[SPARK-23270][Streaming][WEB-UI]FileInputDStream Streaming UI 's records should not be set to the default value of 0, it should be the total number of rows of new files. #20437
Conversation
…rds should not be set to the default value of 0, it should be the total number of rows of new files.
| "files" -> newFiles.toList, | ||
| StreamInputInfo.METADATA_KEY_DESCRIPTION -> newFiles.mkString("\n")) | ||
| val inputInfo = StreamInputInfo(id, 0, metadata) | ||
| var numRecords = 0L |
There was a problem hiding this comment.
I'm not sure if this change is correct, but, you should write it as rdds.map(_.count).sum
|
Thanks, thank you for your review. |
| "files" -> newFiles.toList, | ||
| StreamInputInfo.METADATA_KEY_DESCRIPTION -> newFiles.mkString("\n")) | ||
| val inputInfo = StreamInputInfo(id, 0, metadata) | ||
| val inputInfo = StreamInputInfo(id, rdds.map(_.count).sum, metadata) |
There was a problem hiding this comment.
This will kick off a new Spark job to read files and count, which will bring in obvious overhead. Whereas count in DirectKafkaInputDStream only calculates offsets.
There was a problem hiding this comment.
Because of this little overhead, that 'Records' is not recorded? This is a obvious bug.
There was a problem hiding this comment.
This is not a small overhead. The changes will read/scan all the new files, this is a big overhead for streaming application (data is unnecessarily read twice).
There was a problem hiding this comment.
I see what you mean. I'll try to make it read once. Can you give me some idea?
There was a problem hiding this comment.
I'm not sure if there's a solution to fix it here.
There was a problem hiding this comment.
Asynchronous processing, does not affect the backbone of the Streaming job, also can get the number of records.
There was a problem hiding this comment.
I'm not in favor of such changes. No matter the process is sync or async, because reportInfo is invoked here, so you have to wait for the process to end.
Anyway I think reading twice is unacceptable for streaming scenario (even for batch scenario). I guess the previous code set to "0" by intention.
There was a problem hiding this comment.
If we can add a switch parameter, the default value is false.
If it is true, then it needs to be count (read the file again), so that the records can be correctly counted.
Of course, it shows that when the parameter is opened to true, the streaming performance problem will be affected.
There was a problem hiding this comment.
I don't think it's a good idea. Actually I'm incline of leaving as it is.
There was a problem hiding this comment.
I am very sad. I'm working on whether there's a better way.
|
Can one of the admins verify this patch? |
Closes apache#17422 Closes apache#17619 Closes apache#18034 Closes apache#18229 Closes apache#18268 Closes apache#17973 Closes apache#18125 Closes apache#18918 Closes apache#19274 Closes apache#19456 Closes apache#19510 Closes apache#19420 Closes apache#20090 Closes apache#20177 Closes apache#20304 Closes apache#20319 Closes apache#20543 Closes apache#20437 Closes apache#21261 Closes apache#21726 Closes apache#14653 Closes apache#13143 Closes apache#17894 Closes apache#19758 Closes apache#12951 Closes apache#17092 Closes apache#21240 Closes apache#16910 Closes apache#12904 Closes apache#21731 Closes apache#21095 Added: Closes apache#19233 Closes apache#20100 Closes apache#21453 Closes apache#21455 Closes apache#18477 Added: Closes apache#21812 Closes apache#21787 Author: hyukjinkwon <[email protected]> Closes apache#21781 from HyukjinKwon/closing-prs.
What changes were proposed in this pull request?
FileInputDStream Streaming UI 's records should not be set to the default value of 0, it should be the total number of rows of new files.
------------------------------------------in FileInputDStream.scala start------------------------------------
val inputInfo = StreamInputInfo(id, 0, metadata) // set to the default value of 0
ssc.scheduler.inputInfoTracker.reportInfo(validTime, inputInfo)
case class StreamInputInfo(
inputStreamId: Int, numRecords: Long, metadata: Map[String, Any] = Map.empty)
------------------------------------in FileInputDStream.scala end--------------------------
------------------------------------------in DirectKafkaInputDStream.scala start------------------------------------
val inputInfo = StreamInputInfo(id, rdd.count, metadata) //set to rdd count as numRecords
ssc.scheduler.inputInfoTracker.reportInfo(validTime, inputInfo)
case class StreamInputInfo(
inputStreamId: Int, numRecords: Long, metadata: Map[String, Any] = Map.empty)
------------------------------------in DirectKafkaInputDStream.scala end----------------------
test method:
./bin/spark-submit --class org.apache.spark.examples.streaming.HdfsWordCount examples/jars/spark-examples_2.11-2.4.0-SNAPSHOT.jar /spark/tmp/
fix after:
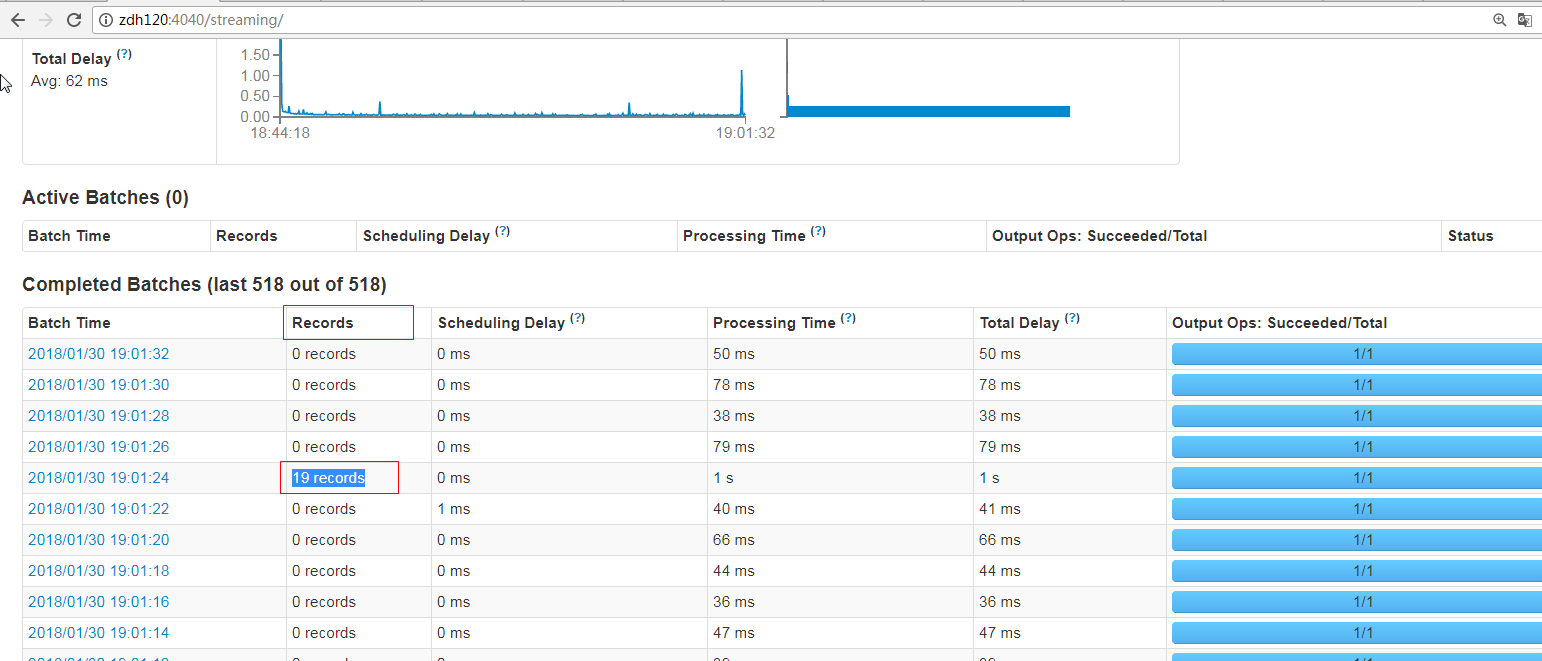
How was this patch tested?
manual tests
Please review http://spark.apache.org/contributing.html before opening a pull request.