[SPARK-27734][CORE][SQL] Add memory based thresholds for shuffle spill #24618
Conversation
|
Jenkins, ok to test. |
core/src/main/java/org/apache/spark/util/collection/unsafe/sort/UnsafeExternalSorter.java
Outdated
Show resolved
Hide resolved
|
Unit tests that need fixing/extending in spark-sql module:
|
3ae6fa0 to
4b52db8
Compare
|
We're closing this PR because it hasn't been updated in a while. If you'd like to revive this PR, please reopen it! |
|
Removed the |
|
/cc @dongjoon-hyun as a committer |
|
Thank you for pinging me, @amuraru . |
|
BTW, this PR is abandoned too long. Please resolve the conflict and see the Jenkins result. |
4b52db8 to
6c667cb
Compare
|
@dongjoon-hyun sorry for dropping the ball here. I rebased on top of
I updated all unit-tests but not sure if net new UT are required - the changes are covered well by existing UTs. Let me know what you think. |
When running large shuffles (700TB input data, 200k map tasks, 50k reducers on a 300 nodes cluster) the job is regularly OOMing in map and reduce phase. IIUC ShuffleExternalSorter (map side) and ExternalAppendOnlyMap and ExternalSorter (reduce side) are trying to max out the available execution memory. This in turn doesn't play nice with the Garbage Collector and executors are failing with OutOfMemoryError when the memory allocation from these in-memory structure is maxing out the available heap size (in our case we are running with 9 cores/executor, 32G per executor) To mitigate this, one can set spark.shuffle.spill.numElementsForceSpillThreshold to force the spill on disk. While this config works, it is not flexible enough as it's expressed in number of elements, and in our case we run multiple shuffles in a single job and element size is different from one stage to another. This patch extends the spill threshold behaviour and adds two new parameters to control the spill based on memory usage: - spark.shuffle.spill.map.maxRecordsSizeForSpillThreshold - spark.shuffle.spill.reduce.maxRecordsSizeForSpillThreshold
6c667cb to
ab410fc
Compare
|
ok to test |
|
add to whitelist |
|
Test build #119010 has finished for PR 24618 at commit
|
|
retest this please. |
|
Test build #119031 has finished for PR 24618 at commit
|
|
At quick glance the java codegen test failure would probably be unrelated, jenkins retest this please. |
|
Test build #119496 has finished for PR 24618 at commit
|
|
Looking into it |
| "until we reach some limitations, like the max page size limitation for the pointer " + | ||
| "array in the sorter.") | ||
| .bytesConf(ByteUnit.BYTE) | ||
| .createWithDefault(Long.MaxValue) |
There was a problem hiding this comment.
@amanomer, you can make this configuration optional via createOptional to represent no limit.
There was a problem hiding this comment.
Just a reminder, we need to attach version info for the new configuration now. Just use .version().
|
cc @dbtsai |
| Platform.copyMemory(recordBase, recordOffset, base, pageCursor, length); | ||
| pageCursor += length; | ||
| inMemSorter.insertRecord(recordAddress, partitionId); | ||
| inMemRecordsSize += length; |
There was a problem hiding this comment.
Should we also include the uaoSize?
There was a problem hiding this comment.
+1, the pageCursor is also increased by uaoSize and length
| numElementsForSpillThreshold); | ||
| spill(); | ||
| } else if (inMemRecordsSize >= maxRecordsSizeForSpillThreshold) { | ||
| logger.info("Spilling data because size of spilledRecords crossed the threshold " + |
There was a problem hiding this comment.
Should we also include the number of records and threshold here?
There was a problem hiding this comment.
| .createWithDefault(Integer.MAX_VALUE) | ||
|
|
||
| private[spark] val SHUFFLE_SPILL_MAP_MAX_SIZE_FORCE_SPILL_THRESHOLD = | ||
| ConfigBuilder("spark.shuffle.spill.map.maxRecordsSizeForSpillThreshold") |
There was a problem hiding this comment.
What does the "map" mean inside this config name?
There was a problem hiding this comment.
Why is it necessary to have different threshold between map task and reduce task?
There was a problem hiding this comment.
I have the same question. What's the use case to separate them differently?
|
This PR looks pretty good, it would be great if we can add some new benchmark case to ensure it doesn't bring in performance regression with config values properly chosen. |
|
@amuraru |
|
Ack @manuzhang - that makes sense |
|
@amuraru I forgot I've been testing Spark Adaptive Query Execution (AQE) recently, where contiguous shuffle partitions are coalesced to avoid too many small tasks. The problem is, IIUC, AQE makes coalesce decisions based on size of serialized map outputs. When data from multiple map tasks get deserialized into memory of one reduce task, it could easily blow up. I have to set extremely large |
| Platform.copyMemory(recordBase, recordOffset, base, pageCursor, length); | ||
| pageCursor += length; | ||
| inMemSorter.insertRecord(recordAddress, prefix, prefixIsNull); | ||
| inMemRecordsSize += length; |
|
I'm not a big fan of having a static size limitation, can we follow the design of Spark memory management and make it more dynamic? e.g. these "memory consumers" should report its memory usage to spark memory manager and spill if the manager asks you to do so. |
| "until we reach some limitations, like the max page size limitation for the pointer " + | ||
| "array in the sorter.") | ||
| .bytesConf(ByteUnit.BYTE) | ||
| .createWithDefault(Long.MaxValue) |
There was a problem hiding this comment.
Just a reminder, we need to attach version info for the new configuration now. Just use .version().
| "until we reach some limitations, like the max page size limitation for the pointer " + | ||
| "array in the sorter.") | ||
| .bytesConf(ByteUnit.BYTE) | ||
| .createWithDefault(Long.MaxValue) |
| if (elementsRead % 32 == 0 && currentMemory >= myMemoryThreshold) { | ||
| // Check number of elements or memory usage limits, whichever is hit first | ||
| if (_elementsRead > numElementsForceSpillThreshold | ||
| || currentMemory > maxSizeForceSpillThreshold) { |
There was a problem hiding this comment.
I just wonder if we need maxSizeForceSpillThreshold here since we've already have memory towards control here?
|
We're closing this PR because it hasn't been updated in a while. This isn't a judgement on the merit of the PR in any way. It's just a way of keeping the PR queue manageable. |
|
Backported this PR in Spark3 version, fixed some compilation issues and SMJ codegen support. Verified in the production environment, the task time is shortened, the number of spill disks is reduced, there is a better chance to compress the shuffle data, and the size of the spill to disk is also significantly reduced. Current
PR
|
|
Can you create a new PR against master @cxzl25 ? We can evaluate it for inclusion in 4.0 |
Addressed some previous comments in new PR, and added tests.
Please help review, thanks in advance! |
Original author: amuraru ### What changes were proposed in this pull request? This PR aims to support add memory based thresholds for shuffle spill. Introduce configuration - spark.shuffle.spill.maxRecordsSizeForSpillThreshold - spark.sql.windowExec.buffer.spill.size.threshold - spark.sql.sessionWindow.buffer.spill.size.threshold - spark.sql.sortMergeJoinExec.buffer.spill.size.threshold - spark.sql.cartesianProductExec.buffer.spill.size.threshold ### Why are the changes needed? #24618 We can only determine the number of spills by configuring `spark.shuffle.spill.numElementsForceSpillThreshold`. In some scenarios, the size of a row may be very large in the memory. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? GA Verified in the production environment, the task time is shortened, the number of spill disks is reduced, there is a better chance to compress the shuffle data, and the size of the spill to disk is also significantly reduced. **Current** <img width="1281" alt="image" src="https://github.com/user-attachments/assets/b6e172b8-0da8-4b60-b456-024880d0987e"> ``` 24/08/19 07:02:54,947 [Executor task launch worker for task 0.0 in stage 53.0 (TID 1393)] INFO ShuffleExternalSorter: Thread 126 spilling sort data of 62.0 MiB to disk (11490 times so far) 24/08/19 07:02:55,029 [Executor task launch worker for task 0.0 in stage 53.0 (TID 1393)] INFO ShuffleExternalSorter: Thread 126 spilling sort data of 62.0 MiB to disk (11491 times so far) 24/08/19 07:02:55,093 [Executor task launch worker for task 0.0 in stage 53.0 (TID 1393)] INFO ShuffleExternalSorter: Thread 126 spilling sort data of 62.0 MiB to disk (11492 times so far) 24/08/19 07:08:59,894 [Executor task launch worker for task 0.0 in stage 53.0 (TID 1393)] INFO Executor: Finished task 0.0 in stage 53.0 (TID 1393). 7409 bytes result sent to driver ``` **PR** <img width="1294" alt="image" src="https://github.com/user-attachments/assets/aedb83a4-c8a1-4ac9-a805-55ba44ebfc9e"> ### Was this patch authored or co-authored using generative AI tooling? No Closes #47856 from cxzl25/SPARK-27734. Lead-authored-by: sychen <[email protected]> Co-authored-by: Adi Muraru <[email protected]> Signed-off-by: attilapiros <[email protected]>
What changes were proposed in this pull request?
When running large shuffles (700TB input data, 200k map tasks, 50k reducers on a 300 nodes cluster) the job is regularly OOMing in map and reduce phase.
IIUC ShuffleExternalSorter (map side) and ExternalAppendOnlyMap and ExternalSorter (reduce side) are trying to max out the available execution memory. This in turn doesn't play nice with the Garbage Collector and executors are failing with OutOfMemoryError when the memory allocation from these in-memory structure is maxing out the available heap size (in our case we are running with 9 cores/executor, 32G per executor)
To mitigate this, one can set
spark.shuffle.spill.numElementsForceSpillThresholdto force the spill on disk. While this config works, it is not flexible enough as it's expressed in number of elements, and in our case we run multiple shuffles in a single job and element size is different from one stage to another.This patch extends the spill threshold behaviour and adds two new parameters to control the spill based on memory usage:
spark.shuffle.spill.map.maxRecordsSizeForSpillThresholdspark.shuffle.spill.reduce.maxRecordsSizeForSpillThresholdHow was this patch tested?
First, in our case for heavy RDD heavy shuffle jobs without setting the existing records based spill threshold (
spark.shuffle.spill.numElementsForceSpillThreshold) the job in unstable and fails consistently with OOME in executors.Trying to find the right value for
numElementsForceSpillThresholdproved to be impossible.Trying to maximize the job throughput (e.g. memory usage) while ensuring stability rendered to us an unbalanced usage across multiple stages of the job (in memory cached "elements" vary in size on map and reduce side combined with multiple map-reduce shuffles where "elements" are different)
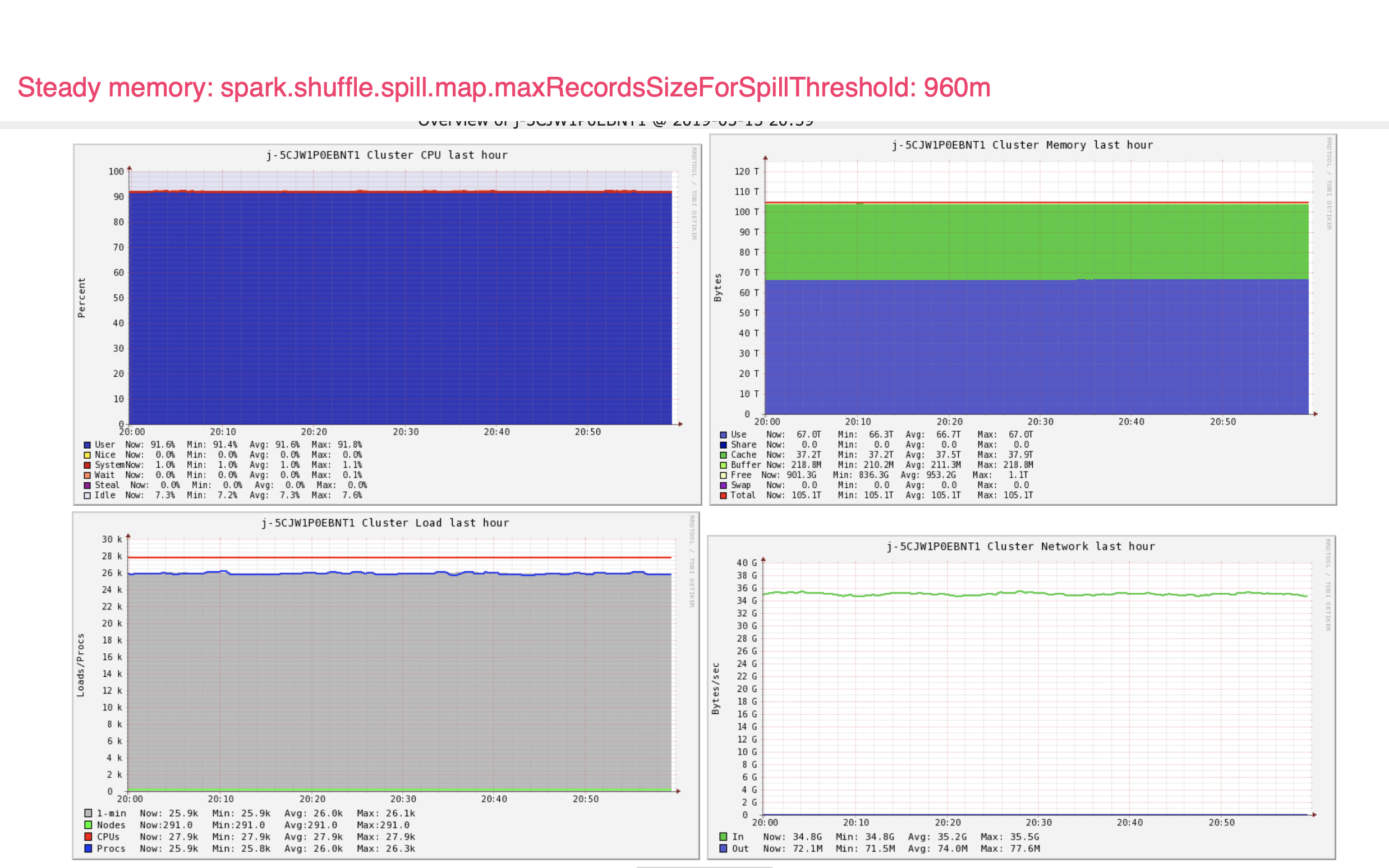
Overall the best we could get in terms of memory usage is depicted in this snapshot:
Working from here, and using
spark.shuffle.spill.map.maxRecordsSizeForSpillThreshold(map side, size-based spill) andspark.shuffle.spill.numElementsForceSpillThreshold(reduce side, size-based spill) we could maximize the memory usage (and in turn job runtime) while still keeping the job stable: