Make compatible with python 2 and python 3 #44
Conversation
For mongo bug SERVER-3946
 hedgepigdaniel
left a comment
hedgepigdaniel
left a comment
There was a problem hiding this comment.
Much easier to look at commit by commit. Click the commits tab, then the first commit, then use
nto go to the next commit automagically
👍
looks good
setup.py
Outdated
| long_description='Mongorm', | ||
| platforms=['any'], | ||
| install_requires=['pymongo >= 2.4.2', 'pysignals'], | ||
| install_requires=['pymongo >= 2.4.2', 'pysignals', 'iso8601'], |
There was a problem hiding this comment.
I wonder if actually pymongo 2.9+ is required (since we updated to support mongo 3.0)
There was a problem hiding this comment.
There's a few comments about using pymongo 3.0+ specific things already it seems (as in breaking changes that mean a version < 3.0 would break). I just think everyones been blissfully unaware because this setup.py pretty much just installs the latest version of pymongo (3.9.0 at the current time). So yeah, I think I'll update this to be a hard >= 3.0.0 requirement
|
|
||
| # For python 2/3 compatibility | ||
| def __bool__( self ): | ||
| return True |
There was a problem hiding this comment.
objects are not truthy by default?
There was a problem hiding this comment.
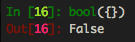
Neither in python 2 or 3 are empty objects considered truthy. But because the file overwrites __getattr__ (so that it returns None instead of an AttributeError), the way the future object class checks truthiness makes it error because it believes the attribute (the __bool__ function) exists on itself, but when it calls it, it dies. But the old behaviour of the library is that an empty Document is truthy, so this just keeps that compatibility
There was a problem hiding this comment.
Neither in python 2 or 3 are empty objects considered
truthy. But because the file overwrites__getattr__(so that it returnsNoneinstead of anAttributeError), the way thefutureobjectclass checks truthiness makes it error because it believes the attribute (the__bool__function) exists on itself, but when it calls it, it dies. But the old behaviour of the library is that an empty Document is truthy, so this just keeps that compatibility
That sounds like a bug; __getattr__ should raise an AttributeError for things that aren't fields. Actually all objects in Python are considered True unless they specify a __bool__ method which returns False or __len__ method which returns 0. Also if you decide to go ahead with this workaround you should probably also specify a __nonzero__ method for Python 2.x (__bool__ was added in Python 3.x)
There was a problem hiding this comment.
Yeah, I don't like that __getattr__ doesn't raise an AttributeError either ahaha. But it's been that way in the library since it's inception it seems, so I don't want to break functionality as core as that in OpenLearning which expects it. After a better inspection across the whole OpenLearning codebase to check it's uses, I'd be more comfortable to recommend that we make that change!
Actually all objects in Python are considered
True
Yeap, whoops. Working on JS my brain confused object and dict. Yeap, it's not that object is falsy, it's that the future version of object that we're importing (aka from builtins import object) first checks if the __bool__ method is available and uses that to determine it's truthiness (because it defines the __nonzero__ method) that python 2 uses. But because of the above AttributeError not being raised, it tries to call that method, and dies because it doesn't actually exist to be called. So this was just there to short circuit it into an acceptable response that we want!
| except pymongo.errors.OperationFailure as err: | ||
| message = 'Could not save document (%s)' | ||
| if u'duplicate key' in unicode(err): | ||
| if u'duplicate key' in str(err): |
There was a problem hiding this comment.
Of all the things Python 2.x. did horribly, strings are definitely at the top of the list! :P I would highly suggest including the six library and using its six.text_type here to save yourself further headaches.
There was a problem hiding this comment.
I ended up using future over six for this migration (just because it seems to better transform the code into something that's py3 compatible, and doesn't require you to do almost two rewrites (one that's six compatible, and one that's solely py3 compatible in the future)). And I used the future library with the from builtins import str at the top :D
| def toMongo( self, document, forUpdate=False, modifier=None ): | ||
| newSearch = {} | ||
| for (name, value) in self.query.iteritems( ): | ||
| for (name, value) in self.query.items( ): |
There was a problem hiding this comment.
This will incur a performance hit on Python 2.x. You might want to consider using six.iteritems instead if you want to avoid it.
There was a problem hiding this comment.
I think the performance impact will be small - most of the larger arrays that were in our mongo documents have been factored out into their own collections (for reasons of mongo/memcached performance).
There was a problem hiding this comment.
Hmm, I'm surprised it makes that one of the default changes as part of the auto upgrade tool actually... I would have expected it to have gone with option 3 from their site: https://python-future.org/compatible_idioms.html#iterating-through-dict-keys-values-items
# Python 2 and 3: option 3
from future.utils import iteritems
# or
from six import iteritems
for (key, value) in iteritems(heights):
...
I guess they try default into making it as python3 compatible as possible from the get go, to hint that you should really be moving to py3 sooner rather than later :P
There's a few places that have this change (aka, the Convert iterX methods to use py3 syntax commit). Do you think it's worth updating them to use that import?
|
Also hi @johnnyg, nice to hear from you! Hope life is good. |
|
And thanks for the review @johnnyg 😄 I appreciate you taking the time out to do it! |
Actually not as crazy as expected. I'm still going to be pushing new tests to this branch so that we can confirm things a bit better...
Much easier to look at commit by commit. Click the commits tab, then the first commit, then use
nto go to the next commit automagically