[SPARK-28901][SQL] SparkThriftServer's Cancel SQL Operation show it in JDBC Tab UI #25611
There are no files selected for viewing
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -72,9 +72,8 @@ private[hive] class SparkExecuteStatementOperation( | |
|
|
||
| override def close(): Unit = { | ||
| // RDDs will be cleaned automatically upon garbage collection. | ||
| logInfo(s"Close statement with $statementId") | ||
| cleanup(OperationState.CLOSED) | ||
| HiveThriftServer2.listener.onOperationClosed(statementId) | ||
| } | ||
|
|
||
|
|
@@ -159,6 +158,14 @@ private[hive] class SparkExecuteStatementOperation( | |
|
|
||
| override def runInternal(): Unit = { | ||
| setState(OperationState.PENDING) | ||
| statementId = UUID.randomUUID().toString | ||
| logInfo(s"Submitting query '$statement' with $statementId") | ||
| HiveThriftServer2.listener.onStatementStart( | ||
|
Contributor
There was a problem hiding this comment. Could you add
Contributor
Author
There was a problem hiding this comment.
done
Contributor
There was a problem hiding this comment. ocd formatting nit: move |
||
| statementId, | ||
| parentSession.getSessionHandle.getSessionId.toString, | ||
| statement, | ||
| statementId, | ||
| parentSession.getUsername) | ||
| setHasResultSet(true) // avoid no resultset for async run | ||
|
|
||
| if (!runInBackground) { | ||
|
|
@@ -201,33 +208,38 @@ private[hive] class SparkExecuteStatementOperation( | |
| setBackgroundHandle(backgroundHandle) | ||
| } catch { | ||
| case rejected: RejectedExecutionException => | ||
| logError("Error submitting query in background, query rejected", rejected) | ||
| setState(OperationState.ERROR) | ||
| HiveThriftServer2.listener.onStatementError( | ||
| statementId, rejected.getMessage, SparkUtils.exceptionString(rejected)) | ||
| throw new HiveSQLException("The background threadpool cannot accept" + | ||
| " new task for execution, please retry the operation", rejected) | ||
| case NonFatal(e) => | ||
| logError(s"Error executing query in background", e) | ||
| setState(OperationState.ERROR) | ||
| HiveThriftServer2.listener.onStatementError( | ||
| statementId, e.getMessage, SparkUtils.exceptionString(e)) | ||
| throw new HiveSQLException(e) | ||
| } | ||
| } | ||
| } | ||
|
|
||
| private def execute(): Unit = withSchedulerPool { | ||
| try { | ||
| synchronized { | ||
| if (getStatus.getState.isTerminal) { | ||
| logInfo(s"Query with $statementId in terminal state before it started running") | ||
| return | ||
| } else { | ||
| logInfo(s"Running query with $statementId") | ||
| setState(OperationState.RUNNING) | ||
| } | ||
| } | ||
| // Always use the latest class loader provided by executionHive's state. | ||
| val executionHiveClassLoader = sqlContext.sharedState.jarClassLoader | ||
| Thread.currentThread().setContextClassLoader(executionHiveClassLoader) | ||
|
|
||
|
Contributor
Author
There was a problem hiding this comment. @juliuszsompolski call cancel here for run statement in sync mode. seems can't stop task running . |
||
| sqlContext.sparkContext.setJobGroup(statementId, statement) | ||
|
Contributor
Author
There was a problem hiding this comment. How about move judgement to this place . I think
Contributor
There was a problem hiding this comment. @AngersZhuuuu
Contributor
Author
There was a problem hiding this comment. But when
Contributor
There was a problem hiding this comment. Let's have
I think that the only way to prevent this, is to call another cancelJobGroup from the catch block when an exception comes.
Contributor
Author
There was a problem hiding this comment. Get your point. |
||
| result = sqlContext.sql(statement) | ||
| logDebug(result.queryExecution.toString()) | ||
| result.queryExecution.logical match { | ||
|
|
@@ -249,32 +261,43 @@ private[hive] class SparkExecuteStatementOperation( | |
| } | ||
| dataTypes = result.queryExecution.analyzed.output.map(_.dataType).toArray | ||
| } catch { | ||
| // Actually do need to catch Throwable as some failures don't inherit from Exception and | ||
| // HiveServer will silently swallow them. | ||
| case e: Throwable => | ||
|
Contributor
There was a problem hiding this comment. @AngersZhuuuu I think it can be fixed by:
Contributor
Author
There was a problem hiding this comment. Got you point. But cancelJobGroup here seem can't stop |
||
| val currentState = getStatus().getState() | ||
| if (currentState.isTerminal) { | ||
|
Contributor
There was a problem hiding this comment. ocd nit:
Contributor
Author
There was a problem hiding this comment.
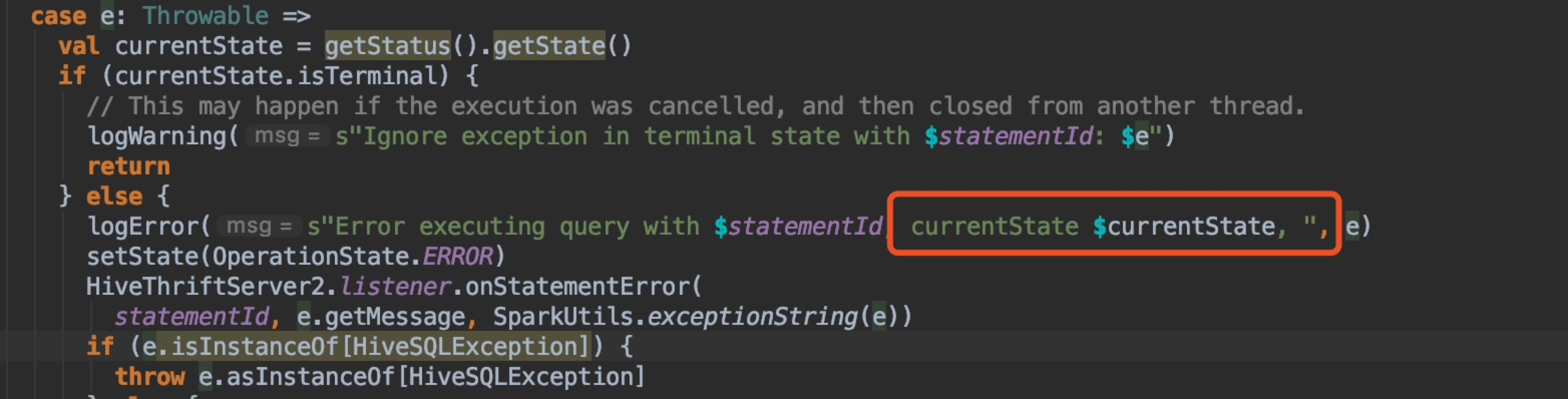
We should show currentState in |
||
| // This may happen if the execution was cancelled, and then closed from another thread. | ||
| logWarning(s"Ignore exception in terminal state with $statementId: $e") | ||
| } else { | ||
| logError(s"Error executing query with $statementId, currentState $currentState, ", e) | ||
| setState(OperationState.ERROR) | ||
| HiveThriftServer2.listener.onStatementError( | ||
| statementId, e.getMessage, SparkUtils.exceptionString(e)) | ||
| if (e.isInstanceOf[HiveSQLException]) { | ||
| throw e.asInstanceOf[HiveSQLException] | ||
| } else { | ||
| throw new HiveSQLException("Error running query: " + e.toString, e) | ||
| } | ||
| } | ||
| } finally { | ||
| synchronized { | ||
|
Contributor
There was a problem hiding this comment. collateral fix: please move
Contributor
Author
There was a problem hiding this comment.
Miss this point , fix it. |
||
| if (!getStatus.getState.isTerminal) { | ||
| setState(OperationState.FINISHED) | ||
| HiveThriftServer2.listener.onStatementFinish(statementId) | ||
| } | ||
| } | ||
|
Contributor
There was a problem hiding this comment. nit: I think this could become a
Contributor
Author
There was a problem hiding this comment.
Reasonable, I add too much control. |
||
| sqlContext.sparkContext.clearJobGroup() | ||
| } | ||
| } | ||
|
|
||
| override def cancel(): Unit = { | ||
| synchronized { | ||
| if (!getStatus.getState.isTerminal) { | ||
| logInfo(s"Cancel query with $statementId") | ||
| cleanup(OperationState.CANCELED) | ||
| HiveThriftServer2.listener.onStatementCanceled(statementId) | ||
| } | ||
| } | ||
| } | ||
|
|
||
| private def cleanup(state: OperationState) { | ||
|
|
||
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Nit: make that logDebug
logInfo(s"Closed statement with $statementId"), to make it consistent with other logs.There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
maybe
logInfo(s"Close statement with $statementId")?There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
I'm fine with both Close and Closed. I see that you already committed Closed.