|
| 1 | +>"Pay attention to what you hear; the measure you give will be the measure you get, and still more will be given you. For to those who have, more will be given; and from those who have nothing, even what they have will be taken away."(MARK 4:24-25) |
| 2 | +
|
| 3 | +#模板转义 |
| 4 | + |
| 5 | +列位看官曾记否?在[《玩转字符串(1)》](https://github.com/qiwsir/ITArticles/blob/master/BasicPython/107.md)中,有专门讲到了有关“转义”问题,就是在python的字符串中,有的符号要想表达其本意,需要在前面加上`\`符号,例如单引号,如果要在字符串中表现它,必须写成`\'单引号里面\'`样式,才能实现一对单引号以及里面的内容,否则,它就表示字符串了。 |
| 6 | + |
| 7 | +在HTML代码中,也有类似的问题,比如`>`等,就是代码的一部分,如果直接写,就不会显示在网页里,要向显示,同样需要转义。另外,如果在网页中有表单,总会有别有用心的人向表单中写点包含`>`等字符的东西,目的就是要攻击你的网站,为了防治邪恶之辈,也需要将用户输入的字符进行转义,转化为字符实体,让它不具有HTML代码的含义。 |
| 8 | + |
| 9 | +>转义字符串(Escape Sequence)也称字符实体(Character Entity)。在HTML中,定义转义字符串的原因有两个:第一个原因是像“<”和“>”这类符号已经用来表示HTML标签,因此就不能直接当作文本中的符号来使用。为了在HTML文档中使用这些符号,就需要定义它的转义字符串。当解释程序遇到这类字符串时就把它解释为真实的字符。在输入转义字符串时,要严格遵守字母大小写的规则。第二个原因是,有些字符在ASCII字符集中没有定义,因此需要使用转义字符串来表示。 |
| 10 | +
|
| 11 | +##模板自动转义 |
| 12 | + |
| 13 | +Tornado 2 开始的模板具有自动转义的功能,这让开发者省却了不少事情。看一个例子。就利用上一讲中建立的开发框架。要在首页模板中增加一个表单提交功能。 |
| 14 | + |
| 15 | +修改template/index.html文件,内容如下: |
| 16 | + |
| 17 | + <DOCTYPE html> |
| 18 | + <html> |
| 19 | + <head> |
| 20 | + <title>Loop in template</title> |
| 21 | + <link rel="stylesheet" type="text/css" href="{{ static_url('css/style.css')}}"> |
| 22 | + </head> |
| 23 | + <body> |
| 24 | + <h1>aaaAAA</h1> |
| 25 | + <p>There is a list, it is <b>{{info}}</b></p> |
| 26 | + <p>I will print the elements of this list in order.</p> |
| 27 | + {% for element in info %} |
| 28 | + <p>{{element}}</p> |
| 29 | + {% end %} |
| 30 | + <br> |
| 31 | + {% for index,element in enumerate(info) %} |
| 32 | + <p>info[{{index}}] is {{element}} |
| 33 | + {% if element == "python" %} |
| 34 | + <p> <b>I love this language--{{element}}</b></p> |
| 35 | + {% end %} |
| 36 | + {% end %} |
| 37 | + |
| 38 | + {% if "[email protected]" in info %} |
| 39 | + <p><b>A Ha, this the python lesson of LaoQi, It is good! His email is {{info[2]}}</b></p> |
| 40 | + {% end %} |
| 41 | + <h2>Next, I set "python-tornado"(a string) to a variable(var)</h2> |
| 42 | + {% set var="python-tornado" %} |
| 43 | + <p>Would you like {{var}}?</p> |
| 44 | + <!--增加表单--> |
| 45 | + <form method="post" action="/option"> |
| 46 | + <p>WebSite:<input id="website" name="website" type="text"></p> |
| 47 | + <p><input type="submit" value="ok,submit"></p> |
| 48 | + </form> |
| 49 | + </body> |
| 50 | + </html> |
| 51 | + |
| 52 | +在增加的表单中,要将内容以`post`方法提交到`"/option"`,所以,要在url.py中设置路径,并且要建立相应的类。 |
| 53 | + |
| 54 | +然后就在handler目录中建立一个新的文件,命名为optform.py,其内容就是一个类,用来接收index.html中`post`过来的表单内容。 |
| 55 | + |
| 56 | + #!/usr/bin/env python |
| 57 | + #coding:utf-8 |
| 58 | + |
| 59 | + import tornado.web |
| 60 | + |
| 61 | + import sys |
| 62 | + reload(sys) |
| 63 | + sys.setdefaultencoding('utf-8') |
| 64 | + |
| 65 | + class OptionForm(tornado.web.RequestHandler): |
| 66 | + def post(self): |
| 67 | + website = self.get_argument("website") #接收名称为'website'的表单内容 |
| 68 | + self.render("info.html",web=website) |
| 69 | + |
| 70 | +为了达到接收表单post到上述类中内容的目的,还需要对url.py进行如下改写: |
| 71 | + |
| 72 | + #!/usr/bin/env python |
| 73 | + #coding:utf-8 |
| 74 | + |
| 75 | + import sys |
| 76 | + reload(sys) |
| 77 | + sys.setdefaultencoding('utf-8') |
| 78 | + |
| 79 | + from handler.index import IndexHandler |
| 80 | + from handler.optform import OptionForm |
| 81 | + url=[ |
| 82 | + (r'/', IndexHandler), |
| 83 | + (r'/option', OptionForm), |
| 84 | + |
| 85 | + ] |
| 86 | + |
| 87 | +看官还要注意,我在新建立的optform.py中,当接收到来自表单内容之后,就用另外一个模板`info.html`显示所接收到的内容。这个文件放在template目录中,代码是: |
| 88 | + |
| 89 | + <DOCTYPE html> |
| 90 | + <html> |
| 91 | + <head> |
| 92 | + <title>Loop in template</title> |
| 93 | + <link rel="stylesheet" type="text/css" href="{{ static_url('css/style.css')}}"> |
| 94 | + </head> |
| 95 | + <body> |
| 96 | + <h1>My Website is:</h1> |
| 97 | + <p>{{web}}</p> |
| 98 | + </body> |
| 99 | + </html> |
| 100 | + |
| 101 | +这样我们就完成表单内容的提交和显示过程。 |
| 102 | + |
| 103 | +从上面的流程中,看官是否体验到这个框架的优势了?不用重复敲代码,只需要在框架内的不同地方增加内容,即可完成网站。 |
| 104 | + |
| 105 | +演示运行效果: |
| 106 | + |
| 107 | +我在表单中输入了`<script>alert('bad script')</script>`,这是多么阴险毒辣呀。 |
| 108 | + |
| 109 | +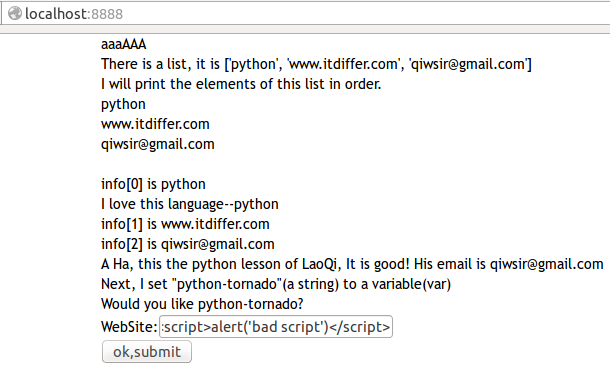 |
| 110 | + |
| 111 | +然而我们的tornado是不惧怕这种攻击的,因为它的模板自动转义了。当点击按钮提交内容的时候,就将那些阴险的符号实体化,成为转义之后的符号了。于是就这样了: |
| 112 | + |
| 113 | +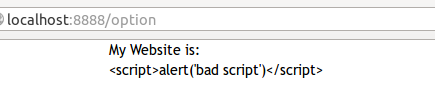 |
| 114 | + |
| 115 | +输入什么,就显示什么,不会因为输入的内容含有阴险毒辣的符号而网站无法正常工作。这就是转义的功劳。 |
| 116 | + |
| 117 | +##不转义的办法 |
| 118 | + |
| 119 | +在tornado中,模板实现了自动转义,省却了开发者很多事,但是,事情往往没有十全十美的,这里省事了,一定要在别的地方费事。例如在上面那个info.html文件中,我打算在里面加入我的电子信箱,但是要像下面代码这样,设置一个变量,主要是为了以后修改方便和在其它地方也可以随意使用。 |
| 120 | + |
| 121 | + <DOCTYPE html> |
| 122 | + <html> |
| 123 | + ...(省略) |
| 124 | + <body> |
| 125 | + <h1>My Website is:</h1> |
| 126 | + <p>{{web}}</p> |
| 127 | + {% set email="<a href='mailto:[email protected]'>Connect to me</a>"%} |
| 128 | + <p>{{email}}</p> |
| 129 | + </body> |
| 130 | + </html> |
| 131 | + |
| 132 | +本来希望在页面中出现的是`Connect to me`,点击它之后,就直接连接到发送电子邮件。结果,由于转义,出现的是下面的显示结果: |
| 133 | + |
| 134 | +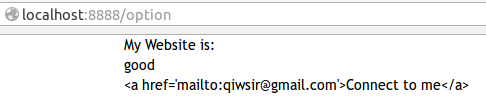 |
| 135 | + |
| 136 | +实现电子邮件超链接未遂。 |
| 137 | + |
| 138 | +这时候,就需要不让模板转义。tornado提供的方法是: |
| 139 | + |
| 140 | +- 在Application函数实例化的时候,设置参数:autoescape=None。这种方法不推荐适应,因为这样就让全站模板都不转意了,看官愿意尝试,不妨进行修改试一试,我这里就不展示了。 |
| 141 | +- 在每个页面中设置{% autoescape None %},表示这个页面不转义。也不推荐。理由,自己琢磨。 |
| 142 | +- 以上都不推荐,我推荐的是:{% raw email %},想让哪里不转义,就在那里用这种方式,比如要在email超级链接那里不转移,就写成这样好了。于是修改上面的代码,看结果为: |
| 143 | + |
| 144 | +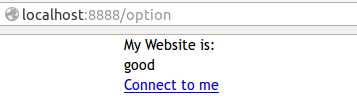 |
| 145 | + |
| 146 | +如此,实现了不转义。 |
| 147 | + |
| 148 | +以上都实现了模板的转义和不转义。 |
| 149 | + |
| 150 | +##url转义 |
| 151 | + |
| 152 | +本来模板转义和不转义问题已经交代清楚了。怎奈上周六一个朋友问了一个问题,那个问题涉及到url转义问题,于是在这里再补上一段,专门谈谈url转义的问题。 |
| 153 | + |
| 154 | +有些符号在URL中是不能直接传递的,如果要在URL中传递这些特殊符号,那么就要使用它们的编码了。编码的格式为:%加字符的ASCII码,即一个百分号%,后面跟对应字符的ASCII(16进制)码值。例如 空格的编码值是"%20"。 |
| 155 | + |
| 156 | +在python中,如果用utf-8写了一段地址,如何转义成url能够接收的字符呢? |
| 157 | + |
| 158 | +在python中有一个urllib模块: |
| 159 | + |
| 160 | + >>> import urllib |
| 161 | + |
| 162 | + >>> #假设下面的url,是utf-8编码 |
| 163 | + >>> url_mail='http://www.itdiffer.com/[email protected]' |
| 164 | + |
| 165 | + >>> #转义为url能够接受的 |
| 166 | + >>> urllib.quote(url_mail) |
| 167 | + 'http%3A//www.itdiffer.com/email%3F%3Dqiwsir%40gmail.com' |
| 168 | + |
| 169 | +反过来,一个url也能转移为utf-8编码格式,请用urllib.unquote() |
| 170 | + |
| 171 | +下面抄录帮助文档中的内容,供用到的朋友参考: |
| 172 | + |
| 173 | + quote(s, safe='/') |
| 174 | + quote('abc def') -> 'abc%20def' |
| 175 | + |
| 176 | + Each part of a URL, e.g. the path info, the query, etc., has a |
| 177 | + different set of reserved characters that must be quoted. |
| 178 | + |
| 179 | + RFC 2396 Uniform Resource Identifiers (URI): Generic Syntax lists |
| 180 | + the following reserved characters. |
| 181 | + |
| 182 | + reserved = ";" | "/" | "?" | ":" | "@" | "&" | "=" | "+" | |
| 183 | + "$" | "," |
| 184 | + |
| 185 | + Each of these characters is reserved in some component of a URL, |
| 186 | + but not necessarily in all of them. |
| 187 | + |
| 188 | + By default, the quote function is intended for quoting the path |
| 189 | + section of a URL. Thus, it will not encode '/'. This character |
| 190 | + is reserved, but in typical usage the quote function is being |
| 191 | + called on a path where the existing slash characters are used as |
| 192 | + reserved characters. |
| 193 | + |
| 194 | + unquote(s) |
| 195 | + unquote('abc%20def') -> 'abc def'. |
| 196 | + |
| 197 | + quote_plus(s, safe='') |
| 198 | + Quote the query fragment of a URL; replacing ' ' with '+' |
| 199 | + |
| 200 | + unquote_plus(s) |
| 201 | + unquote('%7e/abc+def') -> '~/abc def' |
| 202 | + |
| 203 | +转义是网站开发中要特别注意的地方,不小心或者忘记了,就会纠结。 |
| 204 | + |
0 commit comments