This project is part of the Udacity Azure ML Nanodegree. In this project, we build and optimize an Azure ML pipeline using the Python SDK and a provided Scikit-learn model. This model is then compared to an Azure AutoML run.
This dataset contains data pertaining to direct marketing campaigns of a banking institution. The marketing campaigns were based on phone calls to convince potenitial clients to subscribe to bank's term deposit. We seek to predict whether the potential client would accept and make a term deposit at the bank or not.
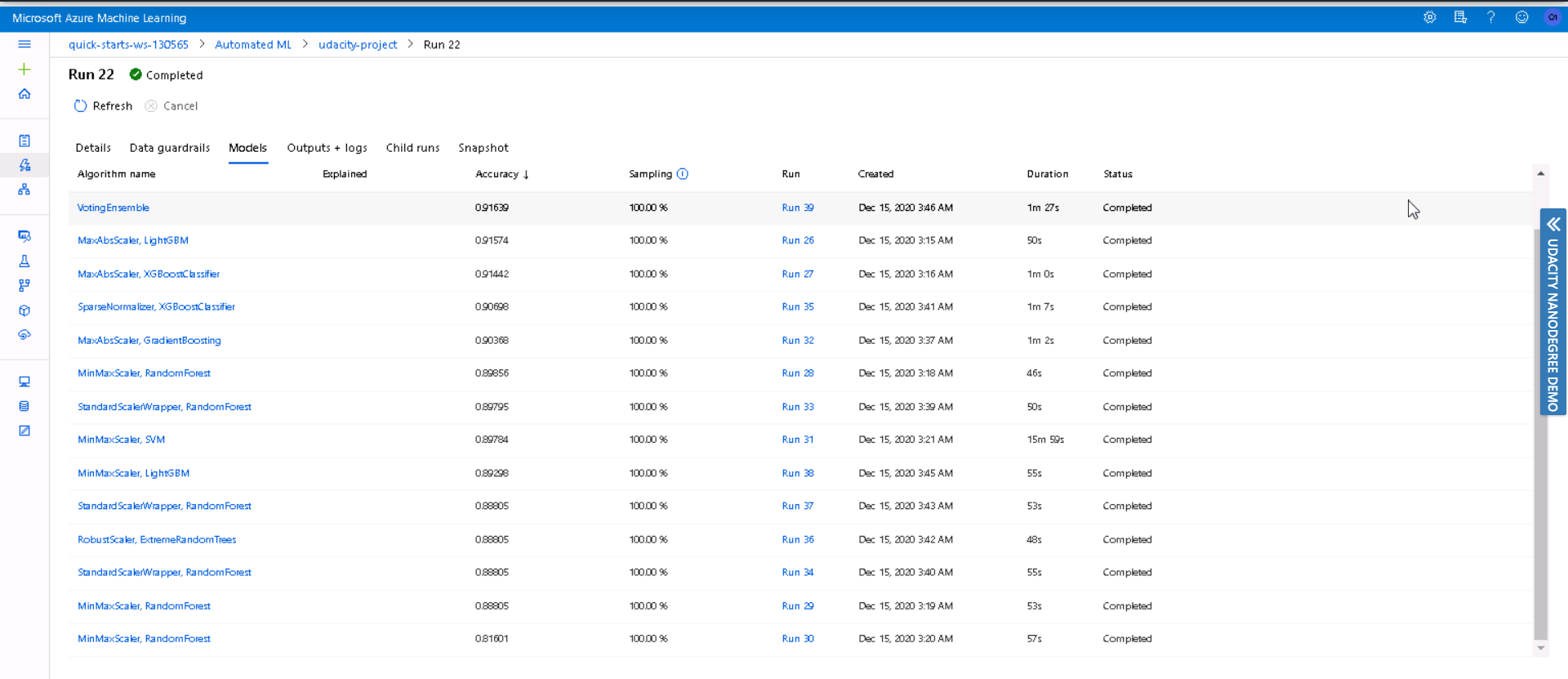
The best performing model found using AutoML was a Voting Ensemble with 91.6% accuracy, while the accuarcy of Logistic classifier implemented using hyperdrive was 90.7%
Explain the pipeline architecture, including data, hyperparameter tuning, and classification algorithm.
-
The data is accessed from url - "https://automlsamplenotebookdata.blob.core.windows.net/automl-sample-notebook-data/bankmarketing_train.csv", and a Tabular Dataset is created using TabularDatasetFactory
-
Data is then cleaned and pre-processed using clean_data function, this includes Binary encoding and One Hot Encoding of categorical features
-
Data is then split into 80:20 ratio for training and testing
-
Define a Scikit-learn based Logistic Regression model and set up a parameter sampler. We define 2 hyperparameters to be tuned, namely C and max_iter. C represents the inverse regularization parameter and max_iter represents the maximum number of iterations
-
HyperDrive configuration is created using a SKLearn estimator and parameter sampler
-
Accuracy is calculated on the test set for each run and the best model is saved
What are the benefits of the parameter sampler you chose?
Performed random sampling over the hyperparameter search space using RandomParameterSampling in our parameter sampler, this drastically reduces computation time and we are still able to find reasonably good models when compared to GridParameterSampling methodology where all the possible values from the search space are used, and it supports early termination of low-performance runs
What are the benefits of the early stopping policy you chose?
BanditPolicy is used here which is an "aggressive" early stopping policy. It cuts more runs than a conservative policy like the MedianStoppingPolicy, hence saving the computational time significantly. Configuration Parameters:-
-
slack_factor/slack_amount : (factor)The slack allowed with respect to the best performing training run.(amount) Specifies the allowable slack as an absolute amount, instead of a ratio. Set to 0.1.
-
evaluation_interval : (optional) The frequency for applying the policy. Set to 1.
-
delay_evaluation : (optional) Delays the first policy evaluation for a specified number of intervals. Set to 5.
AutoML provided the ability to run multiple experiments and choose best clasfication model.
Overall 14 classification models were run, VotingEnsemble algorithm proved to be the best model with an accuracy of 91.6%. VotingEnsemble takes a majority vote of several algorithms, this make it extremely robust and helps reduce the bias associated with individual algorithms.
LightGBM Classifier was one of the algorithms used in VotingEnsemble, below are the hyperparameters associated with it -
0 - lightgbmclassifier
{'boosting_type': 'gbdt',
'class_weight': None,
'colsample_bytree': 1.0,
'importance_type': 'split',
'learning_rate': 0.1,
'max_depth': -1,
'min_child_samples': 20,
'min_child_weight': 0.001,
'min_split_gain': 0.0,
'n_estimators': 100,
'n_jobs': 1,
'num_leaves': 31,
'objective': None,
'random_state': None,
'reg_alpha': 0.0,
'reg_lambda': 0.0,
'silent': True,
'subsample': 1.0,
'subsample_for_bin': 200000,
'subsample_freq': 0,
'verbose': -10}
Below screenshot lists all the classification models executed by AutoML
-
With AutoML the accuracy of best model (Voting Ensemble) was 91.6% and accuracy of HyperDrive model (Logistic Classifier) was 90.7%
-
Using AutoML one could try several classification models, this activity if performed using HyperDrive will entail some effort as it would require configuring pipeline for each model.
-
While running AutoML pipeline Class Imbalance alert was generated, this is one of the future improvements that should be implemented. We can look at different ways to combat class imbalance, such as - resampling training data, generate synthetic samples using SMOTE or the Synthetic Minority Over-sampling Technique, etc.
-
Look at other performance metric such as Precision, Recall and F1 Score as Accuracy metric can be misleading while working with class imbalanced dataset