[SPARK-23649][SQL] Skipping chars disallowed in UTF-8 #20796
Conversation
|
Could you add more tests for all the invalid range @HyukjinKwon Could you trigger this test? Also, kindly pinging cuz this is probably your domain? |
|
ok to test |
|
test this please |
|
retest this please |
|
Test build #88174 has finished for PR 20796 at commit
|
|
add to whitelist |
|
Test build #88196 has finished for PR 20796 at commit
|
| @@ -0,0 +1,3 @@ | |||
| channel,code | |||
| United,123 | |||
| ABGUN�,456 No newline at end of file | |||
There was a problem hiding this comment.
how did you create this file?
|
the fix LGTM, we can add more tests for different ranges of the invalid chars. |
|
LGTM for the fix. +1 for more tests. |
|
|
||
| assert(df.schema == expectedSchema) | ||
|
|
||
| val badStr = new String("ABGUN".getBytes :+ 0xff.toByte) |
There was a problem hiding this comment.
Shall we explicitly give encoding?
…t byte of UTF-8 char
|
Test build #88313 has finished for PR 20796 at commit
|
|
test this please |
|
Test build #88316 has finished for PR 20796 at commit
|
|
Test build #88320 has finished for PR 20796 at commit
|
|
Test build #88340 has finished for PR 20796 at commit
|
|
@HyukjinKwon @maropu @cloud-fan @gatorsmile Please, review it. |
| * Binary Hex Comments | ||
| * 0xxxxxxx 0x00..0x7F Only byte of a 1-byte character encoding | ||
| * 10xxxxxx 0x80..0xBF Continuation bytes (1-3 continuation bytes) | ||
| * 110xxxxx 0xC0..0xDF First byte of a 2-byte character encoding |
There was a problem hiding this comment.
yea, seems we should need to list 0xC0, 0xC1 here.
There was a problem hiding this comment.
Actually this table is from the unicode standard (10.0, Table 3-6, page 126):
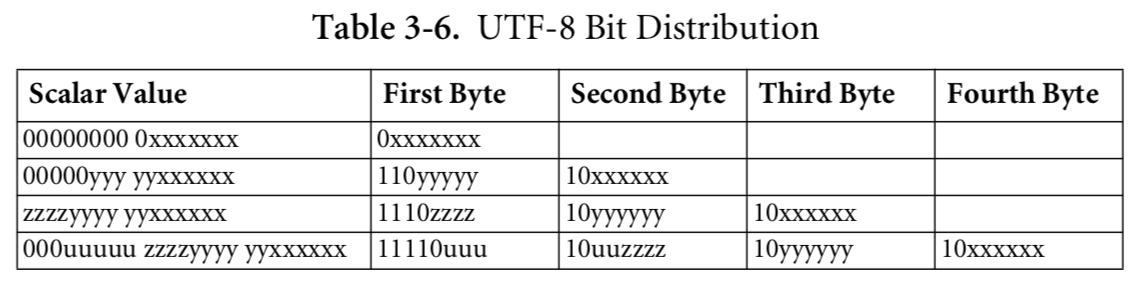
0xC0, 0xC1 are first bytes of 2 bytes chars disallowed by UTF-8 (for now)
There was a problem hiding this comment.
Here is the table of allowed first bytes:
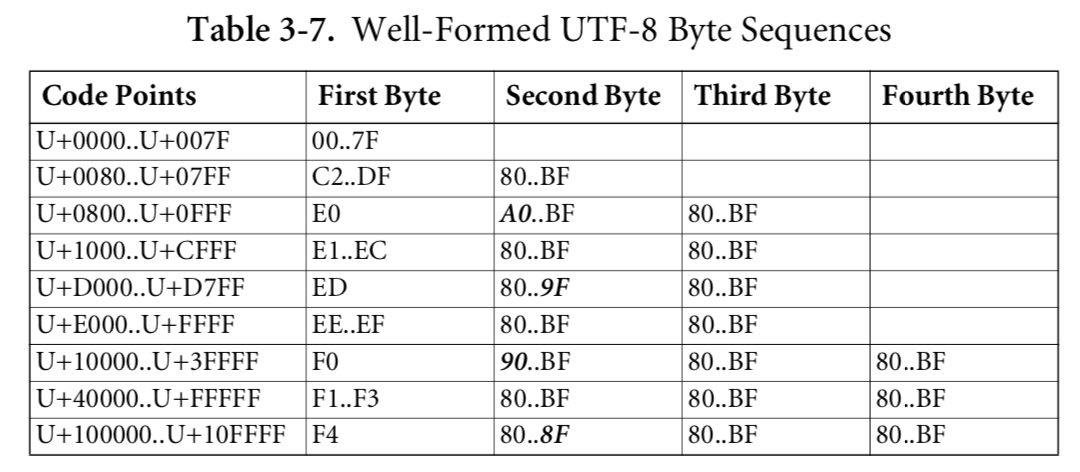
There was a problem hiding this comment.
Yes, it looks a bit inconsistent with the content of bytesOfCodePointInUTF8. I agree with @cloud-fan that we should list 0xC0, 0xC1 here.
There was a problem hiding this comment.
I added a comment about the first bytes disallowed by UTF-8. The comment describes from where the byte ranges and restrictions come otherwise the comments just duplicate the implementation.
| * 10xxxxxx 0x80..0xBF Continuation bytes (1-3 continuation bytes) | ||
| * 110xxxxx 0xC0..0xDF First byte of a 2-byte character encoding | ||
| * 1110xxxx 0xE0..0xEF First byte of a 3-byte character encoding | ||
| * 11110xxx 0xF0..0xF4 First byte of a 4-byte character encoding |
There was a problem hiding this comment.
I will add additional comment about which bytes are not allowed according to the table:
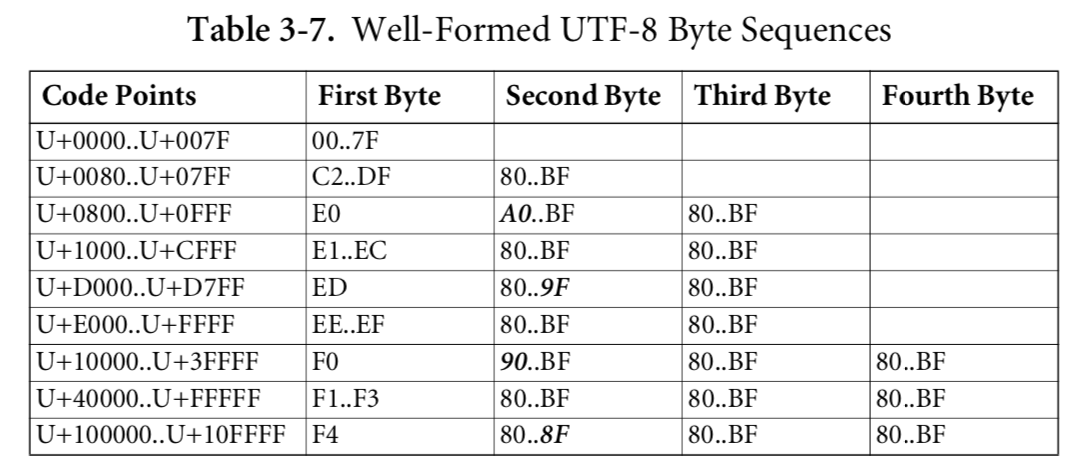
|
|
||
| @Test | ||
| public void skipWrongFirstByte() { | ||
| int[] wrongFirstBytes = { |
There was a problem hiding this comment.
what will happen if we print UTF8String with invalid bytes?
There was a problem hiding this comment.
The bytes are not filtered by UTF8String methods. For instance, in the case of csv datasource the invalid bytes are just passed to the final result. See https://issues.apache.org/jira/browse/SPARK-23649
I have created a separate ticket to fix the issue: https://issues.apache.org/jira/browse/SPARK-23741 .
I am not sure that the issue of output of wrong UTF-8 chars should be addressed by this PR (this pr just fixes crashes on wrong input) because it could impact on users and other Spark components. Need to discuss it and test it carefully.
|
LGTM, pending jenkins |
|
Test build #88384 has finished for PR 20796 at commit
|
|
retest this please. |
| return (offset >= 0) ? bytesOfCodePointInUTF8[offset] : 1; | ||
| final int offset = b & 0xFF; | ||
| byte numBytes = bytesOfCodePointInUTF8[offset]; | ||
| return (numBytes == 0) ? 1: numBytes; // Skip the first byte disallowed in UTF-8 |
There was a problem hiding this comment.
Is the comment valid? Do we skip it? Don't we still count the disallowed byte as one code point in numChars?
There was a problem hiding this comment.
I think so. We jump over (skip by definition) such bytes and count it as one entity. If we don't count the bytes, we break substring, toUpperCase, toLowerCase, trimRight/trimLeft and etc. The reason of the changes is to not crash on bad input as previously we threw IndexOutOfBoundsexception on some wrong chars but could pass (count as 1) another wrong chars. This PR allows to cover whole range. I believe ignoring/removing of wrong chars should be addressed in changes for https://issues.apache.org/jira/browse/SPARK-23741
|
Test build #88394 has finished for PR 20796 at commit
|
|
retest this please. |
|
Test build #88413 has finished for PR 20796 at commit
|
|
LGTM |
## What changes were proposed in this pull request? The mapping of UTF-8 char's first byte to char's size doesn't cover whole range 0-255. It is defined only for 0-253: https://github.com/apache/spark/blob/master/common/unsafe/src/main/java/org/apache/spark/unsafe/types/UTF8String.java#L60-L65 https://github.com/apache/spark/blob/master/common/unsafe/src/main/java/org/apache/spark/unsafe/types/UTF8String.java#L190 If the first byte of a char is 253-255, IndexOutOfBoundsException is thrown. Besides of that values for 244-252 are not correct according to recent unicode standard for UTF-8: http://www.unicode.org/versions/Unicode10.0.0/UnicodeStandard-10.0.pdf As a consequence of the exception above, the length of input string in UTF-8 encoding cannot be calculated if the string contains chars started from 253 code. It is visible on user's side as for example crashing of schema inferring of csv file which contains such chars but the file can be read if the schema is specified explicitly or if the mode set to multiline. The proposed changes build correct mapping of first byte of UTF-8 char to its size (now it covers all cases) and skip disallowed chars (counts it as one octet). ## How was this patch tested? Added a test and a file with a char which is disallowed in UTF-8 - 0xFF. Author: Maxim Gekk <[email protected]> Closes #20796 from MaxGekk/skip-wrong-utf8-chars. (cherry picked from commit 5e7bc2a) Signed-off-by: Wenchen Fan <[email protected]>
|
thanks, merging to master/2.3/2.2! |
The mapping of UTF-8 char's first byte to char's size doesn't cover whole range 0-255. It is defined only for 0-253: https://github.com/apache/spark/blob/master/common/unsafe/src/main/java/org/apache/spark/unsafe/types/UTF8String.java#L60-L65 https://github.com/apache/spark/blob/master/common/unsafe/src/main/java/org/apache/spark/unsafe/types/UTF8String.java#L190 If the first byte of a char is 253-255, IndexOutOfBoundsException is thrown. Besides of that values for 244-252 are not correct according to recent unicode standard for UTF-8: http://www.unicode.org/versions/Unicode10.0.0/UnicodeStandard-10.0.pdf As a consequence of the exception above, the length of input string in UTF-8 encoding cannot be calculated if the string contains chars started from 253 code. It is visible on user's side as for example crashing of schema inferring of csv file which contains such chars but the file can be read if the schema is specified explicitly or if the mode set to multiline. The proposed changes build correct mapping of first byte of UTF-8 char to its size (now it covers all cases) and skip disallowed chars (counts it as one octet). Added a test and a file with a char which is disallowed in UTF-8 - 0xFF. Author: Maxim Gekk <[email protected]> Closes #20796 from MaxGekk/skip-wrong-utf8-chars. (cherry picked from commit 5e7bc2a) Signed-off-by: Wenchen Fan <[email protected]>
The mapping of UTF-8 char's first byte to char's size doesn't cover whole range 0-255. It is defined only for 0-253: https://github.com/apache/spark/blob/master/common/unsafe/src/main/java/org/apache/spark/unsafe/types/UTF8String.java#L60-L65 https://github.com/apache/spark/blob/master/common/unsafe/src/main/java/org/apache/spark/unsafe/types/UTF8String.java#L190 If the first byte of a char is 253-255, IndexOutOfBoundsException is thrown. Besides of that values for 244-252 are not correct according to recent unicode standard for UTF-8: http://www.unicode.org/versions/Unicode10.0.0/UnicodeStandard-10.0.pdf As a consequence of the exception above, the length of input string in UTF-8 encoding cannot be calculated if the string contains chars started from 253 code. It is visible on user's side as for example crashing of schema inferring of csv file which contains such chars but the file can be read if the schema is specified explicitly or if the mode set to multiline. The proposed changes build correct mapping of first byte of UTF-8 char to its size (now it covers all cases) and skip disallowed chars (counts it as one octet). Added a test and a file with a char which is disallowed in UTF-8 - 0xFF. Author: Maxim Gekk <[email protected]> Closes apache#20796 from MaxGekk/skip-wrong-utf8-chars. (cherry picked from commit 5e7bc2a) Signed-off-by: Wenchen Fan <[email protected]>
## What changes were proposed in this pull request? The mapping of UTF-8 char's first byte to char's size doesn't cover whole range 0-255. It is defined only for 0-253: https://github.com/apache/spark/blob/master/common/unsafe/src/main/java/org/apache/spark/unsafe/types/UTF8String.java#L60-L65 https://github.com/apache/spark/blob/master/common/unsafe/src/main/java/org/apache/spark/unsafe/types/UTF8String.java#L190 If the first byte of a char is 253-255, IndexOutOfBoundsException is thrown. Besides of that values for 244-252 are not correct according to recent unicode standard for UTF-8: http://www.unicode.org/versions/Unicode10.0.0/UnicodeStandard-10.0.pdf As a consequence of the exception above, the length of input string in UTF-8 encoding cannot be calculated if the string contains chars started from 253 code. It is visible on user's side as for example crashing of schema inferring of csv file which contains such chars but the file can be read if the schema is specified explicitly or if the mode set to multiline. The proposed changes build correct mapping of first byte of UTF-8 char to its size (now it covers all cases) and skip disallowed chars (counts it as one octet). ## How was this patch tested? Added a test and a file with a char which is disallowed in UTF-8 - 0xFF. Author: Maxim Gekk <[email protected]> Closes apache#20796 from MaxGekk/skip-wrong-utf8-chars. (cherry picked from commit 5e7bc2a) Signed-off-by: Wenchen Fan <[email protected]>
What changes were proposed in this pull request?
The mapping of UTF-8 char's first byte to char's size doesn't cover whole range 0-255. It is defined only for 0-253:
https://github.com/apache/spark/blob/master/common/unsafe/src/main/java/org/apache/spark/unsafe/types/UTF8String.java#L60-L65
https://github.com/apache/spark/blob/master/common/unsafe/src/main/java/org/apache/spark/unsafe/types/UTF8String.java#L190
If the first byte of a char is 253-255, IndexOutOfBoundsException is thrown. Besides of that values for 244-252 are not correct according to recent unicode standard for UTF-8: http://www.unicode.org/versions/Unicode10.0.0/UnicodeStandard-10.0.pdf
As a consequence of the exception above, the length of input string in UTF-8 encoding cannot be calculated if the string contains chars started from 253 code. It is visible on user's side as for example crashing of schema inferring of csv file which contains such chars but the file can be read if the schema is specified explicitly or if the mode set to multiline.
The proposed changes build correct mapping of first byte of UTF-8 char to its size (now it covers all cases) and skip disallowed chars (counts it as one octet).
How was this patch tested?
Added a test and a file with a char which is disallowed in UTF-8 - 0xFF.