[SPARK-37196][SQL] HiveDecimal enforcePrecisionScale failed return null #34519
Conversation
|
ping @dongjoon-hyun @cloud-fan |
|
Kubernetes integration test starting |
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
|
Kubernetes integration test status failure |
| |CREATE EXTERNAL TABLE test_precision(name STRING, value DECIMAL(18,6)) | ||
| |STORED AS PARQUET LOCATION '${dir.getAbsolutePath}' | ||
| |""".stripMargin) | ||
| checkAnswer(sql("SELECT * FROM test_precision"), Row("dummy", null)) |
There was a problem hiding this comment.
what's the behavior of builtin file source tables? do we also return null?
There was a problem hiding this comment.
and what's the behavior if we do it purely in Hive?
There was a problem hiding this comment.
what's the behavior of builtin file source tables? do we also return null?
Hmmm, non vectorized parquet reader return null as well, vectorized reader throw below exception
[info] Cause: org.apache.spark.sql.execution.QueryExecutionException: Parquet column cannot be converted in file file:///Users/yi.zhu/Documents/project/Angerszhuuuu/spark/sql/hive/target/tmp/hive_execution_test_group/spark-628e3c21-15ee-4473-b207-60a530ced804/part-00000-3f384838-d11f-4c3b-83a1-396efad6df79-c000.snappy.parquet. Column: [value], Expected: decimal(18,6), Found: FIXED_LEN_BYTE_ARRAY
[info] at org.apache.spark.sql.errors.QueryExecutionErrors$.unsupportedSchemaColumnConvertError(QueryExecutionErrors.scala:635)
[info] at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.nextIterator(FileScanRDD.scala:195)
[info] at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.hasNext(FileScanRDD.scala:104)
[info] at org.apache.spark.sql.execution.FileSourceScanExec$$anon$1.hasNext(DataSourceScanExec.scala:531)
[info] at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.columnartorow_nextBatch_0$(generated.java:29)
[info] at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(generated.java:42)
[info] at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
[info] at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:759)
[info] at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
[info] at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
[info] at org.apache.spark.util.Utils$.getIteratorSize(Utils.scala:1895)
[info] at org.apache.spark.rdd.RDD.$anonfun$count$1(RDD.scala:1274)
[info] at org.apache.spark.rdd.RDD.$anonfun$count$1$adapted(RDD.scala:1274)
[info] at org.apache.spark.SparkContext.$anonfun$runJob$5(SparkContext.scala:2267)
[info] at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
[info] at org.apache.spark.scheduler.Task.run(Task.scala:136)
[info] at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:507)
[info] at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1468)
[info] at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:510)
[info] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
[info] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
[info] at java.lang.Thread.run(Thread.java:748)
[info] Cause: org.apache.spark.sql.execution.datasources.SchemaColumnConvertNotSupportedException:
[info] at org.apache.spark.sql.execution.datasources.parquet.ParquetVectorUpdaterFactory.constructConvertNotSupportedException(ParquetVectorUpdaterFactory.java:1079)
[info] at org.apache.spark.sql.execution.datasources.parquet.ParquetVectorUpdaterFactory.getUpdater(ParquetVectorUpdaterFactory.java:174)
[info] at org.apache.spark.sql.execution.datasources.parquet.VectorizedColumnReader.readBatch(VectorizedColumnReader.java:154)
[info] at org.apache.spark.sql.execution.datasources.parquet.VectorizedParquetRecordReader.nextBatch(VectorizedParquetRecordReader.java:296)
[info] at org.apache.spark.sql.execution.datasources.parquet.VectorizedParquetRecordReader.nextKeyValue(VectorizedParquetRecordReader.java:194)
[info] at org.apache.spark.sql.execution.datasources.RecordReaderIterator.hasNext(RecordReaderIterator.scala:39)
[info] at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.hasNext(FileScanRDD.scala:104)
[info] at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.nextIterator(FileScanRDD.scala:191)
[info] at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.hasNext(FileScanRDD.scala:104)
[info] at org.apache.spark.sql.execution.FileSourceScanExec$$anon$1.hasNext(DataSourceScanExec.scala:531)
[info] at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.columnartorow_nextBatch_0$(generated.java:29)
[info] at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(generated.java:42)
[info] at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
[info] at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:759)
[info] at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
[info] at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
[info] at org.apache.spark.util.Utils$.getIteratorSize(Utils.scala:1895)
[info] at org.apache.spark.rdd.RDD.$anonfun$count$1(RDD.scala:1274)
[info] at org.apache.spark.rdd.RDD.$anonfun$count$1$adapted(RDD.scala:1274)
[info] at org.apache.spark.SparkContext.$anonfun$runJob$5(SparkContext.scala:2267)
[info] at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
[info] at org.apache.spark.scheduler.Task.run(Task.scala:136)
[info] at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:507)
[info] at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1468)
[info] at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:510)
[info] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
[info] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
[info] at java.lang.Thread.run(Thread.java:748)
There was a problem hiding this comment.
Hive return NULL too
|
Test build #144998 has finished for PR 34519 at commit
|
| withTempDir { dir => | ||
| withSQLConf(HiveUtils.CONVERT_METASTORE_PARQUET.key -> "false") { | ||
| withTable("test_precision") { | ||
| val df = sql("SELECT 'dummy' AS name, 1000000000000000000010.7000000000000010 AS value") |
There was a problem hiding this comment.
can we use CAST(1.2 AS DECIMAL(38, 16)) instead of writing a long decimal literal?
There was a problem hiding this comment.
CAST(1.2 AS DECIMAL(38, 16))
Can't, it's an enforce convert.
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
|
Test build #145005 has finished for PR 34519 at commit
|
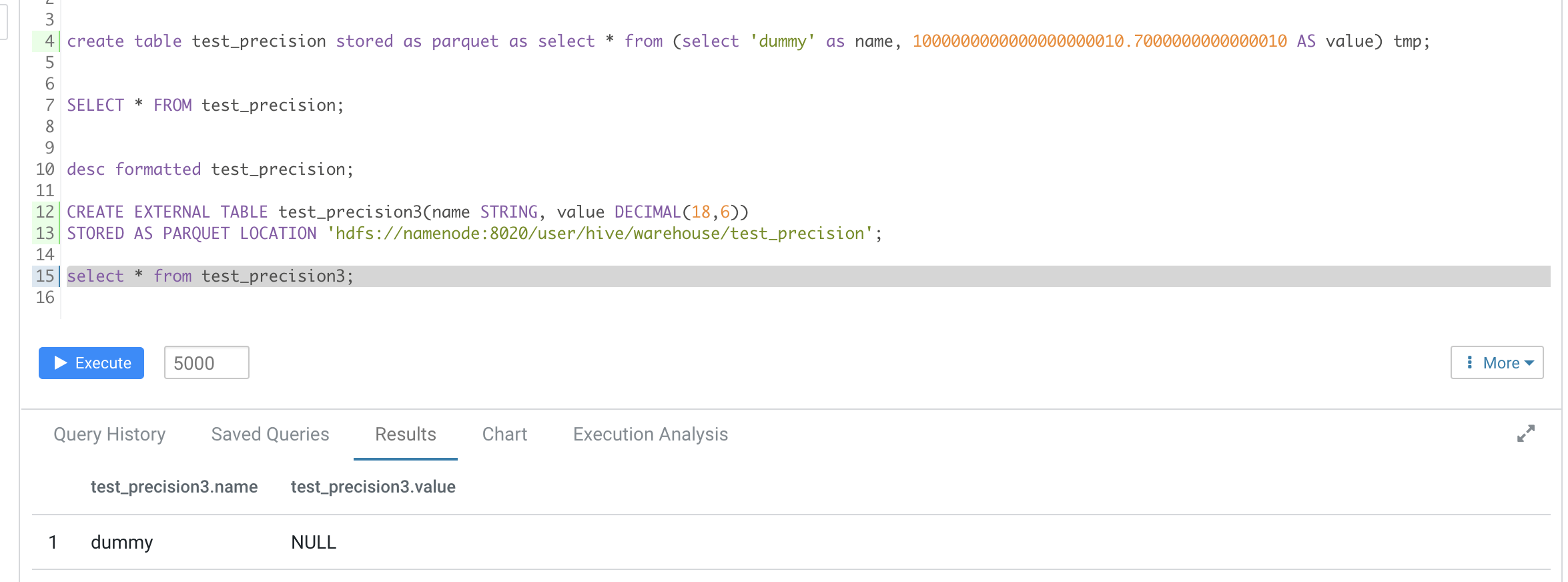
### What changes were proposed in this pull request?
For case
```
withTempDir { dir =>
withSQLConf(HiveUtils.CONVERT_METASTORE_PARQUET.key -> "false") {
withTable("test_precision") {
val df = sql("SELECT 'dummy' AS name, 1000000000000000000010.7000000000000010 AS value")
df.write.mode("Overwrite").parquet(dir.getAbsolutePath)
sql(
s"""
|CREATE EXTERNAL TABLE test_precision(name STRING, value DECIMAL(18,6))
|STORED AS PARQUET LOCATION '${dir.getAbsolutePath}'
|""".stripMargin)
checkAnswer(sql("SELECT * FROM test_precision"), Row("dummy", null))
}
}
}
```
We write a data with schema
It's caused by you create a df with
```
root
|-- name: string (nullable = false)
|-- value: decimal(38,16) (nullable = false)
```
but create table schema
```
root
|-- name: string (nullable = false)
|-- value: decimal(18,6) (nullable = false)
```
This will cause enforcePrecisionScale return `null`
```
public HiveDecimal getPrimitiveJavaObject(Object o) {
return o == null ? null : this.enforcePrecisionScale(((HiveDecimalWritable)o).getHiveDecimal());
}
```
Then throw NPE when call `toCatalystDecimal `
We should judge if the return value is `null` to avoid throw NPE
### Why are the changes needed?
Fix bug
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes #34519 from AngersZhuuuu/SPARK-37196.
Authored-by: Angerszhuuuu <[email protected]>
Signed-off-by: Dongjoon Hyun <[email protected]>
(cherry picked from commit a4f8ffb)
Signed-off-by: Dongjoon Hyun <[email protected]>
For case
```
withTempDir { dir =>
withSQLConf(HiveUtils.CONVERT_METASTORE_PARQUET.key -> "false") {
withTable("test_precision") {
val df = sql("SELECT 'dummy' AS name, 1000000000000000000010.7000000000000010 AS value")
df.write.mode("Overwrite").parquet(dir.getAbsolutePath)
sql(
s"""
|CREATE EXTERNAL TABLE test_precision(name STRING, value DECIMAL(18,6))
|STORED AS PARQUET LOCATION '${dir.getAbsolutePath}'
|""".stripMargin)
checkAnswer(sql("SELECT * FROM test_precision"), Row("dummy", null))
}
}
}
```
We write a data with schema
It's caused by you create a df with
```
root
|-- name: string (nullable = false)
|-- value: decimal(38,16) (nullable = false)
```
but create table schema
```
root
|-- name: string (nullable = false)
|-- value: decimal(18,6) (nullable = false)
```
This will cause enforcePrecisionScale return `null`
```
public HiveDecimal getPrimitiveJavaObject(Object o) {
return o == null ? null : this.enforcePrecisionScale(((HiveDecimalWritable)o).getHiveDecimal());
}
```
Then throw NPE when call `toCatalystDecimal `
We should judge if the return value is `null` to avoid throw NPE
Fix bug
No
Added UT
Closes #34519 from AngersZhuuuu/SPARK-37196.
Authored-by: Angerszhuuuu <[email protected]>
Signed-off-by: Dongjoon Hyun <[email protected]>
(cherry picked from commit a4f8ffb)
Signed-off-by: Dongjoon Hyun <[email protected]>
|
Merged to master/3.2/3.1/3.0. Thank you, @AngersZhuuuu and @cloud-fan . |
For case
```
withTempDir { dir =>
withSQLConf(HiveUtils.CONVERT_METASTORE_PARQUET.key -> "false") {
withTable("test_precision") {
val df = sql("SELECT 'dummy' AS name, 1000000000000000000010.7000000000000010 AS value")
df.write.mode("Overwrite").parquet(dir.getAbsolutePath)
sql(
s"""
|CREATE EXTERNAL TABLE test_precision(name STRING, value DECIMAL(18,6))
|STORED AS PARQUET LOCATION '${dir.getAbsolutePath}'
|""".stripMargin)
checkAnswer(sql("SELECT * FROM test_precision"), Row("dummy", null))
}
}
}
```
We write a data with schema
It's caused by you create a df with
```
root
|-- name: string (nullable = false)
|-- value: decimal(38,16) (nullable = false)
```
but create table schema
```
root
|-- name: string (nullable = false)
|-- value: decimal(18,6) (nullable = false)
```
This will cause enforcePrecisionScale return `null`
```
public HiveDecimal getPrimitiveJavaObject(Object o) {
return o == null ? null : this.enforcePrecisionScale(((HiveDecimalWritable)o).getHiveDecimal());
}
```
Then throw NPE when call `toCatalystDecimal `
We should judge if the return value is `null` to avoid throw NPE
Fix bug
No
Added UT
Closes #34519 from AngersZhuuuu/SPARK-37196.
Authored-by: Angerszhuuuu <[email protected]>
Signed-off-by: Dongjoon Hyun <[email protected]>
(cherry picked from commit a4f8ffb)
Signed-off-by: Dongjoon Hyun <[email protected]>
### What changes were proposed in this pull request?
For case
```
withTempDir { dir =>
withSQLConf(HiveUtils.CONVERT_METASTORE_PARQUET.key -> "false") {
withTable("test_precision") {
val df = sql("SELECT 'dummy' AS name, 1000000000000000000010.7000000000000010 AS value")
df.write.mode("Overwrite").parquet(dir.getAbsolutePath)
sql(
s"""
|CREATE EXTERNAL TABLE test_precision(name STRING, value DECIMAL(18,6))
|STORED AS PARQUET LOCATION '${dir.getAbsolutePath}'
|""".stripMargin)
checkAnswer(sql("SELECT * FROM test_precision"), Row("dummy", null))
}
}
}
```
We write a data with schema
It's caused by you create a df with
```
root
|-- name: string (nullable = false)
|-- value: decimal(38,16) (nullable = false)
```
but create table schema
```
root
|-- name: string (nullable = false)
|-- value: decimal(18,6) (nullable = false)
```
This will cause enforcePrecisionScale return `null`
```
public HiveDecimal getPrimitiveJavaObject(Object o) {
return o == null ? null : this.enforcePrecisionScale(((HiveDecimalWritable)o).getHiveDecimal());
}
```
Then throw NPE when call `toCatalystDecimal `
We should judge if the return value is `null` to avoid throw NPE
### Why are the changes needed?
Fix bug
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes apache#34519 from AngersZhuuuu/SPARK-37196.
Authored-by: Angerszhuuuu <[email protected]>
Signed-off-by: Dongjoon Hyun <[email protected]>
(cherry picked from commit a4f8ffb)
Signed-off-by: Dongjoon Hyun <[email protected]>
For case
```
withTempDir { dir =>
withSQLConf(HiveUtils.CONVERT_METASTORE_PARQUET.key -> "false") {
withTable("test_precision") {
val df = sql("SELECT 'dummy' AS name, 1000000000000000000010.7000000000000010 AS value")
df.write.mode("Overwrite").parquet(dir.getAbsolutePath)
sql(
s"""
|CREATE EXTERNAL TABLE test_precision(name STRING, value DECIMAL(18,6))
|STORED AS PARQUET LOCATION '${dir.getAbsolutePath}'
|""".stripMargin)
checkAnswer(sql("SELECT * FROM test_precision"), Row("dummy", null))
}
}
}
```
We write a data with schema
It's caused by you create a df with
```
root
|-- name: string (nullable = false)
|-- value: decimal(38,16) (nullable = false)
```
but create table schema
```
root
|-- name: string (nullable = false)
|-- value: decimal(18,6) (nullable = false)
```
This will cause enforcePrecisionScale return `null`
```
public HiveDecimal getPrimitiveJavaObject(Object o) {
return o == null ? null : this.enforcePrecisionScale(((HiveDecimalWritable)o).getHiveDecimal());
}
```
Then throw NPE when call `toCatalystDecimal `
We should judge if the return value is `null` to avoid throw NPE
Fix bug
No
Added UT
Closes apache#34519 from AngersZhuuuu/SPARK-37196.
Authored-by: Angerszhuuuu <[email protected]>
Signed-off-by: Dongjoon Hyun <[email protected]>
(cherry picked from commit a4f8ffb)
Signed-off-by: Dongjoon Hyun <[email protected]>
### What changes were proposed in this pull request?
For case
```
withTempDir { dir =>
withSQLConf(HiveUtils.CONVERT_METASTORE_PARQUET.key -> "false") {
withTable("test_precision") {
val df = sql("SELECT 'dummy' AS name, 1000000000000000000010.7000000000000010 AS value")
df.write.mode("Overwrite").parquet(dir.getAbsolutePath)
sql(
s"""
|CREATE EXTERNAL TABLE test_precision(name STRING, value DECIMAL(18,6))
|STORED AS PARQUET LOCATION '${dir.getAbsolutePath}'
|""".stripMargin)
checkAnswer(sql("SELECT * FROM test_precision"), Row("dummy", null))
}
}
}
```
We write a data with schema
It's caused by you create a df with
```
root
|-- name: string (nullable = false)
|-- value: decimal(38,16) (nullable = false)
```
but create table schema
```
root
|-- name: string (nullable = false)
|-- value: decimal(18,6) (nullable = false)
```
This will cause enforcePrecisionScale return `null`
```
public HiveDecimal getPrimitiveJavaObject(Object o) {
return o == null ? null : this.enforcePrecisionScale(((HiveDecimalWritable)o).getHiveDecimal());
}
```
Then throw NPE when call `toCatalystDecimal `
We should judge if the return value is `null` to avoid throw NPE
### Why are the changes needed?
Fix bug
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes apache#34519 from AngersZhuuuu/SPARK-37196.
Authored-by: Angerszhuuuu <[email protected]>
Signed-off-by: Dongjoon Hyun <[email protected]>
(cherry picked from commit a4f8ffb)
Signed-off-by: Dongjoon Hyun <[email protected]>
### What changes were proposed in this pull request?
For case
```
withTempDir { dir =>
withSQLConf(HiveUtils.CONVERT_METASTORE_PARQUET.key -> "false") {
withTable("test_precision") {
val df = sql("SELECT 'dummy' AS name, 1000000000000000000010.7000000000000010 AS value")
df.write.mode("Overwrite").parquet(dir.getAbsolutePath)
sql(
s"""
|CREATE EXTERNAL TABLE test_precision(name STRING, value DECIMAL(18,6))
|STORED AS PARQUET LOCATION '${dir.getAbsolutePath}'
|""".stripMargin)
checkAnswer(sql("SELECT * FROM test_precision"), Row("dummy", null))
}
}
}
```
We write a data with schema
It's caused by you create a df with
```
root
|-- name: string (nullable = false)
|-- value: decimal(38,16) (nullable = false)
```
but create table schema
```
root
|-- name: string (nullable = false)
|-- value: decimal(18,6) (nullable = false)
```
This will cause enforcePrecisionScale return `null`
```
public HiveDecimal getPrimitiveJavaObject(Object o) {
return o == null ? null : this.enforcePrecisionScale(((HiveDecimalWritable)o).getHiveDecimal());
}
```
Then throw NPE when call `toCatalystDecimal `
We should judge if the return value is `null` to avoid throw NPE
### Why are the changes needed?
Fix bug
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes apache#34519 from AngersZhuuuu/SPARK-37196.
Authored-by: Angerszhuuuu <[email protected]>
Signed-off-by: Dongjoon Hyun <[email protected]>
(cherry picked from commit a4f8ffb)
Signed-off-by: Dongjoon Hyun <[email protected]>
For case
```
withTempDir { dir =>
withSQLConf(HiveUtils.CONVERT_METASTORE_PARQUET.key -> "false") {
withTable("test_precision") {
val df = sql("SELECT 'dummy' AS name, 1000000000000000000010.7000000000000010 AS value")
df.write.mode("Overwrite").parquet(dir.getAbsolutePath)
sql(
s"""
|CREATE EXTERNAL TABLE test_precision(name STRING, value DECIMAL(18,6))
|STORED AS PARQUET LOCATION '${dir.getAbsolutePath}'
|""".stripMargin)
checkAnswer(sql("SELECT * FROM test_precision"), Row("dummy", null))
}
}
}
```
We write a data with schema
It's caused by you create a df with
```
root
|-- name: string (nullable = false)
|-- value: decimal(38,16) (nullable = false)
```
but create table schema
```
root
|-- name: string (nullable = false)
|-- value: decimal(18,6) (nullable = false)
```
This will cause enforcePrecisionScale return `null`
```
public HiveDecimal getPrimitiveJavaObject(Object o) {
return o == null ? null : this.enforcePrecisionScale(((HiveDecimalWritable)o).getHiveDecimal());
}
```
Then throw NPE when call `toCatalystDecimal `
We should judge if the return value is `null` to avoid throw NPE
Fix bug
No
Added UT
Closes #34519 from AngersZhuuuu/SPARK-37196.
Authored-by: Angerszhuuuu <[email protected]>
Signed-off-by: Dongjoon Hyun <[email protected]>
What changes were proposed in this pull request?
For case
We write a data with schema
It's caused by you create a df with
but create table schema
This will cause enforcePrecisionScale return
nullThen throw NPE when call
toCatalystDecimalWe should judge if the return value is
nullto avoid throw NPEWhy are the changes needed?
Fix bug
Does this PR introduce any user-facing change?
No
How was this patch tested?
Added UT