
![]()
Track AI coding assistant usage, token consumption, cost, and tool calls across Claude Code, Codex, OpenClaw, OpenCode, Hermes, and Qoder.
aiusage gives you one local-first place to understand how your AI coding tools are being used: tokens, cost, model mix, tool activity, projects, sessions, and multi-machine sync when you need it.
English | 中文
Prerequisites: Node.js 18 or later
npm install -g @juliantanx/aiusage
aiusage parse
aiusage serveOpen http://localhost:3847 to explore the dashboard.
If aiusage is useful, consider starring the repo to help more developers discover it.
aiusage does not run a built-in background parser. If you want automatic imports, schedule aiusage parse with cron or Task Scheduler.
Build from source
git clone https://github.com/juliantanx/aiusage.git
cd aiusage
pnpm install
pnpm build
cd packages/cli
npm linkAfter pulling updates, rebuild to pick up changes:
pnpm buildIf you switch Node.js versions locally, recompile the better-sqlite3 native module for the new version:
pnpm rebuild:sqliteThis is only needed when developing from source. Users who install via
npm install -gdo not need to do this — the module is compiled automatically during installation.
AI coding assistant usage is scattered by default: different tools, different local logs, different machines, and no shared view of tokens or cost.
aiusage brings that data into one local-first dashboard so you can:
- Track token usage, cost, model mix, and tool-call activity in one place.
- Aggregate usage across Claude Code, Codex, OpenClaw, OpenCode, Hermes, and Qoder.
- Understand usage over time through overview, token, cost, model, session, and project views.
- Sync across multiple machines with GitHub, S3, or R2 when shared visibility matters.
- Keep your data local by default, with optional sync only when you choose it.
aiusage is built for:
- Developers using Claude Code, Codex, or other AI coding assistants every day.
- People who want visibility into token usage and spend over time.
- Multi-tool users who want one dashboard instead of multiple disconnected logs.
- Multi-machine workflows that need optional aggregation and sync.
aiusage currently supports:
- Claude Code
- Codex
- OpenClaw
- OpenCode
- Hermes
- Qoder

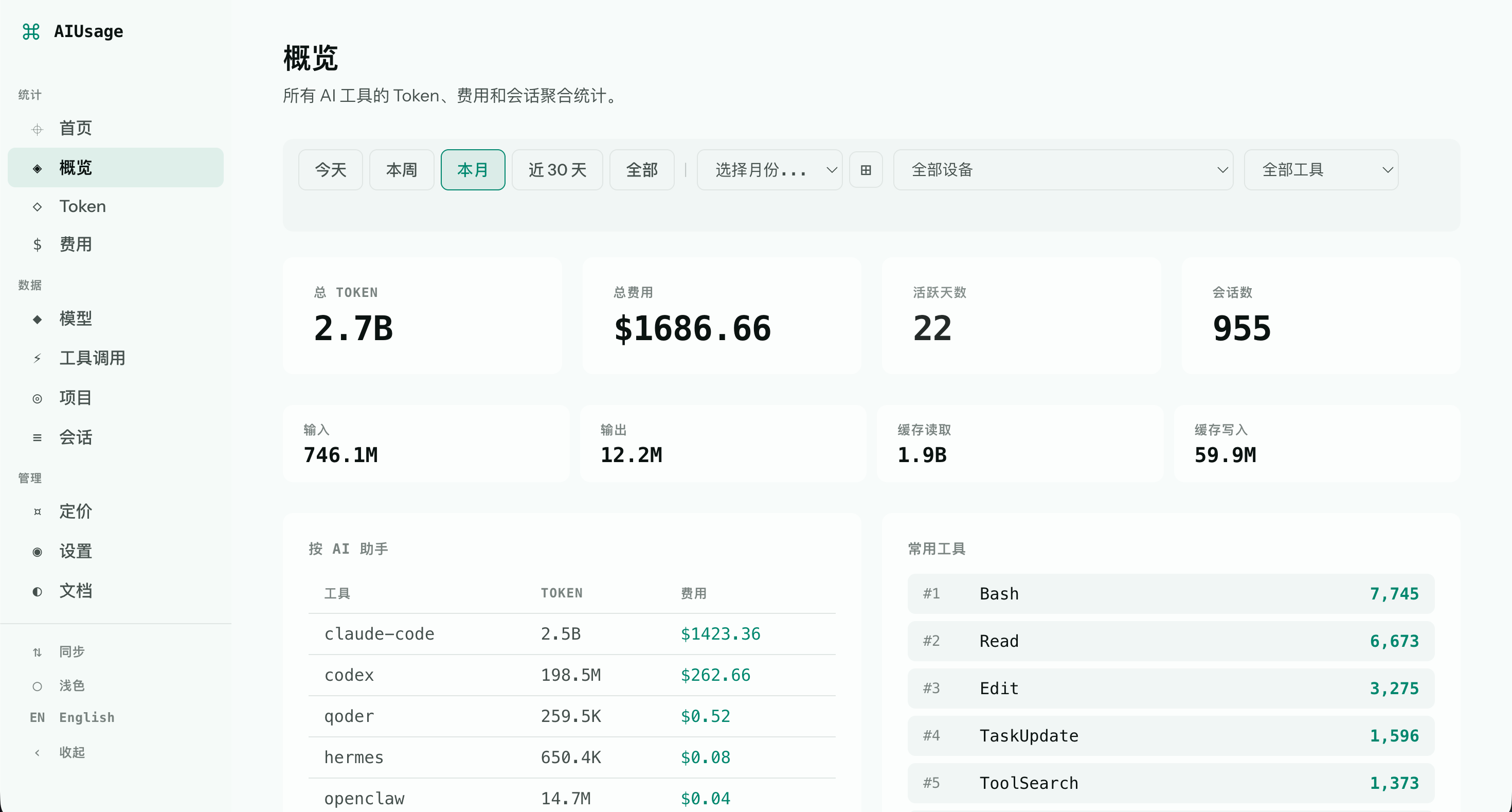
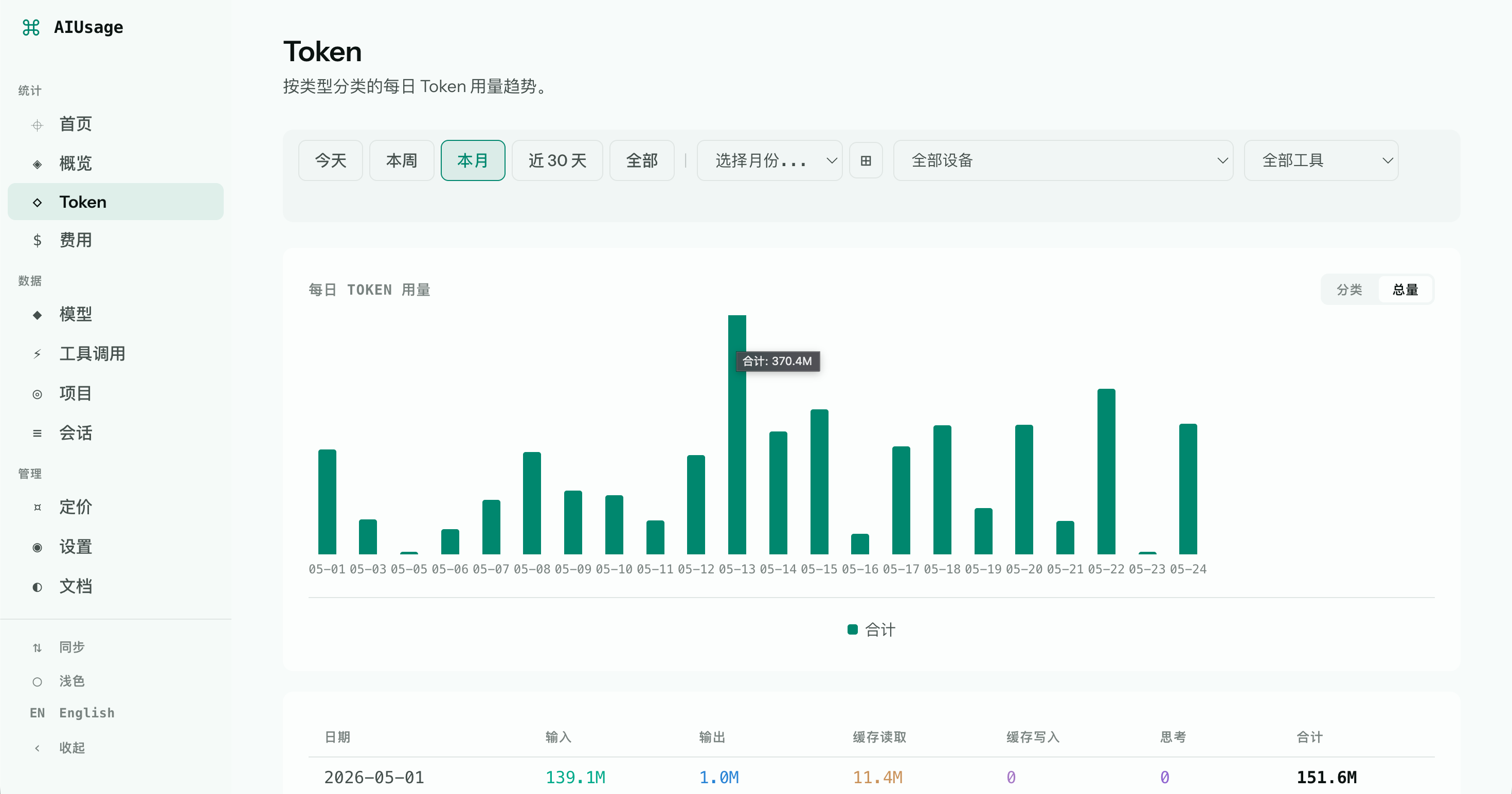
Use aiusage to:
- Track token and cost trends across AI coding assistants.
- Compare model usage and activity over time.
- Inspect tool-call volume and session-level behavior.
- Aggregate usage across multiple machines into one view.
- Run a local or Docker-hosted dashboard for ongoing visibility.
Print a usage summary to the terminal (same as aiusage summary).
Import newly appended local session data from discovered source paths.
| Option | Description |
|---|---|
--tool <tool> |
Only parse a specific tool: claude-code, codex, openclaw, opencode, hermes, qoder |
--progress |
Show real-time progress bar on stderr (TTY only, silent in pipes/CI) |
aiusage parse # Parse all tools
aiusage parse --tool claude-code # Only parse Claude Code logs
aiusage parse --progress # Show progress bar while parsingStart the local web dashboard and runtime settings controller.
| Option | Description | Default |
|---|---|---|
-p, --port <port> |
Port number | 3847 |
aiusage serve # Start on port 3847
aiusage serve -p 8080 # Start on port 8080Print a usage summary in the terminal.
| Option | Description |
|---|---|
--device <id> |
Filter by device instance ID |
--tool <tool> |
Filter by tool type |
aiusage summary # All-time summary
aiusage summary --tool claude-code # Single toolShow version, device name, DB path, schema version, table/view counts, record count, DB size, and sync status.
Export records as CSV, JSON, or NDJSON.
| Option | Description | Required |
|---|---|---|
--format <format> |
Output format: csv, json, ndjson |
Yes |
-o, --output <file> |
Output file path (default: stdout) | No |
aiusage export --format csv # CSV to stdout
aiusage export --format json -o report.json # JSON to file
aiusage export --format ndjson # NDJSON to stdoutRemove old records from the local database based on age.
| Option | Description | Default |
|---|---|---|
--before <duration> |
Delete data older than this duration (e.g. 30d, 180d) |
180d |
aiusage clean # Delete records older than 180 days
aiusage clean --before 30d # Delete records older than 30 days
aiusage clean --before 90d --yes # Delete records older than 90 days, skip confirmDelete all parsed records, tool calls, synced data, and the parse watermark. Source log files (~/.claude, ~/.codex, etc.) are not affected. Use this to re-import everything from scratch.
| Option | Description |
|---|---|
--yes |
Skip confirmation prompt (required to execute) |
aiusage reset --yes # Wipe all data, then run `aiusage parse` to re-importRecalculate costs using the latest pricing data.
aiusage recalcConfigure a sync backend for multi-machine data aggregation.
| Option | Description |
|---|---|
--backend <backend> |
Sync backend: github, s3, skip |
--repo <repo> |
GitHub repository (format: username/repo-name) |
--token <token> |
GitHub Personal Access Token |
--bucket <bucket> |
S3 bucket name |
--prefix <prefix> |
S3 object prefix (default: aiusage/) |
--endpoint <endpoint> |
S3 endpoint URL |
--region <region> |
S3 region (default: auto) |
--access-key-id <id> |
S3 access key ID |
--secret-access-key <key> |
S3 secret access key |
--device <alias> |
Device alias |
aiusage init --backend github --repo user/aiusage-data --token ghp_xxx
aiusage init --backend s3 --bucket my-bucket --endpoint https://xxx.r2.cloudflarestorage.com --access-key-id AKIAxxx --secret-access-key xxxPush and pull data with the configured remote backend.
aiusage syncaiusage serve
# Open http://localhost:3847aiusage serve hosts the following dashboard pages:
- Home (
/) — live counter homepage. On first load it calls/api/refresh, runs one incremental local parse, then loads summary data. After that, it refreshes on the configured dashboard poll interval. - Overview (
/overview) — totals, cost, active days, and per-tool breakdowns for Today, This Week, This Month, Last 30d, or All Time. - Tokens — token usage trends over time, with breakdown-by-type or combined total view.
- Cost — cost trends with by-tool and by-model breakdowns.
- Models — model share and distribution.
- Tool Calls — tool call frequency and ranking.
- Projects — project-level usage rollups.
- Sessions — session browsing with filters and pagination.
- Pricing — active model pricing reference.
- Settings — configure device name, week start day, dashboard poll interval, auto-parse interval, source paths, sync backend, credentials, and local data retention without editing config files manually.
- Docs — in-app documentation with CLI reference and feature guides.
Settings behavior
- Dashboard Poll Interval is in milliseconds and only controls the homepage refresh cycle after the initial load.
- Auto-Parse Interval is in milliseconds and schedules background
aiusage parseruns only whileaiusage serveis running. Set0or leave it blank to disable it. - Local Data Retention runs periodic cleanup only while
aiusage serveis running. Set0or leave it blank to keep data forever. - Source path changes take effect on the next parse.
- Sync backend and credential changes take effect on the next sync.
Need multi-machine aggregation or cloud access? Choose your scenario:
| Scenario | Method | Description |
|---|---|---|
| Multiple machines, aggregate data | Multi-Machine Sync | Sync via GitHub/S3/R2 |
| Multiple machines + unified dashboard | Docker Deployment | Run a 24/7 dashboard from synced data |
For single-machine usage, Quick Start is enough.
Use this to aggregate token usage from multiple machines into one dashboard. Works with Claude Code, Codex, OpenClaw, OpenCode, Hermes, and Qoder.
Architecture:
Machine A ──┐
Machine B ──┼──▶ GitHub / S3 / R2 (shared storage) ──▶ Any machine: aiusage summary / serve
Machine C ──┘
Step 1 — Choose a sync backend
Option A: GitHub (recommended)
- Create a private repository on GitHub (for example
aiusage-data) - Generate a Personal Access Token with
reposcope
Option B: AWS S3 / Cloudflare R2
- Create an S3 or R2 bucket
- Create an IAM user or role with read/write permissions
- Note the access key ID, secret access key, and endpoint
Step 2 — Install and configure on each machine
On every machine that uses Claude Code, Codex, OpenClaw, OpenCode, Hermes, or Qoder:
# Install aiusage CLI
npm install -g @juliantanx/aiusage
# Configure sync backend — GitHub
aiusage init --backend github \
--repo <user>/aiusage-data \
--token ghp_xxxxxxxxxxxxxxxxxxxx
# OR configure sync backend — S3 / R2
aiusage init --backend s3 \
--bucket my-aiusage-bucket \
--prefix aiusage/ \
--endpoint https://<account-id>.r2.cloudflarestorage.com \
--region auto \
--access-key-id AKIAxxxxxxxxxxxx \
--secret-access-key xxxxxxxxxxxxxxxxxxxxxxxxxxStep 3 — Parse and sync on each machine
aiusage parse
aiusage syncStep 4 — View aggregated data on any machine
aiusage sync
aiusage summary
aiusage serveAutomate (recommended)
# Linux/macOS
crontab -e
# Add:
*/30 * * * * /usr/local/bin/aiusage parse && /usr/local/bin/aiusage sync >> ~/.aiusage/cron.log 2>&1
# Windows
schtasks /create /tn "AiusageSync" /tr "aiusage parse && aiusage sync" /sc minute /mo 30How sync works
- Each machine has a unique
deviceInstanceIdgenerated on first run. - Each device writes to its own daily file (
{deviceInstanceId}/YYYY/MM/DD.ndjson) in the remote backend. - Pull reads other devices' files into the local
synced_recordstable; upload writes only this device's files. - Device-partitioned files avoid write conflicts, so no locking is needed.
- Sync frequency comes from your external scheduler or manual runs; aiusage does not include a built-in sync daemon.
- Session IDs are anonymized via
sha256(device + sessionId).
Run the pre-built image on a server for a 24/7 dashboard. The container does not run any AI coding tools itself — it serves the web dashboard, can run the same runtime settings controller as aiusage serve, and can pull synced data from GitHub, S3, or R2.
Architecture:
Machine A ──┐ ┌── Browser: https://aiusage.your-domain.com
Machine B ──┼──▶ GitHub / S3 / R2 ──▶ Cloud Server (Docker)
Machine C ──┘ └── port 3847
How data flows
- Each dev machine runs
aiusage parse && aiusage syncto upload local usage data. - The Docker container runs
aiusage syncto pull that data into its local SQLite database. - The web dashboard reads from the local database and displays aggregated stats.
Data storage in Docker
| Item | Container path | Description |
|---|---|---|
| Database | /root/.aiusage/cache.db |
SQLite database with aggregated usage data |
| Config | /root/.aiusage/config.json |
Sync backend config, runtime settings, and credentials |
| State | /root/.aiusage/state.json |
Consent and sync runtime state |
| Watermarks | /root/.aiusage/watermark.json |
Incremental parse cursors |
All data lives under /root/.aiusage, which is declared as a VOLUME. You must mount this volume to persist data across container restarts.
Step 1 — Pull image and run
# Pull image
docker pull juliantanx/aiusage
# Run container (mount volume for data persistence)
docker run -d \
--name aiusage \
-p 3847:3847 \
-v aiusage-data:/root/.aiusage \
juliantanx/aiusage
# Configure sync backend
docker exec -it aiusage aiusage init \
--backend github \
--repo <user>/aiusage-data \
--token ghp_xxxxxxxxxxxxxxxxxxxx
# Initial data pull
docker exec -it aiusage aiusage syncWithout the
-vflag, data is lost when the container is removed.
Step 2 — Scheduled sync
# Install cron in container and create scheduled task
docker exec -it aiusage bash -c "apt-get update && apt-get install -y cron"
docker exec -it aiusage bash -c \
'echo "*/30 * * * * aiusage sync >> /root/.aiusage/cron.log 2>&1" | crontab -'
docker restart aiusageNote:
parseis not needed here unless you also mount local AI session logs into the container. In the standard deployment, onlysyncis needed to pull data from the remote backend.
Step 3 — Access
Open http://<server-ip>:3847.
For HTTPS with a custom domain:
# Caddy (auto HTTPS, recommended)
caddy reverse-proxy --from aiusage.your-domain.com --to localhost:3847
# Or Nginx
server {
listen 80;
server_name aiusage.your-domain.com;
location / {
proxy_pass http://127.0.0.1:3847;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}Build image yourself (optional)
A Dockerfile is included in the project root:
docker build -t aiusage .| Item | Path |
|---|---|
| Local database | ~/.aiusage/cache.db |
| Config | ~/.aiusage/config.json |
| Sync state | ~/.aiusage/state.json |
| Parse watermarks | ~/.aiusage/watermark.json |
aiusage parse auto-discovers session logs from the following default locations:
| Tool | macOS | Linux | Windows |
|---|---|---|---|
| Claude Code | ~/.claude/projects/ |
~/.claude/projects/ |
%USERPROFILE%\.claude\projects\ |
| Codex | ~/.codex/sessions/ |
~/.codex/sessions/ |
%USERPROFILE%\.codex\sessions\ |
| OpenClaw | ~/.openclaw/agents/*/sessions/ |
~/.openclaw/agents/*/sessions/ |
%USERPROFILE%\.openclaw\agents\*\sessions\ |
| OpenCode | ~/Library/Application Support/opencode/opencode.db |
~/.local/share/opencode/opencode.db |
%APPDATA%\opencode\opencode.db |
| Hermes | ~/.hermes/state.db |
~/.hermes/state.db |
%USERPROFILE%\.hermes\state.db |
| Qoder (sessions) | ~/.qoder/logs/sessions/ |
~/.qoder/logs/sessions/ plus WSL-mounted Windows user homes |
%USERPROFILE%\.qoder\logs\sessions\ |
| Qoder (SQLite) | ~/Library/Application Support/Qoder/SharedClientCache/cache/db/local.db |
~/.local/share/Qoder/SharedClientCache/cache/db/local.db |
%LOCALAPPDATA%\Qoder\SharedClientCache\cache\db\local.db |
Discovery behavior:
- Claude Code — recursively scans
~/.claude/projects/**for.jsonlfiles, including nested subagent logs. - Codex — recursively scans
~/.codex/sessions/**for.jsonlfiles. - OpenClaw — scans each agent's
sessions/directory under~/.openclaw/agents/*/sessions/and skips checkpoint files. - OpenCode — reads the SQLite database file directly instead of
.jsonllogs. - Hermes — reads the SQLite database file (
state.db) directly. Sessions without a recorded end time are still imported if they have token data (e.g. sessions from a force-quit). - Qoder (sessions) — recursively scans structured session segment logs (
logs/sessions/**/segments/*.jsonl) and importsmodel.response.completedtoken events. On WSL, aiusage also checks mounted Windows user homes such as/mnt/c/Users/<user>,/mnt/d/Users/<user>, and/mnt/e/Users/<user>for the same Qoder session-log layout. - Qoder (SQLite) — reads the
local.dbSQLite database directly (SharedClientCache/cache/db/local.db) and imports assistant messages from thechat_messagetable, joined withchat_recordfor model information. This is the primary source on macOS and is tried alongside the sessions directory.
On Linux, OpenCode respects
$XDG_DATA_HOMEif set.
Qoder Desktop also creates installation files under Program Files, UI/cache data under AppData/Roaming/Qoder and AppData/Local/.qoder, and transcripts under %USERPROFILE%\.qoder\projects or %USERPROFILE%\.qoder\cache. These are not imported as token records: desktop Context usage update log lines are repeated context-window snapshots, and transcripts/conversation-history files do not contain per-request token usage.
If you installed a tool to a non-default location, override the paths in the Settings page of the web dashboard (http://localhost:3847/settings → Sources section), or edit ~/.aiusage/config.json directly:
{
"sources": {
"claude-code": "/custom/path/.claude/projects",
"codex": "/custom/path/.codex/sessions",
"openclaw": "/custom/sessions-dir",
"opencode": "/custom/path/opencode.db",
"hermes": "/custom/path/.hermes/state.db",
"qoder": "/custom/path/.qoder/logs/sessions",
"qoder-db": "/custom/path/local.db"
}
}Only the paths you specify are overridden; unspecified tools fall back to their defaults. qoder points to the session logs directory; qoder-db points directly to the local.db SQLite file.
The local database is a standard SQLite file, so you can open it directly in DBeaver, TablePlus, DataGrip, DB Browser for SQLite, or any similar tool.
aiusage status
# Shows the exact DB Path, schema version, and object counts- Open
~/.aiusage/cache.dbas a SQLite database. - Prefer read-only mode in your database tool.
aiusagewrites to the same file and uses WAL mode. - If your tool asks about sidecar files, keep
cache.db-walandcache.db-shmalongside the main database file. - Start with the read-only views:
v_usage_records: one row per usage record with normalized timestamp and token totalsv_tool_calls: tool call rows joined with their parent usage recordv_sessions: session-level aggregates for pivoting and charting
- Raw internal tables remain available for advanced inspection:
recordstool_callssynced_recordssync_tombstones
- Runtime: Node.js, TypeScript
- Database: better-sqlite3 (local, WAL mode)
- CLI: Commander.js
- Web: SvelteKit + adapter-static
- Build: tsup (core/cli), Vite (web)
- Sync: GitHub API, AWS S3 / Cloudflare R2
packages/
core/ - Shared types, database schema, pricing data
cli/ - CLI tool for parsing logs, querying data, cloud sync
web/ - SvelteKit web dashboard (SPA)
No. aiusage is local-first. Your usage data stays on your machine unless you explicitly configure a sync backend.
Yes. You can sync usage data through GitHub, S3, or R2 and then view the combined result from any configured machine or Docker deployment.
No. By default, you run aiusage parse manually. You can automate parsing and syncing with cron, Task Scheduler, or your own scheduler.
aiusage currently supports Claude Code, Codex, OpenClaw, OpenCode, Hermes, and Qoder.
Yes. aiusage stores data in a local SQLite database, and the README already documents how to open it in tools like DBeaver, TablePlus, DataGrip, or DB Browser for SQLite.
linux.do — Thanks to the linux.do community for their support and inspiration during the development of this project.
Contributions are welcome! See CONTRIBUTING.md for how to get started.