[SPARK-28293][SQL] Implement Spark's own GetTableTypesOperation #25073
Conversation
|
@juliuszsompolski What do you think of this change? |
| listener.onStatementError(statementId, e.getMessage, SparkUtils.exceptionString(e)) | ||
| throw e | ||
| } | ||
| listener.onStatementFinish(statementId) |
| try { | ||
| CatalogTableType.tableTypes.foreach { tableType => | ||
| if (tableType == EXTERNAL || tableType == EXTERNAL) { | ||
| rowSet.addRow(Array[AnyRef]("TABLE")) |
There was a problem hiding this comment.
I think you meant (tableType == EXTERNAL || tableType == MANAGED), but then you want to add "TABLE" to the results only once.
I think you want
tableTypes.foreach { tableType => tableTypeString(tableType) }.toSet.foreach { type => rowset.addRow(Array[AnyRef](type) }
tableTypeString can be shared with SparkGetTablesOperation.
To share some such functions between the operatoins, how about a mixin utils trait
trait SparkOperationUtils { this: Operation =>
def tableTypeString(tableType: CatalogTableType) = ...
}
e.g. at the bottom of SparkSQLOperationManager.scala?
| parentSession: HiveSession): GetTableTypesOperation = synchronized { | ||
| val sqlContext = sessionToContexts.get(parentSession.getSessionHandle) | ||
| require(sqlContext != null, s"Session handle: ${parentSession.getSessionHandle} has not been" + | ||
| s" initialized or had already closed.") |
There was a problem hiding this comment.
nit: no string interpolation here.
|
Test build #107334 has finished for PR 25073 at commit
|
 juliuszsompolski
left a comment
juliuszsompolski
left a comment
There was a problem hiding this comment.
LGTM pending merge with #25062 (whichever comes first).
cc @gatorsmile
|
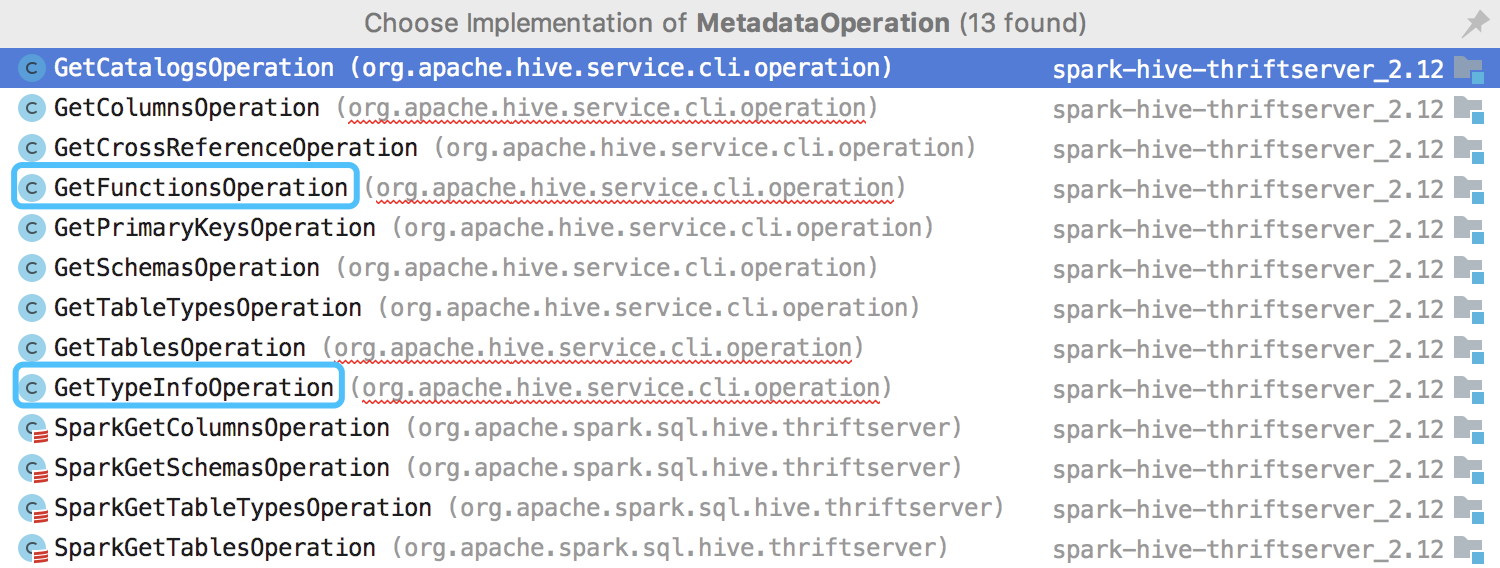
@juliuszsompolski Do we need to implement |
|
Hi @wangyum,
As for others:
|
|
Test build #107353 has finished for PR 25073 at commit
|
|
|
||
| override def runInternal(): Unit = { | ||
| val statementId = UUID.randomUUID().toString | ||
| val logMsg = s"Listing table types" |
|
The PR #25062 has been merged. Could you update this PR? |
|
Test build #107622 has finished for PR 25073 at commit
|
|
LGTM. Thanks! |
|
@gatorsmile WDYT about #25073 (comment) ? |
|
retest this please |
|
Test build #108060 has finished for PR 25073 at commit
|
|
SparkGetFunctionsOperations is useful, but I am also not sure about SparkGetTypeInfoOperation. Do it only when somebody is asking for it? |
 gatorsmile
left a comment
gatorsmile
left a comment
There was a problem hiding this comment.
LGTM
Thanks! Merged to master.
As commented in #25277: maybe we should override GetTypeInfo, to filter out the types that Spark thriftserver actually does not support: INTERVAL_YEAR_MONTH, INTERVAL_DAY_TIME, ARRAY, MAP, STRUCT, UNIONTYPE and USER_DEFINED, all of which Spark turns into string. |
What changes were proposed in this pull request?
The table type is from Hive now. This will have some issues. For example, we don't support
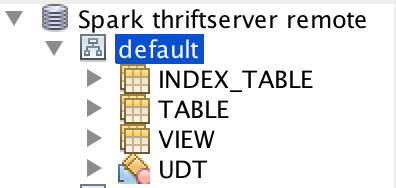
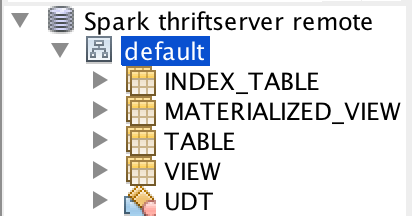
index_table, different Hive supports different table types:Build with Hive 1.2.1:
Build with Hive 2.3.5:
This pr implement Spark's own
GetTableTypesOperation.How was this patch tested?
unit tests and manual tests:
