[SPARK-27402][SQL][test-hadoop3.2][test-maven] Fix hadoop-3.2 test issue(except the hive-thriftserver module) #24391
There are no files selected for viewing
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -15,9 +15,17 @@ | |
| # limitations under the License. | ||
| # | ||
|
|
||
| from __future__ import print_function | ||
| from functools import total_ordering | ||
| import itertools | ||
| import re | ||
| import os | ||
|
|
||
| if os.environ.get("AMPLAB_JENKINS"): | ||
| hadoop_version = os.environ.get("AMPLAB_JENKINS_BUILD_PROFILE", "hadoop2.7") | ||
| else: | ||
| hadoop_version = os.environ.get("HADOOP_PROFILE", "hadoop2.7") | ||
| print("[info] Choosing supported modules with Hadoop profile", hadoop_version) | ||
|
|
||
| all_modules = [] | ||
|
|
||
|
Member
There was a problem hiding this comment. We should have a log message to show which profile we are using; otherwise, it is hard for us to know which profile is activated.
Member
Author
There was a problem hiding this comment. Yes. we already have these log message:
Member
There was a problem hiding this comment. What I mean, we should have a log message to show which profile is being actually used. Just relying on the command parameter lists does not sound very reliable |
||
|
|
@@ -72,7 +80,11 @@ def __init__(self, name, dependencies, source_file_regexes, build_profile_flags= | |
| self.dependent_modules = set() | ||
| for dep in dependencies: | ||
| dep.dependent_modules.add(self) | ||
| # TODO: Skip hive-thriftserver module for hadoop-3.2. remove this once hadoop-3.2 support it | ||
| if name == "hive-thriftserver" and hadoop_version == "hadoop3.2": | ||
|
Member
Author
There was a problem hiding this comment. Used to skip hive-thriftserver module for hadoop-3.2. Will revert this change once we can merge.
Member
There was a problem hiding this comment. Maybe leave a TODO here just to try to make sure that doesn't get lost |
||
| print("[info] Skip unsupported module:", name) | ||
| else: | ||
| all_modules.append(self) | ||
|
|
||
| def contains_file(self, filename): | ||
| return any(re.match(p, filename) for p in self.source_file_prefixes) | ||
|
|
||
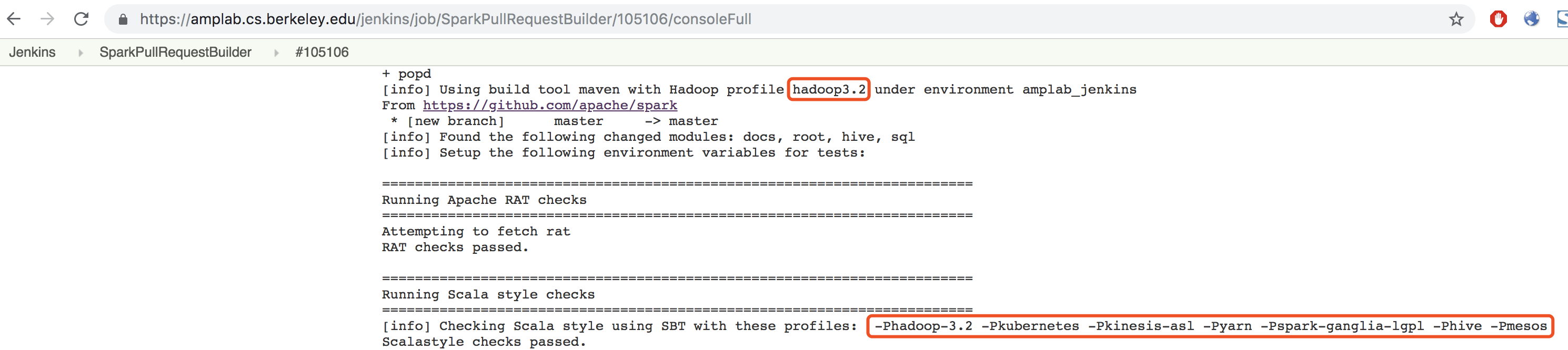

There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
@wangyum, this will shows the info every time this modules is imported. why did we do this here?
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
okay. it's a temp fix so I'm fine. I will make a followup to handle https://github.com/apache/spark/pull/24639/files
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Skip the
hive-thriftservermodule when running the hadoop-3.2 test. Will remove it in another PR: https://github.com/apache/spark/pull/24628/filesThere was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Thank you @HyukjinKwon