[SPARK-23303][SQL] improve the explain result for data source v2 relations #20647
Conversation
|
Test build #87577 has finished for PR 20647 at commit
|
|
Test build #87578 has finished for PR 20647 at commit
|
There was a problem hiding this comment.
Currently the streaming execution creates the reader once. The reader is mutable and contains 2 kinds of states:
- operator push-down states, e.g. the filters being pushed down.
- streaming related states, like offsets, kafka connection, etc.
For continues mode, it's fine. We create the reader, set offsets, construct the plan, get the physical plan, and process. We mutate the reader states at the beginning and never mutate it again.
For micro-batch mode, we have a problem. We create the reader at the beginning, set reader offset, construct the plan and get the physical plan for every batch. This means we apply operator push-down to this reader many times, and data source v2 doesn't define what the behavior should be for this case. Thus we can't apply operator push-down for streaming data sources.
@marmbrus @tdas @zsxwing @jose-torres I have 2 proposals to support operator push down for streaming relation:
- Introduce a
resetAPI toDataSourceReaderto clear out the operator push-down states. Then we can callresetfor every micro-batch and safely apply operator pushdown. - Do plan analyzing/optimizing/planning only once for micro-batch mode. Theoretically it's not good, as different micro-batch may have different statistics and the optimal physical plan is different, we should rerun the planner for each batch. The benefit is, plan analyzing/optimizing/planning may be costly, doing it once can mitigate the cost. Also adaptive execution can help so it's not that bad to reuse the same physical plan.
There was a problem hiding this comment.
I guess I had assumed that data source v2 guaranteed it would call all the supported stateful methods during planning, and that the most recent call won.
Proposal 2 I don't think will work, since the planning for each batch is required at a fairly deep level and adaptive execution is disabled for streaming. Proposal 1 sounds fine to me, although I'd like to note that this kinda seems like it's working around an issue with having stateful pushdown methods. From an abstract perspective, they're really just action-at-a-distance parameters for createReadTasks().
There was a problem hiding this comment.
@rdblue as well.
I agree that we really need to define the contract here, and personally I would really benefit from seeing a life cycle diagram for all of the different pieces of the API. @tdas and @jose-torres made one for just the write side of streaming and it was super useful for me as someone at a distance that wants to understand what was going on.
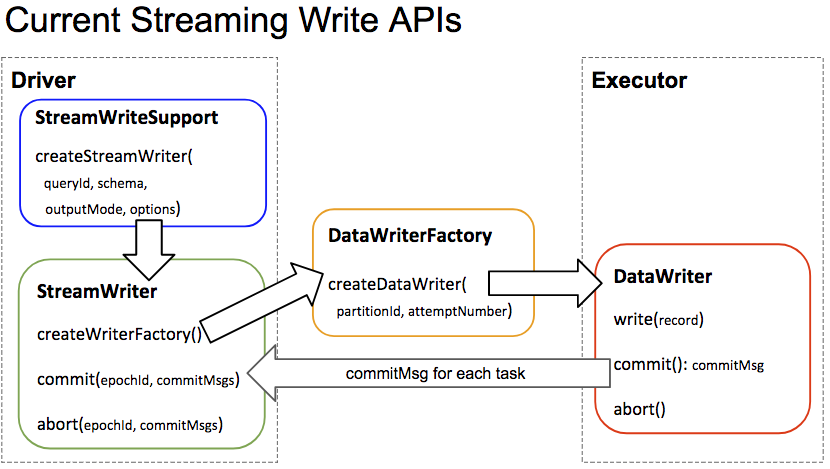
Something like this diagram that also covered when things are resolved, when pushdown happens, and that shows the differences between read/write, microbatch, batch and continuous would be awesome.
Regarding the actual question, I'm not a huge fan of option 2 as it still seems like an implicit contract with this mutable object (assuming I understand the proposal correctly). Option 1 at least means that we could say, "whenever its time to do pushdown: call reset(), do pushdown in some defined order, then call createX(). It is invalid to do more pushdown after createX has been called".
Even better than a reset() might be a cleanClone() method that gives you a fresh copy. As I said above, I don't really understand the lifecycle of the API, but given how we reuse query plan fragments I'm really nervous about mutable objects that are embedded in operators.
I also agree with @jose-torres point that this mechanism looks like action at a distance, but the reset() contract at least localizes it to some degree, and I don't have a better suggestion for a way to support evolvable pushdown.
There was a problem hiding this comment.
We can also ask the implementations to clear out all the state after createX is called, then we don't need to add any new APIs. Anyway there should be a detailed design doc for data source v2 operator push down, it doesn't block this PR.
There was a problem hiding this comment.
I agree that a diagram would really help us follow what's happening and the assumptions that are going into these proposals.
I'd also like to see this discussion happen on the dev list, where more people can participate. The streaming API for v2 wasn't really discussed there (unless I missed it) and given these challenges I think we should go back and have a design and discussion on it. This PR probably isn't the right place to get into these details.
|
Test build #87579 has finished for PR 20647 at commit
|
|
retest this please |
|
Test build #87584 has finished for PR 20647 at commit
|
|
Test build #87588 has finished for PR 20647 at commit
|
| filters: Option[Seq[Expression]] = None, | ||
| userSpecifiedSchema: Option[StructType] = None) extends LeafNode with MultiInstanceRelation { | ||
| userSpecifiedSchema: Option[StructType] = None) | ||
| extends LeafNode with MultiInstanceRelation with DataSourceV2QueryPlan { |
There was a problem hiding this comment.
Extending DataSourceV2QueryPlan changes the definition of equality, which I don't think is correct. At a minimum, I would say that two relations are equal if they produce the same sequence of records. Equality as implemented in this PR would allow completely different folders of data to be considered equal as long as they produce the same schema and have the same filters.
In general, I don't see the utility of DataSourceV2QueryPlan for the purpose of this PR, which is to improve explain results. This doesn't use the source name if it is named, which is a regression in the explain results. It also doesn't indicate that the source is v2. And finally, it doesn't show the most important part of the scan, which is where the data comes from.
There was a problem hiding this comment.
Sorry I didn't realize you removed the extending of DataSourceReaderHolder, otherwise I would point it out in your PR. In general the question is, how should we define the equality of data source relation? It was defined by output, reader.getClass, filters before, and your PR changed it to the default equality of DataSourceV2Relation silently.
The major difference is, should options take part in the equality? The answer is obviously yes, like path, so I'll add options to the equality.
BTW DataSourceV2QueryPlan is needed, as there are 3 plans need to implement explain: DataSourceV2Relation, StreamingDataSourceV2Relation, DataSourceV2ScanExec.
This doesn't use the source name if it is named
I missed that, let me add back.
doesn't indicate that the source is v2
I'll improve it
it doesn't show the most important part of the scan
Do you mean the path option? First I don't think showing all the options is a good idea, as it can be a lot. My future plan is to show these standard options like path, table, etc. Again this is something added silently, there is no consensus about how to explain a data source v2 relation, my PR tries to have people focus on this part and have a consensus.
There was a problem hiding this comment.
Part of the utility of an immutable plan is to make equality work correctly. I thought that was clear, but sorry if it was not. Maybe I should have pointed it out explicitly.
Equality should definitely be based on all of the inputs that affect the output rows. That includes location or table identifier, user schema, filters, requested projection, implementation, and other options. I think case class equality is correct here.
there is no consensus about how to explain a data source v2 relation, my PR tries to have people focus on this part and have a consensus.
That's a good goal for this PR, so I think you should roll back the changes to the relation so equality is not affected by it.
Do you mean the path option?
Yes. The data that will be scanned is an important part. As you know, I think this should be part of the relation itself and not options. That would solve this problem.
| * to the non-streaming relation. | ||
| * A specialization of [[DataSourceV2Relation]] with the streaming bit set to true. | ||
| * | ||
| * Note that, this plan has a mutable reader, so Spark won't apply operator push-down for this plan, |
There was a problem hiding this comment.
I'm -0 on including this in a PR to improve explain results. This could needlessly cause commit conflicts when maintaining a branch. But, this is small and needs to go in somewhere. I would remove it, though.
There was a problem hiding this comment.
are you suggesting we should open a JIRA to fix the internal document? We usually fix them in related PRs that touch the class...
There was a problem hiding this comment.
No, I think it is okay, but I would not add it if it were my commit. It is unlikely that this will cause commit conflicts so it should be fine. I would just prefer to have a docs commit later to keep track of this.
| override def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match { | ||
| case relation: DataSourceV2Relation => | ||
| DataSourceV2ScanExec(relation.output, relation.reader) :: Nil | ||
| case r: DataSourceV2Relation => |
There was a problem hiding this comment.
relation is called many times in the next line, renaming it to r can shorten the code below.
There was a problem hiding this comment.
I don't think this change is necessary and it just makes the patch larger.
There was a problem hiding this comment.
Strictly speaking, if I don't change this line, then I need to split the next line into 2 lines, as I need to pass more parameters, so it's still a 2-line diff.
I think tiny things like this is really not worth to be pointed during code review, we should save our effort to focus more on the actual code logic. What do you think?
There was a problem hiding this comment.
I'm pointing it out because I think it is significant. This is also why I sent a note to the dev list. Changes like this make it much harder to work with Spark because little things change that are not necessary and cause conflicts. That's a problem not just when I'm maintaining a branch, but also when I'm trying to get a PR committed. These changes cause more work because we have to rebase PRs and update for variables that have changed names in the name of style.
In this particular case, I would probably wrap the line that is too long. If you want to rename to fix it, I'd consider that reasonable. But all the other cases that aren't necessary should be reverted.
| plan: LogicalPlan): LogicalPlan = plan transformUp { | ||
| // PhysicalOperation guarantees that filters are deterministic; no need to check | ||
| case PhysicalOperation(project, newFilters, relation : DataSourceV2Relation) => | ||
| case PhysicalOperation(project, newFilters, relation: DataSourceV2Relation) => |
There was a problem hiding this comment.
While I'd rather not have this space there either (looks like an accident), there are no other changes to this file and this "fix" is not necessary. The risk of this causing commit conflicts outweighs the benefit of conforming to style so it should be removed.
| val _logicalPlan = analyzedPlan.transform { | ||
| case streamingRelation@StreamingRelation(dataSourceV1, sourceName, output) => | ||
| toExecutionRelationMap.getOrElseUpdate(streamingRelation, { | ||
| case s @ StreamingRelation(dsV1, sourceName, output) => |
There was a problem hiding this comment.
These renames are cosmetic, and unnecessary changes like this cause commit conflicts. I think these changes should be reverted.
There was a problem hiding this comment.
This is to make the naming consistent, see https://github.com/apache/spark/pull/20647/files#diff-c2959c723f334c32806217216014362eL89
In general we don't forbid users to fix some code style issue in related PRs, otherwise we need to have code-style-fix-only PRs, which is not the common case.
There was a problem hiding this comment.
If you are touching that specific code then its fine to fix the style, but in general I tend to agree that it makes the diff harder to read and commit harder to back port if you include spurious changes.
I've even seen guidelines that specifically prohibit fixing style just to fix style since it obfuscates the history.
There was a problem hiding this comment.
yea I was touching the code here to retain the DataSourceV2 instance, and fixed the code style.
There was a problem hiding this comment.
I don't think this counts as touching the code. This is near code you needed to change, but it makes the changes in this patch larger and more likely to conflict.
Changes like this make maintenance much more difficult because they can cause conflicts that weren't necessary. After this change, commits would use s instead of streamingRelation, which would prevent any commit after this to be applied to a branch without this one. If that is avoidable because the change is not necessary, I want to avoid it.
| reader.setOffsetRange( | ||
| toJava(current), | ||
| Optional.of(availableV2)) | ||
| reader.setOffsetRange(toJava(current), Optional.of(availableV2)) |
There was a problem hiding this comment.
This is another style-only change that will cause conflicts.
| logDebug(s"Retrieving data from $reader: $current -> $availableV2") | ||
| Some(reader -> | ||
| new StreamingDataSourceV2Relation(reader.readSchema().toAttributes, reader)) | ||
| Some(reader -> StreamingDataSourceV2Relation( |
There was a problem hiding this comment.
I realize that this is a pre-existing problem, but why is it necessary to create a relation from a reader here? The addition of FakeDataSourceV2 and the readerToDataSourceMap aren't unresonable because the relation should have a reference to the DataSourceV2 instance, but I doubt that the relation should be created here.
There was a problem hiding this comment.
It's an artifact of the current implementation of streaming progress reporting, which assumes at a deep and hard to untangle level that new data is represented by a map of source -> logical plan.
There was a problem hiding this comment.
Sounds like this isn't something that should hold up this commit then.
Is there a design doc for what you're describing that I can read to familiarize myself with the issues here? I'd like to participate more on the streaming side as it relates to the new data source API.
There was a problem hiding this comment.
When it comes to the streaming execution code, the basic problem is that it was more evolved than designed. For example, there's no particular reason to use a logical plan; the map is only ever used in order to construct another map of source -> physical plan stats. Untangling StreamExecution is definitely something we need to do, but that's going to be annoying and I think it's sufficiently orthogonal to the V2 migration to put off.
There's currently no design doc for the streaming aspects of DataSourceV2. We kinda rushed an experimental version out the door, because it was coupled with the experimental ContinuousExecution streaming mode. I'm working on going back and cleaning things up; I'll send docs to the dev list and make sure to @ you on the changes.
There was a problem hiding this comment.
@rdblue There was a doc as part of this SPIP: https://issues.apache.org/jira/browse/SPARK-20928, but it has definitely evolved enough past that we should update and send to the dev list again.
Things like the logical plan requirement in execution will likely be significantly easier to remove once we have a full V2 API and can remove the legacy internal API for streaming.
| assert("StreamingDataSourceV2Relation".r.findAllMatchIn(explainWithoutExtended).size === 0) | ||
| assert("DataSourceV2Scan".r.findAllMatchIn(explainWithoutExtended).size === 1) | ||
| assert("Streaming Relation".r.findAllMatchIn(explainWithoutExtended).size === 0) | ||
| assert("Scan FakeDataSourceV2".r.findAllMatchIn(explainWithoutExtended).size === 1) |
There was a problem hiding this comment.
Why is this using the fake?
|
|
||
| package org.apache.spark.sql.streaming.continuous | ||
|
|
||
| import java.util.UUID |
There was a problem hiding this comment.
This is another cosmetic change that could cause conflicts.
|
Test build #87624 has finished for PR 20647 at commit
|
|
Test build #87634 has finished for PR 20647 at commit
|
|
Thanks for removing the equality methods. This changes equality for the scan and streaming relation, though. Are those significant changes? I still think this should not be committed until the style-only changes are rolled back. This is a significant source of headache for branch maintainers and contributors. |
If we think this is the right equality for I've rolled back unnecessary style-only changes, but leave the one that clean up unused imports. I think this should be encouraged, it's very hard to find out unused imports during code review, and they are mostly fixed post-hoc: people find and fix them while touching files in the PR, some IDE can even do it automatically when you save the file. |
|
Test build #87640 has finished for PR 20647 at commit
|
| override def simpleString: String = "ScanV2 " + metadataString | ||
|
|
||
| override def equals(other: Any): Boolean = other match { | ||
| case other: StreamingDataSourceV2Relation => |
There was a problem hiding this comment.
Should be DataSourceV2ScanExec.
|
@cloud-fan, I found a couple new problems but otherwise this looks good. I see you rolled back the equality changes for the scan node and streaming relation. What is the JIRA issue to update v2 equality? |
|
One more thing on matching the behavior of other nodes for the schema: since you agree that the scan nodes should report types, can you open an issue for it? I'm also fine adding it here instead of doing it later since it makes sense as part of these changes. It's up to you. |
|
Test build #87724 has finished for PR 20647 at commit
|
|
Hi @rdblue , I've opened https://issues.apache.org/jira/browse/SPARK-23531 to include the type info. I'd like to do it later as it's a general problem in Spark SQL and many plans need to be updated like leaf nodes other than data source scan. |
| // TODO: unify the equal/hashCode implementation for all data source v2 query plans. | ||
| override def equals(other: Any): Boolean = other match { | ||
| case other: StreamingDataSourceV2Relation => | ||
| output == other.output && reader.getClass == other.reader.getClass && options == other.options |
There was a problem hiding this comment.
Now it's exactly same as before. We should clean it up after figure out how to push down operators to streaming relation.
|
|
||
| val entriesStr = if (entries.nonEmpty) { | ||
| Utils.truncatedString(entries.map { | ||
| case (key, value) => StringUtils.abbreviate(redact(key + ":" + value), 100) |
There was a problem hiding this comment.
Now users can match password by password:.+ to redact password.
There was a problem hiding this comment.
Why not redact the map? That would work with the default redaction pattern. If I understand correctly, this will require customization.
There was a problem hiding this comment.
If you look at the SQLConf.stringRedationPattern, the default pattern is empty. So it needs customization anyway, and this implementation is easier to customize. If we redact the entire map, I'm not sure how to write a regex to precisely match the password part.
There was a problem hiding this comment.
Yes, part of the problem is that we're using that pattern and not the secret redaction pattern, which defaults to "(?i)secret|password|url|user|username".r: https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/internal/config/package.scala#L328-L335
If you used the map redaction method, it would use the default pattern to match keys that should be redacted: https://github.com/apache/spark/blob/a5a4b83/core/src/main/scala/org/apache/spark/util/Utils.scala#L2723-L2729
|
Test build #87750 has finished for PR 20647 at commit
|
|
retest this please |
|
Test build #87762 has finished for PR 20647 at commit
|
| entries += "Pushed Filters" -> filters.mkString("[", ", ", "]") | ||
| } | ||
|
|
||
| // TODO: we should only display some standard options like path, table, etc. |
There was a problem hiding this comment.
For followup, there are 2 proposals:
- define some standard options and only display standard options, if they are specified.
- Create a new mix-in interface to allow data source implementations to decide which options they want to show during explain.
|
Test build #87818 has finished for PR 20647 at commit
|
|
|
||
| val entriesStr = if (entries.nonEmpty) { | ||
| Utils.truncatedString(entries.map { | ||
| case (key, value) => key + ": " + StringUtils.abbreviate(redact(value), 100) |
There was a problem hiding this comment.
Nit: Why redact options twice? Is there anything in entries but not options that needs to be redacted?
| "" | ||
| } | ||
|
|
||
| s"$sourceName$outputStr$entriesStr" |
There was a problem hiding this comment.
Should there be spaces? I don't see spaces added to the components, so it looks like this might look squished together.
There was a problem hiding this comment.
outputStr doesn't need space, we want Relation[a: int] instead of Relation [a: int]. This is also what data source v1 explains.
entriesStr has space. It's added via the paramter of mkString: " (", ", ", ")". It's mostly to avoid the extra space if entriesStr is empty.
| val entries = scala.collection.mutable.ArrayBuffer.empty[(String, String)] | ||
|
|
||
| if (filters.nonEmpty) { | ||
| entries += "Pushed Filters" -> filters.mkString("[", ", ", "]") |
There was a problem hiding this comment.
Nit: Does this need "Pushed"?
|
Looks like there's an unnecessary redact call in there and I found a couple of nits, but I think this is ready to go. +1 |
|
Test build #87877 has finished for PR 20647 at commit
|
|
Test build #87981 has finished for PR 20647 at commit
|
|
thanks, merging to master! |
…tions
The proposed explain format:
**[streaming header] [RelationV2/ScanV2] [data source name] [output] [pushed filters] [options]**
**streaming header**: if it's a streaming relation, put a "Streaming" at the beginning.
**RelationV2/ScanV2**: if it's a logical plan, put a "RelationV2", else, put a "ScanV2"
**data source name**: the simple class name of the data source implementation
**output**: a string of the plan output attributes
**pushed filters**: a string of all the filters that have been pushed to this data source
**options**: all the options to create the data source reader.
The current explain result for data source v2 relation is unreadable:
```
== Parsed Logical Plan ==
'Filter ('i > 6)
+- AnalysisBarrier
+- Project [j#1]
+- DataSourceV2Relation [i#0, j#1], org.apache.spark.sql.sources.v2.AdvancedDataSourceV2$Reader3b415940
== Analyzed Logical Plan ==
j: int
Project [j#1]
+- Filter (i#0 > 6)
+- Project [j#1, i#0]
+- DataSourceV2Relation [i#0, j#1], org.apache.spark.sql.sources.v2.AdvancedDataSourceV2$Reader3b415940
== Optimized Logical Plan ==
Project [j#1]
+- Filter isnotnull(i#0)
+- DataSourceV2Relation [i#0, j#1], org.apache.spark.sql.sources.v2.AdvancedDataSourceV2$Reader3b415940
== Physical Plan ==
*(1) Project [j#1]
+- *(1) Filter isnotnull(i#0)
+- *(1) DataSourceV2Scan [i#0, j#1], org.apache.spark.sql.sources.v2.AdvancedDataSourceV2$Reader3b415940
```
after this PR
```
== Parsed Logical Plan ==
'Project [unresolvedalias('j, None)]
+- AnalysisBarrier
+- RelationV2 AdvancedDataSourceV2[i#0, j#1]
== Analyzed Logical Plan ==
j: int
Project [j#1]
+- RelationV2 AdvancedDataSourceV2[i#0, j#1]
== Optimized Logical Plan ==
RelationV2 AdvancedDataSourceV2[j#1]
== Physical Plan ==
*(1) ScanV2 AdvancedDataSourceV2[j#1]
```
-------
```
== Analyzed Logical Plan ==
i: int, j: int
Filter (i#88 > 3)
+- RelationV2 JavaAdvancedDataSourceV2[i#88, j#89]
== Optimized Logical Plan ==
Filter isnotnull(i#88)
+- RelationV2 JavaAdvancedDataSourceV2[i#88, j#89] (Pushed Filters: [GreaterThan(i,3)])
== Physical Plan ==
*(1) Filter isnotnull(i#88)
+- *(1) ScanV2 JavaAdvancedDataSourceV2[i#88, j#89] (Pushed Filters: [GreaterThan(i,3)])
```
an example for streaming query
```
== Parsed Logical Plan ==
Aggregate [value#6], [value#6, count(1) AS count(1)#11L]
+- SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, input[0, java.lang.String, true], true, false) AS value#6]
+- MapElements <function1>, class java.lang.String, [StructField(value,StringType,true)], obj#5: java.lang.String
+- DeserializeToObject cast(value#25 as string).toString, obj#4: java.lang.String
+- Streaming RelationV2 MemoryStreamDataSource[value#25]
== Analyzed Logical Plan ==
value: string, count(1): bigint
Aggregate [value#6], [value#6, count(1) AS count(1)#11L]
+- SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, input[0, java.lang.String, true], true, false) AS value#6]
+- MapElements <function1>, class java.lang.String, [StructField(value,StringType,true)], obj#5: java.lang.String
+- DeserializeToObject cast(value#25 as string).toString, obj#4: java.lang.String
+- Streaming RelationV2 MemoryStreamDataSource[value#25]
== Optimized Logical Plan ==
Aggregate [value#6], [value#6, count(1) AS count(1)#11L]
+- SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, input[0, java.lang.String, true], true, false) AS value#6]
+- MapElements <function1>, class java.lang.String, [StructField(value,StringType,true)], obj#5: java.lang.String
+- DeserializeToObject value#25.toString, obj#4: java.lang.String
+- Streaming RelationV2 MemoryStreamDataSource[value#25]
== Physical Plan ==
*(4) HashAggregate(keys=[value#6], functions=[count(1)], output=[value#6, count(1)#11L])
+- StateStoreSave [value#6], state info [ checkpoint = *********(redacted)/cloud/dev/spark/target/tmp/temporary-549f264b-2531-4fcb-a52f-433c77347c12/state, runId = f84d9da9-2f8c-45c1-9ea1-70791be684de, opId = 0, ver = 0, numPartitions = 5], Complete, 0
+- *(3) HashAggregate(keys=[value#6], functions=[merge_count(1)], output=[value#6, count#16L])
+- StateStoreRestore [value#6], state info [ checkpoint = *********(redacted)/cloud/dev/spark/target/tmp/temporary-549f264b-2531-4fcb-a52f-433c77347c12/state, runId = f84d9da9-2f8c-45c1-9ea1-70791be684de, opId = 0, ver = 0, numPartitions = 5]
+- *(2) HashAggregate(keys=[value#6], functions=[merge_count(1)], output=[value#6, count#16L])
+- Exchange hashpartitioning(value#6, 5)
+- *(1) HashAggregate(keys=[value#6], functions=[partial_count(1)], output=[value#6, count#16L])
+- *(1) SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, input[0, java.lang.String, true], true, false) AS value#6]
+- *(1) MapElements <function1>, obj#5: java.lang.String
+- *(1) DeserializeToObject value#25.toString, obj#4: java.lang.String
+- *(1) ScanV2 MemoryStreamDataSource[value#25]
```
N/A
Author: Wenchen Fan <[email protected]>
Closes apache#20647 from cloud-fan/explain.
(cherry picked from commit ad640a5)
Conflicts:
external/kafka-0-10-sql/src/test/scala/org/apache/spark/sql/kafka010/KafkaSourceSuite.scala
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/DataSourceReaderHolder.scala
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/DataSourceV2Relation.scala
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/MicroBatchExecution.scala
sql/core/src/test/scala/org/apache/spark/sql/streaming/StreamSuite.scala
sql/core/src/test/scala/org/apache/spark/sql/streaming/StreamTest.scala
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/MicroBatchExecution.scala
…tions
The proposed explain format:
**[streaming header] [RelationV2/ScanV2] [data source name] [output] [pushed filters] [options]**
**streaming header**: if it's a streaming relation, put a "Streaming" at the beginning.
**RelationV2/ScanV2**: if it's a logical plan, put a "RelationV2", else, put a "ScanV2"
**data source name**: the simple class name of the data source implementation
**output**: a string of the plan output attributes
**pushed filters**: a string of all the filters that have been pushed to this data source
**options**: all the options to create the data source reader.
The current explain result for data source v2 relation is unreadable:
```
== Parsed Logical Plan ==
'Filter ('i > 6)
+- AnalysisBarrier
+- Project [j#1]
+- DataSourceV2Relation [i#0, j#1], org.apache.spark.sql.sources.v2.AdvancedDataSourceV2$Reader3b415940
== Analyzed Logical Plan ==
j: int
Project [j#1]
+- Filter (i#0 > 6)
+- Project [j#1, i#0]
+- DataSourceV2Relation [i#0, j#1], org.apache.spark.sql.sources.v2.AdvancedDataSourceV2$Reader3b415940
== Optimized Logical Plan ==
Project [j#1]
+- Filter isnotnull(i#0)
+- DataSourceV2Relation [i#0, j#1], org.apache.spark.sql.sources.v2.AdvancedDataSourceV2$Reader3b415940
== Physical Plan ==
*(1) Project [j#1]
+- *(1) Filter isnotnull(i#0)
+- *(1) DataSourceV2Scan [i#0, j#1], org.apache.spark.sql.sources.v2.AdvancedDataSourceV2$Reader3b415940
```
after this PR
```
== Parsed Logical Plan ==
'Project [unresolvedalias('j, None)]
+- AnalysisBarrier
+- RelationV2 AdvancedDataSourceV2[i#0, j#1]
== Analyzed Logical Plan ==
j: int
Project [j#1]
+- RelationV2 AdvancedDataSourceV2[i#0, j#1]
== Optimized Logical Plan ==
RelationV2 AdvancedDataSourceV2[j#1]
== Physical Plan ==
*(1) ScanV2 AdvancedDataSourceV2[j#1]
```
-------
```
== Analyzed Logical Plan ==
i: int, j: int
Filter (i#88 > 3)
+- RelationV2 JavaAdvancedDataSourceV2[i#88, j#89]
== Optimized Logical Plan ==
Filter isnotnull(i#88)
+- RelationV2 JavaAdvancedDataSourceV2[i#88, j#89] (Pushed Filters: [GreaterThan(i,3)])
== Physical Plan ==
*(1) Filter isnotnull(i#88)
+- *(1) ScanV2 JavaAdvancedDataSourceV2[i#88, j#89] (Pushed Filters: [GreaterThan(i,3)])
```
an example for streaming query
```
== Parsed Logical Plan ==
Aggregate [value#6], [value#6, count(1) AS count(1)#11L]
+- SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, input[0, java.lang.String, true], true, false) AS value#6]
+- MapElements <function1>, class java.lang.String, [StructField(value,StringType,true)], obj#5: java.lang.String
+- DeserializeToObject cast(value#25 as string).toString, obj#4: java.lang.String
+- Streaming RelationV2 MemoryStreamDataSource[value#25]
== Analyzed Logical Plan ==
value: string, count(1): bigint
Aggregate [value#6], [value#6, count(1) AS count(1)#11L]
+- SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, input[0, java.lang.String, true], true, false) AS value#6]
+- MapElements <function1>, class java.lang.String, [StructField(value,StringType,true)], obj#5: java.lang.String
+- DeserializeToObject cast(value#25 as string).toString, obj#4: java.lang.String
+- Streaming RelationV2 MemoryStreamDataSource[value#25]
== Optimized Logical Plan ==
Aggregate [value#6], [value#6, count(1) AS count(1)#11L]
+- SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, input[0, java.lang.String, true], true, false) AS value#6]
+- MapElements <function1>, class java.lang.String, [StructField(value,StringType,true)], obj#5: java.lang.String
+- DeserializeToObject value#25.toString, obj#4: java.lang.String
+- Streaming RelationV2 MemoryStreamDataSource[value#25]
== Physical Plan ==
*(4) HashAggregate(keys=[value#6], functions=[count(1)], output=[value#6, count(1)#11L])
+- StateStoreSave [value#6], state info [ checkpoint = *********(redacted)/cloud/dev/spark/target/tmp/temporary-549f264b-2531-4fcb-a52f-433c77347c12/state, runId = f84d9da9-2f8c-45c1-9ea1-70791be684de, opId = 0, ver = 0, numPartitions = 5], Complete, 0
+- *(3) HashAggregate(keys=[value#6], functions=[merge_count(1)], output=[value#6, count#16L])
+- StateStoreRestore [value#6], state info [ checkpoint = *********(redacted)/cloud/dev/spark/target/tmp/temporary-549f264b-2531-4fcb-a52f-433c77347c12/state, runId = f84d9da9-2f8c-45c1-9ea1-70791be684de, opId = 0, ver = 0, numPartitions = 5]
+- *(2) HashAggregate(keys=[value#6], functions=[merge_count(1)], output=[value#6, count#16L])
+- Exchange hashpartitioning(value#6, 5)
+- *(1) HashAggregate(keys=[value#6], functions=[partial_count(1)], output=[value#6, count#16L])
+- *(1) SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, input[0, java.lang.String, true], true, false) AS value#6]
+- *(1) MapElements <function1>, obj#5: java.lang.String
+- *(1) DeserializeToObject value#25.toString, obj#4: java.lang.String
+- *(1) ScanV2 MemoryStreamDataSource[value#25]
```
N/A
Author: Wenchen Fan <[email protected]>
Closes apache#20647 from cloud-fan/explain.
(cherry picked from commit ad640a5)
Conflicts:
external/kafka-0-10-sql/src/test/scala/org/apache/spark/sql/kafka010/KafkaSourceSuite.scala
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/DataSourceReaderHolder.scala
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/DataSourceV2Relation.scala
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/MicroBatchExecution.scala
sql/core/src/test/scala/org/apache/spark/sql/streaming/StreamSuite.scala
sql/core/src/test/scala/org/apache/spark/sql/streaming/StreamTest.scala
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/MicroBatchExecution.scala
…tions
The proposed explain format:
**[streaming header] [RelationV2/ScanV2] [data source name] [output] [pushed filters] [options]**
**streaming header**: if it's a streaming relation, put a "Streaming" at the beginning.
**RelationV2/ScanV2**: if it's a logical plan, put a "RelationV2", else, put a "ScanV2"
**data source name**: the simple class name of the data source implementation
**output**: a string of the plan output attributes
**pushed filters**: a string of all the filters that have been pushed to this data source
**options**: all the options to create the data source reader.
The current explain result for data source v2 relation is unreadable:
```
== Parsed Logical Plan ==
'Filter ('i > 6)
+- AnalysisBarrier
+- Project [j#1]
+- DataSourceV2Relation [i#0, j#1], org.apache.spark.sql.sources.v2.AdvancedDataSourceV2$Reader3b415940
== Analyzed Logical Plan ==
j: int
Project [j#1]
+- Filter (i#0 > 6)
+- Project [j#1, i#0]
+- DataSourceV2Relation [i#0, j#1], org.apache.spark.sql.sources.v2.AdvancedDataSourceV2$Reader3b415940
== Optimized Logical Plan ==
Project [j#1]
+- Filter isnotnull(i#0)
+- DataSourceV2Relation [i#0, j#1], org.apache.spark.sql.sources.v2.AdvancedDataSourceV2$Reader3b415940
== Physical Plan ==
*(1) Project [j#1]
+- *(1) Filter isnotnull(i#0)
+- *(1) DataSourceV2Scan [i#0, j#1], org.apache.spark.sql.sources.v2.AdvancedDataSourceV2$Reader3b415940
```
after this PR
```
== Parsed Logical Plan ==
'Project [unresolvedalias('j, None)]
+- AnalysisBarrier
+- RelationV2 AdvancedDataSourceV2[i#0, j#1]
== Analyzed Logical Plan ==
j: int
Project [j#1]
+- RelationV2 AdvancedDataSourceV2[i#0, j#1]
== Optimized Logical Plan ==
RelationV2 AdvancedDataSourceV2[j#1]
== Physical Plan ==
*(1) ScanV2 AdvancedDataSourceV2[j#1]
```
-------
```
== Analyzed Logical Plan ==
i: int, j: int
Filter (i#88 > 3)
+- RelationV2 JavaAdvancedDataSourceV2[i#88, j#89]
== Optimized Logical Plan ==
Filter isnotnull(i#88)
+- RelationV2 JavaAdvancedDataSourceV2[i#88, j#89] (Pushed Filters: [GreaterThan(i,3)])
== Physical Plan ==
*(1) Filter isnotnull(i#88)
+- *(1) ScanV2 JavaAdvancedDataSourceV2[i#88, j#89] (Pushed Filters: [GreaterThan(i,3)])
```
an example for streaming query
```
== Parsed Logical Plan ==
Aggregate [value#6], [value#6, count(1) AS count(1)#11L]
+- SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, input[0, java.lang.String, true], true, false) AS value#6]
+- MapElements <function1>, class java.lang.String, [StructField(value,StringType,true)], obj#5: java.lang.String
+- DeserializeToObject cast(value#25 as string).toString, obj#4: java.lang.String
+- Streaming RelationV2 MemoryStreamDataSource[value#25]
== Analyzed Logical Plan ==
value: string, count(1): bigint
Aggregate [value#6], [value#6, count(1) AS count(1)#11L]
+- SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, input[0, java.lang.String, true], true, false) AS value#6]
+- MapElements <function1>, class java.lang.String, [StructField(value,StringType,true)], obj#5: java.lang.String
+- DeserializeToObject cast(value#25 as string).toString, obj#4: java.lang.String
+- Streaming RelationV2 MemoryStreamDataSource[value#25]
== Optimized Logical Plan ==
Aggregate [value#6], [value#6, count(1) AS count(1)#11L]
+- SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, input[0, java.lang.String, true], true, false) AS value#6]
+- MapElements <function1>, class java.lang.String, [StructField(value,StringType,true)], obj#5: java.lang.String
+- DeserializeToObject value#25.toString, obj#4: java.lang.String
+- Streaming RelationV2 MemoryStreamDataSource[value#25]
== Physical Plan ==
*(4) HashAggregate(keys=[value#6], functions=[count(1)], output=[value#6, count(1)#11L])
+- StateStoreSave [value#6], state info [ checkpoint = *********(redacted)/cloud/dev/spark/target/tmp/temporary-549f264b-2531-4fcb-a52f-433c77347c12/state, runId = f84d9da9-2f8c-45c1-9ea1-70791be684de, opId = 0, ver = 0, numPartitions = 5], Complete, 0
+- *(3) HashAggregate(keys=[value#6], functions=[merge_count(1)], output=[value#6, count#16L])
+- StateStoreRestore [value#6], state info [ checkpoint = *********(redacted)/cloud/dev/spark/target/tmp/temporary-549f264b-2531-4fcb-a52f-433c77347c12/state, runId = f84d9da9-2f8c-45c1-9ea1-70791be684de, opId = 0, ver = 0, numPartitions = 5]
+- *(2) HashAggregate(keys=[value#6], functions=[merge_count(1)], output=[value#6, count#16L])
+- Exchange hashpartitioning(value#6, 5)
+- *(1) HashAggregate(keys=[value#6], functions=[partial_count(1)], output=[value#6, count#16L])
+- *(1) SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, input[0, java.lang.String, true], true, false) AS value#6]
+- *(1) MapElements <function1>, obj#5: java.lang.String
+- *(1) DeserializeToObject value#25.toString, obj#4: java.lang.String
+- *(1) ScanV2 MemoryStreamDataSource[value#25]
```
N/A
Author: Wenchen Fan <[email protected]>
Closes apache#20647 from cloud-fan/explain.
Ref: LIHADOOP-48531
RB=1842516
A=
What changes were proposed in this pull request?
The proposed explain format:
[streaming header] [RelationV2/ScanV2] [data source name] [output] [pushed filters] [options]
streaming header: if it's a streaming relation, put a "Streaming" at the beginning.
RelationV2/ScanV2: if it's a logical plan, put a "RelationV2", else, put a "ScanV2"
data source name: the simple class name of the data source implementation
output: a string of the plan output attributes
pushed filters: a string of all the filters that have been pushed to this data source
options: all the options to create the data source reader.
The current explain result for data source v2 relation is unreadable:
after this PR
an example for streaming query
How was this patch tested?
N/A