ChatGLM2 Support #1261
ChatGLM2 Support #1261
Conversation
|
Thank you for the contribution, unfortunately this PR seems to have some merge conflict and ChatGLM3 also came out. Feel free to coordinate the contribution here if you have bandwidth! |
7591e13 to
7c8fd1a
Compare
7c8fd1a to
251f70c
Compare
|
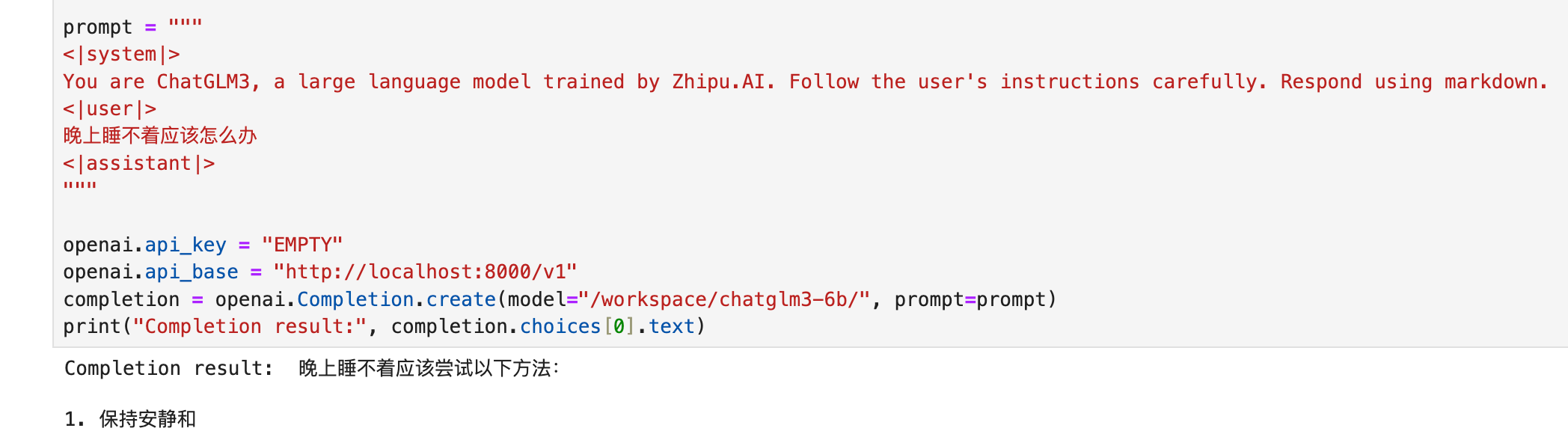
@simon-mo Hi, we have resolved the code conflict, and it can be directly merged into the main branch. As chatglm3 does not change the model structure, this implementation can be directly adopted to chatglm3. Below is the testing code: The output will be |
 zhuohan123
left a comment
zhuohan123
left a comment
There was a problem hiding this comment.
LGTM! Merged with main and fixed a small style issue. The code works with both ChatGLM2 and ChatGLM3 on one GPU in my case. Thank you for your contribution!
add support modelscope mode revert not affect file Support Yi model (vllm-project#1567) ChatGLM Support (vllm-project#1261)
|
hi ,can u tell me how to use it , I still have this problem: AttributeError: 'ChatGLMConfig' object has no attribute 'num_hidden_layers', Currently, I have updated to the latest version of VLLM |
|
This is problem is caused by old version of transformers. I suggest upgrading both your transformers package and ChatGLM model to the recent versions. |
Yes, I have tried,transformers==4.35.0 |
Please provide more information of installed packages, and I will try to reproduce your problem later. |
|
@GoHomeToMacDonal If you use other prompts, it shows big difference between the native model.. Did you try more examples? this is one example, seems it stopped after meeting some token |

I guess you used the default In addition, as ChatGLM3 added some special tokens, e.g., |
|
@GoHomeToMacDonal It is the max_tokens setting issue. adding
|
|
Hello, I am using ChatGLM2 but it seems sometimes the output is not aligned with huggingface version. Could anyone help to take a look at #1670 ? |
|
The latest version already supports GLM. Can GLM3 support official tool calls and other functions? Does it support dialogue function? |
You need to implement the corresponding code for function calls and prompt building. The |
Using vllm to infer the GLM3 model, the speed is only about 13% faster, is it normal? |
|
@GoHomeToMacDonal This is still not supported for the Chatglm2-6b-32k version ,I have a message for the issue #1725 |
) <!-- Thanks for sending a pull request! BEFORE SUBMITTING, PLEASE READ https://docs.vllm.ai/en/latest/contributing/overview.html --> ### What this PR does / why we need it? <!-- - Please clarify what changes you are proposing. The purpose of this section is to outline the changes and how this PR fixes the issue. If possible, please consider writing useful notes for better and faster reviews in your PR. - Please clarify why the changes are needed. For instance, the use case and bug description. - Fixes # --> Refactor the token-wise padding mechanism to a more elegant implementation, correcting the padding logic errors introduced by the previous multimodal commit vllm-project#736 . This is a clean version of vllm-project#1259 . ### Does this PR introduce _any_ user-facing change? <!-- Note that it means *any* user-facing change including all aspects such as API, interface or other behavior changes. Documentation-only updates are not considered user-facing changes. --> ### How was this patch tested? <!-- CI passed with new added/existing test. If it was tested in a way different from regular unit tests, please clarify how you tested step by step, ideally copy and paste-able, so that other reviewers can test and check, and descendants can verify in the future. If tests were not added, please describe why they were not added and/or why it was difficult to add. --> --------- Signed-off-by: Yizhou Liu <[email protected]>
An implementation of ChatGLM 2 based on vLLM. This implementation adapts
PagedAttentionWithRoPEandParallelLinearlayers for model inference.