[SPARK-34591][MLLIB][WIP] Add decision tree pruning as a parameter #32813
Conversation
### What changes were proposed in this pull request?
This PR disables a feature created in SPARK-3159 where LearningNodes are
merged after a RF model is trained.
### Why are the changes needed?
2 Reasons:
1. In addition to basic classification, another use case for decision trees are the
probabilities associated with predictions. Once pruned, these predictions are lost
and it makes the trees/predictions challenging to work with if not unusable.
2. It is not in line with the default behavior in sklearn. In sklearn, the trees
are left unpruned by default.
### Does this PR introduce _any_ user-facing change?
No, it's dev-only.
### How was this patch tested?
Locally ran `./build/mvn -pl mllib package` and verified tests passed
Additionally, running through git workflow as described here:
https://spark.apache.org/developer-tools.html#github-workflow-tests
|
Can one of the admins verify this patch? |
|
Hello, I am the author of the Jira ticket https://issues.apache.org/jira/browse/SPARK-34591. In my view, the behaviour described in the ticket is a serious problem - it makes the DecisionTreeClassifier and the RandomForestClassifier seriously unreliable for probability estimation problems for Spark 2.4.0 and all later versions. Additionally, the original implementation of the feature did not update the Spark ML documentation to describe this non-standard modification to the tree algorithm. The only way I could trace the behaviour (given that it was in conflict with the Spark documentation) was to examine every Jira ticket referenced in the release notes after Spark 2.3.0 (where I knew this problem did not exist) to identify ones that might be responsible. In my own experience, I have three clients which have been directly affected by this issue. The Jira ticket gives a minimal example with "maximally worst" behaviour - a tree that is pruned (outside the user's control) so that there are no splits at all. |
|
@srowen @asolimando @sethah Tagging you as you were heavily contributors to the original pull request which this bugfix undoes (#20632). Deeply grateful for your input and attention here. |
|
The Appveyor error is not apparent to me from the console output. Can someone let me know if there are some more logs? Or possibly if you know the solution? |
This PR disables a feature created in SPARK-3159 where LearningNodes are merged after a RF model is trained.
2 Reasons:
1. In addition to basic classification, another use case for decision trees are the probabilities associated with predictions.
Once pruned, these predictions are lost and it makes the trees/predictions challenging to work with if not unusable.
2. It is not in line with the default behavior in sklearn. In sklearn, the trees are left unpruned by default.
Please see Jira ticket for more explanation.
No, it's dev-only.
I modified the two tests introduced with this change to verify postive/negative use of feature. I also added assertions for default behavior
Locally ran `./build/mvn -pl mllib package` and verified tests passed
Additionally, running through git workflow as described here:
https://spark.apache.org/developer-tools.html#github-workflow-tests
…are merged after a RF model is trained.
2 Reasons:
1. In addition to basic classification, another use case for decision trees are the probabilities associated with predictions.
Once pruned, these predictions are lost and it makes the trees/predictions challenging to work with if not unusable.
2. It is not in line with the default behavior in sklearn. In sklearn, the trees are left unpruned by default.
Please see Jira ticket for more explanation.
No, it's dev-only.
I modified the two tests introduced with this change to verify postive/negative use of feature. I also added assertions for default behavior
Locally ran `./build/mvn -pl mllib package` and verified tests passed
Locally ran `./dev/scalafmt` which resulted in some minor cosmetic changes
Additionally, running through git workflow as described here:
https://spark.apache.org/developer-tools.html#github-workflow-tests
|
I'm a little reluctant to change behavior but that could be the right thing. What about just exposing this param at least? Im still kind of curious how this happens. Is the pruning logic just not correct? Or do you have sense of what the tree is like before and after pruning? |
|
Sorry for not replying before! I think too that exposing the parameter is the safest option, since the pruning leads to a (sometimes sensible) performance improvement and, at least for prediction tasks, does not have any downside. Removing the feature entirely might entail a performance regression for many Spark users. Do you have an idea why the probabilities you use are impacted by this change? I don't have the details of the specific Decision Tree flavour implemented here, but if the probability is the probability to belong to a given class, then there must be a bug (some metadata might get messed up during the merge phase of the pruning process), because the assignment to a given class, is by construction preserved (we never merge no two nodes with distinct labels). The fact that no split happens at times does not seem an issue to me, if all your labels are the same, you have nothing to build at all, so the whole learning task seems pointless. |
|
Process wise - could most of the other change here be reverted? I think a lot of it's formatting. The change itself is simple, it seemed. If you have a moment, drop in the unit test #2 as well @asolimando thank you for weighing in. In the 2 examples in the JIRA, the labels are not all the same. I wouldn't have though pruning would be the problem - whatever the problem is here - but if disabling it changes the answer, that's pretty convincing. Anything I can think of doesn't sound right - not getting enough min info gain? but the default min is 0. The randomness? but the DF is cached(). I guess I'm also wondering why existing tests didn't pick up on a problem; entirely possible it's a test coverage thing. Maybe one step forward is to throw in some debug logging about what happens during pruning to verify basic things like whether you get a big tree to begin with (or maybe you already determined that) |
@asolimando this is fundamentally not correct, and this assumption is precisely the root cause of this bug. There are roughly three use cases for decision trees (and random forests that derive from them):
Use case 3 is facilitated by random forest models, which are provably convergent probability estimators - see Biau et al (2008) "Consistency of random forests and other averaging classifiers" Journal of Machine Learning Research, 9, 2015-2033. As described in https://issues.apache.org/jira/browse/SPARK-3159?focusedCommentId=17115343&page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel#comment-17115343 the logic of the pruning code only looks at the class prediction, not the probability of the node. See direct code link here: The code makes the assumption "merging nodes where the class prediction is the same is safe", regardless of the fact that the nodes may predict different probabilities. Use cases 2 and 3 above are radically affected by this bug, which derives from the assumption that the class prediction is the only thing of interest. The more imbalanced the data set, the worse the problem is, as the examples on the Jira ticket illustrate. It is no good answer to say "just rebalance the classes", because in use case 3 then accurate probabilities are precisely the goal of the problem, and trees trained on class rebalanced data do not give correct probability predictions without additional post hoc processing. Yes, there is a reduction in run time from this pruning, but there is no benefit at training time, and it's no good having a reduction in prediction time if the answer is wrong. As per the example on the Spark Jira, in a fairly simple example the resulting DecisionTreeClassifier is not usable. So, the performance improvement here might be characterised as "fast but wrong". Some extra context from my personal experience here I am a partner at BCG Gamma, one of the world's largest employers of data scientists and data engineers. (We have around 1000 data scientists and data engineers working on advanced analytics problems with clients). I have multiple clients in my personal experience who are have been significantly affected by this. Comments across multiple client situations include the following:
After reaching out through my network, I have identified other people who have also had poor experiences using the DecisionTreeClassifier and RandomForestClassifier for use cases (2) and (3) above but couldn't work out why given the fact that the Spark documentation is silent on this, and were grateful for being alerted to the undocumented pruning behaviour. Some of my clients have concluded that DecisionTreeClassifier and RandomForestClassifier are functionally broken and should not be used under any circumstances until this is fixed. I'm sorry if this all sounds very negative, but this is a much bigger problem than I think you are grasping at this stage. I am happy to get on a phone call to discuss this further if that's helpful. |
The pruning logic is implemented correctly (on the basis of class predictions) but a bad idea for the reasons given above (namely it considers the class, not the probability of the node). The logic could be fixed by doing the following: merge two nodes only if the probability predicted from both nodes is identical. |
|
@137alpha thanks for the detailed explanation, now it's clear what you meant (I have missed the example from "xujiajin". What my comment meant was talking exclusively at cases revolving around (1), that is what I have worked on when I contributed the PR (performance improvement of classification tasks, and rule extraction from DecisionTrees and RandomForests). For (2) and (3) this indeed seems problematic, because we disregard the probability entirely. If possible, it would be great to either fix the current "optimization" by looking at more information than the class prediction (notably, the probability), or at least provide a user-facing parameter to control the behaviour, so who needs (2)/(3) can disable it, who is happy with just (1) can benefit from it. Regarding the documentation update, at the time it did not seem relevant, because the contribution seemed an internal optimization (that is, an iso-functional improvement), it's probably a good idea to add a comment for describing the behaviour of the controlling parameter proposed by @srowen. As a closing remark, I understand that this have caused some issues and frustrations to some people including yourself, but sometimes trying to make things better (maybe by volunteering in our spare time, like it was the case for me for this PR), we can cause other issues, which can in turn be tackled and hopefully solved, that's the beauty of OSS. |
|
@asolimando @srowen Here's a simple example that illustrates this.
A decision tree which exactly fits this data is:
The pruning algorithm as currently implemented would prune this to:
Whilst the class predictions are unchanged, the trees are not functionality identical. the first one exactly identifies the conditional relationship in the data. The pruned tree is totally useless for understanding the conditional probability relationship that exists. |
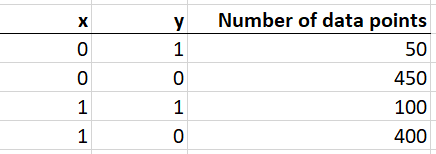
|
Yeah, great explanation. I'm still remembering how all this code works so probably asking dumb questions. Is the problem that the leaves' impurity stats are not combined, but just use the parent node's? or is that also not quite the point. Where do you get class probabilities out from the API, or are you reaching into the model to figure that out? sorry if I've just forgotten that possibility in the API, but didn't recall or see it. Just trying to trace back how probability connects to the LeafNodes -- via impurity right? your example doesn't seem to retrieve probabilities. The scikit tree shows a lot of "redundant" decision nodes, but if they're redundant, I wonder what else is stores, thus what we need to look at when deciding to prune or not in Spark. I think this does indeed affect a certain type of use case, hardly fully broken, but I do believe you that there's a problem of some size - no need to collect more evidence! The simplest fix I would definitely support is making this, at least, optional rather than disable it by default. Huge forests can be an issue too to load, on the flipside. I'm still hoping there's a fix or misunderstanding somewhere we can save this with, but maybe there is nothing reasonable, and correctness is incompatible with what you're doing. |
|
Right on @137alpha - would it be correct to say the pruning would be 'correct' if they had the same class probs? If that's the kind of thing that could make it work, OK. But I then wonder how much is prunable under that definition, rendering the process possibly far less useful for speedup. |
|
@srowen @asolimando Agreed that the ideal outcome would be to expose this as a parameter so the user can change this. I think the default behaviour here should be Prune = False in order to be compliant with the standard behaviour expected from decision trees. As an alternative (although less ideal), the web documentation and the API documentation needs a substantial warning that the default behaviour of Prune = True will give poor performance on unbalanced data sets and for probability estimation use cases. As you observe @asolimando, changing the default behaviour to Prune = False would trigger an unexpected performance regression for users at prediction time.
Exactly right. You'll still get the current pruning behaviour in the trivial cases "probability = 0" and "probability = 1", and some other cases where minInstancesPerNode is small. (Eg, if you have minInstancesPerNode = 3 then the terminal node probabilities can be 0, 1/3, 2/3 or 3/3=1, so you might get some speedup there. If you have minInstancesPerNode = 1 then you will get similar pruning of terminal nodes with only one data point in as the current case). But if minInstancesPerNode is >> 1 then in general there will be minimal speedup. |
We definitely appreciate the all the time volunteers like yourself have spent improving the code. We wouldn't be able to do our work without it :) My comments above were intended to convey the fact that I personally know significant numbers of people who have encountered this in one form or another and therefore this isn't a rare side effect - it's actually a common one. There are workarounds too (although not ideal):
Thankfully it's an easily addressable issue, notwithstanding the performance hit. |
|
To recap what I think we can do here is:
A followup, which maybe I can look into then, is:
|
|
To elaborate on the merge condition part, can I propose the following. Expose a
Default setting being either Prior to implementing, does this sound good? Also, the formatting was prescribed by the Scala style check described here: https://spark.apache.org/contributing.html Should I remove it or leave? |
|
We could take that in two steps. First step: expose the true/false parameter and document (yes this is a better way to say it) that you only want this turned on if you only care about the prediction class. Later if I/we can figure out how to fix this to narrow the pruning, then maybe some other means of exposing a third possibility, but will depend on whether changing the API is worth it to keep the current behavior, or just 'fix' the current behavior to always do the more conservative, correct pruning. |
|
I'm not at all familiar with the code, but it looks like the nodes may have a .prob() method which could be a drop in replacement for the .predict() method (the latter of which gives the class prediction). So a change to use probability pruning rather than class pruning could be quite straightforward. |
|
If you'd like to update the PR per the first part of #32813 (comment) I'd merge it. If you're busy I could reproduce that change myself, too. |
|
Hello @srowen, Yes I was able to do most last Friday. Some things I still need to do are:
For 1+2 above, if off hand you can point me to the code where that is done then great. If you don't have time no worries, I'll find it. Assuming you are happy with the change in RandomForestClassifier, I can do the same for DecisionTree and Gradient boosted versions as well. Let me know! |
| /** | ||
| * If true, the trained tree will undergo a 'pruning' process after training in which nodes | ||
| * that have the same class predictions will be merged. The benefit being that at prediction | ||
| * time the tree will be 'leaner' |
There was a problem hiding this comment.
I think the key point for users is that this is a good thing if only interested in class predictions. If interested in class probabilities, it won't necessarily give the right result and should be set to false. The text here is fine just wanting to make the tradeoffs explicit. I.e. leaner means smaller and faster.
| * time the tree will be 'leaner' | ||
| * If false, the post-training tree will undergo no pruning. The benefit being that you | ||
| * maintain the class prediction probabilities | ||
| * (default = false) |
There was a problem hiding this comment.
I think as a first step we should keep it to 'true'.
| import org.apache.spark.ml.util.TestingUtils._ | ||
| import org.apache.spark.mllib.tree.{DecisionTreeSuite => OldDTSuite, EnsembleTestHelper} | ||
| import org.apache.spark.mllib.tree.configuration.{Algo => OldAlgo, QuantileStrategy, Strategy => OldStrategy} | ||
| import org.apache.spark.mllib.tree.configuration.{ |
There was a problem hiding this comment.
Undo the formatting changes here if you would - just makes it easier to understand and avoids code churn in the git log
|
No big hurry on this, but the branch cut date for 3.2 is approaching in a week or two and I'd love to get this in for 3.2. |
|
Hey @srowen, Is there an easy way to test in python like I think its about 95% there. Can you suggest where I should add the test for the interface change? I have them in a notebook already. Thanks! |
|
I'm not sure you could except by perhaps setting the env variable in a unit test - do you need it here? |
|
Well I have verified in a scala jupyter notebook that parameter works for scala. This was easy to do with For testing in Python, is the easiest way to add |
|
If not no worries I will test tonight and make a draft/final pr for review. Just if there is a mechanism to facilitate let me know. |
|
I think you could build the project with your change and just run bin/pyspark to check out the API. |
|
I think this still has formatting-change problems. I also see the default is 'true'. I think those two at least need to be reverted in this first change. |
|
Should I take up this change in a separate PR, to just make the basic changes? |
|
We're closing this PR because it hasn't been updated in a while. This isn't a judgement on the merit of the PR in any way. It's just a way of keeping the PR queue manageable. |
Hello, |
What changes were proposed in this pull request?
This PR adds a parameter to enable/disable a featuer where LearningNodes are merged after a RF model is trained.
Why are the changes needed?
2 Reasons:
In addition to basic classification, another use case for decision trees are the probabilities associated with predictions.
Once pruned, these predictions are lost and it makes the trees/predictions challenging to work with if not unusable.
It is not in line with the default behavior in sklearn. In sklearn, the trees are left unpruned by default.
Please see Jira ticket for more explanation.
Does this PR introduce any user-facing change?
Yes, it adds a parameter that is exposed to the Tree based classifiers. Will add tests here to ensure parameter is exposed correctly.
How was this patch tested?
I modified the two tests introduced with this change to verify postive/negative use of feature. I also added assertions for default behavior
Will add tests that ensure user exposed API is validated.
Locally ran
./build/mvn -pl mllib packageand verified tests passedAdditionally, running through git workflow as described here:
https://spark.apache.org/developer-tools.html#github-workflow-tests