,将其他相关资源一并推送给客户端,从而减少了客户端的请求次数和延迟。而 HTTP/1.1 需要客户端自己发送请求来获取相关资源。
@@ -203,7 +204,7 @@ HTTP/2.0 多路复用效果图(图源: [HTTP/2 For Web Developers](https://b
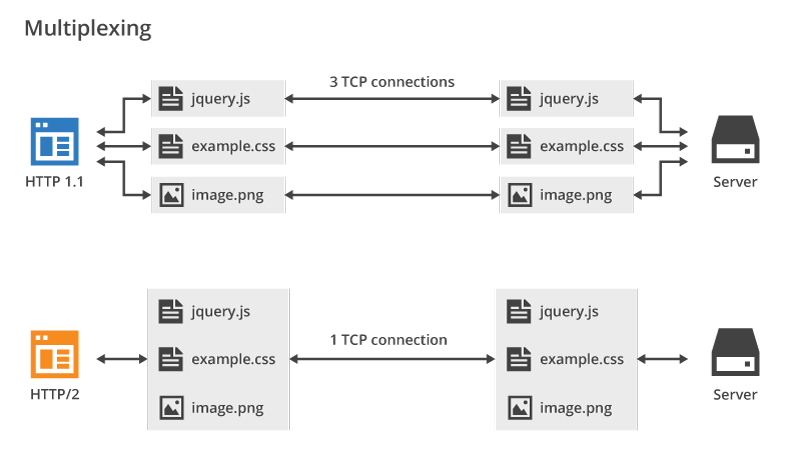
-可以看到,HTTP/2.0 的多路复用使得不同的请求可以共用一个 TCP 连接,避免建立多个连接带来不必要的额外开销,而 HTTP/1.1 中的每个请求都会建立一个单独的连接
+可以看到,HTTP/2 的多路复用机制允许多个请求和响应共享一个 TCP 连接,从而避免了 HTTP/1.1 在应对并发请求时需要建立多个并行连接的情况,减少了重复连接建立和维护的额外开销。而在 HTTP/1.1 中,尽管支持持久连接,但为了缓解队头阻塞问题,浏览器通常会为同一域名建立多个并行连接。
### HTTP/2.0 和 HTTP/3.0 有什么区别?
@@ -232,15 +233,89 @@ HTTP/1.0、HTTP/2.0 和 HTTP/3.0 的协议栈比较:
关于 HTTP/1.0 -> HTTP/3.0 更详细的演进介绍,推荐阅读[HTTP1 到 HTTP3 的工程优化](https://dbwu.tech/posts/http_evolution/)。
-### HTTP 是不保存状态的协议, 如何保存用户状态?
+### HTTP/1.1 和 HTTP/2.0 的队头阻塞有什么不同?
-HTTP 是一种不保存状态,即无状态(stateless)协议。也就是说 HTTP 协议自身不对请求和响应之间的通信状态进行保存。那么我们如何保存用户状态呢?Session 机制的存在就是为了解决这个问题,Session 的主要作用就是通过服务端记录用户的状态。典型的场景是购物车,当你要添加商品到购物车的时候,系统不知道是哪个用户操作的,因为 HTTP 协议是无状态的。服务端给特定的用户创建特定的 Session 之后就可以标识这个用户并且跟踪这个用户了(一般情况下,服务器会在一定时间内保存这个 Session,过了时间限制,就会销毁这个 Session)。
+HTTP/1.1 队头阻塞的主要原因是无法多路复用:
-在服务端保存 Session 的方法很多,最常用的就是内存和数据库(比如是使用内存数据库 redis 保存)。既然 Session 存放在服务器端,那么我们如何实现 Session 跟踪呢?大部分情况下,我们都是通过在 Cookie 中附加一个 Session ID 来方式来跟踪。
+- 在一个 TCP 连接中,资源的请求和响应是按顺序处理的。如果一个大的资源(如一个大文件)正在传输,后续的小资源(如较小的 CSS 文件)需要等待前面的资源传输完成后才能被发送。
+- 如果浏览器需要同时加载多个资源(如多个 CSS、JS 文件等),它通常会开启多个并行的 TCP 连接(一般限制为 6 个)。但每个连接仍然受限于顺序的请求-响应机制,因此仍然会发生 **应用层的队头阻塞**。
-**Cookie 被禁用怎么办?**
+虽然 HTTP/2.0 引入了多路复用技术,允许多个请求和响应在单个 TCP 连接上并行交错传输,解决了 **HTTP/1.1 应用层的队头阻塞问题**,但 HTTP/2.0 依然受到 **TCP 层队头阻塞** 的影响:
-最常用的就是利用 URL 重写把 Session ID 直接附加在 URL 路径的后面。
+- HTTP/2.0 通过帧(frame)机制将每个资源分割成小块,并为每个资源分配唯一的流 ID,这样多个资源的数据可以在同一 TCP 连接中交错传输。
+- TCP 作为传输层协议,要求数据按顺序交付。如果某个数据包在传输过程中丢失,即使后续的数据包已经到达,也必须等待丢失的数据包重传后才能继续处理。这种传输层的顺序性导致了 **TCP 层的队头阻塞**。
+- 举例来说,如果 HTTP/2 的一个 TCP 数据包中携带了多个资源的数据(例如 JS 和 CSS),而该数据包丢失了,那么后续数据包中的所有资源数据都需要等待丢失的数据包重传回来,导致所有流(streams)都被阻塞。
+
+最后,来一张表格总结补充一下:
+
+| **方面** | **HTTP/1.1 的队头阻塞** | **HTTP/2.0 的队头阻塞** |
+| -------------- | ---------------------------------------- | ---------------------------------------------------------------- |
+| **层级** | 应用层(HTTP 协议本身的限制) | 传输层(TCP 协议的限制) |
+| **根本原因** | 无法多路复用,请求和响应必须按顺序传输 | TCP 要求数据包按顺序交付,丢包时阻塞整个连接 |
+| **受影响范围** | 单个 HTTP 请求/响应会阻塞后续请求/响应。 | 单个 TCP 包丢失会影响所有 HTTP/2.0 流(依赖于同一个底层 TCP 连接) |
+| **缓解方法** | 开启多个并行的 TCP 连接 | 减少网络掉包或者使用基于 UDP 的 QUIC 协议 |
+| **影响场景** | 每次都会发生,尤其是大文件阻塞小文件时。 | 丢包率较高的网络环境下更容易发生。 |
+
+### ⭐️HTTP 是不保存状态的协议, 如何保存用户状态?
+
+HTTP 协议本身是 **无状态的 (stateless)** 。这意味着服务器默认情况下无法区分两个连续的请求是否来自同一个用户,或者同一个用户之前的操作是什么。这就像一个“健忘”的服务员,每次你跟他说话,他都不知道你是谁,也不知道你之前点过什么菜。
+
+但在实际的 Web 应用中,比如网上购物、用户登录等场景,我们显然需要记住用户的状态(例如购物车里的商品、用户的登录信息)。为了解决这个问题,主要有以下几种常用机制:
+
+**方案一:Session (会话) 配合 Cookie (主流方式):**
+
+
+
+这可以说是最经典也是最常用的方法了。基本流程是这样的:
+
+1. 用户向服务器发送用户名、密码、验证码用于登陆系统。
+2. 服务器验证通过后,会为这个用户创建一个专属的 Session 对象(可以理解为服务器上的一块内存,存放该用户的状态数据,如购物车、登录信息等)存储起来,并给这个 Session 分配一个唯一的 `SessionID`。
+3. 服务器通过 HTTP 响应头中的 `Set-Cookie` 指令,把这个 `SessionID` 发送给用户的浏览器。
+4. 浏览器接收到 `SessionID` 后,会将其以 Cookie 的形式保存在本地。当用户保持登录状态时,每次向该服务器发请求,浏览器都会自动带上这个存有 `SessionID` 的 Cookie。
+5. 服务器收到请求后,从 Cookie 中拿出 `SessionID`,就能找到之前保存的那个 Session 对象,从而知道这是哪个用户以及他之前的状态了。
+
+使用 Session 的时候需要注意下面几个点:
+
+- **客户端 Cookie 支持**:依赖 Session 的核心功能要确保用户浏览器开启了 Cookie。
+- **Session 过期管理**:合理设置 Session 的过期时间,平衡安全性和用户体验。
+- **Session ID 安全**:为包含 `SessionID` 的 Cookie 设置 `HttpOnly` 标志可以防止客户端脚本(如 JavaScript)窃取,设置 Secure 标志可以保证 `SessionID` 只在 HTTPS 连接下传输,增加安全性。
+
+Session 数据本身存储在服务器端。常见的存储方式有:
+
+- **服务器内存**:实现简单,访问速度快,但服务器重启数据会丢失,且不利于多服务器间的负载均衡。这种方式适合简单且用户量不大的业务场景。
+- **数据库 (如 MySQL, PostgreSQL)**:数据持久化,但读写性能相对较低,一般不会使用这种方式。
+- **分布式缓存 (如 Redis)**:性能高,支持分布式部署,是目前大规模应用中非常主流的方案。
+
+**方案二:当 Cookie 被禁用时:URL 重写 (URL Rewriting)**
+
+如果用户的浏览器禁用了 Cookie,或者某些情况下不便使用 Cookie,还有一种备选方案是 URL 重写。这种方式会将 `SessionID` 直接附加到 URL 的末尾,作为参数传递。例如:
+
+这句话表面上看似有道理,但实际上却暴露了一个人的**无知和偏执**。
+
+**知识越贫乏的人,相信的东西就越绝对**,因为他们从未认真了解过与自己观点相对立的角度,也缺乏对技术发展的全局认识。
+
+举个例子,我刚开始学习 Java 后端开发的时候,完全没什么经验,就随便买了一本书开始看。当时看的是 **《Java Web 整合开发王者归来》** 这本书(梦开始的地方)。
+
+在我上大学那会儿,这本书的很多内容其实已经过时了,比如它花了大量篇幅介绍 JSP、Struts、Hibernate、EJB 和 SVN 等技术。不过,直到现在,我依然非常感谢这本书,带我走进了 Java 后端开发的大门。
+
+
+
+这本书一共 **1010** 页,我当时可以说是废寝忘食地学,花了很长时间才把整本书完全“啃”下来。
+
+回头来看,我如果能有意识地避免学习这些已经淘汰的技术,真的可以节省大量时间去学习更加主流和实用的内容。
+
+那么,这些被淘汰的技术有用吗?说句实话,**屁用没有,纯粹浪费时间**。
+
+**既然都要花时间学习,为什么不去学那些更主流、更有实际价值的技术呢?**
+
+现在本身就很卷,不管是 Java 方向还是其他技术方向,要学习的技术都很多。
+
+想要理解所谓的“底层思想”,与其浪费时间在 JSP 这种已经不具备实际应用价值的技术上,不如深入学习一下 Servlet,研究 Spring 的 AOP 和 IoC 原理,从源码角度理解 Spring MVC 的工作机制。
+
+这些内容,不仅能帮助你掌握核心的思想,还能在实际开发中真正派上用场,这难道不比花大量时间在 JSP 上更有意义吗?
+
+## 还有公司在用的技术就要学吗?
+
+我把这篇文章的相关言论发表在我的[公众号](https://mp.weixin.qq.com/s/lf2dXHcrUSU1pn28Ercj0w)之后,又收到另外一类在我看来非常傻叉的言论:
+
+- “虽然 JSP 很老了,但还是得学学,会用就行,因为我们很多老项目还在用。”
+- “很多央企和国企的老项目还在用,肯定得学学啊!”
+
+这种观点完全是钻牛角尖!如果按这种逻辑,那你还需要去学 Struts2、SVN、JavaFX 等过时技术,因为它们也还有公司在用。我有一位大学同学毕业后去了武汉的一家国企,写了一年 JavaFX 就受不了跑了。他在之前从来没有接触过 JavaFX,招聘时也没被问过相关问题。
+
+一定不要假设自己要面对的是过时技术栈的项目。你要找工作肯定要用主流技术栈去找,还要尽量找能让自己技术有成长,干着也舒服点。真要是找不到合适的工作,去维护老项目,那都是后话,现学现卖就行了。
+
+**对于初学者来说别人劝了还非要学习淘汰的技术,多少脑子有点不够用,基本可以告别这一行了!**
diff --git a/docs/about-the-author/readme.md b/docs/about-the-author/readme.md
deleted file mode 100644
index 12f6eab7f3f..00000000000
--- a/docs/about-the-author/readme.md
+++ /dev/null
@@ -1,70 +0,0 @@
----
-title: 个人介绍 Q&A
-category: 走近作者
----
-
-
-
-这篇文章我会通过 Q&A 的形式简单介绍一下我自己。
-
-## 我是什么时候毕业的?
-
-很多老读者应该比较清楚,我是 19 年本科毕业的,刚毕业就去了某家外企“养老”。
-
-我的学校背景是比较差的,高考失利,勉强过了一本线 20 来分,去了荆州的一所很普通的双非一本。不过,还好我没有因为学校而放弃自己,反倒是比身边的同学都要更努力,整个大学还算过的比较充实。
-
-下面这张是当时拍的毕业照(后排最中间的就是我):
-
-
-
-## 我坚持写了多久博客?
-
-时间真快啊!我自己是从大二开始写博客的。那时候就是随意地在博客平台上发发自己的学习笔记和自己写的程序。就比如 [谢希仁老师的《计算机网络》内容总结](../cs-basics/network/computer-network-xiexiren-summary.md) 这篇文章就是我在大二学习计算机网络这门课的时候对照着教材总结的。
-
-身边也有很多小伙伴经常问我:“我现在写博客还晚么?”
-
-我觉得哈!如果你想做什么事情,尽量少问迟不迟,多问自己值不值得,只要你觉得有意义,就尽快开始做吧!人生很奇妙,我们每一步的重大决定,都会对自己未来的人生轨迹产生影响。是好还是坏,也只有我们自己知道了!
-
-对我自己来说,坚持写博客这一项决定对我人生轨迹产生的影响是非常正面的!所以,我也推荐大家养成坚持写博客的习惯。
-
-## 我在大学期间赚了多少钱?
-
-在校期间,我还通过办培训班、接私活、技术培训、编程竞赛等方式变现 20w+,成功实现“经济独立”。我用自己赚的钱去了重庆、三亚、恩施、青岛等地旅游,还给家里补贴了很多,减轻了父母的负担。
-
-下面这张是我大一下学期办补习班的时候拍的(离开前的最后一顿饭):
-
-
-
-下面这张是我大三去三亚的时候拍的:
-
-
-
-其实,我在大学就这么努力地开始赚钱,也主要是因为家庭条件太一般,父母赚钱都太辛苦了!也正是因为我自己迫切地想要减轻父母的负担,所以才会去尝试这么多赚钱的方法。
-
-我发现做咱们程序员这行的,很多人的家庭条件都挺一般的,选择这个行业的很大原因不是因为自己喜欢,而是为了多赚点钱。
-
-如果你也想通过接私活变现的话,可以在我的公众号后台回复“**接私活**”来了解一些我的个人经验分享。
-
-::: center
-
-
-
-:::
-
-## 为什么自称 Guide?
-
-可能是因为我的项目名字叫做 JavaGuide , 所以导致有很多人称呼我为 **Guide 哥**。
-
-后面,为了读者更方便称呼,我就将自己的笔名改成了 **Guide**。
-
-我早期写文章用的笔名是 SnailClimb 。很多人不知道这个名字是啥意思,给大家拆解一下就清楚了。SnailClimb=Snail(蜗牛)+Climb(攀登)。我从小就非常喜欢听周杰伦的歌曲,特别是他的《蜗牛》🐌 这首歌曲,另外,当年我高考发挥的算是比较失常,上了大学之后还算是比较“奋青”,所以,我就给自己起的笔名叫做 SnailClimb ,寓意自己要不断向上攀登,嘿嘿 😁
-
-
-
-## 后记
-
-凡心所向,素履所往,生如逆旅,一苇以航。
-
-生活本就是有苦有甜。共勉!
-
-
diff --git a/docs/books/readme.md b/docs/books/README.md
similarity index 100%
rename from docs/books/readme.md
rename to docs/books/README.md
diff --git a/docs/cs-basics/algorithms/10-classical-sorting-algorithms.md b/docs/cs-basics/algorithms/10-classical-sorting-algorithms.md
index 355875f9658..d583b936a12 100644
--- a/docs/cs-basics/algorithms/10-classical-sorting-algorithms.md
+++ b/docs/cs-basics/algorithms/10-classical-sorting-algorithms.md
@@ -367,31 +367,60 @@ public static int[] merge(int[] arr_1, int[] arr_2) {
### 代码实现
-> 来源:[使用 Java 实现快速排序(详解)](https://segmentfault.com/a/1190000040022056)
-
```java
-public static int partition(int[] array, int low, int high) {
- int pivot = array[high];
- int pointer = low;
- for (int i = low; i < high; i++) {
- if (array[i] <= pivot) {
- int temp = array[i];
- array[i] = array[pointer];
- array[pointer] = temp;
- pointer++;
+import java.util.concurrent.ThreadLocalRandom;
+
+class Solution {
+ public int[] sortArray(int[] a) {
+ quick(a, 0, a.length - 1);
+ return a;
+ }
+
+ // 快速排序的核心递归函数
+ void quick(int[] a, int left, int right) {
+ if (left >= right) { // 递归终止条件:区间只有一个或没有元素
+ return;
}
- System.out.println(Arrays.toString(array));
+ int p = partition(a, left, right); // 分区操作,返回分区点索引
+ quick(a, left, p - 1); // 对左侧子数组递归排序
+ quick(a, p + 1, right); // 对右侧子数组递归排序
}
- int temp = array[pointer];
- array[pointer] = array[high];
- array[high] = temp;
- return pointer;
-}
-public static void quickSort(int[] array, int low, int high) {
- if (low < high) {
- int position = partition(array, low, high);
- quickSort(array, low, position - 1);
- quickSort(array, position + 1, high);
+
+ // 分区函数:将数组分为两部分,小于基准值的在左,大于基准值的在右
+ int partition(int[] a, int left, int right) {
+ // 随机选择一个基准点,避免最坏情况(如数组接近有序)
+ int idx = ThreadLocalRandom.current().nextInt(right - left + 1) + left;
+ swap(a, left, idx); // 将基准点放在数组的最左端
+ int pv = a[left]; // 基准值
+ int i = left + 1; // 左指针,指向当前需要检查的元素
+ int j = right; // 右指针,从右往左寻找比基准值小的元素
+
+ while (i <= j) {
+ // 左指针向右移动,直到找到一个大于等于基准值的元素
+ while (i <= j && a[i] < pv) {
+ i++;
+ }
+ // 右指针向左移动,直到找到一个小于等于基准值的元素
+ while (i <= j && a[j] > pv) {
+ j--;
+ }
+ // 如果左指针尚未越过右指针,交换两个不符合位置的元素
+ if (i <= j) {
+ swap(a, i, j);
+ i++;
+ j--;
+ }
+ }
+ // 将基准值放到分区点位置,使得基准值左侧小于它,右侧大于它
+ swap(a, j, left);
+ return j;
+ }
+
+ // 交换数组中两个元素的位置
+ void swap(int[] a, int i, int j) {
+ int t = a[i];
+ a[i] = a[j];
+ a[j] = t;
}
}
```
diff --git a/docs/cs-basics/data-structure/linear-data-structure.md b/docs/cs-basics/data-structure/linear-data-structure.md
index cc5cc6a5db2..e8ae63a19d5 100644
--- a/docs/cs-basics/data-structure/linear-data-structure.md
+++ b/docs/cs-basics/data-structure/linear-data-structure.md
@@ -326,9 +326,9 @@ myStack.pop();//报错:java.lang.IllegalArgumentException: Stack is empty.
当我们需要按照一定顺序来处理数据的时候可以考虑使用队列这个数据结构。
- **阻塞队列:** 阻塞队列可以看成在队列基础上加了阻塞操作的队列。当队列为空的时候,出队操作阻塞,当队列满的时候,入队操作阻塞。使用阻塞队列我们可以很容易实现“生产者 - 消费者“模型。
-- **线程池中的请求/任务队列:** 线程池中没有空闲线程时,新的任务请求线程资源时,线程池该如何处理呢?答案是将这些请求放在队列中,当有空闲线程的时候,会循环中反复从队列中获取任务来执行。队列分为无界队列(基于链表)和有界队列(基于数组)。无界队列的特点就是可以一直入列,除非系统资源耗尽,比如:`FixedThreadPool` 使用无界队列 `LinkedBlockingQueue`。但是有界队列就不一样了,当队列满的话后面再有任务/请求就会拒绝,在 Java 中的体现就是会抛出`java.util.concurrent.RejectedExecutionException` 异常。
-- 栈:双端队列天生便可以实现栈的全部功能(`push`、`pop` 和 `peek`),并且在 Deque 接口中已经实现了相关方法。Stack 类已经和 Vector 一样被遗弃,现在在 Java 中普遍使用双端队列(Deque)来实现栈。
-- 广度优先搜索(BFS),在图的广度优先搜索过程中,队列被用于存储待访问的节点,保证按照层次顺序遍历图的节点。
+- **线程池中的请求/任务队列:** 当线程池中没有空闲线程时,新的任务请求线程资源会被如何处理呢?答案是这些任务会被放入任务队列中,等待线程池中的线程空闲后再从队列中取出任务执行。任务队列分为无界队列(基于链表实现)和有界队列(基于数组实现)。无界队列的特点是队列容量理论上没有限制,任务可以持续入队,直到系统资源耗尽。例如:`FixedThreadPool` 使用的阻塞队列 `LinkedBlockingQueue`,其默认容量为 `Integer.MAX_VALUE`,因此可以被视为“无界队列”。而有界队列则不同,当队列已满时,如果再有新任务提交,由于队列无法继续容纳任务,线程池会拒绝这些任务,并抛出 `java.util.concurrent.RejectedExecutionException` 异常。
+- **栈**:双端队列天生便可以实现栈的全部功能(`push`、`pop` 和 `peek`),并且在 Deque 接口中已经实现了相关方法。Stack 类已经和 Vector 一样被遗弃,现在在 Java 中普遍使用双端队列(Deque)来实现栈。
+- **广度优先搜索(BFS)**:在图的广度优先搜索过程中,队列被用于存储待访问的节点,保证按照层次顺序遍历图的节点。
- Linux 内核进程队列(按优先级排队)
- 现实生活中的派对,播放器上的播放列表;
- 消息队列
diff --git a/docs/cs-basics/network/application-layer-protocol.md b/docs/cs-basics/network/application-layer-protocol.md
index 5764a72c020..cb809b9157d 100644
--- a/docs/cs-basics/network/application-layer-protocol.md
+++ b/docs/cs-basics/network/application-layer-protocol.md
@@ -15,7 +15,7 @@ HTTP 使用客户端-服务器模型,客户端向服务器发送 HTTP Request
HTTP 协议基于 TCP 协议,发送 HTTP 请求之前首先要建立 TCP 连接也就是要经历 3 次握手。目前使用的 HTTP 协议大部分都是 1.1。在 1.1 的协议里面,默认是开启了 Keep-Alive 的,这样的话建立的连接就可以在多次请求中被复用了。
-另外, HTTP 协议是”无状态”的协议,它无法记录客户端用户的状态,一般我们都是通过 Session 来记录客户端用户的状态。
+另外, HTTP 协议是“无状态”的协议,它无法记录客户端用户的状态,一般我们都是通过 Session 来记录客户端用户的状态。
## Websocket:全双工通信协议
diff --git a/docs/cs-basics/network/arp.md b/docs/cs-basics/network/arp.md
index c4ece76011c..d8b647b1762 100644
--- a/docs/cs-basics/network/arp.md
+++ b/docs/cs-basics/network/arp.md
@@ -21,7 +21,7 @@ tag:
MAC 地址的全称是 **媒体访问控制地址(Media Access Control Address)**。如果说,互联网中每一个资源都由 IP 地址唯一标识(IP 协议内容),那么一切网络设备都由 MAC 地址唯一标识。
-
+
可以理解为,MAC 地址是一个网络设备真正的身份证号,IP 地址只是一种不重复的定位方式(比如说住在某省某市某街道的张三,这种逻辑定位是 IP 地址,他的身份证号才是他的 MAC 地址),也可以理解为 MAC 地址是身份证号,IP 地址是邮政地址。MAC 地址也有一些别称,如 LAN 地址、物理地址、以太网地址等。
diff --git a/docs/cs-basics/network/computer-network-xiexiren-summary.md b/docs/cs-basics/network/computer-network-xiexiren-summary.md
index fc9f60fd39a..85f7c3f54d2 100644
--- a/docs/cs-basics/network/computer-network-xiexiren-summary.md
+++ b/docs/cs-basics/network/computer-network-xiexiren-summary.md
@@ -191,7 +191,7 @@ tag:
5. **子网掩码(subnet mask )**:它是一种用来指明一个 IP 地址的哪些位标识的是主机所在的子网以及哪些位标识的是主机的位掩码。子网掩码不能单独存在,它必须结合 IP 地址一起使用。
6. **CIDR( Classless Inter-Domain Routing )**:无分类域间路由选择 (特点是消除了传统的 A 类、B 类和 C 类地址以及划分子网的概念,并使用各种长度的“网络前缀”(network-prefix)来代替分类地址中的网络号和子网号)。
7. **默认路由(default route)**:当在路由表中查不到能到达目的地址的路由时,路由器选择的路由。默认路由还可以减小路由表所占用的空间和搜索路由表所用的时间。
-8. **路由选择算法(Virtual Circuit)**:路由选择协议的核心部分。因特网采用自适应的,分层次的路由选择协议。
+8. **路由选择算法(Routing Algorithm)**:路由选择协议的核心部分。因特网采用自适应的,分层次的路由选择协议。
### 4.2. 重要知识点总结
diff --git a/docs/cs-basics/network/images/arp/2008410143049281.png b/docs/cs-basics/network/images/arp/2008410143049281.png
deleted file mode 100644
index 759fb441f6c..00000000000
Binary files a/docs/cs-basics/network/images/arp/2008410143049281.png and /dev/null differ
diff --git a/docs/cs-basics/network/nat.md b/docs/cs-basics/network/nat.md
index 5634ba07387..4567719b81e 100644
--- a/docs/cs-basics/network/nat.md
+++ b/docs/cs-basics/network/nat.md
@@ -45,7 +45,7 @@ SOHO 子网的“代理人”,也就是和外界的窗口,通常由路由器
针对以上过程,有以下几个重点需要强调:
1. 当请求报文到达路由器,并被指定了新端口号时,由于端口号有 16 位,因此,通常来说,一个路由器管理的 LAN 中的最大主机数 $≈65500$($2^{16}$ 的地址空间),但通常 SOHO 子网内不会有如此多的主机数量。
-2. 对于目的服务器来说,从来不知道“到底是哪个主机给我发送的请求”,它只知道是来自`138.76.29.7:5001`的路由器转发的请求。因此,可以说,**路由器在 WAN 和 LAN 之间起到了屏蔽作用,**所有内部主机发送到外部的报文,都具有同一个 IP 地址(不同的端口号),所有外部发送到内部的报文,也都只有一个目的地(不同端口号),是经过了 NAT 转换后,外部报文才得以正确地送达内部主机。
+2. 对于目的服务器来说,从来不知道“到底是哪个主机给我发送的请求”,它只知道是来自`138.76.29.7:5001`的路由器转发的请求。因此,可以说,**路由器在 WAN 和 LAN 之间起到了屏蔽作用**,所有内部主机发送到外部的报文,都具有同一个 IP 地址(不同的端口号),所有外部发送到内部的报文,也都只有一个目的地(不同端口号),是经过了 NAT 转换后,外部报文才得以正确地送达内部主机。
3. 在报文穿过路由器,发生 NAT 转换时,如果 LAN 主机 IP 已经在 NAT 转换表中注册过了,则不需要路由器新指派端口,而是直接按照转换记录穿过路由器。同理,外部报文发送至内部时也如此。
总结 NAT 协议的特点,有以下几点:
@@ -55,6 +55,6 @@ SOHO 子网的“代理人”,也就是和外界的窗口,通常由路由器
3. WAN 的 ISP 变更接口地址时,无需通告 LAN 内主机。
4. LAN 主机对 WAN 不可见,不可直接寻址,可以保证一定程度的安全性。
-然而,NAT 协议由于其独特性,存在着一些争议。比如,可能你已经注意到了,**NAT 协议在 LAN 以外,标识一个内部主机时,使用的是端口号,因为 IP 地址都是相同的。**这种将端口号作为主机寻址的行为,可能会引发一些误会。此外,路由器作为网络层的设备,修改了传输层的分组内容(修改了源 IP 地址和端口号),同样是不规范的行为。但是,尽管如此,NAT 协议作为 IPv4 时代的产物,极大地方便了一些本来棘手的问题,一直被沿用至今。
+然而,NAT 协议由于其独特性,存在着一些争议。比如,可能你已经注意到了,**NAT 协议在 LAN 以外,标识一个内部主机时,使用的是端口号,因为 IP 地址都是相同的**。这种将端口号作为主机寻址的行为,可能会引发一些误会。此外,路由器作为网络层的设备,修改了传输层的分组内容(修改了源 IP 地址和端口号),同样是不规范的行为。但是,尽管如此,NAT 协议作为 IPv4 时代的产物,极大地方便了一些本来棘手的问题,一直被沿用至今。
diff --git a/docs/cs-basics/network/network-attack-means.md b/docs/cs-basics/network/network-attack-means.md
index 86a1d7f6393..748999d6eba 100644
--- a/docs/cs-basics/network/network-attack-means.md
+++ b/docs/cs-basics/network/network-attack-means.md
@@ -363,11 +363,11 @@ MD5 可以用来生成一个 128 位的消息摘要,它是目前应用比较
**SHA**
-安全散列算法。**SHA** 分为 **SHA1** 和 **SH2** 两个版本。该算法的思想是接收一段明文,然后以一种不可逆的方式将它转换成一段(通常更小)密文,也可以简单的理解为取一串输入码(称为预映射或信息),并把它们转化为长度较短、位数固定的输出序列即散列值(也称为信息摘要或信息认证代码)的过程。
+安全散列算法。**SHA** 包括**SHA-1**、**SHA-2**和**SHA-3**三个版本。该算法的基本思想是:接收一段明文数据,通过不可逆的方式将其转换为固定长度的密文。简单来说,SHA 将输入数据(即预映射或消息)转化为固定长度、较短的输出值,称为散列值(或信息摘要、信息认证码)。SHA-1 已被证明不够安全,因此逐渐被 SHA-2 取代,而 SHA-3 则作为 SHA 系列的最新版本,采用不同的结构(Keccak 算法)提供更高的安全性和灵活性。
**SM3**
-国密算法**SM3**。加密强度和 SHA-256算法 相差不多。主要是受到了国家的支持。
+国密算法**SM3**。加密强度和 SHA-256 算法 相差不多。主要是受到了国家的支持。
**总结**:
diff --git a/docs/cs-basics/network/other-network-questions.md b/docs/cs-basics/network/other-network-questions.md
index 2f3617dbe5b..8a266d5496b 100644
--- a/docs/cs-basics/network/other-network-questions.md
+++ b/docs/cs-basics/network/other-network-questions.md
@@ -27,7 +27,7 @@ tag:

-#### TCP/IP 四层模型是什么?每一层的作用是什么?
+#### ⭐️TCP/IP 四层模型是什么?每一层的作用是什么?
**TCP/IP 四层模型** 是目前被广泛采用的一种模型,我们可以将 TCP / IP 模型看作是 OSI 七层模型的精简版本,由以下 4 层组成:
@@ -40,7 +40,7 @@ tag:

-关于每一层作用的详细介绍,请看 [OSI 和 TCP/IP 网络分层模型详解(基础)](./osi-and-tcp-ip-model.md) 这篇文章。
+关于每一层作用的详细介绍,请看 [OSI 和 TCP/IP 网络分层模型详解(基础)](https://javaguide.cn/cs-basics/network/osi-and-tcp-ip-model.html) 这篇文章。
#### 为什么网络要分层?
@@ -64,7 +64,7 @@ tag:
### 常见网络协议
-#### 应用层有哪些常见的协议?
+#### ⭐️应用层有哪些常见的协议?

@@ -100,7 +100,7 @@ tag:
## HTTP
-### 从输入 URL 到页面展示到底发生了什么?(非常重要)
+### ⭐️从输入 URL 到页面展示到底发生了什么?(非常重要)
> 类似的问题:打开一个网页,整个过程会使用哪些协议?
@@ -120,15 +120,15 @@ tag:
6. 浏览器收到 HTTP 响应报文后,解析响应体中的 HTML 代码,渲染网页的结构和样式,同时根据 HTML 中的其他资源的 URL(如图片、CSS、JS 等),再次发起 HTTP 请求,获取这些资源的内容,直到网页完全加载显示。
7. 浏览器在不需要和服务器通信时,可以主动关闭 TCP 连接,或者等待服务器的关闭请求。
-详细介绍可以查看这篇文章:[访问网页的全过程(知识串联)](./the-whole-process-of-accessing-web-pages.md)(强烈推荐)。
+详细介绍可以查看这篇文章:[访问网页的全过程(知识串联)](https://javaguide.cn/cs-basics/network/the-whole-process-of-accessing-web-pages.html)(强烈推荐)。
-### HTTP 状态码有哪些?
+### ⭐️HTTP 状态码有哪些?
HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被成功处理。

-关于 HTTP 状态码更详细的总结,可以看我写的这篇文章:[HTTP 常见状态码总结(应用层)](./http-status-codes.md)。
+关于 HTTP 状态码更详细的总结,可以看我写的这篇文章:[HTTP 常见状态码总结(应用层)](https://javaguide.cn/cs-basics/network/http-status-codes.html)。
### HTTP Header 中常见的字段有哪些?
@@ -167,7 +167,7 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
| Via | 向服务器告知,这个请求是由哪些代理发出的。 | Via: 1.0 fred, 1.1 example.com (Apache/1.1) |
| Warning | 一个一般性的警告,告知,在实体内容体中可能存在错误。 | Warning: 199 Miscellaneous warning |
-### HTTP 和 HTTPS 有什么区别?(重要)
+### ⭐️HTTP 和 HTTPS 有什么区别?(重要)

@@ -176,7 +176,7 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
- **安全性和资源消耗**:HTTP 协议运行在 TCP 之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS 是运行在 SSL/TLS 之上的 HTTP 协议,SSL/TLS 运行在 TCP 之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。所以说,HTTP 安全性没有 HTTPS 高,但是 HTTPS 比 HTTP 耗费更多服务器资源。
- **SEO(搜索引擎优化)**:搜索引擎通常会更青睐使用 HTTPS 协议的网站,因为 HTTPS 能够提供更高的安全性和用户隐私保护。使用 HTTPS 协议的网站在搜索结果中可能会被优先显示,从而对 SEO 产生影响。
-关于 HTTP 和 HTTPS 更详细的对比总结,可以看我写的这篇文章:[HTTP vs HTTPS(应用层)](./http-vs-https.md) 。
+关于 HTTP 和 HTTPS 更详细的对比总结,可以看我写的这篇文章:[HTTP vs HTTPS(应用层)](https://javaguide.cn/cs-basics/network/http-vs-https.html) 。
### HTTP/1.0 和 HTTP/1.1 有什么区别?
@@ -188,14 +188,15 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
- **带宽**:HTTP/1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP/1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
- **Host 头(Host Header)处理** :HTTP/1.1 引入了 Host 头字段,允许在同一 IP 地址上托管多个域名,从而支持虚拟主机的功能。而 HTTP/1.0 没有 Host 头字段,无法实现虚拟主机。
-关于 HTTP/1.0 和 HTTP/1.1 更详细的对比总结,可以看我写的这篇文章:[HTTP/1.0 vs HTTP/1.1(应用层)](./http1.0-vs-http1.1.md) 。
+关于 HTTP/1.0 和 HTTP/1.1 更详细的对比总结,可以看我写的这篇文章:[HTTP/1.0 vs HTTP/1.1(应用层)](https://javaguide.cn/cs-basics/network/http1.0-vs-http1.1.html) 。
-### HTTP/1.1 和 HTTP/2.0 有什么区别?
+### ⭐️HTTP/1.1 和 HTTP/2.0 有什么区别?

-- **多路复用(Multiplexing)**:HTTP/2.0 在同一连接上可以同时传输多个请求和响应(可以看作是 HTTP/1.1 中长链接的升级版本),互不干扰。HTTP/1.1 则使用串行方式,每个请求和响应都需要独立的连接,而浏览器为了控制资源会有 6-8 个 TCP 连接的限制。。这使得 HTTP/2.0 在处理多个请求时更加高效,减少了网络延迟和提高了性能。
+- **多路复用(Multiplexing)**:HTTP/2.0 在同一连接上可以同时传输多个请求和响应(可以看作是 HTTP/1.1 中长链接的升级版本),互不干扰。HTTP/1.1 则使用串行方式,每个请求和响应都需要独立的连接,而浏览器为了控制资源会有 6-8 个 TCP 连接的限制。这使得 HTTP/2.0 在处理多个请求时更加高效,减少了网络延迟和提高了性能。
- **二进制帧(Binary Frames)**:HTTP/2.0 使用二进制帧进行数据传输,而 HTTP/1.1 则使用文本格式的报文。二进制帧更加紧凑和高效,减少了传输的数据量和带宽消耗。
+- **队头阻塞**:HTTP/2 引入了多路复用技术,允许多个请求和响应在单个 TCP 连接上并行交错传输,解决了 HTTP/1.1 应用层的队头阻塞问题,但 HTTP/2 依然受到 TCP 层队头阻塞 的影响。
- **头部压缩(Header Compression)**:HTTP/1.1 支持`Body`压缩,`Header`不支持压缩。HTTP/2.0 支持对`Header`压缩,使用了专门为`Header`压缩而设计的 HPACK 算法,减少了网络开销。
- **服务器推送(Server Push)**:HTTP/2.0 支持服务器推送,可以在客户端请求一个资源时,将其他相关资源一并推送给客户端,从而减少了客户端的请求次数和延迟。而 HTTP/1.1 需要客户端自己发送请求来获取相关资源。
@@ -203,7 +204,7 @@ HTTP/2.0 多路复用效果图(图源: [HTTP/2 For Web Developers](https://b

-可以看到,HTTP/2.0 的多路复用使得不同的请求可以共用一个 TCP 连接,避免建立多个连接带来不必要的额外开销,而 HTTP/1.1 中的每个请求都会建立一个单独的连接
+可以看到,HTTP/2 的多路复用机制允许多个请求和响应共享一个 TCP 连接,从而避免了 HTTP/1.1 在应对并发请求时需要建立多个并行连接的情况,减少了重复连接建立和维护的额外开销。而在 HTTP/1.1 中,尽管支持持久连接,但为了缓解队头阻塞问题,浏览器通常会为同一域名建立多个并行连接。
### HTTP/2.0 和 HTTP/3.0 有什么区别?
@@ -232,15 +233,89 @@ HTTP/1.0、HTTP/2.0 和 HTTP/3.0 的协议栈比较:
关于 HTTP/1.0 -> HTTP/3.0 更详细的演进介绍,推荐阅读[HTTP1 到 HTTP3 的工程优化](https://dbwu.tech/posts/http_evolution/)。
-### HTTP 是不保存状态的协议, 如何保存用户状态?
+### HTTP/1.1 和 HTTP/2.0 的队头阻塞有什么不同?
-HTTP 是一种不保存状态,即无状态(stateless)协议。也就是说 HTTP 协议自身不对请求和响应之间的通信状态进行保存。那么我们如何保存用户状态呢?Session 机制的存在就是为了解决这个问题,Session 的主要作用就是通过服务端记录用户的状态。典型的场景是购物车,当你要添加商品到购物车的时候,系统不知道是哪个用户操作的,因为 HTTP 协议是无状态的。服务端给特定的用户创建特定的 Session 之后就可以标识这个用户并且跟踪这个用户了(一般情况下,服务器会在一定时间内保存这个 Session,过了时间限制,就会销毁这个 Session)。
+HTTP/1.1 队头阻塞的主要原因是无法多路复用:
-在服务端保存 Session 的方法很多,最常用的就是内存和数据库(比如是使用内存数据库 redis 保存)。既然 Session 存放在服务器端,那么我们如何实现 Session 跟踪呢?大部分情况下,我们都是通过在 Cookie 中附加一个 Session ID 来方式来跟踪。
+- 在一个 TCP 连接中,资源的请求和响应是按顺序处理的。如果一个大的资源(如一个大文件)正在传输,后续的小资源(如较小的 CSS 文件)需要等待前面的资源传输完成后才能被发送。
+- 如果浏览器需要同时加载多个资源(如多个 CSS、JS 文件等),它通常会开启多个并行的 TCP 连接(一般限制为 6 个)。但每个连接仍然受限于顺序的请求-响应机制,因此仍然会发生 **应用层的队头阻塞**。
-**Cookie 被禁用怎么办?**
+虽然 HTTP/2.0 引入了多路复用技术,允许多个请求和响应在单个 TCP 连接上并行交错传输,解决了 **HTTP/1.1 应用层的队头阻塞问题**,但 HTTP/2.0 依然受到 **TCP 层队头阻塞** 的影响:
-最常用的就是利用 URL 重写把 Session ID 直接附加在 URL 路径的后面。
+- HTTP/2.0 通过帧(frame)机制将每个资源分割成小块,并为每个资源分配唯一的流 ID,这样多个资源的数据可以在同一 TCP 连接中交错传输。
+- TCP 作为传输层协议,要求数据按顺序交付。如果某个数据包在传输过程中丢失,即使后续的数据包已经到达,也必须等待丢失的数据包重传后才能继续处理。这种传输层的顺序性导致了 **TCP 层的队头阻塞**。
+- 举例来说,如果 HTTP/2 的一个 TCP 数据包中携带了多个资源的数据(例如 JS 和 CSS),而该数据包丢失了,那么后续数据包中的所有资源数据都需要等待丢失的数据包重传回来,导致所有流(streams)都被阻塞。
+
+最后,来一张表格总结补充一下:
+
+| **方面** | **HTTP/1.1 的队头阻塞** | **HTTP/2.0 的队头阻塞** |
+| -------------- | ---------------------------------------- | ---------------------------------------------------------------- |
+| **层级** | 应用层(HTTP 协议本身的限制) | 传输层(TCP 协议的限制) |
+| **根本原因** | 无法多路复用,请求和响应必须按顺序传输 | TCP 要求数据包按顺序交付,丢包时阻塞整个连接 |
+| **受影响范围** | 单个 HTTP 请求/响应会阻塞后续请求/响应。 | 单个 TCP 包丢失会影响所有 HTTP/2.0 流(依赖于同一个底层 TCP 连接) |
+| **缓解方法** | 开启多个并行的 TCP 连接 | 减少网络掉包或者使用基于 UDP 的 QUIC 协议 |
+| **影响场景** | 每次都会发生,尤其是大文件阻塞小文件时。 | 丢包率较高的网络环境下更容易发生。 |
+
+### ⭐️HTTP 是不保存状态的协议, 如何保存用户状态?
+
+HTTP 协议本身是 **无状态的 (stateless)** 。这意味着服务器默认情况下无法区分两个连续的请求是否来自同一个用户,或者同一个用户之前的操作是什么。这就像一个“健忘”的服务员,每次你跟他说话,他都不知道你是谁,也不知道你之前点过什么菜。
+
+但在实际的 Web 应用中,比如网上购物、用户登录等场景,我们显然需要记住用户的状态(例如购物车里的商品、用户的登录信息)。为了解决这个问题,主要有以下几种常用机制:
+
+**方案一:Session (会话) 配合 Cookie (主流方式):**
+
+
+
+这可以说是最经典也是最常用的方法了。基本流程是这样的:
+
+1. 用户向服务器发送用户名、密码、验证码用于登陆系统。
+2. 服务器验证通过后,会为这个用户创建一个专属的 Session 对象(可以理解为服务器上的一块内存,存放该用户的状态数据,如购物车、登录信息等)存储起来,并给这个 Session 分配一个唯一的 `SessionID`。
+3. 服务器通过 HTTP 响应头中的 `Set-Cookie` 指令,把这个 `SessionID` 发送给用户的浏览器。
+4. 浏览器接收到 `SessionID` 后,会将其以 Cookie 的形式保存在本地。当用户保持登录状态时,每次向该服务器发请求,浏览器都会自动带上这个存有 `SessionID` 的 Cookie。
+5. 服务器收到请求后,从 Cookie 中拿出 `SessionID`,就能找到之前保存的那个 Session 对象,从而知道这是哪个用户以及他之前的状态了。
+
+使用 Session 的时候需要注意下面几个点:
+
+- **客户端 Cookie 支持**:依赖 Session 的核心功能要确保用户浏览器开启了 Cookie。
+- **Session 过期管理**:合理设置 Session 的过期时间,平衡安全性和用户体验。
+- **Session ID 安全**:为包含 `SessionID` 的 Cookie 设置 `HttpOnly` 标志可以防止客户端脚本(如 JavaScript)窃取,设置 Secure 标志可以保证 `SessionID` 只在 HTTPS 连接下传输,增加安全性。
+
+Session 数据本身存储在服务器端。常见的存储方式有:
+
+- **服务器内存**:实现简单,访问速度快,但服务器重启数据会丢失,且不利于多服务器间的负载均衡。这种方式适合简单且用户量不大的业务场景。
+- **数据库 (如 MySQL, PostgreSQL)**:数据持久化,但读写性能相对较低,一般不会使用这种方式。
+- **分布式缓存 (如 Redis)**:性能高,支持分布式部署,是目前大规模应用中非常主流的方案。
+
+**方案二:当 Cookie 被禁用时:URL 重写 (URL Rewriting)**
+
+如果用户的浏览器禁用了 Cookie,或者某些情况下不便使用 Cookie,还有一种备选方案是 URL 重写。这种方式会将 `SessionID` 直接附加到 URL 的末尾,作为参数传递。例如: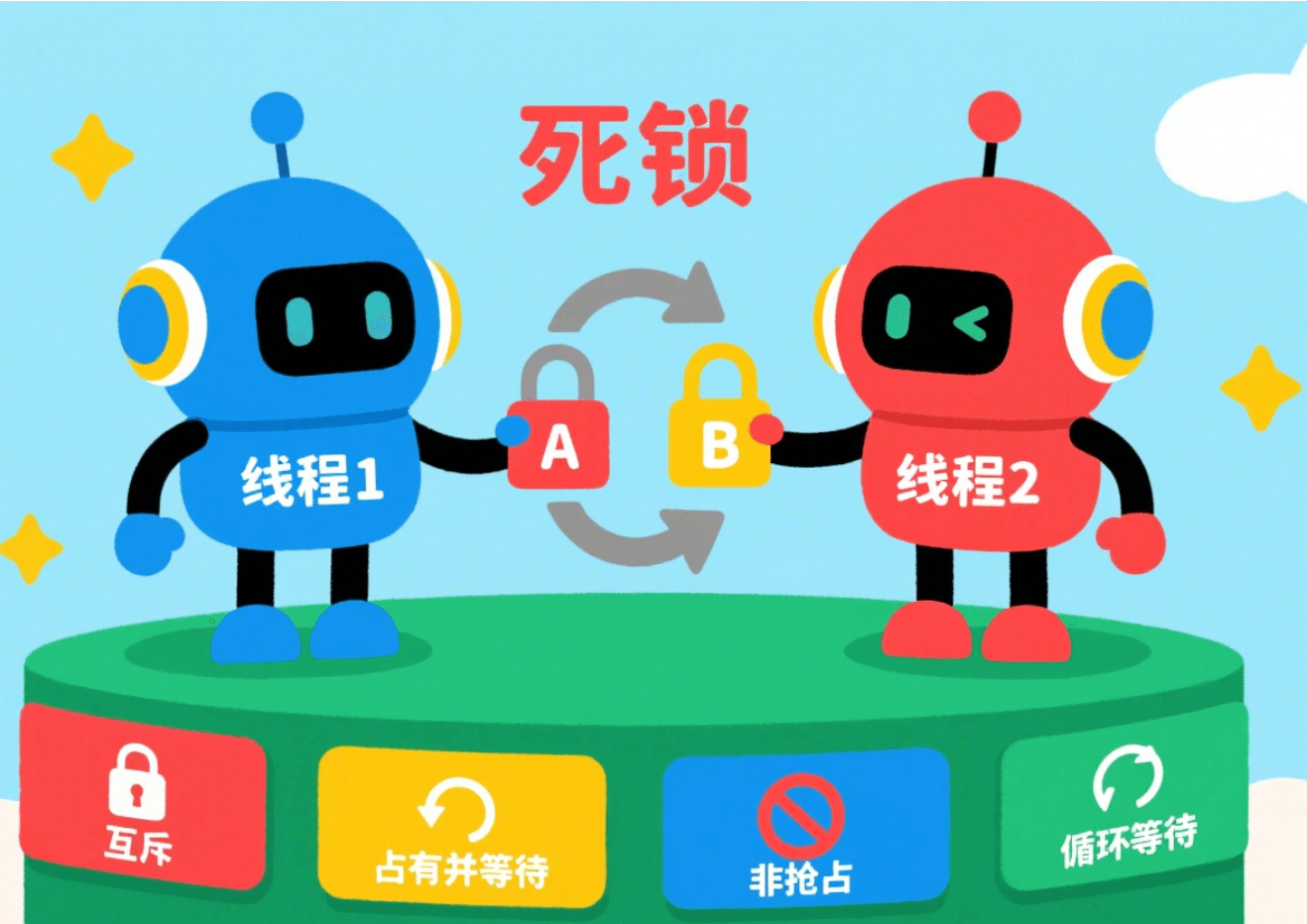 ### 产生死锁的四个必要条件是什么?
+死锁的发生并不是偶然的,它需要同时满足**四个必要条件**:
+
1. **互斥**:资源必须处于非共享模式,即一次只有一个进程可以使用。如果另一进程申请该资源,那么必须等待直到该资源被释放为止。
2. **占有并等待**:一个进程至少应该占有一个资源,并等待另一资源,而该资源被其他进程所占有。
3. **非抢占**:资源不能被抢占。只能在持有资源的进程完成任务后,该资源才会被释放。
-4. **循环等待**:有一组等待进程 `{P0, P1,..., Pn}`, `P0` 等待的资源被 `P1` 占有,`P1` 等待的资源被 `P2` 占有,……,`Pn-1` 等待的资源被 `Pn` 占有,`Pn` 等待的资源被 `P0` 占有。
+4. **循环等待**:有一组等待进程 {P0, P1,..., Pn}, P0 等待的资源被 P1 占有,P1 等待的资源被 P2 占有,……,Pn-1 等待的资源被 Pn 占有,Pn 等待的资源被 P0 占有。
**注意 ⚠️**:这四个条件是产生死锁的 **必要条件** ,也就是说只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
@@ -371,12 +380,9 @@ Thread[线程 2,5,main]waiting get resource1
解决死锁的方法可以从多个角度去分析,一般的情况下,有**预防,避免,检测和解除四种**。
-- **预防** 是采用某种策略,**限制并发进程对资源的请求**,从而使得死锁的必要条件在系统执行的任何时间上都不满足。
-
-- **避免**则是系统在分配资源时,根据资源的使用情况**提前做出预测**,从而**避免死锁的发生**
-
-- **检测**是指系统设有**专门的机构**,当死锁发生时,该机构能够检测死锁的发生,并精确地确定与死锁有关的进程和资源。
-- **解除** 是与检测相配套的一种措施,用于**将进程从死锁状态下解脱出来**。
+- **死锁预防:** 这是我们程序员最常用的方法。通过编码规范来破坏条件。最经典的就是**破坏循环等待**,比如规定所有线程都必须**按相同的顺序**来获取锁(比如先 A 后 B),这样就不会形成环路。
+- **死锁避免:** 这是一种更动态的方法,比如操作系统的**银行家算法**。它会在分配资源前进行预测,如果这次分配可能导致未来发生死锁,就拒绝分配。但这种方法开销很大,在通用系统中用得比较少。
+- **死锁检测与解除:** 这是一种“事后补救”的策略,就像乐观锁。系统允许死锁发生,但会有一个后台线程(或机制)定期检测是否存在死锁环路(比如通过分析线程等待图)。一旦发现,就会采取措施解除,比如**强制剥夺某个线程的资源或直接终止它**。数据库系统中的死锁处理就常常采用这种方式。
#### 死锁的预防
diff --git a/docs/cs-basics/operating-system/operating-system-basic-questions-02.md b/docs/cs-basics/operating-system/operating-system-basic-questions-02.md
index 5e1c0a67fa7..68f6b42cc76 100644
--- a/docs/cs-basics/operating-system/operating-system-basic-questions-02.md
+++ b/docs/cs-basics/operating-system/operating-system-basic-questions-02.md
@@ -188,7 +188,7 @@ MMU 将虚拟地址翻译为物理地址的主要机制有 3 种:
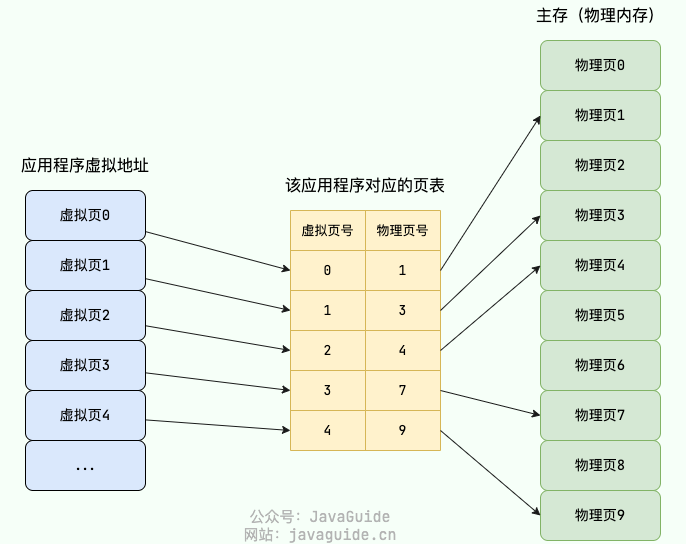
-在分页机制下,每个应用程序都会有一个对应的页表。
+在分页机制下,每个进程都会有一个对应的页表。
分页机制下的虚拟地址由两部分组成:
@@ -317,12 +317,16 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
### 段页机制
-结合了段式管理和页式管理的一种内存管理机制,把物理内存先分成若干段,每个段又继续分成若干大小相等的页。
+结合了段式管理和页式管理的一种内存管理机制。程序视角中,内存被划分为多个逻辑段,每个逻辑段进一步被划分为固定大小的页。
在段页式机制下,地址翻译的过程分为两个步骤:
-1. 段式地址映射。
-2. 页式地址映射。
+1. **段式地址映射(虚拟地址 → 线性地址):**
+ - 虚拟地址 = 段选择符(段号)+ 段内偏移。
+ - 根据段号查段表,找到段基址,加上段内偏移得到线性地址。
+2. **页式地址映射(线性地址 → 物理地址):**
+ - 线性地址 = 页号 + 页内偏移。
+ - 根据页号查页表,找到物理页框号,加上页内偏移得到物理地址。
### 局部性原理
@@ -375,7 +379,7 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
### 提高文件系统性能的方式有哪些?
-- **优化硬件**:使用高速硬件设备(如 SSD、NVMe)替代传统的机械硬盘,使用 RAID(Redundant Array of Inexpensive Disks)等技术提高磁盘性能。
+- **优化硬件**:使用高速硬件设备(如 SSD、NVMe)替代传统的机械硬盘,使用 RAID(Redundant Array of Independent Disks)等技术提高磁盘性能。
- **选择合适的文件系统选型**:不同的文件系统具有不同的特性,对于不同的应用场景选择合适的文件系统可以提高系统性能。
- **运用缓存**:访问磁盘的效率比较低,可以运用缓存来减少磁盘的访问次数。不过,需要注意缓存命中率,缓存命中率过低的话,效果太差。
- **避免磁盘过度使用**:注意磁盘的使用率,避免将磁盘用满,尽量留一些剩余空间,以免对文件系统的性能产生负面影响。
diff --git a/docs/database/basis.md b/docs/database/basis.md
index 34ee65f1242..1df5d538fb8 100644
--- a/docs/database/basis.md
+++ b/docs/database/basis.md
@@ -86,7 +86,7 @@ ER 图由下面 3 个要素组成:
为什么不要用外键呢?大部分人可能会这样回答:
-1. **增加了复杂性:** a. 每次做 DELETE 或者 UPDATE 都必须考虑外键约束,会导致开发的时候很痛苦, 测试数据极为不方便; b. 外键的主从关系是定的,假如那天需求有变化,数据库中的这个字段根本不需要和其他表有关联的话就会增加很多麻烦。
+1. **增加了复杂性:** a. 每次做 DELETE 或者 UPDATE 都必须考虑外键约束,会导致开发的时候很痛苦, 测试数据极为不方便; b. 外键的主从关系是定的,假如哪天需求有变化,数据库中的这个字段根本不需要和其他表有关联的话就会增加很多麻烦。
2. **增加了额外工作**:数据库需要增加维护外键的工作,比如当我们做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,保证数据的的一致性和正确性,这样会不得不消耗数据库资源。如果在应用层面去维护的话,可以减小数据库压力;
3. **对分库分表不友好**:因为分库分表下外键是无法生效的。
4. ……
diff --git a/docs/database/mysql/a-thousand-lines-of-mysql-study-notes.md b/docs/database/mysql/a-thousand-lines-of-mysql-study-notes.md
index 42384aaec7e..cb30376687b 100644
--- a/docs/database/mysql/a-thousand-lines-of-mysql-study-notes.md
+++ b/docs/database/mysql/a-thousand-lines-of-mysql-study-notes.md
@@ -621,7 +621,7 @@ CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] VIEW view_name
### 锁表
-```mysql
+```sql
/* 锁表 */
表锁定只用于防止其它客户端进行不正当地读取和写入
MyISAM 支持表锁,InnoDB 支持行锁
@@ -633,7 +633,7 @@ MyISAM 支持表锁,InnoDB 支持行锁
### 触发器
-```mysql
+```sql
/* 触发器 */ ------------------
触发程序是与表有关的命名数据库对象,当该表出现特定事件时,将激活该对象
监听:记录的增加、修改、删除。
@@ -686,7 +686,7 @@ end
### SQL 编程
-```mysql
+```sql
/* SQL编程 */ ------------------
--// 局部变量 ----------
-- 变量声明
@@ -821,7 +821,7 @@ INOUT,表示混合型
### 存储过程
-```mysql
+```sql
/* 存储过程 */ ------------------
存储过程是一段可执行性代码的集合。相比函数,更偏向于业务逻辑。
调用:CALL 过程名
@@ -842,7 +842,7 @@ END
### 用户和权限管理
-```mysql
+```sql
/* 用户和权限管理 */ ------------------
-- root密码重置
1. 停止MySQL服务
@@ -924,7 +924,7 @@ GRANT OPTION -- 允许授予权限
### 表维护
-```mysql
+```sql
/* 表维护 */
-- 分析和存储表的关键字分布
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE 表名 ...
@@ -937,7 +937,7 @@ OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
### 杂项
-```mysql
+```sql
/* 杂项 */ ------------------
1. 可用反引号(`)为标识符(库名、表名、字段名、索引、别名)包裹,以避免与关键字重名!中文也可以作为标识符!
2. 每个库目录存在一个保存当前数据库的选项文件db.opt。
diff --git a/docs/database/mysql/mysql-high-performance-optimization-specification-recommendations.md b/docs/database/mysql/mysql-high-performance-optimization-specification-recommendations.md
index 1fe8ea3c788..38c333b3308 100644
--- a/docs/database/mysql/mysql-high-performance-optimization-specification-recommendations.md
+++ b/docs/database/mysql/mysql-high-performance-optimization-specification-recommendations.md
@@ -11,17 +11,17 @@ tag:
## 数据库命名规范
-- 所有数据库对象名称必须使用小写字母并用下划线分割
-- 所有数据库对象名称禁止使用 MySQL 保留关键字(如果表名中包含关键字查询时,需要将其用单引号括起来)
-- 数据库对象的命名要能做到见名识意,并且最后不要超过 32 个字符
-- 临时库表必须以 `tmp_` 为前缀并以日期为后缀,备份表必须以 `bak_` 为前缀并以日期 (时间戳) 为后缀
-- 所有存储相同数据的列名和列类型必须一致(一般作为关联列,如果查询时关联列类型不一致会自动进行数据类型隐式转换,会造成列上的索引失效,导致查询效率降低)
+- 所有数据库对象名称必须使用小写字母并用下划线分割。
+- 所有数据库对象名称禁止使用 MySQL 保留关键字(如果表名中包含关键字查询时,需要将其用单引号括起来)。
+- 数据库对象的命名要能做到见名识义,并且最好不要超过 32 个字符。
+- 临时库表必须以 `tmp_` 为前缀并以日期为后缀,备份表必须以 `bak_` 为前缀并以日期 (时间戳) 为后缀。
+- 所有存储相同数据的列名和列类型必须一致(一般作为关联列,如果查询时关联列类型不一致会自动进行数据类型隐式转换,会造成列上的索引失效,导致查询效率降低)。
## 数据库基本设计规范
### 所有表必须使用 InnoDB 存储引擎
-没有特殊要求(即 InnoDB 无法满足的功能如:列存储,存储空间数据等)的情况下,所有表必须使用 InnoDB 存储引擎(MySQL5.5 之前默认使用 Myisam,5.6 以后默认的为 InnoDB)。
+没有特殊要求(即 InnoDB 无法满足的功能如:列存储、存储空间数据等)的情况下,所有表必须使用 InnoDB 存储引擎(MySQL5.5 之前默认使用 MyISAM,5.6 以后默认的为 InnoDB)。
InnoDB 支持事务,支持行级锁,更好的恢复性,高并发下性能更好。
@@ -33,19 +33,19 @@ InnoDB 支持事务,支持行级锁,更好的恢复性,高并发下性能
### 所有表和字段都需要添加注释
-使用 comment 从句添加表和列的备注,从一开始就进行数据字典的维护
+使用 comment 从句添加表和列的备注,从一开始就进行数据字典的维护。
### 尽量控制单表数据量的大小,建议控制在 500 万以内
500 万并不是 MySQL 数据库的限制,过大会造成修改表结构,备份,恢复都会有很大的问题。
-可以用历史数据归档(应用于日志数据),分库分表(应用于业务数据)等手段来控制数据量大小
+可以用历史数据归档(应用于日志数据),分库分表(应用于业务数据)等手段来控制数据量大小。
### 谨慎使用 MySQL 分区表
-分区表在物理上表现为多个文件,在逻辑上表现为一个表;
+分区表在物理上表现为多个文件,在逻辑上表现为一个表。
-谨慎选择分区键,跨分区查询效率可能更低;
+谨慎选择分区键,跨分区查询效率可能更低。
建议采用物理分表的方式管理大数据。
@@ -71,7 +71,7 @@ InnoDB 支持事务,支持行级锁,更好的恢复性,高并发下性能
### 禁止在线上做数据库压力测试
-### 禁止从开发环境,测试环境直接连接生产环境数据库
+### 禁止从开发环境、测试环境直接连接生产环境数据库
安全隐患极大,要对生产环境抱有敬畏之心!
@@ -79,22 +79,22 @@ InnoDB 支持事务,支持行级锁,更好的恢复性,高并发下性能
### 优先选择符合存储需要的最小的数据类型
-存储字节越小,占用也就空间越小,性能也越好。
+存储字节越小,占用空间也就越小,性能也越好。
-**a.某些字符串可以转换成数字类型存储比如可以将 IP 地址转换成整型数据。**
+**a.某些字符串可以转换成数字类型存储,比如可以将 IP 地址转换成整型数据。**
数字是连续的,性能更好,占用空间也更小。
-MySQL 提供了两个方法来处理 ip 地址
+MySQL 提供了两个方法来处理 ip 地址:
-- `INET_ATON()`:把 ip 转为无符号整型 (4-8 位)
-- `INET_NTOA()` :把整型的 ip 转为地址
+- `INET_ATON()`:把 ip 转为无符号整型 (4-8 位);
+- `INET_NTOA()`:把整型的 ip 转为地址。
-插入数据前,先用 `INET_ATON()` 把 ip 地址转为整型,显示数据时,使用 `INET_NTOA()` 把整型的 ip 地址转为地址显示即可。
+插入数据前,先用 `INET_ATON()` 把 ip 地址转为整型;显示数据时,使用 `INET_NTOA()` 把整型的 ip 地址转为地址显示即可。
-**b.对于非负型的数据 (如自增 ID,整型 IP,年龄) 来说,要优先使用无符号整型来存储。**
+**b.对于非负型的数据 (如自增 ID、整型 IP、年龄) 来说,要优先使用无符号整型来存储。**
-无符号相对于有符号可以多出一倍的存储空间
+无符号相对于有符号可以多出一倍的存储空间:
```sql
SIGNED INT -2147483648~2147483647
@@ -103,7 +103,7 @@ UNSIGNED INT 0~4294967295
**c.小数值类型(比如年龄、状态表示如 0/1)优先使用 TINYINT 类型。**
-### 避免使用 TEXT,BLOB 数据类型,最常见的 TEXT 类型可以存储 64k 的数据
+### 避免使用 TEXT、BLOB 数据类型,最常见的 TEXT 类型可以存储 64k 的数据
**a. 建议把 BLOB 或是 TEXT 列分离到单独的扩展表中。**
@@ -113,30 +113,30 @@ MySQL 内存临时表不支持 TEXT、BLOB 这样的大数据类型,如果查
**2、TEXT 或 BLOB 类型只能使用前缀索引**
-因为 MySQL 对索引字段长度是有限制的,所以 TEXT 类型只能使用前缀索引,并且 TEXT 列上是不能有默认值的
+因为 MySQL 对索引字段长度是有限制的,所以 TEXT 类型只能使用前缀索引,并且 TEXT 列上是不能有默认值的。
### 避免使用 ENUM 类型
-- 修改 ENUM 值需要使用 ALTER 语句;
-- ENUM 类型的 ORDER BY 操作效率低,需要额外操作;
-- ENUM 数据类型存在一些限制比如建议不要使用数值作为 ENUM 的枚举值。
+- 修改 ENUM 值需要使用 ALTER 语句。
+- ENUM 类型的 ORDER BY 操作效率低,需要额外操作。
+- ENUM 数据类型存在一些限制,比如建议不要使用数值作为 ENUM 的枚举值。
相关阅读:[是否推荐使用 MySQL 的 enum 类型? - 架构文摘 - 知乎](https://www.zhihu.com/question/404422255/answer/1661698499) 。
### 尽可能把所有列定义为 NOT NULL
-除非有特别的原因使用 NULL 值,应该总是让字段保持 NOT NULL。
+除非有特别的原因使用 NULL 值,否则应该总是让字段保持 NOT NULL。
-- 索引 NULL 列需要额外的空间来保存,所以要占用更多的空间;
+- 索引 NULL 列需要额外的空间来保存,所以要占用更多的空间。
- 进行比较和计算时要对 NULL 值做特别的处理。
相关阅读:[技术分享 | MySQL 默认值选型(是空,还是 NULL)](https://opensource.actionsky.com/20190710-mysql/) 。
### 一定不要用字符串存储日期
-对于日期类型来说, 一定不要用字符串存储日期。可以考虑 DATETIME、TIMESTAMP 和 数值型时间戳。
+对于日期类型来说,一定不要用字符串存储日期。可以考虑 DATETIME、TIMESTAMP 和数值型时间戳。
-这三种种方式都有各自的优势,根据实际场景选择最合适的才是王道。下面再对这三种方式做一个简单的对比,以供大家实际开发中选择正确的存放时间的数据类型:
+这三种种方式都有各自的优势,根据实际场景选择最合适的才是王道。下面再对这三种方式做一个简单的对比,以供大家在实际开发中选择正确的存放时间的数据类型:
| 类型 | 存储空间 | 日期格式 | 日期范围 | 是否带时区信息 |
| ------------ | -------- | ------------------------------ | ------------------------------------------------------------ | -------------- |
@@ -148,10 +148,10 @@ MySQL 时间类型选择的详细介绍请看这篇:[MySQL 时间类型数据
### 同财务相关的金额类数据必须使用 decimal 类型
-- **非精准浮点**:float,double
+- **非精准浮点**:float、double
- **精准浮点**:decimal
-decimal 类型为精准浮点数,在计算时不会丢失精度。占用空间由定义的宽度决定,每 4 个字节可以存储 9 位数字,并且小数点要占用一个字节。并且,decimal 可用于存储比 bigint 更大的整型数据
+decimal 类型为精准浮点数,在计算时不会丢失精度。占用空间由定义的宽度决定,每 4 个字节可以存储 9 位数字,并且小数点要占用一个字节。并且,decimal 可用于存储比 bigint 更大的整型数据。
不过, 由于 decimal 需要额外的空间和计算开销,应该尽量只在需要对数据进行精确计算时才使用 decimal 。
@@ -161,13 +161,13 @@ decimal 类型为精准浮点数,在计算时不会丢失精度。占用空间
## 索引设计规范
-### 限制每张表上的索引数量,建议单张表索引不超过 5 个
+### 限制每张表上的索引数量,建议单张表索引不超过 5 个
-索引并不是越多越好!索引可以提高效率同样可以降低效率。
+索引并不是越多越好!索引可以提高效率,同样可以降低效率。
索引可以增加查询效率,但同样也会降低插入和更新的效率,甚至有些情况下会降低查询效率。
-因为 MySQL 优化器在选择如何优化查询时,会根据统一信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能。
+因为 MySQL 优化器在选择如何优化查询时,会根据统一信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划。如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能。
### 禁止使用全文索引
@@ -175,46 +175,46 @@ decimal 类型为精准浮点数,在计算时不会丢失精度。占用空间
### 禁止给表中的每一列都建立单独的索引
-5.6 版本之前,一个 sql 只能使用到一个表中的一个索引,5.6 以后,虽然有了合并索引的优化方式,但是还是远远没有使用一个联合索引的查询方式好。
+5.6 版本之前,一个 sql 只能使用到一个表中的一个索引;5.6 以后,虽然有了合并索引的优化方式,但是还是远远没有使用一个联合索引的查询方式好。
### 每个 InnoDB 表必须有个主键
InnoDB 是一种索引组织表:数据的存储的逻辑顺序和索引的顺序是相同的。每个表都可以有多个索引,但是表的存储顺序只能有一种。
-InnoDB 是按照主键索引的顺序来组织表的
+InnoDB 是按照主键索引的顺序来组织表的。
-- 不要使用更新频繁的列作为主键,不使用多列主键(相当于联合索引)
-- 不要使用 UUID,MD5,HASH,字符串列作为主键(无法保证数据的顺序增长)
-- 主键建议使用自增 ID 值
+- 不要使用更新频繁的列作为主键,不使用多列主键(相当于联合索引)。
+- 不要使用 UUID、MD5、HASH、字符串列作为主键(无法保证数据的顺序增长)。
+- 主键建议使用自增 ID 值。
### 常见索引列建议
-- 出现在 SELECT、UPDATE、DELETE 语句的 WHERE 从句中的列
-- 包含在 ORDER BY、GROUP BY、DISTINCT 中的字段
-- 并不要将符合 1 和 2 中的字段的列都建立一个索引, 通常将 1、2 中的字段建立联合索引效果更好
-- 多表 join 的关联列
+- 出现在 SELECT、UPDATE、DELETE 语句的 WHERE 从句中的列。
+- 包含在 ORDER BY、GROUP BY、DISTINCT 中的字段。
+- 不要将符合 1 和 2 中的字段的列都建立一个索引,通常将 1、2 中的字段建立联合索引效果更好。
+- 多表 join 的关联列。
### 如何选择索引列的顺序
-建立索引的目的是:希望通过索引进行数据查找,减少随机 IO,增加查询性能 ,索引能过滤出越少的数据,则从磁盘中读入的数据也就越少。
+建立索引的目的是:希望通过索引进行数据查找,减少随机 IO,增加查询性能,索引能过滤出越少的数据,则从磁盘中读入的数据也就越少。
-- **区分度最高的列放在联合索引的最左侧:** 这是最重要的原则。区分度越高,通过索引筛选出的数据就越少,I/O 操作也就越少。计算区分度的方法是 `count(distinct column) / count(*)`。
-- **最频繁使用的列放在联合索引的左侧:** 这符合最左前缀匹配原则。将最常用的查询条件列放在最左侧,可以最大程度地利用索引。
-- **字段长度:** 字段长度对联合索引非叶子节点的影响很小,因为它存储了所有联合索引字段的值。字段长度主要影响主键和包含在其他索引中的字段的存储空间,以及这些索引的叶子节点的大小。因此,在选择联合索引列的顺序时,字段长度的优先级最低。 对于主键和包含在其他索引中的字段,选择较短的字段长度可以节省存储空间和提高 I/O 性能。
+- **区分度最高的列放在联合索引的最左侧**:这是最重要的原则。区分度越高,通过索引筛选出的数据就越少,I/O 操作也就越少。计算区分度的方法是 `count(distinct column) / count(*)`。
+- **最频繁使用的列放在联合索引的左侧**:这符合最左前缀匹配原则。将最常用的查询条件列放在最左侧,可以最大程度地利用索引。
+- **字段长度**:字段长度对联合索引非叶子节点的影响很小,因为它存储了所有联合索引字段的值。字段长度主要影响主键和包含在其他索引中的字段的存储空间,以及这些索引的叶子节点的大小。因此,在选择联合索引列的顺序时,字段长度的优先级最低。对于主键和包含在其他索引中的字段,选择较短的字段长度可以节省存储空间和提高 I/O 性能。
### 避免建立冗余索引和重复索引(增加了查询优化器生成执行计划的时间)
-- 重复索引示例:primary key(id)、index(id)、unique index(id)
-- 冗余索引示例:index(a,b,c)、index(a,b)、index(a)
+- 重复索引示例:primary key(id)、index(id)、unique index(id)。
+- 冗余索引示例:index(a,b,c)、index(a,b)、index(a)。
-### 对于频繁的查询优先考虑使用覆盖索引
+### 对于频繁的查询,优先考虑使用覆盖索引
-> 覆盖索引:就是包含了所有查询字段 (where,select,order by,group by 包含的字段) 的索引
+> 覆盖索引:就是包含了所有查询字段 (where、select、order by、group by 包含的字段) 的索引
-**覆盖索引的好处:**
+**覆盖索引的好处**:
-- **避免 InnoDB 表进行索引的二次查询,也就是回表操作:** InnoDB 是以聚集索引的顺序来存储的,对于 InnoDB 来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据的话,在查找到相应的键值后,还要通过主键进行二次查询才能获取我们真实所需要的数据。而在覆盖索引中,二级索引的键值中可以获取所有的数据,避免了对主键的二次查询(回表),减少了 IO 操作,提升了查询效率。
-- **可以把随机 IO 变成顺序 IO 加快查询效率:** 由于覆盖索引是按键值的顺序存储的,对于 IO 密集型的范围查找来说,对比随机从磁盘读取每一行的数据 IO 要少的多,因此利用覆盖索引在访问时也可以把磁盘的随机读取的 IO 转变成索引查找的顺序 IO。
+- **避免 InnoDB 表进行索引的二次查询,也就是回表操作**:InnoDB 是以聚集索引的顺序来存储的,对于 InnoDB 来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据的话,在查找到相应的键值后,还要通过主键进行二次查询才能获取我们真实所需要的数据。而在覆盖索引中,二级索引的键值中可以获取所有的数据,避免了对主键的二次查询(回表),减少了 IO 操作,提升了查询效率。
+- **可以把随机 IO 变成顺序 IO 加快查询效率**:由于覆盖索引是按键值的顺序存储的,对于 IO 密集型的范围查找来说,对比随机从磁盘读取每一行的数据 IO 要少的多,因此利用覆盖索引在访问时也可以把磁盘的随机读取的 IO 转变成索引查找的顺序 IO。
---
@@ -222,9 +222,9 @@ InnoDB 是按照主键索引的顺序来组织表的
**尽量避免使用外键约束**
-- 不建议使用外键约束(foreign key),但一定要在表与表之间的关联键上建立索引
-- 外键可用于保证数据的参照完整性,但建议在业务端实现
-- 外键会影响父表和子表的写操作从而降低性能
+- 不建议使用外键约束(foreign key),但一定要在表与表之间的关联键上建立索引。
+- 外键可用于保证数据的参照完整性,但建议在业务端实现。
+- 外键会影响父表和子表的写操作从而降低性能。
## 数据库 SQL 开发规范
@@ -238,7 +238,7 @@ InnoDB 是按照主键索引的顺序来组织表的
### 充分利用表上已经存在的索引
-避免使用双%号的查询条件。如:`a like '%123%'`,(如果无前置%,只有后置%,是可以用到列上的索引的)
+避免使用双%号的查询条件。如:`a like '%123%'`(如果无前置%,只有后置%,是可以用到列上的索引的)。
一个 SQL 只能利用到复合索引中的一列进行范围查询。如:有 a,b,c 列的联合索引,在查询条件中有 a 列的范围查询,则在 b,c 列上的索引将不会被用到。
@@ -248,18 +248,18 @@ InnoDB 是按照主键索引的顺序来组织表的
- `SELECT *` 会消耗更多的 CPU。
- `SELECT *` 无用字段增加网络带宽资源消耗,增加数据传输时间,尤其是大字段(如 varchar、blob、text)。
-- `SELECT *` 无法使用 MySQL 优化器覆盖索引的优化(基于 MySQL 优化器的“覆盖索引”策略又是速度极快,效率极高,业界极为推荐的查询优化方式)
-- `SELECT <字段列表>` 可减少表结构变更带来的影响、
+- `SELECT *` 无法使用 MySQL 优化器覆盖索引的优化(基于 MySQL 优化器的“覆盖索引”策略又是速度极快、效率极高、业界极为推荐的查询优化方式)。
+- `SELECT <字段列表>` 可减少表结构变更带来的影响。
### 禁止使用不含字段列表的 INSERT 语句
-如:
+**不推荐**:
```sql
insert into t values ('a','b','c');
```
-应使用:
+**推荐**:
```sql
insert into t(c1,c2,c3) values ('a','b','c');
@@ -273,7 +273,7 @@ insert into t(c1,c2,c3) values ('a','b','c');
### 避免数据类型的隐式转换
-隐式转换会导致索引失效如:
+隐式转换会导致索引失效,如:
```sql
select name,phone from customer where id = '111';
@@ -283,9 +283,9 @@ select name,phone from customer where id = '111';
### 避免使用子查询,可以把子查询优化为 join 操作
-通常子查询在 in 子句中,且子查询中为简单 SQL(不包含 union、group by、order by、limit 从句) 时,才可以把子查询转化为关联查询进行优化。
+通常子查询在 in 子句中,且子查询中为简单 SQL(不包含 union、group by、order by、limit 从句) 时,才可以把子查询转化为关联查询进行优化。
-**子查询性能差的原因:** 子查询的结果集无法使用索引,通常子查询的结果集会被存储到临时表中,不论是内存临时表还是磁盘临时表都不会存在索引,所以查询性能会受到一定的影响。特别是对于返回结果集比较大的子查询,其对查询性能的影响也就越大。由于子查询会产生大量的临时表也没有索引,所以会消耗过多的 CPU 和 IO 资源,产生大量的慢查询。
+**子查询性能差的原因**:子查询的结果集无法使用索引,通常子查询的结果集会被存储到临时表中,不论是内存临时表还是磁盘临时表都不会存在索引,所以查询性能会受到一定的影响。特别是对于返回结果集比较大的子查询,其对查询性能的影响也就越大。由于子查询会产生大量的临时表也没有索引,所以会消耗过多的 CPU 和 IO 资源,产生大量的慢查询。
### 避免使用 JOIN 关联太多的表
@@ -293,7 +293,7 @@ select name,phone from customer where id = '111';
在 MySQL 中,对于同一个 SQL 多关联(join)一个表,就会多分配一个关联缓存,如果在一个 SQL 中关联的表越多,所占用的内存也就越大。
-如果程序中大量的使用了多表关联的操作,同时 join_buffer_size 设置的也不合理的情况下,就容易造成服务器内存溢出的情况,就会影响到服务器数据库性能的稳定性。
+如果程序中大量地使用了多表关联的操作,同时 join_buffer_size 设置得也不合理,就容易造成服务器内存溢出的情况,就会影响到服务器数据库性能的稳定性。
同时对于关联操作来说,会产生临时表操作,影响查询效率,MySQL 最多允许关联 61 个表,建议不超过 5 个。
@@ -303,25 +303,25 @@ select name,phone from customer where id = '111';
### 对应同一列进行 or 判断时,使用 in 代替 or
-in 的值不要超过 500 个,in 操作可以更有效的利用索引,or 大多数情况下很少能利用到索引。
+in 的值不要超过 500 个。in 操作可以更有效的利用索引,or 大多数情况下很少能利用到索引。
### 禁止使用 order by rand() 进行随机排序
-order by rand() 会把表中所有符合条件的数据装载到内存中,然后在内存中对所有数据根据随机生成的值进行排序,并且可能会对每一行都生成一个随机值,如果满足条件的数据集非常大,就会消耗大量的 CPU 和 IO 及内存资源。
+order by rand() 会把表中所有符合条件的数据装载到内存中,然后在内存中对所有数据根据随机生成的值进行排序,并且可能会对每一行都生成一个随机值。如果满足条件的数据集非常大,就会消耗大量的 CPU 和 IO 及内存资源。
推荐在程序中获取一个随机值,然后从数据库中获取数据的方式。
### WHERE 从句中禁止对列进行函数转换和计算
-对列进行函数转换或计算时会导致无法使用索引
+对列进行函数转换或计算时会导致无法使用索引。
-**不推荐:**
+**不推荐**:
```sql
where date(create_time)='20190101'
```
-**推荐:**
+**推荐**:
```sql
where create_time >= '20190101' and create_time < '20190102'
@@ -329,43 +329,43 @@ where create_time >= '20190101' and create_time < '20190102'
### 在明显不会有重复值时使用 UNION ALL 而不是 UNION
-- UNION 会把两个结果集的所有数据放到临时表中后再进行去重操作
-- UNION ALL 不会再对结果集进行去重操作
+- UNION 会把两个结果集的所有数据放到临时表中后再进行去重操作。
+- UNION ALL 不会再对结果集进行去重操作。
### 拆分复杂的大 SQL 为多个小 SQL
-- 大 SQL 逻辑上比较复杂,需要占用大量 CPU 进行计算的 SQL
-- MySQL 中,一个 SQL 只能使用一个 CPU 进行计算
-- SQL 拆分后可以通过并行执行来提高处理效率
+- 大 SQL 逻辑上比较复杂,需要占用大量 CPU 进行计算的 SQL。
+- MySQL 中,一个 SQL 只能使用一个 CPU 进行计算。
+- SQL 拆分后可以通过并行执行来提高处理效率。
### 程序连接不同的数据库使用不同的账号,禁止跨库查询
-- 为数据库迁移和分库分表留出余地
-- 降低业务耦合度
-- 避免权限过大而产生的安全风险
+- 为数据库迁移和分库分表留出余地。
+- 降低业务耦合度。
+- 避免权限过大而产生的安全风险。
## 数据库操作行为规范
-### 超 100 万行的批量写 (UPDATE,DELETE,INSERT) 操作,要分批多次进行操作
+### 超 100 万行的批量写 (UPDATE、DELETE、INSERT) 操作,要分批多次进行操作
**大批量操作可能会造成严重的主从延迟**
-主从环境中,大批量操作可能会造成严重的主从延迟,大批量的写操作一般都需要执行一定长的时间,而只有当主库上执行完成后,才会在其他从库上执行,所以会造成主库与从库长时间的延迟情况
+主从环境中,大批量操作可能会造成严重的主从延迟,大批量的写操作一般都需要执行一定长的时间,而只有当主库上执行完成后,才会在其他从库上执行,所以会造成主库与从库长时间的延迟情况。
**binlog 日志为 row 格式时会产生大量的日志**
-大批量写操作会产生大量日志,特别是对于 row 格式二进制数据而言,由于在 row 格式中会记录每一行数据的修改,我们一次修改的数据越多,产生的日志量也就会越多,日志的传输和恢复所需要的时间也就越长,这也是造成主从延迟的一个原因
+大批量写操作会产生大量日志,特别是对于 row 格式二进制数据而言,由于在 row 格式中会记录每一行数据的修改,我们一次修改的数据越多,产生的日志量也就会越多,日志的传输和恢复所需要的时间也就越长,这也是造成主从延迟的一个原因。
**避免产生大事务操作**
大批量修改数据,一定是在一个事务中进行的,这就会造成表中大批量数据进行锁定,从而导致大量的阻塞,阻塞会对 MySQL 的性能产生非常大的影响。
-特别是长时间的阻塞会占满所有数据库的可用连接,这会使生产环境中的其他应用无法连接到数据库,因此一定要注意大批量写操作要进行分批
+特别是长时间的阻塞会占满所有数据库的可用连接,这会使生产环境中的其他应用无法连接到数据库,因此一定要注意大批量写操作要进行分批。
### 对于大表使用 pt-online-schema-change 修改表结构
-- 避免大表修改产生的主从延迟
-- 避免在对表字段进行修改时进行锁表
+- 避免大表修改产生的主从延迟。
+- 避免在对表字段进行修改时进行锁表。
对大表数据结构的修改一定要谨慎,会造成严重的锁表操作,尤其是生产环境,是不能容忍的。
@@ -373,13 +373,13 @@ pt-online-schema-change 它会首先建立一个与原表结构相同的新表
### 禁止为程序使用的账号赋予 super 权限
-- 当达到最大连接数限制时,还运行 1 个有 super 权限的用户连接
-- super 权限只能留给 DBA 处理问题的账号使用
+- 当达到最大连接数限制时,还运行 1 个有 super 权限的用户连接。
+- super 权限只能留给 DBA 处理问题的账号使用。
-### 对于程序连接数据库账号,遵循权限最小原则
+### 对于程序连接数据库账号,遵循权限最小原则
-- 程序使用数据库账号只能在一个 DB 下使用,不准跨库
-- 程序使用的账号原则上不准有 drop 权限
+- 程序使用数据库账号只能在一个 DB 下使用,不准跨库。
+- 程序使用的账号原则上不准有 drop 权限。
## 推荐阅读
diff --git a/docs/database/mysql/mysql-index.md b/docs/database/mysql/mysql-index.md
index ab0dc7f6760..afed110b9b4 100644
--- a/docs/database/mysql/mysql-index.md
+++ b/docs/database/mysql/mysql-index.md
@@ -15,31 +15,37 @@ tag:
**索引是一种用于快速查询和检索数据的数据结构,其本质可以看成是一种排序好的数据结构。**
-索引的作用就相当于书的目录。打个比方: 我们在查字典的时候,如果没有目录,那我们就只能一页一页的去找我们需要查的那个字,速度很慢。如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
+索引的作用就相当于书的目录。打个比方:我们在查字典的时候,如果没有目录,那我们就只能一页一页地去找我们需要查的那个字,速度很慢;如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
-索引底层数据结构存在很多种类型,常见的索引结构有: B 树, B+树 和 Hash、红黑树。在 MySQL 中,无论是 Innodb 还是 MyIsam,都使用了 B+树作为索引结构。
+索引底层数据结构存在很多种类型,常见的索引结构有:B 树、 B+ 树 和 Hash、红黑树。在 MySQL 中,无论是 Innodb 还是 MyISAM,都使用了 B+ 树作为索引结构。
## 索引的优缺点
-**优点**:
+**索引的优点:**
-- 使用索引可以大大加快数据的检索速度(大大减少检索的数据量), 减少 IO 次数,这也是创建索引的最主要的原因。
-- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
+1. **查询速度起飞 (主要目的)**:通过索引,数据库可以**大幅减少需要扫描的数据量**,直接定位到符合条件的记录,从而显著加快数据检索速度,减少磁盘 I/O 次数。
+2. **保证数据唯一性**:通过创建**唯一索引 (Unique Index)**,可以确保表中的某一列(或几列组合)的值是独一无二的,比如用户 ID、邮箱等。主键本身就是一种唯一索引。
+3. **加速排序和分组**:如果查询中的 ORDER BY 或 GROUP BY 子句涉及的列建有索引,数据库往往可以直接利用索引已经排好序的特性,避免额外的排序操作,从而提升性能。
-**缺点**:
+**索引的缺点:**
+
+1. **创建和维护耗时**:创建索引本身需要时间,特别是对大表操作时。更重要的是,当对表中的数据进行**增、删、改 (DML 操作)** 时,不仅要操作数据本身,相关的索引也必须动态更新和维护,这会**降低这些 DML 操作的执行效率**。
+2. **占用存储空间**:索引本质上也是一种数据结构,需要以物理文件(或内存结构)的形式存储,因此会**额外占用一定的磁盘空间**。索引越多、越大,占用的空间也就越多。
+3. **可能被误用或失效**:如果索引设计不当,或者查询语句写得不好,数据库优化器可能不会选择使用索引(或者选错索引),反而导致性能下降。
-- 创建索引和维护索引需要耗费许多时间。当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低 SQL 执行效率。
-- 索引需要使用物理文件存储,也会耗费一定空间。
+**那么,用了索引就一定能提高查询性能吗?**
-但是,**使用索引一定能提高查询性能吗?**
+**不一定。** 大多数情况下,合理使用索引确实比全表扫描快得多。但也有例外:
-大多数情况下,索引查询都是比全表扫描要快的。但是如果数据库的数据量不大,那么使用索引也不一定能够带来很大提升。
+- **数据量太小**:如果表里的数据非常少(比如就几百条),全表扫描可能比通过索引查找更快,因为走索引本身也有开销。
+- **查询结果集占比过大**:如果要查询的数据占了整张表的大部分(比如超过 20%-30%),优化器可能会认为全表扫描更划算,因为通过索引多次回表(随机 I/O)的成本可能高于一次顺序的全表扫描。
+- **索引维护不当或统计信息过时**:导致优化器做出错误判断。
## 索引底层数据结构选型
### Hash 表
-哈希表是键值对的集合,通过键(key)即可快速取出对应的值(value),因此哈希表可以快速检索数据(接近 O(1))。
+哈希表是键值对的集合,通过键(key)即可快速取出对应的值(value),因此哈希表可以快速检索数据(接近 O(1))。
**为何能够通过 key 快速取出 value 呢?** 原因在于 **哈希算法**(也叫散列算法)。通过哈希算法,我们可以快速找到 key 对应的 index,找到了 index 也就找到了对应的 value。
@@ -50,7 +56,7 @@ index = hash % array_size
-但是!哈希算法有个 **Hash 冲突** 问题,也就是说多个不同的 key 最后得到的 index 相同。通常情况下,我们常用的解决办法是 **链地址法**。链地址法就是将哈希冲突数据存放在链表中。就比如 JDK1.8 之前 `HashMap` 就是通过链地址法来解决哈希冲突的。不过,JDK1.8 以后`HashMap`为了减少链表过长的时候搜索时间过长引入了红黑树。
+但是!哈希算法有个 **Hash 冲突** 问题,也就是说多个不同的 key 最后得到的 index 相同。通常情况下,我们常用的解决办法是 **链地址法**。链地址法就是将哈希冲突数据存放在链表中。就比如 JDK1.8 之前 `HashMap` 就是通过链地址法来解决哈希冲突的。不过,JDK1.8 以后`HashMap`为了提高链表过长时的搜索效率,引入了红黑树。
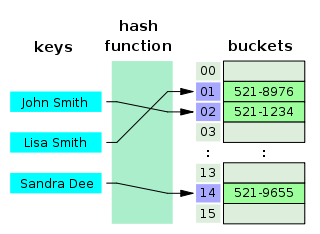
@@ -60,15 +66,15 @@ MySQL 的 InnoDB 存储引擎不直接支持常规的哈希索引,但是,Inn
既然哈希表这么快,**为什么 MySQL 没有使用其作为索引的数据结构呢?** 主要是因为 Hash 索引不支持顺序和范围查询。假如我们要对表中的数据进行排序或者进行范围查询,那 Hash 索引可就不行了。并且,每次 IO 只能取一个。
-试想一种情况:
+试想一种情况:
```java
SELECT * FROM tb1 WHERE id < 500;
```
-在这种范围查询中,优势非常大,直接遍历比 500 小的叶子节点就够了。而 Hash 索引是根据 hash 算法来定位的,难不成还要把 1 - 499 的数据,每个都进行一次 hash 计算来定位吗?这就是 Hash 最大的缺点了。
+在这种范围查询中,优势非常大,直接遍历比 500 小的叶子节点就够了。而 Hash 索引是根据 hash 算法来定位的,难不成还要把 1 - 499 的数据,每个都进行一次 hash 计算来定位吗?这就是 Hash 最大的缺点了。
-### 二叉查找树(BST)
+### 二叉查找树(BST)
二叉查找树(Binary Search Tree)是一种基于二叉树的数据结构,它具有以下特点:
@@ -76,7 +82,7 @@ SELECT * FROM tb1 WHERE id < 500;
2. 右子树所有节点的值均大于根节点的值。
3. 左右子树也分别为二叉查找树。
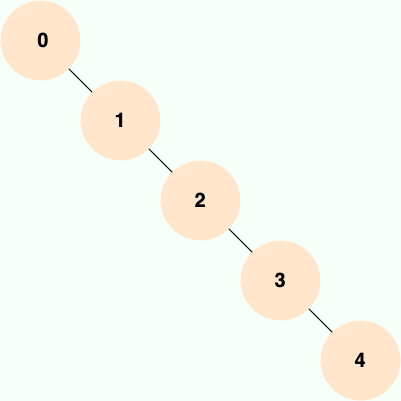
-当二叉查找树是平衡的时候,也就是树的每个节点的左右子树深度相差不超过 1 的时候,查询的时间复杂度为 O(log2(N)),具有比较高的效率。然而,当二叉查找树不平衡时,例如在最坏情况下(有序插入节点),树会退化成线性链表(也被称为斜树),导致查询效率急剧下降,时间复杂退化为 O(N)。
+当二叉查找树是平衡的时候,也就是树的每个节点的左右子树深度相差不超过 1 的时候,查询的时间复杂度为 O(log2(N)),具有比较高的效率。然而,当二叉查找树不平衡时,例如在最坏情况下(有序插入节点),树会退化成线性链表(也被称为斜树),导致查询效率急剧下降,时间复杂退化为 O(N)。
@@ -92,7 +98,7 @@ AVL 树是计算机科学中最早被发明的自平衡二叉查找树,它的
AVL 树采用了旋转操作来保持平衡。主要有四种旋转操作:LL 旋转、RR 旋转、LR 旋转和 RL 旋转。其中 LL 旋转和 RR 旋转分别用于处理左左和右右失衡,而 LR 旋转和 RL 旋转则用于处理左右和右左失衡。
-由于 AVL 树需要频繁地进行旋转操作来保持平衡,因此会有较大的计算开销进而降低了数据库写操作的性能。并且, 在使用 AVL 树时,每个树节点仅存储一个数据,而每次进行磁盘 IO 时只能读取一个节点的数据,如果需要查询的数据分布在多个节点上,那么就需要进行多次磁盘 IO。 **磁盘 IO 是一项耗时的操作,在设计数据库索引时,我们需要优先考虑如何最大限度地减少磁盘 IO 操作的次数。**
+由于 AVL 树需要频繁地进行旋转操作来保持平衡,因此会有较大的计算开销进而降低了数据库写操作的性能。并且, 在使用 AVL 树时,每个树节点仅存储一个数据,而每次进行磁盘 IO 时只能读取一个节点的数据,如果需要查询的数据分布在多个节点上,那么就需要进行多次磁盘 IO。**磁盘 IO 是一项耗时的操作,在设计数据库索引时,我们需要优先考虑如何最大限度地减少磁盘 IO 操作的次数。**
实际应用中,AVL 树使用的并不多。
@@ -112,26 +118,26 @@ AVL 树采用了旋转操作来保持平衡。主要有四种旋转操作:LL
**红黑树的应用还是比较广泛的,TreeMap、TreeSet 以及 JDK1.8 的 HashMap 底层都用到了红黑树。对于数据在内存中的这种情况来说,红黑树的表现是非常优异的。**
-### B 树& B+树
+### B 树& B+ 树
-B 树也称 B-树,全称为 **多路平衡查找树** ,B+ 树是 B 树的一种变体。B 树和 B+树中的 B 是 `Balanced` (平衡)的意思。
+B 树也称 B- 树,全称为 **多路平衡查找树**,B+ 树是 B 树的一种变体。B 树和 B+ 树中的 B 是 `Balanced`(平衡)的意思。
目前大部分数据库系统及文件系统都采用 B-Tree 或其变种 B+Tree 作为索引结构。
-**B 树& B+树两者有何异同呢?**
+**B 树& B+ 树两者有何异同呢?**
-- B 树的所有节点既存放键(key) 也存放数据(data),而 B+树只有叶子节点存放 key 和 data,其他内节点只存放 key。
-- B 树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点。
-- B 树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而 B+树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
-- 在 B 树中进行范围查询时,首先找到要查找的下限,然后对 B 树进行中序遍历,直到找到查找的上限;而 B+树的范围查询,只需要对链表进行遍历即可。
+- B 树的所有节点既存放键(key)也存放数据(data),而 B+ 树只有叶子节点存放 key 和 data,其他内节点只存放 key。
+- B 树的叶子节点都是独立的;B+ 树的叶子节点有一条引用链指向与它相邻的叶子节点。
+- B 树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而 B+ 树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
+- 在 B 树中进行范围查询时,首先找到要查找的下限,然后对 B 树进行中序遍历,直到找到查找的上限;而 B+ 树的范围查询,只需要对链表进行遍历即可。
-综上,B+树与 B 树相比,具备更少的 IO 次数、更稳定的查询效率和更适于范围查询这些优势。
+综上,B+ 树与 B 树相比,具备更少的 IO 次数、更稳定的查询效率和更适于范围查询这些优势。
在 MySQL 中,MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,但是,两者的实现方式不太一样。(下面的内容整理自《Java 工程师修炼之道》)
> MyISAM 引擎中,B+Tree 叶节点的 data 域存放的是数据记录的地址。在索引检索的时候,首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“**非聚簇索引(非聚集索引)**”。
>
-> InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。这被称为“**聚簇索引(聚集索引)**”,而其余的索引都作为 **辅助索引** ,辅助索引的 data 域存储相应记录主键的值而不是地址,这也是和 MyISAM 不同的地方。在根据主索引搜索时,直接找到 key 所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
+> InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。这被称为“**聚簇索引(聚集索引)**”,而其余的索引都作为 **辅助索引**,辅助索引的 data 域存储相应记录主键的值而不是地址,这也是和 MyISAM 不同的地方。在根据主索引搜索时,直接找到 key 所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
## 索引类型总结
@@ -140,12 +146,12 @@ B 树也称 B-树,全称为 **多路平衡查找树** ,B+ 树是 B 树的一
- BTree 索引:MySQL 里默认和最常用的索引类型。只有叶子节点存储 value,非叶子节点只有指针和 key。存储引擎 MyISAM 和 InnoDB 实现 BTree 索引都是使用 B+Tree,但二者实现方式不一样(前面已经介绍了)。
- 哈希索引:类似键值对的形式,一次即可定位。
- RTree 索引:一般不会使用,仅支持 geometry 数据类型,优势在于范围查找,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
-- 全文索引:对文本的内容进行分词,进行搜索。目前只有 `CHAR`、`VARCHAR` ,`TEXT` 列上可以创建全文索引。一般不会使用,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
+- 全文索引:对文本的内容进行分词,进行搜索。目前只有 `CHAR`、`VARCHAR`、`TEXT` 列上可以创建全文索引。一般不会使用,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
按照底层存储方式角度划分:
- 聚簇索引(聚集索引):索引结构和数据一起存放的索引,InnoDB 中的主键索引就属于聚簇索引。
-- 非聚簇索引(非聚集索引):索引结构和数据分开存放的索引,二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。
+- 非聚簇索引(非聚集索引):索引结构和数据分开存放的索引,二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。
按照应用维度划分:
@@ -154,7 +160,7 @@ B 树也称 B-树,全称为 **多路平衡查找树** ,B+ 树是 B 树的一
- 唯一索引:加速查询 + 列值唯一(可以有 NULL)。
- 覆盖索引:一个索引包含(或者说覆盖)所有需要查询的字段的值。
- 联合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并。
-- 全文索引:对文本的内容进行分词,进行搜索。目前只有 `CHAR`、`VARCHAR` ,`TEXT` 列上可以创建全文索引。一般不会使用,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
+- 全文索引:对文本的内容进行分词,进行搜索。目前只有 `CHAR`、`VARCHAR`、`TEXT` 列上可以创建全文索引。一般不会使用,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
- 前缀索引:对文本的前几个字符创建索引,相比普通索引建立的数据更小,因为只取前几个字符。
MySQL 8.x 中实现的索引新特性:
@@ -163,7 +169,7 @@ MySQL 8.x 中实现的索引新特性:
- 降序索引:之前的版本就支持通过 desc 来指定索引为降序,但实际上创建的仍然是常规的升序索引。直到 MySQL 8.x 版本才开始真正支持降序索引。另外,在 MySQL 8.x 版本中,不再对 GROUP BY 语句进行隐式排序。
- 函数索引:从 MySQL 8.0.13 版本开始支持在索引中使用函数或者表达式的值,也就是在索引中可以包含函数或者表达式。
-## 主键索引(Primary Key)
+## 主键索引(Primary Key)
数据表的主键列使用的就是主键索引。
@@ -177,16 +183,16 @@ MySQL 8.x 中实现的索引新特性:
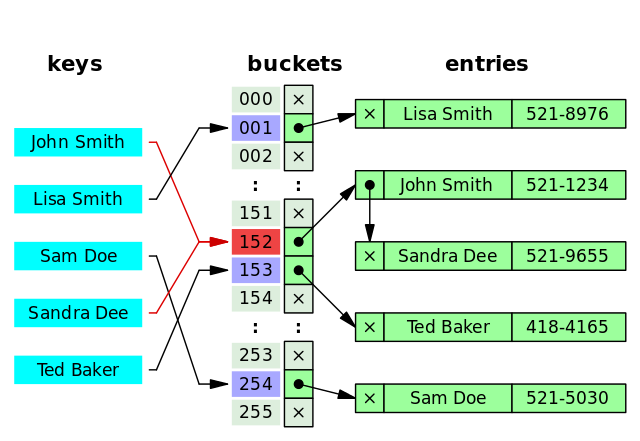
二级索引(Secondary Index)的叶子节点存储的数据是主键的值,也就是说,通过二级索引可以定位主键的位置,二级索引又称为辅助索引/非主键索引。
-唯一索引,普通索引,前缀索引等索引都属于二级索引。
+唯一索引、普通索引、前缀索引等索引都属于二级索引。
-PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,也可以自行搜索。
+PS:不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,也可以自行搜索。
-1. **唯一索引(Unique Key)**:唯一索引也是一种约束。唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引。 建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
-2. **普通索引(Index)**:普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和 NULL。
-3. **前缀索引(Prefix)**:前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,因为只取前几个字符。
-4. **全文索引(Full Text)**:全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6 之前只有 MYISAM 引擎支持全文索引,5.6 之后 InnoDB 也支持了全文索引。
+1. **唯一索引(Unique Key)**:唯一索引也是一种约束。唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引。 建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
+2. **普通索引(Index)**:普通索引的唯一作用就是为了快速查询数据。一张表允许创建多个普通索引,并允许数据重复和 NULL。
+3. **前缀索引(Prefix)**:前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,因为只取前几个字符。
+4. **全文索引(Full Text)**:全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6 之前只有 MyISAM 引擎支持全文索引,5.6 之后 InnoDB 也支持了全文索引。
-二级索引:
+二级索引:
@@ -198,25 +204,25 @@ PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,
聚簇索引(Clustered Index)即索引结构和数据一起存放的索引,并不是一种单独的索引类型。InnoDB 中的主键索引就属于聚簇索引。
-在 MySQL 中,InnoDB 引擎的表的 `.ibd`文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
+在 MySQL 中,InnoDB 引擎的表的 `.ibd`文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+ 树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
#### 聚簇索引的优缺点
**优点**:
-- **查询速度非常快**:聚簇索引的查询速度非常的快,因为整个 B+树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。相比于非聚簇索引, 聚簇索引少了一次读取数据的 IO 操作。
+- **查询速度非常快**:聚簇索引的查询速度非常的快,因为整个 B+ 树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。相比于非聚簇索引, 聚簇索引少了一次读取数据的 IO 操作。
- **对排序查找和范围查找优化**:聚簇索引对于主键的排序查找和范围查找速度非常快。
**缺点**:
-- **依赖于有序的数据**:因为 B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或 UUID 这种又长又难比较的数据,插入或查找的速度肯定比较慢。
+- **依赖于有序的数据**:因为 B+ 树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或 UUID 这种又长又难比较的数据,插入或查找的速度肯定比较慢。
- **更新代价大**:如果对索引列的数据被修改时,那么对应的索引也将会被修改,而且聚簇索引的叶子节点还存放着数据,修改代价肯定是较大的,所以对于主键索引来说,主键一般都是不可被修改的。
### 非聚簇索引(非聚集索引)
#### 非聚簇索引介绍
-非聚簇索引(Non-Clustered Index)即索引结构和数据分开存放的索引,并不是一种单独的索引类型。二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。
+非聚簇索引(Non-Clustered Index)即索引结构和数据分开存放的索引,并不是一种单独的索引类型。二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。
非聚簇索引的叶子节点并不一定存放数据的指针,因为二级索引的叶子节点就存放的是主键,根据主键再回表查数据。
@@ -224,22 +230,22 @@ PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,
**优点**:
-更新代价比聚簇索引要小 。非聚簇索引的更新代价就没有聚簇索引那么大了,非聚簇索引的叶子节点是不存放数据的。
+更新代价比聚簇索引要小。非聚簇索引的更新代价就没有聚簇索引那么大了,非聚簇索引的叶子节点是不存放数据的。
**缺点**:
-- **依赖于有序的数据**:跟聚簇索引一样,非聚簇索引也依赖于有序的数据
-- **可能会二次查询(回表)**:这应该是非聚簇索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
+- **依赖于有序的数据**:跟聚簇索引一样,非聚簇索引也依赖于有序的数据。
+- **可能会二次查询(回表)**:这应该是非聚簇索引最大的缺点了。当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
-这是 MySQL 的表的文件截图:
+这是 MySQL 的表的文件截图:
-聚簇索引和非聚簇索引:
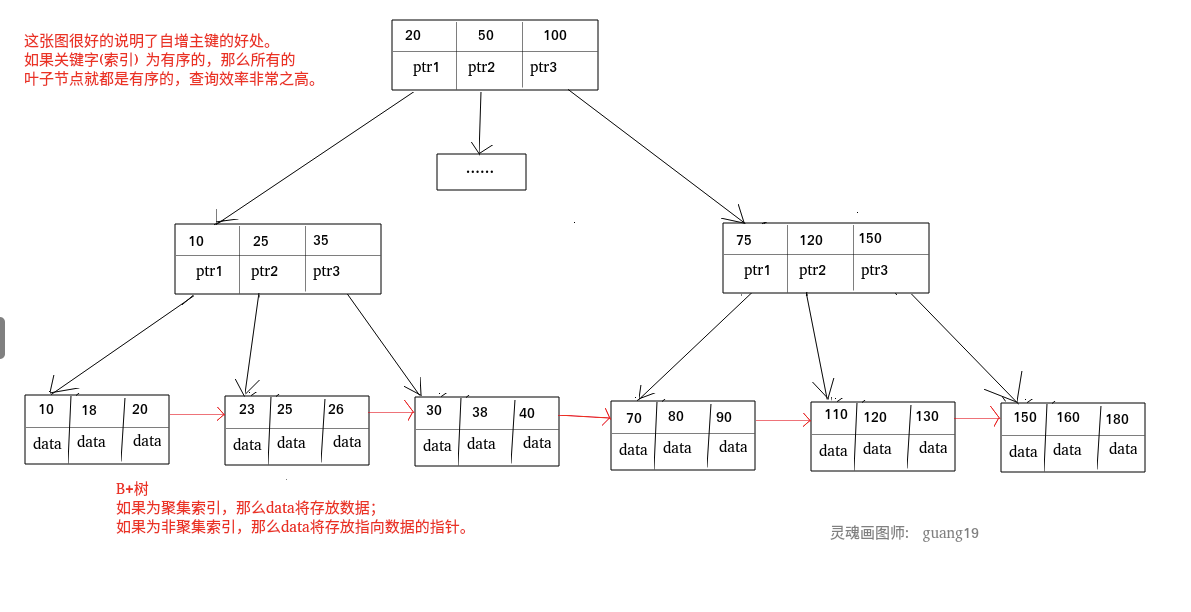
+聚簇索引和非聚簇索引:
-#### 非聚簇索引一定回表查询吗(覆盖索引)?
+#### 非聚簇索引一定回表查询吗(覆盖索引)?
**非聚簇索引不一定回表查询。**
@@ -251,7 +257,7 @@ PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,
那么这个索引的 key 本身就是 name,查到对应的 name 直接返回就行了,无需回表查询。
-即使是 MYISAM 也是这样,虽然 MYISAM 的主键索引确实需要回表,因为它的主键索引的叶子节点存放的是指针。但是!**如果 SQL 查的就是主键呢?**
+即使是 MyISAM 也是这样,虽然 MyISAM 的主键索引确实需要回表,因为它的主键索引的叶子节点存放的是指针。但是!**如果 SQL 查的就是主键呢?**
```sql
SELECT id FROM table WHERE id=1;
@@ -263,7 +269,7 @@ SELECT id FROM table WHERE id=1;
### 覆盖索引
-如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为 **覆盖索引(Covering Index)** 。
+如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为 **覆盖索引(Covering Index)**。
在 InnoDB 存储引擎中,非主键索引的叶子节点包含的是主键的值。这意味着,当使用非主键索引进行查询时,数据库会先找到对应的主键值,然后再通过主键索引来定位和检索完整的行数据。这个过程被称为“回表”。
@@ -276,7 +282,7 @@ SELECT id FROM table WHERE id=1;
我们这里简单演示一下覆盖索引的效果。
-1、创建一个名为 `cus_order` 的表,来实际测试一下这种排序方式。为了测试方便, `cus_order` 这张表只有 `id`、`score`、`name`这 3 个字段。
+1、创建一个名为 `cus_order` 的表,来实际测试一下这种排序方式。为了测试方便,`cus_order` 这张表只有 `id`、`score`、`name` 这 3 个字段。
```sql
CREATE TABLE `cus_order` (
@@ -320,7 +326,7 @@ CALL BatchinsertDataToCusOder(1, 1000000); # 插入100w+的随机数据
SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
```
-使用 `EXPLAIN` 命令分析这条 SQL 语句,通过 `Extra` 这一列的 `Using filesort` ,我们发现是没有用到覆盖索引的。
+使用 `EXPLAIN` 命令分析这条 SQL 语句,通过 `Extra` 这一列的 `Using filesort`,我们发现是没有用到覆盖索引的。

@@ -336,7 +342,7 @@ ALTER TABLE `cus_order` ADD INDEX id_score_name(score, name);

-通过 `Extra` 这一列的 `Using index` ,说明这条 SQL 语句成功使用了覆盖索引。
+通过 `Extra` 这一列的 `Using index`,说明这条 SQL 语句成功使用了覆盖索引。
关于 `EXPLAIN` 命令的详细介绍请看:[MySQL 执行计划分析](./mysql-query-execution-plan.md)这篇文章。
@@ -356,13 +362,13 @@ ALTER TABLE `cus_order` ADD INDEX id_score_name(score, name);
最左匹配原则会一直向右匹配,直到遇到范围查询(如 >、<)为止。对于 >=、<=、BETWEEN 以及前缀匹配 LIKE 的范围查询,不会停止匹配(相关阅读:[联合索引的最左匹配原则全网都在说的一个错误结论](https://mp.weixin.qq.com/s/8qemhRg5MgXs1So5YCv0fQ))。
-假设有一个联合索引`(column1, column2, column3)`,其从左到右的所有前缀为`(column1)`、`(column1, column2)`、`(column1, column2, column3)`(创建 1 个联合索引相当于创建了 3 个索引),包含这些列的所有查询都会走索引而不会全表扫描。
+假设有一个联合索引 `(column1, column2, column3)`,其从左到右的所有前缀为 `(column1)`、`(column1, column2)`、`(column1, column2, column3)`(创建 1 个联合索引相当于创建了 3 个索引),包含这些列的所有查询都会走索引而不会全表扫描。
我们在使用联合索引时,可以将区分度高的字段放在最左边,这也可以过滤更多数据。
我们这里简单演示一下最左前缀匹配的效果。
-1、创建一个名为 `student` 的表,这张表只有 `id`、`name`、`class`这 3 个字段。
+1、创建一个名为 `student` 的表,这张表只有 `id`、`name`、`class` 这 3 个字段。
```sql
CREATE TABLE `student` (
@@ -386,21 +392,22 @@ EXPLAIN SELECT * FROM student WHERE name = 'Anne Henry' AND class = 'lIrm08RYVk'
SELECT * FROM student WHERE class = 'lIrm08RYVk';
```
-再来看一个常见的面试题:如果有索引 `联合索引(a,b,c)`,查询 `a=1 AND c=1`会走索引么?`c=1` 呢?`b=1 AND c=1`呢?
+再来看一个常见的面试题:如果有索引 `联合索引(a,b,c)`,查询 `a=1 AND c=1` 会走索引么?`c=1` 呢?`b=1 AND c=1` 呢? `b = 1 AND a = 1 AND c = 1` 呢?
先不要往下看答案,给自己 3 分钟时间想一想。
1. 查询 `a=1 AND c=1`:根据最左前缀匹配原则,查询可以使用索引的前缀部分。因此,该查询仅在 `a=1` 上使用索引,然后对结果进行 `c=1` 的过滤。
-2. 查询 `c=1` :由于查询中不包含最左列 `a`,根据最左前缀匹配原则,整个索引都无法被使用。
-3. 查询`b=1 AND c=1`:和第二种一样的情况,整个索引都不会使用。
+2. 查询 `c=1`:由于查询中不包含最左列 `a`,根据最左前缀匹配原则,整个索引都无法被使用。
+3. 查询 `b=1 AND c=1`:和第二种一样的情况,整个索引都不会使用。
+4. 查询 `b=1 AND a=1 AND c=1`:这个查询是可以用到索引的。查询优化器分析 SQL 语句时,对于联合索引,会对查询条件进行重排序,以便用到索引。会将 `b=1` 和 `a=1` 的条件进行重排序,变成 `a=1 AND b=1 AND c=1`。
MySQL 8.0.13 版本引入了索引跳跃扫描(Index Skip Scan,简称 ISS),它可以在某些索引查询场景下提高查询效率。在没有 ISS 之前,不满足最左前缀匹配原则的联合索引查询中会执行全表扫描。而 ISS 允许 MySQL 在某些情况下避免全表扫描,即使查询条件不符合最左前缀。不过,这个功能比较鸡肋, 和 Oracle 中的没法比,MySQL 8.0.31 还报告了一个 bug:[Bug #109145 Using index for skip scan cause incorrect result](https://bugs.mysql.com/bug.php?id=109145)(后续版本已经修复)。个人建议知道有这个东西就好,不需要深究,实际项目也不一定能用上。
## 索引下推
-**索引下推(Index Condition Pushdown,简称 ICP)** 是 **MySQL 5.6** 版本中提供的一项索引优化功能,它允许存储引擎在索引遍历过程中,执行部分 `WHERE`字句的判断条件,直接过滤掉不满足条件的记录,从而减少回表次数,提高查询效率。
+**索引下推(Index Condition Pushdown,简称 ICP)** 是 **MySQL 5.6** 版本中提供的一项索引优化功能,它允许存储引擎在索引遍历过程中,执行部分 `WHERE` 字句的判断条件,直接过滤掉不满足条件的记录,从而减少回表次数,提高查询效率。
-假设我们有一个名为 `user` 的表,其中包含 `id`, `username`, `zipcode`和 `birthdate` 4 个字段,创建了联合索引`(zipcode, birthdate)`。
+假设我们有一个名为 `user` 的表,其中包含 `id`、`username`、`zipcode` 和 `birthdate` 4 个字段,创建了联合索引 `(zipcode, birthdate)`。
```sql
CREATE TABLE `user` (
@@ -417,7 +424,7 @@ SELECT * FROM user WHERE zipcode = '431200' AND MONTH(birthdate) = 3;
```
- 没有索引下推之前,即使 `zipcode` 字段利用索引可以帮助我们快速定位到 `zipcode = '431200'` 的用户,但我们仍然需要对每一个找到的用户进行回表操作,获取完整的用户数据,再去判断 `MONTH(birthdate) = 3`。
-- 有了索引下推之后,存储引擎会在使用`zipcode` 字段索引查找`zipcode = '431200'` 的用户时,同时判断`MONTH(birthdate) = 3`。这样,只有同时满足条件的记录才会被返回,减少了回表次数。
+- 有了索引下推之后,存储引擎会在使用 `zipcode` 字段索引查找 `zipcode = '431200'` 的用户时,同时判断 `MONTH(birthdate) = 3`。这样,只有同时满足条件的记录才会被返回,减少了回表次数。

@@ -429,14 +436,14 @@ SELECT * FROM user WHERE zipcode = '431200' AND MONTH(birthdate) = 3;
MySQL 可以简单分为 Server 层和存储引擎层这两层。Server 层处理查询解析、分析、优化、缓存以及与客户端的交互等操作,而存储引擎层负责数据的存储和读取,MySQL 支持 InnoDB、MyISAM、Memory 等多种存储引擎。
-索引下推的**下推**其实就是指将部分上层(Server 层)负责的事情,交给了下层(存储引擎层)去处理。
+索引下推的 **下推** 其实就是指将部分上层(Server 层)负责的事情,交给了下层(存储引擎层)去处理。
我们这里结合索引下推原理再对上面提到的例子进行解释。
没有索引下推之前:
- 存储引擎层先根据 `zipcode` 索引字段找到所有 `zipcode = '431200'` 的用户的主键 ID,然后二次回表查询,获取完整的用户数据;
-- 存储引擎层把所有 `zipcode = '431200'` 的用户数据全部交给 Server 层,Server 层根据`MONTH(birthdate) = 3`这一条件再进一步做筛选。
+- 存储引擎层把所有 `zipcode = '431200'` 的用户数据全部交给 Server 层,Server 层根据 `MONTH(birthdate) = 3` 这一条件再进一步做筛选。
有了索引下推之后:
@@ -449,8 +456,8 @@ MySQL 可以简单分为 Server 层和存储引擎层这两层。Server 层处
最后,总结一下索引下推应用范围:
1. 适用于 InnoDB 引擎和 MyISAM 引擎的查询。
-2. 适用于执行计划是 range, ref, eq_ref, ref_or_null 的范围查询。
-3. 对于 InnoDB 表,仅用于非聚簇索引。索引下推的目标是减少全行读取次数,从而减少 I/O 操作。对于 InnoDB 聚集索引,完整的记录已经读入 InnoDB 缓冲区。在这种情况下使用索引下推 不会减少 I/O。
+2. 适用于执行计划是 range、ref、eq_ref、ref_or_null 的范围查询。
+3. 对于 InnoDB 表,仅用于非聚簇索引。索引下推的目标是减少全行读取次数,从而减少 I/O 操作。对于 InnoDB 聚集索引,完整的记录已经读入 InnoDB 缓冲区。在这种情况下使用索引下推不会减少 I/O。
4. 子查询不能使用索引下推,因为子查询通常会创建临时表来处理结果,而这些临时表是没有索引的。
5. 存储过程不能使用索引下推,因为存储引擎无法调用存储函数。
@@ -458,7 +465,7 @@ MySQL 可以简单分为 Server 层和存储引擎层这两层。Server 层处
### 选择合适的字段创建索引
-- **不为 NULL 的字段**:索引字段的数据应该尽量不为 NULL,因为对于数据为 NULL 的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为 NULL,建议使用 0,1,true,false 这样语义较为清晰的短值或短字符作为替代。
+- **不为 NULL 的字段**:索引字段的数据应该尽量不为 NULL,因为对于数据为 NULL 的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为 NULL,建议使用 0、1、true、false 这样语义较为清晰的短值或短字符作为替代。
- **被频繁查询的字段**:我们创建索引的字段应该是查询操作非常频繁的字段。
- **被作为条件查询的字段**:被作为 WHERE 条件查询的字段,应该被考虑建立索引。
- **频繁需要排序的字段**:索引已经排序,这样查询可以利用索引的排序,加快排序查询时间。
@@ -470,19 +477,19 @@ MySQL 可以简单分为 Server 层和存储引擎层这两层。Server 层处
### 限制每张表上的索引数量
-索引并不是越多越好,建议单张表索引不超过 5 个!索引可以提高效率同样可以降低效率。
+索引并不是越多越好,建议单张表索引不超过 5 个!索引可以提高效率,同样可以降低效率。
索引可以增加查询效率,但同样也会降低插入和更新的效率,甚至有些情况下会降低查询效率。
-因为 MySQL 优化器在选择如何优化查询时,会根据统一信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能。
+因为 MySQL 优化器在选择如何优化查询时,会根据统计信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能。
### 尽可能的考虑建立联合索引而不是单列索引
-因为索引是需要占用磁盘空间的,可以简单理解为每个索引都对应着一颗 B+树。如果一个表的字段过多,索引过多,那么当这个表的数据达到一个体量后,索引占用的空间也是很多的,且修改索引时,耗费的时间也是较多的。如果是联合索引,多个字段在一个索引上,那么将会节约很大磁盘空间,且修改数据的操作效率也会提升。
+因为索引是需要占用磁盘空间的,可以简单理解为每个索引都对应着一颗 B+ 树。如果一个表的字段过多,索引过多,那么当这个表的数据达到一个体量后,索引占用的空间也是很多的,且修改索引时,耗费的时间也是较多的。如果是联合索引,多个字段在一个索引上,那么将会节约很大磁盘空间,且修改数据的操作效率也会提升。
### 注意避免冗余索引
-冗余索引指的是索引的功能相同,能够命中索引(a, b)就肯定能命中索引(a) ,那么索引(a)就是冗余索引。如(name,city )和(name )这两个索引就是冗余索引,能够命中前者的查询肯定是能够命中后者的 在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
+冗余索引指的是索引的功能相同,能够命中索引(a, b)就肯定能命中索引(a) ,那么索引(a)就是冗余索引。如(name,city)和(name)这两个索引就是冗余索引,能够命中前者的查询肯定是能够命中后者的。在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
### 字符串类型的字段使用前缀索引代替普通索引
@@ -492,13 +499,13 @@ MySQL 可以简单分为 Server 层和存储引擎层这两层。Server 层处
索引失效也是慢查询的主要原因之一,常见的导致索引失效的情况有下面这些:
-- ~~使用 `SELECT *` 进行查询;~~ `SELECT *` 不会直接导致索引失效(如果不走索引大概率是因为 where 查询范围过大导致的),但它可能会带来一些其他的性能问题比如造成网络传输和数据处理的浪费、无法使用索引覆盖;
-- 创建了组合索引,但查询条件未遵守最左匹配原则;
-- 在索引列上进行计算、函数、类型转换等操作;
-- 以 % 开头的 LIKE 查询比如 `LIKE '%abc';`;
-- 查询条件中使用 OR,且 OR 的前后条件中有一个列没有索引,涉及的索引都不会被使用到;
-- IN 的取值范围较大时会导致索引失效,走全表扫描(NOT IN 和 IN 的失效场景相同);
-- 发生[隐式转换](https://javaguide.cn/database/mysql/index-invalidation-caused-by-implicit-conversion.html);
+- ~~使用 `SELECT *` 进行查询;~~ `SELECT *` 不会直接导致索引失效(如果不走索引大概率是因为 where 查询范围过大导致的),但它可能会带来一些其他的性能问题比如造成网络传输和数据处理的浪费、无法使用索引覆盖;
+- 创建了组合索引,但查询条件未遵守最左匹配原则;
+- 在索引列上进行计算、函数、类型转换等操作;
+- 以 % 开头的 LIKE 查询比如 `LIKE '%abc';`;
+- 查询条件中使用 OR,且 OR 的前后条件中有一个列没有索引,涉及的索引都不会被使用到;
+- IN 的取值范围较大时会导致索引失效,走全表扫描(NOT IN 和 IN 的失效场景相同);
+- 发生[隐式转换](https://javaguide.cn/database/mysql/index-invalidation-caused-by-implicit-conversion.html);
- ……
推荐阅读这篇文章:[美团暑期实习一面:MySQl 索引失效的场景有哪些?](https://mp.weixin.qq.com/s/mwME3qukHBFul57WQLkOYg)。
diff --git a/docs/database/mysql/mysql-questions-01.md b/docs/database/mysql/mysql-questions-01.md
index 1564f364bc8..7f93eb605e6 100644
--- a/docs/database/mysql/mysql-questions-01.md
+++ b/docs/database/mysql/mysql-questions-01.md
@@ -158,19 +158,28 @@ DATETIME 类型没有时区信息,TIMESTAMP 和时区有关。
TIMESTAMP 只需要使用 4 个字节的存储空间,但是 DATETIME 需要耗费 8 个字节的存储空间。但是,这样同样造成了一个问题,Timestamp 表示的时间范围更小。
-- DATETIME:1000-01-01 00:00:00 ~ 9999-12-31 23:59:59
-- Timestamp:1970-01-01 00:00:01 ~ 2037-12-31 23:59:59
+- DATETIME:'1000-01-01 00:00:00.000000' 到 '9999-12-31 23:59:59.999999'
+- Timestamp:'1970-01-01 00:00:01.000000' UTC 到 '2038-01-19 03:14:07.999999' UTC
-关于两者的详细对比,请参考我写的[MySQL 时间类型数据存储建议](./some-thoughts-on-database-storage-time.md)。
+关于两者的详细对比,请参考我写的 [MySQL 时间类型数据存储建议](./some-thoughts-on-database-storage-time.md)。
### NULL 和 '' 的区别是什么?
-`NULL` 跟 `''`(空字符串)是两个完全不一样的值,区别如下:
-
-- `NULL` 代表一个不确定的值,就算是两个 `NULL`,它俩也不一定相等。例如,`SELECT NULL=NULL`的结果为 false,但是在我们使用`DISTINCT`,`GROUP BY`,`ORDER BY`时,`NULL`又被认为是相等的。
-- `''`的长度是 0,是不占用空间的,而`NULL` 是需要占用空间的。
-- `NULL` 会影响聚合函数的结果。例如,`SUM`、`AVG`、`MIN`、`MAX` 等聚合函数会忽略 `NULL` 值。 `COUNT` 的处理方式取决于参数的类型。如果参数是 `*`(`COUNT(*)`),则会统计所有的记录数,包括 `NULL` 值;如果参数是某个字段名(`COUNT(列名)`),则会忽略 `NULL` 值,只统计非空值的个数。
-- 查询 `NULL` 值时,必须使用 `IS NULL` 或 `IS NOT NULLl` 来判断,而不能使用 =、!=、 <、> 之类的比较运算符。而`''`是可以使用这些比较运算符的。
+`NULL` 和 `''` (空字符串) 是两个完全不同的值,它们分别表示不同的含义,并在数据库中有着不同的行为。`NULL` 代表缺失或未知的数据,而 `''` 表示一个已知存在的空字符串。它们的主要区别如下:
+
+1. **含义**:
+ - `NULL` 代表一个不确定的值,它不等于任何值,包括它自身。因此,`SELECT NULL = NULL` 的结果是 `NULL`,而不是 `true` 或 `false`。 `NULL` 意味着缺失或未知的信息。虽然 `NULL` 不等于任何值,但在某些操作中,数据库系统会将 `NULL` 值视为相同的类别进行处理,例如:`DISTINCT`,`GROUP BY`,`ORDER BY`。需要注意的是,这些操作将 `NULL` 值视为相同的类别进行处理,并不意味着 `NULL` 值之间是相等的。 它们只是在特定操作中被特殊处理,以保证结果的正确性和一致性。 这种处理方式是为了方便数据操作,而不是改变了 `NULL` 的语义。
+ - `''` 表示一个空字符串,它是一个已知的值。
+2. **存储空间**:
+ - `NULL` 的存储空间占用取决于数据库的实现,通常需要一些空间来标记该值为空。
+ - `''` 的存储空间占用通常较小,因为它只存储一个空字符串的标志,不需要存储实际的字符。
+3. **比较运算**:
+ - 任何值与 `NULL` 进行比较(例如 `=`, `!=`, `>`, `<` 等)的结果都是 `NULL`,表示结果不确定。要判断一个值是否为 `NULL`,必须使用 `IS NULL` 或 `IS NOT NULL`。
+ - `''` 可以像其他字符串一样进行比较运算。例如,`'' = ''` 的结果是 `true`。
+4. **聚合函数**:
+ - 大多数聚合函数(例如 `SUM`, `AVG`, `MIN`, `MAX`)会忽略 `NULL` 值。
+ - `COUNT(*)` 会统计所有行数,包括包含 `NULL` 值的行。`COUNT(列名)` 会统计指定列中非 `NULL` 值的行数。
+ - 空字符串 `''` 会被聚合函数计算在内。例如,`SUM` 会将其视为 0,`MIN` 和 `MAX` 会将其视为一个空字符串。
看了上面的介绍之后,相信你对另外一个高频面试题:“为什么 MySQL 不建议使用 `NULL` 作为列默认值?”也有了答案。
@@ -178,6 +187,37 @@ TIMESTAMP 只需要使用 4 个字节的存储空间,但是 DATETIME 需要耗
MySQL 中没有专门的布尔类型,而是用 TINYINT(1) 类型来表示布尔值。TINYINT(1) 类型可以存储 0 或 1,分别对应 false 或 true。
+### 手机号存储用 INT 还是 VARCHAR?
+
+存储手机号,**强烈推荐使用 VARCHAR 类型**,而不是 INT 或 BIGINT。主要原因如下:
+
+1. **格式兼容性与完整性:**
+ - 手机号可能包含前导零(如某些地区的固话区号)、国家代码前缀('+'),甚至可能带有分隔符('-' 或空格)。INT 或 BIGINT 这种数字类型会自动丢失这些重要的格式信息(比如前导零会被去掉,'+' 和 '-' 无法存储)。
+ - VARCHAR 可以原样存储各种格式的号码,无论是国内的 11 位手机号,还是带有国家代码的国际号码,都能完美兼容。
+2. **非算术性:**手机号虽然看起来是数字,但我们从不对它进行数学运算(比如求和、平均值)。它本质上是一个标识符,更像是一个字符串。用 VARCHAR 更符合其数据性质。
+3. **查询灵活性:**
+ - 业务中常常需要根据号段(前缀)进行查询,例如查找所有 "138" 开头的用户。使用 VARCHAR 类型配合 `LIKE '138%'` 这样的 SQL 查询既直观又高效。
+ - 如果使用数字类型,进行类似的前缀匹配通常需要复杂的函数转换(如 CAST 或 SUBSTRING),或者使用范围查询(如 `WHERE phone >= 13800000000 AND phone < 13900000000`),这不仅写法繁琐,而且可能无法有效利用索引,导致性能下降。
+4. **加密存储的要求(非常关键):**
+ - 出于数据安全和隐私合规的要求,手机号这类敏感个人信息通常必须加密存储在数据库中。
+ - 加密后的数据(密文)是一长串字符串(通常由字母、数字、符号组成,或经过 Base64/Hex 编码),INT 或 BIGINT 类型根本无法存储这种密文。只有 VARCHAR、TEXT 或 BLOB 等类型可以。
+
+**关于 VARCHAR 长度的选择:**
+
+- **如果不加密存储(强烈不推荐!):** 考虑到国际号码和可能的格式符,VARCHAR(20) 到 VARCHAR(32) 通常是一个比较安全的范围,足以覆盖全球绝大多数手机号格式。VARCHAR(15) 可能对某些带国家码和格式符的号码来说不够用。
+- **如果进行加密存储(推荐的标准做法):** 长度必须根据所选加密算法产生的密文最大长度,以及可能的编码方式(如 Base64 会使长度增加约 1/3)来精确计算和设定。通常会需要更长的 VARCHAR 长度,例如 VARCHAR(128), VARCHAR(256) 甚至更长。
+
+最后,来一张表格总结一下:
+
+| 对比维度 | VARCHAR 类型(推荐) | INT/BIGINT 类型(不推荐) | 说明/备注 |
+| ---------------- | --------------------------------- | ---------------------------- | --------------------------------------------------------------------------- |
+| **格式兼容性** | ✔ 能存前导零、"+"、"-"、空格等 | ✘ 自动丢失前导零,不能存符号 | VARCHAR 能原样存储各种手机号格式,INT/BIGINT 只支持单纯数字,且前导零会消失 |
+| **完整性** | ✔ 不丢失任何格式信息 | ✘ 丢失格式信息 | 例如 "013800012345" 存进 INT 会变成 13800012345,"+" 也无法存储 |
+| **非算术性** | ✔ 适合存储“标识符” | ✘ 只适合做数值运算 | 手机号本质是字符串标识符,不做数学运算,VARCHAR 更贴合实际用途 |
+| **查询灵活性** | ✔ 支持 `LIKE '138%'` 等 | ✘ 查询前缀不方便或性能差 | 使用 VARCHAR 可高效按号段/前缀查询,数字类型需转为字符串或其他复杂处理 |
+| **加密存储支持** | ✔ 可存储加密密文(字母、符号等) | ✘ 无法存储密文 | 加密手机号后密文是字符串/二进制,只有 VARCHAR、TEXT、BLOB 等能兼容 |
+| **长度设置建议** | 15~20(未加密),加密视情况而定 | 无意义 | 不加密时 VARCHAR(15~20) 通用,加密后长度取决于算法和编码方式 |
+
## MySQL 基础架构
> 建议配合 [SQL 语句在 MySQL 中的执行过程](./how-sql-executed-in-mysql.md) 这篇文章来理解 MySQL 基础架构。另外,“一个 SQL 语句在 MySQL 中的执行流程”也是面试中比较常问的一个问题。
@@ -193,7 +233,7 @@ MySQL 中没有专门的布尔类型,而是用 TINYINT(1) 类型来表示布
- **分析器:** 没有命中缓存的话,SQL 语句就会经过分析器,分析器说白了就是要先看你的 SQL 语句要干嘛,再检查你的 SQL 语句语法是否正确。
- **优化器:** 按照 MySQL 认为最优的方案去执行。
- **执行器:** 执行语句,然后从存储引擎返回数据。 执行语句之前会先判断是否有权限,如果没有权限的话,就会报错。
-- **插件式存储引擎**:主要负责数据的存储和读取,采用的是插件式架构,支持 InnoDB、MyISAM、Memory 等多种存储引擎。
+- **插件式存储引擎**:主要负责数据的存储和读取,采用的是插件式架构,支持 InnoDB、MyISAM、Memory 等多种存储引擎。InnoDB 是 MySQL 的默认存储引擎,绝大部分场景使用 InnoDB 就是最好的选择。
## MySQL 存储引擎
@@ -544,31 +584,26 @@ MVCC 在 MySQL 中实现所依赖的手段主要是: **隐藏字段、read view
### SQL 标准定义了哪些事务隔离级别?
-SQL 标准定义了四个隔离级别:
+SQL 标准定义了四种事务隔离级别,用来平衡事务的隔离性(Isolation)和并发性能。级别越高,数据一致性越好,但并发性能可能越低。这四个级别是:
-- **READ-UNCOMMITTED(读取未提交)** :最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
-- **READ-COMMITTED(读取已提交)** :允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
-- **REPEATABLE-READ(可重复读)** :对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
+- **READ-UNCOMMITTED(读取未提交)** :最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。这种级别在实际应用中很少使用,因为它对数据一致性的保证太弱。
+- **READ-COMMITTED(读取已提交)** :允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。这是大多数数据库(如 Oracle, SQL Server)的默认隔离级别。
+- **REPEATABLE-READ(可重复读)** :对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。MySQL InnoDB 存储引擎的默认隔离级别正是 REPEATABLE READ。并且,InnoDB 在此级别下通过 MVCC(多版本并发控制) 和 Next-Key Locks(间隙锁+行锁) 机制,在很大程度上解决了幻读问题。
- **SERIALIZABLE(可串行化)** :最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
----
-
-| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
-| :--------------: | :--: | :--------: | :--: |
-| READ-UNCOMMITTED | √ | √ | √ |
-| READ-COMMITTED | × | √ | √ |
-| REPEATABLE-READ | × | × | √ |
-| SERIALIZABLE | × | × | × |
-
-### MySQL 的隔离级别是基于锁实现的吗?
-
-MySQL 的隔离级别基于锁和 MVCC 机制共同实现的。
-
-SERIALIZABLE 隔离级别是通过锁来实现的,READ-COMMITTED 和 REPEATABLE-READ 隔离级别是基于 MVCC 实现的。不过, SERIALIZABLE 之外的其他隔离级别可能也需要用到锁机制,就比如 REPEATABLE-READ 在当前读情况下需要使用加锁读来保证不会出现幻读。
+| 隔离级别 | 脏读 (Dirty Read) | 不可重复读 (Non-Repeatable Read) | 幻读 (Phantom Read) |
+| ---------------- | ----------------- | -------------------------------- | ---------------------- |
+| READ UNCOMMITTED | √ | √ | √ |
+| READ COMMITTED | × | √ | √ |
+| REPEATABLE READ | × | × | √ (标准) / ≈× (InnoDB) |
+| SERIALIZABLE | × | × | × |
### MySQL 的默认隔离级别是什么?
-MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看,MySQL 8.0 该命令改为`SELECT @@transaction_isolation;`
+MySQL InnoDB 存储引擎的默认隔离级别是 **REPEATABLE READ**。可以通过以下命令查看:
+
+- MySQL 8.0 之前:`SELECT @@tx_isolation;`
+- MySQL 8.0 及之后:`SELECT @@transaction_isolation;`
```sql
mysql> SELECT @@tx_isolation;
@@ -581,6 +616,12 @@ mysql> SELECT @@tx_isolation;
关于 MySQL 事务隔离级别的详细介绍,可以看看我写的这篇文章:[MySQL 事务隔离级别详解](./transaction-isolation-level.md)。
+### MySQL 的隔离级别是基于锁实现的吗?
+
+MySQL 的隔离级别基于锁和 MVCC 机制共同实现的。
+
+SERIALIZABLE 隔离级别是通过锁来实现的,READ-COMMITTED 和 REPEATABLE-READ 隔离级别是基于 MVCC 实现的。不过, SERIALIZABLE 之外的其他隔离级别可能也需要用到锁机制,就比如 REPEATABLE-READ 在当前读情况下需要使用加锁读来保证不会出现幻读。
+
## MySQL 锁
锁是一种常见的并发事务的控制方式。
@@ -854,7 +895,7 @@ MySQL 性能优化是一个系统性工程,涉及多个方面,在面试中
- **读写分离:** 将读操作和写操作分离到不同的数据库实例,提升数据库的并发处理能力。
- **分库分表:** 将数据分散到多个数据库实例或数据表中,降低单表数据量,提升查询效率。但要权衡其带来的复杂性和维护成本,谨慎使用。
-- **数据冷热分离**:根据数据的访问频率和业务重要性,将数据分为冷数据和热数据,冷数据一般存储在存储在低成本、低性能的介质中,热数据高性能存储介质中。
+- **数据冷热分离**:根据数据的访问频率和业务重要性,将数据分为冷数据和热数据,冷数据一般存储在低成本、低性能的介质中,热数据存储在高性能存储介质中。
- **缓存机制:** 使用 Redis 等缓存中间件,将热点数据缓存到内存中,减轻数据库压力。这个非常常用,提升效果非常明显,性价比极高!
**4. 其他优化手段**
diff --git a/docs/database/mysql/some-thoughts-on-database-storage-time.md b/docs/database/mysql/some-thoughts-on-database-storage-time.md
index 75329434c1b..e22ce2800da 100644
--- a/docs/database/mysql/some-thoughts-on-database-storage-time.md
+++ b/docs/database/mysql/some-thoughts-on-database-storage-time.md
@@ -3,30 +3,43 @@ title: MySQL日期类型选择建议
category: 数据库
tag:
- MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL 日期类型选择, MySQL 时间存储最佳实践, MySQL 时间存储效率, MySQL DATETIME 和 TIMESTAMP 区别, MySQL 时间戳存储, MySQL 数据库时间存储类型, MySQL 开发日期推荐, MySQL 字符串存储日期的缺点, MySQL 时区设置方法, MySQL 日期范围对比, 高性能 MySQL 日期存储, MySQL UNIX_TIMESTAMP 用法, 数值型时间戳优缺点, MySQL 时间存储性能优化, MySQL TIMESTAMP 时区转换, MySQL 时间格式转换, MySQL 时间存储空间对比, MySQL 时间类型选择建议, MySQL 日期类型性能分析, 数据库时间存储优化
---
-我们平时开发中不可避免的就是要存储时间,比如我们要记录操作表中这条记录的时间、记录转账的交易时间、记录出发时间、用户下单时间等等。你会发现时间这个东西与我们开发的联系还是非常紧密的,用的好与不好会给我们的业务甚至功能带来很大的影响。所以,我们有必要重新出发,好好认识一下这个东西。
+在日常的软件开发工作中,存储时间是一项基础且常见的需求。无论是记录数据的操作时间、金融交易的发生时间,还是行程的出发时间、用户的下单时间等等,时间信息与我们的业务逻辑和系统功能紧密相关。因此,正确选择和使用 MySQL 的日期时间类型至关重要,其恰当与否甚至可能对业务的准确性和系统的稳定性产生显著影响。
+
+本文旨在帮助开发者重新审视并深入理解 MySQL 中不同的时间存储方式,以便做出更合适项目业务场景的选择。
## 不要用字符串存储日期
-和绝大部分对数据库不太了解的新手一样,我在大学的时候就这样干过,甚至认为这样是一个不错的表示日期的方法。毕竟简单直白,容易上手。
+和许多数据库初学者一样,笔者在早期学习阶段也曾尝试使用字符串(如 VARCHAR)类型来存储日期和时间,甚至一度认为这是一种简单直观的方法。毕竟,'YYYY-MM-DD HH:MM:SS' 这样的格式看起来清晰易懂。
但是,这是不正确的做法,主要会有下面两个问题:
-1. 字符串占用的空间更大!
-2. 字符串存储的日期效率比较低(逐个字符进行比对),无法用日期相关的 API 进行计算和比较。
+1. **空间效率**:与 MySQL 内建的日期时间类型相比,字符串通常需要占用更多的存储空间来表示相同的时间信息。
+2. **查询与计算效率低下**:
+ - **比较操作复杂且低效**:基于字符串的日期比较需要按照字典序逐字符进行,这不仅不直观(例如,'2024-05-01' 会小于 '2024-1-10'),而且效率远低于使用原生日期时间类型进行的数值或时间点比较。
+ - **计算功能受限**:无法直接利用数据库提供的丰富日期时间函数进行运算(例如,计算两个日期之间的间隔、对日期进行加减操作等),需要先转换格式,增加了复杂性。
+ - **索引性能不佳**:基于字符串的索引在处理范围查询(如查找特定时间段内的数据)时,其效率和灵活性通常不如原生日期时间类型的索引。
-## Datetime 和 Timestamp 之间的抉择
+## DATETIME 和 TIMESTAMP 选择
-Datetime 和 Timestamp 是 MySQL 提供的两种比较相似的保存时间的数据类型,可以精确到秒。他们两者究竟该如何选择呢?
+`DATETIME` 和 `TIMESTAMP` 是 MySQL 中两种非常常用的、用于存储包含日期和时间信息的数据类型。它们都可以存储精确到秒(MySQL 5.6.4+ 支持更高精度的小数秒)的时间值。那么,在实际应用中,我们应该如何在这两者之间做出选择呢?
-下面我们来简单对比一下二者。
+下面我们从几个关键维度对它们进行对比:
### 时区信息
-**DateTime 类型是没有时区信息的(时区无关)** ,DateTime 类型保存的时间都是当前会话所设置的时区对应的时间。这样就会有什么问题呢?当你的时区更换之后,比如你的服务器更换地址或者更换客户端连接时区设置的话,就会导致你从数据库中读出的时间错误。
+`DATETIME` 类型存储的是**字面量的日期和时间值**,它本身**不包含任何时区信息**。当你插入一个 `DATETIME` 值时,MySQL 存储的就是你提供的那个确切的时间,不会进行任何时区转换。
+
+**这样就会有什么问题呢?** 如果你的应用需要支持多个时区,或者服务器、客户端的时区可能发生变化,那么使用 `DATETIME` 时,应用程序需要自行处理时区的转换和解释。如果处理不当(例如,假设所有存储的时间都属于同一个时区,但实际环境变化了),可能会导致时间显示或计算上的混乱。
-**Timestamp 和时区有关**。Timestamp 类型字段的值会随着服务器时区的变化而变化,自动换算成相应的时间,说简单点就是在不同时区,查询到同一个条记录此字段的值会不一样。
+**`TIMESTAMP` 和时区有关**。存储时,MySQL 会将当前会话时区下的时间值转换成 UTC(协调世界时)进行内部存储。当查询 `TIMESTAMP` 字段时,MySQL 又会将存储的 UTC 时间转换回当前会话所设置的时区来显示。
+
+这意味着,对于同一条记录的 `TIMESTAMP` 字段,在不同的会话时区设置下查询,可能会看到不同的本地时间表示,但它们都对应着同一个绝对时间点(UTC 时间)。这对于需要全球化、多时区支持的应用来说非常有用。
下面实际演示一下!
@@ -41,16 +54,16 @@ CREATE TABLE `time_zone_test` (
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
```
-插入数据:
+插入一条数据(假设当前会话时区为系统默认,例如 UTC+0)::
```sql
INSERT INTO time_zone_test(date_time,time_stamp) VALUES(NOW(),NOW());
```
-查看数据:
+查询数据(在同一时区会话下):
```sql
-select date_time,time_stamp from time_zone_test;
+SELECT date_time, time_stamp FROM time_zone_test;
```
结果:
@@ -63,17 +76,16 @@ select date_time,time_stamp from time_zone_test;
+---------------------+---------------------+
```
-现在我们运行
-
-修改当前会话的时区:
+现在,修改当前会话的时区为东八区 (UTC+8):
```sql
-set time_zone='+8:00';
+SET time_zone = '+8:00';
```
-再次查看数据:
+再次查询数据:
-```plain
+```bash
+# TIMESTAMP 的值自动转换为 UTC+8 时间
+---------------------+---------------------+
| date_time | time_stamp |
+---------------------+---------------------+
@@ -81,7 +93,7 @@ set time_zone='+8:00';
+---------------------+---------------------+
```
-**扩展:一些关于 MySQL 时区设置的一个常用 sql 命令**
+**扩展:MySQL 时区设置常用 SQL 命令**
```sql
# 查看当前会话时区
@@ -102,28 +114,26 @@ SET GLOBAL time_zone = 'Europe/Helsinki';
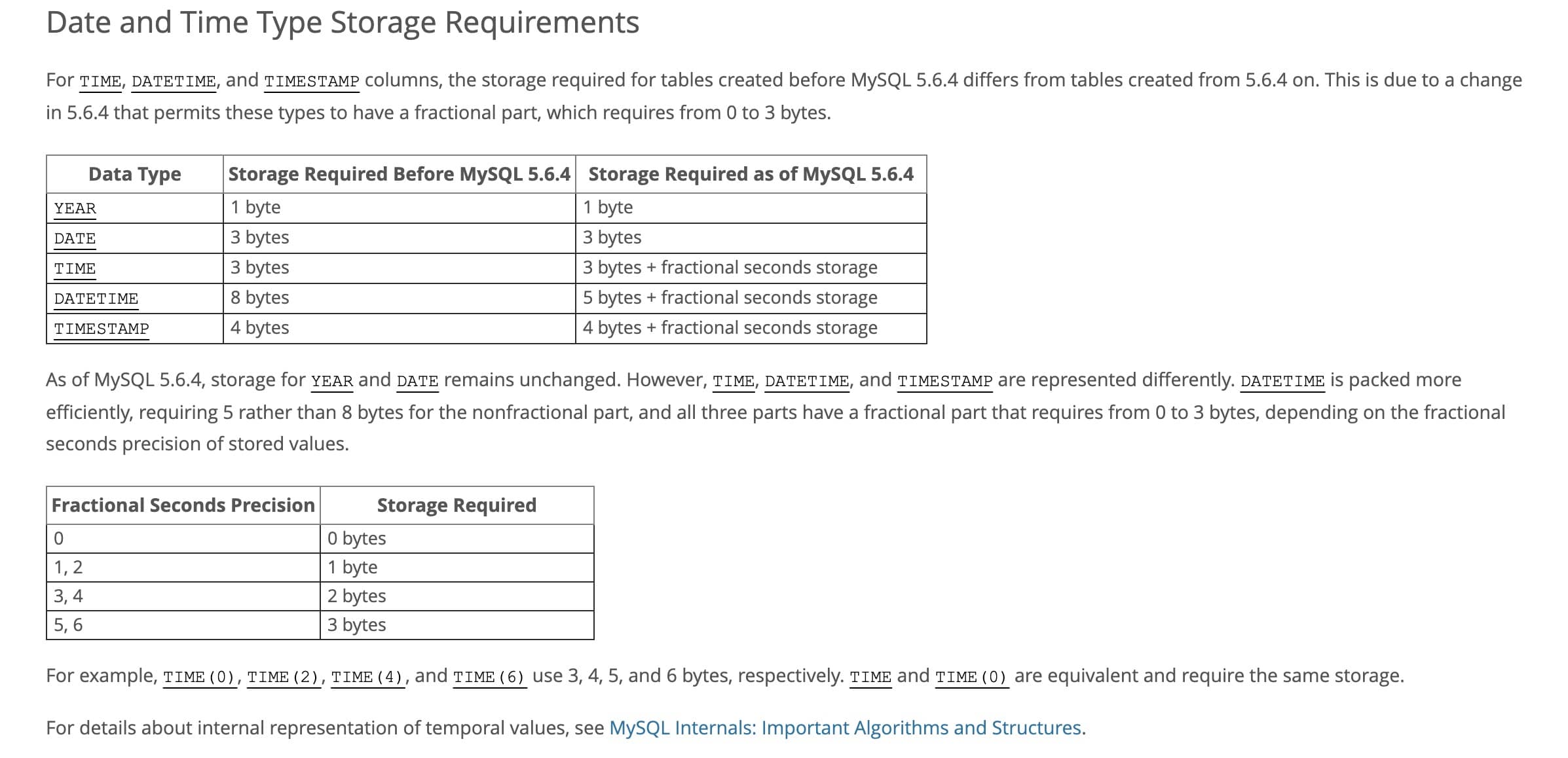
-在 MySQL 5.6.4 之前,DateTime 和 Timestamp 的存储空间是固定的,分别为 8 字节和 4 字节。但是从 MySQL 5.6.4 开始,它们的存储空间会根据毫秒精度的不同而变化,DateTime 的范围是 5~8 字节,Timestamp 的范围是 4~7 字节。
+在 MySQL 5.6.4 之前,DateTime 和 TIMESTAMP 的存储空间是固定的,分别为 8 字节和 4 字节。但是从 MySQL 5.6.4 开始,它们的存储空间会根据毫秒精度的不同而变化,DateTime 的范围是 5~8 字节,TIMESTAMP 的范围是 4~7 字节。
### 表示范围
-Timestamp 表示的时间范围更小,只能到 2038 年:
+`TIMESTAMP` 表示的时间范围更小,只能到 2038 年:
-- DateTime:1000-01-01 00:00:00.000000 ~ 9999-12-31 23:59:59.499999
-- Timestamp:1970-01-01 00:00:01.000000 ~ 2038-01-19 03:14:07.499999
+- `DATETIME`:'1000-01-01 00:00:00.000000' 到 '9999-12-31 23:59:59.999999'
+- `TIMESTAMP`:'1970-01-01 00:00:01.000000' UTC 到 '2038-01-19 03:14:07.999999' UTC
### 性能
-由于 TIMESTAMP 需要根据时区进行转换,所以从毫秒数转换到 TIMESTAMP 时,不仅要调用一个简单的函数,还要调用操作系统底层的系统函数。这个系统函数为了保证操作系统时区的一致性,需要进行加锁操作,这就降低了效率。
-
-DATETIME 不涉及时区转换,所以不会有这个问题。
+由于 `TIMESTAMP` 在存储和检索时需要进行 UTC 与当前会话时区的转换,这个过程可能涉及到额外的计算开销,尤其是在需要调用操作系统底层接口获取或处理时区信息时。虽然现代数据库和操作系统对此进行了优化,但在某些极端高并发或对延迟极其敏感的场景下,`DATETIME` 因其不涉及时区转换,处理逻辑相对更简单直接,可能会表现出微弱的性能优势。
-为了避免 TIMESTAMP 的时区转换问题,建议使用指定的时区,而不是依赖于操作系统时区。
+为了获得可预测的行为并可能减少 `TIMESTAMP` 的转换开销,推荐的做法是在应用程序层面统一管理时区,或者在数据库连接/会话级别显式设置 `time_zone` 参数,而不是依赖服务器的默认或操作系统时区。
## 数值时间戳是更好的选择吗?
-很多时候,我们也会使用 int 或者 bigint 类型的数值也就是数值时间戳来表示时间。
+除了上述两种类型,实践中也常用整数类型(`INT` 或 `BIGINT`)来存储所谓的“Unix 时间戳”(即从 1970 年 1 月 1 日 00:00:00 UTC 起至目标时间的总秒数,或毫秒数)。
-这种存储方式的具有 Timestamp 类型的所具有一些优点,并且使用它的进行日期排序以及对比等操作的效率会更高,跨系统也很方便,毕竟只是存放的数值。缺点也很明显,就是数据的可读性太差了,你无法直观的看到具体时间。
+这种存储方式的具有 `TIMESTAMP` 类型的所具有一些优点,并且使用它的进行日期排序以及对比等操作的效率会更高,跨系统也很方便,毕竟只是存放的数值。缺点也很明显,就是数据的可读性太差了,你无法直观的看到具体时间。
时间戳的定义如下:
@@ -132,7 +142,8 @@ DATETIME 不涉及时区转换,所以不会有这个问题。
数据库中实际操作:
```sql
-mysql> select UNIX_TIMESTAMP('2020-01-11 09:53:32');
+-- 将日期时间字符串转换为 Unix 时间戳 (秒)
+mysql> SELECT UNIX_TIMESTAMP('2020-01-11 09:53:32');
+---------------------------------------+
| UNIX_TIMESTAMP('2020-01-11 09:53:32') |
+---------------------------------------+
@@ -140,7 +151,8 @@ mysql> select UNIX_TIMESTAMP('2020-01-11 09:53:32');
+---------------------------------------+
1 row in set (0.00 sec)
-mysql> select FROM_UNIXTIME(1578707612);
+-- 将 Unix 时间戳 (秒) 转换为日期时间格式
+mysql> SELECT FROM_UNIXTIME(1578707612);
+---------------------------+
| FROM_UNIXTIME(1578707612) |
+---------------------------+
@@ -149,13 +161,26 @@ mysql> select FROM_UNIXTIME(1578707612);
1 row in set (0.01 sec)
```
+## PostgreSQL 中没有 DATETIME
+
+由于有读者提到 PostgreSQL(PG) 的时间类型,因此这里拓展补充一下。PG 官方文档对时间类型的描述地址:
### 产生死锁的四个必要条件是什么?
+死锁的发生并不是偶然的,它需要同时满足**四个必要条件**:
+
1. **互斥**:资源必须处于非共享模式,即一次只有一个进程可以使用。如果另一进程申请该资源,那么必须等待直到该资源被释放为止。
2. **占有并等待**:一个进程至少应该占有一个资源,并等待另一资源,而该资源被其他进程所占有。
3. **非抢占**:资源不能被抢占。只能在持有资源的进程完成任务后,该资源才会被释放。
-4. **循环等待**:有一组等待进程 `{P0, P1,..., Pn}`, `P0` 等待的资源被 `P1` 占有,`P1` 等待的资源被 `P2` 占有,……,`Pn-1` 等待的资源被 `Pn` 占有,`Pn` 等待的资源被 `P0` 占有。
+4. **循环等待**:有一组等待进程 {P0, P1,..., Pn}, P0 等待的资源被 P1 占有,P1 等待的资源被 P2 占有,……,Pn-1 等待的资源被 Pn 占有,Pn 等待的资源被 P0 占有。
**注意 ⚠️**:这四个条件是产生死锁的 **必要条件** ,也就是说只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
@@ -371,12 +380,9 @@ Thread[线程 2,5,main]waiting get resource1
解决死锁的方法可以从多个角度去分析,一般的情况下,有**预防,避免,检测和解除四种**。
-- **预防** 是采用某种策略,**限制并发进程对资源的请求**,从而使得死锁的必要条件在系统执行的任何时间上都不满足。
-
-- **避免**则是系统在分配资源时,根据资源的使用情况**提前做出预测**,从而**避免死锁的发生**
-
-- **检测**是指系统设有**专门的机构**,当死锁发生时,该机构能够检测死锁的发生,并精确地确定与死锁有关的进程和资源。
-- **解除** 是与检测相配套的一种措施,用于**将进程从死锁状态下解脱出来**。
+- **死锁预防:** 这是我们程序员最常用的方法。通过编码规范来破坏条件。最经典的就是**破坏循环等待**,比如规定所有线程都必须**按相同的顺序**来获取锁(比如先 A 后 B),这样就不会形成环路。
+- **死锁避免:** 这是一种更动态的方法,比如操作系统的**银行家算法**。它会在分配资源前进行预测,如果这次分配可能导致未来发生死锁,就拒绝分配。但这种方法开销很大,在通用系统中用得比较少。
+- **死锁检测与解除:** 这是一种“事后补救”的策略,就像乐观锁。系统允许死锁发生,但会有一个后台线程(或机制)定期检测是否存在死锁环路(比如通过分析线程等待图)。一旦发现,就会采取措施解除,比如**强制剥夺某个线程的资源或直接终止它**。数据库系统中的死锁处理就常常采用这种方式。
#### 死锁的预防
diff --git a/docs/cs-basics/operating-system/operating-system-basic-questions-02.md b/docs/cs-basics/operating-system/operating-system-basic-questions-02.md
index 5e1c0a67fa7..68f6b42cc76 100644
--- a/docs/cs-basics/operating-system/operating-system-basic-questions-02.md
+++ b/docs/cs-basics/operating-system/operating-system-basic-questions-02.md
@@ -188,7 +188,7 @@ MMU 将虚拟地址翻译为物理地址的主要机制有 3 种:

-在分页机制下,每个应用程序都会有一个对应的页表。
+在分页机制下,每个进程都会有一个对应的页表。
分页机制下的虚拟地址由两部分组成:
@@ -317,12 +317,16 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
### 段页机制
-结合了段式管理和页式管理的一种内存管理机制,把物理内存先分成若干段,每个段又继续分成若干大小相等的页。
+结合了段式管理和页式管理的一种内存管理机制。程序视角中,内存被划分为多个逻辑段,每个逻辑段进一步被划分为固定大小的页。
在段页式机制下,地址翻译的过程分为两个步骤:
-1. 段式地址映射。
-2. 页式地址映射。
+1. **段式地址映射(虚拟地址 → 线性地址):**
+ - 虚拟地址 = 段选择符(段号)+ 段内偏移。
+ - 根据段号查段表,找到段基址,加上段内偏移得到线性地址。
+2. **页式地址映射(线性地址 → 物理地址):**
+ - 线性地址 = 页号 + 页内偏移。
+ - 根据页号查页表,找到物理页框号,加上页内偏移得到物理地址。
### 局部性原理
@@ -375,7 +379,7 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
### 提高文件系统性能的方式有哪些?
-- **优化硬件**:使用高速硬件设备(如 SSD、NVMe)替代传统的机械硬盘,使用 RAID(Redundant Array of Inexpensive Disks)等技术提高磁盘性能。
+- **优化硬件**:使用高速硬件设备(如 SSD、NVMe)替代传统的机械硬盘,使用 RAID(Redundant Array of Independent Disks)等技术提高磁盘性能。
- **选择合适的文件系统选型**:不同的文件系统具有不同的特性,对于不同的应用场景选择合适的文件系统可以提高系统性能。
- **运用缓存**:访问磁盘的效率比较低,可以运用缓存来减少磁盘的访问次数。不过,需要注意缓存命中率,缓存命中率过低的话,效果太差。
- **避免磁盘过度使用**:注意磁盘的使用率,避免将磁盘用满,尽量留一些剩余空间,以免对文件系统的性能产生负面影响。
diff --git a/docs/database/basis.md b/docs/database/basis.md
index 34ee65f1242..1df5d538fb8 100644
--- a/docs/database/basis.md
+++ b/docs/database/basis.md
@@ -86,7 +86,7 @@ ER 图由下面 3 个要素组成:
为什么不要用外键呢?大部分人可能会这样回答:
-1. **增加了复杂性:** a. 每次做 DELETE 或者 UPDATE 都必须考虑外键约束,会导致开发的时候很痛苦, 测试数据极为不方便; b. 外键的主从关系是定的,假如那天需求有变化,数据库中的这个字段根本不需要和其他表有关联的话就会增加很多麻烦。
+1. **增加了复杂性:** a. 每次做 DELETE 或者 UPDATE 都必须考虑外键约束,会导致开发的时候很痛苦, 测试数据极为不方便; b. 外键的主从关系是定的,假如哪天需求有变化,数据库中的这个字段根本不需要和其他表有关联的话就会增加很多麻烦。
2. **增加了额外工作**:数据库需要增加维护外键的工作,比如当我们做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,保证数据的的一致性和正确性,这样会不得不消耗数据库资源。如果在应用层面去维护的话,可以减小数据库压力;
3. **对分库分表不友好**:因为分库分表下外键是无法生效的。
4. ……
diff --git a/docs/database/mysql/a-thousand-lines-of-mysql-study-notes.md b/docs/database/mysql/a-thousand-lines-of-mysql-study-notes.md
index 42384aaec7e..cb30376687b 100644
--- a/docs/database/mysql/a-thousand-lines-of-mysql-study-notes.md
+++ b/docs/database/mysql/a-thousand-lines-of-mysql-study-notes.md
@@ -621,7 +621,7 @@ CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] VIEW view_name
### 锁表
-```mysql
+```sql
/* 锁表 */
表锁定只用于防止其它客户端进行不正当地读取和写入
MyISAM 支持表锁,InnoDB 支持行锁
@@ -633,7 +633,7 @@ MyISAM 支持表锁,InnoDB 支持行锁
### 触发器
-```mysql
+```sql
/* 触发器 */ ------------------
触发程序是与表有关的命名数据库对象,当该表出现特定事件时,将激活该对象
监听:记录的增加、修改、删除。
@@ -686,7 +686,7 @@ end
### SQL 编程
-```mysql
+```sql
/* SQL编程 */ ------------------
--// 局部变量 ----------
-- 变量声明
@@ -821,7 +821,7 @@ INOUT,表示混合型
### 存储过程
-```mysql
+```sql
/* 存储过程 */ ------------------
存储过程是一段可执行性代码的集合。相比函数,更偏向于业务逻辑。
调用:CALL 过程名
@@ -842,7 +842,7 @@ END
### 用户和权限管理
-```mysql
+```sql
/* 用户和权限管理 */ ------------------
-- root密码重置
1. 停止MySQL服务
@@ -924,7 +924,7 @@ GRANT OPTION -- 允许授予权限
### 表维护
-```mysql
+```sql
/* 表维护 */
-- 分析和存储表的关键字分布
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE 表名 ...
@@ -937,7 +937,7 @@ OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
### 杂项
-```mysql
+```sql
/* 杂项 */ ------------------
1. 可用反引号(`)为标识符(库名、表名、字段名、索引、别名)包裹,以避免与关键字重名!中文也可以作为标识符!
2. 每个库目录存在一个保存当前数据库的选项文件db.opt。
diff --git a/docs/database/mysql/mysql-high-performance-optimization-specification-recommendations.md b/docs/database/mysql/mysql-high-performance-optimization-specification-recommendations.md
index 1fe8ea3c788..38c333b3308 100644
--- a/docs/database/mysql/mysql-high-performance-optimization-specification-recommendations.md
+++ b/docs/database/mysql/mysql-high-performance-optimization-specification-recommendations.md
@@ -11,17 +11,17 @@ tag:
## 数据库命名规范
-- 所有数据库对象名称必须使用小写字母并用下划线分割
-- 所有数据库对象名称禁止使用 MySQL 保留关键字(如果表名中包含关键字查询时,需要将其用单引号括起来)
-- 数据库对象的命名要能做到见名识意,并且最后不要超过 32 个字符
-- 临时库表必须以 `tmp_` 为前缀并以日期为后缀,备份表必须以 `bak_` 为前缀并以日期 (时间戳) 为后缀
-- 所有存储相同数据的列名和列类型必须一致(一般作为关联列,如果查询时关联列类型不一致会自动进行数据类型隐式转换,会造成列上的索引失效,导致查询效率降低)
+- 所有数据库对象名称必须使用小写字母并用下划线分割。
+- 所有数据库对象名称禁止使用 MySQL 保留关键字(如果表名中包含关键字查询时,需要将其用单引号括起来)。
+- 数据库对象的命名要能做到见名识义,并且最好不要超过 32 个字符。
+- 临时库表必须以 `tmp_` 为前缀并以日期为后缀,备份表必须以 `bak_` 为前缀并以日期 (时间戳) 为后缀。
+- 所有存储相同数据的列名和列类型必须一致(一般作为关联列,如果查询时关联列类型不一致会自动进行数据类型隐式转换,会造成列上的索引失效,导致查询效率降低)。
## 数据库基本设计规范
### 所有表必须使用 InnoDB 存储引擎
-没有特殊要求(即 InnoDB 无法满足的功能如:列存储,存储空间数据等)的情况下,所有表必须使用 InnoDB 存储引擎(MySQL5.5 之前默认使用 Myisam,5.6 以后默认的为 InnoDB)。
+没有特殊要求(即 InnoDB 无法满足的功能如:列存储、存储空间数据等)的情况下,所有表必须使用 InnoDB 存储引擎(MySQL5.5 之前默认使用 MyISAM,5.6 以后默认的为 InnoDB)。
InnoDB 支持事务,支持行级锁,更好的恢复性,高并发下性能更好。
@@ -33,19 +33,19 @@ InnoDB 支持事务,支持行级锁,更好的恢复性,高并发下性能
### 所有表和字段都需要添加注释
-使用 comment 从句添加表和列的备注,从一开始就进行数据字典的维护
+使用 comment 从句添加表和列的备注,从一开始就进行数据字典的维护。
### 尽量控制单表数据量的大小,建议控制在 500 万以内
500 万并不是 MySQL 数据库的限制,过大会造成修改表结构,备份,恢复都会有很大的问题。
-可以用历史数据归档(应用于日志数据),分库分表(应用于业务数据)等手段来控制数据量大小
+可以用历史数据归档(应用于日志数据),分库分表(应用于业务数据)等手段来控制数据量大小。
### 谨慎使用 MySQL 分区表
-分区表在物理上表现为多个文件,在逻辑上表现为一个表;
+分区表在物理上表现为多个文件,在逻辑上表现为一个表。
-谨慎选择分区键,跨分区查询效率可能更低;
+谨慎选择分区键,跨分区查询效率可能更低。
建议采用物理分表的方式管理大数据。
@@ -71,7 +71,7 @@ InnoDB 支持事务,支持行级锁,更好的恢复性,高并发下性能
### 禁止在线上做数据库压力测试
-### 禁止从开发环境,测试环境直接连接生产环境数据库
+### 禁止从开发环境、测试环境直接连接生产环境数据库
安全隐患极大,要对生产环境抱有敬畏之心!
@@ -79,22 +79,22 @@ InnoDB 支持事务,支持行级锁,更好的恢复性,高并发下性能
### 优先选择符合存储需要的最小的数据类型
-存储字节越小,占用也就空间越小,性能也越好。
+存储字节越小,占用空间也就越小,性能也越好。
-**a.某些字符串可以转换成数字类型存储比如可以将 IP 地址转换成整型数据。**
+**a.某些字符串可以转换成数字类型存储,比如可以将 IP 地址转换成整型数据。**
数字是连续的,性能更好,占用空间也更小。
-MySQL 提供了两个方法来处理 ip 地址
+MySQL 提供了两个方法来处理 ip 地址:
-- `INET_ATON()`:把 ip 转为无符号整型 (4-8 位)
-- `INET_NTOA()` :把整型的 ip 转为地址
+- `INET_ATON()`:把 ip 转为无符号整型 (4-8 位);
+- `INET_NTOA()`:把整型的 ip 转为地址。
-插入数据前,先用 `INET_ATON()` 把 ip 地址转为整型,显示数据时,使用 `INET_NTOA()` 把整型的 ip 地址转为地址显示即可。
+插入数据前,先用 `INET_ATON()` 把 ip 地址转为整型;显示数据时,使用 `INET_NTOA()` 把整型的 ip 地址转为地址显示即可。
-**b.对于非负型的数据 (如自增 ID,整型 IP,年龄) 来说,要优先使用无符号整型来存储。**
+**b.对于非负型的数据 (如自增 ID、整型 IP、年龄) 来说,要优先使用无符号整型来存储。**
-无符号相对于有符号可以多出一倍的存储空间
+无符号相对于有符号可以多出一倍的存储空间:
```sql
SIGNED INT -2147483648~2147483647
@@ -103,7 +103,7 @@ UNSIGNED INT 0~4294967295
**c.小数值类型(比如年龄、状态表示如 0/1)优先使用 TINYINT 类型。**
-### 避免使用 TEXT,BLOB 数据类型,最常见的 TEXT 类型可以存储 64k 的数据
+### 避免使用 TEXT、BLOB 数据类型,最常见的 TEXT 类型可以存储 64k 的数据
**a. 建议把 BLOB 或是 TEXT 列分离到单独的扩展表中。**
@@ -113,30 +113,30 @@ MySQL 内存临时表不支持 TEXT、BLOB 这样的大数据类型,如果查
**2、TEXT 或 BLOB 类型只能使用前缀索引**
-因为 MySQL 对索引字段长度是有限制的,所以 TEXT 类型只能使用前缀索引,并且 TEXT 列上是不能有默认值的
+因为 MySQL 对索引字段长度是有限制的,所以 TEXT 类型只能使用前缀索引,并且 TEXT 列上是不能有默认值的。
### 避免使用 ENUM 类型
-- 修改 ENUM 值需要使用 ALTER 语句;
-- ENUM 类型的 ORDER BY 操作效率低,需要额外操作;
-- ENUM 数据类型存在一些限制比如建议不要使用数值作为 ENUM 的枚举值。
+- 修改 ENUM 值需要使用 ALTER 语句。
+- ENUM 类型的 ORDER BY 操作效率低,需要额外操作。
+- ENUM 数据类型存在一些限制,比如建议不要使用数值作为 ENUM 的枚举值。
相关阅读:[是否推荐使用 MySQL 的 enum 类型? - 架构文摘 - 知乎](https://www.zhihu.com/question/404422255/answer/1661698499) 。
### 尽可能把所有列定义为 NOT NULL
-除非有特别的原因使用 NULL 值,应该总是让字段保持 NOT NULL。
+除非有特别的原因使用 NULL 值,否则应该总是让字段保持 NOT NULL。
-- 索引 NULL 列需要额外的空间来保存,所以要占用更多的空间;
+- 索引 NULL 列需要额外的空间来保存,所以要占用更多的空间。
- 进行比较和计算时要对 NULL 值做特别的处理。
相关阅读:[技术分享 | MySQL 默认值选型(是空,还是 NULL)](https://opensource.actionsky.com/20190710-mysql/) 。
### 一定不要用字符串存储日期
-对于日期类型来说, 一定不要用字符串存储日期。可以考虑 DATETIME、TIMESTAMP 和 数值型时间戳。
+对于日期类型来说,一定不要用字符串存储日期。可以考虑 DATETIME、TIMESTAMP 和数值型时间戳。
-这三种种方式都有各自的优势,根据实际场景选择最合适的才是王道。下面再对这三种方式做一个简单的对比,以供大家实际开发中选择正确的存放时间的数据类型:
+这三种种方式都有各自的优势,根据实际场景选择最合适的才是王道。下面再对这三种方式做一个简单的对比,以供大家在实际开发中选择正确的存放时间的数据类型:
| 类型 | 存储空间 | 日期格式 | 日期范围 | 是否带时区信息 |
| ------------ | -------- | ------------------------------ | ------------------------------------------------------------ | -------------- |
@@ -148,10 +148,10 @@ MySQL 时间类型选择的详细介绍请看这篇:[MySQL 时间类型数据
### 同财务相关的金额类数据必须使用 decimal 类型
-- **非精准浮点**:float,double
+- **非精准浮点**:float、double
- **精准浮点**:decimal
-decimal 类型为精准浮点数,在计算时不会丢失精度。占用空间由定义的宽度决定,每 4 个字节可以存储 9 位数字,并且小数点要占用一个字节。并且,decimal 可用于存储比 bigint 更大的整型数据
+decimal 类型为精准浮点数,在计算时不会丢失精度。占用空间由定义的宽度决定,每 4 个字节可以存储 9 位数字,并且小数点要占用一个字节。并且,decimal 可用于存储比 bigint 更大的整型数据。
不过, 由于 decimal 需要额外的空间和计算开销,应该尽量只在需要对数据进行精确计算时才使用 decimal 。
@@ -161,13 +161,13 @@ decimal 类型为精准浮点数,在计算时不会丢失精度。占用空间
## 索引设计规范
-### 限制每张表上的索引数量,建议单张表索引不超过 5 个
+### 限制每张表上的索引数量,建议单张表索引不超过 5 个
-索引并不是越多越好!索引可以提高效率同样可以降低效率。
+索引并不是越多越好!索引可以提高效率,同样可以降低效率。
索引可以增加查询效率,但同样也会降低插入和更新的效率,甚至有些情况下会降低查询效率。
-因为 MySQL 优化器在选择如何优化查询时,会根据统一信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能。
+因为 MySQL 优化器在选择如何优化查询时,会根据统一信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划。如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能。
### 禁止使用全文索引
@@ -175,46 +175,46 @@ decimal 类型为精准浮点数,在计算时不会丢失精度。占用空间
### 禁止给表中的每一列都建立单独的索引
-5.6 版本之前,一个 sql 只能使用到一个表中的一个索引,5.6 以后,虽然有了合并索引的优化方式,但是还是远远没有使用一个联合索引的查询方式好。
+5.6 版本之前,一个 sql 只能使用到一个表中的一个索引;5.6 以后,虽然有了合并索引的优化方式,但是还是远远没有使用一个联合索引的查询方式好。
### 每个 InnoDB 表必须有个主键
InnoDB 是一种索引组织表:数据的存储的逻辑顺序和索引的顺序是相同的。每个表都可以有多个索引,但是表的存储顺序只能有一种。
-InnoDB 是按照主键索引的顺序来组织表的
+InnoDB 是按照主键索引的顺序来组织表的。
-- 不要使用更新频繁的列作为主键,不使用多列主键(相当于联合索引)
-- 不要使用 UUID,MD5,HASH,字符串列作为主键(无法保证数据的顺序增长)
-- 主键建议使用自增 ID 值
+- 不要使用更新频繁的列作为主键,不使用多列主键(相当于联合索引)。
+- 不要使用 UUID、MD5、HASH、字符串列作为主键(无法保证数据的顺序增长)。
+- 主键建议使用自增 ID 值。
### 常见索引列建议
-- 出现在 SELECT、UPDATE、DELETE 语句的 WHERE 从句中的列
-- 包含在 ORDER BY、GROUP BY、DISTINCT 中的字段
-- 并不要将符合 1 和 2 中的字段的列都建立一个索引, 通常将 1、2 中的字段建立联合索引效果更好
-- 多表 join 的关联列
+- 出现在 SELECT、UPDATE、DELETE 语句的 WHERE 从句中的列。
+- 包含在 ORDER BY、GROUP BY、DISTINCT 中的字段。
+- 不要将符合 1 和 2 中的字段的列都建立一个索引,通常将 1、2 中的字段建立联合索引效果更好。
+- 多表 join 的关联列。
### 如何选择索引列的顺序
-建立索引的目的是:希望通过索引进行数据查找,减少随机 IO,增加查询性能 ,索引能过滤出越少的数据,则从磁盘中读入的数据也就越少。
+建立索引的目的是:希望通过索引进行数据查找,减少随机 IO,增加查询性能,索引能过滤出越少的数据,则从磁盘中读入的数据也就越少。
-- **区分度最高的列放在联合索引的最左侧:** 这是最重要的原则。区分度越高,通过索引筛选出的数据就越少,I/O 操作也就越少。计算区分度的方法是 `count(distinct column) / count(*)`。
-- **最频繁使用的列放在联合索引的左侧:** 这符合最左前缀匹配原则。将最常用的查询条件列放在最左侧,可以最大程度地利用索引。
-- **字段长度:** 字段长度对联合索引非叶子节点的影响很小,因为它存储了所有联合索引字段的值。字段长度主要影响主键和包含在其他索引中的字段的存储空间,以及这些索引的叶子节点的大小。因此,在选择联合索引列的顺序时,字段长度的优先级最低。 对于主键和包含在其他索引中的字段,选择较短的字段长度可以节省存储空间和提高 I/O 性能。
+- **区分度最高的列放在联合索引的最左侧**:这是最重要的原则。区分度越高,通过索引筛选出的数据就越少,I/O 操作也就越少。计算区分度的方法是 `count(distinct column) / count(*)`。
+- **最频繁使用的列放在联合索引的左侧**:这符合最左前缀匹配原则。将最常用的查询条件列放在最左侧,可以最大程度地利用索引。
+- **字段长度**:字段长度对联合索引非叶子节点的影响很小,因为它存储了所有联合索引字段的值。字段长度主要影响主键和包含在其他索引中的字段的存储空间,以及这些索引的叶子节点的大小。因此,在选择联合索引列的顺序时,字段长度的优先级最低。对于主键和包含在其他索引中的字段,选择较短的字段长度可以节省存储空间和提高 I/O 性能。
### 避免建立冗余索引和重复索引(增加了查询优化器生成执行计划的时间)
-- 重复索引示例:primary key(id)、index(id)、unique index(id)
-- 冗余索引示例:index(a,b,c)、index(a,b)、index(a)
+- 重复索引示例:primary key(id)、index(id)、unique index(id)。
+- 冗余索引示例:index(a,b,c)、index(a,b)、index(a)。
-### 对于频繁的查询优先考虑使用覆盖索引
+### 对于频繁的查询,优先考虑使用覆盖索引
-> 覆盖索引:就是包含了所有查询字段 (where,select,order by,group by 包含的字段) 的索引
+> 覆盖索引:就是包含了所有查询字段 (where、select、order by、group by 包含的字段) 的索引
-**覆盖索引的好处:**
+**覆盖索引的好处**:
-- **避免 InnoDB 表进行索引的二次查询,也就是回表操作:** InnoDB 是以聚集索引的顺序来存储的,对于 InnoDB 来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据的话,在查找到相应的键值后,还要通过主键进行二次查询才能获取我们真实所需要的数据。而在覆盖索引中,二级索引的键值中可以获取所有的数据,避免了对主键的二次查询(回表),减少了 IO 操作,提升了查询效率。
-- **可以把随机 IO 变成顺序 IO 加快查询效率:** 由于覆盖索引是按键值的顺序存储的,对于 IO 密集型的范围查找来说,对比随机从磁盘读取每一行的数据 IO 要少的多,因此利用覆盖索引在访问时也可以把磁盘的随机读取的 IO 转变成索引查找的顺序 IO。
+- **避免 InnoDB 表进行索引的二次查询,也就是回表操作**:InnoDB 是以聚集索引的顺序来存储的,对于 InnoDB 来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据的话,在查找到相应的键值后,还要通过主键进行二次查询才能获取我们真实所需要的数据。而在覆盖索引中,二级索引的键值中可以获取所有的数据,避免了对主键的二次查询(回表),减少了 IO 操作,提升了查询效率。
+- **可以把随机 IO 变成顺序 IO 加快查询效率**:由于覆盖索引是按键值的顺序存储的,对于 IO 密集型的范围查找来说,对比随机从磁盘读取每一行的数据 IO 要少的多,因此利用覆盖索引在访问时也可以把磁盘的随机读取的 IO 转变成索引查找的顺序 IO。
---
@@ -222,9 +222,9 @@ InnoDB 是按照主键索引的顺序来组织表的
**尽量避免使用外键约束**
-- 不建议使用外键约束(foreign key),但一定要在表与表之间的关联键上建立索引
-- 外键可用于保证数据的参照完整性,但建议在业务端实现
-- 外键会影响父表和子表的写操作从而降低性能
+- 不建议使用外键约束(foreign key),但一定要在表与表之间的关联键上建立索引。
+- 外键可用于保证数据的参照完整性,但建议在业务端实现。
+- 外键会影响父表和子表的写操作从而降低性能。
## 数据库 SQL 开发规范
@@ -238,7 +238,7 @@ InnoDB 是按照主键索引的顺序来组织表的
### 充分利用表上已经存在的索引
-避免使用双%号的查询条件。如:`a like '%123%'`,(如果无前置%,只有后置%,是可以用到列上的索引的)
+避免使用双%号的查询条件。如:`a like '%123%'`(如果无前置%,只有后置%,是可以用到列上的索引的)。
一个 SQL 只能利用到复合索引中的一列进行范围查询。如:有 a,b,c 列的联合索引,在查询条件中有 a 列的范围查询,则在 b,c 列上的索引将不会被用到。
@@ -248,18 +248,18 @@ InnoDB 是按照主键索引的顺序来组织表的
- `SELECT *` 会消耗更多的 CPU。
- `SELECT *` 无用字段增加网络带宽资源消耗,增加数据传输时间,尤其是大字段(如 varchar、blob、text)。
-- `SELECT *` 无法使用 MySQL 优化器覆盖索引的优化(基于 MySQL 优化器的“覆盖索引”策略又是速度极快,效率极高,业界极为推荐的查询优化方式)
-- `SELECT <字段列表>` 可减少表结构变更带来的影响、
+- `SELECT *` 无法使用 MySQL 优化器覆盖索引的优化(基于 MySQL 优化器的“覆盖索引”策略又是速度极快、效率极高、业界极为推荐的查询优化方式)。
+- `SELECT <字段列表>` 可减少表结构变更带来的影响。
### 禁止使用不含字段列表的 INSERT 语句
-如:
+**不推荐**:
```sql
insert into t values ('a','b','c');
```
-应使用:
+**推荐**:
```sql
insert into t(c1,c2,c3) values ('a','b','c');
@@ -273,7 +273,7 @@ insert into t(c1,c2,c3) values ('a','b','c');
### 避免数据类型的隐式转换
-隐式转换会导致索引失效如:
+隐式转换会导致索引失效,如:
```sql
select name,phone from customer where id = '111';
@@ -283,9 +283,9 @@ select name,phone from customer where id = '111';
### 避免使用子查询,可以把子查询优化为 join 操作
-通常子查询在 in 子句中,且子查询中为简单 SQL(不包含 union、group by、order by、limit 从句) 时,才可以把子查询转化为关联查询进行优化。
+通常子查询在 in 子句中,且子查询中为简单 SQL(不包含 union、group by、order by、limit 从句) 时,才可以把子查询转化为关联查询进行优化。
-**子查询性能差的原因:** 子查询的结果集无法使用索引,通常子查询的结果集会被存储到临时表中,不论是内存临时表还是磁盘临时表都不会存在索引,所以查询性能会受到一定的影响。特别是对于返回结果集比较大的子查询,其对查询性能的影响也就越大。由于子查询会产生大量的临时表也没有索引,所以会消耗过多的 CPU 和 IO 资源,产生大量的慢查询。
+**子查询性能差的原因**:子查询的结果集无法使用索引,通常子查询的结果集会被存储到临时表中,不论是内存临时表还是磁盘临时表都不会存在索引,所以查询性能会受到一定的影响。特别是对于返回结果集比较大的子查询,其对查询性能的影响也就越大。由于子查询会产生大量的临时表也没有索引,所以会消耗过多的 CPU 和 IO 资源,产生大量的慢查询。
### 避免使用 JOIN 关联太多的表
@@ -293,7 +293,7 @@ select name,phone from customer where id = '111';
在 MySQL 中,对于同一个 SQL 多关联(join)一个表,就会多分配一个关联缓存,如果在一个 SQL 中关联的表越多,所占用的内存也就越大。
-如果程序中大量的使用了多表关联的操作,同时 join_buffer_size 设置的也不合理的情况下,就容易造成服务器内存溢出的情况,就会影响到服务器数据库性能的稳定性。
+如果程序中大量地使用了多表关联的操作,同时 join_buffer_size 设置得也不合理,就容易造成服务器内存溢出的情况,就会影响到服务器数据库性能的稳定性。
同时对于关联操作来说,会产生临时表操作,影响查询效率,MySQL 最多允许关联 61 个表,建议不超过 5 个。
@@ -303,25 +303,25 @@ select name,phone from customer where id = '111';
### 对应同一列进行 or 判断时,使用 in 代替 or
-in 的值不要超过 500 个,in 操作可以更有效的利用索引,or 大多数情况下很少能利用到索引。
+in 的值不要超过 500 个。in 操作可以更有效的利用索引,or 大多数情况下很少能利用到索引。
### 禁止使用 order by rand() 进行随机排序
-order by rand() 会把表中所有符合条件的数据装载到内存中,然后在内存中对所有数据根据随机生成的值进行排序,并且可能会对每一行都生成一个随机值,如果满足条件的数据集非常大,就会消耗大量的 CPU 和 IO 及内存资源。
+order by rand() 会把表中所有符合条件的数据装载到内存中,然后在内存中对所有数据根据随机生成的值进行排序,并且可能会对每一行都生成一个随机值。如果满足条件的数据集非常大,就会消耗大量的 CPU 和 IO 及内存资源。
推荐在程序中获取一个随机值,然后从数据库中获取数据的方式。
### WHERE 从句中禁止对列进行函数转换和计算
-对列进行函数转换或计算时会导致无法使用索引
+对列进行函数转换或计算时会导致无法使用索引。
-**不推荐:**
+**不推荐**:
```sql
where date(create_time)='20190101'
```
-**推荐:**
+**推荐**:
```sql
where create_time >= '20190101' and create_time < '20190102'
@@ -329,43 +329,43 @@ where create_time >= '20190101' and create_time < '20190102'
### 在明显不会有重复值时使用 UNION ALL 而不是 UNION
-- UNION 会把两个结果集的所有数据放到临时表中后再进行去重操作
-- UNION ALL 不会再对结果集进行去重操作
+- UNION 会把两个结果集的所有数据放到临时表中后再进行去重操作。
+- UNION ALL 不会再对结果集进行去重操作。
### 拆分复杂的大 SQL 为多个小 SQL
-- 大 SQL 逻辑上比较复杂,需要占用大量 CPU 进行计算的 SQL
-- MySQL 中,一个 SQL 只能使用一个 CPU 进行计算
-- SQL 拆分后可以通过并行执行来提高处理效率
+- 大 SQL 逻辑上比较复杂,需要占用大量 CPU 进行计算的 SQL。
+- MySQL 中,一个 SQL 只能使用一个 CPU 进行计算。
+- SQL 拆分后可以通过并行执行来提高处理效率。
### 程序连接不同的数据库使用不同的账号,禁止跨库查询
-- 为数据库迁移和分库分表留出余地
-- 降低业务耦合度
-- 避免权限过大而产生的安全风险
+- 为数据库迁移和分库分表留出余地。
+- 降低业务耦合度。
+- 避免权限过大而产生的安全风险。
## 数据库操作行为规范
-### 超 100 万行的批量写 (UPDATE,DELETE,INSERT) 操作,要分批多次进行操作
+### 超 100 万行的批量写 (UPDATE、DELETE、INSERT) 操作,要分批多次进行操作
**大批量操作可能会造成严重的主从延迟**
-主从环境中,大批量操作可能会造成严重的主从延迟,大批量的写操作一般都需要执行一定长的时间,而只有当主库上执行完成后,才会在其他从库上执行,所以会造成主库与从库长时间的延迟情况
+主从环境中,大批量操作可能会造成严重的主从延迟,大批量的写操作一般都需要执行一定长的时间,而只有当主库上执行完成后,才会在其他从库上执行,所以会造成主库与从库长时间的延迟情况。
**binlog 日志为 row 格式时会产生大量的日志**
-大批量写操作会产生大量日志,特别是对于 row 格式二进制数据而言,由于在 row 格式中会记录每一行数据的修改,我们一次修改的数据越多,产生的日志量也就会越多,日志的传输和恢复所需要的时间也就越长,这也是造成主从延迟的一个原因
+大批量写操作会产生大量日志,特别是对于 row 格式二进制数据而言,由于在 row 格式中会记录每一行数据的修改,我们一次修改的数据越多,产生的日志量也就会越多,日志的传输和恢复所需要的时间也就越长,这也是造成主从延迟的一个原因。
**避免产生大事务操作**
大批量修改数据,一定是在一个事务中进行的,这就会造成表中大批量数据进行锁定,从而导致大量的阻塞,阻塞会对 MySQL 的性能产生非常大的影响。
-特别是长时间的阻塞会占满所有数据库的可用连接,这会使生产环境中的其他应用无法连接到数据库,因此一定要注意大批量写操作要进行分批
+特别是长时间的阻塞会占满所有数据库的可用连接,这会使生产环境中的其他应用无法连接到数据库,因此一定要注意大批量写操作要进行分批。
### 对于大表使用 pt-online-schema-change 修改表结构
-- 避免大表修改产生的主从延迟
-- 避免在对表字段进行修改时进行锁表
+- 避免大表修改产生的主从延迟。
+- 避免在对表字段进行修改时进行锁表。
对大表数据结构的修改一定要谨慎,会造成严重的锁表操作,尤其是生产环境,是不能容忍的。
@@ -373,13 +373,13 @@ pt-online-schema-change 它会首先建立一个与原表结构相同的新表
### 禁止为程序使用的账号赋予 super 权限
-- 当达到最大连接数限制时,还运行 1 个有 super 权限的用户连接
-- super 权限只能留给 DBA 处理问题的账号使用
+- 当达到最大连接数限制时,还运行 1 个有 super 权限的用户连接。
+- super 权限只能留给 DBA 处理问题的账号使用。
-### 对于程序连接数据库账号,遵循权限最小原则
+### 对于程序连接数据库账号,遵循权限最小原则
-- 程序使用数据库账号只能在一个 DB 下使用,不准跨库
-- 程序使用的账号原则上不准有 drop 权限
+- 程序使用数据库账号只能在一个 DB 下使用,不准跨库。
+- 程序使用的账号原则上不准有 drop 权限。
## 推荐阅读
diff --git a/docs/database/mysql/mysql-index.md b/docs/database/mysql/mysql-index.md
index ab0dc7f6760..afed110b9b4 100644
--- a/docs/database/mysql/mysql-index.md
+++ b/docs/database/mysql/mysql-index.md
@@ -15,31 +15,37 @@ tag:
**索引是一种用于快速查询和检索数据的数据结构,其本质可以看成是一种排序好的数据结构。**
-索引的作用就相当于书的目录。打个比方: 我们在查字典的时候,如果没有目录,那我们就只能一页一页的去找我们需要查的那个字,速度很慢。如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
+索引的作用就相当于书的目录。打个比方:我们在查字典的时候,如果没有目录,那我们就只能一页一页地去找我们需要查的那个字,速度很慢;如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
-索引底层数据结构存在很多种类型,常见的索引结构有: B 树, B+树 和 Hash、红黑树。在 MySQL 中,无论是 Innodb 还是 MyIsam,都使用了 B+树作为索引结构。
+索引底层数据结构存在很多种类型,常见的索引结构有:B 树、 B+ 树 和 Hash、红黑树。在 MySQL 中,无论是 Innodb 还是 MyISAM,都使用了 B+ 树作为索引结构。
## 索引的优缺点
-**优点**:
+**索引的优点:**
-- 使用索引可以大大加快数据的检索速度(大大减少检索的数据量), 减少 IO 次数,这也是创建索引的最主要的原因。
-- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
+1. **查询速度起飞 (主要目的)**:通过索引,数据库可以**大幅减少需要扫描的数据量**,直接定位到符合条件的记录,从而显著加快数据检索速度,减少磁盘 I/O 次数。
+2. **保证数据唯一性**:通过创建**唯一索引 (Unique Index)**,可以确保表中的某一列(或几列组合)的值是独一无二的,比如用户 ID、邮箱等。主键本身就是一种唯一索引。
+3. **加速排序和分组**:如果查询中的 ORDER BY 或 GROUP BY 子句涉及的列建有索引,数据库往往可以直接利用索引已经排好序的特性,避免额外的排序操作,从而提升性能。
-**缺点**:
+**索引的缺点:**
+
+1. **创建和维护耗时**:创建索引本身需要时间,特别是对大表操作时。更重要的是,当对表中的数据进行**增、删、改 (DML 操作)** 时,不仅要操作数据本身,相关的索引也必须动态更新和维护,这会**降低这些 DML 操作的执行效率**。
+2. **占用存储空间**:索引本质上也是一种数据结构,需要以物理文件(或内存结构)的形式存储,因此会**额外占用一定的磁盘空间**。索引越多、越大,占用的空间也就越多。
+3. **可能被误用或失效**:如果索引设计不当,或者查询语句写得不好,数据库优化器可能不会选择使用索引(或者选错索引),反而导致性能下降。
-- 创建索引和维护索引需要耗费许多时间。当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低 SQL 执行效率。
-- 索引需要使用物理文件存储,也会耗费一定空间。
+**那么,用了索引就一定能提高查询性能吗?**
-但是,**使用索引一定能提高查询性能吗?**
+**不一定。** 大多数情况下,合理使用索引确实比全表扫描快得多。但也有例外:
-大多数情况下,索引查询都是比全表扫描要快的。但是如果数据库的数据量不大,那么使用索引也不一定能够带来很大提升。
+- **数据量太小**:如果表里的数据非常少(比如就几百条),全表扫描可能比通过索引查找更快,因为走索引本身也有开销。
+- **查询结果集占比过大**:如果要查询的数据占了整张表的大部分(比如超过 20%-30%),优化器可能会认为全表扫描更划算,因为通过索引多次回表(随机 I/O)的成本可能高于一次顺序的全表扫描。
+- **索引维护不当或统计信息过时**:导致优化器做出错误判断。
## 索引底层数据结构选型
### Hash 表
-哈希表是键值对的集合,通过键(key)即可快速取出对应的值(value),因此哈希表可以快速检索数据(接近 O(1))。
+哈希表是键值对的集合,通过键(key)即可快速取出对应的值(value),因此哈希表可以快速检索数据(接近 O(1))。
**为何能够通过 key 快速取出 value 呢?** 原因在于 **哈希算法**(也叫散列算法)。通过哈希算法,我们可以快速找到 key 对应的 index,找到了 index 也就找到了对应的 value。
@@ -50,7 +56,7 @@ index = hash % array_size

-但是!哈希算法有个 **Hash 冲突** 问题,也就是说多个不同的 key 最后得到的 index 相同。通常情况下,我们常用的解决办法是 **链地址法**。链地址法就是将哈希冲突数据存放在链表中。就比如 JDK1.8 之前 `HashMap` 就是通过链地址法来解决哈希冲突的。不过,JDK1.8 以后`HashMap`为了减少链表过长的时候搜索时间过长引入了红黑树。
+但是!哈希算法有个 **Hash 冲突** 问题,也就是说多个不同的 key 最后得到的 index 相同。通常情况下,我们常用的解决办法是 **链地址法**。链地址法就是将哈希冲突数据存放在链表中。就比如 JDK1.8 之前 `HashMap` 就是通过链地址法来解决哈希冲突的。不过,JDK1.8 以后`HashMap`为了提高链表过长时的搜索效率,引入了红黑树。

@@ -60,15 +66,15 @@ MySQL 的 InnoDB 存储引擎不直接支持常规的哈希索引,但是,Inn
既然哈希表这么快,**为什么 MySQL 没有使用其作为索引的数据结构呢?** 主要是因为 Hash 索引不支持顺序和范围查询。假如我们要对表中的数据进行排序或者进行范围查询,那 Hash 索引可就不行了。并且,每次 IO 只能取一个。
-试想一种情况:
+试想一种情况:
```java
SELECT * FROM tb1 WHERE id < 500;
```
-在这种范围查询中,优势非常大,直接遍历比 500 小的叶子节点就够了。而 Hash 索引是根据 hash 算法来定位的,难不成还要把 1 - 499 的数据,每个都进行一次 hash 计算来定位吗?这就是 Hash 最大的缺点了。
+在这种范围查询中,优势非常大,直接遍历比 500 小的叶子节点就够了。而 Hash 索引是根据 hash 算法来定位的,难不成还要把 1 - 499 的数据,每个都进行一次 hash 计算来定位吗?这就是 Hash 最大的缺点了。
-### 二叉查找树(BST)
+### 二叉查找树(BST)
二叉查找树(Binary Search Tree)是一种基于二叉树的数据结构,它具有以下特点:
@@ -76,7 +82,7 @@ SELECT * FROM tb1 WHERE id < 500;
2. 右子树所有节点的值均大于根节点的值。
3. 左右子树也分别为二叉查找树。
-当二叉查找树是平衡的时候,也就是树的每个节点的左右子树深度相差不超过 1 的时候,查询的时间复杂度为 O(log2(N)),具有比较高的效率。然而,当二叉查找树不平衡时,例如在最坏情况下(有序插入节点),树会退化成线性链表(也被称为斜树),导致查询效率急剧下降,时间复杂退化为 O(N)。
+当二叉查找树是平衡的时候,也就是树的每个节点的左右子树深度相差不超过 1 的时候,查询的时间复杂度为 O(log2(N)),具有比较高的效率。然而,当二叉查找树不平衡时,例如在最坏情况下(有序插入节点),树会退化成线性链表(也被称为斜树),导致查询效率急剧下降,时间复杂退化为 O(N)。

@@ -92,7 +98,7 @@ AVL 树是计算机科学中最早被发明的自平衡二叉查找树,它的
AVL 树采用了旋转操作来保持平衡。主要有四种旋转操作:LL 旋转、RR 旋转、LR 旋转和 RL 旋转。其中 LL 旋转和 RR 旋转分别用于处理左左和右右失衡,而 LR 旋转和 RL 旋转则用于处理左右和右左失衡。
-由于 AVL 树需要频繁地进行旋转操作来保持平衡,因此会有较大的计算开销进而降低了数据库写操作的性能。并且, 在使用 AVL 树时,每个树节点仅存储一个数据,而每次进行磁盘 IO 时只能读取一个节点的数据,如果需要查询的数据分布在多个节点上,那么就需要进行多次磁盘 IO。 **磁盘 IO 是一项耗时的操作,在设计数据库索引时,我们需要优先考虑如何最大限度地减少磁盘 IO 操作的次数。**
+由于 AVL 树需要频繁地进行旋转操作来保持平衡,因此会有较大的计算开销进而降低了数据库写操作的性能。并且, 在使用 AVL 树时,每个树节点仅存储一个数据,而每次进行磁盘 IO 时只能读取一个节点的数据,如果需要查询的数据分布在多个节点上,那么就需要进行多次磁盘 IO。**磁盘 IO 是一项耗时的操作,在设计数据库索引时,我们需要优先考虑如何最大限度地减少磁盘 IO 操作的次数。**
实际应用中,AVL 树使用的并不多。
@@ -112,26 +118,26 @@ AVL 树采用了旋转操作来保持平衡。主要有四种旋转操作:LL
**红黑树的应用还是比较广泛的,TreeMap、TreeSet 以及 JDK1.8 的 HashMap 底层都用到了红黑树。对于数据在内存中的这种情况来说,红黑树的表现是非常优异的。**
-### B 树& B+树
+### B 树& B+ 树
-B 树也称 B-树,全称为 **多路平衡查找树** ,B+ 树是 B 树的一种变体。B 树和 B+树中的 B 是 `Balanced` (平衡)的意思。
+B 树也称 B- 树,全称为 **多路平衡查找树**,B+ 树是 B 树的一种变体。B 树和 B+ 树中的 B 是 `Balanced`(平衡)的意思。
目前大部分数据库系统及文件系统都采用 B-Tree 或其变种 B+Tree 作为索引结构。
-**B 树& B+树两者有何异同呢?**
+**B 树& B+ 树两者有何异同呢?**
-- B 树的所有节点既存放键(key) 也存放数据(data),而 B+树只有叶子节点存放 key 和 data,其他内节点只存放 key。
-- B 树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点。
-- B 树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而 B+树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
-- 在 B 树中进行范围查询时,首先找到要查找的下限,然后对 B 树进行中序遍历,直到找到查找的上限;而 B+树的范围查询,只需要对链表进行遍历即可。
+- B 树的所有节点既存放键(key)也存放数据(data),而 B+ 树只有叶子节点存放 key 和 data,其他内节点只存放 key。
+- B 树的叶子节点都是独立的;B+ 树的叶子节点有一条引用链指向与它相邻的叶子节点。
+- B 树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而 B+ 树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
+- 在 B 树中进行范围查询时,首先找到要查找的下限,然后对 B 树进行中序遍历,直到找到查找的上限;而 B+ 树的范围查询,只需要对链表进行遍历即可。
-综上,B+树与 B 树相比,具备更少的 IO 次数、更稳定的查询效率和更适于范围查询这些优势。
+综上,B+ 树与 B 树相比,具备更少的 IO 次数、更稳定的查询效率和更适于范围查询这些优势。
在 MySQL 中,MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,但是,两者的实现方式不太一样。(下面的内容整理自《Java 工程师修炼之道》)
> MyISAM 引擎中,B+Tree 叶节点的 data 域存放的是数据记录的地址。在索引检索的时候,首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“**非聚簇索引(非聚集索引)**”。
>
-> InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。这被称为“**聚簇索引(聚集索引)**”,而其余的索引都作为 **辅助索引** ,辅助索引的 data 域存储相应记录主键的值而不是地址,这也是和 MyISAM 不同的地方。在根据主索引搜索时,直接找到 key 所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
+> InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。这被称为“**聚簇索引(聚集索引)**”,而其余的索引都作为 **辅助索引**,辅助索引的 data 域存储相应记录主键的值而不是地址,这也是和 MyISAM 不同的地方。在根据主索引搜索时,直接找到 key 所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
## 索引类型总结
@@ -140,12 +146,12 @@ B 树也称 B-树,全称为 **多路平衡查找树** ,B+ 树是 B 树的一
- BTree 索引:MySQL 里默认和最常用的索引类型。只有叶子节点存储 value,非叶子节点只有指针和 key。存储引擎 MyISAM 和 InnoDB 实现 BTree 索引都是使用 B+Tree,但二者实现方式不一样(前面已经介绍了)。
- 哈希索引:类似键值对的形式,一次即可定位。
- RTree 索引:一般不会使用,仅支持 geometry 数据类型,优势在于范围查找,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
-- 全文索引:对文本的内容进行分词,进行搜索。目前只有 `CHAR`、`VARCHAR` ,`TEXT` 列上可以创建全文索引。一般不会使用,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
+- 全文索引:对文本的内容进行分词,进行搜索。目前只有 `CHAR`、`VARCHAR`、`TEXT` 列上可以创建全文索引。一般不会使用,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
按照底层存储方式角度划分:
- 聚簇索引(聚集索引):索引结构和数据一起存放的索引,InnoDB 中的主键索引就属于聚簇索引。
-- 非聚簇索引(非聚集索引):索引结构和数据分开存放的索引,二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。
+- 非聚簇索引(非聚集索引):索引结构和数据分开存放的索引,二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。
按照应用维度划分:
@@ -154,7 +160,7 @@ B 树也称 B-树,全称为 **多路平衡查找树** ,B+ 树是 B 树的一
- 唯一索引:加速查询 + 列值唯一(可以有 NULL)。
- 覆盖索引:一个索引包含(或者说覆盖)所有需要查询的字段的值。
- 联合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并。
-- 全文索引:对文本的内容进行分词,进行搜索。目前只有 `CHAR`、`VARCHAR` ,`TEXT` 列上可以创建全文索引。一般不会使用,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
+- 全文索引:对文本的内容进行分词,进行搜索。目前只有 `CHAR`、`VARCHAR`、`TEXT` 列上可以创建全文索引。一般不会使用,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
- 前缀索引:对文本的前几个字符创建索引,相比普通索引建立的数据更小,因为只取前几个字符。
MySQL 8.x 中实现的索引新特性:
@@ -163,7 +169,7 @@ MySQL 8.x 中实现的索引新特性:
- 降序索引:之前的版本就支持通过 desc 来指定索引为降序,但实际上创建的仍然是常规的升序索引。直到 MySQL 8.x 版本才开始真正支持降序索引。另外,在 MySQL 8.x 版本中,不再对 GROUP BY 语句进行隐式排序。
- 函数索引:从 MySQL 8.0.13 版本开始支持在索引中使用函数或者表达式的值,也就是在索引中可以包含函数或者表达式。
-## 主键索引(Primary Key)
+## 主键索引(Primary Key)
数据表的主键列使用的就是主键索引。
@@ -177,16 +183,16 @@ MySQL 8.x 中实现的索引新特性:
二级索引(Secondary Index)的叶子节点存储的数据是主键的值,也就是说,通过二级索引可以定位主键的位置,二级索引又称为辅助索引/非主键索引。
-唯一索引,普通索引,前缀索引等索引都属于二级索引。
+唯一索引、普通索引、前缀索引等索引都属于二级索引。
-PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,也可以自行搜索。
+PS:不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,也可以自行搜索。
-1. **唯一索引(Unique Key)**:唯一索引也是一种约束。唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引。 建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
-2. **普通索引(Index)**:普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和 NULL。
-3. **前缀索引(Prefix)**:前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,因为只取前几个字符。
-4. **全文索引(Full Text)**:全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6 之前只有 MYISAM 引擎支持全文索引,5.6 之后 InnoDB 也支持了全文索引。
+1. **唯一索引(Unique Key)**:唯一索引也是一种约束。唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引。 建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
+2. **普通索引(Index)**:普通索引的唯一作用就是为了快速查询数据。一张表允许创建多个普通索引,并允许数据重复和 NULL。
+3. **前缀索引(Prefix)**:前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,因为只取前几个字符。
+4. **全文索引(Full Text)**:全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6 之前只有 MyISAM 引擎支持全文索引,5.6 之后 InnoDB 也支持了全文索引。
-二级索引:
+二级索引:

@@ -198,25 +204,25 @@ PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,
聚簇索引(Clustered Index)即索引结构和数据一起存放的索引,并不是一种单独的索引类型。InnoDB 中的主键索引就属于聚簇索引。
-在 MySQL 中,InnoDB 引擎的表的 `.ibd`文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
+在 MySQL 中,InnoDB 引擎的表的 `.ibd`文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+ 树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
#### 聚簇索引的优缺点
**优点**:
-- **查询速度非常快**:聚簇索引的查询速度非常的快,因为整个 B+树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。相比于非聚簇索引, 聚簇索引少了一次读取数据的 IO 操作。
+- **查询速度非常快**:聚簇索引的查询速度非常的快,因为整个 B+ 树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。相比于非聚簇索引, 聚簇索引少了一次读取数据的 IO 操作。
- **对排序查找和范围查找优化**:聚簇索引对于主键的排序查找和范围查找速度非常快。
**缺点**:
-- **依赖于有序的数据**:因为 B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或 UUID 这种又长又难比较的数据,插入或查找的速度肯定比较慢。
+- **依赖于有序的数据**:因为 B+ 树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或 UUID 这种又长又难比较的数据,插入或查找的速度肯定比较慢。
- **更新代价大**:如果对索引列的数据被修改时,那么对应的索引也将会被修改,而且聚簇索引的叶子节点还存放着数据,修改代价肯定是较大的,所以对于主键索引来说,主键一般都是不可被修改的。
### 非聚簇索引(非聚集索引)
#### 非聚簇索引介绍
-非聚簇索引(Non-Clustered Index)即索引结构和数据分开存放的索引,并不是一种单独的索引类型。二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。
+非聚簇索引(Non-Clustered Index)即索引结构和数据分开存放的索引,并不是一种单独的索引类型。二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。
非聚簇索引的叶子节点并不一定存放数据的指针,因为二级索引的叶子节点就存放的是主键,根据主键再回表查数据。
@@ -224,22 +230,22 @@ PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,
**优点**:
-更新代价比聚簇索引要小 。非聚簇索引的更新代价就没有聚簇索引那么大了,非聚簇索引的叶子节点是不存放数据的。
+更新代价比聚簇索引要小。非聚簇索引的更新代价就没有聚簇索引那么大了,非聚簇索引的叶子节点是不存放数据的。
**缺点**:
-- **依赖于有序的数据**:跟聚簇索引一样,非聚簇索引也依赖于有序的数据
-- **可能会二次查询(回表)**:这应该是非聚簇索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
+- **依赖于有序的数据**:跟聚簇索引一样,非聚簇索引也依赖于有序的数据。
+- **可能会二次查询(回表)**:这应该是非聚簇索引最大的缺点了。当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
-这是 MySQL 的表的文件截图:
+这是 MySQL 的表的文件截图:

-聚簇索引和非聚簇索引:
+聚簇索引和非聚簇索引:

-#### 非聚簇索引一定回表查询吗(覆盖索引)?
+#### 非聚簇索引一定回表查询吗(覆盖索引)?
**非聚簇索引不一定回表查询。**
@@ -251,7 +257,7 @@ PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,
那么这个索引的 key 本身就是 name,查到对应的 name 直接返回就行了,无需回表查询。
-即使是 MYISAM 也是这样,虽然 MYISAM 的主键索引确实需要回表,因为它的主键索引的叶子节点存放的是指针。但是!**如果 SQL 查的就是主键呢?**
+即使是 MyISAM 也是这样,虽然 MyISAM 的主键索引确实需要回表,因为它的主键索引的叶子节点存放的是指针。但是!**如果 SQL 查的就是主键呢?**
```sql
SELECT id FROM table WHERE id=1;
@@ -263,7 +269,7 @@ SELECT id FROM table WHERE id=1;
### 覆盖索引
-如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为 **覆盖索引(Covering Index)** 。
+如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为 **覆盖索引(Covering Index)**。
在 InnoDB 存储引擎中,非主键索引的叶子节点包含的是主键的值。这意味着,当使用非主键索引进行查询时,数据库会先找到对应的主键值,然后再通过主键索引来定位和检索完整的行数据。这个过程被称为“回表”。
@@ -276,7 +282,7 @@ SELECT id FROM table WHERE id=1;
我们这里简单演示一下覆盖索引的效果。
-1、创建一个名为 `cus_order` 的表,来实际测试一下这种排序方式。为了测试方便, `cus_order` 这张表只有 `id`、`score`、`name`这 3 个字段。
+1、创建一个名为 `cus_order` 的表,来实际测试一下这种排序方式。为了测试方便,`cus_order` 这张表只有 `id`、`score`、`name` 这 3 个字段。
```sql
CREATE TABLE `cus_order` (
@@ -320,7 +326,7 @@ CALL BatchinsertDataToCusOder(1, 1000000); # 插入100w+的随机数据
SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
```
-使用 `EXPLAIN` 命令分析这条 SQL 语句,通过 `Extra` 这一列的 `Using filesort` ,我们发现是没有用到覆盖索引的。
+使用 `EXPLAIN` 命令分析这条 SQL 语句,通过 `Extra` 这一列的 `Using filesort`,我们发现是没有用到覆盖索引的。

@@ -336,7 +342,7 @@ ALTER TABLE `cus_order` ADD INDEX id_score_name(score, name);

-通过 `Extra` 这一列的 `Using index` ,说明这条 SQL 语句成功使用了覆盖索引。
+通过 `Extra` 这一列的 `Using index`,说明这条 SQL 语句成功使用了覆盖索引。
关于 `EXPLAIN` 命令的详细介绍请看:[MySQL 执行计划分析](./mysql-query-execution-plan.md)这篇文章。
@@ -356,13 +362,13 @@ ALTER TABLE `cus_order` ADD INDEX id_score_name(score, name);
最左匹配原则会一直向右匹配,直到遇到范围查询(如 >、<)为止。对于 >=、<=、BETWEEN 以及前缀匹配 LIKE 的范围查询,不会停止匹配(相关阅读:[联合索引的最左匹配原则全网都在说的一个错误结论](https://mp.weixin.qq.com/s/8qemhRg5MgXs1So5YCv0fQ))。
-假设有一个联合索引`(column1, column2, column3)`,其从左到右的所有前缀为`(column1)`、`(column1, column2)`、`(column1, column2, column3)`(创建 1 个联合索引相当于创建了 3 个索引),包含这些列的所有查询都会走索引而不会全表扫描。
+假设有一个联合索引 `(column1, column2, column3)`,其从左到右的所有前缀为 `(column1)`、`(column1, column2)`、`(column1, column2, column3)`(创建 1 个联合索引相当于创建了 3 个索引),包含这些列的所有查询都会走索引而不会全表扫描。
我们在使用联合索引时,可以将区分度高的字段放在最左边,这也可以过滤更多数据。
我们这里简单演示一下最左前缀匹配的效果。
-1、创建一个名为 `student` 的表,这张表只有 `id`、`name`、`class`这 3 个字段。
+1、创建一个名为 `student` 的表,这张表只有 `id`、`name`、`class` 这 3 个字段。
```sql
CREATE TABLE `student` (
@@ -386,21 +392,22 @@ EXPLAIN SELECT * FROM student WHERE name = 'Anne Henry' AND class = 'lIrm08RYVk'
SELECT * FROM student WHERE class = 'lIrm08RYVk';
```
-再来看一个常见的面试题:如果有索引 `联合索引(a,b,c)`,查询 `a=1 AND c=1`会走索引么?`c=1` 呢?`b=1 AND c=1`呢?
+再来看一个常见的面试题:如果有索引 `联合索引(a,b,c)`,查询 `a=1 AND c=1` 会走索引么?`c=1` 呢?`b=1 AND c=1` 呢? `b = 1 AND a = 1 AND c = 1` 呢?
先不要往下看答案,给自己 3 分钟时间想一想。
1. 查询 `a=1 AND c=1`:根据最左前缀匹配原则,查询可以使用索引的前缀部分。因此,该查询仅在 `a=1` 上使用索引,然后对结果进行 `c=1` 的过滤。
-2. 查询 `c=1` :由于查询中不包含最左列 `a`,根据最左前缀匹配原则,整个索引都无法被使用。
-3. 查询`b=1 AND c=1`:和第二种一样的情况,整个索引都不会使用。
+2. 查询 `c=1`:由于查询中不包含最左列 `a`,根据最左前缀匹配原则,整个索引都无法被使用。
+3. 查询 `b=1 AND c=1`:和第二种一样的情况,整个索引都不会使用。
+4. 查询 `b=1 AND a=1 AND c=1`:这个查询是可以用到索引的。查询优化器分析 SQL 语句时,对于联合索引,会对查询条件进行重排序,以便用到索引。会将 `b=1` 和 `a=1` 的条件进行重排序,变成 `a=1 AND b=1 AND c=1`。
MySQL 8.0.13 版本引入了索引跳跃扫描(Index Skip Scan,简称 ISS),它可以在某些索引查询场景下提高查询效率。在没有 ISS 之前,不满足最左前缀匹配原则的联合索引查询中会执行全表扫描。而 ISS 允许 MySQL 在某些情况下避免全表扫描,即使查询条件不符合最左前缀。不过,这个功能比较鸡肋, 和 Oracle 中的没法比,MySQL 8.0.31 还报告了一个 bug:[Bug #109145 Using index for skip scan cause incorrect result](https://bugs.mysql.com/bug.php?id=109145)(后续版本已经修复)。个人建议知道有这个东西就好,不需要深究,实际项目也不一定能用上。
## 索引下推
-**索引下推(Index Condition Pushdown,简称 ICP)** 是 **MySQL 5.6** 版本中提供的一项索引优化功能,它允许存储引擎在索引遍历过程中,执行部分 `WHERE`字句的判断条件,直接过滤掉不满足条件的记录,从而减少回表次数,提高查询效率。
+**索引下推(Index Condition Pushdown,简称 ICP)** 是 **MySQL 5.6** 版本中提供的一项索引优化功能,它允许存储引擎在索引遍历过程中,执行部分 `WHERE` 字句的判断条件,直接过滤掉不满足条件的记录,从而减少回表次数,提高查询效率。
-假设我们有一个名为 `user` 的表,其中包含 `id`, `username`, `zipcode`和 `birthdate` 4 个字段,创建了联合索引`(zipcode, birthdate)`。
+假设我们有一个名为 `user` 的表,其中包含 `id`、`username`、`zipcode` 和 `birthdate` 4 个字段,创建了联合索引 `(zipcode, birthdate)`。
```sql
CREATE TABLE `user` (
@@ -417,7 +424,7 @@ SELECT * FROM user WHERE zipcode = '431200' AND MONTH(birthdate) = 3;
```
- 没有索引下推之前,即使 `zipcode` 字段利用索引可以帮助我们快速定位到 `zipcode = '431200'` 的用户,但我们仍然需要对每一个找到的用户进行回表操作,获取完整的用户数据,再去判断 `MONTH(birthdate) = 3`。
-- 有了索引下推之后,存储引擎会在使用`zipcode` 字段索引查找`zipcode = '431200'` 的用户时,同时判断`MONTH(birthdate) = 3`。这样,只有同时满足条件的记录才会被返回,减少了回表次数。
+- 有了索引下推之后,存储引擎会在使用 `zipcode` 字段索引查找 `zipcode = '431200'` 的用户时,同时判断 `MONTH(birthdate) = 3`。这样,只有同时满足条件的记录才会被返回,减少了回表次数。

@@ -429,14 +436,14 @@ SELECT * FROM user WHERE zipcode = '431200' AND MONTH(birthdate) = 3;
MySQL 可以简单分为 Server 层和存储引擎层这两层。Server 层处理查询解析、分析、优化、缓存以及与客户端的交互等操作,而存储引擎层负责数据的存储和读取,MySQL 支持 InnoDB、MyISAM、Memory 等多种存储引擎。
-索引下推的**下推**其实就是指将部分上层(Server 层)负责的事情,交给了下层(存储引擎层)去处理。
+索引下推的 **下推** 其实就是指将部分上层(Server 层)负责的事情,交给了下层(存储引擎层)去处理。
我们这里结合索引下推原理再对上面提到的例子进行解释。
没有索引下推之前:
- 存储引擎层先根据 `zipcode` 索引字段找到所有 `zipcode = '431200'` 的用户的主键 ID,然后二次回表查询,获取完整的用户数据;
-- 存储引擎层把所有 `zipcode = '431200'` 的用户数据全部交给 Server 层,Server 层根据`MONTH(birthdate) = 3`这一条件再进一步做筛选。
+- 存储引擎层把所有 `zipcode = '431200'` 的用户数据全部交给 Server 层,Server 层根据 `MONTH(birthdate) = 3` 这一条件再进一步做筛选。
有了索引下推之后:
@@ -449,8 +456,8 @@ MySQL 可以简单分为 Server 层和存储引擎层这两层。Server 层处
最后,总结一下索引下推应用范围:
1. 适用于 InnoDB 引擎和 MyISAM 引擎的查询。
-2. 适用于执行计划是 range, ref, eq_ref, ref_or_null 的范围查询。
-3. 对于 InnoDB 表,仅用于非聚簇索引。索引下推的目标是减少全行读取次数,从而减少 I/O 操作。对于 InnoDB 聚集索引,完整的记录已经读入 InnoDB 缓冲区。在这种情况下使用索引下推 不会减少 I/O。
+2. 适用于执行计划是 range、ref、eq_ref、ref_or_null 的范围查询。
+3. 对于 InnoDB 表,仅用于非聚簇索引。索引下推的目标是减少全行读取次数,从而减少 I/O 操作。对于 InnoDB 聚集索引,完整的记录已经读入 InnoDB 缓冲区。在这种情况下使用索引下推不会减少 I/O。
4. 子查询不能使用索引下推,因为子查询通常会创建临时表来处理结果,而这些临时表是没有索引的。
5. 存储过程不能使用索引下推,因为存储引擎无法调用存储函数。
@@ -458,7 +465,7 @@ MySQL 可以简单分为 Server 层和存储引擎层这两层。Server 层处
### 选择合适的字段创建索引
-- **不为 NULL 的字段**:索引字段的数据应该尽量不为 NULL,因为对于数据为 NULL 的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为 NULL,建议使用 0,1,true,false 这样语义较为清晰的短值或短字符作为替代。
+- **不为 NULL 的字段**:索引字段的数据应该尽量不为 NULL,因为对于数据为 NULL 的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为 NULL,建议使用 0、1、true、false 这样语义较为清晰的短值或短字符作为替代。
- **被频繁查询的字段**:我们创建索引的字段应该是查询操作非常频繁的字段。
- **被作为条件查询的字段**:被作为 WHERE 条件查询的字段,应该被考虑建立索引。
- **频繁需要排序的字段**:索引已经排序,这样查询可以利用索引的排序,加快排序查询时间。
@@ -470,19 +477,19 @@ MySQL 可以简单分为 Server 层和存储引擎层这两层。Server 层处
### 限制每张表上的索引数量
-索引并不是越多越好,建议单张表索引不超过 5 个!索引可以提高效率同样可以降低效率。
+索引并不是越多越好,建议单张表索引不超过 5 个!索引可以提高效率,同样可以降低效率。
索引可以增加查询效率,但同样也会降低插入和更新的效率,甚至有些情况下会降低查询效率。
-因为 MySQL 优化器在选择如何优化查询时,会根据统一信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能。
+因为 MySQL 优化器在选择如何优化查询时,会根据统计信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能。
### 尽可能的考虑建立联合索引而不是单列索引
-因为索引是需要占用磁盘空间的,可以简单理解为每个索引都对应着一颗 B+树。如果一个表的字段过多,索引过多,那么当这个表的数据达到一个体量后,索引占用的空间也是很多的,且修改索引时,耗费的时间也是较多的。如果是联合索引,多个字段在一个索引上,那么将会节约很大磁盘空间,且修改数据的操作效率也会提升。
+因为索引是需要占用磁盘空间的,可以简单理解为每个索引都对应着一颗 B+ 树。如果一个表的字段过多,索引过多,那么当这个表的数据达到一个体量后,索引占用的空间也是很多的,且修改索引时,耗费的时间也是较多的。如果是联合索引,多个字段在一个索引上,那么将会节约很大磁盘空间,且修改数据的操作效率也会提升。
### 注意避免冗余索引
-冗余索引指的是索引的功能相同,能够命中索引(a, b)就肯定能命中索引(a) ,那么索引(a)就是冗余索引。如(name,city )和(name )这两个索引就是冗余索引,能够命中前者的查询肯定是能够命中后者的 在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
+冗余索引指的是索引的功能相同,能够命中索引(a, b)就肯定能命中索引(a) ,那么索引(a)就是冗余索引。如(name,city)和(name)这两个索引就是冗余索引,能够命中前者的查询肯定是能够命中后者的。在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
### 字符串类型的字段使用前缀索引代替普通索引
@@ -492,13 +499,13 @@ MySQL 可以简单分为 Server 层和存储引擎层这两层。Server 层处
索引失效也是慢查询的主要原因之一,常见的导致索引失效的情况有下面这些:
-- ~~使用 `SELECT *` 进行查询;~~ `SELECT *` 不会直接导致索引失效(如果不走索引大概率是因为 where 查询范围过大导致的),但它可能会带来一些其他的性能问题比如造成网络传输和数据处理的浪费、无法使用索引覆盖;
-- 创建了组合索引,但查询条件未遵守最左匹配原则;
-- 在索引列上进行计算、函数、类型转换等操作;
-- 以 % 开头的 LIKE 查询比如 `LIKE '%abc';`;
-- 查询条件中使用 OR,且 OR 的前后条件中有一个列没有索引,涉及的索引都不会被使用到;
-- IN 的取值范围较大时会导致索引失效,走全表扫描(NOT IN 和 IN 的失效场景相同);
-- 发生[隐式转换](https://javaguide.cn/database/mysql/index-invalidation-caused-by-implicit-conversion.html);
+- ~~使用 `SELECT *` 进行查询;~~ `SELECT *` 不会直接导致索引失效(如果不走索引大概率是因为 where 查询范围过大导致的),但它可能会带来一些其他的性能问题比如造成网络传输和数据处理的浪费、无法使用索引覆盖;
+- 创建了组合索引,但查询条件未遵守最左匹配原则;
+- 在索引列上进行计算、函数、类型转换等操作;
+- 以 % 开头的 LIKE 查询比如 `LIKE '%abc';`;
+- 查询条件中使用 OR,且 OR 的前后条件中有一个列没有索引,涉及的索引都不会被使用到;
+- IN 的取值范围较大时会导致索引失效,走全表扫描(NOT IN 和 IN 的失效场景相同);
+- 发生[隐式转换](https://javaguide.cn/database/mysql/index-invalidation-caused-by-implicit-conversion.html);
- ……
推荐阅读这篇文章:[美团暑期实习一面:MySQl 索引失效的场景有哪些?](https://mp.weixin.qq.com/s/mwME3qukHBFul57WQLkOYg)。
diff --git a/docs/database/mysql/mysql-questions-01.md b/docs/database/mysql/mysql-questions-01.md
index 1564f364bc8..7f93eb605e6 100644
--- a/docs/database/mysql/mysql-questions-01.md
+++ b/docs/database/mysql/mysql-questions-01.md
@@ -158,19 +158,28 @@ DATETIME 类型没有时区信息,TIMESTAMP 和时区有关。
TIMESTAMP 只需要使用 4 个字节的存储空间,但是 DATETIME 需要耗费 8 个字节的存储空间。但是,这样同样造成了一个问题,Timestamp 表示的时间范围更小。
-- DATETIME:1000-01-01 00:00:00 ~ 9999-12-31 23:59:59
-- Timestamp:1970-01-01 00:00:01 ~ 2037-12-31 23:59:59
+- DATETIME:'1000-01-01 00:00:00.000000' 到 '9999-12-31 23:59:59.999999'
+- Timestamp:'1970-01-01 00:00:01.000000' UTC 到 '2038-01-19 03:14:07.999999' UTC
-关于两者的详细对比,请参考我写的[MySQL 时间类型数据存储建议](./some-thoughts-on-database-storage-time.md)。
+关于两者的详细对比,请参考我写的 [MySQL 时间类型数据存储建议](./some-thoughts-on-database-storage-time.md)。
### NULL 和 '' 的区别是什么?
-`NULL` 跟 `''`(空字符串)是两个完全不一样的值,区别如下:
-
-- `NULL` 代表一个不确定的值,就算是两个 `NULL`,它俩也不一定相等。例如,`SELECT NULL=NULL`的结果为 false,但是在我们使用`DISTINCT`,`GROUP BY`,`ORDER BY`时,`NULL`又被认为是相等的。
-- `''`的长度是 0,是不占用空间的,而`NULL` 是需要占用空间的。
-- `NULL` 会影响聚合函数的结果。例如,`SUM`、`AVG`、`MIN`、`MAX` 等聚合函数会忽略 `NULL` 值。 `COUNT` 的处理方式取决于参数的类型。如果参数是 `*`(`COUNT(*)`),则会统计所有的记录数,包括 `NULL` 值;如果参数是某个字段名(`COUNT(列名)`),则会忽略 `NULL` 值,只统计非空值的个数。
-- 查询 `NULL` 值时,必须使用 `IS NULL` 或 `IS NOT NULLl` 来判断,而不能使用 =、!=、 <、> 之类的比较运算符。而`''`是可以使用这些比较运算符的。
+`NULL` 和 `''` (空字符串) 是两个完全不同的值,它们分别表示不同的含义,并在数据库中有着不同的行为。`NULL` 代表缺失或未知的数据,而 `''` 表示一个已知存在的空字符串。它们的主要区别如下:
+
+1. **含义**:
+ - `NULL` 代表一个不确定的值,它不等于任何值,包括它自身。因此,`SELECT NULL = NULL` 的结果是 `NULL`,而不是 `true` 或 `false`。 `NULL` 意味着缺失或未知的信息。虽然 `NULL` 不等于任何值,但在某些操作中,数据库系统会将 `NULL` 值视为相同的类别进行处理,例如:`DISTINCT`,`GROUP BY`,`ORDER BY`。需要注意的是,这些操作将 `NULL` 值视为相同的类别进行处理,并不意味着 `NULL` 值之间是相等的。 它们只是在特定操作中被特殊处理,以保证结果的正确性和一致性。 这种处理方式是为了方便数据操作,而不是改变了 `NULL` 的语义。
+ - `''` 表示一个空字符串,它是一个已知的值。
+2. **存储空间**:
+ - `NULL` 的存储空间占用取决于数据库的实现,通常需要一些空间来标记该值为空。
+ - `''` 的存储空间占用通常较小,因为它只存储一个空字符串的标志,不需要存储实际的字符。
+3. **比较运算**:
+ - 任何值与 `NULL` 进行比较(例如 `=`, `!=`, `>`, `<` 等)的结果都是 `NULL`,表示结果不确定。要判断一个值是否为 `NULL`,必须使用 `IS NULL` 或 `IS NOT NULL`。
+ - `''` 可以像其他字符串一样进行比较运算。例如,`'' = ''` 的结果是 `true`。
+4. **聚合函数**:
+ - 大多数聚合函数(例如 `SUM`, `AVG`, `MIN`, `MAX`)会忽略 `NULL` 值。
+ - `COUNT(*)` 会统计所有行数,包括包含 `NULL` 值的行。`COUNT(列名)` 会统计指定列中非 `NULL` 值的行数。
+ - 空字符串 `''` 会被聚合函数计算在内。例如,`SUM` 会将其视为 0,`MIN` 和 `MAX` 会将其视为一个空字符串。
看了上面的介绍之后,相信你对另外一个高频面试题:“为什么 MySQL 不建议使用 `NULL` 作为列默认值?”也有了答案。
@@ -178,6 +187,37 @@ TIMESTAMP 只需要使用 4 个字节的存储空间,但是 DATETIME 需要耗
MySQL 中没有专门的布尔类型,而是用 TINYINT(1) 类型来表示布尔值。TINYINT(1) 类型可以存储 0 或 1,分别对应 false 或 true。
+### 手机号存储用 INT 还是 VARCHAR?
+
+存储手机号,**强烈推荐使用 VARCHAR 类型**,而不是 INT 或 BIGINT。主要原因如下:
+
+1. **格式兼容性与完整性:**
+ - 手机号可能包含前导零(如某些地区的固话区号)、国家代码前缀('+'),甚至可能带有分隔符('-' 或空格)。INT 或 BIGINT 这种数字类型会自动丢失这些重要的格式信息(比如前导零会被去掉,'+' 和 '-' 无法存储)。
+ - VARCHAR 可以原样存储各种格式的号码,无论是国内的 11 位手机号,还是带有国家代码的国际号码,都能完美兼容。
+2. **非算术性:**手机号虽然看起来是数字,但我们从不对它进行数学运算(比如求和、平均值)。它本质上是一个标识符,更像是一个字符串。用 VARCHAR 更符合其数据性质。
+3. **查询灵活性:**
+ - 业务中常常需要根据号段(前缀)进行查询,例如查找所有 "138" 开头的用户。使用 VARCHAR 类型配合 `LIKE '138%'` 这样的 SQL 查询既直观又高效。
+ - 如果使用数字类型,进行类似的前缀匹配通常需要复杂的函数转换(如 CAST 或 SUBSTRING),或者使用范围查询(如 `WHERE phone >= 13800000000 AND phone < 13900000000`),这不仅写法繁琐,而且可能无法有效利用索引,导致性能下降。
+4. **加密存储的要求(非常关键):**
+ - 出于数据安全和隐私合规的要求,手机号这类敏感个人信息通常必须加密存储在数据库中。
+ - 加密后的数据(密文)是一长串字符串(通常由字母、数字、符号组成,或经过 Base64/Hex 编码),INT 或 BIGINT 类型根本无法存储这种密文。只有 VARCHAR、TEXT 或 BLOB 等类型可以。
+
+**关于 VARCHAR 长度的选择:**
+
+- **如果不加密存储(强烈不推荐!):** 考虑到国际号码和可能的格式符,VARCHAR(20) 到 VARCHAR(32) 通常是一个比较安全的范围,足以覆盖全球绝大多数手机号格式。VARCHAR(15) 可能对某些带国家码和格式符的号码来说不够用。
+- **如果进行加密存储(推荐的标准做法):** 长度必须根据所选加密算法产生的密文最大长度,以及可能的编码方式(如 Base64 会使长度增加约 1/3)来精确计算和设定。通常会需要更长的 VARCHAR 长度,例如 VARCHAR(128), VARCHAR(256) 甚至更长。
+
+最后,来一张表格总结一下:
+
+| 对比维度 | VARCHAR 类型(推荐) | INT/BIGINT 类型(不推荐) | 说明/备注 |
+| ---------------- | --------------------------------- | ---------------------------- | --------------------------------------------------------------------------- |
+| **格式兼容性** | ✔ 能存前导零、"+"、"-"、空格等 | ✘ 自动丢失前导零,不能存符号 | VARCHAR 能原样存储各种手机号格式,INT/BIGINT 只支持单纯数字,且前导零会消失 |
+| **完整性** | ✔ 不丢失任何格式信息 | ✘ 丢失格式信息 | 例如 "013800012345" 存进 INT 会变成 13800012345,"+" 也无法存储 |
+| **非算术性** | ✔ 适合存储“标识符” | ✘ 只适合做数值运算 | 手机号本质是字符串标识符,不做数学运算,VARCHAR 更贴合实际用途 |
+| **查询灵活性** | ✔ 支持 `LIKE '138%'` 等 | ✘ 查询前缀不方便或性能差 | 使用 VARCHAR 可高效按号段/前缀查询,数字类型需转为字符串或其他复杂处理 |
+| **加密存储支持** | ✔ 可存储加密密文(字母、符号等) | ✘ 无法存储密文 | 加密手机号后密文是字符串/二进制,只有 VARCHAR、TEXT、BLOB 等能兼容 |
+| **长度设置建议** | 15~20(未加密),加密视情况而定 | 无意义 | 不加密时 VARCHAR(15~20) 通用,加密后长度取决于算法和编码方式 |
+
## MySQL 基础架构
> 建议配合 [SQL 语句在 MySQL 中的执行过程](./how-sql-executed-in-mysql.md) 这篇文章来理解 MySQL 基础架构。另外,“一个 SQL 语句在 MySQL 中的执行流程”也是面试中比较常问的一个问题。
@@ -193,7 +233,7 @@ MySQL 中没有专门的布尔类型,而是用 TINYINT(1) 类型来表示布
- **分析器:** 没有命中缓存的话,SQL 语句就会经过分析器,分析器说白了就是要先看你的 SQL 语句要干嘛,再检查你的 SQL 语句语法是否正确。
- **优化器:** 按照 MySQL 认为最优的方案去执行。
- **执行器:** 执行语句,然后从存储引擎返回数据。 执行语句之前会先判断是否有权限,如果没有权限的话,就会报错。
-- **插件式存储引擎**:主要负责数据的存储和读取,采用的是插件式架构,支持 InnoDB、MyISAM、Memory 等多种存储引擎。
+- **插件式存储引擎**:主要负责数据的存储和读取,采用的是插件式架构,支持 InnoDB、MyISAM、Memory 等多种存储引擎。InnoDB 是 MySQL 的默认存储引擎,绝大部分场景使用 InnoDB 就是最好的选择。
## MySQL 存储引擎
@@ -544,31 +584,26 @@ MVCC 在 MySQL 中实现所依赖的手段主要是: **隐藏字段、read view
### SQL 标准定义了哪些事务隔离级别?
-SQL 标准定义了四个隔离级别:
+SQL 标准定义了四种事务隔离级别,用来平衡事务的隔离性(Isolation)和并发性能。级别越高,数据一致性越好,但并发性能可能越低。这四个级别是:
-- **READ-UNCOMMITTED(读取未提交)** :最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
-- **READ-COMMITTED(读取已提交)** :允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
-- **REPEATABLE-READ(可重复读)** :对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
+- **READ-UNCOMMITTED(读取未提交)** :最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。这种级别在实际应用中很少使用,因为它对数据一致性的保证太弱。
+- **READ-COMMITTED(读取已提交)** :允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。这是大多数数据库(如 Oracle, SQL Server)的默认隔离级别。
+- **REPEATABLE-READ(可重复读)** :对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。MySQL InnoDB 存储引擎的默认隔离级别正是 REPEATABLE READ。并且,InnoDB 在此级别下通过 MVCC(多版本并发控制) 和 Next-Key Locks(间隙锁+行锁) 机制,在很大程度上解决了幻读问题。
- **SERIALIZABLE(可串行化)** :最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
----
-
-| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
-| :--------------: | :--: | :--------: | :--: |
-| READ-UNCOMMITTED | √ | √ | √ |
-| READ-COMMITTED | × | √ | √ |
-| REPEATABLE-READ | × | × | √ |
-| SERIALIZABLE | × | × | × |
-
-### MySQL 的隔离级别是基于锁实现的吗?
-
-MySQL 的隔离级别基于锁和 MVCC 机制共同实现的。
-
-SERIALIZABLE 隔离级别是通过锁来实现的,READ-COMMITTED 和 REPEATABLE-READ 隔离级别是基于 MVCC 实现的。不过, SERIALIZABLE 之外的其他隔离级别可能也需要用到锁机制,就比如 REPEATABLE-READ 在当前读情况下需要使用加锁读来保证不会出现幻读。
+| 隔离级别 | 脏读 (Dirty Read) | 不可重复读 (Non-Repeatable Read) | 幻读 (Phantom Read) |
+| ---------------- | ----------------- | -------------------------------- | ---------------------- |
+| READ UNCOMMITTED | √ | √ | √ |
+| READ COMMITTED | × | √ | √ |
+| REPEATABLE READ | × | × | √ (标准) / ≈× (InnoDB) |
+| SERIALIZABLE | × | × | × |
### MySQL 的默认隔离级别是什么?
-MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看,MySQL 8.0 该命令改为`SELECT @@transaction_isolation;`
+MySQL InnoDB 存储引擎的默认隔离级别是 **REPEATABLE READ**。可以通过以下命令查看:
+
+- MySQL 8.0 之前:`SELECT @@tx_isolation;`
+- MySQL 8.0 及之后:`SELECT @@transaction_isolation;`
```sql
mysql> SELECT @@tx_isolation;
@@ -581,6 +616,12 @@ mysql> SELECT @@tx_isolation;
关于 MySQL 事务隔离级别的详细介绍,可以看看我写的这篇文章:[MySQL 事务隔离级别详解](./transaction-isolation-level.md)。
+### MySQL 的隔离级别是基于锁实现的吗?
+
+MySQL 的隔离级别基于锁和 MVCC 机制共同实现的。
+
+SERIALIZABLE 隔离级别是通过锁来实现的,READ-COMMITTED 和 REPEATABLE-READ 隔离级别是基于 MVCC 实现的。不过, SERIALIZABLE 之外的其他隔离级别可能也需要用到锁机制,就比如 REPEATABLE-READ 在当前读情况下需要使用加锁读来保证不会出现幻读。
+
## MySQL 锁
锁是一种常见的并发事务的控制方式。
@@ -854,7 +895,7 @@ MySQL 性能优化是一个系统性工程,涉及多个方面,在面试中
- **读写分离:** 将读操作和写操作分离到不同的数据库实例,提升数据库的并发处理能力。
- **分库分表:** 将数据分散到多个数据库实例或数据表中,降低单表数据量,提升查询效率。但要权衡其带来的复杂性和维护成本,谨慎使用。
-- **数据冷热分离**:根据数据的访问频率和业务重要性,将数据分为冷数据和热数据,冷数据一般存储在存储在低成本、低性能的介质中,热数据高性能存储介质中。
+- **数据冷热分离**:根据数据的访问频率和业务重要性,将数据分为冷数据和热数据,冷数据一般存储在低成本、低性能的介质中,热数据存储在高性能存储介质中。
- **缓存机制:** 使用 Redis 等缓存中间件,将热点数据缓存到内存中,减轻数据库压力。这个非常常用,提升效果非常明显,性价比极高!
**4. 其他优化手段**
diff --git a/docs/database/mysql/some-thoughts-on-database-storage-time.md b/docs/database/mysql/some-thoughts-on-database-storage-time.md
index 75329434c1b..e22ce2800da 100644
--- a/docs/database/mysql/some-thoughts-on-database-storage-time.md
+++ b/docs/database/mysql/some-thoughts-on-database-storage-time.md
@@ -3,30 +3,43 @@ title: MySQL日期类型选择建议
category: 数据库
tag:
- MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL 日期类型选择, MySQL 时间存储最佳实践, MySQL 时间存储效率, MySQL DATETIME 和 TIMESTAMP 区别, MySQL 时间戳存储, MySQL 数据库时间存储类型, MySQL 开发日期推荐, MySQL 字符串存储日期的缺点, MySQL 时区设置方法, MySQL 日期范围对比, 高性能 MySQL 日期存储, MySQL UNIX_TIMESTAMP 用法, 数值型时间戳优缺点, MySQL 时间存储性能优化, MySQL TIMESTAMP 时区转换, MySQL 时间格式转换, MySQL 时间存储空间对比, MySQL 时间类型选择建议, MySQL 日期类型性能分析, 数据库时间存储优化
---
-我们平时开发中不可避免的就是要存储时间,比如我们要记录操作表中这条记录的时间、记录转账的交易时间、记录出发时间、用户下单时间等等。你会发现时间这个东西与我们开发的联系还是非常紧密的,用的好与不好会给我们的业务甚至功能带来很大的影响。所以,我们有必要重新出发,好好认识一下这个东西。
+在日常的软件开发工作中,存储时间是一项基础且常见的需求。无论是记录数据的操作时间、金融交易的发生时间,还是行程的出发时间、用户的下单时间等等,时间信息与我们的业务逻辑和系统功能紧密相关。因此,正确选择和使用 MySQL 的日期时间类型至关重要,其恰当与否甚至可能对业务的准确性和系统的稳定性产生显著影响。
+
+本文旨在帮助开发者重新审视并深入理解 MySQL 中不同的时间存储方式,以便做出更合适项目业务场景的选择。
## 不要用字符串存储日期
-和绝大部分对数据库不太了解的新手一样,我在大学的时候就这样干过,甚至认为这样是一个不错的表示日期的方法。毕竟简单直白,容易上手。
+和许多数据库初学者一样,笔者在早期学习阶段也曾尝试使用字符串(如 VARCHAR)类型来存储日期和时间,甚至一度认为这是一种简单直观的方法。毕竟,'YYYY-MM-DD HH:MM:SS' 这样的格式看起来清晰易懂。
但是,这是不正确的做法,主要会有下面两个问题:
-1. 字符串占用的空间更大!
-2. 字符串存储的日期效率比较低(逐个字符进行比对),无法用日期相关的 API 进行计算和比较。
+1. **空间效率**:与 MySQL 内建的日期时间类型相比,字符串通常需要占用更多的存储空间来表示相同的时间信息。
+2. **查询与计算效率低下**:
+ - **比较操作复杂且低效**:基于字符串的日期比较需要按照字典序逐字符进行,这不仅不直观(例如,'2024-05-01' 会小于 '2024-1-10'),而且效率远低于使用原生日期时间类型进行的数值或时间点比较。
+ - **计算功能受限**:无法直接利用数据库提供的丰富日期时间函数进行运算(例如,计算两个日期之间的间隔、对日期进行加减操作等),需要先转换格式,增加了复杂性。
+ - **索引性能不佳**:基于字符串的索引在处理范围查询(如查找特定时间段内的数据)时,其效率和灵活性通常不如原生日期时间类型的索引。
-## Datetime 和 Timestamp 之间的抉择
+## DATETIME 和 TIMESTAMP 选择
-Datetime 和 Timestamp 是 MySQL 提供的两种比较相似的保存时间的数据类型,可以精确到秒。他们两者究竟该如何选择呢?
+`DATETIME` 和 `TIMESTAMP` 是 MySQL 中两种非常常用的、用于存储包含日期和时间信息的数据类型。它们都可以存储精确到秒(MySQL 5.6.4+ 支持更高精度的小数秒)的时间值。那么,在实际应用中,我们应该如何在这两者之间做出选择呢?
-下面我们来简单对比一下二者。
+下面我们从几个关键维度对它们进行对比:
### 时区信息
-**DateTime 类型是没有时区信息的(时区无关)** ,DateTime 类型保存的时间都是当前会话所设置的时区对应的时间。这样就会有什么问题呢?当你的时区更换之后,比如你的服务器更换地址或者更换客户端连接时区设置的话,就会导致你从数据库中读出的时间错误。
+`DATETIME` 类型存储的是**字面量的日期和时间值**,它本身**不包含任何时区信息**。当你插入一个 `DATETIME` 值时,MySQL 存储的就是你提供的那个确切的时间,不会进行任何时区转换。
+
+**这样就会有什么问题呢?** 如果你的应用需要支持多个时区,或者服务器、客户端的时区可能发生变化,那么使用 `DATETIME` 时,应用程序需要自行处理时区的转换和解释。如果处理不当(例如,假设所有存储的时间都属于同一个时区,但实际环境变化了),可能会导致时间显示或计算上的混乱。
-**Timestamp 和时区有关**。Timestamp 类型字段的值会随着服务器时区的变化而变化,自动换算成相应的时间,说简单点就是在不同时区,查询到同一个条记录此字段的值会不一样。
+**`TIMESTAMP` 和时区有关**。存储时,MySQL 会将当前会话时区下的时间值转换成 UTC(协调世界时)进行内部存储。当查询 `TIMESTAMP` 字段时,MySQL 又会将存储的 UTC 时间转换回当前会话所设置的时区来显示。
+
+这意味着,对于同一条记录的 `TIMESTAMP` 字段,在不同的会话时区设置下查询,可能会看到不同的本地时间表示,但它们都对应着同一个绝对时间点(UTC 时间)。这对于需要全球化、多时区支持的应用来说非常有用。
下面实际演示一下!
@@ -41,16 +54,16 @@ CREATE TABLE `time_zone_test` (
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
```
-插入数据:
+插入一条数据(假设当前会话时区为系统默认,例如 UTC+0)::
```sql
INSERT INTO time_zone_test(date_time,time_stamp) VALUES(NOW(),NOW());
```
-查看数据:
+查询数据(在同一时区会话下):
```sql
-select date_time,time_stamp from time_zone_test;
+SELECT date_time, time_stamp FROM time_zone_test;
```
结果:
@@ -63,17 +76,16 @@ select date_time,time_stamp from time_zone_test;
+---------------------+---------------------+
```
-现在我们运行
-
-修改当前会话的时区:
+现在,修改当前会话的时区为东八区 (UTC+8):
```sql
-set time_zone='+8:00';
+SET time_zone = '+8:00';
```
-再次查看数据:
+再次查询数据:
-```plain
+```bash
+# TIMESTAMP 的值自动转换为 UTC+8 时间
+---------------------+---------------------+
| date_time | time_stamp |
+---------------------+---------------------+
@@ -81,7 +93,7 @@ set time_zone='+8:00';
+---------------------+---------------------+
```
-**扩展:一些关于 MySQL 时区设置的一个常用 sql 命令**
+**扩展:MySQL 时区设置常用 SQL 命令**
```sql
# 查看当前会话时区
@@ -102,28 +114,26 @@ SET GLOBAL time_zone = 'Europe/Helsinki';

-在 MySQL 5.6.4 之前,DateTime 和 Timestamp 的存储空间是固定的,分别为 8 字节和 4 字节。但是从 MySQL 5.6.4 开始,它们的存储空间会根据毫秒精度的不同而变化,DateTime 的范围是 5~8 字节,Timestamp 的范围是 4~7 字节。
+在 MySQL 5.6.4 之前,DateTime 和 TIMESTAMP 的存储空间是固定的,分别为 8 字节和 4 字节。但是从 MySQL 5.6.4 开始,它们的存储空间会根据毫秒精度的不同而变化,DateTime 的范围是 5~8 字节,TIMESTAMP 的范围是 4~7 字节。
### 表示范围
-Timestamp 表示的时间范围更小,只能到 2038 年:
+`TIMESTAMP` 表示的时间范围更小,只能到 2038 年:
-- DateTime:1000-01-01 00:00:00.000000 ~ 9999-12-31 23:59:59.499999
-- Timestamp:1970-01-01 00:00:01.000000 ~ 2038-01-19 03:14:07.499999
+- `DATETIME`:'1000-01-01 00:00:00.000000' 到 '9999-12-31 23:59:59.999999'
+- `TIMESTAMP`:'1970-01-01 00:00:01.000000' UTC 到 '2038-01-19 03:14:07.999999' UTC
### 性能
-由于 TIMESTAMP 需要根据时区进行转换,所以从毫秒数转换到 TIMESTAMP 时,不仅要调用一个简单的函数,还要调用操作系统底层的系统函数。这个系统函数为了保证操作系统时区的一致性,需要进行加锁操作,这就降低了效率。
-
-DATETIME 不涉及时区转换,所以不会有这个问题。
+由于 `TIMESTAMP` 在存储和检索时需要进行 UTC 与当前会话时区的转换,这个过程可能涉及到额外的计算开销,尤其是在需要调用操作系统底层接口获取或处理时区信息时。虽然现代数据库和操作系统对此进行了优化,但在某些极端高并发或对延迟极其敏感的场景下,`DATETIME` 因其不涉及时区转换,处理逻辑相对更简单直接,可能会表现出微弱的性能优势。
-为了避免 TIMESTAMP 的时区转换问题,建议使用指定的时区,而不是依赖于操作系统时区。
+为了获得可预测的行为并可能减少 `TIMESTAMP` 的转换开销,推荐的做法是在应用程序层面统一管理时区,或者在数据库连接/会话级别显式设置 `time_zone` 参数,而不是依赖服务器的默认或操作系统时区。
## 数值时间戳是更好的选择吗?
-很多时候,我们也会使用 int 或者 bigint 类型的数值也就是数值时间戳来表示时间。
+除了上述两种类型,实践中也常用整数类型(`INT` 或 `BIGINT`)来存储所谓的“Unix 时间戳”(即从 1970 年 1 月 1 日 00:00:00 UTC 起至目标时间的总秒数,或毫秒数)。
-这种存储方式的具有 Timestamp 类型的所具有一些优点,并且使用它的进行日期排序以及对比等操作的效率会更高,跨系统也很方便,毕竟只是存放的数值。缺点也很明显,就是数据的可读性太差了,你无法直观的看到具体时间。
+这种存储方式的具有 `TIMESTAMP` 类型的所具有一些优点,并且使用它的进行日期排序以及对比等操作的效率会更高,跨系统也很方便,毕竟只是存放的数值。缺点也很明显,就是数据的可读性太差了,你无法直观的看到具体时间。
时间戳的定义如下:
@@ -132,7 +142,8 @@ DATETIME 不涉及时区转换,所以不会有这个问题。
数据库中实际操作:
```sql
-mysql> select UNIX_TIMESTAMP('2020-01-11 09:53:32');
+-- 将日期时间字符串转换为 Unix 时间戳 (秒)
+mysql> SELECT UNIX_TIMESTAMP('2020-01-11 09:53:32');
+---------------------------------------+
| UNIX_TIMESTAMP('2020-01-11 09:53:32') |
+---------------------------------------+
@@ -140,7 +151,8 @@ mysql> select UNIX_TIMESTAMP('2020-01-11 09:53:32');
+---------------------------------------+
1 row in set (0.00 sec)
-mysql> select FROM_UNIXTIME(1578707612);
+-- 将 Unix 时间戳 (秒) 转换为日期时间格式
+mysql> SELECT FROM_UNIXTIME(1578707612);
+---------------------------+
| FROM_UNIXTIME(1578707612) |
+---------------------------+
@@ -149,13 +161,26 @@ mysql> select FROM_UNIXTIME(1578707612);
1 row in set (0.01 sec)
```
+## PostgreSQL 中没有 DATETIME
+
+由于有读者提到 PostgreSQL(PG) 的时间类型,因此这里拓展补充一下。PG 官方文档对时间类型的描述地址: @@ -167,4 +192,10 @@ MySQL 中时间到底怎么存储才好?Datetime?Timestamp?还是数值时间
| TIMESTAMP | 4~7 字节 | YYYY-MM-DD hh:mm:ss[.fraction] | 1970-01-01 00:00:01[.000000] ~ 2038-01-19 03:14:07[.999999] | 是 |
| 数值型时间戳 | 4 字节 | 全数字如 1578707612 | 1970-01-01 00:00:01 之后的时间 | 否 |
+**选择建议小结:**
+
+- `TIMESTAMP` 的核心优势在于其内建的时区处理能力。数据库负责 UTC 存储和基于会话时区的自动转换,简化了需要处理多时区应用的开发。如果应用需要处理多时区,或者希望数据库能自动管理时区转换,`TIMESTAMP` 是自然的选择(注意其时间范围限制,也就是 2038 年问题)。
+- 如果应用场景不涉及时区转换,或者希望应用程序完全控制时区逻辑,并且需要表示 2038 年之后的时间,`DATETIME` 是更稳妥的选择。
+- 如果极度关注比较性能,或者需要频繁跨系统传递时间数据,并且可以接受可读性的牺牲(或总是在应用层转换),数值时间戳是一个强大的选项。
+
diff --git a/docs/database/mysql/transaction-isolation-level.md b/docs/database/mysql/transaction-isolation-level.md
index 52ad40f4a47..8b706640ea6 100644
--- a/docs/database/mysql/transaction-isolation-level.md
+++ b/docs/database/mysql/transaction-isolation-level.md
@@ -11,43 +11,46 @@ tag:
## 事务隔离级别总结
-SQL 标准定义了四个隔离级别:
+SQL 标准定义了四种事务隔离级别,用来平衡事务的隔离性(Isolation)和并发性能。级别越高,数据一致性越好,但并发性能可能越低。这四个级别是:
-- **READ-UNCOMMITTED(读取未提交)** :最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
-- **READ-COMMITTED(读取已提交)** :允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
-- **REPEATABLE-READ(可重复读)** :对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
+- **READ-UNCOMMITTED(读取未提交)** :最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。这种级别在实际应用中很少使用,因为它对数据一致性的保证太弱。
+- **READ-COMMITTED(读取已提交)** :允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。这是大多数数据库(如 Oracle, SQL Server)的默认隔离级别。
+- **REPEATABLE-READ(可重复读)** :对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。MySQL InnoDB 存储引擎的默认隔离级别正是 REPEATABLE READ。并且,InnoDB 在此级别下通过 MVCC(多版本并发控制) 和 Next-Key Locks(间隙锁+行锁) 机制,在很大程度上解决了幻读问题。
- **SERIALIZABLE(可串行化)** :最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
----
+| 隔离级别 | 脏读 (Dirty Read) | 不可重复读 (Non-Repeatable Read) | 幻读 (Phantom Read) |
+| ---------------- | ----------------- | -------------------------------- | ---------------------- |
+| READ UNCOMMITTED | √ | √ | √ |
+| READ COMMITTED | × | √ | √ |
+| REPEATABLE READ | × | × | √ (标准) / ≈× (InnoDB) |
+| SERIALIZABLE | × | × | × |
-| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
-| :--------------: | :--: | :--------: | :--: |
-| READ-UNCOMMITTED | √ | √ | √ |
-| READ-COMMITTED | × | √ | √ |
-| REPEATABLE-READ | × | × | √ |
-| SERIALIZABLE | × | × | × |
+**默认级别查询:**
-MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看,MySQL 8.0 该命令改为`SELECT @@transaction_isolation;`
+MySQL InnoDB 存储引擎的默认隔离级别是 **REPEATABLE READ**。可以通过以下命令查看:
-```sql
-MySQL> SELECT @@tx_isolation;
-+-----------------+
-| @@tx_isolation |
-+-----------------+
-| REPEATABLE-READ |
-+-----------------+
+- MySQL 8.0 之前:`SELECT @@tx_isolation;`
+- MySQL 8.0 及之后:`SELECT @@transaction_isolation;`
+
+```bash
+mysql> SELECT @@transaction_isolation;
++-------------------------+
+| @@transaction_isolation |
++-------------------------+
+| REPEATABLE-READ |
++-------------------------+
```
-从上面对 SQL 标准定义了四个隔离级别的介绍可以看出,标准的 SQL 隔离级别定义里,REPEATABLE-READ(可重复读)是不可以防止幻读的。
+**InnoDB 的 REPEATABLE READ 对幻读的处理:**
-但是!InnoDB 实现的 REPEATABLE-READ 隔离级别其实是可以解决幻读问题发生的,主要有下面两种情况:
+标准的 SQL 隔离级别定义里,REPEATABLE READ 是无法防止幻读的。但 InnoDB 的实现通过以下机制很大程度上避免了幻读:
-- **快照读**:由 MVCC 机制来保证不出现幻读。
-- **当前读**:使用 Next-Key Lock 进行加锁来保证不出现幻读,Next-Key Lock 是行锁(Record Lock)和间隙锁(Gap Lock)的结合,行锁只能锁住已经存在的行,为了避免插入新行,需要依赖间隙锁。
+- **快照读 (Snapshot Read)**:普通的 SELECT 语句,通过 **MVCC** 机制实现。事务启动时创建一个数据快照,后续的快照读都读取这个版本的数据,从而避免了看到其他事务新插入的行(幻读)或修改的行(不可重复读)。
+- **当前读 (Current Read)**:像 `SELECT ... FOR UPDATE`, `SELECT ... LOCK IN SHARE MODE`, `INSERT`, `UPDATE`, `DELETE` 这些操作。InnoDB 使用 **Next-Key Lock** 来锁定扫描到的索引记录及其间的范围(间隙),防止其他事务在这个范围内插入新的记录,从而避免幻读。Next-Key Lock 是行锁(Record Lock)和间隙锁(Gap Lock)的组合。
-因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是 **READ-COMMITTED** ,但是你要知道的是 InnoDB 存储引擎默认使用 **REPEATABLE-READ** 并不会有任何性能损失。
+值得注意的是,虽然通常认为隔离级别越高、并发性越差,但 InnoDB 存储引擎通过 MVCC 机制优化了 REPEATABLE READ 级别。对于许多常见的只读或读多写少的场景,其性能**与 READ COMMITTED 相比可能没有显著差异**。不过,在写密集型且并发冲突较高的场景下,RR 的间隙锁机制可能会比 RC 带来更多的锁等待。
-InnoDB 存储引擎在分布式事务的情况下一般会用到 SERIALIZABLE 隔离级别。
+此外,在某些特定场景下,如需要严格一致性的分布式事务(XA Transactions),InnoDB 可能要求或推荐使用 SERIALIZABLE 隔离级别来确保全局数据的一致性。
《MySQL 技术内幕:InnoDB 存储引擎(第 2 版)》7.7 章这样写到:
diff --git a/docs/database/redis/redis-cluster.md b/docs/database/redis/redis-cluster.md
index 60cd7dda858..e3ef2efd04c 100644
--- a/docs/database/redis/redis-cluster.md
+++ b/docs/database/redis/redis-cluster.md
@@ -7,7 +7,7 @@ tag:
**Redis 集群** 相关的面试题为我的 [知识星球](../../about-the-author/zhishixingqiu-two-years.md)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了[《Java 面试指北》](../../zhuanlan/java-mian-shi-zhi-bei.md)中。
-
+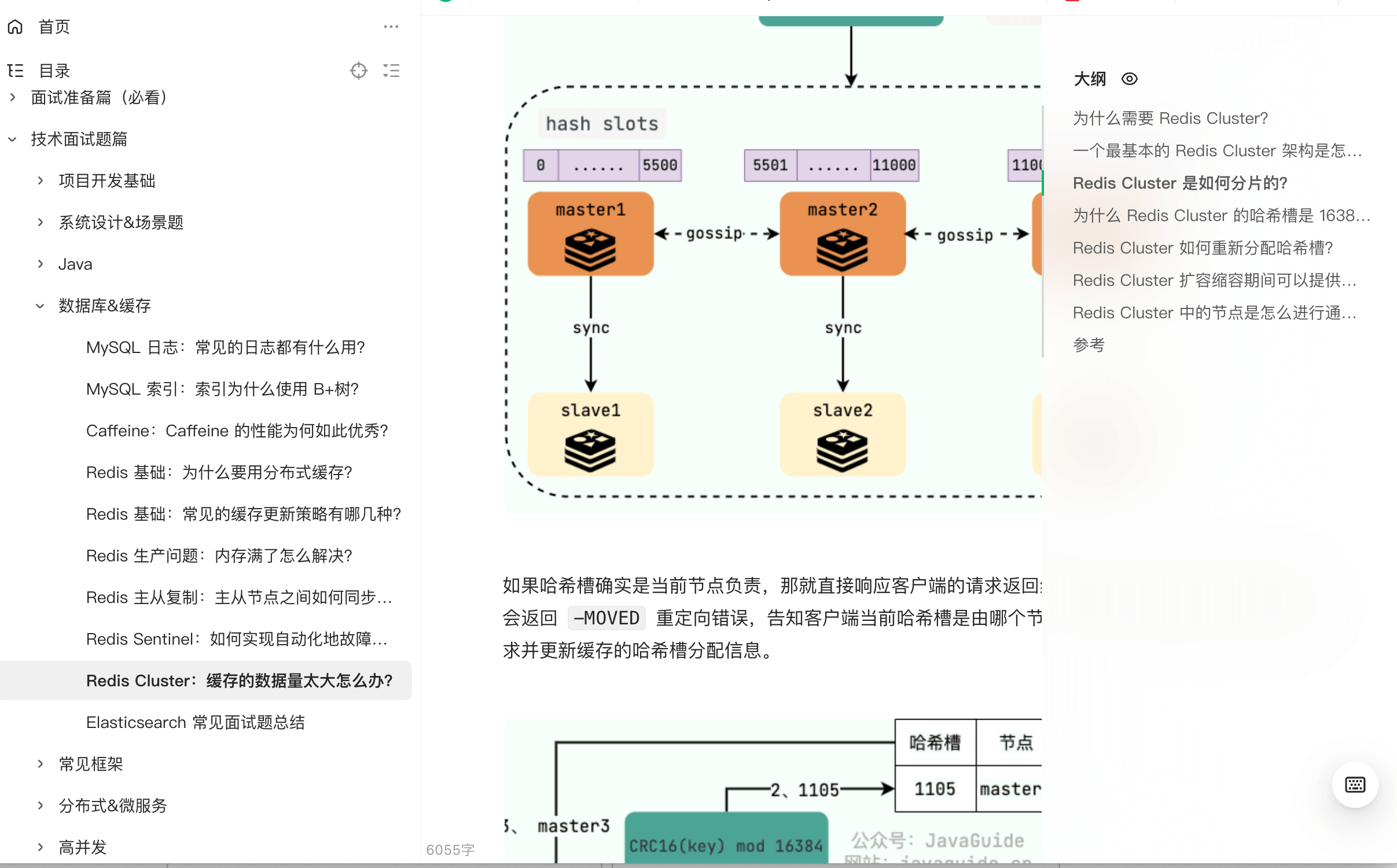
diff --git a/docs/database/redis/redis-data-structures-01.md b/docs/database/redis/redis-data-structures-01.md
index 9dfb0c3eaa5..7d993752138 100644
--- a/docs/database/redis/redis-data-structures-01.md
+++ b/docs/database/redis/redis-data-structures-01.md
@@ -182,7 +182,7 @@ Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据
"value3"
```
-我专门画了一个图方便大家理解 `RPUSH` , `LPOP` , `lpush` , `RPOP` 命令:
+我专门画了一个图方便大家理解 `RPUSH` , `LPOP` , `LPUSH` , `RPOP` 命令:

diff --git a/docs/database/redis/redis-data-structures-02.md b/docs/database/redis/redis-data-structures-02.md
index 634860949fd..9e5fbcee59b 100644
--- a/docs/database/redis/redis-data-structures-02.md
+++ b/docs/database/redis/redis-data-structures-02.md
@@ -123,9 +123,9 @@ HyperLogLog 相关的命令非常少,最常用的也就 3 个。
### 应用场景
-**数量量巨大(百万、千万级别以上)的计数场景**
+**数量巨大(百万、千万级别以上)的计数场景**
-- 举例:热门网站每日/每周/每月访问 ip 数统计、热门帖子 uv 统计、
+- 举例:热门网站每日/每周/每月访问 ip 数统计、热门帖子 uv 统计。
- 相关命令:`PFADD`、`PFCOUNT` 。
## Geospatial (地理位置)
diff --git a/docs/database/redis/redis-delayed-task.md b/docs/database/redis/redis-delayed-task.md
index bd95cb46bbb..35f9304321f 100644
--- a/docs/database/redis/redis-delayed-task.md
+++ b/docs/database/redis/redis-delayed-task.md
@@ -33,7 +33,7 @@ Redis 中有很多默认的 channel,这些 channel 是由 Redis 本身向它
我们只需要监听这个 channel,就可以拿到过期的 key 的消息,进而实现了延时任务功能。
-这个功能被 Redis 官方称为 **keyspace notifications** ,作用是实时监控实时监控 Redis 键和值的变化。
+这个功能被 Redis 官方称为 **keyspace notifications** ,作用是实时监控 Redis 键和值的变化。
### Redis 过期事件监听实现延时任务功能有什么缺陷?
@@ -72,7 +72,7 @@ Redisson 是一个开源的 Java 语言 Redis 客户端,提供了很多开箱
Redisson 的延迟队列 RDelayedQueue 是基于 Redis 的 SortedSet 来实现的。SortedSet 是一个有序集合,其中的每个元素都可以设置一个分数,代表该元素的权重。Redisson 利用这一特性,将需要延迟执行的任务插入到 SortedSet 中,并给它们设置相应的过期时间作为分数。
-Redisson 使用 `zrangebyscore` 命令扫描 SortedSet 中过期的元素,然后将这些过期元素从 SortedSet 中移除,并将它们加入到就绪消息列表中。就绪消息列表是一个阻塞队列,有消息进入就会被监听到。这样做可以避免对整个 SortedSet 进行轮询,提高了执行效率。
+Redisson 定期使用 `zrangebyscore` 命令扫描 SortedSet 中过期的元素,然后将这些过期元素从 SortedSet 中移除,并将它们加入到就绪消息列表中。就绪消息列表是一个阻塞队列,有消息进入就会被消费者监听到。这样做可以避免消费者对整个 SortedSet 进行轮询,提高了执行效率。
相比于 Redis 过期事件监听实现延时任务功能,这种方式具备下面这些优势:
diff --git a/docs/database/redis/redis-persistence.md b/docs/database/redis/redis-persistence.md
index 1e51df93448..2b61a1250ad 100644
--- a/docs/database/redis/redis-persistence.md
+++ b/docs/database/redis/redis-persistence.md
@@ -71,7 +71,7 @@ AOF 持久化功能的实现可以简单分为 5 步:
1. **命令追加(append)**:所有的写命令会追加到 AOF 缓冲区中。
2. **文件写入(write)**:将 AOF 缓冲区的数据写入到 AOF 文件中。这一步需要调用`write`函数(系统调用),`write`将数据写入到了系统内核缓冲区之后直接返回了(延迟写)。注意!!!此时并没有同步到磁盘。
-3. **文件同步(fsync)**:AOF 缓冲区根据对应的持久化方式( `fsync` 策略)向硬盘做同步操作。这一步需要调用 `fsync` 函数(系统调用), `fsync` 针对单个文件操作,对其进行强制硬盘同步,`fsync` 将阻塞直到写入磁盘完成后返回,保证了数据持久化。
+3. **文件同步(fsync)**:这一步才是持久化的核心!根据你在 `redis.conf` 文件里 `appendfsync` 配置的策略,Redis 会在不同的时机,调用 `fsync` 函数(系统调用)。`fsync` 针对单个文件操作,对其进行强制硬盘同步(文件在内核缓冲区里的数据写到硬盘),`fsync` 将阻塞直到写入磁盘完成后返回,保证了数据持久化。
4. **文件重写(rewrite)**:随着 AOF 文件越来越大,需要定期对 AOF 文件进行重写,达到压缩的目的。
5. **重启加载(load)**:当 Redis 重启时,可以加载 AOF 文件进行数据恢复。
@@ -90,9 +90,9 @@ AOF 工作流程图如下:
在 Redis 的配置文件中存在三种不同的 AOF 持久化方式( `fsync`策略),它们分别是:
-1. `appendfsync always`:主线程调用 `write` 执行写操作后,后台线程( `aof_fsync` 线程)立即会调用 `fsync` 函数同步 AOF 文件(刷盘),`fsync` 完成后线程返回,这样会严重降低 Redis 的性能(`write` + `fsync`)。
-2. `appendfsync everysec`:主线程调用 `write` 执行写操作后立即返回,由后台线程( `aof_fsync` 线程)每秒钟调用 `fsync` 函数(系统调用)同步一次 AOF 文件(`write`+`fsync`,`fsync`间隔为 1 秒)
-3. `appendfsync no`:主线程调用 `write` 执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(`write`但不`fsync`,`fsync` 的时机由操作系统决定)。
+1. `appendfsync always`:主线程调用 `write` 执行写操作后,会立刻调用 `fsync` 函数同步 AOF 文件(刷盘)。主线程会阻塞,直到 `fsync` 将数据完全刷到磁盘后才会返回。这种方式数据最安全,理论上不会有任何数据丢失。但因为每个写操作都会同步阻塞主线程,所以性能极差。
+2. `appendfsync everysec`:主线程调用 `write` 执行写操作后立即返回,由后台线程( `aof_fsync` 线程)每秒钟调用 `fsync` 函数(系统调用)同步一次 AOF 文件(`write`+`fsync`,`fsync`间隔为 1 秒)。这种方式主线程的性能基本不受影响。在性能和数据安全之间做出了绝佳的平衡。不过,在 Redis 异常宕机时,最多可能丢失最近 1 秒内的数据。
+3. `appendfsync no`:主线程调用 `write` 执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(`write`但不`fsync`,`fsync` 的时机由操作系统决定)。 这种方式性能最好,因为避免了 `fsync` 的阻塞。但数据安全性最差,宕机时丢失的数据量不可控,取决于操作系统上一次同步的时间点。
可以看出:**这 3 种持久化方式的主要区别在于 `fsync` 同步 AOF 文件的时机(刷盘)**。
@@ -153,9 +153,27 @@ Redis 7.0 版本之后,AOF 重写机制得到了优化改进。下面这段内
### AOF 校验机制了解吗?
-AOF 校验机制是 Redis 在启动时对 AOF 文件进行检查,以判断文件是否完整,是否有损坏或者丢失的数据。这个机制的原理其实非常简单,就是通过使用一种叫做 **校验和(checksum)** 的数字来验证 AOF 文件。这个校验和是通过对整个 AOF 文件内容进行 CRC64 算法计算得出的数字。如果文件内容发生了变化,那么校验和也会随之改变。因此,Redis 在启动时会比较计算出的校验和与文件末尾保存的校验和(计算的时候会把最后一行保存校验和的内容给忽略点),从而判断 AOF 文件是否完整。如果发现文件有问题,Redis 就会拒绝启动并提供相应的错误信息。AOF 校验机制十分简单有效,可以提高 Redis 数据的可靠性。
+纯 AOF 模式下,Redis 不会对整个 AOF 文件使用校验和(如 CRC64),而是通过逐条解析文件中的命令来验证文件的有效性。如果解析过程中发现语法错误(如命令不完整、格式错误),Redis 会终止加载并报错,从而避免错误数据载入内存。
-类似地,RDB 文件也有类似的校验机制来保证 RDB 文件的正确性,这里就不重复进行介绍了。
+在 **混合持久化模式**(Redis 4.0 引入)下,AOF 文件由两部分组成:
+
+- **RDB 快照部分**:文件以固定的 `REDIS` 字符开头,存储某一时刻的内存数据快照,并在快照数据末尾附带一个 CRC64 校验和(位于 RDB 数据块尾部、AOF 增量部分之前)。
+- **AOF 增量部分**:紧随 RDB 快照部分之后,记录 RDB 快照生成后的增量写命令。这部分增量命令以 Redis 协议格式逐条记录,无整体或全局校验和。
+
+RDB 文件结构的核心部分如下:
+
+| **字段** | **解释** |
+| ----------------- | ---------------------------------------------- |
+| `"REDIS"` | 固定以该字符串开始 |
+| `RDB_VERSION` | RDB 文件的版本号 |
+| `DB_NUM` | Redis 数据库编号,指明数据需要存放到哪个数据库 |
+| `KEY_VALUE_PAIRS` | Redis 中具体键值对的存储 |
+| `EOF` | RDB 文件结束标志 |
+| `CHECK_SUM` | 8 字节确保 RDB 完整性的校验和 |
+
+Redis 启动并加载 AOF 文件时,首先会校验文件开头 RDB 快照部分的数据完整性,即计算该部分数据的 CRC64 校验和,并与紧随 RDB 数据之后、AOF 增量部分之前存储的 CRC64 校验和值进行比较。如果 CRC64 校验和不匹配,Redis 将拒绝启动并报告错误。
+
+RDB 部分校验通过后,Redis 随后逐条解析 AOF 部分的增量命令。如果解析过程中出现错误(如不完整的命令或格式错误),Redis 会停止继续加载后续命令,并报告错误,但此时 Redis 已经成功加载了 RDB 快照部分的数据。
## Redis 4.0 对于持久化机制做了什么优化?
diff --git a/docs/database/redis/redis-questions-01.md b/docs/database/redis/redis-questions-01.md
index 40c266b5d73..913ad8b2e51 100644
--- a/docs/database/redis/redis-questions-01.md
+++ b/docs/database/redis/redis-questions-01.md
@@ -30,22 +30,22 @@ Redis 没有外部依赖,Linux 和 OS X 是 Redis 开发和测试最多的两
-全世界有非常多的网站使用到了 Redis ,[techstacks.io](https://techstacks.io/) 专门维护了一个[使用 Redis 的热门站点列表](https://techstacks.io/tech/redis) ,感兴趣的话可以看看。
+全世界有非常多的网站使用到了 Redis,[techstacks.io](https://techstacks.io/) 专门维护了一个[使用 Redis 的热门站点列表](https://techstacks.io/tech/redis),感兴趣的话可以看看。
### Redis 为什么这么快?
-Redis 内部做了非常多的性能优化,比较重要的有下面 3 点:
+Redis 内部做了非常多的性能优化,比较重要的有下面 4 点:
-1. Redis 基于内存,内存的访问速度比磁盘快很多;
-2. Redis 基于 Reactor 模式设计开发了一套高效的事件处理模型,主要是单线程事件循环和 IO 多路复用(Redis 线程模式后面会详细介绍到);
-3. Redis 内置了多种优化过后的数据类型/结构实现,性能非常高。
-4. Redis 通信协议实现简单且解析高效。
+1. **纯内存操作 (Memory-Based Storage)** :这是最主要的原因。Redis 数据读写操作都发生在内存中,访问速度是纳秒级别,而传统数据库频繁读写磁盘的速度是毫秒级别,两者相差数个数量级。
+2. **高效的 I/O 模型 (I/O Multiplexing & Single-Threaded Event Loop)** :Redis 使用单线程事件循环配合 I/O 多路复用技术,让单个线程可以同时处理多个网络连接上的 I/O 事件(如读写),避免了多线程模型中的上下文切换和锁竞争问题。虽然是单线程,但结合内存操作的高效性和 I/O 多路复用,使得 Redis 能轻松处理大量并发请求(Redis 线程模型会在后文中详细介绍到)。
+3. **优化的内部数据结构 (Optimized Data Structures)** :Redis 提供多种数据类型(如 String, List, Hash, Set, Sorted Set 等),其内部实现采用高度优化的编码方式(如 ziplist, quicklist, skiplist, hashtable 等)。Redis 会根据数据大小和类型动态选择最合适的内部编码,以在性能和空间效率之间取得最佳平衡。
+4. **简洁高效的通信协议 (Simple Protocol - RESP)** :Redis 使用的是自己设计的 RESP (REdis Serialization Protocol) 协议。这个协议实现简单、解析性能好,并且是二进制安全的。客户端和服务端之间通信的序列化/反序列化开销很小,有助于提升整体的交互速度。
-> 下面这张图片总结的挺不错的,分享一下,出自 [Why is Redis so fast?](https://twitter.com/alexxubyte/status/1498703822528544770) 。
+> 下面这张图片总结的挺不错的,分享一下,出自 [Why is Redis so fast?](https://twitter.com/alexxubyte/status/1498703822528544770)。

-那既然都这么快了,为什么不直接用 Redis 当主数据库呢?主要是因为内存成本太高且 Redis 提供的数据持久化仍然有数据丢失的风险。
+那既然都这么快了,为什么不直接用 Redis 当主数据库呢?主要是因为内存成本太高,并且 Redis 提供的数据持久化仍然有数据丢失的风险。
### 除了 Redis,你还知道其他分布式缓存方案吗?
@@ -62,16 +62,16 @@ Redis 内部做了非常多的性能优化,比较重要的有下面 3 点:
Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来,随着 Redis 的发展,大家慢慢都转而使用更加强大的 Redis 了。
-有一些大厂也开源了类似于 Redis 的分布式高性能 KV 存储数据库,例如,腾讯开源的 [**Tendis**](https://github.com/Tencent/Tendis) 。Tendis 基于知名开源项目 [RocksDB](https://github.com/facebook/rocksdb) 作为存储引擎 ,100% 兼容 Redis 协议和 Redis4.0 所有数据模型。关于 Redis 和 Tendis 的对比,腾讯官方曾经发过一篇文章:[Redis vs Tendis:冷热混合存储版架构揭秘](https://mp.weixin.qq.com/s/MeYkfOIdnU6LYlsGb24KjQ) ,可以简单参考一下。
+有一些大厂也开源了类似于 Redis 的分布式高性能 KV 存储数据库,例如,腾讯开源的 [**Tendis**](https://github.com/Tencent/Tendis)。Tendis 基于知名开源项目 [RocksDB](https://github.com/facebook/rocksdb) 作为存储引擎 ,100% 兼容 Redis 协议和 Redis4.0 所有数据模型。关于 Redis 和 Tendis 的对比,腾讯官方曾经发过一篇文章:[Redis vs Tendis:冷热混合存储版架构揭秘](https://mp.weixin.qq.com/s/MeYkfOIdnU6LYlsGb24KjQ),可以简单参考一下。
不过,从 Tendis 这个项目的 Github 提交记录可以看出,Tendis 开源版几乎已经没有被维护更新了,加上其关注度并不高,使用的公司也比较少。因此,不建议你使用 Tendis 来实现分布式缓存。
目前,比较业界认可的 Redis 替代品还是下面这两个开源分布式缓存(都是通过碰瓷 Redis 火的):
- [Dragonfly](https://github.com/dragonflydb/dragonfly):一种针对现代应用程序负荷需求而构建的内存数据库,完全兼容 Redis 和 Memcached 的 API,迁移时无需修改任何代码,号称全世界最快的内存数据库。
-- [KeyDB](https://github.com/Snapchat/KeyDB): Redis 的一个高性能分支,专注于多线程、内存效率和高吞吐量。
+- [KeyDB](https://github.com/Snapchat/KeyDB):Redis 的一个高性能分支,专注于多线程、内存效率和高吞吐量。
-不过,个人还是建议分布式缓存首选 Redis ,毕竟经过这么多年的生考验,生态也这么优秀,资料也很全面!
+不过,个人还是建议分布式缓存首选 Redis,毕竟经过了这么多年的考验,生态非常优秀,资料也很全面!
PS:篇幅问题,我这并没有对上面提到的分布式缓存选型做详细介绍和对比,感兴趣的话,可以自行研究一下。
@@ -87,10 +87,10 @@ PS:篇幅问题,我这并没有对上面提到的分布式缓存选型做详
**区别**:
-1. **数据类型**:Redis 支持更丰富的数据类型(支持更复杂的应用场景)。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。Memcached 只支持最简单的 k/v 数据类型。
-2. **数据持久化**:Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memcached 把数据全部存在内存之中。也就是说,Redis 有灾难恢复机制而 Memcached 没有。
-3. **集群模式支持**:Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 Redis 自 3.0 版本起是原生支持集群模式的。
-4. **线程模型**:Memcached 是多线程,非阻塞 IO 复用的网络模型;Redis 使用单线程的多路 IO 复用模型。 (Redis 6.0 针对网络数据的读写引入了多线程)
+1. **数据类型**:Redis 支持更丰富的数据类型(支持更复杂的应用场景)。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list、set、zset、hash 等数据结构的存储;而 Memcached 只支持最简单的 k/v 数据类型。
+2. **数据持久化**:Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用;而 Memcached 把数据全部存在内存之中。也就是说,Redis 有灾难恢复机制,而 Memcached 没有。
+3. **集群模式支持**:Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;而 Redis 自 3.0 版本起是原生支持集群模式的。
+4. **线程模型**:Memcached 是多线程、非阻塞 IO 复用的网络模型;而 Redis 使用单线程的多路 IO 复用模型(Redis 6.0 针对网络数据的读写引入了多线程)。
5. **特性支持**:Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持。并且,Redis 支持更多的编程语言。
6. **过期数据删除**:Memcached 过期数据的删除策略只用了惰性删除,而 Redis 同时使用了惰性删除与定期删除。
@@ -104,7 +104,7 @@ PS:篇幅问题,我这并没有对上面提到的分布式缓存选型做详
**2、高并发**
-一般像 MySQL 这类的数据库的 QPS 大概都在 4k 左右(4 核 8g) ,但是使用 Redis 缓存之后很容易达到 5w+,甚至能达到 10w+(就单机 Redis 的情况,Redis 集群的话会更高)。
+一般像 MySQL 这类的数据库的 QPS 大概都在 4k 左右(4 核 8g),但是使用 Redis 缓存之后很容易达到 5w+,甚至能达到 10w+(就单机 Redis 的情况,Redis 集群的话会更高)。
> QPS(Query Per Second):服务器每秒可以执行的查询次数;
@@ -114,9 +114,19 @@ PS:篇幅问题,我这并没有对上面提到的分布式缓存选型做详
Redis 除了可以用作缓存之外,还可以用于分布式锁、限流、消息队列、延时队列等场景,功能强大!
+### 为什么用 Redis 而不用本地缓存呢?
+
+| 特性 | 本地缓存 | Redis |
+| ------------ | ------------------------------------ | -------------------------------- |
+| 数据一致性 | 多服务器部署时存在数据不一致问题 | 数据一致 |
+| 内存限制 | 受限于单台服务器内存 | 独立部署,内存空间更大 |
+| 数据丢失风险 | 服务器宕机数据丢失 | 可持久化,数据不易丢失 |
+| 管理维护 | 分散,管理不便 | 集中管理,提供丰富的管理工具 |
+| 功能丰富性 | 功能有限,通常只提供简单的键值对存储 | 功能丰富,支持多种数据结构和功能 |
+
### 常见的缓存读写策略有哪些?
-关于常见的缓存读写策略的详细介绍,可以看我写的这篇文章:[3 种常用的缓存读写策略详解](https://javaguide.cn/database/redis/3-commonly-used-cache-read-and-write-strategies.html) 。
+关于常见的缓存读写策略的详细介绍,可以看我写的这篇文章:[3 种常用的缓存读写策略详解](https://javaguide.cn/database/redis/3-commonly-used-cache-read-and-write-strategies.html)。
### 什么是 Redis Module?有什么用?
@@ -141,17 +151,17 @@ Redis 从 4.0 版本开始,支持通过 Module 来扩展其功能以满足特
### Redis 除了做缓存,还能做什么?
-- **分布式锁**:通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html) 。
+- **分布式锁**:通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html)。
- **限流**:一般是通过 Redis + Lua 脚本的方式来实现限流。如果不想自己写 Lua 脚本的话,也可以直接利用 Redisson 中的 `RRateLimiter` 来实现分布式限流,其底层实现就是基于 Lua 代码+令牌桶算法。
- **消息队列**:Redis 自带的 List 数据结构可以作为一个简单的队列使用。Redis 5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
- **延时队列**:Redisson 内置了延时队列(基于 Sorted Set 实现的)。
-- **分布式 Session** :利用 String 或者 Hash 数据类型保存 Session 数据,所有的服务器都可以访问。
-- **复杂业务场景**:通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景比如通过 Bitmap 统计活跃用户、通过 Sorted Set 维护排行榜。
+- **分布式 Session**:利用 String 或者 Hash 数据类型保存 Session 数据,所有的服务器都可以访问。
+- **复杂业务场景**:通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景,比如通过 Bitmap 统计活跃用户、通过 Sorted Set 维护排行榜、通过 HyperLogLog 统计网站 UV 和 PV。
- ……
### 如何基于 Redis 实现分布式锁?
-关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock-implementations.html) 。
+关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock-implementations.html)。
### Redis 可以做消息队列么?
@@ -161,7 +171,7 @@ Redis 从 4.0 版本开始,支持通过 Module 来扩展其功能以满足特
**Redis 2.0 之前,如果想要使用 Redis 来做消息队列的话,只能通过 List 来实现。**
-通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP`即可实现简易版消息队列:
+通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP` 即可实现简易版消息队列:
```bash
# 生产者生产消息
@@ -174,7 +184,7 @@ Redis 从 4.0 版本开始,支持通过 Module 来扩展其功能以满足特
"msg1"
```
-不过,通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP`这样的方式存在性能问题,我们需要不断轮询去调用 `RPOP` 或 `LPOP` 来消费消息。当 List 为空时,大部分的轮询的请求都是无效请求,这种方式大量浪费了系统资源。
+不过,通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP` 这样的方式存在性能问题,我们需要不断轮询去调用 `RPOP` 或 `LPOP` 来消费消息。当 List 为空时,大部分的轮询的请求都是无效请求,这种方式大量浪费了系统资源。
因此,Redis 还提供了 `BLPOP`、`BRPOP` 这种阻塞式读取的命令(带 B-Blocking 的都是阻塞式),并且还支持一个超时参数。如果 List 为空,Redis 服务端不会立刻返回结果,它会等待 List 中有新数据后再返回或者是等待最多一个超时时间后返回空。如果将超时时间设置为 0 时,即可无限等待,直到弹出消息
@@ -206,11 +216,11 @@ pub/sub 既能单播又能广播,还支持 channel 的简单正则匹配。不
为此,Redis 5.0 新增加的一个数据结构 `Stream` 来做消息队列。`Stream` 支持:
-- 发布 / 订阅模式
-- 按照消费者组进行消费(借鉴了 Kafka 消费者组的概念)
-- 消息持久化( RDB 和 AOF)
-- ACK 机制(通过确认机制来告知已经成功处理了消息)
-- 阻塞式获取消息
+- 发布 / 订阅模式;
+- 按照消费者组进行消费(借鉴了 Kafka 消费者组的概念);
+- 消息持久化( RDB 和 AOF);
+- ACK 机制(通过确认机制来告知已经成功处理了消息);
+- 阻塞式获取消息。
`Stream` 的结构如下:
@@ -220,7 +230,7 @@ pub/sub 既能单播又能广播,还支持 channel 的简单正则匹配。不
这里再对图中涉及到的一些概念,进行简单解释:
-- `Consumer Group`:消费者组用于组织和管理多个消费者。消费者组本身不处理消息,而是再将消息分发给消费者,由消费者进行真正的消费
+- `Consumer Group`:消费者组用于组织和管理多个消费者。消费者组本身不处理消息,而是再将消息分发给消费者,由消费者进行真正的消费。
- `last_delivered_id`:标识消费者组当前消费位置的游标,消费者组中任意一个消费者读取了消息都会使 last_delivered_id 往前移动。
- `pending_ids`:记录已经被客户端消费但没有 ack 的消息的 ID。
@@ -235,25 +245,25 @@ pub/sub 既能单播又能广播,还支持 channel 的简单正则匹配。不
- `XTRIM`:修剪流的长度,可以指定修建策略(`MAXLEN`/`MINID`)。
- `XLEN`:获取流的长度。
- `XGROUP CREATE`:创建消费者组。
-- `XGROUP DESTROY` : 删除消费者组
+- `XGROUP DESTROY`:删除消费者组。
- `XGROUP DELCONSUMER`:从消费者组中删除一个消费者。
-- `XGROUP SETID`:为消费者组设置新的最后递送消息 ID
+- `XGROUP SETID`:为消费者组设置新的最后递送消息 ID。
- `XACK`:确认消费组中的消息已被处理。
- `XPENDING`:查询消费组中挂起(未确认)的消息。
- `XCLAIM`:将挂起的消息从一个消费者转移到另一个消费者。
-- `XINFO`:获取流(`XINFO STREAM`)、消费组(`XINFO GROUPS`)或消费者(`XINFO CONSUMERS`)的详细信息。
+- `XINFO`:获取流(`XINFO STREAM`)、消费组(`XINFO GROUPS`)或消费者(`XINFO CONSUMERS`)的详细信息。
`Stream` 使用起来相对要麻烦一些,这里就不演示了。
-总的来说,`Stream` 已经可以满足一个消息队列的基本要求了。不过,`Stream` 在实际使用中依然会有一些小问题不太好解决比如在 Redis 发生故障恢复后不能保证消息至少被消费一次。
+总的来说,`Stream` 已经可以满足一个消息队列的基本要求了。不过,`Stream` 在实际使用中依然会有一些小问题不太好解决,比如在 Redis 发生故障恢复后不能保证消息至少被消费一次。
-综上,和专业的消息队列相比,使用 Redis 来实现消息队列还是有很多欠缺的地方比如消息丢失和堆积问题不好解决。因此,我们通常建议不要使用 Redis 来做消息队列,你完全可以选择市面上比较成熟的一些消息队列比如 RocketMQ、Kafka。不过,如果你就是想要用 Redis 来做消息队列的话,那我建议你优先考虑 `Stream`,这是目前相对最优的 Redis 消息队列实现。
+综上,和专业的消息队列相比,使用 Redis 来实现消息队列还是有很多欠缺的地方,比如消息丢失和堆积问题不好解决。因此,我们通常建议不要使用 Redis 来做消息队列,你完全可以选择市面上比较成熟的一些消息队列,比如 RocketMQ、Kafka。不过,如果你就是想要用 Redis 来做消息队列的话,那我建议你优先考虑 `Stream`,这是目前相对最优的 Redis 消息队列实现。
相关阅读:[Redis 消息队列发展历程 - 阿里开发者 - 2022](https://mp.weixin.qq.com/s/gCUT5TcCQRAxYkTJfTRjJw)。
### Redis 可以做搜索引擎么?
-Redis 是可以实现全文搜索引擎功能的,需要借助 **RediSearch** ,这是一个基于 Redis 的搜索引擎模块。
+Redis 是可以实现全文搜索引擎功能的,需要借助 **RediSearch**,这是一个基于 Redis 的搜索引擎模块。
RediSearch 支持中文分词、聚合统计、停用词、同义词、拼写检查、标签查询、向量相似度查询、多关键词搜索、分页搜索等功能,算是一个功能比较完善的全文搜索引擎了。
@@ -264,7 +274,7 @@ RediSearch 支持中文分词、聚合统计、停用词、同义词、拼写检
对于小型项目的简单搜索场景来说,使用 RediSearch 来作为搜索引擎还是没有问题的(搭配 RedisJSON 使用)。
-对于比较复杂或者数据规模较大的搜索场景还是不太建议使用 RediSearch 来作为搜索引擎,主要是因为下面这些限制和问题:
+对于比较复杂或者数据规模较大的搜索场景,还是不太建议使用 RediSearch 来作为搜索引擎,主要是因为下面这些限制和问题:
1. 数据量限制:Elasticsearch 可以支持 PB 级别的数据量,可以轻松扩展到多个节点,利用分片机制提高可用性和性能。RedisSearch 是基于 Redis 实现的,其能存储的数据量受限于 Redis 的内存容量,不太适合存储大规模的数据(内存昂贵,扩展能力较差)。
2. 分布式能力较差:Elasticsearch 是为分布式环境设计的,可以轻松扩展到多个节点。虽然 RedisSearch 支持分布式部署,但在实际应用中可能会面临一些挑战,如数据分片、节点间通信、数据一致性等问题。
@@ -282,10 +292,10 @@ Elasticsearch 适用于全文搜索、复杂查询、实时数据分析和聚合
基于 Redis 实现延时任务的功能无非就下面两种方案:
-1. Redis 过期事件监听
-2. Redisson 内置的延时队列
+1. Redis 过期事件监听。
+2. Redisson 内置的延时队列。
-Redis 过期事件监听的存在时效性较差、丢消息、多服务实例下消息重复消费等问题,不被推荐使用。
+Redis 过期事件监听存在时效性较差、丢消息、多服务实例下消息重复消费等问题,不被推荐使用。
Redisson 内置的延时队列具备下面这些优势:
@@ -296,7 +306,7 @@ Redisson 内置的延时队列具备下面这些优势:
## Redis 数据类型
-关于 Redis 5 种基础数据类型和 3 种特殊数据类型的详细介绍请看下面这两篇文章以及 [Redis 官方文档](https://redis.io/docs/data-types/) :
+关于 Redis 5 种基础数据类型和 3 种特殊数据类型的详细介绍请看下面这两篇文章以及 [Redis 官方文档](https://redis.io/docs/data-types/):
- [Redis 5 种基本数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-01.html)
- [Redis 3 种特殊数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-02.html)
@@ -318,7 +328,7 @@ String 的常见应用场景如下:
- 常规数据(比如 Session、Token、序列化后的对象、图片的路径)的缓存;
- 计数比如用户单位时间的请求数(简单限流可以用到)、页面单位时间的访问数;
-- 分布式锁(利用 `SETNX key value` 命令可以实现一个最简易的分布式锁);
+- 分布式锁(利用 `SETNX key value` 命令可以实现一个最简易的分布式锁);
- ……
关于 String 的详细介绍请看这篇文章:[Redis 5 种基本数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-01.html)。
@@ -339,11 +349,11 @@ String 的常见应用场景如下:
### String 的底层实现是什么?
-Redis 是基于 C 语言编写的,但 Redis 的 String 类型的底层实现并不是 C 语言中的字符串(即以空字符 `\0` 结尾的字符数组),而是自己编写了 [SDS](https://github.com/antirez/sds)(Simple Dynamic String,简单动态字符串) 来作为底层实现。
+Redis 是基于 C 语言编写的,但 Redis 的 String 类型的底层实现并不是 C 语言中的字符串(即以空字符 `\0` 结尾的字符数组),而是自己编写了 [SDS](https://github.com/antirez/sds)(Simple Dynamic String,简单动态字符串)来作为底层实现。
SDS 最早是 Redis 作者为日常 C 语言开发而设计的 C 字符串,后来被应用到了 Redis 上,并经过了大量的修改完善以适合高性能操作。
-Redis7.0 的 SDS 的部分源码如下(
@@ -167,4 +192,10 @@ MySQL 中时间到底怎么存储才好?Datetime?Timestamp?还是数值时间
| TIMESTAMP | 4~7 字节 | YYYY-MM-DD hh:mm:ss[.fraction] | 1970-01-01 00:00:01[.000000] ~ 2038-01-19 03:14:07[.999999] | 是 |
| 数值型时间戳 | 4 字节 | 全数字如 1578707612 | 1970-01-01 00:00:01 之后的时间 | 否 |
+**选择建议小结:**
+
+- `TIMESTAMP` 的核心优势在于其内建的时区处理能力。数据库负责 UTC 存储和基于会话时区的自动转换,简化了需要处理多时区应用的开发。如果应用需要处理多时区,或者希望数据库能自动管理时区转换,`TIMESTAMP` 是自然的选择(注意其时间范围限制,也就是 2038 年问题)。
+- 如果应用场景不涉及时区转换,或者希望应用程序完全控制时区逻辑,并且需要表示 2038 年之后的时间,`DATETIME` 是更稳妥的选择。
+- 如果极度关注比较性能,或者需要频繁跨系统传递时间数据,并且可以接受可读性的牺牲(或总是在应用层转换),数值时间戳是一个强大的选项。
+
diff --git a/docs/database/mysql/transaction-isolation-level.md b/docs/database/mysql/transaction-isolation-level.md
index 52ad40f4a47..8b706640ea6 100644
--- a/docs/database/mysql/transaction-isolation-level.md
+++ b/docs/database/mysql/transaction-isolation-level.md
@@ -11,43 +11,46 @@ tag:
## 事务隔离级别总结
-SQL 标准定义了四个隔离级别:
+SQL 标准定义了四种事务隔离级别,用来平衡事务的隔离性(Isolation)和并发性能。级别越高,数据一致性越好,但并发性能可能越低。这四个级别是:
-- **READ-UNCOMMITTED(读取未提交)** :最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
-- **READ-COMMITTED(读取已提交)** :允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
-- **REPEATABLE-READ(可重复读)** :对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
+- **READ-UNCOMMITTED(读取未提交)** :最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。这种级别在实际应用中很少使用,因为它对数据一致性的保证太弱。
+- **READ-COMMITTED(读取已提交)** :允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。这是大多数数据库(如 Oracle, SQL Server)的默认隔离级别。
+- **REPEATABLE-READ(可重复读)** :对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。MySQL InnoDB 存储引擎的默认隔离级别正是 REPEATABLE READ。并且,InnoDB 在此级别下通过 MVCC(多版本并发控制) 和 Next-Key Locks(间隙锁+行锁) 机制,在很大程度上解决了幻读问题。
- **SERIALIZABLE(可串行化)** :最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
----
+| 隔离级别 | 脏读 (Dirty Read) | 不可重复读 (Non-Repeatable Read) | 幻读 (Phantom Read) |
+| ---------------- | ----------------- | -------------------------------- | ---------------------- |
+| READ UNCOMMITTED | √ | √ | √ |
+| READ COMMITTED | × | √ | √ |
+| REPEATABLE READ | × | × | √ (标准) / ≈× (InnoDB) |
+| SERIALIZABLE | × | × | × |
-| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
-| :--------------: | :--: | :--------: | :--: |
-| READ-UNCOMMITTED | √ | √ | √ |
-| READ-COMMITTED | × | √ | √ |
-| REPEATABLE-READ | × | × | √ |
-| SERIALIZABLE | × | × | × |
+**默认级别查询:**
-MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看,MySQL 8.0 该命令改为`SELECT @@transaction_isolation;`
+MySQL InnoDB 存储引擎的默认隔离级别是 **REPEATABLE READ**。可以通过以下命令查看:
-```sql
-MySQL> SELECT @@tx_isolation;
-+-----------------+
-| @@tx_isolation |
-+-----------------+
-| REPEATABLE-READ |
-+-----------------+
+- MySQL 8.0 之前:`SELECT @@tx_isolation;`
+- MySQL 8.0 及之后:`SELECT @@transaction_isolation;`
+
+```bash
+mysql> SELECT @@transaction_isolation;
++-------------------------+
+| @@transaction_isolation |
++-------------------------+
+| REPEATABLE-READ |
++-------------------------+
```
-从上面对 SQL 标准定义了四个隔离级别的介绍可以看出,标准的 SQL 隔离级别定义里,REPEATABLE-READ(可重复读)是不可以防止幻读的。
+**InnoDB 的 REPEATABLE READ 对幻读的处理:**
-但是!InnoDB 实现的 REPEATABLE-READ 隔离级别其实是可以解决幻读问题发生的,主要有下面两种情况:
+标准的 SQL 隔离级别定义里,REPEATABLE READ 是无法防止幻读的。但 InnoDB 的实现通过以下机制很大程度上避免了幻读:
-- **快照读**:由 MVCC 机制来保证不出现幻读。
-- **当前读**:使用 Next-Key Lock 进行加锁来保证不出现幻读,Next-Key Lock 是行锁(Record Lock)和间隙锁(Gap Lock)的结合,行锁只能锁住已经存在的行,为了避免插入新行,需要依赖间隙锁。
+- **快照读 (Snapshot Read)**:普通的 SELECT 语句,通过 **MVCC** 机制实现。事务启动时创建一个数据快照,后续的快照读都读取这个版本的数据,从而避免了看到其他事务新插入的行(幻读)或修改的行(不可重复读)。
+- **当前读 (Current Read)**:像 `SELECT ... FOR UPDATE`, `SELECT ... LOCK IN SHARE MODE`, `INSERT`, `UPDATE`, `DELETE` 这些操作。InnoDB 使用 **Next-Key Lock** 来锁定扫描到的索引记录及其间的范围(间隙),防止其他事务在这个范围内插入新的记录,从而避免幻读。Next-Key Lock 是行锁(Record Lock)和间隙锁(Gap Lock)的组合。
-因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是 **READ-COMMITTED** ,但是你要知道的是 InnoDB 存储引擎默认使用 **REPEATABLE-READ** 并不会有任何性能损失。
+值得注意的是,虽然通常认为隔离级别越高、并发性越差,但 InnoDB 存储引擎通过 MVCC 机制优化了 REPEATABLE READ 级别。对于许多常见的只读或读多写少的场景,其性能**与 READ COMMITTED 相比可能没有显著差异**。不过,在写密集型且并发冲突较高的场景下,RR 的间隙锁机制可能会比 RC 带来更多的锁等待。
-InnoDB 存储引擎在分布式事务的情况下一般会用到 SERIALIZABLE 隔离级别。
+此外,在某些特定场景下,如需要严格一致性的分布式事务(XA Transactions),InnoDB 可能要求或推荐使用 SERIALIZABLE 隔离级别来确保全局数据的一致性。
《MySQL 技术内幕:InnoDB 存储引擎(第 2 版)》7.7 章这样写到:
diff --git a/docs/database/redis/redis-cluster.md b/docs/database/redis/redis-cluster.md
index 60cd7dda858..e3ef2efd04c 100644
--- a/docs/database/redis/redis-cluster.md
+++ b/docs/database/redis/redis-cluster.md
@@ -7,7 +7,7 @@ tag:
**Redis 集群** 相关的面试题为我的 [知识星球](../../about-the-author/zhishixingqiu-two-years.md)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了[《Java 面试指北》](../../zhuanlan/java-mian-shi-zhi-bei.md)中。
-
+
diff --git a/docs/database/redis/redis-data-structures-01.md b/docs/database/redis/redis-data-structures-01.md
index 9dfb0c3eaa5..7d993752138 100644
--- a/docs/database/redis/redis-data-structures-01.md
+++ b/docs/database/redis/redis-data-structures-01.md
@@ -182,7 +182,7 @@ Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据
"value3"
```
-我专门画了一个图方便大家理解 `RPUSH` , `LPOP` , `lpush` , `RPOP` 命令:
+我专门画了一个图方便大家理解 `RPUSH` , `LPOP` , `LPUSH` , `RPOP` 命令:

diff --git a/docs/database/redis/redis-data-structures-02.md b/docs/database/redis/redis-data-structures-02.md
index 634860949fd..9e5fbcee59b 100644
--- a/docs/database/redis/redis-data-structures-02.md
+++ b/docs/database/redis/redis-data-structures-02.md
@@ -123,9 +123,9 @@ HyperLogLog 相关的命令非常少,最常用的也就 3 个。
### 应用场景
-**数量量巨大(百万、千万级别以上)的计数场景**
+**数量巨大(百万、千万级别以上)的计数场景**
-- 举例:热门网站每日/每周/每月访问 ip 数统计、热门帖子 uv 统计、
+- 举例:热门网站每日/每周/每月访问 ip 数统计、热门帖子 uv 统计。
- 相关命令:`PFADD`、`PFCOUNT` 。
## Geospatial (地理位置)
diff --git a/docs/database/redis/redis-delayed-task.md b/docs/database/redis/redis-delayed-task.md
index bd95cb46bbb..35f9304321f 100644
--- a/docs/database/redis/redis-delayed-task.md
+++ b/docs/database/redis/redis-delayed-task.md
@@ -33,7 +33,7 @@ Redis 中有很多默认的 channel,这些 channel 是由 Redis 本身向它
我们只需要监听这个 channel,就可以拿到过期的 key 的消息,进而实现了延时任务功能。
-这个功能被 Redis 官方称为 **keyspace notifications** ,作用是实时监控实时监控 Redis 键和值的变化。
+这个功能被 Redis 官方称为 **keyspace notifications** ,作用是实时监控 Redis 键和值的变化。
### Redis 过期事件监听实现延时任务功能有什么缺陷?
@@ -72,7 +72,7 @@ Redisson 是一个开源的 Java 语言 Redis 客户端,提供了很多开箱
Redisson 的延迟队列 RDelayedQueue 是基于 Redis 的 SortedSet 来实现的。SortedSet 是一个有序集合,其中的每个元素都可以设置一个分数,代表该元素的权重。Redisson 利用这一特性,将需要延迟执行的任务插入到 SortedSet 中,并给它们设置相应的过期时间作为分数。
-Redisson 使用 `zrangebyscore` 命令扫描 SortedSet 中过期的元素,然后将这些过期元素从 SortedSet 中移除,并将它们加入到就绪消息列表中。就绪消息列表是一个阻塞队列,有消息进入就会被监听到。这样做可以避免对整个 SortedSet 进行轮询,提高了执行效率。
+Redisson 定期使用 `zrangebyscore` 命令扫描 SortedSet 中过期的元素,然后将这些过期元素从 SortedSet 中移除,并将它们加入到就绪消息列表中。就绪消息列表是一个阻塞队列,有消息进入就会被消费者监听到。这样做可以避免消费者对整个 SortedSet 进行轮询,提高了执行效率。
相比于 Redis 过期事件监听实现延时任务功能,这种方式具备下面这些优势:
diff --git a/docs/database/redis/redis-persistence.md b/docs/database/redis/redis-persistence.md
index 1e51df93448..2b61a1250ad 100644
--- a/docs/database/redis/redis-persistence.md
+++ b/docs/database/redis/redis-persistence.md
@@ -71,7 +71,7 @@ AOF 持久化功能的实现可以简单分为 5 步:
1. **命令追加(append)**:所有的写命令会追加到 AOF 缓冲区中。
2. **文件写入(write)**:将 AOF 缓冲区的数据写入到 AOF 文件中。这一步需要调用`write`函数(系统调用),`write`将数据写入到了系统内核缓冲区之后直接返回了(延迟写)。注意!!!此时并没有同步到磁盘。
-3. **文件同步(fsync)**:AOF 缓冲区根据对应的持久化方式( `fsync` 策略)向硬盘做同步操作。这一步需要调用 `fsync` 函数(系统调用), `fsync` 针对单个文件操作,对其进行强制硬盘同步,`fsync` 将阻塞直到写入磁盘完成后返回,保证了数据持久化。
+3. **文件同步(fsync)**:这一步才是持久化的核心!根据你在 `redis.conf` 文件里 `appendfsync` 配置的策略,Redis 会在不同的时机,调用 `fsync` 函数(系统调用)。`fsync` 针对单个文件操作,对其进行强制硬盘同步(文件在内核缓冲区里的数据写到硬盘),`fsync` 将阻塞直到写入磁盘完成后返回,保证了数据持久化。
4. **文件重写(rewrite)**:随着 AOF 文件越来越大,需要定期对 AOF 文件进行重写,达到压缩的目的。
5. **重启加载(load)**:当 Redis 重启时,可以加载 AOF 文件进行数据恢复。
@@ -90,9 +90,9 @@ AOF 工作流程图如下:
在 Redis 的配置文件中存在三种不同的 AOF 持久化方式( `fsync`策略),它们分别是:
-1. `appendfsync always`:主线程调用 `write` 执行写操作后,后台线程( `aof_fsync` 线程)立即会调用 `fsync` 函数同步 AOF 文件(刷盘),`fsync` 完成后线程返回,这样会严重降低 Redis 的性能(`write` + `fsync`)。
-2. `appendfsync everysec`:主线程调用 `write` 执行写操作后立即返回,由后台线程( `aof_fsync` 线程)每秒钟调用 `fsync` 函数(系统调用)同步一次 AOF 文件(`write`+`fsync`,`fsync`间隔为 1 秒)
-3. `appendfsync no`:主线程调用 `write` 执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(`write`但不`fsync`,`fsync` 的时机由操作系统决定)。
+1. `appendfsync always`:主线程调用 `write` 执行写操作后,会立刻调用 `fsync` 函数同步 AOF 文件(刷盘)。主线程会阻塞,直到 `fsync` 将数据完全刷到磁盘后才会返回。这种方式数据最安全,理论上不会有任何数据丢失。但因为每个写操作都会同步阻塞主线程,所以性能极差。
+2. `appendfsync everysec`:主线程调用 `write` 执行写操作后立即返回,由后台线程( `aof_fsync` 线程)每秒钟调用 `fsync` 函数(系统调用)同步一次 AOF 文件(`write`+`fsync`,`fsync`间隔为 1 秒)。这种方式主线程的性能基本不受影响。在性能和数据安全之间做出了绝佳的平衡。不过,在 Redis 异常宕机时,最多可能丢失最近 1 秒内的数据。
+3. `appendfsync no`:主线程调用 `write` 执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(`write`但不`fsync`,`fsync` 的时机由操作系统决定)。 这种方式性能最好,因为避免了 `fsync` 的阻塞。但数据安全性最差,宕机时丢失的数据量不可控,取决于操作系统上一次同步的时间点。
可以看出:**这 3 种持久化方式的主要区别在于 `fsync` 同步 AOF 文件的时机(刷盘)**。
@@ -153,9 +153,27 @@ Redis 7.0 版本之后,AOF 重写机制得到了优化改进。下面这段内
### AOF 校验机制了解吗?
-AOF 校验机制是 Redis 在启动时对 AOF 文件进行检查,以判断文件是否完整,是否有损坏或者丢失的数据。这个机制的原理其实非常简单,就是通过使用一种叫做 **校验和(checksum)** 的数字来验证 AOF 文件。这个校验和是通过对整个 AOF 文件内容进行 CRC64 算法计算得出的数字。如果文件内容发生了变化,那么校验和也会随之改变。因此,Redis 在启动时会比较计算出的校验和与文件末尾保存的校验和(计算的时候会把最后一行保存校验和的内容给忽略点),从而判断 AOF 文件是否完整。如果发现文件有问题,Redis 就会拒绝启动并提供相应的错误信息。AOF 校验机制十分简单有效,可以提高 Redis 数据的可靠性。
+纯 AOF 模式下,Redis 不会对整个 AOF 文件使用校验和(如 CRC64),而是通过逐条解析文件中的命令来验证文件的有效性。如果解析过程中发现语法错误(如命令不完整、格式错误),Redis 会终止加载并报错,从而避免错误数据载入内存。
-类似地,RDB 文件也有类似的校验机制来保证 RDB 文件的正确性,这里就不重复进行介绍了。
+在 **混合持久化模式**(Redis 4.0 引入)下,AOF 文件由两部分组成:
+
+- **RDB 快照部分**:文件以固定的 `REDIS` 字符开头,存储某一时刻的内存数据快照,并在快照数据末尾附带一个 CRC64 校验和(位于 RDB 数据块尾部、AOF 增量部分之前)。
+- **AOF 增量部分**:紧随 RDB 快照部分之后,记录 RDB 快照生成后的增量写命令。这部分增量命令以 Redis 协议格式逐条记录,无整体或全局校验和。
+
+RDB 文件结构的核心部分如下:
+
+| **字段** | **解释** |
+| ----------------- | ---------------------------------------------- |
+| `"REDIS"` | 固定以该字符串开始 |
+| `RDB_VERSION` | RDB 文件的版本号 |
+| `DB_NUM` | Redis 数据库编号,指明数据需要存放到哪个数据库 |
+| `KEY_VALUE_PAIRS` | Redis 中具体键值对的存储 |
+| `EOF` | RDB 文件结束标志 |
+| `CHECK_SUM` | 8 字节确保 RDB 完整性的校验和 |
+
+Redis 启动并加载 AOF 文件时,首先会校验文件开头 RDB 快照部分的数据完整性,即计算该部分数据的 CRC64 校验和,并与紧随 RDB 数据之后、AOF 增量部分之前存储的 CRC64 校验和值进行比较。如果 CRC64 校验和不匹配,Redis 将拒绝启动并报告错误。
+
+RDB 部分校验通过后,Redis 随后逐条解析 AOF 部分的增量命令。如果解析过程中出现错误(如不完整的命令或格式错误),Redis 会停止继续加载后续命令,并报告错误,但此时 Redis 已经成功加载了 RDB 快照部分的数据。
## Redis 4.0 对于持久化机制做了什么优化?
diff --git a/docs/database/redis/redis-questions-01.md b/docs/database/redis/redis-questions-01.md
index 40c266b5d73..913ad8b2e51 100644
--- a/docs/database/redis/redis-questions-01.md
+++ b/docs/database/redis/redis-questions-01.md
@@ -30,22 +30,22 @@ Redis 没有外部依赖,Linux 和 OS X 是 Redis 开发和测试最多的两

-全世界有非常多的网站使用到了 Redis ,[techstacks.io](https://techstacks.io/) 专门维护了一个[使用 Redis 的热门站点列表](https://techstacks.io/tech/redis) ,感兴趣的话可以看看。
+全世界有非常多的网站使用到了 Redis,[techstacks.io](https://techstacks.io/) 专门维护了一个[使用 Redis 的热门站点列表](https://techstacks.io/tech/redis),感兴趣的话可以看看。
### Redis 为什么这么快?
-Redis 内部做了非常多的性能优化,比较重要的有下面 3 点:
+Redis 内部做了非常多的性能优化,比较重要的有下面 4 点:
-1. Redis 基于内存,内存的访问速度比磁盘快很多;
-2. Redis 基于 Reactor 模式设计开发了一套高效的事件处理模型,主要是单线程事件循环和 IO 多路复用(Redis 线程模式后面会详细介绍到);
-3. Redis 内置了多种优化过后的数据类型/结构实现,性能非常高。
-4. Redis 通信协议实现简单且解析高效。
+1. **纯内存操作 (Memory-Based Storage)** :这是最主要的原因。Redis 数据读写操作都发生在内存中,访问速度是纳秒级别,而传统数据库频繁读写磁盘的速度是毫秒级别,两者相差数个数量级。
+2. **高效的 I/O 模型 (I/O Multiplexing & Single-Threaded Event Loop)** :Redis 使用单线程事件循环配合 I/O 多路复用技术,让单个线程可以同时处理多个网络连接上的 I/O 事件(如读写),避免了多线程模型中的上下文切换和锁竞争问题。虽然是单线程,但结合内存操作的高效性和 I/O 多路复用,使得 Redis 能轻松处理大量并发请求(Redis 线程模型会在后文中详细介绍到)。
+3. **优化的内部数据结构 (Optimized Data Structures)** :Redis 提供多种数据类型(如 String, List, Hash, Set, Sorted Set 等),其内部实现采用高度优化的编码方式(如 ziplist, quicklist, skiplist, hashtable 等)。Redis 会根据数据大小和类型动态选择最合适的内部编码,以在性能和空间效率之间取得最佳平衡。
+4. **简洁高效的通信协议 (Simple Protocol - RESP)** :Redis 使用的是自己设计的 RESP (REdis Serialization Protocol) 协议。这个协议实现简单、解析性能好,并且是二进制安全的。客户端和服务端之间通信的序列化/反序列化开销很小,有助于提升整体的交互速度。
-> 下面这张图片总结的挺不错的,分享一下,出自 [Why is Redis so fast?](https://twitter.com/alexxubyte/status/1498703822528544770) 。
+> 下面这张图片总结的挺不错的,分享一下,出自 [Why is Redis so fast?](https://twitter.com/alexxubyte/status/1498703822528544770)。

-那既然都这么快了,为什么不直接用 Redis 当主数据库呢?主要是因为内存成本太高且 Redis 提供的数据持久化仍然有数据丢失的风险。
+那既然都这么快了,为什么不直接用 Redis 当主数据库呢?主要是因为内存成本太高,并且 Redis 提供的数据持久化仍然有数据丢失的风险。
### 除了 Redis,你还知道其他分布式缓存方案吗?
@@ -62,16 +62,16 @@ Redis 内部做了非常多的性能优化,比较重要的有下面 3 点:
Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来,随着 Redis 的发展,大家慢慢都转而使用更加强大的 Redis 了。
-有一些大厂也开源了类似于 Redis 的分布式高性能 KV 存储数据库,例如,腾讯开源的 [**Tendis**](https://github.com/Tencent/Tendis) 。Tendis 基于知名开源项目 [RocksDB](https://github.com/facebook/rocksdb) 作为存储引擎 ,100% 兼容 Redis 协议和 Redis4.0 所有数据模型。关于 Redis 和 Tendis 的对比,腾讯官方曾经发过一篇文章:[Redis vs Tendis:冷热混合存储版架构揭秘](https://mp.weixin.qq.com/s/MeYkfOIdnU6LYlsGb24KjQ) ,可以简单参考一下。
+有一些大厂也开源了类似于 Redis 的分布式高性能 KV 存储数据库,例如,腾讯开源的 [**Tendis**](https://github.com/Tencent/Tendis)。Tendis 基于知名开源项目 [RocksDB](https://github.com/facebook/rocksdb) 作为存储引擎 ,100% 兼容 Redis 协议和 Redis4.0 所有数据模型。关于 Redis 和 Tendis 的对比,腾讯官方曾经发过一篇文章:[Redis vs Tendis:冷热混合存储版架构揭秘](https://mp.weixin.qq.com/s/MeYkfOIdnU6LYlsGb24KjQ),可以简单参考一下。
不过,从 Tendis 这个项目的 Github 提交记录可以看出,Tendis 开源版几乎已经没有被维护更新了,加上其关注度并不高,使用的公司也比较少。因此,不建议你使用 Tendis 来实现分布式缓存。
目前,比较业界认可的 Redis 替代品还是下面这两个开源分布式缓存(都是通过碰瓷 Redis 火的):
- [Dragonfly](https://github.com/dragonflydb/dragonfly):一种针对现代应用程序负荷需求而构建的内存数据库,完全兼容 Redis 和 Memcached 的 API,迁移时无需修改任何代码,号称全世界最快的内存数据库。
-- [KeyDB](https://github.com/Snapchat/KeyDB): Redis 的一个高性能分支,专注于多线程、内存效率和高吞吐量。
+- [KeyDB](https://github.com/Snapchat/KeyDB):Redis 的一个高性能分支,专注于多线程、内存效率和高吞吐量。
-不过,个人还是建议分布式缓存首选 Redis ,毕竟经过这么多年的生考验,生态也这么优秀,资料也很全面!
+不过,个人还是建议分布式缓存首选 Redis,毕竟经过了这么多年的考验,生态非常优秀,资料也很全面!
PS:篇幅问题,我这并没有对上面提到的分布式缓存选型做详细介绍和对比,感兴趣的话,可以自行研究一下。
@@ -87,10 +87,10 @@ PS:篇幅问题,我这并没有对上面提到的分布式缓存选型做详
**区别**:
-1. **数据类型**:Redis 支持更丰富的数据类型(支持更复杂的应用场景)。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。Memcached 只支持最简单的 k/v 数据类型。
-2. **数据持久化**:Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memcached 把数据全部存在内存之中。也就是说,Redis 有灾难恢复机制而 Memcached 没有。
-3. **集群模式支持**:Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 Redis 自 3.0 版本起是原生支持集群模式的。
-4. **线程模型**:Memcached 是多线程,非阻塞 IO 复用的网络模型;Redis 使用单线程的多路 IO 复用模型。 (Redis 6.0 针对网络数据的读写引入了多线程)
+1. **数据类型**:Redis 支持更丰富的数据类型(支持更复杂的应用场景)。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list、set、zset、hash 等数据结构的存储;而 Memcached 只支持最简单的 k/v 数据类型。
+2. **数据持久化**:Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用;而 Memcached 把数据全部存在内存之中。也就是说,Redis 有灾难恢复机制,而 Memcached 没有。
+3. **集群模式支持**:Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;而 Redis 自 3.0 版本起是原生支持集群模式的。
+4. **线程模型**:Memcached 是多线程、非阻塞 IO 复用的网络模型;而 Redis 使用单线程的多路 IO 复用模型(Redis 6.0 针对网络数据的读写引入了多线程)。
5. **特性支持**:Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持。并且,Redis 支持更多的编程语言。
6. **过期数据删除**:Memcached 过期数据的删除策略只用了惰性删除,而 Redis 同时使用了惰性删除与定期删除。
@@ -104,7 +104,7 @@ PS:篇幅问题,我这并没有对上面提到的分布式缓存选型做详
**2、高并发**
-一般像 MySQL 这类的数据库的 QPS 大概都在 4k 左右(4 核 8g) ,但是使用 Redis 缓存之后很容易达到 5w+,甚至能达到 10w+(就单机 Redis 的情况,Redis 集群的话会更高)。
+一般像 MySQL 这类的数据库的 QPS 大概都在 4k 左右(4 核 8g),但是使用 Redis 缓存之后很容易达到 5w+,甚至能达到 10w+(就单机 Redis 的情况,Redis 集群的话会更高)。
> QPS(Query Per Second):服务器每秒可以执行的查询次数;
@@ -114,9 +114,19 @@ PS:篇幅问题,我这并没有对上面提到的分布式缓存选型做详
Redis 除了可以用作缓存之外,还可以用于分布式锁、限流、消息队列、延时队列等场景,功能强大!
+### 为什么用 Redis 而不用本地缓存呢?
+
+| 特性 | 本地缓存 | Redis |
+| ------------ | ------------------------------------ | -------------------------------- |
+| 数据一致性 | 多服务器部署时存在数据不一致问题 | 数据一致 |
+| 内存限制 | 受限于单台服务器内存 | 独立部署,内存空间更大 |
+| 数据丢失风险 | 服务器宕机数据丢失 | 可持久化,数据不易丢失 |
+| 管理维护 | 分散,管理不便 | 集中管理,提供丰富的管理工具 |
+| 功能丰富性 | 功能有限,通常只提供简单的键值对存储 | 功能丰富,支持多种数据结构和功能 |
+
### 常见的缓存读写策略有哪些?
-关于常见的缓存读写策略的详细介绍,可以看我写的这篇文章:[3 种常用的缓存读写策略详解](https://javaguide.cn/database/redis/3-commonly-used-cache-read-and-write-strategies.html) 。
+关于常见的缓存读写策略的详细介绍,可以看我写的这篇文章:[3 种常用的缓存读写策略详解](https://javaguide.cn/database/redis/3-commonly-used-cache-read-and-write-strategies.html)。
### 什么是 Redis Module?有什么用?
@@ -141,17 +151,17 @@ Redis 从 4.0 版本开始,支持通过 Module 来扩展其功能以满足特
### Redis 除了做缓存,还能做什么?
-- **分布式锁**:通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html) 。
+- **分布式锁**:通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html)。
- **限流**:一般是通过 Redis + Lua 脚本的方式来实现限流。如果不想自己写 Lua 脚本的话,也可以直接利用 Redisson 中的 `RRateLimiter` 来实现分布式限流,其底层实现就是基于 Lua 代码+令牌桶算法。
- **消息队列**:Redis 自带的 List 数据结构可以作为一个简单的队列使用。Redis 5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
- **延时队列**:Redisson 内置了延时队列(基于 Sorted Set 实现的)。
-- **分布式 Session** :利用 String 或者 Hash 数据类型保存 Session 数据,所有的服务器都可以访问。
-- **复杂业务场景**:通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景比如通过 Bitmap 统计活跃用户、通过 Sorted Set 维护排行榜。
+- **分布式 Session**:利用 String 或者 Hash 数据类型保存 Session 数据,所有的服务器都可以访问。
+- **复杂业务场景**:通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景,比如通过 Bitmap 统计活跃用户、通过 Sorted Set 维护排行榜、通过 HyperLogLog 统计网站 UV 和 PV。
- ……
### 如何基于 Redis 实现分布式锁?
-关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock-implementations.html) 。
+关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock-implementations.html)。
### Redis 可以做消息队列么?
@@ -161,7 +171,7 @@ Redis 从 4.0 版本开始,支持通过 Module 来扩展其功能以满足特
**Redis 2.0 之前,如果想要使用 Redis 来做消息队列的话,只能通过 List 来实现。**
-通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP`即可实现简易版消息队列:
+通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP` 即可实现简易版消息队列:
```bash
# 生产者生产消息
@@ -174,7 +184,7 @@ Redis 从 4.0 版本开始,支持通过 Module 来扩展其功能以满足特
"msg1"
```
-不过,通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP`这样的方式存在性能问题,我们需要不断轮询去调用 `RPOP` 或 `LPOP` 来消费消息。当 List 为空时,大部分的轮询的请求都是无效请求,这种方式大量浪费了系统资源。
+不过,通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP` 这样的方式存在性能问题,我们需要不断轮询去调用 `RPOP` 或 `LPOP` 来消费消息。当 List 为空时,大部分的轮询的请求都是无效请求,这种方式大量浪费了系统资源。
因此,Redis 还提供了 `BLPOP`、`BRPOP` 这种阻塞式读取的命令(带 B-Blocking 的都是阻塞式),并且还支持一个超时参数。如果 List 为空,Redis 服务端不会立刻返回结果,它会等待 List 中有新数据后再返回或者是等待最多一个超时时间后返回空。如果将超时时间设置为 0 时,即可无限等待,直到弹出消息
@@ -206,11 +216,11 @@ pub/sub 既能单播又能广播,还支持 channel 的简单正则匹配。不
为此,Redis 5.0 新增加的一个数据结构 `Stream` 来做消息队列。`Stream` 支持:
-- 发布 / 订阅模式
-- 按照消费者组进行消费(借鉴了 Kafka 消费者组的概念)
-- 消息持久化( RDB 和 AOF)
-- ACK 机制(通过确认机制来告知已经成功处理了消息)
-- 阻塞式获取消息
+- 发布 / 订阅模式;
+- 按照消费者组进行消费(借鉴了 Kafka 消费者组的概念);
+- 消息持久化( RDB 和 AOF);
+- ACK 机制(通过确认机制来告知已经成功处理了消息);
+- 阻塞式获取消息。
`Stream` 的结构如下:
@@ -220,7 +230,7 @@ pub/sub 既能单播又能广播,还支持 channel 的简单正则匹配。不
这里再对图中涉及到的一些概念,进行简单解释:
-- `Consumer Group`:消费者组用于组织和管理多个消费者。消费者组本身不处理消息,而是再将消息分发给消费者,由消费者进行真正的消费
+- `Consumer Group`:消费者组用于组织和管理多个消费者。消费者组本身不处理消息,而是再将消息分发给消费者,由消费者进行真正的消费。
- `last_delivered_id`:标识消费者组当前消费位置的游标,消费者组中任意一个消费者读取了消息都会使 last_delivered_id 往前移动。
- `pending_ids`:记录已经被客户端消费但没有 ack 的消息的 ID。
@@ -235,25 +245,25 @@ pub/sub 既能单播又能广播,还支持 channel 的简单正则匹配。不
- `XTRIM`:修剪流的长度,可以指定修建策略(`MAXLEN`/`MINID`)。
- `XLEN`:获取流的长度。
- `XGROUP CREATE`:创建消费者组。
-- `XGROUP DESTROY` : 删除消费者组
+- `XGROUP DESTROY`:删除消费者组。
- `XGROUP DELCONSUMER`:从消费者组中删除一个消费者。
-- `XGROUP SETID`:为消费者组设置新的最后递送消息 ID
+- `XGROUP SETID`:为消费者组设置新的最后递送消息 ID。
- `XACK`:确认消费组中的消息已被处理。
- `XPENDING`:查询消费组中挂起(未确认)的消息。
- `XCLAIM`:将挂起的消息从一个消费者转移到另一个消费者。
-- `XINFO`:获取流(`XINFO STREAM`)、消费组(`XINFO GROUPS`)或消费者(`XINFO CONSUMERS`)的详细信息。
+- `XINFO`:获取流(`XINFO STREAM`)、消费组(`XINFO GROUPS`)或消费者(`XINFO CONSUMERS`)的详细信息。
`Stream` 使用起来相对要麻烦一些,这里就不演示了。
-总的来说,`Stream` 已经可以满足一个消息队列的基本要求了。不过,`Stream` 在实际使用中依然会有一些小问题不太好解决比如在 Redis 发生故障恢复后不能保证消息至少被消费一次。
+总的来说,`Stream` 已经可以满足一个消息队列的基本要求了。不过,`Stream` 在实际使用中依然会有一些小问题不太好解决,比如在 Redis 发生故障恢复后不能保证消息至少被消费一次。
-综上,和专业的消息队列相比,使用 Redis 来实现消息队列还是有很多欠缺的地方比如消息丢失和堆积问题不好解决。因此,我们通常建议不要使用 Redis 来做消息队列,你完全可以选择市面上比较成熟的一些消息队列比如 RocketMQ、Kafka。不过,如果你就是想要用 Redis 来做消息队列的话,那我建议你优先考虑 `Stream`,这是目前相对最优的 Redis 消息队列实现。
+综上,和专业的消息队列相比,使用 Redis 来实现消息队列还是有很多欠缺的地方,比如消息丢失和堆积问题不好解决。因此,我们通常建议不要使用 Redis 来做消息队列,你完全可以选择市面上比较成熟的一些消息队列,比如 RocketMQ、Kafka。不过,如果你就是想要用 Redis 来做消息队列的话,那我建议你优先考虑 `Stream`,这是目前相对最优的 Redis 消息队列实现。
相关阅读:[Redis 消息队列发展历程 - 阿里开发者 - 2022](https://mp.weixin.qq.com/s/gCUT5TcCQRAxYkTJfTRjJw)。
### Redis 可以做搜索引擎么?
-Redis 是可以实现全文搜索引擎功能的,需要借助 **RediSearch** ,这是一个基于 Redis 的搜索引擎模块。
+Redis 是可以实现全文搜索引擎功能的,需要借助 **RediSearch**,这是一个基于 Redis 的搜索引擎模块。
RediSearch 支持中文分词、聚合统计、停用词、同义词、拼写检查、标签查询、向量相似度查询、多关键词搜索、分页搜索等功能,算是一个功能比较完善的全文搜索引擎了。
@@ -264,7 +274,7 @@ RediSearch 支持中文分词、聚合统计、停用词、同义词、拼写检
对于小型项目的简单搜索场景来说,使用 RediSearch 来作为搜索引擎还是没有问题的(搭配 RedisJSON 使用)。
-对于比较复杂或者数据规模较大的搜索场景还是不太建议使用 RediSearch 来作为搜索引擎,主要是因为下面这些限制和问题:
+对于比较复杂或者数据规模较大的搜索场景,还是不太建议使用 RediSearch 来作为搜索引擎,主要是因为下面这些限制和问题:
1. 数据量限制:Elasticsearch 可以支持 PB 级别的数据量,可以轻松扩展到多个节点,利用分片机制提高可用性和性能。RedisSearch 是基于 Redis 实现的,其能存储的数据量受限于 Redis 的内存容量,不太适合存储大规模的数据(内存昂贵,扩展能力较差)。
2. 分布式能力较差:Elasticsearch 是为分布式环境设计的,可以轻松扩展到多个节点。虽然 RedisSearch 支持分布式部署,但在实际应用中可能会面临一些挑战,如数据分片、节点间通信、数据一致性等问题。
@@ -282,10 +292,10 @@ Elasticsearch 适用于全文搜索、复杂查询、实时数据分析和聚合
基于 Redis 实现延时任务的功能无非就下面两种方案:
-1. Redis 过期事件监听
-2. Redisson 内置的延时队列
+1. Redis 过期事件监听。
+2. Redisson 内置的延时队列。
-Redis 过期事件监听的存在时效性较差、丢消息、多服务实例下消息重复消费等问题,不被推荐使用。
+Redis 过期事件监听存在时效性较差、丢消息、多服务实例下消息重复消费等问题,不被推荐使用。
Redisson 内置的延时队列具备下面这些优势:
@@ -296,7 +306,7 @@ Redisson 内置的延时队列具备下面这些优势:
## Redis 数据类型
-关于 Redis 5 种基础数据类型和 3 种特殊数据类型的详细介绍请看下面这两篇文章以及 [Redis 官方文档](https://redis.io/docs/data-types/) :
+关于 Redis 5 种基础数据类型和 3 种特殊数据类型的详细介绍请看下面这两篇文章以及 [Redis 官方文档](https://redis.io/docs/data-types/):
- [Redis 5 种基本数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-01.html)
- [Redis 3 种特殊数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-02.html)
@@ -318,7 +328,7 @@ String 的常见应用场景如下:
- 常规数据(比如 Session、Token、序列化后的对象、图片的路径)的缓存;
- 计数比如用户单位时间的请求数(简单限流可以用到)、页面单位时间的访问数;
-- 分布式锁(利用 `SETNX key value` 命令可以实现一个最简易的分布式锁);
+- 分布式锁(利用 `SETNX key value` 命令可以实现一个最简易的分布式锁);
- ……
关于 String 的详细介绍请看这篇文章:[Redis 5 种基本数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-01.html)。
@@ -339,11 +349,11 @@ String 的常见应用场景如下:
### String 的底层实现是什么?
-Redis 是基于 C 语言编写的,但 Redis 的 String 类型的底层实现并不是 C 语言中的字符串(即以空字符 `\0` 结尾的字符数组),而是自己编写了 [SDS](https://github.com/antirez/sds)(Simple Dynamic String,简单动态字符串) 来作为底层实现。
+Redis 是基于 C 语言编写的,但 Redis 的 String 类型的底层实现并不是 C 语言中的字符串(即以空字符 `\0` 结尾的字符数组),而是自己编写了 [SDS](https://github.com/antirez/sds)(Simple Dynamic String,简单动态字符串)来作为底层实现。
SDS 最早是 Redis 作者为日常 C 语言开发而设计的 C 字符串,后来被应用到了 Redis 上,并经过了大量的修改完善以适合高性能操作。
-Redis7.0 的 SDS 的部分源码如下(