Minor fixes to write barriers #75478
Conversation
|
@VSadov Please take a look. |
| bhi Exit | ||
| ldr x12, wbs_ephemeral_high | ||
| cmp x15, x12 | ||
| bhs Exit |
There was a problem hiding this comment.
The .S version is using ccmp here. I think we should use the same pattern in both cases.
I wonder which would be better though. In theory the ephemeral check should more often fail than pass, statistically. In a large heap most objects are tenured. Ephemeral set is supposed to be small.
On the other hand both patterns probably work the same on a speculative CPU, but the predicated pattern is shorter by one instruction.
There was a problem hiding this comment.
And on server GC ephemeral check will always pass. I think, since we are touching this, it should be switched to the predicated form like in .S
|
@AntonLapounov @VSadov is this something we need to continue to fix? |
|
The changes from edge inclusive to edge exclusive compare are bug fixes. These kind of issues would be difficult to hit, but it makes sense to have correct comparisons. I am not very concerned about My only comment on that was that since we are using predicated form in unix ARM64 helper, perhaps we should use predicated form in the windows counterpart as well. It likely does not matter much which form is used, that would be mostly for consistency and predicated form is one instruction shorter. I could do the change if @AntonLapounov is ok with that. Otherwise this change LGTM |
|
I will try to complete it this week. |
|
Now that Anton has been reassigned to other work outside of .NET, can someone on @dotnet/gc and / or @dotnet/jit-contrib chime in who would be best suited to finalize and merge this PR? |
|
There was only one actionable suggestion - to use similar code in win-arm64 as in unix-arm64 in one place. There is no reason for the difference. |
|
I think @cshung was making use of GC shadow at one point when he was debugging some WB stuff and jit folks probably use it for the most part. |
|
I've made the change to address my earlier concern - no need to use different ways to compare on windows and on unix. |
|
I may need another signoff on this, or it would look like I am signing off on my own PR |
|
Thanks!! |
|
Thanks to everyone involved for getting this finished! |
|
Improvements on arm64: |
|
Switching to predicated bounds check resulted in measurable improvement. I mostly expected just more compact code. I was considering making the same change to NativeAOT barriers, but just shortening the code was not enough motivation. |
|
@EgorBo - in addition to 14 improvements there was one regression in |
We can revise that one in a week since there are not enough data point to judge yet
|
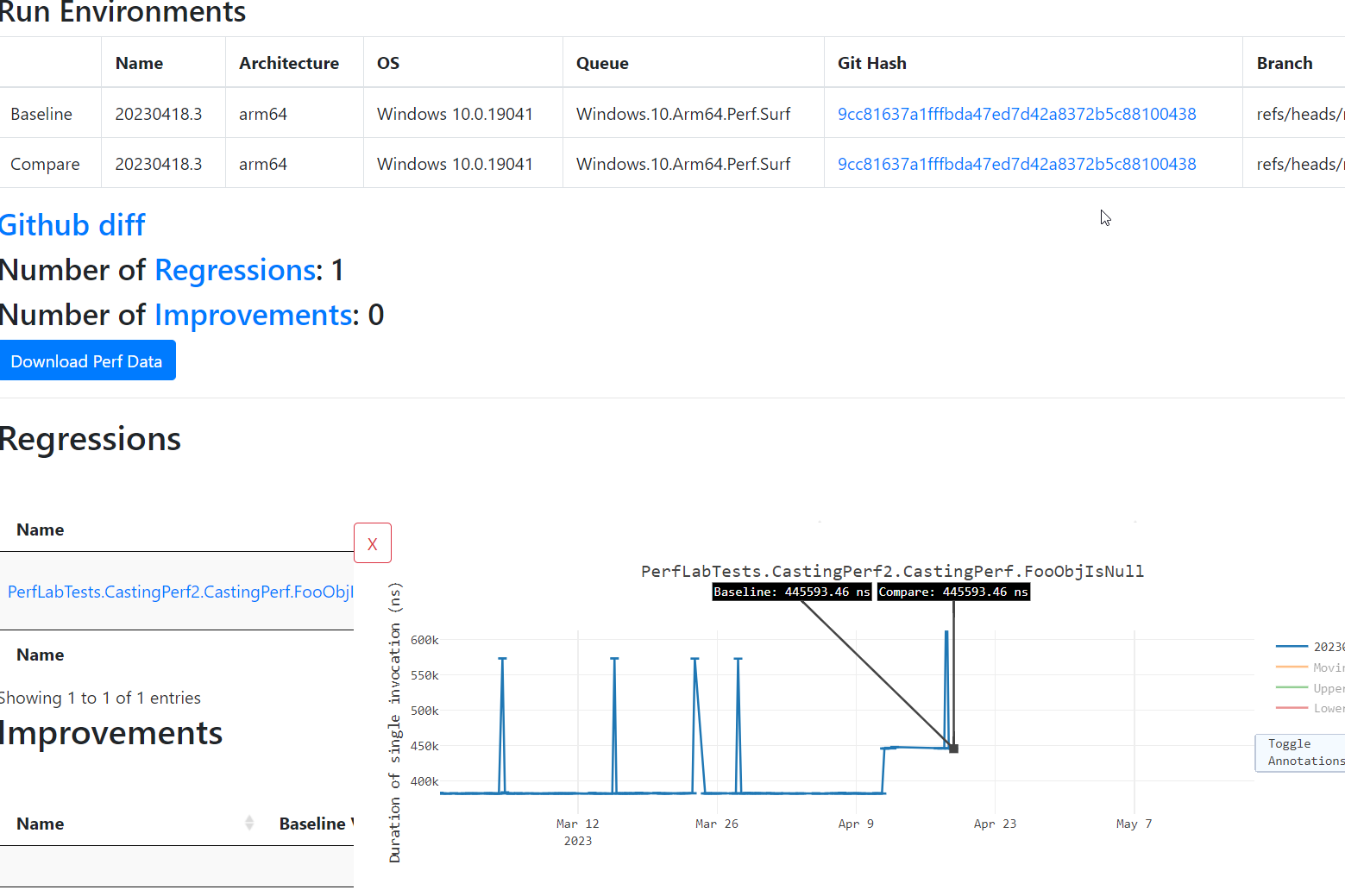
|
This ended up being a lasting regression. 
|
The changed code performs two comparisons (like in logical Either flavor of this code would penalize one case or another. Considering we have many more improvements and the new variant is shorter, I think this regression is acceptable. |
Similar to #74325, uniformly exclude the
g_GCShadowEnd,g_ephemeral_high, andg_highest_addressupper bounds in the corresponding range checks.Note that
JNB,JAE, andJNCmnemonics correspond to the same processor instruction (jump if CF = 0). I usedJNBfor amd64 andJAEfor i386 for "local consistency" with other range checks in the corresponding files.The Windows ARM64 version would trash the
x16register in theCheckCardTableblock. That was not reflected in the comments — neither in this file nor insrc\coreclr\jit\targetarm64.h. I am not convinced thatldpimproves performance here as it requires an additionaladrinstruction and increases the average number of retired instructions. The Linux ARM64 version uses twoldrinstructions instead and I decided to use the same for Windows.