'\n",
+ " html += '
'\n",
+ " html += '| Rank #1, Score:{:.2f} | '.format(scores[sorted_ix[0]])\n",
+ " html += 'Rank #2, Score:{:.2f} | '.format(scores[sorted_ix[1]])\n",
+ " html += 'Rank #3, Score:{:.2f} |
|---|
'.format(scores[sorted_ix[2]])\n",
+ " for i, idx in enumerate(sorted_ix):\n",
+ " url = urls[sorted_ix[i]];\n",
+ " html += ''\n",
+ " html += ' '.format(url)\n",
+ " html += ' '.format(url)\n",
+ " html += ' | '\n",
+ " html += '
'\n",
+ " return html\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Ime5V4kDewh8"
+ },
+ "outputs": [],
+ "source": [
+ "# @title Load example videos and define text queries { display-mode: \"form\" }\n",
+ "\n",
+ "video_1_url = 'https://upload.wikimedia.org/wikipedia/commons/b/b0/YosriAirTerjun.gif' # @param {type:\"string\"}\n",
+ "video_2_url = 'https://upload.wikimedia.org/wikipedia/commons/e/e6/Guitar_solo_gif.gif' # @param {type:\"string\"}\n",
+ "video_3_url = 'https://upload.wikimedia.org/wikipedia/commons/3/30/2009-08-16-autodrift-by-RalfR-gif-by-wau.gif' # @param {type:\"string\"}\n",
+ "\n",
+ "video_1 = load_video(video_1_url)\n",
+ "video_2 = load_video(video_2_url)\n",
+ "video_3 = load_video(video_3_url)\n",
+ "all_videos = [video_1, video_2, video_3]\n",
+ "\n",
+ "query_1_video = 'waterfall' # @param {type:\"string\"}\n",
+ "query_2_video = 'playing guitar' # @param {type:\"string\"}\n",
+ "query_3_video = 'car drifting' # @param {type:\"string\"}\n",
+ "all_queries_video = [query_1_video, query_2_video, query_3_video]\n",
+ "all_videos_urls = [video_1_url, video_2_url, video_3_url]\n",
+ "display_video(all_videos_urls)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "NCLKv_L_8Anc"
+ },
+ "source": [
+ "## Demonstrate text to video retrieval\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "9oX8ItFUjybi"
+ },
+ "outputs": [],
+ "source": [
+ "# Prepare video inputs.\n",
+ "videos_np = np.stack(all_videos, axis=0)\n",
+ "\n",
+ "# Prepare text input.\n",
+ "words_np = np.array(all_queries_video)\n",
+ "\n",
+ "# Generate the video and text embeddings.\n",
+ "video_embd, text_embd = generate_embeddings(hub_model, videos_np, words_np)\n",
+ "\n",
+ "# Scores between video and text is computed by dot products.\n",
+ "all_scores = np.dot(text_embd, tf.transpose(video_embd))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "d4AwYmODmE9Y"
+ },
+ "outputs": [],
+ "source": [
+ "# Display results.\n",
+ "html = ''\n",
+ "for i, words in enumerate(words_np):\n",
+ " html += display_query_and_results_video(words, all_videos_urls, all_scores[i, :])\n",
+ " html += '
'\n",
+ "display.HTML(html)"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "collapsed_sections": [],
+ "name": "text_to_video_retrieval_with_s3d_milnce.ipynb",
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/site/en/hub/tutorials/tf2_arbitrary_image_stylization.ipynb b/site/en/hub/tutorials/tf2_arbitrary_image_stylization.ipynb
new file mode 100644
index 00000000000..3a0cb09113e
--- /dev/null
+++ b/site/en/hub/tutorials/tf2_arbitrary_image_stylization.ipynb
@@ -0,0 +1,375 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ScitaPqhKtuW"
+ },
+ "source": [
+ "##### Copyright 2019 The TensorFlow Hub Authors.\n",
+ "\n",
+ "Licensed under the Apache License, Version 2.0 (the \"License\");"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "jvztxQ6VsK2k"
+ },
+ "outputs": [],
+ "source": [
+ "# Copyright 2019 The TensorFlow Hub Authors. All Rights Reserved.\n",
+ "#\n",
+ "# Licensed under the Apache License, Version 2.0 (the \"License\");\n",
+ "# you may not use this file except in compliance with the License.\n",
+ "# You may obtain a copy of the License at\n",
+ "#\n",
+ "# http://www.apache.org/licenses/LICENSE-2.0\n",
+ "#\n",
+ "# Unless required by applicable law or agreed to in writing, software\n",
+ "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
+ "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
+ "# See the License for the specific language governing permissions and\n",
+ "# limitations under the License.\n",
+ "# =============================================================================="
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "oXlcl8lqBgAD"
+ },
+ "source": [
+ "# Fast Style Transfer for Arbitrary Styles\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "MfBg1C5NB3X0"
+ },
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "YeeuYzbZcJzs"
+ },
+ "source": [
+ "Based on the model code in [magenta](https://github.com/tensorflow/magenta/tree/master/magenta/models/arbitrary_image_stylization) and the publication:\n",
+ "\n",
+ "[Exploring the structure of a real-time, arbitrary neural artistic stylization\n",
+ "network](https://arxiv.org/abs/1705.06830).\n",
+ "*Golnaz Ghiasi, Honglak Lee,\n",
+ "Manjunath Kudlur, Vincent Dumoulin, Jonathon Shlens*,\n",
+ "Proceedings of the British Machine Vision Conference (BMVC), 2017.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "TaM8BVxrCA2E"
+ },
+ "source": [
+ "## Setup"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "J65jog2ncJzt"
+ },
+ "source": [
+ "Let's start with importing TF2 and all relevant dependencies."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "v-KXRY5XBu2u"
+ },
+ "outputs": [],
+ "source": [
+ "import functools\n",
+ "import os\n",
+ "\n",
+ "from matplotlib import gridspec\n",
+ "import matplotlib.pylab as plt\n",
+ "import numpy as np\n",
+ "import tensorflow as tf\n",
+ "import tensorflow_hub as hub\n",
+ "\n",
+ "print(\"TF Version: \", tf.__version__)\n",
+ "print(\"TF Hub version: \", hub.__version__)\n",
+ "print(\"Eager mode enabled: \", tf.executing_eagerly())\n",
+ "print(\"GPU available: \", tf.config.list_physical_devices('GPU'))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "tsoDv_9geoZn"
+ },
+ "outputs": [],
+ "source": [
+ "# @title Define image loading and visualization functions { display-mode: \"form\" }\n",
+ "\n",
+ "def crop_center(image):\n",
+ " \"\"\"Returns a cropped square image.\"\"\"\n",
+ " shape = image.shape\n",
+ " new_shape = min(shape[1], shape[2])\n",
+ " offset_y = max(shape[1] - shape[2], 0) // 2\n",
+ " offset_x = max(shape[2] - shape[1], 0) // 2\n",
+ " image = tf.image.crop_to_bounding_box(\n",
+ " image, offset_y, offset_x, new_shape, new_shape)\n",
+ " return image\n",
+ "\n",
+ "@functools.lru_cache(maxsize=None)\n",
+ "def load_image(image_url, image_size=(256, 256), preserve_aspect_ratio=True):\n",
+ " \"\"\"Loads and preprocesses images.\"\"\"\n",
+ " # Cache image file locally.\n",
+ " image_path = tf.keras.utils.get_file(os.path.basename(image_url)[-128:], image_url)\n",
+ " # Load and convert to float32 numpy array, add batch dimension, and normalize to range [0, 1].\n",
+ " img = tf.io.decode_image(\n",
+ " tf.io.read_file(image_path),\n",
+ " channels=3, dtype=tf.float32)[tf.newaxis, ...]\n",
+ " img = crop_center(img)\n",
+ " img = tf.image.resize(img, image_size, preserve_aspect_ratio=True)\n",
+ " return img\n",
+ "\n",
+ "def show_n(images, titles=('',)):\n",
+ " n = len(images)\n",
+ " image_sizes = [image.shape[1] for image in images]\n",
+ " w = (image_sizes[0] * 6) // 320\n",
+ " plt.figure(figsize=(w * n, w))\n",
+ " gs = gridspec.GridSpec(1, n, width_ratios=image_sizes)\n",
+ " for i in range(n):\n",
+ " plt.subplot(gs[i])\n",
+ " plt.imshow(images[i][0], aspect='equal')\n",
+ " plt.axis('off')\n",
+ " plt.title(titles[i] if len(titles) > i else '')\n",
+ " plt.show()\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "8etHh05-CJHc"
+ },
+ "source": [
+ "Let's get as well some images to play with."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "dRc0vat3Alzo"
+ },
+ "outputs": [],
+ "source": [
+ "# @title Load example images { display-mode: \"form\" }\n",
+ "\n",
+ "content_image_url = 'https://upload.wikimedia.org/wikipedia/commons/thumb/f/fd/Golden_Gate_Bridge_from_Battery_Spencer.jpg/640px-Golden_Gate_Bridge_from_Battery_Spencer.jpg' # @param {type:\"string\"}\n",
+ "style_image_url = 'https://upload.wikimedia.org/wikipedia/commons/0/0a/The_Great_Wave_off_Kanagawa.jpg' # @param {type:\"string\"}\n",
+ "output_image_size = 384 # @param {type:\"integer\"}\n",
+ "\n",
+ "# The content image size can be arbitrary.\n",
+ "content_img_size = (output_image_size, output_image_size)\n",
+ "# The style prediction model was trained with image size 256 and it's the \n",
+ "# recommended image size for the style image (though, other sizes work as \n",
+ "# well but will lead to different results).\n",
+ "style_img_size = (256, 256) # Recommended to keep it at 256.\n",
+ "\n",
+ "content_image = load_image(content_image_url, content_img_size)\n",
+ "style_image = load_image(style_image_url, style_img_size)\n",
+ "style_image = tf.nn.avg_pool(style_image, ksize=[3,3], strides=[1,1], padding='SAME')\n",
+ "show_n([content_image, style_image], ['Content image', 'Style image'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "yL2Bn5ThR1nY"
+ },
+ "source": [
+ "## Import TF Hub module"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "467AVDSuzBPc"
+ },
+ "outputs": [],
+ "source": [
+ "# Load TF Hub module.\n",
+ "\n",
+ "hub_handle = 'https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2'\n",
+ "hub_module = hub.load(hub_handle)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "uAR70_3wLEDB"
+ },
+ "source": [
+ "The signature of this hub module for image stylization is:\n",
+ "```\n",
+ "outputs = hub_module(content_image, style_image)\n",
+ "stylized_image = outputs[0]\n",
+ "```\n",
+ "Where `content_image`, `style_image`, and `stylized_image` are expected to be 4-D Tensors with shapes `[batch_size, image_height, image_width, 3]`.\n",
+ "\n",
+ "In the current example we provide only single images and therefore the batch dimension is 1, but one can use the same module to process more images at the same time.\n",
+ "\n",
+ "The input and output values of the images should be in the range [0, 1].\n",
+ "\n",
+ "The shapes of content and style image don't have to match. Output image shape\n",
+ "is the same as the content image shape."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "qEhYJno1R7rP"
+ },
+ "source": [
+ "## Demonstrate image stylization"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "lnAv-F3O9fLV"
+ },
+ "outputs": [],
+ "source": [
+ "# Stylize content image with given style image.\n",
+ "# This is pretty fast within a few milliseconds on a GPU.\n",
+ "\n",
+ "outputs = hub_module(tf.constant(content_image), tf.constant(style_image))\n",
+ "stylized_image = outputs[0]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "OEAPEdq698gs"
+ },
+ "outputs": [],
+ "source": [
+ "# Visualize input images and the generated stylized image.\n",
+ "\n",
+ "show_n([content_image, style_image, stylized_image], titles=['Original content image', 'Style image', 'Stylized image'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "v-gYvjTWK-lx"
+ },
+ "source": [
+ "## Let's try it on more images"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "WSMaY0YBNfkK"
+ },
+ "outputs": [],
+ "source": [
+ "# @title To Run: Load more images { display-mode: \"form\" }\n",
+ "\n",
+ "content_urls = dict(\n",
+ " sea_turtle='https://upload.wikimedia.org/wikipedia/commons/d/d7/Green_Sea_Turtle_grazing_seagrass.jpg',\n",
+ " tuebingen='https://upload.wikimedia.org/wikipedia/commons/0/00/Tuebingen_Neckarfront.jpg',\n",
+ " grace_hopper='https://storage.googleapis.com/download.tensorflow.org/example_images/grace_hopper.jpg',\n",
+ " )\n",
+ "style_urls = dict(\n",
+ " kanagawa_great_wave='https://upload.wikimedia.org/wikipedia/commons/0/0a/The_Great_Wave_off_Kanagawa.jpg',\n",
+ " kandinsky_composition_7='https://upload.wikimedia.org/wikipedia/commons/b/b4/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg',\n",
+ " hubble_pillars_of_creation='https://upload.wikimedia.org/wikipedia/commons/6/68/Pillars_of_creation_2014_HST_WFC3-UVIS_full-res_denoised.jpg',\n",
+ " van_gogh_starry_night='https://upload.wikimedia.org/wikipedia/commons/thumb/e/ea/Van_Gogh_-_Starry_Night_-_Google_Art_Project.jpg/1024px-Van_Gogh_-_Starry_Night_-_Google_Art_Project.jpg',\n",
+ " turner_nantes='https://upload.wikimedia.org/wikipedia/commons/b/b7/JMW_Turner_-_Nantes_from_the_Ile_Feydeau.jpg',\n",
+ " munch_scream='https://upload.wikimedia.org/wikipedia/commons/c/c5/Edvard_Munch%2C_1893%2C_The_Scream%2C_oil%2C_tempera_and_pastel_on_cardboard%2C_91_x_73_cm%2C_National_Gallery_of_Norway.jpg',\n",
+ " picasso_demoiselles_avignon='https://upload.wikimedia.org/wikipedia/en/4/4c/Les_Demoiselles_d%27Avignon.jpg',\n",
+ " picasso_violin='https://upload.wikimedia.org/wikipedia/en/3/3c/Pablo_Picasso%2C_1911-12%2C_Violon_%28Violin%29%2C_oil_on_canvas%2C_Kr%C3%B6ller-M%C3%BCller_Museum%2C_Otterlo%2C_Netherlands.jpg',\n",
+ " picasso_bottle_of_rum='https://upload.wikimedia.org/wikipedia/en/7/7f/Pablo_Picasso%2C_1911%2C_Still_Life_with_a_Bottle_of_Rum%2C_oil_on_canvas%2C_61.3_x_50.5_cm%2C_Metropolitan_Museum_of_Art%2C_New_York.jpg',\n",
+ " fire='https://upload.wikimedia.org/wikipedia/commons/3/36/Large_bonfire.jpg',\n",
+ " derkovits_woman_head='https://upload.wikimedia.org/wikipedia/commons/0/0d/Derkovits_Gyula_Woman_head_1922.jpg',\n",
+ " amadeo_style_life='https://upload.wikimedia.org/wikipedia/commons/8/8e/Untitled_%28Still_life%29_%281913%29_-_Amadeo_Souza-Cardoso_%281887-1918%29_%2817385824283%29.jpg',\n",
+ " derkovtis_talig='https://upload.wikimedia.org/wikipedia/commons/3/37/Derkovits_Gyula_Talig%C3%A1s_1920.jpg',\n",
+ " amadeo_cardoso='https://upload.wikimedia.org/wikipedia/commons/7/7d/Amadeo_de_Souza-Cardoso%2C_1915_-_Landscape_with_black_figure.jpg'\n",
+ ")\n",
+ "\n",
+ "content_image_size = 384\n",
+ "style_image_size = 256\n",
+ "content_images = {k: load_image(v, (content_image_size, content_image_size)) for k, v in content_urls.items()}\n",
+ "style_images = {k: load_image(v, (style_image_size, style_image_size)) for k, v in style_urls.items()}\n",
+ "style_images = {k: tf.nn.avg_pool(style_image, ksize=[3,3], strides=[1,1], padding='SAME') for k, style_image in style_images.items()}\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "dqB6aNTLNVkK"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Specify the main content image and the style you want to use. { display-mode: \"form\" }\n",
+ "\n",
+ "content_name = 'sea_turtle' # @param ['sea_turtle', 'tuebingen', 'grace_hopper']\n",
+ "style_name = 'munch_scream' # @param ['kanagawa_great_wave', 'kandinsky_composition_7', 'hubble_pillars_of_creation', 'van_gogh_starry_night', 'turner_nantes', 'munch_scream', 'picasso_demoiselles_avignon', 'picasso_violin', 'picasso_bottle_of_rum', 'fire', 'derkovits_woman_head', 'amadeo_style_life', 'derkovtis_talig', 'amadeo_cardoso']\n",
+ "\n",
+ "stylized_image = hub_module(tf.constant(content_images[content_name]),\n",
+ " tf.constant(style_images[style_name]))[0]\n",
+ "\n",
+ "show_n([content_images[content_name], style_images[style_name], stylized_image],\n",
+ " titles=['Original content image', 'Style image', 'Stylized image'])"
+ ]
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "collapsed_sections": [],
+ "name": "tf2_arbitrary_image_stylization.ipynb",
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/site/en/hub/tutorials/tf2_image_retraining.ipynb b/site/en/hub/tutorials/tf2_image_retraining.ipynb
new file mode 100644
index 00000000000..0266f4683c1
--- /dev/null
+++ b/site/en/hub/tutorials/tf2_image_retraining.ipynb
@@ -0,0 +1,605 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ScitaPqhKtuW"
+ },
+ "source": [
+ "##### Copyright 2021 The TensorFlow Hub Authors.\n",
+ "\n",
+ "Licensed under the Apache License, Version 2.0 (the \"License\");"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "jvztxQ6VsK2k"
+ },
+ "outputs": [],
+ "source": [
+ "# Copyright 2021 The TensorFlow Hub Authors. All Rights Reserved.\n",
+ "#\n",
+ "# Licensed under the Apache License, Version 2.0 (the \"License\");\n",
+ "# you may not use this file except in compliance with the License.\n",
+ "# You may obtain a copy of the License at\n",
+ "#\n",
+ "# http://www.apache.org/licenses/LICENSE-2.0\n",
+ "#\n",
+ "# Unless required by applicable law or agreed to in writing, software\n",
+ "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
+ "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
+ "# See the License for the specific language governing permissions and\n",
+ "# limitations under the License.\n",
+ "# =============================================================================="
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "oYM61xrTsP5d"
+ },
+ "source": [
+ "# Retraining an Image Classifier\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "MfBg1C5NB3X0"
+ },
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "L1otmJgmbahf"
+ },
+ "source": [
+ "## Introduction\n",
+ "\n",
+ "Image classification models have millions of parameters. Training them from\n",
+ "scratch requires a lot of labeled training data and a lot of computing power. Transfer learning is a technique that shortcuts much of this by taking a piece of a model that has already been trained on a related task and reusing it in a new model.\n",
+ "\n",
+ "This Colab demonstrates how to build a Keras model for classifying five species of flowers by using a pre-trained TF2 SavedModel from TensorFlow Hub for image feature extraction, trained on the much larger and more general ImageNet dataset. Optionally, the feature extractor can be trained (\"fine-tuned\") alongside the newly added classifier.\n",
+ "\n",
+ "### Looking for a tool instead?\n",
+ "\n",
+ "This is a TensorFlow coding tutorial. If you want a tool that just builds the TensorFlow or TFLite model for, take a look at the [make_image_classifier](https://github.com/tensorflow/hub/tree/master/tensorflow_hub/tools/make_image_classifier) command-line tool that gets [installed](https://www.tensorflow.org/hub/installation) by the PIP package `tensorflow-hub[make_image_classifier]`, or at [this](https://colab.sandbox.google.com/github/tensorflow/examples/blob/master/tensorflow_examples/lite/model_maker/demo/image_classification.ipynb) TFLite colab.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "bL54LWCHt5q5"
+ },
+ "source": [
+ "## Setup"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "dlauq-4FWGZM"
+ },
+ "outputs": [],
+ "source": [
+ "import itertools\n",
+ "import os\n",
+ "\n",
+ "import matplotlib.pylab as plt\n",
+ "import numpy as np\n",
+ "\n",
+ "import tensorflow as tf\n",
+ "import tensorflow_hub as hub\n",
+ "\n",
+ "print(\"TF version:\", tf.__version__)\n",
+ "print(\"Hub version:\", hub.__version__)\n",
+ "print(\"GPU is\", \"available\" if tf.config.list_physical_devices('GPU') else \"NOT AVAILABLE\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "mmaHHH7Pvmth"
+ },
+ "source": [
+ "## Select the TF2 SavedModel module to use\n",
+ "\n",
+ "For starters, use [https://tfhub.dev/google/imagenet/mobilenet_v2_100_224/feature_vector/4](https://tfhub.dev/google/imagenet/mobilenet_v2_100_224/feature_vector/4). The same URL can be used in code to identify the SavedModel and in your browser to show its documentation. (Note that models in TF1 Hub format won't work here.)\n",
+ "\n",
+ "You can find more TF2 models that generate image feature vectors [here](https://tfhub.dev/s?module-type=image-feature-vector&tf-version=tf2).\n",
+ "\n",
+ "There are multiple possible models to try. All you need to do is select a different one on the cell below and follow up with the notebook."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "FlsEcKVeuCnf"
+ },
+ "outputs": [],
+ "source": [
+ "#@title\n",
+ "\n",
+ "model_name = \"efficientnetv2-xl-21k\" # @param ['efficientnetv2-s', 'efficientnetv2-m', 'efficientnetv2-l', 'efficientnetv2-s-21k', 'efficientnetv2-m-21k', 'efficientnetv2-l-21k', 'efficientnetv2-xl-21k', 'efficientnetv2-b0-21k', 'efficientnetv2-b1-21k', 'efficientnetv2-b2-21k', 'efficientnetv2-b3-21k', 'efficientnetv2-s-21k-ft1k', 'efficientnetv2-m-21k-ft1k', 'efficientnetv2-l-21k-ft1k', 'efficientnetv2-xl-21k-ft1k', 'efficientnetv2-b0-21k-ft1k', 'efficientnetv2-b1-21k-ft1k', 'efficientnetv2-b2-21k-ft1k', 'efficientnetv2-b3-21k-ft1k', 'efficientnetv2-b0', 'efficientnetv2-b1', 'efficientnetv2-b2', 'efficientnetv2-b3', 'efficientnet_b0', 'efficientnet_b1', 'efficientnet_b2', 'efficientnet_b3', 'efficientnet_b4', 'efficientnet_b5', 'efficientnet_b6', 'efficientnet_b7', 'bit_s-r50x1', 'inception_v3', 'inception_resnet_v2', 'resnet_v1_50', 'resnet_v1_101', 'resnet_v1_152', 'resnet_v2_50', 'resnet_v2_101', 'resnet_v2_152', 'nasnet_large', 'nasnet_mobile', 'pnasnet_large', 'mobilenet_v2_100_224', 'mobilenet_v2_130_224', 'mobilenet_v2_140_224', 'mobilenet_v3_small_100_224', 'mobilenet_v3_small_075_224', 'mobilenet_v3_large_100_224', 'mobilenet_v3_large_075_224']\n",
+ "\n",
+ "model_handle_map = {\n",
+ " \"efficientnetv2-s\": \"https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet1k_s/feature_vector/2\",\n",
+ " \"efficientnetv2-m\": \"https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet1k_m/feature_vector/2\",\n",
+ " \"efficientnetv2-l\": \"https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet1k_l/feature_vector/2\",\n",
+ " \"efficientnetv2-s-21k\": \"https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_s/feature_vector/2\",\n",
+ " \"efficientnetv2-m-21k\": \"https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_m/feature_vector/2\",\n",
+ " \"efficientnetv2-l-21k\": \"https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_l/feature_vector/2\",\n",
+ " \"efficientnetv2-xl-21k\": \"https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_xl/feature_vector/2\",\n",
+ " \"efficientnetv2-b0-21k\": \"https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_b0/feature_vector/2\",\n",
+ " \"efficientnetv2-b1-21k\": \"https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_b1/feature_vector/2\",\n",
+ " \"efficientnetv2-b2-21k\": \"https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_b2/feature_vector/2\",\n",
+ " \"efficientnetv2-b3-21k\": \"https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_b3/feature_vector/2\",\n",
+ " \"efficientnetv2-s-21k-ft1k\": \"https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_s/feature_vector/2\",\n",
+ " \"efficientnetv2-m-21k-ft1k\": \"https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_m/feature_vector/2\",\n",
+ " \"efficientnetv2-l-21k-ft1k\": \"https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_l/feature_vector/2\",\n",
+ " \"efficientnetv2-xl-21k-ft1k\": \"https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_xl/feature_vector/2\",\n",
+ " \"efficientnetv2-b0-21k-ft1k\": \"https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_b0/feature_vector/2\",\n",
+ " \"efficientnetv2-b1-21k-ft1k\": \"https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_b1/feature_vector/2\",\n",
+ " \"efficientnetv2-b2-21k-ft1k\": \"https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_b2/feature_vector/2\",\n",
+ " \"efficientnetv2-b3-21k-ft1k\": \"https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_b3/feature_vector/2\",\n",
+ " \"efficientnetv2-b0\": \"https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet1k_b0/feature_vector/2\",\n",
+ " \"efficientnetv2-b1\": \"https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet1k_b1/feature_vector/2\",\n",
+ " \"efficientnetv2-b2\": \"https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet1k_b2/feature_vector/2\",\n",
+ " \"efficientnetv2-b3\": \"https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet1k_b3/feature_vector/2\",\n",
+ " \"efficientnet_b0\": \"https://tfhub.dev/tensorflow/efficientnet/b0/feature-vector/1\",\n",
+ " \"efficientnet_b1\": \"https://tfhub.dev/tensorflow/efficientnet/b1/feature-vector/1\",\n",
+ " \"efficientnet_b2\": \"https://tfhub.dev/tensorflow/efficientnet/b2/feature-vector/1\",\n",
+ " \"efficientnet_b3\": \"https://tfhub.dev/tensorflow/efficientnet/b3/feature-vector/1\",\n",
+ " \"efficientnet_b4\": \"https://tfhub.dev/tensorflow/efficientnet/b4/feature-vector/1\",\n",
+ " \"efficientnet_b5\": \"https://tfhub.dev/tensorflow/efficientnet/b5/feature-vector/1\",\n",
+ " \"efficientnet_b6\": \"https://tfhub.dev/tensorflow/efficientnet/b6/feature-vector/1\",\n",
+ " \"efficientnet_b7\": \"https://tfhub.dev/tensorflow/efficientnet/b7/feature-vector/1\",\n",
+ " \"bit_s-r50x1\": \"https://tfhub.dev/google/bit/s-r50x1/1\",\n",
+ " \"inception_v3\": \"https://tfhub.dev/google/imagenet/inception_v3/feature-vector/4\",\n",
+ " \"inception_resnet_v2\": \"https://tfhub.dev/google/imagenet/inception_resnet_v2/feature-vector/4\",\n",
+ " \"resnet_v1_50\": \"https://tfhub.dev/google/imagenet/resnet_v1_50/feature-vector/4\",\n",
+ " \"resnet_v1_101\": \"https://tfhub.dev/google/imagenet/resnet_v1_101/feature-vector/4\",\n",
+ " \"resnet_v1_152\": \"https://tfhub.dev/google/imagenet/resnet_v1_152/feature-vector/4\",\n",
+ " \"resnet_v2_50\": \"https://tfhub.dev/google/imagenet/resnet_v2_50/feature-vector/4\",\n",
+ " \"resnet_v2_101\": \"https://tfhub.dev/google/imagenet/resnet_v2_101/feature-vector/4\",\n",
+ " \"resnet_v2_152\": \"https://tfhub.dev/google/imagenet/resnet_v2_152/feature-vector/4\",\n",
+ " \"nasnet_large\": \"https://tfhub.dev/google/imagenet/nasnet_large/feature_vector/4\",\n",
+ " \"nasnet_mobile\": \"https://tfhub.dev/google/imagenet/nasnet_mobile/feature_vector/4\",\n",
+ " \"pnasnet_large\": \"https://tfhub.dev/google/imagenet/pnasnet_large/feature_vector/4\",\n",
+ " \"mobilenet_v2_100_224\": \"https://tfhub.dev/google/imagenet/mobilenet_v2_100_224/feature_vector/4\",\n",
+ " \"mobilenet_v2_130_224\": \"https://tfhub.dev/google/imagenet/mobilenet_v2_130_224/feature_vector/4\",\n",
+ " \"mobilenet_v2_140_224\": \"https://tfhub.dev/google/imagenet/mobilenet_v2_140_224/feature_vector/4\",\n",
+ " \"mobilenet_v3_small_100_224\": \"https://tfhub.dev/google/imagenet/mobilenet_v3_small_100_224/feature_vector/5\",\n",
+ " \"mobilenet_v3_small_075_224\": \"https://tfhub.dev/google/imagenet/mobilenet_v3_small_075_224/feature_vector/5\",\n",
+ " \"mobilenet_v3_large_100_224\": \"https://tfhub.dev/google/imagenet/mobilenet_v3_large_100_224/feature_vector/5\",\n",
+ " \"mobilenet_v3_large_075_224\": \"https://tfhub.dev/google/imagenet/mobilenet_v3_large_075_224/feature_vector/5\",\n",
+ "}\n",
+ "\n",
+ "model_image_size_map = {\n",
+ " \"efficientnetv2-s\": 384,\n",
+ " \"efficientnetv2-m\": 480,\n",
+ " \"efficientnetv2-l\": 480,\n",
+ " \"efficientnetv2-b0\": 224,\n",
+ " \"efficientnetv2-b1\": 240,\n",
+ " \"efficientnetv2-b2\": 260,\n",
+ " \"efficientnetv2-b3\": 300,\n",
+ " \"efficientnetv2-s-21k\": 384,\n",
+ " \"efficientnetv2-m-21k\": 480,\n",
+ " \"efficientnetv2-l-21k\": 480,\n",
+ " \"efficientnetv2-xl-21k\": 512,\n",
+ " \"efficientnetv2-b0-21k\": 224,\n",
+ " \"efficientnetv2-b1-21k\": 240,\n",
+ " \"efficientnetv2-b2-21k\": 260,\n",
+ " \"efficientnetv2-b3-21k\": 300,\n",
+ " \"efficientnetv2-s-21k-ft1k\": 384,\n",
+ " \"efficientnetv2-m-21k-ft1k\": 480,\n",
+ " \"efficientnetv2-l-21k-ft1k\": 480,\n",
+ " \"efficientnetv2-xl-21k-ft1k\": 512,\n",
+ " \"efficientnetv2-b0-21k-ft1k\": 224,\n",
+ " \"efficientnetv2-b1-21k-ft1k\": 240,\n",
+ " \"efficientnetv2-b2-21k-ft1k\": 260,\n",
+ " \"efficientnetv2-b3-21k-ft1k\": 300, \n",
+ " \"efficientnet_b0\": 224,\n",
+ " \"efficientnet_b1\": 240,\n",
+ " \"efficientnet_b2\": 260,\n",
+ " \"efficientnet_b3\": 300,\n",
+ " \"efficientnet_b4\": 380,\n",
+ " \"efficientnet_b5\": 456,\n",
+ " \"efficientnet_b6\": 528,\n",
+ " \"efficientnet_b7\": 600,\n",
+ " \"inception_v3\": 299,\n",
+ " \"inception_resnet_v2\": 299,\n",
+ " \"nasnet_large\": 331,\n",
+ " \"pnasnet_large\": 331,\n",
+ "}\n",
+ "\n",
+ "model_handle = model_handle_map.get(model_name)\n",
+ "pixels = model_image_size_map.get(model_name, 224)\n",
+ "\n",
+ "print(f\"Selected model: {model_name} : {model_handle}\")\n",
+ "\n",
+ "IMAGE_SIZE = (pixels, pixels)\n",
+ "print(f\"Input size {IMAGE_SIZE}\")\n",
+ "\n",
+ "BATCH_SIZE = 16#@param {type:\"integer\"}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "yTY8qzyYv3vl"
+ },
+ "source": [
+ "## Set up the Flowers dataset\n",
+ "\n",
+ "Inputs are suitably resized for the selected module. Dataset augmentation (i.e., random distortions of an image each time it is read) improves training, esp. when fine-tuning."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "WBtFK1hO8KsO"
+ },
+ "outputs": [],
+ "source": [
+ "data_dir = tf.keras.utils.get_file(\n",
+ " 'flower_photos',\n",
+ " 'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',\n",
+ " untar=True)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "umB5tswsfTEQ"
+ },
+ "outputs": [],
+ "source": [
+ "def build_dataset(subset):\n",
+ " return tf.keras.preprocessing.image_dataset_from_directory(\n",
+ " data_dir,\n",
+ " validation_split=.20,\n",
+ " subset=subset,\n",
+ " label_mode=\"categorical\",\n",
+ " # Seed needs to provided when using validation_split and shuffle = True.\n",
+ " # A fixed seed is used so that the validation set is stable across runs.\n",
+ " seed=123,\n",
+ " image_size=IMAGE_SIZE,\n",
+ " batch_size=1)\n",
+ "\n",
+ "train_ds = build_dataset(\"training\")\n",
+ "class_names = tuple(train_ds.class_names)\n",
+ "train_size = train_ds.cardinality().numpy()\n",
+ "train_ds = train_ds.unbatch().batch(BATCH_SIZE)\n",
+ "train_ds = train_ds.repeat()\n",
+ "\n",
+ "normalization_layer = tf.keras.layers.Rescaling(1. / 255)\n",
+ "preprocessing_model = tf.keras.Sequential([normalization_layer])\n",
+ "do_data_augmentation = False #@param {type:\"boolean\"}\n",
+ "if do_data_augmentation:\n",
+ " preprocessing_model.add(\n",
+ " tf.keras.layers.RandomRotation(40))\n",
+ " preprocessing_model.add(\n",
+ " tf.keras.layers.RandomTranslation(0, 0.2))\n",
+ " preprocessing_model.add(\n",
+ " tf.keras.layers.RandomTranslation(0.2, 0))\n",
+ " # Like the old tf.keras.preprocessing.image.ImageDataGenerator(),\n",
+ " # image sizes are fixed when reading, and then a random zoom is applied.\n",
+ " # If all training inputs are larger than image_size, one could also use\n",
+ " # RandomCrop with a batch size of 1 and rebatch later.\n",
+ " preprocessing_model.add(\n",
+ " tf.keras.layers.RandomZoom(0.2, 0.2))\n",
+ " preprocessing_model.add(\n",
+ " tf.keras.layers.RandomFlip(mode=\"horizontal\"))\n",
+ "train_ds = train_ds.map(lambda images, labels:\n",
+ " (preprocessing_model(images), labels))\n",
+ "\n",
+ "val_ds = build_dataset(\"validation\")\n",
+ "valid_size = val_ds.cardinality().numpy()\n",
+ "val_ds = val_ds.unbatch().batch(BATCH_SIZE)\n",
+ "val_ds = val_ds.map(lambda images, labels:\n",
+ " (normalization_layer(images), labels))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "FS_gVStowW3G"
+ },
+ "source": [
+ "## Defining the model\n",
+ "\n",
+ "All it takes is to put a linear classifier on top of the `feature_extractor_layer` with the Hub module.\n",
+ "\n",
+ "For speed, we start out with a non-trainable `feature_extractor_layer`, but you can also enable fine-tuning for greater accuracy."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "RaJW3XrPyFiF"
+ },
+ "outputs": [],
+ "source": [
+ "do_fine_tuning = False #@param {type:\"boolean\"}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "50FYNIb1dmJH"
+ },
+ "outputs": [],
+ "source": [
+ "print(\"Building model with\", model_handle)\n",
+ "model = tf.keras.Sequential([\n",
+ " # Explicitly define the input shape so the model can be properly\n",
+ " # loaded by the TFLiteConverter\n",
+ " tf.keras.layers.InputLayer(input_shape=IMAGE_SIZE + (3,)),\n",
+ " hub.KerasLayer(model_handle, trainable=do_fine_tuning),\n",
+ " tf.keras.layers.Dropout(rate=0.2),\n",
+ " tf.keras.layers.Dense(len(class_names),\n",
+ " kernel_regularizer=tf.keras.regularizers.l2(0.0001))\n",
+ "])\n",
+ "model.build((None,)+IMAGE_SIZE+(3,))\n",
+ "model.summary()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "u2e5WupIw2N2"
+ },
+ "source": [
+ "## Training the model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "9f3yBUvkd_VJ"
+ },
+ "outputs": [],
+ "source": [
+ "model.compile(\n",
+ " optimizer=tf.keras.optimizers.SGD(learning_rate=0.005, momentum=0.9), \n",
+ " loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True, label_smoothing=0.1),\n",
+ " metrics=['accuracy'])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "w_YKX2Qnfg6x"
+ },
+ "outputs": [],
+ "source": [
+ "steps_per_epoch = train_size // BATCH_SIZE\n",
+ "validation_steps = valid_size // BATCH_SIZE\n",
+ "hist = model.fit(\n",
+ " train_ds,\n",
+ " epochs=5, steps_per_epoch=steps_per_epoch,\n",
+ " validation_data=val_ds,\n",
+ " validation_steps=validation_steps).history"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "CYOw0fTO1W4x"
+ },
+ "outputs": [],
+ "source": [
+ "plt.figure()\n",
+ "plt.ylabel(\"Loss (training and validation)\")\n",
+ "plt.xlabel(\"Training Steps\")\n",
+ "plt.ylim([0,2])\n",
+ "plt.plot(hist[\"loss\"])\n",
+ "plt.plot(hist[\"val_loss\"])\n",
+ "\n",
+ "plt.figure()\n",
+ "plt.ylabel(\"Accuracy (training and validation)\")\n",
+ "plt.xlabel(\"Training Steps\")\n",
+ "plt.ylim([0,1])\n",
+ "plt.plot(hist[\"accuracy\"])\n",
+ "plt.plot(hist[\"val_accuracy\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "jZ8DKKgeKv4-"
+ },
+ "source": [
+ "Try out the model on an image from the validation data:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "oi1iCNB9K1Ai"
+ },
+ "outputs": [],
+ "source": [
+ "x, y = next(iter(val_ds))\n",
+ "image = x[0, :, :, :]\n",
+ "true_index = np.argmax(y[0])\n",
+ "plt.imshow(image)\n",
+ "plt.axis('off')\n",
+ "plt.show()\n",
+ "\n",
+ "# Expand the validation image to (1, 224, 224, 3) before predicting the label\n",
+ "prediction_scores = model.predict(np.expand_dims(image, axis=0))\n",
+ "predicted_index = np.argmax(prediction_scores)\n",
+ "print(\"True label: \" + class_names[true_index])\n",
+ "print(\"Predicted label: \" + class_names[predicted_index])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "YCsAsQM1IRvA"
+ },
+ "source": [
+ "Finally, the trained model can be saved for deployment to TF Serving or TFLite (on mobile) as follows."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "LGvTi69oIc2d"
+ },
+ "outputs": [],
+ "source": [
+ "saved_model_path = f\"/tmp/saved_flowers_model_{model_name}\"\n",
+ "tf.saved_model.save(model, saved_model_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "QzW4oNRjILaq"
+ },
+ "source": [
+ "## Optional: Deployment to TensorFlow Lite\n",
+ "\n",
+ "[TensorFlow Lite](https://www.tensorflow.org/lite) lets you deploy TensorFlow models to mobile and IoT devices. The code below shows how to convert the trained model to TFLite and apply post-training tools from the [TensorFlow Model Optimization Toolkit](https://www.tensorflow.org/model_optimization). Finally, it runs it in the TFLite Interpreter to examine the resulting quality\n",
+ "\n",
+ " * Converting without optimization provides the same results as before (up to roundoff error).\n",
+ " * Converting with optimization without any data quantizes the model weights to 8 bits, but inference still uses floating-point computation for the neural network activations. This reduces model size almost by a factor of 4 and improves CPU latency on mobile devices.\n",
+ " * On top, computation of the neural network activations can be quantized to 8-bit integers as well if a small reference dataset is provided to calibrate the quantization range. On a mobile device, this accelerates inference further and makes it possible to run on accelerators like Edge TPU."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Va1Vo92fSyV6"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Optimization settings\n",
+ "optimize_lite_model = False #@param {type:\"boolean\"}\n",
+ "#@markdown Setting a value greater than zero enables quantization of neural network activations. A few dozen is already a useful amount.\n",
+ "num_calibration_examples = 60 #@param {type:\"slider\", min:0, max:1000, step:1}\n",
+ "representative_dataset = None\n",
+ "if optimize_lite_model and num_calibration_examples:\n",
+ " # Use a bounded number of training examples without labels for calibration.\n",
+ " # TFLiteConverter expects a list of input tensors, each with batch size 1.\n",
+ " representative_dataset = lambda: itertools.islice(\n",
+ " ([image[None, ...]] for batch, _ in train_ds for image in batch),\n",
+ " num_calibration_examples)\n",
+ "\n",
+ "converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_path)\n",
+ "if optimize_lite_model:\n",
+ " converter.optimizations = [tf.lite.Optimize.DEFAULT]\n",
+ " if representative_dataset: # This is optional, see above.\n",
+ " converter.representative_dataset = representative_dataset\n",
+ "lite_model_content = converter.convert()\n",
+ "\n",
+ "with open(f\"/tmp/lite_flowers_model_{model_name}.tflite\", \"wb\") as f:\n",
+ " f.write(lite_model_content)\n",
+ "print(\"Wrote %sTFLite model of %d bytes.\" %\n",
+ " (\"optimized \" if optimize_lite_model else \"\", len(lite_model_content)))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "_wqEmD0xIqeG"
+ },
+ "outputs": [],
+ "source": [
+ "interpreter = tf.lite.Interpreter(model_content=lite_model_content)\n",
+ "# This little helper wraps the TFLite Interpreter as a numpy-to-numpy function.\n",
+ "def lite_model(images):\n",
+ " interpreter.allocate_tensors()\n",
+ " interpreter.set_tensor(interpreter.get_input_details()[0]['index'], images)\n",
+ " interpreter.invoke()\n",
+ " return interpreter.get_tensor(interpreter.get_output_details()[0]['index'])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "JMMK-fZrKrk8"
+ },
+ "outputs": [],
+ "source": [
+ "#@markdown For rapid experimentation, start with a moderate number of examples.\n",
+ "num_eval_examples = 50 #@param {type:\"slider\", min:0, max:700}\n",
+ "eval_dataset = ((image, label) # TFLite expects batch size 1.\n",
+ " for batch in train_ds\n",
+ " for (image, label) in zip(*batch))\n",
+ "count = 0\n",
+ "count_lite_tf_agree = 0\n",
+ "count_lite_correct = 0\n",
+ "for image, label in eval_dataset:\n",
+ " probs_lite = lite_model(image[None, ...])[0]\n",
+ " probs_tf = model(image[None, ...]).numpy()[0]\n",
+ " y_lite = np.argmax(probs_lite)\n",
+ " y_tf = np.argmax(probs_tf)\n",
+ " y_true = np.argmax(label)\n",
+ " count +=1\n",
+ " if y_lite == y_tf: count_lite_tf_agree += 1\n",
+ " if y_lite == y_true: count_lite_correct += 1\n",
+ " if count >= num_eval_examples: break\n",
+ "print(\"TFLite model agrees with original model on %d of %d examples (%g%%).\" %\n",
+ " (count_lite_tf_agree, count, 100.0 * count_lite_tf_agree / count))\n",
+ "print(\"TFLite model is accurate on %d of %d examples (%g%%).\" %\n",
+ " (count_lite_correct, count, 100.0 * count_lite_correct / count))"
+ ]
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "collapsed_sections": [
+ "ScitaPqhKtuW"
+ ],
+ "name": "tf2_image_retraining.ipynb",
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/site/en/hub/tutorials/tf2_object_detection.ipynb b/site/en/hub/tutorials/tf2_object_detection.ipynb
new file mode 100644
index 00000000000..d06ad401824
--- /dev/null
+++ b/site/en/hub/tutorials/tf2_object_detection.ipynb
@@ -0,0 +1,616 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "98rds-2OU-Rd"
+ },
+ "source": [
+ "##### Copyright 2020 The TensorFlow Hub Authors.\n",
+ "\n",
+ "Licensed under the Apache License, Version 2.0 (the \"License\");"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "1c95xMGcU5_Z"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Copyright 2020 The TensorFlow Hub Authors. All Rights Reserved.\n",
+ "#\n",
+ "# Licensed under the Apache License, Version 2.0 (the \"License\");\n",
+ "# you may not use this file except in compliance with the License.\n",
+ "# You may obtain a copy of the License at\n",
+ "#\n",
+ "# http://www.apache.org/licenses/LICENSE-2.0\n",
+ "#\n",
+ "# Unless required by applicable law or agreed to in writing, software\n",
+ "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
+ "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
+ "# See the License for the specific language governing permissions and\n",
+ "# limitations under the License.\n",
+ "# =============================================================================="
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "V1UUX8SUUiMO"
+ },
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "rOvvWAVTkMR7"
+ },
+ "source": [
+ "# TensorFlow Hub Object Detection Colab\n",
+ "\n",
+ "Welcome to the TensorFlow Hub Object Detection Colab! This notebook will take you through the steps of running an \"out-of-the-box\" object detection model on images."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IRImnk_7WOq1"
+ },
+ "source": [
+ "### More models\n",
+ "[This](https://tfhub.dev/tensorflow/collections/object_detection/1) collection contains TF2 object detection models that have been trained on the COCO 2017 dataset. [Here](https://tfhub.dev/s?module-type=image-object-detection) you can find all object detection models that are currently hosted on [tfhub.dev](https://tfhub.dev/)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "vPs64QA1Zdov"
+ },
+ "source": [
+ "## Imports and Setup\n",
+ "\n",
+ "Let's start with the base imports."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Xk4FU-jx9kc3"
+ },
+ "outputs": [],
+ "source": [
+ "# This Colab requires a recent numpy version.\n",
+ "!pip install numpy==1.24.3\n",
+ "!pip install protobuf==3.20.3\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "yn5_uV1HLvaz"
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import pathlib\n",
+ "\n",
+ "import matplotlib\n",
+ "import matplotlib.pyplot as plt\n",
+ "\n",
+ "import io\n",
+ "import scipy.misc\n",
+ "import numpy as np\n",
+ "from six import BytesIO\n",
+ "from PIL import Image, ImageDraw, ImageFont\n",
+ "from six.moves.urllib.request import urlopen\n",
+ "\n",
+ "import tensorflow as tf\n",
+ "import tensorflow_hub as hub\n",
+ "\n",
+ "tf.get_logger().setLevel('ERROR')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IogyryF2lFBL"
+ },
+ "source": [
+ "## Utilities\n",
+ "\n",
+ "Run the following cell to create some utils that will be needed later:\n",
+ "\n",
+ "- Helper method to load an image\n",
+ "- Map of Model Name to TF Hub handle\n",
+ "- List of tuples with Human Keypoints for the COCO 2017 dataset. This is needed for models with keypoints."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "-y9R0Xllefec"
+ },
+ "outputs": [],
+ "source": [
+ "# @title Run this!!\n",
+ "\n",
+ "def load_image_into_numpy_array(path):\n",
+ " \"\"\"Load an image from file into a numpy array.\n",
+ "\n",
+ " Puts image into numpy array to feed into tensorflow graph.\n",
+ " Note that by convention we put it into a numpy array with shape\n",
+ " (height, width, channels), where channels=3 for RGB.\n",
+ "\n",
+ " Args:\n",
+ " path: the file path to the image\n",
+ "\n",
+ " Returns:\n",
+ " uint8 numpy array with shape (img_height, img_width, 3)\n",
+ " \"\"\"\n",
+ " image = None\n",
+ " if(path.startswith('http')):\n",
+ " response = urlopen(path)\n",
+ " image_data = response.read()\n",
+ " image_data = BytesIO(image_data)\n",
+ " image = Image.open(image_data)\n",
+ " else:\n",
+ " image_data = tf.io.gfile.GFile(path, 'rb').read()\n",
+ " image = Image.open(BytesIO(image_data))\n",
+ "\n",
+ " (im_width, im_height) = image.size\n",
+ " return np.array(image.getdata()).reshape(\n",
+ " (1, im_height, im_width, 3)).astype(np.uint8)\n",
+ "\n",
+ "\n",
+ "ALL_MODELS = {\n",
+ "'CenterNet HourGlass104 512x512' : 'https://tfhub.dev/tensorflow/centernet/hourglass_512x512/1',\n",
+ "'CenterNet HourGlass104 Keypoints 512x512' : 'https://tfhub.dev/tensorflow/centernet/hourglass_512x512_kpts/1',\n",
+ "'CenterNet HourGlass104 1024x1024' : 'https://tfhub.dev/tensorflow/centernet/hourglass_1024x1024/1',\n",
+ "'CenterNet HourGlass104 Keypoints 1024x1024' : 'https://tfhub.dev/tensorflow/centernet/hourglass_1024x1024_kpts/1',\n",
+ "'CenterNet Resnet50 V1 FPN 512x512' : 'https://tfhub.dev/tensorflow/centernet/resnet50v1_fpn_512x512/1',\n",
+ "'CenterNet Resnet50 V1 FPN Keypoints 512x512' : 'https://tfhub.dev/tensorflow/centernet/resnet50v1_fpn_512x512_kpts/1',\n",
+ "'CenterNet Resnet101 V1 FPN 512x512' : 'https://tfhub.dev/tensorflow/centernet/resnet101v1_fpn_512x512/1',\n",
+ "'CenterNet Resnet50 V2 512x512' : 'https://tfhub.dev/tensorflow/centernet/resnet50v2_512x512/1',\n",
+ "'CenterNet Resnet50 V2 Keypoints 512x512' : 'https://tfhub.dev/tensorflow/centernet/resnet50v2_512x512_kpts/1',\n",
+ "'EfficientDet D0 512x512' : 'https://tfhub.dev/tensorflow/efficientdet/d0/1',\n",
+ "'EfficientDet D1 640x640' : 'https://tfhub.dev/tensorflow/efficientdet/d1/1',\n",
+ "'EfficientDet D2 768x768' : 'https://tfhub.dev/tensorflow/efficientdet/d2/1',\n",
+ "'EfficientDet D3 896x896' : 'https://tfhub.dev/tensorflow/efficientdet/d3/1',\n",
+ "'EfficientDet D4 1024x1024' : 'https://tfhub.dev/tensorflow/efficientdet/d4/1',\n",
+ "'EfficientDet D5 1280x1280' : 'https://tfhub.dev/tensorflow/efficientdet/d5/1',\n",
+ "'EfficientDet D6 1280x1280' : 'https://tfhub.dev/tensorflow/efficientdet/d6/1',\n",
+ "'EfficientDet D7 1536x1536' : 'https://tfhub.dev/tensorflow/efficientdet/d7/1',\n",
+ "'SSD MobileNet v2 320x320' : 'https://tfhub.dev/tensorflow/ssd_mobilenet_v2/2',\n",
+ "'SSD MobileNet V1 FPN 640x640' : 'https://tfhub.dev/tensorflow/ssd_mobilenet_v1/fpn_640x640/1',\n",
+ "'SSD MobileNet V2 FPNLite 320x320' : 'https://tfhub.dev/tensorflow/ssd_mobilenet_v2/fpnlite_320x320/1',\n",
+ "'SSD MobileNet V2 FPNLite 640x640' : 'https://tfhub.dev/tensorflow/ssd_mobilenet_v2/fpnlite_640x640/1',\n",
+ "'SSD ResNet50 V1 FPN 640x640 (RetinaNet50)' : 'https://tfhub.dev/tensorflow/retinanet/resnet50_v1_fpn_640x640/1',\n",
+ "'SSD ResNet50 V1 FPN 1024x1024 (RetinaNet50)' : 'https://tfhub.dev/tensorflow/retinanet/resnet50_v1_fpn_1024x1024/1',\n",
+ "'SSD ResNet101 V1 FPN 640x640 (RetinaNet101)' : 'https://tfhub.dev/tensorflow/retinanet/resnet101_v1_fpn_640x640/1',\n",
+ "'SSD ResNet101 V1 FPN 1024x1024 (RetinaNet101)' : 'https://tfhub.dev/tensorflow/retinanet/resnet101_v1_fpn_1024x1024/1',\n",
+ "'SSD ResNet152 V1 FPN 640x640 (RetinaNet152)' : 'https://tfhub.dev/tensorflow/retinanet/resnet152_v1_fpn_640x640/1',\n",
+ "'SSD ResNet152 V1 FPN 1024x1024 (RetinaNet152)' : 'https://tfhub.dev/tensorflow/retinanet/resnet152_v1_fpn_1024x1024/1',\n",
+ "'Faster R-CNN ResNet50 V1 640x640' : 'https://tfhub.dev/tensorflow/faster_rcnn/resnet50_v1_640x640/1',\n",
+ "'Faster R-CNN ResNet50 V1 1024x1024' : 'https://tfhub.dev/tensorflow/faster_rcnn/resnet50_v1_1024x1024/1',\n",
+ "'Faster R-CNN ResNet50 V1 800x1333' : 'https://tfhub.dev/tensorflow/faster_rcnn/resnet50_v1_800x1333/1',\n",
+ "'Faster R-CNN ResNet101 V1 640x640' : 'https://tfhub.dev/tensorflow/faster_rcnn/resnet101_v1_640x640/1',\n",
+ "'Faster R-CNN ResNet101 V1 1024x1024' : 'https://tfhub.dev/tensorflow/faster_rcnn/resnet101_v1_1024x1024/1',\n",
+ "'Faster R-CNN ResNet101 V1 800x1333' : 'https://tfhub.dev/tensorflow/faster_rcnn/resnet101_v1_800x1333/1',\n",
+ "'Faster R-CNN ResNet152 V1 640x640' : 'https://tfhub.dev/tensorflow/faster_rcnn/resnet152_v1_640x640/1',\n",
+ "'Faster R-CNN ResNet152 V1 1024x1024' : 'https://tfhub.dev/tensorflow/faster_rcnn/resnet152_v1_1024x1024/1',\n",
+ "'Faster R-CNN ResNet152 V1 800x1333' : 'https://tfhub.dev/tensorflow/faster_rcnn/resnet152_v1_800x1333/1',\n",
+ "'Faster R-CNN Inception ResNet V2 640x640' : 'https://tfhub.dev/tensorflow/faster_rcnn/inception_resnet_v2_640x640/1',\n",
+ "'Faster R-CNN Inception ResNet V2 1024x1024' : 'https://tfhub.dev/tensorflow/faster_rcnn/inception_resnet_v2_1024x1024/1',\n",
+ "'Mask R-CNN Inception ResNet V2 1024x1024' : 'https://tfhub.dev/tensorflow/mask_rcnn/inception_resnet_v2_1024x1024/1'\n",
+ "}\n",
+ "\n",
+ "IMAGES_FOR_TEST = {\n",
+ " 'Beach' : 'models/research/object_detection/test_images/image2.jpg',\n",
+ " 'Dogs' : 'models/research/object_detection/test_images/image1.jpg',\n",
+ " # By Heiko Gorski, Source: https://commons.wikimedia.org/wiki/File:Naxos_Taverna.jpg\n",
+ " 'Naxos Taverna' : 'https://upload.wikimedia.org/wikipedia/commons/6/60/Naxos_Taverna.jpg',\n",
+ " # Source: https://commons.wikimedia.org/wiki/File:The_Coleoptera_of_the_British_islands_(Plate_125)_(8592917784).jpg\n",
+ " 'Beatles' : 'https://upload.wikimedia.org/wikipedia/commons/1/1b/The_Coleoptera_of_the_British_islands_%28Plate_125%29_%288592917784%29.jpg',\n",
+ " # By Américo Toledano, Source: https://commons.wikimedia.org/wiki/File:Biblioteca_Maim%C3%B3nides,_Campus_Universitario_de_Rabanales_007.jpg\n",
+ " 'Phones' : 'https://upload.wikimedia.org/wikipedia/commons/thumb/0/0d/Biblioteca_Maim%C3%B3nides%2C_Campus_Universitario_de_Rabanales_007.jpg/1024px-Biblioteca_Maim%C3%B3nides%2C_Campus_Universitario_de_Rabanales_007.jpg',\n",
+ " # Source: https://commons.wikimedia.org/wiki/File:The_smaller_British_birds_(8053836633).jpg\n",
+ " 'Birds' : 'https://upload.wikimedia.org/wikipedia/commons/0/09/The_smaller_British_birds_%288053836633%29.jpg',\n",
+ "}\n",
+ "\n",
+ "COCO17_HUMAN_POSE_KEYPOINTS = [(0, 1),\n",
+ " (0, 2),\n",
+ " (1, 3),\n",
+ " (2, 4),\n",
+ " (0, 5),\n",
+ " (0, 6),\n",
+ " (5, 7),\n",
+ " (7, 9),\n",
+ " (6, 8),\n",
+ " (8, 10),\n",
+ " (5, 6),\n",
+ " (5, 11),\n",
+ " (6, 12),\n",
+ " (11, 12),\n",
+ " (11, 13),\n",
+ " (13, 15),\n",
+ " (12, 14),\n",
+ " (14, 16)]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "14bNk1gzh0TN"
+ },
+ "source": [
+ "## Visualization tools\n",
+ "\n",
+ "To visualize the images with the proper detected boxes, keypoints and segmentation, we will use the TensorFlow Object Detection API. To install it we will clone the repo."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "oi28cqGGFWnY"
+ },
+ "outputs": [],
+ "source": [
+ "# Clone the tensorflow models repository\n",
+ "!git clone --depth 1 https://github.com/tensorflow/models"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "yX3pb_pXDjYA"
+ },
+ "source": [
+ "Installing the Object Detection API"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "NwdsBdGhFanc"
+ },
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "sudo apt install -y protobuf-compiler\n",
+ "cd models/research/\n",
+ "protoc object_detection/protos/*.proto --python_out=.\n",
+ "cp object_detection/packages/tf2/setup.py .\n",
+ "python -m pip install .\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "3yDNgIx-kV7X"
+ },
+ "source": [
+ "Now we can import the dependencies we will need later"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "2JCeQU3fkayh"
+ },
+ "outputs": [],
+ "source": [
+ "from object_detection.utils import label_map_util\n",
+ "from object_detection.utils import visualization_utils as viz_utils\n",
+ "from object_detection.utils import ops as utils_ops\n",
+ "\n",
+ "%matplotlib inline"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "NKtD0IeclbL5"
+ },
+ "source": [
+ "### Load label map data (for plotting).\n",
+ "\n",
+ "Label maps correspond index numbers to category names, so that when our convolution network predicts `5`, we know that this corresponds to `airplane`. Here we use internal utility functions, but anything that returns a dictionary mapping integers to appropriate string labels would be fine.\n",
+ "\n",
+ "We are going, for simplicity, to load from the repository that we loaded the Object Detection API code"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "5mucYUS6exUJ"
+ },
+ "outputs": [],
+ "source": [
+ "PATH_TO_LABELS = './models/research/object_detection/data/mscoco_label_map.pbtxt'\n",
+ "category_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS, use_display_name=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "6917xnUSlp9x"
+ },
+ "source": [
+ "## Build a detection model and load pre-trained model weights\n",
+ "\n",
+ "Here we will choose which Object Detection model we will use.\n",
+ "Select the architecture and it will be loaded automatically.\n",
+ "If you want to change the model to try other architectures later, just change the next cell and execute following ones.\n",
+ "\n",
+ "**Tip:** if you want to read more details about the selected model, you can follow the link (model handle) and read additional documentation on TF Hub. After you select a model, we will print the handle to make it easier."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "HtwrSqvakTNn"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Model Selection { display-mode: \"form\", run: \"auto\" }\n",
+ "model_display_name = 'CenterNet HourGlass104 Keypoints 512x512' # @param ['CenterNet HourGlass104 512x512','CenterNet HourGlass104 Keypoints 512x512','CenterNet HourGlass104 1024x1024','CenterNet HourGlass104 Keypoints 1024x1024','CenterNet Resnet50 V1 FPN 512x512','CenterNet Resnet50 V1 FPN Keypoints 512x512','CenterNet Resnet101 V1 FPN 512x512','CenterNet Resnet50 V2 512x512','CenterNet Resnet50 V2 Keypoints 512x512','EfficientDet D0 512x512','EfficientDet D1 640x640','EfficientDet D2 768x768','EfficientDet D3 896x896','EfficientDet D4 1024x1024','EfficientDet D5 1280x1280','EfficientDet D6 1280x1280','EfficientDet D7 1536x1536','SSD MobileNet v2 320x320','SSD MobileNet V1 FPN 640x640','SSD MobileNet V2 FPNLite 320x320','SSD MobileNet V2 FPNLite 640x640','SSD ResNet50 V1 FPN 640x640 (RetinaNet50)','SSD ResNet50 V1 FPN 1024x1024 (RetinaNet50)','SSD ResNet101 V1 FPN 640x640 (RetinaNet101)','SSD ResNet101 V1 FPN 1024x1024 (RetinaNet101)','SSD ResNet152 V1 FPN 640x640 (RetinaNet152)','SSD ResNet152 V1 FPN 1024x1024 (RetinaNet152)','Faster R-CNN ResNet50 V1 640x640','Faster R-CNN ResNet50 V1 1024x1024','Faster R-CNN ResNet50 V1 800x1333','Faster R-CNN ResNet101 V1 640x640','Faster R-CNN ResNet101 V1 1024x1024','Faster R-CNN ResNet101 V1 800x1333','Faster R-CNN ResNet152 V1 640x640','Faster R-CNN ResNet152 V1 1024x1024','Faster R-CNN ResNet152 V1 800x1333','Faster R-CNN Inception ResNet V2 640x640','Faster R-CNN Inception ResNet V2 1024x1024','Mask R-CNN Inception ResNet V2 1024x1024']\n",
+ "model_handle = ALL_MODELS[model_display_name]\n",
+ "\n",
+ "print('Selected model:'+ model_display_name)\n",
+ "print('Model Handle at TensorFlow Hub: {}'.format(model_handle))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "muhUt-wWL582"
+ },
+ "source": [
+ "## Loading the selected model from TensorFlow Hub\n",
+ "\n",
+ "Here we just need the model handle that was selected and use the Tensorflow Hub library to load it to memory.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "rBuD07fLlcEO"
+ },
+ "outputs": [],
+ "source": [
+ "print('loading model...')\n",
+ "hub_model = hub.load(model_handle)\n",
+ "print('model loaded!')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "GIawRDKPPnd4"
+ },
+ "source": [
+ "## Loading an image\n",
+ "\n",
+ "Let's try the model on a simple image. To help with this, we provide a list of test images.\n",
+ "\n",
+ "Here are some simple things to try out if you are curious:\n",
+ "* Try running inference on your own images, just upload them to colab and load the same way it's done in the cell below.\n",
+ "* Modify some of the input images and see if detection still works. Some simple things to try out here include flipping the image horizontally, or converting to grayscale (note that we still expect the input image to have 3 channels).\n",
+ "\n",
+ "**Be careful:** when using images with an alpha channel, the model expect 3 channels images and the alpha will count as a 4th.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "hX-AWUQ1wIEr"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Image Selection (don't forget to execute the cell!) { display-mode: \"form\"}\n",
+ "selected_image = 'Beach' # @param ['Beach', 'Dogs', 'Naxos Taverna', 'Beatles', 'Phones', 'Birds']\n",
+ "flip_image_horizontally = False #@param {type:\"boolean\"}\n",
+ "convert_image_to_grayscale = False #@param {type:\"boolean\"}\n",
+ "\n",
+ "image_path = IMAGES_FOR_TEST[selected_image]\n",
+ "image_np = load_image_into_numpy_array(image_path)\n",
+ "\n",
+ "# Flip horizontally\n",
+ "if(flip_image_horizontally):\n",
+ " image_np[0] = np.fliplr(image_np[0]).copy()\n",
+ "\n",
+ "# Convert image to grayscale\n",
+ "if(convert_image_to_grayscale):\n",
+ " image_np[0] = np.tile(\n",
+ " np.mean(image_np[0], 2, keepdims=True), (1, 1, 3)).astype(np.uint8)\n",
+ "\n",
+ "plt.figure(figsize=(24,32))\n",
+ "plt.imshow(image_np[0])\n",
+ "plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "FTHsFjR6HNwb"
+ },
+ "source": [
+ "## Doing the inference\n",
+ "\n",
+ "To do the inference we just need to call our TF Hub loaded model.\n",
+ "\n",
+ "Things you can try:\n",
+ "* Print out `result['detection_boxes']` and try to match the box locations to the boxes in the image. Notice that coordinates are given in normalized form (i.e., in the interval [0, 1]).\n",
+ "* inspect other output keys present in the result. A full documentation can be seen on the models documentation page (pointing your browser to the model handle printed earlier)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Gb_siXKcnnGC"
+ },
+ "outputs": [],
+ "source": [
+ "# running inference\n",
+ "results = hub_model(image_np)\n",
+ "\n",
+ "# different object detection models have additional results\n",
+ "# all of them are explained in the documentation\n",
+ "result = {key:value.numpy() for key,value in results.items()}\n",
+ "print(result.keys())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IZ5VYaBoeeFM"
+ },
+ "source": [
+ "## Visualizing the results\n",
+ "\n",
+ "Here is where we will need the TensorFlow Object Detection API to show the squares from the inference step (and the keypoints when available).\n",
+ "\n",
+ "the full documentation of this method can be seen [here](https://github.com/tensorflow/models/blob/master/research/object_detection/utils/visualization_utils.py)\n",
+ "\n",
+ "Here you can, for example, set `min_score_thresh` to other values (between 0 and 1) to allow more detections in or to filter out more detections."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "2O7rV8g9s8Bz"
+ },
+ "outputs": [],
+ "source": [
+ "label_id_offset = 0\n",
+ "image_np_with_detections = image_np.copy()\n",
+ "\n",
+ "# Use keypoints if available in detections\n",
+ "keypoints, keypoint_scores = None, None\n",
+ "if 'detection_keypoints' in result:\n",
+ " keypoints = result['detection_keypoints'][0]\n",
+ " keypoint_scores = result['detection_keypoint_scores'][0]\n",
+ "\n",
+ "viz_utils.visualize_boxes_and_labels_on_image_array(\n",
+ " image_np_with_detections[0],\n",
+ " result['detection_boxes'][0],\n",
+ " (result['detection_classes'][0] + label_id_offset).astype(int),\n",
+ " result['detection_scores'][0],\n",
+ " category_index,\n",
+ " use_normalized_coordinates=True,\n",
+ " max_boxes_to_draw=200,\n",
+ " min_score_thresh=.30,\n",
+ " agnostic_mode=False,\n",
+ " keypoints=keypoints,\n",
+ " keypoint_scores=keypoint_scores,\n",
+ " keypoint_edges=COCO17_HUMAN_POSE_KEYPOINTS)\n",
+ "\n",
+ "plt.figure(figsize=(24,32))\n",
+ "plt.imshow(image_np_with_detections[0])\n",
+ "plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Qaw6Xi08NpEP"
+ },
+ "source": [
+ "## [Optional]\n",
+ "\n",
+ "Among the available object detection models there's Mask R-CNN and the output of this model allows instance segmentation.\n",
+ "\n",
+ "To visualize it we will use the same method we did before but adding an additional parameter: `instance_masks=output_dict.get('detection_masks_reframed', None)`\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "zl3qdtR1OvM_"
+ },
+ "outputs": [],
+ "source": [
+ "# Handle models with masks:\n",
+ "image_np_with_mask = image_np.copy()\n",
+ "\n",
+ "if 'detection_masks' in result:\n",
+ " # we need to convert np.arrays to tensors\n",
+ " detection_masks = tf.convert_to_tensor(result['detection_masks'][0])\n",
+ " detection_boxes = tf.convert_to_tensor(result['detection_boxes'][0])\n",
+ "\n",
+ " # Reframe the bbox mask to the image size.\n",
+ " detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks(\n",
+ " detection_masks, detection_boxes,\n",
+ " image_np.shape[1], image_np.shape[2])\n",
+ " detection_masks_reframed = tf.cast(detection_masks_reframed > 0.5,\n",
+ " tf.uint8)\n",
+ " result['detection_masks_reframed'] = detection_masks_reframed.numpy()\n",
+ "\n",
+ "viz_utils.visualize_boxes_and_labels_on_image_array(\n",
+ " image_np_with_mask[0],\n",
+ " result['detection_boxes'][0],\n",
+ " (result['detection_classes'][0] + label_id_offset).astype(int),\n",
+ " result['detection_scores'][0],\n",
+ " category_index,\n",
+ " use_normalized_coordinates=True,\n",
+ " max_boxes_to_draw=200,\n",
+ " min_score_thresh=.30,\n",
+ " agnostic_mode=False,\n",
+ " instance_masks=result.get('detection_masks_reframed', None),\n",
+ " line_thickness=8)\n",
+ "\n",
+ "plt.figure(figsize=(24,32))\n",
+ "plt.imshow(image_np_with_mask[0])\n",
+ "plt.show()"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "collapsed_sections": [],
+ "name": "tf2_object_detection.ipynb",
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/site/en/hub/tutorials/tf2_semantic_approximate_nearest_neighbors.ipynb b/site/en/hub/tutorials/tf2_semantic_approximate_nearest_neighbors.ipynb
new file mode 100644
index 00000000000..786065ff5a5
--- /dev/null
+++ b/site/en/hub/tutorials/tf2_semantic_approximate_nearest_neighbors.ipynb
@@ -0,0 +1,790 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ACbjNjyO4f_8"
+ },
+ "source": [
+ "##### Copyright 2019 The TensorFlow Hub Authors.\n",
+ "\n",
+ "Licensed under the Apache License, Version 2.0 (the \"License\");"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "MCM50vaM4jiK"
+ },
+ "outputs": [],
+ "source": [
+ "# Copyright 2018 The TensorFlow Hub Authors. All Rights Reserved.\n",
+ "#\n",
+ "# Licensed under the Apache License, Version 2.0 (the \"License\");\n",
+ "# you may not use this file except in compliance with the License.\n",
+ "# You may obtain a copy of the License at\n",
+ "#\n",
+ "# http://www.apache.org/licenses/LICENSE-2.0\n",
+ "#\n",
+ "# Unless required by applicable law or agreed to in writing, software\n",
+ "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
+ "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
+ "# See the License for the specific language governing permissions and\n",
+ "# limitations under the License.\n",
+ "# =============================================================================="
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "9qOVy-_vmuUP"
+ },
+ "source": [
+ "# Semantic Search with Approximate Nearest Neighbors and Text Embeddings\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "MfBg1C5NB3X0"
+ },
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "3T4d77AJaKte"
+ },
+ "source": [
+ "This tutorial illustrates how to generate embeddings from a [TensorFlow Hub](https://tfhub.dev) (TF-Hub) model given input data, and build an approximate nearest neighbours (ANN) index using the extracted embeddings. The index can then be used for real-time similarity matching and retrieval.\n",
+ "\n",
+ "When dealing with a large corpus of data, it's not efficient to perform exact matching by scanning the whole repository to find the most similar items to a given query in real-time. Thus, we use an approximate similarity matching algorithm which allows us to trade off a little bit of accuracy in finding exact nearest neighbor matches for a significant boost in speed.\n",
+ "\n",
+ "In this tutorial, we show an example of real-time text search over a corpus of news headlines to find the headlines that are most similar to a query. Unlike keyword search, this captures the semantic similarity encoded in the text embedding.\n",
+ "\n",
+ "The steps of this tutorial are:\n",
+ "1. Download sample data.\n",
+ "2. Generate embeddings for the data using a TF-Hub model\n",
+ "3. Build an ANN index for the embeddings\n",
+ "4. Use the index for similarity matching\n",
+ "\n",
+ "We use [Apache Beam](https://beam.apache.org/documentation/programming-guide/) to generate the embeddings from the TF-Hub model. We also use Spotify's [ANNOY](https://github.com/spotify/annoy) library to build the approximate nearest neighbor index."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nM17v_mEVSnd"
+ },
+ "source": [
+ "### More models\n",
+ "For models that have the same architecture but were trained on a different language, refer to [this](https://tfhub.dev/google/collections/nnlm/1) collection. [Here](https://tfhub.dev/s?module-type=text-embedding) you can find all text embeddings that are currently hosted on [tfhub.dev](https://tfhub.dev/). "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Q0jr0QK9qO5P"
+ },
+ "source": [
+ "## Setup"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "whMRj9qeqed4"
+ },
+ "source": [
+ "Install the required libraries."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "qmXkLPoaqS--"
+ },
+ "outputs": [],
+ "source": [
+ "!pip install apache_beam\n",
+ "!pip install 'scikit_learn~=0.23.0' # For gaussian_random_matrix.\n",
+ "!pip install annoy"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "A-vBZiCCqld0"
+ },
+ "source": [
+ "Import the required libraries"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "6NTYbdWcseuK"
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import sys\n",
+ "import pickle\n",
+ "from collections import namedtuple\n",
+ "from datetime import datetime\n",
+ "import numpy as np\n",
+ "import apache_beam as beam\n",
+ "from apache_beam.transforms import util\n",
+ "import tensorflow as tf\n",
+ "import tensorflow_hub as hub\n",
+ "import annoy\n",
+ "from sklearn.random_projection import gaussian_random_matrix"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "tx0SZa6-7b-f"
+ },
+ "outputs": [],
+ "source": [
+ "print('TF version: {}'.format(tf.__version__))\n",
+ "print('TF-Hub version: {}'.format(hub.__version__))\n",
+ "print('Apache Beam version: {}'.format(beam.__version__))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "P6Imq876rLWx"
+ },
+ "source": [
+ "## 1. Download Sample Data\n",
+ "\n",
+ "[A Million News Headlines](https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/SYBGZL#) dataset contains news headlines published over a period of 15 years sourced from the reputable Australian Broadcasting Corp. (ABC). This news dataset has a summarised historical record of noteworthy events in the globe from early-2003 to end-2017 with a more granular focus on Australia. \n",
+ "\n",
+ "**Format**: Tab-separated two-column data: 1) publication date and 2) headline text. We are only interested in the headline text.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "OpF57n8e5C9D"
+ },
+ "outputs": [],
+ "source": [
+ "!wget 'https://dataverse.harvard.edu/api/access/datafile/3450625?format=tab&gbrecs=true' -O raw.tsv\n",
+ "!wc -l raw.tsv\n",
+ "!head raw.tsv"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Reeoc9z0zTxJ"
+ },
+ "source": [
+ "For simplicity, we only keep the headline text and remove the publication date"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "INPWa4upv_yJ"
+ },
+ "outputs": [],
+ "source": [
+ "!rm -r corpus\n",
+ "!mkdir corpus\n",
+ "\n",
+ "with open('corpus/text.txt', 'w') as out_file:\n",
+ " with open('raw.tsv', 'r') as in_file:\n",
+ " for line in in_file:\n",
+ " headline = line.split('\\t')[1].strip().strip('\"')\n",
+ " out_file.write(headline+\"\\n\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "5-oedX40z6o2"
+ },
+ "outputs": [],
+ "source": [
+ "!tail corpus/text.txt"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "2AngMtH50jNb"
+ },
+ "source": [
+ "## 2. Generate Embeddings for the Data.\n",
+ "\n",
+ "In this tutorial, we use the [Neural Network Language Model (NNLM)](https://tfhub.dev/google/nnlm-en-dim128/2) to generate embeddings for the headline data. The sentence embeddings can then be easily used to compute sentence level meaning similarity. We run the embedding generation process using Apache Beam."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "F_DvXnDB1pEX"
+ },
+ "source": [
+ "### Embedding extraction method"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "yL7OEY1E0A35"
+ },
+ "outputs": [],
+ "source": [
+ "embed_fn = None\n",
+ "\n",
+ "def generate_embeddings(text, model_url, random_projection_matrix=None):\n",
+ " # Beam will run this function in different processes that need to\n",
+ " # import hub and load embed_fn (if not previously loaded)\n",
+ " global embed_fn\n",
+ " if embed_fn is None:\n",
+ " embed_fn = hub.load(model_url)\n",
+ " embedding = embed_fn(text).numpy()\n",
+ " if random_projection_matrix is not None:\n",
+ " embedding = embedding.dot(random_projection_matrix)\n",
+ " return text, embedding\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "g6pXBVxsVUbm"
+ },
+ "source": [
+ "### Convert to tf.Example method"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "JMjqjWZNVVzd"
+ },
+ "outputs": [],
+ "source": [
+ "def to_tf_example(entries):\n",
+ " examples = []\n",
+ "\n",
+ " text_list, embedding_list = entries\n",
+ " for i in range(len(text_list)):\n",
+ " text = text_list[i]\n",
+ " embedding = embedding_list[i]\n",
+ "\n",
+ " features = {\n",
+ " 'text': tf.train.Feature(\n",
+ " bytes_list=tf.train.BytesList(value=[text.encode('utf-8')])),\n",
+ " 'embedding': tf.train.Feature(\n",
+ " float_list=tf.train.FloatList(value=embedding.tolist()))\n",
+ " }\n",
+ " \n",
+ " example = tf.train.Example(\n",
+ " features=tf.train.Features(\n",
+ " feature=features)).SerializeToString(deterministic=True)\n",
+ " \n",
+ " examples.append(example)\n",
+ " \n",
+ " return examples"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "gDiV4uQCVYGH"
+ },
+ "source": [
+ "### Beam pipeline"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "jCGUIB172m2G"
+ },
+ "outputs": [],
+ "source": [
+ "def run_hub2emb(args):\n",
+ " '''Runs the embedding generation pipeline'''\n",
+ "\n",
+ " options = beam.options.pipeline_options.PipelineOptions(**args)\n",
+ " args = namedtuple(\"options\", args.keys())(*args.values())\n",
+ "\n",
+ " with beam.Pipeline(args.runner, options=options) as pipeline:\n",
+ " (\n",
+ " pipeline\n",
+ " | 'Read sentences from files' >> beam.io.ReadFromText(\n",
+ " file_pattern=args.data_dir)\n",
+ " | 'Batch elements' >> util.BatchElements(\n",
+ " min_batch_size=args.batch_size, max_batch_size=args.batch_size)\n",
+ " | 'Generate embeddings' >> beam.Map(\n",
+ " generate_embeddings, args.model_url, args.random_projection_matrix)\n",
+ " | 'Encode to tf example' >> beam.FlatMap(to_tf_example)\n",
+ " | 'Write to TFRecords files' >> beam.io.WriteToTFRecord(\n",
+ " file_path_prefix='{}/emb'.format(args.output_dir),\n",
+ " file_name_suffix='.tfrecords')\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nlbQdiYNVvne"
+ },
+ "source": [
+ "### Generating Random Projection Weight Matrix\n",
+ "\n",
+ "[Random projection](https://en.wikipedia.org/wiki/Random_projection) is a simple, yet powerful technique used to reduce the dimensionality of a set of points which lie in Euclidean space. For a theoretical background, see the [Johnson-Lindenstrauss lemma](https://en.wikipedia.org/wiki/Johnson%E2%80%93Lindenstrauss_lemma).\n",
+ "\n",
+ "Reducing the dimensionality of the embeddings with random projection means less time needed to build and query the ANN index.\n",
+ "\n",
+ "In this tutorial we use [Gaussian Random Projection](https://en.wikipedia.org/wiki/Random_projection#Gaussian_random_projection) from the [Scikit-learn](https://scikit-learn.org/stable/modules/random_projection.html#gaussian-random-projection) library."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "1yw1xgtNVv52"
+ },
+ "outputs": [],
+ "source": [
+ "def generate_random_projection_weights(original_dim, projected_dim):\n",
+ " random_projection_matrix = None\n",
+ " random_projection_matrix = gaussian_random_matrix(\n",
+ " n_components=projected_dim, n_features=original_dim).T\n",
+ " print(\"A Gaussian random weight matrix was creates with shape of {}\".format(random_projection_matrix.shape))\n",
+ " print('Storing random projection matrix to disk...')\n",
+ " with open('random_projection_matrix', 'wb') as handle:\n",
+ " pickle.dump(random_projection_matrix, \n",
+ " handle, protocol=pickle.HIGHEST_PROTOCOL)\n",
+ " \n",
+ " return random_projection_matrix"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "aJZUfT3NE7kj"
+ },
+ "source": [
+ "### Set parameters\n",
+ "If you want to build an index using the original embedding space without random projection, set the `projected_dim` parameter to `None`. Note that this will slow down the indexing step for high-dimensional embeddings."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "77-Cow7uE74T"
+ },
+ "outputs": [],
+ "source": [
+ "model_url = 'https://tfhub.dev/google/nnlm-en-dim128/2' #@param {type:\"string\"}\n",
+ "projected_dim = 64 #@param {type:\"number\"}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "On-MbzD922kb"
+ },
+ "source": [
+ "### Run pipeline"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Y3I1Wv4i21yY"
+ },
+ "outputs": [],
+ "source": [
+ "import tempfile\n",
+ "\n",
+ "output_dir = tempfile.mkdtemp()\n",
+ "original_dim = hub.load(model_url)(['']).shape[1]\n",
+ "random_projection_matrix = None\n",
+ "\n",
+ "if projected_dim:\n",
+ " random_projection_matrix = generate_random_projection_weights(\n",
+ " original_dim, projected_dim)\n",
+ "\n",
+ "args = {\n",
+ " 'job_name': 'hub2emb-{}'.format(datetime.utcnow().strftime('%y%m%d-%H%M%S')),\n",
+ " 'runner': 'DirectRunner',\n",
+ " 'batch_size': 1024,\n",
+ " 'data_dir': 'corpus/*.txt',\n",
+ " 'output_dir': output_dir,\n",
+ " 'model_url': model_url,\n",
+ " 'random_projection_matrix': random_projection_matrix,\n",
+ "}\n",
+ "\n",
+ "print(\"Pipeline args are set.\")\n",
+ "args"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "iS9obmeP4ZOA"
+ },
+ "outputs": [],
+ "source": [
+ "print(\"Running pipeline...\")\n",
+ "%time run_hub2emb(args)\n",
+ "print(\"Pipeline is done.\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "JAwOo7gQWvVd"
+ },
+ "outputs": [],
+ "source": [
+ "!ls {output_dir}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "HVnee4e6U90u"
+ },
+ "source": [
+ "Read some of the generated embeddings..."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "-K7pGXlXOj1N"
+ },
+ "outputs": [],
+ "source": [
+ "embed_file = os.path.join(output_dir, 'emb-00000-of-00001.tfrecords')\n",
+ "sample = 5\n",
+ "\n",
+ "# Create a description of the features.\n",
+ "feature_description = {\n",
+ " 'text': tf.io.FixedLenFeature([], tf.string),\n",
+ " 'embedding': tf.io.FixedLenFeature([projected_dim], tf.float32)\n",
+ "}\n",
+ "\n",
+ "def _parse_example(example):\n",
+ " # Parse the input `tf.Example` proto using the dictionary above.\n",
+ " return tf.io.parse_single_example(example, feature_description)\n",
+ "\n",
+ "dataset = tf.data.TFRecordDataset(embed_file)\n",
+ "for record in dataset.take(sample).map(_parse_example):\n",
+ " print(\"{}: {}\".format(record['text'].numpy().decode('utf-8'), record['embedding'].numpy()[:10]))\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "agGoaMSgY8wN"
+ },
+ "source": [
+ "## 3. Build the ANN Index for the Embeddings\n",
+ "\n",
+ "[ANNOY](https://github.com/spotify/annoy) (Approximate Nearest Neighbors Oh Yeah) is a C++ library with Python bindings to search for points in space that are close to a given query point. It also creates large read-only file-based data structures that are mapped into memory. It is built and used by [Spotify](https://www.spotify.com) for music recommendations. If you are interested you can play along with other alternatives to ANNOY such as [NGT](https://github.com/yahoojapan/NGT), [FAISS](https://github.com/facebookresearch/faiss), etc. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "UcPDspU3WjgH"
+ },
+ "outputs": [],
+ "source": [
+ "def build_index(embedding_files_pattern, index_filename, vector_length, \n",
+ " metric='angular', num_trees=100):\n",
+ " '''Builds an ANNOY index'''\n",
+ "\n",
+ " annoy_index = annoy.AnnoyIndex(vector_length, metric=metric)\n",
+ " # Mapping between the item and its identifier in the index\n",
+ " mapping = {}\n",
+ "\n",
+ " embed_files = tf.io.gfile.glob(embedding_files_pattern)\n",
+ " num_files = len(embed_files)\n",
+ " print('Found {} embedding file(s).'.format(num_files))\n",
+ "\n",
+ " item_counter = 0\n",
+ " for i, embed_file in enumerate(embed_files):\n",
+ " print('Loading embeddings in file {} of {}...'.format(i+1, num_files))\n",
+ " dataset = tf.data.TFRecordDataset(embed_file)\n",
+ " for record in dataset.map(_parse_example):\n",
+ " text = record['text'].numpy().decode(\"utf-8\")\n",
+ " embedding = record['embedding'].numpy()\n",
+ " mapping[item_counter] = text\n",
+ " annoy_index.add_item(item_counter, embedding)\n",
+ " item_counter += 1\n",
+ " if item_counter % 100000 == 0:\n",
+ " print('{} items loaded to the index'.format(item_counter))\n",
+ "\n",
+ " print('A total of {} items added to the index'.format(item_counter))\n",
+ "\n",
+ " print('Building the index with {} trees...'.format(num_trees))\n",
+ " annoy_index.build(n_trees=num_trees)\n",
+ " print('Index is successfully built.')\n",
+ " \n",
+ " print('Saving index to disk...')\n",
+ " annoy_index.save(index_filename)\n",
+ " print('Index is saved to disk.')\n",
+ " print(\"Index file size: {} GB\".format(\n",
+ " round(os.path.getsize(index_filename) / float(1024 ** 3), 2)))\n",
+ " annoy_index.unload()\n",
+ "\n",
+ " print('Saving mapping to disk...')\n",
+ " with open(index_filename + '.mapping', 'wb') as handle:\n",
+ " pickle.dump(mapping, handle, protocol=pickle.HIGHEST_PROTOCOL)\n",
+ " print('Mapping is saved to disk.')\n",
+ " print(\"Mapping file size: {} MB\".format(\n",
+ " round(os.path.getsize(index_filename + '.mapping') / float(1024 ** 2), 2)))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "AgyOQhUq6FNE"
+ },
+ "outputs": [],
+ "source": [
+ "embedding_files = \"{}/emb-*.tfrecords\".format(output_dir)\n",
+ "embedding_dimension = projected_dim\n",
+ "index_filename = \"index\"\n",
+ "\n",
+ "!rm {index_filename}\n",
+ "!rm {index_filename}.mapping\n",
+ "\n",
+ "%time build_index(embedding_files, index_filename, embedding_dimension)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Ic31Tm5cgAd5"
+ },
+ "outputs": [],
+ "source": [
+ "!ls"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "maGxDl8ufP-p"
+ },
+ "source": [
+ "## 4. Use the Index for Similarity Matching\n",
+ "Now we can use the ANN index to find news headlines that are semantically close to an input query."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "_dIs8W78fYPp"
+ },
+ "source": [
+ "### Load the index and the mapping files"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "jlTTrbQHayvb"
+ },
+ "outputs": [],
+ "source": [
+ "index = annoy.AnnoyIndex(embedding_dimension)\n",
+ "index.load(index_filename, prefault=True)\n",
+ "print('Annoy index is loaded.')\n",
+ "with open(index_filename + '.mapping', 'rb') as handle:\n",
+ " mapping = pickle.load(handle)\n",
+ "print('Mapping file is loaded.')\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "y6liFMSUh08J"
+ },
+ "source": [
+ "### Similarity matching method"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "mUxjTag8hc16"
+ },
+ "outputs": [],
+ "source": [
+ "def find_similar_items(embedding, num_matches=5):\n",
+ " '''Finds similar items to a given embedding in the ANN index'''\n",
+ " ids = index.get_nns_by_vector(\n",
+ " embedding, num_matches, search_k=-1, include_distances=False)\n",
+ " items = [mapping[i] for i in ids]\n",
+ " return items"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "hjerNpmZja0A"
+ },
+ "source": [
+ "### Extract embedding from a given query"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "a0IIXzfBjZ19"
+ },
+ "outputs": [],
+ "source": [
+ "# Load the TF-Hub model\n",
+ "print(\"Loading the TF-Hub model...\")\n",
+ "%time embed_fn = hub.load(model_url)\n",
+ "print(\"TF-Hub model is loaded.\")\n",
+ "\n",
+ "random_projection_matrix = None\n",
+ "if os.path.exists('random_projection_matrix'):\n",
+ " print(\"Loading random projection matrix...\")\n",
+ " with open('random_projection_matrix', 'rb') as handle:\n",
+ " random_projection_matrix = pickle.load(handle)\n",
+ " print('random projection matrix is loaded.')\n",
+ "\n",
+ "def extract_embeddings(query):\n",
+ " '''Generates the embedding for the query'''\n",
+ " query_embedding = embed_fn([query])[0].numpy()\n",
+ " if random_projection_matrix is not None:\n",
+ " query_embedding = query_embedding.dot(random_projection_matrix)\n",
+ " return query_embedding\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "kCoCNROujEIO"
+ },
+ "outputs": [],
+ "source": [
+ "extract_embeddings(\"Hello Machine Learning!\")[:10]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "koINo8Du--8C"
+ },
+ "source": [
+ "### Enter a query to find the most similar items"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "wC0uLjvfk5nB"
+ },
+ "outputs": [],
+ "source": [
+ "#@title { run: \"auto\" }\n",
+ "query = \"confronting global challenges\" #@param {type:\"string\"}\n",
+ "\n",
+ "print(\"Generating embedding for the query...\")\n",
+ "%time query_embedding = extract_embeddings(query)\n",
+ "\n",
+ "print(\"\")\n",
+ "print(\"Finding relevant items in the index...\")\n",
+ "%time items = find_similar_items(query_embedding, 10)\n",
+ "\n",
+ "print(\"\")\n",
+ "print(\"Results:\")\n",
+ "print(\"=========\")\n",
+ "for item in items:\n",
+ " print(item)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "TkRSqs77tDuX"
+ },
+ "source": [
+ "## Want to learn more?\n",
+ "\n",
+ "You can learn more about TensorFlow at [tensorflow.org](https://www.tensorflow.org/) and see the TF-Hub API documentation at [tensorflow.org/hub](https://www.tensorflow.org/hub/). Find available TensorFlow Hub models at [tfhub.dev](https://tfhub.dev/) including more text embedding models and image feature vector models.\n",
+ "\n",
+ "Also check out the [Machine Learning Crash Course](https://developers.google.com/machine-learning/crash-course/) which is Google's fast-paced, practical introduction to machine learning."
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "collapsed_sections": [
+ "ACbjNjyO4f_8",
+ "g6pXBVxsVUbm"
+ ],
+ "name": "tf2_semantic_approximate_nearest_neighbors.ipynb",
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/site/en/hub/tutorials/tf2_text_classification.ipynb b/site/en/hub/tutorials/tf2_text_classification.ipynb
new file mode 100644
index 00000000000..e2dae15bde0
--- /dev/null
+++ b/site/en/hub/tutorials/tf2_text_classification.ipynb
@@ -0,0 +1,571 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Ic4_occAAiAT"
+ },
+ "source": [
+ "##### Copyright 2019 The TensorFlow Hub Authors.\n",
+ "\n",
+ "Licensed under the Apache License, Version 2.0 (the \"License\");"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "both",
+ "id": "ioaprt5q5US7"
+ },
+ "outputs": [],
+ "source": [
+ "# Copyright 2019 The TensorFlow Hub Authors. All Rights Reserved.\n",
+ "#\n",
+ "# Licensed under the Apache License, Version 2.0 (the \"License\");\n",
+ "# you may not use this file except in compliance with the License.\n",
+ "# You may obtain a copy of the License at\n",
+ "#\n",
+ "# http://www.apache.org/licenses/LICENSE-2.0\n",
+ "#\n",
+ "# Unless required by applicable law or agreed to in writing, software\n",
+ "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
+ "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
+ "# See the License for the specific language governing permissions and\n",
+ "# limitations under the License.\n",
+ "# =============================================================================="
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "yCl0eTNH5RS3"
+ },
+ "outputs": [],
+ "source": [
+ "#@title MIT License\n",
+ "#\n",
+ "# Copyright (c) 2017 François Chollet # IGNORE_COPYRIGHT: cleared by OSS licensing\n",
+ "#\n",
+ "# Permission is hereby granted, free of charge, to any person obtaining a\n",
+ "# copy of this software and associated documentation files (the \"Software\"),\n",
+ "# to deal in the Software without restriction, including without limitation\n",
+ "# the rights to use, copy, modify, merge, publish, distribute, sublicense,\n",
+ "# and/or sell copies of the Software, and to permit persons to whom the\n",
+ "# Software is furnished to do so, subject to the following conditions:\n",
+ "#\n",
+ "# The above copyright notice and this permission notice shall be included in\n",
+ "# all copies or substantial portions of the Software.\n",
+ "#\n",
+ "# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n",
+ "# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n",
+ "# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL\n",
+ "# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n",
+ "# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING\n",
+ "# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER\n",
+ "# DEALINGS IN THE SOFTWARE."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ItXfxkxvosLH"
+ },
+ "source": [
+ "# Text Classification with Movie Reviews"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "MfBg1C5NB3X0"
+ },
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Eg62Pmz3o83v"
+ },
+ "source": [
+ "This notebook classifies movie reviews as *positive* or *negative* using the text of the review. This is an example of *binary*—or two-class—classification, an important and widely applicable kind of machine learning problem. \n",
+ "\n",
+ "We'll use the [IMDB dataset](https://www.tensorflow.org/api_docs/python/tf/keras/datasets/imdb) that contains the text of 50,000 movie reviews from the [Internet Movie Database](https://www.imdb.com/). These are split into 25,000 reviews for training and 25,000 reviews for testing. The training and testing sets are *balanced*, meaning they contain an equal number of positive and negative reviews. \n",
+ "\n",
+ "This notebook uses [tf.keras](https://www.tensorflow.org/api_docs/python/tf/keras), a high-level API to build and train models in TensorFlow, and [TensorFlow Hub](https://www.tensorflow.org/hub), a library and platform for transfer learning. For a more advanced text classification tutorial using `tf.keras`, see the [MLCC Text Classification Guide](https://developers.google.com/machine-learning/guides/text-classification/)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "qrk8NjzhSBh-"
+ },
+ "source": [
+ "### More models\n",
+ "[Here](https://tfhub.dev/s?module-type=text-embedding) you can find more expressive or performant models that you could use to generate the text embedding."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Q4DN769E2O_R"
+ },
+ "source": [
+ "## Setup"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "2ew7HTbPpCJH"
+ },
+ "outputs": [],
+ "source": [
+ "import numpy as np\n",
+ "\n",
+ "import tensorflow as tf\n",
+ "import tensorflow_hub as hub\n",
+ "import tensorflow_datasets as tfds\n",
+ "\n",
+ "import matplotlib.pyplot as plt\n",
+ "\n",
+ "print(\"Version: \", tf.__version__)\n",
+ "print(\"Eager mode: \", tf.executing_eagerly())\n",
+ "print(\"Hub version: \", hub.__version__)\n",
+ "print(\"GPU is\", \"available\" if tf.config.list_physical_devices('GPU') else \"NOT AVAILABLE\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "iAsKG535pHep"
+ },
+ "source": [
+ "## Download the IMDB dataset\n",
+ "\n",
+ "The IMDB dataset is available on [TensorFlow datasets](https://github.com/tensorflow/datasets). The following code downloads the IMDB dataset to your machine (or the colab runtime):"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "zXXx5Oc3pOmN"
+ },
+ "outputs": [],
+ "source": [
+ "train_data, test_data = tfds.load(name=\"imdb_reviews\", split=[\"train\", \"test\"], \n",
+ " batch_size=-1, as_supervised=True)\n",
+ "\n",
+ "train_examples, train_labels = tfds.as_numpy(train_data)\n",
+ "test_examples, test_labels = tfds.as_numpy(test_data)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "l50X3GfjpU4r"
+ },
+ "source": [
+ "## Explore the data \n",
+ "\n",
+ "Let's take a moment to understand the format of the data. Each example is a sentence representing the movie review and a corresponding label. The sentence is not preprocessed in any way. The label is an integer value of either 0 or 1, where 0 is a negative review, and 1 is a positive review."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "y8qCnve_-lkO"
+ },
+ "outputs": [],
+ "source": [
+ "print(\"Training entries: {}, test entries: {}\".format(len(train_examples), len(test_examples)))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "RnKvHWW4-lkW"
+ },
+ "source": [
+ "Let's print first 10 examples."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "QtTS4kpEpjbi"
+ },
+ "outputs": [],
+ "source": [
+ "train_examples[:10]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IFtaCHTdc-GY"
+ },
+ "source": [
+ "Let's also print the first 10 labels."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "tvAjVXOWc6Mj"
+ },
+ "outputs": [],
+ "source": [
+ "train_labels[:10]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "LLC02j2g-llC"
+ },
+ "source": [
+ "## Build the model\n",
+ "\n",
+ "The neural network is created by stacking layers—this requires three main architectural decisions:\n",
+ "\n",
+ "* How to represent the text?\n",
+ "* How many layers to use in the model?\n",
+ "* How many *hidden units* to use for each layer?\n",
+ "\n",
+ "In this example, the input data consists of sentences. The labels to predict are either 0 or 1.\n",
+ "\n",
+ "One way to represent the text is to convert sentences into embeddings vectors. We can use a pre-trained text embedding as the first layer, which will have two advantages:\n",
+ "* we don't have to worry about text preprocessing,\n",
+ "* we can benefit from transfer learning.\n",
+ "\n",
+ "For this example we will use a model from [TensorFlow Hub](https://www.tensorflow.org/hub) called [google/nnlm-en-dim50/2](https://tfhub.dev/google/nnlm-en-dim50/2).\n",
+ "\n",
+ "There are two other models to test for the sake of this tutorial:\n",
+ "* [google/nnlm-en-dim50-with-normalization/2](https://tfhub.dev/google/nnlm-en-dim50-with-normalization/2) - same as [google/nnlm-en-dim50/2](https://tfhub.dev/google/nnlm-en-dim50/2), but with additional text normalization to remove punctuation. This can help to get better coverage of in-vocabulary embeddings for tokens on your input text.\n",
+ "* [google/nnlm-en-dim128-with-normalization/2](https://tfhub.dev/google/nnlm-en-dim128-with-normalization/2) - A larger model with an embedding dimension of 128 instead of the smaller 50."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "In2nDpTLkgKa"
+ },
+ "source": [
+ "Let's first create a Keras layer that uses a TensorFlow Hub model to embed the sentences, and try it out on a couple of input examples. Note that the output shape of the produced embeddings is a expected: `(num_examples, embedding_dimension)`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "_NUbzVeYkgcO"
+ },
+ "outputs": [],
+ "source": [
+ "model = \"https://tfhub.dev/google/nnlm-en-dim50/2\"\n",
+ "hub_layer = hub.KerasLayer(model, input_shape=[], dtype=tf.string, trainable=True)\n",
+ "hub_layer(train_examples[:3])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "dfSbV6igl1EH"
+ },
+ "source": [
+ "Let's now build the full model:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "xpKOoWgu-llD"
+ },
+ "outputs": [],
+ "source": [
+ "model = tf.keras.Sequential()\n",
+ "model.add(hub_layer)\n",
+ "model.add(tf.keras.layers.Dense(16, activation='relu'))\n",
+ "model.add(tf.keras.layers.Dense(1))\n",
+ "\n",
+ "model.summary()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "6PbKQ6mucuKL"
+ },
+ "source": [
+ "The layers are stacked sequentially to build the classifier:\n",
+ "\n",
+ "1. The first layer is a TensorFlow Hub layer. This layer uses a pre-trained Saved Model to map a sentence into its embedding vector. The model that we are using ([google/nnlm-en-dim50/2](https://tfhub.dev/google/nnlm-en-dim50/2)) splits the sentence into tokens, embeds each token and then combines the embedding. The resulting dimensions are: `(num_examples, embedding_dimension)`.\n",
+ "2. This fixed-length output vector is piped through a fully-connected (`Dense`) layer with 16 hidden units.\n",
+ "3. The last layer is densely connected with a single output node. This outputs logits: the log-odds of the true class, according to the model."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0XMwnDOp-llH"
+ },
+ "source": [
+ "### Hidden units\n",
+ "\n",
+ "The above model has two intermediate or \"hidden\" layers, between the input and output. The number of outputs (units, nodes, or neurons) is the dimension of the representational space for the layer. In other words, the amount of freedom the network is allowed when learning an internal representation.\n",
+ "\n",
+ "If a model has more hidden units (a higher-dimensional representation space), and/or more layers, then the network can learn more complex representations. However, it makes the network more computationally expensive and may lead to learning unwanted patterns—patterns that improve performance on training data but not on the test data. This is called *overfitting*, and we'll explore it later."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "L4EqVWg4-llM"
+ },
+ "source": [
+ "### Loss function and optimizer\n",
+ "\n",
+ "A model needs a loss function and an optimizer for training. Since this is a binary classification problem and the model outputs a probability (a single-unit layer with a sigmoid activation), we'll use the `binary_crossentropy` loss function. \n",
+ "\n",
+ "This isn't the only choice for a loss function, you could, for instance, choose `mean_squared_error`. But, generally, `binary_crossentropy` is better for dealing with probabilities—it measures the \"distance\" between probability distributions, or in our case, between the ground-truth distribution and the predictions.\n",
+ "\n",
+ "Later, when we are exploring regression problems (say, to predict the price of a house), we will see how to use another loss function called mean squared error.\n",
+ "\n",
+ "Now, configure the model to use an optimizer and a loss function:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Mr0GP-cQ-llN"
+ },
+ "outputs": [],
+ "source": [
+ "model.compile(optimizer='adam',\n",
+ " loss=tf.losses.BinaryCrossentropy(from_logits=True),\n",
+ " metrics=[tf.metrics.BinaryAccuracy(threshold=0.0, name='accuracy')])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "hCWYwkug-llQ"
+ },
+ "source": [
+ "## Create a validation set\n",
+ "\n",
+ "When training, we want to check the accuracy of the model on data it hasn't seen before. Create a *validation set* by setting apart 10,000 examples from the original training data. (Why not use the testing set now? Our goal is to develop and tune our model using only the training data, then use the test data just once to evaluate our accuracy)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "-NpcXY9--llS"
+ },
+ "outputs": [],
+ "source": [
+ "x_val = train_examples[:10000]\n",
+ "partial_x_train = train_examples[10000:]\n",
+ "\n",
+ "y_val = train_labels[:10000]\n",
+ "partial_y_train = train_labels[10000:]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "35jv_fzP-llU"
+ },
+ "source": [
+ "## Train the model\n",
+ "\n",
+ "Train the model for 40 epochs in mini-batches of 512 samples. This is 40 iterations over all samples in the `x_train` and `y_train` tensors. While training, monitor the model's loss and accuracy on the 10,000 samples from the validation set:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "tXSGrjWZ-llW"
+ },
+ "outputs": [],
+ "source": [
+ "history = model.fit(partial_x_train,\n",
+ " partial_y_train,\n",
+ " epochs=40,\n",
+ " batch_size=512,\n",
+ " validation_data=(x_val, y_val),\n",
+ " verbose=1)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "9EEGuDVuzb5r"
+ },
+ "source": [
+ "## Evaluate the model\n",
+ "\n",
+ "And let's see how the model performs. Two values will be returned. Loss (a number which represents our error, lower values are better), and accuracy."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "zOMKywn4zReN"
+ },
+ "outputs": [],
+ "source": [
+ "results = model.evaluate(test_examples, test_labels)\n",
+ "\n",
+ "print(results)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "z1iEXVTR0Z2t"
+ },
+ "source": [
+ "This fairly naive approach achieves an accuracy of about 87%. With more advanced approaches, the model should get closer to 95%."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "5KggXVeL-llZ"
+ },
+ "source": [
+ "## Create a graph of accuracy and loss over time\n",
+ "\n",
+ "`model.fit()` returns a `History` object that contains a dictionary with everything that happened during training:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "VcvSXvhp-llb"
+ },
+ "outputs": [],
+ "source": [
+ "history_dict = history.history\n",
+ "history_dict.keys()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nRKsqL40-lle"
+ },
+ "source": [
+ "There are four entries: one for each monitored metric during training and validation. We can use these to plot the training and validation loss for comparison, as well as the training and validation accuracy:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "nGoYf2Js-lle"
+ },
+ "outputs": [],
+ "source": [
+ "acc = history_dict['accuracy']\n",
+ "val_acc = history_dict['val_accuracy']\n",
+ "loss = history_dict['loss']\n",
+ "val_loss = history_dict['val_loss']\n",
+ "\n",
+ "epochs = range(1, len(acc) + 1)\n",
+ "\n",
+ "# \"bo\" is for \"blue dot\"\n",
+ "plt.plot(epochs, loss, 'bo', label='Training loss')\n",
+ "# b is for \"solid blue line\"\n",
+ "plt.plot(epochs, val_loss, 'b', label='Validation loss')\n",
+ "plt.title('Training and validation loss')\n",
+ "plt.xlabel('Epochs')\n",
+ "plt.ylabel('Loss')\n",
+ "plt.legend()\n",
+ "\n",
+ "plt.show()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "6hXx-xOv-llh"
+ },
+ "outputs": [],
+ "source": [
+ "plt.clf() # clear figure\n",
+ "\n",
+ "plt.plot(epochs, acc, 'bo', label='Training acc')\n",
+ "plt.plot(epochs, val_acc, 'b', label='Validation acc')\n",
+ "plt.title('Training and validation accuracy')\n",
+ "plt.xlabel('Epochs')\n",
+ "plt.ylabel('Accuracy')\n",
+ "plt.legend()\n",
+ "\n",
+ "plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "oFEmZ5zq-llk"
+ },
+ "source": [
+ "In this plot, the dots represent the training loss and accuracy, and the solid lines are the validation loss and accuracy.\n",
+ "\n",
+ "Notice the training loss *decreases* with each epoch and the training accuracy *increases* with each epoch. This is expected when using a gradient descent optimization—it should minimize the desired quantity on every iteration.\n",
+ "\n",
+ "This isn't the case for the validation loss and accuracy—they seem to peak after about twenty epochs. This is an example of overfitting: the model performs better on the training data than it does on data it has never seen before. After this point, the model over-optimizes and learns representations *specific* to the training data that do not *generalize* to test data.\n",
+ "\n",
+ "For this particular case, we could prevent overfitting by simply stopping the training after twenty or so epochs. Later, you'll see how to do this automatically with a callback."
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "collapsed_sections": [],
+ "name": "tf2_text_classification.ipynb",
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/site/en/hub/tutorials/tf_hub_delf_module.ipynb b/site/en/hub/tutorials/tf_hub_delf_module.ipynb
new file mode 100644
index 00000000000..b6dec2eae00
--- /dev/null
+++ b/site/en/hub/tutorials/tf_hub_delf_module.ipynb
@@ -0,0 +1,372 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "RUymE2l9GZfO"
+ },
+ "source": [
+ "##### Copyright 2018 The TensorFlow Hub Authors.\n",
+ "\n",
+ "Licensed under the Apache License, Version 2.0 (the \"License\");"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "code",
+ "id": "JMyTNwSJGGWg"
+ },
+ "outputs": [],
+ "source": [
+ "# Copyright 2018 The TensorFlow Hub Authors. All Rights Reserved.\n",
+ "#\n",
+ "# Licensed under the Apache License, Version 2.0 (the \"License\");\n",
+ "# you may not use this file except in compliance with the License.\n",
+ "# You may obtain a copy of the License at\n",
+ "#\n",
+ "# http://www.apache.org/licenses/LICENSE-2.0\n",
+ "#\n",
+ "# Unless required by applicable law or agreed to in writing, software\n",
+ "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
+ "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
+ "# See the License for the specific language governing permissions and\n",
+ "# limitations under the License.\n",
+ "# =============================================================================="
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0DmDwGPOGfaQ"
+ },
+ "source": [
+ "# How to match images using DELF and TensorFlow Hub\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "MfBg1C5NB3X0"
+ },
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "f3nk38tIKytQ"
+ },
+ "source": [
+ "TensorFlow Hub (TF-Hub) is a platform to share machine learning expertise packaged in reusable resources, notably pre-trained **modules**.\n",
+ "\n",
+ "In this colab, we will use a module that packages the [DELF](https://github.com/tensorflow/models/tree/master/research/delf) neural network and logic for processing images to identify keypoints and their descriptors. The weights of the neural network were trained on images of landmarks as described in [this paper](https://arxiv.org/abs/1612.06321)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Q4DN769E2O_R"
+ },
+ "source": [
+ "## Setup"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "lrKaWOB_cuS3"
+ },
+ "outputs": [],
+ "source": [
+ "!pip install scikit-image"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "SI7eVflHHxvi"
+ },
+ "outputs": [],
+ "source": [
+ "from absl import logging\n",
+ "\n",
+ "import matplotlib.pyplot as plt\n",
+ "import numpy as np\n",
+ "from PIL import Image, ImageOps\n",
+ "from scipy.spatial import cKDTree\n",
+ "from skimage.feature import plot_matched_features\n",
+ "from skimage.measure import ransac\n",
+ "from skimage.transform import AffineTransform\n",
+ "from six import BytesIO\n",
+ "\n",
+ "import tensorflow as tf\n",
+ "\n",
+ "import tensorflow_hub as hub\n",
+ "from six.moves.urllib.request import urlopen"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "qquo2HiONiDK"
+ },
+ "source": [
+ "## The data\n",
+ "\n",
+ "In the next cell, we specify the URLs of two images we would like to process with DELF in order to match and compare them."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "l93ye4WFIqIV"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Choose images\n",
+ "images = \"Bridge of Sighs\" #@param [\"Bridge of Sighs\", \"Golden Gate\", \"Acropolis\", \"Eiffel tower\"]\n",
+ "if images == \"Bridge of Sighs\":\n",
+ " # from: https://commons.wikimedia.org/wiki/File:Bridge_of_Sighs,_Oxford.jpg\n",
+ " # by: N.H. Fischer\n",
+ " IMAGE_1_URL = 'https://upload.wikimedia.org/wikipedia/commons/2/28/Bridge_of_Sighs%2C_Oxford.jpg'\n",
+ " # from https://commons.wikimedia.org/wiki/File:The_Bridge_of_Sighs_and_Sheldonian_Theatre,_Oxford.jpg\n",
+ " # by: Matthew Hoser\n",
+ " IMAGE_2_URL = 'https://upload.wikimedia.org/wikipedia/commons/c/c3/The_Bridge_of_Sighs_and_Sheldonian_Theatre%2C_Oxford.jpg'\n",
+ "elif images == \"Golden Gate\":\n",
+ " IMAGE_1_URL = 'https://upload.wikimedia.org/wikipedia/commons/1/1e/Golden_gate2.jpg'\n",
+ " IMAGE_2_URL = 'https://upload.wikimedia.org/wikipedia/commons/3/3e/GoldenGateBridge.jpg'\n",
+ "elif images == \"Acropolis\":\n",
+ " IMAGE_1_URL = 'https://upload.wikimedia.org/wikipedia/commons/c/ce/2006_01_21_Ath%C3%A8nes_Parth%C3%A9non.JPG'\n",
+ " IMAGE_2_URL = 'https://upload.wikimedia.org/wikipedia/commons/5/5c/ACROPOLIS_1969_-_panoramio_-_jean_melis.jpg'\n",
+ "else:\n",
+ " IMAGE_1_URL = 'https://upload.wikimedia.org/wikipedia/commons/d/d8/Eiffel_Tower%2C_November_15%2C_2011.jpg'\n",
+ " IMAGE_2_URL = 'https://upload.wikimedia.org/wikipedia/commons/a/a8/Eiffel_Tower_from_immediately_beside_it%2C_Paris_May_2008.jpg'"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ttlHtcmiN6QF"
+ },
+ "source": [
+ "Download, resize, save and display the images."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "E6RMomGJSfeb"
+ },
+ "outputs": [],
+ "source": [
+ "def download_and_resize(name, url, new_width=256, new_height=256):\n",
+ " path = tf.keras.utils.get_file(url.split('/')[-1], url)\n",
+ " image = Image.open(path)\n",
+ " image = ImageOps.fit(image, (new_width, new_height), Image.LANCZOS)\n",
+ " return image"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "reajtO7XSj7Y"
+ },
+ "outputs": [],
+ "source": [
+ "image1 = download_and_resize('image_1.jpg', IMAGE_1_URL)\n",
+ "image2 = download_and_resize('image_2.jpg', IMAGE_2_URL)\n",
+ "\n",
+ "plt.subplot(1,2,1)\n",
+ "plt.imshow(image1)\n",
+ "plt.subplot(1,2,2)\n",
+ "plt.imshow(image2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "leKqkoT9OP7r"
+ },
+ "source": [
+ "## Apply the DELF module to the data"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "A3WoT1-SPoTI"
+ },
+ "source": [
+ "The DELF module takes an image as input and will describe noteworthy points with vectors. The following cell contains the core of this colab's logic."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "pXr2tUhvp1Ue"
+ },
+ "outputs": [],
+ "source": [
+ "delf = hub.load('https://tfhub.dev/google/delf/1').signatures['default']"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "pvAU_gUHoYcY"
+ },
+ "outputs": [],
+ "source": [
+ "def run_delf(image):\n",
+ " np_image = np.array(image)\n",
+ " float_image = tf.image.convert_image_dtype(np_image, tf.float32)\n",
+ "\n",
+ " return delf(\n",
+ " image=float_image,\n",
+ " score_threshold=tf.constant(100.0),\n",
+ " image_scales=tf.constant([0.25, 0.3536, 0.5, 0.7071, 1.0, 1.4142, 2.0]),\n",
+ " max_feature_num=tf.constant(1000))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "FEzgHAT0UDNP"
+ },
+ "outputs": [],
+ "source": [
+ "result1 = run_delf(image1)\n",
+ "result2 = run_delf(image2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "NByyBA5yOL2b"
+ },
+ "source": [
+ "## Use the locations and description vectors to match the images"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "both",
+ "id": "mVaKXT3cMSib"
+ },
+ "outputs": [],
+ "source": [
+ "#@title TensorFlow is not needed for this post-processing and visualization\n",
+ "def match_images(image1, image2, result1, result2):\n",
+ " distance_threshold = 0.8\n",
+ "\n",
+ " # Read features.\n",
+ " num_features_1 = result1['locations'].shape[0]\n",
+ " print(\"Loaded image 1's %d features\" % num_features_1)\n",
+ " \n",
+ " num_features_2 = result2['locations'].shape[0]\n",
+ " print(\"Loaded image 2's %d features\" % num_features_2)\n",
+ "\n",
+ " # Find nearest-neighbor matches using a KD tree.\n",
+ " d1_tree = cKDTree(result1['descriptors'])\n",
+ " _, indices = d1_tree.query(\n",
+ " result2['descriptors'],\n",
+ " distance_upper_bound=distance_threshold)\n",
+ "\n",
+ " # Select feature locations for putative matches.\n",
+ " locations_2_to_use = np.array([\n",
+ " result2['locations'][i,]\n",
+ " for i in range(num_features_2)\n",
+ " if indices[i] != num_features_1\n",
+ " ])\n",
+ " locations_1_to_use = np.array([\n",
+ " result1['locations'][indices[i],]\n",
+ " for i in range(num_features_2)\n",
+ " if indices[i] != num_features_1\n",
+ " ])\n",
+ "\n",
+ " # Perform geometric verification using RANSAC.\n",
+ " _, inliers = ransac(\n",
+ " (locations_1_to_use, locations_2_to_use),\n",
+ " AffineTransform,\n",
+ " min_samples=3,\n",
+ " residual_threshold=20,\n",
+ " max_trials=1000)\n",
+ "\n",
+ " print('Found %d inliers' % sum(inliers))\n",
+ "\n",
+ " # Visualize correspondences.\n",
+ " _, ax = plt.subplots()\n",
+ " inlier_idxs = np.nonzero(inliers)[0]\n",
+ " plot_matched_features(\n",
+ " image1,\n",
+ " image2,\n",
+ " keypoints0=locations_1_to_use,\n",
+ " keypoints1=locations_2_to_use,\n",
+ " matches=np.column_stack((inlier_idxs, inlier_idxs)),\n",
+ " ax=ax,\n",
+ " )\n",
+ "\n",
+ " ax.axis('off')\n",
+ " ax.set_title('DELF correspondences')\n",
+ "\n",
+ " for line in ax.lines:\n",
+ " line.set_color('b')\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "tpEgqOvCYlPY"
+ },
+ "outputs": [],
+ "source": [
+ "match_images(image1, image2, result1, result2)"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "collapsed_sections": [
+ "RUymE2l9GZfO"
+ ],
+ "name": "tf_hub_delf_module.ipynb",
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/site/en/hub/tutorials/tf_hub_film_example.ipynb b/site/en/hub/tutorials/tf_hub_film_example.ipynb
new file mode 100644
index 00000000000..83bcd4bd12c
--- /dev/null
+++ b/site/en/hub/tutorials/tf_hub_film_example.ipynb
@@ -0,0 +1,576 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "qNLUPuRpkFv_"
+ },
+ "source": [
+ "##### Copyright 2022 The TensorFlow Hub Authors.\n",
+ "\n",
+ "Licensed under the Apache License, Version 2.0 (the \"License\");"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "DQcWZm0FkPk-"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Copyright 2022 The TensorFlow Hub Authors. All Rights Reserved.\n",
+ "#\n",
+ "# Licensed under the Apache License, Version 2.0 (the \"License\");\n",
+ "# you may not use this file except in compliance with the License.\n",
+ "# You may obtain a copy of the License at\n",
+ "#\n",
+ "# http://www.apache.org/licenses/LICENSE-2.0\n",
+ "#\n",
+ "# Unless required by applicable law or agreed to in writing, software\n",
+ "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
+ "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
+ "# See the License for the specific language governing permissions and\n",
+ "# limitations under the License.\n",
+ "# =============================================================================="
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Exbxve1rHlrF"
+ },
+ "source": [
+ "# Frame interpolation using the FILM model\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "jMWFVTlbrQ8m"
+ },
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "61H28S7ArUAZ"
+ },
+ "source": [
+ "Frame interpolation is the task of synthesizing many in-between images from a given set of images. The technique is often used for frame rate upsampling or creating slow-motion video effects.\n",
+ "\n",
+ "In this colab, you will use the FILM model to do frame interpolation. The colab also provides code snippets to create videos from the interpolated in-between images.\n",
+ "\n",
+ "For more information on FILM research, you can read more here:\n",
+ "- Google AI Blog: [Large Motion Frame Interpolation](https://ai.googleblog.com/2022/10/large-motion-frame-interpolation.html)\n",
+ "- Project Page: FILM: [Frame Interpolation for Large Motion](https://film-net.github.io/)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "dVX7s6zMulsu"
+ },
+ "source": [
+ "## Setup"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "oi5t2OEJsGBW"
+ },
+ "outputs": [],
+ "source": [
+ "!pip install mediapy\n",
+ "!sudo apt-get install -y ffmpeg"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "BA1tq39MjOiF"
+ },
+ "outputs": [],
+ "source": [
+ "import tensorflow as tf\n",
+ "import tensorflow_hub as hub\n",
+ "\n",
+ "import requests\n",
+ "import numpy as np\n",
+ "\n",
+ "from typing import Generator, Iterable, List, Optional\n",
+ "import mediapy as media"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "GTgXmeYGnT7q"
+ },
+ "source": [
+ "## Load the model from TFHub\n",
+ "\n",
+ "To load a model from TensorFlow Hub you need the tfhub library and the model handle which is its documentation url."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "GojhvyAtjUt0"
+ },
+ "outputs": [],
+ "source": [
+ "model = hub.load(\"https://tfhub.dev/google/film/1\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "DOQJPsu2CwPk"
+ },
+ "source": [
+ "## Util function to load images from a url or locally\n",
+ "\n",
+ "This function loads an image and make it ready to be used by the model later."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "BPnh5uhQvFln"
+ },
+ "outputs": [],
+ "source": [
+ "_UINT8_MAX_F = float(np.iinfo(np.uint8).max)\n",
+ "\n",
+ "def load_image(img_url: str):\n",
+ " \"\"\"Returns an image with shape [height, width, num_channels], with pixels in [0..1] range, and type np.float32.\"\"\"\n",
+ "\n",
+ " if (img_url.startswith(\"https\")):\n",
+ " user_agent = {'User-agent': 'Colab Sample (https://tensorflow.org)'}\n",
+ " response = requests.get(img_url, headers=user_agent)\n",
+ " image_data = response.content\n",
+ " else:\n",
+ " image_data = tf.io.read_file(img_url)\n",
+ "\n",
+ " image = tf.io.decode_image(image_data, channels=3)\n",
+ " image_numpy = tf.cast(image, dtype=tf.float32).numpy()\n",
+ " return image_numpy / _UINT8_MAX_F\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "yjDFns1zp5y6"
+ },
+ "source": [
+ "FILM's model input is a dictionary with the keys `time`, `x0`, `x1`:\n",
+ "\n",
+ "- `time`: position of the interpolated frame. Midway is `0.5`.\n",
+ "- `x0`: is the initial frame.\n",
+ "- `x1`: is the final frame.\n",
+ "\n",
+ "Both frames need to be normalized (done in the function `load_image` above) where each pixel is in the range of `[0..1]`.\n",
+ "\n",
+ "`time` is a value between `[0..1]` and it says where the generated image should be. 0.5 is midway between the input images.\n",
+ "\n",
+ "All three values need to have a batch dimension too."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "VEQNQlHGsWSM"
+ },
+ "outputs": [],
+ "source": [
+ "# using images from the FILM repository (https://github.com/google-research/frame-interpolation/)\n",
+ "\n",
+ "image_1_url = \"https://github.com/google-research/frame-interpolation/blob/main/photos/one.png?raw=true\"\n",
+ "image_2_url = \"https://github.com/google-research/frame-interpolation/blob/main/photos/two.png?raw=true\"\n",
+ "\n",
+ "time = np.array([0.5], dtype=np.float32)\n",
+ "\n",
+ "image1 = load_image(image_1_url)\n",
+ "image2 = load_image(image_2_url)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "r6_MQE9EuF_K"
+ },
+ "outputs": [],
+ "source": [
+ "input = {\n",
+ " 'time': np.expand_dims(time, axis=0), # adding the batch dimension to the time\n",
+ " 'x0': np.expand_dims(image1, axis=0), # adding the batch dimension to the image\n",
+ " 'x1': np.expand_dims(image2, axis=0) # adding the batch dimension to the image\n",
+ "}\n",
+ "mid_frame = model(input)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nZkzYE2bptfD"
+ },
+ "source": [
+ "The model outputs a couple of results but what you'll use here is the `image` key, whose value is the interpolated frame."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "eClVbNFhA5Py"
+ },
+ "outputs": [],
+ "source": [
+ "print(mid_frame.keys())"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "rE2csH3u8ePe"
+ },
+ "outputs": [],
+ "source": [
+ "frames = [image1, mid_frame['image'][0].numpy(), image2]\n",
+ "\n",
+ "media.show_images(frames, titles=['input image one', 'generated image', 'input image two'], height=250)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "fS1AT8kn-f_l"
+ },
+ "source": [
+ "Let's create a video from the generated frames"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "oFc53B3p37SH"
+ },
+ "outputs": [],
+ "source": [
+ "media.show_video(frames, fps=3, title='FILM interpolated video')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "x5AOFNkj-lfO"
+ },
+ "source": [
+ "## Define a Frame Interpolator Library\n",
+ "\n",
+ "As you can see, the transition is not too smooth. \n",
+ "\n",
+ "To improve that you'll need many more interpolated frames.\n",
+ "\n",
+ "You could just keep running the model many times with intermediary images but there is a better solution.\n",
+ "\n",
+ "To generate many interpolated images and have a smoother video you'll create an interpolator library."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "tsoDv_9geoZn"
+ },
+ "outputs": [],
+ "source": [
+ "\"\"\"A wrapper class for running a frame interpolation based on the FILM model on TFHub\n",
+ "\n",
+ "Usage:\n",
+ " interpolator = Interpolator()\n",
+ " result_batch = interpolator(image_batch_0, image_batch_1, batch_dt)\n",
+ " Where image_batch_1 and image_batch_2 are numpy tensors with TF standard\n",
+ " (B,H,W,C) layout, batch_dt is the sub-frame time in range [0..1], (B,) layout.\n",
+ "\"\"\"\n",
+ "\n",
+ "\n",
+ "def _pad_to_align(x, align):\n",
+ " \"\"\"Pads image batch x so width and height divide by align.\n",
+ "\n",
+ " Args:\n",
+ " x: Image batch to align.\n",
+ " align: Number to align to.\n",
+ "\n",
+ " Returns:\n",
+ " 1) An image padded so width % align == 0 and height % align == 0.\n",
+ " 2) A bounding box that can be fed readily to tf.image.crop_to_bounding_box\n",
+ " to undo the padding.\n",
+ " \"\"\"\n",
+ " # Input checking.\n",
+ " assert np.ndim(x) == 4\n",
+ " assert align > 0, 'align must be a positive number.'\n",
+ "\n",
+ " height, width = x.shape[-3:-1]\n",
+ " height_to_pad = (align - height % align) if height % align != 0 else 0\n",
+ " width_to_pad = (align - width % align) if width % align != 0 else 0\n",
+ "\n",
+ " bbox_to_pad = {\n",
+ " 'offset_height': height_to_pad // 2,\n",
+ " 'offset_width': width_to_pad // 2,\n",
+ " 'target_height': height + height_to_pad,\n",
+ " 'target_width': width + width_to_pad\n",
+ " }\n",
+ " padded_x = tf.image.pad_to_bounding_box(x, **bbox_to_pad)\n",
+ " bbox_to_crop = {\n",
+ " 'offset_height': height_to_pad // 2,\n",
+ " 'offset_width': width_to_pad // 2,\n",
+ " 'target_height': height,\n",
+ " 'target_width': width\n",
+ " }\n",
+ " return padded_x, bbox_to_crop\n",
+ "\n",
+ "\n",
+ "class Interpolator:\n",
+ " \"\"\"A class for generating interpolated frames between two input frames.\n",
+ "\n",
+ " Uses the Film model from TFHub\n",
+ " \"\"\"\n",
+ "\n",
+ " def __init__(self, align: int = 64) -> None:\n",
+ " \"\"\"Loads a saved model.\n",
+ "\n",
+ " Args:\n",
+ " align: 'If >1, pad the input size so it divides with this before\n",
+ " inference.'\n",
+ " \"\"\"\n",
+ " self._model = hub.load(\"https://tfhub.dev/google/film/1\")\n",
+ " self._align = align\n",
+ "\n",
+ " def __call__(self, x0: np.ndarray, x1: np.ndarray,\n",
+ " dt: np.ndarray) -> np.ndarray:\n",
+ " \"\"\"Generates an interpolated frame between given two batches of frames.\n",
+ "\n",
+ " All inputs should be np.float32 datatype.\n",
+ "\n",
+ " Args:\n",
+ " x0: First image batch. Dimensions: (batch_size, height, width, channels)\n",
+ " x1: Second image batch. Dimensions: (batch_size, height, width, channels)\n",
+ " dt: Sub-frame time. Range [0,1]. Dimensions: (batch_size,)\n",
+ "\n",
+ " Returns:\n",
+ " The result with dimensions (batch_size, height, width, channels).\n",
+ " \"\"\"\n",
+ " if self._align is not None:\n",
+ " x0, bbox_to_crop = _pad_to_align(x0, self._align)\n",
+ " x1, _ = _pad_to_align(x1, self._align)\n",
+ "\n",
+ " inputs = {'x0': x0, 'x1': x1, 'time': dt[..., np.newaxis]}\n",
+ " result = self._model(inputs, training=False)\n",
+ " image = result['image']\n",
+ "\n",
+ " if self._align is not None:\n",
+ " image = tf.image.crop_to_bounding_box(image, **bbox_to_crop)\n",
+ " return image.numpy()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ZeGYaNBd_7a5"
+ },
+ "source": [
+ "## Frame and Video Generation Utility Functions"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "gOJxup6s_1DP"
+ },
+ "outputs": [],
+ "source": [
+ "def _recursive_generator(\n",
+ " frame1: np.ndarray, frame2: np.ndarray, num_recursions: int,\n",
+ " interpolator: Interpolator) -> Generator[np.ndarray, None, None]:\n",
+ " \"\"\"Splits halfway to repeatedly generate more frames.\n",
+ "\n",
+ " Args:\n",
+ " frame1: Input image 1.\n",
+ " frame2: Input image 2.\n",
+ " num_recursions: How many times to interpolate the consecutive image pairs.\n",
+ " interpolator: The frame interpolator instance.\n",
+ "\n",
+ " Yields:\n",
+ " The interpolated frames, including the first frame (frame1), but excluding\n",
+ " the final frame2.\n",
+ " \"\"\"\n",
+ " if num_recursions == 0:\n",
+ " yield frame1\n",
+ " else:\n",
+ " # Adds the batch dimension to all inputs before calling the interpolator,\n",
+ " # and remove it afterwards.\n",
+ " time = np.full(shape=(1,), fill_value=0.5, dtype=np.float32)\n",
+ " mid_frame = interpolator(\n",
+ " np.expand_dims(frame1, axis=0), np.expand_dims(frame2, axis=0), time)[0]\n",
+ " yield from _recursive_generator(frame1, mid_frame, num_recursions - 1,\n",
+ " interpolator)\n",
+ " yield from _recursive_generator(mid_frame, frame2, num_recursions - 1,\n",
+ " interpolator)\n",
+ "\n",
+ "\n",
+ "def interpolate_recursively(\n",
+ " frames: List[np.ndarray], num_recursions: int,\n",
+ " interpolator: Interpolator) -> Iterable[np.ndarray]:\n",
+ " \"\"\"Generates interpolated frames by repeatedly interpolating the midpoint.\n",
+ "\n",
+ " Args:\n",
+ " frames: List of input frames. Expected shape (H, W, 3). The colors should be\n",
+ " in the range[0, 1] and in gamma space.\n",
+ " num_recursions: Number of times to do recursive midpoint\n",
+ " interpolation.\n",
+ " interpolator: The frame interpolation model to use.\n",
+ "\n",
+ " Yields:\n",
+ " The interpolated frames (including the inputs).\n",
+ " \"\"\"\n",
+ " n = len(frames)\n",
+ " for i in range(1, n):\n",
+ " yield from _recursive_generator(frames[i - 1], frames[i],\n",
+ " times_to_interpolate, interpolator)\n",
+ " # Separately yield the final frame.\n",
+ " yield frames[-1]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "X1R2KjhEAHu0"
+ },
+ "outputs": [],
+ "source": [
+ "times_to_interpolate = 6\n",
+ "interpolator = Interpolator()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "AZUo8tg1AYvZ"
+ },
+ "source": [
+ "## Running the Interpolator"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "QMMNjs7sAWTG"
+ },
+ "outputs": [],
+ "source": [
+ "input_frames = [image1, image2]\n",
+ "frames = list(\n",
+ " interpolate_recursively(input_frames, times_to_interpolate,\n",
+ " interpolator))\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "s9mHHyCAAhrM"
+ },
+ "outputs": [],
+ "source": [
+ "print(f'video with {len(frames)} frames')\n",
+ "media.show_video(frames, fps=30, title='FILM interpolated video')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "_0AZKeMVFwAc"
+ },
+ "source": [
+ "For more information, you can visit [FILM's model repository](https://github.com/google-research/frame-interpolation).\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "8764ry3SGDks"
+ },
+ "source": [
+ "## Citation\n",
+ "\n",
+ "If you find this model and code useful in your works, please acknowledge it appropriately by citing:\n",
+ "\n",
+ "```\n",
+ "@inproceedings{reda2022film,\n",
+ " title = {FILM: Frame Interpolation for Large Motion},\n",
+ " author = {Fitsum Reda and Janne Kontkanen and Eric Tabellion and Deqing Sun and Caroline Pantofaru and Brian Curless},\n",
+ " booktitle = {The European Conference on Computer Vision (ECCV)},\n",
+ " year = {2022}\n",
+ "}\n",
+ "```\n",
+ "\n",
+ "```\n",
+ "@misc{film-tf,\n",
+ " title = {Tensorflow 2 Implementation of \"FILM: Frame Interpolation for Large Motion\"},\n",
+ " author = {Fitsum Reda and Janne Kontkanen and Eric Tabellion and Deqing Sun and Caroline Pantofaru and Brian Curless},\n",
+ " year = {2022},\n",
+ " publisher = {GitHub},\n",
+ " journal = {GitHub repository},\n",
+ " howpublished = {\\url{https://github.com/google-research/frame-interpolation}}\n",
+ "}\n",
+ "```"
+ ]
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "name": "tf_hub_film_example.ipynb",
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/site/en/hub/tutorials/tf_hub_generative_image_module.ipynb b/site/en/hub/tutorials/tf_hub_generative_image_module.ipynb
new file mode 100644
index 00000000000..4937bc2eb22
--- /dev/null
+++ b/site/en/hub/tutorials/tf_hub_generative_image_module.ipynb
@@ -0,0 +1,447 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "N6ZDpd9XzFeN"
+ },
+ "source": [
+ "##### Copyright 2018 The TensorFlow Hub Authors.\n",
+ "\n",
+ "Licensed under the Apache License, Version 2.0 (the \"License\");"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "both",
+ "id": "KUu4vOt5zI9d"
+ },
+ "outputs": [],
+ "source": [
+ "# Copyright 2018 The TensorFlow Hub Authors. All Rights Reserved.\n",
+ "#\n",
+ "# Licensed under the Apache License, Version 2.0 (the \"License\");\n",
+ "# you may not use this file except in compliance with the License.\n",
+ "# You may obtain a copy of the License at\n",
+ "#\n",
+ "# http://www.apache.org/licenses/LICENSE-2.0\n",
+ "#\n",
+ "# Unless required by applicable law or agreed to in writing, software\n",
+ "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
+ "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
+ "# See the License for the specific language governing permissions and\n",
+ "# limitations under the License.\n",
+ "# =============================================================================="
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "CxmDMK4yupqg"
+ },
+ "source": [
+ "# Generate Artificial Faces with CelebA Progressive GAN Model\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "MfBg1C5NB3X0"
+ },
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Sy553YSVmYiK"
+ },
+ "source": [
+ "This Colab demonstrates use of a TF Hub module based on a generative adversarial network (GAN). The module maps from N-dimensional vectors, called latent space, to RGB images.\n",
+ "\n",
+ "Two examples are provided:\n",
+ "* **Mapping** from latent space to images, and\n",
+ "* Given a target image, **using gradient descent to find** a latent vector that generates an image similar to the target image."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "v4XGxDrCkeip"
+ },
+ "source": [
+ "## Optional prerequisites\n",
+ "\n",
+ "* Familiarity with [low level Tensorflow concepts](https://www.tensorflow.org/guide/eager).\n",
+ "* [Generative Adversarial Network](https://en.wikipedia.org/wiki/Generative_adversarial_network) on Wikipedia.\n",
+ "* Paper on Progressive GANs: [Progressive Growing of GANs for Improved Quality, Stability, and Variation](https://arxiv.org/abs/1710.10196)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "HK3Q2vIaVw56"
+ },
+ "source": [
+ "### More models\n",
+ "[Here](https://tfhub.dev/s?module-type=image-generator) you can find all models currently hosted on [tfhub.dev](https://tfhub.dev/) that can generate images."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Q4DN769E2O_R"
+ },
+ "source": [
+ "## Setup"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "KNM3kA0arrUu"
+ },
+ "outputs": [],
+ "source": [
+ "# Install imageio for creating animations. \n",
+ "!pip -q install imageio\n",
+ "!pip -q install scikit-image\n",
+ "!pip install git+https://github.com/tensorflow/docs"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "both",
+ "id": "6cPY9Ou4sWs_"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Imports and function definitions\n",
+ "from absl import logging\n",
+ "\n",
+ "import imageio\n",
+ "import PIL.Image\n",
+ "import matplotlib.pyplot as plt\n",
+ "import numpy as np\n",
+ "\n",
+ "import tensorflow as tf\n",
+ "tf.random.set_seed(0)\n",
+ "\n",
+ "import tensorflow_hub as hub\n",
+ "from tensorflow_docs.vis import embed\n",
+ "import time\n",
+ "\n",
+ "try:\n",
+ " from google.colab import files\n",
+ "except ImportError:\n",
+ " pass\n",
+ "\n",
+ "from IPython import display\n",
+ "from skimage import transform\n",
+ "\n",
+ "# We could retrieve this value from module.get_input_shapes() if we didn't know\n",
+ "# beforehand which module we will be using.\n",
+ "latent_dim = 512\n",
+ "\n",
+ "\n",
+ "# Interpolates between two vectors that are non-zero and don't both lie on a\n",
+ "# line going through origin. First normalizes v2 to have the same norm as v1. \n",
+ "# Then interpolates between the two vectors on the hypersphere.\n",
+ "def interpolate_hypersphere(v1, v2, num_steps):\n",
+ " v1_norm = tf.norm(v1)\n",
+ " v2_norm = tf.norm(v2)\n",
+ " v2_normalized = v2 * (v1_norm / v2_norm)\n",
+ "\n",
+ " vectors = []\n",
+ " for step in range(num_steps):\n",
+ " interpolated = v1 + (v2_normalized - v1) * step / (num_steps - 1)\n",
+ " interpolated_norm = tf.norm(interpolated)\n",
+ " interpolated_normalized = interpolated * (v1_norm / interpolated_norm)\n",
+ " vectors.append(interpolated_normalized)\n",
+ " return tf.stack(vectors)\n",
+ "\n",
+ "# Simple way to display an image.\n",
+ "def display_image(image):\n",
+ " image = tf.constant(image)\n",
+ " image = tf.image.convert_image_dtype(image, tf.uint8)\n",
+ " return PIL.Image.fromarray(image.numpy())\n",
+ "\n",
+ "# Given a set of images, show an animation.\n",
+ "def animate(images):\n",
+ " images = np.array(images)\n",
+ " converted_images = np.clip(images * 255, 0, 255).astype(np.uint8)\n",
+ " imageio.mimsave('./animation.gif', converted_images)\n",
+ " return embed.embed_file('./animation.gif')\n",
+ "\n",
+ "logging.set_verbosity(logging.ERROR)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "f5EESfBvukYI"
+ },
+ "source": [
+ "## Latent space interpolation"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nJb9gFmRvynZ"
+ },
+ "source": [
+ "### Random vectors\n",
+ "\n",
+ "Latent space interpolation between two randomly initialized vectors. We will use a TF Hub module [progan-128](https://tfhub.dev/google/progan-128/1) that contains a pre-trained Progressive GAN."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "8StEe9x9wGma"
+ },
+ "outputs": [],
+ "source": [
+ "progan = hub.load(\"https://tfhub.dev/google/progan-128/1\").signatures['default']"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "fZ0O5_5Jhwio"
+ },
+ "outputs": [],
+ "source": [
+ "def interpolate_between_vectors():\n",
+ " v1 = tf.random.normal([latent_dim])\n",
+ " v2 = tf.random.normal([latent_dim])\n",
+ " \n",
+ " # Creates a tensor with 25 steps of interpolation between v1 and v2.\n",
+ " vectors = interpolate_hypersphere(v1, v2, 50)\n",
+ "\n",
+ " # Uses module to generate images from the latent space.\n",
+ " interpolated_images = progan(vectors)['default']\n",
+ "\n",
+ " return interpolated_images\n",
+ "\n",
+ "interpolated_images = interpolate_between_vectors()\n",
+ "animate(interpolated_images)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "L9-uXoTHuXQC"
+ },
+ "source": [
+ "## Finding closest vector in latent space\n",
+ "Fix a target image. As an example use an image generated from the module or upload your own."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "both",
+ "id": "phT4W66pMmko"
+ },
+ "outputs": [],
+ "source": [
+ "image_from_module_space = True # @param { isTemplate:true, type:\"boolean\" }\n",
+ "\n",
+ "def get_module_space_image():\n",
+ " vector = tf.random.normal([1, latent_dim])\n",
+ " images = progan(vector)['default'][0]\n",
+ " return images\n",
+ "\n",
+ "def upload_image():\n",
+ " uploaded = files.upload()\n",
+ " image = imageio.imread(uploaded[list(uploaded.keys())[0]])\n",
+ " return transform.resize(image, [128, 128])\n",
+ "\n",
+ "if image_from_module_space:\n",
+ " target_image = get_module_space_image()\n",
+ "else:\n",
+ " target_image = upload_image()\n",
+ "\n",
+ "display_image(target_image)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "rBIt3Q4qvhuq"
+ },
+ "source": [
+ "After defining a loss function between the target image and the image generated by a latent space variable, we can use gradient descent to find variable values that minimize the loss."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "cUGakLdbML2Q"
+ },
+ "outputs": [],
+ "source": [
+ "tf.random.set_seed(42)\n",
+ "initial_vector = tf.random.normal([1, latent_dim])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "u7MGzDE5MU20"
+ },
+ "outputs": [],
+ "source": [
+ "display_image(progan(initial_vector)['default'][0])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "q_4Z7tnyg-ZY"
+ },
+ "outputs": [],
+ "source": [
+ "def find_closest_latent_vector(initial_vector, num_optimization_steps,\n",
+ " steps_per_image):\n",
+ " images = []\n",
+ " losses = []\n",
+ "\n",
+ " vector = tf.Variable(initial_vector) \n",
+ " optimizer = tf.optimizers.Adam(learning_rate=0.01)\n",
+ " loss_fn = tf.losses.MeanAbsoluteError(reduction=\"sum\")\n",
+ "\n",
+ " for step in range(num_optimization_steps):\n",
+ " if (step % 100)==0:\n",
+ " print()\n",
+ " print('.', end='')\n",
+ " with tf.GradientTape() as tape:\n",
+ " image = progan(vector.read_value())['default'][0]\n",
+ " if (step % steps_per_image) == 0:\n",
+ " images.append(image.numpy())\n",
+ " target_image_difference = loss_fn(image, target_image[:,:,:3])\n",
+ " # The latent vectors were sampled from a normal distribution. We can get\n",
+ " # more realistic images if we regularize the length of the latent vector to \n",
+ " # the average length of vector from this distribution.\n",
+ " regularizer = tf.abs(tf.norm(vector) - np.sqrt(latent_dim))\n",
+ " \n",
+ " loss = target_image_difference + regularizer\n",
+ " losses.append(loss.numpy())\n",
+ " grads = tape.gradient(loss, [vector])\n",
+ " optimizer.apply_gradients(zip(grads, [vector]))\n",
+ " \n",
+ " return images, losses\n",
+ "\n",
+ "\n",
+ "num_optimization_steps=200\n",
+ "steps_per_image=5\n",
+ "images, loss = find_closest_latent_vector(initial_vector, num_optimization_steps, steps_per_image)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "pRbeF2oSAcOB"
+ },
+ "outputs": [],
+ "source": [
+ "plt.plot(loss)\n",
+ "plt.ylim([0,max(plt.ylim())])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "KnZkDy2FEsTt"
+ },
+ "outputs": [],
+ "source": [
+ "animate(np.stack(images))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "GGKfuCdfPQKH"
+ },
+ "source": [
+ "Compare the result to the target:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "TK1P5z3bNuIl"
+ },
+ "outputs": [],
+ "source": [
+ "display_image(np.concatenate([images[-1], target_image], axis=1))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "tDt15dLsJwMy"
+ },
+ "source": [
+ "### Playing with the above example\n",
+ "If image is from the module space, the descent is quick and converges to a reasonable sample. Try out descending to an image that is **not from the module space**. The descent will only converge if the image is reasonably close to the space of training images.\n",
+ "\n",
+ "How to make it descend faster and to a more realistic image? One can try:\n",
+ "* using different loss on the image difference, e.g., quadratic,\n",
+ "* using different regularizer on the latent vector,\n",
+ "* initializing from a random vector in multiple runs,\n",
+ "* etc.\n"
+ ]
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "collapsed_sections": [
+ "N6ZDpd9XzFeN"
+ ],
+ "name": "tf_hub_generative_image_module.ipynb",
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/site/en/hub/tutorials/tweening_conv3d.ipynb b/site/en/hub/tutorials/tweening_conv3d.ipynb
new file mode 100644
index 00000000000..8c53929021f
--- /dev/null
+++ b/site/en/hub/tutorials/tweening_conv3d.ipynb
@@ -0,0 +1,297 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "wC0PtNm3Sa_T"
+ },
+ "source": [
+ "##### Copyright 2019 The TensorFlow Hub Authors.\n",
+ "\n",
+ "Licensed under the Apache License, Version 2.0 (the \"License\");"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "hgOqPjRKSa-7"
+ },
+ "outputs": [],
+ "source": [
+ "# Copyright 2019 The TensorFlow Hub Authors. All Rights Reserved.\n",
+ "#\n",
+ "# Licensed under the Apache License, Version 2.0 (the \"License\");\n",
+ "# you may not use this file except in compliance with the License.\n",
+ "# You may obtain a copy of the License at\n",
+ "#\n",
+ "# http://www.apache.org/licenses/LICENSE-2.0\n",
+ "#\n",
+ "# Unless required by applicable law or agreed to in writing, software\n",
+ "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
+ "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
+ "# See the License for the specific language governing permissions and\n",
+ "# limitations under the License.\n",
+ "# =============================================================================="
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "oKAkxAYuONU6"
+ },
+ "source": [
+ "# Video Inbetweening using 3D Convolutions\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "MfBg1C5NB3X0"
+ },
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "cvMgkVIBpT-Y"
+ },
+ "source": [
+ "Yunpeng Li, Dominik Roblek, and Marco Tagliasacchi. From Here to There: Video Inbetweening Using Direct 3D Convolutions, 2019.\n",
+ "\n",
+ "https://arxiv.org/abs/1905.10240\n",
+ "\n",
+ "\n",
+ "Current Hub characteristics:\n",
+ "- has models for BAIR Robot pushing videos and KTH action video dataset (though this colab uses only BAIR)\n",
+ "- BAIR dataset already available in Hub. However, KTH videos need to be supplied by the users themselves.\n",
+ "- only evaluation (video generation) for now\n",
+ "- batch size and frame size are hard-coded\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Q4DN769E2O_R"
+ },
+ "source": [
+ "## Setup"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "EsQFWvxrYrHg"
+ },
+ "source": [
+ "Since `tfds.load('bair_robot_pushing_small', split='test')` would download a 30GB archive that also contains the training data, we download a separated archive that only contains the 190MB test data. The used dataset has been published by [this paper](https://arxiv.org/abs/1710.05268) and is licensed as Creative Commons BY 4.0."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "GhIKakhc7JYL"
+ },
+ "outputs": [],
+ "source": [
+ "import tensorflow as tf\n",
+ "\n",
+ "import matplotlib.pyplot as plt\n",
+ "import numpy as np\n",
+ "import seaborn as sns\n",
+ "import tensorflow_hub as hub\n",
+ "import tensorflow_datasets as tfds\n",
+ "\n",
+ "from tensorflow_datasets.core import SplitGenerator\n",
+ "from tensorflow_datasets.video.bair_robot_pushing import BairRobotPushingSmall\n",
+ "\n",
+ "import tempfile\n",
+ "import pathlib\n",
+ "\n",
+ "TEST_DIR = pathlib.Path(tempfile.mkdtemp()) / \"bair_robot_pushing_small/softmotion30_44k/test/\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "zBMz14GmYkwz"
+ },
+ "outputs": [],
+ "source": [
+ "# Download the test split to $TEST_DIR\n",
+ "!mkdir -p $TEST_DIR\n",
+ "!wget -nv https://storage.googleapis.com/download.tensorflow.org/data/bair_test_traj_0_to_255.tfrecords -O $TEST_DIR/traj_0_to_255.tfrecords"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "irRJ2Q0iYoW0"
+ },
+ "outputs": [],
+ "source": [
+ "# Since the dataset builder expects the train and test split to be downloaded,\n",
+ "# patch it so it only expects the test data to be available\n",
+ "builder = BairRobotPushingSmall()\n",
+ "test_generator = SplitGenerator(name='test', gen_kwargs={\"filedir\": str(TEST_DIR)})\n",
+ "builder._split_generators = lambda _: [test_generator]\n",
+ "builder.download_and_prepare()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "iaGU8hhBPi_6"
+ },
+ "source": [
+ "## BAIR: Demo based on numpy array inputs"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "IgWmW8YzEiDo"
+ },
+ "outputs": [],
+ "source": [
+ "# @title Load some example data (BAIR).\n",
+ "batch_size = 16\n",
+ "\n",
+ "# If unable to download the dataset automatically due to \"not enough disk space\", please download manually to Google Drive and\n",
+ "# load using tf.data.TFRecordDataset.\n",
+ "ds = builder.as_dataset(split=\"test\")\n",
+ "test_videos = ds.batch(batch_size)\n",
+ "first_batch = next(iter(test_videos))\n",
+ "input_frames = first_batch['image_aux1'][:, ::15]\n",
+ "input_frames = tf.cast(input_frames, tf.float32)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "96Jd5XefGHRr"
+ },
+ "outputs": [],
+ "source": [
+ "# @title Visualize loaded videos start and end frames.\n",
+ "\n",
+ "print('Test videos shape [batch_size, start/end frame, height, width, num_channels]: ', input_frames.shape)\n",
+ "sns.set_style('white')\n",
+ "plt.figure(figsize=(4, 2*batch_size))\n",
+ "\n",
+ "for i in range(batch_size)[:4]:\n",
+ " plt.subplot(batch_size, 2, 1 + 2*i)\n",
+ " plt.imshow(input_frames[i, 0] / 255.0)\n",
+ " plt.title('Video {}: First frame'.format(i))\n",
+ " plt.axis('off')\n",
+ " plt.subplot(batch_size, 2, 2 + 2*i)\n",
+ " plt.imshow(input_frames[i, 1] / 255.0)\n",
+ " plt.title('Video {}: Last frame'.format(i))\n",
+ " plt.axis('off')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "w0FFhkikQABy"
+ },
+ "source": [
+ "### Load Hub Module"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "cLAUiWfEQAB5"
+ },
+ "outputs": [],
+ "source": [
+ "hub_handle = 'https://tfhub.dev/google/tweening_conv3d_bair/1'\n",
+ "module = hub.load(hub_handle).signatures['default']"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "PVHTdXnhbGsK"
+ },
+ "source": [
+ "### Generate and show the videos"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "FHAwBW-zyegP"
+ },
+ "outputs": [],
+ "source": [
+ "filled_frames = module(input_frames)['default'] / 255.0"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "tVesWHTnSW1Z"
+ },
+ "outputs": [],
+ "source": [
+ "# Show sequences of generated video frames.\n",
+ "\n",
+ "# Concatenate start/end frames and the generated filled frames for the new videos.\n",
+ "generated_videos = np.concatenate([input_frames[:, :1] / 255.0, filled_frames, input_frames[:, 1:] / 255.0], axis=1)\n",
+ "\n",
+ "for video_id in range(4):\n",
+ " fig = plt.figure(figsize=(10 * 2, 2))\n",
+ " for frame_id in range(1, 16):\n",
+ " ax = fig.add_axes([frame_id * 1 / 16., 0, (frame_id + 1) * 1 / 16., 1],\n",
+ " xmargin=0, ymargin=0)\n",
+ " ax.imshow(generated_videos[video_id, frame_id])\n",
+ " ax.axis('off')"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "collapsed_sections": [
+ "Q4DN769E2O_R"
+ ],
+ "name": "tweening_conv3d.ipynb",
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/site/en/hub/tutorials/wav2vec2_saved_model_finetuning.ipynb b/site/en/hub/tutorials/wav2vec2_saved_model_finetuning.ipynb
new file mode 100644
index 00000000000..879bdbd0edb
--- /dev/null
+++ b/site/en/hub/tutorials/wav2vec2_saved_model_finetuning.ipynb
@@ -0,0 +1,984 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "yCs7P9JTMlzV"
+ },
+ "source": [
+ "##### Copyright 2021 The TensorFlow Hub Authors.\n",
+ "\n",
+ "Licensed under the Apache License, Version 2.0 (the \"License\");"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Jqn-HYw-Mkea"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Copyright 2021 The TensorFlow Hub Authors. All Rights Reserved.\n",
+ "#\n",
+ "# Licensed under the Apache License, Version 2.0 (the \"License\");\n",
+ "# you may not use this file except in compliance with the License.\n",
+ "# You may obtain a copy of the License at\n",
+ "#\n",
+ "# http://www.apache.org/licenses/LICENSE-2.0\n",
+ "#\n",
+ "# Unless required by applicable law or agreed to in writing, software\n",
+ "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
+ "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
+ "# See the License for the specific language governing permissions and\n",
+ "# limitations under the License.\n",
+ "# =============================================================================="
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "stRetE8gMlmZ"
+ },
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ndG8MjmJeicp"
+ },
+ "source": [
+ "# Fine-tuning Wav2Vec2 with an LM head\n",
+ "\n",
+ "In this notebook, we will load the pre-trained wav2vec2 model from [TFHub](https://tfhub.dev) and will fine-tune it on [LibriSpeech dataset](https://huggingface.co/datasets/librispeech_asr) by appending Language Modeling head (LM) over the top of our pre-trained model. The underlying task is to build a model for **Automatic Speech Recognition** i.e. given some speech, the model should be able to transcribe it into text."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "rWk8nL6Ui-_0"
+ },
+ "source": [
+ "## Setting Up\n",
+ "\n",
+ "Before running this notebook, please ensure that you are on GPU runtime (`Runtime` > `Change runtime type` > `GPU`). The following cell will install [`gsoc-wav2vec2`](https://github.com/vasudevgupta7/gsoc-wav2vec2) package & its dependencies."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "seqTlMyeZvM4"
+ },
+ "outputs": [],
+ "source": [
+ "!pip3 install -q git+https://github.com/vasudevgupta7/gsoc-wav2vec2@main\n",
+ "!sudo apt-get install -y libsndfile1-dev\n",
+ "!pip3 install -q SoundFile"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "wvuJL8-f0zn5"
+ },
+ "source": [
+ "## Model setup using `TFHub`\n",
+ "\n",
+ "We will start by importing some libraries/modules."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "M3_fgx4eZvM7"
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "\n",
+ "import tensorflow as tf\n",
+ "import tensorflow_hub as hub\n",
+ "from wav2vec2 import Wav2Vec2Config\n",
+ "\n",
+ "config = Wav2Vec2Config()\n",
+ "\n",
+ "print(\"TF version:\", tf.__version__)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "y0rVUxyWsS5f"
+ },
+ "source": [
+ "First, we will download our model from TFHub & will wrap our model signature with [`hub.KerasLayer`](https://www.tensorflow.org/hub/api_docs/python/hub/KerasLayer) to be able to use this model like any other Keras layer. Fortunately, `hub.KerasLayer` can do both in just 1 line.\n",
+ "\n",
+ "**Note:** When loading model with `hub.KerasLayer`, model becomes a bit opaque but sometimes we need finer controls over the model, then we can load the model with `tf.keras.models.load_model(...)`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "NO6QRC7KZvM9"
+ },
+ "outputs": [],
+ "source": [
+ "pretrained_layer = hub.KerasLayer(\"https://tfhub.dev/vasudevgupta7/wav2vec2/1\", trainable=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "pCputyVBv2e9"
+ },
+ "source": [
+ "You can refer to this [script](https://github.com/vasudevgupta7/gsoc-wav2vec2/blob/main/src/export2hub.py) in case you are interested in the model exporting script. Object `pretrained_layer` is the freezed version of [`Wav2Vec2Model`](https://github.com/vasudevgupta7/gsoc-wav2vec2/blob/main/src/wav2vec2/modeling.py). These pre-trained weights were converted from HuggingFace PyTorch [pre-trained weights](https://huggingface.co/facebook/wav2vec2-base) using [this script](https://github.com/vasudevgupta7/gsoc-wav2vec2/blob/main/src/convert_torch_to_tf.py).\n",
+ "\n",
+ "Originally, wav2vec2 was pre-trained with a masked language modelling approach with the objective to identify the true quantized latent speech representation for a masked time step. You can read more about the training objective in the paper- [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "SseDnCr7hyhC"
+ },
+ "source": [
+ "Now, we will be defining a few constants and hyper-parameters which will be useful in the next few cells. `AUDIO_MAXLEN` is intentionally set to `246000` as the model signature only accepts static sequence length of `246000`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "eiILuMBERxlO"
+ },
+ "outputs": [],
+ "source": [
+ "AUDIO_MAXLEN = 246000\n",
+ "LABEL_MAXLEN = 256\n",
+ "BATCH_SIZE = 2"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "1V4gTgGLgXvO"
+ },
+ "source": [
+ "In the following cell, we will wrap `pretrained_layer` & a dense layer (LM head) with the [Keras's Functional API](https://www.tensorflow.org/guide/keras/functional)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "a3CUN1KEB10Q"
+ },
+ "outputs": [],
+ "source": [
+ "inputs = tf.keras.Input(shape=(AUDIO_MAXLEN,))\n",
+ "hidden_states = pretrained_layer(inputs)\n",
+ "outputs = tf.keras.layers.Dense(config.vocab_size)(hidden_states)\n",
+ "\n",
+ "model = tf.keras.Model(inputs=inputs, outputs=outputs)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "5zDXuoMXhDMo"
+ },
+ "source": [
+ "The dense layer (defined above) is having an output dimension of `vocab_size` as we want to predict probabilities of each token in the vocabulary at each time step."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "oPp18ZHRtnq-"
+ },
+ "source": [
+ "## Setting up training state"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ATQy1ZK3vFr7"
+ },
+ "source": [
+ "In TensorFlow, model weights are built only when `model.call` or `model.build` is called for the first time, so the following cell will build the model weights for us. Further, we will be running `model.summary()` to check the total number of trainable parameters."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "ZgL5wyaXZvM-"
+ },
+ "outputs": [],
+ "source": [
+ "model(tf.random.uniform(shape=(BATCH_SIZE, AUDIO_MAXLEN)))\n",
+ "model.summary()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "EQxxA4Fevp7m"
+ },
+ "source": [
+ "Now, we need to define the `loss_fn` and optimizer to be able to train the model. The following cell will do that for us. We will be using the `Adam` optimizer for simplicity. `CTCLoss` is a common loss type that is used for tasks (like `ASR`) where input sub-parts can't be easily aligned with output sub-parts. You can read more about CTC-loss from this amazing [blog post](https://distill.pub/2017/ctc/).\n",
+ "\n",
+ "\n",
+ "`CTCLoss` (from [`gsoc-wav2vec2`](https://github.com/vasudevgupta7/gsoc-wav2vec2) package) accepts 3 arguments: `config`, `model_input_shape` & `division_factor`. If `division_factor=1`, then loss will simply get summed, so pass `division_factor` accordingly to get mean over batch."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "glDepVEHZvM_"
+ },
+ "outputs": [],
+ "source": [
+ "from wav2vec2 import CTCLoss\n",
+ "\n",
+ "LEARNING_RATE = 5e-5\n",
+ "\n",
+ "loss_fn = CTCLoss(config, (BATCH_SIZE, AUDIO_MAXLEN), division_factor=BATCH_SIZE)\n",
+ "optimizer = tf.keras.optimizers.Adam(LEARNING_RATE)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "1mvTuOXpwsQe"
+ },
+ "source": [
+ "## Loading & Pre-processing data\n",
+ "\n",
+ "Let's now download the LibriSpeech dataset from the [official website](http://www.openslr.org/12) and set it up."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "I4kIEC77cBCM"
+ },
+ "outputs": [],
+ "source": [
+ "!wget https://www.openslr.org/resources/12/dev-clean.tar.gz -P ./data/train/\n",
+ "!tar -xf ./data/train/dev-clean.tar.gz -C ./data/train/"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "LsQpmpn6jrMI"
+ },
+ "source": [
+ "**Note:** We are using `dev-clean` configuration as this notebook is just for demonstration purposes, so we need a small amount of data. Complete training data can be easily downloaded from [LibriSpeech website](http://www.openslr.org/12)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "ynxAjtGHGFpM"
+ },
+ "outputs": [],
+ "source": [
+ "ls ./data/train/"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "yBMiORo0xJD0"
+ },
+ "source": [
+ "Our dataset lies in the LibriSpeech directory. Let's explore these files."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "jkIu_Wt4ZvNA"
+ },
+ "outputs": [],
+ "source": [
+ "data_dir = \"./data/train/LibriSpeech/dev-clean/2428/83705/\"\n",
+ "all_files = os.listdir(data_dir)\n",
+ "\n",
+ "flac_files = [f for f in all_files if f.endswith(\".flac\")]\n",
+ "txt_files = [f for f in all_files if f.endswith(\".txt\")]\n",
+ "\n",
+ "print(\"Transcription files:\", txt_files, \"\\nSound files:\", flac_files)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "XEObi_Apk3ZD"
+ },
+ "source": [
+ "Alright, so each sub-directory has many `.flac` files and a `.txt` file. The `.txt` file contains text transcriptions for all the speech samples (i.e. `.flac` files) present in that sub-directory."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "WYW6WKJflO2e"
+ },
+ "source": [
+ "We can load this text data as follows:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "cEBKxQblHPwq"
+ },
+ "outputs": [],
+ "source": [
+ "def read_txt_file(f):\n",
+ " with open(f, \"r\") as f:\n",
+ " samples = f.read().split(\"\\n\")\n",
+ " samples = {s.split()[0]: \" \".join(s.split()[1:]) for s in samples if len(s.split()) > 2}\n",
+ " return samples"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Ldkf_ceb0_YW"
+ },
+ "source": [
+ "Similarly, we will define a function for loading a speech sample from a `.flac` file.\n",
+ "\n",
+ "`REQUIRED_SAMPLE_RATE` is set to `16000` as wav2vec2 was pre-trained with `16K` frequency and it's recommended to fine-tune it without any major change in data distribution due to frequency."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "YOJ3OzPsTyXv"
+ },
+ "outputs": [],
+ "source": [
+ "import soundfile as sf\n",
+ "\n",
+ "REQUIRED_SAMPLE_RATE = 16000\n",
+ "\n",
+ "def read_flac_file(file_path):\n",
+ " with open(file_path, \"rb\") as f:\n",
+ " audio, sample_rate = sf.read(f)\n",
+ " if sample_rate != REQUIRED_SAMPLE_RATE:\n",
+ " raise ValueError(\n",
+ " f\"sample rate (={sample_rate}) of your files must be {REQUIRED_SAMPLE_RATE}\"\n",
+ " )\n",
+ " file_id = os.path.split(file_path)[-1][:-len(\".flac\")]\n",
+ " return {file_id: audio}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "2sxDN8P4nWkW"
+ },
+ "source": [
+ "Now, we will pick some random samples & will try to visualize them."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "HI5J-2Dfm_wT"
+ },
+ "outputs": [],
+ "source": [
+ "from IPython.display import Audio\n",
+ "import random\n",
+ "\n",
+ "file_id = random.choice([f[:-len(\".flac\")] for f in flac_files])\n",
+ "flac_file_path, txt_file_path = os.path.join(data_dir, f\"{file_id}.flac\"), os.path.join(data_dir, \"2428-83705.trans.txt\")\n",
+ "\n",
+ "print(\"Text Transcription:\", read_txt_file(txt_file_path)[file_id], \"\\nAudio:\")\n",
+ "Audio(filename=flac_file_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "M8jJ7Ed81p_A"
+ },
+ "source": [
+ "Now, we will combine all the speech & text samples and will define the function (in next cell) for that purpose."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "MI-5YCzaTsei"
+ },
+ "outputs": [],
+ "source": [
+ "def fetch_sound_text_mapping(data_dir):\n",
+ " all_files = os.listdir(data_dir)\n",
+ "\n",
+ " flac_files = [os.path.join(data_dir, f) for f in all_files if f.endswith(\".flac\")]\n",
+ " txt_files = [os.path.join(data_dir, f) for f in all_files if f.endswith(\".txt\")]\n",
+ "\n",
+ " txt_samples = {}\n",
+ " for f in txt_files:\n",
+ " txt_samples.update(read_txt_file(f))\n",
+ "\n",
+ " speech_samples = {}\n",
+ " for f in flac_files:\n",
+ " speech_samples.update(read_flac_file(f))\n",
+ "\n",
+ " assert len(txt_samples) == len(speech_samples)\n",
+ "\n",
+ " samples = [(speech_samples[file_id], txt_samples[file_id]) for file_id in speech_samples.keys() if len(speech_samples[file_id]) < AUDIO_MAXLEN]\n",
+ " return samples"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "mx95Lxvu0nT4"
+ },
+ "source": [
+ "It's time to have a look at a few samples ..."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "_Ls7X_jqIz4R"
+ },
+ "outputs": [],
+ "source": [
+ "samples = fetch_sound_text_mapping(data_dir)\n",
+ "samples[:5]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "TUjhSWfsnlCL"
+ },
+ "source": [
+ "Note: We are loading this data into memory as we working with a small amount of dataset in this notebook. But for training on the complete dataset (~300 GBs), you will have to load data lazily. You can refer to [this script](https://github.com/vasudevgupta7/gsoc-wav2vec2/blob/main/src/data_utils.py) to know more on that."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "xg8Zia1kzw0J"
+ },
+ "source": [
+ "Let's pre-process the data now !!!\n",
+ "\n",
+ "We will first define the tokenizer & processor using `gsoc-wav2vec2` package. Then, we will do very simple pre-processing. `processor` will normalize raw speech w.r.to frames axis and `tokenizer` will convert our model outputs into the string (using the defined vocabulary) & will take care of the removal of special tokens (depending on your tokenizer configuration)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "gaat_hMLNVHF"
+ },
+ "outputs": [],
+ "source": [
+ "from wav2vec2 import Wav2Vec2Processor\n",
+ "tokenizer = Wav2Vec2Processor(is_tokenizer=True)\n",
+ "processor = Wav2Vec2Processor(is_tokenizer=False)\n",
+ "\n",
+ "def preprocess_text(text):\n",
+ " label = tokenizer(text)\n",
+ " return tf.constant(label, dtype=tf.int32)\n",
+ "\n",
+ "def preprocess_speech(audio):\n",
+ " audio = tf.constant(audio, dtype=tf.float32)\n",
+ " return processor(tf.transpose(audio))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "GyKl8QP-zRFC"
+ },
+ "source": [
+ "Now, we will define the python generator to call the preprocessing functions we defined in above cells."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "PoQrRalwMpQ6"
+ },
+ "outputs": [],
+ "source": [
+ "def inputs_generator():\n",
+ " for speech, text in samples:\n",
+ " yield preprocess_speech(speech), preprocess_text(text)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "7Vlm3ySFULsG"
+ },
+ "source": [
+ "## Setting up `tf.data.Dataset`\n",
+ "\n",
+ "Following cell will setup `tf.data.Dataset` object using its `.from_generator(...)` method. We will be using the `generator` object, we defined in the above cell.\n",
+ "\n",
+ "**Note:** For distributed training (especially on TPUs), `.from_generator(...)` doesn't work currently and it is recommended to train on data stored in `.tfrecord` format (Note: The TFRecords should ideally be stored inside a GCS Bucket in order for the TPUs to work to the fullest extent).\n",
+ "\n",
+ "You can refer to [this script](https://github.com/vasudevgupta7/gsoc-wav2vec2/blob/main/src/make_tfrecords.py) for more details on how to convert LibriSpeech data into tfrecords."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "LbQ_dMwGO62h"
+ },
+ "outputs": [],
+ "source": [
+ "output_signature = (\n",
+ " tf.TensorSpec(shape=(None), dtype=tf.float32),\n",
+ " tf.TensorSpec(shape=(None), dtype=tf.int32),\n",
+ ")\n",
+ "\n",
+ "dataset = tf.data.Dataset.from_generator(inputs_generator, output_signature=output_signature)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "HXBbNsRyPyw3"
+ },
+ "outputs": [],
+ "source": [
+ "BUFFER_SIZE = len(flac_files)\n",
+ "SEED = 42\n",
+ "\n",
+ "dataset = dataset.shuffle(BUFFER_SIZE, seed=SEED)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "9DAUmns3pXfr"
+ },
+ "source": [
+ "We will pass the dataset into multiple batches, so let's prepare batches in the following cell. Now, all the sequences in a batch should be padded to a constant length. We will use the`.padded_batch(...)` method for that purpose."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Okhko1IWRida"
+ },
+ "outputs": [],
+ "source": [
+ "dataset = dataset.padded_batch(BATCH_SIZE, padded_shapes=(AUDIO_MAXLEN, LABEL_MAXLEN), padding_values=(0.0, 0))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "A45CjQG5qSbV"
+ },
+ "source": [
+ "Accelerators (like GPUs/TPUs) are very fast and often data-loading (& pre-processing) becomes the bottleneck during training as the data-loading part happens on CPUs. This can increase the training time significantly especially when there is a lot of online pre-processing involved or data is streamed online from GCS buckets. To handle those issues, `tf.data.Dataset` offers the `.prefetch(...)` method. This method helps in preparing the next few batches in parallel (on CPUs) while the model is making predictions (on GPUs/TPUs) on the current batch."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "f-bKu2YjRior"
+ },
+ "outputs": [],
+ "source": [
+ "dataset = dataset.prefetch(tf.data.AUTOTUNE)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Lqk2cs6LxVIh"
+ },
+ "source": [
+ "Since this notebook is made for demonstration purposes, we will be taking first `num_train_batches` and will perform training over only that. You are encouraged to train on the whole dataset though. Similarly, we will evaluate only `num_val_batches`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "z6GO5oYUxXtz"
+ },
+ "outputs": [],
+ "source": [
+ "num_train_batches = 10\n",
+ "num_val_batches = 4\n",
+ "\n",
+ "train_dataset = dataset.take(num_train_batches)\n",
+ "val_dataset = dataset.skip(num_train_batches).take(num_val_batches)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "CzAOI78tky08"
+ },
+ "source": [
+ "## Model training\n",
+ "\n",
+ "For training our model, we will be directly calling `.fit(...)` method after compiling our model with `.compile(...)`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "vuBY2sZElgwg"
+ },
+ "outputs": [],
+ "source": [
+ "model.compile(optimizer, loss=loss_fn)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "qswxafSl0HjO"
+ },
+ "source": [
+ "The above cell will set up our training state. Now we can initiate training with the `.fit(...)` method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "vtuSfnj1l-I_"
+ },
+ "outputs": [],
+ "source": [
+ "history = model.fit(train_dataset, validation_data=val_dataset, epochs=3)\n",
+ "history.history"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ySvp8r2E1q_V"
+ },
+ "source": [
+ "Let's save our model with `.save(...)` method to be able to perform inference later. You can also export this SavedModel to TFHub by following [TFHub documentation](https://www.tensorflow.org/hub/publish)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "C0KEYcwydwjF"
+ },
+ "outputs": [],
+ "source": [
+ "save_dir = \"finetuned-wav2vec2\"\n",
+ "model.save(save_dir, include_optimizer=False)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "MkOpp9rZ211t"
+ },
+ "source": [
+ "Note: We are setting `include_optimizer=False` as we want to use this model for inference only."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "SJfPlTgezD0i"
+ },
+ "source": [
+ "## Evaluation\n",
+ "\n",
+ "Now we will be computing Word Error Rate over the validation dataset\n",
+ "\n",
+ "**Word error rate** (WER) is a common metric for measuring the performance of an automatic speech recognition system. The WER is derived from the Levenshtein distance, working at the word level. Word error rate can then be computed as: WER = (S + D + I) / N = (S + D + I) / (S + D + C) where S is the number of substitutions, D is the number of deletions, I is the number of insertions, C is the number of correct words, N is the number of words in the reference (N=S+D+C). This value indicates the percentage of words that were incorrectly predicted. \n",
+ "\n",
+ "You can refer to [this paper](https://www.isca-speech.org/archive_v0/interspeech_2004/i04_2765.html) to learn more about WER."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Io_91Y7-r3xu"
+ },
+ "source": [
+ "We will use `load_metric(...)` function from [HuggingFace datasets](https://huggingface.co/docs/datasets/) library. Let's first install the `datasets` library using `pip` and then define the `metric` object."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "GW9F_oVDU1TZ"
+ },
+ "outputs": [],
+ "source": [
+ "!pip3 install -q datasets\n",
+ "\n",
+ "from datasets import load_metric\n",
+ "metric = load_metric(\"wer\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "ssWXWc7CZvNB"
+ },
+ "outputs": [],
+ "source": [
+ "@tf.function(jit_compile=True)\n",
+ "def eval_fwd(batch):\n",
+ " logits = model(batch, training=False)\n",
+ " return tf.argmax(logits, axis=-1)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "NFh1myg1x4ua"
+ },
+ "source": [
+ "It's time to run the evaluation on validation data now."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "EQTFVjZghckJ"
+ },
+ "outputs": [],
+ "source": [
+ "from tqdm.auto import tqdm\n",
+ "\n",
+ "for speech, labels in tqdm(val_dataset, total=num_val_batches):\n",
+ " predictions = eval_fwd(speech)\n",
+ " predictions = [tokenizer.decode(pred) for pred in predictions.numpy().tolist()]\n",
+ " references = [tokenizer.decode(label, group_tokens=False) for label in labels.numpy().tolist()]\n",
+ " metric.add_batch(references=references, predictions=predictions)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "WWCc8qBesv3e"
+ },
+ "source": [
+ "We are using the `tokenizer.decode(...)` method for decoding our predictions and labels back into the text and will add them to the metric for `WER` computation later."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "XI_URj8Wtb2g"
+ },
+ "source": [
+ "Now, let's calculate the metric value in following cell:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "a83wekLgWMod"
+ },
+ "outputs": [],
+ "source": [
+ "metric.compute()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "c_cD1OgVEjl4"
+ },
+ "source": [
+ "**Note:** Here metric value doesn't make any sense as the model is trained on very small data and ASR-like tasks often require a large amount of data to learn a mapping from speech to text. You should probably train on large data to get some good results. This notebook gives you a template to fine-tune a pre-trained speech model."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "G14o706kdTE1"
+ },
+ "source": [
+ "## Inference\n",
+ "\n",
+ "Now that we are satisfied with the training process & have saved the model in `save_dir`, we will see how this model can be used for inference.\n",
+ "\n",
+ "First, we will load our model using `tf.keras.models.load_model(...)`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "wrTrExiUdaED"
+ },
+ "outputs": [],
+ "source": [
+ "finetuned_model = tf.keras.models.load_model(save_dir)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "luodSroz20SR"
+ },
+ "source": [
+ "Let's download some speech samples for performing inference. You can replace the following sample with your speech sample also."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "HUE0shded6Ej"
+ },
+ "outputs": [],
+ "source": [
+ "!wget https://github.com/vasudevgupta7/gsoc-wav2vec2/raw/main/data/SA2.wav"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ycBjU_U53FjL"
+ },
+ "source": [
+ "Now, we will read the speech sample using `soundfile.read(...)` and pad it to `AUDIO_MAXLEN` to satisfy the model signature. Then we will normalize that speech sample using the `Wav2Vec2Processor` instance & will feed it into the model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "z7CARje4d5_H"
+ },
+ "outputs": [],
+ "source": [
+ "import numpy as np\n",
+ "\n",
+ "speech, _ = sf.read(\"SA2.wav\")\n",
+ "speech = np.pad(speech, (0, AUDIO_MAXLEN - len(speech)))\n",
+ "speech = tf.expand_dims(processor(tf.constant(speech)), 0)\n",
+ "\n",
+ "outputs = finetuned_model(speech)\n",
+ "outputs"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "lUSttSPa30qP"
+ },
+ "source": [
+ "Let's decode numbers back into text sequence using the `Wav2Vec2tokenizer` instance, we defined above."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "RYdJqxQ4llgI"
+ },
+ "outputs": [],
+ "source": [
+ "predictions = tf.argmax(outputs, axis=-1)\n",
+ "predictions = [tokenizer.decode(pred) for pred in predictions.numpy().tolist()]\n",
+ "predictions"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "7DXC757bztJc"
+ },
+ "source": [
+ "This prediction is quite random as the model was never trained on large data in this notebook (as this notebook is not meant for doing complete training). You will get good predictions if you train this model on complete LibriSpeech dataset.\n",
+ "\n",
+ "Finally, we have reached an end to this notebook. But it's not an end of learning TensorFlow for speech-related tasks, this [repository](https://github.com/tulasiram58827/TTS_TFLite) contains some more amazing tutorials. In case you encountered any bug in this notebook, please create an issue [here](https://github.com/vasudevgupta7/gsoc-wav2vec2/issues)."
+ ]
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "collapsed_sections": [
+ "rWk8nL6Ui-_0",
+ "wvuJL8-f0zn5",
+ "oPp18ZHRtnq-",
+ "1mvTuOXpwsQe",
+ "7Vlm3ySFULsG",
+ "CzAOI78tky08",
+ "SJfPlTgezD0i",
+ "G14o706kdTE1"
+ ],
+ "name": "wav2vec2_saved_model_finetuning.ipynb",
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/site/en/hub/tutorials/wiki40b_lm.ipynb b/site/en/hub/tutorials/wiki40b_lm.ipynb
new file mode 100644
index 00000000000..ad94ce0aab8
--- /dev/null
+++ b/site/en/hub/tutorials/wiki40b_lm.ipynb
@@ -0,0 +1,451 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Oxb_tjw13y4G"
+ },
+ "source": [
+ "##### Copyright 2019 The TensorFlow Hub Authors.\n",
+ "\n",
+ "Licensed under the Apache License, Version 2.0 (the \"License\");"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "EAkh2aBJLg6q"
+ },
+ "outputs": [],
+ "source": [
+ "# Copyright 2019 The TensorFlow Hub Authors. All Rights Reserved.\n",
+ "#\n",
+ "# Licensed under the Apache License, Version 2.0 (the \"License\");\n",
+ "# you may not use this file except in compliance with the License.\n",
+ "# You may obtain a copy of the License at\n",
+ "#\n",
+ "# http://www.apache.org/licenses/LICENSE-2.0\n",
+ "#\n",
+ "# Unless required by applicable law or agreed to in writing, software\n",
+ "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
+ "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
+ "# See the License for the specific language governing permissions and\n",
+ "# limitations under the License.\n",
+ "# =============================================================================="
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "owAopeOtirc9"
+ },
+ "source": [
+ "# Wiki40B Language Models\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "T-nCyGRri-KO"
+ },
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "8eY9jkGpjf3d"
+ },
+ "source": [
+ "Generate Wikipedia-like text using the **Wiki40B language models** from [TensorFlow Hub](https://tfhub.dev)!\n",
+ "\n",
+ "This notebook illustrates how to:\n",
+ "* Load the 41 monolingual and 2 multilingual language models that are part of the [Wiki40b-LM collection](https://tfhub.dev/google/collections/wiki40b-lm/1) on TF-Hub\n",
+ "* Use the models to obtain perplexity, per layer activations, and word embeddings for a given piece of text\n",
+ "* Generate text token-by-token from a piece of seed text\n",
+ "\n",
+ "The language models are trained on the newly published, cleaned-up [Wiki40B dataset](https://www.tensorflow.org/datasets/catalog/wiki40b) available on TensorFlow Datasets. The training setup is based on the paper [“Wiki-40B: Multilingual Language Model Dataset”](https://research.google/pubs/pub49029/)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "wK2YnrEhLjDf"
+ },
+ "source": [
+ "## Setup"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "sv2CmI7BdaML"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Installing Dependencies\n",
+ "!pip install --quiet \"tensorflow-text==2.11.*\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "8uSkaQ-Vdon2"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Imports\n",
+ "import numpy as np\n",
+ "import tensorflow.compat.v1 as tf\n",
+ "import tensorflow_hub as hub\n",
+ "import tensorflow_text as tf_text\n",
+ "\n",
+ "tf.disable_eager_execution()\n",
+ "tf.logging.set_verbosity(tf.logging.WARN)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "d2MvP-cyL-BN"
+ },
+ "source": [
+ "## Choose Language\n",
+ "\n",
+ "Let's choose **which language model** to load from TF-Hub and the **length of text** to be generated. \n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "33zYlSXwMA_o"
+ },
+ "outputs": [],
+ "source": [
+ "#@title { run: \"auto\" }\n",
+ "language = \"en\" #@param [\"en\", \"ar\", \"zh-cn\", \"zh-tw\", \"nl\", \"fr\", \"de\", \"it\", \"ja\", \"ko\", \"pl\", \"pt\", \"ru\", \"es\", \"th\", \"tr\", \"bg\", \"ca\", \"cs\", \"da\", \"el\", \"et\", \"fa\", \"fi\", \"he\", \"hi\", \"hr\", \"hu\", \"id\", \"lt\", \"lv\", \"ms\", \"no\", \"ro\", \"sk\", \"sl\", \"sr\", \"sv\", \"tl\", \"uk\", \"vi\", \"multilingual-64k\", \"multilingual-128k\"]\n",
+ "hub_module = \"https://tfhub.dev/google/wiki40b-lm-{}/1\".format(language)\n",
+ "max_gen_len = 20 #@param\n",
+ "\n",
+ "print(\"Using the {} model to generate sequences of max length {}.\".format(hub_module, max_gen_len))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "dgw2qW4xZbMj"
+ },
+ "source": [
+ "## Build the Model\n",
+ "\n",
+ "Okay, now that we've configured which pre-trained model to use, let's configure it to generate text up to `max_gen_len`. We will need to load the language model from TF-Hub, feed in a piece of starter text, and then iteratively feed in tokens as they are generated."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "pUypKuc3Mlpa"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Load the language model pieces\n",
+ "g = tf.Graph()\n",
+ "n_layer = 12\n",
+ "model_dim = 768\n",
+ "\n",
+ "with g.as_default():\n",
+ " text = tf.placeholder(dtype=tf.string, shape=(1,))\n",
+ "\n",
+ " # Load the pretrained model from TF-Hub\n",
+ " module = hub.Module(hub_module)\n",
+ "\n",
+ " # Get the word embeddings, activations at each layer, negative log likelihood\n",
+ " # of the text, and calculate the perplexity.\n",
+ " embeddings = module(dict(text=text), signature=\"word_embeddings\", as_dict=True)[\"word_embeddings\"]\n",
+ " activations = module(dict(text=text), signature=\"activations\", as_dict=True)[\"activations\"]\n",
+ " neg_log_likelihood = module(dict(text=text), signature=\"neg_log_likelihood\", as_dict=True)[\"neg_log_likelihood\"]\n",
+ " ppl = tf.exp(tf.reduce_mean(neg_log_likelihood, axis=1))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "ZOS2Z2n0MsuC"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Construct the per-token generation graph\n",
+ "def feedforward_step(module, inputs, mems):\n",
+ " \"\"\"Generate one step.\"\"\"\n",
+ " # Set up the input dict for one step of generation\n",
+ " inputs = tf.dtypes.cast(inputs, tf.int64)\n",
+ " generation_input_dict = dict(input_tokens=inputs)\n",
+ " mems_dict = {\"mem_{}\".format(i): mems[i] for i in range(n_layer)}\n",
+ " generation_input_dict.update(mems_dict)\n",
+ "\n",
+ " # Generate the tokens from the language model\n",
+ " generation_outputs = module(generation_input_dict, signature=\"prediction\", as_dict=True)\n",
+ "\n",
+ " # Get the probabilities and the inputs for the next steps\n",
+ " probs = generation_outputs[\"probs\"]\n",
+ " new_mems = [generation_outputs[\"new_mem_{}\".format(i)] for i in range(n_layer)]\n",
+ "\n",
+ " return probs, new_mems"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "S9ss6amQMyVY"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Build the statically unrolled graph for `max_gen_len` tokens\n",
+ "with g.as_default():\n",
+ " # Tokenization with the sentencepiece model.\n",
+ " token_ids = module(dict(text=text), signature=\"tokenization\", as_dict=True)[\"token_ids\"]\n",
+ " inputs_np = token_ids\n",
+ " # Generate text by statically unrolling the computational graph\n",
+ " mems_np = [np.zeros([1, 0, model_dim], dtype=np.float32) for _ in range(n_layer)]\n",
+ "\n",
+ " # Generate up to `max_gen_len` tokens\n",
+ " sampled_ids = []\n",
+ " for step in range(max_gen_len):\n",
+ " probs, mems_np = feedforward_step(module, inputs_np, mems_np)\n",
+ " sampled_id = tf.random.categorical(tf.math.log(probs[0]), num_samples=1, dtype=tf.int32)\n",
+ " sampled_id = tf.squeeze(sampled_id)\n",
+ " sampled_ids.append(sampled_id)\n",
+ " inputs_np = tf.reshape(sampled_id, [1, 1])\n",
+ "\n",
+ " # Transform the ids into text\n",
+ " sampled_ids = tf.expand_dims(sampled_ids, axis=0)\n",
+ " generated_text = module(dict(token_ids=sampled_ids), signature=\"detokenization\", as_dict=True)[\"text\"]\n",
+ "\n",
+ " init_op = tf.group([tf.global_variables_initializer(), tf.tables_initializer()])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "K5SYcRrxM7vS"
+ },
+ "source": [
+ "## Generate some text\n",
+ "\n",
+ "Let's generate some text! We'll set a text `seed` to prompt the language model.\n",
+ "\n",
+ "You can use one of the **predefined** seeds or _optionally_ **enter your own**. This text will be used as seed for the language model to help prompt the language model for what to generate next.\n",
+ "\n",
+ "You can use the following special tokens precede special parts of the generated article. Use **`_START_ARTICLE_`** to indicate the beginning of the article, **`_START_SECTION_`** to indicate the beginning of a section, and **`_START_PARAGRAPH_`** to generate text in the article\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "GmZxv7bzMIcL"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Predefined Seeds\n",
+ "lang_to_seed = {\"en\": \"\\n_START_ARTICLE_\\n1882 Prince Edward Island general election\\n_START_PARAGRAPH_\\nThe 1882 Prince Edward Island election was held on May 8, 1882 to elect members of the House of Assembly of the province of Prince Edward Island, Canada.\",\n",
+ " \"ar\": \"\\n_START_ARTICLE_\\nأوليفيا كوك\\n_START_SECTION_\\nنشأتها والتعلي \\n_START_PARAGRAPH_\\nولدت أوليفيا كوك في أولدهام في مانشستر الكبرى لأسرة تتكون من أب يعمل كظابط شرطة، وأمها تعمل كممثلة مبيعات. عندما كانت صغيرة بدأت تأخذ دروساً في الباليه الجمباز. وفي المدرسة شاركت في المسرحيات المدرسية، إضافةً إلى عملها في مسرح سندريلا . وفي سن الرابعة عشر عاماً، حصلت على وكيلة لها في مانشستر وهي وقعت عقداً مع وكالة الفنانين المبدعين في مانشستر،\",\n",
+ " \"zh-cn\": \"\\n_START_ARTICLE_\\n上尾事件\\n_START_SECTION_\\n日本国铁劳资关系恶化\\n_START_PARAGRAPH_\\n由于日本国铁财政恶化,管理层开始重整人手安排,令工会及员工感到受威胁。但日本国铁作为公营企业,其雇员均受公营企业等劳资关系法规管——该法第17条规定公营企业员工不得发动任何罢工行为。为了规避该法例\",\n",
+ " \"zh-tw\": \"\\n_START_ARTICLE_\\n乌森\\n_START_PARAGRAPH_\\n烏森(法語:Houssen,發音:[usən];德語:Hausen;阿爾薩斯語:Hüse)是法國上萊茵省的一個市鎮,位於該省北部,屬於科爾馬-里博維萊區(Colmar-Ribeauvillé)第二科爾馬縣(Colmar-2)。該市鎮總面積6.7平方公里,2009年時的人口為\",\n",
+ " \"nl\": \"\\n_START_ARTICLE_\\n1001 vrouwen uit de Nederlandse geschiedenis\\n_START_SECTION_\\nSelectie van vrouwen\\n_START_PARAGRAPH_\\nDe 'oudste' biografie in het boek is gewijd aan de beschermheilige\",\n",
+ " \"fr\": \"\\n_START_ARTICLE_\\nꝹ\\n_START_SECTION_\\nUtilisation\\n_START_PARAGRAPH_\\nLe d insulaire est utilisé comme lettre additionnelle dans l’édition de 1941 du recueil de chroniques galloises Brut y Tywysogion\",\n",
+ " \"de\": \"\\n_START_ARTICLE_\\nÜnal Demirkıran\\n_START_SECTION_\\nLaufbahn\\n_START_PARAGRAPH_\\nDemirkıran debütierte als junges Talent am 25. September 1999 im Auswärtsspiel des SSV Ulm 1846 bei Werder Bremen (2:2) in der Bundesliga, als er kurz\",\n",
+ " \"it\": \"\\n_START_ARTICLE_\\n28th Street (linea IRT Lexington Avenue)\\n_START_SECTION_\\nStoria\\n_START_PARAGRAPH_\\nLa stazione, i cui lavori di costruzione ebbero inizio nel 1900, venne aperta il 27 ottobre 1904, come\",\n",
+ " \"ja\": \"\\n_START_ARTICLE_\\nしのぶ・まさみshow'05 恋してラララ\\n_START_SECTION_\\n概要\\n_START_PARAGRAPH_\\n『上海ルーキーSHOW』の打ち切り後に放送された年末特番で、同番組MCの大竹しのぶと久本雅美が恋愛にまつわるテーマでトークや音楽企画を展開していた。基本は女\",\n",
+ " \"ko\": \"\\n_START_ARTICLE_\\n녹턴, Op. 9 (쇼팽)\\n_START_SECTION_\\n녹턴 3번 나장조\\n_START_PARAGRAPH_\\n쇼팽의 녹턴 3번은 세도막 형식인 (A-B-A)형식을 취하고 있다. 첫 부분은 알레그레토(Allegretto)의 빠르기가 지시되어 있으며 물 흐르듯이 부드럽게 전개되나\",\n",
+ " \"pl\": \"\\n_START_ARTICLE_\\nAK-176\\n_START_SECTION_\\nHistoria\\n_START_PARAGRAPH_\\nPod koniec lat 60 XX w. w ZSRR dostrzeżono potrzebę posiadania lekkiej armaty uniwersalnej średniego kalibru o stosunkowo dużej mocy ogniowej, która\",\n",
+ " \"pt\": \"\\n_START_ARTICLE_\\nÁcido ribonucleico\\n_START_SECTION_\\nIntermediário da transferência de informação\\n_START_PARAGRAPH_\\nEm 1957 Elliot Volkin e Lawrence Astrachan fizeram uma observação significativa. Eles descobriram que uma das mais marcantes mudanças\",\n",
+ " \"ru\": \"\\n_START_ARTICLE_\\nАрнольд, Ремо\\n_START_SECTION_\\nКлубная карьера\\n_START_PARAGRAPH_\\nАрнольд перешёл в академию «Люцерна» в 12 лет. С 2014 года выступал за вторую команду, где провёл пятнадцать встреч. С сезона 2015/2016 находится в составе основной команды. 27 сентября 2015 года дебютировал\",\n",
+ " \"es\": \"\\n_START_ARTICLE_\\n(200012) 2007 LK20\\n_START_SECTION_\\nDesignación y nombre\\n_START_PARAGRAPH_\\nDesignado provisionalmente como 2007 LK20.\\n_START_SECTION_\\nCaracterísticas orbitales\\n_START_PARAGRAPH_\\n2007 LK20\",\n",
+ " \"th\": \"\\n_START_ARTICLE_\\nการนัดหยุดเรียนเพื่อภูมิอากาศ\\n_START_SECTION_\\nเกรียตา ทืนแบร์ย\\n_START_PARAGRAPH_\\nวันที่ 20 สิงหาคม 2561 เกรียตา ทืนแบร์ย นักกิจกรรมภูมิอากาศชาวสวีเดน ซึ่งขณะนั้นศึกษาอยู่ในชั้นเกรด 9 (เทียบเท่ามัธยมศึกษาปีที่ 3) ตัดสินใจไม่เข้าเรียนจนกระทั่งการเลือกตั้งทั่วไปในประเทศสวีเดนปี\",\n",
+ " \"tr\": \"\\n_START_ARTICLE_\\nİsrail'in Muhafazakar Dostları\\n_START_SECTION_\\nFaaliyetleri\\n_START_PARAGRAPH_\\nGrubun 2005 stratejisi ile aşağıdaki faaliyet alanları tespit edilmiştir:_NEWLINE_İsrail'i destekleme\",\n",
+ " \"bg\": \"\\n_START_ARTICLE_\\nАвтомобил с повишена проходимост\\n_START_SECTION_\\nОсобености на конструкцията\\n_START_PARAGRAPH_\\nВ исторически план леки автомобили с висока проходимост се произвеждат и имат военно\",\n",
+ " \"ca\": \"\\n_START_ARTICLE_\\nAuchy-la-Montagne\\n_START_SECTION_\\nPoblació\\n_START_PARAGRAPH_\\nEl 2007 la població de fet d'Auchy-la-Montagne era de 469 persones. Hi havia 160 famílies de les quals 28\",\n",
+ " \"cs\": \"\\n_START_ARTICLE_\\nŘemeslo\\n_START_PARAGRAPH_\\nŘemeslo je určitý druh manuální dovednosti, provozovaný za účelem obživy, resp. vytváření zisku. Pro řemeslné práce je charakteristický vysoký podíl ruční práce, spojený s používáním specializovaných nástrojů a pomůcek. Řemeslné práce\",\n",
+ " \"da\": \"\\n_START_ARTICLE_\\nÖrenäs slot\\n_START_PARAGRAPH_\\nÖrenäs slot (svensk: Örenäs slott) er et slot nær Glumslöv i Landskrona stad tæt på Øresunds-kysten i Skåne i Sverige._NEWLINE_Örenäs ligger\",\n",
+ " \"el\": \"\\n_START_ARTICLE_\\nΆλβαρο Ρεκόμπα\\n_START_SECTION_\\nΒιογραφικά στοιχεία\\n_START_PARAGRAPH_\\nΟ Άλβαρο Ρεκόμπα γεννήθηκε στις 17 Μαρτίου 1976 στο Μοντεβίδεο της Ουρουγουάης από\",\n",
+ " \"et\": \"\\n_START_ARTICLE_\\nAus deutscher Geistesarbeit\\n_START_PARAGRAPH_\\nAus deutscher Geistesarbeit (alapealkiri Wochenblatt für wissenschaftliche und kulturelle Fragen der Gegenwart) oli ajakiri, mis 1924–1934 ilmus Tallinnas. Ajakirja andis 1932–1934\",\n",
+ " \"fa\": \"\\n_START_ARTICLE_\\nتفسیر بغوی\\n_START_PARAGRAPH_\\nایرانی حسین بن مسعود بغوی است. این کتاب خلاصه ای از تفسیر الکشف و البیان عن تفسیر القرآن ابواسحاق احمد ثعلبی میباشد. این کتاب در ۴ جلد موجود میباش\",\n",
+ " \"fi\": \"\\n_START_ARTICLE_\\nBovesin verilöyly\\n_START_SECTION_\\nVerilöyly\\n_START_PARAGRAPH_\\n19. syyskuuta 1943 partisaaniryhmä saapui Bovesiin tarkoituksenaan ostaa leipää kylästä. Kylässä sattui olemaan kaksi SS-miestä, jotka\",\n",
+ " \"he\": \"\\n_START_ARTICLE_\\nאוגדה 85\\n_START_SECTION_\\nהיסטוריה\\n_START_PARAGRAPH_\\nהאוגדה הוקמה בהתחלה כמשלט העמקים בשנות השבעים. בשנות השמונים הפכה להיות אוגדה מרחבית עם שתי\",\n",
+ " \"hi\": \"\\n_START_ARTICLE_\\nऑडी\\n_START_SECTION_\\nऑडी इंडिया\\n_START_PARAGRAPH_\\nऑडी इंडिया की स्थापना मार्च 2007 में फोक्सवैगन ग्रुप सेल्स इंडिया के एक विभाजन के रूप में की गई थी। दुनिया भर में 110\",\n",
+ " \"hr\": \"\\n_START_ARTICLE_\\nČimariko (jezična porodica)\\n_START_PARAGRAPH_\\nChimarikan.-porodica sjevernoameričkih indijanskih jezika koja prema Powersu obuhvaća jezike Indijanaca Chimariko (Chemaŕeko) sa rijeke Trinity i Chimalakwe\",\n",
+ " \"hu\": \"\\n_START_ARTICLE_\\nÁllami Politikai Igazgatóság\\n_START_PARAGRAPH_\\nAz Állami Politikai Igazgatóság (rövidítve: GPU, oroszul: Государственное политическое управление), majd később Egyesített Állami Politikai Igazgatóság Szovjet-Oroszország\",\n",
+ " \"id\": \"\\n_START_ARTICLE_\\n(257195) 2008 QY41\\n_START_SECTION_\\nPembentukan\\n_START_PARAGRAPH_\\nSeperti asteroid secara keseluruhan, asteroid ini terbentuk dari nebula matahari primordial sebagai pecahan planetisimal, sesuatu di\",\n",
+ " \"lt\": \"\\n_START_ARTICLE_\\nŠavijos–Uardigo regionas\\n_START_SECTION_\\nGeografija\\n_START_PARAGRAPH_\\nŠavijos-Uardigo regionas yra Atlanto vandenynu pakrantės lygumoje\",\n",
+ " \"lv\": \"\\n_START_ARTICLE_\\nApatīts\\n_START_SECTION_\\nĪpašības\\n_START_PARAGRAPH_\\nApatīta kopējā ķīmiskā formula ir Ca₁₀(PO₄)₆(OH,F,Cl)₂, ir trīs atšķirīgi apatīta veidi: apatīts: Ca₁₀(PO₄)₆(OH)₂, fluorapatīts Ca₁₀(PO₄)₆(F)₂ un hlorapatīts: Ca₁₀(PO₄)₆(Cl)₂. Pēc sastāva\",\n",
+ " \"ms\": \"\\n_START_ARTICLE_\\nEdward C. Prescott\\n_START_PARAGRAPH_\\nEdward Christian Prescott (lahir 26 Disember 1940) ialah seorang ahli ekonomi Amerika. Beliau menerima Hadiah Peringatan Nobel dalam Sains Ekonomi pada tahun 2004, berkongsi\",\n",
+ " \"no\": \"\\n_START_ARTICLE_\\nAl-Minya\\n_START_SECTION_\\nEtymologi\\n_START_PARAGRAPH_\\nDet er sprikende forklaringer på bynavnet. Det kan komme fra gammelegyptisk Men'at Khufu, i betydning byen hvor Khufu ble ammet, noe som knytter byen til farao Khufu (Keops), som\",\n",
+ " \"ro\": \"\\n_START_ARTICLE_\\nDealurile Cernăuțiului\\n_START_PARAGRAPH_\\nDealurile Cernăuțiului sunt un lanț deluros striat, care se întinde în partea centrală a interfluviului dintre Prut și Siret, în cadrul regiunii Cernăuți din\",\n",
+ " \"sk\": \"\\n_START_ARTICLE_\\n10. peruť RAAF\\n_START_PARAGRAPH_\\n10. peruť RAAF je námorná hliadkovacia peruť kráľovských austrálskych vzdušných síl (Royal Australian Air Force – RAAF) založená na základni Edinburgh v Južnej Austrálii ako súčasť 92\",\n",
+ " \"sl\": \"\\n_START_ARTICLE_\\n105 Artemida\\n_START_SECTION_\\nOdkritje\\n_START_PARAGRAPH_\\nAsteroid je 16. septembra 1868 odkril James Craig Watson (1838 – 1880). Poimenovan je po Artemidi, boginji Lune iz grške\",\n",
+ " \"sr\": \"\\n_START_ARTICLE_\\nЉанос Морелос 1. Сексион (Истапангахоја)\\n_START_SECTION_\\nСтановништво\\n_START_PARAGRAPH_\\nПрема подацима из 2010. године у насељу је живело 212\",\n",
+ " \"sv\": \"\\n_START_ARTICLE_\\nÖstra Torps landskommun\\n_START_SECTION_\\nAdministrativ historik\\n_START_PARAGRAPH_\\nKommunen bildades i Östra Torps socken i Vemmenhögs härad i Skåne när 1862 års kommunalförordningar trädde i kraft. _NEWLINE_Vid kommunreformen\",\n",
+ " \"tl\": \"\\n_START_ARTICLE_\\nBésame Mucho\\n_START_PARAGRAPH_\\nAng Bésame Mucho ay isang awit na nasa Kastila. Isinulat ito ng Mehikanang si Consuelo Velázquez noong 1940, bago sumapit ang kanyang ika-16 na\",\n",
+ " \"uk\": \"\\n_START_ARTICLE_\\nІслам та інші релігії\\n_START_PARAGRAPH_\\nПротягом багатовікової ісламської історії мусульманські правителі, ісламські вчені і звичайні мусульмани вступали у різні відносини з представниками інших релігій. Стиль цих\",\n",
+ " \"vi\": \"\\n_START_ARTICLE_\\nĐường tỉnh 316\\n_START_PARAGRAPH_\\nĐường tỉnh 316 hay tỉnh lộ 316, viết tắt ĐT316 hay TL316, là đường tỉnh ở các huyện Thanh Sơn, Thanh Thủy, Tam Nông tỉnh Phú Thọ ._NEWLINE_ĐT316 bắt đầu từ xã Tinh Nhuệ\",\n",
+ " \"multilingual-64k\": \"\\n_START_ARTICLE_\\n1882 Prince Edward Island general election\\n_START_PARAGRAPH_\\nThe 1882 Prince Edward Island election was held on May 8, 1882 to elect members of the House of Assembly of the province of Prince Edward Island, Canada.\",\n",
+ " \"multilingual-128k\": \"\\n_START_ARTICLE_\\n1882 Prince Edward Island general election\\n_START_PARAGRAPH_\\nThe 1882 Prince Edward Island election was held on May 8, 1882 to elect members of the House of Assembly of the province of Prince Edward Island, Canada.\"}\n",
+ "\n",
+ "seed = lang_to_seed[language]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "mZDGsSyUM_Mg"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Enter your own seed (Optional).\n",
+ "user_seed = \"\" #@param { type: \"string\" }\n",
+ "if user_seed.strip():\n",
+ " seed = user_seed.strip()\n",
+ "\n",
+ "# The seed must start with \"_START_ARTICLE_\" or the generated text will be gibberish\n",
+ "START_ARTICLE = \"_START_ARTICLE_\"\n",
+ "if START_ARTICLE not in seed:\n",
+ " seed = \"\\n{}\\n{}\".format(START_ARTICLE, seed)\n",
+ "\n",
+ "print(\"Generating text from seed:\\n{}\".format(seed))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "5dMuShi3XuLd"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Initialize session.\n",
+ "with tf.Session(graph=g).as_default() as session:\n",
+ " session.run(init_op)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "aS53xjmbbw0Z"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Generate text\n",
+ "\n",
+ "with session.as_default():\n",
+ " results = session.run([embeddings, neg_log_likelihood, ppl, activations, token_ids, generated_text], feed_dict={text: [seed]})\n",
+ " embeddings_result, neg_log_likelihood_result, ppl_result, activations_result, token_ids_result, generated_text_result = results\n",
+ " generated_text_output = generated_text_result[0].decode('utf-8')\n",
+ "\n",
+ "print(generated_text_output)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "tjQf3N1wdND0"
+ },
+ "source": [
+ "We can also look at the other outputs of the model - the perplexity, the token ids, the intermediate activations, and the embeddings"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "pGfw3CQWNC_n"
+ },
+ "outputs": [],
+ "source": [
+ "ppl_result"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "FLlgJObFNEmj"
+ },
+ "outputs": [],
+ "source": [
+ "token_ids_result"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "5SaH36M-NGXc"
+ },
+ "outputs": [],
+ "source": [
+ "activations_result.shape"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "k9Eb_DPfQdUu"
+ },
+ "outputs": [],
+ "source": [
+ "embeddings_result"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "collapsed_sections": [],
+ "name": "wiki40b_lm.ipynb",
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/site/en/hub/tutorials/yamnet.ipynb b/site/en/hub/tutorials/yamnet.ipynb
new file mode 100644
index 00000000000..e6c9fbca5a1
--- /dev/null
+++ b/site/en/hub/tutorials/yamnet.ipynb
@@ -0,0 +1,359 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "laa9tRjJ59bl"
+ },
+ "source": [
+ "##### Copyright 2020 The TensorFlow Hub Authors.\n",
+ "\n",
+ "Licensed under the Apache License, Version 2.0 (the \"License\");"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "T4ZHtBpK6Dom"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Copyright 2020 The TensorFlow Hub Authors. All Rights Reserved.\n",
+ "#\n",
+ "# Licensed under the Apache License, Version 2.0 (the \"License\");\n",
+ "# you may not use this file except in compliance with the License.\n",
+ "# You may obtain a copy of the License at\n",
+ "#\n",
+ "# http://www.apache.org/licenses/LICENSE-2.0\n",
+ "#\n",
+ "# Unless required by applicable law or agreed to in writing, software\n",
+ "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
+ "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
+ "# See the License for the specific language governing permissions and\n",
+ "# limitations under the License.\n",
+ "# =============================================================================="
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "hk5u_9KN1m-t"
+ },
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "x2ep-q7k_5R-"
+ },
+ "source": [
+ "# Sound classification with YAMNet\n",
+ "\n",
+ "YAMNet is a deep net that predicts 521 audio event [classes](https://github.com/tensorflow/models/blob/master/research/audioset/yamnet/yamnet_class_map.csv) from the [AudioSet-YouTube corpus](http://g.co/audioset) it was trained on. It employs the\n",
+ "[Mobilenet_v1](https://arxiv.org/pdf/1704.04861.pdf) depthwise-separable\n",
+ "convolution architecture."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Bteu7pfkpt_f"
+ },
+ "outputs": [],
+ "source": [
+ "import tensorflow as tf\n",
+ "import tensorflow_hub as hub\n",
+ "import numpy as np\n",
+ "import csv\n",
+ "\n",
+ "import matplotlib.pyplot as plt\n",
+ "from IPython.display import Audio\n",
+ "from scipy.io import wavfile"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "YSVs3zRrrYmY"
+ },
+ "source": [
+ "Load the Model from TensorFlow Hub.\n",
+ "\n",
+ "Note: to read the documentation just follow the model's [url](https://tfhub.dev/google/yamnet/1)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "VX8Vzs6EpwMo"
+ },
+ "outputs": [],
+ "source": [
+ "# Load the model.\n",
+ "model = hub.load('https://tfhub.dev/google/yamnet/1')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "lxWx6tOdtdBP"
+ },
+ "source": [
+ "The labels file will be loaded from the models assets and is present at `model.class_map_path()`.\n",
+ "You will load it on the `class_names` variable."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "EHSToAW--o4U"
+ },
+ "outputs": [],
+ "source": [
+ "# Find the name of the class with the top score when mean-aggregated across frames.\n",
+ "def class_names_from_csv(class_map_csv_text):\n",
+ " \"\"\"Returns list of class names corresponding to score vector.\"\"\"\n",
+ " class_names = []\n",
+ " with tf.io.gfile.GFile(class_map_csv_text) as csvfile:\n",
+ " reader = csv.DictReader(csvfile)\n",
+ " for row in reader:\n",
+ " class_names.append(row['display_name'])\n",
+ "\n",
+ " return class_names\n",
+ "\n",
+ "class_map_path = model.class_map_path().numpy()\n",
+ "class_names = class_names_from_csv(class_map_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "mSFjRwkZ59lU"
+ },
+ "source": [
+ "Add a method to verify and convert a loaded audio is on the proper sample_rate (16K), otherwise it would affect the model's results."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "LizGwWjc5w6A"
+ },
+ "outputs": [],
+ "source": [
+ "def ensure_sample_rate(original_sample_rate, waveform,\n",
+ " desired_sample_rate=16000):\n",
+ " \"\"\"Resample waveform if required.\"\"\"\n",
+ " if original_sample_rate != desired_sample_rate:\n",
+ " desired_length = int(round(float(len(waveform)) /\n",
+ " original_sample_rate * desired_sample_rate))\n",
+ " waveform = scipy.signal.resample(waveform, desired_length)\n",
+ " return desired_sample_rate, waveform"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "AZEgCobA9bWl"
+ },
+ "source": [
+ "## Downloading and preparing the sound file\n",
+ "\n",
+ "Here you will download a wav file and listen to it.\n",
+ "If you have a file already available, just upload it to colab and use it instead.\n",
+ "\n",
+ "Note: The expected audio file should be a mono wav file at 16kHz sample rate."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "WzZHvyTtsJrc"
+ },
+ "outputs": [],
+ "source": [
+ "!curl -O https://storage.googleapis.com/audioset/speech_whistling2.wav"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "D8LKmqvGzZzr"
+ },
+ "outputs": [],
+ "source": [
+ "!curl -O https://storage.googleapis.com/audioset/miaow_16k.wav"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Wo9KJb-5zuz1"
+ },
+ "outputs": [],
+ "source": [
+ "# wav_file_name = 'speech_whistling2.wav'\n",
+ "wav_file_name = 'miaow_16k.wav'\n",
+ "sample_rate, wav_data = wavfile.read(wav_file_name, 'rb')\n",
+ "sample_rate, wav_data = ensure_sample_rate(sample_rate, wav_data)\n",
+ "\n",
+ "# Show some basic information about the audio.\n",
+ "duration = len(wav_data)/sample_rate\n",
+ "print(f'Sample rate: {sample_rate} Hz')\n",
+ "print(f'Total duration: {duration:.2f}s')\n",
+ "print(f'Size of the input: {len(wav_data)}')\n",
+ "\n",
+ "# Listening to the wav file.\n",
+ "Audio(wav_data, rate=sample_rate)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "P9I290COsMBm"
+ },
+ "source": [
+ "The `wav_data` needs to be normalized to values in `[-1.0, 1.0]` (as stated in the model's [documentation](https://tfhub.dev/google/yamnet/1))."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "bKr78aCBsQo3"
+ },
+ "outputs": [],
+ "source": [
+ "waveform = wav_data / tf.int16.max"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "e_Xwd4GPuMsB"
+ },
+ "source": [
+ "## Executing the Model\n",
+ "\n",
+ "Now the easy part: using the data already prepared, you just call the model and get the: scores, embedding and the spectrogram.\n",
+ "\n",
+ "The score is the main result you will use.\n",
+ "The spectrogram you will use to do some visualizations later."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "BJGP6r-At_Jc"
+ },
+ "outputs": [],
+ "source": [
+ "# Run the model, check the output.\n",
+ "scores, embeddings, spectrogram = model(waveform)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Vmo7griQprDk"
+ },
+ "outputs": [],
+ "source": [
+ "scores_np = scores.numpy()\n",
+ "spectrogram_np = spectrogram.numpy()\n",
+ "infered_class = class_names[scores_np.mean(axis=0).argmax()]\n",
+ "print(f'The main sound is: {infered_class}')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Uj2xLf-P_ndS"
+ },
+ "source": [
+ "## Visualization\n",
+ "\n",
+ "YAMNet also returns some additional information that we can use for visualization.\n",
+ "Let's take a look on the Waveform, spectrogram and the top classes inferred."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "_QSTkmv7wr2M"
+ },
+ "outputs": [],
+ "source": [
+ "plt.figure(figsize=(10, 6))\n",
+ "\n",
+ "# Plot the waveform.\n",
+ "plt.subplot(3, 1, 1)\n",
+ "plt.plot(waveform)\n",
+ "plt.xlim([0, len(waveform)])\n",
+ "\n",
+ "# Plot the log-mel spectrogram (returned by the model).\n",
+ "plt.subplot(3, 1, 2)\n",
+ "plt.imshow(spectrogram_np.T, aspect='auto', interpolation='nearest', origin='lower')\n",
+ "\n",
+ "# Plot and label the model output scores for the top-scoring classes.\n",
+ "mean_scores = np.mean(scores, axis=0)\n",
+ "top_n = 10\n",
+ "top_class_indices = np.argsort(mean_scores)[::-1][:top_n]\n",
+ "plt.subplot(3, 1, 3)\n",
+ "plt.imshow(scores_np[:, top_class_indices].T, aspect='auto', interpolation='nearest', cmap='gray_r')\n",
+ "\n",
+ "# patch_padding = (PATCH_WINDOW_SECONDS / 2) / PATCH_HOP_SECONDS\n",
+ "# values from the model documentation\n",
+ "patch_padding = (0.025 / 2) / 0.01\n",
+ "plt.xlim([-patch_padding-0.5, scores.shape[0] + patch_padding-0.5])\n",
+ "# Label the top_N classes.\n",
+ "yticks = range(0, top_n, 1)\n",
+ "plt.yticks(yticks, [class_names[top_class_indices[x]] for x in yticks])\n",
+ "_ = plt.ylim(-0.5 + np.array([top_n, 0]))"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "collapsed_sections": [],
+ "name": "yamnet.ipynb",
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/site/en/install/_index.yaml b/site/en/install/_index.yaml
index 0946e24ef41..71bc660f81d 100644
--- a/site/en/install/_index.yaml
+++ b/site/en/install/_index.yaml
@@ -20,13 +20,14 @@ landing_page:
- - Python 3.6–3.9
+ - Python 3.9–3.12
- Ubuntu 16.04 or later
- Windows 7 or later (with C++ redistributable)
|
- macOS 10.12.6 (Sierra) or later (no GPU support)
+ - WSL2 via Windows 10 19044 or higher including GPUs (Experimental)
|
@@ -40,7 +41,6 @@ landing_page:
Install TensorFlow with Python's pip package manager.
Official packages available for Ubuntu, Windows, and macOS.
-
See the GPU guide for CUDA®-enabled cards.
buttons:
- label: Read the pip install guide
@@ -51,8 +51,10 @@ landing_page:
# Requires the latest pip
pip install --upgrade pip
- # Current stable release for CPU and GPU
+ # Current stable release for CPU
pip install tensorflow
+ # Current stable release for GPU (Linux / WSL2)
+ pip install tensorflow[and-cuda]
# Or try the preview build (unstable)
pip install tf-nightly
@@ -66,8 +68,7 @@ landing_page:
The TensorFlow
Docker images are already configured to run TensorFlow. A
Docker container runs in a
- virtual environment and is the easiest way to set up GPU
- support.
+ virtual environment and is the easiest way to set up GPU support.
docker pull tensorflow/tensorflow:latest # Download latest stable image
diff --git a/site/en/install/_toc.yaml b/site/en/install/_toc.yaml
index c8f60bde852..26cdb270bb8 100644
--- a/site/en/install/_toc.yaml
+++ b/site/en/install/_toc.yaml
@@ -7,8 +7,6 @@ toc:
- title: Docker
path: /install/docker
- heading: Additional setup
-- title: GPU support
- path: /install/gpu
- title: GPU device plugins
path: /install/gpu_plugins
- title: Problems
diff --git a/site/en/install/docker.md b/site/en/install/docker.md
index 30942924688..376ca0820a7 100644
--- a/site/en/install/docker.md
+++ b/site/en/install/docker.md
@@ -1,45 +1,43 @@
# Docker
-[Docker](https://docs.docker.com/install/){:.external} uses *containers* to
+[Docker](https://docs.docker.com/install/) uses *containers* to
create virtual environments that isolate a TensorFlow installation from the rest
of the system. TensorFlow programs are run *within* this virtual environment that
can share resources with its host machine (access directories, use the GPU,
connect to the Internet, etc.). The
-[TensorFlow Docker images](https://hub.docker.com/r/tensorflow/tensorflow/){:.external}
+[TensorFlow Docker images](https://hub.docker.com/r/tensorflow/tensorflow/)
are tested for each release.
-Docker is the easiest way to enable TensorFlow [GPU support](./gpu.md) on Linux since only the
-[NVIDIA® GPU driver](https://github.com/NVIDIA/nvidia-docker/wiki/Frequently-Asked-Questions#how-do-i-install-the-nvidia-driver){:.external}
+Docker is the easiest way to enable TensorFlow [GPU support](./pip.md) on Linux since only the
+[NVIDIA® GPU driver](https://github.com/NVIDIA/nvidia-docker/wiki/Frequently-Asked-Questions#how-do-i-install-the-nvidia-driver)
is required on the *host* machine (the *NVIDIA® CUDA® Toolkit* does not need to
be installed).
## TensorFlow Docker requirements
-1. [Install Docker](https://docs.docker.com/install/){:.external} on
+1. [Install Docker](https://docs.docker.com/install/) on
your local *host* machine.
-2. For GPU support on Linux, [install NVIDIA Docker support](https://github.com/NVIDIA/nvidia-docker){:.external}.
+2. For GPU support on Linux, [install NVIDIA Docker support](https://github.com/NVIDIA/nvidia-container-toolkit).
* Take note of your Docker version with `docker -v`. Versions __earlier than__ 19.03 require nvidia-docker2 and the `--runtime=nvidia` flag. On versions __including and after__ 19.03, you will use the `nvidia-container-toolkit` package and the `--gpus all` flag. Both options are documented on the page linked above.
Note: To run the `docker` command without `sudo`, create the `docker` group and
add your user. For details, see the
-[post-installation steps for Linux](https://docs.docker.com/install/linux/linux-postinstall/){:.external}.
+[post-installation steps for Linux](https://docs.docker.com/install/linux/linux-postinstall/).
## Download a TensorFlow Docker image
The official TensorFlow Docker images are located in the
-[tensorflow/tensorflow](https://hub.docker.com/r/tensorflow/tensorflow/){:.external}
-Docker Hub repository. Image releases [are tagged](https://hub.docker.com/r/tensorflow/tensorflow/tags/){:.external}
+[tensorflow/tensorflow](https://hub.docker.com/r/tensorflow/tensorflow/)
+Docker Hub repository. Image releases [are tagged](https://hub.docker.com/r/tensorflow/tensorflow/tags/)
using the following format:
| Tag | Description |
|-------------|----------------------------------------------------------------------------------------------------------------------|
| `latest` | The latest release of TensorFlow CPU binary image. Default. |
| `nightly` | Nightly builds of the TensorFlow image. (Unstable.) |
-| *`version`* | Specify the *version* of the TensorFlow binary image, for example\: *2.1.0* |
-| `devel` | Nightly builds of a TensorFlow `master` development environment. Includes TensorFlow source code. |
-| `custom-op` | Special experimental image for developing TF custom ops. More info [here](https://github.com/tensorflow/custom-op). |
+| *`version`* | Specify the *version* of the TensorFlow binary image, for example\: *2.8.3* |
Each base *tag* has variants that add or change functionality:
@@ -66,7 +64,7 @@ To start a TensorFlow-configured container, use the following command form:
docker run [-it] [--rm] [-p hostPort:containerPort] tensorflow/tensorflow[:tag] [command]
-For details, see the [docker run reference](https://docs.docker.com/engine/reference/run/){:.external}.
+For details, see the [docker run reference](https://docs.docker.com/engine/reference/run/).
### Examples using CPU-only images
@@ -100,7 +98,7 @@ docker run -it --rm -v $PWD:/tmp -w /tmp tensorflow/tensorflow python ./script.p
Permission issues can arise when files created within a container are exposed to
the host. It's usually best to edit files on the host system.
-Start a [Jupyter Notebook](https://jupyter.org/){:.external} server using
+Start a [Jupyter Notebook](https://jupyter.org/) server using
TensorFlow's nightly build:
@@ -114,13 +112,13 @@ Follow the instructions and open the URL in your host web browser:
## GPU support
Docker is the easiest way to run TensorFlow on a GPU since the *host* machine
-only requires the [NVIDIA® driver](https://github.com/NVIDIA/nvidia-docker/wiki/Frequently-Asked-Questions#how-do-i-install-the-nvidia-driver){:.external}
+only requires the [NVIDIA® driver](https://github.com/NVIDIA/nvidia-docker/wiki/Frequently-Asked-Questions#how-do-i-install-the-nvidia-driver)
(the *NVIDIA® CUDA® Toolkit* is not required).
-Install the [Nvidia Container Toolkit](https://github.com/NVIDIA/nvidia-docker/blob/master/README.md#quickstart){:.external}
+Install the [Nvidia Container Toolkit](https://github.com/NVIDIA/nvidia-docker/blob/master/README.md#quickstart)
to add NVIDIA® GPU support to Docker. `nvidia-container-runtime` is only
available for Linux. See the `nvidia-container-runtime`
-[platform support FAQ](https://github.com/NVIDIA/nvidia-docker/wiki/Frequently-Asked-Questions#platform-support){:.external}
+[platform support FAQ](https://github.com/NVIDIA/nvidia-docker/wiki/Frequently-Asked-Questions#platform-support)
for details.
Check if a GPU is available:
@@ -132,7 +130,7 @@ lspci | grep -i nvidia
Verify your `nvidia-docker` installation:
-docker run --gpus all --rm nvidia/cuda nvidia-smi
+docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
Note: `nvidia-docker` v2 uses `--runtime=nvidia` instead of `--gpus all`. `nvidia-docker` v1 uses the `nvidia-docker` alias,
diff --git a/site/en/install/errors.md b/site/en/install/errors.md
index 0d52c00f898..938ba8b454f 100644
--- a/site/en/install/errors.md
+++ b/site/en/install/errors.md
@@ -1,8 +1,9 @@
# Build and install error messages
-TensorFlow uses [GitHub issues](https://github.com/tensorflow/tensorflow/issues){:.external}
-and [Stack Overflow](https://stackoverflow.com/questions/tagged/tensorflow){:.external}
-to track and document build and installation problems.
+TensorFlow uses [GitHub issues](https://github.com/tensorflow/tensorflow/issues),
+[Stack Overflow](https://stackoverflow.com/questions/tagged/tensorflow) and
+[TensorFlow Forum](https://discuss.tensorflow.org/c/general-discussion/6)
+to track, document, and discuss build and installation problems.
The following list links error messages to a solution or discussion. If you find
an installation or build problem that is not listed, please search the GitHub
@@ -13,10 +14,10 @@ question on Stack Overflow with the `tensorflow` tag.
| GitHub issue or Stack Overflow | Error Message |
|---|
| 38896424
31058 |
- "No matching distribution found for tensorflow":
+ | "No matching distribution found for tensorflow":
Pip can't find a TensorFlow package compatible with your system. Check the
system requirements and
- python version
+ Python version
|
@@ -43,12 +44,12 @@ unzip: cannot find zipfile directory in one of ./bazel-bin/tensorflow/tools/pip_
No such file or directory
- | 36371137 and
- here |
+ 36371137 |
libprotobuf ERROR google/protobuf/src/google/protobuf/io/coded_stream.cc:207] A
protocol message was rejected because it was too big (more than 67108864 bytes).
To increase the limit (or to disable these warnings), see
- CodedInputStream::SetTotalBytesLimit() in google/protobuf/io/coded_stream.h. |
+
+CodedInputStream::SetTotalBytesLimit() in google/protobuf/io/coded_stream.h.
| 35252888 |
@@ -60,7 +61,7 @@ unzip: cannot find zipfile directory in one of ./bazel-bin/tensorflow/tools/pip_
| 33623453 |
IOError: [Errno 2] No such file or directory:
- '/tmp/pip-o6Tpui-build/setup.py'
+ '/tmp/pip-o6Tpui-build/setup.py' |
| 42006320 |
@@ -111,7 +112,7 @@ ImportError: cannot import name 'descriptor'
| 33623453 |
IOError: [Errno 2] No such file or directory:
- '/tmp/pip-o6Tpui-build/setup.py'
+ '/tmp/pip-o6Tpui-build/setup.py' |
| 35190574 |
@@ -226,7 +227,7 @@ ImportError: cannot import name 'descriptor'
| 33623453 |
IOError: [Errno 2] No such file or directory:
- '/tmp/pip-o6Tpui-build/setup.py'
+ '/tmp/pip-o6Tpui-build/setup.py' |
| 35190574 |
diff --git a/site/en/install/gpu.md b/site/en/install/gpu.md
deleted file mode 100644
index 2879873189d..00000000000
--- a/site/en/install/gpu.md
+++ /dev/null
@@ -1,188 +0,0 @@
-# GPU support
-
-Note: GPU support is available for Ubuntu and Windows with CUDA®-enabled cards.
-
-TensorFlow GPU support requires an assortment of drivers and libraries. To
-simplify installation and avoid library conflicts, we recommend using a
-[TensorFlow Docker image with GPU support](./docker.md) (Linux only). This setup
-only requires the [NVIDIA® GPU drivers](https://www.nvidia.com/drivers){:.external}.
-
-These install instructions are for the latest release of TensorFlow. See the
-[tested build configurations](./source.md#gpu) for CUDA® and cuDNN versions to
-use with older TensorFlow releases.
-
-## Pip package
-
-See the [pip install guide](./pip) for available packages, systems requirements,
-and instructions. The TensorFlow `pip` package includes GPU support for
-CUDA®-enabled cards:
-
-
-pip install tensorflow
-
-
-This guide covers GPU support and installation steps for the latest *stable*
-TensorFlow release.
-
-### Older versions of TensorFlow
-
-For releases 1.15 and older, CPU and GPU packages are separate:
-
-
-pip install tensorflow==1.15 # CPU
-pip install tensorflow-gpu==1.15 # GPU
-
-
-## Hardware requirements
-
-The following GPU-enabled devices are supported:
-
-* NVIDIA® GPU card with CUDA® architectures 3.5, 5.0, 6.0, 7.0, 7.5, 8.0 and
- higher than 8.0. See the list of
- CUDA®-enabled
- GPU cards.
-* For GPUs with unsupported CUDA® architectures, or to avoid JIT compilation
- from PTX, or to use different versions of the NVIDIA® libraries, see the
- [Linux build from source](./source.md) guide.
-* Packages do not contain PTX code except for the latest supported CUDA®
- architecture; therefore, TensorFlow fails to load on older GPUs when
- `CUDA_FORCE_PTX_JIT=1` is set. (See
- Application
- Compatibility for details.)
-
-Note: The error message "Status: device kernel image is invalid" indicates that
-the TensorFlow package does not contain PTX for your architecture. You can
-enable compute capabilities by [building TensorFlow from source](./source.md).
-
-## Software requirements
-
-The following NVIDIA® software must be installed on your system:
-
-* [NVIDIA® GPU drivers](https://www.nvidia.com/drivers){:.external} —CUDA®
- 11.2 requires 450.80.02 or higher.
-* [CUDA® Toolkit](https://developer.nvidia.com/cuda-toolkit-archive){:.external}
- —TensorFlow supports CUDA® 11.2 (TensorFlow >= 2.5.0)
-* [CUPTI](http://docs.nvidia.com/cuda/cupti/){:.external} ships with the CUDA®
- Toolkit.
-* [cuDNN SDK 8.1.0](https://developer.nvidia.com/cudnn){:.external}
- [cuDNN versions](https://developer.nvidia.com/rdp/cudnn-archive){:.external}).
-* *(Optional)*
- [TensorRT 6.0](https://docs.nvidia.com/deeplearning/tensorrt/archives/index.html#trt_6){:.external}
- to improve latency and throughput for inference on some models.
-
-## Linux setup
-
-The `apt` instructions below are the easiest way to install the required NVIDIA
-software on Ubuntu. However, if [building TensorFlow from source](./source.md),
-manually install the software requirements listed above, and consider using a
-`-devel` [TensorFlow Docker image](./docker.md) as a base.
-
-Install [CUPTI](http://docs.nvidia.com/cuda/cupti/){:.external} which ships with
-the CUDA® Toolkit. Append its installation directory to the `$LD_LIBRARY_PATH`
-environmental variable:
-
-
-export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/extras/CUPTI/lib64
-
-
-### Install CUDA with apt
-
-This section shows how to install CUDA® 11 (TensorFlow >= 2.4.0) on Ubuntu
-16.04 and 18.04. These instructions may work for other Debian-based distros.
-
-Caution: [Secure Boot](https://wiki.ubuntu.com/UEFI/SecureBoot){:.external}
-complicates installation of the NVIDIA driver and is beyond the scope of these instructions.
-
-
-#### Ubuntu 18.04 (CUDA 11.0)
-
-
-# Add NVIDIA package repositories
-wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-ubuntu1804.pin
-sudo mv cuda-ubuntu1804.pin /etc/apt/preferences.d/cuda-repository-pin-600
-sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub
-sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/ /"
-sudo apt-get update
-
-wget http://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/nvidia-machine-learning-repo-ubuntu1804_1.0.0-1_amd64.deb
-
-sudo apt install ./nvidia-machine-learning-repo-ubuntu1804_1.0.0-1_amd64.deb
-sudo apt-get update
-
-wget https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/libnvinfer7_7.1.3-1+cuda11.0_amd64.deb
-sudo apt install ./libnvinfer7_7.1.3-1+cuda11.0_amd64.deb
-sudo apt-get update
-
-# Install development and runtime libraries (~4GB)
-sudo apt-get install --no-install-recommends \
- cuda-11-0 \
- libcudnn8=8.0.4.30-1+cuda11.0 \
- libcudnn8-dev=8.0.4.30-1+cuda11.0
-
-# Reboot. Check that GPUs are visible using the command: nvidia-smi
-
-# Install TensorRT. Requires that libcudnn8 is installed above.
-sudo apt-get install -y --no-install-recommends libnvinfer7=7.1.3-1+cuda11.0 \
- libnvinfer-dev=7.1.3-1+cuda11.0 \
- libnvinfer-plugin7=7.1.3-1+cuda11.0
-
-
-
-#### Ubuntu 16.04 (CUDA 11.0)
-
-
-# Add NVIDIA package repositories
-# Add HTTPS support for apt-key
-sudo apt-get install gnupg-curl
-wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-ubuntu1604.pin
-sudo mv cuda-ubuntu1604.pin /etc/apt/preferences.d/cuda-repository-pin-600
-sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/7fa2af80.pub
-sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/ /"
-sudo apt-get update
-wget https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1604/x86_64/nvidia-machine-learning-repo-ubuntu1604_1.0.0-1_amd64.deb
-sudo apt install ./nvidia-machine-learning-repo-ubuntu1604_1.0.0-1_amd64.deb
-sudo apt-get update
-wget https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1604/x86_64/libnvinfer7_7.1.3-1+cuda11.0_amd64.deb
-sudo apt install ./libnvinfer7_7.1.3-1+cuda11.0_amd64.deb
-sudo apt-get update
-
-# Install development and runtime libraries (~4GB)
-sudo apt-get install --no-install-recommends \
- cuda-11-0 \
- libcudnn8=8.0.4.30-1+cuda11.0 \
- libcudnn8-dev=8.0.4.30-1+cuda11.0
-
-
-# Reboot. Check that GPUs are visible using the command: nvidia-smi
-
-# Install TensorRT. Requires that libcudnn7 is installed above.
-sudo apt-get install -y --no-install-recommends \
- libnvinfer7=7.1.3-1+cuda11.0 \
- libnvinfer-dev=7.1.3-1+cuda11.0 \
- libnvinfer-plugin7=7.1.3-1+cuda11.0 \
- libnvinfer-plugin-dev=7.1.3-1+cuda11.0
-
-
-
-
-## Windows setup
-
-See the [hardware requirements](#hardware_requirements) and
-[software requirements](#software_requirements) listed above. Read the
-[CUDA® install guide for Windows](https://docs.nvidia.com/cuda/cuda-installation-guide-microsoft-windows/){:.external}.
-
-Make sure the installed NVIDIA software packages match the versions listed above. In
-particular, TensorFlow will not load without the `cuDNN64_8.dll` file. To use a
-different version, see the [Windows build from source](./source_windows.md) guide.
-
-Add the CUDA®, CUPTI, and cuDNN installation directories to the `%PATH%`
-environmental variable. For example, if the CUDA® Toolkit is installed to
-`C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0` and cuDNN to
-`C:\tools\cuda`, update your `%PATH%` to match:
-
-
-SET PATH=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\bin;%PATH%
-SET PATH=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\extras\CUPTI\lib64;%PATH%
-SET PATH=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\include;%PATH%
-SET PATH=C:\tools\cuda\bin;%PATH%
-
diff --git a/site/en/install/gpu_plugins.md b/site/en/install/gpu_plugins.md
index 358db01b312..39e3cf09b29 100644
--- a/site/en/install/gpu_plugins.md
+++ b/site/en/install/gpu_plugins.md
@@ -1,12 +1,12 @@
# GPU device plugins
-Note: This page is for non-NVIDIA® GPU devices. For NVIDIA® GPU support, click
-[here](./gpu.md).
+Note: This page is for non-NVIDIA® GPU devices. For NVIDIA® GPU support, go to
+the [Install TensorFlow with pip](./pip.md) guide.
TensorFlow's
-pluggable
-device architecture adds new device support as separate plug-in packages
-that are installed alongside the official TensorFlow package.
+[pluggable device](https://github.com/tensorflow/community/blob/master/rfcs/20200624-pluggable-device-for-tensorflow.md)
+architecture adds new device support as separate plug-in packages that are
+installed alongside the official TensorFlow package.
The mechanism requires no device-specific changes in the TensorFlow code. It
relies on C APIs to communicate with the TensorFlow binary in a stable manner.
@@ -57,6 +57,24 @@ run() # PluggableDevices also work with tf.function and graph mode.
Metal `PluggableDevice` for macOS GPUs:
-* [Getting started guide](https://developer.apple.com/metal/tensorflow-plugin/){:.external}.
+* Works with TF 2.5 or later.
+* [Getting started guide](https://developer.apple.com/metal/tensorflow-plugin/).
* For questions and feedback, please visit the
- [Apple Developer Forum](https://developer.apple.com/forums/tags/tensorflow-metal){:.external}.
+ [Apple Developer Forum](https://developer.apple.com/forums/tags/tensorflow-metal).
+
+DirectML `PluggableDevice` for Windows and WSL (preview):
+
+* Works with `tensorflow-cpu` package, version 2.10 or later.
+* [PyPI wheel](https://pypi.org/project/tensorflow-directml-plugin/).
+* [GitHub repo](https://github.com/microsoft/tensorflow-directml-plugin).
+* For questions, feedback or to raise issues, please visit the
+ [Issues page of `tensorflow-directml-plugin` on GitHub](https://github.com/microsoft/tensorflow-directml-plugin/issues).
+
+Intel® Extension for TensorFlow `PluggableDevice` for Linux and WSL:
+
+* Works with TF 2.10 or later.
+* [Getting started guide](https://intel.github.io/intel-extension-for-tensorflow/latest/get_started.html)
+* [PyPI wheel](https://pypi.org/project/intel-extension-for-tensorflow/).
+* [GitHub repo](https://github.com/intel/intel-extension-for-tensorflow).
+* For questions, feedback, or to raise issues, please visit the
+ [Issues page of `intel-extension-for-tensorflow` on GitHub](https://github.com/intel/intel-extension-for-tensorflow/issues).
diff --git a/site/en/install/lang_c.ipynb b/site/en/install/lang_c.ipynb
new file mode 100644
index 00000000000..788a5e6c891
--- /dev/null
+++ b/site/en/install/lang_c.ipynb
@@ -0,0 +1,383 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Tce3stUlHN0L"
+ },
+ "source": [
+ "##### Copyright 2018 The TensorFlow Authors.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "tuOe1ymfHZPu"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n",
+ "# you may not use this file except in compliance with the License.\n",
+ "# You may obtain a copy of the License at\n",
+ "#\n",
+ "# https://www.apache.org/licenses/LICENSE-2.0\n",
+ "#\n",
+ "# Unless required by applicable law or agreed to in writing, software\n",
+ "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
+ "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
+ "# See the License for the specific language governing permissions and\n",
+ "# limitations under the License."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "s7Bo2MipUnXX"
+ },
+ "source": [
+ "# Install TensorFlow for C"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Birwb-khUOIq"
+ },
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "kFmEkitOFJSw"
+ },
+ "source": [
+ "TensorFlow provides a C API that can be used to build\n",
+ "[bindings for other languages](https://github.com/tensorflow/docs/tree/master/site/en/r1/guide/extend/bindings.md).\n",
+ "The API is defined in\n",
+ "c_api.h\n",
+ "and designed for simplicity and uniformity rather than convenience.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Vk--31hqIwSV"
+ },
+ "source": [
+ "## Nightly libtensorflow C packages\n",
+ "\n",
+ "libtensorflow packages are built nightly and uploaded to GCS for all supported\n",
+ "platforms. They are uploaded to the\n",
+ "[libtensorflow-nightly GCS bucket](https://storage.googleapis.com/libtensorflow-nightly)\n",
+ "and are indexed by operating system and date built. For MacOS and Linux shared\n",
+ "objects, there is a\n",
+ "[script](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/tools/ci_build/builds/libtensorflow_nightly_symlink.sh)\n",
+ "that renames the `.so` files versioned to the current date copied into the\n",
+ "directory with the artifacts."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "qowtdsijFMYZ"
+ },
+ "source": [
+ "## Supported Platforms\n",
+ "\n",
+ "TensorFlow for C is supported on the following systems:\n",
+ "\n",
+ "* Linux, 64-bit, x86\n",
+ "* macOS, Version 10.12.6 (Sierra) or higher\n",
+ "* Windows, 64-bit x86"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "hnhAk8y-FSBN"
+ },
+ "source": [
+ "## Setup"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "y50y01XUFVb2"
+ },
+ "source": [
+ "### Download and extract\n",
+ "\n",
+ "\n",
+ " | TensorFlow C library | URL |
|---|
\n",
+ " | Linux\n",
+ " \n",
+ " |
\n",
+ " \n",
+ " | Linux CPU only | \n",
+ " https://storage.googleapis.com/tensorflow/versions/2.18.0/libtensorflow-cpu-linux-x86_64.tar.gz | \n",
+ "
\n",
+ " \n",
+ " | Linux GPU support | \n",
+ " https://storage.googleapis.com/tensorflow/versions/2.18.0/libtensorflow-gpu-linux-x86_64.tar.gz | \n",
+ "
\n",
+ " | macOS\n",
+ " \n",
+ " |
\n",
+ " \n",
+ " | macOS CPU only | \n",
+ " https://storage.googleapis.com/tensorflow/versions/2.16.2/libtensorflow-cpu-darwin-x86_64.tar.gz | \n",
+ "
\n",
+ " macOS ARM64 CPU only | \n",
+ " https://storage.googleapis.com/tensorflow/versions/2.18.0/libtensorflow-cpu-darwin-arm64.tar.gz | \n",
+ " \n",
+ " | Windows\n",
+ " \n",
+ " |
\n",
+ " \n",
+ " | Windows CPU only | \n",
+ " https://storage.googleapis.com/tensorflow/versions/2.18.1/libtensorflow-cpu-windows-x86_64.zip | \n",
+ "
\n",
+ " \n",
+ " | Windows GPU only | \n",
+ " https://storage.googleapis.com/tensorflow/libtensorflow/libtensorflow-gpu-windows-x86_64-2.10.0.zip | \n",
+ "
\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "b4kWu6k0FaT9"
+ },
+ "source": [
+ "Extract the downloaded archive, which contains the header files to include in\n",
+ "your C program and the shared libraries to link against.\n",
+ "\n",
+ "On Linux and macOS, you may want to extract to `/usr/local/lib`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "DrjVyjVJFcon"
+ },
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "FILENAME=libtensorflow-cpu-linux-x86_64.tar.gz\n",
+ "wget -q --no-check-certificate https://storage.googleapis.com/tensorflow/versions/2.18.1/${FILENAME}\n",
+ "sudo tar -C /usr/local -xzf ${FILENAME}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "fcBJDdojJDyk"
+ },
+ "source": [
+ "### Linker\n",
+ "\n",
+ "On Linux/macOS, if you extract the TensorFlow C library to a system directory,\n",
+ "such as `/usr/local`, configure the linker with `ldconfig`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "h0STAG82JDZs"
+ },
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "sudo ldconfig /usr/local/lib"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ix4HdnNGH6aF"
+ },
+ "source": [
+ "If you extract the TensorFlow C library to a non-system directory, such as\n",
+ "`~/mydir`, then configure the linker environmental variables:"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "E6E99eJzIJQs"
+ },
+ "source": [
+ "\n",
+ "
\n",
+ "Linux
\n",
+ "\n",
+ "export LIBRARY_PATH=$LIBRARY_PATH:~/mydir/lib\n",
+ "export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/mydir/lib\n",
+ "
\n",
+ "\n",
+ "
\n",
+ "macOS
\n",
+ "\n",
+ "export LIBRARY_PATH=$LIBRARY_PATH:~/mydir/lib\n",
+ "export DYLD_LIBRARY_PATH=$DYLD_LIBRARY_PATH:~/mydir/lib\n",
+ "
\n",
+ "\n",
+ "
c_api.h
-and designed for simplicity and uniformity rather than convenience.
-
-## Nightly Libtensorflow C packages
-
-Libtensorflow packages are built nightly and uploaded to GCS for all supported
-platforms. They are uploaded to the
-[libtensorflow-nightly GCS bucket](https://storage.googleapis.com/libtensorflow-nightly)
-and are indexed by operating system and date built. For MacOS and Linux shared
-objects, we have a
-[script](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/tools/ci_build/builds/libtensorflow_nightly_symlink.sh)
-that renames the .so files versioned to the current date copied into the
-directory with the artifacts.
-
-## Supported Platforms
-
-TensorFlow for C is supported on the following systems:
-
-* Linux, 64-bit, x86
-* macOS, Version 10.12.6 (Sierra) or higher
-* Windows, 64-bit x86
-
-## Setup
-
-### Download
-
-
-
-### Extract
-
-Extract the downloaded archive, which contains the header files to include in
-your C program and the shared libraries to link against.
-
-On Linux and macOS, you may want to extract to `/usr/local/lib`:
-
-
-sudo tar -C /usr/local -xzf (downloaded file)
-
-
-### Linker
-
-On Linux/macOS, if you extract the TensorFlow C library to a system directory,
-such as `/usr/local`, configure the linker with `ldconfig`:
-
-
-sudo ldconfig
-
-
-If you extract the TensorFlow C library to a non-system directory, such as
-`~/mydir`, then configure the linker environmental variables:
-
-
-
-Linux
-
-export LIBRARY_PATH=$LIBRARY_PATH:~/mydir/lib
-export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/mydir/lib
-
-
-
-macOS
-
-export LIBRARY_PATH=$LIBRARY_PATH:~/mydir/lib
-export DYLD_LIBRARY_PATH=$DYLD_LIBRARY_PATH:~/mydir/lib
-
-
-
-gcc hello_tf.c -ltensorflow -o hello_tf
-
-./hello_tf
-
-
-The command outputs: Hello from TensorFlow C library version number
-
-Success: The TensorFlow C library is configured.
-
-If the program doesn't build, make sure that `gcc` can access the TensorFlow C
-library. If extracted to `/usr/local`, explicitly pass the library location to
-the compiler:
-
-
-gcc -I/usr/local/include -L/usr/local/lib hello_tf.c -ltensorflow -o hello_tf
-
-
-
-## Build from source
-
-TensorFlow is open source. Read
-[the instructions](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/tools/lib_package/README.md){:.external}
-to build TensorFlow's C library from source code.
diff --git a/site/en/install/lang_java_legacy.md b/site/en/install/lang_java_legacy.md
index af177dc0950..37341c36659 100644
--- a/site/en/install/lang_java_legacy.md
+++ b/site/en/install/lang_java_legacy.md
@@ -1,7 +1,7 @@
# Install TensorFlow for Java
Warning: TensorFlow for Java is deprecated and will be removed in a future
-version of TensorFlow once the replacement is stable.
+version of TensorFlow once [the replacement](https://www.tensorflow.org/jvm) is stable.
TensorFlow provides a
[Java API](https://www.tensorflow.org/api_docs/java/reference/org/tensorflow/package-summary)—
@@ -27,7 +27,7 @@ To use TensorFlow on Android see [TensorFlow Lite](https://tensorflow.org/lite)
## TensorFlow with Apache Maven
-To use TensorFlow with [Apache Maven](https://maven.apache.org){:.external},
+To use TensorFlow with [Apache Maven](https://maven.apache.org),
add the dependency to the project's `pom.xml` file:
```xml
@@ -40,7 +40,7 @@ add the dependency to the project's `pom.xml` file:
### GPU support
-If your system has [GPU support](./gpu.md), add the following TensorFlow
+If your system has [GPU support](./pip.md), add the following TensorFlow
dependencies to the project's `pom.xml` file:
```xml
@@ -167,11 +167,11 @@ system and processor support:
Note: On Windows, the native library (`tensorflow_jni.dll`) requires
`msvcp140.dll` at runtime. See the
[Windows build from source](./source_windows.md) guide to install the
-[Visual C++ 2019 Redistributable](https://visualstudio.microsoft.com/vs/){:.external}.
+[Visual C++ 2019 Redistributable](https://visualstudio.microsoft.com/vs/).
### Compile
-Using the `HelloTensorFlow.java` file from the [previous example](#example),
+Using the `HelloTensorFlow.java` file from the [previous example](#example-program),
compile a program that uses TensorFlow. Make sure the `libtensorflow.jar` is
accessible to your `classpath`:
@@ -203,5 +203,5 @@ Success: TensorFlow for Java is configured.
## Build from source
TensorFlow is open source. Read
-[the instructions](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/java/README.md){:.external}
+[the instructions](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/java/README.md)
to build TensorFlow's Java and native libraries from source code.
diff --git a/site/en/install/pip.html b/site/en/install/pip.html
deleted file mode 100644
index 3bd415aad9c..00000000000
--- a/site/en/install/pip.html
+++ /dev/null
@@ -1,350 +0,0 @@
-
-
- Install TensorFlow with pip
-
-
-
-
-
-
-TensorFlow 2 packages are available
-
- tensorflow —Latest stable release with CPU and GPU support (Ubuntu and Windows)tf-nightly —Preview build (unstable). Ubuntu and Windows include GPU support.
-
-
-Older versions of TensorFlow
-
-For TensorFlow 1.x, CPU and GPU packages are separate:
-
-
- tensorflow==1.15 —Release for CPU-onlytensorflow-gpu==1.15 —Release with GPU support (Ubuntu and Windows)
-
-
-System requirements
-
- - Python 3.6–3.9
-
- - Python 3.9 support requires TensorFlow 2.5 or later.
- - Python 3.8 support requires TensorFlow 2.2 or later.
-
-
- - pip 19.0 or later (requires
manylinux2010 support)
- - Ubuntu 16.04 or later (64-bit)
- - macOS 10.12.6 (Sierra) or later (64-bit) (no GPU support)
-
- - macOS requires pip 20.3 or later
-
-
- - Windows 7 or later (64-bit)
-
-
- - GPU support requires a CUDA®-enabled card (Ubuntu and Windows)
-
-
-
-
-Hardware requirements
-
- - Starting with TensorFlow 1.6, binaries use AVX instructions which may not run on older CPUs.
- - Read the GPU support guide to set up a CUDA®-enabled GPU card on Ubuntu or Windows.
-
-
-
-1. Install the Python development environment on your system
-
-
- Check if your Python environment is already configured:
-
-
-
-
-
-python3 --version
-pip3 --version
-
-
-
- If these packages are already installed, skip to the next step.
- Otherwise, install Python, the
- pip package manager,
- and venv:
-
-
-
-
-Ubuntu
-
-sudo apt update
-sudo apt install python3-dev python3-pip python3-venv
-
-
-
-
-macOS
-Install using the Homebrew package manager:
-
-/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
-export PATH="/usr/local/opt/python/libexec/bin:$PATH"
-# if you are on macOS 10.12 (Sierra) use `export PATH="/usr/local/bin:/usr/local/sbin:$PATH"`
-brew update
-brew install python # Python 3
-
-
-
-
-Windows
-
- Install the Microsoft Visual C++ Redistributable for Visual Studio 2015, 2017,
- and 2019. Starting with the TensorFlow 2.1.0 version, the msvcp140_1.dll
- file is required from this package (which may not be provided from older redistributable packages).
- The redistributable comes with Visual Studio 2019 but can be installed separately:
-
-
-- Go to the Microsoft Visual C++ downloads,
-- Scroll down the page to the Visual Studio 2015, 2017 and 2019 section.
-- Download and install the Microsoft Visual C++ Redistributable for Visual Studio 2015, 2017 and 2019 for your platform.
-
-Make sure long paths are enabled on Windows.
-Install the 64-bit Python 3 release for Windows (select pip as an optional feature).
-
-
-
-Other
-
-curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
-python get-pip.py
-
-
-
2. Create a virtual environment (recommended)
-
-
- Python virtual environments are used to isolate package installation from the system.
-
-
-
-
-Ubuntu / macOS
-
- Create a new virtual environment by choosing a Python interpreter and making a
- ./venv directory to hold it:
-
-python3 -m venv --system-site-packages ./venv
-
- Activate the virtual environment using a shell-specific command:
-
-source ./venv/bin/activate # sh, bash, or zsh
-. ./venv/bin/activate.fish # fish
-source ./venv/bin/activate.csh # csh or tcsh
-
-
- When the virtual environment is active, your shell prompt is prefixed with (venv).
-
-
- Install packages within a virtual environment without affecting the host system
- setup. Start by upgrading pip:
-
-
-pip install --upgrade pip
-
-pip list # show packages installed within the virtual environment
-
-
- And to exit the virtual environment later:
-
-deactivate # don't exit until you're done using TensorFlow
-
-
-
-
- Windows
-
- Create a new virtual environment by choosing a Python interpreter and making a
- .\venv directory to hold it:
-
-python -m venv --system-site-packages .\venv
-
- Activate the virtual environment:
-
-.\venv\Scripts\activate
-
- Install packages within a virtual environment without affecting the host system
- setup. Start by upgrading pip:
-
-
-pip install --upgrade pip
-
-pip list # show packages installed within the virtual environment
-
-
- And to exit the virtual environment later:
-
-deactivate # don't exit until you're done using TensorFlow
-
-
-
-
-
3. Install the TensorFlow pip package
-
-
- Choose one of the following TensorFlow packages to install from PyPI:
-
-
-
- tensorflow —Latest stable release with CPU and GPU support (Ubuntu and Windows).tf-nightly —Preview build (unstable). Ubuntu and Windows include GPU support.tensorflow==1.15 —The final version of TensorFlow 1.x.
-
-
-
-
-
-Virtual environment install
-pip install --upgrade tensorflow
-Verify the install:
-python -c "import tensorflow as tf;print(tf.reduce_sum(tf.random.normal([1000, 1000])))"
-
-
-
-System install
-pip3 install --user --upgrade tensorflow # install in $HOME
-Verify the install:
-python3 -c "import tensorflow as tf; print(tf.reduce_sum(tf.random.normal([1000, 1000])))"
-
-
Package location
-
-
- A few installation mechanisms require the URL of the TensorFlow Python package.
- The value you specify depends on your Python version.
-
-
-
-
- | Version | URL |
|---|
- | Linux |
-
- | Python 3.6 GPU support |
- https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-2.6.0-cp36-cp36m-manylinux2010_x86_64.whl |
-
-
- | Python 3.6 CPU-only |
- https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow_cpu-2.6.0-cp36-cp36m-manylinux2010_x86_64.whl |
-
-
- | Python 3.7 GPU support |
- https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-2.6.0-cp37-cp37m-manylinux2010_x86_64.whl |
-
-
- | Python 3.7 CPU-only |
- https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow_cpu-2.6.0-cp37-cp37m-manylinux2010_x86_64.whl |
-
-
- | Python 3.8 GPU support |
- https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-2.6.0-cp38-cp38-manylinux2010_x86_64.whl |
-
-
- | Python 3.8 CPU-only |
- https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow_cpu-2.6.0-cp38-cp38-manylinux2010_x86_64.whl |
-
-
- | Python 3.9 GPU support |
- https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-2.6.0-cp39-cp39-manylinux2010_x86_64.whl |
-
-
- | Python 3.9 CPU-only |
- https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow_cpu-2.6.0-cp39-cp39-manylinux2010_x86_64.whl |
-
-
- | macOS (CPU-only) |
-
- | Python 3.6 |
- https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-2.6.0-cp36-cp36m-macosx_10_11_x86_64.whl |
-
-
- | Python 3.7 |
- https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-2.6.0-cp37-cp37m-macosx_10_11_x86_64.whl |
-
-
- | Python 3.8 |
- https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-2.6.0-cp38-cp38-macosx_10_11_x86_64.whl |
-
-
- | Python 3.9 |
- https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-2.6.0-cp39-cp39-macosx_10_11_x86_64.whl |
-
-
- | Windows |
-
- | Python 3.6 GPU support |
- https://storage.googleapis.com/tensorflow/windows/gpu/tensorflow_gpu-2.6.0-cp36-cp36m-win_amd64.whl |
-
-
- | Python 3.6 CPU-only |
- https://storage.googleapis.com/tensorflow/windows/cpu/tensorflow_cpu-2.6.0-cp36-cp36m-win_amd64.whl |
-
-
- | Python 3.7 GPU support |
- https://storage.googleapis.com/tensorflow/windows/gpu/tensorflow_gpu-2.6.0-cp37-cp37m-win_amd64.whl |
-
-
- | Python 3.7 CPU-only |
- https://storage.googleapis.com/tensorflow/windows/cpu/tensorflow_cpu-2.6.0-cp37-cp37m-win_amd64.whl |
-
-
- | Python 3.8 GPU support |
- https://storage.googleapis.com/tensorflow/windows/gpu/tensorflow_gpu-2.6.0-cp38-cp38-win_amd64.whl |
-
-
- | Python 3.8 CPU-only |
- https://storage.googleapis.com/tensorflow/windows/cpu/tensorflow_cpu-2.6.0-cp38-cp38-win_amd64.whl |
-
-
- | Python 3.9 GPU support |
- https://storage.googleapis.com/tensorflow/windows/gpu/tensorflow_gpu-2.6.0-cp39-cp39-win_amd64.whl |
-
-
- | Python 3.9 CPU-only |
- https://storage.googleapis.com/tensorflow/windows/cpu/tensorflow_cpu-2.6.0-cp39-cp39-win_amd64.whl |
-
-
-
-
-
-
diff --git a/site/en/install/pip.md b/site/en/install/pip.md
new file mode 100644
index 00000000000..a9e4bf4bf74
--- /dev/null
+++ b/site/en/install/pip.md
@@ -0,0 +1,658 @@
+
+# Install TensorFlow with pip
+
+
+This guide is for the latest stable version of TensorFlow. For the
+preview build *(nightly)*, use the pip package named
+`tf-nightly`. Refer to [these tables](./source#tested_build_configurations) for
+older TensorFlow version requirements. For the CPU-only build, use the pip
+package named `tensorflow-cpu`.
+
+Here are the quick versions of the install commands. Scroll down for the
+step-by-step instructions.
+
+* {Linux}
+
+ Note: Starting with TensorFlow `2.10`, Linux CPU-builds for Aarch64/ARM64
+ processors are built, maintained, tested and released by a third party:
+ [AWS](https://aws.amazon.com/).
+ Installing the [`tensorflow`](https://pypi.org/project/tensorflow/)
+ package on an ARM machine installs AWS's
+ [`tensorflow-cpu-aws`](https://pypi.org/project/tensorflow-cpu-aws/) package.
+ They are provided as-is. Tensorflow will use reasonable efforts to maintain
+ the availability and integrity of this pip package. There may be delays if
+ the third party fails to release the pip package. See
+ [this blog post](https://blog.tensorflow.org/2022/09/announcing-tensorflow-official-build-collaborators.html)
+ for more information about this collaboration.
+
+ ```bash
+ python3 -m pip install 'tensorflow[and-cuda]'
+ # Verify the installation:
+ python3 -c "import tensorflow as tf; print(tf.config.list_physical_devices('GPU'))"
+ ```
+
+* {MacOS}
+
+ ```bash
+ # There is currently no official GPU support for MacOS.
+ python3 -m pip install tensorflow
+ # Verify the installation:
+ python3 -c "import tensorflow as tf; print(tf.reduce_sum(tf.random.normal([1000, 1000])))"
+ ```
+
+* {Windows Native}
+
+ Caution: TensorFlow `2.10` was the **last** TensorFlow release that
+ supported GPU on native-Windows.
+ Starting with TensorFlow `2.11`, you will need to install
+ [TensorFlow in WSL2](https://tensorflow.org/install/pip#windows-wsl2),
+ or install `tensorflow` or `tensorflow-cpu` and, optionally, try the
+ [TensorFlow-DirectML-Plugin](https://github.com/microsoft/tensorflow-directml-plugin#tensorflow-directml-plugin-)
+
+ ```bash
+ conda install -c conda-forge cudatoolkit=11.2 cudnn=8.1.0
+ # Anything above 2.10 is not supported on the GPU on Windows Native
+ python -m pip install "tensorflow<2.11"
+ # Verify the installation:
+ python -c "import tensorflow as tf; print(tf.config.list_physical_devices('GPU'))"
+ ```
+
+* {Windows WSL2}
+
+ Note: TensorFlow with GPU access is supported for WSL2 on Windows 10 19044 or
+ higher. This corresponds to Windows 10 version 21H2, the November 2021
+ update. You can get the latest update from here:
+ [Download Windows 10](https://www.microsoft.com/software-download/windows10).
+ For instructions, see
+ [Install WSL2](https://docs.microsoft.com/windows/wsl/install)
+ and
+ [NVIDIA’s setup docs](https://docs.nvidia.com/cuda/wsl-user-guide/index.html)
+ for CUDA in WSL.
+
+ ```bash
+ python3 -m pip install tensorflow[and-cuda]
+ # Verify the installation:
+ python3 -c "import tensorflow as tf; print(tf.config.list_physical_devices('GPU'))"
+ ```
+
+* {CPU}
+
+ Note: Starting with TensorFlow `2.10`, Windows CPU-builds for x86/x64
+ processors are built, maintained, tested and released by a third party:
+ [Intel](https://www.intel.com/).
+ Installing the Windows-native [`tensorflow`](https://pypi.org/project/tensorflow/)
+ or [`tensorflow-cpu`](https://pypi.org/project/tensorflow-cpu/)
+ package installs Intel's
+ [`tensorflow-intel`](https://pypi.org/project/tensorflow-intel/)
+ package. These packages are provided as-is. Tensorflow will use reasonable
+ efforts to maintain the availability and integrity of this pip package.
+ There may be delays if the third party fails to release the pip package. See
+ [this blog post](https://blog.tensorflow.org/2022/09/announcing-tensorflow-official-build-collaborators.html)
+ for more information about this
+ collaboration.
+
+ ```bash
+ python3 -m pip install tensorflow
+ # Verify the installation:
+ python3 -c "import tensorflow as tf; print(tf.reduce_sum(tf.random.normal([1000, 1000])))"
+ ```
+
+* {Nightly}
+
+ ```bash
+ python3 -m pip install tf-nightly
+ # Verify the installation:
+ python3 -c "import tensorflow as tf; print(tf.reduce_sum(tf.random.normal([1000, 1000])))"
+ ```
+
+## Hardware requirements
+
+Note: TensorFlow binaries use
+[AVX instructions](https://en.wikipedia.org/wiki/Advanced_Vector_Extensions#CPUs_with_AVX)
+which may not run on older CPUs.
+
+The following GPU-enabled devices are supported:
+
+* NVIDIA® GPU card with CUDA® architectures 3.5, 5.0, 6.0, 7.0, 7.5, 8.0 and
+ higher. See the list of
+ [CUDA®-enabled GPU cards](https://developer.nvidia.com/cuda-gpus).
+* For GPUs with unsupported CUDA® architectures, or to avoid JIT compilation
+ from PTX, or to use different versions of the NVIDIA® libraries, see the
+ [Linux build from source](./source.md) guide.
+* Packages do not contain PTX code except for the latest supported CUDA®
+ architecture; therefore, TensorFlow fails to load on older GPUs when
+ `CUDA_FORCE_PTX_JIT=1` is set. (See
+ [Application Compatibility](https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#application-compatibility)
+ for details.)
+
+Note: The error message "Status: device kernel image is invalid" indicates that
+the TensorFlow package does not contain PTX for your architecture. You can
+enable compute capabilities by [building TensorFlow from source](./source.md).
+
+## System requirements
+
+* Ubuntu 16.04 or higher (64-bit)
+* macOS 12.0 (Monterey) or higher (64-bit) *(no GPU support)*
+* Windows Native - Windows 7 or higher (64-bit) *(no GPU support after TF 2.10)*
+* Windows WSL2 - Windows 10 19044 or higher (64-bit)
+
+Note: GPU support is available for Ubuntu and Windows with CUDA®-enabled cards.
+
+## Software requirements
+
+* Python 3.9–3.12
+* pip version 19.0 or higher for Linux (requires `manylinux2014` support) and
+ Windows. pip version 20.3 or higher for macOS.
+* Windows Native Requires
+ [Microsoft Visual C++ Redistributable for Visual Studio 2015, 2017 and 2019](https://learn.microsoft.com/en-us/cpp/windows/latest-supported-vc-redist)
+
+
+The following NVIDIA® software are only required for GPU support.
+
+* [NVIDIA® GPU drivers](https://www.nvidia.com/drivers)
+ * >= 525.60.13 for Linux
+ * >= 528.33 for WSL on Windows
+* [CUDA® Toolkit 12.3](https://developer.nvidia.com/cuda-toolkit-archive).
+* [cuDNN SDK 8.9.7](https://developer.nvidia.com/cudnn).
+* *(Optional)*
+ [TensorRT](https://docs.nvidia.com/deeplearning/tensorrt/archives/index.html#trt_7)
+ to improve latency and throughput for inference.
+
+## Step-by-step instructions
+
+* {Linux}
+
+ ### 1. System requirements
+
+ * Ubuntu 16.04 or higher (64-bit)
+
+ TensorFlow only officially supports Ubuntu. However, the following
+ instructions may also work for other Linux distros.
+
+ Note: Starting with TensorFlow `2.10`, Linux CPU-builds for Aarch64/ARM64
+ processors are built, maintained, tested and released by a third party:
+ [AWS](https://aws.amazon.com/).
+ Installing the [`tensorflow`](https://pypi.org/project/tensorflow/)
+ package on an ARM machine installs AWS's
+ [`tensorflow-cpu-aws`](https://pypi.org/project/tensorflow-cpu-aws/) package.
+ They are provided as-is. Tensorflow will use reasonable efforts to maintain
+ the availability and integrity of this pip package. There may be delays if
+ the third party fails to release the pip package. See
+ [this blog post](https://blog.tensorflow.org/2022/09/announcing-tensorflow-official-build-collaborators.html)
+ for more information about this collaboration.
+
+ ### 2. GPU setup
+
+ You can skip this section if you only run TensorFlow on the CPU.
+
+ Install the
+ [NVIDIA GPU driver](https://www.nvidia.com/Download/index.aspx)
+ if you have not. You can use the following command to verify it is
+ installed.
+
+ ```bash
+ nvidia-smi
+ ```
+
+ ### 3. Create a virtual environment with [venv](https://docs.python.org/3/library/venv.html){:.external}
+
+ The venv module is part of Python’s standard library and is the officially recommended way to create virtual environments.
+
+ Navigate to your desired virtual environments directory and create a new venv environment named `tf` with the following command.
+
+ ```bash
+ python3 -m venv tf
+ ```
+
+ You can activate it with the following command.
+
+ ```bash
+ source tf/bin/activate
+ ```
+
+ Make sure that the virtual environment is activated for the rest of the installation.
+
+ ### 4. Install TensorFlow
+
+ TensorFlow requires a recent version of pip, so upgrade your pip
+ installation to be sure you're running the latest version.
+
+ ```bash
+ pip install --upgrade pip
+ ```
+
+ Then, install TensorFlow with pip.
+
+ ```bash
+ # For GPU users
+ pip install tensorflow[and-cuda]
+ # For CPU users
+ pip install tensorflow
+ ```
+
+ **Note:** Do not install TensorFlow with `conda`. It may not have the latest stable version. `pip` is recommended since TensorFlow is only officially released to PyPI.
+
+ ### 6. Verify the installation
+
+ Verify the CPU setup:
+
+ ```bash
+ python3 -c "import tensorflow as tf; print(tf.reduce_sum(tf.random.normal([1000, 1000])))"
+ ```
+
+ If a tensor is returned, you've installed TensorFlow successfully.
+
+ Verify the GPU setup:
+
+ ```bash
+ python3 -c "import tensorflow as tf; print(tf.config.list_physical_devices('GPU'))"
+ ```
+
+ If a list of GPU devices is returned, you've installed TensorFlow
+ successfully. **If not continue to the next step**.
+
+ ### 6. [GPU only] Virtual environment configuration
+
+ If the GPU test in the last section was unsuccessful, the most likely cause is that components aren't being detected,
+ and/or conflict with the existing system CUDA installation. So you need to add some symbolic links to fix this.
+
+ * Create symbolic links to NVIDIA shared libraries:
+
+ ```bash
+ pushd $(dirname $(python -c 'print(__import__("tensorflow").__file__)'))
+ ln -svf ../nvidia/*/lib/*.so* .
+ popd
+ ```
+
+ * Create a symbolic link to ptxas:
+
+ ```bash
+ ln -sf $(find $(dirname $(dirname $(python -c "import nvidia.cuda_nvcc;
+ print(nvidia.cuda_nvcc.__file__)"))/*/bin/) -name ptxas -print -quit) $VIRTUAL_ENV/bin/ptxas
+ ```
+
+ Verify the GPU setup:
+
+ ```bash
+ python3 -c "import tensorflow as tf; print(tf.config.list_physical_devices('GPU'))"
+ ```
+
+
+
+
+* {MacOS}
+
+ ### 1. System requirements
+
+ * macOS 10.12.6 (Sierra) or higher (64-bit)
+
+ Note: While TensorFlow supports Apple Silicon (M1), packages that include
+ custom C++ extensions for TensorFlow also need to be compiled for Apple M1.
+ Some packages, like
+ [tensorflow_decision_forests](https://www.tensorflow.org/decision_forests)
+ publish M1-compatible versions, but many packages don't. To use those
+ libraries, you will have to use TensorFlow with x86 emulation and Rosetta.
+
+ Currently there is no official GPU support for running TensorFlow on
+ MacOS. The following instructions are for running on CPU.
+
+ ### 2. Check Python version
+
+ Check if your Python environment is already configured:
+
+ Note: Requires Python 3.9–3.11, and pip >= 20.3 for MacOS.
+
+ ```bash
+ python3 --version
+ python3 -m pip --version
+ ```
+
+ ### 3. Install TensorFlow
+
+ TensorFlow requires a recent version of pip, so upgrade your pip
+ installation to be sure you're running the latest version.
+
+ ```bash
+ pip install --upgrade pip
+ ```
+
+ Then, install TensorFlow with pip.
+
+ ```bash
+ pip install tensorflow
+ ```
+
+ ### 4. Verify the installation
+
+ ```bash
+ python3 -c "import tensorflow as tf; print(tf.reduce_sum(tf.random.normal([1000, 1000])))"
+ ```
+
+ If a tensor is returned, you've installed TensorFlow successfully.
+
+* {Windows Native}
+
+ Caution: TensorFlow `2.10` was the **last** TensorFlow release that
+ supported GPU on native-Windows.
+ Starting with TensorFlow `2.11`, you will need to install
+ [TensorFlow in WSL2](https://tensorflow.org/install/pip#windows-[wsl2]),
+ or install `tensorflow-cpu` and, optionally, try the
+ [TensorFlow-DirectML-Plugin](https://github.com/microsoft/tensorflow-directml-plugin#tensorflow-directml-plugin-)
+
+ ## 1. System requirements
+
+ * Windows 7 or higher (64-bit)
+
+ Note: Starting with TensorFlow `2.10`, Windows CPU-builds for x86/x64
+ processors are built, maintained, tested and released by a third party:
+ [Intel](https://www.intel.com/).
+ Installing the windows-native [`tensorflow`](https://pypi.org/project/tensorflow/)
+ or [`tensorflow-cpu`](https://pypi.org/project/tensorflow-cpu/)
+ package installs Intel's
+ [`tensorflow-intel`](https://pypi.org/project/tensorflow-intel/)
+ package. These packages are provided as-is. Tensorflow will use reasonable
+ efforts to maintain the availability and integrity of this pip package.
+ There may be delays if the third party fails to release the pip package. See
+ [this blog post](https://blog.tensorflow.org/2022/09/announcing-tensorflow-official-build-collaborators.html)
+ for more information about this
+ collaboration.
+
+ ### 2. Install Microsoft Visual C++ Redistributable
+
+ Install the *Microsoft Visual C++ Redistributable for Visual Studio 2015,
+ 2017, and 2019*. Starting with the TensorFlow 2.1.0 version, the
+ `msvcp140_1.dll` file is required from this package (which may not be
+ provided from older redistributable packages). The redistributable comes
+ with *Visual Studio 2019* but can be installed separately:
+
+ 1. Go to the
+ [Microsoft Visual C++ downloads](https://support.microsoft.com/help/2977003/the-latest-supported-visual-c-downloads).
+ 2. Scroll down the page to the *Visual Studio 2015, 2017 and 2019* section.
+ 3. Download and install the *Microsoft Visual C++ Redistributable for
+ Visual Studio 2015, 2017 and 2019* for your platform.
+
+ Make sure
+ [long paths are enabled](https://superuser.com/questions/1119883/windows-10-enable-ntfs-long-paths-policy-option-missing)
+ on Windows.
+
+ ### 3. Install Miniconda
+
+ [Miniconda](https://docs.conda.io/en/latest/miniconda.html)
+ is the recommended approach for installing TensorFlow with GPU support.
+ It creates a separate environment to avoid changing any installed
+ software in your system. This is also the easiest way to install the
+ required software especially for the GPU setup.
+
+ Download the
+ [Miniconda Windows Installer](https://repo.anaconda.com/miniconda/Miniconda3-latest-Windows-x86_64.exe).
+ Double-click the downloaded file and follow the instructions on the screen.
+
+ ### 4. Create a conda environment
+
+ Create a new conda environment named `tf` with the following command.
+
+ ```bash
+ conda create --name tf python=3.9
+ ```
+
+ You can deactivate and activate it with the following commands.
+
+ ```bash
+ conda deactivate
+ conda activate tf
+ ```
+
+ Make sure it is activated for the rest of the installation.
+
+ ### 5. GPU setup
+
+ You can skip this section if you only run TensorFlow on CPU.
+
+ First install
+ [NVIDIA GPU driver](https://www.nvidia.com/Download/index.aspx)
+ if you have not.
+
+ Then install the CUDA, cuDNN with conda.
+
+ ```bash
+ conda install -c conda-forge cudatoolkit=11.2 cudnn=8.1.0
+ ```
+
+ ### 6. Install TensorFlow
+
+ TensorFlow requires a recent version of pip, so upgrade your pip
+ installation to be sure you're running the latest version.
+
+ ```bash
+ pip install --upgrade pip
+ ```
+
+ Then, install TensorFlow with pip.
+
+ Note: Do not install TensorFlow with conda. It may not have the latest stable
+ version. pip is recommended since TensorFlow is only officially released to
+ PyPI.
+
+ ```bash
+ # Anything above 2.10 is not supported on the GPU on Windows Native
+ pip install "tensorflow<2.11"
+ ```
+
+ ### 7. Verify the installation
+
+ Verify the CPU setup:
+
+ ```bash
+ python -c "import tensorflow as tf; print(tf.reduce_sum(tf.random.normal([1000, 1000])))"
+ ```
+
+ If a tensor is returned, you've installed TensorFlow successfully.
+
+ Verify the GPU setup:
+
+ ```bash
+ python -c "import tensorflow as tf; print(tf.config.list_physical_devices('GPU'))"
+ ```
+
+ If a list of GPU devices is returned, you've installed TensorFlow
+ successfully.
+
+* {Windows WSL2}
+
+ ### 1. System requirements
+
+ * Windows 10 19044 or higher (64-bit). This corresponds to Windows 10
+ version 21H2, the November 2021 update.
+
+ See the following documents to:
+
+ * [Download the latest Windows 10 update](https://www.microsoft.com/software-download/windows10).
+ * [Install WSL2](https://docs.microsoft.com/windows/wsl/install)
+ * [Setup NVIDIA® GPU support in WSL2](https://docs.nvidia.com/cuda/wsl-user-guide/index.html)
+
+ ### 2. GPU setup
+
+ You can skip this section if you only run TensorFlow on the CPU.
+
+ Install the
+ [NVIDIA GPU driver](https://www.nvidia.com/Download/index.aspx)
+ if you have not. You can use the following command to verify it is
+ installed.
+
+ ```bash
+ nvidia-smi
+ ```
+
+ ### 3. Install TensorFlow
+
+ TensorFlow requires a recent version of pip, so upgrade your pip
+ installation to be sure you're running the latest version.
+
+ ```bash
+ pip install --upgrade pip
+ ```
+
+ Then, install TensorFlow with pip.
+
+ ```bash
+ # For GPU users
+ pip install tensorflow[and-cuda]
+ # For CPU users
+ pip install tensorflow
+ ```
+
+ ### 4. Verify the installation
+
+ Verify the CPU setup:
+
+ ```bash
+ python3 -c "import tensorflow as tf; print(tf.reduce_sum(tf.random.normal([1000, 1000])))"
+ ```
+
+ If a tensor is returned, you've installed TensorFlow successfully.
+
+ Verify the GPU setup:
+
+ ```bash
+ python3 -c "import tensorflow as tf; print(tf.config.list_physical_devices('GPU'))"
+ ```
+
+ If a list of GPU devices is returned, you've installed TensorFlow
+ successfully.
+
+
+## Package location
+
+A few installation mechanisms require the URL of the TensorFlow Python package.
+The value you specify depends on your Python version.
+
+
+ | Version | URL |
|---|
+ | Linux x86 |
+
+ | Python 3.9 GPU support |
+ https://storage.googleapis.com/tensorflow/versions/2.20.0/tensorflow-2.20.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl |
+
+
+ | Python 3.9 CPU-only |
+ https://storage.googleapis.com/tensorflow/versions/2.20.0/tensorflow_cpu-2.20.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl |
+
+
+ | Python 3.10 GPU support |
+ https://storage.googleapis.com/tensorflow/versions/2.20.0/tensorflow-2.20.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl |
+
+
+ | Python 3.10 CPU-only |
+ https://storage.googleapis.com/tensorflow/versions/2.20.0/tensorflow_cpu-2.20.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl |
+
+
+ | Python 3.11 GPU support |
+ https://storage.googleapis.com/tensorflow/versions/2.20.0/tensorflow-2.20.0-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl |
+
+
+ | Python 3.11 CPU-only |
+ https://storage.googleapis.com/tensorflow/versions/2.20.0/tensorflow_cpu-2.20.0-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl |
+
+
+ | Python 3.12 GPU support |
+ https://storage.googleapis.com/tensorflow/versions/2.20.0/tensorflow-2.20.0-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl |
+
+
+ | Python 3.12 CPU-only |
+ https://storage.googleapis.com/tensorflow/versions/2.20.0/tensorflow_cpu-2.20.0-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl |
+
+
+ | Python 3.13 GPU support |
+ https://storage.googleapis.com/tensorflow/versions/2.20.0/tensorflow-2.20.0-cp313-cp313-manylinux_2_17_x86_64.manylinux2014_x86_64.whl |
+
+
+ | Python 3.13 CPU-only |
+ https://storage.googleapis.com/tensorflow/versions/2.20.0/tensorflow_cpu-2.20.0-cp313-cp313-manylinux_2_17_x86_64.manylinux2014_x86_64.whl |
+
+
+ | Linux Arm64 (CPU-only) |
+
+ | Python 3.9 |
+ https://storage.googleapis.com/tensorflow/versions/2.20.0/tensorflow-2.20.0-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl |
+
+
+ | Python 3.10 |
+ https://storage.googleapis.com/tensorflow/versions/2.20.0/tensorflow-2.20.0-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl |
+
+
+ | Python 3.11 |
+ https://storage.googleapis.com/tensorflow/versions/2.20.0/tensorflow-2.20.0-cp311-cp311-manylinux_2_17_aarch64.manylinux2014_aarch64.whl |
+
+
+ | Python 3.12 |
+ https://storage.googleapis.com/tensorflow/versions/2.20.0/tensorflow-2.20.0-cp312-cp312-manylinux_2_17_aarch64.manylinux2014_aarch64.whl |
+
+
+ | Python 3.13 |
+ https://storage.googleapis.com/tensorflow/versions/2.20.0/tensorflow-2.20.0-cp313-cp313-manylinux_2_17_aarch64.manylinux2014_aarch64.whl |
+
+
+ | macOS x86 (CPU-only) |
+ | Caution: TensorFlow 2.16 was the last TensorFlow release that supported macOS x86 |
+
+ | Python 3.9 |
+ https://storage.googleapis.com/tensorflow/versions/2.16.2/tensorflow-2.16.2-cp39-cp39-macosx_10_15_x86_64.whl |
+
+
+ | Python 3.10 |
+ https://storage.googleapis.com/tensorflow/versions/2.16.2/tensorflow-2.16.2-cp310-cp310-macosx_10_15_x86_64.whl |
+
+
+ | Python 3.11 |
+ https://storage.googleapis.com/tensorflow/versions/2.16.2/tensorflow-2.16.2-cp311-cp311-macosx_10_15_x86_64.whl |
+
+
+ | Python 3.12 |
+ https://storage.googleapis.com/tensorflow/versions/2.16.2/tensorflow-2.16.2-cp312-cp312-macosx_10_15_x86_64.whl |
+
+
+ | macOS Arm64 (CPU-only) |
+
+ | Python 3.9 |
+ https://storage.googleapis.com/tensorflow/versions/2.20.0/tensorflow-2.20.0-cp39-cp39-macosx_12_0_arm64.whl |
+
+
+ | Python 3.10 |
+ https://storage.googleapis.com/tensorflow/versions/2.20.0/tensorflow-2.20.0-cp310-cp310-macosx_12_0_arm64.whl |
+
+
+ | Python 3.11 |
+ https://storage.googleapis.com/tensorflow/versions/2.20.0/tensorflow-2.20.0-cp311-cp311-macosx_12_0_arm64.whl |
+
+
+ | Python 3.12 |
+ https://storage.googleapis.com/tensorflow/versions/2.20.0/tensorflow-2.20.0-cp312-cp312-macosx_12_0_arm64.whl |
+
+
+ | Python 3.13 |
+ https://storage.googleapis.com/tensorflow/versions/2.20.0/tensorflow-2.20.0-cp313-cp313-macosx_12_0_arm64.whl |
+
+
+ | Windows (CPU-only) |
+
+ | Python 3.9 |
+ https://storage.googleapis.com/tensorflow/versions/2.20.0/tensorflow_cpu-2.20.0-cp39-cp39-win_amd64.whl |
+
+
+ | Python 3.10 |
+ https://storage.googleapis.com/tensorflow/versions/2.20.0/tensorflow_cpu-2.20.0-cp310-cp310-win_amd64.whl |
+
+
+ | Python 3.11 |
+ https://storage.googleapis.com/tensorflow/versions/2.20.0/tensorflow_cpu-2.20.0-cp311-cp311-win_amd64.whl |
+
+
+ | Python 3.12 |
+ https://storage.googleapis.com/tensorflow/versions/2.20.0/tensorflow_cpu-2.20.0-cp312-cp312-win_amd64.whl |
+
+
+ | Python 3.13 |
+ https://storage.googleapis.com/tensorflow/versions/2.20.0/tensorflow_cpu-2.20.0-cp313-cp313-win_amd64.whl |
+
+
+
diff --git a/site/en/install/source.md b/site/en/install/source.md
index b2f8ee8cb0b..dc847f017e9 100644
--- a/site/en/install/source.md
+++ b/site/en/install/source.md
@@ -4,8 +4,8 @@ Build a TensorFlow *pip* package from source and install it on Ubuntu Linux and
macOS. While the instructions might work for other systems, it is only tested
and supported for Ubuntu and macOS.
-Note: We already provide well-tested, pre-built
-[TensorFlow packages](./pip.html) for Linux and macOS systems.
+Note: Well-tested, pre-built [TensorFlow packages](./pip.md) for Linux and macOS
+systems are already provided.
## Setup for Linux and macOS
@@ -25,9 +25,6 @@ Install the following build tools to configure your development environment.
Requires Xcode 9.2 or later.
Install using the Homebrew package manager:
-/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
-export PATH="/usr/local/opt/python/libexec/bin:$PATH"
-# if you are on macOS 10.12 (Sierra) use `export PATH="/usr/local/bin:/usr/local/sbin:$PATH"`
brew install python
@@ -37,13 +34,12 @@ Install the TensorFlow *pip* package dependencies (if using a virtual
environment, omit the `--user` argument):
-pip install -U --user pip numpy wheel
-pip install -U --user keras_preprocessing --no-deps
+pip install -U --user pip
Note: A `pip` version >19.0 is required to install the TensorFlow 2 `.whl`
package. Additional required dependencies are listed in the
-setup.py
+setup.py.tpl
file under `REQUIRED_PACKAGES`.
### Install Bazel
@@ -54,32 +50,83 @@ Bazel and automatically downloads the correct Bazel version for TensorFlow. For
ease of use, add Bazelisk as the `bazel` executable in your `PATH`.
If Bazelisk is not available, you can manually
-[install Bazel](https://docs.bazel.build/versions/master/install.html). Make
-sure to install a supported Bazel version: any version between
-`_TF_MIN_BAZEL_VERSION` and `_TF_MAX_BAZEL_VERSION` as specified in
-`tensorflow/configure.py`.
+[install Bazel](https://bazel.build/install). Make
+sure to install the correct Bazel version from TensorFlow's
+[.bazelversion](https://github.com/tensorflow/tensorflow/blob/master/.bazelversion)
+file.
+
+### Install Clang (recommended, Linux only)
+
+Clang is a C/C++/Objective-C compiler that is compiled in C++ based on LLVM. It
+is the default compiler to build TensorFlow starting with TensorFlow 2.13. The
+current supported version is LLVM/Clang 17.
+
+[LLVM Debian/Ubuntu nightly packages](https://apt.llvm.org) provide an automatic
+installation script and packages for manual installation on Linux. Make sure you
+run the following command if you manually add llvm apt repository to your
+package sources:
+
+
+sudo apt-get update && sudo apt-get install -y llvm-17 clang-17
+
+
+Now that `/usr/lib/llvm-17/bin/clang` is the actual path to clang in this case.
+
+Alternatively, you can download and unpack the pre-built
+[Clang + LLVM 17](https://github.com/llvm/llvm-project/releases/tag/llvmorg-17.0.2).
+
+Below is an example of steps you can take to set up the downloaded Clang + LLVM
+17 binaries on Debian/Ubuntu operating systems:
+
+1. Change to the desired destination directory: `cd `
+
+1. Load and extract an archive file...(suitable to your architecture):
+
+ wget https://github.com/llvm/llvm-project/releases/download/llvmorg-17.0.2/clang+llvm-17.0.2-x86_64-linux-gnu-ubuntu-22.04.tar.xz
+
+ tar -xvf clang+llvm-17.0.2-x86_64-linux-gnu-ubuntu-22.04.tar.xz
+
+
+
+1. Copy the extracted contents (directories and files) to `/usr` (you may need
+ sudo permissions, and the correct directory may vary by distribution). This
+ effectively installs Clang and LLVM, and adds it to the path. You should not
+ have to replace anything, unless you have a previous installation, in which
+ case you should replace the files:
+
+ cp -r clang+llvm-17.0.2-x86_64-linux-gnu-ubuntu-22.04/* /usr
+
+
+1. Check the obtained Clang + LLVM 17 binaries version:
+
+ clang --version
+
+
+1. Now that `/usr/bin/clang` is the actual path to your new clang. You can run
+ the `./configure` script or manually set environment variables `CC` and
+ `BAZEL_COMPILER` to this path.
### Install GPU support (optional, Linux only)
There is *no* GPU support for macOS.
-Read the [GPU support](./gpu.md) guide to install the drivers and additional
+Read the [GPU support](./pip.md) guide to install the drivers and additional
software required to run TensorFlow on a GPU.
Note: It is easier to set up one of TensorFlow's GPU-enabled [Docker images](#docker_linux_builds).
### Download the TensorFlow source code
-Use [Git](https://git-scm.com/){:.external} to clone the
-[TensorFlow repository](https://github.com/tensorflow/tensorflow){:.external}:
+Use [Git](https://git-scm.com/) to clone the
+[TensorFlow repository](https://github.com/tensorflow/tensorflow):
git clone https://github.com/tensorflow/tensorflow.git
cd tensorflow
-The repo defaults to the `master` development branch. You can also checkout a
-[release branch](https://github.com/tensorflow/tensorflow/releases){:.external}
+The repo defaults to the `master` development branch. You can also check out a
+[release branch](https://github.com/tensorflow/tensorflow/releases)
to build:
@@ -89,16 +136,21 @@ git checkout branch_name # r2.2, r2.3, etc.
## Configure the build
-Configure your system build by running the `./configure` at the root of your
-TensorFlow source tree. This script prompts you for the location of TensorFlow
-dependencies and asks for additional build configuration options (compiler
-flags, for example).
+TensorFlow builds are configured by the `.bazelrc` file in the repository's
+root directory. The `./configure` or `./configure.py` scripts can be used to
+adjust common settings.
+
+Please run the `./configure` script from the repository's root directory. This
+script will prompt you for the location of TensorFlow dependencies and asks for
+additional build configuration options (compiler flags, for example). Refer to
+the _Sample session_ section for details.
./configure
-If using a virtual environment, `python configure.py` prioritizes paths
+There is also a python version of this script, `./configure.py`. If using a
+virtual environment, `python configure.py` prioritizes paths
within the environment, whereas `./configure` prioritizes paths outside
the environment. In both cases you can change the default.
@@ -111,65 +163,47 @@ session may differ):
View sample configuration session
./configure
-You have bazel 3.0.0 installed.
-Please specify the location of python. [Default is /usr/bin/python3]:
+You have bazel 6.1.0 installed.
+Please specify the location of python. [Default is /Library/Frameworks/Python.framework/Versions/3.9/bin/python3]:
Found possible Python library paths:
- /usr/lib/python3/dist-packages
- /usr/local/lib/python3.6/dist-packages
-Please input the desired Python library path to use. Default is [/usr/lib/python3/dist-packages]
-
-Do you wish to build TensorFlow with OpenCL SYCL support? [y/N]:
-No OpenCL SYCL support will be enabled for TensorFlow.
+ /Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages
+Please input the desired Python library path to use. Default is [/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages]
-Do you wish to build TensorFlow with ROCm support? [y/N]:
+Do you wish to build TensorFlow with ROCm support? [y/N]:
No ROCm support will be enabled for TensorFlow.
-Do you wish to build TensorFlow with CUDA support? [y/N]: Y
-CUDA support will be enabled for TensorFlow.
-
-Do you wish to build TensorFlow with TensorRT support? [y/N]:
-No TensorRT support will be enabled for TensorFlow.
-
-Found CUDA 10.1 in:
- /usr/local/cuda-10.1/targets/x86_64-linux/lib
- /usr/local/cuda-10.1/targets/x86_64-linux/include
-Found cuDNN 7 in:
- /usr/lib/x86_64-linux-gnu
- /usr/include
-
-
-Please specify a list of comma-separated CUDA compute capabilities you want to build with.
-You can find the compute capability of your device at: https://developer.nvidia.com/cuda-gpus. Each capability can be specified as "x.y" or "compute_xy" to include both virtual and binary GPU code, or as "sm_xy" to only include the binary code.
-Please note that each additional compute capability significantly increases your build time and binary size, and that TensorFlow only supports compute capabilities >= 3.5 [Default is: 3.5,7.0]: 6.1
-
+Do you wish to build TensorFlow with CUDA support? [y/N]:
+No CUDA support will be enabled for TensorFlow.
-Do you want to use clang as CUDA compiler? [y/N]:
-nvcc will be used as CUDA compiler.
+Do you want to use Clang to build TensorFlow? [Y/n]:
+Clang will be used to compile TensorFlow.
-Please specify which gcc should be used by nvcc as the host compiler. [Default is /usr/bin/gcc]:
+Please specify the path to clang executable. [Default is /usr/lib/llvm-16/bin/clang]:
+You have Clang 16.0.4 installed.
-Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is -march=native -Wno-sign-compare]:
+Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is -Wno-sign-compare]:
-Would you like to interactively configure ./WORKSPACE for Android builds? [y/N]:
+Would you like to interactively configure ./WORKSPACE for Android builds? [y/N]: n
Not configuring the WORKSPACE for Android builds.
+Do you wish to build TensorFlow with iOS support? [y/N]: n
+No iOS support will be enabled for TensorFlow.
+
Preconfigured Bazel build configs. You can use any of the below by adding "--config=<>" to your build command. See .bazelrc for more details.
--config=mkl # Build with MKL support.
+ --config=mkl_aarch64 # Build with oneDNN and Compute Library for the Arm Architecture (ACL).
--config=monolithic # Config for mostly static monolithic build.
- --config=ngraph # Build with Intel nGraph support.
--config=numa # Build with NUMA support.
--config=dynamic_kernels # (Experimental) Build kernels into separate shared objects.
- --config=v2 # Build TensorFlow 2.x instead of 1.x.
+ --config=v1 # Build with TensorFlow 1 API instead of TF 2 API.
Preconfigured Bazel build configs to DISABLE default on features:
- --config=noaws # Disable AWS S3 filesystem support.
--config=nogcp # Disable GCP support.
- --config=nohdfs # Disable HDFS support.
--config=nonccl # Disable NVIDIA NCCL support.
-Configuration finished
+
@@ -177,7 +211,14 @@ Configuration finished
#### GPU support
-For [GPU support](./gpu.md), set `cuda=Y` during configuration and specify the
+##### from v.2.18.0
+For [GPU support](./pip.md), set `cuda=Y` during configuration and specify the
+versions of CUDA and cuDNN if required. Bazel will download CUDA and CUDNN
+packages automatically or point to CUDA/CUDNN/NCCL redistributions on local file
+system if required.
+
+##### before v.2.18.0
+For [GPU support](./pip.md), set `cuda=Y` during configuration and specify the
versions of CUDA and cuDNN. If your system has multiple versions of CUDA or
cuDNN installed, explicitly set the version instead of relying on the default.
`./configure` creates symbolic links to your system's CUDA libraries—so if you
@@ -188,8 +229,8 @@ building.
For compilation optimization flags, the default (`-march=native`) optimizes the
generated code for your machine's CPU type. However, if building TensorFlow for
-a different CPU type, consider a more specific optimization flag. See the
-[GCC manual](https://gcc.gnu.org/onlinedocs/gcc-4.5.3/gcc/i386-and-x86_002d64-Options.html){:.external}
+a different CPU type, consider a more specific optimization flag. Check the
+[GCC manual](https://gcc.gnu.org/onlinedocs/gcc-4.5.3/gcc/i386-and-x86_002d64-Options.html)
for examples.
#### Preconfigured configurations
@@ -201,81 +242,55 @@ There are some preconfigured build configs available that can be added to the
[CONTRIBUTING.md](https://github.com/tensorflow/tensorflow/blob/master/CONTRIBUTING.md)
for details.
* `--config=mkl` —Support for the
- [Intel® MKL-DNN](https://github.com/intel/mkl-dnn){:.external}.
+ [Intel® MKL-DNN](https://github.com/intel/mkl-dnn).
* `--config=monolithic` —Configuration for a mostly static, monolithic build.
-* `--config=v1` —Build TensorFlow 1.x instead of 2.x.
-
-Note: Starting with TensorFlow 1.6, binaries use AVX instructions which may not
-run on older CPUs.
-
-
-## Build the pip package
-### TensorFlow 2.x
-[Install Bazel](https://docs.bazel.build/versions/master/install.html) and use
-`bazel build` to create the TensorFlow 2.x package with *CPU-only* support:
+## Build and install the pip package
-
-bazel build [--config=option] //tensorflow/tools/pip_package:build_pip_package
-
-
-Note: GPU support can be enabled with `cuda=Y` during the `./configure` stage.
-
-### GPU support
-
-To build a TensorFlow package builder with GPU support:
-
-
-bazel build --config=cuda [--config=option] //tensorflow/tools/pip_package:build_pip_package
-
-
-### TensorFlow 1.x
-
-To build an older TensorFlow 1.x package, use the `--config=v1` option:
-
-
-bazel build --config=v1 [--config=option] //tensorflow/tools/pip_package:build_pip_package
-
+#### Bazel build options
-### Bazel build options
-
-See the Bazel [command-line reference](https://docs.bazel.build/versions/master/command-line-reference.html)
+Refer to the Bazel
+[command-line reference](https://bazel.build/reference/command-line-reference)
for
-[build options](https://docs.bazel.build/versions/master/command-line-reference.html#build-options).
+[build options](https://bazel.build/reference/command-line-reference#build-options).
Building TensorFlow from source can use a lot of RAM. If your system is
memory-constrained, limit Bazel's RAM usage with: `--local_ram_resources=2048`.
-The [official TensorFlow packages](./pip.html) are built with a GCC 7.3
-toolchain that complies with the manylinux2010 package standard.
-
-For GCC 5 and later, compatibility with the older ABI can be built using:
-`--cxxopt="-D_GLIBCXX_USE_CXX11_ABI=0"`. ABI compatibility ensures that custom
-ops built against the official TensorFlow package continue to work with the
-GCC 5 built package.
+The [official TensorFlow packages](./pip.md) are built with a Clang toolchain
+that complies with the manylinux2014 package standard.
### Build the package
-The `bazel build` command creates an executable named `build_pip_package`—this
-is the program that builds the `pip` package. Run the executable as shown
-below to build a `.whl` package in the `/tmp/tensorflow_pkg` directory.
+To build pip package, you need to specify `--repo_env=WHEEL_NAME` flag.
+depending on the provided name, package will be created, e.g:
-To build from a release branch:
+To build tensorflow CPU package:
+
+bazel build //tensorflow/tools/pip_package:wheel --repo_env=USE_PYWRAP_RULES=1 --repo_env=WHEEL_NAME=tensorflow_cpu
+
+To build tensorflow GPU package:
-./bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg
+bazel build //tensorflow/tools/pip_package:wheel --repo_env=USE_PYWRAP_RULES=1 --repo_env=WHEEL_NAME=tensorflow --config=cuda --config=cuda_wheel
-To build from master, use `--nightly_flag` to get the right dependencies:
+To build tensorflow TPU package:
+
+bazel build //tensorflow/tools/pip_package:wheel --repo_env=USE_PYWRAP_RULES=1 --repo_env=WHEEL_NAME=tensorflow_tpu --config=tpu
+
+To build nightly package, set `tf_nightly` instead of `tensorflow`, e.g.
+to build CPU nightly package:
-./bazel-bin/tensorflow/tools/pip_package/build_pip_package --nightly_flag /tmp/tensorflow_pkg
+bazel build //tensorflow/tools/pip_package:wheel --repo_env=USE_PYWRAP_RULES=1 --repo_env=WHEEL_NAME=tf_nightly_cpu
-Although it is possible to build both CUDA and non-CUDA configurations under the
-same source tree, it's recommended to run `bazel clean` when switching between
-these two configurations in the same source tree.
+As a result, generated wheel will be located in
+
+bazel-bin/tensorflow/tools/pip_package/wheel_house/
+
### Install the package
@@ -283,7 +298,7 @@ The filename of the generated `.whl` file depends on the TensorFlow version and
your platform. Use `pip install` to install the package, for example:
-pip install /tmp/tensorflow_pkg/tensorflow-version-tags.whl
+pip install bazel-bin/tensorflow/tools/pip_package/wheel_house/tensorflow-version-tags.whl
Success: TensorFlow is now installed.
@@ -293,17 +308,17 @@ Success: TensorFlow is now installed.
TensorFlow's Docker development images are an easy way to set up an environment
to build Linux packages from source. These images already contain the source
-code and dependencies required to build TensorFlow. See the TensorFlow
-[Docker guide](./docker.md) for installation and the
-[list of available image tags](https://hub.docker.com/r/tensorflow/tensorflow/tags/){:.external}.
+code and dependencies required to build TensorFlow. Go to the TensorFlow
+[Docker guide](./docker.md) for installation instructions and the
+[list of available image tags](https://hub.docker.com/r/tensorflow/tensorflow/tags/).
### CPU-only
The following example uses the `:devel` image to build a CPU-only package from
-the latest TensorFlow source code. See the [Docker guide](./docker.md) for
+the latest TensorFlow source code. Check the [Docker guide](./docker.md) for
available TensorFlow `-devel` tags.
-Download the latest development image and start a Docker container that we'll
+Download the latest development image and start a Docker container that you'll
use to build the *pip* package:
@@ -331,20 +346,20 @@ docker run -it -w /tensorflow -v /path/to/tensorflow:/tensorflow -v $
With the source tree set up, build the TensorFlow package within the container's
virtual environment:
-1. Configure the build—this prompts the user to answer build configuration
- questions.
-2. Build the tool used to create the *pip* package.
-3. Run the tool to create the *pip* package.
-4. Adjust the ownership permissions of the file for outside the container.
+1. Optional: Configure the build—this prompts the user to answer build
+ configuration questions.
+2. Build the *pip* package.
+3. Adjust the ownership permissions of the file for outside the container.
-./configure # answer prompts or use defaults
-
-bazel build --config=opt //tensorflow/tools/pip_package:build_pip_package
-
-./bazel-bin/tensorflow/tools/pip_package/build_pip_package /mnt # create package
-
-chown $HOST_PERMS /mnt/tensorflow-version-tags.whl
+./configure # if necessary
+
+
+bazel build //tensorflow/tools/pip_package:wheel \
+--repo_env=USE_PYWRAP_RULES=1 --repo_env=WHEEL_NAME=tensorflow_cpu --config=opt
+
+`
+chown $HOST_PERMS bazel-bin/tensorflow/tools/pip_package/wheel_house/tensorflow-version-tags.whl
Install and verify the package within the container:
@@ -352,7 +367,7 @@ Install and verify the package within the container:
pip uninstall tensorflow # remove current version
-pip install /mnt/tensorflow-version-tags.whl
+pip install bazel-bin/tensorflow/tools/pip_package/wheel_house/tensorflow-version-tags.whl
cd /tmp # don't import from source directory
python -c "import tensorflow as tf; print(tf.__version__)"
@@ -365,12 +380,15 @@ On your host machine, the TensorFlow *pip* package is in the current directory
### GPU support
+Note: Starting from Tensorflow v.2.18.0 the wheels can be built from
+source on a machine without GPUs and without NVIDIA driver installed.
+
Docker is the easiest way to build GPU support for TensorFlow since the *host*
machine only requires the
-[NVIDIA® driver](https://github.com/NVIDIA/nvidia-docker/wiki/Frequently-Asked-Questions#how-do-i-install-the-nvidia-driver){:.external}
-(the *NVIDIA® CUDA® Toolkit* doesn't have to be installed). See the
-[GPU support guide](./gpu.md) and the TensorFlow [Docker guide](./docker.md) to
-set up [nvidia-docker](https://github.com/NVIDIA/nvidia-docker){:.external}
+[NVIDIA® driver](https://github.com/NVIDIA/nvidia-docker/wiki/Frequently-Asked-Questions#how-do-i-install-the-nvidia-driver)
+(the *NVIDIA® CUDA® Toolkit* doesn't have to be installed). Refer to the
+[GPU support guide](./pip.md) and the TensorFlow [Docker guide](./docker.md) to
+set up [nvidia-docker](https://github.com/NVIDIA/nvidia-docker)
(Linux only).
The following example downloads the TensorFlow `:devel-gpu` image and uses
@@ -388,13 +406,15 @@ Then, within the container's virtual environment, build the TensorFlow package
with GPU support:
-./configure # answer prompts or use defaults
-
-bazel build --config=opt --config=cuda //tensorflow/tools/pip_package:build_pip_package
+./configure # if necessary
-./bazel-bin/tensorflow/tools/pip_package/build_pip_package /mnt # create package
+
+bazel build //tensorflow/tools/pip_package:wheel \
+--repo_env=USE_PYWRAP_RULES=1 --repo_env=WHEEL_NAME=tensorflow --config=cuda \
+--config=cuda_wheel --config=opt
+
-chown $HOST_PERMS /mnt/tensorflow-version-tags.whl
+chown $HOST_PERMS bazel-bin/tensorflow/tools/pip_package/wheel_house/tensorflow-version-tags.whl
Install and verify the package within the container and check for a GPU:
@@ -402,7 +422,7 @@ Install and verify the package within the container and check for a GPU:
pip uninstall tensorflow # remove current version
-pip install /mnt/tensorflow-version-tags.whl
+pip install bazel-bin/tensorflow/tools/pip_package/wheel_house/tensorflow-version-tags.whl
cd /tmp # don't import from source directory
python -c "import tensorflow as tf; print(\"Num GPUs Available: \", len(tf.config.list_physical_devices('GPU')))"
@@ -419,6 +439,20 @@ Success: TensorFlow is now installed.
| Version | Python version | Compiler | Build tools |
|---|
+| tensorflow-2.20.0 | 3.9-3.13 | Clang 18.1.8 | Bazel 7.4.1 |
+| tensorflow-2.19.0 | 3.9-3.12 | Clang 18.1.8 | Bazel 6.5.0 |
+| tensorflow-2.18.0 | 3.9-3.12 | Clang 17.0.6 | Bazel 6.5.0 |
+| tensorflow-2.17.0 | 3.9-3.12 | Clang 17.0.6 | Bazel 6.5.0 |
+| tensorflow-2.16.1 | 3.9-3.12 | Clang 17.0.6 | Bazel 6.5.0 |
+| tensorflow-2.15.0 | 3.9-3.11 | Clang 16.0.0 | Bazel 6.1.0 |
+| tensorflow-2.14.0 | 3.9-3.11 | Clang 16.0.0 | Bazel 6.1.0 |
+| tensorflow-2.13.0 | 3.8-3.11 | Clang 16.0.0 | Bazel 5.3.0 |
+| tensorflow-2.12.0 | 3.8-3.11 | GCC 9.3.1 | Bazel 5.3.0 |
+| tensorflow-2.11.0 | 3.7-3.10 | GCC 9.3.1 | Bazel 5.3.0 |
+| tensorflow-2.10.0 | 3.7-3.10 | GCC 9.3.1 | Bazel 5.1.1 |
+| tensorflow-2.9.0 | 3.7-3.10 | GCC 9.3.1 | Bazel 5.0.0 |
+| tensorflow-2.8.0 | 3.7-3.10 | GCC 7.3.1 | Bazel 4.2.1 |
+| tensorflow-2.7.0 | 3.7-3.9 | GCC 7.3.1 | Bazel 3.7.2 |
| tensorflow-2.6.0 | 3.6-3.9 | GCC 7.3.1 | Bazel 3.7.2 |
| tensorflow-2.5.0 | 3.6-3.9 | GCC 7.3.1 | Bazel 3.7.2 |
| tensorflow-2.4.0 | 3.6-3.8 | GCC 7.3.1 | Bazel 3.1.0 |
@@ -448,6 +482,20 @@ Success: TensorFlow is now installed.
| Version | Python version | Compiler | Build tools | cuDNN | CUDA |
|---|
+| tensorflow-2.20.0 | 3.9-3.13 | Clang 18.1.8 | Bazel 7.4.1 | 9.3 | 12.5 |
+| tensorflow-2.19.0 | 3.9-3.12 | Clang 18.1.8 | Bazel 6.5.0 | 9.3 | 12.5 |
+| tensorflow-2.18.0 | 3.9-3.12 | Clang 17.0.6 | Bazel 6.5.0 | 9.3 | 12.5 |
+| tensorflow-2.17.0 | 3.9-3.12 | Clang 17.0.6 | Bazel 6.5.0 | 8.9 | 12.3 |
+| tensorflow-2.16.1 | 3.9-3.12 | Clang 17.0.6 | Bazel 6.5.0 | 8.9 | 12.3 |
+| tensorflow-2.15.0 | 3.9-3.11 | Clang 16.0.0 | Bazel 6.1.0 | 8.9 | 12.2 |
+| tensorflow-2.14.0 | 3.9-3.11 | Clang 16.0.0 | Bazel 6.1.0 | 8.7 | 11.8 |
+| tensorflow-2.13.0 | 3.8-3.11 | Clang 16.0.0 | Bazel 5.3.0 | 8.6 | 11.8 |
+| tensorflow-2.12.0 | 3.8-3.11 | GCC 9.3.1 | Bazel 5.3.0 | 8.6 | 11.8 |
+| tensorflow-2.11.0 | 3.7-3.10 | GCC 9.3.1 | Bazel 5.3.0 | 8.1 | 11.2 |
+| tensorflow-2.10.0 | 3.7-3.10 | GCC 9.3.1 | Bazel 5.1.1 | 8.1 | 11.2 |
+| tensorflow-2.9.0 | 3.7-3.10 | GCC 9.3.1 | Bazel 5.0.0 | 8.1 | 11.2 |
+| tensorflow-2.8.0 | 3.7-3.10 | GCC 7.3.1 | Bazel 4.2.1 | 8.1 | 11.2 |
+| tensorflow-2.7.0 | 3.7-3.9 | GCC 7.3.1 | Bazel 3.7.2 | 8.1 | 11.2 |
| tensorflow-2.6.0 | 3.6-3.9 | GCC 7.3.1 | Bazel 3.7.2 | 8.1 | 11.2 |
| tensorflow-2.5.0 | 3.6-3.9 | GCC 7.3.1 | Bazel 3.7.2 | 8.1 | 11.2 |
| tensorflow-2.4.0 | 3.6-3.8 | GCC 7.3.1 | Bazel 3.1.0 | 8.0 | 11.0 |
@@ -479,6 +527,16 @@ Success: TensorFlow is now installed.
| Version | Python version | Compiler | Build tools |
|---|
+| tensorflow-2.16.1 | 3.9-3.12 | Clang from Xcode 13.6 | Bazel 6.5.0 |
+| tensorflow-2.15.0 | 3.9-3.11 | Clang from xcode 10.15 | Bazel 6.1.0 |
+| tensorflow-2.14.0 | 3.9-3.11 | Clang from xcode 10.15 | Bazel 6.1.0 |
+| tensorflow-2.13.0 | 3.8-3.11 | Clang from xcode 10.15 | Bazel 5.3.0 |
+| tensorflow-2.12.0 | 3.8-3.11 | Clang from xcode 10.15 | Bazel 5.3.0 |
+| tensorflow-2.11.0 | 3.7-3.10 | Clang from xcode 10.14 | Bazel 5.3.0 |
+| tensorflow-2.10.0 | 3.7-3.10 | Clang from xcode 10.14 | Bazel 5.1.1 |
+| tensorflow-2.9.0 | 3.7-3.10 | Clang from xcode 10.14 | Bazel 5.0.0 |
+| tensorflow-2.8.0 | 3.7-3.10 | Clang from xcode 10.14 | Bazel 4.2.1 |
+| tensorflow-2.7.0 | 3.7-3.9 | Clang from xcode 10.11 | Bazel 3.7.2 |
| tensorflow-2.6.0 | 3.6-3.9 | Clang from xcode 10.11 | Bazel 3.7.2 |
| tensorflow-2.5.0 | 3.6-3.9 | Clang from xcode 10.11 | Bazel 3.7.2 |
| tensorflow-2.4.0 | 3.6-3.8 | Clang from xcode 10.3 | Bazel 3.1.0 |
diff --git a/site/en/install/source_windows.md b/site/en/install/source_windows.md
index cff252e0b9e..efc0f7a9286 100644
--- a/site/en/install/source_windows.md
+++ b/site/en/install/source_windows.md
@@ -1,9 +1,9 @@
# Build from source on Windows
-Build a TensorFlow *pip* package from source and install it on Windows.
+Build a TensorFlow *pip* package from the source and install it on Windows.
Note: We already provide well-tested, pre-built
-[TensorFlow packages](./pip.html) for Windows systems.
+[TensorFlow packages](./pip.md) for Windows systems.
## Setup for Windows
@@ -13,16 +13,16 @@ environment.
### Install Python and the TensorFlow package dependencies
Install a
-[Python 3.6.x 64-bit release for Windows](https://www.python.org/downloads/windows/){:.external}.
+[Python 3.9+ 64-bit release for Windows](https://www.python.org/downloads/windows/).
Select *pip* as an optional feature and add it to your `%PATH%` environmental
variable.
Install the TensorFlow *pip* package dependencies:
-pip3 install six numpy wheel
-pip3 install keras_applications==1.0.6 --no-deps
-pip3 install keras_preprocessing==1.0.5 --no-deps
+pip3 install -U pip
+pip3 install -U six numpy wheel packaging
+pip3 install -U keras_preprocessing --no-deps
The dependencies are listed in the
@@ -42,38 +42,53 @@ Add the location of the Bazel executable to your `%PATH%` environment variable.
### Install MSYS2
-[Install MSYS2](https://www.msys2.org/){:.external} for the bin tools needed to
+[Install MSYS2](https://www.msys2.org/) for the bin tools needed to
build TensorFlow. If MSYS2 is installed to `C:\msys64`, add
`C:\msys64\usr\bin` to your `%PATH%` environment variable. Then, using `cmd.exe`,
run:
+pacman -Syu (requires a console restart)
pacman -S git patch unzip
+pacman -S git patch unzip rsync
-### Install Visual C++ Build Tools 2019
+Note: Clang will be the preferred compiler to build TensorFlow CPU wheels on the Windows Platform starting with TF 2.16.1 The currently supported version is LLVM/clang 17.0.6.
-Install the *Visual C++ build tools 2019*. This comes with *Visual Studio 2019*
+Note: To build with Clang on Windows, it is required to install both LLVM and Visual C++ Build tools as although Windows uses clang-cl.exe as the compiler, Visual C++ Build tools are needed to link to Visual C++ libraries
+
+### Install Visual C++ Build Tools 2022
+
+Install the *Visual C++ build tools 2022*. This comes with *Visual Studio Community 2022*
but can be installed separately:
1. Go to the
- [Visual Studio downloads](https://visualstudio.microsoft.com/downloads/){:.external},
-2. Select *Redistributables and Build Tools*,
+ [Visual Studio downloads](https://visualstudio.microsoft.com/downloads/),
+2. Select *Tools for Visual Studio or Other Tools, Framework and Redistributables*,
3. Download and install:
- - *Microsoft Visual C++ 2019 Redistributable*
- - *Microsoft Build Tools 2019*
+ - *Build Tools for Visual Studio 2022*
+ - *Microsoft Visual C++ Redistributables for Visual Studio 2022*
+
+Note: TensorFlow is tested against the *Visual Studio Community 2022*.
+
+### Install LLVM
+
+1. Go to the
+ [LLVM downloads](https://github.com/llvm/llvm-project/releases/),
+2. Download and install Windows-compatible LLVM in C:/Program Files/LLVM e.g., LLVM-17.0.6-win64.exe
-Note: TensorFlow is tested against the *Visual Studio 2019*.
### Install GPU support (optional)
See the Windows [GPU support](./gpu.md) guide to install the drivers and
additional software required to run TensorFlow on a GPU.
+Note: GPU support on native-Windows is only available for 2.10 or earlier versions, starting in TF 2.11, CUDA build is not supported for Windows. For using TensorFlow GPU on Windows, you will need to build/install TensorFlow in WSL2 or use tensorflow-cpu with TensorFlow-DirectML-Plugin
+
### Download the TensorFlow source code
-Use [Git](https://git-scm.com/){:.external} to clone the
-[TensorFlow repository](https://github.com/tensorflow/tensorflow){:.external}
+Use [Git](https://git-scm.com/) to clone the
+[TensorFlow repository](https://github.com/tensorflow/tensorflow)
(`git` is installed with MSYS2):
@@ -81,8 +96,8 @@ Use [Git](https://git-scm.com/){:.external} to clone the
cd tensorflow
-The repo defaults to the `master` development branch. You can also checkout a
-[release branch](https://github.com/tensorflow/tensorflow/releases){:.external}
+The repo defaults to the `master` development branch. You can also check out a
+[release branch](https://github.com/tensorflow/tensorflow/releases)
to build:
@@ -92,11 +107,38 @@ git checkout branch_name # r1.9, r1.10, etc.
Key Point: If you're having build problems on the latest development branch, try
a release branch that is known to work.
+## Optional: Environmental Variable Set Up
+Run the following commands before running the build command to avoid issues with package creation:
+(If the below commands were set up while installing the packages, please ignore them). Run `set` to check if all the paths were set correctly, run `echo %Environmental Variable%` e.g., `echo %BAZEL_VC%` to check the path set up for a specific Environmental Variable
+
+ Python path set up issue [tensorflow:issue#59943](https://github.com/tensorflow/tensorflow/issues/59943),[tensorflow:issue#9436](https://github.com/tensorflow/tensorflow/issues/9436),[tensorflow:issue#60083](https://github.com/tensorflow/tensorflow/issues/60083)
+
+
+set PATH=path/to/python;%PATH% # [e.g. (C:/Python311)]
+set PATH=path/to/python/Scripts;%PATH% # [e.g. (C:/Python311/Scripts)]
+set PYTHON_BIN_PATH=path/to/python_virtualenv/Scripts/python.exe
+set PYTHON_LIB_PATH=path/to/python virtualenv/lib/site-packages
+set PYTHON_DIRECTORY=path/to/python_virtualenv/Scripts
+
+
+Bazel/MSVC/CLANG path set up issue [tensorflow:issue#54578](https://github.com/tensorflow/tensorflow/issues/54578)
+
+
+set BAZEL_SH=C:/msys64/usr/bin/bash.exe
+set BAZEL_VS=C:/Program Files/Microsoft Visual Studio/2022/BuildTools
+set BAZEL_VC=C:/Program Files/Microsoft Visual Studio/2022/BuildTools/VC
+set Bazel_LLVM=C:/Program Files/LLVM (explicitly tell Bazel where LLVM is installed by BAZEL_LLVM, needed while using CLANG)
+set PATH=C:/Program Files/LLVM/bin;%PATH% (Optional, needed while using CLANG as Compiler)
+
+
+## Optional: Configure the build
-## Configure the build
+TensorFlow builds are configured by the `.bazelrc` file in the repository's
+root directory. The `./configure` or `./configure.py` scripts can be used to
+adjust common settings.
-Configure your system build by running the following at the root of your
-TensorFlow source tree:
+If you need to change the configuration, run the `./configure` script from
+the repository's root directory.
python ./configure.py
@@ -111,92 +153,99 @@ differ):
View sample configuration session
python ./configure.py
-Starting local Bazel server and connecting to it...
-................
-You have bazel 0.15.0 installed.
-Please specify the location of python. [Default is C:\python36\python.exe]:
+You have bazel 6.5.0 installed.
+Please specify the location of python. [Default is C:\Python311\python.exe]:
Found possible Python library paths:
- C:\python36\lib\site-packages
-Please input the desired Python library path to use. Default is [C:\python36\lib\site-packages]
-
-Do you wish to build TensorFlow with CUDA support? [y/N]: Y
-CUDA support will be enabled for TensorFlow.
+C:\Python311\lib\site-packages
+Please input the desired Python library path to use. Default is [C:\Python311\lib\site-packages]
-Please specify the CUDA SDK version you want to use. [Leave empty to default to CUDA 9.0]:
+Do you wish to build TensorFlow with ROCm support? [y/N]:
+No ROCm support will be enabled for TensorFlow.
-Please specify the location where CUDA 9.0 toolkit is installed. Refer to README.md for more details. [Default is C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v9.0]:
+WARNING: Cannot build with CUDA support on Windows.
+Starting in TF 2.11, CUDA build is not supported for Windows. To use TensorFlow GPU on Windows, you will need to build/install TensorFlow in WSL2.
-Please specify the cuDNN version you want to use. [Leave empty to default to cuDNN 7.0]: 7.0
+Do you want to use Clang to build TensorFlow? [Y/n]:
+Add "--config=win_clang" to compile TensorFlow with CLANG.
-Please specify the location where cuDNN 7 library is installed. Refer to README.md for more details. [Default is C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v9.0]: C:\tools\cuda
+Please specify the path to clang executable. [Default is C:\Program Files\LLVM\bin\clang.EXE]:
-Please specify a list of comma-separated Cuda compute capabilities you want to build with.
-You can find the compute capability of your device at: https://developer.nvidia.com/cuda-gpus.
-Please note that each additional compute capability significantly increases your build time and binary size. [Default is: 3.5,7.0]: 3.7
+You have Clang 17.0.6 installed.
Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is /arch:AVX]:
Would you like to override eigen strong inline for some C++ compilation to reduce the compilation time? [Y/n]:
Eigen strong inline overridden.
-Configuration finished
+Would you like to interactively configure ./WORKSPACE for Android builds? [y/N]:
+Not configuring the WORKSPACE for Android builds.
+
+Preconfigured Bazel build configs. You can use any of the below by adding "--config=<>" to your build command. See .bazelrc for more details.
+ --config=mkl # Build with MKL support.
+ --config=mkl_aarch64 # Build with oneDNN and Compute Library for the Arm Architecture (ACL).
+ --config=monolithic # Config for mostly static monolithic build.
+ --config=numa # Build with NUMA support.
+ --config=dynamic_kernels # (Experimental) Build kernels into separate shared objects.
+ --config=v1 # Build with TensorFlow 1 API instead of TF 2 API.
+Preconfigured Bazel build configs to DISABLE default on features:
+ --config=nogcp # Disable GCP support.
+ --config=nonccl # Disable NVIDIA NCCL support.
-### Configuration options
-
-For [GPU support](./gpu.md), specify the versions of CUDA and cuDNN. If your
-system has multiple versions of CUDA or cuDNN installed, explicitly set the
-version instead of relying on the default. `./configure.py` creates symbolic
-links to your system's CUDA libraries—so if you update your CUDA library paths,
-this configuration step must be run again before building.
-
-Note: Starting with TensorFlow 1.6, binaries use AVX instructions which may not
-run on older CPUs.
-
+## Build and install the pip package
-## Build the pip package
+The pip package is built in two steps. A `bazel build` command creates a
+"package-builder" program. You then run the package-builder to create the
+package.
-### TensorFlow 2.x
+### Build the package-builder
tensorflow:master repo has been updated to build 2.x by default.
[Install Bazel](https://docs.bazel.build/versions/master/install.html) and use
-`bazel build ` to create the TensorFlow package.
+`bazel build ` to create the TensorFlow package-builder.
-bazel build //tensorflow/tools/pip_package:build_pip_package
+bazel build //tensorflow/tools/pip_package:wheel
+#### CPU-only
-### TensorFlow 1.x
-
-To build the 1.x version of TensorFlow from master, use
-`bazel build --config=v1` to create a TensorFlow 1.x package.
+Use `bazel` to make the TensorFlow package builder with CPU-only support:
+##### Build with MSVC
-bazel build --config=v1 //tensorflow/tools/pip_package:build_pip_package
+bazel build --config=opt --repo_env=TF_PYTHON_VERSION=3.11 //tensorflow/tools/pip_package:wheel --repo_env=WHEEL_NAME=tensorflow_cpu
-#### CPU-only
-
-Use `bazel` to make the TensorFlow package builder with CPU-only support:
+##### Build with CLANG
+Use --config=`win_clang` to build TenorFlow with the CLANG Compiler:
-bazel build --config=opt //tensorflow/tools/pip_package:build_pip_package
+bazel build --config=win_clang --repo_env=TF_PYTHON_VERSION=3.11 //tensorflow/tools/pip_package:wheel --repo_env=WHEEL_NAME=tensorflow_cpu
#### GPU support
+Note: GPU support on native-Windows is only available for 2.10 or earlier versions, starting in TF 2.11, CUDA build is not supported for Windows. For using TensorFlow GPU on Windows, you will need to build/install TensorFlow in WSL2 or use tensorflow-cpu with TensorFlow-DirectML-Plugin
+
To make the TensorFlow package builder with GPU support:
bazel build --config=opt --config=cuda --define=no_tensorflow_py_deps=true //tensorflow/tools/pip_package:build_pip_package
+Commands to clean the bazel cache to resolve errors due to invalid or outdated cached data, bazel clean with --expunge flag removes files permanently
+
+
+bazel clean
+bazel clean --expunge
+
+
#### Bazel build options
-Use this option when building to avoid issue with package creation:
+Use this option when building to avoid issues with package creation:
[tensorflow:issue#22390](https://github.com/tensorflow/tensorflow/issues/22390)
@@ -215,30 +264,37 @@ to suppress nvcc warning messages.
### Build the package
-The `bazel build` command creates an executable named `build_pip_package`—this
-is the program that builds the `pip` package. For example, the following builds
-a `.whl` package in the `C:/tmp/tensorflow_pkg` directory:
+To build a pip package, you need to specify the --repo_env=WHEEL_NAME flag.
+Depending on the provided name, the package will be created. For example:
-
-bazel-bin\tensorflow\tools\pip_package\build_pip_package C:/tmp/tensorflow_pkg
+To build tensorflow CPU package:
+
+bazel build //tensorflow/tools/pip_package:wheel --repo_env=WHEEL_NAME=tensorflow_cpu
+
+
+To build nightly package, set `tf_nightly` instead of `tensorflow`, e.g.
+to build CPU nightly package:
+
+bazel build //tensorflow/tools/pip_package:wheel --repo_env=WHEEL_NAME=tf_nightly_cpu
+
+
+As a result, generated wheel will be located in
+
+bazel-bin/tensorflow/tools/pip_package/wheel_house/
-Although it is possible to build both CUDA and non-CUDA configs under the
-same source tree, we recommend running `bazel clean` when switching between
-these two configurations in the same source tree.
### Install the package
The filename of the generated `.whl` file depends on the TensorFlow version and
-your platform. Use `pip3 install` to install the package, for example:
+your platform. Use `pip install` to install the package, for example:
-
-pip3 install C:/tmp/tensorflow_pkg/tensorflow-version-cp36-cp36m-win_amd64.whl
+
+pip install bazel-bin/tensorflow/tools/pip_package/wheel_house/tensorflow-version-tags.whl
Success: TensorFlow is now installed.
-
## Build using the MSYS shell
TensorFlow can also be built using the MSYS shell. Make the changes listed
@@ -260,12 +316,12 @@ considered a Unix absolute path since it starts with a slash.)
Add the Bazel and Python installation directories to your `$PATH` environmental
variable. If Bazel is installed to `C:\tools\bazel.exe`, and Python to
-`C:\Python36\python.exe`, set your `PATH` with:
+`C:\Python\python.exe`, set your `PATH` with:
# Use Unix-style with ':' as separator
export PATH="/c/tools:$PATH"
-export PATH="/c/Python36:$PATH"
+export PATH="/c/path/to/Python:$PATH"
For GPU support, add the CUDA and cuDNN bin directories to your `$PATH`:
@@ -276,6 +332,8 @@ For GPU support, add the CUDA and cuDNN bin directories to your `$PATH`:
export PATH="/c/tools/cuda/bin:$PATH"
+Note: Starting in TF 2.11, CUDA build is not supported for Windows. For using TensorFlow GPU on Windows, you will need to build/install TensorFlow in WSL2 or use tensorflow-cpu with TensorFlow-DirectML-Plugin
+
## Tested build configurations
@@ -283,6 +341,19 @@ For GPU support, add the CUDA and cuDNN bin directories to your `$PATH`:
| Version | Python version | Compiler | Build tools |
|---|
+| tensorflow-2.20.0 | 3.9-3.13 | CLANG 18.1.4 | Bazel 7.4.1 |
+| tensorflow-2.19.0 | 3.9-3.12 | CLANG 18.1.4 | Bazel 6.5.0 |
+| tensorflow-2.18.0 | 3.9-3.12 | CLANG 17.0.6 | Bazel 6.5.0 |
+| tensorflow-2.17.0 | 3.9-3.12 | CLANG 17.0.6 | Bazel 6.5.0 |
+| tensorflow-2.16.1 | 3.9-3.12 | CLANG 17.0.6 | Bazel 6.5.0 |
+| tensorflow-2.15.0 | 3.9-3.11 | MSVC 2019 | Bazel 6.1.0 |
+| tensorflow-2.14.0 | 3.9-3.11 | MSVC 2019 | Bazel 6.1.0 |
+| tensorflow-2.12.0 | 3.8-3.11 | MSVC 2019 | Bazel 5.3.0 |
+| tensorflow-2.11.0 | 3.7-3.10 | MSVC 2019 | Bazel 5.3.0 |
+| tensorflow-2.10.0 | 3.7-3.10 | MSVC 2019 | Bazel 5.1.1 |
+| tensorflow-2.9.0 | 3.7-3.10 | MSVC 2019 | Bazel 5.0.0 |
+| tensorflow-2.8.0 | 3.7-3.10 | MSVC 2019 | Bazel 4.2.1 |
+| tensorflow-2.7.0 | 3.7-3.9 | MSVC 2019 | Bazel 3.7.2 |
| tensorflow-2.6.0 | 3.6-3.9 | MSVC 2019 | Bazel 3.7.2 |
| tensorflow-2.5.0 | 3.6-3.9 | MSVC 2019 | Bazel 3.7.2 |
| tensorflow-2.4.0 | 3.6-3.8 | MSVC 2019 | Bazel 3.1.0 |
@@ -309,9 +380,14 @@ For GPU support, add the CUDA and cuDNN bin directories to your `$PATH`:
### GPU
+Note: GPU support on native-Windows is only available for 2.10 or earlier versions, starting in TF 2.11, CUDA build is not supported for Windows. For using TensorFlow GPU on Windows, you will need to build/install TensorFlow in WSL2 or use tensorflow-cpu with TensorFlow-DirectML-Plugin
| Version | Python version | Compiler | Build tools | cuDNN | CUDA |
|---|
+| tensorflow_gpu-2.10.0 | 3.7-3.10 | MSVC 2019 | Bazel 5.1.1 | 8.1 | 11.2 |
+| tensorflow_gpu-2.9.0 | 3.7-3.10 | MSVC 2019 | Bazel 5.0.0 | 8.1 | 11.2 |
+| tensorflow_gpu-2.8.0 | 3.7-3.10 | MSVC 2019 | Bazel 4.2.1 | 8.1 | 11.2 |
+| tensorflow_gpu-2.7.0 | 3.7-3.9 | MSVC 2019 | Bazel 3.7.2 | 8.1 | 11.2 |
| tensorflow_gpu-2.6.0 | 3.6-3.9 | MSVC 2019 | Bazel 3.7.2 | 8.1 | 11.2 |
| tensorflow_gpu-2.5.0 | 3.6-3.9 | MSVC 2019 | Bazel 3.7.2 | 8.1 | 11.2 |
| tensorflow_gpu-2.4.0 | 3.6-3.8 | MSVC 2019 | Bazel 3.1.0 | 8.0 | 11.0 |
diff --git a/site/en/io/README.md b/site/en/io/README.md
deleted file mode 100644
index 24249b7ac03..00000000000
--- a/site/en/io/README.md
+++ /dev/null
@@ -1,5 +0,0 @@
-Welcome to the warp zone!
-
-# TensorFlow SIG IO
-
-These docs are available here: https://github.com/tensorflow/io/tree/master/docs
diff --git a/site/en/js/README.md b/site/en/js/README.md
deleted file mode 100644
index 5a3a34677b4..00000000000
--- a/site/en/js/README.md
+++ /dev/null
@@ -1,5 +0,0 @@
-Welcome to the warp zone!
-
-# TensorFlow.js
-
-These docs are available here: https://github.com/tensorflow/tfjs-website/tree/master/docs
diff --git a/site/en/lattice/README.md b/site/en/lattice/README.md
deleted file mode 100644
index 27ce3c8ce55..00000000000
--- a/site/en/lattice/README.md
+++ /dev/null
@@ -1,5 +0,0 @@
-Welcome to the warp zone!
-
-# TensorFlow Lattice
-
-These docs are available here: https://github.com/tensorflow/lattice/tree/master/docs
diff --git a/site/en/lite/README.md b/site/en/lite/README.md
deleted file mode 100644
index 43c3249dc7b..00000000000
--- a/site/en/lite/README.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Welcome to the warp zone!
-
-# TensorFlow Lite
-
-These docs are available here:
-https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/g3doc
diff --git a/site/en/mlir/README.md b/site/en/mlir/README.md
deleted file mode 100644
index 614f9f693c8..00000000000
--- a/site/en/mlir/README.md
+++ /dev/null
@@ -1,5 +0,0 @@
-Welcome to the warp zone!
-
-# TensorFlow MLIR
-
-These docs are available here: https://github.com/tensorflow/tensorflow/tree/master/tensorflow/compiler/mlir/g3doc
diff --git a/site/en/neural_structured_learning/README.md b/site/en/neural_structured_learning/README.md
deleted file mode 100644
index 85c905af170..00000000000
--- a/site/en/neural_structured_learning/README.md
+++ /dev/null
@@ -1,5 +0,0 @@
-Welcome to the warp zone!
-
-# Neural Structured Learning
-
-These docs are available here: https://github.com/tensorflow/neural-structured-learning/tree/master/g3doc
diff --git a/site/en/probability/README.md b/site/en/probability/README.md
deleted file mode 100644
index c17e5ba447b..00000000000
--- a/site/en/probability/README.md
+++ /dev/null
@@ -1,5 +0,0 @@
-Welcome to the warp zone!
-
-# TensorFlow Probability
-
-These docs are available here: https://github.com/tensorflow/probability/tree/master/tensorflow_probability/g3doc
diff --git a/site/en/quantum/README.md b/site/en/quantum/README.md
deleted file mode 100644
index 78580b3dfd8..00000000000
--- a/site/en/quantum/README.md
+++ /dev/null
@@ -1,5 +0,0 @@
-Welcome to the warp zone!
-
-# TensorFlow Quantum
-
-These docs are available here: https://github.com/tensorflow/quantum/tree/master/docs
diff --git a/site/en/r1/guide/autograph.ipynb b/site/en/r1/guide/autograph.ipynb
index 5d8d7c97999..64d631a52b3 100644
--- a/site/en/r1/guide/autograph.ipynb
+++ b/site/en/r1/guide/autograph.ipynb
@@ -66,7 +66,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
@@ -78,7 +78,7 @@
"id": "CydFK2CL7ZHA"
},
"source": [
- "[AutoGraph](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/autograph/) helps you write complicated graph code using normal Python. Behind the scenes, AutoGraph automatically transforms your code into the equivalent [TensorFlow graph code](https://www.tensorflow.org/r1/guide/graphs). AutoGraph already supports much of the Python language, and that coverage continues to grow. For a list of supported Python language features, see the [Autograph capabilities and limitations](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/autograph/g3doc/reference/limitations.md)."
+ "[AutoGraph](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/autograph/) helps you write complicated graph code using normal Python. Behind the scenes, AutoGraph automatically transforms your code into the equivalent [TensorFlow graph code](https://www.tensorflow.org/r1/guide/graphs). AutoGraph already supports much of the Python language, and that coverage continues to grow. For a list of supported Python language features, see the [Autograph capabilities and limitations](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/autograph/g3doc/reference/limitations.md)."
]
},
{
@@ -241,7 +241,7 @@
"id": "m-jWmsCmByyw"
},
"source": [
- "AutoGraph supports common Python statements like `while`, `for`, `if`, `break`, and `return`, with support for nesting. Compare this function with the complicated graph verson displayed in the following code blocks:"
+ "AutoGraph supports common Python statements like `while`, `for`, `if`, `break`, and `return`, with support for nesting. Compare this function with the complicated graph version displayed in the following code blocks:"
]
},
{
diff --git a/site/en/r1/guide/checkpoints.md b/site/en/r1/guide/checkpoints.md
index 682631449d5..41544f52b25 100644
--- a/site/en/r1/guide/checkpoints.md
+++ b/site/en/r1/guide/checkpoints.md
@@ -56,8 +56,8 @@ Suppose you call the Estimator's `train` method. For example:
```python
classifier.train(
- input_fn=lambda:train_input_fn(train_x, train_y, batch_size=100),
- steps=200)
+ input_fn=lambda: train_input_fn(train_x, train_y, batch_size=100),
+ steps=200)
```
As suggested by the following diagrams, the first call to `train`
diff --git a/site/en/r1/guide/custom_estimators.md b/site/en/r1/guide/custom_estimators.md
index 87dce26a0dc..7bbf3573909 100644
--- a/site/en/r1/guide/custom_estimators.md
+++ b/site/en/r1/guide/custom_estimators.md
@@ -592,10 +592,10 @@ function for custom Estimators; everything else is the same.
For more details, be sure to check out:
* The
- [official TensorFlow implementation of MNIST](https://github.com/tensorflow/models/tree/master/official/r1/mnist),
+ [official TensorFlow implementation of MNIST](https://github.com/tensorflow/models/tree/r1.15/official/r1/mnist),
which uses a custom estimator.
* The TensorFlow
- [official models repository](https://github.com/tensorflow/models/tree/master/official),
+ [official models repository](https://github.com/tensorflow/models/tree/r1.15/official),
which contains more curated examples using custom estimators.
* This [TensorBoard video](https://youtu.be/eBbEDRsCmv4), which introduces
TensorBoard.
diff --git a/site/en/r1/guide/datasets.md b/site/en/r1/guide/datasets.md
index b1ed1b6e113..d7c38bf2f92 100644
--- a/site/en/r1/guide/datasets.md
+++ b/site/en/r1/guide/datasets.md
@@ -437,7 +437,7 @@ dataset = dataset.batch(32)
iterator = dataset.make_initializable_iterator()
# You can feed the initializer with the appropriate filenames for the current
-# phase of execution, e.g. training vs. validation.
+# phase of execution, e.g., training vs. validation.
# Initialize `iterator` with training data.
training_filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"]
@@ -639,7 +639,7 @@ TODO(mrry): Add this section.
The simplest form of batching stacks `n` consecutive elements of a dataset into
a single element. The `Dataset.batch()` transformation does exactly this, with
the same constraints as the `tf.stack()` operator, applied to each component
-of the elements: i.e. for each component *i*, all elements must have a tensor
+of the elements: i.e., for each component *i*, all elements must have a tensor
of the exact same shape.
```python
diff --git a/site/en/r1/guide/debugger.md b/site/en/r1/guide/debugger.md
index 2b4b6497ec4..963765b97db 100644
--- a/site/en/r1/guide/debugger.md
+++ b/site/en/r1/guide/debugger.md
@@ -10,7 +10,7 @@ due to TensorFlow's computation-graph paradigm.
This guide focuses on the command-line interface (CLI) of `tfdbg`. For guide on
how to use the graphical user interface (GUI) of tfdbg, i.e., the
**TensorBoard Debugger Plugin**, please visit
-[its README](https://github.com/tensorflow/tensorboard/blob/master/tensorboard/plugins/debugger/README.md).
+[its README](https://github.com/tensorflow/tensorboard/blob/r1.15/tensorboard/plugins/debugger/README.md).
Note: The TensorFlow debugger uses a
[curses](https://en.wikipedia.org/wiki/Curses_\(programming_library\))-based text
@@ -35,7 +35,7 @@ TensorFlow. Later sections of this document describe how to use **tfdbg** with
higher-level APIs of TensorFlow, including `tf.estimator`, `tf.keras` / `keras`
and `tf.contrib.slim`. To *observe* such an issue, run the following command
without the debugger (the source code can be found
-[here](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/debug/examples/v1/debug_mnist.py)):
+[here](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/debug/examples/v1/debug_mnist.py)):
python -m tensorflow.python.debug.examples.v1.debug_mnist
@@ -64,7 +64,7 @@ numeric problem first surfaced.
To add support for tfdbg in our example, all that is needed is to add the
following lines of code and wrap the Session object with a debugger wrapper.
This code is already added in
-[debug_mnist.py](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/debug/examples/v1/debug_mnist.py),
+[debug_mnist.py](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/debug/examples/v1/debug_mnist.py),
so you can activate tfdbg CLI with the `--debug` flag at the command line.
```python
@@ -370,7 +370,7 @@ traceback of the node's construction.
From the traceback, you can see that the op is constructed at the following
line:
-[`debug_mnist.py`](https://www.tensorflow.org/code/tensorflow/python/debug/examples/v1/debug_mnist.py):
+[`debug_mnist.py`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/debug/examples/v1/debug_mnist.py):
```python
diff = y_ * tf.log(y)
@@ -457,7 +457,7 @@ accuracy_score = classifier.evaluate(eval_input_fn,
predict_results = classifier.predict(predict_input_fn, hooks=hooks)
```
-[debug_tflearn_iris.py](https://www.tensorflow.org/code/tensorflow/python/debug/examples/v1/debug_tflearn_iris.py),
+[debug_tflearn_iris.py](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/debug/examples/v1/debug_tflearn_iris.py),
contains a full example of how to use the tfdbg with `Estimator`s. To run this
example, do:
@@ -501,7 +501,7 @@ TensorFlow backend. You just need to replace `tf.keras.backend` with
## Debugging tf-slim with TFDBG
TFDBG supports debugging of training and evaluation with
-[tf-slim](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/slim).
+[tf-slim](https://github.com/tensorflow/tensorflow/tree/r1.15/tensorflow/contrib/slim).
As detailed below, training and evaluation require slightly different debugging
workflows.
@@ -605,7 +605,7 @@ The `watch_fn` argument accepts a `Callable` that allows you to configure what
If your model code is written in C++ or other languages, you can also
modify the `debug_options` field of `RunOptions` to generate debug dumps that
can be inspected offline. See
-[the proto definition](https://www.tensorflow.org/code/tensorflow/core/protobuf/debug.proto)
+[the proto definition](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/protobuf/debug.proto)
for more details.
### Debugging Remotely-Running Estimators
@@ -648,7 +648,7 @@ python -m tensorflow.python.debug.cli.offline_analyzer \
model, check out
1. The profiling mode of tfdbg: `tfdbg> run -p`.
- 2. [tfprof](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/core/profiler)
+ 2. [tfprof](https://github.com/tensorflow/tensorflow/tree/r1.15/tensorflow/core/profiler)
and other profiling tools for TensorFlow.
**Q**: _How do I link tfdbg against my `Session` in Bazel? Why do I see an
@@ -808,4 +808,4 @@ tensor dumps.
and conditional breakpoints, and tying tensors to their
graph-construction source code, all in the browser environment.
To get started, please visit
- [its README](https://github.com/tensorflow/tensorboard/blob/master/tensorboard/plugins/debugger/README.md).
+ [its README](https://github.com/tensorflow/tensorboard/blob/r1.15/tensorboard/plugins/debugger/README.md).
diff --git a/site/en/r1/guide/distribute_strategy.ipynb b/site/en/r1/guide/distribute_strategy.ipynb
index f6d85912e16..4dd502d331b 100644
--- a/site/en/r1/guide/distribute_strategy.ipynb
+++ b/site/en/r1/guide/distribute_strategy.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
@@ -118,7 +118,7 @@
"## Types of strategies\n",
"`tf.distribute.Strategy` intends to cover a number of use cases along different axes. Some of these combinations are currently supported and others will be added in the future. Some of these axes are:\n",
"\n",
- "* Syncronous vs asynchronous training: These are two common ways of distributing training with data parallelism. In sync training, all workers train over different slices of input data in sync, and aggregating gradients at each step. In async training, all workers are independently training over the input data and updating variables asynchronously. Typically sync training is supported via all-reduce and async through parameter server architecture.\n",
+ "* Synchronous vs asynchronous training: These are two common ways of distributing training with data parallelism. In sync training, all workers train over different slices of input data in sync, and aggregating gradients at each step. In async training, all workers are independently training over the input data and updating variables asynchronously. Typically sync training is supported via all-reduce and async through parameter server architecture.\n",
"* Hardware platform: Users may want to scale their training onto multiple GPUs on one machine, or multiple machines in a network (with 0 or more GPUs each), or on Cloud TPUs.\n",
"\n",
"In order to support these use cases, we have 4 strategies available. In the next section we will talk about which of these are supported in which scenarios in TF."
@@ -223,7 +223,7 @@
"id": "KY1nJHNkMl7b"
},
"source": [
- "This will create a `CentralStorageStrategy` instance which will use all visible GPUs and CPU. Update to variables on replicas will be aggragated before being applied to variables."
+ "This will create a `CentralStorageStrategy` instance which will use all visible GPUs and CPU. Update to variables on replicas will be aggregated before being applied to variables."
]
},
{
@@ -245,7 +245,7 @@
"\n",
"`tf.distribute.experimental.MultiWorkerMirroredStrategy` is very similar to `MirroredStrategy`. It implements synchronous distributed training across multiple workers, each with potentially multiple GPUs. Similar to `MirroredStrategy`, it creates copies of all variables in the model on each device across all workers.\n",
"\n",
- "It uses [CollectiveOps](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/ops/collective_ops.py) as the multi-worker all-reduce communication method used to keep variables in sync. A collective op is a single op in the TensorFlow graph which can automatically choose an all-reduce algorithm in the TensorFlow runtime according to hardware, network topology and tensor sizes.\n",
+ "It uses [CollectiveOps](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/ops/collective_ops.py) as the multi-worker all-reduce communication method used to keep variables in sync. A collective op is a single op in the TensorFlow graph which can automatically choose an all-reduce algorithm in the TensorFlow runtime according to hardware, network topology and tensor sizes.\n",
"\n",
"It also implements additional performance optimizations. For example, it includes a static optimization that converts multiple all-reductions on small tensors into fewer all-reductions on larger tensors. In addition, we are designing it to have a plugin architecture - so that in the future, users will be able to plugin algorithms that are better tuned for their hardware. Note that collective ops also implement other collective operations such as broadcast and all-gather.\n",
"\n",
@@ -371,7 +371,7 @@
"id": "hQv1lm9UPDFy"
},
"source": [
- "So far we've talked about what are the different stategies available and how you can instantiate them. In the next few sections, we will talk about the different ways in which you can use them to distribute your training. We will show short code snippets in this guide and link off to full tutorials which you can run end to end."
+ "So far we've talked about what are the different strategies available and how you can instantiate them. In the next few sections, we will talk about the different ways in which you can use them to distribute your training. We will show short code snippets in this guide and link off to full tutorials which you can run end to end."
]
},
{
@@ -490,8 +490,8 @@
"Here is a list of tutorials and examples that illustrate the above integration end to end with Keras:\n",
"\n",
"1. [Tutorial](../tutorials/distribute/keras.ipynb) to train MNIST with `MirroredStrategy`.\n",
- "2. Official [ResNet50](https://github.com/tensorflow/models/blob/master/official/vision/image_classification/resnet_imagenet_main.py) training with ImageNet data using `MirroredStrategy`.\n",
- "3. [ResNet50](https://github.com/tensorflow/tpu/blob/master/models/experimental/resnet50_keras/resnet50.py) trained with Imagenet data on Cloud TPus with `TPUStrategy`."
+ "2. Official [ResNet50](https://github.com/tensorflow/models/blob/r1.15/official/vision/image_classification/resnet_imagenet_main.py) training with ImageNet data using `MirroredStrategy`.\n",
+ "3. [ResNet50](https://github.com/tensorflow/tpu/blob/1.15/models/experimental/resnet50_keras/resnet50.py) trained with Imagenet data on Cloud TPus with `TPUStrategy`."
]
},
{
@@ -595,9 +595,9 @@
"### Examples and Tutorials\n",
"Here are some examples that show end to end usage of various strategies with Estimator:\n",
"\n",
- "1. [End to end example](https://github.com/tensorflow/ecosystem/tree/master/distribution_strategy) for multi worker training in tensorflow/ecosystem using Kuberentes templates. This example starts with a Keras model and converts it to an Estimator using the `tf.keras.estimator.model_to_estimator` API.\n",
- "2. Official [ResNet50](https://github.com/tensorflow/models/blob/master/official/r1/resnet/imagenet_main.py) model, which can be trained using either `MirroredStrategy` or `MultiWorkerMirroredStrategy`.\n",
- "3. [ResNet50](https://github.com/tensorflow/tpu/blob/master/models/experimental/distribution_strategy/resnet_estimator.py) example with TPUStrategy."
+ "1. [End to end example](https://github.com/tensorflow/ecosystem/tree/r1.15/distribution_strategy) for multi worker training in tensorflow/ecosystem using Kuberentes templates. This example starts with a Keras model and converts it to an Estimator using the `tf.keras.estimator.model_to_estimator` API.\n",
+ "2. Official [ResNet50](https://github.com/tensorflow/models/blob/r1.15/official/r1/resnet/imagenet_main.py) model, which can be trained using either `MirroredStrategy` or `MultiWorkerMirroredStrategy`.\n",
+ "3. [ResNet50](https://github.com/tensorflow/tpu/blob/1.15/models/experimental/distribution_strategy/resnet_estimator.py) example with TPUStrategy."
]
},
{
@@ -607,7 +607,7 @@
},
"source": [
"## Using `tf.distribute.Strategy` with custom training loops\n",
- "As you've seen, using `tf.distrbute.Strategy` with high level APIs is only a couple lines of code change. With a little more effort, `tf.distrbute.Strategy` can also be used by other users who are not using these frameworks.\n",
+ "As you've seen, using `tf.distribute.Strategy` with high level APIs is only a couple lines of code change. With a little more effort, `tf.distribute.Strategy` can also be used by other users who are not using these frameworks.\n",
"\n",
"TensorFlow is used for a wide variety of use cases and some users (such as researchers) require more flexibility and control over their training loops. This makes it hard for them to use the high level frameworks such as Estimator or Keras. For instance, someone using a GAN may want to take a different number of generator or discriminator steps each round. Similarly, the high level frameworks are not very suitable for Reinforcement Learning training. So these users will usually write their own training loops.\n",
"\n",
diff --git a/site/en/r1/guide/eager.ipynb b/site/en/r1/guide/eager.ipynb
index 547e1b02977..f76acb4b702 100644
--- a/site/en/r1/guide/eager.ipynb
+++ b/site/en/r1/guide/eager.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
@@ -95,7 +95,7 @@
"\n",
"Eager execution supports most TensorFlow operations and GPU acceleration. For a\n",
"collection of examples running in eager execution, see:\n",
- "[tensorflow/contrib/eager/python/examples](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/eager/python/examples).\n",
+ "[tensorflow/contrib/eager/python/examples](https://github.com/tensorflow/tensorflow/tree/r1.15/tensorflow/contrib/eager/python/examples).\n",
"\n",
"Note: Some models may experience increased overhead with eager execution\n",
"enabled. Performance improvements are ongoing, but please\n",
@@ -702,7 +702,7 @@
},
"outputs": [],
"source": [
- "if tf.test.is_gpu_available():\n",
+ "if tf.config.list_physical_devices('GPU'):\n",
" with tf.device(\"gpu:0\"):\n",
" v = tf.Variable(tf.random_normal([1000, 1000]))\n",
" v = None # v no longer takes up GPU memory"
@@ -1116,7 +1116,7 @@
" print(\"CPU: {} secs\".format(measure(tf.random_normal(shape), steps)))\n",
"\n",
"# Run on GPU, if available:\n",
- "if tf.test.is_gpu_available():\n",
+ "if tf.config.list_physical_devices('GPU'):\n",
" with tf.device(\"/gpu:0\"):\n",
" print(\"GPU: {} secs\".format(measure(tf.random_normal(shape), steps)))\n",
"else:\n",
@@ -1141,7 +1141,7 @@
},
"outputs": [],
"source": [
- "if tf.test.is_gpu_available():\n",
+ "if tf.config.list_physical_devices('GPU'):\n",
" x = tf.random_normal([10, 10])\n",
"\n",
" x_gpu0 = x.gpu()\n",
@@ -1160,7 +1160,7 @@
"### Benchmarks\n",
"\n",
"For compute-heavy models, such as\n",
- "[ResNet50](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/eager/python/examples/resnet50)\n",
+ "[ResNet50](https://github.com/tensorflow/tensorflow/tree/r1.15/tensorflow/contrib/eager/python/examples/resnet50)\n",
"training on a GPU, eager execution performance is comparable to graph execution.\n",
"But this gap grows larger for models with less computation and there is work to\n",
"be done for optimizing hot code paths for models with lots of small operations."
@@ -1225,7 +1225,7 @@
"production deployment. Use `tf.train.Checkpoint` to save and restore model\n",
"variables, this allows movement between eager and graph execution environments.\n",
"See the examples in:\n",
- "[tensorflow/contrib/eager/python/examples](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/eager/python/examples).\n"
+ "[tensorflow/contrib/eager/python/examples](https://github.com/tensorflow/tensorflow/tree/r1.15/tensorflow/contrib/eager/python/examples).\n"
]
},
{
diff --git a/site/en/r1/guide/extend/architecture.md b/site/en/r1/guide/extend/architecture.md
index 1f2ac53066f..0753824e15e 100644
--- a/site/en/r1/guide/extend/architecture.md
+++ b/site/en/r1/guide/extend/architecture.md
@@ -34,7 +34,7 @@ This document focuses on the following layers:
* **Client**:
* Defines the computation as a dataflow graph.
* Initiates graph execution using a [**session**](
- https://www.tensorflow.org/code/tensorflow/python/client/session.py).
+ https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/client/session.py).
* **Distributed Master**
* Prunes a specific subgraph from the graph, as defined by the arguments
to Session.run().
@@ -144,8 +144,8 @@ The distributed master then ships the graph pieces to the distributed tasks.
### Code
-* [MasterService API definition](https://www.tensorflow.org/code/tensorflow/core/protobuf/master_service.proto)
-* [Master interface](https://www.tensorflow.org/code/tensorflow/core/distributed_runtime/master_interface.h)
+* [MasterService API definition](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/protobuf/master_service.proto)
+* [Master interface](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/distributed_runtime/master_interface.h)
## Worker Service
@@ -178,7 +178,7 @@ For transfers between tasks, TensorFlow uses multiple protocols, including:
We also have preliminary support for NVIDIA's NCCL library for multi-GPU
communication, see:
-[`tf.contrib.nccl`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/ops/nccl_ops.py).
+[`tf.contrib.nccl`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/ops/nccl_ops.py).
 @@ -186,9 +186,9 @@ communication, see:
### Code
-* [WorkerService API definition](https://www.tensorflow.org/code/tensorflow/core/protobuf/worker_service.proto)
-* [Worker interface](https://www.tensorflow.org/code/tensorflow/core/distributed_runtime/worker_interface.h)
-* [Remote rendezvous (for Send and Recv implementations)](https://www.tensorflow.org/code/tensorflow/core/distributed_runtime/rpc/rpc_rendezvous_mgr.h)
+* [WorkerService API definition](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/protobuf/worker_service.proto)
+* [Worker interface](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/distributed_runtime/worker_interface.h)
+* [Remote rendezvous (for Send and Recv implementations)](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/distributed_runtime/rpc/rpc_rendezvous_mgr.h)
## Kernel Implementations
@@ -199,7 +199,7 @@ Many of the operation kernels are implemented using Eigen::Tensor, which uses
C++ templates to generate efficient parallel code for multicore CPUs and GPUs;
however, we liberally use libraries like cuDNN where a more efficient kernel
implementation is possible. We have also implemented
-[quantization](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/g3doc/performance/post_training_quantization.md), which enables
+[quantization](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/lite/g3doc/performance/post_training_quantization.md), which enables
faster inference in environments such as mobile devices and high-throughput
datacenter applications, and use the
[gemmlowp](https://github.com/google/gemmlowp) low-precision matrix library to
@@ -215,4 +215,4 @@ experimental implementation of automatic kernel fusion.
### Code
-* [`OpKernel` interface](https://www.tensorflow.org/code/tensorflow/core/framework/op_kernel.h)
+* [`OpKernel` interface](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op_kernel.h)
diff --git a/site/en/r1/guide/extend/bindings.md b/site/en/r1/guide/extend/bindings.md
index 9c10e90840f..7daa2212106 100644
--- a/site/en/r1/guide/extend/bindings.md
+++ b/site/en/r1/guide/extend/bindings.md
@@ -112,11 +112,11 @@ There are a few ways to get a list of the `OpDef`s for the registered ops:
to interpret the `OpDef` messages.
- The C++ function `OpRegistry::Global()->GetRegisteredOps()` returns the same
list of all registered `OpDef`s (defined in
- [`tensorflow/core/framework/op.h`](https://www.tensorflow.org/code/tensorflow/core/framework/op.h)). This can be used to write the generator
+ [`tensorflow/core/framework/op.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op.h)). This can be used to write the generator
in C++ (particularly useful for languages that do not have protocol buffer
support).
- The ASCII-serialized version of that list is periodically checked in to
- [`tensorflow/core/ops/ops.pbtxt`](https://www.tensorflow.org/code/tensorflow/core/ops/ops.pbtxt) by an automated process.
+ [`tensorflow/core/ops/ops.pbtxt`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/ops/ops.pbtxt) by an automated process.
The `OpDef` specifies the following:
@@ -159,7 +159,7 @@ between the generated code and the `OpDef`s checked into the repository, but is
useful for languages where code is expected to be generated ahead of time like
`go get` for Go and `cargo ops` for Rust. At the other end of the spectrum, for
some languages the code could be generated dynamically from
-[`tensorflow/core/ops/ops.pbtxt`](https://www.tensorflow.org/code/tensorflow/core/ops/ops.pbtxt).
+[`tensorflow/core/ops/ops.pbtxt`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/ops/ops.pbtxt).
#### Handling Constants
@@ -228,4 +228,4 @@ At this time, support for gradients, functions and control flow operations ("if"
and "while") is not available in languages other than Python. This will be
updated when the [C API] provides necessary support.
-[C API]: https://www.tensorflow.org/code/tensorflow/c/c_api.h
+[C API]: https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/c/c_api.h
diff --git a/site/en/r1/guide/extend/filesystem.md b/site/en/r1/guide/extend/filesystem.md
index 4d34c07102e..2d6ea0c4645 100644
--- a/site/en/r1/guide/extend/filesystem.md
+++ b/site/en/r1/guide/extend/filesystem.md
@@ -54,7 +54,7 @@ To implement a custom filesystem plugin, you must do the following:
### The FileSystem interface
The `FileSystem` interface is an abstract C++ interface defined in
-[file_system.h](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/file_system.h).
+[file_system.h](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/file_system.h).
An implementation of the `FileSystem` interface should implement all relevant
the methods defined by the interface. Implementing the interface requires
defining operations such as creating `RandomAccessFile`, `WritableFile`, and
@@ -70,26 +70,26 @@ involves calling `stat()` on the file and then returns the filesize as reported
by the return of the stat object. Similarly, for the `HDFSFileSystem`
implementation, these calls simply delegate to the `libHDFS` implementation of
similar functionality, such as `hdfsDelete` for
-[DeleteFile](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/hadoop/hadoop_file_system.cc#L386).
+[DeleteFile](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/hadoop/hadoop_file_system.cc#L386).
We suggest looking through these code examples to get an idea of how different
filesystem implementations call their existing libraries. Examples include:
* [POSIX
- plugin](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/posix/posix_file_system.h)
+ plugin](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/posix/posix_file_system.h)
* [HDFS
- plugin](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/hadoop/hadoop_file_system.h)
+ plugin](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/hadoop/hadoop_file_system.h)
* [GCS
- plugin](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/cloud/gcs_file_system.h)
+ plugin](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/cloud/gcs_file_system.h)
* [S3
- plugin](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/s3/s3_file_system.h)
+ plugin](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/s3/s3_file_system.h)
#### The File interfaces
Beyond operations that allow you to query and manipulate files and directories
in a filesystem, the `FileSystem` interface requires you to implement factories
that return implementations of abstract objects such as the
-[RandomAccessFile](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/file_system.h#L223),
+[RandomAccessFile](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/file_system.h#L223),
the `WritableFile`, so that TensorFlow code and read and write to files in that
`FileSystem` implementation.
@@ -224,7 +224,7 @@ it will use the `FooBarFileSystem` implementation.
Next, you must build a shared object containing this implementation. An example
of doing so using bazel's `cc_binary` rule can be found
-[here](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/BUILD#L244),
+[here](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/BUILD#L244),
but you may use any build system to do so. See the section on [building the op library](../extend/op.md#build_the_op_library) for similar
instructions.
@@ -236,7 +236,7 @@ passing the path to the shared object. Calling this in your client program loads
the shared object in the process, thus registering your implementation as
available for any file operations going through the `FileSystem` interface. You
can see
-[test_file_system.py](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/framework/file_system_test.py)
+[test_file_system.py](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/framework/file_system_test.py)
for an example.
## What goes through this interface?
diff --git a/site/en/r1/guide/extend/formats.md b/site/en/r1/guide/extend/formats.md
index 3b7b4aafbd6..bdebee5487d 100644
--- a/site/en/r1/guide/extend/formats.md
+++ b/site/en/r1/guide/extend/formats.md
@@ -28,11 +28,11 @@ individual records in a file. There are several examples of "reader" datasets
that are already built into TensorFlow:
* `tf.data.TFRecordDataset`
- ([source in `kernels/data/reader_dataset_ops.cc`](https://www.tensorflow.org/code/tensorflow/core/kernels/data/reader_dataset_ops.cc))
+ ([source in `kernels/data/reader_dataset_ops.cc`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/data/reader_dataset_ops.cc))
* `tf.data.FixedLengthRecordDataset`
- ([source in `kernels/data/reader_dataset_ops.cc`](https://www.tensorflow.org/code/tensorflow/core/kernels/data/reader_dataset_ops.cc))
+ ([source in `kernels/data/reader_dataset_ops.cc`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/data/reader_dataset_ops.cc))
* `tf.data.TextLineDataset`
- ([source in `kernels/data/reader_dataset_ops.cc`](https://www.tensorflow.org/code/tensorflow/core/kernels/data/reader_dataset_ops.cc))
+ ([source in `kernels/data/reader_dataset_ops.cc`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/data/reader_dataset_ops.cc))
Each of these implementations comprises three related classes:
@@ -279,7 +279,7 @@ if __name__ == "__main__":
```
You can see some examples of `Dataset` wrapper classes in
-[`tensorflow/python/data/ops/dataset_ops.py`](https://www.tensorflow.org/code/tensorflow/python/data/ops/dataset_ops.py).
+[`tensorflow/python/data/ops/dataset_ops.py`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/data/ops/dataset_ops.py).
## Writing an Op for a record format
@@ -297,7 +297,7 @@ Examples of Ops useful for decoding records:
Note that it can be useful to use multiple Ops to decode a particular record
format. For example, you may have an image saved as a string in
-[a `tf.train.Example` protocol buffer](https://www.tensorflow.org/code/tensorflow/core/example/example.proto).
+[a `tf.train.Example` protocol buffer](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/example/example.proto).
Depending on the format of that image, you might take the corresponding output
from a `tf.parse_single_example` op and call `tf.image.decode_jpeg`,
`tf.image.decode_png`, or `tf.decode_raw`. It is common to take the output
diff --git a/site/en/r1/guide/extend/model_files.md b/site/en/r1/guide/extend/model_files.md
index 30e73a5169e..e590fcf1f27 100644
--- a/site/en/r1/guide/extend/model_files.md
+++ b/site/en/r1/guide/extend/model_files.md
@@ -28,7 +28,7 @@ by calling `as_graph_def()`, which returns a `GraphDef` object.
The GraphDef class is an object created by the ProtoBuf library from the
definition in
-[tensorflow/core/framework/graph.proto](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/graph.proto). The protobuf tools parse
+[tensorflow/core/framework/graph.proto](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/graph.proto). The protobuf tools parse
this text file, and generate the code to load, store, and manipulate graph
definitions. If you see a standalone TensorFlow file representing a model, it's
likely to contain a serialized version of one of these `GraphDef` objects
@@ -87,7 +87,7 @@ for node in graph_def.node
```
Each node is a `NodeDef` object, defined in
-[tensorflow/core/framework/node_def.proto](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/node_def.proto). These
+[tensorflow/core/framework/node_def.proto](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/node_def.proto). These
are the fundamental building blocks of TensorFlow graphs, with each one defining
a single operation along with its input connections. Here are the members of a
`NodeDef`, and what they mean.
@@ -107,7 +107,7 @@ This defines what operation to run, for example `"Add"`, `"MatMul"`, or
`"Conv2D"`. When a graph is run, this op name is looked up in a registry to
find an implementation. The registry is populated by calls to the
`REGISTER_OP()` macro, like those in
-[tensorflow/core/ops/nn_ops.cc](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/ops/nn_ops.cc).
+[tensorflow/core/ops/nn_ops.cc](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/ops/nn_ops.cc).
### `input`
@@ -133,7 +133,7 @@ size of filters for convolutions, or the values of constant ops. Because there
can be so many different types of attribute values, from strings, to ints, to
arrays of tensor values, there's a separate protobuf file defining the data
structure that holds them, in
-[tensorflow/core/framework/attr_value.proto](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/attr_value.proto).
+[tensorflow/core/framework/attr_value.proto](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/attr_value.proto).
Each attribute has a unique name string, and the expected attributes are listed
when the operation is defined. If an attribute isn't present in a node, but it
@@ -151,7 +151,7 @@ the file format during training. Instead, they're held in separate checkpoint
files, and there are `Variable` ops in the graph that load the latest values
when they're initialized. It's often not very convenient to have separate files
when you're deploying to production, so there's the
-[freeze_graph.py](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/tools/freeze_graph.py) script that takes a graph definition and a set
+[freeze_graph.py](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/tools/freeze_graph.py) script that takes a graph definition and a set
of checkpoints and freezes them together into a single file.
What this does is load the `GraphDef`, pull in the values for all the variables
@@ -167,7 +167,7 @@ the most common problems is extracting and interpreting the weight values. A
common way to store them, for example in graphs created by the freeze_graph
script, is as `Const` ops containing the weights as `Tensors`. These are
defined in
-[tensorflow/core/framework/tensor.proto](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/tensor.proto), and contain information
+[tensorflow/core/framework/tensor.proto](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/tensor.proto), and contain information
about the size and type of the data, as well as the values themselves. In
Python, you get a `TensorProto` object from a `NodeDef` representing a `Const`
op by calling something like `some_node_def.attr['value'].tensor`.
diff --git a/site/en/r1/guide/extend/op.md b/site/en/r1/guide/extend/op.md
index d006a6251d0..186d9c28c04 100644
--- a/site/en/r1/guide/extend/op.md
+++ b/site/en/r1/guide/extend/op.md
@@ -47,7 +47,7 @@ To incorporate your custom op you'll need to:
test the op in C++. If you define gradients, you can verify them with the
Python `tf.test.compute_gradient_error`.
See
- [`relu_op_test.py`](https://www.tensorflow.org/code/tensorflow/python/kernel_tests/relu_op_test.py) as
+ [`relu_op_test.py`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/kernel_tests/relu_op_test.py) as
an example that tests the forward functions of Relu-like operators and
their gradients.
@@ -155,17 +155,17 @@ REGISTER_KERNEL_BUILDER(Name("ZeroOut").Device(DEVICE_CPU), ZeroOutOp);
> Important: Instances of your OpKernel may be accessed concurrently.
> Your `Compute` method must be thread-safe. Guard any access to class
> members with a mutex. Or better yet, don't share state via class members!
-> Consider using a [`ResourceMgr`](https://www.tensorflow.org/code/tensorflow/core/framework/resource_mgr.h)
+> Consider using a [`ResourceMgr`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/resource_mgr.h)
> to keep track of op state.
### Multi-threaded CPU kernels
To write a multi-threaded CPU kernel, the Shard function in
-[`work_sharder.h`](https://www.tensorflow.org/code/tensorflow/core/util/work_sharder.h)
+[`work_sharder.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/util/work_sharder.h)
can be used. This function shards a computation function across the
threads configured to be used for intra-op threading (see
intra_op_parallelism_threads in
-[`config.proto`](https://www.tensorflow.org/code/tensorflow/core/protobuf/config.proto)).
+[`config.proto`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/protobuf/config.proto)).
### GPU kernels
@@ -348,12 +348,13 @@ g++ -std=c++11 -shared zero_out.cc -o zero_out.so -fPIC ${TF_CFLAGS[@]} ${TF_LFL
On macOS, the additional flag "-undefined dynamic_lookup" is required when
building the `.so` file.
-> Note on `gcc` version `>=5`: gcc uses the new C++
-> [ABI](https://gcc.gnu.org/gcc-5/changes.html#libstdcxx) since version `5`. The binary pip
-> packages available on the TensorFlow website are built with `gcc4` that uses
-> the older ABI. If you compile your op library with `gcc>=5`, add
-> `-D_GLIBCXX_USE_CXX11_ABI=0` to the command line to make the library
-> compatible with the older abi.
+> Note on `gcc` version `>=5`: gcc uses the new C++
+> [ABI](https://gcc.gnu.org/gcc-5/changes.html#libstdcxx) since version `5`.
+> TensorFlow 2.8 and earlier were built with `gcc4` that uses the older ABI. If
+> you are using these versions of TensorFlow and are trying to compile your op
+> library with `gcc>=5`, add `-D_GLIBCXX_USE_CXX11_ABI=0` to the command line to
+> make the library compatible with the older ABI. TensorFlow 2.9+ packages are
+> compatible with the newer ABI by default.
### Compile the op using bazel (TensorFlow source installation)
@@ -485,13 +486,13 @@ This asserts that the input is a vector, and returns having set the
* The `context`, which can either be an `OpKernelContext` or
`OpKernelConstruction` pointer (see
- [`tensorflow/core/framework/op_kernel.h`](https://www.tensorflow.org/code/tensorflow/core/framework/op_kernel.h)),
+ [`tensorflow/core/framework/op_kernel.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op_kernel.h)),
for its `SetStatus()` method.
* The condition. For example, there are functions for validating the shape
of a tensor in
- [`tensorflow/core/framework/tensor_shape.h`](https://www.tensorflow.org/code/tensorflow/core/framework/tensor_shape.h)
+ [`tensorflow/core/framework/tensor_shape.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/tensor_shape.h)
* The error itself, which is represented by a `Status` object, see
- [`tensorflow/core/lib/core/status.h`](https://www.tensorflow.org/code/tensorflow/core/lib/core/status.h). A
+ [`tensorflow/core/lib/core/status.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/lib/core/status.h). A
`Status` has both a type (frequently `InvalidArgument`, but see the list of
types) and a message. Functions for constructing an error may be found in
[`tensorflow/core/lib/core/errors.h`][validation-macros].
@@ -632,7 +633,7 @@ define an attr with constraints, you can use the following ``s:
The specific lists of types allowed by these are defined by the functions
(like `NumberTypes()`) in
- [`tensorflow/core/framework/types.h`](https://www.tensorflow.org/code/tensorflow/core/framework/types.h).
+ [`tensorflow/core/framework/types.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/types.h).
In this example the attr `t` must be one of the numeric types:
```c++
@@ -1179,7 +1180,7 @@ There are several ways to preserve backwards-compatibility.
type into a list of varying types).
The full list of safe and unsafe changes can be found in
-[`tensorflow/core/framework/op_compatibility_test.cc`](https://www.tensorflow.org/code/tensorflow/core/framework/op_compatibility_test.cc).
+[`tensorflow/core/framework/op_compatibility_test.cc`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op_compatibility_test.cc).
If you cannot make your change to an operation backwards compatible, then create
a new operation with a new name with the new semantics.
@@ -1189,23 +1190,23 @@ callers. The Python API may be kept compatible by careful changes in a
hand-written Python wrapper, by keeping the old signature except possibly adding
new optional arguments to the end. Generally incompatible changes may only be
made when TensorFlow changes major versions, and must conform to the
-[`GraphDef` version semantics](../guide/version_compat.md#compatibility_of_graphs_and_checkpoints).
+[`GraphDef` version semantics](../version_compat.md).
### GPU Support
You can implement different OpKernels and register one for CPU and another for
GPU, just like you can [register kernels for different types](#polymorphism).
There are several examples of kernels with GPU support in
-[`tensorflow/core/kernels/`](https://www.tensorflow.org/code/tensorflow/core/kernels/).
+[`tensorflow/core/kernels/`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/).
Notice some kernels have a CPU version in a `.cc` file, a GPU version in a file
ending in `_gpu.cu.cc`, and some code shared in common in a `.h` file.
For example, the `tf.pad` has
everything but the GPU kernel in [`tensorflow/core/kernels/pad_op.cc`][pad_op].
The GPU kernel is in
-[`tensorflow/core/kernels/pad_op_gpu.cu.cc`](https://www.tensorflow.org/code/tensorflow/core/kernels/pad_op_gpu.cu.cc),
+[`tensorflow/core/kernels/pad_op_gpu.cu.cc`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/pad_op_gpu.cu.cc),
and the shared code is a templated class defined in
-[`tensorflow/core/kernels/pad_op.h`](https://www.tensorflow.org/code/tensorflow/core/kernels/pad_op.h).
+[`tensorflow/core/kernels/pad_op.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/pad_op.h).
We organize the code this way for two reasons: it allows you to share common
code among the CPU and GPU implementations, and it puts the GPU implementation
into a separate file so that it can be compiled only by the GPU compiler.
@@ -1226,16 +1227,16 @@ kept on the CPU, add a `HostMemory()` call to the kernel registration, e.g.:
#### Compiling the kernel for the GPU device
Look at
-[cuda_op_kernel.cu.cc](https://www.tensorflow.org/code/tensorflow/examples/adding_an_op/cuda_op_kernel.cu.cc)
+[cuda_op_kernel.cu.cc](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/adding_an_op/cuda_op_kernel.cu.cc)
for an example that uses a CUDA kernel to implement an op. The
`tf_custom_op_library` accepts a `gpu_srcs` argument in which the list of source
files containing the CUDA kernels (`*.cu.cc` files) can be specified. For use
with a binary installation of TensorFlow, the CUDA kernels have to be compiled
with NVIDIA's `nvcc` compiler. Here is the sequence of commands you can use to
compile the
-[cuda_op_kernel.cu.cc](https://www.tensorflow.org/code/tensorflow/examples/adding_an_op/cuda_op_kernel.cu.cc)
+[cuda_op_kernel.cu.cc](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/adding_an_op/cuda_op_kernel.cu.cc)
and
-[cuda_op_kernel.cc](https://www.tensorflow.org/code/tensorflow/examples/adding_an_op/cuda_op_kernel.cc)
+[cuda_op_kernel.cc](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/adding_an_op/cuda_op_kernel.cc)
into a single dynamically loadable library:
```bash
@@ -1360,7 +1361,7 @@ be set to the first input's shape. If the output is selected by its index as in
There are a number of common shape functions
that apply to many ops, such as `shape_inference::UnchangedShape` which can be
-found in [common_shape_fns.h](https://www.tensorflow.org/code/tensorflow/core/framework/common_shape_fns.h) and used as follows:
+found in [common_shape_fns.h](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/common_shape_fns.h) and used as follows:
```c++
REGISTER_OP("ZeroOut")
@@ -1407,7 +1408,7 @@ provides access to the attributes of the op).
Since shape inference is an optional feature, and the shapes of tensors may vary
dynamically, shape functions must be robust to incomplete shape information for
-any of the inputs. The `Merge` method in [`InferenceContext`](https://www.tensorflow.org/code/tensorflow/core/framework/shape_inference.h)
+any of the inputs. The `Merge` method in [`InferenceContext`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/shape_inference.h)
allows the caller to assert that two shapes are the same, even if either
or both of them do not have complete information. Shape functions are defined
for all of the core TensorFlow ops and provide many different usage examples.
@@ -1432,7 +1433,7 @@ If you have a complicated shape function, you should consider adding a test for
validating that various input shape combinations produce the expected output
shape combinations. You can see examples of how to write these tests in some
our
-[core ops tests](https://www.tensorflow.org/code/tensorflow/core/ops/array_ops_test.cc).
+[core ops tests](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/ops/array_ops_test.cc).
(The syntax of `INFER_OK` and `INFER_ERROR` are a little cryptic, but try to be
compact in representing input and output shape specifications in tests. For
now, see the surrounding comments in those tests to get a sense of the shape
@@ -1445,20 +1446,20 @@ To build a `pip` package for your op, see the
guide shows how to build custom ops from the TensorFlow pip package instead
of building TensorFlow from source.
-[core-array_ops]:https://www.tensorflow.org/code/tensorflow/core/ops/array_ops.cc
-[python-user_ops]:https://www.tensorflow.org/code/tensorflow/python/user_ops/user_ops.py
-[tf-kernels]:https://www.tensorflow.org/code/tensorflow/core/kernels/
-[user_ops]:https://www.tensorflow.org/code/tensorflow/core/user_ops/
-[pad_op]:https://www.tensorflow.org/code/tensorflow/core/kernels/pad_op.cc
-[standard_ops-py]:https://www.tensorflow.org/code/tensorflow/python/ops/standard_ops.py
-[standard_ops-cc]:https://www.tensorflow.org/code/tensorflow/cc/ops/standard_ops.h
-[python-BUILD]:https://www.tensorflow.org/code/tensorflow/python/BUILD
-[validation-macros]:https://www.tensorflow.org/code/tensorflow/core/lib/core/errors.h
-[op_def_builder]:https://www.tensorflow.org/code/tensorflow/core/framework/op_def_builder.h
-[register_types]:https://www.tensorflow.org/code/tensorflow/core/framework/register_types.h
-[FinalizeAttr]:https://www.tensorflow.org/code/tensorflow/core/framework/op_def_builder.cc
-[DataTypeString]:https://www.tensorflow.org/code/tensorflow/core/framework/types.cc
-[python-BUILD]:https://www.tensorflow.org/code/tensorflow/python/BUILD
-[types-proto]:https://www.tensorflow.org/code/tensorflow/core/framework/types.proto
-[TensorShapeProto]:https://www.tensorflow.org/code/tensorflow/core/framework/tensor_shape.proto
-[TensorProto]:https://www.tensorflow.org/code/tensorflow/core/framework/tensor.proto
+[core-array_ops]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/ops/array_ops.cc
+[python-user_ops]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/user_ops/user_ops.py
+[tf-kernels]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/
+[user_ops]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/user_ops/
+[pad_op]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/pad_op.cc
+[standard_ops-py]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/ops/standard_ops.py
+[standard_ops-cc]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/cc/ops/standard_ops.h
+[python-BUILD]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/BUILD
+[validation-macros]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/lib/core/errors.h
+[op_def_builder]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op_def_builder.h
+[register_types]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/register_types.h
+[FinalizeAttr]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op_def_builder.cc
+[DataTypeString]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/types.cc
+[python-BUILD]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/BUILD
+[types-proto]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/types.proto
+[TensorShapeProto]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/tensor_shape.proto
+[TensorProto]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/tensor.proto
diff --git a/site/en/r1/guide/feature_columns.md b/site/en/r1/guide/feature_columns.md
index 5a4dfbbf46d..e4259f85e9f 100644
--- a/site/en/r1/guide/feature_columns.md
+++ b/site/en/r1/guide/feature_columns.md
@@ -562,7 +562,7 @@ For more examples on feature columns, view the following:
* The [Low Level Introduction](../guide/low_level_intro.md#feature_columns) demonstrates how
experiment directly with `feature_columns` using TensorFlow's low level APIs.
-* The [Estimator wide and deep learning tutorial](https://github.com/tensorflow/models/tree/master/official/r1/wide_deep)
+* The [Estimator wide and deep learning tutorial](https://github.com/tensorflow/models/tree/r1.15/official/r1/wide_deep)
solves a binary classification problem using `feature_columns` on a variety of
input data types.
diff --git a/site/en/r1/guide/graph_viz.md b/site/en/r1/guide/graph_viz.md
index 1965378e03e..1e3780e7928 100644
--- a/site/en/r1/guide/graph_viz.md
+++ b/site/en/r1/guide/graph_viz.md
@@ -251,7 +251,7 @@ is a snippet from the train and test section of a modification of the
[Estimators MNIST tutorial](../tutorials/estimators/cnn.md), in which we have
recorded summaries and
runtime statistics. See the
-[Tensorboard](https://tensorflow.org/tensorboard)
+[TensorBoard](https://tensorflow.org/tensorboard)
for details on how to record summaries.
Full source is [here](https://github.com/tensorflow/tensorflow/tree/r1.15/tensorflow/examples/tutorials/mnist/mnist_with_summaries.py).
diff --git a/site/en/r1/guide/keras.ipynb b/site/en/r1/guide/keras.ipynb
index 08a778b60a5..3a0cd8e55c5 100644
--- a/site/en/r1/guide/keras.ipynb
+++ b/site/en/r1/guide/keras.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
@@ -1211,8 +1211,7 @@
"colab": {
"collapsed_sections": [],
"name": "keras.ipynb",
- "provenance": [],
- "toc_visible": true
+ "toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
diff --git a/site/en/r1/guide/performance/benchmarks.md b/site/en/r1/guide/performance/benchmarks.md
index 8998c0723db..a56959ea416 100644
--- a/site/en/r1/guide/performance/benchmarks.md
+++ b/site/en/r1/guide/performance/benchmarks.md
@@ -401,7 +401,7 @@ GPUs | InceptionV3 (batch size 32) | ResNet-50 (batch size 32)
## Methodology
This
-[script](https://github.com/tensorflow/benchmarks/tree/master/scripts/tf_cnn_benchmarks)
+[script](https://github.com/tensorflow/benchmarks/tree/r1.15/scripts/tf_cnn_benchmarks)
was run on the various platforms to generate the above results.
In order to create results that are as repeatable as possible, each test was run
diff --git a/site/en/r1/guide/performance/overview.md b/site/en/r1/guide/performance/overview.md
index af74f0f28c6..be7217f4b99 100644
--- a/site/en/r1/guide/performance/overview.md
+++ b/site/en/r1/guide/performance/overview.md
@@ -19,9 +19,9 @@ Reading large numbers of small files significantly impacts I/O performance.
One approach to get maximum I/O throughput is to preprocess input data into
larger (~100MB) `TFRecord` files. For smaller data sets (200MB-1GB), the best
approach is often to load the entire data set into memory. The document
-[Downloading and converting to TFRecord format](https://github.com/tensorflow/models/tree/master/research/slim#downloading-and-converting-to-tfrecord-format)
+[Downloading and converting to TFRecord format](https://github.com/tensorflow/models/tree/r1.15/research/slim#downloading-and-converting-to-tfrecord-format)
includes information and scripts for creating `TFRecord`s, and this
-[script](https://github.com/tensorflow/models/tree/master/research/tutorials/image/cifar10_estimator/generate_cifar10_tfrecords.py)
+[script](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/image/cifar10_estimator/generate_cifar10_tfrecords.py)
converts the CIFAR-10 dataset into `TFRecord`s.
While feeding data using a `feed_dict` offers a high level of flexibility, in
@@ -122,7 +122,7 @@ tf.Session(config=config)
Intel® has added optimizations to TensorFlow for Intel® Xeon® and Intel® Xeon
Phi™ through the use of the Intel® Math Kernel Library for Deep Neural Networks
(Intel® MKL-DNN) optimized primitives. The optimizations also provide speedups
-for the consumer line of processors, e.g. i5 and i7 Intel processors. The Intel
+for the consumer line of processors, e.g., i5 and i7 Intel processors. The Intel
published paper
[TensorFlow* Optimizations on Modern Intel® Architecture](https://software.intel.com/en-us/articles/tensorflow-optimizations-on-modern-intel-architecture)
contains additional details on the implementation.
@@ -255,7 +255,7 @@ bazel build -c opt --copt=-march="broadwell" --config=cuda //tensorflow/tools/pi
a docker container, the data is not cached and the penalty is paid each time
TensorFlow starts. The best practice is to include the
[compute capabilities](http://developer.nvidia.com/cuda-gpus)
- of the GPUs that will be used, e.g. P100: 6.0, Titan X (Pascal): 6.1,
+ of the GPUs that will be used, e.g., P100: 6.0, Titan X (Pascal): 6.1,
Titan X (Maxwell): 5.2, and K80: 3.7.
* Use a version of `gcc` that supports all of the optimizations of the target
CPU. The recommended minimum gcc version is 4.8.3. On macOS, upgrade to the
diff --git a/site/en/r1/guide/ragged_tensors.ipynb b/site/en/r1/guide/ragged_tensors.ipynb
index 61bce66ecfb..289d29ce82e 100644
--- a/site/en/r1/guide/ragged_tensors.ipynb
+++ b/site/en/r1/guide/ragged_tensors.ipynb
@@ -57,7 +57,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
@@ -1010,7 +1010,7 @@
" `tf.RaggedTensor.values`\n",
" and\n",
" `tf.RaggedTensor.row_splits`\n",
- " properties, or row-paritioning methods such as `tf.RaggedTensor.row_lengths()`\n",
+ " properties, or row-partitioning methods such as `tf.RaggedTensor.row_lengths()`\n",
" and `tf.RaggedTensor.value_rowids()`."
]
},
diff --git a/site/en/r1/guide/saved_model.md b/site/en/r1/guide/saved_model.md
index 623863a9df9..34447ffe861 100644
--- a/site/en/r1/guide/saved_model.md
+++ b/site/en/r1/guide/saved_model.md
@@ -23,7 +23,7 @@ TensorFlow saves variables in binary *checkpoint files* that map variable
names to tensor values.
Caution: TensorFlow model files are code. Be careful with untrusted code.
-See [Using TensorFlow Securely](https://github.com/tensorflow/tensorflow/blob/master/SECURITY.md)
+See [Using TensorFlow Securely](https://github.com/tensorflow/tensorflow/blob/r1.15/SECURITY.md)
for details.
### Save variables
@@ -148,7 +148,7 @@ Notes:
`tf.variables_initializer` for more information.
* To inspect the variables in a checkpoint, you can use the
- [`inspect_checkpoint`](https://www.tensorflow.org/code/tensorflow/python/tools/inspect_checkpoint.py)
+ [`inspect_checkpoint`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/tools/inspect_checkpoint.py)
library, particularly the `print_tensors_in_checkpoint_file` function.
* By default, `Saver` uses the value of the `tf.Variable.name` property
@@ -159,7 +159,7 @@ Notes:
### Inspect variables in a checkpoint
We can quickly inspect variables in a checkpoint with the
-[`inspect_checkpoint`](https://www.tensorflow.org/code/tensorflow/python/tools/inspect_checkpoint.py) library.
+[`inspect_checkpoint`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/tools/inspect_checkpoint.py) library.
Continuing from the save/restore examples shown earlier:
@@ -216,7 +216,7 @@ simple_save(session,
This configures the `SavedModel` so it can be loaded by
[TensorFlow serving](https://www.tensorflow.org/tfx/tutorials/serving/rest_simple) and supports the
-[Predict API](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis/predict.proto).
+[Predict API](https://github.com/tensorflow/serving/blob/r1.15/tensorflow_serving/apis/predict.proto).
To access the classify, regress, or multi-inference APIs, use the manual
`SavedModel` builder APIs or an `tf.estimator.Estimator`.
@@ -328,7 +328,7 @@ with tf.Session(graph=tf.Graph()) as sess:
### Load a SavedModel in C++
The C++ version of the SavedModel
-[loader](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/cc/saved_model/loader.h)
+[loader](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/cc/saved_model/loader.h)
provides an API to load a SavedModel from a path, while allowing
`SessionOptions` and `RunOptions`.
You have to specify the tags associated with the graph to be loaded.
@@ -383,20 +383,20 @@ reuse and share across tools consistently.
You may use sets of tags to uniquely identify a `MetaGraphDef` saved in a
SavedModel. A subset of commonly used tags is specified in:
-* [Python](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/saved_model/tag_constants.py)
-* [C++](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/cc/saved_model/tag_constants.h)
+* [Python](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/saved_model/tag_constants.py)
+* [C++](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/cc/saved_model/tag_constants.h)
#### Standard SignatureDef constants
-A [**SignatureDef**](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/protobuf/meta_graph.proto)
+A [**SignatureDef**](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/protobuf/meta_graph.proto)
is a protocol buffer that defines the signature of a computation
supported by a graph.
Commonly used input keys, output keys, and method names are
defined in:
-* [Python](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/saved_model/signature_constants.py)
-* [C++](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/cc/saved_model/signature_constants.h)
+* [Python](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/saved_model/signature_constants.py)
+* [C++](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/cc/saved_model/signature_constants.h)
## Using SavedModel with Estimators
@@ -408,7 +408,7 @@ To prepare a trained Estimator for serving, you must export it in the standard
SavedModel format. This section explains how to:
* Specify the output nodes and the corresponding
- [APIs](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis/prediction_service.proto)
+ [APIs](https://github.com/tensorflow/serving/blob/r1.15/tensorflow_serving/apis/prediction_service.proto)
that can be served (Classify, Regress, or Predict).
* Export your model to the SavedModel format.
* Serve the model from a local server and request predictions.
@@ -506,7 +506,7 @@ Each `output` value must be an `ExportOutput` object such as
`tf.estimator.export.PredictOutput`.
These output types map straightforwardly to the
-[TensorFlow Serving APIs](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis/prediction_service.proto),
+[TensorFlow Serving APIs](https://github.com/tensorflow/serving/blob/r1.15/tensorflow_serving/apis/prediction_service.proto),
and so determine which request types will be honored.
Note: In the multi-headed case, a `SignatureDef` will be generated for each
@@ -515,7 +515,7 @@ the same keys. These `SignatureDef`s differ only in their outputs, as
provided by the corresponding `ExportOutput` entry. The inputs are always
those provided by the `serving_input_receiver_fn`.
An inference request may specify the head by name. One head must be named
-using [`signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY`](https://www.tensorflow.org/code/tensorflow/python/saved_model/signature_constants.py)
+using [`signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/saved_model/signature_constants.py)
indicating which `SignatureDef` will be served when an inference request
does not specify one.
@@ -566,9 +566,9 @@ Now you have a server listening for inference requests via gRPC on port 9000!
### Request predictions from a local server
The server responds to gRPC requests according to the
-[PredictionService](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis/prediction_service.proto#L15)
+[PredictionService](https://github.com/tensorflow/serving/blob/r1.15/tensorflow_serving/apis/prediction_service.proto#L15)
gRPC API service definition. (The nested protocol buffers are defined in
-various [neighboring files](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis)).
+various [neighboring files](https://github.com/tensorflow/serving/blob/r1.15/tensorflow_serving/apis)).
From the API service definition, the gRPC framework generates client libraries
in various languages providing remote access to the API. In a project using the
@@ -620,7 +620,7 @@ The returned result in this example is a `ClassificationResponse` protocol
buffer.
This is a skeletal example; please see the [Tensorflow Serving](../deploy/index.md)
-documentation and [examples](https://github.com/tensorflow/serving/tree/master/tensorflow_serving/example)
+documentation and [examples](https://github.com/tensorflow/serving/tree/r1.15/tensorflow_serving/example)
for more details.
> Note: `ClassificationRequest` and `RegressionRequest` contain a
diff --git a/site/en/r1/guide/using_tpu.md b/site/en/r1/guide/using_tpu.md
index 74169092189..e3e338adf49 100644
--- a/site/en/r1/guide/using_tpu.md
+++ b/site/en/r1/guide/using_tpu.md
@@ -7,8 +7,8 @@ changing the *hardware accelerator* in your notebook settings:
TPU-enabled Colab notebooks are available to test:
1. [A quick test, just to measure FLOPS](https://colab.research.google.com/notebooks/tpu.ipynb).
- 2. [A CNN image classifier with `tf.keras`](https://colab.research.google.com/github/tensorflow/tpu/blob/master/tools/colab/fashion_mnist.ipynb).
- 3. [An LSTM markov chain text generator with `tf.keras`](https://colab.research.google.com/github/tensorflow/tpu/blob/master/tools/colab/shakespeare_with_tpu_and_keras.ipynb)
+ 2. [A CNN image classifier with `tf.keras`](https://colab.research.google.com/github/tensorflow/tpu/blob/r1.15/tools/colab/fashion_mnist.ipynb).
+ 3. [An LSTM markov chain text generator with `tf.keras`](https://colab.research.google.com/github/tensorflow/tpu/blob/r1.15/tools/colab/shakespeare_with_tpu_and_keras.ipynb)
## TPUEstimator
@@ -25,7 +25,7 @@ Cloud TPU is to define the model's inference phase (from inputs to predictions)
outside of the `model_fn`. Then maintain separate implementations of the
`Estimator` setup and `model_fn`, both wrapping this inference step. For an
example of this pattern compare the `mnist.py` and `mnist_tpu.py` implementation in
-[tensorflow/models](https://github.com/tensorflow/models/tree/master/official/r1/mnist).
+[tensorflow/models](https://github.com/tensorflow/models/tree/r1.15/official/r1/mnist).
### Run a TPUEstimator locally
@@ -350,10 +350,10 @@ in bytes. A minimum of a few MB (`buffer_size=8*1024*1024`) is recommended so
that data is available when needed.
The TPU-demos repo includes
-[a script](https://github.com/tensorflow/tpu/blob/master/tools/datasets/imagenet_to_gcs.py)
+[a script](https://github.com/tensorflow/tpu/blob/1.15/tools/datasets/imagenet_to_gcs.py)
for downloading the imagenet dataset and converting it to an appropriate format.
This together with the imagenet
-[models](https://github.com/tensorflow/tpu/tree/master/models)
+[models](https://github.com/tensorflow/tpu/tree/r1.15/models)
included in the repo demonstrate all of these best-practices.
## Next steps
diff --git a/site/en/r1/guide/version_compat.md b/site/en/r1/guide/version_compat.md
index 6702f6e0819..a765620518d 100644
--- a/site/en/r1/guide/version_compat.md
+++ b/site/en/r1/guide/version_compat.md
@@ -49,19 +49,19 @@ patch versions. The public APIs consist of
submodules, but is not documented, then it is **not** considered part of the
public API.
-* The [C API](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/c/c_api.h).
+* The [C API](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/c/c_api.h).
* The following protocol buffer files:
- * [`attr_value`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/attr_value.proto)
- * [`config`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/protobuf/config.proto)
- * [`event`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/util/event.proto)
- * [`graph`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/graph.proto)
- * [`op_def`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/op_def.proto)
- * [`reader_base`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/reader_base.proto)
- * [`summary`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/summary.proto)
- * [`tensor`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/tensor.proto)
- * [`tensor_shape`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/tensor_shape.proto)
- * [`types`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/types.proto)
+ * [`attr_value`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/attr_value.proto)
+ * [`config`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/protobuf/config.proto)
+ * [`event`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/util/event.proto)
+ * [`graph`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/graph.proto)
+ * [`op_def`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op_def.proto)
+ * [`reader_base`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/reader_base.proto)
+ * [`summary`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/summary.proto)
+ * [`tensor`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/tensor.proto)
+ * [`tensor_shape`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/tensor_shape.proto)
+ * [`types`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/types.proto)
## What is *not* covered
@@ -79,7 +79,7 @@ backward incompatible ways between minor releases. These include:
such as:
- [C++](./extend/cc.md) (exposed through header files in
- [`tensorflow/cc`](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/cc)).
+ [`tensorflow/cc`](https://github.com/tensorflow/tensorflow/tree/r1.15/tensorflow/cc)).
- [Java](../api_docs/java/reference/org/tensorflow/package-summary),
- [Go](https://pkg.go.dev/github.com/tensorflow/tensorflow/tensorflow/go)
- [JavaScript](https://js.tensorflow.org)
@@ -209,7 +209,7 @@ guidelines for evolving `GraphDef` versions.
There are different data versions for graphs and checkpoints. The two data
formats evolve at different rates from each other and also at different rates
from TensorFlow. Both versioning systems are defined in
-[`core/public/version.h`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/public/version.h).
+[`core/public/version.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/public/version.h).
Whenever a new version is added, a note is added to the header detailing what
changed and the date.
@@ -224,7 +224,7 @@ We distinguish between the following kinds of data version information:
(`min_producer`).
Each piece of versioned data has a [`VersionDef
-versions`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/versions.proto)
+versions`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/versions.proto)
field which records the `producer` that made the data, the `min_consumer`
that it is compatible with, and a list of `bad_consumers` versions that are
disallowed.
@@ -239,7 +239,7 @@ accept a piece of data if the following are all true:
* `consumer` not in data's `bad_consumers`
Since both producers and consumers come from the same TensorFlow code base,
-[`core/public/version.h`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/public/version.h)
+[`core/public/version.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/public/version.h)
contains a main data version which is treated as either `producer` or
`consumer` depending on context and both `min_consumer` and `min_producer`
(needed by producers and consumers, respectively). Specifically,
@@ -309,7 +309,7 @@ existing producer scripts will not suddenly use the new functionality.
1. Add a new similar op named `SomethingV2` or similar and go through the
process of adding it and switching existing Python wrappers to use it.
To ensure forward compatibility use the checks suggested in
- [compat.py](https://www.tensorflow.org/code/tensorflow/python/compat/compat.py)
+ [compat.py](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/compat/compat.py)
when changing the Python wrappers.
2. Remove the old op (Can only take place with a major version change due to
backward compatibility).
diff --git a/site/en/r1/tutorials/README.md b/site/en/r1/tutorials/README.md
index b6d932041bd..9ff164ad77c 100644
--- a/site/en/r1/tutorials/README.md
+++ b/site/en/r1/tutorials/README.md
@@ -10,7 +10,7 @@ desktop, mobile, web, and cloud. See the sections below to get started.
The high-level Keras API provides building blocks to create and
train deep learning models. Start with these beginner-friendly
-notebook examples, then read the [TensorFlow Keras guide](../guide/keras.ipynb).
+notebook examples, then read the [TensorFlow Keras guide](https://www.tensorflow.org/guide/keras).
* [Basic classification](./keras/basic_classification.ipynb)
* [Text classification](./keras/basic_text_classification.ipynb)
@@ -68,4 +68,4 @@ implement common ML algorithms. See the
* [Boosted trees](./estimators/boosted_trees.ipynb)
* [Gradient Boosted Trees: Model understanding](./estimators/boosted_trees_model_understanding.ipynb)
* [Build a Convolutional Neural Network using Estimators](./estimators/cnn.ipynb)
-* [Wide and deep learning with Estimators](https://github.com/tensorflow/models/tree/master/official/r1/wide_deep)
+* [Wide and deep learning with Estimators](https://github.com/tensorflow/models/tree/r1.15/official/r1/wide_deep)
diff --git a/site/en/r1/tutorials/_index.ipynb b/site/en/r1/tutorials/_index.ipynb
index e2fe960d125..eca1450964f 100644
--- a/site/en/r1/tutorials/_index.ipynb
+++ b/site/en/r1/tutorials/_index.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/distribute/keras.ipynb b/site/en/r1/tutorials/distribute/keras.ipynb
index b8d3c87bfab..14e8bf739a9 100644
--- a/site/en/r1/tutorials/distribute/keras.ipynb
+++ b/site/en/r1/tutorials/distribute/keras.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
@@ -86,7 +86,7 @@
"Essentially, it copies all of the model's variables to each processor.\n",
"Then, it uses [all-reduce](http://mpitutorial.com/tutorials/mpi-reduce-and-allreduce/) to combine the gradients from all processors and applies the combined value to all copies of the model.\n",
"\n",
- "`MirroredStategy` is one of several distribution strategy available in TensorFlow core. You can read about more strategies at [distribution strategy guide](../../guide/distribute_strategy.ipynb).\n"
+ "`MirroredStrategy` is one of several distribution strategy available in TensorFlow core. You can read about more strategies at [distribution strategy guide](../../guide/distribute_strategy.ipynb).\n"
]
},
{
@@ -345,7 +345,7 @@
"source": [
"The callbacks used here are:\n",
"\n",
- "* *Tensorboard*: This callback writes a log for Tensorboard which allows you to visualize the graphs.\n",
+ "* *TensorBoard*: This callback writes a log for TensorBoard which allows you to visualize the graphs.\n",
"* *Model Checkpoint*: This callback saves the model after every epoch.\n",
"* *Learning Rate Scheduler*: Using this callback, you can schedule the learning rate to change after every epoch/batch.\n",
"\n",
@@ -554,7 +554,7 @@
},
"outputs": [],
"source": [
- "tf.keras.experimental.export_saved_model(model, path)"
+ "model.save(path)"
]
},
{
@@ -574,7 +574,7 @@
},
"outputs": [],
"source": [
- "unreplicated_model = tf.keras.experimental.load_from_saved_model(path)\n",
+ "unreplicated_model = tf.keras.models.load_model(path)\n",
"\n",
"unreplicated_model.compile(\n",
" loss='sparse_categorical_crossentropy',\n",
diff --git a/site/en/r1/tutorials/distribute/tpu_custom_training.ipynb b/site/en/r1/tutorials/distribute/tpu_custom_training.ipynb
index 6d09d2623de..c61f893ca4c 100644
--- a/site/en/r1/tutorials/distribute/tpu_custom_training.ipynb
+++ b/site/en/r1/tutorials/distribute/tpu_custom_training.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/distribute/training_loops.ipynb b/site/en/r1/tutorials/distribute/training_loops.ipynb
index 1343e8c8b6b..8eb72c13030 100644
--- a/site/en/r1/tutorials/distribute/training_loops.ipynb
+++ b/site/en/r1/tutorials/distribute/training_loops.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/eager/automatic_differentiation.ipynb b/site/en/r1/tutorials/eager/automatic_differentiation.ipynb
index bbbb689a617..df843bac3b8 100644
--- a/site/en/r1/tutorials/eager/automatic_differentiation.ipynb
+++ b/site/en/r1/tutorials/eager/automatic_differentiation.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/eager/custom_layers.ipynb b/site/en/r1/tutorials/eager/custom_layers.ipynb
index c82458cb857..48b55ed943e 100644
--- a/site/en/r1/tutorials/eager/custom_layers.ipynb
+++ b/site/en/r1/tutorials/eager/custom_layers.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
@@ -230,7 +230,7 @@
"source": [
"## Models: composing layers\n",
"\n",
- "Many interesting layer-like things in machine learning models are implemented by composing existing layers. For example, each residual block in a resnet is a composition of convolutions, batch normalizations, and a shortcut.\n",
+ "Many interesting layer-like things in machine learning models are implemented by composing existing layers. For example, each residual block in a ResNet is a composition of convolutions, batch normalizations, and a shortcut.\n",
"\n",
"The main class used when creating a layer-like thing which contains other layers is tf.keras.Model. Implementing one is done by inheriting from tf.keras.Model."
]
diff --git a/site/en/r1/tutorials/eager/custom_training.ipynb b/site/en/r1/tutorials/eager/custom_training.ipynb
index 72beefe89ad..f0f7faffa7f 100644
--- a/site/en/r1/tutorials/eager/custom_training.ipynb
+++ b/site/en/r1/tutorials/eager/custom_training.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/eager/custom_training_walkthrough.ipynb b/site/en/r1/tutorials/eager/custom_training_walkthrough.ipynb
index a4839429827..3989f3e44bc 100644
--- a/site/en/r1/tutorials/eager/custom_training_walkthrough.ipynb
+++ b/site/en/r1/tutorials/eager/custom_training_walkthrough.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/eager/eager_basics.ipynb b/site/en/r1/tutorials/eager/eager_basics.ipynb
index 9a72f192385..acd00ec2e20 100644
--- a/site/en/r1/tutorials/eager/eager_basics.ipynb
+++ b/site/en/r1/tutorials/eager/eager_basics.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
@@ -236,7 +236,7 @@
"x = tf.random.uniform([3, 3])\n",
"\n",
"print(\"Is there a GPU available: \"),\n",
- "print(tf.test.is_gpu_available())\n",
+ "print(tf.config.list_physical_devices('GPU'))\n",
"\n",
"print(\"Is the Tensor on GPU #0: \"),\n",
"print(x.device.endswith('GPU:0'))"
@@ -292,7 +292,7 @@
" time_matmul(x)\n",
"\n",
"# Force execution on GPU #0 if available\n",
- "if tf.test.is_gpu_available():\n",
+ "if tf.config.list_physical_devices('GPU'):\n",
" with tf.device(\"GPU:0\"): # Or GPU:1 for the 2nd GPU, GPU:2 for the 3rd etc.\n",
" x = tf.random_uniform([1000, 1000])\n",
" assert x.device.endswith(\"GPU:0\")\n",
diff --git a/site/en/r1/tutorials/estimators/boosted_trees.ipynb b/site/en/r1/tutorials/estimators/boosted_trees.ipynb
deleted file mode 100644
index 7452d521095..00000000000
--- a/site/en/r1/tutorials/estimators/boosted_trees.ipynb
+++ /dev/null
@@ -1,606 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "7765UFHoyGx6"
- },
- "source": [
- "##### Copyright 2019 The TensorFlow Authors."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "id": "KVtTDrUNyL7x"
- },
- "outputs": [],
- "source": [
- "#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n",
- "# you may not use this file except in compliance with the License.\n",
- "# You may obtain a copy of the License at\n",
- "#\n",
- "# https://www.apache.org/licenses/LICENSE-2.0\n",
- "#\n",
- "# Unless required by applicable law or agreed to in writing, software\n",
- "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
- "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
- "# See the License for the specific language governing permissions and\n",
- "# limitations under the License."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "xPYxZMrWyA0N"
- },
- "source": [
- "#How to train Boosted Trees models in TensorFlow"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "p_vOREjRx-Y0"
- },
- "source": [
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "6lCDyX3HFWos"
- },
- "source": [
- "> Note: This is an archived TF1 notebook. These are configured\n",
- "to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
- "but will run in TF1 as well. To use TF1 in Colab, use the\n",
- "[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
- "magic."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "dW3r7qVxzqN5"
- },
- "source": [
- "This tutorial is an end-to-end walkthrough of training a Gradient Boosting model using decision trees with the `tf.estimator` API. Boosted Trees models are among the most popular and effective machine learning approaches for both regression and classification. It is an ensemble technique that combines the predictions from several (think 10s, 100s or even 1000s) tree models.\n",
- "\n",
- "Boosted Trees models are popular with many machine learning practioners as they can achieve impressive performance with minimal hyperparameter tuning."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "eylrTPAN3rJV"
- },
- "source": [
- "## Load the titanic dataset\n",
- "You will be using the titanic dataset, where the (rather morbid) goal is to predict passenger survival, given characteristics such as gender, age, class, etc."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "KuhAiPfZ3rJW"
- },
- "outputs": [],
- "source": [
- "from matplotlib import pyplot as plt\n",
- "\n",
- "import numpy as np\n",
- "import pandas as pd\n",
- "import tensorflow.compat.v1 as tf\n",
- "\n",
- "tf.logging.set_verbosity(tf.logging.ERROR)\n",
- "tf.set_random_seed(123)\n",
- "\n",
- "# Load dataset.\n",
- "dftrain = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/train.csv')\n",
- "dfeval = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/eval.csv')\n",
- "y_train = dftrain.pop('survived')\n",
- "y_eval = dfeval.pop('survived')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "3ioodHdVJVdA"
- },
- "source": [
- "The dataset consists of a training set and an evaluation set:\n",
- "\n",
- "* `dftrain` and `y_train` are the *training set*—the data the model uses to learn.\n",
- "* The model is tested against the *eval set*, `dfeval`, and `y_eval`.\n",
- "\n",
- "For training you will use the following features:\n",
- "\n",
- "\n",
- "
@@ -186,9 +186,9 @@ communication, see:
### Code
-* [WorkerService API definition](https://www.tensorflow.org/code/tensorflow/core/protobuf/worker_service.proto)
-* [Worker interface](https://www.tensorflow.org/code/tensorflow/core/distributed_runtime/worker_interface.h)
-* [Remote rendezvous (for Send and Recv implementations)](https://www.tensorflow.org/code/tensorflow/core/distributed_runtime/rpc/rpc_rendezvous_mgr.h)
+* [WorkerService API definition](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/protobuf/worker_service.proto)
+* [Worker interface](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/distributed_runtime/worker_interface.h)
+* [Remote rendezvous (for Send and Recv implementations)](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/distributed_runtime/rpc/rpc_rendezvous_mgr.h)
## Kernel Implementations
@@ -199,7 +199,7 @@ Many of the operation kernels are implemented using Eigen::Tensor, which uses
C++ templates to generate efficient parallel code for multicore CPUs and GPUs;
however, we liberally use libraries like cuDNN where a more efficient kernel
implementation is possible. We have also implemented
-[quantization](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/g3doc/performance/post_training_quantization.md), which enables
+[quantization](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/lite/g3doc/performance/post_training_quantization.md), which enables
faster inference in environments such as mobile devices and high-throughput
datacenter applications, and use the
[gemmlowp](https://github.com/google/gemmlowp) low-precision matrix library to
@@ -215,4 +215,4 @@ experimental implementation of automatic kernel fusion.
### Code
-* [`OpKernel` interface](https://www.tensorflow.org/code/tensorflow/core/framework/op_kernel.h)
+* [`OpKernel` interface](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op_kernel.h)
diff --git a/site/en/r1/guide/extend/bindings.md b/site/en/r1/guide/extend/bindings.md
index 9c10e90840f..7daa2212106 100644
--- a/site/en/r1/guide/extend/bindings.md
+++ b/site/en/r1/guide/extend/bindings.md
@@ -112,11 +112,11 @@ There are a few ways to get a list of the `OpDef`s for the registered ops:
to interpret the `OpDef` messages.
- The C++ function `OpRegistry::Global()->GetRegisteredOps()` returns the same
list of all registered `OpDef`s (defined in
- [`tensorflow/core/framework/op.h`](https://www.tensorflow.org/code/tensorflow/core/framework/op.h)). This can be used to write the generator
+ [`tensorflow/core/framework/op.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op.h)). This can be used to write the generator
in C++ (particularly useful for languages that do not have protocol buffer
support).
- The ASCII-serialized version of that list is periodically checked in to
- [`tensorflow/core/ops/ops.pbtxt`](https://www.tensorflow.org/code/tensorflow/core/ops/ops.pbtxt) by an automated process.
+ [`tensorflow/core/ops/ops.pbtxt`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/ops/ops.pbtxt) by an automated process.
The `OpDef` specifies the following:
@@ -159,7 +159,7 @@ between the generated code and the `OpDef`s checked into the repository, but is
useful for languages where code is expected to be generated ahead of time like
`go get` for Go and `cargo ops` for Rust. At the other end of the spectrum, for
some languages the code could be generated dynamically from
-[`tensorflow/core/ops/ops.pbtxt`](https://www.tensorflow.org/code/tensorflow/core/ops/ops.pbtxt).
+[`tensorflow/core/ops/ops.pbtxt`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/ops/ops.pbtxt).
#### Handling Constants
@@ -228,4 +228,4 @@ At this time, support for gradients, functions and control flow operations ("if"
and "while") is not available in languages other than Python. This will be
updated when the [C API] provides necessary support.
-[C API]: https://www.tensorflow.org/code/tensorflow/c/c_api.h
+[C API]: https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/c/c_api.h
diff --git a/site/en/r1/guide/extend/filesystem.md b/site/en/r1/guide/extend/filesystem.md
index 4d34c07102e..2d6ea0c4645 100644
--- a/site/en/r1/guide/extend/filesystem.md
+++ b/site/en/r1/guide/extend/filesystem.md
@@ -54,7 +54,7 @@ To implement a custom filesystem plugin, you must do the following:
### The FileSystem interface
The `FileSystem` interface is an abstract C++ interface defined in
-[file_system.h](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/file_system.h).
+[file_system.h](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/file_system.h).
An implementation of the `FileSystem` interface should implement all relevant
the methods defined by the interface. Implementing the interface requires
defining operations such as creating `RandomAccessFile`, `WritableFile`, and
@@ -70,26 +70,26 @@ involves calling `stat()` on the file and then returns the filesize as reported
by the return of the stat object. Similarly, for the `HDFSFileSystem`
implementation, these calls simply delegate to the `libHDFS` implementation of
similar functionality, such as `hdfsDelete` for
-[DeleteFile](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/hadoop/hadoop_file_system.cc#L386).
+[DeleteFile](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/hadoop/hadoop_file_system.cc#L386).
We suggest looking through these code examples to get an idea of how different
filesystem implementations call their existing libraries. Examples include:
* [POSIX
- plugin](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/posix/posix_file_system.h)
+ plugin](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/posix/posix_file_system.h)
* [HDFS
- plugin](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/hadoop/hadoop_file_system.h)
+ plugin](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/hadoop/hadoop_file_system.h)
* [GCS
- plugin](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/cloud/gcs_file_system.h)
+ plugin](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/cloud/gcs_file_system.h)
* [S3
- plugin](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/s3/s3_file_system.h)
+ plugin](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/s3/s3_file_system.h)
#### The File interfaces
Beyond operations that allow you to query and manipulate files and directories
in a filesystem, the `FileSystem` interface requires you to implement factories
that return implementations of abstract objects such as the
-[RandomAccessFile](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/platform/file_system.h#L223),
+[RandomAccessFile](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/platform/file_system.h#L223),
the `WritableFile`, so that TensorFlow code and read and write to files in that
`FileSystem` implementation.
@@ -224,7 +224,7 @@ it will use the `FooBarFileSystem` implementation.
Next, you must build a shared object containing this implementation. An example
of doing so using bazel's `cc_binary` rule can be found
-[here](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/BUILD#L244),
+[here](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/BUILD#L244),
but you may use any build system to do so. See the section on [building the op library](../extend/op.md#build_the_op_library) for similar
instructions.
@@ -236,7 +236,7 @@ passing the path to the shared object. Calling this in your client program loads
the shared object in the process, thus registering your implementation as
available for any file operations going through the `FileSystem` interface. You
can see
-[test_file_system.py](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/framework/file_system_test.py)
+[test_file_system.py](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/framework/file_system_test.py)
for an example.
## What goes through this interface?
diff --git a/site/en/r1/guide/extend/formats.md b/site/en/r1/guide/extend/formats.md
index 3b7b4aafbd6..bdebee5487d 100644
--- a/site/en/r1/guide/extend/formats.md
+++ b/site/en/r1/guide/extend/formats.md
@@ -28,11 +28,11 @@ individual records in a file. There are several examples of "reader" datasets
that are already built into TensorFlow:
* `tf.data.TFRecordDataset`
- ([source in `kernels/data/reader_dataset_ops.cc`](https://www.tensorflow.org/code/tensorflow/core/kernels/data/reader_dataset_ops.cc))
+ ([source in `kernels/data/reader_dataset_ops.cc`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/data/reader_dataset_ops.cc))
* `tf.data.FixedLengthRecordDataset`
- ([source in `kernels/data/reader_dataset_ops.cc`](https://www.tensorflow.org/code/tensorflow/core/kernels/data/reader_dataset_ops.cc))
+ ([source in `kernels/data/reader_dataset_ops.cc`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/data/reader_dataset_ops.cc))
* `tf.data.TextLineDataset`
- ([source in `kernels/data/reader_dataset_ops.cc`](https://www.tensorflow.org/code/tensorflow/core/kernels/data/reader_dataset_ops.cc))
+ ([source in `kernels/data/reader_dataset_ops.cc`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/data/reader_dataset_ops.cc))
Each of these implementations comprises three related classes:
@@ -279,7 +279,7 @@ if __name__ == "__main__":
```
You can see some examples of `Dataset` wrapper classes in
-[`tensorflow/python/data/ops/dataset_ops.py`](https://www.tensorflow.org/code/tensorflow/python/data/ops/dataset_ops.py).
+[`tensorflow/python/data/ops/dataset_ops.py`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/data/ops/dataset_ops.py).
## Writing an Op for a record format
@@ -297,7 +297,7 @@ Examples of Ops useful for decoding records:
Note that it can be useful to use multiple Ops to decode a particular record
format. For example, you may have an image saved as a string in
-[a `tf.train.Example` protocol buffer](https://www.tensorflow.org/code/tensorflow/core/example/example.proto).
+[a `tf.train.Example` protocol buffer](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/example/example.proto).
Depending on the format of that image, you might take the corresponding output
from a `tf.parse_single_example` op and call `tf.image.decode_jpeg`,
`tf.image.decode_png`, or `tf.decode_raw`. It is common to take the output
diff --git a/site/en/r1/guide/extend/model_files.md b/site/en/r1/guide/extend/model_files.md
index 30e73a5169e..e590fcf1f27 100644
--- a/site/en/r1/guide/extend/model_files.md
+++ b/site/en/r1/guide/extend/model_files.md
@@ -28,7 +28,7 @@ by calling `as_graph_def()`, which returns a `GraphDef` object.
The GraphDef class is an object created by the ProtoBuf library from the
definition in
-[tensorflow/core/framework/graph.proto](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/graph.proto). The protobuf tools parse
+[tensorflow/core/framework/graph.proto](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/graph.proto). The protobuf tools parse
this text file, and generate the code to load, store, and manipulate graph
definitions. If you see a standalone TensorFlow file representing a model, it's
likely to contain a serialized version of one of these `GraphDef` objects
@@ -87,7 +87,7 @@ for node in graph_def.node
```
Each node is a `NodeDef` object, defined in
-[tensorflow/core/framework/node_def.proto](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/node_def.proto). These
+[tensorflow/core/framework/node_def.proto](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/node_def.proto). These
are the fundamental building blocks of TensorFlow graphs, with each one defining
a single operation along with its input connections. Here are the members of a
`NodeDef`, and what they mean.
@@ -107,7 +107,7 @@ This defines what operation to run, for example `"Add"`, `"MatMul"`, or
`"Conv2D"`. When a graph is run, this op name is looked up in a registry to
find an implementation. The registry is populated by calls to the
`REGISTER_OP()` macro, like those in
-[tensorflow/core/ops/nn_ops.cc](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/ops/nn_ops.cc).
+[tensorflow/core/ops/nn_ops.cc](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/ops/nn_ops.cc).
### `input`
@@ -133,7 +133,7 @@ size of filters for convolutions, or the values of constant ops. Because there
can be so many different types of attribute values, from strings, to ints, to
arrays of tensor values, there's a separate protobuf file defining the data
structure that holds them, in
-[tensorflow/core/framework/attr_value.proto](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/attr_value.proto).
+[tensorflow/core/framework/attr_value.proto](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/attr_value.proto).
Each attribute has a unique name string, and the expected attributes are listed
when the operation is defined. If an attribute isn't present in a node, but it
@@ -151,7 +151,7 @@ the file format during training. Instead, they're held in separate checkpoint
files, and there are `Variable` ops in the graph that load the latest values
when they're initialized. It's often not very convenient to have separate files
when you're deploying to production, so there's the
-[freeze_graph.py](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/tools/freeze_graph.py) script that takes a graph definition and a set
+[freeze_graph.py](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/tools/freeze_graph.py) script that takes a graph definition and a set
of checkpoints and freezes them together into a single file.
What this does is load the `GraphDef`, pull in the values for all the variables
@@ -167,7 +167,7 @@ the most common problems is extracting and interpreting the weight values. A
common way to store them, for example in graphs created by the freeze_graph
script, is as `Const` ops containing the weights as `Tensors`. These are
defined in
-[tensorflow/core/framework/tensor.proto](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/tensor.proto), and contain information
+[tensorflow/core/framework/tensor.proto](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/tensor.proto), and contain information
about the size and type of the data, as well as the values themselves. In
Python, you get a `TensorProto` object from a `NodeDef` representing a `Const`
op by calling something like `some_node_def.attr['value'].tensor`.
diff --git a/site/en/r1/guide/extend/op.md b/site/en/r1/guide/extend/op.md
index d006a6251d0..186d9c28c04 100644
--- a/site/en/r1/guide/extend/op.md
+++ b/site/en/r1/guide/extend/op.md
@@ -47,7 +47,7 @@ To incorporate your custom op you'll need to:
test the op in C++. If you define gradients, you can verify them with the
Python `tf.test.compute_gradient_error`.
See
- [`relu_op_test.py`](https://www.tensorflow.org/code/tensorflow/python/kernel_tests/relu_op_test.py) as
+ [`relu_op_test.py`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/kernel_tests/relu_op_test.py) as
an example that tests the forward functions of Relu-like operators and
their gradients.
@@ -155,17 +155,17 @@ REGISTER_KERNEL_BUILDER(Name("ZeroOut").Device(DEVICE_CPU), ZeroOutOp);
> Important: Instances of your OpKernel may be accessed concurrently.
> Your `Compute` method must be thread-safe. Guard any access to class
> members with a mutex. Or better yet, don't share state via class members!
-> Consider using a [`ResourceMgr`](https://www.tensorflow.org/code/tensorflow/core/framework/resource_mgr.h)
+> Consider using a [`ResourceMgr`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/resource_mgr.h)
> to keep track of op state.
### Multi-threaded CPU kernels
To write a multi-threaded CPU kernel, the Shard function in
-[`work_sharder.h`](https://www.tensorflow.org/code/tensorflow/core/util/work_sharder.h)
+[`work_sharder.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/util/work_sharder.h)
can be used. This function shards a computation function across the
threads configured to be used for intra-op threading (see
intra_op_parallelism_threads in
-[`config.proto`](https://www.tensorflow.org/code/tensorflow/core/protobuf/config.proto)).
+[`config.proto`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/protobuf/config.proto)).
### GPU kernels
@@ -348,12 +348,13 @@ g++ -std=c++11 -shared zero_out.cc -o zero_out.so -fPIC ${TF_CFLAGS[@]} ${TF_LFL
On macOS, the additional flag "-undefined dynamic_lookup" is required when
building the `.so` file.
-> Note on `gcc` version `>=5`: gcc uses the new C++
-> [ABI](https://gcc.gnu.org/gcc-5/changes.html#libstdcxx) since version `5`. The binary pip
-> packages available on the TensorFlow website are built with `gcc4` that uses
-> the older ABI. If you compile your op library with `gcc>=5`, add
-> `-D_GLIBCXX_USE_CXX11_ABI=0` to the command line to make the library
-> compatible with the older abi.
+> Note on `gcc` version `>=5`: gcc uses the new C++
+> [ABI](https://gcc.gnu.org/gcc-5/changes.html#libstdcxx) since version `5`.
+> TensorFlow 2.8 and earlier were built with `gcc4` that uses the older ABI. If
+> you are using these versions of TensorFlow and are trying to compile your op
+> library with `gcc>=5`, add `-D_GLIBCXX_USE_CXX11_ABI=0` to the command line to
+> make the library compatible with the older ABI. TensorFlow 2.9+ packages are
+> compatible with the newer ABI by default.
### Compile the op using bazel (TensorFlow source installation)
@@ -485,13 +486,13 @@ This asserts that the input is a vector, and returns having set the
* The `context`, which can either be an `OpKernelContext` or
`OpKernelConstruction` pointer (see
- [`tensorflow/core/framework/op_kernel.h`](https://www.tensorflow.org/code/tensorflow/core/framework/op_kernel.h)),
+ [`tensorflow/core/framework/op_kernel.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op_kernel.h)),
for its `SetStatus()` method.
* The condition. For example, there are functions for validating the shape
of a tensor in
- [`tensorflow/core/framework/tensor_shape.h`](https://www.tensorflow.org/code/tensorflow/core/framework/tensor_shape.h)
+ [`tensorflow/core/framework/tensor_shape.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/tensor_shape.h)
* The error itself, which is represented by a `Status` object, see
- [`tensorflow/core/lib/core/status.h`](https://www.tensorflow.org/code/tensorflow/core/lib/core/status.h). A
+ [`tensorflow/core/lib/core/status.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/lib/core/status.h). A
`Status` has both a type (frequently `InvalidArgument`, but see the list of
types) and a message. Functions for constructing an error may be found in
[`tensorflow/core/lib/core/errors.h`][validation-macros].
@@ -632,7 +633,7 @@ define an attr with constraints, you can use the following ``s:
The specific lists of types allowed by these are defined by the functions
(like `NumberTypes()`) in
- [`tensorflow/core/framework/types.h`](https://www.tensorflow.org/code/tensorflow/core/framework/types.h).
+ [`tensorflow/core/framework/types.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/types.h).
In this example the attr `t` must be one of the numeric types:
```c++
@@ -1179,7 +1180,7 @@ There are several ways to preserve backwards-compatibility.
type into a list of varying types).
The full list of safe and unsafe changes can be found in
-[`tensorflow/core/framework/op_compatibility_test.cc`](https://www.tensorflow.org/code/tensorflow/core/framework/op_compatibility_test.cc).
+[`tensorflow/core/framework/op_compatibility_test.cc`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op_compatibility_test.cc).
If you cannot make your change to an operation backwards compatible, then create
a new operation with a new name with the new semantics.
@@ -1189,23 +1190,23 @@ callers. The Python API may be kept compatible by careful changes in a
hand-written Python wrapper, by keeping the old signature except possibly adding
new optional arguments to the end. Generally incompatible changes may only be
made when TensorFlow changes major versions, and must conform to the
-[`GraphDef` version semantics](../guide/version_compat.md#compatibility_of_graphs_and_checkpoints).
+[`GraphDef` version semantics](../version_compat.md).
### GPU Support
You can implement different OpKernels and register one for CPU and another for
GPU, just like you can [register kernels for different types](#polymorphism).
There are several examples of kernels with GPU support in
-[`tensorflow/core/kernels/`](https://www.tensorflow.org/code/tensorflow/core/kernels/).
+[`tensorflow/core/kernels/`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/).
Notice some kernels have a CPU version in a `.cc` file, a GPU version in a file
ending in `_gpu.cu.cc`, and some code shared in common in a `.h` file.
For example, the `tf.pad` has
everything but the GPU kernel in [`tensorflow/core/kernels/pad_op.cc`][pad_op].
The GPU kernel is in
-[`tensorflow/core/kernels/pad_op_gpu.cu.cc`](https://www.tensorflow.org/code/tensorflow/core/kernels/pad_op_gpu.cu.cc),
+[`tensorflow/core/kernels/pad_op_gpu.cu.cc`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/pad_op_gpu.cu.cc),
and the shared code is a templated class defined in
-[`tensorflow/core/kernels/pad_op.h`](https://www.tensorflow.org/code/tensorflow/core/kernels/pad_op.h).
+[`tensorflow/core/kernels/pad_op.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/pad_op.h).
We organize the code this way for two reasons: it allows you to share common
code among the CPU and GPU implementations, and it puts the GPU implementation
into a separate file so that it can be compiled only by the GPU compiler.
@@ -1226,16 +1227,16 @@ kept on the CPU, add a `HostMemory()` call to the kernel registration, e.g.:
#### Compiling the kernel for the GPU device
Look at
-[cuda_op_kernel.cu.cc](https://www.tensorflow.org/code/tensorflow/examples/adding_an_op/cuda_op_kernel.cu.cc)
+[cuda_op_kernel.cu.cc](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/adding_an_op/cuda_op_kernel.cu.cc)
for an example that uses a CUDA kernel to implement an op. The
`tf_custom_op_library` accepts a `gpu_srcs` argument in which the list of source
files containing the CUDA kernels (`*.cu.cc` files) can be specified. For use
with a binary installation of TensorFlow, the CUDA kernels have to be compiled
with NVIDIA's `nvcc` compiler. Here is the sequence of commands you can use to
compile the
-[cuda_op_kernel.cu.cc](https://www.tensorflow.org/code/tensorflow/examples/adding_an_op/cuda_op_kernel.cu.cc)
+[cuda_op_kernel.cu.cc](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/adding_an_op/cuda_op_kernel.cu.cc)
and
-[cuda_op_kernel.cc](https://www.tensorflow.org/code/tensorflow/examples/adding_an_op/cuda_op_kernel.cc)
+[cuda_op_kernel.cc](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/adding_an_op/cuda_op_kernel.cc)
into a single dynamically loadable library:
```bash
@@ -1360,7 +1361,7 @@ be set to the first input's shape. If the output is selected by its index as in
There are a number of common shape functions
that apply to many ops, such as `shape_inference::UnchangedShape` which can be
-found in [common_shape_fns.h](https://www.tensorflow.org/code/tensorflow/core/framework/common_shape_fns.h) and used as follows:
+found in [common_shape_fns.h](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/common_shape_fns.h) and used as follows:
```c++
REGISTER_OP("ZeroOut")
@@ -1407,7 +1408,7 @@ provides access to the attributes of the op).
Since shape inference is an optional feature, and the shapes of tensors may vary
dynamically, shape functions must be robust to incomplete shape information for
-any of the inputs. The `Merge` method in [`InferenceContext`](https://www.tensorflow.org/code/tensorflow/core/framework/shape_inference.h)
+any of the inputs. The `Merge` method in [`InferenceContext`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/shape_inference.h)
allows the caller to assert that two shapes are the same, even if either
or both of them do not have complete information. Shape functions are defined
for all of the core TensorFlow ops and provide many different usage examples.
@@ -1432,7 +1433,7 @@ If you have a complicated shape function, you should consider adding a test for
validating that various input shape combinations produce the expected output
shape combinations. You can see examples of how to write these tests in some
our
-[core ops tests](https://www.tensorflow.org/code/tensorflow/core/ops/array_ops_test.cc).
+[core ops tests](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/ops/array_ops_test.cc).
(The syntax of `INFER_OK` and `INFER_ERROR` are a little cryptic, but try to be
compact in representing input and output shape specifications in tests. For
now, see the surrounding comments in those tests to get a sense of the shape
@@ -1445,20 +1446,20 @@ To build a `pip` package for your op, see the
guide shows how to build custom ops from the TensorFlow pip package instead
of building TensorFlow from source.
-[core-array_ops]:https://www.tensorflow.org/code/tensorflow/core/ops/array_ops.cc
-[python-user_ops]:https://www.tensorflow.org/code/tensorflow/python/user_ops/user_ops.py
-[tf-kernels]:https://www.tensorflow.org/code/tensorflow/core/kernels/
-[user_ops]:https://www.tensorflow.org/code/tensorflow/core/user_ops/
-[pad_op]:https://www.tensorflow.org/code/tensorflow/core/kernels/pad_op.cc
-[standard_ops-py]:https://www.tensorflow.org/code/tensorflow/python/ops/standard_ops.py
-[standard_ops-cc]:https://www.tensorflow.org/code/tensorflow/cc/ops/standard_ops.h
-[python-BUILD]:https://www.tensorflow.org/code/tensorflow/python/BUILD
-[validation-macros]:https://www.tensorflow.org/code/tensorflow/core/lib/core/errors.h
-[op_def_builder]:https://www.tensorflow.org/code/tensorflow/core/framework/op_def_builder.h
-[register_types]:https://www.tensorflow.org/code/tensorflow/core/framework/register_types.h
-[FinalizeAttr]:https://www.tensorflow.org/code/tensorflow/core/framework/op_def_builder.cc
-[DataTypeString]:https://www.tensorflow.org/code/tensorflow/core/framework/types.cc
-[python-BUILD]:https://www.tensorflow.org/code/tensorflow/python/BUILD
-[types-proto]:https://www.tensorflow.org/code/tensorflow/core/framework/types.proto
-[TensorShapeProto]:https://www.tensorflow.org/code/tensorflow/core/framework/tensor_shape.proto
-[TensorProto]:https://www.tensorflow.org/code/tensorflow/core/framework/tensor.proto
+[core-array_ops]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/ops/array_ops.cc
+[python-user_ops]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/user_ops/user_ops.py
+[tf-kernels]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/
+[user_ops]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/user_ops/
+[pad_op]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/pad_op.cc
+[standard_ops-py]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/ops/standard_ops.py
+[standard_ops-cc]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/cc/ops/standard_ops.h
+[python-BUILD]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/BUILD
+[validation-macros]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/lib/core/errors.h
+[op_def_builder]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op_def_builder.h
+[register_types]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/register_types.h
+[FinalizeAttr]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op_def_builder.cc
+[DataTypeString]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/types.cc
+[python-BUILD]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/BUILD
+[types-proto]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/types.proto
+[TensorShapeProto]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/tensor_shape.proto
+[TensorProto]:https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/tensor.proto
diff --git a/site/en/r1/guide/feature_columns.md b/site/en/r1/guide/feature_columns.md
index 5a4dfbbf46d..e4259f85e9f 100644
--- a/site/en/r1/guide/feature_columns.md
+++ b/site/en/r1/guide/feature_columns.md
@@ -562,7 +562,7 @@ For more examples on feature columns, view the following:
* The [Low Level Introduction](../guide/low_level_intro.md#feature_columns) demonstrates how
experiment directly with `feature_columns` using TensorFlow's low level APIs.
-* The [Estimator wide and deep learning tutorial](https://github.com/tensorflow/models/tree/master/official/r1/wide_deep)
+* The [Estimator wide and deep learning tutorial](https://github.com/tensorflow/models/tree/r1.15/official/r1/wide_deep)
solves a binary classification problem using `feature_columns` on a variety of
input data types.
diff --git a/site/en/r1/guide/graph_viz.md b/site/en/r1/guide/graph_viz.md
index 1965378e03e..1e3780e7928 100644
--- a/site/en/r1/guide/graph_viz.md
+++ b/site/en/r1/guide/graph_viz.md
@@ -251,7 +251,7 @@ is a snippet from the train and test section of a modification of the
[Estimators MNIST tutorial](../tutorials/estimators/cnn.md), in which we have
recorded summaries and
runtime statistics. See the
-[Tensorboard](https://tensorflow.org/tensorboard)
+[TensorBoard](https://tensorflow.org/tensorboard)
for details on how to record summaries.
Full source is [here](https://github.com/tensorflow/tensorflow/tree/r1.15/tensorflow/examples/tutorials/mnist/mnist_with_summaries.py).
diff --git a/site/en/r1/guide/keras.ipynb b/site/en/r1/guide/keras.ipynb
index 08a778b60a5..3a0cd8e55c5 100644
--- a/site/en/r1/guide/keras.ipynb
+++ b/site/en/r1/guide/keras.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
@@ -1211,8 +1211,7 @@
"colab": {
"collapsed_sections": [],
"name": "keras.ipynb",
- "provenance": [],
- "toc_visible": true
+ "toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
diff --git a/site/en/r1/guide/performance/benchmarks.md b/site/en/r1/guide/performance/benchmarks.md
index 8998c0723db..a56959ea416 100644
--- a/site/en/r1/guide/performance/benchmarks.md
+++ b/site/en/r1/guide/performance/benchmarks.md
@@ -401,7 +401,7 @@ GPUs | InceptionV3 (batch size 32) | ResNet-50 (batch size 32)
## Methodology
This
-[script](https://github.com/tensorflow/benchmarks/tree/master/scripts/tf_cnn_benchmarks)
+[script](https://github.com/tensorflow/benchmarks/tree/r1.15/scripts/tf_cnn_benchmarks)
was run on the various platforms to generate the above results.
In order to create results that are as repeatable as possible, each test was run
diff --git a/site/en/r1/guide/performance/overview.md b/site/en/r1/guide/performance/overview.md
index af74f0f28c6..be7217f4b99 100644
--- a/site/en/r1/guide/performance/overview.md
+++ b/site/en/r1/guide/performance/overview.md
@@ -19,9 +19,9 @@ Reading large numbers of small files significantly impacts I/O performance.
One approach to get maximum I/O throughput is to preprocess input data into
larger (~100MB) `TFRecord` files. For smaller data sets (200MB-1GB), the best
approach is often to load the entire data set into memory. The document
-[Downloading and converting to TFRecord format](https://github.com/tensorflow/models/tree/master/research/slim#downloading-and-converting-to-tfrecord-format)
+[Downloading and converting to TFRecord format](https://github.com/tensorflow/models/tree/r1.15/research/slim#downloading-and-converting-to-tfrecord-format)
includes information and scripts for creating `TFRecord`s, and this
-[script](https://github.com/tensorflow/models/tree/master/research/tutorials/image/cifar10_estimator/generate_cifar10_tfrecords.py)
+[script](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/image/cifar10_estimator/generate_cifar10_tfrecords.py)
converts the CIFAR-10 dataset into `TFRecord`s.
While feeding data using a `feed_dict` offers a high level of flexibility, in
@@ -122,7 +122,7 @@ tf.Session(config=config)
Intel® has added optimizations to TensorFlow for Intel® Xeon® and Intel® Xeon
Phi™ through the use of the Intel® Math Kernel Library for Deep Neural Networks
(Intel® MKL-DNN) optimized primitives. The optimizations also provide speedups
-for the consumer line of processors, e.g. i5 and i7 Intel processors. The Intel
+for the consumer line of processors, e.g., i5 and i7 Intel processors. The Intel
published paper
[TensorFlow* Optimizations on Modern Intel® Architecture](https://software.intel.com/en-us/articles/tensorflow-optimizations-on-modern-intel-architecture)
contains additional details on the implementation.
@@ -255,7 +255,7 @@ bazel build -c opt --copt=-march="broadwell" --config=cuda //tensorflow/tools/pi
a docker container, the data is not cached and the penalty is paid each time
TensorFlow starts. The best practice is to include the
[compute capabilities](http://developer.nvidia.com/cuda-gpus)
- of the GPUs that will be used, e.g. P100: 6.0, Titan X (Pascal): 6.1,
+ of the GPUs that will be used, e.g., P100: 6.0, Titan X (Pascal): 6.1,
Titan X (Maxwell): 5.2, and K80: 3.7.
* Use a version of `gcc` that supports all of the optimizations of the target
CPU. The recommended minimum gcc version is 4.8.3. On macOS, upgrade to the
diff --git a/site/en/r1/guide/ragged_tensors.ipynb b/site/en/r1/guide/ragged_tensors.ipynb
index 61bce66ecfb..289d29ce82e 100644
--- a/site/en/r1/guide/ragged_tensors.ipynb
+++ b/site/en/r1/guide/ragged_tensors.ipynb
@@ -57,7 +57,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
@@ -1010,7 +1010,7 @@
" `tf.RaggedTensor.values`\n",
" and\n",
" `tf.RaggedTensor.row_splits`\n",
- " properties, or row-paritioning methods such as `tf.RaggedTensor.row_lengths()`\n",
+ " properties, or row-partitioning methods such as `tf.RaggedTensor.row_lengths()`\n",
" and `tf.RaggedTensor.value_rowids()`."
]
},
diff --git a/site/en/r1/guide/saved_model.md b/site/en/r1/guide/saved_model.md
index 623863a9df9..34447ffe861 100644
--- a/site/en/r1/guide/saved_model.md
+++ b/site/en/r1/guide/saved_model.md
@@ -23,7 +23,7 @@ TensorFlow saves variables in binary *checkpoint files* that map variable
names to tensor values.
Caution: TensorFlow model files are code. Be careful with untrusted code.
-See [Using TensorFlow Securely](https://github.com/tensorflow/tensorflow/blob/master/SECURITY.md)
+See [Using TensorFlow Securely](https://github.com/tensorflow/tensorflow/blob/r1.15/SECURITY.md)
for details.
### Save variables
@@ -148,7 +148,7 @@ Notes:
`tf.variables_initializer` for more information.
* To inspect the variables in a checkpoint, you can use the
- [`inspect_checkpoint`](https://www.tensorflow.org/code/tensorflow/python/tools/inspect_checkpoint.py)
+ [`inspect_checkpoint`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/tools/inspect_checkpoint.py)
library, particularly the `print_tensors_in_checkpoint_file` function.
* By default, `Saver` uses the value of the `tf.Variable.name` property
@@ -159,7 +159,7 @@ Notes:
### Inspect variables in a checkpoint
We can quickly inspect variables in a checkpoint with the
-[`inspect_checkpoint`](https://www.tensorflow.org/code/tensorflow/python/tools/inspect_checkpoint.py) library.
+[`inspect_checkpoint`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/tools/inspect_checkpoint.py) library.
Continuing from the save/restore examples shown earlier:
@@ -216,7 +216,7 @@ simple_save(session,
This configures the `SavedModel` so it can be loaded by
[TensorFlow serving](https://www.tensorflow.org/tfx/tutorials/serving/rest_simple) and supports the
-[Predict API](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis/predict.proto).
+[Predict API](https://github.com/tensorflow/serving/blob/r1.15/tensorflow_serving/apis/predict.proto).
To access the classify, regress, or multi-inference APIs, use the manual
`SavedModel` builder APIs or an `tf.estimator.Estimator`.
@@ -328,7 +328,7 @@ with tf.Session(graph=tf.Graph()) as sess:
### Load a SavedModel in C++
The C++ version of the SavedModel
-[loader](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/cc/saved_model/loader.h)
+[loader](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/cc/saved_model/loader.h)
provides an API to load a SavedModel from a path, while allowing
`SessionOptions` and `RunOptions`.
You have to specify the tags associated with the graph to be loaded.
@@ -383,20 +383,20 @@ reuse and share across tools consistently.
You may use sets of tags to uniquely identify a `MetaGraphDef` saved in a
SavedModel. A subset of commonly used tags is specified in:
-* [Python](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/saved_model/tag_constants.py)
-* [C++](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/cc/saved_model/tag_constants.h)
+* [Python](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/saved_model/tag_constants.py)
+* [C++](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/cc/saved_model/tag_constants.h)
#### Standard SignatureDef constants
-A [**SignatureDef**](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/protobuf/meta_graph.proto)
+A [**SignatureDef**](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/protobuf/meta_graph.proto)
is a protocol buffer that defines the signature of a computation
supported by a graph.
Commonly used input keys, output keys, and method names are
defined in:
-* [Python](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/saved_model/signature_constants.py)
-* [C++](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/cc/saved_model/signature_constants.h)
+* [Python](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/saved_model/signature_constants.py)
+* [C++](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/cc/saved_model/signature_constants.h)
## Using SavedModel with Estimators
@@ -408,7 +408,7 @@ To prepare a trained Estimator for serving, you must export it in the standard
SavedModel format. This section explains how to:
* Specify the output nodes and the corresponding
- [APIs](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis/prediction_service.proto)
+ [APIs](https://github.com/tensorflow/serving/blob/r1.15/tensorflow_serving/apis/prediction_service.proto)
that can be served (Classify, Regress, or Predict).
* Export your model to the SavedModel format.
* Serve the model from a local server and request predictions.
@@ -506,7 +506,7 @@ Each `output` value must be an `ExportOutput` object such as
`tf.estimator.export.PredictOutput`.
These output types map straightforwardly to the
-[TensorFlow Serving APIs](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis/prediction_service.proto),
+[TensorFlow Serving APIs](https://github.com/tensorflow/serving/blob/r1.15/tensorflow_serving/apis/prediction_service.proto),
and so determine which request types will be honored.
Note: In the multi-headed case, a `SignatureDef` will be generated for each
@@ -515,7 +515,7 @@ the same keys. These `SignatureDef`s differ only in their outputs, as
provided by the corresponding `ExportOutput` entry. The inputs are always
those provided by the `serving_input_receiver_fn`.
An inference request may specify the head by name. One head must be named
-using [`signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY`](https://www.tensorflow.org/code/tensorflow/python/saved_model/signature_constants.py)
+using [`signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/saved_model/signature_constants.py)
indicating which `SignatureDef` will be served when an inference request
does not specify one.
@@ -566,9 +566,9 @@ Now you have a server listening for inference requests via gRPC on port 9000!
### Request predictions from a local server
The server responds to gRPC requests according to the
-[PredictionService](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis/prediction_service.proto#L15)
+[PredictionService](https://github.com/tensorflow/serving/blob/r1.15/tensorflow_serving/apis/prediction_service.proto#L15)
gRPC API service definition. (The nested protocol buffers are defined in
-various [neighboring files](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis)).
+various [neighboring files](https://github.com/tensorflow/serving/blob/r1.15/tensorflow_serving/apis)).
From the API service definition, the gRPC framework generates client libraries
in various languages providing remote access to the API. In a project using the
@@ -620,7 +620,7 @@ The returned result in this example is a `ClassificationResponse` protocol
buffer.
This is a skeletal example; please see the [Tensorflow Serving](../deploy/index.md)
-documentation and [examples](https://github.com/tensorflow/serving/tree/master/tensorflow_serving/example)
+documentation and [examples](https://github.com/tensorflow/serving/tree/r1.15/tensorflow_serving/example)
for more details.
> Note: `ClassificationRequest` and `RegressionRequest` contain a
diff --git a/site/en/r1/guide/using_tpu.md b/site/en/r1/guide/using_tpu.md
index 74169092189..e3e338adf49 100644
--- a/site/en/r1/guide/using_tpu.md
+++ b/site/en/r1/guide/using_tpu.md
@@ -7,8 +7,8 @@ changing the *hardware accelerator* in your notebook settings:
TPU-enabled Colab notebooks are available to test:
1. [A quick test, just to measure FLOPS](https://colab.research.google.com/notebooks/tpu.ipynb).
- 2. [A CNN image classifier with `tf.keras`](https://colab.research.google.com/github/tensorflow/tpu/blob/master/tools/colab/fashion_mnist.ipynb).
- 3. [An LSTM markov chain text generator with `tf.keras`](https://colab.research.google.com/github/tensorflow/tpu/blob/master/tools/colab/shakespeare_with_tpu_and_keras.ipynb)
+ 2. [A CNN image classifier with `tf.keras`](https://colab.research.google.com/github/tensorflow/tpu/blob/r1.15/tools/colab/fashion_mnist.ipynb).
+ 3. [An LSTM markov chain text generator with `tf.keras`](https://colab.research.google.com/github/tensorflow/tpu/blob/r1.15/tools/colab/shakespeare_with_tpu_and_keras.ipynb)
## TPUEstimator
@@ -25,7 +25,7 @@ Cloud TPU is to define the model's inference phase (from inputs to predictions)
outside of the `model_fn`. Then maintain separate implementations of the
`Estimator` setup and `model_fn`, both wrapping this inference step. For an
example of this pattern compare the `mnist.py` and `mnist_tpu.py` implementation in
-[tensorflow/models](https://github.com/tensorflow/models/tree/master/official/r1/mnist).
+[tensorflow/models](https://github.com/tensorflow/models/tree/r1.15/official/r1/mnist).
### Run a TPUEstimator locally
@@ -350,10 +350,10 @@ in bytes. A minimum of a few MB (`buffer_size=8*1024*1024`) is recommended so
that data is available when needed.
The TPU-demos repo includes
-[a script](https://github.com/tensorflow/tpu/blob/master/tools/datasets/imagenet_to_gcs.py)
+[a script](https://github.com/tensorflow/tpu/blob/1.15/tools/datasets/imagenet_to_gcs.py)
for downloading the imagenet dataset and converting it to an appropriate format.
This together with the imagenet
-[models](https://github.com/tensorflow/tpu/tree/master/models)
+[models](https://github.com/tensorflow/tpu/tree/r1.15/models)
included in the repo demonstrate all of these best-practices.
## Next steps
diff --git a/site/en/r1/guide/version_compat.md b/site/en/r1/guide/version_compat.md
index 6702f6e0819..a765620518d 100644
--- a/site/en/r1/guide/version_compat.md
+++ b/site/en/r1/guide/version_compat.md
@@ -49,19 +49,19 @@ patch versions. The public APIs consist of
submodules, but is not documented, then it is **not** considered part of the
public API.
-* The [C API](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/c/c_api.h).
+* The [C API](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/c/c_api.h).
* The following protocol buffer files:
- * [`attr_value`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/attr_value.proto)
- * [`config`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/protobuf/config.proto)
- * [`event`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/util/event.proto)
- * [`graph`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/graph.proto)
- * [`op_def`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/op_def.proto)
- * [`reader_base`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/reader_base.proto)
- * [`summary`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/summary.proto)
- * [`tensor`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/tensor.proto)
- * [`tensor_shape`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/tensor_shape.proto)
- * [`types`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/types.proto)
+ * [`attr_value`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/attr_value.proto)
+ * [`config`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/protobuf/config.proto)
+ * [`event`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/util/event.proto)
+ * [`graph`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/graph.proto)
+ * [`op_def`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/op_def.proto)
+ * [`reader_base`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/reader_base.proto)
+ * [`summary`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/summary.proto)
+ * [`tensor`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/tensor.proto)
+ * [`tensor_shape`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/tensor_shape.proto)
+ * [`types`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/types.proto)
## What is *not* covered
@@ -79,7 +79,7 @@ backward incompatible ways between minor releases. These include:
such as:
- [C++](./extend/cc.md) (exposed through header files in
- [`tensorflow/cc`](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/cc)).
+ [`tensorflow/cc`](https://github.com/tensorflow/tensorflow/tree/r1.15/tensorflow/cc)).
- [Java](../api_docs/java/reference/org/tensorflow/package-summary),
- [Go](https://pkg.go.dev/github.com/tensorflow/tensorflow/tensorflow/go)
- [JavaScript](https://js.tensorflow.org)
@@ -209,7 +209,7 @@ guidelines for evolving `GraphDef` versions.
There are different data versions for graphs and checkpoints. The two data
formats evolve at different rates from each other and also at different rates
from TensorFlow. Both versioning systems are defined in
-[`core/public/version.h`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/public/version.h).
+[`core/public/version.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/public/version.h).
Whenever a new version is added, a note is added to the header detailing what
changed and the date.
@@ -224,7 +224,7 @@ We distinguish between the following kinds of data version information:
(`min_producer`).
Each piece of versioned data has a [`VersionDef
-versions`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/versions.proto)
+versions`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/framework/versions.proto)
field which records the `producer` that made the data, the `min_consumer`
that it is compatible with, and a list of `bad_consumers` versions that are
disallowed.
@@ -239,7 +239,7 @@ accept a piece of data if the following are all true:
* `consumer` not in data's `bad_consumers`
Since both producers and consumers come from the same TensorFlow code base,
-[`core/public/version.h`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/public/version.h)
+[`core/public/version.h`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/public/version.h)
contains a main data version which is treated as either `producer` or
`consumer` depending on context and both `min_consumer` and `min_producer`
(needed by producers and consumers, respectively). Specifically,
@@ -309,7 +309,7 @@ existing producer scripts will not suddenly use the new functionality.
1. Add a new similar op named `SomethingV2` or similar and go through the
process of adding it and switching existing Python wrappers to use it.
To ensure forward compatibility use the checks suggested in
- [compat.py](https://www.tensorflow.org/code/tensorflow/python/compat/compat.py)
+ [compat.py](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/compat/compat.py)
when changing the Python wrappers.
2. Remove the old op (Can only take place with a major version change due to
backward compatibility).
diff --git a/site/en/r1/tutorials/README.md b/site/en/r1/tutorials/README.md
index b6d932041bd..9ff164ad77c 100644
--- a/site/en/r1/tutorials/README.md
+++ b/site/en/r1/tutorials/README.md
@@ -10,7 +10,7 @@ desktop, mobile, web, and cloud. See the sections below to get started.
The high-level Keras API provides building blocks to create and
train deep learning models. Start with these beginner-friendly
-notebook examples, then read the [TensorFlow Keras guide](../guide/keras.ipynb).
+notebook examples, then read the [TensorFlow Keras guide](https://www.tensorflow.org/guide/keras).
* [Basic classification](./keras/basic_classification.ipynb)
* [Text classification](./keras/basic_text_classification.ipynb)
@@ -68,4 +68,4 @@ implement common ML algorithms. See the
* [Boosted trees](./estimators/boosted_trees.ipynb)
* [Gradient Boosted Trees: Model understanding](./estimators/boosted_trees_model_understanding.ipynb)
* [Build a Convolutional Neural Network using Estimators](./estimators/cnn.ipynb)
-* [Wide and deep learning with Estimators](https://github.com/tensorflow/models/tree/master/official/r1/wide_deep)
+* [Wide and deep learning with Estimators](https://github.com/tensorflow/models/tree/r1.15/official/r1/wide_deep)
diff --git a/site/en/r1/tutorials/_index.ipynb b/site/en/r1/tutorials/_index.ipynb
index e2fe960d125..eca1450964f 100644
--- a/site/en/r1/tutorials/_index.ipynb
+++ b/site/en/r1/tutorials/_index.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/distribute/keras.ipynb b/site/en/r1/tutorials/distribute/keras.ipynb
index b8d3c87bfab..14e8bf739a9 100644
--- a/site/en/r1/tutorials/distribute/keras.ipynb
+++ b/site/en/r1/tutorials/distribute/keras.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
@@ -86,7 +86,7 @@
"Essentially, it copies all of the model's variables to each processor.\n",
"Then, it uses [all-reduce](http://mpitutorial.com/tutorials/mpi-reduce-and-allreduce/) to combine the gradients from all processors and applies the combined value to all copies of the model.\n",
"\n",
- "`MirroredStategy` is one of several distribution strategy available in TensorFlow core. You can read about more strategies at [distribution strategy guide](../../guide/distribute_strategy.ipynb).\n"
+ "`MirroredStrategy` is one of several distribution strategy available in TensorFlow core. You can read about more strategies at [distribution strategy guide](../../guide/distribute_strategy.ipynb).\n"
]
},
{
@@ -345,7 +345,7 @@
"source": [
"The callbacks used here are:\n",
"\n",
- "* *Tensorboard*: This callback writes a log for Tensorboard which allows you to visualize the graphs.\n",
+ "* *TensorBoard*: This callback writes a log for TensorBoard which allows you to visualize the graphs.\n",
"* *Model Checkpoint*: This callback saves the model after every epoch.\n",
"* *Learning Rate Scheduler*: Using this callback, you can schedule the learning rate to change after every epoch/batch.\n",
"\n",
@@ -554,7 +554,7 @@
},
"outputs": [],
"source": [
- "tf.keras.experimental.export_saved_model(model, path)"
+ "model.save(path)"
]
},
{
@@ -574,7 +574,7 @@
},
"outputs": [],
"source": [
- "unreplicated_model = tf.keras.experimental.load_from_saved_model(path)\n",
+ "unreplicated_model = tf.keras.models.load_model(path)\n",
"\n",
"unreplicated_model.compile(\n",
" loss='sparse_categorical_crossentropy',\n",
diff --git a/site/en/r1/tutorials/distribute/tpu_custom_training.ipynb b/site/en/r1/tutorials/distribute/tpu_custom_training.ipynb
index 6d09d2623de..c61f893ca4c 100644
--- a/site/en/r1/tutorials/distribute/tpu_custom_training.ipynb
+++ b/site/en/r1/tutorials/distribute/tpu_custom_training.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/distribute/training_loops.ipynb b/site/en/r1/tutorials/distribute/training_loops.ipynb
index 1343e8c8b6b..8eb72c13030 100644
--- a/site/en/r1/tutorials/distribute/training_loops.ipynb
+++ b/site/en/r1/tutorials/distribute/training_loops.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/eager/automatic_differentiation.ipynb b/site/en/r1/tutorials/eager/automatic_differentiation.ipynb
index bbbb689a617..df843bac3b8 100644
--- a/site/en/r1/tutorials/eager/automatic_differentiation.ipynb
+++ b/site/en/r1/tutorials/eager/automatic_differentiation.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/eager/custom_layers.ipynb b/site/en/r1/tutorials/eager/custom_layers.ipynb
index c82458cb857..48b55ed943e 100644
--- a/site/en/r1/tutorials/eager/custom_layers.ipynb
+++ b/site/en/r1/tutorials/eager/custom_layers.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
@@ -230,7 +230,7 @@
"source": [
"## Models: composing layers\n",
"\n",
- "Many interesting layer-like things in machine learning models are implemented by composing existing layers. For example, each residual block in a resnet is a composition of convolutions, batch normalizations, and a shortcut.\n",
+ "Many interesting layer-like things in machine learning models are implemented by composing existing layers. For example, each residual block in a ResNet is a composition of convolutions, batch normalizations, and a shortcut.\n",
"\n",
"The main class used when creating a layer-like thing which contains other layers is tf.keras.Model. Implementing one is done by inheriting from tf.keras.Model."
]
diff --git a/site/en/r1/tutorials/eager/custom_training.ipynb b/site/en/r1/tutorials/eager/custom_training.ipynb
index 72beefe89ad..f0f7faffa7f 100644
--- a/site/en/r1/tutorials/eager/custom_training.ipynb
+++ b/site/en/r1/tutorials/eager/custom_training.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/eager/custom_training_walkthrough.ipynb b/site/en/r1/tutorials/eager/custom_training_walkthrough.ipynb
index a4839429827..3989f3e44bc 100644
--- a/site/en/r1/tutorials/eager/custom_training_walkthrough.ipynb
+++ b/site/en/r1/tutorials/eager/custom_training_walkthrough.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/eager/eager_basics.ipynb b/site/en/r1/tutorials/eager/eager_basics.ipynb
index 9a72f192385..acd00ec2e20 100644
--- a/site/en/r1/tutorials/eager/eager_basics.ipynb
+++ b/site/en/r1/tutorials/eager/eager_basics.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
@@ -236,7 +236,7 @@
"x = tf.random.uniform([3, 3])\n",
"\n",
"print(\"Is there a GPU available: \"),\n",
- "print(tf.test.is_gpu_available())\n",
+ "print(tf.config.list_physical_devices('GPU'))\n",
"\n",
"print(\"Is the Tensor on GPU #0: \"),\n",
"print(x.device.endswith('GPU:0'))"
@@ -292,7 +292,7 @@
" time_matmul(x)\n",
"\n",
"# Force execution on GPU #0 if available\n",
- "if tf.test.is_gpu_available():\n",
+ "if tf.config.list_physical_devices('GPU'):\n",
" with tf.device(\"GPU:0\"): # Or GPU:1 for the 2nd GPU, GPU:2 for the 3rd etc.\n",
" x = tf.random_uniform([1000, 1000])\n",
" assert x.device.endswith(\"GPU:0\")\n",
diff --git a/site/en/r1/tutorials/estimators/boosted_trees.ipynb b/site/en/r1/tutorials/estimators/boosted_trees.ipynb
deleted file mode 100644
index 7452d521095..00000000000
--- a/site/en/r1/tutorials/estimators/boosted_trees.ipynb
+++ /dev/null
@@ -1,606 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "7765UFHoyGx6"
- },
- "source": [
- "##### Copyright 2019 The TensorFlow Authors."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "id": "KVtTDrUNyL7x"
- },
- "outputs": [],
- "source": [
- "#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n",
- "# you may not use this file except in compliance with the License.\n",
- "# You may obtain a copy of the License at\n",
- "#\n",
- "# https://www.apache.org/licenses/LICENSE-2.0\n",
- "#\n",
- "# Unless required by applicable law or agreed to in writing, software\n",
- "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
- "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
- "# See the License for the specific language governing permissions and\n",
- "# limitations under the License."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "xPYxZMrWyA0N"
- },
- "source": [
- "#How to train Boosted Trees models in TensorFlow"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "p_vOREjRx-Y0"
- },
- "source": [
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "6lCDyX3HFWos"
- },
- "source": [
- "> Note: This is an archived TF1 notebook. These are configured\n",
- "to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
- "but will run in TF1 as well. To use TF1 in Colab, use the\n",
- "[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
- "magic."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "dW3r7qVxzqN5"
- },
- "source": [
- "This tutorial is an end-to-end walkthrough of training a Gradient Boosting model using decision trees with the `tf.estimator` API. Boosted Trees models are among the most popular and effective machine learning approaches for both regression and classification. It is an ensemble technique that combines the predictions from several (think 10s, 100s or even 1000s) tree models.\n",
- "\n",
- "Boosted Trees models are popular with many machine learning practioners as they can achieve impressive performance with minimal hyperparameter tuning."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "eylrTPAN3rJV"
- },
- "source": [
- "## Load the titanic dataset\n",
- "You will be using the titanic dataset, where the (rather morbid) goal is to predict passenger survival, given characteristics such as gender, age, class, etc."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "KuhAiPfZ3rJW"
- },
- "outputs": [],
- "source": [
- "from matplotlib import pyplot as plt\n",
- "\n",
- "import numpy as np\n",
- "import pandas as pd\n",
- "import tensorflow.compat.v1 as tf\n",
- "\n",
- "tf.logging.set_verbosity(tf.logging.ERROR)\n",
- "tf.set_random_seed(123)\n",
- "\n",
- "# Load dataset.\n",
- "dftrain = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/train.csv')\n",
- "dfeval = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/eval.csv')\n",
- "y_train = dftrain.pop('survived')\n",
- "y_eval = dfeval.pop('survived')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "3ioodHdVJVdA"
- },
- "source": [
- "The dataset consists of a training set and an evaluation set:\n",
- "\n",
- "* `dftrain` and `y_train` are the *training set*—the data the model uses to learn.\n",
- "* The model is tested against the *eval set*, `dfeval`, and `y_eval`.\n",
- "\n",
- "For training you will use the following features:\n",
- "\n",
- "\n",
- "\n",
- " \n",
- " | Feature Name | \n",
- " Description | \n",
- "
\n",
- " \n",
- " | sex | \n",
- " Gender of passenger | \n",
- "
\n",
- " \n",
- " | age | \n",
- " Age of passenger | \n",
- "
\n",
- " \n",
- " | n_siblings_spouses | \n",
- " # siblings and partners aboard | \n",
- "
\n",
- " \n",
- " | parch | \n",
- " # of parents and children aboard | \n",
- "
\n",
- " \n",
- " | fare | \n",
- " Fare passenger paid. | \n",
- "
\n",
- " \n",
- " | class | \n",
- " Passenger's class on ship | \n",
- "
\n",
- " \n",
- " | deck | \n",
- " Which deck passenger was on | \n",
- "
\n",
- " \n",
- " | embark_town | \n",
- " Which town passenger embarked from | \n",
- "
\n",
- " \n",
- " | alone | \n",
- " If passenger was alone | \n",
- "
\n",
- "
"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AoPiWsJALr-k"
- },
- "source": [
- "## Explore the data"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "slcat1yzmzw5"
- },
- "source": [
- "Let's first preview some of the data and create summary statistics on the training set."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "15PLelXBlxEW"
- },
- "outputs": [],
- "source": [
- "dftrain.head()"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "j2hiM4ETmqP0"
- },
- "outputs": [],
- "source": [
- "dftrain.describe()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "-IR0e8V-LyJ4"
- },
- "source": [
- "There are 627 and 264 examples in the training and evaluation sets, respectively."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "_1NwYqGwDjFf"
- },
- "outputs": [],
- "source": [
- "dftrain.shape[0], dfeval.shape[0]"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "28UFJ4KSMK3V"
- },
- "source": [
- "The majority of passengers are in their 20's and 30's."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "CaVDmZtuDfux"
- },
- "outputs": [],
- "source": [
- "dftrain.age.hist(bins=20)\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "1pifWiCoMbR5"
- },
- "source": [
- "There are approximately twice as male passengers as female passengers aboard."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "-WazAq30MO5J"
- },
- "outputs": [],
- "source": [
- "dftrain.sex.value_counts().plot(kind='barh')\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "7_XkxrpmmVU_"
- },
- "source": [
- "The majority of passengers were in the \"third\" class."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "zZ3PvVy4l4gI"
- },
- "outputs": [],
- "source": [
- "(dftrain['class']\n",
- " .value_counts()\n",
- " .plot(kind='barh'))\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HM5SlwlxmZMT"
- },
- "source": [
- "Most passengers embarked from Southampton."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "RVTSrdr4mZaC"
- },
- "outputs": [],
- "source": [
- "(dftrain['embark_town']\n",
- " .value_counts()\n",
- " .plot(kind='barh'))\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "aTn1niLPob3x"
- },
- "source": [
- "Females have a much higher chance of surviving vs. males. This will clearly be a predictive feature for the model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Eh3KW5oYkaNS"
- },
- "outputs": [],
- "source": [
- "ax = (pd.concat([dftrain, y_train], axis=1)\\\n",
- " .groupby('sex')\n",
- " .survived\n",
- " .mean()\n",
- " .plot(kind='barh'))\n",
- "ax.set_xlabel('% survive')\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "krkRHuMp3rJn"
- },
- "source": [
- "## Create feature columns and input functions\n",
- "The Gradient Boosting estimator can utilize both numeric and categorical features. Feature columns work with all TensorFlow estimators and their purpose is to define the features used for modeling. Additionally they provide some feature engineering capabilities like one-hot-encoding, normalization, and bucketization. In this tutorial, the fields in `CATEGORICAL_COLUMNS` are transformed from categorical columns to one-hot-encoded columns ([indicator column](https://www.tensorflow.org/api_docs/python/tf/feature_column/indicator_column)):"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "upaNWxcF3rJn"
- },
- "outputs": [],
- "source": [
- "fc = tf.feature_column\n",
- "CATEGORICAL_COLUMNS = ['sex', 'n_siblings_spouses', 'parch', 'class', 'deck',\n",
- " 'embark_town', 'alone']\n",
- "NUMERIC_COLUMNS = ['age', 'fare']\n",
- "\n",
- "def one_hot_cat_column(feature_name, vocab):\n",
- " return fc.indicator_column(\n",
- " fc.categorical_column_with_vocabulary_list(feature_name,\n",
- " vocab))\n",
- "feature_columns = []\n",
- "for feature_name in CATEGORICAL_COLUMNS:\n",
- " # Need to one-hot encode categorical features.\n",
- " vocabulary = dftrain[feature_name].unique()\n",
- " feature_columns.append(one_hot_cat_column(feature_name, vocabulary))\n",
- "\n",
- "for feature_name in NUMERIC_COLUMNS:\n",
- " feature_columns.append(fc.numeric_column(feature_name,\n",
- " dtype=tf.float32))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "74GNtFpStSAz"
- },
- "source": [
- "You can view the transformation that a feature column produces. For example, here is the output when using the `indicator_column` on a single example:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Eaq79D9FtmF8"
- },
- "outputs": [],
- "source": [
- "example = dftrain.head(1)\n",
- "class_fc = one_hot_cat_column('class', ('First', 'Second', 'Third'))\n",
- "print('Feature value: \"{}\"'.format(example['class'].iloc[0]))\n",
- "print('One-hot encoded: ', fc.input_layer(dict(example), [class_fc]).numpy())"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "YbCUn3nCusC3"
- },
- "source": [
- "Additionally, you can view all of the feature column transformations together:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "omIYcsVws3g0"
- },
- "outputs": [],
- "source": [
- "fc.input_layer(dict(example), feature_columns).numpy()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "-UOlROp33rJo"
- },
- "source": [
- "Next you need to create the input functions. These will specify how data will be read into our model for both training and inference. You will use the `from_tensor_slices` method in the [`tf.data`](https://www.tensorflow.org/api_docs/python/tf/data) API to read in data directly from Pandas. This is suitable for smaller, in-memory datasets. For larger datasets, the tf.data API supports a variety of file formats (including [csv](https://www.tensorflow.org/api_docs/python/tf/data/experimental/make_csv_dataset)) so that you can process datasets that do not fit in memory."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "9dquwCQB3rJp"
- },
- "outputs": [],
- "source": [
- "# Use entire batch since this is such a small dataset.\n",
- "NUM_EXAMPLES = len(y_train)\n",
- "\n",
- "def make_input_fn(X, y, n_epochs=None, shuffle=True):\n",
- " y = np.expand_dims(y, axis=1)\n",
- " def input_fn():\n",
- " dataset = tf.data.Dataset.from_tensor_slices((dict(X), y))\n",
- " if shuffle:\n",
- " dataset = dataset.shuffle(NUM_EXAMPLES)\n",
- " # For training, cycle thru dataset as many times as need (n_epochs=None).\n",
- " dataset = dataset.repeat(n_epochs)\n",
- " # In memory training doesn't use batching.\n",
- " dataset = dataset.batch(NUM_EXAMPLES)\n",
- " return dataset\n",
- " return input_fn\n",
- "\n",
- "# Training and evaluation input functions.\n",
- "train_input_fn = make_input_fn(dftrain, y_train)\n",
- "eval_input_fn = make_input_fn(dfeval, y_eval, shuffle=False, n_epochs=1)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HttfNNlN3rJr"
- },
- "source": [
- "## Train and evaluate the model\n",
- "\n",
- "Below you will do the following steps:\n",
- "\n",
- "1. Initialize the model, specifying the features and hyperparameters.\n",
- "2. Feed the training data to the model using the `train_input_fn` and train the model using the `train` function.\n",
- "3. You will assess model performance using the evaluation set—in this example, the `dfeval` DataFrame. You will verify that the predictions match the labels from the `y_eval` array.\n",
- "\n",
- "Before training a Boosted Trees model, let's first train a linear classifier (logistic regression model). It is best practice to start with simpler model to establish a benchmark."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "JPOGpmmq3rJr"
- },
- "outputs": [],
- "source": [
- "linear_est = tf.estimator.LinearClassifier(feature_columns)\n",
- "\n",
- "# Train model.\n",
- "linear_est.train(train_input_fn, max_steps=100)\n",
- "\n",
- "# Evaluation.\n",
- "results = linear_est.evaluate(eval_input_fn)\n",
- "print('Accuracy : ', results['accuracy'])\n",
- "print('Dummy model: ', results['accuracy_baseline'])"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "BarkNXwA3rJu"
- },
- "source": [
- "Next let's train a Boosted Trees model. For boosted trees, regression (`BoostedTreesRegressor`) and classification (`BoostedTreesClassifier`) are supported, along with using any twice differentiable custom loss (`BoostedTreesEstimator`). Since the goal is to predict a class - survive or not survive, you will use the `BoostedTreesClassifier`.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "tgEzMtlw3rJu"
- },
- "outputs": [],
- "source": [
- "# Since data fits into memory, use entire dataset per layer. It will be faster.\n",
- "# Above one batch is defined as the entire dataset.\n",
- "n_batches = 1\n",
- "est = tf.estimator.BoostedTreesClassifier(feature_columns,\n",
- " n_batches_per_layer=n_batches)\n",
- "\n",
- "# The model will stop training once the specified number of trees is built, not\n",
- "# based on the number of steps.\n",
- "est.train(train_input_fn, max_steps=100)\n",
- "\n",
- "# Eval.\n",
- "results = est.evaluate(eval_input_fn)\n",
- "print('Accuracy : ', results['accuracy'])\n",
- "print('Dummy model: ', results['accuracy_baseline'])"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "hEflwznXvuMP"
- },
- "source": [
- "Now you can use the train model to make predictions on a passenger from the evaluation set. TensorFlow models are optimized to make predictions on a batch, or collection, of examples at once. Earlier, the `eval_input_fn` is defined using the entire evaluation set."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "6zmIjTr73rJ4"
- },
- "outputs": [],
- "source": [
- "pred_dicts = list(est.predict(eval_input_fn))\n",
- "probs = pd.Series([pred['probabilities'][1] for pred in pred_dicts])\n",
- "\n",
- "probs.plot(kind='hist', bins=20, title='predicted probabilities')\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "mBUaNN1BzJHG"
- },
- "source": [
- "Finally you can also look at the receiver operating characteristic (ROC) of the results, which will give us a better idea of the tradeoff between the true positive rate and false positive rate."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "NzxghvVz3rJ6"
- },
- "outputs": [],
- "source": [
- "from sklearn.metrics import roc_curve\n",
- "\n",
- "fpr, tpr, _ = roc_curve(y_eval, probs)\n",
- "plt.plot(fpr, tpr)\n",
- "plt.title('ROC curve')\n",
- "plt.xlabel('false positive rate')\n",
- "plt.ylabel('true positive rate')\n",
- "plt.xlim(0,)\n",
- "plt.ylim(0,)\n",
- "plt.show()"
- ]
- }
- ],
- "metadata": {
- "colab": {
- "collapsed_sections": [],
- "name": "boosted_trees.ipynb",
- "provenance": [],
- "toc_visible": true
- },
- "kernelspec": {
- "display_name": "Python 3",
- "name": "python3"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
diff --git a/site/en/r1/tutorials/estimators/boosted_trees_model_understanding.ipynb b/site/en/r1/tutorials/estimators/boosted_trees_model_understanding.ipynb
deleted file mode 100644
index 6f3f2c2feb0..00000000000
--- a/site/en/r1/tutorials/estimators/boosted_trees_model_understanding.ipynb
+++ /dev/null
@@ -1,1028 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "7765UFHoyGx6"
- },
- "source": [
- "##### Copyright 2019 The TensorFlow Authors."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "id": "KVtTDrUNyL7x"
- },
- "outputs": [],
- "source": [
- "#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n",
- "# you may not use this file except in compliance with the License.\n",
- "# You may obtain a copy of the License at\n",
- "#\n",
- "# https://www.apache.org/licenses/LICENSE-2.0\n",
- "#\n",
- "# Unless required by applicable law or agreed to in writing, software\n",
- "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
- "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
- "# See the License for the specific language governing permissions and\n",
- "# limitations under the License."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "r0_fqL3ayLHX"
- },
- "source": [
- "# Gradient Boosted Trees: Model understanding"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "PS6_yKSoyLAl"
- },
- "source": [
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "PS6_yKSoyLAl"
- },
- "source": [
- "> Note: This is an archived TF1 notebook. These are configured\n",
- "to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
- "but will run in TF1 as well. To use TF1 in Colab, use the\n",
- "[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
- "magic."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "dW3r7qVxzqN5"
- },
- "source": [
- "For an end-to-end walkthrough of training a Gradient Boosting model check out the [boosted trees tutorial](https://www.tensorflow.org/r1/tutorials/estimators/boosted_trees). In this tutorial you will:\n",
- "\n",
- "* Learn how to interpret a Boosted Trees model both *locally* and *globally*\n",
- "* Gain intution for how a Boosted Trees model fits a dataset\n",
- "\n",
- "## How to interpret Boosted Trees models both locally and globally\n",
- "\n",
- "Local interpretability refers to an understanding of a model’s predictions at the individual example level, while global interpretability refers to an understanding of the model as a whole. Such techniques can help machine learning (ML) practitioners detect bias and bugs during the model development stage\n",
- "\n",
- "For local interpretability, you will learn how to create and visualize per-instance contributions. To distinguish this from feature importances, we refer to these values as directional feature contributions (DFCs).\n",
- "\n",
- "For global interpretability you will retrieve and visualize gain-based feature importances, [permutation feature importances](https://www.stat.berkeley.edu/~breiman/randomforest2001.pdf) and also show aggregated DFCs."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "eylrTPAN3rJV"
- },
- "source": [
- "## Load the titanic dataset\n",
- "You will be using the titanic dataset, where the (rather morbid) goal is to predict passenger survival, given characteristics such as gender, age, class, etc."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "KuhAiPfZ3rJW"
- },
- "outputs": [],
- "source": [
- "import numpy as np\n",
- "import pandas as pd\n",
- "import tensorflow.compat.v1 as tf\n",
- "\n",
- "\n",
- "tf.logging.set_verbosity(tf.logging.ERROR)\n",
- "tf.set_random_seed(123)\n",
- "\n",
- "# Load dataset.\n",
- "dftrain = pd.read_csv('https://storage.googleapis.com/tfbt/titanic_train.csv')\n",
- "dfeval = pd.read_csv('https://storage.googleapis.com/tfbt/titanic_eval.csv')\n",
- "y_train = dftrain.pop('survived')\n",
- "y_eval = dfeval.pop('survived')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "3ioodHdVJVdA"
- },
- "source": [
- "For a description of the features, please review the prior tutorial."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "krkRHuMp3rJn"
- },
- "source": [
- "## Create feature columns, input_fn, and the train the estimator"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "JiJ6K3hr1lXW"
- },
- "source": [
- "### Preprocess the data"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "udMytRJC05oW"
- },
- "source": [
- "Create the feature columns, using the original numeric columns as is and one-hot-encoding categorical variables."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "upaNWxcF3rJn"
- },
- "outputs": [],
- "source": [
- "fc = tf.feature_column\n",
- "CATEGORICAL_COLUMNS = ['sex', 'n_siblings_spouses', 'parch', 'class', 'deck',\n",
- " 'embark_town', 'alone']\n",
- "NUMERIC_COLUMNS = ['age', 'fare']\n",
- "\n",
- "def one_hot_cat_column(feature_name, vocab):\n",
- " return fc.indicator_column(\n",
- " fc.categorical_column_with_vocabulary_list(feature_name,\n",
- " vocab))\n",
- "feature_columns = []\n",
- "for feature_name in CATEGORICAL_COLUMNS:\n",
- " # Need to one-hot encode categorical features.\n",
- " vocabulary = dftrain[feature_name].unique()\n",
- " feature_columns.append(one_hot_cat_column(feature_name, vocabulary))\n",
- "\n",
- "for feature_name in NUMERIC_COLUMNS:\n",
- " feature_columns.append(fc.numeric_column(feature_name,\n",
- " dtype=tf.float32))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "9rTefnXe1n0v"
- },
- "source": [
- "### Build the input pipeline"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "-UOlROp33rJo"
- },
- "source": [
- "Create the input functions using the `from_tensor_slices` method in the [`tf.data`](https://www.tensorflow.org/api_docs/python/tf/data) API to read in data directly from Pandas."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "9dquwCQB3rJp"
- },
- "outputs": [],
- "source": [
- "# Use entire batch since this is such a small dataset.\n",
- "NUM_EXAMPLES = len(y_train)\n",
- "\n",
- "def make_input_fn(X, y, n_epochs=None, shuffle=True):\n",
- " y = np.expand_dims(y, axis=1)\n",
- " def input_fn():\n",
- " dataset = tf.data.Dataset.from_tensor_slices((X.to_dict(orient='list'), y))\n",
- " if shuffle:\n",
- " dataset = dataset.shuffle(NUM_EXAMPLES)\n",
- " # For training, cycle thru dataset as many times as need (n_epochs=None).\n",
- " dataset = (dataset\n",
- " .repeat(n_epochs)\n",
- " .batch(NUM_EXAMPLES))\n",
- " return dataset\n",
- " return input_fn\n",
- "\n",
- "# Training and evaluation input functions.\n",
- "train_input_fn = make_input_fn(dftrain, y_train)\n",
- "eval_input_fn = make_input_fn(dfeval, y_eval, shuffle=False, n_epochs=1)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HttfNNlN3rJr"
- },
- "source": [
- "### Train the model"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "tgEzMtlw3rJu"
- },
- "outputs": [],
- "source": [
- "params = {\n",
- " 'n_trees': 50,\n",
- " 'max_depth': 3,\n",
- " 'n_batches_per_layer': 1,\n",
- " # You must enable center_bias = True to get DFCs. This will force the model to\n",
- " # make an initial prediction before using any features (e.g. use the mean of\n",
- " # the training labels for regression or log odds for classification when\n",
- " # using cross entropy loss).\n",
- " 'center_bias': True\n",
- "}\n",
- "\n",
- "est = tf.estimator.BoostedTreesClassifier(feature_columns, **params)\n",
- "est.train(train_input_fn, max_steps=100)\n",
- "results = est.evaluate(eval_input_fn)\n",
- "pd.Series(results).to_frame()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "cUrakbu6sqKe"
- },
- "source": [
- "For performance reasons, when your data fits in memory, we recommend use the `boosted_trees_classifier_train_in_memory` function. However if training time is not of a concern or if you have a very large dataset and want to do distributed training, use the `tf.estimator.BoostedTrees` API shown above.\n",
- "\n",
- "\n",
- "When using this method, you should not batch your input data, as the method operates on the entire dataset.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "-4_xz3b_D0W5"
- },
- "outputs": [],
- "source": [
- "in_memory_params = dict(params)\n",
- "del in_memory_params['n_batches_per_layer']\n",
- "# In-memory input_fn does not use batching.\n",
- "def make_inmemory_train_input_fn(X, y):\n",
- " y = np.expand_dims(y, axis=1)\n",
- " def input_fn():\n",
- " return dict(X), y\n",
- " return input_fn\n",
- "train_input_fn = make_inmemory_train_input_fn(dftrain, y_train)\n",
- "\n",
- "# Train the model.\n",
- "est = tf.contrib.estimator.boosted_trees_classifier_train_in_memory(\n",
- " train_input_fn,\n",
- " feature_columns,\n",
- " **in_memory_params)\n",
- "print(est.evaluate(eval_input_fn))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "TSZYqNcRuczV"
- },
- "source": [
- "## Model interpretation and plotting"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "BjcfLiI3uczW"
- },
- "outputs": [],
- "source": [
- "import matplotlib.pyplot as plt\n",
- "import seaborn as sns\n",
- "sns_colors = sns.color_palette('colorblind')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "ywTtbBvBuczY"
- },
- "source": [
- "## Local interpretability\n",
- "Next you will output the directional feature contributions (DFCs) to explain individual predictions using the approach outlined in [Palczewska et al](https://arxiv.org/pdf/1312.1121.pdf) and by Saabas in [Interpreting Random Forests](http://blog.datadive.net/interpreting-random-forests/) (this method is also available in scikit-learn for Random Forests in the [`treeinterpreter`](https://github.com/andosa/treeinterpreter) package). The DFCs are generated with:\n",
- "\n",
- "`pred_dicts = list(est.experimental_predict_with_explanations(pred_input_fn))`\n",
- "\n",
- "(Note: The method is named experimental as we may modify the API before dropping the experimental prefix.)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "TIL93B4sDRqE"
- },
- "outputs": [],
- "source": [
- "pred_dicts = list(est.experimental_predict_with_explanations(eval_input_fn))"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "tDPoRx_ZaY1E"
- },
- "outputs": [],
- "source": [
- "# Create DFC Pandas dataframe.\n",
- "labels = y_eval.values\n",
- "probs = pd.Series([pred['probabilities'][1] for pred in pred_dicts])\n",
- "df_dfc = pd.DataFrame([pred['dfc'] for pred in pred_dicts])\n",
- "df_dfc.describe().T"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "EUKSaVoraY1C"
- },
- "source": [
- "A nice property of DFCs is that the sum of the contributions + the bias is equal to the prediction for a given example."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Hd9VuizRaY1H"
- },
- "outputs": [],
- "source": [
- "# Sum of DFCs + bias == probabality.\n",
- "bias = pred_dicts[0]['bias']\n",
- "dfc_prob = df_dfc.sum(axis=1) + bias\n",
- "np.testing.assert_almost_equal(dfc_prob.values,\n",
- " probs.values)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "uIC7qm1gaY1L"
- },
- "source": [
- "Plot DFCs for an individual passenger."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "P3u971LsuczZ"
- },
- "outputs": [],
- "source": [
- "# Plot results.\n",
- "ID = 182\n",
- "example = df_dfc.iloc[ID] # Choose ith example from evaluation set.\n",
- "TOP_N = 8 # View top 8 features.\n",
- "sorted_ix = example.abs().sort_values()[-TOP_N:].index\n",
- "ax = example[sorted_ix].plot(kind='barh', color=sns_colors[3])\n",
- "ax.grid(False, axis='y')\n",
- "\n",
- "ax.set_title('Feature contributions for example {}\\n pred: {:1.2f}; label: {}'.format(ID, probs[ID], labels[ID]))\n",
- "ax.set_xlabel('Contribution to predicted probability')\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "L4i4mjK66FYg"
- },
- "source": [
- "The larger magnitude contributions have a larger impact on the model's prediction. Negative contributions indicate the feature value for this given example reduced the model's prediction, while positive values contribute an increase in the prediction."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "tx5p4vEhuczg"
- },
- "source": [
- "### Improved plotting\n",
- "Let's make the plot nice by color coding based on the contributions' directionality and add the feature values on figure."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "6z_Tq1Pquczj"
- },
- "outputs": [],
- "source": [
- "# Boilerplate code for plotting :)\n",
- "def _get_color(value):\n",
- " \"\"\"To make positive DFCs plot green, negative DFCs plot red.\"\"\"\n",
- " green, red = sns.color_palette()[2:4]\n",
- " if value >= 0: return green\n",
- " return red\n",
- "\n",
- "def _add_feature_values(feature_values, ax):\n",
- " \"\"\"Display feature's values on left of plot.\"\"\"\n",
- " x_coord = ax.get_xlim()[0]\n",
- " OFFSET = 0.15\n",
- " for y_coord, (feat_name, feat_val) in enumerate(feature_values.items()):\n",
- " t = plt.text(x_coord, y_coord - OFFSET, '{}'.format(feat_val), size=12)\n",
- " t.set_bbox(dict(facecolor='white', alpha=0.5))\n",
- " from matplotlib.font_manager import FontProperties\n",
- " font = FontProperties()\n",
- " font.set_weight('bold')\n",
- " t = plt.text(x_coord, y_coord + 1 - OFFSET, 'feature\\nvalue',\n",
- " fontproperties=font, size=12)\n",
- "\n",
- "def plot_example(example):\n",
- " TOP_N = 8 # View top 8 features.\n",
- " sorted_ix = example.abs().sort_values()[-TOP_N:].index # Sort by magnitude.\n",
- " example = example[sorted_ix]\n",
- " colors = example.map(_get_color).tolist()\n",
- " ax = example.to_frame().plot(kind='barh',\n",
- " color=[colors],\n",
- " legend=None,\n",
- " alpha=0.75,\n",
- " figsize=(10,6))\n",
- " ax.grid(False, axis='y')\n",
- " ax.set_yticklabels(ax.get_yticklabels(), size=14)\n",
- "\n",
- " # Add feature values.\n",
- " _add_feature_values(dfeval.iloc[ID][sorted_ix], ax)\n",
- " return ax"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "FlrsuOu8-Yds"
- },
- "source": [
- "Plot example."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Ht1P2-1euczk"
- },
- "outputs": [],
- "source": [
- "example = df_dfc.iloc[ID] # Choose IDth example from evaluation set.\n",
- "ax = plot_example(example)\n",
- "ax.set_title('Feature contributions for example {}\\n pred: {:1.2f}; label: {}'.format(ID, probs[ID], labels[ID]))\n",
- "ax.set_xlabel('Contribution to predicted probability', size=14)\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "0swvlkZFaY1Z"
- },
- "source": [
- "You can also plot the example's DFCs compare with the entire distribution using a voilin plot."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "zo7rNd1v_5e2"
- },
- "outputs": [],
- "source": [
- "# Boilerplate plotting code.\n",
- "def dist_violin_plot(df_dfc, ID):\n",
- " # Initialize plot.\n",
- " fig, ax = plt.subplots(1, 1, figsize=(10, 6))\n",
- "\n",
- " # Create example dataframe.\n",
- " TOP_N = 8 # View top 8 features.\n",
- " example = df_dfc.iloc[ID]\n",
- " ix = example.abs().sort_values()[-TOP_N:].index\n",
- " example = example[ix]\n",
- " example_df = example.to_frame(name='dfc')\n",
- "\n",
- " # Add contributions of entire distribution.\n",
- " parts=ax.violinplot([df_dfc[w] for w in ix],\n",
- " vert=False,\n",
- " showextrema=False,\n",
- " widths=0.7,\n",
- " positions=np.arange(len(ix)))\n",
- " face_color = sns_colors[0]\n",
- " alpha = 0.15\n",
- " for pc in parts['bodies']:\n",
- " pc.set_facecolor(face_color)\n",
- " pc.set_alpha(alpha)\n",
- "\n",
- " # Add feature values.\n",
- " _add_feature_values(dfeval.iloc[ID][sorted_ix], ax)\n",
- "\n",
- " # Add local contributions.\n",
- " ax.scatter(example,\n",
- " np.arange(example.shape[0]),\n",
- " color=sns.color_palette()[2],\n",
- " s=100,\n",
- " marker=\"s\",\n",
- " label='contributions for example')\n",
- "\n",
- " # Legend\n",
- " # Proxy plot, to show violinplot dist on legend.\n",
- " ax.plot([0,0], [1,1], label='eval set contributions\\ndistributions',\n",
- " color=face_color, alpha=alpha, linewidth=10)\n",
- " legend = ax.legend(loc='lower right', shadow=True, fontsize='x-large',\n",
- " frameon=True)\n",
- " legend.get_frame().set_facecolor('white')\n",
- "\n",
- " # Format plot.\n",
- " ax.set_yticks(np.arange(example.shape[0]))\n",
- " ax.set_yticklabels(example.index)\n",
- " ax.grid(False, axis='y')\n",
- " ax.set_xlabel('Contribution to predicted probability', size=14)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "PiLw2tlm_9aK"
- },
- "source": [
- "Plot this example."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "VkCqraA2uczm"
- },
- "outputs": [],
- "source": [
- "dist_violin_plot(df_dfc, ID)\n",
- "plt.title('Feature contributions for example {}\\n pred: {:1.2f}; label: {}'.format(ID, probs[ID], labels[ID]))\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "TVJFM85SAWVq"
- },
- "source": [
- "Finally, third-party tools, such as [LIME](https://github.com/marcotcr/lime) and [shap](https://github.com/slundberg/shap), can also help understand individual predictions for a model."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "PnNXH6mZuczr"
- },
- "source": [
- "## Global feature importances\n",
- "\n",
- "Additionally, you might want to understand the model as a whole, rather than studying individual predictions. Below, you will compute and use:\n",
- "\n",
- "* Gain-based feature importances using `est.experimental_feature_importances`\n",
- "* Permutation importances\n",
- "* Aggregate DFCs using `est.experimental_predict_with_explanations`\n",
- "\n",
- "Gain-based feature importances measure the loss change when splitting on a particular feature, while permutation feature importances are computed by evaluating model performance on the evaluation set by shuffling each feature one-by-one and attributing the change in model performance to the shuffled feature.\n",
- "\n",
- "In general, permutation feature importance are preferred to gain-based feature importance, though both methods can be unreliable in situations where potential predictor variables vary in their scale of measurement or their number of categories and when features are correlated ([source](https://bmcbioinformatics.biomedcentral.com/articles/10.1186/1471-2105-9-307)). Check out [this article](http://explained.ai/rf-importance/index.html) for an in-depth overview and great discussion on different feature importance types."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "3ocBcMatuczs"
- },
- "source": [
- "### Gain-based feature importances"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "gMaxCgPbBJ-j"
- },
- "source": [
- "Gain-based feature importances are built into the TensorFlow Boosted Trees estimators using `est.experimental_feature_importances`."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "pPTxbAaeuczt"
- },
- "outputs": [],
- "source": [
- "importances = est.experimental_feature_importances(normalize=True)\n",
- "df_imp = pd.Series(importances)\n",
- "\n",
- "# Visualize importances.\n",
- "N = 8\n",
- "ax = (df_imp.iloc[0:N][::-1]\n",
- " .plot(kind='barh',\n",
- " color=sns_colors[0],\n",
- " title='Gain feature importances',\n",
- " figsize=(10, 6)))\n",
- "ax.grid(False, axis='y')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "GvfAcBeGuczw"
- },
- "source": [
- "### Average absolute DFCs\n",
- "You can also average the absolute values of DFCs to understand impact at a global level."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "JkvAWLWLuczx"
- },
- "outputs": [],
- "source": [
- "# Plot.\n",
- "dfc_mean = df_dfc.abs().mean()\n",
- "N = 8\n",
- "sorted_ix = dfc_mean.abs().sort_values()[-N:].index # Average and sort by absolute.\n",
- "ax = dfc_mean[sorted_ix].plot(kind='barh',\n",
- " color=sns_colors[1],\n",
- " title='Mean |directional feature contributions|',\n",
- " figsize=(10, 6))\n",
- "ax.grid(False, axis='y')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Z0k_DvPLaY1o"
- },
- "source": [
- "You can also see how DFCs vary as a feature value varies."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "ZcIfN1IpaY1o"
- },
- "outputs": [],
- "source": [
- "FEATURE = 'fare'\n",
- "feature = pd.Series(df_dfc[FEATURE].values, index=dfeval[FEATURE].values).sort_index()\n",
- "ax = sns.regplot(feature.index.values, feature.values, lowess=True)\n",
- "ax.set_ylabel('contribution')\n",
- "ax.set_xlabel(FEATURE)\n",
- "ax.set_xlim(0, 100)\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "lbpG72ULucz0"
- },
- "source": [
- "### Permutation feature importance"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "6esOw1VOucz0"
- },
- "outputs": [],
- "source": [
- "def permutation_importances(est, X_eval, y_eval, metric, features):\n",
- " \"\"\"Column by column, shuffle values and observe effect on eval set.\n",
- "\n",
- " source: http://explained.ai/rf-importance/index.html\n",
- " A similar approach can be done during training. See \"Drop-column importance\"\n",
- " in the above article.\"\"\"\n",
- " baseline = metric(est, X_eval, y_eval)\n",
- " imp = []\n",
- " for col in features:\n",
- " save = X_eval[col].copy()\n",
- " X_eval[col] = np.random.permutation(X_eval[col])\n",
- " m = metric(est, X_eval, y_eval)\n",
- " X_eval[col] = save\n",
- " imp.append(baseline - m)\n",
- " return np.array(imp)\n",
- "\n",
- "def accuracy_metric(est, X, y):\n",
- " \"\"\"TensorFlow estimator accuracy.\"\"\"\n",
- " eval_input_fn = make_input_fn(X,\n",
- " y=y,\n",
- " shuffle=False,\n",
- " n_epochs=1)\n",
- " return est.evaluate(input_fn=eval_input_fn)['accuracy']\n",
- "features = CATEGORICAL_COLUMNS + NUMERIC_COLUMNS\n",
- "importances = permutation_importances(est, dfeval, y_eval, accuracy_metric,\n",
- " features)\n",
- "df_imp = pd.Series(importances, index=features)\n",
- "\n",
- "sorted_ix = df_imp.abs().sort_values().index\n",
- "ax = df_imp[sorted_ix][-5:].plot(kind='barh', color=sns_colors[2], figsize=(10, 6))\n",
- "ax.grid(False, axis='y')\n",
- "ax.set_title('Permutation feature importance')\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "E236y3pVEzHg"
- },
- "source": [
- "## Visualizing model fitting"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "TrcQ-839EzZ6"
- },
- "source": [
- "Lets first simulate/create training data using the following formula:\n",
- "\n",
- "\n",
- "$$z=x* e^{-x^2 - y^2}$$\n",
- "\n",
- "\n",
- "Where \\\\(z\\\\) is the dependent variable you are trying to predict and \\\\(x\\\\) and \\\\(y\\\\) are the features."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "e8woaj81GGE9"
- },
- "outputs": [],
- "source": [
- "from numpy.random import uniform, seed\n",
- "from matplotlib.mlab import griddata\n",
- "\n",
- "# Create fake data\n",
- "seed(0)\n",
- "npts = 5000\n",
- "x = uniform(-2, 2, npts)\n",
- "y = uniform(-2, 2, npts)\n",
- "z = x*np.exp(-x**2 - y**2)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "GRI3KHfLZsGP"
- },
- "outputs": [],
- "source": [
- "# Prep data for training.\n",
- "df = pd.DataFrame({'x': x, 'y': y, 'z': z})\n",
- "\n",
- "xi = np.linspace(-2.0, 2.0, 200),\n",
- "yi = np.linspace(-2.1, 2.1, 210),\n",
- "xi,yi = np.meshgrid(xi, yi)\n",
- "\n",
- "df_predict = pd.DataFrame({\n",
- " 'x' : xi.flatten(),\n",
- " 'y' : yi.flatten(),\n",
- "})\n",
- "predict_shape = xi.shape"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "w0JnH4IhZuAb"
- },
- "outputs": [],
- "source": [
- "def plot_contour(x, y, z, **kwargs):\n",
- " # Grid the data.\n",
- " plt.figure(figsize=(10, 8))\n",
- " # Contour the gridded data, plotting dots at the nonuniform data points.\n",
- " CS = plt.contour(x, y, z, 15, linewidths=0.5, colors='k')\n",
- " CS = plt.contourf(x, y, z, 15,\n",
- " vmax=abs(zi).max(), vmin=-abs(zi).max(), cmap='RdBu_r')\n",
- " plt.colorbar() # Draw colorbar.\n",
- " # Plot data points.\n",
- " plt.xlim(-2, 2)\n",
- " plt.ylim(-2, 2)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "KF7WsIcYGF_E"
- },
- "source": [
- "You can visualize the function. Redder colors correspond to larger function values."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "WrxuqaaXGFOK"
- },
- "outputs": [],
- "source": [
- "zi = griddata(x, y, z, xi, yi, interp='linear')\n",
- "plot_contour(xi, yi, zi)\n",
- "plt.scatter(df.x, df.y, marker='.')\n",
- "plt.title('Contour on training data')\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "hoANr0f2GFrM"
- },
- "outputs": [],
- "source": [
- "fc = [tf.feature_column.numeric_column('x'),\n",
- " tf.feature_column.numeric_column('y')]"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "xVRWyoY3ayTK"
- },
- "outputs": [],
- "source": [
- "def predict(est):\n",
- " \"\"\"Predictions from a given estimator.\"\"\"\n",
- " predict_input_fn = lambda: tf.data.Dataset.from_tensors(dict(df_predict))\n",
- " preds = np.array([p['predictions'][0] for p in est.predict(predict_input_fn)])\n",
- " return preds.reshape(predict_shape)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "uyPu5618GU7K"
- },
- "source": [
- "First let's try to fit a linear model to the data."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "zUIV2IVgGVSk"
- },
- "outputs": [],
- "source": [
- "train_input_fn = make_input_fn(df, df.z)\n",
- "est = tf.estimator.LinearRegressor(fc)\n",
- "est.train(train_input_fn, max_steps=500);"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "_u4WAcCqfbco"
- },
- "outputs": [],
- "source": [
- "plot_contour(xi, yi, predict(est))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "XD_fMAUtSCSa"
- },
- "source": [
- "It's not a very good fit. Next let's try to fit a GBDT model to it and try to understand how the model fits the function."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "ka1GgvqmSCK7"
- },
- "outputs": [],
- "source": [
- "def create_bt_est(n_trees):\n",
- " return tf.estimator.BoostedTreesRegressor(fc,\n",
- " n_batches_per_layer=1,\n",
- " n_trees=n_trees)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "w0s86Kq1R_Fc"
- },
- "outputs": [],
- "source": [
- "N_TREES = [1,2,3,4,10,20,50,100]\n",
- "for n in N_TREES:\n",
- " est = create_bt_est(n)\n",
- " est.train(train_input_fn, max_steps=500)\n",
- " plot_contour(xi, yi, predict(est))\n",
- " plt.text(-1.8, 2.1, '# trees: {}'.format(n), color='w', backgroundcolor='black', size=20)\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "5WcZ9fubh1wT"
- },
- "source": [
- "As you increase the number of trees, the model's predictions better approximates the underlying function."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "SMKoEZnCdrsp"
- },
- "source": [
- "## Conclusion"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "ZSZUSrjXdw9g"
- },
- "source": [
- "In this tutorial you learned how to interpret Boosted Trees models using directional feature contributions and feature importance techniques. These techniques provide insight into how the features impact a model's predictions. Finally, you also gained intution for how a Boosted Tree model fits a complex function by viewing the decision surface for several models."
- ]
- }
- ],
- "metadata": {
- "colab": {
- "collapsed_sections": [],
- "name": "boosted_trees_model_understanding.ipynb",
- "toc_visible": true
- },
- "kernelspec": {
- "display_name": "Python 3",
- "name": "python3"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
diff --git a/site/en/r1/tutorials/estimators/cnn.ipynb b/site/en/r1/tutorials/estimators/cnn.ipynb
deleted file mode 100644
index 6ce033f2d30..00000000000
--- a/site/en/r1/tutorials/estimators/cnn.ipynb
+++ /dev/null
@@ -1,973 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Tce3stUlHN0L"
- },
- "source": [
- "##### Copyright 2018 The TensorFlow Authors.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "id": "tuOe1ymfHZPu"
- },
- "outputs": [],
- "source": [
- "#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n",
- "# you may not use this file except in compliance with the License.\n",
- "# You may obtain a copy of the License at\n",
- "#\n",
- "# https://www.apache.org/licenses/LICENSE-2.0\n",
- "#\n",
- "# Unless required by applicable law or agreed to in writing, software\n",
- "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
- "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
- "# See the License for the specific language governing permissions and\n",
- "# limitations under the License."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "MfBg1C5NB3X0"
- },
- "source": [
- "# Build a Convolutional Neural Network using Estimators\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "MfBg1C5NB3X0"
- },
- "source": [
- "> Note: This is an archived TF1 notebook. These are configured\n",
- "to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
- "but will run in TF1 as well. To use TF1 in Colab, use the\n",
- "[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
- "magic."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "xHxb-dlhMIzW"
- },
- "source": [
- "The `tf.layers` module provides a high-level API that makes\n",
- "it easy to construct a neural network. It provides methods that facilitate the\n",
- "creation of dense (fully connected) layers and convolutional layers, adding\n",
- "activation functions, and applying dropout regularization. In this tutorial,\n",
- "you'll learn how to use `layers` to build a convolutional neural network model\n",
- "to recognize the handwritten digits in the MNIST data set.\n",
- "\n",
- "\n",
- "\n",
- "The [MNIST dataset](http://yann.lecun.com/exdb/mnist/) comprises 60,000\n",
- "training examples and 10,000 test examples of the handwritten digits 0–9,\n",
- "formatted as 28x28-pixel monochrome images."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "wTe-6uXpP2Ts"
- },
- "source": [
- "## Get Started\n",
- "\n",
- "Let's set up the imports for our TensorFlow program:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "6-tpguHLP6Rm"
- },
- "outputs": [],
- "source": [
- "import tensorflow.compat.v1 as tf\n",
- "\n",
- "import numpy as np\n",
- "\n",
- "tf.logging.set_verbosity(tf.logging.INFO)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "4j5yyyDFQgSB"
- },
- "source": [
- "## Intro to Convolutional Neural Networks\n",
- "\n",
- "Convolutional neural networks (CNNs) are the current state-of-the-art model\n",
- "architecture for image classification tasks. CNNs apply a series of filters to\n",
- "the raw pixel data of an image to extract and learn higher-level features, which\n",
- "the model can then use for classification. CNNs contains three components:\n",
- "\n",
- "* **Convolutional layers**, which apply a specified number of convolution\n",
- " filters to the image. For each subregion, the layer performs a set of\n",
- " mathematical operations to produce a single value in the output feature map.\n",
- " Convolutional layers then typically apply a\n",
- " [ReLU activation function](https://en.wikipedia.org/wiki/Rectifier_\\(neural_networks\\)) to\n",
- " the output to introduce nonlinearities into the model.\n",
- "\n",
- "* **Pooling layers**, which\n",
- " [downsample the image data](https://en.wikipedia.org/wiki/Convolutional_neural_network#Pooling_layer)\n",
- " extracted by the convolutional layers to reduce the dimensionality of the\n",
- " feature map in order to decrease processing time. A commonly used pooling\n",
- " algorithm is max pooling, which extracts subregions of the feature map\n",
- " (e.g., 2x2-pixel tiles), keeps their maximum value, and discards all other\n",
- " values.\n",
- "\n",
- "* **Dense (fully connected) layers**, which perform classification on the\n",
- " features extracted by the convolutional layers and downsampled by the\n",
- " pooling layers. In a dense layer, every node in the layer is connected to\n",
- " every node in the preceding layer.\n",
- "\n",
- "Typically, a CNN is composed of a stack of convolutional modules that perform\n",
- "feature extraction. Each module consists of a convolutional layer followed by a\n",
- "pooling layer. The last convolutional module is followed by one or more dense\n",
- "layers that perform classification. The final dense layer in a CNN contains a\n",
- "single node for each target class in the model (all the possible classes the\n",
- "model may predict), with a\n",
- "[softmax](https://en.wikipedia.org/wiki/Softmax_function) activation function to\n",
- "generate a value between 0–1 for each node (the sum of all these softmax values\n",
- "is equal to 1). We can interpret the softmax values for a given image as\n",
- "relative measurements of how likely it is that the image falls into each target\n",
- "class.\n",
- "\n",
- "Note: For a more comprehensive walkthrough of CNN architecture, see Stanford University's [Convolutional Neural Networks for Visual Recognition course material](https://cs231n.github.io/convolutional-networks/)."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "j23E_Z0FQvZB"
- },
- "source": [
- "## Building the CNN MNIST Classifier\n",
- "\n",
- "Let's build a model to classify the images in the MNIST dataset using the\n",
- "following CNN architecture:\n",
- "\n",
- "1. **Convolutional Layer #1**: Applies 32 5x5 filters (extracting 5x5-pixel\n",
- " subregions), with ReLU activation function\n",
- "2. **Pooling Layer #1**: Performs max pooling with a 2x2 filter and stride of 2\n",
- " (which specifies that pooled regions do not overlap)\n",
- "3. **Convolutional Layer #2**: Applies 64 5x5 filters, with ReLU activation\n",
- " function\n",
- "4. **Pooling Layer #2**: Again, performs max pooling with a 2x2 filter and\n",
- " stride of 2\n",
- "5. **Dense Layer #1**: 1,024 neurons, with dropout regularization rate of 0.4\n",
- " (probability of 0.4 that any given element will be dropped during training)\n",
- "6. **Dense Layer #2 (Logits Layer)**: 10 neurons, one for each digit target\n",
- " class (0–9).\n",
- "\n",
- "The `tf.layers` module contains methods to create each of the three layer types\n",
- "above:\n",
- "\n",
- "* `conv2d()`. Constructs a two-dimensional convolutional layer. Takes number\n",
- " of filters, filter kernel size, padding, and activation function as\n",
- " arguments.\n",
- "* `max_pooling2d()`. Constructs a two-dimensional pooling layer using the\n",
- " max-pooling algorithm. Takes pooling filter size and stride as arguments.\n",
- "* `dense()`. Constructs a dense layer. Takes number of neurons and activation\n",
- " function as arguments.\n",
- "\n",
- "Each of these methods accepts a tensor as input and returns a transformed tensor\n",
- "as output. This makes it easy to connect one layer to another: just take the\n",
- "output from one layer-creation method and supply it as input to another.\n",
- "\n",
- "Add the following `cnn_model_fn` function, which\n",
- "conforms to the interface expected by TensorFlow's Estimator API (more on this\n",
- "later in [Create the Estimator](#create-the-estimator)). This function takes\n",
- "MNIST feature data, labels, and mode (from\n",
- "`tf.estimator.ModeKeys`: `TRAIN`, `EVAL`, `PREDICT`) as arguments;\n",
- "configures the CNN; and returns predictions, loss, and a training operation:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "gMR-_3rkRKPa"
- },
- "outputs": [],
- "source": [
- "def cnn_model_fn(features, labels, mode):\n",
- " \"\"\"Model function for CNN.\"\"\"\n",
- " # Input Layer\n",
- " input_layer = tf.reshape(features[\"x\"], [-1, 28, 28, 1])\n",
- "\n",
- " # Convolutional Layer #1\n",
- " conv1 = tf.layers.conv2d(\n",
- " inputs=input_layer,\n",
- " filters=32,\n",
- " kernel_size=[5, 5],\n",
- " padding=\"same\",\n",
- " activation=tf.nn.relu)\n",
- "\n",
- " # Pooling Layer #1\n",
- " pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2)\n",
- "\n",
- " # Convolutional Layer #2 and Pooling Layer #2\n",
- " conv2 = tf.layers.conv2d(\n",
- " inputs=pool1,\n",
- " filters=64,\n",
- " kernel_size=[5, 5],\n",
- " padding=\"same\",\n",
- " activation=tf.nn.relu)\n",
- " pool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=[2, 2], strides=2)\n",
- "\n",
- " # Dense Layer\n",
- " pool2_flat = tf.reshape(pool2, [-1, 7 * 7 * 64])\n",
- " dense = tf.layers.dense(inputs=pool2_flat, units=1024, activation=tf.nn.relu)\n",
- " dropout = tf.layers.dropout(\n",
- " inputs=dense, rate=0.4, training=mode == tf.estimator.ModeKeys.TRAIN)\n",
- "\n",
- " # Logits Layer\n",
- " logits = tf.layers.dense(inputs=dropout, units=10)\n",
- "\n",
- " predictions = {\n",
- " # Generate predictions (for PREDICT and EVAL mode)\n",
- " \"classes\": tf.argmax(input=logits, axis=1),\n",
- " # Add `softmax_tensor` to the graph. It is used for PREDICT and by the\n",
- " # `logging_hook`.\n",
- " \"probabilities\": tf.nn.softmax(logits, name=\"softmax_tensor\")\n",
- " }\n",
- "\n",
- " if mode == tf.estimator.ModeKeys.PREDICT:\n",
- " return tf.estimator.EstimatorSpec(mode=mode, predictions=predictions)\n",
- "\n",
- " # Calculate Loss (for both TRAIN and EVAL modes)\n",
- " loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)\n",
- "\n",
- " # Configure the Training Op (for TRAIN mode)\n",
- " if mode == tf.estimator.ModeKeys.TRAIN:\n",
- " optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001)\n",
- " train_op = optimizer.minimize(\n",
- " loss=loss,\n",
- " global_step=tf.train.get_global_step())\n",
- " return tf.estimator.EstimatorSpec(mode=mode, loss=loss, train_op=train_op)\n",
- "\n",
- " # Add evaluation metrics (for EVAL mode)\n",
- " eval_metric_ops = {\n",
- " \"accuracy\": tf.metrics.accuracy(\n",
- " labels=labels, predictions=predictions[\"classes\"])\n",
- " }\n",
- " return tf.estimator.EstimatorSpec(\n",
- " mode=mode, loss=loss, eval_metric_ops=eval_metric_ops)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "b7z8qC9FRSLB"
- },
- "source": [
- "The following sections (with headings corresponding to each code block above)\n",
- "dive deeper into the `tf.layers` code used to create each layer, as well as how\n",
- "to calculate loss, configure the training op, and generate predictions. If\n",
- "you're already experienced with CNNs and [TensorFlow `Estimator`s](../../guide/custom_estimators.md),\n",
- "and find the above code intuitive, you may want to skim these sections or just\n",
- "skip ahead to [\"Training and Evaluating the CNN MNIST Classifier\"](#train_eval_mnist)."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "sFBXEYRlRUWu"
- },
- "source": [
- "### Input Layer\n",
- "\n",
- "The methods in the `layers` module for creating convolutional and pooling layers\n",
- "for two-dimensional image data expect input tensors to have a shape of\n",
- "[batch_size, image_height, image_width,\n",
- "channels] by default. This behavior can be changed using the\n",
- "data_format parameter; defined as follows:\n",
- "\n",
- "* `batch_size` —Size of the subset of examples to use when performing\n",
- " gradient descent during training.\n",
- "* `image_height` —Height of the example images.\n",
- "* `image_width` —Width of the example images.\n",
- "* `channels` —Number of color channels in the example images. For color\n",
- " images, the number of channels is 3 (red, green, blue). For monochrome\n",
- " images, there is just 1 channel (black).\n",
- "* `data_format` —A string, one of `channels_last` (default) or `channels_first`.\n",
- " `channels_last` corresponds to inputs with shape\n",
- " `(batch, ..., channels)` while `channels_first` corresponds to\n",
- " inputs with shape `(batch, channels, ...)`.\n",
- "\n",
- "Here, our MNIST dataset is composed of monochrome 28x28 pixel images, so the\n",
- "desired shape for our input layer is [batch_size, 28, 28,\n",
- "1].\n",
- "\n",
- "To convert our input feature map (`features`) to this shape, we can perform the\n",
- "following `reshape` operation:\n",
- "\n",
- "```\n",
- "input_layer = tf.reshape(features[\"x\"], [-1, 28, 28, 1])\n",
- "```\n",
- "\n",
- "Note that we've indicated `-1` for batch size, which specifies that this\n",
- "dimension should be dynamically computed based on the number of input values in\n",
- "`features[\"x\"]`, holding the size of all other dimensions constant. This allows\n",
- "us to treat `batch_size` as a hyperparameter that we can tune. For example, if\n",
- "we feed examples into our model in batches of 5, `features[\"x\"]` will contain\n",
- "3,920 values (one value for each pixel in each image), and `input_layer` will\n",
- "have a shape of `[5, 28, 28, 1]`. Similarly, if we feed examples in batches of\n",
- "100, `features[\"x\"]` will contain 78,400 values, and `input_layer` will have a\n",
- "shape of `[100, 28, 28, 1]`."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "iU8Jr1_JRiKA"
- },
- "source": [
- "### Convolutional Layer #1\n",
- "\n",
- "In our first convolutional layer, we want to apply 32 5x5 filters to the input\n",
- "layer, with a ReLU activation function. We can use the `conv2d()` method in the\n",
- "`layers` module to create this layer as follows:\n",
- "\n",
- "```\n",
- "conv1 = tf.layers.conv2d(\n",
- " inputs=input_layer,\n",
- " filters=32,\n",
- " kernel_size=[5, 5],\n",
- " padding=\"same\",\n",
- " activation=tf.nn.relu)\n",
- "```\n",
- "\n",
- "The `inputs` argument specifies our input tensor, which must have the shape\n",
- "[batch_size, image_height, image_width,\n",
- "channels]. Here, we're connecting our first convolutional layer\n",
- "to `input_layer`, which has the shape [batch_size, 28, 28,\n",
- "1].\n",
- "\n",
- "Note: `conv2d()` will instead accept a shape of `[batch_size, channels, image_height, image_width]` when passed the argument `data_format=channels_first`.\n",
- "\n",
- "The `filters` argument specifies the number of filters to apply (here, 32), and\n",
- "`kernel_size` specifies the dimensions of the filters as `[height,\n",
- "width] (here, [5, 5]`).\n",
- "\n",
- "TIP: If filter height and width have the same value, you can instead specify a\n",
- "single integer for kernel_size—e.g., kernel_size=5.
\n",
- "\n",
- "The `padding` argument specifies one of two enumerated values\n",
- "(case-insensitive): `valid` (default value) or `same`. To specify that the\n",
- "output tensor should have the same height and width values as the input tensor,\n",
- "we set `padding=same` here, which instructs TensorFlow to add 0 values to the\n",
- "edges of the input tensor to preserve height and width of 28. (Without padding,\n",
- "a 5x5 convolution over a 28x28 tensor will produce a 24x24 tensor, as there are\n",
- "24x24 locations to extract a 5x5 tile from a 28x28 grid.)\n",
- "\n",
- "The `activation` argument specifies the activation function to apply to the\n",
- "output of the convolution. Here, we specify ReLU activation with\n",
- "`tf.nn.relu`.\n",
- "\n",
- "Our output tensor produced by `conv2d()` has a shape of\n",
- "[batch_size, 28, 28, 32]: the same height and width\n",
- "dimensions as the input, but now with 32 channels holding the output from each\n",
- "of the filters."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "8qzx1ZMFRqt_"
- },
- "source": [
- "### Pooling Layer #1\n",
- "\n",
- "Next, we connect our first pooling layer to the convolutional layer we just\n",
- "created. We can use the `max_pooling2d()` method in `layers` to construct a\n",
- "layer that performs max pooling with a 2x2 filter and stride of 2:\n",
- "\n",
- "```\n",
- "pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2)\n",
- "```\n",
- "\n",
- "Again, `inputs` specifies the input tensor, with a shape of\n",
- "[batch_size, image_height, image_width,\n",
- "channels]. Here, our input tensor is `conv1`, the output from\n",
- "the first convolutional layer, which has a shape of [batch_size,\n",
- "28, 28, 32].\n",
- "\n",
- "Note: As with conv2d(), max_pooling2d() will instead\n",
- "accept a shape of [batch_size, channels,\n",
- "image_height, image_width] when passed the argument\n",
- "data_format=channels_first.\n",
- "\n",
- "The `pool_size` argument specifies the size of the max pooling filter as\n",
- "[height, width] (here, `[2, 2]`). If both\n",
- "dimensions have the same value, you can instead specify a single integer (e.g.,\n",
- "`pool_size=2`).\n",
- "\n",
- "The `strides` argument specifies the size of the stride. Here, we set a stride\n",
- "of 2, which indicates that the subregions extracted by the filter should be\n",
- "separated by 2 pixels in both the height and width dimensions (for a 2x2 filter,\n",
- "this means that none of the regions extracted will overlap). If you want to set\n",
- "different stride values for height and width, you can instead specify a tuple or\n",
- "list (e.g., `stride=[3, 6]`).\n",
- "\n",
- "Our output tensor produced by `max_pooling2d()` (`pool1`) has a shape of\n",
- "[batch_size, 14, 14, 32]: the 2x2 filter reduces height and width by 50% each."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "xXej53NlRzFh"
- },
- "source": [
- "### Convolutional Layer #2 and Pooling Layer #2\n",
- "\n",
- "We can connect a second convolutional and pooling layer to our CNN using\n",
- "`conv2d()` and `max_pooling2d()` as before. For convolutional layer #2, we\n",
- "configure 64 5x5 filters with ReLU activation, and for pooling layer #2, we use\n",
- "the same specs as pooling layer #1 (a 2x2 max pooling filter with stride of 2):\n",
- "\n",
- "```\n",
- "conv2 = tf.layers.conv2d(\n",
- " inputs=pool1,\n",
- " filters=64,\n",
- " kernel_size=[5, 5],\n",
- " padding=\"same\",\n",
- " activation=tf.nn.relu)\n",
- "\n",
- "pool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=[2, 2], strides=2)\n",
- "```\n",
- "\n",
- "Note that convolutional layer #2 takes the output tensor of our first pooling\n",
- "layer (`pool1`) as input, and produces the tensor `conv2` as output. `conv2`\n",
- "has a shape of [batch_size, 14, 14, 64], the same height and width as `pool1` (due to `padding=\"same\"`), and 64 channels for the 64\n",
- "filters applied.\n",
- "\n",
- "Pooling layer #2 takes `conv2` as input, producing `pool2` as output. `pool2`\n",
- "has shape [batch_size, 7, 7, 64] (50% reduction of height and width from `conv2`)."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "jjmLqVP7R7z6"
- },
- "source": [
- "### Dense Layer\n",
- "\n",
- "Next, we want to add a dense layer (with 1,024 neurons and ReLU activation) to\n",
- "our CNN to perform classification on the features extracted by the\n",
- "convolution/pooling layers. Before we connect the layer, however, we'll flatten\n",
- "our feature map (`pool2`) to shape [batch_size,\n",
- "features], so that our tensor has only two dimensions:\n",
- "\n",
- "```\n",
- "pool2_flat = tf.reshape(pool2, [-1, 7 * 7 * 64])\n",
- "```\n",
- "\n",
- "In the `reshape()` operation above, the `-1` signifies that the *`batch_size`*\n",
- "dimension will be dynamically calculated based on the number of examples in our\n",
- "input data. Each example has 7 (`pool2` height) * 7 (`pool2` width) * 64\n",
- "(`pool2` channels) features, so we want the `features` dimension to have a value\n",
- "of 7 * 7 * 64 (3136 in total). The output tensor, `pool2_flat`, has shape\n",
- "[batch_size, 3136].\n",
- "\n",
- "Now, we can use the `dense()` method in `layers` to connect our dense layer as\n",
- "follows:\n",
- "\n",
- "```\n",
- "dense = tf.layers.dense(inputs=pool2_flat, units=1024, activation=tf.nn.relu)\n",
- "```\n",
- "\n",
- "The `inputs` argument specifies the input tensor: our flattened feature map,\n",
- "`pool2_flat`. The `units` argument specifies the number of neurons in the dense\n",
- "layer (1,024). The `activation` argument takes the activation function; again,\n",
- "we'll use `tf.nn.relu` to add ReLU activation.\n",
- "\n",
- "To help improve the results of our model, we also apply dropout regularization\n",
- "to our dense layer, using the `dropout` method in `layers`:\n",
- "\n",
- "```\n",
- "dropout = tf.layers.dropout(\n",
- " inputs=dense, rate=0.4, training=mode == tf.estimator.ModeKeys.TRAIN)\n",
- "```\n",
- "\n",
- "Again, `inputs` specifies the input tensor, which is the output tensor from our\n",
- "dense layer (`dense`).\n",
- "\n",
- "The `rate` argument specifies the dropout rate; here, we use `0.4`, which means\n",
- "40% of the elements will be randomly dropped out during training.\n",
- "\n",
- "The `training` argument takes a boolean specifying whether or not the model is\n",
- "currently being run in training mode; dropout will only be performed if\n",
- "`training` is `True`. Here, we check if the `mode` passed to our model function\n",
- "`cnn_model_fn` is `TRAIN` mode.\n",
- "\n",
- "Our output tensor `dropout` has shape [batch_size, 1024]."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rzUcwkCZSTF7"
- },
- "source": [
- "### Logits Layer\n",
- "\n",
- "The final layer in our neural network is the logits layer, which will return the\n",
- "raw values for our predictions. We create a dense layer with 10 neurons (one for\n",
- "each target class 0–9), with linear activation (the default):\n",
- "\n",
- "```\n",
- "logits = tf.layers.dense(inputs=dropout, units=10)\n",
- "```\n",
- "\n",
- "Our final output tensor of the CNN, `logits`, has shape `[batch_size, 10]`."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "y3uJ0V1KSakc"
- },
- "source": [
- "### Generate Predictions {#generate_predictions}\n",
- "\n",
- "The logits layer of our model returns our predictions as raw values in a\n",
- "[batch_size, 10]-dimensional tensor. Let's convert these\n",
- "raw values into two different formats that our model function can return:\n",
- "\n",
- "* The **predicted class** for each example: a digit from 0–9.\n",
- "* The **probabilities** for each possible target class for each example: the\n",
- " probability that the example is a 0, is a 1, is a 2, etc.\n",
- "\n",
- "For a given example, our predicted class is the element in the corresponding row\n",
- "of the logits tensor with the highest raw value. We can find the index of this\n",
- "element using the `tf.argmax`\n",
- "function:\n",
- "\n",
- "```\n",
- "tf.argmax(input=logits, axis=1)\n",
- "```\n",
- "\n",
- "The `input` argument specifies the tensor from which to extract maximum\n",
- "values—here `logits`. The `axis` argument specifies the axis of the `input`\n",
- "tensor along which to find the greatest value. Here, we want to find the largest\n",
- "value along the dimension with index of 1, which corresponds to our predictions\n",
- "(recall that our logits tensor has shape [batch_size,\n",
- "10]).\n",
- "\n",
- "We can derive probabilities from our logits layer by applying softmax activation\n",
- "using `tf.nn.softmax`:\n",
- "\n",
- "```\n",
- "tf.nn.softmax(logits, name=\"softmax_tensor\")\n",
- "```\n",
- "\n",
- "Note: We use the `name` argument to explicitly name this operation `softmax_tensor`, so we can reference it later. (We'll set up logging for the softmax values in [\"Set Up a Logging Hook\"](#set-up-a-logging-hook)).\n",
- "\n",
- "We compile our predictions in a dict, and return an `EstimatorSpec` object:\n",
- "\n",
- "```\n",
- "predictions = {\n",
- " \"classes\": tf.argmax(input=logits, axis=1),\n",
- " \"probabilities\": tf.nn.softmax(logits, name=\"softmax_tensor\")\n",
- "}\n",
- "if mode == tf.estimator.ModeKeys.PREDICT:\n",
- " return tf.estimator.EstimatorSpec(mode=mode, predictions=predictions)\n",
- "```"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "f2ks_tqSSucg"
- },
- "source": [
- "### Calculate Loss {#calculating-loss}\n",
- "\n",
- "For both training and evaluation, we need to define a\n",
- "[loss function](https://en.wikipedia.org/wiki/Loss_function)\n",
- "that measures how closely the model's predictions match the target classes. For\n",
- "multiclass classification problems like MNIST,\n",
- "[cross entropy](https://en.wikipedia.org/wiki/Cross_entropy) is typically used\n",
- "as the loss metric. The following code calculates cross entropy when the model\n",
- "runs in either `TRAIN` or `EVAL` mode:\n",
- "\n",
- "```\n",
- "loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)\n",
- "```\n",
- "\n",
- "Let's take a closer look at what's happening above.\n",
- "\n",
- "Our `labels` tensor contains a list of prediction indices for our examples, e.g. `[1,\n",
- "9, ...]`. `logits` contains the linear outputs of our last layer.\n",
- "\n",
- "`tf.losses.sparse_softmax_cross_entropy`, calculates the softmax crossentropy\n",
- "(aka: categorical crossentropy, negative log-likelihood) from these two inputs\n",
- "in an efficient, numerically stable way."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "YgE7Ll3pS2FG"
- },
- "source": [
- "### Configure the Training Op\n",
- "\n",
- "In the previous section, we defined loss for our CNN as the softmax\n",
- "cross-entropy of the logits layer and our labels. Let's configure our model to\n",
- "optimize this loss value during training. We'll use a learning rate of 0.001 and\n",
- "[stochastic gradient descent](https://en.wikipedia.org/wiki/Stochastic_gradient_descent)\n",
- "as the optimization algorithm:\n",
- "\n",
- "```\n",
- "if mode == tf.estimator.ModeKeys.TRAIN:\n",
- " optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001)\n",
- " train_op = optimizer.minimize(\n",
- " loss=loss,\n",
- " global_step=tf.train.get_global_step())\n",
- " return tf.estimator.EstimatorSpec(mode=mode, loss=loss, train_op=train_op)\n",
- "```"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rEJPnXAzS6m9"
- },
- "source": [
- "Note: For a more in-depth look at configuring training ops for Estimator model functions, see [\"Defining the training op for the model\"](../../guide/custom_estimators.md#defining-the-training-op-for-the-model) in the [\"Creating Estimations in tf.estimator\"](../../guide/custom_estimators.md) tutorial."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "QQuGDWvHTAib"
- },
- "source": [
- "### Add evaluation metrics\n",
- "\n",
- "To add accuracy metric in our model, we define `eval_metric_ops` dict in EVAL\n",
- "mode as follows:\n",
- "\n",
- "```\n",
- "eval_metric_ops = {\n",
- " \"accuracy\": tf.metrics.accuracy(\n",
- " labels=labels, predictions=predictions[\"classes\"])\n",
- "}\n",
- "return tf.estimator.EstimatorSpec(\n",
- " mode=mode, loss=loss, eval_metric_ops=eval_metric_ops)\n",
- "```"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Y2Bwe-AdTRzX"
- },
- "source": [
- "\n",
- "## Training and Evaluating the CNN MNIST Classifier\n",
- "\n",
- "We've coded our MNIST CNN model function; now we're ready to train and evaluate\n",
- "it."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "6EC9aOY2TTLU"
- },
- "source": [
- "### Load Training and Test Data\n",
- "\n",
- "First, let's load our training and test data with the following code:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "ccobb0qETV-S"
- },
- "outputs": [],
- "source": [
- "# Load training and eval data\n",
- "((train_data, train_labels),\n",
- " (eval_data, eval_labels)) = tf.keras.datasets.mnist.load_data()\n",
- "\n",
- "train_data = train_data/np.float32(255)\n",
- "train_labels = train_labels.astype(np.int32) # not required\n",
- "\n",
- "eval_data = eval_data/np.float32(255)\n",
- "eval_labels = eval_labels.astype(np.int32) # not required"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "8l84-IxSTZnO"
- },
- "source": [
- "We store the training feature data (the raw pixel values for 55,000 images of\n",
- "hand-drawn digits) and training labels (the corresponding value from 0–9 for\n",
- "each image) as [numpy\n",
- "arrays](https://docs.scipy.org/doc/numpy/reference/generated/numpy.array.html)\n",
- "in `train_data` and `train_labels`, respectively. Similarly, we store the\n",
- "evaluation feature data (10,000 images) and evaluation labels in `eval_data`\n",
- "and `eval_labels`, respectively."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "S2_Isc7kTa45"
- },
- "source": [
- "### Create the Estimator {#create-the-estimator}\n",
- "\n",
- "Next, let's create an `Estimator` (a TensorFlow class for performing high-level\n",
- "model training, evaluation, and inference) for our model. Add the following code\n",
- "to `main()`:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "yjC6HdwZTdg4"
- },
- "outputs": [],
- "source": [
- "# Create the Estimator\n",
- "mnist_classifier = tf.estimator.Estimator(\n",
- " model_fn=cnn_model_fn, model_dir=\"/tmp/mnist_convnet_model\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "f78EBcg7TfTU"
- },
- "source": [
- "The `model_fn` argument specifies the model function to use for training,\n",
- "evaluation, and prediction; we pass it the `cnn_model_fn` we created in\n",
- "[\"Building the CNN MNIST Classifier.\"](#building-the-cnn-mnist-classifier) The\n",
- "`model_dir` argument specifies the directory where model data (checkpoints) will\n",
- "be saved (here, we specify the temp directory `/tmp/mnist_convnet_model`, but\n",
- "feel free to change to another directory of your choice).\n",
- "\n",
- "Note: For an in-depth walkthrough of the TensorFlow `Estimator` API, see the tutorial [Creating Estimators in tf.estimator](../../guide/custom_estimators.md)."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "_6ow7hVYTm3f"
- },
- "source": [
- "### Set Up a Logging Hook {#set_up_a_logging_hook}\n",
- "\n",
- "Since CNNs can take a while to train, let's set up some logging so we can track\n",
- "progress during training. We can use TensorFlow's `tf.train.SessionRunHook` to create a\n",
- "`tf.train.LoggingTensorHook`\n",
- "that will log the probability values from the softmax layer of our CNN. Add the\n",
- "following to `main()`:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "S6T10kssTpdz"
- },
- "outputs": [],
- "source": [
- "# Set up logging for predictions\n",
- "tensors_to_log = {\"probabilities\": \"softmax_tensor\"}\n",
- "\n",
- "logging_hook = tf.train.LoggingTensorHook(\n",
- " tensors=tensors_to_log, every_n_iter=50)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "RZdtZ6JQTsmg"
- },
- "source": [
- "We store a dict of the tensors we want to log in `tensors_to_log`. Each key is a\n",
- "label of our choice that will be printed in the log output, and the\n",
- "corresponding label is the name of a `Tensor` in the TensorFlow graph. Here, our\n",
- "`probabilities` can be found in `softmax_tensor`, the name we gave our softmax\n",
- "operation earlier when we generated the probabilities in `cnn_model_fn`.\n",
- "\n",
- "Note: If you don't explicitly assign a name to an operation via the `name` argument, TensorFlow will assign a default name. A couple easy ways to discover the names applied to operations are to visualize your graph on [TensorBoard](../../guide/graph_viz.md)) or to enable the [TensorFlow Debugger (tfdbg)](../../guide/debugger.md).\n",
- "\n",
- "Next, we create the `LoggingTensorHook`, passing `tensors_to_log` to the\n",
- "`tensors` argument. We set `every_n_iter=50`, which specifies that probabilities\n",
- "should be logged after every 50 steps of training."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "brVs1dRMT0NM"
- },
- "source": [
- "### Train the Model\n",
- "\n",
- "Now we're ready to train our model, which we can do by creating `train_input_fn`\n",
- "and calling `train()` on `mnist_classifier`. In the `numpy_input_fn` call, we pass the training feature data and labels to\n",
- "`x` (as a dict) and `y`, respectively. We set a `batch_size` of `100` (which\n",
- "means that the model will train on minibatches of 100 examples at each step).\n",
- "`num_epochs=None` means that the model will train until the specified number of\n",
- "steps is reached. We also set `shuffle=True` to shuffle the training data. Then train the model a single step and log the output:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "h-dewpleT2sk"
- },
- "outputs": [],
- "source": [
- "# Train the model\n",
- "train_input_fn = tf.estimator.inputs.numpy_input_fn(\n",
- " x={\"x\": train_data},\n",
- " y=train_labels,\n",
- " batch_size=100,\n",
- " num_epochs=None,\n",
- " shuffle=True)\n",
- "\n",
- "# train one step and display the probabilties\n",
- "mnist_classifier.train(\n",
- " input_fn=train_input_fn,\n",
- " steps=1,\n",
- " hooks=[logging_hook])"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "gyNSE3e-14Lq"
- },
- "source": [
- "Now—without logging each step—set `steps=1000` to train the model longer, but in a reasonable time to run this example. Training CNNs is computationally intensive. To increase the accuracy of your model, increase the number of `steps` passed to `train()`, like 20,000 steps."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "cri6zqcf2IXY"
- },
- "outputs": [],
- "source": [
- "mnist_classifier.train(input_fn=train_input_fn, steps=1000)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "4bQdkLMeUE5U"
- },
- "source": [
- "### Evaluate the Model\n",
- "\n",
- "Once training is complete, we want to evaluate our model to determine its\n",
- "accuracy on the MNIST test set. We call the `evaluate` method, which evaluates\n",
- "the metrics we specified in `eval_metric_ops` argument in the `model_fn`.\n",
- "Add the following to `main()`:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "I0RGiqd0UF0N"
- },
- "outputs": [],
- "source": [
- "eval_input_fn = tf.estimator.inputs.numpy_input_fn(\n",
- " x={\"x\": eval_data},\n",
- " y=eval_labels,\n",
- " num_epochs=1,\n",
- " shuffle=False)\n",
- "\n",
- "eval_results = mnist_classifier.evaluate(input_fn=eval_input_fn)\n",
- "print(eval_results)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "JIBVID6dUIXT"
- },
- "source": [
- "To create `eval_input_fn`, we set `num_epochs=1`, so that the model evaluates\n",
- "the metrics over one epoch of data and returns the result. We also set\n",
- "`shuffle=False` to iterate through the data sequentially."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "htmLZ-zEUZZk"
- },
- "source": [
- "## Additional Resources\n",
- "\n",
- "To learn more about TensorFlow Estimators and CNNs in TensorFlow, see the\n",
- "following resources:\n",
- "\n",
- "* [Creating Estimators in tf.estimator](../../guide/custom_estimators.md)\n",
- " provides an introduction to the TensorFlow Estimator API. It walks through\n",
- " configuring an Estimator, writing a model function, calculating loss, and\n",
- " defining a training op.\n",
- "* [Advanced Convolutional Neural Networks](../../tutorials/images/deep_cnn.md) walks through how to build a MNIST CNN classification model\n",
- " *without estimators* using lower-level TensorFlow operations."
- ]
- }
- ],
- "metadata": {
- "colab": {
- "collapsed_sections": [
- "Tce3stUlHN0L"
- ],
- "name": "cnn.ipynb",
- "toc_visible": true
- },
- "kernelspec": {
- "display_name": "Python 3",
- "name": "python3"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
diff --git a/site/en/r1/tutorials/estimators/linear.ipynb b/site/en/r1/tutorials/estimators/linear.ipynb
deleted file mode 100644
index 4155e0974a1..00000000000
--- a/site/en/r1/tutorials/estimators/linear.ipynb
+++ /dev/null
@@ -1,1260 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "MWW1TyjaecRh"
- },
- "source": [
- "##### Copyright 2018 The TensorFlow Authors."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "id": "mOtR1FzCef-u"
- },
- "outputs": [],
- "source": [
- "#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n",
- "# you may not use this file except in compliance with the License.\n",
- "# You may obtain a copy of the License at\n",
- "#\n",
- "# https://www.apache.org/licenses/LICENSE-2.0\n",
- "#\n",
- "# Unless required by applicable law or agreed to in writing, software\n",
- "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
- "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
- "# See the License for the specific language governing permissions and\n",
- "# limitations under the License."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Zr7KpBhMcYvE"
- },
- "source": [
- "# Build a linear model with Estimators"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "uJl4gaPFzxQz"
- },
- "source": [
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "uJl4gaPFzxQy"
- },
- "source": [
- "> Note: This is an archived TF1 notebook. These are configured\n",
- "to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
- "but will run in TF1 as well. To use TF1 in Colab, use the\n",
- "[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
- "magic."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "77aETSYDcdoK"
- },
- "source": [
- "This tutorial uses the `tf.estimator` API in TensorFlow to solve a benchmark binary classification problem. Estimators are TensorFlow's most scalable and production-oriented model type. For more information see the [Estimator guide](https://www.tensorflow.org/r1/guide/estimators).\n",
- "\n",
- "## Overview\n",
- "\n",
- "Using census data which contains data about a person's age, education, marital status, and occupation (the *features*), you will try to predict whether or not the person earns more than 50,000 dollars a year (the target *label*). You will train a *logistic regression* model that, given an individual's information, outputs a number between 0 and 1—this can be interpreted as the probability that the individual has an annual income of over 50,000 dollars.\n",
- "\n",
- "Key Point: As a modeler and developer, think about how this data is used and the potential benefits and harm a model's predictions can cause. A model like this could reinforce societal biases and disparities. Is each feature relevant to the problem you want to solve or will it introduce bias? For more information, read about [ML fairness](https://developers.google.com/machine-learning/fairness-overview/).\n",
- "\n",
- "## Setup\n",
- "\n",
- "Import TensorFlow, feature column support, and supporting modules:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "NQgONe5ecYvE"
- },
- "outputs": [],
- "source": [
- "import tensorflow.compat.v1 as tf\n",
- "\n",
- "import tensorflow.feature_column as fc\n",
- "\n",
- "import os\n",
- "import sys\n",
- "\n",
- "import matplotlib.pyplot as plt\n",
- "from IPython.display import clear_output"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Rpb1JSMj1nqk"
- },
- "source": [
- "And let's enable [eager execution](https://www.tensorflow.org/r1/guide/eager) to inspect this program as you run it:"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "-MPr95UccYvL"
- },
- "source": [
- "## Download the official implementation\n",
- "\n",
- "You will use the [wide and deep model](https://github.com/tensorflow/models/tree/master/official/r1/wide_deep/) available in TensorFlow's [model repository](https://github.com/tensorflow/models/). Download the code, add the root directory to your Python path, and jump to the `wide_deep` directory:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "tTwQzWcn8aBu"
- },
- "outputs": [],
- "source": [
- "! pip install requests\n",
- "! git clone --depth 1 --branch r2.1.0 https://github.com/tensorflow/models"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "sRpuysc73Eb-"
- },
- "source": [
- "Add the root directory of the repository to your Python path:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "yVvFyhnkcYvL"
- },
- "outputs": [],
- "source": [
- "models_path = os.path.join(os.getcwd(), 'models')\n",
- "\n",
- "sys.path.append(models_path)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "15Ethw-wcYvP"
- },
- "source": [
- "Download the dataset:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "6QilS4-0cYvQ"
- },
- "outputs": [],
- "source": [
- "from official.r1.wide_deep import census_dataset\n",
- "from official.r1.wide_deep import census_main\n",
- "\n",
- "census_dataset.download(\"/tmp/census_data/\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "cD5e3ibAcYvS"
- },
- "source": [
- "### Command line usage\n",
- "\n",
- "The repo includes a complete program for experimenting with this type of model.\n",
- "\n",
- "To execute the tutorial code from the command line first add the path to tensorflow/models to your `PYTHONPATH`."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "DYOkY8boUptJ"
- },
- "outputs": [],
- "source": [
- "#export PYTHONPATH=${PYTHONPATH}:\"$(pwd)/models\"\n",
- "#running from python you need to set the `os.environ` or the subprocess will not see the directory.\n",
- "\n",
- "if \"PYTHONPATH\" in os.environ:\n",
- " os.environ['PYTHONPATH'] += os.pathsep + models_path\n",
- "else:\n",
- " os.environ['PYTHONPATH'] = models_path"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "5r0V9YUMUyoh"
- },
- "source": [
- "Use `--help` to see what command line options are available:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "1_3tBaLW4YM4"
- },
- "outputs": [],
- "source": [
- "!python -m official.r1.wide_deep.census_main --help"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "RrMLazEN6DMj"
- },
- "source": [
- "Now run the model:\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "py7MarZl5Yh6"
- },
- "outputs": [],
- "source": [
- "!python -m official.r1.wide_deep.census_main --model_type=wide --train_epochs=2"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AmZ4CpaOcYvV"
- },
- "source": [
- "## Read the U.S. Census data\n",
- "\n",
- "This example uses the [U.S Census Income Dataset](https://archive.ics.uci.edu/ml/datasets/Census+Income) from 1994 and 1995. The [census_dataset.py](https://github.com/tensorflow/models/tree/master/official/r1/wide_deep/census_dataset.py) script is provided to download the data and perform a little cleanup.\n",
- "\n",
- "Since the task is a *binary classification problem*, you will construct a label column named \"label\" whose value is 1 if the income is over 50K, and 0 otherwise. For reference, see the `input_fn` in [census_main.py](https://github.com/tensorflow/models/tree/master/official/r1/wide_deep/census_main.py).\n",
- "\n",
- "Let's look at the data to see which columns you can use to predict the target label:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "N6Tgye8bcYvX"
- },
- "outputs": [],
- "source": [
- "!ls /tmp/census_data/"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "6y3mj9zKcYva"
- },
- "outputs": [],
- "source": [
- "train_file = \"/tmp/census_data/adult.data\"\n",
- "test_file = \"/tmp/census_data/adult.test\""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "EO_McKgE5il2"
- },
- "source": [
- "[pandas](https://pandas.pydata.org/) provides some convenient utilities for data analysis. Here's a list of columns available in the Census Income dataset:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "vkn1FNmpcYvb"
- },
- "outputs": [],
- "source": [
- "import pandas\n",
- "\n",
- "train_df = pandas.read_csv(train_file, names=census_dataset._CSV_COLUMNS)\n",
- "test_df = pandas.read_csv(test_file, names=census_dataset._CSV_COLUMNS)\n",
- "\n",
- "train_df.head()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "QZZtXes4cYvf"
- },
- "source": [
- "The columns are grouped into two types: *categorical* and *continuous* columns:\n",
- "\n",
- "* A column is called *categorical* if its value can only be one of the categories in a finite set. For example, the relationship status of a person (wife, husband, unmarried, etc.) or the education level (high school, college, etc.) are categorical columns.\n",
- "* A column is called *continuous* if its value can be any numerical value in a continuous range. For example, the capital gain of a person (e.g. $14,084) is a continuous column.\n",
- "\n",
- "## Converting Data into Tensors\n",
- "\n",
- "When building a `tf.estimator` model, the input data is specified by using an *input function* (or `input_fn`). This builder function returns a `tf.data.Dataset` of batches of `(features-dict, label)` pairs. It is not called until it is passed to `tf.estimator.Estimator` methods such as `train` and `evaluate`.\n",
- "\n",
- "The input builder function returns the following pair:\n",
- "\n",
- "1. `features`: A dict from feature names to `Tensors` or `SparseTensors` containing batches of features.\n",
- "2. `labels`: A `Tensor` containing batches of labels.\n",
- "\n",
- "The keys of the `features` are used to configure the model's input layer.\n",
- "\n",
- "Note: The input function is called while constructing the TensorFlow graph, *not* while running the graph. It is returning a representation of the input data as a sequence of TensorFlow graph operations.\n",
- "\n",
- "For small problems like this, it's easy to make a `tf.data.Dataset` by slicing the `pandas.DataFrame`:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "N7zNJflKcYvg"
- },
- "outputs": [],
- "source": [
- "def easy_input_function(df, label_key, num_epochs, shuffle, batch_size):\n",
- " label = df[label_key]\n",
- " ds = tf.data.Dataset.from_tensor_slices((dict(df),label))\n",
- "\n",
- " if shuffle:\n",
- " ds = ds.shuffle(10000)\n",
- "\n",
- " ds = ds.batch(batch_size).repeat(num_epochs)\n",
- "\n",
- " return ds"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "WeEgNR9AcYvh"
- },
- "source": [
- "Since you have eager execution enabled, it's easy to inspect the resulting dataset:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "ygaKuikecYvi"
- },
- "outputs": [],
- "source": [
- "ds = easy_input_function(train_df, label_key='income_bracket', num_epochs=5, shuffle=True, batch_size=10)\n",
- "\n",
- "for feature_batch, label_batch in ds.take(1):\n",
- " print('Some feature keys:', list(feature_batch.keys())[:5])\n",
- " print()\n",
- " print('A batch of Ages :', feature_batch['age'])\n",
- " print()\n",
- " print('A batch of Labels:', label_batch )"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "O_KZxQUucYvm"
- },
- "source": [
- "But this approach has severly-limited scalability. Larger datasets should be streamed from disk. The `census_dataset.input_fn` provides an example of how to do this using `tf.decode_csv` and `tf.data.TextLineDataset`:\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "vUTeXaEUcYvn"
- },
- "outputs": [],
- "source": [
- "import inspect\n",
- "print(inspect.getsource(census_dataset.input_fn))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "yyGcv_e-cYvq"
- },
- "source": [
- "This `input_fn` returns equivalent output:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Mv3as_CEcYvu"
- },
- "outputs": [],
- "source": [
- "ds = census_dataset.input_fn(train_file, num_epochs=5, shuffle=True, batch_size=10)\n",
- "\n",
- "for feature_batch, label_batch in ds.take(1):\n",
- " print('Feature keys:', list(feature_batch.keys())[:5])\n",
- " print()\n",
- " print('Age batch :', feature_batch['age'])\n",
- " print()\n",
- " print('Label batch :', label_batch )"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "810fnfY5cYvz"
- },
- "source": [
- "Because `Estimators` expect an `input_fn` that takes no arguments, you typically wrap configurable input function into an object with the expected signature. For this notebook configure the `train_inpf` to iterate over the data twice:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "wnQdpEcVcYv0"
- },
- "outputs": [],
- "source": [
- "import functools\n",
- "\n",
- "train_inpf = functools.partial(census_dataset.input_fn, train_file, num_epochs=2, shuffle=True, batch_size=64)\n",
- "test_inpf = functools.partial(census_dataset.input_fn, test_file, num_epochs=1, shuffle=False, batch_size=64)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "pboNpNWhcYv4"
- },
- "source": [
- "## Selecting and Engineering Features for the Model\n",
- "\n",
- "Estimators use a system called [feature columns](https://www.tensorflow.org/r1/guide/feature_columns) to describe how the model should interpret each of the raw input features. An Estimator expects a vector of numeric inputs, and feature columns describe how the model should convert each feature.\n",
- "\n",
- "Selecting and crafting the right set of feature columns is key to learning an effective model. A *feature column* can be either one of the raw inputs in the original features `dict` (a *base feature column*), or any new columns created using transformations defined over one or multiple base columns (a *derived feature columns*).\n",
- "\n",
- "A feature column is an abstract concept of any raw or derived variable that can be used to predict the target label."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "_hh-cWdU__Lq"
- },
- "source": [
- "### Base Feature Columns"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "BKz6LA8_ACI7"
- },
- "source": [
- "#### Numeric columns\n",
- "\n",
- "The simplest `feature_column` is `numeric_column`. This indicates that a feature is a numeric value that should be input to the model directly. For example:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "ZX0r2T5OcYv6"
- },
- "outputs": [],
- "source": [
- "age = fc.numeric_column('age')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "tnLUiaHxcYv-"
- },
- "source": [
- "The model will use the `feature_column` definitions to build the model input. You can inspect the resulting output using the `input_layer` function:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "kREtIPfwcYv_"
- },
- "outputs": [],
- "source": [
- "fc.input_layer(feature_batch, [age]).numpy()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "OPuLduCucYwD"
- },
- "source": [
- "The following will train and evaluate a model using only the `age` feature:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "9R5eSJ1pcYwE"
- },
- "outputs": [],
- "source": [
- "classifier = tf.estimator.LinearClassifier(feature_columns=[age])\n",
- "classifier.train(train_inpf)\n",
- "result = classifier.evaluate(test_inpf)\n",
- "\n",
- "clear_output() # used for display in notebook\n",
- "print(result)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "YDZGcdTdcYwI"
- },
- "source": [
- "Similarly, you can define a `NumericColumn` for each continuous feature column\n",
- "that you want to use in the model:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "uqPbUqlxcYwJ"
- },
- "outputs": [],
- "source": [
- "education_num = tf.feature_column.numeric_column('education_num')\n",
- "capital_gain = tf.feature_column.numeric_column('capital_gain')\n",
- "capital_loss = tf.feature_column.numeric_column('capital_loss')\n",
- "hours_per_week = tf.feature_column.numeric_column('hours_per_week')\n",
- "\n",
- "my_numeric_columns = [age,education_num, capital_gain, capital_loss, hours_per_week]\n",
- "\n",
- "fc.input_layer(feature_batch, my_numeric_columns).numpy()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "cBGDN97IcYwQ"
- },
- "source": [
- "You could retrain a model on these features by changing the `feature_columns` argument to the constructor:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "XN8k5S95cYwR"
- },
- "outputs": [],
- "source": [
- "classifier = tf.estimator.LinearClassifier(feature_columns=my_numeric_columns)\n",
- "classifier.train(train_inpf)\n",
- "\n",
- "result = classifier.evaluate(test_inpf)\n",
- "\n",
- "clear_output()\n",
- "\n",
- "for key,value in sorted(result.items()):\n",
- " print('%s: %s' % (key, value))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "jBRq9_AzcYwU"
- },
- "source": [
- "#### Categorical columns\n",
- "\n",
- "To define a feature column for a categorical feature, create a `CategoricalColumn` using one of the `tf.feature_column.categorical_column*` functions.\n",
- "\n",
- "If you know the set of all possible feature values of a column—and there are only a few of them—use `categorical_column_with_vocabulary_list`. Each key in the list is assigned an auto-incremented ID starting from 0. For example, for the `relationship` column you can assign the feature string `Husband` to an integer ID of 0 and \"Not-in-family\" to 1, etc."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "0IjqSi9tcYwV"
- },
- "outputs": [],
- "source": [
- "relationship = fc.categorical_column_with_vocabulary_list(\n",
- " 'relationship',\n",
- " ['Husband', 'Not-in-family', 'Wife', 'Own-child', 'Unmarried', 'Other-relative'])"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "-RjoWv-7cYwW"
- },
- "source": [
- "This creates a sparse one-hot vector from the raw input feature.\n",
- "\n",
- "The `input_layer` function you are using is designed for DNN models and expects dense inputs. To demonstrate the categorical column you must wrap it in a `tf.feature_column.indicator_column` to create the dense one-hot output (Linear `Estimators` can often skip this dense-step).\n",
- "\n",
- "Note: the other sparse-to-dense option is `tf.feature_column.embedding_column`.\n",
- "\n",
- "Run the input layer, configured with both the `age` and `relationship` columns:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "kI43CYlncYwY"
- },
- "outputs": [],
- "source": [
- "fc.input_layer(feature_batch, [age, fc.indicator_column(relationship)])"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "tTudP7WHcYwb"
- },
- "source": [
- "If you don't know the set of possible values in advance, use the `categorical_column_with_hash_bucket` instead:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "8pSBaliCcYwb"
- },
- "outputs": [],
- "source": [
- "occupation = tf.feature_column.categorical_column_with_hash_bucket(\n",
- " 'occupation', hash_bucket_size=1000)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "fSAPrqQkcYwd"
- },
- "source": [
- "Here, each possible value in the feature column `occupation` is hashed to an integer ID as you encounter them in training. The example batch has a few different occupations:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "dCvQNv36cYwe"
- },
- "outputs": [],
- "source": [
- "for item in feature_batch['occupation'].numpy():\n",
- " print(item.decode())"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "KP5hN2rAcYwh"
- },
- "source": [
- "If you run `input_layer` with the hashed column, you see that the output shape is `(batch_size, hash_bucket_size)`:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "0Y16peWacYwh"
- },
- "outputs": [],
- "source": [
- "occupation_result = fc.input_layer(feature_batch, [fc.indicator_column(occupation)])\n",
- "\n",
- "occupation_result.numpy().shape"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HMW2MzWAcYwk"
- },
- "source": [
- "It's easier to see the actual results if you take the `tf.argmax` over the `hash_bucket_size` dimension. Notice how any duplicate occupations are mapped to the same pseudo-random index:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "q_ryRglmcYwk"
- },
- "outputs": [],
- "source": [
- "tf.argmax(occupation_result, axis=1).numpy()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "j1e5NfyKcYwn"
- },
- "source": [
- "Note: Hash collisions are unavoidable, but often have minimal impact on model quality. The effect may be noticable if the hash buckets are being used to compress the input space.\n",
- "\n",
- "No matter how you choose to define a `SparseColumn`, each feature string is mapped into an integer ID by looking up a fixed mapping or by hashing. Under the hood, the `LinearModel` class is responsible for managing the mapping and creating `tf.Variable` to store the model parameters (model *weights*) for each feature ID. The model parameters are learned through the model training process described later.\n",
- "\n",
- "Let's do the similar trick to define the other categorical features:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "0Z5eUrd_cYwo"
- },
- "outputs": [],
- "source": [
- "education = tf.feature_column.categorical_column_with_vocabulary_list(\n",
- " 'education', [\n",
- " 'Bachelors', 'HS-grad', '11th', 'Masters', '9th', 'Some-college',\n",
- " 'Assoc-acdm', 'Assoc-voc', '7th-8th', 'Doctorate', 'Prof-school',\n",
- " '5th-6th', '10th', '1st-4th', 'Preschool', '12th'])\n",
- "\n",
- "marital_status = tf.feature_column.categorical_column_with_vocabulary_list(\n",
- " 'marital_status', [\n",
- " 'Married-civ-spouse', 'Divorced', 'Married-spouse-absent',\n",
- " 'Never-married', 'Separated', 'Married-AF-spouse', 'Widowed'])\n",
- "\n",
- "workclass = tf.feature_column.categorical_column_with_vocabulary_list(\n",
- " 'workclass', [\n",
- " 'Self-emp-not-inc', 'Private', 'State-gov', 'Federal-gov',\n",
- " 'Local-gov', '?', 'Self-emp-inc', 'Without-pay', 'Never-worked'])\n",
- "\n",
- "\n",
- "my_categorical_columns = [relationship, occupation, education, marital_status, workclass]"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "ASQJM1pEcYwr"
- },
- "source": [
- "It's easy to use both sets of columns to configure a model that uses all these features:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "_i_MLoo9cYws"
- },
- "outputs": [],
- "source": [
- "classifier = tf.estimator.LinearClassifier(feature_columns=my_numeric_columns+my_categorical_columns)\n",
- "classifier.train(train_inpf)\n",
- "result = classifier.evaluate(test_inpf)\n",
- "\n",
- "clear_output()\n",
- "\n",
- "for key,value in sorted(result.items()):\n",
- " print('%s: %s' % (key, value))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "zdKEqF6xcYwv"
- },
- "source": [
- "### Derived feature columns"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "RgYaf_48FSU2"
- },
- "source": [
- "#### Make Continuous Features Categorical through Bucketization\n",
- "\n",
- "Sometimes the relationship between a continuous feature and the label is not linear. For example, *age* and *income*—a person's income may grow in the early stage of their career, then the growth may slow at some point, and finally, the income decreases after retirement. In this scenario, using the raw `age` as a real-valued feature column might not be a good choice because the model can only learn one of the three cases:\n",
- "\n",
- "1. Income always increases at some rate as age grows (positive correlation),\n",
- "2. Income always decreases at some rate as age grows (negative correlation), or\n",
- "3. Income stays the same no matter at what age (no correlation).\n",
- "\n",
- "If you want to learn the fine-grained correlation between income and each age group separately, you can leverage *bucketization*. Bucketization is a process of dividing the entire range of a continuous feature into a set of consecutive buckets, and then converting the original numerical feature into a bucket ID (as a categorical feature) depending on which bucket that value falls into. So, you can define a `bucketized_column` over `age` as:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "KT4pjD9AcYww"
- },
- "outputs": [],
- "source": [
- "age_buckets = tf.feature_column.bucketized_column(\n",
- " age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65])"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "S-XOscrEcYwx"
- },
- "source": [
- "`boundaries` is a list of bucket boundaries. In this case, there are 10 boundaries, resulting in 11 age group buckets (from age 17 and below, 18-24, 25-29, ..., to 65 and over).\n",
- "\n",
- "With bucketing, the model sees each bucket as a one-hot feature:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Lr40vm3qcYwy"
- },
- "outputs": [],
- "source": [
- "fc.input_layer(feature_batch, [age, age_buckets]).numpy()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Z_tQI9j8cYw1"
- },
- "source": [
- "#### Learn complex relationships with crossed column\n",
- "\n",
- "Using each base feature column separately may not be enough to explain the data. For example, the correlation between education and the label (earning > 50,000 dollars) may be different for different occupations. Therefore, if you only learn a single model weight for `education=\"Bachelors\"` and `education=\"Masters\"`, you won't capture every education-occupation combination (e.g. distinguishing between `education=\"Bachelors\"` AND `occupation=\"Exec-managerial\"` AND `education=\"Bachelors\" AND occupation=\"Craft-repair\"`).\n",
- "\n",
- "To learn the differences between different feature combinations, you can add *crossed feature columns* to the model:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "IAPhPzXscYw1"
- },
- "outputs": [],
- "source": [
- "education_x_occupation = tf.feature_column.crossed_column(\n",
- " ['education', 'occupation'], hash_bucket_size=1000)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "UeTxMunbcYw5"
- },
- "source": [
- "You can also create a `crossed_column` over more than two columns. Each constituent column can be either a base feature column that is categorical (`SparseColumn`), a bucketized real-valued feature column, or even another `CrossColumn`. For example:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "y8UaBld9cYw7"
- },
- "outputs": [],
- "source": [
- "age_buckets_x_education_x_occupation = tf.feature_column.crossed_column(\n",
- " [age_buckets, 'education', 'occupation'], hash_bucket_size=1000)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HvKmW6U5cYw8"
- },
- "source": [
- "These crossed columns always use hash buckets to avoid the exponential explosion in the number of categories, and put the control over number of model weights in the hands of the user.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HtjpheB6cYw9"
- },
- "source": [
- "## Define the logistic regression model\n",
- "\n",
- "After processing the input data and defining all the feature columns, you can put them together and build a *logistic regression* model. The previous section showed several types of base and derived feature columns, including:\n",
- "\n",
- "* `CategoricalColumn`\n",
- "* `NumericColumn`\n",
- "* `BucketizedColumn`\n",
- "* `CrossedColumn`\n",
- "\n",
- "All of these are subclasses of the abstract `FeatureColumn` class and can be added to the `feature_columns` field of a model:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Klmf3OxpcYw-"
- },
- "outputs": [],
- "source": [
- "import tempfile\n",
- "\n",
- "base_columns = [\n",
- " education, marital_status, relationship, workclass, occupation,\n",
- " age_buckets,\n",
- "]\n",
- "\n",
- "crossed_columns = [\n",
- " tf.feature_column.crossed_column(\n",
- " ['education', 'occupation'], hash_bucket_size=1000),\n",
- " tf.feature_column.crossed_column(\n",
- " [age_buckets, 'education', 'occupation'], hash_bucket_size=1000),\n",
- "]\n",
- "\n",
- "model = tf.estimator.LinearClassifier(\n",
- " model_dir=tempfile.mkdtemp(),\n",
- " feature_columns=base_columns + crossed_columns,\n",
- " optimizer=tf.train.FtrlOptimizer(learning_rate=0.1))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "jRhnPxUucYxC"
- },
- "source": [
- "The model automatically learns a bias term, which controls the prediction made without observing any features. The learned model files are stored in `model_dir`.\n",
- "\n",
- "## Train and evaluate the model\n",
- "\n",
- "After adding all the features to the model, let's train the model. Training a model is just a single command using the `tf.estimator` API:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "ZlrIBuoecYxD"
- },
- "outputs": [],
- "source": [
- "train_inpf = functools.partial(census_dataset.input_fn, train_file,\n",
- " num_epochs=40, shuffle=True, batch_size=64)\n",
- "\n",
- "model.train(train_inpf)\n",
- "\n",
- "clear_output() # used for notebook display"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "IvY3a9pzcYxH"
- },
- "source": [
- "After the model is trained, evaluate the accuracy of the model by predicting the labels of the holdout data:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "L9nVJEO8cYxI"
- },
- "outputs": [],
- "source": [
- "results = model.evaluate(test_inpf)\n",
- "\n",
- "clear_output()\n",
- "\n",
- "for key,value in sorted(results.items()):\n",
- " print('%s: %0.2f' % (key, value))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "E0fAibNDcYxL"
- },
- "source": [
- "The first line of the output should display something like: `accuracy: 0.84`, which means the accuracy is 84%. You can try using more features and transformations to see if you can do better!\n",
- "\n",
- "After the model is evaluated, you can use it to predict whether an individual has an annual income of over 50,000 dollars given an individual's information input.\n",
- "\n",
- "Let's look in more detail how the model performed:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "8R5bz5CxcYxL"
- },
- "outputs": [],
- "source": [
- "import numpy as np\n",
- "\n",
- "predict_df = test_df[:20].copy()\n",
- "\n",
- "pred_iter = model.predict(\n",
- " lambda:easy_input_function(predict_df, label_key='income_bracket',\n",
- " num_epochs=1, shuffle=False, batch_size=10))\n",
- "\n",
- "classes = np.array(['<=50K', '>50K'])\n",
- "pred_class_id = []\n",
- "\n",
- "for pred_dict in pred_iter:\n",
- " pred_class_id.append(pred_dict['class_ids'])\n",
- "\n",
- "predict_df['predicted_class'] = classes[np.array(pred_class_id)]\n",
- "predict_df['correct'] = predict_df['predicted_class'] == predict_df['income_bracket']\n",
- "\n",
- "clear_output()\n",
- "\n",
- "predict_df[['income_bracket','predicted_class', 'correct']]"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "N_uCpFTicYxN"
- },
- "source": [
- "For a working end-to-end example, download our [example code](https://github.com/tensorflow/models/tree/master/official/r1/wide_deep/census_main.py) and set the `model_type` flag to `wide`."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "oyKy1lM_3gkL"
- },
- "source": [
- "## Adding Regularization to Prevent Overfitting\n",
- "\n",
- "Regularization is a technique used to avoid overfitting. Overfitting happens when a model performs well on the data it is trained on, but worse on test data that the model has not seen before. Overfitting can occur when a model is excessively complex, such as having too many parameters relative to the number of observed training data. Regularization allows you to control the model's complexity and make the model more generalizable to unseen data.\n",
- "\n",
- "You can add L1 and L2 regularizations to the model with the following code:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "lzMUSBQ03hHx"
- },
- "outputs": [],
- "source": [
- "model_l1 = tf.estimator.LinearClassifier(\n",
- " feature_columns=base_columns + crossed_columns,\n",
- " optimizer=tf.train.FtrlOptimizer(\n",
- " learning_rate=0.1,\n",
- " l1_regularization_strength=10.0,\n",
- " l2_regularization_strength=0.0))\n",
- "\n",
- "model_l1.train(train_inpf)\n",
- "\n",
- "results = model_l1.evaluate(test_inpf)\n",
- "clear_output()\n",
- "for key in sorted(results):\n",
- " print('%s: %0.2f' % (key, results[key]))"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "ofmPL212JIy2"
- },
- "outputs": [],
- "source": [
- "model_l2 = tf.estimator.LinearClassifier(\n",
- " feature_columns=base_columns + crossed_columns,\n",
- " optimizer=tf.train.FtrlOptimizer(\n",
- " learning_rate=0.1,\n",
- " l1_regularization_strength=0.0,\n",
- " l2_regularization_strength=10.0))\n",
- "\n",
- "model_l2.train(train_inpf)\n",
- "\n",
- "results = model_l2.evaluate(test_inpf)\n",
- "clear_output()\n",
- "for key in sorted(results):\n",
- " print('%s: %0.2f' % (key, results[key]))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Lp1Rfy_k4e7w"
- },
- "source": [
- "These regularized models don't perform much better than the base model. Let's look at the model's weight distributions to better see the effect of the regularization:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Wb6093N04XlS"
- },
- "outputs": [],
- "source": [
- "def get_flat_weights(model):\n",
- " weight_names = [\n",
- " name for name in model.get_variable_names()\n",
- " if \"linear_model\" in name and \"Ftrl\" not in name]\n",
- "\n",
- " weight_values = [model.get_variable_value(name) for name in weight_names]\n",
- "\n",
- " weights_flat = np.concatenate([item.flatten() for item in weight_values], axis=0)\n",
- "\n",
- " return weights_flat\n",
- "\n",
- "weights_flat = get_flat_weights(model)\n",
- "weights_flat_l1 = get_flat_weights(model_l1)\n",
- "weights_flat_l2 = get_flat_weights(model_l2)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "GskJmtfmL0p-"
- },
- "source": [
- "The models have many zero-valued weights caused by unused hash bins (there are many more hash bins than categories in some columns). You can mask these weights when viewing the weight distributions:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "rM3agZe3MT3D"
- },
- "outputs": [],
- "source": [
- "weight_mask = weights_flat != 0\n",
- "\n",
- "weights_base = weights_flat[weight_mask]\n",
- "weights_l1 = weights_flat_l1[weight_mask]\n",
- "weights_l2 = weights_flat_l2[weight_mask]"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "NqBpxLLQNEBE"
- },
- "source": [
- "Now plot the distributions:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "IdFK7wWa5_0K"
- },
- "outputs": [],
- "source": [
- "plt.figure()\n",
- "_ = plt.hist(weights_base, bins=np.linspace(-3,3,30))\n",
- "plt.title('Base Model')\n",
- "plt.ylim([0,500])\n",
- "\n",
- "plt.figure()\n",
- "_ = plt.hist(weights_l1, bins=np.linspace(-3,3,30))\n",
- "plt.title('L1 - Regularization')\n",
- "plt.ylim([0,500])\n",
- "\n",
- "plt.figure()\n",
- "_ = plt.hist(weights_l2, bins=np.linspace(-3,3,30))\n",
- "plt.title('L2 - Regularization')\n",
- "_=plt.ylim([0,500])"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Mv6knhFa5-iJ"
- },
- "source": [
- "Both types of regularization squeeze the distribution of weights towards zero. L2 regularization has a greater effect in the tails of the distribution eliminating extreme weights. L1 regularization produces more exactly-zero values, in this case it sets ~200 to zero."
- ]
- }
- ],
- "metadata": {
- "colab": {
- "collapsed_sections": [
- "MWW1TyjaecRh"
- ],
- "name": "linear.ipynb",
- "toc_visible": true
- },
- "kernelspec": {
- "display_name": "Python 3",
- "name": "python3"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
diff --git a/site/en/r1/tutorials/images/deep_cnn.md b/site/en/r1/tutorials/images/deep_cnn.md
index 00a914d8976..885f3907aa7 100644
--- a/site/en/r1/tutorials/images/deep_cnn.md
+++ b/site/en/r1/tutorials/images/deep_cnn.md
@@ -80,15 +80,15 @@ for details. It consists of 1,068,298 learnable parameters and requires about
## Code Organization
The code for this tutorial resides in
-[`models/tutorials/image/cifar10/`](https://github.com/tensorflow/models/tree/master/research/tutorials/image/cifar10/).
+[`models/tutorials/image/cifar10/`](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/image/cifar10/).
File | Purpose
--- | ---
-[`cifar10_input.py`](https://github.com/tensorflow/models/tree/master/research/tutorials/image/cifar10/cifar10_input.py) | Loads CIFAR-10 dataset using [tensorflow-datasets library](https://github.com/tensorflow/datasets).
-[`cifar10.py`](https://github.com/tensorflow/models/tree/master/research/tutorials/image/cifar10/cifar10.py) | Builds the CIFAR-10 model.
-[`cifar10_train.py`](https://github.com/tensorflow/models/tree/master/research/tutorials/image/cifar10/cifar10_train.py) | Trains a CIFAR-10 model on a CPU or GPU.
-[`cifar10_multi_gpu_train.py`](https://github.com/tensorflow/models/tree/master/research/tutorials/image/cifar10/cifar10_multi_gpu_train.py) | Trains a CIFAR-10 model on multiple GPUs.
-[`cifar10_eval.py`](https://github.com/tensorflow/models/tree/master/research/tutorials/image/cifar10/cifar10_eval.py) | Evaluates the predictive performance of a CIFAR-10 model.
+[`cifar10_input.py`](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/image/cifar10/cifar10_input.py) | Loads CIFAR-10 dataset using [tensorflow-datasets library](https://github.com/tensorflow/datasets).
+[`cifar10.py`](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/image/cifar10/cifar10.py) | Builds the CIFAR-10 model.
+[`cifar10_train.py`](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/image/cifar10/cifar10_train.py) | Trains a CIFAR-10 model on a CPU or GPU.
+[`cifar10_multi_gpu_train.py`](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/image/cifar10/cifar10_multi_gpu_train.py) | Trains a CIFAR-10 model on multiple GPUs.
+[`cifar10_eval.py`](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/image/cifar10/cifar10_eval.py) | Evaluates the predictive performance of a CIFAR-10 model.
To run this tutorial, you will need to:
@@ -99,7 +99,7 @@ pip install tensorflow-datasets
## CIFAR-10 Model
The CIFAR-10 network is largely contained in
-[`cifar10.py`](https://github.com/tensorflow/models/tree/master/research/tutorials/image/cifar10/cifar10.py).
+[`cifar10.py`](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/image/cifar10/cifar10.py).
The complete training
graph contains roughly 765 operations. We find that we can make the code most
reusable by constructing the graph with the following modules:
@@ -108,7 +108,7 @@ reusable by constructing the graph with the following modules:
operations that read and preprocess CIFAR images for evaluation and training,
respectively.
1. [**Model prediction:**](#model-prediction) `inference()`
-adds operations that perform inference, i.e. classification, on supplied images.
+adds operations that perform inference, i.e., classification, on supplied images.
1. [**Model training:**](#model-training) `loss()` and `train()`
add operations that compute the loss,
gradients, variable updates and visualization summaries.
@@ -405,7 +405,7 @@ a "tower". We must set two attributes for each tower:
* A unique name for all operations within a tower.
`tf.name_scope` provides
this unique name by prepending a scope. For instance, all operations in
-the first tower are prepended with `tower_0`, e.g. `tower_0/conv1/Conv2D`.
+the first tower are prepended with `tower_0`, e.g., `tower_0/conv1/Conv2D`.
* A preferred hardware device to run the operation within a tower.
`tf.device` specifies this. For
diff --git a/site/en/r1/tutorials/images/hub_with_keras.ipynb b/site/en/r1/tutorials/images/hub_with_keras.ipynb
index ece9c0fa4a9..f4e683e8936 100644
--- a/site/en/r1/tutorials/images/hub_with_keras.ipynb
+++ b/site/en/r1/tutorials/images/hub_with_keras.ipynb
@@ -60,7 +60,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
@@ -841,7 +841,7 @@
"t = time.time()\n",
"\n",
"export_path = \"/tmp/saved_models/{}\".format(int(t))\n",
- "tf.keras.experimental.export_saved_model(model, export_path)\n",
+ "model.save(export_path)\n",
"\n",
"export_path"
]
@@ -863,7 +863,7 @@
},
"outputs": [],
"source": [
- "reloaded = tf.keras.experimental.load_from_saved_model(export_path, custom_objects={'KerasLayer':hub.KerasLayer})"
+ "reloaded = tf.keras.models.load_model(export_path, custom_objects={'KerasLayer':hub.KerasLayer})"
]
},
{
diff --git a/site/en/r1/tutorials/images/image_recognition.md b/site/en/r1/tutorials/images/image_recognition.md
index 0be884de403..cb66e594629 100644
--- a/site/en/r1/tutorials/images/image_recognition.md
+++ b/site/en/r1/tutorials/images/image_recognition.md
@@ -140,13 +140,13 @@ score of 0.8.
 -Next, try it out on your own images by supplying the --image= argument, e.g.
+Next, try it out on your own images by supplying the --image= argument, e.g.,
```bash
bazel-bin/tensorflow/examples/label_image/label_image --image=my_image.png
```
-If you look inside the [`tensorflow/examples/label_image/main.cc`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/label_image/main.cc)
+If you look inside the [`tensorflow/examples/label_image/main.cc`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/label_image/main.cc)
file, you can find out
how it works. We hope this code will help you integrate TensorFlow into
your own applications, so we will walk step by step through the main functions:
@@ -164,7 +164,7 @@ training. If you have a graph that you've trained yourself, you'll just need
to adjust the values to match whatever you used during your training process.
You can see how they're applied to an image in the
-[`ReadTensorFromImageFile()`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/label_image/main.cc#L88)
+[`ReadTensorFromImageFile()`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/label_image/main.cc#L88)
function.
```C++
@@ -334,7 +334,7 @@ The `PrintTopLabels()` function takes those sorted results, and prints them out
friendly way. The `CheckTopLabel()` function is very similar, but just makes sure that
the top label is the one we expect, for debugging purposes.
-At the end, [`main()`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/label_image/main.cc#L252)
+At the end, [`main()`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/label_image/main.cc#L252)
ties together all of these calls.
```C++
diff --git a/site/en/r1/tutorials/images/transfer_learning.ipynb b/site/en/r1/tutorials/images/transfer_learning.ipynb
index bdb05a86382..25779babd17 100644
--- a/site/en/r1/tutorials/images/transfer_learning.ipynb
+++ b/site/en/r1/tutorials/images/transfer_learning.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
@@ -364,7 +364,7 @@
},
"outputs": [],
"source": [
- "model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=0.0001),\n",
+ "model.compile(optimizer=tf.keras.optimizers.RMSprop(learning_rate=0.0001),\n",
" loss='binary_crossentropy',\n",
" metrics=['accuracy'])"
]
@@ -547,7 +547,7 @@
"\n",
"# Freeze all the layers before the `fine_tune_at` layer\n",
"for layer in base_model.layers[:fine_tune_at]:\n",
- " layer.trainable = False"
+ " layer.trainable = False"
]
},
{
@@ -569,7 +569,7 @@
},
"outputs": [],
"source": [
- "model.compile(optimizer = tf.keras.optimizers.RMSprop(lr=2e-5),\n",
+ "model.compile(optimizer = tf.keras.optimizers.RMSprop(learning_rate=2e-5),\n",
" loss='binary_crossentropy',\n",
" metrics=['accuracy'])"
]
diff --git a/site/en/r1/tutorials/keras/README.md b/site/en/r1/tutorials/keras/README.md
index 4da2f72dca9..47aca7e0052 100644
--- a/site/en/r1/tutorials/keras/README.md
+++ b/site/en/r1/tutorials/keras/README.md
@@ -4,7 +4,7 @@ This notebook collection is inspired by the book
*[Deep Learning with Python](https://books.google.com/books?id=Yo3CAQAACAAJ)*.
These tutorials use `tf.keras`, TensorFlow's high-level Python API for building
and training deep learning models. To learn more about using Keras with
-TensorFlow, see the [TensorFlow Keras Guide](../../guide/keras.ipynb).
+TensorFlow, see the [TensorFlow Keras Guide](https://www.tensorflow.org/guide/keras).
Publisher's note: *Deep Learning with Python* introduces the field of deep
learning using the Python language and the powerful Keras library. Written by
diff --git a/site/en/r1/tutorials/keras/basic_classification.ipynb b/site/en/r1/tutorials/keras/basic_classification.ipynb
index be7f5e9e8b1..14950538ce4 100644
--- a/site/en/r1/tutorials/keras/basic_classification.ipynb
+++ b/site/en/r1/tutorials/keras/basic_classification.ipynb
@@ -96,7 +96,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/keras/basic_regression.ipynb b/site/en/r1/tutorials/keras/basic_regression.ipynb
index 7d9cb711efa..4bffd62f982 100644
--- a/site/en/r1/tutorials/keras/basic_regression.ipynb
+++ b/site/en/r1/tutorials/keras/basic_regression.ipynb
@@ -96,7 +96,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/keras/basic_text_classification.ipynb b/site/en/r1/tutorials/keras/basic_text_classification.ipynb
index 0303d54d973..5424185bcbd 100644
--- a/site/en/r1/tutorials/keras/basic_text_classification.ipynb
+++ b/site/en/r1/tutorials/keras/basic_text_classification.ipynb
@@ -96,7 +96,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/keras/overfit_and_underfit.ipynb b/site/en/r1/tutorials/keras/overfit_and_underfit.ipynb
index a8f266f9869..8e35b06e556 100644
--- a/site/en/r1/tutorials/keras/overfit_and_underfit.ipynb
+++ b/site/en/r1/tutorials/keras/overfit_and_underfit.ipynb
@@ -96,7 +96,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/keras/save_and_restore_models.ipynb b/site/en/r1/tutorials/keras/save_and_restore_models.ipynb
index 7911e37e139..04cc94417a9 100644
--- a/site/en/r1/tutorials/keras/save_and_restore_models.ipynb
+++ b/site/en/r1/tutorials/keras/save_and_restore_models.ipynb
@@ -96,7 +96,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
@@ -115,7 +115,7 @@
"\n",
"Sharing this data helps others understand how the model works and try it themselves with new data.\n",
"\n",
- "Caution: Be careful with untrusted code—TensorFlow models are code. See [Using TensorFlow Securely](https://github.com/tensorflow/tensorflow/blob/master/SECURITY.md) for details.\n",
+ "Caution: Be careful with untrusted code—TensorFlow models are code. See [Using TensorFlow Securely](https://github.com/tensorflow/tensorflow/blob/r1.15/SECURITY.md) for details.\n",
"\n",
"### Options\n",
"\n",
@@ -698,7 +698,7 @@
"id": "B7qfpvpY9HCe"
},
"source": [
- "Load the the saved model."
+ "Load the saved model."
]
},
{
diff --git a/site/en/r1/tutorials/load_data/images.ipynb b/site/en/r1/tutorials/load_data/images.ipynb
index dbee204323b..923b95130d1 100644
--- a/site/en/r1/tutorials/load_data/images.ipynb
+++ b/site/en/r1/tutorials/load_data/images.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/load_data/tf_records.ipynb b/site/en/r1/tutorials/load_data/tf_records.ipynb
index 8b57d3f2f1e..45635034c69 100644
--- a/site/en/r1/tutorials/load_data/tf_records.ipynb
+++ b/site/en/r1/tutorials/load_data/tf_records.ipynb
@@ -57,7 +57,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
@@ -141,7 +141,7 @@
"source": [
"Fundamentally a `tf.Example` is a `{\"string\": tf.train.Feature}` mapping.\n",
"\n",
- "The `tf.train.Feature` message type can accept one of the following three types (See the [`.proto` file](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/example/feature.proto) for reference). Most other generic types can be coerced into one of these.\n",
+ "The `tf.train.Feature` message type can accept one of the following three types (See the [`.proto` file](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/example/feature.proto) for reference). Most other generic types can be coerced into one of these.\n",
"\n",
"1. `tf.train.BytesList` (the following types can be coerced)\n",
"\n",
@@ -276,7 +276,7 @@
"\n",
"1. We create a map (dictionary) from the feature name string to the encoded feature value produced in #1.\n",
"\n",
- "1. The map produced in #2 is converted to a [`Features` message](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/example/feature.proto#L85)."
+ "1. The map produced in #2 is converted to a [`Features` message](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/example/feature.proto#L85)."
]
},
{
@@ -365,7 +365,7 @@
"id": "XftzX9CN_uGT"
},
"source": [
- "For example, suppose we have a single observation from the dataset, `[False, 4, bytes('goat'), 0.9876]`. We can create and print the `tf.Example` message for this observation using `create_message()`. Each single observation will be written as a `Features` message as per the above. Note that the `tf.Example` [message](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/example/example.proto#L88) is just a wrapper around the `Features` message."
+ "For example, suppose we have a single observation from the dataset, `[False, 4, bytes('goat'), 0.9876]`. We can create and print the `tf.Example` message for this observation using `create_message()`. Each single observation will be written as a `Features` message as per the above. Note that the `tf.Example` [message](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/example/example.proto#L88) is just a wrapper around the `Features` message."
]
},
{
@@ -632,7 +632,7 @@
"source": [
"We can also read the TFRecord file using the `tf.data.TFRecordDataset` class.\n",
"\n",
- "More information on consuming TFRecord files using `tf.data` can be found [here](https://www.tensorflow.org/r1/guide/datasets#consuming_tfrecord_data).\n",
+ "More information on consuming TFRecord files using `tf.data` can be found [here](https://www.tensorflow.org/guide/data#consuming_tfrecord_data).\n",
"\n",
"Using `TFRecordDataset`s can be useful for standardizing input data and optimizing performance."
]
diff --git a/site/en/r1/tutorials/non-ml/mandelbrot.ipynb b/site/en/r1/tutorials/non-ml/mandelbrot.ipynb
index 88177211896..bca8a142be4 100644
--- a/site/en/r1/tutorials/non-ml/mandelbrot.ipynb
+++ b/site/en/r1/tutorials/non-ml/mandelbrot.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/non-ml/pdes.ipynb b/site/en/r1/tutorials/non-ml/pdes.ipynb
index d2646daa8da..832fa450523 100644
--- a/site/en/r1/tutorials/non-ml/pdes.ipynb
+++ b/site/en/r1/tutorials/non-ml/pdes.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/representation/kernel_methods.md b/site/en/r1/tutorials/representation/kernel_methods.md
index 67adc4951c6..227fe81d515 100644
--- a/site/en/r1/tutorials/representation/kernel_methods.md
+++ b/site/en/r1/tutorials/representation/kernel_methods.md
@@ -24,7 +24,7 @@ following sources for an introduction:
Currently, TensorFlow supports explicit kernel mappings for dense features only;
TensorFlow will provide support for sparse features at a later release.
-This tutorial uses [tf.contrib.learn](https://www.tensorflow.org/code/tensorflow/contrib/learn/python/learn)
+This tutorial uses [tf.contrib.learn](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/contrib/learn/python/learn)
(TensorFlow's high-level Machine Learning API) Estimators for our ML models.
If you are not familiar with this API, The [Estimator guide](../../guide/estimators.md)
is a good place to start. We will use the MNIST dataset. The tutorial consists
@@ -131,7 +131,7 @@ In addition to experimenting with the (training) batch size and the number of
training steps, there are a couple other parameters that can be tuned as well.
For instance, you can change the optimization method used to minimize the loss
by explicitly selecting another optimizer from the collection of
-[available optimizers](https://www.tensorflow.org/code/tensorflow/python/training).
+[available optimizers](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/training).
As an example, the following code constructs a LinearClassifier estimator that
uses the Follow-The-Regularized-Leader (FTRL) optimization strategy with a
specific learning rate and L2-regularization.
diff --git a/site/en/r1/tutorials/representation/linear.md b/site/en/r1/tutorials/representation/linear.md
index 5516672b34a..d996a13bc1f 100644
--- a/site/en/r1/tutorials/representation/linear.md
+++ b/site/en/r1/tutorials/representation/linear.md
@@ -12,7 +12,7 @@ those tools. It explains:
Read this overview to decide whether the Estimator's linear model tools might
be useful to you. Then work through the
-[Estimator wide and deep learning tutorial](https://github.com/tensorflow/models/tree/master/official/r1/wide_deep)
+[Estimator wide and deep learning tutorial](https://github.com/tensorflow/models/tree/r1.15/official/r1/wide_deep)
to give it a try. This overview uses code samples from the tutorial, but the
tutorial walks through the code in greater detail.
@@ -177,7 +177,7 @@ the name of a `FeatureColumn`. Each key's value is a tensor containing the
values of that feature for all data instances. See
[Premade Estimators](../../guide/premade_estimators.md#input_fn) for a
more comprehensive look at input functions, and `input_fn` in the
-[wide and deep learning tutorial](https://github.com/tensorflow/models/tree/master/official/r1/wide_deep)
+[wide and deep learning tutorial](https://github.com/tensorflow/models/tree/r1.15/official/r1/wide_deep)
for an example implementation of an input function.
The input function is passed to the `train()` and `evaluate()` calls that
@@ -236,4 +236,4 @@ e = tf.estimator.DNNLinearCombinedClassifier(
dnn_hidden_units=[100, 50])
```
For more information, see the
-[wide and deep learning tutorial](https://github.com/tensorflow/models/tree/master/official/r1/wide_deep).
+[wide and deep learning tutorial](https://github.com/tensorflow/models/tree/r1.15/official/r1/wide_deep).
diff --git a/site/en/r1/tutorials/representation/unicode.ipynb b/site/en/r1/tutorials/representation/unicode.ipynb
index 6762a483a42..f76977c3c92 100644
--- a/site/en/r1/tutorials/representation/unicode.ipynb
+++ b/site/en/r1/tutorials/representation/unicode.ipynb
@@ -57,7 +57,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
@@ -136,7 +136,7 @@
"id": "jsMPnjb6UDJ1"
},
"source": [
- "Note: When using python to construct strings, the handling of unicode differs betweeen v2 and v3. In v2, unicode strings are indicated by the \"u\" prefix, as above. In v3, strings are unicode-encoded by default."
+ "Note: When using python to construct strings, the handling of unicode differs between v2 and v3. In v2, unicode strings are indicated by the \"u\" prefix, as above. In v3, strings are unicode-encoded by default."
]
},
{
@@ -425,7 +425,7 @@
"source": [
"### Character substrings\n",
"\n",
- "Similarly, the `tf.strings.substr` operation accepts the \"`unit`\" parameter, and uses it to determine what kind of offsets the \"`pos`\" and \"`len`\" paremeters contain."
+ "Similarly, the `tf.strings.substr` operation accepts the \"`unit`\" parameter, and uses it to determine what kind of offsets the \"`pos`\" and \"`len`\" parameters contain."
]
},
{
@@ -587,7 +587,7 @@
"id": "CapnbShuGU8i"
},
"source": [
- "First, we decode the sentences into character codepoints, and find the script identifeir for each character."
+ "First, we decode the sentences into character codepoints, and find the script identifier for each character."
]
},
{
diff --git a/site/en/r1/tutorials/representation/word2vec.md b/site/en/r1/tutorials/representation/word2vec.md
index f6a27c68f3c..517a5dbc5c5 100644
--- a/site/en/r1/tutorials/representation/word2vec.md
+++ b/site/en/r1/tutorials/representation/word2vec.md
@@ -36,7 +36,7 @@ like to get your hands dirty with the details.
Image and audio processing systems work with rich, high-dimensional datasets
encoded as vectors of the individual raw pixel-intensities for image data, or
-e.g. power spectral density coefficients for audio data. For tasks like object
+e.g., power spectral density coefficients for audio data. For tasks like object
or speech recognition we know that all the information required to successfully
perform the task is encoded in the data (because humans can perform these tasks
from the raw data). However, natural language processing systems traditionally
@@ -109,7 +109,7 @@ $$
where \\(\text{score}(w_t, h)\\) computes the compatibility of word \\(w_t\\)
with the context \\(h\\) (a dot product is commonly used). We train this model
by maximizing its [log-likelihood](https://en.wikipedia.org/wiki/Likelihood_function)
-on the training set, i.e. by maximizing
+on the training set, i.e., by maximizing
$$
\begin{align}
@@ -176,7 +176,7 @@ As an example, let's consider the dataset
We first form a dataset of words and the contexts in which they appear. We
could define 'context' in any way that makes sense, and in fact people have
looked at syntactic contexts (i.e. the syntactic dependents of the current
-target word, see e.g.
+target word, see e.g.,
[Levy et al.](https://levyomer.files.wordpress.com/2014/04/dependency-based-word-embeddings-acl-2014.pdf)),
words-to-the-left of the target, words-to-the-right of the target, etc. For now,
let's stick to the vanilla definition and define 'context' as the window
@@ -204,7 +204,7 @@ where the goal is to predict `the` from `quick`. We select `num_noise` number
of noisy (contrastive) examples by drawing from some noise distribution,
typically the unigram distribution, \\(P(w)\\). For simplicity let's say
`num_noise=1` and we select `sheep` as a noisy example. Next we compute the
-loss for this pair of observed and noisy examples, i.e. the objective at time
+loss for this pair of observed and noisy examples, i.e., the objective at time
step \\(t\\) becomes
$$J^{(t)}_\text{NEG} = \log Q_\theta(D=1 | \text{the, quick}) +
@@ -212,7 +212,7 @@ $$J^{(t)}_\text{NEG} = \log Q_\theta(D=1 | \text{the, quick}) +
The goal is to make an update to the embedding parameters \\(\theta\\) to improve
(in this case, maximize) this objective function. We do this by deriving the
-gradient of the loss with respect to the embedding parameters \\(\theta\\), i.e.
+gradient of the loss with respect to the embedding parameters \\(\theta\\), i.e.,
\\(\frac{\partial}{\partial \theta} J_\text{NEG}\\) (luckily TensorFlow provides
easy helper functions for doing this!). We then perform an update to the
embeddings by taking a small step in the direction of the gradient. When this
@@ -227,7 +227,7 @@ When we inspect these visualizations it becomes apparent that the vectors
capture some general, and in fact quite useful, semantic information about
words and their relationships to one another. It was very interesting when we
first discovered that certain directions in the induced vector space specialize
-towards certain semantic relationships, e.g. *male-female*, *verb tense* and
+towards certain semantic relationships, e.g., *male-female*, *verb tense* and
even *country-capital* relationships between words, as illustrated in the figure
below (see also for example
[Mikolov et al., 2013](https://www.aclweb.org/anthology/N13-1090)).
@@ -327,7 +327,7 @@ for inputs, labels in generate_batch(...):
```
See the full example code in
-[tensorflow/examples/tutorials/word2vec/word2vec_basic.py](https://www.tensorflow.org/code/tensorflow/examples/tutorials/word2vec/word2vec_basic.py).
+[tensorflow/examples/tutorials/word2vec/word2vec_basic.py](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/tutorials/word2vec/word2vec_basic.py).
## Visualizing the learned embeddings
@@ -341,7 +341,7 @@ t-SNE.
Et voila! As expected, words that are similar end up clustering nearby each
other. For a more heavyweight implementation of word2vec that showcases more of
the advanced features of TensorFlow, see the implementation in
-[models/tutorials/embedding/word2vec.py](https://github.com/tensorflow/models/tree/master/research/tutorials/embedding/word2vec.py).
+[models/tutorials/embedding/word2vec.py](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/embedding/word2vec.py).
## Evaluating embeddings: analogical reasoning
@@ -357,7 +357,7 @@ Download the dataset for this task from
To see how we do this evaluation, have a look at the `build_eval_graph()` and
`eval()` functions in
-[models/tutorials/embedding/word2vec.py](https://github.com/tensorflow/models/tree/master/research/tutorials/embedding/word2vec.py).
+[models/tutorials/embedding/word2vec.py](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/embedding/word2vec.py).
The choice of hyperparameters can strongly influence the accuracy on this task.
To achieve state-of-the-art performance on this task requires training over a
diff --git a/site/en/r1/tutorials/sequences/audio_recognition.md b/site/en/r1/tutorials/sequences/audio_recognition.md
index 8ad71b88a3c..0388514ec92 100644
--- a/site/en/r1/tutorials/sequences/audio_recognition.md
+++ b/site/en/r1/tutorials/sequences/audio_recognition.md
@@ -159,9 +159,9 @@ accuracy. If the training accuracy increases but the validation doesn't, that's
a sign that overfitting is occurring, and your model is only learning things
about the training clips, not broader patterns that generalize.
-## Tensorboard
+## TensorBoard
-A good way to visualize how the training is progressing is using Tensorboard. By
+A good way to visualize how the training is progressing is using TensorBoard. By
default, the script saves out events to /tmp/retrain_logs, and you can load
these by running:
diff --git a/site/en/r1/tutorials/sequences/recurrent.md b/site/en/r1/tutorials/sequences/recurrent.md
index 6654795d944..e7c1f8c0b16 100644
--- a/site/en/r1/tutorials/sequences/recurrent.md
+++ b/site/en/r1/tutorials/sequences/recurrent.md
@@ -2,7 +2,7 @@
## Introduction
-See [Understanding LSTM Networks](https://colah.github.io/posts/2015-08-Understanding-LSTMs/){:.external}
+See [Understanding LSTM Networks](https://colah.github.io/posts/2015-08-Understanding-LSTMs/)
for an introduction to recurrent neural networks and LSTMs.
## Language Modeling
diff --git a/site/en/r1/tutorials/sequences/recurrent_quickdraw.md b/site/en/r1/tutorials/sequences/recurrent_quickdraw.md
index 435076f629c..d6a85377d17 100644
--- a/site/en/r1/tutorials/sequences/recurrent_quickdraw.md
+++ b/site/en/r1/tutorials/sequences/recurrent_quickdraw.md
@@ -109,7 +109,7 @@ This download will take a while and download a bit more than 23GB of data.
To convert the `ndjson` files to
[TFRecord](../../api_guides/python/python_io.md#TFRecords_Format_Details) files containing
-[`tf.train.Example`](https://www.tensorflow.org/code/tensorflow/core/example/example.proto)
+[`tf.train.Example`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/example/example.proto)
protos run the following command.
```shell
@@ -213,7 +213,7 @@ screen coordinates and normalize the size such that the drawing has unit height.
Finally, we compute the differences between consecutive points and store these
as a `VarLenFeature` in a
-[tensorflow.Example](https://www.tensorflow.org/code/tensorflow/core/example/example.proto)
+[tensorflow.Example](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/example/example.proto)
under the key `ink`. In addition we store the `class_index` as a single entry
`FixedLengthFeature` and the `shape` of the `ink` as a `FixedLengthFeature` of
length 2.
diff --git a/site/en/r1/tutorials/sequences/text_generation.ipynb b/site/en/r1/tutorials/sequences/text_generation.ipynb
index 5911d1c7673..84d942c8bd0 100644
--- a/site/en/r1/tutorials/sequences/text_generation.ipynb
+++ b/site/en/r1/tutorials/sequences/text_generation.ipynb
@@ -65,7 +65,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
@@ -77,9 +77,9 @@
"id": "BwpJ5IffzRG6"
},
"source": [
- "This tutorial demonstrates how to generate text using a character-based RNN. We will work with a dataset of Shakespeare's writing from Andrej Karpathy's [The Unreasonable Effectiveness of Recurrent Neural Networks](http://karpathy.github.io/2015/05/21/rnn-effectiveness/). Given a sequence of characters from this data (\"Shakespear\"), train a model to predict the next character in the sequence (\"e\"). Longer sequences of text can be generated by calling the model repeatedly.\n",
+ "This tutorial demonstrates how to generate text using a character-based RNN. You will work with a dataset of Shakespeare's writing from Andrej Karpathy's [The Unreasonable Effectiveness of Recurrent Neural Networks](http://karpathy.github.io/2015/05/21/rnn-effectiveness/). Given a sequence of characters from this data (\"Shakespear\"), train a model to predict the next character in the sequence (\"e\"). Longer sequences of text can be generated by calling the model repeatedly.\n",
"\n",
- "Note: Enable GPU acceleration to execute this notebook faster. In Colab: *Runtime > Change runtime type > Hardware acclerator > GPU*. If running locally make sure TensorFlow version >= 1.11.\n",
+ "Note: Enable GPU acceleration to execute this notebook faster. In Colab: *Runtime > Change runtime type > Hardware accelerator > GPU*. If running locally make sure TensorFlow version >= 1.11.\n",
"\n",
"This tutorial includes runnable code implemented using [tf.keras](https://www.tensorflow.org/programmers_guide/keras) and [eager execution](https://www.tensorflow.org/programmers_guide/eager). The following is sample output when the model in this tutorial trained for 30 epochs, and started with the string \"Q\":\n",
"\n",
@@ -98,7 +98,7 @@
"To watch the next way with his father with his face?\n",
"\n",
"ESCALUS:\n",
- "The cause why then we are all resolved more sons.\n",
+ "The cause why then us all resolved more sons.\n",
"\n",
"VOLUMNIA:\n",
"O, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, it is no sin it should be dead,\n",
@@ -248,7 +248,7 @@
"source": [
"### Vectorize the text\n",
"\n",
- "Before training, we need to map strings to a numerical representation. Create two lookup tables: one mapping characters to numbers, and another for numbers to characters."
+ "Before training, you need to map strings to a numerical representation. Create two lookup tables: one mapping characters to numbers, and another for numbers to characters."
]
},
{
@@ -272,7 +272,7 @@
"id": "tZfqhkYCymwX"
},
"source": [
- "Now we have an integer representation for each character. Notice that we mapped the character as indexes from 0 to `len(unique)`."
+ "Now you have an integer representation for each character. Notice that you mapped the character as indexes from 0 to `len(unique)`."
]
},
{
@@ -316,7 +316,7 @@
"id": "wssHQ1oGymwe"
},
"source": [
- "Given a character, or a sequence of characters, what is the most probable next character? This is the task we're training the model to perform. The input to the model will be a sequence of characters, and we train the model to predict the output—the following character at each time step.\n",
+ "Given a character, or a sequence of characters, what is the most probable next character? This is the task you are training the model to perform. The input to the model will be a sequence of characters, and you train the model to predict the output—the following character at each time step.\n",
"\n",
"Since RNNs maintain an internal state that depends on the previously seen elements, given all the characters computed until this moment, what is the next character?\n"
]
@@ -346,7 +346,7 @@
},
"outputs": [],
"source": [
- "# The maximum length sentence we want for a single input in characters\n",
+ "# The maximum length sentence you want for a single input in characters\n",
"seq_length = 100\n",
"examples_per_epoch = len(text)//seq_length\n",
"\n",
@@ -458,7 +458,7 @@
"source": [
"### Create training batches\n",
"\n",
- "We used `tf.data` to split the text into manageable sequences. But before feeding this data into the model, we need to shuffle the data and pack it into batches."
+ "You used `tf.data` to split the text into manageable sequences. But before feeding this data into the model, you need to shuffle the data and pack it into batches."
]
},
{
@@ -543,7 +543,7 @@
},
"outputs": [],
"source": [
- "if tf.test.is_gpu_available():\n",
+ "if tf.config.list_physical_devices('GPU'):\n",
" rnn = tf.keras.layers.CuDNNGRU\n",
"else:\n",
" import functools\n",
@@ -650,7 +650,7 @@
"id": "uwv0gEkURfx1"
},
"source": [
- "To get actual predictions from the model we need to sample from the output distribution, to get actual character indices. This distribution is defined by the logits over the character vocabulary.\n",
+ "To get actual predictions from the model you need to sample from the output distribution, to get actual character indices. This distribution is defined by the logits over the character vocabulary.\n",
"\n",
"Note: It is important to _sample_ from this distribution as taking the _argmax_ of the distribution can easily get the model stuck in a loop.\n",
"\n",
@@ -746,7 +746,7 @@
"source": [
"The standard `tf.keras.losses.sparse_categorical_crossentropy` loss function works in this case because it is applied across the last dimension of the predictions.\n",
"\n",
- "Because our model returns logits, we need to set the `from_logits` flag.\n"
+ "Because our model returns logits, you need to set the `from_logits` flag.\n"
]
},
{
@@ -771,7 +771,7 @@
"id": "jeOXriLcymww"
},
"source": [
- "Configure the training procedure using the `tf.keras.Model.compile` method. We'll use `tf.train.AdamOptimizer` with default arguments and the loss function."
+ "Configure the training procedure using the `tf.keras.Model.compile` method. You'll use `tf.train.AdamOptimizer` with default arguments and the loss function."
]
},
{
@@ -891,7 +891,7 @@
"\n",
"Because of the way the RNN state is passed from timestep to timestep, the model only accepts a fixed batch size once built.\n",
"\n",
- "To run the model with a different `batch_size`, we need to rebuild the model and restore the weights from the checkpoint.\n"
+ "To run the model with a different `batch_size`, you need to rebuild the model and restore the weights from the checkpoint.\n"
]
},
{
@@ -992,7 +992,7 @@
" predictions = predictions / temperature\n",
" predicted_id = tf.multinomial(predictions, num_samples=1)[-1,0].numpy()\n",
"\n",
- " # We pass the predicted word as the next input to the model\n",
+ " # You pass the predicted word as the next input to the model\n",
" # along with the previous hidden state\n",
" input_eval = tf.expand_dims([predicted_id], 0)\n",
"\n",
@@ -1035,11 +1035,11 @@
"\n",
"So now that you've seen how to run the model manually let's unpack the training loop, and implement it ourselves. This gives a starting point, for example, to implement _curriculum learning_ to help stabilize the model's open-loop output.\n",
"\n",
- "We will use `tf.GradientTape` to track the gradients. You can learn more about this approach by reading the [eager execution guide](https://www.tensorflow.org/r1/guide/eager).\n",
+ "You will use `tf.GradientTape` to track the gradients. You can learn more about this approach by reading the [eager execution guide](https://www.tensorflow.org/r1/guide/eager).\n",
"\n",
"The procedure works as follows:\n",
"\n",
- "* First, initialize the RNN state. We do this by calling the `tf.keras.Model.reset_states` method.\n",
+ "* First, initialize the RNN state. You do this by calling the `tf.keras.Model.reset_states` method.\n",
"\n",
"* Next, iterate over the dataset (batch by batch) and calculate the *predictions* associated with each.\n",
"\n",
diff --git a/site/en/swift/README.md b/site/en/swift/README.md
deleted file mode 100644
index 162a81fa7d3..00000000000
--- a/site/en/swift/README.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Welcome to the warp zone!
-
-# Swift for TensorFlow
-
-These docs are available here:
-https://github.com/tensorflow/swift/tree/main/docs/site
diff --git a/site/en/tensorboard/README.md b/site/en/tensorboard/README.md
deleted file mode 100644
index 7e2126c23d4..00000000000
--- a/site/en/tensorboard/README.md
+++ /dev/null
@@ -1,5 +0,0 @@
-Welcome to the warp zone!
-
-# Tensorboard
-
-These docs are available here: https://github.com/tensorflow/tensorboard/tree/master/docs
diff --git a/site/en/tfx/README.md b/site/en/tfx/README.md
deleted file mode 100644
index c56ad2dbf01..00000000000
--- a/site/en/tfx/README.md
+++ /dev/null
@@ -1,10 +0,0 @@
-Welcome to the warp zone!
-
-# TensorFlow Extended (TFX)
-
-These docs are available here:
-
-* Data Validation: https://github.com/tensorflow/data-validation/tree/master/g3doc
-* Model Analysis: https://github.com/tensorflow/model-analysis/tree/master/g3doc
-* Transform: https://github.com/tensorflow/transform/tree/master/docs
-* Serving: https://github.com/tensorflow/serving/tree/master/tensorflow_serving/g3doc
diff --git a/site/en/tutorials/_index.yaml b/site/en/tutorials/_index.yaml
index e2fc95aff1f..0d09f04c5c7 100644
--- a/site/en/tutorials/_index.yaml
+++ b/site/en/tutorials/_index.yaml
@@ -16,8 +16,9 @@ landing_page:
- description: >
-Next, try it out on your own images by supplying the --image= argument, e.g.
+Next, try it out on your own images by supplying the --image= argument, e.g.,
```bash
bazel-bin/tensorflow/examples/label_image/label_image --image=my_image.png
```
-If you look inside the [`tensorflow/examples/label_image/main.cc`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/label_image/main.cc)
+If you look inside the [`tensorflow/examples/label_image/main.cc`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/label_image/main.cc)
file, you can find out
how it works. We hope this code will help you integrate TensorFlow into
your own applications, so we will walk step by step through the main functions:
@@ -164,7 +164,7 @@ training. If you have a graph that you've trained yourself, you'll just need
to adjust the values to match whatever you used during your training process.
You can see how they're applied to an image in the
-[`ReadTensorFromImageFile()`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/label_image/main.cc#L88)
+[`ReadTensorFromImageFile()`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/label_image/main.cc#L88)
function.
```C++
@@ -334,7 +334,7 @@ The `PrintTopLabels()` function takes those sorted results, and prints them out
friendly way. The `CheckTopLabel()` function is very similar, but just makes sure that
the top label is the one we expect, for debugging purposes.
-At the end, [`main()`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/label_image/main.cc#L252)
+At the end, [`main()`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/label_image/main.cc#L252)
ties together all of these calls.
```C++
diff --git a/site/en/r1/tutorials/images/transfer_learning.ipynb b/site/en/r1/tutorials/images/transfer_learning.ipynb
index bdb05a86382..25779babd17 100644
--- a/site/en/r1/tutorials/images/transfer_learning.ipynb
+++ b/site/en/r1/tutorials/images/transfer_learning.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
@@ -364,7 +364,7 @@
},
"outputs": [],
"source": [
- "model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=0.0001),\n",
+ "model.compile(optimizer=tf.keras.optimizers.RMSprop(learning_rate=0.0001),\n",
" loss='binary_crossentropy',\n",
" metrics=['accuracy'])"
]
@@ -547,7 +547,7 @@
"\n",
"# Freeze all the layers before the `fine_tune_at` layer\n",
"for layer in base_model.layers[:fine_tune_at]:\n",
- " layer.trainable = False"
+ " layer.trainable = False"
]
},
{
@@ -569,7 +569,7 @@
},
"outputs": [],
"source": [
- "model.compile(optimizer = tf.keras.optimizers.RMSprop(lr=2e-5),\n",
+ "model.compile(optimizer = tf.keras.optimizers.RMSprop(learning_rate=2e-5),\n",
" loss='binary_crossentropy',\n",
" metrics=['accuracy'])"
]
diff --git a/site/en/r1/tutorials/keras/README.md b/site/en/r1/tutorials/keras/README.md
index 4da2f72dca9..47aca7e0052 100644
--- a/site/en/r1/tutorials/keras/README.md
+++ b/site/en/r1/tutorials/keras/README.md
@@ -4,7 +4,7 @@ This notebook collection is inspired by the book
*[Deep Learning with Python](https://books.google.com/books?id=Yo3CAQAACAAJ)*.
These tutorials use `tf.keras`, TensorFlow's high-level Python API for building
and training deep learning models. To learn more about using Keras with
-TensorFlow, see the [TensorFlow Keras Guide](../../guide/keras.ipynb).
+TensorFlow, see the [TensorFlow Keras Guide](https://www.tensorflow.org/guide/keras).
Publisher's note: *Deep Learning with Python* introduces the field of deep
learning using the Python language and the powerful Keras library. Written by
diff --git a/site/en/r1/tutorials/keras/basic_classification.ipynb b/site/en/r1/tutorials/keras/basic_classification.ipynb
index be7f5e9e8b1..14950538ce4 100644
--- a/site/en/r1/tutorials/keras/basic_classification.ipynb
+++ b/site/en/r1/tutorials/keras/basic_classification.ipynb
@@ -96,7 +96,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/keras/basic_regression.ipynb b/site/en/r1/tutorials/keras/basic_regression.ipynb
index 7d9cb711efa..4bffd62f982 100644
--- a/site/en/r1/tutorials/keras/basic_regression.ipynb
+++ b/site/en/r1/tutorials/keras/basic_regression.ipynb
@@ -96,7 +96,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/keras/basic_text_classification.ipynb b/site/en/r1/tutorials/keras/basic_text_classification.ipynb
index 0303d54d973..5424185bcbd 100644
--- a/site/en/r1/tutorials/keras/basic_text_classification.ipynb
+++ b/site/en/r1/tutorials/keras/basic_text_classification.ipynb
@@ -96,7 +96,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/keras/overfit_and_underfit.ipynb b/site/en/r1/tutorials/keras/overfit_and_underfit.ipynb
index a8f266f9869..8e35b06e556 100644
--- a/site/en/r1/tutorials/keras/overfit_and_underfit.ipynb
+++ b/site/en/r1/tutorials/keras/overfit_and_underfit.ipynb
@@ -96,7 +96,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/keras/save_and_restore_models.ipynb b/site/en/r1/tutorials/keras/save_and_restore_models.ipynb
index 7911e37e139..04cc94417a9 100644
--- a/site/en/r1/tutorials/keras/save_and_restore_models.ipynb
+++ b/site/en/r1/tutorials/keras/save_and_restore_models.ipynb
@@ -96,7 +96,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
@@ -115,7 +115,7 @@
"\n",
"Sharing this data helps others understand how the model works and try it themselves with new data.\n",
"\n",
- "Caution: Be careful with untrusted code—TensorFlow models are code. See [Using TensorFlow Securely](https://github.com/tensorflow/tensorflow/blob/master/SECURITY.md) for details.\n",
+ "Caution: Be careful with untrusted code—TensorFlow models are code. See [Using TensorFlow Securely](https://github.com/tensorflow/tensorflow/blob/r1.15/SECURITY.md) for details.\n",
"\n",
"### Options\n",
"\n",
@@ -698,7 +698,7 @@
"id": "B7qfpvpY9HCe"
},
"source": [
- "Load the the saved model."
+ "Load the saved model."
]
},
{
diff --git a/site/en/r1/tutorials/load_data/images.ipynb b/site/en/r1/tutorials/load_data/images.ipynb
index dbee204323b..923b95130d1 100644
--- a/site/en/r1/tutorials/load_data/images.ipynb
+++ b/site/en/r1/tutorials/load_data/images.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/load_data/tf_records.ipynb b/site/en/r1/tutorials/load_data/tf_records.ipynb
index 8b57d3f2f1e..45635034c69 100644
--- a/site/en/r1/tutorials/load_data/tf_records.ipynb
+++ b/site/en/r1/tutorials/load_data/tf_records.ipynb
@@ -57,7 +57,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
@@ -141,7 +141,7 @@
"source": [
"Fundamentally a `tf.Example` is a `{\"string\": tf.train.Feature}` mapping.\n",
"\n",
- "The `tf.train.Feature` message type can accept one of the following three types (See the [`.proto` file](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/example/feature.proto) for reference). Most other generic types can be coerced into one of these.\n",
+ "The `tf.train.Feature` message type can accept one of the following three types (See the [`.proto` file](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/example/feature.proto) for reference). Most other generic types can be coerced into one of these.\n",
"\n",
"1. `tf.train.BytesList` (the following types can be coerced)\n",
"\n",
@@ -276,7 +276,7 @@
"\n",
"1. We create a map (dictionary) from the feature name string to the encoded feature value produced in #1.\n",
"\n",
- "1. The map produced in #2 is converted to a [`Features` message](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/example/feature.proto#L85)."
+ "1. The map produced in #2 is converted to a [`Features` message](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/example/feature.proto#L85)."
]
},
{
@@ -365,7 +365,7 @@
"id": "XftzX9CN_uGT"
},
"source": [
- "For example, suppose we have a single observation from the dataset, `[False, 4, bytes('goat'), 0.9876]`. We can create and print the `tf.Example` message for this observation using `create_message()`. Each single observation will be written as a `Features` message as per the above. Note that the `tf.Example` [message](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/example/example.proto#L88) is just a wrapper around the `Features` message."
+ "For example, suppose we have a single observation from the dataset, `[False, 4, bytes('goat'), 0.9876]`. We can create and print the `tf.Example` message for this observation using `create_message()`. Each single observation will be written as a `Features` message as per the above. Note that the `tf.Example` [message](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/example/example.proto#L88) is just a wrapper around the `Features` message."
]
},
{
@@ -632,7 +632,7 @@
"source": [
"We can also read the TFRecord file using the `tf.data.TFRecordDataset` class.\n",
"\n",
- "More information on consuming TFRecord files using `tf.data` can be found [here](https://www.tensorflow.org/r1/guide/datasets#consuming_tfrecord_data).\n",
+ "More information on consuming TFRecord files using `tf.data` can be found [here](https://www.tensorflow.org/guide/data#consuming_tfrecord_data).\n",
"\n",
"Using `TFRecordDataset`s can be useful for standardizing input data and optimizing performance."
]
diff --git a/site/en/r1/tutorials/non-ml/mandelbrot.ipynb b/site/en/r1/tutorials/non-ml/mandelbrot.ipynb
index 88177211896..bca8a142be4 100644
--- a/site/en/r1/tutorials/non-ml/mandelbrot.ipynb
+++ b/site/en/r1/tutorials/non-ml/mandelbrot.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/non-ml/pdes.ipynb b/site/en/r1/tutorials/non-ml/pdes.ipynb
index d2646daa8da..832fa450523 100644
--- a/site/en/r1/tutorials/non-ml/pdes.ipynb
+++ b/site/en/r1/tutorials/non-ml/pdes.ipynb
@@ -64,7 +64,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
diff --git a/site/en/r1/tutorials/representation/kernel_methods.md b/site/en/r1/tutorials/representation/kernel_methods.md
index 67adc4951c6..227fe81d515 100644
--- a/site/en/r1/tutorials/representation/kernel_methods.md
+++ b/site/en/r1/tutorials/representation/kernel_methods.md
@@ -24,7 +24,7 @@ following sources for an introduction:
Currently, TensorFlow supports explicit kernel mappings for dense features only;
TensorFlow will provide support for sparse features at a later release.
-This tutorial uses [tf.contrib.learn](https://www.tensorflow.org/code/tensorflow/contrib/learn/python/learn)
+This tutorial uses [tf.contrib.learn](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/contrib/learn/python/learn)
(TensorFlow's high-level Machine Learning API) Estimators for our ML models.
If you are not familiar with this API, The [Estimator guide](../../guide/estimators.md)
is a good place to start. We will use the MNIST dataset. The tutorial consists
@@ -131,7 +131,7 @@ In addition to experimenting with the (training) batch size and the number of
training steps, there are a couple other parameters that can be tuned as well.
For instance, you can change the optimization method used to minimize the loss
by explicitly selecting another optimizer from the collection of
-[available optimizers](https://www.tensorflow.org/code/tensorflow/python/training).
+[available optimizers](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/python/training).
As an example, the following code constructs a LinearClassifier estimator that
uses the Follow-The-Regularized-Leader (FTRL) optimization strategy with a
specific learning rate and L2-regularization.
diff --git a/site/en/r1/tutorials/representation/linear.md b/site/en/r1/tutorials/representation/linear.md
index 5516672b34a..d996a13bc1f 100644
--- a/site/en/r1/tutorials/representation/linear.md
+++ b/site/en/r1/tutorials/representation/linear.md
@@ -12,7 +12,7 @@ those tools. It explains:
Read this overview to decide whether the Estimator's linear model tools might
be useful to you. Then work through the
-[Estimator wide and deep learning tutorial](https://github.com/tensorflow/models/tree/master/official/r1/wide_deep)
+[Estimator wide and deep learning tutorial](https://github.com/tensorflow/models/tree/r1.15/official/r1/wide_deep)
to give it a try. This overview uses code samples from the tutorial, but the
tutorial walks through the code in greater detail.
@@ -177,7 +177,7 @@ the name of a `FeatureColumn`. Each key's value is a tensor containing the
values of that feature for all data instances. See
[Premade Estimators](../../guide/premade_estimators.md#input_fn) for a
more comprehensive look at input functions, and `input_fn` in the
-[wide and deep learning tutorial](https://github.com/tensorflow/models/tree/master/official/r1/wide_deep)
+[wide and deep learning tutorial](https://github.com/tensorflow/models/tree/r1.15/official/r1/wide_deep)
for an example implementation of an input function.
The input function is passed to the `train()` and `evaluate()` calls that
@@ -236,4 +236,4 @@ e = tf.estimator.DNNLinearCombinedClassifier(
dnn_hidden_units=[100, 50])
```
For more information, see the
-[wide and deep learning tutorial](https://github.com/tensorflow/models/tree/master/official/r1/wide_deep).
+[wide and deep learning tutorial](https://github.com/tensorflow/models/tree/r1.15/official/r1/wide_deep).
diff --git a/site/en/r1/tutorials/representation/unicode.ipynb b/site/en/r1/tutorials/representation/unicode.ipynb
index 6762a483a42..f76977c3c92 100644
--- a/site/en/r1/tutorials/representation/unicode.ipynb
+++ b/site/en/r1/tutorials/representation/unicode.ipynb
@@ -57,7 +57,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
@@ -136,7 +136,7 @@
"id": "jsMPnjb6UDJ1"
},
"source": [
- "Note: When using python to construct strings, the handling of unicode differs betweeen v2 and v3. In v2, unicode strings are indicated by the \"u\" prefix, as above. In v3, strings are unicode-encoded by default."
+ "Note: When using python to construct strings, the handling of unicode differs between v2 and v3. In v2, unicode strings are indicated by the \"u\" prefix, as above. In v3, strings are unicode-encoded by default."
]
},
{
@@ -425,7 +425,7 @@
"source": [
"### Character substrings\n",
"\n",
- "Similarly, the `tf.strings.substr` operation accepts the \"`unit`\" parameter, and uses it to determine what kind of offsets the \"`pos`\" and \"`len`\" paremeters contain."
+ "Similarly, the `tf.strings.substr` operation accepts the \"`unit`\" parameter, and uses it to determine what kind of offsets the \"`pos`\" and \"`len`\" parameters contain."
]
},
{
@@ -587,7 +587,7 @@
"id": "CapnbShuGU8i"
},
"source": [
- "First, we decode the sentences into character codepoints, and find the script identifeir for each character."
+ "First, we decode the sentences into character codepoints, and find the script identifier for each character."
]
},
{
diff --git a/site/en/r1/tutorials/representation/word2vec.md b/site/en/r1/tutorials/representation/word2vec.md
index f6a27c68f3c..517a5dbc5c5 100644
--- a/site/en/r1/tutorials/representation/word2vec.md
+++ b/site/en/r1/tutorials/representation/word2vec.md
@@ -36,7 +36,7 @@ like to get your hands dirty with the details.
Image and audio processing systems work with rich, high-dimensional datasets
encoded as vectors of the individual raw pixel-intensities for image data, or
-e.g. power spectral density coefficients for audio data. For tasks like object
+e.g., power spectral density coefficients for audio data. For tasks like object
or speech recognition we know that all the information required to successfully
perform the task is encoded in the data (because humans can perform these tasks
from the raw data). However, natural language processing systems traditionally
@@ -109,7 +109,7 @@ $$
where \\(\text{score}(w_t, h)\\) computes the compatibility of word \\(w_t\\)
with the context \\(h\\) (a dot product is commonly used). We train this model
by maximizing its [log-likelihood](https://en.wikipedia.org/wiki/Likelihood_function)
-on the training set, i.e. by maximizing
+on the training set, i.e., by maximizing
$$
\begin{align}
@@ -176,7 +176,7 @@ As an example, let's consider the dataset
We first form a dataset of words and the contexts in which they appear. We
could define 'context' in any way that makes sense, and in fact people have
looked at syntactic contexts (i.e. the syntactic dependents of the current
-target word, see e.g.
+target word, see e.g.,
[Levy et al.](https://levyomer.files.wordpress.com/2014/04/dependency-based-word-embeddings-acl-2014.pdf)),
words-to-the-left of the target, words-to-the-right of the target, etc. For now,
let's stick to the vanilla definition and define 'context' as the window
@@ -204,7 +204,7 @@ where the goal is to predict `the` from `quick`. We select `num_noise` number
of noisy (contrastive) examples by drawing from some noise distribution,
typically the unigram distribution, \\(P(w)\\). For simplicity let's say
`num_noise=1` and we select `sheep` as a noisy example. Next we compute the
-loss for this pair of observed and noisy examples, i.e. the objective at time
+loss for this pair of observed and noisy examples, i.e., the objective at time
step \\(t\\) becomes
$$J^{(t)}_\text{NEG} = \log Q_\theta(D=1 | \text{the, quick}) +
@@ -212,7 +212,7 @@ $$J^{(t)}_\text{NEG} = \log Q_\theta(D=1 | \text{the, quick}) +
The goal is to make an update to the embedding parameters \\(\theta\\) to improve
(in this case, maximize) this objective function. We do this by deriving the
-gradient of the loss with respect to the embedding parameters \\(\theta\\), i.e.
+gradient of the loss with respect to the embedding parameters \\(\theta\\), i.e.,
\\(\frac{\partial}{\partial \theta} J_\text{NEG}\\) (luckily TensorFlow provides
easy helper functions for doing this!). We then perform an update to the
embeddings by taking a small step in the direction of the gradient. When this
@@ -227,7 +227,7 @@ When we inspect these visualizations it becomes apparent that the vectors
capture some general, and in fact quite useful, semantic information about
words and their relationships to one another. It was very interesting when we
first discovered that certain directions in the induced vector space specialize
-towards certain semantic relationships, e.g. *male-female*, *verb tense* and
+towards certain semantic relationships, e.g., *male-female*, *verb tense* and
even *country-capital* relationships between words, as illustrated in the figure
below (see also for example
[Mikolov et al., 2013](https://www.aclweb.org/anthology/N13-1090)).
@@ -327,7 +327,7 @@ for inputs, labels in generate_batch(...):
```
See the full example code in
-[tensorflow/examples/tutorials/word2vec/word2vec_basic.py](https://www.tensorflow.org/code/tensorflow/examples/tutorials/word2vec/word2vec_basic.py).
+[tensorflow/examples/tutorials/word2vec/word2vec_basic.py](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/examples/tutorials/word2vec/word2vec_basic.py).
## Visualizing the learned embeddings
@@ -341,7 +341,7 @@ t-SNE.
Et voila! As expected, words that are similar end up clustering nearby each
other. For a more heavyweight implementation of word2vec that showcases more of
the advanced features of TensorFlow, see the implementation in
-[models/tutorials/embedding/word2vec.py](https://github.com/tensorflow/models/tree/master/research/tutorials/embedding/word2vec.py).
+[models/tutorials/embedding/word2vec.py](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/embedding/word2vec.py).
## Evaluating embeddings: analogical reasoning
@@ -357,7 +357,7 @@ Download the dataset for this task from
To see how we do this evaluation, have a look at the `build_eval_graph()` and
`eval()` functions in
-[models/tutorials/embedding/word2vec.py](https://github.com/tensorflow/models/tree/master/research/tutorials/embedding/word2vec.py).
+[models/tutorials/embedding/word2vec.py](https://github.com/tensorflow/models/tree/r1.15/research/tutorials/embedding/word2vec.py).
The choice of hyperparameters can strongly influence the accuracy on this task.
To achieve state-of-the-art performance on this task requires training over a
diff --git a/site/en/r1/tutorials/sequences/audio_recognition.md b/site/en/r1/tutorials/sequences/audio_recognition.md
index 8ad71b88a3c..0388514ec92 100644
--- a/site/en/r1/tutorials/sequences/audio_recognition.md
+++ b/site/en/r1/tutorials/sequences/audio_recognition.md
@@ -159,9 +159,9 @@ accuracy. If the training accuracy increases but the validation doesn't, that's
a sign that overfitting is occurring, and your model is only learning things
about the training clips, not broader patterns that generalize.
-## Tensorboard
+## TensorBoard
-A good way to visualize how the training is progressing is using Tensorboard. By
+A good way to visualize how the training is progressing is using TensorBoard. By
default, the script saves out events to /tmp/retrain_logs, and you can load
these by running:
diff --git a/site/en/r1/tutorials/sequences/recurrent.md b/site/en/r1/tutorials/sequences/recurrent.md
index 6654795d944..e7c1f8c0b16 100644
--- a/site/en/r1/tutorials/sequences/recurrent.md
+++ b/site/en/r1/tutorials/sequences/recurrent.md
@@ -2,7 +2,7 @@
## Introduction
-See [Understanding LSTM Networks](https://colah.github.io/posts/2015-08-Understanding-LSTMs/){:.external}
+See [Understanding LSTM Networks](https://colah.github.io/posts/2015-08-Understanding-LSTMs/)
for an introduction to recurrent neural networks and LSTMs.
## Language Modeling
diff --git a/site/en/r1/tutorials/sequences/recurrent_quickdraw.md b/site/en/r1/tutorials/sequences/recurrent_quickdraw.md
index 435076f629c..d6a85377d17 100644
--- a/site/en/r1/tutorials/sequences/recurrent_quickdraw.md
+++ b/site/en/r1/tutorials/sequences/recurrent_quickdraw.md
@@ -109,7 +109,7 @@ This download will take a while and download a bit more than 23GB of data.
To convert the `ndjson` files to
[TFRecord](../../api_guides/python/python_io.md#TFRecords_Format_Details) files containing
-[`tf.train.Example`](https://www.tensorflow.org/code/tensorflow/core/example/example.proto)
+[`tf.train.Example`](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/example/example.proto)
protos run the following command.
```shell
@@ -213,7 +213,7 @@ screen coordinates and normalize the size such that the drawing has unit height.
Finally, we compute the differences between consecutive points and store these
as a `VarLenFeature` in a
-[tensorflow.Example](https://www.tensorflow.org/code/tensorflow/core/example/example.proto)
+[tensorflow.Example](https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/example/example.proto)
under the key `ink`. In addition we store the `class_index` as a single entry
`FixedLengthFeature` and the `shape` of the `ink` as a `FixedLengthFeature` of
length 2.
diff --git a/site/en/r1/tutorials/sequences/text_generation.ipynb b/site/en/r1/tutorials/sequences/text_generation.ipynb
index 5911d1c7673..84d942c8bd0 100644
--- a/site/en/r1/tutorials/sequences/text_generation.ipynb
+++ b/site/en/r1/tutorials/sequences/text_generation.ipynb
@@ -65,7 +65,7 @@
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
- "[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
+ "[compatibility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
@@ -77,9 +77,9 @@
"id": "BwpJ5IffzRG6"
},
"source": [
- "This tutorial demonstrates how to generate text using a character-based RNN. We will work with a dataset of Shakespeare's writing from Andrej Karpathy's [The Unreasonable Effectiveness of Recurrent Neural Networks](http://karpathy.github.io/2015/05/21/rnn-effectiveness/). Given a sequence of characters from this data (\"Shakespear\"), train a model to predict the next character in the sequence (\"e\"). Longer sequences of text can be generated by calling the model repeatedly.\n",
+ "This tutorial demonstrates how to generate text using a character-based RNN. You will work with a dataset of Shakespeare's writing from Andrej Karpathy's [The Unreasonable Effectiveness of Recurrent Neural Networks](http://karpathy.github.io/2015/05/21/rnn-effectiveness/). Given a sequence of characters from this data (\"Shakespear\"), train a model to predict the next character in the sequence (\"e\"). Longer sequences of text can be generated by calling the model repeatedly.\n",
"\n",
- "Note: Enable GPU acceleration to execute this notebook faster. In Colab: *Runtime > Change runtime type > Hardware acclerator > GPU*. If running locally make sure TensorFlow version >= 1.11.\n",
+ "Note: Enable GPU acceleration to execute this notebook faster. In Colab: *Runtime > Change runtime type > Hardware accelerator > GPU*. If running locally make sure TensorFlow version >= 1.11.\n",
"\n",
"This tutorial includes runnable code implemented using [tf.keras](https://www.tensorflow.org/programmers_guide/keras) and [eager execution](https://www.tensorflow.org/programmers_guide/eager). The following is sample output when the model in this tutorial trained for 30 epochs, and started with the string \"Q\":\n",
"\n",
@@ -98,7 +98,7 @@
"To watch the next way with his father with his face?\n",
"\n",
"ESCALUS:\n",
- "The cause why then we are all resolved more sons.\n",
+ "The cause why then us all resolved more sons.\n",
"\n",
"VOLUMNIA:\n",
"O, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, it is no sin it should be dead,\n",
@@ -248,7 +248,7 @@
"source": [
"### Vectorize the text\n",
"\n",
- "Before training, we need to map strings to a numerical representation. Create two lookup tables: one mapping characters to numbers, and another for numbers to characters."
+ "Before training, you need to map strings to a numerical representation. Create two lookup tables: one mapping characters to numbers, and another for numbers to characters."
]
},
{
@@ -272,7 +272,7 @@
"id": "tZfqhkYCymwX"
},
"source": [
- "Now we have an integer representation for each character. Notice that we mapped the character as indexes from 0 to `len(unique)`."
+ "Now you have an integer representation for each character. Notice that you mapped the character as indexes from 0 to `len(unique)`."
]
},
{
@@ -316,7 +316,7 @@
"id": "wssHQ1oGymwe"
},
"source": [
- "Given a character, or a sequence of characters, what is the most probable next character? This is the task we're training the model to perform. The input to the model will be a sequence of characters, and we train the model to predict the output—the following character at each time step.\n",
+ "Given a character, or a sequence of characters, what is the most probable next character? This is the task you are training the model to perform. The input to the model will be a sequence of characters, and you train the model to predict the output—the following character at each time step.\n",
"\n",
"Since RNNs maintain an internal state that depends on the previously seen elements, given all the characters computed until this moment, what is the next character?\n"
]
@@ -346,7 +346,7 @@
},
"outputs": [],
"source": [
- "# The maximum length sentence we want for a single input in characters\n",
+ "# The maximum length sentence you want for a single input in characters\n",
"seq_length = 100\n",
"examples_per_epoch = len(text)//seq_length\n",
"\n",
@@ -458,7 +458,7 @@
"source": [
"### Create training batches\n",
"\n",
- "We used `tf.data` to split the text into manageable sequences. But before feeding this data into the model, we need to shuffle the data and pack it into batches."
+ "You used `tf.data` to split the text into manageable sequences. But before feeding this data into the model, you need to shuffle the data and pack it into batches."
]
},
{
@@ -543,7 +543,7 @@
},
"outputs": [],
"source": [
- "if tf.test.is_gpu_available():\n",
+ "if tf.config.list_physical_devices('GPU'):\n",
" rnn = tf.keras.layers.CuDNNGRU\n",
"else:\n",
" import functools\n",
@@ -650,7 +650,7 @@
"id": "uwv0gEkURfx1"
},
"source": [
- "To get actual predictions from the model we need to sample from the output distribution, to get actual character indices. This distribution is defined by the logits over the character vocabulary.\n",
+ "To get actual predictions from the model you need to sample from the output distribution, to get actual character indices. This distribution is defined by the logits over the character vocabulary.\n",
"\n",
"Note: It is important to _sample_ from this distribution as taking the _argmax_ of the distribution can easily get the model stuck in a loop.\n",
"\n",
@@ -746,7 +746,7 @@
"source": [
"The standard `tf.keras.losses.sparse_categorical_crossentropy` loss function works in this case because it is applied across the last dimension of the predictions.\n",
"\n",
- "Because our model returns logits, we need to set the `from_logits` flag.\n"
+ "Because our model returns logits, you need to set the `from_logits` flag.\n"
]
},
{
@@ -771,7 +771,7 @@
"id": "jeOXriLcymww"
},
"source": [
- "Configure the training procedure using the `tf.keras.Model.compile` method. We'll use `tf.train.AdamOptimizer` with default arguments and the loss function."
+ "Configure the training procedure using the `tf.keras.Model.compile` method. You'll use `tf.train.AdamOptimizer` with default arguments and the loss function."
]
},
{
@@ -891,7 +891,7 @@
"\n",
"Because of the way the RNN state is passed from timestep to timestep, the model only accepts a fixed batch size once built.\n",
"\n",
- "To run the model with a different `batch_size`, we need to rebuild the model and restore the weights from the checkpoint.\n"
+ "To run the model with a different `batch_size`, you need to rebuild the model and restore the weights from the checkpoint.\n"
]
},
{
@@ -992,7 +992,7 @@
" predictions = predictions / temperature\n",
" predicted_id = tf.multinomial(predictions, num_samples=1)[-1,0].numpy()\n",
"\n",
- " # We pass the predicted word as the next input to the model\n",
+ " # You pass the predicted word as the next input to the model\n",
" # along with the previous hidden state\n",
" input_eval = tf.expand_dims([predicted_id], 0)\n",
"\n",
@@ -1035,11 +1035,11 @@
"\n",
"So now that you've seen how to run the model manually let's unpack the training loop, and implement it ourselves. This gives a starting point, for example, to implement _curriculum learning_ to help stabilize the model's open-loop output.\n",
"\n",
- "We will use `tf.GradientTape` to track the gradients. You can learn more about this approach by reading the [eager execution guide](https://www.tensorflow.org/r1/guide/eager).\n",
+ "You will use `tf.GradientTape` to track the gradients. You can learn more about this approach by reading the [eager execution guide](https://www.tensorflow.org/r1/guide/eager).\n",
"\n",
"The procedure works as follows:\n",
"\n",
- "* First, initialize the RNN state. We do this by calling the `tf.keras.Model.reset_states` method.\n",
+ "* First, initialize the RNN state. You do this by calling the `tf.keras.Model.reset_states` method.\n",
"\n",
"* Next, iterate over the dataset (batch by batch) and calculate the *predictions* associated with each.\n",
"\n",
diff --git a/site/en/swift/README.md b/site/en/swift/README.md
deleted file mode 100644
index 162a81fa7d3..00000000000
--- a/site/en/swift/README.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Welcome to the warp zone!
-
-# Swift for TensorFlow
-
-These docs are available here:
-https://github.com/tensorflow/swift/tree/main/docs/site
diff --git a/site/en/tensorboard/README.md b/site/en/tensorboard/README.md
deleted file mode 100644
index 7e2126c23d4..00000000000
--- a/site/en/tensorboard/README.md
+++ /dev/null
@@ -1,5 +0,0 @@
-Welcome to the warp zone!
-
-# Tensorboard
-
-These docs are available here: https://github.com/tensorflow/tensorboard/tree/master/docs
diff --git a/site/en/tfx/README.md b/site/en/tfx/README.md
deleted file mode 100644
index c56ad2dbf01..00000000000
--- a/site/en/tfx/README.md
+++ /dev/null
@@ -1,10 +0,0 @@
-Welcome to the warp zone!
-
-# TensorFlow Extended (TFX)
-
-These docs are available here:
-
-* Data Validation: https://github.com/tensorflow/data-validation/tree/master/g3doc
-* Model Analysis: https://github.com/tensorflow/model-analysis/tree/master/g3doc
-* Transform: https://github.com/tensorflow/transform/tree/master/docs
-* Serving: https://github.com/tensorflow/serving/tree/master/tensorflow_serving/g3doc
diff --git a/site/en/tutorials/_index.yaml b/site/en/tutorials/_index.yaml
index e2fc95aff1f..0d09f04c5c7 100644
--- a/site/en/tutorials/_index.yaml
+++ b/site/en/tutorials/_index.yaml
@@ -16,8 +16,9 @@ landing_page:
- description: >
The TensorFlow tutorials are written as Jupyter notebooks and run
- directly in Google Colab—a hosted notebook environment that requires
- no setup. Click the Run in Google Colab button.
+ directly in Google Colab—a hosted notebook environment that requires
+ no setup. At the top of each tutorial, you'll see a Run in Google Colab button. Click
+ the button to open the notebook and run the code yourself.
- classname: devsite-landing-row-100
@@ -84,38 +85,16 @@ landing_page:
- classname: devsite-landing-row-100
items:
- description: >
- Video and blog updates
- Subscribe to the
- TensorFlow blog,
- YouTube channel,
- and Twitter
- for the latest updates.
+ Video tutorials
+ Check out these videos for an introduction to machine learning with TensorFlow:
- items:
- - heading: "Intro to Machine Learning"
- path: "https://www.youtube.com/watch?v=KNAWp2S3w94"
+ - heading: "TensorFlow ML Zero to Hero"
+ path: "https://www.youtube.com/watch?v=KNAWp2S3w94&list=PLQY2H8rRoyvwWuPiWnuTDBHe7I0fMSsfO"
youtube_id: "KNAWp2S3w94?rel=0&show_info=0"
- - heading: "TensorFlow 2.0 and Keras"
- path: "https://www.youtube.com/watch?v=wGI_VtE9CJM"
- youtube_id: "wGI_VtE9CJM?rel=0&show_info=0"
-
- - classname: devsite-landing-row-cards
- items:
- - heading: "Looking Back at 2019"
- path: https://blog.tensorflow.org/2019/12/looking-back-at-2019.html
- buttons:
- - label: "Read on the TensorFlow blog"
- path: https://blog.tensorflow.org/2019/12/looking-back-at-2019.html
- - heading: "TensorFlow 2 is now available"
- path: https://blog.tensorflow.org/2019/09/tensorflow-20-is-now-available.html
- buttons:
- - label: "Read on the TensorFlow blog"
- path: https://blog.tensorflow.org/2019/09/tensorflow-20-is-now-available.html
- - heading: "Standardizing on Keras: Guidance on High-level APIs in TensorFlow 2"
- path: https://blog.tensorflow.org/2018/12/standardizing-on-keras-guidance.html
- buttons:
- - label: "Read on the TensorFlow blog"
- path: https://blog.tensorflow.org/2018/12/standardizing-on-keras-guidance.html
+ - heading: "Basic Computer Vision with ML"
+ path: "https://www.youtube.com/watch?v=bemDFpNooA8&list=PLQY2H8rRoyvwWuPiWnuTDBHe7I0fMSsfO"
+ youtube_id: "bemDFpNooA8?rel=0&show_info=0"
- classname: devsite-landing-row-100
items:
@@ -132,8 +111,8 @@ landing_page:
- description: >
TensorBoard
path: /tensorboard
icon:
@@ -243,7 +222,7 @@ landing_page:
XLA
path: /xla
icon:
@@ -295,3 +274,13 @@ landing_page:
icon_name: chevron_right
foreground: theme
background: grey
+
+ - classname: devsite-landing-row-100
+ items:
+ - description: >
+ TensorFlow updates
+ Subscribe to the
+ TensorFlow blog,
+ YouTube channel,
+ and Twitter
+ for the latest updates.
diff --git a/site/en/tutorials/_toc.yaml b/site/en/tutorials/_toc.yaml
index 27c1d422823..a3907ffe9a4 100644
--- a/site/en/tutorials/_toc.yaml
+++ b/site/en/tutorials/_toc.yaml
@@ -35,6 +35,9 @@ toc:
section:
- title: "Images"
path: /tutorials/load_data/images
+ - title: "Video"
+ path: /tutorials/load_data/video
+ status: new
- title: "CSV"
path: /tutorials/load_data/csv
- title: "NumPy"
@@ -74,6 +77,12 @@ toc:
section:
- title: "Distributed training with Keras"
path: /tutorials/distribute/keras
+ - title: "Distributed training with DTensors"
+ path: /tutorials/distribute/dtensor_ml_tutorial
+ status: experimental
+ - title: "Using DTensors with Keras"
+ path: /tutorials/distribute/dtensor_keras_tutorial
+ status: experimental
- title: "Custom training loops"
path: /tutorials/distribute/custom_training
- title: "Multi-worker training with Keras"
@@ -88,9 +97,14 @@ toc:
- title: "Distributed input"
path: /tutorials/distribute/input
-- title: "Images"
+- title: "Vision"
style: accordion
section:
+ - title: "Computer vision"
+ path: /tutorials/images
+ - title: "KerasCV"
+ path: https://keras.io/keras_cv/
+ status: external
- title: "Convolutional Neural Network"
path: /tutorials/images/cnn
- title: "Image classification"
@@ -104,31 +118,27 @@ toc:
- title: "Image segmentation"
path: /tutorials/images/segmentation
- title: "Object detection with TF Hub"
- path: https://github.com/tensorflow/hub/blob/master/examples/colab/tf2_object_detection.ipynb
+ path: /hub/tutorials/tf2_object_detection
status: external
+ - title: "Video classification"
+ status: new
+ path: /tutorials/video/video_classification
+ - title: "Transfer learning with MoViNet"
+ status: new
+ path: /tutorials/video/transfer_learning_with_movinet
- title: "Text"
style: accordion
section:
- - title: "Word embeddings"
- path: /text/guide/word_embeddings
- status: external
- - title: "Word2Vec"
- path: /tutorials/text/word2vec
- - title: "Text classification with an RNN"
- path: /text/tutorials/text_classification_rnn
- status: external
- - title: "Classify Text with BERT"
- path: /text/tutorials/classify_text_with_bert
- status: external
- - title: "Solve GLUE tasks using BERT on TPU"
- path: /text/tutorials/bert_glue
+ - title: "Text and natural language processing"
+ path: /tutorials/text/index
+ - title: "Get started with KerasNLP"
+ path: https://keras.io/guides/keras_nlp/getting_started/
status: external
- - title: "Neural machine translation with attention"
- path: /text/tutorials/nmt_with_attention
+ - title: "Text and NLP guide"
+ path: /text
status: external
- - title: "Image captioning"
- path: /tutorials/text/image_captioning
+
- title: "Audio"
style: accordion
section:
@@ -136,10 +146,8 @@ toc:
path: /tutorials/audio/simple_audio
- title: "Transfer learning for audio recognition"
path: /tutorials/audio/transfer_learning_audio
- status: new
- title: "Generate music with an RNN"
path: /tutorials/audio/music_generation
- status: new
- title: "Structured data"
style: accordion
@@ -160,6 +168,9 @@ toc:
- title: "Generative"
style: accordion
section:
+ - title: "Stable Diffusion"
+ status: new
+ path: /tutorials/generative/generate_images_with_stable_diffusion
- title: "Neural style transfer"
path: /tutorials/generative/style_transfer
- title: "DeepDream"
@@ -176,6 +187,17 @@ toc:
path: /tutorials/generative/autoencoder
- title: "Variational Autoencoder"
path: /tutorials/generative/cvae
+ - title: "Lossy data compression"
+ path: /tutorials/generative/data_compression
+
+- title: "Model optimization"
+ style: accordion
+ section:
+ - title: "Scalable model compression with EPR"
+ path: /tutorials/optimization/compression
+ - title: "TensorFlow model optimization"
+ status: external
+ path: /model_optimization
- title: "Model Understanding"
style: accordion
@@ -184,9 +206,10 @@ toc:
path: /tutorials/interpretability/integrated_gradients
- title: "Uncertainty quantification with SNGP"
path: /tutorials/understanding/sngp
- - title: "Probabalistic regression"
+ - title: "Probabilistic regression"
path: /probability/examples/Probabilistic_Layers_Regression
status: external
+
- title: "Reinforcement learning"
style: accordion
section:
@@ -198,15 +221,12 @@ toc:
- title: "tf.Estimator"
style: accordion
+ status: deprecated
section:
- title: "Premade estimator"
path: /tutorials/estimator/premade
- title: "Linear model"
path: /tutorials/estimator/linear
- - title: "Boosted trees"
- path: /tutorials/estimator/boosted_trees
- - title: "Boosted trees model understanding"
- path: /tutorials/estimator/boosted_trees_model_understanding
- title: "Keras model to Estimator"
path: /tutorials/estimator/keras_model_to_estimator
- title: "Multi-worker training with Estimator"
diff --git a/site/en/tutorials/audio/music_generation.ipynb b/site/en/tutorials/audio/music_generation.ipynb
index 89802d0447b..e1423ef7cf2 100644
--- a/site/en/tutorials/audio/music_generation.ipynb
+++ b/site/en/tutorials/audio/music_generation.ipynb
@@ -68,9 +68,9 @@
"id": "hr78EkAY-FFg"
},
"source": [
- "This tutorial shows you how to generate musical notes using a simple RNN. You will train a model using a collection of piano MIDI files from the [MAESTRO dataset](https://magenta.tensorflow.org/datasets/maestro). Given a sequence of notes, your model will learn to predict the next note in the sequence. You can generate a longer sequences of notes by calling the model repeatedly.\n",
+ "This tutorial shows you how to generate musical notes using a simple recurrent neural network (RNN). You will train a model using a collection of piano MIDI files from the [MAESTRO dataset](https://magenta.tensorflow.org/datasets/maestro). Given a sequence of notes, your model will learn to predict the next note in the sequence. You can generate longer sequences of notes by calling the model repeatedly.\n",
"\n",
- "This tutorial contains complete code to parse and create MIDI files. You can learn more about how RNNs work by visiting [Text generation with an RNN](https://www.tensorflow.org/text/tutorials/text_generation)."
+ "This tutorial contains complete code to parse and create MIDI files. You can learn more about how RNNs work by visiting the [Text generation with an RNN](https://www.tensorflow.org/text/tutorials/text_generation) tutorial."
]
},
{
@@ -145,7 +145,7 @@
"\n",
"from IPython import display\n",
"from matplotlib import pyplot as plt\n",
- "from typing import Dict, List, Optional, Sequence, Tuple"
+ "from typing import Optional"
]
},
{
@@ -680,7 +680,7 @@
"id": "xIBLvj-cODWS"
},
"source": [
- "Next, create a [tf.data.Dataset](https://www.tensorflow.org/datasets) from the parsed notes."
+ "Next, create a `tf.data.Dataset` from the parsed notes."
]
},
{
@@ -713,7 +713,7 @@
"id": "Sj9SXRCjt3I7"
},
"source": [
- "You will train the model on batches of sequences of notes. Each example will consist of a sequence of notes as the input features, and next note as the label. In this way, the model will be trained to predict the next note in a sequence. You can find a diagram explaining this process (and more details) in [Text classification with an RNN](https://www.tensorflow.org/text/tutorials/text_generation).\n",
+ "You will train the model on batches of sequences of notes. Each example will consist of a sequence of notes as the input features, and the next note as the label. In this way, the model will be trained to predict the next note in a sequence. You can find a diagram describing this process (and more details) in [Text classification with an RNN](https://www.tensorflow.org/text/tutorials/text_generation).\n",
"\n",
"You can use the handy [window](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#window) function with size `seq_length` to create the features and labels in this format."
]
@@ -857,7 +857,7 @@
"id": "iGQn32q-hdK2"
},
"source": [
- "The model will have three outputs, one for each note variable. For `pitch` and `duration`, you will use a custom loss function based on mean squared error that encourages the model to output non-negative values."
+ "The model will have three outputs, one for each note variable. For `step` and `duration`, you will use a custom loss function based on mean squared error that encourages the model to output non-negative values."
]
},
{
@@ -1056,7 +1056,7 @@
"source": [
"To use the model to generate notes, you will first need to provide a starting sequence of notes. The function below generates one note from a sequence of notes. \n",
"\n",
- "For note pitch, it draws a sample from softmax distribution of notes produced by the model, and does not simply pick the note with the highest probability.\n",
+ "For note pitch, it draws a sample from the softmax distribution of notes produced by the model, and does not simply pick the note with the highest probability.\n",
"Always picking the note with the highest probability would lead to repetitive sequences of notes being generated.\n",
"\n",
"The `temperature` parameter can be used to control the randomness of notes generated. You can find more details on temperature in [Text generation with an RNN](https://www.tensorflow.org/text/tutorials/text_generation)."
@@ -1072,9 +1072,9 @@
"source": [
"def predict_next_note(\n",
" notes: np.ndarray, \n",
- " keras_model: tf.keras.Model, \n",
- " temperature: float = 1.0) -> int:\n",
- " \"\"\"Generates a note IDs using a trained sequence model.\"\"\"\n",
+ " model: tf.keras.Model, \n",
+ " temperature: float = 1.0) -> tuple[int, float, float]:\n",
+ " \"\"\"Generates a note as a tuple of (pitch, step, duration), using a trained sequence model.\"\"\"\n",
"\n",
" assert temperature > 0\n",
"\n",
@@ -1229,9 +1229,8 @@
"source": [
"In the above plots, you will notice the change in distribution of the note variables.\n",
"Since there is a feedback loop between the model's outputs and inputs, the model tends to generate similar sequences of outputs to reduce the loss. \n",
- "This is particularly relevant for `step` and `duration`, which has uses MSE loss.\n",
- "For `pitch`, you can increase the randomness by increasing the `temperature` in `predict_next_note`.\n",
- "\n"
+ "This is particularly relevant for `step` and `duration`, which uses the MSE loss.\n",
+ "For `pitch`, you can increase the randomness by increasing the `temperature` in `predict_next_note`.\n"
]
},
{
@@ -1244,7 +1243,7 @@
"\n",
"This tutorial demonstrated the mechanics of using an RNN to generate sequences of notes from a dataset of MIDI files. To learn more, you can visit the closely related [Text generation with an RNN](https://www.tensorflow.org/text/tutorials/text_generation) tutorial, which contains additional diagrams and explanations. \n",
"\n",
- "An alternative to using RNNs for music generation is using GANs. Rather than generating audio, a GAN-based approach can generate a entire sequence in parallel. The Magenta team has done impressive work on this approach with [GANSynth](https://magenta.tensorflow.org/gansynth). You can also find many wonderful music and art projects and open-source code on [Magenta project website](https://magenta.tensorflow.org/)."
+ "One of the alternatives to using RNNs for music generation is using GANs. Rather than generating audio, a GAN-based approach can generate an entire sequence in parallel. The Magenta team has done impressive work on this approach with [GANSynth](https://magenta.tensorflow.org/gansynth). You can also find many wonderful music and art projects and open-source code on [Magenta project website](https://magenta.tensorflow.org/)."
]
}
],
@@ -1253,7 +1252,6 @@
"colab": {
"collapsed_sections": [],
"name": "music_generation.ipynb",
- "provenance": [],
"toc_visible": true
},
"kernelspec": {
diff --git a/site/en/tutorials/audio/simple_audio.ipynb b/site/en/tutorials/audio/simple_audio.ipynb
index 3d208668d4e..9d79742fbb7 100644
--- a/site/en/tutorials/audio/simple_audio.ipynb
+++ b/site/en/tutorials/audio/simple_audio.ipynb
@@ -74,7 +74,9 @@
"id": "SPfDNFlb66XF"
},
"source": [
- "This tutorial will show you how to build a basic speech recognition network that recognizes ten different words. It's important to know that real speech and audio recognition systems are much more complex, but like MNIST for images, it should give you a basic understanding of the techniques involved. Once you've completed this tutorial, you'll have a model that tries to classify a one second audio clip as \"down\", \"go\", \"left\", \"no\", \"right\", \"stop\", \"up\" and \"yes\"."
+ "This tutorial demonstrates how to preprocess audio files in the WAV format and build and train a basic [automatic speech recognition](https://en.wikipedia.org/wiki/Speech_recognition) (ASR) model for recognizing ten different words. You will use a portion of the [Speech Commands dataset](https://www.tensorflow.org/datasets/catalog/speech_commands) ([Warden, 2018](https://arxiv.org/abs/1804.03209)), which contains short (one-second or less) audio clips of commands, such as \"down\", \"go\", \"left\", \"no\", \"right\", \"stop\", \"up\" and \"yes\".\n",
+ "\n",
+ "Real-world speech and audio recognition [systems](https://ai.googleblog.com/search/label/Speech%20Recognition) are complex. But, like [image classification with the MNIST dataset](../quickstart/beginner.ipynb), this tutorial should give you a basic understanding of the techniques involved."
]
},
{
@@ -85,7 +87,18 @@
"source": [
"## Setup\n",
"\n",
- "Import necessary modules and dependencies."
+ "Import necessary modules and dependencies. You'll be using `tf.keras.utils.audio_dataset_from_directory` (introduced in TensorFlow 2.10), which helps generate audio classification datasets from directories of `.wav` files. You'll also need [seaborn](https://seaborn.pydata.org) for visualization in this tutorial."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "hhNW45sjDEDe"
+ },
+ "outputs": [],
+ "source": [
+ "!pip install -U -q tensorflow tensorflow_datasets"
]
},
{
@@ -104,13 +117,11 @@
"import seaborn as sns\n",
"import tensorflow as tf\n",
"\n",
- "from tensorflow.keras.layers.experimental import preprocessing\n",
"from tensorflow.keras import layers\n",
"from tensorflow.keras import models\n",
"from IPython import display\n",
"\n",
- "\n",
- "# Set seed for experiment reproducibility\n",
+ "# Set the seed value for experiment reproducibility.\n",
"seed = 42\n",
"tf.random.set_seed(seed)\n",
"np.random.seed(seed)"
@@ -122,11 +133,11 @@
"id": "yR0EdgrLCaWR"
},
"source": [
- "## Import the Speech Commands dataset\n",
+ "## Import the mini Speech Commands dataset\n",
"\n",
- "You'll write a script to download a portion of the [Speech Commands dataset](https://www.tensorflow.org/datasets/catalog/speech_commands). The original dataset consists of over 105,000 WAV audio files of people saying thirty different words. This data was collected by Google and released under a CC BY license.\n",
+ "To save time with data loading, you will be working with a smaller version of the Speech Commands dataset. The [original dataset](https://www.tensorflow.org/datasets/catalog/speech_commands) consists of over 105,000 audio files in the [WAV (Waveform) audio file format](https://www.aelius.com/njh/wavemetatools/doc/riffmci.pdf) of people saying 35 different words. This data was collected by Google and released under a CC BY license.\n",
"\n",
- "You'll be using a portion of the dataset to save time with data loading. Extract the `mini_speech_commands.zip` and load it in using the `tf.data` API."
+ "Download and extract the `mini_speech_commands.zip` file containing the smaller Speech Commands datasets with `tf.keras.utils.get_file`:"
]
},
{
@@ -137,7 +148,9 @@
},
"outputs": [],
"source": [
- "data_dir = pathlib.Path('data/mini_speech_commands')\n",
+ "DATASET_PATH = 'data/mini_speech_commands'\n",
+ "\n",
+ "data_dir = pathlib.Path(DATASET_PATH)\n",
"if not data_dir.exists():\n",
" tf.keras.utils.get_file(\n",
" 'mini_speech_commands.zip',\n",
@@ -152,7 +165,7 @@
"id": "BgvFq3uYiS5G"
},
"source": [
- "Check basic statistics about the dataset."
+ "The dataset's audio clips are stored in eight folders corresponding to each speech command: `no`, `yes`, `down`, `go`, `left`, `up`, `right`, and `stop`:"
]
},
{
@@ -164,178 +177,140 @@
"outputs": [],
"source": [
"commands = np.array(tf.io.gfile.listdir(str(data_dir)))\n",
- "commands = commands[commands != 'README.md']\n",
+ "commands = commands[(commands != 'README.md') & (commands != '.DS_Store')]\n",
"print('Commands:', commands)"
]
},
{
"cell_type": "markdown",
"metadata": {
- "id": "aMvdU9SY8WXN"
+ "id": "TZ7GJjDvHqtt"
},
"source": [
- "Extract the audio files into a list and shuffle it."
+ "Divided into directories this way, you can easily load the data using `keras.utils.audio_dataset_from_directory`. \n",
+ "\n",
+ "The audio clips are 1 second or less at 16kHz. The `output_sequence_length=16000` pads the short ones to exactly 1 second (and would trim longer ones) so that they can be easily batched."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "hlX685l1wD9k"
+ "id": "mFM4c3aMC8Qv"
},
"outputs": [],
"source": [
- "filenames = tf.io.gfile.glob(str(data_dir) + '/*/*')\n",
- "filenames = tf.random.shuffle(filenames)\n",
- "num_samples = len(filenames)\n",
- "print('Number of total examples:', num_samples)\n",
- "print('Number of examples per label:',\n",
- " len(tf.io.gfile.listdir(str(data_dir/commands[0]))))\n",
- "print('Example file tensor:', filenames[0])"
+ "train_ds, val_ds = tf.keras.utils.audio_dataset_from_directory(\n",
+ " directory=data_dir,\n",
+ " batch_size=64,\n",
+ " validation_split=0.2,\n",
+ " seed=0,\n",
+ " output_sequence_length=16000,\n",
+ " subset='both')\n",
+ "\n",
+ "label_names = np.array(train_ds.class_names)\n",
+ "print()\n",
+ "print(\"label names:\", label_names)"
]
},
{
"cell_type": "markdown",
"metadata": {
- "id": "9vK3ymy23MCP"
+ "id": "cestp83qFnU5"
},
"source": [
- "Split the files into training, validation and test sets using a 80:10:10 ratio, respectively."
+ "The dataset now contains batches of audio clips and integer labels. The audio clips have a shape of `(batch, samples, channels)`. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "Cv_wts-l3KgD"
+ "id": "3yU6SQGIFb3H"
},
"outputs": [],
"source": [
- "train_files = filenames[:6400]\n",
- "val_files = filenames[6400: 6400 + 800]\n",
- "test_files = filenames[-800:]\n",
- "\n",
- "print('Training set size', len(train_files))\n",
- "print('Validation set size', len(val_files))\n",
- "print('Test set size', len(test_files))"
+ "train_ds.element_spec"
]
},
{
"cell_type": "markdown",
"metadata": {
- "id": "g2Cj9FyvfweD"
+ "id": "ppG9Dgq2Ex8R"
},
"source": [
- "## Reading audio files and their labels"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "j1zjcWteOcBy"
- },
- "source": [
- "The audio file will initially be read as a binary file, which you'll want to convert into a numerical tensor.\n",
- "\n",
- "To load an audio file, you will use [`tf.audio.decode_wav`](https://www.tensorflow.org/api_docs/python/tf/audio/decode_wav), which returns the WAV-encoded audio as a Tensor and the sample rate.\n",
- "\n",
- "A WAV file contains time series data with a set number of samples per second. \n",
- "Each sample represents the amplitude of the audio signal at that specific time. In a 16-bit system, like the files in `mini_speech_commands`, the values range from -32768 to 32767. \n",
- "The sample rate for this dataset is 16kHz.\n",
- "Note that `tf.audio.decode_wav` will normalize the values to the range [-1.0, 1.0]."
+ "This dataset only contains single channel audio, so use the `tf.squeeze` function to drop the extra axis:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "9PjJ2iXYwftD"
+ "id": "Xl-tnniUIBlM"
},
"outputs": [],
"source": [
- "def decode_audio(audio_binary):\n",
- " audio, _ = tf.audio.decode_wav(audio_binary)\n",
- " return tf.squeeze(audio, axis=-1)"
+ "def squeeze(audio, labels):\n",
+ " audio = tf.squeeze(audio, axis=-1)\n",
+ " return audio, labels\n",
+ "\n",
+ "train_ds = train_ds.map(squeeze, tf.data.AUTOTUNE)\n",
+ "val_ds = val_ds.map(squeeze, tf.data.AUTOTUNE)"
]
},
{
"cell_type": "markdown",
"metadata": {
- "id": "GPQseZElOjVN"
+ "id": "DtsCSWZN5ILv"
},
"source": [
- "The label for each WAV file is its parent directory."
+ "The `utils.audio_dataset_from_directory` function only returns up to two splits. It's a good idea to keep a test set separate from your validation set.\n",
+ "Ideally you'd keep it in a separate directory, but in this case you can use `Dataset.shard` to split the validation set into two halves. Note that iterating over **any** shard will load **all** the data, and only keep its fraction. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "8VTtX1nr3YT-"
+ "id": "u5UEGsqM5Gss"
},
"outputs": [],
"source": [
- "def get_label(file_path):\n",
- " parts = tf.strings.split(file_path, os.path.sep)\n",
- "\n",
- " # Note: You'll use indexing here instead of tuple unpacking to enable this \n",
- " # to work in a TensorFlow graph.\n",
- " return parts[-2] "
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "E8Y9w_5MOsr-"
- },
- "source": [
- "Let's define a method that will take in the filename of the WAV file and output a tuple containing the audio and labels for supervised training."
+ "test_ds = val_ds.shard(num_shards=2, index=0)\n",
+ "val_ds = val_ds.shard(num_shards=2, index=1)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "WdgUD5T93NyT"
+ "id": "xIeoJcwJH5h9"
},
"outputs": [],
"source": [
- "def get_waveform_and_label(file_path):\n",
- " label = get_label(file_path)\n",
- " audio_binary = tf.io.read_file(file_path)\n",
- " waveform = decode_audio(audio_binary)\n",
- " return waveform, label"
+ "for example_audio, example_labels in train_ds.take(1): \n",
+ " print(example_audio.shape)\n",
+ " print(example_labels.shape)"
]
},
{
"cell_type": "markdown",
"metadata": {
- "id": "nvN8W_dDjYjc"
+ "id": "voxGEwvuh2L7"
},
"source": [
- "You will now apply `process_path` to build your training set to extract the audio-label pairs and check the results. You'll build the validation and test sets using a similar procedure later on."
+ "Let's plot a few audio waveforms:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "0SQl8yXl3kNP"
+ "id": "dYtGq2zYNHuT"
},
"outputs": [],
"source": [
- "AUTOTUNE = tf.data.AUTOTUNE\n",
- "files_ds = tf.data.Dataset.from_tensor_slices(train_files)\n",
- "waveform_ds = files_ds.map(get_waveform_and_label, num_parallel_calls=AUTOTUNE)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "voxGEwvuh2L7"
- },
- "source": [
- "Let's examine a few audio waveforms with their corresponding labels."
+ "label_names[[1,1,3,0]]"
]
},
{
@@ -346,20 +321,17 @@
},
"outputs": [],
"source": [
+ "plt.figure(figsize=(16, 10))\n",
"rows = 3\n",
"cols = 3\n",
- "n = rows*cols\n",
- "fig, axes = plt.subplots(rows, cols, figsize=(10, 12))\n",
- "for i, (audio, label) in enumerate(waveform_ds.take(n)):\n",
- " r = i // cols\n",
- " c = i % cols\n",
- " ax = axes[r][c]\n",
- " ax.plot(audio.numpy())\n",
- " ax.set_yticks(np.arange(-1.2, 1.2, 0.2))\n",
- " label = label.numpy().decode('utf-8')\n",
- " ax.set_title(label)\n",
- "\n",
- "plt.show()"
+ "n = rows * cols\n",
+ "for i in range(n):\n",
+ " plt.subplot(rows, cols, i+1)\n",
+ " audio_signal = example_audio[i]\n",
+ " plt.plot(audio_signal)\n",
+ " plt.title(label_names[example_labels[i]])\n",
+ " plt.yticks(np.arange(-1.2, 1.2, 0.2))\n",
+ " plt.ylim([-1.1, 1.1])"
]
},
{
@@ -368,17 +340,17 @@
"id": "EWXPphxm0B4m"
},
"source": [
- "## Spectrogram\n",
+ "## Convert waveforms to spectrograms\n",
"\n",
- "You'll convert the waveform into a spectrogram, which shows frequency changes over time and can be represented as a 2D image. This can be done by applying the short-time Fourier transform (STFT) to convert the audio into the time-frequency domain.\n",
+ "The waveforms in the dataset are represented in the time domain. Next, you'll transform the waveforms from the time-domain signals into the time-frequency-domain signals by computing the [short-time Fourier transform (STFT)](https://en.wikipedia.org/wiki/Short-time_Fourier_transform) to convert the waveforms to as [spectrograms](https://en.wikipedia.org/wiki/Spectrogram), which show frequency changes over time and can be represented as 2D images. You will feed the spectrogram images into your neural network to train the model.\n",
"\n",
- "A Fourier transform ([`tf.signal.fft`](https://www.tensorflow.org/api_docs/python/tf/signal/fft)) converts a signal to its component frequencies, but loses all time information. The STFT ([`tf.signal.stft`](https://www.tensorflow.org/api_docs/python/tf/signal/stft)) splits the signal into windows of time and runs a Fourier transform on each window, preserving some time information, and returning a 2D tensor that you can run standard convolutions on.\n",
+ "A Fourier transform (`tf.signal.fft`) converts a signal to its component frequencies, but loses all time information. In comparison, STFT (`tf.signal.stft`) splits the signal into windows of time and runs a Fourier transform on each window, preserving some time information, and returning a 2D tensor that you can run standard convolutions on.\n",
"\n",
- "STFT produces an array of complex numbers representing magnitude and phase. However, you'll only need the magnitude for this tutorial, which can be derived by applying `tf.abs` on the output of `tf.signal.stft`. \n",
+ "Create a utility function for converting waveforms to spectrograms:\n",
"\n",
- "Choose `frame_length` and `frame_step` parameters such that the generated spectrogram \"image\" is almost square. For more information on STFT parameters choice, you can refer to [this video](https://www.coursera.org/lecture/audio-signal-processing/stft-2-tjEQe) on audio signal processing. \n",
- "\n",
- "You also want the waveforms to have the same length, so that when you convert it to a spectrogram image, the results will have similar dimensions. This can be done by simply zero padding the audio clips that are shorter than one second.\n"
+ "- The waveforms need to be of the same length, so that when you convert them to spectrograms, the results have similar dimensions. This can be done by simply zero-padding the audio clips that are shorter than one second (using `tf.zeros`).\n",
+ "- When calling `tf.signal.stft`, choose the `frame_length` and `frame_step` parameters such that the generated spectrogram \"image\" is almost square. For more information on the STFT parameters choice, refer to [this Coursera video](https://www.coursera.org/lecture/audio-signal-processing/stft-2-tjEQe) on audio signal processing and STFT.\n",
+ "- The STFT produces an array of complex numbers representing magnitude and phase. However, in this tutorial you'll only use the magnitude, which you can derive by applying `tf.abs` on the output of `tf.signal.stft`."
]
},
{
@@ -390,18 +362,15 @@
"outputs": [],
"source": [
"def get_spectrogram(waveform):\n",
- " # Padding for files with less than 16000 samples\n",
- " zero_padding = tf.zeros([16000] - tf.shape(waveform), dtype=tf.float32)\n",
- "\n",
- " # Concatenate audio with padding so that all audio clips will be of the \n",
- " # same length\n",
- " waveform = tf.cast(waveform, tf.float32)\n",
- " equal_length = tf.concat([waveform, zero_padding], 0)\n",
+ " # Convert the waveform to a spectrogram via a STFT.\n",
" spectrogram = tf.signal.stft(\n",
- " equal_length, frame_length=255, frame_step=128)\n",
- " \n",
+ " waveform, frame_length=255, frame_step=128)\n",
+ " # Obtain the magnitude of the STFT.\n",
" spectrogram = tf.abs(spectrogram)\n",
- "\n",
+ " # Add a `channels` dimension, so that the spectrogram can be used\n",
+ " # as image-like input data with convolution layers (which expect\n",
+ " # shape (`batch_size`, `height`, `width`, `channels`).\n",
+ " spectrogram = spectrogram[..., tf.newaxis]\n",
" return spectrogram"
]
},
@@ -411,7 +380,7 @@
"id": "5rdPiPYJphs2"
},
"source": [
- "Next, you will explore the data. Compare the waveform, the spectrogram and the actual audio of one example from the dataset."
+ "Next, start exploring the data. Print the shapes of one example's tensorized waveform and the corresponding spectrogram, and play the original audio:"
]
},
{
@@ -422,15 +391,25 @@
},
"outputs": [],
"source": [
- "for waveform, label in waveform_ds.take(1):\n",
- " label = label.numpy().decode('utf-8')\n",
+ "for i in range(3):\n",
+ " label = label_names[example_labels[i]]\n",
+ " waveform = example_audio[i]\n",
" spectrogram = get_spectrogram(waveform)\n",
"\n",
- "print('Label:', label)\n",
- "print('Waveform shape:', waveform.shape)\n",
- "print('Spectrogram shape:', spectrogram.shape)\n",
- "print('Audio playback')\n",
- "display.display(display.Audio(waveform, rate=16000))"
+ " print('Label:', label)\n",
+ " print('Waveform shape:', waveform.shape)\n",
+ " print('Spectrogram shape:', spectrogram.shape)\n",
+ " print('Audio playback')\n",
+ " display.display(display.Audio(waveform, rate=16000))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "xnSuqyxJ1isF"
+ },
+ "source": [
+ "Now, define a function for displaying a spectrogram:"
]
},
{
@@ -442,154 +421,136 @@
"outputs": [],
"source": [
"def plot_spectrogram(spectrogram, ax):\n",
- " # Convert to frequencies to log scale and transpose so that the time is\n",
- " # represented in the x-axis (columns). An epsilon is added to avoid log of zero.\n",
- " log_spec = np.log(spectrogram.T+np.finfo(float).eps)\n",
+ " if len(spectrogram.shape) > 2:\n",
+ " assert len(spectrogram.shape) == 3\n",
+ " spectrogram = np.squeeze(spectrogram, axis=-1)\n",
+ " # Convert the frequencies to log scale and transpose, so that the time is\n",
+ " # represented on the x-axis (columns).\n",
+ " # Add an epsilon to avoid taking a log of zero.\n",
+ " log_spec = np.log(spectrogram.T + np.finfo(float).eps)\n",
" height = log_spec.shape[0]\n",
" width = log_spec.shape[1]\n",
" X = np.linspace(0, np.size(spectrogram), num=width, dtype=int)\n",
" Y = range(height)\n",
- " ax.pcolormesh(X, Y, log_spec)\n",
- "\n",
- "\n",
- "fig, axes = plt.subplots(2, figsize=(12, 8))\n",
- "timescale = np.arange(waveform.shape[0])\n",
- "axes[0].plot(timescale, waveform.numpy())\n",
- "axes[0].set_title('Waveform')\n",
- "axes[0].set_xlim([0, 16000])\n",
- "plot_spectrogram(spectrogram.numpy(), axes[1])\n",
- "axes[1].set_title('Spectrogram')\n",
- "plt.show()"
+ " ax.pcolormesh(X, Y, log_spec)"
]
},
{
"cell_type": "markdown",
"metadata": {
- "id": "GyYXjW07jCHA"
+ "id": "baa5c91e8603"
},
"source": [
- "Now transform the waveform dataset to have spectrogram images and their corresponding labels as integer IDs."
+ "Plot the example's waveform over time and the corresponding spectrogram (frequencies over time):"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "43IS2IouEV40"
+ "id": "d2_CikgY1tjv"
},
"outputs": [],
"source": [
- "def get_spectrogram_and_label_id(audio, label):\n",
- " spectrogram = get_spectrogram(audio)\n",
- " spectrogram = tf.expand_dims(spectrogram, -1)\n",
- " label_id = tf.argmax(label == commands)\n",
- " return spectrogram, label_id"
+ "fig, axes = plt.subplots(2, figsize=(12, 8))\n",
+ "timescale = np.arange(waveform.shape[0])\n",
+ "axes[0].plot(timescale, waveform.numpy())\n",
+ "axes[0].set_title('Waveform')\n",
+ "axes[0].set_xlim([0, 16000])\n",
+ "\n",
+ "plot_spectrogram(spectrogram.numpy(), axes[1])\n",
+ "axes[1].set_title('Spectrogram')\n",
+ "plt.suptitle(label.title())\n",
+ "plt.show()"
]
},
{
- "cell_type": "code",
- "execution_count": null,
+ "cell_type": "markdown",
"metadata": {
- "id": "yEVb_oK0oBLQ"
+ "id": "GyYXjW07jCHA"
},
- "outputs": [],
"source": [
- "spectrogram_ds = waveform_ds.map(\n",
- " get_spectrogram_and_label_id, num_parallel_calls=AUTOTUNE)"
+ "Now, create spectrogram datasets from the audio datasets:"
]
},
{
- "cell_type": "markdown",
+ "cell_type": "code",
+ "execution_count": null,
"metadata": {
- "id": "6gQpAAgMnyDi"
+ "id": "mAD0LpkgqtQo"
},
+ "outputs": [],
"source": [
- "Examine the spectrogram \"images\" for different samples of the dataset."
+ "def make_spec_ds(ds):\n",
+ " return ds.map(\n",
+ " map_func=lambda audio,label: (get_spectrogram(audio), label),\n",
+ " num_parallel_calls=tf.data.AUTOTUNE)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "QUbHfTuon4iF"
+ "id": "yEVb_oK0oBLQ"
},
"outputs": [],
"source": [
- "rows = 3\n",
- "cols = 3\n",
- "n = rows*cols\n",
- "fig, axes = plt.subplots(rows, cols, figsize=(10, 10))\n",
- "for i, (spectrogram, label_id) in enumerate(spectrogram_ds.take(n)):\n",
- " r = i // cols\n",
- " c = i % cols\n",
- " ax = axes[r][c]\n",
- " plot_spectrogram(np.squeeze(spectrogram.numpy()), ax)\n",
- " ax.set_title(commands[label_id.numpy()])\n",
- " ax.axis('off')\n",
- " \n",
- "plt.show()"
+ "train_spectrogram_ds = make_spec_ds(train_ds)\n",
+ "val_spectrogram_ds = make_spec_ds(val_ds)\n",
+ "test_spectrogram_ds = make_spec_ds(test_ds)"
]
},
{
"cell_type": "markdown",
"metadata": {
- "id": "z5KdY8IF8rkt"
+ "id": "6gQpAAgMnyDi"
},
"source": [
- "## Build and train the model\n",
- "\n",
- "Now you can build and train your model. But before you do that, you'll need to repeat the training set preprocessing on the validation and test sets."
+ "Examine the spectrograms for different examples of the dataset:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "10UI32QH_45b"
+ "id": "EaM2q5aGis-d"
},
"outputs": [],
"source": [
- "def preprocess_dataset(files):\n",
- " files_ds = tf.data.Dataset.from_tensor_slices(files)\n",
- " output_ds = files_ds.map(get_waveform_and_label, num_parallel_calls=AUTOTUNE)\n",
- " output_ds = output_ds.map(\n",
- " get_spectrogram_and_label_id, num_parallel_calls=AUTOTUNE)\n",
- " return output_ds"
+ "for example_spectrograms, example_spect_labels in train_spectrogram_ds.take(1):\n",
+ " break"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "HNv4xwYkB2P6"
+ "id": "QUbHfTuon4iF"
},
"outputs": [],
"source": [
- "train_ds = spectrogram_ds\n",
- "val_ds = preprocess_dataset(val_files)\n",
- "test_ds = preprocess_dataset(test_files)"
+ "rows = 3\n",
+ "cols = 3\n",
+ "n = rows*cols\n",
+ "fig, axes = plt.subplots(rows, cols, figsize=(16, 9))\n",
+ "\n",
+ "for i in range(n):\n",
+ " r = i // cols\n",
+ " c = i % cols\n",
+ " ax = axes[r][c]\n",
+ " plot_spectrogram(example_spectrograms[i].numpy(), ax)\n",
+ " ax.set_title(label_names[example_spect_labels[i].numpy()])\n",
+ "\n",
+ "plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
- "id": "assnWo6SB3lR"
- },
- "source": [
- "Batch the training and validation sets for model training."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "UgY9WYzn61EX"
+ "id": "z5KdY8IF8rkt"
},
- "outputs": [],
"source": [
- "batch_size = 64\n",
- "train_ds = train_ds.batch(batch_size)\n",
- "val_ds = val_ds.batch(batch_size)"
+ "## Build and train the model"
]
},
{
@@ -598,7 +559,7 @@
"id": "GS1uIh6F_TN9"
},
"source": [
- "Add dataset [`cache()`](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#cache) and [`prefetch()`](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#prefetch) operations to reduce read latency while training the model."
+ "Add `Dataset.cache` and `Dataset.prefetch` operations to reduce read latency while training the model:"
]
},
{
@@ -609,8 +570,9 @@
},
"outputs": [],
"source": [
- "train_ds = train_ds.cache().prefetch(AUTOTUNE)\n",
- "val_ds = val_ds.cache().prefetch(AUTOTUNE)"
+ "train_spectrogram_ds = train_spectrogram_ds.cache().shuffle(10000).prefetch(tf.data.AUTOTUNE)\n",
+ "val_spectrogram_ds = val_spectrogram_ds.cache().prefetch(tf.data.AUTOTUNE)\n",
+ "test_spectrogram_ds = test_spectrogram_ds.cache().prefetch(tf.data.AUTOTUNE)"
]
},
{
@@ -620,11 +582,13 @@
},
"source": [
"For the model, you'll use a simple convolutional neural network (CNN), since you have transformed the audio files into spectrogram images.\n",
- "The model also has the following additional preprocessing layers:\n",
- "- A [`Resizing`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/experimental/preprocessing/Resizing) layer to downsample the input to enable the model to train faster.\n",
- "- A [`Normalization`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/experimental/preprocessing/Normalization) layer to normalize each pixel in the image based on its mean and standard deviation.\n",
"\n",
- "For the `Normalization` layer, its `adapt` method would first need to be called on the training data in order to compute aggregate statistics (i.e. mean and standard deviation)."
+ "Your `tf.keras.Sequential` model will use the following Keras preprocessing layers:\n",
+ "\n",
+ "- `tf.keras.layers.Resizing`: to downsample the input to enable the model to train faster.\n",
+ "- `tf.keras.layers.Normalization`: to normalize each pixel in the image based on its mean and standard deviation.\n",
+ "\n",
+ "For the `Normalization` layer, its `adapt` method would first need to be called on the training data in order to compute aggregate statistics (that is, the mean and the standard deviation)."
]
},
{
@@ -635,17 +599,21 @@
},
"outputs": [],
"source": [
- "for spectrogram, _ in spectrogram_ds.take(1):\n",
- " input_shape = spectrogram.shape\n",
+ "input_shape = example_spectrograms.shape[1:]\n",
"print('Input shape:', input_shape)\n",
- "num_labels = len(commands)\n",
+ "num_labels = len(label_names)\n",
"\n",
- "norm_layer = preprocessing.Normalization()\n",
- "norm_layer.adapt(spectrogram_ds.map(lambda x, _: x))\n",
+ "# Instantiate the `tf.keras.layers.Normalization` layer.\n",
+ "norm_layer = layers.Normalization()\n",
+ "# Fit the state of the layer to the spectrograms\n",
+ "# with `Normalization.adapt`.\n",
+ "norm_layer.adapt(data=train_spectrogram_ds.map(map_func=lambda spec, label: spec))\n",
"\n",
"model = models.Sequential([\n",
" layers.Input(shape=input_shape),\n",
- " preprocessing.Resizing(32, 32), \n",
+ " # Downsample the input.\n",
+ " layers.Resizing(32, 32),\n",
+ " # Normalize.\n",
" norm_layer,\n",
" layers.Conv2D(32, 3, activation='relu'),\n",
" layers.Conv2D(64, 3, activation='relu'),\n",
@@ -660,6 +628,15 @@
"model.summary()"
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "de52e5afa2f3"
+ },
+ "source": [
+ "Configure the Keras model with the Adam optimizer and the cross-entropy loss:"
+ ]
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -675,6 +652,15 @@
")"
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "f42b9e3a4705"
+ },
+ "source": [
+ "Train the model over 10 epochs for demonstration purposes:"
+ ]
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -685,8 +671,8 @@
"source": [
"EPOCHS = 10\n",
"history = model.fit(\n",
- " train_ds, \n",
- " validation_data=val_ds, \n",
+ " train_spectrogram_ds,\n",
+ " validation_data=val_spectrogram_ds,\n",
" epochs=EPOCHS,\n",
" callbacks=tf.keras.callbacks.EarlyStopping(verbose=1, patience=2),\n",
")"
@@ -698,7 +684,7 @@
"id": "gjpCDeQ4mUfS"
},
"source": [
- "Let's check the training and validation loss curves to see how your model has improved during training."
+ "Let's plot the training and validation loss curves to check how your model has improved during training:"
]
},
{
@@ -710,9 +696,20 @@
"outputs": [],
"source": [
"metrics = history.history\n",
+ "plt.figure(figsize=(16,6))\n",
+ "plt.subplot(1,2,1)\n",
"plt.plot(history.epoch, metrics['loss'], metrics['val_loss'])\n",
"plt.legend(['loss', 'val_loss'])\n",
- "plt.show()"
+ "plt.ylim([0, max(plt.ylim())])\n",
+ "plt.xlabel('Epoch')\n",
+ "plt.ylabel('Loss [CrossEntropy]')\n",
+ "\n",
+ "plt.subplot(1,2,2)\n",
+ "plt.plot(history.epoch, 100*np.array(metrics['accuracy']), 100*np.array(metrics['val_accuracy']))\n",
+ "plt.legend(['accuracy', 'val_accuracy'])\n",
+ "plt.ylim([0, 100])\n",
+ "plt.xlabel('Epoch')\n",
+ "plt.ylabel('Accuracy [%]')"
]
},
{
@@ -721,54 +718,64 @@
"id": "5ZTt3kO3mfm4"
},
"source": [
- "## Evaluate test set performance\n",
+ "## Evaluate the model performance\n",
"\n",
- "Let's run the model on the test set and check performance."
+ "Run the model on the test set and check the model's performance:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "biU2MwzyAo8o"
+ "id": "FapuRT_SsWGQ"
},
"outputs": [],
"source": [
- "test_audio = []\n",
- "test_labels = []\n",
- "\n",
- "for audio, label in test_ds:\n",
- " test_audio.append(audio.numpy())\n",
- " test_labels.append(label.numpy())\n",
+ "model.evaluate(test_spectrogram_ds, return_dict=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "en9Znt1NOabH"
+ },
+ "source": [
+ "### Display a confusion matrix\n",
"\n",
- "test_audio = np.array(test_audio)\n",
- "test_labels = np.array(test_labels)"
+ "Use a [confusion matrix](https://developers.google.com/machine-learning/glossary#confusion-matrix) to check how well the model did classifying each of the commands in the test set:\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "ktUanr9mRZky"
+ "id": "5Y6vmWWQuuT1"
},
"outputs": [],
"source": [
- "y_pred = np.argmax(model.predict(test_audio), axis=1)\n",
- "y_true = test_labels\n",
- "\n",
- "test_acc = sum(y_pred == y_true) / len(y_true)\n",
- "print(f'Test set accuracy: {test_acc:.0%}')"
+ "y_pred = model.predict(test_spectrogram_ds)"
]
},
{
- "cell_type": "markdown",
+ "cell_type": "code",
+ "execution_count": null,
"metadata": {
- "id": "en9Znt1NOabH"
+ "id": "d6F0il82u7lW"
},
+ "outputs": [],
"source": [
- "### Display a confusion matrix\n",
- "\n",
- "A confusion matrix is helpful to see how well the model did on each of the commands in the test set."
+ "y_pred = tf.argmax(y_pred, axis=1)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "vHSNoBYLvX81"
+ },
+ "outputs": [],
+ "source": [
+ "y_true = tf.concat(list(test_spectrogram_ds.map(lambda s,lab: lab)), axis=0)"
]
},
{
@@ -779,9 +786,11 @@
},
"outputs": [],
"source": [
- "confusion_mtx = tf.math.confusion_matrix(y_true, y_pred) \n",
+ "confusion_mtx = tf.math.confusion_matrix(y_true, y_pred)\n",
"plt.figure(figsize=(10, 8))\n",
- "sns.heatmap(confusion_mtx, xticklabels=commands, yticklabels=commands, \n",
+ "sns.heatmap(confusion_mtx,\n",
+ " xticklabels=label_names,\n",
+ " yticklabels=label_names,\n",
" annot=True, fmt='g')\n",
"plt.xlabel('Prediction')\n",
"plt.ylabel('Label')\n",
@@ -796,7 +805,7 @@
"source": [
"## Run inference on an audio file\n",
"\n",
- "Finally, verify the model's prediction output using an input audio file of someone saying \"no.\" How well does your model perform?"
+ "Finally, verify the model's prediction output using an input audio file of someone saying \"no\". How well does your model perform?"
]
},
{
@@ -807,15 +816,21 @@
},
"outputs": [],
"source": [
- "sample_file = data_dir/'no/01bb6a2a_nohash_0.wav'\n",
+ "x = data_dir/'no/01bb6a2a_nohash_0.wav'\n",
+ "x = tf.io.read_file(str(x))\n",
+ "x, sample_rate = tf.audio.decode_wav(x, desired_channels=1, desired_samples=16000,)\n",
+ "x = tf.squeeze(x, axis=-1)\n",
+ "waveform = x\n",
+ "x = get_spectrogram(x)\n",
+ "x = x[tf.newaxis,...]\n",
"\n",
- "sample_ds = preprocess_dataset([str(sample_file)])\n",
+ "prediction = model(x)\n",
+ "x_labels = ['no', 'yes', 'down', 'go', 'left', 'up', 'right', 'stop']\n",
+ "plt.bar(x_labels, tf.nn.softmax(prediction[0]))\n",
+ "plt.title('No')\n",
+ "plt.show()\n",
"\n",
- "for spectrogram, label in sample_ds.batch(1):\n",
- " prediction = model(spectrogram)\n",
- " plt.bar(commands, tf.nn.softmax(prediction[0]))\n",
- " plt.title(f'Predictions for \"{commands[label[0]]}\"')\n",
- " plt.show()"
+ "display.display(display.Audio(waveform, rate=16000))"
]
},
{
@@ -824,7 +839,107 @@
"id": "VgWICqdqQNaQ"
},
"source": [
- "You can see that your model very clearly recognized the audio command as \"no.\""
+ "As the output suggests, your model should have recognized the audio command as \"no\"."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "h1icqlM3ISW0"
+ },
+ "source": [
+ "## Export the model with preprocessing"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "r7HX-MjgIbji"
+ },
+ "source": [
+ "The model's not very easy to use if you have to apply those preprocessing steps before passing data to the model for inference. So build an end-to-end version:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "2lIeXdWjIbDE"
+ },
+ "outputs": [],
+ "source": [
+ "class ExportModel(tf.Module):\n",
+ " def __init__(self, model):\n",
+ " self.model = model\n",
+ "\n",
+ " # Accept either a string-filename or a batch of waveforms.\n",
+ " # You could add additional signatures for a single wave, or a ragged-batch. \n",
+ " self.__call__.get_concrete_function(\n",
+ " x=tf.TensorSpec(shape=(), dtype=tf.string))\n",
+ " self.__call__.get_concrete_function(\n",
+ " x=tf.TensorSpec(shape=[None, 16000], dtype=tf.float32))\n",
+ "\n",
+ "\n",
+ " @tf.function\n",
+ " def __call__(self, x):\n",
+ " # If they pass a string, load the file and decode it. \n",
+ " if x.dtype == tf.string:\n",
+ " x = tf.io.read_file(x)\n",
+ " x, _ = tf.audio.decode_wav(x, desired_channels=1, desired_samples=16000,)\n",
+ " x = tf.squeeze(x, axis=-1)\n",
+ " x = x[tf.newaxis, :]\n",
+ " \n",
+ " x = get_spectrogram(x) \n",
+ " result = self.model(x, training=False)\n",
+ " \n",
+ " class_ids = tf.argmax(result, axis=-1)\n",
+ " class_names = tf.gather(label_names, class_ids)\n",
+ " return {'predictions':result,\n",
+ " 'class_ids': class_ids,\n",
+ " 'class_names': class_names}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "gtZBmUiB9HGY"
+ },
+ "source": [
+ "Test run the \"export\" model:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Z1_8TYaCIRue"
+ },
+ "outputs": [],
+ "source": [
+ "export = ExportModel(model)\n",
+ "export(tf.constant(str(data_dir/'no/01bb6a2a_nohash_0.wav')))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "1J6Iuz829Cxo"
+ },
+ "source": [
+ "Save and reload the model, the reloaded model gives identical output:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "wTAg4vsn3oEb"
+ },
+ "outputs": [],
+ "source": [
+ "tf.saved_model.save(export, \"saved\")\n",
+ "imported = tf.saved_model.load(\"saved\")\n",
+ "imported(waveform[tf.newaxis, :])"
]
},
{
@@ -835,18 +950,20 @@
"source": [
"## Next steps\n",
"\n",
- "This tutorial showed how you could do simple audio classification using a convolutional neural network with TensorFlow and Python.\n",
- "\n",
- "* To learn how to use transfer learning for audio classification, check out the [Sound classification with YAMNet](https://www.tensorflow.org/hub/tutorials/yamnet) tutorial.\n",
- "\n",
- "* To build your own interactive web app for audio classification, consider taking the [TensorFlow.js - Audio recognition using transfer learning codelab](https://codelabs.developers.google.com/codelabs/tensorflowjs-audio-codelab/index.html#0).\n",
+ "This tutorial demonstrated how to carry out simple audio classification/automatic speech recognition using a convolutional neural network with TensorFlow and Python. To learn more, consider the following resources:\n",
"\n",
- "* TensorFlow also has additional support for [audio data preparation and augmentation](https://www.tensorflow.org/io/tutorials/audio) to help with your own audio-based projects.\n"
+ "- The [Sound classification with YAMNet](https://www.tensorflow.org/hub/tutorials/yamnet) tutorial shows how to use transfer learning for audio classification.\n",
+ "- The notebooks from [Kaggle's TensorFlow speech recognition challenge](https://www.kaggle.com/c/tensorflow-speech-recognition-challenge/overview).\n",
+ "- The \n",
+ "[TensorFlow.js - Audio recognition using transfer learning codelab](https://codelabs.developers.google.com/codelabs/tensorflowjs-audio-codelab/index.html#0) teaches how to build your own interactive web app for audio classification.\n",
+ "- [A tutorial on deep learning for music information retrieval](https://arxiv.org/abs/1709.04396) (Choi et al., 2017) on arXiv.\n",
+ "- TensorFlow also has additional support for [audio data preparation and augmentation](https://www.tensorflow.org/io/tutorials/audio) to help with your own audio-based projects.\n",
+ "- Consider using the [librosa](https://librosa.org/) library for music and audio analysis."
]
}
],
"metadata": {
- "accelerator": "GPU",
+ "accelerator": "CPU",
"colab": {
"collapsed_sections": [],
"name": "simple_audio.ipynb",
diff --git a/site/en/tutorials/audio/transfer_learning_audio.ipynb b/site/en/tutorials/audio/transfer_learning_audio.ipynb
index 16c679aed61..160aeeb7103 100644
--- a/site/en/tutorials/audio/transfer_learning_audio.ipynb
+++ b/site/en/tutorials/audio/transfer_learning_audio.ipynb
@@ -99,7 +99,9 @@
},
"outputs": [],
"source": [
- "!pip install tensorflow_io"
+ "!pip install -q \"tensorflow==2.11.*\"\n",
+ "# tensorflow_io 0.28 is compatible with TensorFlow 2.11\n",
+ "!pip install -q \"tensorflow_io==0.28.*\""
]
},
{
@@ -235,7 +237,7 @@
"_ = plt.plot(testing_wav_data)\n",
"\n",
"# Play the audio file.\n",
- "display.Audio(testing_wav_data,rate=16000)"
+ "display.Audio(testing_wav_data, rate=16000)"
]
},
{
@@ -286,7 +288,7 @@
"source": [
"scores, embeddings, spectrogram = yamnet_model(testing_wav_data)\n",
"class_scores = tf.reduce_mean(scores, axis=0)\n",
- "top_class = tf.argmax(class_scores)\n",
+ "top_class = tf.math.argmax(class_scores)\n",
"inferred_class = class_names[top_class]\n",
"\n",
"print(f'The main sound is: {inferred_class}')\n",
@@ -736,7 +738,7 @@
"outputs": [],
"source": [
"reloaded_results = reloaded_model(testing_wav_data)\n",
- "cat_or_dog = my_classes[tf.argmax(reloaded_results)]\n",
+ "cat_or_dog = my_classes[tf.math.argmax(reloaded_results)]\n",
"print(f'The main sound is: {cat_or_dog}')"
]
},
@@ -758,7 +760,7 @@
"outputs": [],
"source": [
"serving_results = reloaded_model.signatures['serving_default'](testing_wav_data)\n",
- "cat_or_dog = my_classes[tf.argmax(serving_results['classifier'])]\n",
+ "cat_or_dog = my_classes[tf.math.argmax(serving_results['classifier'])]\n",
"print(f'The main sound is: {cat_or_dog}')\n"
]
},
@@ -805,13 +807,13 @@
"# Run the model, check the output.\n",
"scores, embeddings, spectrogram = yamnet_model(waveform)\n",
"class_scores = tf.reduce_mean(scores, axis=0)\n",
- "top_class = tf.argmax(class_scores)\n",
+ "top_class = tf.math.argmax(class_scores)\n",
"inferred_class = class_names[top_class]\n",
"top_score = class_scores[top_class]\n",
"print(f'[YAMNet] The main sound is: {inferred_class} ({top_score})')\n",
"\n",
"reloaded_results = reloaded_model(waveform)\n",
- "your_top_class = tf.argmax(reloaded_results)\n",
+ "your_top_class = tf.math.argmax(reloaded_results)\n",
"your_inferred_class = my_classes[your_top_class]\n",
"class_probabilities = tf.nn.softmax(reloaded_results, axis=-1)\n",
"your_top_score = class_probabilities[your_top_class]\n",
diff --git a/site/en/tutorials/customization/basics.ipynb b/site/en/tutorials/customization/basics.ipynb
index 314738300e3..2df0840ad5e 100644
--- a/site/en/tutorials/customization/basics.ipynb
+++ b/site/en/tutorials/customization/basics.ipynb
@@ -70,10 +70,10 @@
"source": [
"This is an introductory TensorFlow tutorial that shows how to:\n",
"\n",
- "* Import the required package\n",
- "* Create and use tensors\n",
- "* Use GPU acceleration\n",
- "* Demonstrate `tf.data.Dataset`"
+ "* Import the required package.\n",
+ "* Create and use tensors.\n",
+ "* Use GPU acceleration.\n",
+ "* Build a data pipeline with `tf.data.Dataset`."
]
},
{
@@ -84,7 +84,7 @@
"source": [
"## Import TensorFlow\n",
"\n",
- "To get started, import the `tensorflow` module. As of TensorFlow 2, eager execution is turned on by default. This enables a more interactive frontend to TensorFlow, the details of which we will discuss much later."
+ "To get started, import the `tensorflow` module. As of TensorFlow 2, eager execution is turned on by default. Eager execution enables a more interactive frontend to TensorFlow, which you will later explore in more detail."
]
},
{
@@ -106,7 +106,7 @@
"source": [
"## Tensors\n",
"\n",
- "A Tensor is a multi-dimensional array. Similar to NumPy `ndarray` objects, `tf.Tensor` objects have a data type and a shape. Additionally, `tf.Tensor`s can reside in accelerator memory (like a GPU). TensorFlow offers a rich library of operations ([tf.add](https://www.tensorflow.org/api_docs/python/tf/add), [tf.matmul](https://www.tensorflow.org/api_docs/python/tf/matmul), [tf.linalg.inv](https://www.tensorflow.org/api_docs/python/tf/linalg/inv) etc.) that consume and produce `tf.Tensor`s. These operations automatically convert native Python types, for example:\n"
+ "A Tensor is a multi-dimensional array. Similar to NumPy `ndarray` objects, `tf.Tensor` objects have a data type and a shape. Additionally, `tf.Tensor`s can reside in accelerator memory (like a GPU). TensorFlow offers a rich library of operations (for example, `tf.math.add`, `tf.linalg.matmul`, and `tf.linalg.inv`) that consume and produce `tf.Tensor`s. These operations automatically convert built-in Python types. For example:\n"
]
},
{
@@ -118,13 +118,13 @@
},
"outputs": [],
"source": [
- "print(tf.add(1, 2))\n",
- "print(tf.add([1, 2], [3, 4]))\n",
- "print(tf.square(5))\n",
- "print(tf.reduce_sum([1, 2, 3]))\n",
+ "print(tf.math.add(1, 2))\n",
+ "print(tf.math.add([1, 2], [3, 4]))\n",
+ "print(tf.math.square(5))\n",
+ "print(tf.math.reduce_sum([1, 2, 3]))\n",
"\n",
"# Operator overloading is also supported\n",
- "print(tf.square(2) + tf.square(3))"
+ "print(tf.math.square(2) + tf.math.square(3))"
]
},
{
@@ -144,7 +144,7 @@
},
"outputs": [],
"source": [
- "x = tf.matmul([[1]], [[2, 3]])\n",
+ "x = tf.linalg.matmul([[1]], [[2, 3]])\n",
"print(x)\n",
"print(x.shape)\n",
"print(x.dtype)"
@@ -168,9 +168,9 @@
"id": "Dwi1tdW3JBw6"
},
"source": [
- "### NumPy Compatibility\n",
+ "### NumPy compatibility\n",
"\n",
- "Converting between a TensorFlow `tf.Tensor`s and a NumPy `ndarray` is easy:\n",
+ "Converting between a TensorFlow `tf.Tensor` and a NumPy `ndarray` is easy:\n",
"\n",
"* TensorFlow operations automatically convert NumPy ndarrays to Tensors.\n",
"* NumPy operations automatically convert Tensors to NumPy ndarrays.\n",
@@ -191,11 +191,11 @@
"ndarray = np.ones([3, 3])\n",
"\n",
"print(\"TensorFlow operations convert numpy arrays to Tensors automatically\")\n",
- "tensor = tf.multiply(ndarray, 42)\n",
+ "tensor = tf.math.multiply(ndarray, 42)\n",
"print(tensor)\n",
"\n",
"\n",
- "print(\"And NumPy operations convert Tensors to numpy arrays automatically\")\n",
+ "print(\"And NumPy operations convert Tensors to NumPy arrays automatically\")\n",
"print(np.add(tensor, 1))\n",
"\n",
"print(\"The .numpy() method explicitly converts a Tensor to a numpy array\")\n",
@@ -210,7 +210,7 @@
"source": [
"## GPU acceleration\n",
"\n",
- "Many TensorFlow operations are accelerated using the GPU for computation. Without any annotations, TensorFlow automatically decides whether to use the GPU or CPU for an operation—copying the tensor between CPU and GPU memory, if necessary. Tensors produced by an operation are typically backed by the memory of the device on which the operation executed, for example:"
+ "Many TensorFlow operations are accelerated using the GPU for computation. Without any annotations, TensorFlow automatically decides whether to use the GPU or CPU for an operation—copying the tensor between CPU and GPU memory, if necessary. Tensors produced by an operation are typically backed by the memory of the device on which the operation executed. For example:"
]
},
{
@@ -237,7 +237,7 @@
"id": "vpgYzgVXW2Ud"
},
"source": [
- "### Device Names\n",
+ "### Device names\n",
"\n",
"The `Tensor.device` property provides a fully qualified string name of the device hosting the contents of the tensor. This name encodes many details, such as an identifier of the network address of the host on which this program is executing and the device within that host. This is required for distributed execution of a TensorFlow program. The string ends with `GPU:` if the tensor is placed on the `N`-th GPU on the host."
]
@@ -248,9 +248,11 @@
"id": "ZWZQCimzuqyP"
},
"source": [
- "### Explicit Device Placement\n",
+ "### Explicit device placement\n",
"\n",
- "In TensorFlow, *placement* refers to how individual operations are assigned (placed on) a device for execution. As mentioned, when there is no explicit guidance provided, TensorFlow automatically decides which device to execute an operation and copies tensors to that device, if needed. However, TensorFlow operations can be explicitly placed on specific devices using the `tf.device` context manager, for example:"
+ "In TensorFlow, *placement* refers to how individual operations are assigned (placed on) a device for execution. As mentioned, when there is no explicit guidance provided, TensorFlow automatically decides which device to execute an operation and copies tensors to that device, if needed.\n",
+ "\n",
+ "However, TensorFlow operations can be explicitly placed on specific devices using the `tf.device` context manager. For example:"
]
},
{
@@ -266,7 +268,7 @@
"def time_matmul(x):\n",
" start = time.time()\n",
" for loop in range(10):\n",
- " tf.matmul(x, x)\n",
+ " tf.linalg.matmul(x, x)\n",
"\n",
" result = time.time()-start\n",
"\n",
@@ -296,7 +298,7 @@
"source": [
"## Datasets\n",
"\n",
- "This section uses the [`tf.data.Dataset` API](https://www.tensorflow.org/guide/datasets) to build a pipeline for feeding data to your model. The `tf.data.Dataset` API is used to build performant, complex input pipelines from simple, re-usable pieces that will feed your model's training or evaluation loops."
+ "This section uses the `tf.data.Dataset` API to build a pipeline for feeding data to your model. `tf.data.Dataset` is used to build performant, complex input pipelines from simple, re-usable pieces that will feed your model's training or evaluation loops. (Refer to the [tf.data: Build TensorFlow input pipelines](../../guide/data.ipynb) guide to learn more.)"
]
},
{
@@ -307,7 +309,7 @@
"source": [
"### Create a source `Dataset`\n",
"\n",
- "Create a *source* dataset using one of the factory functions like [`Dataset.from_tensors`](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#from_tensors), [`Dataset.from_tensor_slices`](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#from_tensor_slices), or using objects that read from files like [`TextLineDataset`](https://www.tensorflow.org/api_docs/python/tf/data/TextLineDataset) or [`TFRecordDataset`](https://www.tensorflow.org/api_docs/python/tf/data/TFRecordDataset). See the [TensorFlow Dataset guide](https://www.tensorflow.org/guide/datasets#reading_input_data) for more information."
+ "Create a *source* dataset using one of the factory functions like `tf.data.Dataset.from_tensors`, `tf.data.Dataset.from_tensor_slices`, or using objects that read from files like `tf.data.TextLineDataset` or `tf.data.TFRecordDataset`. Refer to the _Reading input data_ section of the [tf.data: Build TensorFlow input pipelines](../../guide/data.ipynb) guide for more information."
]
},
{
@@ -341,7 +343,7 @@
"source": [
"### Apply transformations\n",
"\n",
- "Use the transformations functions like [`map`](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#map), [`batch`](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#batch), and [`shuffle`](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#shuffle) to apply transformations to dataset records."
+ "Use the transformations functions like `tf.data.Dataset.map`, `tf.data.Dataset.batch`, and `tf.data.Dataset.shuffle` to apply transformations to dataset records."
]
},
{
@@ -352,7 +354,7 @@
},
"outputs": [],
"source": [
- "ds_tensors = ds_tensors.map(tf.square).shuffle(2).batch(2)\n",
+ "ds_tensors = ds_tensors.map(tf.math.square).shuffle(2).batch(2)\n",
"\n",
"ds_file = ds_file.batch(2)"
]
diff --git a/site/en/tutorials/customization/custom_layers.ipynb b/site/en/tutorials/customization/custom_layers.ipynb
index 97c0e8f8ba6..8bfe0a01b09 100644
--- a/site/en/tutorials/customization/custom_layers.ipynb
+++ b/site/en/tutorials/customization/custom_layers.ipynb
@@ -90,7 +90,7 @@
},
"outputs": [],
"source": [
- "print(tf.test.is_gpu_available())"
+ "print(tf.config.list_physical_devices('GPU'))"
]
},
{
@@ -103,7 +103,7 @@
"\n",
"Most of the time when writing code for machine learning models you want to operate at a higher level of abstraction than individual operations and manipulation of individual variables.\n",
"\n",
- "Many machine learning models are expressible as the composition and stacking of relatively simple layers, and TensorFlow provides both a set of many common layers as a well as easy ways for you to write your own application-specific layers either from scratch or as the composition of existing layers.\n",
+ "Many machine learning models are expressible as the composition and stacking of relatively simple layers, and TensorFlow provides both a set of many common layers as well as easy ways for you to write your own application-specific layers either from scratch or as the composition of existing layers.\n",
"\n",
"TensorFlow includes the full [Keras](https://keras.io) API in the tf.keras package, and the Keras layers are very useful when building your own models.\n"
]
@@ -256,7 +256,7 @@
"\n",
"Many interesting layer-like things in machine learning models are implemented by composing existing layers. For example, each residual block in a resnet is a composition of convolutions, batch normalizations, and a shortcut. Layers can be nested inside other layers.\n",
"\n",
- "Typically you inherit from `keras.Model` when you need the model methods like: `Model.fit`,`Model.evaluate`, and `Model.save` (see [Custom Keras layers and models](../../guide/keras/custom_layers_and_models.ipynb) for details).\n",
+ "Typically you inherit from `keras.Model` when you need the model methods like: `Model.fit`,`Model.evaluate`, and `Model.save` (see [Custom Keras layers and models](https://www.tensorflow.org/guide/keras/custom_layers_and_models) for details).\n",
"\n",
"One other feature provided by `keras.Model` (instead of `keras.layers.Layer`) is that in addition to tracking variables, a `keras.Model` also tracks its internal layers, making them easier to inspect.\n",
"\n",
diff --git a/site/en/tutorials/customization/custom_training_walkthrough.ipynb b/site/en/tutorials/customization/custom_training_walkthrough.ipynb
index 45cc7e8c39d..9a05d864815 100644
--- a/site/en/tutorials/customization/custom_training_walkthrough.ipynb
+++ b/site/en/tutorials/customization/custom_training_walkthrough.ipynb
@@ -68,81 +68,20 @@
"id": "LDrzLFXE8T1l"
},
"source": [
- "This guide uses machine learning to *categorize* Iris flowers by species. It uses TensorFlow to:\n",
- "1. Build a model,\n",
- "2. Train this model on example data, and\n",
- "3. Use the model to make predictions about unknown data.\n",
+ "This tutorial shows you how to train a machine learning model with a custom training loop to *categorize* penguins by species. In this notebook, you use TensorFlow to accomplish the following:\n",
"\n",
- "## TensorFlow programming\n",
- "\n",
- "This guide uses these high-level TensorFlow concepts:\n",
+ "1. Import a dataset\n",
+ "2. Build a simple linear model\n",
+ "3. Train the model\n",
+ "4. Evaluate the model's effectiveness\n",
+ "5. Use the trained model to make predictions\n",
"\n",
- "* Use TensorFlow's default [eager execution](../../guide/eager.ipynb) development environment,\n",
- "* Import data with the [Datasets API](../../guide/datasets.ipynb),\n",
- "* Build models and layers with TensorFlow's [Keras API](../../guide/keras/overview.ipynb).\n",
+ "## TensorFlow programming\n",
"\n",
- "This tutorial is structured like many TensorFlow programs:\n",
+ "This tutorial demonstrates the following TensorFlow programming tasks:\n",
"\n",
- "1. Import and parse the dataset.\n",
- "2. Select the type of model.\n",
- "3. Train the model.\n",
- "4. Evaluate the model's effectiveness.\n",
- "5. Use the trained model to make predictions."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "yNr7H-AIoLOR"
- },
- "source": [
- "## Setup program"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "1J3AuPBT9gyR"
- },
- "source": [
- "### Configure imports\n",
- "\n",
- "Import TensorFlow and the other required Python modules. By default, TensorFlow uses [eager execution](../../guide/eager.ipynb) to evaluate operations immediately, returning concrete values instead of creating a computational graph that is executed later. If you are used to a REPL or the `python` interactive console, this feels familiar."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "jElLULrDhQZR"
- },
- "outputs": [],
- "source": [
- "import os\n",
- "import matplotlib.pyplot as plt"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "bfV2Dai0Ow2o"
- },
- "outputs": [],
- "source": [
- "import tensorflow as tf"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "g4Wzg69bnwK2"
- },
- "outputs": [],
- "source": [
- "print(\"TensorFlow version: {}\".format(tf.__version__))\n",
- "print(\"Eager execution: {}\".format(tf.executing_eagerly()))"
+ "* Importing data with the [TensorFlow Datasets API](https://www.tensorflow.org/datasets/overview#load_a_dataset)\n",
+ "* Building models and layers with the [Keras API](https://www.tensorflow.org/guide/keras/)\n"
]
},
{
@@ -151,293 +90,255 @@
"id": "Zx7wc0LuuxaJ"
},
"source": [
- "## The Iris classification problem\n",
+ "## Penguin classification problem \n",
"\n",
- "Imagine you are a botanist seeking an automated way to categorize each Iris flower you find. Machine learning provides many algorithms to classify flowers statistically. For instance, a sophisticated machine learning program could classify flowers based on photographs. Our ambitions are more modest—we're going to classify Iris flowers based on the length and width measurements of their [sepals](https://en.wikipedia.org/wiki/Sepal) and [petals](https://en.wikipedia.org/wiki/Petal).\n",
+ "Imagine you are an ornithologist seeking an automated way to categorize each penguin you find. Machine learning provides many algorithms to classify penguins statistically. For instance, a sophisticated machine learning program could classify penguins based on photographs. The model you build in this tutorial is a little simpler. It classifies penguins based on their body weight, flipper length, and beaks, specifically the length and width measurements of their [culmen](https://en.wikipedia.org/wiki/Beak#Culmen).\n",
"\n",
- "The Iris genus entails about 300 species, but our program will only classify the following three:\n",
+ "There are 18 species of penguins, but in this tutorial you will only attempt to classify the following three:\n",
"\n",
- "* Iris setosa\n",
- "* Iris virginica\n",
- "* Iris versicolor\n",
+ "* Chinstrap penguins\n",
+ "* Gentoo penguins\n",
+ "* Adélie penguins\n",
"\n",
"\n",
" \n",
- "  \n",
+ " \n",
+ "  \n",
" \n",
" |
\n",
" \n",
- " Figure 1. Iris setosa (by Radomil, CC BY-SA 3.0), Iris versicolor, (by Dlanglois, CC BY-SA 3.0), and Iris virginica (by Frank Mayfield, CC BY-SA 2.0).
\n",
+ " Figure 1. Chinstratp, Gentoo, and Adélie penguins (Artwork by @allison_horst, CC BY-SA 2.0).
\n",
" |
\n",
"
\n",
"\n",
- "Fortunately, someone has already created a [dataset of 120 Iris flowers](https://en.wikipedia.org/wiki/Iris_flower_data_set) with the sepal and petal measurements. This is a classic dataset that is popular for beginner machine learning classification problems."
+ "Fortunately, a research team has already created and shared a [dataset of 334 penguins](https://allisonhorst.github.io/palmerpenguins/) with body weight, flipper length, beak measurements, and other data. This dataset is also conveniently available as the [penguins](https://www.tensorflow.org/datasets/catalog/penguins) TensorFlow Dataset. "
]
},
{
"cell_type": "markdown",
"metadata": {
- "id": "3Px6KAg0Jowz"
+ "id": "1J3AuPBT9gyR"
},
"source": [
- "## Import and parse the training dataset\n",
+ "## Setup\n",
"\n",
- "Download the dataset file and convert it into a structure that can be used by this Python program.\n",
- "\n",
- "### Download the dataset\n",
- "\n",
- "Download the training dataset file using the `tf.keras.utils.get_file` function. This returns the file path of the downloaded file:"
+ "Install the `tfds-nightly` package for the penguins dataset. The `tfds-nightly` package is the nightly released version of the TensorFlow Datasets (TFDS). For more information on TFDS, see [TensorFlow Datasets overview](https://www.tensorflow.org/datasets/overview)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "J6c7uEU9rjRM"
+ "id": "4XXWn1eDZmET"
},
"outputs": [],
"source": [
- "train_dataset_url = \"https://storage.googleapis.com/download.tensorflow.org/data/iris_training.csv\"\n",
- "\n",
- "train_dataset_fp = tf.keras.utils.get_file(fname=os.path.basename(train_dataset_url),\n",
- " origin=train_dataset_url)\n",
- "\n",
- "print(\"Local copy of the dataset file: {}\".format(train_dataset_fp))"
+ "!pip install -q tfds-nightly"
]
},
{
"cell_type": "markdown",
"metadata": {
- "id": "qnX1-aLors4S"
+ "id": "DtGeMicKRGzU"
},
"source": [
- "### Inspect the data\n",
+ "Then select **Runtime > Restart Runtime** from the Colab menu to restart the Colab runtime.\n",
"\n",
- "This dataset, `iris_training.csv`, is a plain text file that stores tabular data formatted as comma-separated values (CSV). Use the `head -n5` command to take a peek at the first five entries:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "FQvb_JYdrpPm"
- },
- "outputs": [],
- "source": [
- "!head -n5 {train_dataset_fp}"
+ "Do not proceed with the rest of this tutorial without first restarting the runtime."
]
},
{
"cell_type": "markdown",
"metadata": {
- "id": "kQhzD6P-uBoq"
+ "id": "G9onjGZWZbA-"
},
"source": [
- "From this view of the dataset, notice the following:\n",
- "\n",
- "1. The first line is a header containing information about the dataset:\n",
- " * There are 120 total examples. Each example has four features and one of three possible label names.\n",
- "2. Subsequent rows are data records, one *[example](https://developers.google.com/machine-learning/glossary/#example)* per line, where:\n",
- " * The first four fields are *[features](https://developers.google.com/machine-learning/glossary/#feature)*: these are the characteristics of an example. Here, the fields hold float numbers representing flower measurements.\n",
- " * The last column is the *[label](https://developers.google.com/machine-learning/glossary/#label)*: this is the value we want to predict. For this dataset, it's an integer value of 0, 1, or 2 that corresponds to a flower name.\n",
- "\n",
- "Let's write that out in code:"
+ "Import TensorFlow and the other required Python modules. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "9Edhevw7exl6"
+ "id": "jElLULrDhQZR"
},
"outputs": [],
"source": [
- "# column order in CSV file\n",
- "column_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']\n",
- "\n",
- "feature_names = column_names[:-1]\n",
- "label_name = column_names[-1]\n",
+ "import os\n",
+ "import tensorflow as tf\n",
+ "import tensorflow_datasets as tfds\n",
+ "import matplotlib.pyplot as plt\n",
"\n",
- "print(\"Features: {}\".format(feature_names))\n",
- "print(\"Label: {}\".format(label_name))"
+ "print(\"TensorFlow version: {}\".format(tf.__version__))\n",
+ "print(\"TensorFlow Datasets version: \",tfds.__version__)"
]
},
{
"cell_type": "markdown",
"metadata": {
- "id": "CCtwLoJhhDNc"
+ "id": "3Px6KAg0Jowz"
},
"source": [
- "Each label is associated with string name (for example, \"setosa\"), but machine learning typically relies on numeric values. The label numbers are mapped to a named representation, such as:\n",
- "\n",
- "* `0`: Iris setosa\n",
- "* `1`: Iris versicolor\n",
- "* `2`: Iris virginica\n",
+ "## Import the dataset\n",
"\n",
- "For more information about features and labels, see the [ML Terminology section of the Machine Learning Crash Course](https://developers.google.com/machine-learning/crash-course/framing/ml-terminology)."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "sVNlJlUOhkoX"
- },
- "outputs": [],
- "source": [
- "class_names = ['Iris setosa', 'Iris versicolor', 'Iris virginica']"
+ "The default [penguins/processed](https://www.tensorflow.org/datasets/catalog/penguins) TensorFlow Dataset is already cleaned, normalized, and ready for building a model. Before you download the processed data, preview a simplified version to get familiar with the original penguin survey data.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
- "id": "dqPkQExM2Pwt"
+ "id": "qnX1-aLors4S"
},
"source": [
- "### Create a `tf.data.Dataset`\n",
+ "### Preview the data\n",
"\n",
- "TensorFlow's [Dataset API](../../guide/data.ipynb) handles many common cases for loading data into a model. This is a high-level API for reading data and transforming it into a form used for training.\n",
- "\n",
- "\n",
- "Since the dataset is a CSV-formatted text file, use the `tf.data.experimental.make_csv_dataset` function to parse the data into a suitable format. Since this function generates data for training models, the default behavior is to shuffle the data (`shuffle=True, shuffle_buffer_size=10000`), and repeat the dataset forever (`num_epochs=None`). We also set the [batch_size](https://developers.google.com/machine-learning/glossary/#batch_size) parameter:"
+ "Download the simplified version of the penguins dataset (`penguins/simple`) using the TensorFlow Datasets [`tfds.load`](https://www.tensorflow.org/datasets/api_docs/python/tfds/load) method. There are 344 data records in this dataset. Extract the first five records into a [`DataFrame`](https://www.tensorflow.org/datasets/api_docs/python/tfds/as_dataframe) object to inspect a sample of the values in this dataset:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "WsxHnz1ebJ2S"
+ "id": "FQvb_JYdrpPm"
},
"outputs": [],
"source": [
- "batch_size = 32\n",
- "\n",
- "train_dataset = tf.data.experimental.make_csv_dataset(\n",
- " train_dataset_fp,\n",
- " batch_size,\n",
- " column_names=column_names,\n",
- " label_name=label_name,\n",
- " num_epochs=1)"
+ "ds_preview, info = tfds.load('penguins/simple', split='train', with_info=True)\n",
+ "df = tfds.as_dataframe(ds_preview.take(5), info)\n",
+ "print(df)\n",
+ "print(info.features)"
]
},
{
"cell_type": "markdown",
"metadata": {
- "id": "gB_RSn62c-3G"
+ "id": "kQhzD6P-uBoq"
},
"source": [
- "The `make_csv_dataset` function returns a `tf.data.Dataset` of `(features, label)` pairs, where `features` is a dictionary: `{'feature_name': value}`\n",
- "\n",
- "These `Dataset` objects are iterable. Let's look at a batch of features:"
+ "The numbered rows are data records, one _[example](https://developers.google.com/machine-learning/glossary/#example)_ per line, where:\n",
+ " * The first six fields are _[features](https://developers.google.com/machine-learning/glossary/#feature)_: these are the characteristics of an example. Here, the fields hold numbers representing penguin measurements.\n",
+ " * The last column is the _[label](https://developers.google.com/machine-learning/glossary/#label)_: this is the value you want to predict. For this dataset, it's an integer value of 0, 1, or 2 that corresponds to a penguin species name."
]
},
{
- "cell_type": "code",
- "execution_count": null,
+ "cell_type": "markdown",
"metadata": {
- "id": "iDuG94H-C122"
+ "id": "CCtwLoJhhDNc"
},
- "outputs": [],
"source": [
- "features, labels = next(iter(train_dataset))\n",
+ "In the dataset, the label for the penguin species is represented as a number to make it easier to work with in the model you are building. These numbers correspond to the following penguin species:\n",
+ "\n",
+ "* `0`: Adélie penguin\n",
+ "* `1`: Chinstrap penguin\n",
+ "* `2`: Gentoo penguin\n",
"\n",
- "print(features)"
+ "Create a list containing the penguin species names in this order. You will use this list to interpret the output of the classification model:"
]
},
{
- "cell_type": "markdown",
+ "cell_type": "code",
+ "execution_count": null,
"metadata": {
- "id": "E63mArnQaAGz"
+ "id": "sVNlJlUOhkoX"
},
+ "outputs": [],
"source": [
- "Notice that like-features are grouped together, or *batched*. Each example row's fields are appended to the corresponding feature array. Change the `batch_size` to set the number of examples stored in these feature arrays.\n",
- "\n",
- "You can start to see some clusters by plotting a few features from the batch:"
+ "class_names = ['Adélie', 'Chinstrap', 'Gentoo']"
]
},
{
- "cell_type": "code",
- "execution_count": null,
+ "cell_type": "markdown",
"metadata": {
- "id": "me5Wn-9FcyyO"
+ "id": "iav9kEgxpY0s"
},
- "outputs": [],
"source": [
- "plt.scatter(features['petal_length'],\n",
- " features['sepal_length'],\n",
- " c=labels,\n",
- " cmap='viridis')\n",
- "\n",
- "plt.xlabel(\"Petal length\")\n",
- "plt.ylabel(\"Sepal length\")\n",
- "plt.show()"
+ "For more information about features and labels, refer to the [ML Terminology section of the Machine Learning Crash Course](https://developers.google.com/machine-learning/crash-course/framing/ml-terminology)."
]
},
{
"cell_type": "markdown",
"metadata": {
- "id": "YlxpSyHlhT6M"
+ "id": "PD33PxSmCrtL"
},
"source": [
- "To simplify the model building step, create a function to repackage the features dictionary into a single array with shape: `(batch_size, num_features)`.\n",
+ "### Download the preprocessed dataset\n",
"\n",
- "This function uses the `tf.stack` method which takes values from a list of tensors and creates a combined tensor at the specified dimension:"
+ "Now, download the preprocessed penguins dataset (`penguins/processed`) with the `tfds.load` method, which returns a list of `tf.data.Dataset` objects. Note that the `penguins/processed` dataset doesn't come with its own test set, so use an 80:20 split to [slice the full dataset](https://www.tensorflow.org/datasets/splits) into the training and test sets. You will use the test dataset later to verify your model."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "jm932WINcaGU"
+ "id": "EVV96zIYYAi8"
},
"outputs": [],
"source": [
- "def pack_features_vector(features, labels):\n",
- " \"\"\"Pack the features into a single array.\"\"\"\n",
- " features = tf.stack(list(features.values()), axis=1)\n",
- " return features, labels"
+ "ds_split, info = tfds.load(\"penguins/processed\", split=['train[:20%]', 'train[20%:]'], as_supervised=True, with_info=True)\n",
+ "\n",
+ "ds_test = ds_split[0]\n",
+ "ds_train = ds_split[1]\n",
+ "assert isinstance(ds_test, tf.data.Dataset)\n",
+ "\n",
+ "print(info.features)\n",
+ "df_test = tfds.as_dataframe(ds_test.take(5), info)\n",
+ "print(\"Test dataset sample: \")\n",
+ "print(df_test)\n",
+ "\n",
+ "df_train = tfds.as_dataframe(ds_train.take(5), info)\n",
+ "print(\"Train dataset sample: \")\n",
+ "print(df_train)\n",
+ "\n",
+ "ds_train_batch = ds_train.batch(32)"
]
},
{
"cell_type": "markdown",
"metadata": {
- "id": "V1Vuph_eDl8x"
+ "id": "xX2NfLyQOK1y"
},
"source": [
- "Then use the `tf.data.Dataset#map` method to pack the `features` of each `(features,label)` pair into the training dataset:"
+ "Notice that this version of the dataset has been processed by reducing the data down to four normalized features and a species label. In this format, the data can be quickly used to train a model without further processing."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "ZbDkzGZIkpXf"
+ "id": "iDuG94H-C122"
},
"outputs": [],
"source": [
- "train_dataset = train_dataset.map(pack_features_vector)"
+ "features, labels = next(iter(ds_train_batch))\n",
+ "\n",
+ "print(features)\n",
+ "print(labels)"
]
},
{
"cell_type": "markdown",
"metadata": {
- "id": "NLy0Q1xCldVO"
+ "id": "E63mArnQaAGz"
},
"source": [
- "The features element of the `Dataset` are now arrays with shape `(batch_size, num_features)`. Let's look at the first few examples:"
+ "You can visualize some clusters by plotting a few features from the batch:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "kex9ibEek6Tr"
+ "id": "me5Wn-9FcyyO"
},
"outputs": [],
"source": [
- "features, labels = next(iter(train_dataset))\n",
+ "plt.scatter(features[:,0],\n",
+ " features[:,2],\n",
+ " c=labels,\n",
+ " cmap='viridis')\n",
"\n",
- "print(features[:5])"
+ "plt.xlabel(\"Body Mass\")\n",
+ "plt.ylabel(\"Culmen Length\")\n",
+ "plt.show()"
]
},
{
@@ -446,29 +347,31 @@
"id": "LsaVrtNM3Tx5"
},
"source": [
- "## Select the type of model\n",
+ "## Build a simple linear model\n",
"\n",
"### Why model?\n",
"\n",
- "A *[model](https://developers.google.com/machine-learning/crash-course/glossary#model)* is a relationship between features and the label. For the Iris classification problem, the model defines the relationship between the sepal and petal measurements and the predicted Iris species. Some simple models can be described with a few lines of algebra, but complex machine learning models have a large number of parameters that are difficult to summarize.\n",
+ "A *[model](https://developers.google.com/machine-learning/crash-course/glossary#model)* is a relationship between features and the label. For the penguin classification problem, the model defines the relationship between the body mass, flipper and culmen measurements and the predicted penguin species. Some simple models can be described with a few lines of algebra, but complex machine learning models have a large number of parameters that are difficult to summarize.\n",
"\n",
- "Could you determine the relationship between the four features and the Iris species *without* using machine learning? That is, could you use traditional programming techniques (for example, a lot of conditional statements) to create a model? Perhaps—if you analyzed the dataset long enough to determine the relationships between petal and sepal measurements to a particular species. And this becomes difficult—maybe impossible—on more complicated datasets. A good machine learning approach *determines the model for you*. If you feed enough representative examples into the right machine learning model type, the program will figure out the relationships for you.\n",
+ "Could you determine the relationship between the four features and the penguin species *without* using machine learning? That is, could you use traditional programming techniques (for example, a lot of conditional statements) to create a model? Perhaps—if you analyzed the dataset long enough to determine the relationships between body mass and culmen measurements to a particular species. And this becomes difficult—maybe impossible—on more complicated datasets. A good machine learning approach *determines the model for you*. If you feed enough representative examples into the right machine learning model type, the program figures out the relationships for you.\n",
"\n",
"### Select the model\n",
"\n",
- "We need to select the kind of model to train. There are many types of models and picking a good one takes experience. This tutorial uses a neural network to solve the Iris classification problem. *[Neural networks](https://developers.google.com/machine-learning/glossary/#neural_network)* can find complex relationships between features and the label. It is a highly-structured graph, organized into one or more *[hidden layers](https://developers.google.com/machine-learning/glossary/#hidden_layer)*. Each hidden layer consists of one or more *[neurons](https://developers.google.com/machine-learning/glossary/#neuron)*. There are several categories of neural networks and this program uses a dense, or *[fully-connected neural network](https://developers.google.com/machine-learning/glossary/#fully_connected_layer)*: the neurons in one layer receive input connections from *every* neuron in the previous layer. For example, Figure 2 illustrates a dense neural network consisting of an input layer, two hidden layers, and an output layer:\n",
+ "Next you need to select the kind of model to train. There are many types of models and picking a good one takes experience. This tutorial uses a neural network to solve the penguin classification problem. [*Neural networks*](https://developers.google.com/machine-learning/glossary/#neural_network) can find complex relationships between features and the label. It is a highly-structured graph, organized into one or more [*hidden layers*](https://developers.google.com/machine-learning/glossary/#hidden_layer). Each hidden layer consists of one or more [*neurons*](https://developers.google.com/machine-learning/glossary/#neuron). There are several categories of neural networks and this program uses a dense, or [*fully-connected neural network*](https://developers.google.com/machine-learning/glossary/#fully_connected_layer): the neurons in one layer receive input connections from *every* neuron in the previous layer. For example, Figure 2 illustrates a dense neural network consisting of an input layer, two hidden layers, and an output layer:\n",
+ "\n",
+ "\n",
"\n",
"\n",
" \n",
- "  \n",
+ " \n",
+ "  \n",
" \n",
" |
\n",
" \n",
" Figure 2. A neural network with features, hidden layers, and predictions.
\n",
" |
\n",
"
\n",
"\n",
- "When the model from Figure 2 is trained and fed an unlabeled example, it yields three predictions: the likelihood that this flower is the given Iris species. This prediction is called *[inference](https://developers.google.com/machine-learning/crash-course/glossary#inference)*. For this example, the sum of the output predictions is 1.0. In Figure 2, this prediction breaks down as: `0.02` for *Iris setosa*, `0.95` for *Iris versicolor*, and `0.03` for *Iris virginica*. This means that the model predicts—with 95% probability—that an unlabeled example flower is an *Iris versicolor*."
+ "When you train the model from Figure 2 and feed it an unlabeled example, it yields three predictions: the likelihood that this penguin is the given penguin species. This prediction is called [*inference*](https://developers.google.com/machine-learning/crash-course/glossary#inference). For this example, the sum of the output predictions is 1.0. In Figure 2, this prediction breaks down as: `0.02` for *Adelie*, `0.95` for *Chinstrap*, and `0.03` for *Gentoo* species. This means that the model predicts—with 95% probability—that an unlabeled example penguin is a *Chinstrap* penguin."
]
},
{
@@ -481,7 +384,7 @@
"\n",
"The TensorFlow `tf.keras` API is the preferred way to create models and layers. This makes it easy to build models and experiment while Keras handles the complexity of connecting everything together.\n",
"\n",
- "The `tf.keras.Sequential` model is a linear stack of layers. Its constructor takes a list of layer instances, in this case, two `tf.keras.layers.Dense` layers with 10 nodes each, and an output layer with 3 nodes representing our label predictions. The first layer's `input_shape` parameter corresponds to the number of features from the dataset, and is required:"
+ "The `tf.keras.Sequential` model is a linear stack of layers. Its constructor takes a list of layer instances, in this case, two `tf.keras.layers.Dense` layers with 10 nodes each, and an output layer with 3 nodes representing your label predictions. The first layer's `input_shape` parameter corresponds to the number of features from the dataset, and is required:"
]
},
{
@@ -505,7 +408,7 @@
"id": "FHcbEzMpxbHL"
},
"source": [
- "The *[activation function](https://developers.google.com/machine-learning/crash-course/glossary#activation_function)* determines the output shape of each node in the layer. These non-linearities are important—without them the model would be equivalent to a single layer. There are many `tf.keras.activations`, but [ReLU](https://developers.google.com/machine-learning/crash-course/glossary#ReLU) is common for hidden layers.\n",
+ "The [*activation function*](https://developers.google.com/machine-learning/crash-course/glossary#activation_function) determines the output shape of each node in the layer. These non-linearities are important—without them the model would be equivalent to a single layer. There are many `tf.keras.activations`, but [ReLU](https://developers.google.com/machine-learning/crash-course/glossary#ReLU) is common for hidden layers.\n",
"\n",
"The ideal number of hidden layers and neurons depends on the problem and the dataset. Like many aspects of machine learning, picking the best shape of the neural network requires a mixture of knowledge and experimentation. As a rule of thumb, increasing the number of hidden layers and neurons typically creates a more powerful model, which requires more data to train effectively."
]
@@ -516,7 +419,7 @@
"id": "2wFKnhWCpDSS"
},
"source": [
- "### Using the model\n",
+ "### Use the model\n",
"\n",
"Let's have a quick look at what this model does to a batch of features:"
]
@@ -561,7 +464,7 @@
"id": "uRZmchElo481"
},
"source": [
- "Taking the `tf.argmax` across classes gives us the predicted class index. But, the model hasn't been trained yet, so these aren't good predictions:"
+ "Taking the `tf.math.argmax` across classes gives us the predicted class index. But, the model hasn't been trained yet, so these aren't good predictions:"
]
},
{
@@ -572,7 +475,7 @@
},
"outputs": [],
"source": [
- "print(\"Prediction: {}\".format(tf.argmax(predictions, axis=1)))\n",
+ "print(\"Prediction: {}\".format(tf.math.argmax(predictions, axis=1)))\n",
"print(\" Labels: {}\".format(labels))"
]
},
@@ -584,9 +487,9 @@
"source": [
"## Train the model\n",
"\n",
- "*[Training](https://developers.google.com/machine-learning/crash-course/glossary#training)* is the stage of machine learning when the model is gradually optimized, or the model *learns* the dataset. The goal is to learn enough about the structure of the training dataset to make predictions about unseen data. If you learn *too much* about the training dataset, then the predictions only work for the data it has seen and will not be generalizable. This problem is called *[overfitting](https://developers.google.com/machine-learning/crash-course/glossary#overfitting)*—it's like memorizing the answers instead of understanding how to solve a problem.\n",
+ "[*Training*](https://developers.google.com/machine-learning/crash-course/glossary#training) is the stage of machine learning when the model is gradually optimized, or the model *learns* the dataset. The goal is to learn enough about the structure of the training dataset to make predictions about unseen data. If you learn *too much* about the training dataset, then the predictions only work for the data it has seen and will not be generalizable. This problem is called [*overfitting*](https://developers.google.com/machine-learning/crash-course/glossary#overfitting)—it's like memorizing the answers instead of understanding how to solve a problem.\n",
"\n",
- "The Iris classification problem is an example of *[supervised machine learning](https://developers.google.com/machine-learning/glossary/#supervised_machine_learning)*: the model is trained from examples that contain labels. In *[unsupervised machine learning](https://developers.google.com/machine-learning/glossary/#unsupervised_machine_learning)*, the examples don't contain labels. Instead, the model typically finds patterns among the features."
+ "The penguin classification problem is an example of [*supervised machine learning*](https://developers.google.com/machine-learning/glossary/#supervised_machine_learning): the model is trained from examples that contain labels. In [*unsupervised machine learning*](https://developers.google.com/machine-learning/glossary/#unsupervised_machine_learning), the examples don't contain labels. Instead, the model typically finds patterns among the features."
]
},
{
@@ -595,11 +498,11 @@
"id": "RaKp8aEjKX6B"
},
"source": [
- "### Define the loss and gradient function\n",
+ "### Define the loss and gradients function\n",
"\n",
- "Both training and evaluation stages need to calculate the model's *[loss](https://developers.google.com/machine-learning/crash-course/glossary#loss)*. This measures how off a model's predictions are from the desired label, in other words, how bad the model is performing. We want to minimize, or optimize, this value.\n",
+ "Both training and evaluation stages need to calculate the model's [*loss*](https://developers.google.com/machine-learning/crash-course/glossary#loss). This measures how off a model's predictions are from the desired label, in other words, how bad the model is performing. You want to minimize, or optimize, this value.\n",
"\n",
- "Our model will calculate its loss using the `tf.keras.losses.SparseCategoricalCrossentropy` function which takes the model's class probability predictions and the desired label, and returns the average loss across the examples."
+ "Your model will calculate its loss using the `tf.keras.losses.SparseCategoricalCrossentropy` function which takes the model's class probability predictions and the desired label, and returns the average loss across the examples."
]
},
{
@@ -628,7 +531,6 @@
"\n",
" return loss_object(y_true=y, y_pred=y_)\n",
"\n",
- "\n",
"l = loss(model, features, labels, training=False)\n",
"print(\"Loss test: {}\".format(l))"
]
@@ -639,7 +541,7 @@
"id": "3IcPqA24QM6B"
},
"source": [
- "Use the `tf.GradientTape` context to calculate the *[gradients](https://developers.google.com/machine-learning/crash-course/glossary#gradient)* used to optimize your model:"
+ "Use the `tf.GradientTape` context to calculate the [*gradients*](https://developers.google.com/machine-learning/crash-course/glossary#gradient) used to optimize your model:"
]
},
{
@@ -664,7 +566,7 @@
"source": [
"### Create an optimizer\n",
"\n",
- "An *[optimizer](https://developers.google.com/machine-learning/crash-course/glossary#optimizer)* applies the computed gradients to the model's variables to minimize the `loss` function. You can think of the loss function as a curved surface (see Figure 3) and we want to find its lowest point by walking around. The gradients point in the direction of steepest ascent—so we'll travel the opposite way and move down the hill. By iteratively calculating the loss and gradient for each batch, we'll adjust the model during training. Gradually, the model will find the best combination of weights and bias to minimize loss. And the lower the loss, the better the model's predictions.\n",
+ "An [*optimizer*](https://developers.google.com/machine-learning/crash-course/glossary#optimizer) applies the computed gradients to the model's parameters to minimize the `loss` function. You can think of the loss function as a curved surface (refer to Figure 3) and you want to find its lowest point by walking around. The gradients point in the direction of steepest ascent—so you'll travel the opposite way and move down the hill. By iteratively calculating the loss and gradient for each batch, you'll adjust the model during training. Gradually, the model will find the best combination of weights and bias to minimize the loss. And the lower the loss, the better the model's predictions.\n",
"\n",
"\n",
" | \n",
@@ -676,7 +578,7 @@
" |
\n",
"
\n",
"\n",
- "TensorFlow has many optimization algorithms available for training. This model uses the `tf.keras.optimizers.SGD` that implements the *[stochastic gradient descent](https://developers.google.com/machine-learning/crash-course/glossary#gradient_descent)* (SGD) algorithm. The `learning_rate` sets the step size to take for each iteration down the hill. This is a *hyperparameter* that you'll commonly adjust to achieve better results."
+ "TensorFlow has many optimization algorithms available for training. In this tutorial, you will use the `tf.keras.optimizers.SGD` that implements the [*stochastic gradient descent*](https://developers.google.com/machine-learning/crash-course/glossary#gradient_descent) (SGD) algorithm. The `learning_rate` parameter sets the step size to take for each iteration down the hill. This rate is a [*hyperparameter*](https://developers.google.com/machine-learning/glossary/#hyperparameter) that you'll commonly adjust to achieve better results."
]
},
{
@@ -685,7 +587,7 @@
"id": "XkUd6UiZa_dF"
},
"source": [
- "Let's setup the optimizer:"
+ "Instantiate the optimizer with a [*learning rate*](https://developers.google.com/machine-learning/glossary#learning-rate) of `0.01`, a scalar value that is multiplied by the gradient at each iteration of the training:"
]
},
{
@@ -705,7 +607,7 @@
"id": "pJVRZ0hP52ZB"
},
"source": [
- "We'll use this to calculate a single optimization step:"
+ "Then use this object to calculate a single optimization step:"
]
},
{
@@ -740,11 +642,11 @@
"1. Iterate each *epoch*. An epoch is one pass through the dataset.\n",
"2. Within an epoch, iterate over each example in the training `Dataset` grabbing its *features* (`x`) and *label* (`y`).\n",
"3. Using the example's features, make a prediction and compare it with the label. Measure the inaccuracy of the prediction and use that to calculate the model's loss and gradients.\n",
- "4. Use an `optimizer` to update the model's variables.\n",
+ "4. Use an `optimizer` to update the model's parameters.\n",
"5. Keep track of some stats for visualization.\n",
"6. Repeat for each epoch.\n",
"\n",
- "The `num_epochs` variable is the number of times to loop over the dataset collection. Counter-intuitively, training a model longer does not guarantee a better model. `num_epochs` is a *[hyperparameter](https://developers.google.com/machine-learning/glossary/#hyperparameter)* that you can tune. Choosing the right number usually requires both experience and experimentation:"
+ "The `num_epochs` variable is the number of times to loop over the dataset collection. In the code below, `num_epochs` is set to 201 which means this training loop will run 201 times. Counter-intuitively, training a model longer does not guarantee a better model. `num_epochs` is a [*hyperparameter*](https://developers.google.com/machine-learning/glossary/#hyperparameter) that you can tune. Choosing the right number usually requires both experience and experimentation:"
]
},
{
@@ -755,7 +657,7 @@
},
"outputs": [],
"source": [
- "## Note: Rerunning this cell uses the same model variables\n",
+ "## Note: Rerunning this cell uses the same model parameters\n",
"\n",
"# Keep results for plotting\n",
"train_loss_results = []\n",
@@ -768,7 +670,7 @@
" epoch_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()\n",
"\n",
" # Training loop - using batches of 32\n",
- " for x, y in train_dataset:\n",
+ " for x, y in ds_train_batch:\n",
" # Optimize the model\n",
" loss_value, grads = grad(model, x, y)\n",
" optimizer.apply_gradients(zip(grads, model.trainable_variables))\n",
@@ -790,6 +692,15 @@
" epoch_accuracy.result()))"
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Diep-ROEuKyl"
+ },
+ "source": [
+ "Alternatively, you could use the built-in Keras [`Model.fit(ds_train_batch)`](https://www.tensorflow.org/api_docs/python/tf/keras/Model#fit) method to train your model. "
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {
@@ -805,9 +716,9 @@
"id": "j3wdbmtLVTyr"
},
"source": [
- "While it's helpful to print out the model's training progress, it's often *more* helpful to see this progress. [TensorBoard](https://www.tensorflow.org/tensorboard) is a nice visualization tool that is packaged with TensorFlow, but we can create basic charts using the `matplotlib` module.\n",
+ "While it's helpful to print out the model's training progress, you can visualize the progress with [TensorBoard](https://www.tensorflow.org/tensorboard) - a visualization and metrics tool that is packaged with TensorFlow. For this simple example, you will create basic charts using the `matplotlib` module.\n",
"\n",
- "Interpreting these charts takes some experience, but you really want to see the *loss* go down and the *accuracy* go up:"
+ "Interpreting these charts takes some experience, but in general you want to see the *loss* decrease and the *accuracy* increase:"
]
},
{
@@ -838,9 +749,9 @@
"source": [
"## Evaluate the model's effectiveness\n",
"\n",
- "Now that the model is trained, we can get some statistics on its performance.\n",
+ "Now that the model is trained, you can get some statistics on its performance.\n",
"\n",
- "*Evaluating* means determining how effectively the model makes predictions. To determine the model's effectiveness at Iris classification, pass some sepal and petal measurements to the model and ask the model to predict what Iris species they represent. Then compare the model's predictions against the actual label. For example, a model that picked the correct species on half the input examples has an *[accuracy](https://developers.google.com/machine-learning/glossary/#accuracy)* of `0.5`. Figure 4 shows a slightly more effective model, getting 4 out of 5 predictions correct at 80% accuracy:\n",
+ "*Evaluating* means determining how effectively the model makes predictions. To determine the model's effectiveness at penguin classification, pass some measurements to the model and ask the model to predict what penguin species they represent. Then compare the model's predictions against the actual label. For example, a model that picked the correct species on half the input examples has an [*accuracy*](https://developers.google.com/machine-learning/glossary/#accuracy) of `0.5`. Figure 4 shows a slightly more effective model, getting 4 out of 5 predictions correct at 80% accuracy:\n",
"\n",
"\n",
" \n",
@@ -869,7 +780,7 @@
" | 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 | \n",
" \n",
" \n",
- " Figure 4. An Iris classifier that is 80% accurate.
\n",
+ " Figure 4. A penguin classifier that is 80% accurate.
\n",
" |
\n",
"
"
]
@@ -880,44 +791,11 @@
"id": "z-EvK7hGL0d8"
},
"source": [
- "### Setup the test dataset\n",
+ "### Set up the test set\n",
"\n",
"Evaluating the model is similar to training the model. The biggest difference is the examples come from a separate *[test set](https://developers.google.com/machine-learning/crash-course/glossary#test_set)* rather than the training set. To fairly assess a model's effectiveness, the examples used to evaluate a model must be different from the examples used to train the model.\n",
"\n",
- "The setup for the test `Dataset` is similar to the setup for training `Dataset`. Download the CSV text file and parse that values, then give it a little shuffle:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Ps3_9dJ3Lodk"
- },
- "outputs": [],
- "source": [
- "test_url = \"https://storage.googleapis.com/download.tensorflow.org/data/iris_test.csv\"\n",
- "\n",
- "test_fp = tf.keras.utils.get_file(fname=os.path.basename(test_url),\n",
- " origin=test_url)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "SRMWCu30bnxH"
- },
- "outputs": [],
- "source": [
- "test_dataset = tf.data.experimental.make_csv_dataset(\n",
- " test_fp,\n",
- " batch_size,\n",
- " column_names=column_names,\n",
- " label_name='species',\n",
- " num_epochs=1,\n",
- " shuffle=False)\n",
- "\n",
- "test_dataset = test_dataset.map(pack_features_vector)"
+ "The penguin dataset doesn't have a separate test dataset so in the previous Download the dataset section, you split the original dataset into test and train datasets. Use the `ds_test_batch` dataset for the evaluation."
]
},
{
@@ -928,7 +806,7 @@
"source": [
"### Evaluate the model on the test dataset\n",
"\n",
- "Unlike the training stage, the model only evaluates a single [epoch](https://developers.google.com/machine-learning/glossary/#epoch) of the test data. In the following code cell, we iterate over each example in the test set and compare the model's prediction against the actual label. This is used to measure the model's accuracy across the entire test set:"
+ "Unlike the training stage, the model only evaluates a single [epoch](https://developers.google.com/machine-learning/glossary/#epoch) of the test data. The following code iterates over each example in the test set and compare the model's prediction against the actual label. This comparison is used to measure the model's accuracy across the entire test set:"
]
},
{
@@ -940,24 +818,34 @@
"outputs": [],
"source": [
"test_accuracy = tf.keras.metrics.Accuracy()\n",
+ "ds_test_batch = ds_test.batch(10)\n",
"\n",
- "for (x, y) in test_dataset:\n",
+ "for (x, y) in ds_test_batch:\n",
" # training=False is needed only if there are layers with different\n",
" # behavior during training versus inference (e.g. Dropout).\n",
" logits = model(x, training=False)\n",
- " prediction = tf.argmax(logits, axis=1, output_type=tf.int32)\n",
+ " prediction = tf.math.argmax(logits, axis=1, output_type=tf.int64)\n",
" test_accuracy(prediction, y)\n",
"\n",
"print(\"Test set accuracy: {:.3%}\".format(test_accuracy.result()))"
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Fel8ql2qzGlK"
+ },
+ "source": [
+ "You can also use the `model.evaluate(ds_test, return_dict=True)` keras function to get accuracy information on your test dataset. "
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {
"id": "HcKEZMtCOeK-"
},
"source": [
- "We can see on the last batch, for example, the model is usually correct:"
+ "By inspecting the last batch, for example, you can observe that the model predictions are usually correct.\n"
]
},
{
@@ -979,13 +867,13 @@
"source": [
"## Use the trained model to make predictions\n",
"\n",
- "We've trained a model and \"proven\" that it's good—but not perfect—at classifying Iris species. Now let's use the trained model to make some predictions on [unlabeled examples](https://developers.google.com/machine-learning/glossary/#unlabeled_example); that is, on examples that contain features but not a label.\n",
+ "You've trained a model and \"proven\" that it's good—but not perfect—at classifying penguin species. Now let's use the trained model to make some predictions on [*unlabeled examples*](https://developers.google.com/machine-learning/glossary/#unlabeled_example); that is, on examples that contain features but not labels.\n",
"\n",
- "In real-life, the unlabeled examples could come from lots of different sources including apps, CSV files, and data feeds. For now, we're going to manually provide three unlabeled examples to predict their labels. Recall, the label numbers are mapped to a named representation as:\n",
+ "In real-life, the unlabeled examples could come from lots of different sources including apps, CSV files, and data feeds. For this tutorial, manually provide three unlabeled examples to predict their labels. Recall, the label numbers are mapped to a named representation as:\n",
"\n",
- "* `0`: Iris setosa\n",
- "* `1`: Iris versicolor\n",
- "* `2`: Iris virginica"
+ "* `0`: Adélie penguin\n",
+ "* `1`: Chinstrap penguin\n",
+ "* `2`: Gentoo penguin"
]
},
{
@@ -997,9 +885,9 @@
"outputs": [],
"source": [
"predict_dataset = tf.convert_to_tensor([\n",
- " [5.1, 3.3, 1.7, 0.5,],\n",
- " [5.9, 3.0, 4.2, 1.5,],\n",
- " [6.9, 3.1, 5.4, 2.1]\n",
+ " [0.3, 0.8, 0.4, 0.5,],\n",
+ " [0.4, 0.1, 0.8, 0.5,],\n",
+ " [0.7, 0.9, 0.8, 0.4]\n",
"])\n",
"\n",
"# training=False is needed only if there are layers with different\n",
@@ -1007,7 +895,7 @@
"predictions = model(predict_dataset, training=False)\n",
"\n",
"for i, logits in enumerate(predictions):\n",
- " class_idx = tf.argmax(logits).numpy()\n",
+ " class_idx = tf.math.argmax(logits).numpy()\n",
" p = tf.nn.softmax(logits)[class_idx]\n",
" name = class_names[class_idx]\n",
" print(\"Example {} prediction: {} ({:4.1f}%)\".format(i, name, 100*p))"
diff --git a/site/en/tutorials/customization/images/full_network_penguin.png b/site/en/tutorials/customization/images/full_network_penguin.png
new file mode 100644
index 00000000000..3fb940bd8bf
Binary files /dev/null and b/site/en/tutorials/customization/images/full_network_penguin.png differ
diff --git a/site/en/tutorials/customization/images/penguins_ds_species.png b/site/en/tutorials/customization/images/penguins_ds_species.png
new file mode 100644
index 00000000000..736ae89b686
Binary files /dev/null and b/site/en/tutorials/customization/images/penguins_ds_species.png differ
diff --git a/site/en/tutorials/distribute/custom_training.ipynb b/site/en/tutorials/distribute/custom_training.ipynb
index da45c340b1a..d14b0ac003c 100644
--- a/site/en/tutorials/distribute/custom_training.ipynb
+++ b/site/en/tutorials/distribute/custom_training.ipynb
@@ -68,9 +68,9 @@
"id": "FbVhjPpzn6BM"
},
"source": [
- "This tutorial demonstrates how to use [`tf.distribute.Strategy`](https://www.tensorflow.org/guide/distributed_training) with custom training loops. We will train a simple CNN model on the fashion MNIST dataset. The fashion MNIST dataset contains 60000 train images of size 28 x 28 and 10000 test images of size 28 x 28.\n",
+ "This tutorial demonstrates how to use `tf.distribute.Strategy`—a TensorFlow API that provides an abstraction for [distributing your training](../../guide/distributed_training.ipynb) across multiple processing units (GPUs, multiple machines, or TPUs)—with custom training loops. In this example, you will train a simple convolutional neural network on the [Fashion MNIST dataset](https://github.com/zalandoresearch/fashion-mnist) containing 70,000 images of size 28 x 28.\n",
"\n",
- "We are using custom training loops to train our model because they give us flexibility and a greater control on training. Moreover, it is easier to debug the model and the training loop."
+ "[Custom training loops](../customization/custom_training_walkthrough.ipynb) provide flexibility and a greater control on training. They also make it easier to debug the model and the training loop."
]
},
{
@@ -97,7 +97,7 @@
"id": "MM6W__qraV55"
},
"source": [
- "## Download the fashion MNIST dataset"
+ "## Download the Fashion MNIST dataset"
]
},
{
@@ -112,14 +112,14 @@
"\n",
"(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()\n",
"\n",
- "# Adding a dimension to the array -> new shape == (28, 28, 1)\n",
- "# We are doing this because the first layer in our model is a convolutional\n",
+ "# Add a dimension to the array -> new shape == (28, 28, 1)\n",
+ "# This is done because the first layer in our model is a convolutional\n",
"# layer and it requires a 4D input (batch_size, height, width, channels).\n",
"# batch_size dimension will be added later on.\n",
"train_images = train_images[..., None]\n",
"test_images = test_images[..., None]\n",
"\n",
- "# Getting the images in [0, 1] range.\n",
+ "# Scale the images to the [0, 1] range.\n",
"train_images = train_images / np.float32(255)\n",
"test_images = test_images / np.float32(255)"
]
@@ -141,13 +141,13 @@
"source": [
"How does `tf.distribute.MirroredStrategy` strategy work?\n",
"\n",
- "* All the variables and the model graph is replicated on the replicas.\n",
+ "* All the variables and the model graph are replicated across the replicas.\n",
"* Input is evenly distributed across the replicas.\n",
"* Each replica calculates the loss and gradients for the input it received.\n",
- "* The gradients are synced across all the replicas by summing them.\n",
+ "* The gradients are synced across all the replicas by **summing** them.\n",
"* After the sync, the same update is made to the copies of the variables on each replica.\n",
"\n",
- "Note: You can put all the code below inside a single scope. We are dividing it into several code cells for illustration purposes.\n"
+ "Note: You can put all the code below inside a single scope. This example divides it into several code cells for illustration purposes.\n"
]
},
{
@@ -158,8 +158,8 @@
},
"outputs": [],
"source": [
- "# If the list of devices is not specified in the\n",
- "# `tf.distribute.MirroredStrategy` constructor, it will be auto-detected.\n",
+ "# If the list of devices is not specified in\n",
+ "# `tf.distribute.MirroredStrategy` constructor, they will be auto-detected.\n",
"strategy = tf.distribute.MirroredStrategy()"
]
},
@@ -171,7 +171,7 @@
},
"outputs": [],
"source": [
- "print ('Number of devices: {}'.format(strategy.num_replicas_in_sync))"
+ "print('Number of devices: {}'.format(strategy.num_replicas_in_sync))"
]
},
{
@@ -183,15 +183,6 @@
"## Setup input pipeline"
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "0Qb6nDgxiN_n"
- },
- "source": [
- "Export the graph and the variables to the platform-agnostic SavedModel format. After your model is saved, you can load it with or without the scope."
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -225,8 +216,8 @@
},
"outputs": [],
"source": [
- "train_dataset = tf.data.Dataset.from_tensor_slices((train_images, train_labels)).shuffle(BUFFER_SIZE).batch(GLOBAL_BATCH_SIZE) \n",
- "test_dataset = tf.data.Dataset.from_tensor_slices((test_images, test_labels)).batch(GLOBAL_BATCH_SIZE) \n",
+ "train_dataset = tf.data.Dataset.from_tensor_slices((train_images, train_labels)).shuffle(BUFFER_SIZE).batch(GLOBAL_BATCH_SIZE)\n",
+ "test_dataset = tf.data.Dataset.from_tensor_slices((test_images, test_labels)).batch(GLOBAL_BATCH_SIZE)\n",
"\n",
"train_dist_dataset = strategy.experimental_distribute_dataset(train_dataset)\n",
"test_dist_dataset = strategy.experimental_distribute_dataset(test_dataset)"
@@ -240,7 +231,7 @@
"source": [
"## Create the model\n",
"\n",
- "Create a model using `tf.keras.Sequential`. You can also use the Model Subclassing API to do this."
+ "Create a model using `tf.keras.Sequential`. You can also use the [Model Subclassing API](https://www.tensorflow.org/guide/keras/custom_layers_and_models) or the [functional API](https://www.tensorflow.org/guide/keras/functional) to do this."
]
},
{
@@ -252,14 +243,21 @@
"outputs": [],
"source": [
"def create_model():\n",
+ " regularizer = tf.keras.regularizers.L2(1e-5)\n",
" model = tf.keras.Sequential([\n",
- " tf.keras.layers.Conv2D(32, 3, activation='relu'),\n",
+ " tf.keras.layers.Conv2D(32, 3,\n",
+ " activation='relu',\n",
+ " kernel_regularizer=regularizer),\n",
" tf.keras.layers.MaxPooling2D(),\n",
- " tf.keras.layers.Conv2D(64, 3, activation='relu'),\n",
+ " tf.keras.layers.Conv2D(64, 3,\n",
+ " activation='relu',\n",
+ " kernel_regularizer=regularizer),\n",
" tf.keras.layers.MaxPooling2D(),\n",
" tf.keras.layers.Flatten(),\n",
- " tf.keras.layers.Dense(64, activation='relu'),\n",
- " tf.keras.layers.Dense(10)\n",
+ " tf.keras.layers.Dense(64,\n",
+ " activation='relu',\n",
+ " kernel_regularizer=regularizer),\n",
+ " tf.keras.layers.Dense(10, kernel_regularizer=regularizer)\n",
" ])\n",
"\n",
" return model"
@@ -286,25 +284,29 @@
"source": [
"## Define the loss function\n",
"\n",
- "Normally, on a single machine with 1 GPU/CPU, loss is divided by the number of examples in the batch of input.\n",
+ "Recall that the loss function consists of one or two parts:\n",
"\n",
- "*So, how should the loss be calculated when using a `tf.distribute.Strategy`?*\n",
+ " * The **prediction loss** measures how far off the model's predictions are from the training labels for a batch of training examples. It is computed for each labeled example and then reduced across the batch by computing the average value.\n",
+ " * Optionally, **regularization loss** terms can be added to the prediction loss, to steer the model away from overfitting the training data. A common choice is L2 regularization, which adds a small fixed multiple of the sum of squares of all model weights, independent of the number of examples. The model above uses L2 regularization to demonstrate its handling in the training loop below.\n",
"\n",
- "* For an example, let's say you have 4 GPU's and a batch size of 64. One batch of input is distributed\n",
- "across the replicas (4 GPUs), each replica getting an input of size 16.\n",
+ "For training on a single machine with a single GPU/CPU, this works as follows:\n",
"\n",
- "* The model on each replica does a forward pass with its respective input and calculates the loss. Now, instead of dividing the loss by the number of examples in its respective input (BATCH_SIZE_PER_REPLICA = 16), the loss should be divided by the GLOBAL_BATCH_SIZE (64)."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "OCIcsaeoIHJX"
- },
- "source": [
- "*Why do this?*\n",
+ " * The prediction loss is computed for each example in the batch, summed across the batch, and then divided by the batch size.\n",
+ " * The regularization loss is added to the prediction loss.\n",
+ " * The gradient of the total loss is computed w.r.t. each model weight, and the optimizer updates each model weight from the corresponding gradient.\n",
+ "\n",
+ "With `tf.distribute.Strategy`, the input batch is split between replicas.\n",
+ "For example, let's say you have 4 GPUs, each with one replica of the model. One batch of 256 input examples is distributed evenly across the 4 replicas, so each replica gets a batch of size 64: We have `256 = 4*64`, or generally `GLOBAL_BATCH_SIZE = num_replicas_in_sync * BATCH_SIZE_PER_REPLICA`.\n",
"\n",
- "* This needs to be done because after the gradients are calculated on each replica, they are synced across the replicas by **summing** them."
+ "Each replica computes the loss from the training examples it gets and computes the gradients of the loss w.r.t. each model weight. The optimizer takes care that these **gradients are summed up across replicas** before using them to update the copies of the model weights on each replica.\n",
+ "\n",
+ "*So, how should the loss be calculated when using a `tf.distribute.Strategy`?*\n",
+ "\n",
+ " * Each replica computes the prediction loss for all examples distributed to it, sums up the results and divides them by `num_replicas_in_sync * BATCH_SIZE_PER_REPLICA`, or equivently, `GLOBAL_BATCH_SIZE`.\n",
+ " * Each replica compues the regularization loss(es) and divides them by\n",
+ " `num_replicas_in_sync`.\n",
+ "\n",
+ "Compared to non-distributed training, all per-replica loss terms are scaled down by a factor of `1/num_replicas_in_sync`. On the other hand, all loss terms -- or rather, their gradients -- are summed across that number of replicas before the optimizer applies them. In effect, the optimizer on each replica uses the same gradients as if a non-distributed computation with `GLOBAL_BATCH_SIZE` had happened. This is consistent with the distributed and undistributed behavior of Keras `Model.fit`. See the [Distributed training with Keras](./keras.ipynb) tutorial on how a larger gloabl batch size enables to scale up the learning rate."
]
},
{
@@ -315,31 +317,18 @@
"source": [
"*How to do this in TensorFlow?*\n",
"\n",
- "* If you're writing a custom training loop, as in this tutorial, you should sum the per example losses and divide the sum by the GLOBAL_BATCH_SIZE: \n",
- "`scale_loss = tf.reduce_sum(loss) * (1. / GLOBAL_BATCH_SIZE)`\n",
- "or you can use `tf.nn.compute_average_loss` which takes the per example loss,\n",
- "optional sample weights, and GLOBAL_BATCH_SIZE as arguments and returns the scaled loss.\n",
- "\n",
- "* If you are using regularization losses in your model then you need to scale\n",
- "the loss value by number of replicas. You can do this by using the `tf.nn.scale_regularization_loss` function.\n",
+ " * Loss reduction and scaling is done automatically in Keras `Model.compile` and `Model.fit`\n",
"\n",
- "* Using `tf.reduce_mean` is not recommended. Doing so divides the loss by actual per replica batch size which may vary step to step.\n",
+ " * If you're writing a custom training loop, as in this tutorial, you should sum the per-example losses and divide the sum by the global batch size using `tf.nn.compute_average_loss`, which takes the per-example losses and\n",
+ "optional sample weights as arguments and returns the scaled loss.\n",
"\n",
- "* This reduction and scaling is done automatically in keras `model.compile` and `model.fit`\n",
+ " * If using `tf.keras.losses` classes (as in the example below), the loss reduction needs to be explicitly specified to be one of `NONE` or `SUM`. The default `AUTO` and `SUM_OVER_BATCH_SIZE` are disallowed outside `Model.fit`.\n",
+ " * `AUTO` is disallowed because the user should explicitly think about what reduction they want to make sure it is correct in the distributed case.\n",
+ " * `SUM_OVER_BATCH_SIZE` is disallowed because currently it would only divide by per replica batch size, and leave the dividing by number of replicas to the user, which might be easy to miss. So, instead, you need to do the reduction yourself explicitly.\n",
"\n",
- "* If using `tf.keras.losses` classes (as in the example below), the loss reduction needs to be explicitly specified to be one of `NONE` or `SUM`. `AUTO` and `SUM_OVER_BATCH_SIZE` are disallowed when used with `tf.distribute.Strategy`. `AUTO` is disallowed because the user should explicitly think about what reduction they want to make sure it is correct in the distributed case. `SUM_OVER_BATCH_SIZE` is disallowed because currently it would only divide by per replica batch size, and leave the dividing by number of replicas to the user, which might be easy to miss. So instead we ask the user do the reduction themselves explicitly.\n",
- "* If `labels` is multi-dimensional, then average the `per_example_loss` across the number of elements in each sample. For example, if the shape of `predictions` is `(batch_size, H, W, n_classes)` and `labels` is `(batch_size, H, W)`, you will need to update `per_example_loss` like: `per_example_loss /= tf.cast(tf.reduce_prod(tf.shape(labels)[1:]), tf.float32)`\n",
+ " * If you're writing a custom training loop for a model with a non-empty list of `Model.losses` (e.g., weight regularizers), you should sum them up and divide the sum by the number of replicas. You can do this by using the `tf.nn.scale_regularization_loss` function. The model code itself remains unaware of the number of replicas.\n",
"\n",
- " Caution: **Verify the shape of your loss**. \n",
- " Loss functions in `tf.losses`/`tf.keras.losses` typically\n",
- " return the average over the last dimension of the input. The loss\n",
- " classes wrap these functions. Passing `reduction=Reduction.NONE` when\n",
- " creating an instance of a loss class means \"no **additional** reduction\".\n",
- " For categorical losses with an example input shape of `[batch, W, H, n_classes]` the `n_classes`\n",
- " dimension is reduced. For pointwise losses like\n",
- " `losses.mean_squared_error` or `losses.binary_crossentropy` include a\n",
- " dummy axis so that `[batch, W, H, 1]` is reduced to `[batch, W, H]`. Without\n",
- " the dummy axis `[batch, W, H]` will be incorrectly reduced to `[batch, W]`.\n"
+ " However, models can define input-dependent regularization losses with Keras APIs such as `Layer.add_loss(...)` and `Layer(activity_regularizer=...)`. For `Layer.add_loss(...)`, it falls on the modeling code to perform the division of the summed per-example terms by the per-replica(!) batch size, e.g., by using `tf.math.reduce_mean()`."
]
},
{
@@ -351,14 +340,51 @@
"outputs": [],
"source": [
"with strategy.scope():\n",
- " # Set reduction to `none` so we can do the reduction afterwards and divide by\n",
- " # global batch size.\n",
+ " # Set reduction to `NONE` so you can do the reduction yourself.\n",
" loss_object = tf.keras.losses.SparseCategoricalCrossentropy(\n",
" from_logits=True,\n",
" reduction=tf.keras.losses.Reduction.NONE)\n",
- " def compute_loss(labels, predictions):\n",
+ " def compute_loss(labels, predictions, model_losses):\n",
" per_example_loss = loss_object(labels, predictions)\n",
- " return tf.nn.compute_average_loss(per_example_loss, global_batch_size=GLOBAL_BATCH_SIZE)"
+ " loss = tf.nn.compute_average_loss(per_example_loss)\n",
+ " if model_losses:\n",
+ " loss += tf.nn.scale_regularization_loss(tf.add_n(model_losses))\n",
+ " return loss"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "6pM96bqQY52D"
+ },
+ "source": [
+ "### Special cases\n",
+ "\n",
+ "Advanced users should also consider the following special cases.\n",
+ "\n",
+ " * Input batches shorter than `GLOBAL_BATCH_SIZE` create unpleasant corner cases in several places. In practice, it often works best to avoid them by allowing batches to span epoch boundaries using `Dataset.repeat().batch()` and defining approximate epochs by step counts, not dataset ends. Alternatively, `Dataset.batch(drop_remainder=True)` maintains the notion of epoch but drops the last few examples.\n",
+ "\n",
+ " For illustration, this example goes the harder route and allows short batches, so that each training epoch contains each training example exactly once.\n",
+ " \n",
+ " Which denominator should be used by `tf.nn.compute_average_loss()`?\n",
+ "\n",
+ " * By default, in the example code above and equivalently in `Keras.fit()`, the sum of prediction losses is divided by `num_replicas_in_sync` times the actual batch size seen on the replica (with empty batches silently ignored). This preserves the balance between the prediction loss on the one hand and the regularization losses on the other hand. It is particularly appropriate for models that use input-dependent regularization losses. Plain L2 regularization just superimposes weight decay onto the gradients of the prediction loss and is less in need of such a balance.\n",
+ " * In practice, many custom training loops pass as a constant Python value into `tf.nn.compute_average_loss(..., global_batch_size=GLOBAL_BATCH_SIZE)` to use it as the denominator. This preserves the relative weighting of training examples between batches. Without it, the smaller denominator in short batches effectively upweights the examples in those. (Before TensorFlow 2.13, this was also needed to avoid NaNs in case some replica received an actual batch size of zero.)\n",
+ " \n",
+ " Both options are equivalent if short batches are avoided, as suggested above.\n",
+ "\n",
+ " * Multi-dimensional `labels` require you to average the `per_example_loss` across the number of predictions in each example. Consider a classification task for all pixels of an input image, with `predictions` of shape `(batch_size, H, W, n_classes)` and `labels` of shape `(batch_size, H, W)`. You will need to update `per_example_loss` like: `per_example_loss /= tf.cast(tf.reduce_prod(tf.shape(labels)[1:]), tf.float32)`\n",
+ "\n",
+ " Caution: **Verify the shape of your loss**.\n",
+ " Loss functions in `tf.losses`/`tf.keras.losses` typically\n",
+ " return the average over the last dimension of the input. The loss\n",
+ " classes wrap these functions. Passing `reduction=Reduction.NONE` when\n",
+ " creating an instance of a loss class means \"no **additional** reduction\".\n",
+ " For categorical losses with an example input shape of `[batch, W, H, n_classes]` the `n_classes`\n",
+ " dimension is reduced. For pointwise losses like\n",
+ " `losses.mean_squared_error` or `losses.binary_crossentropy` include a\n",
+ " dummy axis so that `[batch, W, H, 1]` is reduced to `[batch, W, H]`. Without\n",
+ " the dummy axis `[batch, W, H]` will be incorrectly reduced to `[batch, W]`."
]
},
{
@@ -406,11 +432,11 @@
},
"outputs": [],
"source": [
- "# model, optimizer, and checkpoint must be created under `strategy.scope`.\n",
+ "# A model, an optimizer, and a checkpoint must be created under `strategy.scope`.\n",
"with strategy.scope():\n",
" model = create_model()\n",
"\n",
- " optimizer = tf.keras.optimizers.Adam()\n",
+ " optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)\n",
"\n",
" checkpoint = tf.train.Checkpoint(optimizer=optimizer, model=model)"
]
@@ -428,13 +454,13 @@
"\n",
" with tf.GradientTape() as tape:\n",
" predictions = model(images, training=True)\n",
- " loss = compute_loss(labels, predictions)\n",
+ " loss = compute_loss(labels, predictions, model.losses)\n",
"\n",
" gradients = tape.gradient(loss, model.trainable_variables)\n",
" optimizer.apply_gradients(zip(gradients, model.trainable_variables))\n",
"\n",
" train_accuracy.update_state(labels, predictions)\n",
- " return loss \n",
+ " return loss\n",
"\n",
"def test_step(inputs):\n",
" images, labels = inputs\n",
@@ -484,9 +510,9 @@
"\n",
" template = (\"Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, \"\n",
" \"Test Accuracy: {}\")\n",
- " print (template.format(epoch+1, train_loss,\n",
- " train_accuracy.result()*100, test_loss.result(),\n",
- " test_accuracy.result()*100))\n",
+ " print(template.format(epoch + 1, train_loss,\n",
+ " train_accuracy.result() * 100, test_loss.result(),\n",
+ " test_accuracy.result() * 100))\n",
"\n",
" test_loss.reset_states()\n",
" train_accuracy.reset_states()\n",
@@ -499,12 +525,12 @@
"id": "Z1YvXqOpwy08"
},
"source": [
- "Things to note in the example above:\n",
+ "### Things to note in the example above\n",
"\n",
- "* We are iterating over the `train_dist_dataset` and `test_dist_dataset` using a `for x in ...` construct.\n",
+ "* Iterate over the `train_dist_dataset` and `test_dist_dataset` using a `for x in ...` construct.\n",
"* The scaled loss is the return value of the `distributed_train_step`. This value is aggregated across replicas using the `tf.distribute.Strategy.reduce` call and then across batches by summing the return value of the `tf.distribute.Strategy.reduce` calls.\n",
"* `tf.keras.Metrics` should be updated inside `train_step` and `test_step` that gets executed by `tf.distribute.Strategy.run`.\n",
- "*`tf.distribute.Strategy.run` returns results from each local replica in the strategy, and there are multiple ways to consume this result. You can do `tf.distribute.Strategy.reduce` to get an aggregated value. You can also do `tf.distribute.Strategy.experimental_local_results` to get the list of values contained in the result, one per local replica.\n"
+ "* `tf.distribute.Strategy.run` returns results from each local replica in the strategy, and there are multiple ways to consume this result. You can do `tf.distribute.Strategy.reduce` to get an aggregated value. You can also do `tf.distribute.Strategy.experimental_local_results` to get the list of values contained in the result, one per local replica.\n"
]
},
{
@@ -570,8 +596,8 @@
"for images, labels in test_dataset:\n",
" eval_step(images, labels)\n",
"\n",
- "print ('Accuracy after restoring the saved model without strategy: {}'.format(\n",
- " eval_accuracy.result()*100))"
+ "print('Accuracy after restoring the saved model without strategy: {}'.format(\n",
+ " eval_accuracy.result() * 100))"
]
},
{
@@ -584,7 +610,7 @@
"\n",
"### Using iterators\n",
"\n",
- "If you want to iterate over a given number of steps and not through the entire dataset you can create an iterator using the `iter` call and explicity call `next` on the iterator. You can choose to iterate over the dataset both inside and outside the tf.function. Here is a small snippet demonstrating iteration of the dataset outside the tf.function using an iterator.\n"
+ "If you want to iterate over a given number of steps and not through the entire dataset, you can create an iterator using the `iter` call and explicitly call `next` on the iterator. You can choose to iterate over the dataset both inside and outside the `tf.function`. Here is a small snippet demonstrating iteration of the dataset outside the `tf.function` using an iterator.\n"
]
},
{
@@ -606,7 +632,7 @@
" average_train_loss = total_loss / num_batches\n",
"\n",
" template = (\"Epoch {}, Loss: {}, Accuracy: {}\")\n",
- " print (template.format(epoch+1, average_train_loss, train_accuracy.result()*100))\n",
+ " print(template.format(epoch + 1, average_train_loss, train_accuracy.result() * 100))\n",
" train_accuracy.reset_states()"
]
},
@@ -616,8 +642,9 @@
"id": "GxVp48Oy0m6y"
},
"source": [
- "### Iterating inside a tf.function\n",
- "You can also iterate over the entire input `train_dist_dataset` inside a tf.function using the `for x in ...` construct or by creating iterators like we did above. The example below demonstrates wrapping one epoch of training in a tf.function and iterating over `train_dist_dataset` inside the function."
+ "### Iterating inside a `tf.function`\n",
+ "\n",
+ "You can also iterate over the entire input `train_dist_dataset` inside a `tf.function` using the `for x in ...` construct or by creating iterators like you did above. The example below demonstrates wrapping one epoch of training with a `@tf.function` decorator and iterating over `train_dist_dataset` inside the function."
]
},
{
@@ -643,7 +670,7 @@
" train_loss = distributed_train_epoch(train_dist_dataset)\n",
"\n",
" template = (\"Epoch {}, Loss: {}, Accuracy: {}\")\n",
- " print (template.format(epoch+1, train_loss, train_accuracy.result()*100))\n",
+ " print(template.format(epoch + 1, train_loss, train_accuracy.result() * 100))\n",
"\n",
" train_accuracy.reset_states()"
]
@@ -658,17 +685,18 @@
"\n",
"Note: As a general rule, you should use `tf.keras.Metrics` to track per-sample values and avoid values that have been aggregated within a replica.\n",
"\n",
- "We do *not* recommend using `tf.metrics.Mean` to track the training loss across different replicas, because of the loss scaling computation that is carried out.\n",
+ "Because of the loss scaling computation that is carried out, it's not recommended to use `tf.keras.metrics.Mean` to track the training loss across different replicas.\n",
"\n",
"For example, if you run a training job with the following characteristics:\n",
+ "\n",
"* Two replicas\n",
"* Two samples are processed on each replica\n",
"* Resulting loss values: [2, 3] and [4, 5] on each replica\n",
"* Global batch size = 4\n",
"\n",
- "With loss scaling, you calculate the per-sample value of loss on each replica by adding the loss values, and then dividing by the global batch size. In this case: `(2 + 3) / 4 = 1.25` and `(4 + 5) / 4 = 2.25`. \n",
+ "With loss scaling, you calculate the per-sample value of loss on each replica by adding the loss values, and then dividing by the global batch size. In this case: `(2 + 3) / 4 = 1.25` and `(4 + 5) / 4 = 2.25`.\n",
"\n",
- "If you use `tf.metrics.Mean` to track loss across the two replicas, the result is different. In this example, you end up with a `total` of 3.50 and `count` of 2, which results in `total`/`count` = 1.75 when `result()` is called on the metric. Loss calculated with `tf.keras.Metrics` is scaled by an additional factor that is equal to the number of replicas in sync."
+ "If you use `tf.keras.metrics.Mean` to track loss across the two replicas, the result is different. In this example, you end up with a `total` of 3.50 and `count` of 2, which results in `total`/`count` = 1.75 when `result()` is called on the metric. Loss calculated with `tf.keras.Metrics` is scaled by an additional factor that is equal to the number of replicas in sync."
]
},
{
@@ -678,16 +706,17 @@
},
"source": [
"### Guide and examples\n",
+ "\n",
"Here are some examples for using distribution strategy with custom training loops:\n",
"\n",
"1. [Distributed training guide](../../guide/distributed_training)\n",
"2. [DenseNet](https://github.com/tensorflow/examples/blob/master/tensorflow_examples/models/densenet/distributed_train.py) example using `MirroredStrategy`.\n",
- "1. [BERT](https://github.com/tensorflow/models/blob/master/official/nlp/bert/run_classifier.py) example trained using `MirroredStrategy` and `TPUStrategy`.\n",
+ "1. [BERT](https://github.com/tensorflow/models/blob/master/official/legacy/bert/run_classifier.py) example trained using `MirroredStrategy` and `TPUStrategy`.\n",
"This example is particularly helpful for understanding how to load from a checkpoint and generate periodic checkpoints during distributed training etc.\n",
"2. [NCF](https://github.com/tensorflow/models/blob/master/official/recommendation/ncf_keras_main.py) example trained using `MirroredStrategy` that can be enabled using the `keras_use_ctl` flag.\n",
"3. [NMT](https://github.com/tensorflow/examples/blob/master/tensorflow_examples/models/nmt_with_attention/distributed_train.py) example trained using `MirroredStrategy`.\n",
"\n",
- "More examples listed in the [Distribution strategy guide](../../guide/distributed_training.ipynb#examples_and_tutorials)."
+ "You can find more examples listed under _Examples and tutorials_ in the [Distribution strategy guide](../../guide/distributed_training.ipynb)."
]
},
{
@@ -699,7 +728,8 @@
"## Next steps\n",
"\n",
"* Try out the new `tf.distribute.Strategy` API on your models.\n",
- "* Visit the [Performance section](../../guide/function.ipynb) in the guide to learn more about other strategies and [tools](../../guide/profiler.md) you can use to optimize the performance of your TensorFlow models."
+ "* Visit the [Better performance with `tf.function`](../../guide/function.ipynb) and [TensorFlow Profiler](../../guide/profiler.md) guides to learn more about tools to optimize the performance of your TensorFlow models.\n",
+ "* Check out the [Distributed training in TensorFlow](../../guide/distributed_training.ipynb) guide, which provides an overview of the available distribution strategies."
]
}
],
@@ -707,7 +737,6 @@
"colab": {
"collapsed_sections": [],
"name": "custom_training.ipynb",
- "provenance": [],
"toc_visible": true
},
"kernelspec": {
diff --git a/site/en/tutorials/distribute/dtensor_keras_tutorial.ipynb b/site/en/tutorials/distribute/dtensor_keras_tutorial.ipynb
new file mode 100644
index 00000000000..84f6478c2b5
--- /dev/null
+++ b/site/en/tutorials/distribute/dtensor_keras_tutorial.ipynb
@@ -0,0 +1,760 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Tce3stUlHN0L"
+ },
+ "source": [
+ "##### Copyright 2019 The TensorFlow Authors.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "tuOe1ymfHZPu"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n",
+ "# you may not use this file except in compliance with the License.\n",
+ "# You may obtain a copy of the License at\n",
+ "#\n",
+ "# https://www.apache.org/licenses/LICENSE-2.0\n",
+ "#\n",
+ "# Unless required by applicable law or agreed to in writing, software\n",
+ "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
+ "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
+ "# See the License for the specific language governing permissions and\n",
+ "# limitations under the License."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "MT-LkFOl2axM"
+ },
+ "source": [
+ "# Using DTensors with Keras"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "r6P32iYYV27b"
+ },
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "vTe9dcbUAwqx"
+ },
+ "source": [
+ "## Overview\n",
+ "\n",
+ "In this tutorial, you will learn how to use DTensors with Keras.\n",
+ "\n",
+ "Through DTensor integration with Keras, you can reuse your existing Keras layers and models to build and train distributed machine learning models.\n",
+ "\n",
+ "You will train a multi-layer classification model with the MNIST data. Setting the layout for subclassing model, Sequential model, and functional model will be demonstrated.\n",
+ "\n",
+ "This tutorial assumes that you have already read the [DTensor programing guide](/guide/dtensor_overview), and are familiar with basic DTensor concepts like `Mesh` and `Layout`.\n",
+ "\n",
+ "This tutorial is based on [Training a neural network on MNIST with Keras](https://www.tensorflow.org/datasets/keras_example)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "keIyP3IoA1o4"
+ },
+ "source": [
+ "## Setup\n",
+ "\n",
+ "DTensor (`tf.experimental.dtensor`) has been part of TensorFlow since the 2.9.0 release.\n",
+ "\n",
+ "First, install or upgrade TensorFlow Datasets:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "4dHik7NYA5vm"
+ },
+ "outputs": [],
+ "source": [
+ "!pip install --quiet --upgrade tensorflow-datasets"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "VttBMZngDx8x"
+ },
+ "source": [
+ "Next, import TensorFlow and `dtensor`, and configure TensorFlow to use 8 virtual CPUs.\n",
+ "\n",
+ "Even though this example uses virtual CPUs, DTensor works the same way on CPU, GPU or TPU devices."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "CodX6idGBGSm"
+ },
+ "outputs": [],
+ "source": [
+ "import tensorflow as tf\n",
+ "import tensorflow_datasets as tfds\n",
+ "from tensorflow.experimental import dtensor"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "aAtvrpasDpDD"
+ },
+ "outputs": [],
+ "source": [
+ "def configure_virtual_cpus(ncpu):\n",
+ " phy_devices = tf.config.list_physical_devices('CPU')\n",
+ " tf.config.set_logical_device_configuration(\n",
+ " phy_devices[0], \n",
+ " [tf.config.LogicalDeviceConfiguration()] * ncpu)\n",
+ " \n",
+ "configure_virtual_cpus(8)\n",
+ "tf.config.list_logical_devices('CPU')\n",
+ "\n",
+ "devices = [f'CPU:{i}' for i in range(8)]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ogULE1OHtyd9"
+ },
+ "source": [
+ "## Deterministic pseudo-random number generators\n",
+ "One thing you should note is that DTensor API requires each of the running client to have the same random seeds, so that it could have deterministic behavior for initializing the weights. You can achieve this by setting the global seeds in keras via `tf.keras.utils.set_random_seed()`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "9u85YypguL8N"
+ },
+ "outputs": [],
+ "source": [
+ "tf.keras.backend.experimental.enable_tf_random_generator()\n",
+ "tf.keras.utils.set_random_seed(1337)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "tO11XvPDAu3_"
+ },
+ "source": [
+ "## Creating a Data Parallel Mesh\n",
+ "\n",
+ "This tutorial demonstrates Data Parallel training. Adapting to Model Parallel training and Spatial Parallel training can be as simple as switching to a different set of `Layout` objects. Refer to the [Distributed training with DTensors](dtensor_ml_tutorial.ipynb) tutorial for more information on distributed training beyond Data Parallel.\n",
+ "\n",
+ "Data Parallel training is a commonly used parallel training scheme, also used by, for example, `tf.distribute.MirroredStrategy`.\n",
+ "\n",
+ "With DTensor, a Data Parallel training loop uses a `Mesh` that consists of a single 'batch' dimension, where each device runs a replica of the model that receives a shard from the global batch."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "6sT6s6z4j9H-"
+ },
+ "outputs": [],
+ "source": [
+ "mesh = dtensor.create_mesh([(\"batch\", 8)], devices=devices)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "rouFcF6FE0aF"
+ },
+ "source": [
+ "As each device runs a full replica of the model, the model variables shall be fully replicated across the mesh (unsharded). As an example, a fully replicated Layout for a rank-2 weight on this `Mesh` would be as follows:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "U8OxvkDKE1Nu"
+ },
+ "outputs": [],
+ "source": [
+ "example_weight_layout = dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh) # or\n",
+ "example_weight_layout = dtensor.Layout.replicated(mesh, rank=2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "6Bnic98RE0xi"
+ },
+ "source": [
+ "A layout for a rank-2 data tensor on this `Mesh` would be sharded along the first dimension (sometimes known as `batch_sharded`),"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "PhYp0EKBFfxt"
+ },
+ "outputs": [],
+ "source": [
+ "example_data_layout = dtensor.Layout(['batch', dtensor.UNSHARDED], mesh) # or\n",
+ "example_data_layout = dtensor.Layout.batch_sharded(mesh, 'batch', rank=2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "4U-6n0DericV"
+ },
+ "source": [
+ "## Create Keras layers with layout\n",
+ "\n",
+ "In the data parallel scheme, you usually create your model weights with a fully replicated layout, so that each replica of the model can do calculations with the sharded input data. \n",
+ "\n",
+ "In order to configure the layout information for your layers' weights, Keras has exposed an extra parameter in the layer constructor for most of the built-in layers.\n",
+ "\n",
+ "The following example builds a small image classification model with fully replicated weight layout. You can specify layout information `kernel` and `bias` in `tf.keras.layers.Dense` via arguments `kernel_layout` and `bias_layout`. Most of the built-in keras layers are ready for explicitly specifying the `Layout` for the layer weights."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Koc5GlA1tFXY"
+ },
+ "outputs": [],
+ "source": [
+ "unsharded_layout_2d = dtensor.Layout.replicated(mesh, 2)\n",
+ "unsharded_layout_1d = dtensor.Layout.replicated(mesh, 1)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "GfOGTIxGs5Ql"
+ },
+ "outputs": [],
+ "source": [
+ "model = tf.keras.models.Sequential([\n",
+ " tf.keras.layers.Flatten(input_shape=(28, 28)),\n",
+ " tf.keras.layers.Dense(128, \n",
+ " activation='relu',\n",
+ " name='d1',\n",
+ " kernel_layout=unsharded_layout_2d, \n",
+ " bias_layout=unsharded_layout_1d),\n",
+ " tf.keras.layers.Dense(10,\n",
+ " name='d2',\n",
+ " kernel_layout=unsharded_layout_2d, \n",
+ " bias_layout=unsharded_layout_1d)\n",
+ "])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0frf3jsVtx_n"
+ },
+ "source": [
+ "You can check the layout information by examining the `layout` property on the weights."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Z_nqv_VdwcXo"
+ },
+ "outputs": [],
+ "source": [
+ "for weight in model.weights:\n",
+ " print(f'Weight name: {weight.name} with layout: {weight.layout}')\n",
+ " break"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "6FMGB-QsxPtU"
+ },
+ "source": [
+ "## Load a dataset and build input pipeline\n",
+ "\n",
+ "Load a MNIST dataset and configure some pre-processing input pipeline for it. The dataset itself is not associated with any DTensor layout information."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "zGt4kwltxOt4"
+ },
+ "outputs": [],
+ "source": [
+ "(ds_train, ds_test), ds_info = tfds.load(\n",
+ " 'mnist',\n",
+ " split=['train', 'test'],\n",
+ " shuffle_files=True,\n",
+ " as_supervised=True,\n",
+ " with_info=True,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "HkUaOB_ryaLH"
+ },
+ "outputs": [],
+ "source": [
+ "def normalize_img(image, label):\n",
+ " \"\"\"Normalizes images: `uint8` -> `float32`.\"\"\"\n",
+ " return tf.cast(image, tf.float32) / 255., label"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Efm2H1iqydan"
+ },
+ "outputs": [],
+ "source": [
+ "batch_size = 128\n",
+ "\n",
+ "ds_train = ds_train.map(\n",
+ " normalize_img, num_parallel_calls=tf.data.AUTOTUNE)\n",
+ "ds_train = ds_train.cache()\n",
+ "ds_train = ds_train.shuffle(ds_info.splits['train'].num_examples)\n",
+ "ds_train = ds_train.batch(batch_size)\n",
+ "ds_train = ds_train.prefetch(tf.data.AUTOTUNE)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Lcrg6QAtyis4"
+ },
+ "outputs": [],
+ "source": [
+ "ds_test = ds_test.map(\n",
+ " normalize_img, num_parallel_calls=tf.data.AUTOTUNE)\n",
+ "ds_test = ds_test.batch(batch_size)\n",
+ "ds_test = ds_test.cache()\n",
+ "ds_test = ds_test.prefetch(tf.data.AUTOTUNE)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "fHEZwib7lhqn"
+ },
+ "source": [
+ "## Define the training logic for the model\n",
+ "\n",
+ "Next, define the training and evaluation logic for the model. \n",
+ "\n",
+ "As of TensorFlow 2.9, you have to write a custom-training-loop for a DTensor-enabled Keras model. This is to pack the input data with proper layout information, which is not integrated with the standard `tf.keras.Model.fit()` or `tf.keras.Model.eval()` functions from Keras. you will get more `tf.data` support in the upcoming release. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "CAx11gMjzzjs"
+ },
+ "outputs": [],
+ "source": [
+ "@tf.function\n",
+ "def train_step(model, x, y, optimizer, metrics):\n",
+ " with tf.GradientTape() as tape:\n",
+ " logits = model(x, training=True)\n",
+ " # tf.reduce_sum sums the batch sharded per-example loss to a replicated\n",
+ " # global loss (scalar).\n",
+ " loss = tf.reduce_sum(tf.keras.losses.sparse_categorical_crossentropy(\n",
+ " y, logits, from_logits=True))\n",
+ " \n",
+ " gradients = tape.gradient(loss, model.trainable_variables)\n",
+ " optimizer.apply_gradients(zip(gradients, model.trainable_variables))\n",
+ "\n",
+ " for metric in metrics.values():\n",
+ " metric.update_state(y_true=y, y_pred=logits)\n",
+ "\n",
+ " loss_per_sample = loss / len(x)\n",
+ " results = {'loss': loss_per_sample}\n",
+ " return results"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "maSTWeRemO0P"
+ },
+ "outputs": [],
+ "source": [
+ "@tf.function\n",
+ "def eval_step(model, x, y, metrics):\n",
+ " logits = model(x, training=False)\n",
+ " loss = tf.reduce_sum(tf.keras.losses.sparse_categorical_crossentropy(\n",
+ " y, logits, from_logits=True))\n",
+ "\n",
+ " for metric in metrics.values():\n",
+ " metric.update_state(y_true=y, y_pred=logits)\n",
+ "\n",
+ " loss_per_sample = loss / len(x)\n",
+ " results = {'eval_loss': loss_per_sample}\n",
+ " return results"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "dt00axcLmvLr"
+ },
+ "outputs": [],
+ "source": [
+ "def pack_dtensor_inputs(images, labels, image_layout, label_layout):\n",
+ " num_local_devices = image_layout.mesh.num_local_devices()\n",
+ " images = tf.split(images, num_local_devices)\n",
+ " labels = tf.split(labels, num_local_devices)\n",
+ " images = dtensor.pack(images, image_layout)\n",
+ " labels = dtensor.pack(labels, label_layout)\n",
+ " return images, labels"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "9Eb-qIJGrxB9"
+ },
+ "source": [
+ "## Metrics and optimizers\n",
+ "\n",
+ "When using DTensor API with Keras `Metric` and `Optimizer`, you will need to provide the extra mesh information, so that any internal state variables and tensors can work with variables in the model.\n",
+ "\n",
+ "- For an optimizer, DTensor introduces a new experimental namespace `keras.dtensor.experimental.optimizers`, where many existing Keras Optimizers are extended to receive an additional `mesh` argument. In future releases, it may be merged with Keras core optimizers.\n",
+ "\n",
+ "- For metrics, you can directly specify the `mesh` to the constructor as an argument to make it a DTensor compatible `Metric`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "1lu_0mz1sxrl"
+ },
+ "outputs": [],
+ "source": [
+ "optimizer = tf.keras.dtensor.experimental.optimizers.Adam(0.01, mesh=mesh)\n",
+ "metrics = {'accuracy': tf.keras.metrics.SparseCategoricalAccuracy(mesh=mesh)}\n",
+ "eval_metrics = {'eval_accuracy': tf.keras.metrics.SparseCategoricalAccuracy(mesh=mesh)}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "QzufrkistELx"
+ },
+ "source": [
+ "## Train the model\n",
+ "\n",
+ "The following example demonstrates how to shard the data from input pipeline on the batch dimension, and train with the model, which has fully replicated weights. \n",
+ "\n",
+ "After 3 epochs, the model should achieve about 97% of accuracy:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "kZW568Dk0vvL"
+ },
+ "outputs": [],
+ "source": [
+ "num_epochs = 3\n",
+ "\n",
+ "image_layout = dtensor.Layout.batch_sharded(mesh, 'batch', rank=4)\n",
+ "label_layout = dtensor.Layout.batch_sharded(mesh, 'batch', rank=1)\n",
+ "\n",
+ "for epoch in range(num_epochs):\n",
+ " print(\"============================\") \n",
+ " print(\"Epoch: \", epoch)\n",
+ " for metric in metrics.values():\n",
+ " metric.reset_state()\n",
+ " step = 0\n",
+ " results = {}\n",
+ " pbar = tf.keras.utils.Progbar(target=None, stateful_metrics=[])\n",
+ " for input in ds_train:\n",
+ " images, labels = input[0], input[1]\n",
+ " images, labels = pack_dtensor_inputs(\n",
+ " images, labels, image_layout, label_layout)\n",
+ "\n",
+ " results.update(train_step(model, images, labels, optimizer, metrics))\n",
+ " for metric_name, metric in metrics.items():\n",
+ " results[metric_name] = metric.result()\n",
+ "\n",
+ " pbar.update(step, values=results.items(), finalize=False)\n",
+ " step += 1\n",
+ " pbar.update(step, values=results.items(), finalize=True)\n",
+ "\n",
+ " for metric in eval_metrics.values():\n",
+ " metric.reset_state()\n",
+ " for input in ds_test:\n",
+ " images, labels = input[0], input[1]\n",
+ " images, labels = pack_dtensor_inputs(\n",
+ " images, labels, image_layout, label_layout)\n",
+ " results.update(eval_step(model, images, labels, eval_metrics))\n",
+ "\n",
+ " for metric_name, metric in eval_metrics.items():\n",
+ " results[metric_name] = metric.result()\n",
+ " \n",
+ " for metric_name, metric in results.items():\n",
+ " print(f\"{metric_name}: {metric.numpy()}\")\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "HYEXF6qCuoSr"
+ },
+ "source": [
+ "## Specify Layout for existing model code\n",
+ "\n",
+ "Often you have models that work well for your use case. Specifying `Layout` information to each individual layer within the model will be a large amount of work requiring a lot of edits.\n",
+ "\n",
+ "To help you easily convert your existing Keras model to work with DTensor API you can use the new `tf.keras.dtensor.experimental.LayoutMap` API that allow you to specify the `Layout` from a global point of view.\n",
+ "\n",
+ "First, you need to create a `LayoutMap` instance, which is a dictionary-like object that contains all the `Layout` you would like to specify for your model weights.\n",
+ "\n",
+ "`LayoutMap` needs a `Mesh` instance at init, which can be used to provide default replicated `Layout` for any weights that doesn't have Layout configured. In case you would like all your model weights to be just fully replicated, you can provide empty `LayoutMap`, and the default mesh will be used to create replicated `Layout`.\n",
+ "\n",
+ "`LayoutMap` uses a string as key and a `Layout` as value. There is a behavior difference between a normal Python dict and this class. The string key will be treated as a regex when retrieving the value."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "SCq5Nl-UP_dS"
+ },
+ "source": [
+ "### Subclassed Model\n",
+ "\n",
+ "Consider the following model defined using the Keras subclassing Model syntax."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "LZ0hRFs8unu0"
+ },
+ "outputs": [],
+ "source": [
+ "class SubclassedModel(tf.keras.Model):\n",
+ "\n",
+ " def __init__(self, name=None):\n",
+ " super().__init__(name=name)\n",
+ " self.feature = tf.keras.layers.Dense(16)\n",
+ " self.feature_2 = tf.keras.layers.Dense(24)\n",
+ " self.dropout = tf.keras.layers.Dropout(0.1)\n",
+ "\n",
+ " def call(self, inputs, training=None):\n",
+ " x = self.feature(inputs)\n",
+ " x = self.dropout(x, training=training)\n",
+ " return self.feature_2(x)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "1njxqPB-yS97"
+ },
+ "source": [
+ "There are 4 weights in this model, which are `kernel` and `bias` for two `Dense` layers. Each of them are mapped based on the object path:\n",
+ "\n",
+ "* `model.feature.kernel`\n",
+ "* `model.feature.bias`\n",
+ "* `model.feature_2.kernel`\n",
+ "* `model.feature_2.bias`\n",
+ "\n",
+ "Note: For subclassed Models, the attribute name, rather than the `.name` attribute of the layer, is used as the key to retrieve the Layout from the mapping. This is consistent with the convention followed by `tf.Module` checkpointing. For complex models with more than a few layers, you can [manually inspect checkpoints](https://www.tensorflow.org/guide/checkpoint#manually_inspecting_checkpoints) to view the attribute mappings. \n",
+ "\n",
+ "Now define the following `LayoutMap` and apply it to the model:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "goVX6iIZw468"
+ },
+ "outputs": [],
+ "source": [
+ "layout_map = tf.keras.dtensor.experimental.LayoutMap(mesh=mesh)\n",
+ "\n",
+ "layout_map['feature.*kernel'] = dtensor.Layout.batch_sharded(mesh, 'batch', rank=2)\n",
+ "layout_map['feature.*bias'] = dtensor.Layout.batch_sharded(mesh, 'batch', rank=1)\n",
+ "\n",
+ "with layout_map.scope():\n",
+ " subclassed_model = SubclassedModel()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "M32HcSp_PyWs"
+ },
+ "source": [
+ "The model weights are created on the first call, so call the model with a DTensor input and confirm the weights have the expected layouts:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "c3CbD9l7qUNq"
+ },
+ "outputs": [],
+ "source": [
+ "dtensor_input = dtensor.copy_to_mesh(tf.zeros((16, 16)), layout=unsharded_layout_2d)\n",
+ "# Trigger the weights creation for subclass model\n",
+ "subclassed_model(dtensor_input)\n",
+ "\n",
+ "print(subclassed_model.feature.kernel.layout)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ZyCnfd-4Q2jk"
+ },
+ "source": [
+ "With this, you can quickly map the `Layout` to your models without updating any of your existing code. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "6GliUdWTQnKC"
+ },
+ "source": [
+ "### Sequential and Functional Models"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "6zzvTqAR2Teu"
+ },
+ "source": [
+ "For Keras Functional and Sequential models, you can use `tf.keras.dtensor.experimental.LayoutMap` as well.\n",
+ "\n",
+ "Note: For Functional and Sequential models, the mappings are slightly different. The layers in the model don't have a public attribute attached to the model (though you can access them via `Model.layers` as a list). Use the string name as the key in this case. The string name is guaranteed to be unique within a model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "gXK2EquIRJCC"
+ },
+ "outputs": [],
+ "source": [
+ "layout_map = tf.keras.dtensor.experimental.LayoutMap(mesh=mesh)\n",
+ "\n",
+ "layout_map['feature.*kernel'] = dtensor.Layout.batch_sharded(mesh, 'batch', rank=2)\n",
+ "layout_map['feature.*bias'] = dtensor.Layout.batch_sharded(mesh, 'batch', rank=1)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "cBzwJqrg2TH3"
+ },
+ "outputs": [],
+ "source": [
+ "with layout_map.scope():\n",
+ " inputs = tf.keras.Input((16,), batch_size=16)\n",
+ " x = tf.keras.layers.Dense(16, name='feature')(inputs)\n",
+ " x = tf.keras.layers.Dropout(0.1)(x)\n",
+ " output = tf.keras.layers.Dense(32, name='feature_2')(x)\n",
+ " model = tf.keras.Model(inputs, output)\n",
+ "\n",
+ "print(model.layers[1].kernel.layout)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "pPuh1NlE3-wO"
+ },
+ "outputs": [],
+ "source": [
+ "with layout_map.scope():\n",
+ " model = tf.keras.Sequential([\n",
+ " tf.keras.layers.Dense(16, name='feature', input_shape=(16,)),\n",
+ " tf.keras.layers.Dropout(0.1),\n",
+ " tf.keras.layers.Dense(32, name='feature_2')\n",
+ " ])\n",
+ "\n",
+ "print(model.layers[2].kernel.layout)"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "name": "dtensor_keras_tutorial.ipynb",
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/site/en/tutorials/distribute/dtensor_ml_tutorial.ipynb b/site/en/tutorials/distribute/dtensor_ml_tutorial.ipynb
new file mode 100644
index 00000000000..55557be6368
--- /dev/null
+++ b/site/en/tutorials/distribute/dtensor_ml_tutorial.ipynb
@@ -0,0 +1,1070 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Tce3stUlHN0L"
+ },
+ "source": [
+ "##### Copyright 2019 The TensorFlow Authors.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "tuOe1ymfHZPu"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n",
+ "# you may not use this file except in compliance with the License.\n",
+ "# You may obtain a copy of the License at\n",
+ "#\n",
+ "# https://www.apache.org/licenses/LICENSE-2.0\n",
+ "#\n",
+ "# Unless required by applicable law or agreed to in writing, software\n",
+ "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
+ "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
+ "# See the License for the specific language governing permissions and\n",
+ "# limitations under the License."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "MfBg1C5NB3X0"
+ },
+ "source": [
+ "# Distributed training with DTensors"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "r6P32iYYV27b"
+ },
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "kiF4jjX4O1mF"
+ },
+ "source": [
+ "## Overview\n",
+ "\n",
+ "DTensor provides a way for you to distribute the training of your model across devices to improve efficiency, reliability and scalability. For more details, check out the [DTensor concepts](../../guide/dtensor_overview.ipynb) guide.\n",
+ "\n",
+ "In this tutorial, you will train a sentiment analysis model using DTensors. The example demonstrates three distributed training schemes:\n",
+ "\n",
+ " - Data Parallel training, where the training samples are sharded (partitioned) to devices.\n",
+ " - Model Parallel training, where the model variables are sharded to devices.\n",
+ " - Spatial Parallel training, where the features of input data are sharded to devices (also known as [Spatial Partitioning](https://cloud.google.com/blog/products/ai-machine-learning/train-ml-models-on-large-images-and-3d-volumes-with-spatial-partitioning-on-cloud-tpus)).\n",
+ "\n",
+ "The training portion of this tutorial is inspired by a Kaggle notebook called [A Kaggle guide on sentiment analysis](https://www.kaggle.com/code/anasofiauzsoy/yelp-review-sentiment-analysis-tensorflow-tfds/notebook). To learn about the complete training and evaluation workflow (without DTensor), refer to that notebook.\n",
+ "\n",
+ "This tutorial will walk through the following steps:\n",
+ "\n",
+ "- Some data cleaning to obtain a `tf.data.Dataset` of tokenized sentences and their polarity.\n",
+ "- Then, building an MLP model with custom Dense and BatchNorm layers using a `tf.Module` to track the inference variables. The model constructor will take additional `Layout` arguments to control the sharding of variables.\n",
+ "- For training, you will first use data parallel training together with `tf.experimental.dtensor`'s checkpoint feature. Then, you will continue with Model Parallel Training and Spatial Parallel Training.\n",
+ "- The final section briefly describes the interaction between `tf.saved_model` and `tf.experimental.dtensor` as of TensorFlow 2.9."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "YD80veeg7QtW"
+ },
+ "source": [
+ "## Setup\n",
+ "\n",
+ "DTensor (`tf.experimental.dtensor`) has been part of TensorFlow since the 2.9.0 release.\n",
+ "\n",
+ "First, install or upgrade TensorFlow Datasets:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "-RKXLJN-7Yyb"
+ },
+ "outputs": [],
+ "source": [
+ "!pip install --quiet --upgrade tensorflow-datasets"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "tcxP4_Zu7ciQ"
+ },
+ "source": [
+ "Next, import `tensorflow` and `dtensor`, and configure TensorFlow to use 8 virtual CPUs.\n",
+ "\n",
+ "Even though this example uses virtual CPUs, DTensor works the same way on CPU, GPU or TPU devices."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "dXcB26oP7dUd"
+ },
+ "outputs": [],
+ "source": [
+ "import tempfile\n",
+ "import numpy as np\n",
+ "import tensorflow_datasets as tfds\n",
+ "\n",
+ "import tensorflow as tf\n",
+ "\n",
+ "from tensorflow.experimental import dtensor\n",
+ "\n",
+ "print('TensorFlow version:', tf.__version__)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "oHtO6MJLUXlz"
+ },
+ "outputs": [],
+ "source": [
+ "def configure_virtual_cpus(ncpu):\n",
+ " phy_devices = tf.config.list_physical_devices('CPU')\n",
+ " tf.config.set_logical_device_configuration(phy_devices[0], [\n",
+ " tf.config.LogicalDeviceConfiguration(),\n",
+ " ] * ncpu)\n",
+ "\n",
+ "configure_virtual_cpus(8)\n",
+ "DEVICES = [f'CPU:{i}' for i in range(8)]\n",
+ "\n",
+ "tf.config.list_logical_devices('CPU')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "omYd4jbF7j_I"
+ },
+ "source": [
+ "## Download the dataset\n",
+ "\n",
+ "Download the IMDB reviews data set to train the sentiment analysis model:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "fW4w4QlFVHhx"
+ },
+ "outputs": [],
+ "source": [
+ "train_data = tfds.load('imdb_reviews', split='train', shuffle_files=True, batch_size=64)\n",
+ "train_data"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ki3mpfi4aZH8"
+ },
+ "source": [
+ "## Prepare the data\n",
+ "\n",
+ "First tokenize the text. Here use an extension of one-hot encoding, the `'tf_idf'` mode of `tf.keras.layers.TextVectorization`.\n",
+ "\n",
+ "- For the sake of speed, limit the number of tokens to 1200.\n",
+ "- To keep the `tf.Module` simple, run `TextVectorization` as a preprocessing step before the training.\n",
+ "\n",
+ "The final result of the data cleaning section is a `Dataset` with the tokenized text as `x` and label as `y`.\n",
+ "\n",
+ "**Note**: Running `TextVectorization` as a preprocessing step is **neither a usual practice nor a recommended one** as doing so assumes the training data fits into the client memory, which is not always the case.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "zNpxjku_57Lg"
+ },
+ "outputs": [],
+ "source": [
+ "text_vectorization = tf.keras.layers.TextVectorization(output_mode='tf_idf', max_tokens=1200, output_sequence_length=None)\n",
+ "text_vectorization.adapt(data=train_data.map(lambda x: x['text']))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "q16bjngoVwQp"
+ },
+ "outputs": [],
+ "source": [
+ "def vectorize(features):\n",
+ " return text_vectorization(features['text']), features['label']\n",
+ "\n",
+ "train_data_vec = train_data.map(vectorize)\n",
+ "train_data_vec"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "atTqL9kE5wz4"
+ },
+ "source": [
+ "## Build a neural network with DTensor\n",
+ "\n",
+ "Now build a Multi-Layer Perceptron (MLP) network with `DTensor`. The network will use fully connected Dense and BatchNorm layers.\n",
+ "\n",
+ "`DTensor` expands TensorFlow through single-program multi-data (SPMD) expansion of regular TensorFlow Ops according to the `dtensor.Layout` attributes of their input `Tensor` and variables.\n",
+ "\n",
+ "Variables of `DTensor` aware layers are `dtensor.DVariable`, and the constructors of `DTensor` aware layer objects take additional `Layout` inputs in addition to the usual layer parameters.\n",
+ "\n",
+ "Note: As of TensorFlow 2.9, Keras layers such as `tf.keras.layer.Dense`, and `tf.keras.layer.BatchNormalization` accepts `dtensor.Layout` arguments. Refer to the [DTensor Keras Integration Tutorial](/tutorials/distribute/dtensor_keras_tutorial) for more information using Keras with DTensor."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "PMCt-Gj3b3Jy"
+ },
+ "source": [
+ "### Dense Layer\n",
+ "\n",
+ "The following custom Dense layer defines 2 layer variables: $W_{ij}$ is the variable for weights, and $b_i$ is the variable for the biases.\n",
+ "\n",
+ "$$\n",
+ "y_j = \\sigma(\\sum_i x_i W_{ij} + b_j)\n",
+ "$$\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nYlFUJWNjl4N"
+ },
+ "source": [
+ "### Layout deduction\n",
+ "\n",
+ "This result comes from the following observations:\n",
+ "\n",
+ "- The preferred DTensor sharding for operands to a matrix dot product $t_j = \\sum_i x_i W_{ij}$ is to shard $\\mathbf{W}$ and $\\mathbf{x}$ the same way along the $i$-axis.\n",
+ "\n",
+ "- The preferred DTensor sharding for operands to a matrix sum $t_j + b_j$, is to shard $\\mathbf{t}$ and $\\mathbf{b}$ the same way along the $j$-axis.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "VpKblz7Yb16G"
+ },
+ "outputs": [],
+ "source": [
+ "class Dense(tf.Module):\n",
+ "\n",
+ " def __init__(self, input_size, output_size,\n",
+ " init_seed, weight_layout, activation=None):\n",
+ " super().__init__()\n",
+ "\n",
+ " random_normal_initializer = tf.function(tf.random.stateless_normal)\n",
+ "\n",
+ " self.weight = dtensor.DVariable(\n",
+ " dtensor.call_with_layout(\n",
+ " random_normal_initializer, weight_layout,\n",
+ " shape=[input_size, output_size],\n",
+ " seed=init_seed\n",
+ " ))\n",
+ " if activation is None:\n",
+ " activation = lambda x:x\n",
+ " self.activation = activation\n",
+ " \n",
+ " # bias is sharded the same way as the last axis of weight.\n",
+ " bias_layout = weight_layout.delete([0])\n",
+ "\n",
+ " self.bias = dtensor.DVariable(\n",
+ " dtensor.call_with_layout(tf.zeros, bias_layout, [output_size]))\n",
+ "\n",
+ " def __call__(self, x):\n",
+ " y = tf.matmul(x, self.weight) + self.bias\n",
+ " y = self.activation(y)\n",
+ "\n",
+ " return y"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "tfVY_vAKbxM0"
+ },
+ "source": [
+ "### BatchNorm\n",
+ "\n",
+ "A batch normalization layer helps avoid collapsing modes while training. In this case, adding batch normalization layers helps model training avoid producing a model that only produces zeros.\n",
+ "\n",
+ "The constructor of the custom `BatchNorm` layer below does not take a `Layout` argument. This is because `BatchNorm` has no layer variables. This still works with DTensor because 'x', the only input to the layer, is already a DTensor that represents the global batch.\n",
+ "\n",
+ "Note: With DTensor, the input Tensor 'x' always represents the global batch. Therefore `tf.nn.batch_normalization` is applied to the global batch. This differs from training with `tf.distribute.MirroredStrategy`, where Tensor 'x' only represents the per-replica shard of the batch (the local batch)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "riBA9pfhlPFq"
+ },
+ "outputs": [],
+ "source": [
+ "class BatchNorm(tf.Module):\n",
+ "\n",
+ " def __init__(self):\n",
+ " super().__init__()\n",
+ "\n",
+ " def __call__(self, x, training=True):\n",
+ " if not training:\n",
+ " # This branch is not used in the Tutorial.\n",
+ " pass\n",
+ " mean, variance = tf.nn.moments(x, axes=[0])\n",
+ " return tf.nn.batch_normalization(x, mean, variance, 0.0, 1.0, 1e-5)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "q4R4MPz5prh4"
+ },
+ "source": [
+ "A full featured batch normalization layer (such as `tf.keras.layers.BatchNormalization`) will need Layout arguments for its variables."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "unFcP99zprJj"
+ },
+ "outputs": [],
+ "source": [
+ "def make_keras_bn(bn_layout):\n",
+ " return tf.keras.layers.BatchNormalization(gamma_layout=bn_layout,\n",
+ " beta_layout=bn_layout,\n",
+ " moving_mean_layout=bn_layout,\n",
+ " moving_variance_layout=bn_layout,\n",
+ " fused=False)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "v8Dj7AJ_lPs0"
+ },
+ "source": [
+ "### Putting Layers Together\n",
+ "\n",
+ "Next, build a Multi-layer perceptron (MLP) network with the building blocks above. The diagram below shows the axis relationships between the input `x` and the weight matrices for the two `Dense` layers without any DTensor sharding or replication applied."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "udFGAO-NrZw6"
+ },
+ "source": [
+ " \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "8DCQ0aQ5rQtB"
+ },
+ "source": [
+ "The output of the first `Dense` layer is passed into the input of the second `Dense` layer (after the `BatchNorm`). Therefore, the preferred DTensor sharding for the output of first `Dense` layer ($\\mathbf{W_1}$) and the input of second `Dense` layer ($\\mathbf{W_2}$) is to shard $\\mathbf{W_1}$ and $\\mathbf{W_2}$ the same way along the common axis $\\hat{j}$,\n",
+ "\n",
+ "$$\n",
+ "\\mathsf{Layout}[{W_{1,ij}}; i, j] = \\left[\\hat{i}, \\hat{j}\\right] \\\\\n",
+ "\\mathsf{Layout}[{W_{2,jk}}; j, k] = \\left[\\hat{j}, \\hat{k} \\right]\n",
+ "$$\n",
+ "\n",
+ "Even though the layout deduction shows that the 2 layouts are not independent, for the sake of simplicity of the model interface, `MLP` will take 2 `Layout` arguments, one per Dense layer."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "junyS-965opl"
+ },
+ "outputs": [],
+ "source": [
+ "from typing import Tuple\n",
+ "\n",
+ "class MLP(tf.Module):\n",
+ "\n",
+ " def __init__(self, dense_layouts: Tuple[dtensor.Layout, dtensor.Layout]):\n",
+ " super().__init__()\n",
+ "\n",
+ " self.dense1 = Dense(\n",
+ " 1200, 48, (1, 2), dense_layouts[0], activation=tf.nn.relu)\n",
+ " self.bn = BatchNorm()\n",
+ " self.dense2 = Dense(48, 2, (3, 4), dense_layouts[1])\n",
+ "\n",
+ " def __call__(self, x):\n",
+ " y = x\n",
+ " y = self.dense1(y)\n",
+ " y = self.bn(y)\n",
+ " y = self.dense2(y)\n",
+ " return y\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "9dgLmebHhr7h"
+ },
+ "source": [
+ "The trade-off between correctness in layout deduction constraints and simplicity of API is a common design point of APIs that uses DTensor.\n",
+ "It is also possible to capture the dependency between `Layout`'s with a different API. For example, the `MLPStricter` class creates the `Layout` objects in the constructor."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "wEZR7UlihsYX"
+ },
+ "outputs": [],
+ "source": [
+ "class MLPStricter(tf.Module):\n",
+ "\n",
+ " def __init__(self, mesh, input_mesh_dim, inner_mesh_dim1, output_mesh_dim):\n",
+ " super().__init__()\n",
+ "\n",
+ " self.dense1 = Dense(\n",
+ " 1200, 48, (1, 2), dtensor.Layout([input_mesh_dim, inner_mesh_dim1], mesh),\n",
+ " activation=tf.nn.relu)\n",
+ " self.bn = BatchNorm()\n",
+ " self.dense2 = Dense(48, 2, (3, 4), dtensor.Layout([inner_mesh_dim1, output_mesh_dim], mesh))\n",
+ "\n",
+ "\n",
+ " def __call__(self, x):\n",
+ " y = x\n",
+ " y = self.dense1(y)\n",
+ " y = self.bn(y)\n",
+ " y = self.dense2(y)\n",
+ " return y"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "GcQi7D5mal2L"
+ },
+ "source": [
+ "To make sure the model runs, probe your model with fully replicated layouts and a fully replicated batch of `'x'` input."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "zOPuYeQwallh"
+ },
+ "outputs": [],
+ "source": [
+ "WORLD = dtensor.create_mesh([(\"world\", 8)], devices=DEVICES)\n",
+ "\n",
+ "model = MLP([dtensor.Layout.replicated(WORLD, rank=2),\n",
+ " dtensor.Layout.replicated(WORLD, rank=2)])\n",
+ "\n",
+ "sample_x, sample_y = train_data_vec.take(1).get_single_element()\n",
+ "sample_x = dtensor.copy_to_mesh(sample_x, dtensor.Layout.replicated(WORLD, rank=2))\n",
+ "print(model(sample_x))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "akrjDstEpDv9"
+ },
+ "source": [
+ "## Moving data to the device\n",
+ "\n",
+ "Usually, `tf.data` iterators (and other data fetching methods) yield tensor objects backed by the local host device memory. This data must be transferred to the accelerator device memory that backs DTensor's component tensors.\n",
+ "\n",
+ "`dtensor.copy_to_mesh` is unsuitable for this situation because it replicates input tensors to all devices due to DTensor's global perspective. So in this tutorial, you will use a helper function `repack_local_tensor`, to facilitate the transfer of data. This helper function uses `dtensor.pack` to send (and only send) the shard of the global batch that is intended for a replica to the device backing the replica.\n",
+ "\n",
+ "This simplified function assumes single-client. Determining the correct way to split the local tensor and the mapping between the pieces of the split and the local devices can be laboring in a multi-client application.\n",
+ "\n",
+ "Additional DTensor API to simplify `tf.data` integration is planned, supporting both single-client and multi-client applications. Please stay tuned."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "3t5WvQR4Hvo4"
+ },
+ "outputs": [],
+ "source": [
+ "def repack_local_tensor(x, layout):\n",
+ " \"\"\"Repacks a local Tensor-like to a DTensor with layout.\n",
+ "\n",
+ " This function assumes a single-client application.\n",
+ " \"\"\"\n",
+ " x = tf.convert_to_tensor(x)\n",
+ " sharded_dims = []\n",
+ "\n",
+ " # For every sharded dimension, use tf.split to split the along the dimension.\n",
+ " # The result is a nested list of split-tensors in queue[0].\n",
+ " queue = [x]\n",
+ " for axis, dim in enumerate(layout.sharding_specs):\n",
+ " if dim == dtensor.UNSHARDED:\n",
+ " continue\n",
+ " num_splits = layout.shape[axis]\n",
+ " queue = tf.nest.map_structure(lambda x: tf.split(x, num_splits, axis=axis), queue)\n",
+ " sharded_dims.append(dim)\n",
+ "\n",
+ " # Now we can build the list of component tensors by looking up the location in\n",
+ " # the nested list of split-tensors created in queue[0].\n",
+ " components = []\n",
+ " for locations in layout.mesh.local_device_locations():\n",
+ " t = queue[0]\n",
+ " for dim in sharded_dims:\n",
+ " split_index = locations[dim] # Only valid on single-client mesh.\n",
+ " t = t[split_index]\n",
+ " components.append(t)\n",
+ "\n",
+ " return dtensor.pack(components, layout)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "2KKCDcjG7zj2"
+ },
+ "source": [
+ "## Data parallel training\n",
+ "\n",
+ "In this section, you will train your MLP model with data parallel training. The following sections will demonstrate model parallel training and spatial parallel training.\n",
+ "\n",
+ "Data parallel training is a commonly used scheme for distributed machine learning:\n",
+ "\n",
+ " - Model variables are replicated on N devices each.\n",
+ " - A global batch is split into N per-replica batches.\n",
+ " - Each per-replica batch is trained on the replica device.\n",
+ " - The gradient is reduced before weight up data is collectively performed on all replicas.\n",
+ "\n",
+ "Data parallel training provides nearly linear speedup regarding the number of devices."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "UMsLUyTGq3oL"
+ },
+ "source": [
+ "### Creating a data parallel mesh\n",
+ "\n",
+ "A typical data parallelism training loop uses a DTensor `Mesh` that consists of a single `batch` dimension, where each device becomes a replica that receives a shard from the global batch.\n",
+ "\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "8DCQ0aQ5rQtB"
+ },
+ "source": [
+ "The output of the first `Dense` layer is passed into the input of the second `Dense` layer (after the `BatchNorm`). Therefore, the preferred DTensor sharding for the output of first `Dense` layer ($\\mathbf{W_1}$) and the input of second `Dense` layer ($\\mathbf{W_2}$) is to shard $\\mathbf{W_1}$ and $\\mathbf{W_2}$ the same way along the common axis $\\hat{j}$,\n",
+ "\n",
+ "$$\n",
+ "\\mathsf{Layout}[{W_{1,ij}}; i, j] = \\left[\\hat{i}, \\hat{j}\\right] \\\\\n",
+ "\\mathsf{Layout}[{W_{2,jk}}; j, k] = \\left[\\hat{j}, \\hat{k} \\right]\n",
+ "$$\n",
+ "\n",
+ "Even though the layout deduction shows that the 2 layouts are not independent, for the sake of simplicity of the model interface, `MLP` will take 2 `Layout` arguments, one per Dense layer."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "junyS-965opl"
+ },
+ "outputs": [],
+ "source": [
+ "from typing import Tuple\n",
+ "\n",
+ "class MLP(tf.Module):\n",
+ "\n",
+ " def __init__(self, dense_layouts: Tuple[dtensor.Layout, dtensor.Layout]):\n",
+ " super().__init__()\n",
+ "\n",
+ " self.dense1 = Dense(\n",
+ " 1200, 48, (1, 2), dense_layouts[0], activation=tf.nn.relu)\n",
+ " self.bn = BatchNorm()\n",
+ " self.dense2 = Dense(48, 2, (3, 4), dense_layouts[1])\n",
+ "\n",
+ " def __call__(self, x):\n",
+ " y = x\n",
+ " y = self.dense1(y)\n",
+ " y = self.bn(y)\n",
+ " y = self.dense2(y)\n",
+ " return y\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "9dgLmebHhr7h"
+ },
+ "source": [
+ "The trade-off between correctness in layout deduction constraints and simplicity of API is a common design point of APIs that uses DTensor.\n",
+ "It is also possible to capture the dependency between `Layout`'s with a different API. For example, the `MLPStricter` class creates the `Layout` objects in the constructor."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "wEZR7UlihsYX"
+ },
+ "outputs": [],
+ "source": [
+ "class MLPStricter(tf.Module):\n",
+ "\n",
+ " def __init__(self, mesh, input_mesh_dim, inner_mesh_dim1, output_mesh_dim):\n",
+ " super().__init__()\n",
+ "\n",
+ " self.dense1 = Dense(\n",
+ " 1200, 48, (1, 2), dtensor.Layout([input_mesh_dim, inner_mesh_dim1], mesh),\n",
+ " activation=tf.nn.relu)\n",
+ " self.bn = BatchNorm()\n",
+ " self.dense2 = Dense(48, 2, (3, 4), dtensor.Layout([inner_mesh_dim1, output_mesh_dim], mesh))\n",
+ "\n",
+ "\n",
+ " def __call__(self, x):\n",
+ " y = x\n",
+ " y = self.dense1(y)\n",
+ " y = self.bn(y)\n",
+ " y = self.dense2(y)\n",
+ " return y"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "GcQi7D5mal2L"
+ },
+ "source": [
+ "To make sure the model runs, probe your model with fully replicated layouts and a fully replicated batch of `'x'` input."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "zOPuYeQwallh"
+ },
+ "outputs": [],
+ "source": [
+ "WORLD = dtensor.create_mesh([(\"world\", 8)], devices=DEVICES)\n",
+ "\n",
+ "model = MLP([dtensor.Layout.replicated(WORLD, rank=2),\n",
+ " dtensor.Layout.replicated(WORLD, rank=2)])\n",
+ "\n",
+ "sample_x, sample_y = train_data_vec.take(1).get_single_element()\n",
+ "sample_x = dtensor.copy_to_mesh(sample_x, dtensor.Layout.replicated(WORLD, rank=2))\n",
+ "print(model(sample_x))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "akrjDstEpDv9"
+ },
+ "source": [
+ "## Moving data to the device\n",
+ "\n",
+ "Usually, `tf.data` iterators (and other data fetching methods) yield tensor objects backed by the local host device memory. This data must be transferred to the accelerator device memory that backs DTensor's component tensors.\n",
+ "\n",
+ "`dtensor.copy_to_mesh` is unsuitable for this situation because it replicates input tensors to all devices due to DTensor's global perspective. So in this tutorial, you will use a helper function `repack_local_tensor`, to facilitate the transfer of data. This helper function uses `dtensor.pack` to send (and only send) the shard of the global batch that is intended for a replica to the device backing the replica.\n",
+ "\n",
+ "This simplified function assumes single-client. Determining the correct way to split the local tensor and the mapping between the pieces of the split and the local devices can be laboring in a multi-client application.\n",
+ "\n",
+ "Additional DTensor API to simplify `tf.data` integration is planned, supporting both single-client and multi-client applications. Please stay tuned."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "3t5WvQR4Hvo4"
+ },
+ "outputs": [],
+ "source": [
+ "def repack_local_tensor(x, layout):\n",
+ " \"\"\"Repacks a local Tensor-like to a DTensor with layout.\n",
+ "\n",
+ " This function assumes a single-client application.\n",
+ " \"\"\"\n",
+ " x = tf.convert_to_tensor(x)\n",
+ " sharded_dims = []\n",
+ "\n",
+ " # For every sharded dimension, use tf.split to split the along the dimension.\n",
+ " # The result is a nested list of split-tensors in queue[0].\n",
+ " queue = [x]\n",
+ " for axis, dim in enumerate(layout.sharding_specs):\n",
+ " if dim == dtensor.UNSHARDED:\n",
+ " continue\n",
+ " num_splits = layout.shape[axis]\n",
+ " queue = tf.nest.map_structure(lambda x: tf.split(x, num_splits, axis=axis), queue)\n",
+ " sharded_dims.append(dim)\n",
+ "\n",
+ " # Now we can build the list of component tensors by looking up the location in\n",
+ " # the nested list of split-tensors created in queue[0].\n",
+ " components = []\n",
+ " for locations in layout.mesh.local_device_locations():\n",
+ " t = queue[0]\n",
+ " for dim in sharded_dims:\n",
+ " split_index = locations[dim] # Only valid on single-client mesh.\n",
+ " t = t[split_index]\n",
+ " components.append(t)\n",
+ "\n",
+ " return dtensor.pack(components, layout)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "2KKCDcjG7zj2"
+ },
+ "source": [
+ "## Data parallel training\n",
+ "\n",
+ "In this section, you will train your MLP model with data parallel training. The following sections will demonstrate model parallel training and spatial parallel training.\n",
+ "\n",
+ "Data parallel training is a commonly used scheme for distributed machine learning:\n",
+ "\n",
+ " - Model variables are replicated on N devices each.\n",
+ " - A global batch is split into N per-replica batches.\n",
+ " - Each per-replica batch is trained on the replica device.\n",
+ " - The gradient is reduced before weight up data is collectively performed on all replicas.\n",
+ "\n",
+ "Data parallel training provides nearly linear speedup regarding the number of devices."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "UMsLUyTGq3oL"
+ },
+ "source": [
+ "### Creating a data parallel mesh\n",
+ "\n",
+ "A typical data parallelism training loop uses a DTensor `Mesh` that consists of a single `batch` dimension, where each device becomes a replica that receives a shard from the global batch.\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "The replicated model runs on the replica, therefore the model variables are fully replicated (unsharded)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "C0IyOlxmeu4I"
+ },
+ "outputs": [],
+ "source": [
+ "mesh = dtensor.create_mesh([(\"batch\", 8)], devices=DEVICES)\n",
+ "\n",
+ "model = MLP([dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh),\n",
+ " dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh),])\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "OREKwBybo1gZ"
+ },
+ "source": [
+ "### Packing training data to DTensors\n",
+ "\n",
+ "The training data batch should be packed into DTensors sharded along the `'batch'`(first) axis, such that DTensor will evenly distribute the training data to the `'batch'` mesh dimension.\n",
+ "\n",
+ "**Note**: In DTensor, the `batch size` always refers to the global batch size. The batch size should be chosen such that it can be divided evenly by the size of the `batch` mesh dimension."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "8xMYkTpGocY8"
+ },
+ "outputs": [],
+ "source": [
+ "def repack_batch(x, y, mesh):\n",
+ " x = repack_local_tensor(x, layout=dtensor.Layout(['batch', dtensor.UNSHARDED], mesh))\n",
+ " y = repack_local_tensor(y, layout=dtensor.Layout(['batch'], mesh))\n",
+ " return x, y\n",
+ "\n",
+ "sample_x, sample_y = train_data_vec.take(1).get_single_element()\n",
+ "sample_x, sample_y = repack_batch(sample_x, sample_y, mesh)\n",
+ "\n",
+ "print('x', sample_x[:, 0])\n",
+ "print('y', sample_y)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "uONSiqOIkFL1"
+ },
+ "source": [
+ "### Training step\n",
+ "\n",
+ "This example uses a Stochastic Gradient Descent optimizer with the Custom Training Loop (CTL). Consult the [Custom Training Loop guide](https://www.tensorflow.org/guide/keras/writing_a_training_loop_from_scratch) and [Walk through](https://www.tensorflow.org/tutorials/customization/custom_training_walkthrough) for more information on those topics.\n",
+ "\n",
+ "The `train_step` is encapsulated as a `tf.function` to indicate this body is to be traced as a TensorFlow Graph. The body of `train_step` consists of a forward inference pass, a backward gradient pass, and the variable update.\n",
+ "\n",
+ "Note that the body of `train_step` does not contain any special DTensor annotations. Instead, `train_step` only contains high-level TensorFlow operations that process the input `x` and `y` from the global view of the input batch and the model. All of the DTensor annotations (`Mesh`, `Layout`) are factored out of the train step."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "BwUFzLGDtQT6"
+ },
+ "outputs": [],
+ "source": [
+ "# Refer to the CTL (custom training loop guide)\n",
+ "@tf.function\n",
+ "def train_step(model, x, y, learning_rate=tf.constant(1e-4)):\n",
+ " with tf.GradientTape() as tape:\n",
+ " logits = model(x)\n",
+ " # tf.reduce_sum sums the batch sharded per-example loss to a replicated\n",
+ " # global loss (scalar).\n",
+ " loss = tf.reduce_sum(\n",
+ " tf.nn.sparse_softmax_cross_entropy_with_logits(\n",
+ " logits=logits, labels=y))\n",
+ " parameters = model.trainable_variables\n",
+ " gradients = tape.gradient(loss, parameters)\n",
+ " for parameter, parameter_gradient in zip(parameters, gradients):\n",
+ " parameter.assign_sub(learning_rate * parameter_gradient)\n",
+ "\n",
+ " # Define some metrics\n",
+ " accuracy = 1.0 - tf.reduce_sum(tf.cast(tf.argmax(logits, axis=-1, output_type=tf.int64) != y, tf.float32)) / x.shape[0]\n",
+ " loss_per_sample = loss / len(x)\n",
+ " return {'loss': loss_per_sample, 'accuracy': accuracy}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0OYTu4j0evWT"
+ },
+ "source": [
+ "### Checkpointing\n",
+ "\n",
+ "You can checkpoint a DTensor model using `tf.train.Checkpoint` out of the box. Saving and restoring sharded DVariables will perform an efficient sharded save and restore. Currently, when using `tf.train.Checkpoint.save` and `tf.train.Checkpoint.restore`, all DVariables must be on the same host mesh, and DVariables and regular variables cannot be saved together. You can learn more about checkpointing in [this guide](../../guide/checkpoint.ipynb).\n",
+ "\n",
+ "When a DTensor checkpoint is restored, `Layout`s of variables can be different from when the checkpoint is saved. That is, saving DTensor models is layout- and mesh-agnostic, and only affects the efficiency of sharded saving. You can save a DTensor model with one mesh and layout and restore it on a different mesh and layout. This tutorial makes use of this feature to continue the training in the Model Parallel training and Spatial Parallel training sections.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "rsInFFJg7x9t"
+ },
+ "outputs": [],
+ "source": [
+ "CHECKPOINT_DIR = tempfile.mkdtemp()\n",
+ "\n",
+ "def start_checkpoint_manager(model):\n",
+ " ckpt = tf.train.Checkpoint(root=model)\n",
+ " manager = tf.train.CheckpointManager(ckpt, CHECKPOINT_DIR, max_to_keep=3)\n",
+ "\n",
+ " if manager.latest_checkpoint:\n",
+ " print(\"Restoring a checkpoint\")\n",
+ " ckpt.restore(manager.latest_checkpoint).assert_consumed()\n",
+ " else:\n",
+ " print(\"New training\")\n",
+ " return manager\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "9r77ky5Jgp1j"
+ },
+ "source": [
+ "### Training loop\n",
+ "\n",
+ "For the data parallel training scheme, train for epochs and report the progress. 3 epochs is insufficient for training the model -- an accuracy of 50% is as good as randomly guessing.\n",
+ "\n",
+ "Enable checkpointing so that you can pick up the training later. In the following section, you will load the checkpoint and train with a different parallel scheme."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "UaLn-vGZgqbS"
+ },
+ "outputs": [],
+ "source": [
+ "num_epochs = 2\n",
+ "manager = start_checkpoint_manager(model)\n",
+ "\n",
+ "for epoch in range(num_epochs):\n",
+ " step = 0\n",
+ " pbar = tf.keras.utils.Progbar(target=int(train_data_vec.cardinality()), stateful_metrics=[])\n",
+ " metrics = {'epoch': epoch}\n",
+ " for x,y in train_data_vec:\n",
+ "\n",
+ " x, y = repack_batch(x, y, mesh)\n",
+ "\n",
+ " metrics.update(train_step(model, x, y, 1e-2))\n",
+ "\n",
+ " pbar.update(step, values=metrics.items(), finalize=False)\n",
+ " step += 1\n",
+ " manager.save()\n",
+ " pbar.update(step, values=metrics.items(), finalize=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "YRFJEhum7EGD"
+ },
+ "source": [
+ "## Model Parallel Training\n",
+ "\n",
+ "If you switch to a 2 dimensional `Mesh`, and shard the model variables along the second mesh dimension, then the training becomes Model Parallel.\n",
+ "\n",
+ "In Model Parallel training, each model replica spans multiple devices (2 in this case):\n",
+ "\n",
+ "- There are 4 model replicas, and the training data batch is distributed to the 4 replicas.\n",
+ "- The 2 devices within a single model replica receive replicated training data.\n",
+ "\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "The replicated model runs on the replica, therefore the model variables are fully replicated (unsharded)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "C0IyOlxmeu4I"
+ },
+ "outputs": [],
+ "source": [
+ "mesh = dtensor.create_mesh([(\"batch\", 8)], devices=DEVICES)\n",
+ "\n",
+ "model = MLP([dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh),\n",
+ " dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh),])\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "OREKwBybo1gZ"
+ },
+ "source": [
+ "### Packing training data to DTensors\n",
+ "\n",
+ "The training data batch should be packed into DTensors sharded along the `'batch'`(first) axis, such that DTensor will evenly distribute the training data to the `'batch'` mesh dimension.\n",
+ "\n",
+ "**Note**: In DTensor, the `batch size` always refers to the global batch size. The batch size should be chosen such that it can be divided evenly by the size of the `batch` mesh dimension."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "8xMYkTpGocY8"
+ },
+ "outputs": [],
+ "source": [
+ "def repack_batch(x, y, mesh):\n",
+ " x = repack_local_tensor(x, layout=dtensor.Layout(['batch', dtensor.UNSHARDED], mesh))\n",
+ " y = repack_local_tensor(y, layout=dtensor.Layout(['batch'], mesh))\n",
+ " return x, y\n",
+ "\n",
+ "sample_x, sample_y = train_data_vec.take(1).get_single_element()\n",
+ "sample_x, sample_y = repack_batch(sample_x, sample_y, mesh)\n",
+ "\n",
+ "print('x', sample_x[:, 0])\n",
+ "print('y', sample_y)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "uONSiqOIkFL1"
+ },
+ "source": [
+ "### Training step\n",
+ "\n",
+ "This example uses a Stochastic Gradient Descent optimizer with the Custom Training Loop (CTL). Consult the [Custom Training Loop guide](https://www.tensorflow.org/guide/keras/writing_a_training_loop_from_scratch) and [Walk through](https://www.tensorflow.org/tutorials/customization/custom_training_walkthrough) for more information on those topics.\n",
+ "\n",
+ "The `train_step` is encapsulated as a `tf.function` to indicate this body is to be traced as a TensorFlow Graph. The body of `train_step` consists of a forward inference pass, a backward gradient pass, and the variable update.\n",
+ "\n",
+ "Note that the body of `train_step` does not contain any special DTensor annotations. Instead, `train_step` only contains high-level TensorFlow operations that process the input `x` and `y` from the global view of the input batch and the model. All of the DTensor annotations (`Mesh`, `Layout`) are factored out of the train step."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "BwUFzLGDtQT6"
+ },
+ "outputs": [],
+ "source": [
+ "# Refer to the CTL (custom training loop guide)\n",
+ "@tf.function\n",
+ "def train_step(model, x, y, learning_rate=tf.constant(1e-4)):\n",
+ " with tf.GradientTape() as tape:\n",
+ " logits = model(x)\n",
+ " # tf.reduce_sum sums the batch sharded per-example loss to a replicated\n",
+ " # global loss (scalar).\n",
+ " loss = tf.reduce_sum(\n",
+ " tf.nn.sparse_softmax_cross_entropy_with_logits(\n",
+ " logits=logits, labels=y))\n",
+ " parameters = model.trainable_variables\n",
+ " gradients = tape.gradient(loss, parameters)\n",
+ " for parameter, parameter_gradient in zip(parameters, gradients):\n",
+ " parameter.assign_sub(learning_rate * parameter_gradient)\n",
+ "\n",
+ " # Define some metrics\n",
+ " accuracy = 1.0 - tf.reduce_sum(tf.cast(tf.argmax(logits, axis=-1, output_type=tf.int64) != y, tf.float32)) / x.shape[0]\n",
+ " loss_per_sample = loss / len(x)\n",
+ " return {'loss': loss_per_sample, 'accuracy': accuracy}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0OYTu4j0evWT"
+ },
+ "source": [
+ "### Checkpointing\n",
+ "\n",
+ "You can checkpoint a DTensor model using `tf.train.Checkpoint` out of the box. Saving and restoring sharded DVariables will perform an efficient sharded save and restore. Currently, when using `tf.train.Checkpoint.save` and `tf.train.Checkpoint.restore`, all DVariables must be on the same host mesh, and DVariables and regular variables cannot be saved together. You can learn more about checkpointing in [this guide](../../guide/checkpoint.ipynb).\n",
+ "\n",
+ "When a DTensor checkpoint is restored, `Layout`s of variables can be different from when the checkpoint is saved. That is, saving DTensor models is layout- and mesh-agnostic, and only affects the efficiency of sharded saving. You can save a DTensor model with one mesh and layout and restore it on a different mesh and layout. This tutorial makes use of this feature to continue the training in the Model Parallel training and Spatial Parallel training sections.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "rsInFFJg7x9t"
+ },
+ "outputs": [],
+ "source": [
+ "CHECKPOINT_DIR = tempfile.mkdtemp()\n",
+ "\n",
+ "def start_checkpoint_manager(model):\n",
+ " ckpt = tf.train.Checkpoint(root=model)\n",
+ " manager = tf.train.CheckpointManager(ckpt, CHECKPOINT_DIR, max_to_keep=3)\n",
+ "\n",
+ " if manager.latest_checkpoint:\n",
+ " print(\"Restoring a checkpoint\")\n",
+ " ckpt.restore(manager.latest_checkpoint).assert_consumed()\n",
+ " else:\n",
+ " print(\"New training\")\n",
+ " return manager\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "9r77ky5Jgp1j"
+ },
+ "source": [
+ "### Training loop\n",
+ "\n",
+ "For the data parallel training scheme, train for epochs and report the progress. 3 epochs is insufficient for training the model -- an accuracy of 50% is as good as randomly guessing.\n",
+ "\n",
+ "Enable checkpointing so that you can pick up the training later. In the following section, you will load the checkpoint and train with a different parallel scheme."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "UaLn-vGZgqbS"
+ },
+ "outputs": [],
+ "source": [
+ "num_epochs = 2\n",
+ "manager = start_checkpoint_manager(model)\n",
+ "\n",
+ "for epoch in range(num_epochs):\n",
+ " step = 0\n",
+ " pbar = tf.keras.utils.Progbar(target=int(train_data_vec.cardinality()), stateful_metrics=[])\n",
+ " metrics = {'epoch': epoch}\n",
+ " for x,y in train_data_vec:\n",
+ "\n",
+ " x, y = repack_batch(x, y, mesh)\n",
+ "\n",
+ " metrics.update(train_step(model, x, y, 1e-2))\n",
+ "\n",
+ " pbar.update(step, values=metrics.items(), finalize=False)\n",
+ " step += 1\n",
+ " manager.save()\n",
+ " pbar.update(step, values=metrics.items(), finalize=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "YRFJEhum7EGD"
+ },
+ "source": [
+ "## Model Parallel Training\n",
+ "\n",
+ "If you switch to a 2 dimensional `Mesh`, and shard the model variables along the second mesh dimension, then the training becomes Model Parallel.\n",
+ "\n",
+ "In Model Parallel training, each model replica spans multiple devices (2 in this case):\n",
+ "\n",
+ "- There are 4 model replicas, and the training data batch is distributed to the 4 replicas.\n",
+ "- The 2 devices within a single model replica receive replicated training data.\n",
+ "\n",
+ "\n",
+ " \n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "5gZE9IT5Dzwl"
+ },
+ "outputs": [],
+ "source": [
+ "mesh = dtensor.create_mesh([(\"batch\", 4), (\"model\", 2)], devices=DEVICES)\n",
+ "model = MLP([dtensor.Layout([dtensor.UNSHARDED, \"model\"], mesh), \n",
+ " dtensor.Layout([\"model\", dtensor.UNSHARDED], mesh)])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Ihof3DkMFKnf"
+ },
+ "source": [
+ "As the training data is still sharded along the batch dimension, you can reuse the same `repack_batch` function as the Data Parallel training case. DTensor will automatically replicate the per-replica batch to all devices inside the replica along the `\"model\"` mesh dimension."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "dZf56ynbE_p1"
+ },
+ "outputs": [],
+ "source": [
+ "def repack_batch(x, y, mesh):\n",
+ " x = repack_local_tensor(x, layout=dtensor.Layout(['batch', dtensor.UNSHARDED], mesh))\n",
+ " y = repack_local_tensor(y, layout=dtensor.Layout(['batch'], mesh))\n",
+ " return x, y"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "UW3OXdhNFfpv"
+ },
+ "source": [
+ "Next run the training loop. The training loop reuses the same checkpoint manager as the Data Parallel training example, and the code looks identical.\n",
+ "\n",
+ "You can continue training the data parallel trained model under model parallel training."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "LLC0wgii7EgA"
+ },
+ "outputs": [],
+ "source": [
+ "num_epochs = 2\n",
+ "manager = start_checkpoint_manager(model)\n",
+ "\n",
+ "for epoch in range(num_epochs):\n",
+ " step = 0\n",
+ " pbar = tf.keras.utils.Progbar(target=int(train_data_vec.cardinality()))\n",
+ " metrics = {'epoch': epoch}\n",
+ " for x,y in train_data_vec:\n",
+ " x, y = repack_batch(x, y, mesh)\n",
+ " metrics.update(train_step(model, x, y, 1e-2))\n",
+ " pbar.update(step, values=metrics.items(), finalize=False)\n",
+ " step += 1\n",
+ " manager.save()\n",
+ " pbar.update(step, values=metrics.items(), finalize=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "BZH-aMrVzi2L"
+ },
+ "source": [
+ "## Spatial Parallel Training"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "u-bK6IZ9GCS9"
+ },
+ "source": [
+ "When training data of very high dimensionality (e.g. a very large image or a video), it may be desirable to shard along the feature dimension. This is called [Spatial Partitioning](https://cloud.google.com/blog/products/ai-machine-learning/train-ml-models-on-large-images-and-3d-volumes-with-spatial-partitioning-on-cloud-tpus), which was first introduced into TensorFlow for training models with large 3-d input samples.\n",
+ "\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "5gZE9IT5Dzwl"
+ },
+ "outputs": [],
+ "source": [
+ "mesh = dtensor.create_mesh([(\"batch\", 4), (\"model\", 2)], devices=DEVICES)\n",
+ "model = MLP([dtensor.Layout([dtensor.UNSHARDED, \"model\"], mesh), \n",
+ " dtensor.Layout([\"model\", dtensor.UNSHARDED], mesh)])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Ihof3DkMFKnf"
+ },
+ "source": [
+ "As the training data is still sharded along the batch dimension, you can reuse the same `repack_batch` function as the Data Parallel training case. DTensor will automatically replicate the per-replica batch to all devices inside the replica along the `\"model\"` mesh dimension."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "dZf56ynbE_p1"
+ },
+ "outputs": [],
+ "source": [
+ "def repack_batch(x, y, mesh):\n",
+ " x = repack_local_tensor(x, layout=dtensor.Layout(['batch', dtensor.UNSHARDED], mesh))\n",
+ " y = repack_local_tensor(y, layout=dtensor.Layout(['batch'], mesh))\n",
+ " return x, y"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "UW3OXdhNFfpv"
+ },
+ "source": [
+ "Next run the training loop. The training loop reuses the same checkpoint manager as the Data Parallel training example, and the code looks identical.\n",
+ "\n",
+ "You can continue training the data parallel trained model under model parallel training."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "LLC0wgii7EgA"
+ },
+ "outputs": [],
+ "source": [
+ "num_epochs = 2\n",
+ "manager = start_checkpoint_manager(model)\n",
+ "\n",
+ "for epoch in range(num_epochs):\n",
+ " step = 0\n",
+ " pbar = tf.keras.utils.Progbar(target=int(train_data_vec.cardinality()))\n",
+ " metrics = {'epoch': epoch}\n",
+ " for x,y in train_data_vec:\n",
+ " x, y = repack_batch(x, y, mesh)\n",
+ " metrics.update(train_step(model, x, y, 1e-2))\n",
+ " pbar.update(step, values=metrics.items(), finalize=False)\n",
+ " step += 1\n",
+ " manager.save()\n",
+ " pbar.update(step, values=metrics.items(), finalize=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "BZH-aMrVzi2L"
+ },
+ "source": [
+ "## Spatial Parallel Training"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "u-bK6IZ9GCS9"
+ },
+ "source": [
+ "When training data of very high dimensionality (e.g. a very large image or a video), it may be desirable to shard along the feature dimension. This is called [Spatial Partitioning](https://cloud.google.com/blog/products/ai-machine-learning/train-ml-models-on-large-images-and-3d-volumes-with-spatial-partitioning-on-cloud-tpus), which was first introduced into TensorFlow for training models with large 3-d input samples.\n",
+ "\n",
+ " \n",
+ "\n",
+ "DTensor also supports this case. The only change you need to do is to create a Mesh that includes a `feature` dimension, and apply the corresponding `Layout`.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "jpc9mqURGpmK"
+ },
+ "outputs": [],
+ "source": [
+ "mesh = dtensor.create_mesh([(\"batch\", 2), (\"feature\", 2), (\"model\", 2)], devices=DEVICES)\n",
+ "model = MLP([dtensor.Layout([\"feature\", \"model\"], mesh), \n",
+ " dtensor.Layout([\"model\", dtensor.UNSHARDED], mesh)])\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "i07Wrv-jHBc1"
+ },
+ "source": [
+ "Shard the input data along the `feature` dimension when packing the input tensors to DTensors. You do this with a slightly different repack function, `repack_batch_for_spt`, where `spt` stands for Spatial Parallel Training."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "DWR8qF6BGtFL"
+ },
+ "outputs": [],
+ "source": [
+ "def repack_batch_for_spt(x, y, mesh):\n",
+ " # Shard data on feature dimension, too\n",
+ " x = repack_local_tensor(x, layout=dtensor.Layout([\"batch\", 'feature'], mesh))\n",
+ " y = repack_local_tensor(y, layout=dtensor.Layout([\"batch\"], mesh))\n",
+ " return x, y"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Ygl9dqMUHTVN"
+ },
+ "source": [
+ "The Spatial parallel training can also continue from a checkpoint created with other parallell training schemes."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "p3NnpHSKo-hx"
+ },
+ "outputs": [],
+ "source": [
+ "num_epochs = 2\n",
+ "\n",
+ "manager = start_checkpoint_manager(model)\n",
+ "for epoch in range(num_epochs):\n",
+ " step = 0\n",
+ " metrics = {'epoch': epoch}\n",
+ " pbar = tf.keras.utils.Progbar(target=int(train_data_vec.cardinality()))\n",
+ "\n",
+ " for x, y in train_data_vec:\n",
+ " x, y = repack_batch_for_spt(x, y, mesh)\n",
+ " metrics.update(train_step(model, x, y, 1e-2))\n",
+ "\n",
+ " pbar.update(step, values=metrics.items(), finalize=False)\n",
+ " step += 1\n",
+ " manager.save()\n",
+ " pbar.update(step, values=metrics.items(), finalize=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "vp4L59CpJjYr"
+ },
+ "source": [
+ "## SavedModel and DTensor\n",
+ "\n",
+ "The integration of DTensor and SavedModel is still under development. \n",
+ "\n",
+ "As of TensorFlow `2.11`, `tf.saved_model` can save sharded and replicated DTensor models, and saving will do an efficient sharded save on different devices of the mesh. However, after a model is saved, all DTensor annotations are lost and the saved signatures can only be used with regular Tensors, not DTensors."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "49HfIq_SJZoj"
+ },
+ "outputs": [],
+ "source": [
+ "mesh = dtensor.create_mesh([(\"world\", 1)], devices=DEVICES[:1])\n",
+ "mlp = MLP([dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh), \n",
+ " dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh)])\n",
+ "\n",
+ "manager = start_checkpoint_manager(mlp)\n",
+ "\n",
+ "model_for_saving = tf.keras.Sequential([\n",
+ " text_vectorization,\n",
+ " mlp\n",
+ "])\n",
+ "\n",
+ "@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])\n",
+ "def run(inputs):\n",
+ " return {'result': model_for_saving(inputs)}\n",
+ "\n",
+ "tf.saved_model.save(\n",
+ " model_for_saving, \"/tmp/saved_model\",\n",
+ " signatures=run)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "h6Csim_VMGxQ"
+ },
+ "source": [
+ "As of TensorFlow 2.9.0, you can only call a loaded signature with a regular Tensor, or a fully replicated DTensor (which will be converted to a regular Tensor)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "HG_ASSzR4IWW"
+ },
+ "outputs": [],
+ "source": [
+ "sample_batch = train_data.take(1).get_single_element()\n",
+ "sample_batch"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "qW8yKPrhKQ5b"
+ },
+ "outputs": [],
+ "source": [
+ "loaded = tf.saved_model.load(\"/tmp/saved_model\")\n",
+ "\n",
+ "run_sig = loaded.signatures[\"serving_default\"]\n",
+ "result = run_sig(sample_batch['text'])['result']"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "GahGbv0ZmkJb"
+ },
+ "outputs": [],
+ "source": [
+ "np.mean(tf.argmax(result, axis=-1) == sample_batch['label'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Ks-Vs9qsH6jO"
+ },
+ "source": [
+ "## What's next?\n",
+ "\n",
+ "This tutorial demonstrated building and training an MLP sentiment analysis model with DTensor.\n",
+ "\n",
+ "Through `Mesh` and `Layout` primitives, DTensor can transform a TensorFlow `tf.function` to a distributed program suitable for a variety of training schemes.\n",
+ "\n",
+ "In a real-world machine learning application, evaluation and cross-validation should be applied to avoid producing an over-fitted model. The techniques introduced in this tutorial can also be applied to introduce parallelism to evaluation.\n",
+ "\n",
+ "Composing a model with `tf.Module` from scratch is a lot of work, and reusing existing building blocks such as layers and helper functions can drastically speed up model development.\n",
+ "As of TensorFlow 2.9, all Keras Layers under `tf.keras.layers` accepts DTensor layouts as their arguments, and can be used to build DTensor models. You can even directly reuse a Keras model with DTensor without modifying the model implementation. Refer to the [DTensor Keras Integration Tutorial](https://www.tensorflow.org/tutorials/distribute/dtensor_keras_tutorial) for information on using DTensor Keras. "
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "collapsed_sections": [],
+ "name": "dtensor_ml_tutorial.ipynb",
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/site/en/tutorials/distribute/input.ipynb b/site/en/tutorials/distribute/input.ipynb
index e1cdca6788e..f779c4f19a6 100644
--- a/site/en/tutorials/distribute/input.ipynb
+++ b/site/en/tutorials/distribute/input.ipynb
@@ -73,7 +73,7 @@
"This guide will show you the different ways in which you can create distributed dataset and iterators using `tf.distribute` APIs. Additionally, the following topics will be covered:\n",
"- Usage, sharding and batching options when using `tf.distribute.Strategy.experimental_distribute_dataset` and `tf.distribute.Strategy.distribute_datasets_from_function`.\n",
"- Different ways in which you can iterate over the distributed dataset.\n",
- "- Differences between `tf.distribute.Strategy.experimental_distribute_dataset`/`tf.distribute.Strategy.distribute_datasets_from_function` APIs and `tf.data` APIs as well any limitations that users may come across in their usage.\n",
+ "- Differences between `tf.distribute.Strategy.experimental_distribute_dataset`/`tf.distribute.Strategy.distribute_datasets_from_function` APIs and `tf.data` APIs as well as any limitations that users may come across in their usage.\n",
"\n",
"This guide does not cover usage of distributed input with Keras APIs."
]
@@ -84,7 +84,7 @@
"id": "MM6W__qraV55"
},
"source": [
- "## Distributed Datasets"
+ "## Distributed datasets"
]
},
{
@@ -93,8 +93,8 @@
"id": "lNy9GxjSlMKQ"
},
"source": [
- "To use `tf.distribute` APIs to scale, it is recommended that users use `tf.data.Dataset` to represent their input. `tf.distribute` has been made to work efficiently with `tf.data.Dataset` (for example, automatic prefetch of data onto each accelerator device) with performance optimizations being regularly incorporated into the implementation. If you have a use case for using something other than `tf.data.Dataset`, please refer a later [section](\"tensorinputs\") in this guide.\n",
- "In a non distributed training loop, users first create a `tf.data.Dataset` instance and then iterate over the elements. For example:\n"
+ "To use `tf.distribute` APIs to scale, use `tf.data.Dataset` to represent their input. `tf.distribute` works efficiently with `tf.data.Dataset`—for example, via automatic prefetching onto each accelerator device and regular performance updates. If you have a use case for using something other than `tf.data.Dataset`, please refer to the [Tensor inputs section](#tensorinputs) in this guide.\n",
+ "In a non-distributed training loop, first create a `tf.data.Dataset` instance and then iterate over the elements. For example:\n"
]
},
{
@@ -114,6 +114,34 @@
"print(tf.__version__)"
]
},
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "6cnilUtmKwpa"
+ },
+ "outputs": [],
+ "source": [
+ "# Simulate multiple CPUs with virtual devices\n",
+ "N_VIRTUAL_DEVICES = 2\n",
+ "physical_devices = tf.config.list_physical_devices(\"CPU\")\n",
+ "tf.config.set_logical_device_configuration(\n",
+ " physical_devices[0], [tf.config.LogicalDeviceConfiguration() for _ in range(N_VIRTUAL_DEVICES)])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "zd4l1ySeLRk1"
+ },
+ "outputs": [],
+ "source": [
+ "print(\"Available devices:\")\n",
+ "for i, device in enumerate(tf.config.list_logical_devices()):\n",
+ " print(\"%d) %s\" % (i, device))"
+ ]
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -214,14 +242,14 @@
" * Replica 1:[0, 1]\n",
" * Replica 2:[2, 3]\n",
" * Batch 2:\n",
- " * Replica 2: [4]\n",
+ " * Replica 1: [4]\n",
" * Replica 2: [5]\n",
"\n",
"\n",
"\n",
"* `tf.data.Dataset.range(4).batch(4)`\n",
" * Without distribution:\n",
- " * Batch 1: [[0], [1], [2], [3]]\n",
+ " * Batch 1: [0, 1, 2, 3]\n",
" * With distribution over 5 replicas:\n",
" * Batch 1:\n",
" * Replica 1: [0]\n",
@@ -246,7 +274,7 @@
"\n",
"Note: The above examples only illustrate how a global batch is split on different replicas. It is not advisable to depend on the actual values that might end up on each replica as it can change depending on the implementation.\n",
"\n",
- "Rebatching the dataset has a space complexity that increases linearly with the number of replicas. This means that for the multi worker training use case the input pipeline can run into OOM errors. "
+ "Rebatching the dataset has a space complexity that increases linearly with the number of replicas. This means that for the multi-worker training use case the input pipeline can run into OOM errors. "
]
},
{
@@ -257,7 +285,7 @@
"source": [
"##### Sharding\n",
"\n",
- "`tf.distribute` also autoshards the input dataset in multi worker training with `MultiWorkerMirroredStrategy` and `TPUStrategy`. Each dataset is created on the CPU device of the worker. Autosharding a dataset over a set of workers means that each worker is assigned a subset of the entire dataset (if the right `tf.data.experimental.AutoShardPolicy` is set). This is to ensure that at each step, a global batch size of non overlapping dataset elements will be processed by each worker. Autosharding has a couple of different options that can be specified using `tf.data.experimental.DistributeOptions`. Note that there is no autosharding in multi worker training with `ParameterServerStrategy`, and more information on dataset creation with this strategy can be found in the [Parameter Server Strategy tutorial](parameter_server_training.ipynb). "
+ "`tf.distribute` also autoshards the input dataset in multi-worker training with `MultiWorkerMirroredStrategy` and `TPUStrategy`. Each dataset is created on the CPU device of the worker. Autosharding a dataset over a set of workers means that each worker is assigned a subset of the entire dataset (if the right `tf.data.experimental.AutoShardPolicy` is set). This is to ensure that at each step, a global batch size of non-overlapping dataset elements will be processed by each worker. Autosharding has a couple of different options that can be specified using `tf.data.experimental.DistributeOptions`. Note that there is no autosharding in multi-worker training with `ParameterServerStrategy`, and more information on dataset creation with this strategy can be found in the [ParameterServerStrategy tutorial](parameter_server_training.ipynb). "
]
},
{
@@ -268,7 +296,7 @@
},
"outputs": [],
"source": [
- "dataset = tf.data.Dataset.from_tensors(([1.],[1.])).repeat(64).batch(16)\n",
+ "dataset = tf.data.Dataset.from_tensors(([1.], [1.])).repeat(64).batch(16)\n",
"options = tf.data.Options()\n",
"options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.DATA\n",
"dataset = dataset.with_options(options)"
@@ -358,7 +386,7 @@
"source": [
"#### Usage\n",
"\n",
- "This API takes an input function and returns a `tf.distribute.DistributedDataset` instance. The input function that users pass in has a `tf.distribute.InputContext` argument and should return a `tf.data.Dataset` instance. With this API, `tf.distribute` does not make any further changes to the user’s `tf.data.Dataset` instance returned from the input function. It is the responsibility of the user to batch and shard the dataset. `tf.distribute` calls the input function on the CPU device of each of the workers. Apart from allowing users to specify their own batching and sharding logic, this API also demonstrates better scalability and performance compared to `tf.distribute.Strategy.experimental_distribute_dataset` when used for multi worker training."
+ "This API takes an input function and returns a `tf.distribute.DistributedDataset` instance. The input function that users pass in has a `tf.distribute.InputContext` argument and should return a `tf.data.Dataset` instance. With this API, `tf.distribute` does not make any further changes to the user’s `tf.data.Dataset` instance returned from the input function. It is the responsibility of the user to batch and shard the dataset. `tf.distribute` calls the input function on the CPU device of each of the workers. Apart from allowing users to specify their own batching and sharding logic, this API also demonstrates better scalability and performance compared to `tf.distribute.Strategy.experimental_distribute_dataset` when used for multi-worker training."
]
},
{
@@ -373,11 +401,11 @@
"\n",
"def dataset_fn(input_context):\n",
" batch_size = input_context.get_per_replica_batch_size(global_batch_size)\n",
- " dataset = tf.data.Dataset.from_tensors(([1.],[1.])).repeat(64).batch(16)\n",
+ " dataset = tf.data.Dataset.from_tensors(([1.], [1.])).repeat(64).batch(16)\n",
" dataset = dataset.shard(\n",
- " input_context.num_input_pipelines, input_context.input_pipeline_id)\n",
+ " input_context.num_input_pipelines, input_context.input_pipeline_id)\n",
" dataset = dataset.batch(batch_size)\n",
- " dataset = dataset.prefetch(2) # This prefetches 2 batches per device.\n",
+ " dataset = dataset.prefetch(2) # This prefetches 2 batches per device.\n",
" return dataset\n",
"\n",
"dist_dataset = mirrored_strategy.distribute_datasets_from_function(dataset_fn)"
@@ -411,7 +439,7 @@
"source": [
"##### Sharding\n",
"\n",
- "The `tf.distribute.InputContext` object that is implicitly passed as an argument to the user’s input function is created by `tf.distribute` under the hood. It has information about the number of workers, current worker id etc. This input function can handle sharding as per policies set by the user using these properties that are part of the `tf.distribute.InputContext` object.\n"
+ "The `tf.distribute.InputContext` object that is implicitly passed as an argument to the user’s input function is created by `tf.distribute` under the hood. It has information about the number of workers, current worker ID etc. This input function can handle sharding as per policies set by the user using these properties that are part of the `tf.distribute.InputContext` object.\n"
]
},
{
@@ -422,7 +450,7 @@
"source": [
"##### Prefetching\n",
"\n",
- "`tf.distribute` does not add a prefetch transformation at the end of the `tf.data.Dataset` returned by the user provided input function."
+ "`tf.distribute` does not add a prefetch transformation at the end of the `tf.data.Dataset` returned by the user-provided input function, so you explicitly call `Dataset.prefetch` in the example above."
]
},
{
@@ -442,7 +470,7 @@
"id": "dL3XbI1gzEjO"
},
"source": [
- "## Distributed Iterators"
+ "## Distributed iterators"
]
},
{
@@ -452,7 +480,7 @@
},
"source": [
"Similar to non-distributed `tf.data.Dataset` instances, you will need to create an iterator on the `tf.distribute.DistributedDataset` instances to iterate over it and access the elements in the `tf.distribute.DistributedDataset`.\n",
- "The following are the ways in which you can create an `tf.distribute.DistributedIterator` and use it to train your model:\n"
+ "The following are the ways in which you can create a `tf.distribute.DistributedIterator` and use it to train your model:\n"
]
},
{
@@ -486,7 +514,7 @@
"global_batch_size = 16\n",
"mirrored_strategy = tf.distribute.MirroredStrategy()\n",
"\n",
- "dataset = tf.data.Dataset.from_tensors(([1.],[1.])).repeat(100).batch(global_batch_size)\n",
+ "dataset = tf.data.Dataset.from_tensors(([1.], [1.])).repeat(100).batch(global_batch_size)\n",
"dist_dataset = mirrored_strategy.experimental_distribute_dataset(dataset)\n",
"\n",
"@tf.function\n",
@@ -536,14 +564,16 @@
"id": "UpJXIlxjqPYg"
},
"source": [
- "With `next()` or `tf.distribute.DistributedIterator.get_next()`, if the `tf.distribute.DistributedIterator` has reached its end, an OutOfRange error will be thrown. The client can catch the error on python side and continue doing other work such as checkpointing and evaluation. However, this will not work if you are using a host training loop (i.e., run multiple steps per `tf.function`), which looks like:\n",
+ "With `next` or `tf.distribute.DistributedIterator.get_next`, if the `tf.distribute.DistributedIterator` has reached its end, an OutOfRange error will be thrown. The client can catch the error on python side and continue doing other work such as checkpointing and evaluation. However, this will not work if you are using a host training loop (i.e., run multiple steps per `tf.function`), which looks like:\n",
+ "\n",
"```\n",
"@tf.function\n",
"def train_fn(iterator):\n",
" for _ in tf.range(steps_per_loop):\n",
" strategy.run(step_fn, args=(next(iterator),))\n",
"```\n",
- " `train_fn` contains multiple steps by wrapping the step body inside a `tf.range`. In this case, different iterations in the loop with no dependency could start in parallel, so an OutOfRange error can be triggered in later iterations before the computation of previous iterations finishes. Once an OutOfRange error is thrown, all the ops in the function will be terminated right away. If this is some case that you would like to avoid, an alternative that does not throw an OutOfRange error is `tf.distribute.DistributedIterator.get_next_as_optional()`. `get_next_as_optional` returns a `tf.experimental.Optional` which contains the next element or no value if the `tf.distribute.DistributedIterator` has reached to an end."
+ "\n",
+ "This example `train_fn` contains multiple steps by wrapping the step body inside a `tf.range`. In this case, different iterations in the loop with no dependency could start in parallel, so an OutOfRange error can be triggered in later iterations before the computation of previous iterations finishes. Once an OutOfRange error is thrown, all the ops in the function will be terminated right away. If this is some case that you would like to avoid, an alternative that does not throw an OutOfRange error is `tf.distribute.DistributedIterator.get_next_as_optional`. `get_next_as_optional` returns a `tf.experimental.Optional` which contains the next element or no value if the `tf.distribute.DistributedIterator` has reached an end."
]
},
{
@@ -554,10 +584,10 @@
},
"outputs": [],
"source": [
- "# You can break the loop with get_next_as_optional by checking if the Optional contains value\n",
+ "# You can break the loop with `get_next_as_optional` by checking if the `Optional` contains a value\n",
"global_batch_size = 4\n",
"steps_per_loop = 5\n",
- "strategy = tf.distribute.MirroredStrategy(devices=[\"GPU:0\", \"CPU:0\"])\n",
+ "strategy = tf.distribute.MirroredStrategy()\n",
"\n",
"dataset = tf.data.Dataset.range(9).batch(global_batch_size)\n",
"distributed_iterator = iter(strategy.experimental_distribute_dataset(dataset))\n",
@@ -568,7 +598,7 @@
" optional_data = distributed_iterator.get_next_as_optional()\n",
" if not optional_data.has_value():\n",
" break\n",
- " per_replica_results = strategy.run(lambda x:x, args=(optional_data.get_value(),))\n",
+ " per_replica_results = strategy.run(lambda x: x, args=(optional_data.get_value(),))\n",
" tf.print(strategy.experimental_local_results(per_replica_results))\n",
"train_fn(distributed_iterator)"
]
@@ -579,7 +609,7 @@
"id": "LaclbKnqzLjf"
},
"source": [
- "## Using `element_spec` property"
+ "## Using the `element_spec` property"
]
},
{
@@ -588,7 +618,7 @@
"id": "Z1YvXqOpwy08"
},
"source": [
- "If you pass the elements of a distributed dataset to a `tf.function` and want a `tf.TypeSpec` guarantee, you can specify the `input_signature` argument of the `tf.function`. The output of a distributed dataset is `tf.distribute.DistributedValues` which can represent the input to a single device or multiple devices. To get the `tf.TypeSpec` corresponding to this distributed value you can use the `element_spec` property of the distributed dataset or distributed iterator object."
+ "If you pass the elements of a distributed dataset to a `tf.function` and want a `tf.TypeSpec` guarantee, you can specify the `input_signature` argument of the `tf.function`. The output of a distributed dataset is `tf.distribute.DistributedValues` which can represent the input to a single device or multiple devices. To get the `tf.TypeSpec` corresponding to this distributed value, you can use `tf.distribute.DistributedDataset.element_spec` or `tf.distribute.DistributedIterator.element_spec`."
]
},
{
@@ -604,7 +634,7 @@
"steps_per_epoch = 5\n",
"mirrored_strategy = tf.distribute.MirroredStrategy()\n",
"\n",
- "dataset = tf.data.Dataset.from_tensors(([1.],[1.])).repeat(100).batch(global_batch_size)\n",
+ "dataset = tf.data.Dataset.from_tensors(([1.], [1.])).repeat(100).batch(global_batch_size)\n",
"dist_dataset = mirrored_strategy.experimental_distribute_dataset(dataset)\n",
"\n",
"@tf.function(input_signature=[dist_dataset.element_spec])\n",
@@ -627,7 +657,246 @@
"id": "-OAa6svUzuWm"
},
"source": [
- "## Partial Batches"
+ "## Data preprocessing"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "pSMrs3kJQexW"
+ },
+ "source": [
+ "So far, you have learned how to distribute a `tf.data.Dataset`. Yet before the data is ready for the model, it needs to be preprocessed, for example by cleansing, transforming, and augmenting it. Two sets of those handy tools are:\n",
+ "\n",
+ "* [Keras preprocessing layers](https://www.tensorflow.org/guide/keras/preprocessing_layers): a set of Keras layers that allow developers to build Keras-native input processing pipelines. Some Keras preprocessing layers contain non-trainable states, which can be set on initialization or `adapt`ed (refer to the `adapt` section of the [Keras preprocessing layers guide](https://www.tensorflow.org/guide/keras/preprocessing_layers)). When distributing stateful preprocessing layers, the states should be replicated to all workers. To use these layers, you can either make them part of the model or apply them to the datasets.\n",
+ "\n",
+ "* [TensorFlow Transform (tf.Transform)](https://www.tensorflow.org/tfx/transform/get_started): a library for TensorFlow that allows you to define both instance-level and full-pass data transformation through data preprocessing pipelines. Tensorflow Transform has two phases. The first is the Analyze phase, where the raw training data is analyzed in a full-pass process to compute the statistics needed for the transformations, and the transformation logic is generated as instance-level operations. The second is the Transform phase, where the raw training data is transformed in an instance-level process.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Pd4aUCFdVlZ1"
+ },
+ "source": [
+ "### Keras preprocessing layers vs. Tensorflow Transform \n",
+ "\n",
+ "Both Tensorflow Transform and Keras preprocessing layers provide a way to split out preprocessing during training and bundle preprocessing with a model during inference, reducing train/serve skew.\n",
+ "\n",
+ "Tensorflow Transform, deeply integrated with [TFX](https://www.tensorflow.org/tfx), provides a scalable map-reduce solution to analyzing and transforming datasets of any size in a job separate from the training pipeline. If you need to run an analysis on a dataset that cannot fit on a single machine, Tensorflow Transform should be your first choice.\n",
+ "\n",
+ "Keras preprocessing layers are more geared towards preprocessing applied during training, after reading data from disk. They fit seamlessly with model development in the Keras library. They support analysis of a smaller dataset via [`adapt`](https://www.tensorflow.org/guide/keras/preprocessing_layers#the_adapt_method) and supports use cases like image data augmentation, where each pass over the input dataset will yield different examples for training.\n",
+ "\n",
+ "The two libraries can also be mixed, where Tensorflow Transform is used for analysis and static transformations of input data, and Keras preprocessing layers are used for train-time transformations (e.g., one-hot encoding or data augmentation).\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "MReKhhZpHUpj"
+ },
+ "source": [
+ "### Best Practice with tf.distribute\n",
+ "\n",
+ "Working with both tools involves initializing the transformation logic to apply to data, which might create Tensorflow resources. These resources or states should be replicated to all workers to save inter-workers or worker-coordinator communication. To do so, you are recommended to create Keras preprocessing layers, `tft.TFTransformOutput.transform_features_layer`, or `tft.TransformFeaturesLayer` under `tf.distribute.Strategy.scope`, just like you would for any other Keras layers.\n",
+ "\n",
+ "The following examples demonstrate usage of the `tf.distribute.Strategy` API with the high-level Keras `Model.fit` API and with a custom training loop separately."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "rwEGMWuoX7kJ"
+ },
+ "source": [
+ "#### Extra notes for Keras preprocessing layers users:\n",
+ "\n",
+ "**Preprocessing layers and large vocabularies**\n",
+ "\n",
+ "When dealing with large vocabularies (over one gigabyte) in a multi-worker setting (for example, `tf.distribute.MultiWorkerMirroredStrategy`, `tf.distribute.experimental.ParameterServerStrategy`, `tf.distribute.TPUStrategy`), it is recommended to save the vocabulary to a static file accessible from all workers (for example, with Cloud Storage). This will reduce the time spent replicating the vocabulary to all workers during training.\n",
+ "\n",
+ "**Preprocessing in the `tf.data` pipeline versus in the model**\n",
+ "\n",
+ "While Keras preprocessing layers can be applied either as part of the model or directly to a `tf.data.Dataset`, each of the options come with their edge:\n",
+ "\n",
+ "* Applying the preprocessing layers within the model makes your model portable, and it helps reduce the training/serving skew. (For more details, refer to the _Benefits of doing preprocessing inside the model at inference time_ section in the [Working with preprocessing layers guide](https://www.tensorflow.org/guide/keras/preprocessing_layers#benefits_of_doing_preprocessing_inside_the_model_at_inference_time))\n",
+ "* Applying within the `tf.data` pipeline allows prefetching or offloading to the CPU, which generally gives better performance when using accelerators.\n",
+ "\n",
+ "When running on one or more TPUs, users should almost always place Keras preprocessing layers in the `tf.data` pipeline, as not all layers support TPUs, and string ops do not execute on TPUs. (The two exceptions are `tf.keras.layers.Normalization` and `tf.keras.layers.Rescaling`, which run fine on TPUs and are commonly used as the first layer in an image model.)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "hNCYZ9L-BD2R"
+ },
+ "source": [
+ "### Preprocessing with `Model.fit`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "NhRB2Xe8B6bX"
+ },
+ "source": [
+ "When using Keras `Model.fit`, you do not need to distribute data with `tf.distribute.Strategy.experimental_distribute_dataset` nor `tf.distribute.Strategy.distribute_datasets_from_function` themselves. Check out the [Working with preprocessing layers](https://www.tensorflow.org/guide/keras/preprocessing_layers) guide and the [Distributed training with Keras](https://www.tensorflow.org/tutorials/distribute/keras) guide for details. A shortened example may look as below:\n",
+ "\n",
+ "```\n",
+ "strategy = tf.distribute.MirroredStrategy()\n",
+ "with strategy.scope():\n",
+ " # Create the layer(s) under scope.\n",
+ " integer_preprocessing_layer = tf.keras.layers.IntegerLookup(vocabulary=FILE_PATH)\n",
+ " model = ...\n",
+ " model.compile(...)\n",
+ "dataset = dataset.map(lambda x, y: (integer_preprocessing_layer(x), y))\n",
+ "model.fit(dataset)\n",
+ "```\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "3zL2vzJ-G0yg"
+ },
+ "source": [
+ "Users of `tf.distribute.experimental.ParameterServerStrategy` with the `Model.fit` API need to use a `tf.keras.utils.experimental.DatasetCreator` as the input. (See the [Parameter Server Training](https://www.tensorflow.org/tutorials/distribute/parameter_server_training#parameter_server_training_with_modelfit_api) guide for more)\n",
+ "\n",
+ "```\n",
+ "strategy = tf.distribute.experimental.ParameterServerStrategy(\n",
+ " cluster_resolver,\n",
+ " variable_partitioner=variable_partitioner)\n",
+ "\n",
+ "with strategy.scope():\n",
+ " preprocessing_layer = tf.keras.layers.StringLookup(vocabulary=FILE_PATH)\n",
+ " model = ...\n",
+ " model.compile(...)\n",
+ "\n",
+ "def dataset_fn(input_context):\n",
+ " ...\n",
+ " dataset = dataset.map(preprocessing_layer)\n",
+ " ...\n",
+ " return dataset\n",
+ "\n",
+ "dataset_creator = tf.keras.utils.experimental.DatasetCreator(dataset_fn)\n",
+ "model.fit(dataset_creator, epochs=5, steps_per_epoch=20, callbacks=callbacks)\n",
+ "\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "imZLQUOYBJyW"
+ },
+ "source": [
+ "### Preprocessing with a custom training loop"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "r2PX1QH_OwU3"
+ },
+ "source": [
+ "When writing a [custom training loop](https://www.tensorflow.org/tutorials/distribute/custom_training), you will distribute your data with either the `tf.distribute.Strategy.experimental_distribute_dataset` API or the `tf.distribute.Strategy.distribute_datasets_from_function` API. If you distribute your dataset through `tf.distribute.Strategy.experimental_distribute_dataset`, applying these preprocessing APIs in your data pipeline will lead the resources automatically co-located with the data pipeline to avoid remote resource access. Thus the examples here will all use `tf.distribute.Strategy.distribute_datasets_from_function`, in which case it is crucial to place initialization of these APIs under `strategy.scope()` for efficiency:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "wJS1UmcWQeab"
+ },
+ "outputs": [],
+ "source": [
+ "strategy = tf.distribute.MirroredStrategy()\n",
+ "vocab = [\"a\", \"b\", \"c\", \"d\", \"f\"]\n",
+ "\n",
+ "with strategy.scope():\n",
+ " # Create the layer(s) under scope.\n",
+ " layer = tf.keras.layers.StringLookup(vocabulary=vocab)\n",
+ "\n",
+ "def dataset_fn(input_context):\n",
+ " # a tf.data.Dataset\n",
+ " dataset = tf.data.Dataset.from_tensor_slices([\"a\", \"c\", \"e\"]).repeat()\n",
+ "\n",
+ " # Custom your batching, sharding, prefetching, etc.\n",
+ " global_batch_size = 4\n",
+ " batch_size = input_context.get_per_replica_batch_size(global_batch_size)\n",
+ " dataset = dataset.batch(batch_size)\n",
+ " dataset = dataset.shard(\n",
+ " input_context.num_input_pipelines,\n",
+ " input_context.input_pipeline_id)\n",
+ "\n",
+ " # Apply the preprocessing layer(s) to the tf.data.Dataset\n",
+ " def preprocess_with_kpl(input):\n",
+ " return layer(input)\n",
+ "\n",
+ " processed_ds = dataset.map(preprocess_with_kpl)\n",
+ " return processed_ds\n",
+ "\n",
+ "distributed_dataset = strategy.distribute_datasets_from_function(dataset_fn)\n",
+ "\n",
+ "# Print out a few example batches.\n",
+ "distributed_dataset_iterator = iter(distributed_dataset)\n",
+ "for _ in range(3):\n",
+ " print(next(distributed_dataset_iterator))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "PVl1cblWQy8b"
+ },
+ "source": [
+ "Note that if you are training with `tf.distribute.experimental.ParameterServerStrategy`, you'll also call `tf.distribute.experimental.coordinator.ClusterCoordinator.create_per_worker_dataset`\n",
+ "\n",
+ "```\n",
+ "@tf.function\n",
+ "def per_worker_dataset_fn():\n",
+ " return strategy.distribute_datasets_from_function(dataset_fn)\n",
+ "\n",
+ "per_worker_dataset = coordinator.create_per_worker_dataset(per_worker_dataset_fn)\n",
+ "per_worker_iterator = iter(per_worker_dataset)\n",
+ "```\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Ol7SmPID1dAt"
+ },
+ "source": [
+ "For Tensorflow Transform, as mentioned above, the Analyze stage is done separately from training and thus omitted here. See the [tutorial](https://www.tensorflow.org/tfx/tutorials/transform/census) for a detailed how-to. Usually, this stage includes creating a `tf.Transform` preprocessing function and transforming the data in an [Apache Beam](https://beam.apache.org/) pipeline with this preprocessing function. At the end of the Analyze stage, the output can be exported as a TensorFlow graph which you can use for both training and serving. Our example covers only the training pipeline part:\n",
+ "\n",
+ "```\n",
+ "with strategy.scope():\n",
+ " # working_dir contains the tf.Transform output.\n",
+ " tf_transform_output = tft.TFTransformOutput(working_dir)\n",
+ " # Loading from working_dir to create a Keras layer for applying the tf.Transform output to data\n",
+ " tft_layer = tf_transform_output.transform_features_layer()\n",
+ " ...\n",
+ "\n",
+ "def dataset_fn(input_context):\n",
+ " ...\n",
+ " dataset.map(tft_layer, num_parallel_calls=tf.data.AUTOTUNE)\n",
+ " ...\n",
+ " return dataset\n",
+ "\n",
+ "distributed_dataset = strategy.distribute_datasets_from_function(dataset_fn)\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "3_IQxRXxQWof"
+ },
+ "source": [
+ "## Partial batches"
]
},
{
@@ -636,7 +905,7 @@
"id": "hW2_gVkiztUG"
},
"source": [
- "Partial batches are encountered when `tf.data.Dataset` instances that users create may contain batch sizes that are not evenly divisible by the number of replicas or when the cardinality of the dataset instance is not divisible by the batch size. This means that when the dataset is distributed over multiple replicas, the `next` call on some iterators will result in an OutOfRangeError. To handle this use case, `tf.distribute` returns dummy batches of batch size 0 on replicas that do not have any more data to process.\n"
+ "Partial batches are encountered when: 1) `tf.data.Dataset` instances that users create may contain batch sizes that are not evenly divisible by the number of replicas; or 2) when the cardinality of the dataset instance is not divisible by the batch size. This means that when the dataset is distributed over multiple replicas, the `next` call on some iterators will result in an `tf.errors.OutOfRangeError`. To handle this use case, `tf.distribute` returns dummy batches of batch size `0` on replicas that do not have any more data to process.\n"
]
},
{
@@ -645,9 +914,9 @@
"id": "rqutdpqtPcCH"
},
"source": [
- "For the single worker case, if data is not returned by the `next` call on the iterator, dummy batches of 0 batch size are created and used along with the real data in the dataset. In the case of partial batches, the last global batch of data will contain real data alongside dummy batches of data. The stopping condition for processing data now checks if any of the replicas have data. If there is no data on any of the replicas, an OutOfRange error is thrown.\n",
+ "For the single-worker case, if the data is not returned by the `next` call on the iterator, dummy batches of 0 batch size are created and used along with the real data in the dataset. In the case of partial batches, the last global batch of data will contain real data alongside dummy batches of data. The stopping condition for processing data now checks if any of the replicas have data. If there is no data on any of the replicas, you will get a `tf.errors.OutOfRangeError`.\n",
"\n",
- "For the multi worker case, the boolean value representing presence of data on each of the workers is aggregated using cross replica communication and this is used to identify if all the workers have finished processing the distributed dataset. Since this involves cross worker communication there is some performance penalty involved.\n"
+ "For the multi-worker case, the boolean value representing presence of data on each of the workers is aggregated using cross replica communication and this is used to identify if all the workers have finished processing the distributed dataset. Since this involves cross worker communication there is some performance penalty involved.\n"
]
},
{
@@ -665,11 +934,11 @@
"id": "Nx4jyN_Az-Dy"
},
"source": [
- "* When using `tf.distribute.Strategy.experimental_distribute_dataset` APIs with a multiple worker setup, users pass a `tf.data.Dataset` that reads from files. If the `tf.data.experimental.AutoShardPolicy` is set to `AUTO` or `FILE`, the actual per step batch size may be smaller than the user defined global batch size. This can happen when the remaining elements in the file are less than the global batch size. Users can either exhaust the dataset without depending on the number of steps to run or set `tf.data.experimental.AutoShardPolicy` to `DATA` to work around it.\n",
+ "* When using `tf.distribute.Strategy.experimental_distribute_dataset` APIs with a multi-worker setup, you pass a `tf.data.Dataset` that reads from files. If the `tf.data.experimental.AutoShardPolicy` is set to `AUTO` or `FILE`, the actual per-step batch size may be smaller than the one you defined for the global batch size. This can happen when the remaining elements in the file are less than the global batch size. You can either exhaust the dataset without depending on the number of steps to run, or set `tf.data.experimental.AutoShardPolicy` to `DATA` to work around it.\n",
"\n",
"* Stateful dataset transformations are currently not supported with `tf.distribute` and any stateful ops that the dataset may have are currently ignored. For example, if your dataset has a `map_fn` that uses `tf.random.uniform` to rotate an image, then you have a dataset graph that depends on state (i.e the random seed) on the local machine where the python process is being executed.\n",
"\n",
- "* Experimental `tf.data.experimental.OptimizationOptions` that are disabled by default can in certain contexts -- such as when used together with `tf.distribute` -- cause a performance degradation. You should only enable them after you validate that they benefit the performance of your workload in a distribute setting.\n",
+ "* Experimental `tf.data.experimental.OptimizationOptions` that are disabled by default can in certain contexts—such as when used together with `tf.distribute`—cause a performance degradation. You should only enable them after you validate that they benefit the performance of your workload in a distribute setting.\n",
"\n",
"* Please refer to [this guide](https://www.tensorflow.org/guide/data_performance) for how to optimize your input pipeline with `tf.data` in general. A few additional tips:\n",
" * If you have multiple workers and are using `tf.data.Dataset.list_files` to create a dataset from all files matching one or more glob patterns, remember to set the `seed` argument or set `shuffle=False` so that each worker shard the file consistently.\n",
@@ -695,7 +964,7 @@
"source": [
"* The order in which the data is processed by the workers when using `tf.distribute.experimental_distribute_dataset` or `tf.distribute.distribute_datasets_from_function` is not guaranteed. This is typically required if you are using `tf.distribute` to scale prediction. You can however insert an index for each element in the batch and order outputs accordingly. The following snippet is an example of how to order outputs.\n",
"\n",
- "Note: `tf.distribute.MirroredStrategy()` is used here for the sake of convenience. We only need to reorder inputs when we are using multiple workers and `tf.distribute.MirroredStrategy` is used to distribute training on a single worker."
+ "Note: `tf.distribute.MirroredStrategy` is used here for the sake of convenience. You only need to reorder inputs when you are using multiple workers, but `tf.distribute.MirroredStrategy` is used to distribute training on a single worker."
]
},
{
@@ -740,7 +1009,7 @@
},
"source": [
"\n",
- "## How do I distribute my data if I am not using a canonical tf.data.Dataset instance?"
+ "## Tensor inputs instead of tf.data"
]
},
{
@@ -756,8 +1025,8 @@
"### Use experimental_distribute_values_from_function for arbitrary tensor inputs\n",
"`strategy.run` accepts `tf.distribute.DistributedValues` which is the output of\n",
"`next(iterator)`. To pass the tensor values, use\n",
- "`experimental_distribute_values_from_function` to construct\n",
- "`tf.distribute.DistributedValues` from raw tensors."
+ "`tf.distribute.Strategy.experimental_distribute_values_from_function` to construct\n",
+ "`tf.distribute.DistributedValues` from raw tensors. The user will have to specify their own batching and sharding logic in the input function with this option, which can be done using the `tf.distribute.experimental.ValueContext` input object."
]
},
{
@@ -769,14 +1038,13 @@
"outputs": [],
"source": [
"mirrored_strategy = tf.distribute.MirroredStrategy()\n",
- "worker_devices = mirrored_strategy.extended.worker_devices\n",
"\n",
"def value_fn(ctx):\n",
- " return tf.constant(1.0)\n",
+ " return tf.constant(ctx.replica_id_in_sync_group)\n",
"\n",
"distributed_values = mirrored_strategy.experimental_distribute_values_from_function(value_fn)\n",
"for _ in range(4):\n",
- " result = mirrored_strategy.run(lambda x:x, args=(distributed_values,))\n",
+ " result = mirrored_strategy.run(lambda x: x, args=(distributed_values,))\n",
" print(result)"
]
},
@@ -819,7 +1087,8 @@
"dist_dataset = mirrored_strategy.experimental_distribute_dataset(dataset)\n",
"iterator = iter(dist_dataset)\n",
"for _ in range(4):\n",
- " mirrored_strategy.run(lambda x:x, args=(next(iterator),))"
+ " result = mirrored_strategy.run(lambda x: x, args=(next(iterator),))\n",
+ " print(result)"
]
}
],
@@ -827,8 +1096,7 @@
"colab": {
"collapsed_sections": [],
"name": "input.ipynb",
- "provenance": [],
- "toc_visible": true
+ "toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
diff --git a/site/en/tutorials/distribute/keras.ipynb b/site/en/tutorials/distribute/keras.ipynb
index c75e5f88af5..b96656d4436 100644
--- a/site/en/tutorials/distribute/keras.ipynb
+++ b/site/en/tutorials/distribute/keras.ipynb
@@ -76,7 +76,7 @@
"\n",
"You will use the `tf.keras` APIs to build the model and `Model.fit` for training it. (To learn about distributed training with a custom training loop and the `MirroredStrategy`, check out [this tutorial](custom_training.ipynb).)\n",
"\n",
- "`MirroredStrategy` trains your model on multiple GPUs on a single machine. For _synchronous training on many GPUs on multiple workers_, use the `tf.distribute.MultiWorkerMirroredStrategy` [with the Keras Model.fit](multi_worker_with_keras.ipynb) or [a custom training loop](multi_worker_with_ctl.ipynb). For other options, refer to the [Distributed training guide](../../guide/distributed_training.ipynb).\n",
+ "`MirroredStrategy` trains your model on multiple GPUs on a single machine. For _synchronous training on many GPUs on multiple workers_, use the `tf.distribute.MultiWorkerMirroredStrategy` with the [Keras Model.fit](multi_worker_with_keras.ipynb) or [a custom training loop](multi_worker_with_ctl.ipynb). For other options, refer to the [Distributed training guide](../../guide/distributed_training.ipynb).\n",
"\n",
"To learn about various other strategies, there is the [Distributed training with TensorFlow](../../guide/distributed_training.ipynb) guide."
]
@@ -280,7 +280,7 @@
"id": "4xsComp8Kz5H"
},
"source": [
- "## Create the model"
+ "## Create the model and instantiate the optimizer"
]
},
{
@@ -289,7 +289,7 @@
"id": "1BnQYQTpB3YA"
},
"source": [
- "Create and compile the Keras model in the context of `Strategy.scope`:"
+ "Within the context of `Strategy.scope`, create and compile the model using the Keras API:"
]
},
{
@@ -310,10 +310,21 @@
" ])\n",
"\n",
" model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n",
- " optimizer=tf.keras.optimizers.Adam(),\n",
+ " optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),\n",
" metrics=['accuracy'])"
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "DCDKFcNJzdcd"
+ },
+ "source": [
+ "For this toy example with the MNIST dataset, you will be using the Adam optimizer's default learning rate of 0.001.\n",
+ "\n",
+ "For larger datasets, the key benefit of distributed training is to learn more in each training step, because each step processes more training data in parallel, which allows for a larger learning rate (within the limits of the model and dataset)."
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {
@@ -329,13 +340,16 @@
"id": "YOXO5nvvK3US"
},
"source": [
- "Define the following `tf.keras.callbacks`:\n",
+ "Define the following [Keras Callbacks](https://www.tensorflow.org/guide/keras/train_and_evaluate):\n",
"\n",
"- `tf.keras.callbacks.TensorBoard`: writes a log for TensorBoard, which allows you to visualize the graphs.\n",
"- `tf.keras.callbacks.ModelCheckpoint`: saves the model at a certain frequency, such as after every epoch.\n",
+ "- `tf.keras.callbacks.BackupAndRestore`: provides the fault tolerance functionality by backing up the model and current epoch number. Learn more in the _Fault tolerance_ section of the [Multi-worker training with Keras](multi_worker_with_keras.ipynb) tutorial.\n",
"- `tf.keras.callbacks.LearningRateScheduler`: schedules the learning rate to change after, for example, every epoch/batch.\n",
"\n",
- "For illustrative purposes, add a custom callback called `PrintLR` to display the *learning rate* in the notebook."
+ "For illustrative purposes, add a [custom callback](https://www.tensorflow.org/guide/keras/custom_callback) called `PrintLR` to display the *learning rate* in the notebook.\n",
+ "\n",
+ "**Note:** Use the `BackupAndRestore` callback instead of `ModelCheckpoint` as the main mechanism to restore the training state upon a restart from a job failure. Since `BackupAndRestore` only supports eager mode, in graph mode consider using `ModelCheckpoint`."
]
},
{
@@ -349,7 +363,7 @@
"# Define the checkpoint directory to store the checkpoints.\n",
"checkpoint_dir = './training_checkpoints'\n",
"# Define the name of the checkpoint files.\n",
- "checkpoint_prefix = os.path.join(checkpoint_dir, \"ckpt_{epoch}\")"
+ "checkpoint_prefix = os.path.join(checkpoint_dir, \"ckpt_{epoch:04d}.weights.h5\")"
]
},
{
@@ -382,8 +396,7 @@
"# Define a callback for printing the learning rate at the end of each epoch.\n",
"class PrintLR(tf.keras.callbacks.Callback):\n",
" def on_epoch_end(self, epoch, logs=None):\n",
- " print('\\nLearning rate for epoch {} is {}'.format(epoch + 1,\n",
- " model.optimizer.lr.numpy()))"
+ " print('\\nLearning rate for epoch {} is {}'.format(epoch + 1, model.optimizer.learning_rate.numpy()))"
]
},
{
@@ -419,7 +432,7 @@
"id": "6EophnOAB3YD"
},
"source": [
- "Now, train the model in the usual way by calling `Model.fit` on the model and passing in the dataset created at the beginning of the tutorial. This step is the same whether you are distributing the training or not."
+ "Now, train the model in the usual way by calling Keras `Model.fit` on the model and passing in the dataset created at the beginning of the tutorial. This step is the same whether you are distributing the training or not."
]
},
{
@@ -473,7 +486,10 @@
},
"outputs": [],
"source": [
- "model.load_weights(tf.train.latest_checkpoint(checkpoint_dir))\n",
+ "import pathlib\n",
+ "latest_checkpoint = sorted(pathlib.Path(checkpoint_dir).glob('*'))[-1]\n",
+ "\n",
+ "model.load_weights(latest_checkpoint)\n",
"\n",
"eval_loss, eval_acc = model.evaluate(eval_dataset)\n",
"\n",
@@ -526,7 +542,7 @@
"id": "kBLlogrDvMgg"
},
"source": [
- "## Export to SavedModel"
+ "## Save the model"
]
},
{
@@ -535,7 +551,7 @@
"id": "Xa87y_A0vRma"
},
"source": [
- "Export the graph and the variables to the platform-agnostic SavedModel format using `Model.save`. After your model is saved, you can load it with or without the `Strategy.scope`."
+ "Save the model to a `.keras` zip archive using `Model.save`. After your model is saved, you can load it with or without the `Strategy.scope`."
]
},
{
@@ -546,7 +562,7 @@
},
"outputs": [],
"source": [
- "path = 'saved_model/'"
+ "path = 'my_model.keras'"
]
},
{
@@ -557,7 +573,7 @@
},
"outputs": [],
"source": [
- "model.save(path, save_format='tf')"
+ "model.save(path)"
]
},
{
@@ -626,7 +642,7 @@
"\n",
"More examples that use different distribution strategies with the Keras `Model.fit` API:\n",
"\n",
- "1. The [Solve GLUE tasks using BERT on TPU](https://www.tensorflow.org/text/tutorials/bert_glue) tutorial uses `tf.distribute.MirroredStrategy` for training on GPUs and `tf.distribute.TPUStrategy`—on TPUs.\n",
+ "1. The [Solve GLUE tasks using BERT on TPU](https://www.tensorflow.org/text/tutorials/bert_glue) tutorial uses `tf.distribute.MirroredStrategy` for training on GPUs and `tf.distribute.TPUStrategy` on TPUs.\n",
"1. The [Save and load a model using a distribution strategy](save_and_load.ipynb) tutorial demonstates how to use the SavedModel APIs with `tf.distribute.Strategy`.\n",
"1. The [official TensorFlow models](https://github.com/tensorflow/models/tree/master/official) can be configured to run multiple distribution strategies.\n",
"\n",
diff --git a/site/en/tutorials/distribute/multi_worker_with_ctl.ipynb b/site/en/tutorials/distribute/multi_worker_with_ctl.ipynb
index ef3b4a73201..0361eea9328 100644
--- a/site/en/tutorials/distribute/multi_worker_with_ctl.ipynb
+++ b/site/en/tutorials/distribute/multi_worker_with_ctl.ipynb
@@ -63,11 +63,9 @@
"source": [
"## Overview\n",
"\n",
- "This tutorial demonstrates multi-worker training with custom training loop API, distributed via MultiWorkerMirroredStrategy, so a Keras model designed to run on [single-worker](https://www.tensorflow.org/tutorials/distribute/custom_training) can seamlessly work on multiple workers with minimal code change.\n",
+ "This tutorial demonstrates how to perform multi-worker distributed training with a Keras model and with [custom training loops](https://www.tensorflow.org/guide/keras/writing_a_training_loop_from_scratch) using the `tf.distribute.Strategy` API. The training loop is distributed via `tf.distribute.MultiWorkerMirroredStrategy`, such that a `tf.keras` model—designed to run on [single-worker](custom_training.ipynb)—can seamlessly work on multiple workers with minimal code changes. Custom training loops provide flexibility and a greater control on training, while also making it easier to debug the model. Learn more about [writing a basic training loop](../../guide/basic_training_loops.ipynb), [writing a training loop from scratch](https://www.tensorflow.org/guide/keras/writing_a_training_loop_from_scratch) and [custom training](../customization/custom_training_walkthrough.ipynb).\n",
"\n",
- "We are using custom training loops to train our model because they give us flexibility and a greater control on training. Moreover, it is easier to debug the model and the training loop. More detailed information is available in [Writing a training loop from scratch](https://www.tensorflow.org/guide/keras/writing_a_training_loop_from_scratch).\n",
- "\n",
- "If you are looking for how to use `MultiWorkerMirroredStrategy` with keras `model.fit`, refer to this [tutorial](https://www.tensorflow.org/tutorials/distribute/multi_worker_with_keras) instead.\n",
+ "If you are looking for how to use `MultiWorkerMirroredStrategy` with `tf.keras.Model.fit`, refer to this [tutorial](multi_worker_with_keras.ipynb) instead.\n",
"\n",
"[Distributed Training in TensorFlow](../../guide/distributed_training.ipynb) guide is available for an overview of the distribution strategies TensorFlow supports for those interested in a deeper understanding of `tf.distribute.Strategy` APIs."
]
@@ -102,9 +100,8 @@
"id": "Zz0EY91y3mxy"
},
"source": [
- "Before importing TensorFlow, make a few changes to the environment.\n",
- "\n",
- "Disable all GPUs. This prevents errors caused by the workers all trying to use the same GPU. For a real application each worker would be on a different machine."
+ "Before importing TensorFlow, make a few changes to the environment:\n",
+ "* Disable all GPUs. This prevents errors caused by all workers trying to use the same GPU. In a real-world application, each worker would be on a different machine."
]
},
{
@@ -124,7 +121,7 @@
"id": "7X1MS6385BWi"
},
"source": [
- "Reset the `TF_CONFIG` environment variable, you'll see more about this later."
+ "* Reset the `'TF_CONFIG'` environment variable (you'll see more about this later)."
]
},
{
@@ -144,7 +141,7 @@
"id": "Rd4L9Ii77SS8"
},
"source": [
- "Be sure that the current directory is on python's path. This allows the notebook to import the files written by `%%writefile` later.\n"
+ "* Make sure that the current directory is on Python's path. This allows the notebook to import the files written by `%%writefile` later.\n"
]
},
{
@@ -194,7 +191,7 @@
"id": "fLW6D2TzvC-4"
},
"source": [
- "Next create an `mnist.py` file with a simple model and dataset setup. This python file will be used by the worker-processes in this tutorial:"
+ "Next, create an `mnist.py` file with a simple model and dataset setup. This Python file will be used by the worker-processes in this tutorial:"
]
},
{
@@ -230,13 +227,18 @@
" return dataset\n",
"\n",
"def build_cnn_model():\n",
+ " regularizer = tf.keras.regularizers.L2(1e-5)\n",
" return tf.keras.Sequential([\n",
" tf.keras.Input(shape=(28, 28)),\n",
" tf.keras.layers.Reshape(target_shape=(28, 28, 1)),\n",
- " tf.keras.layers.Conv2D(32, 3, activation='relu'),\n",
+ " tf.keras.layers.Conv2D(32, 3,\n",
+ " activation='relu',\n",
+ " kernel_regularizer=regularizer),\n",
" tf.keras.layers.Flatten(),\n",
- " tf.keras.layers.Dense(128, activation='relu'),\n",
- " tf.keras.layers.Dense(10)\n",
+ " tf.keras.layers.Dense(128,\n",
+ " activation='relu',\n",
+ " kernel_regularizer=regularizer),\n",
+ " tf.keras.layers.Dense(10, kernel_regularizer=regularizer)\n",
" ])"
]
},
@@ -246,9 +248,9 @@
"id": "JmgZwwymxqt5"
},
"source": [
- "## Multi-worker Configuration\n",
+ "## Multi-worker configuration\n",
"\n",
- "Now let's enter the world of multi-worker training. In TensorFlow, the `TF_CONFIG` environment variable is required for training on multiple machines, each of which possibly has a different role. `TF_CONFIG` used below, is a JSON string used to specify the cluster configuration on each worker that is part of the cluster. This is the default method for specifying a cluster, using `cluster_resolver.TFConfigClusterResolver`, but there are other options available in the `distribute.cluster_resolver` module."
+ "Now let's enter the world of multi-worker training. In TensorFlow, the `'TF_CONFIG'` environment variable is required for training on multiple machines. Each machine may have a different role. The `'TF_CONFIG'` variable used below is a JSON string that specifies the cluster configuration on each worker that is part of the cluster. This is the default method for specifying a cluster, using `cluster_resolver.TFConfigClusterResolver`, but there are other options available in the `distribute.cluster_resolver` module. Learn more about setting up the `'TF_CONFIG'` variable in the [Distributed training guide](../../guide/distributed_training.ipynb)."
]
},
{
@@ -283,7 +285,7 @@
"id": "JjgwJbPKZkJL"
},
"source": [
- "Here is the same `TF_CONFIG` serialized as a JSON string:"
+ "Note that `tf_config` is just a local variable in Python. To use it for training configuration, serialize it as a JSON and place it in a `'TF_CONFIG'` environment variable. Here is the same `'TF_CONFIG'` serialized as a JSON string:"
]
},
{
@@ -303,11 +305,11 @@
"id": "AUBmYRZqxthH"
},
"source": [
- "There are two components of `TF_CONFIG`: `cluster` and `task`.\n",
+ "There are two components of `'TF_CONFIG'`: `'cluster'` and `'task'`.\n",
"\n",
- "* `cluster` is the same for all workers and provides information about the training cluster, which is a dict consisting of different types of jobs such as `worker`. In multi-worker training with `MultiWorkerMirroredStrategy`, there is usually one `worker` that takes on a little more responsibility like saving checkpoint and writing summary file for TensorBoard in addition to what a regular `worker` does. Such a worker is referred to as the `chief` worker, and it is customary that the `worker` with `index` 0 is appointed as the chief `worker` (in fact this is how `tf.distribute.Strategy` is implemented).\n",
+ "* `'cluster'` is the same for all workers and provides information about the training cluster, which is a dict consisting of different types of jobs such as `'worker'`. In multi-worker training with `MultiWorkerMirroredStrategy`, there is usually one `'worker'` that takes on a little more responsibility like saving checkpoints and writing summary files for TensorBoard in addition to what a regular `'worker'` does. Such a worker is referred to as the `'chief'` worker, and it is customary that the `'worker'` with `'index'` 0 is appointed as the chief `worker`.\n",
"\n",
- "* `task` provides information of the current task and is different on each worker. It specifies the `type` and `index` of that worker."
+ "* `'task'` provides information of the current task and is different on each worker. It specifies the `'type'` and `'index'` of that worker."
]
},
{
@@ -316,7 +318,7 @@
"id": "8YFpxrcsZ2xG"
},
"source": [
- "In this example, you set the task `type` to `\"worker\"` and the task `index` to `0`. This machine is the first worker and will be appointed as the chief worker and do more work than the others. Note that other machines will need to have the `TF_CONFIG` environment variable set as well, and it should have the same `cluster` dict, but different task `type` or task `index` depending on what the roles of those machines are.\n"
+ "In this example, you set the task `'type'` to `'worker'` and the task `'index'` to `0`. This machine is the first worker and will be appointed as the chief worker and do more work than the others. Note that other machines will need to have the `'TF_CONFIG'` environment variable set as well, and it should have the same `'cluster'` dict, but different task `'type'` or task `'index'` depending on what the roles of those machines are.\n"
]
},
{
@@ -325,18 +327,9 @@
"id": "aogb74kHxynz"
},
"source": [
- "For illustration purposes, this tutorial shows how one may set a `TF_CONFIG` with 2 workers on `localhost`. In practice, users would create multiple workers on external IP addresses/ports, and set `TF_CONFIG` on each worker appropriately.\n",
+ "For illustration purposes, this tutorial shows how one may set a `'TF_CONFIG'` with two workers on `'localhost'`. In practice, users would create multiple workers on external IP addresses/ports, and set `'TF_CONFIG'` on each worker appropriately.\n",
"\n",
- "In this example you will use 2 workers, the first worker's `TF_CONFIG` is shown above. For the second worker you would set `tf_config['task']['index']=1`"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "f83FVYqDX3aX"
- },
- "source": [
- "Above, `tf_config` is just a local variable in python. To actually use it to configure training, this dictionary needs to be serialized as JSON, and placed in the `TF_CONFIG` environment variable."
+ "This example uses two workers. The first worker's `'TF_CONFIG'` is shown above. For the second worker, set `tf_config['task']['index']=1`."
]
},
{
@@ -354,7 +347,7 @@
"id": "FcjAbuGY1ACJ"
},
"source": [
- "Subprocesses inherit environment variables from their parent. So if you set an environment variable in this `jupyter notebook` process:"
+ "Subprocesses inherit environment variables from their parent. So if you set an environment variable in this Jupyter Notebook process:"
]
},
{
@@ -374,7 +367,7 @@
"id": "gQkIX-cg18md"
},
"source": [
- "You can access the environment variable from a subprocesses:"
+ "you can then access the environment variable from a subprocess:"
]
},
{
@@ -395,7 +388,7 @@
"id": "af6BCA-Y2fpz"
},
"source": [
- "In the next section, you'll use this to pass the `TF_CONFIG` to the worker subprocesses. You would never really launch your jobs this way, but it's sufficient for the purposes of this tutorial: To demonstrate a minimal multi-worker example."
+ "In the next section, you'll use this to pass the `'TF_CONFIG'` to the worker subprocesses. You would never really launch your jobs this way, but it's sufficient for the purposes of this tutorial: To demonstrate a minimal multi-worker example."
]
},
{
@@ -406,7 +399,7 @@
"source": [
"## MultiWorkerMirroredStrategy\n",
"\n",
- "To train the model, use an instance of `tf.distribute.MultiWorkerMirroredStrategy`, which creates copies of all variables in the model's layers on each device across all workers. The [`tf.distribute.Strategy` guide](../../guide/distributed_training.ipynb) has more details about this strategy."
+ "Before training the model, first create an instance of `tf.distribute.MultiWorkerMirroredStrategy`:"
]
},
{
@@ -426,7 +419,7 @@
"id": "N0iv7SyyAohc"
},
"source": [
- "Note: `TF_CONFIG` is parsed and TensorFlow's GRPC servers are started at the time `MultiWorkerMirroredStrategy()` is called, so the `TF_CONFIG` environment variable must be set before a `tf.distribute.Strategy` instance is created."
+ "Note: `'TF_CONFIG'` is parsed and TensorFlow's GRPC servers are started at the time you call `tf.distribute.MultiWorkerMirroredStrategy.` Therefore, you must set the `'TF_CONFIG'` environment variable before you instantiate a `tf.distribute.Strategy`. To save time in this illustrative example, this is not demonstrated in this tutorial, so that servers do not need to start. You can find a full example in the last section of this tutorial."
]
},
{
@@ -435,7 +428,7 @@
"id": "TS4S-faBHHam"
},
"source": [
- "Use `tf.distribute.Strategy.scope` to specify that a strategy should be used when building your model. This puts you in the \"[cross-replica context](https://www.tensorflow.org/guide/distributed_training?hl=en#mirroredstrategy)\" for this strategy, which means the strategy is put in control of things like variable placement."
+ "Use `tf.distribute.Strategy.scope` to specify that a strategy should be used when building your model. This allows the strategy to control things like variable placement—it will create copies of all variables in the model's layers on each device across all workers."
]
},
{
@@ -459,9 +452,8 @@
},
"source": [
"## Auto-shard your data across workers\n",
- "In multi-worker training, dataset sharding is not necessarily needed, however it gives you exactly once semantic which makes more training more reproducible, i.e. training on multiple workers should be the same as training on one worker. Note: performance can be affected in some cases.\n",
"\n",
- "See: [`distribute_datasets_from_function`](https://www.tensorflow.org/api_docs/python/tf/distribute/Strategy?version=nightly#distribute_datasets_from_function)"
+ "In multi-worker training, _dataset sharding_ is needed to ensure convergence and reproducibility. Sharding means handing each worker a subset of the entire dataset—it helps create the experience similar to training on a single worker. In the example below, you're relying on the default autosharding policy of `tf.distribute`. You can also customize it by setting the `tf.data.experimental.AutoShardPolicy` of the `tf.data.experimental.DistributeOptions`. To learn more, refer to the _Sharding_ section of the [Distributed input tutorial](input.ipynb)."
]
},
{
@@ -487,8 +479,8 @@
"id": "rkNzSR3g60iP"
},
"source": [
- "## Define Custom Training Loop and Train the model\n",
- "Specify an optimizer"
+ "## Define a custom training loop and train the model\n",
+ "Specify an optimizer:"
]
},
{
@@ -500,7 +492,7 @@
"outputs": [],
"source": [
"with strategy.scope():\n",
- " # The creation of optimizer and train_accuracy will need to be in\n",
+ " # The creation of optimizer and train_accuracy needs to be in\n",
" # `strategy.scope()` as well, since they create variables.\n",
" optimizer = tf.keras.optimizers.RMSprop(learning_rate=0.001)\n",
" train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(\n",
@@ -513,7 +505,7 @@
"id": "RmrDcAii4B5O"
},
"source": [
- "Define a training step with `tf.function`\n"
+ "Define a training step with `tf.function`:\n"
]
},
{
@@ -533,11 +525,13 @@
" x, y = inputs\n",
" with tf.GradientTape() as tape:\n",
" predictions = multi_worker_model(x, training=True)\n",
- " per_batch_loss = tf.keras.losses.SparseCategoricalCrossentropy(\n",
+ " per_example_loss = tf.keras.losses.SparseCategoricalCrossentropy(\n",
" from_logits=True,\n",
" reduction=tf.keras.losses.Reduction.NONE)(y, predictions)\n",
- " loss = tf.nn.compute_average_loss(\n",
- " per_batch_loss, global_batch_size=global_batch_size)\n",
+ " loss = tf.nn.compute_average_loss(per_example_loss)\n",
+ " model_losses = multi_worker_model.losses\n",
+ " if model_losses:\n",
+ " loss += tf.nn.scale_regularization_loss(tf.add_n(model_losses))\n",
"\n",
" grads = tape.gradient(loss, multi_worker_model.trainable_variables)\n",
" optimizer.apply_gradients(\n",
@@ -558,7 +552,7 @@
"source": [
"### Checkpoint saving and restoring\n",
"\n",
- "Checkpointing implementation in a Custom Training Loop requires the user to handle it instead of using a keras callback. It allows you to save model's weights and restore them without having to save the whole model."
+ "As you write a custom training loop, you need to handle [checkpoint saving](../../guide/checkpoint.ipynb) manually instead of relying on a Keras callback. Note that for `MultiWorkerMirroredStrategy`, saving a checkpoint or a complete model requires the participation of all workers, because attempting to save only on the chief worker could lead to a deadlock. Workers also need to write to different paths to avoid overwriting each other. Here's an example of how to configure the directories:"
]
},
{
@@ -572,40 +566,34 @@
"from multiprocessing import util\n",
"checkpoint_dir = os.path.join(util.get_temp_dir(), 'ckpt')\n",
"\n",
- "def _is_chief(task_type, task_id):\n",
- " return task_type is None or task_type == 'chief' or (task_type == 'worker' and\n",
- " task_id == 0)\n",
+ "def _is_chief(task_type, task_id, cluster_spec):\n",
+ " return (task_type is None\n",
+ " or task_type == 'chief'\n",
+ " or (task_type == 'worker'\n",
+ " and task_id == 0\n",
+ " and \"chief\" not in cluster_spec.as_dict()))\n",
+ "\n",
"def _get_temp_dir(dirpath, task_id):\n",
" base_dirpath = 'workertemp_' + str(task_id)\n",
" temp_dir = os.path.join(dirpath, base_dirpath)\n",
" tf.io.gfile.makedirs(temp_dir)\n",
" return temp_dir\n",
"\n",
- "def write_filepath(filepath, task_type, task_id):\n",
+ "def write_filepath(filepath, task_type, task_id, cluster_spec):\n",
" dirpath = os.path.dirname(filepath)\n",
" base = os.path.basename(filepath)\n",
- " if not _is_chief(task_type, task_id):\n",
+ " if not _is_chief(task_type, task_id, cluster_spec):\n",
" dirpath = _get_temp_dir(dirpath, task_id)\n",
" return os.path.join(dirpath, base)"
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "P7fabUIEW7-M"
- },
- "source": [
- "Note: Checkpointing and Saving need to happen on each worker and they need to write to different paths as they would override each others.\n",
- "If you chose to only checkpoint/save on the chief, this can lead to deadlock and is not recommended."
- ]
- },
{
"cell_type": "markdown",
"metadata": {
"id": "nrcdPHtG4ObO"
},
"source": [
- " Here, you'll create one `tf.train.Checkpoint` that tracks the model, which is managed by a `tf.train.CheckpointManager` so that only the latest checkpoint is preserved."
+ "Create one `tf.train.Checkpoint` that tracks the model, which is managed by a `tf.train.CheckpointManager`, so that only the latest checkpoints are preserved:"
]
},
{
@@ -623,11 +611,16 @@
" name='step_in_epoch')\n",
"task_type, task_id = (strategy.cluster_resolver.task_type,\n",
" strategy.cluster_resolver.task_id)\n",
+ "# Normally, you don't need to manually instantiate a `ClusterSpec`, but in this\n",
+ "# illustrative example you did not set `'TF_CONFIG'` before initializing the\n",
+ "# strategy. Check out the next section for \"real-world\" usage.\n",
+ "cluster_spec = tf.train.ClusterSpec(tf_config['cluster'])\n",
"\n",
"checkpoint = tf.train.Checkpoint(\n",
" model=multi_worker_model, epoch=epoch, step_in_epoch=step_in_epoch)\n",
"\n",
- "write_checkpoint_dir = write_filepath(checkpoint_dir, task_type, task_id)\n",
+ "write_checkpoint_dir = write_filepath(checkpoint_dir, task_type, task_id,\n",
+ " cluster_spec)\n",
"checkpoint_manager = tf.train.CheckpointManager(\n",
" checkpoint, directory=write_checkpoint_dir, max_to_keep=1)"
]
@@ -638,7 +631,7 @@
"id": "RO7cbN40XD5v"
},
"source": [
- "Now, when you need to restore, you can find the latest checkpoint saved using the convenient `tf.train.latest_checkpoint` function."
+ "Now, when you need to restore a checkpoint, you can find the latest checkpoint saved using the convenient `tf.train.latest_checkpoint` function (or by calling `tf.train.CheckpointManager.restore_or_initialize`)."
]
},
{
@@ -693,7 +686,7 @@
" # Once the `CheckpointManager` is set up, you're now ready to save, and remove\n",
" # the checkpoints non-chief workers saved.\n",
" checkpoint_manager.save()\n",
- " if not _is_chief(task_type, task_id):\n",
+ " if not _is_chief(task_type, task_id, cluster_spec):\n",
" tf.io.gfile.rmtree(write_checkpoint_dir)\n",
"\n",
" epoch.assign_add(1)\n",
@@ -706,7 +699,7 @@
"id": "0W1Osks466DE"
},
"source": [
- "## Full code setup on workers"
+ "## Complete code at a glance"
]
},
{
@@ -715,10 +708,11 @@
"id": "jfYpmIxO6Jck"
},
"source": [
- "To actually run with `MultiWorkerMirroredStrategy` you'll need to run worker processes and pass a `TF_CONFIG` to them.\n",
+ "To sum up all the procedures discussed so far:\n",
"\n",
- "Like the `mnist.py` file written earlier, here is the `main.py` that \n",
- "contain the same code we walked through step by step previously in this colab, we're just writing it to a file so each of the workers will run it:"
+ "1. You create worker processes.\n",
+ "2. Pass `'TF_CONFIG'`s to the worker processes.\n",
+ "3. Let each work process run the script below that contains the training code."
]
},
{
@@ -746,19 +740,23 @@
"num_steps_per_epoch=70\n",
"\n",
"# Checkpoint saving and restoring\n",
- "def _is_chief(task_type, task_id):\n",
- " return task_type is None or task_type == 'chief' or (task_type == 'worker' and\n",
- " task_id == 0)\n",
+ "def _is_chief(task_type, task_id, cluster_spec):\n",
+ " return (task_type is None\n",
+ " or task_type == 'chief'\n",
+ " or (task_type == 'worker'\n",
+ " and task_id == 0\n",
+ " and 'chief' not in cluster_spec.as_dict()))\n",
+ "\n",
"def _get_temp_dir(dirpath, task_id):\n",
" base_dirpath = 'workertemp_' + str(task_id)\n",
" temp_dir = os.path.join(dirpath, base_dirpath)\n",
" tf.io.gfile.makedirs(temp_dir)\n",
" return temp_dir\n",
"\n",
- "def write_filepath(filepath, task_type, task_id):\n",
+ "def write_filepath(filepath, task_type, task_id, cluster_spec):\n",
" dirpath = os.path.dirname(filepath)\n",
" base = os.path.basename(filepath)\n",
- " if not _is_chief(task_type, task_id):\n",
+ " if not _is_chief(task_type, task_id, cluster_spec):\n",
" dirpath = _get_temp_dir(dirpath, task_id)\n",
" return os.path.join(dirpath, base)\n",
"\n",
@@ -768,11 +766,11 @@
"strategy = tf.distribute.MultiWorkerMirroredStrategy()\n",
"\n",
"with strategy.scope():\n",
- " # Model building/compiling need to be within `strategy.scope()`.\n",
+ " # Model building/compiling need to be within `tf.distribute.Strategy.scope`.\n",
" multi_worker_model = mnist.build_cnn_model()\n",
"\n",
" multi_worker_dataset = strategy.distribute_datasets_from_function(\n",
- " lambda input_context: mnist.dataset_fn(global_batch_size, input_context)) \n",
+ " lambda input_context: mnist.dataset_fn(global_batch_size, input_context))\n",
" optimizer = tf.keras.optimizers.RMSprop(learning_rate=0.001)\n",
" train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(\n",
" name='train_accuracy')\n",
@@ -786,11 +784,13 @@
" x, y = inputs\n",
" with tf.GradientTape() as tape:\n",
" predictions = multi_worker_model(x, training=True)\n",
- " per_batch_loss = tf.keras.losses.SparseCategoricalCrossentropy(\n",
+ " per_example_loss = tf.keras.losses.SparseCategoricalCrossentropy(\n",
" from_logits=True,\n",
" reduction=tf.keras.losses.Reduction.NONE)(y, predictions)\n",
- " loss = tf.nn.compute_average_loss(\n",
- " per_batch_loss, global_batch_size=global_batch_size)\n",
+ " loss = tf.nn.compute_average_loss(per_example_loss)\n",
+ " model_losses = multi_worker_model.losses\n",
+ " if model_losses:\n",
+ " loss += tf.nn.scale_regularization_loss(tf.add_n(model_losses))\n",
"\n",
" grads = tape.gradient(loss, multi_worker_model.trainable_variables)\n",
" optimizer.apply_gradients(\n",
@@ -809,13 +809,15 @@
" initial_value=tf.constant(0, dtype=tf.dtypes.int64),\n",
" name='step_in_epoch')\n",
"\n",
- "task_type, task_id = (strategy.cluster_resolver.task_type,\n",
- " strategy.cluster_resolver.task_id)\n",
+ "task_type, task_id, cluster_spec = (strategy.cluster_resolver.task_type,\n",
+ " strategy.cluster_resolver.task_id,\n",
+ " strategy.cluster_resolver.cluster_spec())\n",
"\n",
"checkpoint = tf.train.Checkpoint(\n",
" model=multi_worker_model, epoch=epoch, step_in_epoch=step_in_epoch)\n",
"\n",
- "write_checkpoint_dir = write_filepath(checkpoint_dir, task_type, task_id)\n",
+ "write_checkpoint_dir = write_filepath(checkpoint_dir, task_type, task_id,\n",
+ " cluster_spec)\n",
"checkpoint_manager = tf.train.CheckpointManager(\n",
" checkpoint, directory=write_checkpoint_dir, max_to_keep=1)\n",
"\n",
@@ -838,11 +840,11 @@
" train_loss = total_loss / num_batches\n",
" print('Epoch: %d, accuracy: %f, train_loss: %f.'\n",
" %(epoch.numpy(), train_accuracy.result(), train_loss))\n",
- " \n",
+ "\n",
" train_accuracy.reset_states()\n",
"\n",
" checkpoint_manager.save()\n",
- " if not _is_chief(task_type, task_id):\n",
+ " if not _is_chief(task_type, task_id, cluster_spec):\n",
" tf.io.gfile.rmtree(write_checkpoint_dir)\n",
"\n",
" epoch.assign_add(1)\n",
@@ -855,7 +857,6 @@
"id": "ItVOvPN1qnZ6"
},
"source": [
- "## Train and Evaluate\n",
"The current directory now contains both Python files:"
]
},
@@ -877,7 +878,7 @@
"id": "qmEEStPS6vR_"
},
"source": [
- "So json-serialize the `TF_CONFIG` and add it to the environment variables:"
+ "So JSON-serialize the `'TF_CONFIG'` and add it to the environment variables:"
]
},
{
@@ -897,7 +898,7 @@
"id": "MsY3dQLK7jdf"
},
"source": [
- "Now, you can launch a worker process that will run the `main.py` and use the `TF_CONFIG`:"
+ "Now, you can launch a worker process that will run the `main.py` and use the `'TF_CONFIG'`:"
]
},
{
@@ -935,9 +936,9 @@
"1. It uses the `%%bash` which is a [notebook \"magic\"](https://ipython.readthedocs.io/en/stable/interactive/magics.html) to run some bash commands.\n",
"2. It uses the `--bg` flag to run the `bash` process in the background, because this worker will not terminate. It waits for all the workers before it starts.\n",
"\n",
- "The backgrounded worker process won't print output to this notebook, so the `&>` redirects its output to a file, so you can see what happened.\n",
+ "The backgrounded worker process won't print the output to this notebook. The `&>` redirects its output to a file, so that you can inspect what happened.\n",
"\n",
- "So, wait a few seconds for the process to start up:"
+ "Wait a few seconds for the process to start up:"
]
},
{
@@ -958,7 +959,7 @@
"id": "ZFPoNxg_9_Mx"
},
"source": [
- "Now look what's been output to the worker's logfile so far:"
+ "Now, check the output to the worker's log file so far:"
]
},
{
@@ -988,7 +989,7 @@
"id": "Pi8vPNNA_l4a"
},
"source": [
- "So update the `tf_config` for the second worker's process to pick up:"
+ "Update the `tf_config` for the second worker's process to pick up:"
]
},
{
@@ -1030,7 +1031,7 @@
"id": "hX4FA2O2AuAn"
},
"source": [
- "Now if you recheck the logs written by the first worker you'll see that it participated in training that model:"
+ "If you recheck the logs written by the first worker, notice that it participated in training that model:"
]
},
{
@@ -1053,7 +1054,7 @@
},
"outputs": [],
"source": [
- "# Delete the `TF_CONFIG`, and kill any background tasks so they don't affect the next section.\n",
+ "# Delete the `'TF_CONFIG'`, and kill any background tasks so they don't affect the next section.\n",
"os.environ.pop('TF_CONFIG', None)\n",
"%killbgscripts"
]
@@ -1064,9 +1065,9 @@
"id": "bhxMXa0AaZkK"
},
"source": [
- "## Multi worker training in depth\n",
+ "## Multi-worker training in depth\n",
"\n",
- "This tutorial has demonstrated a `Custom Training Loop` workflow of the multi-worker setup. A detailed description of other topics is available in the [`model.fit's guide`](https://colab.sandbox.google.com/github/tensorflow/docs/blob/master/site/en/tutorials/distribute/multi_worker_with_keras.ipynb) of the multi-worker setup and applicable to CTLs."
+ "This tutorial has demonstrated a custom training loop workflow of the multi-worker setup. Detailed descriptions of other topics is available in the [Multi-worker training with Keras (`tf.keras.Model.fit`)](multi_worker_with_keras.ipynb) tutorial applicable to custom training loops."
]
},
{
@@ -1075,10 +1076,11 @@
"id": "ega2hdOQEmy_"
},
"source": [
- "## See also\n",
- "1. [Distributed Training in TensorFlow](https://www.tensorflow.org/guide/distributed_training) guide provides an overview of the available distribution strategies.\n",
+ "## Learn more\n",
+ "\n",
+ "1. The [Distributed training in TensorFlow](../../guide/distributed_training.ipynb) guide provides an overview of the available distribution strategies.\n",
"2. [Official models](https://github.com/tensorflow/models/tree/master/official), many of which can be configured to run multiple distribution strategies.\n",
- "3. The [Performance section](../../guide/function.ipynb) in the guide provides information about other strategies and [tools](../../guide/profiler.md) you can use to optimize the performance of your TensorFlow models.\n"
+ "3. The [Performance section](../../guide/function.ipynb) in the `tf.function` guide provides information about other strategies and [tools](../../guide/profiler.md) you can use to optimize the performance of your TensorFlow models.\n"
]
}
],
@@ -1086,7 +1088,7 @@
"colab": {
"collapsed_sections": [],
"name": "multi_worker_with_ctl.ipynb",
- "toc_visible": true
+ "toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
diff --git a/site/en/tutorials/distribute/multi_worker_with_estimator.ipynb b/site/en/tutorials/distribute/multi_worker_with_estimator.ipynb
index b4fffa60fb4..fcee0618854 100644
--- a/site/en/tutorials/distribute/multi_worker_with_estimator.ipynb
+++ b/site/en/tutorials/distribute/multi_worker_with_estimator.ipynb
@@ -186,7 +186,7 @@
"\n",
"There are two components of `TF_CONFIG`: `cluster` and `task`. `cluster` provides information about the entire cluster, namely the workers and parameter servers in the cluster. `task` provides information about the current task. The first component `cluster` is the same for all workers and parameter servers in the cluster, and the second component `task` is different on each worker and parameter server and specifies its own `type` and `index`. In this example, the task `type` is `worker` and the task `index` is `0`.\n",
"\n",
- "For illustration purposes, this tutorial shows how to set a `TF_CONFIG` with 2 workers on `localhost`. In practice, you would create multiple workers on an external IP address and port, and set `TF_CONFIG` on each worker appropriately, i.e. modify the task `index`.\n",
+ "For illustration purposes, this tutorial shows how to set a `TF_CONFIG` with 2 workers on `localhost`. In practice, you would create multiple workers on an external IP address and port, and set `TF_CONFIG` on each worker appropriately, i.e., modify the task `index`.\n",
"\n",
"Warning: *Do not execute the following code in Colab.* TensorFlow's runtime will attempt to create a gRPC server at the specified IP address and port, which will likely fail. See the [keras version](multi_worker_with_keras.ipynb) of this tutorial for an example of how you can test run multiple workers on a single machine.\n",
"\n",
@@ -351,8 +351,7 @@
"Tce3stUlHN0L"
],
"name": "multi_worker_with_estimator.ipynb",
- "provenance": [],
- "toc_visible": true
+ "toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
diff --git a/site/en/tutorials/distribute/multi_worker_with_keras.ipynb b/site/en/tutorials/distribute/multi_worker_with_keras.ipynb
index 1f00bb99e5b..c972e8b7fb6 100644
--- a/site/en/tutorials/distribute/multi_worker_with_keras.ipynb
+++ b/site/en/tutorials/distribute/multi_worker_with_keras.ipynb
@@ -63,13 +63,36 @@
"source": [
"## Overview\n",
"\n",
- "This tutorial demonstrates how to perform multi-worker distributed training with a Keras model and the `Model.fit` API using the `tf.distribute.Strategy` API—specifically the `tf.distribute.MultiWorkerMirroredStrategy` class. With the help of this strategy, a Keras model that was designed to run on a single-worker can seamlessly work on multiple workers with minimal code changes.\n",
- "\n",
- "For those interested in a deeper understanding of `tf.distribute.Strategy` APIs, the [Distributed training in TensorFlow](../../guide/distributed_training.ipynb) guide is available for an overview of the distribution strategies TensorFlow supports.\n",
+ "This tutorial demonstrates how to perform multi-worker distributed training with a Keras model and the `Model.fit` API using the `tf.distribute.MultiWorkerMirroredStrategy` API. With the help of this strategy, a Keras model that was designed to run on a single-worker can seamlessly work on multiple workers with minimal code changes.\n",
"\n",
"To learn how to use the `MultiWorkerMirroredStrategy` with Keras and a custom training loop, refer to [Custom training loop with Keras and MultiWorkerMirroredStrategy](multi_worker_with_ctl.ipynb).\n",
"\n",
- "Note that the purpose of this tutorial is to demonstrate a minimal multi-worker example with two workers."
+ "This tutorial contains a minimal multi-worker example with two workers for demonstration purposes."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "JUdRerXg6yz3"
+ },
+ "source": [
+ "### Choose the right strategy"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "YAiCV_oL63GM"
+ },
+ "source": [
+ "Before you dive in, make sure that `tf.distribute.MultiWorkerMirroredStrategy` is the right choice for your accelerator(s) and training. These are two common ways of distributing training with data parallelism:\n",
+ "\n",
+ "* _Synchronous training_, where the steps of training are synced across the workers and replicas, such as `tf.distribute.MirroredStrategy`, `tf.distribute.TPUStrategy`, and `tf.distribute.MultiWorkerMirroredStrategy`. All workers train over different slices of input data in sync, and aggregating gradients at each step.\n",
+ "* _Asynchronous training_, where the training steps are not strictly synced, such as `tf.distribute.experimental.ParameterServerStrategy`. All workers are independently training over the input data and updating variables asynchronously.\n",
+ "\n",
+ "If you are looking for multi-worker synchronous training without TPU, then `tf.distribute.MultiWorkerMirroredStrategy` is your choice. It creates copies of all variables in the model's layers on each device across all workers. It uses `CollectiveOps`, a TensorFlow op for collective communication, to aggregate gradients and keeps the variables in sync. For those interested, check out the `tf.distribute.experimental.CommunicationOptions` parameter for the collective implementation options.\n",
+ "\n",
+ "For an overview of `tf.distribute.Strategy` APIs, refer to [Distributed training in TensorFlow](../../guide/distributed_training.ipynb)."
]
},
{
@@ -104,14 +127,14 @@
"source": [
"Before importing TensorFlow, make a few changes to the environment:\n",
"\n",
- "1. Disable all GPUs. This prevents errors caused by the workers all trying to use the same GPU. In a real-world application, each worker would be on a different machine."
+ "* In a real-world application, each worker would be on a different machine. For the purposes of this tutorial, all the workers will run on the **this** machine. Therefore, disable all GPUs to prevent errors caused by all workers trying to use the same GPU."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "685pbYEY3jGC"
+ "id": "rpEIVI5upIzM"
},
"outputs": [],
"source": [
@@ -124,7 +147,7 @@
"id": "7X1MS6385BWi"
},
"source": [
- "2. Reset the `TF_CONFIG` environment variable (you'll learn more about this later):"
+ "* Reset the `TF_CONFIG` environment variable (you'll learn more about this later):"
]
},
{
@@ -144,7 +167,7 @@
"id": "Rd4L9Ii77SS8"
},
"source": [
- "3. Make sure that the current directory is on Python's path—this allows the notebook to import the files written by `%%writefile` later:\n"
+ "* Make sure that the current directory is on Python's path—this allows the notebook to import the files written by `%%writefile` later:\n"
]
},
{
@@ -162,10 +185,30 @@
{
"cell_type": "markdown",
"metadata": {
- "id": "pDhHuMjb7bfU"
+ "id": "9hLpDZhAz2q-"
},
"source": [
- "Now import TensorFlow:"
+ "Install `tf-nightly`, as the frequency of checkpoint saving at a particular step with the `save_freq` argument in `tf.keras.callbacks.BackupAndRestore` is introduced from TensorFlow 2.10:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "-XqozLfzz30N"
+ },
+ "outputs": [],
+ "source": [
+ "!pip install tf-nightly"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "524e38dab658"
+ },
+ "source": [
+ "Finally, import TensorFlow:"
]
},
{
@@ -194,7 +237,7 @@
"id": "fLW6D2TzvC-4"
},
"source": [
- "Next, create an `mnist.py` file with a simple model and dataset setup. This Python file will be used by the worker-processes in this tutorial:"
+ "Next, create an `mnist_setup.py` file with a simple model and dataset setup. This Python file will be used by the worker processes in this tutorial:"
]
},
{
@@ -205,7 +248,7 @@
},
"outputs": [],
"source": [
- "%%writefile mnist.py\n",
+ "%%writefile mnist_setup.py\n",
"\n",
"import os\n",
"import tensorflow as tf\n",
@@ -256,11 +299,11 @@
},
"outputs": [],
"source": [
- "import mnist\n",
+ "import mnist_setup\n",
"\n",
"batch_size = 64\n",
- "single_worker_dataset = mnist.mnist_dataset(batch_size)\n",
- "single_worker_model = mnist.build_and_compile_cnn_model()\n",
+ "single_worker_dataset = mnist_setup.mnist_dataset(batch_size)\n",
+ "single_worker_model = mnist_setup.build_and_compile_cnn_model()\n",
"single_worker_model.fit(single_worker_dataset, epochs=3, steps_per_epoch=70)"
]
},
@@ -276,7 +319,7 @@
"\n",
"### A cluster with jobs and tasks\n",
"\n",
- "In TensorFlow, distributed training involves: a `'cluster'`\n",
+ "In TensorFlow, distributed training involves a `'cluster'`\n",
"with several jobs, and each of the jobs may have one or more `'task'`s.\n",
"\n",
"You will need the `TF_CONFIG` configuration environment variable for training on multiple machines, each of which possibly has a different role. `TF_CONFIG` is a JSON string used to specify the cluster configuration for each worker that is part of the cluster.\n",
@@ -284,10 +327,10 @@
"There are two components of a `TF_CONFIG` variable: `'cluster'` and `'task'`.\n",
"\n",
"* A `'cluster'` is the same for all workers and provides information about the training cluster, which is a dict consisting of different types of jobs, such as `'worker'` or `'chief'`.\n",
- " - In multi-worker training with `tf.distribute.MultiWorkerMirroredStrategy`, there is usually one `'worker'` that takes on responsibilities, such as saving a checkpoint and writing a summary file for TensorBoard, in addition to what a regular `'worker'` does. Such `'worker'` is referred to as the chief worker (with a job name `'chief'`).\n",
- " - It is customary for the `'chief'` to have `'index'` `0` be appointed to (in fact, this is how `tf.distribute.Strategy` is implemented).\n",
+ " - In multi-worker training with `tf.distribute.MultiWorkerMirroredStrategy`, there is usually one `'worker'` that takes on more responsibilities, such as saving a checkpoint and writing a summary file for TensorBoard, in addition to what a regular `'worker'` does. Such `'worker'` is referred to as the chief worker (with a job name `'chief'`).\n",
+ " - It is customary for the worker with `'index'` `0` to be the `'chief'`.\n",
"\n",
- "* A `'task'` provides information of the current task and is different for each worker. It specifies the `'type'` and `'index'` of that worker.\n",
+ "* A `'task'` provides information on the current task and is different for each worker. It specifies the `'type'` and `'index'` of that worker.\n",
"\n",
"Below is an example configuration:"
]
@@ -314,7 +357,7 @@
"id": "JjgwJbPKZkJL"
},
"source": [
- "Here is the same `TF_CONFIG` serialized as a JSON string:"
+ "Note that `tf_config` is just a local variable in Python. To use it for training configuration, serialize it as a JSON and place it in a `TF_CONFIG` environment variable."
]
},
{
@@ -328,22 +371,13 @@
"json.dumps(tf_config)"
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "f83FVYqDX3aX"
- },
- "source": [
- "Note that`tf_config` is just a local variable in Python. To be able to use it for a training configuration, this dict needs to be serialized as a JSON and placed in a `TF_CONFIG` environment variable."
- ]
- },
{
"cell_type": "markdown",
"metadata": {
"id": "8YFpxrcsZ2xG"
},
"source": [
- "In the example configuration above, you set the task `'type'` to `'worker'` and the task `'index'` to `0`. Therefore, this machine is the _first_ worker. It will be appointed as the `'chief'` worker and do more work than the others.\n",
+ "In the example configuration above, you set the task `'type'` to `'worker'` and the task `'index'` to `0`. Therefore, this machine is the _first_ worker. It will be appointed as the `'chief'` worker.\n",
"\n",
"Note: Other machines will need to have the `TF_CONFIG` environment variable set as well, and it should have the same `'cluster'` dict, but different task `'type'`s or task `'index'`es, depending on the roles of those machines."
]
@@ -354,12 +388,8 @@
"id": "aogb74kHxynz"
},
"source": [
- "For illustration purposes, this tutorial shows how you may set up a `TF_CONFIG` variable with two workers on a `localhost`.\n",
- "\n",
- "In practice, you would create multiple workers on external IP addresses/ports and set a `TF_CONFIG` variable on each worker accordingly.\n",
- "\n",
- "In this tutorial, you will use two workers:\n",
- "- The first (`'chief'`) worker's `TF_CONFIG` is shown above.\n",
+ "In practice, you would create multiple workers on external IP addresses/ports and set a `TF_CONFIG` variable on each worker accordingly. For illustration purposes, this tutorial shows how you may set up a `TF_CONFIG` variable with two workers on a `localhost`:\n",
+ "- The first (`'chief'`) worker's `TF_CONFIG` as shown above.\n",
"- For the second worker, you will set `tf_config['task']['index']=1`"
]
},
@@ -378,9 +408,7 @@
"id": "FcjAbuGY1ACJ"
},
"source": [
- "Subprocesses inherit environment variables from their parent.\n",
- "\n",
- "For example, you can set an environment variable in this Jupyter Notebook process as follows:"
+ "Subprocesses inherit environment variables from their parent. So if you set an environment variable in this Jupyter Notebook process:"
]
},
{
@@ -400,7 +428,7 @@
"id": "gQkIX-cg18md"
},
"source": [
- "Then, you can access the environment variable from a subprocesses:"
+ "... then you can access the environment variable from the subprocesses:"
]
},
{
@@ -421,7 +449,16 @@
"id": "af6BCA-Y2fpz"
},
"source": [
- "In the next section, you'll use a similar method to pass the `TF_CONFIG` to the worker subprocesses. In a real-world scenario, you wouldn't launch your jobs this way, but it's sufficient in this example."
+ "In the next section, you'll use this method to pass the `TF_CONFIG` to the worker subprocesses. You would never really launch your jobs this way in a real-world scenario—this tutorial is just showing how to do it with a minimal multi-worker example."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "dnDJmaRA9qnf"
+ },
+ "source": [
+ "## Train the model"
]
},
{
@@ -430,16 +467,7 @@
"id": "UhNtHfuxCGVy"
},
"source": [
- "## Choose the right strategy\n",
- "\n",
- "In TensorFlow, there are two main forms of distributed training:\n",
- "\n",
- "* _Synchronous training_, where the steps of training are synced across the workers and replicas, and\n",
- "* _Asynchronous training_, where the training steps are not strictly synced (for example, [parameter server training](parameter_server_training.ipynb)).\n",
- "\n",
- "This tutorial demonstrates how to perform synchronous multi-worker training using an instance of `tf.distribute.MultiWorkerMirroredStrategy`.\n",
- "\n",
- "`MultiWorkerMirroredStrategy` creates copies of all variables in the model's layers on each device across all workers. It uses `CollectiveOps`, a TensorFlow op for collective communication, to aggregate gradients and keep the variables in sync. The [`tf.distribute.Strategy` guide](../../guide/distributed_training.ipynb) has more details about this strategy."
+ "To train the model, firstly create an instance of the `tf.distribute.MultiWorkerMirroredStrategy`:"
]
},
{
@@ -459,16 +487,7 @@
"id": "N0iv7SyyAohc"
},
"source": [
- "Note: `TF_CONFIG` is parsed and TensorFlow's GRPC servers are started at the time `MultiWorkerMirroredStrategy()` is called, so the `TF_CONFIG` environment variable must be set before a `tf.distribute.Strategy` instance is created. Since `TF_CONFIG` is not set yet, the above strategy is effectively single-worker training."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "FMy2VM4Akzpr"
- },
- "source": [
- "`MultiWorkerMirroredStrategy` provides multiple implementations via the [`CommunicationOptions`](https://www.tensorflow.org/api_docs/python/tf/distribute/experimental/CommunicationOptions) parameter: 1) `RING` implements ring-based collectives using gRPC as the cross-host communication layer; 2) `NCCL` uses the [NVIDIA Collective Communication Library](https://developer.nvidia.com/nccl) to implement collectives; and 3) `AUTO` defers the choice to the runtime. The best choice of collective implementation depends upon the number and kind of GPUs, and the network interconnect in the cluster."
+ "Note: `TF_CONFIG` is parsed and TensorFlow's GRPC servers are started at the time `MultiWorkerMirroredStrategy` is called, so the `TF_CONFIG` environment variable must be set before a `tf.distribute.Strategy` instance is created. Since `TF_CONFIG` is not set yet, the above strategy is effectively single-worker training."
]
},
{
@@ -477,8 +496,6 @@
"id": "H47DDcOgfzm7"
},
"source": [
- "## Train the model\n",
- "\n",
"With the integration of `tf.distribute.Strategy` API into `tf.keras`, the only change you will make to distribute the training to multiple-workers is enclosing the model building and `model.compile()` call inside `strategy.scope()`. The distribution strategy's scope dictates how and where the variables are created, and in the case of `MultiWorkerMirroredStrategy`, the variables created are `MirroredVariable`s, and they are replicated on each of the workers.\n"
]
},
@@ -492,7 +509,7 @@
"source": [
"with strategy.scope():\n",
" # Model building/compiling need to be within `strategy.scope()`.\n",
- " multi_worker_model = mnist.build_and_compile_cnn_model()"
+ " multi_worker_model = mnist_setup.build_and_compile_cnn_model()"
]
},
{
@@ -512,7 +529,7 @@
"source": [
"To actually run with `MultiWorkerMirroredStrategy` you'll need to run worker processes and pass a `TF_CONFIG` to them.\n",
"\n",
- "Like the `mnist.py` file written earlier, here is the `main.py` that each of the workers will run:"
+ "Like the `mnist_setup.py` file written earlier, here is the `main.py` that each of the workers will run:"
]
},
{
@@ -529,7 +546,7 @@
"import json\n",
"\n",
"import tensorflow as tf\n",
- "import mnist\n",
+ "import mnist_setup\n",
"\n",
"per_worker_batch_size = 64\n",
"tf_config = json.loads(os.environ['TF_CONFIG'])\n",
@@ -538,11 +555,11 @@
"strategy = tf.distribute.MultiWorkerMirroredStrategy()\n",
"\n",
"global_batch_size = per_worker_batch_size * num_workers\n",
- "multi_worker_dataset = mnist.mnist_dataset(global_batch_size)\n",
+ "multi_worker_dataset = mnist_setup.mnist_dataset(global_batch_size)\n",
"\n",
"with strategy.scope():\n",
" # Model building/compiling need to be within `strategy.scope()`.\n",
- " multi_worker_model = mnist.build_and_compile_cnn_model()\n",
+ " multi_worker_model = mnist_setup.build_and_compile_cnn_model()\n",
"\n",
"\n",
"multi_worker_model.fit(multi_worker_dataset, epochs=3, steps_per_epoch=70)"
@@ -584,7 +601,7 @@
"id": "qmEEStPS6vR_"
},
"source": [
- "So json-serialize the `TF_CONFIG` and add it to the environment variables:"
+ "Serialize the `TF_CONFIG` to JSON and add it to the environment variables:"
]
},
{
@@ -686,7 +703,7 @@
"id": "RqZhVF7L_KOy"
},
"source": [
- "The last line of the log file should say: `Started server with target: grpc://localhost:12345`. The first worker is now ready, and is waiting for all the other worker(s) to be ready to proceed."
+ "The last line of the log file should say: `Started server with target: grpc://localhost:12345`. The first worker is now ready and is waiting for all the other worker(s) to be ready to proceed."
]
},
{
@@ -758,11 +775,7 @@
"id": "zL79ak5PMzEg"
},
"source": [
- "Unsurprisingly, this ran _slower_ than the test run at the beginning of this tutorial.\n",
- "\n",
- "Running multiple workers on a single machine only adds overhead.\n",
- "\n",
- "The goal here was not to improve the training time, but only to give an example of multi-worker training."
+ "Note: This may run slower than the test run at the beginning of this tutorial because running multiple workers on a single machine only adds overhead. The goal here is not to improve the training time but to give an example of multi-worker training.\n"
]
},
{
@@ -784,11 +797,16 @@
"id": "9j2FJVHoUIrE"
},
"source": [
- "## Multi-worker training in depth\n",
- "\n",
- "So far, you have learned how to perform a basic multi-worker setup.\n",
- "\n",
- "During the rest of the tutorial, you will learn about other factors, which may be useful or important for real use cases, in detail."
+ "## Multi-worker training in depth\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "C1hBks_dAZmT"
+ },
+ "source": [
+ "So far, you have learned how to perform a basic multi-worker setup. The rest of the tutorial goes over other factors, which may be useful or important for real use cases, in detail."
]
},
{
@@ -820,25 +838,41 @@
"options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.OFF\n",
"\n",
"global_batch_size = 64\n",
- "multi_worker_dataset = mnist.mnist_dataset(batch_size=64)\n",
+ "multi_worker_dataset = mnist_setup.mnist_dataset(batch_size=64)\n",
"dataset_no_auto_shard = multi_worker_dataset.with_options(options)"
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "z85hElxsBQsT"
+ },
+ "source": [
+ "### Evaluation"
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {
"id": "gmqvlh5LhAoU"
},
"source": [
- "### Evaluation\n",
- "\n",
- "If you pass the `validation_data` into `Model.fit`, it will alternate between training and evaluation for each epoch. The evaluation taking the `validation_data` is distributed across the same set of workers and the evaluation results are aggregated and available for all workers.\n",
+ "If you pass the `validation_data` into `Model.fit` as well, it will alternate between training and evaluation for each epoch. The evaluation work is distributed across the same set of workers, and its results are aggregated and available to all workers.\n",
"\n",
"Similar to training, the validation dataset is automatically sharded at the file level. You need to set a global batch size in the validation dataset and set the `validation_steps`.\n",
"\n",
- "A repeated dataset is also recommended for evaluation.\n",
+ "A repeated dataset (by calling `tf.data.Dataset.repeat`) is recommended for evaluation.\n",
"\n",
- "Alternatively, you can also create another task that periodically reads checkpoints and runs the evaluation. This is what Estimator does. But this is not a recommended way to perform evaluation and thus its details are omitted."
+ "Alternatively, you can also create another task that periodically reads checkpoints and runs the evaluation. This is what an Estimator does. But this is not a recommended way to perform evaluation and thus its details are omitted."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "FNkoxUPJBNTb"
+ },
+ "source": [
+ "### Performance"
]
},
{
@@ -847,25 +881,21 @@
"id": "XVk4ftYx6JAO"
},
"source": [
- "### Performance\n",
- "\n",
- "You now have a Keras model that is all set up to run in multiple workers with the `MultiWorkerMirroredStrategy`.\n",
- "\n",
- "To tweak performance of multi-worker training, you can try the following:\n",
+ "To tweak the performance of multi-worker training, you can try the following:\n",
"\n",
"- `tf.distribute.MultiWorkerMirroredStrategy` provides multiple [collective communication implementations](https://www.tensorflow.org/api_docs/python/tf/distribute/experimental/CommunicationImplementation):\n",
" - `RING` implements ring-based collectives using gRPC as the cross-host communication layer.\n",
" - `NCCL` uses the [NVIDIA Collective Communication Library](https://developer.nvidia.com/nccl) to implement collectives.\n",
" - `AUTO` defers the choice to the runtime.\n",
" \n",
- " The best choice of collective implementation depends upon the number of GPUs, the type of GPUs, and the network interconnect in the cluster. To override the automatic choice, specify the `communication_options` parameter of `MultiWorkerMirroredStrategy`'s constructor. For example:\n",
+ " The best choice of collective implementation depends upon the number of GPUs, the type of GPUs, and the network interconnects in the cluster. To override the automatic choice, specify the `communication_options` parameter of `MultiWorkerMirroredStrategy`'s constructor. For example:\n",
" \n",
" ```python\n",
- " communication_options=tf.distribute.experimental.CommunicationOptions(implementation=tf.distribute.experimental.CollectiveCommunication.NCCL)\n",
+ " communication_options=tf.distribute.experimental.CommunicationOptions(implementation=tf.distribute.experimental.CommunicationImplementation.NCCL)\n",
" ```\n",
"\n",
"- Cast the variables to `tf.float` if possible:\n",
- " - The official ResNet model includes [an example](https://github.com/tensorflow/models/blob/8367cf6dabe11adf7628541706b660821f397dce/official/resnet/resnet_model.py#L466) of how this can be done."
+ " - The official ResNet model includes [an example](https://github.com/tensorflow/models/blob/8367cf6dabe11adf7628541706b660821f397dce/official/resnet/resnet_model.py#L466) of how to do this."
]
},
{
@@ -882,7 +912,7 @@
"\n",
"When a worker becomes unavailable, other workers will fail (possibly after a timeout). In such cases, the unavailable worker needs to be restarted, as well as other workers that have failed.\n",
"\n",
- "Note: Previously, the `ModelCheckpoint` callback provided a mechanism to restore the training state upon a restart from a job failure for multi-worker training. The TensorFlow team are introducing a new [`BackupAndRestore`](#scrollTo=kmH8uCUhfn4w) callback, to also add the support to single worker training for a consistent experience, and removed fault tolerance functionality from existing `ModelCheckpoint` callback. From now on, applications that rely on this behavior should migrate to the new callback."
+ "Note: Previously, the `ModelCheckpoint` callback provided a mechanism to restore the training state upon a restart from a job failure for multi-worker training. The TensorFlow team is introducing a new [`BackupAndRestore`](#scrollTo=kmH8uCUhfn4w) callback, which also adds the support to single-worker training for a consistent experience, and removed the fault tolerance functionality from existing `ModelCheckpoint` callback. From now on, applications that rely on this behavior should migrate to the new `BackupAndRestore` callback."
]
},
{
@@ -891,13 +921,13 @@
"id": "KvHPjGlyyFt6"
},
"source": [
- "#### ModelCheckpoint callback\n",
+ "#### The `ModelCheckpoint` callback\n",
"\n",
"`ModelCheckpoint` callback no longer provides fault tolerance functionality, please use [`BackupAndRestore`](#scrollTo=kmH8uCUhfn4w) callback instead.\n",
"\n",
"The `ModelCheckpoint` callback can still be used to save checkpoints. But with this, if training was interrupted or successfully finished, in order to continue training from the checkpoint, the user is responsible to load the model manually.\n",
"\n",
- "Optionally the user can choose to save and restore model/weights outside `ModelCheckpoint` callback."
+ "Optionally, users can choose to save and restore model/weights outside `ModelCheckpoint` callback."
]
},
{
@@ -919,14 +949,14 @@
"\n",
"You should have some cleanup logic that deletes the temporary directories created by the workers once your training has completed.\n",
"\n",
- "The reason for saving on the chief and workers at the same time is because you might be aggregating variables during checkpointing which requires both the chief and workers to participate in the allreduce communication protocol. On the other hand, letting chief and workers save to the same model directory will result in errors due to contention.\n",
+ "The reason for saving on the chief and workers at the same time is because you might be aggregating variables during checkpointing, which requires both the chief and workers to participate in the allreduce communication protocol. On the other hand, letting chief and workers save to the same model directory will result in errors due to contention.\n",
"\n",
- "Using the `MultiWorkerMirroredStrategy`, the program is run on every worker, and in order to know whether the current worker is chief, it takes advantage of the cluster resolver object that has attributes `task_type` and `task_id`:\n",
- "- `task_type` tells you what the current job is (e.g. `'worker'`).\n",
+ "Using the `MultiWorkerMirroredStrategy`, the program is run on every worker, and in order to know whether the current worker is the chief, it takes advantage of the cluster resolver object that has attributes `task_type` and `task_id`:\n",
+ "- `task_type` tells you what the current job is (for example, `'worker'`).\n",
"- `task_id` tells you the identifier of the worker.\n",
"- The worker with `task_id == 0` is designated as the chief worker.\n",
"\n",
- "In the code snippet below, the `write_filepath` function provides the file path to write, which depends on the the worker's `task_id`:\n",
+ "In the code snippet below, the `write_filepath` function provides the file path to write, which depends on the worker's `task_id`:\n",
"\n",
"- For the chief worker (with `task_id == 0`), it writes to the original file path. \n",
"- For other workers, it creates a temporary directory—`temp_dir`—with the `task_id` in the directory path to write in:"
@@ -943,14 +973,14 @@
"model_path = '/tmp/keras-model'\n",
"\n",
"def _is_chief(task_type, task_id):\n",
- " # Note: there are two possible `TF_CONFIG` configuration.\n",
+ " # Note: there are two possible `TF_CONFIG` configurations.\n",
" # 1) In addition to `worker` tasks, a `chief` task type is use;\n",
" # in this case, this function should be modified to\n",
" # `return task_type == 'chief'`.\n",
" # 2) Only `worker` task type is used; in this case, worker 0 is\n",
" # regarded as the chief. The implementation demonstrated here\n",
" # is for this case.\n",
- " # For the purpose of this Colab section, the `task_type is None` case\n",
+ " # For the purpose of this Colab section, the `task_type` is `None` case\n",
" # is added because it is effectively run with only a single worker.\n",
" return (task_type == 'worker' and task_id == 0) or task_type is None\n",
"\n",
@@ -981,6 +1011,15 @@
"With that, you're now ready to save:"
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "XnToxeIcg_6O"
+ },
+ "source": [
+ "Deprecated: For Keras objects, it's recommended to use the new high-level `.keras` format and `tf.keras.Model.export`, as demonstrated in the guide [here](https://www.tensorflow.org/guide/keras/save_and_serialize). The low-level SavedModel format continues to be supported for existing code."
+ ]
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -998,7 +1037,7 @@
"id": "8LXUVVl9_v5x"
},
"source": [
- "As described above, later on the model should only be loaded from the path chief saved to, so let's remove the temporary ones the non-chief workers saved:"
+ "As described above, later on the model should only be loaded from the file path the chief worker saved to. Therefore, remove the temporary ones the non-chief workers have saved:"
]
},
{
@@ -1019,7 +1058,7 @@
"id": "Nr-2PKlHAPBT"
},
"source": [
- "Now, when it's time to load, let's use convenient `tf.keras.models.load_model` API, and continue with further work.\n",
+ "Now, when it's time to load, use the convenient `tf.keras.models.load_model` API, and continue with further work.\n",
"\n",
"Here, assume only using single worker to load and continue training, in which case you do not call `tf.keras.models.load_model` within another `strategy.scope()` (note that `strategy = tf.distribute.MultiWorkerMirroredStrategy()`, as defined earlier):"
]
@@ -1117,20 +1156,23 @@
"id": "kmH8uCUhfn4w"
},
"source": [
- "#### BackupAndRestore callback\n",
+ "#### The `BackupAndRestore` callback\n",
+ "\n",
+ "The `tf.keras.callbacks.BackupAndRestore` callback provides the fault tolerance functionality by backing up the model and current training state in a temporary checkpoint file under `backup_dir` argument to `BackupAndRestore`. \n",
"\n",
- "The `tf.keras.callbacks.experimental.BackupAndRestore` callback provides the fault tolerance functionality by backing up the model and current epoch number in a temporary checkpoint file under `backup_dir` argument to `BackupAndRestore`. This is done at the end of each epoch.\n",
+ "Note: In Tensorflow 2.9, the current model and the training state is backed up at epoch boundaries. In the `tf-nightly` version and from TensorFlow 2.10, the `BackupAndRestore` callback can back up the model and the training state at epoch or step boundaries. `BackupAndRestore` accepts an optional `save_freq` argument. `save_freq` accepts either `'epoch'` or an `int` value. If `save_freq` is set to `'epoch'` the model is backed up after every epoch. If `save_freq` is set to an integer value greater than `0`, the model is backed up after every `save_freq` number of batches.\n",
"\n",
- "Once jobs get interrupted and restart, the callback restores the last checkpoint, and training continues from the beginning of the interrupted epoch. Any partial training already done in the unfinished epoch before interruption will be thrown away, so that it doesn't affect the final model state.\n",
+ "Once the jobs get interrupted and restarted, the `BackupAndRestore` callback restores the last checkpoint, and you can continue training from the beginning of the epoch and step at which the training state was last saved.\n",
"\n",
- "To use it, provide an instance of `tf.keras.callbacks.experimental.BackupAndRestore` at the `Model.fit` call.\n",
+ "To use it, provide an instance of `tf.keras.callbacks.BackupAndRestore` at the `Model.fit` call.\n",
"\n",
- "With `MultiWorkerMirroredStrategy`, if a worker gets interrupted, the whole cluster pauses until the interrupted worker is restarted. Other workers will also restart, and the interrupted worker rejoins the cluster. Then, every worker reads the checkpoint file that was previously saved and picks up its former state, thereby allowing the cluster to get back in sync. Then, the training continues.\n",
+ "With `MultiWorkerMirroredStrategy`, if a worker gets interrupted, the whole cluster will pause until the interrupted worker is restarted. Other workers will also restart, and the interrupted worker will rejoin the cluster. Then, every worker will read the checkpoint file that was previously saved and pick up its former state, thereby allowing the cluster to get back in sync. Then, the training will continue. The distributed dataset iterator state will be re-initialized and not restored.\n",
"\n",
"The `BackupAndRestore` callback uses the `CheckpointManager` to save and restore the training state, which generates a file called checkpoint that tracks existing checkpoints together with the latest one. For this reason, `backup_dir` should not be re-used to store other checkpoints in order to avoid name collision.\n",
"\n",
- "Currently, the `BackupAndRestore` callback supports single worker with no strategy, MirroredStrategy, and multi-worker with MultiWorkerMirroredStrategy.\n",
- "Below are two examples for both multi-worker training and single worker training."
+ "Currently, the `BackupAndRestore` callback supports single-worker training with no strategy—`MirroredStrategy`—and multi-worker training with `MultiWorkerMirroredStrategy`.\n",
+ "\n",
+ "Below are two examples for both multi-worker training and single-worker training:"
]
},
{
@@ -1141,12 +1183,73 @@
},
"outputs": [],
"source": [
- "# Multi-worker training with MultiWorkerMirroredStrategy\n",
- "# and the BackupAndRestore callback.\n",
+ "# Multi-worker training with `MultiWorkerMirroredStrategy`\n",
+ "# and the `BackupAndRestore` callback. The training state \n",
+ "# is backed up at epoch boundaries by default.\n",
+ "\n",
+ "callbacks = [tf.keras.callbacks.BackupAndRestore(backup_dir='/tmp/backup')]\n",
+ "with strategy.scope():\n",
+ " multi_worker_model = mnist_setup.build_and_compile_cnn_model()\n",
+ "multi_worker_model.fit(multi_worker_dataset,\n",
+ " epochs=3,\n",
+ " steps_per_epoch=70,\n",
+ " callbacks=callbacks)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "f8e86TAp0Rsl"
+ },
+ "source": [
+ "If the `save_freq` argument in the `BackupAndRestore` callback is set to `'epoch'`, the model is backed up after every epoch."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "rZjQGPsF0aEI"
+ },
+ "outputs": [],
+ "source": [
+ "# The training state is backed up at epoch boundaries because `save_freq` is\n",
+ "# set to `epoch`.\n",
+ "\n",
+ "callbacks = [tf.keras.callbacks.BackupAndRestore(backup_dir='/tmp/backup')]\n",
+ "with strategy.scope():\n",
+ " multi_worker_model = mnist_setup.build_and_compile_cnn_model()\n",
+ "multi_worker_model.fit(multi_worker_dataset,\n",
+ " epochs=3,\n",
+ " steps_per_epoch=70,\n",
+ " callbacks=callbacks)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "p-r44kCM0jc6"
+ },
+ "source": [
+ "Note: The next code block uses features that are only available in `tf-nightly` until Tensorflow 2.10 is released.\n",
+ "\n",
+ "If the `save_freq` argument in the `BackupAndRestore` callback is set to an integer value greater than `0`, the model is backed up after every `save_freq` number of batches."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "bSJUyLSF0moC"
+ },
+ "outputs": [],
+ "source": [
+ "# The training state is backed up at every 30 steps because `save_freq` is set\n",
+ "# to an integer value of `30`.\n",
"\n",
- "callbacks = [tf.keras.callbacks.experimental.BackupAndRestore(backup_dir='/tmp/backup')]\n",
+ "callbacks = [tf.keras.callbacks.BackupAndRestore(backup_dir='/tmp/backup', save_freq=30)]\n",
"with strategy.scope():\n",
- " multi_worker_model = mnist.build_and_compile_cnn_model()\n",
+ " multi_worker_model = mnist_setup.build_and_compile_cnn_model()\n",
"multi_worker_model.fit(multi_worker_dataset,\n",
" epochs=3,\n",
" steps_per_epoch=70,\n",
@@ -1161,7 +1264,7 @@
"source": [
"If you inspect the directory of `backup_dir` you specified in `BackupAndRestore`, you may notice some temporarily generated checkpoint files. Those files are needed for recovering the previously lost instances, and they will be removed by the library at the end of `Model.fit` upon successful exiting of your training.\n",
"\n",
- "Note: Currently the `BackupAndRestore` callback only supports eager mode. In graph mode, consider using [Save/Restore Model](#model_saving_and_loading) mentioned above, and by providing `initial_epoch` in `Model.fit`."
+ "Note: Currently the `BackupAndRestore` callback only supports eager mode. In graph mode, consider using `Model.save`/`tf.saved_model.save` and `tf.keras.models.load_model` for saving and restoring models, respectively, as described in the _Model saving and loading_ section above, and by providing `initial_epoch` in `Model.fit` during training."
]
},
{
@@ -1172,7 +1275,7 @@
"source": [
"## Additional resources\n",
"\n",
- "1. The [Distributed training in TensorFlow](https://www.tensorflow.org/guide/distributed_training) guide provides an overview of the available distribution strategies.\n",
+ "1. The [Distributed training in TensorFlow](../../guide/distributed_training.ipynb) guide provides an overview of the available distribution strategies.\n",
"1. The [Custom training loop with Keras and MultiWorkerMirroredStrategy](multi_worker_with_ctl.ipynb) tutorial shows how to use the `MultiWorkerMirroredStrategy` with Keras and a custom training loop.\n",
"1. Check out the [official models](https://github.com/tensorflow/models/tree/master/official), many of which can be configured to run multiple distribution strategies.\n",
"1. The [Better performance with tf.function](../../guide/function.ipynb) guide provides information about other strategies and tools, such as the [TensorFlow Profiler](../../guide/profiler.md) you can use to optimize the performance of your TensorFlow models."
@@ -1181,9 +1284,8 @@
],
"metadata": {
"colab": {
- "collapsed_sections": [],
"name": "multi_worker_with_keras.ipynb",
- "toc_visible": true
+ "toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
diff --git a/site/en/tutorials/distribute/parameter_server_training.ipynb b/site/en/tutorials/distribute/parameter_server_training.ipynb
index fae0a2d3576..2e6bb0cfce2 100644
--- a/site/en/tutorials/distribute/parameter_server_training.ipynb
+++ b/site/en/tutorials/distribute/parameter_server_training.ipynb
@@ -74,7 +74,7 @@
"\n",
"A parameter server training cluster consists of _workers_ and _parameter servers_. Variables are created on parameter servers and they are read and updated by workers in each step. By default, workers read and update these variables independently without synchronizing with each other. This is why sometimes parameter server-style training is called _asynchronous training_.\n",
"\n",
- "In TensorFlow 2, parameter server training is powered by the `tf.distribute.experimental.ParameterServerStrategy` class, which distributes the training steps to a cluster that scales up to thousands of workers (accompanied by parameter servers)."
+ "In TensorFlow 2, parameter server training is powered by the `tf.distribute.ParameterServerStrategy` class, which distributes the training steps to a cluster that scales up to thousands of workers (accompanied by parameter servers)."
]
},
{
@@ -87,9 +87,9 @@
"\n",
"There are two main supported training methods:\n",
"\n",
- "- The Keras `Model.fit` API, which is recommended when you prefer a high-level abstraction and handling of training.\n",
- "- A custom training loop (you can refer to [Custom training](https://www.tensorflow.org/tutorials/customization/custom_training_walkthrough#train_the_model), [Writing a training loop from scratch\n",
- "](https://www.tensorflow.org/guide/keras/writing_a_training_loop_from_scratch) and [Custom training loop with Keras and MultiWorkerMirroredStrategy](https://www.tensorflow.org/tutorials/distribute/multi_worker_with_ctl) for more details.) Custom loop training is recommended when you prefer to define the details of their training loop."
+ "- The Keras `Model.fit` API: if you prefer a high-level abstraction and handling of training. This is generally recommended if you are training a `tf.keras.Model`.\n",
+ "- A custom training loop: if you prefer to define the details of your training loop (you can refer to guides on [Custom training](../customization/custom_training_walkthrough.ipynb), [Writing a training loop from scratch\n",
+ "](https://www.tensorflow.org/guide/keras/writing_a_training_loop_from_scratch) and [Custom training loop with Keras and MultiWorkerMirroredStrategy](multi_worker_with_ctl.ipynb) for more details)."
]
},
{
@@ -100,15 +100,15 @@
"source": [
"### A cluster with jobs and tasks\n",
"\n",
- "Regardless of the API of choice (`Model.fit` or a custom training loop), distributed training in TensorFlow 2 involves: a `'cluster'` with several `'jobs'`, and each of the jobs may have one or more `'tasks'`.\n",
+ "Regardless of the API of choice (`Model.fit` or a custom training loop), distributed training in TensorFlow 2 involves a `'cluster'` with several `'jobs'`, and each of the jobs may have one or more `'tasks'`.\n",
"\n",
"When using parameter server training, it is recommended to have:\n",
"\n",
"- One _coordinator_ job (which has the job name `chief`)\n",
- "- Multiple _worker_ jobs (job name `worker`); and\n",
+ "- Multiple _worker_ jobs (job name `worker`)\n",
"- Multiple _parameter server_ jobs (job name `ps`)\n",
"\n",
- "While the _coordinator_ creates resources, dispatches training tasks, writes checkpoints, and deals with task failures, _workers_ and _parameter servers_ run `tf.distribute.Server` that listen for requests from the coordinator."
+ "The _coordinator_ creates resources, dispatches training tasks, writes checkpoints, and deals with task failures. The _workers_ and _parameter servers_ run `tf.distribute.Server` instances that listen for requests from the coordinator."
]
},
{
@@ -117,10 +117,9 @@
"id": "oLV1FbpLtqtB"
},
"source": [
- "### Parameter server training with `Model.fit` API\n",
+ "### Parameter server training with the `Model.fit` API\n",
"\n",
- "Parameter server training with the `Model.fit` API requires the coordinator to use a `tf.distribute.experimental.ParameterServerStrategy` object, and a `tf.keras.utils.experimental.DatasetCreator` as the input. Similar to `Model.fit` usage with no strategy, or with other strategies, the workflow involves creating and compiling the model, preparing the callbacks, followed by\n",
- "a `Model.fit` call."
+ "Parameter server training with the `Model.fit` API requires the coordinator to use a `tf.distribute.ParameterServerStrategy` object. Similar to `Model.fit` usage with no strategy, or with other strategies, the workflow involves creating and compiling the model, preparing the callbacks, and calling `Model.fit`."
]
},
{
@@ -131,12 +130,11 @@
"source": [
"### Parameter server training with a custom training loop\n",
"\n",
- "With custom training loops, the `tf.distribute.experimental.coordinator.ClusterCoordinator` class is the key component used for the coordinator.\n",
+ "With custom training loops, the `tf.distribute.coordinator.ClusterCoordinator` class is the key component used for the coordinator.\n",
"\n",
- "- The `ClusterCoordinator` class needs to work in conjunction with a `tf.distribute.Strategy` object.\n",
- "- This `tf.distribute.Strategy` object is needed to provide the information of the cluster and is used to define a training step, as demonstrated in [Custom training with tf.distribute.Strategy](https://www.tensorflow.org/tutorials/distribute/custom_training#training_loop).\n",
+ "- The `ClusterCoordinator` class needs to work in conjunction with a `tf.distribute.ParameterServerStrategy` object.\n",
+ "- This `tf.distribute.Strategy` object is needed to provide the information of the cluster and is used to define a training step, as demonstrated in [Custom training with tf.distribute.Strategy](custom_training.ipynb).\n",
"- The `ClusterCoordinator` object then dispatches the execution of these training steps to remote workers.\n",
- "- For parameter server training, the `ClusterCoordinator` needs to work with a `tf.distribute.experimental.ParameterServerStrategy`.\n",
"\n",
"The most important API provided by the `ClusterCoordinator` object is `schedule`:\n",
"\n",
@@ -144,7 +142,7 @@
"- The queued functions will be dispatched to remote workers in background threads and their `RemoteValue`s will be filled asynchronously.\n",
"- Since `schedule` doesn’t require worker assignment, the `tf.function` passed in can be executed on any available worker.\n",
"- If the worker it is executed on becomes unavailable before its completion, the function will be retried on another available worker.\n",
- "- Because of this fact and the fact that function execution is not atomic, a function may be executed more than once.\n",
+ "- Because of this fact and the fact that function execution is not atomic, a single function call may be executed more than once.\n",
"\n",
"In addition to dispatching remote functions, the `ClusterCoordinator` also helps\n",
"to create datasets on all the workers and rebuild these datasets when a worker recovers from failure."
@@ -169,9 +167,7 @@
},
"outputs": [],
"source": [
- "!pip install portpicker\n",
- "!pip uninstall tensorflow keras -y\n",
- "!pip install tf-nightly"
+ "!pip install portpicker"
]
},
{
@@ -187,8 +183,7 @@
"import os\n",
"import random\n",
"import portpicker\n",
- "import tensorflow as tf\n",
- "from tensorflow.keras.layers.experimental import preprocessing"
+ "import tensorflow as tf"
]
},
{
@@ -199,9 +194,9 @@
"source": [
"## Cluster setup\n",
"\n",
- "As mentioned above, a parameter server training cluster requires a coordinator task that runs your training program, one or several workers and parameter server tasks that run TensorFlow servers—`tf.distribute.Server`—and possibly an additional evaluation task that runs side-car evaluation (see the side-car evaluation section below). The requirements to set them up are:\n",
+ "As mentioned above, a parameter server training cluster requires a coordinator task that runs your training program, one or several workers and parameter server tasks that run TensorFlow servers—`tf.distribute.Server`—and possibly an additional evaluation task that runs sidecar evaluation (refer to the [sidecar evaluation section](#sidecar_evaluation) below). The requirements to set them up are:\n",
"\n",
- "- The coordinator task needs to know the addresses and ports of all other TensorFlow servers except the evaluator.\n",
+ "- The coordinator task needs to know the addresses and ports of all other TensorFlow servers, except the evaluator.\n",
"- The workers and parameter servers need to know which port they need to listen to. For the sake of simplicity, you can usually pass in the complete cluster information when creating TensorFlow servers on these tasks.\n",
"- The evaluator task doesn’t have to know the setup of the training cluster. If it does, it should not attempt to connect to the training cluster.\n",
"- Workers and parameter servers should have task types as `\"worker\"` and `\"ps\"`, respectively. The coordinator should use `\"chief\"` as the task type for legacy reasons.\n",
@@ -217,7 +212,7 @@
"source": [
"### In-process cluster\n",
"\n",
- "You will start by creating several TensorFlow servers in advance and connect to them later. Note that this is only for the purpose of this tutorial's demonstration, and in real training the servers will be started on `\"worker\"` and `\"ps\"` machines."
+ "You will start by creating several TensorFlow servers in advance and you will connect to them later. Note that this is only for the purpose of this tutorial's demonstration, and in real training the servers will be started on `\"worker\"` and `\"ps\"` machines."
]
},
{
@@ -279,9 +274,9 @@
"id": "pX_91OByt0J2"
},
"source": [
- "The in-process cluster setup is frequently used in unit testing, such as [here](https://github.com/tensorflow/tensorflow/blob/7621d31921c2ed979f212da066631ddfda37adf5/tensorflow/python/distribute/coordinator/cluster_coordinator_test.py#L437).\n",
+ "The in-process cluster setup is frequently used in unit testing, such as [here](https://github.com/tensorflow/tensorflow/blob/eb4c40fc91da260199fa2aed6fe67d36ad49fafd/tensorflow/python/distribute/coordinator/cluster_coordinator_test.py#L447).\n",
"\n",
- "Another option for local testing is to launch processes on the local machine—check out [Multi-worker training with Keras](https://www.tensorflow.org/tutorials/distribute/multi_worker_with_keras) for an example of this approach."
+ "Another option for local testing is to launch processes on the local machine—check out [Multi-worker training with Keras](multi_worker_with_keras.ipynb) for an example of this approach."
]
},
{
@@ -292,7 +287,7 @@
"source": [
"## Instantiate a ParameterServerStrategy\n",
"\n",
- "Before you dive into the training code, let's instantiate a `ParameterServerStrategy` object. Note that this is needed regardless of whether you are proceeding with `Model.fit` or a custom training loop. The `variable_partitioner` argument will be explained in the [Variable sharding section](#variable-sharding)."
+ "Before you dive into the training code, let's instantiate a `tf.distribute.ParameterServerStrategy` object. Note that this is needed regardless of whether you are proceeding with `Model.fit` or a custom training loop. The `variable_partitioner` argument will be explained in the [Variable sharding section](#variable_sharding)."
]
},
{
@@ -308,7 +303,7 @@
" min_shard_bytes=(256 << 10),\n",
" max_shards=NUM_PS))\n",
"\n",
- "strategy = tf.distribute.experimental.ParameterServerStrategy(\n",
+ "strategy = tf.distribute.ParameterServerStrategy(\n",
" cluster_resolver,\n",
" variable_partitioner=variable_partitioner)"
]
@@ -331,7 +326,8 @@
"### Variable sharding\n",
"\n",
"Variable sharding refers to splitting a variable into multiple smaller\n",
- "variables, which are called _shards_. Variable sharding may be useful to distribute the network load when accessing these shards. It is also useful to distribute computation and storage of a normal variable across multiple parameter servers.\n",
+ "variables, which are called _shards_. Variable sharding may be useful to distribute the network load when accessing these shards. It is also useful to distribute computation and storage of a normal variable across multiple parameter servers, for example, when using very large embeddings\n",
+ "that may not fit in a single machine's memory.\n",
"\n",
"To enable variable sharding, you can pass in a `variable_partitioner` when\n",
"constructing a `ParameterServerStrategy` object. The `variable_partitioner` will\n",
@@ -340,7 +336,7 @@
"`variable_partitioner`s are provided such as\n",
"`tf.distribute.experimental.partitioners.MinSizePartitioner`. It is recommended to use size-based partitioners like\n",
"`tf.distribute.experimental.partitioners.MinSizePartitioner` to avoid\n",
- "partitioning small variables, which could have negative impact on model training\n",
+ "partitioning small variables, which could have a negative impact on model training\n",
"speed."
]
},
@@ -350,16 +346,16 @@
"id": "1--SxlxtsOb7"
},
"source": [
- "When a `variable_partitioner` is passed in and if you create a variable directly\n",
- "under `strategy.scope()`, it will become a container type with a `variables`\n",
- "property which provides access to the list of shards. In most cases, this\n",
+ "When a `variable_partitioner` is passed in, and you create a variable directly\n",
+ "under `Strategy.scope`, the variable will become a container type with a `variables`\n",
+ "property, which provides access to the list of shards. In most cases, this\n",
"container will be automatically converted to a Tensor by concatenating all the\n",
"shards. As a result, it can be used as a normal variable. On the other hand,\n",
"some TensorFlow methods such as `tf.nn.embedding_lookup` provide efficient\n",
"implementation for this container type and in these methods automatic\n",
"concatenation will be avoided.\n",
"\n",
- "Please see the API docs of `tf.distribute.experimental.ParameterServerStrategy` for more details."
+ "Refer to the API docs of `tf.distribute.ParameterServerStrategy` for more details."
]
},
{
@@ -371,7 +367,7 @@
"## Training with `Model.fit`\n",
"\n",
"\n",
- "Keras provides an easy-to-use training API via `Model.fit` that handles the training loop under the hood, with the flexibility of overridable `train_step`, and callbacks, which provide functionalities such as checkpoint saving or summary saving for TensorBoard. With `Model.fit`, the same training code can be used for other strategies with a simple swap of the strategy object."
+ "Keras provides an easy-to-use training API via `Model.fit` that handles the training loop under the hood, with the flexibility of an overridable `train_step`, and callbacks which provide functionalities such as checkpoint saving or summary saving for TensorBoard. With `Model.fit`, the same training code can be used with other strategies with a simple swap of the strategy object."
]
},
{
@@ -382,12 +378,14 @@
"source": [
"### Input data\n",
"\n",
- "`Model.fit` with parameter server training requires that the input data be\n",
- "provided in a callable that takes a single argument of type `tf.distribute.InputContext`, and returns a `tf.data.Dataset`. Then, create a `tf.keras.utils.experimental.DatasetCreator` object that takes such `callable`, and an optional `tf.distribute.InputOptions` object via `input_options` argument.\n",
+ "Keras `Model.fit` with `tf.distribute.ParameterServerStrategy` can take input data in the form of a `tf.data.Dataset`, `tf.distribute.DistributedDataset`, or a `tf.keras.utils.experimental.DatasetCreator`, with `Dataset` being the recommended option for ease of use. If you encounter memory issues using `Dataset`, however, you may need to use `DatasetCreator` with a callable `dataset_fn` argument (refer to the `tf.keras.utils.experimental.DatasetCreator` API documentation for details).\n",
"\n",
- "Note that it is recommended to shuffle and repeat the data with parameter server training, and specify `steps_per_epoch` in `fit` call so the library knows the epoch boundaries.\n",
+ "If you transform your dataset into a `tf.data.Dataset`, you should use `Dataset.shuffle` and `Dataset.repeat`, as demonstrated in the code example below.\n",
"\n",
- "Please see the [Distributed input](https://www.tensorflow.org/tutorials/distribute/input#usage_2) tutorial for more information about the `InputContext` argument."
+ "- Keras `Model.fit` with parameter server training assumes that each worker receives the same dataset, except when it is shuffled differently. Therefore, by calling `Dataset.shuffle`, you ensure more even iterations over the data.\n",
+ "- Because workers do not synchronize, they may finish processing their datasets at different times. Therefore, the easiest way to define epochs with parameter server training is to use `Dataset.repeat`—which repeats a dataset indefinitely when called without an argument—and specify the `steps_per_epoch` argument in the `Model.fit` call.\n",
+ "\n",
+ "Refer to the \"Training workflows\" section of the [tf.data guide](../../guide/data.ipynb) for more details on `shuffle` and `repeat`."
]
},
{
@@ -398,23 +396,14 @@
},
"outputs": [],
"source": [
- "def dataset_fn(input_context):\n",
- " global_batch_size = 64\n",
- " batch_size = input_context.get_per_replica_batch_size(global_batch_size)\n",
- "\n",
- " x = tf.random.uniform((10, 10))\n",
- " y = tf.random.uniform((10,))\n",
- "\n",
- " dataset = tf.data.Dataset.from_tensor_slices((x, y)).shuffle(10).repeat()\n",
- " dataset = dataset.shard(\n",
- " input_context.num_input_pipelines,\n",
- " input_context.input_pipeline_id)\n",
- " dataset = dataset.batch(batch_size)\n",
- " dataset = dataset.prefetch(2)\n",
+ "global_batch_size = 64\n",
"\n",
- " return dataset\n",
+ "x = tf.random.uniform((10, 10))\n",
+ "y = tf.random.uniform((10,))\n",
"\n",
- "dc = tf.keras.utils.experimental.DatasetCreator(dataset_fn)"
+ "dataset = tf.data.Dataset.from_tensor_slices((x, y)).shuffle(10).repeat()\n",
+ "dataset = dataset.batch(global_batch_size)\n",
+ "dataset = dataset.prefetch(2)"
]
},
{
@@ -423,11 +412,18 @@
"id": "v_jhF70K7zON"
},
"source": [
- "The code in `dataset_fn` will be invoked on the input device, which is usually the CPU, on each of the worker machines.\n",
- "\n",
+ "If you instead create your dataset with `tf.keras.utils.experimental.DatasetCreator`, the code in `dataset_fn` will be invoked on the input device, which is usually the CPU, on each of the worker machines.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "w60PuWrWwBD4"
+ },
+ "source": [
"### Model construction and compiling\n",
"\n",
- "Now, you will create a `tf.keras.Model`—a trivial `tf.keras.models.Sequential` model for demonstration purposes—followed by a `Model.compile` call to incorporate components, such as an optimizer, metrics, or parameters such as `steps_per_execution`:"
+ "Now, you will create a `tf.keras.Model`—a trivial `tf.keras.models.Sequential` model for demonstration purposes—followed by a `Model.compile` call to incorporate components, such as an optimizer, metrics, and other parameters such as `steps_per_execution`:"
]
},
{
@@ -441,7 +437,7 @@
"with strategy.scope():\n",
" model = tf.keras.models.Sequential([tf.keras.layers.Dense(10)])\n",
"\n",
- "model.compile(tf.keras.optimizers.SGD(), loss='mse', steps_per_execution=10)"
+ " model.compile(tf.keras.optimizers.legacy.SGD(), loss=\"mse\", steps_per_execution=10)"
]
},
{
@@ -454,13 +450,13 @@
"\n",
" \n",
"\n",
- "Before you call `model.fit` for the actual training, let's prepare the needed callbacks for common tasks, such as:\n",
+ "Before you call Keras `Model.fit` for the actual training, prepare any needed [callbacks](https://www.tensorflow.org/guide/keras/train_and_evaluate) for common tasks, such as:\n",
"\n",
- "- `ModelCheckpoint`: to save the model weights.\n",
- "- `BackupAndRestore`: to make sure the training progress is automatically backed up, and recovered if the cluster experiences unavailability (such as abort or preemption); or\n",
- "- `TensorBoard`: to save the progress reports into summary files, which get visualized in TensorBoard tool.\n",
+ "- `tf.keras.callbacks.ModelCheckpoint`: saves the model at a certain frequency, such as after every epoch.\n",
+ "- `tf.keras.callbacks.BackupAndRestore`: provides fault tolerance by backing up the model and current epoch number, if the cluster experiences unavailability (such as abort or preemption). You can then restore the training state upon a restart from a job failure, and continue training from the beginning of the interrupted epoch.\n",
+ "- `tf.keras.callbacks.TensorBoard`: periodically writes model logs in summary files that can be visualized in the TensorBoard tool.\n",
"\n",
- "Note: Due to performance consideration, custom callbacks cannot have batch level callbacks overridden when used with `ParameterServerStrategy`. Please modify your custom callbacks to make them epoch level calls, and adjust `steps_per_epoch` to a suitable value. In addition, `steps_per_epoch` is a required argument for `Model.fit` when used with `ParameterServerStrategy`."
+ "Note: Due to performance considerations, custom callbacks cannot have batch level callbacks overridden when used with `ParameterServerStrategy`. Please modify your custom callbacks to make them epoch level calls, and adjust `steps_per_epoch` to a suitable value. In addition, `steps_per_epoch` is a required argument for `Model.fit` when used with `ParameterServerStrategy`."
]
},
{
@@ -471,18 +467,18 @@
},
"outputs": [],
"source": [
- "working_dir = '/tmp/my_working_dir'\n",
- "log_dir = os.path.join(working_dir, 'log')\n",
- "ckpt_filepath = os.path.join(working_dir, 'ckpt')\n",
- "backup_dir = os.path.join(working_dir, 'backup')\n",
+ "working_dir = \"/tmp/my_working_dir\"\n",
+ "log_dir = os.path.join(working_dir, \"log\")\n",
+ "ckpt_filepath = os.path.join(working_dir, \"ckpt\")\n",
+ "backup_dir = os.path.join(working_dir, \"backup\")\n",
"\n",
"callbacks = [\n",
" tf.keras.callbacks.TensorBoard(log_dir=log_dir),\n",
" tf.keras.callbacks.ModelCheckpoint(filepath=ckpt_filepath),\n",
- " tf.keras.callbacks.experimental.BackupAndRestore(backup_dir=backup_dir),\n",
+ " tf.keras.callbacks.BackupAndRestore(backup_dir=backup_dir),\n",
"]\n",
"\n",
- "model.fit(dc, epochs=5, steps_per_epoch=20, callbacks=callbacks)"
+ "model.fit(dataset, epochs=5, steps_per_epoch=20, callbacks=callbacks)"
]
},
{
@@ -493,7 +489,7 @@
"source": [
"### Direct usage with `ClusterCoordinator` (optional)\n",
"\n",
- "Even if you choose the `Model.fit` training path, you can optionally instantiate a `tf.distribute.experimental.coordinator.ClusterCoordinator` object to schedule other functions you would like to be executed on the workers. See the [Training with a custom training loop](#training_with_custom_training_loop) section for more details and examples."
+ "Even if you choose the `Model.fit` training path, you can optionally instantiate a `tf.distribute.coordinator.ClusterCoordinator` object to schedule other functions you would like to be executed on the workers. Refer to the [Training with a custom training loop](#training_with_custom_training_loop) section for more details and examples."
]
},
{
@@ -506,11 +502,11 @@
"\n",
" \n",
"\n",
- "Using custom training loops with `tf.distribute.Strategy` provides great flexibility to define training loops. With the `ParameterServerStrategy` defined above (as `strategy`), you will use a `tf.distribute.experimental.coordinator.ClusterCoordinator` to dispatch the execution of training steps to remote workers.\n",
+ "Using custom training loops with `tf.distribute.Strategy` provides great flexibility to define training loops. With the `ParameterServerStrategy` defined above (as `strategy`), you will use a `tf.distribute.coordinator.ClusterCoordinator` to dispatch the execution of training steps to remote workers.\n",
"\n",
- "Then, you will create a model, define a dataset and a step function, as you have done in the training loop with other `tf.distribute.Strategy`s. You can find more details in the [Custom training with tf.distribute.Strategy](https://www.tensorflow.org/tutorials/distribute/custom_training) tutorial.\n",
+ "Then, you will create a model, define a dataset, and define a step function, as you have done in the training loop with other `tf.distribute.Strategy`s. You can find more details in the [Custom training with tf.distribute.Strategy](custom_training.ipynb) tutorial.\n",
"\n",
- "To ensure efficient dataset prefetching, use the recommended distributed dataset creation APIs mentioned in the [Dispatch training steps to remote workers](https://www.tensorflow.org/tutorials/distribute/parameter_server_training#dispatch_training_steps_to_remote_workers) section below. Also, make sure to call `Strategy.run` inside `worker_fn` to take full advantage of GPUs allocated to workers. The rest of the steps are the same for training with or without GPUs.\n",
+ "To ensure efficient dataset prefetching, use the recommended distributed dataset creation APIs mentioned in the [Dispatch training steps to remote workers](#dispatch_training_steps_to_remote_workers) section below. Also, make sure to call `Strategy.run` inside `worker_fn` to take full advantage of GPUs allocated to workers. The rest of the steps are the same for training with or without GPUs.\n",
"\n",
"Let’s create these components in the following steps:\n"
]
@@ -523,11 +519,13 @@
"source": [
"### Set up the data\n",
"\n",
- "First, write a function that creates a dataset that includes preprocessing logic implemented by [Keras preprocessing layers](https://www.tensorflow.org/guide/keras/preprocessing_layers).\n",
+ "First, write a function that creates a dataset.\n",
+ "\n",
+ "If you would like to preprocess the data with [Keras preprocessing layers](https://www.tensorflow.org/guide/keras/preprocessing_layers) or [Tensorflow Transform layers](https://www.tensorflow.org/tfx/tutorials/transform/simple), create these layers **outside the `dataset_fn`** and **under `Strategy.scope`**, like you would do for any other Keras layers. This is because the `dataset_fn` will be wrapped into a `tf.function` and then executed on each worker to generate the data pipeline.\n",
"\n",
- "You will create these layers outside the `dataset_fn` but apply the transformation inside the `dataset_fn`, since you will wrap the `dataset_fn` into a `tf.function`, which doesn't allow variables to be created inside it.\n",
+ "If you don't follow the above procedure, creating the layers might create Tensorflow states which will be lifted out of the `tf.function` to the coordinator. Thus, accessing them on workers would incur repetitive RPC calls between coordinator and workers, and cause significant slowdown.\n",
"\n",
- "Note: There is a known performance implication when using lookup table resources, which layers, such as `tf.keras.layers.experimental.preprocessing.StringLookup`, employ. Refer to the [Known limitations](#known_limitations) section for more information."
+ "Placing the layers under `Strategy.scope` will instead create them on all workers. Then, you will apply the transformation inside the `dataset_fn` via `tf.data.Dataset.map`. Refer to _Data preprocessing_ in the [Distributed input](input.ipynb) tutorial for more information on data preprocessing with distributed input."
]
},
{
@@ -544,10 +542,10 @@
"label_vocab = [\"yes\", \"no\"]\n",
"\n",
"with strategy.scope():\n",
- " feature_lookup_layer = preprocessing.StringLookup(\n",
+ " feature_lookup_layer = tf.keras.layers.StringLookup(\n",
" vocabulary=feature_vocab,\n",
" mask_token=None)\n",
- " label_lookup_layer = preprocessing.StringLookup(\n",
+ " label_lookup_layer = tf.keras.layers.StringLookup(\n",
" vocabulary=label_vocab,\n",
" num_oov_indices=0,\n",
" mask_token=None)\n",
@@ -637,7 +635,7 @@
"source": [
"### Build the model\n",
"\n",
- "Next, create the model and other objects. Make sure to create all variables under `strategy.scope`."
+ "Next, create the model and other objects. Make sure to create all variables under `Strategy.scope`."
]
},
{
@@ -648,7 +646,7 @@
},
"outputs": [],
"source": [
- "# These variables created under the `strategy.scope` will be placed on parameter\n",
+ "# These variables created under the `Strategy.scope` will be placed on parameter\n",
"# servers in a round-robin fashion.\n",
"with strategy.scope():\n",
" # Create the model. The input needs to be compatible with Keras processing layers.\n",
@@ -658,10 +656,13 @@
" emb_layer = tf.keras.layers.Embedding(\n",
" input_dim=len(feature_lookup_layer.get_vocabulary()), output_dim=16384)\n",
" emb_output = tf.reduce_mean(emb_layer(model_input), axis=1)\n",
- " dense_output = tf.keras.layers.Dense(units=1, activation=\"sigmoid\")(emb_output)\n",
+ " dense_output = tf.keras.layers.Dense(\n",
+ " units=1, activation=\"sigmoid\",\n",
+ " kernel_regularizer=tf.keras.regularizers.L2(1e-4),\n",
+ " )(emb_output)\n",
" model = tf.keras.Model({\"features\": model_input}, dense_output)\n",
"\n",
- " optimizer = tf.keras.optimizers.RMSprop(learning_rate=0.1)\n",
+ " optimizer = tf.keras.optimizers.legacy.RMSprop(learning_rate=0.1)\n",
" accuracy = tf.keras.metrics.Accuracy()"
]
},
@@ -671,7 +672,7 @@
"id": "iyuxiqCQU50m"
},
"source": [
- "Let's confirm that the use of `FixedShardsPartitioner` split all variables into two shards and each shard was assigned to different parameter servers:"
+ "Let's confirm that the use of `FixedShardsPartitioner` split all variables into two shards and that each shard was assigned to a different parameter server:"
]
},
{
@@ -685,8 +686,9 @@
"assert len(emb_layer.weights) == 2\n",
"assert emb_layer.weights[0].shape == (4, 16384)\n",
"assert emb_layer.weights[1].shape == (4, 16384)\n",
- "assert emb_layer.weights[0].device == \"/job:ps/replica:0/task:0/device:CPU:0\"\n",
- "assert emb_layer.weights[1].device == \"/job:ps/replica:0/task:1/device:CPU:0\""
+ "\n",
+ "print(emb_layer.weights[0].device)\n",
+ "print(emb_layer.weights[1].device)\n"
]
},
{
@@ -714,9 +716,12 @@
" with tf.GradientTape() as tape:\n",
" pred = model(batch_data, training=True)\n",
" per_example_loss = tf.keras.losses.BinaryCrossentropy(\n",
- " reduction=tf.keras.losses.Reduction.NONE)(labels, pred)\n",
+ " reduction=tf.keras.losses.Reduction.NONE)(labels, pred)\n",
" loss = tf.nn.compute_average_loss(per_example_loss)\n",
- " gradients = tape.gradient(loss, model.trainable_variables)\n",
+ " model_losses = model.losses\n",
+ " if model_losses:\n",
+ " loss += tf.nn.scale_regularization_loss(tf.add_n(model_losses))\n",
+ " gradients = tape.gradient(loss, model.trainable_variables)\n",
"\n",
" optimizer.apply_gradients(zip(gradients, model.trainable_variables))\n",
"\n",
@@ -735,7 +740,7 @@
"id": "rvrYQUeYiLNy"
},
"source": [
- "In the above training step function, calling `Strategy.run` and `Strategy.reduce` in the `step_fn` can support multiple GPUs per worker. If the workers have GPUs allocated, `Strategy.run` will distribute the datasets on multiple replicas.\n"
+ "In the above training step function, calling `Strategy.run` and `Strategy.reduce` in the `step_fn` can support multiple GPUs per worker. If the workers have GPUs allocated, `Strategy.run` will distribute the datasets on multiple replicas (GPUs). Their parallel calls to `tf.nn.compute_average_loss()` compute the average of the loss across the replicas (GPUs) of one worker, independent of the total number of workers."
]
},
{
@@ -747,7 +752,7 @@
"### Dispatch training steps to remote workers\n",
" \n",
"\n",
- "After all the computations are defined by `ParameterServerStrategy`, you will use the `tf.distribute.experimental.coordinator.ClusterCoordinator` class to create resources and distribute the training steps to remote workers.\n",
+ "After all the computations are defined by `ParameterServerStrategy`, you will use the `tf.distribute.coordinator.ClusterCoordinator` class to create resources and distribute the training steps to remote workers.\n",
"\n",
"Let’s first create a `ClusterCoordinator` object and pass in the strategy object:"
]
@@ -760,7 +765,7 @@
},
"outputs": [],
"source": [
- "coordinator = tf.distribute.experimental.coordinator.ClusterCoordinator(strategy)"
+ "coordinator = tf.distribute.coordinator.ClusterCoordinator(strategy)"
]
},
{
@@ -769,7 +774,7 @@
"id": "-xRIgKxciOSe"
},
"source": [
- "Then, create a per-worker dataset and an iterator. In the `per_worker_dataset_fn` below, wrapping the `dataset_fn` into `strategy.distribute_datasets_from_function` is recommended to allow efficient prefetching to GPUs seamlessly."
+ "Then, create a per-worker dataset and an iterator using the `ClusterCoordinator.create_per_worker_dataset` API, which replicates the dataset to all workers. In the `per_worker_dataset_fn` below, wrapping the `dataset_fn` into `strategy.distribute_datasets_from_function` is recommended to allow efficient prefetching to GPUs seamlessly."
]
},
{
@@ -808,15 +813,15 @@
},
"outputs": [],
"source": [
- "num_epoches = 4\n",
+ "num_epochs = 4\n",
"steps_per_epoch = 5\n",
- "for i in range(num_epoches):\n",
+ "for i in range(num_epochs):\n",
" accuracy.reset_states()\n",
" for _ in range(steps_per_epoch):\n",
" coordinator.schedule(step_fn, args=(per_worker_iterator,))\n",
" # Wait at epoch boundaries.\n",
" coordinator.join()\n",
- " print (\"Finished epoch %d, accuracy is %f.\" % (i, accuracy.result().numpy()))"
+ " print(\"Finished epoch %d, accuracy is %f.\" % (i, accuracy.result().numpy()))"
]
},
{
@@ -837,7 +842,7 @@
"outputs": [],
"source": [
"loss = coordinator.schedule(step_fn, args=(per_worker_iterator,))\n",
- "print (\"Final loss is %f\" % loss.fetch())"
+ "print(\"Final loss is %f\" % loss.fetch())"
]
},
{
@@ -857,7 +862,7 @@
" # Do something like logging metrics or writing checkpoints.\n",
"```\n",
"\n",
- "For the complete training and serving workflow for this particular example, please check out this [test](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/keras/distribute/parameter_server_training_test.py).\n"
+ "For the complete training and serving workflow for this particular example, please check out this [test](https://github.com/keras-team/keras/blob/master/keras/integration_test/parameter_server_keras_preprocessing_test.py).\n"
]
},
{
@@ -868,11 +873,11 @@
"source": [
"### More about dataset creation\n",
"\n",
- "The dataset in the above code is created using the `ClusterCoordinator.create_per_worker_dataset` API). It creates one dataset per worker and returns a container object. You can call the `iter` method on it to create a per-worker iterator. The per-worker iterator contains one iterator per worker and the corresponding slice of a worker will be substituted in the input argument of the function passed to the `ClusterCoordinator.schedule` method before the function is executed on a particular worker.\n",
+ "The dataset in the above code is created using the `ClusterCoordinator.create_per_worker_dataset` API. It creates one dataset per worker and returns a container object. You can call the `iter` method on it to create a per-worker iterator. The per-worker iterator contains one iterator per worker and the corresponding slice of a worker will be substituted in the input argument of the function passed to the `ClusterCoordinator.schedule` method before the function is executed on a particular worker.\n",
"\n",
- "Currently, the `ClusterCoordinator.schedule` method assumes workers are equivalent and thus assumes the datasets on different workers are the same except they may be shuffled differently if they contain a `Dataset.shuffle` operation. Because of this, it is also recommended that the datasets to be repeated indefinitely and you schedule a finite number of steps instead of relying on the `OutOfRangeError` from a dataset.\n",
+ "The `ClusterCoordinator.schedule` method assumes workers are equivalent and thus assumes the datasets on different workers are the same (except that they may be shuffled differently). Because of this, it is also recommended to repeat datasets, and schedule a finite number of steps instead of relying on receiving an `OutOfRangeError` from a dataset.\n",
"\n",
- "Another important note is that `tf.data` datasets don’t support implicit serialization and deserialization across task boundaries. So it is important to create the whole dataset inside the function passed to `ClusterCoordinator.create_per_worker_dataset`."
+ "Another important note is that `tf.data` datasets don’t support implicit serialization and deserialization across task boundaries. So it is important to create the whole dataset inside the function passed to `ClusterCoordinator.create_per_worker_dataset`. The `create_per_worker_dataset` API can also directly take a `tf.data.Dataset` or `tf.distribute.DistributedDataset` as input."
]
},
{
@@ -883,7 +888,7 @@
"source": [
"## Evaluation\n",
"\n",
- "There is more than one way to define and run an evaluation loop in distributed training. Each has its own pros and cons as described below. The inline evaluation method is recommended if you don't have a preference."
+ "The two main approaches to performing evaluation with `tf.distribute.ParameterServerStrategy` training are inline evaluation and sidecar evaluation. Each has its own pros and cons as described below. The inline evaluation method is recommended if you don't have a preference. For users using `Model.fit`, `Model.evaluate` uses inline (distributed) evaluation under the hood."
]
},
{
@@ -894,12 +899,12 @@
"source": [
"### Inline evaluation\n",
"\n",
- "In this method, the coordinator alternates between training and evaluation and thus it is called it _inline evaluation_.\n",
+ "In this method, the coordinator alternates between training and evaluation, and thus it is called _inline evaluation_.\n",
"\n",
"There are several benefits of inline evaluation. For example:\n",
"\n",
"- It can support large evaluation models and evaluation datasets that a single task cannot hold.\n",
- "- The evaluation results can be used to make decisions for training the next epoch.\n",
+ "- The evaluation results can be used to make decisions for training the next epoch, for example, whether to stop training early.\n",
"\n",
"There are two ways to implement inline evaluation: direct evaluation and distributed evaluation.\n",
"\n",
@@ -915,7 +920,7 @@
"outputs": [],
"source": [
"eval_dataset = tf.data.Dataset.from_tensor_slices(\n",
- " feature_and_label_gen(num_examples=16)).map(\n",
+ " feature_and_label_gen(num_examples=16)).map(\n",
" lambda x: (\n",
" {\"features\": feature_preprocess_stage(x[\"features\"])},\n",
" label_preprocess_stage(x[\"label\"])\n",
@@ -928,7 +933,7 @@
" actual_pred = tf.cast(tf.greater(pred, 0.5), tf.int64)\n",
" eval_accuracy.update_state(labels, actual_pred)\n",
"\n",
- "print (\"Evaluation accuracy: %f\" % eval_accuracy.result())"
+ "print(\"Evaluation accuracy: %f\" % eval_accuracy.result())"
]
},
{
@@ -976,7 +981,7 @@
"for _ in range(eval_steps_per_epoch):\n",
" coordinator.schedule(eval_step, args=(per_worker_eval_iterator,))\n",
"coordinator.join()\n",
- "print (\"Evaluation accuracy: %f\" % eval_accuracy.result())"
+ "print(\"Evaluation accuracy: %f\" % eval_accuracy.result())"
]
},
{
@@ -985,7 +990,23 @@
"id": "cKrQktZX5z7a"
},
"source": [
- "Note: Currently, the `schedule` and `join` methods of `tf.distribute.experimental.coordinator.ClusterCoordinator` don’t support visitation guarantee or exactly-once semantics. In other words, there is no guarantee that all evaluation examples in a dataset will be evaluated exactly once; some may not be visited and some may be evaluated multiple times. Visitation guarantee on evaluation dataset is being worked on."
+ "#### Enabling exactly-once evaluation\n",
+ "\n",
+ "\n",
+ "The `schedule` and `join` methods of `tf.distribute.coordinator.ClusterCoordinator` don’t support visitation guarantees or exactly-once semantics by default. In other words, in the above example there is no guarantee that all evaluation examples in a dataset will be evaluated exactly once; some may not be visited and some may be evaluated multiple times.\n",
+ "\n",
+ "Exactly-once evaluation may be preferred to reduce the variance of evaluation across epochs, and improve model selection done via early stopping, hyperparameter tuning, or other methods. There are different ways to enable exactly-once evaluation:\n",
+ "\n",
+ "- With a `Model.fit/.evaluate` workflow, it can be enabled by adding an argument to `Model.compile`. Refer to docs for the `pss_evaluation_shards` argument.\n",
+ "- The `tf.data` service API can be used to provide exactly-once visitation for evaluation when using `ParameterServerStrategy` (refer to the _Dynamic Sharding_ section of the `tf.data.experimental.service` API documentation).\n",
+ "- [Sidecar evaluation](#sidecar_evaluation) provides exactly-once evaluation by default, since the evaluation happens on a single machine. However this can be much slower than performing evaluation distributed across many workers.\n",
+ "\n",
+ "The first option, using `Model.compile`, is the suggested solution for most users.\n",
+ "\n",
+ "Exactly-once evaluation has some limitations:\n",
+ "\n",
+ "- It is not supported to write a custom distributed evaluation loop with an exactly-once visitation guarantee. File a GitHub issue if you need support for this.\n",
+ "- It cannot automatically handle computation of metrics that use the `Layer.add_metric` API. These should be excluded from evaluation, or reworked into `Metric` objects."
]
},
{
@@ -994,9 +1015,69 @@
"id": "H40X-9Gs3i7_"
},
"source": [
- "### Side-car evaluation\n",
+ "### Sidecar evaluation\n",
+ "\n",
+ "\n",
+ "Another method for defining and running an evaluation loop in `tf.distribute.ParameterServerStrategy` training is called _sidecar evaluation_, in which you create a dedicated evaluator task that repeatedly reads checkpoints and runs evaluation on the latest checkpoint (refer to [this guide](../../guide/checkpoint.ipynb) for more details on checkpointing). The coordinator and worker tasks do not spend any time on evaluation, so for a fixed number of iterations the overall training time should be shorter than using other evaluation methods. However, it requires an additional evaluator task and periodic checkpointing to trigger evaluation."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "HonyjnXK9-ys"
+ },
+ "source": [
+ "To write an evaluation loop for sidecar evaluation, you have two\n",
+ "options:\n",
+ "\n",
+ "1. Use the `tf.keras.utils.SidecarEvaluator` API.\n",
+ "2. Create a custom evaluation loop.\n",
"\n",
- "Another method is called _side-car evaluation_ where you create a dedicated evaluator task that repeatedly reads checkpoints and runs evaluation on a latest checkpoint. It allows your training program to finish early if you don't need to change your training loop based on evaluation results. However, it requires an additional evaluator task and periodic checkpointing to trigger evaluation. Following is a possible side-car evaluation loop:\n",
+ "Refer to the `tf.keras.utils.SidecarEvaluator` API documentation for more details on option 1."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "U_c0EiwB88OG"
+ },
+ "source": [
+ "Sidecar evaluation is supported only with a single task. This means:\n",
+ "\n",
+ "* It is guaranteed that each example is evaluated once. In the event the\n",
+ " evaluator is preempted or restarted, it simply restarts the\n",
+ " evaluation loop from the latest checkpoint, and the partial evaluation\n",
+ " progress made before the restart is discarded.\n",
+ "\n",
+ "* However, running evaluation on a single task implies that a full evaluation\n",
+ " can possibly take a long time.\n",
+ "\n",
+ "* If the size of the model is too large to fit into an evaluator's memory,\n",
+ " single sidecar evaluation is not applicable."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "VNJoWVc797B1"
+ },
+ "source": [
+ "Another caveat is that the `tf.keras.utils.SidecarEvaluator` implementation, and the custom\n",
+ "evaluation loop below, may skip some checkpoints because it always picks up the\n",
+ "latest checkpoint available, and during an evaluation epoch, multiple\n",
+ "checkpoints can be produced from the training cluster. You can write a custom\n",
+ "evaluation loop that evaluates every checkpoint, but it is not covered in this\n",
+ "tutorial. On the other hand, it may sit idle if checkpoints are produced less\n",
+ "frequently than how long it takes to run evaluation."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "G5jopxBd85Ji"
+ },
+ "source": [
+ "A custom evaluation loop provides more control over the details, such as choosing which checkpoint to evaluate, or providing any additional logic to run along with evaluation. The following is a possible custom sidecar evaluation loop:\n",
"\n",
"```python\n",
"checkpoint_dir = ...\n",
@@ -1016,7 +1097,7 @@
" eval_model.evaluate(eval_data)\n",
"\n",
" # Evaluation finishes when it has evaluated the last epoch.\n",
- " if latest_checkpoint.endswith('-{}'.format(train_epoches)):\n",
+ " if latest_checkpoint.endswith('-{}'.format(train_epochs)):\n",
" break\n",
"```"
]
@@ -1034,9 +1115,9 @@
"\n",
"In a real production environment, you will run all tasks in different processes on different machines. The simplest way to configure cluster information on each task is to set `\"TF_CONFIG\"` environment variables and use a `tf.distribute.cluster_resolver.TFConfigClusterResolver` to parse `\"TF_CONFIG\"`.\n",
"\n",
- "For a general description about `\"TF_CONFIG\"` environment variables, refer to the [Distributed training](https://www.tensorflow.org/guide/distributed_training#setting_up_tf_config_environment_variable) guide.\n",
+ "For a general description of `\"TF_CONFIG\"` environment variables, refer to \"Setting up the `TF_CONFIG` environment variable\" in the [Distributed training](../../guide/distributed_training.ipynb) guide.\n",
"\n",
- "If you start your training tasks using Kubernetes or other configuration templates, it is very likely that these templates have already set `“TF_CONFIG\"` for you."
+ "If you start your training tasks using Kubernetes or other configuration templates, likely, these templates have already set `“TF_CONFIG\"` for you."
]
},
{
@@ -1047,7 +1128,7 @@
"source": [
"### Set the `\"TF_CONFIG\"` environment variable\n",
"\n",
- "Suppose you have 3 workers and 2 parameter servers, the `\"TF_CONFIG\"` of worker 1 can be:\n",
+ "Suppose you have 3 workers and 2 parameter servers. Then the `\"TF_CONFIG\"` of worker 1 can be:\n",
"\n",
"```python\n",
"os.environ[\"TF_CONFIG\"] = json.dumps({\n",
@@ -1089,12 +1170,12 @@
"if cluster_resolver.task_type in (\"worker\", \"ps\"):\n",
" # Start a TensorFlow server and wait.\n",
"elif cluster_resolver.task_type == \"evaluator\":\n",
- " # Run side-car evaluation\n",
+ " # Run sidecar evaluation\n",
"else:\n",
" # Run the coordinator.\n",
"```\n",
"\n",
- "The following code starts a TensorFlow server and waits:\n",
+ "The following code starts a TensorFlow server and waits, useful for the `\"worker\"` and `\"ps\"` roles:\n",
"\n",
"```python\n",
"# Set the environment variable to allow reporting worker and ps failure to the\n",
@@ -1128,7 +1209,7 @@
"source": [
"### Worker failure\n",
"\n",
- "`tf.distribute.experimental.coordinator.ClusterCoordinator` or `Model.fit` provide built-in fault tolerance for worker failure. Upon worker recovery, the previously provided dataset function (either to `ClusterCoordinator.create_per_worker_dataset` for a custom training loop, or `tf.keras.utils.experimental.DatasetCreator` for `Model.fit`) will be invoked on the workers to re-create the datasets."
+ "Both the `tf.distribute.coordinator.ClusterCoordinator` custom training loop and `Model.fit` approaches provide built-in fault tolerance for worker failure. Upon worker recovery, the `ClusterCoordinator` invokes dataset re-creation on the workers."
]
},
{
@@ -1172,7 +1253,7 @@
"global_steps = int(optimizer.iterations.numpy())\n",
"starting_epoch = global_steps // steps_per_epoch\n",
"\n",
- "for _ in range(starting_epoch, num_epoches):\n",
+ "for _ in range(starting_epoch, num_epochs):\n",
" for _ in range(steps_per_epoch):\n",
" coordinator.schedule(step_fn, args=(per_worker_iterator,))\n",
" coordinator.join()\n",
@@ -1212,17 +1293,21 @@
"source": [
"## Performance improvement\n",
"\n",
- "There are several possible reasons if you see performance issues when you train with `ParameterServerStrategy` and `ClusterResolver`.\n",
+ "There are several possible reasons you may experience performance issues when you train with `tf.distribute.ParameterServerStrategy` and `tf.distribute.coordinator.ClusterCoordinator`.\n",
"\n",
- "One common reason is parameter servers have unbalanced load and some heavily-loaded parameter servers have reached capacity. There can also be multiple root causes. Some simple methods to mitigate this issue are to:\n",
+ "One common reason is that the parameter servers have unbalanced load and some heavily-loaded parameter servers have reached capacity. There can also be multiple root causes. Some simple methods to mitigate this issue are to:\n",
"\n",
"1. Shard your large model variables via specifying a `variable_partitioner` when constructing a `ParameterServerStrategy`.\n",
- "2. Avoid creating a hotspot variable that is required by all parameter servers in a single step if possible. For example, use a constant learning rate or subclass `tf.keras.optimizers.schedules.LearningRateSchedule` in optimizers since the default behavior is that the learning rate will become a variable placed on a particular parameter server and requested by all other parameter servers in each step.\n",
+ "2. Avoid creating a hotspot variable that is required by all parameter servers in a single step, by both:\n",
+ "\n",
+ " 1) Using a constant learning rate or subclass `tf.keras.optimizers.schedules.LearningRateSchedule` in optimizers. This is because the default behavior is that the learning rate will become a variable placed on a particular parameter server, and requested by all other parameter servers in each step); and\n",
+ "\n",
+ " 2) Using a `tf.keras.optimizers.legacy.Optimizer` (the standard `tf.keras.optimizers.Optimizer`s could still lead to hotspot variables).\n",
"3. Shuffle your large vocabularies before passing them to Keras preprocessing layers.\n",
"\n",
- "Another possible reason for performance issues is the coordinator. Your first implementation of `schedule`/`join` is Python-based and thus may have threading overhead. Also the latency between the coordinator and the workers can be large. If this is the case,\n",
+ "Another possible reason for performance issues is the coordinator. The implementation of `schedule`/`join` is Python-based and thus may have threading overhead. Also, the latency between the coordinator and the workers can be large. If this is the case:\n",
"\n",
- "- For `Model.fit`, you can set `steps_per_execution` argument provided at `Model.compile` to a value larger than 1.\n",
+ "- For `Model.fit`, you can set the `steps_per_execution` argument provided at `Model.compile` to a value larger than 1.\n",
"\n",
"- For a custom training loop, you can pack multiple steps into a single `tf.function`:\n",
"\n",
@@ -1241,7 +1326,7 @@
"\n",
"As the library is optimized further, hopefully most users won't have to manually pack steps in the future.\n",
"\n",
- "In addition, a small trick for performance improvement is to schedule functions without a return value as explained in the handling task failure section above."
+ "In addition, a small trick for performance improvement is to schedule functions without a return value as explained in the [handling task failure section](#handling_task_failure) above."
]
},
{
@@ -1261,22 +1346,35 @@
"- `os.environment[\"grpc_fail_fast\"]=\"use_caller\"` is needed on every task including the coordinator, to make fault tolerance work properly.\n",
"- Synchronous parameter server training is not supported.\n",
"- It is usually necessary to pack multiple steps into a single function to achieve optimal performance.\n",
- "- It is not supported to load a saved_model via `tf.saved_model.load` containing sharded variables. Note loading such a saved_model using TensorFlow Serving is expected to work.\n",
- "- It is not supported to load a checkpoint containing sharded optimizer slot variables into a different number of shards.\n",
+ "- It is not supported to load a saved_model via `tf.saved_model.load` containing sharded variables. Note loading such a saved_model using TensorFlow Serving is expected to work (refer to the [serving tutorial](https://www.tensorflow.org/tfx/tutorials/serving/rest_simple) for details).\n",
"- It is not supported to recover from parameter server failure without restarting the coordinator task.\n",
- "- Usage of `tf.lookup.StaticHashTable` (which is commonly employed by some `tf.keras.layers.experimental.preprocessing` layers, such as `IntegerLookup`, `StringLookup`, and `TextVectorization`) results in resources placed on the coordinator at this time with parameter server training. This has performance implications for lookup RPCs from workers to the coordinator. This is a current high priority to address.\n",
- "\n",
+ "- Creation of `tf.lookup.StaticHashTable`, commonly employed by some Keras preprocessing layers, such as `tf.keras.layers.IntegerLookup`, `tf.keras.layers.StringLookup`, and `tf.keras.layers.TextVectorization`, should be placed under `Strategy.scope`. Otherwise, resources will be placed on the coordinator, and lookup RPCs from workers to the coordinator incur performance implications.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "2MKBF0RPSvzB"
+ },
+ "source": [
"### `Model.fit` specifics\n",
"\n",
"- `steps_per_epoch` argument is required in `Model.fit`. You can select a value that provides appropriate intervals in an epoch.\n",
"- `ParameterServerStrategy` does not have support for custom callbacks that have batch-level calls for performance reasons. You should convert those calls into epoch-level calls with suitably picked `steps_per_epoch`, so that they are called every `steps_per_epoch` number of steps. Built-in callbacks are not affected: their batch-level calls have been modified to be performant. Supporting batch-level calls for `ParameterServerStrategy` is being planned.\n",
- "- For the same reason, unlike other strategies, progress bar and metrics are logged only at epoch boundaries.\n",
- "- `run_eagerly` is not supported.\n",
- "\n",
+ "- For the same reason, unlike other strategies, progress bars and metrics are logged only at epoch boundaries.\n",
+ "- `run_eagerly` is not supported.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "wvY-mg35Sx5L"
+ },
+ "source": [
"### Custom training loop specifics\n",
"\n",
- "- `ClusterCoordinator.schedule` doesn't support visitation guarantees for a dataset.\n",
- "- When `ClusterCoordinator.create_per_worker_dataset` is used, the whole dataset must be created inside the function passed to it.\n",
+ "- `ClusterCoordinator.schedule` doesn't support visitation guarantees for a dataset in general, although a visitation guarantee for evaluation is possible through `Model.fit/.evaluate`. See [Enabling exactly-once evaluation](#exactly_once_evaluation).\n",
+ "- When `ClusterCoordinator.create_per_worker_dataset` is used with a callable as input, the whole dataset must be created inside the function passed to it.\n",
"- `tf.data.Options` is ignored in a dataset created by `ClusterCoordinator.create_per_worker_dataset`."
]
}
@@ -1284,9 +1382,8 @@
"metadata": {
"accelerator": "GPU",
"colab": {
- "collapsed_sections": [],
"name": "parameter_server_training.ipynb",
- "toc_visible": true
+ "toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
diff --git a/site/en/tutorials/distribute/save_and_load.ipynb b/site/en/tutorials/distribute/save_and_load.ipynb
index 7317b277c45..c53a9b8bf0b 100644
--- a/site/en/tutorials/distribute/save_and_load.ipynb
+++ b/site/en/tutorials/distribute/save_and_load.ipynb
@@ -71,7 +71,12 @@
"source": [
"## Overview\n",
"\n",
- "It's common to save and load a model during training. There are two sets of APIs for saving and loading a keras model: a high-level API, and a low-level API. This tutorial demonstrates how you can use the SavedModel APIs when using `tf.distribute.Strategy`. To learn about SavedModel and serialization in general, please read the [saved model guide](../../guide/saved_model.ipynb), and the [Keras model serialization guide](../../guide/keras/save_and_serialize.ipynb). Let's start with a simple example: "
+ "This tutorial demonstrates how you can save and load models in a SavedModel format with `tf.distribute.Strategy` during or after training. There are two kinds of APIs for saving and loading a Keras model: high-level (`tf.keras.Model.save` and `tf.keras.models.load_model`) and low-level (`tf.saved_model.save` and `tf.saved_model.load`).\n",
+ "\n",
+ "To learn about SavedModel and serialization in general, please read the [saved model guide](../../guide/saved_model.ipynb), and the [Keras model serialization guide](https://www.tensorflow.org/guide/keras/save_and_serialize). Let's start with a simple example.\n",
+ "\n",
+ "Caution: TensorFlow models are code and it is important to be careful with untrusted code. Learn more in [Using TensorFlow securely](https://github.com/tensorflow/tensorflow/blob/master/SECURITY.md).\n",
+ "\n"
]
},
{
@@ -102,7 +107,7 @@
"id": "qqapWj98ptNV"
},
"source": [
- "Prepare the data and model using `tf.distribute.Strategy`:"
+ "Load and prepare the data with TensorFlow Datasets and `tf.data`, and create the model using `tf.distribute.MirroredStrategy`:"
]
},
{
@@ -116,7 +121,7 @@
"mirrored_strategy = tf.distribute.MirroredStrategy()\n",
"\n",
"def get_data():\n",
- " datasets, ds_info = tfds.load(name='mnist', with_info=True, as_supervised=True)\n",
+ " datasets = tfds.load(name='mnist', as_supervised=True)\n",
" mnist_train, mnist_test = datasets['train'], datasets['test']\n",
"\n",
" BUFFER_SIZE = 10000\n",
@@ -157,7 +162,7 @@
"id": "qmU4Y3feS9Na"
},
"source": [
- "Train the model: "
+ "Train the model with `tf.keras.Model.fit`: "
]
},
{
@@ -181,11 +186,11 @@
"source": [
"## Save and load the model\n",
"\n",
- "Now that you have a simple model to work with, let's take a look at the saving/loading APIs. \n",
- "There are two sets of APIs available:\n",
+ "Now that you have a simple model to work with, let's explore the saving/loading APIs. \n",
+ "There are two kinds of APIs available:\n",
"\n",
- "* High level keras `model.save` and `tf.keras.models.load_model`\n",
- "* Low level `tf.saved_model.save` and `tf.saved_model.load`\n"
+ "* High-level (Keras): `Model.save` and `tf.keras.models.load_model` (`.keras` zip archive format)\n",
+ "* Low-level: `tf.saved_model.save` and `tf.saved_model.load` (TF SavedModel format)\n"
]
},
{
@@ -194,7 +199,7 @@
"id": "FX_IF2F1tvFs"
},
"source": [
- "### The Keras APIs"
+ "### The Keras API"
]
},
{
@@ -203,7 +208,7 @@
"id": "O8xfceg4Z3H_"
},
"source": [
- "Here is an example of saving and loading a model with the Keras APIs:"
+ "Here is an example of saving and loading a model with the Keras API:"
]
},
{
@@ -214,7 +219,7 @@
},
"outputs": [],
"source": [
- "keras_model_path = \"/tmp/keras_save\"\n",
+ "keras_model_path = '/tmp/keras_save.keras'\n",
"model.save(keras_model_path)"
]
},
@@ -245,9 +250,9 @@
"id": "gYAnskzorda-"
},
"source": [
- "After restoring the model, you can continue training on it, even without needing to call `compile()` again, since it is already compiled before saving. The model is saved in the TensorFlow's standard `SavedModel` proto format. For more information, please refer to [the guide to `saved_model` format](../../guide/saved_model.ipynb).\n",
+ "After restoring the model, you can continue training on it, even without needing to call `Model.compile` again, since it was already compiled before saving. The model is saved a Keras zip archive format, marked by the `.keras` extension. For more information, please refer to [the guide on Keras saving](https://www.tensorflow.org/guide/keras/save_and_serialize).\n",
"\n",
- "Now to load the model and train it using a `tf.distribute.Strategy`:"
+ "Now, restore the model and train it using a `tf.distribute.Strategy`:"
]
},
{
@@ -258,7 +263,7 @@
},
"outputs": [],
"source": [
- "another_strategy = tf.distribute.OneDeviceStrategy(\"/cpu:0\")\n",
+ "another_strategy = tf.distribute.OneDeviceStrategy('/cpu:0')\n",
"with another_strategy.scope():\n",
" restored_keras_model_ds = tf.keras.models.load_model(keras_model_path)\n",
" restored_keras_model_ds.fit(train_dataset, epochs=2)"
@@ -270,7 +275,7 @@
"id": "PdiiPmL5tQk5"
},
"source": [
- "As you can see, loading works as expected with `tf.distribute.Strategy`. The strategy used here does not have to be the same strategy used before saving. "
+ "As the `Model.fit` output shows, loading works as expected with `tf.distribute.Strategy`. The strategy used here does not have to be the same strategy used before saving. "
]
},
{
@@ -279,7 +284,7 @@
"id": "3CrXIbmFt0f6"
},
"source": [
- "### The `tf.saved_model` APIs"
+ "### The `tf.saved_model` API"
]
},
{
@@ -288,7 +293,7 @@
"id": "HtGzPp6et4Em"
},
"source": [
- "Now let's take a look at the lower level APIs. Saving the model is similar to the keras API:"
+ "Saving the model with lower-level API is similar to the Keras API:"
]
},
{
@@ -300,7 +305,7 @@
"outputs": [],
"source": [
"model = get_model() # get a fresh model\n",
- "saved_model_path = \"/tmp/tf_save\"\n",
+ "saved_model_path = '/tmp/tf_save'\n",
"tf.saved_model.save(model, saved_model_path)"
]
},
@@ -310,7 +315,7 @@
"id": "q1QNRYcwuRll"
},
"source": [
- "Loading can be done with `tf.saved_model.load()`. However, since it is an API that is on the lower level (and hence has a wider range of use cases), it does not return a Keras model. Instead, it returns an object that contain functions that can be used to do inference. For example:"
+ "Loading can be done with `tf.saved_model.load`. However, since it is a lower-level API (and hence has a wider range of use cases), it does not return a Keras model. Instead, it returns an object that contain functions that can be used to do inference. For example:"
]
},
{
@@ -321,7 +326,7 @@
},
"outputs": [],
"source": [
- "DEFAULT_FUNCTION_KEY = \"serving_default\"\n",
+ "DEFAULT_FUNCTION_KEY = 'serving_default'\n",
"loaded = tf.saved_model.load(saved_model_path)\n",
"inference_func = loaded.signatures[DEFAULT_FUNCTION_KEY]"
]
@@ -332,7 +337,7 @@
"id": "x65l7AaHUZCA"
},
"source": [
- "The loaded object may contain multiple functions, each associated with a key. The `\"serving_default\"` is the default key for the inference function with a saved Keras model. To do an inference with this function: "
+ "The loaded object may contain multiple functions, each associated with a key. The `\"serving_default\"` key is the default key for the inference function with a saved Keras model. To do inference with this function: "
]
},
{
@@ -375,7 +380,9 @@
"\n",
" # Calling the function in a distributed manner\n",
" for batch in dist_predict_dataset:\n",
- " another_strategy.run(inference_func,args=(batch,))"
+ " result = another_strategy.run(inference_func, args=(batch,))\n",
+ " print(result)\n",
+ " break"
]
},
{
@@ -384,7 +391,7 @@
"id": "hWGSukoyw3fF"
},
"source": [
- "Calling the restored function is just a forward pass on the saved model (predict). What if yout want to continue training the loaded function? Or embed the loaded function into a bigger model? A common practice is to wrap this loaded object to a Keras layer to achieve this. Luckily, [TF Hub](https://www.tensorflow.org/hub) has [hub.KerasLayer](https://github.com/tensorflow/hub/blob/master/tensorflow_hub/keras_layer.py) for this purpose, shown here:"
+ "Calling the restored function is just a forward pass on the saved model (`tf.keras.Model.predict`). What if you want to continue training the loaded function? Or what if you need to embed the loaded function into a bigger model? A common practice is to wrap this loaded object into a Keras layer to achieve this. Luckily, [TF Hub](https://www.tensorflow.org/hub) has [`hub.KerasLayer`](https://github.com/tensorflow/hub/blob/master/tensorflow_hub/keras_layer.py) for this purpose, shown here:"
]
},
{
@@ -421,7 +428,7 @@
"id": "Oe1z_OtSJlu2"
},
"source": [
- "As you can see, `hub.KerasLayer` wraps the result loaded back from `tf.saved_model.load()` into a Keras layer that can be used to build another model. This is very useful for transfer learning. "
+ "In the above example, Tensorflow Hub's `hub.KerasLayer` wraps the result loaded back from `tf.saved_model.load` into a Keras layer that is used to build another model. This is very useful for transfer learning. "
]
},
{
@@ -439,11 +446,11 @@
"id": "GC6GQ9HDLxD6"
},
"source": [
- "For saving, if you are working with a keras model, it is almost always recommended to use the Keras's `model.save()` API. If what you are saving is not a Keras model, then the lower level API is your only choice. \n",
+ "For saving, if you are working with a Keras model, use the Keras `Model.save` API unless you need the additional control allowed by the low-level API. If what you are saving is not a Keras model, then the lower-level API, `tf.saved_model.save`, is your only choice. \n",
"\n",
- "For loading, which API you use depends on what you want to get from the loading API. If you cannot (or do not want to) get a Keras model, then use `tf.saved_model.load()`. Otherwise, use `tf.keras.models.load_model()`. Note that you can get a Keras model back only if you saved a Keras model. \n",
+ "For loading, your API choice depends on what you want to get from the model loading API. If you cannot (or do not want to) get a Keras model, then use `tf.saved_model.load`. Otherwise, use `tf.keras.models.load_model`. Note that you can get a Keras model back only if you saved a Keras model. \n",
"\n",
- "It is possible to mix and match the APIs. You can save a Keras model with `model.save`, and load a non-Keras model with the low-level API, `tf.saved_model.load`. "
+ "It is possible to mix and match the APIs. You can save a Keras model with `Model.save`, and load a non-Keras model with the low-level API, `tf.saved_model.load`. "
]
},
{
@@ -456,13 +463,13 @@
"source": [
"model = get_model()\n",
"\n",
- "# Saving the model using Keras's save() API\n",
- "model.save(keras_model_path) \n",
+ "# Saving the model using Keras `Model.save`\n",
+ "model.save(saved_model_path)\n",
"\n",
"another_strategy = tf.distribute.MirroredStrategy()\n",
- "# Loading the model using lower level API\n",
+ "# Loading the model using the lower-level API\n",
"with another_strategy.scope():\n",
- " loaded = tf.saved_model.load(keras_model_path)"
+ " loaded = tf.saved_model.load(saved_model_path)"
]
},
{
@@ -471,7 +478,7 @@
"id": "0Z7lSj8nZiW5"
},
"source": [
- "### Saving/Loading from local device"
+ "### Saving/Loading from a local device"
]
},
{
@@ -480,7 +487,7 @@
"id": "NVAjWcosZodw"
},
"source": [
- "When saving and loading from a local io device while running remotely, for example using a cloud TPU, the option `experimental_io_device` must be used to set the io device to localhost."
+ "When saving and loading from a local I/O device while training on remote devices—for example, when using a Cloud TPU—you must use the option `experimental_io_device` in `tf.saved_model.SaveOptions` and `tf.saved_model.LoadOptions` to set the I/O device to `localhost`. For example:"
]
},
{
@@ -494,7 +501,7 @@
"model = get_model()\n",
"\n",
"# Saving the model to a path on localhost.\n",
- "saved_model_path = \"/tmp/tf_save\"\n",
+ "saved_model_path = '/tmp/tf_save'\n",
"save_options = tf.saved_model.SaveOptions(experimental_io_device='/job:localhost')\n",
"model.save(saved_model_path, options=save_options)\n",
"\n",
@@ -517,14 +524,10 @@
{
"cell_type": "markdown",
"metadata": {
- "id": "Tzog2ti7YYgy"
+ "id": "2cCSZrD7VCxe"
},
"source": [
- "A special case is when you have a Keras model that does not have well-defined inputs. For example, a Sequential model can be created without any input shapes (`Sequential([Dense(3), ...]`). Subclassed models also do not have well-defined inputs after initialization. In this case, you should stick with the lower level APIs on both saving and loading, otherwise you will get an error. \n",
- "\n",
- "To check if your model has well-defined inputs, just check if `model.inputs` is `None`. If it is not `None`, you are all good. Input shapes are automatically defined when the model is used in `.fit`, `.evaluate`, `.predict`, or when calling the model (`model(inputs)`). \n",
- "\n",
- "Here is an example:"
+ "One special case is when you create Keras models in certain ways, and then save them before training. For example:"
]
},
{
@@ -536,6 +539,7 @@
"outputs": [],
"source": [
"class SubclassedModel(tf.keras.Model):\n",
+ " \"\"\"Example model defined by subclassing `tf.keras.Model`.\"\"\"\n",
"\n",
" output_name = 'output_layer'\n",
"\n",
@@ -548,8 +552,89 @@
" return self._dense_layer(inputs)\n",
"\n",
"my_model = SubclassedModel()\n",
- "# my_model.save(keras_model_path) # ERROR! \n",
- "tf.saved_model.save(my_model, saved_model_path)"
+ "try:\n",
+ " my_model.save(saved_model_path)\n",
+ "except ValueError as e:\n",
+ " print(f'{type(e).__name__}: ', *e.args)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "D4qMyXFDSPDO"
+ },
+ "source": [
+ "A SavedModel saves the `tf.types.experimental.ConcreteFunction` objects generated when you trace a `tf.function` (check _When is a Function tracing?_ in the [Introduction to graphs and tf.function](../../guide/intro_to_graphs.ipynb) guide to learn more). If you get a `ValueError` like this it's because `Model.save` was not able to find or create a traced `ConcreteFunction`.\n",
+ "\n",
+ "**Caution:** You shouldn't save a model without at least one `ConcreteFunction`, since the low-level API will otherwise generate a SavedModel with no `ConcreteFunction` signatures ([learn more](../../guide/saved_model.ipynb) about the SavedModel format). For example:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "064SE47mYDj8"
+ },
+ "outputs": [],
+ "source": [
+ "tf.saved_model.save(my_model, saved_model_path)\n",
+ "x = tf.saved_model.load(saved_model_path)\n",
+ "x.signatures"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "LRTxlASJX-cY"
+ },
+ "source": [
+ "\n",
+ "Usually the model's forward pass—the `call` method—will be traced automatically when the model is called for the first time, often via the Keras `Model.fit` method. A `ConcreteFunction` can also be generated by the Keras [Sequential](https://www.tensorflow.org/guide/keras/sequential_model) and [Functional](https://www.tensorflow.org/guide/keras/functional) APIs, if you set the input shape, for example, by making the first layer either a `tf.keras.layers.InputLayer` or another layer type, and passing it the `input_shape` keyword argument. \n",
+ "\n",
+ "To verify if your model has any traced `ConcreteFunction`s, check if `Model.save_spec` is `None`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "xAXise4eR0YJ"
+ },
+ "outputs": [],
+ "source": [
+ "print(my_model.save_spec() is None)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "G2G_FQrWJAO3"
+ },
+ "source": [
+ "Let's use `tf.keras.Model.fit` to train the model, and notice that the `save_spec` gets defined and model saving will work:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "cv5LTi0zDkKS"
+ },
+ "outputs": [],
+ "source": [
+ "BATCH_SIZE_PER_REPLICA = 4\n",
+ "BATCH_SIZE = BATCH_SIZE_PER_REPLICA * mirrored_strategy.num_replicas_in_sync\n",
+ "\n",
+ "dataset_size = 100\n",
+ "dataset = tf.data.Dataset.from_tensors(\n",
+ " (tf.range(5, dtype=tf.float32), tf.range(5, dtype=tf.float32))\n",
+ " ).repeat(dataset_size).batch(BATCH_SIZE)\n",
+ "\n",
+ "my_model.compile(optimizer='adam', loss='mean_squared_error')\n",
+ "my_model.fit(dataset, epochs=2)\n",
+ "\n",
+ "print(my_model.save_spec() is None)\n",
+ "my_model.save(saved_model_path)"
]
}
],
diff --git a/site/en/tutorials/estimator/boosted_trees.ipynb b/site/en/tutorials/estimator/boosted_trees.ipynb
deleted file mode 100644
index 4c1bb1890c0..00000000000
--- a/site/en/tutorials/estimator/boosted_trees.ipynb
+++ /dev/null
@@ -1,612 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "7765UFHoyGx6"
- },
- "source": [
- "##### Copyright 2019 The TensorFlow Authors."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "id": "KVtTDrUNyL7x"
- },
- "outputs": [],
- "source": [
- "#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n",
- "# you may not use this file except in compliance with the License.\n",
- "# You may obtain a copy of the License at\n",
- "#\n",
- "# https://www.apache.org/licenses/LICENSE-2.0\n",
- "#\n",
- "# Unless required by applicable law or agreed to in writing, software\n",
- "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
- "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
- "# See the License for the specific language governing permissions and\n",
- "# limitations under the License."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "xPYxZMrWyA0N"
- },
- "source": [
- "# Boosted trees using Estimators"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "p_vOREjRx-Y0"
- },
- "source": [
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "6gWdn5lrlkhR"
- },
- "source": [
- "> Warning: Estimators are not recommended for new code. Estimators run `v1.Session`-style code which is more difficult to write correctly, and can behave unexpectedly, especially when combined with TF 2 code. Estimators do fall under our [compatibility guarantees] (https://tensorflow.org/guide/versions), but will receive no fixes other than security vulnerabilities. See the [migration guide](https://tensorflow.org/guide/migrate) for details."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "qNW3c_rop5J8"
- },
- "source": [
- "**Note**: Modern Keras based implementations of many state of the art decision forest algorithms are available in [TensorFlow Decision Forests](https://tensorflow.org/decision_forests)."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "dW3r7qVxzqN5"
- },
- "source": [
- "This tutorial is an end-to-end walkthrough of training a Gradient Boosting model using decision trees with the `tf.estimator` API. Boosted Trees models are among the most popular and effective machine learning approaches for both regression and classification. It is an ensemble technique that combines the predictions from several (think 10s, 100s or even 1000s) tree models.\n",
- "\n",
- "Boosted Trees models are popular with many machine learning practitioners as they can achieve impressive performance with minimal hyperparameter tuning."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "eylrTPAN3rJV"
- },
- "source": [
- "## Load the titanic dataset\n",
- "You will be using the titanic dataset, where the (rather morbid) goal is to predict passenger survival, given characteristics such as gender, age, class, etc."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "KuhAiPfZ3rJW"
- },
- "outputs": [],
- "source": [
- "import numpy as np\n",
- "import pandas as pd\n",
- "from IPython.display import clear_output\n",
- "from matplotlib import pyplot as plt\n",
- "\n",
- "# Load dataset.\n",
- "dftrain = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/train.csv')\n",
- "dfeval = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/eval.csv')\n",
- "y_train = dftrain.pop('survived')\n",
- "y_eval = dfeval.pop('survived')"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "NFtnFm1T0kMf"
- },
- "outputs": [],
- "source": [
- "import tensorflow as tf\n",
- "tf.random.set_seed(123)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "3ioodHdVJVdA"
- },
- "source": [
- "The dataset consists of a training set and an evaluation set:\n",
- "\n",
- "* `dftrain` and `y_train` are the *training set*—the data the model uses to learn.\n",
- "* The model is tested against the *eval set*, `dfeval`, and `y_eval`.\n",
- "\n",
- "For training you will use the following features:\n",
- "\n",
- "\n",
- "
\n",
+ "\n",
+ "DTensor also supports this case. The only change you need to do is to create a Mesh that includes a `feature` dimension, and apply the corresponding `Layout`.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "jpc9mqURGpmK"
+ },
+ "outputs": [],
+ "source": [
+ "mesh = dtensor.create_mesh([(\"batch\", 2), (\"feature\", 2), (\"model\", 2)], devices=DEVICES)\n",
+ "model = MLP([dtensor.Layout([\"feature\", \"model\"], mesh), \n",
+ " dtensor.Layout([\"model\", dtensor.UNSHARDED], mesh)])\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "i07Wrv-jHBc1"
+ },
+ "source": [
+ "Shard the input data along the `feature` dimension when packing the input tensors to DTensors. You do this with a slightly different repack function, `repack_batch_for_spt`, where `spt` stands for Spatial Parallel Training."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "DWR8qF6BGtFL"
+ },
+ "outputs": [],
+ "source": [
+ "def repack_batch_for_spt(x, y, mesh):\n",
+ " # Shard data on feature dimension, too\n",
+ " x = repack_local_tensor(x, layout=dtensor.Layout([\"batch\", 'feature'], mesh))\n",
+ " y = repack_local_tensor(y, layout=dtensor.Layout([\"batch\"], mesh))\n",
+ " return x, y"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Ygl9dqMUHTVN"
+ },
+ "source": [
+ "The Spatial parallel training can also continue from a checkpoint created with other parallell training schemes."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "p3NnpHSKo-hx"
+ },
+ "outputs": [],
+ "source": [
+ "num_epochs = 2\n",
+ "\n",
+ "manager = start_checkpoint_manager(model)\n",
+ "for epoch in range(num_epochs):\n",
+ " step = 0\n",
+ " metrics = {'epoch': epoch}\n",
+ " pbar = tf.keras.utils.Progbar(target=int(train_data_vec.cardinality()))\n",
+ "\n",
+ " for x, y in train_data_vec:\n",
+ " x, y = repack_batch_for_spt(x, y, mesh)\n",
+ " metrics.update(train_step(model, x, y, 1e-2))\n",
+ "\n",
+ " pbar.update(step, values=metrics.items(), finalize=False)\n",
+ " step += 1\n",
+ " manager.save()\n",
+ " pbar.update(step, values=metrics.items(), finalize=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "vp4L59CpJjYr"
+ },
+ "source": [
+ "## SavedModel and DTensor\n",
+ "\n",
+ "The integration of DTensor and SavedModel is still under development. \n",
+ "\n",
+ "As of TensorFlow `2.11`, `tf.saved_model` can save sharded and replicated DTensor models, and saving will do an efficient sharded save on different devices of the mesh. However, after a model is saved, all DTensor annotations are lost and the saved signatures can only be used with regular Tensors, not DTensors."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "49HfIq_SJZoj"
+ },
+ "outputs": [],
+ "source": [
+ "mesh = dtensor.create_mesh([(\"world\", 1)], devices=DEVICES[:1])\n",
+ "mlp = MLP([dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh), \n",
+ " dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh)])\n",
+ "\n",
+ "manager = start_checkpoint_manager(mlp)\n",
+ "\n",
+ "model_for_saving = tf.keras.Sequential([\n",
+ " text_vectorization,\n",
+ " mlp\n",
+ "])\n",
+ "\n",
+ "@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])\n",
+ "def run(inputs):\n",
+ " return {'result': model_for_saving(inputs)}\n",
+ "\n",
+ "tf.saved_model.save(\n",
+ " model_for_saving, \"/tmp/saved_model\",\n",
+ " signatures=run)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "h6Csim_VMGxQ"
+ },
+ "source": [
+ "As of TensorFlow 2.9.0, you can only call a loaded signature with a regular Tensor, or a fully replicated DTensor (which will be converted to a regular Tensor)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "HG_ASSzR4IWW"
+ },
+ "outputs": [],
+ "source": [
+ "sample_batch = train_data.take(1).get_single_element()\n",
+ "sample_batch"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "qW8yKPrhKQ5b"
+ },
+ "outputs": [],
+ "source": [
+ "loaded = tf.saved_model.load(\"/tmp/saved_model\")\n",
+ "\n",
+ "run_sig = loaded.signatures[\"serving_default\"]\n",
+ "result = run_sig(sample_batch['text'])['result']"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "GahGbv0ZmkJb"
+ },
+ "outputs": [],
+ "source": [
+ "np.mean(tf.argmax(result, axis=-1) == sample_batch['label'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Ks-Vs9qsH6jO"
+ },
+ "source": [
+ "## What's next?\n",
+ "\n",
+ "This tutorial demonstrated building and training an MLP sentiment analysis model with DTensor.\n",
+ "\n",
+ "Through `Mesh` and `Layout` primitives, DTensor can transform a TensorFlow `tf.function` to a distributed program suitable for a variety of training schemes.\n",
+ "\n",
+ "In a real-world machine learning application, evaluation and cross-validation should be applied to avoid producing an over-fitted model. The techniques introduced in this tutorial can also be applied to introduce parallelism to evaluation.\n",
+ "\n",
+ "Composing a model with `tf.Module` from scratch is a lot of work, and reusing existing building blocks such as layers and helper functions can drastically speed up model development.\n",
+ "As of TensorFlow 2.9, all Keras Layers under `tf.keras.layers` accepts DTensor layouts as their arguments, and can be used to build DTensor models. You can even directly reuse a Keras model with DTensor without modifying the model implementation. Refer to the [DTensor Keras Integration Tutorial](https://www.tensorflow.org/tutorials/distribute/dtensor_keras_tutorial) for information on using DTensor Keras. "
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "collapsed_sections": [],
+ "name": "dtensor_ml_tutorial.ipynb",
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/site/en/tutorials/distribute/input.ipynb b/site/en/tutorials/distribute/input.ipynb
index e1cdca6788e..f779c4f19a6 100644
--- a/site/en/tutorials/distribute/input.ipynb
+++ b/site/en/tutorials/distribute/input.ipynb
@@ -73,7 +73,7 @@
"This guide will show you the different ways in which you can create distributed dataset and iterators using `tf.distribute` APIs. Additionally, the following topics will be covered:\n",
"- Usage, sharding and batching options when using `tf.distribute.Strategy.experimental_distribute_dataset` and `tf.distribute.Strategy.distribute_datasets_from_function`.\n",
"- Different ways in which you can iterate over the distributed dataset.\n",
- "- Differences between `tf.distribute.Strategy.experimental_distribute_dataset`/`tf.distribute.Strategy.distribute_datasets_from_function` APIs and `tf.data` APIs as well any limitations that users may come across in their usage.\n",
+ "- Differences between `tf.distribute.Strategy.experimental_distribute_dataset`/`tf.distribute.Strategy.distribute_datasets_from_function` APIs and `tf.data` APIs as well as any limitations that users may come across in their usage.\n",
"\n",
"This guide does not cover usage of distributed input with Keras APIs."
]
@@ -84,7 +84,7 @@
"id": "MM6W__qraV55"
},
"source": [
- "## Distributed Datasets"
+ "## Distributed datasets"
]
},
{
@@ -93,8 +93,8 @@
"id": "lNy9GxjSlMKQ"
},
"source": [
- "To use `tf.distribute` APIs to scale, it is recommended that users use `tf.data.Dataset` to represent their input. `tf.distribute` has been made to work efficiently with `tf.data.Dataset` (for example, automatic prefetch of data onto each accelerator device) with performance optimizations being regularly incorporated into the implementation. If you have a use case for using something other than `tf.data.Dataset`, please refer a later [section](\"tensorinputs\") in this guide.\n",
- "In a non distributed training loop, users first create a `tf.data.Dataset` instance and then iterate over the elements. For example:\n"
+ "To use `tf.distribute` APIs to scale, use `tf.data.Dataset` to represent their input. `tf.distribute` works efficiently with `tf.data.Dataset`—for example, via automatic prefetching onto each accelerator device and regular performance updates. If you have a use case for using something other than `tf.data.Dataset`, please refer to the [Tensor inputs section](#tensorinputs) in this guide.\n",
+ "In a non-distributed training loop, first create a `tf.data.Dataset` instance and then iterate over the elements. For example:\n"
]
},
{
@@ -114,6 +114,34 @@
"print(tf.__version__)"
]
},
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "6cnilUtmKwpa"
+ },
+ "outputs": [],
+ "source": [
+ "# Simulate multiple CPUs with virtual devices\n",
+ "N_VIRTUAL_DEVICES = 2\n",
+ "physical_devices = tf.config.list_physical_devices(\"CPU\")\n",
+ "tf.config.set_logical_device_configuration(\n",
+ " physical_devices[0], [tf.config.LogicalDeviceConfiguration() for _ in range(N_VIRTUAL_DEVICES)])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "zd4l1ySeLRk1"
+ },
+ "outputs": [],
+ "source": [
+ "print(\"Available devices:\")\n",
+ "for i, device in enumerate(tf.config.list_logical_devices()):\n",
+ " print(\"%d) %s\" % (i, device))"
+ ]
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -214,14 +242,14 @@
" * Replica 1:[0, 1]\n",
" * Replica 2:[2, 3]\n",
" * Batch 2:\n",
- " * Replica 2: [4]\n",
+ " * Replica 1: [4]\n",
" * Replica 2: [5]\n",
"\n",
"\n",
"\n",
"* `tf.data.Dataset.range(4).batch(4)`\n",
" * Without distribution:\n",
- " * Batch 1: [[0], [1], [2], [3]]\n",
+ " * Batch 1: [0, 1, 2, 3]\n",
" * With distribution over 5 replicas:\n",
" * Batch 1:\n",
" * Replica 1: [0]\n",
@@ -246,7 +274,7 @@
"\n",
"Note: The above examples only illustrate how a global batch is split on different replicas. It is not advisable to depend on the actual values that might end up on each replica as it can change depending on the implementation.\n",
"\n",
- "Rebatching the dataset has a space complexity that increases linearly with the number of replicas. This means that for the multi worker training use case the input pipeline can run into OOM errors. "
+ "Rebatching the dataset has a space complexity that increases linearly with the number of replicas. This means that for the multi-worker training use case the input pipeline can run into OOM errors. "
]
},
{
@@ -257,7 +285,7 @@
"source": [
"##### Sharding\n",
"\n",
- "`tf.distribute` also autoshards the input dataset in multi worker training with `MultiWorkerMirroredStrategy` and `TPUStrategy`. Each dataset is created on the CPU device of the worker. Autosharding a dataset over a set of workers means that each worker is assigned a subset of the entire dataset (if the right `tf.data.experimental.AutoShardPolicy` is set). This is to ensure that at each step, a global batch size of non overlapping dataset elements will be processed by each worker. Autosharding has a couple of different options that can be specified using `tf.data.experimental.DistributeOptions`. Note that there is no autosharding in multi worker training with `ParameterServerStrategy`, and more information on dataset creation with this strategy can be found in the [Parameter Server Strategy tutorial](parameter_server_training.ipynb). "
+ "`tf.distribute` also autoshards the input dataset in multi-worker training with `MultiWorkerMirroredStrategy` and `TPUStrategy`. Each dataset is created on the CPU device of the worker. Autosharding a dataset over a set of workers means that each worker is assigned a subset of the entire dataset (if the right `tf.data.experimental.AutoShardPolicy` is set). This is to ensure that at each step, a global batch size of non-overlapping dataset elements will be processed by each worker. Autosharding has a couple of different options that can be specified using `tf.data.experimental.DistributeOptions`. Note that there is no autosharding in multi-worker training with `ParameterServerStrategy`, and more information on dataset creation with this strategy can be found in the [ParameterServerStrategy tutorial](parameter_server_training.ipynb). "
]
},
{
@@ -268,7 +296,7 @@
},
"outputs": [],
"source": [
- "dataset = tf.data.Dataset.from_tensors(([1.],[1.])).repeat(64).batch(16)\n",
+ "dataset = tf.data.Dataset.from_tensors(([1.], [1.])).repeat(64).batch(16)\n",
"options = tf.data.Options()\n",
"options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.DATA\n",
"dataset = dataset.with_options(options)"
@@ -358,7 +386,7 @@
"source": [
"#### Usage\n",
"\n",
- "This API takes an input function and returns a `tf.distribute.DistributedDataset` instance. The input function that users pass in has a `tf.distribute.InputContext` argument and should return a `tf.data.Dataset` instance. With this API, `tf.distribute` does not make any further changes to the user’s `tf.data.Dataset` instance returned from the input function. It is the responsibility of the user to batch and shard the dataset. `tf.distribute` calls the input function on the CPU device of each of the workers. Apart from allowing users to specify their own batching and sharding logic, this API also demonstrates better scalability and performance compared to `tf.distribute.Strategy.experimental_distribute_dataset` when used for multi worker training."
+ "This API takes an input function and returns a `tf.distribute.DistributedDataset` instance. The input function that users pass in has a `tf.distribute.InputContext` argument and should return a `tf.data.Dataset` instance. With this API, `tf.distribute` does not make any further changes to the user’s `tf.data.Dataset` instance returned from the input function. It is the responsibility of the user to batch and shard the dataset. `tf.distribute` calls the input function on the CPU device of each of the workers. Apart from allowing users to specify their own batching and sharding logic, this API also demonstrates better scalability and performance compared to `tf.distribute.Strategy.experimental_distribute_dataset` when used for multi-worker training."
]
},
{
@@ -373,11 +401,11 @@
"\n",
"def dataset_fn(input_context):\n",
" batch_size = input_context.get_per_replica_batch_size(global_batch_size)\n",
- " dataset = tf.data.Dataset.from_tensors(([1.],[1.])).repeat(64).batch(16)\n",
+ " dataset = tf.data.Dataset.from_tensors(([1.], [1.])).repeat(64).batch(16)\n",
" dataset = dataset.shard(\n",
- " input_context.num_input_pipelines, input_context.input_pipeline_id)\n",
+ " input_context.num_input_pipelines, input_context.input_pipeline_id)\n",
" dataset = dataset.batch(batch_size)\n",
- " dataset = dataset.prefetch(2) # This prefetches 2 batches per device.\n",
+ " dataset = dataset.prefetch(2) # This prefetches 2 batches per device.\n",
" return dataset\n",
"\n",
"dist_dataset = mirrored_strategy.distribute_datasets_from_function(dataset_fn)"
@@ -411,7 +439,7 @@
"source": [
"##### Sharding\n",
"\n",
- "The `tf.distribute.InputContext` object that is implicitly passed as an argument to the user’s input function is created by `tf.distribute` under the hood. It has information about the number of workers, current worker id etc. This input function can handle sharding as per policies set by the user using these properties that are part of the `tf.distribute.InputContext` object.\n"
+ "The `tf.distribute.InputContext` object that is implicitly passed as an argument to the user’s input function is created by `tf.distribute` under the hood. It has information about the number of workers, current worker ID etc. This input function can handle sharding as per policies set by the user using these properties that are part of the `tf.distribute.InputContext` object.\n"
]
},
{
@@ -422,7 +450,7 @@
"source": [
"##### Prefetching\n",
"\n",
- "`tf.distribute` does not add a prefetch transformation at the end of the `tf.data.Dataset` returned by the user provided input function."
+ "`tf.distribute` does not add a prefetch transformation at the end of the `tf.data.Dataset` returned by the user-provided input function, so you explicitly call `Dataset.prefetch` in the example above."
]
},
{
@@ -442,7 +470,7 @@
"id": "dL3XbI1gzEjO"
},
"source": [
- "## Distributed Iterators"
+ "## Distributed iterators"
]
},
{
@@ -452,7 +480,7 @@
},
"source": [
"Similar to non-distributed `tf.data.Dataset` instances, you will need to create an iterator on the `tf.distribute.DistributedDataset` instances to iterate over it and access the elements in the `tf.distribute.DistributedDataset`.\n",
- "The following are the ways in which you can create an `tf.distribute.DistributedIterator` and use it to train your model:\n"
+ "The following are the ways in which you can create a `tf.distribute.DistributedIterator` and use it to train your model:\n"
]
},
{
@@ -486,7 +514,7 @@
"global_batch_size = 16\n",
"mirrored_strategy = tf.distribute.MirroredStrategy()\n",
"\n",
- "dataset = tf.data.Dataset.from_tensors(([1.],[1.])).repeat(100).batch(global_batch_size)\n",
+ "dataset = tf.data.Dataset.from_tensors(([1.], [1.])).repeat(100).batch(global_batch_size)\n",
"dist_dataset = mirrored_strategy.experimental_distribute_dataset(dataset)\n",
"\n",
"@tf.function\n",
@@ -536,14 +564,16 @@
"id": "UpJXIlxjqPYg"
},
"source": [
- "With `next()` or `tf.distribute.DistributedIterator.get_next()`, if the `tf.distribute.DistributedIterator` has reached its end, an OutOfRange error will be thrown. The client can catch the error on python side and continue doing other work such as checkpointing and evaluation. However, this will not work if you are using a host training loop (i.e., run multiple steps per `tf.function`), which looks like:\n",
+ "With `next` or `tf.distribute.DistributedIterator.get_next`, if the `tf.distribute.DistributedIterator` has reached its end, an OutOfRange error will be thrown. The client can catch the error on python side and continue doing other work such as checkpointing and evaluation. However, this will not work if you are using a host training loop (i.e., run multiple steps per `tf.function`), which looks like:\n",
+ "\n",
"```\n",
"@tf.function\n",
"def train_fn(iterator):\n",
" for _ in tf.range(steps_per_loop):\n",
" strategy.run(step_fn, args=(next(iterator),))\n",
"```\n",
- " `train_fn` contains multiple steps by wrapping the step body inside a `tf.range`. In this case, different iterations in the loop with no dependency could start in parallel, so an OutOfRange error can be triggered in later iterations before the computation of previous iterations finishes. Once an OutOfRange error is thrown, all the ops in the function will be terminated right away. If this is some case that you would like to avoid, an alternative that does not throw an OutOfRange error is `tf.distribute.DistributedIterator.get_next_as_optional()`. `get_next_as_optional` returns a `tf.experimental.Optional` which contains the next element or no value if the `tf.distribute.DistributedIterator` has reached to an end."
+ "\n",
+ "This example `train_fn` contains multiple steps by wrapping the step body inside a `tf.range`. In this case, different iterations in the loop with no dependency could start in parallel, so an OutOfRange error can be triggered in later iterations before the computation of previous iterations finishes. Once an OutOfRange error is thrown, all the ops in the function will be terminated right away. If this is some case that you would like to avoid, an alternative that does not throw an OutOfRange error is `tf.distribute.DistributedIterator.get_next_as_optional`. `get_next_as_optional` returns a `tf.experimental.Optional` which contains the next element or no value if the `tf.distribute.DistributedIterator` has reached an end."
]
},
{
@@ -554,10 +584,10 @@
},
"outputs": [],
"source": [
- "# You can break the loop with get_next_as_optional by checking if the Optional contains value\n",
+ "# You can break the loop with `get_next_as_optional` by checking if the `Optional` contains a value\n",
"global_batch_size = 4\n",
"steps_per_loop = 5\n",
- "strategy = tf.distribute.MirroredStrategy(devices=[\"GPU:0\", \"CPU:0\"])\n",
+ "strategy = tf.distribute.MirroredStrategy()\n",
"\n",
"dataset = tf.data.Dataset.range(9).batch(global_batch_size)\n",
"distributed_iterator = iter(strategy.experimental_distribute_dataset(dataset))\n",
@@ -568,7 +598,7 @@
" optional_data = distributed_iterator.get_next_as_optional()\n",
" if not optional_data.has_value():\n",
" break\n",
- " per_replica_results = strategy.run(lambda x:x, args=(optional_data.get_value(),))\n",
+ " per_replica_results = strategy.run(lambda x: x, args=(optional_data.get_value(),))\n",
" tf.print(strategy.experimental_local_results(per_replica_results))\n",
"train_fn(distributed_iterator)"
]
@@ -579,7 +609,7 @@
"id": "LaclbKnqzLjf"
},
"source": [
- "## Using `element_spec` property"
+ "## Using the `element_spec` property"
]
},
{
@@ -588,7 +618,7 @@
"id": "Z1YvXqOpwy08"
},
"source": [
- "If you pass the elements of a distributed dataset to a `tf.function` and want a `tf.TypeSpec` guarantee, you can specify the `input_signature` argument of the `tf.function`. The output of a distributed dataset is `tf.distribute.DistributedValues` which can represent the input to a single device or multiple devices. To get the `tf.TypeSpec` corresponding to this distributed value you can use the `element_spec` property of the distributed dataset or distributed iterator object."
+ "If you pass the elements of a distributed dataset to a `tf.function` and want a `tf.TypeSpec` guarantee, you can specify the `input_signature` argument of the `tf.function`. The output of a distributed dataset is `tf.distribute.DistributedValues` which can represent the input to a single device or multiple devices. To get the `tf.TypeSpec` corresponding to this distributed value, you can use `tf.distribute.DistributedDataset.element_spec` or `tf.distribute.DistributedIterator.element_spec`."
]
},
{
@@ -604,7 +634,7 @@
"steps_per_epoch = 5\n",
"mirrored_strategy = tf.distribute.MirroredStrategy()\n",
"\n",
- "dataset = tf.data.Dataset.from_tensors(([1.],[1.])).repeat(100).batch(global_batch_size)\n",
+ "dataset = tf.data.Dataset.from_tensors(([1.], [1.])).repeat(100).batch(global_batch_size)\n",
"dist_dataset = mirrored_strategy.experimental_distribute_dataset(dataset)\n",
"\n",
"@tf.function(input_signature=[dist_dataset.element_spec])\n",
@@ -627,7 +657,246 @@
"id": "-OAa6svUzuWm"
},
"source": [
- "## Partial Batches"
+ "## Data preprocessing"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "pSMrs3kJQexW"
+ },
+ "source": [
+ "So far, you have learned how to distribute a `tf.data.Dataset`. Yet before the data is ready for the model, it needs to be preprocessed, for example by cleansing, transforming, and augmenting it. Two sets of those handy tools are:\n",
+ "\n",
+ "* [Keras preprocessing layers](https://www.tensorflow.org/guide/keras/preprocessing_layers): a set of Keras layers that allow developers to build Keras-native input processing pipelines. Some Keras preprocessing layers contain non-trainable states, which can be set on initialization or `adapt`ed (refer to the `adapt` section of the [Keras preprocessing layers guide](https://www.tensorflow.org/guide/keras/preprocessing_layers)). When distributing stateful preprocessing layers, the states should be replicated to all workers. To use these layers, you can either make them part of the model or apply them to the datasets.\n",
+ "\n",
+ "* [TensorFlow Transform (tf.Transform)](https://www.tensorflow.org/tfx/transform/get_started): a library for TensorFlow that allows you to define both instance-level and full-pass data transformation through data preprocessing pipelines. Tensorflow Transform has two phases. The first is the Analyze phase, where the raw training data is analyzed in a full-pass process to compute the statistics needed for the transformations, and the transformation logic is generated as instance-level operations. The second is the Transform phase, where the raw training data is transformed in an instance-level process.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Pd4aUCFdVlZ1"
+ },
+ "source": [
+ "### Keras preprocessing layers vs. Tensorflow Transform \n",
+ "\n",
+ "Both Tensorflow Transform and Keras preprocessing layers provide a way to split out preprocessing during training and bundle preprocessing with a model during inference, reducing train/serve skew.\n",
+ "\n",
+ "Tensorflow Transform, deeply integrated with [TFX](https://www.tensorflow.org/tfx), provides a scalable map-reduce solution to analyzing and transforming datasets of any size in a job separate from the training pipeline. If you need to run an analysis on a dataset that cannot fit on a single machine, Tensorflow Transform should be your first choice.\n",
+ "\n",
+ "Keras preprocessing layers are more geared towards preprocessing applied during training, after reading data from disk. They fit seamlessly with model development in the Keras library. They support analysis of a smaller dataset via [`adapt`](https://www.tensorflow.org/guide/keras/preprocessing_layers#the_adapt_method) and supports use cases like image data augmentation, where each pass over the input dataset will yield different examples for training.\n",
+ "\n",
+ "The two libraries can also be mixed, where Tensorflow Transform is used for analysis and static transformations of input data, and Keras preprocessing layers are used for train-time transformations (e.g., one-hot encoding or data augmentation).\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "MReKhhZpHUpj"
+ },
+ "source": [
+ "### Best Practice with tf.distribute\n",
+ "\n",
+ "Working with both tools involves initializing the transformation logic to apply to data, which might create Tensorflow resources. These resources or states should be replicated to all workers to save inter-workers or worker-coordinator communication. To do so, you are recommended to create Keras preprocessing layers, `tft.TFTransformOutput.transform_features_layer`, or `tft.TransformFeaturesLayer` under `tf.distribute.Strategy.scope`, just like you would for any other Keras layers.\n",
+ "\n",
+ "The following examples demonstrate usage of the `tf.distribute.Strategy` API with the high-level Keras `Model.fit` API and with a custom training loop separately."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "rwEGMWuoX7kJ"
+ },
+ "source": [
+ "#### Extra notes for Keras preprocessing layers users:\n",
+ "\n",
+ "**Preprocessing layers and large vocabularies**\n",
+ "\n",
+ "When dealing with large vocabularies (over one gigabyte) in a multi-worker setting (for example, `tf.distribute.MultiWorkerMirroredStrategy`, `tf.distribute.experimental.ParameterServerStrategy`, `tf.distribute.TPUStrategy`), it is recommended to save the vocabulary to a static file accessible from all workers (for example, with Cloud Storage). This will reduce the time spent replicating the vocabulary to all workers during training.\n",
+ "\n",
+ "**Preprocessing in the `tf.data` pipeline versus in the model**\n",
+ "\n",
+ "While Keras preprocessing layers can be applied either as part of the model or directly to a `tf.data.Dataset`, each of the options come with their edge:\n",
+ "\n",
+ "* Applying the preprocessing layers within the model makes your model portable, and it helps reduce the training/serving skew. (For more details, refer to the _Benefits of doing preprocessing inside the model at inference time_ section in the [Working with preprocessing layers guide](https://www.tensorflow.org/guide/keras/preprocessing_layers#benefits_of_doing_preprocessing_inside_the_model_at_inference_time))\n",
+ "* Applying within the `tf.data` pipeline allows prefetching or offloading to the CPU, which generally gives better performance when using accelerators.\n",
+ "\n",
+ "When running on one or more TPUs, users should almost always place Keras preprocessing layers in the `tf.data` pipeline, as not all layers support TPUs, and string ops do not execute on TPUs. (The two exceptions are `tf.keras.layers.Normalization` and `tf.keras.layers.Rescaling`, which run fine on TPUs and are commonly used as the first layer in an image model.)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "hNCYZ9L-BD2R"
+ },
+ "source": [
+ "### Preprocessing with `Model.fit`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "NhRB2Xe8B6bX"
+ },
+ "source": [
+ "When using Keras `Model.fit`, you do not need to distribute data with `tf.distribute.Strategy.experimental_distribute_dataset` nor `tf.distribute.Strategy.distribute_datasets_from_function` themselves. Check out the [Working with preprocessing layers](https://www.tensorflow.org/guide/keras/preprocessing_layers) guide and the [Distributed training with Keras](https://www.tensorflow.org/tutorials/distribute/keras) guide for details. A shortened example may look as below:\n",
+ "\n",
+ "```\n",
+ "strategy = tf.distribute.MirroredStrategy()\n",
+ "with strategy.scope():\n",
+ " # Create the layer(s) under scope.\n",
+ " integer_preprocessing_layer = tf.keras.layers.IntegerLookup(vocabulary=FILE_PATH)\n",
+ " model = ...\n",
+ " model.compile(...)\n",
+ "dataset = dataset.map(lambda x, y: (integer_preprocessing_layer(x), y))\n",
+ "model.fit(dataset)\n",
+ "```\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "3zL2vzJ-G0yg"
+ },
+ "source": [
+ "Users of `tf.distribute.experimental.ParameterServerStrategy` with the `Model.fit` API need to use a `tf.keras.utils.experimental.DatasetCreator` as the input. (See the [Parameter Server Training](https://www.tensorflow.org/tutorials/distribute/parameter_server_training#parameter_server_training_with_modelfit_api) guide for more)\n",
+ "\n",
+ "```\n",
+ "strategy = tf.distribute.experimental.ParameterServerStrategy(\n",
+ " cluster_resolver,\n",
+ " variable_partitioner=variable_partitioner)\n",
+ "\n",
+ "with strategy.scope():\n",
+ " preprocessing_layer = tf.keras.layers.StringLookup(vocabulary=FILE_PATH)\n",
+ " model = ...\n",
+ " model.compile(...)\n",
+ "\n",
+ "def dataset_fn(input_context):\n",
+ " ...\n",
+ " dataset = dataset.map(preprocessing_layer)\n",
+ " ...\n",
+ " return dataset\n",
+ "\n",
+ "dataset_creator = tf.keras.utils.experimental.DatasetCreator(dataset_fn)\n",
+ "model.fit(dataset_creator, epochs=5, steps_per_epoch=20, callbacks=callbacks)\n",
+ "\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "imZLQUOYBJyW"
+ },
+ "source": [
+ "### Preprocessing with a custom training loop"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "r2PX1QH_OwU3"
+ },
+ "source": [
+ "When writing a [custom training loop](https://www.tensorflow.org/tutorials/distribute/custom_training), you will distribute your data with either the `tf.distribute.Strategy.experimental_distribute_dataset` API or the `tf.distribute.Strategy.distribute_datasets_from_function` API. If you distribute your dataset through `tf.distribute.Strategy.experimental_distribute_dataset`, applying these preprocessing APIs in your data pipeline will lead the resources automatically co-located with the data pipeline to avoid remote resource access. Thus the examples here will all use `tf.distribute.Strategy.distribute_datasets_from_function`, in which case it is crucial to place initialization of these APIs under `strategy.scope()` for efficiency:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "wJS1UmcWQeab"
+ },
+ "outputs": [],
+ "source": [
+ "strategy = tf.distribute.MirroredStrategy()\n",
+ "vocab = [\"a\", \"b\", \"c\", \"d\", \"f\"]\n",
+ "\n",
+ "with strategy.scope():\n",
+ " # Create the layer(s) under scope.\n",
+ " layer = tf.keras.layers.StringLookup(vocabulary=vocab)\n",
+ "\n",
+ "def dataset_fn(input_context):\n",
+ " # a tf.data.Dataset\n",
+ " dataset = tf.data.Dataset.from_tensor_slices([\"a\", \"c\", \"e\"]).repeat()\n",
+ "\n",
+ " # Custom your batching, sharding, prefetching, etc.\n",
+ " global_batch_size = 4\n",
+ " batch_size = input_context.get_per_replica_batch_size(global_batch_size)\n",
+ " dataset = dataset.batch(batch_size)\n",
+ " dataset = dataset.shard(\n",
+ " input_context.num_input_pipelines,\n",
+ " input_context.input_pipeline_id)\n",
+ "\n",
+ " # Apply the preprocessing layer(s) to the tf.data.Dataset\n",
+ " def preprocess_with_kpl(input):\n",
+ " return layer(input)\n",
+ "\n",
+ " processed_ds = dataset.map(preprocess_with_kpl)\n",
+ " return processed_ds\n",
+ "\n",
+ "distributed_dataset = strategy.distribute_datasets_from_function(dataset_fn)\n",
+ "\n",
+ "# Print out a few example batches.\n",
+ "distributed_dataset_iterator = iter(distributed_dataset)\n",
+ "for _ in range(3):\n",
+ " print(next(distributed_dataset_iterator))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "PVl1cblWQy8b"
+ },
+ "source": [
+ "Note that if you are training with `tf.distribute.experimental.ParameterServerStrategy`, you'll also call `tf.distribute.experimental.coordinator.ClusterCoordinator.create_per_worker_dataset`\n",
+ "\n",
+ "```\n",
+ "@tf.function\n",
+ "def per_worker_dataset_fn():\n",
+ " return strategy.distribute_datasets_from_function(dataset_fn)\n",
+ "\n",
+ "per_worker_dataset = coordinator.create_per_worker_dataset(per_worker_dataset_fn)\n",
+ "per_worker_iterator = iter(per_worker_dataset)\n",
+ "```\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Ol7SmPID1dAt"
+ },
+ "source": [
+ "For Tensorflow Transform, as mentioned above, the Analyze stage is done separately from training and thus omitted here. See the [tutorial](https://www.tensorflow.org/tfx/tutorials/transform/census) for a detailed how-to. Usually, this stage includes creating a `tf.Transform` preprocessing function and transforming the data in an [Apache Beam](https://beam.apache.org/) pipeline with this preprocessing function. At the end of the Analyze stage, the output can be exported as a TensorFlow graph which you can use for both training and serving. Our example covers only the training pipeline part:\n",
+ "\n",
+ "```\n",
+ "with strategy.scope():\n",
+ " # working_dir contains the tf.Transform output.\n",
+ " tf_transform_output = tft.TFTransformOutput(working_dir)\n",
+ " # Loading from working_dir to create a Keras layer for applying the tf.Transform output to data\n",
+ " tft_layer = tf_transform_output.transform_features_layer()\n",
+ " ...\n",
+ "\n",
+ "def dataset_fn(input_context):\n",
+ " ...\n",
+ " dataset.map(tft_layer, num_parallel_calls=tf.data.AUTOTUNE)\n",
+ " ...\n",
+ " return dataset\n",
+ "\n",
+ "distributed_dataset = strategy.distribute_datasets_from_function(dataset_fn)\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "3_IQxRXxQWof"
+ },
+ "source": [
+ "## Partial batches"
]
},
{
@@ -636,7 +905,7 @@
"id": "hW2_gVkiztUG"
},
"source": [
- "Partial batches are encountered when `tf.data.Dataset` instances that users create may contain batch sizes that are not evenly divisible by the number of replicas or when the cardinality of the dataset instance is not divisible by the batch size. This means that when the dataset is distributed over multiple replicas, the `next` call on some iterators will result in an OutOfRangeError. To handle this use case, `tf.distribute` returns dummy batches of batch size 0 on replicas that do not have any more data to process.\n"
+ "Partial batches are encountered when: 1) `tf.data.Dataset` instances that users create may contain batch sizes that are not evenly divisible by the number of replicas; or 2) when the cardinality of the dataset instance is not divisible by the batch size. This means that when the dataset is distributed over multiple replicas, the `next` call on some iterators will result in an `tf.errors.OutOfRangeError`. To handle this use case, `tf.distribute` returns dummy batches of batch size `0` on replicas that do not have any more data to process.\n"
]
},
{
@@ -645,9 +914,9 @@
"id": "rqutdpqtPcCH"
},
"source": [
- "For the single worker case, if data is not returned by the `next` call on the iterator, dummy batches of 0 batch size are created and used along with the real data in the dataset. In the case of partial batches, the last global batch of data will contain real data alongside dummy batches of data. The stopping condition for processing data now checks if any of the replicas have data. If there is no data on any of the replicas, an OutOfRange error is thrown.\n",
+ "For the single-worker case, if the data is not returned by the `next` call on the iterator, dummy batches of 0 batch size are created and used along with the real data in the dataset. In the case of partial batches, the last global batch of data will contain real data alongside dummy batches of data. The stopping condition for processing data now checks if any of the replicas have data. If there is no data on any of the replicas, you will get a `tf.errors.OutOfRangeError`.\n",
"\n",
- "For the multi worker case, the boolean value representing presence of data on each of the workers is aggregated using cross replica communication and this is used to identify if all the workers have finished processing the distributed dataset. Since this involves cross worker communication there is some performance penalty involved.\n"
+ "For the multi-worker case, the boolean value representing presence of data on each of the workers is aggregated using cross replica communication and this is used to identify if all the workers have finished processing the distributed dataset. Since this involves cross worker communication there is some performance penalty involved.\n"
]
},
{
@@ -665,11 +934,11 @@
"id": "Nx4jyN_Az-Dy"
},
"source": [
- "* When using `tf.distribute.Strategy.experimental_distribute_dataset` APIs with a multiple worker setup, users pass a `tf.data.Dataset` that reads from files. If the `tf.data.experimental.AutoShardPolicy` is set to `AUTO` or `FILE`, the actual per step batch size may be smaller than the user defined global batch size. This can happen when the remaining elements in the file are less than the global batch size. Users can either exhaust the dataset without depending on the number of steps to run or set `tf.data.experimental.AutoShardPolicy` to `DATA` to work around it.\n",
+ "* When using `tf.distribute.Strategy.experimental_distribute_dataset` APIs with a multi-worker setup, you pass a `tf.data.Dataset` that reads from files. If the `tf.data.experimental.AutoShardPolicy` is set to `AUTO` or `FILE`, the actual per-step batch size may be smaller than the one you defined for the global batch size. This can happen when the remaining elements in the file are less than the global batch size. You can either exhaust the dataset without depending on the number of steps to run, or set `tf.data.experimental.AutoShardPolicy` to `DATA` to work around it.\n",
"\n",
"* Stateful dataset transformations are currently not supported with `tf.distribute` and any stateful ops that the dataset may have are currently ignored. For example, if your dataset has a `map_fn` that uses `tf.random.uniform` to rotate an image, then you have a dataset graph that depends on state (i.e the random seed) on the local machine where the python process is being executed.\n",
"\n",
- "* Experimental `tf.data.experimental.OptimizationOptions` that are disabled by default can in certain contexts -- such as when used together with `tf.distribute` -- cause a performance degradation. You should only enable them after you validate that they benefit the performance of your workload in a distribute setting.\n",
+ "* Experimental `tf.data.experimental.OptimizationOptions` that are disabled by default can in certain contexts—such as when used together with `tf.distribute`—cause a performance degradation. You should only enable them after you validate that they benefit the performance of your workload in a distribute setting.\n",
"\n",
"* Please refer to [this guide](https://www.tensorflow.org/guide/data_performance) for how to optimize your input pipeline with `tf.data` in general. A few additional tips:\n",
" * If you have multiple workers and are using `tf.data.Dataset.list_files` to create a dataset from all files matching one or more glob patterns, remember to set the `seed` argument or set `shuffle=False` so that each worker shard the file consistently.\n",
@@ -695,7 +964,7 @@
"source": [
"* The order in which the data is processed by the workers when using `tf.distribute.experimental_distribute_dataset` or `tf.distribute.distribute_datasets_from_function` is not guaranteed. This is typically required if you are using `tf.distribute` to scale prediction. You can however insert an index for each element in the batch and order outputs accordingly. The following snippet is an example of how to order outputs.\n",
"\n",
- "Note: `tf.distribute.MirroredStrategy()` is used here for the sake of convenience. We only need to reorder inputs when we are using multiple workers and `tf.distribute.MirroredStrategy` is used to distribute training on a single worker."
+ "Note: `tf.distribute.MirroredStrategy` is used here for the sake of convenience. You only need to reorder inputs when you are using multiple workers, but `tf.distribute.MirroredStrategy` is used to distribute training on a single worker."
]
},
{
@@ -740,7 +1009,7 @@
},
"source": [
"\n",
- "## How do I distribute my data if I am not using a canonical tf.data.Dataset instance?"
+ "## Tensor inputs instead of tf.data"
]
},
{
@@ -756,8 +1025,8 @@
"### Use experimental_distribute_values_from_function for arbitrary tensor inputs\n",
"`strategy.run` accepts `tf.distribute.DistributedValues` which is the output of\n",
"`next(iterator)`. To pass the tensor values, use\n",
- "`experimental_distribute_values_from_function` to construct\n",
- "`tf.distribute.DistributedValues` from raw tensors."
+ "`tf.distribute.Strategy.experimental_distribute_values_from_function` to construct\n",
+ "`tf.distribute.DistributedValues` from raw tensors. The user will have to specify their own batching and sharding logic in the input function with this option, which can be done using the `tf.distribute.experimental.ValueContext` input object."
]
},
{
@@ -769,14 +1038,13 @@
"outputs": [],
"source": [
"mirrored_strategy = tf.distribute.MirroredStrategy()\n",
- "worker_devices = mirrored_strategy.extended.worker_devices\n",
"\n",
"def value_fn(ctx):\n",
- " return tf.constant(1.0)\n",
+ " return tf.constant(ctx.replica_id_in_sync_group)\n",
"\n",
"distributed_values = mirrored_strategy.experimental_distribute_values_from_function(value_fn)\n",
"for _ in range(4):\n",
- " result = mirrored_strategy.run(lambda x:x, args=(distributed_values,))\n",
+ " result = mirrored_strategy.run(lambda x: x, args=(distributed_values,))\n",
" print(result)"
]
},
@@ -819,7 +1087,8 @@
"dist_dataset = mirrored_strategy.experimental_distribute_dataset(dataset)\n",
"iterator = iter(dist_dataset)\n",
"for _ in range(4):\n",
- " mirrored_strategy.run(lambda x:x, args=(next(iterator),))"
+ " result = mirrored_strategy.run(lambda x: x, args=(next(iterator),))\n",
+ " print(result)"
]
}
],
@@ -827,8 +1096,7 @@
"colab": {
"collapsed_sections": [],
"name": "input.ipynb",
- "provenance": [],
- "toc_visible": true
+ "toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
diff --git a/site/en/tutorials/distribute/keras.ipynb b/site/en/tutorials/distribute/keras.ipynb
index c75e5f88af5..b96656d4436 100644
--- a/site/en/tutorials/distribute/keras.ipynb
+++ b/site/en/tutorials/distribute/keras.ipynb
@@ -76,7 +76,7 @@
"\n",
"You will use the `tf.keras` APIs to build the model and `Model.fit` for training it. (To learn about distributed training with a custom training loop and the `MirroredStrategy`, check out [this tutorial](custom_training.ipynb).)\n",
"\n",
- "`MirroredStrategy` trains your model on multiple GPUs on a single machine. For _synchronous training on many GPUs on multiple workers_, use the `tf.distribute.MultiWorkerMirroredStrategy` [with the Keras Model.fit](multi_worker_with_keras.ipynb) or [a custom training loop](multi_worker_with_ctl.ipynb). For other options, refer to the [Distributed training guide](../../guide/distributed_training.ipynb).\n",
+ "`MirroredStrategy` trains your model on multiple GPUs on a single machine. For _synchronous training on many GPUs on multiple workers_, use the `tf.distribute.MultiWorkerMirroredStrategy` with the [Keras Model.fit](multi_worker_with_keras.ipynb) or [a custom training loop](multi_worker_with_ctl.ipynb). For other options, refer to the [Distributed training guide](../../guide/distributed_training.ipynb).\n",
"\n",
"To learn about various other strategies, there is the [Distributed training with TensorFlow](../../guide/distributed_training.ipynb) guide."
]
@@ -280,7 +280,7 @@
"id": "4xsComp8Kz5H"
},
"source": [
- "## Create the model"
+ "## Create the model and instantiate the optimizer"
]
},
{
@@ -289,7 +289,7 @@
"id": "1BnQYQTpB3YA"
},
"source": [
- "Create and compile the Keras model in the context of `Strategy.scope`:"
+ "Within the context of `Strategy.scope`, create and compile the model using the Keras API:"
]
},
{
@@ -310,10 +310,21 @@
" ])\n",
"\n",
" model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n",
- " optimizer=tf.keras.optimizers.Adam(),\n",
+ " optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),\n",
" metrics=['accuracy'])"
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "DCDKFcNJzdcd"
+ },
+ "source": [
+ "For this toy example with the MNIST dataset, you will be using the Adam optimizer's default learning rate of 0.001.\n",
+ "\n",
+ "For larger datasets, the key benefit of distributed training is to learn more in each training step, because each step processes more training data in parallel, which allows for a larger learning rate (within the limits of the model and dataset)."
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {
@@ -329,13 +340,16 @@
"id": "YOXO5nvvK3US"
},
"source": [
- "Define the following `tf.keras.callbacks`:\n",
+ "Define the following [Keras Callbacks](https://www.tensorflow.org/guide/keras/train_and_evaluate):\n",
"\n",
"- `tf.keras.callbacks.TensorBoard`: writes a log for TensorBoard, which allows you to visualize the graphs.\n",
"- `tf.keras.callbacks.ModelCheckpoint`: saves the model at a certain frequency, such as after every epoch.\n",
+ "- `tf.keras.callbacks.BackupAndRestore`: provides the fault tolerance functionality by backing up the model and current epoch number. Learn more in the _Fault tolerance_ section of the [Multi-worker training with Keras](multi_worker_with_keras.ipynb) tutorial.\n",
"- `tf.keras.callbacks.LearningRateScheduler`: schedules the learning rate to change after, for example, every epoch/batch.\n",
"\n",
- "For illustrative purposes, add a custom callback called `PrintLR` to display the *learning rate* in the notebook."
+ "For illustrative purposes, add a [custom callback](https://www.tensorflow.org/guide/keras/custom_callback) called `PrintLR` to display the *learning rate* in the notebook.\n",
+ "\n",
+ "**Note:** Use the `BackupAndRestore` callback instead of `ModelCheckpoint` as the main mechanism to restore the training state upon a restart from a job failure. Since `BackupAndRestore` only supports eager mode, in graph mode consider using `ModelCheckpoint`."
]
},
{
@@ -349,7 +363,7 @@
"# Define the checkpoint directory to store the checkpoints.\n",
"checkpoint_dir = './training_checkpoints'\n",
"# Define the name of the checkpoint files.\n",
- "checkpoint_prefix = os.path.join(checkpoint_dir, \"ckpt_{epoch}\")"
+ "checkpoint_prefix = os.path.join(checkpoint_dir, \"ckpt_{epoch:04d}.weights.h5\")"
]
},
{
@@ -382,8 +396,7 @@
"# Define a callback for printing the learning rate at the end of each epoch.\n",
"class PrintLR(tf.keras.callbacks.Callback):\n",
" def on_epoch_end(self, epoch, logs=None):\n",
- " print('\\nLearning rate for epoch {} is {}'.format(epoch + 1,\n",
- " model.optimizer.lr.numpy()))"
+ " print('\\nLearning rate for epoch {} is {}'.format(epoch + 1, model.optimizer.learning_rate.numpy()))"
]
},
{
@@ -419,7 +432,7 @@
"id": "6EophnOAB3YD"
},
"source": [
- "Now, train the model in the usual way by calling `Model.fit` on the model and passing in the dataset created at the beginning of the tutorial. This step is the same whether you are distributing the training or not."
+ "Now, train the model in the usual way by calling Keras `Model.fit` on the model and passing in the dataset created at the beginning of the tutorial. This step is the same whether you are distributing the training or not."
]
},
{
@@ -473,7 +486,10 @@
},
"outputs": [],
"source": [
- "model.load_weights(tf.train.latest_checkpoint(checkpoint_dir))\n",
+ "import pathlib\n",
+ "latest_checkpoint = sorted(pathlib.Path(checkpoint_dir).glob('*'))[-1]\n",
+ "\n",
+ "model.load_weights(latest_checkpoint)\n",
"\n",
"eval_loss, eval_acc = model.evaluate(eval_dataset)\n",
"\n",
@@ -526,7 +542,7 @@
"id": "kBLlogrDvMgg"
},
"source": [
- "## Export to SavedModel"
+ "## Save the model"
]
},
{
@@ -535,7 +551,7 @@
"id": "Xa87y_A0vRma"
},
"source": [
- "Export the graph and the variables to the platform-agnostic SavedModel format using `Model.save`. After your model is saved, you can load it with or without the `Strategy.scope`."
+ "Save the model to a `.keras` zip archive using `Model.save`. After your model is saved, you can load it with or without the `Strategy.scope`."
]
},
{
@@ -546,7 +562,7 @@
},
"outputs": [],
"source": [
- "path = 'saved_model/'"
+ "path = 'my_model.keras'"
]
},
{
@@ -557,7 +573,7 @@
},
"outputs": [],
"source": [
- "model.save(path, save_format='tf')"
+ "model.save(path)"
]
},
{
@@ -626,7 +642,7 @@
"\n",
"More examples that use different distribution strategies with the Keras `Model.fit` API:\n",
"\n",
- "1. The [Solve GLUE tasks using BERT on TPU](https://www.tensorflow.org/text/tutorials/bert_glue) tutorial uses `tf.distribute.MirroredStrategy` for training on GPUs and `tf.distribute.TPUStrategy`—on TPUs.\n",
+ "1. The [Solve GLUE tasks using BERT on TPU](https://www.tensorflow.org/text/tutorials/bert_glue) tutorial uses `tf.distribute.MirroredStrategy` for training on GPUs and `tf.distribute.TPUStrategy` on TPUs.\n",
"1. The [Save and load a model using a distribution strategy](save_and_load.ipynb) tutorial demonstates how to use the SavedModel APIs with `tf.distribute.Strategy`.\n",
"1. The [official TensorFlow models](https://github.com/tensorflow/models/tree/master/official) can be configured to run multiple distribution strategies.\n",
"\n",
diff --git a/site/en/tutorials/distribute/multi_worker_with_ctl.ipynb b/site/en/tutorials/distribute/multi_worker_with_ctl.ipynb
index ef3b4a73201..0361eea9328 100644
--- a/site/en/tutorials/distribute/multi_worker_with_ctl.ipynb
+++ b/site/en/tutorials/distribute/multi_worker_with_ctl.ipynb
@@ -63,11 +63,9 @@
"source": [
"## Overview\n",
"\n",
- "This tutorial demonstrates multi-worker training with custom training loop API, distributed via MultiWorkerMirroredStrategy, so a Keras model designed to run on [single-worker](https://www.tensorflow.org/tutorials/distribute/custom_training) can seamlessly work on multiple workers with minimal code change.\n",
+ "This tutorial demonstrates how to perform multi-worker distributed training with a Keras model and with [custom training loops](https://www.tensorflow.org/guide/keras/writing_a_training_loop_from_scratch) using the `tf.distribute.Strategy` API. The training loop is distributed via `tf.distribute.MultiWorkerMirroredStrategy`, such that a `tf.keras` model—designed to run on [single-worker](custom_training.ipynb)—can seamlessly work on multiple workers with minimal code changes. Custom training loops provide flexibility and a greater control on training, while also making it easier to debug the model. Learn more about [writing a basic training loop](../../guide/basic_training_loops.ipynb), [writing a training loop from scratch](https://www.tensorflow.org/guide/keras/writing_a_training_loop_from_scratch) and [custom training](../customization/custom_training_walkthrough.ipynb).\n",
"\n",
- "We are using custom training loops to train our model because they give us flexibility and a greater control on training. Moreover, it is easier to debug the model and the training loop. More detailed information is available in [Writing a training loop from scratch](https://www.tensorflow.org/guide/keras/writing_a_training_loop_from_scratch).\n",
- "\n",
- "If you are looking for how to use `MultiWorkerMirroredStrategy` with keras `model.fit`, refer to this [tutorial](https://www.tensorflow.org/tutorials/distribute/multi_worker_with_keras) instead.\n",
+ "If you are looking for how to use `MultiWorkerMirroredStrategy` with `tf.keras.Model.fit`, refer to this [tutorial](multi_worker_with_keras.ipynb) instead.\n",
"\n",
"[Distributed Training in TensorFlow](../../guide/distributed_training.ipynb) guide is available for an overview of the distribution strategies TensorFlow supports for those interested in a deeper understanding of `tf.distribute.Strategy` APIs."
]
@@ -102,9 +100,8 @@
"id": "Zz0EY91y3mxy"
},
"source": [
- "Before importing TensorFlow, make a few changes to the environment.\n",
- "\n",
- "Disable all GPUs. This prevents errors caused by the workers all trying to use the same GPU. For a real application each worker would be on a different machine."
+ "Before importing TensorFlow, make a few changes to the environment:\n",
+ "* Disable all GPUs. This prevents errors caused by all workers trying to use the same GPU. In a real-world application, each worker would be on a different machine."
]
},
{
@@ -124,7 +121,7 @@
"id": "7X1MS6385BWi"
},
"source": [
- "Reset the `TF_CONFIG` environment variable, you'll see more about this later."
+ "* Reset the `'TF_CONFIG'` environment variable (you'll see more about this later)."
]
},
{
@@ -144,7 +141,7 @@
"id": "Rd4L9Ii77SS8"
},
"source": [
- "Be sure that the current directory is on python's path. This allows the notebook to import the files written by `%%writefile` later.\n"
+ "* Make sure that the current directory is on Python's path. This allows the notebook to import the files written by `%%writefile` later.\n"
]
},
{
@@ -194,7 +191,7 @@
"id": "fLW6D2TzvC-4"
},
"source": [
- "Next create an `mnist.py` file with a simple model and dataset setup. This python file will be used by the worker-processes in this tutorial:"
+ "Next, create an `mnist.py` file with a simple model and dataset setup. This Python file will be used by the worker-processes in this tutorial:"
]
},
{
@@ -230,13 +227,18 @@
" return dataset\n",
"\n",
"def build_cnn_model():\n",
+ " regularizer = tf.keras.regularizers.L2(1e-5)\n",
" return tf.keras.Sequential([\n",
" tf.keras.Input(shape=(28, 28)),\n",
" tf.keras.layers.Reshape(target_shape=(28, 28, 1)),\n",
- " tf.keras.layers.Conv2D(32, 3, activation='relu'),\n",
+ " tf.keras.layers.Conv2D(32, 3,\n",
+ " activation='relu',\n",
+ " kernel_regularizer=regularizer),\n",
" tf.keras.layers.Flatten(),\n",
- " tf.keras.layers.Dense(128, activation='relu'),\n",
- " tf.keras.layers.Dense(10)\n",
+ " tf.keras.layers.Dense(128,\n",
+ " activation='relu',\n",
+ " kernel_regularizer=regularizer),\n",
+ " tf.keras.layers.Dense(10, kernel_regularizer=regularizer)\n",
" ])"
]
},
@@ -246,9 +248,9 @@
"id": "JmgZwwymxqt5"
},
"source": [
- "## Multi-worker Configuration\n",
+ "## Multi-worker configuration\n",
"\n",
- "Now let's enter the world of multi-worker training. In TensorFlow, the `TF_CONFIG` environment variable is required for training on multiple machines, each of which possibly has a different role. `TF_CONFIG` used below, is a JSON string used to specify the cluster configuration on each worker that is part of the cluster. This is the default method for specifying a cluster, using `cluster_resolver.TFConfigClusterResolver`, but there are other options available in the `distribute.cluster_resolver` module."
+ "Now let's enter the world of multi-worker training. In TensorFlow, the `'TF_CONFIG'` environment variable is required for training on multiple machines. Each machine may have a different role. The `'TF_CONFIG'` variable used below is a JSON string that specifies the cluster configuration on each worker that is part of the cluster. This is the default method for specifying a cluster, using `cluster_resolver.TFConfigClusterResolver`, but there are other options available in the `distribute.cluster_resolver` module. Learn more about setting up the `'TF_CONFIG'` variable in the [Distributed training guide](../../guide/distributed_training.ipynb)."
]
},
{
@@ -283,7 +285,7 @@
"id": "JjgwJbPKZkJL"
},
"source": [
- "Here is the same `TF_CONFIG` serialized as a JSON string:"
+ "Note that `tf_config` is just a local variable in Python. To use it for training configuration, serialize it as a JSON and place it in a `'TF_CONFIG'` environment variable. Here is the same `'TF_CONFIG'` serialized as a JSON string:"
]
},
{
@@ -303,11 +305,11 @@
"id": "AUBmYRZqxthH"
},
"source": [
- "There are two components of `TF_CONFIG`: `cluster` and `task`.\n",
+ "There are two components of `'TF_CONFIG'`: `'cluster'` and `'task'`.\n",
"\n",
- "* `cluster` is the same for all workers and provides information about the training cluster, which is a dict consisting of different types of jobs such as `worker`. In multi-worker training with `MultiWorkerMirroredStrategy`, there is usually one `worker` that takes on a little more responsibility like saving checkpoint and writing summary file for TensorBoard in addition to what a regular `worker` does. Such a worker is referred to as the `chief` worker, and it is customary that the `worker` with `index` 0 is appointed as the chief `worker` (in fact this is how `tf.distribute.Strategy` is implemented).\n",
+ "* `'cluster'` is the same for all workers and provides information about the training cluster, which is a dict consisting of different types of jobs such as `'worker'`. In multi-worker training with `MultiWorkerMirroredStrategy`, there is usually one `'worker'` that takes on a little more responsibility like saving checkpoints and writing summary files for TensorBoard in addition to what a regular `'worker'` does. Such a worker is referred to as the `'chief'` worker, and it is customary that the `'worker'` with `'index'` 0 is appointed as the chief `worker`.\n",
"\n",
- "* `task` provides information of the current task and is different on each worker. It specifies the `type` and `index` of that worker."
+ "* `'task'` provides information of the current task and is different on each worker. It specifies the `'type'` and `'index'` of that worker."
]
},
{
@@ -316,7 +318,7 @@
"id": "8YFpxrcsZ2xG"
},
"source": [
- "In this example, you set the task `type` to `\"worker\"` and the task `index` to `0`. This machine is the first worker and will be appointed as the chief worker and do more work than the others. Note that other machines will need to have the `TF_CONFIG` environment variable set as well, and it should have the same `cluster` dict, but different task `type` or task `index` depending on what the roles of those machines are.\n"
+ "In this example, you set the task `'type'` to `'worker'` and the task `'index'` to `0`. This machine is the first worker and will be appointed as the chief worker and do more work than the others. Note that other machines will need to have the `'TF_CONFIG'` environment variable set as well, and it should have the same `'cluster'` dict, but different task `'type'` or task `'index'` depending on what the roles of those machines are.\n"
]
},
{
@@ -325,18 +327,9 @@
"id": "aogb74kHxynz"
},
"source": [
- "For illustration purposes, this tutorial shows how one may set a `TF_CONFIG` with 2 workers on `localhost`. In practice, users would create multiple workers on external IP addresses/ports, and set `TF_CONFIG` on each worker appropriately.\n",
+ "For illustration purposes, this tutorial shows how one may set a `'TF_CONFIG'` with two workers on `'localhost'`. In practice, users would create multiple workers on external IP addresses/ports, and set `'TF_CONFIG'` on each worker appropriately.\n",
"\n",
- "In this example you will use 2 workers, the first worker's `TF_CONFIG` is shown above. For the second worker you would set `tf_config['task']['index']=1`"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "f83FVYqDX3aX"
- },
- "source": [
- "Above, `tf_config` is just a local variable in python. To actually use it to configure training, this dictionary needs to be serialized as JSON, and placed in the `TF_CONFIG` environment variable."
+ "This example uses two workers. The first worker's `'TF_CONFIG'` is shown above. For the second worker, set `tf_config['task']['index']=1`."
]
},
{
@@ -354,7 +347,7 @@
"id": "FcjAbuGY1ACJ"
},
"source": [
- "Subprocesses inherit environment variables from their parent. So if you set an environment variable in this `jupyter notebook` process:"
+ "Subprocesses inherit environment variables from their parent. So if you set an environment variable in this Jupyter Notebook process:"
]
},
{
@@ -374,7 +367,7 @@
"id": "gQkIX-cg18md"
},
"source": [
- "You can access the environment variable from a subprocesses:"
+ "you can then access the environment variable from a subprocess:"
]
},
{
@@ -395,7 +388,7 @@
"id": "af6BCA-Y2fpz"
},
"source": [
- "In the next section, you'll use this to pass the `TF_CONFIG` to the worker subprocesses. You would never really launch your jobs this way, but it's sufficient for the purposes of this tutorial: To demonstrate a minimal multi-worker example."
+ "In the next section, you'll use this to pass the `'TF_CONFIG'` to the worker subprocesses. You would never really launch your jobs this way, but it's sufficient for the purposes of this tutorial: To demonstrate a minimal multi-worker example."
]
},
{
@@ -406,7 +399,7 @@
"source": [
"## MultiWorkerMirroredStrategy\n",
"\n",
- "To train the model, use an instance of `tf.distribute.MultiWorkerMirroredStrategy`, which creates copies of all variables in the model's layers on each device across all workers. The [`tf.distribute.Strategy` guide](../../guide/distributed_training.ipynb) has more details about this strategy."
+ "Before training the model, first create an instance of `tf.distribute.MultiWorkerMirroredStrategy`:"
]
},
{
@@ -426,7 +419,7 @@
"id": "N0iv7SyyAohc"
},
"source": [
- "Note: `TF_CONFIG` is parsed and TensorFlow's GRPC servers are started at the time `MultiWorkerMirroredStrategy()` is called, so the `TF_CONFIG` environment variable must be set before a `tf.distribute.Strategy` instance is created."
+ "Note: `'TF_CONFIG'` is parsed and TensorFlow's GRPC servers are started at the time you call `tf.distribute.MultiWorkerMirroredStrategy.` Therefore, you must set the `'TF_CONFIG'` environment variable before you instantiate a `tf.distribute.Strategy`. To save time in this illustrative example, this is not demonstrated in this tutorial, so that servers do not need to start. You can find a full example in the last section of this tutorial."
]
},
{
@@ -435,7 +428,7 @@
"id": "TS4S-faBHHam"
},
"source": [
- "Use `tf.distribute.Strategy.scope` to specify that a strategy should be used when building your model. This puts you in the \"[cross-replica context](https://www.tensorflow.org/guide/distributed_training?hl=en#mirroredstrategy)\" for this strategy, which means the strategy is put in control of things like variable placement."
+ "Use `tf.distribute.Strategy.scope` to specify that a strategy should be used when building your model. This allows the strategy to control things like variable placement—it will create copies of all variables in the model's layers on each device across all workers."
]
},
{
@@ -459,9 +452,8 @@
},
"source": [
"## Auto-shard your data across workers\n",
- "In multi-worker training, dataset sharding is not necessarily needed, however it gives you exactly once semantic which makes more training more reproducible, i.e. training on multiple workers should be the same as training on one worker. Note: performance can be affected in some cases.\n",
"\n",
- "See: [`distribute_datasets_from_function`](https://www.tensorflow.org/api_docs/python/tf/distribute/Strategy?version=nightly#distribute_datasets_from_function)"
+ "In multi-worker training, _dataset sharding_ is needed to ensure convergence and reproducibility. Sharding means handing each worker a subset of the entire dataset—it helps create the experience similar to training on a single worker. In the example below, you're relying on the default autosharding policy of `tf.distribute`. You can also customize it by setting the `tf.data.experimental.AutoShardPolicy` of the `tf.data.experimental.DistributeOptions`. To learn more, refer to the _Sharding_ section of the [Distributed input tutorial](input.ipynb)."
]
},
{
@@ -487,8 +479,8 @@
"id": "rkNzSR3g60iP"
},
"source": [
- "## Define Custom Training Loop and Train the model\n",
- "Specify an optimizer"
+ "## Define a custom training loop and train the model\n",
+ "Specify an optimizer:"
]
},
{
@@ -500,7 +492,7 @@
"outputs": [],
"source": [
"with strategy.scope():\n",
- " # The creation of optimizer and train_accuracy will need to be in\n",
+ " # The creation of optimizer and train_accuracy needs to be in\n",
" # `strategy.scope()` as well, since they create variables.\n",
" optimizer = tf.keras.optimizers.RMSprop(learning_rate=0.001)\n",
" train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(\n",
@@ -513,7 +505,7 @@
"id": "RmrDcAii4B5O"
},
"source": [
- "Define a training step with `tf.function`\n"
+ "Define a training step with `tf.function`:\n"
]
},
{
@@ -533,11 +525,13 @@
" x, y = inputs\n",
" with tf.GradientTape() as tape:\n",
" predictions = multi_worker_model(x, training=True)\n",
- " per_batch_loss = tf.keras.losses.SparseCategoricalCrossentropy(\n",
+ " per_example_loss = tf.keras.losses.SparseCategoricalCrossentropy(\n",
" from_logits=True,\n",
" reduction=tf.keras.losses.Reduction.NONE)(y, predictions)\n",
- " loss = tf.nn.compute_average_loss(\n",
- " per_batch_loss, global_batch_size=global_batch_size)\n",
+ " loss = tf.nn.compute_average_loss(per_example_loss)\n",
+ " model_losses = multi_worker_model.losses\n",
+ " if model_losses:\n",
+ " loss += tf.nn.scale_regularization_loss(tf.add_n(model_losses))\n",
"\n",
" grads = tape.gradient(loss, multi_worker_model.trainable_variables)\n",
" optimizer.apply_gradients(\n",
@@ -558,7 +552,7 @@
"source": [
"### Checkpoint saving and restoring\n",
"\n",
- "Checkpointing implementation in a Custom Training Loop requires the user to handle it instead of using a keras callback. It allows you to save model's weights and restore them without having to save the whole model."
+ "As you write a custom training loop, you need to handle [checkpoint saving](../../guide/checkpoint.ipynb) manually instead of relying on a Keras callback. Note that for `MultiWorkerMirroredStrategy`, saving a checkpoint or a complete model requires the participation of all workers, because attempting to save only on the chief worker could lead to a deadlock. Workers also need to write to different paths to avoid overwriting each other. Here's an example of how to configure the directories:"
]
},
{
@@ -572,40 +566,34 @@
"from multiprocessing import util\n",
"checkpoint_dir = os.path.join(util.get_temp_dir(), 'ckpt')\n",
"\n",
- "def _is_chief(task_type, task_id):\n",
- " return task_type is None or task_type == 'chief' or (task_type == 'worker' and\n",
- " task_id == 0)\n",
+ "def _is_chief(task_type, task_id, cluster_spec):\n",
+ " return (task_type is None\n",
+ " or task_type == 'chief'\n",
+ " or (task_type == 'worker'\n",
+ " and task_id == 0\n",
+ " and \"chief\" not in cluster_spec.as_dict()))\n",
+ "\n",
"def _get_temp_dir(dirpath, task_id):\n",
" base_dirpath = 'workertemp_' + str(task_id)\n",
" temp_dir = os.path.join(dirpath, base_dirpath)\n",
" tf.io.gfile.makedirs(temp_dir)\n",
" return temp_dir\n",
"\n",
- "def write_filepath(filepath, task_type, task_id):\n",
+ "def write_filepath(filepath, task_type, task_id, cluster_spec):\n",
" dirpath = os.path.dirname(filepath)\n",
" base = os.path.basename(filepath)\n",
- " if not _is_chief(task_type, task_id):\n",
+ " if not _is_chief(task_type, task_id, cluster_spec):\n",
" dirpath = _get_temp_dir(dirpath, task_id)\n",
" return os.path.join(dirpath, base)"
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "P7fabUIEW7-M"
- },
- "source": [
- "Note: Checkpointing and Saving need to happen on each worker and they need to write to different paths as they would override each others.\n",
- "If you chose to only checkpoint/save on the chief, this can lead to deadlock and is not recommended."
- ]
- },
{
"cell_type": "markdown",
"metadata": {
"id": "nrcdPHtG4ObO"
},
"source": [
- " Here, you'll create one `tf.train.Checkpoint` that tracks the model, which is managed by a `tf.train.CheckpointManager` so that only the latest checkpoint is preserved."
+ "Create one `tf.train.Checkpoint` that tracks the model, which is managed by a `tf.train.CheckpointManager`, so that only the latest checkpoints are preserved:"
]
},
{
@@ -623,11 +611,16 @@
" name='step_in_epoch')\n",
"task_type, task_id = (strategy.cluster_resolver.task_type,\n",
" strategy.cluster_resolver.task_id)\n",
+ "# Normally, you don't need to manually instantiate a `ClusterSpec`, but in this\n",
+ "# illustrative example you did not set `'TF_CONFIG'` before initializing the\n",
+ "# strategy. Check out the next section for \"real-world\" usage.\n",
+ "cluster_spec = tf.train.ClusterSpec(tf_config['cluster'])\n",
"\n",
"checkpoint = tf.train.Checkpoint(\n",
" model=multi_worker_model, epoch=epoch, step_in_epoch=step_in_epoch)\n",
"\n",
- "write_checkpoint_dir = write_filepath(checkpoint_dir, task_type, task_id)\n",
+ "write_checkpoint_dir = write_filepath(checkpoint_dir, task_type, task_id,\n",
+ " cluster_spec)\n",
"checkpoint_manager = tf.train.CheckpointManager(\n",
" checkpoint, directory=write_checkpoint_dir, max_to_keep=1)"
]
@@ -638,7 +631,7 @@
"id": "RO7cbN40XD5v"
},
"source": [
- "Now, when you need to restore, you can find the latest checkpoint saved using the convenient `tf.train.latest_checkpoint` function."
+ "Now, when you need to restore a checkpoint, you can find the latest checkpoint saved using the convenient `tf.train.latest_checkpoint` function (or by calling `tf.train.CheckpointManager.restore_or_initialize`)."
]
},
{
@@ -693,7 +686,7 @@
" # Once the `CheckpointManager` is set up, you're now ready to save, and remove\n",
" # the checkpoints non-chief workers saved.\n",
" checkpoint_manager.save()\n",
- " if not _is_chief(task_type, task_id):\n",
+ " if not _is_chief(task_type, task_id, cluster_spec):\n",
" tf.io.gfile.rmtree(write_checkpoint_dir)\n",
"\n",
" epoch.assign_add(1)\n",
@@ -706,7 +699,7 @@
"id": "0W1Osks466DE"
},
"source": [
- "## Full code setup on workers"
+ "## Complete code at a glance"
]
},
{
@@ -715,10 +708,11 @@
"id": "jfYpmIxO6Jck"
},
"source": [
- "To actually run with `MultiWorkerMirroredStrategy` you'll need to run worker processes and pass a `TF_CONFIG` to them.\n",
+ "To sum up all the procedures discussed so far:\n",
"\n",
- "Like the `mnist.py` file written earlier, here is the `main.py` that \n",
- "contain the same code we walked through step by step previously in this colab, we're just writing it to a file so each of the workers will run it:"
+ "1. You create worker processes.\n",
+ "2. Pass `'TF_CONFIG'`s to the worker processes.\n",
+ "3. Let each work process run the script below that contains the training code."
]
},
{
@@ -746,19 +740,23 @@
"num_steps_per_epoch=70\n",
"\n",
"# Checkpoint saving and restoring\n",
- "def _is_chief(task_type, task_id):\n",
- " return task_type is None or task_type == 'chief' or (task_type == 'worker' and\n",
- " task_id == 0)\n",
+ "def _is_chief(task_type, task_id, cluster_spec):\n",
+ " return (task_type is None\n",
+ " or task_type == 'chief'\n",
+ " or (task_type == 'worker'\n",
+ " and task_id == 0\n",
+ " and 'chief' not in cluster_spec.as_dict()))\n",
+ "\n",
"def _get_temp_dir(dirpath, task_id):\n",
" base_dirpath = 'workertemp_' + str(task_id)\n",
" temp_dir = os.path.join(dirpath, base_dirpath)\n",
" tf.io.gfile.makedirs(temp_dir)\n",
" return temp_dir\n",
"\n",
- "def write_filepath(filepath, task_type, task_id):\n",
+ "def write_filepath(filepath, task_type, task_id, cluster_spec):\n",
" dirpath = os.path.dirname(filepath)\n",
" base = os.path.basename(filepath)\n",
- " if not _is_chief(task_type, task_id):\n",
+ " if not _is_chief(task_type, task_id, cluster_spec):\n",
" dirpath = _get_temp_dir(dirpath, task_id)\n",
" return os.path.join(dirpath, base)\n",
"\n",
@@ -768,11 +766,11 @@
"strategy = tf.distribute.MultiWorkerMirroredStrategy()\n",
"\n",
"with strategy.scope():\n",
- " # Model building/compiling need to be within `strategy.scope()`.\n",
+ " # Model building/compiling need to be within `tf.distribute.Strategy.scope`.\n",
" multi_worker_model = mnist.build_cnn_model()\n",
"\n",
" multi_worker_dataset = strategy.distribute_datasets_from_function(\n",
- " lambda input_context: mnist.dataset_fn(global_batch_size, input_context)) \n",
+ " lambda input_context: mnist.dataset_fn(global_batch_size, input_context))\n",
" optimizer = tf.keras.optimizers.RMSprop(learning_rate=0.001)\n",
" train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(\n",
" name='train_accuracy')\n",
@@ -786,11 +784,13 @@
" x, y = inputs\n",
" with tf.GradientTape() as tape:\n",
" predictions = multi_worker_model(x, training=True)\n",
- " per_batch_loss = tf.keras.losses.SparseCategoricalCrossentropy(\n",
+ " per_example_loss = tf.keras.losses.SparseCategoricalCrossentropy(\n",
" from_logits=True,\n",
" reduction=tf.keras.losses.Reduction.NONE)(y, predictions)\n",
- " loss = tf.nn.compute_average_loss(\n",
- " per_batch_loss, global_batch_size=global_batch_size)\n",
+ " loss = tf.nn.compute_average_loss(per_example_loss)\n",
+ " model_losses = multi_worker_model.losses\n",
+ " if model_losses:\n",
+ " loss += tf.nn.scale_regularization_loss(tf.add_n(model_losses))\n",
"\n",
" grads = tape.gradient(loss, multi_worker_model.trainable_variables)\n",
" optimizer.apply_gradients(\n",
@@ -809,13 +809,15 @@
" initial_value=tf.constant(0, dtype=tf.dtypes.int64),\n",
" name='step_in_epoch')\n",
"\n",
- "task_type, task_id = (strategy.cluster_resolver.task_type,\n",
- " strategy.cluster_resolver.task_id)\n",
+ "task_type, task_id, cluster_spec = (strategy.cluster_resolver.task_type,\n",
+ " strategy.cluster_resolver.task_id,\n",
+ " strategy.cluster_resolver.cluster_spec())\n",
"\n",
"checkpoint = tf.train.Checkpoint(\n",
" model=multi_worker_model, epoch=epoch, step_in_epoch=step_in_epoch)\n",
"\n",
- "write_checkpoint_dir = write_filepath(checkpoint_dir, task_type, task_id)\n",
+ "write_checkpoint_dir = write_filepath(checkpoint_dir, task_type, task_id,\n",
+ " cluster_spec)\n",
"checkpoint_manager = tf.train.CheckpointManager(\n",
" checkpoint, directory=write_checkpoint_dir, max_to_keep=1)\n",
"\n",
@@ -838,11 +840,11 @@
" train_loss = total_loss / num_batches\n",
" print('Epoch: %d, accuracy: %f, train_loss: %f.'\n",
" %(epoch.numpy(), train_accuracy.result(), train_loss))\n",
- " \n",
+ "\n",
" train_accuracy.reset_states()\n",
"\n",
" checkpoint_manager.save()\n",
- " if not _is_chief(task_type, task_id):\n",
+ " if not _is_chief(task_type, task_id, cluster_spec):\n",
" tf.io.gfile.rmtree(write_checkpoint_dir)\n",
"\n",
" epoch.assign_add(1)\n",
@@ -855,7 +857,6 @@
"id": "ItVOvPN1qnZ6"
},
"source": [
- "## Train and Evaluate\n",
"The current directory now contains both Python files:"
]
},
@@ -877,7 +878,7 @@
"id": "qmEEStPS6vR_"
},
"source": [
- "So json-serialize the `TF_CONFIG` and add it to the environment variables:"
+ "So JSON-serialize the `'TF_CONFIG'` and add it to the environment variables:"
]
},
{
@@ -897,7 +898,7 @@
"id": "MsY3dQLK7jdf"
},
"source": [
- "Now, you can launch a worker process that will run the `main.py` and use the `TF_CONFIG`:"
+ "Now, you can launch a worker process that will run the `main.py` and use the `'TF_CONFIG'`:"
]
},
{
@@ -935,9 +936,9 @@
"1. It uses the `%%bash` which is a [notebook \"magic\"](https://ipython.readthedocs.io/en/stable/interactive/magics.html) to run some bash commands.\n",
"2. It uses the `--bg` flag to run the `bash` process in the background, because this worker will not terminate. It waits for all the workers before it starts.\n",
"\n",
- "The backgrounded worker process won't print output to this notebook, so the `&>` redirects its output to a file, so you can see what happened.\n",
+ "The backgrounded worker process won't print the output to this notebook. The `&>` redirects its output to a file, so that you can inspect what happened.\n",
"\n",
- "So, wait a few seconds for the process to start up:"
+ "Wait a few seconds for the process to start up:"
]
},
{
@@ -958,7 +959,7 @@
"id": "ZFPoNxg_9_Mx"
},
"source": [
- "Now look what's been output to the worker's logfile so far:"
+ "Now, check the output to the worker's log file so far:"
]
},
{
@@ -988,7 +989,7 @@
"id": "Pi8vPNNA_l4a"
},
"source": [
- "So update the `tf_config` for the second worker's process to pick up:"
+ "Update the `tf_config` for the second worker's process to pick up:"
]
},
{
@@ -1030,7 +1031,7 @@
"id": "hX4FA2O2AuAn"
},
"source": [
- "Now if you recheck the logs written by the first worker you'll see that it participated in training that model:"
+ "If you recheck the logs written by the first worker, notice that it participated in training that model:"
]
},
{
@@ -1053,7 +1054,7 @@
},
"outputs": [],
"source": [
- "# Delete the `TF_CONFIG`, and kill any background tasks so they don't affect the next section.\n",
+ "# Delete the `'TF_CONFIG'`, and kill any background tasks so they don't affect the next section.\n",
"os.environ.pop('TF_CONFIG', None)\n",
"%killbgscripts"
]
@@ -1064,9 +1065,9 @@
"id": "bhxMXa0AaZkK"
},
"source": [
- "## Multi worker training in depth\n",
+ "## Multi-worker training in depth\n",
"\n",
- "This tutorial has demonstrated a `Custom Training Loop` workflow of the multi-worker setup. A detailed description of other topics is available in the [`model.fit's guide`](https://colab.sandbox.google.com/github/tensorflow/docs/blob/master/site/en/tutorials/distribute/multi_worker_with_keras.ipynb) of the multi-worker setup and applicable to CTLs."
+ "This tutorial has demonstrated a custom training loop workflow of the multi-worker setup. Detailed descriptions of other topics is available in the [Multi-worker training with Keras (`tf.keras.Model.fit`)](multi_worker_with_keras.ipynb) tutorial applicable to custom training loops."
]
},
{
@@ -1075,10 +1076,11 @@
"id": "ega2hdOQEmy_"
},
"source": [
- "## See also\n",
- "1. [Distributed Training in TensorFlow](https://www.tensorflow.org/guide/distributed_training) guide provides an overview of the available distribution strategies.\n",
+ "## Learn more\n",
+ "\n",
+ "1. The [Distributed training in TensorFlow](../../guide/distributed_training.ipynb) guide provides an overview of the available distribution strategies.\n",
"2. [Official models](https://github.com/tensorflow/models/tree/master/official), many of which can be configured to run multiple distribution strategies.\n",
- "3. The [Performance section](../../guide/function.ipynb) in the guide provides information about other strategies and [tools](../../guide/profiler.md) you can use to optimize the performance of your TensorFlow models.\n"
+ "3. The [Performance section](../../guide/function.ipynb) in the `tf.function` guide provides information about other strategies and [tools](../../guide/profiler.md) you can use to optimize the performance of your TensorFlow models.\n"
]
}
],
@@ -1086,7 +1088,7 @@
"colab": {
"collapsed_sections": [],
"name": "multi_worker_with_ctl.ipynb",
- "toc_visible": true
+ "toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
diff --git a/site/en/tutorials/distribute/multi_worker_with_estimator.ipynb b/site/en/tutorials/distribute/multi_worker_with_estimator.ipynb
index b4fffa60fb4..fcee0618854 100644
--- a/site/en/tutorials/distribute/multi_worker_with_estimator.ipynb
+++ b/site/en/tutorials/distribute/multi_worker_with_estimator.ipynb
@@ -186,7 +186,7 @@
"\n",
"There are two components of `TF_CONFIG`: `cluster` and `task`. `cluster` provides information about the entire cluster, namely the workers and parameter servers in the cluster. `task` provides information about the current task. The first component `cluster` is the same for all workers and parameter servers in the cluster, and the second component `task` is different on each worker and parameter server and specifies its own `type` and `index`. In this example, the task `type` is `worker` and the task `index` is `0`.\n",
"\n",
- "For illustration purposes, this tutorial shows how to set a `TF_CONFIG` with 2 workers on `localhost`. In practice, you would create multiple workers on an external IP address and port, and set `TF_CONFIG` on each worker appropriately, i.e. modify the task `index`.\n",
+ "For illustration purposes, this tutorial shows how to set a `TF_CONFIG` with 2 workers on `localhost`. In practice, you would create multiple workers on an external IP address and port, and set `TF_CONFIG` on each worker appropriately, i.e., modify the task `index`.\n",
"\n",
"Warning: *Do not execute the following code in Colab.* TensorFlow's runtime will attempt to create a gRPC server at the specified IP address and port, which will likely fail. See the [keras version](multi_worker_with_keras.ipynb) of this tutorial for an example of how you can test run multiple workers on a single machine.\n",
"\n",
@@ -351,8 +351,7 @@
"Tce3stUlHN0L"
],
"name": "multi_worker_with_estimator.ipynb",
- "provenance": [],
- "toc_visible": true
+ "toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
diff --git a/site/en/tutorials/distribute/multi_worker_with_keras.ipynb b/site/en/tutorials/distribute/multi_worker_with_keras.ipynb
index 1f00bb99e5b..c972e8b7fb6 100644
--- a/site/en/tutorials/distribute/multi_worker_with_keras.ipynb
+++ b/site/en/tutorials/distribute/multi_worker_with_keras.ipynb
@@ -63,13 +63,36 @@
"source": [
"## Overview\n",
"\n",
- "This tutorial demonstrates how to perform multi-worker distributed training with a Keras model and the `Model.fit` API using the `tf.distribute.Strategy` API—specifically the `tf.distribute.MultiWorkerMirroredStrategy` class. With the help of this strategy, a Keras model that was designed to run on a single-worker can seamlessly work on multiple workers with minimal code changes.\n",
- "\n",
- "For those interested in a deeper understanding of `tf.distribute.Strategy` APIs, the [Distributed training in TensorFlow](../../guide/distributed_training.ipynb) guide is available for an overview of the distribution strategies TensorFlow supports.\n",
+ "This tutorial demonstrates how to perform multi-worker distributed training with a Keras model and the `Model.fit` API using the `tf.distribute.MultiWorkerMirroredStrategy` API. With the help of this strategy, a Keras model that was designed to run on a single-worker can seamlessly work on multiple workers with minimal code changes.\n",
"\n",
"To learn how to use the `MultiWorkerMirroredStrategy` with Keras and a custom training loop, refer to [Custom training loop with Keras and MultiWorkerMirroredStrategy](multi_worker_with_ctl.ipynb).\n",
"\n",
- "Note that the purpose of this tutorial is to demonstrate a minimal multi-worker example with two workers."
+ "This tutorial contains a minimal multi-worker example with two workers for demonstration purposes."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "JUdRerXg6yz3"
+ },
+ "source": [
+ "### Choose the right strategy"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "YAiCV_oL63GM"
+ },
+ "source": [
+ "Before you dive in, make sure that `tf.distribute.MultiWorkerMirroredStrategy` is the right choice for your accelerator(s) and training. These are two common ways of distributing training with data parallelism:\n",
+ "\n",
+ "* _Synchronous training_, where the steps of training are synced across the workers and replicas, such as `tf.distribute.MirroredStrategy`, `tf.distribute.TPUStrategy`, and `tf.distribute.MultiWorkerMirroredStrategy`. All workers train over different slices of input data in sync, and aggregating gradients at each step.\n",
+ "* _Asynchronous training_, where the training steps are not strictly synced, such as `tf.distribute.experimental.ParameterServerStrategy`. All workers are independently training over the input data and updating variables asynchronously.\n",
+ "\n",
+ "If you are looking for multi-worker synchronous training without TPU, then `tf.distribute.MultiWorkerMirroredStrategy` is your choice. It creates copies of all variables in the model's layers on each device across all workers. It uses `CollectiveOps`, a TensorFlow op for collective communication, to aggregate gradients and keeps the variables in sync. For those interested, check out the `tf.distribute.experimental.CommunicationOptions` parameter for the collective implementation options.\n",
+ "\n",
+ "For an overview of `tf.distribute.Strategy` APIs, refer to [Distributed training in TensorFlow](../../guide/distributed_training.ipynb)."
]
},
{
@@ -104,14 +127,14 @@
"source": [
"Before importing TensorFlow, make a few changes to the environment:\n",
"\n",
- "1. Disable all GPUs. This prevents errors caused by the workers all trying to use the same GPU. In a real-world application, each worker would be on a different machine."
+ "* In a real-world application, each worker would be on a different machine. For the purposes of this tutorial, all the workers will run on the **this** machine. Therefore, disable all GPUs to prevent errors caused by all workers trying to use the same GPU."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "685pbYEY3jGC"
+ "id": "rpEIVI5upIzM"
},
"outputs": [],
"source": [
@@ -124,7 +147,7 @@
"id": "7X1MS6385BWi"
},
"source": [
- "2. Reset the `TF_CONFIG` environment variable (you'll learn more about this later):"
+ "* Reset the `TF_CONFIG` environment variable (you'll learn more about this later):"
]
},
{
@@ -144,7 +167,7 @@
"id": "Rd4L9Ii77SS8"
},
"source": [
- "3. Make sure that the current directory is on Python's path—this allows the notebook to import the files written by `%%writefile` later:\n"
+ "* Make sure that the current directory is on Python's path—this allows the notebook to import the files written by `%%writefile` later:\n"
]
},
{
@@ -162,10 +185,30 @@
{
"cell_type": "markdown",
"metadata": {
- "id": "pDhHuMjb7bfU"
+ "id": "9hLpDZhAz2q-"
},
"source": [
- "Now import TensorFlow:"
+ "Install `tf-nightly`, as the frequency of checkpoint saving at a particular step with the `save_freq` argument in `tf.keras.callbacks.BackupAndRestore` is introduced from TensorFlow 2.10:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "-XqozLfzz30N"
+ },
+ "outputs": [],
+ "source": [
+ "!pip install tf-nightly"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "524e38dab658"
+ },
+ "source": [
+ "Finally, import TensorFlow:"
]
},
{
@@ -194,7 +237,7 @@
"id": "fLW6D2TzvC-4"
},
"source": [
- "Next, create an `mnist.py` file with a simple model and dataset setup. This Python file will be used by the worker-processes in this tutorial:"
+ "Next, create an `mnist_setup.py` file with a simple model and dataset setup. This Python file will be used by the worker processes in this tutorial:"
]
},
{
@@ -205,7 +248,7 @@
},
"outputs": [],
"source": [
- "%%writefile mnist.py\n",
+ "%%writefile mnist_setup.py\n",
"\n",
"import os\n",
"import tensorflow as tf\n",
@@ -256,11 +299,11 @@
},
"outputs": [],
"source": [
- "import mnist\n",
+ "import mnist_setup\n",
"\n",
"batch_size = 64\n",
- "single_worker_dataset = mnist.mnist_dataset(batch_size)\n",
- "single_worker_model = mnist.build_and_compile_cnn_model()\n",
+ "single_worker_dataset = mnist_setup.mnist_dataset(batch_size)\n",
+ "single_worker_model = mnist_setup.build_and_compile_cnn_model()\n",
"single_worker_model.fit(single_worker_dataset, epochs=3, steps_per_epoch=70)"
]
},
@@ -276,7 +319,7 @@
"\n",
"### A cluster with jobs and tasks\n",
"\n",
- "In TensorFlow, distributed training involves: a `'cluster'`\n",
+ "In TensorFlow, distributed training involves a `'cluster'`\n",
"with several jobs, and each of the jobs may have one or more `'task'`s.\n",
"\n",
"You will need the `TF_CONFIG` configuration environment variable for training on multiple machines, each of which possibly has a different role. `TF_CONFIG` is a JSON string used to specify the cluster configuration for each worker that is part of the cluster.\n",
@@ -284,10 +327,10 @@
"There are two components of a `TF_CONFIG` variable: `'cluster'` and `'task'`.\n",
"\n",
"* A `'cluster'` is the same for all workers and provides information about the training cluster, which is a dict consisting of different types of jobs, such as `'worker'` or `'chief'`.\n",
- " - In multi-worker training with `tf.distribute.MultiWorkerMirroredStrategy`, there is usually one `'worker'` that takes on responsibilities, such as saving a checkpoint and writing a summary file for TensorBoard, in addition to what a regular `'worker'` does. Such `'worker'` is referred to as the chief worker (with a job name `'chief'`).\n",
- " - It is customary for the `'chief'` to have `'index'` `0` be appointed to (in fact, this is how `tf.distribute.Strategy` is implemented).\n",
+ " - In multi-worker training with `tf.distribute.MultiWorkerMirroredStrategy`, there is usually one `'worker'` that takes on more responsibilities, such as saving a checkpoint and writing a summary file for TensorBoard, in addition to what a regular `'worker'` does. Such `'worker'` is referred to as the chief worker (with a job name `'chief'`).\n",
+ " - It is customary for the worker with `'index'` `0` to be the `'chief'`.\n",
"\n",
- "* A `'task'` provides information of the current task and is different for each worker. It specifies the `'type'` and `'index'` of that worker.\n",
+ "* A `'task'` provides information on the current task and is different for each worker. It specifies the `'type'` and `'index'` of that worker.\n",
"\n",
"Below is an example configuration:"
]
@@ -314,7 +357,7 @@
"id": "JjgwJbPKZkJL"
},
"source": [
- "Here is the same `TF_CONFIG` serialized as a JSON string:"
+ "Note that `tf_config` is just a local variable in Python. To use it for training configuration, serialize it as a JSON and place it in a `TF_CONFIG` environment variable."
]
},
{
@@ -328,22 +371,13 @@
"json.dumps(tf_config)"
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "f83FVYqDX3aX"
- },
- "source": [
- "Note that`tf_config` is just a local variable in Python. To be able to use it for a training configuration, this dict needs to be serialized as a JSON and placed in a `TF_CONFIG` environment variable."
- ]
- },
{
"cell_type": "markdown",
"metadata": {
"id": "8YFpxrcsZ2xG"
},
"source": [
- "In the example configuration above, you set the task `'type'` to `'worker'` and the task `'index'` to `0`. Therefore, this machine is the _first_ worker. It will be appointed as the `'chief'` worker and do more work than the others.\n",
+ "In the example configuration above, you set the task `'type'` to `'worker'` and the task `'index'` to `0`. Therefore, this machine is the _first_ worker. It will be appointed as the `'chief'` worker.\n",
"\n",
"Note: Other machines will need to have the `TF_CONFIG` environment variable set as well, and it should have the same `'cluster'` dict, but different task `'type'`s or task `'index'`es, depending on the roles of those machines."
]
@@ -354,12 +388,8 @@
"id": "aogb74kHxynz"
},
"source": [
- "For illustration purposes, this tutorial shows how you may set up a `TF_CONFIG` variable with two workers on a `localhost`.\n",
- "\n",
- "In practice, you would create multiple workers on external IP addresses/ports and set a `TF_CONFIG` variable on each worker accordingly.\n",
- "\n",
- "In this tutorial, you will use two workers:\n",
- "- The first (`'chief'`) worker's `TF_CONFIG` is shown above.\n",
+ "In practice, you would create multiple workers on external IP addresses/ports and set a `TF_CONFIG` variable on each worker accordingly. For illustration purposes, this tutorial shows how you may set up a `TF_CONFIG` variable with two workers on a `localhost`:\n",
+ "- The first (`'chief'`) worker's `TF_CONFIG` as shown above.\n",
"- For the second worker, you will set `tf_config['task']['index']=1`"
]
},
@@ -378,9 +408,7 @@
"id": "FcjAbuGY1ACJ"
},
"source": [
- "Subprocesses inherit environment variables from their parent.\n",
- "\n",
- "For example, you can set an environment variable in this Jupyter Notebook process as follows:"
+ "Subprocesses inherit environment variables from their parent. So if you set an environment variable in this Jupyter Notebook process:"
]
},
{
@@ -400,7 +428,7 @@
"id": "gQkIX-cg18md"
},
"source": [
- "Then, you can access the environment variable from a subprocesses:"
+ "... then you can access the environment variable from the subprocesses:"
]
},
{
@@ -421,7 +449,16 @@
"id": "af6BCA-Y2fpz"
},
"source": [
- "In the next section, you'll use a similar method to pass the `TF_CONFIG` to the worker subprocesses. In a real-world scenario, you wouldn't launch your jobs this way, but it's sufficient in this example."
+ "In the next section, you'll use this method to pass the `TF_CONFIG` to the worker subprocesses. You would never really launch your jobs this way in a real-world scenario—this tutorial is just showing how to do it with a minimal multi-worker example."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "dnDJmaRA9qnf"
+ },
+ "source": [
+ "## Train the model"
]
},
{
@@ -430,16 +467,7 @@
"id": "UhNtHfuxCGVy"
},
"source": [
- "## Choose the right strategy\n",
- "\n",
- "In TensorFlow, there are two main forms of distributed training:\n",
- "\n",
- "* _Synchronous training_, where the steps of training are synced across the workers and replicas, and\n",
- "* _Asynchronous training_, where the training steps are not strictly synced (for example, [parameter server training](parameter_server_training.ipynb)).\n",
- "\n",
- "This tutorial demonstrates how to perform synchronous multi-worker training using an instance of `tf.distribute.MultiWorkerMirroredStrategy`.\n",
- "\n",
- "`MultiWorkerMirroredStrategy` creates copies of all variables in the model's layers on each device across all workers. It uses `CollectiveOps`, a TensorFlow op for collective communication, to aggregate gradients and keep the variables in sync. The [`tf.distribute.Strategy` guide](../../guide/distributed_training.ipynb) has more details about this strategy."
+ "To train the model, firstly create an instance of the `tf.distribute.MultiWorkerMirroredStrategy`:"
]
},
{
@@ -459,16 +487,7 @@
"id": "N0iv7SyyAohc"
},
"source": [
- "Note: `TF_CONFIG` is parsed and TensorFlow's GRPC servers are started at the time `MultiWorkerMirroredStrategy()` is called, so the `TF_CONFIG` environment variable must be set before a `tf.distribute.Strategy` instance is created. Since `TF_CONFIG` is not set yet, the above strategy is effectively single-worker training."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "FMy2VM4Akzpr"
- },
- "source": [
- "`MultiWorkerMirroredStrategy` provides multiple implementations via the [`CommunicationOptions`](https://www.tensorflow.org/api_docs/python/tf/distribute/experimental/CommunicationOptions) parameter: 1) `RING` implements ring-based collectives using gRPC as the cross-host communication layer; 2) `NCCL` uses the [NVIDIA Collective Communication Library](https://developer.nvidia.com/nccl) to implement collectives; and 3) `AUTO` defers the choice to the runtime. The best choice of collective implementation depends upon the number and kind of GPUs, and the network interconnect in the cluster."
+ "Note: `TF_CONFIG` is parsed and TensorFlow's GRPC servers are started at the time `MultiWorkerMirroredStrategy` is called, so the `TF_CONFIG` environment variable must be set before a `tf.distribute.Strategy` instance is created. Since `TF_CONFIG` is not set yet, the above strategy is effectively single-worker training."
]
},
{
@@ -477,8 +496,6 @@
"id": "H47DDcOgfzm7"
},
"source": [
- "## Train the model\n",
- "\n",
"With the integration of `tf.distribute.Strategy` API into `tf.keras`, the only change you will make to distribute the training to multiple-workers is enclosing the model building and `model.compile()` call inside `strategy.scope()`. The distribution strategy's scope dictates how and where the variables are created, and in the case of `MultiWorkerMirroredStrategy`, the variables created are `MirroredVariable`s, and they are replicated on each of the workers.\n"
]
},
@@ -492,7 +509,7 @@
"source": [
"with strategy.scope():\n",
" # Model building/compiling need to be within `strategy.scope()`.\n",
- " multi_worker_model = mnist.build_and_compile_cnn_model()"
+ " multi_worker_model = mnist_setup.build_and_compile_cnn_model()"
]
},
{
@@ -512,7 +529,7 @@
"source": [
"To actually run with `MultiWorkerMirroredStrategy` you'll need to run worker processes and pass a `TF_CONFIG` to them.\n",
"\n",
- "Like the `mnist.py` file written earlier, here is the `main.py` that each of the workers will run:"
+ "Like the `mnist_setup.py` file written earlier, here is the `main.py` that each of the workers will run:"
]
},
{
@@ -529,7 +546,7 @@
"import json\n",
"\n",
"import tensorflow as tf\n",
- "import mnist\n",
+ "import mnist_setup\n",
"\n",
"per_worker_batch_size = 64\n",
"tf_config = json.loads(os.environ['TF_CONFIG'])\n",
@@ -538,11 +555,11 @@
"strategy = tf.distribute.MultiWorkerMirroredStrategy()\n",
"\n",
"global_batch_size = per_worker_batch_size * num_workers\n",
- "multi_worker_dataset = mnist.mnist_dataset(global_batch_size)\n",
+ "multi_worker_dataset = mnist_setup.mnist_dataset(global_batch_size)\n",
"\n",
"with strategy.scope():\n",
" # Model building/compiling need to be within `strategy.scope()`.\n",
- " multi_worker_model = mnist.build_and_compile_cnn_model()\n",
+ " multi_worker_model = mnist_setup.build_and_compile_cnn_model()\n",
"\n",
"\n",
"multi_worker_model.fit(multi_worker_dataset, epochs=3, steps_per_epoch=70)"
@@ -584,7 +601,7 @@
"id": "qmEEStPS6vR_"
},
"source": [
- "So json-serialize the `TF_CONFIG` and add it to the environment variables:"
+ "Serialize the `TF_CONFIG` to JSON and add it to the environment variables:"
]
},
{
@@ -686,7 +703,7 @@
"id": "RqZhVF7L_KOy"
},
"source": [
- "The last line of the log file should say: `Started server with target: grpc://localhost:12345`. The first worker is now ready, and is waiting for all the other worker(s) to be ready to proceed."
+ "The last line of the log file should say: `Started server with target: grpc://localhost:12345`. The first worker is now ready and is waiting for all the other worker(s) to be ready to proceed."
]
},
{
@@ -758,11 +775,7 @@
"id": "zL79ak5PMzEg"
},
"source": [
- "Unsurprisingly, this ran _slower_ than the test run at the beginning of this tutorial.\n",
- "\n",
- "Running multiple workers on a single machine only adds overhead.\n",
- "\n",
- "The goal here was not to improve the training time, but only to give an example of multi-worker training."
+ "Note: This may run slower than the test run at the beginning of this tutorial because running multiple workers on a single machine only adds overhead. The goal here is not to improve the training time but to give an example of multi-worker training.\n"
]
},
{
@@ -784,11 +797,16 @@
"id": "9j2FJVHoUIrE"
},
"source": [
- "## Multi-worker training in depth\n",
- "\n",
- "So far, you have learned how to perform a basic multi-worker setup.\n",
- "\n",
- "During the rest of the tutorial, you will learn about other factors, which may be useful or important for real use cases, in detail."
+ "## Multi-worker training in depth\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "C1hBks_dAZmT"
+ },
+ "source": [
+ "So far, you have learned how to perform a basic multi-worker setup. The rest of the tutorial goes over other factors, which may be useful or important for real use cases, in detail."
]
},
{
@@ -820,25 +838,41 @@
"options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.OFF\n",
"\n",
"global_batch_size = 64\n",
- "multi_worker_dataset = mnist.mnist_dataset(batch_size=64)\n",
+ "multi_worker_dataset = mnist_setup.mnist_dataset(batch_size=64)\n",
"dataset_no_auto_shard = multi_worker_dataset.with_options(options)"
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "z85hElxsBQsT"
+ },
+ "source": [
+ "### Evaluation"
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {
"id": "gmqvlh5LhAoU"
},
"source": [
- "### Evaluation\n",
- "\n",
- "If you pass the `validation_data` into `Model.fit`, it will alternate between training and evaluation for each epoch. The evaluation taking the `validation_data` is distributed across the same set of workers and the evaluation results are aggregated and available for all workers.\n",
+ "If you pass the `validation_data` into `Model.fit` as well, it will alternate between training and evaluation for each epoch. The evaluation work is distributed across the same set of workers, and its results are aggregated and available to all workers.\n",
"\n",
"Similar to training, the validation dataset is automatically sharded at the file level. You need to set a global batch size in the validation dataset and set the `validation_steps`.\n",
"\n",
- "A repeated dataset is also recommended for evaluation.\n",
+ "A repeated dataset (by calling `tf.data.Dataset.repeat`) is recommended for evaluation.\n",
"\n",
- "Alternatively, you can also create another task that periodically reads checkpoints and runs the evaluation. This is what Estimator does. But this is not a recommended way to perform evaluation and thus its details are omitted."
+ "Alternatively, you can also create another task that periodically reads checkpoints and runs the evaluation. This is what an Estimator does. But this is not a recommended way to perform evaluation and thus its details are omitted."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "FNkoxUPJBNTb"
+ },
+ "source": [
+ "### Performance"
]
},
{
@@ -847,25 +881,21 @@
"id": "XVk4ftYx6JAO"
},
"source": [
- "### Performance\n",
- "\n",
- "You now have a Keras model that is all set up to run in multiple workers with the `MultiWorkerMirroredStrategy`.\n",
- "\n",
- "To tweak performance of multi-worker training, you can try the following:\n",
+ "To tweak the performance of multi-worker training, you can try the following:\n",
"\n",
"- `tf.distribute.MultiWorkerMirroredStrategy` provides multiple [collective communication implementations](https://www.tensorflow.org/api_docs/python/tf/distribute/experimental/CommunicationImplementation):\n",
" - `RING` implements ring-based collectives using gRPC as the cross-host communication layer.\n",
" - `NCCL` uses the [NVIDIA Collective Communication Library](https://developer.nvidia.com/nccl) to implement collectives.\n",
" - `AUTO` defers the choice to the runtime.\n",
" \n",
- " The best choice of collective implementation depends upon the number of GPUs, the type of GPUs, and the network interconnect in the cluster. To override the automatic choice, specify the `communication_options` parameter of `MultiWorkerMirroredStrategy`'s constructor. For example:\n",
+ " The best choice of collective implementation depends upon the number of GPUs, the type of GPUs, and the network interconnects in the cluster. To override the automatic choice, specify the `communication_options` parameter of `MultiWorkerMirroredStrategy`'s constructor. For example:\n",
" \n",
" ```python\n",
- " communication_options=tf.distribute.experimental.CommunicationOptions(implementation=tf.distribute.experimental.CollectiveCommunication.NCCL)\n",
+ " communication_options=tf.distribute.experimental.CommunicationOptions(implementation=tf.distribute.experimental.CommunicationImplementation.NCCL)\n",
" ```\n",
"\n",
"- Cast the variables to `tf.float` if possible:\n",
- " - The official ResNet model includes [an example](https://github.com/tensorflow/models/blob/8367cf6dabe11adf7628541706b660821f397dce/official/resnet/resnet_model.py#L466) of how this can be done."
+ " - The official ResNet model includes [an example](https://github.com/tensorflow/models/blob/8367cf6dabe11adf7628541706b660821f397dce/official/resnet/resnet_model.py#L466) of how to do this."
]
},
{
@@ -882,7 +912,7 @@
"\n",
"When a worker becomes unavailable, other workers will fail (possibly after a timeout). In such cases, the unavailable worker needs to be restarted, as well as other workers that have failed.\n",
"\n",
- "Note: Previously, the `ModelCheckpoint` callback provided a mechanism to restore the training state upon a restart from a job failure for multi-worker training. The TensorFlow team are introducing a new [`BackupAndRestore`](#scrollTo=kmH8uCUhfn4w) callback, to also add the support to single worker training for a consistent experience, and removed fault tolerance functionality from existing `ModelCheckpoint` callback. From now on, applications that rely on this behavior should migrate to the new callback."
+ "Note: Previously, the `ModelCheckpoint` callback provided a mechanism to restore the training state upon a restart from a job failure for multi-worker training. The TensorFlow team is introducing a new [`BackupAndRestore`](#scrollTo=kmH8uCUhfn4w) callback, which also adds the support to single-worker training for a consistent experience, and removed the fault tolerance functionality from existing `ModelCheckpoint` callback. From now on, applications that rely on this behavior should migrate to the new `BackupAndRestore` callback."
]
},
{
@@ -891,13 +921,13 @@
"id": "KvHPjGlyyFt6"
},
"source": [
- "#### ModelCheckpoint callback\n",
+ "#### The `ModelCheckpoint` callback\n",
"\n",
"`ModelCheckpoint` callback no longer provides fault tolerance functionality, please use [`BackupAndRestore`](#scrollTo=kmH8uCUhfn4w) callback instead.\n",
"\n",
"The `ModelCheckpoint` callback can still be used to save checkpoints. But with this, if training was interrupted or successfully finished, in order to continue training from the checkpoint, the user is responsible to load the model manually.\n",
"\n",
- "Optionally the user can choose to save and restore model/weights outside `ModelCheckpoint` callback."
+ "Optionally, users can choose to save and restore model/weights outside `ModelCheckpoint` callback."
]
},
{
@@ -919,14 +949,14 @@
"\n",
"You should have some cleanup logic that deletes the temporary directories created by the workers once your training has completed.\n",
"\n",
- "The reason for saving on the chief and workers at the same time is because you might be aggregating variables during checkpointing which requires both the chief and workers to participate in the allreduce communication protocol. On the other hand, letting chief and workers save to the same model directory will result in errors due to contention.\n",
+ "The reason for saving on the chief and workers at the same time is because you might be aggregating variables during checkpointing, which requires both the chief and workers to participate in the allreduce communication protocol. On the other hand, letting chief and workers save to the same model directory will result in errors due to contention.\n",
"\n",
- "Using the `MultiWorkerMirroredStrategy`, the program is run on every worker, and in order to know whether the current worker is chief, it takes advantage of the cluster resolver object that has attributes `task_type` and `task_id`:\n",
- "- `task_type` tells you what the current job is (e.g. `'worker'`).\n",
+ "Using the `MultiWorkerMirroredStrategy`, the program is run on every worker, and in order to know whether the current worker is the chief, it takes advantage of the cluster resolver object that has attributes `task_type` and `task_id`:\n",
+ "- `task_type` tells you what the current job is (for example, `'worker'`).\n",
"- `task_id` tells you the identifier of the worker.\n",
"- The worker with `task_id == 0` is designated as the chief worker.\n",
"\n",
- "In the code snippet below, the `write_filepath` function provides the file path to write, which depends on the the worker's `task_id`:\n",
+ "In the code snippet below, the `write_filepath` function provides the file path to write, which depends on the worker's `task_id`:\n",
"\n",
"- For the chief worker (with `task_id == 0`), it writes to the original file path. \n",
"- For other workers, it creates a temporary directory—`temp_dir`—with the `task_id` in the directory path to write in:"
@@ -943,14 +973,14 @@
"model_path = '/tmp/keras-model'\n",
"\n",
"def _is_chief(task_type, task_id):\n",
- " # Note: there are two possible `TF_CONFIG` configuration.\n",
+ " # Note: there are two possible `TF_CONFIG` configurations.\n",
" # 1) In addition to `worker` tasks, a `chief` task type is use;\n",
" # in this case, this function should be modified to\n",
" # `return task_type == 'chief'`.\n",
" # 2) Only `worker` task type is used; in this case, worker 0 is\n",
" # regarded as the chief. The implementation demonstrated here\n",
" # is for this case.\n",
- " # For the purpose of this Colab section, the `task_type is None` case\n",
+ " # For the purpose of this Colab section, the `task_type` is `None` case\n",
" # is added because it is effectively run with only a single worker.\n",
" return (task_type == 'worker' and task_id == 0) or task_type is None\n",
"\n",
@@ -981,6 +1011,15 @@
"With that, you're now ready to save:"
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "XnToxeIcg_6O"
+ },
+ "source": [
+ "Deprecated: For Keras objects, it's recommended to use the new high-level `.keras` format and `tf.keras.Model.export`, as demonstrated in the guide [here](https://www.tensorflow.org/guide/keras/save_and_serialize). The low-level SavedModel format continues to be supported for existing code."
+ ]
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -998,7 +1037,7 @@
"id": "8LXUVVl9_v5x"
},
"source": [
- "As described above, later on the model should only be loaded from the path chief saved to, so let's remove the temporary ones the non-chief workers saved:"
+ "As described above, later on the model should only be loaded from the file path the chief worker saved to. Therefore, remove the temporary ones the non-chief workers have saved:"
]
},
{
@@ -1019,7 +1058,7 @@
"id": "Nr-2PKlHAPBT"
},
"source": [
- "Now, when it's time to load, let's use convenient `tf.keras.models.load_model` API, and continue with further work.\n",
+ "Now, when it's time to load, use the convenient `tf.keras.models.load_model` API, and continue with further work.\n",
"\n",
"Here, assume only using single worker to load and continue training, in which case you do not call `tf.keras.models.load_model` within another `strategy.scope()` (note that `strategy = tf.distribute.MultiWorkerMirroredStrategy()`, as defined earlier):"
]
@@ -1117,20 +1156,23 @@
"id": "kmH8uCUhfn4w"
},
"source": [
- "#### BackupAndRestore callback\n",
+ "#### The `BackupAndRestore` callback\n",
+ "\n",
+ "The `tf.keras.callbacks.BackupAndRestore` callback provides the fault tolerance functionality by backing up the model and current training state in a temporary checkpoint file under `backup_dir` argument to `BackupAndRestore`. \n",
"\n",
- "The `tf.keras.callbacks.experimental.BackupAndRestore` callback provides the fault tolerance functionality by backing up the model and current epoch number in a temporary checkpoint file under `backup_dir` argument to `BackupAndRestore`. This is done at the end of each epoch.\n",
+ "Note: In Tensorflow 2.9, the current model and the training state is backed up at epoch boundaries. In the `tf-nightly` version and from TensorFlow 2.10, the `BackupAndRestore` callback can back up the model and the training state at epoch or step boundaries. `BackupAndRestore` accepts an optional `save_freq` argument. `save_freq` accepts either `'epoch'` or an `int` value. If `save_freq` is set to `'epoch'` the model is backed up after every epoch. If `save_freq` is set to an integer value greater than `0`, the model is backed up after every `save_freq` number of batches.\n",
"\n",
- "Once jobs get interrupted and restart, the callback restores the last checkpoint, and training continues from the beginning of the interrupted epoch. Any partial training already done in the unfinished epoch before interruption will be thrown away, so that it doesn't affect the final model state.\n",
+ "Once the jobs get interrupted and restarted, the `BackupAndRestore` callback restores the last checkpoint, and you can continue training from the beginning of the epoch and step at which the training state was last saved.\n",
"\n",
- "To use it, provide an instance of `tf.keras.callbacks.experimental.BackupAndRestore` at the `Model.fit` call.\n",
+ "To use it, provide an instance of `tf.keras.callbacks.BackupAndRestore` at the `Model.fit` call.\n",
"\n",
- "With `MultiWorkerMirroredStrategy`, if a worker gets interrupted, the whole cluster pauses until the interrupted worker is restarted. Other workers will also restart, and the interrupted worker rejoins the cluster. Then, every worker reads the checkpoint file that was previously saved and picks up its former state, thereby allowing the cluster to get back in sync. Then, the training continues.\n",
+ "With `MultiWorkerMirroredStrategy`, if a worker gets interrupted, the whole cluster will pause until the interrupted worker is restarted. Other workers will also restart, and the interrupted worker will rejoin the cluster. Then, every worker will read the checkpoint file that was previously saved and pick up its former state, thereby allowing the cluster to get back in sync. Then, the training will continue. The distributed dataset iterator state will be re-initialized and not restored.\n",
"\n",
"The `BackupAndRestore` callback uses the `CheckpointManager` to save and restore the training state, which generates a file called checkpoint that tracks existing checkpoints together with the latest one. For this reason, `backup_dir` should not be re-used to store other checkpoints in order to avoid name collision.\n",
"\n",
- "Currently, the `BackupAndRestore` callback supports single worker with no strategy, MirroredStrategy, and multi-worker with MultiWorkerMirroredStrategy.\n",
- "Below are two examples for both multi-worker training and single worker training."
+ "Currently, the `BackupAndRestore` callback supports single-worker training with no strategy—`MirroredStrategy`—and multi-worker training with `MultiWorkerMirroredStrategy`.\n",
+ "\n",
+ "Below are two examples for both multi-worker training and single-worker training:"
]
},
{
@@ -1141,12 +1183,73 @@
},
"outputs": [],
"source": [
- "# Multi-worker training with MultiWorkerMirroredStrategy\n",
- "# and the BackupAndRestore callback.\n",
+ "# Multi-worker training with `MultiWorkerMirroredStrategy`\n",
+ "# and the `BackupAndRestore` callback. The training state \n",
+ "# is backed up at epoch boundaries by default.\n",
+ "\n",
+ "callbacks = [tf.keras.callbacks.BackupAndRestore(backup_dir='/tmp/backup')]\n",
+ "with strategy.scope():\n",
+ " multi_worker_model = mnist_setup.build_and_compile_cnn_model()\n",
+ "multi_worker_model.fit(multi_worker_dataset,\n",
+ " epochs=3,\n",
+ " steps_per_epoch=70,\n",
+ " callbacks=callbacks)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "f8e86TAp0Rsl"
+ },
+ "source": [
+ "If the `save_freq` argument in the `BackupAndRestore` callback is set to `'epoch'`, the model is backed up after every epoch."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "rZjQGPsF0aEI"
+ },
+ "outputs": [],
+ "source": [
+ "# The training state is backed up at epoch boundaries because `save_freq` is\n",
+ "# set to `epoch`.\n",
+ "\n",
+ "callbacks = [tf.keras.callbacks.BackupAndRestore(backup_dir='/tmp/backup')]\n",
+ "with strategy.scope():\n",
+ " multi_worker_model = mnist_setup.build_and_compile_cnn_model()\n",
+ "multi_worker_model.fit(multi_worker_dataset,\n",
+ " epochs=3,\n",
+ " steps_per_epoch=70,\n",
+ " callbacks=callbacks)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "p-r44kCM0jc6"
+ },
+ "source": [
+ "Note: The next code block uses features that are only available in `tf-nightly` until Tensorflow 2.10 is released.\n",
+ "\n",
+ "If the `save_freq` argument in the `BackupAndRestore` callback is set to an integer value greater than `0`, the model is backed up after every `save_freq` number of batches."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "bSJUyLSF0moC"
+ },
+ "outputs": [],
+ "source": [
+ "# The training state is backed up at every 30 steps because `save_freq` is set\n",
+ "# to an integer value of `30`.\n",
"\n",
- "callbacks = [tf.keras.callbacks.experimental.BackupAndRestore(backup_dir='/tmp/backup')]\n",
+ "callbacks = [tf.keras.callbacks.BackupAndRestore(backup_dir='/tmp/backup', save_freq=30)]\n",
"with strategy.scope():\n",
- " multi_worker_model = mnist.build_and_compile_cnn_model()\n",
+ " multi_worker_model = mnist_setup.build_and_compile_cnn_model()\n",
"multi_worker_model.fit(multi_worker_dataset,\n",
" epochs=3,\n",
" steps_per_epoch=70,\n",
@@ -1161,7 +1264,7 @@
"source": [
"If you inspect the directory of `backup_dir` you specified in `BackupAndRestore`, you may notice some temporarily generated checkpoint files. Those files are needed for recovering the previously lost instances, and they will be removed by the library at the end of `Model.fit` upon successful exiting of your training.\n",
"\n",
- "Note: Currently the `BackupAndRestore` callback only supports eager mode. In graph mode, consider using [Save/Restore Model](#model_saving_and_loading) mentioned above, and by providing `initial_epoch` in `Model.fit`."
+ "Note: Currently the `BackupAndRestore` callback only supports eager mode. In graph mode, consider using `Model.save`/`tf.saved_model.save` and `tf.keras.models.load_model` for saving and restoring models, respectively, as described in the _Model saving and loading_ section above, and by providing `initial_epoch` in `Model.fit` during training."
]
},
{
@@ -1172,7 +1275,7 @@
"source": [
"## Additional resources\n",
"\n",
- "1. The [Distributed training in TensorFlow](https://www.tensorflow.org/guide/distributed_training) guide provides an overview of the available distribution strategies.\n",
+ "1. The [Distributed training in TensorFlow](../../guide/distributed_training.ipynb) guide provides an overview of the available distribution strategies.\n",
"1. The [Custom training loop with Keras and MultiWorkerMirroredStrategy](multi_worker_with_ctl.ipynb) tutorial shows how to use the `MultiWorkerMirroredStrategy` with Keras and a custom training loop.\n",
"1. Check out the [official models](https://github.com/tensorflow/models/tree/master/official), many of which can be configured to run multiple distribution strategies.\n",
"1. The [Better performance with tf.function](../../guide/function.ipynb) guide provides information about other strategies and tools, such as the [TensorFlow Profiler](../../guide/profiler.md) you can use to optimize the performance of your TensorFlow models."
@@ -1181,9 +1284,8 @@
],
"metadata": {
"colab": {
- "collapsed_sections": [],
"name": "multi_worker_with_keras.ipynb",
- "toc_visible": true
+ "toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
diff --git a/site/en/tutorials/distribute/parameter_server_training.ipynb b/site/en/tutorials/distribute/parameter_server_training.ipynb
index fae0a2d3576..2e6bb0cfce2 100644
--- a/site/en/tutorials/distribute/parameter_server_training.ipynb
+++ b/site/en/tutorials/distribute/parameter_server_training.ipynb
@@ -74,7 +74,7 @@
"\n",
"A parameter server training cluster consists of _workers_ and _parameter servers_. Variables are created on parameter servers and they are read and updated by workers in each step. By default, workers read and update these variables independently without synchronizing with each other. This is why sometimes parameter server-style training is called _asynchronous training_.\n",
"\n",
- "In TensorFlow 2, parameter server training is powered by the `tf.distribute.experimental.ParameterServerStrategy` class, which distributes the training steps to a cluster that scales up to thousands of workers (accompanied by parameter servers)."
+ "In TensorFlow 2, parameter server training is powered by the `tf.distribute.ParameterServerStrategy` class, which distributes the training steps to a cluster that scales up to thousands of workers (accompanied by parameter servers)."
]
},
{
@@ -87,9 +87,9 @@
"\n",
"There are two main supported training methods:\n",
"\n",
- "- The Keras `Model.fit` API, which is recommended when you prefer a high-level abstraction and handling of training.\n",
- "- A custom training loop (you can refer to [Custom training](https://www.tensorflow.org/tutorials/customization/custom_training_walkthrough#train_the_model), [Writing a training loop from scratch\n",
- "](https://www.tensorflow.org/guide/keras/writing_a_training_loop_from_scratch) and [Custom training loop with Keras and MultiWorkerMirroredStrategy](https://www.tensorflow.org/tutorials/distribute/multi_worker_with_ctl) for more details.) Custom loop training is recommended when you prefer to define the details of their training loop."
+ "- The Keras `Model.fit` API: if you prefer a high-level abstraction and handling of training. This is generally recommended if you are training a `tf.keras.Model`.\n",
+ "- A custom training loop: if you prefer to define the details of your training loop (you can refer to guides on [Custom training](../customization/custom_training_walkthrough.ipynb), [Writing a training loop from scratch\n",
+ "](https://www.tensorflow.org/guide/keras/writing_a_training_loop_from_scratch) and [Custom training loop with Keras and MultiWorkerMirroredStrategy](multi_worker_with_ctl.ipynb) for more details)."
]
},
{
@@ -100,15 +100,15 @@
"source": [
"### A cluster with jobs and tasks\n",
"\n",
- "Regardless of the API of choice (`Model.fit` or a custom training loop), distributed training in TensorFlow 2 involves: a `'cluster'` with several `'jobs'`, and each of the jobs may have one or more `'tasks'`.\n",
+ "Regardless of the API of choice (`Model.fit` or a custom training loop), distributed training in TensorFlow 2 involves a `'cluster'` with several `'jobs'`, and each of the jobs may have one or more `'tasks'`.\n",
"\n",
"When using parameter server training, it is recommended to have:\n",
"\n",
"- One _coordinator_ job (which has the job name `chief`)\n",
- "- Multiple _worker_ jobs (job name `worker`); and\n",
+ "- Multiple _worker_ jobs (job name `worker`)\n",
"- Multiple _parameter server_ jobs (job name `ps`)\n",
"\n",
- "While the _coordinator_ creates resources, dispatches training tasks, writes checkpoints, and deals with task failures, _workers_ and _parameter servers_ run `tf.distribute.Server` that listen for requests from the coordinator."
+ "The _coordinator_ creates resources, dispatches training tasks, writes checkpoints, and deals with task failures. The _workers_ and _parameter servers_ run `tf.distribute.Server` instances that listen for requests from the coordinator."
]
},
{
@@ -117,10 +117,9 @@
"id": "oLV1FbpLtqtB"
},
"source": [
- "### Parameter server training with `Model.fit` API\n",
+ "### Parameter server training with the `Model.fit` API\n",
"\n",
- "Parameter server training with the `Model.fit` API requires the coordinator to use a `tf.distribute.experimental.ParameterServerStrategy` object, and a `tf.keras.utils.experimental.DatasetCreator` as the input. Similar to `Model.fit` usage with no strategy, or with other strategies, the workflow involves creating and compiling the model, preparing the callbacks, followed by\n",
- "a `Model.fit` call."
+ "Parameter server training with the `Model.fit` API requires the coordinator to use a `tf.distribute.ParameterServerStrategy` object. Similar to `Model.fit` usage with no strategy, or with other strategies, the workflow involves creating and compiling the model, preparing the callbacks, and calling `Model.fit`."
]
},
{
@@ -131,12 +130,11 @@
"source": [
"### Parameter server training with a custom training loop\n",
"\n",
- "With custom training loops, the `tf.distribute.experimental.coordinator.ClusterCoordinator` class is the key component used for the coordinator.\n",
+ "With custom training loops, the `tf.distribute.coordinator.ClusterCoordinator` class is the key component used for the coordinator.\n",
"\n",
- "- The `ClusterCoordinator` class needs to work in conjunction with a `tf.distribute.Strategy` object.\n",
- "- This `tf.distribute.Strategy` object is needed to provide the information of the cluster and is used to define a training step, as demonstrated in [Custom training with tf.distribute.Strategy](https://www.tensorflow.org/tutorials/distribute/custom_training#training_loop).\n",
+ "- The `ClusterCoordinator` class needs to work in conjunction with a `tf.distribute.ParameterServerStrategy` object.\n",
+ "- This `tf.distribute.Strategy` object is needed to provide the information of the cluster and is used to define a training step, as demonstrated in [Custom training with tf.distribute.Strategy](custom_training.ipynb).\n",
"- The `ClusterCoordinator` object then dispatches the execution of these training steps to remote workers.\n",
- "- For parameter server training, the `ClusterCoordinator` needs to work with a `tf.distribute.experimental.ParameterServerStrategy`.\n",
"\n",
"The most important API provided by the `ClusterCoordinator` object is `schedule`:\n",
"\n",
@@ -144,7 +142,7 @@
"- The queued functions will be dispatched to remote workers in background threads and their `RemoteValue`s will be filled asynchronously.\n",
"- Since `schedule` doesn’t require worker assignment, the `tf.function` passed in can be executed on any available worker.\n",
"- If the worker it is executed on becomes unavailable before its completion, the function will be retried on another available worker.\n",
- "- Because of this fact and the fact that function execution is not atomic, a function may be executed more than once.\n",
+ "- Because of this fact and the fact that function execution is not atomic, a single function call may be executed more than once.\n",
"\n",
"In addition to dispatching remote functions, the `ClusterCoordinator` also helps\n",
"to create datasets on all the workers and rebuild these datasets when a worker recovers from failure."
@@ -169,9 +167,7 @@
},
"outputs": [],
"source": [
- "!pip install portpicker\n",
- "!pip uninstall tensorflow keras -y\n",
- "!pip install tf-nightly"
+ "!pip install portpicker"
]
},
{
@@ -187,8 +183,7 @@
"import os\n",
"import random\n",
"import portpicker\n",
- "import tensorflow as tf\n",
- "from tensorflow.keras.layers.experimental import preprocessing"
+ "import tensorflow as tf"
]
},
{
@@ -199,9 +194,9 @@
"source": [
"## Cluster setup\n",
"\n",
- "As mentioned above, a parameter server training cluster requires a coordinator task that runs your training program, one or several workers and parameter server tasks that run TensorFlow servers—`tf.distribute.Server`—and possibly an additional evaluation task that runs side-car evaluation (see the side-car evaluation section below). The requirements to set them up are:\n",
+ "As mentioned above, a parameter server training cluster requires a coordinator task that runs your training program, one or several workers and parameter server tasks that run TensorFlow servers—`tf.distribute.Server`—and possibly an additional evaluation task that runs sidecar evaluation (refer to the [sidecar evaluation section](#sidecar_evaluation) below). The requirements to set them up are:\n",
"\n",
- "- The coordinator task needs to know the addresses and ports of all other TensorFlow servers except the evaluator.\n",
+ "- The coordinator task needs to know the addresses and ports of all other TensorFlow servers, except the evaluator.\n",
"- The workers and parameter servers need to know which port they need to listen to. For the sake of simplicity, you can usually pass in the complete cluster information when creating TensorFlow servers on these tasks.\n",
"- The evaluator task doesn’t have to know the setup of the training cluster. If it does, it should not attempt to connect to the training cluster.\n",
"- Workers and parameter servers should have task types as `\"worker\"` and `\"ps\"`, respectively. The coordinator should use `\"chief\"` as the task type for legacy reasons.\n",
@@ -217,7 +212,7 @@
"source": [
"### In-process cluster\n",
"\n",
- "You will start by creating several TensorFlow servers in advance and connect to them later. Note that this is only for the purpose of this tutorial's demonstration, and in real training the servers will be started on `\"worker\"` and `\"ps\"` machines."
+ "You will start by creating several TensorFlow servers in advance and you will connect to them later. Note that this is only for the purpose of this tutorial's demonstration, and in real training the servers will be started on `\"worker\"` and `\"ps\"` machines."
]
},
{
@@ -279,9 +274,9 @@
"id": "pX_91OByt0J2"
},
"source": [
- "The in-process cluster setup is frequently used in unit testing, such as [here](https://github.com/tensorflow/tensorflow/blob/7621d31921c2ed979f212da066631ddfda37adf5/tensorflow/python/distribute/coordinator/cluster_coordinator_test.py#L437).\n",
+ "The in-process cluster setup is frequently used in unit testing, such as [here](https://github.com/tensorflow/tensorflow/blob/eb4c40fc91da260199fa2aed6fe67d36ad49fafd/tensorflow/python/distribute/coordinator/cluster_coordinator_test.py#L447).\n",
"\n",
- "Another option for local testing is to launch processes on the local machine—check out [Multi-worker training with Keras](https://www.tensorflow.org/tutorials/distribute/multi_worker_with_keras) for an example of this approach."
+ "Another option for local testing is to launch processes on the local machine—check out [Multi-worker training with Keras](multi_worker_with_keras.ipynb) for an example of this approach."
]
},
{
@@ -292,7 +287,7 @@
"source": [
"## Instantiate a ParameterServerStrategy\n",
"\n",
- "Before you dive into the training code, let's instantiate a `ParameterServerStrategy` object. Note that this is needed regardless of whether you are proceeding with `Model.fit` or a custom training loop. The `variable_partitioner` argument will be explained in the [Variable sharding section](#variable-sharding)."
+ "Before you dive into the training code, let's instantiate a `tf.distribute.ParameterServerStrategy` object. Note that this is needed regardless of whether you are proceeding with `Model.fit` or a custom training loop. The `variable_partitioner` argument will be explained in the [Variable sharding section](#variable_sharding)."
]
},
{
@@ -308,7 +303,7 @@
" min_shard_bytes=(256 << 10),\n",
" max_shards=NUM_PS))\n",
"\n",
- "strategy = tf.distribute.experimental.ParameterServerStrategy(\n",
+ "strategy = tf.distribute.ParameterServerStrategy(\n",
" cluster_resolver,\n",
" variable_partitioner=variable_partitioner)"
]
@@ -331,7 +326,8 @@
"### Variable sharding\n",
"\n",
"Variable sharding refers to splitting a variable into multiple smaller\n",
- "variables, which are called _shards_. Variable sharding may be useful to distribute the network load when accessing these shards. It is also useful to distribute computation and storage of a normal variable across multiple parameter servers.\n",
+ "variables, which are called _shards_. Variable sharding may be useful to distribute the network load when accessing these shards. It is also useful to distribute computation and storage of a normal variable across multiple parameter servers, for example, when using very large embeddings\n",
+ "that may not fit in a single machine's memory.\n",
"\n",
"To enable variable sharding, you can pass in a `variable_partitioner` when\n",
"constructing a `ParameterServerStrategy` object. The `variable_partitioner` will\n",
@@ -340,7 +336,7 @@
"`variable_partitioner`s are provided such as\n",
"`tf.distribute.experimental.partitioners.MinSizePartitioner`. It is recommended to use size-based partitioners like\n",
"`tf.distribute.experimental.partitioners.MinSizePartitioner` to avoid\n",
- "partitioning small variables, which could have negative impact on model training\n",
+ "partitioning small variables, which could have a negative impact on model training\n",
"speed."
]
},
@@ -350,16 +346,16 @@
"id": "1--SxlxtsOb7"
},
"source": [
- "When a `variable_partitioner` is passed in and if you create a variable directly\n",
- "under `strategy.scope()`, it will become a container type with a `variables`\n",
- "property which provides access to the list of shards. In most cases, this\n",
+ "When a `variable_partitioner` is passed in, and you create a variable directly\n",
+ "under `Strategy.scope`, the variable will become a container type with a `variables`\n",
+ "property, which provides access to the list of shards. In most cases, this\n",
"container will be automatically converted to a Tensor by concatenating all the\n",
"shards. As a result, it can be used as a normal variable. On the other hand,\n",
"some TensorFlow methods such as `tf.nn.embedding_lookup` provide efficient\n",
"implementation for this container type and in these methods automatic\n",
"concatenation will be avoided.\n",
"\n",
- "Please see the API docs of `tf.distribute.experimental.ParameterServerStrategy` for more details."
+ "Refer to the API docs of `tf.distribute.ParameterServerStrategy` for more details."
]
},
{
@@ -371,7 +367,7 @@
"## Training with `Model.fit`\n",
"\n",
"\n",
- "Keras provides an easy-to-use training API via `Model.fit` that handles the training loop under the hood, with the flexibility of overridable `train_step`, and callbacks, which provide functionalities such as checkpoint saving or summary saving for TensorBoard. With `Model.fit`, the same training code can be used for other strategies with a simple swap of the strategy object."
+ "Keras provides an easy-to-use training API via `Model.fit` that handles the training loop under the hood, with the flexibility of an overridable `train_step`, and callbacks which provide functionalities such as checkpoint saving or summary saving for TensorBoard. With `Model.fit`, the same training code can be used with other strategies with a simple swap of the strategy object."
]
},
{
@@ -382,12 +378,14 @@
"source": [
"### Input data\n",
"\n",
- "`Model.fit` with parameter server training requires that the input data be\n",
- "provided in a callable that takes a single argument of type `tf.distribute.InputContext`, and returns a `tf.data.Dataset`. Then, create a `tf.keras.utils.experimental.DatasetCreator` object that takes such `callable`, and an optional `tf.distribute.InputOptions` object via `input_options` argument.\n",
+ "Keras `Model.fit` with `tf.distribute.ParameterServerStrategy` can take input data in the form of a `tf.data.Dataset`, `tf.distribute.DistributedDataset`, or a `tf.keras.utils.experimental.DatasetCreator`, with `Dataset` being the recommended option for ease of use. If you encounter memory issues using `Dataset`, however, you may need to use `DatasetCreator` with a callable `dataset_fn` argument (refer to the `tf.keras.utils.experimental.DatasetCreator` API documentation for details).\n",
"\n",
- "Note that it is recommended to shuffle and repeat the data with parameter server training, and specify `steps_per_epoch` in `fit` call so the library knows the epoch boundaries.\n",
+ "If you transform your dataset into a `tf.data.Dataset`, you should use `Dataset.shuffle` and `Dataset.repeat`, as demonstrated in the code example below.\n",
"\n",
- "Please see the [Distributed input](https://www.tensorflow.org/tutorials/distribute/input#usage_2) tutorial for more information about the `InputContext` argument."
+ "- Keras `Model.fit` with parameter server training assumes that each worker receives the same dataset, except when it is shuffled differently. Therefore, by calling `Dataset.shuffle`, you ensure more even iterations over the data.\n",
+ "- Because workers do not synchronize, they may finish processing their datasets at different times. Therefore, the easiest way to define epochs with parameter server training is to use `Dataset.repeat`—which repeats a dataset indefinitely when called without an argument—and specify the `steps_per_epoch` argument in the `Model.fit` call.\n",
+ "\n",
+ "Refer to the \"Training workflows\" section of the [tf.data guide](../../guide/data.ipynb) for more details on `shuffle` and `repeat`."
]
},
{
@@ -398,23 +396,14 @@
},
"outputs": [],
"source": [
- "def dataset_fn(input_context):\n",
- " global_batch_size = 64\n",
- " batch_size = input_context.get_per_replica_batch_size(global_batch_size)\n",
- "\n",
- " x = tf.random.uniform((10, 10))\n",
- " y = tf.random.uniform((10,))\n",
- "\n",
- " dataset = tf.data.Dataset.from_tensor_slices((x, y)).shuffle(10).repeat()\n",
- " dataset = dataset.shard(\n",
- " input_context.num_input_pipelines,\n",
- " input_context.input_pipeline_id)\n",
- " dataset = dataset.batch(batch_size)\n",
- " dataset = dataset.prefetch(2)\n",
+ "global_batch_size = 64\n",
"\n",
- " return dataset\n",
+ "x = tf.random.uniform((10, 10))\n",
+ "y = tf.random.uniform((10,))\n",
"\n",
- "dc = tf.keras.utils.experimental.DatasetCreator(dataset_fn)"
+ "dataset = tf.data.Dataset.from_tensor_slices((x, y)).shuffle(10).repeat()\n",
+ "dataset = dataset.batch(global_batch_size)\n",
+ "dataset = dataset.prefetch(2)"
]
},
{
@@ -423,11 +412,18 @@
"id": "v_jhF70K7zON"
},
"source": [
- "The code in `dataset_fn` will be invoked on the input device, which is usually the CPU, on each of the worker machines.\n",
- "\n",
+ "If you instead create your dataset with `tf.keras.utils.experimental.DatasetCreator`, the code in `dataset_fn` will be invoked on the input device, which is usually the CPU, on each of the worker machines.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "w60PuWrWwBD4"
+ },
+ "source": [
"### Model construction and compiling\n",
"\n",
- "Now, you will create a `tf.keras.Model`—a trivial `tf.keras.models.Sequential` model for demonstration purposes—followed by a `Model.compile` call to incorporate components, such as an optimizer, metrics, or parameters such as `steps_per_execution`:"
+ "Now, you will create a `tf.keras.Model`—a trivial `tf.keras.models.Sequential` model for demonstration purposes—followed by a `Model.compile` call to incorporate components, such as an optimizer, metrics, and other parameters such as `steps_per_execution`:"
]
},
{
@@ -441,7 +437,7 @@
"with strategy.scope():\n",
" model = tf.keras.models.Sequential([tf.keras.layers.Dense(10)])\n",
"\n",
- "model.compile(tf.keras.optimizers.SGD(), loss='mse', steps_per_execution=10)"
+ " model.compile(tf.keras.optimizers.legacy.SGD(), loss=\"mse\", steps_per_execution=10)"
]
},
{
@@ -454,13 +450,13 @@
"\n",
" \n",
"\n",
- "Before you call `model.fit` for the actual training, let's prepare the needed callbacks for common tasks, such as:\n",
+ "Before you call Keras `Model.fit` for the actual training, prepare any needed [callbacks](https://www.tensorflow.org/guide/keras/train_and_evaluate) for common tasks, such as:\n",
"\n",
- "- `ModelCheckpoint`: to save the model weights.\n",
- "- `BackupAndRestore`: to make sure the training progress is automatically backed up, and recovered if the cluster experiences unavailability (such as abort or preemption); or\n",
- "- `TensorBoard`: to save the progress reports into summary files, which get visualized in TensorBoard tool.\n",
+ "- `tf.keras.callbacks.ModelCheckpoint`: saves the model at a certain frequency, such as after every epoch.\n",
+ "- `tf.keras.callbacks.BackupAndRestore`: provides fault tolerance by backing up the model and current epoch number, if the cluster experiences unavailability (such as abort or preemption). You can then restore the training state upon a restart from a job failure, and continue training from the beginning of the interrupted epoch.\n",
+ "- `tf.keras.callbacks.TensorBoard`: periodically writes model logs in summary files that can be visualized in the TensorBoard tool.\n",
"\n",
- "Note: Due to performance consideration, custom callbacks cannot have batch level callbacks overridden when used with `ParameterServerStrategy`. Please modify your custom callbacks to make them epoch level calls, and adjust `steps_per_epoch` to a suitable value. In addition, `steps_per_epoch` is a required argument for `Model.fit` when used with `ParameterServerStrategy`."
+ "Note: Due to performance considerations, custom callbacks cannot have batch level callbacks overridden when used with `ParameterServerStrategy`. Please modify your custom callbacks to make them epoch level calls, and adjust `steps_per_epoch` to a suitable value. In addition, `steps_per_epoch` is a required argument for `Model.fit` when used with `ParameterServerStrategy`."
]
},
{
@@ -471,18 +467,18 @@
},
"outputs": [],
"source": [
- "working_dir = '/tmp/my_working_dir'\n",
- "log_dir = os.path.join(working_dir, 'log')\n",
- "ckpt_filepath = os.path.join(working_dir, 'ckpt')\n",
- "backup_dir = os.path.join(working_dir, 'backup')\n",
+ "working_dir = \"/tmp/my_working_dir\"\n",
+ "log_dir = os.path.join(working_dir, \"log\")\n",
+ "ckpt_filepath = os.path.join(working_dir, \"ckpt\")\n",
+ "backup_dir = os.path.join(working_dir, \"backup\")\n",
"\n",
"callbacks = [\n",
" tf.keras.callbacks.TensorBoard(log_dir=log_dir),\n",
" tf.keras.callbacks.ModelCheckpoint(filepath=ckpt_filepath),\n",
- " tf.keras.callbacks.experimental.BackupAndRestore(backup_dir=backup_dir),\n",
+ " tf.keras.callbacks.BackupAndRestore(backup_dir=backup_dir),\n",
"]\n",
"\n",
- "model.fit(dc, epochs=5, steps_per_epoch=20, callbacks=callbacks)"
+ "model.fit(dataset, epochs=5, steps_per_epoch=20, callbacks=callbacks)"
]
},
{
@@ -493,7 +489,7 @@
"source": [
"### Direct usage with `ClusterCoordinator` (optional)\n",
"\n",
- "Even if you choose the `Model.fit` training path, you can optionally instantiate a `tf.distribute.experimental.coordinator.ClusterCoordinator` object to schedule other functions you would like to be executed on the workers. See the [Training with a custom training loop](#training_with_custom_training_loop) section for more details and examples."
+ "Even if you choose the `Model.fit` training path, you can optionally instantiate a `tf.distribute.coordinator.ClusterCoordinator` object to schedule other functions you would like to be executed on the workers. Refer to the [Training with a custom training loop](#training_with_custom_training_loop) section for more details and examples."
]
},
{
@@ -506,11 +502,11 @@
"\n",
" \n",
"\n",
- "Using custom training loops with `tf.distribute.Strategy` provides great flexibility to define training loops. With the `ParameterServerStrategy` defined above (as `strategy`), you will use a `tf.distribute.experimental.coordinator.ClusterCoordinator` to dispatch the execution of training steps to remote workers.\n",
+ "Using custom training loops with `tf.distribute.Strategy` provides great flexibility to define training loops. With the `ParameterServerStrategy` defined above (as `strategy`), you will use a `tf.distribute.coordinator.ClusterCoordinator` to dispatch the execution of training steps to remote workers.\n",
"\n",
- "Then, you will create a model, define a dataset and a step function, as you have done in the training loop with other `tf.distribute.Strategy`s. You can find more details in the [Custom training with tf.distribute.Strategy](https://www.tensorflow.org/tutorials/distribute/custom_training) tutorial.\n",
+ "Then, you will create a model, define a dataset, and define a step function, as you have done in the training loop with other `tf.distribute.Strategy`s. You can find more details in the [Custom training with tf.distribute.Strategy](custom_training.ipynb) tutorial.\n",
"\n",
- "To ensure efficient dataset prefetching, use the recommended distributed dataset creation APIs mentioned in the [Dispatch training steps to remote workers](https://www.tensorflow.org/tutorials/distribute/parameter_server_training#dispatch_training_steps_to_remote_workers) section below. Also, make sure to call `Strategy.run` inside `worker_fn` to take full advantage of GPUs allocated to workers. The rest of the steps are the same for training with or without GPUs.\n",
+ "To ensure efficient dataset prefetching, use the recommended distributed dataset creation APIs mentioned in the [Dispatch training steps to remote workers](#dispatch_training_steps_to_remote_workers) section below. Also, make sure to call `Strategy.run` inside `worker_fn` to take full advantage of GPUs allocated to workers. The rest of the steps are the same for training with or without GPUs.\n",
"\n",
"Let’s create these components in the following steps:\n"
]
@@ -523,11 +519,13 @@
"source": [
"### Set up the data\n",
"\n",
- "First, write a function that creates a dataset that includes preprocessing logic implemented by [Keras preprocessing layers](https://www.tensorflow.org/guide/keras/preprocessing_layers).\n",
+ "First, write a function that creates a dataset.\n",
+ "\n",
+ "If you would like to preprocess the data with [Keras preprocessing layers](https://www.tensorflow.org/guide/keras/preprocessing_layers) or [Tensorflow Transform layers](https://www.tensorflow.org/tfx/tutorials/transform/simple), create these layers **outside the `dataset_fn`** and **under `Strategy.scope`**, like you would do for any other Keras layers. This is because the `dataset_fn` will be wrapped into a `tf.function` and then executed on each worker to generate the data pipeline.\n",
"\n",
- "You will create these layers outside the `dataset_fn` but apply the transformation inside the `dataset_fn`, since you will wrap the `dataset_fn` into a `tf.function`, which doesn't allow variables to be created inside it.\n",
+ "If you don't follow the above procedure, creating the layers might create Tensorflow states which will be lifted out of the `tf.function` to the coordinator. Thus, accessing them on workers would incur repetitive RPC calls between coordinator and workers, and cause significant slowdown.\n",
"\n",
- "Note: There is a known performance implication when using lookup table resources, which layers, such as `tf.keras.layers.experimental.preprocessing.StringLookup`, employ. Refer to the [Known limitations](#known_limitations) section for more information."
+ "Placing the layers under `Strategy.scope` will instead create them on all workers. Then, you will apply the transformation inside the `dataset_fn` via `tf.data.Dataset.map`. Refer to _Data preprocessing_ in the [Distributed input](input.ipynb) tutorial for more information on data preprocessing with distributed input."
]
},
{
@@ -544,10 +542,10 @@
"label_vocab = [\"yes\", \"no\"]\n",
"\n",
"with strategy.scope():\n",
- " feature_lookup_layer = preprocessing.StringLookup(\n",
+ " feature_lookup_layer = tf.keras.layers.StringLookup(\n",
" vocabulary=feature_vocab,\n",
" mask_token=None)\n",
- " label_lookup_layer = preprocessing.StringLookup(\n",
+ " label_lookup_layer = tf.keras.layers.StringLookup(\n",
" vocabulary=label_vocab,\n",
" num_oov_indices=0,\n",
" mask_token=None)\n",
@@ -637,7 +635,7 @@
"source": [
"### Build the model\n",
"\n",
- "Next, create the model and other objects. Make sure to create all variables under `strategy.scope`."
+ "Next, create the model and other objects. Make sure to create all variables under `Strategy.scope`."
]
},
{
@@ -648,7 +646,7 @@
},
"outputs": [],
"source": [
- "# These variables created under the `strategy.scope` will be placed on parameter\n",
+ "# These variables created under the `Strategy.scope` will be placed on parameter\n",
"# servers in a round-robin fashion.\n",
"with strategy.scope():\n",
" # Create the model. The input needs to be compatible with Keras processing layers.\n",
@@ -658,10 +656,13 @@
" emb_layer = tf.keras.layers.Embedding(\n",
" input_dim=len(feature_lookup_layer.get_vocabulary()), output_dim=16384)\n",
" emb_output = tf.reduce_mean(emb_layer(model_input), axis=1)\n",
- " dense_output = tf.keras.layers.Dense(units=1, activation=\"sigmoid\")(emb_output)\n",
+ " dense_output = tf.keras.layers.Dense(\n",
+ " units=1, activation=\"sigmoid\",\n",
+ " kernel_regularizer=tf.keras.regularizers.L2(1e-4),\n",
+ " )(emb_output)\n",
" model = tf.keras.Model({\"features\": model_input}, dense_output)\n",
"\n",
- " optimizer = tf.keras.optimizers.RMSprop(learning_rate=0.1)\n",
+ " optimizer = tf.keras.optimizers.legacy.RMSprop(learning_rate=0.1)\n",
" accuracy = tf.keras.metrics.Accuracy()"
]
},
@@ -671,7 +672,7 @@
"id": "iyuxiqCQU50m"
},
"source": [
- "Let's confirm that the use of `FixedShardsPartitioner` split all variables into two shards and each shard was assigned to different parameter servers:"
+ "Let's confirm that the use of `FixedShardsPartitioner` split all variables into two shards and that each shard was assigned to a different parameter server:"
]
},
{
@@ -685,8 +686,9 @@
"assert len(emb_layer.weights) == 2\n",
"assert emb_layer.weights[0].shape == (4, 16384)\n",
"assert emb_layer.weights[1].shape == (4, 16384)\n",
- "assert emb_layer.weights[0].device == \"/job:ps/replica:0/task:0/device:CPU:0\"\n",
- "assert emb_layer.weights[1].device == \"/job:ps/replica:0/task:1/device:CPU:0\""
+ "\n",
+ "print(emb_layer.weights[0].device)\n",
+ "print(emb_layer.weights[1].device)\n"
]
},
{
@@ -714,9 +716,12 @@
" with tf.GradientTape() as tape:\n",
" pred = model(batch_data, training=True)\n",
" per_example_loss = tf.keras.losses.BinaryCrossentropy(\n",
- " reduction=tf.keras.losses.Reduction.NONE)(labels, pred)\n",
+ " reduction=tf.keras.losses.Reduction.NONE)(labels, pred)\n",
" loss = tf.nn.compute_average_loss(per_example_loss)\n",
- " gradients = tape.gradient(loss, model.trainable_variables)\n",
+ " model_losses = model.losses\n",
+ " if model_losses:\n",
+ " loss += tf.nn.scale_regularization_loss(tf.add_n(model_losses))\n",
+ " gradients = tape.gradient(loss, model.trainable_variables)\n",
"\n",
" optimizer.apply_gradients(zip(gradients, model.trainable_variables))\n",
"\n",
@@ -735,7 +740,7 @@
"id": "rvrYQUeYiLNy"
},
"source": [
- "In the above training step function, calling `Strategy.run` and `Strategy.reduce` in the `step_fn` can support multiple GPUs per worker. If the workers have GPUs allocated, `Strategy.run` will distribute the datasets on multiple replicas.\n"
+ "In the above training step function, calling `Strategy.run` and `Strategy.reduce` in the `step_fn` can support multiple GPUs per worker. If the workers have GPUs allocated, `Strategy.run` will distribute the datasets on multiple replicas (GPUs). Their parallel calls to `tf.nn.compute_average_loss()` compute the average of the loss across the replicas (GPUs) of one worker, independent of the total number of workers."
]
},
{
@@ -747,7 +752,7 @@
"### Dispatch training steps to remote workers\n",
" \n",
"\n",
- "After all the computations are defined by `ParameterServerStrategy`, you will use the `tf.distribute.experimental.coordinator.ClusterCoordinator` class to create resources and distribute the training steps to remote workers.\n",
+ "After all the computations are defined by `ParameterServerStrategy`, you will use the `tf.distribute.coordinator.ClusterCoordinator` class to create resources and distribute the training steps to remote workers.\n",
"\n",
"Let’s first create a `ClusterCoordinator` object and pass in the strategy object:"
]
@@ -760,7 +765,7 @@
},
"outputs": [],
"source": [
- "coordinator = tf.distribute.experimental.coordinator.ClusterCoordinator(strategy)"
+ "coordinator = tf.distribute.coordinator.ClusterCoordinator(strategy)"
]
},
{
@@ -769,7 +774,7 @@
"id": "-xRIgKxciOSe"
},
"source": [
- "Then, create a per-worker dataset and an iterator. In the `per_worker_dataset_fn` below, wrapping the `dataset_fn` into `strategy.distribute_datasets_from_function` is recommended to allow efficient prefetching to GPUs seamlessly."
+ "Then, create a per-worker dataset and an iterator using the `ClusterCoordinator.create_per_worker_dataset` API, which replicates the dataset to all workers. In the `per_worker_dataset_fn` below, wrapping the `dataset_fn` into `strategy.distribute_datasets_from_function` is recommended to allow efficient prefetching to GPUs seamlessly."
]
},
{
@@ -808,15 +813,15 @@
},
"outputs": [],
"source": [
- "num_epoches = 4\n",
+ "num_epochs = 4\n",
"steps_per_epoch = 5\n",
- "for i in range(num_epoches):\n",
+ "for i in range(num_epochs):\n",
" accuracy.reset_states()\n",
" for _ in range(steps_per_epoch):\n",
" coordinator.schedule(step_fn, args=(per_worker_iterator,))\n",
" # Wait at epoch boundaries.\n",
" coordinator.join()\n",
- " print (\"Finished epoch %d, accuracy is %f.\" % (i, accuracy.result().numpy()))"
+ " print(\"Finished epoch %d, accuracy is %f.\" % (i, accuracy.result().numpy()))"
]
},
{
@@ -837,7 +842,7 @@
"outputs": [],
"source": [
"loss = coordinator.schedule(step_fn, args=(per_worker_iterator,))\n",
- "print (\"Final loss is %f\" % loss.fetch())"
+ "print(\"Final loss is %f\" % loss.fetch())"
]
},
{
@@ -857,7 +862,7 @@
" # Do something like logging metrics or writing checkpoints.\n",
"```\n",
"\n",
- "For the complete training and serving workflow for this particular example, please check out this [test](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/keras/distribute/parameter_server_training_test.py).\n"
+ "For the complete training and serving workflow for this particular example, please check out this [test](https://github.com/keras-team/keras/blob/master/keras/integration_test/parameter_server_keras_preprocessing_test.py).\n"
]
},
{
@@ -868,11 +873,11 @@
"source": [
"### More about dataset creation\n",
"\n",
- "The dataset in the above code is created using the `ClusterCoordinator.create_per_worker_dataset` API). It creates one dataset per worker and returns a container object. You can call the `iter` method on it to create a per-worker iterator. The per-worker iterator contains one iterator per worker and the corresponding slice of a worker will be substituted in the input argument of the function passed to the `ClusterCoordinator.schedule` method before the function is executed on a particular worker.\n",
+ "The dataset in the above code is created using the `ClusterCoordinator.create_per_worker_dataset` API. It creates one dataset per worker and returns a container object. You can call the `iter` method on it to create a per-worker iterator. The per-worker iterator contains one iterator per worker and the corresponding slice of a worker will be substituted in the input argument of the function passed to the `ClusterCoordinator.schedule` method before the function is executed on a particular worker.\n",
"\n",
- "Currently, the `ClusterCoordinator.schedule` method assumes workers are equivalent and thus assumes the datasets on different workers are the same except they may be shuffled differently if they contain a `Dataset.shuffle` operation. Because of this, it is also recommended that the datasets to be repeated indefinitely and you schedule a finite number of steps instead of relying on the `OutOfRangeError` from a dataset.\n",
+ "The `ClusterCoordinator.schedule` method assumes workers are equivalent and thus assumes the datasets on different workers are the same (except that they may be shuffled differently). Because of this, it is also recommended to repeat datasets, and schedule a finite number of steps instead of relying on receiving an `OutOfRangeError` from a dataset.\n",
"\n",
- "Another important note is that `tf.data` datasets don’t support implicit serialization and deserialization across task boundaries. So it is important to create the whole dataset inside the function passed to `ClusterCoordinator.create_per_worker_dataset`."
+ "Another important note is that `tf.data` datasets don’t support implicit serialization and deserialization across task boundaries. So it is important to create the whole dataset inside the function passed to `ClusterCoordinator.create_per_worker_dataset`. The `create_per_worker_dataset` API can also directly take a `tf.data.Dataset` or `tf.distribute.DistributedDataset` as input."
]
},
{
@@ -883,7 +888,7 @@
"source": [
"## Evaluation\n",
"\n",
- "There is more than one way to define and run an evaluation loop in distributed training. Each has its own pros and cons as described below. The inline evaluation method is recommended if you don't have a preference."
+ "The two main approaches to performing evaluation with `tf.distribute.ParameterServerStrategy` training are inline evaluation and sidecar evaluation. Each has its own pros and cons as described below. The inline evaluation method is recommended if you don't have a preference. For users using `Model.fit`, `Model.evaluate` uses inline (distributed) evaluation under the hood."
]
},
{
@@ -894,12 +899,12 @@
"source": [
"### Inline evaluation\n",
"\n",
- "In this method, the coordinator alternates between training and evaluation and thus it is called it _inline evaluation_.\n",
+ "In this method, the coordinator alternates between training and evaluation, and thus it is called _inline evaluation_.\n",
"\n",
"There are several benefits of inline evaluation. For example:\n",
"\n",
"- It can support large evaluation models and evaluation datasets that a single task cannot hold.\n",
- "- The evaluation results can be used to make decisions for training the next epoch.\n",
+ "- The evaluation results can be used to make decisions for training the next epoch, for example, whether to stop training early.\n",
"\n",
"There are two ways to implement inline evaluation: direct evaluation and distributed evaluation.\n",
"\n",
@@ -915,7 +920,7 @@
"outputs": [],
"source": [
"eval_dataset = tf.data.Dataset.from_tensor_slices(\n",
- " feature_and_label_gen(num_examples=16)).map(\n",
+ " feature_and_label_gen(num_examples=16)).map(\n",
" lambda x: (\n",
" {\"features\": feature_preprocess_stage(x[\"features\"])},\n",
" label_preprocess_stage(x[\"label\"])\n",
@@ -928,7 +933,7 @@
" actual_pred = tf.cast(tf.greater(pred, 0.5), tf.int64)\n",
" eval_accuracy.update_state(labels, actual_pred)\n",
"\n",
- "print (\"Evaluation accuracy: %f\" % eval_accuracy.result())"
+ "print(\"Evaluation accuracy: %f\" % eval_accuracy.result())"
]
},
{
@@ -976,7 +981,7 @@
"for _ in range(eval_steps_per_epoch):\n",
" coordinator.schedule(eval_step, args=(per_worker_eval_iterator,))\n",
"coordinator.join()\n",
- "print (\"Evaluation accuracy: %f\" % eval_accuracy.result())"
+ "print(\"Evaluation accuracy: %f\" % eval_accuracy.result())"
]
},
{
@@ -985,7 +990,23 @@
"id": "cKrQktZX5z7a"
},
"source": [
- "Note: Currently, the `schedule` and `join` methods of `tf.distribute.experimental.coordinator.ClusterCoordinator` don’t support visitation guarantee or exactly-once semantics. In other words, there is no guarantee that all evaluation examples in a dataset will be evaluated exactly once; some may not be visited and some may be evaluated multiple times. Visitation guarantee on evaluation dataset is being worked on."
+ "#### Enabling exactly-once evaluation\n",
+ "\n",
+ "\n",
+ "The `schedule` and `join` methods of `tf.distribute.coordinator.ClusterCoordinator` don’t support visitation guarantees or exactly-once semantics by default. In other words, in the above example there is no guarantee that all evaluation examples in a dataset will be evaluated exactly once; some may not be visited and some may be evaluated multiple times.\n",
+ "\n",
+ "Exactly-once evaluation may be preferred to reduce the variance of evaluation across epochs, and improve model selection done via early stopping, hyperparameter tuning, or other methods. There are different ways to enable exactly-once evaluation:\n",
+ "\n",
+ "- With a `Model.fit/.evaluate` workflow, it can be enabled by adding an argument to `Model.compile`. Refer to docs for the `pss_evaluation_shards` argument.\n",
+ "- The `tf.data` service API can be used to provide exactly-once visitation for evaluation when using `ParameterServerStrategy` (refer to the _Dynamic Sharding_ section of the `tf.data.experimental.service` API documentation).\n",
+ "- [Sidecar evaluation](#sidecar_evaluation) provides exactly-once evaluation by default, since the evaluation happens on a single machine. However this can be much slower than performing evaluation distributed across many workers.\n",
+ "\n",
+ "The first option, using `Model.compile`, is the suggested solution for most users.\n",
+ "\n",
+ "Exactly-once evaluation has some limitations:\n",
+ "\n",
+ "- It is not supported to write a custom distributed evaluation loop with an exactly-once visitation guarantee. File a GitHub issue if you need support for this.\n",
+ "- It cannot automatically handle computation of metrics that use the `Layer.add_metric` API. These should be excluded from evaluation, or reworked into `Metric` objects."
]
},
{
@@ -994,9 +1015,69 @@
"id": "H40X-9Gs3i7_"
},
"source": [
- "### Side-car evaluation\n",
+ "### Sidecar evaluation\n",
+ "\n",
+ "\n",
+ "Another method for defining and running an evaluation loop in `tf.distribute.ParameterServerStrategy` training is called _sidecar evaluation_, in which you create a dedicated evaluator task that repeatedly reads checkpoints and runs evaluation on the latest checkpoint (refer to [this guide](../../guide/checkpoint.ipynb) for more details on checkpointing). The coordinator and worker tasks do not spend any time on evaluation, so for a fixed number of iterations the overall training time should be shorter than using other evaluation methods. However, it requires an additional evaluator task and periodic checkpointing to trigger evaluation."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "HonyjnXK9-ys"
+ },
+ "source": [
+ "To write an evaluation loop for sidecar evaluation, you have two\n",
+ "options:\n",
+ "\n",
+ "1. Use the `tf.keras.utils.SidecarEvaluator` API.\n",
+ "2. Create a custom evaluation loop.\n",
"\n",
- "Another method is called _side-car evaluation_ where you create a dedicated evaluator task that repeatedly reads checkpoints and runs evaluation on a latest checkpoint. It allows your training program to finish early if you don't need to change your training loop based on evaluation results. However, it requires an additional evaluator task and periodic checkpointing to trigger evaluation. Following is a possible side-car evaluation loop:\n",
+ "Refer to the `tf.keras.utils.SidecarEvaluator` API documentation for more details on option 1."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "U_c0EiwB88OG"
+ },
+ "source": [
+ "Sidecar evaluation is supported only with a single task. This means:\n",
+ "\n",
+ "* It is guaranteed that each example is evaluated once. In the event the\n",
+ " evaluator is preempted or restarted, it simply restarts the\n",
+ " evaluation loop from the latest checkpoint, and the partial evaluation\n",
+ " progress made before the restart is discarded.\n",
+ "\n",
+ "* However, running evaluation on a single task implies that a full evaluation\n",
+ " can possibly take a long time.\n",
+ "\n",
+ "* If the size of the model is too large to fit into an evaluator's memory,\n",
+ " single sidecar evaluation is not applicable."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "VNJoWVc797B1"
+ },
+ "source": [
+ "Another caveat is that the `tf.keras.utils.SidecarEvaluator` implementation, and the custom\n",
+ "evaluation loop below, may skip some checkpoints because it always picks up the\n",
+ "latest checkpoint available, and during an evaluation epoch, multiple\n",
+ "checkpoints can be produced from the training cluster. You can write a custom\n",
+ "evaluation loop that evaluates every checkpoint, but it is not covered in this\n",
+ "tutorial. On the other hand, it may sit idle if checkpoints are produced less\n",
+ "frequently than how long it takes to run evaluation."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "G5jopxBd85Ji"
+ },
+ "source": [
+ "A custom evaluation loop provides more control over the details, such as choosing which checkpoint to evaluate, or providing any additional logic to run along with evaluation. The following is a possible custom sidecar evaluation loop:\n",
"\n",
"```python\n",
"checkpoint_dir = ...\n",
@@ -1016,7 +1097,7 @@
" eval_model.evaluate(eval_data)\n",
"\n",
" # Evaluation finishes when it has evaluated the last epoch.\n",
- " if latest_checkpoint.endswith('-{}'.format(train_epoches)):\n",
+ " if latest_checkpoint.endswith('-{}'.format(train_epochs)):\n",
" break\n",
"```"
]
@@ -1034,9 +1115,9 @@
"\n",
"In a real production environment, you will run all tasks in different processes on different machines. The simplest way to configure cluster information on each task is to set `\"TF_CONFIG\"` environment variables and use a `tf.distribute.cluster_resolver.TFConfigClusterResolver` to parse `\"TF_CONFIG\"`.\n",
"\n",
- "For a general description about `\"TF_CONFIG\"` environment variables, refer to the [Distributed training](https://www.tensorflow.org/guide/distributed_training#setting_up_tf_config_environment_variable) guide.\n",
+ "For a general description of `\"TF_CONFIG\"` environment variables, refer to \"Setting up the `TF_CONFIG` environment variable\" in the [Distributed training](../../guide/distributed_training.ipynb) guide.\n",
"\n",
- "If you start your training tasks using Kubernetes or other configuration templates, it is very likely that these templates have already set `“TF_CONFIG\"` for you."
+ "If you start your training tasks using Kubernetes or other configuration templates, likely, these templates have already set `“TF_CONFIG\"` for you."
]
},
{
@@ -1047,7 +1128,7 @@
"source": [
"### Set the `\"TF_CONFIG\"` environment variable\n",
"\n",
- "Suppose you have 3 workers and 2 parameter servers, the `\"TF_CONFIG\"` of worker 1 can be:\n",
+ "Suppose you have 3 workers and 2 parameter servers. Then the `\"TF_CONFIG\"` of worker 1 can be:\n",
"\n",
"```python\n",
"os.environ[\"TF_CONFIG\"] = json.dumps({\n",
@@ -1089,12 +1170,12 @@
"if cluster_resolver.task_type in (\"worker\", \"ps\"):\n",
" # Start a TensorFlow server and wait.\n",
"elif cluster_resolver.task_type == \"evaluator\":\n",
- " # Run side-car evaluation\n",
+ " # Run sidecar evaluation\n",
"else:\n",
" # Run the coordinator.\n",
"```\n",
"\n",
- "The following code starts a TensorFlow server and waits:\n",
+ "The following code starts a TensorFlow server and waits, useful for the `\"worker\"` and `\"ps\"` roles:\n",
"\n",
"```python\n",
"# Set the environment variable to allow reporting worker and ps failure to the\n",
@@ -1128,7 +1209,7 @@
"source": [
"### Worker failure\n",
"\n",
- "`tf.distribute.experimental.coordinator.ClusterCoordinator` or `Model.fit` provide built-in fault tolerance for worker failure. Upon worker recovery, the previously provided dataset function (either to `ClusterCoordinator.create_per_worker_dataset` for a custom training loop, or `tf.keras.utils.experimental.DatasetCreator` for `Model.fit`) will be invoked on the workers to re-create the datasets."
+ "Both the `tf.distribute.coordinator.ClusterCoordinator` custom training loop and `Model.fit` approaches provide built-in fault tolerance for worker failure. Upon worker recovery, the `ClusterCoordinator` invokes dataset re-creation on the workers."
]
},
{
@@ -1172,7 +1253,7 @@
"global_steps = int(optimizer.iterations.numpy())\n",
"starting_epoch = global_steps // steps_per_epoch\n",
"\n",
- "for _ in range(starting_epoch, num_epoches):\n",
+ "for _ in range(starting_epoch, num_epochs):\n",
" for _ in range(steps_per_epoch):\n",
" coordinator.schedule(step_fn, args=(per_worker_iterator,))\n",
" coordinator.join()\n",
@@ -1212,17 +1293,21 @@
"source": [
"## Performance improvement\n",
"\n",
- "There are several possible reasons if you see performance issues when you train with `ParameterServerStrategy` and `ClusterResolver`.\n",
+ "There are several possible reasons you may experience performance issues when you train with `tf.distribute.ParameterServerStrategy` and `tf.distribute.coordinator.ClusterCoordinator`.\n",
"\n",
- "One common reason is parameter servers have unbalanced load and some heavily-loaded parameter servers have reached capacity. There can also be multiple root causes. Some simple methods to mitigate this issue are to:\n",
+ "One common reason is that the parameter servers have unbalanced load and some heavily-loaded parameter servers have reached capacity. There can also be multiple root causes. Some simple methods to mitigate this issue are to:\n",
"\n",
"1. Shard your large model variables via specifying a `variable_partitioner` when constructing a `ParameterServerStrategy`.\n",
- "2. Avoid creating a hotspot variable that is required by all parameter servers in a single step if possible. For example, use a constant learning rate or subclass `tf.keras.optimizers.schedules.LearningRateSchedule` in optimizers since the default behavior is that the learning rate will become a variable placed on a particular parameter server and requested by all other parameter servers in each step.\n",
+ "2. Avoid creating a hotspot variable that is required by all parameter servers in a single step, by both:\n",
+ "\n",
+ " 1) Using a constant learning rate or subclass `tf.keras.optimizers.schedules.LearningRateSchedule` in optimizers. This is because the default behavior is that the learning rate will become a variable placed on a particular parameter server, and requested by all other parameter servers in each step); and\n",
+ "\n",
+ " 2) Using a `tf.keras.optimizers.legacy.Optimizer` (the standard `tf.keras.optimizers.Optimizer`s could still lead to hotspot variables).\n",
"3. Shuffle your large vocabularies before passing them to Keras preprocessing layers.\n",
"\n",
- "Another possible reason for performance issues is the coordinator. Your first implementation of `schedule`/`join` is Python-based and thus may have threading overhead. Also the latency between the coordinator and the workers can be large. If this is the case,\n",
+ "Another possible reason for performance issues is the coordinator. The implementation of `schedule`/`join` is Python-based and thus may have threading overhead. Also, the latency between the coordinator and the workers can be large. If this is the case:\n",
"\n",
- "- For `Model.fit`, you can set `steps_per_execution` argument provided at `Model.compile` to a value larger than 1.\n",
+ "- For `Model.fit`, you can set the `steps_per_execution` argument provided at `Model.compile` to a value larger than 1.\n",
"\n",
"- For a custom training loop, you can pack multiple steps into a single `tf.function`:\n",
"\n",
@@ -1241,7 +1326,7 @@
"\n",
"As the library is optimized further, hopefully most users won't have to manually pack steps in the future.\n",
"\n",
- "In addition, a small trick for performance improvement is to schedule functions without a return value as explained in the handling task failure section above."
+ "In addition, a small trick for performance improvement is to schedule functions without a return value as explained in the [handling task failure section](#handling_task_failure) above."
]
},
{
@@ -1261,22 +1346,35 @@
"- `os.environment[\"grpc_fail_fast\"]=\"use_caller\"` is needed on every task including the coordinator, to make fault tolerance work properly.\n",
"- Synchronous parameter server training is not supported.\n",
"- It is usually necessary to pack multiple steps into a single function to achieve optimal performance.\n",
- "- It is not supported to load a saved_model via `tf.saved_model.load` containing sharded variables. Note loading such a saved_model using TensorFlow Serving is expected to work.\n",
- "- It is not supported to load a checkpoint containing sharded optimizer slot variables into a different number of shards.\n",
+ "- It is not supported to load a saved_model via `tf.saved_model.load` containing sharded variables. Note loading such a saved_model using TensorFlow Serving is expected to work (refer to the [serving tutorial](https://www.tensorflow.org/tfx/tutorials/serving/rest_simple) for details).\n",
"- It is not supported to recover from parameter server failure without restarting the coordinator task.\n",
- "- Usage of `tf.lookup.StaticHashTable` (which is commonly employed by some `tf.keras.layers.experimental.preprocessing` layers, such as `IntegerLookup`, `StringLookup`, and `TextVectorization`) results in resources placed on the coordinator at this time with parameter server training. This has performance implications for lookup RPCs from workers to the coordinator. This is a current high priority to address.\n",
- "\n",
+ "- Creation of `tf.lookup.StaticHashTable`, commonly employed by some Keras preprocessing layers, such as `tf.keras.layers.IntegerLookup`, `tf.keras.layers.StringLookup`, and `tf.keras.layers.TextVectorization`, should be placed under `Strategy.scope`. Otherwise, resources will be placed on the coordinator, and lookup RPCs from workers to the coordinator incur performance implications.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "2MKBF0RPSvzB"
+ },
+ "source": [
"### `Model.fit` specifics\n",
"\n",
"- `steps_per_epoch` argument is required in `Model.fit`. You can select a value that provides appropriate intervals in an epoch.\n",
"- `ParameterServerStrategy` does not have support for custom callbacks that have batch-level calls for performance reasons. You should convert those calls into epoch-level calls with suitably picked `steps_per_epoch`, so that they are called every `steps_per_epoch` number of steps. Built-in callbacks are not affected: their batch-level calls have been modified to be performant. Supporting batch-level calls for `ParameterServerStrategy` is being planned.\n",
- "- For the same reason, unlike other strategies, progress bar and metrics are logged only at epoch boundaries.\n",
- "- `run_eagerly` is not supported.\n",
- "\n",
+ "- For the same reason, unlike other strategies, progress bars and metrics are logged only at epoch boundaries.\n",
+ "- `run_eagerly` is not supported.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "wvY-mg35Sx5L"
+ },
+ "source": [
"### Custom training loop specifics\n",
"\n",
- "- `ClusterCoordinator.schedule` doesn't support visitation guarantees for a dataset.\n",
- "- When `ClusterCoordinator.create_per_worker_dataset` is used, the whole dataset must be created inside the function passed to it.\n",
+ "- `ClusterCoordinator.schedule` doesn't support visitation guarantees for a dataset in general, although a visitation guarantee for evaluation is possible through `Model.fit/.evaluate`. See [Enabling exactly-once evaluation](#exactly_once_evaluation).\n",
+ "- When `ClusterCoordinator.create_per_worker_dataset` is used with a callable as input, the whole dataset must be created inside the function passed to it.\n",
"- `tf.data.Options` is ignored in a dataset created by `ClusterCoordinator.create_per_worker_dataset`."
]
}
@@ -1284,9 +1382,8 @@
"metadata": {
"accelerator": "GPU",
"colab": {
- "collapsed_sections": [],
"name": "parameter_server_training.ipynb",
- "toc_visible": true
+ "toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
diff --git a/site/en/tutorials/distribute/save_and_load.ipynb b/site/en/tutorials/distribute/save_and_load.ipynb
index 7317b277c45..c53a9b8bf0b 100644
--- a/site/en/tutorials/distribute/save_and_load.ipynb
+++ b/site/en/tutorials/distribute/save_and_load.ipynb
@@ -71,7 +71,12 @@
"source": [
"## Overview\n",
"\n",
- "It's common to save and load a model during training. There are two sets of APIs for saving and loading a keras model: a high-level API, and a low-level API. This tutorial demonstrates how you can use the SavedModel APIs when using `tf.distribute.Strategy`. To learn about SavedModel and serialization in general, please read the [saved model guide](../../guide/saved_model.ipynb), and the [Keras model serialization guide](../../guide/keras/save_and_serialize.ipynb). Let's start with a simple example: "
+ "This tutorial demonstrates how you can save and load models in a SavedModel format with `tf.distribute.Strategy` during or after training. There are two kinds of APIs for saving and loading a Keras model: high-level (`tf.keras.Model.save` and `tf.keras.models.load_model`) and low-level (`tf.saved_model.save` and `tf.saved_model.load`).\n",
+ "\n",
+ "To learn about SavedModel and serialization in general, please read the [saved model guide](../../guide/saved_model.ipynb), and the [Keras model serialization guide](https://www.tensorflow.org/guide/keras/save_and_serialize). Let's start with a simple example.\n",
+ "\n",
+ "Caution: TensorFlow models are code and it is important to be careful with untrusted code. Learn more in [Using TensorFlow securely](https://github.com/tensorflow/tensorflow/blob/master/SECURITY.md).\n",
+ "\n"
]
},
{
@@ -102,7 +107,7 @@
"id": "qqapWj98ptNV"
},
"source": [
- "Prepare the data and model using `tf.distribute.Strategy`:"
+ "Load and prepare the data with TensorFlow Datasets and `tf.data`, and create the model using `tf.distribute.MirroredStrategy`:"
]
},
{
@@ -116,7 +121,7 @@
"mirrored_strategy = tf.distribute.MirroredStrategy()\n",
"\n",
"def get_data():\n",
- " datasets, ds_info = tfds.load(name='mnist', with_info=True, as_supervised=True)\n",
+ " datasets = tfds.load(name='mnist', as_supervised=True)\n",
" mnist_train, mnist_test = datasets['train'], datasets['test']\n",
"\n",
" BUFFER_SIZE = 10000\n",
@@ -157,7 +162,7 @@
"id": "qmU4Y3feS9Na"
},
"source": [
- "Train the model: "
+ "Train the model with `tf.keras.Model.fit`: "
]
},
{
@@ -181,11 +186,11 @@
"source": [
"## Save and load the model\n",
"\n",
- "Now that you have a simple model to work with, let's take a look at the saving/loading APIs. \n",
- "There are two sets of APIs available:\n",
+ "Now that you have a simple model to work with, let's explore the saving/loading APIs. \n",
+ "There are two kinds of APIs available:\n",
"\n",
- "* High level keras `model.save` and `tf.keras.models.load_model`\n",
- "* Low level `tf.saved_model.save` and `tf.saved_model.load`\n"
+ "* High-level (Keras): `Model.save` and `tf.keras.models.load_model` (`.keras` zip archive format)\n",
+ "* Low-level: `tf.saved_model.save` and `tf.saved_model.load` (TF SavedModel format)\n"
]
},
{
@@ -194,7 +199,7 @@
"id": "FX_IF2F1tvFs"
},
"source": [
- "### The Keras APIs"
+ "### The Keras API"
]
},
{
@@ -203,7 +208,7 @@
"id": "O8xfceg4Z3H_"
},
"source": [
- "Here is an example of saving and loading a model with the Keras APIs:"
+ "Here is an example of saving and loading a model with the Keras API:"
]
},
{
@@ -214,7 +219,7 @@
},
"outputs": [],
"source": [
- "keras_model_path = \"/tmp/keras_save\"\n",
+ "keras_model_path = '/tmp/keras_save.keras'\n",
"model.save(keras_model_path)"
]
},
@@ -245,9 +250,9 @@
"id": "gYAnskzorda-"
},
"source": [
- "After restoring the model, you can continue training on it, even without needing to call `compile()` again, since it is already compiled before saving. The model is saved in the TensorFlow's standard `SavedModel` proto format. For more information, please refer to [the guide to `saved_model` format](../../guide/saved_model.ipynb).\n",
+ "After restoring the model, you can continue training on it, even without needing to call `Model.compile` again, since it was already compiled before saving. The model is saved a Keras zip archive format, marked by the `.keras` extension. For more information, please refer to [the guide on Keras saving](https://www.tensorflow.org/guide/keras/save_and_serialize).\n",
"\n",
- "Now to load the model and train it using a `tf.distribute.Strategy`:"
+ "Now, restore the model and train it using a `tf.distribute.Strategy`:"
]
},
{
@@ -258,7 +263,7 @@
},
"outputs": [],
"source": [
- "another_strategy = tf.distribute.OneDeviceStrategy(\"/cpu:0\")\n",
+ "another_strategy = tf.distribute.OneDeviceStrategy('/cpu:0')\n",
"with another_strategy.scope():\n",
" restored_keras_model_ds = tf.keras.models.load_model(keras_model_path)\n",
" restored_keras_model_ds.fit(train_dataset, epochs=2)"
@@ -270,7 +275,7 @@
"id": "PdiiPmL5tQk5"
},
"source": [
- "As you can see, loading works as expected with `tf.distribute.Strategy`. The strategy used here does not have to be the same strategy used before saving. "
+ "As the `Model.fit` output shows, loading works as expected with `tf.distribute.Strategy`. The strategy used here does not have to be the same strategy used before saving. "
]
},
{
@@ -279,7 +284,7 @@
"id": "3CrXIbmFt0f6"
},
"source": [
- "### The `tf.saved_model` APIs"
+ "### The `tf.saved_model` API"
]
},
{
@@ -288,7 +293,7 @@
"id": "HtGzPp6et4Em"
},
"source": [
- "Now let's take a look at the lower level APIs. Saving the model is similar to the keras API:"
+ "Saving the model with lower-level API is similar to the Keras API:"
]
},
{
@@ -300,7 +305,7 @@
"outputs": [],
"source": [
"model = get_model() # get a fresh model\n",
- "saved_model_path = \"/tmp/tf_save\"\n",
+ "saved_model_path = '/tmp/tf_save'\n",
"tf.saved_model.save(model, saved_model_path)"
]
},
@@ -310,7 +315,7 @@
"id": "q1QNRYcwuRll"
},
"source": [
- "Loading can be done with `tf.saved_model.load()`. However, since it is an API that is on the lower level (and hence has a wider range of use cases), it does not return a Keras model. Instead, it returns an object that contain functions that can be used to do inference. For example:"
+ "Loading can be done with `tf.saved_model.load`. However, since it is a lower-level API (and hence has a wider range of use cases), it does not return a Keras model. Instead, it returns an object that contain functions that can be used to do inference. For example:"
]
},
{
@@ -321,7 +326,7 @@
},
"outputs": [],
"source": [
- "DEFAULT_FUNCTION_KEY = \"serving_default\"\n",
+ "DEFAULT_FUNCTION_KEY = 'serving_default'\n",
"loaded = tf.saved_model.load(saved_model_path)\n",
"inference_func = loaded.signatures[DEFAULT_FUNCTION_KEY]"
]
@@ -332,7 +337,7 @@
"id": "x65l7AaHUZCA"
},
"source": [
- "The loaded object may contain multiple functions, each associated with a key. The `\"serving_default\"` is the default key for the inference function with a saved Keras model. To do an inference with this function: "
+ "The loaded object may contain multiple functions, each associated with a key. The `\"serving_default\"` key is the default key for the inference function with a saved Keras model. To do inference with this function: "
]
},
{
@@ -375,7 +380,9 @@
"\n",
" # Calling the function in a distributed manner\n",
" for batch in dist_predict_dataset:\n",
- " another_strategy.run(inference_func,args=(batch,))"
+ " result = another_strategy.run(inference_func, args=(batch,))\n",
+ " print(result)\n",
+ " break"
]
},
{
@@ -384,7 +391,7 @@
"id": "hWGSukoyw3fF"
},
"source": [
- "Calling the restored function is just a forward pass on the saved model (predict). What if yout want to continue training the loaded function? Or embed the loaded function into a bigger model? A common practice is to wrap this loaded object to a Keras layer to achieve this. Luckily, [TF Hub](https://www.tensorflow.org/hub) has [hub.KerasLayer](https://github.com/tensorflow/hub/blob/master/tensorflow_hub/keras_layer.py) for this purpose, shown here:"
+ "Calling the restored function is just a forward pass on the saved model (`tf.keras.Model.predict`). What if you want to continue training the loaded function? Or what if you need to embed the loaded function into a bigger model? A common practice is to wrap this loaded object into a Keras layer to achieve this. Luckily, [TF Hub](https://www.tensorflow.org/hub) has [`hub.KerasLayer`](https://github.com/tensorflow/hub/blob/master/tensorflow_hub/keras_layer.py) for this purpose, shown here:"
]
},
{
@@ -421,7 +428,7 @@
"id": "Oe1z_OtSJlu2"
},
"source": [
- "As you can see, `hub.KerasLayer` wraps the result loaded back from `tf.saved_model.load()` into a Keras layer that can be used to build another model. This is very useful for transfer learning. "
+ "In the above example, Tensorflow Hub's `hub.KerasLayer` wraps the result loaded back from `tf.saved_model.load` into a Keras layer that is used to build another model. This is very useful for transfer learning. "
]
},
{
@@ -439,11 +446,11 @@
"id": "GC6GQ9HDLxD6"
},
"source": [
- "For saving, if you are working with a keras model, it is almost always recommended to use the Keras's `model.save()` API. If what you are saving is not a Keras model, then the lower level API is your only choice. \n",
+ "For saving, if you are working with a Keras model, use the Keras `Model.save` API unless you need the additional control allowed by the low-level API. If what you are saving is not a Keras model, then the lower-level API, `tf.saved_model.save`, is your only choice. \n",
"\n",
- "For loading, which API you use depends on what you want to get from the loading API. If you cannot (or do not want to) get a Keras model, then use `tf.saved_model.load()`. Otherwise, use `tf.keras.models.load_model()`. Note that you can get a Keras model back only if you saved a Keras model. \n",
+ "For loading, your API choice depends on what you want to get from the model loading API. If you cannot (or do not want to) get a Keras model, then use `tf.saved_model.load`. Otherwise, use `tf.keras.models.load_model`. Note that you can get a Keras model back only if you saved a Keras model. \n",
"\n",
- "It is possible to mix and match the APIs. You can save a Keras model with `model.save`, and load a non-Keras model with the low-level API, `tf.saved_model.load`. "
+ "It is possible to mix and match the APIs. You can save a Keras model with `Model.save`, and load a non-Keras model with the low-level API, `tf.saved_model.load`. "
]
},
{
@@ -456,13 +463,13 @@
"source": [
"model = get_model()\n",
"\n",
- "# Saving the model using Keras's save() API\n",
- "model.save(keras_model_path) \n",
+ "# Saving the model using Keras `Model.save`\n",
+ "model.save(saved_model_path)\n",
"\n",
"another_strategy = tf.distribute.MirroredStrategy()\n",
- "# Loading the model using lower level API\n",
+ "# Loading the model using the lower-level API\n",
"with another_strategy.scope():\n",
- " loaded = tf.saved_model.load(keras_model_path)"
+ " loaded = tf.saved_model.load(saved_model_path)"
]
},
{
@@ -471,7 +478,7 @@
"id": "0Z7lSj8nZiW5"
},
"source": [
- "### Saving/Loading from local device"
+ "### Saving/Loading from a local device"
]
},
{
@@ -480,7 +487,7 @@
"id": "NVAjWcosZodw"
},
"source": [
- "When saving and loading from a local io device while running remotely, for example using a cloud TPU, the option `experimental_io_device` must be used to set the io device to localhost."
+ "When saving and loading from a local I/O device while training on remote devices—for example, when using a Cloud TPU—you must use the option `experimental_io_device` in `tf.saved_model.SaveOptions` and `tf.saved_model.LoadOptions` to set the I/O device to `localhost`. For example:"
]
},
{
@@ -494,7 +501,7 @@
"model = get_model()\n",
"\n",
"# Saving the model to a path on localhost.\n",
- "saved_model_path = \"/tmp/tf_save\"\n",
+ "saved_model_path = '/tmp/tf_save'\n",
"save_options = tf.saved_model.SaveOptions(experimental_io_device='/job:localhost')\n",
"model.save(saved_model_path, options=save_options)\n",
"\n",
@@ -517,14 +524,10 @@
{
"cell_type": "markdown",
"metadata": {
- "id": "Tzog2ti7YYgy"
+ "id": "2cCSZrD7VCxe"
},
"source": [
- "A special case is when you have a Keras model that does not have well-defined inputs. For example, a Sequential model can be created without any input shapes (`Sequential([Dense(3), ...]`). Subclassed models also do not have well-defined inputs after initialization. In this case, you should stick with the lower level APIs on both saving and loading, otherwise you will get an error. \n",
- "\n",
- "To check if your model has well-defined inputs, just check if `model.inputs` is `None`. If it is not `None`, you are all good. Input shapes are automatically defined when the model is used in `.fit`, `.evaluate`, `.predict`, or when calling the model (`model(inputs)`). \n",
- "\n",
- "Here is an example:"
+ "One special case is when you create Keras models in certain ways, and then save them before training. For example:"
]
},
{
@@ -536,6 +539,7 @@
"outputs": [],
"source": [
"class SubclassedModel(tf.keras.Model):\n",
+ " \"\"\"Example model defined by subclassing `tf.keras.Model`.\"\"\"\n",
"\n",
" output_name = 'output_layer'\n",
"\n",
@@ -548,8 +552,89 @@
" return self._dense_layer(inputs)\n",
"\n",
"my_model = SubclassedModel()\n",
- "# my_model.save(keras_model_path) # ERROR! \n",
- "tf.saved_model.save(my_model, saved_model_path)"
+ "try:\n",
+ " my_model.save(saved_model_path)\n",
+ "except ValueError as e:\n",
+ " print(f'{type(e).__name__}: ', *e.args)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "D4qMyXFDSPDO"
+ },
+ "source": [
+ "A SavedModel saves the `tf.types.experimental.ConcreteFunction` objects generated when you trace a `tf.function` (check _When is a Function tracing?_ in the [Introduction to graphs and tf.function](../../guide/intro_to_graphs.ipynb) guide to learn more). If you get a `ValueError` like this it's because `Model.save` was not able to find or create a traced `ConcreteFunction`.\n",
+ "\n",
+ "**Caution:** You shouldn't save a model without at least one `ConcreteFunction`, since the low-level API will otherwise generate a SavedModel with no `ConcreteFunction` signatures ([learn more](../../guide/saved_model.ipynb) about the SavedModel format). For example:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "064SE47mYDj8"
+ },
+ "outputs": [],
+ "source": [
+ "tf.saved_model.save(my_model, saved_model_path)\n",
+ "x = tf.saved_model.load(saved_model_path)\n",
+ "x.signatures"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "LRTxlASJX-cY"
+ },
+ "source": [
+ "\n",
+ "Usually the model's forward pass—the `call` method—will be traced automatically when the model is called for the first time, often via the Keras `Model.fit` method. A `ConcreteFunction` can also be generated by the Keras [Sequential](https://www.tensorflow.org/guide/keras/sequential_model) and [Functional](https://www.tensorflow.org/guide/keras/functional) APIs, if you set the input shape, for example, by making the first layer either a `tf.keras.layers.InputLayer` or another layer type, and passing it the `input_shape` keyword argument. \n",
+ "\n",
+ "To verify if your model has any traced `ConcreteFunction`s, check if `Model.save_spec` is `None`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "xAXise4eR0YJ"
+ },
+ "outputs": [],
+ "source": [
+ "print(my_model.save_spec() is None)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "G2G_FQrWJAO3"
+ },
+ "source": [
+ "Let's use `tf.keras.Model.fit` to train the model, and notice that the `save_spec` gets defined and model saving will work:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "cv5LTi0zDkKS"
+ },
+ "outputs": [],
+ "source": [
+ "BATCH_SIZE_PER_REPLICA = 4\n",
+ "BATCH_SIZE = BATCH_SIZE_PER_REPLICA * mirrored_strategy.num_replicas_in_sync\n",
+ "\n",
+ "dataset_size = 100\n",
+ "dataset = tf.data.Dataset.from_tensors(\n",
+ " (tf.range(5, dtype=tf.float32), tf.range(5, dtype=tf.float32))\n",
+ " ).repeat(dataset_size).batch(BATCH_SIZE)\n",
+ "\n",
+ "my_model.compile(optimizer='adam', loss='mean_squared_error')\n",
+ "my_model.fit(dataset, epochs=2)\n",
+ "\n",
+ "print(my_model.save_spec() is None)\n",
+ "my_model.save(saved_model_path)"
]
}
],
diff --git a/site/en/tutorials/estimator/boosted_trees.ipynb b/site/en/tutorials/estimator/boosted_trees.ipynb
deleted file mode 100644
index 4c1bb1890c0..00000000000
--- a/site/en/tutorials/estimator/boosted_trees.ipynb
+++ /dev/null
@@ -1,612 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "7765UFHoyGx6"
- },
- "source": [
- "##### Copyright 2019 The TensorFlow Authors."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "id": "KVtTDrUNyL7x"
- },
- "outputs": [],
- "source": [
- "#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n",
- "# you may not use this file except in compliance with the License.\n",
- "# You may obtain a copy of the License at\n",
- "#\n",
- "# https://www.apache.org/licenses/LICENSE-2.0\n",
- "#\n",
- "# Unless required by applicable law or agreed to in writing, software\n",
- "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
- "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
- "# See the License for the specific language governing permissions and\n",
- "# limitations under the License."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "xPYxZMrWyA0N"
- },
- "source": [
- "# Boosted trees using Estimators"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "p_vOREjRx-Y0"
- },
- "source": [
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "6gWdn5lrlkhR"
- },
- "source": [
- "> Warning: Estimators are not recommended for new code. Estimators run `v1.Session`-style code which is more difficult to write correctly, and can behave unexpectedly, especially when combined with TF 2 code. Estimators do fall under our [compatibility guarantees] (https://tensorflow.org/guide/versions), but will receive no fixes other than security vulnerabilities. See the [migration guide](https://tensorflow.org/guide/migrate) for details."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "qNW3c_rop5J8"
- },
- "source": [
- "**Note**: Modern Keras based implementations of many state of the art decision forest algorithms are available in [TensorFlow Decision Forests](https://tensorflow.org/decision_forests)."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "dW3r7qVxzqN5"
- },
- "source": [
- "This tutorial is an end-to-end walkthrough of training a Gradient Boosting model using decision trees with the `tf.estimator` API. Boosted Trees models are among the most popular and effective machine learning approaches for both regression and classification. It is an ensemble technique that combines the predictions from several (think 10s, 100s or even 1000s) tree models.\n",
- "\n",
- "Boosted Trees models are popular with many machine learning practitioners as they can achieve impressive performance with minimal hyperparameter tuning."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "eylrTPAN3rJV"
- },
- "source": [
- "## Load the titanic dataset\n",
- "You will be using the titanic dataset, where the (rather morbid) goal is to predict passenger survival, given characteristics such as gender, age, class, etc."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "KuhAiPfZ3rJW"
- },
- "outputs": [],
- "source": [
- "import numpy as np\n",
- "import pandas as pd\n",
- "from IPython.display import clear_output\n",
- "from matplotlib import pyplot as plt\n",
- "\n",
- "# Load dataset.\n",
- "dftrain = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/train.csv')\n",
- "dfeval = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/eval.csv')\n",
- "y_train = dftrain.pop('survived')\n",
- "y_eval = dfeval.pop('survived')"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "NFtnFm1T0kMf"
- },
- "outputs": [],
- "source": [
- "import tensorflow as tf\n",
- "tf.random.set_seed(123)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "3ioodHdVJVdA"
- },
- "source": [
- "The dataset consists of a training set and an evaluation set:\n",
- "\n",
- "* `dftrain` and `y_train` are the *training set*—the data the model uses to learn.\n",
- "* The model is tested against the *eval set*, `dfeval`, and `y_eval`.\n",
- "\n",
- "For training you will use the following features:\n",
- "\n",
- "\n",
- "\n",
- " \n",
- " | Feature Name | \n",
- " Description | \n",
- "
\n",
- " \n",
- " | sex | \n",
- " Gender of passenger | \n",
- "
\n",
- " \n",
- " | age | \n",
- " Age of passenger | \n",
- "
\n",
- " \n",
- " | n_siblings_spouses | \n",
- " siblings and partners aboard | \n",
- "
\n",
- " \n",
- " | parch | \n",
- " of parents and children aboard | \n",
- "
\n",
- " \n",
- " | fare | \n",
- " Fare passenger paid. | \n",
- "
\n",
- " \n",
- " | class | \n",
- " Passenger's class on ship | \n",
- "
\n",
- " \n",
- " | deck | \n",
- " Which deck passenger was on | \n",
- "
\n",
- " \n",
- " | embark_town | \n",
- " Which town passenger embarked from | \n",
- "
\n",
- " \n",
- " | alone | \n",
- " If passenger was alone | \n",
- "
\n",
- "
"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AoPiWsJALr-k"
- },
- "source": [
- "## Explore the data"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "slcat1yzmzw5"
- },
- "source": [
- "Let's first preview some of the data and create summary statistics on the training set."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "15PLelXBlxEW"
- },
- "outputs": [],
- "source": [
- "dftrain.head()"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "j2hiM4ETmqP0"
- },
- "outputs": [],
- "source": [
- "dftrain.describe()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "-IR0e8V-LyJ4"
- },
- "source": [
- "There are 627 and 264 examples in the training and evaluation sets, respectively."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "_1NwYqGwDjFf"
- },
- "outputs": [],
- "source": [
- "dftrain.shape[0], dfeval.shape[0]"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "28UFJ4KSMK3V"
- },
- "source": [
- "The majority of passengers are in their 20's and 30's."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "CaVDmZtuDfux"
- },
- "outputs": [],
- "source": [
- "dftrain.age.hist(bins=20)\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "1pifWiCoMbR5"
- },
- "source": [
- "There are approximately twice as male passengers as female passengers aboard."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "-WazAq30MO5J"
- },
- "outputs": [],
- "source": [
- "dftrain.sex.value_counts().plot(kind='barh')\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "7_XkxrpmmVU_"
- },
- "source": [
- "The majority of passengers were in the \"third\" class."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "zZ3PvVy4l4gI"
- },
- "outputs": [],
- "source": [
- "dftrain['class'].value_counts().plot(kind='barh')\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HM5SlwlxmZMT"
- },
- "source": [
- "Most passengers embarked from Southampton."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "RVTSrdr4mZaC"
- },
- "outputs": [],
- "source": [
- "dftrain['embark_town'].value_counts().plot(kind='barh')\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "aTn1niLPob3x"
- },
- "source": [
- "Females have a much higher chance of surviving vs. males. This will clearly be a predictive feature for the model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Eh3KW5oYkaNS"
- },
- "outputs": [],
- "source": [
- "pd.concat([dftrain, y_train], axis=1).groupby('sex').survived.mean().plot(kind='barh').set_xlabel('% survive')\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "krkRHuMp3rJn"
- },
- "source": [
- "## Create feature columns and input functions\n",
- "The Gradient Boosting estimator can utilize both numeric and categorical features. Feature columns work with all TensorFlow estimators and their purpose is to define the features used for modeling. Additionally they provide some feature engineering capabilities like one-hot-encoding, normalization, and bucketization. In this tutorial, the fields in `CATEGORICAL_COLUMNS` are transformed from categorical columns to one-hot-encoded columns ([indicator column](https://www.tensorflow.org/api_docs/python/tf/feature_column/indicator_column)):"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "upaNWxcF3rJn"
- },
- "outputs": [],
- "source": [
- "CATEGORICAL_COLUMNS = ['sex', 'n_siblings_spouses', 'parch', 'class', 'deck',\n",
- " 'embark_town', 'alone']\n",
- "NUMERIC_COLUMNS = ['age', 'fare']\n",
- "\n",
- "def one_hot_cat_column(feature_name, vocab):\n",
- " return tf.feature_column.indicator_column(\n",
- " tf.feature_column.categorical_column_with_vocabulary_list(feature_name,\n",
- " vocab))\n",
- "feature_columns = []\n",
- "for feature_name in CATEGORICAL_COLUMNS:\n",
- " # Need to one-hot encode categorical features.\n",
- " vocabulary = dftrain[feature_name].unique()\n",
- " feature_columns.append(one_hot_cat_column(feature_name, vocabulary))\n",
- "\n",
- "for feature_name in NUMERIC_COLUMNS:\n",
- " feature_columns.append(tf.feature_column.numeric_column(feature_name,\n",
- " dtype=tf.float32))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "74GNtFpStSAz"
- },
- "source": [
- "You can view the transformation that a feature column produces. For example, here is the output when using the `indicator_column` on a single example:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Eaq79D9FtmF8"
- },
- "outputs": [],
- "source": [
- "example = dict(dftrain.head(1))\n",
- "class_fc = tf.feature_column.indicator_column(tf.feature_column.categorical_column_with_vocabulary_list('class', ('First', 'Second', 'Third')))\n",
- "print('Feature value: \"{}\"'.format(example['class'].iloc[0]))\n",
- "print('One-hot encoded: ', tf.keras.layers.DenseFeatures([class_fc])(example).numpy())"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "YbCUn3nCusC3"
- },
- "source": [
- "Additionally, you can view all of the feature column transformations together:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "omIYcsVws3g0"
- },
- "outputs": [],
- "source": [
- "tf.keras.layers.DenseFeatures(feature_columns)(example).numpy()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "-UOlROp33rJo"
- },
- "source": [
- "Next you need to create the input functions. These will specify how data will be read into our model for both training and inference. You will use the `from_tensor_slices` method in the [`tf.data`](https://www.tensorflow.org/api_docs/python/tf/data) API to read in data directly from Pandas. This is suitable for smaller, in-memory datasets. For larger datasets, the tf.data API supports a variety of file formats (including [csv](https://www.tensorflow.org/api_docs/python/tf/data/experimental/make_csv_dataset)) so that you can process datasets that do not fit in memory."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "9dquwCQB3rJp"
- },
- "outputs": [],
- "source": [
- "# Use entire batch since this is such a small dataset.\n",
- "NUM_EXAMPLES = len(y_train)\n",
- "\n",
- "def make_input_fn(X, y, n_epochs=None, shuffle=True):\n",
- " def input_fn():\n",
- " dataset = tf.data.Dataset.from_tensor_slices((dict(X), y))\n",
- " if shuffle:\n",
- " dataset = dataset.shuffle(NUM_EXAMPLES)\n",
- " # For training, cycle thru dataset as many times as need (n_epochs=None).\n",
- " dataset = dataset.repeat(n_epochs)\n",
- " # In memory training doesn't use batching.\n",
- " dataset = dataset.batch(NUM_EXAMPLES)\n",
- " return dataset\n",
- " return input_fn\n",
- "\n",
- "# Training and evaluation input functions.\n",
- "train_input_fn = make_input_fn(dftrain, y_train)\n",
- "eval_input_fn = make_input_fn(dfeval, y_eval, shuffle=False, n_epochs=1)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HttfNNlN3rJr"
- },
- "source": [
- "## Train and evaluate the model\n",
- "\n",
- "Below you will do the following steps:\n",
- "\n",
- "1. Initialize the model, specifying the features and hyperparameters.\n",
- "2. Feed the training data to the model using the `train_input_fn` and train the model using the `train` function.\n",
- "3. You will assess model performance using the evaluation set—in this example, the `dfeval` DataFrame. You will verify that the predictions match the labels from the `y_eval` array.\n",
- "\n",
- "Before training a Boosted Trees model, let's first train a linear classifier (logistic regression model). It is best practice to start with a simpler model to establish a benchmark."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "JPOGpmmq3rJr"
- },
- "outputs": [],
- "source": [
- "linear_est = tf.estimator.LinearClassifier(feature_columns)\n",
- "\n",
- "# Train model.\n",
- "linear_est.train(train_input_fn, max_steps=100)\n",
- "\n",
- "# Evaluation.\n",
- "result = linear_est.evaluate(eval_input_fn)\n",
- "clear_output()\n",
- "print(pd.Series(result))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "BarkNXwA3rJu"
- },
- "source": [
- "Next let's train a Boosted Trees model. For boosted trees, regression (`BoostedTreesRegressor`) and classification (`BoostedTreesClassifier`) are supported. Since the goal is to predict a class - survive or not survive, you will use the `BoostedTreesClassifier`.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "tgEzMtlw3rJu"
- },
- "outputs": [],
- "source": [
- "# Since data fits into memory, use entire dataset per layer. It will be faster.\n",
- "# Above one batch is defined as the entire dataset.\n",
- "n_batches = 1\n",
- "est = tf.estimator.BoostedTreesClassifier(feature_columns,\n",
- " n_batches_per_layer=n_batches)\n",
- "\n",
- "# The model will stop training once the specified number of trees is built, not\n",
- "# based on the number of steps.\n",
- "est.train(train_input_fn, max_steps=100)\n",
- "\n",
- "# Eval.\n",
- "result = est.evaluate(eval_input_fn)\n",
- "clear_output()\n",
- "print(pd.Series(result))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "hEflwznXvuMP"
- },
- "source": [
- "Now you can use the train model to make predictions on a passenger from the evaluation set. TensorFlow models are optimized to make predictions on a batch, or collection, of examples at once. Earlier, the `eval_input_fn` is defined using the entire evaluation set."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "6zmIjTr73rJ4"
- },
- "outputs": [],
- "source": [
- "pred_dicts = list(est.predict(eval_input_fn))\n",
- "probs = pd.Series([pred['probabilities'][1] for pred in pred_dicts])\n",
- "\n",
- "probs.plot(kind='hist', bins=20, title='predicted probabilities')\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "mBUaNN1BzJHG"
- },
- "source": [
- "Finally you can also look at the receiver operating characteristic (ROC) of the results, which will give us a better idea of the tradeoff between the true positive rate and false positive rate."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "NzxghvVz3rJ6"
- },
- "outputs": [],
- "source": [
- "from sklearn.metrics import roc_curve\n",
- "\n",
- "fpr, tpr, _ = roc_curve(y_eval, probs)\n",
- "plt.plot(fpr, tpr)\n",
- "plt.title('ROC curve')\n",
- "plt.xlabel('false positive rate')\n",
- "plt.ylabel('true positive rate')\n",
- "plt.xlim(0,)\n",
- "plt.ylim(0,)\n",
- "plt.show()"
- ]
- }
- ],
- "metadata": {
- "colab": {
- "collapsed_sections": [],
- "name": "boosted_trees.ipynb",
- "toc_visible": true
- },
- "kernelspec": {
- "display_name": "Python 3",
- "name": "python3"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
diff --git a/site/en/tutorials/estimator/boosted_trees_model_understanding.ipynb b/site/en/tutorials/estimator/boosted_trees_model_understanding.ipynb
deleted file mode 100644
index c437574a13a..00000000000
--- a/site/en/tutorials/estimator/boosted_trees_model_understanding.ipynb
+++ /dev/null
@@ -1,1027 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "7765UFHoyGx6"
- },
- "source": [
- "##### Copyright 2019 The TensorFlow Authors."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "id": "KVtTDrUNyL7x"
- },
- "outputs": [],
- "source": [
- "#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n",
- "# you may not use this file except in compliance with the License.\n",
- "# You may obtain a copy of the License at\n",
- "#\n",
- "# https://www.apache.org/licenses/LICENSE-2.0\n",
- "#\n",
- "# Unless required by applicable law or agreed to in writing, software\n",
- "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
- "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
- "# See the License for the specific language governing permissions and\n",
- "# limitations under the License."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "r0_fqL3ayLHX"
- },
- "source": [
- "# Gradient Boosted Trees: Model understanding"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "PS6_yKSoyLAl"
- },
- "source": [
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "pV4mnvs7l40o"
- },
- "source": [
- "> Warning: Estimators are not recommended for new code. Estimators run `v1.Session`-style code which is more difficult to write correctly, and can behave unexpectedly, especially when combined with TF 2 code. Estimators do fall under our [compatibility guarantees](https://tensorflow.org/guide/versions), but will receive no fixes other than security vulnerabilities. See the [migration guide](https://tensorflow.org/guide/migrate) for details."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "f4L1ffaFp2gT"
- },
- "source": [
- "**Note**: Modern Keras based implementations of many state of the art decision forest algorithms are available in [TensorFlow Decision Forests](https://tensorflow.org/decision_forests)."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "dW3r7qVxzqN5"
- },
- "source": [
- "For an end-to-end walkthrough of training a Gradient Boosting model check out the [boosted trees tutorial](./boosted_trees). In this tutorial you will:\n",
- "\n",
- "* Learn how to interpret a Boosted Trees model both *locally* and *globally*\n",
- "* Gain intution for how a Boosted Trees model fits a dataset\n",
- "\n",
- "## How to interpret Boosted Trees models both locally and globally\n",
- "\n",
- "Local interpretability refers to an understanding of a model’s predictions at the individual example level, while global interpretability refers to an understanding of the model as a whole. Such techniques can help machine learning (ML) practitioners detect bias and bugs during the model development stage.\n",
- "\n",
- "For local interpretability, you will learn how to create and visualize per-instance contributions. To distinguish this from feature importances, we refer to these values as directional feature contributions (DFCs).\n",
- "\n",
- "For global interpretability you will retrieve and visualize gain-based feature importances, [permutation feature importances](https://www.stat.berkeley.edu/~breiman/randomforest2001.pdf) and also show aggregated DFCs."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "eylrTPAN3rJV"
- },
- "source": [
- "## Load the titanic dataset\n",
- "You will be using the titanic dataset, where the (rather morbid) goal is to predict passenger survival, given characteristics such as gender, age, class, etc."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "132V3PZ8V8VA"
- },
- "outputs": [],
- "source": [
- "!pip install statsmodels"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "KuhAiPfZ3rJW"
- },
- "outputs": [],
- "source": [
- "import numpy as np\n",
- "import pandas as pd\n",
- "from IPython.display import clear_output\n",
- "\n",
- "# Load dataset.\n",
- "dftrain = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/train.csv')\n",
- "dfeval = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/eval.csv')\n",
- "y_train = dftrain.pop('survived')\n",
- "y_eval = dfeval.pop('survived')"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "sp1ShjJJeyH3"
- },
- "outputs": [],
- "source": [
- "import tensorflow as tf\n",
- "tf.random.set_seed(123)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "3ioodHdVJVdA"
- },
- "source": [
- "For a description of the features, please review the prior tutorial."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "krkRHuMp3rJn"
- },
- "source": [
- "## Create feature columns, input_fn, and the train the estimator"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "JiJ6K3hr1lXW"
- },
- "source": [
- "### Preprocess the data"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "udMytRJC05oW"
- },
- "source": [
- "Create the feature columns, using the original numeric columns as is and one-hot-encoding categorical variables."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "upaNWxcF3rJn"
- },
- "outputs": [],
- "source": [
- "fc = tf.feature_column\n",
- "CATEGORICAL_COLUMNS = ['sex', 'n_siblings_spouses', 'parch', 'class', 'deck',\n",
- " 'embark_town', 'alone']\n",
- "NUMERIC_COLUMNS = ['age', 'fare']\n",
- "\n",
- "def one_hot_cat_column(feature_name, vocab):\n",
- " return fc.indicator_column(\n",
- " fc.categorical_column_with_vocabulary_list(feature_name,\n",
- " vocab))\n",
- "feature_columns = []\n",
- "for feature_name in CATEGORICAL_COLUMNS:\n",
- " # Need to one-hot encode categorical features.\n",
- " vocabulary = dftrain[feature_name].unique()\n",
- " feature_columns.append(one_hot_cat_column(feature_name, vocabulary))\n",
- "\n",
- "for feature_name in NUMERIC_COLUMNS:\n",
- " feature_columns.append(fc.numeric_column(feature_name,\n",
- " dtype=tf.float32))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "9rTefnXe1n0v"
- },
- "source": [
- "### Build the input pipeline"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "-UOlROp33rJo"
- },
- "source": [
- "Create the input functions using the `from_tensor_slices` method in the [`tf.data`](https://www.tensorflow.org/api_docs/python/tf/data) API to read in data directly from Pandas."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "9dquwCQB3rJp"
- },
- "outputs": [],
- "source": [
- "# Use entire batch since this is such a small dataset.\n",
- "NUM_EXAMPLES = len(y_train)\n",
- "\n",
- "def make_input_fn(X, y, n_epochs=None, shuffle=True):\n",
- " def input_fn():\n",
- " dataset = tf.data.Dataset.from_tensor_slices((X.to_dict(orient='list'), y))\n",
- " if shuffle:\n",
- " dataset = dataset.shuffle(NUM_EXAMPLES)\n",
- " # For training, cycle thru dataset as many times as need (n_epochs=None).\n",
- " dataset = (dataset\n",
- " .repeat(n_epochs)\n",
- " .batch(NUM_EXAMPLES))\n",
- " return dataset\n",
- " return input_fn\n",
- "\n",
- "# Training and evaluation input functions.\n",
- "train_input_fn = make_input_fn(dftrain, y_train)\n",
- "eval_input_fn = make_input_fn(dfeval, y_eval, shuffle=False, n_epochs=1)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "HttfNNlN3rJr"
- },
- "source": [
- "### Train the model"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "tgEzMtlw3rJu"
- },
- "outputs": [],
- "source": [
- "params = {\n",
- " 'n_trees': 50,\n",
- " 'max_depth': 3,\n",
- " 'n_batches_per_layer': 1,\n",
- " # You must enable center_bias = True to get DFCs. This will force the model to\n",
- " # make an initial prediction before using any features (e.g. use the mean of\n",
- " # the training labels for regression or log odds for classification when\n",
- " # using cross entropy loss).\n",
- " 'center_bias': True\n",
- "}\n",
- "\n",
- "est = tf.estimator.BoostedTreesClassifier(feature_columns, **params)\n",
- "# Train model.\n",
- "est.train(train_input_fn, max_steps=100)\n",
- "\n",
- "# Evaluation.\n",
- "results = est.evaluate(eval_input_fn)\n",
- "clear_output()\n",
- "pd.Series(results).to_frame()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "JgAz3jDa_tRA"
- },
- "source": [
- "For performance reasons, when your data fits in memory, we recommend use the arg `train_in_memory=True` in the `tf.estimator.BoostedTreesClassifier` function. However if training time is not of a concern or if you have a very large dataset and want to do distributed training, use the `tf.estimator.BoostedTrees` API shown above.\n",
- "\n",
- "\n",
- "When using this method, you should not batch your input data, as the method operates on the entire dataset.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "y7ztzoSk_vjY"
- },
- "outputs": [],
- "source": [
- "in_memory_params = dict(params)\n",
- "in_memory_params['n_batches_per_layer'] = 1\n",
- "# In-memory input_fn does not use batching.\n",
- "def make_inmemory_train_input_fn(X, y):\n",
- " y = np.expand_dims(y, axis=1)\n",
- " def input_fn():\n",
- " return dict(X), y\n",
- " return input_fn\n",
- "train_input_fn = make_inmemory_train_input_fn(dftrain, y_train)\n",
- "\n",
- "# Train the model.\n",
- "est = tf.estimator.BoostedTreesClassifier(\n",
- " feature_columns, \n",
- " train_in_memory=True, \n",
- " **in_memory_params)\n",
- "\n",
- "est.train(train_input_fn)\n",
- "print(est.evaluate(eval_input_fn))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "TSZYqNcRuczV"
- },
- "source": [
- "## Model interpretation and plotting"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "BjcfLiI3uczW"
- },
- "outputs": [],
- "source": [
- "import matplotlib.pyplot as plt\n",
- "import seaborn as sns\n",
- "sns_colors = sns.color_palette('colorblind')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "ywTtbBvBuczY"
- },
- "source": [
- "## Local interpretability\n",
- "Next you will output the directional feature contributions (DFCs) to explain individual predictions using the approach outlined in [Palczewska et al](https://arxiv.org/pdf/1312.1121.pdf) and by Saabas in [Interpreting Random Forests](http://blog.datadive.net/interpreting-random-forests/) (this method is also available in scikit-learn for Random Forests in the [`treeinterpreter`](https://github.com/andosa/treeinterpreter) package). The DFCs are generated with:\n",
- "\n",
- "`pred_dicts = list(est.experimental_predict_with_explanations(pred_input_fn))`\n",
- "\n",
- "(Note: The method is named experimental as we may modify the API before dropping the experimental prefix.)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "TIL93B4sDRqE"
- },
- "outputs": [],
- "source": [
- "pred_dicts = list(est.experimental_predict_with_explanations(eval_input_fn))"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "tDPoRx_ZaY1E"
- },
- "outputs": [],
- "source": [
- "# Create DFC Pandas dataframe.\n",
- "labels = y_eval.values\n",
- "probs = pd.Series([pred['probabilities'][1] for pred in pred_dicts])\n",
- "df_dfc = pd.DataFrame([pred['dfc'] for pred in pred_dicts])\n",
- "df_dfc.describe().T"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "EUKSaVoraY1C"
- },
- "source": [
- "A nice property of DFCs is that the sum of the contributions + the bias is equal to the prediction for a given example."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Hd9VuizRaY1H"
- },
- "outputs": [],
- "source": [
- "# Sum of DFCs + bias == probabality.\n",
- "bias = pred_dicts[0]['bias']\n",
- "dfc_prob = df_dfc.sum(axis=1) + bias\n",
- "np.testing.assert_almost_equal(dfc_prob.values,\n",
- " probs.values)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "tx5p4vEhuczg"
- },
- "source": [
- "Plot DFCs for an individual passenger. Let's make the plot nice by color coding based on the contributions' directionality and add the feature values on figure."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "6z_Tq1Pquczj"
- },
- "outputs": [],
- "source": [
- "# Boilerplate code for plotting :)\n",
- "def _get_color(value):\n",
- " \"\"\"To make positive DFCs plot green, negative DFCs plot red.\"\"\"\n",
- " green, red = sns.color_palette()[2:4]\n",
- " if value >= 0: return green\n",
- " return red\n",
- "\n",
- "def _add_feature_values(feature_values, ax):\n",
- " \"\"\"Display feature's values on left of plot.\"\"\"\n",
- " x_coord = ax.get_xlim()[0]\n",
- " OFFSET = 0.15\n",
- " for y_coord, (feat_name, feat_val) in enumerate(feature_values.items()):\n",
- " t = plt.text(x_coord, y_coord - OFFSET, '{}'.format(feat_val), size=12)\n",
- " t.set_bbox(dict(facecolor='white', alpha=0.5))\n",
- " from matplotlib.font_manager import FontProperties\n",
- " font = FontProperties()\n",
- " font.set_weight('bold')\n",
- " t = plt.text(x_coord, y_coord + 1 - OFFSET, 'feature\\nvalue',\n",
- " fontproperties=font, size=12)\n",
- "\n",
- "def plot_example(example):\n",
- " TOP_N = 8 # View top 8 features.\n",
- " sorted_ix = example.abs().sort_values()[-TOP_N:].index # Sort by magnitude.\n",
- " example = example[sorted_ix]\n",
- " colors = example.map(_get_color).tolist()\n",
- " ax = example.to_frame().plot(kind='barh',\n",
- " color=colors,\n",
- " legend=None,\n",
- " alpha=0.75,\n",
- " figsize=(10,6))\n",
- " ax.grid(False, axis='y')\n",
- " ax.set_yticklabels(ax.get_yticklabels(), size=14)\n",
- "\n",
- " # Add feature values.\n",
- " _add_feature_values(dfeval.iloc[ID][sorted_ix], ax)\n",
- " return ax"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Ht1P2-1euczk"
- },
- "outputs": [],
- "source": [
- "# Plot results.\n",
- "ID = 182\n",
- "example = df_dfc.iloc[ID] # Choose ith example from evaluation set.\n",
- "TOP_N = 8 # View top 8 features.\n",
- "sorted_ix = example.abs().sort_values()[-TOP_N:].index\n",
- "ax = plot_example(example)\n",
- "ax.set_title('Feature contributions for example {}\\n pred: {:1.2f}; label: {}'.format(ID, probs[ID], labels[ID]))\n",
- "ax.set_xlabel('Contribution to predicted probability', size=14)\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "aPXgWyFcfzAc"
- },
- "source": [
- "The larger magnitude contributions have a larger impact on the model's prediction. Negative contributions indicate the feature value for this given example reduced the model's prediction, while positive values contribute an increase in the prediction."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "0swvlkZFaY1Z"
- },
- "source": [
- "You can also plot the example's DFCs compare with the entire distribution using a voilin plot."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "zo7rNd1v_5e2"
- },
- "outputs": [],
- "source": [
- "# Boilerplate plotting code.\n",
- "def dist_violin_plot(df_dfc, ID):\n",
- " # Initialize plot.\n",
- " fig, ax = plt.subplots(1, 1, figsize=(10, 6))\n",
- "\n",
- " # Create example dataframe.\n",
- " TOP_N = 8 # View top 8 features.\n",
- " example = df_dfc.iloc[ID]\n",
- " ix = example.abs().sort_values()[-TOP_N:].index\n",
- " example = example[ix]\n",
- " example_df = example.to_frame(name='dfc')\n",
- "\n",
- " # Add contributions of entire distribution.\n",
- " parts=ax.violinplot([df_dfc[w] for w in ix],\n",
- " vert=False,\n",
- " showextrema=False,\n",
- " widths=0.7,\n",
- " positions=np.arange(len(ix)))\n",
- " face_color = sns_colors[0]\n",
- " alpha = 0.15\n",
- " for pc in parts['bodies']:\n",
- " pc.set_facecolor(face_color)\n",
- " pc.set_alpha(alpha)\n",
- "\n",
- " # Add feature values.\n",
- " _add_feature_values(dfeval.iloc[ID][sorted_ix], ax)\n",
- "\n",
- " # Add local contributions.\n",
- " ax.scatter(example,\n",
- " np.arange(example.shape[0]),\n",
- " color=sns.color_palette()[2],\n",
- " s=100,\n",
- " marker=\"s\",\n",
- " label='contributions for example')\n",
- "\n",
- " # Legend\n",
- " # Proxy plot, to show violinplot dist on legend.\n",
- " ax.plot([0,0], [1,1], label='eval set contributions\\ndistributions',\n",
- " color=face_color, alpha=alpha, linewidth=10)\n",
- " legend = ax.legend(loc='lower right', shadow=True, fontsize='x-large',\n",
- " frameon=True)\n",
- " legend.get_frame().set_facecolor('white')\n",
- "\n",
- " # Format plot.\n",
- " ax.set_yticks(np.arange(example.shape[0]))\n",
- " ax.set_yticklabels(example.index)\n",
- " ax.grid(False, axis='y')\n",
- " ax.set_xlabel('Contribution to predicted probability', size=14)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "PiLw2tlm_9aK"
- },
- "source": [
- "Plot this example."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "VkCqraA2uczm"
- },
- "outputs": [],
- "source": [
- "dist_violin_plot(df_dfc, ID)\n",
- "plt.title('Feature contributions for example {}\\n pred: {:1.2f}; label: {}'.format(ID, probs[ID], labels[ID]))\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "TVJFM85SAWVq"
- },
- "source": [
- "Finally, third-party tools, such as [LIME](https://github.com/marcotcr/lime) and [shap](https://github.com/slundberg/shap), can also help understand individual predictions for a model."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "PnNXH6mZuczr"
- },
- "source": [
- "## Global feature importances\n",
- "\n",
- "Additionally, you might want to understand the model as a whole, rather than studying individual predictions. Below, you will compute and use:\n",
- "\n",
- "* Gain-based feature importances using `est.experimental_feature_importances`\n",
- "* Permutation importances\n",
- "* Aggregate DFCs using `est.experimental_predict_with_explanations`\n",
- "\n",
- "Gain-based feature importances measure the loss change when splitting on a particular feature, while permutation feature importances are computed by evaluating model performance on the evaluation set by shuffling each feature one-by-one and attributing the change in model performance to the shuffled feature.\n",
- "\n",
- "In general, permutation feature importance are preferred to gain-based feature importance, though both methods can be unreliable in situations where potential predictor variables vary in their scale of measurement or their number of categories and when features are correlated ([source](https://bmcbioinformatics.biomedcentral.com/articles/10.1186/1471-2105-9-307)). Check out [this article](http://explained.ai/rf-importance/index.html) for an in-depth overview and great discussion on different feature importance types."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "3ocBcMatuczs"
- },
- "source": [
- "### Gain-based feature importances"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "gMaxCgPbBJ-j"
- },
- "source": [
- "Gain-based feature importances are built into the TensorFlow Boosted Trees estimators using `est.experimental_feature_importances`."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "pPTxbAaeuczt"
- },
- "outputs": [],
- "source": [
- "importances = est.experimental_feature_importances(normalize=True)\n",
- "df_imp = pd.Series(importances)\n",
- "\n",
- "# Visualize importances.\n",
- "N = 8\n",
- "ax = (df_imp.iloc[0:N][::-1]\n",
- " .plot(kind='barh',\n",
- " color=sns_colors[0],\n",
- " title='Gain feature importances',\n",
- " figsize=(10, 6)))\n",
- "ax.grid(False, axis='y')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "GvfAcBeGuczw"
- },
- "source": [
- "### Average absolute DFCs\n",
- "You can also average the absolute values of DFCs to understand impact at a global level."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "JkvAWLWLuczx"
- },
- "outputs": [],
- "source": [
- "# Plot.\n",
- "dfc_mean = df_dfc.abs().mean()\n",
- "N = 8\n",
- "sorted_ix = dfc_mean.abs().sort_values()[-N:].index # Average and sort by absolute.\n",
- "ax = dfc_mean[sorted_ix].plot(kind='barh',\n",
- " color=sns_colors[1],\n",
- " title='Mean |directional feature contributions|',\n",
- " figsize=(10, 6))\n",
- "ax.grid(False, axis='y')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Z0k_DvPLaY1o"
- },
- "source": [
- "You can also see how DFCs vary as a feature value varies."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "ZcIfN1IpaY1o"
- },
- "outputs": [],
- "source": [
- "FEATURE = 'fare'\n",
- "feature = pd.Series(df_dfc[FEATURE].values, index=dfeval[FEATURE].values).sort_index()\n",
- "ax = sns.regplot(feature.index.values, feature.values, lowess=True)\n",
- "ax.set_ylabel('contribution')\n",
- "ax.set_xlabel(FEATURE)\n",
- "ax.set_xlim(0, 100)\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "lbpG72ULucz0"
- },
- "source": [
- "### Permutation feature importance"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "6esOw1VOucz0"
- },
- "outputs": [],
- "source": [
- "def permutation_importances(est, X_eval, y_eval, metric, features):\n",
- " \"\"\"Column by column, shuffle values and observe effect on eval set.\n",
- "\n",
- " source: http://explained.ai/rf-importance/index.html\n",
- " A similar approach can be done during training. See \"Drop-column importance\"\n",
- " in the above article.\"\"\"\n",
- " baseline = metric(est, X_eval, y_eval)\n",
- " imp = []\n",
- " for col in features:\n",
- " save = X_eval[col].copy()\n",
- " X_eval[col] = np.random.permutation(X_eval[col])\n",
- " m = metric(est, X_eval, y_eval)\n",
- " X_eval[col] = save\n",
- " imp.append(baseline - m)\n",
- " return np.array(imp)\n",
- "\n",
- "def accuracy_metric(est, X, y):\n",
- " \"\"\"TensorFlow estimator accuracy.\"\"\"\n",
- " eval_input_fn = make_input_fn(X,\n",
- " y=y,\n",
- " shuffle=False,\n",
- " n_epochs=1)\n",
- " return est.evaluate(input_fn=eval_input_fn)['accuracy']\n",
- "features = CATEGORICAL_COLUMNS + NUMERIC_COLUMNS\n",
- "importances = permutation_importances(est, dfeval, y_eval, accuracy_metric,\n",
- " features)\n",
- "df_imp = pd.Series(importances, index=features)\n",
- "\n",
- "sorted_ix = df_imp.abs().sort_values().index\n",
- "ax = df_imp[sorted_ix][-5:].plot(kind='barh', color=sns_colors[2], figsize=(10, 6))\n",
- "ax.grid(False, axis='y')\n",
- "ax.set_title('Permutation feature importance')\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "E236y3pVEzHg"
- },
- "source": [
- "## Visualizing model fitting"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "TrcQ-839EzZ6"
- },
- "source": [
- "Lets first simulate/create training data using the following formula:\n",
- "\n",
- "\n",
- "$$z=x* e^{-x^2 - y^2}$$\n",
- "\n",
- "\n",
- "Where \\(z\\) is the dependent variable you are trying to predict and \\(x\\) and \\(y\\) are the features."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "e8woaj81GGE9"
- },
- "outputs": [],
- "source": [
- "from numpy.random import uniform, seed\n",
- "from scipy.interpolate import griddata\n",
- "\n",
- "# Create fake data\n",
- "seed(0)\n",
- "npts = 5000\n",
- "x = uniform(-2, 2, npts)\n",
- "y = uniform(-2, 2, npts)\n",
- "z = x*np.exp(-x**2 - y**2)\n",
- "xy = np.zeros((2,np.size(x)))\n",
- "xy[0] = x\n",
- "xy[1] = y\n",
- "xy = xy.T"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "GRI3KHfLZsGP"
- },
- "outputs": [],
- "source": [
- "# Prep data for training.\n",
- "df = pd.DataFrame({'x': x, 'y': y, 'z': z})\n",
- "\n",
- "xi = np.linspace(-2.0, 2.0, 200),\n",
- "yi = np.linspace(-2.1, 2.1, 210),\n",
- "xi,yi = np.meshgrid(xi, yi)\n",
- "\n",
- "df_predict = pd.DataFrame({\n",
- " 'x' : xi.flatten(),\n",
- " 'y' : yi.flatten(),\n",
- "})\n",
- "predict_shape = xi.shape"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "w0JnH4IhZuAb"
- },
- "outputs": [],
- "source": [
- "def plot_contour(x, y, z, **kwargs):\n",
- " # Grid the data.\n",
- " plt.figure(figsize=(10, 8))\n",
- " # Contour the gridded data, plotting dots at the nonuniform data points.\n",
- " CS = plt.contour(x, y, z, 15, linewidths=0.5, colors='k')\n",
- " CS = plt.contourf(x, y, z, 15,\n",
- " vmax=abs(zi).max(), vmin=-abs(zi).max(), cmap='RdBu_r')\n",
- " plt.colorbar() # Draw colorbar.\n",
- " # Plot data points.\n",
- " plt.xlim(-2, 2)\n",
- " plt.ylim(-2, 2)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "KF7WsIcYGF_E"
- },
- "source": [
- "You can visualize the function. Redder colors correspond to larger function values."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "WrxuqaaXGFOK"
- },
- "outputs": [],
- "source": [
- "zi = griddata(xy, z, (xi, yi), method='linear', fill_value='0')\n",
- "plot_contour(xi, yi, zi)\n",
- "plt.scatter(df.x, df.y, marker='.')\n",
- "plt.title('Contour on training data')\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "hoANr0f2GFrM"
- },
- "outputs": [],
- "source": [
- "fc = [tf.feature_column.numeric_column('x'),\n",
- " tf.feature_column.numeric_column('y')]"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "xVRWyoY3ayTK"
- },
- "outputs": [],
- "source": [
- "def predict(est):\n",
- " \"\"\"Predictions from a given estimator.\"\"\"\n",
- " predict_input_fn = lambda: tf.data.Dataset.from_tensors(dict(df_predict))\n",
- " preds = np.array([p['predictions'][0] for p in est.predict(predict_input_fn)])\n",
- " return preds.reshape(predict_shape)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "uyPu5618GU7K"
- },
- "source": [
- "First let's try to fit a linear model to the data."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "zUIV2IVgGVSk"
- },
- "outputs": [],
- "source": [
- "train_input_fn = make_input_fn(df, df.z)\n",
- "est = tf.estimator.LinearRegressor(fc)\n",
- "est.train(train_input_fn, max_steps=500);"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "_u4WAcCqfbco"
- },
- "outputs": [],
- "source": [
- "plot_contour(xi, yi, predict(est))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "XD_fMAUtSCSa"
- },
- "source": [
- "It's not a very good fit. Next let's try to fit a GBDT model to it and try to understand how the model fits the function."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "-dHlKFlFgHDQ"
- },
- "outputs": [],
- "source": [
- "n_trees = 37 #@param {type: \"slider\", min: 1, max: 80, step: 1}\n",
- "\n",
- "est = tf.estimator.BoostedTreesRegressor(fc, n_batches_per_layer=1, n_trees=n_trees)\n",
- "est.train(train_input_fn, max_steps=500)\n",
- "clear_output()\n",
- "plot_contour(xi, yi, predict(est))\n",
- "plt.text(-1.8, 2.1, '# trees: {}'.format(n_trees), color='w', backgroundcolor='black', size=20)\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "5WcZ9fubh1wT"
- },
- "source": [
- "As you increase the number of trees, the model's predictions better approximates the underlying function."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "cj8u3NCG-IKX"
- },
- "source": [
- "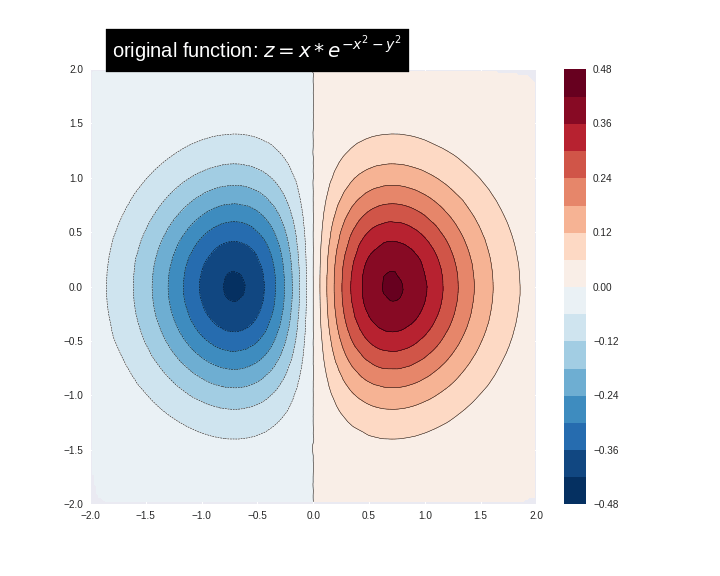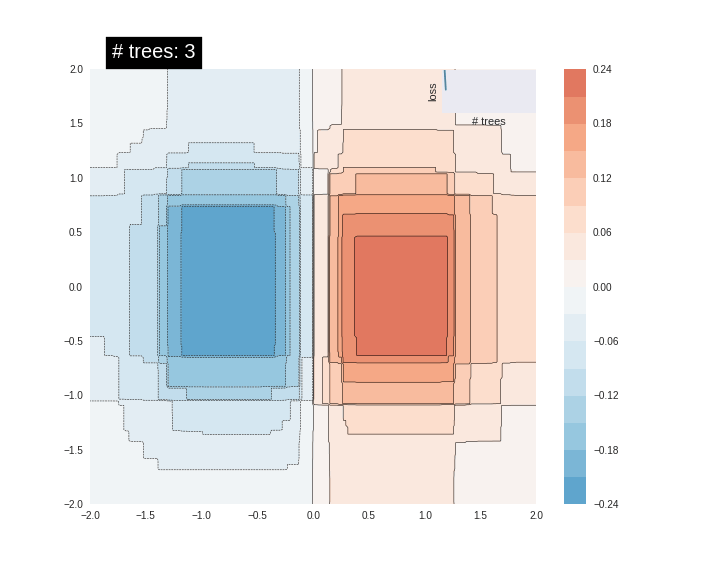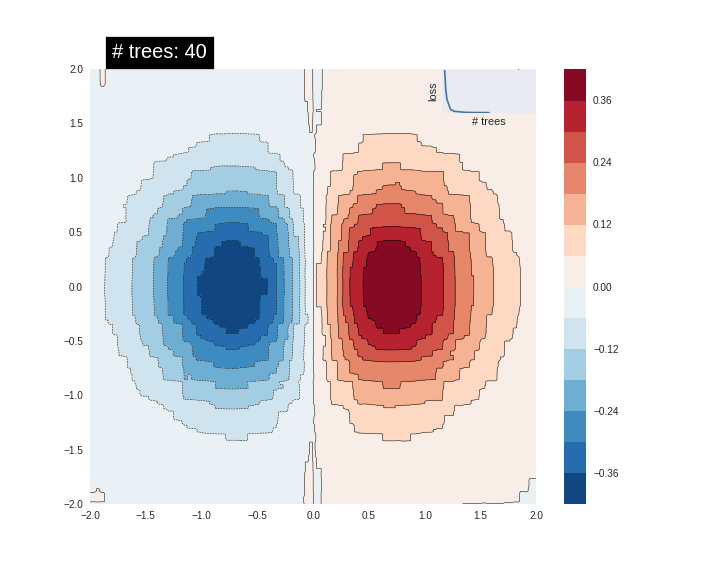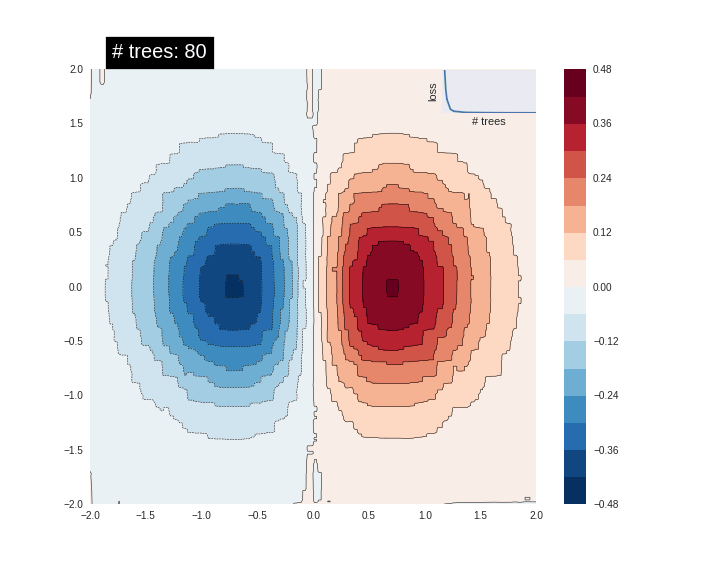"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "SMKoEZnCdrsp"
- },
- "source": [
- "## Conclusion"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "ZSZUSrjXdw9g"
- },
- "source": [
- "In this tutorial you learned how to interpret Boosted Trees models using directional feature contributions and feature importance techniques. These techniques provide insight into how the features impact a model's predictions. Finally, you also gained intution for how a Boosted Tree model fits a complex function by viewing the decision surface for several models."
- ]
- }
- ],
- "metadata": {
- "accelerator": "GPU",
- "colab": {
- "collapsed_sections": [],
- "name": "boosted_trees_model_understanding.ipynb",
- "toc_visible": true
- },
- "kernelspec": {
- "display_name": "Python 3",
- "name": "python3"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
diff --git a/site/en/tutorials/estimator/keras_model_to_estimator.ipynb b/site/en/tutorials/estimator/keras_model_to_estimator.ipynb
index e41380908f5..be97a38b6eb 100644
--- a/site/en/tutorials/estimator/keras_model_to_estimator.ipynb
+++ b/site/en/tutorials/estimator/keras_model_to_estimator.ipynb
@@ -68,7 +68,7 @@
"id": "Dhcq8Ds4mCtm"
},
"source": [
- "> Warning: Estimators are not recommended for new code. Estimators run `v1.Session`-style code which is more difficult to write correctly, and can behave unexpectedly, especially when combined with TF 2 code. Estimators do fall under our [compatibility guarantees](https://tensorflow.org/guide/versions), but will receive no fixes other than security vulnerabilities. See the [migration guide](https://tensorflow.org/guide/migrate) for details."
+ "> Warning: TensorFlow 2.15 included the final release of the `tf-estimator` package. Estimators will not be available in TensorFlow 2.16 or after. See the [migration guide](https://tensorflow.org/guide/migrate/migrating_estimator) for more information about how to convert off of Estimators."
]
},
{
@@ -272,8 +272,7 @@
"colab": {
"collapsed_sections": [],
"name": "keras_model_to_estimator.ipynb",
- "provenance": [],
- "toc_visible": true
+ "toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
diff --git a/site/en/tutorials/estimator/linear.ipynb b/site/en/tutorials/estimator/linear.ipynb
index ea46d41ede1..a26ffe2df4f 100644
--- a/site/en/tutorials/estimator/linear.ipynb
+++ b/site/en/tutorials/estimator/linear.ipynb
@@ -61,7 +61,7 @@
"id": "JOccPOFMm5Tc"
},
"source": [
- "> Warning: Estimators are not recommended for new code. Estimators run `v1.Session`-style code which is more difficult to write correctly, and can behave unexpectedly, especially when combined with TF 2 code. Estimators do fall under our [compatibility guarantees](https://tensorflow.org/guide/versions), but will receive no fixes other than security vulnerabilities. See the [migration guide](https://tensorflow.org/guide/migrate) for details."
+ "> Warning: TensorFlow 2.15 included the final release of the `tf-estimator` package. Estimators will not be available in TensorFlow 2.16 or after. See the [migration guide](https://tensorflow.org/guide/migrate/migrating_estimator) for more information about how to convert off of Estimators."
]
},
{
@@ -293,14 +293,31 @@
"pd.concat([dftrain, y_train], axis=1).groupby('sex').survived.mean().plot(kind='barh').set_xlabel('% survive')"
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "qCHvgeorEsHa"
+ },
+ "source": [
+ "## Feature Engineering for the Model"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Dhcq8Ds4mCtm"
+ },
+ "source": [
+ "> Warning: The tf.feature_columns module described in this tutorial is not recommended for new code. Keras preprocessing layers cover this functionality, for migration instructions see the [Migrating feature columns guide](https://www.tensorflow.org/guide/migrate/migrating_feature_columns). The tf.feature_columns module was designed for use with TF1 Estimators. It does fall under our [compatibility guarantees](https://tensorflow.org/guide/versions), but will receive no fixes other than security vulnerabilities."
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {
"id": "VqDKQLZn8L-B"
},
"source": [
- "## Feature Engineering for the Model\n",
- "Estimators use a system called [feature columns](https://www.tensorflow.org/guide/feature_columns) to describe how the model should interpret each of the raw input features. An Estimator expects a vector of numeric inputs, and *feature columns* describe how the model should convert each feature.\n",
+ "Estimators use a system called [feature columns](https://www.tensorflow.org/tutorials/structured_data/feature_columns) to describe how the model should interpret each of the raw input features. An Estimator expects a vector of numeric inputs, and *feature columns* describe how the model should convert each feature.\n",
"\n",
"Selecting and crafting the right set of feature columns is key to learning an effective model. A feature column can be either one of the raw inputs in the original features `dict` (a *base feature column*), or any new columns created using transformations defined over one or multiple base columns (a *derived feature columns*).\n",
"\n",
@@ -583,8 +600,7 @@
"colab": {
"collapsed_sections": [],
"name": "linear.ipynb",
- "provenance": [],
- "toc_visible": true
+ "toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
diff --git a/site/en/tutorials/estimator/premade.ipynb b/site/en/tutorials/estimator/premade.ipynb
index a34096ea2b8..dc81847c7cd 100644
--- a/site/en/tutorials/estimator/premade.ipynb
+++ b/site/en/tutorials/estimator/premade.ipynb
@@ -68,7 +68,7 @@
"id": "stQiPWL6ni6_"
},
"source": [
- "> Warning: Estimators are not recommended for new code. Estimators run `v1.Session`-style code which is more difficult to write correctly, and can behave unexpectedly, especially when combined with TF 2 code. Estimators do fall under [compatibility guarantees](https://tensorflow.org/guide/versions), but will receive no fixes other than security vulnerabilities. See the [migration guide](https://tensorflow.org/guide/migrate) for details."
+ "> Warning: TensorFlow 2.15 included the final release of the `tf-estimator` package. Estimators will not be available in TensorFlow 2.16 or after. See the [migration guide](https://tensorflow.org/guide/migrate/migrating_estimator) for more information about how to convert off of Estimators."
]
},
{
diff --git a/site/en/tutorials/generative/autoencoder.ipynb b/site/en/tutorials/generative/autoencoder.ipynb
index d2af1c3a345..1b2a6fcd2a8 100644
--- a/site/en/tutorials/generative/autoencoder.ipynb
+++ b/site/en/tutorials/generative/autoencoder.ipynb
@@ -6,9 +6,16 @@
"id": "Ndo4ERqnwQOU"
},
"source": [
- "##### Copyright 2020 The TensorFlow Authors."
+ "##### Copyright 2024 The TensorFlow Authors."
]
},
+ {
+ "metadata": {
+ "id": "13rwRG5Jec7n"
+ },
+ "cell_type": "markdown",
+ "source": []
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -76,7 +83,7 @@
"source": [
"This tutorial introduces autoencoders with three examples: the basics, image denoising, and anomaly detection.\n",
"\n",
- "An autoencoder is a special type of neural network that is trained to copy its input to its output. For example, given an image of a handwritten digit, an autoencoder first encodes the image into a lower dimensional latent representation, then decodes the latent representation back to an image. An autoencoder learns to compress the data while minimizing the reconstruction error. \n",
+ "An autoencoder is a special type of neural network that is trained to copy its input to its output. For example, given an image of a handwritten digit, an autoencoder first encodes the image into a lower dimensional latent representation, then decodes the latent representation back to an image. An autoencoder learns to compress the data while minimizing the reconstruction error.\n",
"\n",
"To learn more about autoencoders, please consider reading chapter 14 from [Deep Learning](https://www.deeplearningbook.org/) by Ian Goodfellow, Yoshua Bengio, and Aaron Courville."
]
@@ -117,7 +124,7 @@
},
"source": [
"## Load the dataset\n",
- "To start, you will train the basic autoencoder using the Fashon MNIST dataset. Each image in this dataset is 28x28 pixels. "
+ "To start, you will train the basic autoencoder using the Fashion MNIST dataset. Each image in this dataset is 28x28 pixels."
]
},
{
@@ -159,27 +166,29 @@
},
"outputs": [],
"source": [
- "latent_dim = 64 \n",
- "\n",
"class Autoencoder(Model):\n",
- " def __init__(self, latent_dim):\n",
+ " def __init__(self, latent_dim, shape):\n",
" super(Autoencoder, self).__init__()\n",
- " self.latent_dim = latent_dim \n",
+ " self.latent_dim = latent_dim\n",
+ " self.shape = shape\n",
" self.encoder = tf.keras.Sequential([\n",
" layers.Flatten(),\n",
" layers.Dense(latent_dim, activation='relu'),\n",
" ])\n",
" self.decoder = tf.keras.Sequential([\n",
- " layers.Dense(784, activation='sigmoid'),\n",
- " layers.Reshape((28, 28))\n",
+ " layers.Dense(tf.math.reduce_prod(shape).numpy(), activation='sigmoid'),\n",
+ " layers.Reshape(shape)\n",
" ])\n",
"\n",
" def call(self, x):\n",
" encoded = self.encoder(x)\n",
" decoded = self.decoder(encoded)\n",
" return decoded\n",
- " \n",
- "autoencoder = Autoencoder(latent_dim) "
+ "\n",
+ "\n",
+ "shape = x_test.shape[1:]\n",
+ "latent_dim = 64\n",
+ "autoencoder = Autoencoder(latent_dim, shape)\n"
]
},
{
@@ -329,8 +338,8 @@
"outputs": [],
"source": [
"noise_factor = 0.2\n",
- "x_train_noisy = x_train + noise_factor * tf.random.normal(shape=x_train.shape) \n",
- "x_test_noisy = x_test + noise_factor * tf.random.normal(shape=x_test.shape) \n",
+ "x_train_noisy = x_train + noise_factor * tf.random.normal(shape=x_train.shape)\n",
+ "x_test_noisy = x_test + noise_factor * tf.random.normal(shape=x_test.shape)\n",
"\n",
"x_train_noisy = tf.clip_by_value(x_train_noisy, clip_value_min=0., clip_value_max=1.)\n",
"x_test_noisy = tf.clip_by_value(x_test_noisy, clip_value_min=0., clip_value_max=1.)"
@@ -492,7 +501,7 @@
},
"outputs": [],
"source": [
- "encoded_imgs = autoencoder.encoder(x_test).numpy()\n",
+ "encoded_imgs = autoencoder.encoder(x_test_noisy).numpy()\n",
"decoded_imgs = autoencoder.decoder(encoded_imgs).numpy()"
]
},
@@ -655,7 +664,7 @@
"id": "wVcTBDo-CqFS"
},
"source": [
- "Plot a normal ECG. "
+ "Plot a normal ECG."
]
},
{
@@ -719,12 +728,12 @@
" layers.Dense(32, activation=\"relu\"),\n",
" layers.Dense(16, activation=\"relu\"),\n",
" layers.Dense(8, activation=\"relu\")])\n",
- " \n",
+ "\n",
" self.decoder = tf.keras.Sequential([\n",
" layers.Dense(16, activation=\"relu\"),\n",
" layers.Dense(32, activation=\"relu\"),\n",
" layers.Dense(140, activation=\"sigmoid\")])\n",
- " \n",
+ "\n",
" def call(self, x):\n",
" encoded = self.encoder(x)\n",
" decoded = self.decoder(encoded)\n",
@@ -761,8 +770,8 @@
},
"outputs": [],
"source": [
- "history = autoencoder.fit(normal_train_data, normal_train_data, \n",
- " epochs=20, \n",
+ "history = autoencoder.fit(normal_train_data, normal_train_data,\n",
+ " epochs=20,\n",
" batch_size=512,\n",
" validation_data=(test_data, test_data),\n",
" shuffle=True)"
@@ -906,7 +915,7 @@
"id": "uEGlA1Be50Nj"
},
"source": [
- "Note: There are other strategies you could use to select a threshold value above which test examples should be classified as anomalous, the correct approach will depend on your dataset. You can learn more with the links at the end of this tutorial. "
+ "Note: There are other strategies you could use to select a threshold value above which test examples should be classified as anomalous, the correct approach will depend on your dataset. You can learn more with the links at the end of this tutorial."
]
},
{
@@ -915,7 +924,7 @@
"id": "zpLSDAeb51D_"
},
"source": [
- "If you examine the reconstruction error for the anomalous examples in the test set, you'll notice most have greater reconstruction error than the threshold. By varing the threshold, you can adjust the [precision](https://developers.google.com/machine-learning/glossary#precision) and [recall](https://developers.google.com/machine-learning/glossary#recall) of your classifier. "
+ "If you examine the reconstruction error for the anomalous examples in the test set, you'll notice most have greater reconstruction error than the threshold. By varing the threshold, you can adjust the [precision](https://developers.google.com/machine-learning/glossary#precision) and [recall](https://developers.google.com/machine-learning/glossary#recall) of your classifier."
]
},
{
@@ -990,8 +999,18 @@
"metadata": {
"accelerator": "GPU",
"colab": {
- "collapsed_sections": [],
- "name": "autoencoder.ipynb",
+ "gpuType": "T4",
+ "private_outputs": true,
+ "provenance": [
+ {
+ "file_id": "17gKB2bKebV2DzoYIMFzyEXA5uDnwWOvT",
+ "timestamp": 1712793165979
+ },
+ {
+ "file_id": "https://github.com/tensorflow/docs/blob/master/site/en/tutorials/generative/autoencoder.ipynb",
+ "timestamp": 1712792176273
+ }
+ ],
"toc_visible": true
},
"kernelspec": {
diff --git a/site/en/tutorials/generative/cyclegan.ipynb b/site/en/tutorials/generative/cyclegan.ipynb
index 7136dd143ef..313be519591 100644
--- a/site/en/tutorials/generative/cyclegan.ipynb
+++ b/site/en/tutorials/generative/cyclegan.ipynb
@@ -154,7 +154,7 @@
"This is similar to what was done in [pix2pix](https://www.tensorflow.org/tutorials/generative/pix2pix#load_the_dataset)\n",
"\n",
"* In random jittering, the image is resized to `286 x 286` and then randomly cropped to `256 x 256`.\n",
- "* In random mirroring, the image is randomly flipped horizontally i.e left to right."
+ "* In random mirroring, the image is randomly flipped horizontally i.e., left to right."
]
},
{
@@ -634,7 +634,7 @@
"source": [
"## Training\n",
"\n",
- "Note: This example model is trained for fewer epochs (40) than the paper (200) to keep training time reasonable for this tutorial. Predictions may be less accurate. "
+ "Note: This example model is trained for fewer epochs (10) than the paper (200) to keep training time reasonable for this tutorial. The generated images will have much lower quality."
]
},
{
@@ -645,7 +645,7 @@
},
"outputs": [],
"source": [
- "EPOCHS = 40"
+ "EPOCHS = 10"
]
},
{
@@ -830,8 +830,7 @@
"colab": {
"collapsed_sections": [],
"name": "cyclegan.ipynb",
- "provenance": [],
- "toc_visible": true
+ "toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
diff --git a/site/en/tutorials/generative/data_compression.ipynb b/site/en/tutorials/generative/data_compression.ipynb
new file mode 100644
index 00000000000..f756f088acd
--- /dev/null
+++ b/site/en/tutorials/generative/data_compression.ipynb
@@ -0,0 +1,901 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Tce3stUlHN0L"
+ },
+ "source": [
+ "##### Copyright 2022 The TensorFlow Compression Authors."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "tuOe1ymfHZPu"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n",
+ "# you may not use this file except in compliance with the License.\n",
+ "# You may obtain a copy of the License at\n",
+ "#\n",
+ "# https://www.apache.org/licenses/LICENSE-2.0\n",
+ "#\n",
+ "# Unless required by applicable law or agreed to in writing, software\n",
+ "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
+ "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
+ "# See the License for the specific language governing permissions and\n",
+ "# limitations under the License."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "qFdPvlXBOdUN"
+ },
+ "source": [
+ "# Learned data compression"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "MfBg1C5NB3X0"
+ },
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "xHxb-dlhMIzW"
+ },
+ "source": [
+ "## Overview\n",
+ "\n",
+ "This notebook shows how to do lossy data compression using neural networks and [TensorFlow Compression](https://github.com/tensorflow/compression).\n",
+ "\n",
+ "Lossy compression involves making a trade-off between **rate**, the expected number of bits needed to encode a sample, and **distortion**, the expected error in the reconstruction of the sample.\n",
+ "\n",
+ "The examples below use an autoencoder-like model to compress images from the MNIST dataset. The method is based on the paper [End-to-end Optimized Image Compression](https://arxiv.org/abs/1611.01704).\n",
+ "\n",
+ "More background on learned data compression can be found in [this paper](https://arxiv.org/abs/2007.03034) targeted at people familiar with classical data compression, or [this survey](https://arxiv.org/abs/2202.06533) targeted at a machine learning audience.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "MUXex9ctTuDB"
+ },
+ "source": [
+ "## Setup\n",
+ "\n",
+ "Install Tensorflow Compression via `pip`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "K489KsEgxuLI"
+ },
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "# Installs the latest version of TFC compatible with the installed TF version.\n",
+ "\n",
+ "read MAJOR MINOR <<< \"$(pip show tensorflow | perl -p -0777 -e 's/.*Version: (\\d+)\\.(\\d+).*/\\1 \\2/sg')\"\n",
+ "pip install \"tensorflow-compression<$MAJOR.$(($MINOR+1))\"\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "WfVAmHCVxpTS"
+ },
+ "source": [
+ "Import library dependencies."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "IqR2PQG4ZaZ0"
+ },
+ "outputs": [],
+ "source": [
+ "import matplotlib.pyplot as plt\n",
+ "import tensorflow as tf\n",
+ "import tensorflow_compression as tfc\n",
+ "import tensorflow_datasets as tfds\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "wsncKT2iymgQ"
+ },
+ "source": [
+ "## Define the trainer model.\n",
+ "\n",
+ "Because the model resembles an autoencoder, and we need to perform a different set of functions during training and inference, the setup is a little different from, say, a classifier.\n",
+ "\n",
+ "The training model consists of three parts:\n",
+ "- the **analysis** (or encoder) transform, converting from the image into a latent space,\n",
+ "- the **synthesis** (or decoder) transform, converting from the latent space back into image space, and\n",
+ "- a **prior** and entropy model, modeling the marginal probabilities of the latents.\n",
+ "\n",
+ "First, define the transforms:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "8yZESLgW-vp1"
+ },
+ "outputs": [],
+ "source": [
+ "def make_analysis_transform(latent_dims):\n",
+ " \"\"\"Creates the analysis (encoder) transform.\"\"\"\n",
+ " return tf.keras.Sequential([\n",
+ " tf.keras.layers.Conv2D(\n",
+ " 20, 5, use_bias=True, strides=2, padding=\"same\",\n",
+ " activation=\"leaky_relu\", name=\"conv_1\"),\n",
+ " tf.keras.layers.Conv2D(\n",
+ " 50, 5, use_bias=True, strides=2, padding=\"same\",\n",
+ " activation=\"leaky_relu\", name=\"conv_2\"),\n",
+ " tf.keras.layers.Flatten(),\n",
+ " tf.keras.layers.Dense(\n",
+ " 500, use_bias=True, activation=\"leaky_relu\", name=\"fc_1\"),\n",
+ " tf.keras.layers.Dense(\n",
+ " latent_dims, use_bias=True, activation=None, name=\"fc_2\"),\n",
+ " ], name=\"analysis_transform\")\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "2sHdYBzF2xcu"
+ },
+ "outputs": [],
+ "source": [
+ "def make_synthesis_transform():\n",
+ " \"\"\"Creates the synthesis (decoder) transform.\"\"\"\n",
+ " return tf.keras.Sequential([\n",
+ " tf.keras.layers.Dense(\n",
+ " 500, use_bias=True, activation=\"leaky_relu\", name=\"fc_1\"),\n",
+ " tf.keras.layers.Dense(\n",
+ " 2450, use_bias=True, activation=\"leaky_relu\", name=\"fc_2\"),\n",
+ " tf.keras.layers.Reshape((7, 7, 50)),\n",
+ " tf.keras.layers.Conv2DTranspose(\n",
+ " 20, 5, use_bias=True, strides=2, padding=\"same\",\n",
+ " activation=\"leaky_relu\", name=\"conv_1\"),\n",
+ " tf.keras.layers.Conv2DTranspose(\n",
+ " 1, 5, use_bias=True, strides=2, padding=\"same\",\n",
+ " activation=\"leaky_relu\", name=\"conv_2\"),\n",
+ " ], name=\"synthesis_transform\")\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "lYC8tHhkxTlK"
+ },
+ "source": [
+ "The trainer holds an instance of both transforms, as well as the parameters of the prior.\n",
+ "\n",
+ "Its `call` method is set up to compute:\n",
+ "- **rate**, an estimate of the number of bits needed to represent the batch of digits, and\n",
+ "- **distortion**, the mean absolute difference between the pixels of the original digits and their reconstructions.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "ROn2DbzsBirI"
+ },
+ "outputs": [],
+ "source": [
+ "class MNISTCompressionTrainer(tf.keras.Model):\n",
+ " \"\"\"Model that trains a compressor/decompressor for MNIST.\"\"\"\n",
+ "\n",
+ " def __init__(self, latent_dims):\n",
+ " super().__init__()\n",
+ " self.analysis_transform = make_analysis_transform(latent_dims)\n",
+ " self.synthesis_transform = make_synthesis_transform()\n",
+ " self.prior_log_scales = tf.Variable(tf.zeros((latent_dims,)))\n",
+ "\n",
+ " @property\n",
+ " def prior(self):\n",
+ " return tfc.NoisyLogistic(loc=0., scale=tf.exp(self.prior_log_scales))\n",
+ "\n",
+ " def call(self, x, training):\n",
+ " \"\"\"Computes rate and distortion losses.\"\"\"\n",
+ " # Ensure inputs are floats in the range (0, 1).\n",
+ " x = tf.cast(x, self.compute_dtype) / 255.\n",
+ " x = tf.reshape(x, (-1, 28, 28, 1))\n",
+ "\n",
+ " # Compute latent space representation y, perturb it and model its entropy,\n",
+ " # then compute the reconstructed pixel-level representation x_hat.\n",
+ " y = self.analysis_transform(x)\n",
+ " entropy_model = tfc.ContinuousBatchedEntropyModel(\n",
+ " self.prior, coding_rank=1, compression=False)\n",
+ " y_tilde, rate = entropy_model(y, training=training)\n",
+ " x_tilde = self.synthesis_transform(y_tilde)\n",
+ "\n",
+ " # Average number of bits per MNIST digit.\n",
+ " rate = tf.reduce_mean(rate)\n",
+ "\n",
+ " # Mean absolute difference across pixels.\n",
+ " distortion = tf.reduce_mean(abs(x - x_tilde))\n",
+ "\n",
+ " return dict(rate=rate, distortion=distortion)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "vEXbp9RV3kRX"
+ },
+ "source": [
+ "### Compute rate and distortion.\n",
+ "\n",
+ "Let's walk through this step by step, using one image from the training set. Load the MNIST dataset for training and validation:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "7FV99WTrIBen"
+ },
+ "outputs": [],
+ "source": [
+ "training_dataset, validation_dataset = tfds.load(\n",
+ " \"mnist\",\n",
+ " split=[\"train\", \"test\"],\n",
+ " shuffle_files=True,\n",
+ " as_supervised=True,\n",
+ " with_info=False,\n",
+ ")\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "SwKgNTg_QfjH"
+ },
+ "source": [
+ "And extract one image $x$:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "O-BSdeHcPBBf"
+ },
+ "outputs": [],
+ "source": [
+ "(x, _), = validation_dataset.take(1)\n",
+ "\n",
+ "plt.imshow(tf.squeeze(x))\n",
+ "print(f\"Data type: {x.dtype}\")\n",
+ "print(f\"Shape: {x.shape}\")\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "V8IvuFkrRJIa"
+ },
+ "source": [
+ "To get the latent representation $y$, we need to cast it to `float32`, add a batch dimension, and pass it through the analysis transform."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "jA0DOWq23lEq"
+ },
+ "outputs": [],
+ "source": [
+ "x = tf.cast(x, tf.float32) / 255.\n",
+ "x = tf.reshape(x, (-1, 28, 28, 1))\n",
+ "y = make_analysis_transform(10)(x)\n",
+ "\n",
+ "print(\"y:\", y)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "rTojJQvZT8SX"
+ },
+ "source": [
+ "The latents will be quantized at test time. To model this in a differentiable way during training, we add uniform noise in the interval $(-.5, .5)$ and call the result $\\tilde y$. This is the same terminology as used in the paper [End-to-end Optimized Image Compression](https://arxiv.org/abs/1611.01704)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Spr3503OUOFQ"
+ },
+ "outputs": [],
+ "source": [
+ "y_tilde = y + tf.random.uniform(y.shape, -.5, .5)\n",
+ "\n",
+ "print(\"y_tilde:\", y_tilde)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "7hRN89R7SA3U"
+ },
+ "source": [
+ "The \"prior\" is a probability density that we train to model the marginal distribution of the noisy latents. For example, it could be a set of independent [logistic distributions](https://en.wikipedia.org/wiki/Logistic_distribution) with different scales for each latent dimension. `tfc.NoisyLogistic` accounts for the fact that the latents have additive noise. As the scale approaches zero, a logistic distribution approaches a dirac delta (spike), but the added noise causes the \"noisy\" distribution to approach the uniform distribution instead."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "2tmA1Bw7ReMY"
+ },
+ "outputs": [],
+ "source": [
+ "prior = tfc.NoisyLogistic(loc=0., scale=tf.linspace(.01, 2., 10))\n",
+ "\n",
+ "_ = tf.linspace(-6., 6., 501)[:, None]\n",
+ "plt.plot(_, prior.prob(_));\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "2NSWtBZmUvVY"
+ },
+ "source": [
+ "During training, `tfc.ContinuousBatchedEntropyModel` adds uniform noise, and uses the noise and the prior to compute a (differentiable) upper bound on the rate (the average number of bits necessary to encode the latent representation). That bound can be minimized as a loss."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "hFuGlyJuThBC"
+ },
+ "outputs": [],
+ "source": [
+ "entropy_model = tfc.ContinuousBatchedEntropyModel(\n",
+ " prior, coding_rank=1, compression=False)\n",
+ "y_tilde, rate = entropy_model(y, training=True)\n",
+ "\n",
+ "print(\"rate:\", rate)\n",
+ "print(\"y_tilde:\", y_tilde)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Cyr8DGgmWd32"
+ },
+ "source": [
+ "Lastly, the noisy latents are passed back through the synthesis transform to produce an image reconstruction $\\tilde x$. Distortion is the error between original image and reconstruction. Obviously, with the transforms untrained, the reconstruction is not very useful."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "gtmI0xGEVym0"
+ },
+ "outputs": [],
+ "source": [
+ "x_tilde = make_synthesis_transform()(y_tilde)\n",
+ "\n",
+ "# Mean absolute difference across pixels.\n",
+ "distortion = tf.reduce_mean(abs(x - x_tilde))\n",
+ "print(\"distortion:\", distortion)\n",
+ "\n",
+ "x_tilde = tf.saturate_cast(x_tilde[0] * 255, tf.uint8)\n",
+ "plt.imshow(tf.squeeze(x_tilde))\n",
+ "print(f\"Data type: {x_tilde.dtype}\")\n",
+ "print(f\"Shape: {x_tilde.shape}\")\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "UVz3I7E8ecij"
+ },
+ "source": [
+ "For every batch of digits, calling the `MNISTCompressionTrainer` produces the rate and distortion as an average over that batch:\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "ICJnjj1LeB8L"
+ },
+ "outputs": [],
+ "source": [
+ "(example_batch, _), = validation_dataset.batch(32).take(1)\n",
+ "trainer = MNISTCompressionTrainer(10)\n",
+ "example_output = trainer(example_batch)\n",
+ "\n",
+ "print(\"rate: \", example_output[\"rate\"])\n",
+ "print(\"distortion: \", example_output[\"distortion\"])\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "lgdfRtmee5Mn"
+ },
+ "source": [
+ "In the next section, we set up the model to do gradient descent on these two losses."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "fKGVwv5MAq6w"
+ },
+ "source": [
+ "## Train the model.\n",
+ "\n",
+ "We compile the trainer in a way that it optimizes the rate–distortion Lagrangian, that is, a sum of rate and distortion, where one of the terms is weighted by Lagrange parameter $\\lambda$.\n",
+ "\n",
+ "This loss function affects the different parts of the model differently:\n",
+ "- The analysis transform is trained to produce a latent representation that achieves the desired trade-off between rate and distortion.\n",
+ "- The synthesis transform is trained to minimize distortion, given the latent representation.\n",
+ "- The parameters of the prior are trained to minimize the rate given the latent representation. This is identical to fitting the prior to the marginal distribution of latents in a maximum likelihood sense."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "k5mm1aDkcgAf"
+ },
+ "outputs": [],
+ "source": [
+ "def pass_through_loss(_, x):\n",
+ " # Since rate and distortion are unsupervised, the loss doesn't need a target.\n",
+ " return x\n",
+ "\n",
+ "def make_mnist_compression_trainer(lmbda, latent_dims=50):\n",
+ " trainer = MNISTCompressionTrainer(latent_dims)\n",
+ " trainer.compile(\n",
+ " optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),\n",
+ " # Just pass through rate and distortion as losses/metrics.\n",
+ " loss=dict(rate=pass_through_loss, distortion=pass_through_loss),\n",
+ " metrics=dict(rate=pass_through_loss, distortion=pass_through_loss),\n",
+ " loss_weights=dict(rate=1., distortion=lmbda),\n",
+ " )\n",
+ " return trainer\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "DPwd4DTs3Mfr"
+ },
+ "source": [
+ "Next, train the model. The human annotations are not necessary here, since we just want to compress the images, so we drop them using a `map` and instead add \"dummy\" targets for rate and distortion."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "QNBpCTgzAV7M"
+ },
+ "outputs": [],
+ "source": [
+ "def add_rd_targets(image, label):\n",
+ " # Training is unsupervised, so labels aren't necessary here. However, we\n",
+ " # need to add \"dummy\" targets for rate and distortion.\n",
+ " return image, dict(rate=0., distortion=0.)\n",
+ "\n",
+ "def train_mnist_model(lmbda):\n",
+ " trainer = make_mnist_compression_trainer(lmbda)\n",
+ " trainer.fit(\n",
+ " training_dataset.map(add_rd_targets).batch(128).prefetch(8),\n",
+ " epochs=15,\n",
+ " validation_data=validation_dataset.map(add_rd_targets).batch(128).cache(),\n",
+ " validation_freq=1,\n",
+ " verbose=1,\n",
+ " )\n",
+ " return trainer\n",
+ "\n",
+ "trainer = train_mnist_model(lmbda=2000)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Td4xuttmCd7T"
+ },
+ "source": [
+ "## Compress some MNIST images.\n",
+ "\n",
+ "For compression and decompression at test time, we split the trained model in two parts:\n",
+ "\n",
+ "- The encoder side consists of the analysis transform and the entropy model.\n",
+ "- The decoder side consists of the synthesis transform and the same entropy model.\n",
+ "\n",
+ "At test time, the latents will not have additive noise, but they will be quantized and then losslessly compressed, so we give them new names. We call them and the image reconstruction $\\hat x$ and $\\hat y$, respectively (following [End-to-end Optimized Image Compression](https://arxiv.org/abs/1611.01704))."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "sBRAPa5jksss"
+ },
+ "outputs": [],
+ "source": [
+ "class MNISTCompressor(tf.keras.Model):\n",
+ " \"\"\"Compresses MNIST images to strings.\"\"\"\n",
+ "\n",
+ " def __init__(self, analysis_transform, entropy_model):\n",
+ " super().__init__()\n",
+ " self.analysis_transform = analysis_transform\n",
+ " self.entropy_model = entropy_model\n",
+ "\n",
+ " def call(self, x):\n",
+ " # Ensure inputs are floats in the range (0, 1).\n",
+ " x = tf.cast(x, self.compute_dtype) / 255.\n",
+ " y = self.analysis_transform(x)\n",
+ " # Also return the exact information content of each digit.\n",
+ " _, bits = self.entropy_model(y, training=False)\n",
+ " return self.entropy_model.compress(y), bits\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "sSZ0X2xPnkN-"
+ },
+ "outputs": [],
+ "source": [
+ "class MNISTDecompressor(tf.keras.Model):\n",
+ " \"\"\"Decompresses MNIST images from strings.\"\"\"\n",
+ "\n",
+ " def __init__(self, entropy_model, synthesis_transform):\n",
+ " super().__init__()\n",
+ " self.entropy_model = entropy_model\n",
+ " self.synthesis_transform = synthesis_transform\n",
+ "\n",
+ " def call(self, string):\n",
+ " y_hat = self.entropy_model.decompress(string, ())\n",
+ " x_hat = self.synthesis_transform(y_hat)\n",
+ " # Scale and cast back to 8-bit integer.\n",
+ " return tf.saturate_cast(tf.round(x_hat * 255.), tf.uint8)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "GI7rxeOUDnaC"
+ },
+ "source": [
+ "When instantiated with `compression=True`, the entropy model converts the learned prior into tables for a range coding algorithm. When calling `compress()`, this algorithm is invoked to convert the latent space vector into bit sequences. The length of each binary string approximates the information content of the latent (the negative log likelihood of the latent under the prior).\n",
+ "\n",
+ "The entropy model for compression and decompression must be the same instance, because the range coding tables need to be exactly identical on both sides. Otherwise, decoding errors can occur."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Dnm_p7mbnigo"
+ },
+ "outputs": [],
+ "source": [
+ "def make_mnist_codec(trainer, **kwargs):\n",
+ " # The entropy model must be created with `compression=True` and the same\n",
+ " # instance must be shared between compressor and decompressor.\n",
+ " entropy_model = tfc.ContinuousBatchedEntropyModel(\n",
+ " trainer.prior, coding_rank=1, compression=True, **kwargs)\n",
+ " compressor = MNISTCompressor(trainer.analysis_transform, entropy_model)\n",
+ " decompressor = MNISTDecompressor(entropy_model, trainer.synthesis_transform)\n",
+ " return compressor, decompressor\n",
+ "\n",
+ "compressor, decompressor = make_mnist_codec(trainer)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "SYu5sVVH3YMv"
+ },
+ "source": [
+ "Grab 16 images from the validation dataset. You can select a different subset by changing the argument to `skip`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "qAxArlU728K5"
+ },
+ "outputs": [],
+ "source": [
+ "(originals, _), = validation_dataset.batch(16).skip(3).take(1)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "CHeN_ny929YS"
+ },
+ "source": [
+ "Compress them to strings, and keep track of each of their information content in bits."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "smOk42gQ3IXv"
+ },
+ "outputs": [],
+ "source": [
+ "strings, entropies = compressor(originals)\n",
+ "\n",
+ "print(f\"String representation of first digit in hexadecimal: 0x{strings[0].numpy().hex()}\")\n",
+ "print(f\"Number of bits actually needed to represent it: {entropies[0]:0.2f}\")\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "5j9R4bTT3Qhl"
+ },
+ "source": [
+ "Decompress the images back from the strings."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "yOP6pEqU3P0w"
+ },
+ "outputs": [],
+ "source": [
+ "reconstructions = decompressor(strings)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "JWo0Q-vy23tt"
+ },
+ "source": [
+ "Display each of the 16 original digits together with its compressed binary representation, and the reconstructed digit."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "jU5IqzZzeEpf"
+ },
+ "outputs": [],
+ "source": [
+ "#@title\n",
+ "\n",
+ "def display_digits(originals, strings, entropies, reconstructions):\n",
+ " \"\"\"Visualizes 16 digits together with their reconstructions.\"\"\"\n",
+ " fig, axes = plt.subplots(4, 4, sharex=True, sharey=True, figsize=(12.5, 5))\n",
+ " axes = axes.ravel()\n",
+ " for i in range(len(axes)):\n",
+ " image = tf.concat([\n",
+ " tf.squeeze(originals[i]),\n",
+ " tf.zeros((28, 14), tf.uint8),\n",
+ " tf.squeeze(reconstructions[i]),\n",
+ " ], 1)\n",
+ " axes[i].imshow(image)\n",
+ " axes[i].text(\n",
+ " .5, .5, f\"→ 0x{strings[i].numpy().hex()} →\\n{entropies[i]:0.2f} bits\",\n",
+ " ha=\"center\", va=\"top\", color=\"white\", fontsize=\"small\",\n",
+ " transform=axes[i].transAxes)\n",
+ " axes[i].axis(\"off\")\n",
+ " plt.subplots_adjust(wspace=0, hspace=0, left=0, right=1, bottom=0, top=1)\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "km9PqVEtPJPc"
+ },
+ "outputs": [],
+ "source": [
+ "display_digits(originals, strings, entropies, reconstructions)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "EzlrIOiYOzJc"
+ },
+ "source": [
+ "Note that the length of the encoded string differs from the information content of each digit.\n",
+ "\n",
+ "This is because the range coding process works with discrete probabilities, and has a small amount of overhead. So, especially for short strings, the correspondence is only approximate. However, range coding is **asymptotically optimal**: in the limit, the expected bit count will approach the cross entropy (the expected information content), for which the rate term in the training model is an upper bound."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "78qIG8t8FvJW"
+ },
+ "source": [
+ "## The rate–distortion trade-off\n",
+ "\n",
+ "Above, the model was trained for a specific trade-off (given by `lmbda=2000`) between the average number of bits used to represent each digit and the incurred error in the reconstruction.\n",
+ "\n",
+ "What happens when we repeat the experiment with different values?\n",
+ "\n",
+ "Let's start by reducing $\\lambda$ to 500."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "1iFcAD0WF78p"
+ },
+ "outputs": [],
+ "source": [
+ "def train_and_visualize_model(lmbda):\n",
+ " trainer = train_mnist_model(lmbda=lmbda)\n",
+ " compressor, decompressor = make_mnist_codec(trainer)\n",
+ " strings, entropies = compressor(originals)\n",
+ " reconstructions = decompressor(strings)\n",
+ " display_digits(originals, strings, entropies, reconstructions)\n",
+ "\n",
+ "train_and_visualize_model(lmbda=500)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Uy5OkgJMObMc"
+ },
+ "source": [
+ "The bit rate of our code goes down, as does the fidelity of the digits. However, most of the digits remain recognizable.\n",
+ "\n",
+ "Let's reduce $\\lambda$ further."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "NQp9_9_5GcxH"
+ },
+ "outputs": [],
+ "source": [
+ "train_and_visualize_model(lmbda=300)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "3ELLMANN1OwMQ"
+ },
+ "source": [
+ "The strings begin to get much shorter now, on the order of one byte per digit. However, this comes at a cost. More digits are becoming unrecognizable.\n",
+ "\n",
+ "This demonstrates that this model is agnostic to human perceptions of error, it just measures the absolute deviation in terms of pixel values. To achieve a better perceived image quality, we would need to replace the pixel loss with a perceptual loss."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "v9cWHtH0LP_r"
+ },
+ "source": [
+ "## Use the decoder as a generative model.\n",
+ "\n",
+ "If we feed the decoder random bits, this will effectively sample from the distribution that the model learned to represent digits.\n",
+ "\n",
+ "First, re-instantiate the compressor/decompressor without a sanity check that would detect if the input string isn't completely decoded."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "qnic8YsM0_ke"
+ },
+ "outputs": [],
+ "source": [
+ "compressor, decompressor = make_mnist_codec(trainer, decode_sanity_check=False)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "86uc9_Is1eeo"
+ },
+ "source": [
+ "Now, feed long enough random strings into the decompressor so that it can decode/sample digits from them."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "o4fP7BkqKCHY"
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "\n",
+ "strings = tf.constant([os.urandom(8) for _ in range(16)])\n",
+ "samples = decompressor(strings)\n",
+ "\n",
+ "fig, axes = plt.subplots(4, 4, sharex=True, sharey=True, figsize=(5, 5))\n",
+ "axes = axes.ravel()\n",
+ "for i in range(len(axes)):\n",
+ " axes[i].imshow(tf.squeeze(samples[i]))\n",
+ " axes[i].axis(\"off\")\n",
+ "plt.subplots_adjust(wspace=0, hspace=0, left=0, right=1, bottom=0, top=1)\n"
+ ]
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "collapsed_sections": [],
+ "name": "data_compression.ipynb",
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/site/en/tutorials/generative/deepdream.ipynb b/site/en/tutorials/generative/deepdream.ipynb
index e6d0d85fc17..e4a675ebed6 100644
--- a/site/en/tutorials/generative/deepdream.ipynb
+++ b/site/en/tutorials/generative/deepdream.ipynb
@@ -103,9 +103,7 @@
"import matplotlib as mpl\n",
"\n",
"import IPython.display as display\n",
- "import PIL.Image\n",
- "\n",
- "from tensorflow.keras.preprocessing import image"
+ "import PIL.Image"
]
},
{
@@ -514,19 +512,20 @@
" @tf.function(\n",
" input_signature=(\n",
" tf.TensorSpec(shape=[None,None,3], dtype=tf.float32),\n",
+ " tf.TensorSpec(shape=[2], dtype=tf.int32),\n",
" tf.TensorSpec(shape=[], dtype=tf.int32),)\n",
" )\n",
- " def __call__(self, img, tile_size=512):\n",
+ " def __call__(self, img, img_size, tile_size=512):\n",
" shift, img_rolled = random_roll(img, tile_size)\n",
"\n",
" # Initialize the image gradients to zero.\n",
" gradients = tf.zeros_like(img_rolled)\n",
" \n",
" # Skip the last tile, unless there's only one tile.\n",
- " xs = tf.range(0, img_rolled.shape[0], tile_size)[:-1]\n",
+ " xs = tf.range(0, img_size[1], tile_size)[:-1]\n",
" if not tf.cast(len(xs), bool):\n",
" xs = tf.constant([0])\n",
- " ys = tf.range(0, img_rolled.shape[1], tile_size)[:-1]\n",
+ " ys = tf.range(0, img_size[0], tile_size)[:-1]\n",
" if not tf.cast(len(ys), bool):\n",
" ys = tf.constant([0])\n",
"\n",
@@ -539,7 +538,7 @@
" tape.watch(img_rolled)\n",
"\n",
" # Extract a tile out of the image.\n",
- " img_tile = img_rolled[x:x+tile_size, y:y+tile_size]\n",
+ " img_tile = img_rolled[y:y+tile_size, x:x+tile_size]\n",
" loss = calc_loss(img_tile, self.model)\n",
"\n",
" # Update the image gradients for this tile.\n",
@@ -585,7 +584,7 @@
"def run_deep_dream_with_octaves(img, steps_per_octave=100, step_size=0.01, \n",
" octaves=range(-2,3), octave_scale=1.3):\n",
" base_shape = tf.shape(img)\n",
- " img = tf.keras.preprocessing.image.img_to_array(img)\n",
+ " img = tf.keras.utils.img_to_array(img)\n",
" img = tf.keras.applications.inception_v3.preprocess_input(img)\n",
"\n",
" initial_shape = img.shape[:-1]\n",
@@ -593,10 +592,11 @@
" for octave in octaves:\n",
" # Scale the image based on the octave\n",
" new_size = tf.cast(tf.convert_to_tensor(base_shape[:-1]), tf.float32)*(octave_scale**octave)\n",
- " img = tf.image.resize(img, tf.cast(new_size, tf.int32))\n",
+ " new_size = tf.cast(new_size, tf.int32)\n",
+ " img = tf.image.resize(img, new_size)\n",
"\n",
" for step in range(steps_per_octave):\n",
- " gradients = get_tiled_gradients(img)\n",
+ " gradients = get_tiled_gradients(img, new_size)\n",
" img = img + gradients*step_size\n",
" img = tf.clip_by_value(img, -1, 1)\n",
"\n",
diff --git a/site/en/tutorials/generative/pix2pix.ipynb b/site/en/tutorials/generative/pix2pix.ipynb
index 82cf08dfab7..e380924d04d 100644
--- a/site/en/tutorials/generative/pix2pix.ipynb
+++ b/site/en/tutorials/generative/pix2pix.ipynb
@@ -72,13 +72,13 @@
"source": [
"This tutorial demonstrates how to build and train a conditional generative adversarial network (cGAN) called pix2pix that learns a mapping from input images to output images, as described in [Image-to-image translation with conditional adversarial networks](https://arxiv.org/abs/1611.07004) by Isola et al. (2017). pix2pix is not application specific—it can be applied to a wide range of tasks, including synthesizing photos from label maps, generating colorized photos from black and white images, turning Google Maps photos into aerial images, and even transforming sketches into photos.\n",
"\n",
- "In this example, your network will generate images of building facades using the [CMP Facade Database](http://cmp.felk.cvut.cz/~tylecr1/facade/) provided by the [Center for Machine Perception](http://cmp.felk.cvut.cz/) at the [Czech Technical University in Prague](https://www.cvut.cz/). To keep it short, you will use a [preprocessed copy]((https://people.eecs.berkeley.edu/~tinghuiz/projects/pix2pix/datasets/)) of this dataset created by the pix2pix authors.\n",
+ "In this example, your network will generate images of building facades using the [CMP Facade Database](http://cmp.felk.cvut.cz/~tylecr1/facade/) provided by the [Center for Machine Perception](http://cmp.felk.cvut.cz/) at the [Czech Technical University in Prague](https://www.cvut.cz/). To keep it short, you will use a [preprocessed copy](https://efrosgans.eecs.berkeley.edu/pix2pix/datasets/) of this dataset created by the pix2pix authors.\n",
"\n",
"In the pix2pix cGAN, you condition on input images and generate corresponding output images. cGANs were first proposed in [Conditional Generative Adversarial Nets](https://arxiv.org/abs/1411.1784) (Mirza and Osindero, 2014)\n",
"\n",
"The architecture of your network will contain:\n",
"\n",
- "- A generator with a [U-Net]([U-Net](https://arxiv.org/abs/1505.04597))-based architecture.\n",
+ "- A generator with a [U-Net](https://arxiv.org/abs/1505.04597)-based architecture.\n",
"- A discriminator represented by a convolutional PatchGAN classifier (proposed in the [pix2pix paper](https://arxiv.org/abs/1611.07004)).\n",
"\n",
"Note that each epoch can take around 15 seconds on a single V100 GPU.\n",
@@ -125,7 +125,7 @@
"source": [
"## Load the dataset\n",
"\n",
- "Download the CMP Facade Database data (30MB). Additional datasets are available in the same format [here](http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/). In Colab you can select other datasets from the drop-down menu. Note that some of the other datasets are significantly larger (`edges2handbags` is 8GB). "
+ "Download the CMP Facade Database data (30MB). Additional datasets are available in the same format [here](http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/). In Colab you can select other datasets from the drop-down menu. Note that some of the other datasets are significantly larger (`edges2handbags` is 8GB in size). "
]
},
{
@@ -156,7 +156,9 @@
"\n",
"path_to_zip = pathlib.Path(path_to_zip)\n",
"\n",
- "PATH = path_to_zip.parent/dataset_name"
+ "extraction_dir = f'{dataset_name}_extracted/{dataset_name}'\n",
+ "\n",
+ "PATH = path_to_zip.parent/extraction_dir"
]
},
{
@@ -226,7 +228,7 @@
"def load(image_file):\n",
" # Read and decode an image file to a uint8 tensor\n",
" image = tf.io.read_file(image_file)\n",
- " image = tf.image.decode_jpeg(image)\n",
+ " image = tf.io.decode_jpeg(image)\n",
"\n",
" # Split each image tensor into two tensors:\n",
" # - one with a real building facade image\n",
@@ -280,7 +282,7 @@
"\n",
"1. Resize each `256 x 256` image to a larger height and width—`286 x 286`.\n",
"2. Randomly crop it back to `256 x 256`.\n",
- "3. Randomly flip the image horizontally i.e. left to right (random mirroring).\n",
+ "3. Randomly flip the image horizontally i.e., left to right (random mirroring).\n",
"4. Normalize the images to the `[-1, 1]` range."
]
},
@@ -490,7 +492,7 @@
"source": [
"## Build the generator\n",
"\n",
- "The generator of your pix2pix cGAN is a _modified_ [U-Net](https://arxiv.org/abs/1505.04597). A U-Net consists of an encoder (downsampler) and decoder (upsampler). (You can find out more about it in the [Image segmentation](https://www.tensorflow.org/tutorials/images/segmentation) tutorial and on the [U-Net project website](https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/).)\n",
+ "The generator of your pix2pix cGAN is a _modified_ [U-Net](https://arxiv.org/abs/1505.04597). A U-Net consists of an encoder (downsampler) and decoder (upsampler). (You can find out more about it in the [Image segmentation](../images/segmentation.ipynb) tutorial and on the [U-Net project website](https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/).)\n",
"\n",
"- Each block in the encoder is: Convolution -> Batch normalization -> Leaky ReLU\n",
"- Each block in the decoder is: Transposed convolution -> Batch normalization -> Dropout (applied to the first 3 blocks) -> ReLU\n",
@@ -1007,8 +1009,7 @@
"id": "Rb0QQFHF-JfS"
},
"source": [
- "Note: The `training=True` is intentional here since\n",
- "you want the batch statistics, while running the model on the test dataset. If you use `training=False`, you get the accumulated statistics learned from the training dataset (which you don't want)."
+ "Note: The `training=True` is intentional here since you want the batch statistics, while running the model on the test dataset. If you use `training=False`, you get the accumulated statistics learned from the training dataset (which you don't want)."
]
},
{
@@ -1181,7 +1182,8 @@
"\n",
"If you work on a local machine, you would launch a separate TensorBoard process. When working in a notebook, launch the viewer before starting the training to monitor with TensorBoard.\n",
"\n",
- "To launch the viewer paste the following into a code-cell:"
+ "Launch the TensorBoard viewer (Sorry, this doesn't\n",
+ "display on tensorflow.org):"
]
},
{
@@ -1199,72 +1201,30 @@
{
"cell_type": "markdown",
"metadata": {
- "id": "Pe0-8Bzg22ox"
- },
- "source": [
- "Finally, run the training loop:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "a1zZmKmvOH85"
- },
- "outputs": [],
- "source": [
- "fit(train_dataset, test_dataset, steps=40000)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "oeq9sByu86-B"
- },
- "source": [
- "If you want to share the TensorBoard results _publicly_, you can upload the logs to [TensorBoard.dev](https://tensorboard.dev/) by copying the following into a code-cell.\n",
- "\n",
- "Note: This requires a Google account.\n",
- "\n",
- "```\n",
- "!tensorboard dev upload --logdir {log_dir}\n",
- "```"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "l-kT7WHRKz-E"
+ "id": "fyjixlMlBybN"
},
"source": [
- "Caution: This command does not terminate. It's designed to continuously upload the results of long-running experiments. Once your data is uploaded you need to stop it using the \"interrupt execution\" option in your notebook tool."
+ "You can view the [results of a previous run](https://tensorboard.dev/experiment/lZ0C6FONROaUMfjYkVyJqw) of this notebook on [TensorBoard.dev](https://tensorboard.dev/)."
]
},
{
"cell_type": "markdown",
"metadata": {
- "id": "-lGhS_LfwQoL"
+ "id": "Pe0-8Bzg22ox"
},
"source": [
- "You can view the [results of a previous run](https://tensorboard.dev/experiment/lZ0C6FONROaUMfjYkVyJqw) of this notebook on [TensorBoard.dev](https://tensorboard.dev/).\n",
- "\n",
- "TensorBoard.dev is a managed experience for hosting, tracking, and sharing ML experiments with everyone.\n",
- "\n",
- "It can also included inline using an `
 View source on GitHub\n",
+ "
View source on GitHub\n",
+ "  +
+* Building non-traditional models or layers that do not fully fit the
+ structures supported by high-level APIs
+* Building custom layers, losses, models, and optimizers within Keras
+* Implementing new optimization techniques to expedite convergence during
+ training
+* Creating custom metrics for performance evaluation
+* Designing highly-configurable training loops with support for features like
+ batching, cross-validation, and distribution strategies
+
+### Build frameworks and tools
+
+The TensorFlow Core APIs can also serve as the building blocks for new
+high-level frameworks. Here are some examples of tools and frameworks that are
+created with the low-level APIs:
+
+
+* Building non-traditional models or layers that do not fully fit the
+ structures supported by high-level APIs
+* Building custom layers, losses, models, and optimizers within Keras
+* Implementing new optimization techniques to expedite convergence during
+ training
+* Creating custom metrics for performance evaluation
+* Designing highly-configurable training loops with support for features like
+ batching, cross-validation, and distribution strategies
+
+### Build frameworks and tools
+
+The TensorFlow Core APIs can also serve as the building blocks for new
+high-level frameworks. Here are some examples of tools and frameworks that are
+created with the low-level APIs:
+ +
+* Data structures : `tf.Tensor`, `tf.Variable`, `tf.TensorArray`
+* Primitive APIs: `tf.shape`,
+ [slicing](https://www.tensorflow.org/guide/tensor_slicing), `tf.concat`,
+ `tf.bitwise`
+* Numerical: `tf.math`, `tf.linalg`, `tf.random`
+* Functional components: `tf.function`, `tf.GradientTape`
+* Distribution: [DTensor](https://www.tensorflow.org/guide/dtensor_overview)
+* Export: `tf.saved_model`
+
+## Next steps
+
+The *Build with Core* documentation provides tutorials of basic machine learning
+concepts from scratch. The tutorials in this section help you get comfortable
+with writing low-level code with Core APIs that you can then apply to more
+complex use cases of your own.
+
+Note: You should not use the Core APIs to simply re-implement high-level APIs,
+and it is possible to use high-level APIs, such as Keras, with the Core APIs.
+
+To get started using and learning more about the Core APIs, check out the
+[Quickstart for TensorFlow Core](https://www.tensorflow.org/guide/core/quickstart_core).
diff --git a/site/en/guide/core/logistic_regression_core.ipynb b/site/en/guide/core/logistic_regression_core.ipynb
new file mode 100644
index 00000000000..5a9af324ad5
--- /dev/null
+++ b/site/en/guide/core/logistic_regression_core.ipynb
@@ -0,0 +1,935 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "FhGuhbZ6M5tl"
+ },
+ "source": [
+ "##### Copyright 2022 The TensorFlow Authors."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "AwOEIRJC6Une"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n",
+ "# you may not use this file except in compliance with the License.\n",
+ "# You may obtain a copy of the License at\n",
+ "#\n",
+ "# https://www.apache.org/licenses/LICENSE-2.0\n",
+ "#\n",
+ "# Unless required by applicable law or agreed to in writing, software\n",
+ "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
+ "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
+ "# See the License for the specific language governing permissions and\n",
+ "# limitations under the License."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "EIdT9iu_Z4Rb"
+ },
+ "source": [
+ "# Logistic regression for binary classification with Core APIs"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "bBIlTPscrIT9"
+ },
+ "source": [
+ "
+
+* Data structures : `tf.Tensor`, `tf.Variable`, `tf.TensorArray`
+* Primitive APIs: `tf.shape`,
+ [slicing](https://www.tensorflow.org/guide/tensor_slicing), `tf.concat`,
+ `tf.bitwise`
+* Numerical: `tf.math`, `tf.linalg`, `tf.random`
+* Functional components: `tf.function`, `tf.GradientTape`
+* Distribution: [DTensor](https://www.tensorflow.org/guide/dtensor_overview)
+* Export: `tf.saved_model`
+
+## Next steps
+
+The *Build with Core* documentation provides tutorials of basic machine learning
+concepts from scratch. The tutorials in this section help you get comfortable
+with writing low-level code with Core APIs that you can then apply to more
+complex use cases of your own.
+
+Note: You should not use the Core APIs to simply re-implement high-level APIs,
+and it is possible to use high-level APIs, such as Keras, with the Core APIs.
+
+To get started using and learning more about the Core APIs, check out the
+[Quickstart for TensorFlow Core](https://www.tensorflow.org/guide/core/quickstart_core).
diff --git a/site/en/guide/core/logistic_regression_core.ipynb b/site/en/guide/core/logistic_regression_core.ipynb
new file mode 100644
index 00000000000..5a9af324ad5
--- /dev/null
+++ b/site/en/guide/core/logistic_regression_core.ipynb
@@ -0,0 +1,935 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "FhGuhbZ6M5tl"
+ },
+ "source": [
+ "##### Copyright 2022 The TensorFlow Authors."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "AwOEIRJC6Une"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n",
+ "# you may not use this file except in compliance with the License.\n",
+ "# You may obtain a copy of the License at\n",
+ "#\n",
+ "# https://www.apache.org/licenses/LICENSE-2.0\n",
+ "#\n",
+ "# Unless required by applicable law or agreed to in writing, software\n",
+ "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
+ "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
+ "# See the License for the specific language governing permissions and\n",
+ "# limitations under the License."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "EIdT9iu_Z4Rb"
+ },
+ "source": [
+ "# Logistic regression for binary classification with Core APIs"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "bBIlTPscrIT9"
+ },
+ "source": [
+ " \n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "QLH5fgdBmA58"
+ },
+ "outputs": [],
+ "source": [
+ "mesh_1d = dtensor.create_mesh([('x', 6)], devices=DEVICES)\n",
+ "print(mesh_1d)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "hSZwaUwnEgXB"
+ },
+ "source": [
+ "A `Mesh` can be multi dimensional as well. In the following example, 6 CPU devices form a `3x2` mesh, where the `'x'` mesh dimension has a size of 3 devices, and the `'y'` mesh dimension has a size of 2 devices:\n",
+ "\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "QLH5fgdBmA58"
+ },
+ "outputs": [],
+ "source": [
+ "mesh_1d = dtensor.create_mesh([('x', 6)], devices=DEVICES)\n",
+ "print(mesh_1d)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "hSZwaUwnEgXB"
+ },
+ "source": [
+ "A `Mesh` can be multi dimensional as well. In the following example, 6 CPU devices form a `3x2` mesh, where the `'x'` mesh dimension has a size of 3 devices, and the `'y'` mesh dimension has a size of 2 devices:\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "op6TmKUQE-sZ"
+ },
+ "outputs": [],
+ "source": [
+ "mesh_2d = dtensor.create_mesh([('x', 3), ('y', 2)], devices=DEVICES)\n",
+ "print(mesh_2d)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "deAqdrDPFn2f"
+ },
+ "source": [
+ "### Layout\n",
+ "\n",
+ "**`Layout`** specifies how a tensor is distributed, or sharded, on a `Mesh`.\n",
+ "\n",
+ "Note: In order to avoid confusions between `Mesh` and `Layout`, the term *dimension* is always associated with `Mesh`, and the term *axis* with `Tensor` and `Layout` in this guide.\n",
+ "\n",
+ "The rank of `Layout` should be the same as the rank of the `Tensor` where the `Layout` is applied. For each of the `Tensor`'s axes the `Layout` may specify a mesh dimension to shard the tensor across, or specify the axis as \"unsharded\".\n",
+ "The tensor is replicated across any mesh dimensions that it is not sharded across.\n",
+ "\n",
+ "The rank of a `Layout` and the number of dimensions of a `Mesh` do not need to match. The `unsharded` axes of a `Layout` do not need to be associated to a mesh dimension, and `unsharded` mesh dimensions do not need to be associated with a `layout` axis.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "op6TmKUQE-sZ"
+ },
+ "outputs": [],
+ "source": [
+ "mesh_2d = dtensor.create_mesh([('x', 3), ('y', 2)], devices=DEVICES)\n",
+ "print(mesh_2d)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "deAqdrDPFn2f"
+ },
+ "source": [
+ "### Layout\n",
+ "\n",
+ "**`Layout`** specifies how a tensor is distributed, or sharded, on a `Mesh`.\n",
+ "\n",
+ "Note: In order to avoid confusions between `Mesh` and `Layout`, the term *dimension* is always associated with `Mesh`, and the term *axis* with `Tensor` and `Layout` in this guide.\n",
+ "\n",
+ "The rank of `Layout` should be the same as the rank of the `Tensor` where the `Layout` is applied. For each of the `Tensor`'s axes the `Layout` may specify a mesh dimension to shard the tensor across, or specify the axis as \"unsharded\".\n",
+ "The tensor is replicated across any mesh dimensions that it is not sharded across.\n",
+ "\n",
+ "The rank of a `Layout` and the number of dimensions of a `Mesh` do not need to match. The `unsharded` axes of a `Layout` do not need to be associated to a mesh dimension, and `unsharded` mesh dimensions do not need to be associated with a `layout` axis.\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Px_bF1c-bQ7e"
+ },
+ "source": [
+ "Let's analyze a few examples of `Layout` for the `Mesh`'s created in the previous section."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "fqzCNlWAbm-c"
+ },
+ "source": [
+ "On a 1-dimensional mesh such as `[(\"x\", 6)]` (`mesh_1d` in the previous section), `Layout([\"unsharded\", \"unsharded\"], mesh_1d)` is a layout for a rank-2 tensor replicated across 6 devices.\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Px_bF1c-bQ7e"
+ },
+ "source": [
+ "Let's analyze a few examples of `Layout` for the `Mesh`'s created in the previous section."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "fqzCNlWAbm-c"
+ },
+ "source": [
+ "On a 1-dimensional mesh such as `[(\"x\", 6)]` (`mesh_1d` in the previous section), `Layout([\"unsharded\", \"unsharded\"], mesh_1d)` is a layout for a rank-2 tensor replicated across 6 devices.\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "-a3EnmZag6x1"
+ },
+ "outputs": [],
+ "source": [
+ "layout = dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh_1d)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ywRJwuLDt2Qq"
+ },
+ "source": [
+ "Using the same tensor and mesh the layout `Layout(['unsharded', 'x'])` would shard the second axis of the tensor across the 6 devices.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "-a3EnmZag6x1"
+ },
+ "outputs": [],
+ "source": [
+ "layout = dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh_1d)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ywRJwuLDt2Qq"
+ },
+ "source": [
+ "Using the same tensor and mesh the layout `Layout(['unsharded', 'x'])` would shard the second axis of the tensor across the 6 devices.\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "7BgqL0jUvV5a"
+ },
+ "outputs": [],
+ "source": [
+ "layout = dtensor.Layout([dtensor.UNSHARDED, 'x'], mesh_1d)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "DgciDNmK76l9"
+ },
+ "source": [
+ "Given a 2-dimensional 3x2 mesh such as `[(\"x\", 3), (\"y\", 2)]`, (`mesh_2d` from the previous section), `Layout([\"y\", \"x\"], mesh_2d)` is a layout for a rank-2 `Tensor` whose first axis is sharded across mesh dimension `\"y\"`, and whose second axis is sharded across mesh dimension `\"x\"`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Eyp_qOSyvieo"
+ },
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "7BgqL0jUvV5a"
+ },
+ "outputs": [],
+ "source": [
+ "layout = dtensor.Layout([dtensor.UNSHARDED, 'x'], mesh_1d)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "DgciDNmK76l9"
+ },
+ "source": [
+ "Given a 2-dimensional 3x2 mesh such as `[(\"x\", 3), (\"y\", 2)]`, (`mesh_2d` from the previous section), `Layout([\"y\", \"x\"], mesh_2d)` is a layout for a rank-2 `Tensor` whose first axis is sharded across mesh dimension `\"y\"`, and whose second axis is sharded across mesh dimension `\"x\"`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Eyp_qOSyvieo"
+ },
+ "source": [
+ " \n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "p8OrehEuhPbS"
+ },
+ "outputs": [],
+ "source": [
+ "layout = dtensor.Layout(['y', 'x'], mesh_2d)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "1Kyg0V3ehMNJ"
+ },
+ "source": [
+ "For the same `mesh_2d`, the layout `Layout([\"x\", dtensor.UNSHARDED], mesh_2d)` is a layout for a rank-2 `Tensor` that is replicated across `\"y\"`, and whose first axis is sharded on mesh dimension `x`.\n",
+ "\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "p8OrehEuhPbS"
+ },
+ "outputs": [],
+ "source": [
+ "layout = dtensor.Layout(['y', 'x'], mesh_2d)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "1Kyg0V3ehMNJ"
+ },
+ "source": [
+ "For the same `mesh_2d`, the layout `Layout([\"x\", dtensor.UNSHARDED], mesh_2d)` is a layout for a rank-2 `Tensor` that is replicated across `\"y\"`, and whose first axis is sharded on mesh dimension `x`.\n",
+ "\n",
+ " \n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "IkWe6mVl7uRb"
+ },
+ "outputs": [],
+ "source": [
+ "layout = dtensor.Layout([\"x\", dtensor.UNSHARDED], mesh_2d)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "TTalu6M-ISYb"
+ },
+ "source": [
+ "### Single-client and multi-client applications\n",
+ "\n",
+ "DTensor supports both single-client and multi-client applications. The colab Python kernel is an example of a single client DTensor application, where there is a single Python process.\n",
+ "\n",
+ "In a multi-client DTensor application, multiple Python processes collectively perform as a coherent application. The Cartisian grid of a `Mesh` in a multi-client DTensor application can span across devices regardless of whether they are attached locally to the current client or attached remotely to another client. The set of all devices used by a `Mesh` are called the *global device list*.\n",
+ "\n",
+ "The creation of a `Mesh` in a multi-client DTensor application is a collective operation where the *global device list* is identical for all of the participating clients, and the creation of the `Mesh` serves as a global barrier.\n",
+ "\n",
+ "During `Mesh` creation, each client provides its *local device list* together with the expected *global device list*. DTensor validates that both lists are consistent. Please refer to the API documentation for `dtensor.create_mesh` and `dtensor.create_distributed_mesh`\n",
+ " for more information on multi-client mesh creation and the *global device list*.\n",
+ "\n",
+ "Single-client can be thought of as a special case of multi-client, with 1 client. In a single-client application, the *global device list* is identical to the *local device list*.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "P_F7DWkXkB4w"
+ },
+ "source": [
+ "## DTensor as a sharded tensor\n",
+ "\n",
+ "Now, start coding with `DTensor`. The helper function, `dtensor_from_array`, demonstrates creating DTensors from something that looks like a `tf.Tensor`. The function performs two steps:\n",
+ "\n",
+ " - Replicates the tensor to every device on the mesh.\n",
+ " - Shards the copy according to the layout requested in its arguments."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "s6aws-b8dN9L"
+ },
+ "outputs": [],
+ "source": [
+ "def dtensor_from_array(arr, layout, shape=None, dtype=None):\n",
+ " \"\"\"Convert a DTensor from something that looks like an array or Tensor.\n",
+ "\n",
+ " This function is convenient for quick doodling DTensors from a known,\n",
+ " unsharded data object in a single-client environment. This is not the\n",
+ " most efficient way of creating a DTensor, but it will do for this\n",
+ " tutorial.\n",
+ " \"\"\"\n",
+ " if shape is not None or dtype is not None:\n",
+ " arr = tf.constant(arr, shape=shape, dtype=dtype)\n",
+ "\n",
+ " # replicate the input to the mesh\n",
+ " a = dtensor.copy_to_mesh(arr,\n",
+ " layout=dtensor.Layout.replicated(layout.mesh, rank=layout.rank))\n",
+ " # shard the copy to the desirable layout\n",
+ " return dtensor.relayout(a, layout=layout)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "r3o6IysrlGMu"
+ },
+ "source": [
+ "### Anatomy of a DTensor\n",
+ "\n",
+ "A DTensor is a `tf.Tensor` object, but augumented with the `Layout` annotation that defines its sharding behavior. A DTensor consists of the following:\n",
+ "\n",
+ " - Global tensor meta-data, including the global shape and dtype of the tensor.\n",
+ " - A `Layout`, which defines the `Mesh` the `Tensor` belongs to, and how the `Tensor` is sharded onto the `Mesh`.\n",
+ " - A list of **component tensors**, one item per local device in the `Mesh`.\n",
+ "\n",
+ "With `dtensor_from_array`, you can create your first DTensor, `my_first_dtensor`, and examine its contents:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "mQu_nScGUvYH"
+ },
+ "outputs": [],
+ "source": [
+ "mesh = dtensor.create_mesh([(\"x\", 6)], devices=DEVICES)\n",
+ "layout = dtensor.Layout([dtensor.UNSHARDED], mesh)\n",
+ "\n",
+ "my_first_dtensor = dtensor_from_array([0, 1], layout)\n",
+ "\n",
+ "# Examine the DTensor content\n",
+ "print(my_first_dtensor)\n",
+ "print(\"global shape:\", my_first_dtensor.shape)\n",
+ "print(\"dtype:\", my_first_dtensor.dtype)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "r8LQy1nqmvFy"
+ },
+ "source": [
+ "#### Layout and `fetch_layout`\n",
+ "\n",
+ "The layout of a DTensor is not a regular attribute of `tf.Tensor`. Instead, DTensor provides a function, `dtensor.fetch_layout` to access the layout of a DTensor:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "dCSFyaAjmzGu"
+ },
+ "outputs": [],
+ "source": [
+ "print(dtensor.fetch_layout(my_first_dtensor))\n",
+ "assert layout == dtensor.fetch_layout(my_first_dtensor)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ed7i3l2lmatm"
+ },
+ "source": [
+ "#### Component tensors, `pack` and `unpack`\n",
+ "\n",
+ "A DTensor consists of a list of **component tensors**. The component tensor for a device in the `Mesh` is the `Tensor` object representing the piece of the global DTensor that is stored on this device.\n",
+ "\n",
+ "A DTensor can be unpacked into component tensors through `dtensor.unpack`. You can make use of `dtensor.unpack` to inspect the components of the DTensor, and confirm they are on all devices of the `Mesh`.\n",
+ "\n",
+ "Note that the positions of component tensors in the global view may overlap each other. For example, in the case of a fully replicated layout, all components are identical replicas of the global tensor."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "BGbjqVAOnXMk"
+ },
+ "outputs": [],
+ "source": [
+ "for component_tensor in dtensor.unpack(my_first_dtensor):\n",
+ " print(\"Device:\", component_tensor.device, \",\", component_tensor)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-tqIQM52k788"
+ },
+ "source": [
+ "As shown, `my_first_dtensor` is a tensor of `[0, 1]` replicated to all 6 devices."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "6By3k-CGn3yv"
+ },
+ "source": [
+ "The inverse operation of `dtensor.unpack` is `dtensor.pack`. Component tensors can be packed back into a DTensor.\n",
+ "\n",
+ "The components must have the same rank and dtype, which will be the rank and dtype of the returned DTensor. However, there is no strict requirement on the device placement of component tensors as inputs of `dtensor.unpack`: the function will automatically copy the component tensors to their respective corresponding devices.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "9lT-6qQwxOgf"
+ },
+ "outputs": [],
+ "source": [
+ "packed_dtensor = dtensor.pack(\n",
+ " [[0, 1], [0, 1], [0, 1],\n",
+ " [0, 1], [0, 1], [0, 1]],\n",
+ " layout=layout\n",
+ ")\n",
+ "print(packed_dtensor)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "zvS3autrpK2U"
+ },
+ "source": [
+ "### Sharding a DTensor to a Mesh\n",
+ "\n",
+ "So far you've worked with the `my_first_dtensor`, which is a rank-1 DTensor fully replicated across a dim-1 `Mesh`.\n",
+ "\n",
+ "Next, create and inspect DTensors that are sharded across a dim-2 `Mesh`. The following example does this with a 3x2 `Mesh` on 6 CPU devices, where size of mesh dimension `'x'` is 3 devices, and size of mesh dimension`'y'` is 2 devices:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "KWb9Ae0VJ-Rc"
+ },
+ "outputs": [],
+ "source": [
+ "mesh = dtensor.create_mesh([(\"x\", 3), (\"y\", 2)], devices=DEVICES)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ndSeQSFWKQk9"
+ },
+ "source": [
+ "#### Fully sharded rank-2 Tensor on a dim-2 Mesh\n",
+ "\n",
+ "Create a 3x2 rank-2 DTensor, sharding its first axis along the `'x'` mesh dimension, and its second axis along the `'y'` mesh dimension.\n",
+ "\n",
+ "- Because the tensor shape equals to the mesh dimension along all of the sharded axes, each device receives a single element of the DTensor.\n",
+ "- The rank of the component tensor is always the same as the rank of the global shape. DTensor adopts this convention as a simple way to preserve information for locating the relation between a component tensor and the global DTensor."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "ax_ZHouJp1MX"
+ },
+ "outputs": [],
+ "source": [
+ "fully_sharded_dtensor = dtensor_from_array(\n",
+ " tf.reshape(tf.range(6), (3, 2)),\n",
+ " layout=dtensor.Layout([\"x\", \"y\"], mesh))\n",
+ "\n",
+ "for raw_component in dtensor.unpack(fully_sharded_dtensor):\n",
+ " print(\"Device:\", raw_component.device, \",\", raw_component)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "zhsLC-NgrC2p"
+ },
+ "source": [
+ "#### Fully replicated rank-2 Tensor on a dim-2 Mesh\n",
+ "\n",
+ "For comparison, create a 3x2 rank-2 DTensor, fully replicated to the same dim-2 Mesh.\n",
+ "\n",
+ " - Because the DTensor is fully replicated, each device receives a full replica of the 3x2 DTensor.\n",
+ " - The rank of the component tensors are the same as the rank of the global shape -- this fact is trivial, because in this case, the shape of the component tensors are the same as the global shape anyway."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "xmyC6H6Ec90P"
+ },
+ "outputs": [],
+ "source": [
+ "fully_replicated_dtensor = dtensor_from_array(\n",
+ " tf.reshape(tf.range(6), (3, 2)),\n",
+ " layout=dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh))\n",
+ "# Or, layout=tensor.Layout.fully_replicated(mesh, rank=2)\n",
+ "\n",
+ "for component_tensor in dtensor.unpack(fully_replicated_dtensor):\n",
+ " print(\"Device:\", component_tensor.device, \",\", component_tensor)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "KWoyv_oHMzk1"
+ },
+ "source": [
+ "#### Hybrid rank-2 Tensor on a dim-2 Mesh\n",
+ "\n",
+ "What about somewhere between fully sharded and fully replicated?\n",
+ "\n",
+ "DTensor allows a `Layout` to be a hybrid, sharded along some axes, but replicated along others.\n",
+ "\n",
+ "For example, you can shard the same 3x2 rank-2 DTensor in the following way:\n",
+ "\n",
+ " - 1st axis sharded along the `'x'` mesh dimension.\n",
+ " - 2nd axis replicated along the `'y'` mesh dimension.\n",
+ "\n",
+ "To achieve this sharding scheme, you just need to replace the sharding spec of the 2nd axis from `'y'` to `dtensor.UNSHARDED`, to indicate your intention of replicating along the 2nd axis. The layout object will look like `Layout(['x', dtensor.UNSHARDED], mesh)`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "DygnbkQ1Lu42"
+ },
+ "outputs": [],
+ "source": [
+ "hybrid_sharded_dtensor = dtensor_from_array(\n",
+ " tf.reshape(tf.range(6), (3, 2)),\n",
+ " layout=dtensor.Layout(['x', dtensor.UNSHARDED], mesh))\n",
+ "\n",
+ "for component_tensor in dtensor.unpack(hybrid_sharded_dtensor):\n",
+ " print(\"Device:\", component_tensor.device, \",\", component_tensor)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "T7FtZ9kQRZgE"
+ },
+ "source": [
+ "You can inspect the component tensors of the created DTensor and verify they are indeed sharded according to your scheme. It may be helpful to illustrate the situation with a chart:\n",
+ "\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "IkWe6mVl7uRb"
+ },
+ "outputs": [],
+ "source": [
+ "layout = dtensor.Layout([\"x\", dtensor.UNSHARDED], mesh_2d)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "TTalu6M-ISYb"
+ },
+ "source": [
+ "### Single-client and multi-client applications\n",
+ "\n",
+ "DTensor supports both single-client and multi-client applications. The colab Python kernel is an example of a single client DTensor application, where there is a single Python process.\n",
+ "\n",
+ "In a multi-client DTensor application, multiple Python processes collectively perform as a coherent application. The Cartisian grid of a `Mesh` in a multi-client DTensor application can span across devices regardless of whether they are attached locally to the current client or attached remotely to another client. The set of all devices used by a `Mesh` are called the *global device list*.\n",
+ "\n",
+ "The creation of a `Mesh` in a multi-client DTensor application is a collective operation where the *global device list* is identical for all of the participating clients, and the creation of the `Mesh` serves as a global barrier.\n",
+ "\n",
+ "During `Mesh` creation, each client provides its *local device list* together with the expected *global device list*. DTensor validates that both lists are consistent. Please refer to the API documentation for `dtensor.create_mesh` and `dtensor.create_distributed_mesh`\n",
+ " for more information on multi-client mesh creation and the *global device list*.\n",
+ "\n",
+ "Single-client can be thought of as a special case of multi-client, with 1 client. In a single-client application, the *global device list* is identical to the *local device list*.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "P_F7DWkXkB4w"
+ },
+ "source": [
+ "## DTensor as a sharded tensor\n",
+ "\n",
+ "Now, start coding with `DTensor`. The helper function, `dtensor_from_array`, demonstrates creating DTensors from something that looks like a `tf.Tensor`. The function performs two steps:\n",
+ "\n",
+ " - Replicates the tensor to every device on the mesh.\n",
+ " - Shards the copy according to the layout requested in its arguments."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "s6aws-b8dN9L"
+ },
+ "outputs": [],
+ "source": [
+ "def dtensor_from_array(arr, layout, shape=None, dtype=None):\n",
+ " \"\"\"Convert a DTensor from something that looks like an array or Tensor.\n",
+ "\n",
+ " This function is convenient for quick doodling DTensors from a known,\n",
+ " unsharded data object in a single-client environment. This is not the\n",
+ " most efficient way of creating a DTensor, but it will do for this\n",
+ " tutorial.\n",
+ " \"\"\"\n",
+ " if shape is not None or dtype is not None:\n",
+ " arr = tf.constant(arr, shape=shape, dtype=dtype)\n",
+ "\n",
+ " # replicate the input to the mesh\n",
+ " a = dtensor.copy_to_mesh(arr,\n",
+ " layout=dtensor.Layout.replicated(layout.mesh, rank=layout.rank))\n",
+ " # shard the copy to the desirable layout\n",
+ " return dtensor.relayout(a, layout=layout)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "r3o6IysrlGMu"
+ },
+ "source": [
+ "### Anatomy of a DTensor\n",
+ "\n",
+ "A DTensor is a `tf.Tensor` object, but augumented with the `Layout` annotation that defines its sharding behavior. A DTensor consists of the following:\n",
+ "\n",
+ " - Global tensor meta-data, including the global shape and dtype of the tensor.\n",
+ " - A `Layout`, which defines the `Mesh` the `Tensor` belongs to, and how the `Tensor` is sharded onto the `Mesh`.\n",
+ " - A list of **component tensors**, one item per local device in the `Mesh`.\n",
+ "\n",
+ "With `dtensor_from_array`, you can create your first DTensor, `my_first_dtensor`, and examine its contents:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "mQu_nScGUvYH"
+ },
+ "outputs": [],
+ "source": [
+ "mesh = dtensor.create_mesh([(\"x\", 6)], devices=DEVICES)\n",
+ "layout = dtensor.Layout([dtensor.UNSHARDED], mesh)\n",
+ "\n",
+ "my_first_dtensor = dtensor_from_array([0, 1], layout)\n",
+ "\n",
+ "# Examine the DTensor content\n",
+ "print(my_first_dtensor)\n",
+ "print(\"global shape:\", my_first_dtensor.shape)\n",
+ "print(\"dtype:\", my_first_dtensor.dtype)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "r8LQy1nqmvFy"
+ },
+ "source": [
+ "#### Layout and `fetch_layout`\n",
+ "\n",
+ "The layout of a DTensor is not a regular attribute of `tf.Tensor`. Instead, DTensor provides a function, `dtensor.fetch_layout` to access the layout of a DTensor:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "dCSFyaAjmzGu"
+ },
+ "outputs": [],
+ "source": [
+ "print(dtensor.fetch_layout(my_first_dtensor))\n",
+ "assert layout == dtensor.fetch_layout(my_first_dtensor)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ed7i3l2lmatm"
+ },
+ "source": [
+ "#### Component tensors, `pack` and `unpack`\n",
+ "\n",
+ "A DTensor consists of a list of **component tensors**. The component tensor for a device in the `Mesh` is the `Tensor` object representing the piece of the global DTensor that is stored on this device.\n",
+ "\n",
+ "A DTensor can be unpacked into component tensors through `dtensor.unpack`. You can make use of `dtensor.unpack` to inspect the components of the DTensor, and confirm they are on all devices of the `Mesh`.\n",
+ "\n",
+ "Note that the positions of component tensors in the global view may overlap each other. For example, in the case of a fully replicated layout, all components are identical replicas of the global tensor."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "BGbjqVAOnXMk"
+ },
+ "outputs": [],
+ "source": [
+ "for component_tensor in dtensor.unpack(my_first_dtensor):\n",
+ " print(\"Device:\", component_tensor.device, \",\", component_tensor)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-tqIQM52k788"
+ },
+ "source": [
+ "As shown, `my_first_dtensor` is a tensor of `[0, 1]` replicated to all 6 devices."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "6By3k-CGn3yv"
+ },
+ "source": [
+ "The inverse operation of `dtensor.unpack` is `dtensor.pack`. Component tensors can be packed back into a DTensor.\n",
+ "\n",
+ "The components must have the same rank and dtype, which will be the rank and dtype of the returned DTensor. However, there is no strict requirement on the device placement of component tensors as inputs of `dtensor.unpack`: the function will automatically copy the component tensors to their respective corresponding devices.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "9lT-6qQwxOgf"
+ },
+ "outputs": [],
+ "source": [
+ "packed_dtensor = dtensor.pack(\n",
+ " [[0, 1], [0, 1], [0, 1],\n",
+ " [0, 1], [0, 1], [0, 1]],\n",
+ " layout=layout\n",
+ ")\n",
+ "print(packed_dtensor)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "zvS3autrpK2U"
+ },
+ "source": [
+ "### Sharding a DTensor to a Mesh\n",
+ "\n",
+ "So far you've worked with the `my_first_dtensor`, which is a rank-1 DTensor fully replicated across a dim-1 `Mesh`.\n",
+ "\n",
+ "Next, create and inspect DTensors that are sharded across a dim-2 `Mesh`. The following example does this with a 3x2 `Mesh` on 6 CPU devices, where size of mesh dimension `'x'` is 3 devices, and size of mesh dimension`'y'` is 2 devices:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "KWb9Ae0VJ-Rc"
+ },
+ "outputs": [],
+ "source": [
+ "mesh = dtensor.create_mesh([(\"x\", 3), (\"y\", 2)], devices=DEVICES)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ndSeQSFWKQk9"
+ },
+ "source": [
+ "#### Fully sharded rank-2 Tensor on a dim-2 Mesh\n",
+ "\n",
+ "Create a 3x2 rank-2 DTensor, sharding its first axis along the `'x'` mesh dimension, and its second axis along the `'y'` mesh dimension.\n",
+ "\n",
+ "- Because the tensor shape equals to the mesh dimension along all of the sharded axes, each device receives a single element of the DTensor.\n",
+ "- The rank of the component tensor is always the same as the rank of the global shape. DTensor adopts this convention as a simple way to preserve information for locating the relation between a component tensor and the global DTensor."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "ax_ZHouJp1MX"
+ },
+ "outputs": [],
+ "source": [
+ "fully_sharded_dtensor = dtensor_from_array(\n",
+ " tf.reshape(tf.range(6), (3, 2)),\n",
+ " layout=dtensor.Layout([\"x\", \"y\"], mesh))\n",
+ "\n",
+ "for raw_component in dtensor.unpack(fully_sharded_dtensor):\n",
+ " print(\"Device:\", raw_component.device, \",\", raw_component)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "zhsLC-NgrC2p"
+ },
+ "source": [
+ "#### Fully replicated rank-2 Tensor on a dim-2 Mesh\n",
+ "\n",
+ "For comparison, create a 3x2 rank-2 DTensor, fully replicated to the same dim-2 Mesh.\n",
+ "\n",
+ " - Because the DTensor is fully replicated, each device receives a full replica of the 3x2 DTensor.\n",
+ " - The rank of the component tensors are the same as the rank of the global shape -- this fact is trivial, because in this case, the shape of the component tensors are the same as the global shape anyway."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "xmyC6H6Ec90P"
+ },
+ "outputs": [],
+ "source": [
+ "fully_replicated_dtensor = dtensor_from_array(\n",
+ " tf.reshape(tf.range(6), (3, 2)),\n",
+ " layout=dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh))\n",
+ "# Or, layout=tensor.Layout.fully_replicated(mesh, rank=2)\n",
+ "\n",
+ "for component_tensor in dtensor.unpack(fully_replicated_dtensor):\n",
+ " print(\"Device:\", component_tensor.device, \",\", component_tensor)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "KWoyv_oHMzk1"
+ },
+ "source": [
+ "#### Hybrid rank-2 Tensor on a dim-2 Mesh\n",
+ "\n",
+ "What about somewhere between fully sharded and fully replicated?\n",
+ "\n",
+ "DTensor allows a `Layout` to be a hybrid, sharded along some axes, but replicated along others.\n",
+ "\n",
+ "For example, you can shard the same 3x2 rank-2 DTensor in the following way:\n",
+ "\n",
+ " - 1st axis sharded along the `'x'` mesh dimension.\n",
+ " - 2nd axis replicated along the `'y'` mesh dimension.\n",
+ "\n",
+ "To achieve this sharding scheme, you just need to replace the sharding spec of the 2nd axis from `'y'` to `dtensor.UNSHARDED`, to indicate your intention of replicating along the 2nd axis. The layout object will look like `Layout(['x', dtensor.UNSHARDED], mesh)`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "DygnbkQ1Lu42"
+ },
+ "outputs": [],
+ "source": [
+ "hybrid_sharded_dtensor = dtensor_from_array(\n",
+ " tf.reshape(tf.range(6), (3, 2)),\n",
+ " layout=dtensor.Layout(['x', dtensor.UNSHARDED], mesh))\n",
+ "\n",
+ "for component_tensor in dtensor.unpack(hybrid_sharded_dtensor):\n",
+ " print(\"Device:\", component_tensor.device, \",\", component_tensor)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "T7FtZ9kQRZgE"
+ },
+ "source": [
+ "You can inspect the component tensors of the created DTensor and verify they are indeed sharded according to your scheme. It may be helpful to illustrate the situation with a chart:\n",
+ "\n",
+ "  \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "auAkA38XjL-q"
+ },
+ "source": [
+ "#### Tensor.numpy() and sharded DTensor\n",
+ "\n",
+ "Be aware that calling the `.numpy()` method on a sharded DTensor raises an error. The rationale for erroring is to protect against unintended gathering of data from multiple computing devices to the host CPU device backing the returned NumPy array:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "hNdwmnL0jAXS"
+ },
+ "outputs": [],
+ "source": [
+ "print(fully_replicated_dtensor.numpy())\n",
+ "\n",
+ "try:\n",
+ " fully_sharded_dtensor.numpy()\n",
+ "except tf.errors.UnimplementedError:\n",
+ " print(\"got an error as expected for fully_sharded_dtensor\")\n",
+ "\n",
+ "try:\n",
+ " hybrid_sharded_dtensor.numpy()\n",
+ "except tf.errors.UnimplementedError:\n",
+ " print(\"got an error as expected for hybrid_sharded_dtensor\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "8WcMkiagPF_6"
+ },
+ "source": [
+ "## TensorFlow API on DTensor\n",
+ "\n",
+ "DTensor strives to be a drop-in replacement for tensor in your program. The TensorFlow Python API that consume `tf.Tensor`, such as the Ops library functions, `tf.function`, `tf.GradientTape`, also work with DTensor.\n",
+ "\n",
+ "To accomplish this, for each [TensorFlow Graph](https://www.tensorflow.org/guide/intro_to_graphs), DTensor produces and executes an equivalent [SPMD](https://en.wikipedia.org/wiki/SPMD) graph in a procedure called *SPMD expansion*. A few critical steps in DTensor SPMD expansion are:\n",
+ "\n",
+ " - Propagating the sharding `Layout` of DTensor in the TensorFlow graph\n",
+ " - Rewriting TensorFlow Ops on the global DTensor with equivalent TensorFlow Ops on the component tensors, inserting collective and communication Ops when necessary\n",
+ " - Lowering backend neutral TensorFlow Ops to backend specific TensorFlow Ops.\n",
+ "\n",
+ "The final result is that **DTensor is a drop-in replacement for Tensor**.\n",
+ "\n",
+ "Note: DTensor is still an experimental API which means you will be exploring and pushing the boundaries and limits of the DTensor programming model.\n",
+ "\n",
+ "There are 2 ways of triggering DTensor execution:\n",
+ "\n",
+ " - DTensor as operands of a Python function, such as `tf.matmul(a, b)`, will run through DTensor if `a`, `b`, or both are DTensors.\n",
+ " - Requesting the result of a Python function to be a DTensor, such as `dtensor.call_with_layout(tf.ones, layout, shape=(3, 2))`, will run through DTensor because we requested the output of `tf.ones` to be sharded according to a `layout`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "urKzmqAoPssT"
+ },
+ "source": [
+ "### DTensor as operands\n",
+ "\n",
+ "Many TensorFlow API functions take `tf.Tensor` as their operands, and returns `tf.Tensor` as their results. For these functions, you can express intention to run a function through DTensor by passing in DTensor as operands. This section uses `tf.matmul(a, b)` as an example."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "7LO8ZT7iWVga"
+ },
+ "source": [
+ "#### Fully replicated input and output\n",
+ "\n",
+ "In this case, the DTensors are fully replicated. On each of the devices of the `Mesh`,\n",
+ " - the component tensor for operand `a` is `[[1, 2, 3], [4, 5, 6]]` (2x3)\n",
+ " - the component tensor for operand `b` is `[[6, 5], [4, 3], [2, 1]]` (3x2)\n",
+ " - the computation consists of a single `MatMul` of `(2x3, 3x2) -> 2x2`,\n",
+ " - the component tensor for result `c` is `[[20, 14], [56,41]]` (2x2)\n",
+ "\n",
+ "Total number of floating point mul operations is `6 device * 4 result * 3 mul = 72`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "TiZf2J9JNd2D"
+ },
+ "outputs": [],
+ "source": [
+ "mesh = dtensor.create_mesh([(\"x\", 6)], devices=DEVICES)\n",
+ "layout = dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh)\n",
+ "a = dtensor_from_array([[1, 2, 3], [4, 5, 6]], layout=layout)\n",
+ "b = dtensor_from_array([[6, 5], [4, 3], [2, 1]], layout=layout)\n",
+ "\n",
+ "c = tf.matmul(a, b) # runs 6 identical matmuls in parallel on 6 devices\n",
+ "\n",
+ "# `c` is a DTensor replicated on all devices (same as `a` and `b`)\n",
+ "print('Sharding spec:', dtensor.fetch_layout(c).sharding_specs)\n",
+ "print(\"components:\")\n",
+ "for component_tensor in dtensor.unpack(c):\n",
+ " print(component_tensor.device, component_tensor.numpy())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "QXtR9qgKWgWV"
+ },
+ "source": [
+ "#### Sharding operands along the contracted axis\n",
+ "\n",
+ "You can reduce the amount of computation per device by sharding the operands `a` and `b`. A popular sharding scheme for `tf.matmul` is to shard the operands along the axis of the contraction, which means sharding `a` along the second axis, and `b` along the first axis.\n",
+ "\n",
+ "The global matrix product sharded under this scheme can be performed efficiently, by local matmuls that runs concurrently, followed by a collective reduction to aggregate the local results. This is also the [canonical way](https://github.com/open-mpi/ompi/blob/ee87ec391f48512d3718fc7c8b13596403a09056/docs/man-openmpi/man3/MPI_Reduce.3.rst?plain=1#L265) of implementing a distributed matrix dot product.\n",
+ "\n",
+ "Total number of floating point mul operations is `6 devices * 4 result * 1 = 24`, a factor of 3 reduction compared to the fully replicated case (72) above. The factor of 3 is due to the sharding along `x` mesh dimension with a size of `3` devices.\n",
+ "\n",
+ "The reduction of the number of operations run sequentially is the main mechansism with which synchronuous model parallelism accelerates training."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "EyVAUvMePbms"
+ },
+ "outputs": [],
+ "source": [
+ "mesh = dtensor.create_mesh([(\"x\", 3), (\"y\", 2)], devices=DEVICES)\n",
+ "a_layout = dtensor.Layout([dtensor.UNSHARDED, 'x'], mesh)\n",
+ "a = dtensor_from_array([[1, 2, 3], [4, 5, 6]], layout=a_layout)\n",
+ "b_layout = dtensor.Layout(['x', dtensor.UNSHARDED], mesh)\n",
+ "b = dtensor_from_array([[6, 5], [4, 3], [2, 1]], layout=b_layout)\n",
+ "\n",
+ "c = tf.matmul(a, b)\n",
+ "# `c` is a DTensor replicated on all devices (same as `a` and `b`)\n",
+ "print('Sharding spec:', dtensor.fetch_layout(c).sharding_specs)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IhD8yYgJiCEh"
+ },
+ "source": [
+ "#### Additional sharding\n",
+ "\n",
+ "You can perform additional sharding on the inputs, and they are appropriately carried over to the results. For example, you can apply additional sharding of operand `a` along its first axis to the `'y'` mesh dimension. The additional sharding will be carried over to the first axis of the result `c`.\n",
+ "\n",
+ "Total number of floating point mul operations is `6 devices * 2 result * 1 = 12`, an additional factor of 2 reduction compared to the case (24) above. The factor of 2 is due to the sharding along `y` mesh dimension with a size of `2` devices."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "0PYqe0neiOpR"
+ },
+ "outputs": [],
+ "source": [
+ "mesh = dtensor.create_mesh([(\"x\", 3), (\"y\", 2)], devices=DEVICES)\n",
+ "\n",
+ "a_layout = dtensor.Layout(['y', 'x'], mesh)\n",
+ "a = dtensor_from_array([[1, 2, 3], [4, 5, 6]], layout=a_layout)\n",
+ "b_layout = dtensor.Layout(['x', dtensor.UNSHARDED], mesh)\n",
+ "b = dtensor_from_array([[6, 5], [4, 3], [2, 1]], layout=b_layout)\n",
+ "\n",
+ "c = tf.matmul(a, b)\n",
+ "# The sharding of `a` on the first axis is carried to `c'\n",
+ "print('Sharding spec:', dtensor.fetch_layout(c).sharding_specs)\n",
+ "print(\"components:\")\n",
+ "for component_tensor in dtensor.unpack(c):\n",
+ " print(component_tensor.device, component_tensor.numpy())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "c-1NazCVmLWZ"
+ },
+ "source": [
+ "### DTensor as output\n",
+ "\n",
+ "What about Python functions that do not take operands, but returns a Tensor result that can be sharded? Examples of such functions are:\n",
+ "\n",
+ " - `tf.ones`, `tf.zeros`, `tf.random.stateless_normal`\n",
+ "\n",
+ "For these Python functions, DTensor provides `dtensor.call_with_layout` which eagerly executes a Python function with DTensor, and ensures that the returned Tensor is a DTensor with the requested `Layout`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "J0jo_8NPtJiO"
+ },
+ "outputs": [],
+ "source": [
+ "help(dtensor.call_with_layout)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "V-YdLvfytM7g"
+ },
+ "source": [
+ "The eagerly executed Python function usually only contain a single non-trivial TensorFlow Op.\n",
+ "\n",
+ "To use a Python function that emits multiple TensorFlow Ops with `dtensor.call_with_layout`, the function should be converted to a `tf.function`. Calling a `tf.function` is a single TensorFlow Op. When the `tf.function` is called, DTensor can perform layout propagation when it analyzes the computing graph of the `tf.function`, before any of the intermediate tensors are materialized."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "DLrksgFjqRLS"
+ },
+ "source": [
+ "#### APIs that emit a single TensorFlow Op\n",
+ "\n",
+ "If a function emits a single TensorFlow Op, you can directly apply `dtensor.call_with_layout` to the function:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "G1CuKYSFtFeM"
+ },
+ "outputs": [],
+ "source": [
+ "help(tf.ones)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "2m_EAwy-ozOh"
+ },
+ "outputs": [],
+ "source": [
+ "mesh = dtensor.create_mesh([(\"x\", 3), (\"y\", 2)], devices=DEVICES)\n",
+ "ones = dtensor.call_with_layout(tf.ones, dtensor.Layout(['x', 'y'], mesh), shape=(6, 4))\n",
+ "print(ones)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "bx-7Xo8Cpb8S"
+ },
+ "source": [
+ "#### APIs that emit multiple TensorFlow Ops\n",
+ "\n",
+ "If the API emits multiple TensorFlow Ops, convert the function into a single Op through `tf.function`. For example, `tf.random.stateleess_normal`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "H8BQSTRFtCih"
+ },
+ "outputs": [],
+ "source": [
+ "help(tf.random.stateless_normal)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "TvP81eYopSPm"
+ },
+ "outputs": [],
+ "source": [
+ "ones = dtensor.call_with_layout(\n",
+ " tf.function(tf.random.stateless_normal),\n",
+ " dtensor.Layout(['x', 'y'], mesh),\n",
+ " shape=(6, 4),\n",
+ " seed=(1, 1))\n",
+ "print(ones)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "qKoojp9ZyWzW"
+ },
+ "source": [
+ "Wrapping a Python function that emits a single TensorFlow Op with `tf.function` is allowed. The only caveat is paying the associated cost and complexity of creating a `tf.function` from a Python function."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "LbAtKrSkpOaq"
+ },
+ "outputs": [],
+ "source": [
+ "ones = dtensor.call_with_layout(\n",
+ " tf.function(tf.ones),\n",
+ " dtensor.Layout(['x', 'y'], mesh),\n",
+ " shape=(6, 4))\n",
+ "print(ones)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "D-m1816JP3CE"
+ },
+ "source": [
+ "### From `tf.Variable` to `dtensor.DVariable`\n",
+ "\n",
+ "In Tensorflow, `tf.Variable` is the holder for a mutable `Tensor` value.\n",
+ "With DTensor, the corresponding variable semantics is provided by `dtensor.DVariable`.\n",
+ "\n",
+ "The reason a new type `DVariable` was introduced for DTensor variable is because DVariables have an additional requirement that the layout cannot change from its initial value."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "awRPuR26P0Sc"
+ },
+ "outputs": [],
+ "source": [
+ "mesh = dtensor.create_mesh([(\"x\", 6)], devices=DEVICES)\n",
+ "layout = dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh)\n",
+ "\n",
+ "v = dtensor.DVariable(\n",
+ " initial_value=dtensor.call_with_layout(\n",
+ " tf.function(tf.random.stateless_normal),\n",
+ " layout=layout,\n",
+ " shape=tf.TensorShape([64, 32]),\n",
+ " seed=[1, 1],\n",
+ " dtype=tf.float32))\n",
+ "\n",
+ "print(v.handle)\n",
+ "assert layout == dtensor.fetch_layout(v)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Pb9jn473prC_"
+ },
+ "source": [
+ "Other than the requirement on matching the `layout`, a `DVariable` behaves the same as a `tf.Variable`. For example, you can add a DVariable to a DTensor,\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "adxFw9wJpqQQ"
+ },
+ "outputs": [],
+ "source": [
+ "a = dtensor.call_with_layout(tf.ones, layout=layout, shape=(64, 32))\n",
+ "b = v + a # add DVariable and DTensor\n",
+ "print(b)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "QxBdNHWSu-kV"
+ },
+ "source": [
+ "You can also assign a DTensor to a DVariable:\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "oYwfiyw5P94U"
+ },
+ "outputs": [],
+ "source": [
+ "v.assign(a) # assign a DTensor to a DVariable\n",
+ "print(a)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "4fvSk_VUvGnj"
+ },
+ "source": [
+ "Attempting to mutate the layout of a `DVariable`, by assigning a DTensor with an incompatible layout produces an error:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "3pckUugYP_r-"
+ },
+ "outputs": [],
+ "source": [
+ "# variable's layout is immutable.\n",
+ "another_mesh = dtensor.create_mesh([(\"x\", 3), (\"y\", 2)], devices=DEVICES)\n",
+ "b = dtensor.call_with_layout(tf.ones,\n",
+ " layout=dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], another_mesh),\n",
+ " shape=(64, 32))\n",
+ "try:\n",
+ " v.assign(b)\n",
+ "except:\n",
+ " print(\"exception raised\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "3LadIcwRvR6f"
+ },
+ "source": [
+ "## What's next?\n",
+ "\n",
+ "In this colab, you learned about DTensor, an extension to TensorFlow for distributed computing. To try out these concepts in a tutorial, check out [Distributed training with DTensor](../tutorials/distribute/dtensor_ml_tutorial.ipynb)."
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "collapsed_sections": [],
+ "name": "dtensor_overview.ipynb",
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/site/en/guide/eager.ipynb b/site/en/guide/eager.ipynb
deleted file mode 100644
index 44e2e624d43..00000000000
--- a/site/en/guide/eager.ipynb
+++ /dev/null
@@ -1,1146 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "CCQY7jpBfMur"
- },
- "source": [
- "##### Copyright 2018 The TensorFlow Authors."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "id": "z6X9omPnfO_h"
- },
- "outputs": [],
- "source": [
- "#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n",
- "# you may not use this file except in compliance with the License.\n",
- "# You may obtain a copy of the License at\n",
- "#\n",
- "# https://www.apache.org/licenses/LICENSE-2.0\n",
- "#\n",
- "# Unless required by applicable law or agreed to in writing, software\n",
- "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
- "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
- "# See the License for the specific language governing permissions and\n",
- "# limitations under the License."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "2QQJJyDzqGRb"
- },
- "source": [
- "# Eager execution\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "B1xdylywqUSX"
- },
- "source": [
- "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "auAkA38XjL-q"
+ },
+ "source": [
+ "#### Tensor.numpy() and sharded DTensor\n",
+ "\n",
+ "Be aware that calling the `.numpy()` method on a sharded DTensor raises an error. The rationale for erroring is to protect against unintended gathering of data from multiple computing devices to the host CPU device backing the returned NumPy array:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "hNdwmnL0jAXS"
+ },
+ "outputs": [],
+ "source": [
+ "print(fully_replicated_dtensor.numpy())\n",
+ "\n",
+ "try:\n",
+ " fully_sharded_dtensor.numpy()\n",
+ "except tf.errors.UnimplementedError:\n",
+ " print(\"got an error as expected for fully_sharded_dtensor\")\n",
+ "\n",
+ "try:\n",
+ " hybrid_sharded_dtensor.numpy()\n",
+ "except tf.errors.UnimplementedError:\n",
+ " print(\"got an error as expected for hybrid_sharded_dtensor\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "8WcMkiagPF_6"
+ },
+ "source": [
+ "## TensorFlow API on DTensor\n",
+ "\n",
+ "DTensor strives to be a drop-in replacement for tensor in your program. The TensorFlow Python API that consume `tf.Tensor`, such as the Ops library functions, `tf.function`, `tf.GradientTape`, also work with DTensor.\n",
+ "\n",
+ "To accomplish this, for each [TensorFlow Graph](https://www.tensorflow.org/guide/intro_to_graphs), DTensor produces and executes an equivalent [SPMD](https://en.wikipedia.org/wiki/SPMD) graph in a procedure called *SPMD expansion*. A few critical steps in DTensor SPMD expansion are:\n",
+ "\n",
+ " - Propagating the sharding `Layout` of DTensor in the TensorFlow graph\n",
+ " - Rewriting TensorFlow Ops on the global DTensor with equivalent TensorFlow Ops on the component tensors, inserting collective and communication Ops when necessary\n",
+ " - Lowering backend neutral TensorFlow Ops to backend specific TensorFlow Ops.\n",
+ "\n",
+ "The final result is that **DTensor is a drop-in replacement for Tensor**.\n",
+ "\n",
+ "Note: DTensor is still an experimental API which means you will be exploring and pushing the boundaries and limits of the DTensor programming model.\n",
+ "\n",
+ "There are 2 ways of triggering DTensor execution:\n",
+ "\n",
+ " - DTensor as operands of a Python function, such as `tf.matmul(a, b)`, will run through DTensor if `a`, `b`, or both are DTensors.\n",
+ " - Requesting the result of a Python function to be a DTensor, such as `dtensor.call_with_layout(tf.ones, layout, shape=(3, 2))`, will run through DTensor because we requested the output of `tf.ones` to be sharded according to a `layout`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "urKzmqAoPssT"
+ },
+ "source": [
+ "### DTensor as operands\n",
+ "\n",
+ "Many TensorFlow API functions take `tf.Tensor` as their operands, and returns `tf.Tensor` as their results. For these functions, you can express intention to run a function through DTensor by passing in DTensor as operands. This section uses `tf.matmul(a, b)` as an example."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "7LO8ZT7iWVga"
+ },
+ "source": [
+ "#### Fully replicated input and output\n",
+ "\n",
+ "In this case, the DTensors are fully replicated. On each of the devices of the `Mesh`,\n",
+ " - the component tensor for operand `a` is `[[1, 2, 3], [4, 5, 6]]` (2x3)\n",
+ " - the component tensor for operand `b` is `[[6, 5], [4, 3], [2, 1]]` (3x2)\n",
+ " - the computation consists of a single `MatMul` of `(2x3, 3x2) -> 2x2`,\n",
+ " - the component tensor for result `c` is `[[20, 14], [56,41]]` (2x2)\n",
+ "\n",
+ "Total number of floating point mul operations is `6 device * 4 result * 3 mul = 72`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "TiZf2J9JNd2D"
+ },
+ "outputs": [],
+ "source": [
+ "mesh = dtensor.create_mesh([(\"x\", 6)], devices=DEVICES)\n",
+ "layout = dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh)\n",
+ "a = dtensor_from_array([[1, 2, 3], [4, 5, 6]], layout=layout)\n",
+ "b = dtensor_from_array([[6, 5], [4, 3], [2, 1]], layout=layout)\n",
+ "\n",
+ "c = tf.matmul(a, b) # runs 6 identical matmuls in parallel on 6 devices\n",
+ "\n",
+ "# `c` is a DTensor replicated on all devices (same as `a` and `b`)\n",
+ "print('Sharding spec:', dtensor.fetch_layout(c).sharding_specs)\n",
+ "print(\"components:\")\n",
+ "for component_tensor in dtensor.unpack(c):\n",
+ " print(component_tensor.device, component_tensor.numpy())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "QXtR9qgKWgWV"
+ },
+ "source": [
+ "#### Sharding operands along the contracted axis\n",
+ "\n",
+ "You can reduce the amount of computation per device by sharding the operands `a` and `b`. A popular sharding scheme for `tf.matmul` is to shard the operands along the axis of the contraction, which means sharding `a` along the second axis, and `b` along the first axis.\n",
+ "\n",
+ "The global matrix product sharded under this scheme can be performed efficiently, by local matmuls that runs concurrently, followed by a collective reduction to aggregate the local results. This is also the [canonical way](https://github.com/open-mpi/ompi/blob/ee87ec391f48512d3718fc7c8b13596403a09056/docs/man-openmpi/man3/MPI_Reduce.3.rst?plain=1#L265) of implementing a distributed matrix dot product.\n",
+ "\n",
+ "Total number of floating point mul operations is `6 devices * 4 result * 1 = 24`, a factor of 3 reduction compared to the fully replicated case (72) above. The factor of 3 is due to the sharding along `x` mesh dimension with a size of `3` devices.\n",
+ "\n",
+ "The reduction of the number of operations run sequentially is the main mechansism with which synchronuous model parallelism accelerates training."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "EyVAUvMePbms"
+ },
+ "outputs": [],
+ "source": [
+ "mesh = dtensor.create_mesh([(\"x\", 3), (\"y\", 2)], devices=DEVICES)\n",
+ "a_layout = dtensor.Layout([dtensor.UNSHARDED, 'x'], mesh)\n",
+ "a = dtensor_from_array([[1, 2, 3], [4, 5, 6]], layout=a_layout)\n",
+ "b_layout = dtensor.Layout(['x', dtensor.UNSHARDED], mesh)\n",
+ "b = dtensor_from_array([[6, 5], [4, 3], [2, 1]], layout=b_layout)\n",
+ "\n",
+ "c = tf.matmul(a, b)\n",
+ "# `c` is a DTensor replicated on all devices (same as `a` and `b`)\n",
+ "print('Sharding spec:', dtensor.fetch_layout(c).sharding_specs)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IhD8yYgJiCEh"
+ },
+ "source": [
+ "#### Additional sharding\n",
+ "\n",
+ "You can perform additional sharding on the inputs, and they are appropriately carried over to the results. For example, you can apply additional sharding of operand `a` along its first axis to the `'y'` mesh dimension. The additional sharding will be carried over to the first axis of the result `c`.\n",
+ "\n",
+ "Total number of floating point mul operations is `6 devices * 2 result * 1 = 12`, an additional factor of 2 reduction compared to the case (24) above. The factor of 2 is due to the sharding along `y` mesh dimension with a size of `2` devices."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "0PYqe0neiOpR"
+ },
+ "outputs": [],
+ "source": [
+ "mesh = dtensor.create_mesh([(\"x\", 3), (\"y\", 2)], devices=DEVICES)\n",
+ "\n",
+ "a_layout = dtensor.Layout(['y', 'x'], mesh)\n",
+ "a = dtensor_from_array([[1, 2, 3], [4, 5, 6]], layout=a_layout)\n",
+ "b_layout = dtensor.Layout(['x', dtensor.UNSHARDED], mesh)\n",
+ "b = dtensor_from_array([[6, 5], [4, 3], [2, 1]], layout=b_layout)\n",
+ "\n",
+ "c = tf.matmul(a, b)\n",
+ "# The sharding of `a` on the first axis is carried to `c'\n",
+ "print('Sharding spec:', dtensor.fetch_layout(c).sharding_specs)\n",
+ "print(\"components:\")\n",
+ "for component_tensor in dtensor.unpack(c):\n",
+ " print(component_tensor.device, component_tensor.numpy())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "c-1NazCVmLWZ"
+ },
+ "source": [
+ "### DTensor as output\n",
+ "\n",
+ "What about Python functions that do not take operands, but returns a Tensor result that can be sharded? Examples of such functions are:\n",
+ "\n",
+ " - `tf.ones`, `tf.zeros`, `tf.random.stateless_normal`\n",
+ "\n",
+ "For these Python functions, DTensor provides `dtensor.call_with_layout` which eagerly executes a Python function with DTensor, and ensures that the returned Tensor is a DTensor with the requested `Layout`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "J0jo_8NPtJiO"
+ },
+ "outputs": [],
+ "source": [
+ "help(dtensor.call_with_layout)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "V-YdLvfytM7g"
+ },
+ "source": [
+ "The eagerly executed Python function usually only contain a single non-trivial TensorFlow Op.\n",
+ "\n",
+ "To use a Python function that emits multiple TensorFlow Ops with `dtensor.call_with_layout`, the function should be converted to a `tf.function`. Calling a `tf.function` is a single TensorFlow Op. When the `tf.function` is called, DTensor can perform layout propagation when it analyzes the computing graph of the `tf.function`, before any of the intermediate tensors are materialized."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "DLrksgFjqRLS"
+ },
+ "source": [
+ "#### APIs that emit a single TensorFlow Op\n",
+ "\n",
+ "If a function emits a single TensorFlow Op, you can directly apply `dtensor.call_with_layout` to the function:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "G1CuKYSFtFeM"
+ },
+ "outputs": [],
+ "source": [
+ "help(tf.ones)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "2m_EAwy-ozOh"
+ },
+ "outputs": [],
+ "source": [
+ "mesh = dtensor.create_mesh([(\"x\", 3), (\"y\", 2)], devices=DEVICES)\n",
+ "ones = dtensor.call_with_layout(tf.ones, dtensor.Layout(['x', 'y'], mesh), shape=(6, 4))\n",
+ "print(ones)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "bx-7Xo8Cpb8S"
+ },
+ "source": [
+ "#### APIs that emit multiple TensorFlow Ops\n",
+ "\n",
+ "If the API emits multiple TensorFlow Ops, convert the function into a single Op through `tf.function`. For example, `tf.random.stateleess_normal`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "H8BQSTRFtCih"
+ },
+ "outputs": [],
+ "source": [
+ "help(tf.random.stateless_normal)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "TvP81eYopSPm"
+ },
+ "outputs": [],
+ "source": [
+ "ones = dtensor.call_with_layout(\n",
+ " tf.function(tf.random.stateless_normal),\n",
+ " dtensor.Layout(['x', 'y'], mesh),\n",
+ " shape=(6, 4),\n",
+ " seed=(1, 1))\n",
+ "print(ones)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "qKoojp9ZyWzW"
+ },
+ "source": [
+ "Wrapping a Python function that emits a single TensorFlow Op with `tf.function` is allowed. The only caveat is paying the associated cost and complexity of creating a `tf.function` from a Python function."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "LbAtKrSkpOaq"
+ },
+ "outputs": [],
+ "source": [
+ "ones = dtensor.call_with_layout(\n",
+ " tf.function(tf.ones),\n",
+ " dtensor.Layout(['x', 'y'], mesh),\n",
+ " shape=(6, 4))\n",
+ "print(ones)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "D-m1816JP3CE"
+ },
+ "source": [
+ "### From `tf.Variable` to `dtensor.DVariable`\n",
+ "\n",
+ "In Tensorflow, `tf.Variable` is the holder for a mutable `Tensor` value.\n",
+ "With DTensor, the corresponding variable semantics is provided by `dtensor.DVariable`.\n",
+ "\n",
+ "The reason a new type `DVariable` was introduced for DTensor variable is because DVariables have an additional requirement that the layout cannot change from its initial value."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "awRPuR26P0Sc"
+ },
+ "outputs": [],
+ "source": [
+ "mesh = dtensor.create_mesh([(\"x\", 6)], devices=DEVICES)\n",
+ "layout = dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh)\n",
+ "\n",
+ "v = dtensor.DVariable(\n",
+ " initial_value=dtensor.call_with_layout(\n",
+ " tf.function(tf.random.stateless_normal),\n",
+ " layout=layout,\n",
+ " shape=tf.TensorShape([64, 32]),\n",
+ " seed=[1, 1],\n",
+ " dtype=tf.float32))\n",
+ "\n",
+ "print(v.handle)\n",
+ "assert layout == dtensor.fetch_layout(v)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Pb9jn473prC_"
+ },
+ "source": [
+ "Other than the requirement on matching the `layout`, a `DVariable` behaves the same as a `tf.Variable`. For example, you can add a DVariable to a DTensor,\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "adxFw9wJpqQQ"
+ },
+ "outputs": [],
+ "source": [
+ "a = dtensor.call_with_layout(tf.ones, layout=layout, shape=(64, 32))\n",
+ "b = v + a # add DVariable and DTensor\n",
+ "print(b)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "QxBdNHWSu-kV"
+ },
+ "source": [
+ "You can also assign a DTensor to a DVariable:\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "oYwfiyw5P94U"
+ },
+ "outputs": [],
+ "source": [
+ "v.assign(a) # assign a DTensor to a DVariable\n",
+ "print(a)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "4fvSk_VUvGnj"
+ },
+ "source": [
+ "Attempting to mutate the layout of a `DVariable`, by assigning a DTensor with an incompatible layout produces an error:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "3pckUugYP_r-"
+ },
+ "outputs": [],
+ "source": [
+ "# variable's layout is immutable.\n",
+ "another_mesh = dtensor.create_mesh([(\"x\", 3), (\"y\", 2)], devices=DEVICES)\n",
+ "b = dtensor.call_with_layout(tf.ones,\n",
+ " layout=dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], another_mesh),\n",
+ " shape=(64, 32))\n",
+ "try:\n",
+ " v.assign(b)\n",
+ "except:\n",
+ " print(\"exception raised\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "3LadIcwRvR6f"
+ },
+ "source": [
+ "## What's next?\n",
+ "\n",
+ "In this colab, you learned about DTensor, an extension to TensorFlow for distributed computing. To try out these concepts in a tutorial, check out [Distributed training with DTensor](../tutorials/distribute/dtensor_ml_tutorial.ipynb)."
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "collapsed_sections": [],
+ "name": "dtensor_overview.ipynb",
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/site/en/guide/eager.ipynb b/site/en/guide/eager.ipynb
deleted file mode 100644
index 44e2e624d43..00000000000
--- a/site/en/guide/eager.ipynb
+++ /dev/null
@@ -1,1146 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "CCQY7jpBfMur"
- },
- "source": [
- "##### Copyright 2018 The TensorFlow Authors."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "id": "z6X9omPnfO_h"
- },
- "outputs": [],
- "source": [
- "#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n",
- "# you may not use this file except in compliance with the License.\n",
- "# You may obtain a copy of the License at\n",
- "#\n",
- "# https://www.apache.org/licenses/LICENSE-2.0\n",
- "#\n",
- "# Unless required by applicable law or agreed to in writing, software\n",
- "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
- "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
- "# See the License for the specific language governing permissions and\n",
- "# limitations under the License."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "2QQJJyDzqGRb"
- },
- "source": [
- "# Eager execution\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "B1xdylywqUSX"
- },
- "source": [
- " |\n",
+ "|:--:|\n",
+ "| *By
|\n",
+ "|:--:|\n",
+ "| *By  \n",
+ "\n",
+ "*Images downloaded from Pexels (https://www.pexels.com/)\n",
+ "\n",
+ "This Colab walks you through the details of how to load MoveNet, and run inference on the input image and video below.\n",
+ "\n",
+ "Note: check out the [live demo](https://storage.googleapis.com/tfjs-models/demos/pose-detection/index.html?model=movenet) for how the model works!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "10_zkgbZBkIE"
+ },
+ "source": [
+ "# Human Pose Estimation with MoveNet"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "9u_VGR6_BmbZ"
+ },
+ "source": [
+ "## Visualization libraries & Imports"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "TtcwSIcgbIVN"
+ },
+ "outputs": [],
+ "source": [
+ "!pip install -q imageio\n",
+ "!pip install -q opencv-python\n",
+ "!pip install -q git+https://github.com/tensorflow/docs"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "9BLeJv-pCCld"
+ },
+ "outputs": [],
+ "source": [
+ "import tensorflow as tf\n",
+ "import tensorflow_hub as hub\n",
+ "from tensorflow_docs.vis import embed\n",
+ "import numpy as np\n",
+ "import cv2\n",
+ "\n",
+ "# Import matplotlib libraries\n",
+ "from matplotlib import pyplot as plt\n",
+ "from matplotlib.collections import LineCollection\n",
+ "import matplotlib.patches as patches\n",
+ "\n",
+ "# Some modules to display an animation using imageio.\n",
+ "import imageio\n",
+ "from IPython.display import HTML, display"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "bEJBMeRb3YUy"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Helper functions for visualization\n",
+ "\n",
+ "# Dictionary that maps from joint names to keypoint indices.\n",
+ "KEYPOINT_DICT = {\n",
+ " 'nose': 0,\n",
+ " 'left_eye': 1,\n",
+ " 'right_eye': 2,\n",
+ " 'left_ear': 3,\n",
+ " 'right_ear': 4,\n",
+ " 'left_shoulder': 5,\n",
+ " 'right_shoulder': 6,\n",
+ " 'left_elbow': 7,\n",
+ " 'right_elbow': 8,\n",
+ " 'left_wrist': 9,\n",
+ " 'right_wrist': 10,\n",
+ " 'left_hip': 11,\n",
+ " 'right_hip': 12,\n",
+ " 'left_knee': 13,\n",
+ " 'right_knee': 14,\n",
+ " 'left_ankle': 15,\n",
+ " 'right_ankle': 16\n",
+ "}\n",
+ "\n",
+ "# Maps bones to a matplotlib color name.\n",
+ "KEYPOINT_EDGE_INDS_TO_COLOR = {\n",
+ " (0, 1): 'm',\n",
+ " (0, 2): 'c',\n",
+ " (1, 3): 'm',\n",
+ " (2, 4): 'c',\n",
+ " (0, 5): 'm',\n",
+ " (0, 6): 'c',\n",
+ " (5, 7): 'm',\n",
+ " (7, 9): 'm',\n",
+ " (6, 8): 'c',\n",
+ " (8, 10): 'c',\n",
+ " (5, 6): 'y',\n",
+ " (5, 11): 'm',\n",
+ " (6, 12): 'c',\n",
+ " (11, 12): 'y',\n",
+ " (11, 13): 'm',\n",
+ " (13, 15): 'm',\n",
+ " (12, 14): 'c',\n",
+ " (14, 16): 'c'\n",
+ "}\n",
+ "\n",
+ "def _keypoints_and_edges_for_display(keypoints_with_scores,\n",
+ " height,\n",
+ " width,\n",
+ " keypoint_threshold=0.11):\n",
+ " \"\"\"Returns high confidence keypoints and edges for visualization.\n",
+ "\n",
+ " Args:\n",
+ " keypoints_with_scores: A numpy array with shape [1, 1, 17, 3] representing\n",
+ " the keypoint coordinates and scores returned from the MoveNet model.\n",
+ " height: height of the image in pixels.\n",
+ " width: width of the image in pixels.\n",
+ " keypoint_threshold: minimum confidence score for a keypoint to be\n",
+ " visualized.\n",
+ "\n",
+ " Returns:\n",
+ " A (keypoints_xy, edges_xy, edge_colors) containing:\n",
+ " * the coordinates of all keypoints of all detected entities;\n",
+ " * the coordinates of all skeleton edges of all detected entities;\n",
+ " * the colors in which the edges should be plotted.\n",
+ " \"\"\"\n",
+ " keypoints_all = []\n",
+ " keypoint_edges_all = []\n",
+ " edge_colors = []\n",
+ " num_instances, _, _, _ = keypoints_with_scores.shape\n",
+ " for idx in range(num_instances):\n",
+ " kpts_x = keypoints_with_scores[0, idx, :, 1]\n",
+ " kpts_y = keypoints_with_scores[0, idx, :, 0]\n",
+ " kpts_scores = keypoints_with_scores[0, idx, :, 2]\n",
+ " kpts_absolute_xy = np.stack(\n",
+ " [width * np.array(kpts_x), height * np.array(kpts_y)], axis=-1)\n",
+ " kpts_above_thresh_absolute = kpts_absolute_xy[\n",
+ " kpts_scores > keypoint_threshold, :]\n",
+ " keypoints_all.append(kpts_above_thresh_absolute)\n",
+ "\n",
+ " for edge_pair, color in KEYPOINT_EDGE_INDS_TO_COLOR.items():\n",
+ " if (kpts_scores[edge_pair[0]] > keypoint_threshold and\n",
+ " kpts_scores[edge_pair[1]] > keypoint_threshold):\n",
+ " x_start = kpts_absolute_xy[edge_pair[0], 0]\n",
+ " y_start = kpts_absolute_xy[edge_pair[0], 1]\n",
+ " x_end = kpts_absolute_xy[edge_pair[1], 0]\n",
+ " y_end = kpts_absolute_xy[edge_pair[1], 1]\n",
+ " line_seg = np.array([[x_start, y_start], [x_end, y_end]])\n",
+ " keypoint_edges_all.append(line_seg)\n",
+ " edge_colors.append(color)\n",
+ " if keypoints_all:\n",
+ " keypoints_xy = np.concatenate(keypoints_all, axis=0)\n",
+ " else:\n",
+ " keypoints_xy = np.zeros((0, 17, 2))\n",
+ "\n",
+ " if keypoint_edges_all:\n",
+ " edges_xy = np.stack(keypoint_edges_all, axis=0)\n",
+ " else:\n",
+ " edges_xy = np.zeros((0, 2, 2))\n",
+ " return keypoints_xy, edges_xy, edge_colors\n",
+ "\n",
+ "\n",
+ "def draw_prediction_on_image(\n",
+ " image, keypoints_with_scores, crop_region=None, close_figure=False,\n",
+ " output_image_height=None):\n",
+ " \"\"\"Draws the keypoint predictions on image.\n",
+ "\n",
+ " Args:\n",
+ " image: A numpy array with shape [height, width, channel] representing the\n",
+ " pixel values of the input image.\n",
+ " keypoints_with_scores: A numpy array with shape [1, 1, 17, 3] representing\n",
+ " the keypoint coordinates and scores returned from the MoveNet model.\n",
+ " crop_region: A dictionary that defines the coordinates of the bounding box\n",
+ " of the crop region in normalized coordinates (see the init_crop_region\n",
+ " function below for more detail). If provided, this function will also\n",
+ " draw the bounding box on the image.\n",
+ " output_image_height: An integer indicating the height of the output image.\n",
+ " Note that the image aspect ratio will be the same as the input image.\n",
+ "\n",
+ " Returns:\n",
+ " A numpy array with shape [out_height, out_width, channel] representing the\n",
+ " image overlaid with keypoint predictions.\n",
+ " \"\"\"\n",
+ " height, width, channel = image.shape\n",
+ " aspect_ratio = float(width) / height\n",
+ " fig, ax = plt.subplots(figsize=(12 * aspect_ratio, 12))\n",
+ " # To remove the huge white borders\n",
+ " fig.tight_layout(pad=0)\n",
+ " ax.margins(0)\n",
+ " ax.set_yticklabels([])\n",
+ " ax.set_xticklabels([])\n",
+ " plt.axis('off')\n",
+ "\n",
+ " im = ax.imshow(image)\n",
+ " line_segments = LineCollection([], linewidths=(4), linestyle='solid')\n",
+ " ax.add_collection(line_segments)\n",
+ " # Turn off tick labels\n",
+ " scat = ax.scatter([], [], s=60, color='#FF1493', zorder=3)\n",
+ "\n",
+ " (keypoint_locs, keypoint_edges,\n",
+ " edge_colors) = _keypoints_and_edges_for_display(\n",
+ " keypoints_with_scores, height, width)\n",
+ "\n",
+ " line_segments.set_segments(keypoint_edges)\n",
+ " line_segments.set_color(edge_colors)\n",
+ " if keypoint_edges.shape[0]:\n",
+ " line_segments.set_segments(keypoint_edges)\n",
+ " line_segments.set_color(edge_colors)\n",
+ " if keypoint_locs.shape[0]:\n",
+ " scat.set_offsets(keypoint_locs)\n",
+ "\n",
+ " if crop_region is not None:\n",
+ " xmin = max(crop_region['x_min'] * width, 0.0)\n",
+ " ymin = max(crop_region['y_min'] * height, 0.0)\n",
+ " rec_width = min(crop_region['x_max'], 0.99) * width - xmin\n",
+ " rec_height = min(crop_region['y_max'], 0.99) * height - ymin\n",
+ " rect = patches.Rectangle(\n",
+ " (xmin,ymin),rec_width,rec_height,\n",
+ " linewidth=1,edgecolor='b',facecolor='none')\n",
+ " ax.add_patch(rect)\n",
+ "\n",
+ " fig.canvas.draw()\n",
+ " image_from_plot = np.frombuffer(fig.canvas.tostring_rgb(), dtype=np.uint8)\n",
+ " image_from_plot = image_from_plot.reshape(\n",
+ " fig.canvas.get_width_height()[::-1] + (3,))\n",
+ " plt.close(fig)\n",
+ " if output_image_height is not None:\n",
+ " output_image_width = int(output_image_height / height * width)\n",
+ " image_from_plot = cv2.resize(\n",
+ " image_from_plot, dsize=(output_image_width, output_image_height),\n",
+ " interpolation=cv2.INTER_CUBIC)\n",
+ " return image_from_plot\n",
+ "\n",
+ "def to_gif(images, duration):\n",
+ " \"\"\"Converts image sequence (4D numpy array) to gif.\"\"\"\n",
+ " imageio.mimsave('./animation.gif', images, duration=duration)\n",
+ " return embed.embed_file('./animation.gif')\n",
+ "\n",
+ "def progress(value, max=100):\n",
+ " return HTML(\"\"\"\n",
+ "
\n",
+ "\n",
+ "*Images downloaded from Pexels (https://www.pexels.com/)\n",
+ "\n",
+ "This Colab walks you through the details of how to load MoveNet, and run inference on the input image and video below.\n",
+ "\n",
+ "Note: check out the [live demo](https://storage.googleapis.com/tfjs-models/demos/pose-detection/index.html?model=movenet) for how the model works!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "10_zkgbZBkIE"
+ },
+ "source": [
+ "# Human Pose Estimation with MoveNet"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "9u_VGR6_BmbZ"
+ },
+ "source": [
+ "## Visualization libraries & Imports"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "TtcwSIcgbIVN"
+ },
+ "outputs": [],
+ "source": [
+ "!pip install -q imageio\n",
+ "!pip install -q opencv-python\n",
+ "!pip install -q git+https://github.com/tensorflow/docs"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "9BLeJv-pCCld"
+ },
+ "outputs": [],
+ "source": [
+ "import tensorflow as tf\n",
+ "import tensorflow_hub as hub\n",
+ "from tensorflow_docs.vis import embed\n",
+ "import numpy as np\n",
+ "import cv2\n",
+ "\n",
+ "# Import matplotlib libraries\n",
+ "from matplotlib import pyplot as plt\n",
+ "from matplotlib.collections import LineCollection\n",
+ "import matplotlib.patches as patches\n",
+ "\n",
+ "# Some modules to display an animation using imageio.\n",
+ "import imageio\n",
+ "from IPython.display import HTML, display"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "bEJBMeRb3YUy"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Helper functions for visualization\n",
+ "\n",
+ "# Dictionary that maps from joint names to keypoint indices.\n",
+ "KEYPOINT_DICT = {\n",
+ " 'nose': 0,\n",
+ " 'left_eye': 1,\n",
+ " 'right_eye': 2,\n",
+ " 'left_ear': 3,\n",
+ " 'right_ear': 4,\n",
+ " 'left_shoulder': 5,\n",
+ " 'right_shoulder': 6,\n",
+ " 'left_elbow': 7,\n",
+ " 'right_elbow': 8,\n",
+ " 'left_wrist': 9,\n",
+ " 'right_wrist': 10,\n",
+ " 'left_hip': 11,\n",
+ " 'right_hip': 12,\n",
+ " 'left_knee': 13,\n",
+ " 'right_knee': 14,\n",
+ " 'left_ankle': 15,\n",
+ " 'right_ankle': 16\n",
+ "}\n",
+ "\n",
+ "# Maps bones to a matplotlib color name.\n",
+ "KEYPOINT_EDGE_INDS_TO_COLOR = {\n",
+ " (0, 1): 'm',\n",
+ " (0, 2): 'c',\n",
+ " (1, 3): 'm',\n",
+ " (2, 4): 'c',\n",
+ " (0, 5): 'm',\n",
+ " (0, 6): 'c',\n",
+ " (5, 7): 'm',\n",
+ " (7, 9): 'm',\n",
+ " (6, 8): 'c',\n",
+ " (8, 10): 'c',\n",
+ " (5, 6): 'y',\n",
+ " (5, 11): 'm',\n",
+ " (6, 12): 'c',\n",
+ " (11, 12): 'y',\n",
+ " (11, 13): 'm',\n",
+ " (13, 15): 'm',\n",
+ " (12, 14): 'c',\n",
+ " (14, 16): 'c'\n",
+ "}\n",
+ "\n",
+ "def _keypoints_and_edges_for_display(keypoints_with_scores,\n",
+ " height,\n",
+ " width,\n",
+ " keypoint_threshold=0.11):\n",
+ " \"\"\"Returns high confidence keypoints and edges for visualization.\n",
+ "\n",
+ " Args:\n",
+ " keypoints_with_scores: A numpy array with shape [1, 1, 17, 3] representing\n",
+ " the keypoint coordinates and scores returned from the MoveNet model.\n",
+ " height: height of the image in pixels.\n",
+ " width: width of the image in pixels.\n",
+ " keypoint_threshold: minimum confidence score for a keypoint to be\n",
+ " visualized.\n",
+ "\n",
+ " Returns:\n",
+ " A (keypoints_xy, edges_xy, edge_colors) containing:\n",
+ " * the coordinates of all keypoints of all detected entities;\n",
+ " * the coordinates of all skeleton edges of all detected entities;\n",
+ " * the colors in which the edges should be plotted.\n",
+ " \"\"\"\n",
+ " keypoints_all = []\n",
+ " keypoint_edges_all = []\n",
+ " edge_colors = []\n",
+ " num_instances, _, _, _ = keypoints_with_scores.shape\n",
+ " for idx in range(num_instances):\n",
+ " kpts_x = keypoints_with_scores[0, idx, :, 1]\n",
+ " kpts_y = keypoints_with_scores[0, idx, :, 0]\n",
+ " kpts_scores = keypoints_with_scores[0, idx, :, 2]\n",
+ " kpts_absolute_xy = np.stack(\n",
+ " [width * np.array(kpts_x), height * np.array(kpts_y)], axis=-1)\n",
+ " kpts_above_thresh_absolute = kpts_absolute_xy[\n",
+ " kpts_scores > keypoint_threshold, :]\n",
+ " keypoints_all.append(kpts_above_thresh_absolute)\n",
+ "\n",
+ " for edge_pair, color in KEYPOINT_EDGE_INDS_TO_COLOR.items():\n",
+ " if (kpts_scores[edge_pair[0]] > keypoint_threshold and\n",
+ " kpts_scores[edge_pair[1]] > keypoint_threshold):\n",
+ " x_start = kpts_absolute_xy[edge_pair[0], 0]\n",
+ " y_start = kpts_absolute_xy[edge_pair[0], 1]\n",
+ " x_end = kpts_absolute_xy[edge_pair[1], 0]\n",
+ " y_end = kpts_absolute_xy[edge_pair[1], 1]\n",
+ " line_seg = np.array([[x_start, y_start], [x_end, y_end]])\n",
+ " keypoint_edges_all.append(line_seg)\n",
+ " edge_colors.append(color)\n",
+ " if keypoints_all:\n",
+ " keypoints_xy = np.concatenate(keypoints_all, axis=0)\n",
+ " else:\n",
+ " keypoints_xy = np.zeros((0, 17, 2))\n",
+ "\n",
+ " if keypoint_edges_all:\n",
+ " edges_xy = np.stack(keypoint_edges_all, axis=0)\n",
+ " else:\n",
+ " edges_xy = np.zeros((0, 2, 2))\n",
+ " return keypoints_xy, edges_xy, edge_colors\n",
+ "\n",
+ "\n",
+ "def draw_prediction_on_image(\n",
+ " image, keypoints_with_scores, crop_region=None, close_figure=False,\n",
+ " output_image_height=None):\n",
+ " \"\"\"Draws the keypoint predictions on image.\n",
+ "\n",
+ " Args:\n",
+ " image: A numpy array with shape [height, width, channel] representing the\n",
+ " pixel values of the input image.\n",
+ " keypoints_with_scores: A numpy array with shape [1, 1, 17, 3] representing\n",
+ " the keypoint coordinates and scores returned from the MoveNet model.\n",
+ " crop_region: A dictionary that defines the coordinates of the bounding box\n",
+ " of the crop region in normalized coordinates (see the init_crop_region\n",
+ " function below for more detail). If provided, this function will also\n",
+ " draw the bounding box on the image.\n",
+ " output_image_height: An integer indicating the height of the output image.\n",
+ " Note that the image aspect ratio will be the same as the input image.\n",
+ "\n",
+ " Returns:\n",
+ " A numpy array with shape [out_height, out_width, channel] representing the\n",
+ " image overlaid with keypoint predictions.\n",
+ " \"\"\"\n",
+ " height, width, channel = image.shape\n",
+ " aspect_ratio = float(width) / height\n",
+ " fig, ax = plt.subplots(figsize=(12 * aspect_ratio, 12))\n",
+ " # To remove the huge white borders\n",
+ " fig.tight_layout(pad=0)\n",
+ " ax.margins(0)\n",
+ " ax.set_yticklabels([])\n",
+ " ax.set_xticklabels([])\n",
+ " plt.axis('off')\n",
+ "\n",
+ " im = ax.imshow(image)\n",
+ " line_segments = LineCollection([], linewidths=(4), linestyle='solid')\n",
+ " ax.add_collection(line_segments)\n",
+ " # Turn off tick labels\n",
+ " scat = ax.scatter([], [], s=60, color='#FF1493', zorder=3)\n",
+ "\n",
+ " (keypoint_locs, keypoint_edges,\n",
+ " edge_colors) = _keypoints_and_edges_for_display(\n",
+ " keypoints_with_scores, height, width)\n",
+ "\n",
+ " line_segments.set_segments(keypoint_edges)\n",
+ " line_segments.set_color(edge_colors)\n",
+ " if keypoint_edges.shape[0]:\n",
+ " line_segments.set_segments(keypoint_edges)\n",
+ " line_segments.set_color(edge_colors)\n",
+ " if keypoint_locs.shape[0]:\n",
+ " scat.set_offsets(keypoint_locs)\n",
+ "\n",
+ " if crop_region is not None:\n",
+ " xmin = max(crop_region['x_min'] * width, 0.0)\n",
+ " ymin = max(crop_region['y_min'] * height, 0.0)\n",
+ " rec_width = min(crop_region['x_max'], 0.99) * width - xmin\n",
+ " rec_height = min(crop_region['y_max'], 0.99) * height - ymin\n",
+ " rect = patches.Rectangle(\n",
+ " (xmin,ymin),rec_width,rec_height,\n",
+ " linewidth=1,edgecolor='b',facecolor='none')\n",
+ " ax.add_patch(rect)\n",
+ "\n",
+ " fig.canvas.draw()\n",
+ " image_from_plot = np.frombuffer(fig.canvas.tostring_rgb(), dtype=np.uint8)\n",
+ " image_from_plot = image_from_plot.reshape(\n",
+ " fig.canvas.get_width_height()[::-1] + (3,))\n",
+ " plt.close(fig)\n",
+ " if output_image_height is not None:\n",
+ " output_image_width = int(output_image_height / height * width)\n",
+ " image_from_plot = cv2.resize(\n",
+ " image_from_plot, dsize=(output_image_width, output_image_height),\n",
+ " interpolation=cv2.INTER_CUBIC)\n",
+ " return image_from_plot\n",
+ "\n",
+ "def to_gif(images, duration):\n",
+ " \"\"\"Converts image sequence (4D numpy array) to gif.\"\"\"\n",
+ " imageio.mimsave('./animation.gif', images, duration=duration)\n",
+ " return embed.embed_file('./animation.gif')\n",
+ "\n",
+ "def progress(value, max=100):\n",
+ " return HTML(\"\"\"\n",
+ "