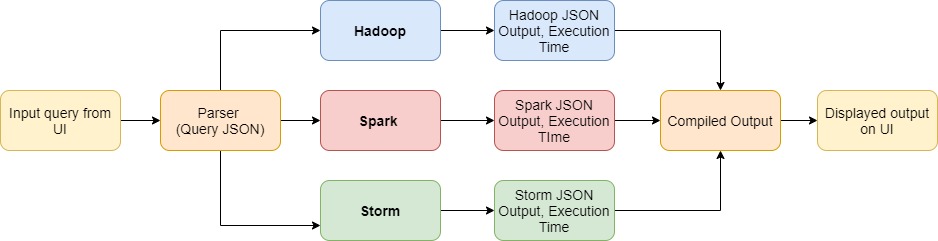
Implementation of SQL queries and executing them using three different frameworks of parallel processing:
- Spark
- Hadoop
- Storm
Detailed Problem Statement can be found here
We are receiving the queries from a single input text file called query.txt. Following are the general query formats:

Example queries:
SELECT * FROM users WHERE gender = "M";SELECT * FROM users INNER JOIN rating ON users.userid = rating.userid WHERE gender = "F";SELECT occupation, COUNT(userid) FROM users WHERE gender = "M" GROUP BY occupation HAVING COUNT(userid) > 10;
We will be testing our code on these queries and displaying the respective outputs of all the three frameworks.
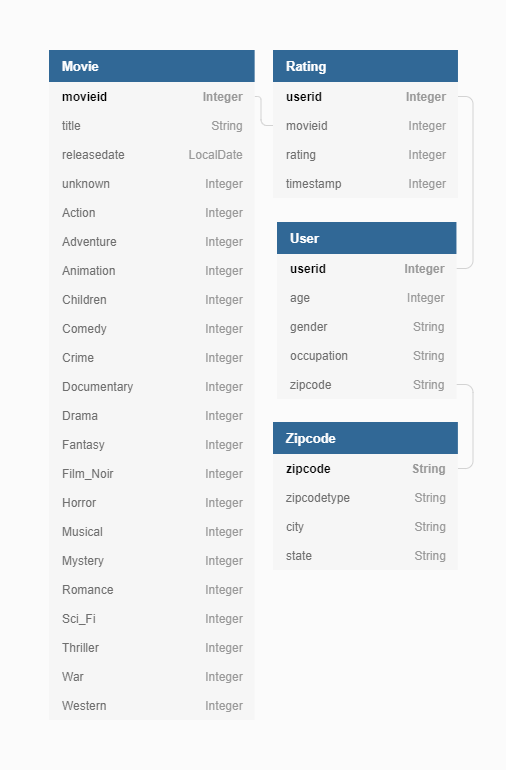
There are four input tables: users, movies, zipcodes, rating.
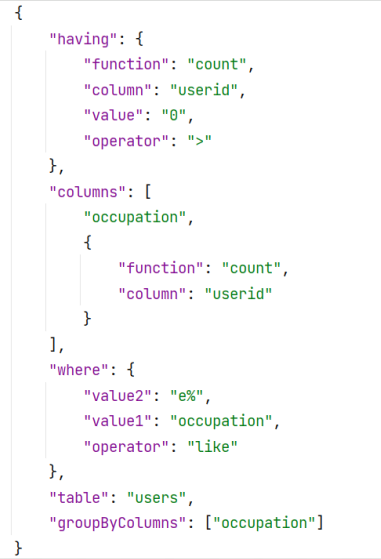
We get the query input from the user as a String. The parseSQL() method parses the input string and outputs a JSONObject called queryJSON. For example,
Input Query:
SELECT occupation, COUNT(userid) FROM users WHERE occupation like e% GROUP BY occupation having COUNT(userid) > 0;
Parsed queryJSON:
Version 3.1.2
- Apache Spark achieves high performance for both batch and streaming data, using a state-of-the-art DAG scheduler, a query optimizer, and a physical execution engine.
- Based on the input query, we get the table name from the generated queryJSON. Using the Spark read() function, we get the relevant CSVs loaded into a Spark Dataset.
- We have created separate methods in Java to execute different aspects of SQL like SELECT, WHERE, JOIN, GROUP BY, etc.
- The query is executed by initiating a SparkSession and calling the relevant methods.
- The output is a JSONObject containing the time taken and the output generated.
Storm version used- 2.2.0
Zookeeper version used- 3.6.3
-
Trident Topology is used for processing SQL queries captured in JSON objects. The topology is built on the fly depending on the operations present in the SQL JSON object. A typical topology consists of Spouts and Bolts. A Spout is used for ingesting data into the topology while Bolts are used for processing the ingested data. Data moves along the topology in the form of Tuple stream.
-
For our use case, a Spout is created for each table, i.e., 4 Spouts in total for reading data from the csv file and converting it into Tuple Stream. Bolts or Operations in Trident Topology are created for different keywords like WHERE, GROUPBY, HAVING, JOIN and SELECT. Finally, the Tuple Stream coming out of the SELECT Bolt is final output of the query and is written to the final output file along with total execution time.
Version 3.2.1
SQL query is parsed and a json object is constructed, which is accessed by mapper and reducer
-
Each Mapper recieves one row of the table as the input and outputs a key value pair which acts as the input to the reducer. The Key-Value pair depicts differnt things for different query types.
-
Depending on the query type, different mapper classes are executed.
-
For query type 1, The Mapper applies the WHEREfunction on each row and outputs the resulting columns as keys to the reducer.The reducer simply prints the keys to the output.
-
For query type 3, The mapper applies the where function to each row, and then outputs the value of the column mentioned in the GROUP BY field in the queryJSON as keys of its output and the row as its value. The reducer calculates the aggregate function mentioned in the HAVINNG field of the queryJSON on the rows which are recieved as values in its input key value pairs and outputs the results.
-
For query type 2, Hadoop had to be configured to take in inputs from multiple sources. Two different classes are executed to process data from 2 different tables. The mapper simply outputs the value of the column on which the tables are joined as the key of its output and the entire row with a tag that indicates which table the row is from, as its value. The reducer recieves the rows from both the tables for a particular key(the value of the column on which the tables are joined) and applies different logic depending on the type of join. It finally outputs the required columns from both the rows in the output file.
The outputs from the reducer are the final outputs of the queries which are written in the output files.