JVM本身是介于JAVA编译器和操作系统之间的程序,这个程序提供了一个无视操作系统和硬件平台的运行环境

所有线程共享的数据区:
- 方法区: 存储已被虚拟机加载的类信息、静态变量、即时编译后代码等数据。并使用永久代来实现方法区,1.8后被元空间替代,元空间并不在虚拟机中,而是使用本地内存,要画到上图那就是图外了。
- 堆区: 我们常说用于存放对象的区域,1.7之后字符串常量池移到这里。
每个线程私有的数据区:
- 虚拟机栈: 方法执行时创建一个栈帧,用于存储局部变量、操作数栈、动态链接、方法出口等信息。每个方法一个栈帧,互不干扰。
- 本地方法栈: 用于存放执行native方法的运行数据。
- 程序计数器: 当前线程所执行的字节码的指示器,通过改变计数器来选取下一条需要执行的字节码指令。
直接内存:
- 直接内存并非Java标准。
- JDK1.4 加入了新的 NIO 机制,目的是防止 Java 堆 和 Native 堆之间往复的数据复制带来的性能损耗,此后 NIO 可以使用 Native 的方式直接在 Native 堆分配内存。
- 直接内存区域是全局共享的内存区域。
new、静态字段或方法被使用、反射、父类、main函数调用
- 加载(获取字节流并转换成运行时数据结构,然后生成Class对象)
- 验证(验证字节流信息符合当前虚拟机的要求)
- 准备(为类变量分配内存并设置初始值)
- 解析(将常量池的符号引用替换为直接引用)
- 初始化(执行类构造器-类变量赋值和静态块的过程)

优先选择在新生代的Eden区被分配。
- 大对象,-XX:PretenureSizeThreshold 大于这个参数的对象直接在老年代分配,来避免新生代GC以及分配担保机制和Eden与Survivor之间的复制
- 经过第一次Minor GC仍然存在,能被Survivor容纳,就会被移动到Survivor中,此时年龄为1,当年龄大于预设值就进入老年代
- 如果Survivor中相同年龄所有对象大小的总和大于Survivor空间的一半,年龄大于等于该年龄的对象进入老年代
- 如果Survivor空间无法容纳新生代中Minor GC之后还存活的对象
不可达对象:通过一系列的GC Roots的对象作为起点,从这些节点开始向下搜索,搜索所走过的路径称为引用链,当一个对象到GC Roots没有任何引用链相连时则此对象是不可用的。
GC Roots包括:虚拟机栈中引用的对象、方法区中类静态属性引用的对象、方法区中常量引用的对象、本地方法栈中JNI(Native方法)引用的对象。
彻底死亡条件:
条件1:通过GC Roots作为起点的向下搜索形成引用链,没有搜到该对象,这是第一次标记。
条件2:在finalize方法中没有逃脱回收(将自身被其他对象引用),这是第一次标记的清理。
新生代因为每次GC都有大批对象死去,只需要付出少量存活对象的复制成本且无碎片所以使用“复制算法”
老年代因为存活率高、没有分配担保空间,所以使用“标记-清理”或者“标记-整理”算法
复制算法:将可用内存按容量划分为Eden、from survivor、to survivor,分配的时候使用Eden和一个survivor,Minor GC后将存活的对象复制到另一个survivor,然后将原来已使用的内存一次清理掉。这样没有内存碎片。
标记-清除:首先标记出所有需要回收的对象,标记完成后统一回收被标记的对象。会产生大量碎片,导致无法分配大对象从而导致频繁GC。
标记-整理:首先标记出所有需要回收的对象,让所有存活的对象向一端移动。
当Eden区空间不足以继续分配对象,发起Minor GC。
- 调用System.gc时,系统建议执行Full GC,但是不必然执行
- 老年代空间不足(通过Minor GC后进入老年代的大小大于老年代的可用内存)
- 方法区空间不足
Set中的对象不按特定方式排序,并且没有重复对象。但它的有些实现类能对集合中的对象按特定方式排序,例如TreeSet类,它可以按照默认排序,也可以通过实现java.util.Comparator接口来自定义排序方式。
List中的对象按照索引位置排序,可以有重复对象,允许按照对象在集合中的索引位置检索对象,如通过list.get(i)方式来获得List集合中的元素。
Map中的每一个元素包含一个键对象和值对象,它们成对出现。键对象不能重复,值对象可以重复。
- Hashtable中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。
- Hashtable中,key和value都不允许出现null值。HashMap中,null可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为null。
- 哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
- Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。
http://www.jasongj.com/java/concurrenthashmap/
HashTable 在每次同步执行时都要锁住整个结构。ConcurrentHashMap 锁的方式是稍微细粒度的。 ConcurrentHashMap 将 hash 表分为 16 个桶(默认值)

ConcurrentHashMap 类中包含两个静态内部类 HashEntry 和 Segment。HashEntry 用来封装映射表的键 / 值对;Segment 用来充当锁的角色,每个 Segment 对象守护整个散列映射表的若干个桶。每个桶是由若干个 HashEntry 对象链接起来的链表。一个 ConcurrentHashMap 实例中包含由若干个 Segment 对象组成的数组。

Java 8为进一步提高并发性,摒弃了分段锁的方案,而是直接使用一个大的数组。同时为了提高哈希碰撞下的寻址性能,Java 8在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为O(N))转换为红黑树(寻址时间复杂度为O(long(N))
Java 8的ConcurrentHashMap同样是通过Key的哈希值与数组长度取模确定该Key在数组中的索引。
对于put操作,如果Key对应的数组元素为null,则通过CAS操作将其设置为当前值。如果Key对应的数组元素(也即链表表头或者树的根元素)不为null,则对该元素使用synchronized关键字申请锁,然后进行操作。如果该put操作使得当前链表长度超过一定阈值,则将该链表转换为树,从而提高寻址效率。
新建 -- 就绪 -- 运行 -- 阻塞 -- 死亡
- 继承Thread类
- 实现Runnable接口
- 扩展一种:实现Callable接口。这个得和线程池结合
https://fangjian0423.github.io/2016/04/18/java-synchronize-way/
- 对经常查询的列建立索引,为了避免全表扫描,建多了当数据改变时修改索引浪费资源
- 建立主键,根据主键查询,关联查询使用主键关联外键
- 使用精确列名查询而不是*
- 减少嵌套查询
- 不用NOT IN,IS NULL,NOT IS NULL,无法使用索引
https://www.jianshu.com/p/4e3edbedb9a8
https://segmentfault.com/a/1190000012773157
https://www.jianshu.com/p/f5ff017db62a
工厂模式、生成器模式
桥接模式、适配器模式、外观模式、组合模式
策略模式、迭代器模式、访问者模式、观察者模式、命令模式、中介者模式、状态模式
Spring是个包含一系列功能的合集,如快速开发的Spring Boot,支持微服务的Spring Cloud,支持认证与鉴权的Spring Security,Web框架Spring MVC。IOC与AOP依然是核心。
控制反转:原来是自己主动去new一个对象去用,现在是由容器工具配置文件创建实例让自己用,以前是自己去找妹子亲近,现在是有中介帮你找妹子,让你去挑选,说白了就是用面向接口编程和配置文件减少对象间的耦合,同时解决硬编码的问题(XML)
依赖注入:在运行过程中当你需要这个对象才给你实例化并注入其中,不需要管什么时候注入的,只需要写好成员变量和set方法
面向切面的编程,是一种编程技术,是OOP(面向对象编程)的补充和完善。OOP的执行是一种从上往下的流程,并没有从左到右的关系。因此在OOP编程中,会有大量的重复代码。而AOP则是将这些与业务无关的重复代码抽取出来,然后再嵌入到业务代码当中。常见的应用有:权限管理、日志、事务管理等。
实现AOP的技术,主要分为两大类:一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行;二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码。Spring AOP实现用的是动态代理的方式。
jdk反射:通过反射机制生成代理类的字节码文件,调用具体方法前调用InvokeHandler来处理
cglib工具:利用asm开源包,对代理对象类的class文件加载进来,通过修改其字节码生成子类来处理
- 如果目标对象实现了接口,默认情况下会采用JDK的动态代理实现AOP
- 如果目标对象实现了接口,可以强制使用CGLIB实现AOP
- 如果目标对象没有实现了接口,必须采用CGLIB库,spring会自动在JDK动态代理和CGLIB之间转换
https://blog.csdn.net/qq_18425655/article/details/52163228

首先任意选取一个数据(通常选用数组的第一个数)作为关键数据,然后将所有比它小的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一趟快速排序。
不稳定,如果最小的值在最后面,那么在第一次排序就被放到第一位,后面有与该值相等的元素也不会交换。
最好情况:每次划分过程产生的区间大小都为n/2,一共需要划分log2n次,每次需要比较n-1次,O(nlog2n)
最坏情况:每次划分过程产生的两个区间分别包含n-1个元素和1个元素,一共需要划分n-1次,每次最多交换n-1次,这就是冒泡排序了,O(n2)
问题:比较耗CPU的任务摆在这里,程序也无法提升性能了,该怎么办?
- 先判断能否使用缓存,还是重新耗费CPU资源来创建一个
- 用偏重CPU性能的机器来做这个功能的专项负载均衡
- 请求太多的话,搞个消息队列排着,慢慢消费,同时前端提示需要一会才行
问题:数据库连接池就那么几个,但是有很多来拿怎么办?加个超时限制怎么加?
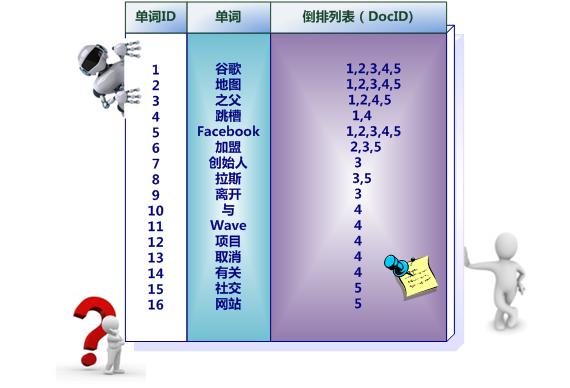
不是由记录来确定属性值,而是由属性值来确定记录的位置。
构建过程:分词 - Hash去重 - 根据单词生成索引表,同时得到“词典文件”(词-> 单词Id),最后得到“倒排索引文件”(单词Id -> 倒排列表)
词典文件

倒排索引文件
模拟登录之后将sessionId保存到request header的cookie中
- 买个支持ADSL的拨号服务器,便宜的一个月80,然后在上面搭建代理服务器,用爬虫连上去
- 自己探索不同网站的访问频率限制规则
- 寻找网站访问频率访问限制漏洞