[SPARK-28982][SQL] Implementation Spark's own GetTypeInfoOperation #25694
Conversation
|
gently ping @wangyum @juliuszsompolski Implement this operation. |
| * limitations under the License. | ||
| */ | ||
|
|
||
| package org.apache.spark.sql.hive.thriftserver.cli |
There was a problem hiding this comment.
This is essentially copied from Hive Type.java, removing the types that we don't support, right?
Maybe instead of cloning it like that, still use the Hive types that Hive's GetTypeInfoOperation uses, and just have a filter like
val unsupportedTypes = Set("INTERVAL_YEAR_MONTH", "INTERVAL_DAY_TIME", "ARRAY", "MAP", "STRUCT", "UNIONTYPE", "USER_DEFINED")
...
if (!unsupportedTypes.contains(typeInfoGetName)) {
val rowData = ...
}
There may be value in the future in cloning that, if our types would diverge more from Hive types, but I think for now we can just reuse it instead of cloning these several hundred lines of code.
There was a problem hiding this comment.
emmmm since for Hive.
In 1.2.1 Type class is org.apache.hive.service.cli.Type
In 2.3.x Type class is org.apache.hadoop.hive.serde2.thrift.Type
Spark only return it's DataType, I add a new Class(Type) for Spark.
If not we may need to add more method to ThriftServerShimUtils.
There was a problem hiding this comment.
I am working on make Spark's own ThriftServer, don't rely on hive version.
In my subconscious,don't want to add method on ThriftserverShimUtils.
There was a problem hiding this comment.
If this only clones the Hive types, skipping the ones we don't support, I'd prefer adding it to the shim and not cloning the code.
I don't think Spark would further diverge from Hive types. If it happens, we could clone it at that point.
@wangyum what do you think?
There was a problem hiding this comment.
Not all same, such as INTEGER, Spark IntegerType's simpleStringName is INTEGER, in hive Types, there is INT. for NULL, change the name to NULL, in hive is void.
There was a problem hiding this comment.
Ok. That seems like a good enough argument to just clone it.
Please list these differences in the PR description.
There was a problem hiding this comment.
OK, I will add to description.
| if (isPrimitiveType) { | ||
| DatabaseMetaData.typeSearchable.toShort | ||
| } else { | ||
| DatabaseMetaData.typePredNone.toShort |
There was a problem hiding this comment.
out of curiosity (I know it's copied from Hive): shouldn't a type like e.g. String be searchable?
There was a problem hiding this comment.
String is searchable. In my return it's 3, means searchable.
There was a problem hiding this comment.
Sorry, I misread "isPrimitiveType" and somehow read "isNumericType".
can this return "null" now instead of "void"? |
NO, my pr only cover !typeinfo, other things can't change. Since FiledSchema is hive's class. Build a Spark's ThriftServer by it's own API is what needs to be done. |
| } | ||
|
|
||
| case object INTEGER extends Type { | ||
| override def getName: String = "INTEGER" |
There was a problem hiding this comment.
Out of curiosity: where is this actually defined?
IntergerType.simpleString is "int", but parser definitely accepts INTEGER and I can't seem to find where it's defined.
There was a problem hiding this comment.
Out of curiosity: where is this actually defined?
IntergerType.simpleStringis "int", but parser definitely accepts INTEGER and I can't seem to find where it's defined.
When I check for simpleString, miss this place, then through IntergerType.simpleString is Integer.
So add a method of filter un-support Type is better.
|
@juliuszsompolski change to use Hive 1.2.1 result : |
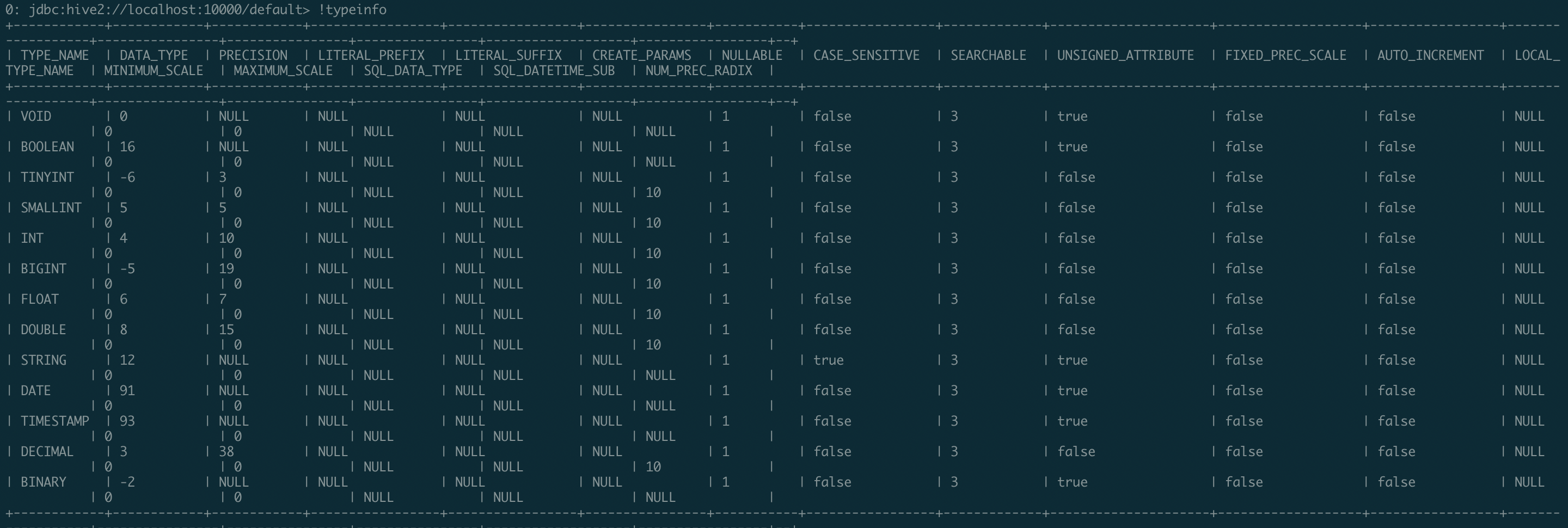
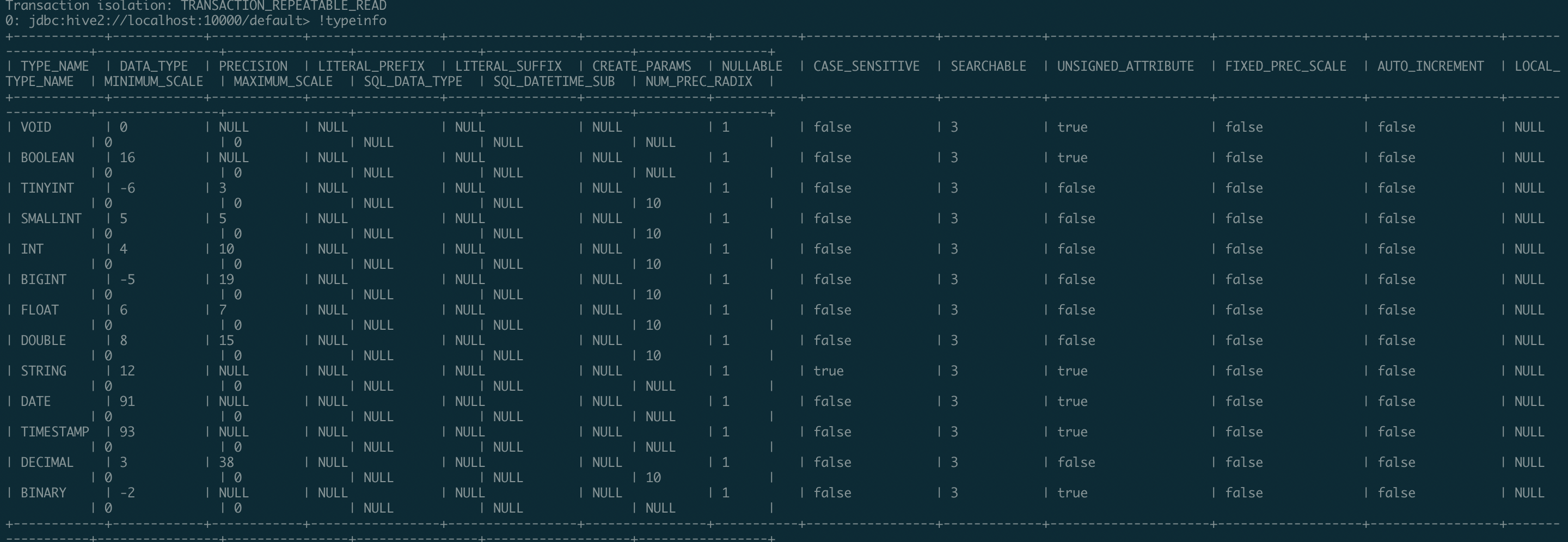
 juliuszsompolski
left a comment
juliuszsompolski
left a comment
There was a problem hiding this comment.
LGTM.
I think it's good now.
It can be thought between "NULL" and "VOID", but I think it's fine as is - NULL is a weird type, and it's name cannot be directly used as a type name in a CREATE TABLE statement anyway (CREATE TABLE foo (col NULL) would fail), so I think it doesn't matter if the name is NULL or VOID.
| Type.BIGINT_TYPE, Type.FLOAT_TYPE, Type.DOUBLE_TYPE, Type.STRING_TYPE, Type.DATE_TYPE, | ||
| Type.TIMESTAMP_TYPE, Type.DECIMAL_TYPE, Type.BINARY_TYPE) | ||
| } | ||
| private[thriftserver] def addToClassPath( |
There was a problem hiding this comment.
nit: empty line between functions.
Yes, and in |
| Array(Type.NULL_TYPE, Type.BOOLEAN_TYPE, Type.TINYINT_TYPE, Type.SMALLINT_TYPE, Type.INT_TYPE, | ||
| Type.BIGINT_TYPE, Type.FLOAT_TYPE, Type.DOUBLE_TYPE, Type.STRING_TYPE, Type.DATE_TYPE, | ||
| Type.TIMESTAMP_TYPE, Type.DECIMAL_TYPE, Type.BINARY_TYPE) | ||
| } |
There was a problem hiding this comment.
Why do we skip ARRAY_TYPE, MAP_TYPE, STRUCT_TYPE and USER_DEFINED_TYPE?
There was a problem hiding this comment.
Why do we skip
ARRAY_TYPE,MAP_TYPE,STRUCT_TYPEandUSER_DEFINED_TYPE?
Support this type just convert to string to show. Should add .
There was a problem hiding this comment.
I think we should add these types. Hive-3.1.2 also converted these types to strings.
@juliuszsompolski What do you think?
There was a problem hiding this comment.
How does the client handle it?
If you do
val stmt = conn.prepareStatement("SELECT array, map, struct, interval FROM table")
val rs = stmt.executeQuery()
val md = rs.getMetaData()
Then what does md.getColumnType(i) return for each of these columns?
What type of rs.getXXX call should the user use for each of these columns? For the array column, should it be rs.getArray(i) or rs.getString(i)?
What is the mapping of types returned by md.getColumnType(i), with the getters that should be used for them in rs.getXXX(i)?
There was a problem hiding this comment.
For getMetadataResult, it truly return ARRAY, MAP, STRUCT.
Return content is organized by HiveResult.toHiveString() method as each's DataType.
There was a problem hiding this comment.
OK. We can not fully support these type. Please remove them @AngersZhuuuu
Thanks @juliuszsompolski for you example.
There was a problem hiding this comment.
Actually, thanks for explaining it @AngersZhuuuu, and you convinced me that ARRAY, MAP and STRUCT must be included.
scala> md.getColumnType(1)
res11: Int = 2003 (== java.sql.Types.ARRAY)
but then
scala> md.getColumnClassName(1)
res10: String = java.lang.String
so that tells to the client that it is actually returned as String, and I should retrieve it as such, either with rs.getObject(1).asInstance[String] or as convenient shorthand with rs.getString(1).
It would actually be incorrect to not include Array, Map, Struct, because we do return them in ResultSet schema (through SparkExecuteStatement.getTableSchema), so the client can get these type returned, and for any type that can be returned to the client there should be an entry in GetTypeInfo.
We therefore should not include INTERVAL (because we explicitly turn it to String return type after #25277), and not include UNIONTYPE or USER_DEFINED because they don't have any Spark equivalent, but ARRAY, MAP and STRUCT should be there.
Thank you for the explanation 👍
There was a problem hiding this comment.
case Types.OTHER:
case Types.JAVA_OBJECT: {
switch (hiveType) {
case INTERVAL_YEAR_MONTH_TYPE:
return HiveIntervalYearMonth.class.getName();
case INTERVAL_DAY_TIME_TYPE:
return HiveIntervalDayTime.class.getName();
default:
return String.class.getName();
}
}
USER_DEFINED in java.sql.Types is OTHERS, in the convert progress, it's also converted to String , same as ARRAY, MAP, STRUCT.
Maybe we should add USER_DEFINED.
There was a problem hiding this comment.
But Spark will never return a USER_DEFINED type.
The current implementation of org.apache.spark.sql.types.UserDefinedType will return the underlying sqlType.simpleString as it's catalogString, so Thriftserver queries will return the underlying type in the schema.
Hence for USER_DEFINED (and UNIONTYPE) the argument is not that they wouldn't potentially work, but that Spark does not use them.
There was a problem hiding this comment.
But Spark will never return a USER_DEFINED type.
The current implementation of org.apache.spark.sql.types.UserDefinedType will return the underlying sqlType.simpleString as it's catalogString, so Thriftserver queries will return the underlying type in the schema.
Hence for USER_DEFINED (and UNIONTYPE) the argument is not that they wouldn't potentially work, but that Spark does not use them.
Remove it and resolve conflicts.
 wangyum
left a comment
wangyum
left a comment
There was a problem hiding this comment.
Could we add a test for this change, e.g.
def checkResult(rs: ResultSet, typeNames: Seq[String]): Unit = {
for (i <- typeNames.indices) {
assert(rs.next())
assert(rs.getString("TYPE_NAME") === typeNames(i))
}
// Make sure there are no more elements
assert(!rs.next())
}
withJdbcStatement() { statement =>
val metaData = statement.getConnection.getMetaData
checkResult(metaData.getTypeInfo, ThriftserverShimUtils.supportedType().map(_.getName))
}
...ver/v1.2.1/src/main/scala/org/apache/spark/sql/hive/thriftserver/ThriftserverShimUtils.scala
Show resolved
Hide resolved
|
ok to test |
|
Test build #110306 has finished for PR 25694 at commit
|
juliuszsompolski
left a comment
There was a problem hiding this comment.
LGTM
Thank you @AngersZhuuuu and @wangyum for a great discussion and examples that helped me learn the interfaces of Java JDBC java.sql.ResultSetMetaData to understand which types should GetTypeInfo return!
Thank you all the same, your deep question prompted me to dive into these questions. Also learn a lot for the JDBC process. |
|
Test build #110413 has finished for PR 25694 at commit
|
|
retest this please |
|
Test build #110414 has finished for PR 25694 at commit
|
|
Result: |
|
Thank you @AngersZhuuuu and @juliuszsompolski |
|
Merged to master |
### What changes were proposed in this pull request? Current Spark Thrift Server return TypeInfo includes 1. INTERVAL_YEAR_MONTH 2. INTERVAL_DAY_TIME 3. UNION 4. USER_DEFINED Spark doesn't support INTERVAL_YEAR_MONTH, INTERVAL_YEAR_MONTH, UNION and won't return USER)DEFINED type. This PR overwrite GetTypeInfoOperation with SparkGetTypeInfoOperation to exclude types which we don't need. In hive-1.2.1 Type class is `org.apache.hive.service.cli.Type` In hive-2.3.x Type class is `org.apache.hadoop.hive.serde2.thrift.Type` Use ThrifrserverShimUtils to fit version problem and exclude types we don't need ### Why are the changes needed? We should return type info of Spark's own type info ### Does this PR introduce any user-facing change? No ### How was this patch tested? Manuel test & Added UT Closes apache#25694 from AngersZhuuuu/SPARK-28982. Lead-authored-by: angerszhu <[email protected]> Co-authored-by: AngersZhuuuu <[email protected]> Signed-off-by: Yuming Wang <[email protected]>
What changes were proposed in this pull request?
Current Spark Thrift Server return TypeInfo includes
Spark doesn't support INTERVAL_YEAR_MONTH, INTERVAL_YEAR_MONTH, UNION
and won't return USER)DEFINED type.
This PR overwrite GetTypeInfoOperation with SparkGetTypeInfoOperation to exclude types which we don't need.
In hive-1.2.1 Type class is
org.apache.hive.service.cli.TypeIn hive-2.3.x Type class is
org.apache.hadoop.hive.serde2.thrift.TypeUse ThrifrserverShimUtils to fit version problem and exclude types we don't need
Why are the changes needed?
We should return type info of Spark's own type info
Does this PR introduce any user-facing change?
No
How was this patch tested?
Manuel test & Added UT