



Warning
autopreso is in alpha and under active development. Expect rough edges, breaking changes, and the occasional weird drawing. Bug reports welcome.
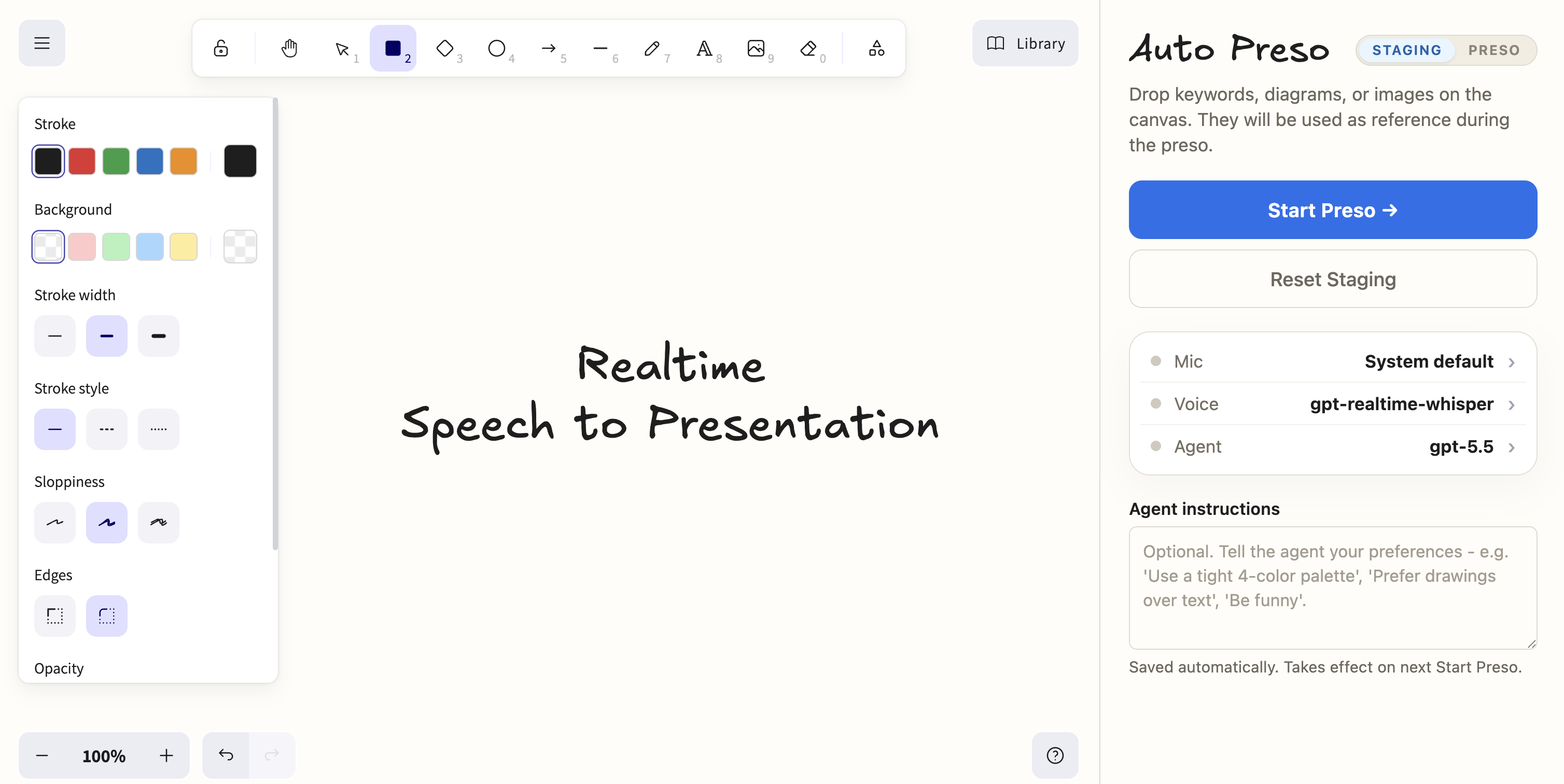
You wanted to give the talk, not build the deck.
autopreso runs a local web app with a live Excalidraw canvas and a listening agent. You speak; transcripts stream to a model; the model draws, labels, and rearranges the whiteboard in real time. Stage a few seed elements, hit start, and present.
- Hands free - your speech drives an agent that edits an Excalidraw scene as you talk, no clicking required.
- Bring your own model - use your OpenAI API key or Codex subscription. Auto Preso itself is completely free and open source.
- Can run locally - use Moonshine for transcription and Ollama for the agent and you get a fully local setup.
$ npx autopreso # boots the server, opens the browser
autopreso listening at http://127.0.0.1:3210
# In the browser:
# 1. Drop reference materials onto the staging canvas (title, agenda, etc).
# 2. Pick your microphone, transcription model, agent model, and optional Agent instructions.
# 3. Click "Start Preso" and start talking.npm (recommended)
npm install -g autopreso
autopresonpx (no install)
npx autopresoFrom source
git clone https://github.com/kunchenguid/autopreso.git
cd autopreso
npm install
npm start ┌──────────┐ audio ┌──────────────┐ text ┌──────────────┐
│ mic │──────────► │ STT │────────► │ whiteboard │
│ (browser)│ 24kHz │ Moonshine / │ chunks │ agent │
└──────────┘ │ OpenAI WS │ │ (OpenAI / │
└──────────────┘ │ Codex / │
│ Ollama) │
└──────┬───────┘
│ tool calls
▼
┌────────────────┐
│ Excalidraw │
│ scene (live) │
└────────────────┘
- Two modes - "staging" lets you sketch seed content client-side; "live" hands the canvas over to the agent, biases OpenAI Realtime transcription toward staging text and labels, and starts streaming transcripts.
- Local server, local network only - the Express + WebSocket server binds to 127.0.0.1; nothing is exposed beyond your machine.
- Persistent settings - models, API keys, STT engine choices, and Agent instructions live in
~/.config/autopreso/settings.jsonand survive restarts. - Warmup loop - after you hit start the agent primes itself against your staging content and Agent instructions so the first sentence you say doesn't get a cold model.
| Command | Description |
|---|---|
autopreso |
Start the local server and open the browser. |
autopreso -h |
Show help. |
| Flag | Description |
|---|---|
--no-open |
Start the server without opening the browser. |
-h, --help |
Show help. |
Settings persist at ~/.config/autopreso/settings.json and are managed from the in-app status panel.
Agent instructions are saved automatically from staging, can be up to 100,000 characters, and take effect on the next Start Preso.
The live Session cost card estimates agent token costs and OpenAI Realtime audio costs for the current presentation, resetting on Start Preso or session reset.
OpenAI prices use the built-in May 2026 rate table; local providers show $0.0000, Codex shows token volume because it routes through your subscription, and unknown models show n/a.
When no settings file exists, autopreso picks providers based on what it finds in your environment:
| You have... | Agent provider | Transcription |
|---|---|---|
| Nothing | OpenAI gpt-5.5 (needs a key) |
Moonshine medium (macOS) |
OPENAI_API_KEY in env |
OpenAI gpt-5.5 |
OpenAI Realtime |
Codex CLI signed in (~/.codex/auth.json) |
Codex gpt-5.5-fast |
Moonshine medium |
Codex CLI signed in + OPENAI_API_KEY |
Codex gpt-5.5-fast |
OpenAI Realtime |
OLLAMA_MODEL set |
Ollama (your model) | Moonshine medium |
Auto-detection precedence: Codex CLI auth wins over OLLAMA_MODEL wins over OPENAI_API_KEY for the agent. Transcription flips to OpenAI Realtime any time an OpenAI key is present, otherwise Moonshine. After first run, this auto-detection no longer applies - change providers from the in-app status panel.
Provider variables only seed settings.json on first run. Once the file exists, they're ignored - edit the file or use the in-app panel. Log path variables are read on each process start.
| Variable | Purpose |
|---|---|
PORT |
Port to listen on. Default: 3210. |
OPENAI_API_KEY |
Seeds the OpenAI key for both agent and Realtime STT. |
OPENAI_MODEL |
Seeds the OpenAI agent model. |
OPENAI_BASE_URL |
Seeds the OpenAI agent API base URL. |
CODEX_MODEL |
Seeds the Codex model. |
OLLAMA_MODEL |
Seeds the Ollama model. |
AUTOPRESO_CACHE_LOG |
Cache usage log path. Default: ~/.config/autopreso/logs/cache.log. |
AUTOPRESO_DEBUG_LOG |
Agent debug log path. Default: ~/.config/autopreso/logs/debug.log. |
Local Moonshine transcription ships as an optional native sidecar for darwin-arm64 and darwin-x64. On other platforms, choose OpenAI Realtime in the STT panel.
- Excalidraw - the whiteboard canvas, scene model, and rendering.
- Moonshine the local speech-to-text model that makes the offline path possible.
- Vercel AI SDK - tool-calling agent loop and provider abstraction.
npm install # install deps
npm run dev # run the CLI from source
npm run typecheck # tsc --noEmit
npm test # node --test
npm run build:moonshine-sidecars # build the Python sidecar binaries