Counting Distinct string token in very large textfiles The program idea is very simple it trades space for speed , utilizing the ability to look up an element in a hash table in O(1) , it reduces the time of finding a unique word in a tokenized string from O(n^2) to O(n).
Linear complexity is great but not real world solution ,so we need parallelism to maximise usage of the hardware. Insertion costs to hashtable is O(n), inserting a 1M milion unique string tokes ,it will dramatically impact the system performance. High memory usage , the system should be intelligently designed to deal with documents.
memory leaks could kill system performance .we must free all heap blocks to have posible leaks
Each operating system provides functions to map chunks from a file to a memory region. This will speed up the file reading process and make it memory efficient (Caching file to computer memory).
Unordered sets are containers that store unique elements in no particular order, and which allow for fast retrieval of individual elements based on their value.I used it minimize the critical section block size in the parallel.
Parallelize the code to handle large datasets efficiently , parallelism could be done on different scales such as each thread takes one file and that's bad for one reason , not all files have the same size, a better object is where each thread handle a line , so multiple threads works on the same file.
Solving the problem using hash table could lead to critical section overhead problem , what i mean that each thread must wait to until the other thread finished from hash table , so it will lead to writing a huge ctrialk section block inside of the source code in order synchronize threads work ,and to eliminate race condition.
such as concurrent maps lets you call some of its functions concurrently – even in combinations where the map is modified. It lets you call insert from multiple threads, with no mutual exclusion. Using it you could scale code very effimcely and runit on multiple threads,plus the critical section in minzmed to pair minim with reduction Openmp and concurrent data structures. The best performance data structure is junction . Sets : it minimize the number of operation in critical section block into only one operation which is insert to sets , which is lead to waiting much less time for a thread to come out form the critical section. To scale the code on sets ,there is concurrent or lock frees set available.
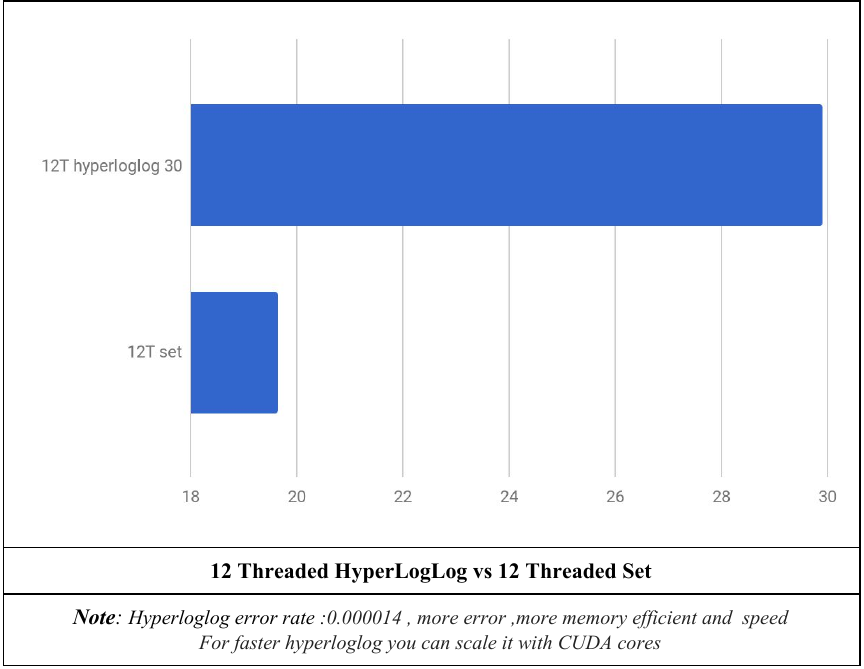
This is an algorithm for the counting distinct or unique objects using approximation ,it aproximatie the number of distinct elements in a set . Calculating the exact cardinality (number of distinct elements) of a multiset requires an amount of memory proportional to the cardinality, it uses significantly less memory than hash table or set ,its able to estimate cardinalities of > 109 with a typical accuracy of 2%, using 1.5 kB of memory.[1] More improvements you can Scale Hyperloglog using CUDA. 
The performance of program running on 20.69 million token , 12.35 million of them are unique ,file size is 180mb. System specs are: CPU:AMD Ryzen 1600 6 core 12 threads |Ram : 16gb 2400mhz |SSD: 25gb 500MB/s write 550MB/S read.

This a proposed Cluster architecture to solve this problem using hybrid parallel programing of core’s and GPU’s across all nodes ,it could be done by MPI,CUDA,OpenMP.The cluster start working by cache pieces of the data into the nodes using window caching,Then Map the files into memory using bit buffer , each node compute a set or hyperloglog until it finishes all of the cached files , then compute another data strip or window from data storage .After all nodes finish the combine their sets,hyperloglog into the master node then compute number of unique tokens which is the case the size of the set or The HIP of hyperloglog.
