diff --git a/.circleci/test.yml b/.circleci/test.yml
index f86b54acee..2e2d7e767a 100644
--- a/.circleci/test.yml
+++ b/.circleci/test.yml
@@ -236,8 +236,8 @@ workflows:
- build_without_ops
- build_cpu:
name: maximum_version_cpu
- torch: 1.12.1
- torchvision: 0.13.1
+ torch: 1.13.0
+ torchvision: 0.14.0
python: 3.9.0
requires:
- minimum_version_cpu
diff --git a/.github/workflows/build_macos_wheel.yml b/.github/workflows/build_macos_wheel.yml
index 9b0263b12d..2bf5a6165f 100644
--- a/.github/workflows/build_macos_wheel.yml
+++ b/.github/workflows/build_macos_wheel.yml
@@ -12,7 +12,7 @@ jobs:
if: contains(github.event.head_commit.message, 'Bump version to')
strategy:
matrix:
- torch: [1.6.0, 1.7.0, 1.8.0, 1.9.0, 1.10.0, 1.11.0, 1.12.0]
+ torch: [1.6.0, 1.7.0, 1.8.0, 1.9.0, 1.10.0, 1.11.0, 1.12.0, 1.13.0]
python-version: [3.6, 3.7, 3.8, 3.9, '3.10']
include:
- torch: 1.6.0
@@ -29,6 +29,8 @@ jobs:
torchvision: 0.12.0
- torch: 1.12.0
torchvision: 0.13.0
+ - torch: 1.13.0
+ torchvision: 0.14.0
exclude:
- torch: 1.6.0
python-version: 3.9
@@ -48,6 +50,8 @@ jobs:
python-version: 3.6
- torch: 1.12.0
python-version: 3.6
+ - torch: 1.13.0
+ python-version: 3.6
steps:
- uses: actions/checkout@v2
- name: Set up Python
diff --git a/.github/workflows/merge_stage_test.yml b/.github/workflows/merge_stage_test.yml
index a43919ea9e..e2a5f582c5 100644
--- a/.github/workflows/merge_stage_test.yml
+++ b/.github/workflows/merge_stage_test.yml
@@ -116,7 +116,7 @@ jobs:
strategy:
matrix:
python-version: [3.7]
- torch: [1.6.0, 1.7.1, 1.8.1, 1.9.1, 1.10.1, 1.11.0, 1.12.0]
+ torch: [1.6.0, 1.7.1, 1.8.1, 1.9.1, 1.10.1, 1.11.0, 1.12.0, 1.13.0]
include:
- torch: 1.6.0
torchvision: 0.7.0
@@ -132,6 +132,8 @@ jobs:
torchvision: 0.12.0
- torch: 1.12.0
torchvision: 0.13.0
+ - torch: 1.13.0
+ torchvision: 0.14.0
steps:
- uses: actions/checkout@v2
- name: Set up Python ${{ matrix.python-version }}
@@ -201,6 +203,40 @@ jobs:
coverage run --branch --source mmcv -m pytest tests/
coverage xml
coverage report -m
+ build_cu116:
+ runs-on: ubuntu-18.04
+ container:
+ image: pytorch/pytorch:1.13.0-cuda11.6-cudnn8-devel
+ strategy:
+ matrix:
+ python-version: [3.7]
+ steps:
+ - uses: actions/checkout@v2
+ - name: Set up Python ${{ matrix.python-version }}
+ uses: actions/setup-python@v2
+ with:
+ python-version: ${{ matrix.python-version }}
+ - name: Upgrade pip
+ run: pip install pip --upgrade
+ - name: Fetch GPG keys
+ run: |
+ apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/3bf863cc.pub
+ apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/7fa2af80.pub
+ - name: Install system dependencies
+ run: apt-get update && apt-get install -y git ffmpeg libturbojpeg
+ - name: Install MMEngine from main branch
+ run: pip install git+https://github.com/open-mmlab/mmengine.git@main
+ - name: Install ninja to speed the compilation
+ run: pip install ninja
+ - name: Build MMCV from source
+ run: pip install -e . -v
+ - name: Install unit tests dependencies
+ run: pip install -r requirements/test.txt
+ - name: Run unittests and generate coverage report
+ run: |
+ coverage run --branch --source mmcv -m pytest tests
+ coverage xml
+ coverage report -m
build_windows_without_ops:
runs-on: ${{ matrix.os }}
env:
@@ -216,7 +252,7 @@ jobs:
with:
python-version: 3.7
- name: Upgrade pip
- run: pip install pip --upgrade
+ run: python -m pip install pip --upgrade
- name: Install PyTorch
run: pip install torch==1.8.1+cpu torchvision==0.9.1+cpu -f https://download.pytorch.org/whl/torch_stable.html
- name: Install MMEngine from main branch
@@ -249,7 +285,7 @@ jobs:
with:
python-version: ${{ matrix.python-version }}
- name: Upgrade pip
- run: pip install pip --upgrade
+ run: python -m pip install pip --upgrade
- name: Install PyTorch
run: pip install torch==1.8.1+${{matrix.platform}} torchvision==0.9.1+${{matrix.platform}} -f https://download.pytorch.org/whl/lts/1.8/torch_lts.html
- name: Install MMEngine from main branch
@@ -267,14 +303,14 @@ jobs:
strategy:
matrix:
python-version: [3.7]
- torch: [1.6.0, 1.8.1, 1.12.0]
+ torch: [1.6.0, 1.8.1, 1.13.0]
include:
- torch: 1.6.0
torchvision: 0.7.0
- torch: 1.8.1
torchvision: 0.9.1
- - torch: 1.12.0
- torchvision: 0.13.0
+ - torch: 1.13.0
+ torchvision: 0.14.0
steps:
- uses: actions/checkout@v2
- name: Set up Python 3.7
diff --git a/.github/workflows/pr_stage_test.yml b/.github/workflows/pr_stage_test.yml
index 21143c0b8e..276abec3e1 100644
--- a/.github/workflows/pr_stage_test.yml
+++ b/.github/workflows/pr_stage_test.yml
@@ -110,7 +110,7 @@ jobs:
with:
python-version: 3.7
- name: Upgrade pip
- run: pip install pip --upgrade
+ run: python -m pip install pip --upgrade
- name: Install PyTorch
run: pip install torch==1.8.1+cpu torchvision==0.9.1+cpu -f https://download.pytorch.org/whl/torch_stable.html
- name: Install MMEngine from main branch
@@ -137,7 +137,7 @@ jobs:
with:
python-version: ${{ matrix.python-version }}
- name: Upgrade pip
- run: pip install pip --upgrade
+ run: python -m pip install pip --upgrade
- name: Install PyTorch
run: pip install torch==1.8.1+${{matrix.platform}} torchvision==0.9.1+${{matrix.platform}} -f https://download.pytorch.org/whl/lts/1.8/torch_lts.html
- name: Install MMEngine from main branch
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index eea0b2544f..a60cd99430 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -1,20 +1,214 @@
## Contributing to OpenMMLab
-All kinds of contributions are welcome, including but not limited to the following.
+Welcome to the MMCV community, we are committed to building a cutting-edge computer vision foundational library and all kinds of contributions are welcomed, including but not limited to
-- Fix typo or bugs
-- Add documentation or translate the documentation into other languages
-- Add new features and components
+**Fix bug**
-### Workflow
+You can directly post a Pull Request to fix typo in code or documents
-1. fork and pull the latest OpenMMLab repository
-2. checkout a new branch (do not use master branch for PRs)
-3. commit your changes
-4. create a PR
+The steps to fix the bug of code implementation are as follows.
-```{note}
-If you plan to add some new features that involve large changes, it is encouraged to open an issue for discussion first.
+1. If the modification involve significant changes, you should create an issue first and describe the error information and how to trigger the bug. Other developers will discuss with you and propose an proper solution.
+
+2. Posting a pull request after fixing the bug and adding corresponding unit test.
+
+**New Feature or Enhancement**
+
+1. If the modification involve significant changes, you should create an issue to discuss with our developers to propose an proper design.
+2. Post a Pull Request after implementing the new feature or enhancement and add corresponding unit test.
+
+**Document**
+
+You can directly post a pull request to fix documents. If you want to add a document, you should first create an issue to check if it is reasonable.
+
+### Pull Request Workflow
+
+If you're not familiar with Pull Request, don't worry! The following guidance will tell you how to create a Pull Request step by step. If you want to dive into the develop mode of Pull Request, you can refer to the [official documents](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests)
+
+#### 1. Fork and clone
+
+If you are posting a pull request for the first time, you should fork the OpenMMLab repositories by clicking the **Fork** button in the top right corner of the GitHub page, and the forked repositories will appear under your GitHub profile.
+
+ +
+Then, you can clone the repositories to local:
+
+```shell
+git clone git@github.com:{username}/mmcv.git
+```
+
+After that, you should ddd official repository as the upstream repository
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmcv
+```
+
+Check whether remote repository has been added successfully by `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmcv.git (fetch)
+origin git@github.com:{username}/mmcv.git (push)
+upstream git@github.com:open-mmlab/mmcv (fetch)
+upstream git@github.com:open-mmlab/mmcv (push)
+```
+
+> Here's a brief introduction to origin and upstream. When we use "git clone", we create an "origin" remote by default, which points to the repository cloned from. As for "upstream", we add it ourselves to point to the target repository. Of course, if you don't like the name "upstream", you could name it as you wish. Usually, we'll push the code to "origin". If the pushed code conflicts with the latest code in official("upstream"), we should pull the latest code from upstream to resolve the conflicts, and then push to "origin" again. The posted Pull Request will be updated automatically.
+
+#### 2. Configure pre-commit
+
+You should configure [pre-commit](https://pre-commit.com/#intro) in the local development environment to make sure the code style matches that of OpenMMLab. **Note**: The following code should be executed under the MMCV directory.
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
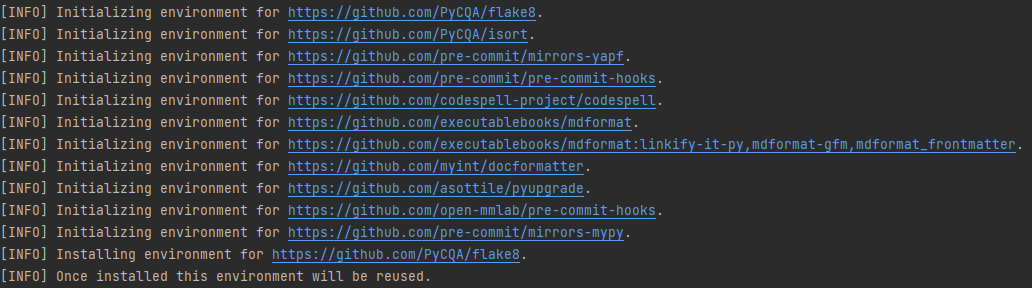
+Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+Then, you can clone the repositories to local:
+
+```shell
+git clone git@github.com:{username}/mmcv.git
+```
+
+After that, you should ddd official repository as the upstream repository
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmcv
+```
+
+Check whether remote repository has been added successfully by `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmcv.git (fetch)
+origin git@github.com:{username}/mmcv.git (push)
+upstream git@github.com:open-mmlab/mmcv (fetch)
+upstream git@github.com:open-mmlab/mmcv (push)
+```
+
+> Here's a brief introduction to origin and upstream. When we use "git clone", we create an "origin" remote by default, which points to the repository cloned from. As for "upstream", we add it ourselves to point to the target repository. Of course, if you don't like the name "upstream", you could name it as you wish. Usually, we'll push the code to "origin". If the pushed code conflicts with the latest code in official("upstream"), we should pull the latest code from upstream to resolve the conflicts, and then push to "origin" again. The posted Pull Request will be updated automatically.
+
+#### 2. Configure pre-commit
+
+You should configure [pre-commit](https://pre-commit.com/#intro) in the local development environment to make sure the code style matches that of OpenMMLab. **Note**: The following code should be executed under the MMCV directory.
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
+
+```shell
+pre-commit run --all-files
+```
+
+ +
+
+
+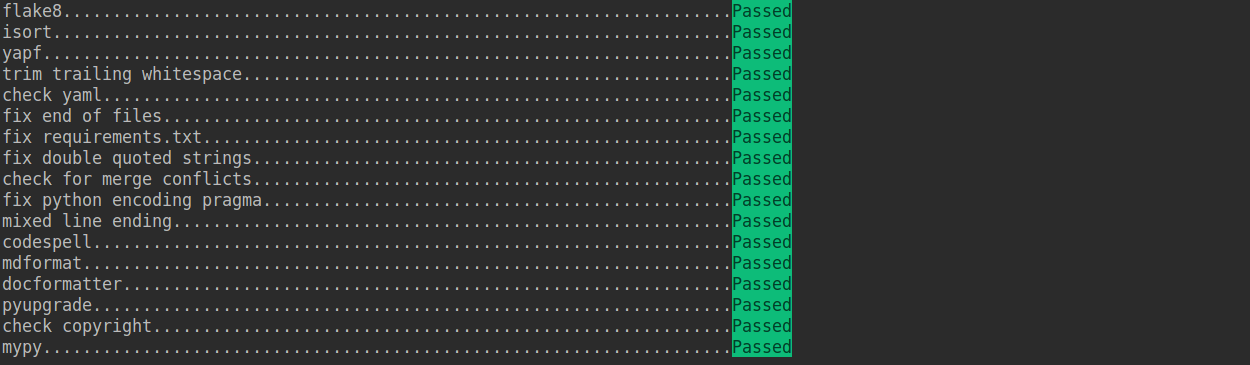 +
+If the installation process is interrupted, you can repeatedly run `pre-commit run ... ` to continue the installation.
+
+If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
+
+
+
+If the installation process is interrupted, you can repeatedly run `pre-commit run ... ` to continue the installation.
+
+If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
+
+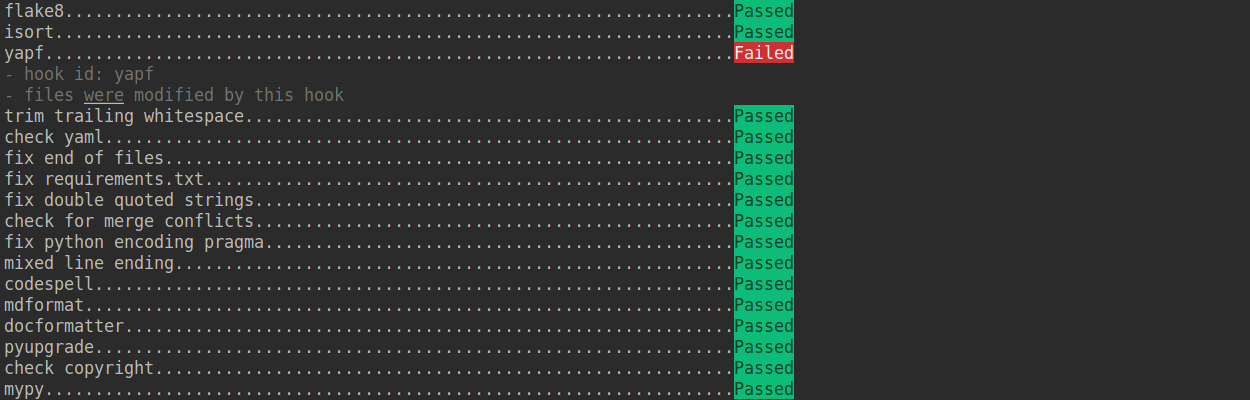 +
+If we want to commit our code bypassing the pre-commit hook, we can use the `--no-verify` option(**only for temporarily commit**).
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. Create a development branch
+
+After configuring the pre-commit, we should create a branch based on the master branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+In subsequent development, if the master branch of the local repository is behind the master branch of "upstream", we need to pull the upstream for synchronization, and then execute the above command:
+
+```shell
+git pull upstream master
+```
+
+#### 4. Commit the code and pass the unit test
+
+- MMCV introduces mypy to do static type checking to increase the robustness of the code. Therefore, we need to add Type Hints to our code and pass the mypy check. If you are not familiar with Type Hints, you can refer to [this tutorial](https://docs.python.org/3/library/typing.html).
+
+- The committed code should pass through the unit test
+
+ ```shell
+ # Pass all unit tests
+ pytest tests
+
+ # Pass the unit test of runner
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ If the unit test fails for lack of dependencies, you can install the dependencies referring to the [guidance](#unit-test)
+
+- If the documents are modified/added, we should check the rendering result referring to [guidance](#document-rendering)
+
+#### 5. Push the code to remote
+
+We could push the local commits to remote after passing through the check of unit test and pre-commit. You can associate the local branch with remote branch by adding `-u` option.
+
+```shell
+git push -u origin {branch_name}
+```
+
+This will allow you to use the `git push` command to push code directly next time, without having to specify a branch or the remote repository.
+
+#### 6. Create a Pull Request
+
+(1) Create a pull request in GitHub's Pull request interface
+
+
+
+If we want to commit our code bypassing the pre-commit hook, we can use the `--no-verify` option(**only for temporarily commit**).
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. Create a development branch
+
+After configuring the pre-commit, we should create a branch based on the master branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+In subsequent development, if the master branch of the local repository is behind the master branch of "upstream", we need to pull the upstream for synchronization, and then execute the above command:
+
+```shell
+git pull upstream master
+```
+
+#### 4. Commit the code and pass the unit test
+
+- MMCV introduces mypy to do static type checking to increase the robustness of the code. Therefore, we need to add Type Hints to our code and pass the mypy check. If you are not familiar with Type Hints, you can refer to [this tutorial](https://docs.python.org/3/library/typing.html).
+
+- The committed code should pass through the unit test
+
+ ```shell
+ # Pass all unit tests
+ pytest tests
+
+ # Pass the unit test of runner
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ If the unit test fails for lack of dependencies, you can install the dependencies referring to the [guidance](#unit-test)
+
+- If the documents are modified/added, we should check the rendering result referring to [guidance](#document-rendering)
+
+#### 5. Push the code to remote
+
+We could push the local commits to remote after passing through the check of unit test and pre-commit. You can associate the local branch with remote branch by adding `-u` option.
+
+```shell
+git push -u origin {branch_name}
+```
+
+This will allow you to use the `git push` command to push code directly next time, without having to specify a branch or the remote repository.
+
+#### 6. Create a Pull Request
+
+(1) Create a pull request in GitHub's Pull request interface
+
+ +
+(2) Modify the PR description according to the guidelines so that other developers can better understand your changes
+
+
+
+(2) Modify the PR description according to the guidelines so that other developers can better understand your changes
+
+ +
+Find more details about Pull Request description in [pull request guidelines](#pr-specs).
+
+**note**
+
+(a) The Pull Request description should contain the reason for the change, the content of the change, and the impact of the change, and be associated with the relevant Issue (see [documentation](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue)
+
+(b) If it is your first contribution, please sign the CLA
+
+
+
+Find more details about Pull Request description in [pull request guidelines](#pr-specs).
+
+**note**
+
+(a) The Pull Request description should contain the reason for the change, the content of the change, and the impact of the change, and be associated with the relevant Issue (see [documentation](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue)
+
+(b) If it is your first contribution, please sign the CLA
+
+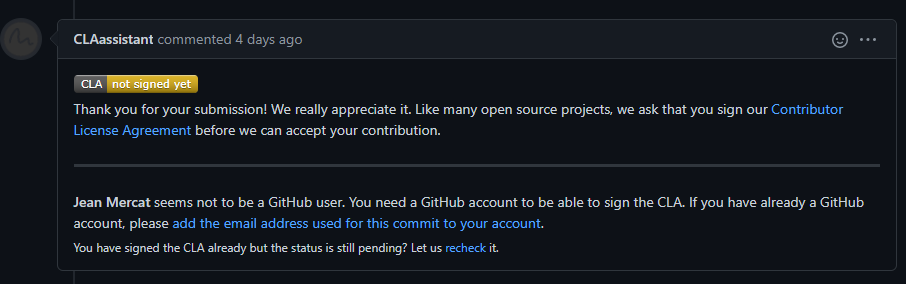 +
+(c) Check whether the Pull Request pass through the CI
+
+
+
+(c) Check whether the Pull Request pass through the CI
+
+ +
+MMCV will run unit test for the posted Pull Request on different platforms (Linux, Window, Mac), based on different versions of Python, PyTorch, CUDA to make sure the code is correct. We can see the specific test information by clicking `Details` in the above image so that we can modify the code.
+
+(3) If the Pull Request passes the CI, then you can wait for the review from other developers. You'll modify the code based on the reviewer's comments, and repeat the steps [4](#4-commit-the-code-and-pass-the-unit-test)-[5](#5-push-the-code-to-remote) until all reviewers approve it. Then, we will merge it ASAP.
+
+
+
+MMCV will run unit test for the posted Pull Request on different platforms (Linux, Window, Mac), based on different versions of Python, PyTorch, CUDA to make sure the code is correct. We can see the specific test information by clicking `Details` in the above image so that we can modify the code.
+
+(3) If the Pull Request passes the CI, then you can wait for the review from other developers. You'll modify the code based on the reviewer's comments, and repeat the steps [4](#4-commit-the-code-and-pass-the-unit-test)-[5](#5-push-the-code-to-remote) until all reviewers approve it. Then, we will merge it ASAP.
+
+ +
+#### 7. Resolve conflicts
+
+If your local branch conflicts with the latest master branch of "upstream", you'll need to resolove them. There are two ways to do this:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+or
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are not familiar with `rebase`, then you can use `merge` to resolve conflicts.
+
+### Guidance
+
+#### Unit test
+
+If you cannot run the unit test of some modules for lacking of some dependencies, such as [video](https://github.com/open-mmlab/mmcv/tree/master/mmcv/video) module, you can try to install the following dependencies:
+
+```shell
+# Linux
+sudo apt-get update -y
+sudo apt-get install -y libturbojpeg
+sudo apt-get install -y ffmpeg
+
+# Windows
+conda install ffmpeg
+```
+
+We should also make sure the committed code will not decrease the coverage of unit test, we could run the following command to check the coverage of unit test:
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### Document rendering
+
+If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
```
### Code style
@@ -38,22 +232,27 @@ We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `f
fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
The config for a pre-commit hook is stored in [.pre-commit-config](./.pre-commit-config.yaml).
-After you clone the repository, you will need to install initialize pre-commit hook.
+#### C++ and CUDA
-```shell
-pip install -U pre-commit
-```
+We follow the [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html).
-From the repository folder
+### PR Specs
-```shell
-pre-commit install
-```
+1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
-After this on every commit check code linters and formatter will be enforced.
+2. One short-time branch should be matched with only one PR
-> Before you create a PR, make sure that your code lints and is formatted by yapf.
+3. Accomplish a detailed change in one PR. Avoid large PR
-#### C++ and CUDA
+ - Bad: Support Faster R-CNN
+ - Acceptable: Add a box head to Faster R-CNN
+ - Good: Add a parameter to box head to support custom conv-layer number
-We follow the [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html).
+4. Provide clear and significant commit message
+
+5. Provide clear and meaningful PR description
+
+ - Task name should be clarified in title. The general format is: \[Prefix\] Short description of the PR (Suffix)
+ - Prefix: add new feature \[Feature\], fix bug \[Fix\], related to documents \[Docs\], in developing \[WIP\] (which will not be reviewed temporarily)
+ - Introduce main changes, results and influences on other modules in short description
+ - Associate related issues and pull requests with a milestone
diff --git a/CONTRIBUTING_zh-CN.md b/CONTRIBUTING_zh-CN.md
new file mode 100644
index 0000000000..00622031dd
--- /dev/null
+++ b/CONTRIBUTING_zh-CN.md
@@ -0,0 +1,274 @@
+## 贡献代码
+
+欢迎加入 MMCV 社区,我们致力于打造最前沿的计算机视觉基础库,我们欢迎任何类型的贡献,包括但不限于
+
+**修复错误**
+
+修复代码实现错误的步骤如下:
+
+1. 如果提交的代码改动较大,建议先提交 issue,并正确描述 issue 的现象、原因和复现方式,讨论后确认修复方案。
+2. 修复错误并补充相应的单元测试,提交拉取请求。
+
+**新增功能或组件**
+
+1. 如果新功能或模块涉及较大的代码改动,建议先提交 issue,确认功能的必要性。
+2. 实现新增功能并添单元测试,提交拉取请求。
+
+**文档补充**
+
+修复文档可以直接提交拉取请求
+
+添加文档或将文档翻译成其他语言步骤如下
+
+1. 提交 issue,确认添加文档的必要性。
+2. 添加文档,提交拉取请求。
+
+### 拉取请求工作流
+
+如果你对拉取请求不了解,没关系,接下来的内容将会从零开始,一步一步地指引你如何创建一个拉取请求。如果你想深入了解拉取请求的开发模式,可以参考 github [官方文档](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests)
+
+#### 1. 复刻仓库
+
+当你第一次提交拉取请求时,先复刻 OpenMMLab 原代码库,点击 GitHub 页面右上角的 **Fork** 按钮,复刻后的代码库将会出现在你的 GitHub 个人主页下。
+
+
+
+将代码克隆到本地
+
+```shell
+git clone git@github.com:{username}/mmcv.git
+```
+
+添加原代码库为上游代码库
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmcv
+```
+
+检查 remote 是否添加成功,在终端输入 `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmcv.git (fetch)
+origin git@github.com:{username}/mmcv.git (push)
+upstream git@github.com:open-mmlab/mmcv (fetch)
+upstream git@github.com:open-mmlab/mmcv (push)
+```
+
+> 这里对 origin 和 upstream 进行一个简单的介绍,当我们使用 git clone 来克隆代码时,会默认创建一个 origin 的 remote,它指向我们克隆的代码库地址,而 upstream 则是我们自己添加的,用来指向原始代码库地址。当然如果你不喜欢他叫 upstream,也可以自己修改,比如叫 open-mmlab。我们通常向 origin 提交代码(即 fork 下来的远程仓库),然后向 upstream 提交一个 pull request。如果提交的代码和最新的代码发生冲突,再从 upstream 拉取最新的代码,和本地分支解决冲突,再提交到 origin。
+
+#### 2. 配置 pre-commit
+
+在本地开发环境中,我们使用 [pre-commit](https://pre-commit.com/#intro) 来检查代码风格,以确保代码风格的统一。在提交代码,需要先安装 pre-commit(需要在 MMCV 目录下执行):
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+检查 pre-commit 是否配置成功,并安装 `.pre-commit-config.yaml` 中的钩子:
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+
+
+> 如果你是中国用户,由于网络原因,可能会出现安装失败的情况,这时可以使用国内源
+
+> pre-commit install -c .pre-commit-config-zh-cn.yaml
+
+> pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
+
+如果安装过程被中断,可以重复执行 `pre-commit run ...` 继续安装。
+
+如果提交的代码不符合代码风格规范,pre-commit 会发出警告,并自动修复部分错误。
+
+
+
+如果我们想临时绕开 pre-commit 的检查提交一次代码,可以在 `git commit` 时加上 `--no-verify`(需要保证最后推送至远程仓库的代码能够通过 pre-commit 检查)。
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. 创建开发分支
+
+安装完 pre-commit 之后,我们需要基于 master 创建开发分支,建议的分支命名规则为 `username/pr_name`。
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+在后续的开发中,如果本地仓库的 master 分支落后于 upstream 的 master 分支,我们需要先拉取 upstream 的代码进行同步,再执行上面的命令
+
+```shell
+git pull upstream master
+```
+
+#### 4. 提交代码并在本地通过单元测试
+
+- MMCV 引入了 mypy 来做静态类型检查,以增加代码的鲁棒性。因此我们在提交代码时,需要补充 Type Hints。具体规则可以参考[教程](https://zhuanlan.zhihu.com/p/519335398)。
+
+- 提交的代码同样需要通过单元测试
+
+ ```shell
+ # 通过全量单元测试
+ pytest tests
+
+ # 我们需要保证提交的代码能够通过修改模块的单元测试,以 runner 为例
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ 如果你由于缺少依赖无法运行修改模块的单元测试,可以参考[指引-单元测试](#单元测试)
+
+- 如果修改/添加了文档,参考[指引](#文档渲染)确认文档渲染正常。
+
+#### 5. 推送代码到远程
+
+代码通过单元测试和 pre-commit 检查后,将代码推送到远程仓库,如果是第一次推送,可以在 `git push` 后加上 `-u` 参数以关联远程分支
+
+```shell
+git push -u origin {branch_name}
+```
+
+这样下次就可以直接使用 `git push` 命令推送代码了,而无需指定分支和远程仓库。
+
+#### 6. 提交拉取请求(PR)
+
+(1) 在 GitHub 的 Pull request 界面创建拉取请求
+
+
+(2) 根据指引修改 PR 描述,以便于其他开发者更好地理解你的修改
+
+
+
+描述规范详见[拉取请求规范](#拉取请求规范)
+
+
+
+**注意事项**
+
+(a) PR 描述应该包含修改理由、修改内容以及修改后带来的影响,并关联相关 Issue(具体方式见[文档](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))
+
+(b) 如果是第一次为 OpenMMLab 做贡献,需要签署 CLA
+
+
+
+(c) 检查提交的 PR 是否通过 CI(集成测试)
+
+
+
+MMCV 会在不同的平台(Linux、Window、Mac),基于不同版本的 Python、PyTorch、CUDA 对提交的代码进行单元测试,以保证代码的正确性,如果有任何一个没有通过,我们可点击上图中的 `Details` 来查看具体的测试信息,以便于我们修改代码。
+
+(3) 如果 PR 通过了 CI,那么就可以等待其他开发者的 review,并根据 reviewer 的意见,修改代码,并重复 [4](#4-提交代码并本地通过单元测试)-[5](#5-推送代码到远程) 步骤,直到 reviewer 同意合入 PR。
+
+
+
+所有 reviewer 同意合入 PR 后,我们会尽快将 PR 合并到主分支。
+
+#### 7. 解决冲突
+
+随着时间的推移,我们的代码库会不断更新,这时候,如果你的 PR 与主分支存在冲突,你需要解决冲突,解决冲突的方式有两种:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+或者
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+如果你非常善于处理冲突,那么可以使用 rebase 的方式来解决冲突,因为这能够保证你的 commit log 的整洁。如果你不太熟悉 `rebase` 的使用,那么可以使用 `merge` 的方式来解决冲突。
+
+### 指引
+
+#### 单元测试
+
+如果你无法正常执行部分模块的单元测试,例如 [video](https://github.com/open-mmlab/mmcv/tree/master/mmcv/video) 模块,可能是你的当前环境没有安装以下依赖
+
+```shell
+# Linux
+sudo apt-get update -y
+sudo apt-get install -y libturbojpeg
+sudo apt-get install -y ffmpeg
+
+# Windows
+conda install ffmpeg
+```
+
+在提交修复代码错误或新增特性的拉取请求时,我们应该尽可能的让单元测试覆盖所有提交的代码,计算单元测试覆盖率的方法如下
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### 文档渲染
+
+在提交修复代码错误或新增特性的拉取请求时,可能会需要修改/新增模块的 docstring。我们需要确认渲染后的文档样式是正确的。
+本地生成渲染后的文档的方法如下
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### 代码风格
+
+#### Python
+
+[PEP8](https://www.python.org/dev/peps/pep-0008/) 作为 OpenMMLab 算法库首选的代码规范,我们使用以下工具检查和格式化代码
+
+- [flake8](https://github.com/PyCQA/flake8): Python 官方发布的代码规范检查工具,是多个检查工具的封装
+- [isort](https://github.com/timothycrosley/isort): 自动调整模块导入顺序的工具
+- [yapf](https://github.com/google/yapf): Google 发布的代码规范检查工具
+- [codespell](https://github.com/codespell-project/codespell): 检查单词拼写是否有误
+- [mdformat](https://github.com/executablebooks/mdformat): 检查 markdown 文件的工具
+- [docformatter](https://github.com/myint/docformatter): 格式化 docstring 的工具
+
+yapf 和 isort 的配置可以在 [setup.cfg](./setup.cfg) 找到
+
+通过配置 [pre-commit hook](https://pre-commit.com/) ,我们可以在提交代码时自动检查和格式化 `flake8`、`yapf`、`isort`、`trailing whitespaces`、`markdown files`,
+修复 `end-of-files`、`double-quoted-strings`、`python-encoding-pragma`、`mixed-line-ending`,调整 `requirments.txt` 的包顺序。
+pre-commit 钩子的配置可以在 [.pre-commit-config](./.pre-commit-config.yaml) 找到。
+
+pre-commit 具体的安装使用方式见[拉取请求](#2-配置-pre-commit)。
+
+更具体的规范请参考 [OpenMMLab 代码规范](code_style.md)。
+
+#### C++ and CUDA
+
+C++ 和 CUDA 的代码规范遵从 [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html)
+
+### 拉取请求规范
+
+1. 使用 [pre-commit hook](https://pre-commit.com),尽量减少代码风格相关问题
+
+2. 一个`拉取请求`对应一个短期分支
+
+3. 粒度要细,一个`拉取请求`只做一件事情,避免超大的`拉取请求`
+
+ - Bad:实现 Faster R-CNN
+ - Acceptable:给 Faster R-CNN 添加一个 box head
+ - Good:给 box head 增加一个参数来支持自定义的 conv 层数
+
+4. 每次 Commit 时需要提供清晰且有意义 commit 信息
+
+5. 提供清晰且有意义的`拉取请求`描述
+
+ - 标题写明白任务名称,一般格式:\[Prefix\] Short description of the pull request (Suffix)
+ - prefix: 新增功能 \[Feature\], 修 bug \[Fix\], 文档相关 \[Docs\], 开发中 \[WIP\] (暂时不会被review)
+ - 描述里介绍`拉取请求`的主要修改内容,结果,以及对其他部分的影响, 参考`拉取请求`模板
+ - 关联相关的`议题` (issue) 和其他`拉取请求`
+
+6. 如果引入了其他三方库,或借鉴了三方库的代码,请确认他们的许可证和 mmcv 兼容,并在借鉴的代码上补充 `This code is inspired from http://`
diff --git a/README.md b/README.md
index eb228d5d8d..e791a0a3de 100644
--- a/README.md
+++ b/README.md
@@ -60,13 +60,13 @@ There are two versions of MMCV:
### Install mmcv
-Before installing mmcv, make sure that PyTorch has been successfully installed following the [PyTorch official installation guide](https://github.com/pytorch/pytorch#installation). For macOS M1 users, please make sure you are using `PyTorch Nightly`.
+Before installing mmcv, make sure that PyTorch has been successfully installed following the [PyTorch official installation guide](https://github.com/pytorch/pytorch#installation). For apple silicon users, please use PyTorch 1.13+.
The command to install mmcv on Linux or Windows platforms is as follows (if your system is macOS, please refer to [build mmcv from source](https://mmcv.readthedocs.io/en/2.x/get_started/build.html#macos-mmcv))
```bash
pip install -U openmim
-mim install 'mmcv>=2.0.0rc1'
+mim install "mmcv>=2.0.0rc1"
```
If you need to specify the version of mmcv, you can use the following command
@@ -103,7 +103,7 @@ If you need to use PyTorch-related modules, make sure PyTorch has been successfu
```bash
pip install -U openmim
-mim install 'mmcv-lite>=2.0.0rc1'
+mim install "mmcv-lite>=2.0.0rc1"
```
## FAQ
diff --git a/README_zh-CN.md b/README_zh-CN.md
index 031f65cb5e..b128946a63 100644
--- a/README_zh-CN.md
+++ b/README_zh-CN.md
@@ -60,13 +60,13 @@ MMCV 有两个版本:
### 安装 mmcv
-在安装 mmcv 之前,请确保 PyTorch 已经成功安装在环境中,可以参考 [PyTorch 官方安装文档](https://github.com/pytorch/pytorch#installation)。
+在安装 mmcv 之前,请确保 PyTorch 已经成功安装在环境中,可以参考 [PyTorch 官方安装文档](https://github.com/pytorch/pytorch#installation)。如果你使用的是搭载 apple silicon 的 mac 设备,请安装 PyTorch 1.13+ 的版本。
在 Linux 和 Windows 平台安装 mmcv 的命令如下(如果你的系统是 macOS,请参考[源码安装 mmcv](https://mmcv.readthedocs.io/zh_CN/2.x/get_started/build.html#macos-mmcv))
```bash
pip install -U openmim
-mim install 'mmcv>=2.0.0rc1'
+mim install "mmcv>=2.0.0rc1"
```
如果需要指定 mmcv 的版本,可以使用以下命令
@@ -103,7 +103,7 @@ Collecting mmcv==2.0.0rc1
+
+#### 7. Resolve conflicts
+
+If your local branch conflicts with the latest master branch of "upstream", you'll need to resolove them. There are two ways to do this:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+or
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are not familiar with `rebase`, then you can use `merge` to resolve conflicts.
+
+### Guidance
+
+#### Unit test
+
+If you cannot run the unit test of some modules for lacking of some dependencies, such as [video](https://github.com/open-mmlab/mmcv/tree/master/mmcv/video) module, you can try to install the following dependencies:
+
+```shell
+# Linux
+sudo apt-get update -y
+sudo apt-get install -y libturbojpeg
+sudo apt-get install -y ffmpeg
+
+# Windows
+conda install ffmpeg
+```
+
+We should also make sure the committed code will not decrease the coverage of unit test, we could run the following command to check the coverage of unit test:
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### Document rendering
+
+If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
```
### Code style
@@ -38,22 +232,27 @@ We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `f
fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
The config for a pre-commit hook is stored in [.pre-commit-config](./.pre-commit-config.yaml).
-After you clone the repository, you will need to install initialize pre-commit hook.
+#### C++ and CUDA
-```shell
-pip install -U pre-commit
-```
+We follow the [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html).
-From the repository folder
+### PR Specs
-```shell
-pre-commit install
-```
+1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
-After this on every commit check code linters and formatter will be enforced.
+2. One short-time branch should be matched with only one PR
-> Before you create a PR, make sure that your code lints and is formatted by yapf.
+3. Accomplish a detailed change in one PR. Avoid large PR
-#### C++ and CUDA
+ - Bad: Support Faster R-CNN
+ - Acceptable: Add a box head to Faster R-CNN
+ - Good: Add a parameter to box head to support custom conv-layer number
-We follow the [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html).
+4. Provide clear and significant commit message
+
+5. Provide clear and meaningful PR description
+
+ - Task name should be clarified in title. The general format is: \[Prefix\] Short description of the PR (Suffix)
+ - Prefix: add new feature \[Feature\], fix bug \[Fix\], related to documents \[Docs\], in developing \[WIP\] (which will not be reviewed temporarily)
+ - Introduce main changes, results and influences on other modules in short description
+ - Associate related issues and pull requests with a milestone
diff --git a/CONTRIBUTING_zh-CN.md b/CONTRIBUTING_zh-CN.md
new file mode 100644
index 0000000000..00622031dd
--- /dev/null
+++ b/CONTRIBUTING_zh-CN.md
@@ -0,0 +1,274 @@
+## 贡献代码
+
+欢迎加入 MMCV 社区,我们致力于打造最前沿的计算机视觉基础库,我们欢迎任何类型的贡献,包括但不限于
+
+**修复错误**
+
+修复代码实现错误的步骤如下:
+
+1. 如果提交的代码改动较大,建议先提交 issue,并正确描述 issue 的现象、原因和复现方式,讨论后确认修复方案。
+2. 修复错误并补充相应的单元测试,提交拉取请求。
+
+**新增功能或组件**
+
+1. 如果新功能或模块涉及较大的代码改动,建议先提交 issue,确认功能的必要性。
+2. 实现新增功能并添单元测试,提交拉取请求。
+
+**文档补充**
+
+修复文档可以直接提交拉取请求
+
+添加文档或将文档翻译成其他语言步骤如下
+
+1. 提交 issue,确认添加文档的必要性。
+2. 添加文档,提交拉取请求。
+
+### 拉取请求工作流
+
+如果你对拉取请求不了解,没关系,接下来的内容将会从零开始,一步一步地指引你如何创建一个拉取请求。如果你想深入了解拉取请求的开发模式,可以参考 github [官方文档](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests)
+
+#### 1. 复刻仓库
+
+当你第一次提交拉取请求时,先复刻 OpenMMLab 原代码库,点击 GitHub 页面右上角的 **Fork** 按钮,复刻后的代码库将会出现在你的 GitHub 个人主页下。
+
+
+
+将代码克隆到本地
+
+```shell
+git clone git@github.com:{username}/mmcv.git
+```
+
+添加原代码库为上游代码库
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmcv
+```
+
+检查 remote 是否添加成功,在终端输入 `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmcv.git (fetch)
+origin git@github.com:{username}/mmcv.git (push)
+upstream git@github.com:open-mmlab/mmcv (fetch)
+upstream git@github.com:open-mmlab/mmcv (push)
+```
+
+> 这里对 origin 和 upstream 进行一个简单的介绍,当我们使用 git clone 来克隆代码时,会默认创建一个 origin 的 remote,它指向我们克隆的代码库地址,而 upstream 则是我们自己添加的,用来指向原始代码库地址。当然如果你不喜欢他叫 upstream,也可以自己修改,比如叫 open-mmlab。我们通常向 origin 提交代码(即 fork 下来的远程仓库),然后向 upstream 提交一个 pull request。如果提交的代码和最新的代码发生冲突,再从 upstream 拉取最新的代码,和本地分支解决冲突,再提交到 origin。
+
+#### 2. 配置 pre-commit
+
+在本地开发环境中,我们使用 [pre-commit](https://pre-commit.com/#intro) 来检查代码风格,以确保代码风格的统一。在提交代码,需要先安装 pre-commit(需要在 MMCV 目录下执行):
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+检查 pre-commit 是否配置成功,并安装 `.pre-commit-config.yaml` 中的钩子:
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+
+
+> 如果你是中国用户,由于网络原因,可能会出现安装失败的情况,这时可以使用国内源
+
+> pre-commit install -c .pre-commit-config-zh-cn.yaml
+
+> pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
+
+如果安装过程被中断,可以重复执行 `pre-commit run ...` 继续安装。
+
+如果提交的代码不符合代码风格规范,pre-commit 会发出警告,并自动修复部分错误。
+
+
+
+如果我们想临时绕开 pre-commit 的检查提交一次代码,可以在 `git commit` 时加上 `--no-verify`(需要保证最后推送至远程仓库的代码能够通过 pre-commit 检查)。
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. 创建开发分支
+
+安装完 pre-commit 之后,我们需要基于 master 创建开发分支,建议的分支命名规则为 `username/pr_name`。
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+在后续的开发中,如果本地仓库的 master 分支落后于 upstream 的 master 分支,我们需要先拉取 upstream 的代码进行同步,再执行上面的命令
+
+```shell
+git pull upstream master
+```
+
+#### 4. 提交代码并在本地通过单元测试
+
+- MMCV 引入了 mypy 来做静态类型检查,以增加代码的鲁棒性。因此我们在提交代码时,需要补充 Type Hints。具体规则可以参考[教程](https://zhuanlan.zhihu.com/p/519335398)。
+
+- 提交的代码同样需要通过单元测试
+
+ ```shell
+ # 通过全量单元测试
+ pytest tests
+
+ # 我们需要保证提交的代码能够通过修改模块的单元测试,以 runner 为例
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ 如果你由于缺少依赖无法运行修改模块的单元测试,可以参考[指引-单元测试](#单元测试)
+
+- 如果修改/添加了文档,参考[指引](#文档渲染)确认文档渲染正常。
+
+#### 5. 推送代码到远程
+
+代码通过单元测试和 pre-commit 检查后,将代码推送到远程仓库,如果是第一次推送,可以在 `git push` 后加上 `-u` 参数以关联远程分支
+
+```shell
+git push -u origin {branch_name}
+```
+
+这样下次就可以直接使用 `git push` 命令推送代码了,而无需指定分支和远程仓库。
+
+#### 6. 提交拉取请求(PR)
+
+(1) 在 GitHub 的 Pull request 界面创建拉取请求
+
+
+(2) 根据指引修改 PR 描述,以便于其他开发者更好地理解你的修改
+
+
+
+描述规范详见[拉取请求规范](#拉取请求规范)
+
+
+
+**注意事项**
+
+(a) PR 描述应该包含修改理由、修改内容以及修改后带来的影响,并关联相关 Issue(具体方式见[文档](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))
+
+(b) 如果是第一次为 OpenMMLab 做贡献,需要签署 CLA
+
+
+
+(c) 检查提交的 PR 是否通过 CI(集成测试)
+
+
+
+MMCV 会在不同的平台(Linux、Window、Mac),基于不同版本的 Python、PyTorch、CUDA 对提交的代码进行单元测试,以保证代码的正确性,如果有任何一个没有通过,我们可点击上图中的 `Details` 来查看具体的测试信息,以便于我们修改代码。
+
+(3) 如果 PR 通过了 CI,那么就可以等待其他开发者的 review,并根据 reviewer 的意见,修改代码,并重复 [4](#4-提交代码并本地通过单元测试)-[5](#5-推送代码到远程) 步骤,直到 reviewer 同意合入 PR。
+
+
+
+所有 reviewer 同意合入 PR 后,我们会尽快将 PR 合并到主分支。
+
+#### 7. 解决冲突
+
+随着时间的推移,我们的代码库会不断更新,这时候,如果你的 PR 与主分支存在冲突,你需要解决冲突,解决冲突的方式有两种:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+或者
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+如果你非常善于处理冲突,那么可以使用 rebase 的方式来解决冲突,因为这能够保证你的 commit log 的整洁。如果你不太熟悉 `rebase` 的使用,那么可以使用 `merge` 的方式来解决冲突。
+
+### 指引
+
+#### 单元测试
+
+如果你无法正常执行部分模块的单元测试,例如 [video](https://github.com/open-mmlab/mmcv/tree/master/mmcv/video) 模块,可能是你的当前环境没有安装以下依赖
+
+```shell
+# Linux
+sudo apt-get update -y
+sudo apt-get install -y libturbojpeg
+sudo apt-get install -y ffmpeg
+
+# Windows
+conda install ffmpeg
+```
+
+在提交修复代码错误或新增特性的拉取请求时,我们应该尽可能的让单元测试覆盖所有提交的代码,计算单元测试覆盖率的方法如下
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### 文档渲染
+
+在提交修复代码错误或新增特性的拉取请求时,可能会需要修改/新增模块的 docstring。我们需要确认渲染后的文档样式是正确的。
+本地生成渲染后的文档的方法如下
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### 代码风格
+
+#### Python
+
+[PEP8](https://www.python.org/dev/peps/pep-0008/) 作为 OpenMMLab 算法库首选的代码规范,我们使用以下工具检查和格式化代码
+
+- [flake8](https://github.com/PyCQA/flake8): Python 官方发布的代码规范检查工具,是多个检查工具的封装
+- [isort](https://github.com/timothycrosley/isort): 自动调整模块导入顺序的工具
+- [yapf](https://github.com/google/yapf): Google 发布的代码规范检查工具
+- [codespell](https://github.com/codespell-project/codespell): 检查单词拼写是否有误
+- [mdformat](https://github.com/executablebooks/mdformat): 检查 markdown 文件的工具
+- [docformatter](https://github.com/myint/docformatter): 格式化 docstring 的工具
+
+yapf 和 isort 的配置可以在 [setup.cfg](./setup.cfg) 找到
+
+通过配置 [pre-commit hook](https://pre-commit.com/) ,我们可以在提交代码时自动检查和格式化 `flake8`、`yapf`、`isort`、`trailing whitespaces`、`markdown files`,
+修复 `end-of-files`、`double-quoted-strings`、`python-encoding-pragma`、`mixed-line-ending`,调整 `requirments.txt` 的包顺序。
+pre-commit 钩子的配置可以在 [.pre-commit-config](./.pre-commit-config.yaml) 找到。
+
+pre-commit 具体的安装使用方式见[拉取请求](#2-配置-pre-commit)。
+
+更具体的规范请参考 [OpenMMLab 代码规范](code_style.md)。
+
+#### C++ and CUDA
+
+C++ 和 CUDA 的代码规范遵从 [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html)
+
+### 拉取请求规范
+
+1. 使用 [pre-commit hook](https://pre-commit.com),尽量减少代码风格相关问题
+
+2. 一个`拉取请求`对应一个短期分支
+
+3. 粒度要细,一个`拉取请求`只做一件事情,避免超大的`拉取请求`
+
+ - Bad:实现 Faster R-CNN
+ - Acceptable:给 Faster R-CNN 添加一个 box head
+ - Good:给 box head 增加一个参数来支持自定义的 conv 层数
+
+4. 每次 Commit 时需要提供清晰且有意义 commit 信息
+
+5. 提供清晰且有意义的`拉取请求`描述
+
+ - 标题写明白任务名称,一般格式:\[Prefix\] Short description of the pull request (Suffix)
+ - prefix: 新增功能 \[Feature\], 修 bug \[Fix\], 文档相关 \[Docs\], 开发中 \[WIP\] (暂时不会被review)
+ - 描述里介绍`拉取请求`的主要修改内容,结果,以及对其他部分的影响, 参考`拉取请求`模板
+ - 关联相关的`议题` (issue) 和其他`拉取请求`
+
+6. 如果引入了其他三方库,或借鉴了三方库的代码,请确认他们的许可证和 mmcv 兼容,并在借鉴的代码上补充 `This code is inspired from http://`
diff --git a/README.md b/README.md
index eb228d5d8d..e791a0a3de 100644
--- a/README.md
+++ b/README.md
@@ -60,13 +60,13 @@ There are two versions of MMCV:
### Install mmcv
-Before installing mmcv, make sure that PyTorch has been successfully installed following the [PyTorch official installation guide](https://github.com/pytorch/pytorch#installation). For macOS M1 users, please make sure you are using `PyTorch Nightly`.
+Before installing mmcv, make sure that PyTorch has been successfully installed following the [PyTorch official installation guide](https://github.com/pytorch/pytorch#installation). For apple silicon users, please use PyTorch 1.13+.
The command to install mmcv on Linux or Windows platforms is as follows (if your system is macOS, please refer to [build mmcv from source](https://mmcv.readthedocs.io/en/2.x/get_started/build.html#macos-mmcv))
```bash
pip install -U openmim
-mim install 'mmcv>=2.0.0rc1'
+mim install "mmcv>=2.0.0rc1"
```
If you need to specify the version of mmcv, you can use the following command
@@ -103,7 +103,7 @@ If you need to use PyTorch-related modules, make sure PyTorch has been successfu
```bash
pip install -U openmim
-mim install 'mmcv-lite>=2.0.0rc1'
+mim install "mmcv-lite>=2.0.0rc1"
```
## FAQ
diff --git a/README_zh-CN.md b/README_zh-CN.md
index 031f65cb5e..b128946a63 100644
--- a/README_zh-CN.md
+++ b/README_zh-CN.md
@@ -60,13 +60,13 @@ MMCV 有两个版本:
### 安装 mmcv
-在安装 mmcv 之前,请确保 PyTorch 已经成功安装在环境中,可以参考 [PyTorch 官方安装文档](https://github.com/pytorch/pytorch#installation)。
+在安装 mmcv 之前,请确保 PyTorch 已经成功安装在环境中,可以参考 [PyTorch 官方安装文档](https://github.com/pytorch/pytorch#installation)。如果你使用的是搭载 apple silicon 的 mac 设备,请安装 PyTorch 1.13+ 的版本。
在 Linux 和 Windows 平台安装 mmcv 的命令如下(如果你的系统是 macOS,请参考[源码安装 mmcv](https://mmcv.readthedocs.io/zh_CN/2.x/get_started/build.html#macos-mmcv))
```bash
pip install -U openmim
-mim install 'mmcv>=2.0.0rc1'
+mim install "mmcv>=2.0.0rc1"
```
如果需要指定 mmcv 的版本,可以使用以下命令
@@ -103,7 +103,7 @@ Collecting mmcv==2.0.0rc1
```bash
pip install -U openmim
-mim install 'mmcv-lite>=2.0.0rc1'
+mim install "mmcv-lite>=2.0.0rc1"
```
## FAQ
diff --git a/docs/en/community/contributing.md b/docs/en/community/contributing.md
deleted file mode 120000
index 7272339644..0000000000
--- a/docs/en/community/contributing.md
+++ /dev/null
@@ -1 +0,0 @@
-../../../CONTRIBUTING.md
diff --git a/docs/en/community/contributing.md b/docs/en/community/contributing.md
new file mode 100644
index 0000000000..e339935778
--- /dev/null
+++ b/docs/en/community/contributing.md
@@ -0,0 +1,267 @@
+## Contributing to OpenMMLab
+
+Welcome to the MMCV community, we are committed to building a cutting-edge computer vision foundational library and all kinds of contributions are welcomed, including but not limited to
+
+**Fix bug**
+
+You can directly post a Pull Request to fix typo in code or documents
+
+The steps to fix the bug of code implementation are as follows.
+
+1. If the modification involve significant changes, you should create an issue first and describe the error information and how to trigger the bug. Other developers will discuss with you and propose an proper solution.
+
+2. Posting a pull request after fixing the bug and adding corresponding unit test.
+
+**New Feature or Enhancement**
+
+1. If the modification involve significant changes, you should create an issue to discuss with our developers to propose an proper design.
+2. Post a Pull Request after implementing the new feature or enhancement and add corresponding unit test.
+
+**Document**
+
+You can directly post a pull request to fix documents. If you want to add a document, you should first create an issue to check if it is reasonable.
+
+### Pull Request Workflow
+
+If you're not familiar with Pull Request, don't worry! The following guidance will tell you how to create a Pull Request step by step. If you want to dive into the develop mode of Pull Request, you can refer to the [official documents](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests)
+
+#### 1. Fork and clone
+
+If you are posting a pull request for the first time, you should fork the OpenMMLab repositories by clicking the **Fork** button in the top right corner of the GitHub page, and the forked repositories will appear under your GitHub profile.
+
+
+
+Then, you can clone the repositories to local:
+
+```shell
+git clone git@github.com:{username}/mmcv.git
+```
+
+After that, you should ddd official repository as the upstream repository
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmcv
+```
+
+Check whether remote repository has been added successfully by `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmcv.git (fetch)
+origin git@github.com:{username}/mmcv.git (push)
+upstream git@github.com:open-mmlab/mmcv (fetch)
+upstream git@github.com:open-mmlab/mmcv (push)
+```
+
+```{note}
+Here's a brief introduction to origin and upstream. When we use "git clone", we create an "origin" remote by default, which points to the repository cloned from. As for "upstream", we add it ourselves to point to the target repository. Of course, if you don't like the name "upstream", you could name it as you wish. Usually, we'll push the code to "origin". If the pushed code conflicts with the latest code in official("upstream"), we should pull the latest code from upstream to resolve the conflicts, and then push to "origin" again. The posted Pull Request will be updated automatically.
+```
+
+#### 2. Configure pre-commit
+
+You should configure [pre-commit](https://pre-commit.com/#intro) in the local development environment to make sure the code style matches that of OpenMMLab. **Note**: The following code should be executed under the MMCV directory.
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+
+
+```{note}
+Chinese users may fail to download the pre-commit hooks due to the network issue. In this case, you could download these hooks from gitee by setting the .pre-commit-config-zh-cn.yaml
+
+pre-commit install -c .pre-commit-config-zh-cn.yaml
+pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
+```
+
+If the installation process is interrupted, you can repeatedly run `pre-commit run ... ` to continue the installation.
+
+If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
+
+
+
+If we want to commit our code bypassing the pre-commit hook, we can use the `--no-verify` option(**only for temporarily commit**.
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. Create a development branch
+
+After configuring the pre-commit, we should create a branch based on the master branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+In subsequent development, if the master branch of the local repository is behind the master branch of "upstream", we need to pull the upstream for synchronization, and then execute the above command:
+
+```shell
+git pull upstream master
+```
+
+#### 4. Commit the code and pass the unit test
+
+- MMCV introduces mypy to do static type checking to increase the robustness of the code. Therefore, we need to add Type Hints to our code and pass the mypy check. If you are not familiar with Type Hints, you can refer to [this tutorial](https://docs.python.org/3/library/typing.html).
+
+- The committed code should pass through the unit test
+
+ ```shell
+ # Pass all unit tests
+ pytest tests
+
+ # Pass the unit test of runner
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ If the unit test fails for lack of dependencies, you can install the dependencies referring to the [guidance](#unit-test)
+
+- If the documents are modified/added, we should check the rendering result referring to [guidance](#document-rendering)
+
+#### 5. Push the code to remote
+
+We could push the local commits to remote after passing through the check of unit test and pre-commit. You can associate the local branch with remote branch by adding `-u` option.
+
+```shell
+git push -u origin {branch_name}
+```
+
+This will allow you to use the `git push` command to push code directly next time, without having to specify a branch or the remote repository.
+
+#### 6. Create a Pull Request
+
+(1) Create a pull request in GitHub's Pull request interface
+
+
+
+(2) Modify the PR description according to the guidelines so that other developers can better understand your changes
+
+
+
+Find more details about Pull Request description in [pull request guidelines](#pr-specs).
+
+**note**
+
+(a) The Pull Request description should contain the reason for the change, the content of the change, and the impact of the change, and be associated with the relevant Issue (see [documentation](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue)
+
+(b) If it is your first contribution, please sign the CLA
+
+
+
+(c) Check whether the Pull Request pass through the CI
+
+
+
+MMCV will run unit test for the posted Pull Request on different platforms (Linux, Window, Mac), based on different versions of Python, PyTorch, CUDA to make sure the code is correct. We can see the specific test information by clicking `Details` in the above image so that we can modify the code.
+
+(3) If the Pull Request passes the CI, then you can wait for the review from other developers. You'll modify the code based on the reviewer's comments, and repeat the steps [4](#4-commit-the-code-and-pass-the-unit-test)-[5](#5-push-the-code-to-remote) until all reviewers approve it. Then, we will merge it ASAP.
+
+
+
+#### 7. Resolve conflicts
+
+If your local branch conflicts with the latest master branch of "upstream", you'll need to resolove them. There are two ways to do this:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+or
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are not familiar with `rebase`, then you can use `merge` to resolve conflicts.
+
+### Guidance
+
+#### Unit test
+
+If you cannot run the unit test of some modules for lacking of some dependencies, such as [video](https://github.com/open-mmlab/mmcv/tree/master/mmcv/video) module, you can try to install the following dependencies:
+
+```shell
+# Linux
+sudo apt-get update -y
+sudo apt-get install -y libturbojpeg
+sudo apt-get install -y ffmpeg
+
+# Windows
+conda install ffmpeg
+```
+
+We should also make sure the committed code will not decrease the coverage of unit test, we could run the following command to check the coverage of unit test:
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### Document rendering
+
+If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### Code style
+
+#### Python
+
+We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
+
+We use the following tools for linting and formatting:
+
+- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
+- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
+- [yapf](https://github.com/google/yapf): A formatter for Python files.
+- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
+- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
+- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
+
+Style configurations of yapf and isort can be found in [setup.cfg](./setup.cfg).
+
+We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
+fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
+The config for a pre-commit hook is stored in [.pre-commit-config](./.pre-commit-config.yaml).
+
+#### C++ and CUDA
+
+We follow the [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html).
+
+### PR Specs
+
+1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
+
+2. One short-time branch should be matched with only one PR
+
+3. Accomplish a detailed change in one PR. Avoid large PR
+
+ - Bad: Support Faster R-CNN
+ - Acceptable: Add a box head to Faster R-CNN
+ - Good: Add a parameter to box head to support custom conv-layer number
+
+4. Provide clear and significant commit message
+
+5. Provide clear and meaningful PR description
+
+ - Task name should be clarified in title. The general format is: \[Prefix\] Short description of the PR (Suffix)
+ - Prefix: add new feature \[Feature\], fix bug \[Fix\], related to documents \[Docs\], in developing \[WIP\] (which will not be reviewed temporarily)
+ - Introduce main changes, results and influences on other modules in short description
+ - Associate related issues and pull requests with a milestone
diff --git a/docs/en/community/pr.md b/docs/en/community/pr.md
index 12b7535e74..1bdd90f2bc 100644
--- a/docs/en/community/pr.md
+++ b/docs/en/community/pr.md
@@ -1,114 +1,3 @@
## Pull Request (PR)
-### What is PR
-
-`PR` is the abbreviation of `Pull Request`. Here's the definition of `PR` in the [official document](https://docs.github.com/en/github/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/about-pull-requests) of Github.
-
-```
-Pull requests let you tell others about changes you have pushed to a branch in a repository on GitHub. Once a pull request is opened, you can discuss and review the potential changes with collaborators and add follow-up commits before your changes are merged into the base branch.
-```
-
-### Basic Workflow
-
-1. Get the most recent codebase
-2. Checkout a new branch from the master branch
-3. Commit your changes
-4. Push your changes and create a PR
-5. Discuss and review your code
-6. Merge your branch to the master branch
-
-### Procedures in detail
-
-#### 1. Get the most recent codebase
-
-- When you work on your first PR
-
- Fork the OpenMMLab repository: click the **fork** button at the top right corner of Github page
- 
-
- Clone forked repository to local
-
- ```bash
- git clone git@github.com:XXX/mmcv.git
- ```
-
- Add source repository to upstream
-
- ```bash
- git remote add upstream git@github.com:open-mmlab/mmcv
- ```
-
-- After your first PR
-
- Checkout master branch of the local repository and pull the latest master branch of the source repository
-
- ```bash
- git checkout master
- git pull upstream master
- ```
-
-#### 2. Checkout a new branch from the master branch
-
-```bash
-git checkout -b branchname
-```
-
-```{tip}
-To make commit history clear, we strongly recommend you checkout the master branch before create a new branch.
-```
-
-#### 3. Commit your changes
-
-```bash
-# coding
-git add [files]
-git commit -m 'messages'
-```
-
-#### 4. Push your changes to the forked repository and create a PR
-
-- Push the branch to your forked remote repository
-
- ```bash
- git push origin branchname
- ```
-
-- Create a PR
- 
-
-- Revise PR message template to describe your motivation and modifications made in this PR. You can also link the related issue to the PR manually in the PR message (For more information, checkout the [official guidance](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue)).
-
-#### 5. Discuss and review your code
-
-- After creating a pull request, you can ask a specific person to review the changes you've proposed
- 
-
-- Modify your codes according to reviewers' suggestions and then push your changes
-
-#### 6. Merge your branch to the master branch and delete the branch
-
-```bash
-git branch -d branchname # delete local branch
-git push origin --delete branchname # delete remote branch
-```
-
-### PR Specs
-
-1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
-
-2. One short-time branch should be matched with only one PR
-
-3. Accomplish a detailed change in one PR. Avoid large PR
-
- - Bad: Support Faster R-CNN
- - Acceptable: Add a box head to Faster R-CNN
- - Good: Add a parameter to box head to support custom conv-layer number
-
-4. Provide clear and significant commit message
-
-5. Provide clear and meaningful PR description
-
- - Task name should be clarified in title. The general format is: \[Prefix\] Short description of the PR (Suffix)
- - Prefix: add new feature \[Feature\], fix bug \[Fix\], related to documents \[Docs\], in developing \[WIP\] (which will not be reviewed temporarily)
- - Introduce main changes, results and influences on other modules in short description
- - Associate related issues and pull requests with a milestone
+Content has been migrated to [contributing guidance](contributing.md).
diff --git a/docs/en/get_started/build.md b/docs/en/get_started/build.md
index 793e602822..e3d48ec7cf 100644
--- a/docs/en/get_started/build.md
+++ b/docs/en/get_started/build.md
@@ -76,7 +76,7 @@ you can first install it before installing MMCV to skip the installation of `ope
#### Build on macOS
```{note}
-If you are using a mac with an M1 chip, install the nightly version of PyTorch, otherwise you will encounter the problem in [issues#2218](https://github.com/open-mmlab/mmcv/issues/2218).
+If you are using a mac with apple silicon chip, install the PyTorch 1.13+, otherwise you will encounter the problem in [issues#2218](https://github.com/open-mmlab/mmcv/issues/2218).
```
1. Clone the repo
diff --git a/docs/en/get_started/installation.md b/docs/en/get_started/installation.md
index 8236828148..513fde7a66 100644
--- a/docs/en/get_started/installation.md
+++ b/docs/en/get_started/installation.md
@@ -29,7 +29,7 @@ If version information is output, then PyTorch is installed.
```bash
pip install -U openmim
-mim install 'mmcv>=2.0.0rc1'
+mim install "mmcv>=2.0.0rc1"
```
If you find that the above installation command does not use a pre-built package ending with `.whl` but a source package ending with `.tar.gz`, you may not have a pre-build package corresponding to the PyTorch or CUDA or mmcv version, in which case you can [build mmcv from source](build.md).
@@ -66,7 +66,7 @@ you can first install it before installing MMCV to skip the installation of `ope
Alternatively, if it takes too long to install a dependency library, you can specify the pypi source
```bash
-mim install 'mmcv>=2.0.0rc1' -i https://pypi.tuna.tsinghua.edu.cn/simple
+mim install "mmcv>=2.0.0rc1" -i https://pypi.tuna.tsinghua.edu.cn/simple
```
:::
@@ -296,7 +296,7 @@ you can first install it before installing MMCV to skip the installation of `ope
Alternatively, if it takes too long to install a dependency library, you can specify the pypi source
```bash
-mim install mmcv -i https://pypi.tuna.tsinghua.edu.cn/simple
+mim install "mmcv>=2.0.0rc1" -i https://pypi.tuna.tsinghua.edu.cn/simple
```
:::
diff --git a/docs/en/understand_mmcv/ops.md b/docs/en/understand_mmcv/ops.md
index af0a4d5b6b..e0a9a3648c 100644
--- a/docs/en/understand_mmcv/ops.md
+++ b/docs/en/understand_mmcv/ops.md
@@ -27,13 +27,13 @@ We implement common ops used in detection, segmentation, etc.
| FusedBiasLeakyrelu | | √ | | |
| GatherPoints | | √ | | |
| GroupPoints | | √ | | |
-| Iou3d | | √ | | |
+| Iou3d | | √ | √ | |
| KNN | | √ | | |
| MaskedConv | | √ | √ | |
| MergeCells | | √ | | |
| MinAreaPolygon | | √ | | |
| ModulatedDeformConv2d | √ | √ | | |
-| MultiScaleDeformableAttn | | √ | | |
+| MultiScaleDeformableAttn | | √ | √ | |
| NMS | √ | √ | √ | |
| NMSRotated | √ | √ | | |
| NMSQuadri | √ | √ | | |
@@ -47,7 +47,7 @@ We implement common ops used in detection, segmentation, etc.
| RoIAlignRotated | √ | √ | √ | |
| RiRoIAlignRotated | | √ | | |
| RoIAlign | √ | √ | √ | |
-| RoIAwarePool3d | | √ | | |
+| RoIAwarePool3d | | √ | √ | |
| SAConv2d | | √ | | |
| SigmoidFocalLoss | | √ | √ | |
| SoftmaxFocalLoss | | √ | | |
diff --git a/docs/zh_cn/community/code_style.md b/docs/zh_cn/community/code_style.md
new file mode 100644
index 0000000000..8ddb87c239
--- /dev/null
+++ b/docs/zh_cn/community/code_style.md
@@ -0,0 +1,609 @@
+## 代码规范
+
+### 代码规范标准
+
+#### PEP 8 —— Python 官方代码规范
+
+[Python 官方的代码风格指南](https://www.python.org/dev/peps/pep-0008/),包含了以下几个方面的内容:
+
+- 代码布局,介绍了 Python 中空行、断行以及导入相关的代码风格规范。比如一个常见的问题:当我的代码较长,无法在一行写下时,何处可以断行?
+
+- 表达式,介绍了 Python 中表达式空格相关的一些风格规范。
+
+- 尾随逗号相关的规范。当列表较长,无法一行写下而写成如下逐行列表时,推荐在末项后加逗号,从而便于追加选项、版本控制等。
+
+ ```python
+ # Correct:
+ FILES = ['setup.cfg', 'tox.ini']
+ # Correct:
+ FILES = [
+ 'setup.cfg',
+ 'tox.ini',
+ ]
+ # Wrong:
+ FILES = ['setup.cfg', 'tox.ini',]
+ # Wrong:
+ FILES = [
+ 'setup.cfg',
+ 'tox.ini'
+ ]
+ ```
+
+- 命名相关规范、注释相关规范、类型注解相关规范,我们将在后续章节中做详细介绍。
+
+ "A style guide is about consistency. Consistency with this style guide is important. Consistency within a project is more important. Consistency within one module or function is the most important." PEP 8 -- Style Guide for Python Code
+
+:::{note}
+PEP 8 的代码规范并不是绝对的,项目内的一致性要优先于 PEP 8 的规范。OpenMMLab 各个项目都在 setup.cfg 设定了一些代码规范的设置,请遵照这些设置。一个例子是在 PEP 8 中有如下一个例子:
+
+```python
+# Correct:
+hypot2 = x*x + y*y
+# Wrong:
+hypot2 = x * x + y * y
+```
+
+这一规范是为了指示不同优先级,但 OpenMMLab 的设置中通常没有启用 yapf 的 `ARITHMETIC_PRECEDENCE_INDICATION` 选项,因而格式规范工具不会按照推荐样式格式化,以设置为准。
+:::
+
+#### Google 开源项目风格指南
+
+[Google 使用的编程风格指南](https://google.github.io/styleguide/pyguide.html),包括了 Python 相关的章节。相较于 PEP 8,该指南提供了更为详尽的代码指南。该指南包括了语言规范和风格规范两个部分。
+
+其中,语言规范对 Python 中很多语言特性进行了优缺点的分析,并给出了使用指导意见,如异常、Lambda 表达式、列表推导式、metaclass 等。
+
+风格规范的内容与 PEP 8 较为接近,大部分约定建立在 PEP 8 的基础上,也有一些更为详细的约定,如函数长度、TODO 注释、文件与 socket 对象的访问等。
+
+推荐将该指南作为参考进行开发,但不必严格遵照,一来该指南存在一些 Python 2 兼容需求,例如指南中要求所有无基类的类应当显式地继承 Object, 而在仅使用 Python 3 的环境中,这一要求是不必要的,依本项目中的惯例即可。二来 OpenMMLab 的项目作为框架级的开源软件,不必对一些高级技巧过于避讳,尤其是 MMCV。但尝试使用这些技巧前应当认真考虑是否真的有必要,并寻求其他开发人员的广泛评估。
+
+另外需要注意的一处规范是关于包的导入,在该指南中,要求导入本地包时必须使用路径全称,且导入的每一个模块都应当单独成行,通常这是不必要的,而且也不符合目前项目的开发惯例,此处进行如下约定:
+
+```python
+# Correct
+from mmcv.cnn.bricks import (Conv2d, build_norm_layer, DropPath, MaxPool2d,
+ Linear)
+from ..utils import ext_loader
+
+# Wrong
+from mmcv.cnn.bricks import Conv2d, build_norm_layer, DropPath, MaxPool2d, \
+ Linear # 使用括号进行连接,而不是反斜杠
+from ...utils import is_str # 最多向上回溯一层,过多的回溯容易导致结构混乱
+```
+
+OpenMMLab 项目使用 pre-commit 工具自动格式化代码,详情见[贡献代码](./contributing.md#代码风格)。
+
+### 命名规范
+
+#### 命名规范的重要性
+
+优秀的命名是良好代码可读的基础。基础的命名规范对各类变量的命名做了要求,使读者可以方便地根据代码名了解变量是一个类 / 局部变量 / 全局变量等。而优秀的命名则需要代码作者对于变量的功能有清晰的认识,以及良好的表达能力,从而使读者根据名称就能了解其含义,甚至帮助了解该段代码的功能。
+
+#### 基础命名规范
+
+| 类型 | 公有 | 私有 |
+| --------------- | ---------------- | ------------------ |
+| 模块 | lower_with_under | \_lower_with_under |
+| 包 | lower_with_under | |
+| 类 | CapWords | \_CapWords |
+| 异常 | CapWordsError | |
+| 函数(方法) | lower_with_under | \_lower_with_under |
+| 函数 / 方法参数 | lower_with_under | |
+| 全局 / 类内常量 | CAPS_WITH_UNDER | \_CAPS_WITH_UNDER |
+| 全局 / 类内变量 | lower_with_under | \_lower_with_under |
+| 变量 | lower_with_under | \_lower_with_under |
+| 局部变量 | lower_with_under | |
+
+注意:
+
+- 尽量避免变量名与保留字冲突,特殊情况下如不可避免,可使用一个后置下划线,如 class\_
+- 尽量不要使用过于简单的命名,除了约定俗成的循环变量 i,文件变量 f,错误变量 e 等。
+- 不会被用到的变量可以命名为 \_,逻辑检查器会将其忽略。
+
+#### 命名技巧
+
+良好的变量命名需要保证三点:
+
+1. 含义准确,没有歧义
+2. 长短适中
+3. 前后统一
+
+```python
+# Wrong
+class Masks(metaclass=ABCMeta): # 命名无法表现基类;Instance or Semantic?
+ pass
+
+# Correct
+class BaseInstanceMasks(metaclass=ABCMeta):
+ pass
+
+# Wrong,不同地方含义相同的变量尽量用统一的命名
+def __init__(self, inplanes, planes):
+ pass
+
+def __init__(self, in_channels, out_channels):
+ pass
+```
+
+常见的函数命名方法:
+
+- 动宾命名法:crop_img, init_weights
+- 动宾倒置命名法:imread, bbox_flip
+
+注意函数命名与参数的顺序,保证主语在前,符合语言习惯:
+
+- check_keys_exist(key, container)
+- check_keys_contain(container, key)
+
+注意避免非常规或统一约定的缩写,如 nb -> num_blocks,in_nc -> in_channels
+
+### docstring 规范
+
+#### 为什么要写 docstring
+
+docstring 是对一个类、一个函数功能与 API 接口的详细描述,有两个功能,一是帮助其他开发者了解代码功能,方便 debug 和复用代码;二是在 Readthedocs 文档中自动生成相关的 API reference 文档,帮助不了解源代码的社区用户使用相关功能。
+
+#### 如何写 docstring
+
+与注释不同,一份规范的 docstring 有着严格的格式要求,以便于 Python 解释器以及 sphinx 进行文档解析,详细的 docstring 约定参见 [PEP 257](https://www.python.org/dev/peps/pep-0257/)。此处以例子的形式介绍各种文档的标准格式,参考格式为 [Google 风格](https://zh-google-styleguide.readthedocs.io/en/latest/google-python-styleguide/python_style_rules/#comments)。
+
+1. 模块文档
+
+ 代码风格规范推荐为每一个模块(即 Python 文件)编写一个 docstring,但目前 OpenMMLab 项目大部分没有此类 docstring,因此不做硬性要求。
+
+ ```python
+ """A one line summary of the module or program, terminated by a period.
+
+ Leave one blank line. The rest of this docstring should contain an
+ overall description of the module or program. Optionally, it may also
+ contain a brief description of exported classes and functions and/or usage
+ examples.
+
+ Typical usage example:
+
+ foo = ClassFoo()
+ bar = foo.FunctionBar()
+ """
+ ```
+
+2. 类文档
+
+ 类文档是我们最常需要编写的,此处,按照 OpenMMLab 的惯例,我们使用了与 Google 风格不同的写法。如下例所示,文档中没有使用 Attributes 描述类属性,而是使用 Args 描述 __init__ 函数的参数。
+
+ 在 Args 中,遵照 `parameter (type): Description.` 的格式,描述每一个参数类型和功能。其中,多种类型可使用 `(float or str)` 的写法,可以为 None 的参数可以写为 `(int, optional)`。
+
+ ```python
+ class BaseRunner(metaclass=ABCMeta):
+ """The base class of Runner, a training helper for PyTorch.
+
+ All subclasses should implement the following APIs:
+
+ - ``run()``
+ - ``train()``
+ - ``val()``
+ - ``save_checkpoint()``
+
+ Args:
+ model (:obj:`torch.nn.Module`): The model to be run.
+ batch_processor (callable, optional): A callable method that process
+ a data batch. The interface of this method should be
+ ``batch_processor(model, data, train_mode) -> dict``.
+ Defaults to None.
+ optimizer (dict or :obj:`torch.optim.Optimizer`, optional): It can be
+ either an optimizer (in most cases) or a dict of optimizers
+ (in models that requires more than one optimizer, e.g., GAN).
+ Defaults to None.
+ work_dir (str, optional): The working directory to save checkpoints
+ and logs. Defaults to None.
+ logger (:obj:`logging.Logger`): Logger used during training.
+ Defaults to None. (The default value is just for backward
+ compatibility)
+ meta (dict, optional): A dict records some import information such as
+ environment info and seed, which will be logged in logger hook.
+ Defaults to None.
+ max_epochs (int, optional): Total training epochs. Defaults to None.
+ max_iters (int, optional): Total training iterations. Defaults to None.
+ """
+
+ def __init__(self,
+ model,
+ batch_processor=None,
+ optimizer=None,
+ work_dir=None,
+ logger=None,
+ meta=None,
+ max_iters=None,
+ max_epochs=None):
+ ...
+ ```
+
+ 另外,在一些算法实现的主体类中,建议加入原论文的链接;如果参考了其他开源代码的实现,则应加入 modified from,而如果是直接复制了其他代码库的实现,则应加入 copied from ,并注意源码的 License。如有必要,也可以通过 .. math:: 来加入数学公式
+
+ ```python
+ # 参考实现
+ # This func is modified from `detectron2
+ # `_.
+
+ # 复制代码
+ # This code was copied from the `ubelt
+ # library`_.
+
+ # 引用论文 & 添加公式
+ class LabelSmoothLoss(nn.Module):
+ r"""Initializer for the label smoothed cross entropy loss.
+
+ Refers to `Rethinking the Inception Architecture for Computer Vision
+ `_.
+
+ This decreases gap between output scores and encourages generalization.
+ Labels provided to forward can be one-hot like vectors (NxC) or class
+ indices (Nx1).
+ And this accepts linear combination of one-hot like labels from mixup or
+ cutmix except multi-label task.
+
+ Args:
+ label_smooth_val (float): The degree of label smoothing.
+ num_classes (int, optional): Number of classes. Defaults to None.
+ mode (str): Refers to notes, Options are "original", "classy_vision",
+ "multi_label". Defaults to "classy_vision".
+ reduction (str): The method used to reduce the loss.
+ Options are "none", "mean" and "sum". Defaults to 'mean'.
+ loss_weight (float): Weight of the loss. Defaults to 1.0.
+
+ Note:
+ if the ``mode`` is "original", this will use the same label smooth
+ method as the original paper as:
+
+ .. math::
+ (1-\epsilon)\delta_{k, y} + \frac{\epsilon}{K}
+
+ where :math:`\epsilon` is the ``label_smooth_val``, :math:`K` is
+ the ``num_classes`` and :math:`\delta_{k,y}` is Dirac delta,
+ which equals 1 for k=y and 0 otherwise.
+
+ if the ``mode`` is "classy_vision", this will use the same label
+ smooth method as the `facebookresearch/ClassyVision
+ `_ repo as:
+
+ .. math::
+ \frac{\delta_{k, y} + \epsilon/K}{1+\epsilon}
+
+ if the ``mode`` is "multi_label", this will accept labels from
+ multi-label task and smoothing them as:
+
+ .. math::
+ (1-2\epsilon)\delta_{k, y} + \epsilon
+ ```
+
+```{note}
+注意 \`\`here\`\`、\`here\`、"here" 三种引号功能是不同。
+
+在 reStructured 语法中,\`\`here\`\` 表示一段代码;\`here\` 表示斜体;"here" 无特殊含义,一般可用来表示字符串。其中 \`here\` 的用法与 Markdown 中不同,需要多加留意。
+另外还有 :obj:\`type\` 这种更规范的表示类的写法,但鉴于长度,不做特别要求,一般仅用于表示非常用类型。
+```
+
+3. 方法(函数)文档
+
+ 函数文档与类文档的结构基本一致,但需要加入返回值文档。对于较为复杂的函数和类,可以使用 Examples 字段加入示例;如果需要对参数加入一些较长的备注,可以加入 Note 字段进行说明。
+
+ 对于使用较为复杂的类或函数,比起看大段大段的说明文字和参数文档,添加合适的示例更能帮助用户迅速了解其用法。需要注意的是,这些示例最好是能够直接在 Python 交互式环境中运行的,并给出一些相对应的结果。如果存在多个示例,可以使用注释简单说明每段示例,也能起到分隔作用。
+
+ ```python
+ def import_modules_from_strings(imports, allow_failed_imports=False):
+ """Import modules from the given list of strings.
+
+ Args:
+ imports (list | str | None): The given module names to be imported.
+ allow_failed_imports (bool): If True, the failed imports will return
+ None. Otherwise, an ImportError is raise. Defaults to False.
+
+ Returns:
+ List[module] | module | None: The imported modules.
+ All these three lines in docstring will be compiled into the same
+ line in readthedocs.
+
+ Examples:
+ >>> osp, sys = import_modules_from_strings(
+ ... ['os.path', 'sys'])
+ >>> import os.path as osp_
+ >>> import sys as sys_
+ >>> assert osp == osp_
+ >>> assert sys == sys_
+ """
+ ...
+ ```
+
+ 如果函数接口在某个版本发生了变化,需要在 docstring 中加入相关的说明,必要时添加 Note 或者 Warning 进行说明,例如:
+
+ ```python
+ class CheckpointHook(Hook):
+ """Save checkpoints periodically.
+
+ Args:
+ out_dir (str, optional): The root directory to save checkpoints. If
+ not specified, ``runner.work_dir`` will be used by default. If
+ specified, the ``out_dir`` will be the concatenation of
+ ``out_dir`` and the last level directory of ``runner.work_dir``.
+ Defaults to None. `Changed in version 1.3.15.`
+ file_client_args (dict, optional): Arguments to instantiate a
+ FileClient. See :class:`mmcv.fileio.FileClient` for details.
+ Defaults to None. `New in version 1.3.15.`
+
+ Warning:
+ Before v1.3.15, the ``out_dir`` argument indicates the path where the
+ checkpoint is stored. However, in v1.3.15 and later, ``out_dir``
+ indicates the root directory and the final path to save checkpoint is
+ the concatenation of out_dir and the last level directory of
+ ``runner.work_dir``. Suppose the value of ``out_dir`` is
+ "/path/of/A" and the value of ``runner.work_dir`` is "/path/of/B",
+ then the final path will be "/path/of/A/B".
+ ```
+
+ 如果参数或返回值里带有需要展开描述字段的 dict,则应该采用如下格式:
+
+ ```python
+ def func(x):
+ r"""
+ Args:
+ x (None): A dict with 2 keys, ``padded_targets``, and ``targets``.
+
+ - ``targets`` (list[Tensor]): A list of tensors.
+ Each tensor has the shape of :math:`(T_i)`. Each
+ element is the index of a character.
+ - ``padded_targets`` (Tensor): A tensor of shape :math:`(N)`.
+ Each item is the length of a word.
+
+ Returns:
+ dict: A dict with 2 keys, ``padded_targets``, and ``targets``.
+
+ - ``targets`` (list[Tensor]): A list of tensors.
+ Each tensor has the shape of :math:`(T_i)`. Each
+ element is the index of a character.
+ - ``padded_targets`` (Tensor): A tensor of shape :math:`(N)`.
+ Each item is the length of a word.
+ """
+ return x
+ ```
+
+```{important}
+为了生成 readthedocs 文档,文档的编写需要按照 ReStructrued 文档格式,否则会产生文档渲染错误,在提交 PR 前,最好生成并预览一下文档效果。
+语法规范参考:
+
+- [reStructuredText Primer - Sphinx documentation](https://www.sphinx-doc.org/en/master/usage/restructuredtext/basics.html#)
+- [Example Google Style Python Docstrings ‒ napoleon 0.7 documentation](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html#example-google)
+```
+
+### 注释规范
+
+#### 为什么要写注释
+
+对于一个开源项目,团队合作以及社区之间的合作是必不可少的,因而尤其要重视合理的注释。不写注释的代码,很有可能过几个月自己也难以理解,造成额外的阅读和修改成本。
+
+#### 如何写注释
+
+最需要写注释的是代码中那些技巧性的部分。如果你在下次代码审查的时候必须解释一下,那么你应该现在就给它写注释。对于复杂的操作,应该在其操作开始前写上若干行注释。对于不是一目了然的代码,应在其行尾添加注释。
+—— Google 开源项目风格指南
+
+```python
+# We use a weighted dictionary search to find out where i is in
+# the array. We extrapolate position based on the largest num
+# in the array and the array size and then do binary search to
+# get the exact number.
+if i & (i-1) == 0: # True if i is 0 or a power of 2.
+```
+
+为了提高可读性, 注释应该至少离开代码2个空格.
+另一方面, 绝不要描述代码. 假设阅读代码的人比你更懂Python, 他只是不知道你的代码要做什么.
+—— Google 开源项目风格指南
+
+```python
+# Wrong:
+# Now go through the b array and make sure whenever i occurs
+# the next element is i+1
+
+# Wrong:
+if i & (i-1) == 0: # True if i bitwise and i-1 is 0.
+```
+
+在注释中,可以使用 Markdown 语法,因为开发人员通常熟悉 Markdown 语法,这样可以便于交流理解,如可使用单反引号表示代码和变量(注意不要和 docstring 中的 ReStructured 语法混淆)
+
+```python
+# `_reversed_padding_repeated_twice` is the padding to be passed to
+# `F.pad` if needed (e.g., for non-zero padding types that are
+# implemented as two ops: padding + conv). `F.pad` accepts paddings in
+# reverse order than the dimension.
+self._reversed_padding_repeated_twice = _reverse_repeat_tuple(self.padding, 2)
+```
+
+#### 注释示例
+
+1. 出自 `mmcv/utils/registry.py`,对于较为复杂的逻辑结构,通过注释,明确了优先级关系。
+
+ ```python
+ # self.build_func will be set with the following priority:
+ # 1. build_func
+ # 2. parent.build_func
+ # 3. build_from_cfg
+ if build_func is None:
+ if parent is not None:
+ self.build_func = parent.build_func
+ else:
+ self.build_func = build_from_cfg
+ else:
+ self.build_func = build_func
+ ```
+
+2. 出自 `mmcv/runner/checkpoint.py`,对于 bug 修复中的一些特殊处理,可以附带相关的 issue 链接,帮助其他人了解 bug 背景。
+
+ ```python
+ def _save_ckpt(checkpoint, file):
+ # The 1.6 release of PyTorch switched torch.save to use a new
+ # zipfile-based file format. It will cause RuntimeError when a
+ # checkpoint was saved in high version (PyTorch version>=1.6.0) but
+ # loaded in low version (PyTorch version<1.6.0). More details at
+ # https://github.com/open-mmlab/mmpose/issues/904
+ if digit_version(TORCH_VERSION) >= digit_version('1.6.0'):
+ torch.save(checkpoint, file, _use_new_zipfile_serialization=False)
+ else:
+ torch.save(checkpoint, file)
+ ```
+
+### 类型注解
+
+#### 为什么要写类型注解
+
+类型注解是对函数中变量的类型做限定或提示,为代码的安全性提供保障、增强代码的可读性、避免出现类型相关的错误。
+Python 没有对类型做强制限制,类型注解只起到一个提示作用,通常你的 IDE 会解析这些类型注解,然后在你调用相关代码时对类型做提示。另外也有类型注解检查工具,这些工具会根据类型注解,对代码中可能出现的问题进行检查,减少 bug 的出现。
+需要注意的是,通常我们不需要注释模块中的所有函数:
+
+1. 公共的 API 需要注释
+2. 在代码的安全性,清晰性和灵活性上进行权衡是否注释
+3. 对于容易出现类型相关的错误的代码进行注释
+4. 难以理解的代码请进行注释
+5. 若代码中的类型已经稳定,可以进行注释. 对于一份成熟的代码,多数情况下,即使注释了所有的函数,也不会丧失太多的灵活性.
+
+#### 如何写类型注解
+
+1. 函数 / 方法类型注解,通常不对 self 和 cls 注释。
+
+ ```python
+ from typing import Optional, List, Tuple
+
+ # 全部位于一行
+ def my_method(self, first_var: int) -> int:
+ pass
+
+ # 另起一行
+ def my_method(
+ self, first_var: int,
+ second_var: float) -> Tuple[MyLongType1, MyLongType1, MyLongType1]:
+ pass
+
+ # 单独成行(具体的应用场合与行宽有关,建议结合 yapf 自动化格式使用)
+ def my_method(
+ self, first_var: int, second_var: float
+ ) -> Tuple[MyLongType1, MyLongType1, MyLongType1]:
+ pass
+
+ # 引用尚未被定义的类型
+ class MyClass:
+ def __init__(self,
+ stack: List["MyClass"]) -> None:
+ pass
+ ```
+
+ 注:类型注解中的类型可以是 Python 内置类型,也可以是自定义类,还可以使用 Python 提供的 wrapper 类对类型注解进行装饰,一些常见的注解如下:
+
+ ```python
+ # 数值类型
+ from numbers import Number
+
+ # 可选类型,指参数可以为 None
+ from typing import Optional
+ def foo(var: Optional[int] = None):
+ pass
+
+ # 联合类型,指同时接受多种类型
+ from typing import Union
+ def foo(var: Union[float, str]):
+ pass
+
+ from typing import Sequence # 序列类型
+ from typing import Iterable # 可迭代类型
+ from typing import Any # 任意类型
+ from typing import Callable # 可调用类型
+
+ from typing import List, Dict # 列表和字典的泛型类型
+ from typing import Tuple # 元组的特殊格式
+ # 虽然在 Python 3.9 中,list, tuple 和 dict 本身已支持泛型,但为了支持之前的版本
+ # 我们在进行类型注解时还是需要使用 List, Tuple, Dict 类型
+ # 另外,在对参数类型进行注解时,尽量使用 Sequence & Iterable & Mapping
+ # List, Tuple, Dict 主要用于返回值类型注解
+ # 参见 https://docs.python.org/3/library/typing.html#typing.List
+ ```
+
+2. 变量类型注解,一般用于难以直接推断其类型时
+
+ ```python
+ # Recommend: 带类型注解的赋值
+ a: Foo = SomeUndecoratedFunction()
+ a: List[int]: [1, 2, 3] # List 只支持单一类型泛型,可使用 Union
+ b: Tuple[int, int] = (1, 2) # 长度固定为 2
+ c: Tuple[int, ...] = (1, 2, 3) # 变长
+ d: Dict[str, int] = {'a': 1, 'b': 2}
+
+ # Not Recommend:行尾类型注释
+ # 虽然这种方式被写在了 Google 开源指南中,但这是一种为了支持 Python 2.7 版本
+ # 而补充的注释方式,鉴于我们只支持 Python 3, 为了风格统一,不推荐使用这种方式。
+ a = SomeUndecoratedFunction() # type: Foo
+ a = [1, 2, 3] # type: List[int]
+ b = (1, 2, 3) # type: Tuple[int, ...]
+ c = (1, "2", 3.5) # type: Tuple[int, Text, float]
+ ```
+
+3. 泛型
+
+ 上文中我们知道,typing 中提供了 list 和 dict 的泛型类型,那么我们自己是否可以定义类似的泛型呢?
+
+ ```python
+ from typing import TypeVar, Generic
+
+ KT = TypeVar('KT')
+ VT = TypeVar('VT')
+
+ class Mapping(Generic[KT, VT]):
+ def __init__(self, data: Dict[KT, VT]):
+ self._data = data
+
+ def __getitem__(self, key: KT) -> VT:
+ return self._data[key]
+ ```
+
+ 使用上述方法,我们定义了一个拥有泛型能力的映射类,实际用法如下:
+
+ ```python
+ mapping = Mapping[str, float]({'a': 0.5})
+ value: float = example['a']
+ ```
+
+ 另外,我们也可以利用 TypeVar 在函数签名中指定联动的多个类型:
+
+ ```python
+ from typing import TypeVar, List
+
+ T = TypeVar('T') # Can be anything
+ A = TypeVar('A', str, bytes) # Must be str or bytes
+
+
+ def repeat(x: T, n: int) -> List[T]:
+ """Return a list containing n references to x."""
+ return [x]*n
+
+
+ def longest(x: A, y: A) -> A:
+ """Return the longest of two strings."""
+ return x if len(x) >= len(y) else y
+ ```
+
+更多关于类型注解的写法请参考 [typing](https://docs.python.org/3/library/typing.html)。
+
+#### 类型注解检查工具
+
+[mypy](https://mypy.readthedocs.io/en/stable/) 是一个 Python 静态类型检查工具。根据你的类型注解,mypy 会检查传参、赋值等操作是否符合类型注解,从而避免可能出现的 bug。
+
+例如如下的一个 Python 脚本文件 test.py:
+
+```python
+def foo(var: int) -> float:
+ return float(var)
+
+a: str = foo('2.0')
+b: int = foo('3.0') # type: ignore
+```
+
+运行 mypy test.py 可以得到如下检查结果,分别指出了第 4 行在函数调用和返回值赋值两处类型错误。而第 5 行同样存在两个类型错误,由于使用了 type: ignore 而被忽略了,只有部分特殊情况可能需要此类忽略。
+
+```
+test.py:4: error: Incompatible types in assignment (expression has type "float", variable has type "int")
+test.py:4: error: Argument 1 to "foo" has incompatible type "str"; expected "int"
+Found 2 errors in 1 file (checked 1 source file)
+```
diff --git a/docs/zh_cn/community/contributing.md b/docs/zh_cn/community/contributing.md
index b7bc1d22d9..e3aa781a5a 100644
--- a/docs/zh_cn/community/contributing.md
+++ b/docs/zh_cn/community/contributing.md
@@ -1,22 +1,230 @@
## 贡献代码
-欢迎任何类型的贡献,包括但不限于
+欢迎加入 MMCV 社区,我们致力于打造最前沿的计算机视觉基础库,我们欢迎任何类型的贡献,包括但不限于
-- 修改拼写错误或代码错误
-- 添加文档或将文档翻译成其他语言
-- 添加新功能和新组件
+**修复错误**
-### 工作流
+修复代码实现错误的步骤如下:
-| 详细工作流见 [拉取请求](pr.md)
+1. 如果提交的代码改动较大,建议先提交 issue,并正确描述 issue 的现象、原因和复现方式,讨论后确认修复方案。
+2. 修复错误并补充相应的单元测试,提交拉取请求。
-1. 复刻并拉取最新的 OpenMMLab 算法库
-2. 创建新的分支(不建议使用主分支提拉取请求)
-3. 提交你的修改
-4. 创建拉取请求
+**新增功能或组件**
+
+1. 如果新功能或模块涉及较大的代码改动,建议先提交 issue,确认功能的必要性。
+2. 实现新增功能并添单元测试,提交拉取请求。
+
+**文档补充**
+
+修复文档可以直接提交拉取请求
+
+添加文档或将文档翻译成其他语言步骤如下
+
+1. 提交 issue,确认添加文档的必要性。
+2. 添加文档,提交拉取请求。
+
+### 拉取请求工作流
+
+如果你对拉取请求不了解,没关系,接下来的内容将会从零开始,一步一步地指引你如何创建一个拉取请求。如果你想深入了解拉取请求的开发模式,可以参考 github [官方文档](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests)
+
+#### 1. 复刻仓库
+
+当你第一次提交拉取请求时,先复刻 OpenMMLab 原代码库,点击 GitHub 页面右上角的 **Fork** 按钮,复刻后的代码库将会出现在你的 GitHub 个人主页下。
+
+
+
+将代码克隆到本地
+
+```shell
+git clone git@github.com:{username}/mmcv.git
+```
+
+添加原代码库为上游代码库
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmcv
+```
+
+检查 remote 是否添加成功,在终端输入 `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmcv.git (fetch)
+origin git@github.com:{username}/mmcv.git (push)
+upstream git@github.com:open-mmlab/mmcv (fetch)
+upstream git@github.com:open-mmlab/mmcv (push)
+```
```{note}
-如果你计划添加新功能并且该功能包含比较大的改动,建议先开 issue 讨论
+这里对 origin 和 upstream 进行一个简单的介绍,当我们使用 git clone 来克隆代码时,会默认创建一个 origin 的 remote,它指向我们克隆的代码库地址,而 upstream 则是我们自己添加的,用来指向原始代码库地址。当然如果你不喜欢他叫 upstream,也可以自己修改,比如叫 open-mmlab。我们通常向 origin 提交代码(即 fork 下来的远程仓库),然后向 upstream 提交一个 pull request。如果提交的代码和最新的代码发生冲突,再从 upstream 拉取最新的代码,和本地分支解决冲突,再提交到 origin。
+```
+
+#### 2. 配置 pre-commit
+
+在本地开发环境中,我们使用 [pre-commit](https://pre-commit.com/#intro) 来检查代码风格,以确保代码风格的统一。在提交代码,需要先安装 pre-commit(需要在 MMCV 目录下执行):
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+检查 pre-commit 是否配置成功,并安装 `.pre-commit-config.yaml` 中的钩子:
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+
+
+```{note}
+如果你是中国用户,由于网络原因,可能会出现安装失败的情况,这时可以使用国内源
+
+pre-commit install -c .pre-commit-config-zh-cn.yaml
+
+pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
+```
+
+如果安装过程被中断,可以重复执行 `pre-commit run ...` 继续安装。
+
+如果提交的代码不符合代码风格规范,pre-commit 会发出警告,并自动修复部分错误。
+
+
+
+如果我们想临时绕开 pre-commit 的检查提交一次代码,可以在 `git commit` 时加上 `--no-verify`(需要保证最后推送至远程仓库的代码能够通过 pre-commit 检查)。
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. 创建开发分支
+
+安装完 pre-commit 之后,我们需要基于 master 创建开发分支,建议的分支命名规则为 `username/pr_name`。
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+在后续的开发中,如果本地仓库的 master 分支落后于 upstream 的 master 分支,我们需要先拉取 upstream 的代码进行同步,再执行上面的命令
+
+```shell
+git pull upstream master
+```
+
+#### 4. 提交代码并在本地通过单元测试
+
+- MMCV 引入了 mypy 来做静态类型检查,以增加代码的鲁棒性。因此我们在提交代码时,需要补充 Type Hints。具体规则可以参考[教程](https://zhuanlan.zhihu.com/p/519335398)。
+
+- 提交的代码同样需要通过单元测试
+
+ ```shell
+ # 通过全量单元测试
+ pytest tests
+
+ # 我们需要保证提交的代码能够通过修改模块的单元测试,以 runner 为例
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ 如果你由于缺少依赖无法运行修改模块的单元测试,可以参考[指引-单元测试](#单元测试)
+
+- 如果修改/添加了文档,参考[指引](#文档渲染)确认文档渲染正常。
+
+#### 5. 推送代码到远程
+
+代码通过单元测试和 pre-commit 检查后,将代码推送到远程仓库,如果是第一次推送,可以在 `git push` 后加上 `-u` 参数以关联远程分支
+
+```shell
+git push -u origin {branch_name}
+```
+
+这样下次就可以直接使用 `git push` 命令推送代码了,而无需指定分支和远程仓库。
+
+#### 6. 提交拉取请求(PR)
+
+(1) 在 GitHub 的 Pull request 界面创建拉取请求
+
+
+(2) 根据指引修改 PR 描述,以便于其他开发者更好地理解你的修改
+
+
+
+描述规范详见[拉取请求规范](#拉取请求规范)
+
+
+
+**注意事项**
+
+(a) PR 描述应该包含修改理由、修改内容以及修改后带来的影响,并关联相关 Issue(具体方式见[文档](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))
+
+(b) 如果是第一次为 OpenMMLab 做贡献,需要签署 CLA
+
+
+
+(c) 检查提交的 PR 是否通过 CI(集成测试)
+
+
+
+MMCV 会在不同的平台(Linux、Window、Mac),基于不同版本的 Python、PyTorch、CUDA 对提交的代码进行单元测试,以保证代码的正确性,如果有任何一个没有通过,我们可点击上图中的 `Details` 来查看具体的测试信息,以便于我们修改代码。
+
+(3) 如果 PR 通过了 CI,那么就可以等待其他开发者的 review,并根据 reviewer 的意见,修改代码,并重复 [4](#4-提交代码并本地通过单元测试)-[5](#5-推送代码到远程) 步骤,直到 reviewer 同意合入 PR。
+
+
+
+所有 reviewer 同意合入 PR 后,我们会尽快将 PR 合并到主分支。
+
+#### 7. 解决冲突
+
+随着时间的推移,我们的代码库会不断更新,这时候,如果你的 PR 与主分支存在冲突,你需要解决冲突,解决冲突的方式有两种:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+或者
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+如果你非常善于处理冲突,那么可以使用 rebase 的方式来解决冲突,因为这能够保证你的 commit log 的整洁。如果你不太熟悉 `rebase` 的使用,那么可以使用 `merge` 的方式来解决冲突。
+
+### 指引
+
+#### 单元测试
+
+如果你无法正常执行部分模块的单元测试,例如 [video](https://github.com/open-mmlab/mmcv/tree/master/mmcv/video) 模块,可能是你的当前环境没有安装以下依赖
+
+```shell
+# Linux
+sudo apt-get update -y
+sudo apt-get install -y libturbojpeg
+sudo apt-get install -y ffmpeg
+
+# Windows
+conda install ffmpeg
+```
+
+在提交修复代码错误或新增特性的拉取请求时,我们应该尽可能的让单元测试覆盖所有提交的代码,计算单元测试覆盖率的方法如下
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### 文档渲染
+
+在提交修复代码错误或新增特性的拉取请求时,可能会需要修改/新增模块的 docstring。我们需要确认渲染后的文档样式是正确的。
+本地生成渲染后的文档的方法如下
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
```
### 代码风格
@@ -38,20 +246,33 @@ yapf 和 isort 的配置可以在 [setup.cfg](./setup.cfg) 找到
修复 `end-of-files`、`double-quoted-strings`、`python-encoding-pragma`、`mixed-line-ending`,调整 `requirments.txt` 的包顺序。
pre-commit 钩子的配置可以在 [.pre-commit-config](./.pre-commit-config.yaml) 找到。
-在克隆算法库后,你需要安装并初始化 pre-commit 钩子
+pre-commit 具体的安装使用方式见[拉取请求](#2-配置-pre-commit)。
-```shell
-pip install -U pre-commit
-```
+更具体的规范请参考 [OpenMMLab 代码规范](code_style.md)。
-切换算法库根目录
+#### C++ and CUDA
-```shell
-pre-commit install
-```
+C++ 和 CUDA 的代码规范遵从 [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html)
-> 提交拉取请求前,请确保你的代码符合 yapf 的格式
+### 拉取请求规范
-#### C++ and CUDA
+1. 使用 [pre-commit hook](https://pre-commit.com),尽量减少代码风格相关问题
-C++ 和 CUDA 的代码规范遵从 [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html)
+2. 一个`拉取请求`对应一个短期分支
+
+3. 粒度要细,一个`拉取请求`只做一件事情,避免超大的`拉取请求`
+
+ - Bad:实现 Faster R-CNN
+ - Acceptable:给 Faster R-CNN 添加一个 box head
+ - Good:给 box head 增加一个参数来支持自定义的 conv 层数
+
+4. 每次 Commit 时需要提供清晰且有意义 commit 信息
+
+5. 提供清晰且有意义的`拉取请求`描述
+
+ - 标题写明白任务名称,一般格式:\[Prefix\] Short description of the pull request (Suffix)
+ - prefix: 新增功能 \[Feature\], 修 bug \[Fix\], 文档相关 \[Docs\], 开发中 \[WIP\] (暂时不会被review)
+ - 描述里介绍`拉取请求`的主要修改内容,结果,以及对其他部分的影响, 参考`拉取请求`模板
+ - 关联相关的`议题` (issue) 和其他`拉取请求`
+
+6. 如果引入了其他三方库,或借鉴了三方库的代码,请确认他们的许可证和 mmcv 兼容,并在借鉴的代码上补充 `This code is inspired from http://`
diff --git a/docs/zh_cn/community/pr.md b/docs/zh_cn/community/pr.md
index 720f389863..427fdf9e49 100644
--- a/docs/zh_cn/community/pr.md
+++ b/docs/zh_cn/community/pr.md
@@ -1,114 +1,3 @@
## 拉取请求
-### 什么是拉取请求?
-
-`拉取请求` (Pull Request), [GitHub 官方文档](https://docs.github.com/en/github/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/about-pull-requests)定义如下。
-
-```
-拉取请求是一种通知机制。你修改了他人的代码,将你的修改通知原来作者,希望他合并你的修改。
-```
-
-### 基本的工作流:
-
-1. 获取最新的代码库
-2. 从主分支创建最新的分支进行开发
-3. 提交修改
-4. 推送你的修改并创建一个 `拉取请求`
-5. 讨论、审核代码
-6. 将开发分支合并到主分支
-
-### 具体步骤
-
-#### 1. 获取最新的代码库
-
-- 当你第一次提 PR 时
-
- 复刻 OpenMMLab 原代码库,点击 GitHub 页面右上角的 **Fork** 按钮即可
- 
-
- 克隆复刻的代码库到本地
-
- ```bash
- git clone git@github.com:XXX/mmcv.git
- ```
-
- 添加原代码库为上游代码库
-
- ```bash
- git remote add upstream git@github.com:open-mmlab/mmcv
- ```
-
-- 从第二个 PR 起
-
- 检出本地代码库的主分支,然后从最新的原代码库的主分支拉取更新
-
- ```bash
- git checkout master
- git pull upstream master
- ```
-
-#### 2. 从主分支创建一个新的开发分支
-
-```bash
-git checkout -b branchname
-```
-
-```{tip}
-为了保证提交历史清晰可读,我们强烈推荐您先检出主分支 (master),再创建新的分支。
-```
-
-#### 3. 提交你的修改
-
-```bash
-# coding
-git add [files]
-git commit -m 'messages'
-```
-
-#### 4. 推送你的修改到复刻的代码库,并创建一个`拉取请求`
-
-- 推送当前分支到远端复刻的代码库
-
- ```bash
- git push origin branchname
- ```
-
-- 创建一个`拉取请求`
- 
-
-- 修改`拉取请求`信息模板,描述修改原因和修改内容。还可以在 PR 描述中,手动关联到相关的`议题` (issue),(更多细节,请参考[官方文档](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))。
-
-#### 5. 讨论并评审你的代码
-
-- 创建`拉取请求`时,可以关联给相关人员进行评审
- 
-
-- 根据评审人员的意见修改代码,并推送修改
-
-#### 6. `拉取请求`合并之后删除该分支
-
-```bash
-git branch -d branchname # delete local branch
-git push origin --delete branchname # delete remote branch
-```
-
-### PR 规范
-
-1. 使用 [pre-commit hook](https://pre-commit.com),尽量减少代码风格相关问题
-
-2. 一个 PR 对应一个短期分支
-
-3. 粒度要细,一个PR只做一件事情,避免超大的PR
-
- - Bad:实现 Faster R-CNN
- - Acceptable:给 Faster R-CNN 添加一个 box head
- - Good:给 box head 增加一个参数来支持自定义的 conv 层数
-
-4. 每次 Commit 时需要提供清晰且有意义 commit 信息
-
-5. 提供清晰且有意义的`拉取请求`描述
-
- - 标题写明白任务名称,一般格式:\[Prefix\] Short description of the pull request (Suffix)
- - prefix: 新增功能 \[Feature\], 修 bug \[Fix\], 文档相关 \[Docs\], 开发中 \[WIP\] (暂时不会被review)
- - 描述里介绍`拉取请求`的主要修改内容,结果,以及对其他部分的影响, 参考`拉取请求`模板
- - 关联相关的`议题` (issue) 和其他`拉取请求`
+本文档的内容已迁移到[贡献指南](contributing.md)。
diff --git a/docs/zh_cn/get_started/build.md b/docs/zh_cn/get_started/build.md
index efbaebff4a..95f611bc2e 100644
--- a/docs/zh_cn/get_started/build.md
+++ b/docs/zh_cn/get_started/build.md
@@ -90,7 +90,7 @@ pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
| TODO: 视频教程
```{note}
-如果你使用的 mac 是 M1 芯片,请安装 PyTorch 的 nightly 版本,否则会遇到 [issues#2218](https://github.com/open-mmlab/mmcv/issues/2218) 中的问题。
+如果你使用的是搭载 apple silicon 的 mac 设备,请安装 PyTorch 1.13+ 的版本,否则会遇到 [issues#2218](https://github.com/open-mmlab/mmcv/issues/2218) 中的问题。
```
1. 克隆代码仓库
diff --git a/docs/zh_cn/get_started/installation.md b/docs/zh_cn/get_started/installation.md
index 3e72a72363..86e3454b96 100644
--- a/docs/zh_cn/get_started/installation.md
+++ b/docs/zh_cn/get_started/installation.md
@@ -29,7 +29,7 @@ python -c 'import torch;print(torch.__version__)'
```bash
pip install -U openmim
-mim install 'mmcv>=2.0.0rc1'
+mim install "mmcv>=2.0.0rc1"
```
如果发现上述的安装命令没有使用预编译包(以 `.whl` 结尾)而是使用源码包(以 `.tar.gz` 结尾)安装,则有可能是我们没有提供和当前环境的 PyTorch 版本、CUDA 版本相匹配的 mmcv 预编译包,此时,你可以[源码安装 mmcv](build.md)。
@@ -64,7 +64,7 @@ mim install mmcv==2.0.0rc1
另外,如果安装依赖库的时间过长,可以指定 pypi 源
```bash
-mim install 'mmcv>=2.0.0rc1' -i https://pypi.tuna.tsinghua.edu.cn/simple
+mim install "mmcv>=2.0.0rc1" -i https://pypi.tuna.tsinghua.edu.cn/simple
```
:::
@@ -317,7 +317,7 @@ PyTorch 版本是 1.8.1,你可以放心选择 1.8.x。
另外,如果安装依赖库的时间过长,可以指定 pypi 源
```bash
-pip install mmcv -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.9.0/index.html -i https://pypi.tuna.tsinghua.edu.cn/simple
+pip install "mmcv>=2.0.0rc1" -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.9.0/index.html -i https://pypi.tuna.tsinghua.edu.cn/simple
```
:::
diff --git a/docs/zh_cn/index.rst b/docs/zh_cn/index.rst
index 2d3525131b..98cf088906 100644
--- a/docs/zh_cn/index.rst
+++ b/docs/zh_cn/index.rst
@@ -43,6 +43,7 @@
community/contributing.md
community/pr.md
+ community/code_style.md
.. toctree::
:maxdepth: 1
diff --git a/docs/zh_cn/understand_mmcv/ops.md b/docs/zh_cn/understand_mmcv/ops.md
index 242cf6b7b0..6b4622146c 100644
--- a/docs/zh_cn/understand_mmcv/ops.md
+++ b/docs/zh_cn/understand_mmcv/ops.md
@@ -27,13 +27,13 @@ MMCV 提供了检测、分割等任务中常用的算子
| FusedBiasLeakyrelu | | √ | | |
| GatherPoints | | √ | | |
| GroupPoints | | √ | | |
-| Iou3d | | √ | | |
+| Iou3d | | √ | √ | |
| KNN | | √ | | |
| MaskedConv | | √ | √ | |
| MergeCells | | √ | | |
| MinAreaPolygon | | √ | | |
| ModulatedDeformConv2d | √ | √ | | |
-| MultiScaleDeformableAttn | | √ | | |
+| MultiScaleDeformableAttn | | √ | √ | |
| NMS | √ | √ | √ | |
| NMSRotated | √ | √ | | |
| NMSQuadri | √ | √ | | |
@@ -47,7 +47,7 @@ MMCV 提供了检测、分割等任务中常用的算子
| RoIAlignRotated | √ | √ | √ | |
| RiRoIAlignRotated | | √ | | |
| RoIAlign | √ | √ | √ | |
-| RoIAwarePool3d | | √ | | |
+| RoIAwarePool3d | | √ | √ | |
| SAConv2d | | √ | | |
| SigmoidFocalLoss | | √ | √ | |
| SoftmaxFocalLoss | | √ | | |
diff --git a/mmcv/ops/ball_query.py b/mmcv/ops/ball_query.py
index d24e0446ca..a89b36b52b 100644
--- a/mmcv/ops/ball_query.py
+++ b/mmcv/ops/ball_query.py
@@ -1,28 +1,44 @@
# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Tuple
+from typing import Optional, Tuple
import torch
from torch.autograd import Function
from ..utils import ext_loader
-ext_module = ext_loader.load_ext('_ext', ['ball_query_forward'])
+ext_module = ext_loader.load_ext(
+ '_ext', ['ball_query_forward', 'stack_ball_query_forward'])
class BallQuery(Function):
"""Find nearby points in spherical space."""
@staticmethod
- def forward(ctx, min_radius: float, max_radius: float, sample_num: int,
- xyz: torch.Tensor, center_xyz: torch.Tensor) -> torch.Tensor:
+ def forward(
+ ctx,
+ min_radius: float,
+ max_radius: float,
+ sample_num: int,
+ xyz: torch.Tensor,
+ center_xyz: torch.Tensor,
+ xyz_batch_cnt: Optional[torch.Tensor] = None,
+ center_xyz_batch_cnt: Optional[torch.Tensor] = None
+ ) -> torch.Tensor:
"""
Args:
min_radius (float): minimum radius of the balls.
max_radius (float): maximum radius of the balls.
sample_num (int): maximum number of features in the balls.
- xyz (torch.Tensor): (B, N, 3) xyz coordinates of the features.
+ xyz (torch.Tensor): (B, N, 3) xyz coordinates of the features,
+ or staked input (N1 + N2 ..., 3).
center_xyz (torch.Tensor): (B, npoint, 3) centers of the ball
- query.
+ query, or staked input (M1 + M2 ..., 3).
+ xyz_batch_cnt: (batch_size): Stacked input xyz coordinates nums in
+ each batch, just like (N1, N2, ...). Defaults to None.
+ New in version 1.7.0.
+ center_xyz_batch_cnt: (batch_size): Stacked centers coordinates
+ nums in each batch, just line (M1, M2, ...). Defaults to None.
+ New in version 1.7.0.
Returns:
torch.Tensor: (B, npoint, nsample) tensor with the indices of the
@@ -31,21 +47,34 @@ def forward(ctx, min_radius: float, max_radius: float, sample_num: int,
assert center_xyz.is_contiguous()
assert xyz.is_contiguous()
assert min_radius < max_radius
-
- B, N, _ = xyz.size()
- npoint = center_xyz.size(1)
- idx = xyz.new_zeros(B, npoint, sample_num, dtype=torch.int)
-
- ext_module.ball_query_forward(
- center_xyz,
- xyz,
- idx,
- b=B,
- n=N,
- m=npoint,
- min_radius=min_radius,
- max_radius=max_radius,
- nsample=sample_num)
+ if xyz_batch_cnt is not None and center_xyz_batch_cnt is not None:
+ assert xyz_batch_cnt.dtype == torch.int
+ assert center_xyz_batch_cnt.dtype == torch.int
+ idx = center_xyz.new_zeros((center_xyz.shape[0], sample_num),
+ dtype=torch.int32)
+ ext_module.stack_ball_query_forward(
+ center_xyz,
+ center_xyz_batch_cnt,
+ xyz,
+ xyz_batch_cnt,
+ idx,
+ max_radius=max_radius,
+ nsample=sample_num,
+ )
+ else:
+ B, N, _ = xyz.size()
+ npoint = center_xyz.size(1)
+ idx = xyz.new_zeros(B, npoint, sample_num, dtype=torch.int32)
+ ext_module.ball_query_forward(
+ center_xyz,
+ xyz,
+ idx,
+ b=B,
+ n=N,
+ m=npoint,
+ min_radius=min_radius,
+ max_radius=max_radius,
+ nsample=sample_num)
if torch.__version__ != 'parrots':
ctx.mark_non_differentiable(idx)
return idx
diff --git a/mmcv/ops/csrc/common/cuda/correlation_cuda.cuh b/mmcv/ops/csrc/common/cuda/correlation_cuda.cuh
index 703de8232d..f910561ec3 100644
--- a/mmcv/ops/csrc/common/cuda/correlation_cuda.cuh
+++ b/mmcv/ops/csrc/common/cuda/correlation_cuda.cuh
@@ -36,7 +36,8 @@ template
__global__ void correlation_forward_cuda_kernel(
const TensorAcc4R rInput1, const TensorAcc4R rInput2, TensorAcc5R output,
int kH, int kW, int patchH, int patchW, int padH, int padW, int dilationH,
- int dilationW, int dilation_patchH, int dilation_patchW, int dH, int dW) {
+ int dilationW, int dilation_patchH, int dilation_patchW, int dH, int dW,
+ int oH, int oW) {
const int iH = rInput1.size(1);
const int iW = rInput1.size(2);
const int C = rInput1.size(3);
@@ -44,6 +45,9 @@ __global__ void correlation_forward_cuda_kernel(
const int n = blockIdx.x;
const int h = blockIdx.y * blockDim.y + threadIdx.y;
const int w = blockIdx.z * blockDim.z + threadIdx.z;
+
+ if (h >= oH || w >= oW) return;
+
const int thread = threadIdx.x;
const int start_i = -padH + h * dH;
@@ -60,21 +64,19 @@ __global__ void correlation_forward_cuda_kernel(
for (int i = 0; i < kH; ++i) {
int i1 = start_i + i * dilationH;
int i2 = i1 + ph_dilated;
- if
- WITHIN_BOUNDS(i1, i2, iH, iH) {
- for (int j = 0; j < kW; ++j) {
- int j1 = start_j + j * dilationW;
- int j2 = j1 + pw_dilated;
- if
- WITHIN_BOUNDS(j1, j2, iW, iW) {
- for (int c = thread; c < C; c += WARP_SIZE) {
- scalar_t v1 = rInput1[n][i1][j1][c];
- scalar_t v2 = rInput2[n][i2][j2][c];
- prod_sum += v1 * v2;
- }
- }
+ if (WITHIN_BOUNDS(i1, i2, iH, iH)) {
+ for (int j = 0; j < kW; ++j) {
+ int j1 = start_j + j * dilationW;
+ int j2 = j1 + pw_dilated;
+ if (WITHIN_BOUNDS(j1, j2, iW, iW)) {
+ for (int c = thread; c < C; c += WARP_SIZE) {
+ scalar_t v1 = rInput1[n][i1][j1][c];
+ scalar_t v2 = rInput2[n][i2][j2][c];
+ prod_sum += v1 * v2;
+ }
}
}
+ }
}
// accumulate
for (int offset = 16; offset > 0; offset /= 2)
diff --git a/mmcv/ops/csrc/common/cuda/stack_ball_query_cuda_kernel.cuh b/mmcv/ops/csrc/common/cuda/stack_ball_query_cuda_kernel.cuh
new file mode 100644
index 0000000000..06caefa18d
--- /dev/null
+++ b/mmcv/ops/csrc/common/cuda/stack_ball_query_cuda_kernel.cuh
@@ -0,0 +1,68 @@
+// Copyright (c) OpenMMLab. All rights reserved
+// Modified from
+// https://github.com/sshaoshuai/Pointnet2.PyTorch/tree/master/pointnet2/src/ball_query_gpu.cu
+#ifndef STACK_BALL_QUERY_CUDA_KERNEL_CUH
+#define STACK_BALL_QUERY_CUDA_KERNEL_CUH
+
+#ifdef MMCV_USE_PARROTS
+#include "parrots_cuda_helper.hpp"
+#else
+#include "pytorch_cuda_helper.hpp"
+#endif
+
+template
+__global__ void stack_ball_query_forward_cuda_kernel(
+ int B, int M, float radius, int nsample, const T *new_xyz,
+ const int *new_xyz_batch_cnt, const T *xyz, const int *xyz_batch_cnt,
+ int *idx) {
+ // :param xyz: (N1 + N2 ..., 3) xyz coordinates of the features
+ // :param xyz_batch_cnt: (batch_size), [N1, N2, ...]
+ // :param new_xyz: (M1 + M2 ..., 3) centers of the ball query
+ // :param new_xyz_batch_cnt: (batch_size), [M1, M2, ...]
+ // output:
+ // idx: (M, nsample)
+ const T *cur_xyz = xyz;
+ int *cur_idx = idx;
+ CUDA_1D_KERNEL_LOOP(pt_idx, M) {
+ int bs_idx = 0;
+ for (int pt_cnt = 0; bs_idx < B; bs_idx++) {
+ pt_cnt += new_xyz_batch_cnt[bs_idx];
+ if (pt_idx < pt_cnt) break;
+ }
+
+ int xyz_batch_start_idx = 0;
+ for (int k = 0; k < bs_idx; k++) xyz_batch_start_idx += xyz_batch_cnt[k];
+
+ const T *new_xyz_p = new_xyz + pt_idx * 3;
+ cur_xyz += xyz_batch_start_idx * 3;
+ cur_idx += pt_idx * nsample;
+
+ float radius2 = radius * radius;
+ T new_x = new_xyz_p[0];
+ T new_y = new_xyz_p[1];
+ T new_z = new_xyz_p[2];
+ int n = xyz_batch_cnt[bs_idx];
+
+ int cnt = 0;
+ for (int k = 0; k < n; ++k) {
+ T x = cur_xyz[k * 3 + 0];
+ T y = cur_xyz[k * 3 + 1];
+ T z = cur_xyz[k * 3 + 2];
+ T d2 = (new_x - x) * (new_x - x) + (new_y - y) * (new_y - y) +
+ (new_z - z) * (new_z - z);
+ if (d2 < radius2) {
+ if (cnt == 0) {
+ for (int l = 0; l < nsample; ++l) {
+ cur_idx[l] = k;
+ }
+ }
+ cur_idx[cnt] = k;
+ ++cnt;
+ if (cnt >= nsample) break;
+ }
+ }
+ if (cnt == 0) cur_idx[0] = -1;
+ }
+}
+
+#endif // STACK_BALL_QUERY_CUDA_KERNEL_CUH
diff --git a/mmcv/ops/csrc/common/cuda/stack_group_points_cuda_kernel.cuh b/mmcv/ops/csrc/common/cuda/stack_group_points_cuda_kernel.cuh
new file mode 100644
index 0000000000..4ef3663d05
--- /dev/null
+++ b/mmcv/ops/csrc/common/cuda/stack_group_points_cuda_kernel.cuh
@@ -0,0 +1,97 @@
+// Copyright (c) OpenMMLab. All rights reserved.
+// Modified from
+// https://github.com/sshaoshuai/Pointnet2.PyTorch/tree/master/pointnet2/src/group_points_gpu.cu
+#ifndef STACK_GROUP_POINTS_CUDA_KERNEL_CUH
+#define STACK_GROUP_POINTS_CUDA_KERNEL_CUH
+#ifdef MMCV_USE_PARROTS
+#include "parrots_cuda_helper.hpp"
+#else
+#include "pytorch_cuda_helper.hpp"
+#endif
+#include
+template
+__global__ void stack_group_points_forward_cuda_kernel(
+ int b, int c, int m, int nsample, const T *features,
+ const int *features_batch_cnt, const int *idx, const int *idx_batch_cnt,
+ T *out) {
+ // :param features: (N1 + N2 ..., C) tensor of features to group
+ // :param features_batch_cnt: (batch_size) [N1 + N2 ...] tensor containing the
+ // indices of features to group with :param idx: (M1 + M2 ..., nsample) tensor
+ // containing the indices of features to group with :param idx_batch_cnt:
+ // (batch_size) [M1 + M2 ...] tensor containing the indices of features to
+ // group with :return:
+ // output: (M1 + M2, C, nsample) tensor
+ CUDA_1D_KERNEL_LOOP(index, m * c * nsample) {
+ const T *cur_features = features;
+ const int *cur_idx = idx;
+ int sample_idx = index % nsample;
+ int c_idx = (index / nsample) % c;
+ int pt_idx = (index / nsample / c);
+
+ if (pt_idx >= m || c_idx >= c || sample_idx >= nsample) return;
+ int bs_idx = 0, pt_cnt = idx_batch_cnt[0];
+ for (int k = 1; k < b; k++) {
+ if (pt_idx < pt_cnt) break;
+ pt_cnt += idx_batch_cnt[k];
+ bs_idx = k;
+ }
+
+ int features_batch_start_idx = 0;
+ int features_batch_end_idx = features_batch_cnt[0];
+ for (int k = 0; k < bs_idx; k++) {
+ features_batch_start_idx += features_batch_cnt[k];
+ features_batch_end_idx =
+ features_batch_start_idx + features_batch_cnt[k + 1];
+ }
+ cur_features += features_batch_start_idx * c;
+
+ cur_idx += pt_idx * nsample + sample_idx;
+ int in_idx = cur_idx[0] * c + c_idx;
+ int out_idx = pt_idx * c * nsample + c_idx * nsample + sample_idx;
+ if (in_idx < features_batch_end_idx * c) {
+ out[out_idx] = cur_features[in_idx];
+ }
+ }
+}
+
+template
+__global__ void stack_group_points_backward_cuda_kernel(
+ int b, int c, int m, int n, int nsample, const T *grad_out, const int *idx,
+ const int *idx_batch_cnt, const int *features_batch_cnt, T *grad_features) {
+ // :param grad_out: (M1 + M2 ..., C, nsample) tensor of the gradients of the
+ // output from forward :param idx: (M1 + M2 ..., nsample) tensor containing
+ // the indices of features to group with :param idx_batch_cnt: (batch_size)
+ // [M1 + M2 ...] tensor containing the indices of features to group with
+ // :param features_batch_cnt: (batch_size) [N1 + N2 ...] tensor containing the
+ // indices of features to group with :return:
+ // grad_features: (N1 + N2 ..., C) gradient of the features
+ CUDA_1D_KERNEL_LOOP(index, m * c * nsample) {
+ const T *cur_grad_out = grad_out;
+ const int *cur_idx = idx;
+ T *cur_grad_features = grad_features;
+ int sample_idx = index % nsample;
+ int c_idx = (index / nsample) % c;
+ int pt_idx = (index / nsample / c);
+
+ if (pt_idx >= m || c_idx >= c || sample_idx >= nsample) return;
+
+ int bs_idx = 0, pt_cnt = idx_batch_cnt[0];
+ for (int k = 1; k < b; k++) {
+ if (pt_idx < pt_cnt) break;
+ pt_cnt += idx_batch_cnt[k];
+ bs_idx = k;
+ }
+
+ int features_batch_start_idx = 0;
+ for (int k = 0; k < bs_idx; k++)
+ features_batch_start_idx += features_batch_cnt[k];
+
+ cur_grad_out += pt_idx * c * nsample + c_idx * nsample + sample_idx;
+ cur_idx += pt_idx * nsample + sample_idx;
+ cur_grad_features += (features_batch_start_idx + cur_idx[0]) * c + c_idx;
+
+ atomicAdd(cur_grad_features, cur_grad_out[0]);
+ }
+}
+
+#endif // GROUP_POINTS_CUDA_KERNEL_CUH
diff --git a/mmcv/ops/csrc/common/mlu/bbox_overlaps_mlu_kernel.mlu b/mmcv/ops/csrc/common/mlu/bbox_overlaps_mlu_kernel.mlu
index 58e695a015..0f273d2508 100644
--- a/mmcv/ops/csrc/common/mlu/bbox_overlaps_mlu_kernel.mlu
+++ b/mmcv/ops/csrc/common/mlu/bbox_overlaps_mlu_kernel.mlu
@@ -88,14 +88,14 @@ __mlu_func__ void bboxOverlapsWorkflow(
// right - left + offset ---> left
__bang_sub(vec_left, vec_right, vec_left, batches_stride);
- __bang_add_const(vec_left, vec_left, (T)offset, batches_stride);
+ __bang_add_scalar(vec_left, vec_left, (T)offset, batches_stride);
// bottom - top + offset ---> right
__bang_sub(vec_right, vec_bottom, vec_top, batches_stride);
- __bang_add_const(vec_right, vec_right, (T)offset, batches_stride);
+ __bang_add_scalar(vec_right, vec_right, (T)offset, batches_stride);
// zero vector ---> bottom
- __nramset(vec_bottom, batches_stride, 0.f);
+ __bang_write_value(vec_bottom, batches_stride, 0.f);
// width --> vec_left
__bang_maxequal(vec_left, vec_bottom, vec_left, batches_stride);
@@ -107,11 +107,11 @@ __mlu_func__ void bboxOverlapsWorkflow(
// get the b1_area
// (b1_x2 - b1_x1 + offset) ---> vec_top
__bang_sub(vec_top, vec_b1_x2, vec_b1_x1, batches_stride);
- __bang_add_const(vec_top, vec_top, (T)offset, batches_stride);
+ __bang_add_scalar(vec_top, vec_top, (T)offset, batches_stride);
// (b1_y2 - b1_y1 + offset) ---> vec_bottom
__bang_sub(vec_bottom, vec_b1_y2, vec_b1_y1, batches_stride);
- __bang_add_const(vec_bottom, vec_bottom, (T)offset, batches_stride);
+ __bang_add_scalar(vec_bottom, vec_bottom, (T)offset, batches_stride);
// b1_area = (b1_x2 - b1_x1 + offset) * (b1_y2 - b1_y1 + offset)
// ---> vec_top;
@@ -121,11 +121,11 @@ __mlu_func__ void bboxOverlapsWorkflow(
// get the b2_area
// (b2_x2 - b2_x1 + offset) ---> b2_x1
__bang_sub(vec_b2_x1, vec_b2_x2, vec_b2_x1, batches_stride);
- __bang_add_const(vec_b2_x1, vec_b2_x1, (T)offset, batches_stride);
+ __bang_add_scalar(vec_b2_x1, vec_b2_x1, (T)offset, batches_stride);
// (b2_y2 - b2_y1 + offset) ---> b2_y1
__bang_sub(vec_b2_y1, vec_b2_y2, vec_b2_y1, batches_stride);
- __bang_add_const(vec_b2_y1, vec_b2_y1, (T)offset, batches_stride);
+ __bang_add_scalar(vec_b2_y1, vec_b2_y1, (T)offset, batches_stride);
// b2_area = (b2_x2 - b2_x1 + offset) * (b2_y2 - b2_y1 + offset)
// ---> b2_x1;
@@ -137,7 +137,7 @@ __mlu_func__ void bboxOverlapsWorkflow(
T *inter_s = height;
// offset vector ---> vec_b2_y1
- __nramset(vec_b2_y1, batches_stride, T(offset));
+ __bang_write_value(vec_b2_y1, batches_stride, T(offset));
T *vec_offset = vec_b2_y1;
if (mode == 0) {
@@ -164,10 +164,10 @@ __mlu_func__ void bboxOverlapsWorkflow(
int32_t base1 = b1 * COORD_NUM;
// set bbox1 and bbox2 to nram
- __nramset(vec_b1_x1, batches_stride, bbox1[base1]);
- __nramset(vec_b1_y1, batches_stride, bbox1[base1 + 1]);
- __nramset(vec_b1_x2, batches_stride, bbox1[base1 + 2]);
- __nramset(vec_b1_y2, batches_stride, bbox1[base1 + 3]);
+ __bang_write_value(vec_b1_x1, batches_stride, bbox1[base1]);
+ __bang_write_value(vec_b1_y1, batches_stride, bbox1[base1 + 1]);
+ __bang_write_value(vec_b1_x2, batches_stride, bbox1[base1 + 2]);
+ __bang_write_value(vec_b1_y2, batches_stride, bbox1[base1 + 3]);
for (int32_t j = 0; j < num_loop_cpy; j++) {
int32_t index2 = j * batches_stride;
@@ -195,13 +195,13 @@ __mlu_func__ void bboxOverlapsWorkflow(
// right - left + offset ---> left
__bang_sub(vec_left, vec_right, vec_left, batches_stride);
- __bang_add_const(vec_left, vec_left, (T)offset, batches_stride);
+ __bang_add_scalar(vec_left, vec_left, (T)offset, batches_stride);
// bottom - top + offset ---> right
__bang_sub(vec_right, vec_bottom, vec_top, batches_stride);
- __bang_add_const(vec_right, vec_right, (T)offset, batches_stride);
+ __bang_add_scalar(vec_right, vec_right, (T)offset, batches_stride);
// zero vector ---> bottom
- __nramset(vec_bottom, batches_stride, (T)0);
+ __bang_write_value(vec_bottom, batches_stride, (T)0);
// width --> vec_left
__bang_maxequal(vec_left, vec_bottom, vec_left, batches_stride);
@@ -213,10 +213,10 @@ __mlu_func__ void bboxOverlapsWorkflow(
// get the b1_area
// (b1_x2 - b1_x1 + offset) ---> vec_top
__bang_sub(vec_top, vec_b1_x2, vec_b1_x1, batches_stride);
- __bang_add_const(vec_top, vec_top, (T)offset, batches_stride);
+ __bang_add_scalar(vec_top, vec_top, (T)offset, batches_stride);
// (b1_y2 - b1_y1 + offset) ---> vec_bottom
__bang_sub(vec_bottom, vec_b1_y2, vec_b1_y1, batches_stride);
- __bang_add_const(vec_bottom, vec_bottom, (T)offset, batches_stride);
+ __bang_add_scalar(vec_bottom, vec_bottom, (T)offset, batches_stride);
// b1_area = (b1_x2 - b1_x1 + offset) * (b1_y2 - b1_y1 + offset)
// ---> vec_top;
__bang_mul(vec_top, vec_top, vec_bottom, batches_stride);
@@ -225,10 +225,10 @@ __mlu_func__ void bboxOverlapsWorkflow(
// get the b2_area
// (b2_x2 - b2_x1 + offset) ---> b2_x1
__bang_sub(vec_b2_x1, vec_b2_x2, vec_b2_x1, batches_stride);
- __bang_add_const(vec_b2_x1, vec_b2_x1, (T)offset, batches_stride);
+ __bang_add_scalar(vec_b2_x1, vec_b2_x1, (T)offset, batches_stride);
// (b2_y2 - b2_y1 + offset) ---> b2_y1
__bang_sub(vec_b2_y1, vec_b2_y2, vec_b2_y1, batches_stride);
- __bang_add_const(vec_b2_y1, vec_b2_y1, (T)offset, batches_stride);
+ __bang_add_scalar(vec_b2_y1, vec_b2_y1, (T)offset, batches_stride);
// b2_area = (b2_x2 - b2_x1 + offset) * (b2_y2 - b2_y1 + offset)
// ---> b2_x1;
__bang_mul(vec_b2_x1, vec_b2_x1, vec_b2_y1, batches_stride);
@@ -239,7 +239,7 @@ __mlu_func__ void bboxOverlapsWorkflow(
T *inter_s = height;
// offset vector ---> vec_b2_y1
- __nramset(vec_b2_y1, batches_stride, T(offset));
+ __bang_write_value(vec_b2_y1, batches_stride, T(offset));
T *vec_offset = vec_b2_y1;
if (mode == 0) {
diff --git a/mmcv/ops/csrc/common/mlu/carafe_mlu_kernel.mlu b/mmcv/ops/csrc/common/mlu/carafe_mlu_kernel.mlu
index ac5ea0d653..8dd6a8e582 100644
--- a/mmcv/ops/csrc/common/mlu/carafe_mlu_kernel.mlu
+++ b/mmcv/ops/csrc/common/mlu/carafe_mlu_kernel.mlu
@@ -139,7 +139,7 @@ __mlu_func__ void carafeForwardBLOCK(T *input, T *mask,
blkEnd.Wo = blkStart.Wo + blkSize.Wo - 1;
// set output_nram to zero
- __nramset(output_nram, param.output_nram_size, T(0));
+ __bang_write_value(output_nram, param.output_nram_size, T(0));
// loop blocks of kernel window: grid_dim.(Kh, Kw)
for (blkId.Kh = 0; blkId.Kh < grid_dim.Kh; ++blkId.Kh) {
@@ -313,8 +313,8 @@ __mlu_func__ void carafeForwardBLOCK(T *input, T *mask,
T *sum = sum_array;
for (int g = 0; g < blkSize.G; ++g) {
- __bang_mul_const(sum, src, mask_array[mask_index],
- param.block_Cg_NFU);
+ __bang_mul_scalar(sum, src, mask_array[mask_index],
+ param.block_Cg_NFU);
//
// NOTE: Since block_Cg_NFU >= block_Cg_stride,
// overlapped writing may occur on sum_array.
@@ -446,8 +446,8 @@ __mlu_func__ void CarafeCompute(T *input, T *mask, T *grad_output,
T *base_grad_input = (T *)grad_input + input_index;
__memcpy((T *)input_buff, (T *)base_input, num_align * sizeof(T),
GDRAM2NRAM);
- __bang_mul_const((T *)grad_input_buff, (T *)grad_output_buff,
- ((T *)mask_buff)[mask_index], num_align);
+ __bang_mul_scalar((T *)grad_input_buff, (T *)grad_output_buff,
+ ((T *)mask_buff)[mask_index], num_align);
__bang_atomic_add((T *)grad_input_buff, (T *)base_grad_input,
(T *)grad_input_buff, num_align);
__bang_mul((T *)input_buff, (T *)grad_output_buff, (T *)input_buff,
@@ -485,8 +485,8 @@ __mlu_func__ void CarafeCompute(T *input, T *mask, T *grad_output,
T *base_grad_input = (T *)grad_input + input_index;
__memcpy((T *)input_buff, (T *)base_input, rem_for_loop * sizeof(T),
GDRAM2NRAM);
- __bang_mul_const((T *)grad_input_buff, (T *)grad_output_buff,
- ((T *)mask_buff)[mask_index], rem_for_loop_align);
+ __bang_mul_scalar((T *)grad_input_buff, (T *)grad_output_buff,
+ ((T *)mask_buff)[mask_index], rem_for_loop_align);
__bang_atomic_add((T *)grad_input_buff, (T *)base_grad_input,
(T *)grad_input_buff, rem_for_loop);
__bang_mul((T *)input_buff, (T *)grad_output_buff, (T *)input_buff,
@@ -541,12 +541,12 @@ void KernelCarafeBackward(cnrtDim3_t k_dim, cnrtFunctionType_t k_type,
const int wi, const int c, const int k_up,
const int group, const int scale) {
if (dtype == CNRT_FLOAT16) {
- backward::MLUUnion1KernelCarafeBackward
- <<>>(input, mask, grad_output, grad_input,
- grad_mask, n, hi, wi, c, k_up, group, scale);
+ backward::MLUUnion1KernelCarafeBackward<<>>(
+ input, mask, grad_output, grad_input, grad_mask, n, hi, wi, c, k_up,
+ group, scale);
} else {
- backward::MLUUnion1KernelCarafeBackward
- <<>>(input, mask, grad_output, grad_input,
- grad_mask, n, hi, wi, c, k_up, group, scale);
+ backward::MLUUnion1KernelCarafeBackward<<>>(
+ input, mask, grad_output, grad_input, grad_mask, n, hi, wi, c, k_up,
+ group, scale);
}
}
diff --git a/mmcv/ops/csrc/common/mlu/common_mlu_helper.hpp b/mmcv/ops/csrc/common/mlu/common_mlu_helper.hpp
index e59099ae8f..88805ba8e9 100644
--- a/mmcv/ops/csrc/common/mlu/common_mlu_helper.hpp
+++ b/mmcv/ops/csrc/common/mlu/common_mlu_helper.hpp
@@ -211,51 +211,52 @@ __mlu_func__ void convertInt2Float(float *dst, float *dst_addition, int *src,
// get sign bit
const float move_23bit = 8388608.0;
// 0x80000000 = 1,000000000,0000000000000000000000000000
- __nramset((unsigned *)src_addition, NFU_ALIGN_SIZE / sizeof(float),
- 0x80000000);
+ __bang_write_value((unsigned *)src_addition, NFU_ALIGN_SIZE / sizeof(float),
+ 0x80000000);
__bang_cycle_band((char *)dst_addition, (char *)src, (char *)src_addition,
src_count * sizeof(float), NFU_ALIGN_SIZE);
// get 1 or 0 from sign bit
// judg is Odd
- __nramset((unsigned *)src_addition, NFU_ALIGN_SIZE / sizeof(float),
- 0x00000001);
+ __bang_write_value((unsigned *)src_addition, NFU_ALIGN_SIZE / sizeof(float),
+ 0x00000001);
__bang_cycle_bor((char *)dst_addition, (char *)dst_addition,
(char *)src_addition, src_count * sizeof(float),
NFU_ALIGN_SIZE);
- __nramset((unsigned *)src_addition, NFU_ALIGN_SIZE / sizeof(float),
- 0x80000001);
+ __bang_write_value((unsigned *)src_addition, NFU_ALIGN_SIZE / sizeof(float),
+ 0x80000001);
__bang_cycle_eq(dst_addition, dst_addition, src_addition, src_count,
NFU_ALIGN_SIZE / sizeof(float));
// minus xor, positive num invariant
- __nramset((unsigned *)src_addition, NFU_ALIGN_SIZE / sizeof(float),
- 0xffffffff);
+ __bang_write_value((unsigned *)src_addition, NFU_ALIGN_SIZE / sizeof(float),
+ 0xffffffff);
__bang_cycle_mul(dst, dst_addition, src_addition, src_count,
NFU_ALIGN_SIZE / sizeof(float));
__bang_bxor((char *)dst, (char *)src, (char *)dst, src_count * sizeof(float));
// convert int32 to float32
- __nramset((unsigned *)src_addition, NFU_ALIGN_SIZE / sizeof(float), 0x7fffff);
+ __bang_write_value((unsigned *)src_addition, NFU_ALIGN_SIZE / sizeof(float),
+ 0x7fffff);
__bang_cycle_band((char *)dst, (char *)dst, (char *)src_addition,
src_count * sizeof(float), NFU_ALIGN_SIZE);
- __nramset((unsigned *)src_addition, NFU_ALIGN_SIZE / sizeof(float),
- 0x4b000000);
+ __bang_write_value((unsigned *)src_addition, NFU_ALIGN_SIZE / sizeof(float),
+ 0x4b000000);
__bang_cycle_bor((char *)dst, (char *)dst, (char *)src_addition,
src_count * sizeof(float), NFU_ALIGN_SIZE);
- __bang_sub_const(dst, dst, move_23bit, src_count);
+ __bang_sub_scalar(dst, dst, move_23bit, src_count);
// add one
__bang_add(dst, dst, dst_addition, src_count);
// set sign for float32
- __nramset((unsigned *)src_addition, NFU_ALIGN_SIZE / sizeof(float),
- 0xffffffff);
+ __bang_write_value((unsigned *)src_addition, NFU_ALIGN_SIZE / sizeof(float),
+ 0xffffffff);
__bang_cycle_mul(dst_addition, dst_addition, src_addition, src_count,
NFU_ALIGN_SIZE / sizeof(float));
- __nramset((unsigned *)src_addition, NFU_ALIGN_SIZE / sizeof(float),
- 0x00000001);
+ __bang_write_value((unsigned *)src_addition, NFU_ALIGN_SIZE / sizeof(float),
+ 0x00000001);
__bang_cycle_add(dst_addition, dst_addition, src_addition, src_count,
NFU_ALIGN_SIZE / sizeof(float));
- __nramset((unsigned *)src_addition, NFU_ALIGN_SIZE / sizeof(float),
- 0x80000000);
+ __bang_write_value((unsigned *)src_addition, NFU_ALIGN_SIZE / sizeof(float),
+ 0x80000000);
__bang_cycle_band((char *)dst_addition, (char *)dst_addition,
(char *)src_addition, src_count * 4, 128);
__bang_bor((char *)dst, (char *)dst, (char *)dst_addition, src_count * 4);
@@ -291,18 +292,20 @@ __mlu_func__ void convertFloat2Int(int *dst, float *dst_addition, float *src,
// dst_addition = abs(src)
__bang_mul(dst_addition, src, (float *)dst, src_count);
// if dst_addition < 1.0 , then src_addition + 1, to fix add error.
- __nramset((float *)src_addition, NFU_ALIGN_SIZE / sizeof(float), 1.0f);
+ __bang_write_value((float *)src_addition, NFU_ALIGN_SIZE / sizeof(float),
+ 1.0f);
__bang_cycle_lt(dst_addition, dst_addition, (float *)src_addition, src_count,
NFU_ALIGN_SIZE / sizeof(float));
__bang_add_tz((float *)dst, (float *)dst, (float *)dst_addition, src_count);
- __nramset((unsigned *)src_addition, NFU_ALIGN_SIZE / sizeof(float),
- 0xbf800000);
+ __bang_write_value((unsigned *)src_addition, NFU_ALIGN_SIZE / sizeof(float),
+ 0xbf800000);
// set negative flag -1.0 = 0xbf80000
__bang_cycle_eq(
(float *)dst, (float *)dst, (float *)src_addition, src_count,
NFU_ALIGN_SIZE / sizeof(float)); // to mark all src in [x<-1.0]
__bang_active_abs(dst_addition, src, src_count);
- __nramset((float *)src_addition, NFU_ALIGN_SIZE / sizeof(float), 8388608.0f);
+ __bang_write_value((float *)src_addition, NFU_ALIGN_SIZE / sizeof(float),
+ 8388608.0f);
// mask shift move 23
__bang_cycle_add_tz(
dst_addition, dst_addition, src_addition, src_count,
@@ -314,12 +317,12 @@ __mlu_func__ void convertFloat2Int(int *dst, float *dst_addition, float *src,
// to fix max value
// 0 1001 0110 111 1111 1111 1111 1111 1111 <=> 0xcb7fffff <=> 16777215.0,
// means max value.
- __bang_mul_const((float *)dst, (float *)dst, 16777215.0, src_count);
+ __bang_mul_scalar((float *)dst, (float *)dst, 16777215.0, src_count);
__bang_bxor((char *)dst_addition, (char *)dst_addition, (char *)dst,
src_count * floatDchar);
// get low 23bit
- __nramset((unsigned *)src_addition, NFU_ALIGN_SIZE / sizeof(float),
- (unsigned)0x007fffff);
+ __bang_write_value((unsigned *)src_addition, NFU_ALIGN_SIZE / sizeof(float),
+ (unsigned)0x007fffff);
// mask low 23bit is 1
__bang_cycle_band((char *)dst_addition, (char *)dst_addition,
(char *)src_addition, src_count * floatDchar,
@@ -327,16 +330,69 @@ __mlu_func__ void convertFloat2Int(int *dst, float *dst_addition, float *src,
// set 9 high bit ===> dst
// -2.0 <=> 0xc0000000 <=> 1100 0000 0000 0000 0000 0000 0000 0000
// 1.0 <=> 0x3f800000 <=> 0011 1111 1000 0000 0000 0000 0000 0000
- __nramset(src_addition, NFU_ALIGN_SIZE / sizeof(float), 0x3f800000);
+ __bang_write_value(src_addition, NFU_ALIGN_SIZE / sizeof(float), 0x3f800000);
__bang_cycle_and((float *)dst, (float *)dst, src_addition, src_count,
NFU_ALIGN_SIZE / sizeof(float));
// src or dst_addition
__bang_bor((char *)dst_addition, (char *)dst, (char *)dst_addition,
src_count * floatDchar);
- __bang_mul_const((float *)dst, (float *)dst, -2.0, src_count);
+ __bang_mul_scalar((float *)dst, (float *)dst, -2.0, src_count);
__bang_bor((char *)dst, (char *)dst, (char *)dst_addition,
src_count * floatDchar);
#endif // __BANG_ARCH__ >= 300
}
+/*!
+ * @brief Converts float32 to half data type,
+ * the rounding mode on MLU200 is rd, on MLU300 is rn.
+ *
+ * @param[out] dst
+ * Pointer to NRAM that stores half type data.
+ * @param[in] src
+ * Pointer to NRAM that stores float32 type data.
+ * @param[in] src_count
+ * The count of elements in src.
+ */
+__mlu_func__ inline void convertFloat2half(half *dst, float *src,
+ int src_count) {
+#if __BANG_ARCH__ >= 300
+ __bang_float2half_rn(dst, src, src_count);
+#else
+ __bang_float2half_rd(dst, src, src_count);
+#endif
+}
+
+/*!
+ * @brief recursiveSumPool.
+ * @param[in,out] dst
+ * Pointer to NRAM that stores the input and output data.
+ * @param[in] low_dim
+ * Which is the number of low dim.
+ * @param[in] high_dim
+ * Which is the number of high dim.
+ * @param[in] kernel_limit
+ * Which is the high_dim of sumpool per time.
+ ******************************************************************************/
+template
+__mlu_func__ void recursiveSumPool(T *dst, int low_dim, int high_dim,
+ int kernel_limit) {
+ for (; high_dim > 1;) {
+ int repeat_s = high_dim / kernel_limit;
+ int remain_s = high_dim % kernel_limit;
+
+ if (remain_s) {
+ __bang_sumpool((T *)dst, (T *)dst, low_dim, 1, remain_s, 1, remain_s, 1,
+ 1);
+ }
+ if (repeat_s) {
+ __bang_sumpool((T *)dst + (remain_s > 0 ? low_dim : 0),
+ (T *)dst + remain_s * low_dim, low_dim,
+ kernel_limit * repeat_s, 1, kernel_limit, 1, 1,
+ kernel_limit);
+ }
+ high_dim = repeat_s + (bool)remain_s;
+ }
+ return;
+}
+
#endif // COMMON_MLU_HELPER_HPP_
diff --git a/mmcv/ops/csrc/common/mlu/iou3d_mlu_kernel.mlu b/mmcv/ops/csrc/common/mlu/iou3d_mlu_kernel.mlu
new file mode 100644
index 0000000000..84e53aa1f3
--- /dev/null
+++ b/mmcv/ops/csrc/common/mlu/iou3d_mlu_kernel.mlu
@@ -0,0 +1,431 @@
+/*************************************************************************
+ * Copyright (C) 2022 Cambricon.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
+ * OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
+ * MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
+ * IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
+ * CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
+ * TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
+ * SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
+ *************************************************************************/
+
+#include "common_mlu_helper.hpp"
+#include "iou3d_utils.hpp"
+
+#define SIZE_SRAM_BUF (MAX_SRAM_SIZE)
+
+/* NRAM buffer
+ * Suppose deal N boxes once time.
+----------------------------------------------------------------
+| Basic |score (1N)+ |intersect_pts(48N)| |
+| |valid_box(1N) |+ ordered_pts(48N)| temp_long(72N) |
+| |+ temp_buffer(10N)| | |
+|--------------------------|------------------|----------------|
+| Reuse | null | null |rotated_pts(16N)|
+|-------|------------------|------------------|----------------|
+
+---------------------------------------------------------------------------
+| Basic | dist_ram(24N) | valid_pts(24N) |box1(5N) |box1_buffer(5KB) |
+| | |+ nums_in_ram(1N)|+ box2(5N)|+nram_save(5KB) |
+|--------------------------|-----------------|----------|-----------------|
+| Reuse | vec_buffer(5N) | null | null | null |
+|-------|------------------|-----------------|----------|-----------------|
+Total Basic Memory Size = 239N * sizeof(float) + 10KB
+*/
+
+__nram__ char nram_buffer[MAX_NRAM_SIZE];
+__mlu_shared__ char sram_buffer[SIZE_SRAM_BUF];
+
+template
+__mlu_func__ void iou3D_detection(int32_t &result_box_num, int32_t *output_data,
+ const T *boxes_data, float *scores_data,
+ const int core_limit, const int input_box_num,
+ const float iou_threshold,
+ mluMemcpyDirection_t scores_load_dir,
+ mluMemcpyDirection_t scores_store_dir,
+ mluMemcpyDirection_t boxes_load_dir) {
+ // NRAM divide by (2+4*COMPUTE_COUNT_ALIGN) copies of NRAM, counted by bytes
+ const int nram_save_limit_count = 256;
+ int box_read_limit_count = 256;
+ float div_thresh_iou = 1.0 / iou_threshold;
+ // every box require 239 * sizeof(float) space in nram;
+ const int32_t copies_of_nram = 239 * sizeof(float);
+ const int32_t limit = (MAX_NRAM_SIZE - 5 * box_read_limit_count * sizeof(T) -
+ nram_save_limit_count * sizeof(int32_t)) /
+ copies_of_nram;
+
+ // x,y,z,dx,dy,dz,angle
+ const T *input_x_ptr = boxes_data;
+ const T *input_y_ptr = input_x_ptr + input_box_num;
+ const T *input_dx_ptr = input_y_ptr + 2 * input_box_num;
+ const T *input_dy_ptr = input_dx_ptr + input_box_num;
+ const T *input_angle_ptr = input_dy_ptr + 2 * input_box_num;
+ float *input_score_ptr = scores_data;
+
+ // data split
+ int avg_cluster = 0;
+ int rem_cluster = 0;
+ int len_cluster = 0;
+ int cluster_offset = 0;
+ if (clusterDim > 0) {
+ // union
+ avg_cluster = input_box_num / clusterDim;
+ rem_cluster = input_box_num % clusterDim;
+ len_cluster = avg_cluster + (clusterId < rem_cluster ? 1 : 0);
+ cluster_offset = avg_cluster * clusterId +
+ (clusterId <= rem_cluster ? clusterId : rem_cluster);
+ } else {
+ // block
+ len_cluster = input_box_num;
+ cluster_offset = 0;
+ }
+ int len_core = input_box_num;
+ int input_offset = 0;
+ if (core_limit > 1) {
+ int avg_core = len_cluster / coreDim;
+ int rem_core = len_cluster % coreDim;
+ len_core = avg_core + (coreId < rem_core ? 1 : 0);
+ int core_offset =
+ avg_core * coreId + (coreId <= rem_core ? coreId : rem_core);
+ input_offset = cluster_offset + core_offset;
+ }
+
+ int32_t max_seg_pad = IOU3D_DOWN(limit, IOU3D_SIZE);
+ int repeat_iou_compute = len_core / max_seg_pad;
+ int remain_iou_compute = len_core % max_seg_pad;
+
+ // basic consistent memory layout
+ void *score = ((char *)nram_buffer);
+ void *valid_box = ((char *)score) + 1 * max_seg_pad * sizeof(float);
+ void *temp_buffer = ((char *)valid_box) + 1 * max_seg_pad * sizeof(float);
+ void *intersect_pts_x =
+ ((char *)temp_buffer) + 10 * max_seg_pad * sizeof(float);
+ void *intersect_pts_y =
+ ((char *)intersect_pts_x) + 24 * max_seg_pad * sizeof(float);
+ void *ordered_pts_x =
+ ((char *)intersect_pts_y) + 24 * max_seg_pad * sizeof(float);
+ void *ordered_pts_y =
+ ((char *)ordered_pts_x) + 24 * max_seg_pad * sizeof(float);
+ void *temp_long_1 =
+ ((char *)ordered_pts_y) + 24 * max_seg_pad * sizeof(float);
+ void *temp_long_2 = ((char *)temp_long_1) + 24 * max_seg_pad * sizeof(float);
+ void *temp_long_3 = ((char *)temp_long_2) + 24 * max_seg_pad * sizeof(float);
+ void *dist_ram = ((char *)temp_long_3) + 24 * max_seg_pad * sizeof(float);
+ void *valid_pts = ((char *)dist_ram) + 24 * max_seg_pad * sizeof(float);
+ void *nums_in_ram = ((char *)valid_pts) + 24 * max_seg_pad * sizeof(float);
+ T *box1 = (T *)(((char *)nums_in_ram) + 1 * max_seg_pad * sizeof(float));
+ T *box2 = (T *)(((char *)box1) + 5 * max_seg_pad * sizeof(float));
+ void *box1_buffer = ((char *)box2) + 5 * max_seg_pad * sizeof(float);
+ int32_t *nram_save =
+ (int32_t *)(((char *)box1_buffer) + 5 * box_read_limit_count * sizeof(T));
+ // nram_save ~ nram_save_limit_count * sizeof(int32_t)
+ int nram_save_count = 0;
+
+ // reuse memory
+ void *rotated_pts1_x = ((char *)dist_ram);
+ void *rotated_pts1_y =
+ ((char *)rotated_pts1_x) + 4 * max_seg_pad * sizeof(float);
+ void *rotated_pts2_x =
+ ((char *)rotated_pts1_y) + 4 * max_seg_pad * sizeof(float);
+ void *rotated_pts2_y =
+ ((char *)rotated_pts2_x) + 4 * max_seg_pad * sizeof(float);
+ void *vec_buffer = ((char *)temp_long_1) + 5 * max_seg_pad * sizeof(float);
+ // vec_buffer ~ 16 * max_seg_pad * sizeof(float)
+
+ // First, initialize ram with all 0, or could cause nan/inf unexcepted results
+ __bang_write_zero((unsigned char *)nram_buffer, copies_of_nram * max_seg_pad);
+ // number 8 and 0xff relay on box_read_limit_count initial as 256
+ const int max_box_seg_id = (input_box_num - 1) >> 8;
+ const int last_rem_box_number = ((input_box_num - 1) & 0xff) + 1;
+ for (int32_t cur_box = 0; cur_box < input_box_num; ++cur_box) {
+ __sync_all();
+ int box_seg_id = cur_box >> 8, box_id = cur_box & 0xff;
+ box_read_limit_count = box_seg_id == max_box_seg_id ? last_rem_box_number
+ : box_read_limit_count;
+ if (box_id == 0) {
+ // x,y,z,dx,dy,dz,angle
+ int offset_num = box_seg_id << 8;
+ // x
+ __memcpy((char *)box1_buffer, input_x_ptr + offset_num,
+ box_read_limit_count * 1 * sizeof(T), boxes_load_dir,
+ box_read_limit_count * 1 * sizeof(T),
+ box_read_limit_count * 1 * sizeof(T), 0);
+ // y
+ __memcpy((char *)box1_buffer + box_read_limit_count * 1 * sizeof(T),
+ input_y_ptr + offset_num, box_read_limit_count * 1 * sizeof(T),
+ boxes_load_dir, box_read_limit_count * 1 * sizeof(T),
+ box_read_limit_count * 1 * sizeof(T), 0);
+ // dx
+ __memcpy((char *)box1_buffer + box_read_limit_count * 2 * sizeof(T),
+ input_dx_ptr + offset_num, box_read_limit_count * 1 * sizeof(T),
+ boxes_load_dir, box_read_limit_count * 1 * sizeof(T),
+ box_read_limit_count * 1 * sizeof(T), 0);
+ // dy
+ __memcpy((char *)box1_buffer + box_read_limit_count * 3 * sizeof(T),
+ input_dy_ptr + offset_num, box_read_limit_count * 1 * sizeof(T),
+ boxes_load_dir, box_read_limit_count * 1 * sizeof(T),
+ box_read_limit_count * 1 * sizeof(T), 0);
+ // angle
+ __memcpy((char *)box1_buffer + box_read_limit_count * 4 * sizeof(T),
+ input_angle_ptr + offset_num,
+ box_read_limit_count * 1 * sizeof(T), boxes_load_dir,
+ box_read_limit_count * 1 * sizeof(T),
+ box_read_limit_count * 1 * sizeof(T), 0);
+ }
+ if (((float *)input_score_ptr)[cur_box] == 0) {
+ continue;
+ }
+ // save result
+ nram_save[nram_save_count] = cur_box;
+ result_box_num++;
+ nram_save_count++;
+ if (clusterId == 0 && coreId == 0 &&
+ nram_save_count == nram_save_limit_count) {
+ pvLock();
+ __memcpy(output_data, nram_save, nram_save_count * sizeof(int32_t),
+ NRAM2GDRAM);
+ pvUnlock();
+ output_data += nram_save_count;
+ nram_save_count = 0;
+ }
+ // prepare box1
+ // x
+ __bang_write_value((float *)box1, max_seg_pad,
+ float(((T *)box1_buffer)[box_id]));
+ // y
+ __bang_write_value(
+ (float *)box1 + max_seg_pad, max_seg_pad,
+ float(((T *)box1_buffer)[box_id + 1 * box_read_limit_count]));
+ // dx
+ __bang_write_value(
+ (float *)box1 + max_seg_pad * 2, max_seg_pad,
+ float(((T *)box1_buffer)[box_id + 2 * box_read_limit_count]));
+ // dy
+ __bang_write_value(
+ (float *)box1 + max_seg_pad * 3, max_seg_pad,
+ float(((T *)box1_buffer)[box_id + 3 * box_read_limit_count]));
+ // angle
+ __bang_write_value(
+ (float *)box1 + max_seg_pad * 4, max_seg_pad,
+ float(((T *)box1_buffer)[box_id + 4 * box_read_limit_count]));
+
+ float max_area = 1.0f *
+ ((T *)box1_buffer)[box_id + 2 * box_read_limit_count] *
+ ((T *)box1_buffer)[box_id + 3 * box_read_limit_count];
+ // update score
+
+ for (int i = 0; i <= repeat_iou_compute; i++) {
+ if (i == repeat_iou_compute && remain_iou_compute == 0) {
+ break;
+ }
+ int seg_len = max_seg_pad;
+ int cpy_len =
+ (i == repeat_iou_compute) ? remain_iou_compute : max_seg_pad;
+ // int half_offset = std::is_same::value ? max_seg_pad * 5 : 0;
+ int half_offset = (sizeof(T) == sizeof(half)) ? max_seg_pad * 5 : 0;
+ // score
+ __memcpy(score, input_score_ptr + input_offset + i * max_seg_pad,
+ cpy_len * sizeof(float), scores_load_dir,
+ cpy_len * sizeof(float), cpy_len * sizeof(float), 0);
+ // x
+ __memcpy(box2 + half_offset, input_x_ptr + input_offset + i * max_seg_pad,
+ cpy_len * 1 * sizeof(T), boxes_load_dir, cpy_len * 1 * sizeof(T),
+ cpy_len * 1 * sizeof(T), 0);
+ // y
+ __memcpy(box2 + half_offset + seg_len * 1,
+ input_y_ptr + input_offset + i * max_seg_pad,
+ cpy_len * 1 * sizeof(T), boxes_load_dir, cpy_len * 1 * sizeof(T),
+ cpy_len * 1 * sizeof(T), 0);
+ // dx
+ __memcpy(box2 + half_offset + seg_len * 2,
+ input_dx_ptr + input_offset + i * max_seg_pad,
+ cpy_len * 1 * sizeof(T), boxes_load_dir, cpy_len * 1 * sizeof(T),
+ cpy_len * 1 * sizeof(T), 0);
+ // dy
+ __memcpy(box2 + half_offset + seg_len * 3,
+ input_dy_ptr + input_offset + i * max_seg_pad,
+ cpy_len * 1 * sizeof(T), boxes_load_dir, cpy_len * 1 * sizeof(T),
+ cpy_len * 1 * sizeof(T), 0);
+ // angle
+ __memcpy(box2 + half_offset + seg_len * 4,
+ input_angle_ptr + input_offset + i * max_seg_pad,
+ cpy_len * 1 * sizeof(T), boxes_load_dir, cpy_len * 1 * sizeof(T),
+ cpy_len * 1 * sizeof(T), 0);
+ // if (std::is_same::value) {
+ if (sizeof(T) == sizeof(half)) {
+ __bang_half2float((float *)box2, (half *)(box2 + half_offset),
+ seg_len * 5);
+ }
+
+ // Calculate rotated vertices
+ void *temp1_ram = ((char *)temp_buffer);
+ void *temp2_ram = ((char *)temp_buffer) + seg_len * sizeof(float);
+ void *temp3_ram = ((char *)temp_buffer) + 2 * seg_len * sizeof(float);
+ void *temp4_ram = ((char *)temp_buffer) + 3 * seg_len * sizeof(float);
+ getRotatedVertices((float *)rotated_pts1_x, (float *)rotated_pts1_y,
+ (float *)box1, (float *)temp1_ram, (float *)temp2_ram,
+ (float *)temp3_ram, (float *)temp4_ram, seg_len);
+ getRotatedVertices((float *)rotated_pts2_x, (float *)rotated_pts2_y,
+ (float *)box2, (float *)temp1_ram, (float *)temp2_ram,
+ (float *)temp3_ram, (float *)temp4_ram, seg_len);
+
+ __bang_write_zero((float *)valid_pts, 24 * seg_len);
+ __bang_write_zero((float *)nums_in_ram, seg_len);
+ __bang_write_value(((float *)valid_box), seg_len, 1.0f);
+ void *vec1_x = ((char *)vec_buffer);
+ void *vec1_y = ((char *)vec1_x) + 4 * seg_len * sizeof(float);
+ void *vec2_x = ((char *)vec1_y) + 4 * seg_len * sizeof(float);
+ void *vec2_y = ((char *)vec2_x) + 4 * seg_len * sizeof(float);
+ void *temp5_ram = ((char *)temp_buffer) + 4 * seg_len * sizeof(float);
+ void *temp6_ram = ((char *)temp_buffer) + 5 * seg_len * sizeof(float);
+ void *temp7_ram = ((char *)temp_buffer) + 6 * seg_len * sizeof(float);
+ void *temp8_ram = ((char *)temp_buffer) + 7 * seg_len * sizeof(float);
+ void *temp9_ram = ((char *)temp_buffer) + 8 * seg_len * sizeof(float);
+ void *temp10_ram = ((char *)temp_buffer) + 9 * seg_len * sizeof(float);
+
+ // Get all intersection points
+ getIntersectPts(
+ (float *)rotated_pts1_x, (float *)rotated_pts1_y,
+ (float *)rotated_pts2_x, (float *)rotated_pts2_y, (float *)vec1_x,
+ (float *)vec1_y, (float *)vec2_x, (float *)vec2_y,
+ (float *)intersect_pts_x, (float *)intersect_pts_y,
+ (float *)valid_pts, (float *)nums_in_ram, (float *)temp1_ram,
+ (float *)temp2_ram, (float *)temp3_ram, (float *)temp4_ram,
+ (float *)temp5_ram, (float *)temp6_ram, (float *)temp7_ram,
+ (float *)temp8_ram, (float *)temp9_ram, (float *)temp10_ram, seg_len);
+
+ // Where nums_in <= 2, set valid_box to false
+ __bang_write_value((float *)temp9_ram, COMPUTE_COUNT_ALIGN, (float)2);
+ __bang_cycle_gt((float *)temp1_ram, (float *)nums_in_ram,
+ (float *)temp9_ram, seg_len, COMPUTE_COUNT_ALIGN);
+ __bang_and((float *)valid_box, (float *)valid_box, (float *)temp1_ram,
+ seg_len);
+ __bang_cycle_and((float *)valid_pts, (float *)valid_pts,
+ (float *)valid_box, 24 * seg_len, seg_len);
+
+ // Convex-hull-graham to order the intersection points in clockwise order
+ // and find the contour area
+
+ convexHullGraham(
+ (float *)intersect_pts_x, (float *)intersect_pts_y,
+ (float *)ordered_pts_x, (float *)ordered_pts_y, (float *)dist_ram,
+ (float *)valid_box, (float *)valid_pts, (float *)nums_in_ram,
+ (float *)temp7_ram, (float *)temp8_ram, (float *)temp9_ram,
+ (float *)temp_long_1, (float *)temp_long_2, (float *)temp_long_3,
+ seg_len, seg_len);
+ // Calculate polygon area
+ // set temp1 = intersection part area
+ polygonArea((float *)ordered_pts_x, (float *)ordered_pts_y,
+ (float *)valid_box, (float *)valid_pts, (float *)nums_in_ram,
+ (float *)temp1_ram, (float *)temp2_ram, (float *)temp3_ram,
+ (float *)temp4_ram, (float *)temp5_ram, (float *)temp6_ram,
+ (float *)temp7_ram, (float *)temp8_ram, (float *)temp9_ram,
+ seg_len);
+ // area
+ __bang_mul((float *)temp2_ram, (float *)box2 + seg_len * 2,
+ (float *)box2 + seg_len * 3, seg_len);
+ // get the area_U: area + max_area - area_I
+ __bang_add_scalar((float *)temp2_ram, (float *)temp2_ram, float(max_area),
+ seg_len);
+ __bang_sub((float *)temp2_ram, (float *)temp2_ram, (float *)temp1_ram,
+ seg_len); // area_U
+ if (iou_threshold > 0.0) {
+ __bang_mul_scalar((float *)temp1_ram, (float *)temp1_ram,
+ div_thresh_iou, seg_len);
+ } else {
+ __bang_mul_scalar((float *)temp2_ram, (float *)temp2_ram, iou_threshold,
+ seg_len);
+ }
+ __bang_ge((float *)temp1_ram, (float *)temp2_ram, (float *)temp1_ram,
+ seg_len);
+ __bang_mul((float *)score, (float *)score, (float *)temp1_ram, seg_len);
+
+ pvLock();
+ __memcpy(input_score_ptr + input_offset + i * max_seg_pad, score,
+ cpy_len * sizeof(float), scores_store_dir,
+ cpy_len * sizeof(float), cpy_len * sizeof(float), 0);
+ pvUnlock();
+ }
+ }
+ if (clusterId == 0 && coreId == 0 && nram_save_count) {
+ pvLock();
+ __memcpy(output_data, nram_save, nram_save_count * sizeof(int32_t),
+ NRAM2GDRAM);
+ pvUnlock();
+ }
+}
+__mlu_global__ void MLUBlockorUnionIKernelOU3D(
+ const void *input_boxes, const int input_box_num, const float iou_threshold,
+ const cnrtDataType_t data_type_input, void *workspace, void *result_num,
+ void *output) {
+ int input_dwidth = (data_type_input == CNRT_FLOAT32) ? 4 : 2;
+ mluMemcpyDirection_t scores_load_dir = GDRAM2NRAM;
+ mluMemcpyDirection_t scores_store_dir = NRAM2GDRAM;
+ mluMemcpyDirection_t boxes_load_dir = GDRAM2NRAM;
+ float *scores_data = (float *)workspace;
+ float *boxes_data = (float *)input_boxes;
+ const int cluster_score_size = input_box_num * sizeof(float);
+ const int cluster_boxes_size = input_box_num * 7 * input_dwidth;
+ char *sram_score = (char *)sram_buffer;
+ char *sram_boxes = (char *)sram_buffer + cluster_score_size;
+ if (clusterDim == 1 && SIZE_SRAM_BUF > cluster_score_size) {
+ scores_data = (float *)sram_score;
+ scores_load_dir = SRAM2NRAM;
+ scores_store_dir = NRAM2SRAM;
+ if (coreId == 0x80) {
+ __sramset((void *)sram_buffer, input_box_num, 1.0f);
+ }
+ } else {
+ if (coreId == 0) {
+ __gdramset(scores_data, input_box_num, 1.0f);
+ }
+ }
+ if (clusterDim == 1 &&
+ SIZE_SRAM_BUF - cluster_score_size >= cluster_boxes_size) {
+ boxes_load_dir = SRAM2NRAM;
+ boxes_data = (float *)sram_boxes;
+ if (coreId == 0x80) {
+ __memcpy((char *)boxes_data, (char *)input_boxes, cluster_boxes_size,
+ GDRAM2SRAM);
+ }
+ }
+ __sync_cluster();
+
+ int32_t result_box_num = 0;
+ int32_t *out_data = (int32_t *)output;
+
+ switch (data_type_input) {
+ default: { return; }
+ case CNRT_FLOAT16: {
+ iou3D_detection(result_box_num, out_data, (half *)boxes_data, scores_data,
+ taskDim, input_box_num, iou_threshold, scores_load_dir,
+ scores_store_dir, boxes_load_dir);
+ }; break;
+ case CNRT_FLOAT32: {
+ iou3D_detection(result_box_num, out_data, boxes_data, scores_data,
+ taskDim, input_box_num, iou_threshold, scores_load_dir,
+ scores_store_dir, boxes_load_dir);
+ }; break;
+ }
+ ((int32_t *)result_num)[0] = result_box_num;
+}
+
+void KernelIou3d(cnrtDim3_t k_dim, cnrtFunctionType_t k_type, cnrtQueue_t queue,
+ const cnrtDataType_t data_type_input, const void *boxes_dram,
+ const int input_box_num, const float iou_threshold,
+ void *workspace, void *output_size, void *output) {
+ switch (k_type) {
+ default: { return; }
+ case CNRT_FUNC_TYPE_BLOCK:
+ case CNRT_FUNC_TYPE_UNION1:
+ case CNRT_FUNC_TYPE_UNION2:
+ case CNRT_FUNC_TYPE_UNION4:
+ case CNRT_FUNC_TYPE_UNION8:
+ case CNRT_FUNC_TYPE_UNION16: {
+ MLUBlockorUnionIKernelOU3D<<>>(
+ (void *)boxes_dram, input_box_num, iou_threshold, data_type_input,
+ workspace, output_size, output);
+ }; break;
+ }
+}
diff --git a/mmcv/ops/csrc/common/mlu/iou3d_utils.hpp b/mmcv/ops/csrc/common/mlu/iou3d_utils.hpp
new file mode 100644
index 0000000000..b98ffe2fca
--- /dev/null
+++ b/mmcv/ops/csrc/common/mlu/iou3d_utils.hpp
@@ -0,0 +1,695 @@
+/*************************************************************************
+ * Copyright (C) 2022 Cambricon.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
+ * OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
+ * MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
+ * IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
+ * CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
+ * TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
+ * SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
+ *************************************************************************/
+
+#ifndef IOU3D_UTILS_HPP_
+#define IOU3D_UTILS_HPP_
+#include "common_mlu_helper.hpp"
+
+#define IOU3D_SIZE 64
+#define IOU3D_UP(x, y) (x / y + (int)(x % y > 0)) * y
+#define IOU3D_DOWN(x, y) (x / y) * y
+#define SIZE_NRAM_BUF (MAX_NRAM_SIZE)
+#define SIZE_SRAM_BUF (MAX_SRAM_SIZE)
+#define COMPUTE_COUNT_ALIGN 64
+#define INFO_NUM (5) // score, x1, y1, x2, y2
+#define REDUCE_NUM \
+ (7) // score, x1, y1, x2, y2, max_index (reserve 2 num for half-type input)
+#define SINGLE_BOX_DIM 5
+#define MEMORY_CORE (0x80)
+__mlu_func__ void pvLock() {
+#if __BANG_ARCH__ == 270
+ if (coreId != MEMORY_CORE) {
+ __bang_lock(0, 0);
+ }
+#endif
+}
+
+__mlu_func__ void pvUnlock() {
+#if __BANG_ARCH__ == 270
+ if (coreId != MEMORY_CORE) {
+ __bang_unlock(0, 0);
+ }
+#endif
+}
+
+// cross2d(A, B) = A.x * B.y - A.y * B.x;
+template
+inline __mlu_func__ void cross2d(T *result, const T *p1_x, const T *p1_y,
+ const T *p2_x, const T *p2_y,
+ const int &length, T *temp_ram) {
+ __bang_mul((T *)temp_ram, (T *)p1_x, (T *)p2_y, length);
+ __bang_mul((T *)result, (T *)p1_y, (T *)p2_x, length);
+ __bang_sub((T *)result, (T *)temp_ram, (T *)result, length);
+}
+
+// dot2d(A, B) = A.x * B.x + A.y * B.y
+template
+inline __mlu_func__ void dot2d(T *result, const T *p1_x, const T *p1_y,
+ const T *p2_x, const T *p2_y, const int &length,
+ T *temp_ram) {
+ __bang_mul((T *)temp_ram, (T *)p1_x, (T *)p2_x, length);
+ __bang_mul((T *)result, (T *)p1_y, (T *)p2_y, length);
+ __bang_add((T *)result, (T *)temp_ram, (T *)result, length);
+}
+
+template
+__mlu_func__ void getRotatedVertices(T *pts_x, T *pts_y, T *box, T *temp1,
+ T *temp2, T *temp3, T *temp4,
+ const uint32_t &actual_compute_box_num) {
+// T cosTheta2 = (T)cos(theta) * 0.5f; -- temp1
+// T sinTheta2 = (T)sin(theta) * 0.5f; -- temp2
+// theta is the box's 5th data: a, rotated radian;
+#if __BANG_ARCH__ >= 300
+ __bang_cos((float *)temp1, ((float *)box) + 4 * actual_compute_box_num,
+ actual_compute_box_num);
+ __bang_sin((float *)temp2, ((float *)box) + 4 * actual_compute_box_num,
+ actual_compute_box_num);
+#else
+ __bang_taylor4_cos((T *)temp1, ((T *)box) + 4 * actual_compute_box_num,
+ (T *)temp3, (T *)temp4, actual_compute_box_num);
+ __bang_taylor4_sin((T *)temp2, ((T *)box) + 4 * actual_compute_box_num,
+ (T *)temp3, (T *)temp4, actual_compute_box_num);
+#endif
+ __bang_mul_scalar((T *)temp1, (T *)temp1, (T)0.5, actual_compute_box_num);
+ __bang_mul_scalar((T *)temp2, (T *)temp2, (T)0.5, actual_compute_box_num);
+
+ // Temp3 = sinTheta2 * box.h;
+ // Temp4 = cosTheta2 * box.w;
+ __bang_mul((T *)temp3, (T *)temp2, ((T *)box) + 3 * actual_compute_box_num,
+ actual_compute_box_num);
+ __bang_mul((T *)temp4, (T *)temp1, ((T *)box) + 2 * actual_compute_box_num,
+ actual_compute_box_num);
+ // pts[0].x = box.x_ctr - sinTheta2 * box.h - cosTheta2 * box.w;
+ // pts[1].x = box.x_ctr + sinTheta2 * box.h - cosTheta2 * box.w;
+ __bang_sub((T *)pts_x, (T *)box, (T *)temp3, actual_compute_box_num);
+ __bang_sub((T *)pts_x, (T *)pts_x, (T *)temp4, actual_compute_box_num);
+ __bang_add((T *)pts_x + 1 * actual_compute_box_num, (T *)box, (T *)temp3,
+ actual_compute_box_num);
+ __bang_sub((T *)pts_x + 1 * actual_compute_box_num,
+ (T *)pts_x + 1 * actual_compute_box_num, (T *)temp4,
+ actual_compute_box_num);
+ // Temp3 = cosTheta2 * box.h;
+ // Temp4 = sinTheta2 * box.w;
+ __bang_mul((T *)temp3, (T *)temp1, box + 3 * actual_compute_box_num,
+ actual_compute_box_num);
+ __bang_mul((T *)temp4, (T *)temp2, box + 2 * actual_compute_box_num,
+ actual_compute_box_num);
+ // pts[0].y = box.y_ctr + cosTheta2 * box.h - sinTheta2 * box.w;
+ // pts[1].y = box.y_ctr - cosTheta2 * box.h - sinTheta2 * box.w;
+ __bang_add((T *)pts_y, (T *)box + 1 * actual_compute_box_num, (T *)temp3,
+ actual_compute_box_num);
+ __bang_sub((T *)pts_y, (T *)pts_y, (T *)temp4, actual_compute_box_num);
+ __bang_sub((T *)pts_y + 1 * actual_compute_box_num,
+ (T *)box + 1 * actual_compute_box_num, (T *)temp3,
+ actual_compute_box_num);
+ __bang_sub((T *)pts_y + 1 * actual_compute_box_num,
+ (T *)pts_y + 1 * actual_compute_box_num, (T *)temp4,
+ actual_compute_box_num);
+ // pts[2].x = 2 * box.x_ctr - pts[0].x;
+ // pts[3].x = 2 * box.x_ctr - pts[1].x;
+ __bang_add((T *)pts_x + 2 * actual_compute_box_num, (T *)box, (T *)box,
+ actual_compute_box_num);
+ __bang_sub((T *)pts_x + 2 * actual_compute_box_num,
+ (T *)pts_x + 2 * actual_compute_box_num, (T *)pts_x,
+ actual_compute_box_num);
+ __bang_add((T *)pts_x + 3 * actual_compute_box_num, (T *)box, (T *)box,
+ actual_compute_box_num);
+ __bang_sub((T *)pts_x + 3 * actual_compute_box_num,
+ (T *)pts_x + 3 * actual_compute_box_num,
+ (T *)pts_x + 1 * actual_compute_box_num, actual_compute_box_num);
+ // pts[2].y = 2 * box.y_ctr - pts[0].y;
+ // pts[3].y = 2 * box.y_ctr - pts[1].y;
+ __bang_add((T *)pts_y + 2 * actual_compute_box_num,
+ (T *)box + 1 * actual_compute_box_num,
+ (T *)box + 1 * actual_compute_box_num, actual_compute_box_num);
+ __bang_sub((T *)pts_y + 2 * actual_compute_box_num,
+ (T *)pts_y + 2 * actual_compute_box_num, (T *)pts_y,
+ actual_compute_box_num);
+ __bang_add((T *)pts_y + 3 * actual_compute_box_num,
+ (T *)box + 1 * actual_compute_box_num,
+ (T *)box + 1 * actual_compute_box_num, actual_compute_box_num);
+ __bang_sub((T *)pts_y + 3 * actual_compute_box_num,
+ (T *)pts_y + 3 * actual_compute_box_num,
+ (T *)pts_y + 1 * actual_compute_box_num, actual_compute_box_num);
+}
+
+template
+__mlu_func__ void getIntersectPts(T *rotated_pts1_x, T *rotated_pts1_y,
+ T *rotated_pts2_x, T *rotated_pts2_y,
+ T *vec1_x, T *vec1_y, T *vec2_x, T *vec2_y,
+ T *intersect_pts_x, T *intersect_pts_y,
+ T *valid_pts, T *nums_in_ram, T *temp1_ram,
+ T *temp2_ram, T *temp3_ram, T *temp4_ram,
+ T *temp5_ram, T *temp6_ram, T *temp7_ram,
+ T *temp8_ram, T *temp9_ram, T *temp10_ram,
+ const uint32_t &actual_compute_box_num) {
+// Initialize const data to ram
+// temp3 = const 1e-14(@float), length = COMPUTE_COUNT_ALIGN
+#if __BANG_ARCH__ >= 300
+ __bang_write_value((T *)temp3_ram, COMPUTE_COUNT_ALIGN, (T)1e-14);
+#else
+ // NOTE: Since active_reciphp function has strict value range,
+ // [2.2205e-16, 2e6]@float, [0.00391, 65504]@half
+ __bang_write_value((T *)temp3_ram, COMPUTE_COUNT_ALIGN, (float)1e-14);
+#endif
+ // temp4 = const T(0), length = COMPUTE_COUNT_ALIGN
+ __bang_write_value((T *)temp4_ram, COMPUTE_COUNT_ALIGN, (T)0);
+ // temp5 = const T(1), length = COMPUTE_COUNT_ALIGN
+ __bang_write_value((T *)temp5_ram, COMPUTE_COUNT_ALIGN, (T)1);
+
+ // Line vector, from p1 to p2 is: p1+(p2-p1)*t, t=[0,1]
+ // for i = 0~3, vec[i] = pts[(i+1)%4] - pts[i]
+ __bang_sub((T *)vec1_x, (T *)rotated_pts1_x + actual_compute_box_num,
+ (T *)rotated_pts1_x, 3 * actual_compute_box_num);
+ __bang_sub((T *)vec1_x + 3 * actual_compute_box_num, (T *)rotated_pts1_x,
+ (T *)rotated_pts1_x + 3 * actual_compute_box_num,
+ actual_compute_box_num);
+ __bang_sub((T *)vec1_y, (T *)rotated_pts1_y + actual_compute_box_num,
+ (T *)rotated_pts1_y, 3 * actual_compute_box_num);
+ __bang_sub((T *)vec1_y + 3 * actual_compute_box_num, (T *)rotated_pts1_y,
+ (T *)rotated_pts1_y + 3 * actual_compute_box_num,
+ actual_compute_box_num);
+
+ __bang_sub((T *)vec2_x, (T *)rotated_pts2_x + actual_compute_box_num,
+ (T *)rotated_pts2_x, 3 * actual_compute_box_num);
+ __bang_sub((T *)vec2_x + 3 * actual_compute_box_num, (T *)rotated_pts2_x,
+ (T *)rotated_pts2_x + 3 * actual_compute_box_num,
+ actual_compute_box_num);
+ __bang_sub((T *)vec2_y, (T *)rotated_pts2_y + actual_compute_box_num,
+ (T *)rotated_pts2_y, 3 * actual_compute_box_num);
+ __bang_sub((T *)vec2_y + 3 * actual_compute_box_num, (T *)rotated_pts2_y,
+ (T *)rotated_pts2_y + 3 * actual_compute_box_num,
+ actual_compute_box_num);
+
+ // First, line test - test all line combos for intersection, 4x4 possible
+ for (int i = 0; i < 4; i++) {
+ for (int j = 0; j < 4; j++) {
+ // T det = cross2d(vec2[j], vec1[i]) -- temp2
+ cross2d((T *)temp2_ram, (T *)vec2_x + j * actual_compute_box_num,
+ (T *)vec2_y + j * actual_compute_box_num,
+ (T *)vec1_x + i * actual_compute_box_num,
+ (T *)vec1_y + i * actual_compute_box_num,
+ actual_compute_box_num, (T *)temp1_ram);
+ // temp8 = sign(det), since active_reciphp only receive positive values
+ __bang_active_sign((T *)temp8_ram, (T *)temp2_ram,
+ actual_compute_box_num);
+ // deal with parallel lines, temp2 = fabs(det), temp1 = temp2 > 1e-14
+ __bang_active_abs((T *)temp2_ram, (T *)temp2_ram, actual_compute_box_num);
+ __bang_cycle_gt((T *)temp1_ram, (T *)temp2_ram, (T *)temp3_ram,
+ actual_compute_box_num, COMPUTE_COUNT_ALIGN);
+ // Where temp1 = false, set recip input to 1, avoiding recip(0), cause inf
+ __bang_not((T *)temp9_ram, (T *)temp1_ram, actual_compute_box_num);
+ __bang_mul((T *)temp2_ram, (T *)temp2_ram, (T *)temp1_ram,
+ actual_compute_box_num);
+ __bang_add((T *)temp2_ram, (T *)temp2_ram, (T *)temp9_ram,
+ actual_compute_box_num);
+// temp2 = 1/temp2, use mult (1/temp2) instead of div temp2
+#if __BANG_ARCH__ >= 300
+ __bang_recip((float *)temp2_ram, (float *)temp2_ram,
+ actual_compute_box_num);
+#else
+ // NOTE: active_reciphp function has strict value range:
+ // [2.2205e-16, 2e6]@float, [0.00391, 65504]@half
+ __bang_active_reciphp((T *)temp2_ram, (T *)temp2_ram,
+ actual_compute_box_num);
+#endif
+ // Restore temp2 invalid box value 1 and sign-bit
+ __bang_mul((T *)temp2_ram, (T *)temp2_ram, (T *)temp1_ram,
+ actual_compute_box_num);
+ __bang_mul((T *)temp2_ram, (T *)temp2_ram, (T *)temp8_ram,
+ actual_compute_box_num);
+
+ // auto vec12 = pts2[j] - pts1[i], (temp6, temp7) = (x, y)
+ __bang_sub((T *)temp6_ram,
+ (T *)rotated_pts2_x + j * actual_compute_box_num,
+ (T *)rotated_pts1_x + i * actual_compute_box_num,
+ actual_compute_box_num);
+ __bang_sub((T *)temp7_ram,
+ (T *)rotated_pts2_y + j * actual_compute_box_num,
+ (T *)rotated_pts1_y + i * actual_compute_box_num,
+ actual_compute_box_num);
+
+ // T t1 = cross2d(vec2[j], vec12) mult (1/det) -- temp8
+ cross2d((T *)temp8_ram, (T *)vec2_x + j * actual_compute_box_num,
+ (T *)vec2_y + j * actual_compute_box_num, (T *)temp6_ram,
+ (T *)temp7_ram, actual_compute_box_num, (T *)temp9_ram);
+ __bang_mul((T *)temp8_ram, (T *)temp8_ram, (T *)temp2_ram,
+ actual_compute_box_num);
+
+ // temp1 &= (t1 >= 0.0f && t1 <= 1.0f) -- temp9
+ __bang_cycle_ge((T *)temp9_ram, (T *)temp8_ram, (T *)temp4_ram,
+ actual_compute_box_num, COMPUTE_COUNT_ALIGN);
+ __bang_and((T *)temp1_ram, (T *)temp1_ram, (T *)temp9_ram,
+ actual_compute_box_num);
+ __bang_cycle_le((T *)temp9_ram, (T *)temp8_ram, (T *)temp5_ram,
+ actual_compute_box_num, COMPUTE_COUNT_ALIGN);
+ __bang_and((T *)temp1_ram, (T *)temp1_ram, (T *)temp9_ram,
+ actual_compute_box_num);
+
+ // T t2 = cross2d(vec1[i], vec12) mult temp2 -- temp9
+ // NOTE: temp8(t1) is used after, reuse temp7(p2_y) as cross2d temp ram
+ cross2d((T *)temp9_ram, (T *)vec1_x + i * actual_compute_box_num,
+ (T *)vec1_y + i * actual_compute_box_num, (T *)temp6_ram,
+ (T *)temp7_ram, actual_compute_box_num, (T *)temp7_ram);
+ __bang_mul((T *)temp9_ram, (T *)temp9_ram, (T *)temp2_ram,
+ actual_compute_box_num);
+
+ // temp1 &= (t2 >= 0.0f && t2 <= 1.0f) -- temp9
+ __bang_cycle_ge((T *)temp7_ram, (T *)temp9_ram, (T *)temp4_ram,
+ actual_compute_box_num, COMPUTE_COUNT_ALIGN);
+ __bang_and((T *)temp1_ram, (T *)temp1_ram, (T *)temp7_ram,
+ actual_compute_box_num);
+ __bang_cycle_le((T *)temp7_ram, (T *)temp9_ram, (T *)temp5_ram,
+ actual_compute_box_num, COMPUTE_COUNT_ALIGN);
+ __bang_and((T *)temp1_ram, (T *)temp1_ram, (T *)temp7_ram,
+ actual_compute_box_num);
+
+ // intersections = (pts1[i] + vec1[i] * t1) * temp1
+ __bang_mul((T *)temp9_ram, (T *)vec1_x + i * actual_compute_box_num,
+ (T *)temp8_ram, actual_compute_box_num);
+ __bang_add((T *)temp9_ram,
+ (T *)rotated_pts1_x + i * actual_compute_box_num,
+ (T *)temp9_ram, actual_compute_box_num);
+ __bang_mul((T *)intersect_pts_x + (4 * i + j) * actual_compute_box_num,
+ (T *)temp9_ram, (T *)temp1_ram, actual_compute_box_num);
+ __bang_mul((T *)temp9_ram, (T *)vec1_y + i * actual_compute_box_num,
+ (T *)temp8_ram, actual_compute_box_num);
+ __bang_add((T *)temp9_ram,
+ (T *)rotated_pts1_y + i * actual_compute_box_num,
+ (T *)temp9_ram, actual_compute_box_num);
+ __bang_mul((T *)intersect_pts_y + (4 * i + j) * actual_compute_box_num,
+ (T *)temp9_ram, (T *)temp1_ram, actual_compute_box_num);
+
+ // Assign `valid_pts` bit and accumulate `nums_in` of valid points of each
+ // box pair
+ __bang_or((T *)valid_pts + (4 * i + j) * actual_compute_box_num,
+ (T *)valid_pts + (4 * i + j) * actual_compute_box_num,
+ (T *)temp1_ram, actual_compute_box_num);
+ __bang_add((T *)nums_in_ram, (T *)nums_in_ram, (T *)temp1_ram,
+ actual_compute_box_num);
+ }
+ }
+
+ // Check for vertices of rect1 inside rect2
+ // temp5 = ABdotAB
+ dot2d((T *)temp5_ram, (T *)vec2_x, (T *)vec2_y, (T *)vec2_x, (T *)vec2_y,
+ actual_compute_box_num, (T *)temp9_ram);
+ // temp6 = ADdotAD
+ dot2d((T *)temp6_ram, (T *)vec2_x + 3 * actual_compute_box_num,
+ (T *)vec2_y + 3 * actual_compute_box_num,
+ (T *)vec2_x + 3 * actual_compute_box_num,
+ (T *)vec2_y + 3 * actual_compute_box_num, actual_compute_box_num,
+ (T *)temp9_ram);
+ // assume ABCD is the rectangle, and P is the point to be judged
+ // P is inside ABCD iff. P's projection on AB lines within AB
+ // and P's projection on AD lies within AD
+ for (int i = 0; i < 4; i++) {
+ // AP = pts1[i] - pts2[0] = (temp7, temp8)
+ __bang_sub((T *)temp7_ram, (T *)rotated_pts1_x + i * actual_compute_box_num,
+ (T *)rotated_pts2_x, actual_compute_box_num);
+ __bang_sub((T *)temp8_ram, (T *)rotated_pts1_y + i * actual_compute_box_num,
+ (T *)rotated_pts2_y, actual_compute_box_num);
+
+ // temp9 = APdotAB = dot2d(AP, AB)
+ dot2d((T *)temp9_ram, (T *)temp7_ram, (T *)temp8_ram, (T *)vec2_x,
+ (T *)vec2_y, actual_compute_box_num, (T *)temp2_ram);
+ // temp10 = APdotAD = -dot2d(AP, DA)
+ dot2d((T *)temp10_ram, (T *)temp7_ram, (T *)temp8_ram,
+ (T *)vec2_x + 3 * actual_compute_box_num,
+ (T *)vec2_y + 3 * actual_compute_box_num, actual_compute_box_num,
+ (T *)temp2_ram);
+ __bang_mul_scalar((T *)temp10_ram, (T *)temp10_ram, (T)-1,
+ actual_compute_box_num);
+
+ // ((APdotAB >= 0) && (APdotAD >= 0) && (APdotAB <= ABdotAB) && (APdotAD <=
+ // ADdotAD))
+ __bang_cycle_ge((T *)temp1_ram, (T *)temp9_ram, (T *)temp4_ram,
+ actual_compute_box_num, COMPUTE_COUNT_ALIGN);
+ __bang_cycle_ge((T *)temp2_ram, (T *)temp10_ram, (T *)temp4_ram,
+ actual_compute_box_num, COMPUTE_COUNT_ALIGN);
+ __bang_and((T *)temp1_ram, (T *)temp1_ram, (T *)temp2_ram,
+ actual_compute_box_num);
+ __bang_le((T *)temp2_ram, (T *)temp9_ram, (T *)temp5_ram,
+ actual_compute_box_num);
+ __bang_and((T *)temp1_ram, (T *)temp1_ram, (T *)temp2_ram,
+ actual_compute_box_num);
+ __bang_le((T *)temp2_ram, (T *)temp10_ram, (T *)temp6_ram,
+ actual_compute_box_num);
+ __bang_and((T *)temp1_ram, (T *)temp1_ram, (T *)temp2_ram,
+ actual_compute_box_num);
+
+ // 16 means the 4x4 possible intersection points above
+ __bang_mul((T *)intersect_pts_x + (16 + i) * actual_compute_box_num,
+ (T *)temp1_ram, (T *)rotated_pts1_x + i * actual_compute_box_num,
+ actual_compute_box_num);
+ __bang_mul((T *)intersect_pts_y + (16 + i) * actual_compute_box_num,
+ (T *)temp1_ram, (T *)rotated_pts1_y + i * actual_compute_box_num,
+ actual_compute_box_num);
+
+ // assign valid_pts bit and accumulate nums of valid points of each box pair
+ __bang_or((T *)valid_pts + (16 + i) * actual_compute_box_num,
+ (T *)valid_pts + (16 + i) * actual_compute_box_num,
+ (T *)temp1_ram, actual_compute_box_num);
+ __bang_add((T *)nums_in_ram, (T *)nums_in_ram, (T *)temp1_ram,
+ actual_compute_box_num);
+ }
+
+ // Reverse the check - check for vertices of rect2 inside rect1
+ // temp5 = ABdotAB
+ dot2d((T *)temp5_ram, (T *)vec1_x, (T *)vec1_y, (T *)vec1_x, (T *)vec1_y,
+ actual_compute_box_num, (T *)temp9_ram);
+ // temp6 = ADdotAD
+ dot2d((T *)temp6_ram, (T *)vec1_x + 3 * actual_compute_box_num,
+ (T *)vec1_y + 3 * actual_compute_box_num,
+ (T *)vec1_x + 3 * actual_compute_box_num,
+ (T *)vec1_y + 3 * actual_compute_box_num, actual_compute_box_num,
+ (T *)temp9_ram);
+ for (int i = 0; i < 4; i++) {
+ // AP = pts2[i] - pts1[0] = (temp7, temp8)
+ __bang_sub((T *)temp7_ram, (T *)rotated_pts2_x + i * actual_compute_box_num,
+ (T *)rotated_pts1_x, actual_compute_box_num);
+ __bang_sub((T *)temp8_ram, (T *)rotated_pts2_y + i * actual_compute_box_num,
+ (T *)rotated_pts1_y, actual_compute_box_num);
+
+ // temp9 = APdotAB = dot2d(AP, AB)
+ dot2d((T *)temp9_ram, (T *)temp7_ram, (T *)temp8_ram, (T *)vec1_x,
+ (T *)vec1_y, actual_compute_box_num, (T *)temp2_ram);
+ // temp10 = APdotAD = -dot2d(AP, DA)
+ dot2d((T *)temp10_ram, (T *)temp7_ram, (T *)temp8_ram,
+ (T *)vec1_x + 3 * actual_compute_box_num,
+ (T *)vec1_y + 3 * actual_compute_box_num, actual_compute_box_num,
+ (T *)temp2_ram);
+ __bang_mul_scalar((T *)temp10_ram, (T *)temp10_ram, (T)-1,
+ actual_compute_box_num);
+
+ // ((APdotAB >= 0) && (APdotAD >= 0) && (APdotAB <= ABdotAB) && (APdotAD <=
+ // ADdotAD))
+ __bang_cycle_ge((T *)temp1_ram, (T *)temp9_ram, (T *)temp4_ram,
+ actual_compute_box_num, COMPUTE_COUNT_ALIGN);
+ __bang_cycle_ge((T *)temp2_ram, (T *)temp10_ram, (T *)temp4_ram,
+ actual_compute_box_num, COMPUTE_COUNT_ALIGN);
+ __bang_and((T *)temp1_ram, (T *)temp1_ram, (T *)temp2_ram,
+ actual_compute_box_num);
+ __bang_le((T *)temp2_ram, (T *)temp9_ram, (T *)temp5_ram,
+ actual_compute_box_num);
+ __bang_and((T *)temp1_ram, (T *)temp1_ram, (T *)temp2_ram,
+ actual_compute_box_num);
+ __bang_le((T *)temp2_ram, (T *)temp10_ram, (T *)temp6_ram,
+ actual_compute_box_num);
+ __bang_and((T *)temp1_ram, (T *)temp1_ram, (T *)temp2_ram,
+ actual_compute_box_num);
+
+ // 20 means the (4x4+4) possible intersection points above
+ __bang_mul((T *)intersect_pts_x + (20 + i) * actual_compute_box_num,
+ (T *)temp1_ram, (T *)rotated_pts2_x + i * actual_compute_box_num,
+ actual_compute_box_num);
+ __bang_mul((T *)intersect_pts_y + (20 + i) * actual_compute_box_num,
+ (T *)temp1_ram, (T *)rotated_pts2_y + i * actual_compute_box_num,
+ actual_compute_box_num);
+
+ // assign valid_pts bit and accumulate nums of valid points of each box pair
+ __bang_or((T *)valid_pts + (20 + i) * actual_compute_box_num,
+ (T *)valid_pts + (20 + i) * actual_compute_box_num,
+ (T *)temp1_ram, actual_compute_box_num);
+ __bang_add((T *)nums_in_ram, (T *)nums_in_ram, (T *)temp1_ram,
+ actual_compute_box_num);
+ }
+}
+
+template
+__mlu_func__ void convexHullGraham(
+ T *intersect_pts_x, T *intersect_pts_y, T *ordered_pts_x, T *ordered_pts_y,
+ T *dist_ram, T *valid_box, T *valid_pts, T *nums_in_ram, T *temp1_ram,
+ T *temp2_ram, T *temp3_ram, T *temp_long_1, T *temp_long_2, T *temp_long_3,
+ const uint32_t &actual_box_num, const uint32_t &actual_compute_box_num) {
+ // Step1. Find the point with minimum y, if more than 1 points have the same
+ // minimum y,
+ // pick the one with the minimum x.
+ // set p[i].y to max_y_value if not valid_pts, to avoid invalid result
+ // 24 means all possible intersection points
+ __bang_max((T *)temp2_ram, (T *)intersect_pts_y, 24 * actual_compute_box_num);
+ __bang_write_value((T *)temp3_ram, COMPUTE_COUNT_ALIGN, ((T *)temp2_ram)[0]);
+ __bang_not((T *)temp_long_1, (T *)valid_pts, 24 * actual_compute_box_num);
+ __bang_cycle_mul((T *)temp_long_1, (T *)temp_long_1, (T *)temp3_ram,
+ 24 * actual_compute_box_num, COMPUTE_COUNT_ALIGN);
+ __bang_mul((T *)temp_long_2, (T *)intersect_pts_y, (T *)valid_pts,
+ 24 * actual_compute_box_num);
+ __bang_add((T *)temp_long_2, (T *)temp_long_2, (T *)temp_long_1,
+ 24 * actual_compute_box_num);
+ // temp2 = min_y_value(temp_long_2), use min_pool, channel=box_num, h=1, w=24
+ __bang_minpool((T *)temp2_ram, (T *)temp_long_2, actual_compute_box_num, 1,
+ 24, 1, 24, 1, 24);
+ __bang_mul((T *)temp2_ram, (T *)temp2_ram, (T *)valid_box,
+ actual_compute_box_num);
+
+ // set p[i].x to max_x_value if not min_y point
+ __bang_max((T *)temp1_ram, (T *)intersect_pts_x, 24 * actual_compute_box_num);
+ __bang_write_value((T *)temp3_ram, COMPUTE_COUNT_ALIGN, ((T *)temp1_ram)[0]);
+ __bang_cycle_eq((T *)temp_long_1, (T *)temp_long_2, (T *)temp2_ram,
+ 24 * actual_compute_box_num, actual_compute_box_num);
+ __bang_and((T *)temp_long_1, (T *)temp_long_1, (T *)valid_pts,
+ 24 * actual_compute_box_num);
+ __bang_not((T *)temp_long_3, (T *)temp_long_1, 24 * actual_compute_box_num);
+ __bang_cycle_mul((T *)temp_long_3, (T *)temp_long_3, (T *)temp3_ram,
+ 24 * actual_compute_box_num, COMPUTE_COUNT_ALIGN);
+ __bang_mul((T *)temp_long_1, (T *)intersect_pts_x, (T *)temp_long_1,
+ 24 * actual_compute_box_num);
+ __bang_add((T *)temp_long_1, (T *)temp_long_1, (T *)temp_long_3,
+ 24 * actual_compute_box_num);
+ // temp3 = min_x_value(temp_long_1), use min_pool, channel=box_num, h=1, w=24
+ __bang_minpool((T *)temp3_ram, (T *)temp_long_1, actual_compute_box_num, 1,
+ 24, 1, 24, 1, 24);
+ __bang_mul((T *)temp3_ram, (T *)temp3_ram, (T *)valid_box,
+ actual_compute_box_num);
+
+ // Step2. All points subtract starting-point (for sorting in the next step)
+ __bang_cycle_sub((T *)ordered_pts_x, (T *)intersect_pts_x, (T *)temp3_ram,
+ 24 * actual_compute_box_num, actual_compute_box_num);
+ __bang_cycle_sub((T *)ordered_pts_y, (T *)intersect_pts_y, (T *)temp2_ram,
+ 24 * actual_compute_box_num, actual_compute_box_num);
+ __bang_mul((T *)ordered_pts_x, (T *)ordered_pts_x, (T *)valid_pts,
+ 24 * actual_compute_box_num);
+ __bang_mul((T *)ordered_pts_y, (T *)ordered_pts_y, (T *)valid_pts,
+ 24 * actual_compute_box_num);
+
+ // Step3. Sort every intersection point according to their relative
+ // cross-product values (essentially sorting according to angles)
+ // If the angles are the same, sort according to distance to origin
+ dot2d((T *)dist_ram, (T *)ordered_pts_x, (T *)ordered_pts_y,
+ (T *)ordered_pts_x, (T *)ordered_pts_y, 24 * actual_compute_box_num,
+ (T *)temp_long_3);
+
+ T temp, temp_nums_in, temp_dist_1, temp_dist_2;
+ T temp1_x, temp1_y;
+ T temp2_x, temp2_y;
+ for (int i = 0; i < actual_box_num; i++) {
+ if (((T *)valid_box)[i]) {
+ // make sure all nums_in[i] points are at the front
+ for (int ii = 0; ii < 23; ii++) {
+ for (int jj = ii + 1; jj < 24; jj++) {
+ int ii_index = ii * actual_compute_box_num + i;
+ int jj_index = jj * actual_compute_box_num + i;
+ // ii point is not valid and jj point is valid, swap jj for ii
+ if ((!((T *)valid_pts)[ii_index]) && ((T *)valid_pts)[jj_index]) {
+ ((T *)ordered_pts_x)[ii_index] = ((T *)ordered_pts_x)[jj_index];
+ ((T *)ordered_pts_y)[ii_index] = ((T *)ordered_pts_y)[jj_index];
+ ((T *)dist_ram)[ii_index] = ((T *)dist_ram)[jj_index];
+ ((T *)valid_pts)[ii_index] = true;
+ ((T *)ordered_pts_x)[jj_index] = 0;
+ ((T *)ordered_pts_y)[jj_index] = 0;
+ ((T *)dist_ram)[jj_index] = 0;
+ ((T *)valid_pts)[jj_index] = false;
+ break;
+ }
+ }
+ }
+ temp_nums_in = ((T *)nums_in_ram)[i];
+ // make original q[0] = min_x, min_y before sort
+ for (int ii = 1; ii < temp_nums_in; ii++) {
+ int ii_index = ii * actual_compute_box_num + i;
+ if (((T *)dist_ram)[ii_index] == 0) {
+ // swap q[ii_index] and q[0]
+ ((T *)ordered_pts_x)[ii_index] = ((T *)ordered_pts_x)[i];
+ ((T *)ordered_pts_y)[ii_index] = ((T *)ordered_pts_y)[i];
+ ((T *)dist_ram)[ii_index] = ((T *)dist_ram)[i];
+ ((T *)ordered_pts_x)[i] = 0;
+ ((T *)ordered_pts_y)[i] = 0;
+ ((T *)dist_ram)[i] = 0;
+ break;
+ }
+ }
+ for (int ii = 1; ii < temp_nums_in - 1; ii++) {
+ for (int jj = ii + 1; jj < temp_nums_in; jj++) {
+ int ii_index = ii * actual_compute_box_num + i;
+ int jj_index = jj * actual_compute_box_num + i;
+ temp1_x = ((T *)ordered_pts_x)[ii_index];
+ temp1_y = ((T *)ordered_pts_y)[ii_index];
+ temp2_x = ((T *)ordered_pts_x)[jj_index];
+ temp2_y = ((T *)ordered_pts_y)[jj_index];
+ // calculate cross product and sort q (ordered_pts)
+ temp = (temp1_x * temp2_y) - (temp1_y * temp2_x);
+ temp_dist_1 = ((T *)dist_ram)[ii_index];
+ temp_dist_2 = ((T *)dist_ram)[jj_index];
+ if ((temp < (T)-1e-6) ||
+ ((fabs(temp) < (T)1e-6) && (temp_dist_1 > temp_dist_2))) {
+ ((T *)ordered_pts_x)[ii_index] = temp2_x;
+ ((T *)ordered_pts_y)[ii_index] = temp2_y;
+ ((T *)ordered_pts_x)[jj_index] = temp1_x;
+ ((T *)ordered_pts_y)[jj_index] = temp1_y;
+ ((T *)dist_ram)[ii_index] = temp_dist_2;
+ ((T *)dist_ram)[jj_index] = temp_dist_1;
+ }
+ }
+ }
+
+ // Step4:
+ // Make sure there are at least 2 points(that don't overlap with each
+ // other) in the stack
+ int k; // index of the non-overlapped second point
+ for (k = 1; k < temp_nums_in; k++) {
+ if (((T *)dist_ram)[k * actual_compute_box_num + i] > (T)1e-8) {
+ break;
+ }
+ }
+ if (k == temp_nums_in) {
+ // We reach the end, which means the convex hull is just one point
+ // set valid_box = 0, to get ious = 0
+ ((T *)valid_box)[i] = 0;
+ continue;
+ }
+ // q[1] = q[k];
+ ((T *)ordered_pts_x)[actual_compute_box_num + i] =
+ ((T *)ordered_pts_x)[k * actual_compute_box_num + i];
+ ((T *)ordered_pts_y)[actual_compute_box_num + i] =
+ ((T *)ordered_pts_y)[k * actual_compute_box_num + i];
+
+ // Step 5:
+ // Finally we can start the scanning process.
+ // When a non-convex relationship between the 3 points is found
+ // (either concave shape or duplicated points),
+ // we pop the previous point from the stack
+ // until the 3-point relationship is convex again, or
+ // until the stack only contains two points
+ int m = 2; // 2 points in the stack
+ for (int j = k + 1; j < temp_nums_in; j++) {
+ // while (m > 1 && cross2d(q[j] - q[m - 2], q[m - 1] - q[m - 2]) >=
+ // 0) {
+ // m--;
+ // }
+ temp1_x = ((T *)ordered_pts_x)[j * actual_compute_box_num + i] -
+ ((T *)ordered_pts_x)[(m - 2) * actual_compute_box_num + i];
+ temp1_y = ((T *)ordered_pts_y)[j * actual_compute_box_num + i] -
+ ((T *)ordered_pts_y)[(m - 2) * actual_compute_box_num + i];
+ temp2_x = ((T *)ordered_pts_x)[(m - 1) * actual_compute_box_num + i] -
+ ((T *)ordered_pts_x)[(m - 2) * actual_compute_box_num + i];
+ temp2_y = ((T *)ordered_pts_y)[(m - 1) * actual_compute_box_num + i] -
+ ((T *)ordered_pts_y)[(m - 2) * actual_compute_box_num + i];
+ temp = (temp1_x * temp2_y) - (temp1_y * temp2_x);
+ while ((m > 1) && (temp >= 0)) {
+ m--;
+ if (m > 1) {
+ temp1_x =
+ ((T *)ordered_pts_x)[j * actual_compute_box_num + i] -
+ ((T *)ordered_pts_x)[(m - 2) * actual_compute_box_num + i];
+ temp1_y =
+ ((T *)ordered_pts_y)[j * actual_compute_box_num + i] -
+ ((T *)ordered_pts_y)[(m - 2) * actual_compute_box_num + i];
+ temp2_x =
+ ((T *)ordered_pts_x)[(m - 1) * actual_compute_box_num + i] -
+ ((T *)ordered_pts_x)[(m - 2) * actual_compute_box_num + i];
+ temp2_y =
+ ((T *)ordered_pts_y)[(m - 1) * actual_compute_box_num + i] -
+ ((T *)ordered_pts_y)[(m - 2) * actual_compute_box_num + i];
+ temp = (temp1_x * temp2_y) - (temp1_y * temp2_x);
+ }
+ }
+ // q[m++] = q[j];
+ ((T *)ordered_pts_x)[m * actual_compute_box_num + i] =
+ ((T *)ordered_pts_x)[j * actual_compute_box_num + i];
+ ((T *)ordered_pts_y)[m * actual_compute_box_num + i] =
+ ((T *)ordered_pts_y)[j * actual_compute_box_num + i];
+ m++;
+ }
+ // set last(24-m) valid_pts to false, to erase invalid q in polygon area
+ for (int j = m; j < temp_nums_in; j++) {
+ ((T *)valid_pts)[j * actual_compute_box_num + i] = 0;
+ }
+ ((T *)nums_in_ram)[i] = m;
+ }
+ }
+}
+
+template
+__mlu_func__ void polygonArea(T *ordered_pts_x, T *ordered_pts_y, T *valid_box,
+ T *valid_pts, T *nums_in_ram, T *temp1_ram,
+ T *temp2_ram, T *temp3_ram, T *temp4_ram,
+ T *temp5_ram, T *temp6_ram, T *temp7_ram,
+ T *temp8_ram, T *temp9_ram,
+ const uint32_t &actual_compute_box_num) {
+ // Set where nums_in <= 2, valid_box = false
+ __bang_write_value((T *)temp9_ram, COMPUTE_COUNT_ALIGN, (T)2);
+ __bang_cycle_gt((T *)temp1_ram, (T *)nums_in_ram, (T *)temp9_ram,
+ actual_compute_box_num, COMPUTE_COUNT_ALIGN);
+ __bang_and((T *)valid_box, (T *)valid_box, (T *)temp1_ram,
+ actual_compute_box_num);
+
+ // temp1 = area, initialize with all 0
+ __bang_write_zero((T *)temp1_ram, actual_compute_box_num);
+ __bang_max((T *)temp7_ram, (T *)nums_in_ram, actual_compute_box_num);
+
+ // temp_nums_in = max(nums_in)
+ T temp_nums_in = ((T *)temp7_ram)[0];
+ for (int i = 1; i < temp_nums_in - 1; i++) {
+ // q[i] - q[0]: (temp6, temp7)
+ __bang_sub((T *)temp6_ram, (T *)ordered_pts_x + i * actual_compute_box_num,
+ (T *)ordered_pts_x, actual_compute_box_num);
+ __bang_sub((T *)temp7_ram, (T *)ordered_pts_y + i * actual_compute_box_num,
+ (T *)ordered_pts_y, actual_compute_box_num);
+ __bang_mul((T *)temp6_ram, (T *)temp6_ram,
+ (T *)valid_pts + (i + 1) * actual_compute_box_num,
+ actual_compute_box_num);
+ __bang_mul((T *)temp7_ram, (T *)temp7_ram,
+ (T *)valid_pts + (i + 1) * actual_compute_box_num,
+ actual_compute_box_num);
+ // q[i + 1] - q[0]: (temp8, temp9)
+ __bang_sub((T *)temp8_ram,
+ (T *)ordered_pts_x + (i + 1) * actual_compute_box_num,
+ (T *)ordered_pts_x, actual_compute_box_num);
+ __bang_sub((T *)temp9_ram,
+ (T *)ordered_pts_y + (i + 1) * actual_compute_box_num,
+ (T *)ordered_pts_y, actual_compute_box_num);
+ __bang_mul((T *)temp8_ram, (T *)temp8_ram,
+ (T *)valid_pts + (i + 1) * actual_compute_box_num,
+ actual_compute_box_num);
+ __bang_mul((T *)temp9_ram, (T *)temp9_ram,
+ (T *)valid_pts + (i + 1) * actual_compute_box_num,
+ actual_compute_box_num);
+ // area += fabs(cross2d(q[i] - q[0], q[i + 1] - q[0]));
+ __bang_mul((T *)temp4_ram, (T *)temp6_ram, (T *)temp9_ram,
+ actual_compute_box_num);
+ __bang_mul((T *)temp5_ram, (T *)temp7_ram, (T *)temp8_ram,
+ actual_compute_box_num);
+ __bang_sub((T *)temp3_ram, (T *)temp4_ram, (T *)temp5_ram,
+ actual_compute_box_num);
+ __bang_active_abs((T *)temp3_ram, (T *)temp3_ram, actual_compute_box_num);
+ __bang_add((T *)temp1_ram, (T *)temp1_ram, (T *)temp3_ram,
+ actual_compute_box_num);
+ }
+ // Set where valid_box = false, intersection = 0
+ __bang_mul((T *)temp1_ram, (T *)temp1_ram, (T *)valid_box,
+ actual_compute_box_num);
+ // area = area / 2.0
+ __bang_mul_scalar((T *)temp1_ram, (T *)temp1_ram, (T)0.5,
+ actual_compute_box_num);
+}
+
+#endif // IOU3D_UTILS_HPP_
diff --git a/mmcv/ops/csrc/common/mlu/ms_deform_attn_mlu_kernel.mlu b/mmcv/ops/csrc/common/mlu/ms_deform_attn_mlu_kernel.mlu
new file mode 100644
index 0000000000..7899e52cd3
--- /dev/null
+++ b/mmcv/ops/csrc/common/mlu/ms_deform_attn_mlu_kernel.mlu
@@ -0,0 +1,853 @@
+/*************************************************************************
+ * Copyright (C) 2022 by Cambricon.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
+ * OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
+ * MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
+ * IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
+ * CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
+ * TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
+ * SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
+ *************************************************************************/
+
+#include "common_mlu_helper.hpp"
+#include
+
+/****************************************************************************************
+ *
+ * NRAM partition forward:
+ * | spatial_shapes | data_value_p1_ping | data_value_p2_ping |
+ * | data_value_p3_ping | data_value_p4_ping | data_col_ping |
+ * | data_value_p1_pong | data_value_p2_pong | data_value_p3_pong |
+ * | data_value_p4_pong | data_col_pong | auxiliary_a |
+ * | auxiliary_b |
+ * | 128bytes | deal_size | deal_size |
+ * | deal_size | deal_size | deal_size |
+ * | deal_size | deal_size | deal_size |
+ * | deal_size | deal_size | deal_size |
+ * | deal_size |
+ *
+ ****************************************************************************************/
+
+/****************************************************************************************
+ *
+ * NRAM partition backward:
+ * | grad_output_nram | grad_output_nram_temp | grad_weight |
+ * | grad_h_weight | grad_w_weight | top_grad |
+ * | top_grad_temp | spatial_shapes_nram | sampling_loc_nram |
+ * | deal_size | deal_size | deal_size |
+ * | deal_size | deal_size | deal_size |
+ * | deal_size | deal_size | 64bytes |
+ *
+ ****************************************************************************************/
+
+#define TWELVE_SPLIT 12
+#define ALIGN_NUM 64
+#define ALIGN_NUM_FOR_REDUCE 32
+
+__nram__ char nram_buffer[MAX_NRAM_SIZE];
+
+template
+__mlu_func__ void loadNeighborPointsData(
+ const T *data_value_gdram, T *data_value_p1_nram, T *data_value_p2_nram,
+ T *data_value_p3_nram, T *data_value_p4_nram, const size_t deal_num,
+ const int32_t &width, const int32_t &height, const int32_t &num_heads,
+ const int32_t &channels, const T &x, const T &y, const int32_t &head_idx) {
+ const int32_t w_low = floorf(x);
+ const int32_t h_low = floorf(y);
+ const int32_t w_high = w_low + 1;
+ const int32_t h_high = h_low + 1;
+
+ const int32_t w_stride = num_heads * channels;
+ const int32_t h_stride = width * w_stride;
+ const int32_t h_low_ptr_offset = h_low * h_stride;
+ const int32_t h_high_ptr_offset = h_low_ptr_offset + h_stride;
+ const int32_t w_low_ptr_offset = w_low * w_stride;
+ const int32_t w_high_ptr_offset = w_low_ptr_offset + w_stride;
+ const int32_t base_ptr_offset = head_idx * channels;
+
+ // top-left point
+ if (h_low >= 0 && w_low >= 0) {
+ const int32_t v1_offset =
+ h_low_ptr_offset + w_low_ptr_offset + base_ptr_offset;
+ __memcpy_async(data_value_p1_nram, data_value_gdram + v1_offset,
+ deal_num * sizeof(T), GDRAM2NRAM);
+ }
+
+ // top-right point
+ if (h_low >= 0 && w_high <= width - 1) {
+ const int32_t v2_offset =
+ h_low_ptr_offset + w_high_ptr_offset + base_ptr_offset;
+ __memcpy_async(data_value_p2_nram, data_value_gdram + v2_offset,
+ deal_num * sizeof(T), GDRAM2NRAM);
+ }
+
+ // bottom-left point
+ if (h_high <= height - 1 && w_low >= 0) {
+ const int32_t v3_offset =
+ h_high_ptr_offset + w_low_ptr_offset + base_ptr_offset;
+ __memcpy_async(data_value_p3_nram, data_value_gdram + v3_offset,
+ deal_num * sizeof(T), GDRAM2NRAM);
+ }
+
+ // bottom-right point
+ if (h_high <= height - 1 && w_high <= width - 1) {
+ const int32_t v4_offset =
+ h_high_ptr_offset + w_high_ptr_offset + base_ptr_offset;
+ __memcpy_async(data_value_p4_nram, data_value_gdram + v4_offset,
+ deal_num * sizeof(T), GDRAM2NRAM);
+ }
+}
+
+template
+__mlu_func__ void bilinearInterpolation(
+ T *data_value_p1_nram, T *data_value_p2_nram, T *data_value_p3_nram,
+ T *data_value_p4_nram, T *sample_point_value, T *auxiliary_b,
+ const size_t deal_num, const int32_t &width, const int32_t &height,
+ const T &x, const T &y) {
+ const int32_t w_low = floorf(x);
+ const int32_t h_low = floorf(y);
+ const int32_t w_high = w_low + 1;
+ const int32_t h_high = h_low + 1;
+
+ const T lw = x - w_low;
+ const T lh = y - h_low;
+ const T hw = 1 - lw;
+ const T hh = 1 - lh;
+ const T w1 = hh * hw;
+ const T w2 = hh * lw;
+ const T w3 = lh * hw;
+ const T w4 = lh * lw;
+
+ __bang_write_value((T *)sample_point_value, deal_num, (T)0);
+
+ // top-left point
+ if (h_low >= 0 && w_low >= 0) {
+ // sample_point_value += v1 * w1
+ __bang_mul_scalar((T *)auxiliary_b, (T *)data_value_p1_nram, (T)w1,
+ deal_num);
+ __bang_add((T *)sample_point_value, (T *)sample_point_value,
+ (T *)auxiliary_b, deal_num);
+ }
+
+ // top-right point
+ if (h_low >= 0 && w_high <= width - 1) {
+ // sample_point_value += v2 * w2
+ __bang_mul_scalar((T *)auxiliary_b, (T *)data_value_p2_nram, (T)w2,
+ deal_num);
+ __bang_add((T *)sample_point_value, (T *)sample_point_value,
+ (T *)auxiliary_b, deal_num);
+ }
+
+ // bottom-left point
+ if (h_high <= height - 1 && w_low >= 0) {
+ // sample_point_value += v3 * w3
+ __bang_mul_scalar((T *)auxiliary_b, (T *)data_value_p3_nram, (T)w3,
+ deal_num);
+ __bang_add((T *)sample_point_value, (T *)sample_point_value,
+ (T *)auxiliary_b, deal_num);
+ }
+
+ // bottom-right point
+ if (h_high <= height - 1 && w_high <= width - 1) {
+ // sample_point_value += v4 * w4
+ __bang_mul_scalar((T *)auxiliary_b, (T *)data_value_p4_nram, (T)w4,
+ deal_num);
+ __bang_add((T *)sample_point_value, (T *)sample_point_value,
+ (T *)auxiliary_b, deal_num);
+ }
+}
+
+template
+__mlu_global__ void MLUKernelMsDeformAttnForward(
+ const char *data_value_gdram, const char *data_spatial_shapes_gdram,
+ const char *data_level_start_index_gdram,
+ const char *data_sampling_loc_gdram, const char *data_attn_weight_gdram,
+ const int32_t batch_size, const int32_t num_keys, const int32_t num_heads,
+ const int32_t channels, const int32_t num_levels, const int32_t num_queries,
+ const int32_t num_points, char *data_col_gdram) {
+ if (coreId == 0x80) {
+ return;
+ }
+
+ const size_t spatial_size = PAD_UP(2 * sizeof(int32_t), NFU_ALIGN_SIZE);
+ const size_t span_num_deal =
+ PAD_DOWN((MAX_NRAM_SIZE - spatial_size) / TWELVE_SPLIT / sizeof(T),
+ NFU_ALIGN_SIZE);
+ const size_t align_num = NFU_ALIGN_SIZE;
+ const int32_t channels_seg_num = channels / span_num_deal;
+ const size_t channels_rem = channels % span_num_deal;
+ const size_t channels_align_rem = CEIL_ALIGN(channels_rem, align_num);
+ char *data_spatial_shapes_nram = nram_buffer;
+ char *ping_data_value_p1_nram = data_spatial_shapes_nram + spatial_size;
+ char *ping_data_value_p2_nram =
+ ping_data_value_p1_nram + span_num_deal * sizeof(T);
+ char *ping_data_value_p3_nram =
+ ping_data_value_p2_nram + span_num_deal * sizeof(T);
+ char *ping_data_value_p4_nram =
+ ping_data_value_p3_nram + span_num_deal * sizeof(T);
+ char *ping_data_col_nram =
+ ping_data_value_p4_nram + span_num_deal * sizeof(T);
+ char *pong_data_value_p1_nram =
+ ping_data_col_nram + span_num_deal * sizeof(T);
+ char *pong_data_value_p2_nram =
+ pong_data_value_p1_nram + span_num_deal * sizeof(T);
+ char *pong_data_value_p3_nram =
+ pong_data_value_p2_nram + span_num_deal * sizeof(T);
+ char *pong_data_value_p4_nram =
+ pong_data_value_p3_nram + span_num_deal * sizeof(T);
+ char *pong_data_col_nram =
+ pong_data_value_p4_nram + span_num_deal * sizeof(T);
+ char *auxiliary_a = pong_data_col_nram + span_num_deal * sizeof(T);
+ char *auxiliary_b = auxiliary_a + span_num_deal * sizeof(T);
+ const size_t ping_pong_gap = 5 * span_num_deal * sizeof(T);
+ size_t data_col_ping_pong_idx = 0;
+
+ int32_t block_num_per_core = (batch_size * num_queries * num_heads) / taskDim;
+ const int32_t block_num_rem =
+ (batch_size * num_queries * num_heads) % taskDim;
+ const int32_t idx_start = taskId < (block_num_rem + 1)
+ ? taskId * (block_num_per_core + 1)
+ : taskId * block_num_per_core + block_num_rem;
+ block_num_per_core =
+ taskId < block_num_rem
+ ? (batch_size * num_queries * num_heads) / taskDim + 1
+ : (batch_size * num_queries * num_heads) / taskDim;
+
+ for (int32_t cur_idx = idx_start; cur_idx < idx_start + block_num_per_core;
+ ++cur_idx) {
+ // cur_idx = batch_idx * num_queries * num_heads + query_idx * num_heads +
+ // head_idx
+ const int32_t head_idx = cur_idx % num_heads;
+ const int32_t batch_idx = (cur_idx / num_heads) / num_queries;
+
+ const char *data_value_gdram_start =
+ data_value_gdram +
+ batch_idx * num_keys * num_heads * channels * sizeof(T);
+ const char *data_sampling_loc_gdram_start =
+ data_sampling_loc_gdram +
+ cur_idx * num_levels * num_points * 2 * sizeof(T);
+ const char *data_attn_weight_gdram_start =
+ data_attn_weight_gdram + cur_idx * num_levels * num_points * sizeof(T);
+ char *data_col_gdram_start =
+ data_col_gdram + cur_idx * channels * sizeof(T);
+
+ for (int32_t c_seg_idx = 0; c_seg_idx < channels_seg_num; ++c_seg_idx) {
+ __bang_write_value(
+ (T *)(ping_data_col_nram + data_col_ping_pong_idx * ping_pong_gap),
+ span_num_deal, (T)0);
+ // load data
+ // level_idx = 0, point_idx = 0
+ __memcpy(data_spatial_shapes_nram, data_spatial_shapes_gdram,
+ 2 * sizeof(int32_t), GDRAM2NRAM);
+ int32_t spatial_h = ((int32_t *)data_spatial_shapes_nram)[0];
+ int32_t spatial_w = ((int32_t *)data_spatial_shapes_nram)[1];
+ const char *data_value_ptr =
+ data_value_gdram_start + c_seg_idx * span_num_deal * sizeof(T);
+ T loc_w = ((T *)data_sampling_loc_gdram_start)[0];
+ T loc_h = ((T *)data_sampling_loc_gdram_start)[1];
+ T weight = ((T *)data_attn_weight_gdram_start)[0];
+ T x = loc_w * spatial_w - 0.5;
+ T y = loc_h * spatial_h - 0.5;
+ if (y > -1 && x > -1 && y < spatial_h && x < spatial_w) {
+ loadNeighborPointsData(
+ (T *)data_value_ptr, (T *)ping_data_value_p1_nram,
+ (T *)ping_data_value_p2_nram, (T *)ping_data_value_p3_nram,
+ (T *)ping_data_value_p4_nram, span_num_deal, spatial_w, spatial_h,
+ num_heads, channels, x, y, head_idx);
+ }
+ T spatial_h_next_point = 0;
+ T spatial_w_next_point = 0;
+ T weight_next_point = 0;
+ T x_next_point = 0;
+ T y_next_point = 0;
+ __asm__ volatile("sync;");
+
+ for (int32_t level_idx = 0; level_idx < num_levels; ++level_idx) {
+ for (int32_t point_idx = 0; point_idx < num_points; ++point_idx) {
+ // load data
+ if (point_idx == num_points - 1 && level_idx == num_levels - 1) {
+ // last point no need to load data, continue to compute
+ } else if (point_idx == num_points - 1) {
+ const int32_t level_start_id =
+ ((int32_t *)data_level_start_index_gdram)[level_idx + 1];
+ const int32_t spatial_h_ptr = (level_idx + 1) << 1;
+ __memcpy(
+ data_spatial_shapes_nram,
+ data_spatial_shapes_gdram + spatial_h_ptr * sizeof(int32_t),
+ 2 * sizeof(int32_t), GDRAM2NRAM);
+ spatial_h_next_point = ((int32_t *)data_spatial_shapes_nram)[0];
+ spatial_w_next_point = ((int32_t *)data_spatial_shapes_nram)[1];
+ data_value_ptr = data_value_gdram_start +
+ (level_start_id * num_heads * channels +
+ c_seg_idx * span_num_deal) *
+ sizeof(T);
+ loc_w = ((T *)data_sampling_loc_gdram_start)
+ [(level_idx * num_points + point_idx + 1) * 2];
+ loc_h = ((T *)data_sampling_loc_gdram_start)
+ [(level_idx * num_points + point_idx + 1) * 2 + 1];
+ weight_next_point =
+ ((T *)data_attn_weight_gdram_start)[level_idx * num_points +
+ point_idx + 1];
+ x_next_point = loc_w * spatial_w_next_point - 0.5;
+ y_next_point = loc_h * spatial_h_next_point - 0.5;
+ if (y_next_point > -1 && x_next_point > -1 &&
+ y_next_point < spatial_h_next_point &&
+ x_next_point < spatial_w_next_point) {
+ loadNeighborPointsData(
+ (T *)data_value_ptr,
+ (T *)(ping_data_value_p1_nram +
+ ((level_idx * num_points + point_idx + 1) % 2) *
+ ping_pong_gap),
+ (T *)(ping_data_value_p2_nram +
+ ((level_idx * num_points + point_idx + 1) % 2) *
+ ping_pong_gap),
+ (T *)(ping_data_value_p3_nram +
+ ((level_idx * num_points + point_idx + 1) % 2) *
+ ping_pong_gap),
+ (T *)(ping_data_value_p4_nram +
+ ((level_idx * num_points + point_idx + 1) % 2) *
+ ping_pong_gap),
+ span_num_deal, spatial_w_next_point, spatial_h_next_point,
+ num_heads, channels, x_next_point, y_next_point, head_idx);
+ }
+ } else {
+ spatial_h_next_point = spatial_h;
+ spatial_w_next_point = spatial_w;
+ loc_w = ((T *)data_sampling_loc_gdram_start)
+ [(level_idx * num_points + point_idx + 1) * 2];
+ loc_h = ((T *)data_sampling_loc_gdram_start)
+ [(level_idx * num_points + point_idx + 1) * 2 + 1];
+ weight_next_point =
+ ((T *)data_attn_weight_gdram_start)[level_idx * num_points +
+ point_idx + 1];
+ x_next_point = loc_w * spatial_w - 0.5;
+ y_next_point = loc_h * spatial_h - 0.5;
+ if (y_next_point > -1 && x_next_point > -1 &&
+ y_next_point < spatial_h && x_next_point < spatial_w) {
+ loadNeighborPointsData(
+ (T *)data_value_ptr,
+ (T *)(ping_data_value_p1_nram +
+ ((level_idx * num_points + point_idx + 1) % 2) *
+ ping_pong_gap),
+ (T *)(ping_data_value_p2_nram +
+ ((level_idx * num_points + point_idx + 1) % 2) *
+ ping_pong_gap),
+ (T *)(ping_data_value_p3_nram +
+ ((level_idx * num_points + point_idx + 1) % 2) *
+ ping_pong_gap),
+ (T *)(ping_data_value_p4_nram +
+ ((level_idx * num_points + point_idx + 1) % 2) *
+ ping_pong_gap),
+ span_num_deal, spatial_w, spatial_h, num_heads, channels,
+ x_next_point, y_next_point, head_idx);
+ }
+ }
+
+ // compute
+ if (y > -1 && x > -1 && y < spatial_h && x < spatial_w) {
+ bilinearInterpolation(
+ (T *)(ping_data_value_p1_nram +
+ ((level_idx * num_points + point_idx) % 2) *
+ ping_pong_gap),
+ (T *)(ping_data_value_p2_nram +
+ ((level_idx * num_points + point_idx) % 2) *
+ ping_pong_gap),
+ (T *)(ping_data_value_p3_nram +
+ ((level_idx * num_points + point_idx) % 2) *
+ ping_pong_gap),
+ (T *)(ping_data_value_p4_nram +
+ ((level_idx * num_points + point_idx) % 2) *
+ ping_pong_gap),
+ (T *)auxiliary_a, (T *)auxiliary_b, span_num_deal, spatial_w,
+ spatial_h, x, y);
+ __bang_mul_scalar((T *)auxiliary_a, (T *)auxiliary_a, (T)weight,
+ span_num_deal);
+ __bang_add((T *)(ping_data_col_nram +
+ data_col_ping_pong_idx * ping_pong_gap),
+ (T *)(ping_data_col_nram +
+ data_col_ping_pong_idx * ping_pong_gap),
+ (T *)auxiliary_a, span_num_deal);
+ }
+
+ spatial_w = spatial_w_next_point;
+ spatial_h = spatial_h_next_point;
+ weight = weight_next_point;
+ x = x_next_point;
+ y = y_next_point;
+ __asm__ volatile("sync;");
+ }
+ }
+ // store
+ __memcpy_async(
+ data_col_gdram_start + c_seg_idx * span_num_deal * sizeof(T),
+ ping_data_col_nram + data_col_ping_pong_idx * ping_pong_gap,
+ span_num_deal * sizeof(T), NRAM2GDRAM);
+ data_col_ping_pong_idx = (data_col_ping_pong_idx + 1) % 2;
+ }
+
+ if (channels_rem > 0) {
+ __bang_write_value(
+ (T *)(ping_data_col_nram + data_col_ping_pong_idx * ping_pong_gap),
+ channels_align_rem, (T)0);
+ // load data
+ // level_idx = 0, point_idx = 0
+ __memcpy(data_spatial_shapes_nram, data_spatial_shapes_gdram,
+ 2 * sizeof(int32_t), GDRAM2NRAM);
+ int32_t spatial_h = ((int32_t *)data_spatial_shapes_nram)[0];
+ int32_t spatial_w = ((int32_t *)data_spatial_shapes_nram)[1];
+ const char *data_value_ptr =
+ data_value_gdram_start + channels_seg_num * span_num_deal * sizeof(T);
+ T loc_w = ((T *)data_sampling_loc_gdram_start)[0];
+ T loc_h = ((T *)data_sampling_loc_gdram_start)[1];
+ T weight = ((T *)data_attn_weight_gdram_start)[0];
+ T x = loc_w * spatial_w - 0.5;
+ T y = loc_h * spatial_h - 0.5;
+ if (y > -1 && x > -1 && y < spatial_h && x < spatial_w) {
+ loadNeighborPointsData(
+ (T *)data_value_ptr, (T *)ping_data_value_p1_nram,
+ (T *)ping_data_value_p2_nram, (T *)ping_data_value_p3_nram,
+ (T *)ping_data_value_p4_nram, channels_rem, spatial_w, spatial_h,
+ num_heads, channels, x, y, head_idx);
+ }
+ T spatial_h_next_point = 0;
+ T spatial_w_next_point = 0;
+ T weight_next_point = 0;
+ T x_next_point = 0;
+ T y_next_point = 0;
+ __asm__ volatile("sync;");
+
+ for (int32_t level_idx = 0; level_idx < num_levels; ++level_idx) {
+ for (int32_t point_idx = 0; point_idx < num_points; ++point_idx) {
+ // load data
+ if (point_idx == num_points - 1 && level_idx == num_levels - 1) {
+ // last point no need to load data, continue to compute
+ } else if (point_idx == num_points - 1) {
+ const int32_t level_start_id =
+ ((int32_t *)data_level_start_index_gdram)[level_idx + 1];
+ const int32_t spatial_h_ptr = (level_idx + 1) << 1;
+ __memcpy(
+ data_spatial_shapes_nram,
+ data_spatial_shapes_gdram + spatial_h_ptr * sizeof(int32_t),
+ 2 * sizeof(int32_t), GDRAM2NRAM);
+ spatial_h_next_point = ((int32_t *)data_spatial_shapes_nram)[0];
+ spatial_w_next_point = ((int32_t *)data_spatial_shapes_nram)[1];
+ data_value_ptr = data_value_gdram_start +
+ (level_start_id * num_heads * channels +
+ channels_seg_num * span_num_deal) *
+ sizeof(T);
+ loc_w = ((T *)data_sampling_loc_gdram_start)
+ [(level_idx * num_points + point_idx + 1) * 2];
+ loc_h = ((T *)data_sampling_loc_gdram_start)
+ [(level_idx * num_points + point_idx + 1) * 2 + 1];
+ weight_next_point =
+ ((T *)data_attn_weight_gdram_start)[level_idx * num_points +
+ point_idx + 1];
+ x_next_point = loc_w * spatial_w_next_point - 0.5;
+ y_next_point = loc_h * spatial_h_next_point - 0.5;
+ if (y_next_point > -1 && x_next_point > -1 &&
+ y_next_point < spatial_h_next_point &&
+ x_next_point < spatial_w_next_point) {
+ loadNeighborPointsData(
+ (T *)data_value_ptr,
+ (T *)(ping_data_value_p1_nram +
+ ((level_idx * num_points + point_idx + 1) % 2) *
+ ping_pong_gap),
+ (T *)(ping_data_value_p2_nram +
+ ((level_idx * num_points + point_idx + 1) % 2) *
+ ping_pong_gap),
+ (T *)(ping_data_value_p3_nram +
+ ((level_idx * num_points + point_idx + 1) % 2) *
+ ping_pong_gap),
+ (T *)(ping_data_value_p4_nram +
+ ((level_idx * num_points + point_idx + 1) % 2) *
+ ping_pong_gap),
+ channels_rem, spatial_w_next_point, spatial_h_next_point,
+ num_heads, channels, x_next_point, y_next_point, head_idx);
+ }
+ } else {
+ spatial_w_next_point = spatial_w;
+ spatial_h_next_point = spatial_h;
+ loc_w = ((T *)data_sampling_loc_gdram_start)
+ [(level_idx * num_points + point_idx + 1) * 2];
+ loc_h = ((T *)data_sampling_loc_gdram_start)
+ [(level_idx * num_points + point_idx + 1) * 2 + 1];
+ weight_next_point =
+ ((T *)data_attn_weight_gdram_start)[level_idx * num_points +
+ point_idx + 1];
+ x_next_point = loc_w * spatial_w - 0.5;
+ y_next_point = loc_h * spatial_h - 0.5;
+ if (y_next_point > -1 && x_next_point > -1 &&
+ y_next_point < spatial_h && x_next_point < spatial_w) {
+ loadNeighborPointsData(
+ (T *)data_value_ptr,
+ (T *)(ping_data_value_p1_nram +
+ ((level_idx * num_points + point_idx + 1) % 2) *
+ ping_pong_gap),
+ (T *)(ping_data_value_p2_nram +
+ ((level_idx * num_points + point_idx + 1) % 2) *
+ ping_pong_gap),
+ (T *)(ping_data_value_p3_nram +
+ ((level_idx * num_points + point_idx + 1) % 2) *
+ ping_pong_gap),
+ (T *)(ping_data_value_p4_nram +
+ ((level_idx * num_points + point_idx + 1) % 2) *
+ ping_pong_gap),
+ channels_rem, spatial_w, spatial_h, num_heads, channels,
+ x_next_point, y_next_point, head_idx);
+ }
+ }
+
+ // compute
+ if (y > -1 && x > -1 && y < spatial_h && x < spatial_w) {
+ bilinearInterpolation(
+ (T *)(ping_data_value_p1_nram +
+ ((level_idx * num_points + point_idx) % 2) *
+ ping_pong_gap),
+ (T *)(ping_data_value_p2_nram +
+ ((level_idx * num_points + point_idx) % 2) *
+ ping_pong_gap),
+ (T *)(ping_data_value_p3_nram +
+ ((level_idx * num_points + point_idx) % 2) *
+ ping_pong_gap),
+ (T *)(ping_data_value_p4_nram +
+ ((level_idx * num_points + point_idx) % 2) *
+ ping_pong_gap),
+ (T *)auxiliary_a, (T *)auxiliary_b, channels_align_rem,
+ spatial_w, spatial_h, x, y);
+ __bang_mul_scalar((T *)auxiliary_a, (T *)auxiliary_a, (T)weight,
+ channels_align_rem);
+ __bang_add((T *)(ping_data_col_nram +
+ data_col_ping_pong_idx * ping_pong_gap),
+ (T *)(ping_data_col_nram +
+ data_col_ping_pong_idx * ping_pong_gap),
+ (T *)auxiliary_a, channels_align_rem);
+ }
+
+ spatial_w = spatial_w_next_point;
+ spatial_h = spatial_h_next_point;
+ weight = weight_next_point;
+ x = x_next_point;
+ y = y_next_point;
+ __asm__ volatile("sync;");
+ }
+ }
+ // store
+ __memcpy_async(
+ data_col_gdram_start + channels_seg_num * span_num_deal * sizeof(T),
+ ping_data_col_nram + data_col_ping_pong_idx * ping_pong_gap,
+ channels_rem * sizeof(T), NRAM2GDRAM);
+ data_col_ping_pong_idx = (data_col_ping_pong_idx + 1) % 2;
+ }
+ }
+ __asm__ volatile("sync;");
+ return;
+}
+
+template __mlu_global__ void MLUKernelMsDeformAttnForward(
+ const char *data_value_gdram, const char *data_spatial_shapes_gdram,
+ const char *data_level_start_index_gdram,
+ const char *data_sampling_loc_gdram, const char *data_attn_weight_gdram,
+ const int32_t batch_size, const int32_t num_keys, const int32_t num_heads,
+ const int32_t channels, const int32_t num_levels, const int32_t num_queries,
+ const int32_t num_points, char *data_col_gdram);
+
+void KernelMsDeformAttnForward(
+ cnrtDim3_t k_dim, cnrtFunctionType_t k_type, cnrtQueue_t queue,
+ const cnrtDataType_t d_type, const char *data_value_gdram,
+ const char *data_spatial_shapes_gdram,
+ const char *data_level_start_index_gdram,
+ const char *data_sampling_loc_gdram, const char *data_attn_weight_gdram,
+ const int32_t batch_size, const int32_t num_keys, const int32_t num_heads,
+ const int32_t channels, const int32_t num_levels, const int32_t num_queries,
+ const int32_t num_points, char *data_col_gdram) {
+ MLUKernelMsDeformAttnForward<<>>(
+ data_value_gdram, data_spatial_shapes_gdram, data_level_start_index_gdram,
+ data_sampling_loc_gdram, data_attn_weight_gdram, batch_size, num_keys,
+ num_heads, channels, num_levels, num_queries, num_points, data_col_gdram);
+}
+
+template
+void __mlu_func__ msDeformAttnCol2imBilinear(
+ T *top_grad_temp, const int32_t &height, const int32_t &width, const T &w1,
+ const T &w2, const T &w3, const T &w4, const int32_t &h_low,
+ const int32_t &w_low, const int32_t &h_high, const int32_t &w_high,
+ const int32_t &base_ptr, const int32_t &h_low_ptr_offset,
+ const int32_t &w_low_ptr_offset, const int32_t &h_high_ptr_offset,
+ const int32_t &w_high_ptr_offset, const T &hh, const T &hw, const T &lh,
+ const T &lw, T *top_grad, const T &data_attn_weight, T *grad_h_weight,
+ T *grad_w_weight, T *grad_value, T *grad_output_nram, T *grad_weight,
+ T *grad_sampling_loc, T *grad_attn_weight, T *grad_output_nram_temp,
+ const int32_t &deal_num, const int32_t &deal_num_real,
+ const T *data_value_ptr) {
+ if (h_low >= 0 && w_low >= 0) {
+ int32_t offset1 = h_low_ptr_offset + w_low_ptr_offset + base_ptr;
+ __memcpy(grad_output_nram, data_value_ptr + offset1,
+ deal_num_real * sizeof(T), GDRAM2NRAM);
+ __bang_mul_scalar(grad_weight, grad_output_nram, hw, deal_num);
+ __bang_sub(grad_h_weight, grad_h_weight, grad_weight, deal_num);
+ __bang_mul_scalar(grad_weight, grad_output_nram, hh, deal_num);
+ __bang_sub(grad_w_weight, grad_w_weight, grad_weight, deal_num);
+
+ __bang_mul_scalar(top_grad_temp, top_grad, data_attn_weight, deal_num);
+ __bang_mul_scalar(top_grad_temp, top_grad_temp, w1, deal_num);
+ // for calc grad_attn_weight
+ __bang_mul_scalar(grad_output_nram, grad_output_nram, w1, deal_num);
+ __bang_atomic_add((T *)top_grad_temp, (T *)(grad_value + offset1),
+ (T *)top_grad_temp, deal_num_real);
+ }
+ if (h_low >= 0 && w_high <= width - 1) {
+ int32_t offset2 = h_low_ptr_offset + w_high_ptr_offset + base_ptr;
+ __memcpy(grad_output_nram_temp, data_value_ptr + offset2,
+ deal_num_real * sizeof(T), GDRAM2NRAM);
+ __bang_mul_scalar(grad_weight, grad_output_nram_temp, lw, deal_num);
+ __bang_sub(grad_h_weight, grad_h_weight, grad_weight, deal_num);
+ __bang_mul_scalar(grad_weight, grad_output_nram_temp, hh, deal_num);
+ __bang_add(grad_w_weight, grad_w_weight, grad_weight, deal_num);
+
+ __bang_mul_scalar(top_grad_temp, top_grad, data_attn_weight, deal_num);
+ __bang_mul_scalar(top_grad_temp, top_grad_temp, w2, deal_num);
+
+ __bang_mul_scalar(grad_output_nram_temp, grad_output_nram_temp, w2,
+ deal_num);
+ __bang_add(grad_output_nram, grad_output_nram, grad_output_nram_temp,
+ deal_num);
+ __bang_atomic_add((T *)top_grad_temp, (T *)(grad_value + offset2),
+ (T *)top_grad_temp, deal_num_real);
+ }
+ if (h_high <= height - 1 && w_low >= 0) {
+ int32_t offset3 = h_high_ptr_offset + w_low_ptr_offset + base_ptr;
+ __memcpy(grad_output_nram_temp, data_value_ptr + offset3,
+ deal_num_real * sizeof(T), GDRAM2NRAM);
+ __bang_mul_scalar(grad_weight, grad_output_nram_temp, hw, deal_num);
+ __bang_add(grad_h_weight, grad_h_weight, grad_weight, deal_num);
+ __bang_mul_scalar(grad_weight, grad_output_nram_temp, lh, deal_num);
+ __bang_sub(grad_w_weight, grad_w_weight, grad_weight, deal_num);
+
+ __bang_mul_scalar(top_grad_temp, top_grad, data_attn_weight, deal_num);
+ __bang_mul_scalar(top_grad_temp, top_grad_temp, w3, deal_num);
+ // for calc grad_attn_weight
+ __bang_mul_scalar(grad_output_nram_temp, grad_output_nram_temp, w3,
+ deal_num);
+ __bang_add(grad_output_nram, grad_output_nram, grad_output_nram_temp,
+ deal_num);
+ __bang_atomic_add((T *)top_grad_temp, (T *)(grad_value + offset3),
+ (T *)top_grad_temp, deal_num_real);
+ }
+ if (h_high <= height - 1 && w_high <= width - 1) {
+ int32_t offset4 = h_high_ptr_offset + w_high_ptr_offset + base_ptr;
+ __memcpy(grad_output_nram_temp, data_value_ptr + offset4,
+ deal_num_real * sizeof(T), GDRAM2NRAM);
+ __bang_mul_scalar(grad_weight, grad_output_nram_temp, lw, deal_num);
+ __bang_add(grad_h_weight, grad_h_weight, grad_weight, deal_num);
+ __bang_mul_scalar(grad_weight, grad_output_nram_temp, lh, deal_num);
+ __bang_add(grad_w_weight, grad_w_weight, grad_weight, deal_num);
+
+ __bang_mul_scalar(top_grad_temp, top_grad, data_attn_weight, deal_num);
+ __bang_mul_scalar(top_grad_temp, top_grad_temp, w4, deal_num);
+ // for calc grad_attn_weight
+ __bang_mul_scalar(grad_output_nram_temp, grad_output_nram_temp, w4,
+ deal_num);
+ __bang_add(grad_output_nram, grad_output_nram, grad_output_nram_temp,
+ deal_num);
+
+ __bang_atomic_add((T *)top_grad_temp, (T *)(grad_value + offset4),
+ (T *)top_grad_temp, deal_num_real);
+ }
+ __bang_mul(grad_output_nram, grad_output_nram, top_grad, deal_num);
+#if __BANG_ARCH__ >= 322
+ recursiveSumPool(grad_output_nram, 1, deal_num_real, ALIGN_NUM_FOR_REDUCE);
+#else
+ const int32_t align_num_on_200 = NFU_ALIGN_SIZE / sizeof(float);
+ recursiveSumPool(grad_output_nram, align_num_on_200,
+ deal_num / align_num_on_200, ALIGN_NUM_FOR_REDUCE);
+ __bang_reduce_sum(grad_output_nram, grad_output_nram,
+ NFU_ALIGN_SIZE / sizeof(float));
+#endif
+ __bang_atomic_add((T *)grad_output_nram, (T *)grad_attn_weight,
+ (T *)grad_output_nram, 1);
+ __bang_mul_scalar(grad_w_weight, grad_w_weight, width, deal_num);
+ __bang_mul_scalar(top_grad_temp, top_grad, data_attn_weight, deal_num);
+ __bang_mul(grad_w_weight, grad_w_weight, top_grad_temp, deal_num);
+#if __BANG_ARCH__ >= 322
+ recursiveSumPool(grad_w_weight, 1, deal_num_real, ALIGN_NUM_FOR_REDUCE);
+#else
+ recursiveSumPool(grad_w_weight, align_num_on_200, deal_num / align_num_on_200,
+ ALIGN_NUM_FOR_REDUCE);
+ __bang_reduce_sum(grad_w_weight, grad_w_weight,
+ NFU_ALIGN_SIZE / sizeof(float));
+#endif
+ __bang_atomic_add((T *)grad_w_weight, (T *)(grad_sampling_loc),
+ (T *)grad_w_weight, 1);
+
+ __bang_mul_scalar(grad_h_weight, grad_h_weight, height, deal_num);
+ __bang_mul(grad_h_weight, grad_h_weight, top_grad_temp, deal_num);
+#if __BANG_ARCH__ >= 322
+ recursiveSumPool(grad_h_weight, 1, deal_num_real, ALIGN_NUM_FOR_REDUCE);
+#else
+ recursiveSumPool(grad_h_weight, align_num_on_200, deal_num / align_num_on_200,
+ ALIGN_NUM_FOR_REDUCE);
+ __bang_reduce_sum(grad_h_weight, grad_h_weight,
+ NFU_ALIGN_SIZE / sizeof(float));
+#endif
+ __bang_atomic_add((T *)grad_h_weight, (T *)(grad_sampling_loc + 1),
+ (T *)grad_h_weight, 1);
+}
+
+__mlu_global__ void MLUUnion1KernelMsDeformAttnBackward(
+ const float *data_value, const int32_t *spatial_shapes,
+ const int32_t *data_level_start_index, const float *data_sampling_loc,
+ const float *data_attn_weight, const float *grad_output,
+ const int32_t batch, const int32_t spatial_size, const int32_t num_heads,
+ const int32_t channels, const int32_t num_levels, const int32_t num_query,
+ const int32_t num_points, float *grad_value, float *grad_sampling_loc,
+ float *grad_attn_weight) {
+ if (coreId == 0x80) {
+ return;
+ }
+ const int32_t split_num = 8;
+ const int32_t spatial_shapes_size = 64;
+ int32_t deal_num = PAD_DOWN(
+ (MAX_NRAM_SIZE - spatial_shapes_size) / split_num / sizeof(float),
+ ALIGN_NUM);
+ float *grad_output_nram = (float *)nram_buffer;
+ float *grad_output_nram_temp = (float *)nram_buffer + deal_num;
+ float *grad_weight = (float *)nram_buffer + 2 * deal_num;
+ float *grad_h_weight = (float *)nram_buffer + 3 * deal_num;
+ float *grad_w_weight = (float *)nram_buffer + 4 * deal_num;
+ float *top_grad = (float *)nram_buffer + 5 * deal_num;
+ float *top_grad_temp = (float *)nram_buffer + 6 * deal_num;
+ int32_t *spatial_shapes_nram =
+ (int32_t *)((float *)nram_buffer + 7 * deal_num);
+ float *sampling_loc_nram =
+ (float *)nram_buffer + 7 * deal_num + 2 * sizeof(int32_t);
+ const int32_t total_num = batch * num_query * num_heads * num_levels;
+ int32_t num_per_core = total_num / taskDim;
+ int32_t num_rem = total_num % taskDim;
+ num_per_core = num_per_core + int32_t(taskId < num_rem);
+ int32_t start_per_core =
+ num_rem > taskId
+ ? (taskId * num_per_core)
+ : ((num_per_core + 1) * num_rem + (taskId - num_rem) * num_per_core);
+ int32_t end_per_core = start_per_core + num_per_core;
+ const int32_t C_repeat = channels / deal_num;
+ const int32_t C_tail = channels % deal_num;
+ const int32_t qid_stride = num_heads * channels;
+ int32_t base_ptr = 0;
+ for (int32_t num_loop = start_per_core; num_loop < end_per_core; ++num_loop) {
+ const int32_t l_col = num_loop % num_levels;
+ const int32_t m_col = num_loop / num_levels % num_heads;
+ const int32_t q_col = num_loop / num_levels / num_heads % num_query;
+ const int32_t b_col = num_loop / num_query / num_heads / num_levels;
+ int32_t data_weight_ptr = num_loop * num_points;
+ int32_t data_loc_w_ptr = data_weight_ptr << 1;
+ const int32_t value_offset = b_col * spatial_size * num_heads * channels;
+ const int32_t level_start_id = data_level_start_index[l_col];
+ int32_t spatial_h_ptr = l_col << 1;
+ int32_t grad_output_offset = b_col * num_query * num_heads * channels +
+ q_col * num_heads * channels +
+ m_col * channels;
+ __memcpy(spatial_shapes_nram, spatial_shapes + spatial_h_ptr,
+ 2 * sizeof(int32_t), GDRAM2NRAM);
+ const int32_t spatial_h = spatial_shapes_nram[0];
+ const int32_t spatial_w = spatial_shapes_nram[1];
+ const int32_t value_ptr_offset = value_offset + level_start_id * qid_stride;
+ const float *data_value_ptr = data_value + value_ptr_offset;
+ float *grad_value_ptr = grad_value + value_ptr_offset;
+ const int32_t grad_attn_weight_out = num_loop * num_points;
+ const int32_t grad_sampling_loc_out = num_loop * num_points * 2;
+ for (int32_t p_col = 0; p_col < num_points; ++p_col) {
+ __memcpy(sampling_loc_nram, data_sampling_loc + data_loc_w_ptr,
+ 2 * sizeof(float), GDRAM2NRAM);
+ const float loc_w = sampling_loc_nram[0];
+ const float loc_h = sampling_loc_nram[1];
+ const float weight = data_attn_weight[data_weight_ptr];
+ const float h_im = loc_h * spatial_h - 0.5;
+ const float w_im = loc_w * spatial_w - 0.5;
+ if (h_im > -1 && w_im > -1 && h_im < spatial_h && w_im < spatial_w) {
+ const int32_t h_low = floorf(h_im);
+ const int32_t w_low = floorf(w_im);
+ const int32_t h_high = h_low + 1;
+ const int32_t w_high = w_low + 1;
+
+ const float lh = h_im - h_low;
+ const float lw = w_im - w_low;
+ const float hh = 1.0 - lh;
+ const float hw = 1.0 - lw;
+
+ const int32_t w_stride = num_heads * channels;
+ const int32_t h_stride = spatial_w * w_stride;
+ const int32_t h_low_ptr_offset = h_low * h_stride;
+ const int32_t h_high_ptr_offset = h_low_ptr_offset + h_stride;
+ const int32_t w_low_ptr_offset = w_low * w_stride;
+ const int32_t w_high_ptr_offset = w_low_ptr_offset + w_stride;
+
+ float w1 = hh * hw;
+ float w2 = hh * lw;
+ float w3 = lh * hw;
+ float w4 = lh * lw;
+
+ for (int32_t C_loop = 0; C_loop < C_repeat; ++C_loop) {
+ base_ptr = m_col * channels + C_loop * deal_num;
+ __bang_write_zero(grad_weight, 3 * deal_num);
+ __bang_write_zero(grad_output_nram, deal_num);
+ __memcpy(top_grad,
+ grad_output + grad_output_offset + C_loop * deal_num,
+ deal_num * sizeof(float), GDRAM2NRAM);
+ msDeformAttnCol2imBilinear(
+ top_grad_temp, spatial_h, spatial_w, w1, w2, w3, w4, h_low, w_low,
+ h_high, w_high, base_ptr, h_low_ptr_offset, w_low_ptr_offset,
+ h_high_ptr_offset, w_high_ptr_offset, hh, hw, lh, lw, top_grad,
+ weight, grad_h_weight, grad_w_weight, grad_value_ptr,
+ grad_output_nram, grad_weight,
+ grad_sampling_loc + grad_sampling_loc_out + p_col * 2,
+ grad_attn_weight + grad_attn_weight_out + p_col,
+ grad_output_nram_temp, deal_num, deal_num, data_value_ptr);
+ }
+ if (C_tail != 0) {
+ base_ptr = m_col * channels + C_repeat * deal_num;
+ __bang_write_zero(grad_output_nram, 8 * deal_num);
+ __memcpy(top_grad,
+ grad_output + grad_output_offset + C_repeat * deal_num,
+ C_tail * sizeof(float), GDRAM2NRAM);
+ msDeformAttnCol2imBilinear(
+ top_grad_temp, spatial_h, spatial_w, w1, w2, w3, w4, h_low, w_low,
+ h_high, w_high, base_ptr, h_low_ptr_offset, w_low_ptr_offset,
+ h_high_ptr_offset, w_high_ptr_offset, hh, hw, lh, lw, top_grad,
+ weight, grad_h_weight, grad_w_weight, grad_value_ptr,
+ grad_output_nram, grad_weight,
+ grad_sampling_loc + grad_sampling_loc_out + p_col * 2,
+ grad_attn_weight + grad_attn_weight_out + p_col,
+ grad_output_nram_temp, deal_num, C_tail, data_value_ptr);
+ }
+ }
+ data_weight_ptr += 1;
+ data_loc_w_ptr += 2;
+ }
+ }
+}
+
+__mlu_global__ void MLUUnion1KernelMsDeformAttnBackward(
+ const float *data_value, const int32_t *spatial_shapes,
+ const int32_t *data_level_start_index, const float *data_sampling_loc,
+ const float *data_attn_weight, const float *grad_output,
+ const int32_t batch, const int32_t spatial_size, const int32_t num_heads,
+ const int32_t channels, const int32_t num_levels, const int32_t num_query,
+ const int32_t num_points, float *grad_value, float *grad_sampling_loc,
+ float *grad_attn_weight);
+
+void KernelMsDeformAttnBackward(
+ cnrtDim3_t k_dim, cnrtFunctionType_t k_type, cnrtQueue_t queue,
+ const cnrtDataType_t d_type, const float *data_value,
+ const int32_t *spatial_shapes, const int32_t *data_level_start_index,
+ const float *data_sampling_loc, const float *data_attn_weight,
+ const float *grad_output, const int32_t batch, const int32_t spatial_size,
+ const int32_t num_heads, const int32_t channels, const int32_t num_levels,
+ const int32_t num_query, const int32_t num_points, float *grad_value,
+ float *grad_sampling_loc, float *grad_attn_weight) {
+ MLUUnion1KernelMsDeformAttnBackward<<>>(
+ data_value, spatial_shapes, data_level_start_index, data_sampling_loc,
+ data_attn_weight, grad_output, batch, spatial_size, num_heads, channels,
+ num_levels, num_query, num_points, grad_value, grad_sampling_loc,
+ grad_attn_weight);
+}
diff --git a/mmcv/ops/csrc/common/mlu/nms_mlu_kernel.mlu b/mmcv/ops/csrc/common/mlu/nms_mlu_kernel.mlu
index 7cb16bb100..dcc722d854 100644
--- a/mmcv/ops/csrc/common/mlu/nms_mlu_kernel.mlu
+++ b/mmcv/ops/csrc/common/mlu/nms_mlu_kernel.mlu
@@ -9,14 +9,9 @@
* TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
* SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
*************************************************************************/
-#include "common_mlu_helper.hpp"
+#include "nms_utils.hpp"
-#define NMS_SIZE (64)
#define COORD_DIM (4)
-#define MEMORY_CORE (0x80)
-#define INFO_NUM (5) // 5 means x1, x2, y1, y2 and score
-#define REDUCE_NUM \
- (7) // score, x1, y1, x2, y2, max_index (reserve 2 num for half-type input)
#define SIZE_NRAM_BUF (MAX_NRAM_SIZE + REM_FOR_STACK - 62 * 1024)
#define SIZE_SRAM_BUF (MAX_SRAM_SIZE)
@@ -24,348 +19,129 @@
__nram__ int8_t nram_buffer[SIZE_NRAM_BUF];
__mlu_shared__ int8_t sram_buffer[SIZE_SRAM_BUF];
-__mlu_func__ void pvLock() {
-#if __BANG_ARCH__ == 270
- if (coreId != MEMORY_CORE) {
- __bang_lock(0, 0);
- }
-#endif
-}
-
-__mlu_func__ void pvUnlock() {
-#if __BANG_ARCH__ == 270
- if (coreId != MEMORY_CORE) {
- __bang_unlock(0, 0);
- }
-#endif
-}
-
enum Addr { SRAM, GDRAM };
template
__mlu_func__ void nms_detection(
- uint32_t *output_box_num, const int output_mode, const int input_layout,
- OUT_DT *output_data, const Addr dst, IN_DT *input_data_score,
- const IN_DT *input_data_box, const Addr src, IN_DT *buffer,
- const int buffer_size, IN_DT *sram, const int core_limit,
- const int input_box_num, const int input_stride, const int output_stride,
- const int keepNum, const float thresh_iou, const float thresh_score,
+ uint32_t &output_box_num, const int output_mode, OUT_DT *output_dram,
+ IN_DT *input_data_score, const IN_DT *input_data_box, const Addr input_ram,
+ IN_DT *sram, const int core_limit, const int input_num_boxes,
+ const int max_output_size, const float thresh_iou, const float thresh_score,
const float offset, const int algo) {
- // global value, it is stored in sram with a offset from the begin.
- const int flag_offset_size = 28;
- int32_t *loop_end_flag = (int32_t *)(sram + flag_offset_size);
- loop_end_flag[0] = 0;
+ // global value
+ int32_t *exit_flag = (int32_t *)(sram + 28);
+ exit_flag[0] = 0;
// score, x1, y1, x2, y2, inter_x1, inter_y1, inter_x2, inter_y2
- const int nms_buffer_count1 = 9;
+ int nms_buffer_count1 = 9;
// temp nram buffer to store selected target.
- const int nram_save_limit_count = 256;
+ int nram_save_limit_count = 256;
float div_thresh_iou = 1.0 / thresh_iou;
// input data ptr
- IN_DT *input_score_ptr;
- const IN_DT *input_x1_ptr;
- const IN_DT *input_y1_ptr;
- const IN_DT *input_x2_ptr;
- const IN_DT *input_y2_ptr;
- input_score_ptr = input_data_score;
- input_x1_ptr = input_data_box;
- if (input_layout == 0) {
- // [boxes_num, 4]
- input_y1_ptr = input_x1_ptr + 1;
- input_x2_ptr = input_x1_ptr + 2;
- input_y2_ptr = input_x1_ptr + 3;
- } else if (input_layout == 1) {
- // [4, boxes_num]
- input_y1_ptr = input_x1_ptr + input_stride;
- input_x2_ptr = input_y1_ptr + input_stride;
- input_y2_ptr = input_x2_ptr + input_stride;
- }
-
- // nram data ptr
- IN_DT *x1;
- IN_DT *y1;
- IN_DT *x2;
- IN_DT *y2;
- IN_DT *score;
- IN_DT *inter_x1;
- IN_DT *inter_y1;
- IN_DT *inter_x2;
- IN_DT *inter_y2;
- IN_DT *max_box; // the max score, x1, y1, x2, y2
- IN_DT *x1_mask;
- IN_DT *y1_mask;
- IN_DT *x2_mask;
- IN_DT *y2_mask;
- OUT_DT *nram_save;
+ const IN_DT *input_x1_ptr = input_data_box;
+ const IN_DT *input_y1_ptr = input_x1_ptr + input_num_boxes;
+ const IN_DT *input_x2_ptr = input_y1_ptr + input_num_boxes;
+ const IN_DT *input_y2_ptr = input_x2_ptr + input_num_boxes;
int limit = 0; // find limit when GDRAM or SRAM
- int len_core = 0; // the length deal by every core
int max_seg_pad = 0; // the max length every repeat
int repeat = 0;
int remain = 0;
int remain_pad = 0;
int input_offset = 0; // offset of input_data for current core
int nram_save_count = 0;
- // mask for collect x1, y1, x2, y2. each mask has 128 elements
- const int mask_size = 128;
- const int total_mask_size = 512;
if (output_mode == 0) {
- limit = (buffer_size - 128 /*for max_box*/ * sizeof(IN_DT) -
- nram_save_limit_count * sizeof(OUT_DT) -
- total_mask_size * sizeof(IN_DT)) /
+ limit = (SIZE_NRAM_BUF - NFU_ALIGN_SIZE /*for max_box*/ * sizeof(IN_DT) -
+ nram_save_limit_count * sizeof(OUT_DT)) /
(nms_buffer_count1 * sizeof(IN_DT));
} else {
- limit = (buffer_size - 128 /*for max_box*/ * sizeof(IN_DT) -
- nram_save_limit_count * INFO_NUM * sizeof(OUT_DT) -
- total_mask_size * sizeof(IN_DT)) /
+ // 5 maens: score, x1, y1, x2, y2
+ limit = (SIZE_NRAM_BUF - NFU_ALIGN_SIZE /*for max_box*/ * sizeof(IN_DT) -
+ nram_save_limit_count * 5 * sizeof(OUT_DT)) /
(nms_buffer_count1 * sizeof(IN_DT));
}
- if (core_limit == 1) {
- len_core = input_box_num;
- input_offset = 0;
- } else {
- int avg_core = input_box_num / core_limit;
- int rem = input_box_num % core_limit;
- len_core = avg_core + (taskId < rem ? 1 : 0);
- input_offset = avg_core * taskId + (taskId <= rem ? taskId : rem);
- }
- max_seg_pad = PAD_DOWN(limit, NMS_SIZE);
- repeat = len_core / max_seg_pad;
- remain = len_core % max_seg_pad;
- remain_pad = PAD_UP(remain, NMS_SIZE);
+ int max_seg_iou_compute = 0;
+ int repeat_iou_compute = 0;
+ int remain_iou_compute = 0;
+ int remain_pad_iou_compute = 0;
- // if datatype is half, we should convert it to float when compute the IoU
- int max_seg_iou_compute =
- PAD_DOWN(max_seg_pad / (sizeof(float) / sizeof(IN_DT)), NMS_SIZE);
- int repeat_iou_compute = len_core / max_seg_iou_compute;
- int remain_iou_compute = len_core % max_seg_iou_compute;
- int remain_pad_iou_compute = PAD_UP(remain_iou_compute, NMS_SIZE);
- // initial the address point
- score = buffer;
- x1 = score + max_seg_pad;
- y1 = x1 + max_seg_pad;
- x2 = y1 + max_seg_pad;
- y2 = x2 + max_seg_pad;
- inter_x1 = y2 + max_seg_pad;
- inter_y1 = inter_x1 + max_seg_pad;
- inter_x2 = inter_y1 + max_seg_pad;
- inter_y2 = inter_x2 + max_seg_pad;
- x1_mask = inter_y2 + max_seg_pad;
- y1_mask = x1_mask + mask_size;
- x2_mask = y1_mask + mask_size;
- y2_mask = x2_mask + mask_size;
- max_box = y2_mask + mask_size; // the max score, x1, y1, x2, y2
- // offset two line from max_box
- nram_save = (OUT_DT *)((char *)max_box + NFU_ALIGN_SIZE);
+ getComputeParamsBlockOrU1(sizeof(IN_DT), input_num_boxes, limit, core_limit,
+ input_offset, max_seg_pad, repeat, remain,
+ remain_pad, max_seg_iou_compute, repeat_iou_compute,
+ remain_iou_compute, remain_pad_iou_compute);
- // set mask for __bang_collect instruction
- if (input_layout == 0) {
- __nramset((IN_DT *)x1_mask, total_mask_size, (IN_DT)0);
- for (int idx = 0; idx < mask_size; idx++) {
- int index = (idx % COORD_DIM) * mask_size + idx;
- x1_mask[index] = (IN_DT)1.0;
- }
- }
+ // init the data ptr
+ IN_DT *score = (IN_DT *)nram_buffer;
+ IN_DT *x1 = score + max_seg_pad;
+ IN_DT *y1 = x1 + max_seg_pad;
+ IN_DT *x2 = y1 + max_seg_pad;
+ IN_DT *y2 = x2 + max_seg_pad;
+ IN_DT *inter_x1 = y2 + max_seg_pad;
+ IN_DT *inter_y1 = inter_x1 + max_seg_pad;
+ IN_DT *inter_x2 = inter_y1 + max_seg_pad;
+ IN_DT *inter_y2 = inter_x2 + max_seg_pad;
+ IN_DT *max_box = inter_y2 + max_seg_pad; // the max score, x1, y1, x2, y2
+ OUT_DT *nram_save =
+ (OUT_DT *)((char *)max_box +
+ NFU_ALIGN_SIZE); // offset two line from max_box
- for (int keep = 0; keep < keepNum; keep++) { // loop until the max_score <= 0
+#if __BANG_ARCH__ >= 300
+ float max_box_x1 = 0;
+ float max_box_y1 = 0;
+ float max_box_x2 = 0;
+ float max_box_y2 = 0;
+#endif
+ mluMemcpyDirection_t load_dir = SRAM2NRAM;
+ mluMemcpyDirection_t store_dir = NRAM2SRAM;
+ load_dir = (input_ram == SRAM) ? SRAM2NRAM : GDRAM2NRAM;
+ store_dir = (input_ram == SRAM) ? NRAM2SRAM : NRAM2GDRAM;
+
+ for (int keep = 0; keep < max_output_size;
+ keep++) { // loop until the max_score <= 0
if (core_limit != 1) {
__sync_cluster(); // sync before current loop
}
- /******find max start******/
+ /******FIND MAX START******/
int max_index = 0; // the max score index
int global_max_index = 0; // for U1
- float max_area = 0; // the max score area
+ float max_area = 0; // the max socre area
max_box[0] = 0; // init 0
-
- for (int i = 0; i <= repeat; i++) {
- if (i == repeat && remain == 0) {
- break;
- }
- int seg_len = 0; // the length every nms compute
- int cpy_len = 0; // the length every nms memcpy
- i == repeat ? seg_len = remain_pad : seg_len = max_seg_pad;
- // check seg_len exceeds the limit of fp16 or not. 65536 is the largest
- // num that half data type could express.
- if (sizeof(IN_DT) == sizeof(half) && seg_len > 65536) {
- // seg length exceeds the max num for fp16 datatype!
- return;
- }
- i == repeat ? cpy_len = remain : cpy_len = max_seg_pad;
- /******nms load start******/
- mluMemcpyDirection_t load_dir = SRAM2NRAM;
- if (src == SRAM) {
- load_dir = SRAM2NRAM;
- } else {
- load_dir = GDRAM2NRAM;
- }
- __nramset(score, seg_len, (IN_DT)0);
- __memcpy(score, input_score_ptr + input_offset + i * max_seg_pad,
- cpy_len * sizeof(IN_DT), load_dir, cpy_len * sizeof(IN_DT),
- cpy_len * sizeof(IN_DT), 0);
-
- /******nms load end******/
-
- __bang_max(inter_x1, score, seg_len);
- if (inter_x1[0] > max_box[0]) {
- max_box[0] = inter_x1[0];
-
- if (sizeof(IN_DT) == sizeof(half)) {
- max_index = ((uint16_t *)inter_x1)[1] + input_offset +
- i * max_seg_pad; // offset start from head of input_data
- } else if (sizeof(IN_DT) == sizeof(float)) {
- max_index = ((uint32_t *)inter_x1)[1] + input_offset +
- i * max_seg_pad; // offset start from head of input_data
- }
- }
- } // for repeat
-
- int stride = 1;
- if (input_layout == 0) {
- stride = input_stride;
- } else if (input_layout == 1) {
- stride = 1;
- }
+ findCoreMaxBox(input_data_score, score, inter_x1, max_box, input_x1_ptr,
+ input_y1_ptr, input_x2_ptr, input_y2_ptr, load_dir,
+ input_offset, repeat, remain, remain_pad, max_seg_pad,
+ max_index);
if (core_limit == 1) {
- max_box[1] = input_x1_ptr[max_index * stride];
- max_box[2] = input_y1_ptr[max_index * stride];
- max_box[3] = input_x2_ptr[max_index * stride];
- max_box[4] = input_y2_ptr[max_index * stride];
- if (algo == 0 || offset == 0.0) {
- max_area = ((float)max_box[3] - (float)max_box[1]) *
- ((float)max_box[4] - (float)max_box[2]);
- } else {
- max_area = ((float)max_box[3] - (float)max_box[1] + offset) *
- ((float)max_box[4] - (float)max_box[2] + offset);
- }
- input_score_ptr[max_index] = 0;
+#if __BANG_ARCH__ >= 300
+ calMaxArea(max_box, algo, offset, max_area, max_box_x1, max_box_y1,
+ max_box_x2, max_box_y2);
+#else
+ calMaxArea(max_box, algo, offset, max_area);
+#endif
+ input_data_score[max_index] = 0;
global_max_index = max_index;
- ((uint32_t *)(max_box + INFO_NUM))[0] = max_index;
} else if (core_limit == 4) {
- // find the max with sram
- // the max box's x1, y1, x2, y2 on every core
- if (coreId != MEMORY_CORE) {
- max_box[1] = input_x1_ptr[max_index * stride];
- max_box[2] = input_y1_ptr[max_index * stride];
- max_box[3] = input_x2_ptr[max_index * stride];
- max_box[4] = input_y2_ptr[max_index * stride];
- }
- ((uint32_t *)(max_box + INFO_NUM))[0] = max_index;
- // copy every core's box info to sram, form: score---x1---y1---x2---y2---
- for (int i = 0; i < INFO_NUM; i++) {
- __memcpy(sram + i * core_limit + taskId, max_box + i, 1 * sizeof(IN_DT),
- NRAM2SRAM);
- }
- // copy every core's max_index to sram, use 2 half to store max_index
- __memcpy(sram + INFO_NUM * core_limit + taskId * 2, max_box + INFO_NUM,
- sizeof(uint32_t),
- NRAM2SRAM); // int32_t datatype
__sync_cluster();
+ findClusterMaxBox(sram, max_box, inter_x1, input_data_score, core_limit);
- // copy score from sram to nram and find the max
- __nramset(inter_x1, NMS_SIZE, (IN_DT)0);
- __memcpy(inter_x1, sram, core_limit * sizeof(IN_DT), SRAM2NRAM);
- __bang_max(max_box, inter_x1, NMS_SIZE);
- int max_core = 0;
- if (sizeof(IN_DT) == sizeof(half)) {
- max_core = ((uint16_t *)max_box)[1];
- } else if (sizeof(IN_DT) == sizeof(float)) {
- max_core = ((uint32_t *)max_box)[1];
- }
-
- // copy the max box from SRAM to NRAM
- __memcpy(max_box + 1, sram + 1 * core_limit + max_core, 1 * sizeof(IN_DT),
- SRAM2NRAM); // x1
- __memcpy(max_box + 2, sram + 2 * core_limit + max_core, 1 * sizeof(IN_DT),
- SRAM2NRAM); // y1
- __memcpy(max_box + 3, sram + 3 * core_limit + max_core, 1 * sizeof(IN_DT),
- SRAM2NRAM); // x2
- __memcpy(max_box + 4, sram + 4 * core_limit + max_core, 1 * sizeof(IN_DT),
- SRAM2NRAM); // y2
- __memcpy(max_box + 5, sram + 5 * core_limit + 2 * max_core,
- sizeof(uint32_t), SRAM2NRAM);
- if (algo == 0 || offset == 0.0) {
- max_area = ((float)max_box[3] - (float)max_box[1]) *
- ((float)max_box[4] - (float)max_box[2]);
- } else {
- max_area = ((float)max_box[3] - (float)max_box[1] + offset) *
- ((float)max_box[4] - (float)max_box[2] + offset);
- }
- global_max_index = ((uint32_t *)(max_box + INFO_NUM))[0];
- input_score_ptr[global_max_index] = 0;
+#if __BANG_ARCH__ >= 300
+ calMaxArea(max_box, algo, offset, max_area, max_box_x1, max_box_y1,
+ max_box_x2, max_box_y2);
+#else
+ calMaxArea(max_box, algo, offset, max_area);
+#endif
+ global_max_index = ((uint32_t *)(max_box + 5))[0];
+ input_data_score[global_max_index] = 0;
}
// by now, we get: max_score|max_index|max_box|max_area
- /******find max end******/
-
- /******nms store start******/
- // store to nram
- if (float(max_box[0]) > thresh_score) {
- OUT_DT *save_ptr;
- int save_offset = 0;
- int save_str_num = 0;
- save_ptr = nram_save;
- save_offset = nram_save_count;
- save_str_num = nram_save_limit_count;
- if (coreId == 0) {
- if (output_mode == 0) { // index1, index2, ...
- __memcpy(save_ptr + save_offset, (uint32_t *)(max_box + INFO_NUM),
- 1 * sizeof(uint32_t), NRAM2NRAM, 1 * sizeof(uint32_t),
- 1 * sizeof(uint32_t), 0);
- } else if (output_mode == 1) { // score, x1, y1, x2, y2
- __memcpy(save_ptr + save_offset * INFO_NUM, max_box,
- INFO_NUM * sizeof(IN_DT), NRAM2NRAM,
- INFO_NUM * sizeof(IN_DT), INFO_NUM * sizeof(IN_DT), 0);
- } else if (output_mode == 2) { // score---, x1---, y1---, x2---, y2---
- __memcpy(save_ptr + save_offset, max_box, 1 * sizeof(IN_DT),
- NRAM2NRAM, save_str_num * sizeof(IN_DT), 1 * sizeof(IN_DT),
- 4);
- }
- }
- nram_save_count++;
- (*output_box_num)++;
- }
+ /******FIND MAX END******/
- // store to sram/gdram
- if (*output_box_num != 0) {
- mluMemcpyDirection_t store_dir = NRAM2GDRAM;
- if (dst == SRAM) {
- store_dir = NRAM2SRAM;
- } else { // dst == GDRAM
- store_dir = NRAM2GDRAM;
- }
- if ((nram_save_count == nram_save_limit_count) ||
- (float(max_box[0]) <= thresh_score) || keep == keepNum - 1) {
- if (nram_save_count != 0) {
- if (coreId == 0) {
- if (output_mode == 0) { // index1, index2, ...
- pvLock();
- __memcpy(output_data, nram_save,
- nram_save_count * sizeof(uint32_t), store_dir);
- pvUnlock();
- output_data += nram_save_count;
- } else if (output_mode == 1) { // score, x1, y1, x2, y2
- pvLock();
- __memcpy(output_data, nram_save,
- nram_save_count * INFO_NUM * sizeof(IN_DT), store_dir);
- pvUnlock();
- output_data += nram_save_count * INFO_NUM;
- } else if (output_mode ==
- 2) { // score---, x1---, y1---, x2---, y2---
- pvLock();
- __memcpy(output_data, nram_save, nram_save_count * sizeof(IN_DT),
- store_dir, output_stride * sizeof(IN_DT),
- nram_save_limit_count * sizeof(IN_DT), 4);
- pvUnlock();
- output_data += nram_save_count;
- }
- nram_save_count = 0;
- }
- }
- } // if move data nram->sram/gdram
- } // if dst
+ storeResult(max_box, nram_save, output_dram, keep, nram_save_limit_count,
+ max_output_size, thresh_score, output_mode, nram_save_count,
+ output_box_num);
// if the max score <= 0, end
if (core_limit == 1) {
@@ -375,190 +151,40 @@ __mlu_func__ void nms_detection(
} else {
if (float(max_box[0]) <= thresh_score) {
if (coreId == 0) {
- loop_end_flag[0] = 1;
+ exit_flag[0] = 1;
}
}
__sync_cluster();
- if (loop_end_flag[0] == 1) {
+ if (exit_flag[0] == 1) {
break;
}
}
- /******nms store end******/
-
- // To solve half data accuracy, we convert half to float to calculate IoU.
- for (int i = 0; i <= repeat_iou_compute; i++) {
- if (i == repeat_iou_compute && remain_iou_compute == 0) {
- break;
- }
- int seg_len = 0; // the length every nms compute
- int cpy_len = 0; // the length every nms memcpy
- i == repeat_iou_compute ? seg_len = remain_pad_iou_compute
- : seg_len = max_seg_iou_compute;
- i == repeat_iou_compute ? cpy_len = remain_iou_compute
- : cpy_len = max_seg_iou_compute;
-
- /******nms load start******/
- mluMemcpyDirection_t load_dir = SRAM2NRAM;
- if (src == SRAM) {
- load_dir = SRAM2NRAM;
- } else {
- load_dir = GDRAM2NRAM;
- }
-
- __nramset((float *)score, seg_len, 0.0f);
- int dt_offset = 0;
- if (sizeof(IN_DT) == sizeof(float)) {
- __memcpy(score, input_score_ptr + input_offset + i * max_seg_pad,
- cpy_len * sizeof(IN_DT), load_dir, cpy_len * sizeof(IN_DT),
- cpy_len * sizeof(IN_DT), 0);
- dt_offset = 0;
- } else if (sizeof(IN_DT) == sizeof(half)) {
- __nramset(x1, seg_len, half(0));
- __memcpy(x1, input_score_ptr + input_offset + i * max_seg_iou_compute,
- cpy_len * sizeof(IN_DT), load_dir, cpy_len * sizeof(IN_DT),
- cpy_len * sizeof(IN_DT), 0);
- __bang_half2float((float *)score, (half *)x1, seg_len);
- dt_offset = max_seg_iou_compute;
- }
-
- if (input_layout == 0) {
- // the following number 4 means x1, y1, x2, y2
- __memcpy(
- inter_x1,
- input_x1_ptr + (input_offset + i * max_seg_iou_compute) * COORD_DIM,
- cpy_len * COORD_DIM * sizeof(IN_DT), load_dir,
- cpy_len * COORD_DIM * sizeof(IN_DT),
- cpy_len * COORD_DIM * sizeof(IN_DT), 0);
- // here use collect instruction to transpose the [n, 4] shape into [4,
- // n] shape to avoid
- // discrete memory accessing.
- for (int c_i = 0; c_i < COORD_DIM * seg_len / mask_size; c_i++) {
- // the following number 32 means 32 elements will be selected out by
- // once operation
- __bang_collect(x1 + dt_offset + c_i * 32, inter_x1 + c_i * mask_size,
- x1_mask, mask_size);
- __bang_collect(y1 + dt_offset + c_i * 32, inter_x1 + c_i * mask_size,
- y1_mask, mask_size);
- __bang_collect(x2 + dt_offset + c_i * 32, inter_x1 + c_i * mask_size,
- x2_mask, mask_size);
- __bang_collect(y2 + dt_offset + c_i * 32, inter_x1 + c_i * mask_size,
- y2_mask, mask_size);
- }
- } else if (input_layout == 1) {
- __memcpy(x1 + dt_offset,
- input_x1_ptr + input_offset + i * max_seg_iou_compute,
- cpy_len * sizeof(IN_DT), load_dir, cpy_len * sizeof(IN_DT),
- cpy_len * sizeof(IN_DT), 0);
- __memcpy(y1 + dt_offset,
- input_y1_ptr + input_offset + i * max_seg_iou_compute,
- cpy_len * sizeof(IN_DT), load_dir, cpy_len * sizeof(IN_DT),
- cpy_len * sizeof(IN_DT), 0);
- __memcpy(x2 + dt_offset,
- input_x2_ptr + input_offset + i * max_seg_iou_compute,
- cpy_len * sizeof(IN_DT), load_dir, cpy_len * sizeof(IN_DT),
- cpy_len * sizeof(IN_DT), 0);
- __memcpy(y2 + dt_offset,
- input_y2_ptr + input_offset + i * max_seg_iou_compute,
- cpy_len * sizeof(IN_DT), load_dir, cpy_len * sizeof(IN_DT),
- cpy_len * sizeof(IN_DT), 0);
- }
- /******nms load end******/
-
- /******nms compute start******/
- if (sizeof(IN_DT) == sizeof(half)) {
- __bang_half2float((float *)x1, (half *)x1 + max_seg_iou_compute,
- seg_len);
- __bang_half2float((float *)y1, (half *)y1 + max_seg_iou_compute,
- seg_len);
- __bang_half2float((float *)x2, (half *)x2 + max_seg_iou_compute,
- seg_len);
- __bang_half2float((float *)y2, (half *)y2 + max_seg_iou_compute,
- seg_len);
- }
- // 1、 compute IOU
- // get the area_I
- __nramset((float *)inter_y1, seg_len, float(max_box[1])); // max_x1
- __bang_maxequal((float *)inter_x1, (float *)x1, (float *)inter_y1,
- seg_len); // inter_x1
- __nramset((float *)inter_y2, seg_len, float(max_box[3])); // max_x2
- __bang_minequal((float *)inter_x2, (float *)x2, (float *)inter_y2,
- seg_len); // inter_x2
- __bang_sub((float *)inter_x1, (float *)inter_x2, (float *)inter_x1,
- seg_len);
- if (algo == 1 && offset != 0.0) {
- __bang_add_const((float *)inter_x1, (float *)inter_x1, offset, seg_len);
- }
- __bang_active_relu((float *)inter_x1, (float *)inter_x1,
- seg_len); // inter_w
- __nramset((float *)inter_x2, seg_len, float(max_box[2])); // max_y1
- __bang_maxequal((float *)inter_y1, (float *)y1, (float *)inter_x2,
- seg_len); // inter_y1
- __nramset((float *)inter_x2, seg_len, float(max_box[4])); // max_y2
- __bang_minequal((float *)inter_y2, (float *)y2, (float *)inter_x2,
- seg_len); // inter_y2
- __bang_sub((float *)inter_y1, (float *)inter_y2, (float *)inter_y1,
- seg_len);
- if (algo == 1 && offset != 0.0) {
- __bang_add_const((float *)inter_y1, (float *)inter_y1, offset, seg_len);
- }
- __bang_active_relu((float *)inter_y1, (float *)inter_y1,
- seg_len); // inter_h
- __bang_mul((float *)inter_x1, (float *)inter_x1, (float *)inter_y1,
- seg_len); // area_I
- // get the area of input_box: area = (x2 - x1) * (y2 - y1);
- __bang_sub((float *)inter_y1, (float *)x2, (float *)x1, seg_len);
- __bang_sub((float *)inter_y2, (float *)y2, (float *)y1, seg_len);
- if (algo == 1 && offset != 0.0) {
- __bang_add_const((float *)inter_y1, (float *)inter_y1, offset, seg_len);
- __bang_add_const((float *)inter_y2, (float *)inter_y2, offset, seg_len);
- }
- __bang_mul((float *)inter_x2, (float *)inter_y1, (float *)inter_y2,
- seg_len); // area
- // get the area_U: area + max_area - area_I
- __bang_add_const((float *)inter_x2, (float *)inter_x2, float(max_area),
- seg_len);
- __bang_sub((float *)inter_x2, (float *)inter_x2, (float *)inter_x1,
- seg_len); // area_U
- // 2、 select the box
- // if IOU greater than thres, set the score to zero, abort it: area_U >
- // area_I * (1 / thresh)?
- if (thresh_iou > 0.0) {
- __bang_mul_const((float *)inter_x1, (float *)inter_x1, div_thresh_iou,
- seg_len);
- } else {
- __bang_mul_const((float *)inter_x2, (float *)inter_x2, thresh_iou,
- seg_len);
- }
- __bang_ge((float *)inter_x1, (float *)inter_x2, (float *)inter_x1,
- seg_len);
- __bang_mul((float *)score, (float *)score, (float *)inter_x1, seg_len);
- /******nms compute end******/
-
- // update the score
- mluMemcpyDirection_t update_dir = NRAM2SRAM;
- if (dst == SRAM) {
- update_dir = NRAM2SRAM;
- } else {
- update_dir = NRAM2GDRAM;
- }
- if (sizeof(IN_DT) == sizeof(half)) {
- __bang_float2half_rd((half *)score, (float *)score, seg_len);
- }
- pvLock();
- __memcpy(input_score_ptr + input_offset + i * max_seg_iou_compute, score,
- cpy_len * sizeof(IN_DT), update_dir, cpy_len * sizeof(IN_DT),
- cpy_len * sizeof(IN_DT), 0);
- pvUnlock();
- } // for repeat
- } // for keepNum
+/******NMS STORE END******/
+#if __BANG_ARCH__ >= 300
+ scoreUpdate(input_data_score, load_dir, store_dir, input_x1_ptr,
+ input_y1_ptr, input_x2_ptr, input_y2_ptr, x1, y1, x2, y2, score,
+ inter_x1, inter_y1, inter_x2, inter_y2, max_box, max_box_x1,
+ max_box_y1, max_box_x2, max_box_y2, nram_save,
+ repeat_iou_compute, remain_iou_compute, remain_pad_iou_compute,
+ max_seg_iou_compute, max_seg_pad, thresh_iou, div_thresh_iou,
+ input_offset, offset, max_area, input_num_boxes, algo);
+#else
+ scoreUpdate(input_data_score, load_dir, store_dir, input_x1_ptr,
+ input_y1_ptr, input_x2_ptr, input_y2_ptr, x1, y1, x2, y2, score,
+ inter_x1, inter_y1, inter_x2, inter_y2, max_box, max_box[1],
+ max_box[2], max_box[3], max_box[4], nram_save,
+ repeat_iou_compute, remain_iou_compute, remain_pad_iou_compute,
+ max_seg_iou_compute, max_seg_pad, thresh_iou, div_thresh_iou,
+ input_offset, offset, max_area, input_num_boxes, algo);
+#endif
+ } // for max_output_size
}
__mlu_global__ void MLUUnion1KernelNMS(
const void *input_boxes, const void *input_confidence,
- const int input_num_boxes, const int input_stride,
- const int max_output_size, const float iou_threshold,
- const float confidence_threshold, const int mode, const int input_layout,
- void *workspace, void *result_num, void *output,
+ const int input_num_boxes, const int max_output_size,
+ const float iou_threshold, const float confidence_threshold,
+ const int output_mode, void *workspace, void *result_num, void *output,
const cnrtDataType_t data_type_input, const float offset, const int algo) {
if (data_type_input == CNRT_FLOAT16) {
__memcpy(workspace, input_confidence, input_num_boxes * sizeof(half),
@@ -569,82 +195,48 @@ __mlu_global__ void MLUUnion1KernelNMS(
} else {
}
- int output_stride = max_output_size;
- uint32_t result_box_num = 0;
- if (mode == 0) {
- uint32_t *out_data = (uint32_t *)output;
- switch (data_type_input) {
- default: { return; }
- case CNRT_FLOAT16: {
- half *boxes_data = (half *)input_boxes;
- half *confi_data = (half *)workspace;
- half *buffer = (half *)nram_buffer;
- half *sram = (half *)sram_buffer;
-
- nms_detection(&result_box_num, mode, input_layout, out_data, GDRAM,
- confi_data, boxes_data, GDRAM, buffer, SIZE_NRAM_BUF,
- sram, taskDim, input_num_boxes, input_stride,
- output_stride, max_output_size, iou_threshold,
- confidence_threshold, offset, algo);
- ((uint32_t *)result_num)[0] = result_box_num;
- }; break;
- case CNRT_FLOAT32: {
- float *boxes_data = (float *)input_boxes;
- float *confi_data = (float *)workspace;
- float *buffer = (float *)nram_buffer;
- float *sram = (float *)sram_buffer;
+ uint32_t output_box_num = 0;
+ float *score_data = (float *)workspace;
+ float *boxes_data = (float *)input_boxes;
+ float *sram = (float *)sram_buffer;
- nms_detection(&result_box_num, mode, input_layout, out_data, GDRAM,
- confi_data, boxes_data, GDRAM, buffer, SIZE_NRAM_BUF,
- sram, taskDim, input_num_boxes, input_stride,
- output_stride, max_output_size, iou_threshold,
- confidence_threshold, offset, algo);
- ((uint32_t *)result_num)[0] = result_box_num;
- }; break;
+ if (output_mode == 0) {
+ if (data_type_input == CNRT_FLOAT32) {
+ nms_detection(output_box_num, output_mode, (uint32_t *)output, score_data,
+ boxes_data, GDRAM, sram, taskDim, input_num_boxes,
+ max_output_size, iou_threshold, confidence_threshold,
+ offset, algo);
+ } else {
+ nms_detection(output_box_num, output_mode, (uint32_t *)output,
+ (half *)score_data, (half *)boxes_data, GDRAM, (half *)sram,
+ taskDim, input_num_boxes, max_output_size, iou_threshold,
+ confidence_threshold, offset, algo);
}
} else {
- switch (data_type_input) {
- default: { return; }
- case CNRT_FLOAT16: {
- half *boxes_data = (half *)input_boxes;
- half *confi_data = (half *)workspace;
- half *out_data = (half *)output;
- half *buffer = (half *)nram_buffer;
- half *sram = (half *)sram_buffer;
-
- nms_detection(&result_box_num, mode, input_layout, out_data, GDRAM,
- confi_data, boxes_data, GDRAM, buffer, SIZE_NRAM_BUF,
- sram, taskDim, input_num_boxes, input_stride,
- output_stride, max_output_size, iou_threshold,
- confidence_threshold, offset, algo);
- ((uint32_t *)result_num)[0] = result_box_num;
- }; break;
- case CNRT_FLOAT32: {
- float *boxes_data = (float *)input_boxes;
- float *confi_data = (float *)workspace;
- float *out_data = (float *)output;
- float *buffer = (float *)nram_buffer;
- float *sram = (float *)sram_buffer;
-
- nms_detection(&result_box_num, mode, input_layout, out_data, GDRAM,
- confi_data, boxes_data, GDRAM, buffer, SIZE_NRAM_BUF,
- sram, taskDim, input_num_boxes, input_stride,
- output_stride, max_output_size, iou_threshold,
- confidence_threshold, offset, algo);
- ((uint32_t *)result_num)[0] = result_box_num;
- }; break;
+ if (data_type_input == CNRT_FLOAT32) {
+ nms_detection(output_box_num, output_mode, (float *)output, score_data,
+ boxes_data, GDRAM, sram, taskDim, input_num_boxes,
+ max_output_size, iou_threshold, confidence_threshold,
+ offset, algo);
+ } else {
+ nms_detection(output_box_num, output_mode, (half *)output,
+ (half *)score_data, (half *)boxes_data, GDRAM, (half *)sram,
+ taskDim, input_num_boxes, max_output_size, iou_threshold,
+ confidence_threshold, offset, algo);
}
}
+ ((uint32_t *)result_num)[0] = output_box_num;
}
template
__mlu_func__ void nms_detection_ux(
- int32_t *loop_end_flag, uint32_t &output_box_num, OUT_DT *output_dram,
+ int32_t *exit_flag, uint32_t &output_box_num, OUT_DT *output_dram,
IN_DT *score_data, const IN_DT *boxes_data, const Addr input_ram,
- const int input_layout, const int input_num_boxes, const int input_stride,
- const int max_output_size, const float thresh_iou, const float thresh_score,
- const float offset, const int output_mode, const int algo) {
- loop_end_flag[0] = 0;
+ const int input_num_boxes, const int max_output_size,
+ const float thresh_iou, const float thresh_score, const float offset,
+ const int output_mode, const int algo, char *cdma_gdram) {
+ exit_flag[0] = 0;
+
IN_DT *sram = (IN_DT *)sram_buffer;
// score, x1, y1, x2, y2, inter_x1, inter_y1, inter_x2, inter_y2
@@ -654,16 +246,10 @@ __mlu_func__ void nms_detection_ux(
float div_thresh_iou = 1.0 / thresh_iou;
// input data ptr
- IN_DT *input_score_ptr;
- const IN_DT *input_x1_ptr;
- const IN_DT *input_y1_ptr;
- const IN_DT *input_x2_ptr;
- const IN_DT *input_y2_ptr;
- input_score_ptr = score_data;
- input_x1_ptr = boxes_data;
- input_y1_ptr = input_x1_ptr + input_stride;
- input_x2_ptr = input_y1_ptr + input_stride;
- input_y2_ptr = input_x2_ptr + input_stride;
+ const IN_DT *input_x1_ptr = boxes_data;
+ const IN_DT *input_y1_ptr = input_x1_ptr + input_num_boxes;
+ const IN_DT *input_x2_ptr = input_y1_ptr + input_num_boxes;
+ const IN_DT *input_y2_ptr = input_x2_ptr + input_num_boxes;
int limit = 0; // find limit when GDRAM or SRAM
int max_seg_pad = 0; // the max length every repeat
@@ -682,41 +268,16 @@ __mlu_func__ void nms_detection_ux(
(nms_buffer_count1 * sizeof(IN_DT));
}
- // data split
- int avg_cluster = input_num_boxes / clusterDim;
- int rem_cluster = input_num_boxes % clusterDim;
- int len_cluster = avg_cluster + (clusterId < rem_cluster ? 1 : 0);
- int cluster_offset = avg_cluster * clusterId +
- (clusterId <= rem_cluster ? clusterId : rem_cluster);
-
- int avg_core = len_cluster / coreDim;
- int rem_core = len_cluster % coreDim;
- int len_core = avg_core + (coreId < rem_core ? 1 : 0);
- int core_offset =
- avg_core * coreId + (coreId <= rem_core ? coreId : rem_core);
- int input_offset = cluster_offset + core_offset;
-
- max_seg_pad = PAD_DOWN(limit, NMS_SIZE);
-
- // core 0 of each cluster calculate the max score index
- int max_index_avg_core = input_num_boxes / clusterDim;
- int max_index_rem_core = input_num_boxes % clusterDim;
- int max_index_len_core =
- max_index_avg_core + (clusterId < max_index_rem_core ? 1 : 0);
- int max_index_input_offset =
- max_index_avg_core * clusterId +
- (clusterId <= max_index_rem_core ? clusterId : max_index_rem_core);
- repeat = max_index_len_core / max_seg_pad;
- remain = max_index_len_core % max_seg_pad;
- remain_pad = PAD_UP(remain, NMS_SIZE);
-
- // if datatype is fp16, we should cvt to fp32 when compute iou
- int max_seg_iou_compute =
- PAD_DOWN(max_seg_pad / (sizeof(float) / sizeof(IN_DT)), NMS_SIZE);
- int repeat_iou_compute = len_core / max_seg_iou_compute;
- int remain_iou_compute = len_core % max_seg_iou_compute;
- int remain_pad_iou_compute = PAD_UP(remain_iou_compute, NMS_SIZE);
+ int input_offset = 0;
+ int max_seg_iou_compute = 0;
+ int repeat_iou_compute = 0;
+ int remain_iou_compute = 0;
+ int remain_pad_iou_compute = 0;
+ getComputeParamsUx(sizeof(IN_DT), input_num_boxes, limit, input_offset,
+ max_seg_pad, repeat, remain, remain_pad,
+ max_seg_iou_compute, repeat_iou_compute,
+ remain_iou_compute, remain_pad_iou_compute);
// init the nram ptr
IN_DT *score = (IN_DT *)nram_buffer;
IN_DT *x1 = score + max_seg_pad;
@@ -731,320 +292,113 @@ __mlu_func__ void nms_detection_ux(
OUT_DT *nram_save =
(OUT_DT *)((char *)max_box +
NFU_ALIGN_SIZE); // offset two line from max_box
-
- mluMemcpyDirection_t input_load_dir = SRAM2NRAM;
- mluMemcpyDirection_t input_store_dir = NRAM2SRAM;
- input_load_dir = (input_ram == SRAM) ? SRAM2NRAM : GDRAM2NRAM;
- input_store_dir = (input_ram == SRAM) ? NRAM2SRAM : NRAM2GDRAM;
+#if __BANG_ARCH__ >= 300
+ float max_box_x1 = 0;
+ float max_box_y1 = 0;
+ float max_box_x2 = 0;
+ float max_box_y2 = 0;
+#endif
+ mluMemcpyDirection_t load_dir = SRAM2NRAM;
+ mluMemcpyDirection_t store_dir = NRAM2SRAM;
+ load_dir = (input_ram == SRAM) ? SRAM2NRAM : GDRAM2NRAM;
+ store_dir = (input_ram == SRAM) ? NRAM2SRAM : NRAM2GDRAM;
for (int keep = 0; keep < max_output_size;
keep++) { // loop until the max_score <= 0
__sync_all();
- /******FIND MAX START******/
int max_index = 0;
int global_max_index = 0; // for Ux
float max_area = 0; // the max socre area
max_box[0] = 0; // init 0
if (coreId == 0) {
- for (int i = 0; i <= repeat; i++) {
- if (i == repeat && remain == 0) {
- break;
- }
-
- int seg_len = (i == repeat)
- ? remain_pad
- : max_seg_pad; // the length every nms compute
- // check seg_len exceeds the limit of fp16 or not. 65536 is the largest
- // num
- // that fp16 could express.
- if (sizeof(IN_DT) == sizeof(half) && seg_len > 65536) {
- return;
- }
- int cpy_len = (i == repeat)
- ? remain
- : max_seg_pad; // the length every nms memcpy
-
- /******NMS LOAD START******/
- __bang_write_zero(score, seg_len);
- __memcpy(score,
- input_score_ptr + max_index_input_offset + i * max_seg_pad,
- cpy_len * sizeof(IN_DT), input_load_dir,
- cpy_len * sizeof(IN_DT), cpy_len * sizeof(IN_DT), 0);
-
- /******NMS LOAD END******/
-
- __bang_max(inter_x1, score, seg_len);
- if (inter_x1[0] > max_box[0]) {
- max_box[0] = inter_x1[0];
- if (sizeof(IN_DT) == sizeof(half)) {
- max_index =
- ((uint16_t *)inter_x1)[1] + max_index_input_offset +
- i * max_seg_pad; // offset start from head of input_data
- } else if (sizeof(IN_DT) == sizeof(float)) {
- max_index =
- ((uint32_t *)inter_x1)[1] + max_index_input_offset +
- i * max_seg_pad; // offset start from head of input_data
- }
- }
- } // for repeat
-
- // the max box's x1, y1, x2, y2 on every cluster
- max_box[1] = input_x1_ptr[max_index];
- max_box[2] = input_y1_ptr[max_index];
- max_box[3] = input_x2_ptr[max_index];
- max_box[4] = input_y2_ptr[max_index];
- ((uint32_t *)(max_box + 5))[0] = max_index;
+ findCoreMaxBox(score_data, score, inter_x1, max_box, input_x1_ptr,
+ input_y1_ptr, input_x2_ptr, input_y2_ptr, load_dir,
+ input_offset, repeat, remain, remain_pad, max_seg_pad,
+ max_index);
// copy max box info to sram
__memcpy(sram, max_box, REDUCE_NUM * sizeof(IN_DT), NRAM2SRAM);
}
__sync_all();
- // copy all partial max to the sram of cluster 0
- if (clusterId != 0) {
- __memcpy(sram + REDUCE_NUM * clusterId, sram, REDUCE_NUM * sizeof(IN_DT),
- SRAM2SRAM, 0);
- }
+#if __BANG_ARCH__ >= 590
+ __memcpy((char *)cdma_gdram + REDUCE_NUM * clusterId * sizeof(IN_DT), sram,
+ REDUCE_NUM * sizeof(IN_DT), SRAM2GDRAM);
__sync_all();
-
- // reduce between clusters to get the global max box
- if (clusterId == 0) {
- if (coreId == 0) {
- __bang_write_zero(inter_x1, NMS_SIZE);
- __memcpy(inter_x1, sram, sizeof(IN_DT), SRAM2NRAM, sizeof(IN_DT),
- REDUCE_NUM * sizeof(IN_DT), clusterDim - 1);
- __bang_max(max_box, inter_x1, NMS_SIZE);
- int max_cluster = (sizeof(IN_DT) == sizeof(half))
- ? ((uint16_t *)max_box)[1]
- : ((uint32_t *)max_box)[1];
- __memcpy(max_box, sram + max_cluster * REDUCE_NUM,
- REDUCE_NUM * sizeof(IN_DT), SRAM2NRAM);
- __memcpy(sram, max_box, REDUCE_NUM * sizeof(IN_DT), NRAM2SRAM);
- }
- __sync_cluster();
- if (coreId == 0x80 && clusterDim > 1) {
- // broadcast global max box to each cluster's sram
- for (int cluster_idx = 1; cluster_idx < clusterDim; ++cluster_idx) {
- __memcpy(sram, sram, REDUCE_NUM * sizeof(IN_DT), SRAM2SRAM,
- cluster_idx);
- }
- }
- __sync_cluster();
+ if (clusterId == 0 && coreId == 0) {
+ __bang_write_zero(inter_x1, NMS_SIZE);
+ __memcpy((char *)inter_x1, (char *)cdma_gdram, sizeof(IN_DT), GDRAM2NRAM,
+ sizeof(IN_DT), REDUCE_NUM * sizeof(IN_DT), clusterDim - 1);
+ __bang_max(max_box, inter_x1, NMS_SIZE);
+ int max_cluster = (sizeof(IN_DT) == sizeof(half))
+ ? ((uint16_t *)max_box)[1]
+ : ((uint32_t *)max_box)[1];
+ __memcpy((char *)cdma_gdram,
+ (char *)cdma_gdram + max_cluster * REDUCE_NUM * sizeof(IN_DT),
+ REDUCE_NUM * sizeof(IN_DT), GDRAM2GDRAM);
}
__sync_all();
+ __memcpy(max_box, cdma_gdram, REDUCE_NUM * sizeof(IN_DT), GDRAM2NRAM);
+#else
+ findGlobalMaxBox(max_box, sram, inter_x1);
+#endif
- // copy the global max box to max_box
- __memcpy(max_box, sram, REDUCE_NUM * sizeof(IN_DT), SRAM2NRAM);
- if (algo == 0 || offset == 0.0) {
- max_area = ((float)max_box[3] - (float)max_box[1]) *
- ((float)max_box[4] - (float)max_box[2]);
- } else {
- max_area = ((float)max_box[3] - (float)max_box[1] + offset) *
- ((float)max_box[4] - (float)max_box[2] + offset);
- }
+#if __BANG_ARCH__ >= 300
+ calMaxArea(max_box, algo, offset, max_area, max_box_x1, max_box_y1,
+ max_box_x2, max_box_y2);
+#else
+ calMaxArea(max_box, algo, offset, max_area);
+#endif
global_max_index = ((uint32_t *)(max_box + 5))[0];
- if (coreId != 0x80) {
- input_score_ptr[global_max_index] = 0;
+ if (coreId != MEMORY_CORE) {
+ score_data[global_max_index] = 0;
}
- // by now, we get: max_score|max_index|max_box|max_area
- /******FIND MAX END******/
- /******NMS STORE START******/
- // store to nram
- if (float(max_box[0]) > thresh_score) {
- OUT_DT *save_ptr;
- int save_offset = 0;
- int save_str_num = 0;
- save_ptr = nram_save;
- save_offset = nram_save_count;
- save_str_num = nram_save_limit_count;
- if (clusterId == 0 && coreId == 0) {
- if (output_mode == 0) { // index1, index2, ...
- save_ptr[save_offset] = ((uint32_t *)(max_box + INFO_NUM))[0];
- } else if (output_mode == 1) { // score, x1, y1, x2, y2
- __memcpy(save_ptr + save_offset * INFO_NUM, max_box,
- INFO_NUM * sizeof(IN_DT), NRAM2NRAM,
- INFO_NUM * sizeof(IN_DT), INFO_NUM * sizeof(IN_DT), 0);
- } else if (output_mode == 2) { // score---, x1---, y1---, x2---, y2---
- __memcpy(save_ptr + save_offset, max_box, 1 * sizeof(IN_DT),
- NRAM2NRAM, save_str_num * sizeof(IN_DT), 1 * sizeof(IN_DT),
- 4);
- }
- }
- nram_save_count++;
- output_box_num++;
- }
-
- // store to sram/gdram
- if (output_box_num != 0) {
- if ((nram_save_count == nram_save_limit_count) ||
- (float(max_box[0]) <= thresh_score) || keep == max_output_size - 1) {
- if (nram_save_count != 0) {
- if (clusterId == 0 && coreId == 0) {
- if (output_mode == 0) { // index1, index2, ...
- pvLock();
- __memcpy(output_dram, nram_save,
- nram_save_count * sizeof(uint32_t), NRAM2GDRAM);
- pvUnlock();
- output_dram += nram_save_count;
- } else if (output_mode == 1) { // score, x1, y1, x2, y2
- pvLock();
- __memcpy(output_dram, nram_save,
- nram_save_count * INFO_NUM * sizeof(IN_DT), NRAM2GDRAM);
- pvUnlock();
- output_dram += nram_save_count * INFO_NUM;
- } else if (output_mode ==
- 2) { // score---, x1---, y1---, x2---, y2---
- pvLock();
- __memcpy(output_dram, nram_save, nram_save_count * sizeof(IN_DT),
- NRAM2GDRAM, max_output_size * sizeof(IN_DT),
- nram_save_limit_count * sizeof(IN_DT), 4);
- pvUnlock();
- output_dram += nram_save_count;
- }
- nram_save_count = 0;
- }
- }
- } // if move data nram->sram/gdram
- } // if dst
+ storeResult(max_box, nram_save, output_dram, keep, nram_save_limit_count,
+ max_output_size, thresh_score, output_mode, nram_save_count,
+ output_box_num);
if (float(max_box[0]) <= thresh_score) {
if (clusterId == 0 && coreId == 0) {
- loop_end_flag[0] = 1; // dram
+ exit_flag[0] = 1; // dram
}
}
__sync_all();
- if (loop_end_flag[0] == 1) {
+ if (exit_flag[0] == 1) {
break;
}
- /******NMS STORE END******/
-
- // To solve fp16 accuracy, we convert fp16 to fp32 to calculate IoU.
- for (int i = 0; i <= repeat_iou_compute; i++) {
- if (i == repeat_iou_compute && remain_iou_compute == 0) {
- break;
- }
- int seg_len = (i == repeat_iou_compute) ? remain_pad_iou_compute
- : max_seg_iou_compute;
- int cpy_len =
- (i == repeat_iou_compute) ? remain_iou_compute : max_seg_iou_compute;
-
- /******NMS LOAD START******/
- __nramset((float *)score, seg_len, 0.0f);
- int dt_offset = 0;
- if (sizeof(IN_DT) == sizeof(float)) {
- __memcpy(score, input_score_ptr + input_offset + i * max_seg_pad,
- cpy_len * sizeof(IN_DT), input_load_dir,
- cpy_len * sizeof(IN_DT), cpy_len * sizeof(IN_DT), 0);
- dt_offset = 0;
- } else if (sizeof(IN_DT) == sizeof(half)) {
- __nramset(x1, seg_len, half(0));
- __memcpy(x1, input_score_ptr + input_offset + i * max_seg_iou_compute,
- cpy_len * sizeof(IN_DT), input_load_dir,
- cpy_len * sizeof(IN_DT), cpy_len * sizeof(IN_DT), 0);
- __bang_half2float((float *)score, (half *)x1, seg_len);
- dt_offset = max_seg_iou_compute;
- }
-
- __memcpy(x1 + dt_offset,
- input_x1_ptr + input_offset + i * max_seg_iou_compute,
- cpy_len * sizeof(IN_DT), input_load_dir,
- max_seg_pad * sizeof(IN_DT), input_num_boxes * sizeof(IN_DT), 3);
- /******NMS LOAD END******/
-
- /******NMS COMPUTE START******/
- if (sizeof(IN_DT) == sizeof(half)) {
- __bang_half2float((float *)x1, (half *)x1 + max_seg_iou_compute,
- seg_len);
- __bang_half2float((float *)y1, (half *)y1 + max_seg_iou_compute,
- seg_len);
- __bang_half2float((float *)x2, (half *)x2 + max_seg_iou_compute,
- seg_len);
- __bang_half2float((float *)y2, (half *)y2 + max_seg_iou_compute,
- seg_len);
- }
- // 1、 compute IOU
- // get the area_I
- __nramset((float *)inter_y1, seg_len, float(max_box[1])); // max_x1
- __bang_maxequal((float *)inter_x1, (float *)x1, (float *)inter_y1,
- seg_len); // inter_x1
- __nramset((float *)inter_y2, seg_len, float(max_box[3])); // max_x2
- __bang_minequal((float *)inter_x2, (float *)x2, (float *)inter_y2,
- seg_len); // inter_x2
- __bang_sub((float *)inter_x1, (float *)inter_x2, (float *)inter_x1,
- seg_len);
- if (algo == 1 && offset != 0.0) {
- __bang_add_const((float *)inter_x1, (float *)inter_x1, offset, seg_len);
- }
- __bang_active_relu((float *)inter_x1, (float *)inter_x1,
- seg_len); // inter_w
- __nramset((float *)inter_x2, seg_len, float(max_box[2])); // max_y1
- __bang_maxequal((float *)inter_y1, (float *)y1, (float *)inter_x2,
- seg_len); // inter_y1
- __nramset((float *)inter_x2, seg_len, float(max_box[4])); // max_y2
- __bang_minequal((float *)inter_y2, (float *)y2, (float *)inter_x2,
- seg_len); // inter_y2
- __bang_sub((float *)inter_y1, (float *)inter_y2, (float *)inter_y1,
- seg_len);
- if (algo == 1 && offset != 0.0) {
- __bang_add_const((float *)inter_y1, (float *)inter_y1, offset, seg_len);
- }
- __bang_active_relu((float *)inter_y1, (float *)inter_y1,
- seg_len); // inter_h
- __bang_mul((float *)inter_x1, (float *)inter_x1, (float *)inter_y1,
- seg_len); // area_I
- // get the area of input_box: area = (x2 - x1) * (y2 - y1);
- __bang_sub((float *)inter_y1, (float *)x2, (float *)x1, seg_len);
- __bang_sub((float *)inter_y2, (float *)y2, (float *)y1, seg_len);
- if (algo == 1 && offset != 0.0) {
- __bang_add_const((float *)inter_y1, (float *)inter_y1, offset, seg_len);
- __bang_add_const((float *)inter_y2, (float *)inter_y2, offset, seg_len);
- }
- __bang_mul((float *)inter_x2, (float *)inter_y1, (float *)inter_y2,
- seg_len); // area
- // get the area_U: area + max_area - area_I
- __bang_add_const((float *)inter_x2, (float *)inter_x2, float(max_area),
- seg_len);
- __bang_sub((float *)inter_x2, (float *)inter_x2, (float *)inter_x1,
- seg_len); // area_U
- // 2、 select the box
- // if IOU greater than thres, set the score to zero, abort it: area_U >
- // area_I * (1 / thresh)?
- if (thresh_iou > 0.0) {
- __bang_mul_const((float *)inter_x1, (float *)inter_x1, div_thresh_iou,
- seg_len);
- } else {
- __bang_mul_const((float *)inter_x2, (float *)inter_x2, thresh_iou,
- seg_len);
- }
- __bang_ge((float *)inter_x1, (float *)inter_x2, (float *)inter_x1,
- seg_len);
- __bang_mul((float *)score, (float *)score, (float *)inter_x1, seg_len);
- /******NMS COMPUTE END******/
-
- if (sizeof(IN_DT) == 2) {
- __bang_float2half_rd((half *)score, (float *)score, seg_len);
- }
- pvLock();
- __memcpy(input_score_ptr + input_offset + i * max_seg_iou_compute, score,
- cpy_len * sizeof(IN_DT), input_store_dir,
- cpy_len * sizeof(IN_DT), cpy_len * sizeof(IN_DT), 0);
- pvUnlock();
- } // for repeat
- } // for max_output_size
+/******NMS STORE END******/
+#if __BANG_ARCH__ >= 300
+ scoreUpdate(score_data, load_dir, store_dir, input_x1_ptr, input_y1_ptr,
+ input_x2_ptr, input_y2_ptr, x1, y1, x2, y2, score, inter_x1,
+ inter_y1, inter_x2, inter_y2, max_box, max_box_x1, max_box_y1,
+ max_box_x2, max_box_y2, nram_save, repeat_iou_compute,
+ remain_iou_compute, remain_pad_iou_compute, max_seg_iou_compute,
+ max_seg_pad, thresh_iou, div_thresh_iou, input_offset, offset,
+ max_area, input_num_boxes, algo);
+#else
+ scoreUpdate(score_data, load_dir, store_dir, input_x1_ptr, input_y1_ptr,
+ input_x2_ptr, input_y2_ptr, x1, y1, x2, y2, score, inter_x1,
+ inter_y1, inter_x2, inter_y2, max_box, max_box[1], max_box[2],
+ max_box[3], max_box[4], nram_save, repeat_iou_compute,
+ remain_iou_compute, remain_pad_iou_compute, max_seg_iou_compute,
+ max_seg_pad, thresh_iou, div_thresh_iou, input_offset, offset,
+ max_area, input_num_boxes, algo);
+#endif
+ } // for max_output_size
}
__mlu_global__ void MLUUionXKernelNMS(
const void *input_boxes, const void *input_confidence,
- const int input_num_boxes, const int input_layout, const int input_stride,
- const int max_output_size, const float iou_threshold,
- const float confidence_threshold, const float offset,
- const cnrtDataType_t data_type_input, const int output_mode, const int algo,
- void *workspace, void *result_num, void *output) {
+ const int input_num_boxes, const int max_output_size,
+ const float iou_threshold, const float confidence_threshold,
+ const float offset, const cnrtDataType_t data_type_input,
+ const int output_mode, const int algo, void *workspace, void *result_num,
+ void *output) {
int input_dwidth = (data_type_input == CNRT_FLOAT32) ? 4 : 2;
- int32_t *loop_end_flag =
- (int32_t *)((char *)workspace +
- INFO_NUM * input_num_boxes * input_dwidth);
+ int32_t *exit_flag = (int32_t *)((char *)workspace +
+ INFO_NUM * input_num_boxes * input_dwidth);
+ char *cdma_addr = (char *)exit_flag + sizeof(int32_t);
int reduce_sram_size = NFU_ALIGN_SIZE * REDUCE_NUM * input_dwidth;
int availbale_sram_size = SIZE_SRAM_BUF - reduce_sram_size;
@@ -1062,88 +416,57 @@ __mlu_global__ void MLUUionXKernelNMS(
__memcpy(workspace, input_confidence, cluster_score_size, GDRAM2GDRAM);
}
__sync_cluster();
+
uint32_t output_box_num = 0;
+ float *score_data;
+ float *boxes_data;
+ score_data = (input_ram == SRAM) ? (float *)sram_score : (float *)workspace;
+ boxes_data = (input_ram == SRAM) ? (float *)sram_boxes : (float *)input_boxes;
+
if (output_mode == 0) {
- uint32_t *output_dram = (uint32_t *)output;
- switch (data_type_input) {
- default: { return; }
- case CNRT_FLOAT16: {
- half *score_data;
- half *boxes_data;
- score_data =
- (input_ram == SRAM) ? (half *)sram_score : (half *)workspace;
- boxes_data =
- (input_ram == SRAM) ? (half *)sram_boxes : (half *)input_boxes;
- nms_detection_ux(loop_end_flag, output_box_num, output_dram, score_data,
- boxes_data, input_ram, input_layout, input_num_boxes,
- input_stride, max_output_size, iou_threshold,
- confidence_threshold, offset, output_mode, algo);
- ((uint32_t *)result_num)[0] = output_box_num;
- }; break;
- case CNRT_FLOAT32: {
- float *score_data;
- float *boxes_data;
- score_data =
- (input_ram == SRAM) ? (float *)sram_score : (float *)workspace;
- boxes_data =
- (input_ram == SRAM) ? (float *)sram_boxes : (float *)input_boxes;
- nms_detection_ux(loop_end_flag, output_box_num, output_dram, score_data,
- boxes_data, input_ram, input_layout, input_num_boxes,
- input_stride, max_output_size, iou_threshold,
- confidence_threshold, offset, output_mode, algo);
- ((uint32_t *)result_num)[0] = output_box_num;
- }; break;
+ if (data_type_input == CNRT_FLOAT32) {
+ nms_detection_ux(exit_flag, output_box_num, (uint32_t *)output,
+ score_data, boxes_data, input_ram, input_num_boxes,
+ max_output_size, iou_threshold, confidence_threshold,
+ offset, output_mode, algo, cdma_addr);
+ } else {
+ nms_detection_ux(exit_flag, output_box_num, (uint32_t *)output,
+ (half *)score_data, (half *)boxes_data, input_ram,
+ input_num_boxes, max_output_size, iou_threshold,
+ confidence_threshold, offset, output_mode, algo,
+ cdma_addr);
}
} else {
- switch (data_type_input) {
- default: { return; }
- case CNRT_FLOAT16: {
- half *output_dram = (half *)output;
- half *score_data;
- half *boxes_data;
- score_data =
- (input_ram == SRAM) ? (half *)sram_score : (half *)workspace;
- boxes_data =
- (input_ram == SRAM) ? (half *)sram_boxes : (half *)input_boxes;
- nms_detection_ux(loop_end_flag, output_box_num, output_dram, score_data,
- boxes_data, input_ram, input_layout, input_num_boxes,
- input_stride, max_output_size, iou_threshold,
- confidence_threshold, offset, output_mode, algo);
- ((uint32_t *)result_num)[0] = output_box_num;
- }; break;
- case CNRT_FLOAT32: {
- float *output_dram = (float *)output;
- float *score_data;
- float *boxes_data;
- score_data =
- (input_ram == SRAM) ? (float *)sram_score : (float *)workspace;
- boxes_data =
- (input_ram == SRAM) ? (float *)sram_boxes : (float *)input_boxes;
- nms_detection_ux(loop_end_flag, output_box_num, output_dram, score_data,
- boxes_data, input_ram, input_layout, input_num_boxes,
- input_stride, max_output_size, iou_threshold,
- confidence_threshold, offset, output_mode, algo);
- ((uint32_t *)result_num)[0] = output_box_num;
- }; break;
+ if (data_type_input == CNRT_FLOAT32) {
+ nms_detection_ux(exit_flag, output_box_num, (float *)output, score_data,
+ boxes_data, input_ram, input_num_boxes, max_output_size,
+ iou_threshold, confidence_threshold, offset, output_mode,
+ algo, cdma_addr);
+ } else {
+ nms_detection_ux(exit_flag, output_box_num, (half *)output,
+ (half *)score_data, (half *)boxes_data, input_ram,
+ input_num_boxes, max_output_size, iou_threshold,
+ confidence_threshold, offset, output_mode, algo,
+ cdma_addr);
}
}
+ ((uint32_t *)result_num)[0] = output_box_num;
}
void KernelNms(cnrtDim3_t k_dim, cnrtFunctionType_t k_type, cnrtQueue_t queue,
const cnrtDataType_t data_type_input, const void *boxes_ptr,
const void *scores_ptr, const int input_num_boxes,
- const int input_stride, const int max_output_boxes,
- const float iou_threshold, const float offset,
- void *workspace_ptr, void *output_size_ptr, void *output_ptr) {
+ const int max_output_boxes, const float iou_threshold,
+ const float offset, void *workspace_ptr, void *output_size_ptr,
+ void *output_ptr) {
switch (k_type) {
default: { return; }
case CNRT_FUNC_TYPE_BLOCK:
case CNRT_FUNC_TYPE_UNION1: {
MLUUnion1KernelNMS<<>>(
- boxes_ptr, scores_ptr, input_num_boxes, input_stride,
+ (void *)boxes_ptr, (void *)scores_ptr, input_num_boxes,
max_output_boxes, iou_threshold, /*confidence_threshold=*/0.0,
- /*output_mode=*/0,
- /*input_layout=*/1, workspace_ptr, output_size_ptr, output_ptr,
+ /*output_mode=*/0, workspace_ptr, output_size_ptr, output_ptr,
data_type_input, offset, /*algo=*/1);
}; break;
case CNRT_FUNC_TYPE_UNION2:
@@ -1151,11 +474,10 @@ void KernelNms(cnrtDim3_t k_dim, cnrtFunctionType_t k_type, cnrtQueue_t queue,
case CNRT_FUNC_TYPE_UNION8:
case CNRT_FUNC_TYPE_UNION16: {
MLUUionXKernelNMS<<>>(
- boxes_ptr, scores_ptr, input_num_boxes, /*input_layout=*/1,
- input_stride, max_output_boxes, iou_threshold,
- /*confidence_threshold=*/0.0, offset, data_type_input,
- /*output_mode=*/0, /*algo=*/1, workspace_ptr, output_size_ptr,
- output_ptr);
+ (void *)boxes_ptr, (void *)scores_ptr, input_num_boxes,
+ max_output_boxes, iou_threshold, /*confidence_threshold=*/0.0, offset,
+ data_type_input, /*output_mode=*/0, /*algo=*/1, workspace_ptr,
+ output_size_ptr, output_ptr);
}; break;
}
}
diff --git a/mmcv/ops/csrc/common/mlu/nms_utils.hpp b/mmcv/ops/csrc/common/mlu/nms_utils.hpp
new file mode 100644
index 0000000000..61f5ba95df
--- /dev/null
+++ b/mmcv/ops/csrc/common/mlu/nms_utils.hpp
@@ -0,0 +1,553 @@
+/*************************************************************************
+ * Copyright (C) [2019-2022] by Cambricon, Inc.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
+ * OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
+ * MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
+ * IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
+ * CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
+ * TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
+ * SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
+ *************************************************************************/
+#ifndef NMS_UTILS_HPP_
+#define NMS_UTILS_HPP_
+#include "common_mlu_helper.hpp"
+
+#define NMS_SIZE (64)
+#define NMS_UP(x, y) (x / y + (int)(x % y > 0)) * y
+#define NMS_DOWN(x, y) (x / y) * y
+#define INFO_NUM (5) // 5 means x1, x2, y1, y2 and score
+#define MEMORY_CORE (0x80)
+#define REDUCE_NUM \
+ (7) // score, x1, y1, x2, y2, max_index (reserve 2 num for half-type input)
+
+__mlu_func__ void pvLock() {
+#if __BANG_ARCH__ == 270
+ if (coreId != MEMORY_CORE) {
+ __bang_lock(0, 0);
+ }
+#endif
+}
+
+__mlu_func__ void pvUnlock() {
+#if __BANG_ARCH__ == 270
+ if (coreId != MEMORY_CORE) {
+ __bang_unlock(0, 0);
+ }
+#endif
+}
+
+template
+static __mlu_func__ void computeReluN(T *nram_dst, T *nram_src, void *nram_tmp,
+ const int deal_num,
+ const T threshold = 0) {
+ if (threshold < 0) {
+ return;
+ }
+ if (threshold) {
+#if __BANG_ARCH__ >= 300
+ __bang_relun(nram_dst, nram_src, deal_num, threshold);
+#else
+ int align_num = NFU_ALIGN_SIZE / sizeof(T);
+ T *nram_aux_a = (T *)nram_tmp;
+ T *nram_aux_b = nram_aux_a + deal_num;
+ T *nram_zero = nram_aux_b + align_num;
+ __bang_write_value(nram_aux_b, align_num, threshold);
+ __bang_write_zero(nram_zero, align_num);
+ __bang_cycle_lt((T *)nram_aux_a, nram_src, (T *)nram_aux_b, deal_num,
+ align_num);
+ __bang_mul(nram_dst, nram_src, (T *)nram_aux_a, deal_num);
+ __bang_cycle_eq((T *)nram_aux_a, (T *)nram_aux_a, (T *)nram_zero, deal_num,
+ align_num);
+ __bang_cycle_mul((T *)nram_aux_a, (T *)nram_aux_a, (T *)nram_aux_b,
+ deal_num, align_num);
+ __bang_add(nram_dst, nram_dst, (T *)nram_aux_a, deal_num);
+ __bang_cycle_gt((T *)nram_aux_a, nram_dst, (T *)nram_zero, deal_num,
+ align_num);
+ __bang_mul(nram_dst, nram_dst, (T *)nram_aux_a, deal_num);
+#endif
+ } else {
+#if __BANG_ARCH__ >= 300
+ __bang_relu(nram_dst, nram_src, deal_num);
+#else
+ __bang_active_relu(nram_dst, nram_src, deal_num);
+#endif
+ }
+}
+
+__mlu_func__ void getComputeParamsBlockOrU1(
+ const int input_dwidth, const int input_box_num, const int limit,
+ const int core_limit, int &input_offset, int &max_seg_pad, int &repeat,
+ int &remain, int &remain_pad, int &max_seg_iou_compute,
+ int &repeat_iou_compute, int &remain_iou_compute,
+ int &remain_pad_iou_compute) {
+ int avg_core = input_box_num / core_limit;
+ int rem = input_box_num % core_limit;
+ int len_core = avg_core + (coreId < rem ? 1 : 0);
+ input_offset = avg_core * coreId + (coreId <= rem ? coreId : rem);
+ max_seg_pad = NMS_DOWN(limit, NMS_SIZE);
+ repeat = len_core / max_seg_pad;
+ remain = len_core % max_seg_pad;
+ remain_pad = NMS_UP(remain, NMS_SIZE);
+
+ // if datatype is fp16, we should cvt to fp32 when compute iou
+ max_seg_iou_compute = NMS_DOWN(max_seg_pad / (4 / input_dwidth), NMS_SIZE);
+ repeat_iou_compute = len_core / max_seg_iou_compute;
+ remain_iou_compute = len_core % max_seg_iou_compute;
+ remain_pad_iou_compute = NMS_UP(remain_iou_compute, NMS_SIZE);
+}
+
+__mlu_func__ void getComputeParamsUx(
+ const int input_dwidth, const int input_num_boxes, const int limit,
+ int &input_offset, int &max_seg_pad, int &repeat, int &remain,
+ int &remain_pad, int &max_seg_iou_compute, int &repeat_iou_compute,
+ int &remain_iou_compute, int &remain_pad_iou_compute) {
+ // data split
+ int avg_cluster = input_num_boxes / clusterDim;
+ int rem_cluster = input_num_boxes % clusterDim;
+ int len_cluster = avg_cluster + (clusterId < rem_cluster);
+ int cluster_offset = avg_cluster * clusterId +
+ (clusterId <= rem_cluster ? clusterId : rem_cluster);
+
+ int avg_core = len_cluster / coreDim;
+ int rem_core = len_cluster % coreDim;
+ int len_core = avg_core + (coreId < rem_core);
+ int core_offset =
+ avg_core * coreId + (coreId <= rem_core ? coreId : rem_core);
+ input_offset = cluster_offset + core_offset;
+
+ max_seg_pad = NMS_DOWN(limit, NMS_SIZE);
+
+ // core 0 of each cluster calculate the max score index
+ int max_index_len_core = avg_cluster + (clusterId < rem_cluster);
+ repeat = max_index_len_core / max_seg_pad;
+ remain = max_index_len_core % max_seg_pad;
+ remain_pad = NMS_UP(remain, NMS_SIZE);
+ // if datatype is fp16, we should cvt to fp32 when compute iou
+ max_seg_iou_compute =
+ NMS_DOWN(max_seg_pad / (sizeof(float) / input_dwidth), NMS_SIZE);
+ repeat_iou_compute = len_core / max_seg_iou_compute;
+ remain_iou_compute = len_core % max_seg_iou_compute;
+ remain_pad_iou_compute = NMS_UP(remain_iou_compute, NMS_SIZE);
+}
+
+template
+__mlu_func__ void findGlobalMaxBox(IN_DT *max_box, IN_DT *sram,
+ IN_DT *inter_x1) {
+ // copy all partial max to the sram of cluster 0
+ if (clusterId != 0) {
+ __memcpy(sram + REDUCE_NUM * clusterId, sram, REDUCE_NUM * sizeof(IN_DT),
+ SRAM2SRAM, 0);
+ }
+ __sync_all();
+
+ // reduce between clusters to get the global max box
+ if (clusterId == 0) {
+ if (coreId == 0) {
+ __bang_write_zero(inter_x1, NMS_SIZE);
+ __memcpy(inter_x1, sram, sizeof(IN_DT), SRAM2NRAM, sizeof(IN_DT),
+ REDUCE_NUM * sizeof(IN_DT), clusterDim - 1);
+ __bang_max(max_box, inter_x1, NMS_SIZE);
+ int max_cluster = (sizeof(IN_DT) == sizeof(half))
+ ? ((uint16_t *)max_box)[1]
+ : ((uint32_t *)max_box)[1];
+ __memcpy(max_box, sram + max_cluster * REDUCE_NUM,
+ REDUCE_NUM * sizeof(IN_DT), SRAM2NRAM);
+ __memcpy(sram, max_box, REDUCE_NUM * sizeof(IN_DT), NRAM2SRAM);
+ }
+ __sync_cluster();
+ if (coreId == 0x80 && clusterDim > 1) {
+ // broadcast global max box to each cluster's sram
+ for (int cluster_idx = 1; cluster_idx < clusterDim; ++cluster_idx) {
+ __memcpy(sram, sram, REDUCE_NUM * sizeof(IN_DT), SRAM2SRAM,
+ cluster_idx);
+ }
+ }
+ __sync_cluster();
+ }
+ __sync_all();
+
+ // copy the global max box to max_box
+ __memcpy(max_box, sram, REDUCE_NUM * sizeof(IN_DT), SRAM2NRAM);
+}
+
+template
+__mlu_func__ void findCoreMaxBox(
+ IN_DT *input_score_ptr, IN_DT *score, IN_DT *inter_x1, IN_DT *max_box,
+ const IN_DT *input_x1_ptr, const IN_DT *input_y1_ptr,
+ const IN_DT *input_x2_ptr, const IN_DT *input_y2_ptr,
+ const mluMemcpyDirection_t load_dir, const int input_offset,
+ const int repeat, const int remain, const int remain_pad,
+ const int max_seg_pad, int &max_index) {
+ if (coreId != 0x80) {
+ for (int i = 0; i <= repeat; i++) {
+ if (i == repeat && remain == 0) {
+ break;
+ }
+ int seg_len = 0; // the length every nms compute
+ int cpy_len = 0; // the length every nms memcpy
+ i == repeat ? seg_len = remain_pad : seg_len = max_seg_pad;
+ i == repeat ? cpy_len = remain : cpy_len = max_seg_pad;
+ /******NMS LOAD START******/
+ __bang_write_zero(score, seg_len);
+ __memcpy(score, input_score_ptr + input_offset + i * max_seg_pad,
+ cpy_len * sizeof(IN_DT), load_dir, cpy_len * sizeof(IN_DT),
+ cpy_len * sizeof(IN_DT), 0);
+
+ /******NMS LOAD END******/
+
+ __bang_max(inter_x1, score, seg_len);
+ if (inter_x1[0] > max_box[0]) {
+ max_box[0] = inter_x1[0];
+ if (sizeof(IN_DT) == sizeof(half)) {
+ max_index = ((uint16_t *)inter_x1)[1] + input_offset +
+ i * max_seg_pad; // offset start from head of input_data
+ } else if (sizeof(IN_DT) == sizeof(float)) {
+ max_index = ((uint32_t *)inter_x1)[1] + input_offset +
+ i * max_seg_pad; // offset start from head of input_data
+ }
+ }
+ } // for repeat
+ // the max box's x1, y1, x2, y2 on every core
+ max_box[1] = input_x1_ptr[max_index];
+ max_box[2] = input_y1_ptr[max_index];
+ max_box[3] = input_x2_ptr[max_index];
+ max_box[4] = input_y2_ptr[max_index];
+ ((uint32_t *)(max_box + 5))[0] = max_index;
+ }
+}
+
+template
+__mlu_func__ void findClusterMaxBox(IN_DT *sram, IN_DT *max_box,
+ IN_DT *inter_x1, IN_DT *input_data_score,
+ const int core_limit) {
+ // find the max with sram
+ // copy every core's box info to sram, form: score---x1---y1---x2---y2---
+ __memcpy(sram + REDUCE_NUM * coreId, max_box, REDUCE_NUM * sizeof(IN_DT),
+ NRAM2SRAM); // int32_t datatype
+ __sync_cluster();
+
+ // copy score from sram to nram and find the max
+ __bang_write_zero(inter_x1, 64);
+ __memcpy(inter_x1, sram, sizeof(IN_DT), SRAM2NRAM, sizeof(IN_DT),
+ REDUCE_NUM * sizeof(IN_DT), coreDim - 1);
+ __bang_max(max_box, inter_x1, 64);
+ int max_core = sizeof(IN_DT) == sizeof(half) ? ((uint16_t *)max_box)[1]
+ : ((uint32_t *)max_box)[1];
+ // copy the max box to max_box
+ __memcpy(max_box, sram + max_core * REDUCE_NUM, REDUCE_NUM * sizeof(IN_DT),
+ SRAM2NRAM);
+}
+
+/*****************************************************************************/
+/*******************************CALCULATE MAX AREA****************************/
+/*****************************************************************************/
+
+template
+__mlu_func__ void calMaxArea(IN_DT *max_box, const int algo, float offset,
+ float &max_area) {
+ if (algo == 0 || offset == 0.0) {
+ max_area = ((float)max_box[3] - (float)max_box[1]) *
+ ((float)max_box[4] - (float)max_box[2]);
+ } else {
+ max_area = ((float)max_box[3] - (float)max_box[1] + offset) *
+ ((float)max_box[4] - (float)max_box[2] + offset);
+ }
+}
+
+template
+__mlu_func__ void calMaxArea(IN_DT *max_box, const int algo, float offset,
+ float &max_area, float &max_box_x1,
+ float &max_box_y1, float &max_box_x2,
+ float &max_box_y2) {
+ // the case of random inf will break the requirement of x1<=x2, y1<=y2
+ // so exchange it if it happens.
+ max_box_x1 = float(max_box[1]);
+ max_box_x2 = float(max_box[3]);
+ if (max_box[1] > max_box[3]) {
+ max_box_x1 = float(max_box[3]);
+ max_box_x2 = float(max_box[1]);
+ }
+ max_box_y1 = float(max_box[2]);
+ max_box_y2 = float(max_box[4]);
+ if (max_box[2] > max_box[4]) {
+ max_box_y1 = float(max_box[4]);
+ max_box_y2 = float(max_box[2]);
+ }
+ if (algo == 0 || offset == 0.0) {
+ max_area = (max_box_x2 - max_box_x1) * (max_box_y2 - max_box_y1);
+ } else {
+ max_area =
+ (max_box_x2 - max_box_x1 + offset) * (max_box_y2 - max_box_y1 + offset);
+ }
+}
+
+/***********************************************************************/
+/*******************************STORE RESULT****************************/
+/***********************************************************************/
+template
+__mlu_func__ void storeResult(IN_DT *max_box, OUT_DT *nram_save,
+ OUT_DT *&output_dram, const int keep,
+ const int nram_save_limit_count,
+ const int max_output_size,
+ const float thresh_score, const int output_mode,
+ int &nram_save_count, uint32_t &output_box_num) {
+ /******NMS STORE START******/
+ // store to nram
+ if (float(max_box[0]) > thresh_score) {
+ OUT_DT *save_ptr;
+ int save_offset = 0;
+ int save_str_num = 0;
+ save_ptr = nram_save;
+ save_offset = nram_save_count;
+ save_str_num = nram_save_limit_count;
+ if (clusterId == 0 && coreId == 0) {
+ if (output_mode == 0) { // index1, index2, ...
+ save_ptr[save_offset] = ((uint32_t *)(max_box + INFO_NUM))[0];
+ } else if (output_mode == 1) { // score, x1, y1, x2, y2
+ __memcpy(save_ptr + save_offset * INFO_NUM, max_box,
+ INFO_NUM * sizeof(IN_DT), NRAM2NRAM, INFO_NUM * sizeof(IN_DT),
+ INFO_NUM * sizeof(IN_DT), 0);
+ } else if (output_mode == 2) { // score---, x1---, y1---, x2---, y2---
+ __memcpy(save_ptr + save_offset, max_box, 1 * sizeof(IN_DT), NRAM2NRAM,
+ save_str_num * sizeof(IN_DT), 1 * sizeof(IN_DT), 4);
+ }
+ }
+ nram_save_count++;
+ output_box_num++;
+ }
+
+ // store to sram/gdram
+ if (output_box_num != 0) {
+ if ((nram_save_count == nram_save_limit_count) ||
+ (float(max_box[0]) <= thresh_score) || keep == max_output_size - 1) {
+ if (nram_save_count != 0) {
+ if (clusterId == 0 && coreId == 0) {
+ if (output_mode == 0) { // index1, index2, ...
+ pvLock();
+ __memcpy(output_dram, nram_save, nram_save_count * sizeof(uint32_t),
+ NRAM2GDRAM);
+ pvUnlock();
+ output_dram += nram_save_count;
+ } else if (output_mode == 1) { // score, x1, y1, x2, y2
+ pvLock();
+ __memcpy(output_dram, nram_save,
+ nram_save_count * INFO_NUM * sizeof(IN_DT), NRAM2GDRAM);
+ pvUnlock();
+ output_dram += nram_save_count * INFO_NUM;
+ } else if (output_mode ==
+ 2) { // score---, x1---, y1---, x2---, y2---
+ pvLock();
+ __memcpy(output_dram, nram_save, nram_save_count * sizeof(IN_DT),
+ NRAM2GDRAM, max_output_size * sizeof(IN_DT),
+ nram_save_limit_count * sizeof(IN_DT), 4);
+ pvUnlock();
+ output_dram += nram_save_count;
+ }
+ nram_save_count = 0;
+ }
+ }
+ } // if move data nram->sram/gdram
+ } // if dst
+}
+
+template
+__mlu_func__ void scoreUpdate(
+ IN_DT *input_score_ptr, const mluMemcpyDirection_t load_dir,
+ const mluMemcpyDirection_t store_dir, const IN_DT *input_x1_ptr,
+ const IN_DT *input_y1_ptr, const IN_DT *input_x2_ptr,
+ const IN_DT *input_y2_ptr, IN_DT *x1, IN_DT *y1, IN_DT *x2, IN_DT *y2,
+ IN_DT *score, IN_DT *inter_x1, IN_DT *inter_y1, IN_DT *inter_x2,
+ IN_DT *inter_y2, IN_DT *max_box, const float max_box_x1,
+ const float max_box_y1, const float max_box_x2, const float max_box_y2,
+ OUT_DT *nram_save, int repeat_iou_compute, int remain_iou_compute,
+ int remain_pad_iou_compute, int max_seg_iou_compute, int max_seg_pad,
+ const float thresh_iou, const float div_thresh_iou, const int input_offset,
+ const float offset, const float max_area, const int input_num_boxes,
+ const int algo) {
+ for (int i = 0; i <= repeat_iou_compute; i++) {
+ if (i == repeat_iou_compute && remain_iou_compute == 0) {
+ break;
+ }
+ int seg_len = (i == repeat_iou_compute) ? remain_pad_iou_compute
+ : max_seg_iou_compute;
+ int cpy_len =
+ (i == repeat_iou_compute) ? remain_iou_compute : max_seg_iou_compute;
+ /******NMS LOAD START******/
+ int dt_offset = 0;
+ if (sizeof(IN_DT) == sizeof(float)) {
+ __memcpy(score, input_score_ptr + input_offset + i * max_seg_pad,
+ cpy_len * sizeof(IN_DT), load_dir, cpy_len * sizeof(IN_DT),
+ cpy_len * sizeof(IN_DT), 0);
+ dt_offset = 0;
+ } else if (sizeof(IN_DT) == sizeof(half)) {
+ __memcpy(x1, input_score_ptr + input_offset + i * max_seg_iou_compute,
+ cpy_len * sizeof(IN_DT), load_dir, cpy_len * sizeof(IN_DT),
+ cpy_len * sizeof(IN_DT), 0);
+ __bang_half2float((float *)score, (half *)x1, seg_len);
+ dt_offset = max_seg_iou_compute;
+ }
+#if __BANG_ARCH__ >= 300
+ __memcpy(inter_x1 + dt_offset,
+ input_x1_ptr + input_offset + i * max_seg_iou_compute,
+ cpy_len * sizeof(IN_DT), load_dir, max_seg_pad * sizeof(IN_DT),
+ input_num_boxes * sizeof(IN_DT), 3);
+
+ if (sizeof(IN_DT) == sizeof(half)) {
+ __bang_half2float((float *)inter_x1,
+ (half *)inter_x1 + max_seg_iou_compute, seg_len);
+ __bang_half2float((float *)inter_y1,
+ (half *)inter_y1 + max_seg_iou_compute, seg_len);
+ __bang_half2float((float *)inter_x2,
+ (half *)inter_x2 + max_seg_iou_compute, seg_len);
+ __bang_half2float((float *)inter_y2,
+ (half *)inter_y2 + max_seg_iou_compute, seg_len);
+ }
+ // box transfer
+ __bang_minequal((float *)x1, (float *)inter_x1, (float *)inter_x2, seg_len);
+ __bang_maxequal((float *)x2, (float *)inter_x1, (float *)inter_x2, seg_len);
+ __bang_minequal((float *)y1, (float *)inter_y1, (float *)inter_y2, seg_len);
+ __bang_maxequal((float *)y2, (float *)inter_y1, (float *)inter_y2, seg_len);
+ // 1、 compute IOU
+ // get the area_I
+ __bang_maxeq_scalar((float *)inter_x1, (float *)x1, max_box_x1,
+ seg_len); // inter_x1
+ __bang_mineq_scalar((float *)inter_x2, (float *)x2, max_box_x2,
+ seg_len); // inter_x2
+ __bang_sub((float *)inter_x1, (float *)inter_x2, (float *)inter_x1,
+ seg_len);
+ if (algo == 1 && offset != 0.0) {
+ __bang_add_scalar((float *)inter_x1, (float *)inter_x1, offset, seg_len);
+ }
+ computeReluN((float *)inter_x1, (float *)inter_x1, NULL,
+ seg_len); // inter_w
+ __bang_maxeq_scalar((float *)inter_y1, (float *)y1, float(max_box_y1),
+ seg_len); // inter_y1
+ __bang_mineq_scalar((float *)inter_y2, (float *)y2, float(max_box_y2),
+ seg_len); // inter_y2
+ __bang_sub((float *)inter_y1, (float *)inter_y2, (float *)inter_y1,
+ seg_len);
+ if (algo == 1 && offset != 0.0) {
+ __bang_add_scalar((float *)inter_y1, (float *)inter_y1, offset, seg_len);
+ }
+ computeReluN((float *)inter_y1, (float *)inter_y1, NULL,
+ seg_len); // inter_h
+ __bang_mul((float *)inter_x1, (float *)inter_x1, (float *)inter_y1,
+ seg_len); // area_I
+ // get the area of input_box: area = (x2 - x1) * (y2 - y1);
+ if (algo == 1 && offset != 0.0) {
+ __bang_fusion(FUSION_FSA, (float *)inter_y1, (float *)x2, (float *)x1,
+ offset, seg_len, seg_len);
+ __bang_fusion(FUSION_FSA, (float *)inter_y2, (float *)y2, (float *)y1,
+ offset, seg_len, seg_len);
+ __bang_mul((float *)inter_x2, (float *)inter_y1, (float *)inter_y2,
+ seg_len); // area
+ } else {
+ __bang_sub((float *)inter_y1, (float *)x2, (float *)x1, seg_len);
+ __bang_fusion(FUSION_FSM, (float *)inter_x2, (float *)y2, (float *)y1,
+ (float *)inter_y1, seg_len, seg_len);
+ }
+ // get the area_U: area + max_area - area_I
+ __bang_fusion(FUSION_FAS, (float *)inter_x2, (float *)inter_x2, max_area,
+ (float *)inter_x1, seg_len, seg_len);
+ // 2、 select the box
+ // if IOU greater than thres, set the score to zero, abort it: area_U >
+ // area_I * (1 / thresh)?
+ if (thresh_iou > 0.0) {
+ __bang_mul_scalar((float *)inter_x1, (float *)inter_x1, div_thresh_iou,
+ seg_len);
+ } else {
+ __bang_mul_scalar((float *)inter_x2, (float *)inter_x2, thresh_iou,
+ seg_len);
+ }
+ // process for nan
+ __bang_lt((float *)inter_x1, (float *)inter_x2, (float *)inter_x1, seg_len);
+ __bang_not((float *)inter_x1, (float *)inter_x1, seg_len);
+ __bang_mul((float *)score, (float *)score, (float *)inter_x1, seg_len);
+/******NMS COMPUTE END******/
+#else
+ __memcpy(x1 + dt_offset,
+ input_x1_ptr + input_offset + i * max_seg_iou_compute,
+ cpy_len * sizeof(IN_DT), load_dir, max_seg_pad * sizeof(IN_DT),
+ input_num_boxes * sizeof(IN_DT), 3);
+ if (sizeof(IN_DT) == sizeof(half)) {
+ __bang_half2float((float *)x1, (half *)x1 + max_seg_iou_compute, seg_len);
+ __bang_half2float((float *)y1, (half *)y1 + max_seg_iou_compute, seg_len);
+ __bang_half2float((float *)x2, (half *)x2 + max_seg_iou_compute, seg_len);
+ __bang_half2float((float *)y2, (half *)y2 + max_seg_iou_compute, seg_len);
+ }
+ // 1、 compute IOU
+ // get the area_I
+ __bang_write_value((float *)inter_y1, seg_len,
+ float(max_box[1])); // max_x1
+ __bang_maxequal((float *)inter_x1, (float *)x1, (float *)inter_y1,
+ seg_len); // inter_x1
+ __bang_write_value((float *)inter_y2, seg_len,
+ float(max_box[3])); // max_x2
+ __bang_minequal((float *)inter_x2, (float *)x2, (float *)inter_y2,
+ seg_len); // inter_x2
+ __bang_sub((float *)inter_x1, (float *)inter_x2, (float *)inter_x1,
+ seg_len);
+ if (algo == 1 && offset != 0.0) {
+ __bang_add_scalar((float *)inter_x1, (float *)inter_x1, offset, seg_len);
+ }
+ computeReluN((float *)inter_x1, (float *)inter_x1, NULL,
+ seg_len); // inter_w
+ __bang_write_value((float *)inter_x2, seg_len,
+ float(max_box[2])); // max_y1
+ __bang_maxequal((float *)inter_y1, (float *)y1, (float *)inter_x2,
+ seg_len); // inter_y1
+ __bang_write_value((float *)inter_x2, seg_len,
+ float(max_box[4])); // max_y2
+ __bang_minequal((float *)inter_y2, (float *)y2, (float *)inter_x2,
+ seg_len); // inter_y2
+ __bang_sub((float *)inter_y1, (float *)inter_y2, (float *)inter_y1,
+ seg_len);
+ if (algo == 1 && offset != 0.0) {
+ __bang_add_scalar((float *)inter_y1, (float *)inter_y1, offset, seg_len);
+ }
+ computeReluN((float *)inter_y1, (float *)inter_y1, NULL,
+ seg_len); // inter_h
+ __bang_mul((float *)inter_x1, (float *)inter_x1, (float *)inter_y1,
+ seg_len); // area_I
+ // get the area of input_box: area = (x2 - x1) * (y2 - y1);
+ __bang_sub((float *)inter_y1, (float *)x2, (float *)x1, seg_len);
+ __bang_sub((float *)inter_y2, (float *)y2, (float *)y1, seg_len);
+ if (algo == 1 && offset != 0.0) {
+ __bang_add_scalar((float *)inter_y1, (float *)inter_y1, offset, seg_len);
+ __bang_add_scalar((float *)inter_y2, (float *)inter_y2, offset, seg_len);
+ }
+ __bang_mul((float *)inter_x2, (float *)inter_y1, (float *)inter_y2,
+ seg_len); // area
+ // get the area_U: area + max_area - area_I
+ __bang_add_scalar((float *)inter_x2, (float *)inter_x2, float(max_area),
+ seg_len);
+ __bang_sub((float *)inter_x2, (float *)inter_x2, (float *)inter_x1,
+ seg_len); // area_U
+ // 2、 select the box
+ // if IOU greater than thresh, set the score to zero, abort it: area_U >
+ // area_I * (1 / thresh)?
+ if (thresh_iou > 0.0) {
+ __bang_mul_scalar((float *)inter_x1, (float *)inter_x1, div_thresh_iou,
+ seg_len);
+ } else {
+ __bang_mul_scalar((float *)inter_x2, (float *)inter_x2, thresh_iou,
+ seg_len);
+ }
+ __bang_ge((float *)inter_x1, (float *)inter_x2, (float *)inter_x1, seg_len);
+ __bang_mul((float *)score, (float *)score, (float *)inter_x1, seg_len);
+/******NMS COMPUTE END******/
+#endif
+ // update the score
+ if (sizeof(IN_DT) == sizeof(half)) {
+ convertFloat2half((half *)score, (float *)score, seg_len);
+ }
+ pvLock();
+ __memcpy(input_score_ptr + input_offset + i * max_seg_iou_compute, score,
+ cpy_len * sizeof(IN_DT), store_dir, cpy_len * sizeof(IN_DT),
+ cpy_len * sizeof(IN_DT), 0);
+ pvUnlock();
+ }
+}
+
+#endif // NMS_UTILS_HPP_
diff --git a/mmcv/ops/csrc/common/mlu/psamask_mlu_kernel.mlu b/mmcv/ops/csrc/common/mlu/psamask_mlu_kernel.mlu
index 13b4af19f6..055ee4f4d0 100644
--- a/mmcv/ops/csrc/common/mlu/psamask_mlu_kernel.mlu
+++ b/mmcv/ops/csrc/common/mlu/psamask_mlu_kernel.mlu
@@ -53,9 +53,8 @@ __mlu_func__ void loadDataFromDramToNram(T *dst, const T *src,
int w_seg = position.w_end - position.w_start;
int size = h_seg * w_seg * shape_full.c;
- __memcpy(dst,
- src + position.n_start * n_offset + position.h_start * h_offset +
- position.w_start * w_offset,
+ __memcpy(dst, src + position.n_start * n_offset +
+ position.h_start * h_offset + position.w_start * w_offset,
size * sizeof(T), GDRAM2NRAM, size * sizeof(T), n_offset * sizeof(T),
n_seg - 1);
}
@@ -89,7 +88,7 @@ __mlu_func__ void psamaskCollectForward(
int elem_count =
CEIL_ALIGN(shape_seg.n * shape_seg.h * shape_seg.w * y_full.c,
NFU_ALIGN_SIZE / sizeof(T));
- __nramset(y_nram, elem_count, (T)0);
+ __bang_write_value(y_nram, elem_count, (T)0);
int y_n_offset = shape_seg.h * shape_seg.w * shape_seg.c;
int y_h_offset = shape_seg.w * shape_seg.c;
@@ -155,7 +154,7 @@ __mlu_func__ void psamaskDistributeForward(
CEIL_ALIGN(shape_seg.h * shape_seg.w, COMPUTE_COUNT_ALIGN / sizeof(T));
int elem_count =
CEIL_ALIGN(shape_seg.n * align_c * align_hw, NFU_ALIGN_SIZE / sizeof(T));
- __nramset(y_nram_temp, elem_count, (T)0);
+ __bang_write_value(y_nram_temp, elem_count, (T)0);
int y_n_offset = align_hw * align_c;
int y_h_offset = shape_seg.w * align_c;
@@ -242,7 +241,7 @@ __mlu_func__ void psamaskCollectBackward(
int elem_count =
CEIL_ALIGN(shape_seg.n * shape_seg.h * shape_seg.w * shape_seg.c,
NFU_ALIGN_SIZE / sizeof(T));
- __nramset(dx_nram, elem_count, (T)0);
+ __bang_write_value(dx_nram, elem_count, (T)0);
int dy_n_offset = shape_seg.h * shape_seg.w * dy_full.c;
int dy_h_offset = shape_seg.w * dy_full.c;
@@ -331,7 +330,8 @@ __mlu_func__ void psamaskDistributeBackward(
// fill zeros to dx
T *dx_nram = dy_nram + shape_seg.n * align_hw * align_c;
int dx_size = shape_seg.n * shape_seg.h * shape_seg.w * dx_full.c;
- __nramset(dx_nram, CEIL_ALIGN(dx_size, NFU_ALIGN_SIZE / sizeof(T)), (T)0);
+ __bang_write_value(dx_nram, CEIL_ALIGN(dx_size, NFU_ALIGN_SIZE / sizeof(T)),
+ (T)0);
int dy_n_offset_seg = align_hw * align_c;
int dy_h_offset_seg = shape_seg.w * align_c;
diff --git a/mmcv/ops/csrc/common/mlu/roi_align_mlu_kernel.mlu b/mmcv/ops/csrc/common/mlu/roi_align_mlu_kernel.mlu
index f62554d0ef..c99176ab20 100644
--- a/mmcv/ops/csrc/common/mlu/roi_align_mlu_kernel.mlu
+++ b/mmcv/ops/csrc/common/mlu/roi_align_mlu_kernel.mlu
@@ -130,10 +130,10 @@ __mlu_func__ void computeChannel(T *input_core, T *nram_in, T *output_core,
__memcpy(tmp_cyc4, input4, real_size, GDRAM2NRAM);
// interpolation value = w1 * p1 + w2 * p2 + w3 * p3 + w4 * p4
- __bang_mul_const(tmp_cyc1, tmp_cyc1, w1, align_channel);
- __bang_mul_const(tmp_cyc2, tmp_cyc2, w2, align_channel);
- __bang_mul_const(tmp_cyc3, tmp_cyc3, w3, align_channel);
- __bang_mul_const(tmp_cyc4, tmp_cyc4, w4, align_channel);
+ __bang_mul_scalar(tmp_cyc1, tmp_cyc1, w1, align_channel);
+ __bang_mul_scalar(tmp_cyc2, tmp_cyc2, w2, align_channel);
+ __bang_mul_scalar(tmp_cyc3, tmp_cyc3, w3, align_channel);
+ __bang_mul_scalar(tmp_cyc4, tmp_cyc4, w4, align_channel);
__bang_add(nram_in, tmp_cyc1, nram_in, align_channel);
__bang_add(nram_in, tmp_cyc2, nram_in, align_channel);
@@ -146,7 +146,7 @@ __mlu_func__ void computeChannel(T *input_core, T *nram_in, T *output_core,
} // loop_roi_grid_w
} // loop_roi_grid_h
T count_value = (T)(1.0 / count);
- __bang_mul_const(nram_out, nram_out, count_value, align_channel);
+ __bang_mul_scalar(nram_out, nram_out, count_value, align_channel);
__memcpy(output_core + i * cyc_channel, nram_out, real_size, NRAM2GDRAM);
} // loop_cyc_num
}
@@ -242,8 +242,8 @@ __mlu_global__ void MLUUnion1KernelRoiAlignAvg(
case CNRT_FLOAT16: {
roialignForwardAvg((half *)input, (half *)rois, (half *)output, aligned,
channels, pooled_height, pooled_width, input_height,
- input_width, sampling_ratio,
- (half)spatial_scale, num_rois);
+ input_width, sampling_ratio, (half)spatial_scale,
+ num_rois);
}; break;
case CNRT_FLOAT32: {
roialignForwardAvg((float *)input, (float *)rois, (float *)output,
@@ -346,31 +346,31 @@ __mlu_func__ void unionRoiAlignBp(
&x_high, &y_low, &y_high);
if (x_low >= 0 && y_low >= 0) {
__memcpy(buffer, grads_, c * sizeof(T), GDRAM2NRAM);
- __bang_mul_const((T *)buffer + c_align, (T *)buffer, (T)w1,
- c_align);
- __bang_mul_const((T *)buffer + c_align, (T *)buffer + c_align,
- 1 / count, c_align);
+ __bang_mul_scalar((T *)buffer + c_align, (T *)buffer, (T)w1,
+ c_align);
+ __bang_mul_scalar((T *)buffer + c_align, (T *)buffer + c_align,
+ 1 / count, c_align);
__bang_atomic_add((T *)buffer + c_align,
image_offset + y_low * wo * c + x_low * c,
(T *)buffer + c_align, c);
- __bang_mul_const((T *)buffer + c_align, (T *)buffer, (T)w2,
- c_align);
- __bang_mul_const((T *)buffer + c_align, (T *)buffer + c_align,
- 1 / count, c_align);
+ __bang_mul_scalar((T *)buffer + c_align, (T *)buffer, (T)w2,
+ c_align);
+ __bang_mul_scalar((T *)buffer + c_align, (T *)buffer + c_align,
+ 1 / count, c_align);
__bang_atomic_add((T *)buffer + c_align,
image_offset + y_low * wo * c + x_high * c,
(T *)buffer + c_align, c);
- __bang_mul_const((T *)buffer + c_align, (T *)buffer, (T)w3,
- c_align);
- __bang_mul_const((T *)buffer + c_align, (T *)buffer + c_align,
- 1 / count, c_align);
+ __bang_mul_scalar((T *)buffer + c_align, (T *)buffer, (T)w3,
+ c_align);
+ __bang_mul_scalar((T *)buffer + c_align, (T *)buffer + c_align,
+ 1 / count, c_align);
__bang_atomic_add((T *)buffer + c_align,
image_offset + y_high * wo * c + x_low * c,
(T *)buffer + c_align, c);
- __bang_mul_const((T *)buffer + c_align, (T *)buffer, (T)w4,
- c_align);
- __bang_mul_const((T *)buffer + c_align, (T *)buffer + c_align,
- 1 / count, c_align);
+ __bang_mul_scalar((T *)buffer + c_align, (T *)buffer, (T)w4,
+ c_align);
+ __bang_mul_scalar((T *)buffer + c_align, (T *)buffer + c_align,
+ 1 / count, c_align);
__bang_atomic_add((T *)buffer + c_align,
image_offset + y_high * wo * c + x_high * c,
(T *)buffer + c_align, c);
@@ -401,34 +401,34 @@ __mlu_func__ void unionRoiAlignBp(
}
__memcpy(buffer, grads_ + i * deal_once, deal_c * sizeof(T),
GDRAM2NRAM);
- __bang_mul_const((T *)buffer + align_c, (T *)buffer, (T)w1,
- align_c);
- __bang_mul_const((T *)buffer + align_c, (T *)buffer + align_c,
- 1 / count, align_c);
+ __bang_mul_scalar((T *)buffer + align_c, (T *)buffer, (T)w1,
+ align_c);
+ __bang_mul_scalar((T *)buffer + align_c, (T *)buffer + align_c,
+ 1 / count, align_c);
__bang_atomic_add(
(T *)buffer + align_c,
image_offset + y_low * wo * c + x_low * c + i * deal_once,
(T *)buffer + align_c, deal_c);
- __bang_mul_const((T *)buffer + align_c, (T *)buffer, (T)w2,
- align_c);
- __bang_mul_const((T *)buffer + align_c, (T *)buffer + align_c,
- 1 / count, align_c);
+ __bang_mul_scalar((T *)buffer + align_c, (T *)buffer, (T)w2,
+ align_c);
+ __bang_mul_scalar((T *)buffer + align_c, (T *)buffer + align_c,
+ 1 / count, align_c);
__bang_atomic_add(
(T *)buffer + align_c,
image_offset + y_low * wo * c + x_high * c + i * deal_once,
(T *)buffer + align_c, deal_c);
- __bang_mul_const((T *)buffer + align_c, (T *)buffer, (T)w3,
- align_c);
- __bang_mul_const((T *)buffer + align_c, (T *)buffer + align_c,
- 1 / count, align_c);
+ __bang_mul_scalar((T *)buffer + align_c, (T *)buffer, (T)w3,
+ align_c);
+ __bang_mul_scalar((T *)buffer + align_c, (T *)buffer + align_c,
+ 1 / count, align_c);
__bang_atomic_add(
(T *)buffer + align_c,
image_offset + y_high * wo * c + x_low * c + i * deal_once,
(T *)buffer + align_c, deal_c);
- __bang_mul_const((T *)buffer + align_c, (T *)buffer, (T)w4,
- align_c);
- __bang_mul_const((T *)buffer + align_c, (T *)buffer + align_c,
- 1 / count, align_c);
+ __bang_mul_scalar((T *)buffer + align_c, (T *)buffer, (T)w4,
+ align_c);
+ __bang_mul_scalar((T *)buffer + align_c, (T *)buffer + align_c,
+ 1 / count, align_c);
__bang_atomic_add(
(T *)buffer + align_c,
image_offset + y_high * wo * c + x_high * c + i * deal_once,
diff --git a/mmcv/ops/csrc/common/mlu/roi_pool_mlu_kernel.mlu b/mmcv/ops/csrc/common/mlu/roi_pool_mlu_kernel.mlu
index 7186cdfac3..3a6d2d3ba6 100644
--- a/mmcv/ops/csrc/common/mlu/roi_pool_mlu_kernel.mlu
+++ b/mmcv/ops/csrc/common/mlu/roi_pool_mlu_kernel.mlu
@@ -204,11 +204,11 @@ __mlu_func__ void MLUUnion1Roipool(T *input_v, T *rois_v, int batch,
}
if (is_empty) {
- __nramset((T *)nram_out, c_slice_align, (T)0);
+ __bang_write_value((T *)nram_out, c_slice_align, (T)0);
__memcpy((T *)output_base + dst_offset + c_offset, (T *)nram_out,
c_slice * t_size, NRAM2GDRAM);
if (NULL != argmax) {
- __nramset((int32_t *)nram_out, c_slice_align, (int32_t)(-1));
+ __bang_write_value((int32_t *)nram_out, c_slice_align, (int32_t)(-1));
__memcpy((int32_t *)argmax_base + dst_offset + c_offset,
(int32_t *)nram_out, c_slice * sizeof(int32_t), NRAM2GDRAM);
}
@@ -238,18 +238,18 @@ __mlu_func__ void MLUUnion1Roipool(T *input_v, T *rois_v, int batch,
for (int i = 0; i < c_slice; i++) {
nram_out[i] = (float)(((uint32_t *)nram_out)[i] / bin_wdim);
}
- __bang_add_const((float *)nram_a, (float *)nram_out, (float)bin_y1,
- c_slice_align);
- __bang_mul_const((float *)nram_ping, (float *)nram_a, (float)width,
- c_slice_align);
+ __bang_add_scalar((float *)nram_a, (float *)nram_out, (float)bin_y1,
+ c_slice_align);
+ __bang_mul_scalar((float *)nram_ping, (float *)nram_a, (float)width,
+ c_slice_align);
/*compute input_w*/
- __bang_mul_const((float *)nram_a, (float *)nram_out, (float)bin_wdim,
- c_slice_align);
+ __bang_mul_scalar((float *)nram_a, (float *)nram_out, (float)bin_wdim,
+ c_slice_align);
__bang_sub((float *)nram_a, (float *)nram_argmax, (float *)nram_a,
c_slice_align);
- __bang_add_const((float *)nram_a, (float *)nram_a, (float)bin_x1,
- c_slice_align);
+ __bang_add_scalar((float *)nram_a, (float *)nram_a, (float)bin_x1,
+ c_slice_align);
__bang_add((float *)nram_out, (float *)nram_ping, (float *)nram_a,
c_slice_align);
convertFloat2Int((int32_t *)nram_argmax, (float *)nram_a,
@@ -290,9 +290,7 @@ __mlu_global__ void MLUKernelRoiPool(cnrtDataType_t data_type,
rois_num, (float)spatial_scale, (float *)output_data,
argmax);
}; break;
- default: {
- break;
- }
+ default: { break; }
}
}
} // namespace forward
@@ -328,30 +326,30 @@ __mlu_func__ void convertIndex(
align_c);
// Perform 'temp_result - hstart' operation
- __bang_sub_const((float *)nram_argmax_fp_h, (float *)nram_argmax_fp, hstart,
- align_c);
+ __bang_sub_scalar((float *)nram_argmax_fp_h, (float *)nram_argmax_fp, hstart,
+ align_c);
// Perform 'temp_result1 - temp_result2 * width' operation
- __bang_mul_const((float *)nram_argmax_fp_w, (float *)nram_argmax_fp, width,
- align_c);
+ __bang_mul_scalar((float *)nram_argmax_fp_w, (float *)nram_argmax_fp, width,
+ align_c);
convertInt2Float((float *)nram_argmax_fp, (float *)nram_argmax_fp_bk1,
(int *)nram_argmax, (float *)nram_argmax_fp_bk2, align_c);
__bang_sub((float *)nram_argmax_fp_w, (float *)nram_argmax_fp,
(float *)nram_argmax_fp_w, align_c);
// Perform 'temp_result - wstart' operation
- __bang_sub_const((float *)nram_argmax_fp_w, (float *)nram_argmax_fp_w, wstart,
- align_c);
+ __bang_sub_scalar((float *)nram_argmax_fp_w, (float *)nram_argmax_fp_w,
+ wstart, align_c);
// Perform 'temp_result = h * w_compute + w' operation
- __bang_mul_const((float *)nram_argmax_fp_h, (float *)nram_argmax_fp_h,
- w_compute, align_c);
+ __bang_mul_scalar((float *)nram_argmax_fp_h, (float *)nram_argmax_fp_h,
+ w_compute, align_c);
__bang_add((float *)nram_argmax_fp_h, (float *)nram_argmax_fp_h,
(float *)nram_argmax_fp_w, align_c);
if (loop_flag == 1) {
- __bang_sub_const((float *)nram_argmax_fp_h, (float *)nram_argmax_fp_h,
- (loop_id * true_limit), align_c);
+ __bang_sub_scalar((float *)nram_argmax_fp_h, (float *)nram_argmax_fp_h,
+ (loop_id * true_limit), align_c);
}
convertFloat2Int((int *)nram_argmax_int, (float *)nram_argmax_fp_bk1,
(float *)nram_argmax_fp_h, (float *)nram_argmax_fp_bk2,
@@ -460,21 +458,22 @@ __mlu_func__ void MLUUnion1Roipool(const T *rois, const T *grads,
*/
// Load the data from GDRAM to NRAM.
- __memcpy((T *)nram_grads + align_c * high_precision,
- (const T *)grads + (n * pooled_height * pooled_width +
- ph * pooled_width + pw) *
- channels,
- channels * sizeof(T), GDRAM2NRAM);
+ __memcpy(
+ (T *)nram_grads + align_c * high_precision,
+ (const T *)grads +
+ (n * pooled_height * pooled_width + ph * pooled_width + pw) *
+ channels,
+ channels * sizeof(T), GDRAM2NRAM);
if (high_precision) {
__bang_half2float((float *)nram_grads,
(half *)nram_grads + align_c * high_precision,
align_c);
}
- __memcpy((int32_t *)nram_argmax,
- (const int32_t *)argmax + (n * pooled_height * pooled_width +
- ph * pooled_width + pw) *
- channels,
+ __memcpy((int32_t *)nram_argmax, (const int32_t *)argmax +
+ (n * pooled_height * pooled_width +
+ ph * pooled_width + pw) *
+ channels,
channels * sizeof(int32_t), GDRAM2NRAM);
// Perform pooling operation on NRAM.
@@ -523,20 +522,21 @@ __mlu_func__ void MLUUnion1Roipool(const T *rois, const T *grads,
*/
// Load the data from GDRAM to NRAM.
- __memcpy((T *)nram_grads + align_c * high_precision,
- (const T *)grads + (n * pooled_height * pooled_width +
- ph * pooled_width + pw) *
- channels,
- channels * sizeof(T), GDRAM2NRAM);
+ __memcpy(
+ (T *)nram_grads + align_c * high_precision,
+ (const T *)grads +
+ (n * pooled_height * pooled_width + ph * pooled_width + pw) *
+ channels,
+ channels * sizeof(T), GDRAM2NRAM);
if (high_precision) {
__bang_half2float((float *)nram_grads,
(half *)nram_grads + align_c * high_precision,
align_c);
}
- __memcpy((int32_t *)nram_argmax,
- (const int32_t *)argmax + (n * pooled_height * pooled_width +
- ph * pooled_width + pw) *
- channels,
+ __memcpy((int32_t *)nram_argmax, (const int32_t *)argmax +
+ (n * pooled_height * pooled_width +
+ ph * pooled_width + pw) *
+ channels,
channels * sizeof(int32_t), GDRAM2NRAM);
int ping_pong = 0;
@@ -713,9 +713,7 @@ __mlu_global__ void MLUKernelRoiPoolBackward(
height, width, pooled_height, pooled_width, rois_num,
(const float)spatial_scale, high_precision);
}; break;
- default: {
- break;
- }
+ default: { break; }
}
}
} // namespace backward
diff --git a/mmcv/ops/csrc/common/mlu/roiaware_pool3d_mlu_kernel.mlu b/mmcv/ops/csrc/common/mlu/roiaware_pool3d_mlu_kernel.mlu
new file mode 100644
index 0000000000..4c1edf0bf5
--- /dev/null
+++ b/mmcv/ops/csrc/common/mlu/roiaware_pool3d_mlu_kernel.mlu
@@ -0,0 +1,747 @@
+/*************************************************************************
+ * Copyright (C) 2022 Cambricon.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
+ * OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
+ * MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
+ * IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
+ * CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
+ * TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
+ * SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
+ *************************************************************************/
+
+#include "common_mlu_helper.hpp"
+
+#define ROI_OFFSET 7
+#define FLOAT_NRAM_BUFFER_NUM 14
+#define HALF_NRAM_BUFFER_NUM 25
+#define ALIGN_NUM 64
+
+__nram__ char data_nram[MAX_NRAM_SIZE];
+
+template
+__mlu_global__ void MLUUnion1KernelPtsIdxOfVoxels(
+ const int pool_method, const int boxes_num, const int pts_num,
+ const int max_pts_each_voxel, const int out_x, const int out_y,
+ const int out_z, const T *rois, const T *pts, int *pts_idx_of_voxels) {
+ // params (T)rois: (boxes_num, 7)
+ // params (T)pts: (3, pts_num)
+ // params (int)pts_idx_of_voxels: (boxes_num, out_x, out_y, out_z,
+ // max_pts_each_voxel)
+
+ // make sure that memcore is not used
+ if (coreId == 0x80) {
+ return;
+ }
+ int nram_pts_num = 0;
+ if (sizeof(T) == sizeof(float)) {
+ nram_pts_num = PAD_DOWN(
+ (MAX_NRAM_SIZE / sizeof(float) / FLOAT_NRAM_BUFFER_NUM), ALIGN_NUM);
+ } else {
+ nram_pts_num = PAD_DOWN(
+ (MAX_NRAM_SIZE / sizeof(half) / HALF_NRAM_BUFFER_NUM), ALIGN_NUM);
+ }
+
+ char *X = NULL;
+ char *Y = NULL;
+ char *Z = NULL;
+ char *local_X = NULL;
+ char *local_Y = NULL;
+ char *local_Z = NULL;
+ char *nram_pts_in_flag = NULL;
+ float *temp_buffer1 = NULL;
+ float *temp_buffer2 = NULL;
+ float *temp_buffer3 = NULL;
+ float *temp_buffer4 = NULL;
+ float *temp_buffer5 = NULL;
+ float *nram_voxel_offset = NULL;
+ int *nram_pts_idx_seq = NULL;
+ float *fp_local_X = NULL;
+ float *fp_local_Y = NULL;
+ float *fp_local_Z = NULL;
+ float *fp_nram_pts_in_flag = NULL;
+ if (sizeof(T) == sizeof(float)) {
+ X = (char *)((float *)data_nram);
+ Y = (char *)((float *)data_nram + nram_pts_num);
+ Z = (char *)((float *)data_nram + nram_pts_num * 2);
+ local_X = (char *)((float *)data_nram + nram_pts_num * 3);
+ local_Y = (char *)((float *)data_nram + nram_pts_num * 4);
+ local_Z = (char *)((float *)data_nram + nram_pts_num * 5);
+ nram_pts_in_flag = (char *)((float *)data_nram + nram_pts_num * 6);
+ temp_buffer1 = (float *)data_nram + nram_pts_num * 7;
+ temp_buffer2 = (float *)data_nram + nram_pts_num * 8;
+ temp_buffer3 = (float *)data_nram + nram_pts_num * 9;
+ temp_buffer4 = (float *)data_nram + nram_pts_num * 10;
+ temp_buffer5 = (float *)data_nram + nram_pts_num * 11;
+ nram_voxel_offset = (float *)data_nram + nram_pts_num * 12;
+ nram_pts_idx_seq = (int *)((float *)data_nram + nram_pts_num * 13);
+ fp_local_X = (float *)local_X;
+ fp_local_Y = (float *)local_Y;
+ fp_local_Z = (float *)local_Z;
+ fp_nram_pts_in_flag = (float *)nram_pts_in_flag;
+ } else {
+ X = (char *)((half *)data_nram);
+ Y = (char *)((half *)data_nram + nram_pts_num);
+ Z = (char *)((half *)data_nram + nram_pts_num * 2);
+ local_X = (char *)((half *)data_nram + nram_pts_num * 4);
+ local_Y = (char *)((half *)data_nram + nram_pts_num * 6);
+ local_Z = (char *)((half *)data_nram + nram_pts_num * 8);
+ nram_pts_in_flag = (char *)((half *)data_nram + nram_pts_num * 10);
+ temp_buffer1 = (float *)((half *)data_nram + nram_pts_num * 11);
+ temp_buffer2 = (float *)((half *)data_nram + nram_pts_num * 13);
+ temp_buffer3 = (float *)((half *)data_nram + nram_pts_num * 15);
+ temp_buffer4 = (float *)((half *)data_nram + nram_pts_num * 17);
+ temp_buffer5 = (float *)((half *)data_nram + nram_pts_num * 19);
+ nram_voxel_offset = (float *)((half *)data_nram + nram_pts_num * 21);
+ nram_pts_idx_seq = (int *)((half *)data_nram + nram_pts_num * 23);
+ fp_local_X = (float *)((half *)local_X - nram_pts_num);
+ fp_local_Y = (float *)((half *)local_Y - nram_pts_num);
+ fp_local_Z = (float *)((half *)local_Z - nram_pts_num);
+ fp_nram_pts_in_flag = (float *)((half *)nram_pts_in_flag - nram_pts_num);
+ }
+
+ for (int i = 0; i < nram_pts_num; i++) {
+ nram_pts_idx_seq[i] = i;
+ }
+
+ int nram_pts_loop_times = pts_num / nram_pts_num;
+ int rem_nram_num = pts_num % nram_pts_num;
+
+ for (int roi_index = taskId; roi_index < boxes_num; roi_index += taskDim) {
+ const T *cur_roi = rois + roi_index * ROI_OFFSET;
+ T cx = cur_roi[0];
+ T cy = cur_roi[1];
+ T cz = cur_roi[2];
+ T dx = cur_roi[3];
+ T dy = cur_roi[4];
+ T dz = cur_roi[5];
+ T rz = cur_roi[6];
+
+ T dx_2 = dx / 2.0;
+ T dy_2 = dy / 2.0;
+ T dz_2 = dz / 2.0;
+
+ for (int loop_idx = 0; loop_idx <= nram_pts_loop_times; loop_idx++) {
+ int load_pts_num =
+ (loop_idx == nram_pts_loop_times) ? rem_nram_num : nram_pts_num;
+ if (load_pts_num == 0) {
+ break;
+ }
+ int pts_offset_cur_loop = nram_pts_num * loop_idx;
+ int compute_pts_num = (loop_idx == nram_pts_loop_times)
+ ? PAD_UP(rem_nram_num, ALIGN_NUM)
+ : nram_pts_num;
+ // load pts
+ __memcpy((void *)X, (T *)pts + pts_offset_cur_loop,
+ load_pts_num * sizeof(T), GDRAM2NRAM);
+ __memcpy((void *)Y, (T *)pts + pts_num + pts_offset_cur_loop,
+ load_pts_num * sizeof(T), GDRAM2NRAM);
+ __memcpy((void *)Z, (T *)pts + pts_num * 2 + pts_offset_cur_loop,
+ load_pts_num * sizeof(T), GDRAM2NRAM);
+ // fabs(local_z)
+ __bang_sub_scalar((T *)local_Z, (T *)Z, (T)cz, compute_pts_num);
+ __bang_sub_scalar((T *)temp_buffer1, (T *)Z, (T)(cz + dz_2),
+ compute_pts_num);
+ __bang_active_abs((T *)temp_buffer1, (T *)temp_buffer1, compute_pts_num);
+#if __BANG_ARCH__ >= 322
+ __bang_le_scalar((T *)nram_pts_in_flag, (T *)temp_buffer1, (T)(dz_2),
+ compute_pts_num);
+#else
+ __bang_write_value((void *)temp_buffer2, compute_pts_num, (T)(dz_2));
+ __bang_le((T *)nram_pts_in_flag, (T *)temp_buffer1, (T *)temp_buffer2,
+ compute_pts_num);
+#endif
+ T cosa = std::cos(-rz);
+ T sina = std::sin(-rz);
+ __bang_sub_scalar((T *)temp_buffer3, (T *)X, (T)cx, compute_pts_num);
+ __bang_sub_scalar((T *)temp_buffer4, (T *)Y, (T)cy, compute_pts_num);
+ __bang_mul_scalar((T *)temp_buffer1, (T *)temp_buffer3, (T)cosa,
+ compute_pts_num);
+ __bang_mul_scalar((T *)temp_buffer2, (T *)temp_buffer4, (T)sina,
+ compute_pts_num);
+ // local_x
+ __bang_sub((T *)local_X, (T *)temp_buffer1, (T *)temp_buffer2,
+ compute_pts_num);
+ // fabs(local_x)
+ __bang_active_abs((T *)temp_buffer1, (T *)local_X, compute_pts_num);
+ // fabs(local_x) < dx/2 ? 1 : 0
+#if __BANG_ARCH__ >= 322
+ __bang_lt_scalar((T *)temp_buffer1, (T *)temp_buffer1, (T)(dx_2),
+ compute_pts_num);
+#else
+ __bang_write_value((void *)temp_buffer2, compute_pts_num, (T)(dx_2));
+ __bang_lt((T *)temp_buffer1, (T *)temp_buffer1, (T *)temp_buffer2,
+ compute_pts_num);
+#endif
+ __bang_and((T *)nram_pts_in_flag, (T *)nram_pts_in_flag,
+ (T *)temp_buffer1,
+ compute_pts_num); // flush res
+
+ __bang_mul_scalar((T *)temp_buffer1, (T *)temp_buffer3, (T)sina,
+ compute_pts_num);
+ __bang_mul_scalar((T *)temp_buffer2, (T *)temp_buffer4, (T)cosa,
+ compute_pts_num);
+ // local_y
+ __bang_add((T *)local_Y, (T *)temp_buffer1, (T *)temp_buffer2,
+ compute_pts_num);
+ // fabs(local_y)
+ __bang_active_abs((T *)temp_buffer1, (T *)local_Y, compute_pts_num);
+ // fabs(local_y) < dy/2 ? 1 : 0
+#if __BANG_ARCH__ >= 322
+ __bang_lt_scalar((T *)temp_buffer1, (T *)temp_buffer1, (T)(dy_2),
+ compute_pts_num);
+#else
+ __bang_write_value((void *)temp_buffer2, compute_pts_num, (T)(dy_2));
+ __bang_lt((T *)temp_buffer1, (T *)temp_buffer1, (T *)temp_buffer2,
+ compute_pts_num);
+#endif
+ __bang_and((T *)nram_pts_in_flag, (T *)nram_pts_in_flag,
+ (T *)temp_buffer1,
+ compute_pts_num); // flush res
+ T x_res = dx / out_x;
+ T y_res = dy / out_y;
+ T z_res = dz / out_z;
+ __bang_add_scalar((T *)local_X, (T *)local_X, (T)(dx_2), compute_pts_num);
+ __bang_add_scalar((T *)local_Y, (T *)local_Y, (T)(dy_2), compute_pts_num);
+ // local_Z do not need to add dz/2.0
+
+#if (__BANG_ARCH__ >= 322) && (__BANG_ARCH__ != 372)
+ __bang_div((T *)local_X, (T *)local_X, (T)x_res, compute_pts_num);
+ __bang_div((T *)local_Y, (T *)local_Y, (T)y_res, compute_pts_num);
+ __bang_div((T *)local_Z, (T *)local_Z, (T)z_res, compute_pts_num);
+#else
+ __bang_mul_scalar((T *)local_X, (T *)local_X, (T)(1 / x_res),
+ compute_pts_num);
+ __bang_mul_scalar((T *)local_Y, (T *)local_Y, (T)(1 / y_res),
+ compute_pts_num);
+ __bang_mul_scalar((T *)local_Z, (T *)local_Z, (T)(1 / z_res),
+ compute_pts_num);
+#endif
+ // float = float2int + int2float, half = half2int + int2float
+ if (sizeof(T) == sizeof(float)) {
+#if __BANG_ARCH__ >= 322
+ __bang_float2int32_tz((int *)temp_buffer1, (float *)local_X,
+ compute_pts_num, 0);
+ __bang_float2int32_tz((int *)temp_buffer2, (float *)local_Y,
+ compute_pts_num, 0);
+ __bang_float2int32_tz((int *)temp_buffer3, (float *)local_Z,
+ compute_pts_num, 0);
+ __bang_int322float_rn((float *)fp_local_X, (int *)temp_buffer1,
+ compute_pts_num, 0);
+ __bang_int322float_rn((float *)fp_local_Y, (int *)temp_buffer2,
+ compute_pts_num, 0);
+ __bang_int322float_rn((float *)fp_local_Z, (int *)temp_buffer3,
+ compute_pts_num, 0);
+#else
+ convertFloat2Int((int *)temp_buffer1, (float *)temp_buffer2,
+ (float *)fp_local_X, (float *)temp_buffer3,
+ compute_pts_num);
+ convertFloat2Int((int *)temp_buffer2, (float *)temp_buffer3,
+ (float *)fp_local_Y, (float *)temp_buffer4,
+ compute_pts_num);
+ convertFloat2Int((int *)temp_buffer3, (float *)temp_buffer4,
+ (float *)fp_local_Z, (float *)temp_buffer5,
+ compute_pts_num);
+ convertInt2Float((float *)fp_local_X, (float *)temp_buffer4,
+ (int *)temp_buffer1, (float *)temp_buffer5,
+ compute_pts_num);
+ convertInt2Float((float *)fp_local_Y, (float *)temp_buffer4,
+ (int *)temp_buffer2, (float *)temp_buffer5,
+ compute_pts_num);
+ convertInt2Float((float *)fp_local_Z, (float *)temp_buffer4,
+ (int *)temp_buffer3, (float *)temp_buffer5,
+ compute_pts_num);
+#endif
+ } else {
+ __bang_half2float((float *)temp_buffer4, (half *)nram_pts_in_flag,
+ compute_pts_num);
+ __bang_move((void *)fp_nram_pts_in_flag, (void *)temp_buffer4,
+ compute_pts_num * sizeof(float));
+#if __BANG_ARCH__ >= 322
+ __bang_half2int32_tz((int *)temp_buffer1, (half *)local_X,
+ compute_pts_num, 0);
+ __bang_half2int32_tz((int *)temp_buffer2, (half *)local_Y,
+ compute_pts_num, 0);
+ __bang_half2int32_tz((int *)temp_buffer3, (half *)local_Z,
+ compute_pts_num, 0);
+ __bang_int322float_rn((float *)fp_local_X, (int *)temp_buffer1,
+ compute_pts_num, 0);
+ __bang_int322float_rn((float *)fp_local_Y, (int *)temp_buffer2,
+ compute_pts_num, 0);
+ __bang_int322float_rn((float *)fp_local_Z, (int *)temp_buffer3,
+ compute_pts_num, 0);
+#else
+ __bang_half2int16_tz((int16_t *)temp_buffer1, (half *)local_X,
+ compute_pts_num, 0);
+ __bang_half2int16_tz((int16_t *)temp_buffer2, (half *)local_Y,
+ compute_pts_num, 0);
+ __bang_half2int16_tz((int16_t *)temp_buffer3, (half *)local_Z,
+ compute_pts_num, 0);
+ __bang_int162float((float *)fp_local_X, (int16_t *)temp_buffer1,
+ compute_pts_num, 0);
+ __bang_int162float((float *)fp_local_Y, (int16_t *)temp_buffer2,
+ compute_pts_num, 0);
+ __bang_int162float((float *)fp_local_Z, (int16_t *)temp_buffer3,
+ compute_pts_num, 0);
+#endif
+ }
+ // process index >= 0
+ __bang_write_value((float *)temp_buffer4, compute_pts_num, (float)0.0f);
+ __bang_maxequal((float *)fp_local_X, (float *)fp_local_X,
+ (float *)temp_buffer4, compute_pts_num);
+ __bang_maxequal((float *)fp_local_Y, (float *)fp_local_Y,
+ (float *)temp_buffer4, compute_pts_num);
+ __bang_maxequal((float *)fp_local_Z, (float *)fp_local_Z,
+ (float *)temp_buffer4, compute_pts_num);
+ // process index <= (out_x - 1)
+ __bang_write_value((float *)temp_buffer5, compute_pts_num,
+ (float)(out_x - 1));
+ __bang_minequal((float *)fp_local_X, (float *)fp_local_X,
+ (float *)temp_buffer5, compute_pts_num);
+ __bang_write_value((float *)temp_buffer5, compute_pts_num,
+ (float)(out_y - 1));
+ __bang_minequal((float *)fp_local_Y, (float *)fp_local_Y,
+ (float *)temp_buffer5, compute_pts_num);
+ __bang_write_value((float *)temp_buffer5, compute_pts_num,
+ (float)(out_z - 1));
+ __bang_minequal((float *)fp_local_Z, (float *)fp_local_Z,
+ (float *)temp_buffer5, compute_pts_num);
+ __bang_mul_scalar((float *)temp_buffer1, (float *)fp_local_X,
+ (float)(out_y * out_z), compute_pts_num);
+ __bang_mul_scalar((float *)temp_buffer2, (float *)fp_local_Y,
+ (float)out_z, compute_pts_num);
+ __bang_mul_scalar((float *)temp_buffer3, (float *)fp_local_Z, (float)1.0,
+ compute_pts_num);
+ __bang_add((float *)nram_voxel_offset, (float *)temp_buffer1,
+ (float *)temp_buffer2, compute_pts_num);
+ __bang_add((float *)nram_voxel_offset, (float *)nram_voxel_offset,
+ (float *)temp_buffer3, compute_pts_num);
+ __bang_mul_scalar((float *)nram_voxel_offset, (float *)nram_voxel_offset,
+ (float)max_pts_each_voxel, compute_pts_num);
+ if (compute_pts_num != load_pts_num) {
+ __memset_nram((float *)fp_nram_pts_in_flag + load_pts_num,
+ compute_pts_num - load_pts_num, (float)0.0);
+ }
+ __bang_collect((float *)temp_buffer4, (float *)nram_pts_idx_seq,
+ (float *)fp_nram_pts_in_flag, compute_pts_num);
+ int pts_num_in_cur_roi =
+ (int)__bang_count((float *)fp_nram_pts_in_flag, compute_pts_num);
+ int *pts_idx_cur_voxels =
+ (int *)pts_idx_of_voxels +
+ roi_index * out_x * out_y * out_z * max_pts_each_voxel;
+ for (int idx = 0; idx < pts_num_in_cur_roi; idx++) {
+ int cur_pts_idx = *((int *)temp_buffer4 + idx);
+ int offset = (int)(*((float *)nram_voxel_offset + cur_pts_idx));
+ int cnt = pts_idx_cur_voxels[offset];
+ if (cnt < max_pts_each_voxel - 1) {
+ pts_idx_cur_voxels[offset + cnt + 1] =
+ cur_pts_idx + loop_idx * nram_pts_num;
+ pts_idx_cur_voxels[offset]++;
+ }
+ }
+ }
+ }
+}
+
+template
+__mlu_global__ void MLUUnion1KernelRoiawarePool3dForward(
+ const int pool_method, const int boxes_num, const int pts_num,
+ const int channels, const int max_pts_each_voxel, const int out_x,
+ const int out_y, const int out_z, const T *pts_feature,
+ const int *pts_idx_of_voxels, T *pooled_features, int *argmax) {
+ // params (T)pts_feature: (channels, pts_num)
+ // params (int)pts_idx_of_voxels: (boxes_num, out_x, out_y, out_z,
+ // max_pts_each_voxel) params (int)argmax: (boxes_num, out_x, out_y, out_z,
+ // channels) params (T)pooled_features: (boxes_num, out_x, out_y, out_z,
+ // channels)
+
+ // make sure that memcore is not used
+ if (coreId == 0x80) {
+ return;
+ }
+ int align_num = NFU_ALIGN_SIZE / sizeof(T);
+ int align_max_pts_each_voxel = PAD_UP(max_pts_each_voxel, align_num);
+ int nram_channels_limit =
+ PAD_DOWN((MAX_NRAM_SIZE - 128 -
+ align_max_pts_each_voxel * (sizeof(int) + sizeof(T))) /
+ ((align_max_pts_each_voxel + 1) * sizeof(T) + sizeof(int)),
+ align_num);
+ int *nram_pts_idx_cur_voxel = (int *)data_nram;
+ // nram_pts_idx_cur_voxel [align_max_pts_each_voxel]
+ T *nram_max_pts_feature_tmp =
+ (T *)((int *)nram_pts_idx_cur_voxel + align_max_pts_each_voxel);
+ // nram_max_pts_feature_tmp [align_max_pts_each_voxel]
+ T *nram_pts_feature_in_voxel =
+ ((T *)nram_max_pts_feature_tmp + align_max_pts_each_voxel);
+ // nram_pts_feature_in_voxel [nram_channels_limit, align_max_pts_each_voxel]
+ T *nram_pooled_features_cur_voxel =
+ ((T *)nram_pts_feature_in_voxel +
+ nram_channels_limit * align_max_pts_each_voxel);
+ // nram_pooled_features_cur_voxel [nram_channels_limit]
+ int *nram_argmax_cur_voxel =
+ (int *)((T *)nram_pooled_features_cur_voxel + nram_channels_limit);
+ // nram_argmax_cur_voxel [nram_channels_limit]
+ char *one_pooled_feature =
+ (char *)((int *)nram_argmax_cur_voxel + nram_channels_limit);
+ // one_pooled_feature [128]
+ int channels_loop_times = channels / nram_channels_limit;
+ int rem_channels = channels % nram_channels_limit;
+ for (int voxel_index = taskId;
+ voxel_index < boxes_num * out_x * out_y * out_z;
+ voxel_index += taskDim) {
+ int *pts_idx_cur_voxels =
+ (int *)pts_idx_of_voxels + voxel_index * max_pts_each_voxel;
+ __memcpy((void *)nram_pts_idx_cur_voxel, (void *)pts_idx_cur_voxels,
+ max_pts_each_voxel * sizeof(int), GDRAM2NRAM);
+ int pts_num_cur_voxel = nram_pts_idx_cur_voxel[0];
+ if (pts_num_cur_voxel == 0) {
+ continue;
+ }
+ for (int channels_loop_idx = 0; channels_loop_idx <= channels_loop_times;
+ channels_loop_idx++) {
+ int actual_channels_num = (channels_loop_idx == channels_loop_times)
+ ? rem_channels
+ : nram_channels_limit;
+ if (actual_channels_num == 0) {
+ break;
+ }
+ int channels_offset = nram_channels_limit * channels_loop_idx;
+
+#if ((__BANG_ARCH__ >= 200) && (__BANG_ARCH__ < 300))
+ int compute_channels_num = (channels_loop_idx == channels_loop_times)
+ ? PAD_UP(rem_channels, align_num)
+ : nram_channels_limit;
+ if (pool_method == 0) {
+ __bang_write_value((void *)nram_pts_feature_in_voxel,
+ compute_channels_num * align_max_pts_each_voxel,
+ (T)-INFINITY);
+ }
+#endif
+
+ T *pts_feature_cur_loop = (T *)pts_feature + channels_offset * pts_num;
+ for (int idx = 0; idx < pts_num_cur_voxel; idx++) {
+ __memcpy((T *)nram_pts_feature_in_voxel + idx,
+ (T *)pts_feature_cur_loop + nram_pts_idx_cur_voxel[idx + 1],
+ sizeof(T), GDRAM2NRAM, align_max_pts_each_voxel * sizeof(T),
+ pts_num * sizeof(T), actual_channels_num - 1);
+ }
+ for (int channel_idx = 0; channel_idx < actual_channels_num;
+ channel_idx++) {
+ if (pool_method == 0) {
+#if __BANG_ARCH__ >= 322
+ __bang_argmax((T *)one_pooled_feature,
+ (T *)nram_pts_feature_in_voxel +
+ channel_idx * align_max_pts_each_voxel,
+ pts_num_cur_voxel);
+ T max_val = ((T *)one_pooled_feature)[0];
+ int max_idx = (int)(*(uint32_t *)((T *)one_pooled_feature + 1));
+ nram_pooled_features_cur_voxel[channel_idx] =
+ (max_val == -INFINITY) ? 0 : max_val;
+ nram_argmax_cur_voxel[channel_idx] =
+ (max_val == -INFINITY) ? -1 : nram_pts_idx_cur_voxel[max_idx + 1];
+#else
+ // __bang_max need align num on mlu200 series
+ if (sizeof(T) == sizeof(float)) {
+ __bang_max((float *)one_pooled_feature,
+ (float *)nram_pts_feature_in_voxel +
+ channel_idx * align_max_pts_each_voxel,
+ align_max_pts_each_voxel);
+ float max_val = ((float *)one_pooled_feature)[0];
+ __bang_write_value((void *)nram_max_pts_feature_tmp,
+ align_max_pts_each_voxel, (float)max_val);
+ __bang_eq((float *)nram_max_pts_feature_tmp,
+ (float *)nram_pts_feature_in_voxel +
+ channel_idx * align_max_pts_each_voxel,
+ (float *)nram_max_pts_feature_tmp,
+ align_max_pts_each_voxel);
+ int max_idx = (int)__bang_findfirst1(
+ (float *)nram_max_pts_feature_tmp, align_max_pts_each_voxel);
+ nram_pooled_features_cur_voxel[channel_idx] =
+ (max_val == -INFINITY) ? 0 : max_val;
+ nram_argmax_cur_voxel[channel_idx] =
+ (max_val == -INFINITY) ? -1
+ : nram_pts_idx_cur_voxel[max_idx + 1];
+ } else {
+ int max_idx = -1;
+ float max_val = -INFINITY;
+ for (int k = 0; k < pts_num_cur_voxel; k++) {
+ float pts_feature_cur_channel = __half2float_rd(
+ *((half *)nram_pts_feature_in_voxel +
+ channel_idx * align_max_pts_each_voxel + k));
+ if (pts_feature_cur_channel > max_val) {
+ max_val = pts_feature_cur_channel;
+ max_idx = k;
+ }
+ }
+ nram_pooled_features_cur_voxel[channel_idx] =
+ (max_idx == -1) ? 0 : max_val;
+ nram_argmax_cur_voxel[channel_idx] =
+ (max_idx == -1) ? -1 : nram_pts_idx_cur_voxel[max_idx + 1];
+ }
+#endif
+ } else if (pool_method == 1) {
+ float sum_val_cur_channel = 0;
+ for (int k = 0; k < pts_num_cur_voxel; k++) {
+ sum_val_cur_channel += static_cast(
+ ((T *)nram_pts_feature_in_voxel)[channel_idx *
+ align_max_pts_each_voxel +
+ k]);
+ }
+ nram_pooled_features_cur_voxel[channel_idx] =
+ (T)(sum_val_cur_channel / pts_num_cur_voxel);
+ }
+ }
+ // store
+ __memcpy((T *)pooled_features + voxel_index * channels + channels_offset,
+ (void *)nram_pooled_features_cur_voxel,
+ actual_channels_num * sizeof(T), NRAM2GDRAM);
+ if (pool_method == 0) {
+ __memcpy((int *)argmax + voxel_index * channels + channels_offset,
+ (void *)nram_argmax_cur_voxel,
+ actual_channels_num * sizeof(int), NRAM2GDRAM);
+ }
+ }
+ }
+}
+
+void KernelPtsIdxOfVoxels(cnrtDim3_t k_dim, cnrtFunctionType_t k_type,
+ cnrtQueue_t queue, const cnrtDataType_t d_type,
+ const int pool_method, const int boxes_num,
+ const int pts_num, const int max_pts_each_voxel,
+ const int out_x, const int out_y, const int out_z,
+ const void *rois, const void *pts,
+ int *pts_idx_of_voxels) {
+ switch (d_type) {
+ case CNRT_FLOAT32: {
+ MLUUnion1KernelPtsIdxOfVoxels<<>>(
+ pool_method, boxes_num, pts_num, max_pts_each_voxel, out_x, out_y,
+ out_z, (float *)rois, (float *)pts, (int *)pts_idx_of_voxels);
+ }; break;
+ case CNRT_FLOAT16: {
+ MLUUnion1KernelPtsIdxOfVoxels<<>>(
+ pool_method, boxes_num, pts_num, max_pts_each_voxel, out_x, out_y,
+ out_z, (half *)rois, (half *)pts, (int *)pts_idx_of_voxels);
+ }; break;
+ default: {
+ break;
+ }
+ }
+}
+
+void KernelRoiawarePool3dForward(
+ cnrtDim3_t k_dim, cnrtFunctionType_t k_type, cnrtQueue_t queue,
+ const cnrtDataType_t d_type, const int pool_method, const int boxes_num,
+ const int pts_num, const int channels, const int max_pts_each_voxel,
+ const int out_x, const int out_y, const int out_z, const void *pts_feature,
+ const int *pts_idx_of_voxels, void *pooled_features, int *argmax) {
+ switch (d_type) {
+ case CNRT_FLOAT32: {
+ MLUUnion1KernelRoiawarePool3dForward<<>>(
+ pool_method, boxes_num, pts_num, channels, max_pts_each_voxel, out_x,
+ out_y, out_z, (float *)pts_feature, (int *)pts_idx_of_voxels,
+ (float *)pooled_features, (int *)argmax);
+ }; break;
+ case CNRT_FLOAT16: {
+ MLUUnion1KernelRoiawarePool3dForward<<>>(
+ pool_method, boxes_num, pts_num, channels, max_pts_each_voxel, out_x,
+ out_y, out_z, (half *)pts_feature, (int *)pts_idx_of_voxels,
+ (half *)pooled_features, (int *)argmax);
+ }; break;
+ default: {
+ break;
+ }
+ }
+}
+
+template
+__mlu_global__ void MLUUnion1KernelRoiawareMaxPool3dBackward(
+ const int boxes_num, const int out_x, const int out_y, const int out_z,
+ const int channels, const int *argmax, const T *grad_out, T *grad_in) {
+ // params (int)argmax: (boxes_num, out_x, out_y, out_z, channels)
+ // params (T)grad_out: (boxes_num, out_x, out_y, out_z, channels)
+ // params (T)grad_in: (pts_num, channels)
+
+ // make sure that memcore is not used
+ if (coreId == 0x80) {
+ return;
+ }
+ int nram_channels_limit =
+ (MAX_NRAM_SIZE - sizeof(T) * 1) / (sizeof(T) + sizeof(int));
+ int *nram_argmax_cur_loop = (int *)data_nram;
+ // nram_argmax_cur_loop [nram_channels_limit]
+ T *nram_grad_out_cur_loop =
+ (T *)((int *)nram_argmax_cur_loop + nram_channels_limit);
+ // nram_grad_out_cur_loop [nram_channels_limit]
+ T *nram_grad_in_cur_channel =
+ (T *)nram_grad_out_cur_loop + nram_channels_limit;
+ // nram_grad_in_cur_channel [1]
+ int channels_loop_times = channels / nram_channels_limit;
+ int rem_channels = channels % nram_channels_limit;
+ int voxels_num = boxes_num * out_x * out_y * out_z;
+
+ for (int voxel_index = taskId; voxel_index < voxels_num;
+ voxel_index += taskDim) {
+ const int *argmax_cur_voxel = argmax + voxel_index * channels;
+ const T *grad_out_cur_voxel = grad_out + voxel_index * channels;
+
+ for (int channels_loop_idx = 0; channels_loop_idx <= channels_loop_times;
+ channels_loop_idx++) {
+ int actual_channels_num = (channels_loop_idx == channels_loop_times)
+ ? rem_channels
+ : nram_channels_limit;
+ if (actual_channels_num == 0) {
+ break;
+ }
+ const int *argmax_cur_loop =
+ argmax_cur_voxel + nram_channels_limit * channels_loop_idx;
+ const T *grad_out_cur_loop =
+ grad_out_cur_voxel + nram_channels_limit * channels_loop_idx;
+ __memcpy((void *)nram_argmax_cur_loop, (void *)argmax_cur_loop,
+ actual_channels_num * sizeof(int), GDRAM2NRAM);
+ __memcpy((void *)nram_grad_out_cur_loop, (void *)grad_out_cur_loop,
+ actual_channels_num * sizeof(T), GDRAM2NRAM);
+
+ for (int channel_idx = 0; channel_idx < actual_channels_num;
+ channel_idx++) {
+ int *nram_argmax_cur_channel = nram_argmax_cur_loop + channel_idx;
+ T *nram_grad_out_cur_channel = nram_grad_out_cur_loop + channel_idx;
+ if (nram_argmax_cur_channel[0] == -1) {
+ continue;
+ }
+ T *grad_in_cur_channel =
+ grad_in + nram_argmax_cur_channel[0] * channels +
+ nram_channels_limit * channels_loop_idx + channel_idx;
+ __bang_atomic_add((T *)nram_grad_in_cur_channel,
+ (T *)grad_in_cur_channel,
+ (T *)(nram_grad_out_cur_channel), 1);
+ }
+ }
+ }
+}
+
+template
+__mlu_global__ void MLUUnion1KernelRoiawareAvgPool3dBackward(
+ const int boxes_num, const int out_x, const int out_y, const int out_z,
+ const int channels, const int max_pts_each_voxel,
+ const int *pts_idx_of_voxels, const T *grad_out, T *grad_in) {
+ // params (int)pts_idx_of_voxels: (boxes_num, out_x, out_y, out_z,
+ // max_pts_each_voxel) params (T)grad_out: (boxes_num, out_x, out_y, out_z,
+ // channels) params (T)grad_in: (pts_num, channels)
+
+ // make sure that memcore is not used
+ if (coreId == 0x80) {
+ return;
+ }
+ int align_num = NFU_ALIGN_SIZE / sizeof(T);
+ int align_max_pts_each_voxel = PAD_UP(max_pts_each_voxel, align_num);
+ int nram_channels_limit = PAD_DOWN(
+ (MAX_NRAM_SIZE - align_max_pts_each_voxel * sizeof(int)) / 2 / sizeof(T),
+ align_num);
+ int *nram_pts_idx_cur_voxel = (int *)data_nram;
+ // nram_pts_idx_cur_voxel [align_max_pts_each_voxel]
+ T *nram_grad_out_cur_loop =
+ (T *)((int *)nram_pts_idx_cur_voxel + align_max_pts_each_voxel);
+ // nram_grad_out_cur_loop [nram_channels_limit]
+ T *nram_grad_in_cur_loop = (T *)nram_grad_out_cur_loop + nram_channels_limit;
+ // nram_grad_in_cur_loop [nram_channels_limit]
+ int channels_loop_times = channels / nram_channels_limit;
+ int rem_channels = channels % nram_channels_limit;
+ int voxels_num = boxes_num * out_x * out_y * out_z;
+
+ for (int voxel_index = taskId; voxel_index < voxels_num;
+ voxel_index += taskDim) {
+ const T *grad_out_cur_voxel = grad_out + voxel_index * channels;
+ const int *pts_idx_cur_voxel =
+ pts_idx_of_voxels + voxel_index * max_pts_each_voxel;
+ __memcpy((void *)nram_pts_idx_cur_voxel, (void *)pts_idx_cur_voxel,
+ max_pts_each_voxel * sizeof(int), GDRAM2NRAM);
+ int total_pts_of_voxel = nram_pts_idx_cur_voxel[0];
+ if (total_pts_of_voxel <= 0) {
+ continue;
+ }
+ float cur_grad = 1.0 / ((float)total_pts_of_voxel);
+
+ for (int channels_loop_idx = 0; channels_loop_idx <= channels_loop_times;
+ channels_loop_idx++) {
+ int actual_channels_num = (channels_loop_idx == channels_loop_times)
+ ? rem_channels
+ : nram_channels_limit;
+ if (actual_channels_num == 0) {
+ break;
+ }
+ const T *grad_out_cur_loop =
+ grad_out_cur_voxel + nram_channels_limit * channels_loop_idx;
+ __memcpy((void *)nram_grad_in_cur_loop, (void *)grad_out_cur_loop,
+ actual_channels_num * sizeof(T), GDRAM2NRAM);
+
+ int align_actual_channels_num = PAD_UP(actual_channels_num, align_num);
+
+ if (sizeof(T) == sizeof(half)) {
+ __bang_half2float((float *)nram_grad_out_cur_loop,
+ (half *)nram_grad_in_cur_loop,
+ align_actual_channels_num);
+ __bang_mul_scalar((float *)nram_grad_out_cur_loop,
+ (float *)nram_grad_out_cur_loop, (float)cur_grad,
+ align_actual_channels_num);
+ convertFloat2half((half *)nram_grad_out_cur_loop,
+ (float *)nram_grad_out_cur_loop,
+ align_actual_channels_num);
+ } else {
+ __bang_mul_scalar((float *)nram_grad_out_cur_loop,
+ (float *)nram_grad_in_cur_loop, (float)cur_grad,
+ align_actual_channels_num);
+ }
+ for (int k = 1; k <= total_pts_of_voxel; k++) {
+ T *grad_in_cur_loop = grad_in + nram_pts_idx_cur_voxel[k] * channels +
+ nram_channels_limit * channels_loop_idx;
+ __bang_atomic_add((T *)nram_grad_in_cur_loop, (T *)grad_in_cur_loop,
+ (T *)nram_grad_out_cur_loop, actual_channels_num);
+ }
+ }
+ }
+}
+
+void KernelRoiawarePool3dBackward(
+ cnrtDim3_t k_dim, cnrtFunctionType_t k_type, cnrtQueue_t queue,
+ const cnrtDataType_t d_type, const int pool_method, const int boxes_num,
+ const int out_x, const int out_y, const int out_z, const int channels,
+ const int max_pts_each_voxel, const int *pts_idx_of_voxels,
+ const int *argmax, const void *grad_out, void *grad_in) {
+ if (pool_method == 0) {
+ switch (d_type) {
+ case CNRT_FLOAT32: {
+ MLUUnion1KernelRoiawareMaxPool3dBackward
+ <<>>(boxes_num, out_x, out_y, out_z, channels,
+ (int *)argmax, (float *)grad_out,
+ (float *)grad_in);
+ }; break;
+ case CNRT_FLOAT16: {
+ MLUUnion1KernelRoiawareMaxPool3dBackward
+ <<>>(boxes_num, out_x, out_y, out_z, channels,
+ (int *)argmax, (half *)grad_out,
+ (half *)grad_in);
+ }; break;
+ default: {
+ break;
+ }
+ }
+ } else {
+ switch (d_type) {
+ case CNRT_FLOAT32: {
+ MLUUnion1KernelRoiawareAvgPool3dBackward
+ <<>>(
+ boxes_num, out_x, out_y, out_z, channels, max_pts_each_voxel,
+ (int *)pts_idx_of_voxels, (float *)grad_out, (float *)grad_in);
+ }; break;
+ case CNRT_FLOAT16: {
+ MLUUnion1KernelRoiawareAvgPool3dBackward
+ <<>>(
+ boxes_num, out_x, out_y, out_z, channels, max_pts_each_voxel,
+ (int *)pts_idx_of_voxels, (half *)grad_out, (half *)grad_in);
+ }; break;
+ default: {
+ break;
+ }
+ }
+ }
+}
diff --git a/mmcv/ops/csrc/common/mlu/tin_shift_mlu_kernel.mlu b/mmcv/ops/csrc/common/mlu/tin_shift_mlu_kernel.mlu
index 7cb6df0e5d..ed64c2b68c 100644
--- a/mmcv/ops/csrc/common/mlu/tin_shift_mlu_kernel.mlu
+++ b/mmcv/ops/csrc/common/mlu/tin_shift_mlu_kernel.mlu
@@ -26,7 +26,7 @@ __mlu_func__ void mluMultiKernelTinShift(
int t_shift = shifts[n_index * group_size + group_id];
int index = cur_channel_index % channel_size * hw_size +
n_index * time_size * channel_size * hw_size;
- __nramset(data_nram, MAX_NRAM_SIZE, (char)0);
+ __bang_write_value(data_nram, MAX_NRAM_SIZE, (char)0);
__asm__ volatile("sync;");
if (abs(t_shift) >= time_size) {
__memcpy(output + index, data_nram, hw_size * sizeof(T), NRAM2GDRAM,
@@ -109,7 +109,7 @@ __mlu_func__ void mluMultiKernelTinShiftSplitSequence(
int next_sequence_index =
index / hw_size / channel_size % time_size + segmentime_size;
int cur_sequence_index = index / hw_size / channel_size % time_size;
- __nramset(data_nram, MAX_NRAM_SIZE, (char)0);
+ __bang_write_value(data_nram, MAX_NRAM_SIZE, (char)0);
__asm__ volatile("sync;");
if (max_number_hw_per_core == 0) {
mluHwSplit(input, t_shift, time_size, hw_size, channel_size, index,
diff --git a/mmcv/ops/csrc/common/pytorch_cuda_helper.hpp b/mmcv/ops/csrc/common/pytorch_cuda_helper.hpp
index 9869b535f8..52e512695a 100644
--- a/mmcv/ops/csrc/common/pytorch_cuda_helper.hpp
+++ b/mmcv/ops/csrc/common/pytorch_cuda_helper.hpp
@@ -15,5 +15,6 @@ using at::Tensor;
using phalf = at::Half;
#define __PHALF(x) (x)
+#define DIVUP(m, n) ((m) / (n) + ((m) % (n) > 0))
#endif // PYTORCH_CUDA_HELPER
diff --git a/mmcv/ops/csrc/common/pytorch_mlu_helper.hpp b/mmcv/ops/csrc/common/pytorch_mlu_helper.hpp
index 3e1141ec21..e49572ca84 100644
--- a/mmcv/ops/csrc/common/pytorch_mlu_helper.hpp
+++ b/mmcv/ops/csrc/common/pytorch_mlu_helper.hpp
@@ -36,6 +36,26 @@ inline int32_t getJobLimitCapability() {
return (int32_t)ctx_conf_param.unionLimit;
}
+inline int32_t getCoreNumOfJobLimitCapability() {
+ switch (getJobLimitCapability()) {
+ default:
+ return torch_mlu::getDeviceAttr(cnrtAttrMcorePerCluster) *
+ getJobLimitCapability();
+ case CN_KERNEL_CLASS_BLOCK:
+ return 1;
+ case CN_KERNEL_CLASS_UNION:
+ return torch_mlu::getDeviceAttr(cnrtAttrMcorePerCluster);
+ case CN_KERNEL_CLASS_UNION2:
+ return torch_mlu::getDeviceAttr(cnrtAttrMcorePerCluster) * 2;
+ case CN_KERNEL_CLASS_UNION4:
+ return torch_mlu::getDeviceAttr(cnrtAttrMcorePerCluster) * 4;
+ case CN_KERNEL_CLASS_UNION8:
+ return torch_mlu::getDeviceAttr(cnrtAttrMcorePerCluster) * 8;
+ case CN_KERNEL_CLASS_UNION16:
+ return torch_mlu::getDeviceAttr(cnrtAttrMcorePerCluster) * 16;
+ }
+}
+
#endif // MMCV_WITH_MLU
#endif // PYTORCH_MLU_HELPER_HPP_
diff --git a/mmcv/ops/csrc/pytorch/ball_query.cpp b/mmcv/ops/csrc/pytorch/ball_query.cpp
index 1c9e7a2078..b0534db5ce 100644
--- a/mmcv/ops/csrc/pytorch/ball_query.cpp
+++ b/mmcv/ops/csrc/pytorch/ball_query.cpp
@@ -18,3 +18,21 @@ void ball_query_forward(Tensor new_xyz_tensor, Tensor xyz_tensor,
ball_query_forward_impl(b, n, m, min_radius, max_radius, nsample,
new_xyz_tensor, xyz_tensor, idx_tensor);
}
+
+void stack_ball_query_forward_impl(float max_radius, int nsample,
+ const Tensor new_xyz,
+ const Tensor new_xyz_batch_cnt,
+ const Tensor xyz, const Tensor xyz_batch_cnt,
+ Tensor idx) {
+ DISPATCH_DEVICE_IMPL(stack_ball_query_forward_impl, max_radius, nsample,
+ new_xyz, new_xyz_batch_cnt, xyz, xyz_batch_cnt, idx);
+}
+
+void stack_ball_query_forward(Tensor new_xyz_tensor, Tensor new_xyz_batch_cnt,
+ Tensor xyz_tensor, Tensor xyz_batch_cnt,
+ Tensor idx_tensor, float max_radius,
+ int nsample) {
+ stack_ball_query_forward_impl(max_radius, nsample, new_xyz_tensor,
+ new_xyz_batch_cnt, xyz_tensor, xyz_batch_cnt,
+ idx_tensor);
+}
diff --git a/mmcv/ops/csrc/pytorch/cuda/correlation_cuda.cu b/mmcv/ops/csrc/pytorch/cuda/correlation_cuda.cu
index c10e9d40e0..6a43cfc70d 100644
--- a/mmcv/ops/csrc/pytorch/cuda/correlation_cuda.cu
+++ b/mmcv/ops/csrc/pytorch/cuda/correlation_cuda.cu
@@ -42,7 +42,7 @@ void CorrelationForwardCUDAKernelLauncher(Tensor input1, Tensor input2,
<<>>(
trInput1_acc, trInput2_acc, output_acc, kH, kW, patchH, patchW,
padH, padW, dilationH, dilationW, dilation_patchH,
- dilation_patchW, dH, dW);
+ dilation_patchW, dH, dW, oH, oW);
}));
}
diff --git a/mmcv/ops/csrc/pytorch/cuda/cudabind.cpp b/mmcv/ops/csrc/pytorch/cuda/cudabind.cpp
index ade111d141..e558634068 100644
--- a/mmcv/ops/csrc/pytorch/cuda/cudabind.cpp
+++ b/mmcv/ops/csrc/pytorch/cuda/cudabind.cpp
@@ -67,6 +67,30 @@ void ball_query_forward_impl(int b, int n, int m, float min_radius,
Tensor idx);
REGISTER_DEVICE_IMPL(ball_query_forward_impl, CUDA, ball_query_forward_cuda);
+void StackBallQueryForwardCUDAKernelLauncher(float max_radius, int nsample,
+ const Tensor new_xyz,
+ const Tensor new_xyz_batch_cnt,
+ const Tensor xyz,
+ const Tensor xyz_batch_cnt,
+ Tensor idx);
+
+void stack_ball_query_forward_cuda(float max_radius, int nsample,
+ const Tensor new_xyz,
+ const Tensor new_xyz_batch_cnt,
+ const Tensor xyz, const Tensor xyz_batch_cnt,
+ Tensor idx) {
+ StackBallQueryForwardCUDAKernelLauncher(
+ max_radius, nsample, new_xyz, new_xyz_batch_cnt, xyz, xyz_batch_cnt, idx);
+};
+
+void stack_ball_query_forward_impl(float max_radius, int nsample,
+ const Tensor new_xyz,
+ const Tensor new_xyz_batch_cnt,
+ const Tensor xyz, const Tensor xyz_batch_cnt,
+ Tensor idx);
+REGISTER_DEVICE_IMPL(stack_ball_query_forward_impl, CUDA,
+ stack_ball_query_forward_cuda);
+
void BBoxOverlapsCUDAKernelLauncher(const Tensor bboxes1, const Tensor bboxes2,
Tensor ious, const int mode,
const bool aligned, const int offset);
@@ -571,6 +595,56 @@ REGISTER_DEVICE_IMPL(group_points_forward_impl, CUDA,
REGISTER_DEVICE_IMPL(group_points_backward_impl, CUDA,
group_points_backward_cuda);
+void StackGroupPointsForwardCUDAKernelLauncher(
+ int b, int c, int m, int nsample, const Tensor features_tensor,
+ const Tensor features_batch_cnt_tensor, const Tensor idx_tensor,
+ const Tensor idx_batch_cnt_tensor, Tensor out_tensor);
+void StackGroupPointsBackwardCUDAKernelLauncher(
+ int b, int c, int m, int n, int nsample, const Tensor grad_out_tensor,
+ const Tensor idx_tensor, const Tensor idx_batch_cnt_tensor,
+ const Tensor features_batch_cnt_tensor, Tensor grad_features_tensor);
+
+void stack_group_points_forward_cuda(int b, int c, int m, int nsample,
+ const Tensor features_tensor,
+ const Tensor features_batch_cnt_tensor,
+ const Tensor idx_tensor,
+ const Tensor idx_batch_cnt_tensor,
+ Tensor out_tensor) {
+ StackGroupPointsForwardCUDAKernelLauncher(
+ b, c, m, nsample, features_tensor, features_batch_cnt_tensor, idx_tensor,
+ idx_batch_cnt_tensor, out_tensor);
+};
+
+void stack_group_points_backward_cuda(int b, int c, int m, int n, int nsample,
+ const Tensor grad_out_tensor,
+ const Tensor idx_tensor,
+ const Tensor idx_batch_cnt_tensor,
+ const Tensor features_batch_cnt_tensor,
+ Tensor grad_features_tensor) {
+ StackGroupPointsBackwardCUDAKernelLauncher(
+ b, c, m, n, nsample, grad_out_tensor, idx_tensor, idx_batch_cnt_tensor,
+ features_batch_cnt_tensor, grad_features_tensor);
+};
+
+void stack_group_points_forward_impl(int b, int c, int m, int nsample,
+ const Tensor features_tensor,
+ const Tensor features_batch_cnt_tensor,
+ const Tensor idx_tensor,
+ const Tensor idx_batch_cnt_tensor,
+ Tensor out_tensor);
+
+void stack_group_points_backward_impl(int b, int c, int m, int n, int nsample,
+ const Tensor grad_out_tensor,
+ const Tensor idx_tensor,
+ const Tensor idx_batch_cnt_tensor,
+ const Tensor features_batch_cnt_tensor,
+ Tensor grad_features_tensor);
+
+REGISTER_DEVICE_IMPL(stack_group_points_forward_impl, CUDA,
+ stack_group_points_forward_cuda);
+REGISTER_DEVICE_IMPL(stack_group_points_backward_impl, CUDA,
+ stack_group_points_backward_cuda);
+
void IoU3DBoxesOverlapBevForwardCUDAKernelLauncher(const int num_a,
const Tensor boxes_a,
const int num_b,
diff --git a/mmcv/ops/csrc/pytorch/cuda/stack_ball_query_cuda.cu b/mmcv/ops/csrc/pytorch/cuda/stack_ball_query_cuda.cu
new file mode 100644
index 0000000000..3095df5ee3
--- /dev/null
+++ b/mmcv/ops/csrc/pytorch/cuda/stack_ball_query_cuda.cu
@@ -0,0 +1,45 @@
+// Copyright (c) OpenMMLab. All rights reserved
+// Modified from
+// https://github.com/sshaoshuai/Pointnet2.PyTorch/tree/master/pointnet2/src/ball_query_gpu.cu
+
+#include
+#include
+#include
+
+#include "pytorch_cuda_helper.hpp"
+#include "stack_ball_query_cuda_kernel.cuh"
+#define DIVUP(m, n) ((m) / (n) + ((m) % (n) > 0))
+
+void StackBallQueryForwardCUDAKernelLauncher(float max_radius, int nsample,
+ const Tensor new_xyz,
+ const Tensor new_xyz_batch_cnt,
+ const Tensor xyz,
+ const Tensor xyz_batch_cnt,
+ Tensor idx) {
+ at::cuda::CUDAGuard device_guard(new_xyz.device());
+ cudaStream_t stream = at::cuda::getCurrentCUDAStream();
+
+ // const float *new_xyz_ptr = new_xyz.data_ptr();
+ // const float *xyz_ptr = xyz.data_ptr();
+ // const int *new_xyz_batch_cnt_ptr = new_xyz_batch_cnt.data_ptr();
+ // const int *xyz_batch_cnt_ptr = xyz_batch_cnt.data_ptr();
+ // int *idx_ptr = idx.data_ptr();
+
+ int B = xyz_batch_cnt.size(0);
+ int M = new_xyz.size(0);
+
+ // blockIdx.x(col), blockIdx.y(row)
+ dim3 blocks(DIVUP(M, THREADS_PER_BLOCK));
+ dim3 threads(THREADS_PER_BLOCK);
+
+ AT_DISPATCH_FLOATING_TYPES_AND_HALF(
+ new_xyz.scalar_type(), "stack_ball_query_forward_cuda_kernel", [&] {
+ stack_ball_query_forward_cuda_kernel
+ <<>>(
+ B, M, max_radius, nsample, new_xyz.data_ptr(),
+ new_xyz_batch_cnt.data_ptr(), xyz.data_ptr(),
+ xyz_batch_cnt.data_ptr(), idx.data_ptr());
+ });
+
+ AT_CUDA_CHECK(cudaGetLastError());
+}
diff --git a/mmcv/ops/csrc/pytorch/cuda/stack_group_points_cuda.cu b/mmcv/ops/csrc/pytorch/cuda/stack_group_points_cuda.cu
new file mode 100644
index 0000000000..9f903b02a6
--- /dev/null
+++ b/mmcv/ops/csrc/pytorch/cuda/stack_group_points_cuda.cu
@@ -0,0 +1,62 @@
+// Copyright (c) OpenMMLab. All rights reserved.
+// Modified from
+// https://github.com/sshaoshuai/Pointnet2.PyTorch/tree/master/pointnet2/src/group_points_gpu.cu
+#include
+#include
+
+#include "pytorch_cuda_helper.hpp"
+#include "stack_group_points_cuda_kernel.cuh"
+
+void StackGroupPointsForwardCUDAKernelLauncher(
+ int b, int c, int m, int nsample, const Tensor features_tensor,
+ const Tensor features_batch_cnt_tensor, const Tensor idx_tensor,
+ const Tensor idx_batch_cnt_tensor, Tensor out_tensor) {
+ // points: (B, C, N)
+ // idx: (B, npoints, nsample)
+ // output:
+ // out: (B, C, npoints, nsample)
+ at::cuda::CUDAGuard device_guard(features_tensor.device());
+ cudaStream_t stream = at::cuda::getCurrentCUDAStream();
+
+ dim3 blocks(DIVUP(m * c * nsample, THREADS_PER_BLOCK));
+ dim3 threads(THREADS_PER_BLOCK);
+
+ AT_DISPATCH_FLOATING_TYPES_AND_HALF(
+ features_tensor.scalar_type(), "stack_group_points_forward_cuda_kernel",
+ [&] {
+ stack_group_points_forward_cuda_kernel
+ <<>>(
+ b, c, m, nsample, features_tensor.data_ptr(),
+ features_batch_cnt_tensor.data_ptr(),
+ idx_tensor.data_ptr(),
+ idx_batch_cnt_tensor.data_ptr(),
+ out_tensor.data_ptr());
+ });
+
+ AT_CUDA_CHECK(cudaGetLastError());
+}
+
+void StackGroupPointsBackwardCUDAKernelLauncher(
+ int b, int c, int m, int n, int nsample, const Tensor grad_out_tensor,
+ const Tensor idx_tensor, const Tensor idx_batch_cnt_tensor,
+ const Tensor features_batch_cnt_tensor, Tensor grad_features_tensor) {
+ at::cuda::CUDAGuard device_guard(grad_features_tensor.device());
+ cudaStream_t stream = at::cuda::getCurrentCUDAStream();
+
+ dim3 blocks(DIVUP(m * c * nsample, THREADS_PER_BLOCK));
+ dim3 threads(THREADS_PER_BLOCK);
+
+ AT_DISPATCH_FLOATING_TYPES_AND_HALF(
+ grad_features_tensor.scalar_type(),
+ "stack_group_points_backward_cuda_kernel", [&] {
+ stack_group_points_backward_cuda_kernel
+ <<>>(
+ b, c, m, n, nsample, grad_out_tensor.data_ptr(),
+ idx_tensor.data_ptr(),
+ idx_batch_cnt_tensor.data_ptr(),
+ features_batch_cnt_tensor.data_ptr(),
+ grad_features_tensor.data_ptr());
+ });
+
+ AT_CUDA_CHECK(cudaGetLastError());
+}
diff --git a/mmcv/ops/csrc/pytorch/group_points.cpp b/mmcv/ops/csrc/pytorch/group_points.cpp
index cdd190d40b..850deed986 100644
--- a/mmcv/ops/csrc/pytorch/group_points.cpp
+++ b/mmcv/ops/csrc/pytorch/group_points.cpp
@@ -32,3 +32,45 @@ void group_points_backward(Tensor grad_out_tensor, Tensor idx_tensor,
group_points_backward_impl(b, c, n, npoints, nsample, grad_out_tensor,
idx_tensor, grad_points_tensor);
}
+
+void stack_group_points_backward_impl(int b, int c, int m, int n, int nsample,
+ const Tensor grad_out_tensor,
+ const Tensor idx_tensor,
+ const Tensor idx_batch_cnt_tensor,
+ const Tensor features_batch_cnt_tensor,
+ Tensor grad_features_tensor) {
+ DISPATCH_DEVICE_IMPL(stack_group_points_backward_impl, b, c, m, n, nsample,
+ grad_out_tensor, idx_tensor, idx_batch_cnt_tensor,
+ features_batch_cnt_tensor, grad_features_tensor);
+}
+
+void stack_group_points_backward(Tensor grad_out_tensor, Tensor idx_tensor,
+ Tensor idx_batch_cnt_tensor,
+ Tensor features_batch_cnt_tensor,
+ Tensor grad_features_tensor, int b, int c,
+ int m, int n, int nsample) {
+ stack_group_points_backward_impl(
+ b, c, m, n, nsample, grad_out_tensor, idx_tensor, idx_batch_cnt_tensor,
+ features_batch_cnt_tensor, grad_features_tensor);
+}
+
+void stack_group_points_forward_impl(int b, int c, int m, int nsample,
+ const Tensor features_tensor,
+ const Tensor features_batch_cnt_tensor,
+ const Tensor idx_tensor,
+ const Tensor idx_batch_cnt_tensor,
+ Tensor out_tensor) {
+ DISPATCH_DEVICE_IMPL(stack_group_points_forward_impl, b, c, m, nsample,
+ features_tensor, features_batch_cnt_tensor, idx_tensor,
+ idx_batch_cnt_tensor, out_tensor);
+}
+
+void stack_group_points_forward(Tensor features_tensor,
+ Tensor features_batch_cnt_tensor,
+ Tensor idx_tensor, Tensor idx_batch_cnt_tensor,
+ Tensor out_tensor, int b, int c, int m,
+ int nsample) {
+ DISPATCH_DEVICE_IMPL(stack_group_points_forward_impl, b, c, m, nsample,
+ features_tensor, features_batch_cnt_tensor, idx_tensor,
+ idx_batch_cnt_tensor, out_tensor);
+}
diff --git a/mmcv/ops/csrc/pytorch/mlu/iou3d_mlu.cpp b/mmcv/ops/csrc/pytorch/mlu/iou3d_mlu.cpp
new file mode 100644
index 0000000000..5348d16e01
--- /dev/null
+++ b/mmcv/ops/csrc/pytorch/mlu/iou3d_mlu.cpp
@@ -0,0 +1,144 @@
+/*************************************************************************
+ * Copyright (C) 2022 Cambricon.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
+ * OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
+ * MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
+ * IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
+ * CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
+ * TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
+ * SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
+ *************************************************************************/
+
+#include "pytorch_device_registry.hpp"
+#include "pytorch_mlu_helper.hpp"
+
+void KernelIou3d(cnrtDim3_t k_dim, cnrtFunctionType_t k_type, cnrtQueue_t queue,
+ const cnrtDataType_t data_type_input, const void *boxes_dram,
+ const int input_box_num, const float iou_threshold,
+ void *workspace, void *output_size, void *output);
+
+int selectType(uint32_t use_job, int box_num_per_core) {
+ // the box_num_per_core should be at least 256, otherwise the real IO
+ // bandwidth would be very low
+ while (box_num_per_core < 256 && use_job >= 4) {
+ box_num_per_core *= 2;
+ use_job /= 2;
+ }
+ return use_job;
+}
+static cnnlStatus_t policyFunc(cnrtDim3_t *k_dim, cnrtFunctionType_t *k_type,
+ int &core_num_per_class,
+ const int input_box_num) {
+ uint32_t core_dim = torch_mlu::getDeviceAttr(cnrtAttrMcorePerCluster);
+ uint32_t job_limit = getJobLimitCapability();
+ uint32_t core_number = job_limit;
+
+ int box_num_per_core = (input_box_num + core_number - 1) / core_number;
+ int use_job = selectType(job_limit, box_num_per_core);
+ // initiate k_type as Union1
+ k_dim->x = core_dim;
+ k_dim->y = 1;
+ k_dim->z = 1;
+ *k_type = CNRT_FUNC_TYPE_UNION1;
+ switch (job_limit) {
+ case CN_KERNEL_CLASS_BLOCK:
+ case CN_KERNEL_CLASS_UNION:
+ case CN_KERNEL_CLASS_UNION2:
+ case CN_KERNEL_CLASS_UNION4:
+ case CN_KERNEL_CLASS_UNION8:
+ case CN_KERNEL_CLASS_UNION16: {
+ if (use_job < 4) {
+ k_dim->x = 1;
+ *k_type = CNRT_FUNC_TYPE_BLOCK;
+ } else if (use_job == 4) {
+ k_dim->x = core_dim;
+ *k_type = CNRT_FUNC_TYPE_UNION1;
+ } else {
+ k_dim->x = use_job;
+ *k_type = (cnrtFunctionType_t)use_job;
+ }
+ }; break;
+ default:
+ LOG(WARNING) << "[cnnlNms_v2]: got unsupported job limit number."
+ << " Use default CN_KERNEL_CLASS_UNION1 with UNION1 task.";
+ }
+ return CNNL_STATUS_SUCCESS;
+}
+
+void IoU3DNMS3DMLUKernelLauncher(Tensor boxes, Tensor &keep, Tensor &keep_num,
+ float iou_threshold) {
+ // dimension parameters check
+ TORCH_CHECK(boxes.dim() == 2, "boxes should be a 2d tensor, got ",
+ boxes.dim(), "D");
+ TORCH_CHECK(boxes.size(1) == 7,
+ "boxes should have 7 elements in dimension 1, got ",
+ boxes.size(1));
+
+ // data type check
+ TORCH_CHECK(
+ boxes.scalar_type() == at::kFloat || boxes.scalar_type() == at::kHalf,
+ "data type of boxes should be Float or Half, got ", boxes.scalar_type());
+
+ if (boxes.numel() == 0) {
+ return;
+ }
+ const size_t max_input_num = 2147483648; // 2^31, 2G num
+ TORCH_CHECK(boxes.numel() < max_input_num,
+ "boxes.numel() should be less than 2147483648, got ",
+ boxes.numel());
+ int input_box_num = boxes.size(0);
+
+ cnrtDataType_t data_type_input = torch_mlu::toCnrtDtype(boxes.dtype());
+ cnrtDim3_t k_dim;
+ cnrtJobType_t k_type;
+
+ int core_num_per_class;
+ policyFunc(&k_dim, &k_type, core_num_per_class, input_box_num);
+
+ // transpose boxes (n, 7) to (7, n) for better performance
+ auto boxes_t = boxes.transpose(0, 1);
+ auto boxes_ = torch_mlu::cnnl::ops::cnnl_contiguous(boxes_t);
+
+ auto output = at::empty({input_box_num}, boxes.options().dtype(at::kLong));
+ auto output_size = at::empty({1}, boxes.options().dtype(at::kInt));
+
+ // workspace
+ const int info_num = 7; // x, y,z, dx, dy, dz,angle
+ size_t space_size = 0;
+ if (boxes.scalar_type() == at::kHalf) {
+ space_size = input_box_num * sizeof(int16_t) * info_num +
+ input_box_num * sizeof(float) + sizeof(float);
+ } else {
+ space_size = input_box_num * sizeof(float) * (info_num + 1) + sizeof(float);
+ }
+
+ auto workspace = at::empty(space_size, boxes.options().dtype(at::kByte));
+
+ // get compute queue
+ auto queue = torch_mlu::getCurQueue();
+
+ auto boxes_impl = torch_mlu::getMluTensorImpl(boxes_);
+ auto boxes_ptr = boxes_impl->cnnlMalloc();
+ auto workspace_impl = torch_mlu::getMluTensorImpl(workspace);
+ auto workspace_ptr = workspace_impl->cnnlMalloc();
+ auto output_impl = torch_mlu::getMluTensorImpl(keep);
+ auto output_ptr = output_impl->cnnlMalloc();
+ auto output_size_impl = torch_mlu::getMluTensorImpl(keep_num);
+ auto output_size_ptr = output_size_impl->cnnlMalloc();
+
+ uint32_t core_dim = torch_mlu::getDeviceAttr(cnrtAttrMcorePerCluster);
+ CNLOG(INFO) << "Launch Kernel KernelIou3d<<>>";
+ KernelIou3d(k_dim, k_type, queue, data_type_input, boxes_ptr, input_box_num,
+ iou_threshold, workspace_ptr, output_size_ptr, output_ptr);
+}
+
+void iou3d_nms3d_forward_mlu(const Tensor boxes, Tensor &keep, Tensor &keep_num,
+ float nms_overlap_thresh) {
+ IoU3DNMS3DMLUKernelLauncher(boxes, keep, keep_num, nms_overlap_thresh);
+}
+
+void iou3d_nms3d_forward_impl(const Tensor boxes, Tensor &keep,
+ Tensor &keep_num, float nms_overlap_thresh);
+REGISTER_DEVICE_IMPL(iou3d_nms3d_forward_impl, MLU, iou3d_nms3d_forward_mlu);
diff --git a/mmcv/ops/csrc/pytorch/mlu/ms_deform_attn_mlu.cpp b/mmcv/ops/csrc/pytorch/mlu/ms_deform_attn_mlu.cpp
new file mode 100644
index 0000000000..e93fd984aa
--- /dev/null
+++ b/mmcv/ops/csrc/pytorch/mlu/ms_deform_attn_mlu.cpp
@@ -0,0 +1,420 @@
+/*************************************************************************
+ * Copyright (C) 2022 by Cambricon.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
+ * OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
+ * MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
+ * IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
+ * CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
+ * TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
+ * SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
+ *************************************************************************/
+#include "pytorch_device_registry.hpp"
+#include "pytorch_mlu_helper.hpp"
+
+#define MIN(a, b) (((a) < (b)) ? (a) : (b))
+
+void KernelMsDeformAttnForward(
+ cnrtDim3_t k_dim, cnrtFunctionType_t k_type, cnrtQueue_t queue,
+ const cnrtDataType_t d_type, const char* data_value_gdram,
+ const char* data_spatial_shapes_gdram,
+ const char* data_level_start_index_gdram,
+ const char* data_sampling_loc_gdram, const char* data_attn_weight_gdram,
+ const int32_t batch_size, const int32_t num_keys, const int32_t num_heads,
+ const int32_t channels, const int32_t num_levels, const int32_t num_queries,
+ const int32_t num_points, char* data_col_gdram);
+void KernelMsDeformAttnBackward(
+ cnrtDim3_t k_dim, cnrtFunctionType_t k_type, cnrtQueue_t queue,
+ const cnrtDataType_t d_type, const float* data_value,
+ const int32_t* spatial_shapes, const int32_t* data_level_start_index,
+ const float* data_sampling_loc, const float* data_attn_weight,
+ const float* grad_output, const int32_t batch_size, const int32_t num_keys,
+ const int32_t num_heads, const int32_t channels, const int32_t num_levels,
+ const int32_t num_queries, const int32_t num_points, float* grad_value,
+ float* grad_sampling_loc, float* grad_attn_weight);
+// policy function
+static void policyFuncForward(cnrtDim3_t* k_dim, cnrtFunctionType_t* k_type,
+ const int batch_size, const int num_queries,
+ const int num_heads) {
+ k_dim->x = torch_mlu::getDeviceAttr(cnrtAttrMcorePerCluster);
+ k_dim->y =
+ MIN((batch_size * num_queries * num_heads + k_dim->x - 1) / k_dim->x,
+ torch_mlu::getDeviceAttr(cnrtAttrClusterCount));
+ k_dim->z = 1;
+#if __BANG_ARCH__ == 520
+ *k_type = CNRT_FUNC_TYPE_BLOCK;
+#else
+ *k_type = CNRT_FUNC_TYPE_UNION1;
+#endif
+}
+
+// policy function for backward
+static void policyFuncBackward(const int32_t batch_size,
+ const int32_t num_queries,
+ const int32_t num_heads,
+ const int32_t num_levels,
+ cnrtFunctionType_t* k_type, cnrtDim3_t* k_dim) {
+ size_t cluster_limit = torch_mlu::getDeviceAttr(cnrtAttrClusterCount);
+ size_t core_limit = torch_mlu::getDeviceAttr(cnrtAttrMcorePerCluster);
+ k_dim->x = core_limit;
+ int32_t total_num = batch_size * num_queries * num_heads * num_levels;
+ size_t total_num_align = CEIL_ALIGN(total_num, core_limit);
+ k_dim->y = (total_num_align / core_limit) > cluster_limit
+ ? cluster_limit
+ : (total_num_align / core_limit);
+ k_dim->z = 1;
+ *k_type = CNRT_FUNC_TYPE_UNION1;
+}
+
+Tensor ms_deform_attn_mlu_forward(const Tensor& value,
+ const Tensor& spatial_shapes,
+ const Tensor& level_start_index,
+ const Tensor& sampling_loc,
+ const Tensor& attn_weight,
+ const int im2col_step) {
+ // check contiguous
+ AT_ASSERTM(value.is_contiguous(), "value tensor has to be contiguous");
+ AT_ASSERTM(spatial_shapes.is_contiguous(),
+ "spatial_shapes tensor has to be contiguous");
+ AT_ASSERTM(level_start_index.is_contiguous(),
+ "level_start_index tensor has to be contiguous");
+ AT_ASSERTM(sampling_loc.is_contiguous(),
+ "sampling_loc tensor has to be contiguous");
+ AT_ASSERTM(attn_weight.is_contiguous(),
+ "attn_weight tensor has to be contiguous");
+
+ // check datatype
+ TORCH_CHECK((value.scalar_type() == at::kFloat),
+ "value type should be Float, got ", value.scalar_type(), ".");
+ TORCH_CHECK((spatial_shapes.scalar_type() == at::kInt ||
+ spatial_shapes.scalar_type() == at::kLong),
+ "spatial_shapes type should be Int, got ",
+ spatial_shapes.scalar_type(), ".");
+ TORCH_CHECK((level_start_index.scalar_type() == at::kInt ||
+ level_start_index.scalar_type() == at::kLong),
+ "level_start_index type should be Int, got ",
+ level_start_index.scalar_type(), ".");
+ TORCH_CHECK((sampling_loc.scalar_type() == at::kFloat),
+ "sampling_loc type should be Float, got ",
+ sampling_loc.scalar_type(), ".");
+ TORCH_CHECK((attn_weight.scalar_type() == at::kFloat),
+ "attn_weight type should be Float, got ",
+ attn_weight.scalar_type(), ".");
+
+ // check shape
+ TORCH_CHECK(value.dim() == 4, "value should be a 4d tensor, got ",
+ value.dim(), "D.");
+ TORCH_CHECK(spatial_shapes.dim() == 2,
+ "spatial_shapes should be a 2d tensor, got ",
+ spatial_shapes.dim(), "D.");
+ TORCH_CHECK(level_start_index.dim() == 1,
+ "level_start_index should be a 1d tensor, got ",
+ level_start_index.dim(), "D.");
+ TORCH_CHECK(sampling_loc.dim() == 6,
+ "sampling_loc should be a 6d tensor, got ", sampling_loc.dim(),
+ "D.");
+ TORCH_CHECK(attn_weight.dim() == 5, "attn_weight should be a 5d tensor, got ",
+ attn_weight.dim(), "D.");
+
+ const int batch_size = value.size(0);
+ const int num_keys = value.size(1);
+ const int num_heads = value.size(2);
+ const int channels = value.size(3);
+ const int num_levels = spatial_shapes.size(0);
+ const int num_queries = sampling_loc.size(1);
+ const int num_points = sampling_loc.size(4);
+
+ TORCH_CHECK(spatial_shapes.size(1) == 2,
+ "the 2nd dimensions of spatial_shapes should be 2, got ",
+ spatial_shapes.size(1), ".");
+ TORCH_CHECK(sampling_loc.size(5) == 2,
+ "the 6th dimensions of sampling_loc should be 2, got ",
+ sampling_loc.size(5), ".");
+ TORCH_CHECK((sampling_loc.size(0) == batch_size),
+ "the 1st dimensions of sampling_loc should be batch_size, ",
+ "but now the 1st dimension of sampling_loc is ",
+ sampling_loc.size(0), ", and batch_size is ", batch_size, ".");
+ TORCH_CHECK((attn_weight.size(0) == batch_size),
+ "the 1st dimensions of attn_weight should be batch_size, ",
+ "but now the 1st dimension of attn_weight is ",
+ attn_weight.size(0), ", and batch_size is ", batch_size, ".");
+ TORCH_CHECK((sampling_loc.size(2) == num_heads),
+ "the 3rd dimensions of sampling_loc should be num_heads, ",
+ "but now the 3rd dimension of sampling_loc is ",
+ sampling_loc.size(2), ", and num_heads is ", num_heads, ".");
+ TORCH_CHECK((attn_weight.size(2) == num_heads),
+ "the 3rd dimensions of attn_weight should be num_heads, ",
+ "but now the 3rd dimension of attn_weight is ",
+ attn_weight.size(2), ", and num_heads is ", num_heads, ".");
+ TORCH_CHECK((level_start_index.size(0) == num_levels),
+ "the 1st dimensions of level_start_index should be num_levels, ",
+ "but now the 1st dimension of level_start_index is ",
+ level_start_index.size(0), ", and num_levels is ", num_levels,
+ ".");
+ TORCH_CHECK((sampling_loc.size(3) == num_levels),
+ "the 4th dimensions of sampling_loc should be num_levels, ",
+ "but now the 4th dimension of sampling_loc is ",
+ sampling_loc.size(3), ", and num_levels is ", num_levels, ".");
+ TORCH_CHECK((attn_weight.size(3) == num_levels),
+ "the 4th dimensions of attn_weight should be num_levels, ",
+ "but now the 4th dimension of attn_weight is ",
+ attn_weight.size(3), ", and num_levels is ", num_levels, ".");
+ TORCH_CHECK((attn_weight.size(1) == num_queries),
+ "the 2nd dimensions of attn_weight should be num_queries, ",
+ "but now the 2nd dimension of attn_weight is ",
+ attn_weight.size(1), ", and num_queries is ", num_queries, ".");
+ TORCH_CHECK((attn_weight.size(4) == num_points),
+ "the 5th dimensions of attn_weight should be num_points, ",
+ "but now the 5th dimension of attn_weight is ",
+ attn_weight.size(4), ", and num_points is ", num_points, ".");
+
+ auto output = at::zeros({batch_size, num_queries, num_heads, channels},
+ value.options());
+
+ // large tensor check
+ const size_t max_input_size = 2147483648;
+ TORCH_CHECK(value.numel() < max_input_size,
+ "value element num should be less than 2^31, got ", value.numel(),
+ ".");
+ TORCH_CHECK(sampling_loc.numel() < max_input_size,
+ "sampling_loc element num should be less than 2^31, got ",
+ sampling_loc.numel(), ".");
+ TORCH_CHECK(output.numel() < max_input_size,
+ "output element num should be less than 2^31, got ",
+ output.numel(), ".");
+
+ // check zero element
+ TORCH_CHECK(batch_size != 0, "batch_size should not be zero");
+ TORCH_CHECK(num_heads != 0, "num_heads should not be zero");
+ TORCH_CHECK(channels != 0, "channels should not be zero");
+ TORCH_CHECK(num_queries != 0, "num_queries should not be zero");
+
+ if (num_keys == 0 || num_levels == 0 || num_points == 0) {
+ return output;
+ }
+
+ // calculate task dimension
+ cnrtDim3_t k_dim;
+ cnrtFunctionType_t k_type;
+ policyFuncForward(&k_dim, &k_type, batch_size, num_queries, num_heads);
+
+ // get compute queue
+ auto queue = torch_mlu::getCurQueue();
+
+ auto spatial_shapes_ = spatial_shapes.to(at::kInt);
+ auto level_start_index_ = level_start_index.to(at::kInt);
+
+ // get ptr of tensors
+ auto value_impl = torch_mlu::getMluTensorImpl(value);
+ auto value_ptr = value_impl->cnnlMalloc();
+ auto spatial_shapes_impl = torch_mlu::getMluTensorImpl(spatial_shapes_);
+ auto spatial_shapes_ptr = spatial_shapes_impl->cnnlMalloc();
+ auto level_start_index_impl = torch_mlu::getMluTensorImpl(level_start_index_);
+ auto level_start_index_ptr = level_start_index_impl->cnnlMalloc();
+ auto sampling_loc_impl = torch_mlu::getMluTensorImpl(sampling_loc);
+ auto sampling_loc_ptr = sampling_loc_impl->cnnlMalloc();
+ auto attn_weight_impl = torch_mlu::getMluTensorImpl(attn_weight);
+ auto attn_weight_ptr = attn_weight_impl->cnnlMalloc();
+ auto output_impl = torch_mlu::getMluTensorImpl(output);
+ auto output_ptr = output_impl->cnnlMalloc();
+
+ // get compute dtype of input
+ cnrtDataType_t data_type = torch_mlu::toCnrtDtype(value.dtype());
+
+ // launch kernel
+ CNLOG(INFO) << "Launch Kernel MLUKernelMsDeformAttnForward<<<" << k_dim.x
+ << ", " << k_dim.y << ", " << k_dim.z << ">>>";
+
+ KernelMsDeformAttnForward(
+ k_dim, k_type, queue, data_type, (char*)value_ptr,
+ (char*)spatial_shapes_ptr, (char*)level_start_index_ptr,
+ (char*)sampling_loc_ptr, (char*)attn_weight_ptr, batch_size, num_keys,
+ num_heads, channels, num_levels, num_queries, num_points,
+ (char*)output_ptr);
+
+ output = output.view({batch_size, num_queries, num_heads * channels});
+ return output;
+}
+
+void ms_deform_attn_mlu_backward(
+ const Tensor& value, const Tensor& spatial_shapes,
+ const Tensor& level_start_index, const Tensor& sampling_loc,
+ const Tensor& attn_weight, const Tensor& grad_output, Tensor& grad_value,
+ Tensor& grad_sampling_loc, Tensor& grad_attn_weight,
+ const int im2col_step) {
+ // check contiguous
+ AT_ASSERTM(value.is_contiguous(), "value tensor has to be contiguous");
+ AT_ASSERTM(spatial_shapes.is_contiguous(),
+ "spatial_shapes tensor has to be contiguous");
+ AT_ASSERTM(level_start_index.is_contiguous(),
+ "level_start_index tensor has to be contiguous");
+ AT_ASSERTM(sampling_loc.is_contiguous(),
+ "sampling_loc tensor has to be contiguous");
+ AT_ASSERTM(attn_weight.is_contiguous(),
+ "attn_weight tensor has to be contiguous");
+ AT_ASSERTM(grad_output.is_contiguous(),
+ "grad_output tensor has to be contiguous");
+
+ // check datatype
+ TORCH_CHECK((value.scalar_type() == at::kFloat),
+ "value type should be Float, got ", value.scalar_type(), ".");
+ TORCH_CHECK((spatial_shapes.scalar_type() == at::kInt ||
+ spatial_shapes.scalar_type() == at::kLong),
+ "spatial_shapes type should be Int, got ",
+ spatial_shapes.scalar_type(), ".");
+ TORCH_CHECK((level_start_index.scalar_type() == at::kInt ||
+ level_start_index.scalar_type() == at::kLong),
+ "level_start_index type should be Int, got ",
+ level_start_index.scalar_type(), ".");
+ TORCH_CHECK((sampling_loc.scalar_type() == at::kFloat),
+ "sampling_loc type should be Float, got ",
+ sampling_loc.scalar_type(), ".");
+ TORCH_CHECK((attn_weight.scalar_type() == at::kFloat),
+ "attn_weight type should be Float, got ",
+ attn_weight.scalar_type(), ".");
+ TORCH_CHECK((grad_output.scalar_type() == at::kFloat),
+ "grad_output type should be Float, got ",
+ grad_output.scalar_type(), ".");
+
+ const int batch_size = value.size(0);
+ const int num_keys = value.size(1);
+ const int num_heads = value.size(2);
+ const int channels = value.size(3);
+ const int num_levels = spatial_shapes.size(0);
+ const int num_queries = sampling_loc.size(1);
+ const int num_points = sampling_loc.size(4);
+ // Check shape.
+ TORCH_CHECK(spatial_shapes.size(1) == 2,
+ "the 2nd dimensions of spatial_shapes should be 2, got ",
+ spatial_shapes.size(1), ".");
+
+ TORCH_CHECK((level_start_index.size(0) == num_levels),
+ "the 1st dimensions of level_start_index should be num_levels, ",
+ "but now the 1st dimension of level_start_index is ",
+ level_start_index.size(0), ", and num_levels is ", num_levels,
+ ".");
+
+ TORCH_CHECK((sampling_loc.size(0) == batch_size),
+ "the 1st dimensions of sampling_loc should be batch_size, ",
+ "but now the 1st dimension of sampling_loc is ",
+ sampling_loc.size(0), ", and batch_size is ", batch_size, ".");
+ TORCH_CHECK((sampling_loc.size(2) == num_heads),
+ "the 3rd dimensions of sampling_loc should be num_heads, ",
+ "but now the 3rd dimension of sampling_loc is ",
+ sampling_loc.size(2), ", and num_heads is ", num_heads, ".");
+ TORCH_CHECK((sampling_loc.size(3) == num_levels),
+ "the 4th dimensions of sampling_loc should be num_levels, ",
+ "but now the 4th dimension of sampling_loc is ",
+ sampling_loc.size(3), ", and num_levels is ", num_levels, ".");
+ TORCH_CHECK(sampling_loc.size(5) == 2,
+ "the 6th dimensions of sampling_loc should be 2, got ",
+ sampling_loc.size(5), ".");
+
+ TORCH_CHECK((attn_weight.size(0) == batch_size),
+ "the 1st dimensions of attn_weight should be batch_size, ",
+ "but now the 1st dimension of attn_weight is ",
+ attn_weight.size(0), ", and batch_size is ", batch_size, ".");
+ TORCH_CHECK((attn_weight.size(1) == num_queries),
+ "the 2nd dimensions of attn_weight should be num_queries, ",
+ "but now the 2nd dimension of attn_weight is ",
+ attn_weight.size(1), ", and num_queries is ", num_queries, ".");
+
+ TORCH_CHECK((attn_weight.size(2) == num_heads),
+ "the 3rd dimensions of attn_weight should be num_heads, ",
+ "but now the 3rd dimension of attn_weight is ",
+ attn_weight.size(2), ", and num_heads is ", num_heads, ".");
+ TORCH_CHECK((attn_weight.size(3) == num_levels),
+ "the 4th dimensions of attn_weight should be num_levels, ",
+ "but now the 4th dimension of attn_weight is ",
+ attn_weight.size(3), ", and num_levels is ", num_levels, ".");
+ TORCH_CHECK((attn_weight.size(4) == num_points),
+ "the 5th dimensions of attn_weight should be num_points, ",
+ "but now the 5th dimension of attn_weight is ",
+ attn_weight.size(4), ", and num_points is ", num_points, ".");
+
+ TORCH_CHECK((grad_output.size(0) == batch_size),
+ "the 1st dimensions of grad_output should be batch_size, ",
+ "but now the 1st dimension of grad_output is ",
+ grad_output.size(0), ", and batch_size is ", batch_size, ".");
+ TORCH_CHECK((grad_output.size(1) == num_queries),
+ "the 2nd dimensions of grad_output should be num_queries, ",
+ "but now the 2nd dimension of grad_output is ",
+ grad_output.size(1), ", and num_queries is ", num_queries, ".");
+ TORCH_CHECK(
+ (grad_output.size(2) == num_heads * channels),
+ "the 3rd dimensions of grad_output should be num_heads * channels, ",
+ "but now the 3rd dimension of grad_output is ", grad_output.size(2),
+ ", and num_heads * channels is ", num_heads * channels, ".");
+
+ // check zero element
+ TORCH_CHECK(batch_size != 0, "The batch_size is zero.");
+ TORCH_CHECK(channels != 0, "The channels is zero.");
+ TORCH_CHECK(num_keys != 0, "The num_keys is zero.");
+ TORCH_CHECK(num_heads != 0, "The num_heads is zero.");
+ TORCH_CHECK(num_queries != 0, "The num_queries is zero.");
+ if (num_levels == 0 || num_points == 0) {
+ return;
+ }
+
+ // calculate task dimension
+ cnrtDim3_t k_dim;
+ cnrtFunctionType_t k_type;
+ policyFuncBackward(batch_size, num_queries, num_heads, num_levels, &k_type,
+ &k_dim);
+
+ // get compute queue
+ auto queue = torch_mlu::getCurQueue();
+
+ // get ptr of tensors
+ auto value_impl = torch_mlu::getMluTensorImpl(value);
+ auto value_ptr = value_impl->cnnlMalloc();
+ auto spatial_shapes_impl = torch_mlu::getMluTensorImpl(spatial_shapes);
+ auto spatial_shapes_ptr = spatial_shapes_impl->cnnlMalloc();
+ auto level_start_index_impl = torch_mlu::getMluTensorImpl(level_start_index);
+ auto level_start_index_ptr = level_start_index_impl->cnnlMalloc();
+ auto sampling_loc_impl = torch_mlu::getMluTensorImpl(sampling_loc);
+ auto sampling_loc_ptr = sampling_loc_impl->cnnlMalloc();
+ auto attn_weight_impl = torch_mlu::getMluTensorImpl(attn_weight);
+ auto attn_weight_ptr = attn_weight_impl->cnnlMalloc();
+ auto grad_output_impl = torch_mlu::getMluTensorImpl(grad_output);
+ auto grad_output_ptr = grad_output_impl->cnnlMalloc();
+ auto grad_value_impl = torch_mlu::getMluTensorImpl(grad_value);
+ auto grad_value_ptr = grad_value_impl->cnnlMalloc();
+ auto grad_sampling_loc_impl = torch_mlu::getMluTensorImpl(grad_sampling_loc);
+ auto grad_sampling_loc_ptr = grad_sampling_loc_impl->cnnlMalloc();
+ auto grad_attn_weight_impl = torch_mlu::getMluTensorImpl(grad_attn_weight);
+ auto grad_attn_weight_ptr = grad_attn_weight_impl->cnnlMalloc();
+
+ // get comput dtype of input
+ cnrtDataType_t data_type = torch_mlu::toCnrtDtype(value.dtype());
+
+ // launch kernel
+ CNLOG(INFO) << "Launch Kernel MLUKernelMsDeformAttnBackward<<<" << k_dim.x
+ << ", " << k_dim.y << ", " << k_dim.z << ">>>";
+
+ KernelMsDeformAttnBackward(
+ k_dim, k_type, queue, data_type, (float*)value_ptr,
+ (int32_t*)spatial_shapes_ptr, (int32_t*)level_start_index_ptr,
+ (float*)sampling_loc_ptr, (float*)attn_weight_ptr,
+ (float*)grad_output_ptr, batch_size, num_keys, num_heads, channels,
+ num_levels, num_queries, num_points, (float*)grad_value_ptr,
+ (float*)grad_sampling_loc_ptr, (float*)grad_attn_weight_ptr);
+}
+
+Tensor ms_deform_attn_impl_forward(const Tensor& value,
+ const Tensor& spatial_shapes,
+ const Tensor& level_start_index,
+ const Tensor& sampling_loc,
+ const Tensor& attn_weight,
+ const int im2col_step);
+
+void ms_deform_attn_impl_backward(
+ const Tensor& value, const Tensor& spatial_shapes,
+ const Tensor& level_start_index, const Tensor& sampling_loc,
+ const Tensor& attn_weight, const Tensor& grad_output, Tensor& grad_value,
+ Tensor& grad_sampling_loc, Tensor& grad_attn_weight, const int im2col_step);
+
+REGISTER_DEVICE_IMPL(ms_deform_attn_impl_forward, MLU,
+ ms_deform_attn_mlu_forward);
+REGISTER_DEVICE_IMPL(ms_deform_attn_impl_backward, MLU,
+ ms_deform_attn_mlu_backward);
diff --git a/mmcv/ops/csrc/pytorch/mlu/nms_mlu.cpp b/mmcv/ops/csrc/pytorch/mlu/nms_mlu.cpp
index a45a510e89..e2f4322a02 100644
--- a/mmcv/ops/csrc/pytorch/mlu/nms_mlu.cpp
+++ b/mmcv/ops/csrc/pytorch/mlu/nms_mlu.cpp
@@ -1,5 +1,5 @@
/*************************************************************************
- * Copyright (C) 2021 by Cambricon.
+ * Copyright (C) 2021 Cambricon.
*
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
* OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
@@ -34,6 +34,7 @@ static cnnlStatus_t policyFunc(cnrtDim3_t *k_dim, cnrtFunctionType_t *k_type,
int &core_num_per_class,
const int input_box_num) {
uint32_t core_dim = torch_mlu::getDeviceAttr(cnrtAttrMcorePerCluster);
+ uint32_t cluster_number = torch_mlu::getDeviceAttr(cnrtAttrClusterCount);
uint32_t job_limit = getJobLimitCapability();
uint32_t core_number = job_limit;
@@ -116,7 +117,11 @@ Tensor NMSMLUKernelLauncher(Tensor boxes, Tensor scores, float iou_threshold,
} else {
space_size = input_num_boxes * sizeof(float) * info_num + sizeof(float);
}
-
+#if __BANG_ARCH__ > 370
+ int cluster_num = getCoreNumOfJobLimitCapability() /
+ torch_mlu::getDeviceAttr(cnrtAttrMcorePerCluster);
+ space_size += cluster_number * sizeof(float) * 7;
+#endif
auto workspace = at::empty(space_size, boxes.options().dtype(at::kByte));
// get compute queue
diff --git a/mmcv/ops/csrc/pytorch/mlu/roiaware_pool3d_mlu.cpp b/mmcv/ops/csrc/pytorch/mlu/roiaware_pool3d_mlu.cpp
new file mode 100644
index 0000000000..62cb2dc62e
--- /dev/null
+++ b/mmcv/ops/csrc/pytorch/mlu/roiaware_pool3d_mlu.cpp
@@ -0,0 +1,399 @@
+/*************************************************************************
+ * Copyright (C) 2022 by Cambricon.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
+ * OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
+ * MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
+ * IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
+ * CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
+ * TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
+ * SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
+ *************************************************************************/
+#include "pytorch_device_registry.hpp"
+#include "pytorch_mlu_helper.hpp"
+
+void KernelPtsIdxOfVoxels(cnrtDim3_t k_dim, cnrtFunctionType_t k_type,
+ cnrtQueue_t queue, const cnrtDataType_t d_type,
+ const int pool_method, const int boxes_num,
+ const int pts_num, const int max_pts_each_voxel,
+ const int out_x, const int out_y, const int out_z,
+ const void *rois, const void *pts,
+ int *pts_idx_of_voxels);
+
+void KernelRoiawarePool3dForward(
+ cnrtDim3_t k_dim, cnrtFunctionType_t k_type, cnrtQueue_t queue,
+ const cnrtDataType_t d_type, const int pool_method, const int boxes_num,
+ const int pts_num, const int channels, const int max_pts_each_voxel,
+ const int out_x, const int out_y, const int out_z, const void *pts_feature,
+ const int *pts_idx_of_voxels, void *pooled_features, int *argmax);
+
+// policy function
+static void kernelPtsIdxOfVoxelsPolicyFunc(const int boxes_num,
+ cnrtDim3_t *k_dim,
+ cnrtFunctionType_t *k_type) {
+ unsigned int core_num = torch_mlu::getDeviceAttr(cnrtAttrMcorePerCluster);
+ unsigned int cluster_num = torch_mlu::getDeviceAttr(cnrtAttrClusterCount);
+ *k_type = CNRT_FUNC_TYPE_UNION1;
+ k_dim->x = core_num;
+ unsigned int use_cluster = (boxes_num + core_num - 1) / core_num;
+ k_dim->y = use_cluster > cluster_num ? cluster_num : use_cluster;
+ k_dim->z = 1;
+}
+
+static void kernelRoiawarePool3dForwardPolicyFunc(
+ const int boxes_num, const int out_x, const int out_y, const int out_z,
+ cnrtDim3_t *k_dim, cnrtFunctionType_t *k_type) {
+ unsigned int core_num = torch_mlu::getDeviceAttr(cnrtAttrMcorePerCluster);
+ unsigned int cluster_num = torch_mlu::getDeviceAttr(cnrtAttrClusterCount);
+ *k_type = CNRT_FUNC_TYPE_UNION1;
+ k_dim->x = core_num;
+ const int voxels_num = boxes_num * out_x * out_y * out_z;
+ unsigned int use_cluster = (voxels_num + core_num - 1) / core_num;
+ k_dim->y = use_cluster > cluster_num ? cluster_num : use_cluster;
+ k_dim->z = 1;
+}
+
+void RoiawarePool3dForwardMLUKernelLauncher(
+ const int pool_method, const int boxes_num, const int pts_num,
+ const int channels, const int max_pts_each_voxel, const int out_x,
+ const int out_y, const int out_z, const Tensor rois, const Tensor pts,
+ const Tensor pts_feature, Tensor pts_idx_of_voxels, Tensor pooled_features,
+ Tensor argmax) {
+ // check datatype
+ TORCH_CHECK(((pts.scalar_type() == rois.scalar_type()) &&
+ (pts_feature.scalar_type() == rois.scalar_type()) &&
+ (pooled_features.scalar_type() == rois.scalar_type())),
+ "data types of rois, rois, pts_feature and pooled_features "
+ "should be the same, ",
+ "but now rois type is ", rois.scalar_type(), ", pts type is ",
+ pts.scalar_type(), ", pts_feature type is ",
+ pts_feature.scalar_type(), ", pooled_features type is ",
+ pooled_features.scalar_type(), ".");
+ TORCH_CHECK(
+ (rois.scalar_type() == at::kFloat || rois.scalar_type() == at::kHalf),
+ "rois type should be Float or Half, got ", rois.scalar_type(), ".");
+ TORCH_CHECK((pts_idx_of_voxels.scalar_type() == at::kInt),
+ "pts_idx_of_voxels type should be Int, got ",
+ pts_idx_of_voxels.scalar_type(), ".");
+ // check dim
+ TORCH_CHECK(rois.dim() == 2, "rois should be a 2D tensor, got ", rois.dim(),
+ "D.");
+ TORCH_CHECK(pts.dim() == 2, "pts should be a 2D tensor, got ", pts.dim(),
+ "D.");
+ TORCH_CHECK(pts_feature.dim() == 2, "pts_feature should be a 2D tensor, got ",
+ pts_feature.dim(), "D.");
+ TORCH_CHECK(pts_idx_of_voxels.dim() == 5,
+ "pts_idx_of_voxels should be a 5D tensor, got ",
+ pts_idx_of_voxels.dim(), "D.");
+ TORCH_CHECK(pooled_features.dim() == 5,
+ "pooled_features should be a 5D tensor, got ",
+ pooled_features.dim(), "D.");
+ // check shape
+ TORCH_CHECK(((rois.size(0) == boxes_num) && (rois.size(1) == 7)),
+ "the dimensions of rois should be (boxes_num, 7), ", "but got (",
+ rois.size(0), ", ", rois.size(1), ") .");
+ TORCH_CHECK(((pts.size(0) == pts_num) && (pts.size(1) == 3)),
+ "the dimensions of pts should be (pts_num, 3), ", "but got (",
+ pts.size(0), ",", pts.size(1), ").");
+ TORCH_CHECK(
+ ((pts_feature.size(0) == pts_num) && (pts_feature.size(1) == channels)),
+ "the dimensions of pts_feature should be (pts_num, channels), ",
+ "but got (", pts_feature.size(0), ",", pts_feature.size(1), ").");
+ TORCH_CHECK(((pts_idx_of_voxels.size(0) == boxes_num) &&
+ (pts_idx_of_voxels.size(1) == out_x) &&
+ (pts_idx_of_voxels.size(2) == out_y) &&
+ (pts_idx_of_voxels.size(3) == out_z) &&
+ (pts_idx_of_voxels.size(4) == max_pts_each_voxel)),
+ "the dimensions of pts_idx_of_voxels should be (boxes_num, "
+ "out_x, out_y, out_z, max_pts_each_voxel), ",
+ "but got (", pts_idx_of_voxels.size(0), ",",
+ pts_idx_of_voxels.size(1), ",", pts_idx_of_voxels.size(2), ",",
+ pts_idx_of_voxels.size(3), ",", pts_idx_of_voxels.size(4), ").");
+ TORCH_CHECK(((pooled_features.size(0) == boxes_num) &&
+ (pooled_features.size(1) == out_x) &&
+ (pooled_features.size(2) == out_y) &&
+ (pooled_features.size(3) == out_z) &&
+ (pooled_features.size(4) == channels)),
+ "the dimensions of pooled_features should be (boxes_num, out_x, "
+ "out_y, out_z, channels), ",
+ "but got (", pooled_features.size(0), ",",
+ pooled_features.size(1), ",", pooled_features.size(2), ",",
+ pooled_features.size(3), ",", pooled_features.size(4), ").");
+ // check other params : pool_mothod
+ TORCH_CHECK(((pool_method == 0) || (pool_method == 1)),
+ "the num of pool_method should be 0(max) or 1(avg), ", "but got ",
+ pool_method, ".");
+ // check large tensor
+ const size_t max_input_size = 2147483648;
+ TORCH_CHECK(rois.numel() < max_input_size,
+ "rois element num should be less than 2^31, got ", rois.numel(),
+ ".");
+ TORCH_CHECK(pts.numel() < max_input_size,
+ "pts element num should be less than 2^31, got ", pts.numel(),
+ ".");
+ TORCH_CHECK(pts_feature.numel() < max_input_size,
+ "pts_feature element num should be less than 2^31, got ",
+ pts_feature.numel(), ".");
+ TORCH_CHECK(pts_idx_of_voxels.numel() < max_input_size,
+ "pts_idx_of_voxels element num should be less than 2^31, got ",
+ pts_idx_of_voxels.numel(), ".");
+ TORCH_CHECK(pooled_features.numel() < max_input_size,
+ "pooled_features element num should be less than 2^31, got ",
+ pooled_features.numel(), ".");
+ // check zero element
+ TORCH_CHECK(rois.numel() != 0, "rois.numel() should not be zero, got ",
+ rois.numel());
+ TORCH_CHECK(pts.numel() != 0, "pts.numel() should not be zero, got ",
+ pts.numel());
+ TORCH_CHECK(pts_feature.numel() != 0,
+ "pts_feature.numel() should not be zero, got ",
+ pts_feature.numel());
+ TORCH_CHECK(pts_idx_of_voxels.numel() != 0,
+ "pts_idx_of_voxels.numel() should not be zero, got ",
+ pts_idx_of_voxels.numel());
+ TORCH_CHECK(pooled_features.numel() != 0,
+ "pooled_features.numel() should not be zero, got ",
+ pooled_features.numel());
+ if (pool_method == 0) {
+ // check datatype
+ TORCH_CHECK((argmax.scalar_type() == at::kInt),
+ "argmax type should be Int, got ", argmax.scalar_type(), ".");
+ // check dim
+ TORCH_CHECK(argmax.dim() == 5, "argmax should be a 5D tensor, got ",
+ argmax.dim(), "D.");
+ // check shape
+ TORCH_CHECK(((argmax.size(0) == boxes_num) && (argmax.size(1) == out_x) &&
+ (argmax.size(2) == out_y) && (argmax.size(3) == out_z) &&
+ (argmax.size(4) == channels)),
+ "the dimensions of argmax should be (boxes_num, out_x, out_y, "
+ "out_z, channels), ",
+ "but got (", argmax.size(0), ",", argmax.size(1), ",",
+ argmax.size(2), ",", argmax.size(3), ",", argmax.size(4), ").");
+ // check large tensor
+ TORCH_CHECK(argmax.numel() < max_input_size,
+ "argmax element num should be less than 2^31, got ",
+ argmax.numel(), ".");
+ // check zero element
+ TORCH_CHECK(argmax.numel() != 0, "argmax.numel() should not be zero, got ",
+ argmax.numel());
+ // when pool_method is 0, which is max pool, init argmax data value to -1
+ argmax.fill_(static_cast(-1));
+ }
+ // calculate task one dimension
+ cnrtDim3_t k1_dim;
+ cnrtFunctionType_t k1_type;
+ kernelPtsIdxOfVoxelsPolicyFunc(boxes_num, &k1_dim, &k1_type);
+ cnrtDim3_t k2_dim;
+ cnrtFunctionType_t k2_type;
+ kernelRoiawarePool3dForwardPolicyFunc(boxes_num, out_x, out_y, out_z, &k2_dim,
+ &k2_type);
+ // get compute queue
+ auto queue = torch_mlu::getCurQueue();
+ // get ptr of tensors
+ auto rois_impl = torch_mlu::getMluTensorImpl(rois);
+ auto rois_ptr = rois_impl->cnnlMalloc();
+ // transpose points [pts_num, 3] -> [3, pts_num]
+ auto pts_ = pts.permute({1, 0}).contiguous();
+ auto pts_impl = torch_mlu::getMluTensorImpl(pts_);
+ auto pts_ptr = pts_impl->cnnlMalloc();
+ // transpose points_features [pts_num, channels] -> [channels, pts_num]
+ auto pts_feature_ = pts_feature.permute({1, 0}).contiguous();
+ auto pts_feature_impl = torch_mlu::getMluTensorImpl(pts_feature_);
+ auto pts_feature_ptr = pts_feature_impl->cnnlMalloc();
+ auto pts_idx_of_voxels_impl = torch_mlu::getMluTensorImpl(pts_idx_of_voxels);
+ auto pts_idx_of_voxels_ptr = pts_idx_of_voxels_impl->cnnlMalloc();
+ auto pooled_features_impl = torch_mlu::getMluTensorImpl(pooled_features);
+ auto pooled_features_ptr = pooled_features_impl->cnnlMalloc();
+ auto argmax_impl = torch_mlu::getMluTensorImpl(argmax);
+ auto argmax_ptr = argmax_impl->cnnlMalloc();
+ // get compute dtype of input
+ cnrtDataType_t data_type = torch_mlu::toCnrtDtype(rois.dtype());
+ // launch kernel PtsIdxOfVoxels
+ CNLOG(INFO) << "Launch Kernel MLUKernel PtsIdxOfVoxels<<<" << k1_dim.x << ", "
+ << k1_dim.y << ", " << k1_dim.z << ">>>";
+ KernelPtsIdxOfVoxels(k1_dim, k1_type, queue, data_type, pool_method,
+ boxes_num, pts_num, max_pts_each_voxel, out_x, out_y,
+ out_z, rois_ptr, pts_ptr, (int *)pts_idx_of_voxels_ptr);
+ // launch kernel RoiawarePool3dForward
+ CNLOG(INFO) << "Launch Kernel MLUKernel RoiawarePool3dForward<<<" << k2_dim.x
+ << ", " << k2_dim.y << ", " << k2_dim.z << ">>>";
+ KernelRoiawarePool3dForward(
+ k2_dim, k2_type, queue, data_type, pool_method, boxes_num, pts_num,
+ channels, max_pts_each_voxel, out_x, out_y, out_z, pts_feature_ptr,
+ (int *)pts_idx_of_voxels_ptr, pooled_features_ptr, (int *)argmax_ptr);
+}
+
+void roiaware_pool3d_forward_mlu(int boxes_num, int pts_num, int channels,
+ int max_pts_each_voxel, int out_x, int out_y,
+ int out_z, const Tensor rois, const Tensor pts,
+ const Tensor pts_feature, Tensor argmax,
+ Tensor pts_idx_of_voxels,
+ Tensor pooled_features, int pool_method) {
+ RoiawarePool3dForwardMLUKernelLauncher(
+ pool_method, boxes_num, pts_num, channels, max_pts_each_voxel, out_x,
+ out_y, out_z, rois, pts, pts_feature, pts_idx_of_voxels, pooled_features,
+ argmax);
+}
+
+void roiaware_pool3d_forward_impl(int boxes_num, int pts_num, int channels,
+ int max_pts_each_voxel, int out_x, int out_y,
+ int out_z, const Tensor rois,
+ const Tensor pts, const Tensor pts_feature,
+ Tensor argmax, Tensor pts_idx_of_voxels,
+ Tensor pooled_features, int pool_method);
+
+REGISTER_DEVICE_IMPL(roiaware_pool3d_forward_impl, MLU,
+ roiaware_pool3d_forward_mlu);
+
+void KernelRoiawarePool3dBackward(
+ cnrtDim3_t k_dim, cnrtFunctionType_t k_type, cnrtQueue_t queue,
+ const cnrtDataType_t d_type, const int pool_method, const int boxes_num,
+ const int out_x, const int out_y, const int out_z, const int channels,
+ const int max_pts_each_voxel, const int *pts_idx_of_voxels,
+ const int *argmax, const void *grad_out, void *grad_in);
+
+static void kernelRoiawarePool3dBackwardPolicyFunc(
+ const int boxes_num, const int out_x, const int out_y, const int out_z,
+ cnrtDim3_t *k_dim, cnrtFunctionType_t *k_type) {
+ unsigned int core_num = torch_mlu::getDeviceAttr(cnrtAttrMcorePerCluster);
+ unsigned int cluster_num = torch_mlu::getDeviceAttr(cnrtAttrClusterCount);
+ *k_type = CNRT_FUNC_TYPE_UNION1;
+ k_dim->x = core_num;
+ const int voxels_num = boxes_num * out_x * out_y * out_z;
+ unsigned int use_cluster = (voxels_num + core_num - 1) / core_num;
+ k_dim->y = use_cluster > cluster_num ? cluster_num : use_cluster;
+ k_dim->z = 1;
+}
+
+void RoiawarePool3dBackwardMLUKernelLauncher(
+ int pool_method, int boxes_num, int out_x, int out_y, int out_z,
+ int channels, int max_pts_each_voxel, const Tensor pts_idx_of_voxels,
+ const Tensor argmax, const Tensor grad_out, Tensor grad_in) {
+ // check datatype
+ TORCH_CHECK((pts_idx_of_voxels.scalar_type() == at::kInt),
+ "pts_idx_of_voxels type should be Int, got ",
+ pts_idx_of_voxels.scalar_type(), ".");
+ TORCH_CHECK((argmax.scalar_type() == at::kInt),
+ "argmax type should be Int, got ", argmax.scalar_type(), ".");
+ TORCH_CHECK((grad_out.scalar_type() == at::kFloat ||
+ grad_out.scalar_type() == at::kHalf),
+ "grad_out type should be Float or Half, got ",
+ grad_out.scalar_type(), ".");
+ TORCH_CHECK((grad_out.scalar_type() == grad_in.scalar_type()),
+ "data types of grad_out, grad_in, should be the same, ",
+ "but now grad_out type is ", grad_out.scalar_type(),
+ ", grad_in type is ", grad_in.scalar_type(), ".");
+ // check dim
+ TORCH_CHECK(pts_idx_of_voxels.dim() == 5,
+ "pts_idx_of_voxels should be a 5D tensor, got ",
+ pts_idx_of_voxels.dim(), "D.");
+ TORCH_CHECK(argmax.dim() == 5, "argmax should be a 5D tensor, got ",
+ argmax.dim(), "D.");
+ TORCH_CHECK(grad_out.dim() == 5, "grad_out should be a 5D tensor, got ",
+ grad_out.dim(), "D.");
+ TORCH_CHECK(grad_in.dim() == 2, "grad_in should be a 2D tensor, got ",
+ grad_in.dim(), "D.");
+ // check shape
+ TORCH_CHECK(((pts_idx_of_voxels.size(0) == boxes_num) &&
+ (pts_idx_of_voxels.size(1) == out_x) &&
+ (pts_idx_of_voxels.size(2) == out_y) &&
+ (pts_idx_of_voxels.size(3) == out_z) &&
+ (pts_idx_of_voxels.size(4) == max_pts_each_voxel)),
+ "the dimensions of pts_idx_of_voxels should be (boxes_num, "
+ "out_x, out_y, out_z, max_pts_each_voxel), ",
+ "but got (", pts_idx_of_voxels.size(0), ",",
+ pts_idx_of_voxels.size(1), ",", pts_idx_of_voxels.size(2), ",",
+ pts_idx_of_voxels.size(3), ",", pts_idx_of_voxels.size(4), ").");
+ TORCH_CHECK(((argmax.size(0) == boxes_num) && (argmax.size(1) == out_x) &&
+ (argmax.size(2) == out_y) && (argmax.size(3) == out_z) &&
+ (argmax.size(4) == channels)),
+ "the dimensions of argmax should be (boxes_num, out_x, out_y, "
+ "out_z, channels), ",
+ "but got (", argmax.size(0), ",", argmax.size(1), ",",
+ argmax.size(2), ",", argmax.size(3), ",", argmax.size(4), ").");
+ TORCH_CHECK(((grad_out.size(0) == boxes_num) && (grad_out.size(1) == out_x) &&
+ (grad_out.size(2) == out_y) && (grad_out.size(3) == out_z) &&
+ (grad_out.size(4) == channels)),
+ "the dimensions of grad_out should be (boxes_num, out_x, "
+ "out_y, out_z, channels), ",
+ "but got (", grad_out.size(0), ",", grad_out.size(1), ",",
+ grad_out.size(2), ",", grad_out.size(3), ",", grad_out.size(4),
+ ").");
+ TORCH_CHECK((grad_in.size(1) == channels),
+ "the 1st dimensions of grad_in should be channels, ", "but got ",
+ grad_in.size(1), ".");
+ // check other params : pool_mothod
+ TORCH_CHECK(((pool_method == 0) || (pool_method == 1)),
+ "the num of pool_method should be 0(max) or 1(avg), ", "but got ",
+ pool_method, ".");
+ // check large tensor
+ const size_t max_input_size = 2147483648;
+ TORCH_CHECK(pts_idx_of_voxels.numel() < max_input_size,
+ "pts_idx_of_voxels element num should be less than 2^31, got ",
+ pts_idx_of_voxels.numel(), ".");
+ TORCH_CHECK(argmax.numel() < max_input_size,
+ "argmax element num should be less than 2^31, got ",
+ argmax.numel(), ".");
+ TORCH_CHECK(grad_out.numel() < max_input_size,
+ "grad_out element num should be less than 2^31, got ",
+ grad_out.numel(), ".");
+ TORCH_CHECK(grad_in.numel() < max_input_size,
+ "grad_in element num should be less than 2^31, got ",
+ grad_in.numel(), ".");
+ // check zero element
+ TORCH_CHECK(pts_idx_of_voxels.numel() != 0,
+ "pts_idx_of_voxels.numel() should not be zero, got ",
+ pts_idx_of_voxels.numel());
+ TORCH_CHECK(argmax.numel() != 0, "argmax.numel() should not be zero, got ",
+ argmax.numel());
+ TORCH_CHECK(grad_out.numel() != 0,
+ "grad_out.numel() should not be zero, got ", grad_out.numel());
+ TORCH_CHECK(grad_in.numel() != 0, "grad_in.numel() should not be zero, got ",
+ grad_in.numel());
+ // calculate task one dimension
+ cnrtDim3_t k_dim;
+ cnrtFunctionType_t k_type;
+ kernelRoiawarePool3dBackwardPolicyFunc(boxes_num, out_x, out_y, out_z, &k_dim,
+ &k_type);
+ // get compute queue
+ auto queue = torch_mlu::getCurQueue();
+ // transpose points_features [pts_num, channels] -> [channels, pts_num]
+ auto pts_idx_of_voxels_impl = torch_mlu::getMluTensorImpl(pts_idx_of_voxels);
+ auto pts_idx_of_voxels_ptr = pts_idx_of_voxels_impl->cnnlMalloc();
+ auto argmax_impl = torch_mlu::getMluTensorImpl(argmax);
+ auto argmax_ptr = argmax_impl->cnnlMalloc();
+ auto grad_out_impl = torch_mlu::getMluTensorImpl(grad_out);
+ auto grad_out_ptr = grad_out_impl->cnnlMalloc();
+ auto grad_in_impl = torch_mlu::getMluTensorImpl(grad_in);
+ auto grad_in_ptr = grad_in_impl->cnnlMalloc();
+ // get compute dtype of input
+ cnrtDataType_t data_type = torch_mlu::toCnrtDtype(grad_out.dtype());
+ // launch kernel RoiawarePool3dForward
+ CNLOG(INFO) << "Launch Kernel MLUKernel RoiawarePool3dBackward<<<" << k_dim.x
+ << ", " << k_dim.y << ", " << k_dim.z << ">>>";
+ KernelRoiawarePool3dBackward(k_dim, k_type, queue, data_type, pool_method,
+ boxes_num, out_x, out_y, out_z, channels,
+ max_pts_each_voxel, (int *)pts_idx_of_voxels_ptr,
+ (int *)argmax_ptr, grad_out_ptr, grad_in_ptr);
+}
+
+void roiaware_pool3d_backward_mlu(int boxes_num, int out_x, int out_y,
+ int out_z, int channels,
+ int max_pts_each_voxel,
+ const Tensor pts_idx_of_voxels,
+ const Tensor argmax, const Tensor grad_out,
+ Tensor grad_in, int pool_method) {
+ RoiawarePool3dBackwardMLUKernelLauncher(
+ pool_method, boxes_num, out_x, out_y, out_z, channels, max_pts_each_voxel,
+ pts_idx_of_voxels, argmax, grad_out, grad_in);
+}
+
+void roiaware_pool3d_backward_impl(int boxes_num, int out_x, int out_y,
+ int out_z, int channels,
+ int max_pts_each_voxel,
+ const Tensor pts_idx_of_voxels,
+ const Tensor argmax, const Tensor grad_out,
+ Tensor grad_in, int pool_method);
+
+REGISTER_DEVICE_IMPL(roiaware_pool3d_backward_impl, MLU,
+ roiaware_pool3d_backward_mlu);
diff --git a/mmcv/ops/csrc/pytorch/pybind.cpp b/mmcv/ops/csrc/pytorch/pybind.cpp
index 22ff0db440..4947b72152 100644
--- a/mmcv/ops/csrc/pytorch/pybind.cpp
+++ b/mmcv/ops/csrc/pytorch/pybind.cpp
@@ -75,6 +75,18 @@ void group_points_backward(Tensor grad_out_tensor, Tensor idx_tensor,
Tensor grad_points_tensor, int b, int c, int n,
int npoints, int nsample);
+void stack_group_points_forward(Tensor features_tensor,
+ Tensor features_batch_cnt_tensor,
+ Tensor idx_tensor, Tensor idx_batch_cnt_tensor,
+ Tensor out_tensor, int b, int c, int m,
+ int nsample);
+
+void stack_group_points_backward(Tensor grad_out_tensor, Tensor idx_tensor,
+ Tensor idx_batch_cnt_tensor,
+ Tensor features_batch_cnt_tensor,
+ Tensor grad_features_tensor, int b, int c,
+ int m, int n, int nsample);
+
void roipoint_pool3d_forward(Tensor xyz, Tensor boxes3d, Tensor pts_feature,
Tensor pooled_features, Tensor pooled_empty_flag);
@@ -240,6 +252,10 @@ void ball_query_forward(Tensor new_xyz_tensor, Tensor xyz_tensor,
Tensor idx_tensor, int b, int n, int m,
float min_radius, float max_radius, int nsample);
+void stack_ball_query_forward(Tensor new_xyz_tensor, Tensor new_xyz_batch_cnt,
+ Tensor xyz_tensor, Tensor xyz_batch_cnt,
+ Tensor idx_tensor, float max_radius, int nsample);
+
void prroi_pool_forward(Tensor input, Tensor rois, Tensor output,
int pooled_height, int pooled_width,
float spatial_scale);
@@ -557,6 +573,17 @@ PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
"group_points_backward", py::arg("grad_out_tensor"),
py::arg("idx_tensor"), py::arg("grad_points_tensor"), py::arg("b"),
py::arg("c"), py::arg("n"), py::arg("npoints"), py::arg("nsample"));
+ m.def("stack_group_points_forward", &stack_group_points_forward,
+ "stack_group_points_forward", py::arg("features_tensor"),
+ py::arg("features_batch_cnt_tensor"), py::arg("idx_tensor"),
+ py::arg("idx_batch_cnt_tensor"), py::arg("out_tensor"), py::arg("b"),
+ py::arg("c"), py::arg("m"), py::arg("nsample"));
+ m.def("stack_group_points_backward", &stack_group_points_backward,
+ "stack_group_points_backward", py::arg("grad_out_tensor"),
+ py::arg("idx_tensor"), py::arg("idx_batch_cnt_tensor"),
+ py::arg("features_batch_cnt_tensor"), py::arg("grad_features_tensor"),
+ py::arg("b"), py::arg("c"), py::arg("m"), py::arg("n"),
+ py::arg("nsample"));
m.def("knn_forward", &knn_forward, "knn_forward", py::arg("b"), py::arg("n"),
py::arg("m"), py::arg("nsample"), py::arg("xyz_tensor"),
py::arg("new_xyz_tensor"), py::arg("idx_tensor"),
@@ -726,6 +753,11 @@ PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
py::arg("new_xyz_tensor"), py::arg("xyz_tensor"), py::arg("idx_tensor"),
py::arg("b"), py::arg("n"), py::arg("m"), py::arg("min_radius"),
py::arg("max_radius"), py::arg("nsample"));
+ m.def("stack_ball_query_forward", &stack_ball_query_forward,
+ "stack_ball_query_forward", py::arg("new_xyz_tensor"),
+ py::arg("new_xyz_batch_cnt"), py::arg("xyz_tensor"),
+ py::arg("xyz_batch_cnt"), py::arg("idx_tensor"), py::arg("max_radius"),
+ py::arg("nsample"));
m.def("roi_align_rotated_forward", &roi_align_rotated_forward,
"roi_align_rotated forward", py::arg("input"), py::arg("rois"),
py::arg("output"), py::arg("pooled_height"), py::arg("pooled_width"),
diff --git a/mmcv/ops/diff_iou_rotated.py b/mmcv/ops/diff_iou_rotated.py
index cdc6c72f87..ddcf4b4fc2 100644
--- a/mmcv/ops/diff_iou_rotated.py
+++ b/mmcv/ops/diff_iou_rotated.py
@@ -235,9 +235,9 @@ def box2corners(box: Tensor) -> Tensor:
"""
B = box.size()[0]
x, y, w, h, alpha = box.split([1, 1, 1, 1, 1], dim=-1)
- x4 = torch.FloatTensor([0.5, -0.5, -0.5, 0.5]).to(box.device)
+ x4 = box.new_tensor([0.5, -0.5, -0.5, 0.5]).to(box.device)
x4 = x4 * w # (B, N, 4)
- y4 = torch.FloatTensor([0.5, 0.5, -0.5, -0.5]).to(box.device)
+ y4 = box.new_tensor([0.5, 0.5, -0.5, -0.5]).to(box.device)
y4 = y4 * h # (B, N, 4)
corners = torch.stack([x4, y4], dim=-1) # (B, N, 4, 2)
sin = torch.sin(alpha)
diff --git a/mmcv/ops/group_points.py b/mmcv/ops/group_points.py
index 5268a265f1..999728c22a 100644
--- a/mmcv/ops/group_points.py
+++ b/mmcv/ops/group_points.py
@@ -9,8 +9,10 @@
from .ball_query import ball_query
from .knn import knn
-ext_module = ext_loader.load_ext(
- '_ext', ['group_points_forward', 'group_points_backward'])
+ext_module = ext_loader.load_ext('_ext', [
+ 'group_points_forward', 'group_points_backward',
+ 'stack_group_points_forward', 'stack_group_points_backward'
+])
class QueryAndGroup(nn.Module):
@@ -183,39 +185,71 @@ class GroupingOperation(Function):
"""Group feature with given index."""
@staticmethod
- def forward(ctx, features: torch.Tensor,
- indices: torch.Tensor) -> torch.Tensor:
+ def forward(
+ ctx,
+ features: torch.Tensor,
+ indices: torch.Tensor,
+ features_batch_cnt: Optional[torch.Tensor] = None,
+ indices_batch_cnt: Optional[torch.Tensor] = None) -> torch.Tensor:
"""
Args:
- features (Tensor): (B, C, N) tensor of features to group.
- indices (Tensor): (B, npoint, nsample) the indices of
- features to group with.
+ features (Tensor): Tensor of features to group, input shape is
+ (B, C, N) or stacked inputs (N1 + N2 ..., C).
+ indices (Tensor): The indices of features to group with, input
+ shape is (B, npoint, nsample) or stacked inputs
+ (M1 + M2 ..., nsample).
+ features_batch_cnt (Tensor, optional): Input features nums in
+ each batch, just like (N1, N2, ...). Defaults to None.
+ New in version 1.7.0.
+ indices_batch_cnt (Tensor, optional): Input indices nums in
+ each batch, just like (M1, M2, ...). Defaults to None.
+ New in version 1.7.0.
Returns:
- Tensor: (B, C, npoint, nsample) Grouped features.
+ Tensor: Grouped features, the shape is (B, C, npoint, nsample)
+ or (M1 + M2 ..., C, nsample).
"""
features = features.contiguous()
indices = indices.contiguous()
-
- B, nfeatures, nsample = indices.size()
- _, C, N = features.size()
- output = torch.cuda.FloatTensor(B, C, nfeatures, nsample)
-
- ext_module.group_points_forward(
- features,
- indices,
- output,
- b=B,
- c=C,
- n=N,
- npoints=nfeatures,
- nsample=nsample)
-
- ctx.for_backwards = (indices, N)
+ if features_batch_cnt is not None and indices_batch_cnt is not None:
+ assert features_batch_cnt.dtype == torch.int
+ assert indices_batch_cnt.dtype == torch.int
+ M, nsample = indices.size()
+ N, C = features.size()
+ B = indices_batch_cnt.shape[0]
+ output = features.new_zeros((M, C, nsample))
+ ext_module.stack_group_points_forward(
+ features,
+ features_batch_cnt,
+ indices,
+ indices_batch_cnt,
+ output,
+ b=B,
+ m=M,
+ c=C,
+ nsample=nsample)
+ ctx.for_backwards = (B, N, indices, features_batch_cnt,
+ indices_batch_cnt)
+ else:
+ B, nfeatures, nsample = indices.size()
+ _, C, N = features.size()
+ output = features.new_zeros(B, C, nfeatures, nsample)
+
+ ext_module.group_points_forward(
+ features,
+ indices,
+ output,
+ b=B,
+ c=C,
+ n=N,
+ npoints=nfeatures,
+ nsample=nsample)
+
+ ctx.for_backwards = (indices, N)
return output
@staticmethod
- def backward(ctx, grad_out: torch.Tensor) -> Tuple[torch.Tensor, None]:
+ def backward(ctx, grad_out: torch.Tensor) -> Tuple:
"""
Args:
grad_out (Tensor): (B, C, npoint, nsample) tensor of the gradients
@@ -224,22 +258,42 @@ def backward(ctx, grad_out: torch.Tensor) -> Tuple[torch.Tensor, None]:
Returns:
Tensor: (B, C, N) gradient of the features.
"""
- idx, N = ctx.for_backwards
-
- B, C, npoint, nsample = grad_out.size()
- grad_features = torch.cuda.FloatTensor(B, C, N).zero_()
-
- grad_out_data = grad_out.data.contiguous()
- ext_module.group_points_backward(
- grad_out_data,
- idx,
- grad_features.data,
- b=B,
- c=C,
- n=N,
- npoints=npoint,
- nsample=nsample)
- return grad_features, None
+ if len(ctx.for_backwards) != 5:
+ idx, N = ctx.for_backwards
+
+ B, C, npoint, nsample = grad_out.size()
+ grad_features = grad_out.new_zeros(B, C, N)
+
+ grad_out_data = grad_out.data.contiguous()
+ ext_module.group_points_backward(
+ grad_out_data,
+ idx,
+ grad_features.data,
+ b=B,
+ c=C,
+ n=N,
+ npoints=npoint,
+ nsample=nsample)
+ return grad_features, None
+ else:
+ B, N, idx, features_batch_cnt, idx_batch_cnt = ctx.for_backwards
+
+ M, C, nsample = grad_out.size()
+ grad_features = grad_out.new_zeros(N, C)
+
+ grad_out_data = grad_out.data.contiguous()
+ ext_module.stack_group_points_backward(
+ grad_out_data,
+ idx,
+ idx_batch_cnt,
+ features_batch_cnt,
+ grad_features.data,
+ b=B,
+ c=C,
+ m=M,
+ n=N,
+ nsample=nsample)
+ return grad_features, None, None, None
grouping_operation = GroupingOperation.apply
diff --git a/mmcv/ops/multi_scale_deform_attn.py b/mmcv/ops/multi_scale_deform_attn.py
index c26929e13a..509ae5f983 100644
--- a/mmcv/ops/multi_scale_deform_attn.py
+++ b/mmcv/ops/multi_scale_deform_attn.py
@@ -12,6 +12,7 @@
from mmengine.utils import deprecated_api_warning
from torch.autograd.function import Function, once_differentiable
+from mmcv.utils import IS_CUDA_AVAILABLE, IS_MLU_AVAILABLE
from ..utils import ext_loader
ext_module = ext_loader.load_ext(
@@ -26,7 +27,7 @@ def forward(ctx, value: torch.Tensor, value_spatial_shapes: torch.Tensor,
sampling_locations: torch.Tensor,
attention_weights: torch.Tensor,
im2col_step: torch.Tensor) -> torch.Tensor:
- """GPU version of multi-scale deformable attention.
+ """GPU/MLU version of multi-scale deformable attention.
Args:
value (torch.Tensor): The value has shape
@@ -63,7 +64,7 @@ def forward(ctx, value: torch.Tensor, value_spatial_shapes: torch.Tensor,
@staticmethod
@once_differentiable
def backward(ctx, grad_output: torch.Tensor) -> tuple:
- """GPU version of backward function.
+ """GPU/MLU version of backward function.
Args:
grad_output (torch.Tensor): Gradient of output tensor of forward.
@@ -346,7 +347,8 @@ def forward(self,
raise ValueError(
f'Last dim of reference_points must be'
f' 2 or 4, but get {reference_points.shape[-1]} instead.')
- if torch.cuda.is_available() and value.is_cuda:
+ if ((IS_CUDA_AVAILABLE and value.is_cuda)
+ or (IS_MLU_AVAILABLE and value.is_mlu)):
output = MultiScaleDeformableAttnFunction.apply(
value, spatial_shapes, level_start_index, sampling_locations,
attention_weights, self.im2col_step)
diff --git a/mmcv/ops/points_sampler.py b/mmcv/ops/points_sampler.py
index 386b6536de..776abc76ec 100644
--- a/mmcv/ops/points_sampler.py
+++ b/mmcv/ops/points_sampler.py
@@ -23,16 +23,11 @@ def calc_square_dist(point_feat_a: Tensor,
torch.Tensor: (B, N, M) Square distance between each point pair.
"""
num_channel = point_feat_a.shape[-1]
- # [bs, n, 1]
- a_square = torch.sum(point_feat_a.unsqueeze(dim=2).pow(2), dim=-1)
- # [bs, 1, m]
- b_square = torch.sum(point_feat_b.unsqueeze(dim=1).pow(2), dim=-1)
-
- corr_matrix = torch.matmul(point_feat_a, point_feat_b.transpose(1, 2))
-
- dist = a_square + b_square - 2 * corr_matrix
+ dist = torch.cdist(point_feat_a, point_feat_b)
if norm:
- dist = torch.sqrt(dist) / num_channel
+ dist = dist / num_channel
+ else:
+ dist = torch.square(dist)
return dist
diff --git a/mmcv/ops/roi_align.py b/mmcv/ops/roi_align.py
index 839843c7f0..de2bed204d 100644
--- a/mmcv/ops/roi_align.py
+++ b/mmcv/ops/roi_align.py
@@ -20,16 +20,25 @@ class RoIAlignFunction(Function):
def symbolic(g, input, rois, output_size, spatial_scale, sampling_ratio,
pool_mode, aligned):
from torch.onnx import TensorProtoDataType
- from torch.onnx.symbolic_helper import _slice_helper
- from torch.onnx.symbolic_opset9 import squeeze, sub
+ from torch.onnx.symbolic_opset9 import sub
+
+ def _select(g, self, dim, index):
+ return g.op('Gather', self, index, axis_i=dim)
# batch_indices = rois[:, 0].long()
- batch_indices = _slice_helper(g, rois, axes=[1], starts=[0], ends=[1])
- batch_indices = squeeze(g, batch_indices, 1)
+ batch_indices = _select(
+ g, rois, 1,
+ g.op('Constant', value_t=torch.tensor([0], dtype=torch.long)))
+ batch_indices = g.op('Squeeze', batch_indices, axes_i=[1])
batch_indices = g.op(
'Cast', batch_indices, to_i=TensorProtoDataType.INT64)
# rois = rois[:, 1:]
- rois = _slice_helper(g, rois, axes=[1], starts=[1], ends=[5])
+ rois = _select(
+ g, rois, 1,
+ g.op(
+ 'Constant',
+ value_t=torch.tensor([1, 2, 3, 4], dtype=torch.long)))
+
if aligned:
# rois -= 0.5/spatial_scale
aligned_offset = g.op(
diff --git a/mmcv/ops/three_interpolate.py b/mmcv/ops/three_interpolate.py
index 12b2f7611e..286bd0472e 100644
--- a/mmcv/ops/three_interpolate.py
+++ b/mmcv/ops/three_interpolate.py
@@ -38,7 +38,7 @@ def forward(ctx: Any, features: torch.Tensor, indices: torch.Tensor,
B, c, m = features.size()
n = indices.size(1)
ctx.three_interpolate_for_backward = (indices, weight, m)
- output = torch.cuda.FloatTensor(B, c, n)
+ output = features.new_empty(B, c, n)
ext_module.three_interpolate_forward(
features, indices, weight, output, b=B, c=c, m=m, n=n)
@@ -58,7 +58,7 @@ def backward(
idx, weight, m = ctx.three_interpolate_for_backward
B, c, n = grad_out.size()
- grad_features = torch.cuda.FloatTensor(B, c, m).zero_()
+ grad_features = grad_out.new_zeros(B, c, m)
grad_out_data = grad_out.data.contiguous()
ext_module.three_interpolate_backward(
diff --git a/mmcv/ops/three_nn.py b/mmcv/ops/three_nn.py
index 8c4bcf3309..d41b9789cf 100644
--- a/mmcv/ops/three_nn.py
+++ b/mmcv/ops/three_nn.py
@@ -34,8 +34,8 @@ def forward(ctx: Any, target: torch.Tensor,
B, N, _ = target.size()
m = source.size(1)
- dist2 = torch.FloatTensor(B, N, 3).to(target.device)
- idx = torch.IntTensor(B, N, 3).to(target.device)
+ dist2 = target.new_empty(B, N, 3)
+ idx = target.new_empty(B, N, 3, dtype=torch.int32)
ext_module.three_nn_forward(target, source, dist2, idx, b=B, n=N, m=m)
if torch.__version__ != 'parrots':
diff --git a/mmcv/transforms/processing.py b/mmcv/transforms/processing.py
index fef4e608ce..09098f1990 100644
--- a/mmcv/transforms/processing.py
+++ b/mmcv/transforms/processing.py
@@ -1063,7 +1063,7 @@ def __init__(
self.scales = scales
else:
self.scales = [scales]
- assert mmengine.is_list_of(self.scales, tuple)
+ assert mmengine.is_seq_of(self.scales, (tuple, int))
self.resize_cfg = dict(type=resize_type, **resize_kwargs)
# create a empty Resize object
@@ -1079,7 +1079,6 @@ def _random_select(self) -> Tuple[int, int]:
``scale_idx`` is the selected index in the given candidates.
"""
- assert mmengine.is_list_of(self.scales, tuple)
scale_idx = np.random.randint(len(self.scales))
scale = self.scales[scale_idx]
return scale, scale_idx
diff --git a/mmcv/version.py b/mmcv/version.py
index 0b65e31b70..d9c3d5b1b5 100644
--- a/mmcv/version.py
+++ b/mmcv/version.py
@@ -1,5 +1,5 @@
# Copyright (c) OpenMMLab. All rights reserved.
-__version__ = '2.0.0rc2'
+__version__ = '2.0.0rc3'
def parse_version_info(version_str: str, length: int = 4) -> tuple:
@@ -30,6 +30,6 @@ def parse_version_info(version_str: str, length: int = 4) -> tuple:
return tuple(release)
-version_info = (2, 0, 0, 0, 'rc', 2)
+version_info = (2, 0, 0, 0, 'rc', 3)
__all__ = ['__version__', 'version_info', 'parse_version_info']
diff --git a/tests/test_ops/output.pkl b/tests/test_ops/output.pkl
new file mode 100644
index 0000000000..bcb7b2dd60
Binary files /dev/null and b/tests/test_ops/output.pkl differ
diff --git a/tests/test_ops/test_ball_query.py b/tests/test_ops/test_ball_query.py
index 4c78dc6600..d3fc7912c5 100644
--- a/tests/test_ops/test_ball_query.py
+++ b/tests/test_ops/test_ball_query.py
@@ -53,3 +53,50 @@ def test_ball_query():
[7, 7, 7, 7, 7], [0, 0, 0, 0, 0],
[0, 0, 0, 0, 0]]]).cuda()
assert torch.all(idx == expected_idx)
+
+
+@pytest.mark.skipif(
+ not torch.cuda.is_available(), reason='requires CUDA support')
+def test_stack_ball_query():
+ new_xyz = torch.tensor([[-0.0740, 1.3147, -1.3625],
+ [-2.2769, 2.7817, -0.2334],
+ [-0.4003, 2.4666, -0.5116],
+ [-0.0740, 1.3147, -1.3625],
+ [-0.0740, 1.3147, -1.3625],
+ [-2.0289, 2.4952, -0.1708],
+ [-2.0668, 6.0278, -0.4875],
+ [0.4066, 1.4211, -0.2947],
+ [-2.0289, 2.4952, -0.1708],
+ [-2.0289, 2.4952, -0.1708]]).cuda()
+ new_xyz_batch_cnt = torch.tensor([5, 5], dtype=torch.int32).cuda()
+ xyz = torch.tensor([[-0.0740, 1.3147, -1.3625], [0.5555, 1.0399, -1.3634],
+ [-0.4003, 2.4666, -0.5116], [-0.5251, 2.4379, -0.8466],
+ [-0.9691, 1.1418, -1.3733], [-0.2232, 0.9561, -1.3626],
+ [-2.2769, 2.7817, -0.2334], [-0.2822, 1.3192, -1.3645],
+ [0.1533, 1.5024, -1.0432], [0.4917, 1.1529, -1.3496],
+ [-2.0289, 2.4952, -0.1708], [-0.7188, 0.9956, -0.5096],
+ [-2.0668, 6.0278, -0.4875], [-1.9304, 3.3092, 0.6610],
+ [0.0949, 1.4332, 0.3140], [-1.2879, 2.0008, -0.7791],
+ [-0.7252, 0.9611, -0.6371], [0.4066, 1.4211, -0.2947],
+ [0.3220, 1.4447, 0.3548], [-0.9744, 2.3856,
+ -1.2000]]).cuda()
+ xyz_batch_cnt = torch.tensor([10, 10], dtype=torch.int32).cuda()
+ idx = ball_query(0, 0.2, 5, xyz, new_xyz, xyz_batch_cnt, new_xyz_batch_cnt)
+ expected_idx = torch.tensor([[0, 0, 0, 0, 0], [6, 6, 6, 6, 6],
+ [2, 2, 2, 2, 2], [0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0], [0, 0, 0, 0, 0],
+ [2, 2, 2, 2, 2], [7, 7, 7, 7, 7],
+ [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]]).cuda()
+ assert torch.all(idx == expected_idx)
+
+ xyz = xyz.double()
+ new_xyz = new_xyz.double()
+ expected_idx = expected_idx.double()
+ idx = ball_query(0, 0.2, 5, xyz, new_xyz, xyz_batch_cnt, new_xyz_batch_cnt)
+ assert torch.all(idx == expected_idx)
+
+ xyz = xyz.half()
+ new_xyz = new_xyz.half()
+ expected_idx = expected_idx.half()
+ idx = ball_query(0, 0.2, 5, xyz, new_xyz, xyz_batch_cnt, new_xyz_batch_cnt)
+ assert torch.all(idx == expected_idx)
diff --git a/tests/test_ops/test_group_points.py b/tests/test_ops/test_group_points.py
index b295437fb8..8109540cea 100644
--- a/tests/test_ops/test_group_points.py
+++ b/tests/test_ops/test_group_points.py
@@ -7,12 +7,13 @@
@pytest.mark.skipif(
not torch.cuda.is_available(), reason='requires CUDA support')
-def test_grouping_points():
+@pytest.mark.parametrize('dtype', [torch.half, torch.float, torch.double])
+def test_grouping_points(dtype):
idx = torch.tensor([[[0, 0, 0], [3, 3, 3], [8, 8, 8], [0, 0, 0], [0, 0, 0],
[0, 0, 0]],
[[0, 0, 0], [6, 6, 6], [9, 9, 9], [0, 0, 0], [0, 0, 0],
[0, 0, 0]]]).int().cuda()
- festures = torch.tensor([[[
+ features = torch.tensor([[[
0.5798, -0.7981, -0.9280, -1.3311, 1.3687, 0.9277, -0.4164, -1.8274,
0.9268, 0.8414
],
@@ -35,43 +36,129 @@ def test_grouping_points():
[
-0.6646, -0.6870, -0.1125, -0.2224, -0.3445,
-1.4049, 0.4990, -0.7037, -0.9924, 0.0386
- ]]]).cuda()
+ ]]],
+ dtype=dtype).cuda()
- output = grouping_operation(festures, idx)
- expected_output = torch.tensor([[[[0.5798, 0.5798, 0.5798],
- [-1.3311, -1.3311, -1.3311],
- [0.9268, 0.9268, 0.9268],
- [0.5798, 0.5798, 0.5798],
- [0.5798, 0.5798, 0.5798],
- [0.5798, 0.5798, 0.5798]],
- [[5.4247, 5.4247, 5.4247],
- [1.4740, 1.4740, 1.4740],
- [2.1581, 2.1581, 2.1581],
- [5.4247, 5.4247, 5.4247],
- [5.4247, 5.4247, 5.4247],
- [5.4247, 5.4247, 5.4247]],
- [[-1.6266, -1.6266, -1.6266],
- [-1.6931, -1.6931, -1.6931],
- [-1.6786, -1.6786, -1.6786],
- [-1.6266, -1.6266, -1.6266],
- [-1.6266, -1.6266, -1.6266],
- [-1.6266, -1.6266, -1.6266]]],
- [[[-0.0380, -0.0380, -0.0380],
- [-0.3693, -0.3693, -0.3693],
- [-1.8527, -1.8527, -1.8527],
- [-0.0380, -0.0380, -0.0380],
- [-0.0380, -0.0380, -0.0380],
- [-0.0380, -0.0380, -0.0380]],
- [[1.1773, 1.1773, 1.1773],
- [6.0865, 6.0865, 6.0865],
- [2.8229, 2.8229, 2.8229],
- [1.1773, 1.1773, 1.1773],
- [1.1773, 1.1773, 1.1773],
- [1.1773, 1.1773, 1.1773]],
- [[-0.6646, -0.6646, -0.6646],
- [0.4990, 0.4990, 0.4990],
- [0.0386, 0.0386, 0.0386],
- [-0.6646, -0.6646, -0.6646],
- [-0.6646, -0.6646, -0.6646],
- [-0.6646, -0.6646, -0.6646]]]]).cuda()
+ output = grouping_operation(features, idx)
+ expected_output = torch.tensor(
+ [[[[0.5798, 0.5798, 0.5798], [-1.3311, -1.3311, -1.3311],
+ [0.9268, 0.9268, 0.9268], [0.5798, 0.5798, 0.5798],
+ [0.5798, 0.5798, 0.5798], [0.5798, 0.5798, 0.5798]],
+ [[5.4247, 5.4247, 5.4247], [1.4740, 1.4740, 1.4740],
+ [2.1581, 2.1581, 2.1581], [5.4247, 5.4247, 5.4247],
+ [5.4247, 5.4247, 5.4247], [5.4247, 5.4247, 5.4247]],
+ [[-1.6266, -1.6266, -1.6266], [-1.6931, -1.6931, -1.6931],
+ [-1.6786, -1.6786, -1.6786], [-1.6266, -1.6266, -1.6266],
+ [-1.6266, -1.6266, -1.6266], [-1.6266, -1.6266, -1.6266]]],
+ [[[-0.0380, -0.0380, -0.0380], [-0.3693, -0.3693, -0.3693],
+ [-1.8527, -1.8527, -1.8527], [-0.0380, -0.0380, -0.0380],
+ [-0.0380, -0.0380, -0.0380], [-0.0380, -0.0380, -0.0380]],
+ [[1.1773, 1.1773, 1.1773], [6.0865, 6.0865, 6.0865],
+ [2.8229, 2.8229, 2.8229], [1.1773, 1.1773, 1.1773],
+ [1.1773, 1.1773, 1.1773], [1.1773, 1.1773, 1.1773]],
+ [[-0.6646, -0.6646, -0.6646], [0.4990, 0.4990, 0.4990],
+ [0.0386, 0.0386, 0.0386], [-0.6646, -0.6646, -0.6646],
+ [-0.6646, -0.6646, -0.6646], [-0.6646, -0.6646, -0.6646]]]],
+ dtype=dtype).cuda()
+ assert torch.allclose(output, expected_output)
+
+
+@pytest.mark.skipif(
+ not torch.cuda.is_available(), reason='requires CUDA support')
+@pytest.mark.parametrize('dtype', [torch.half, torch.float, torch.double])
+def test_stack_grouping_points(dtype):
+ idx = torch.tensor([[0, 0, 0], [3, 3, 3], [8, 8, 8], [1, 1, 1], [0, 0, 0],
+ [2, 2, 2], [0, 0, 0], [6, 6, 6], [9, 9, 9], [0, 0, 0],
+ [1, 1, 1], [0, 0, 0]]).int().cuda()
+ features = torch.tensor([[
+ 0.5798, -0.7981, -0.9280, -1.3311, 1.3687, 0.9277, -0.4164, -1.8274,
+ 0.9268, 0.8414
+ ],
+ [
+ 5.4247, 1.5113, 2.3944, 1.4740, 5.0300,
+ 5.1030, 1.9360, 2.1939, 2.1581, 3.4666
+ ],
+ [
+ -1.6266, -1.0281, -1.0393, -1.6931, -1.3982,
+ -0.5732, -1.0830, -1.7561, -1.6786, -1.6967
+ ],
+ [
+ -0.0380, -0.1880, -1.5724, 0.6905, -0.3190,
+ 0.7798, -0.3693, -0.9457, -0.2942, -1.8527
+ ],
+ [
+ 1.1773, 1.5009, 2.6399, 5.9242, 1.0962,
+ 2.7346, 6.0865, 1.5555, 4.3303, 2.8229
+ ],
+ [
+ -0.6646, -0.6870, -0.1125, -0.2224, -0.3445,
+ -1.4049, 0.4990, -0.7037, -0.9924, 0.0386
+ ]],
+ dtype=dtype).cuda()
+ features_batch_cnt = torch.tensor([3, 3]).int().cuda()
+ indices_batch_cnt = torch.tensor([6, 6]).int().cuda()
+ output = grouping_operation(features, idx, features_batch_cnt,
+ indices_batch_cnt)
+ expected_output = torch.tensor(
+ [[[0.5798, 0.5798, 0.5798], [-0.7981, -0.7981, -0.7981],
+ [-0.9280, -0.9280, -0.9280], [-1.3311, -1.3311, -1.3311],
+ [1.3687, 1.3687, 1.3687], [0.9277, 0.9277, 0.9277],
+ [-0.4164, -0.4164, -0.4164], [-1.8274, -1.8274, -1.8274],
+ [0.9268, 0.9268, 0.9268], [0.8414, 0.8414, 0.8414]],
+ [[0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000],
+ [0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000],
+ [0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000],
+ [0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000],
+ [0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000]],
+ [[0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000],
+ [0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000],
+ [0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000],
+ [0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000],
+ [0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000]],
+ [[5.4247, 5.4247, 5.4247], [1.5113, 1.5113, 1.5113],
+ [2.3944, 2.3944, 2.3944], [1.4740, 1.4740, 1.4740],
+ [5.0300, 5.0300, 5.0300], [5.1030, 5.1030, 5.1030],
+ [1.9360, 1.9360, 1.9360], [2.1939, 2.1939, 2.1939],
+ [2.1581, 2.1581, 2.1581], [3.4666, 3.4666, 3.4666]],
+ [[0.5798, 0.5798, 0.5798], [-0.7981, -0.7981, -0.7981],
+ [-0.9280, -0.9280, -0.9280], [-1.3311, -1.3311, -1.3311],
+ [1.3687, 1.3687, 1.3687], [0.9277, 0.9277, 0.9277],
+ [-0.4164, -0.4164, -0.4164], [-1.8274, -1.8274, -1.8274],
+ [0.9268, 0.9268, 0.9268], [0.8414, 0.8414, 0.8414]],
+ [[-1.6266, -1.6266, -1.6266], [-1.0281, -1.0281, -1.0281],
+ [-1.0393, -1.0393, -1.0393], [-1.6931, -1.6931, -1.6931],
+ [-1.3982, -1.3982, -1.3982], [-0.5732, -0.5732, -0.5732],
+ [-1.0830, -1.0830, -1.0830], [-1.7561, -1.7561, -1.7561],
+ [-1.6786, -1.6786, -1.6786], [-1.6967, -1.6967, -1.6967]],
+ [[-0.0380, -0.0380, -0.0380], [-0.1880, -0.1880, -0.1880],
+ [-1.5724, -1.5724, -1.5724], [0.6905, 0.6905, 0.6905],
+ [-0.3190, -0.3190, -0.3190], [0.7798, 0.7798, 0.7798],
+ [-0.3693, -0.3693, -0.3693], [-0.9457, -0.9457, -0.9457],
+ [-0.2942, -0.2942, -0.2942], [-1.8527, -1.8527, -1.8527]],
+ [[0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000],
+ [0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000],
+ [0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000],
+ [0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000],
+ [0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000]],
+ [[0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000],
+ [0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000],
+ [0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000],
+ [0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000],
+ [0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000]],
+ [[-0.0380, -0.0380, -0.0380], [-0.1880, -0.1880, -0.1880],
+ [-1.5724, -1.5724, -1.5724], [0.6905, 0.6905, 0.6905],
+ [-0.3190, -0.3190, -0.3190], [0.7798, 0.7798, 0.7798],
+ [-0.3693, -0.3693, -0.3693], [-0.9457, -0.9457, -0.9457],
+ [-0.2942, -0.2942, -0.2942], [-1.8527, -1.8527, -1.8527]],
+ [[1.1773, 1.1773, 1.1773], [1.5009, 1.5009, 1.5009],
+ [2.6399, 2.6399, 2.6399], [5.9242, 5.9242, 5.9242],
+ [1.0962, 1.0962, 1.0962], [2.7346, 2.7346, 2.7346],
+ [6.0865, 6.0865, 6.0865], [1.5555, 1.5555, 1.5555],
+ [4.3303, 4.3303, 4.3303], [2.8229, 2.8229, 2.8229]],
+ [[-0.0380, -0.0380, -0.0380], [-0.1880, -0.1880, -0.1880],
+ [-1.5724, -1.5724, -1.5724], [0.6905, 0.6905, 0.6905],
+ [-0.3190, -0.3190, -0.3190], [0.7798, 0.7798, 0.7798],
+ [-0.3693, -0.3693, -0.3693], [-0.9457, -0.9457, -0.9457],
+ [-0.2942, -0.2942, -0.2942], [-1.8527, -1.8527, -1.8527]]],
+ dtype=dtype).cuda()
assert torch.allclose(output, expected_output)
diff --git a/tests/test_ops/test_iou3d.py b/tests/test_ops/test_iou3d.py
index 0fc855c42b..6bb8c1ccce 100644
--- a/tests/test_ops/test_iou3d.py
+++ b/tests/test_ops/test_iou3d.py
@@ -4,7 +4,7 @@
import torch
from mmcv.ops import boxes_iou3d, boxes_overlap_bev, nms3d, nms3d_normal
-from mmcv.utils import IS_CUDA_AVAILABLE
+from mmcv.utils import IS_CUDA_AVAILABLE, IS_MLU_AVAILABLE
@pytest.mark.parametrize('device', [
@@ -73,7 +73,11 @@ def test_boxes_iou3d(device):
pytest.param(
'cuda',
marks=pytest.mark.skipif(
- not IS_CUDA_AVAILABLE, reason='requires CUDA support'))
+ not IS_CUDA_AVAILABLE, reason='requires CUDA support')),
+ pytest.param(
+ 'mlu',
+ marks=pytest.mark.skipif(
+ not IS_MLU_AVAILABLE, reason='requires MLU support'))
])
def test_nms3d(device):
# test for 5 boxes
@@ -92,14 +96,20 @@ def test_nms3d(device):
assert np.allclose(inds.cpu().numpy(), np_inds)
# test for many boxes
- np.random.seed(42)
- np_boxes = np.random.rand(555, 7).astype(np.float32)
- np_scores = np.random.rand(555).astype(np.float32)
- boxes = torch.from_numpy(np_boxes)
- scores = torch.from_numpy(np_scores)
- inds = nms3d(boxes.to(device), scores.to(device), iou_threshold=0.3)
-
- assert len(inds.cpu().numpy()) == 176
+ # In the float data type calculation process, float will be converted to
+ # double in CUDA kernel (https://github.com/open-mmlab/mmcv/blob
+ # /master/mmcv/ops/csrc/common/box_iou_rotated_utils.hpp#L61),
+ # always use float in MLU kernel. The difference between the mentioned
+ # above leads to different results.
+ if device != 'mlu':
+ np.random.seed(42)
+ np_boxes = np.random.rand(555, 7).astype(np.float32)
+ np_scores = np.random.rand(555).astype(np.float32)
+ boxes = torch.from_numpy(np_boxes)
+ scores = torch.from_numpy(np_scores)
+ inds = nms3d(boxes.to(device), scores.to(device), iou_threshold=0.3)
+
+ assert len(inds.cpu().numpy()) == 176
@pytest.mark.parametrize('device', [
diff --git a/tests/test_ops/test_ms_deformable_attn.py b/tests/test_ops/test_ms_deformable_attn.py
index 3ebbf6bdf5..94223a6420 100644
--- a/tests/test_ops/test_ms_deformable_attn.py
+++ b/tests/test_ops/test_ms_deformable_attn.py
@@ -5,6 +5,7 @@
from mmcv.ops.multi_scale_deform_attn import (
MultiScaleDeformableAttention, MultiScaleDeformableAttnFunction,
multi_scale_deformable_attn_pytorch)
+from mmcv.utils import IS_CUDA_AVAILABLE, IS_MLU_AVAILABLE
_USING_PARROTS = True
try:
@@ -14,22 +15,25 @@
_USING_PARROTS = False
-@pytest.mark.parametrize('device_type', [
+@pytest.mark.parametrize('device', [
'cpu',
pytest.param(
'cuda:0',
marks=pytest.mark.skipif(
- not torch.cuda.is_available(), reason='requires CUDA support'))
+ not IS_CUDA_AVAILABLE, reason='requires CUDA support')),
+ pytest.param(
+ 'mlu',
+ marks=pytest.mark.skipif(
+ not IS_MLU_AVAILABLE, reason='requires MLU support'))
])
-def test_multiscale_deformable_attention(device_type):
-
+def test_multiscale_deformable_attention(device):
with pytest.raises(ValueError):
# embed_dims must be divisible by num_heads,
MultiScaleDeformableAttention(
embed_dims=256,
num_heads=7,
)
- device = torch.device(device_type)
+ device = torch.device(device)
msda = MultiScaleDeformableAttention(
embed_dims=3, num_levels=2, num_heads=3)
msda.init_weights()
@@ -70,20 +74,19 @@ def test_forward_multi_scale_deformable_attn_pytorch():
attention_weights.double()).detach()
-@pytest.mark.skipif(
- not torch.cuda.is_available(), reason='requires CUDA support')
+@pytest.mark.skipif(not IS_CUDA_AVAILABLE, reason='requires CUDA support')
def test_forward_equal_with_pytorch_double():
N, M, D = 1, 2, 2
Lq, L, P = 2, 2, 2
- shapes = torch.as_tensor([(6, 4), (3, 2)], dtype=torch.long).cuda()
+ shapes = torch.as_tensor([(6, 4), (3, 2)], dtype=torch.long)
level_start_index = torch.cat((shapes.new_zeros(
(1, )), shapes.prod(1).cumsum(0)[:-1]))
S = sum((H * W).item() for H, W in shapes)
torch.manual_seed(3)
- value = torch.rand(N, S, M, D).cuda() * 0.01
- sampling_locations = torch.rand(N, Lq, M, L, P, 2).cuda()
- attention_weights = torch.rand(N, Lq, M, L, P).cuda() + 1e-5
+ value = torch.rand(N, S, M, D) * 0.01
+ sampling_locations = torch.rand(N, Lq, M, L, P, 2)
+ attention_weights = torch.rand(N, Lq, M, L, P) + 1e-5
attention_weights /= attention_weights.sum(
-1, keepdim=True).sum(
-2, keepdim=True)
@@ -93,8 +96,9 @@ def test_forward_equal_with_pytorch_double():
attention_weights.double()).detach().cpu()
output_cuda = MultiScaleDeformableAttnFunction.apply(
- value.double(), shapes, level_start_index, sampling_locations.double(),
- attention_weights.double(), im2col_step).detach().cpu()
+ value.cuda().double(), shapes.cuda(), level_start_index.cuda(),
+ sampling_locations.cuda().double(),
+ attention_weights.cuda().double(), im2col_step).detach().cpu()
assert torch.allclose(output_cuda, output_pytorch)
max_abs_err = (output_cuda - output_pytorch).abs().max()
max_rel_err = ((output_cuda - output_pytorch).abs() /
@@ -103,20 +107,28 @@ def test_forward_equal_with_pytorch_double():
assert max_rel_err < 1e-15
-@pytest.mark.skipif(
- not torch.cuda.is_available(), reason='requires CUDA support')
-def test_forward_equal_with_pytorch_float():
+@pytest.mark.parametrize('device', [
+ pytest.param(
+ 'cuda',
+ marks=pytest.mark.skipif(
+ not IS_CUDA_AVAILABLE, reason='requires CUDA support')),
+ pytest.param(
+ 'mlu',
+ marks=pytest.mark.skipif(
+ not IS_MLU_AVAILABLE, reason='requires MLU support'))
+])
+def test_forward_equal_with_pytorch_float(device):
N, M, D = 1, 2, 2
Lq, L, P = 2, 2, 2
- shapes = torch.as_tensor([(6, 4), (3, 2)], dtype=torch.long).cuda()
+ shapes = torch.as_tensor([(6, 4), (3, 2)], dtype=torch.long)
level_start_index = torch.cat((shapes.new_zeros(
(1, )), shapes.prod(1).cumsum(0)[:-1]))
S = sum((H * W).item() for H, W in shapes)
torch.manual_seed(3)
- value = torch.rand(N, S, M, D).cuda() * 0.01
- sampling_locations = torch.rand(N, Lq, M, L, P, 2).cuda()
- attention_weights = torch.rand(N, Lq, M, L, P).cuda() + 1e-5
+ value = torch.rand(N, S, M, D) * 0.01
+ sampling_locations = torch.rand(N, Lq, M, L, P, 2)
+ attention_weights = torch.rand(N, Lq, M, L, P) + 1e-5
attention_weights /= attention_weights.sum(
-1, keepdim=True).sum(
-2, keepdim=True)
@@ -124,19 +136,37 @@ def test_forward_equal_with_pytorch_float():
output_pytorch = multi_scale_deformable_attn_pytorch(
value, shapes, sampling_locations, attention_weights).detach().cpu()
- output_cuda = MultiScaleDeformableAttnFunction.apply(
- value, shapes, level_start_index, sampling_locations,
- attention_weights, im2col_step).detach().cpu()
- assert torch.allclose(output_cuda, output_pytorch, rtol=1e-2, atol=1e-3)
- max_abs_err = (output_cuda - output_pytorch).abs().max()
- max_rel_err = ((output_cuda - output_pytorch).abs() /
+ output_device = MultiScaleDeformableAttnFunction.apply(
+ value.to(device), shapes.to(device), level_start_index.to(device),
+ sampling_locations.to(device), attention_weights.to(device),
+ im2col_step).detach().cpu()
+ assert torch.allclose(output_device, output_pytorch, rtol=1e-2, atol=1e-3)
+ max_abs_err = (output_device - output_pytorch).abs().max()
+ max_rel_err = ((output_device - output_pytorch).abs() /
output_pytorch.abs()).max()
assert max_abs_err < 1e-9
assert max_rel_err < 1e-6
-@pytest.mark.skipif(
- not torch.cuda.is_available(), reason='requires CUDA support')
+@pytest.mark.parametrize('device', [
+ pytest.param(
+ 'cuda',
+ marks=pytest.mark.skipif(
+ not IS_CUDA_AVAILABLE, reason='requires CUDA support')),
+ pytest.param(
+ 'mlu',
+ marks=pytest.mark.skipif(
+ not IS_MLU_AVAILABLE, reason='requires MLU support'))
+])
+@pytest.mark.parametrize('dtype', [
+ torch.float,
+ pytest.param(
+ torch.double,
+ marks=pytest.mark.skipif(
+ IS_MLU_AVAILABLE,
+ reason='MLU does not support for 64-bit floating point')),
+ torch.half
+])
@pytest.mark.parametrize('channels', [
4,
30,
@@ -146,20 +176,22 @@ def test_forward_equal_with_pytorch_float():
1025,
])
def test_gradient_numerical(channels,
+ device,
+ dtype,
grad_value=True,
grad_sampling_loc=True,
grad_attn_weight=True):
N, M, _ = 1, 2, 2
Lq, L, P = 2, 2, 2
- shapes = torch.as_tensor([(3, 2), (2, 1)], dtype=torch.long).cuda()
+ shapes = torch.as_tensor([(3, 2), (2, 1)], dtype=torch.long).to(device)
level_start_index = torch.cat((shapes.new_zeros(
(1, )), shapes.prod(1).cumsum(0)[:-1]))
S = sum((H * W).item() for H, W in shapes)
- value = torch.rand(N, S, M, channels).cuda() * 0.01
- sampling_locations = torch.rand(N, Lq, M, L, P, 2).cuda()
- attention_weights = torch.rand(N, Lq, M, L, P).cuda() + 1e-5
+ value = torch.rand(N, S, M, channels).to(device) * 0.01
+ sampling_locations = torch.rand(N, Lq, M, L, P, 2).to(device)
+ attention_weights = torch.rand(N, Lq, M, L, P).to(device) + 1e-5
attention_weights /= attention_weights.sum(
-1, keepdim=True).sum(
-2, keepdim=True)
@@ -170,13 +202,23 @@ def test_gradient_numerical(channels,
value.requires_grad = grad_value
sampling_locations.requires_grad = grad_sampling_loc
attention_weights.requires_grad = grad_attn_weight
+ if device == 'cuda':
+ dtype = torch.double
+ eps = 1e-6
+ elif device == 'mlu':
+ dtype = torch.float
+ eps = 1e-4
if _USING_PARROTS:
assert gradcheck(
- func, (value.double(), shapes, level_start_index,
- sampling_locations.double(), attention_weights.double(),
+ func, (value.to(dtype), shapes, level_start_index,
+ sampling_locations.to(dtype), attention_weights.to(dtype),
im2col_step),
- no_grads=[shapes, level_start_index])
+ no_grads=[shapes, level_start_index],
+ eps=eps)
else:
- assert gradcheck(func, (value.double(), shapes, level_start_index,
- sampling_locations.double(),
- attention_weights.double(), im2col_step))
+ assert gradcheck(
+ func, (value.to(dtype), shapes, level_start_index,
+ sampling_locations.to(dtype), attention_weights.to(dtype),
+ im2col_step),
+ eps=eps,
+ atol=1e-2)
diff --git a/tests/test_ops/test_roiaware_pool3d.py b/tests/test_ops/test_roiaware_pool3d.py
index 5d043b00f5..2a9cbfd324 100644
--- a/tests/test_ops/test_roiaware_pool3d.py
+++ b/tests/test_ops/test_roiaware_pool3d.py
@@ -5,11 +5,27 @@
from mmcv.ops import (RoIAwarePool3d, points_in_boxes_all, points_in_boxes_cpu,
points_in_boxes_part)
-
-
-@pytest.mark.skipif(
- not torch.cuda.is_available(), reason='requires CUDA support')
-def test_RoIAwarePool3d():
+from mmcv.utils import IS_CUDA_AVAILABLE, IS_MLU_AVAILABLE
+
+
+@pytest.mark.parametrize('device', [
+ pytest.param(
+ 'cuda',
+ marks=pytest.mark.skipif(
+ not IS_CUDA_AVAILABLE, reason='requires CUDA support')),
+ pytest.param(
+ 'mlu',
+ marks=pytest.mark.skipif(
+ not IS_MLU_AVAILABLE, reason='requires MLU support'))
+])
+@pytest.mark.parametrize('dtype', [
+ torch.float, torch.half,
+ pytest.param(
+ torch.double,
+ marks=pytest.mark.skipif(
+ IS_MLU_AVAILABLE, reason='MLU does not support for double'))
+])
+def test_RoIAwarePool3d(device, dtype):
roiaware_pool3d_max = RoIAwarePool3d(
out_size=4, max_pts_per_voxel=128, mode='max')
roiaware_pool3d_avg = RoIAwarePool3d(
@@ -17,27 +33,27 @@ def test_RoIAwarePool3d():
rois = torch.tensor(
[[1.0, 2.0, 3.0, 5.0, 4.0, 6.0, -0.3 - np.pi / 2],
[-10.0, 23.0, 16.0, 20.0, 10.0, 20.0, -0.5 - np.pi / 2]],
- dtype=torch.float32).cuda(
- ) # boxes (m, 7) with bottom center in lidar coordinate
+ dtype=dtype).to(device)
+ # boxes (m, 7) with bottom center in lidar coordinate
pts = torch.tensor(
[[1, 2, 3.3], [1.2, 2.5, 3.0], [0.8, 2.1, 3.5], [1.6, 2.6, 3.6],
[0.8, 1.2, 3.9], [-9.2, 21.0, 18.2], [3.8, 7.9, 6.3],
[4.7, 3.5, -12.2], [3.8, 7.6, -2], [-10.6, -12.9, -20], [-16, -18, 9],
[-21.3, -52, -5], [0, 0, 0], [6, 7, 8], [-2, -3, -4]],
- dtype=torch.float32).cuda() # points (n, 3) in lidar coordinate
+ dtype=dtype).to(device) # points (n, 3) in lidar coordinate
pts_feature = pts.clone()
pooled_features_max = roiaware_pool3d_max(
rois=rois, pts=pts, pts_feature=pts_feature)
assert pooled_features_max.shape == torch.Size([2, 4, 4, 4, 3])
assert torch.allclose(pooled_features_max.sum(),
- torch.tensor(51.100).cuda(), 1e-3)
+ torch.tensor(51.100, dtype=dtype).to(device), 1e-3)
pooled_features_avg = roiaware_pool3d_avg(
rois=rois, pts=pts, pts_feature=pts_feature)
assert pooled_features_avg.shape == torch.Size([2, 4, 4, 4, 3])
assert torch.allclose(pooled_features_avg.sum(),
- torch.tensor(49.750).cuda(), 1e-3)
+ torch.tensor(49.750, dtype=dtype).to(device), 1e-3)
@pytest.mark.skipif(
diff --git a/tests/test_ops/test_three_interpolate.py b/tests/test_ops/test_three_interpolate.py
index 900f451ff8..51a6b87327 100644
--- a/tests/test_ops/test_three_interpolate.py
+++ b/tests/test_ops/test_three_interpolate.py
@@ -7,19 +7,20 @@
@pytest.mark.skipif(
not torch.cuda.is_available(), reason='requires CUDA support')
-def test_three_interpolate():
- features = torch.tensor([[[2.4350, 4.7516, 4.4995, 2.4350, 2.4350, 2.4350],
- [3.1236, 2.6278, 3.0447, 3.1236, 3.1236, 3.1236],
- [2.6732, 2.8677, 2.6436, 2.6732, 2.6732, 2.6732],
- [0.0124, 7.0150, 7.0199, 0.0124, 0.0124, 0.0124],
- [0.3207, 0.0000, 0.3411, 0.3207, 0.3207,
- 0.3207]],
- [[0.0000, 0.9544, 2.4532, 0.0000, 0.0000, 0.0000],
- [0.5346, 1.9176, 1.4715, 0.5346, 0.5346, 0.5346],
- [0.0000, 0.2744, 2.0842, 0.0000, 0.0000, 0.0000],
- [0.3414, 1.5063, 1.6209, 0.3414, 0.3414, 0.3414],
- [0.5814, 0.0103, 0.0000, 0.5814, 0.5814,
- 0.5814]]]).cuda()
+@pytest.mark.parametrize('dtype', [torch.half, torch.float, torch.double])
+def test_three_interpolate(dtype):
+ features = torch.tensor(
+ [[[2.4350, 4.7516, 4.4995, 2.4350, 2.4350, 2.4350],
+ [3.1236, 2.6278, 3.0447, 3.1236, 3.1236, 3.1236],
+ [2.6732, 2.8677, 2.6436, 2.6732, 2.6732, 2.6732],
+ [0.0124, 7.0150, 7.0199, 0.0124, 0.0124, 0.0124],
+ [0.3207, 0.0000, 0.3411, 0.3207, 0.3207, 0.3207]],
+ [[0.0000, 0.9544, 2.4532, 0.0000, 0.0000, 0.0000],
+ [0.5346, 1.9176, 1.4715, 0.5346, 0.5346, 0.5346],
+ [0.0000, 0.2744, 2.0842, 0.0000, 0.0000, 0.0000],
+ [0.3414, 1.5063, 1.6209, 0.3414, 0.3414, 0.3414],
+ [0.5814, 0.0103, 0.0000, 0.5814, 0.5814, 0.5814]]],
+ dtype=dtype).cuda()
idx = torch.tensor([[[0, 1, 2], [2, 3, 4], [2, 3, 4], [0, 1, 2], [0, 1, 2],
[0, 1, 3]],
@@ -37,7 +38,8 @@ def test_three_interpolate():
[1.0000e+00, 1.7148e-08, 1.4070e-08],
[3.3333e-01, 3.3333e-01, 3.3333e-01],
[3.3333e-01, 3.3333e-01, 3.3333e-01],
- [3.3333e-01, 3.3333e-01, 3.3333e-01]]]).cuda()
+ [3.3333e-01, 3.3333e-01, 3.3333e-01]]],
+ dtype=dtype).cuda()
output = three_interpolate(features, idx, weight)
expected_output = torch.tensor([[[
@@ -70,6 +72,7 @@ def test_three_interpolate():
[
3.8760e-01, 1.0300e-02, 8.3569e-09,
3.8760e-01, 3.8760e-01, 1.9723e-01
- ]]]).cuda()
+ ]]],
+ dtype=dtype).cuda()
- assert torch.allclose(output, expected_output, 1e-4)
+ assert torch.allclose(output, expected_output, 1e-3, 1e-4)
diff --git a/tests/test_ops/test_three_nn.py b/tests/test_ops/test_three_nn.py
index 136a757d53..456188b917 100644
--- a/tests/test_ops/test_three_nn.py
+++ b/tests/test_ops/test_three_nn.py
@@ -5,6 +5,40 @@
from mmcv.ops import three_nn
from mmcv.utils import IS_CUDA_AVAILABLE, IS_MLU_AVAILABLE
+known = [[[-1.8373, 3.5605, -0.7867], [0.7615, 2.9420, 0.2314],
+ [-0.6503, 3.6637, -1.0622], [-1.8373, 3.5605, -0.7867],
+ [-1.8373, 3.5605, -0.7867]],
+ [[-1.3399, 1.9991, -0.3698], [-0.0799, 0.9698, -0.8457],
+ [0.0858, 2.4721, -0.1928], [-1.3399, 1.9991, -0.3698],
+ [-1.3399, 1.9991, -0.3698]]]
+
+unknown = [[[-1.8373, 3.5605, -0.7867], [0.7615, 2.9420, 0.2314],
+ [-0.6503, 3.6637, -1.0622], [-1.5237, 2.3976, -0.8097],
+ [-0.0722, 3.4017, -0.2880], [0.5198, 3.0661, -0.4605],
+ [-2.0185, 3.5019, -0.3236], [0.5098, 3.1020, 0.5799],
+ [-1.6137, 3.8443, -0.5269], [0.7341, 2.9626, -0.3189]],
+ [[-1.3399, 1.9991, -0.3698], [-0.0799, 0.9698, -0.8457],
+ [0.0858, 2.4721, -0.1928], [-0.9022, 1.6560, -1.3090],
+ [0.1156, 1.6901, -0.4366], [-0.6477, 2.3576, -0.1563],
+ [-0.8482, 1.1466, -1.2704], [-0.8753, 2.0845, -0.3460],
+ [-0.5621, 1.4233, -1.2858], [-0.5883, 1.3114, -1.2899]]]
+
+expected_dist = [[[0.0000, 0.0000, 0.0000], [0.0000, 2.0463, 2.8588],
+ [0.0000, 1.2229, 1.2229], [1.2047, 1.2047, 1.2047],
+ [1.0011, 1.0845, 1.8411], [0.7433, 1.4451, 2.4304],
+ [0.5007, 0.5007, 0.5007], [0.4587, 2.0875, 2.7544],
+ [0.4450, 0.4450, 0.4450], [0.5514, 1.7206, 2.6811]],
+ [[0.0000, 0.0000, 0.0000], [0.0000, 1.6464, 1.6952],
+ [0.0000, 1.5125, 1.5125], [1.0915, 1.0915, 1.0915],
+ [0.8197, 0.8511, 1.4894], [0.7433, 0.8082, 0.8082],
+ [0.8955, 1.3340, 1.3340], [0.4730, 0.4730, 0.4730],
+ [0.7949, 1.3325, 1.3325], [0.7566, 1.3727, 1.3727]]]
+
+expected_idx = [[[0, 3, 4], [1, 2, 0], [2, 0, 3], [0, 3, 4], [2, 1, 0],
+ [1, 2, 0], [0, 3, 4], [1, 2, 0], [0, 3, 4], [1, 2, 0]],
+ [[0, 3, 4], [1, 2, 0], [2, 0, 3], [0, 3, 4], [2, 1, 0],
+ [2, 0, 3], [1, 0, 3], [0, 3, 4], [1, 0, 3], [1, 0, 3]]]
+
@pytest.mark.parametrize('device', [
pytest.param(
@@ -16,48 +50,16 @@
marks=pytest.mark.skipif(
not IS_MLU_AVAILABLE, reason='requires MLU support'))
])
-def test_three_nn(device):
- known = torch.tensor(
- [[[-1.8373, 3.5605, -0.7867], [0.7615, 2.9420, 0.2314],
- [-0.6503, 3.6637, -1.0622], [-1.8373, 3.5605, -0.7867],
- [-1.8373, 3.5605, -0.7867]],
- [[-1.3399, 1.9991, -0.3698], [-0.0799, 0.9698, -0.8457],
- [0.0858, 2.4721, -0.1928], [-1.3399, 1.9991, -0.3698],
- [-1.3399, 1.9991, -0.3698]]],
- device=device)
-
- unknown = torch.tensor(
- [[[-1.8373, 3.5605, -0.7867], [0.7615, 2.9420, 0.2314],
- [-0.6503, 3.6637, -1.0622], [-1.5237, 2.3976, -0.8097],
- [-0.0722, 3.4017, -0.2880], [0.5198, 3.0661, -0.4605],
- [-2.0185, 3.5019, -0.3236], [0.5098, 3.1020, 0.5799],
- [-1.6137, 3.8443, -0.5269], [0.7341, 2.9626, -0.3189]],
- [[-1.3399, 1.9991, -0.3698], [-0.0799, 0.9698, -0.8457],
- [0.0858, 2.4721, -0.1928], [-0.9022, 1.6560, -1.3090],
- [0.1156, 1.6901, -0.4366], [-0.6477, 2.3576, -0.1563],
- [-0.8482, 1.1466, -1.2704], [-0.8753, 2.0845, -0.3460],
- [-0.5621, 1.4233, -1.2858], [-0.5883, 1.3114, -1.2899]]],
- device=device)
-
- dist, idx = three_nn(unknown, known)
- expected_dist = torch.tensor(
- [[[0.0000, 0.0000, 0.0000], [0.0000, 2.0463, 2.8588],
- [0.0000, 1.2229, 1.2229], [1.2047, 1.2047, 1.2047],
- [1.0011, 1.0845, 1.8411], [0.7433, 1.4451, 2.4304],
- [0.5007, 0.5007, 0.5007], [0.4587, 2.0875, 2.7544],
- [0.4450, 0.4450, 0.4450], [0.5514, 1.7206, 2.6811]],
- [[0.0000, 0.0000, 0.0000], [0.0000, 1.6464, 1.6952],
- [0.0000, 1.5125, 1.5125], [1.0915, 1.0915, 1.0915],
- [0.8197, 0.8511, 1.4894], [0.7433, 0.8082, 0.8082],
- [0.8955, 1.3340, 1.3340], [0.4730, 0.4730, 0.4730],
- [0.7949, 1.3325, 1.3325], [0.7566, 1.3727, 1.3727]]],
- device=device)
- expected_idx = torch.tensor(
- [[[0, 3, 4], [1, 2, 0], [2, 0, 3], [0, 3, 4], [2, 1, 0], [1, 2, 0],
- [0, 3, 4], [1, 2, 0], [0, 3, 4], [1, 2, 0]],
- [[0, 3, 4], [1, 2, 0], [2, 0, 3], [0, 3, 4], [2, 1, 0], [2, 0, 3],
- [1, 0, 3], [0, 3, 4], [1, 0, 3], [1, 0, 3]]],
- device=device)
-
- assert torch.allclose(dist, expected_dist, atol=1e-4)
- assert torch.all(idx == expected_idx)
+@pytest.mark.parametrize('dtype,rtol', [(torch.float, 1e-8),
+ (torch.half, 1e-3)])
+def test_three_nn(device, dtype, rtol):
+ dtype = torch.float
+ known_t = torch.tensor(known, dtype=dtype, device=device)
+ unknown_t = torch.tensor(unknown, dtype=dtype, device=device)
+
+ dist_t, idx_t = three_nn(unknown_t, known_t)
+ expected_dist_t = torch.tensor(expected_dist, dtype=dtype, device=device)
+ expected_idx_t = torch.tensor(expected_idx, device=device)
+
+ assert torch.allclose(dist_t, expected_dist_t, atol=1e-4, rtol=rtol)
+ assert torch.all(idx_t == expected_idx_t)