diff --git a/.idea/vcs.xml b/.idea/vcs.xml
deleted file mode 100644
index 35eb1dd..0000000
--- a/.idea/vcs.xml
+++ /dev/null
@@ -1,6 +0,0 @@
-
-
-
-
-
-
\ No newline at end of file
diff --git "a/MD/Java\345\237\272\347\241\200-IO.md" "b/MD/Java\345\237\272\347\241\200-IO.md"
new file mode 100644
index 0000000..b5c1ee2
--- /dev/null
+++ "b/MD/Java\345\237\272\347\241\200-IO.md"
@@ -0,0 +1,45 @@
+同步/异步关注的是消息通信机制 (synchronous communication/ asynchronous communication) 。所谓同步,就是在发出一个调用时,在没有得到结果之前, 该调用就不返回。异步则是相反,调用在发出之后,这个调用就直接返回了,所以没有返回结果
+
+阻塞/非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态.阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
+
+## BIO
+Block-IO:InputStream和OutputStream,Reader和Writer。属于同步阻塞模型
+
+同步阻塞:一个请求占用一个进程处理,先等待数据准备好,然后从内核向进程复制数据,最后处理完数据后返回
+
+
+
+## NIO
+NonBlock-IO:Channel、Buffer、Selector。属于IO多路复用的同步非阻塞模型
+
+同步非阻塞:进程先将一个套接字在内核中设置成非阻塞再等待数据准备好,在这个过程中反复轮询内核数据是否准备好,准备好之后最后处理数据返回
+
+
+
+IO多路复用:同步非阻塞的优化版本,区别在于IO多路复用阻塞在select,epoll这样的系统调用之上,而没有阻塞在真正的IO系统调用上。换句话说,轮询机制被优化成通知机制,多个连接公用一个阻塞对象,进程只需要在一个阻塞对象上等待,无需再轮询所有连接
+
+
+
+在Java的NIO中,是基于Channel和Buffer进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。Selector用于监听多个通道的事件(比如:连接打开,数据到达)
+
+因此,单个线程可以监听多个数据通道,Selector的底层实现是epoll/poll/select的IO多路复用模型,select方法会一直阻塞,直到channel中有事件就绪:
+
+
+
+与BIO区别如下:
+
+1. 通过缓冲区而非流的方式进行数据的交互,流是进行直接的传输的没有对数据操作的余地,缓冲区提供了灵活的数据处理方式
+2. NIO是非阻塞的,意味着每个socket连接可以让底层操作系统帮我们完成而不需要每次开个线程去保持连接,使用的是selector监听所有channel的状态实现
+3. NIO提供直接内存复制方式,消除了JVM与操作系统之间读写内存的损耗
+
+## AIO
+Asynchronous IO:属于事件和回调机制的异步非阻塞模型
+
+
+
+AIO得到结果的方式:
+
+* 基于回调:实现CompletionHandler接口,调用时触发回调函数
+* 返回Future:通过isDone()查看是否准备好,通过get()等待返回数据
+
+但要实现真正的异步非阻塞IO,需要操作系统支持,Windows支持而Linux不完善
diff --git "a/MD/Java\345\237\272\347\241\200-JVM\345\216\237\347\220\206.md" "b/MD/Java\345\237\272\347\241\200-JVM\345\216\237\347\220\206.md"
index 05d4290..92e8d12 100644
--- "a/MD/Java\345\237\272\347\241\200-JVM\345\216\237\347\220\206.md"
+++ "b/MD/Java\345\237\272\347\241\200-JVM\345\216\237\347\220\206.md"
@@ -1,64 +1,72 @@
-
## JVM原理
-JVM本身是介于JAVA编译器和操作系统之间的程序,这个程序提供了一个无视操作系统和硬件平台的运行环境
+### Java内存区域的分配
+JVM虚拟机内存模型实现规范:
+
+
+
-### 内存分配
+按线程是否共享分为以下区域:
-
+所有线程共享的数据区:
-所有线程共享的数据区:
+1. 方法区(JVM规范中的一部分,不是实际的实现): 存储每一个类的结构信息(运行时常量池、静态变量、方法数据、构造函数和普通方法的字节码、JIT编译后的代码),没有要求使用垃圾回收因为回收效率太低。(运行时常量池:存放编译器生成的各种字面量和符号引用,在类加载后放到运行时常量池中)
+2. 堆区: 最大的一块区域,是大部分类实例、对象、数组分配内存的区域,没有限制只能将对象分配在堆,所以出现逃逸分析的技术
-1. 方法区: 存储已被虚拟机加载的类信息、静态变量、编译后代码等数据。并使用永久代来实现方法区,1.8后被元空间替代,元空间并不在虚拟机中,而是使用本地内存,要画到上图那就是图外了。
-2. 堆区: 我们常说用于存放对象的区域,1.7之后字符串常量池移到这里。
+每个线程都会有一块私有的数据区:
-每个线程私有的数据区:
+1. 虚拟机栈: 虚拟机栈与线程同时创建,每个方法在执行时在其中创建一个栈帧,用于存储局部变量、操作数栈、动态链接、方法返回地址。正常调用完成后恢复调用者的局部变量表、操作数栈、递增程序计数器来跳过刚才执行的指令,或抛出异常不将返回值返回给调用者
+2. 本地方法栈: 功能与虚拟机栈相同,为native方法服务
+3. pc寄存器: 任意时刻线程只会执行一个方法的代码,如果不是native的,就存放当前正在执行的字节码指令的地址,如果是native,则是undefined
-1. 虚拟机栈: 方法执行时创建一个栈帧,用于存储局部变量、操作数栈、动态链接、方法出口等信息。每个方法一个栈帧,互不干扰。
-2. 本地方法栈: 用于存放执行native方法的运行数据。
-3. 程序计数器: 当前线程所执行的字节码的指示器,通过改变计数器来选取下一条需要执行的字节码指令。
+以HotSpot虚拟机实现为例,Java8中内存区域如下:
-直接内存:
+
-* 直接内存并非Java标准。
-* JDK1.4 加入了新的 NIO 机制,目的是防止 Java 堆 和 Native 堆之间往复的数据复制带来的性能损耗,此后 NIO 可以使用 Native 的方式直接在 Native 堆分配内存。
-* 直接内存区域是全局共享的内存区域。
+与规范中的区别:
+
+1. 直接内存:非Java标准,是JVM以外的本地内存,在Java4出现的NIO中,为了防止Java堆和Native堆之间往复的数据复制带来的性能损耗,此后NIO可以使用Native的方式直接在Native堆分配内存。JDK中有一种基于通道(Channel)和缓冲区(Buffer)的内存分配方式,将由C语言实现的native函数库分配在直接内存中,用存储在JVM堆中的DirectByteBuffer来引用。
+2. 元数据区(方法区的实现):Java7以及之前是使用的永久代来实现方法区,大小是在启动时固定的。Java8中用元空间替代了永久代,元空间并不在虚拟机中,而是使用本地内存,并且大小可以是自动增长的,这样减少了OOM的可能性。元空间存储JIT即时编译后的native代码,可能还存在短指针数据区CCS
+3. 堆区: Java7之后运行时常量池从方法区移到这里,为Java8移除永久带的做好准备
### Java对象不都是分配在堆上
-废话,还有线程使用的虚拟机栈上的啊,在方法体中声明的变量以及创建的对象,将直接从该线程所使用的栈中分配空间。
#### 逃逸分析
-逃逸是指在某个方法之内创建的对象,除了在方法体之内被引用之外,还在方法体之外被其它变量引用到;这样带来的后果是在该方法执行完毕之后,该方法中创建的对象将无法被GC回收,由于其被其它变量引用。正常的方法调用中,方法体中创建的对象将在执行完毕之后,将回收其中创建的对象;故由于无法回收,即成为逃逸。
+通过逃逸分析,Java Hotspot编译器能够分析出一个新的对象的引用的使用范围从而决定是否要将这个对象分配到堆上。
-逃逸分析可以分析出某个对象是否永远只在某个方法、线程的范围内,并没有“逃逸”出这个范围,逃逸分析的一个结果就是对于某些未逃逸对象可以直接在栈上分配,由于该对象一定是局部的,所以栈上分配不会有问题。
+逃逸分析的基本行为就是分析对象动态作用域:当一个对象在方法中被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他地方中,称为方法逃逸。
-#### TLAB
-JVM在内存新生代Eden Space中开辟了一小块线程私有的区域TLAB(Thread-local allocation buffer)。在Java程序中很多对象都是小对象且用过即丢,它们不存在线程共享也适合被快速GC,所以对于小对象通常JVM会优先分配在TLAB上,并且TLAB上的分配由于是线程私有所以没有锁开销。因此在实践中分配多个小对象的效率通常比分配一个大对象的效率要高。
-也就是说,Java中每个线程都会有自己的缓冲区称作TLAB,在对象分配的时候不用锁住整个堆,而只需要在自己的缓冲区分配即可。
+使用逃逸分析,编译器可以对代码做如下优化:
-### 类加载机制
-#### 初始化时机
-new、静态字段或方法被使用、反射、父类、main函数调用
+1. 同步省略。如果一个对象被发现只能从一个线程被访问到,那么对于这个对象的操作可以不考虑同步。
+2. 将堆分配转化为栈分配。如果一个对象在子程序中被分配,要使指向该对象的指针永远不会逃逸,对象可能是栈分配的候选,而不是堆分配。
+3. 分离对象或标量替换。有的对象可能不需要作为一个连续的内存结构存在也可以被访问到,那么对象的部分(或全部)可以不存储在内存,而是存储在CPU寄存器中。
+### 类加载机制
#### 加载过程
-1. 加载(获取字节流并转换成运行时数据结构,然后生成Class对象)
-2. 验证(验证字节流信息符合当前虚拟机的要求)
+1. 加载(获取来自任意来源的字节流并转换成运行时数据结构,生成Class对象)
+2. 验证(验证字节流信息符合当前虚拟机的要求,防止被篡改过的字节码危害JVM安全)
3. 准备(为类变量分配内存并设置初始值)
-4. 解析(将常量池的符号引用替换为直接引用)
-5. 初始化(执行类构造器-类变量赋值和静态块的过程)
+4. 解析(将常量池的符号引用替换为直接引用,符号引用是用一组符号来描述所引用的目标,直接引用是指向目标的指针)
+5. 初始化(执行类构造器、类变量赋值、静态语句块)
#### 类加载器
-启动类加载器:是虚拟机自身的一部分,它负责将 /lib路径下的核心类库
-扩展类加载器:它负责加载/lib/ext目录下或者由系统变量-Djava.ext.dir指定位路径中的类库,开发者可以直接使用标准扩展类加载器
-系统类加载器:它负责加载系统类路径java -classpath或-D java.class.path 指定路径下的类库
+启动类加载器:用C++语言实现,是虚拟机自身的一部分,它负责将 /lib路径下的核心类库,无法被Java程序直接引用
+扩展类加载器:用Java语言实现,它负责加载/lib/ext目录下或者由系统变量-Djava.ext.dir指定位路径中的类库,开发者可以直接使用
+系统类加载器:用Java语言实现,它负责加载系统类路径ClassPath指定路径下的类库,开发者可以直接使用
+#### 双亲委派
定义:如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成此加载任务,子加载器才会尝试自己去加载,这就是**双亲委派模式**。
优点:采用双亲委派模式的是好处是Java类随着它的类加载器一起具备了一种带有优先级的层次关系,通过这种层级关可以避免类的重复加载,当父亲已经加载了该类时,就没有必要子ClassLoader再加载一次。其次防止恶意覆盖Java核心API。
-破坏双亲委派模式:是为了实现自己的类加载逻辑,达到比如[热部署重加载](https://blog.csdn.net/u010833547/article/details/54312052)的功能,默认加载器在加载类的时候会检测该类是否已经存在,如果存在则不会去加载,如果不存在则加载该类并缓存。所以默认的ClassLoader是无法实现热替换的。换句话说,要实现热替换就必须实现一个自己的MyClassLoader。双亲委派的逻辑是写在ClassLoader中的loadClass中的,所以继承ClassLoader然后覆盖loadClass方法,读取自己允许热加载的那些类吧~
+三次大型破坏双亲委派模式的事件:
+
+1. 在双亲委派模式出来之前,用户继承ClassLoader就是为了重写loadClass方法,但双亲委派模式需要这个方法,所以1.2之后添加了findClass供以后的用户重写
+2. 如果基础类要调回用户的代码,如JNDI/JDBC需要调用ClassPath下的自己的代码来进行资源管理,Java团队添加了一个线程上下文加载器,如果该加载器没有被设置过,那么就默认是应用程序类加载器
+3. 为了实现代码热替换,OSGi是为了实现自己的类加载逻辑,用平级查找的逻辑替换掉了向下传递的逻辑。但其实可以不破坏双亲委派逻辑而是自定义类加载器来达到代码热替换。比如[这篇文章](https://www.cnblogs.com/pfxiong/p/4070462.html)
### 内存分配(堆上的内存分配)
-
+
#### 新生代
##### 进入条件
优先选择在新生代的Eden区被分配。
@@ -83,8 +91,8 @@ GC Roots包括:虚拟机栈中引用的对象、方法区中类静态属性引
老年代因为存活率高、没有分配担保空间,所以使用“标记-清理”或者“标记-整理”算法
复制算法:将可用内存按容量划分为Eden、from survivor、to survivor,分配的时候使用Eden和一个survivor,Minor GC后将存活的对象复制到另一个survivor,然后将原来已使用的内存一次清理掉。这样没有内存碎片。
-标记-清除:首先标记出所有需要回收的对象,标记完成后统一回收被标记的对象。会产生大量碎片,导致无法分配大对象从而导致频繁GC。
-标记-整理:首先标记出所有需要回收的对象,让所有存活的对象向一端移动。
+标记-清除:标记出存在引用链的对象,回收未被标记的对象。会产生大量碎片,导致无法分配大对象从而导致频繁GC。
+标记-整理:标记出存在引用链的对象,让所有存活的对象向一端移动。
#### Minor GC条件
当Eden区空间不足以继续分配对象,发起Minor GC。
@@ -94,17 +102,123 @@ GC Roots包括:虚拟机栈中引用的对象、方法区中类静态属性引
2. 老年代空间不足(通过Minor GC后进入老年代的大小大于老年代的可用内存)
3. 方法区空间不足
-## Java内存模型
+## 垃圾收集器
+### 串行收集器
+串行收集器Serial是最古老的收集器,只使用一个线程去回收,可能会产生较长的停顿
+
+新生代使用Serial收集器`复制`算法、老年代使用Serial Old`标记-整理`算法
+
+参数:`-XX:+UseSerialGC`,默认开启`-XX:+UseSerialOldGC`
+
+### 并行收集器
+并行收集器Parallel关注**可控的吞吐量**,能精确地控制吞吐量与最大停顿时间是该收集器最大的特点,也是1.8的Server模式的默认收集器,使用多线程收集。ParNew垃圾收集器是Serial收集器的多线程版本。
+
+新生代`复制`算法、老年代`标记-整理`算法
+
+参数:`-XX:+UseParallelGC`,默认开启`-XX:+UseParallelOldGC`
+
+### 并发收集器
+并发收集器CMS是以**最短停顿时间**为目标的收集器。G1关注能在大内存的前提下精确控制**停顿时间**且垃圾回收效率高。
+
+CMS针对老年代,有初始标记、并发标记、重新标记、并发清除四个过程,标记阶段会Stop The World,使用`标记-清除`算法,所以会产生内存碎片。
+
+参数:`-XX:+UseConcMarkSweepGC`,默认开启`-XX:+UseParNewGC`
+
+G1将堆划分为多个大小固定的独立区域,根据每次允许的收集时间优先回收垃圾最多的区域,使用`标记-整理`算法,是1.9的Server模式的默认收集器
+
+参数:`-XX:+UseG1GC`
+
+### G1的原理,相比CMS的优势
+G1的工作原理:
+内存布局:
+G1将堆内存划分为多个大小相等的区域(Region),每个区域可以是Eden、Survivor、老年代的一部分或整个Humongous对象(大对象)。这样的划分使得收集可以更细粒度地进行。
+并发标记-整理:
+G1使用多阶段的并发标记过程来识别存活对象。首先进行初步标记,然后进行根搜索标记,最后进行重新标记,这些步骤尽可能与应用程序线程并发执行。
+基于目标的收集:
+G1根据用户设定的暂停时间目标来决定收集哪些区域。它优先回收垃圾最多(即回收效益最高)的区域,以尽快满足内存需求,这就是“Garbage-First”命名的由来。
+混合收集周期:
+G1执行混合垃圾收集,不仅回收年轻代,也回收一部分老年代区域,这样可以更均匀地分散垃圾回收的压力,减少老年代增长导致的Full GC风险。
+空间整合:
+G1在回收过程中会进行空间整理,减少内存碎片,这是与CMS的一个重要区别,后者使用标记-清除算法,容易产生碎片。
+
+相比CMS的优势:
+更好的内存碎片管理:
+G1通过复制和整理算法减少了内存碎片,提高了内存使用的效率,而CMS使用标记-清除算法后易造成碎片化。
+可预测的暂停时间:
+G1允许用户设定暂停时间目标,通过动态调整收集策略来尽量满足这一目标,使得应用的响应时间更加可预测,适合对延迟敏感的服务。
+自动内存管理:
+G1自动管理年轻代和老年代的大小,不需要手动配置比例,降低了调优难度。
+更大的堆支持:
+G1设计之初就考虑了大容量堆的管理,能够有效管理数十GB甚至上百GB的堆内存,而CMS在大堆上的表现可能不佳。
+整体性能和吞吐量:
+在很多场景下,G1能够提供与CMS相当甚至更好的吞吐量,同时保持较低的暂停时间。
+
+
+## Stop The World
+Java中Stop-The-World机制简称STW,是在执行垃圾收集算法时,Java应用程序的其他所有线程都被挂起。Java中一种全局暂停现象,全局停顿,所有Java代码停止,native代码可以执行,但不能与JVM交互
+
+STW总会发生,不管是新生代还是老年代,比如CMS在初始标记和重复标记阶段会停顿,G1在初始标记阶段也会停顿,所以并不是选择了一款停顿时间低的垃圾收集器就可以避免STW的,我们只能尽量去减少STW的时间。
+
+那么为什么一定要STW?因为在定位堆中的对象时JVM会记录下对所有对象的引用,如果在定位对象过程中,有新的对象被分配或者刚记录下的对象突然变得无法访问,就会导致一些问题,比如部分对象无法被回收,更严重的是如果GC期间分配的一个GC Root对象引用了准备被回收的对象,那么该对象就会被错误地回收。
+
+## [Java内存模型](https://mp.weixin.qq.com/s/ME_rVwhstQ7FGLPVcfpugQ)
+定义:JMM是一种规范,目的是解决由于多线程通过共享内存进行通信时,存在的本地内存数据不一致、编译器会对代码指令重排序、处理器会对代码乱序执行等带来的问题。目的是保证并发编程场景中的原子性、可见性和有序性
+
+实现:volatile、synchronized、final、concurrent包等。其实这些就是Java内存模型封装了底层的实现后提供给程序员使用的一些关键字
+
+
+
主内存:所有变量都保存在主内存中
工作内存:每个线程的独立内存,保存了该线程使用到的变量的主内存副本拷贝,线程对变量的操作必须在工作内存中进行
-
-
每个线程都有自己的本地内存共享副本,如果A线程要更新主内存还要让B线程获取更新后的变量,那么需要:
1. 将本地内存A中更新共享变量
2. 将更新的共享变量刷新到主内存中
3. 线程B从主内存更新最新的共享变量
+## [happens-before](https://www.cnblogs.com/chenssy/p/6393321.html)
+我们无法就所有场景来规定某个线程修改的变量何时对其他线程可见,但是我们可以指定某些规则,这规则就是happens-before。特别关注在多线程之间的内存可见性。
+
+它是判断数据是否存在竞争、线程是否安全的主要依据,依靠这个原则,我们解决在并发环境下两操作之间是否可能存在冲突的所有问题。
+
+1. 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作;
+2. 锁定规则:一个unLock操作先行发生于后面对同一个锁额lock操作;
+3. volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作;
+4. 传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C;
+5. 线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作;
+6. 线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生;
+7. 线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行;
+8. 对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始;
+
## JVM调优
-[https://www.ibm.com/developerworks/cn/java/j-lo-jvm-optimize-experience/index.html](https://www.ibm.com/developerworks/cn/java/j-lo-jvm-optimize-experience/index.html)
+前提:在进行GC优化之前,需要确认项目的架构和代码等已经没有优化空间
+
+目的:优化JVM垃圾收集性能从而增大吞吐量或减少停顿时间,让应用在某个业务场景上发挥最大的价值。吞吐量是指应用程序线程用时占程序总用时的比例。暂停时间是应用程序线程让与GC线程执行而完全暂停的时间段
+
+对于交互性web应用来说,一般都是减少停顿时间,所以有以下方法:
+
+1. 如果应用存在大量的短期对象,应该选择较大的年轻代;如果存在相对较多的持久对象,老年代应该适当增大
+2. 让大对象进入年老代。可以使用参数-XX:PetenureSizeThreshold 设置大对象直接进入年老代的阈值。当对象的大小超过这个值时,将直接在年老代分配
+3. 设置对象进入年老代的年龄。如果对象每经过一次 GC 依然存活,则年龄再加 1。当对象年龄达到阈值时,就移入年老代,成为老年对象
+4. 使用关注系统停顿的 CMS 回收器
+
+基础:https://www.ibm.com/developerworks/cn/java/j-lo-jvm-optimize-experience/index.html
+
+案例:https://www.wangtianyi.top/blog/2018/07/27/jvmdiao-you-ru-men-er-shi-zhan-diao-you-parallelshou-ji-qi/
+
+
+## java中的==和equals有什么区别
+==:
+
+1. ==操作符专门用来比较变量的值是否相同。如果比较的对象是基本数据类型,则比较数值是否相等;如果比较的是引用数据类型,则比较的是对象的内存地址是否相等。
+2. 因为Java只有值传递,所以对于==来说,不管是比较基本数据类型,还是引用数据类型的变量,其本质比较的都是值,只是引用类型变量存的值是对象的地址。引用类型对象变量其实是一个引用,它们的值是指向对象所在的内存地址,而不是对象本身。
+
+equals:
+
+1. equals方法常用来比较对象的内容是否相同。
+2. equals()方法存在于Object类中,而Object类是所有类的直接或间接父类。
+3. 未重写equals方法的类:Object中的equals方法实际使用的也是==操作符,比较的是他们的内存地址是否同一地址。
+4. 重写了equals方法的类:实现该类自己的equals方法比较逻辑(一般是比较对象的内容是否相同)。比如:
+5. String:比较字符串内容,内容相同这相同;
+6. Integer:比较对应的基本数据类型int的值是否相同(==操作符)。
diff --git "a/MD/Java\345\237\272\347\241\200-NIO.md" "b/MD/Java\345\237\272\347\241\200-NIO.md"
deleted file mode 100644
index 3a947e0..0000000
--- "a/MD/Java\345\237\272\347\241\200-NIO.md"
+++ /dev/null
@@ -1,11 +0,0 @@
-## NIO
-一种同步非阻塞的高效IO交互模型,比同步阻塞IO区别如下:
-
-1. 通过缓冲区而非流的方式进行数据的交互,流是进行直接的传输的没有对数据操作的余地,缓冲区提供了灵活的数据处理方式。
-2. NIO是非阻塞的,意味着每个socket连接可以让底层操作系统帮我们完成而不需要每次开个线程去保持连接,使用的是selector监听所有channel的状态实现。
-3. NIO提供直接内存复制方式,消除了JVM与操作系统之间读写内存的损耗。
-
-### 同步异步、阻塞非阻塞
-同步和异步在于多个任务执行过程中,后发起的任务是否必须等先发起的任务完成之后再进行,是方法被调用的顺序。
-
-阻塞和非阻塞在于请求的方法是否立即返回,是方法被执行的方式。
diff --git "a/MD/Java\345\237\272\347\241\200-\345\244\232\347\272\277\347\250\213.md" "b/MD/Java\345\237\272\347\241\200-\345\244\232\347\272\277\347\250\213.md"
index feb7818..a06a026 100644
--- "a/MD/Java\345\237\272\347\241\200-\345\244\232\347\272\277\347\250\213.md"
+++ "b/MD/Java\345\237\272\347\241\200-\345\244\232\347\272\277\347\250\213.md"
@@ -1,4 +1,9 @@
## 多线程
+### 线程的生命周期
+新建 -- 就绪 -- 运行 -- 阻塞 -- 就绪 -- 运行 -- 死亡
+
+
+
### 问:你怎么理解多线程的
1. 定义:多线程是指从软件或者硬件上实现多个线程并发执行的技术。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多于一个线程,进而提升整体处理性能。
@@ -6,9 +11,9 @@
3. 实现:在Java里如何实现线程,Thread、Runnable、Callable。
4. 问题:线程可以获得更大的吞吐量,但是开销很大,线程栈空间的大小、切换线程需要的时间,所以用到线程池进行重复利用,当线程使用完毕之后就放回线程池,避免创建与销毁的开销。
-### 线程同步/线程间通信的方式
-https://fangjian0423.github.io/2016/04/18/java-synchronize-way/
-https://github.com/crossoverJie/Java-Interview/blob/master/MD/concurrent/thread-communication.md
+### 线程间通信的方式
+1. 等待通知机制 wait()、notify()、join()、interrupted()
+2. 并发工具synchronized、lock、CountDownLatch、CyclicBarrier、Semaphore
### 锁
#### 锁是什么
@@ -35,18 +40,41 @@ notifyAll:唤醒等待队列中等待该对象锁的全部线程,让其竞
**我们写同步的时候,优先考虑synchronized,如果有特殊需要,再进一步优化。ReentrantLock和Atomic如果用的不好,不仅不能提高性能,还可能带来灾难。**
-### 有几种锁
-#### 可重入锁
-如果锁具备可重入性,则称作为可重入锁。像synchronized和ReentrantLock都是可重入锁
-#### 可中断锁
-可中断锁:顾名思义,就是可以interrupt()中断的锁。 在Java中,synchronized就不是可中断锁,而Lock是可中断锁。
-如果某一线程A正在执行锁中的代码,另一线程B正在等待获取该锁,可能由于等待时间过长,线程B不想等待了,想先处理其他事情,我们可以让它中断自己或者在别的线程中中断它,这种就是可中断锁。
-#### 公平锁
-公平锁即尽量以请求锁的顺序来获取锁。比如同是有多个线程在等待一个锁,当这个锁被释放时,等待时间最久的线程(最先请求的线程)会获得该所,这种就是公平锁。 非公平锁即无法保证锁的获取是按照请求锁的顺序进行的。这样就可能导致某个或者一些线程永远获取不到锁。
-在Java中,synchronized就是非公平锁,它无法保证等待的线程获取锁的顺序。而对于ReentrantLock和ReentrantReadWriteLock,它默认情况下是非公平锁,但是可以设置为公平锁。
-#### 读写锁
-读写锁将对一个资源(比如文件)的访问分成了2个锁,一个读锁和一个写锁。正因为有了读写锁,才使得多个线程之间的读操作不会发生冲突。
-ReadWriteLock就是读写锁,它是一个接口,ReentrantReadWriteLock实现了这个接口。可以通过readLock()获取读锁,通过writeLock()获取写锁。
+#### 锁的种类
+* 公平锁/非公平锁
+
+公平锁是指多个线程按照申请锁的顺序来获取锁
+ReentrantLock通过构造函数指定该锁是否是公平锁,默认是非公平锁。Synchronized是一种非公平锁
+
+* 可重入锁
+
+指在同一个线程在外层方法获取锁的时候,在进入内层方法会自动获取锁
+ReentrantLock, 他的名字就可以看出是一个可重入锁,其名字是Re entrant Lock重新进入锁
+Synchronized,也是一个可重入锁。可重入锁的一个好处是可一定程度避免死锁
+
+* 独享锁/共享锁
+
+独享锁是指该锁一次只能被一个线程所持有。共享锁是指该锁可被多个线程所持有
+ReentrantLock是独享锁。但是对于Lock的另一个实现类ReadWriteLock,其读锁是共享锁,其写锁是独享锁
+读锁的共享锁可保证并发读是非常高效的,读写,写读 ,写写的过程是互斥的
+Synchronized是独享锁
+
+* 乐观锁/悲观锁
+
+悲观锁在Java中的使用,就是各种锁
+乐观锁在Java中的使用,是CAS算法,典型的例子就是原子类,通过CAS自旋实现原子操作的更新
+
+* 偏向锁/轻量级锁/重量级锁
+
+针对Synchronized的锁状态:
+偏向锁是为了减少无竞争且只有一个线程使用锁的情况下,使用轻量级锁产生的性能消耗。指一段同步代码一直被一个线程所访问,在无竞争情况下把整个同步都消除掉
+轻量级锁是为了减少无实际竞争情况下,使用重量级锁产生的性能消耗。指当锁是偏向锁的时候,被另一个线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过CAS自旋的形式尝试获取锁,不会阻塞
+重量级锁是指当锁为轻量级锁的时候,另一个线程虽然是自旋,但自旋不会一直持续下去,当自旋一定次数的时候,还没有获取到锁,就会进入阻塞,该锁膨胀为重量级锁
+
+* 自旋锁/自适应自旋锁
+
+指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,这样的好处是减少线程上下文切换的消耗,缺点是循环会消耗CPU,默认自旋次数为10
+自适应自旋锁的自旋次数不再固定,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态决定,是虚拟机对锁状况的一个预测
### volatile
功能:
@@ -55,7 +83,16 @@ ReadWriteLock就是读写锁,它是一个接口,ReentrantReadWriteLock实现
2. 禁止 JVM 进行的指令重排序。
### ThreadLocal
-使用`ThreadLocal userInfo = new ThreadLocal()`的方式,让每个线程内部都会维护一个ThreadLocalMap,里边包含若干了 Entry(K-V 键值对),每次存取都会先的都当前线程,然后得到该线程对象中的Map,然后与Map交互。
+1. 定义:ThreadLocal变量每个线程都会有这个变量的一个本地拷贝,多个线程操作这个变量的时候,实际是在操作自己本地内存里面的变量,从而起到线程隔离的作用,避免了并发场景下的线程安全问题。
+2. 原理:Thread线程类有一个类型为ThreadLocal.ThreadLocalMap的实例变量threadLocals,即每个线程都有一个属于自己的ThreadLocalMap。ThreadLocalMap内部维护着Entry数组,每个Entry代表一个完整的对象,key是ThreadLocal本身,value是ThreadLocal的泛型值。并发多线程场景下,每个线程Thread,在往ThreadLocal里设置值的时候,都是往自己的ThreadLocalMap里存,读也是以某个ThreadLocal作为引用,在自己的map里找对应的key,从而可以实现了线程隔离。
+3. Entry的Key为什么要设计成弱引用:如果Key使用强引用:当ThreadLocal的对象被回收了,但是ThreadLocalMap还持有ThreadLocal的强引用的话,如果没有手动删除,ThreadLocal就不会被回收,会出现Entry的内存泄漏问题。如果Key使用弱引用:当ThreadLocal的对象被回收了,因为ThreadLocalMap持有ThreadLocal的弱引用,即使没有手动删除,ThreadLocal也会被回收。value则在下一次ThreadLocalMap调用set,get,remove的时候会被清除。
+
+
+1. 强引用:我们平时new了一个对象就是强引用,例如 Object obj = new Object();即使在内存不足的情况下,JVM宁愿抛出OutOfMemory错误也不会回收这种对象。
+2. 软引用:如果一个对象只具有软引用,则内存空间足够,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存。
+3. 弱引用:具有弱引用的对象拥有更短暂的生命周期。如果一个对象只有弱引用存在了,则下次GC将会回收掉该对象(不管当前内存空间足够与否)。
+4. 虚引用:如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。虚引用主要用来跟踪对象被垃圾回收器回收的活动。
+
### 线程池
#### 起源
@@ -65,9 +102,212 @@ new Thread弊端:
* 线程缺乏统一管理,可以无限制的新建线程,导致OOM。线程池可以控制可以创建、执行的最大并发线程数。
* 缺少工程实践的一些高级的功能如定期执行、线程中断。线程池提供定期执行、并发数控制功能
-[http://www.wangtianyi.top/blog/2018/05/08/javagao-bing-fa-wu-xian-cheng-chi/](http://www.wangtianyi.top/blog/2018/05/08/javagao-bing-fa-wu-xian-cheng-chi/)
-[https://www.jianshu.com/p/edd7cb4eafa0](https://www.jianshu.com/p/edd7cb4eafa0)
+#### 线程池时核心参数
+
+* corePoolSize:核心线程数量,线程池中应该常驻的线程数量
+* maximumPoolSize:线程池允许的最大线程数,非核心线程在超时之后会被清除
+* workQueue:阻塞队列,存储等待执行的任务
+* keepAliveTime:线程没有任务执行时可以保持的时间
+* unit:时间单位
+* threadFactory:线程工厂,来创建线程
+* rejectHandler:当拒绝任务提交时的策略(抛异常、用调用者所在的线程执行任务、丢弃队列中第一个任务执行当前任务、直接丢弃任务)
+
+#### 线程池几个核心参数在CPU密集型、IO密集型业务场景的配置
+核心线程数(Core Pool Size)
+CPU 密集型:CPU 密集型任务主要依赖处理器资源,因此推荐将核心线程数设置为等于 CPU 核心数或稍高于 CPU 核心数(例如 CPU核数 + 1),以充分利用硬件资源,减少上下文切换的开销。
+IO 密集型:IO 密集型任务在等待 IO 操作完成时不会占用 CPU,这时可以设置更多的核心线程,通常可以是 2 * CPU核数 + 1 或者更高,以便在等待 IO 期间能有更多线程准备处理后续的计算任务。
+
+线程保持存活时间(Keep-Alive Time)
+CPU 密集型:通常设置较短的保持存活时间,因为CPU密集型任务一旦完成,线程可能不需要再次激活,过多的空闲线程会浪费资源。
+IO 密集型:可以设置较长的保持存活时间,允许线程在等待下一次 IO 操作时保持一段时间的空闲状态,以备快速响应新的请求。
+
+工作队列(Work Queue)
+CPU 密集型:可以选择较小的有界阻塞队列,比如 SynchronousQueue,这可以防止过多的线程创建,保持核心线程始终忙碌。
+IO 密集型:可以使用较大的有界队列,如 LinkedBlockingQueue,允许更多的任务在等待,减少线程的创建和销毁。
+
+#### 创建线程的逻辑
+以下任务提交逻辑来自ThreadPoolExecutor.execute方法:
+
+1. 如果运行的线程数 < corePoolSize,直接创建新线程,即使有其他线程是空闲的
+2. 如果运行的线程数 >= corePoolSize
+ 2.1 如果插入队列成功,则完成本次任务提交,但不创建新线程
+ 2.2 如果插入队列失败,说明队列满了
+ 2.2.1 如果当前线程数 < maximumPoolSize,创建新的线程放到线程池中
+ 2.2.2 如果当前线程数 >= maximumPoolSize,会执行指定的拒绝策略
+
+#### [阻塞队列的策略](https://blog.csdn.net/hayre/article/details/53291712)
+* 直接提交。SynchronousQueue是一个没有数据缓冲的BlockingQueue,生产者线程对其的插入操作put必须等待消费者的移除操作take。将任务直接提交给线程而不保持它们。
+* 无界队列。当使用无限的 maximumPoolSizes 时,将导致在所有corePoolSize线程都忙时新任务在队列中等待。
+* 有界队列。当使用有限的 maximumPoolSizes 时,有界队列(如ArrayBlockingQueue)有助于防止资源耗尽,但是可能较难调整和控制。
### 并发包工具类
-[http://www.wangtianyi.top/blog/2018/05/01/javagao-bing-fa-xi-lie-si-:juc/](http://www.wangtianyi.top/blog/2018/05/01/javagao-bing-fa-xi-lie-si-:juc/)
-[https://blog.csdn.net/mzh1992/article/details/60957351](https://blog.csdn.net/mzh1992/article/details/60957351)
\ No newline at end of file
+#### CountDownLatch
+计数器闭锁是一个能阻塞主线程,让其他线程满足特定条件下主线程再继续执行的线程同步工具。
+
+
+图中,A为主线程,A首先设置计数器的数到AQS的state中,当调用await方法之后,A线程阻塞,随后每次其他线程调用countDown的时候,将state减1,直到计数器为0的时候,A线程继续执行。
+
+使用场景:
+并行计算:把任务分配给不同线程之后需要等待所有线程计算完成之后主线程才能汇总得到最终结果
+模拟并发:可以作为并发次数的统计变量,当任意多个线程执行完成并发任务之后统计一次即可
+
+#### Semaphore
+信号量是一个能阻塞线程且能控制统一时间请求的并发量的工具。比如能保证同时执行的线程最多200个,模拟出稳定的并发量。
+
+```java
+public class CountDownLatchTest {
+
+ public static void main(String[] args) {
+ ExecutorService executorService = Executors.newCachedThreadPool();
+ Semaphore semaphore = new Semaphore(3); //配置只能发布3个运行许可证
+ for (int i = 0; i < 100; i++) {
+ int finalI = i;
+ executorService.execute(() -> {
+ try {
+ semaphore.acquire(3); //获取3个运行许可,如果获取不到会一直等待,使用tryAcquire则不会等待
+ Thread.sleep(1000);
+ System.out.println(finalI);
+ semaphore.release(3);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ });
+ }
+ executorService.shutdown();
+ }
+}
+```
+
+由于同时获取3个许可,所以即使开启了100个线程,但是每秒只能执行一个任务
+
+使用场景:
+数据库连接并发数,如果超过并发数,等待(acqiure)或者抛出异常(tryAcquire)
+
+#### CyclicBarrier
+可以让一组线程相互等待,当每个线程都准备好之后,所有线程才继续执行的工具类
+
+
+
+与CountDownLatch类似,都是通过计数器实现的,当某个线程调用await之后,计数器减1,当计数器大于0时将等待的线程包装成AQS的Node放入等待队列中,当计数器为0时将等待队列中的Node拿出来执行。
+
+与CountDownLatch的区别:
+1. CountDownLatch是一个线程等其他线程,CyclicBarrier是多个线程相互等待
+2. CyclicBarrier的计数器能重复使用,调用多次
+
+使用场景:
+有四个游戏玩家玩游戏,游戏有三个关卡,每个关卡必须要所有玩家都到达后才能允许通过。其实这个场景里的玩家中如果有玩家A先到了关卡1,他必须等到其他所有玩家都到达关卡1时才能通过,也就是说线程之间需要相互等待。
+
+### 编程题
+交替打印奇偶数
+
+```java
+public class PrintOddAndEvenShu {
+ private int value = 0;
+
+ private synchronized void printOdd() {
+ while (value <= 100) {
+ if (value % 2 == 1) {
+ System.out.println(Thread.currentThread() + ": -" + value++);
+ this.notify();
+ } else {
+ try {
+ this.wait();
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+
+ }
+
+ }
+
+ private synchronized void printEven() {
+ while (value <= 100) {
+ if (value % 2 == 0) {
+ System.out.println(Thread.currentThread() + ": --" + value++);
+ this.notify();
+ } else {
+ try {
+ this.wait();
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+ }
+ }
+
+ public static void main(String[] args) throws InterruptedException {
+ PrintOddAndEvenShu print = new PrintOddAndEvenShu();
+ Thread t1 = new Thread(print::printOdd);
+ Thread t2 = new Thread(print::printEven);
+ t1.start();
+ t2.start();
+ t1.join();
+ t2.join();
+ }
+}
+```
+
+
+多线程交替打印alibaba: https://blog.csdn.net/CX610602108/article/details/106427979
+我自行实现的简单解法:
+```java
+
+public class Test {
+ private int currentI = 0;
+
+ private synchronized void printSpace(int inputLength) {
+ while (true) {
+ if (currentI == inputLength) {
+ currentI = 0;
+ System.out.print(" ");
+ this.notifyAll();
+ } else {
+ try {
+ this.wait();
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+ }
+ }
+
+ private synchronized void printLetter(int i, char c) {
+ while (true) {
+ if (i == currentI) {
+ currentI++;
+ System.out.print(c);
+ this.notifyAll();
+ } else {
+ try {
+ this.wait();
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+ }
+ }
+
+ private synchronized void print(String input) throws Exception {
+ Test test = new Test();
+ for (int i = 0; i < input.length(); i++) {
+ char c = input.charAt(i);
+ int finalI = i;
+ Thread tt = new Thread(() -> test.printLetter(finalI, c));
+ tt.start();
+ }
+ Thread space = new Thread(() -> test.printSpace(input.length()));
+ space.start();
+ space.join();
+ }
+
+
+ public static void main(String[] args) throws Exception {
+ Test test = new Test();
+ test.print("alibaba");
+ }
+}
+
+```
+
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git "a/MD/Java\345\237\272\347\241\200-\351\233\206\345\220\210.md" "b/MD/Java\345\237\272\347\241\200-\351\233\206\345\220\210.md"
index bdbc830..deee610 100644
--- "a/MD/Java\345\237\272\347\241\200-\351\233\206\345\220\210.md"
+++ "b/MD/Java\345\237\272\347\241\200-\351\233\206\345\220\210.md"
@@ -1,9 +1,4 @@
## 集合
-### List、Set、Map区别
-Set中的对象不按特定方式排序,并且没有重复对象。但它的有些实现类能对集合中的对象按特定方式排序,例如TreeSet类,它可以按照默认排序,也可以通过实现java.util.Comparator接口来自定义排序方式。
-List中的对象按照索引位置排序,可以有重复对象,允许按照对象在集合中的索引位置检索对象,如通过list.get(i)方式来获得List集合中的元素。
-Map中的每一个元素包含一个键对象和值对象,它们成对出现。键对象不能重复,值对象可以重复。
-
### ArrayList与LinkedList区别
|ArrayList|LinkedList|
@@ -14,35 +9,39 @@ Map中的每一个元素包含一个键对象和值对象,它们成对出现
|扩容之后容量为原来的1.5倍|无|
### HashMap
-[面试必问的几个点](http://www.importnew.com/7099.html)
-
-(1)JDK 1.8 以前 HashMap 的实现是 数组+链表,即使哈希函数取得再好,也很难达到元素百分百均匀分布。
-
-(2)当 HashMap 中有大量的元素都存放到同一个桶中时,这个桶下有一条长长的链表,这个时候 HashMap 就相当于一个单链表,假如单链表有 n 个元素,遍历的时间复杂度就是 O(n),完全失去了它的优势。
-
-(3)针对这种情况,JDK 1.8 中引入了红黑树(查找时间复杂度为 O(logn))来优化这个问题
-
-### HashMap和HashTable区别
-1. Hashtable中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。
-2. Hashtable中,key和value都不允许出现null值。HashMap中,null可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为null。
-3. 哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
-4. Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。
+1. JDK 1.8 以前 HashMap 的实现是 数组+单链表,即使哈希函数取得再好,也很难达到元素百分百均匀分布。当 HashMap 中有大量的元素都存放到同一个桶中时,这个桶下有一条长长的链表,这个时候 HashMap 就相当于一个单链表,假如单链表有 n 个元素,遍历的时间复杂度就是 O(n),完全失去了它的优势。针对这种情况,JDK 1.8 中引入了红黑树(查找时间复杂度为 O(logn))来优化这个问题
+2. 为什么线程不安全?多线程PUT操作时可能会覆盖刚PUT进去的值;扩容操作会让链表形成环形数据结构,形成死循环
+3. 容量的默认大小是 16,负载因子是 0.75,当 HashMap 的 size > 16*0.75 时就会发生扩容(容量和负载因子都可以自由调整)。
+4. 为什么容量是2的倍数?在根据hashcode查找数组中元素时,取模性能远远低于与性能,且和2^n-1进行与操作能保证各种不同的hashcode对应的元素也能均匀分布在数组中
+
+### HashMap rehash过程:
+1.7:
+1. 空间不够用了,所以需要分配一个大一点的空间,然后保存在里面的内容需要重新计算 hash
+2. 在准备好新的数组后,map会遍历数组的每个“桶”,然后遍历桶中的每个Entity,重新计算其hash值(也有可能不计算),找到新数组中的对应位置,以头插法插入新的链表
+3. 因为是头插法,因此新旧链表的元素位置会发生转置现象。元素迁移的过程中在多线程情境下有可能会触发死循环(无限进行链表反转),因此HashMap线程不安全
+
+1.8:
+1. 底层结构为:数组+单链表/红黑树。因此如果某个桶中的链表长度大于等于8了,则会判断当前的hashmap的容量是否大于64,如果小于64,则会进行扩容;如果大于64,则将链表转为红黑树
+2. java1.8+在扩容时,不需要重新计算元素的hash进行元素迁移。而是用原先位置key的hash值与旧数组的长度(oldCap)进行"与"操作。
+3. 如果结果是0,那么当前元素的桶位置不变。
+4. 如果结果为1,那么桶的位置就是原位置+原数组 长度
+5. 值得注意的是:为了防止java1.7之前元素迁移头插法在多线程是会造成死循环,java1.8+后使用尾插法
### ConcurrentHashMap原理
[http://www.jasongj.com/java/concurrenthashmap/](http://www.jasongj.com/java/concurrenthashmap/)
-HashTable 在每次同步执行时都要锁住整个结构。ConcurrentHashMap 锁的方式是稍微细粒度的。 ConcurrentHashMap 将 hash 表分为 16 个桶(默认值)
-
+HashTable 在每次同步执行时都要锁住整个结构。ConcurrentHashMap 锁的方式是稍微细粒度的。 ConcurrentHashMap 将 hash 表分为 16 个桶(默认值)
+最大并发个数就是Segment的个数,默认值是16,可以通过构造函数改变一经创建不可更改,这个值就是并发的粒度,每一个segment下面管理一个table数组,加锁的时候其实锁住的是整个segment
#### Java7
-
+
ConcurrentHashMap 类中包含两个静态内部类 HashEntry 和 Segment。HashEntry 用来封装映射表的键 / 值对;Segment 用来充当锁的角色,每个 Segment 对象守护整个散列映射表的若干个桶。每个桶是由若干个 HashEntry 对象链接起来的链表。一个 ConcurrentHashMap 实例中包含由若干个 Segment 对象组成的数组。
#### Java8
-
-
-Java 8为进一步提高并发性,摒弃了分段锁的方案,而是直接使用一个大的数组。同时为了提高哈希碰撞下的寻址性能,Java 8在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为O(N))转换为红黑树(寻址时间复杂度为O(long(N))
+
-Java 8的ConcurrentHashMap同样是通过Key的哈希值与数组长度取模确定该Key在数组中的索引。
+1. 为进一步提高并发性,放弃了分段锁,锁的级别控制在了更细粒度的table元素级别,也就是说只需要锁住这个链表的head节点,并不会影响其他的table元素的读写,好处在于并发的粒度更细,影响更小,从而并发效率更好
+2. 使用CAS + synchronized 来保证实现put操作:如果Key对应的数组元素为null,则通过CAS操作将其设置为当前值。如果Key对应的数组元素(也即链表表头或者树的根元素)不为null,则对该元素使用synchronized关键字申请锁,然后进行操作。如果该put操作使得当前链表长度超过一定阈值,则将链表(寻址时间复杂度为O(N))转换为红黑树(寻址时间复杂度为O(log(N)),插入操作完成之后如果所有元素的数量大于当前容量(默认16)*负载因子(默认0.75)就进行扩容。
+
-对于put操作,如果Key对应的数组元素为null,则通过CAS操作将其设置为当前值。如果Key对应的数组元素(也即链表表头或者树的根元素)不为null,则对该元素使用synchronized关键字申请锁,然后进行操作。如果该put操作使得当前链表长度超过一定阈值,则将该链表转换为树,从而提高寻址效率。
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git a/MD/Linux.md b/MD/Linux.md
deleted file mode 100644
index 4abe92f..0000000
--- a/MD/Linux.md
+++ /dev/null
@@ -1,10 +0,0 @@
-## 硬链接与软链接的区别
-每个文件都是创建了一个指针指向inode(代表物理硬盘的一个区块),可以通过`ls -i`查看。
-硬链接是创建另一个文件,也通过创建指针指向inode。当你删除一个文件/硬链接时,它会删除一个到底层inode的指针。当inode的所有指针都被删除时,才会真正删除文件。
-软连接是另外一种类型的文件,保存的是它指向文件的全路径,访问时会替换成绝对路径
-
-## 查看某个进程中的线程
-`ps -T -p `
-
-## 查看某个文件夹中每个文件夹的大小
-`du --max-depth=1 -h`
\ No newline at end of file
diff --git a/MD/TCP.md b/MD/TCP.md
deleted file mode 100644
index fe46332..0000000
--- a/MD/TCP.md
+++ /dev/null
@@ -1,8 +0,0 @@
-## TCP过程
-## 三次握手、四次挥手
-[https://blog.csdn.net/qq_18425655/article/details/52163228](https://blog.csdn.net/qq_18425655/article/details/52163228)
-
-## 与UDP区别
-* TCP提供面向连接的、可靠的数据流传输,而UDP提供的是非面向连接的、不可靠的数据流传输,如QQ
-* TCP注重数据安全性,UDP数据传输快,因为不需要连接等待,少了许多操作,但是其安全性却一般
-* TCP对应的协议(FTP/SMTP/HTTP),UCP(DNS/)
\ No newline at end of file
diff --git "a/MD/Web\346\241\206\346\236\266-Spring.md" "b/MD/Web\346\241\206\346\236\266-Spring.md"
index 0c7fa73..ada11b3 100644
--- "a/MD/Web\346\241\206\346\236\266-Spring.md"
+++ "b/MD/Web\346\241\206\346\236\266-Spring.md"
@@ -30,9 +30,17 @@ Spring是个包含一系列功能的合集,如快速开发的Spring Boot,支
### IOC(DI)
-控制反转:原来是自己主动去new一个对象去用,现在是由容器工具配置文件创建实例让自己用,以前是自己去找妹子亲近,现在是有中介帮你找妹子,让你去挑选,说白了就是用面向接口编程和配置文件减少对象间的耦合,同时解决硬编码的问题(XML)
+* 控制反转
-依赖注入:在运行过程中当你需要这个对象才给你实例化并注入其中,不需要管什么时候注入的,只需要写好成员变量和set方法
+由 Spring IOC 容器来负责对象的生命周期和对象之间的关系。IoC 容器控制对象的创建,依赖对象的获取被反转了
+没有 IoC 的时候我们都是在自己对象中主动去创建被依赖的对象,这是正转。但是有了 IoC 后,所依赖的对象直接由 IoC 容器创建后注入到被注入的对象中,依赖的对象由原来的主动获取变成被动接受,所以是反转
+
+* 依赖注入
+
+组件之间依赖关系由容器在运行期决定,由容器动态的将某个依赖关系注入到组件之中,提升组件重用的频率、灵活、可扩展
+通过依赖注入机制,我们只需要通过简单的配置,而无需任何代码就可指定目标需要的资源,完成自身的业务逻辑,而不需要关心具体的资源来自何处,由谁实现
+
+注入方式:构造器注入、setter 方法注入、接口方式注入
### Spring AOP
#### 介绍
@@ -48,3 +56,5 @@ cglib工具:利用asm开源包,对代理对象类的class文件加载进来
1. 如果目标对象实现了接口,默认情况下会采用JDK的动态代理实现AOP
2. 如果目标对象实现了接口,可以强制使用CGLIB实现AOP
3. 如果目标对象没有实现了接口,必须采用CGLIB库,spring会自动在JDK动态代理和CGLIB之间转换
+
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git "a/MD/\345\210\206\345\270\203\345\274\217-CAP\347\220\206\350\256\272.md" "b/MD/\345\210\206\345\270\203\345\274\217-CAP\347\220\206\350\256\272.md"
new file mode 100644
index 0000000..a509eca
--- /dev/null
+++ "b/MD/\345\210\206\345\270\203\345\274\217-CAP\347\220\206\350\256\272.md"
@@ -0,0 +1,63 @@
+## 理论
+CAP原则又称CAP定理,指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可兼得。
+
+* 一致性(C):对某个指定的客户端来说,读操作能返回最新的写操作结果
+* 可用性(A):非故障节点在合理的时间返回合理的响应
+* 分区容错性(P):分区容错性是指当网络出现分区(两个节点之间无法连通)之后,系统能否继续履行职责
+
+CAP理论就是说在分布式系统中,最多只能实现上面的两点。而由于当前的网络硬件肯定会出现延迟丢包等问题,所以考虑最差情况,分区容忍性是一般是需要实现的
+
+虽然 CAP 理论定义是三个要素中只能取两个,但放到分布式环境下来思考,我们会发现必须选择 P(分区容忍)要素,因为网络本身无法做到 100% 可靠,有可能出故障,所以分区是一个必然的现象。如果我们选择了 CA 而放弃了 P,那么当发生分区现象时,为了保证 C,系统需要禁止写入,当有写入请求时,系统返回 error(例如,当前系统不允许写入),这又和 A 冲突了,因为 A 要求返回 no error 和 no timeout。因此,分布式系统理论上不可能选择 CA 架构,只能选择 CP 或者 AP 架构。
+
+BASE理论的核心思想是:BASE是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)的缩写,它接受在短时间内可能存在的不一致性,但保证最终达到一致性。与ACID(原子性、一致性、隔离性、持久性)相比,BASE更注重系统的可用性和可伸缩性,牺牲了严格的即时一致性。
+
+## 强一致如何实现
+什么是强一致性:在分布式存储系统中,强一致性是指系统保证任意时刻数据是一致的,即无论在任何节点上进行的操作,都能立即在所有节点上访问到最新的数据。
+
+分布式共识算法。其中,Paxos 和 Raft 是两个著名的共识算法,它们可以用于实现分布式系统的强一致性。这些算法通过选举和投票来确保各个节点的操作顺序一致,从而达到强一致性的要求。
+1. Paxos 算法通过多个阶段的提议、投票和决议过程来确保一个值被所有参与者接受。算法包括提议者(Proposer)、接受者(Acceptor)和学习者(Learner)的角色,并且使用一系列编号递增的消息来进行通信,确保在任何时候只有一个提议会被接受。
+2. Raft 使用了明确的领导者(Leader)角色,简化了状态机复制的过程。领导者负责处理所有的客户端请求并维护集群状态的一致性。它通过日志复制、心跳机制以及选举流程确保在任何时刻都有一个有效的领导者,并保持集群内的日志一致性。
+3. Raft 可以看作是对 Paxos 算法的一种工程化改进,它保留了 Paxos 对于分布式一致性问题的核心解决方案,同时通过对算法进行模块化和清晰化设计,极大地降低了开发者理解和实施分布式共识协议的难度
+
+
+## 数据一致性解决方案
+强一致性(Strong Consistency)
+通过事务(如ACID事务)确保每次操作都看到最新的数据状态。这通常需要两阶段提交(2PC)或其他复杂的事务协议,但可能导致性能下降。
+
+最终一致性(Eventual Consistency)
+允许短暂的数据不一致,但保证在一段时间后所有副本间达到一致。这种模型在分布式系统中广泛使用,如Cassandra和Amazon DynamoDB。
+
+分布式事务
+如两阶段提交(2PC)、三阶段提交(3PC)和多阶段提交(MPC)等协议,用于跨节点的事务协调。
+
+复制策略
+同步复制:更新在所有副本之间同步完成,保证强一致性,但可能影响性能。
+异步复制:更新在主节点上完成,副本随后更新,牺牲一致性以换取性能。
+
+PAXOS/Raft共识算法
+用于在分布式系统中选举领导者并达成一致性决策。
+
+幂等性设计
+确保多次执行相同操作不会改变系统状态,有助于防止因重试或网络问题导致的数据不一致
+
+## 高可用多活面试题
+解释什么是“多活”架构,并描述其在高可用性中的作用。
+多活架构是指在一个分布式系统中,多个数据中心或节点同时处于活动状态,每个节点都能独立处理请求,从而提高系统的可用性和容灾能力。当某个节点出现故障时,其他节点仍能继续提供服务。
+
+描述一下典型的多活架构部署策略,例如如何处理数据同步和流量路由。
+多活架构通常采用数据同步机制(如主从复制、分布式数据库)保持数据一致性,同时使用智能DNS、负载均衡器或路由策略将流量分散到各个活节点。在故障发生时,可以快速切换流量路由,确保服务不中断。
+
+如何在多活架构中实现故障检测和自动切换?
+通过心跳检测、健康检查、Zookeeper或Consul等服务发现机制监控各个节点的状态,一旦检测到故障,立即触发流量切换策略,将流量导向其他正常运行的节点。
+
+谈谈多活架构下的数据一致性挑战及解决方案
+数据一致性是多活架构中的主要挑战。可以采用异步复制、分布式事务(如2PC、Saga)、最终一致性等方法来平衡数据一致性和高可用性。
+
+如何设计一个高可用多活系统?请简述关键要素。
+关键要素包括:负载均衡(如DNS轮询、硬件负载均衡器)、数据复制与一致性(如主从复制、分布式数据库)、故障检测与切换机制(如健康检查、心跳检测)、网络连通性保障(如SDN、专线连接)、自动化运维工具(如自动化部署、监控报警)。
+
+多活架构面临的主要挑战有哪些?如何解决?
+主要挑战包括数据一致性、网络延迟、故障检测与恢复、运维复杂度等。解决方案涉及采用合适的数据同步技术、优化网络架构(如使用CDN、专线)、实施自动化运维工具、以及建立完善的监控和告警体系。
+
+在多活架构中,如何处理跨数据中心的事务?
+可以采用分布式事务协调服务(如Seata、LRA),或者通过Saga模式、TCC(Try-Confirm-Cancel)模式来处理跨数据中心的长事务,确保事务的原子性和一致性。
diff --git "a/MD/\345\210\206\345\270\203\345\274\217-ID\347\224\237\346\210\220\346\226\271\345\274\217.md" "b/MD/\345\210\206\345\270\203\345\274\217-ID\347\224\237\346\210\220\346\226\271\345\274\217.md"
new file mode 100644
index 0000000..4fe2f64
--- /dev/null
+++ "b/MD/\345\210\206\345\270\203\345\274\217-ID\347\224\237\346\210\220\346\226\271\345\274\217.md"
@@ -0,0 +1,41 @@
+### UUID
+优:
+
+1. 本地生成没有了网络之类的消耗,效率非常高
+
+缺:
+
+1. 不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用。
+2. 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
+
+### snowflake
+这种方案把64-bit分别划分成多段(机器、时间)
+
+优:
+
+1. 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的
+2. 本地生成没有了网络之类的消耗,效率非常高
+3. 可以根据自身业务特性分配bit位,非常灵活。
+
+缺:
+
+1. 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态
+
+### 数据库
+可以利用 MySQL 中的自增属性 auto_increment 来生成全局唯一 ID,也能保证趋势递增。 但这种方式太依赖 DB,如果数据库挂了那就非常容易出问题。
+
+优:
+
+1. 非常简单,利用现有数据库系统的功能实现,成本小,有DBA专业维护。
+2. ID号单调自增,可以实现一些对ID有特殊要求的业务。
+
+缺:
+
+1. 强依赖DB,当DB异常时整个系统不可用,属于致命问题。配置主从复制可以尽可能的增加可用性,但是数据一致性在特殊情况下难以保证。主从切换时的不一致可能会导致重复发号。
+2. ID发号性能瓶颈限制在单台MySQL的读写性能。
+
+参考:
+https://tech.meituan.com/MT_Leaf.html
+https://github.com/crossoverJie/Java-Interview/blob/master/MD/ID-generator.md
+
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git "a/MD/\345\210\206\345\270\203\345\274\217-\344\270\200\350\207\264\346\200\247hash.md" "b/MD/\345\210\206\345\270\203\345\274\217-\344\270\200\350\207\264\346\200\247hash.md"
new file mode 100644
index 0000000..4e2b9c2
--- /dev/null
+++ "b/MD/\345\210\206\345\270\203\345\274\217-\344\270\200\350\207\264\346\200\247hash.md"
@@ -0,0 +1,74 @@
+# 一致 Hash 算法
+分布式缓存中,如何将数据均匀的分散到各个节点中,并且尽量的在加减节点时能使受影响的数据最少。
+
+## Hash 取模
+随机放置就不说了,会带来很多问题。通常最容易想到的方案就是 `hash 取模`了。
+
+可以将传入的 Key 按照 `index = hash(key) % N` 这样来计算出需要存放的节点。其中 hash 函数是一个将字符串转换为正整数的哈希映射方法,N 就是节点的数量。
+
+这样可以满足数据的均匀分配,但是这个算法的容错性和扩展性都较差。
+
+比如增加或删除了一个节点时,所有的 Key 都需要重新计算,显然这样成本较高,为此需要一个算法满足分布均匀同时也要有良好的容错性和拓展性。
+
+## 一致 Hash 算法
+
+一致 Hash 算法是将所有的哈希值构成了一个环,其范围在 `0 ~ 2^32-1`。如下图:
+
+
+
+之后将各个节点散列到这个环上,可以用节点的 IP、hostname 这样的唯一性字段作为 Key 进行 `hash(key)`,散列之后如下:
+
+
+
+之后需要将数据定位到对应的节点上,使用同样的 `hash 函数` 将 Key 也映射到这个环上。
+
+
+
+这样按照顺时针方向就可以把 k1 定位到 `N1节点`,k2 定位到 `N3节点`,k3 定位到 `N2节点`。
+
+### 容错性
+这时假设 N1 宕机了:
+
+
+
+依然根据顺时针方向,k2 和 k3 保持不变,只有 k1 被重新映射到了 N3。这样就很好的保证了容错性,当一个节点宕机时只会影响到少少部分的数据。
+
+### 拓展性
+
+当新增一个节点时:
+
+
+
+在 N2 和 N3 之间新增了一个节点 N4 ,这时会发现受影响的数据只有 k3,其余数据也是保持不变,所以这样也很好的保证了拓展性。
+
+## 虚拟节点
+到目前为止该算法依然也有点问题:
+
+当节点较少时会出现数据分布不均匀的情况:
+
+
+
+这样会导致大部分数据都在 N1 节点,只有少量的数据在 N2 节点。
+
+为了解决这个问题,一致哈希算法引入了虚拟节点。将每一个节点都进行多次 hash,生成多个节点放置在环上称为虚拟节点:
+
+
+
+计算时可以在 IP 后加上编号来生成哈希值。
+
+这样只需要在原有的基础上多一步由虚拟节点映射到实际节点的步骤即可让少量节点也能满足均匀性。
+
+https://github.com/crossoverJie/JCSprout/blob/master/MD/Consistent-Hash.md
+
+## Redis用了吗?
+降低扩容缩容时传统哈希算法重建映射影响范围,一致性哈希不是唯一的解决办法。
+
+redis 缓存采用了固定哈希槽的方式维护 Key 和存储节点的关系。每个节点负责一部分槽,槽的总数是固定的 16384,无论节点数怎么变, Key 进行哈希运算再对槽总数取模的值都是不变的。
+
+插入数据时,先算出数据应该分配到哪个槽,再去查槽在哪个节点,这样就实现了把 Key 通过哈希算法均匀的分布到大量的槽上。槽分配到哪个节点是人为配置的,只要配置的槽均匀,最终节点上的 Key 就会均匀分布到物理节点,扩容缩容时也只需要迁移部分槽的数据。
+
+在一致性哈希算法中,引入虚拟节点其实和固定哈希槽有异曲同工之妙,都是将最终存储的节点和数据的 Key 之间多做一层转换,避免节点总数的变动影响太多映射关系,虽然固定哈希槽不如一致性哈希加虚拟节点灵活,但是考虑到 redis 的存储的数据量级与多数分布式数据库相比差距很大, 固定哈希槽策略对于 redis 已经完全够用了。
+
+一致性哈希算法的应用非常广泛,在分布式数据库 Cassandra 、缓存Memcache、分布式服务框架Dubbo中都有应用。
+
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git "a/MD/\345\210\206\345\270\203\345\274\217-\344\272\213\345\212\241.md" "b/MD/\345\210\206\345\270\203\345\274\217-\344\272\213\345\212\241.md"
new file mode 100644
index 0000000..0272354
--- /dev/null
+++ "b/MD/\345\210\206\345\270\203\345\274\217-\344\272\213\345\212\241.md"
@@ -0,0 +1,79 @@
+### 两阶段提交方案/XA方案
+所谓的 XA 方案,即:两阶段提交,有一个**事务管理器**的概念,负责协调多个数据库(资源管理器)的事务,事务管理器先问问各个数据库你准备好了吗?如果每个数据库都回复 ok,那么就正式提交事务,在各个数据库上执行操作;如果任何其中一个数据库回答不 ok,那么就回滚事务。
+
+这种分布式事务方案,比较适合单块应用里,跨多个库的分布式事务,而且因为严重依赖于数据库层面来搞定复杂的事务,效率很低,绝对不适合高并发的场景。如果要玩儿,那么基于 `Spring + JTA` 就可以搞定,自己随便搜个 demo 看看就知道了。
+
+这个方案,我们很少用,一般来说**某个系统内部如果出现跨多个库**的这么一个操作,是**不合规**的。我可以给大家介绍一下, 现在微服务,一个大的系统分成几十个甚至几百个服务。一般来说,我们的规定和规范,是要求**每个服务只能操作自己对应的一个数据库**。
+
+如果你要操作别的服务对应的库,不允许直连别的服务的库,违反微服务架构的规范,你随便交叉胡乱访问,几百个服务的话,全体乱套,这样的一套服务是没法管理的,没法治理的,可能会出现数据被别人改错,自己的库被别人写挂等情况。
+
+如果你要操作别人的服务的库,你必须是通过**调用别的服务的接口**来实现,绝对不允许交叉访问别人的数据库。
+
+
+
+### TCC 方案
+TCC 的全称是:Try、Confirm、Cancel。
+
+- Try 阶段:这个阶段说的是对各个服务的资源做检测以及对资源进行**锁定或者预留**。
+- Confirm 阶段:这个阶段说的是在各个服务中**执行实际的操作**。
+- Cancel 阶段:如果任何一个服务的业务方法执行出错,那么这里就需要**进行补偿**,就是执行已经执行成功的业务逻辑的回滚操作。(把那些执行成功的回滚)
+
+这种方案说实话几乎很少人使用,我们用的也比较少,但是也有使用的场景。因为这个**事务回滚**实际上是**严重依赖于你自己写代码来回滚和补偿**了,会造成补偿代码巨大,非常之恶心。
+
+比如说我们,一般来说跟**钱**相关的,跟钱打交道的,**支付**、**交易**相关的场景,我们会用 TCC,严格保证分布式事务要么全部成功,要么全部自动回滚,严格保证资金的正确性,保证在资金上不会出现问题。
+
+而且最好是你的各个业务执行的时间都比较短。
+
+但是说实话,一般尽量别这么搞,自己手写回滚逻辑,或者是补偿逻辑,实在太恶心了,那个业务代码很难维护。
+
+
+
+### 本地消息表
+本地消息表其实是国外的 ebay 搞出来的这么一套思想。
+
+这个大概意思是这样的:
+
+1. A 系统在自己本地一个事务里操作同时,插入一条数据到消息表;
+2. 接着 A 系统将这个消息发送到 MQ 中去;
+3. B 系统接收到消息之后,在一个事务里,往自己本地消息表里插入一条数据,同时执行其他的业务操作,如果这个消息已经被处理过了,那么此时这个事务会回滚,这样**保证不会重复处理消息**;
+4. B 系统执行成功之后,就会更新自己本地消息表的状态以及 A 系统消息表的状态;
+5. 如果 B 系统处理失败了,那么就不会更新消息表状态,那么此时 A 系统会定时扫描自己的消息表,如果有未处理的消息,会再次发送到 MQ 中去,让 B 再次处理;
+6. 这个方案保证了最终一致性,哪怕 B 事务失败了,但是 A 会不断重发消息,直到 B 那边成功为止。
+
+这个方案说实话最大的问题就在于**严重依赖于数据库的消息表来管理事务**啥的,会导致如果是高并发场景咋办呢?咋扩展呢?所以一般确实很少用。
+
+
+
+### 可靠消息最终一致性方案
+这个的意思,就是干脆不要用本地的消息表了,直接基于 MQ 来实现事务。比如阿里的 RocketMQ 就支持消息事务。
+
+大概的意思就是:
+
+1. A 系统先发送一个 prepared 消息到 mq,如果这个 prepared 消息发送失败那么就直接取消操作别执行了;
+2. 如果这个消息发送成功过了,那么接着执行本地事务,如果成功就告诉 mq 发送确认消息,如果失败就告诉 mq 回滚消息;
+3. 如果发送了确认消息,那么此时 B 系统会接收到确认消息,然后执行本地的事务;
+4. mq 会自动**定时轮询**所有 prepared 消息回调你的接口,问你,这个消息是不是本地事务处理失败了,所有没发送确认的消息,是继续重试还是回滚?一般来说这里你就可以查下数据库看之前本地事务是否执行,如果回滚了,那么这里也回滚吧。这个就是避免可能本地事务执行成功了,而确认消息却发送失败了。
+5. 这个方案里,要是系统 B 的事务失败了咋办?重试咯,自动不断重试直到成功,如果实在是不行,要么就是针对重要的资金类业务进行回滚,比如 B 系统本地回滚后,想办法通知系统 A 也回滚;或者是发送报警由人工来手工回滚和补偿。
+6. 这个还是比较合适的,目前国内互联网公司大都是这么玩儿的,要不你举用 RocketMQ 支持的,要不你就自己基于类似 ActiveMQ?RabbitMQ?自己封装一套类似的逻辑出来,总之思路就是这样子的。
+
+
+
+### 最大努力通知方案
+这个方案的大致意思就是:
+
+1. 系统 A 本地事务执行完之后,发送个消息到 MQ;
+2. 这里会有个专门消费 MQ 的**最大努力通知服务**,这个服务会消费 MQ 然后写入数据库中记录下来,或者是放入个内存队列也可以,接着调用系统 B 的接口;
+3. 要是系统 B 执行成功就 ok 了;要是系统 B 执行失败了,那么最大努力通知服务就定时尝试重新调用系统 B,反复 N 次,最后还是不行就放弃。
+
+### 你们公司是如何处理分布式事务的?
+如果你真的被问到,可以这么说,我们某某特别严格的场景,用的是 TCC 来保证强一致性;然后其他的一些场景基于阿里的 RocketMQ 来实现分布式事务。
+
+你找一个严格资金要求绝对不能错的场景,你可以说你是用的 TCC 方案;如果是一般的分布式事务场景,订单插入之后要调用库存服务更新库存,库存数据没有资金那么的敏感,可以用可靠消息最终一致性方案。
+
+友情提示一下,RocketMQ 3.2.6 之前的版本,是可以按照上面的思路来的,但是之后接口做了一些改变,我这里不再赘述了。
+
+当然如果你愿意,你可以参考可靠消息最终一致性方案来自己实现一套分布式事务,比如基于 RocketMQ 来玩儿。
+
+https://github.com/doocs/advanced-java/blob/master/docs/distributed-system/distributed-transaction.md
+
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git "a/MD/\345\210\206\345\270\203\345\274\217-\345\215\217\350\260\203\345\231\250.md" "b/MD/\345\210\206\345\270\203\345\274\217-\345\215\217\350\260\203\345\231\250.md"
new file mode 100644
index 0000000..f82e197
--- /dev/null
+++ "b/MD/\345\210\206\345\270\203\345\274\217-\345\215\217\350\260\203\345\231\250.md"
@@ -0,0 +1,23 @@
+### 分布式协调
+这个其实是 zookeeper 很经典的一个用法,简单来说,就好比,你 A 系统发送个请求到 mq,然后 B 系统消息消费之后处理了。那 A 系统如何知道 B 系统的处理结果?用 zookeeper 就可以实现分布式系统之间的协调工作。A 系统发送请求之后可以在 zookeeper 上**对某个节点的值注册个监听器**,一旦 B 系统处理完了就修改 zookeeper 那个节点的值,A 立马就可以收到通知,完美解决。
+
+
+
+### 分布式锁
+举个栗子。对某一个数据连续发出两个修改操作,两台机器同时收到了请求,但是只能一台机器先执行完另外一个机器再执行。那么此时就可以使用 zookeeper 分布式锁,一个机器接收到了请求之后先获取 zookeeper 上的一把分布式锁,就是可以去创建一个 znode,接着执行操作;然后另外一个机器也**尝试去创建**那个 znode,结果发现自己创建不了,因为被别人创建了,那只能等着,等第一个机器执行完了自己再执行。
+
+
+
+### 元数据/配置信息管理
+zookeeper 可以用作很多系统的配置信息的管理,比如 kafka、storm 等等很多分布式系统都会选用 zookeeper 来做一些元数据、配置信息的管理,包括 dubbo 注册中心不也支持 zookeeper 么?
+
+
+
+### HA高可用性
+这个应该是很常见的,比如 hadoop、hdfs、yarn 等很多大数据系统,都选择基于 zookeeper 来开发 HA 高可用机制,就是一个**重要进程一般会做主备**两个,主进程挂了立马通过 zookeeper 感知到切换到备用进程。
+
+
+
+https://github.com/doocs/advanced-java/blob/master/docs/distributed-system/zookeeper-application-scenarios.md
+
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git "a/MD/\345\210\206\345\270\203\345\274\217-\346\266\210\346\201\257\351\230\237\345\210\227.md" "b/MD/\345\210\206\345\270\203\345\274\217-\346\266\210\346\201\257\351\230\237\345\210\227.md"
index 7551589..02fd880 100644
--- "a/MD/\345\210\206\345\270\203\345\274\217-\346\266\210\346\201\257\351\230\237\345\210\227.md"
+++ "b/MD/\345\210\206\345\270\203\345\274\217-\346\266\210\346\201\257\351\230\237\345\210\227.md"
@@ -1,10 +1,63 @@
-## 消息队列
-消息队列是为了解决**生产和消费的速度不一致**导致的问题,有以下好处:
+## 优点
1. 减少请求响应时间。比如注册功能需要调用第三方接口来发短信,如果等待第三方响应可能会需要很多时间
2. 服务之间解耦。主服务只关心核心的流程,其他不重要的、耗费时间流程是否如何处理完成不需要知道,只通知即可
3. 流量削锋。对于不需要实时处理的请求来说,当并发量特别大的时候,可以先在消息队列中作缓存,然后陆续发送给对应的服务去处理
-如果想要实现一个消息队列,可以参考[这里](https://zhuanlan.zhihu.com/p/21649950)
-最简单的消息队列就是一个消息转发器,基本功能只有三个:消息存储、消息发送、消息删除,可使用LinkedBlockingQueue、ConcurrentLinkedQueue实现
+## 缺点
+1. 系统可用性降低。系统引入的外部依赖越多,越容易挂掉。
+2. 系统复杂度提高。保证消息没有重复消费?处理消息丢失的情况?保证消息传递的顺序性?
-对于消息队列另外一个通俗易懂的[解释](https://www.zhihu.com/question/34243607)
+## 消息重复消费问题
+1. 消费端处理消息的业务逻辑保持幂等性,在消费端实现
+2. 利用一张日志表来记录已经处理成功的消息的ID,如果新到的消息ID已经在日志表中,那么就不再处理这条消息。消息系统实现,也可以消费端实现
+
+## 消息丢失问题
+### 生产者弄丢了数据
+生产者将数据发送到 RabbitMQ 的时候,可能数据就在半路给搞丢了。
+
+RabbitMQ 提供的事务功能,就是生产者发送数据之前开启 RabbitMQ 事务。然后发送消息,如果消息没有成功被 RabbitMQ 接收到,那么生产者会收到异常报错。但吞吐量会下来,因为太耗性能。
+
+可以开启confirm模式,你每次写的消息都会分配一个唯一的 id,然后如果写入了 RabbitMQ 中,RabbitMQ 会给你回传一个ack消息,告诉你说这个消息 ok 了。事务机制是同步的,但confirm机制是异步的,发送个消息之后就可以发送下一个消息,RabbitMQ 接收了之后会异步回调你一个接口通知你这个消息接收到了。所以用confirm机制
+
+### RabbitMQ 弄丢了数据
+RabbitMQ 自己挂掉导致数据丢失
+
+开启 RabbitMQ 的持久化,消息写入之后会持久化到磁盘,哪怕是 RabbitMQ 自己挂了,恢复之后会自动读取之前存储的数据
+
+### 消费端弄丢了数据
+RabbitMQ 如果丢失了数据,主要是因为你消费的时候,刚消费到,还没处理,结果进程挂了,比如重启了,RabbitMQ 认为你都消费了,这数据就丢了。
+
+关闭 RabbitMQ 的自动ack,可以通过一个 api 来调用就行,然后每次你自己代码里确保处理完的时候,再在程序里ack一把。RabbitMQ 就认为你还没处理完,这个时候 RabbitMQ 会把这个消费分配给别的 consumer 去处理,消息是不会丢的。
+
+## 消息顺序性
+消息有序指的是可以按照消息的发送顺序来消费。例如:一笔订单产生了 3 条消息,分别是订单创建、订单付款、订单完成。消费时,要按照顺序依次消费才有意义。
+
+消息体通过hash分派到队列里,每个队列对应唯一一个消费者。比如下面的示例中,订单号相同的消息会被先后发送到同一个队列中:
+
+
+
+在获取到路由信息以后,会根据MessageQueueSelector实现的算法来选择一个队列,同一个订单号获取到的肯定是同一个队列。
+
+## 集群模式
+### 普通集群模式
+在多台机器上启动多个 RabbitMQ 实例。你创建的 queue,只会放在一个 RabbitMQ 实例上,但是每个实例都同步 queue 的元数据(元数据可以认为是 queue 的一些配置信息,通过元数据,可以找到 queue 所在实例)。你消费的时候,实际上如果连接到了另外一个实例,那么那个实例会从 queue 所在实例上拉取数据过来。
+
+缺点是不能保证高可用、还有拉去数据的开销、以及单实例的性能瓶颈,所以这个方案是为了提高吞吐量的
+
+### 镜像集群模式
+每个 RabbitMQ 节点都有这个 queue 的一个完整镜像,包含 queue 的全部数据的意思。然后每次你写消息到 queue 的时候,都会自动把消息同步到多个实例的 queue 上。任何一个机器宕机了,没事儿,其它机器(节点)还包含了这个 queue 的完整数据,别的 consumer 都可以到其它节点上去消费数据。
+
+缺点是即时满足了高可用,但因为同步数据量太重导致难以扩展节点,也没有在架构上实现负载均衡,可以参考Redis的集群模式进行优化。
+
+### Kafka 的高可用性
+Kafka 一个最基本的架构认识:由多个 broker 组成,每个 broker 是一个节点;你创建一个 topic,这个 topic 可以划分为多个 partition,每个 partition 可以存在于不同的 broker 上,每个 partition 就放一部分数据
+
+每个 partition 的数据都会同步到其它机器上,形成自己的多个 replica 副本。所有 replica 会选举一个 leader 出来,那么生产和消费都跟这个 leader 打交道,然后其他 replica 就是 follower。写的时候,leader 会负责把数据同步到所有 follower 上去,读的时候就直接读 leader 上的数据即可。
+
+如果某个 broker 宕机了,没事儿,那个 broker上面的 partition 在其他机器上都有副本的,如果这上面有某个 partition 的 leader,那么此时会从 follower 中重新选举一个新的 leader 出来,大家继续读写那个新的 leader 即可。这就有所谓的高可用性了。
+
+
+
+https://github.com/doocs/advanced-java#%E6%B6%88%E6%81%AF%E9%98%9F%E5%88%97 https://dbaplus.cn/news-73-1123-1.html
+
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git "a/MD/\345\210\206\345\270\203\345\274\217-\351\224\201.md" "b/MD/\345\210\206\345\270\203\345\274\217-\351\224\201.md"
new file mode 100644
index 0000000..a1ced4a
--- /dev/null
+++ "b/MD/\345\210\206\345\270\203\345\274\217-\351\224\201.md"
@@ -0,0 +1,92 @@
+## 为什么用
+在分布式环境中,需要一种跨JVM的互斥机制来控制共享资源的访问。
+
+例如,为避免用户操作重复导致交易执行多次,使用分布式锁可以将第一次以外的请求在所有服务节点上立马取消掉。如果使用事务在数据库层面进行限制也能实现的但会增大数据库的压力。
+
+例如,在分布式任务系统中为避免统一任务重复执行,某个节点执行任务之后可以使用分布式锁避免其他节点在同一时刻得到任务
+
+## 实现方式
+### 数据库
+在数据库中创建一个表,表中包含方法名等字段,并在方法名字段上创建唯一索引,想要执行某个方法,就使用这个方法名向表中插入数据,成功插入则获取锁,执行完成后删除对应的行数据释放锁。
+
+```sql
+DROP TABLE IF EXISTS `method_lock`;
+CREATE TABLE `method_lock` (
+ `id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
+ `method_name` varchar(64) NOT NULL COMMENT '锁定的方法名',
+ `desc` varchar(255) NOT NULL COMMENT '备注信息',
+ `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
+ PRIMARY KEY (`id`),
+ UNIQUE KEY `uidx_method_name` (`method_name`) USING BTREE
+) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 COMMENT='锁定中的方法';
+```
+
+执行某个方法后,插入一条记录
+
+```sql
+INSERT INTO method_lock (method_name, desc) VALUES ('methodName', '测试的methodName');
+```
+
+因为我们对method_name做了唯一性约束,这里如果有多个请求同时提交到数据库的话,数据库会保证只有一个操作可以成功,那么我们就可以认为操作成功的那个线程获得了该方法的锁,可以执行方法体内容。
+
+成功插入则获取锁,执行完成后删除对应的行数据释放锁:
+
+```sql
+delete from method_lock where method_name ='methodName';
+```
+
+优点:易于理解实现
+
+缺点:
+
+1. 没有锁失效自动删除机制,因为有可能出现成功插入数据后,服务器宕机了,对应的数据没有被删除,当服务恢复后一直获取不到锁,所以,需要在表中新增一列,用于记录失效时间,并且需要有定时任务清除这些失效的数据
+2. 吞吐量很低
+3. 单点故障问题
+4. 轮询获取锁状态方式太过低效
+
+### 基于Redis
+NX是Redis提供的一个原子操作,如果指定key存在,那么NX失败,如果不存在会进行set操作并返回成功。我们可以利用这个来实现一个分布式的锁,主要思路就是,set成功表示获取锁,set失败表示获取失败,失败后需要重试。再加上EX参数可以让该key在超时之后自动删除。
+
+```java
+public void lock(String key, String request, int timeout) throws InterruptedException {
+ Jedis jedis = jedisPool.getResource();
+
+ while (timeout >= 0) {
+ String result = jedis.set(LOCK_PREFIX + key, request, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, DEFAULT_EXPIRE_TIME);
+ if (LOCK_MSG.equals(result)) {
+ jedis.close();
+ return;
+ }
+ Thread.sleep(DEFAULT_SLEEP_TIME);
+ timeout -= DEFAULT_SLEEP_TIME;
+ }
+}
+```
+
+优点:
+
+1. 吞吐量高
+2. 有锁失效自动删除机制,保证不会阻塞所有流程
+
+缺点:
+
+1. 单点故障问题
+2. 锁超时问题:如果A拿到锁之后设置了超时时长,但是业务还未执行完成且锁已经被释放,此时其他进程就会拿到锁从而执行相同的业务。如何解决?Redission定时延长超时时长避免过期。为什么不直接设置为永不超时?为了防范业务方没写解锁方法或者发生异常之后无法进行解锁的问题
+3. 轮询获取锁状态方式太过低效
+
+### 基于ZooKeeper
+1. 当客户端对某个方法加锁时,在Zookeeper上的与该方法对应的指定节点的目录下,生成一个临时有序节点
+2. 判断该节点是否是当前目录下最小的节点,如果是则获取成功;如果不是,则获取失败,并获取上一个临时有序节点,对该节点进行监听,当节点删除时通知唯一的客户端
+
+优点:
+
+1. 解决锁超时问题。因为Zookeeper的写入都是顺序的,在一个节点创建之后,其他请求再次创建便会失败,同时可以对这个节点进行Watch,如果节点删除会通知其他节点抢占锁
+2. 能通过watch机制高效通知其他节点获取锁,避免惊群效应
+3. 有锁失效自动删除机制,保证不会阻塞所有流程
+
+缺点:
+
+1. 性能不如Redis
+2. 强依赖zk,如果原来系统不用zk那就需要维护一套zk
+
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git "a/MD/\345\210\206\345\270\203\345\274\217-\351\231\220\346\265\201.md" "b/MD/\345\210\206\345\270\203\345\274\217-\351\231\220\346\265\201.md"
new file mode 100644
index 0000000..25a8611
--- /dev/null
+++ "b/MD/\345\210\206\345\270\203\345\274\217-\351\231\220\346\265\201.md"
@@ -0,0 +1,66 @@
+# 常见算法
+对于限流常见有两种算法:
+
+1. 漏桶算法
+2. 令牌桶算法
+
+漏桶算法比较简单,就是将流量放入桶中,漏桶同时也按照一定的速率流出,如果流量过快的话就会溢出(漏桶并不会提高流出速率)。溢出的流量则直接丢弃。
+
+如下图所示:
+
+
+
+漏桶算法虽说简单,但却不能应对实际场景,比如突然暴增的流量。
+
+这时就需要用到令牌桶算法:令牌桶会以一个恒定的速率向固定容量大小桶中放入令牌,当有流量来时则取走一个或多个令牌。当桶中没有令牌则将当前请求丢弃或阻塞。
+
+
+
+相比之下令牌桶可以应对一定的突发流量.
+
+# RateLimiter实现
+
+对于令牌桶的代码实现,可以直接使用Guava包中的RateLimiter。
+
+```java
+@Override
+public BaseResponse getUserByFeignBatch(@RequestBody UserReqVO userReqVO) {
+ //调用远程服务
+ OrderNoReqVO vo = new OrderNoReqVO() ;
+ vo.setReqNo(userReqVO.getReqNo());
+
+ RateLimiter limiter = RateLimiter.create(2.0) ;
+ //批量调用
+ for (int i = 0 ;i< 10 ; i++){
+ double acquire = limiter.acquire();
+ logger.debug("获取令牌成功!,消耗=" + acquire);
+ BaseResponse orderNo = orderServiceClient.getOrderNo(vo);
+ logger.debug("远程返回:"+JSON.toJSONString(orderNo));
+ }
+
+ UserRes userRes = new UserRes() ;
+ userRes.setUserId(123);
+ userRes.setUserName("张三");
+
+ userRes.setReqNo(userReqVO.getReqNo());
+ userRes.setCode(StatusEnum.SUCCESS.getCode());
+ userRes.setMessage("成功");
+
+ return userRes ;
+}
+```
+
+代码可以看出以每秒向桶中放入两个令牌,请求一次消耗一个令牌。所以每秒钟只能发送两个请求。按照图中的时间来看也确实如此(返回值是获取此令牌所消耗的时间,差不多也是每500ms一个)。
+
+使用RateLimiter 有几个值得注意的地方:
+
+允许先消费,后付款,意思就是它可以来一个请求的时候一次性取走几个或者是剩下所有的令牌甚至多取,但是后面的请求就得为上一次请求买单,它需要等待桶中的令牌补齐之后才能继续获取令牌。
+
+
+# 其他算法
+1. 固定窗口算法又叫计数器算法,是一种简单方便的限流算法。主要通过一个支持原子操作的计数器来累计 1 秒内的请求次数,当 1 秒内计数达到限流阈值时触发拒绝策略。每过 1 秒,计数器重置为 0 开始重新计数。虽然我们限制了 QPS 为 2,但是当遇到时间窗口的临界突变时,如 1s 中的后 500 ms 和第 2s 的前 500ms 时,虽然是加起来是 1s 时间,却可以被请求 4 次。
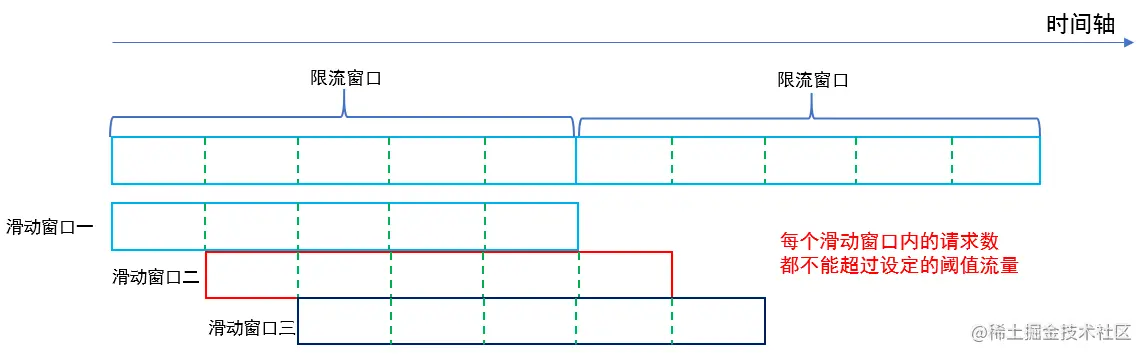
+2. 滑动窗口算法在固定窗口的基础上,将一个计时窗口分成了若干个小窗口,然后每个小窗口维护一个独立的计数器。当请求的时间大于当前窗口的最大时间时,则将计时窗口向前平移一个小窗口。平移时,将第一个小窗口的数据丢弃,然后将第二个小窗口设置为第一个小窗口,同时在最后面新增一个小窗口,将新的请求放在新增的小窗口中。同时要保证整个窗口中所有小窗口的请求数目之后不能超过设定的阈值。有效解决了窗口切换时可能会产生两倍于阈值流量请求的问题。
+
+
+
+
diff --git "a/MD/\345\234\250\347\272\277\347\274\226\347\250\213.md" "b/MD/\345\234\250\347\272\277\347\274\226\347\250\213.md"
deleted file mode 100644
index dbab3ac..0000000
--- "a/MD/\345\234\250\347\272\277\347\274\226\347\250\213.md"
+++ /dev/null
@@ -1,246 +0,0 @@
-### 二叉树反转
-
-原二叉树:
-```text
- 4
- / \
- 2 7
- / \ / \
-1 3 6 9
-
-反转后的二叉树:
-
- 4
- / \
- 7 2
- / \ / \
-9 6 3 1
-```
-
-```java
-import java.util.LinkedList;
-
-class TreeNode {
- public TreeNode left;
- public TreeNode right;
- public int value;
-
- public TreeNode(int value) {
- this.value = value;
- }
-
- public TreeNode invertNode(TreeNode root) {
- if (root == null) {
- return null;
- }
- TreeNode temp = root.left;
- root.left = invertNode(root.right);
- root.right = invertNode(temp);
- return root;
- }
-
- // 该方法是按二叉树每层从左往右的顺序打印结点,不属于本题考察的范围,但也属于面试题目中会考察的问题
- public void printTreeNode() {
- LinkedList queue = new LinkedList<>();
- queue.add(this);
-
- TreeNode currentLineRightestNode = this;
- TreeNode nextLineRightestNode = null;
-
- while (!queue.isEmpty()) {
- TreeNode currentNode = queue.poll();
-
- if (currentNode.left != null) {
- queue.add(currentNode.left);
- nextLineRightestNode = currentNode.left;
- }
- if (currentNode.right != null) {
- queue.add(currentNode.right);
- nextLineRightestNode = currentNode.right;
- }
-
- System.out.print(currentNode.value);
-
- if (currentNode.value == currentLineRightestNode.value) {
- System.out.println();
- currentLineRightestNode.value = nextLineRightestNode.value;
- }
- }
- }
-}
-
-public class ReverseBinaryTree {
- public static void main(String[] args) {
- TreeNode root = new TreeNode(4);
- root.left = new TreeNode(2);
- root.right = new TreeNode(7);
- root.left.left = new TreeNode(1);
- root.left.right = new TreeNode(3);
- root.right.left = new TreeNode(6);
- root.right.right = new TreeNode(9);
- root.printTreeNode();
- System.out.println("-------");
- root.invertNode(root);
- root.printTreeNode();
- }
-}
-```
-### [LRU淘汰算法](https://www.jianshu.com/p/62e829c37adf)
-
-LRU,全称Least Recently Used,最近最少使用缓存。
-
-在设计数据结构时,需要能够保持顺序,且是最近使用过的时间顺序被记录,这样每个item的相对位置代表了最近使用的顺序。满足这样考虑的结构可以是链表或者数组,不过链表更有利于Insert和Delete的操纵。
-
-```java
-import java.util.HashMap;
-import java.util.LinkedList;
-
-public class LRUCache2 {
- private HashMap cacheMap = new HashMap<>();
- private LinkedList recentlyList = new LinkedList<>();
- private int capacity;
-
- public LRUCache2(int capacity) {
- this.capacity = capacity;
- }
-
- private int get(int key) {
- if (!cacheMap.containsKey(key)) {
- return -1;
- }
-
- recentlyList.remove((Integer) key);
- recentlyList.add(key);
-
- return cacheMap.get(key);
- }
-
- private void put(int key, int value) {
- if (cacheMap.containsKey(key)) {
- recentlyList.remove((Integer) key);
- recentlyList.add(key);
- }
-
- if (cacheMap.size() == capacity) {
- cacheMap.remove(recentlyList.removeFirst());
- }
-
- cacheMap.put(key, value);
- recentlyList.add(key);
-
- }
-
- public static void main(String[] args) {
- LRUCache2 cache = new LRUCache2(2);
- cache.put(1, 1);
- cache.put(2, 2);
- System.out.println(cache.get(1)); // returns 1
- cache.put(3, 3); // 驱逐 key 2
- System.out.println(cache.get(2)); // returns -1 (not found)
- cache.put(4, 4); // 驱逐 key 1
- System.out.println(cache.get(1)); // returns -1 (not found)
- System.out.println(cache.get(3)); // returns 3
- System.out.println(cache.get(4)); // returns 4
- }
-}
-```
-
-### 连续子数组最大和
-https://www.nowcoder.com/profile/844008/codeBookDetail?submissionId=1519441
-
-### 快速排序
-```java
-
-import java.util.Arrays;
-
-public class QuickSort {
- public static void sort(int[] a, int low, int high) {
- int base = a[low];
- int lowTemp = low;
- int highTemp = high;
- while (low < high) {
- while (low < high && base < a[high]) {
- high--;
- }
- if (low < high) {
- int temp = a[low];
- a[low] = a[high];
- a[high] = temp;
- low++;
- }
- while (low < high && base > a[low]) {
- low++;
- }
- if (low < high) {
- int temp = a[low];
- a[low] = a[high];
- a[high] = temp;
- high--;
- }
- }
- if (low > lowTemp) {
- sort(a, lowTemp, low - 1);
- }
- if (high < highTemp) {
- sort(a, high + 1, highTemp);
- }
- }
-
- public static void main(String[] args) {
- int[] a = {4, 1, 2, 5, 2, 4, 3, 6, 3, 6, 7, 8, 3};
- sort(a, 0, a.length - 1);
- System.out.println(Arrays.toString(a));
- }
-
-}
-```
-
-### 交替打印奇偶数
-```java
-public class PrintOddAndEvenShu {
- private int value = 0;
-
- private synchronized void printOdd() {
- while (value <= 100) {
- if (value % 2 == 1) {
- System.out.println(Thread.currentThread() + ": -" + value++);
- this.notify();
- } else {
- try {
- this.wait();
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
-
- }
-
- }
-
- private synchronized void printEven() {
- while (value <= 100) {
- if (value % 2 == 0) {
- System.out.println(Thread.currentThread() + ": --" + value++);
- this.notify();
- } else {
- try {
- this.wait();
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- }
- }
-
- public static void main(String[] args) throws InterruptedException {
- PrintOddAndEvenShu print = new PrintOddAndEvenShu();
- Thread t1 = new Thread(print::printOdd);
- Thread t2 = new Thread(print::printEven);
- t1.start();
- t2.start();
- t1.join();
- t2.join();
- }
-}
-
-```
\ No newline at end of file
diff --git "a/MD/\345\276\256\346\234\215\345\212\241-\346\234\215\345\212\241\345\256\271\351\224\231\344\277\235\346\212\244.md" "b/MD/\345\276\256\346\234\215\345\212\241-\346\234\215\345\212\241\345\256\271\351\224\231\344\277\235\346\212\244.md"
new file mode 100644
index 0000000..8774157
--- /dev/null
+++ "b/MD/\345\276\256\346\234\215\345\212\241-\346\234\215\345\212\241\345\256\271\351\224\231\344\277\235\346\212\244.md"
@@ -0,0 +1,42 @@
+## 服务降级
+服务降级类似女生旅行:在用户访问量高峰期,整体资源面临不足的时候,将一些重要优先程度相对较低的服务先关掉,等到过了高峰期再恢复。比如京东商城在双十一期间,可能会对评论服务进行服务降级。
+
+回到微服务系统,服务A调用服务B,当我们对服务B进行降级后,服务A将直接调用预定义的降级逻辑(即方法调用代替跨服务请求),从而快速获取返回结果,而降级方法逻辑的返回结果与真实服务B的返回结果的区别 就好比 残次品与良品的区别,此时我们认为服务B所提供的服务质量降低了,即我所说的降级。
+
+```java
+// 主逻辑
+@FeignClient(value = "mst-goods-service", fallback = GoodClientFallback.class)
+public interface GoodsClient {
+ @RequestMapping(method = RequestMethod.GET, path = "/api/goods/{goods_id}")
+ GoodsDTO getOne(@PathVariable("goods_id") Long goodsId);
+}
+
+// 降级逻辑
+@Component
+public class GoodClientFallback implements GoodsClient {
+ @Override
+ public GoodsDTO getOne(Long goodsId) {
+ return new GoodsDTO(1l, 12.3, 2l, "name");
+ }
+}
+```
+
+## 服务熔断
+在分布式架构中,断路器模式的作用也是类似的,如果某个目标服务调用慢或者有大量超时,此时,熔断该服务的调用,对于后续调用请求,不再调用目标服务,直接返回结果,快速释放资源,避免最终因为服务不可用蔓延导致系统雪崩灾难。
+
+### 断路器什么时候会打开
+这里涉及到断路器的三个重要参数:
+
+1. 快照时间窗:断路器确定是否需要统计一些请求和错误数据,而统计的时间范围就是快照时间窗,默认10秒
+2. 请求总数下限:在快照时间窗内,必须满足请求总数下限才会启用熔断。默认20,意味着在10秒内,如果调用不足20次,即便所有的请求都失败,断路器都不会打开
+3. 错误百分比下限:当请求总数在快照时间内超过了下限,比如发生了30次调用,如果在这 30次调用中,有16次发生了超时异常,也就是超过50%的错误百分比,在默认设定50%下限的情况下,断路器就会打开
+
+### 断路器打开之后发生什么
+熔断打开之后,再有请求调用的时候,将不会调用主逻辑,而是直接调用降级逻辑,这个时候就会快速返回,而不是等待5秒后才返回fallback。通过断路器实现了自动发现错误并将降级逻辑切换为主逻辑,减少响应延迟的效果
+
+### 主逻辑如何恢复
+Hystrix会启动一个休眠时间窗,在这个时间窗内,降级逻辑是临时的成为主逻辑,当休眠时间窗到期,断路器就进入半开状态,释放一次请求到原来的主逻辑上。如果此次请求正常返回,那么断路器将会关闭,主逻辑恢复正常。否则,断路器继续保持打开状态,而休眠时间窗会重新计时
+
+https://sjyuan.cc/service-fault-tolerant-protected-with-hytrix/
+
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git "a/MD/\345\276\256\346\234\215\345\212\241-\346\234\215\345\212\241\346\263\250\345\206\214\344\270\216\345\217\221\347\216\260.md" "b/MD/\345\276\256\346\234\215\345\212\241-\346\234\215\345\212\241\346\263\250\345\206\214\344\270\216\345\217\221\347\216\260.md"
new file mode 100644
index 0000000..a909bf8
--- /dev/null
+++ "b/MD/\345\276\256\346\234\215\345\212\241-\346\234\215\345\212\241\346\263\250\345\206\214\344\270\216\345\217\221\347\216\260.md"
@@ -0,0 +1,18 @@
+## 定义
+在微服务应用中,运行的服务实例集会动态更改。实例能动态分配网络位置。所以为了使客户端向服务端发送请求它必须使用服务发现机制。
+
+客户端应用进程向注册中心发起查询,来获取服务的位置。服务发现的一个重要作用就是提供一个可用的服务列表。
+
+## 原理
+
+
+1. 当User Service启动的时候,会向Consul发送一个POST请求,告诉Consul自己的IP和Port
+2. Consul 接收到User Service的注册后,每隔10s(默认)会向User Service发送一个健康检查的请求,检验User Service是否健康(Consul其实支持其他健康检查机制)
+3. 当Order Service发送 GET 方式请求/api/addresses到User Service时,会先从Consul中拿到一个存储服务 IP 和 Port 的临时表,从表中拿到User Service的IP和Port后再发送GET方式请求/api/addresses
+4. 该临时表每隔10s会更新,只包含有通过了健康检查的Service
+
+上面注册、查询的逻辑不是Consul提供的,一般是你使用的微服务框架中已经封装好的服务注册发现功能,如果没有特殊的需求是不会修改这部分逻辑的
+
+https://sjyuan.cc/service-registration-and-discovery/
+
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git "a/MD/\345\276\256\346\234\215\345\212\241-\346\234\215\345\212\241\351\205\215\347\275\256\344\270\255\345\277\203.md" "b/MD/\345\276\256\346\234\215\345\212\241-\346\234\215\345\212\241\351\205\215\347\275\256\344\270\255\345\277\203.md"
new file mode 100644
index 0000000..640d453
--- /dev/null
+++ "b/MD/\345\276\256\346\234\215\345\212\241-\346\234\215\345\212\241\351\205\215\347\275\256\344\270\255\345\277\203.md"
@@ -0,0 +1,9 @@
+我们的每个服务的配置文件都是在自身代码库中,当服务数量达到一定数量后,管理这些分散的配置文件会成为一个痛点。这节课我么就来解决配置文件管理的痛点
+
+
+
+Spring Cloud Config的目标是将各个微服务的配置文件集中存储一个文件仓库中(比如系统目录,Git仓库等等),然后通过Config Server从文件仓库中去读取配置文件,而各个微服务作为Config Client通过给Config Server发送请求指令来获取特定的Profile的配置文件,从而为自身的应用提供配置信息。同时还提供配置文件自动刷新功能。
+
+https://sjyuan.cc/service-config-server/
+
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git "a/MD/\345\276\256\346\234\215\345\212\241-\347\275\221\345\205\263.md" "b/MD/\345\276\256\346\234\215\345\212\241-\347\275\221\345\205\263.md"
new file mode 100644
index 0000000..486fbe7
--- /dev/null
+++ "b/MD/\345\276\256\346\234\215\345\212\241-\347\275\221\345\205\263.md"
@@ -0,0 +1,24 @@
+## 定义
+API网关。它是系统的单个入口服务器。它类似于面向对象的外观模式。它封装了内部系统架构并且提供了每个客户端定制的API。它可能还有其他的职责比如身份验证、监控、负载均衡、缓存、请求整理和管理还有静态相应处理。
+
+## 优点
+### 流量统一管理、路由
+它用于解决微服务过于分散,没有一个统一的出入口进行流量管理、路由映射、监控、缓存、负载均衡的问题。 我们用两张图来解释:
+
+
+
+如上图所示的mst-user-service, mst-good-service, mst-order-service,这些应用会需要一些通用的功能,比如Authentication, 这些功能过于分散,代码就需要在三个服务中都写一遍,因此需要有一个统一的出入口来管理流量,就像下图
+
+
+
+### 设备适配
+ 还可以针对不同的渠道和客户端提供不同的API Gateway,对于该模式的使用由另外一个大家熟知的方式叫Backend for front-end, 在Backend for front-end模式当中,我们可以针对不同的客户端分别创建其BFF。
+
+
+### 协议转换
+客户端直接调用微服务可能会使用对网络不友好的协议。内部服务之间可能使用Thrift二进制RPC、gRPC协议。两个协议对浏览器不友好并且最好是在内部使用。应用应该在防火墙之外使用HTTP或者WebSocket之类的协议。
+
+## 缺点
+API网关是一个必须被开发、部署、管理的高可用组件。还有一个风险是它变成开发瓶颈。开发人员必须更新API网关来暴露每个微服务接口。因此更新API网关的过程越少越好。然而,对于大多数现实世界的应用,使用API网关是有意义的。
+
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git "a/MD/\346\220\234\347\264\242\345\274\225\346\223\216.md" "b/MD/\346\220\234\347\264\242\345\274\225\346\223\216.md"
deleted file mode 100644
index 5d92af9..0000000
--- "a/MD/\346\220\234\347\264\242\345\274\225\346\223\216.md"
+++ /dev/null
@@ -1,184 +0,0 @@
-
-
-
-* 网页采集
-* 内容过滤
-* 信息存储
-* 信息检索与后台管理
-
-## 爬虫
-### 原理
-仅仅针对网页的源代码进行下载,不包含信息结构化提取
-
-* 下载工具:使用HttlClient下载,放入Vector,用ConcurrentHashMap做爬虫深度控制
-* URL解析逻辑:将网页源代码中的URL过滤出来放入集合
-
-首先在下载队列中,需要安排一些源URL,当下载工具把网页源码下载下来之后,从中解析出能继续当成源URL的URL放入下载集合中,直到下载工具把下载集合中的内容都下载完成
-
-### 为什么用HttpClient为下载工具
-**简单易用,符合需求场景,不需要更高更强的功能**
-
-HttpURLConnection:本身的 API 不够友好,所提供的功能也有限
-HttpClient:功能强大
-OkHttp:是一个专注于性能和易用性的 HTTP 客户端。OkHttp 会使用连接池来复用连接以提高效率。OkHttp 提供了对 GZIP 的默认支持来降低传输内容的大小。OkHttp 也提供了对 HTTP 响应的缓存机制,可以避免不必要的网络请求。当网络出现问题时,OkHttp 会自动重试一个主机的多个 IP 地址
-
-### 为什么用Vector
-**多线程爬虫要保证线程安全,还可以控制容量扩充的大小**
-
-ArrayList,Vector主要区别为以下几点:
-
-1. Vector是线程安全的,源码中有很多的synchronized可以看出,而ArrayList不是。导致Vector效率无法和ArrayList相比;
-2. ArrayList和Vector都采用线性连续存储空间,当存储空间不足的时候,ArrayList默认增加为原来的50%,Vector默认增加为原来的一倍;
-3. Vector可以设置capacityIncrement,而ArrayList不可以,从字面理解就是capacity容量,Increment增加,容量增长的参数。
-
-### 为什么用ConcurrentHashMap做爬虫深度控制
-因为需要保存的是一个【URL -> 深度】的键值对,在爬虫下载的过程中需要通过多个线程高频地对这个键值对集合进行操作,所以在增加元素的时候需要进行同步操作以免元素被覆盖,还需要避免多线程reset导致的循环依赖问题
-
-### URL如何解析并保存
-在下载到网页源码之后,将其中的所有URL通过Jsoup或者对每行内容进行正则表达式提取出来,如果符合预设值的正则表达式就添加到下载集合中。
-
-### 多线程爬虫如何实现
-使用Executors.newFixedThreadPool(),因为我爬虫线程基本固定不会需要销毁重建,并且可以控制线程最大数量,方便日后根据机器性能调整。
-
-如果问到线程池的原理,请参[这里](http://www.wangtianyi.top/blog/2018/05/08/javagao-bing-fa-wu-xian-cheng-chi/)。
-
-### 抵抗反爬虫策略
-#### 动态页面的加载
-phantomjs + selenium
-
-#### 如何抓取需要登录的页面
-模拟登录之后将sessionId保存到request header的cookie中
-
-#### 如何解决IP限制问题
-买个支持ADSL的拨号服务器,便宜的一个月80
-
-
-#### 每分钟访问频率
-寻找网站访问频率访问限制漏洞,自己探索不同网站的访问频率限制规则
-
-#### 验证码
-图像识别
-
-### 如何实现数据库连接池
-1. 连接池的建立。使用外部配置的连接池信息初始化一定数量的连接,结合CopyOnWriteArrayList来存储连接
-2. 连接池的管理。当客户请求数据库连接时,从ThreadLocal或线程共享的连接池查看是否有空闲连接,如果存在空闲连接,则将连接的引用借给客户使用;如果没有空闲连接,则查看当前所开的连接数是否已经达到最大连接数,如果没达到就重新创建一个连接给请求的客户;如果达到就按设定的最大等待时间进行等待,如果超出最大等待时间,则抛出异常给客户。
-3. 连接池的关闭。当应用程序退出时,关闭连接池中所有的连接,释放连接池相关的资源,该过程正好与创建相反。
-
-#### [并发、性能问题](http://0x0010.com/2017/09/performance-promote-of-using-threadlocal-in-hikaricp/)
-使用synchronized、lock可解决多线程分发与回收线程问题。
-
-但性能问题还是很大,主要是因为**加锁、释放锁、挂起、恢复线程的上下文切换的开销**,所以为了提高性能,可进行以下方面的优化:
-避免同步操作,更换为其他操作。使用**ThreadLocal**将线程池的副本保存在每个线程中来减少锁竞争,同时结合**CAS乐观锁**处理连接的分发与回收
-
-#### 增加连接超时功能
-参考HikariCP中CurrentBag中borrow方法:
-
-```
-timeout = timeUnit.toNanos(timeout);
- do {
- final long start = currentTime();
- // 在一定时间内,阻塞地从SynchronousQueue中试图获取生产好的连接实例
- // 如果队列中没有可以用的连接实例,返回null
- // 如果队列中有可以用的实例,那么把状态改成USE并且返回
- final T bagEntry = handoffQueue.poll(timeout, NANOSECONDS);
- if (bagEntry == null || bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
- return bagEntry;
- }
-
- // timeout循环被减小,直到大于0.01毫秒
- timeout -= elapsedNanos(start);
- } while (timeout > 10_000);
-
-```
-
-
-
-### [如何存储查询大量的HTML文件](https://www.zhihu.com/question/26504749)
-
-因为下载下来的HTML文件都是小文件,所以使用HDFS存储需要考虑一下,但为了分布式与扩展还是使用。
-
-由于小文件会导致大量元数据的产生,那么变通的方法就是在文件中再创建文件,比如一个64MB的大文件,比如其中可以包含16384个4KB的小文件,但是这个64MB的大文件只占用了1个inode,而如果存放4KB的文件的话,就需要16384个inode了。
-
-那么如何寻址这个大文件中的小文件呢?方法就是利用一个旁路数据库来记录每个小文件在这个大文件中的起始位置和长度等信息,也就是说将传统文件系统的大部分元数据剥离了开来,拿到了单独的数据库中存放,这样通过查询外部数据库先找到小文件具体对应在哪个大文件中的从哪开始的多长,然后直接发起对这个大文件的对应地址段的读写操作即可。
-
-我们需要两种节点,namenode节点来管理元数据,datanode节点来存储数据。
-
-
-
-#### 实现思路
-
-* 文件被切块存储在多台服务器上
-* HDFS提供一个统一的平台与客户端交互
-* 每个文件都可以保存多个副本
-
-#### 优点
-1. 每个数据的副本数量固定,直接增加一台机器就可以实现线性扩展
-2. 有副本让存储可靠性高
-3. 可以处理的吞吐量增大
-
-## 解析HTML
-* 抽取网页数据放入索引表中,插入待建立索引的信息,等待建立索引
-* 剪切源文件到配置的路径,建立百度快照
-
-所以这里涉及到MySQL的使用,建立这样的一些表:
-
-* S_column:栏目表
-* S_index:配置索引然后创建索引产生的索引表,仅用于Lucene,对Lucene的查询是通过根据columnId来查数据库得到所在索引路径来查找,所以必须要把不同的栏目放在不同的文件夹中
-* S_index_column:上面两个表的多对多关联表
-* S_news:新闻业务表,存放新闻信息和某栏目的外键
-* S_user:用户表
-* T_index:保存仅用于Solr的索引信息,便于myfullretrieve建立Solr索引,对Solr的查询是通过用columnId来过滤得到的所有相关信息
-
-### TF-IDF
-#### 原理
-如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
-
-一个词在本文出现次数/本文总词数
-(文章总数/这个词在所有文章中出现次数)取对数
- 相乘
-
-#### 目的
-去掉网页内容相同或相似的网页
-
-#### 用法
-用TF-IDF统计每个文章中少数重要词(排序后的前几个),用MD5算法把每个词算出一个16进制的数全部加在一起然后比较两个总数,如果相同,那么两篇文章中重要的词就相同的,去掉。
-
-## Lucene原理
-### 搜索原理
-词项查询(TermQuery)
-布尔查询(BooleanQuery)
-短语查询(PhraseQuery)
-范围查询(RangeQuery)
-百搭查询(WildardQuery)
-FuzzQuery(模糊)
-
-### 倒排索引
-不是由记录来确定属性值,而是由属性值来确定记录的位置。
-
-#### 构建过程
-
-1. Analyzer分词
-2. 根据单词生成索引表,同时得到“词典文件”(词-> 单词ID)
-3. 得到“倒排列表”(单词ID -> 文档ID)
-
-设有两篇文章1和2
-文章1的内容为:Tom lives in Guangzhou,I live in Guangzhou too.
-文章2的内容为:He once lived in Shanghai.
-
-|关键词|文章号|出现频率|出现位置|
-|---|---|---|---|
-|guangzhou|1|2|3,6|
-|live|1|2|2,5|
-|live|2|1|2|
-|shanghai|2|1|3|
-|tom|1|1|1|
-
-Lucene将上面三列分别作为词典文件、频率文件、位置文件保存。其中词典文件不仅保存有每个关键词,还保留了指向频率文件和位置文件的指针,通过指针可以找到该关键字的频率信息和位置信息。
-
-#### 词典文件(HashMap)
-
-
-
-#### 倒排表
-
-
diff --git "a/MD/\346\225\260\346\215\256\345\272\223-MySQL.md" "b/MD/\346\225\260\346\215\256\345\272\223-MySQL.md"
index 58c4c7a..c2cebbb 100644
--- "a/MD/\346\225\260\346\215\256\345\272\223-MySQL.md"
+++ "b/MD/\346\225\260\346\215\256\345\272\223-MySQL.md"
@@ -5,31 +5,62 @@
2. InnoDB支持外键
3. InnoDB有行级锁,MyISAM是表级锁
-因为MyISAM相对简单所以在效率上要优于InnoDB。如果系统读多,写少,对原子性要求低。那么MyISAM最好的选择。
-如果系统读少,写多的时候,尤其是并发写入高的时候,还需要事务安全性。InnoDB就是首选了。
+MyISAM相对简单所以在效率上要优于InnoDB。如果系统插入和查询操作多,不需要事务外键。选择MyISAM
+如果需要频繁的更新、删除操作,或者需要事务、外键、行级锁的时候。选择InnoDB。
### [数据库性能优化](https://www.zhihu.com/question/19719997)
-1. 优化SQL语句和索引,在where/group by/order by中用到的字段建立索引,索引字段越小越好,复合索引简历的顺序
+1. 优化SQL语句和索引,在where/group by/order by中用到的字段建立索引,索引字段越小越好,复合索引建立的顺序
2. 加缓存,Memcached, Redis
3. 主从复制,读写分离
4. 垂直拆分,其实就是根据你模块的耦合度,将一个大的系统分为多个小的系统,也就是分布式系统
5. 水平切分,针对数据量大的表,这一步最麻烦,最能考验技术水平,要选择一个合理的sharding key,为了有好的查询效率,表结构也要改动,做一定的冗余,应用也要改,sql中尽量带sharding key,将数据定位到限定的表上去查,而不是扫描全部的表;
### [SQL优化](https://www.imooc.com/video/3711):
+优化步骤:
+
+1. 根据慢日志定位慢查询SQL
+2. 用explain分析SQL(type和extra字段分析)
+3. 修改SQL或加索引(如下)
* 对经常查询的列建立索引,但索引建多了当数据改变时修改索引会增大开销
* 使用精确列名查询而不是*,特别是当数据量大的时候
-* 减少[嵌套查询](http://www.cnblogs.com/zhengyun_ustc/p/slowquery3.html),使用Join替代
+* 减少[子查询](http://www.cnblogs.com/zhengyun_ustc/p/slowquery3.html),使用Join替代
* 不用NOT IN,因为会使用全表扫描而不是索引;不用IS NULL,NOT IS NULL,因为会使索引、索引统计和值更加复杂,并且需要额外一个字节的存储空间。
-问:有个表特别大,字段是姓名、年龄、班级,如果调用`select * from table where name = xxx and age = xxx`该如何通过建立索引的方式优化查询速度?
-答:由于mysql查询每次只能使用一个索引,如果在name、age两列上创建复合索引的话将带来更高的效率。如果我们创建了(name, age, class)的复合索引,那么其实相当于创建了(name, age, class)、(name, age)、(name)三个索引,这被称为最佳左前缀特性。因此我们在创建复合索引时应该将最常用作限制条件的列放在最左边,依次递减。其次还要考虑该列的数据离散程度,如果有很多不同的值的话建议放在左边。
-
问:max(xxx)如何用索引优化?
-答:在xxx列上建立索引,因为索引是B+树顺序排列的,锁在下次查询的时候就会使用索引来查询到最大的值是哪个
+答:在xxx列上建立索引,因为索引是B+树顺序排列的,在下次查询的时候就会使用索引来查询到最大的值是哪个
-问:如何对分页进行优化?
-答:`SELECT * FROM big_table LIMIT 1000000,20`这条语句会查询出1000020条的所有数据然后丢弃掉前1000000条,可以改进成`SELECT a.* FROM big_table a, (select id from big_table where id >= 1000000 LIMIT 0,20) b where a.id=b.id`是用过滤条件将不需要查询的数据直接去除
+问:有个表特别大,字段是姓名、年龄、班级,如果调用`select * from table where name = xxx and age = xxx`该如何通过建立索引的方式优化查询速度?
+答:由于mysql查询每次只能使用一个索引,如果在name、age两列上创建联合索引的话将带来更高的效率。如果我们创建了(name, age)的联合索引,那么其实相当于创建了(name, age)、(name)2个索引。因此我们在创建复合索引时应该将最常用作限制条件的列放在最左边,依次递减。其次还要考虑该列的数据离散程度,如果有很多不同的值的话建议放在左边,name的离散程度也大于age。
+
+问:优化大数据量的分页查询?
+1. 索引优化:确保用于排序和筛选的字段已经建立了索引
+2. 延迟关联:先获取主键,然后再根据主键获取完整的行数据。这样可以减少数据库在排序时需要处理的数据量。通过将 select * 转变为 select id,把符合条件的 id 筛选出来后,最后通过嵌套查询的方式按顺序取出 id 对应的行
+3. 业务限制:查询页数上限
+4. 使用其他数据结构如ES、分表
+
+```sql
+-- 优化前
+select *
+from people
+order by create_time desc
+limit 5000000, 10;
+
+-- 优化后
+select a.*
+from people a
+inner join(
+ select id
+ from people
+ order by create_time desc
+ limit 5000000, 10
+) b ON a.id = b.id;
+```
+
+#### 最左前缀匹配原则
+定义:在检索数据时从联合索引的最左边开始匹配。一直向右匹配直到遇到范围查询(>/ 5 and d = 6,如果建立(a,b,c,d)索引,d是用不到索引的,如果建立(a,b,d,c)索引,则都可以用到,此外a,b,d的顺序可以任意调整
+
+联合索引原理:联合索引是将第一个字段作为非叶子节点形成B+树结构的,在查询索引的时候先根据该字段一步步查询到具体的叶子节点,叶子节点上还会存在第二个字段甚至第三个字段的已排序结果。所以对于(a,b,c,d)这个联合索引会存在(a),(a,b),(a,b,c),(a,b,c,d)四个索引
## 事务隔离级别
1. 原子性(Atomicity):事务作为一个整体被执行 ,要么全部执行,要么全部不执行;
@@ -37,33 +68,152 @@
3. 隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行,然后你可以扯到隔离级别;
4. 持久性(Durability):一个事务一旦提交,对数据库的修改应该永久保存。
-[https://www.jianshu.com/p/4e3edbedb9a8](https://www.jianshu.com/p/4e3edbedb9a8)
+不同事务隔离级别的问题:
+1. 读未提交(Read Uncommitted):在这个级别下,一个事务可以读取到另一个事务尚未提交的数据变更,即脏读(Dirty Read)现象可能发生。这种隔离级别允许最大的并行处理能力,但并发事务间的数据一致性最弱。
+2. 读已提交(Read Committed):在这种级别下,一个事务只能看到其他事务已经提交的数据,解决了脏读的问题。但是,在同一个事务内,前后两次相同的查询可能会返回不同的结果,这被称为不可重复读(Non-repeatable Read)。
+3. 可重复读(Repeatable Read):这是MySQL InnoDB存储引擎默认的事务隔离级别。在这个级别下,事务在整个生命周期内可以看到第一次执行查询时的快照数据,即使其他事务在此期间提交了对这些数据的修改,也不会影响本事务内查询的结果,因此消除了不可重复读的问题。但是,它不能完全避免幻读(Phantom Read),即在同一事务内,前后两次相同的范围查询可能因为其他事务插入新的行而返回不同数量的结果。
-## 锁表、锁行
-[https://segmentfault.com/a/1190000012773157](https://segmentfault.com/a/1190000012773157)
+为什么可重复读不能完全避免幻读:
+1. 幻读的定义: 幻读是指在一个事务内,同一个查询语句多次执行时,由于其他事务提交了新的数据插入或删除操作,导致前后两次查询结果集不一致的情况。具体表现为:即使事务A在开始时已经获取了一个数据范围的快照,当它再次扫描这个范围时,发现出现了之前未读取到的新行,这些新行如同“幻影”一般突然出现。
+2. 可重复读与幻读的关系: 在可重复读隔离级别下,对于已存在的记录,MVCC确保事务能够看到第一次查询时的数据状态,因此不会发生不可重复读。但是,当有新的行被插入到符合事务查询条件的范围内时,MVCC本身并不能阻止这种现象的发生,因为新插入的行对于当前事务是可见的(取决于插入事务的提交时间点和当前事务的Read View)。
+3. 为了减轻幻读的影响,InnoDB在执行某些范围查询时会采用间隙锁(Gap Locks)或者Next-Key Locks来锁定索引区间,防止其他事务在这个范围内插入新的记录,但并非所有的范围查询都会自动加上这样的锁,而且这仅限于使用基于索引的操作,非索引字段的范围查询无法通过间隙锁完全避免幻读。
-### 何时锁
+## 锁表、锁行
+1. InnoDB 支持表锁和行锁,使用索引作为检索条件修改数据时采用行锁,否则采用表锁
+2. InnoDB 自动给修改操作加锁,给查询操作不自动加锁
+3. 行锁相对于表锁来说,优势在于高并发场景下表现更突出,毕竟锁的粒度小
+4. 当表的大部分数据需要被修改,或者是多表复杂关联查询时,建议使用表锁优于行锁
### 悲观锁乐观锁、如何写对应的SQL
-[https://www.jianshu.com/p/f5ff017db62a](https://www.jianshu.com/p/f5ff017db62a)
+悲观锁:在悲观锁机制下,事务认为在它执行期间数据一定会被其他事务修改,因此在读取数据时就立即对其加锁,阻止其他事务对同一数据进行操作,直到当前事务结束并释放锁。SELECT ... FOR UPDATE或SELECT ... LOCK IN SHARE MODE
+乐观锁:乐观锁并不在读取数据时立即加锁,而是在更新数据时检查自上次读取以来数据是否已被其他事务修改过。这通常通过在表中添加一个版本号字段或者时间戳字段来实现。
+
+### 锁的种类
+按功能分类:
+1. 共享锁:Shared Locks,简称S锁。在事务要读取一条记录时,需要先获取该记录的S锁。
+2. 独占锁:排他锁,英文名:Exclusive Locks,简称X锁。在事务要改动一条记录时,需要先获取该记录的X锁。
+
+按粒度分类:
+1. 表锁是对一整张表加锁,虽然可分为读锁和写锁,但毕竟是锁住整张表,会导致并发能力下降,一般是做ddl处理时使用。另外表级别还有AUTO-INC锁:在执行插入语句时就在表级别加一个AUTO-INC锁,然后为每条待插入记录的AUTO_INCREMENT修饰的列分配递增的值,在该语句执行结束后,再把AUTO-INC锁释放掉。这样一个事务在持有AUTO-INC锁的过程中,其他事务的插入语句都要被阻塞,可以保证一个语句中分配的递增值是连续的
+2. 行锁,也称为记录锁,顾名思义就是在记录上加的锁。锁住数据行,这种加锁方法比较复杂,但是由于只锁住有限的数据,对于其它数据不加限制,所以并发能力强,MySQL一般都是用行锁来处理并发事务。下面是行锁的类型:
+ - Record Locks:记录锁,当一个事务获取了一条记录的S型记录锁后,其他事务也可以继续获取该记录的S型记录锁,但不可以继续获取X型记录锁;当一个事务获取了一条记录的X型记录锁后,其他事务既不可以继续获取该记录的S型记录锁,也不可以继续获取X型记录锁;
+ - Gap Locks:是为了防止插入幻影记录而提出的,不允许其他事务往这条记录前面的间隙插入新记录。在REPEATABLE READ隔离级别下是可以解决幻读问题的,解决方案有两种,可以使用MVCC方案解决,也可以采用加锁方案解决,但是在使用加锁方案解决时有个大问题,就是事务在第一次执行读取操作时,那些幻影记录尚不存在,我们无法给这些幻影记录加上记录锁
+ - Next-Key Locks:记录锁和一个gap锁的合体。锁住某条记录,又想阻止其他事务在该记录前面的间隙插入新记录
+ - Insert Intention Locks:插入意向锁。一个事务在插入一条记录时需要判断一下插入位置是不是被别的事务加了所谓的gap锁,如果有的话,插入操作需要等待,直到拥有gap锁的那个事务提交
+ - 隐式锁:当事务需要加锁的时,如果这个锁不可能发生冲突,InnoDB会跳过加锁环节,这种机制称为隐式锁。隐式锁是InnoDB实现的一种延迟加锁机制,其特点是只有在可能发生冲突时才加锁,从而减少了锁的数量,提高了系统整体性能
+
+### MVCC
+MVCC(Multi-Version Concurrency Control,多版本并发控制)是一种用于数据库管理系统中的事务处理机制,它在不使用加锁或者只对数据进行有限锁定的情况下,为并发事务提供了一种相对无冲突的访问方式。MVCC有效地避免了脏读、不可重复读等问题,并极大地提高了数据库系统的并发性能
+
+原理:
+1. 隐式字段:每行记录除了实际的数据列外,还包含额外的系统信息,例如DB_TRX_ID(最近修改该行事务ID)、DB_ROLL_PTR(回滚指针指向undo日志),以及DB_ROW_ID(行ID)等。这些隐藏字段用于跟踪数据的不同版本。
+2. 事务版本号:每个事务都有一个唯一的事务ID,在事务开始时分配。这个ID用来区分不同事务的操作时间点。
+3. Undo日志:当事务对某一行进行修改时,旧版本的数据会被存放在Undo日志中,形成历史版本链。这样当其他事务需要读取旧版本数据时,可以从Undo日志中获取。
+4. Read View:MVCC通过Read View来决定事务可见的行版本。每个读操作都会创建或复用一个Read View,根据Read View的规则判断当前事务能否看到某个版本的数据:如果被读取行的事务ID小于Read View的最低事务ID,则可见;如果大于等于Read View的最高事务ID且未提交,则不可见;否则,检查该行是否在Read View创建之后被其他已提交事务修改过。
+5. 非锁定读:在MVCC中,存在两种类型的读操作:快照读(Snapshot Read)和当前读(Current Read)。快照读就是基于MVCC实现的,它不会阻塞其他事务,并总是返回某一特定时间点的数据视图。而当前读则会获取最新的数据并加锁以确保一致性。
+
### 索引
#### 原理
-我们拿出一本新华字典,它的目录实际上就是一种索引:非聚集索引。我们可以通过目录迅速定位我们要查的字。而字典的内容部分一般都是按照拼音排序的,这实际上又是一种索引:聚集索引。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
-
-主要使用[B+树](https://www.jianshu.com/p/3a1377883742)来构建索引,为什么不用二叉树是因为B+树是多叉的,可以减少树的高度,还有事索引本身较大,不会全部存储在内存中,会以索引文件的形式存储在磁盘上,然后是因为[局部性原理](https://www.cnblogs.com/xyxxs/p/4440187.html),数据库系统巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入,(由于节点中有若干个数组,所以地址连续)。而红黑树这种结构,深度更深。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性
-
-#### 分析
-好处:
-
-1. 快速取数据
-2. 唯一性索引能保证数据记录的唯一性
-3. 实现表与表之间的参照完整性
-
-缺点:
-
-1. 索引需要占物理空间。
-2. 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降低了数据的维护速度。
-
-#### 使用场景
-如果某个字段,或一组字段会出现在一个会被频繁调用的 WHERE 子句中,那么它们应该是被索引的,这样会更快的得到结果。为了避免意外的发生,需要恰当地使用唯一索引
+聚集索引:数据行的物理顺序与列值(一般是主键的那一列)的逻辑顺序相同,所以一个表中只能拥有一个聚集索引。叶子结点即存储了真实的数据行,不再有另外单独的数据页
+非聚集索引:该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同,所以一个表中可以拥有多个非聚集索引。叶子结点包含索引字段值及指向数据页数据行的逻辑指针
+
+#### 索引原理
+为什么使用B+树来构建索引?
+1. b+树的中间节点不保存数据,所以磁盘页能容纳更多节点元素;
+2. b+树查询必须查找到叶子节点,b树只要匹配到即可不用管元素位置,因此b+树查找更稳定
+3. 对于范围查找来说,b+树只需遍历叶子节点链表即可,b树却需要重复地中序遍历
+4. 红黑树最多只有两个子节点,所以高度会非常高,导致遍历查询的次数会多
+5. 红黑树在数组中存储的方式,导致逻辑上很近的父节点与子节点可能在物理上很远,导致无法使用磁盘预读的局部性原理,需要很多次IO才能找到磁盘上的数据。B+树一个节点中可以存储很多个索引的key,且将大小设置为一个页,一次磁盘IO就能读取很多个key
+6. 叶子节点之间还加上了下个叶子节点的指针,遍历索引也会很快。
+
+B+树的高度如何计算?
+1. 假设B+树的高度为2的话,即有一个根结点和若干个叶子结点。这棵B+树的存放总记录数为=根结点指针数 * 单个叶子节点记录行数
+2. 假设一行记录的数据大小为1k,那么单个叶子节点可以存的记录数 =16k/1k =16.
+3. 非叶子节点内存放多少指针呢?我们假设主键ID为bigint类型,长度为8字节(int类型的话,一个int就是32位,4字节),而指针大小是固定的在InnoDB源码中设置为6字节,假设n指主键个数即key的个数,n*8 + (n + 1) * 6 = 16K=16*1024B , 算出n约为 1170,意味着根节点会有1170个key与1171个指针
+4. 一棵高度为2的B+树,能存放1171* 16 = 18736条这样的数据记录。同理一棵高度为3的B+树,能存放1171 * 1171 * 16 = 21939856,也就是说,可以存放两千万左右的记录。B+树高度一般为1-3层,已经满足千万级别的数据存储。
+
+#### 优化
+如何选择合适的列建立索引?
+
+1. WHERE / GROUP BY / ORDER BY / ON 的列
+2. 离散度大(不同的数据多)的列使用索引才有查询效率提升
+3. 索引字段越小越好,因为数据库按页存储的,如果每次查询IO读取的页越少查询效率越高
+
+### count1/count*/count字段 的区别
+
+1. count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL
+2. count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL
+3. count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。
+
+count(\*),自动会优化指定到那一个字段。所以没必要去count(1),用count(\*),sql会帮你完成优化的 因此:count(1)和count(\*)基本没有差别!
+
+### explain详解
+1. id:select 查询序列号。id相同,执行顺序由上至下;id不同,id值越大优先级越高,越先被执行。
+2. select_type:查询数据的操作类型,其值如下:
+ - simple:简单查询,不包含子查询或 union
+ - primary:包含复杂的子查询,最外层查询标记为该值
+ - subquery:在 select 或 where 包含子查询,被标记为该值
+ - derived:在 from 列表中包含的子查询被标记为该值,MySQL 会递归执行这些子查询,把结果放在临时表
+ - union:若第二个 select 出现在 union 之后,则被标记为该值。若 union 包含在 from 的子查询中,外层 select 被标记为 derived
+ - union result:从 union 表获取结果的 select
+3. table:显示该行数据是关于哪张表
+4. partitions:匹配的分区
+5. type:表的连接类型,其值,性能由高到底排列如下:
+ - system:表只有一行记录,相当于系统表
+ - const:通过索引一次就找到,只匹配一行数据
+ - eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常用于主键或唯一索引扫描
+ - ref:非唯一性索引扫描,返回匹配某个单独值的所有行。用于=、< 或 > 操作符带索引的列
+ - range:只检索给定范围的行,使用一个索引来选择行。一般使用between、>、<情况
+ - index:只遍历索引树
+ - ALL:全表扫描,性能最差
+注:前5种情况都是理想情况的索引使用情况。通常优化至少到range级别,最好能优化到 ref
+6. possible_keys:显示 MySQL 理论上使用的索引,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用。如果该值为 NULL,说明没有使用索引,可以建立索引提高性能
+7. key:显示 MySQL 实际使用的索引。如果为 NULL,则没有使用索引查询
+8. key_len:表示索引中使用的字节数,通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好 显示的是索引字段的最大长度,并非实际使用长度
+9. ref:显示该表的索引字段关联了哪张表的哪个字段
+10. rows:根据表统计信息及选用情况,大致估算出找到所需的记录或所需读取的行数,数值越小越好
+11. filtered:返回结果的行数占读取行数的百分比,值越大越好
+12. extra:包含不合适在其他列中显示但十分重要的额外信息,常见的值如下:
+ - using filesort:说明 MySQL 会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。出现该值,应该优化 SQL
+ - using temporary:使用了临时表保存中间结果,MySQL 在对查询结果排序时使用临时表。常见于排序 order by 和分组查询 group by。出现该值,应该优化 SQL
+ - using index:表示相应的 select 操作使用了覆盖索引,避免了访问表的数据行,效率不错
+ - using where:where 子句用于限制哪一行
+ - using join buffer:使用连接缓存
+ - distinct:发现第一个匹配后,停止为当前的行组合搜索更多的行
+
+## 分区分库分表
+分区:把一张表的数据分成N个区块,在逻辑上看最终只是一张表,但底层是由N个物理区块组成的,通过将不同数据按一定规则放到不同的区块中提升表的查询效率。
+
+水平分表:为了解决单标数据量过大(数据量达到千万级别)问题。所以将固定的ID hash之后mod,取若0~N个值,然后将数据划分到不同表中,需要在写入与查询的时候进行ID的路由与统计
+
+垂直分表:为了解决表的宽度问题,同时还能分别优化每张单表的处理能力。所以将表结构根据数据的活跃度拆分成多个表,把不常用的字段单独放到一个表、把大字段单独放到一个表、把经常使用的字段放到一个表
+
+分库:面对高并发的读写访问,当数据库无法承载写操作压力时,不管如何扩展slave服务器,此时都没有意义了。因此数据库进行拆分,从而提高数据库写入能力,这就是分库。
+
+问题:
+
+1. 事务问题。在执行分库之后,由于数据存储到了不同的库上,数据库事务管理出现了困难。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价;如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
+2. 跨库跨表的join问题。在执行了分库分表之后,难以避免会将原本逻辑关联性很强的数据划分到不同的表、不同的库上,我们无法join位于不同分库的表,也无法join分表粒度不同的表,结果原本一次查询能够完成的业务,可能需要多次查询才能完成。
+3. 额外的数据管理负担和数据运算压力。额外的数据管理负担,最显而易见的就是数据的定位问题和数据的增删改查的重复执行问题,这些都可以通过应用程序解决,但必然引起额外的逻辑运算。
+
+
+## MySQL数据库主从延迟同步方案
+什么事主从延迟:为了完成主从复制,从库需要通过 I/O 线程获取主库中 dump 线程读取的 binlog 内容并写入到自己的中继日志 relay log 中,从库的 SQL 线程再读取中继日志,重做中继日志中的日志,相当于再执行一遍 SQL,更新自己的数据库,以达到数据的一致性。主从延迟,就是同一个事务,从库执行完成的时间与主库执行完成的时间之差
+
+1. 「异步复制」:MySQL 默认的复制即是异步的,主库在执行完客户端提交的事务后会立即将结果返给客户端,并不关心从库是否已经接收并处理。这样就会有一个问题,一旦主库宕机,此时主库上已经提交的事务可能因为网络原因并没有传到从库上,如果此时执行故障转移,强行将从提升为主,可能导致新主上的数据不完整。
+2. 「全同步复制」:指当主库执行完一个事务,并且所有的从库都执行了该事务,主库才提交事务并返回结果给客户端。因为需要等待所有从库执行完该事务才能返回,所以全同步复制的性能必然会收到严重的影响。
+3. 「半同步复制」:是介于全同步复制与全异步复制之间的一种,主库只需要等待至少一个从库接收到并写到 Relay Log 文件即可,主库不需要等待所有从库给主库返回 ACK。主库收到这个 ACK 以后,才能给客户端返回 “事务完成” 的确认。这样会出现一个问题,就是实际上主库已经将该事务 commit 到了存储引擎层,应用已经可以看到数据发生了变化,只是在等待返回而已。如果此时主库宕机,可能从库还没写入 Relay Log,就会发生主从库数据不一致。为了解决上述问题,MySQL 5.7 引入了增强半同步复制。针对上面这个图,“Waiting Slave dump” 被调整到了 “Storage Commit” 之前,即主库写数据到 binlog 后,就开始等待从库的应答 ACK,直到至少一个从库写入 Relay Log 后,并将数据落盘,然后返回给主库 ACK,通知主库可以执行 commit 操作,然后主库再将事务提交到事务引擎层,应用此时才可以看到数据发生了变化。
+4. 一主多从:如果从库承担了大量查询请求,那么从库上的查询操作将耗费大量的 CPU 资源,从而影响了同步速度,造成主从延迟。那么我们可以多接几个从库,让这些从库来共同分担读的压力。
+5. 强制走主库:如果某些操作对数据的实时性要求比较苛刻,需要反映实时最新的数据,比如说涉及金钱的金融类系统、在线实时系统、又或者是写入之后马上又读的业务,这时我们就得放弃读写分离,让此类的读请求也走主库,这就不存延迟问题了。
+6. 并行复制:MySQL在5.6版本中使用并行复制来解决主从延迟问题。所谓并行复制,指的就是从库开启多个SQL线程,并行读取relay log中不同库的日志,然后并行重放不同库的日志,这是库级别的并行。MySQL 5.7对并行复制做了进一步改进,开始支持真正的并行复制功能。MySQL5.7的并行复制是基于组提交的并行复制,官方称为enhanced multi-threaded slave(简称MTS),延迟问题已经得到了极大的改善。其核心思想是:一个组提交的事务都是可以并行回放(配合binary log group commit);slave机器的relay log中 last_committed相同的事务(sequence_num不同)可以并发执行。
+
+强制走主库之后,如何在处理大数据量的时候保证实时写查:
+1. 表结构与索引优化:确保表结构设计合理,尽量避免数据冗余和更新异常。根据查询条件创建合适的索引,特别是对于高频查询字段,可以显著提高读取速度。
+2. 分区表(Partitioning):对于非常大的表,可以考虑使用分区表功能,将大表物理分割成多个小表,根据时间、范围或其他业务逻辑进行划分,这样不仅能提高查询效率,还可以通过并行处理提高写入速度。
+3. 分库分表:当单表数据量过大时,采用水平拆分或垂直拆分策略将数据分布到多个数据库或表中,进一步提升读写性能。
+4. 查询优化:避免全表扫描,尽可能使用覆盖索引。编写高效的SQL语句,减少不必要的计算和排序操作。
+5. 缓存机制:在数据库层面,可以考虑使用内存表或者缓存技术(如Redis)来临时存储最近写入的数据,以便快速响应实时查询请求。
+6. 实时分析型数据库:对于大数据量且实时性要求极高的场景,可以考虑引入实时分析型数据库系统,例如ClickHouse、Druid等,它们设计之初就为实时写入和查询提供了高效的支持。
+
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git "a/MD/\346\225\260\346\215\256\345\272\223-Redis.md" "b/MD/\346\225\260\346\215\256\345\272\223-Redis.md"
index 5f43bd2..8b86d69 100644
--- "a/MD/\346\225\260\346\215\256\345\272\223-Redis.md"
+++ "b/MD/\346\225\260\346\215\256\345\272\223-Redis.md"
@@ -1,16 +1,111 @@
+## 数据类型
+来源:https://redisbook.readthedocs.io/en/latest/internal/db.html#id4
-## Redis
-### 原理
-单线程的IO复用模型。便于IO操作,不便于排序、聚合。
+Redis是一个键值对数据库,数据库中的键值对由字典保存。每个数据库都有一个对应的字典,这个字典被称之为键空间。当用户添加一个键值对到数据库时(不论键值对是什么类型), 程序就将该键值对添加到键空间
-### 数据类型
-string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
+字典的键是一个字符串对象。字典的值则可以是包括【字符串、列表、哈希表、集合或有序集】在内的任意一种 Redis 类型对象。
-### 持久化
-RDB 持久化可以在指定的时间间隔内生成数据集的时间点快照(point-in-time snapshot)。
-AOF 持久化记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集。 AOF 文件中的命令全部以 Redis 协议的格式来保存,新命令会被追加到文件的末尾。 Redis 还可以在后台对 AOF 文件进行重写(rewrite),使得 AOF 文件的体积不会超出保存数据集状态所需的实际大小。
-Redis 还可以同时使用 AOF 持久化和 RDB 持久化。 在这种情况下, 当 Redis 重启时, 它会优先使用 AOF 文件来还原数据集, 因为 AOF 文件保存的数据集通常比 RDB 文件所保存的数据集更完整。
+
+
+上图展示了一个包含 number 、 book 、 message 三个键的数据库 —— 其中 number 键是一个列表,列表中包含三个整数值; book 键是一个哈希表,表中包含三个键值对; 而 message 键则指向另一个字符串:
+
+
+
+不同的数据类型的具体实现(压缩列表、跳表必看)请看: https://redisbook.readthedocs.io/en/latest/index.html#id3
+
+在线文档:http://118.25.23.115/
+
+压缩链表原理:
+在内存中是连续存储的,但是不同于数组,为了节省内存,ziplist的每个元素所占的内存大小可以不同
+ziplist将一些必要的偏移量信息记录在了每一个节点里,使之能跳到上一个节点或下一个节点
+
+与跳表应用场景:
+当zset满足以下两个条件的时候,使用ziplist:
+1. 保存的元素少于128个
+2. 保存的所有元素大小都小于64字节
+
+redis数据过期策略:
+定时过期:每个设置过期时间的key都需要创建一个定时器,到过期时间就会立即清除
+惰性过期:只有当访问一个key时,才会判断该key是否已过期,过期则清除
+定期过期:每隔一定的时间,会扫描一定数量的数据库的expires字典中一定数量的key,并清除其中已过期的key
+
+内存淘汰策略:
+no-eviction:当内存不足以容纳新写入数据时,新写入操作会报错
+allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key
+allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key
+volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key
+volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key
+volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除
+
+Redis 是单线程吗?
+1. Redis 单线程指的是「接收客户端请求->解析请求 ->进行数据读写等操作->发生数据给客户端」这个过程是由一个线程(主线程)来完成的但是,Redis 程序并不是单线程的,Redis 在启动的时候,是会启动后台线程(BIO)的:
+2. Redis 在 2.6 版本,会启动 2 个后台线程,分别处理关闭文件、AOF 刷盘这两个任务;
+3. Redis 在 4.0 版本之后,新增了一个新的后台线程,用来异步释放 Redis 内存,也就是 lazyfree 线程。例如执行 unlink key / flushdb async / flushall async 等命令,会把这些删除操作交给后台线程来执行,好处是不会导致 Redis 主线程卡顿。因此,当我们要删除一个大 key 的时候,不要使用 del 命令删除,因为 del 是在主线程处理的,这样会导致 Redis 主线程卡顿,因此我们应该使用 unlink 命令来异步删除大key。
+
+Redis 采用单线程为什么还这么快?
+1. Redis 的大部分操作都在内存中完成,并且采用了高效的数据结构
+2. Redis 采用单线程模型可以避免了多线程之间的竞争,省去了多线程切换带来的时间和性能上的开销,而且也不会导致死锁问题
+3. Redis 采用了I/O 多路复用机制处理大量的客户端 Socket 请求,IO 多路复用机制是指一个线程处理多个 IO 流,就是我们经常听到的 select/epoll 机制。简单来说,在 Redis 只运行单线程的情况下,该机制允许内核中,同时存在多个监听 Socket 和已连接 Socket。内核会一直监听这些 Socket 上的连接请求或数据请求。一旦有请求到达,就会交给 Redis 线程处理,这就实现了一个 Redis 线程处理多个 IO 流的效果。
+
+Redis 6.0 之后为什么引入了多线程?
+1. 随着网络硬件的性能提升,Redis 的性能瓶颈有时会出现在网络 I/O 的处理上。所以为了提高网络请求处理的并行度
+2. 对于读写命令,Redis 仍然使用单线程来处理,Redis 官方表示,Redis 6.0 版本引入的多线程 I/O 特性对性能提升至少是一倍以上。
+
+## 集群模式
+来源:
+https://my.oschina.net/zhangxufeng/blog/905611
+https://www.cnblogs.com/leeSmall/p/8398401.html
+https://docs.aws.amazon.com/zh_cn/AmazonElastiCache/latest/red-ug/CacheNodes.NodeGroups.html
+
+### 主从
+
+
+用一个redis实例作为主机,其余的实例作为从机。主机和从机的数据完全一致,主机支持数据的写入和读取等各项操作,而从机则只支持与主机数据的同步和读取。因而可以将写入数据的命令发送给主机执行,而读取数据的命令发送给不同的从机执行,从而达到读写分离的目的。
+
+问题是主从模式如果所连接的redis实例因为故障下线了,没有提供一定的手段通知客户端另外可连接的客户端地址,因而需要手动更改客户端配置重新连接。如果主节点由于故障下线了,那么从节点因为没有主节点而同步中断,因而需要人工进行故障转移工作。为了解决这两个问题,在2.8版本之后redis正式提供了sentinel(哨兵)架构。
+### 哨兵
+
+
+由Sentinel节点定期监控发现主节点是否出现了故障,当主节点出现故障时,由Redis Sentinel自动完成故障发现和转移,并通知应用方,实现高可用性。
+
+### 集群
+
+redis主从或哨兵模式的每个实例都是全量存储所有数据,浪费内存且有木桶效应。为了最大化利用内存,可以采用集群,就是分布式存储。集群将数据分片存储,每组节点存储一部分数据,从而达到分布式集群的目的。
+
+上图是主从模式与集群模式的区别,redis集群中数据是和槽(slot)挂钩的,其总共定义了16384个槽,所有的数据根据一致哈希算法会被映射到这16384个槽中的某个槽中;另一方面,这16384个槽是按照设置被分配到不同的redis节点上。
+
+但集群模式会直接导致访问数据方式的改变,比如客户端向A节点发送GET命令但该数据在B节点,redis会返回重定向错误给客户端让客户端再次发送请求,这也直接导致了必须在相同节点才能执行的一些高级功能(如Lua、事务、Pipeline)无法使用。另外还会引发数据分配的一致性hash问题可以参看[这里](https://github.com/crossoverJie/JCSprout/blob/master/MD/Consistent-Hash.md)
+
+### 如何选择
+
+1. 集群的优势在于高可用,将写操作分开到不同的节点,如果写的操作较多且数据量巨大,且不需要高级功能则可能考虑集群
+2. 哨兵的优势在于高可用,支持高级功能,且能在读的操作较多的场景下工作,所以在绝大多数场景中是适合的
+3. 主从的优势在于支持高级功能,且能在读的操作较多的场景下工作,但无法保证高可用,不建议在数据要求严格的场景下使用
+
+## 使用策略
+### 延迟加载
+读:当读请求到来时,先从缓存读,如果读不到就从数据库读,读完之后同步到缓存且添加过期时间
+写:当写请求到来时,只写数据库
+
+优点:仅对请求的数据进行一段时间的缓存,没有请求过的数据就不会被缓存,节省缓存空间;节点出现故障并不是致命的,因为可以从数据库中得到
+缺点:缓存数据不是最新的;【缓存击穿】;【缓存失效】
+
+### 直写
+读:当读请求到来时,先从缓存读,如果读不到就从数据库读,读完之后同步到缓存且设置为永不过期
+写:当写请求到来时,先写数据库然后同步到缓存,设置为永不过期
+
+优点:缓存数据是最新的,无需担心缓存击穿、失效问题,编码方便
+缺点:大量数据可能没有被读取的资源浪费;节点故障或重启会导致缓存数据的丢失直到有写操作同步到缓存;每次写入都需要写缓存导致的性能损失
+
+永不过期的缓存会大量占用空间,可以设置过期时间来改进,但是会引进【缓存失效】问题,需要注意解决
+
+### 如何选择
+如果需要缓存与数据库数据保持实时一致,则需要选择直写方式
+如果缓存服务很稳定、缓存的可用空间大、写缓存的性能丢失能够接受,选择直写方式比较方便实现
+否则选择延迟加载,同时注意解决引进的问题
+
+## 缓存问题
### 缓存击穿
查询一个数据库中不存在的数据,比如商品详情,查询一个不存在的ID,每次都会访问DB,如果有人恶意破坏,很可能直接对DB造成过大地压力。
@@ -18,10 +113,31 @@ Redis 还可以同时使用 AOF 持久化和 RDB 持久化。 在这种情况下
### 缓存失效
在高并发的环境下,如果此时key对应的缓存失效,此时有多个进程就会去同时去查询DB,然后再去同时设置缓存。这个时候如果这个key是系统中的热点key或者同时失效的数量比较多时,DB访问量会瞬间增大,造成过大的压力。
-1. 将系统中key的缓存失效时间均匀地错开
-2. 当我们通过key去查询数据时,首先查询缓存,如果此时缓存中查询不到,就通过分布式锁进行加锁
+将系统中key的缓存失效时间均匀地错开
### 热点key
缓存中的某些Key(可能对应用与某个促销商品)对应的value存储在集群中一台机器,使得所有流量涌向同一机器,成为系统的瓶颈,该问题的挑战在于它无法通过增加机器容量来解决。
1. 客户端热点key缓存:将热点key对应value并缓存在客户端本地,并且设置一个失效时间。
2. 将热点key分散为多个子key,然后存储到缓存集群的不同机器上,这些子key对应的value都和热点key是一样的。
+
+## 持久化
+RDB 持久化可以在指定的时间间隔内生成数据集的时间点快照(point-in-time snapshot)。
+1. save:save 是需要占用主线程资源的,会阻塞主线程。
+2. bgsave:使用的是子进程写,不会占用主线程的资源(fork会阻塞主线程,但是copyonwrite过程是纳秒级别相对较快,aof是毫秒级别)。redis使用了操作系统的写时复制技术(COPY -ON-WRITE COW)bgsave子进程是由主进程fork生成的,可以共享主进程的内存,如果主进程有写入命令时候,主进程会把写入的那块内存页先复制一份给fork使用,这样就不影响主进程的写操作,可以继续修改原来的数据,避免了对正常业务的影响。
+
+
+AOF 持久化记录服务器执行的所有写操作命令,aof日志的重写是由后台程序bgrewriteaof子进程完成的,这也是为了避免阻塞主线程,导致数据性能下降。Redis 还可以在后台对 AOF 文件进行重写(rewrite重写机制就是把这条键值对的多次操作压缩成一次操作,这样就大大减少了aof日志文件的大小。),使得 AOF 文件的体积不会超出保存数据集状态所需的实际大小。
+1. always 同步回写:每条命令执行完成后,回立即将日志写回磁盘。always回写回占用主线程资源,每次回写都是一个慢速的罗盘操作,基本上可以避免数据的丢失,会对主线程产生影响,如果你对redis数据的准确性要求非常高,而写入和读取占比不高的话,可以采用这种策略。
+2. everysec 每秒回写:每个命令执行完后回先将日志写入aof文件的内存缓冲区,每隔一秒把缓冲区中的命令写入磁盘。每秒回写采用一秒回写一次的策略,避免了同步回写的性能开销,虽然减少了对系统性能的影响,但是如果1秒内产生了大量的写操作,在aof缓冲区积压了很多日志,这时候还没来得及写入aof日志文件就发生了宕机,就会造成数据的丢失。
+3. no 操作系统控制的回写:每个写命令执行完后只是先把日志写入aof文件的内存缓冲区,何时回写磁盘由操作系统决定。采用操作系统控制的回写,在写完aof缓冲区后就可以继续执行命令,但是如果系统发生宕机了,也同样会造成数据的丢失。
+
+Redis 还可以同时使用 AOF 持久化和 RDB 持久化。 在这种情况下, 当 Redis 重启时, 它会优先使用 AOF 文件来还原数据集, 因为 AOF 文件保存的数据集通常比 RDB 文件所保存的数据集更完整。
+## 渐进式rehash
+以下是哈希表渐进式 rehash 的详细步骤:
+1. 为 ht[1] 分配空间, 让字典同时持有 ht[0] 和 ht[1] 两个哈希表。
+2. 在字典中维持一个索引计数器变量 rehashidx , 并将它的值设置为 0 , 表示 rehash 工作正式开始。
+3. 在 rehash 进行期间, 每次对字典执行添加、删除、查找或者更新操作时, 程序除了执行指定的操作以外, 还会顺带将 ht[0] 哈希表在 rehashidx 索引上的所有键值对 rehash 到 ht[1] , 当 rehash 工作完成之后, 程序将 rehashidx 属性的值增一。
+4. 随着字典操作的不断执行, 最终在某个时间点上, ht[0] 的所有键值对都会被 rehash 至 ht[1] , 这时程序将 rehashidx 属性的值设为 -1 , 表示 rehash 操作已完成。
+渐进式 rehash 的好处在于它采取分而治之的方式, 将 rehash 键值对所需的计算工作均滩到对字典的每个添加、删除、查找和更新操作上, 从而避免了集中式 rehash 而带来的庞大计算量。
+
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git "a/MD/\346\225\260\346\215\256\347\273\223\346\236\204.md" "b/MD/\346\225\260\346\215\256\347\273\223\346\236\204.md"
deleted file mode 100644
index ec12755..0000000
--- "a/MD/\346\225\260\346\215\256\347\273\223\346\236\204.md"
+++ /dev/null
@@ -1,24 +0,0 @@
-## 快速排序
-
-
-
-
-首先任意选取一个数据(通常选用数组的第一个数)作为关键数据,然后将所有比它小的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一趟快速排序。
-
-不稳定,如果最小的值在最后面,那么在第一次排序就被放到第一位,后面有与该值相等的元素也不会交换。
-
-最好情况:每次划分过程产生的区间大小都为n/2,一共需要划分log2n次,每次需要比较n-1次,O(nlog2n)
-最坏情况:每次划分过程产生的两个区间分别包含n-1个元素和1个元素,一共需要划分n-1次,每次最多交换n-1次,这就是冒泡排序了,O(n2)
-
-## 堆排序
-
-堆可以视为一棵完全的二叉树,完全二叉树的一个“优秀”的性质是,除了最底层之外,每一层都是满的,这使得堆可以利用数组来表示
-堆排序就是把最大堆堆顶的最大数取出,将剩余的堆继续调整为最大堆,再次将堆顶的最大数取出,这个过程持续到剩余数只有一个时结束
-
-
-
-
-
-不稳定,27 27 12 3,第一次建堆把第一个27放到最后了,第二次就把第二个27放到第一个27前面了
-
-堆排序过程的时间复杂度是O(nlog2n)。因为建堆的时间复杂度是O(n);调整堆的时间复杂度是log2n,所以堆排序的时间复杂度是O(nlog2n)
\ No newline at end of file
diff --git "a/MD/\347\247\222\346\235\200\346\236\266\346\236\204.md" "b/MD/\347\247\222\346\235\200\346\236\266\346\236\204.md"
index abf52d3..1c451c9 100644
--- "a/MD/\347\247\222\346\235\200\346\236\266\346\236\204.md"
+++ "b/MD/\347\247\222\346\235\200\346\236\266\346\236\204.md"
@@ -1,29 +1,59 @@
-## 解决思路
-1. 尽量将请求拦截在数据库的上游,因为一旦大量请求进入数据库,性能会急剧下降
-2. 尽量利用缓存,不论是前端还是后端缓存,因为缓存的访问速度非常快,也能帮服务器分担压力
+## 业务上适当规避
+1. 根据某些规则对部分用户直接返回没抢到。比如有些用户曾经被系统识别为恶意用户、垃圾用户、僵尸用户,直接告诉用户已经抢完
+2. 分散不同客户端打开活动入口的时间。比如将1秒内的流量分散到10秒
-## 架构
-* 前端模块(页面静态化、CDN、客户端缓存)
-* 排队模块(队列实现)
-* 服务模块(redis页面缓存、对象缓存、业务逻辑)
-* 防刷模块(验证码、限流)
+## 技术上硬核抗压
+1. 限流策略。比如在压力测试中我们测到系统QPS达到了极限,那么超过的部分直接返回已经抢完,通过Nginx的lua脚本可以查redis看到QPS数据从而可以动态调节
+2. 异步削峰。对Redis中的红包预减数量,立即返回抢红包成功请用户等待,然后把发送消息发给消息队列,进行流量的第二次削峰,让后台服务慢慢处理
+3. 服务逻辑。比如业务逻辑是使用事务控制对数据库的创建订单记录,减库存的操作,那么创建操作要放到减库存操作之前,从而避免减数量update的行锁持有时间
+4. 机器配置。当然是服务器机器配置约高越好,数据库配置越猛越好,高并发抢红包主要是CPU与网络IO的负载较高,要选择偏向CPU与网络IO性能的机器
-## 模块解析
-按功能来分会有以下几个模块
+### 架构和实现细节
+* 前端模块(页面静态化、CDN、客户端缓存)
+* 排队模块(Redis、队列实现异步下单)
+* 服务模块(事务处理业务逻辑、避免并发问题)
+* 防刷模块(验证码、限制用户频繁访问)
-### 前端模块
+### 模块解析
+#### 前端模块
1. 页面静态化,将后台渲染模板的方式改成使用HTML文件与AJAX异步请求的方式,减少服务端渲染开销,同时将秒杀页面提前放到CDN
2. 客户端缓存,配置Cache-Control来让客户端缓存一定时间页面,提升用户体验
3. 静态资源优化,CSS/JS/图片压缩,提升用户体验
-### 排队模块
-1. 提供用户轮询查询功能,将热点对象保存在Redis中
-2. 在Redis中预减库存,随后发送消息给RabbitMQ,每个商品对应一个队列保证排队顺序,使用队列是为了降低到达服务器的瞬时流量
+#### 排队模块
+1. 对Redis中的抢购对象预减库存,然后立即返回抢购成功请用户等待,这里利用了Redis将大部分请求拦截住,少部分流量进入下一阶段
+2. 如果参与秒杀的商品太多,进入下一阶段的流量依然比较大,则需要使用消息队列,Redis过滤之后的请求直接放入到消息队列,让消息队列进行流量的第二次削峰
-### 服务模块
-1. 业务逻辑,使用事务控制下订单,减库存操作
+#### 服务模块
+1. 消息队列的消费者,业务逻辑是使用事务控制对数据库的下订单,减库存操作,且下订单操作要放到减库存操作之前,可以避免减库存update的行锁持有时间
-### 防刷模块
+#### 防刷模块
1. 针对恶意用户写脚本去刷,在Redis中保存用户IP与商品ID进行限制
2. 针对普通用户疯狂的点击,使用JS控制抢购按钮,每几秒才能点击一次
3. 在后台生成数学计算型的验证码,使用Graphics、BufferedImage实现图片,ScriptEngineManager计算表达式
+
+#### 异常流程的处理
+1. 如果在秒杀的过程中由于服务崩溃导致秒杀活动中断,那么没有好的办法,只能立即尝试恢复崩溃服务或者申请另寻时间重新进行秒杀活动
+2. 如果在下订单的过程中由于用户的某些限制导致下单失败,那么应该回滚事务,立即告诉用户失败原因
+
+### 总结
+#### 原则
+业务优化思路:业务上适当规避
+技术优化思路:尽量将请求拦截在数据库的上游,因为一旦大量请求进入数据库,性能会急剧下降
+架构原则:合适、简单、演化(以上内容是最终版本,初版可以说没有用到队列,直接使用缓存-数据库这样的架构)
+
+#### 难点
+1. 如何将高并发大流量一步步从业务和技术方面有条不紊地应对过来
+2. 如何在代码中处理好异常情况以及应急预案的准备
+
+#### 坑
+1. 以上的解决方案能通过利用Redis与消息队列集群来承载非常高的并发量,但是运维成本高。比如Redis与消息队列都必须用到集群才能保证稳定性,会导致运维成本太高。所以需要有专业的运维团队维护。
+2. 避免同一用户同时下多个订单,需要写好业务逻辑或在订单表中加上用户ID与商品ID的唯一索引;避免卖超问题,在更新数量的sql上需要加上>0条件
+
+#### 优化
+1. 将7层负载均衡Nginx与4层负载均衡LVS一起使用进一步提高并发量
+2. 以上是应用架构上的优化,在部署的Redis、消息队列、数据库、虚拟机偏向选择带宽与硬盘读写速度高的
+3. 提前预热,将最新的静态资源同步更新到CDN的所有节点上,在Redis中提前加载好需要售卖的产品信息
+4. 使用分布式限流减少Redis访问压力,在Nginx中配置并发连接数与速度限制
+
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git "a/MD/\347\256\227\346\263\225-\344\272\214\345\217\211\346\240\221-\345\244\232\345\217\211\346\240\221\344\270\255\346\234\200\351\225\277\347\232\204\350\277\236\347\273\255\345\272\217\345\210\227.md" "b/MD/\347\256\227\346\263\225-\344\272\214\345\217\211\346\240\221-\345\244\232\345\217\211\346\240\221\344\270\255\346\234\200\351\225\277\347\232\204\350\277\236\347\273\255\345\272\217\345\210\227.md"
new file mode 100644
index 0000000..6ce2af7
--- /dev/null
+++ "b/MD/\347\256\227\346\263\225-\344\272\214\345\217\211\346\240\221-\345\244\232\345\217\211\346\240\221\344\270\255\346\234\200\351\225\277\347\232\204\350\277\236\347\273\255\345\272\217\345\210\227.md"
@@ -0,0 +1,49 @@
+二叉树:https://cheonhyangzhang.gitbooks.io/leetcode-solutions/content/solutions-501-550/549-binary-tree-longest-consecutive-sequence-ii.html
+
+多叉树:https://gist.github.com/thanlau/34bd056dd0b1662d5fd483e157a27dfb
+```java
+/**
+ * Definition for a multi tree node.
+ * public class MultiTreeNode {
+ * int val;
+ * List children;
+ * MultiTreeNode(int x) { val = x; }
+ * }
+ */
+public class Solution {
+ /**
+ * @param root the root of k-ary tree
+ * @return the length of the longest consecutive sequence path
+ */
+ int max = 0;
+
+ public int longestConsecutive3(MultiTreeNode root) {
+ // Write your code here
+ if (root == null){
+ return 0;
+ }
+ helper(root);
+ return max;
+ }
+
+ public int[] helper(MultiTreeNode root) {
+ int up = 0;
+ int down = 0;
+ if (root == null){
+ return new int[]{down, up};
+ }
+ for ( MultiTreeNode node : root.children ){
+ int[] h = helper(node);
+ if (node.val == root.val + 1){
+ down = Math.max(down, h[0] + 1);
+ }
+ if (node.val + 1 == root.val){
+ up = Math.max(up, h[1] + 1);
+ }
+ }
+ max = Math.max(max, down + up + 1);
+ return new int[]{down, up};
+ }
+}
+
+```
diff --git "a/MD/\347\256\227\346\263\225-\344\272\214\345\217\211\346\240\221-\351\200\222\345\275\222-\344\272\214\345\217\211\346\240\221\345\217\215\350\275\254.md" "b/MD/\347\256\227\346\263\225-\344\272\214\345\217\211\346\240\221-\351\200\222\345\275\222-\344\272\214\345\217\211\346\240\221\345\217\215\350\275\254.md"
new file mode 100644
index 0000000..698b21f
--- /dev/null
+++ "b/MD/\347\256\227\346\263\225-\344\272\214\345\217\211\346\240\221-\351\200\222\345\275\222-\344\272\214\345\217\211\346\240\221\345\217\215\350\275\254.md"
@@ -0,0 +1,34 @@
+```text
+原二叉树:
+ 4
+ / \
+ 2 7
+ / \ / \
+1 3 6 9
+
+反转后的二叉树:
+
+ 4
+ / \
+ 7 2
+ / \ / \
+9 6 3 1
+```
+
+```java
+class Solution {
+ public TreeNode invertTree(TreeNode root) {
+ if(root == null){
+ return null;
+ }
+ invertTree(root.left);
+ invertTree(root.right);
+ TreeNode temp = root.left;
+ root.left = root.right;
+ root.right = temp;
+ return root;
+ }
+}
+```
+
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git "a/MD/\347\256\227\346\263\225-\345\205\266\344\273\226-\344\272\214\345\215\201\350\277\233\345\210\266\347\233\270\345\212\240.md" "b/MD/\347\256\227\346\263\225-\345\205\266\344\273\226-\344\272\214\345\215\201\350\277\233\345\210\266\347\233\270\345\212\240.md"
new file mode 100644
index 0000000..d8e0106
--- /dev/null
+++ "b/MD/\347\256\227\346\263\225-\345\205\266\344\273\226-\344\272\214\345\215\201\350\277\233\345\210\266\347\233\270\345\212\240.md"
@@ -0,0 +1,17 @@
+在二十进制中,我们除了使用数字0-9以外,还使用字母a-j(表示10-19),给定两个二十进制整数,求它们的和。 输入是两个二十进制整数,且都大于0,不超过100位; 输出是它们的和(二十进制),且不包含首0。我们用字符串来表示二十进制整数。
+```
+/*
+二十进制相加
+sample
+input
+
+1234567890+abcdefghij
+99999jjjjj+9999900001
+
+output
+
+bdfi02467j
+iiiij00000
+*/
+```
+
diff --git "a/MD/\347\256\227\346\263\225-\345\212\250\346\200\201\350\247\204\345\210\222-\350\277\236\347\273\255\345\255\220\346\225\260\347\273\204\346\234\200\345\244\247\345\222\214.md" "b/MD/\347\256\227\346\263\225-\345\212\250\346\200\201\350\247\204\345\210\222-\350\277\236\347\273\255\345\255\220\346\225\260\347\273\204\346\234\200\345\244\247\345\222\214.md"
new file mode 100644
index 0000000..1f79fda
--- /dev/null
+++ "b/MD/\347\256\227\346\263\225-\345\212\250\346\200\201\350\247\204\345\210\222-\350\277\236\347\273\255\345\255\220\346\225\260\347\273\204\346\234\200\345\244\247\345\222\214.md"
@@ -0,0 +1,44 @@
+https://www.nowcoder.com/profile/844008/codeBookDetail?submissionId=1519441
+
+{6,-3,-2,7,-15,1,2,2},连续子数组的最大和为8(从第0个开始,到第3个为止)。给一个数组,返回它的最大连续子序列的和
+
+```text
+使用动态规划
+F(i):以array[i]为末尾元素的子数组的和的最大值,子数组的元素的相对位置不变
+F(i)=max(F(i-1)+array[i] , array[i])
+res:所有子数组的和的最大值
+res=max(res,F(i))
+
+如数组[6, -3, -2, 7, -15, 1, 2, 2]
+初始状态:
+ F(0)=6
+ res=6
+i=1:
+ F(1)=max(F(0)-3,-3)=max(6-3,3)=3
+ res=max(F(1),res)=max(3,6)=6
+i=2:
+ F(2)=max(F(1)-2,-2)=max(3-2,-2)=1
+ res=max(F(2),res)=max(1,6)=6
+i=3:
+ F(3)=max(F(2)+7,7)=max(1+7,7)=8
+ res=max(F(2),res)=max(8,6)=8
+i=4:
+ F(4)=max(F(3)-15,-15)=max(8-15,-15)=-7
+ res=max(F(4),res)=max(-7,8)=8
+以此类推
+最终res的值为8
+```
+
+```java
+public int FindGreatestSumOfSubArray(int[] array) {
+ int res = array[0]; //记录当前所有子数组的和的最大值
+ int max=array[0]; //包含array[i]的连续数组最大值
+ for (int i = 1; i < array.length; i++) {
+ max=Math.max(max+array[i], array[i]);
+ res=Math.max(max, res);
+ }
+ return res;
+}
+```
+
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git "a/MD/\347\256\227\346\263\225-\346\225\260\346\215\256\347\273\223\346\236\204-LRU\346\267\230\346\261\260\347\256\227\346\263\225.md" "b/MD/\347\256\227\346\263\225-\346\225\260\346\215\256\347\273\223\346\236\204-LRU\346\267\230\346\261\260\347\256\227\346\263\225.md"
new file mode 100644
index 0000000..dd3bf95
--- /dev/null
+++ "b/MD/\347\256\227\346\263\225-\346\225\260\346\215\256\347\273\223\346\236\204-LRU\346\267\230\346\261\260\347\256\227\346\263\225.md"
@@ -0,0 +1,52 @@
+https://leetcode.com/problems/lru-cache/
+
+LRU,全称Least Recently Used,最近最少使用缓存。
+
+```java
+import java.util.HashMap;
+import java.util.LinkedList;
+
+class LRUCache {
+ private HashMap cacheMap = new HashMap<>();
+ private LinkedList recentlyList = new LinkedList<>();
+ private int capacity;
+
+ public LRUCache(int capacity) {
+ this.capacity = capacity;
+ }
+
+ public int get(int key) {
+ if (!cacheMap.containsKey(key)) {
+ return -1;
+ }
+ recentlyList.remove((Integer) key);
+ recentlyList.add(key);
+ return cacheMap.get(key);
+ }
+
+ public void put(int key, int value) {
+ if (cacheMap.containsKey(key)) {
+ recentlyList.remove((Integer) key);
+ }else if(cacheMap.size() == capacity){
+ cacheMap.remove(recentlyList.removeFirst());
+ }
+ recentlyList.add(key);
+ cacheMap.put(key, value);
+ }
+
+ public static void main(String[] args) {
+ LRUCache2 cache = new LRUCache2(2);
+ cache.put(1, 1);
+ cache.put(2, 2);
+ System.out.println(cache.get(1)); // returns 1
+ cache.put(3, 3); // 驱逐 key 2
+ System.out.println(cache.get(2)); // returns -1 (not found)
+ cache.put(4, 4); // 驱逐 key 1
+ System.out.println(cache.get(1)); // returns -1 (not found)
+ System.out.println(cache.get(3)); // returns 3
+ System.out.println(cache.get(4)); // returns 4
+ }
+}
+```
+
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git "a/MD/\347\256\227\346\263\225-\346\225\260\347\273\204-\345\257\271\346\222\236\346\214\207\351\222\210-\346\234\200\345\244\247\350\223\204\346\260\264.md" "b/MD/\347\256\227\346\263\225-\346\225\260\347\273\204-\345\257\271\346\222\236\346\214\207\351\222\210-\346\234\200\345\244\247\350\223\204\346\260\264.md"
new file mode 100644
index 0000000..47bb6bb
--- /dev/null
+++ "b/MD/\347\256\227\346\263\225-\346\225\260\347\273\204-\345\257\271\346\222\236\346\214\207\351\222\210-\346\234\200\345\244\247\350\223\204\346\260\264.md"
@@ -0,0 +1,23 @@
+https://leetcode.com/problems/container-with-most-water/
+
+给出一个非负整数数组,每一个整数表示一个竖立在坐标轴x位置的一堵高度为该整数的墙,选择两堵墙,和x轴构成的容器可以容纳最多的水
+
+```java
+class Solution {
+ public int maxArea(int[] height) {
+ int i = 0, j = height.length - 1;
+ int max = 0;
+ while(i < j){
+ max = Math.max(max, Math.min(height[i], height[j])*(j-i));
+ if(height[i] < height[j]){
+ i++;
+ }else{
+ j--;
+ }
+ }
+ return max;
+ }
+}
+```
+
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git "a/MD/\347\256\227\346\263\225-\346\225\260\347\273\204-\345\275\222\345\271\266\346\216\222\345\272\217-\345\220\210\345\271\266\346\234\211\345\272\217\346\225\260\347\273\204.md" "b/MD/\347\256\227\346\263\225-\346\225\260\347\273\204-\345\275\222\345\271\266\346\216\222\345\272\217-\345\220\210\345\271\266\346\234\211\345\272\217\346\225\260\347\273\204.md"
new file mode 100644
index 0000000..afedc46
--- /dev/null
+++ "b/MD/\347\256\227\346\263\225-\346\225\260\347\273\204-\345\275\222\345\271\266\346\216\222\345\272\217-\345\220\210\345\271\266\346\234\211\345\272\217\346\225\260\347\273\204.md"
@@ -0,0 +1,41 @@
+https://leetcode.com/problems/merge-sorted-array/
+
+Given two sorted integer arrays nums1 and nums2, merge nums2 into nums1 as one sorted array.
+
+Note:
+
+* The number of elements initialized in nums1 and nums2 are m and n respectively.
+* You may assume that nums1 has enough space (size that is greater or equal to m + n) to hold additional elements from nums2.
+Example:
+```
+Input:
+nums1 = [1,2,3,0,0,0], m = 3
+nums2 = [2,5,6], n = 3
+
+Output: [1,2,2,3,5,6]
+```
+
+归并排序的合并操作
+
+```java
+
+class Solution {
+public void merge(int A[], int m, int B[], int n) {
+ int i=m-1;
+ int j=n-1;
+ int k = m+n-1;
+ while(i >=0 && j>=0)
+ {
+ if(A[i] > B[j])
+ A[k--] = A[i--];
+ else
+ A[k--] = B[j--];
+ }
+ while(j>=0)
+ A[k--] = B[j--];
+ }
+}
+```
+
+
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git "a/MD/\347\256\227\346\263\225-\346\225\260\347\273\204-\345\277\253\351\200\237\346\216\222\345\272\217-\347\254\254k\345\244\247\344\270\252\346\225\260.md" "b/MD/\347\256\227\346\263\225-\346\225\260\347\273\204-\345\277\253\351\200\237\346\216\222\345\272\217-\347\254\254k\345\244\247\344\270\252\346\225\260.md"
new file mode 100644
index 0000000..20fbdb9
--- /dev/null
+++ "b/MD/\347\256\227\346\263\225-\346\225\260\347\273\204-\345\277\253\351\200\237\346\216\222\345\272\217-\347\254\254k\345\244\247\344\270\252\346\225\260.md"
@@ -0,0 +1,67 @@
+https://leetcode.com/problems/kth-largest-element-in-an-array/
+
+Find the kth largest element in an unsorted array. Note that it is the kth largest element in the sorted order, not the kth distinct element.
+
+Example 1:
+
+```
+Input: [3,2,1,5,6,4] and k = 2
+Output: 5
+```
+
+Example 2:
+
+```
+Input: [3,2,3,1,2,4,5,5,6] and k = 4
+Output: 4
+```
+
+Note:
+You may assume k is always valid, 1 ≤ k ≤ array's length.
+
+快排的每一次排序就是找到一个第N大的数,修改快排的递归逻辑。算法复杂度为O(N)。
+
+```java
+class Solution {
+ public int findKthLargest(int[] nums, int k) {
+ return sort(nums, 0, nums.length-1, k);
+ }
+
+ private int sort(int[] nums, int left, int right, int k){
+ int base = nums[left];
+ int leftt = left;
+ int rightt = right;
+ while(leftt < rightt){
+ while(leftt < rightt && nums[rightt] > base){
+ rightt--;
+ }
+ if(leftt < rightt){
+ int temp = nums[rightt];
+ nums[rightt] = nums[leftt];
+ nums[leftt] = temp;
+ leftt++;
+ }
+ while(leftt < rightt && nums[leftt] < base){
+ leftt++;
+ }
+ if(leftt < rightt){
+ int temp = nums[rightt];
+ nums[rightt] = nums[leftt];
+ nums[leftt] = temp;
+ rightt--;
+ }
+ }
+ int rank = nums.length - leftt;
+ if(rank == k){
+ return nums[leftt];
+ }else if(rank=s,返回这个最短的连续子数组的长度值
+
+```java
+class Solution {
+ public int minSubArrayLen(int s, int[] nums) {
+ int i = 0, j = -1, sum = 0, minLength = Integer.MAX_VALUE;
+ while(i < nums.length){
+ if(j + 1 < nums.length && sum < s){
+ sum+=nums[++j];
+ }else{
+ sum-=nums[i++];
+ }
+ if(sum >= s){
+ minLength = Math.min(j-i+1, minLength);
+ }
+ }
+ if(minLength == Integer.MAX_VALUE){
+ return 0;
+ }
+ return minLength;
+ }
+}
+```
+
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git "a/MD/\347\256\227\346\263\225-\351\223\276\350\241\250-\345\217\214\346\214\207\351\222\210-\345\210\240\351\231\244\345\200\222\346\225\260\347\254\254n\344\270\252.md" "b/MD/\347\256\227\346\263\225-\351\223\276\350\241\250-\345\217\214\346\214\207\351\222\210-\345\210\240\351\231\244\345\200\222\346\225\260\347\254\254n\344\270\252.md"
new file mode 100644
index 0000000..32d2a26
--- /dev/null
+++ "b/MD/\347\256\227\346\263\225-\351\223\276\350\241\250-\345\217\214\346\214\207\351\222\210-\345\210\240\351\231\244\345\200\222\346\225\260\347\254\254n\344\270\252.md"
@@ -0,0 +1,25 @@
+https://leetcode.com/problems/remove-nth-node-from-end-of-list/
+
+给一个链表,删除倒数第n个节点
+
+```java
+class Solution {
+ public ListNode removeNthFromEnd(ListNode head, int n) {
+ ListNode dummy = new ListNode(0);
+ dummy.next = head;
+
+ ListNode q = dummy, p = dummy;
+ while(n-->-1){
+ p = p.next;
+ }
+ while(p!=null){
+ q = q.next;
+ p = p.next;
+ }
+ q.next = q.next.next; // 优化:释放被删除节点
+ return dummy.next;
+ }
+}
+```
+
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git "a/MD/\347\256\227\346\263\225-\351\223\276\350\241\250-\345\217\215\350\275\254\351\223\276\350\241\250-\351\223\276\350\241\250\347\233\270\345\212\240.md" "b/MD/\347\256\227\346\263\225-\351\223\276\350\241\250-\345\217\215\350\275\254\351\223\276\350\241\250-\351\223\276\350\241\250\347\233\270\345\212\240.md"
new file mode 100644
index 0000000..55ff48d
--- /dev/null
+++ "b/MD/\347\256\227\346\263\225-\351\223\276\350\241\250-\345\217\215\350\275\254\351\223\276\350\241\250-\351\223\276\350\241\250\347\233\270\345\212\240.md"
@@ -0,0 +1,56 @@
+https://leetcode.com/problems/add-two-numbers/
+
+You are given two non-empty linked lists representing two non-negative integers. The digits are stored in reverse order and each of their nodes contain a single digit. Add the two numbers and return it as a linked list.
+
+You may assume the two numbers do not contain any leading zero, except the number 0 itself.
+
+Example:
+```
+Input: (2 -> 4 -> 3) + (5 -> 6 -> 4)
+Output: 7 -> 0 -> 8
+Explanation: 342 + 465 = 807.
+```
+
+ 对于这个问题还有一个很好的方法:
+
+1、将两个链表逆序,这样就可以依次得到从低到高位的数字
+
+2、同步遍历两个逆序后链表,相加生成新链表,同时关注进位
+
+3、当两个链表都遍历完成后,关注进位。
+
+4、将两个逆序的链表再逆序一遍,调整回去
+
+
+```java
+public class ListNode {
+ int val;
+ ListNode next;
+ ListNode(int x) { val = x; }
+}
+
+public class Solution {
+ public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
+ ListNode listNode= new ListNode(0);
+ ListNode p = listNode;
+ int sum = 0;
+
+ while (l1 != null || l2 != null || sum != 0) {
+ if (l1 != null) {
+ sum += l1.val;
+ l1 = l1.next;
+ }
+ if (l2 != null) {
+ sum += l2.val;
+ l2 = l2.next;
+ }
+ p.next = new ListNode(sum % 10);
+ sum = sum / 10;
+ p = p.next;
+ }
+ return listNode.next;
+ }
+}
+```
+
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git "a/MD/\347\263\273\347\273\237\350\256\276\350\256\241-\351\253\230\345\271\266\345\217\221\346\212\242\347\272\242\345\214\205.md" "b/MD/\347\263\273\347\273\237\350\256\276\350\256\241-\351\253\230\345\271\266\345\217\221\346\212\242\347\272\242\345\214\205.md"
new file mode 100644
index 0000000..a4ca649
--- /dev/null
+++ "b/MD/\347\263\273\347\273\237\350\256\276\350\256\241-\351\253\230\345\271\266\345\217\221\346\212\242\347\272\242\345\214\205.md"
@@ -0,0 +1,28 @@
+## 题目
+总共有10亿个红包,在某个时间一起来抢红包,如何设计
+
+## 分析
+主要考察的是如何设计高并发系统,但实际上存在一定变通处理方式,不一定全在技术上
+
+通常在考虑系统QPS时,应当按业务上的极限QPS作为系统必须承担的QPS设计,比如10亿个红包,因为用户量巨大,极限QPS是可能是10亿
+
+但是一般来说几万QPS已经是比较高的并发了,就需要比较大的集群和高并发架构来处理了,所以不可能真正实现10亿的并发架构,而是通过一些变通的方法来处理,比如在业务上做一些处理规避掉部分流量
+
+但尽可能地需要实现高并发架构,思路是将大部分流量拦截在系统承载能力低的模块之前
+
+## 回答
+#### 业务上适当规避
+在相应法律法规、规章制度、活动说明、用户体验允许的情况下,可以做以下处理
+
+1. 根据某些规则对部分用户直接返回没抢到。比如有些用户曾经被系统识别为恶意用户、垃圾用户、僵尸用户,直接告诉用户已经抢完
+2. 分散不同客户端打开活动入口的时间。比如将1秒内的10亿流量分散到10秒,那么平均每秒只有1亿了
+3. 增加客户端入口点击门槛。比如需要手机摇一摇、画一个图案才能触发抢红包的接口
+
+#### 技术上硬核抗压
+网关是会接触实打实10亿流量的地方,也是拦截掉最多无效流量的地方,同理,缓存也是
+
+1. 限流策略。比如在压力测试中我们测到系统1亿QPS达到了极限,那么超过的部分直接返回已经抢完,通过Nginx的lua脚本可以查redis看到QPS数据从而可以动态调节
+2. 作弊拦截。通过对UA、IP规则直接将抢红包的作弊流量拦截掉
+3. 异步削峰。对Redis中的红包预减数量,立即返回抢红包成功请用户等待,然后把发送消息发给消息队列,进行流量的第二次削峰,让后台服务慢慢处理
+4. 服务逻辑。比如业务逻辑是使用事务控制对数据库的创建红包记录,减红包数量的操作,那么创建操作要放到减数量操作之前,从而避免减数量update的行锁持有时间
+5. 机器配置。当然是服务器机器配置约高越好,数据库配置越猛越好,高并发抢红包主要是CPU的负载较高,要选择偏向CPU性能的机器
diff --git "a/MD/\350\256\276\350\256\241\346\250\241\345\274\217.md" "b/MD/\350\256\276\350\256\241\346\250\241\345\274\217.md"
deleted file mode 100644
index f94533a..0000000
--- "a/MD/\350\256\276\350\256\241\346\250\241\345\274\217.md"
+++ /dev/null
@@ -1,33 +0,0 @@
-## 常用模式
-## 单例模式
-[http://wuchong.me/blog/2014/08/28/how-to-correctly-write-singleton-pattern/](http://wuchong.me/blog/2014/08/28/how-to-correctly-write-singleton-pattern/)
-
-1. 懒汉(线程不安全,懒加载):如果没有实例就创建并返回,会有线程安全问题,简单加synchronized解决,但效率不高,升级版本是DCL
-2. 懒汉的升级DCL(线程安全,懒加载):加两个if是因为可能会有多个线程一起进入同步块外的if,如果在同步块内不进行二次检验的话就会生成多个实例了;`instance = new Singleton()`这句会有重排序的问题,用`volidate`解决
-3. 饿汉(线程安全,非懒加载):利用类加载器保证线程安全,但不是懒加载
-4. 饿汉升级静态内部类(线程安全,懒加载):在饿汉的基础上使用静态内部类解决非懒加载问题
-5. 枚举(线程安全,非懒加载):写法最简单,防止反序列化,但不是懒加载
-一般情况下直接使用饿汉式就好了,如果明确要求要懒加载会倾向于使用静态内部类,如果涉及到反序列化创建对象时会试着使用枚举的方式来实现单例。
-
-## 管道-过滤器模式
-[http://www.wangtianyi.top/blog/2017/10/08/shi-yao-shi-hou-neng-yong-shang-she-ji-mo-shi/](http://www.wangtianyi.top/blog/2017/10/08/shi-yao-shi-hou-neng-yong-shang-she-ji-mo-shi/)
-
-## 装饰器模式
-在保持原有功能接口不变的基础上动态扩展功能的模式。
-Java IO包中就使用了该模式,InputStream有太多的实现类如FileInputStream,如果要在每个实现类上加上几种功能如缓冲区读写功能Buffered,则会导致出现ileInputStreamBuffered, StringInputStreamBuffered等等,如果还要加个按行读写的功能,类会更多,代码重复度也太高,你说改原来的接口也行啊,但是这样就是改变接口的内容了,现在我想做到不更改以前的功能,动态地增强原有接口。
-所以使用FilterInputStream这个抽象装饰器来装饰InputStream,使得我们可以用BufferedInputStream来包装FileInputStream得到特定增强版InputStream,且增加装饰器种类也会更加灵活。
-
-缺点在于会引入很多小类,从而增加使用复杂度,多层装饰的时候很容易导致不知道如何使用
-
-
-
-## 适配器模式
-适配器模式就是把一个类的接口变换成客户端所能接受的另一种接口,从而使两个接口不匹配而无法在一起工作的两个类能够在一起工作。
-
-缺点:过多地使用适配器,会让系统非常零乱,不易整体进行把握。比如,明明看到调用的是 A 接口,其实内部被适配成了 B 接口的实现
-
-## 命令模式
-命令模式是对命令的封装。命令模式把发出命令的责任和执行命令的责任分隔开,形成命令、接收者、执行者三个角色
-优点:将命令规范化;允许执行者对请求排队、记录请求日志、提供命令的撤销和恢复
-
-缺点:导致某些系统有过多的具体命令类
\ No newline at end of file
diff --git "a/MD/\351\200\232\347\224\250\345\237\272\347\241\200-\346\216\222\345\272\217\347\256\227\346\263\225.md" "b/MD/\351\200\232\347\224\250\345\237\272\347\241\200-\346\216\222\345\272\217\347\256\227\346\263\225.md"
new file mode 100644
index 0000000..f4d852c
--- /dev/null
+++ "b/MD/\351\200\232\347\224\250\345\237\272\347\241\200-\346\216\222\345\272\217\347\256\227\346\263\225.md"
@@ -0,0 +1,34 @@
+## 快速排序
+
+
+
+
+首先任意选取一个数据(通常选用数组的第一个数)作为关键数据,然后将所有比它小的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一趟快速排序
+
+最好情况:每次划分过程产生的区间大小都为n/2,一共需要划分log2n次,每次需要比较n-1次,O(nlog2n)
+最坏情况:每次划分过程产生的两个区间分别包含n-1个元素和1个元素,一共需要划分n-1次,每次最多交换n-1次,这就是冒泡排序了,O(n2)
+
+## 堆排序
+
+1. 根据初始数组去构造初始堆(构建一个完全二叉树,保证所有的父结点都比它的孩子结点数值大)。
+2. 每次交换第一个和最后一个元素,输出最后一个元素(最大值),然后把剩下元素重新调整为大根堆。
+
+
+
+
+
+堆排序过程的最好和最坏时间复杂度是O(nlog2n)
+
+## TOP K
+如何在N个元素中寻找前K大的数?
+
+快速排序:
+
+* 原理:每次快速排序中的划分过程能找到一个全部大于左边元素的一个值。如果该值的位置等于K,那么这个值和它左边的所有元素就是前K大的数;如果该值的位置小于K,那么对右边的元素继续划分排序;如果该值的位置大于K,那么对左边的元素继续划分排序
+* 问题:但空间复杂度是O(N),如果你要在很多元素中找很少几个top K的元素,或者在一个巨大的数据流里找到top K,快速排序是不合适的,堆排序更省地方
+
+堆排序:
+* 原理:申请一个容量为K的数组,存入数组的前K个元素,创建长度为K的最小堆;从K开始循环数组的剩余元素,如果元素(a)比最小堆的根节点大,将a设置成最小堆的根节点,然后重建最小堆;循环完成后,最小堆中的所有元素就是需要找的最大的K个元素。
+* 优点:可以在N个元素中找到top K,时间复杂度是O(N log K),空间复杂的是O(K)
+
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git "a/MD/\351\200\232\347\224\250\345\237\272\347\241\200-\346\223\215\344\275\234\347\263\273\347\273\237.md" "b/MD/\351\200\232\347\224\250\345\237\272\347\241\200-\346\223\215\344\275\234\347\263\273\347\273\237.md"
new file mode 100644
index 0000000..ad29904
--- /dev/null
+++ "b/MD/\351\200\232\347\224\250\345\237\272\347\241\200-\346\223\215\344\275\234\347\263\273\347\273\237.md"
@@ -0,0 +1,19 @@
+## 线程和进程区别
+1. 进程是资源分配的最小单位,线程是程序执行的最小单位
+2. 进程有自己的独立地址空间,每启动一个进程,系统就会为它分配地址空间,建立数据表来维护代码段、堆栈段和数据段。线程是共享进程的数据空间,因此CPU切换一个线程的花费远比进程要小很多,同时创建一个线程的开销也比进程要小很多
+3. 线程之间的通信更方便,同一进程下的线程共享全局变量、静态变量等数据,而进程之间的通信需要以通信的方式(IPC)进行。不过如何处理好同步与互斥是编写多线程程序的难点。
+
+## 硬链接与软链接的区别
+每个文件都是创建了一个指针指向inode(代表物理硬盘的一个区块),可以通过`ls -i`查看。
+硬链接是创建另一个文件,也通过创建指针指向inode。当你删除一个文件/硬链接时,它会删除一个到底层inode的指针。当inode的所有指针都被删除时,才会真正删除文件。
+软连接是另外一种类型的文件,保存的是它指向文件的全路径,访问时会替换成绝对路径
+
+## 查看某个进程中的线程
+`ps -T -p `
+
+## 查看某个文件夹中每个文件夹的大小
+`du --max-depth=1 -h`
+
+## CPU负载的含义
+一段时间内CPU正在处理和等待处理的进程总数与CPU最大处理进程数的比例。对于多核CPU来说最大LOAD是最大的核心数量。
+使用`top`和`top -Hp`查找到CPU占用比较大的线程,进而使用`jstack`来排查Java程序的问题
\ No newline at end of file
diff --git "a/MD/\351\200\232\347\224\250\345\237\272\347\241\200-\347\275\221\347\273\234\351\200\232\344\277\241\345\215\217\350\256\256.md" "b/MD/\351\200\232\347\224\250\345\237\272\347\241\200-\347\275\221\347\273\234\351\200\232\344\277\241\345\215\217\350\256\256.md"
new file mode 100644
index 0000000..e1f12d9
--- /dev/null
+++ "b/MD/\351\200\232\347\224\250\345\237\272\347\241\200-\347\275\221\347\273\234\351\200\232\344\277\241\345\215\217\350\256\256.md"
@@ -0,0 +1,87 @@
+## TCP/IP
+OSI是一个理论上的七层网络通信模型,而TCP/IP则是实际运行的四层网络协议。TCP/IP包含:
+
+1. 网络接口层,主机必须使用某种协议与网络相连
+2. 网络层,使主机可以把分组发往任何网络,并使分组独立地传向目标。IP协议
+3. 传输层,使源端和目的端机器上的对等实体可以进行会话。TCP和UDP协议
+4. 应用层,包含所有的高层协议,FTP/TELNET/SMTP/DNS/NNTP/HTTP
+
+## HTTP
+HTTP是TCP/IP协议中的【应用层】协议。它不涉及数据包传输,主要规定了客户端和服务器之间的通信格式,是互联网信息交互中最常用的协议
+
+特点:
+
+1. 简单快速。只需要传【请求方法】与【资源路径】就能确定资源
+2. 灵活,传输【任意类型】的数据
+3. 无连接,一般一次连接只处理一个请求,结束后主动释放连接,但在HTTP1.1中可以使用keep-alive来复用相同的TCP连接发送多个请求
+4. 无状态,客户端向服务器发送HTTP请求之后,服务器会给我们发送数据过来,但不会记录任何信息。所以Cookie、Session产生了。
+
+## TCP
+TCP是一种面向连接的、可靠的、基于字节流的TCP/IP协议中的【传输层】协议
+
+
+
+### 建立连接:三次握手
+1. 建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SENT状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)。
+2. 服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
+3. 客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
+
+### 为什么要采用三次握手,两次不行吗
+避免由于网络延迟导致的创建无效连接的问题。比如客户端发出的一个连接请求没有丢失,而是长时间在某个网络节点滞留了,以至于到连接释放之后才到达服务端,如果不使用三次握手,一旦服务端发出请求连接就会建立连接,但是这个连接请求已经失效了,则会浪费服务端的资源。
+
+### 关闭连接:四次挥手
+1. 当主机A的应用程序通知TCP数据已经发送完毕时,TCP向主机B发送一个带有FIN附加标记的报文段(FIN表示英文finish)。
+2. 主机B收到这个FIN报文段之后,并不立即用FIN报文段回复主机A,而是先向主机A发送一个确认序号ACK,同时通知自己相应的应用程序:对方要求关闭连接(先发送ACK的目的是为了防止在这段时间内,对方重传FIN报文段)。
+3. 主机B的应用程序告诉TCP:我要彻底的关闭连接,TCP向主机A送一个FIN报文段。
+4. 主机A收到这个FIN报文段后,向主机B发送一个ACK表示连接彻底释放。
+
+### 为什么连接的时候是三次握手,关闭的时候却是四次握手
+因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,"你发的FIN报文我收到了"。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
+
+### 滑动窗口协议
+滑动窗口协议是传输层进行流控的一种措施,接收方通过通告发送方自己的窗口大小,从而控制发送方的发送速度,从而达到防止发送方发送速度过快而导致自己被淹没的目的。
+
+ACK包含两个非常重要的信息:一是期望接收到的下一字节的序号n,该n代表接收方已经接收到了前n-1字节数据。二是当前的窗口大小m,如此发送方在接收到ACK包含的这两个数据后就可以计算出还可以发送多少字节的数据给对方,这就是滑动窗口控制流量的基本原理
+
+TCP的滑动窗口是动态的,应用程序在需要(如内存不足)时,通过API通知TCP协议栈缩小TCP的接收窗口。然后TCP协议栈在下个段发送时包含新的窗口大小通知给对端,对端按通知的窗口来改变发送窗口,以此达到减缓发送速率的目的。
+
+### 与UDP区别
+* TCP提供面向连接的、可靠的数据流传输,而UDP提供的是非面向连接的、不可靠的数据流传输,如QQ
+* TCP注重数据安全性,UDP数据传输快,因为不需要连接等待,少了许多操作,但是其安全性却一般
+* TCP对应的协议(FTP/SMTP/HTTP),UDP(DNS)
+
+## HTTPS
+HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全,可防止数据在传输过程中被窃取、改变,确保数据的完整性,它大幅增加了中间人攻击的成本。
+
+加密过程:
+
+1. Hello - 握手开始于客户端发送Hello消息。包含服务端为了通过SSL连接到客户端的所有信息,包括客户端支持的各种密码套件和最大SSL版本。服务器也返回一个Hello消息,包含客户端需要的类似信息,包括到底使用哪一个加密算法和SSL版本。
+2. 证书交换 - 现在连接建立起来了,服务器必须通过SSL证书证明他的身份。SSL证书包含各种数据,包含所有者名称,相关属性(域名),证书上的公钥,数字签名和关于证书有效期的信息。客户端检查它是不是被CA验证过的且根据数字签名验证内容是否被修改过。注意服务器被允许需求一个证书去证明客户端的身份,但是这个只发生在敏感应用。
+3. 密钥交换 - 使用RSA非对称公钥加密算法(客户端生成一个对称密钥,然后用SSL证书里带的服务器公钥将该对称密钥加密。随后发送到服务端,服务端用服务器私钥解密,到此,握手阶段完成。)或者DH交换算法在客户端与服务端双方确定将要使用的密钥。这个密钥是双方都同意的一个简单,对称的密钥。这个过程是基于非对称加密方式和服务器的公钥/私钥的。
+4. 加密通信 - 在服务器和客户端加密实际信息是用到对称加密算法,用哪个算法在Hello阶段已经确定。对称加密算法是对于加密和解密都很简单的密钥。这个密钥是基于第三步在客户端与服务端已经商议好的。与需要公钥/私钥的非对称加密算法相反。
+
+## socket线程安全?
+总结来说,虽然系统级别的socket操作本身具备一定程度的并发安全性,但在多线程程序中对socket进行读写时仍需要开发者采取适当的同步策略以保证线程安全。
+
+1. 系统调用级别:在操作系统层面,对同一个socket文件描述符(fd)进行读写操作的系统调用如send、recv、write和read等,通常是线程安全的。这意味着多个线程可以同时调用这些函数而不会导致内核数据结构的混乱。
+2. 应用程序级别:然而,在应用程序中直接对同一个socket进行并发读写时,并非完全线程安全。不同的线程如果不加控制地同时对同一socket进行读写,可能会遇到以下问题:
+ - 数据包边界混淆:TCP是流式传输协议,没有消息边界的概念,两个线程如果并发发送或接收,可能导致接收到的数据边界与发送时不一致。
+ - 竞争条件:当多个线程尝试修改socket的状态或缓冲区时,可能会产生未定义的行为,例如,一个线程正在发送数据时,另一个线程关闭了socket,这可能导致不可预测的结果。
+ - 同步问题:如果没有适当的锁或其他同步机制来保护共享状态,那么不同线程之间对于何时开始和结束I/O操作的协调就可能出现问题。
+3. 最佳实践:为了在多线程环境下正确且安全地使用socket,通常建议采取以下措施:
+ - 互斥访问:使用线程同步机制,如互斥锁(mutex),确保任何时候只有一个线程在执行读写操作。
+ - 生产者-消费者模型:设计成一个线程专门负责接收数据并放入队列,另一个线程从队列取出数据并发送,通过队列实现线程间的通信和同步。
+ - 事件驱动编程:在某些场合下,如使用异步I/O(如epoll/kqueue等)、IOCP(Windows平台)或者事件循环机制,可以避免直接的并发访问,从而在单个线程内处理多个socket连接,减少线程间同步开销。
+
+## java socket跟socket有什么区别
+1. 抽象层次:
+ - 一般意义上的Socket:通常指的是计算机网络编程中的一个抽象概念,是操作系统提供的一种用于进程间通信的机制,通过它可以在网络中不同主机上的进程之间进行双向的数据传输。它是TCP/IP协议栈的一部分,在TCP或UDP等传输层协议之上提供接口。
+ - Java Socket:在Java编程语言中,java.net.Socket和java.net.ServerSocket类是对底层操作系统Socket接口的封装,提供了面向对象的方式来创建、管理和使用网络连接。程序员可以通过Java Socket API实现跨网络的客户端-服务器通信。
+2. API形式:
+ - 通用Socket:在不同的编程语言或环境中,对Socket的操作可能需要直接调用系统API函数(如C语言中的socket()、bind()、listen()、accept()、send()、recv()等)。
+ - Java Socket:Java为开发者提供了一套高级且易于使用的API,如Socket socket = new Socket(host, port)来建立到指定主机和端口的连接,以及socket.getInputStream()和socket.getOutputStream()来获取输入输出流以读写数据。
+3. 平台无关性:
+ - 通用Socket:直接操作系统提供的Socket API时,代码往往具有一定的平台相关性,即在不同的操作系统上可能需要采用不同的API及调用方式。
+ - Java Socket:由于Java语言的跨平台特性,其封装的Socket API能够在支持Java的所有平台上运行,使得基于Java Socket编写的网络程序具有良好的可移植性。
+
+综上所述,Java Socket是在Java编程环境下对通用Socket概念的具体实现和抽象,为开发者提供了一个更加便捷、安全且平台无关的方式来处理网络通信问题。
diff --git "a/MD/\351\200\232\347\224\250\345\237\272\347\241\200-\350\256\276\350\256\241\346\250\241\345\274\217.md" "b/MD/\351\200\232\347\224\250\345\237\272\347\241\200-\350\256\276\350\256\241\346\250\241\345\274\217.md"
new file mode 100644
index 0000000..34aaa51
--- /dev/null
+++ "b/MD/\351\200\232\347\224\250\345\237\272\347\241\200-\350\256\276\350\256\241\346\250\241\345\274\217.md"
@@ -0,0 +1,57 @@
+## 单例模式
+
+1. 懒汉(线程不安全,懒加载):如果没有实例就创建并返回,会有线程安全问题,简单加synchronized解决,但效率不高,升级版本是DCL
+2. 懒汉的升级DCL(线程安全,懒加载):加两个if是因为可能会有多个线程一起进入同步块外的if,如果在同步块内不进行二次检验的话就会生成多个实例了;`instance = new Singleton()`这句会有重排序的问题,用`volidate`解决
+3. 饿汉(线程安全,非懒加载):利用类加载器保证线程安全,但不是懒加载
+4. 饿汉升级静态内部类(线程安全,懒加载):在饿汉的基础上使用静态内部类解决非懒加载问题
+5. 枚举(线程安全,非懒加载):写法最简单,防止反序列化,但不是懒加载
+一般情况下直接使用饿汉式就好了,如果明确要求要懒加载会倾向于使用静态内部类,如果涉及到反序列化创建对象时会试着使用枚举的方式来实现单例。
+
+http://wuchong.me/blog/2014/08/28/how-to-correctly-write-singleton-pattern
+
+## 状态模式
+https://www.cnblogs.com/xyzq/p/11090344.html
+
+## 装饰器模式
+在保持原有功能接口不变的基础上动态扩展功能的模式。
+Java IO包中就使用了该模式,InputStream有太多的实现类如FileInputStream,如果要在每个实现类上加上几种功能如缓冲区读写功能Buffered,则会导致出现ileInputStreamBuffered, StringInputStreamBuffered等等,如果还要加个按行读写的功能,类会更多,代码重复度也太高,你说改原来的接口也行啊,但是这样就是改变接口的内容了,现在我想做到不更改以前的功能,动态地增强原有接口。
+所以使用FilterInputStream这个抽象装饰器来装饰InputStream,使得我们可以用BufferedInputStream来包装FileInputStream得到特定增强版InputStream,且增加装饰器种类也会更加灵活。
+
+缺点:
+会引入很多小类,从而增加使用复杂度,多层装饰的时候很容易导致不知道如何使用
+
+
+
+## 策略模式
+一个类的行为或其算法可以在运行时更改。这种类型的设计模式属于行为型模式。在策略模式中,我们创建表示各种策略的对象和一个行为随着策略对象改变而改变的 context 对象。策略对象改变 context 对象的执行算法。
+
+比如利用策略模式优化过多 if else 代码,将这些if else算法封装成一个一个的类,任意地替换
+
+
+
+整体思路如下:
+
+1. 定义一个 InnerCommand 接口,其中有一个 process 函数交给具体的业务实现。
+2. 根据自己的业务,会有多个类实现 InnerCommand 接口;这些实现类都会注册到 Spring Bean 容器中供之后使用。
+3. 通过客户端输入命令,从 Spring Bean 容器中获取一个 InnerCommand 实例。
+4. 执行最终的 process 函数。
+
+https://juejin.im/post/5c5172d15188256a2334a15d
+
+缺点:
+1. 策略类会增多
+2. 所有策略类都需要对外暴露。
+
+## 观察者模式
+当对象间存在一对多关系时,则使用观察者模式(Observer Pattern)。比如,当一个对象被修改时,则会自动通知它的依赖对象。定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
+
+
+
+观察者模式使用三个类 Subject、Observer 和 Client。Subject 对象带有绑定观察者到 Client 对象和从 Client 对象解绑观察者的方法。我们创建 Subject 类、Observer 抽象类和扩展了抽象类 Observer 的实体类。
+
+缺点:
+1. 如果一个被观察者对象有很多的直接和间接的观察者的话,将所有的观察者都通知到会花费很多时间
+2. 如果在观察者和观察目标之间有循环依赖的话,观察目标会触发它们之间进行循环调用,可能导致系统崩溃
+3. 观察者模式没有相应的机制让观察者知道所观察的目标对象是怎么发生变化的,而仅仅只是知道观察目标发生了变化
+
+欢迎光临[我的博客](http://www.wangtianyi.top/?utm_source=github&utm_medium=github),发现更多技术资源~
diff --git "a/MD/\351\227\256\351\242\230\346\216\222\346\237\245.md" "b/MD/\351\227\256\351\242\230\346\216\222\346\237\245.md"
deleted file mode 100644
index d0efe33..0000000
--- "a/MD/\351\227\256\351\242\230\346\216\222\346\237\245.md"
+++ /dev/null
@@ -1,37 +0,0 @@
-问题:如果某用户反馈,访问我们网站的某一个功能反应很慢,你会如何分析并处理这个问题?
-
-首先告诉面试官,我的思路是先确定问题会发生在哪些环节(用户电脑->运营商网络(DNS)->网站服务商(接入层-中间件或第三方接口-数据层)),然后最有可能发生在我们自己的后台服务器中,其次是代码里的问题,但是需要按以下的流程进行问题的解决:
-
-第一步:问题的重现
-
- 首先假定是我们网站内部的问题并尝试在测试环境来检测是否该功能很慢。
-
- 如果我们自己简单尝试之后无法重现问题,那么我不会去猜测可能是什么问题然后去一个一个排除,这是效率极为低下的解决方式,而是尝试立马与客户沟通,并问以下几个问题:
- 1. 您能录制一下这个问题发生时的视频吗?如果不行,能把重现的步骤告诉我们吗?
- 2. 能方便提供下您的账号吗,方便我们进行错误排查?
-
- 第一步一定是能够重现这个问题,才能开始问题的定位,所以这个两个问题是必须的。
- 如果依然无法重现问题,则可能与用户机器性能、访问时段、访问时的网络环境等等有关系,则需要作进一步交流。
-
-第二步:问题的定位
-
- 如果不能在线上环境重现问题,那么则需要与客户一起来定位问题,比如提供网络监测工具,来测试是否有人影响客户的网络或者客户的网络本身就有问题,提供硬件信息收集工具来收集客户的硬件数据。
-
- 如果此时我能在线上环境重现问题,那么基本上就能排除的客户那边的问题,问题则很可能发生在我们网站内部,进行以下方面的排查,所有步骤可以同时进行:
- 1. 自己在本地创建能调试问题的环境,使用调试工具排查是否是代码中的问题,前后端都包括
- 2. 在线上环境中进行一次问题的重现,收集出现问题时的日志记录与监控情况,特别关注日志中记录错误与耗时的信息、监控CPU/网络/内存/硬盘/数据库是否为正常状态
-
-第三步:问题的解决
-
- 如果是客户的网络问题,建议换个网络供应商或者室友。
-
- 如果是网站内部问题,通过针对性的代码修复或者服务器环境的基础设施的修复之后,再判断该问题的优先级,如果需要紧急修复则在代码的产品环境分支上紧急做一次修复的提交,然后merge回开发分支,最后在产品环境分支上再做一次发布。
- 如果优先级不高,则根据项目安排,放到合适的时机去修复,如在下一次发布的时候一并修复。
-
-第四步:问题的反馈
-
- 假设现在我们已经觉得已经把问题修复了,但是可能客户不这样觉得,我们需要在修复问题之后主动询问或发送一条反馈收集表格来验收我们的修复结果与提升用户满意度。
-
-----------
-
-以上是通用的回答模板,面试官想问的就是解决问题的思路而不是具体的方法,毕竟这种问题涉及的更多的是运维方面的知识,本人也仅仅碰到过两次会问这个问题的面试官,并且要求也不高,至于具体的问题只能具体性的分析,本文不涉及。
\ No newline at end of file
diff --git "a/MD/\351\253\230\345\271\266\345\217\221.md" "b/MD/\351\253\230\345\271\266\345\217\221.md"
deleted file mode 100644
index 2093aeb..0000000
--- "a/MD/\351\253\230\345\271\266\345\217\221.md"
+++ /dev/null
@@ -1,9 +0,0 @@
-## 主流场景与解决思路
-[http://www.wangtianyi.top/blog/2018/05/11/javaduo-xian-cheng-yu-gao-bing-fa-liu-gao-bing-fa-jie-jue-si-lu/](http://www.wangtianyi.top/blog/2018/05/11/javaduo-xian-cheng-yu-gao-bing-fa-liu-gao-bing-fa-jie-jue-si-lu/)
-
-## 高并发怎么处理
-问:比较耗CPU的任务摆在这里,程序也无法提升性能了,该怎么办?
-
-1. 先判断能否使用缓存,还是重新耗费CPU资源来创建一个
-2. 用偏重CPU性能的机器来做这个功能的专项负载均衡
-3. 请求太多的话,搞个消息队列排着,慢慢消费,同时前端提示需要一会才行
diff --git a/README.md b/README.md
index 6124394..c8e9559 100644
--- a/README.md
+++ b/README.md
@@ -1,42 +1,68 @@
-本项目是本人于2018年参加阿里、头条、京东、去哪儿等其他公司电话、现场面试之后总结出来的针对Java面试的知识点或真题,每个点或题目都是在面试中被问过的。
+本项目是本人参加BAT等其他公司电话、现场面试之后总结出来的针对Java面试的知识点或真题,每个点或题目都是在面试中被问过的。
-有疑问欢迎提 Issues 让我们共同解决,有好的想法想加进来的请提 PR ~
-
-PS:除开知识点,一定要准备好以下内容:
-1. 1分钟~3分钟的**个人介绍**
-2. 对抽象概念的**套路**(当面试官问你是如何理解多线程的时候,你要知道从定义、来源、实现、问题、优化、应用方面系统性地回答)
-3. **项目所占的比重是非常大的**,至少与知识点的比例是五五开(纪念),所以必须针对简历中的两个或多个项目,按从业务到技术选型,从正常流程到异常处理,从实现到优化这几个方面来详细地准备一个项目
-4. **压力练习**,面试的时候难免紧张,可能会严重影响发挥,建议通过找人相互提问的方式来改善
-5. **表达练习**,表达能力非常影响在面试中的表现,能否简练地将答案告诉面试官,需要刻意的练习,刻意通过给自己讲解的方式练习
+除开知识点,一定要准备好以下套路:
+1. **个人介绍**,需要准备一个1分钟的介绍,包括学习经历、工作经历、项目经历、个人优势、一句话总结。一定要自己背得滚瓜烂熟,张口就来
+2. **抽象概念**,当面试官问你是如何理解多线程的时候,你要知道从定义、来源、实现、问题、优化、应用方面系统性地回答
+3. **项目强化**,至少与知识点的比例是五五开,所以必须针对简历中的两个以上的项目,形成包括【架构和实现细节】,【正常流程和异常流程的处理】,【难点+坑+复盘优化】三位一体的组合拳
+4. **压力练习**,面试的时候难免紧张,可能会严重影响发挥,通过平时多找机会参与交流分享,或找人做压力面试来改善
+5. **表达练习**,表达能力非常影响在面试中的表现,能否简练地将答案告诉面试官,可以通过给自己讲解的方式刻意练习
+6. **重点针对**,面试官会针对简历提问,所以请针对简历上写的所有技术点进行重点准备
### Java基础
-* [JVM原理](https://github.com/xbox1994/2018-Java-Interview/blob/master/MD/Java基础-JVM原理.md)
-* [集合](https://github.com/xbox1994/2018-Java-Interview/blob/master/MD/Java基础-集合.md)
-* [多线程](https://github.com/xbox1994/2018-Java-Interview/blob/master/MD/Java基础-多线程.md)
-* [NIO](https://github.com/xbox1994/2018-Java-Interview/blob/master/MD/Java基础-NIO.md)
-### Web框架
-* [Spring](https://github.com/xbox1994/2018-Java-Interview/blob/master/MD/Web框架-Spring.md)
-### 数据库
-* [MySQL](https://github.com/xbox1994/2018-Java-Interview/blob/master/MD/数据库-MySQL.md)
-* [Redis](https://github.com/xbox1994/2018-Java-Interview/blob/master/MD/数据库-Redis.md)
-### [设计模式](https://github.com/xbox1994/2018-Java-Interview/blob/master/MD/设计模式.md)
-### [TCP](https://github.com/xbox1994/2018-Java-Interview/blob/master/MD/TCP.md)
-### [数据结构](https://github.com/xbox1994/2018-Java-Interview/blob/master/MD/数据结构.md)
-### [高并发](https://github.com/xbox1994/2018-Java-Interview/blob/master/MD/高并发.md)
+* [JVM原理](MD/Java基础-JVM原理.md)
+* [集合](MD/Java基础-集合.md)
+* [多线程](MD/Java基础-多线程.md)
+* [IO](MD/Java基础-IO.md)
+* [问题排查](https://www.wangtianyi.top/article/2018-07-20-javasheng-chan-huan-jing-xia-wen-ti-pai-cha/?utm_source=github&utm_medium=github)
+### Web框架、数据库
+* [Spring](MD/Web框架-Spring.md)
+* [MySQL](MD/数据库-MySQL.md)
+* [Redis](MD/数据库-Redis.md)
+### 通用基础
+* [操作系统](MD/通用基础-操作系统.md)
+* [网络通信协议](MD/通用基础-网络通信协议.md)
+* [排序算法](MD/通用基础-排序算法.md)
+* [常用设计模式](MD/通用基础-设计模式.md)
+* [从URL到看到网页的过程](https://www.wangtianyi.top/article/2017-10-22-cong-urlkai-shi-,ding-wei-shi-jie/?utm_source=github&utm_medium=github)
### 分布式
-* [缓存](https://www.zhihu.com/question/21419897)
-* [锁](https://www.jianshu.com/p/c2b4aa7a12f1)
-* [事务](https://mp.weixin.qq.com/s/RDnf637MY0IVgv2NpNVByw)
-* [消息队列](https://github.com/xbox1994/2018-Java-Interview/blob/master/MD/分布式-消息队列.md)
-* [存储](https://blog.csdn.net/prettyeva/article/details/60146668)
-* [限流](https://crossoverjie.top/2018/04/28/sbc/sbc7-Distributed-Limit)
-* [ID生成方式](https://github.com/crossoverJie/Java-Interview/blob/master/MD/ID-generator.md)
-* [高并发场景解决思路](http://www.wangtianyi.top/blog/2018/05/11/javaduo-xian-cheng-yu-gao-bing-fa-liu-gao-bing-fa-jie-jue-si-lu/)
-### [在线编程](https://github.com/xbox1994/2018-Java-Interview/blob/master/MD/在线编程.md)
-### [Linux](https://github.com/xbox1994/2018-Java-Interview/blob/master/MD/Linux.md)
-----------------
-### [搜索引擎](https://github.com/xbox1994/2018-Java-Interview/blob/master/MD/搜索引擎.md)
-搜索引擎是因为个人项目关系,那个搜索引擎非常简单,但有很多东西可以问到,可选择性学习借鉴,了解到对项目是如何提问的,还有问题的深度
-### [秒杀架构](https://github.com/xbox1994/2018-Java-Interview/blob/master/MD/秒杀架构.md)
-### [问题排查](https://github.com/xbox1994/2018-Java-Interview/blob/master/MD/问题排查.md)
-### [从按下回车开始,到浏览器呈现出网页之间的发生了什么](http://www.wangtianyi.top/blog/2017/10/22/cong-urlkai-shi-,ding-wei-shi-jie/)
\ No newline at end of file
+* [CAP理论](MD/分布式-CAP理论.md)
+* [锁](MD/分布式-锁.md)
+* [事务](MD/分布式-事务.md)
+* [消息队列](MD/分布式-消息队列.md)
+* [协调器](MD/分布式-协调器.md)
+* [ID生成方式](MD/分布式-ID生成方式.md)
+* [一致性hash](MD/分布式-一致性hash.md)
+* [限流](MD/分布式-限流.md)
+### 微服务
+* [微服务介绍](https://www.wangtianyi.top/article/2017-04-16-microservies-1-introduction-to-microservies/?utm_source=github&utm_medium=github)
+* [服务发现](MD/微服务-服务注册与发现.md)
+* [API网关](MD/微服务-网关.md)
+* [服务容错保护](MD/微服务-服务容错保护.md)
+* [服务配置中心](MD/微服务-服务配置中心.md)
+### 算法
+* [数组-快速排序-第k大个数](MD/算法-数组-快速排序-第k大个数.md)
+* [数组-对撞指针-最大蓄水](MD/算法-数组-对撞指针-最大蓄水.md)
+* [数组-滑动窗口-最小连续子数组](MD/算法-数组-滑动窗口-最小连续子数组.md)
+* [数组-归并排序-合并有序数组](MD/算法-数组-归并排序-合并有序数组.md)
+* [数组-顺时针打印矩形](https://www.nowcoder.com/practice/9b4c81a02cd34f76be2659fa0d54342a)
+* [数组-24点游戏](https://leetcode.cn/problems/24-game/description/)
+* [链表-链表反转-链表相加](MD/算法-链表-反转链表-链表相加.md)
+* [链表-双指针-删除倒数第n个](MD/算法-链表-双指针-删除倒数第n个.md)
+* [链表-双指针-重排链表](https://leetcode.cn/problems/reorder-list/description/)
+* [二叉树-递归-二叉树反转](MD/算法-二叉树-递归-二叉树反转.md)
+* [二叉树-递归-多叉树中最长的连续序列](MD/算法-二叉树-多叉树中最长的连续序列.md)
+* [二叉树-trie树](https://leetcode.cn/problems/implement-trie-prefix-tree/description/)
+* [动态规划-连续子数组最大和](MD/算法-动态规划-连续子数组最大和.md)
+* [数据结构-LRU淘汰算法](MD/算法-数据结构-LRU淘汰算法.md)
+* [其他-二十进制相加](MD/算法-其他-二十进制相加.md)
+* [有序数组中位数](https://leetcode-cn.com/problems/median-of-two-sorted-arrays/solution/xun-zhao-liang-ge-you-xu-shu-zu-de-zhong-wei-s-114/)
+* [数组中的k个最小值](https://leetcode-cn.com/problems/zui-xiao-de-kge-shu-lcof/solution/zui-xiao-de-kge-shu-by-leetcode-solution/)
+### 项目举例
+* [秒杀架构](MD/秒杀架构.md)
+### 系统设计
+* [系统设计-高并发抢红包](MD/系统设计-高并发抢红包.md)
+* [系统设计-在AWS上扩展到数百万用户的系统](https://www.wangtianyi.top/article/2019-03-06-zai-awsshang-kuo-zhan-dao-shu-bai-mo-yong-hu-de-xi-tong/?utm_source=github&utm_medium=github)
+* [系统设计-从面试者角度设计一个系统设计题](https://www.wangtianyi.top/article/2018-08-31-xi-tong-she-ji-mian-shi-ti-zong-he-kao-cha-mian-shi-zhe-de-da-zhao/?utm_source=github&utm_medium=github)
+### 智力题
+* [概率p输出1,概率1-p输出0,等概率输出0和1](https://blog.csdn.net/qq_29108585/article/details/60765640)
+* [判断点是否在多边形内部](https://www.cnblogs.com/muyefeiwu/p/11260366.html)
diff --git a/images/AIO.png b/images/AIO.png
new file mode 100644
index 0000000..e5ca3f8
Binary files /dev/null and b/images/AIO.png differ
diff --git a/images/BIO.png b/images/BIO.png
new file mode 100644
index 0000000..b4c5010
Binary files /dev/null and b/images/BIO.png differ
diff --git a/images/JVM1.8.png b/images/JVM1.8.png
new file mode 100644
index 0000000..92d9d7e
Binary files /dev/null and b/images/JVM1.8.png differ
diff --git "a/images/JVM\350\247\204\350\214\203.png" "b/images/JVM\350\247\204\350\214\203.png"
new file mode 100644
index 0000000..6511ace
Binary files /dev/null and "b/images/JVM\350\247\204\350\214\203.png" differ
diff --git a/images/NIO-1.png b/images/NIO-1.png
new file mode 100644
index 0000000..3aa9418
Binary files /dev/null and b/images/NIO-1.png differ
diff --git a/images/NIO-3.png b/images/NIO-3.png
new file mode 100644
index 0000000..de4a7e6
Binary files /dev/null and b/images/NIO-3.png differ
diff --git a/images/NIO-4.png b/images/NIO-4.png
new file mode 100644
index 0000000..af53c3b
Binary files /dev/null and b/images/NIO-4.png differ
diff --git a/images/api-gateway-1.jpg b/images/api-gateway-1.jpg
new file mode 100644
index 0000000..3832240
Binary files /dev/null and b/images/api-gateway-1.jpg differ
diff --git a/images/api-gateway-2.jpg b/images/api-gateway-2.jpg
new file mode 100644
index 0000000..020eeb4
Binary files /dev/null and b/images/api-gateway-2.jpg differ
diff --git a/images/api-gateway-3.jpg b/images/api-gateway-3.jpg
new file mode 100644
index 0000000..7b87b56
Binary files /dev/null and b/images/api-gateway-3.jpg differ
diff --git a/images/aws1.png b/images/aws1.png
new file mode 100644
index 0000000..22b1764
Binary files /dev/null and b/images/aws1.png differ
diff --git a/images/aws2.png b/images/aws2.png
new file mode 100644
index 0000000..3cb8eca
Binary files /dev/null and b/images/aws2.png differ
diff --git a/images/aws3.png b/images/aws3.png
new file mode 100644
index 0000000..b963291
Binary files /dev/null and b/images/aws3.png differ
diff --git a/images/aws4.png b/images/aws4.png
new file mode 100644
index 0000000..36f9db8
Binary files /dev/null and b/images/aws4.png differ
diff --git a/images/aws5.png b/images/aws5.png
new file mode 100644
index 0000000..1213637
Binary files /dev/null and b/images/aws5.png differ
diff --git a/images/aws6.png b/images/aws6.png
new file mode 100644
index 0000000..e400e5f
Binary files /dev/null and b/images/aws6.png differ
diff --git a/images/config.jpg b/images/config.jpg
new file mode 100644
index 0000000..90f3208
Binary files /dev/null and b/images/config.jpg differ
diff --git a/images/consul.jpg b/images/consul.jpg
new file mode 100644
index 0000000..4db46bd
Binary files /dev/null and b/images/consul.jpg differ
diff --git a/images/countdownlatch.png b/images/countdownlatch.png
new file mode 100644
index 0000000..fe89015
Binary files /dev/null and b/images/countdownlatch.png differ
diff --git a/images/cyclicbarrier.png b/images/cyclicbarrier.png
new file mode 100644
index 0000000..cea60d2
Binary files /dev/null and b/images/cyclicbarrier.png differ
diff --git a/images/heapsort.gif b/images/heapsort.gif
new file mode 100644
index 0000000..f73ccf2
Binary files /dev/null and b/images/heapsort.gif differ
diff --git a/images/j1.jpg b/images/j1.jpg
deleted file mode 100644
index 40034ea..0000000
Binary files a/images/j1.jpg and /dev/null differ
diff --git a/images/j12.jpg b/images/j12.jpg
deleted file mode 100644
index 3f82e45..0000000
Binary files a/images/j12.jpg and /dev/null differ
diff --git a/images/j13.png b/images/j13.png
new file mode 100644
index 0000000..47d74a4
Binary files /dev/null and b/images/j13.png differ
diff --git a/images/j2.jpg b/images/j2.jpg
deleted file mode 100644
index 5a2c8ee..0000000
Binary files a/images/j2.jpg and /dev/null differ
diff --git "a/images/kafka\351\233\206\347\276\244.png" "b/images/kafka\351\233\206\347\276\244.png"
new file mode 100644
index 0000000..97e6cd0
Binary files /dev/null and "b/images/kafka\351\233\206\347\276\244.png" differ
diff --git a/images/pay_wx.png b/images/pay_wx.png
new file mode 100644
index 0000000..0956481
Binary files /dev/null and b/images/pay_wx.png differ
diff --git a/images/quicksort.gif b/images/quicksort.gif
new file mode 100644
index 0000000..c107105
Binary files /dev/null and b/images/quicksort.gif differ
diff --git "a/images/redis\344\270\273\344\273\216.png" "b/images/redis\344\270\273\344\273\216.png"
new file mode 100644
index 0000000..76348c7
Binary files /dev/null and "b/images/redis\344\270\273\344\273\216.png" differ
diff --git "a/images/redis\345\223\250\345\205\265.png" "b/images/redis\345\223\250\345\205\265.png"
new file mode 100644
index 0000000..2f04343
Binary files /dev/null and "b/images/redis\345\223\250\345\205\265.png" differ
diff --git "a/images/redis\346\225\260\346\215\256\347\261\273\345\236\213.png" "b/images/redis\346\225\260\346\215\256\347\261\273\345\236\213.png"
new file mode 100644
index 0000000..e48f7c3
Binary files /dev/null and "b/images/redis\346\225\260\346\215\256\347\261\273\345\236\213.png" differ
diff --git "a/images/redis\351\224\256\347\251\272\351\227\264.png" "b/images/redis\351\224\256\347\251\272\351\227\264.png"
new file mode 100644
index 0000000..0c43cc0
Binary files /dev/null and "b/images/redis\351\224\256\347\251\272\351\227\264.png" differ
diff --git "a/images/redis\351\233\206\347\276\244.png" "b/images/redis\351\233\206\347\276\244.png"
new file mode 100644
index 0000000..f31cdee
Binary files /dev/null and "b/images/redis\351\233\206\347\276\244.png" differ
diff --git a/images/socket.jpg b/images/socket.jpg
new file mode 100644
index 0000000..ebbda5c
Binary files /dev/null and b/images/socket.jpg differ
diff --git a/images/socket.png b/images/socket.png
new file mode 100644
index 0000000..5bc99ca
Binary files /dev/null and b/images/socket.png differ
diff --git a/images/tcp.png b/images/tcp.png
new file mode 100644
index 0000000..f99c4ee
Binary files /dev/null and b/images/tcp.png differ
diff --git a/images/wechat_qrcode.jpg b/images/wechat_qrcode.jpg
new file mode 100644
index 0000000..fd1a042
Binary files /dev/null and b/images/wechat_qrcode.jpg differ
diff --git a/images/wxg.png b/images/wxg.png
new file mode 100644
index 0000000..6f41830
Binary files /dev/null and b/images/wxg.png differ
diff --git a/images/wxg2.jpg b/images/wxg2.jpg
new file mode 100644
index 0000000..97a90a7
Binary files /dev/null and b/images/wxg2.jpg differ
diff --git a/images/wxg2.png b/images/wxg2.png
new file mode 100644
index 0000000..199aed7
Binary files /dev/null and b/images/wxg2.png differ
diff --git a/images/zookeeper1.png b/images/zookeeper1.png
new file mode 100644
index 0000000..ad43c06
Binary files /dev/null and b/images/zookeeper1.png differ
diff --git a/images/zookeeper2.png b/images/zookeeper2.png
new file mode 100644
index 0000000..e33bfa3
Binary files /dev/null and b/images/zookeeper2.png differ
diff --git a/images/zookeeper3.png b/images/zookeeper3.png
new file mode 100644
index 0000000..d81bb20
Binary files /dev/null and b/images/zookeeper3.png differ
diff --git a/images/zookeeper4.png b/images/zookeeper4.png
new file mode 100644
index 0000000..9c6e8ac
Binary files /dev/null and b/images/zookeeper4.png differ
diff --git "a/images/\344\270\200\350\207\264\346\200\247hash1.jpg" "b/images/\344\270\200\350\207\264\346\200\247hash1.jpg"
new file mode 100644
index 0000000..0a1cb33
Binary files /dev/null and "b/images/\344\270\200\350\207\264\346\200\247hash1.jpg" differ
diff --git "a/images/\344\270\200\350\207\264\346\200\247hash2.jpg" "b/images/\344\270\200\350\207\264\346\200\247hash2.jpg"
new file mode 100644
index 0000000..1b1d160
Binary files /dev/null and "b/images/\344\270\200\350\207\264\346\200\247hash2.jpg" differ
diff --git "a/images/\344\270\200\350\207\264\346\200\247hash3.jpg" "b/images/\344\270\200\350\207\264\346\200\247hash3.jpg"
new file mode 100644
index 0000000..179874d
Binary files /dev/null and "b/images/\344\270\200\350\207\264\346\200\247hash3.jpg" differ
diff --git "a/images/\344\270\200\350\207\264\346\200\247hash4.jpg" "b/images/\344\270\200\350\207\264\346\200\247hash4.jpg"
new file mode 100644
index 0000000..661c04b
Binary files /dev/null and "b/images/\344\270\200\350\207\264\346\200\247hash4.jpg" differ
diff --git "a/images/\344\270\200\350\207\264\346\200\247hash5.jpg" "b/images/\344\270\200\350\207\264\346\200\247hash5.jpg"
new file mode 100644
index 0000000..baa95ab
Binary files /dev/null and "b/images/\344\270\200\350\207\264\346\200\247hash5.jpg" differ
diff --git "a/images/\344\270\200\350\207\264\346\200\247hash6.jpg" "b/images/\344\270\200\350\207\264\346\200\247hash6.jpg"
new file mode 100644
index 0000000..69035bf
Binary files /dev/null and "b/images/\344\270\200\350\207\264\346\200\247hash6.jpg" differ
diff --git "a/images/\344\270\200\350\207\264\346\200\247hash7.jpg" "b/images/\344\270\200\350\207\264\346\200\247hash7.jpg"
new file mode 100644
index 0000000..dbb4943
Binary files /dev/null and "b/images/\344\270\200\350\207\264\346\200\247hash7.jpg" differ
diff --git "a/images/\345\210\206\345\270\203\345\274\217-\351\231\220\346\265\201-1.gif" "b/images/\345\210\206\345\270\203\345\274\217-\351\231\220\346\265\201-1.gif"
new file mode 100644
index 0000000..b9d493b
Binary files /dev/null and "b/images/\345\210\206\345\270\203\345\274\217-\351\231\220\346\265\201-1.gif" differ
diff --git "a/images/\345\210\206\345\270\203\345\274\217-\351\231\220\346\265\201-2.png" "b/images/\345\210\206\345\270\203\345\274\217-\351\231\220\346\265\201-2.png"
new file mode 100644
index 0000000..679167c
Binary files /dev/null and "b/images/\345\210\206\345\270\203\345\274\217-\351\231\220\346\265\201-2.png" differ
diff --git "a/images/\345\210\206\345\270\203\345\274\217\344\272\213\345\212\2411.png" "b/images/\345\210\206\345\270\203\345\274\217\344\272\213\345\212\2411.png"
new file mode 100644
index 0000000..f24a62f
Binary files /dev/null and "b/images/\345\210\206\345\270\203\345\274\217\344\272\213\345\212\2411.png" differ
diff --git "a/images/\345\210\206\345\270\203\345\274\217\344\272\213\345\212\2412.png" "b/images/\345\210\206\345\270\203\345\274\217\344\272\213\345\212\2412.png"
new file mode 100644
index 0000000..96dc37b
Binary files /dev/null and "b/images/\345\210\206\345\270\203\345\274\217\344\272\213\345\212\2412.png" differ
diff --git "a/images/\345\210\206\345\270\203\345\274\217\344\272\213\345\212\2413.png" "b/images/\345\210\206\345\270\203\345\274\217\344\272\213\345\212\2413.png"
new file mode 100644
index 0000000..385e7e3
Binary files /dev/null and "b/images/\345\210\206\345\270\203\345\274\217\344\272\213\345\212\2413.png" differ
diff --git "a/images/\345\210\206\345\270\203\345\274\217\344\272\213\345\212\2414.png" "b/images/\345\210\206\345\270\203\345\274\217\344\272\213\345\212\2414.png"
new file mode 100644
index 0000000..f9588d6
Binary files /dev/null and "b/images/\345\210\206\345\270\203\345\274\217\344\272\213\345\212\2414.png" differ
diff --git "a/images/\345\240\206\347\232\204\345\206\205\345\255\230\345\210\206\351\205\215.png" "b/images/\345\240\206\347\232\204\345\206\205\345\255\230\345\210\206\351\205\215.png"
new file mode 100644
index 0000000..00cb903
Binary files /dev/null and "b/images/\345\240\206\347\232\204\345\206\205\345\255\230\345\210\206\351\205\215.png" differ
diff --git "a/images/\346\266\210\346\201\257\351\241\272\345\272\217\346\200\247.jpg" "b/images/\346\266\210\346\201\257\351\241\272\345\272\217\346\200\247.jpg"
new file mode 100644
index 0000000..b30cf4c
Binary files /dev/null and "b/images/\346\266\210\346\201\257\351\241\272\345\272\217\346\200\247.jpg" differ
diff --git "a/images/\347\237\245\350\257\206\346\230\237\347\220\203.JPG" "b/images/\347\237\245\350\257\206\346\230\237\347\220\203.JPG"
new file mode 100644
index 0000000..d6b59ee
Binary files /dev/null and "b/images/\347\237\245\350\257\206\346\230\237\347\220\203.JPG" differ
diff --git "a/images/\347\255\226\347\225\245\346\250\241\345\274\217.png" "b/images/\347\255\226\347\225\245\346\250\241\345\274\217.png"
new file mode 100644
index 0000000..0e9b7b1
Binary files /dev/null and "b/images/\347\255\226\347\225\245\346\250\241\345\274\217.png" differ
diff --git a/images/j9.png "b/images/\350\243\205\351\245\260\345\231\250\346\250\241\345\274\217.png"
similarity index 100%
rename from images/j9.png
rename to "images/\350\243\205\351\245\260\345\231\250\346\250\241\345\274\217.png"
diff --git "a/images/\350\247\202\345\257\237\350\200\205\346\250\241\345\274\217.jpg" "b/images/\350\247\202\345\257\237\350\200\205\346\250\241\345\274\217.jpg"
new file mode 100644
index 0000000..441c471
Binary files /dev/null and "b/images/\350\247\202\345\257\237\350\200\205\346\250\241\345\274\217.jpg" differ