# 前端性能优化-加载篇
点击关注本[公众号](#公众号)获取文档最新更新,并可以领取配套于本指南的 **《前端面试手册》** 以及**最标准的简历模板**.
## 前言
虽然前端开发作为 GUI 开发的一种,但是存在其特殊性,前端的特殊性就在于“动态”二字,传统 GUI 开发,不管是桌面应用还是移动端应用都是需要预先下载的,只有先下载应用程序才会在本地操作系统运行,而前端不同,它是“动态增量”式的,我们的前端应用往往是实时加载执行的,并不需要预先下载,这就造成了一个问题,前端开发中往往最影响性能的不是什么计算或者渲染,而是加载速度,加载速度会直接影响用户体验和网站留存。
[《Designing for Performance》](https://link.juejin.im/?target=http%3A%2F%2Fshop.oreilly.com%2Fproduct%2F0636920033578.do)的作者 [Lara Swanson](https://link.juejin.im/?target=http%3A%2F%2Fradar.oreilly.com%2Flswanson)在2014年写过一篇文章[《Web性能即用户体验》](https://link.juejin.im/?target=https%3A%2F%2Fwww.forbes.com%2Fforbes%2Fwelcome%2F%3FtoURL%3Dhttps%3A%2F%2Fwww.forbes.com%2Fsites%2Foreillymedia%2F2014%2F01%2F16%2Fweb-performance-is-user-experience%2F%26refURL%3D%26referrer%3D%23194909aa5a52),她在文中提到“网站页面的快速加载,能够建立用户对网站的信任,增加回访率,大部分的用户其实都期待页面能够在2秒内加载完成,而当超过3秒以后,[就会有接近40%的用户离开你的网站](https://link.juejin.im/?target=http%3A%2F%2Fwww.mcrinc.com%2FDocuments%2FNewsletters%2F201110_why_web_performance_matters.pdf)”。
值得一提的是,GUI 开发依然有一个共同的特殊之处,那就是 **体验性能** ,体验性能并不指在绝对性能上的性能优化,而是回归用户体验这个根本目的,因为在 GUI 开发的领域,绝大多数情况下追求绝对意义上的性能是没有意义的.
比如一个动画本来就已经有 60 帧了,你通过一个吊炸天的算法优化到了 120 帧,这对于你的 KPI 毫无用处,因为这个优化本身没有意义,因为除了少数特异功能的异人,没有人能分得清 60 帧和 120 帧的区别,这对于用户的体验没有任何提升,相反,一个首屏加载需要 4s 的网站,你没有任何实质意义上的性能优化,只是加了一个设计姐姐设计的 loading 图,那这也是十分有意义的优化,因为好的 loading 可以减少用户焦虑,让用户感觉没有等太久,这就是用户体验级的性能优化.
因此,我们要强调即使没有对性能有实质的优化,通过设计提高用户体验的这个过程,也算是性能优化,因为 GUI 开发直面用户,你让用户有了性能快的 **错觉**,这也叫性能优化了,毕竟用户觉得快,才是真的快...
## 首屏加载
首屏加载是被讨论最多的话题,一方面web 前端首屏的加载性能的确普遍较差,另一方面,首屏的加载速度至关重要,很多时候过长的白屏会导致用户还没有体验到网站功能的时候就流失了,首屏速度是用户留存的关键点。
以用户体验的角度来解读首屏的关键点,如果作为用户我们从输入网址之后的心里过程是怎样的呢?
当我们敲下回车后,我们第一个疑问是:
**"它在运行吗?"**
这个疑问一直到用户看到页面第一个绘制的元素为止,这个时候用户才能确定自己的请求是有效的(而不是被墙了...),然后第二个疑问:
**"它有用吗?"**
如果只绘制出无意义的各种乱序的元素,这对于用户是不可理解的,此时虽然页面开始加载了,但是对于用户没有任何价值,直到文字内容、交互按钮这些元素加载完毕,用户才能理解页面,这个时候用户会尝试与页面交互,会有第三个疑问:
**"它能使用了吗?"**
直到用户成功与页面互动,这才算是首屏加载完毕了.
在第一个疑问和第二个疑问之间的等待期,会出现白屏,这是优化的关键.
### 白屏的定义
不管是我们如何优化性能,首屏必然是会出现白屏的,因为这是前端开发这项技术的特点决定的。
那么我们先定义一下白屏,这样才能方便计算我们的白屏时间,因为白屏的计算逻辑说法不一,有人说要从首次绘制(First Paint,FP)算起到首次内容绘制(First Contentful Paint,FCP)这段时间算白屏,我个人是不同意的,我个人更倾向于是从路由改变起(即用户再按下回车的瞬间)到首次内容绘制(即能看到第一个内容)为止算白屏时间,因为按照用户的心理,在按下回车起就认为自己发起了请求,而直到看到第一个元素被绘制出来之前,用户的心里是焦虑的,因为他不知道这个请求会不会被响应(网站挂了?),不知道要等多久才会被响应到(网站慢?),这期间为用户首次等待期间。
* 白屏时间 = firstPaint - performance.timing.navigationStart
以webapp 版的微博为例(微博为数不多的的良心产品),经过 Lighthouse(谷歌的网站测试工具)它的白屏加载时间为 2s,是非常好的成绩。

### 白屏加载的问题分析
在现代前端应用开发中,我们往往会用 webpack 等打包器进行打包,很多情况下如果我们不进行优化,就会出现很多体积巨大的 chunk,有的甚至在 5M 左右(我第一次用 webpack1.x 打包的时候打出了 8M 的包),这些 chunk 是加载速度的杀手。
浏览器通常都有并发请求的限制,以 Chrome 为例,它的并发请求就为 6 个,这导致我们必须在请求完前 6 个之后,才能继续进行后续请求,这也影响我们资源的加载速度。

当然了,网络、带宽这是自始至终都影响加载速度的因素,白屏也不例外.
### 白屏的性能优化
我们先梳理下白屏时间内发生了什么:
1. 回车按下,浏览器解析网址,进行 DNS 查询,查询返回 IP,通过 IP 发出 HTTP(S) 请求
2. 服务器返回HTML,浏览器开始解析 HTML,此时触发请求 js 和 css 资源
3. js 被加载,开始执行 js,调用各种函数创建 DOM 并渲染到根节点,直到第一个可见元素产生
#### loading 提示
如果你用的是以 webpack 为基础的前端框架工程体系,那么你的index.html 文件一定是这样的:
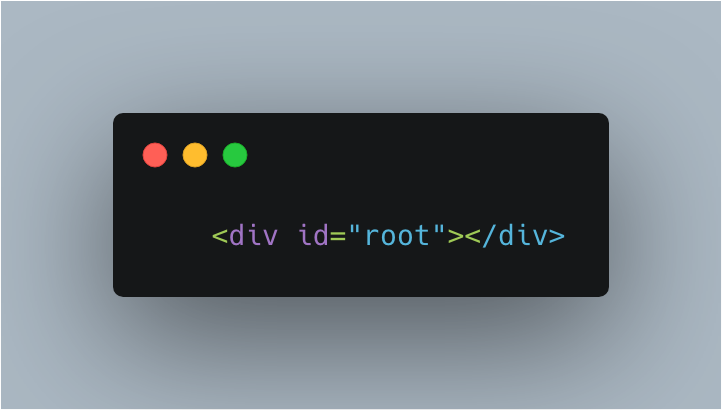
我们将打包好的整个代码都渲染到这个 root 根节点上,而我们如何渲染呢?当然是用 JavaScript 操作各种 dom 渲染,比如 react 肯定是调用各种 `_React_._createElement_()`,这是很耗时的,在此期间虽然 html 被加载了,但是依然是白屏,这就存在操作空间,我们能不能在 js 执行期间先加入提示,增加用户体验呢?
是的,我们一般有一款 webpack 插件叫[html-webpack-plugin](https://github.com/jantimon/html-webpack-plugin) ,在其中配置 html 就可以在文件中插入 loading 图。
webpack 配置:
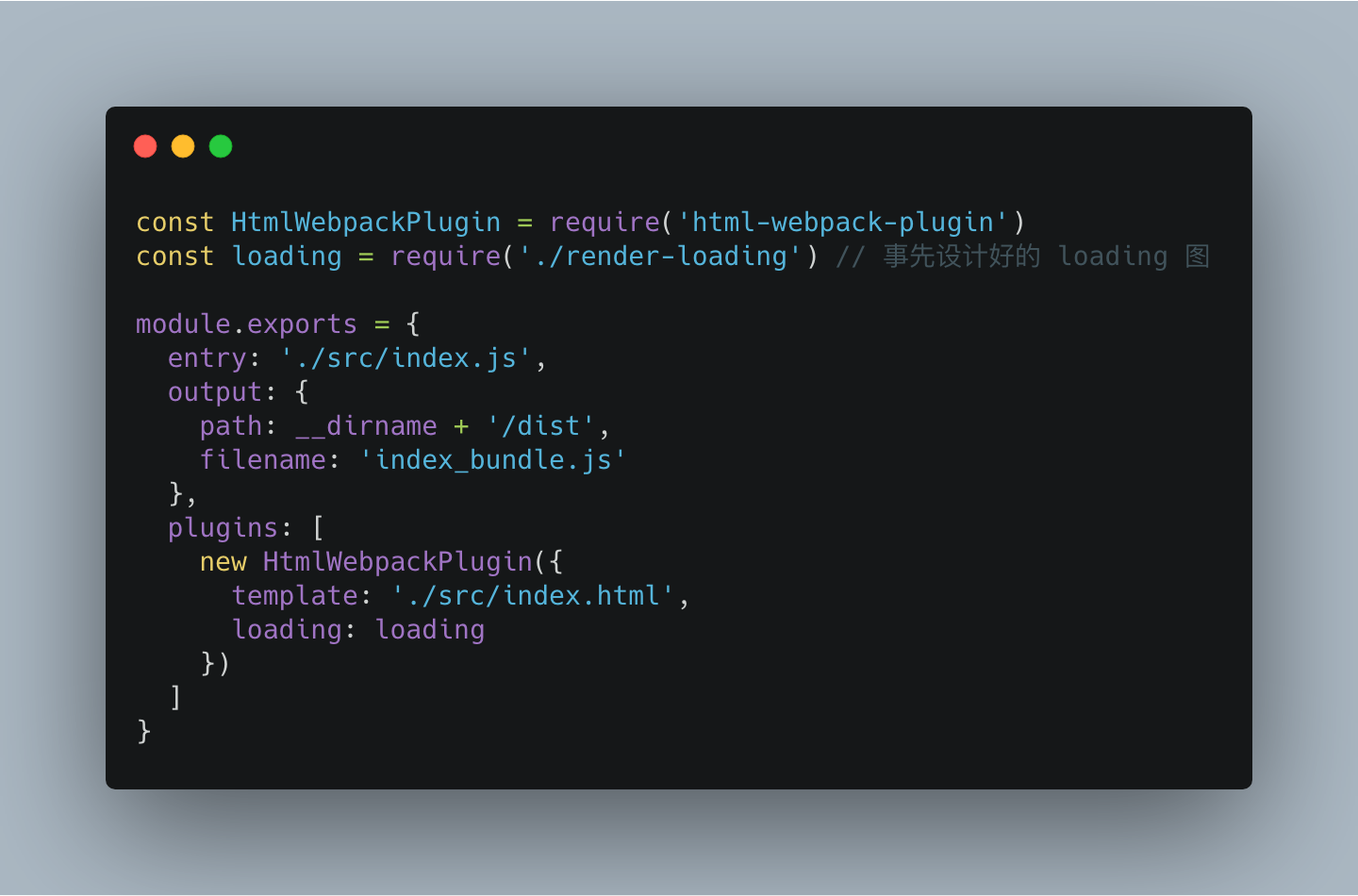
#### (伪)服务端渲染
那么既然在 HTML 加载到 js 执行期间会有时间等待,那么为什么不直接服务端渲染呢?直接返回的 HTML 就是带完整 DOM 结构的,省得还得调用 js 执行各种创建 dom 的工作,不仅如此还对 SEO 友好。
正是有这种需求 vue 和 react 都支持服务端渲染,而相关的框架Nuxt.js、Next.js也大行其道,当然对于已经采用客户端渲染的应用这个成本太高了。
于是有人想到了办法,谷歌开源了一个库Puppeteer,这个库其实是一个无头浏览器,通过这个无头浏览器我们能用代码模拟各种浏览器的操作,比如我们就可以用 node 将 html 保存为 pdf,可以在后端进行模拟点击、提交表单等操作,自然也可以模拟浏览器获取首屏的 HTML 结构。
[prerender-spa-plugin](https://github.com/chrisvfritz/prerender-spa-plugin)就是基于以上原理的插件,此插件在本地模拟浏览器环境,预先执行我们的打包文件,这样通过解析就可以获取首屏的 HTML,在正常环境中,我们就可以返回预先解析好的 HTML 了。
#### 开启 HTTP2
我们看到在获取 html 之后我们需要自上而下解析,在解析到 `script` 相关标签的时候才能请求相关资源,而且由于浏览器并发限制,我们最多一次性请求 6 次,那么有没有办法破解这些困境呢?
http2 是非常好的解决办法,http2 本身的机制就足够快:
1. http2采用二进制分帧的方式进行通信,而 http1.x 是用文本,http2 的效率更高
2. http2 可以进行多路复用,即跟同一个域名通信,仅需要一个 TCP 建立请求通道,请求与响应可以同时基于此通道进行双向通信,而 http1.x 每次请求需要建立 TCP,多次请求需要多次连接,还有并发限制,十分耗时

3. http2 可以头部压缩,能够节省消息头占用的网络的流量,而HTTP/1.x每次请求,都会携带大量冗余头信息,浪费了很多带宽资源
例如:下图中的两个请求, 请求一发送了所有的头部字段,第二个请求则只需要发送差异数据,这样可以减少冗余数据,降低开销

1. http2可以进行服务端推送,我们平时解析 HTML 后碰到相关标签才会进而请求 css 和 js 资源,而 http2 可以直接将相关资源直接推送,无需请求,这大大减少了多次请求的耗时
我们可以点击[此网站](https://http2.akamai.com/demo) 进行 http2 的测试
ps: 我曾经做个一个测试,http2 在网络通畅+高性能设备下的表现没有比 http1.1有明显的优势,但是网络越差,设备越差的情况下 http2 对加载的影响是质的,可以说 http2 是为移动 web 而生的,反而在光纤加持的高性能PC 上优势不太明显.
#### 开启浏览器缓存
既然 http 请求如此麻烦,能不能我们避免 http 请求或者降低 http 请求的负载来实现性能优化呢?
利用浏览器缓存是很好的办法,他能最大程度上减少 http 请求,在此之前我们要先回顾一下 http 缓存的相关知识.
我们先罗列一下和缓存相关的请求响应头。
* Expires: 响应头,代表该资源的过期时间。
* Cache-Control: 请求/响应头,缓存控制字段,精确控制缓存策略。
* If-Modified-Since: 请求头,资源最近修改时间,由浏览器告诉服务器。
* Last-Modified: 响应头,资源最近修改时间,由服务器告诉浏览器。
* Etag: 响应头,资源标识,由服务器告诉浏览器。
* If-None-Match: 请求头,缓存资源标识,由浏览器告诉服务器。
配对使用的字段:
* If-Modified-Since 和 Last-Modified
* Etag 和 If-None-Match
当无本地缓存的时候是这样的:

当有本地缓存但没过期的时候是这样的:

当缓存过期了会进行协商缓存:
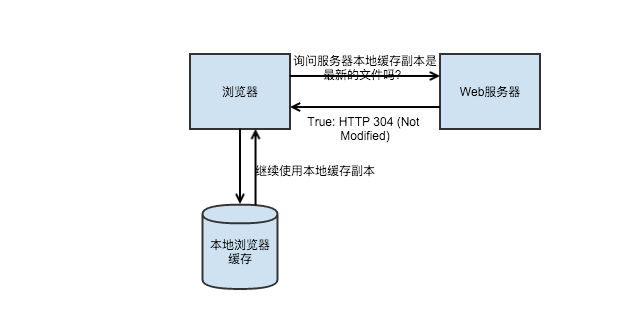
了解到了浏览器的基本缓存机制我们就好进行优化了.
通常情况下我们的 WebApp 是有我们的自身代码和第三方库组成的,我们自身的代码是会常常变动的,而第三方库除非有较大的版本升级,不然是不会变的,所以第三方库和我们的代码需要分开打包,我们可以给第三方库设置一个较长的强缓存时间,这样就不会频繁请求第三方库的代码了。
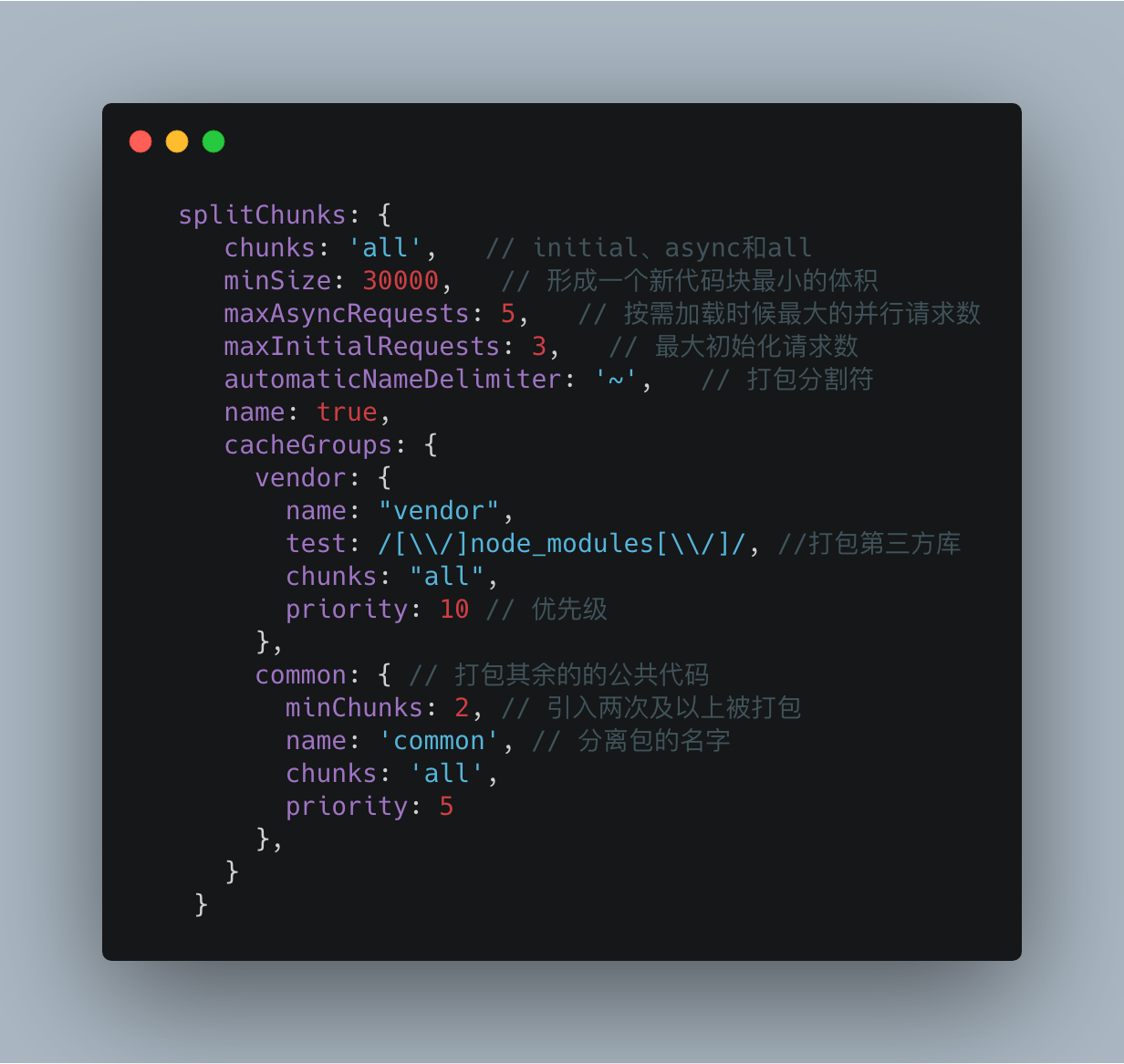
那么如何提取第三方库呢?在 webpack4.x 中, SplitChunksPlugin 插件取代了 CommonsChunkPlugin 插件来进行公共模块抽取,我们可以对SplitChunksPlugin 进行配置进行 **拆包** 操作。
SplitChunksPlugin配置示意如下:
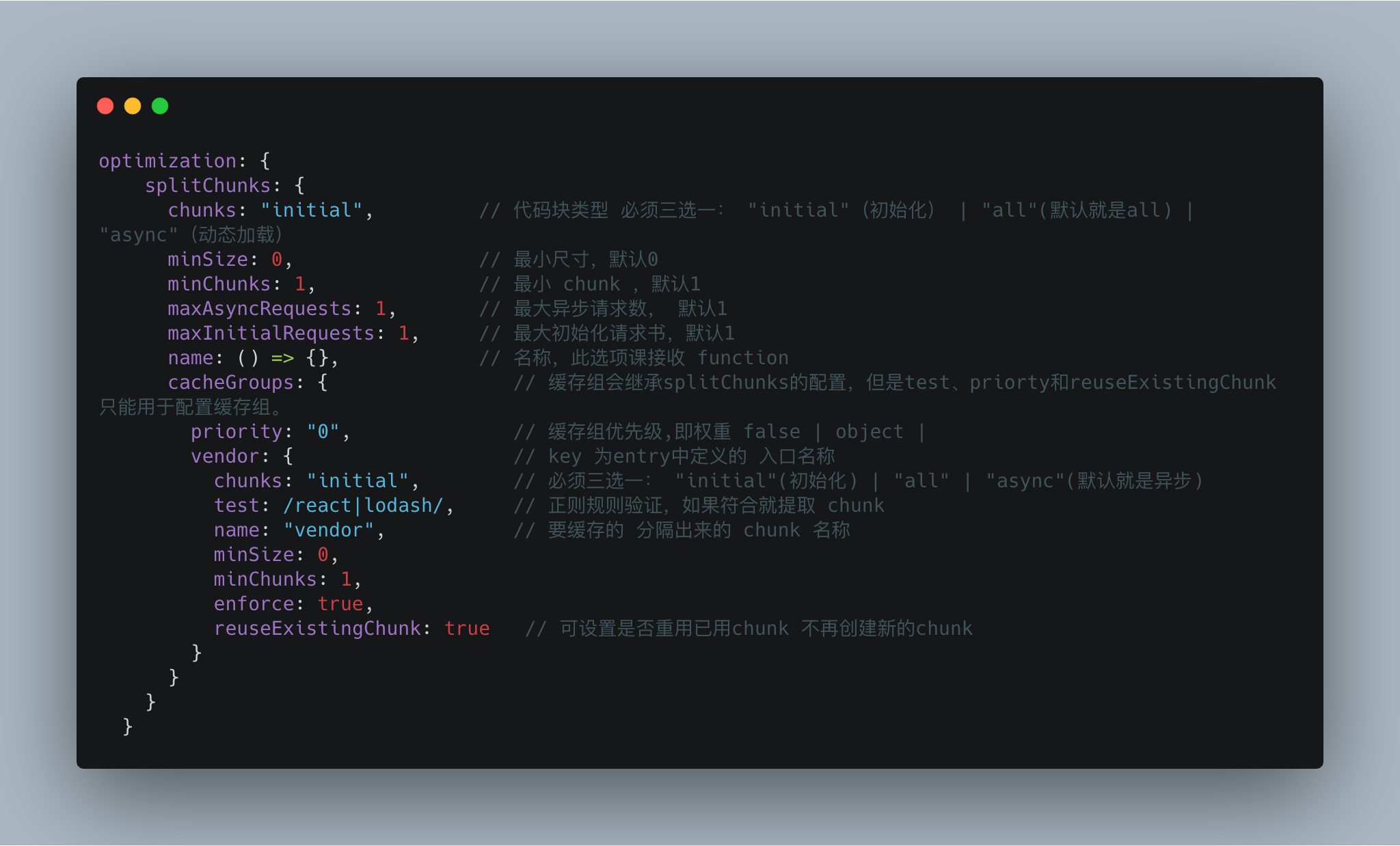
[SplitChunksPlugin](https://webpack.js.org/plugins/split-chunks-plugin/) 的配置项很多,可以先去官网了解如何配置,我们现在只简单列举了一下配置元素。
如果我们想抽取第三方库可以这样简单配置
这样似乎大功告成了?并没有,我们的配置有很大的问题:
1. 我们粗暴得将第三方库一起打包可行吗? 当然是有问题的,因为将第三方库一块打包,只要有一个库我们升级或者引入一个新库,这个 chunk 就会变动,那么这个chunk 的变动性会很高,并不适合长期缓存,还有一点,我们要提高首页加载速度,第一要务是减少首页加载依赖的代码量,请问像 react vue reudx 这种整个应用的基础库我们是首页必须要依赖的之外,像 d3.js three.js这种特定页面才会出现的特殊库是没必要在首屏加载的,所以我们需要将应用基础库和特定依赖的库进行分离。
2. 当 chunk 在强缓存期,但是服务器代码已经变动了我们怎么通知客户端?上面我们的示意图已经看到了,当命中的资源在缓存期内,浏览器是直接读取缓存而不会向服务器确认的,如果这个时候服务器代码已经变动了,怎么办?这个时候我们不能将 index.html 缓存(反正webpack时代的 html 页面小到没有缓存的必要),需要每次引入 script 脚本的时候去服务器更新,并开启 hashchunk,它的作用是当 chunk 发生改变的时候会生成新的 hash 值,如果不变就不发生变动,这样当 index 加载后续 script资源时如果 hashchunk 没变就会命中缓存,如果改变了那么会重新去服务端加载新资源。
下图示意了如何将第三方库进行拆包,基础型的 react 等库与工具性的 lodash 和特定库 Echarts 进行拆分
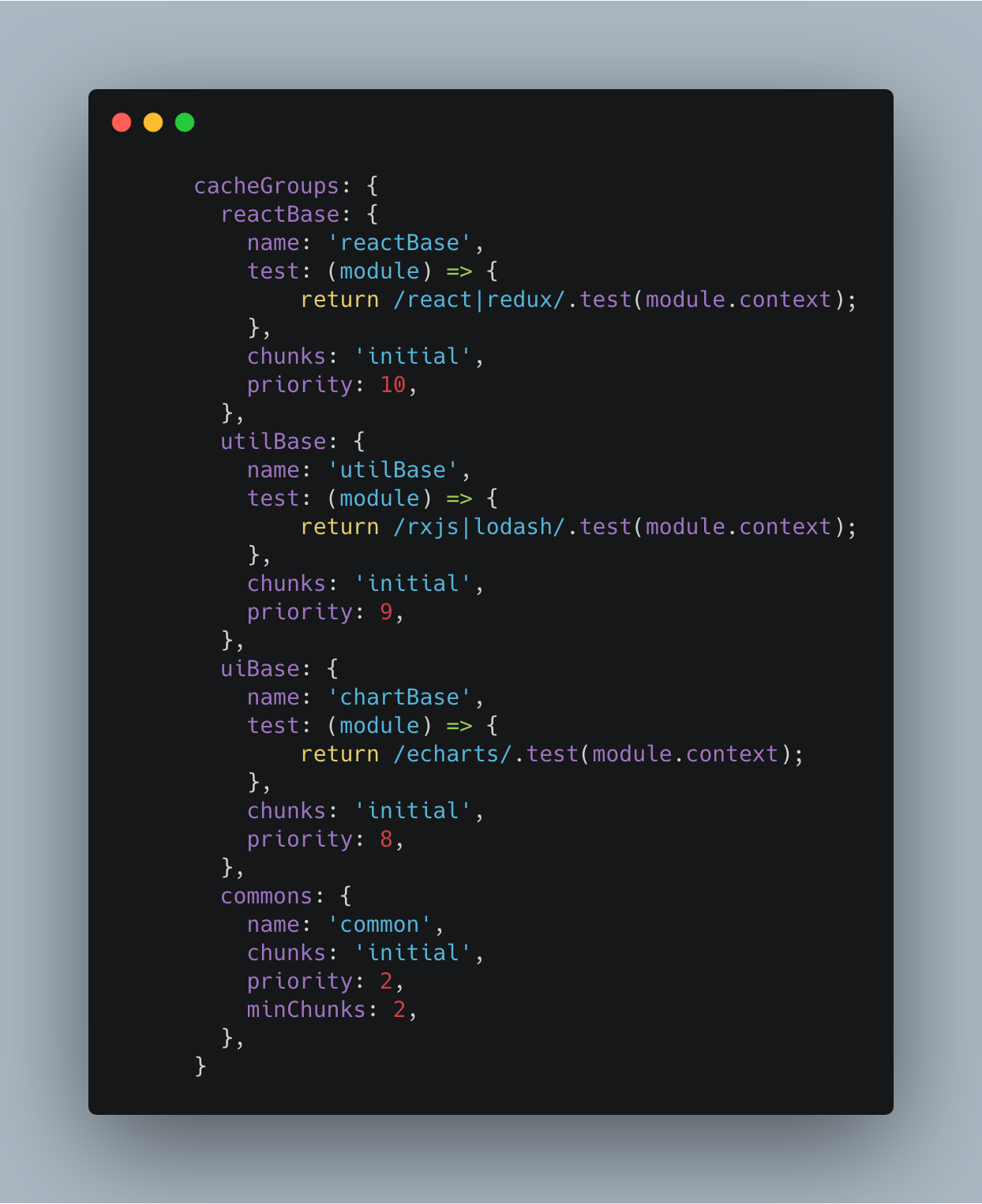
我们对 chunk 进行 hash 化,正如下图所示,我们变动 chunk2 相关的代码后,其它 chunk 都没有变化,只有 chunk2 的 hash 改变了

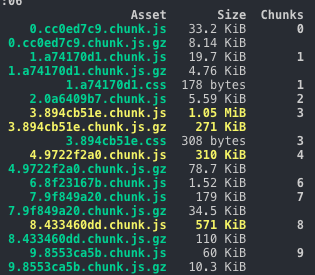

我们通过 http 缓存+webpack hash 缓存策略使得前端项目充分利用了缓存的优势,但是 webpack 之所以需要传说中的 **webpack配置工程师** 是有原因的,因为 webpack 本身是玄学,还是以上图为例,如果你 chunk2的相关代码去除了一个依赖或者引入了新的但是已经存在工程中依赖,会怎么样呢?
我们正常的期望是,只有 chunk2 发生变化了,但是事实上是大量不相干的 chunk 的 hash 发生了变动,这就导致我们缓存策略失效了,下图是变更后的 hash,我们用红圈圈起来的都是 hash 变动的,而事实上我们只变动了 chunk2 相关的代码,为什么会这样呢?
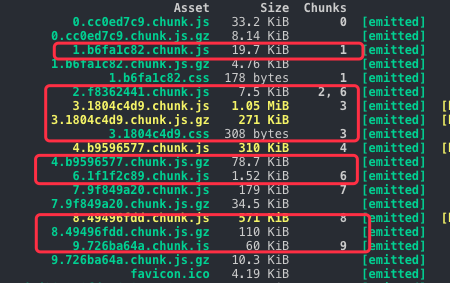
原因是 webpack 会给每个 chunk 搭上 id,这个 id 是自增的,比如 chunk 0 中的id 为 0,一旦我们引入新的依赖,chunk 的自增会被打乱,这个时候又因为 hashchunk 根据内容生成 hash,这就导致了 id 的变动致使 hashchunk 发生巨变,虽然代码内容根本没有变化。

这个问题我们需要额外引入一个插件HashedModuleIdsPlugin,他用非自增的方式进行 chunk id 的命名,可以解决这个问题,虽然 webpack 号称 0 配置了,但是这个常用功能没有内置,要等到下个版本了。

> webpack hash缓存相关内容建议阅读此[文章](https://github.com/pigcan/blog/issues/9) 作为拓展
### FMP(首次有意义绘制)
在白屏结束之后,页面开始渲染,但是此时的页面还只是出现个别无意义的元素,比如下拉菜单按钮、或者乱序的元素、导航等等,这些元素虽然是页面的组成部分但是没有意义.
什么是有意义?
* 对于搜索引擎用户是完整搜索结果
* 对于微博用户是时间线上的微博内容
* 对于淘宝用户是商品页面的展示
那么在FCP 和 FMP 之间虽然开始绘制页面,但是整个页面是没有意义的,用户依然在焦虑等待,而且这个时候可能出现乱序的元素或者闪烁的元素,很影响体验,此时我们可能需要进行用户体验上的一些优化。
Skeleton是一个好方法,Skeleton现在已经很开始被广泛应用了,它的意义在于事先撑开即将渲染的元素,避免闪屏,同时提示用户这要渲染东西了,较少用户焦虑。
比如微博的Skeleton就做的很不错
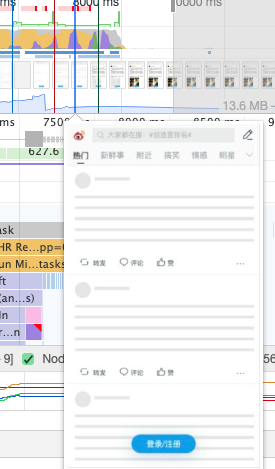
在不同框架上都有相应的Skeleton实现
* React: antd 内置的骨架图[Skeleton](https://ant.design/components/skeleton-cn/)方案
* Vue: [vue-skeleton-webpack-plugin](https://github.com/lavas-project/vue-skeleton-webpack-plugin)
以 vue-cli 3 为例,我们可以直接在vue.config.js 中配置
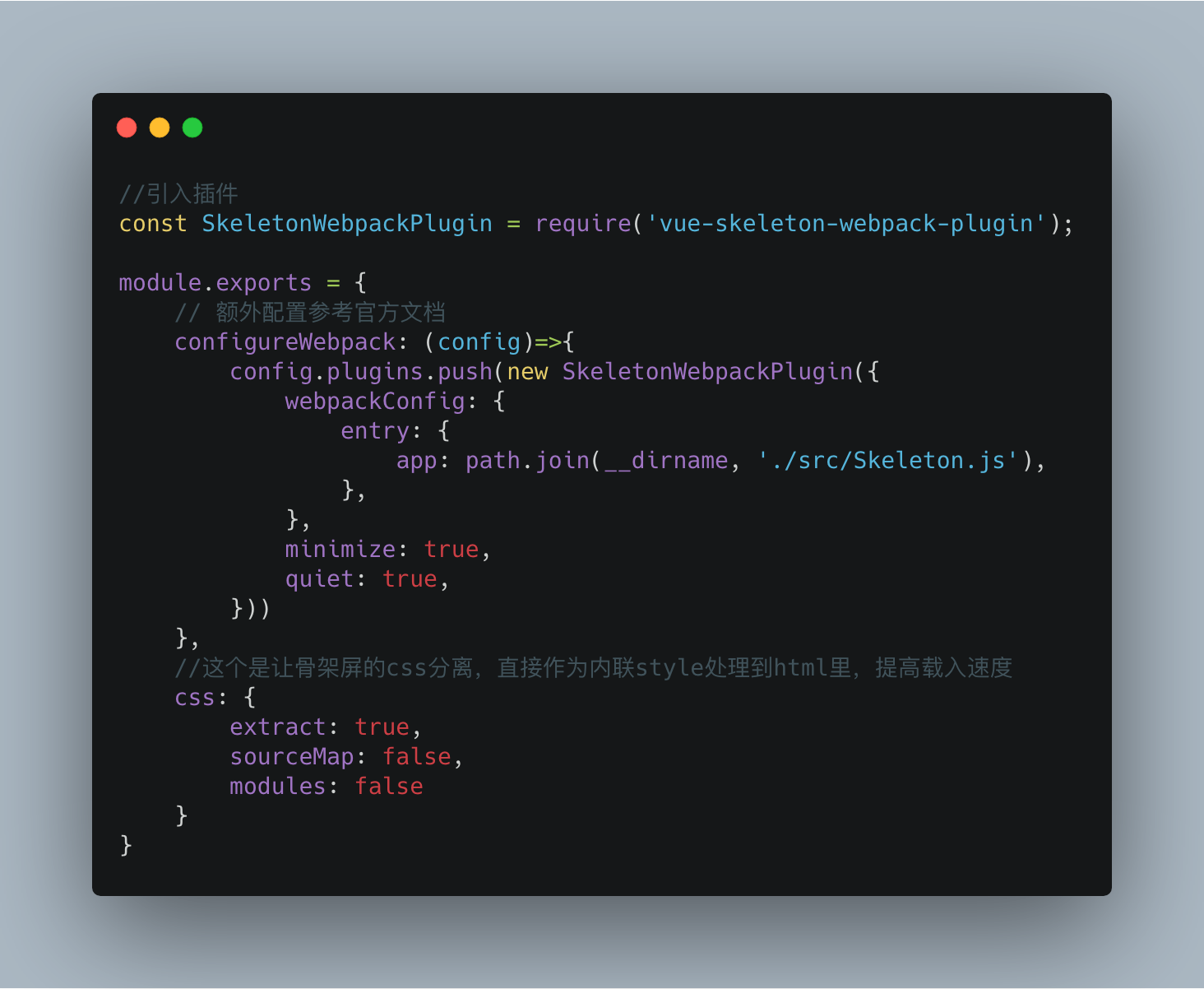
然后就是基本的 vue 文件编写了,直接看文档即可。
### TTI(可交互时间)
当有意义的内容渲染出来之后,用户会尝试与页面交互,这个时候页面并不是加载完毕了,而是看起来页面加载完毕了,事实上这个时候 JavaScript 脚本依然在密集得执行.
> 我们看到在页面已经基本呈现的情况下,依然有大量的脚本在执行
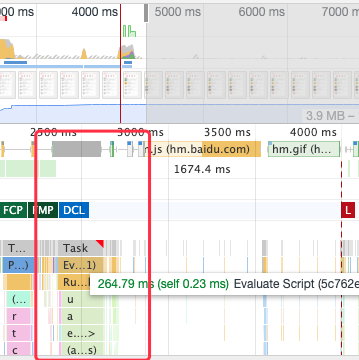
这个时候页面并不是可交互的,直到TTI 的到来,TTI 到来之后用户就可以跟页面进行正常交互的,TTI 一般没有特别精确的测量方法,普遍认为满足**FMP && DOMContentLoader事件触发 && 页面视觉加载85%**这几个条件后,TTI 就算是到来了。
在页面基本呈现到可以交互这段时间,绝大部分的性能消耗都在 JavaScript 的解释和执行上,这个时候决定 JavaScript 解析速度的无非一下两点:
* JavaScript 脚本体积
* JavaScript 本身执行速度
JavaScript 的体积问题我们上一节交代过了一些,我们可以用SplitChunksPlugin拆库的方法减小体积,除此之外还有一些方法,我们下文会交代。
#### Tree Shaking
Tree Shaking虽然出现很早了,比如js基础库的事实标准打包工具 rollup 就是Tree Shaking的祖师爷,react用 rollup 打包之后体积减少了 30%,这就是Tree Shaking的厉害之处。
Tree Shaking的作用就是,通过程序流分析找出你代码中无用的代码并剔除,如果不用Tree Shaking那么很多代码虽然定义了但是永远都不会用到,也会进入用户的客户端执行,这无疑是性能的杀手,Tree Shaking依赖es6的module模块的静态特性,通过分析剔除无用代码.
目前在 webpack4.x 版本之后在生产环境下已经默认支持Tree Shaking了,所以Tree Shaking可以称得上开箱即用的技术了,但是并不代表Tree Shaking真的会起作用,因为这里面还是有很多坑.
坑 1: Babel 转译,我们已经提到用Tree Shaking的时候必须用 es6 的module,如果用 common.js那种动态module,Tree Shaking就失效了,但是 Babel 默认状态下是启用 common.js的,所以需要我们手动关闭.
坑 2: 第三方库不可控,我们已经知道Tree Shaking的程序分析依赖 ESM,但是市面上很多库为了兼容性依然只暴露出了ES5 版本的代码,这导致Tree Shaking对很多第三方库是无效的,所以我们要尽量依赖有 ESM 的库,比如之前有一个 ESM 版的 lodash(lodash-es),我们就可以这样引用了`import { dobounce } from 'lodash-es'`
#### polyfill动态加载
polyfill是为了浏览器兼容性而生,是否需要 polyfill 应该有客户端的浏览器自己决定,而不是开发者决定,但是我们在很长一段时间里都是开发者将各种 polyfill 打包,其实很多情况下导致用户加载了根本没有必要的代码.
解决这个问题的方法很简单,直接引入 `` 即可,而对于 Vue 开发者就更友好了,vue-cli 现在生成的模板就自带这个引用.

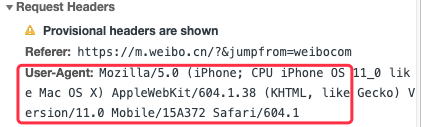
这个原理就是服务商通过识别不同浏览器的浏览器User Agent,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等,然后根据这个信息判断是否需要加载 polyfill,开发者在浏览器的 network 就可以查看User Agent。
#### 动态加载 ES6 代码
既然 polyfill 能动态加载,那么 es5 和 es6+的代码能不能动态加载呢?是的,但是这样有什么意义呢?es6 会更快吗?
我们得首先明确一点,一般情况下在新标准发布后,浏览器厂商会着重优化新标准的性能,而老的标准的性能优化会逐渐停滞,即使面向未来编程,es6 的性能也会往越来越快的方向发展.
其次,我们平时编写的代码可都es6+,而发布的es5是经过babel 或者 ts 转译的,在大多数情况下,经过工具转译的代码往往被比不上手写代码的性能,这个[性能对比网站](http://incaseofstairs.com/six-speed/) 的显示也是如此,虽然 babel 等转译工具都在进步,但是仍然会看到转译后代码的性能下降,尤其是对 class 代码的转译,其性能下降是很明显的.
最后,转译后的代码体积会出现代码膨胀的情况,转译器用了很多奇技淫巧将 es6 转为 es5 导致了代码量剧增,使用 es6就代表了更小的体积.
那么如何动态加载 es6 代码呢?秘诀就是`