# 浏览器与新技术
点击关注本[公众号](#公众号)获取文档最新更新,并可以领取配套于本指南的 **《前端面试手册》** 以及**最标准的简历模板**.
* [常见的浏览器内核有哪些?](#常见的浏览器内核有哪些?)
* [浏览器的主要组成部分是什么?](#浏览器的主要组成部分是什么?)
* [浏览器是如何渲染UI的?](#浏览器是如何渲染ui的?)
* [浏览器如何解析css选择器?](#浏览器如何解析css选择器?)
* [DOM Tree是如何构建的?](#dom-tree是如何构建的?)
* [浏览器重绘与重排的区别?](#浏览器重绘与重排的区别?)
* [如何触发重排和重绘?](#如何触发重排和重绘?)
* [如何避免重绘或者重排?](#如何避免重绘或者重排?)
* [前端如何实现即时通讯?](#前端如何实现即时通讯?)
* [什么是浏览器同源策略?](#什么是浏览器同源策略?)
* [如何实现跨域?](#如何实现跨域?)
本章关于浏览器原理部分的内容主要来源于[浏览器工作原理](http://taligarsiel.com/Projects/howbrowserswork1.htm),这是一篇很长的文章,可以算上一本小书了,有精力的非常建议阅读。
## 常见的浏览器内核有哪些?
| 浏览器/RunTime | 内核(渲染引擎) | JavaScript 引擎 |
| :---: | :---: | :---: |
| Chrome | Blink(28~)
Webkit(Chrome 27) | V8 |
| FireFox | Gecko | SpiderMonkey |
| Safari | Webkit | JavaScriptCore |
| Edge | EdgeHTML | Chakra(for JavaScript) |
| IE | Trident | Chakra(for JScript) |
| PhantomJS | Webkit | JavaScriptCore |
| Node.js | - | V8 |
## 浏览器的主要组成部分是什么?
1. **用户界面** - 包括地址栏、前进/后退按钮、书签菜单等。除了浏览器主窗口显示的您请求的页面外,其他显示的各个部分都属于用户界面。
2. **浏览器引擎** - 在用户界面和呈现引擎之间传送指令。
3. **呈现引擎** - 负责显示请求的内容。如果请求的内容是 HTML,它就负责解析 HTML 和 CSS 内容,并将解析后的内容显示在屏幕上。
4. **网络** - 用于网络调用,比如 HTTP 请求。其接口与平台无关,并为所有平台提供底层实现。
5. **用户界面后端** - 用于绘制基本的窗口小部件,比如组合框和窗口。其公开了与平台无关的通用接口,而在底层使用操作系统的用户界面方法。
6. **JavaScript 解释器**。用于解析和执行 JavaScript 代码。
7. **数据存储**。这是持久层。浏览器需要在硬盘上保存各种数据,例如 Cookie。新的 HTML 规范 (HTML5) 定义了“网络数据库”,这是一个完整(但是轻便)的浏览器内数据库。

> 图:浏览器的主要组件。
值得注意的是,和大多数浏览器不同,Chrome 浏览器的每个标签页都分别对应一个呈现引擎实例。每个标签页都是一个独立的进程。
## 浏览器是如何渲染UI的?
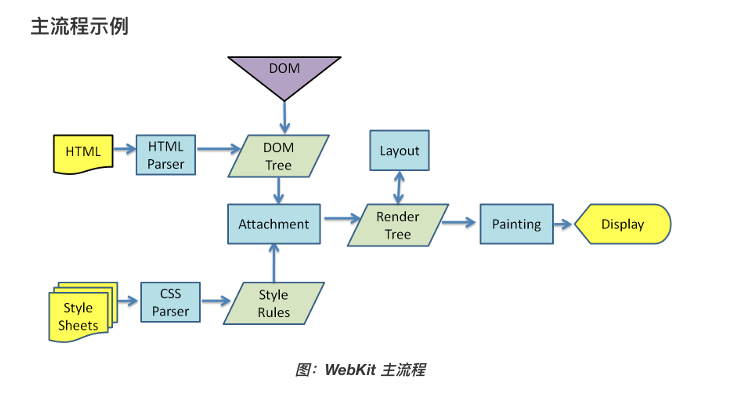
1. 浏览器获取HTML文件,然后对文件进行解析,形成DOM Tree
2. 与此同时,进行CSS解析,生成Style Rules
3. 接着将DOM Tree与Style Rules合成为 Render Tree
4. 接着进入布局(Layout)阶段,也就是为每个节点分配一个应出现在屏幕上的确切坐标
5. 随后调用GPU进行绘制(Paint),遍历Render Tree的节点,并将元素呈现出来
## 浏览器如何解析css选择器?
浏览器会『从右往左』解析CSS选择器。
我们知道DOM Tree与Style Rules合成为 Render Tree,实际上是需要将*Style Rules*附着到DOM Tree上,因此需要根据选择器提供的信息对DOM Tree进行遍历,才能将样式附着到对应的DOM元素上。
以下这段css为例
```css
.mod-nav h3 span {font-size: 16px;}
```
我们对应的DOM Tree 如下
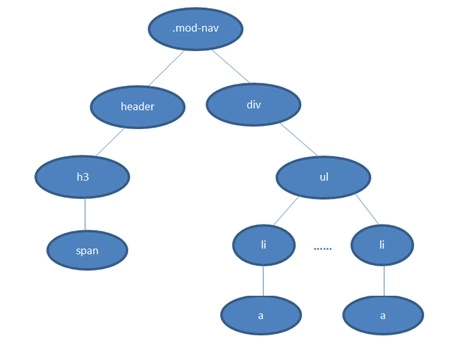
若从左向右的匹配,过程是:
1. 从 .mod-nav 开始,遍历子节点 header 和子节点 div
2. 然后各自向子节点遍历。在右侧 div 的分支中
3. 最后遍历到叶子节点 a ,发现不符合规则,需要回溯到 ul 节点,再遍历下一个 li-a,一颗DOM树的节点动不动上千,这种效率很低。
如果从右至左的匹配:
1. 先找到所有的最右节点 span,对于每一个 span,向上寻找节点 h3
2. 由 h3再向上寻找 class=mod-nav 的节点
3. 最后找到根元素 html 则结束这个分支的遍历。
后者匹配性能更好,是因为从右向左的匹配在第一步就筛选掉了大量的不符合条件的最右节点(叶子节点);而从左向右的匹配规则的性能都浪费在了失败的查找上面。
## DOM Tree是如何构建的?
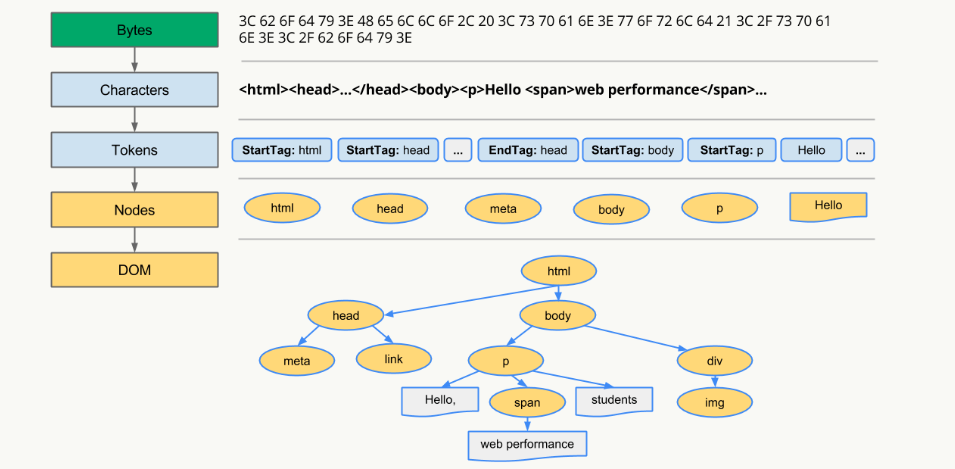
1. 转码: 浏览器将接收到的二进制数据按照指定编码格式转化为HTML字符串
2. 生成Tokens: 之后开始parser,浏览器会将HTML字符串解析成Tokens
3. 构建Nodes: 对Node添加特定的属性,通过指针确定 Node 的父、子、兄弟关系和所属 treeScope
4. 生成DOM Tree: 通过node包含的指针确定的关系构建出DOM
Tree
## 浏览器重绘与重排的区别?
* 重排: 部分渲染树(或者整个渲染树)需要重新分析并且节点尺寸需要重新计算,表现为重新生成布局,重新排列元素
* 重绘: 由于节点的几何属性发生改变或者由于样式发生改变,例如改变元素背景色时,屏幕上的部分内容需要更新,表现为某些元素的外观被改变
单单改变元素的外观,肯定不会引起网页重新生成布局,但当浏览器完成重排之后,将会重新绘制受到此次重排影响的部分
重排和重绘代价是高昂的,它们会破坏用户体验,并且让UI展示非常迟缓,而相比之下重排的性能影响更大,在两者无法避免的情况下,一般我们宁可选择代价更小的重绘。
『重绘』不一定会出现『重排』,『重排』必然会出现『重绘』。
## 如何触发重排和重绘?
任何改变用来构建渲染树的信息都会导致一次重排或重绘:
* 添加、删除、更新DOM节点
* 通过display: none隐藏一个DOM节点-触发重排和重绘
* 通过visibility: hidden隐藏一个DOM节点-只触发重绘,因为没有几何变化
* 移动或者给页面中的DOM节点添加动画
* 添加一个样式表,调整样式属性
* 用户行为,例如调整窗口大小,改变字号,或者滚动。
## 如何避免重绘或者重排?
### 集中改变样式
我们往往通过改变class的方式来集中改变样式
```js
// 判断是否是黑色系样式
const theme = isDark ? 'dark' : 'light'
// 根据判断来设置不同的class
ele.setAttribute('className', theme)
```
### 使用DocumentFragment
我们可以通过createDocumentFragment创建一个游离于DOM树之外的节点,然后在此节点上批量操作,最后插入DOM树中,因此只触发一次重排
```js
var fragment = document.createDocumentFragment();
for (let i = 0;i<10;i++){
let node = document.createElement("p");
node.innerHTML = i;
fragment.appendChild(node);
}
document.body.appendChild(fragment);
```
### 提升为合成层
将元素提升为合成层有以下优点:
* 合成层的位图,会交由 GPU 合成,比 CPU 处理要快
* 当需要 repaint 时,只需要 repaint 本身,不会影响到其他的层
* 对于 transform 和 opacity 效果,不会触发 layout 和 paint
提升合成层的最好方式是使用 CSS 的 will-change 属性:
```css
#target {
will-change: transform;
}
```
> 关于合成层的详解请移步[无线性能优化:Composite](http://taobaofed.org/blog/2016/04/25/performance-composite/)
## 前端如何实现即时通讯?
### 短轮询
短轮询的原理很简单,每隔一段时间客户端就发出一个请求,去获取服务器最新的数据,一定程度上模拟实现了即时通讯。
* 优点:兼容性强,实现非常简单
* 缺点:延迟性高,非常消耗请求资源,影响性能
### comet
comet有两种主要实现手段,一种是基于 AJAX 的长轮询(long-polling)方式,另一种是基于 Iframe 及 htmlfile 的流(streaming)方式,通常被叫做长连接。
> 具体两种手段的操作方法请移步[Comet技术详解:基于HTTP长连接的Web端实时通信技术](http://www.52im.net/thread-334-1-1.html)
长轮询优缺点:
* 优点:兼容性好,资源浪费较小
* 缺点:服务器hold连接会消耗资源,返回数据顺序无保证,难于管理维护
长连接优缺点:
* 优点:兼容性好,消息即时到达,不发无用请求
* 缺点:服务器维护长连接消耗资源
### SSE
> 使用指南请看[Server-Sent Events 教程](https://www.ruanyifeng.com/blog/2017/05/server-sent_events.html)
SSE(Server-Sent Event,服务端推送事件)是一种允许服务端向客户端推送新数据的HTML5技术。
* 优点:基于HTTP而生,因此不需要太多改造就能使用,使用方便,而websocket非常复杂,必须借助成熟的库或框架
* 缺点:基于文本传输效率没有websocket高,不是严格的双向通信,客户端向服务端发送请求无法复用之前的连接,需要重新发出独立的请求

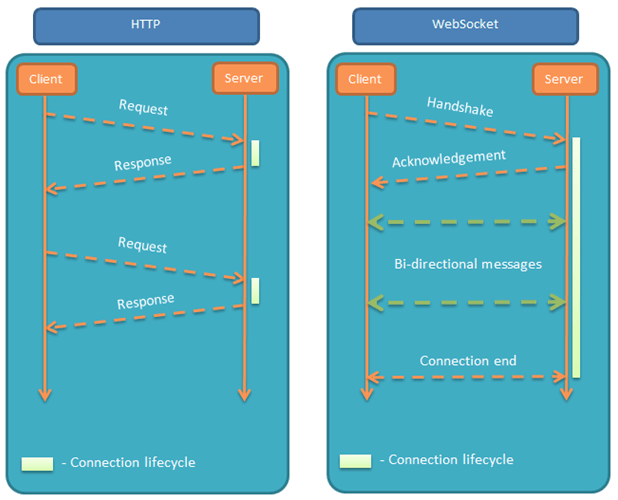
### Websocket
> 使用指南请看[WebSocket 教程](http://www.ruanyifeng.com/blog/2017/05/websocket.html)
Websocket是一个全新的、独立的协议,基于TCP协议,与http协议兼容、却不会融入http协议,仅仅作为html5的一部分,其作用就是在服务器和客户端之间建立实时的双向通信。
* 优点:真正意义上的实时双向通信,性能好,低延迟
* 缺点:独立与http的协议,因此需要额外的项目改造,使用复杂度高,必须引入成熟的库,无法兼容低版本浏览器
### Web Worker
> 后面性能优化部分会用到,先做了解
Web Worker 的作用,就是为 JavaScript 创造多线程环境,允许主线程创建 Worker 线程,将一些任务分配给后者运行
> [Web Worker教程](http://www.ruanyifeng.com/blog/2018/07/web-worker.html)
### Service workers
> 后面性能优化部分会用到,先做了解
Service workers 本质上充当Web应用程序与浏览器之间的代理服务器,也可以在网络可用时作为浏览器和网络间的代理,创建有效的离线体验。
> [Service workers教程](https://developer.mozilla.org/zh-CN/docs/Web/API/Service_Worker_API)
## 什么是浏览器同源策略?
同源策略限制了从同一个源加载的文档或脚本如何与来自另一个源的资源进行交互。这是一个用于隔离潜在恶意文件的重要安全机制。
同源是指"协议+域名+端口"三者相同,即便两个不同的域名指向同一个ip地址,也非同源。
下表给出了相对http://store.company.com/dir/page.html同源检测的示例:
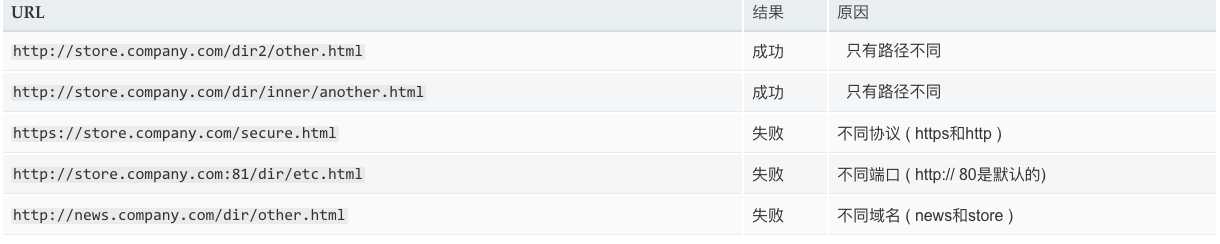
浏览器中的大部分内容都是受同源策略限制的,但是以下三个标签可以不受限制:
* ` `
* ``
* `
`
* ``
* `