
🎉 原创 100+ 架构图,重磅开源!大模型算法一览无余! 涵盖 LLM、VLM 等大模型技术,训练算法(RL、RLHF、GRPO、DPO、SFT 与 CoT 蒸馏等)、效果优化与 RAG 等。
🎉 架构图的文字详解、更多架构图 详见:《大模型算法:强化学习、微调与对齐》
🎉 本项目 长期勘误、更新、追加,欢迎点击右上角 ↗ 的 Star ⭐ 关注!
🎉 鼓励开发者参与共建,PR 提交步骤详见:欢迎共建。
🎉 点击图片可查看高清大图,或浏览仓库目录中的 .svg 格式矢量图(支持无限缩放)
- 大模型算法总体架构(以LLM、VLM为主)
- 强化学习算法图谱 (rl-algo-map).pdf————全网最大!
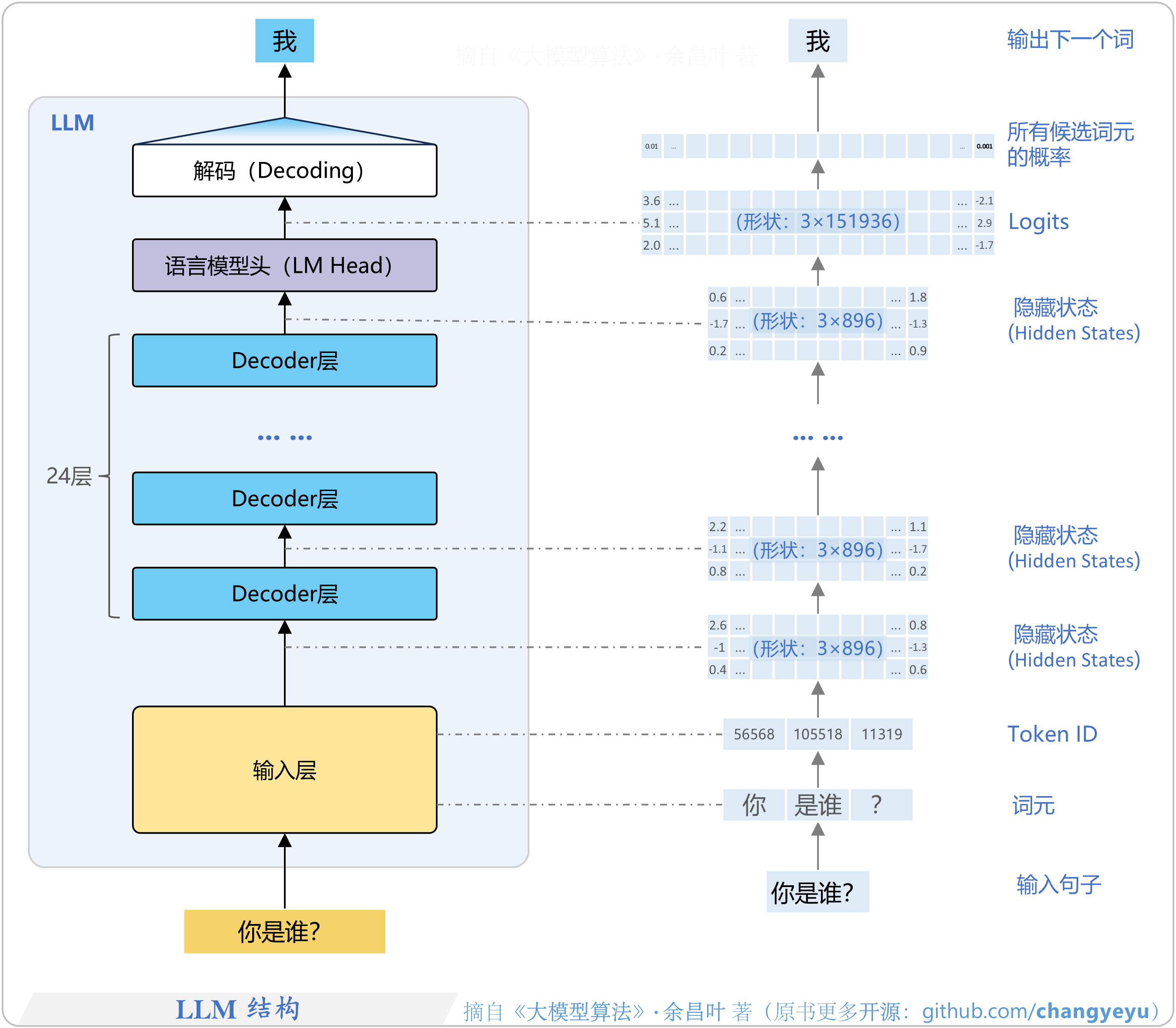
- 【LLM基础】LLM结构总图————全网最大!
- 【LLM基础】LLM(Large Language Model)结构
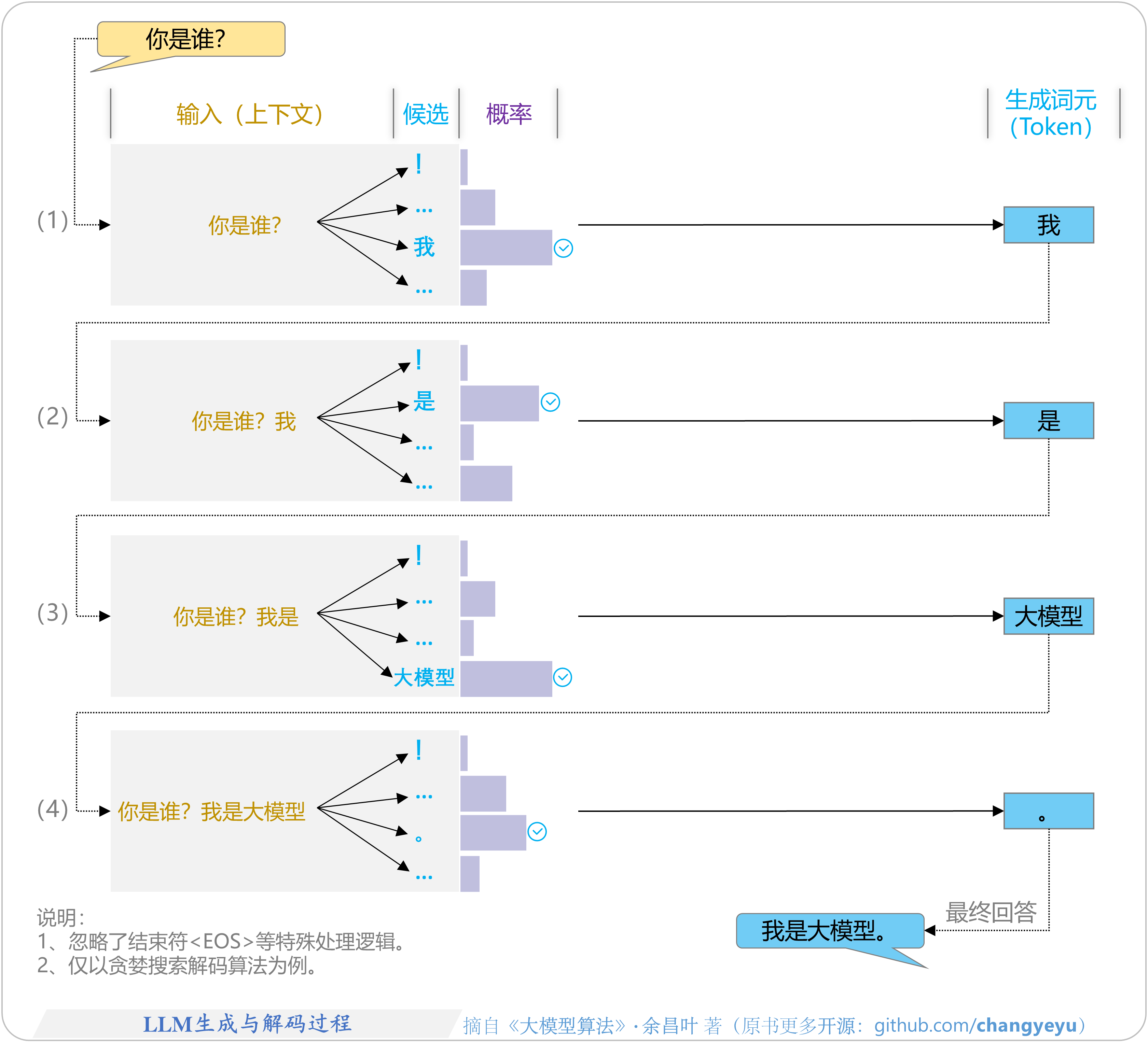
- 【LLM基础】LLM生成与解码(Decoding)过程
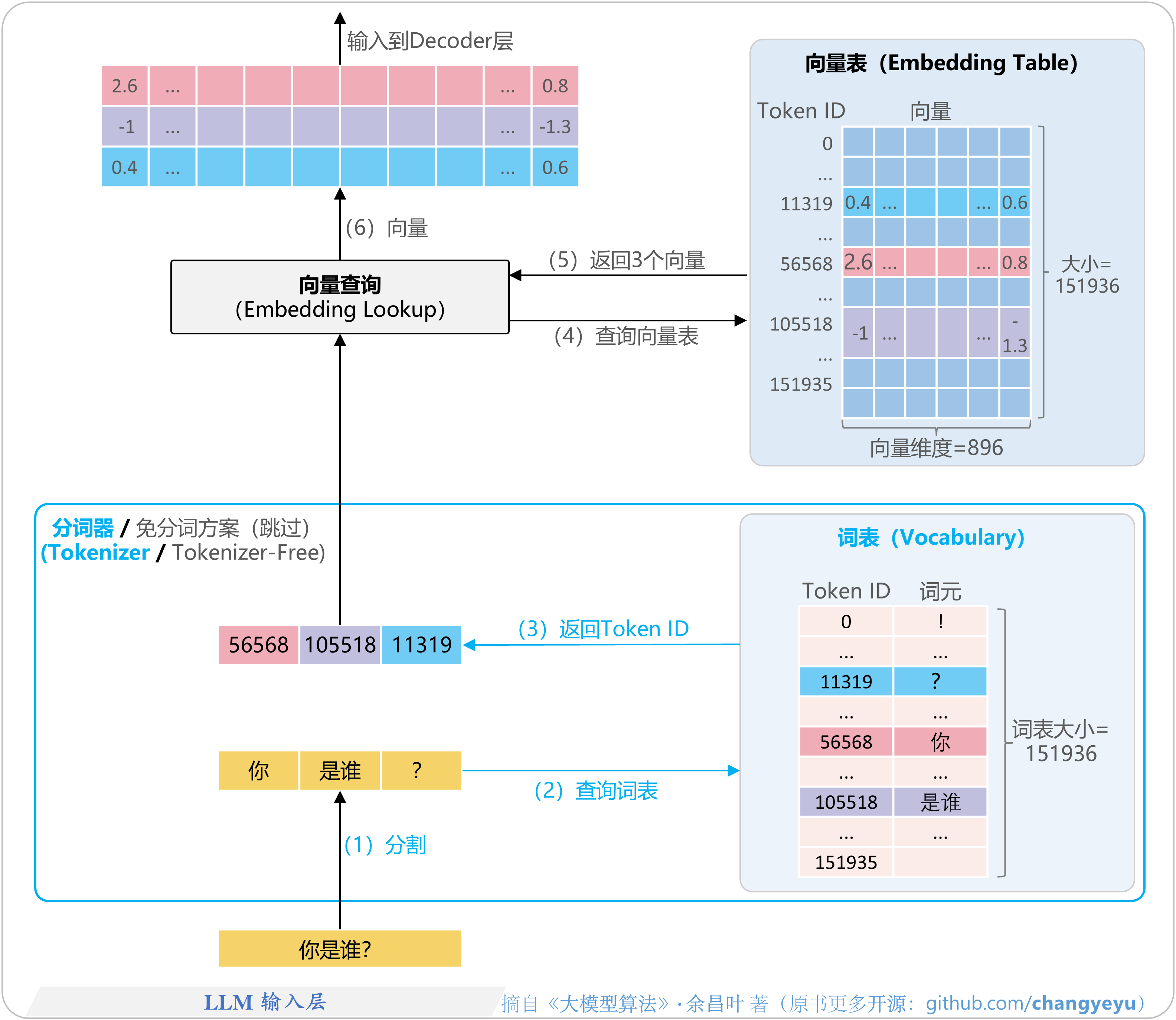
- 【LLM基础】LLM输入层
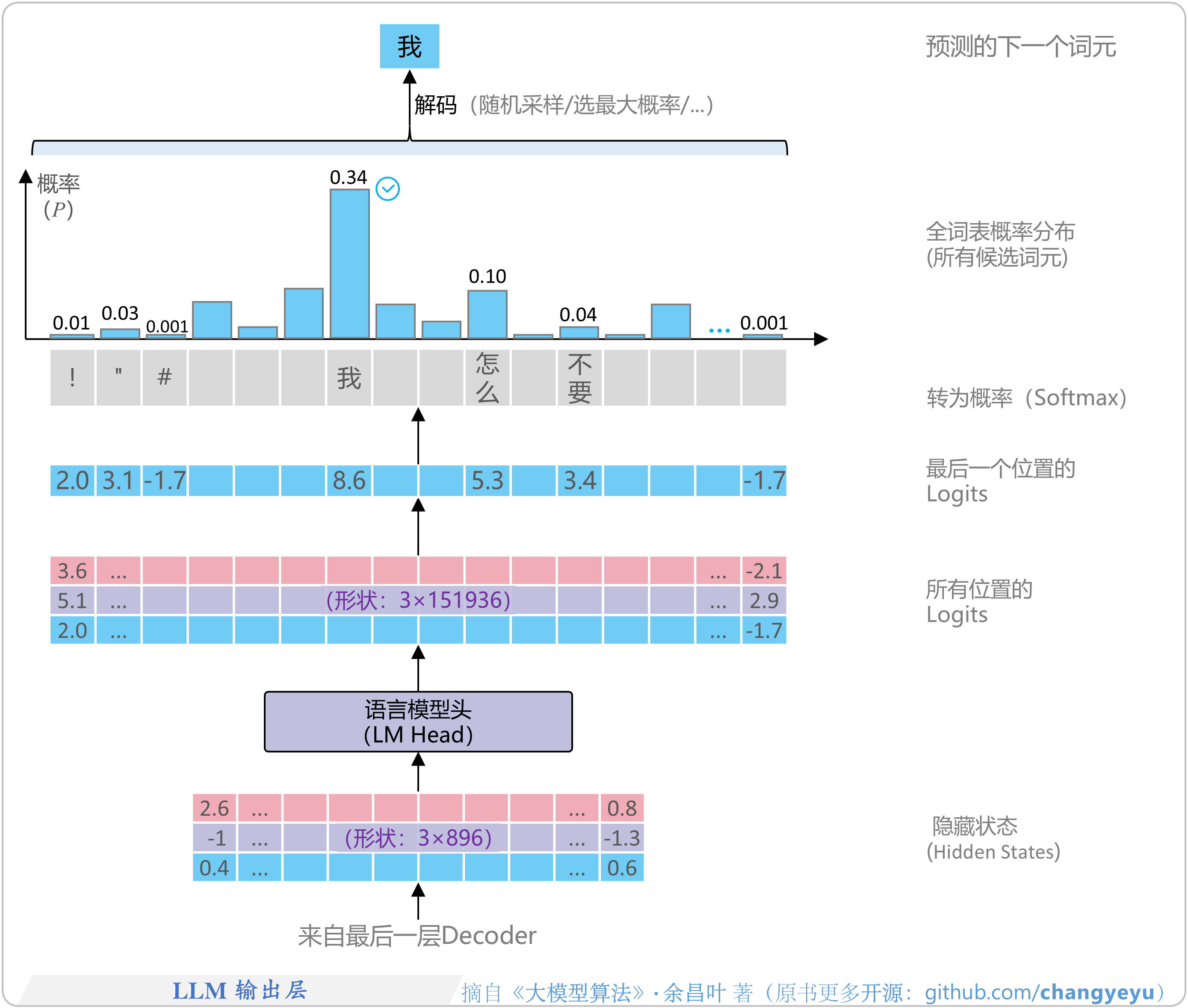
- 【LLM基础】LLM输出层
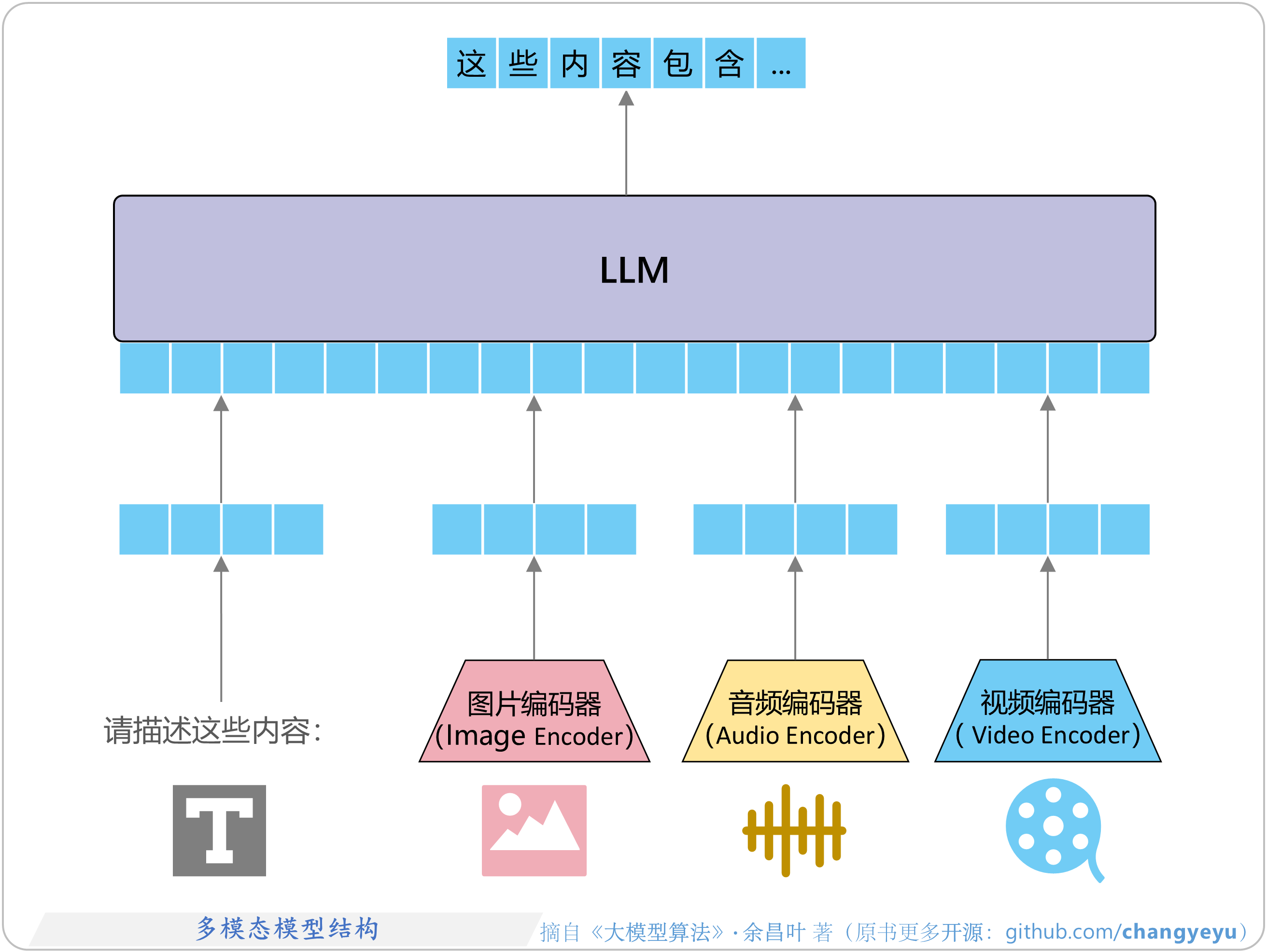
- 【LLM基础】多模态模型结构(VLM、MLLM ...)
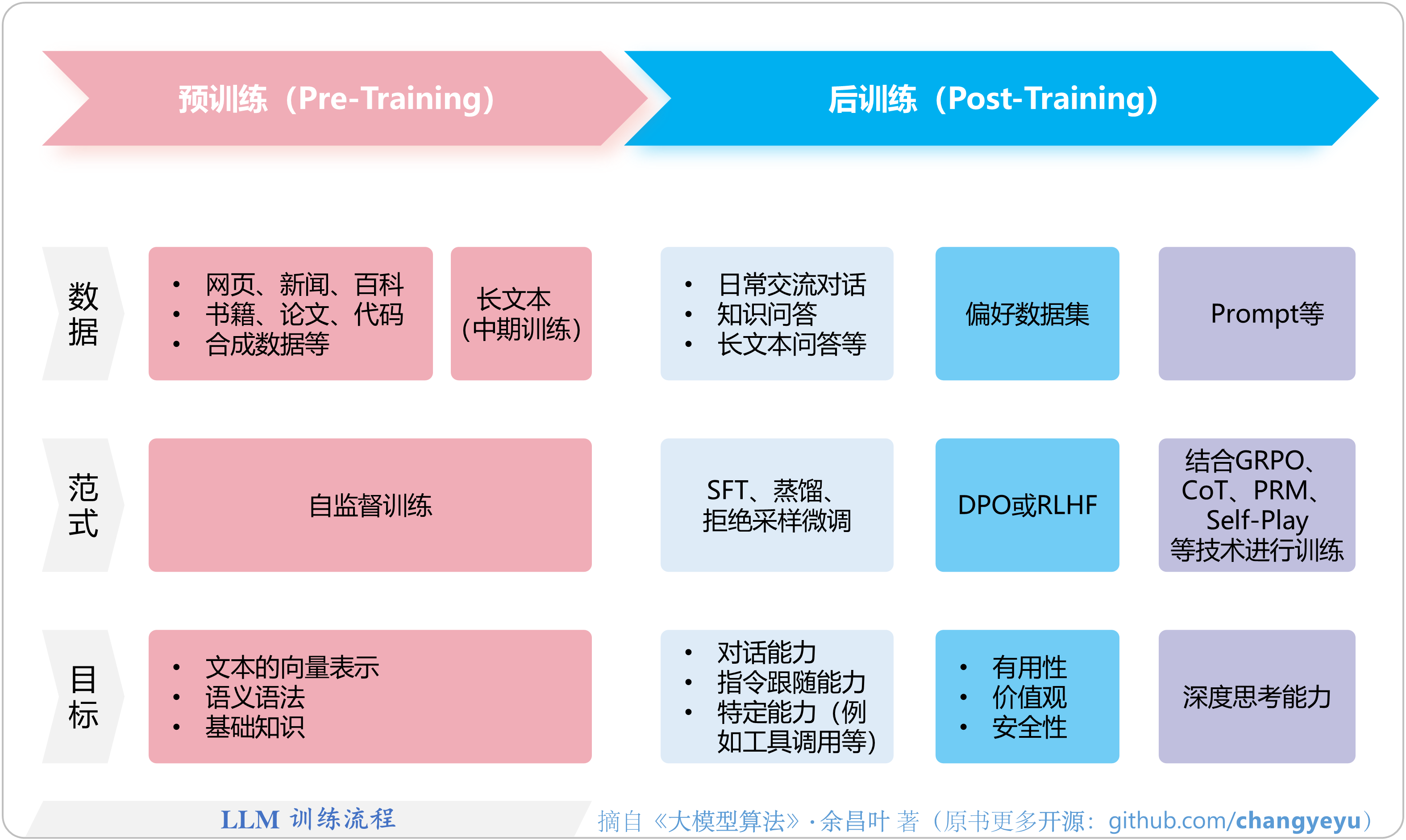
- 【LLM基础】LLM训练流程
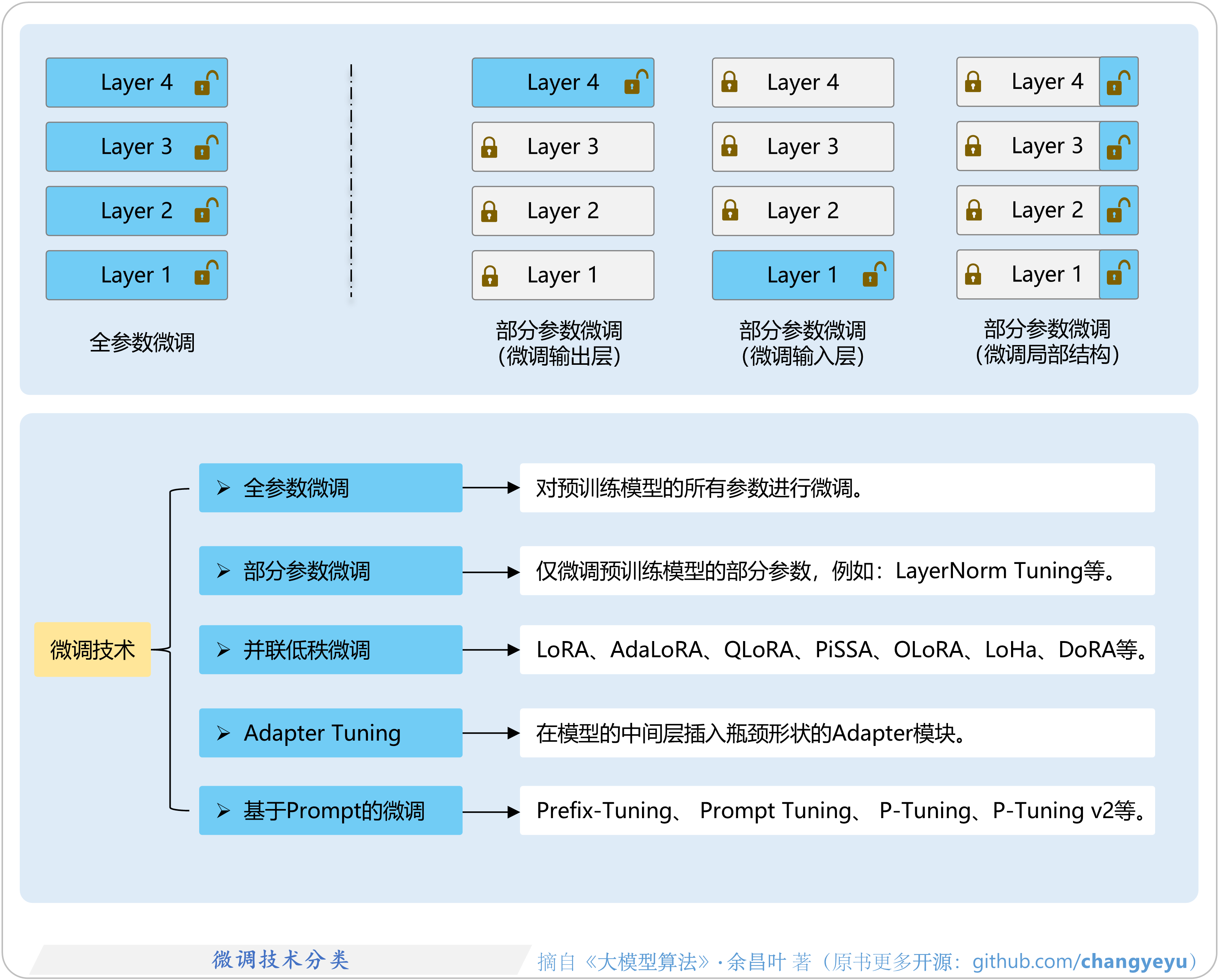
- 【SFT】微调(Fine-Tuning)技术分类
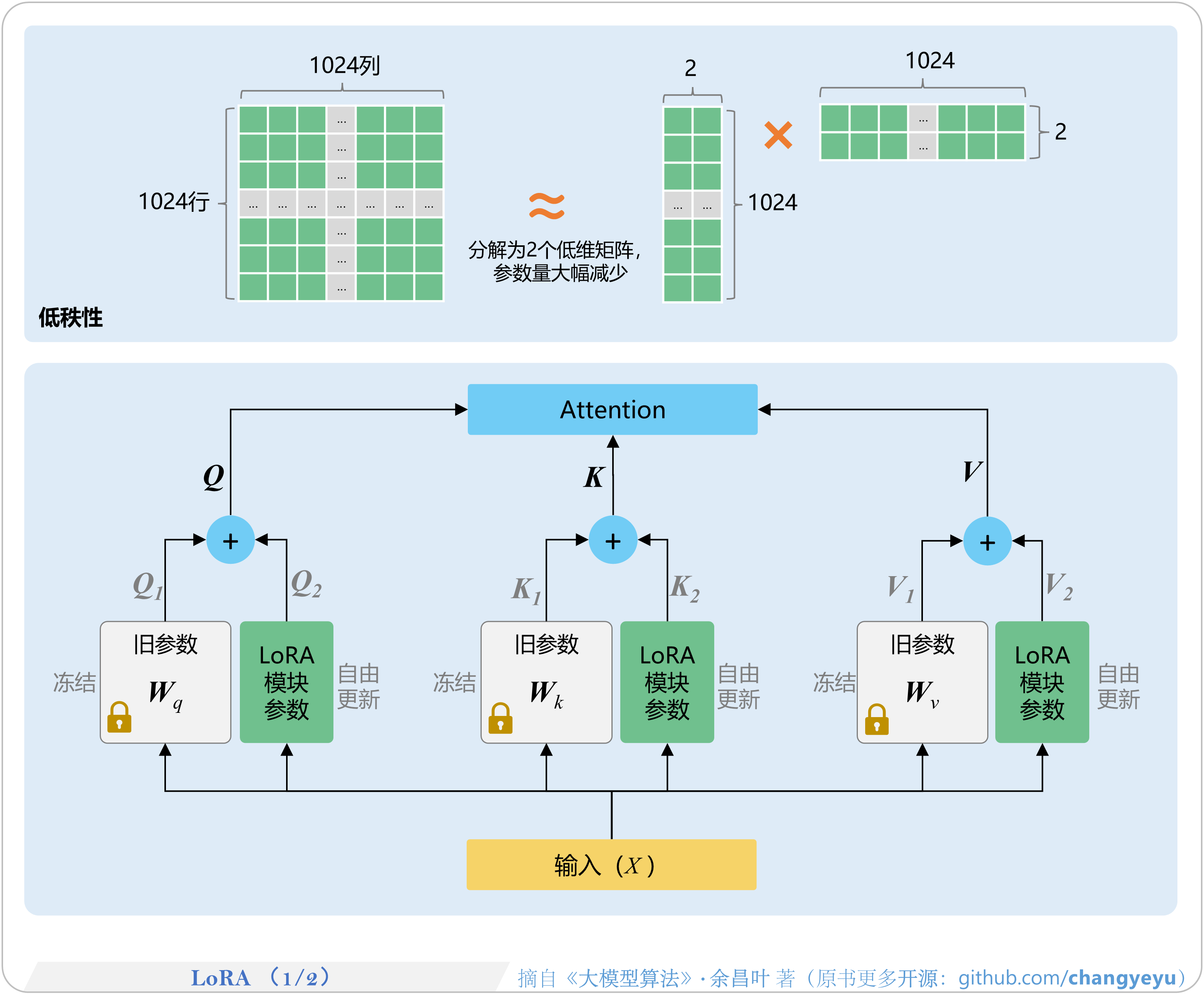
- 【SFT】LoRA(1 of 2)
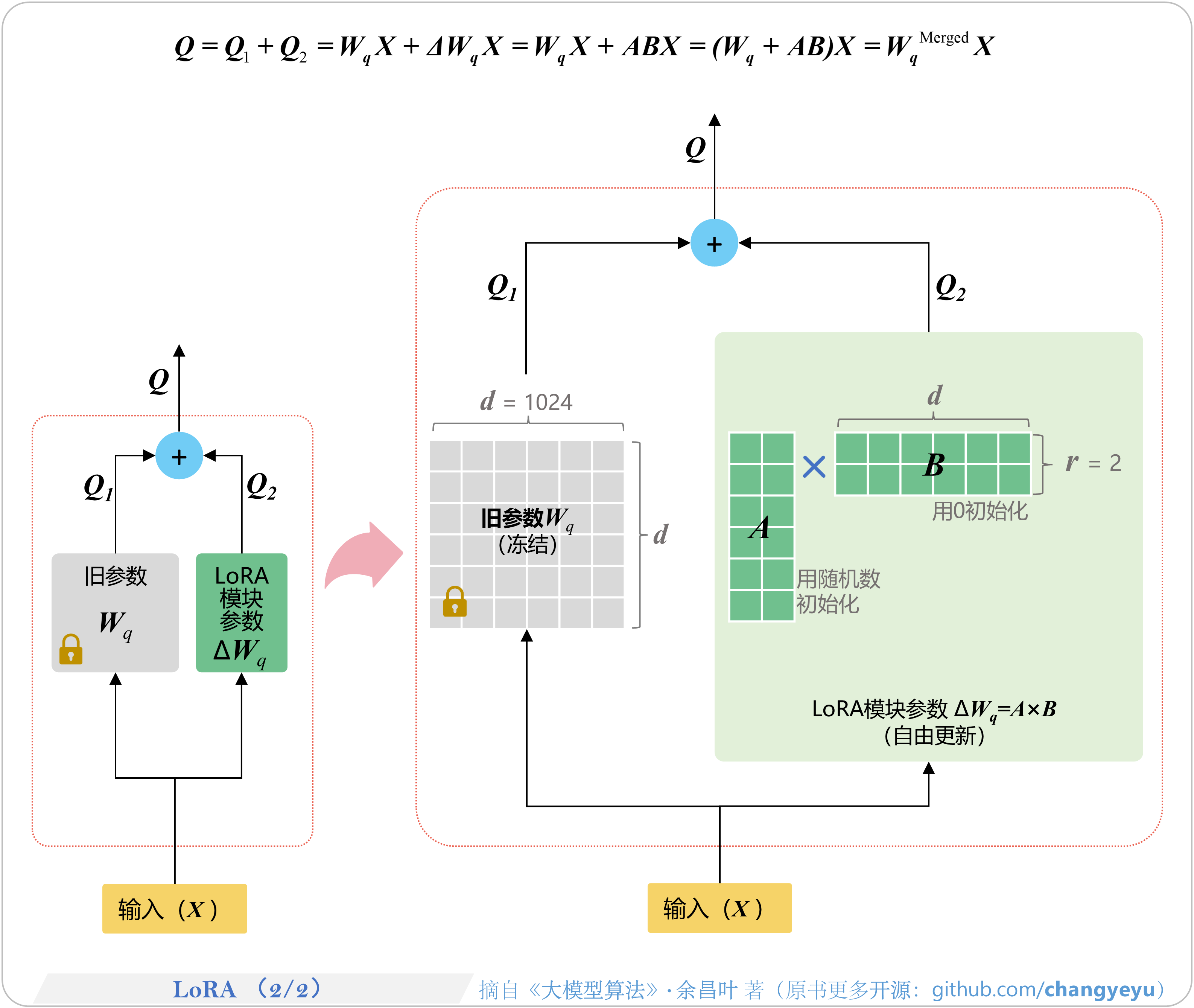
- 【SFT】LoRA(2 of 2)
- 【SFT】Prefix-Tuning
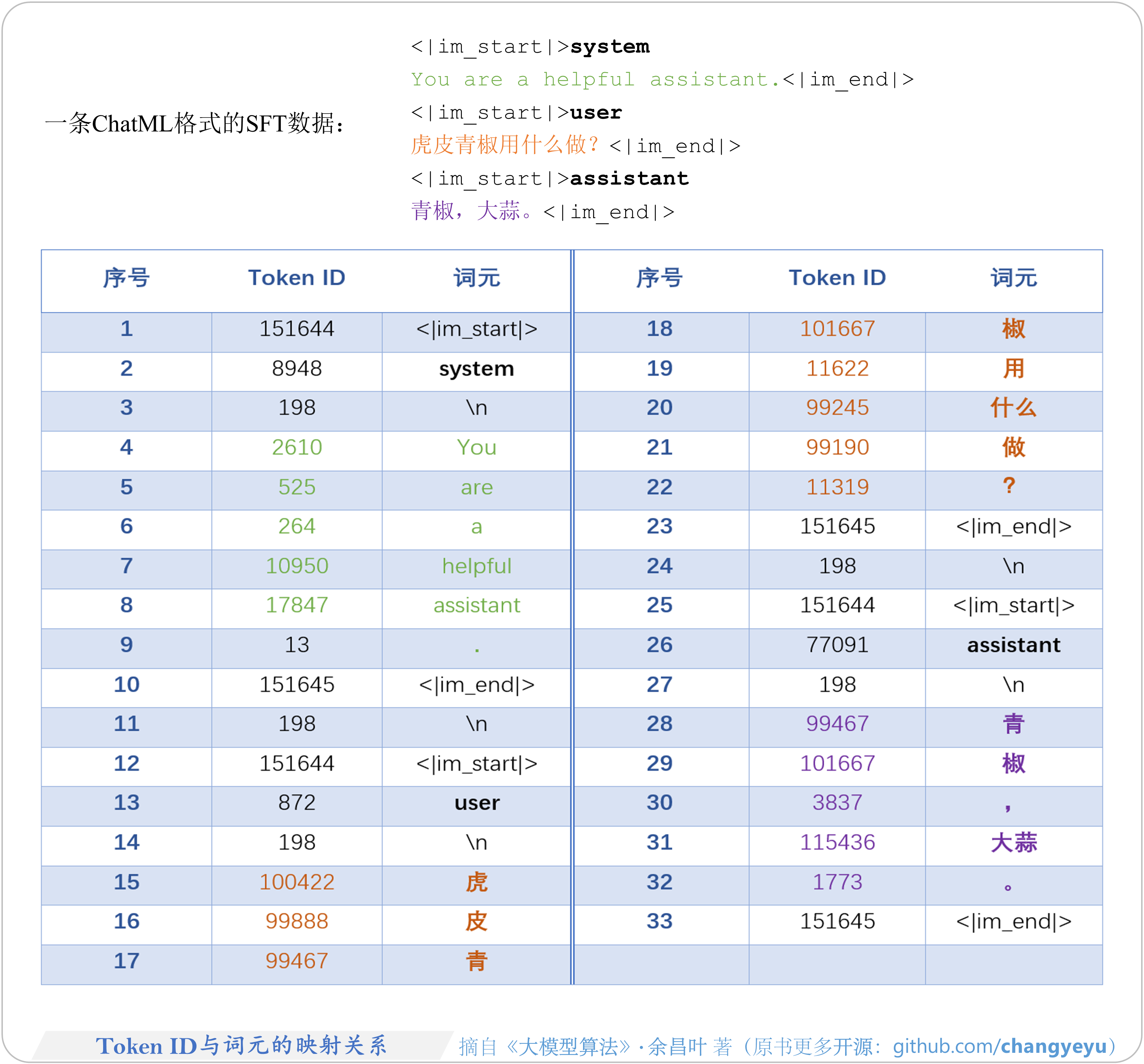
- 【SFT】TokenID与词元的映射关系
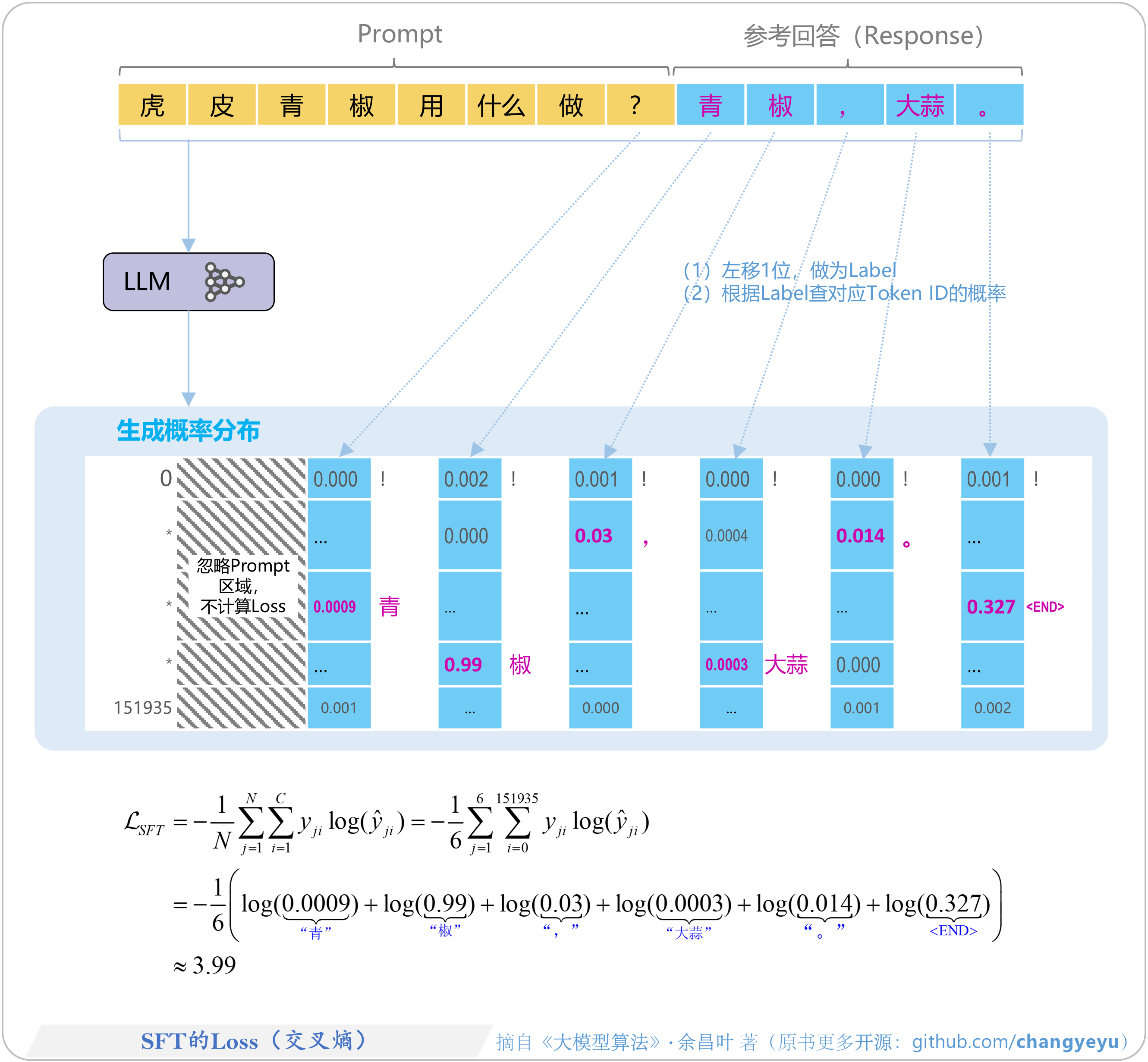
- 【SFT】SFT的Loss(交叉熵)
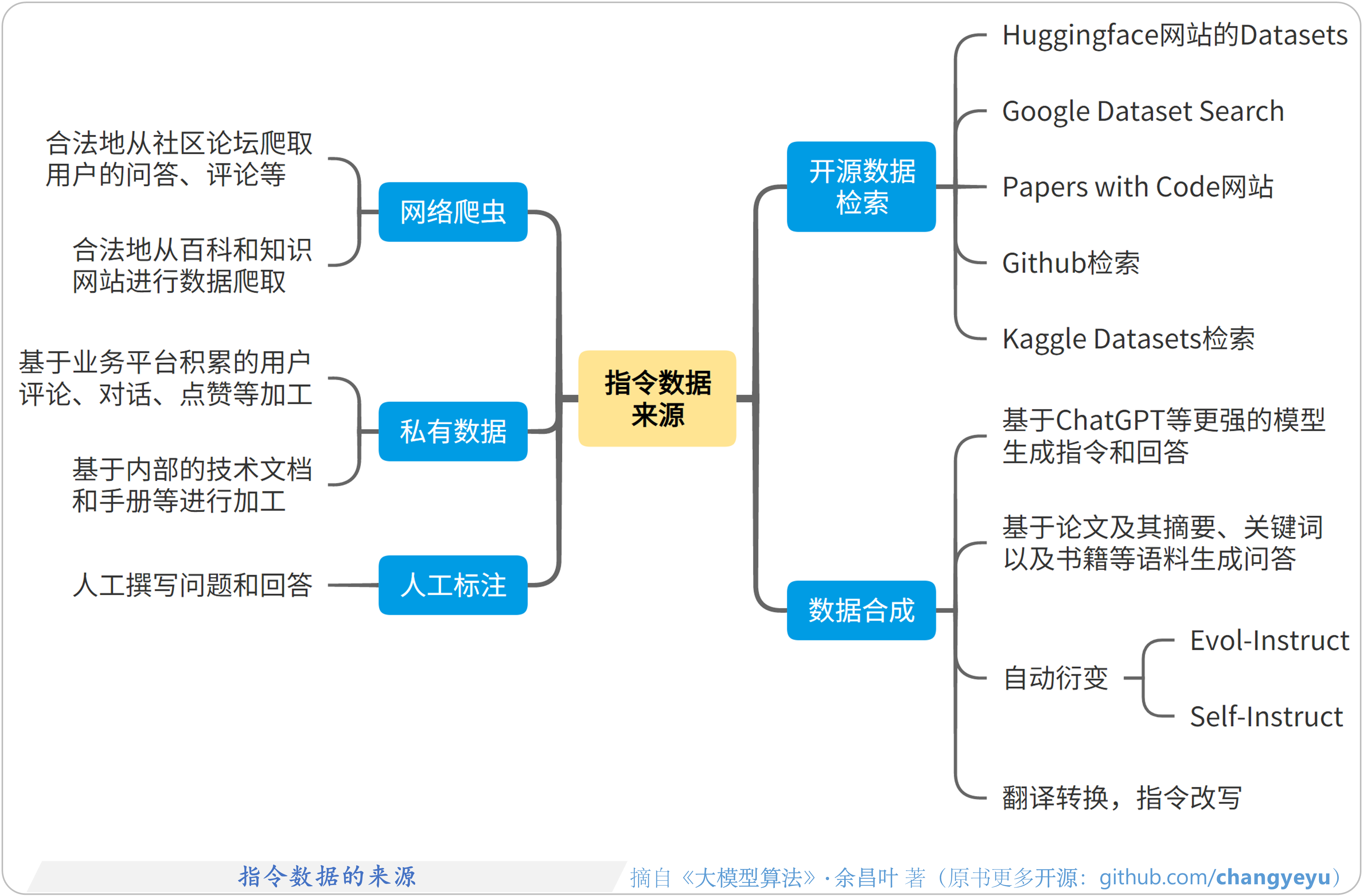
- 【SFT】指令数据的来源
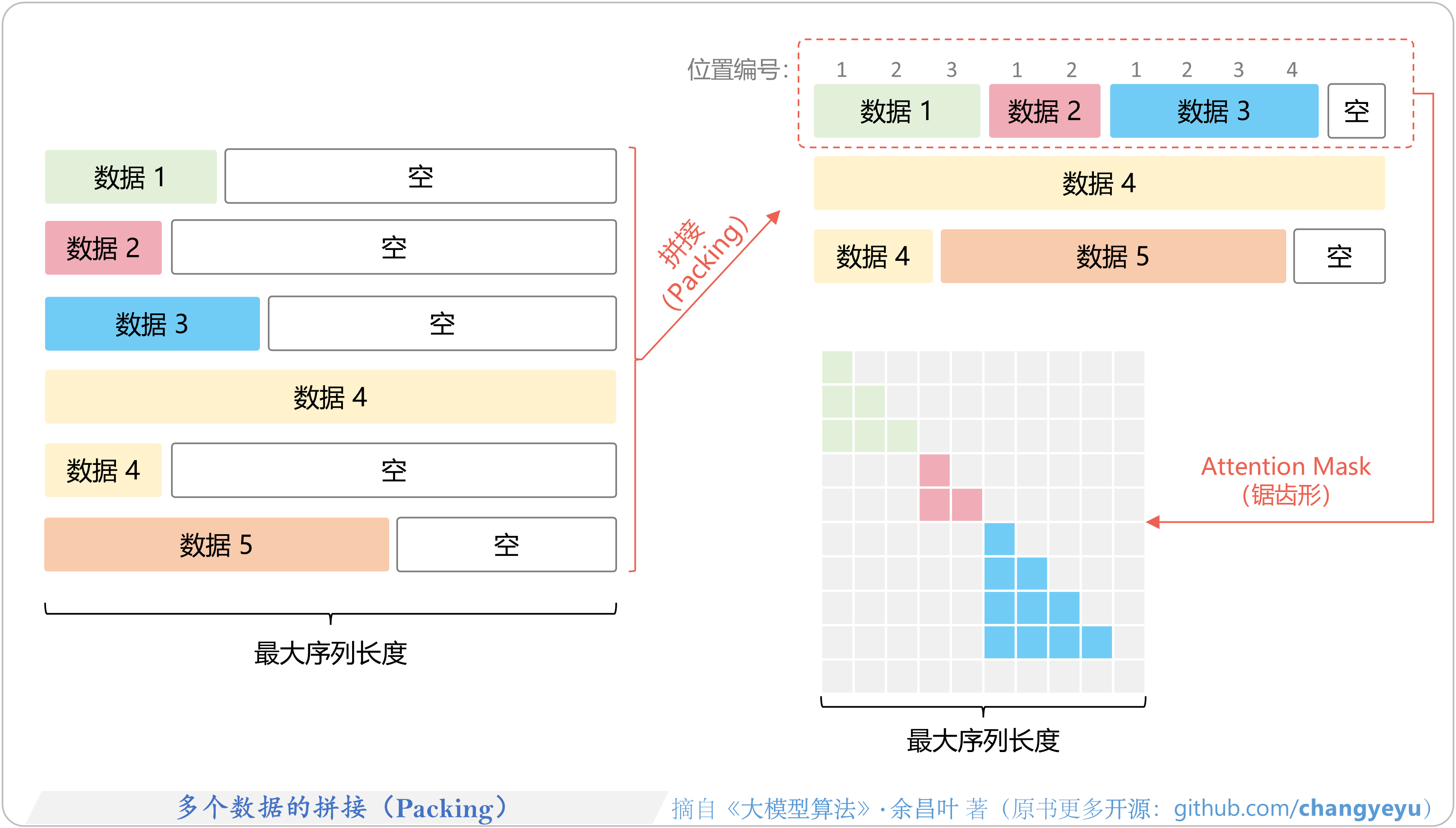
- 【SFT】多个数据的拼接(Packing)
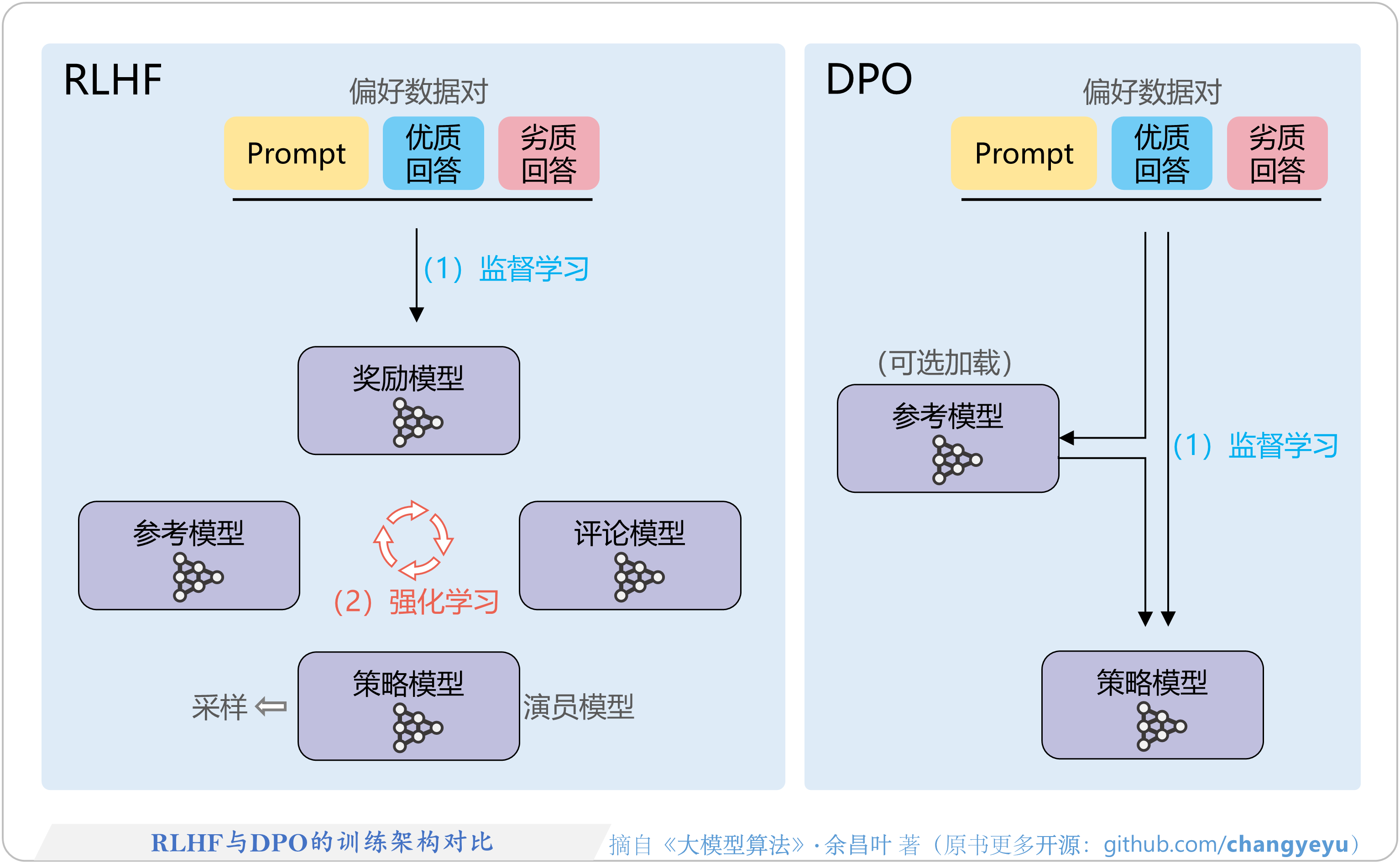
- 【DPO】RLHF与DPO的训练架构对比
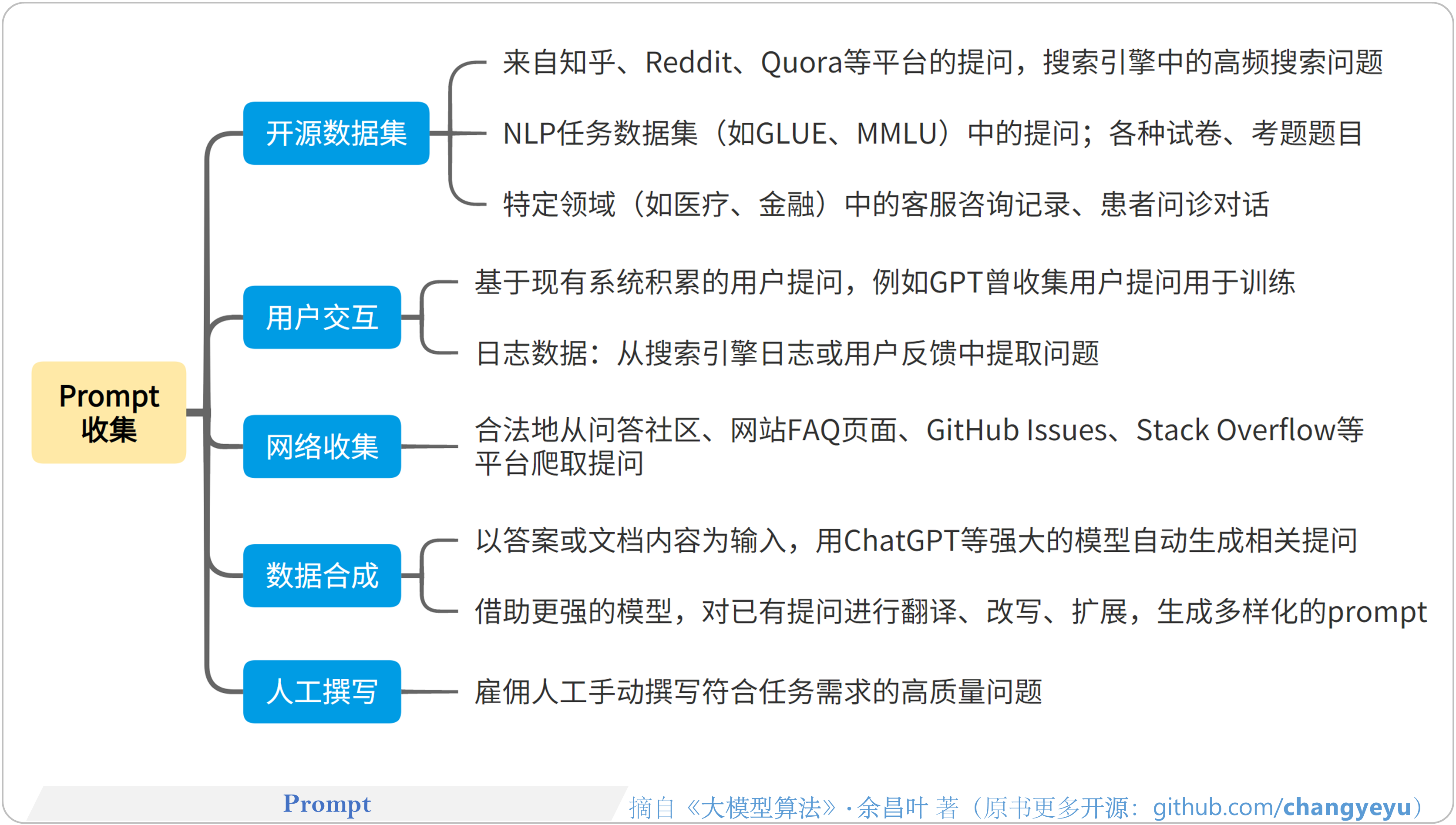
- 【DPO】Prompt的收集
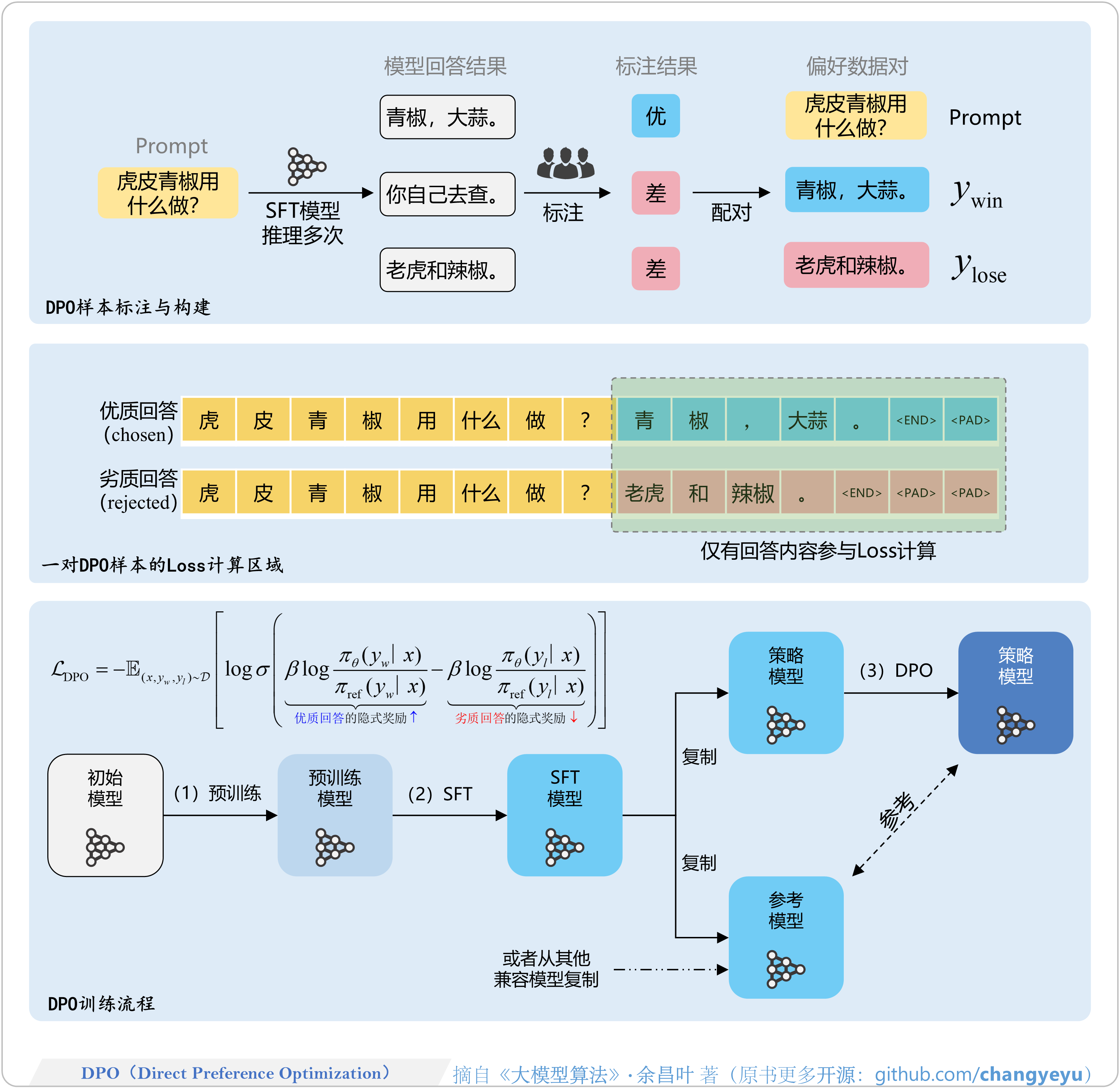
- 【DPO】DPO(Direct Preference Optimization)
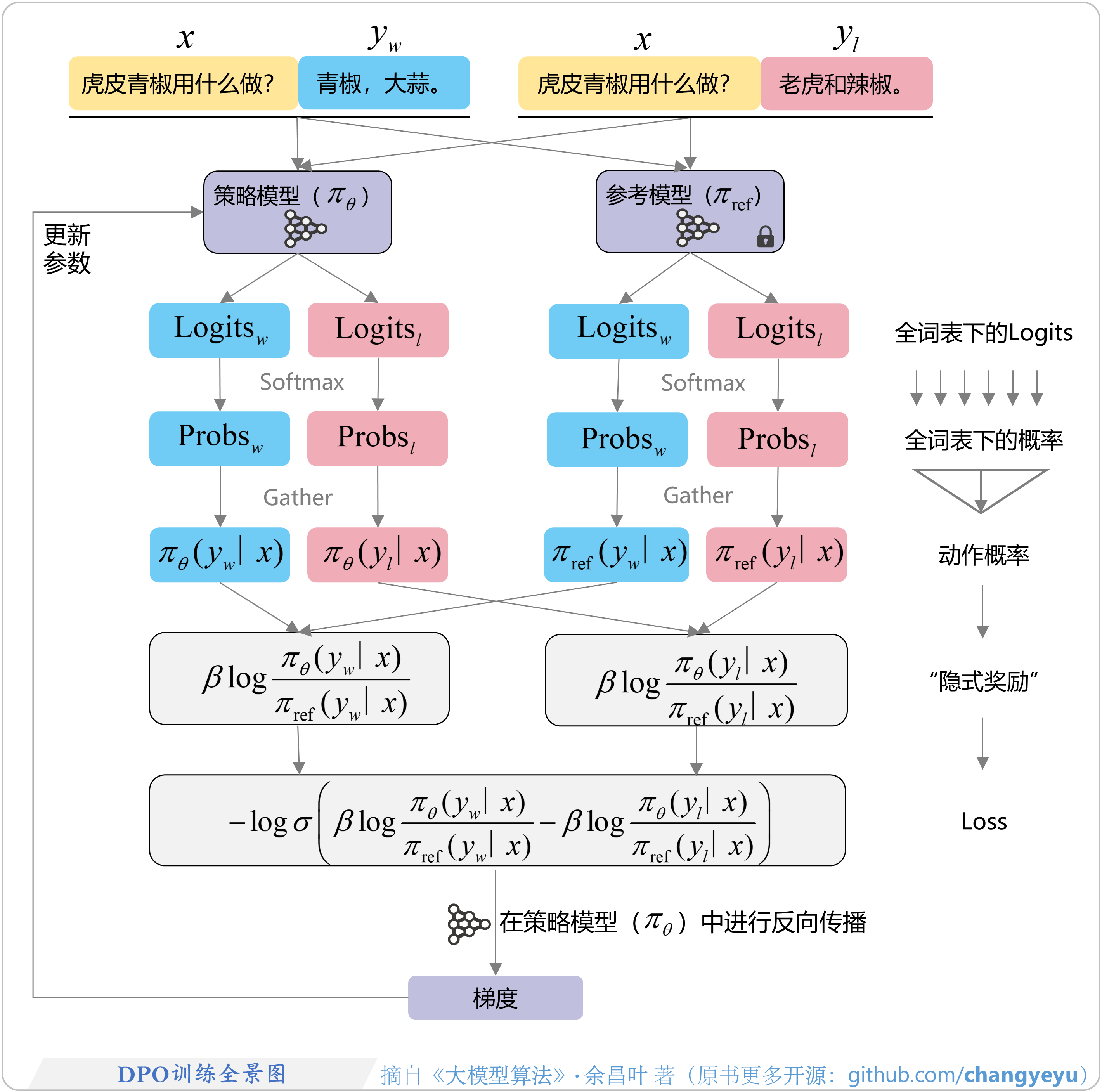
- 【DPO】DPO训练全景图
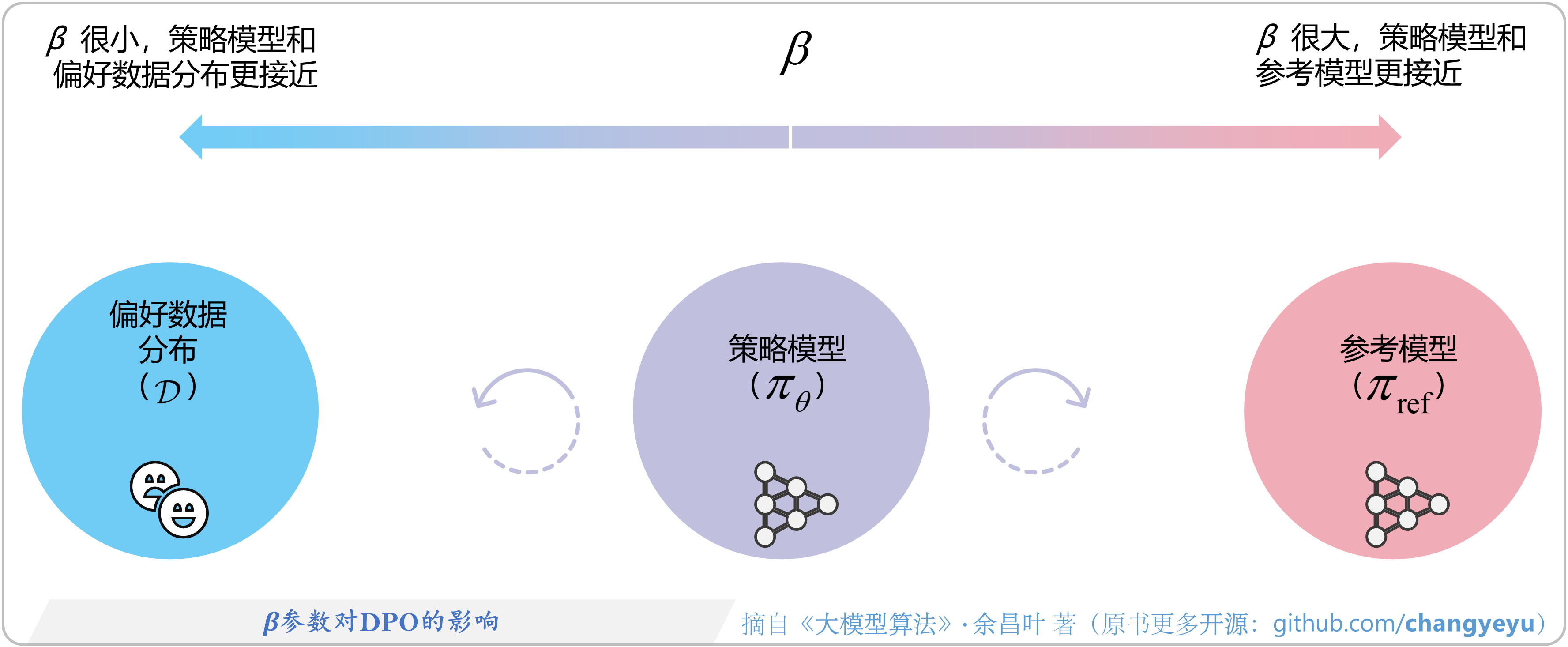
- 【DPO】β参数对DPO的影响
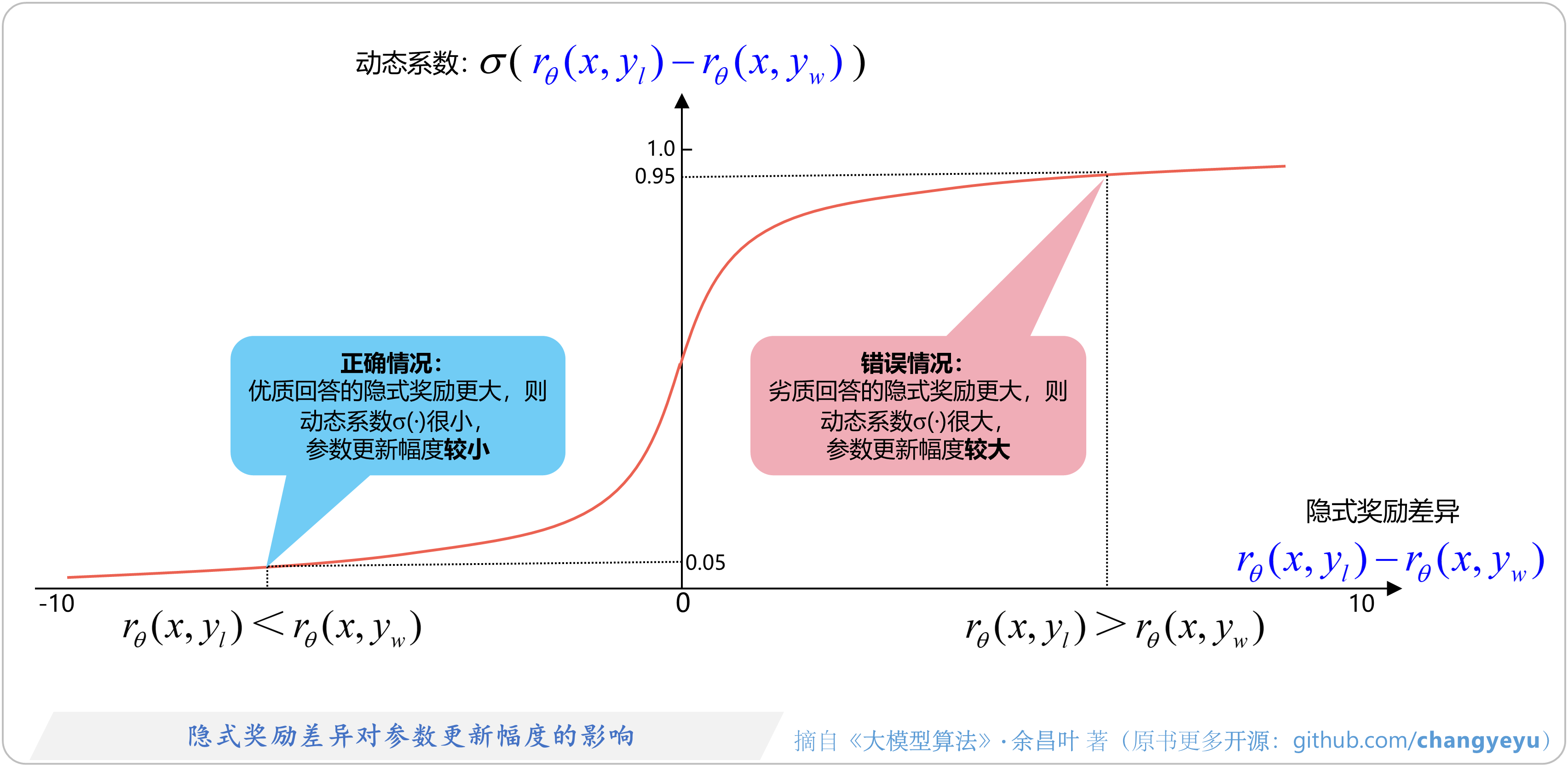
- 【DPO】隐式奖励差异对参数更新幅度的影响
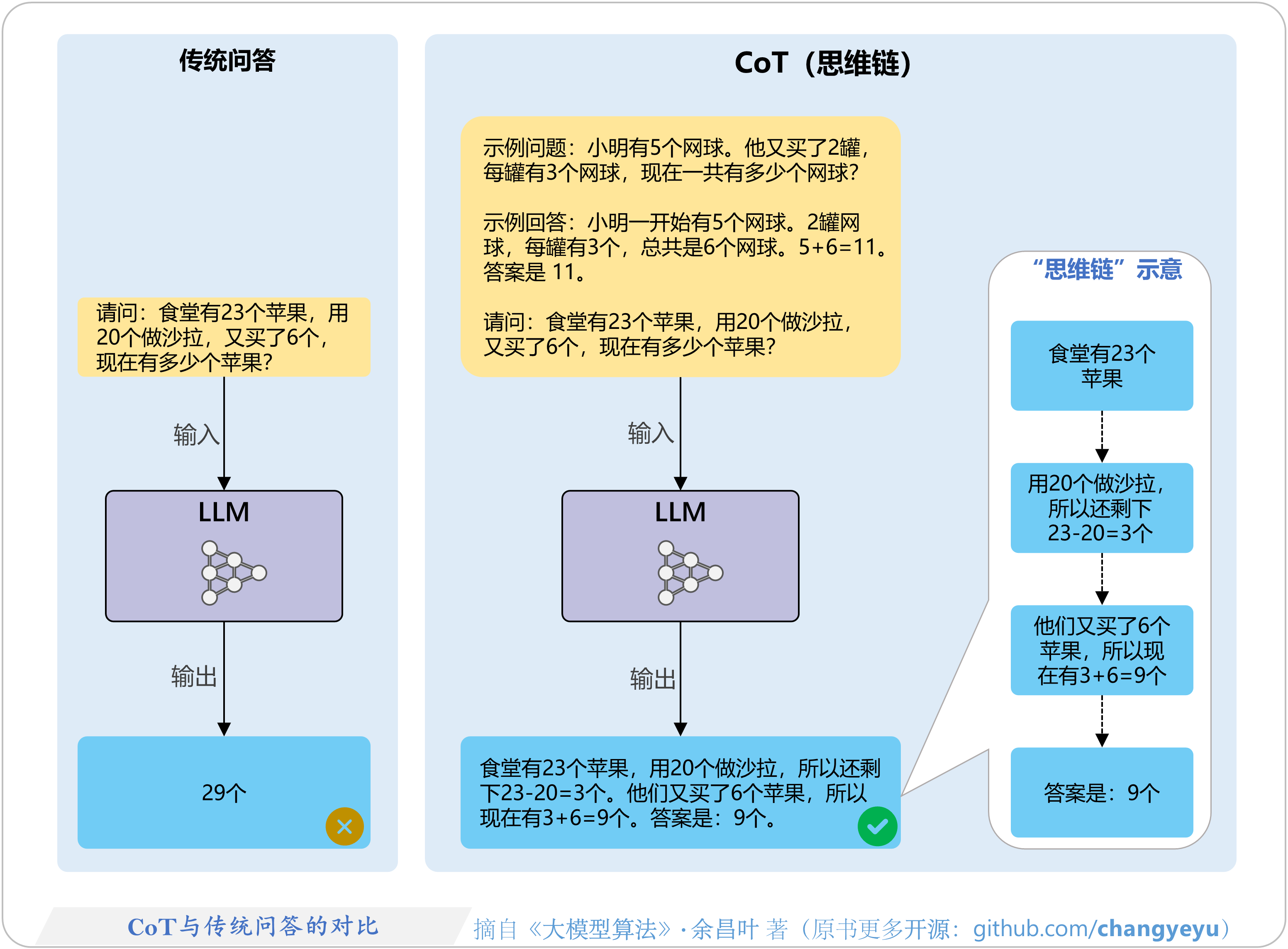
- 【免训练的优化技术】CoT(Chain of Thought)与传统问答的对比
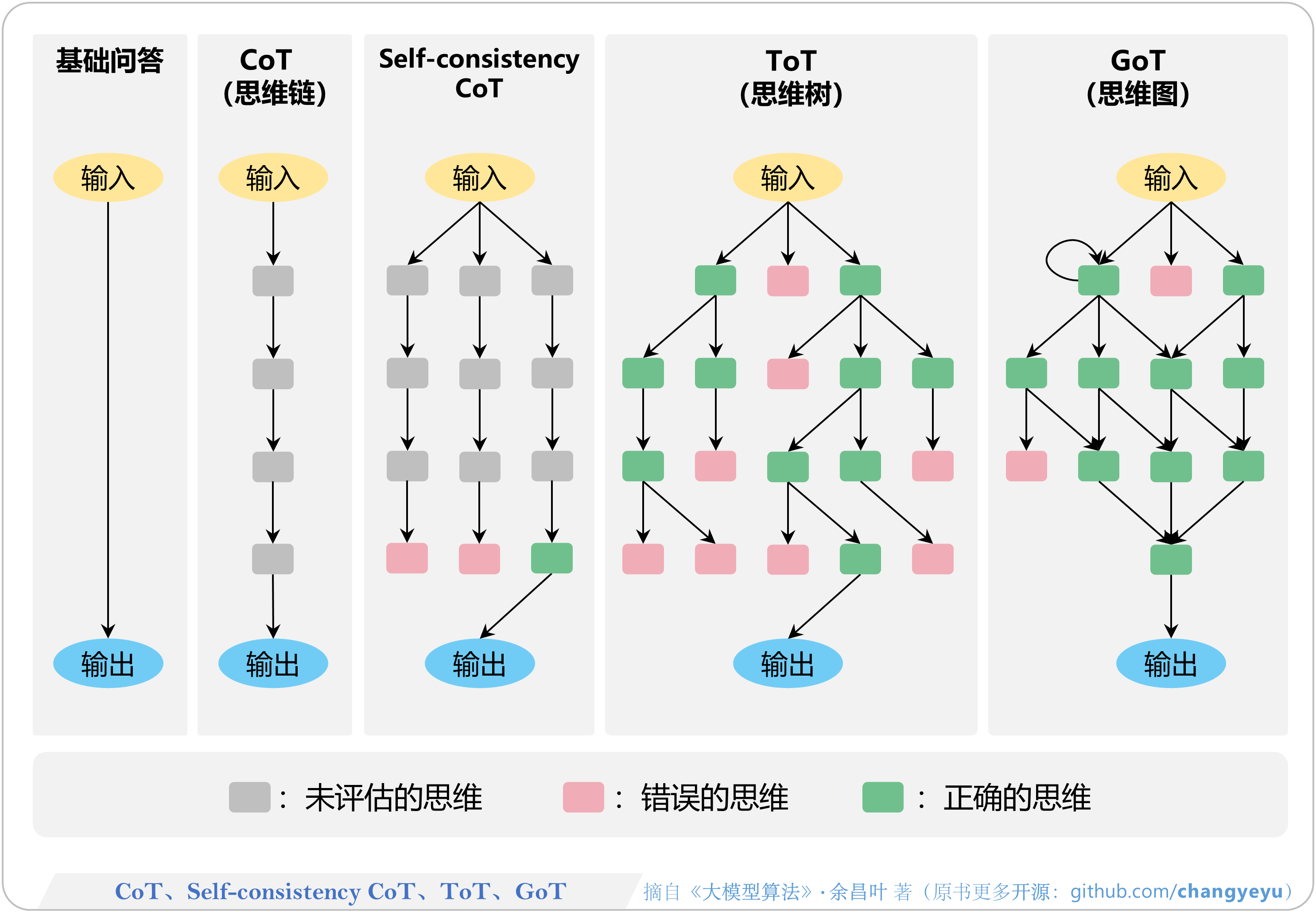
- 【免训练的优化技术】CoT、Self-consistency CoT、ToT、GoT [87]
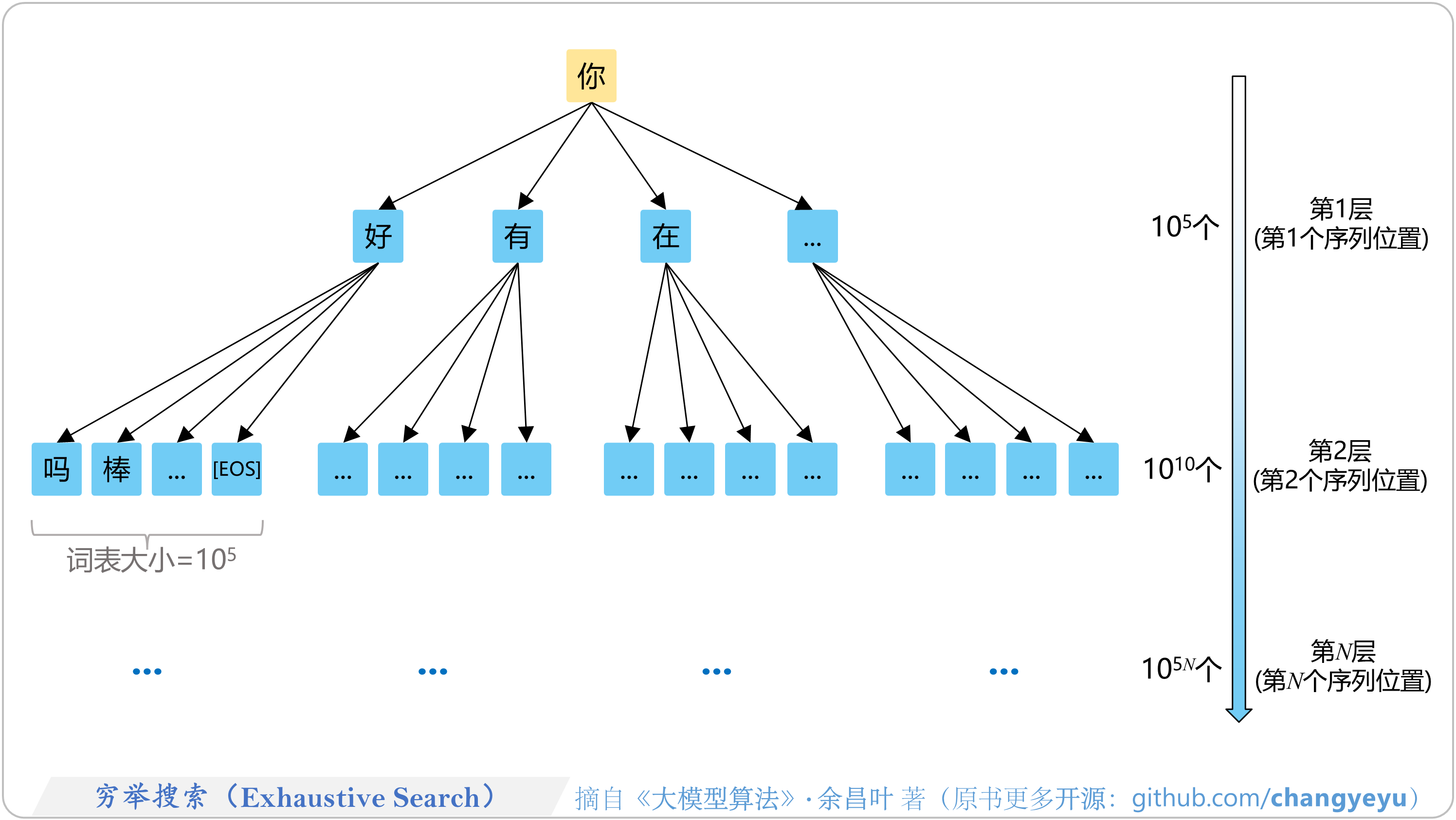
- 【免训练的优化技术】穷举搜索(Exhaustive Search)
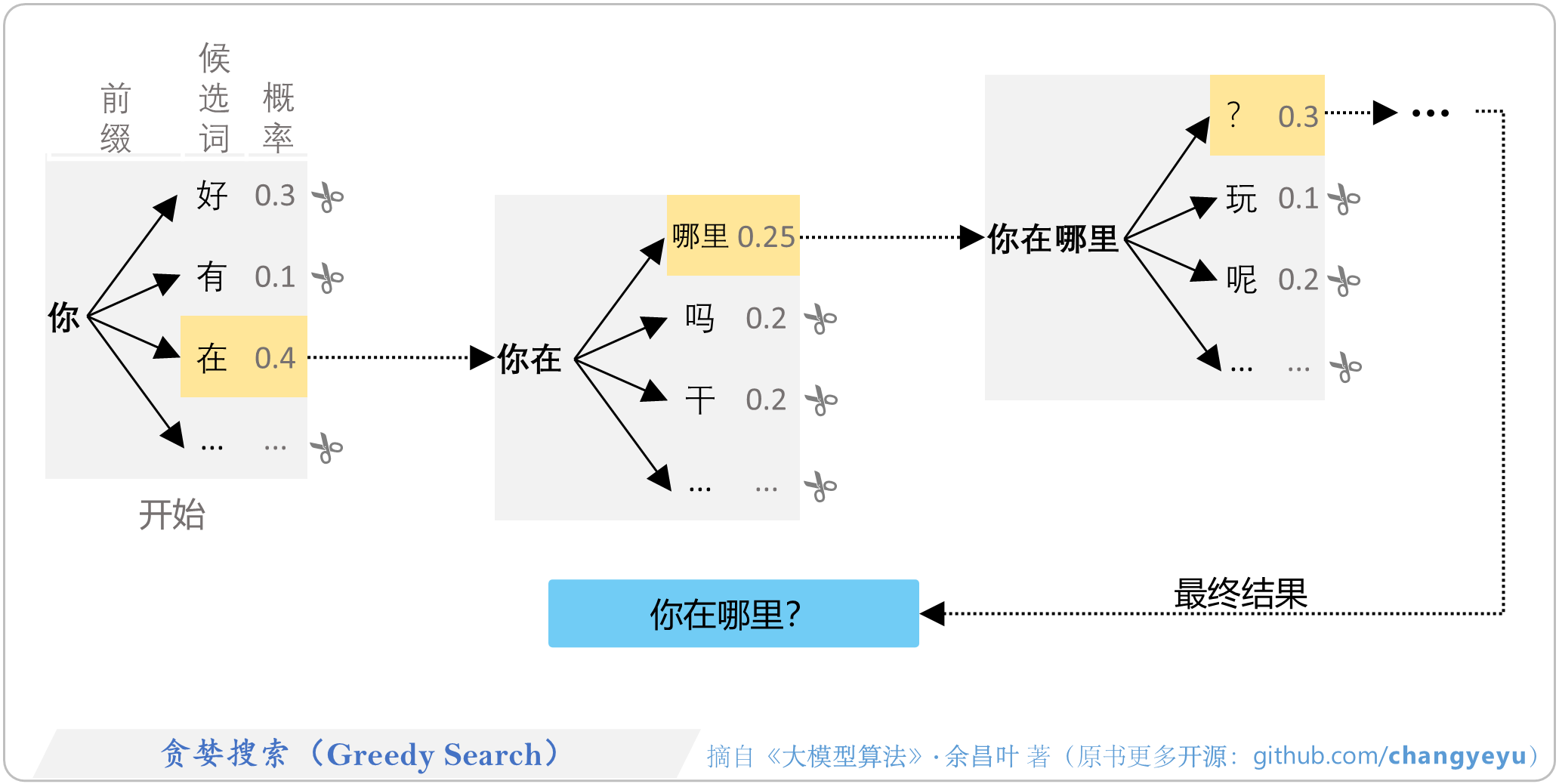
- 【免训练的优化技术】贪婪搜索(Greedy Search)
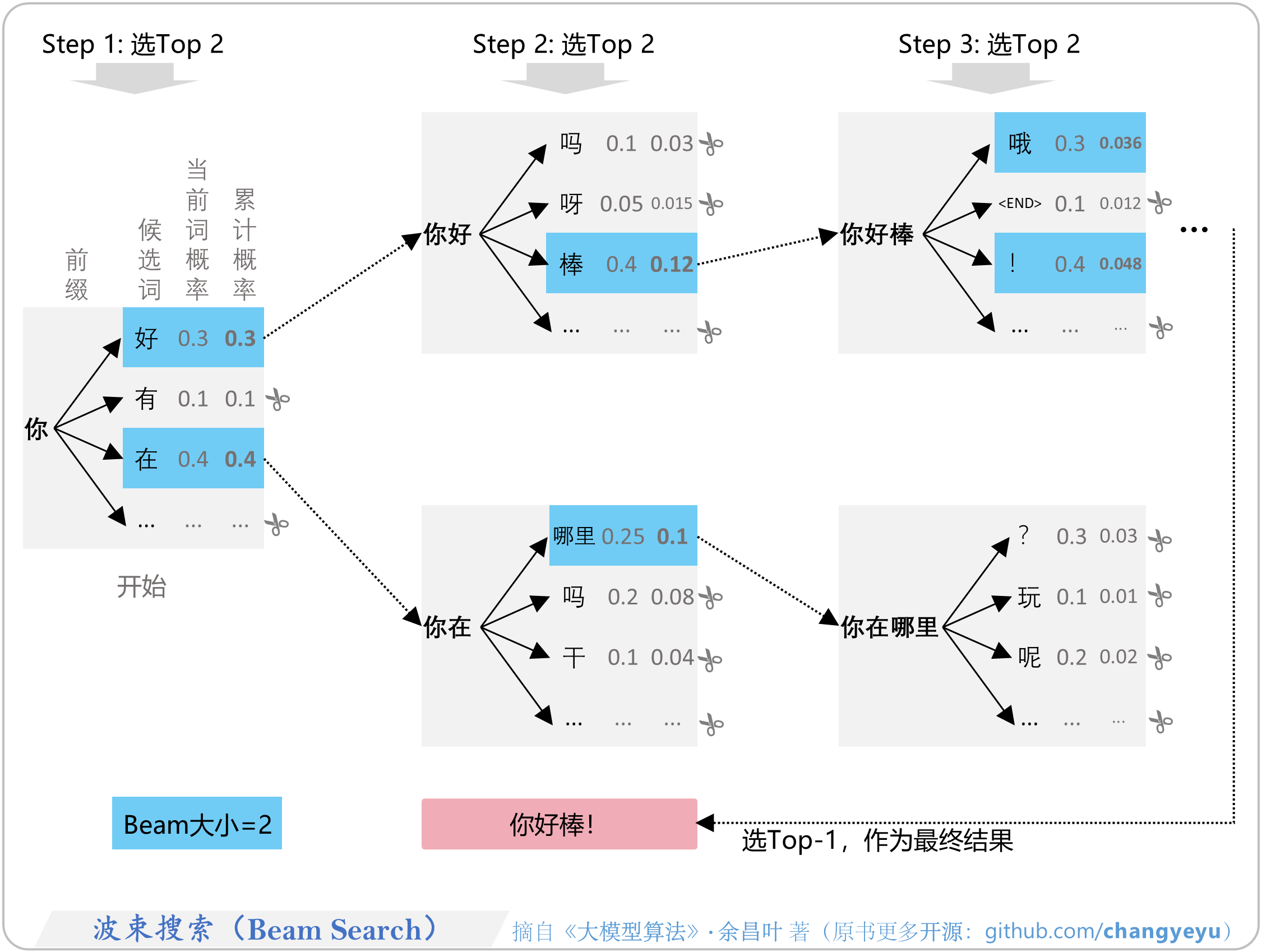
- 【免训练的优化技术】波束搜索(Beam Search)
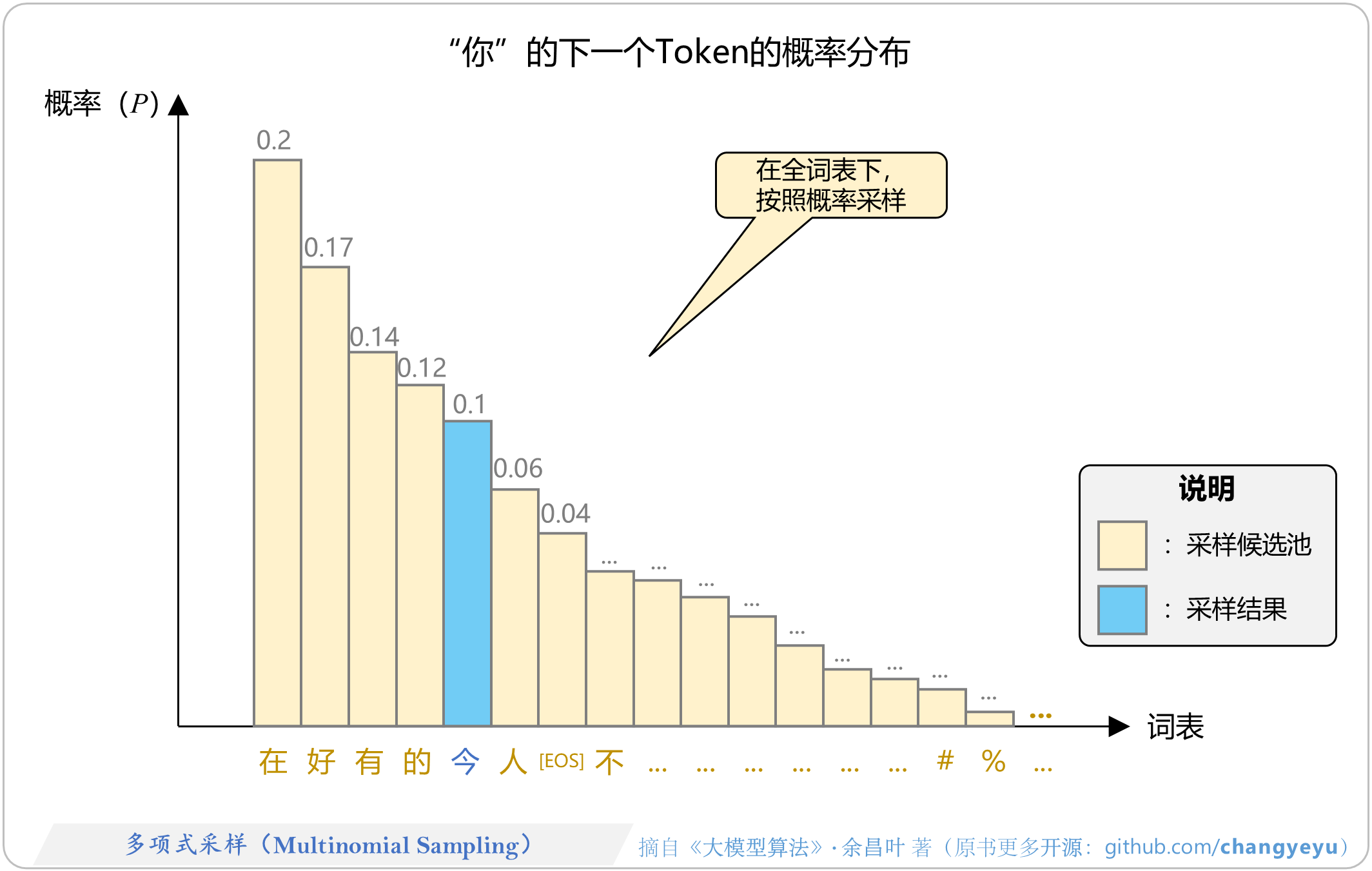
- 【免训练的优化技术】多项式采样(Multinomial Sampling)
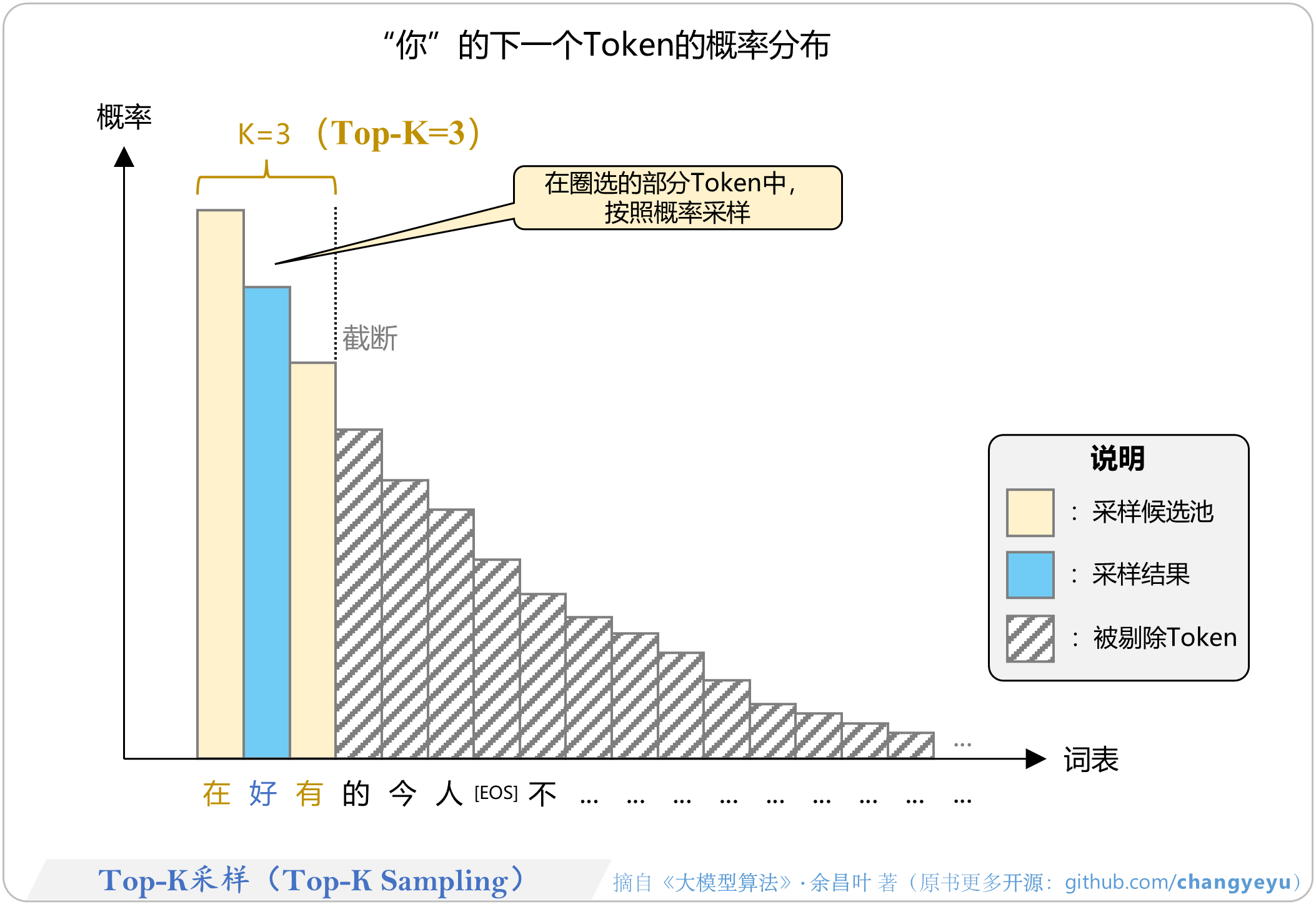
- 【免训练的优化技术】Top-K采样(Top-K Sampling)
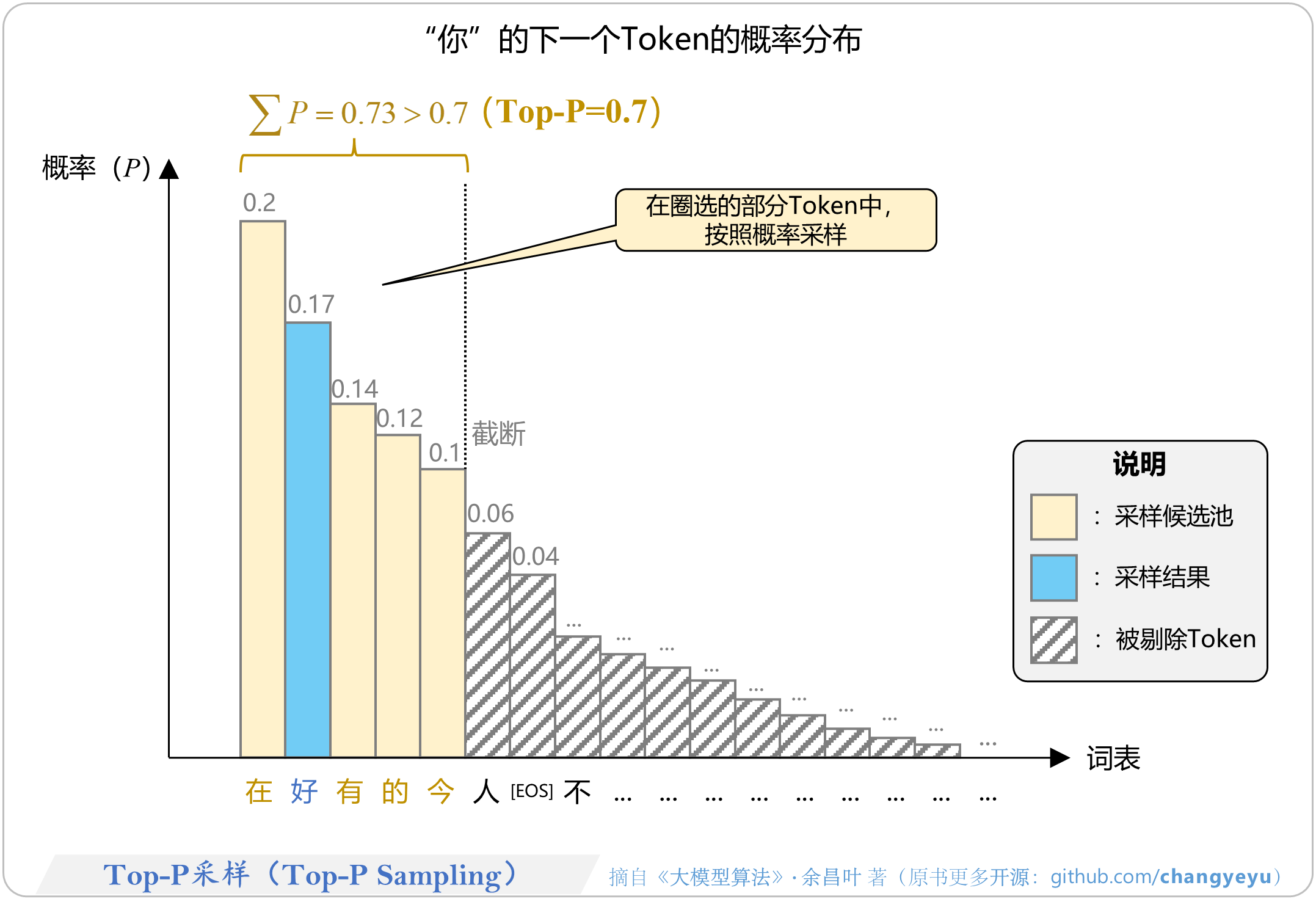
- 【免训练的优化技术】Top-P采样(Top-P Sampling)
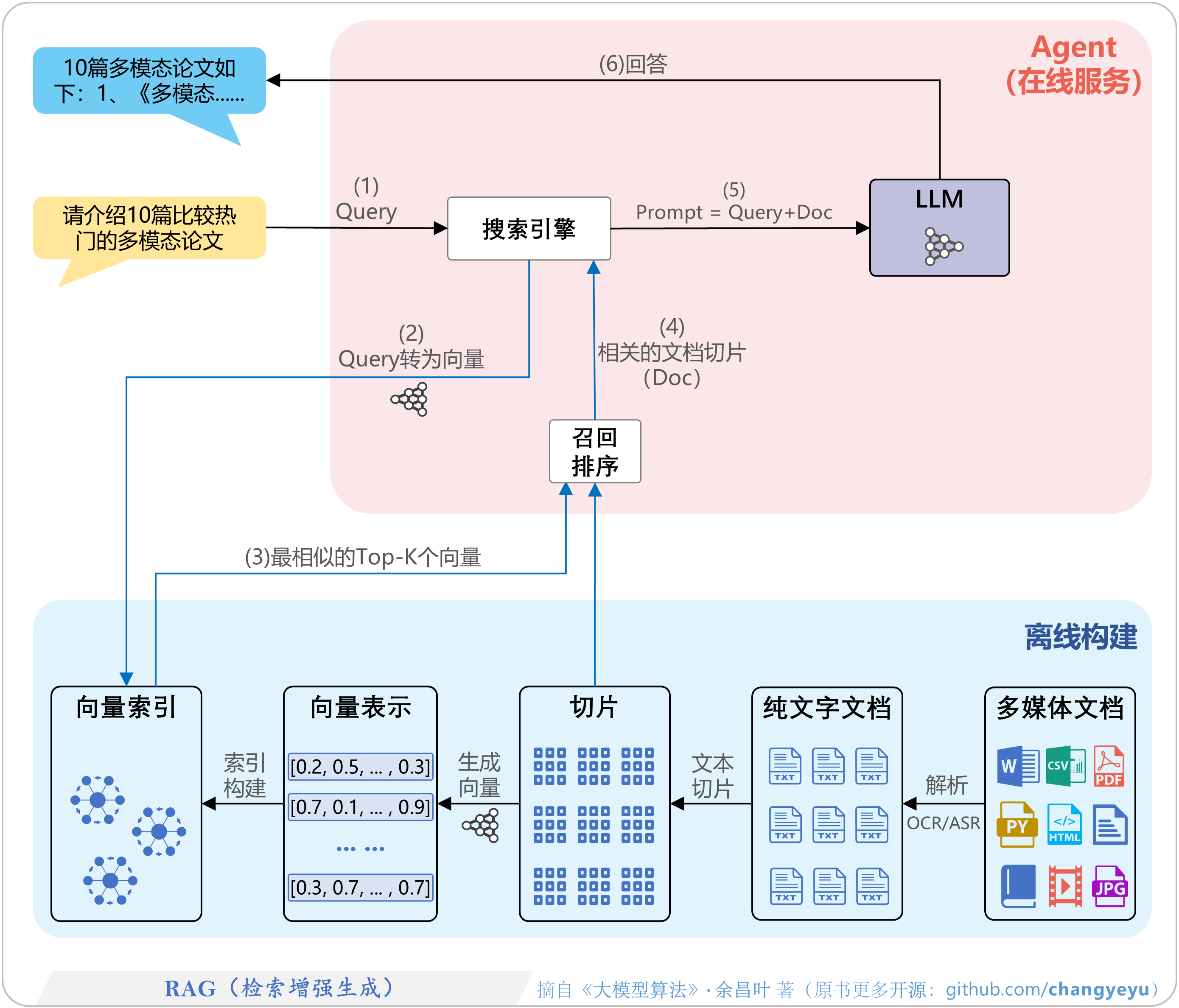
- 【免训练的优化技术】RAG(检索增强生成,Retrieval-Augmented Generation)
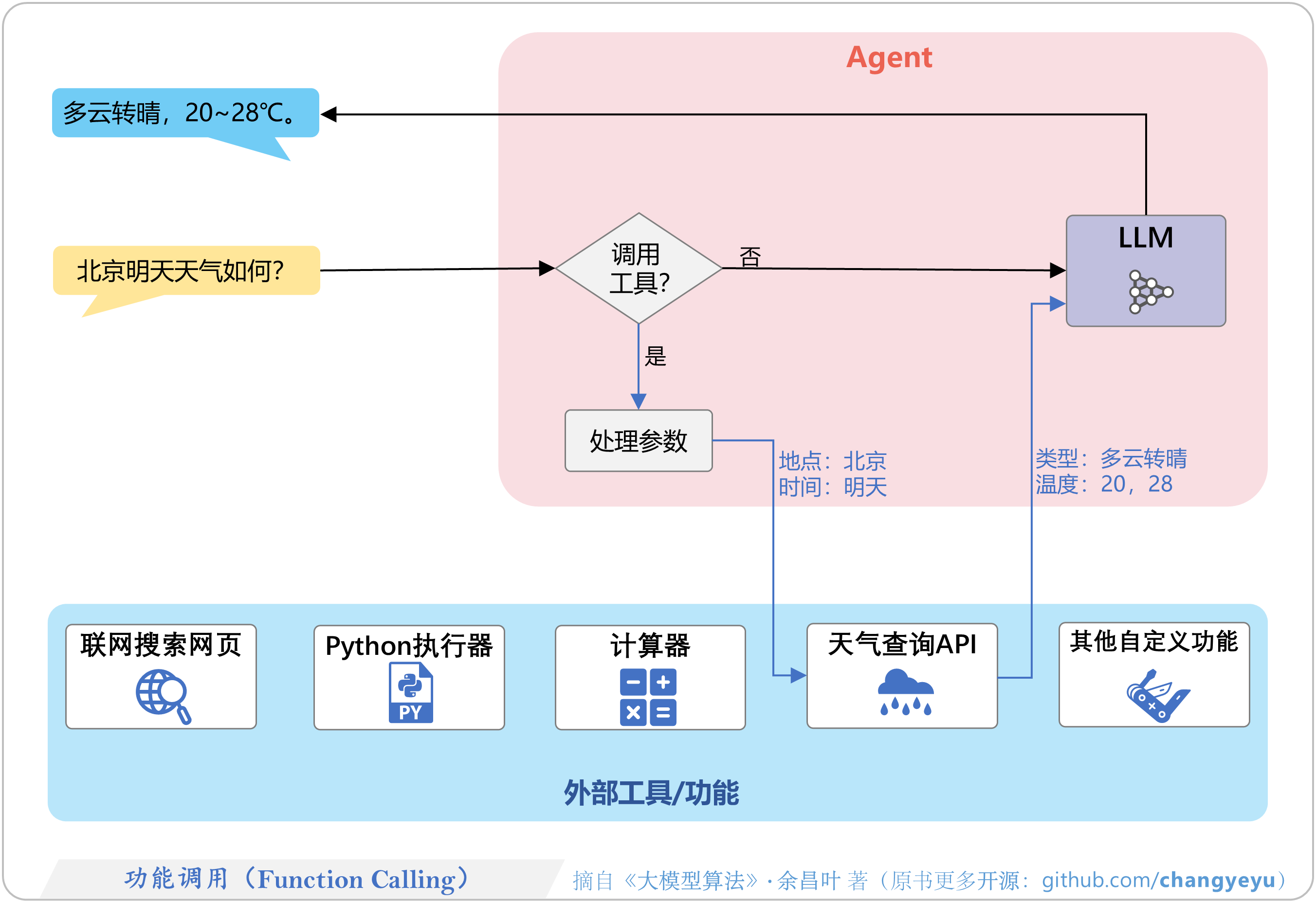
- 【免训练的优化技术】功能调用(Function Calling)
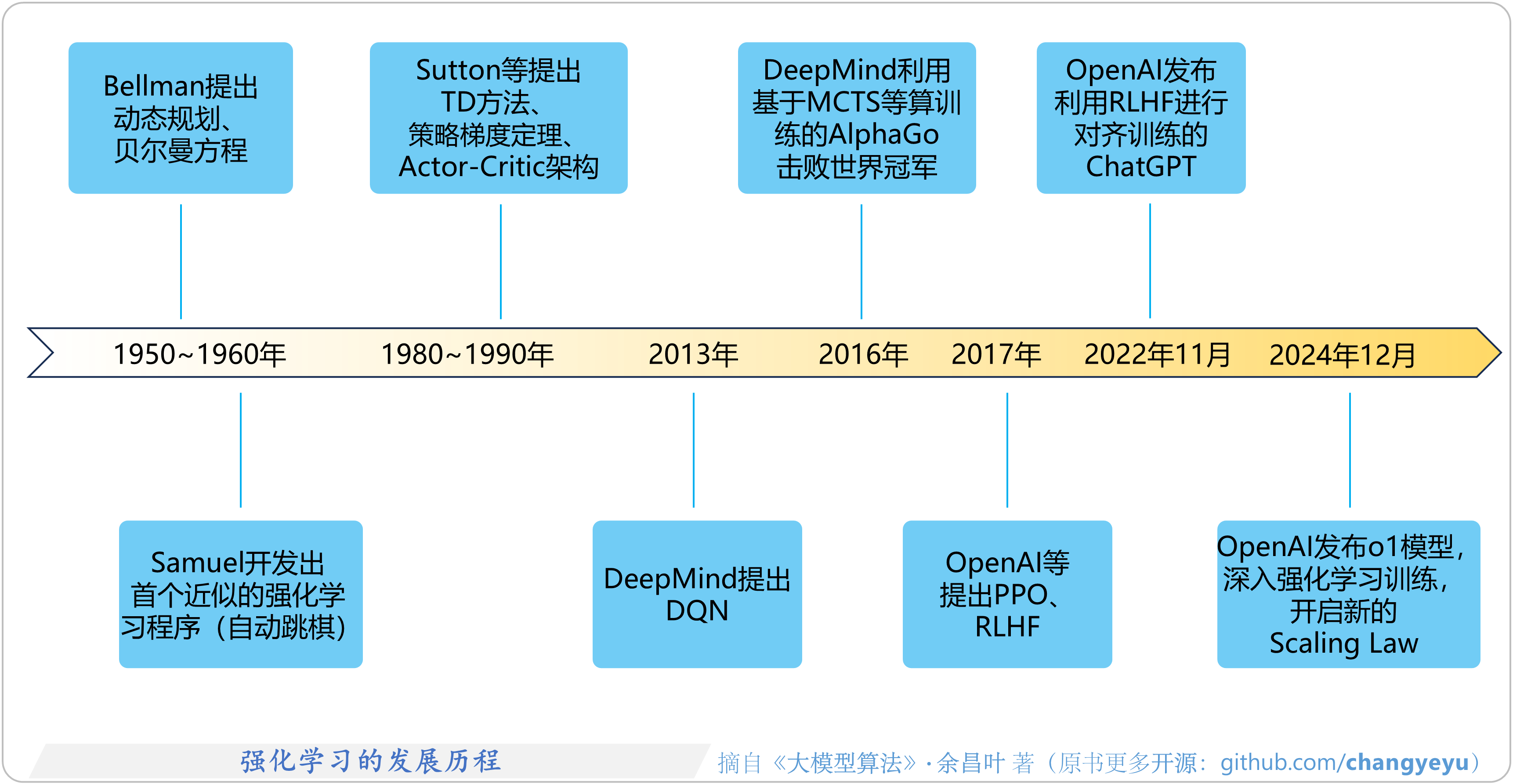
- 【强化学习基础】强化学习(Reinforcement Learning, RL)的发展历程
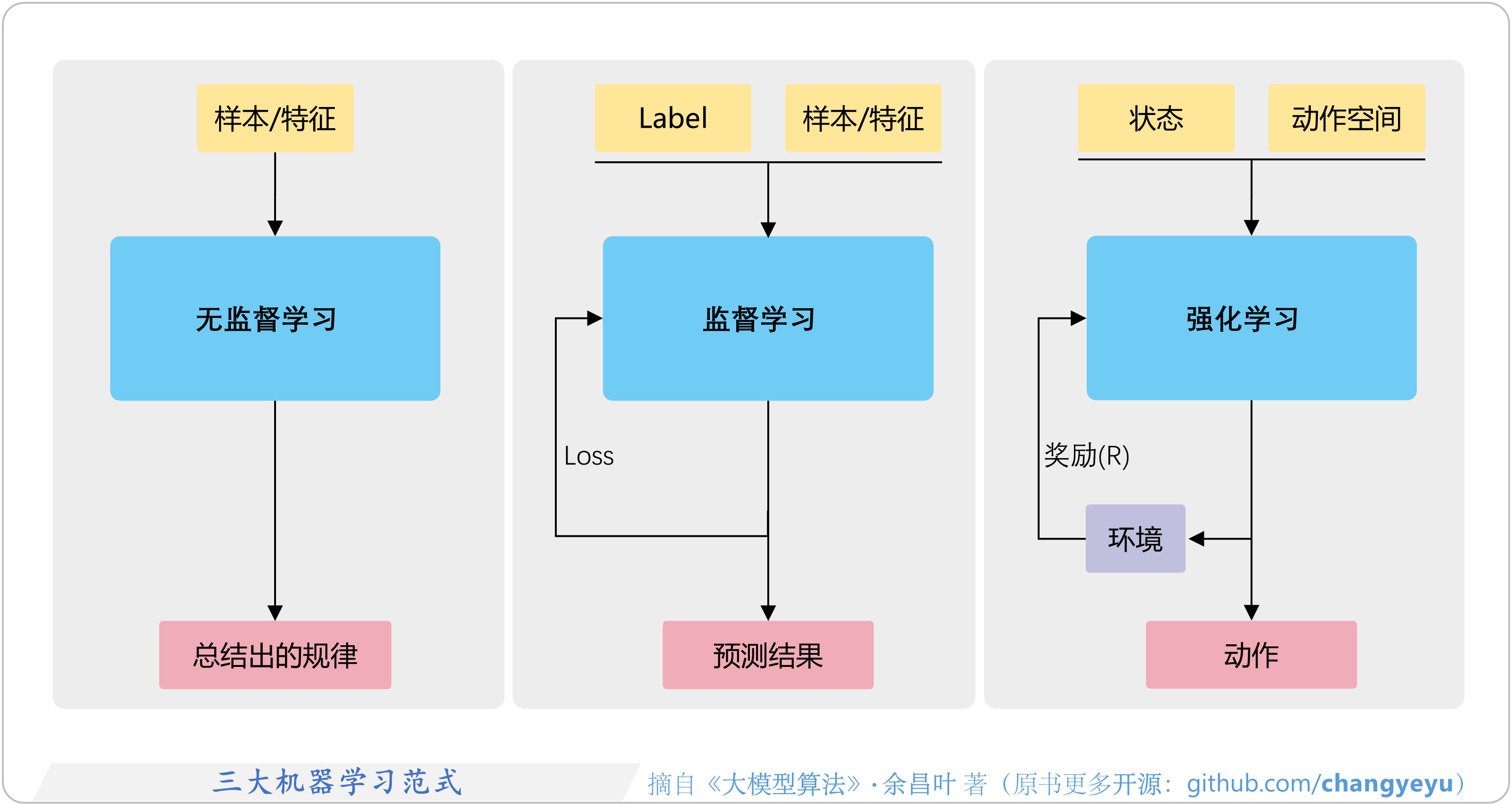
- 【强化学习基础】三大机器学习范式
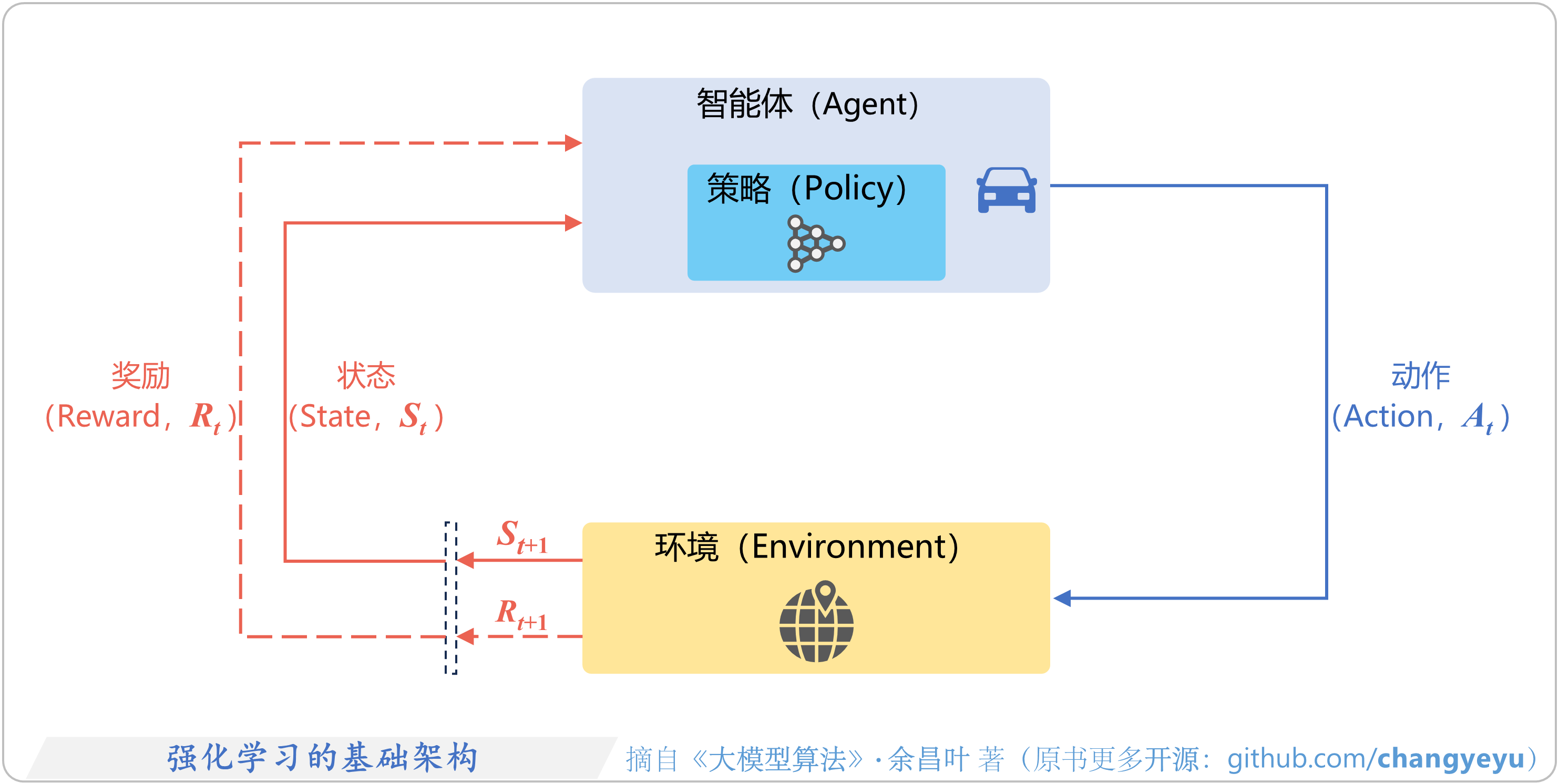
- 【强化学习基础】强化学习的基础架构
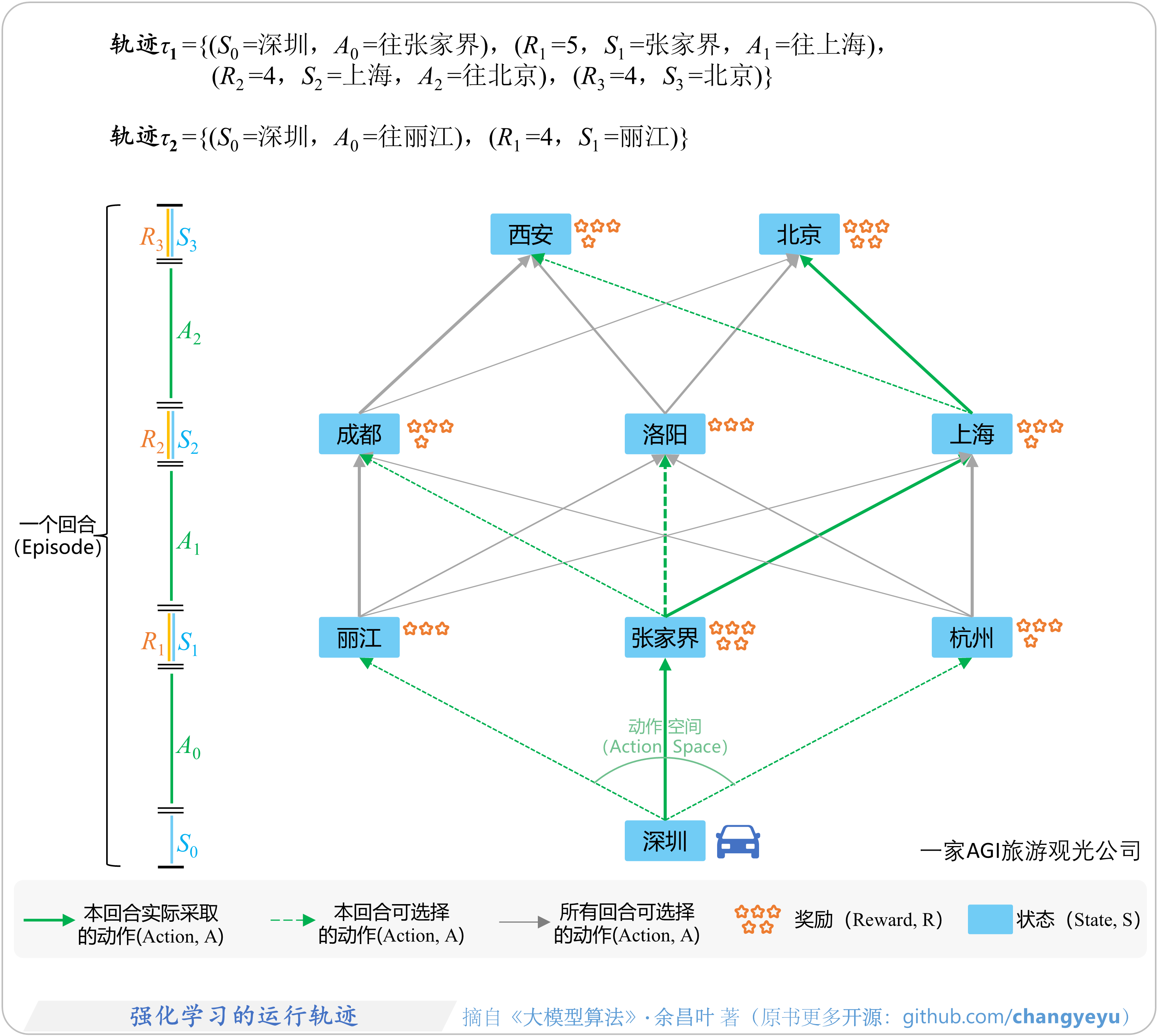
- 【强化学习基础】强化学习的运行轨迹
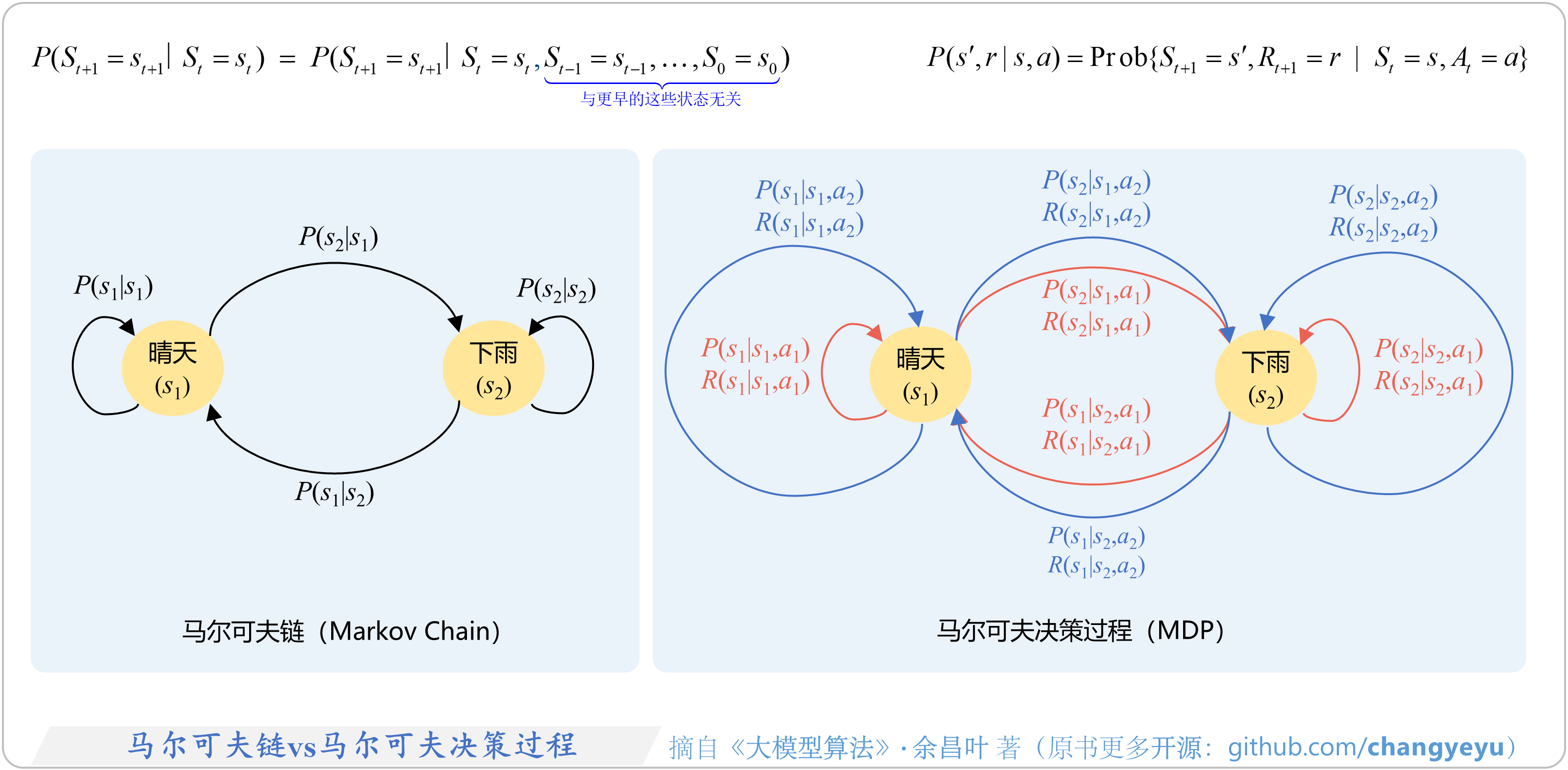
- 【强化学习基础】马尔可夫链vs马尔可夫决策过程(MDP)
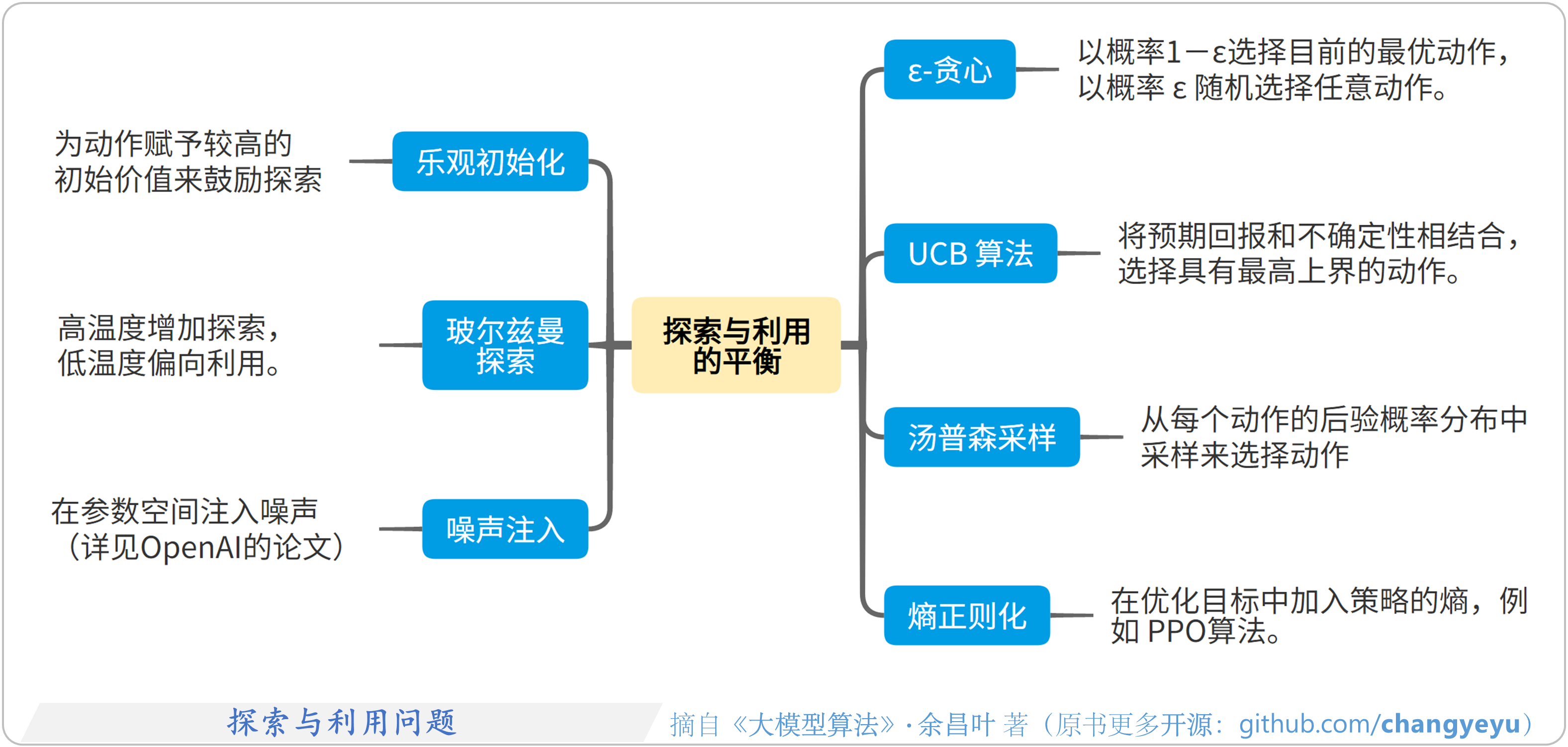
- 【强化学习基础】探索与利用问题(Exploration and Exploitation)
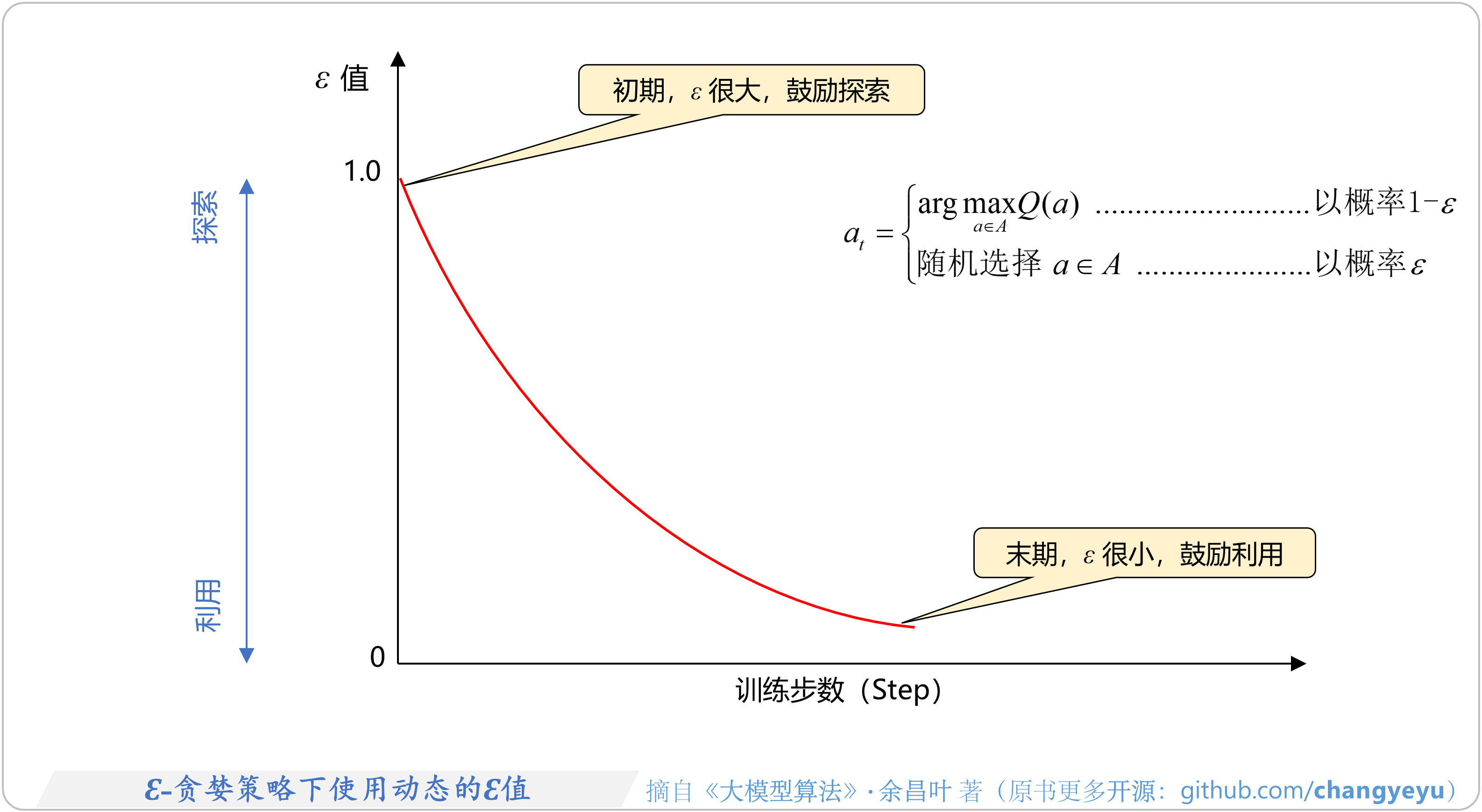
- 【强化学习基础】Ɛ-贪婪策略下使用动态的Ɛ值
- 【强化学习基础】强化学习训练范式的对比
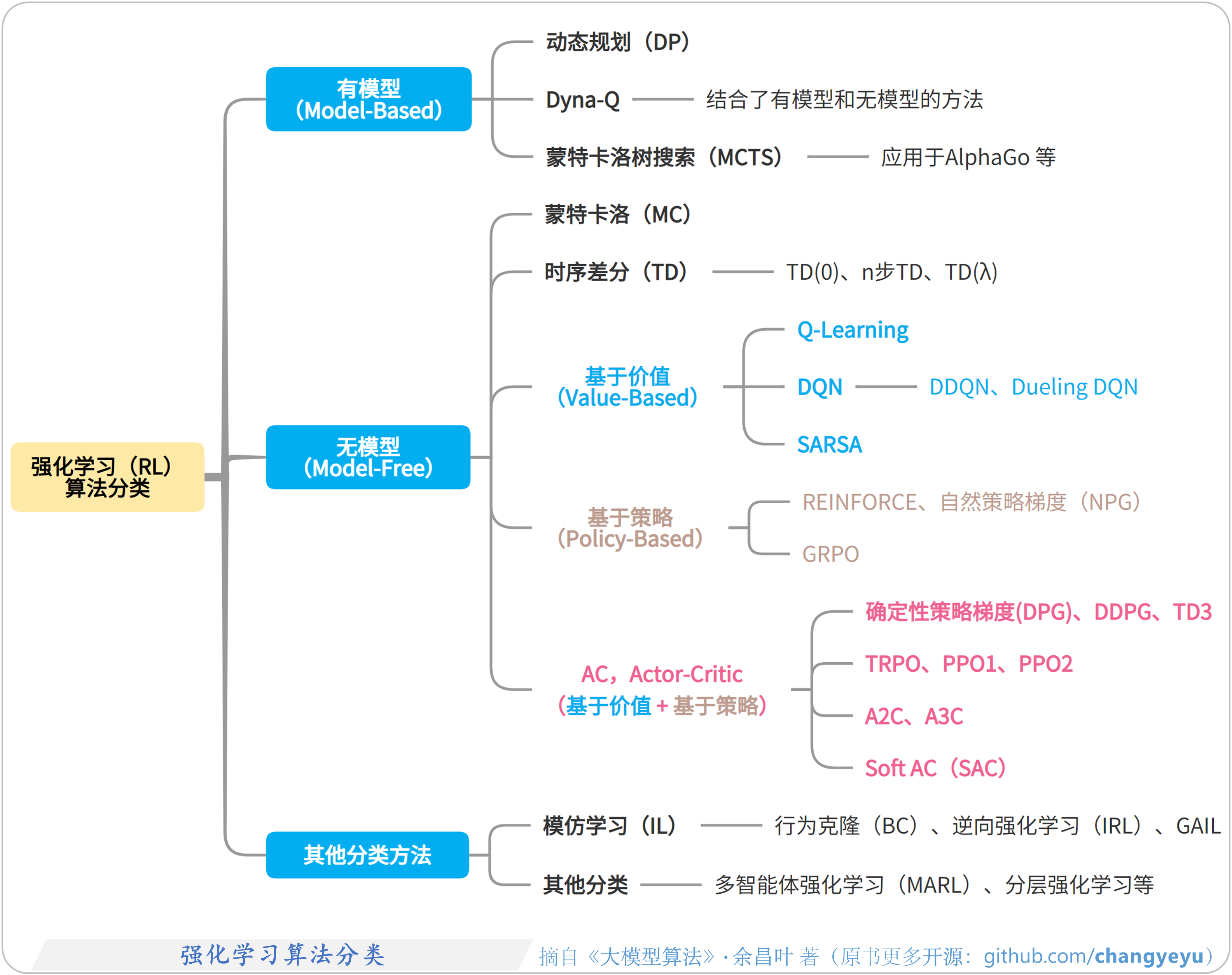
- 【强化学习基础】强化学习算法分类
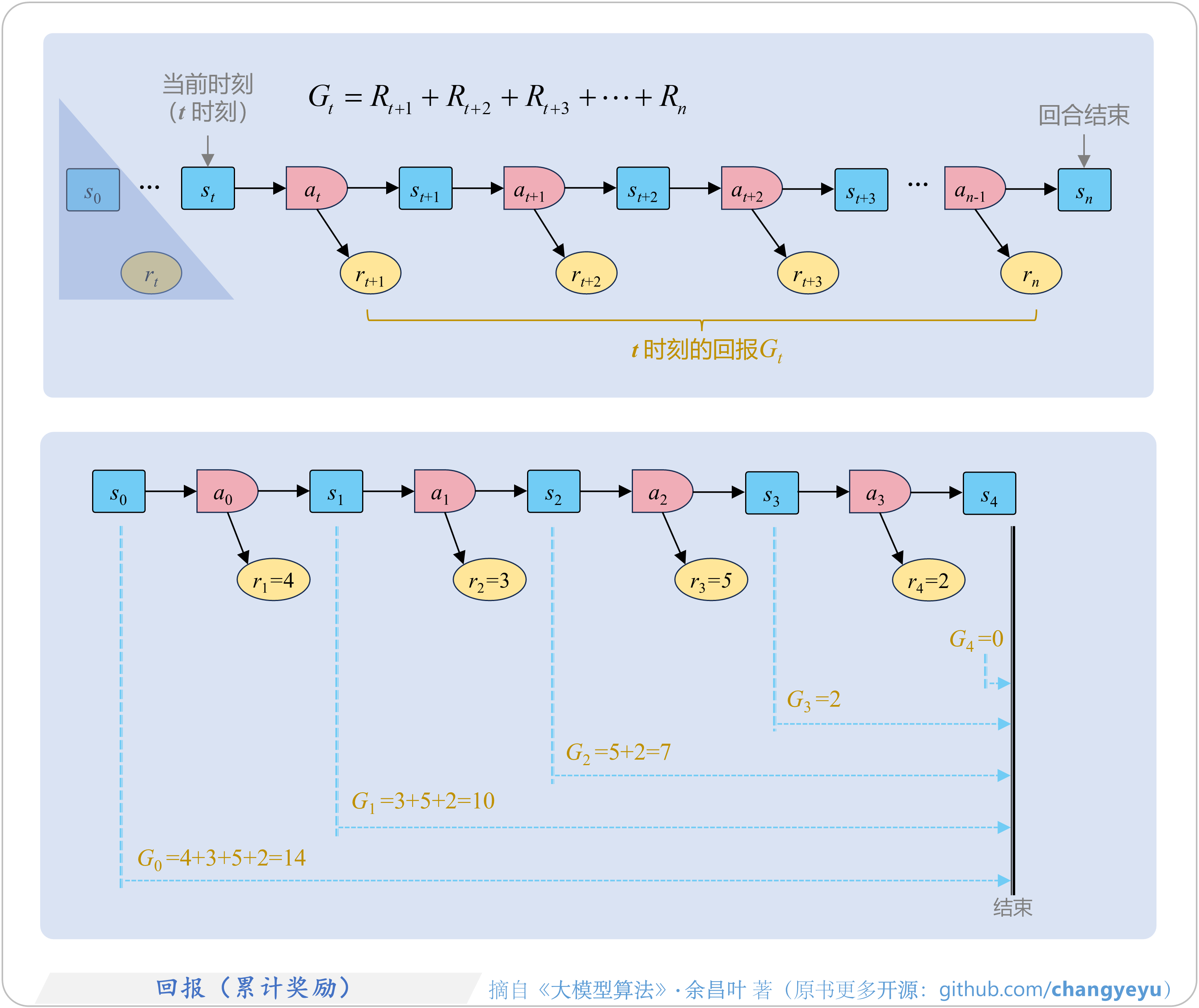
- 【强化学习基础】回报(累计奖励,Return)
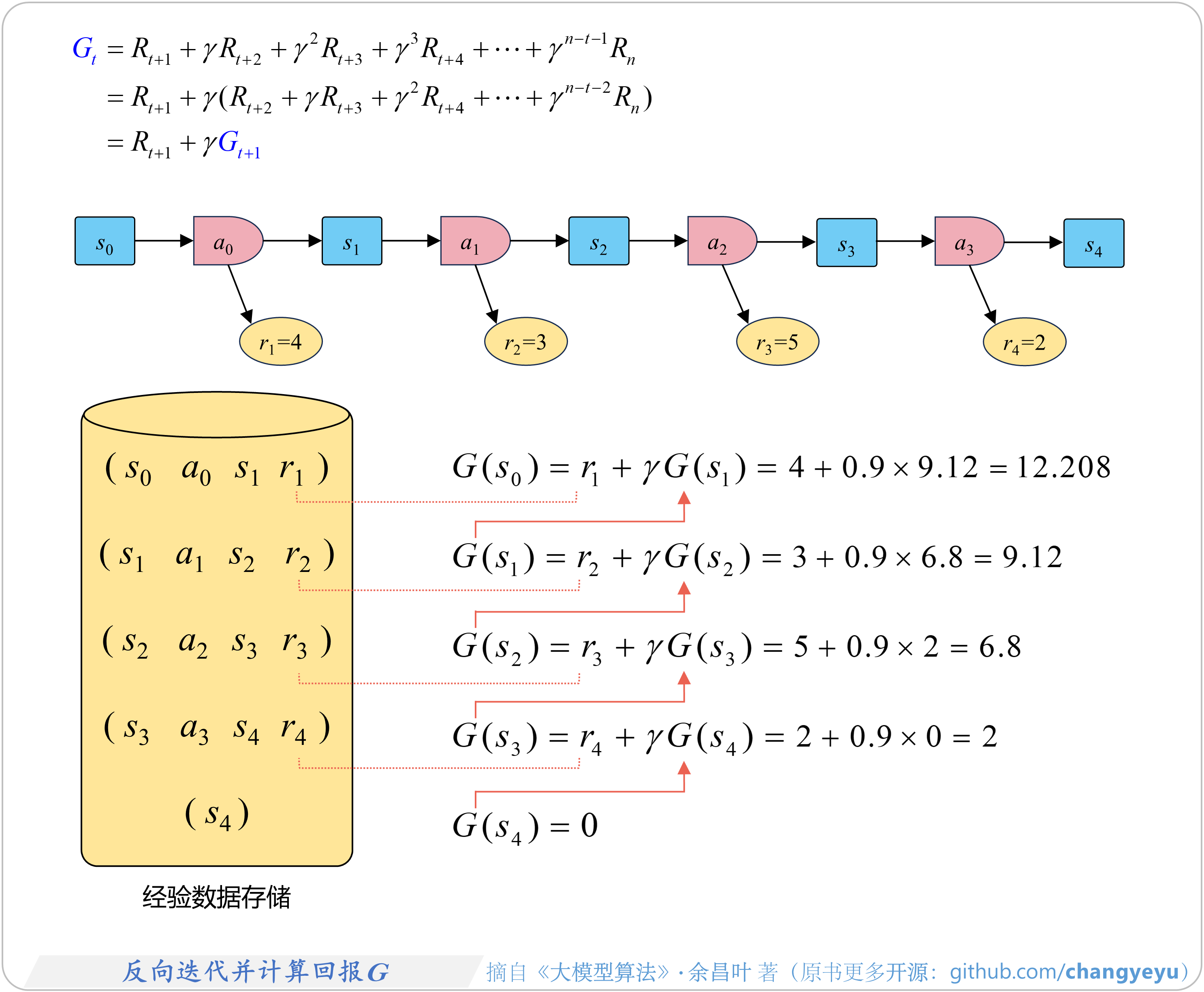
- 【强化学习基础】反向迭代并计算回报G
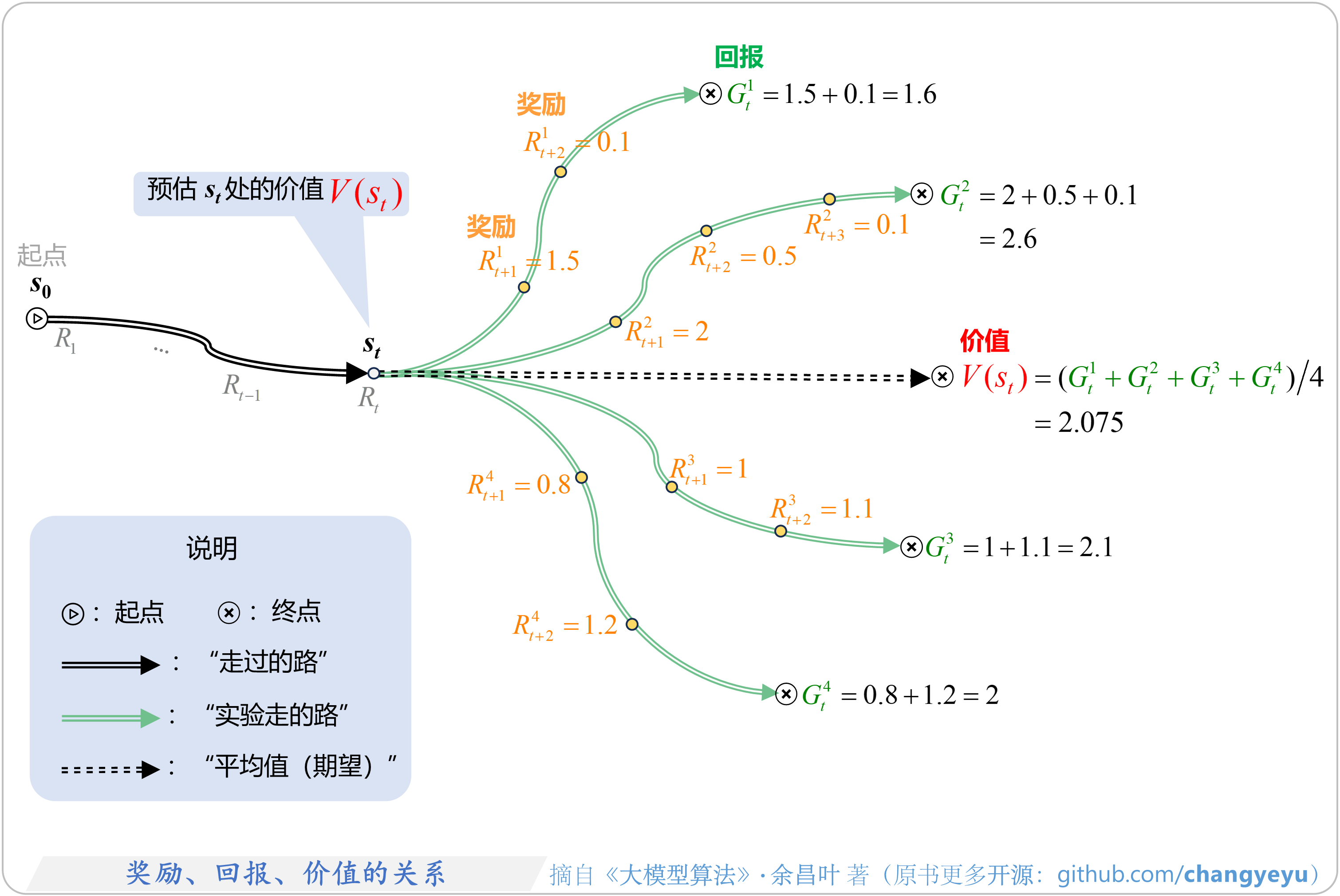
- 【强化学习基础】奖励(Reward)、回报(Return)、价值(Value)的关系
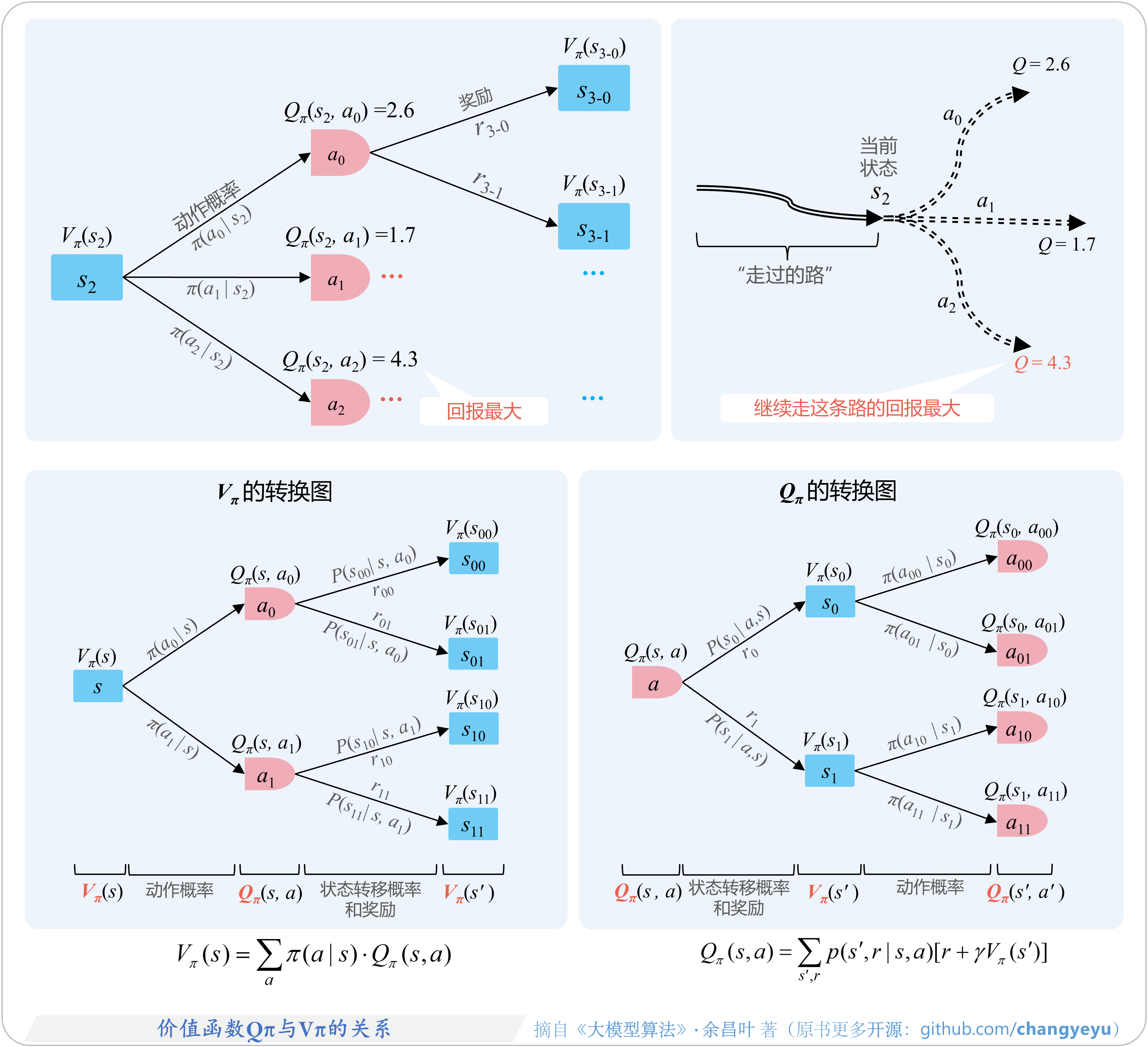
- 【强化学习基础】价值函数Qπ与Vπ的关系
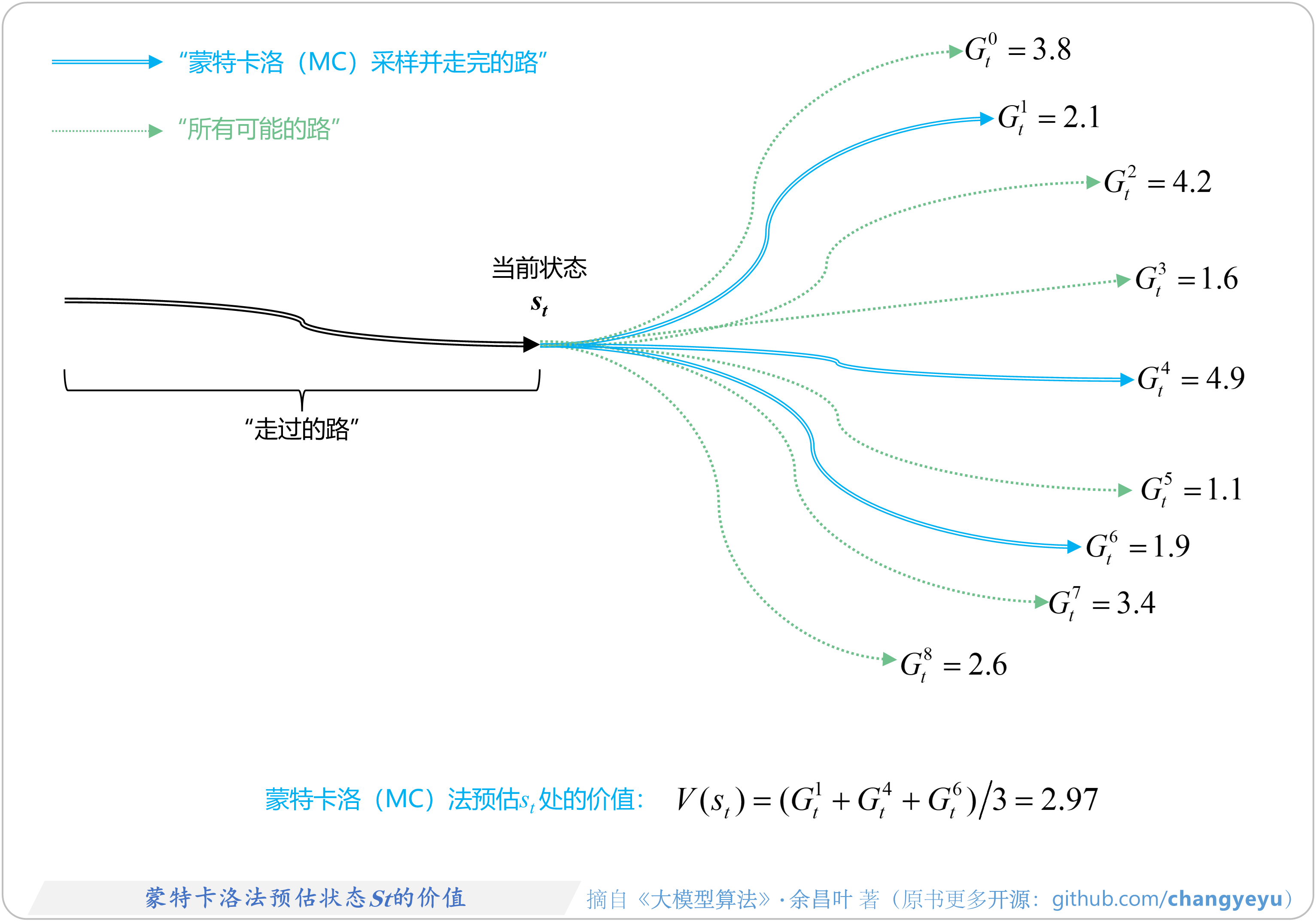
- 【强化学习基础】蒙特卡洛(Monte Carlo,MC)法预估状态St的价值
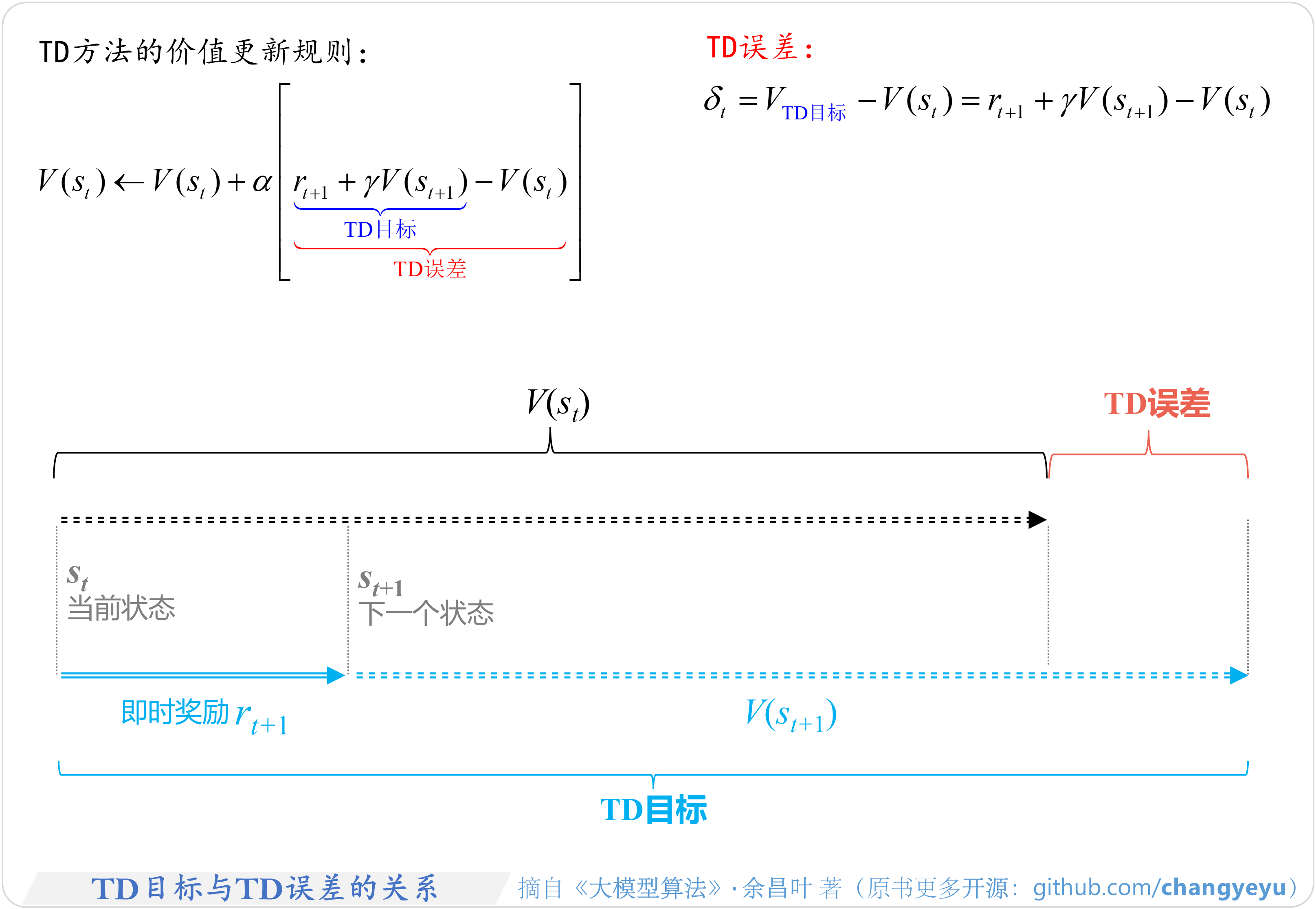
- 【强化学习基础】TD目标与TD误差的关系(TD target and TD error)
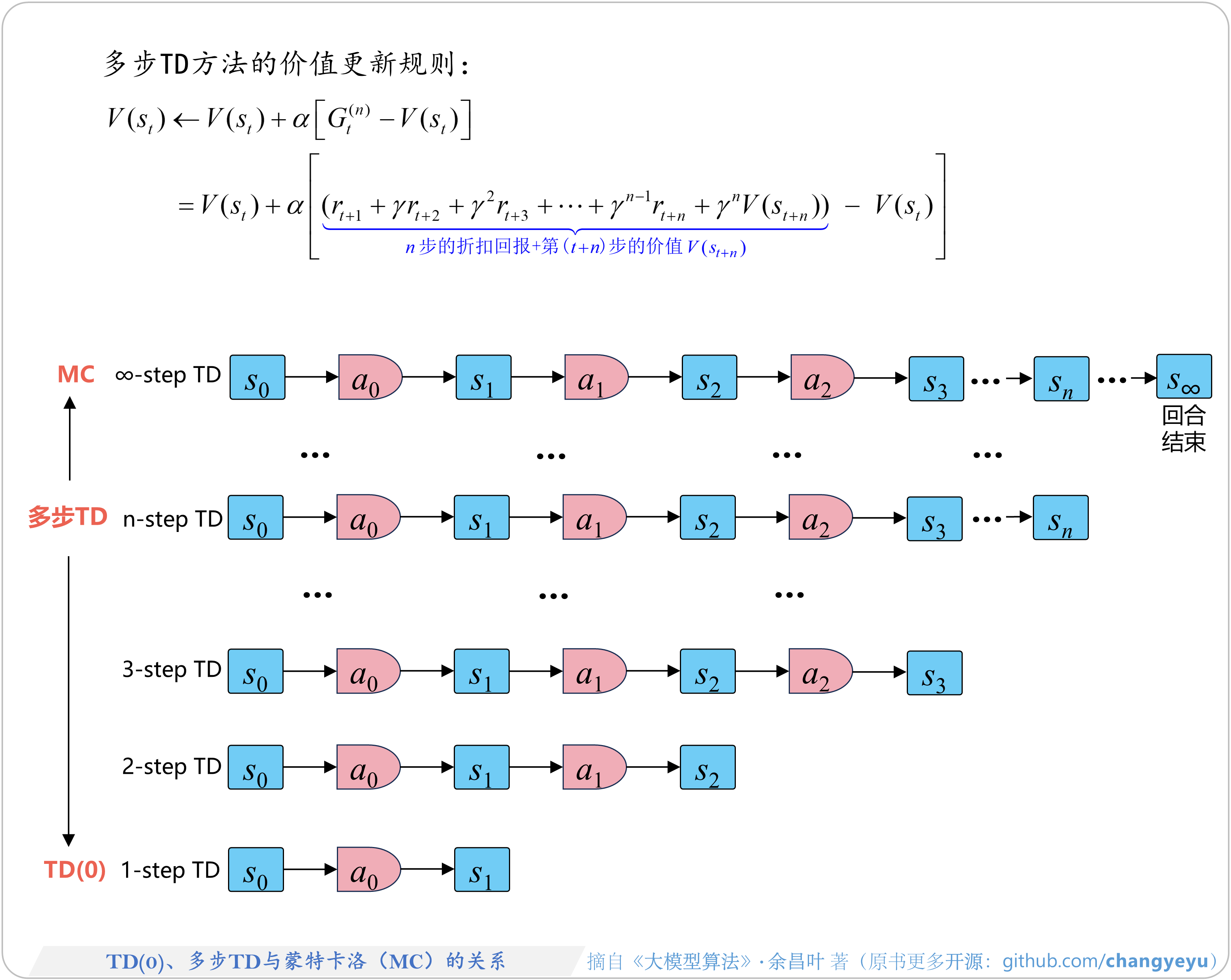
- 【强化学习基础】TD(0)、多步TD与蒙特卡洛(MC)的关系
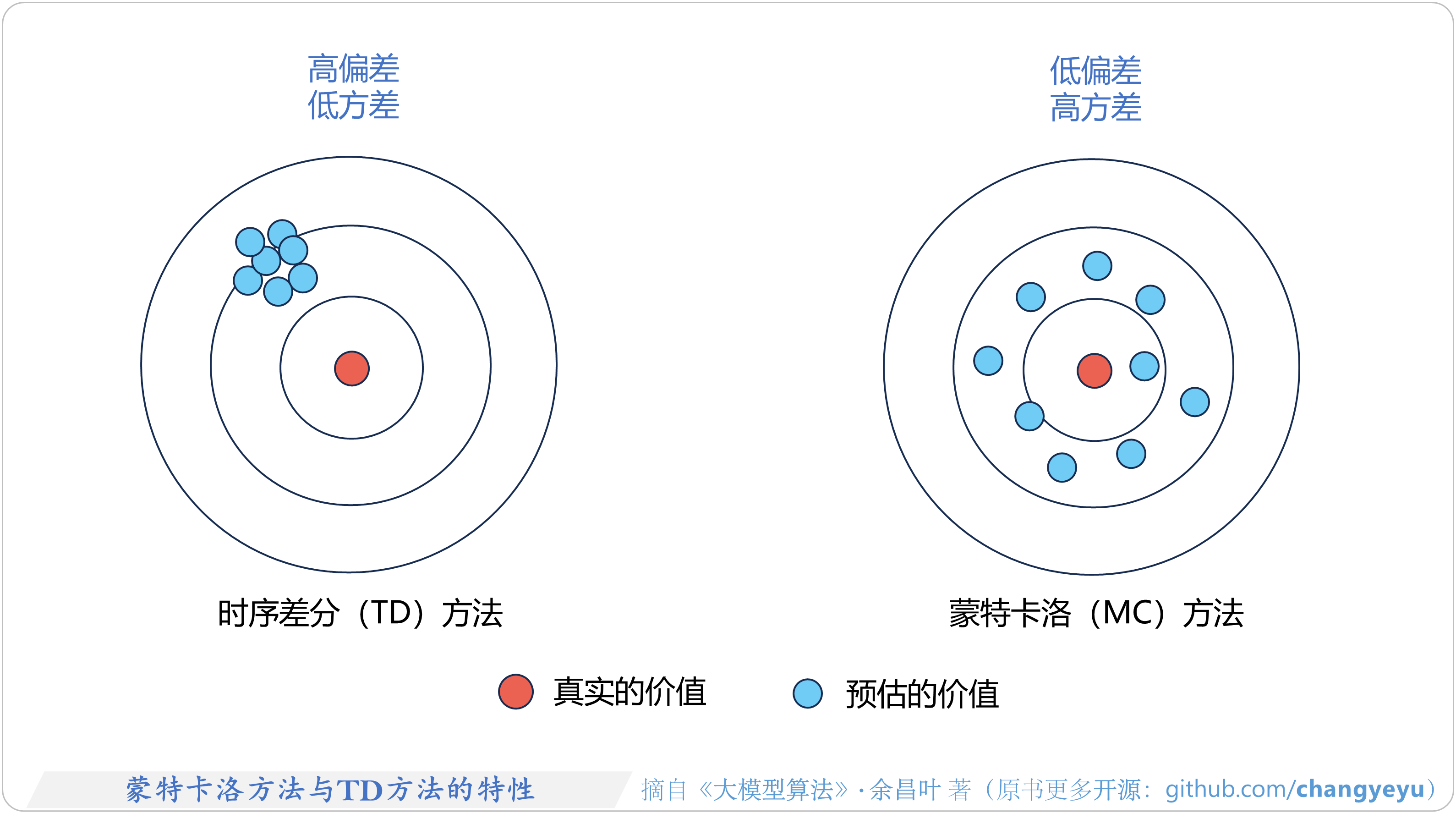
- 【强化学习基础】蒙特卡洛方法与TD方法的特性
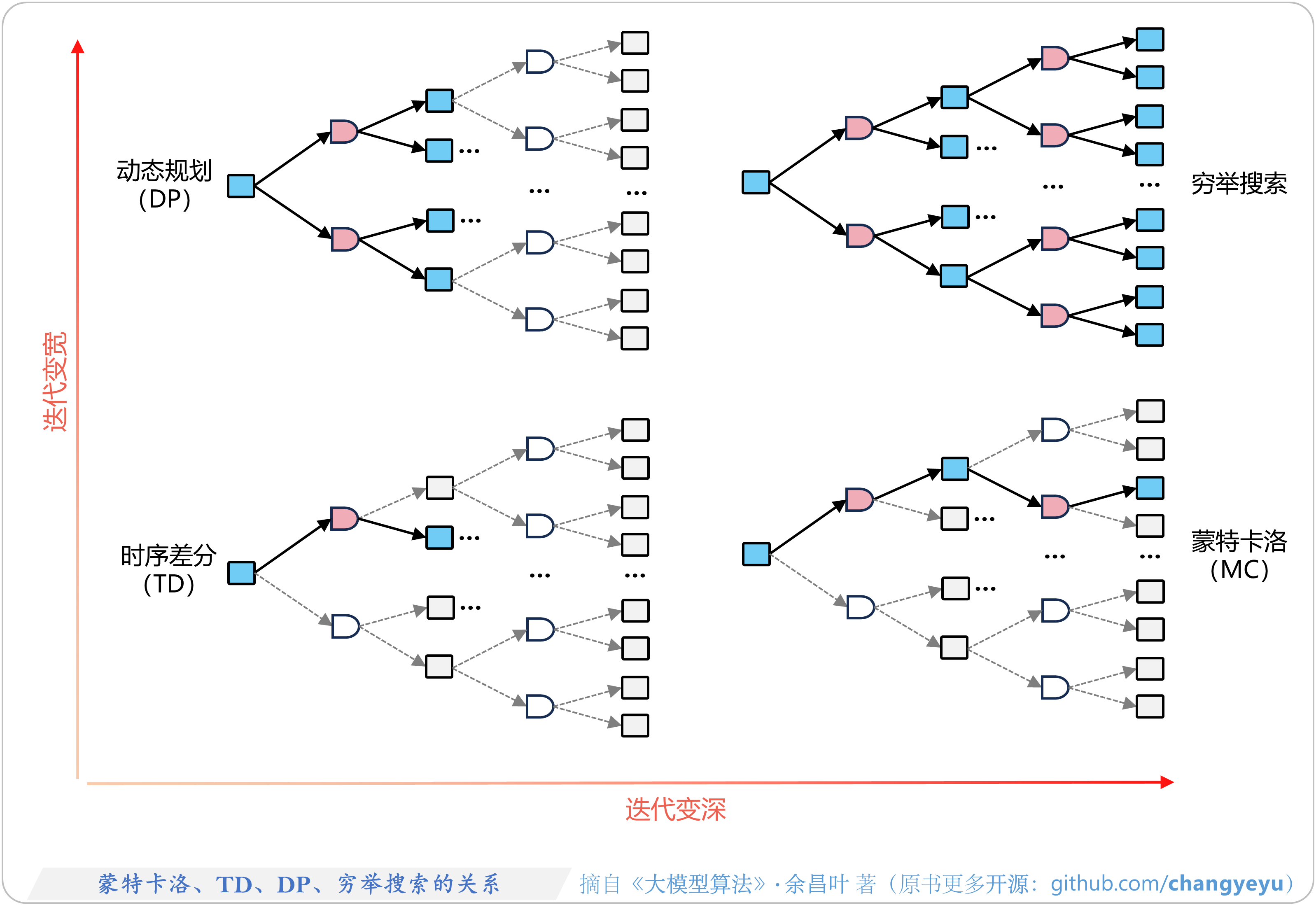
- 【强化学习基础】蒙特卡洛、TD、DP、穷举搜索的关系 [32]
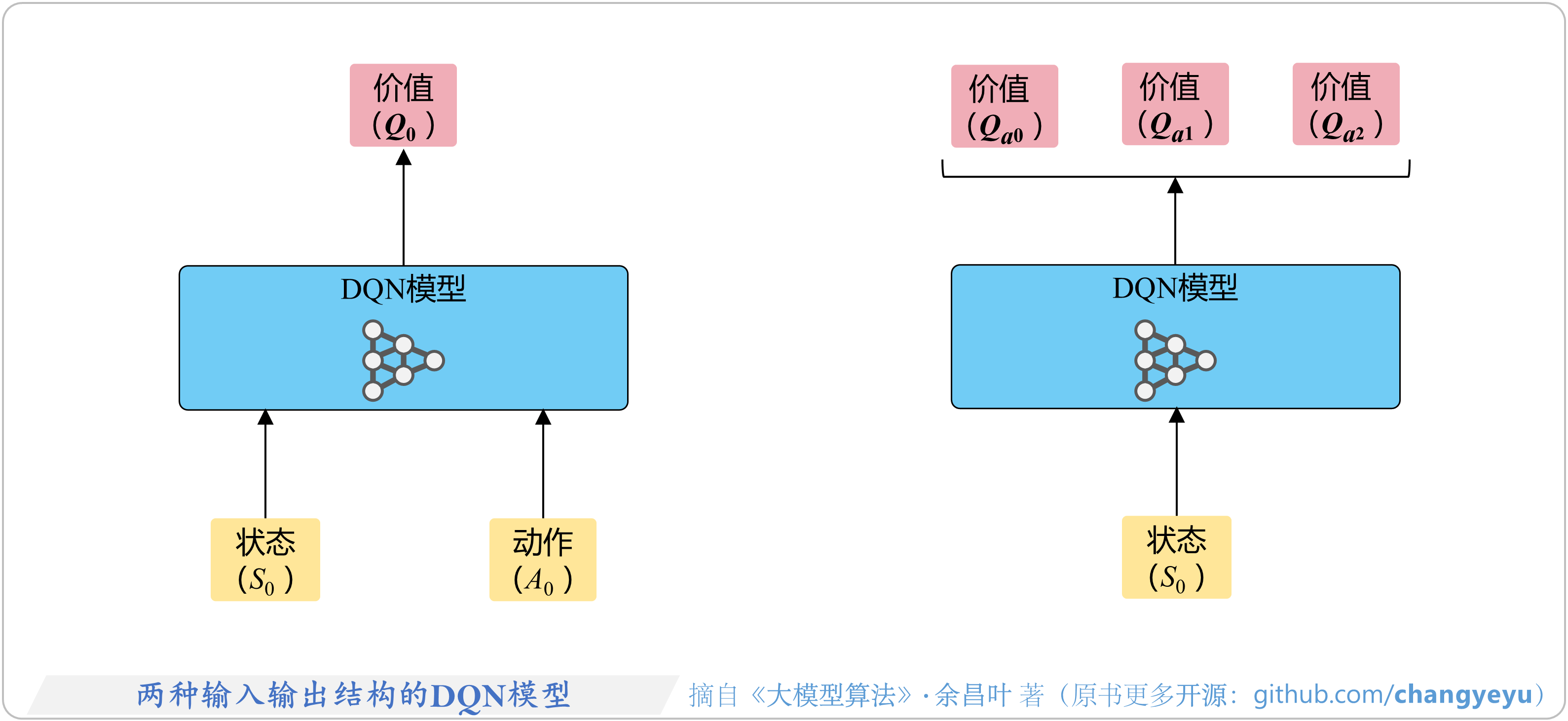
- 【强化学习基础】两种输入输出结构的DQN(Deep Q-Network)模型
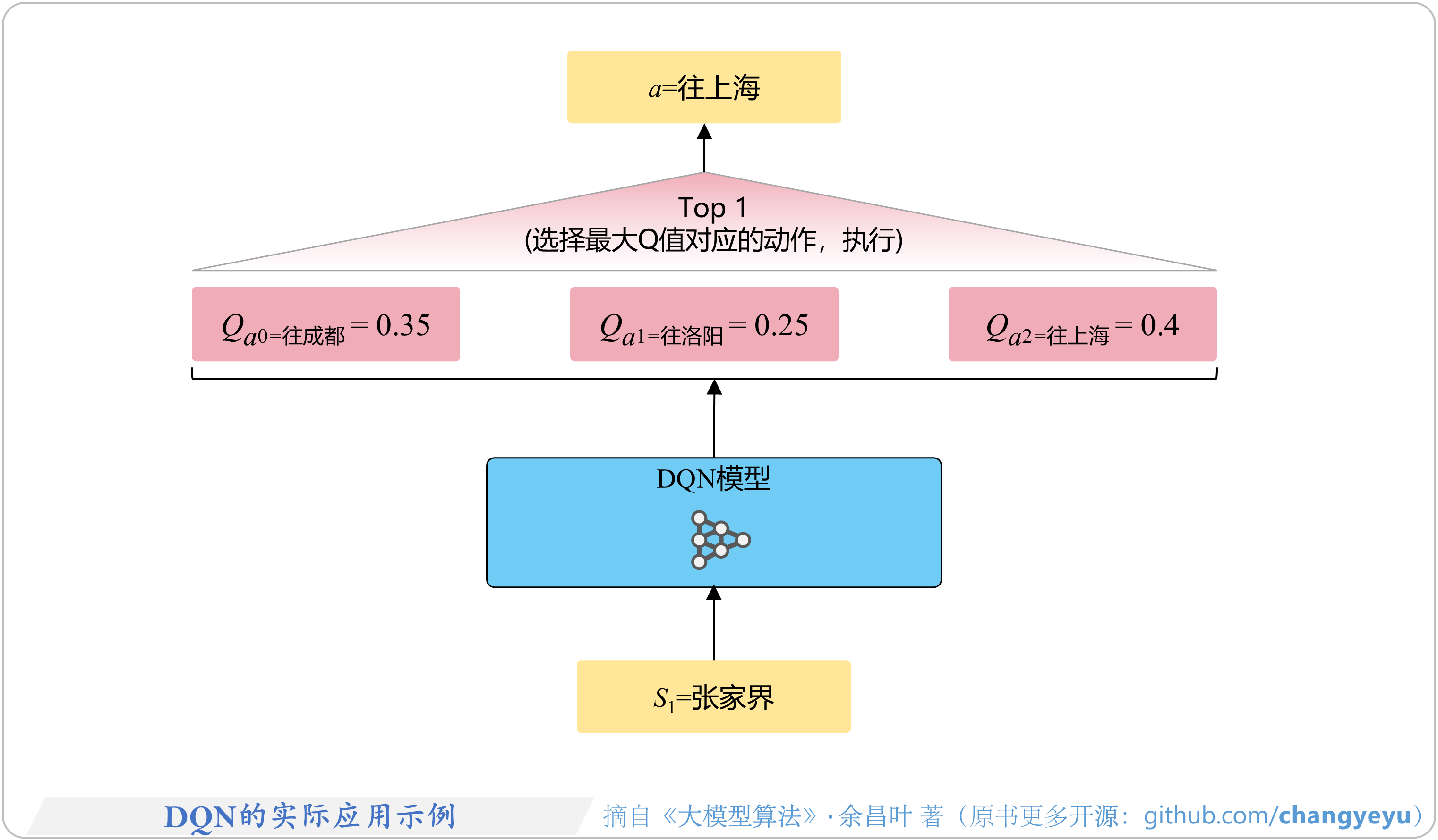
- 【强化学习基础】DQN的实际应用示例
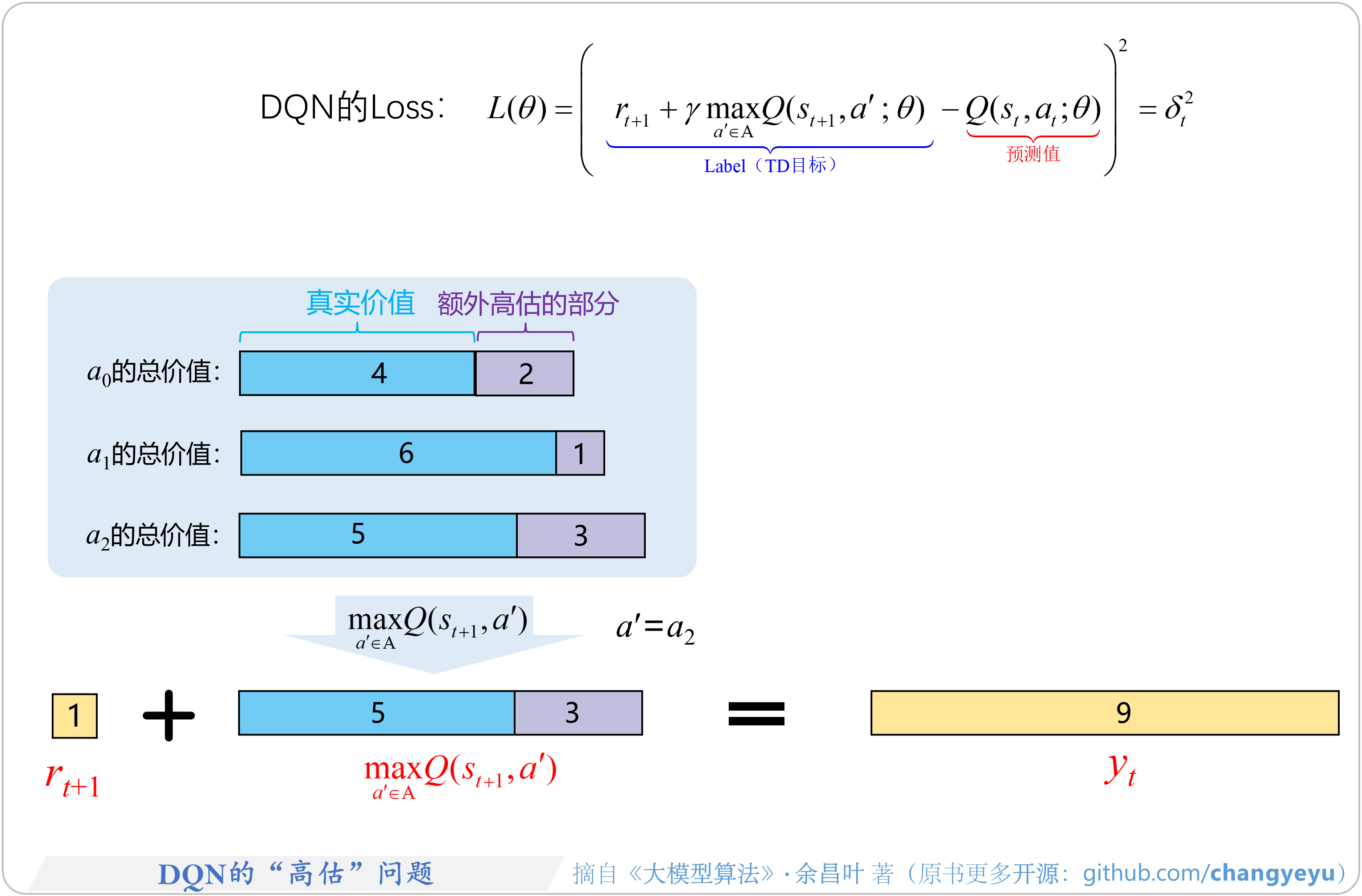
- 【强化学习基础】DQN的“高估”问题
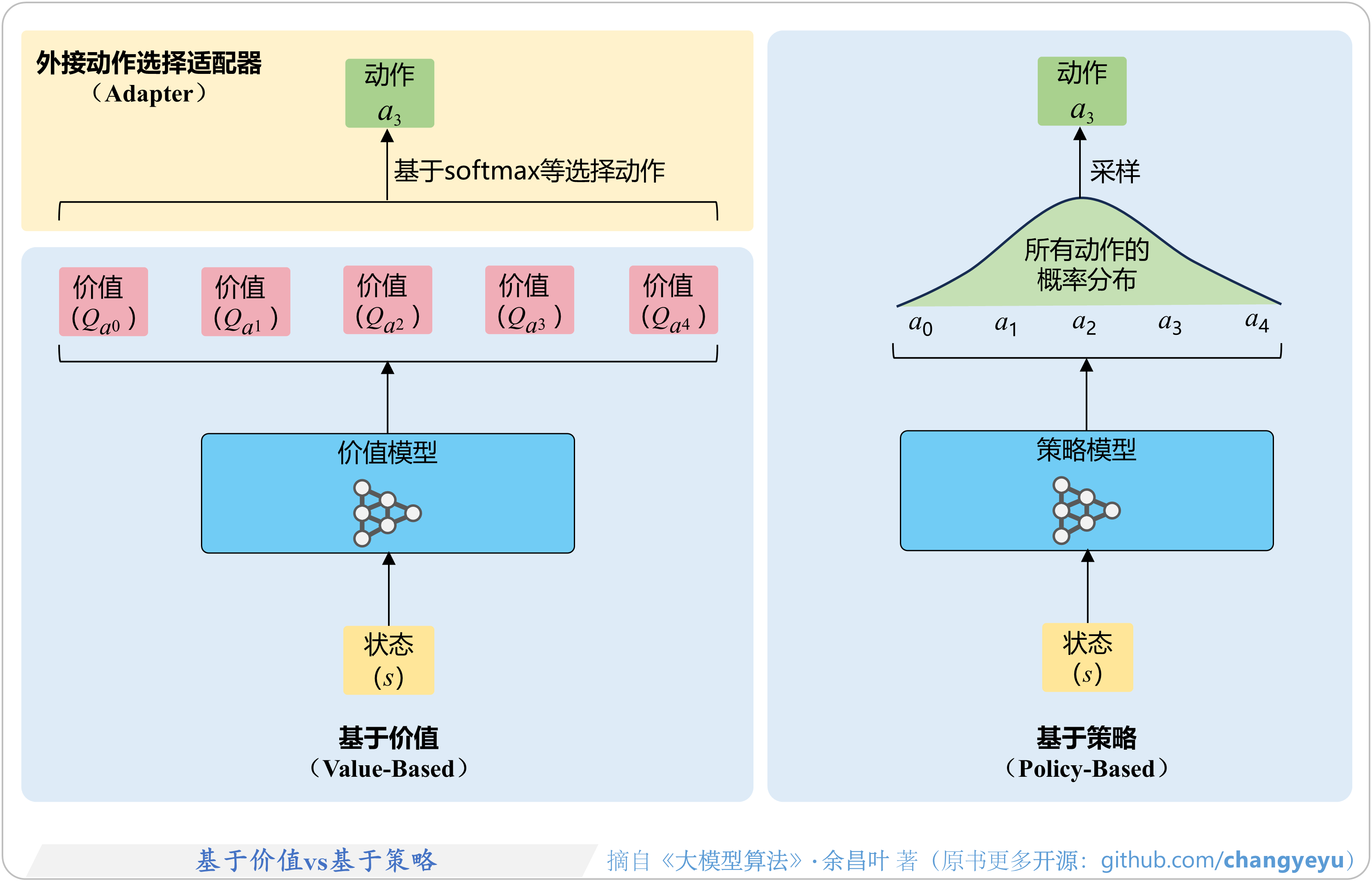
- 【强化学习基础】基于价值vs基于策略(Value-Based vs Policy-Based)
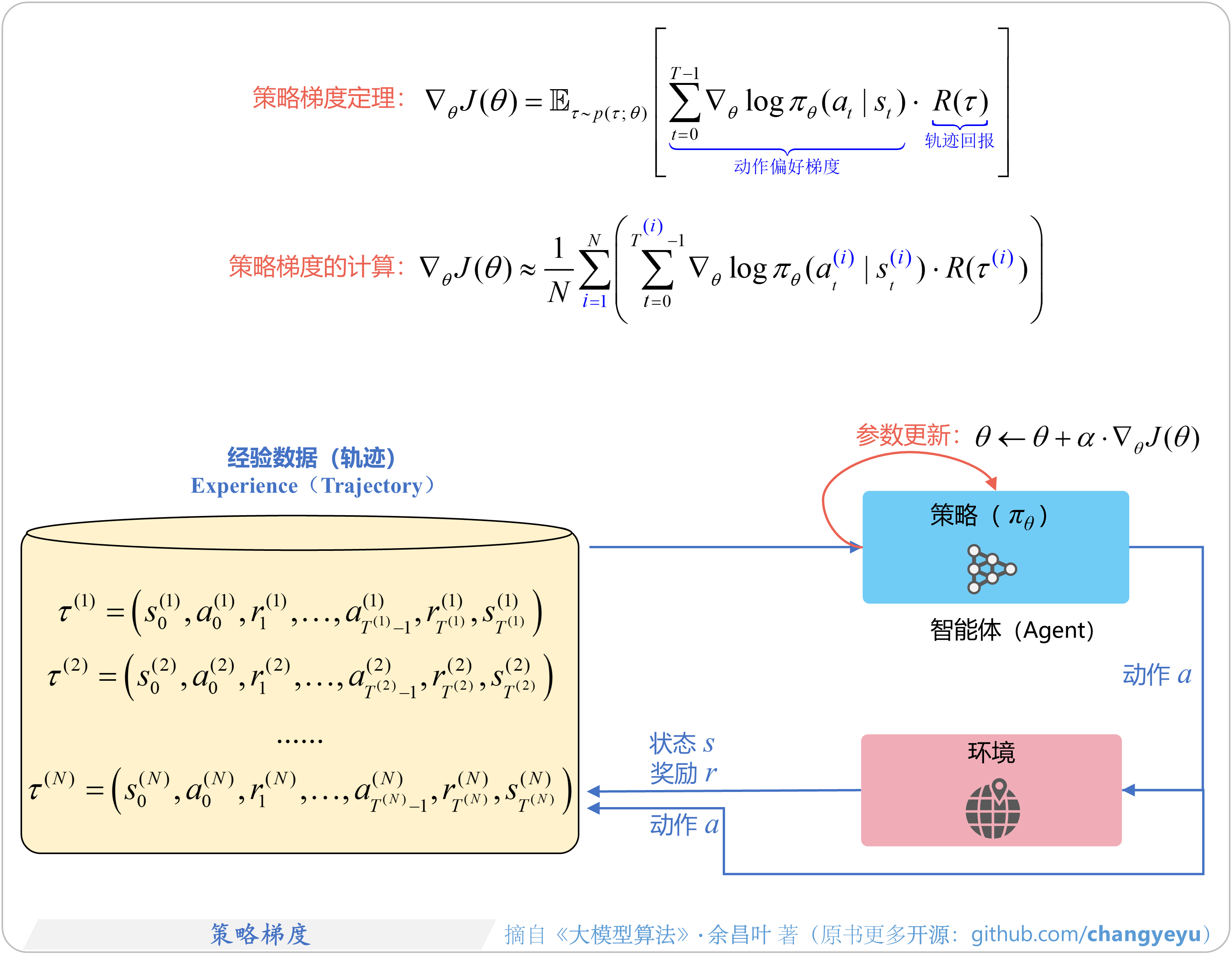
- 【强化学习基础】策略梯度(Policy Gradient)
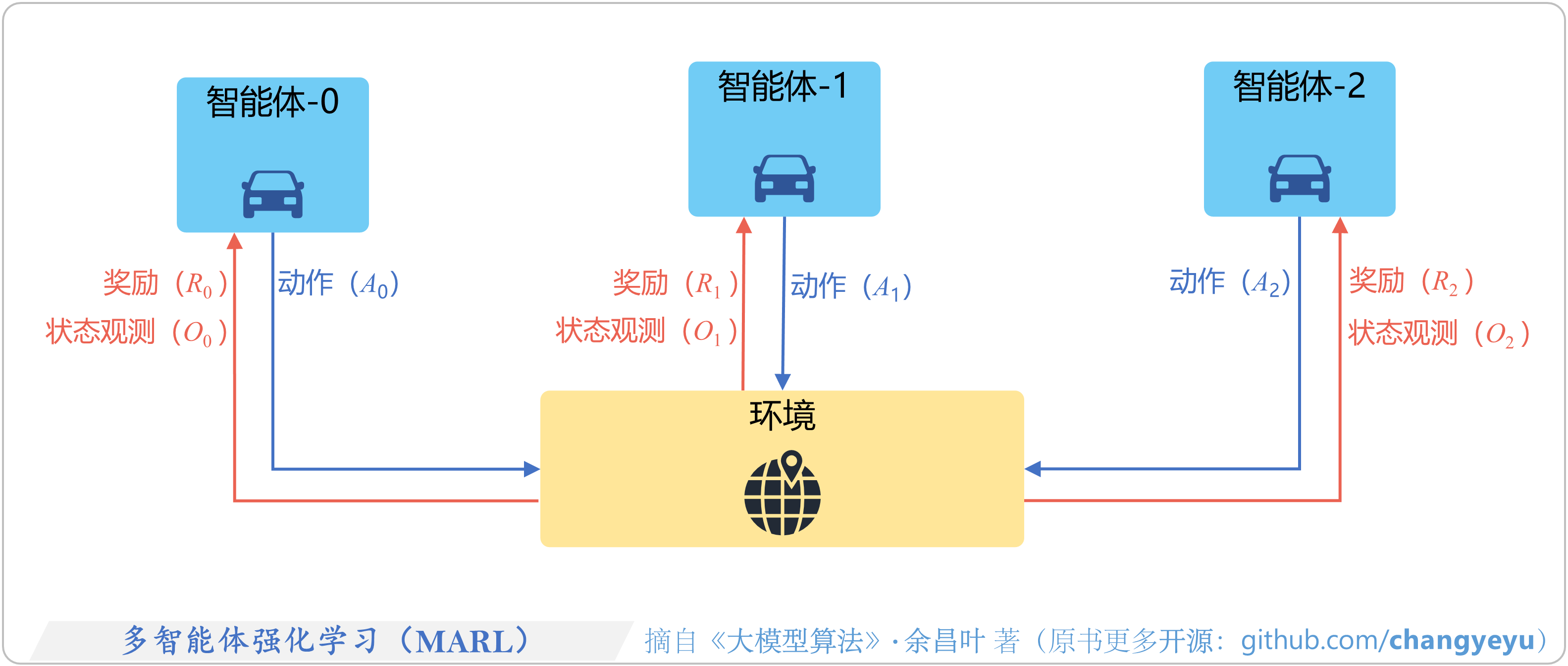
- 【强化学习基础】多智能体强化学习(MARL,Multi-agent reinforcement learning)
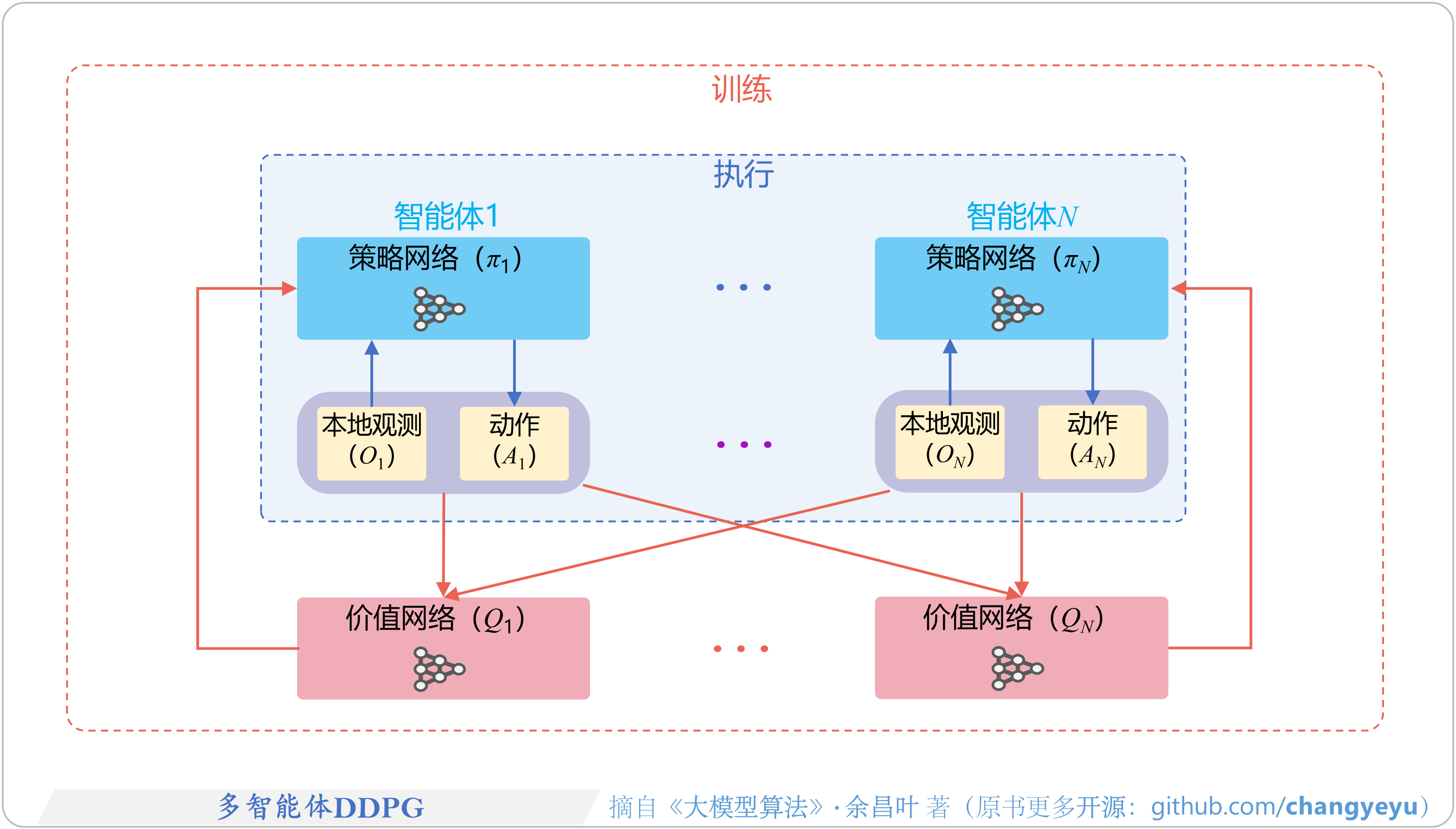
- 【强化学习基础】多智能体DDPG [41]
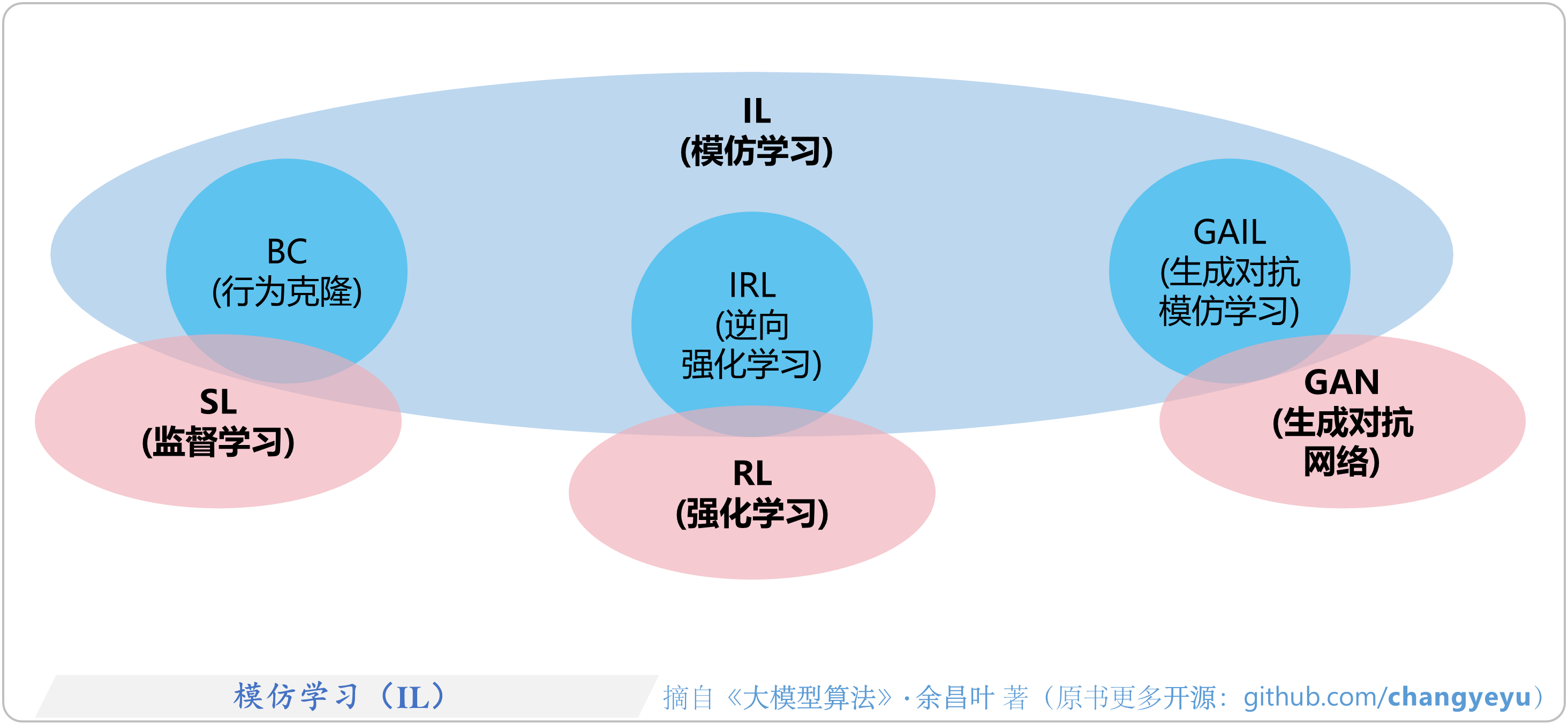
- 【强化学习基础】模仿学习(IL,Imitation Learning)
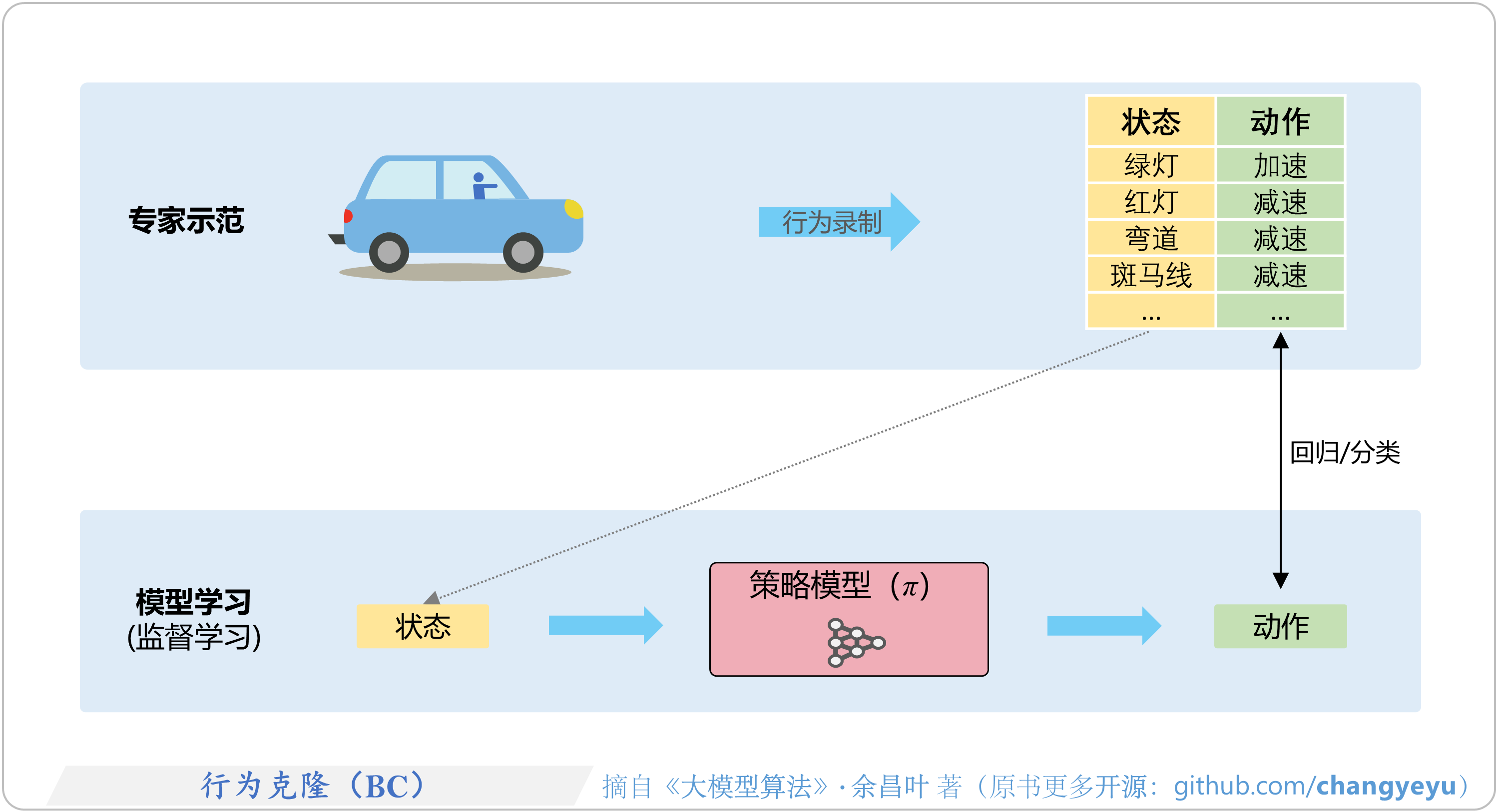
- 【强化学习基础】行为克隆(BC,Behavior Cloning)
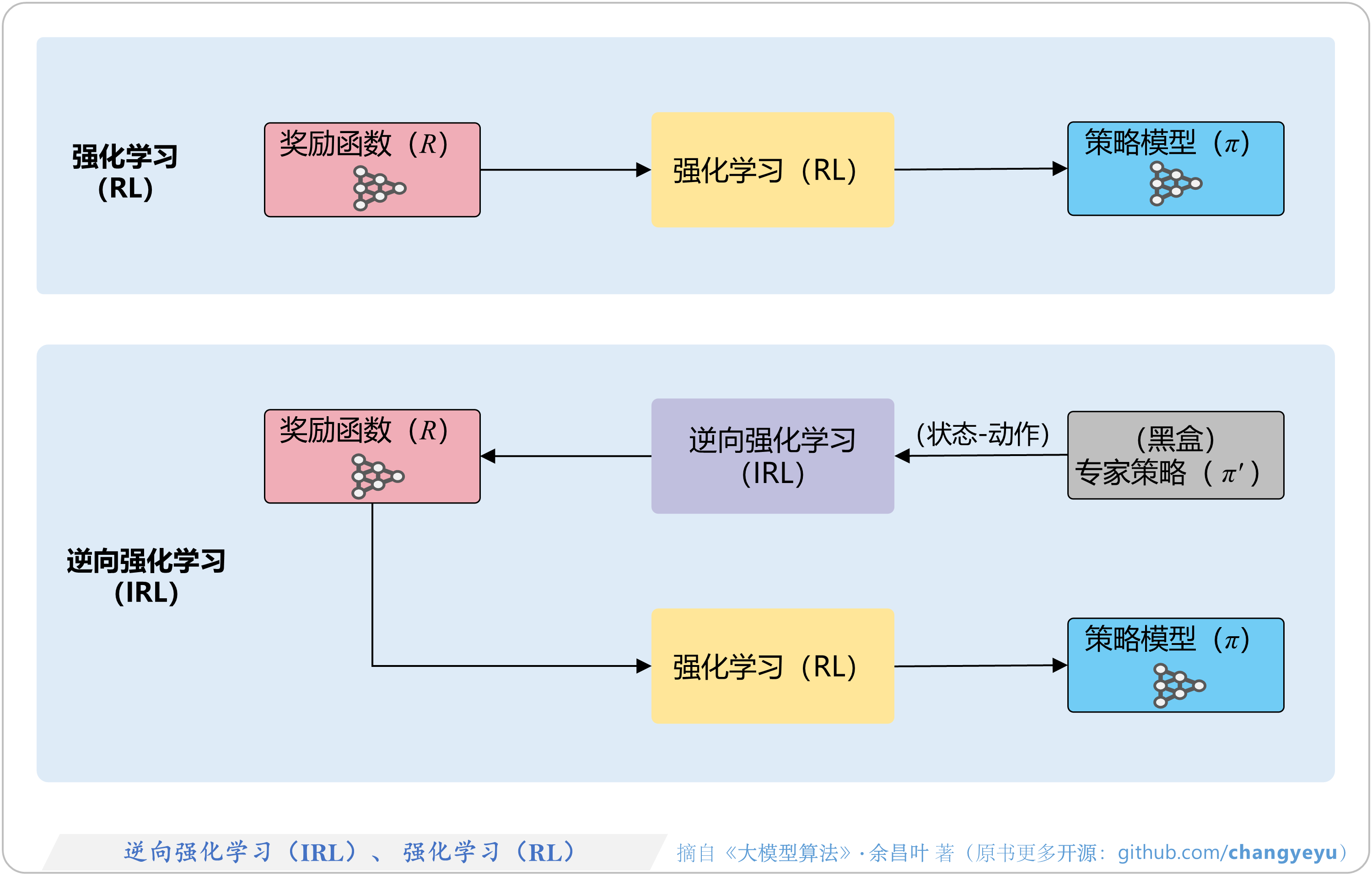
- 【强化学习基础】逆向强化学习(IRL,Inverse RL)、强化学习(RL)
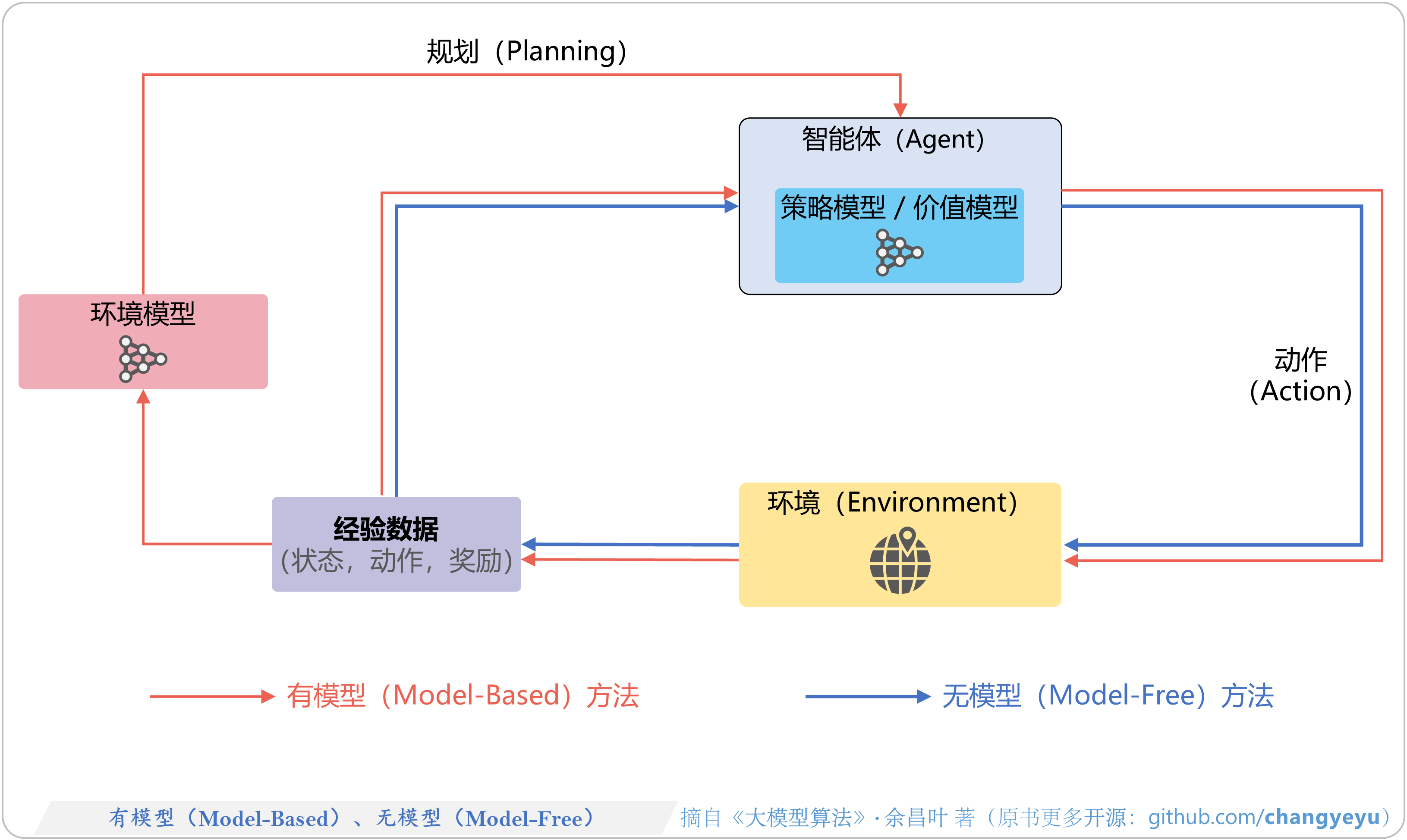
- 【强化学习基础】有模型(Model-Based)、无模型(Model-Free)
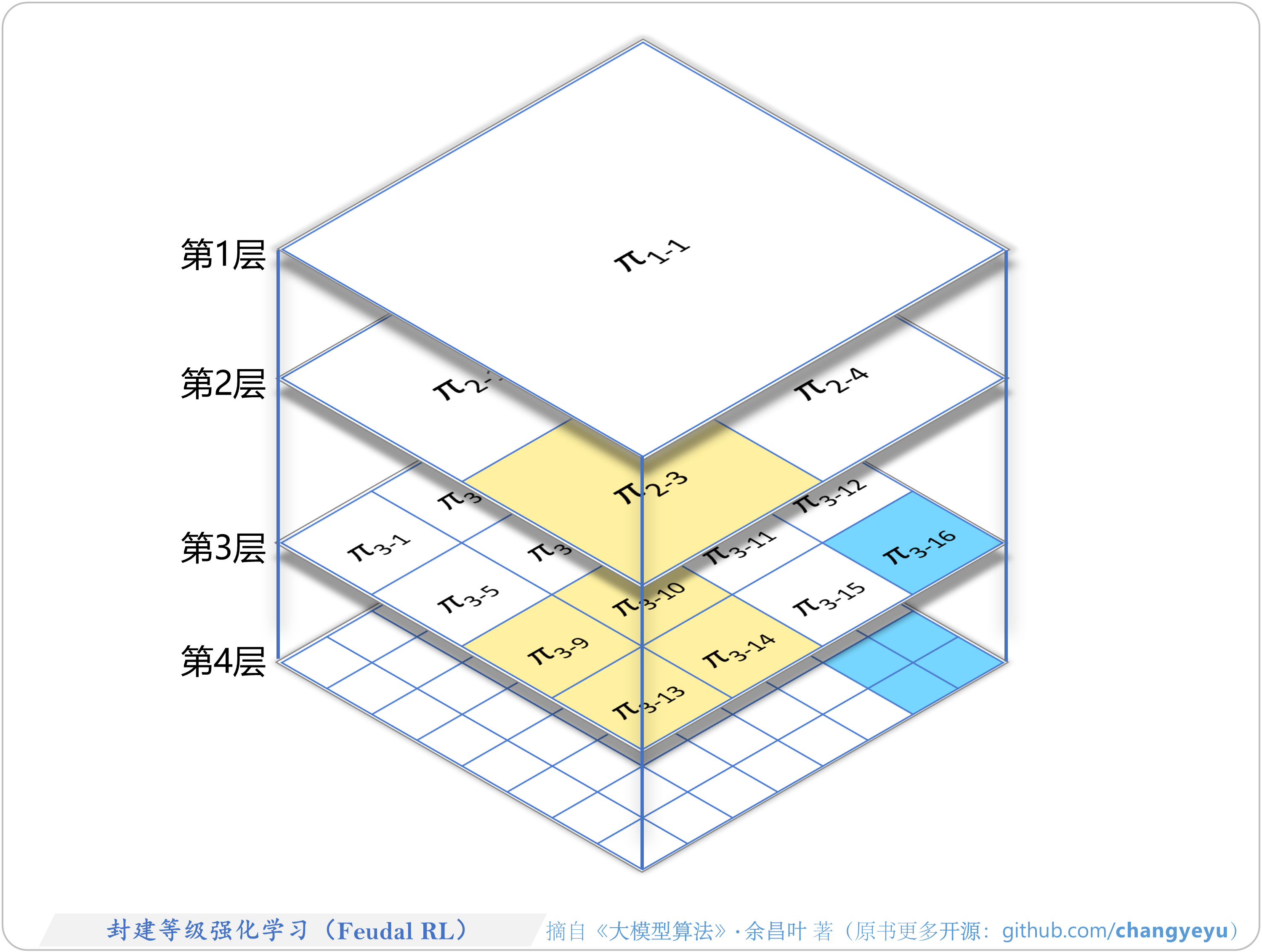
- 【强化学习基础】封建等级强化学习(Feudal RL)
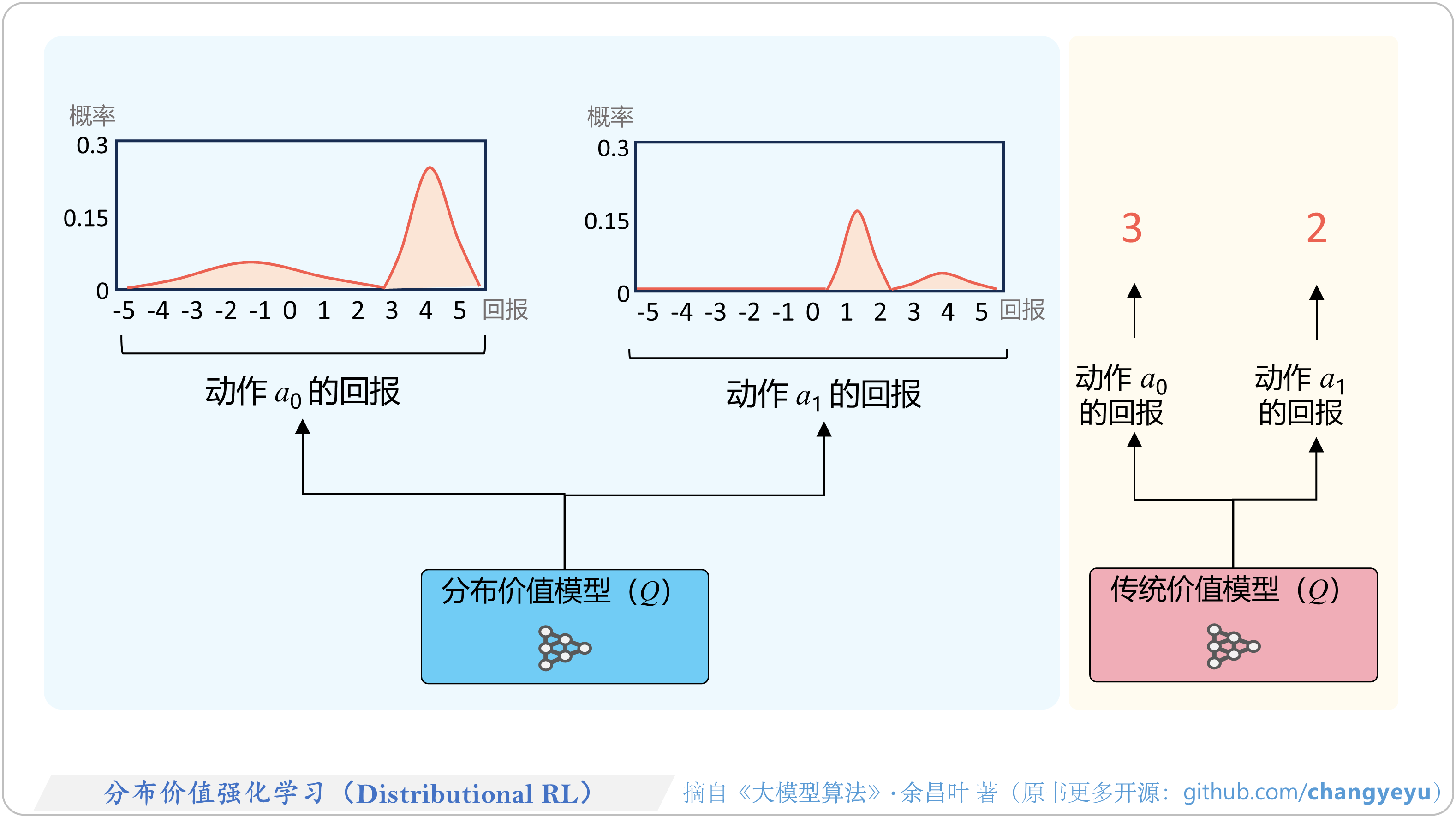
- 【强化学习基础】分布价值强化学习(Distributional RL)
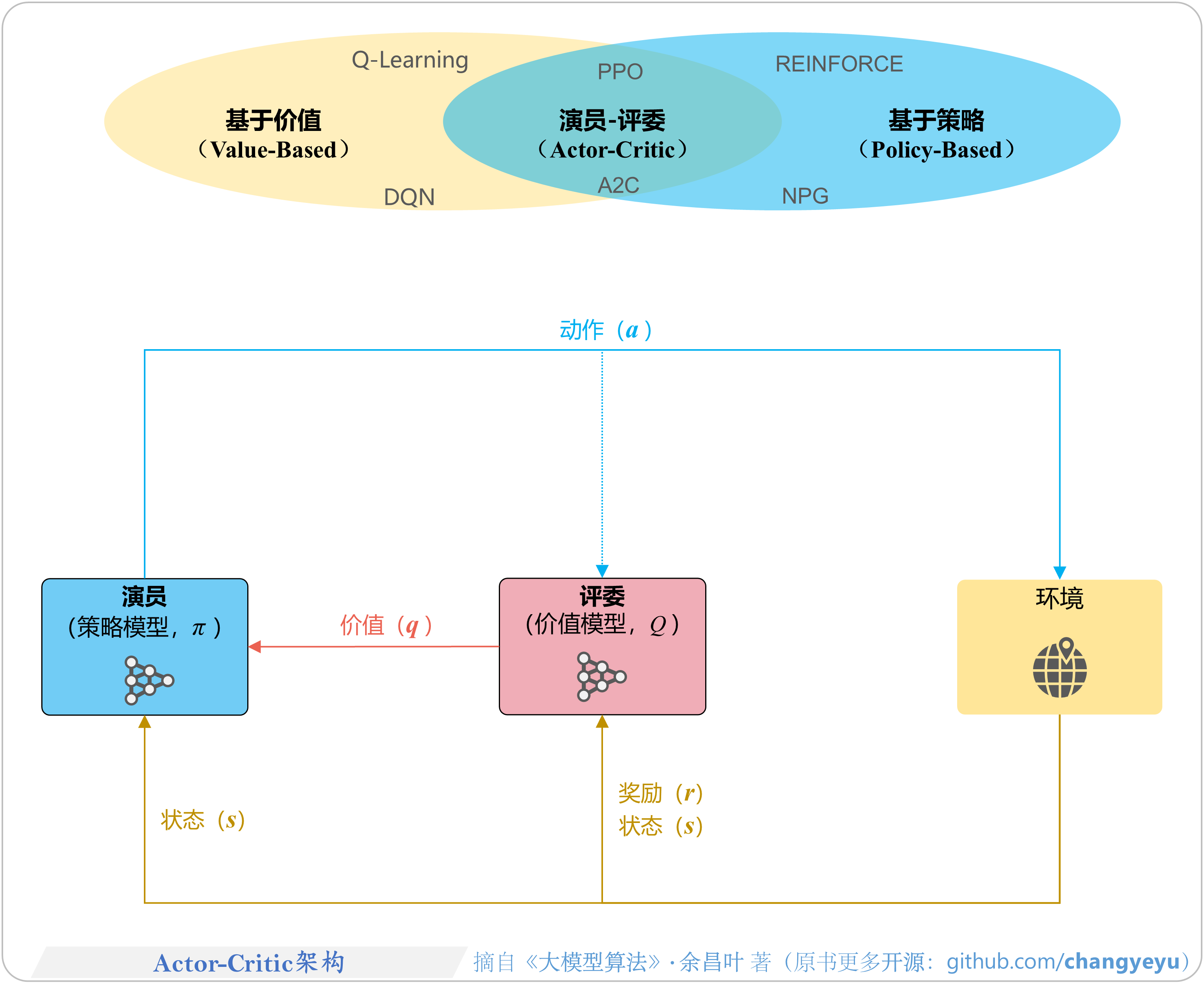
- 【策略优化架构算法及其衍生】Actor-Critic架构
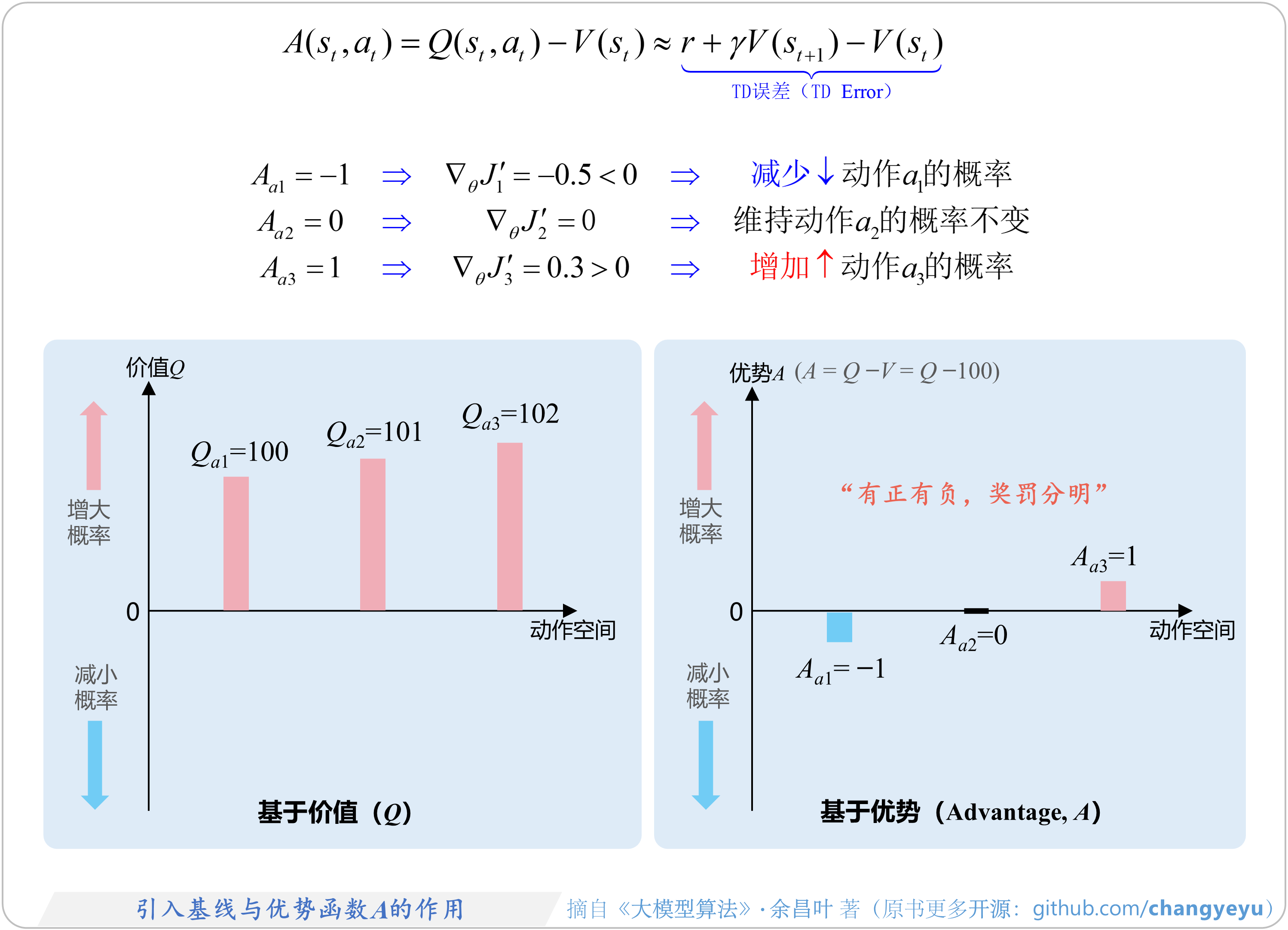
- 【策略优化架构算法及其衍生】引入基线与优势(Advantage)函数A的作用
- 【策略优化架构算法及其衍生】GAE(广义优势估计,Generalized Advantage Estimation)算法
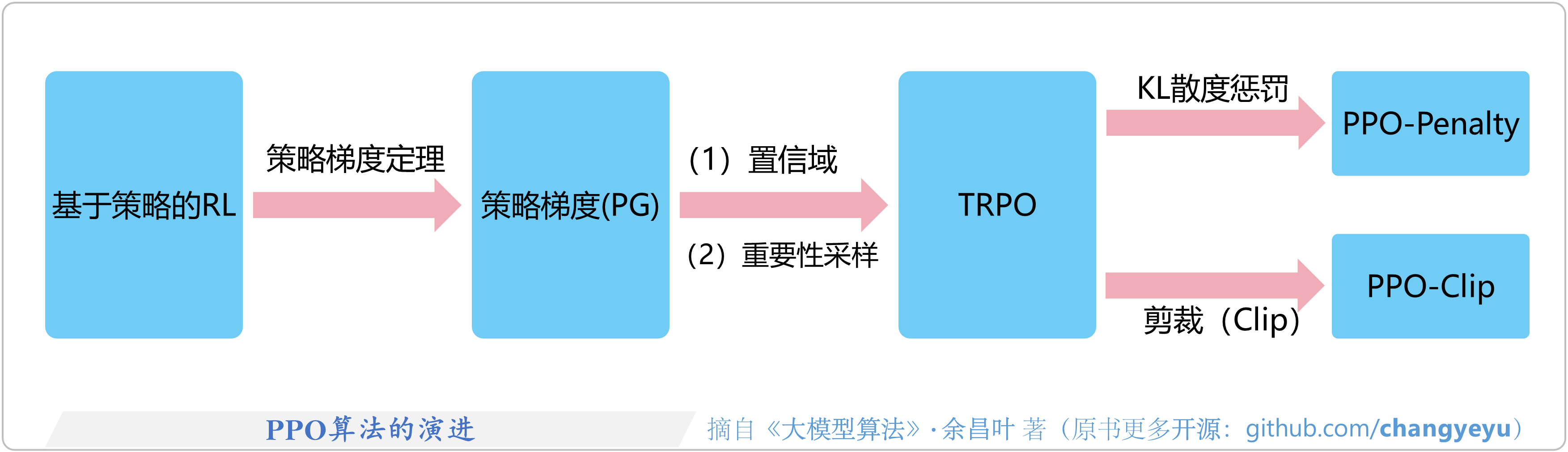
- 【策略优化架构算法及其衍生】PPO(Proximal Policy Optimization)算法的演进
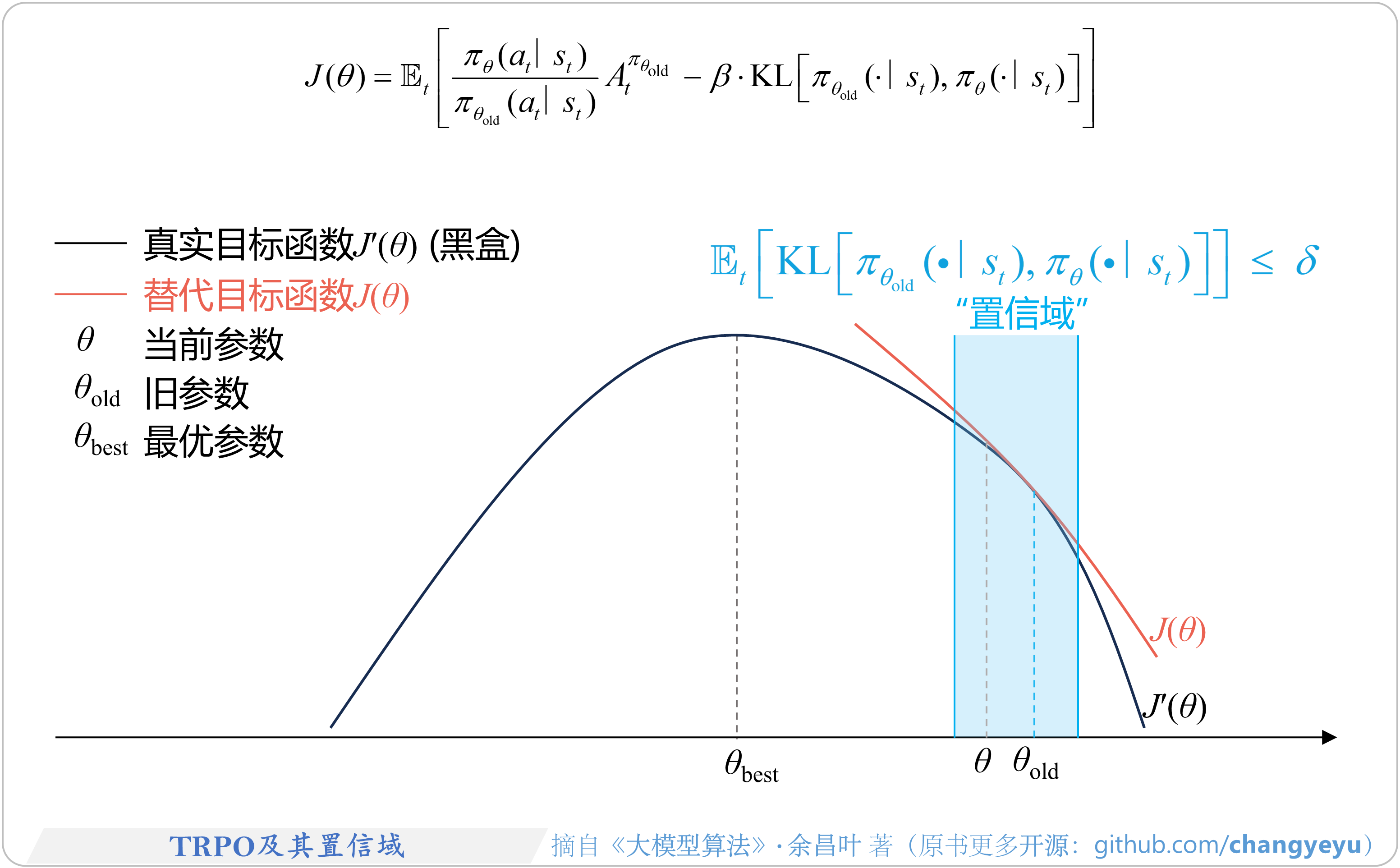
- 【策略优化架构算法及其衍生】TRPO(Trust Region Policy Optimization)及其置信域
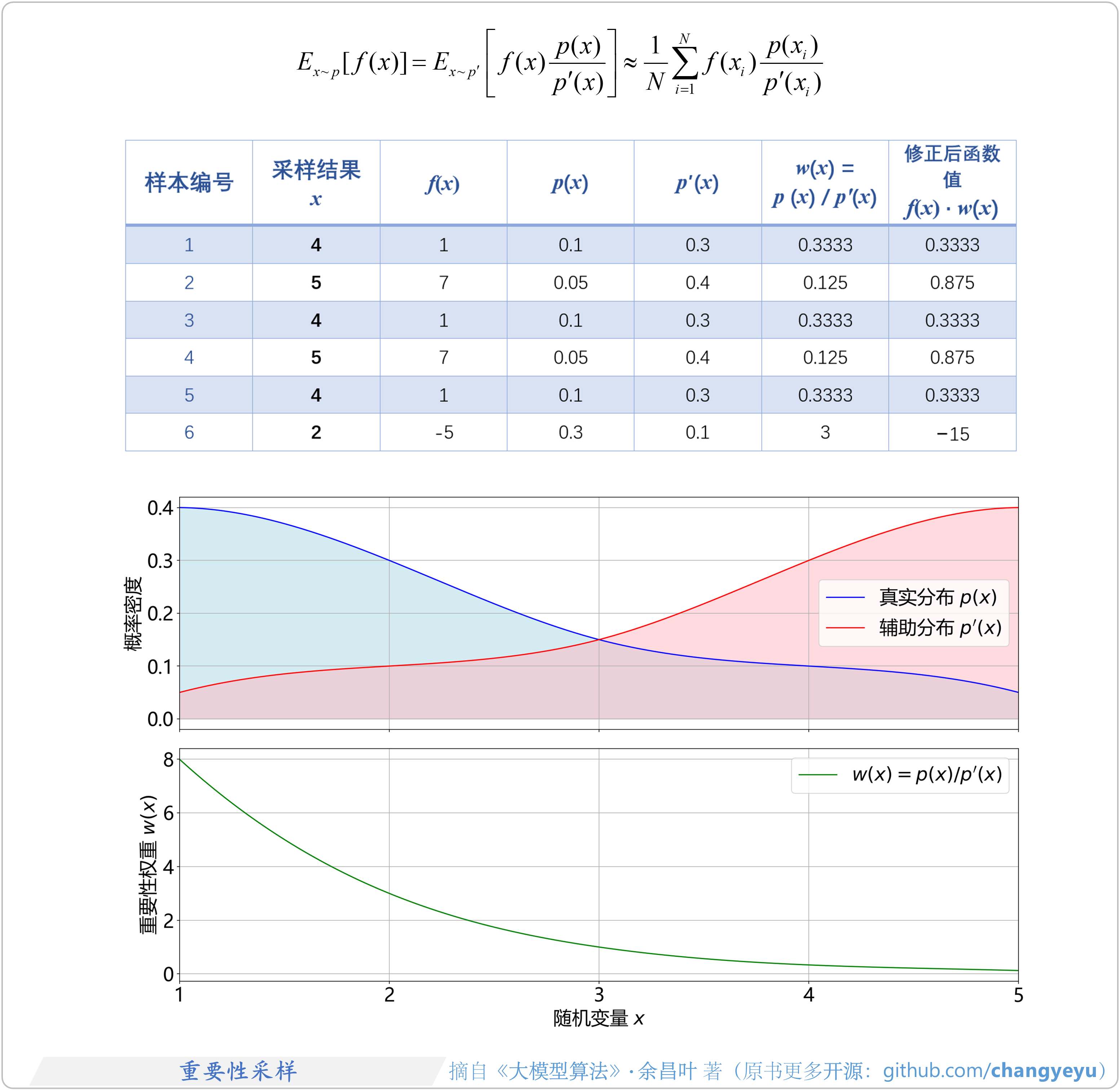
- 【策略优化架构算法及其衍生】重要性采样(Importance sampling)
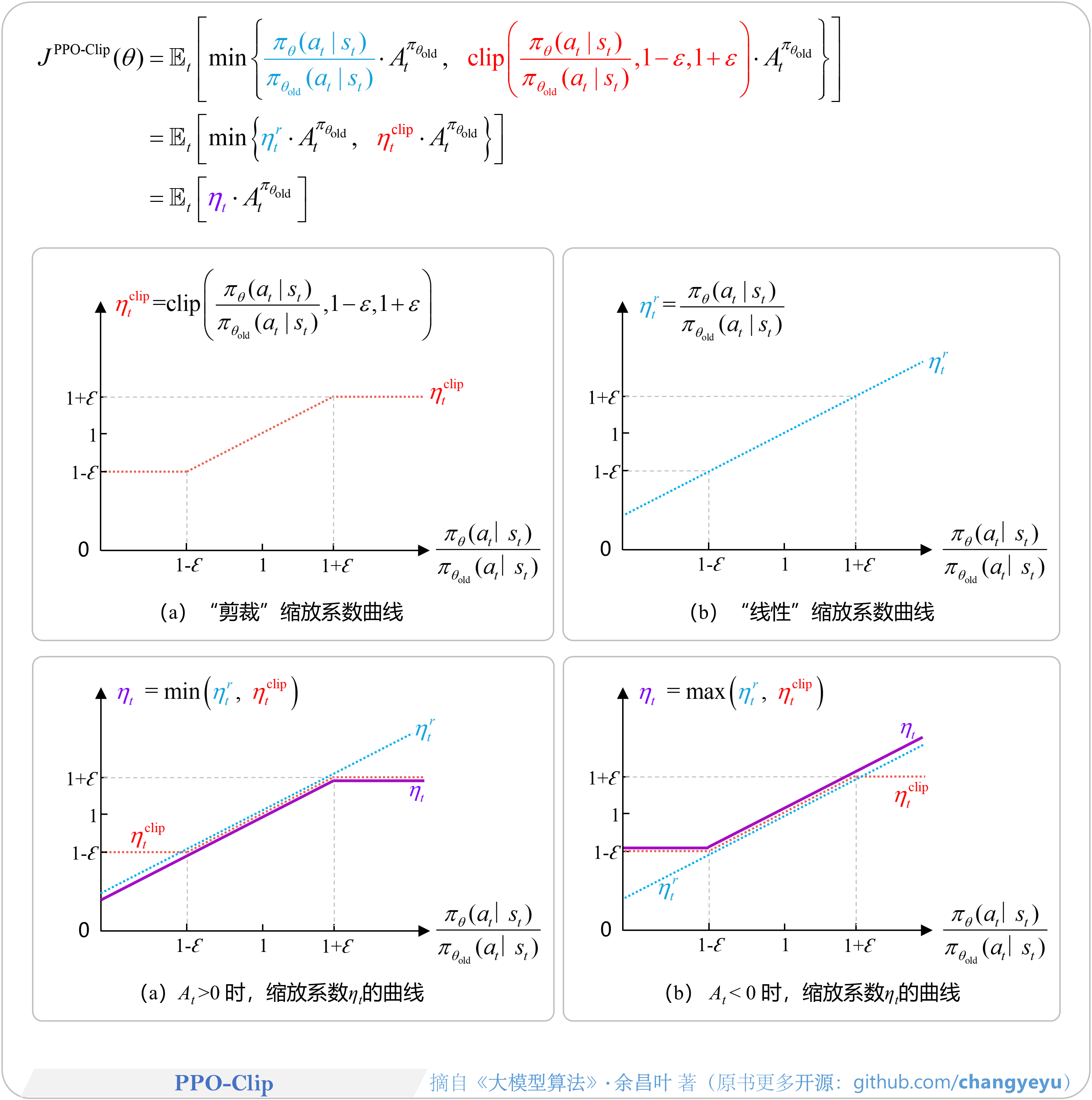
- 【策略优化架构算法及其衍生】PPO-Clip
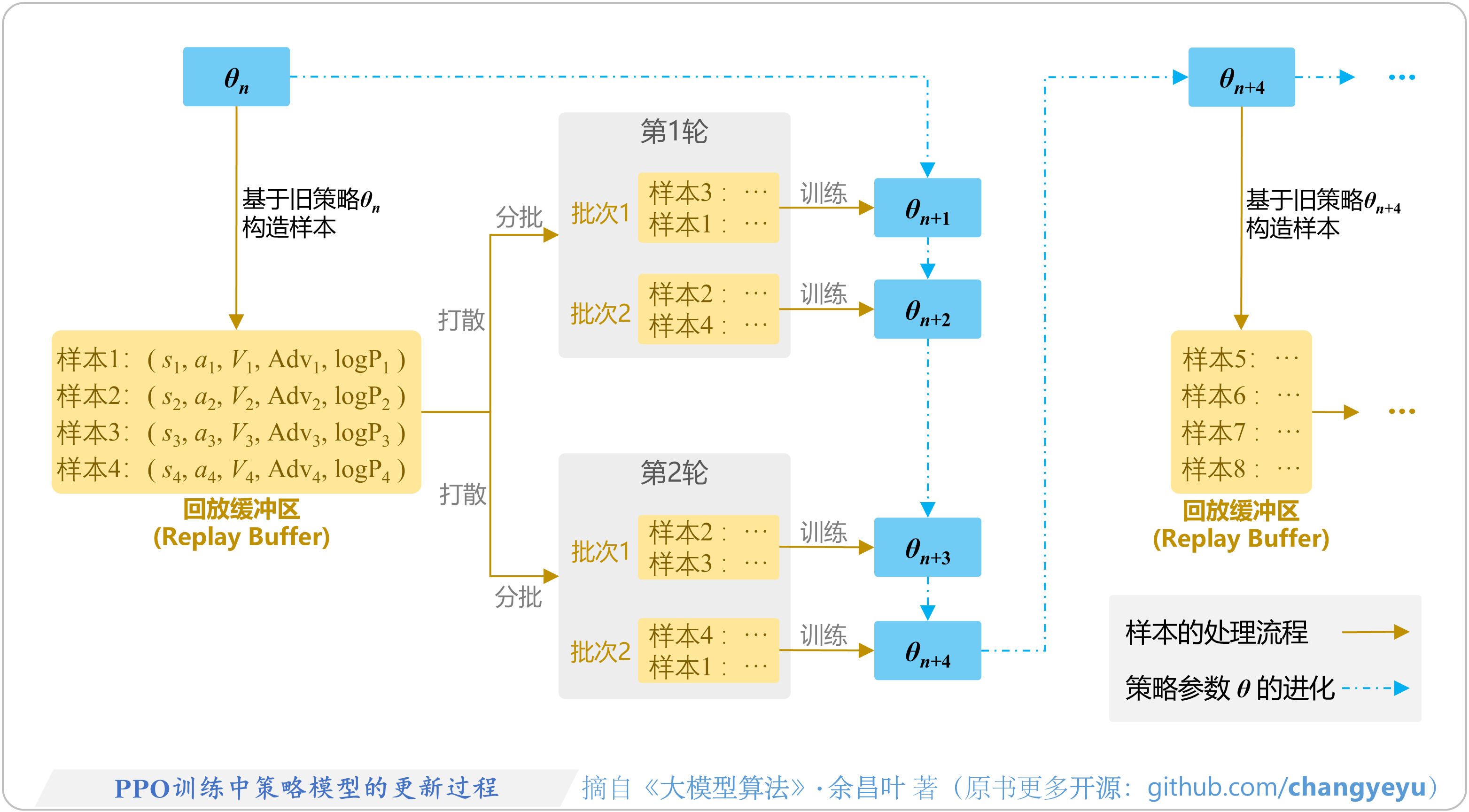
- 【策略优化架构算法及其衍生】PPO训练中策略模型的更新过程
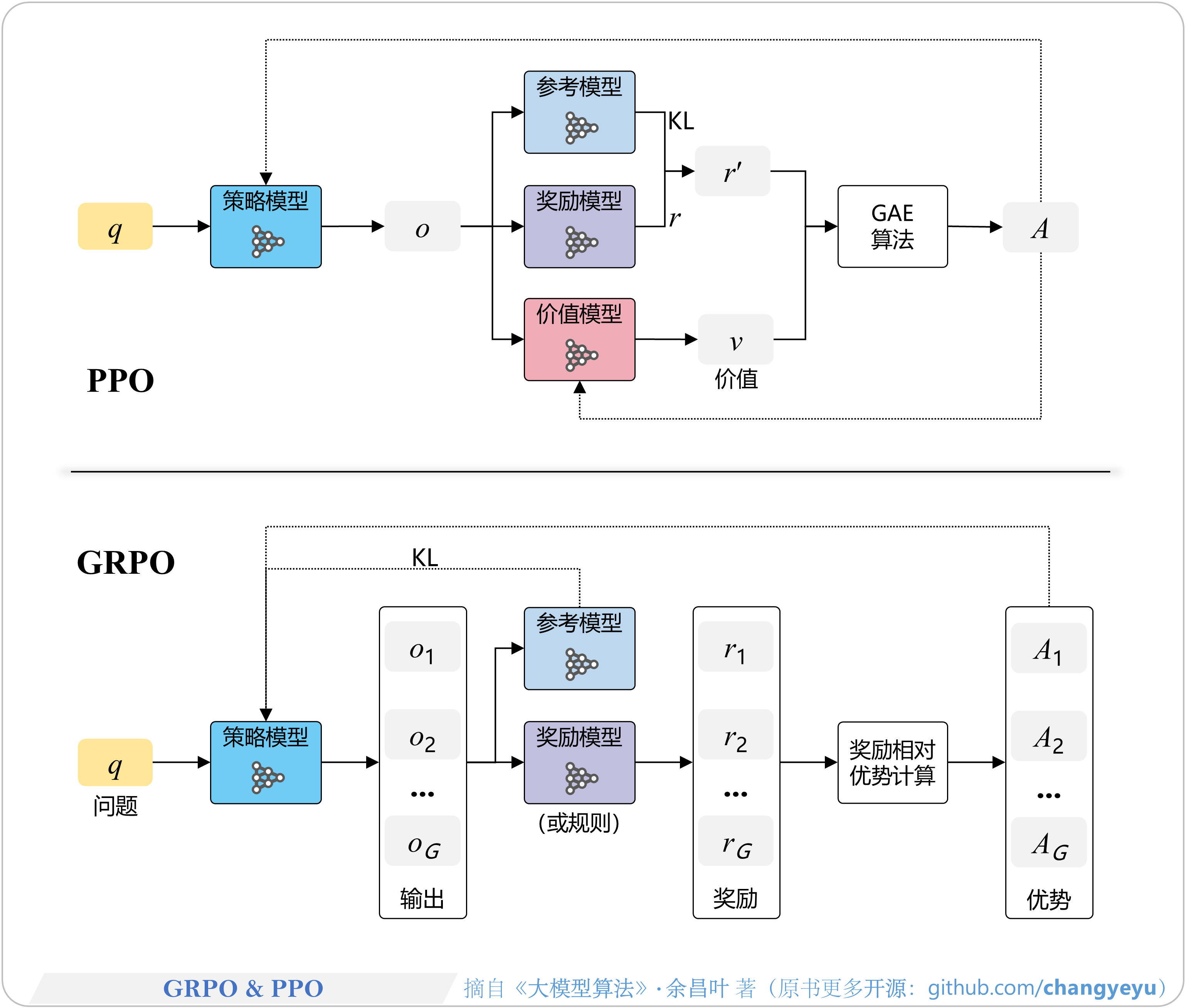
- 【策略优化架构算法及其衍生】PPO与GRPO(Group Relative Policy Optimization) [72]
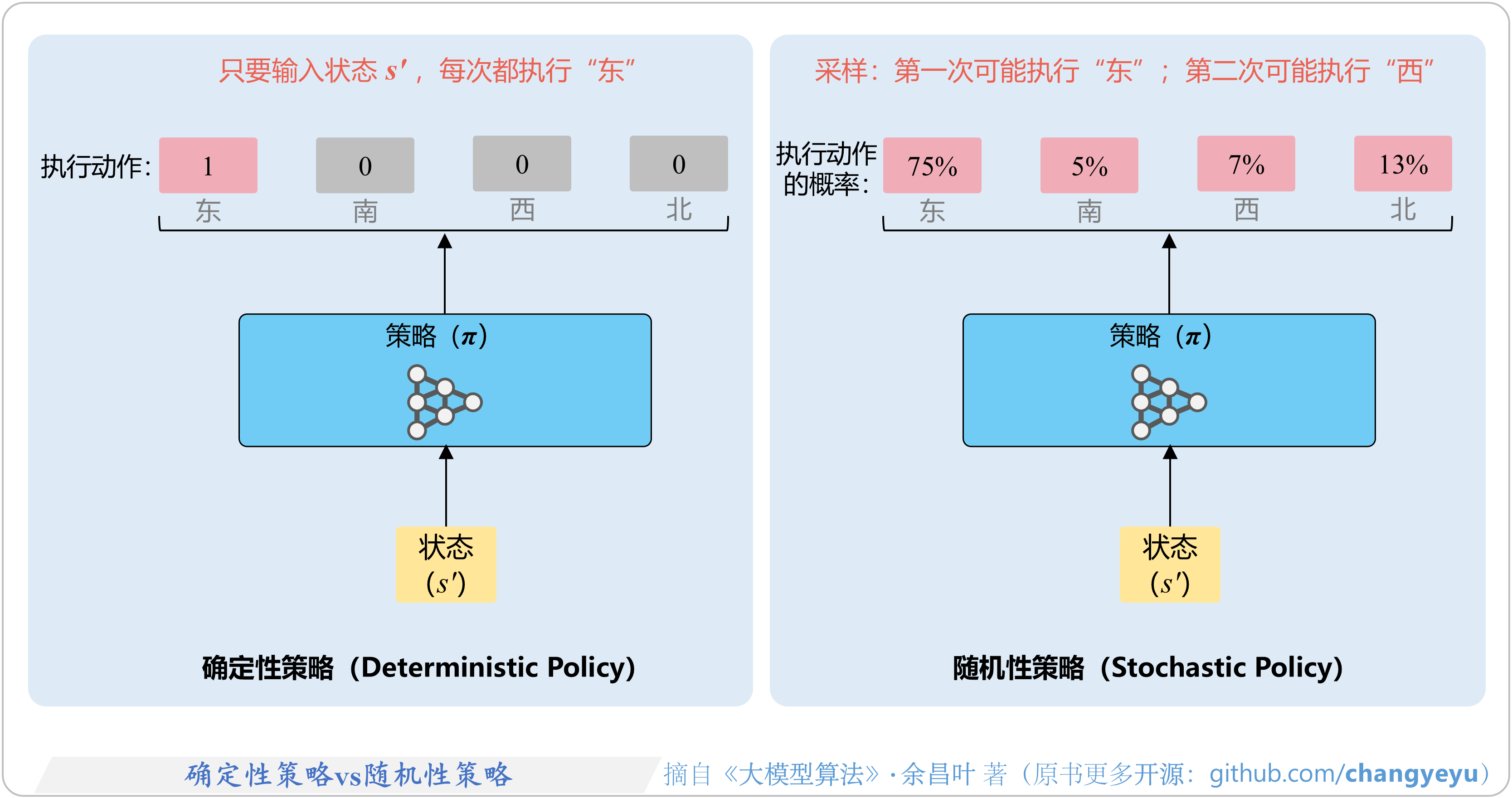
- 【策略优化架构算法及其衍生】确定性策略vs随机性策略(Deterministic policy vs. Stochastic policy)
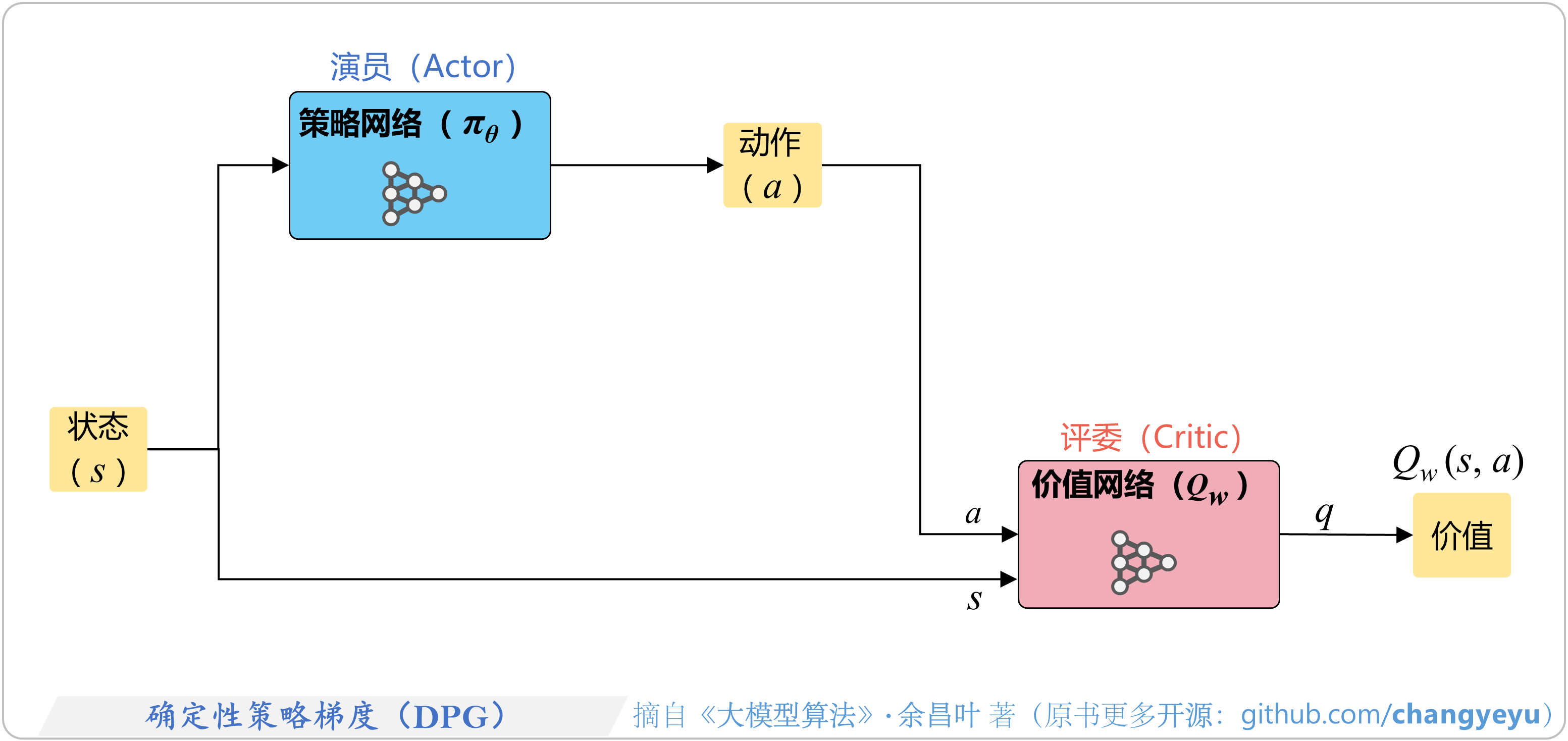
- 【策略优化架构算法及其衍生】确定性策略梯度(DPG)
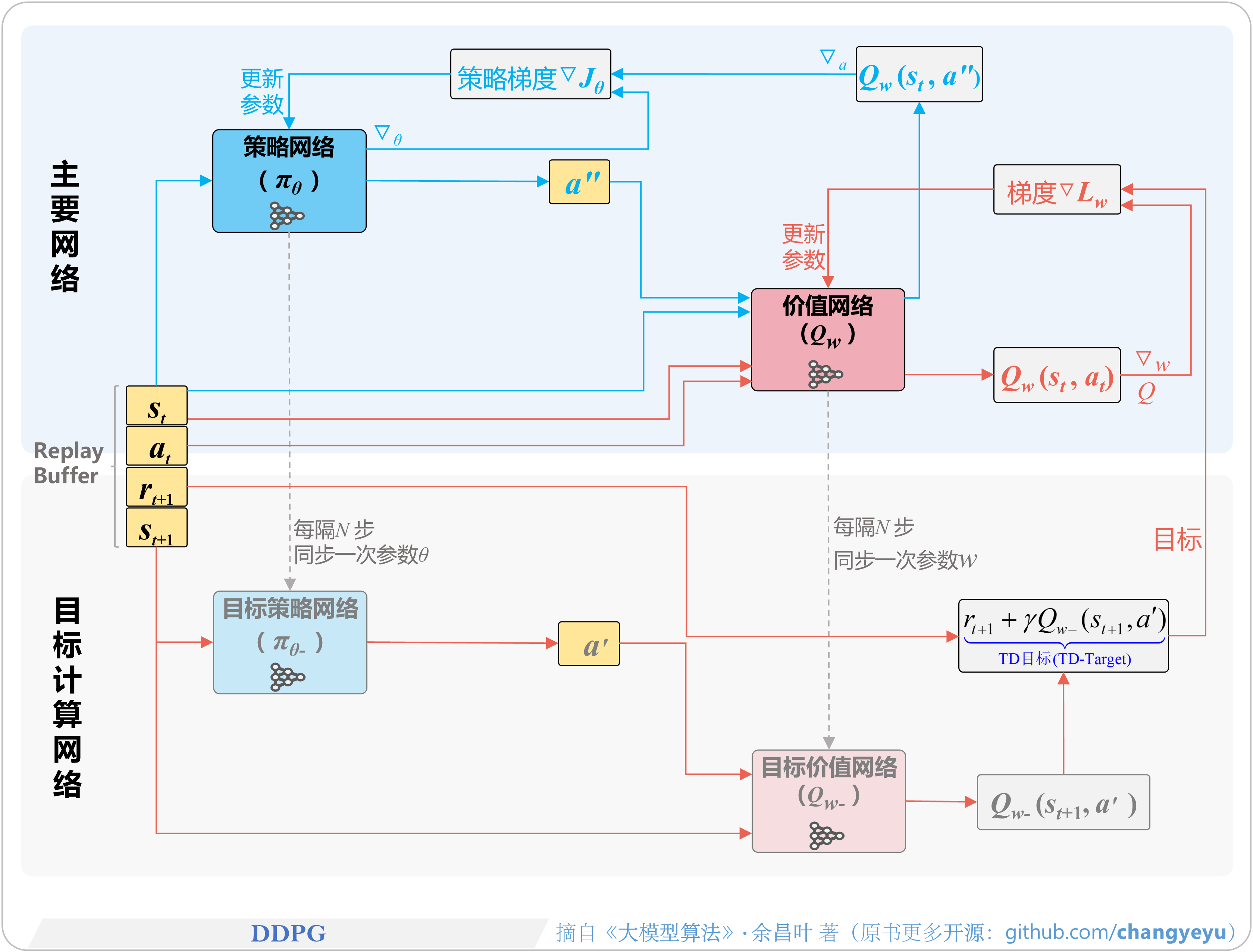
- 【策略优化架构算法及其衍生】DDPG(Deep Deterministic Policy Gradient)
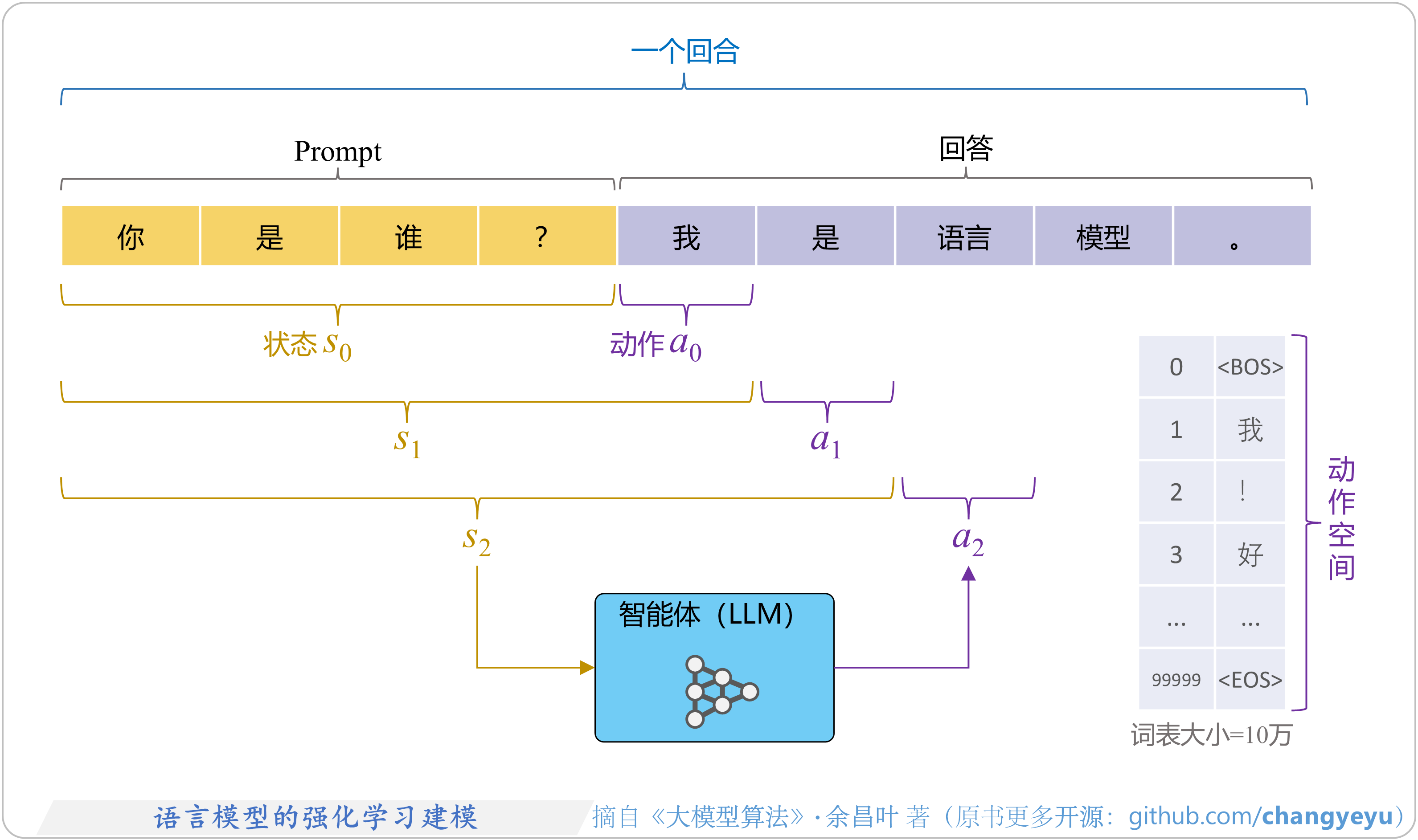
- 【RLHF与RLAIF】语言模型的强化学习建模
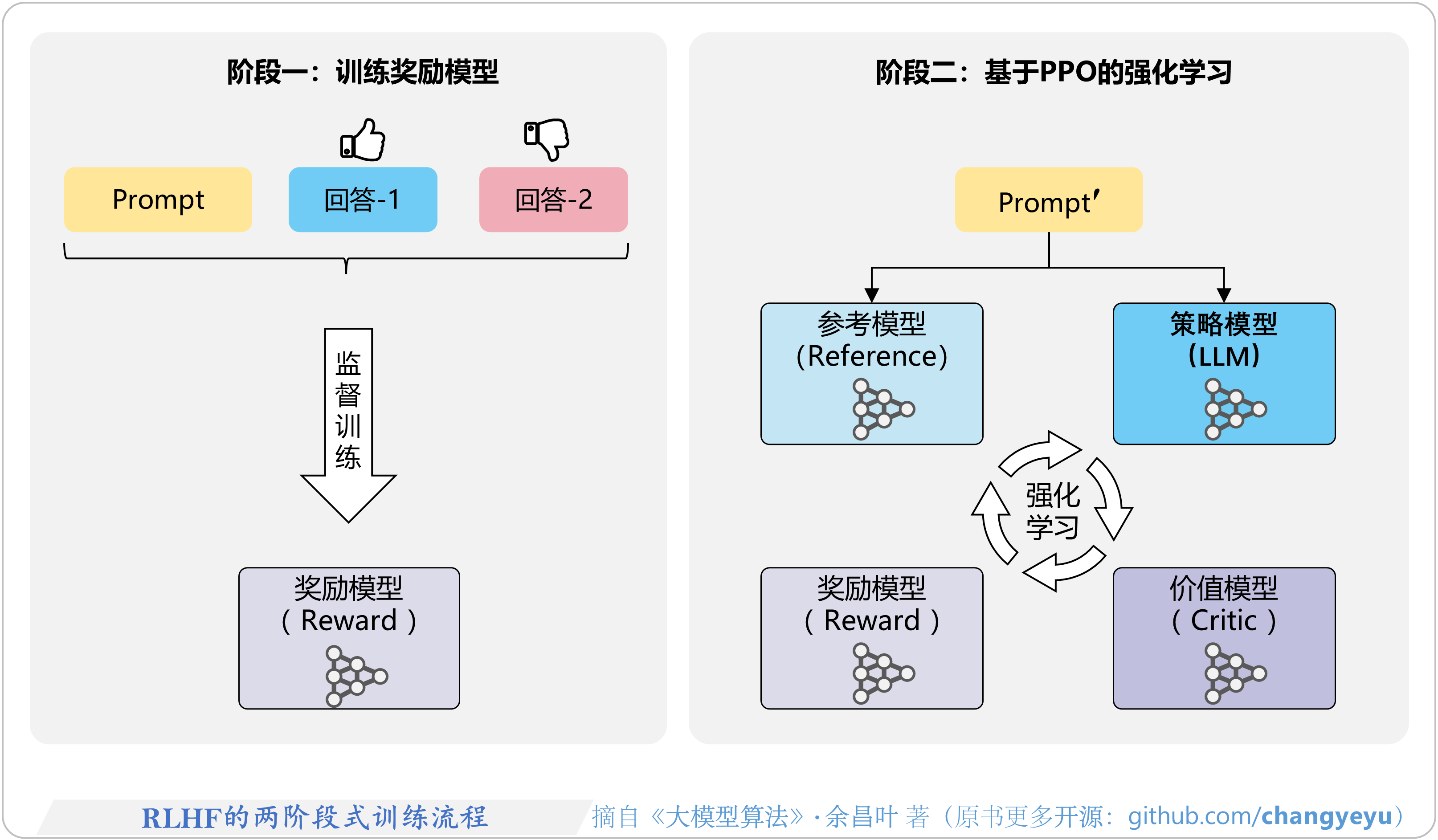
- 【RLHF与RLAIF】RLHF的两阶段式训练流程
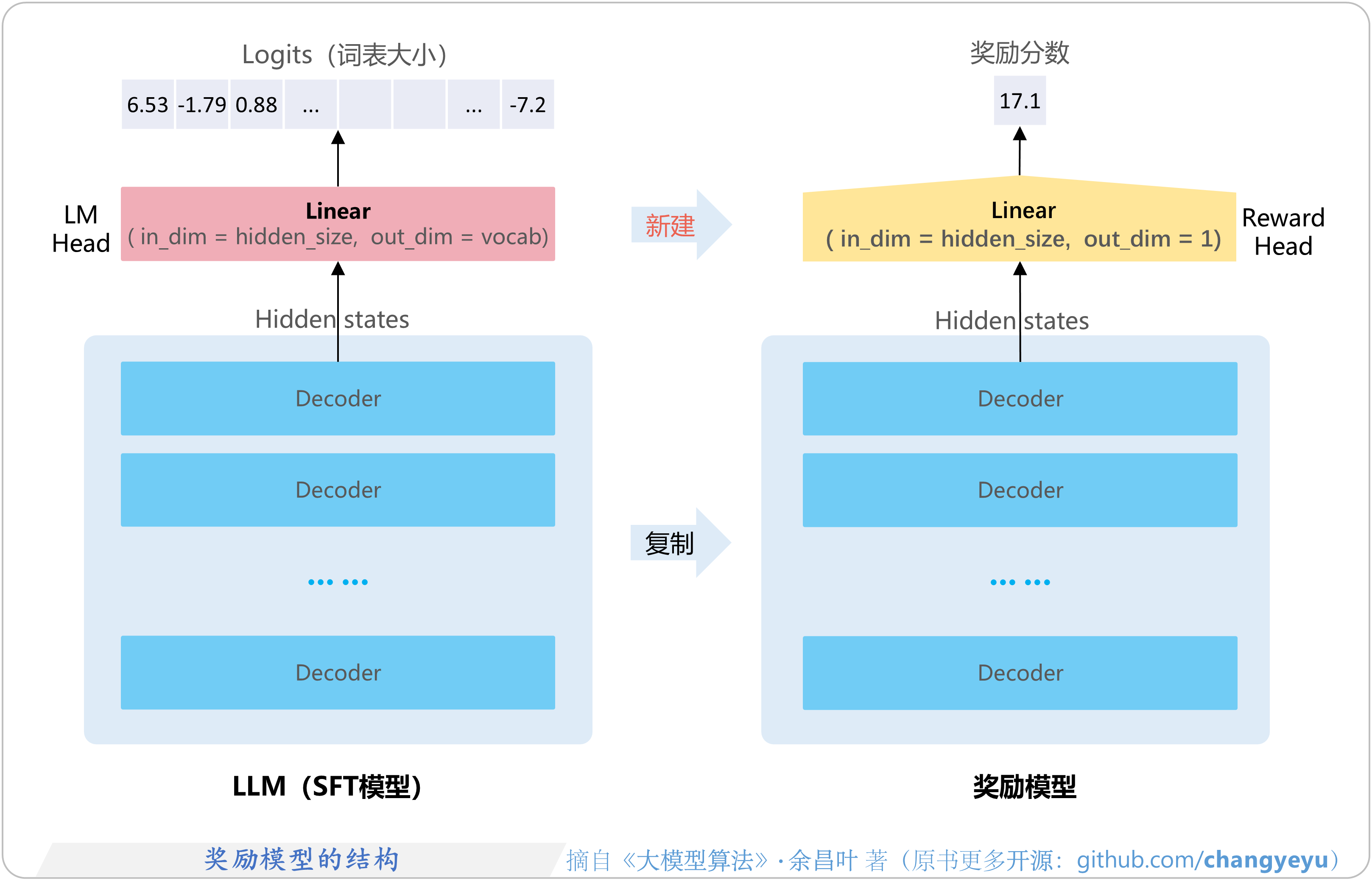
- 【RLHF与RLAIF】奖励模型(RM)的结构
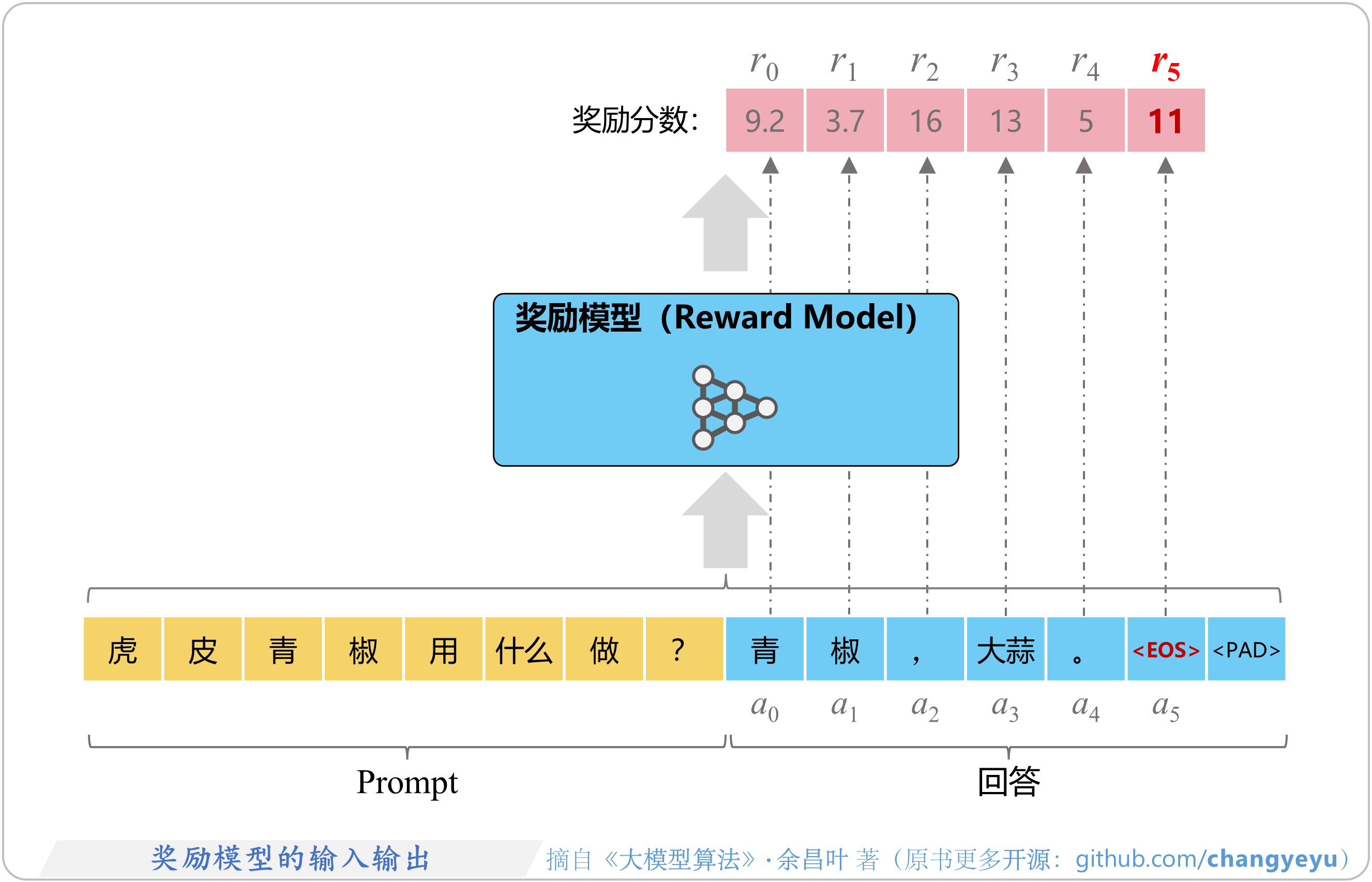
- 【RLHF与RLAIF】奖励模型的输入输出
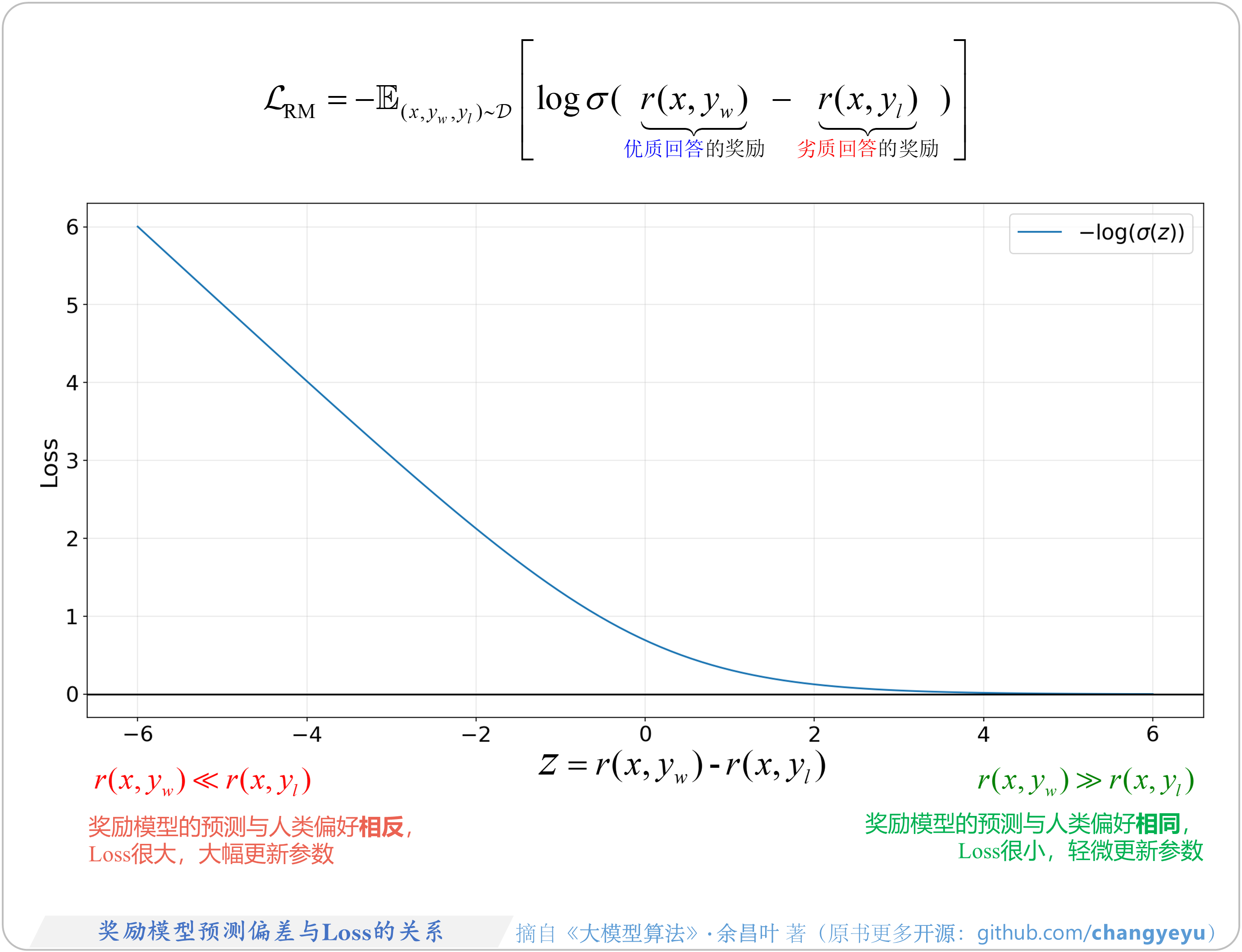
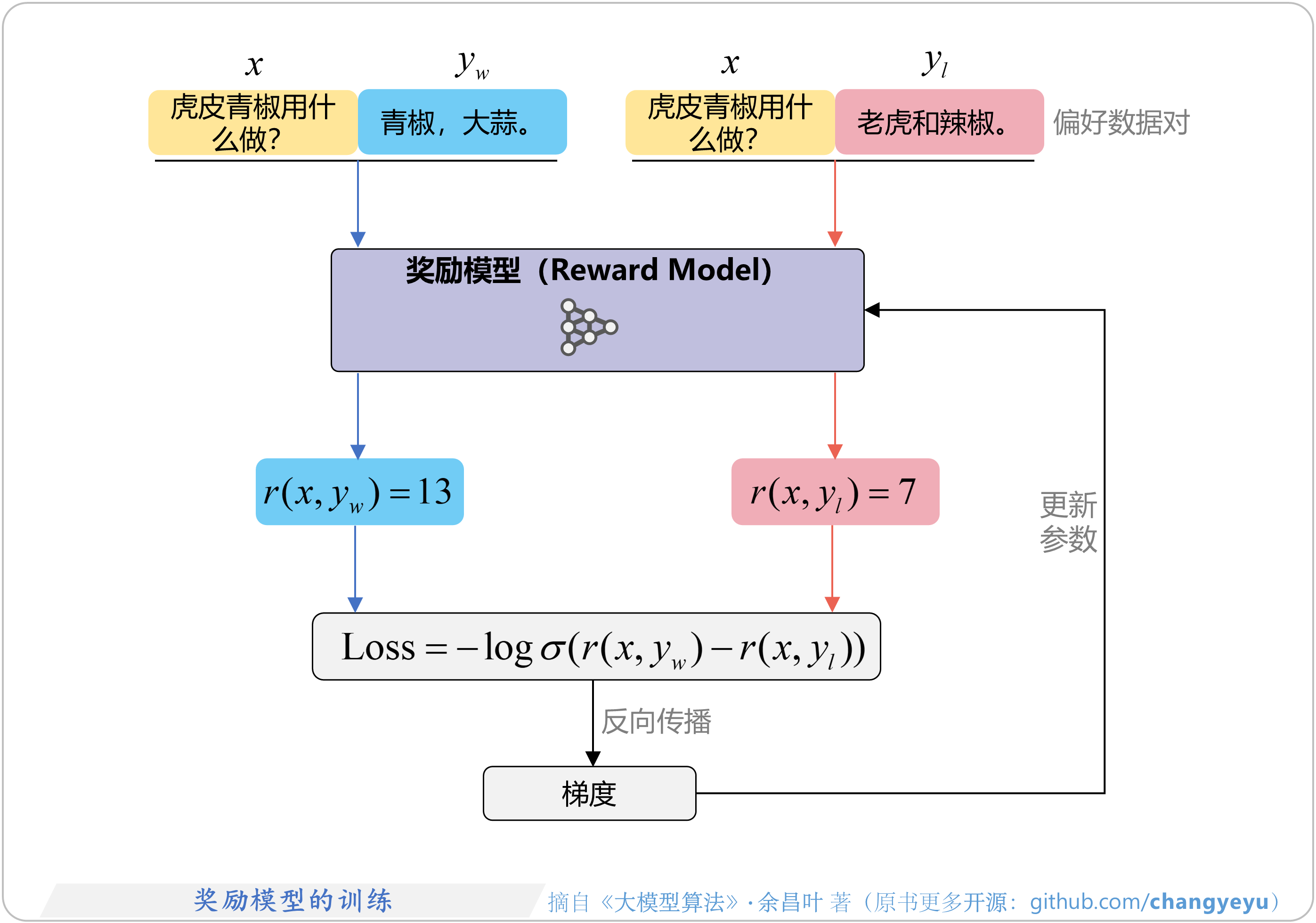
- 【RLHF与RLAIF】奖励模型预测偏差与Loss的关系
- 【RLHF与RLAIF】奖励模型的训练
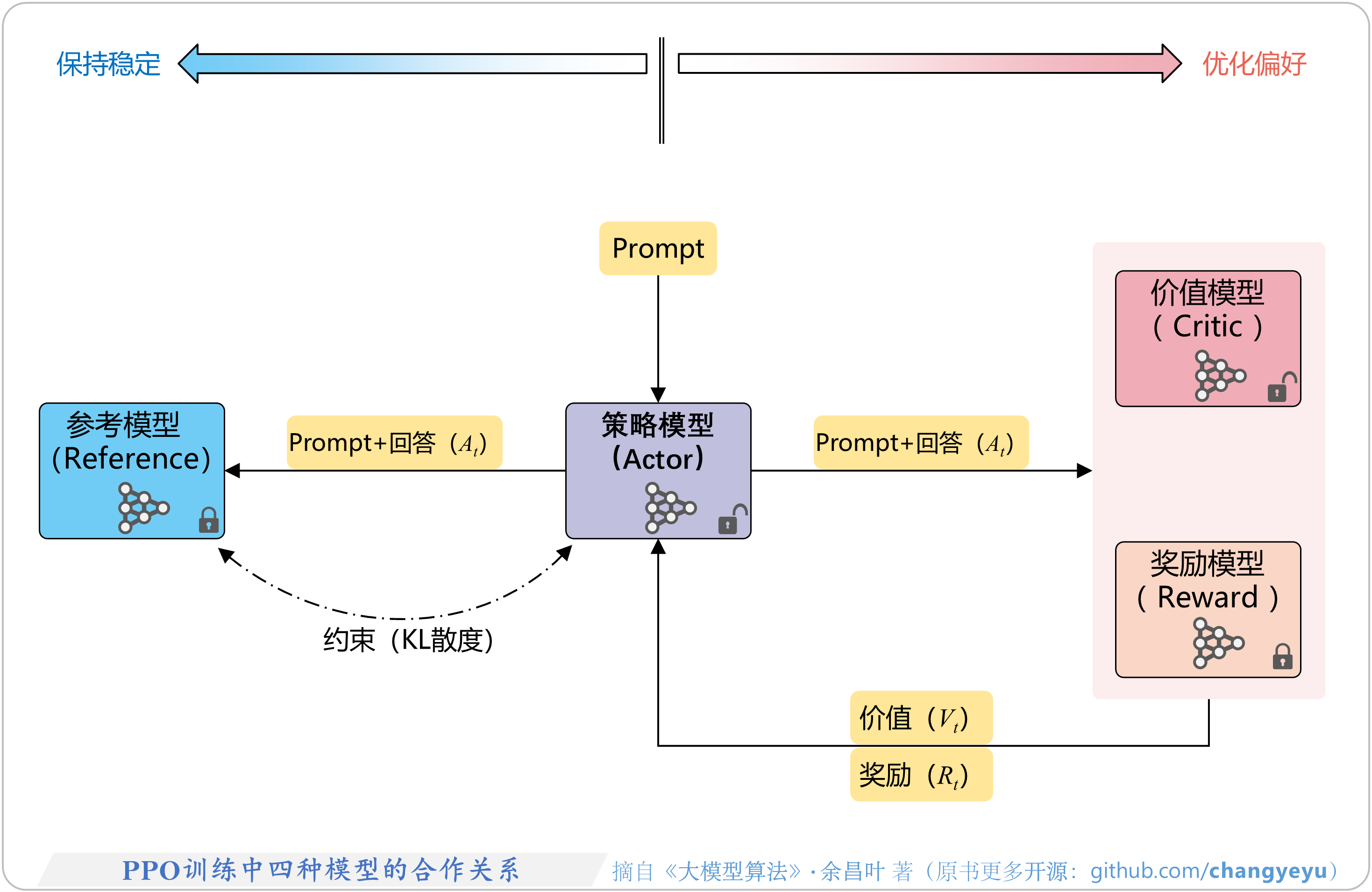
- 【RLHF与RLAIF】PPO训练中四种模型的合作关系
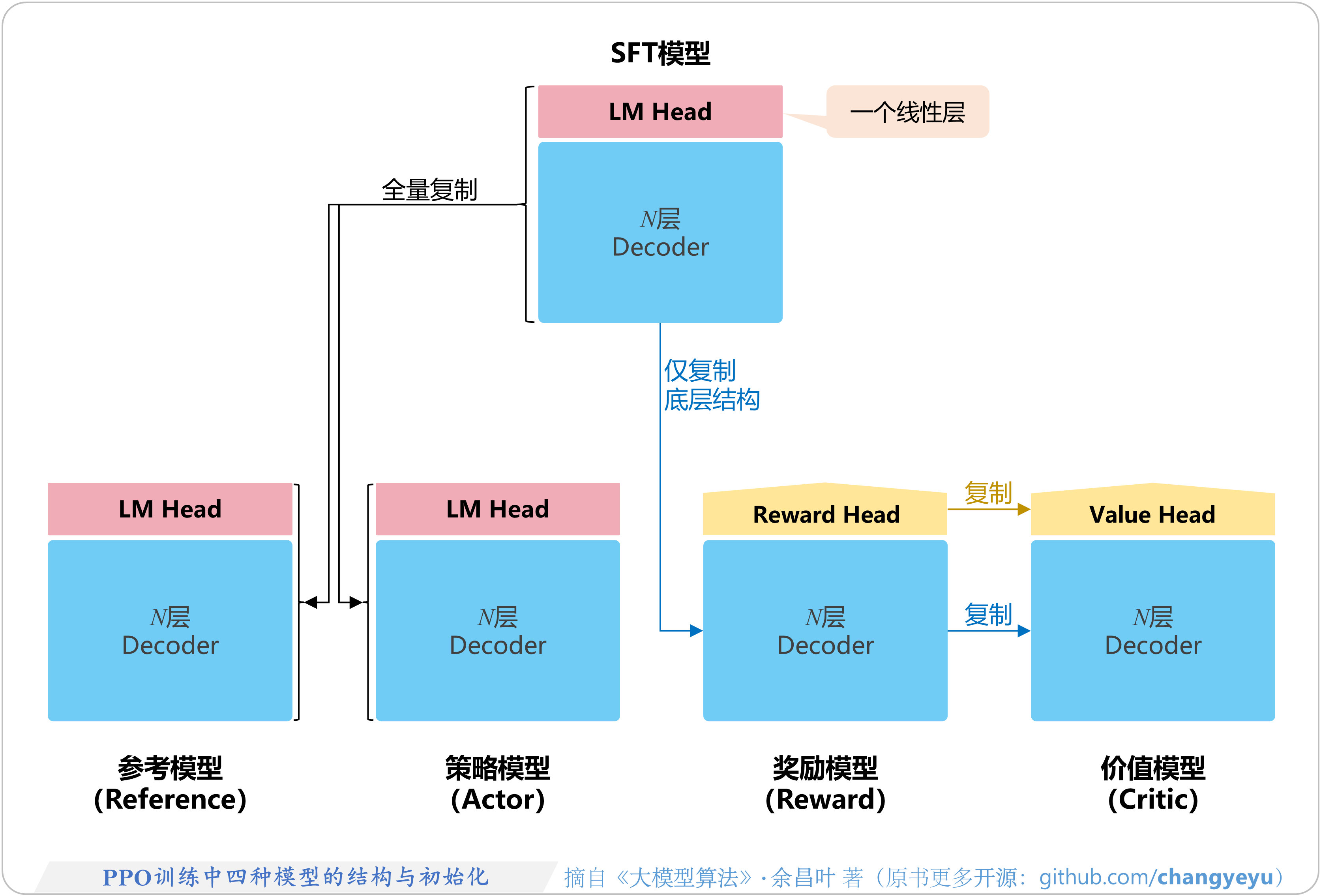
- 【RLHF与RLAIF】PPO训练中四种模型的结构与初始化
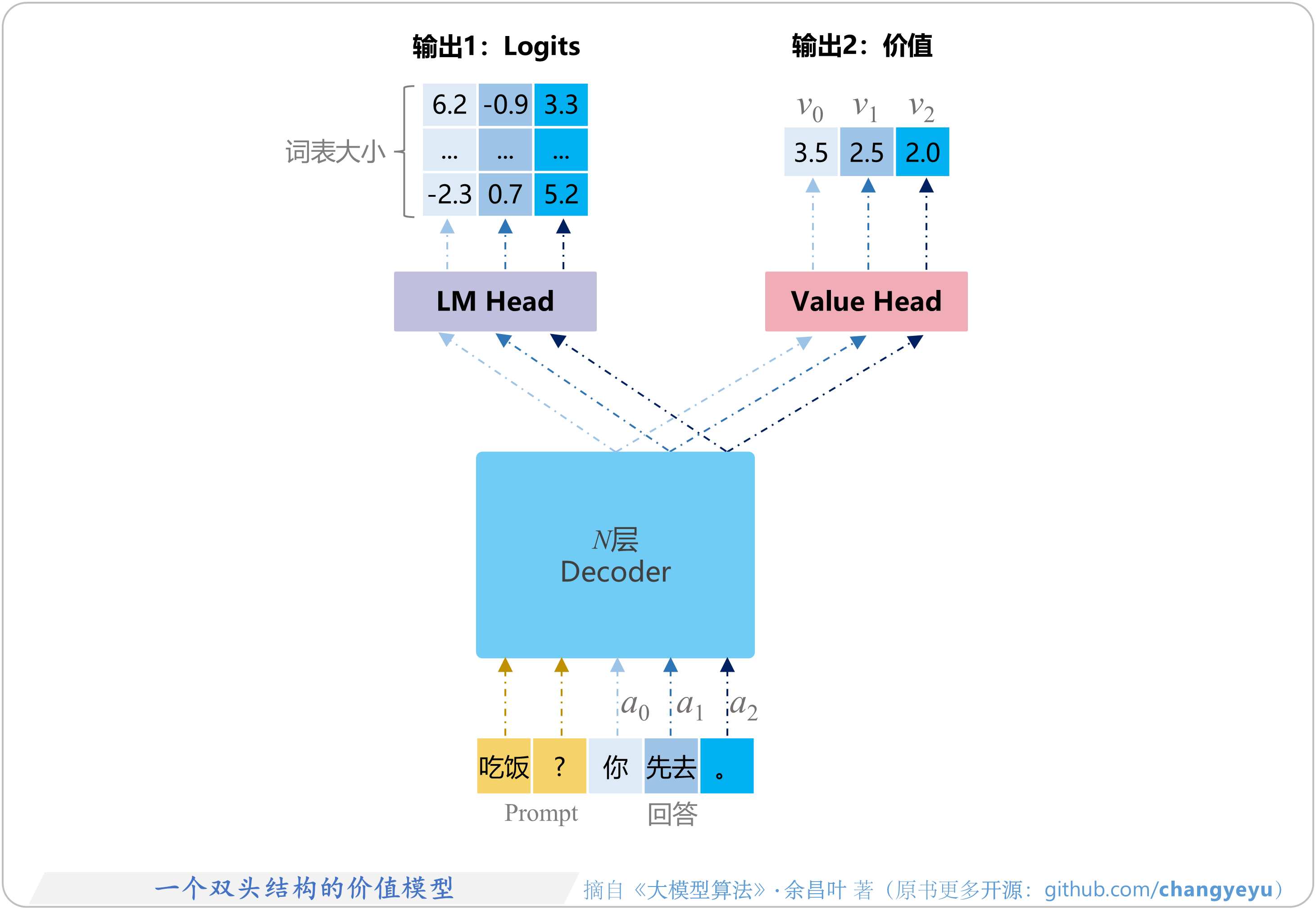
- 【RLHF与RLAIF】一个双头结构的价值模型
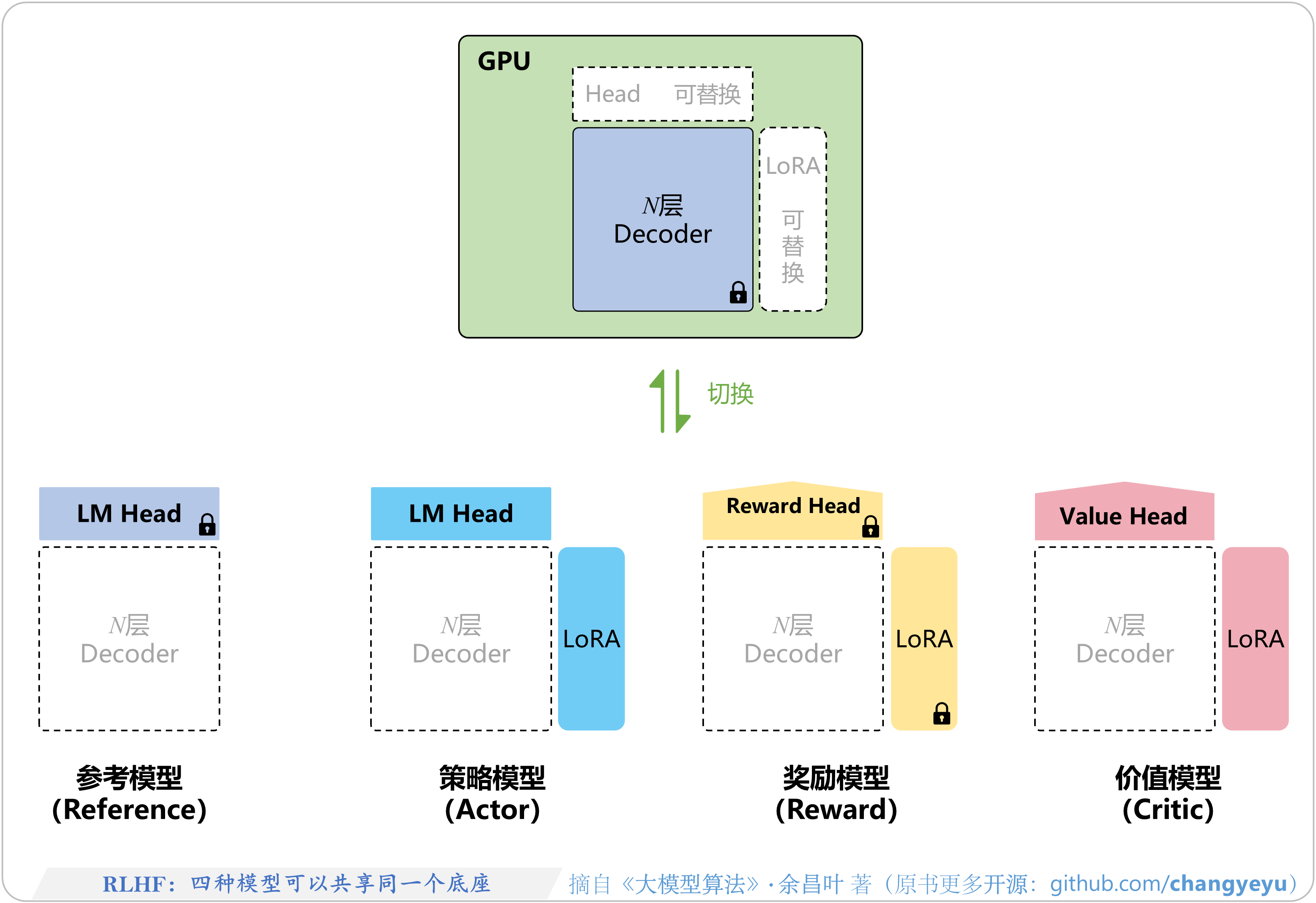
- 【RLHF与RLAIF】RLHF:四种模型可以共享同一个底座
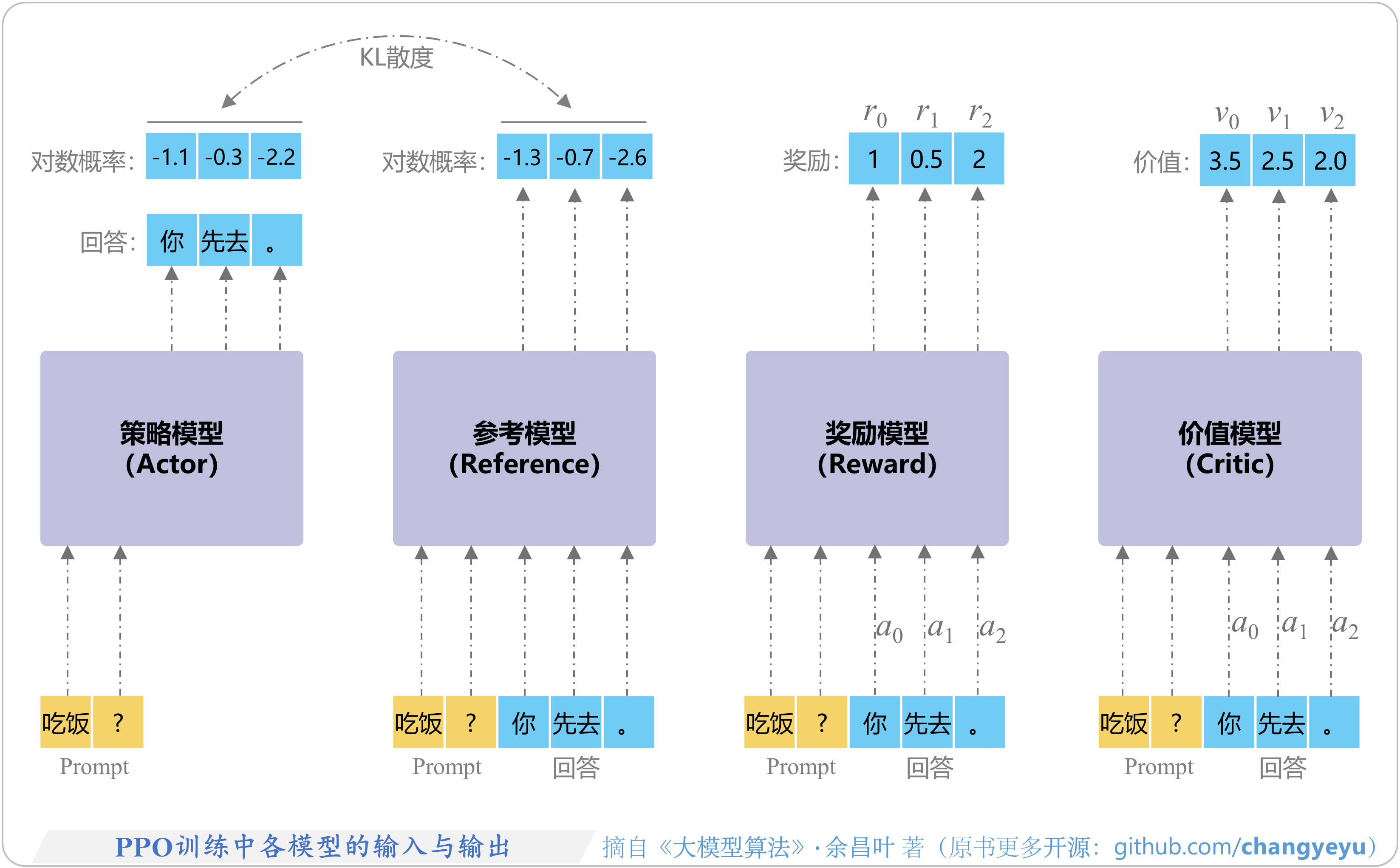
- 【RLHF与RLAIF】PPO训练中各模型的输入与输出
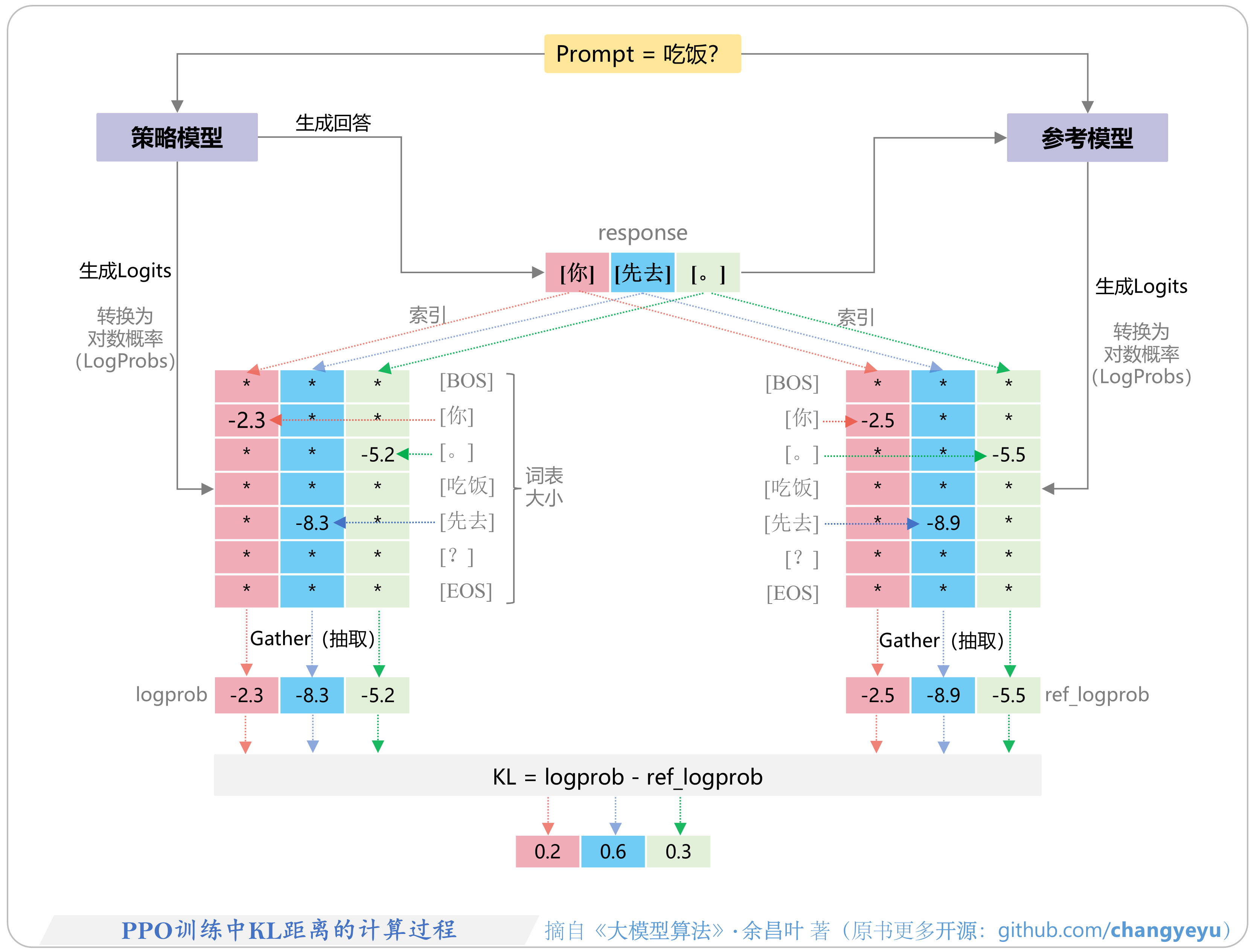
- 【RLHF与RLAIF】PPO训练中KL距离的计算过程
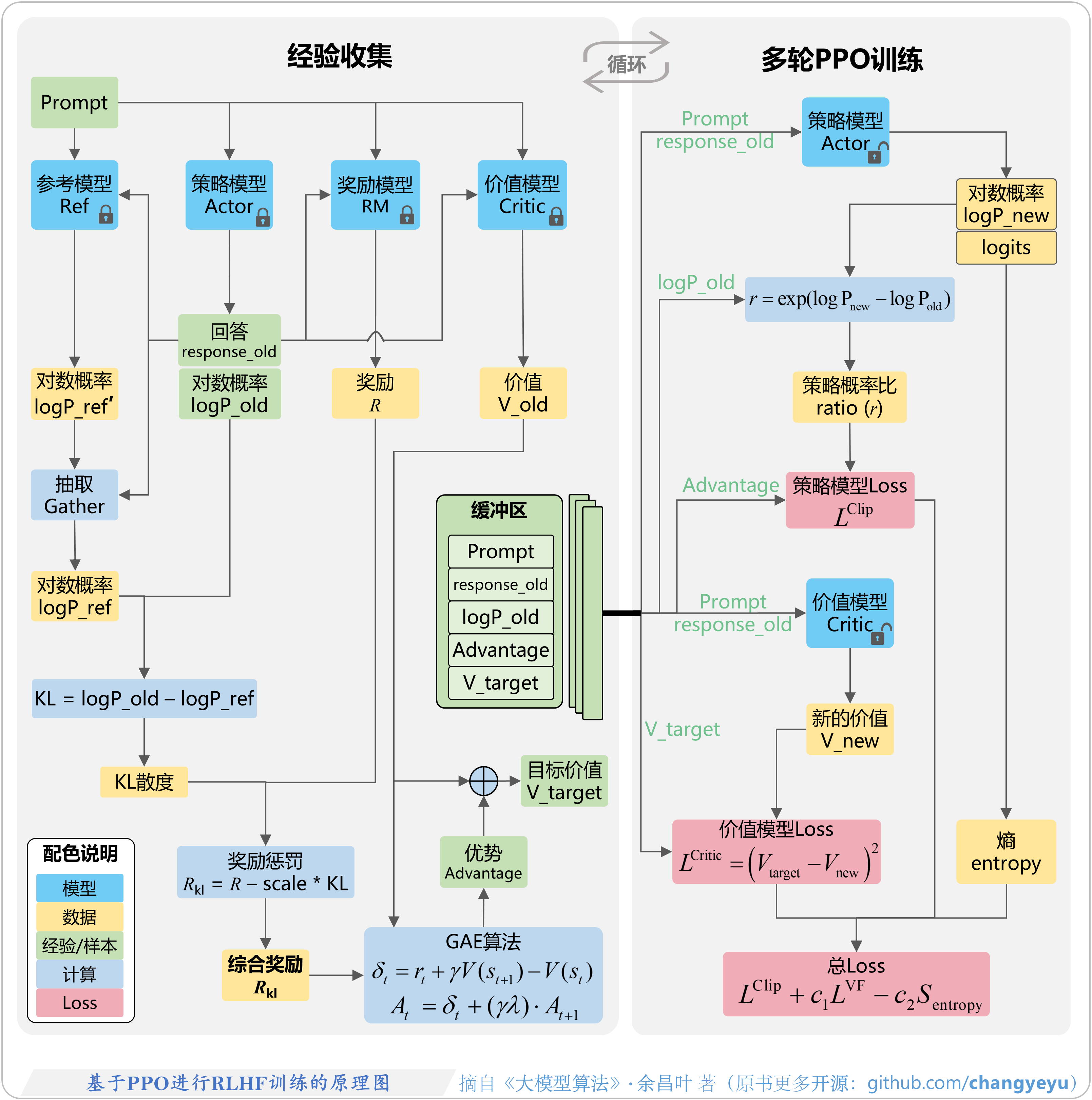
- 【RLHF与RLAIF】基于PPO进行RLHF训练的原理图
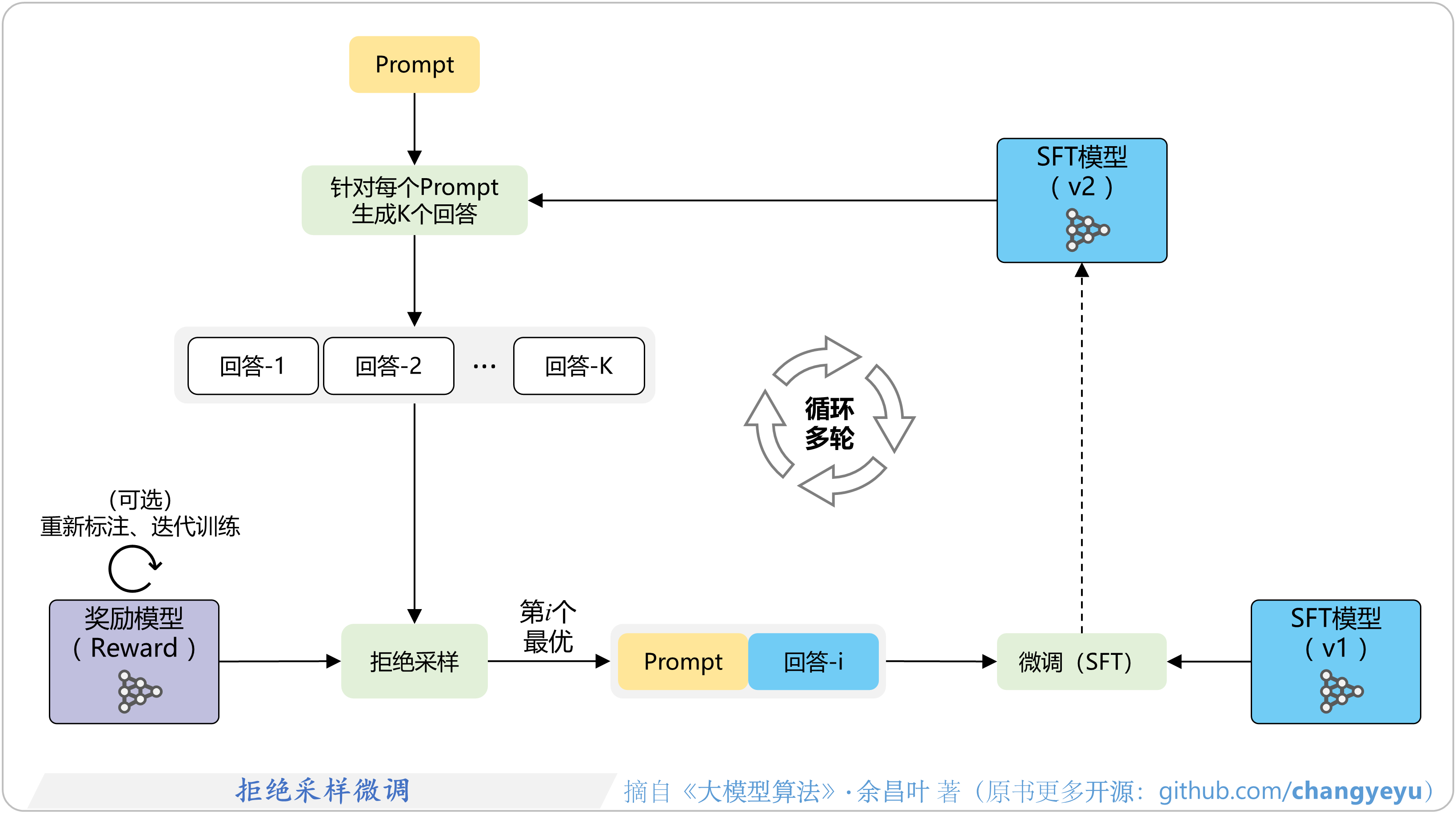
- 【RLHF与RLAIF】拒绝采样(Rejection Sampling)微调
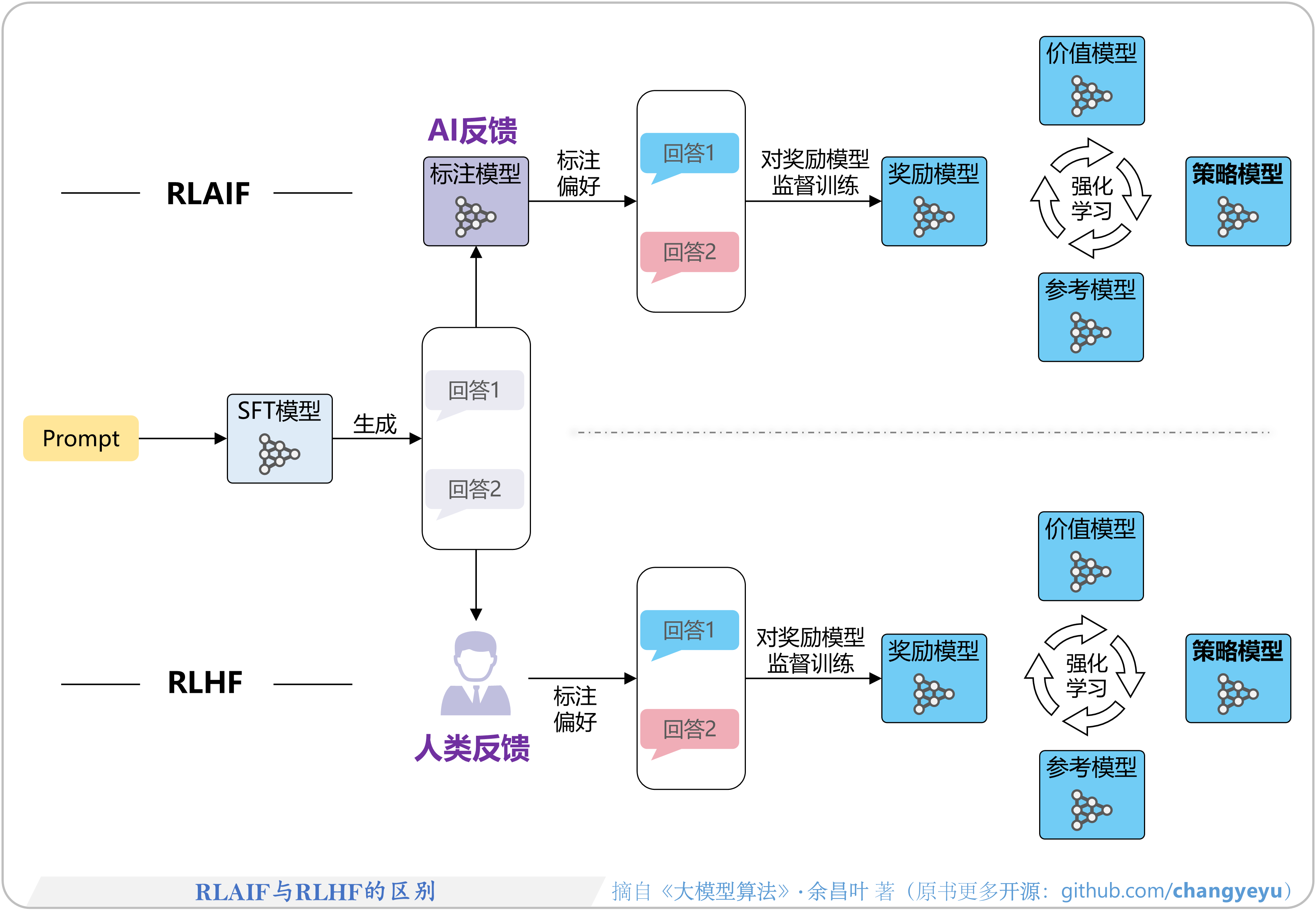
- 【RLHF与RLAIF】RLAIF与RLHF的区别
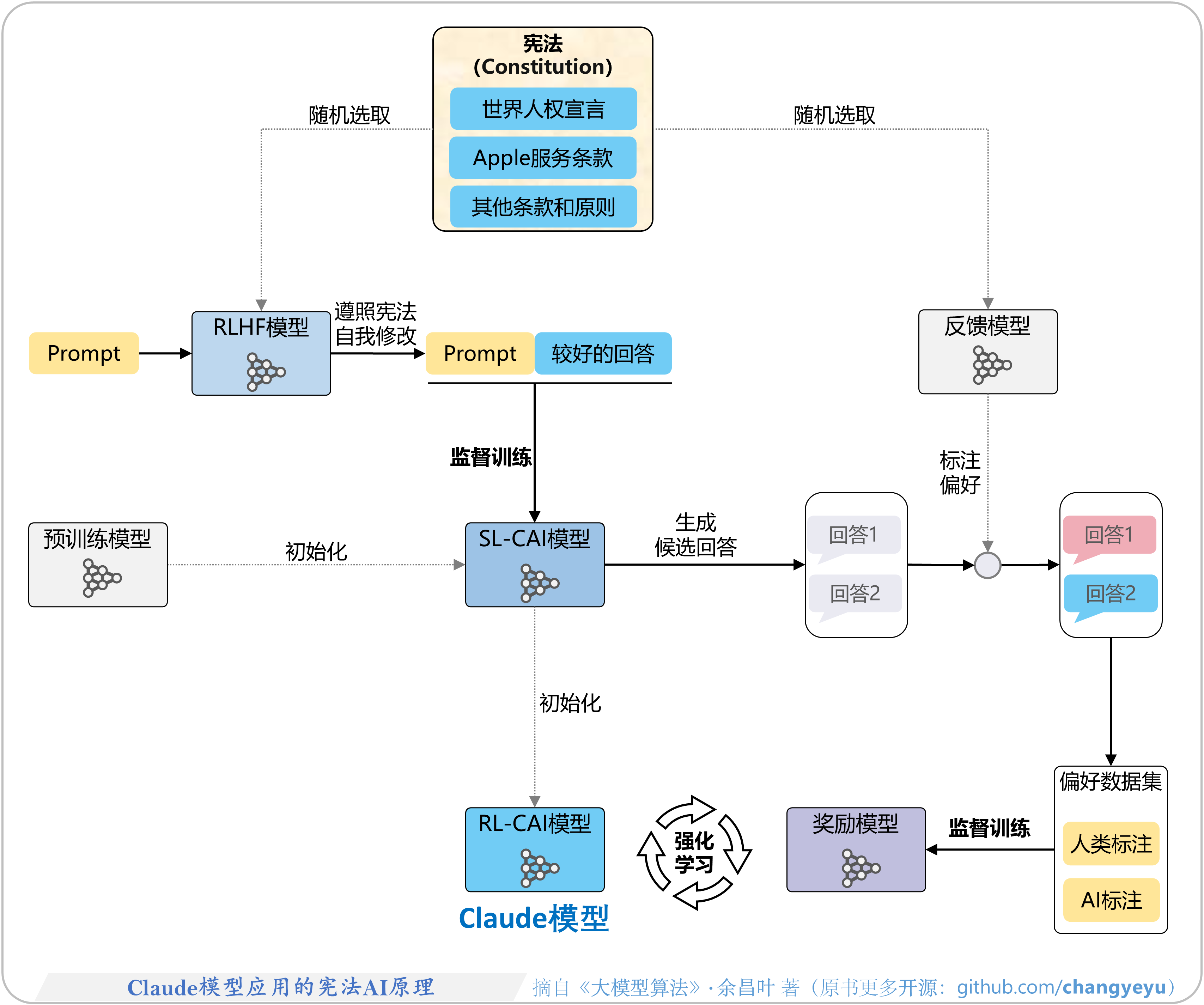
- 【RLHF与RLAIF】Claude模型应用的宪法AI(CAI)原理
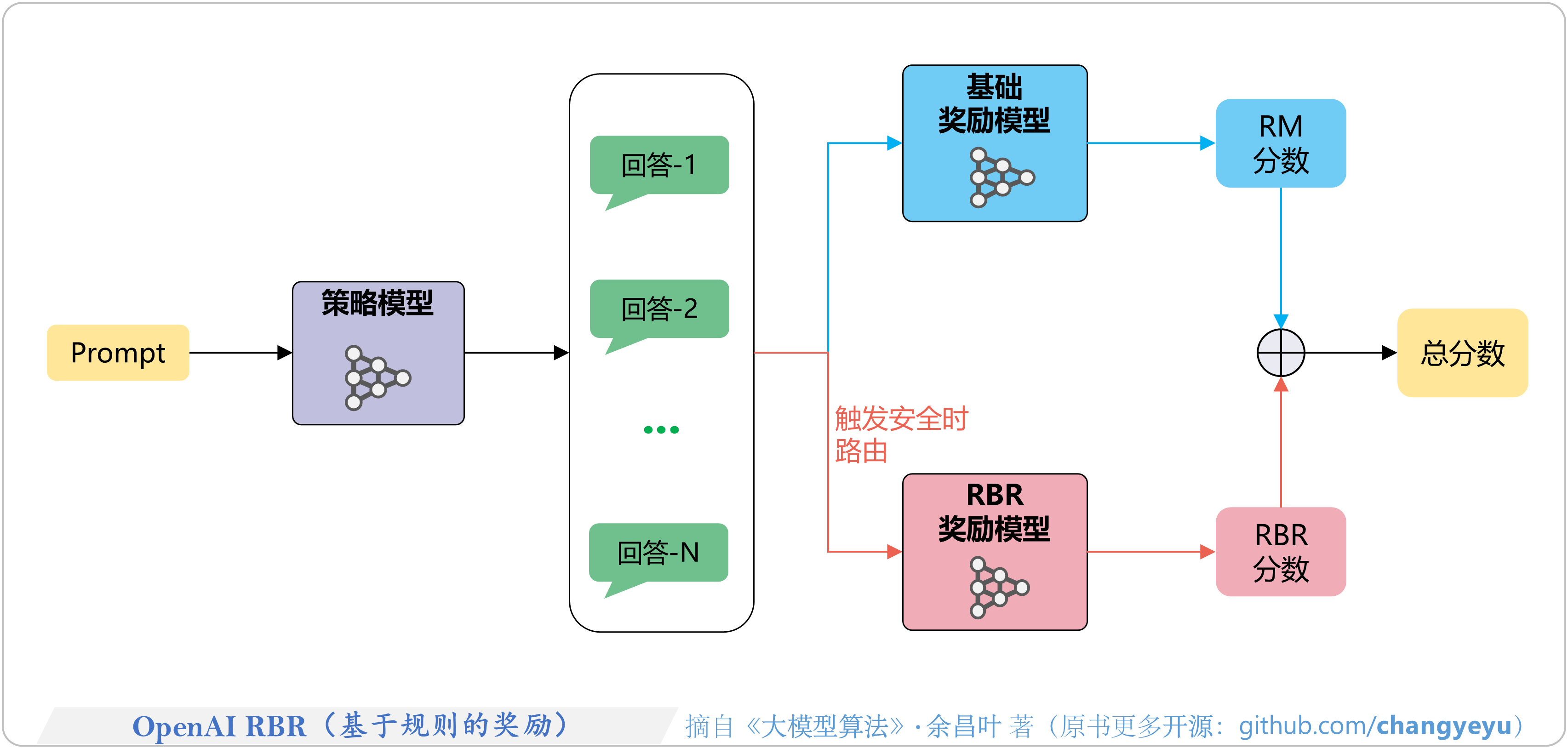
- 【RLHF与RLAIF】OpenAI RBR(基于规则的奖励)
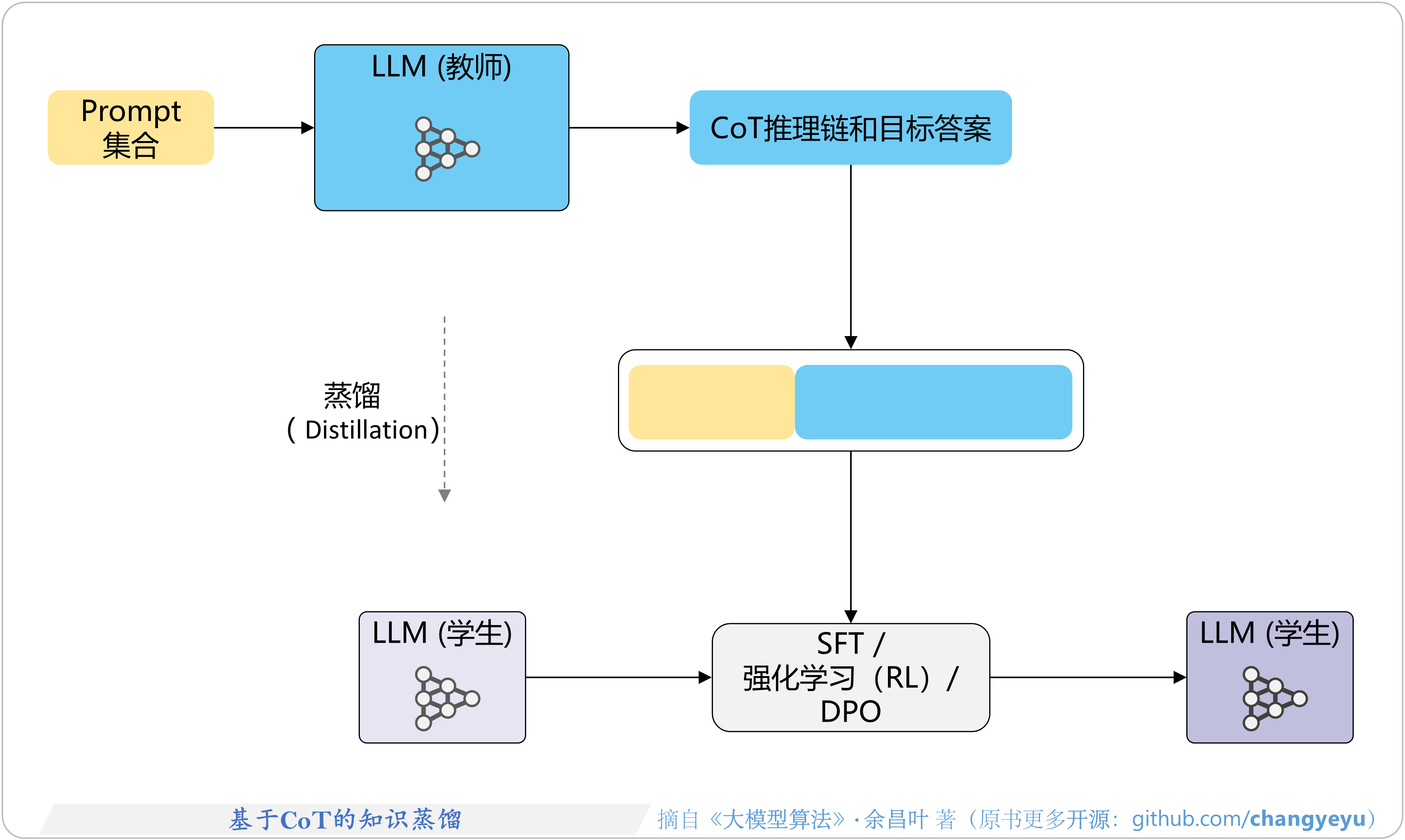
- 【逻辑推理能力优化】基于CoT的知识蒸馏(Knowledge Distillation)
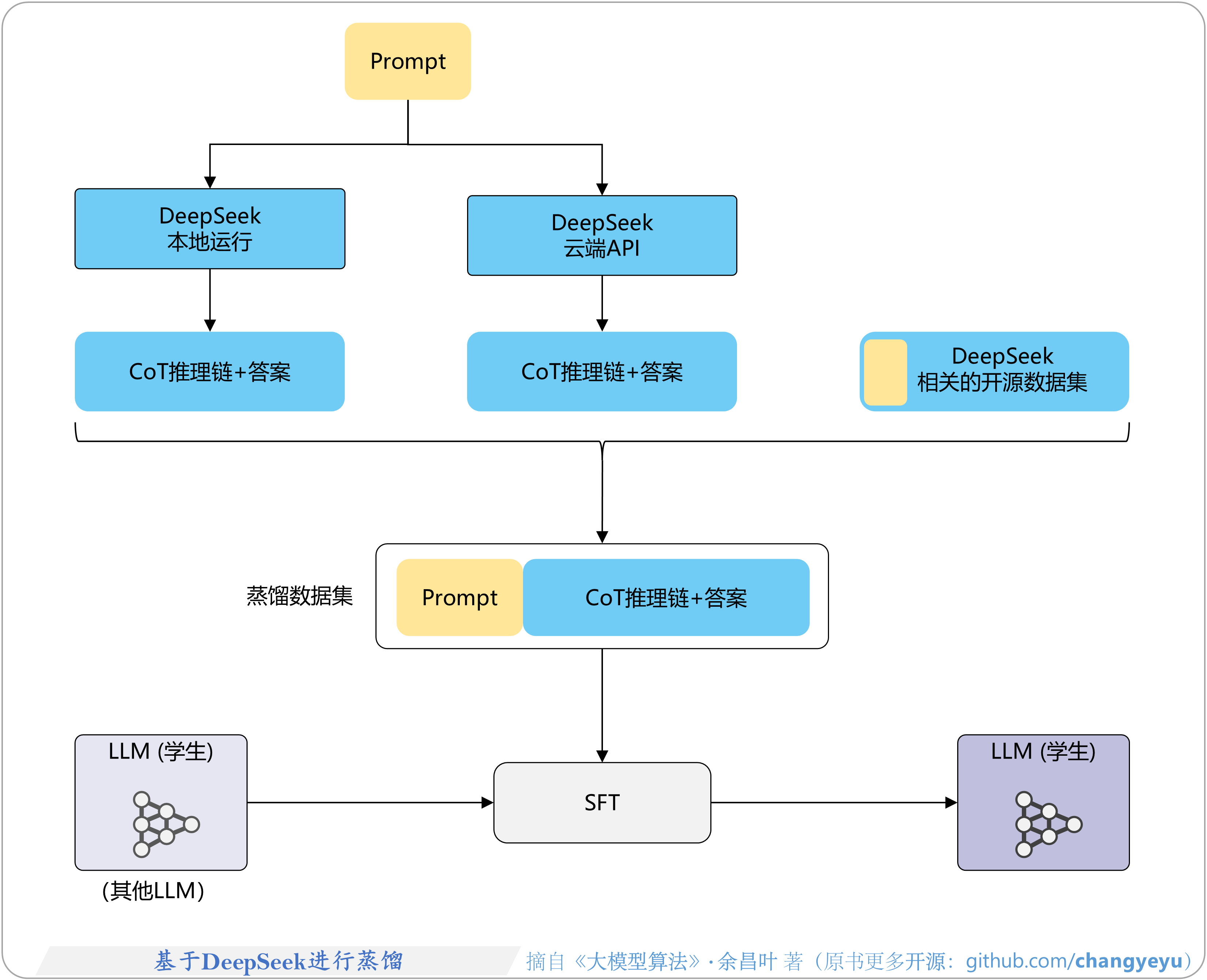
- 【逻辑推理能力优化】基于DeepSeek进行蒸馏
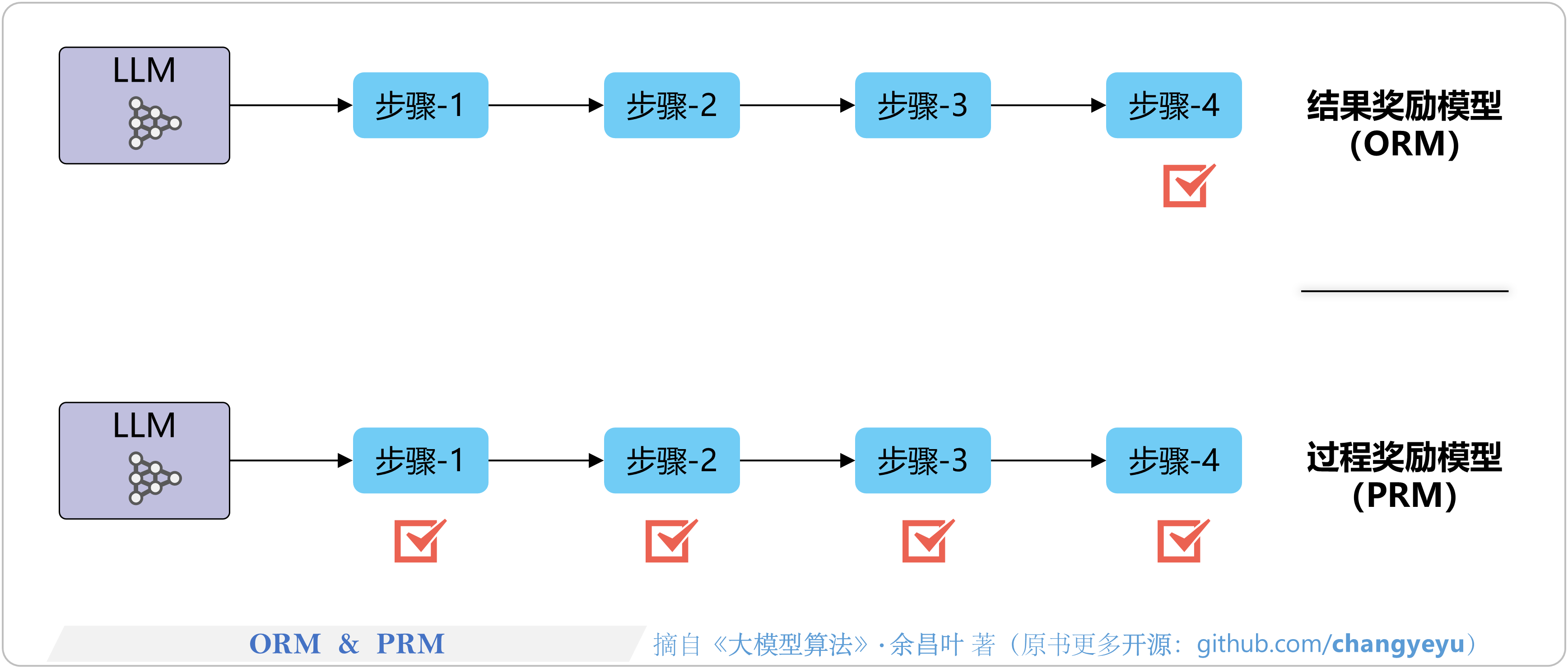
- 【逻辑推理能力优化】ORM和PRM(结果奖励模型和过程奖励模型)
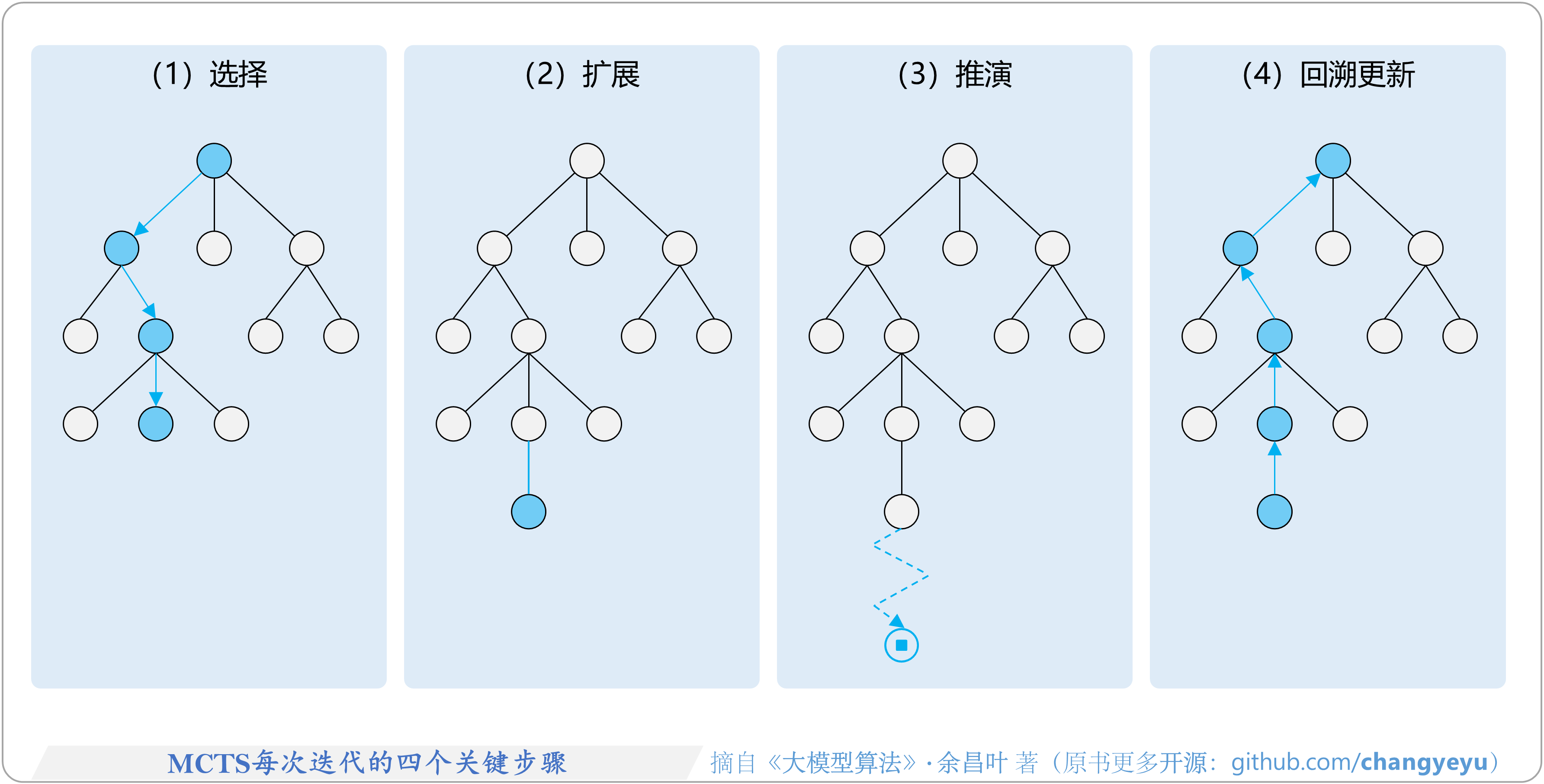
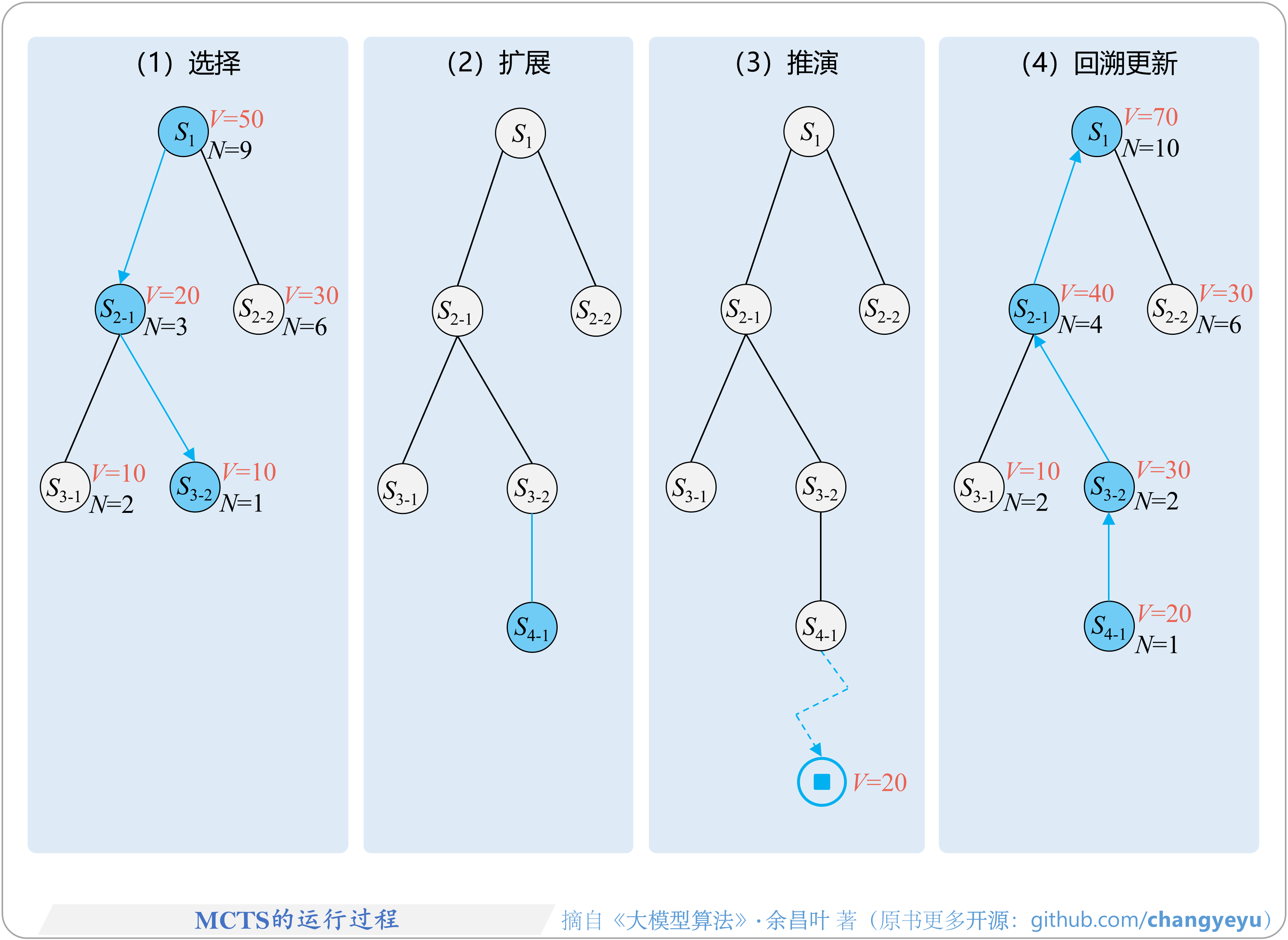
- 【逻辑推理能力优化】MCTS每次迭代的四个关键步骤
- 【逻辑推理能力优化】MCTS的运行过程
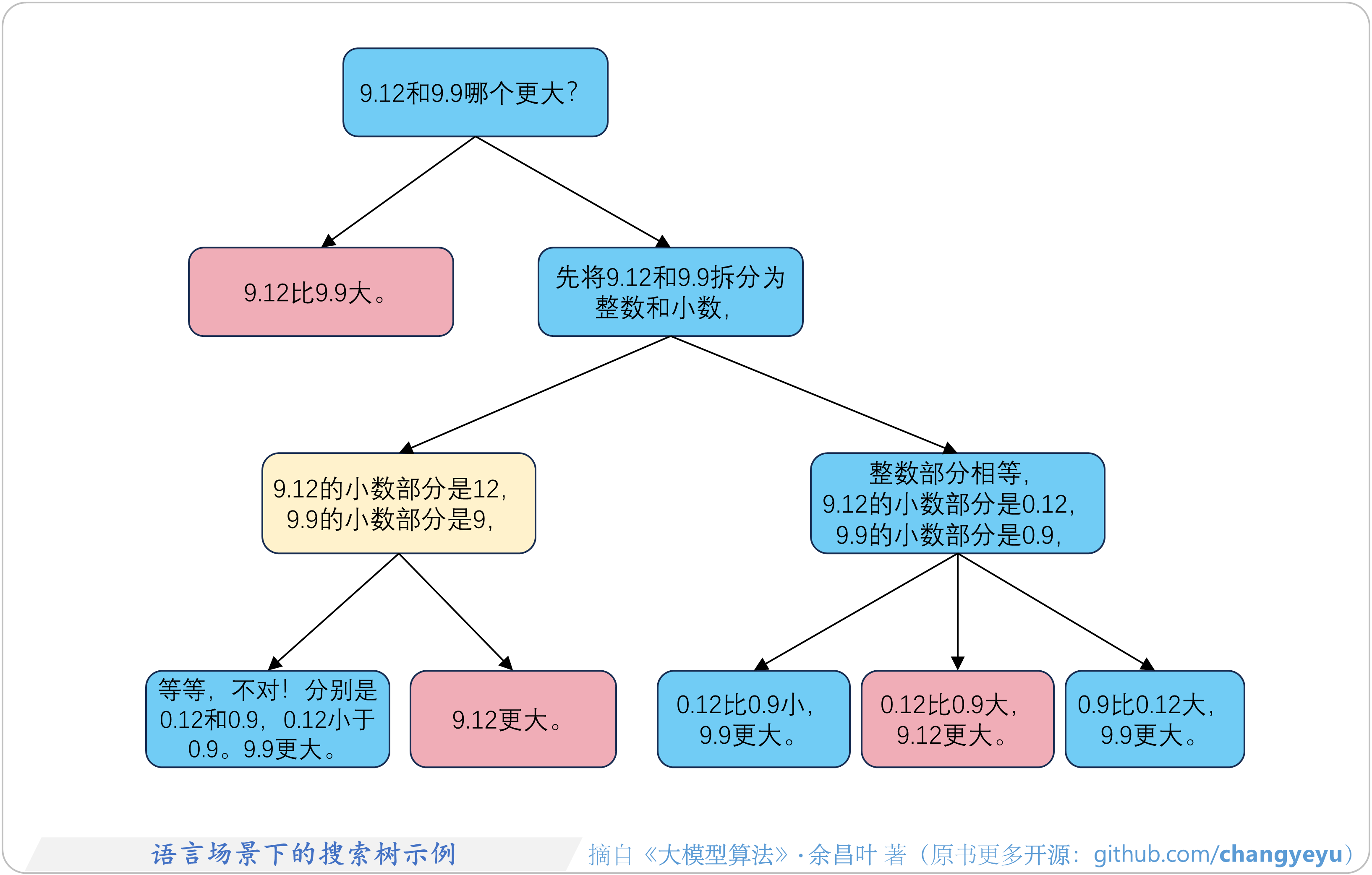
- 【逻辑推理能力优化】语言场景下的搜索树示例
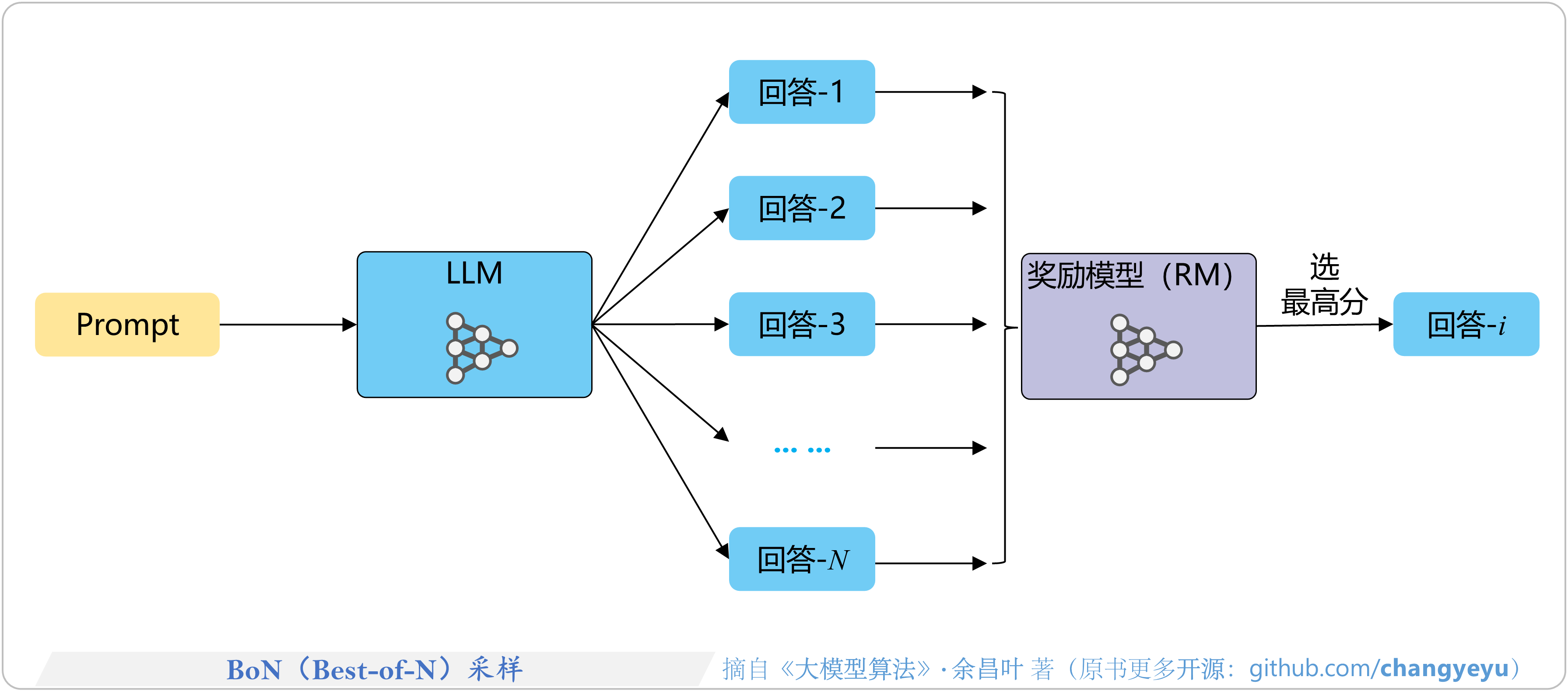
- 【逻辑推理能力优化】BoN(Best-of-N)采样
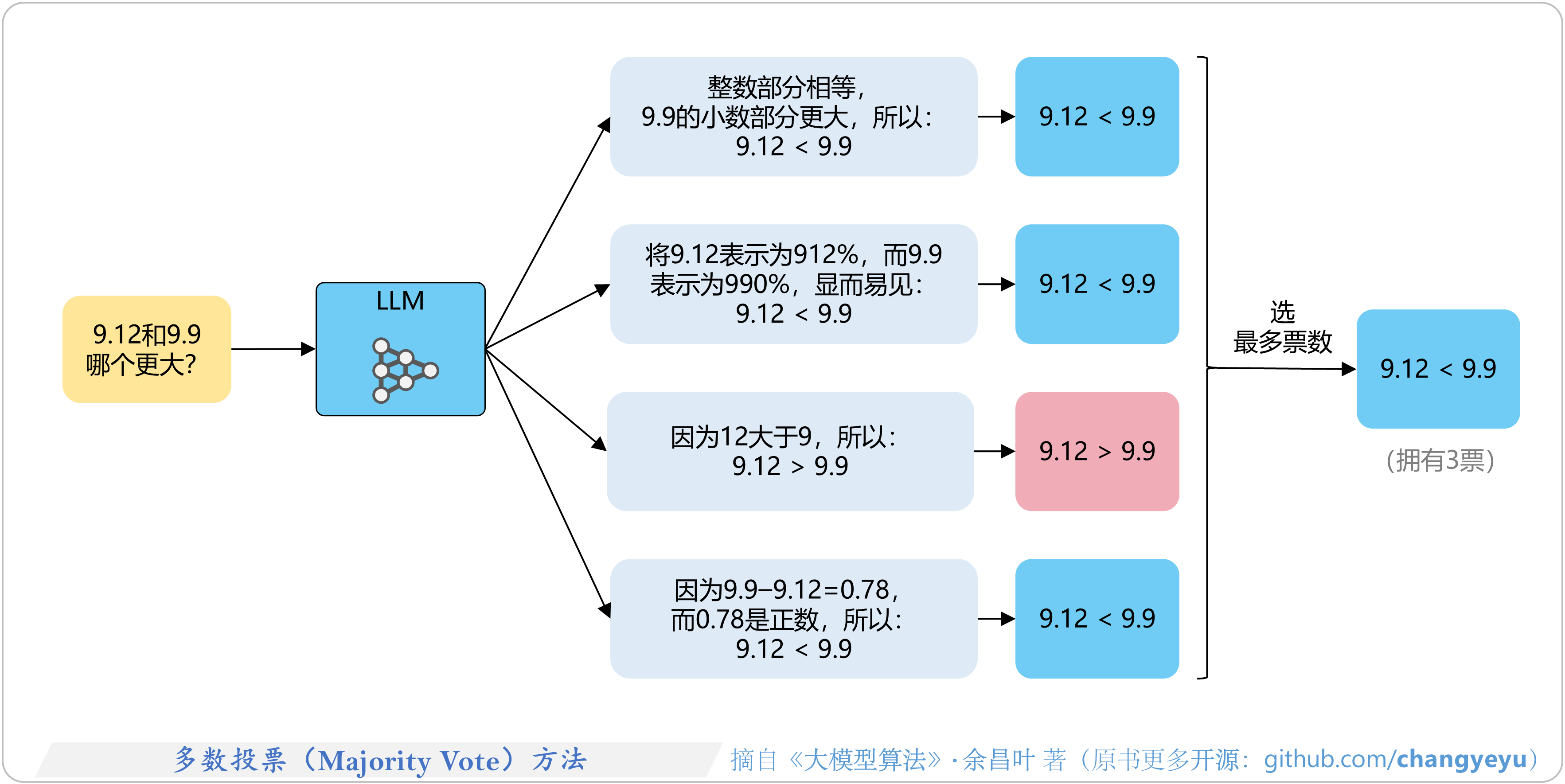
- 【逻辑推理能力优化】多数投票(Majority Vote)方法
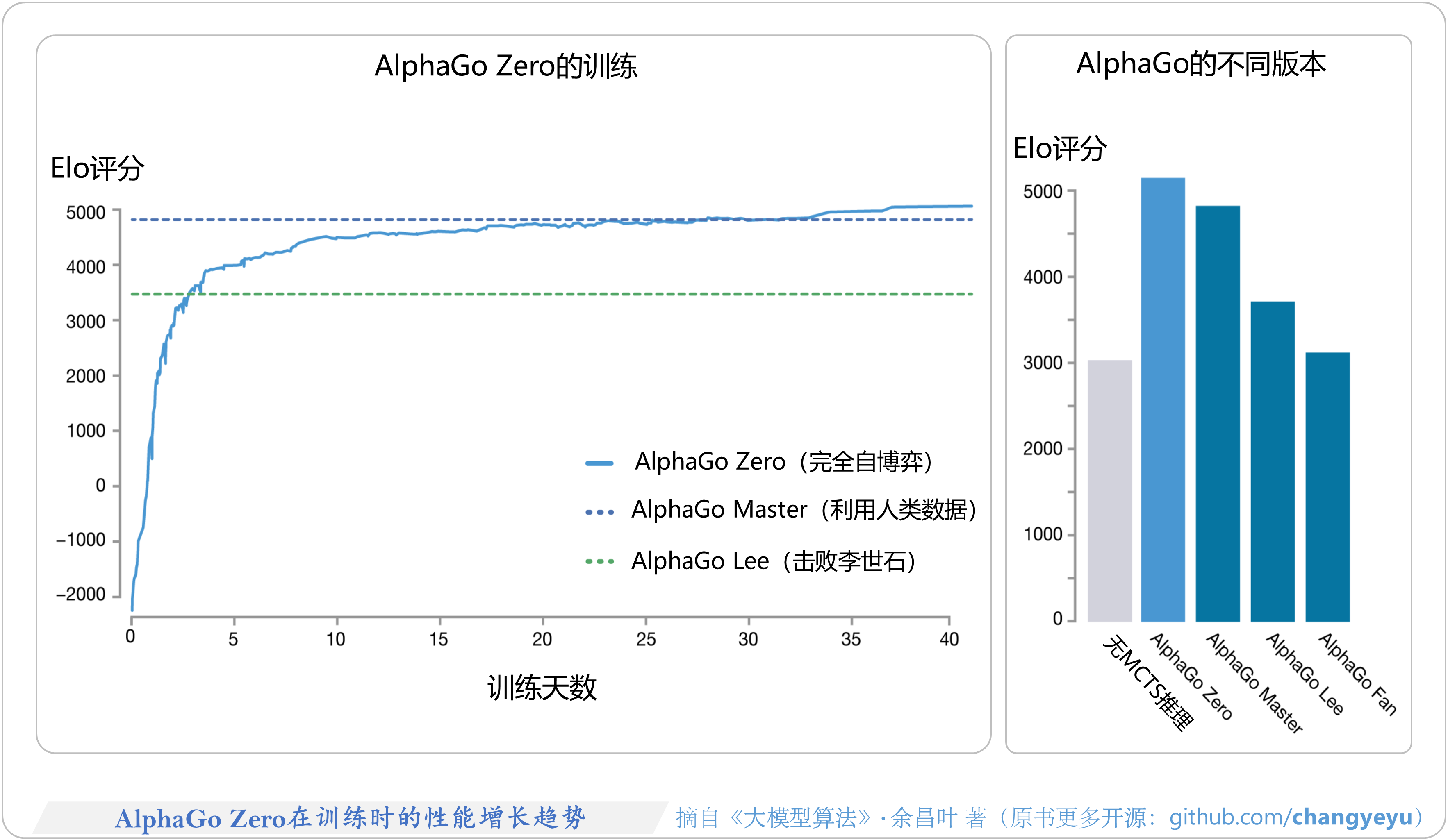
- 【逻辑推理能力优化】AlphaGoZero在训练时的性能增长趋势 [179]
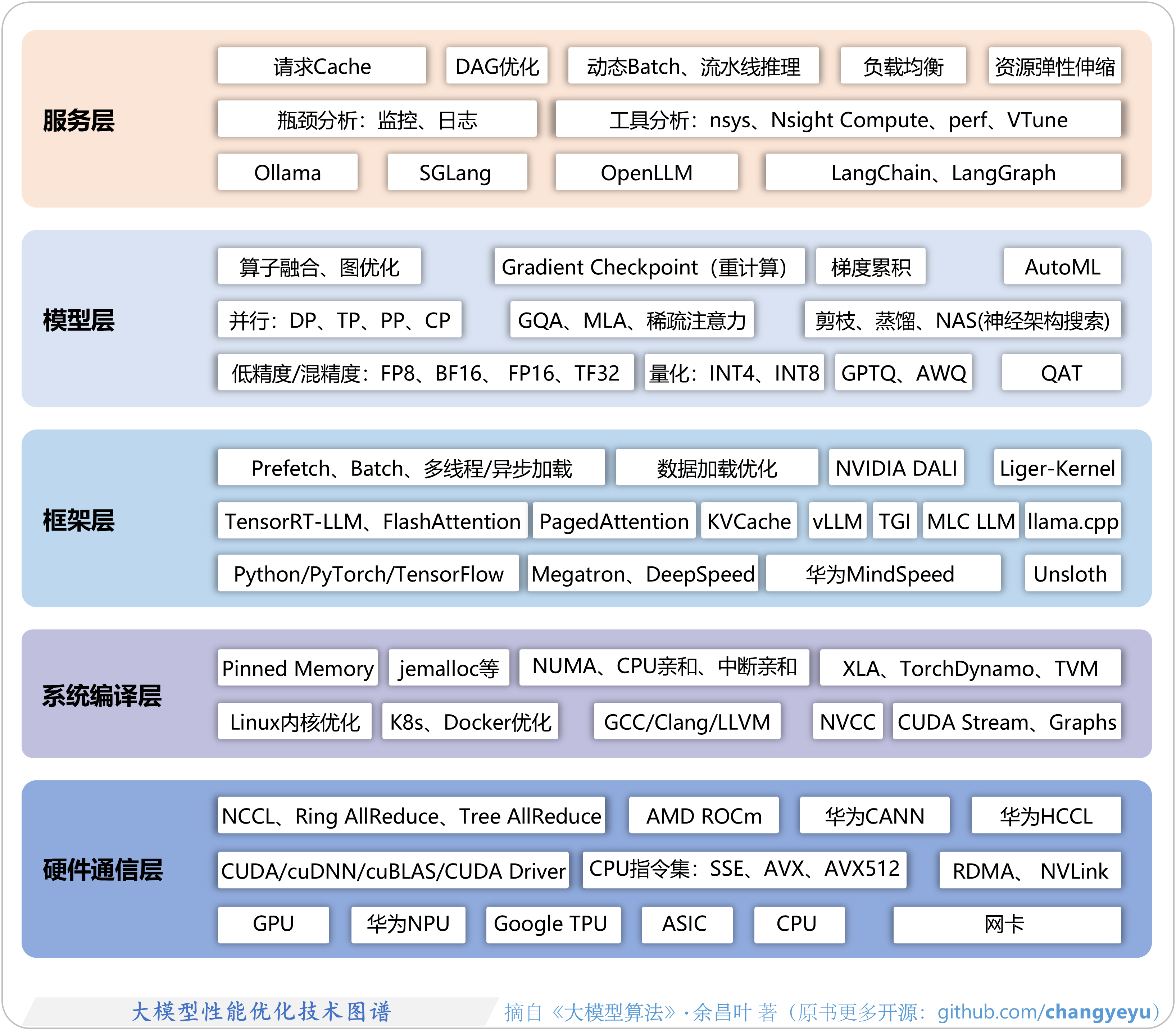
- 【LLM基础拓展】大模型性能优化技术图谱
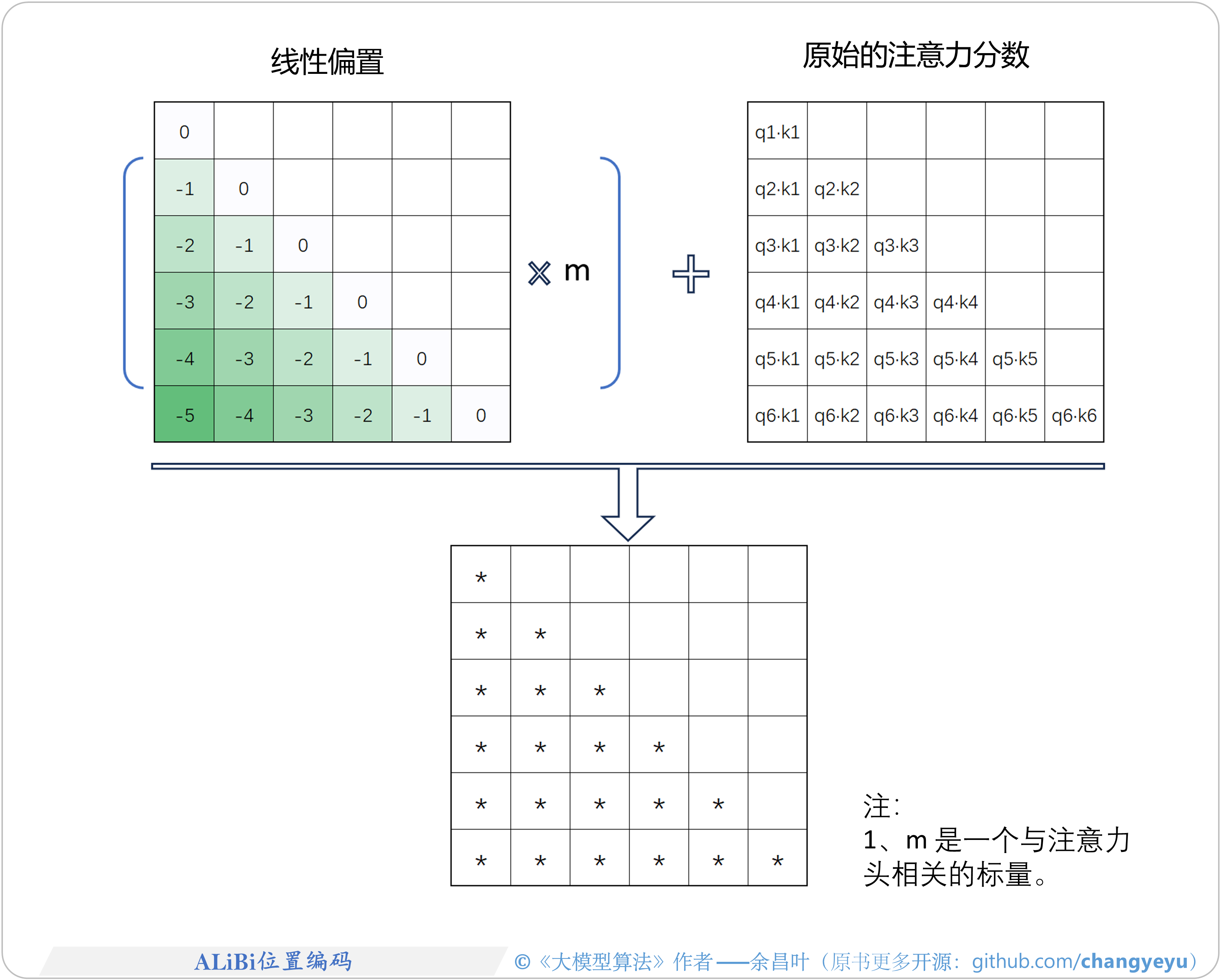
- 【LLM基础拓展】ALiBi位置编码
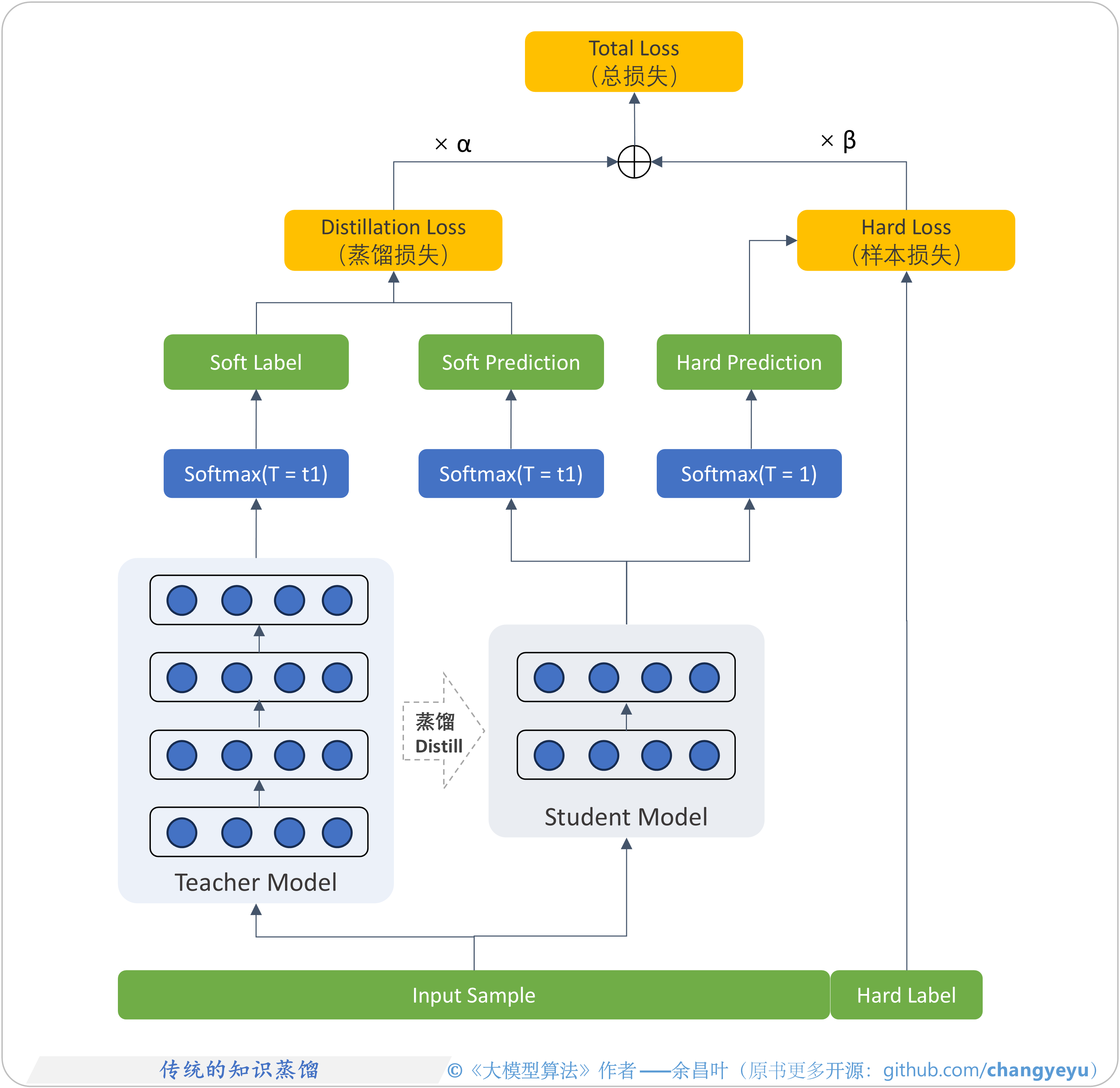
- 【LLM基础拓展】传统的知识蒸馏
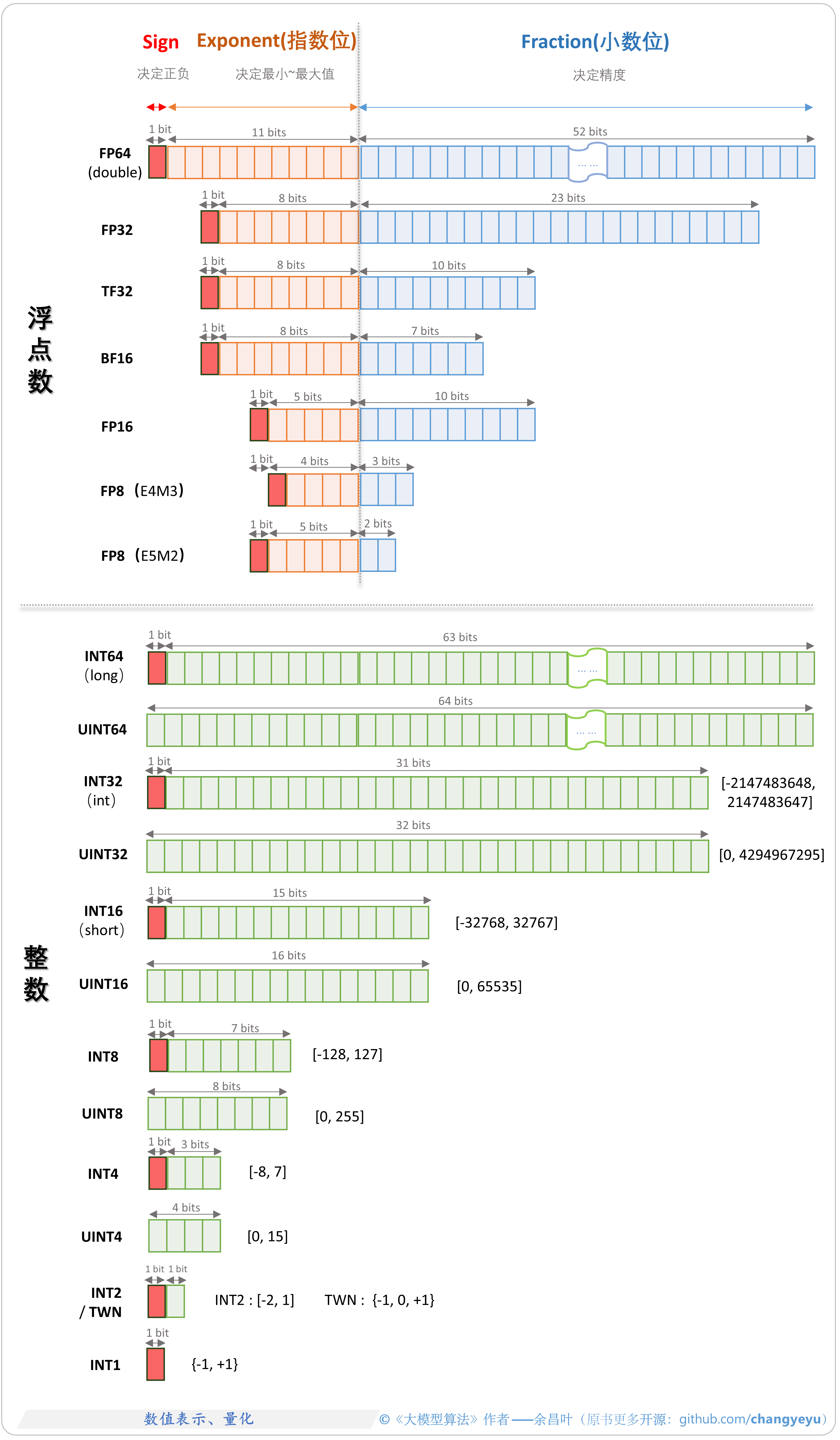
- 【LLM基础拓展】数值表示、量化(Quantization)
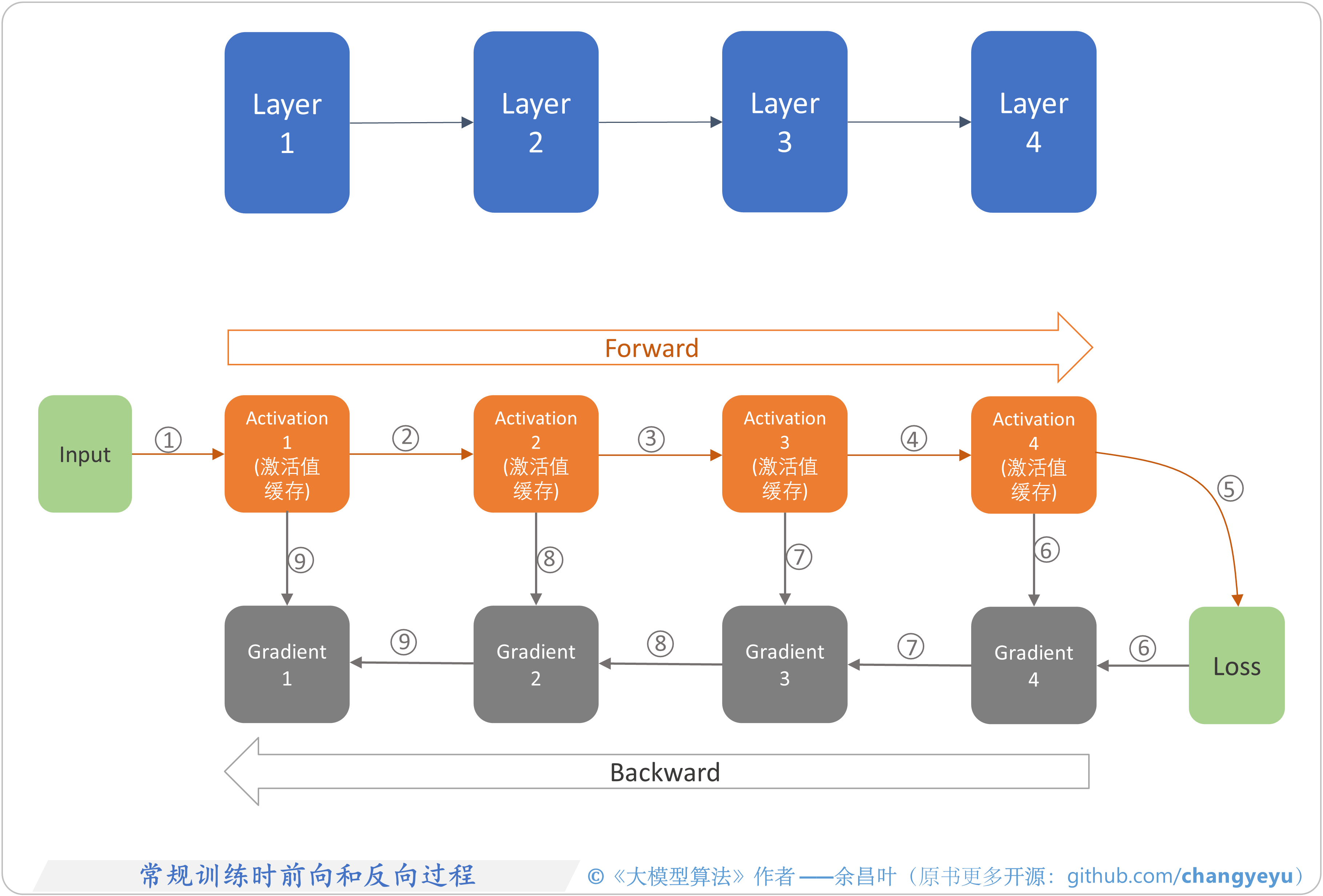
- 【LLM基础拓展】常规训练时前向和反向过程
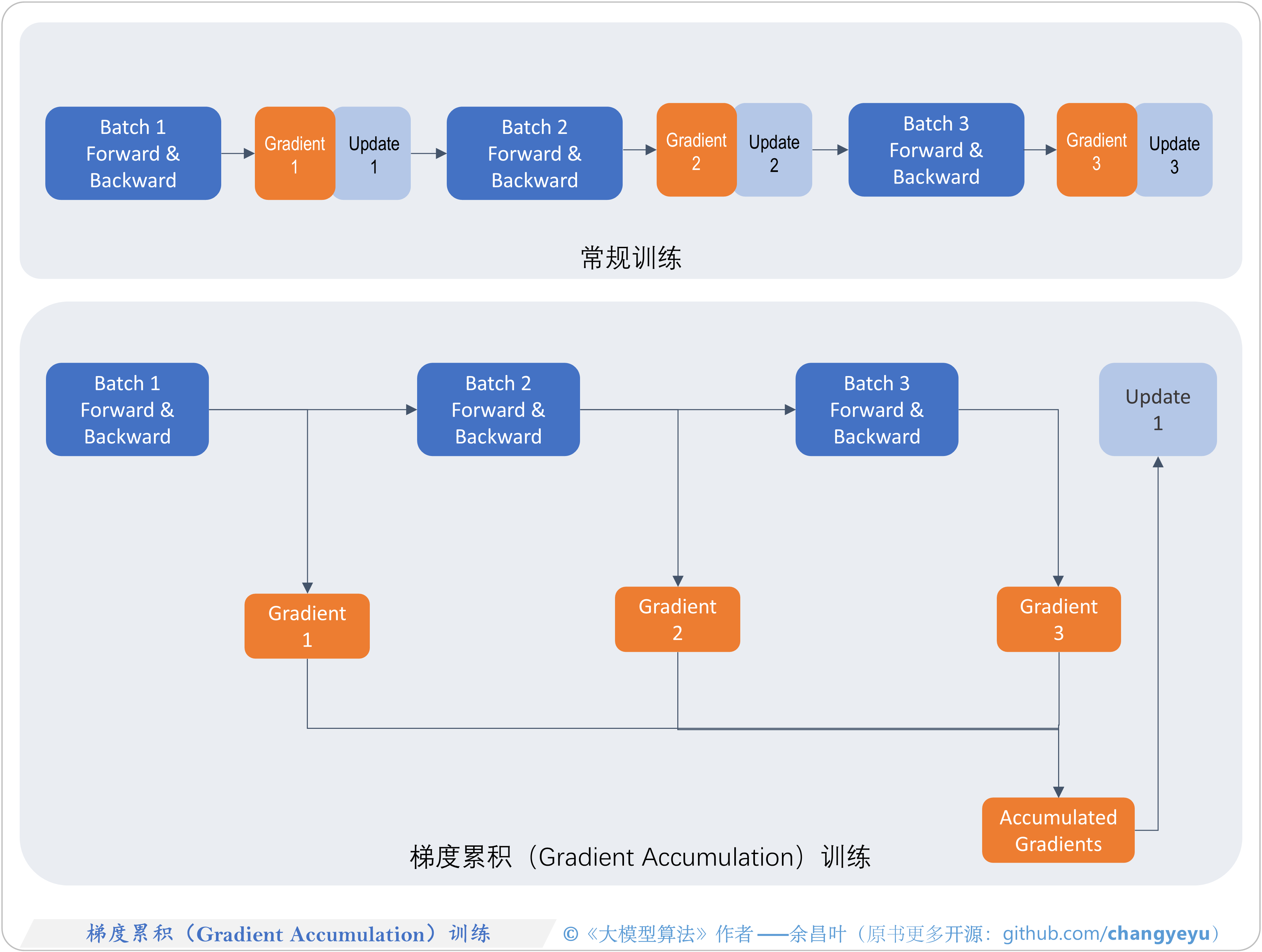
- 【LLM基础拓展】梯度累积(Gradient Accumulation)训练
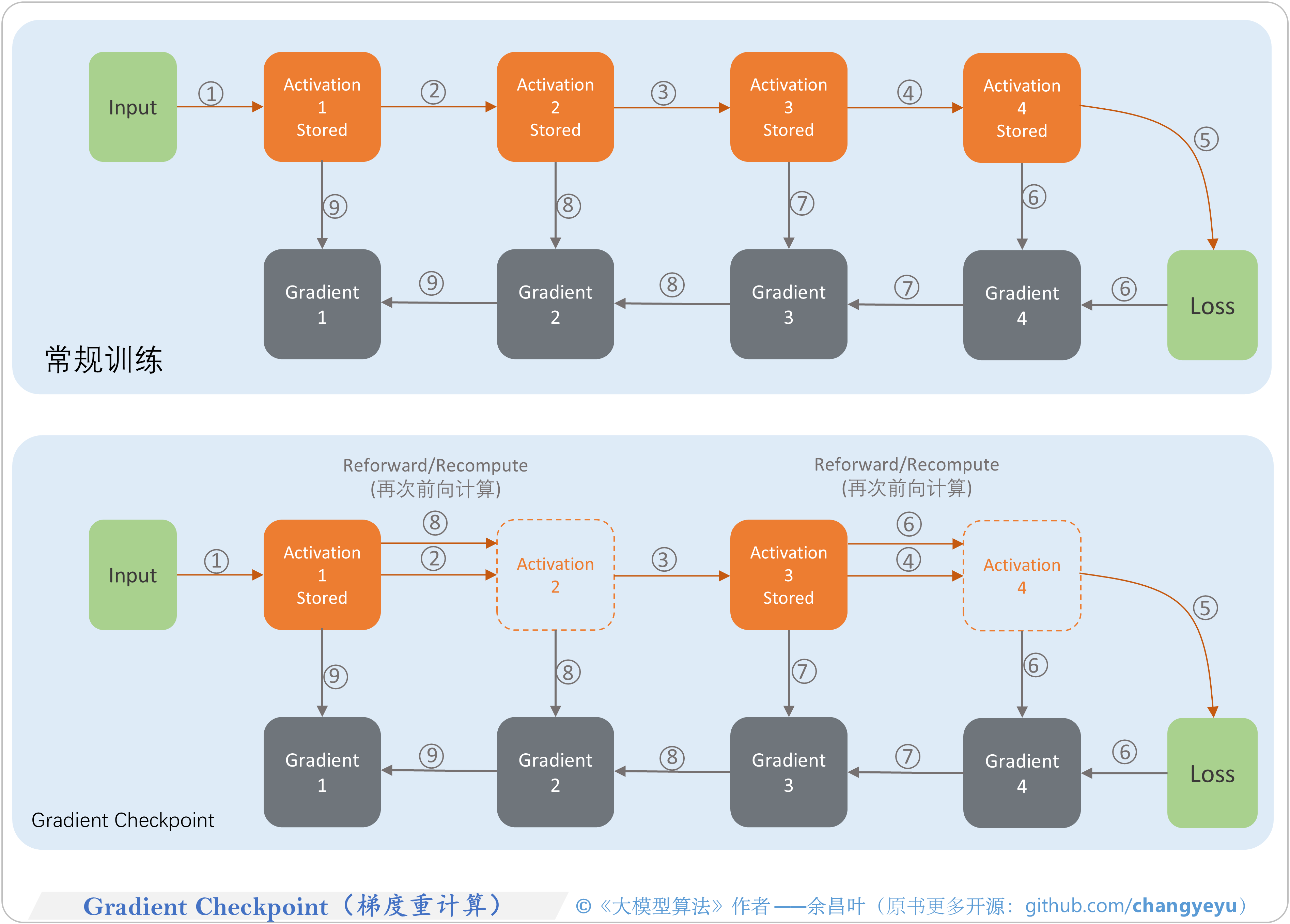
- 【LLM基础拓展】Gradient Checkpoint(梯度重计算)
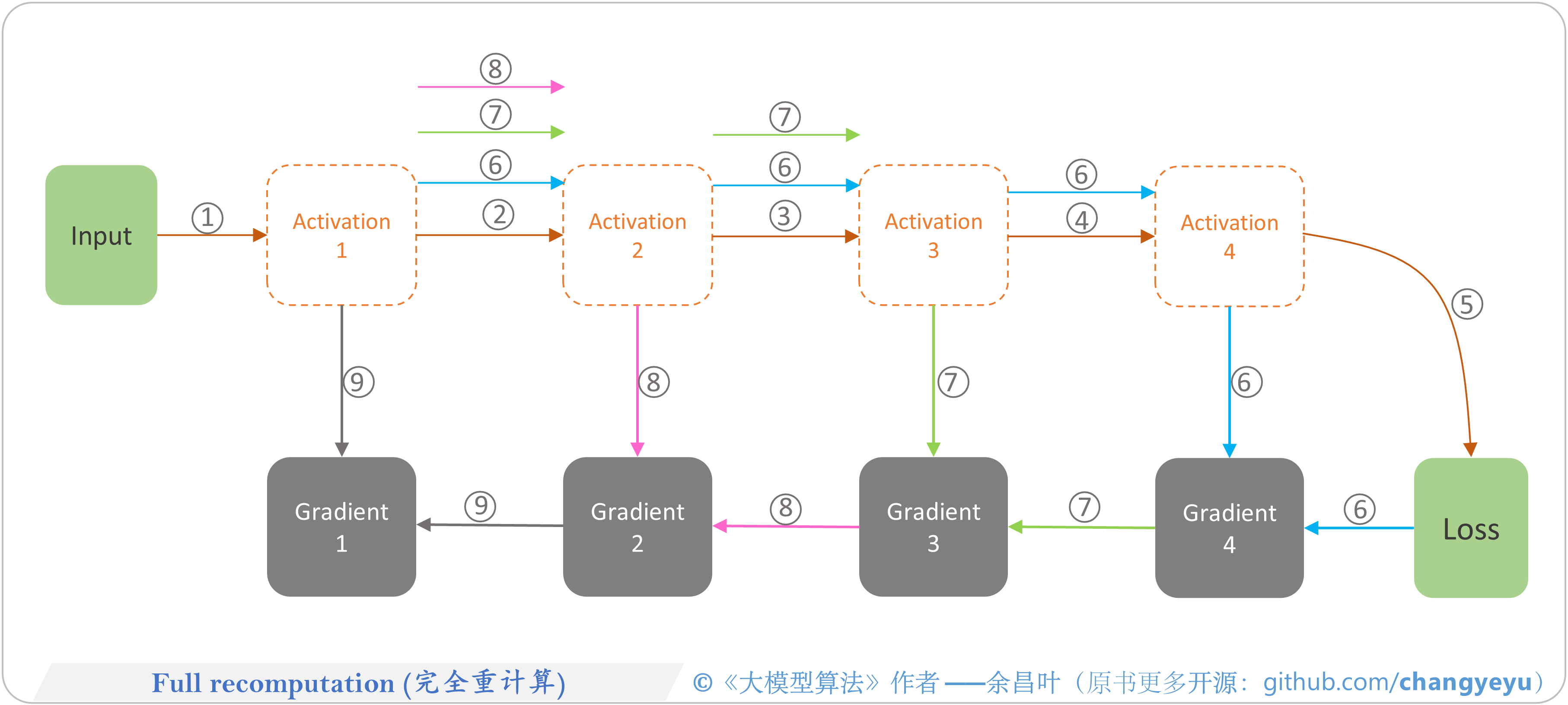
- 【LLM基础拓展】Full recomputation(完全重计算)
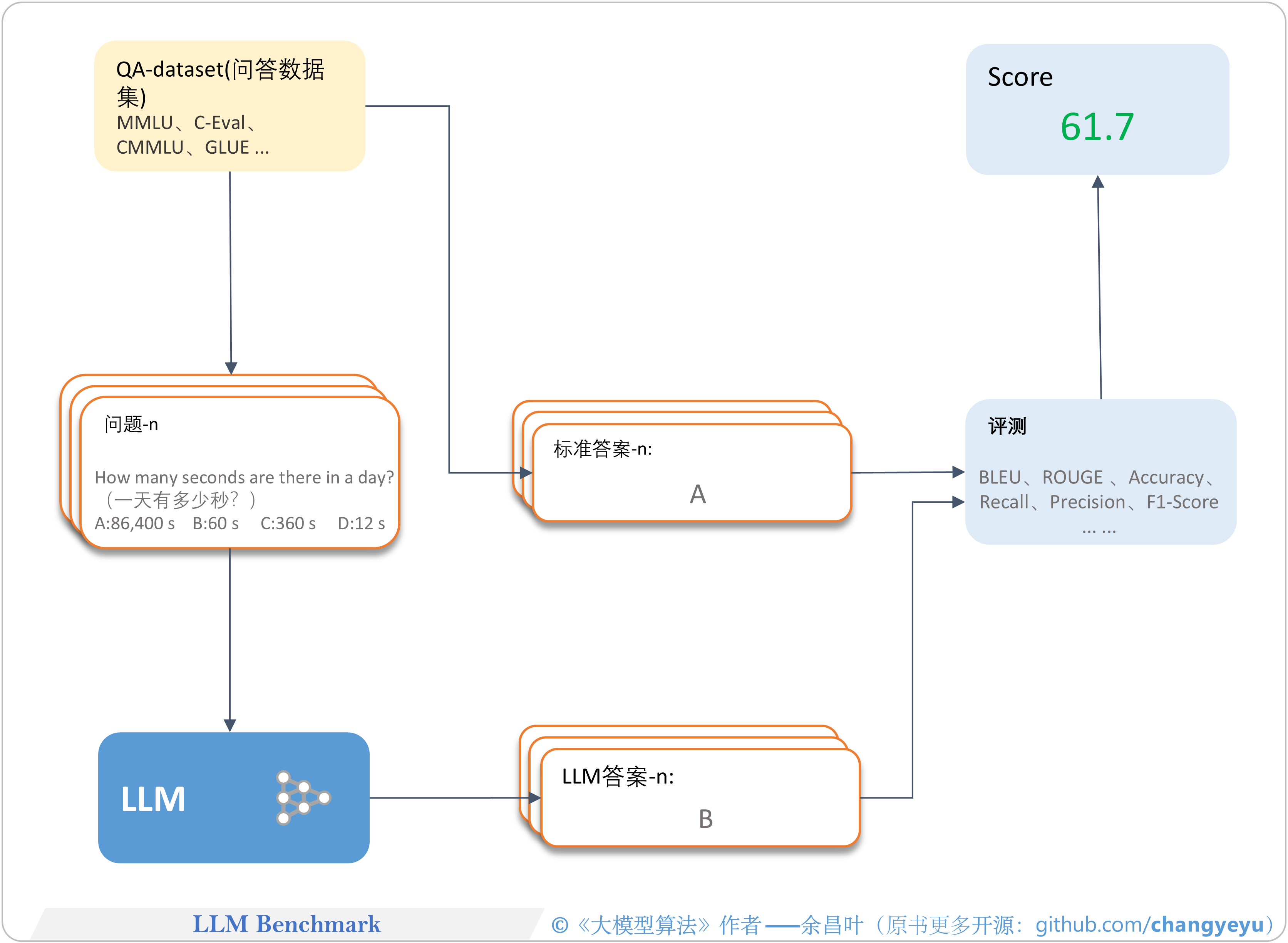
- 【LLM基础拓展】LLM Benchmark
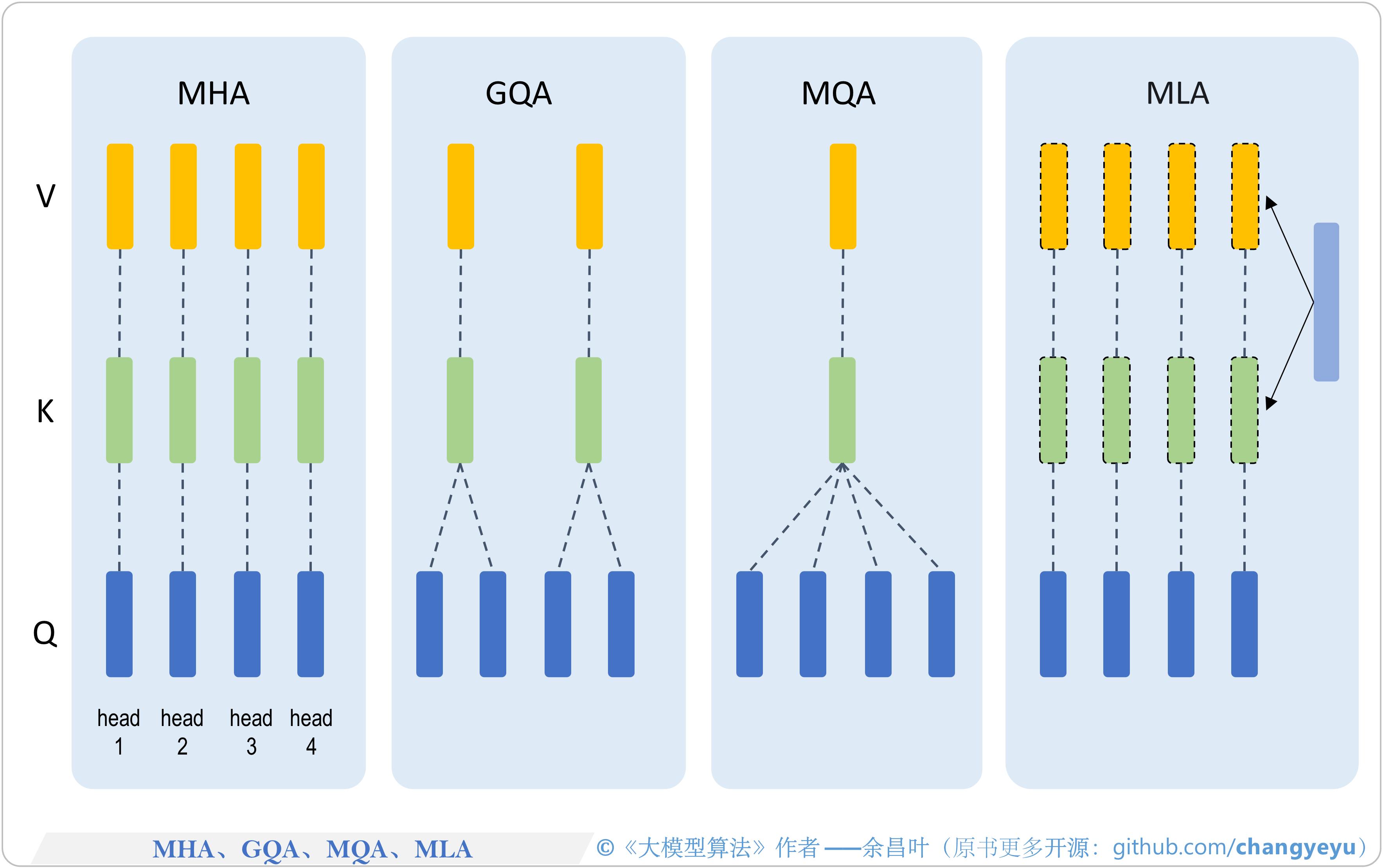
- 【LLM基础拓展】MHA、GQA、MQA、MLA
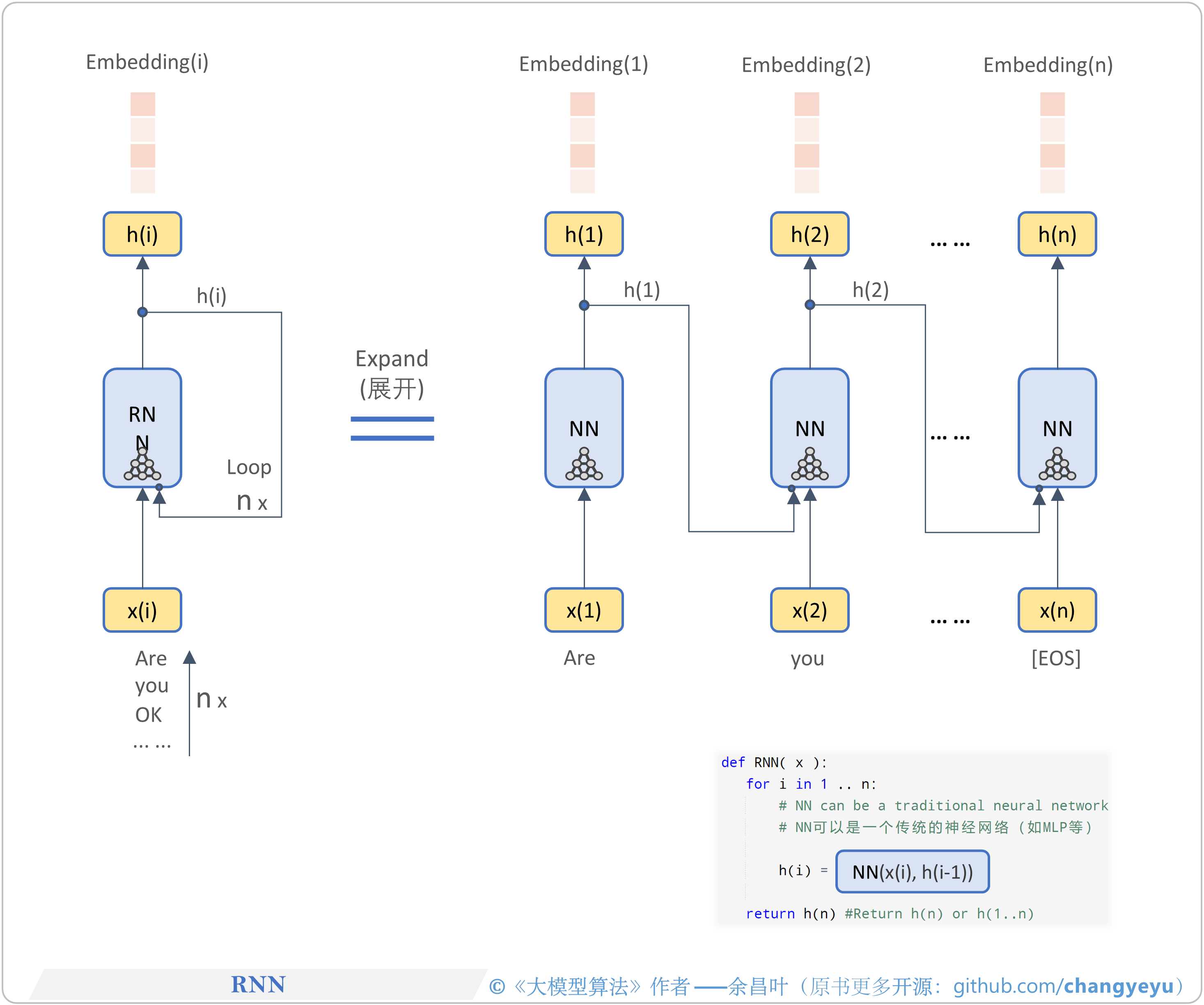
- 【LLM基础拓展】RNN(Recurrent Neural Network)
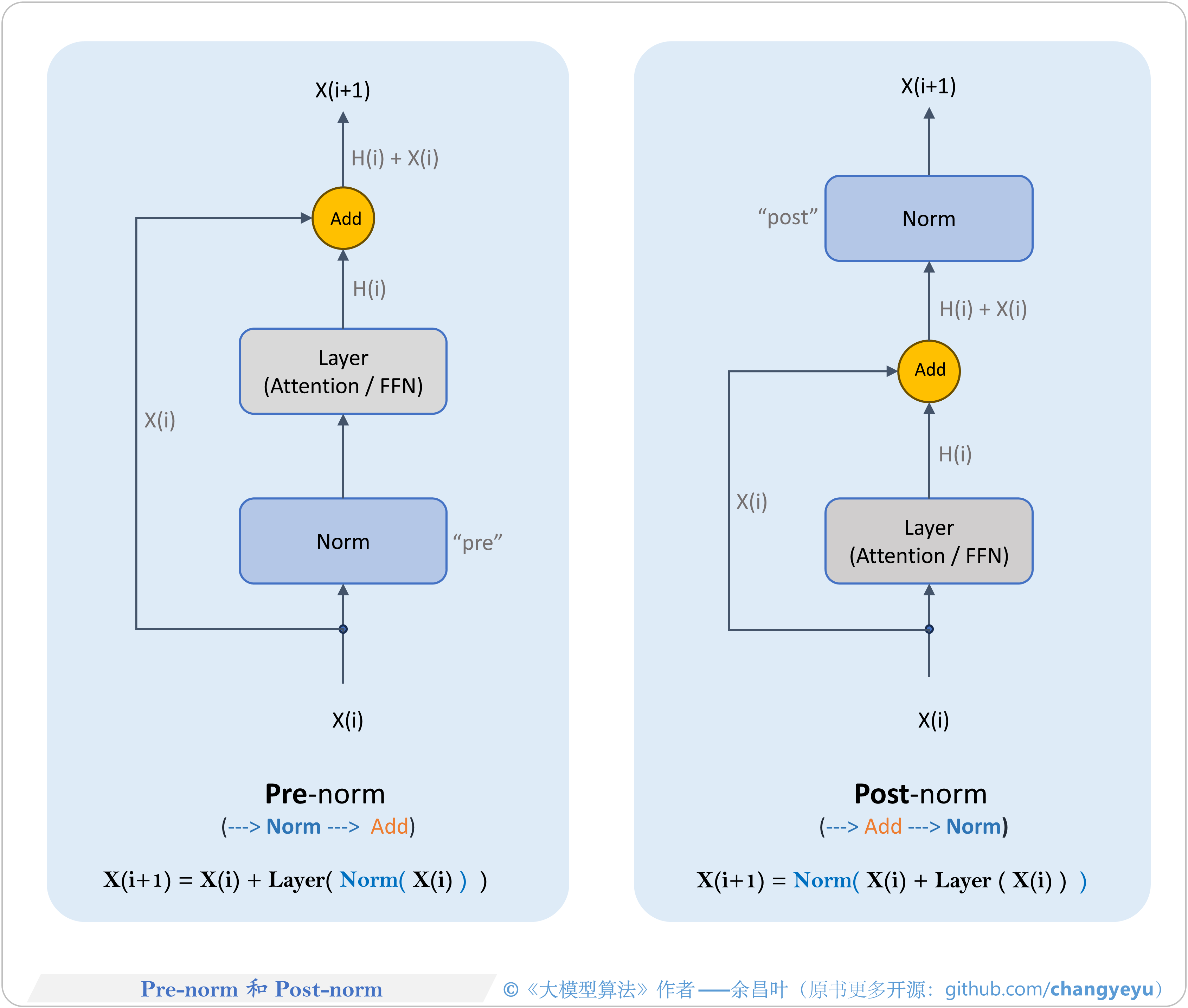
- 【LLM基础拓展】Pre-norm和Post-norm
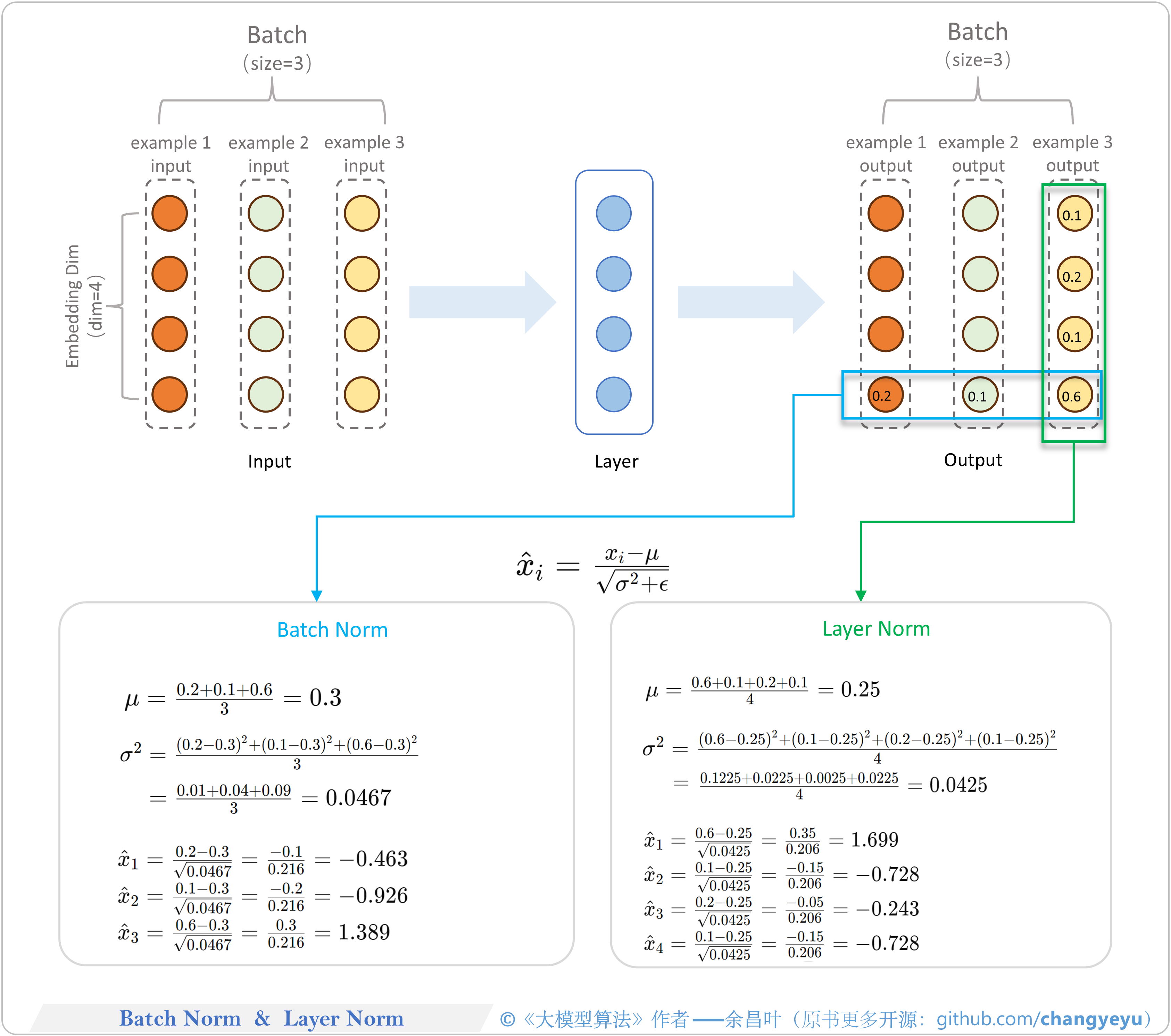
- 【LLM基础拓展】BatchNorm和LayerNorm
- 【LLM基础拓展】RMSNorm
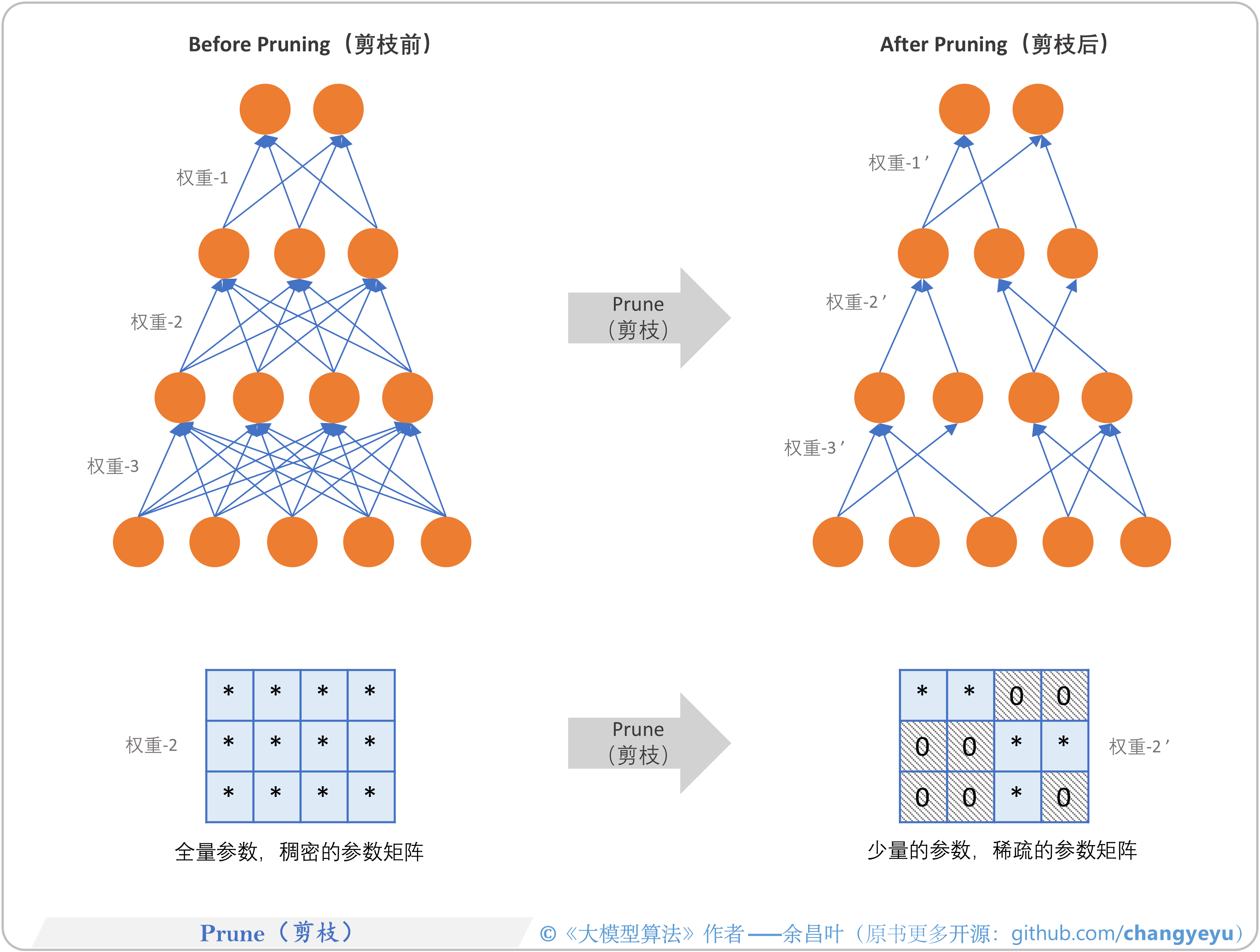
- 【LLM基础拓展】Prune(剪枝)
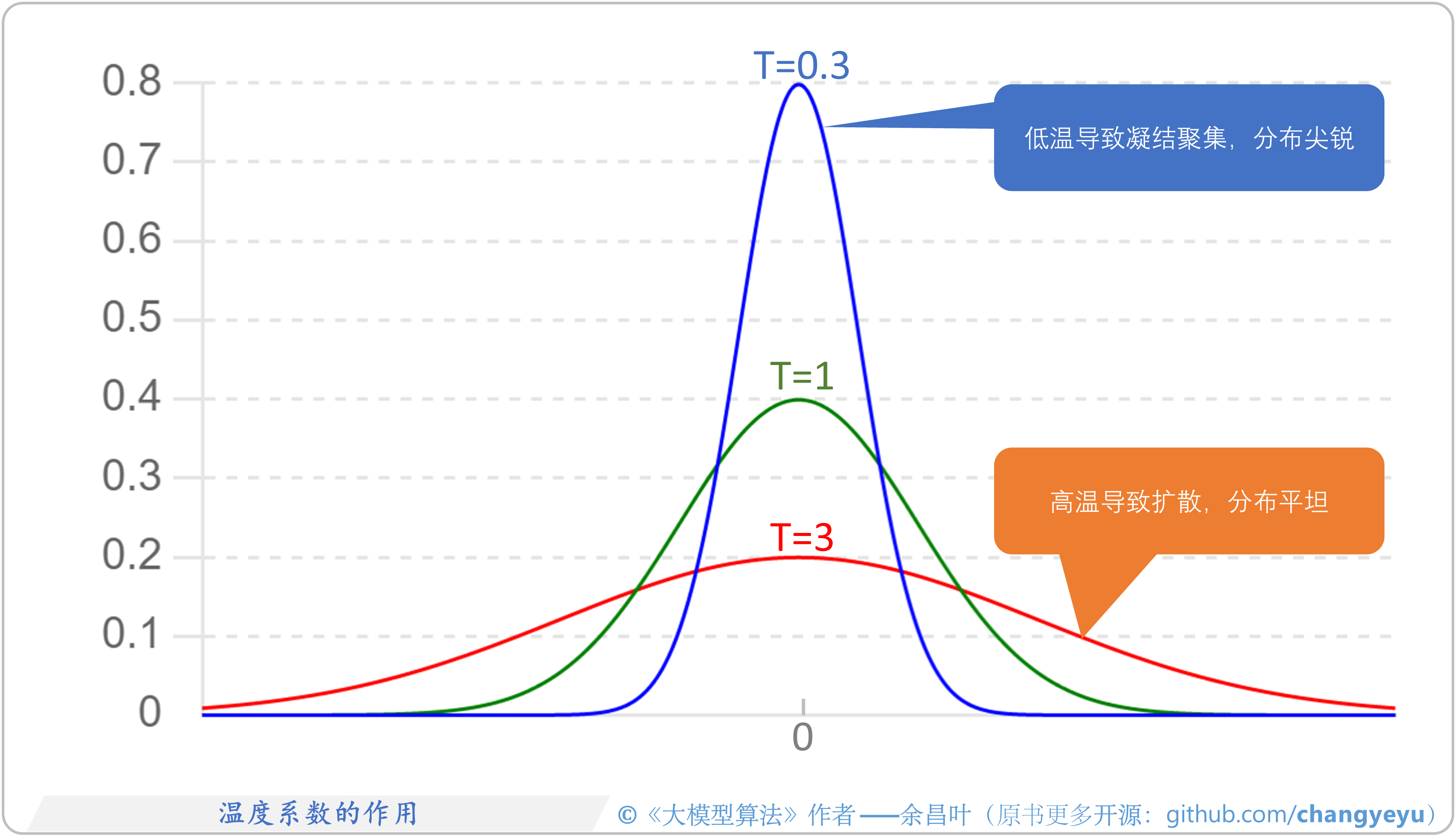
- 【LLM基础拓展】温度系数的作用
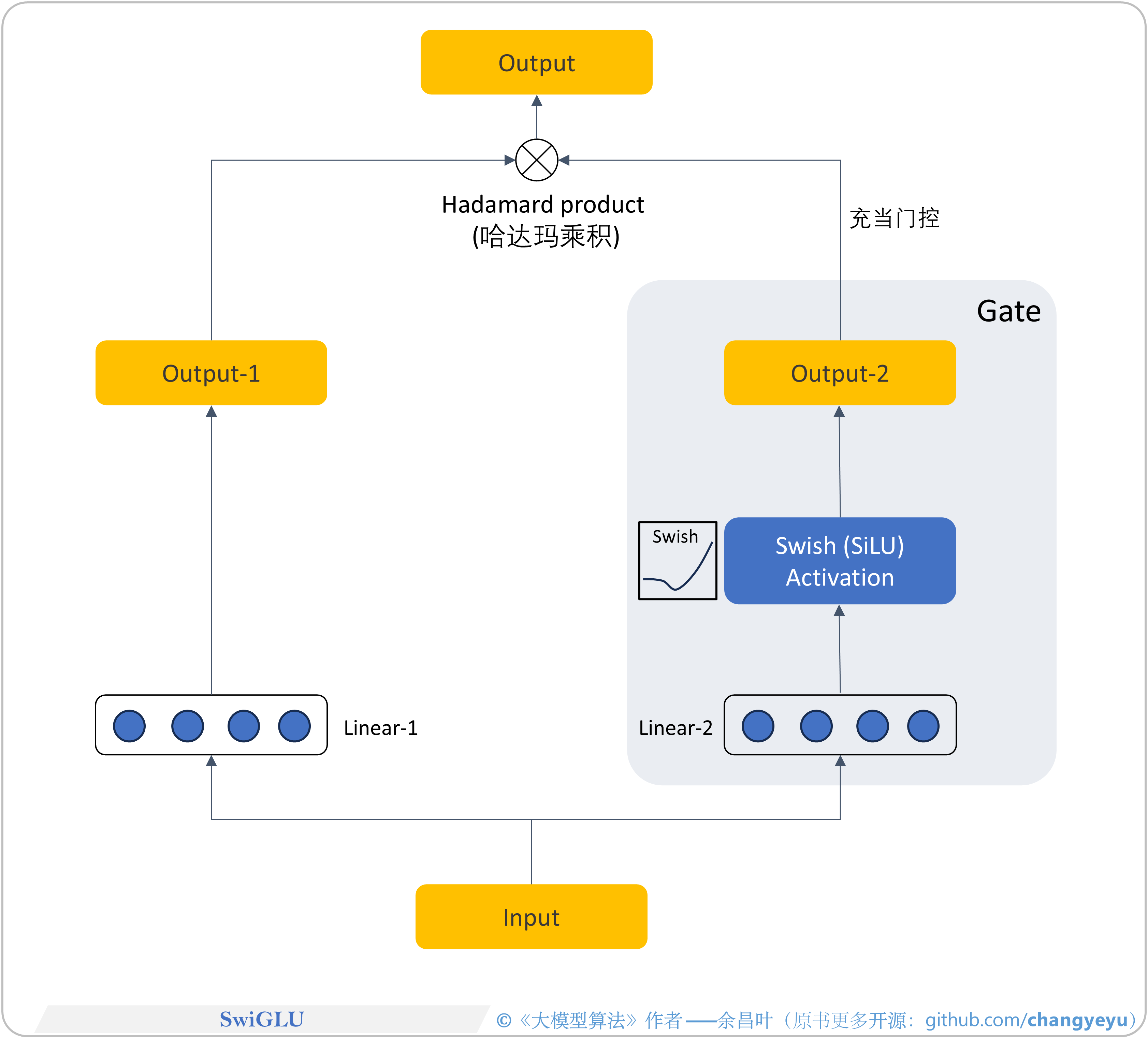
- 【LLM基础拓展】SwiGLU
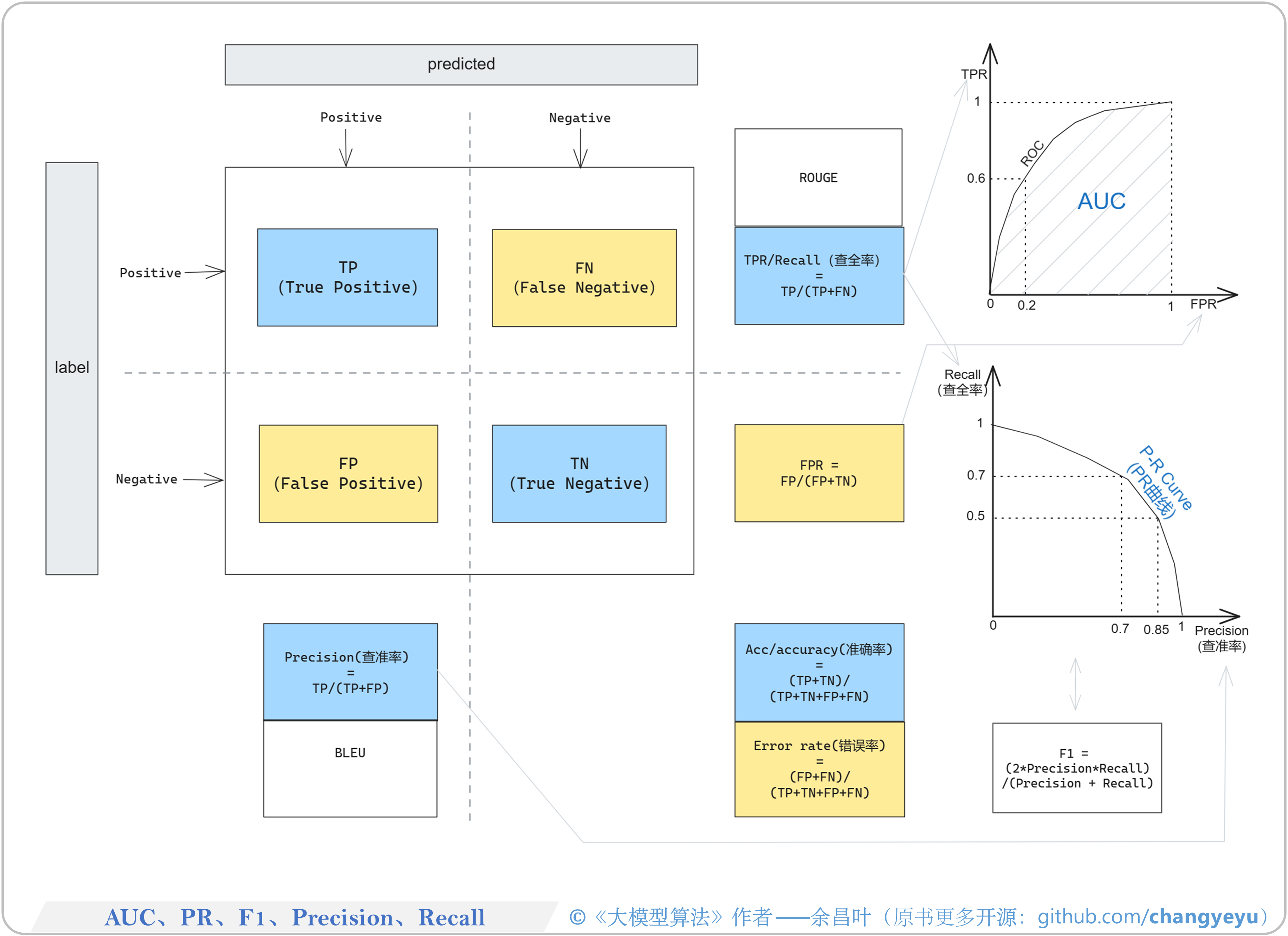
- 【LLM基础拓展】AUC、PR、F1、Precision、Recall
- 【LLM基础拓展】RoPE位置编码
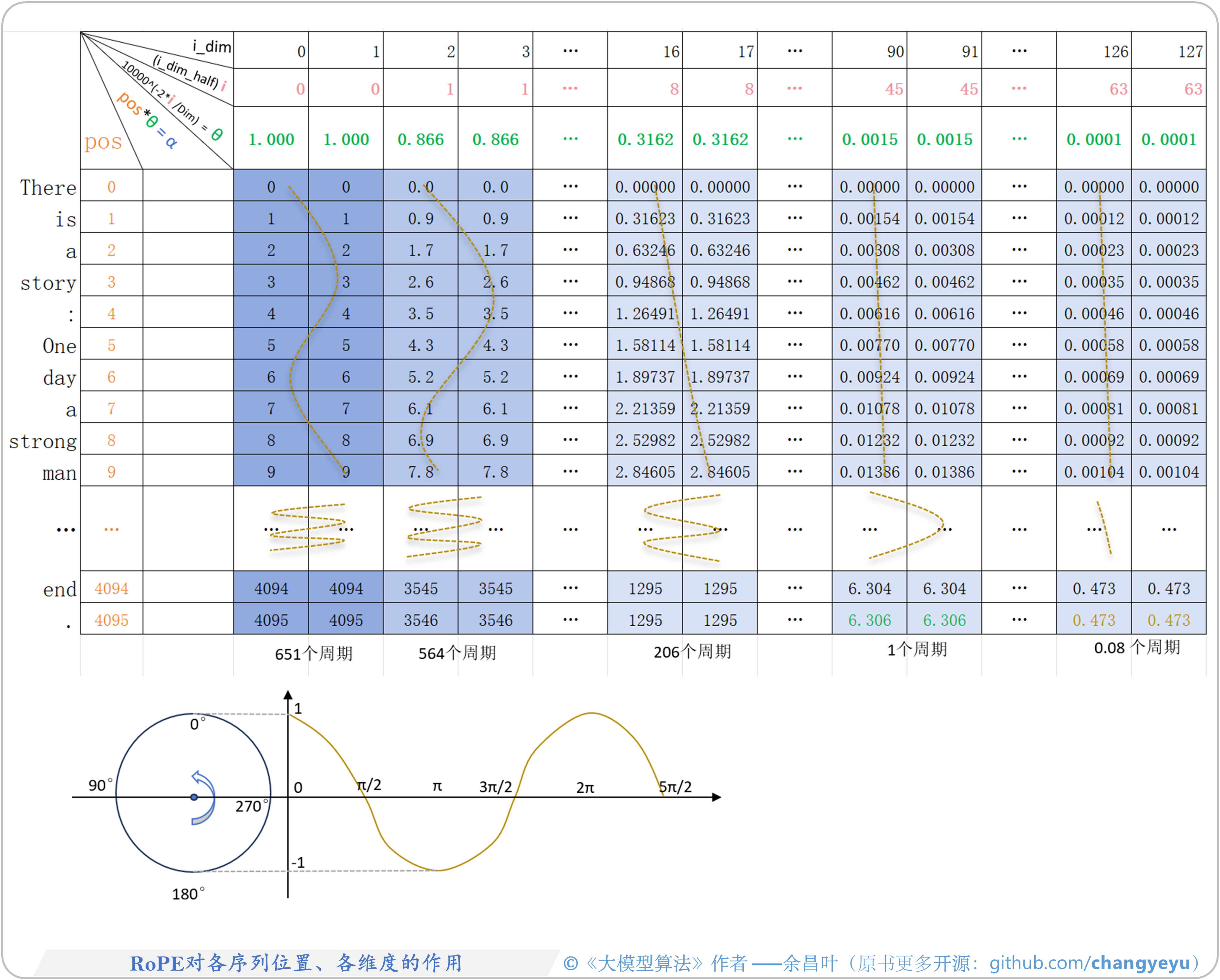
- 【LLM基础拓展】RoPE对各序列位置、各维度的作用
- 所有架构图的 文字详解✍️、更多架构图🖼️
- 书籍参考文献
- 用于参考文献(引用格式)
- BibTeX(引用格式)

- 我几十个小时、呕心沥血之作,点击本仓库右上角 ↗ 的 Star ⭐ ,就是对我最大的鼓励啦!
- 下图仅为预览图,高清图见: 强化学习算法图谱 (rl-algo-map).pdf

- 我几十个小时、呕心沥血之作,点击本仓库右上角 ↗ 的 Star ⭐ ,就是对我最大的鼓励啦!
- LLM主要有Decoder-Only(仅解码器)或MoE(Mixture of Experts, 专家混合模型)两种形式,两者在整体架构上较为相似,主要区别为MoE在FFN(前馈网络)部分引入了多个专家网络。



【免训练的优化技术】CoT、Self-consistency CoT、ToT、GoT [87]
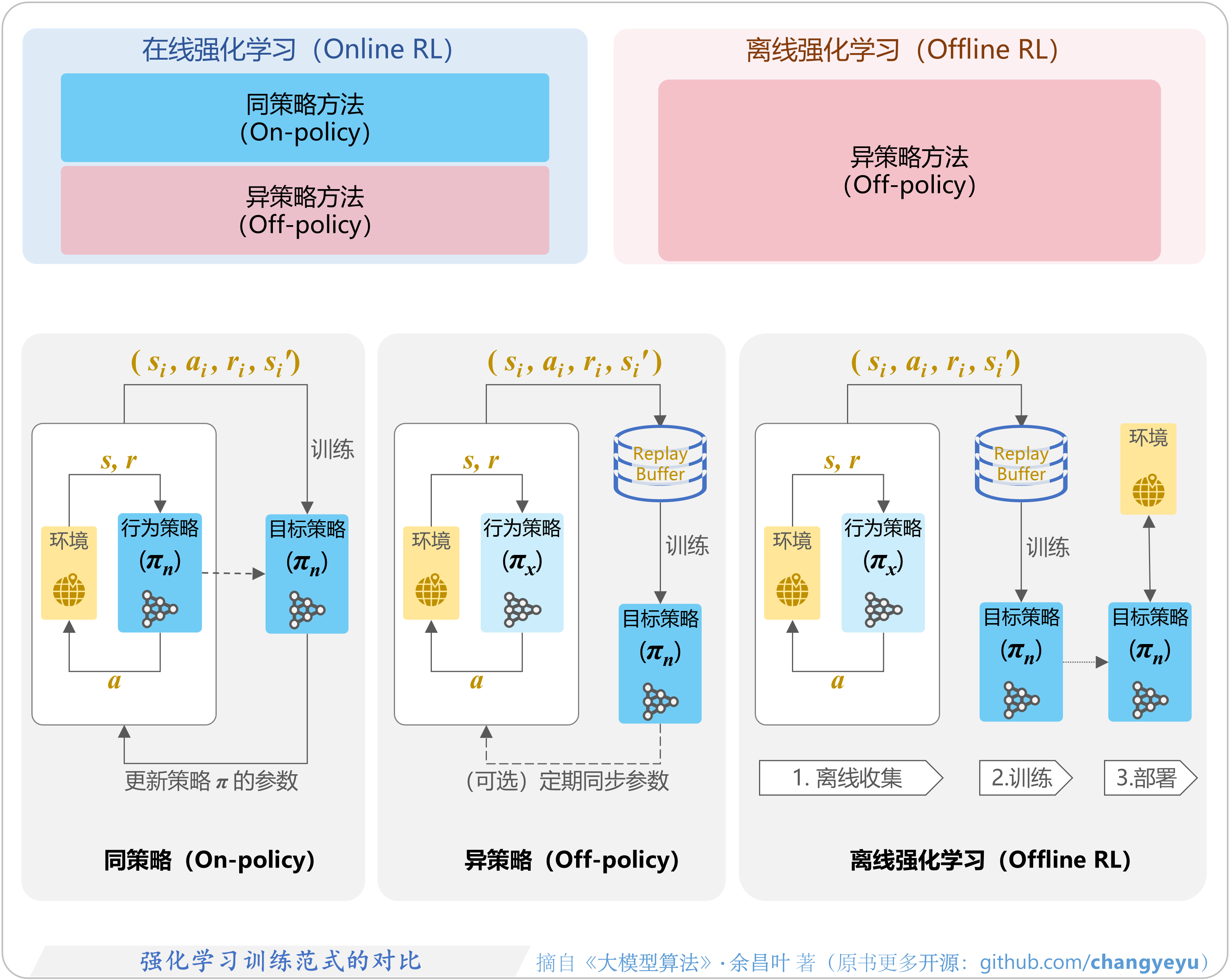
- On-policy,Off-policy,Offline RL

【强化学习基础】蒙特卡洛、TD、DP、穷举搜索的关系 [32]
【强化学习基础】多智能体DDPG [41]

【策略优化架构算法及其衍生】PPO与GRPO(Group Relative Policy Optimization) [72]
【逻辑推理能力优化】AlphaGoZero在训练时的性能增长趋势 [179]

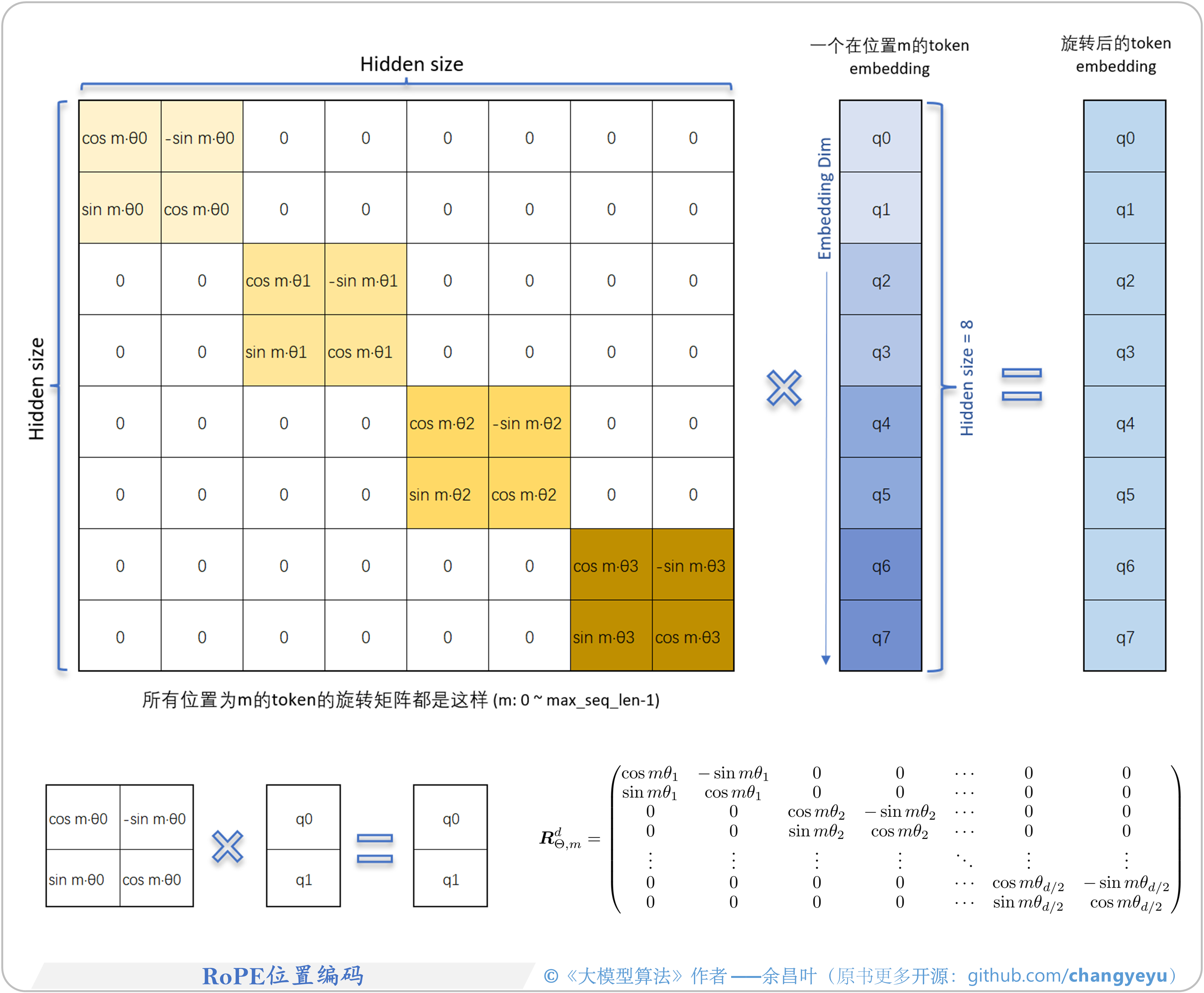
- RoPE原理、Base与θ值、作用机制详见:RoPE-theta-base.xlsx
折叠 / 展开目录
第1章 大模型原理与技术概要
1.1 图解大模型结构
1.1.1 大语言模型(LLM)结构全景图
1.1.2 输入层:分词、Token映射与向量生成
1.1.3 输出层:Logits、概率分布与解码
1.1.4 多模态语言模型(MLLM)与视觉语言模型(VLM)
1.2 大模型训练全景图
1.3 Scaling Law(性能的四大扩展规律)
第2章 SFT(监督微调)
2.1 多种微调技术图解
2.1.1 全参数微调、部分参数微调
2.1.2 LoRA(低秩适配微调)——四两拨千斤
2.1.3 LoRA衍生:QLoRA、AdaLoRA、PiSSA等
2.1.4 基于提示的微调:Prefix-Tuning、Prompt Tuning等
2.1.5 Adapter Tuning
2.1.6 微调技术对比
2.1.7 如何选择微调技术
2.2 SFT原理深入解析
2.2.1 SFT数据与ChatML格式化
2.2.2 Logits与Token概率计算
2.2.3 SFT的Label
2.2.4 SFT的Loss图解
2.2.5 对数概率(LogProbs)与LogSoftmax
2.3 指令收集和处理
2.3.1 收集指令的渠道和方法
2.3.2 清洗指令的四要素
2.3.3 数据预处理及常用工具
2.4 SFT实践指南
2.4.1 如何缓解SFT引入的幻觉?
2.4.2 Token级Batch Size的换算
2.4.3 Batch Size与学习率的Scaling Law
2.4.4 SFT的七个技巧
第3章 DPO(直接偏好优化)
3.1 DPO的核心思想
3.1.1 DPO的提出背景与意义
3.1.2 隐式的奖励模型
3.1.3 Loss和优化目标
3.2 偏好数据集的构建
3.2.1 构建流程总览
3.2.2 Prompt的收集
3.2.3 问答数据对的清洗
3.2.4 封装和预处理
3.3 图解DPO的实现与训练
3.3.1 模型的初始化
3.3.2 DPO训练全景图
3.3.3 DPO核心代码的提炼和解读
3.4 DPO实践经验
3.4.1 β参数如何调节
3.4.2 DPO对模型能力的多维度影响
3.5 DPO进阶
3.5.1 DPO和RLHF(PPO)的对比
3.5.2 理解DPO的梯度
第4章 免训练的效果优化技术
4.1 提示工程
4.1.1 Zero-Shot、One-Shot、Few-Shot
4.1.2 Prompt设计的原则
4.2 CoT(思维链)
4.2.1 CoT原理图解
4.2.2 ToT、GoT、XoT等衍生方法
4.2.3 CoT的应用技巧
4.2.4 CoT在多模态领域的应用
4.3 生成控制和解码策略
4.3.1 解码的原理与分类
4.3.2 贪婪搜索
4.3.3 Beam Search(波束搜索):图解、衍生方法
4.3.4 Top-K、Top-P等采样方法图解
4.3.5 其他解码策略
4.3.6 多种生成控制参数
4.4 RAG(检索增强生成)
4.4.1 RAG技术全景图
4.4.2 RAG相关框架
4.5 功能与工具调用(Function Calling)
4.5.1 功能调用全景图
4.5.2 功能调用的分类
第5章 强化学习基础
5.1 强化学习核心
5.1.1 强化学习:定义与区分
5.1.2 强化学习的基础架构、核心概念
5.1.3 马尔可夫决策过程(MDP)
5.1.4 探索与利用、ε-贪婪策略
5.1.5 同策略(On-policy)、异策略(Off-policy)
5.1.6 在线/离线强化学习(Online/Offline RL)
5.1.7 强化学习分类图
5.2 价值函数、回报预估
5.2.1 奖励、回报、折扣因子(R、G、γ)
5.2.2 反向计算回报
5.2.3 四种价值函数:Qπ、Vπ、V*、Q*
5.2.4 奖励、回报、价值的区别
5.2.5 贝尔曼方程——强化学习的基石
5.2.6 Q和V的转换关系、转换图
5.2.7 蒙特卡洛方法(MC)
5.3 时序差分(TD)
5.3.1 时序差分方法
5.3.2 TD-Target和TD-Error
5.3.3 TD(λ)、多步TD
5.3.4 蒙特卡洛、TD、DP、穷举搜索的区别
5.4 基于价值的算法
5.4.1 Q-learning算法
5.4.2 DQN
5.4.3 DQN的Loss、训练过程
5.4.4 DDQN、Dueling DQN等衍生算法
5.5 策略梯度算法
5.5.1 策略梯度(Policy Gradient)
5.5.2 策略梯度定理
5.5.3 REINFORCE和Actor-Critic:策略梯度的应用
5.6 多智能体强化学习(MARL)
5.6.1 MARL的原理与架构
5.6.2 MARL的建模
5.6.3 MARL的典型算法
5.7 模仿学习(IL)
5.7.1 模仿学习的定义、分类
5.7.2 行为克隆(BC)
5.7.3 逆向强化学习(IRL)
5.7.4 生成对抗模仿学习(GAIL)
5.8 强化学习高级拓展
5.8.1 基于环境模型(Model-Based)的方法
5.8.2 分层强化学习(HRL)
5.8.3 分布价值强化学习(Distributional RL)
第6章 策略优化算法
6.1 Actor-Critic(演员-评委)架构
6.1.1 从策略梯度到Actor-Critic
6.1.2 Actor-Critic架构图解
6.2 优势函数与A2C
6.2.1 优势函数(Advantage)
6.2.2 A2C、A3C、SAC算法
6.2.3 GAE(广义优势估计)算法
6.2.4 γ和λ的调节作用
6.3 PPO及其相关算法
6.3.1 PPO算法的演进
6.3.2 TRPO(置信域策略优化)
6.3.3 重要性采样(Importance Sampling)
6.3.4 PPO-Penalty
6.3.5 PPO-Clip
6.3.6 PPO的Loss的扩展
6.3.7 TRPO与PPO的区别
6.3.8 图解策略模型的训练
6.3.9 深入解析PPO的本质
6.4 GRPO算法
6.4.1 GRPO的原理
6.4.2 GRPO与PPO的区别
6.5 确定性策略梯度(DPG)
6.5.1 确定性策略vs随机性策略
6.5.2 DPG、DDPG、TD3算法
第7章 RLHF与RLAIF
7.1 RLHF(基于人类反馈的强化学习)概要
7.1.1 RLHF的背景、发展
7.1.2 语言模型的强化学习建模
7.1.3 RLHF的训练样本、总流程
7.2 阶段一:图解奖励模型的设计与训练
7.2.1 奖励模型(Reward Model)的结构
7.2.2 奖励模型的输入与奖励分数
7.2.3 奖励模型的Loss解析
7.2.4 奖励模型训练全景图
7.2.5 奖励模型的Scaling Law
7.3 阶段二:多模型联动的PPO训练
7.3.1 四种模型的角色图解
7.3.2 各模型的结构、初始化、实践技巧
7.3.3 各模型的输入、输出
7.3.4 基于KL散度的策略约束
7.3.5 基于PPO的RLHF核心实现
7.3.6 全景图:基于PPO的训练
7.4 RLHF实践技巧
7.4.1 奖励欺骗(Reward Hacking)的挑战与应对
7.4.2 拒绝采样(Rejection Sampling)微调
7.4.3 强化学习与RLHF的训练框架
7.4.4 RLHF的超参数
7.4.5 RLHF的关键监控指标
7.5 基于AI反馈的强化学习
7.5.1 RLAIF的原理图解
7.5.2 CAI:基于宪法的强化学习
7.5.3 RBR:基于规则的奖励
第8章 逻辑推理能力优化
8.1 逻辑推理(Reasoning)相关技术概览
8.1.1 推理时计算与搜索
8.1.2 基于CoT的蒸馏
8.1.3 过程奖励模型与结果奖励模型(PRM/ORM)
8.1.4 数据合成
8.2 推理路径搜索与优化
8.2.1 MCTS(蒙特卡洛树搜索)
8.2.2 A*搜索
8.2.3 BoN采样与蒸馏
8.2.4 其他搜索方法
8.3 强化学习训练
8.3.1 强化学习的多种应用
8.3.2 自博弈(Self-Play)与自我进化
8.3.3 强化学习的多维创新
第9章 综合实践与性能优化
9.1 实践全景图
9.2 训练与部署
9.2.1 数据与环境准备
9.2.2 超参数如何设置
9.2.3 SFT训练
9.2.4 对齐训练:DPO训练、RLHF训练
9.2.5 推理与部署
9.3 DeepSeek的训练与本地部署
9.3.1 DeepSeek的蒸馏与GRPO训练
9.3.2 DeepSeek的本地部署与使用
9.4 效果评估
9.4.1 评估方法分类
9.4.2 LLM与VLM的评测框架
9.5 大模型性能优化技术图谱
- 《大模型算法:强化学习、微调与对齐》原书的参考文献详见: 参考文献
- 公众号 / 知乎 / B站 ,关注:叶子哥AI

- 欢迎为本项目提交原理图、文档、纠错与修正或其他任何改进!你可以在图中署名(使用昵称或姓名),你的 GitHub 账号也将展示在本仓库的 Contributors 中,让更多人了解你和你的工作。绘图模板示例:images-template.pptx
- 提交步骤:(1)Fork: 点击页面上的"Fork" 按钮,在你的主页创建独立的子仓库 → (2)Clone:将你Fork后的子仓库Clone到本地 → (3)本地新建分支 → (4)修改提交 → (5)Push到远程子仓库 → (6)提交PR:回到Github页面,在你的子仓库界面点击“Compare & pull request”发起PR,等待维护者审核&合并到母仓库。
- 绘图配色以这些颜色为主: 浅蓝(编码
#71CCF5) ; 浅黄(编码#FFE699); 蓝紫(编码#C0BFDE) ; 粉红(编码#F0ADB7)。
本仓库内所有图片均依据 LICENSE 进行授权。只要遵守下方条款,你就可以自由地使用、修改及二次创作这些材料:
- 分享 —— 你可以复制并以任何媒介或格式重新发布这些材料。
- 修改 —— 你可以对材料进行混合、转换,并基于其创作衍生作品。
同时,你必须遵守以下条款:
- 如果用于网络 —— 如果将材料用于帖子、博客等网络内容,请务必保留图片中已包含的原创作者信息。
- 如果用于论文、书籍等出版物 —— 如果将材料用于论文、书籍等正式出版物,请按照本仓库规定的引用格式在参考文献中注明出处;在这种情况下,图片中原有的原创作者信息可以删除。
- 非商业性使用 —— 你不得将这些材料用于任何直接的商业用途.
- 如果你在论文、著作或报告中使用了本仓库/本书中的图片等内容,请按以下格式引用:
- 中文引用格式(推荐):
余昌叶. 大模型算法:强化学习、微调与对齐[M]. 北京: 电子工业出版社, 2025. https://github.com/changyeyu/LLM-RL-Visualized
- 英文(English)引用格式:
Yu, Changye. Large Model Algorithms: Reinforcement Learning, Fine-Tuning, and Alignment.
Beijing: Publishing House of Electronics Industry, 2025. https://github.com/changyeyu/LLM-RL-Visualized
中文 BibTeX(推荐):
@book{yu2025largemodel,
title = {大模型算法:强化学习、微调与对齐},
author = {余昌叶},
publisher = {电子工业出版社},
year = {2025},
address = {北京},
isbn = {9787121500725},
url = {https://github.com/changyeyu/LLM-RL-Visualized},
language = {zh}
}英文(English) BibTeX:
@book{yu2025largemodel_en,
title = {Large Model Algorithms: Reinforcement Learning, Fine-Tuning, and Alignment},
author = {Yu, Changye},
publisher = {Publishing House of Electronics Industry},
year = {2025},
address = {Beijing},
isbn = {9787121500725},
url = {https://github.com/changyeyu/LLM-RL-Visualized},
language = {en}
}
以上架构图的文字详解、更多架构图 详见:《大模型算法:强化学习、微调与对齐》
欢迎点击右上角 ↗ 的 Star ⭐ 关注!