[SPARK-40635][YARN][TESTS] Fix yarn module daily test failed with hadoop2
#38079
Conversation
|
Failed as follows: |
.github/workflows/build_and_test.yml
Outdated
| required: false | ||
| type: string | ||
| default: hadoop3 | ||
| default: hadoop2 |
There was a problem hiding this comment.
for test hadoop-2, will revert after confirmation takes effect
|
Manual test :
locally, but they all passed. From the characteristics of the failed case, the am start failed because the start command line is too long maybe due to the classpath contains too many jars(CLASSPATH and SPARK_DIST_CLASSPATH includes all jars in .cache) |
|
|
Thanks for investigating this @LuciferYang. cc @Yikun FYI |
|
https://github.com/LuciferYang/spark/actions/runs/3171106629/jobs/5164233303
It seems that my guess is correct. It is effective to manually filter some unnecessary jars from classpath to reduce the length of the start command, such as So I have the following two ideas:
spark/project/SparkBuild.scala Lines 917 to 922 in 0870822 @HyukjinKwon @Yikun Do you have any other suggestions? In addition, I found that the prefix of a large number of jar packages under the classpath is |
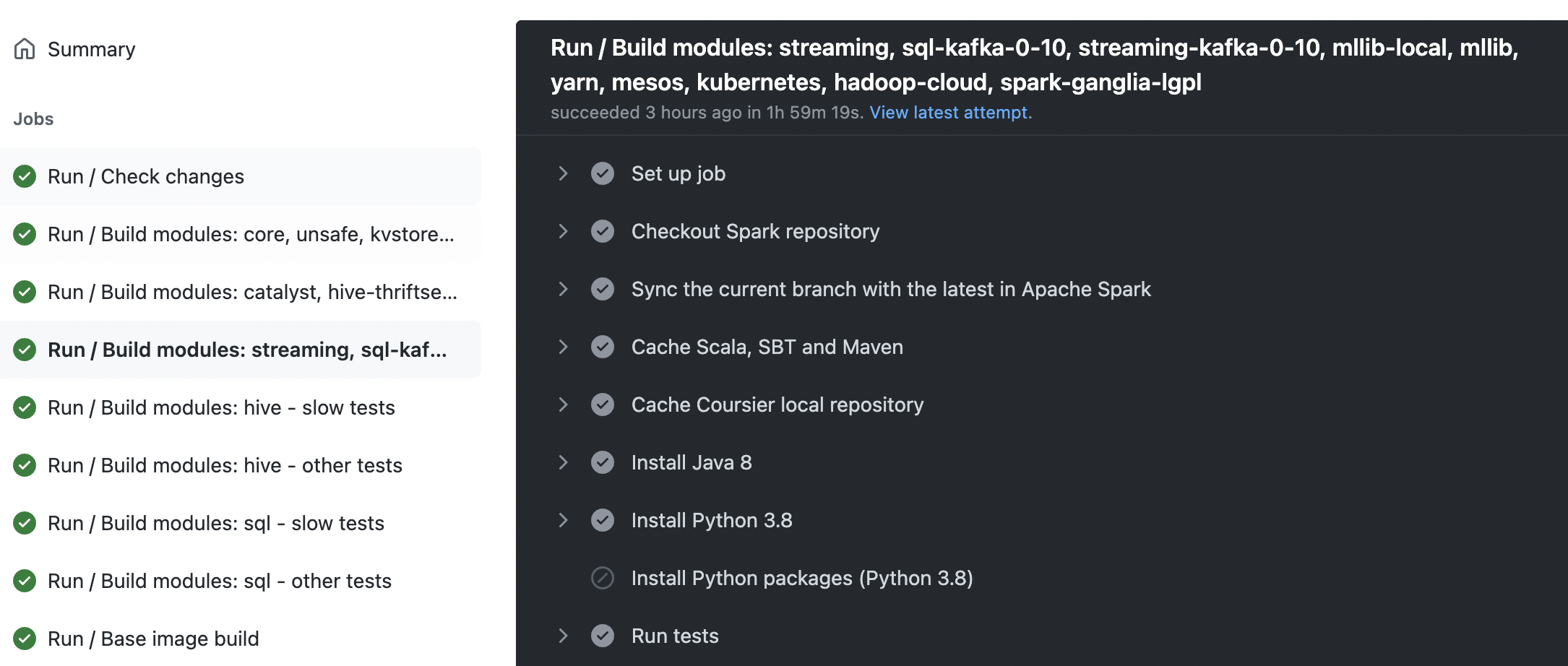
|
The submit job |
| addClasspathEntry(getClusterPath(sparkConf, cp), env) | ||
| val newCp = cp.split(CLASS_PATH_SEPARATOR) | ||
| .filterNot(cpSet.contains).mkString(CLASS_PATH_SEPARATOR) | ||
| addClasspathEntry(getClusterPath(sparkConf, newCp), env) |
There was a problem hiding this comment.
Try to deduplicate jars that have been added to CLASSPATH through extraClassPath
There was a problem hiding this comment.
Is it necessary to change it to
val newCp = if (Utils.isTesting) {
cp.split(File.pathSeparator)
.filterNot(cpSet.contains).mkString(File.pathSeparator)
} else cp
but I think de duplication may also be useful for the production environment
|
64f0e0b seems work normal |
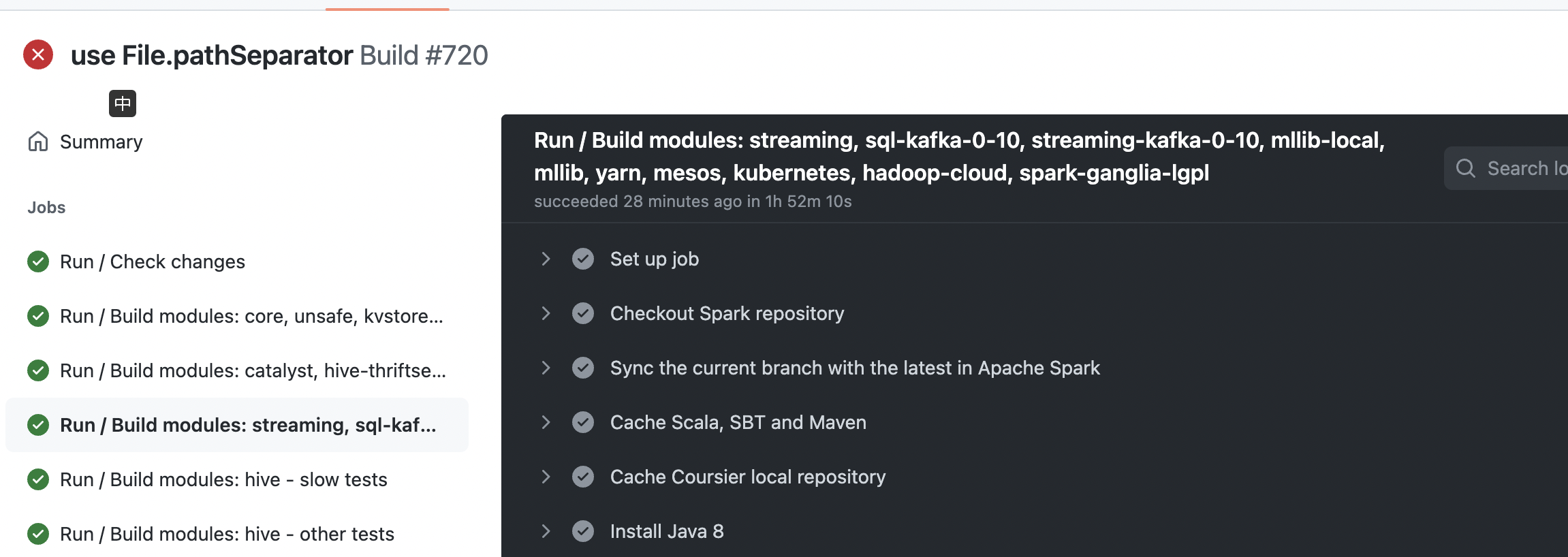
Scala 2.12 + Hadoop 2 + JDK 8 daily testScala 2.12 + Hadoop 2 + JDK 8 daily test
Scala 2.12 + Hadoop 2 + JDK 8 daily testyarn module daily test failed with hadoop2
| } | ||
|
|
||
| val cpSet = extraClassPath match { | ||
| case Some(classPath) => classPath.split(File.pathSeparator).toSet |
There was a problem hiding this comment.
Actually this is risky because it loses the order of classpaths. This matters when multiple jars are provided somehow in the production env. Should use sth like LinkedHashSet (see also HyukjinKwon@c6b8eb7)
There was a problem hiding this comment.
Oh, nvm. okay, it is just used for checking if sth exists. All good.
There was a problem hiding this comment.
I would use getOrElse approach tho.
There was a problem hiding this comment.
Do you mean extraClassPath.getOrElse("").split(File.pathSeparator).toSet?
How about
val cpSet = extraClassPath match {
case Some(classPath) if Utils.isTesting =>
classPath.split(File.pathSeparator).toSet
case _ => Set.empty[String]
}
There was a problem hiding this comment.
If only for testing, we can do split only when Utils.isTesting is true
| sys.env.get(ENV_DIST_CLASSPATH).foreach { cp => | ||
| addClasspathEntry(getClusterPath(sparkConf, cp), env) | ||
| val newCp = cp.split(File.pathSeparator) | ||
| .filterNot(cpSet.contains).mkString(File.pathSeparator) |
There was a problem hiding this comment.
I don't think this is still safe because of classpath order. Let's do this for test only.
There was a problem hiding this comment.
Ok, hmm... but will /rootpath/subdir/a-1.0.jar:/rootpath/subdir/b-1.0.jar:/rootpath/subdir/a-1.0.jar and /rootpath/subdir/a-1.0.jar:/rootpath/subdir/b-1.0.jar have different results?
The de-duplication operation is a full path matching
|
|
||
| sys.env.get(ENV_DIST_CLASSPATH).foreach { cp => | ||
| addClasspathEntry(getClusterPath(sparkConf, cp), env) | ||
| val newCp = if (Utils.isTesting) { |
There was a problem hiding this comment.
Maybe let's add a comment with mentioning the JIRA number.
There was a problem hiding this comment.
ok, will add comments after the hadoop2 check pass
|
2712ae0 add comments and check hadoop3 |
|
Merged to master. |
|
thanks @HyukjinKwon |
|
https://github.com/apache/spark/actions/runs/3190113779 Yeah ~ build success |
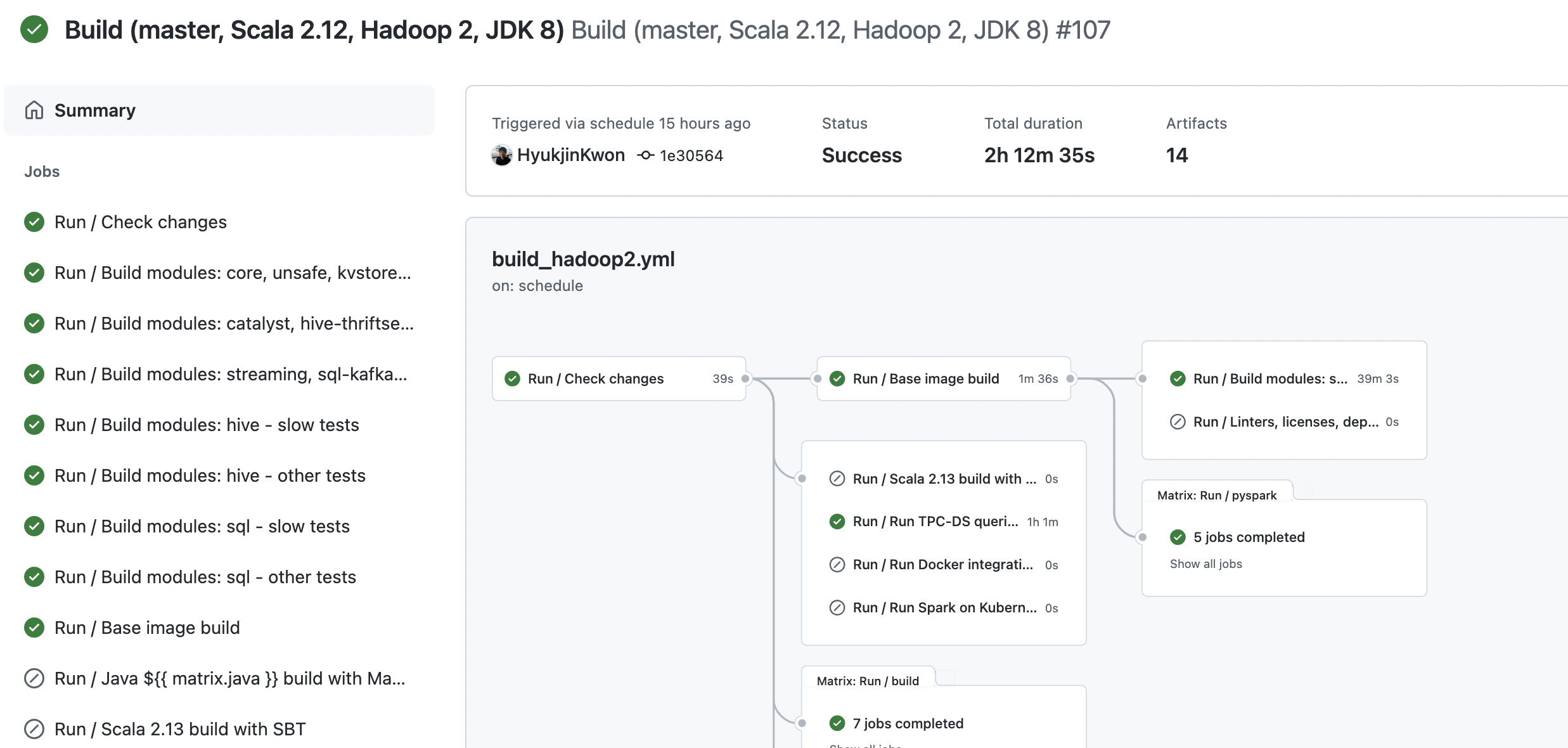
What changes were proposed in this pull request?
This pr adds the de duplication process in the
yarn.Client#populateClasspathmethod whenUtils.isTestingis true to ensure thatENV_DIST_CLASSPATHwill only add the part ofextraClassPaththat does not exist toCLASSPATHto avoidjava.io.IOException: error=7, Argument list too longin this way.Why are the changes needed?
Fix daily test failed of yarn module with
-Phadoop-2.Daily test failed as follows:
Does this PR introduce any user-facing change?
No
How was this patch tested?
hadoop2is successful: https://github.com/LuciferYang/spark/actions/runs/3175111616/jobs/5172833416