[SPARK-23649][SQL] Skipping chars disallowed in UTF-8 #20796
There are no files selected for viewing
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -57,12 +57,43 @@ public final class UTF8String implements Comparable<UTF8String>, Externalizable, | |
| public Object getBaseObject() { return base; } | ||
| public long getBaseOffset() { return offset; } | ||
|
|
||
| /** | ||
| * A char in UTF-8 encoding can take 1-4 bytes depending on the first byte which | ||
| * indicates the size of the char. See Unicode standard in page 126, Table 3-6: | ||
| * http://www.unicode.org/versions/Unicode10.0.0/UnicodeStandard-10.0.pdf | ||
| * | ||
| * Binary Hex Comments | ||
| * 0xxxxxxx 0x00..0x7F Only byte of a 1-byte character encoding | ||
| * 10xxxxxx 0x80..0xBF Continuation bytes (1-3 continuation bytes) | ||
| * 110xxxxx 0xC0..0xDF First byte of a 2-byte character encoding | ||
| * 1110xxxx 0xE0..0xEF First byte of a 3-byte character encoding | ||
| * 11110xxx 0xF0..0xF7 First byte of a 4-byte character encoding | ||
| * | ||
| * As a consequence of the well-formedness conditions specified in | ||
| * Table 3-7 (page 126), the following byte values are disallowed in UTF-8: | ||
| * C0–C1, F5–FF. | ||
| */ | ||
| private static byte[] bytesOfCodePointInUTF8 = { | ||
| 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, // 0x00..0x0F | ||
| 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, // 0x10..0x1F | ||
| 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, // 0x20..0x2F | ||
| 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, // 0x30..0x3F | ||
| 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, // 0x40..0x4F | ||
| 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, // 0x50..0x5F | ||
| 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, // 0x60..0x6F | ||
| 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, // 0x70..0x7F | ||
| // Continuation bytes cannot appear as the first byte | ||
| 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // 0x80..0x8F | ||
| 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // 0x90..0x9F | ||
| 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // 0xA0..0xAF | ||
| 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // 0xB0..0xBF | ||
| 0, 0, // 0xC0..0xC1 - disallowed in UTF-8 | ||
| 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, // 0xC2..0xCF | ||
| 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, // 0xD0..0xDF | ||
| 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, // 0xE0..0xEF | ||
| 4, 4, 4, 4, 4, // 0xF0..0xF4 | ||
| 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 // 0xF5..0xFF - disallowed in UTF-8 | ||
| }; | ||
|
|
||
| private static final boolean IS_LITTLE_ENDIAN = | ||
| ByteOrder.nativeOrder() == ByteOrder.LITTLE_ENDIAN; | ||
|
|
@@ -187,8 +218,9 @@ public void writeTo(OutputStream out) throws IOException { | |
| * @param b The first byte of a code point | ||
| */ | ||
| private static int numBytesForFirstByte(final byte b) { | ||
| final int offset = b & 0xFF; | ||
| byte numBytes = bytesOfCodePointInUTF8[offset]; | ||
| return (numBytes == 0) ? 1: numBytes; // Skip the first byte disallowed in UTF-8 | ||
|
Member
There was a problem hiding this comment. Is the comment valid? Do we skip it? Don't we still count the disallowed byte as one code point in
Member
Author
There was a problem hiding this comment. I think so. We jump over (skip by definition) such bytes and count it as one entity. If we don't count the bytes, we break |
||
| } | ||
|
|
||
| /** | ||
|
|
||
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -58,8 +58,12 @@ private static void checkBasic(String str, int len) { | |
| @Test | ||
| public void basicTest() { | ||
| checkBasic("", 0); | ||
| checkBasic("¡", 1); // 2 bytes char | ||
| checkBasic("ку", 2); // 2 * 2 bytes chars | ||
| checkBasic("hello", 5); // 5 * 1 byte chars | ||
| checkBasic("大 千 世 界", 7); | ||
| checkBasic("︽﹋%", 3); // 3 * 3 bytes chars | ||
| checkBasic("\uD83E\uDD19", 1); // 4 bytes char | ||
| } | ||
|
|
||
| @Test | ||
|
|
@@ -791,4 +795,21 @@ public void trimRightWithTrimString() { | |
| assertEquals(fromString("头"), fromString("头a???/").trimRight(fromString("数?/*&^%a"))); | ||
| assertEquals(fromString("头"), fromString("头数b数数 [").trimRight(fromString(" []数b"))); | ||
| } | ||
|
|
||
| @Test | ||
| public void skipWrongFirstByte() { | ||
| int[] wrongFirstBytes = { | ||
|
Contributor
There was a problem hiding this comment. what will happen if we print UTF8String with invalid bytes?
Member
Author
There was a problem hiding this comment. The bytes are not filtered by UTF8String methods. For instance, in the case of csv datasource the invalid bytes are just passed to the final result. See https://issues.apache.org/jira/browse/SPARK-23649 I have created a separate ticket to fix the issue: https://issues.apache.org/jira/browse/SPARK-23741 . I am not sure that the issue of output of wrong UTF-8 chars should be addressed by this PR (this pr just fixes crashes on wrong input) because it could impact on users and other Spark components. Need to discuss it and test it carefully. |
||
| 0x80, 0x9F, 0xBF, // Skip Continuation bytes | ||
| 0xC0, 0xC2, // 0xC0..0xC1 - disallowed in UTF-8 | ||
| // 0xF5..0xFF - disallowed in UTF-8 | ||
| 0xF5, 0xF6, 0xF7, 0xF8, 0xF9, | ||
| 0xFA, 0xFB, 0xFC, 0xFD, 0xFE, 0xFF | ||
| }; | ||
| byte[] c = new byte[1]; | ||
|
|
||
| for (int i = 0; i < wrongFirstBytes.length; ++i) { | ||
| c[0] = (byte)wrongFirstBytes[i]; | ||
| assertEquals(fromBytes(c).numChars(), 1); | ||
| } | ||
| } | ||
| } | ||
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
hmm, is this
0xC2..0xDF?There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
yea, seems we should need to list
0xC0, 0xC1here.There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Actually this table is from the unicode standard (10.0, Table 3-6, page 126):
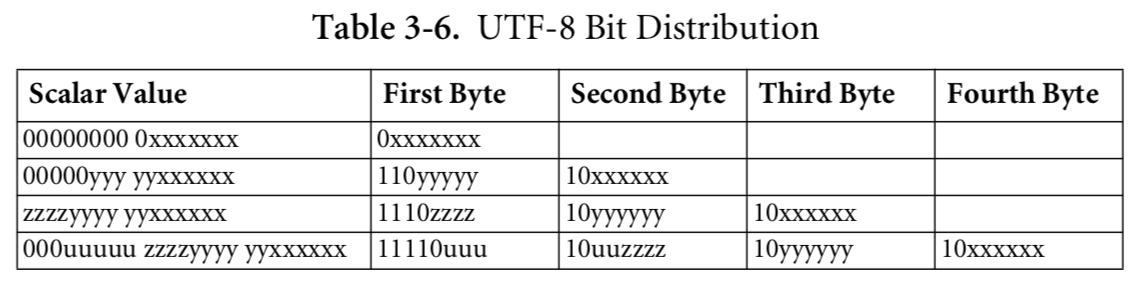
0xC0, 0xC1 are first bytes of 2 bytes chars disallowed by UTF-8 (for now)
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Here is the table of allowed first bytes:
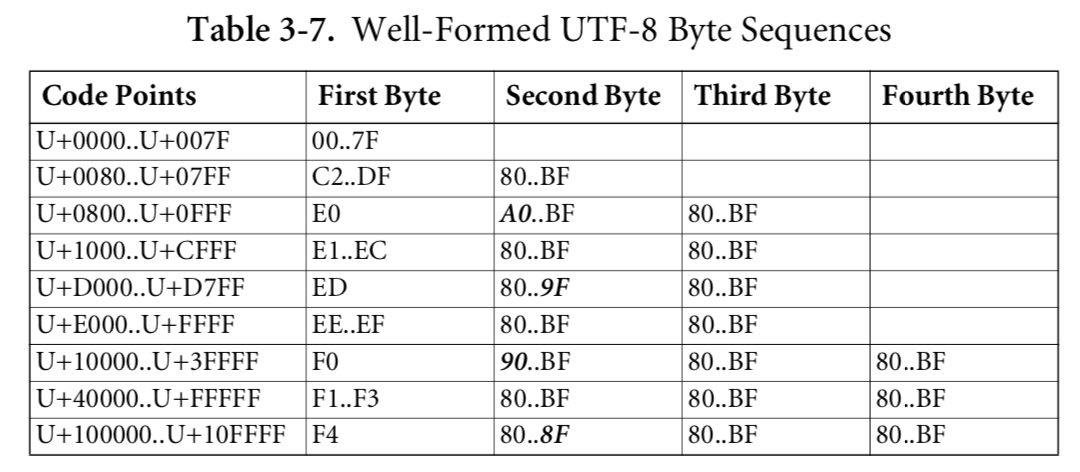
Uh oh!
There was an error while loading. Please reload this page.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Yes, it looks a bit inconsistent with the content of
bytesOfCodePointInUTF8. I agree with @cloud-fan that we should list0xC0, 0xC1here.There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
I added a comment about the first bytes disallowed by UTF-8. The comment describes from where the byte ranges and restrictions come otherwise the comments just duplicate the implementation.