[SPARK-40476][ML][SQL] Reduce the shuffle size of ALS #37918
Conversation
|
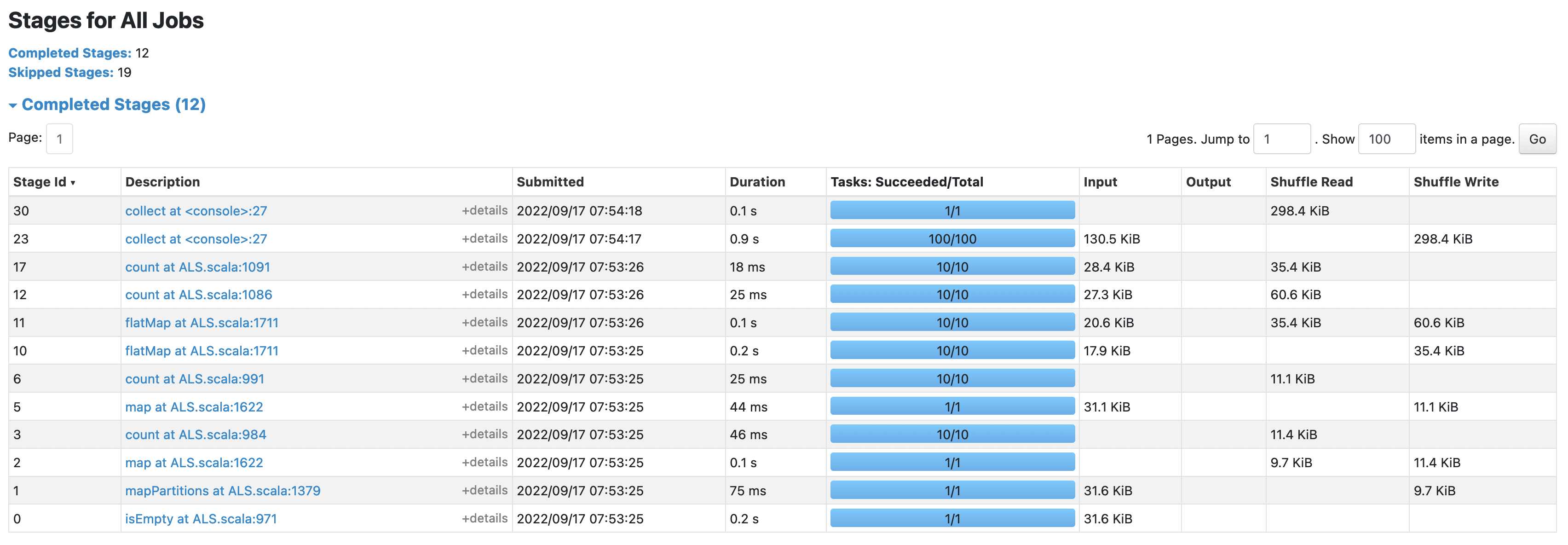
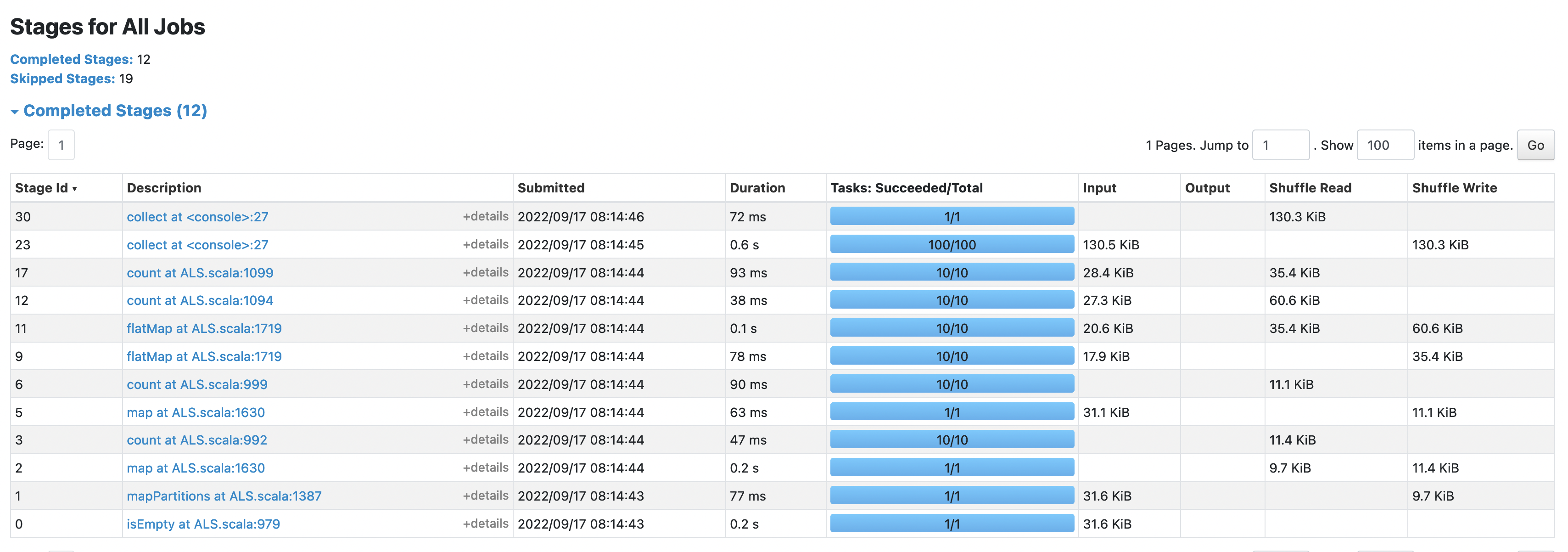
take the before: after: the shuffle size in this case was reduced from |
 dongjoon-hyun
left a comment
dongjoon-hyun
left a comment
There was a problem hiding this comment.
Hi, @zhengruifeng .
- If you don't mind, could you make an independent PR moving
TopByKeyAggregatortoCollectTopKbecause that is orthogonal fromReduce the shuffle size of ALS? - In addition, we need a test coverage for
CollectTopKbecause we removeTopByKeyAggregatorSuite.
It is just the moving from
Sure, will update soon |
|
Thanks. If the PR title is clear, +1 for that. |
c484647 to
8bde0b9
Compare
There was a problem hiding this comment.
The naming is not clear,
Why not call it collect_top_k ?
and we can add it into spark.sql.functions collect_top_k
There was a problem hiding this comment.
I think we can define a spark sql function and wrap this part within the function, like:
def collect_top_k(ratingColumn, outputColumn) = {
CollectOrdered(struct(ratingColumn, outputColumn).expr, num, true).toAggregateExpression(false)
}
There was a problem hiding this comment.
sure, I think we don't want to expose it, so mark it private[spark]
8bde0b9 to
01ad8cb
Compare
| */ | ||
| def collect_set(columnName: String): Column = collect_set(Column(columnName)) | ||
|
|
||
| private[spark] def collect_top_k(e: Column, num: Int, reverse: Boolean): Column = |
There was a problem hiding this comment.
nit: shall we make it public ? It might be a useful function.
We don't need to do it in this PR.
There was a problem hiding this comment.
I don't know, I also think it's useful and may further use it in Pandas-API-on-Spark.
But I don't know whether it is suitable to be public @cloud-fan @HyukjinKwon
There was a problem hiding this comment.
Let's keep it private for now.
|
Merged to master |
|
Thanks for the reviews! |
|
Thanks! :) |
### What changes were proposed in this pull request? Reduce the shuffle size of ALS by using `Array[V]` instead of `BoundedPriorityQueue[V]` in ser/deser this is a corresponding change of #37918 on the `.mllib` side ### Why are the changes needed? Reduce the shuffle size of ALS ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? existing UT Closes #38203 from zhengruifeng/ml_topbykey. Authored-by: Ruifeng Zheng <[email protected]> Signed-off-by: Sean Owen <[email protected]>
What changes were proposed in this pull request?
implement a new expression
CollectTopK, which usesArrayinstead ofBoundedPriorityQueuein ser/deserWhy are the changes needed?
Reduce the shuffle size of ALS in prediction
Does this PR introduce any user-facing change?
No
How was this patch tested?
existing testsuites